元宇宙/虚拟人
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-01-24 更新
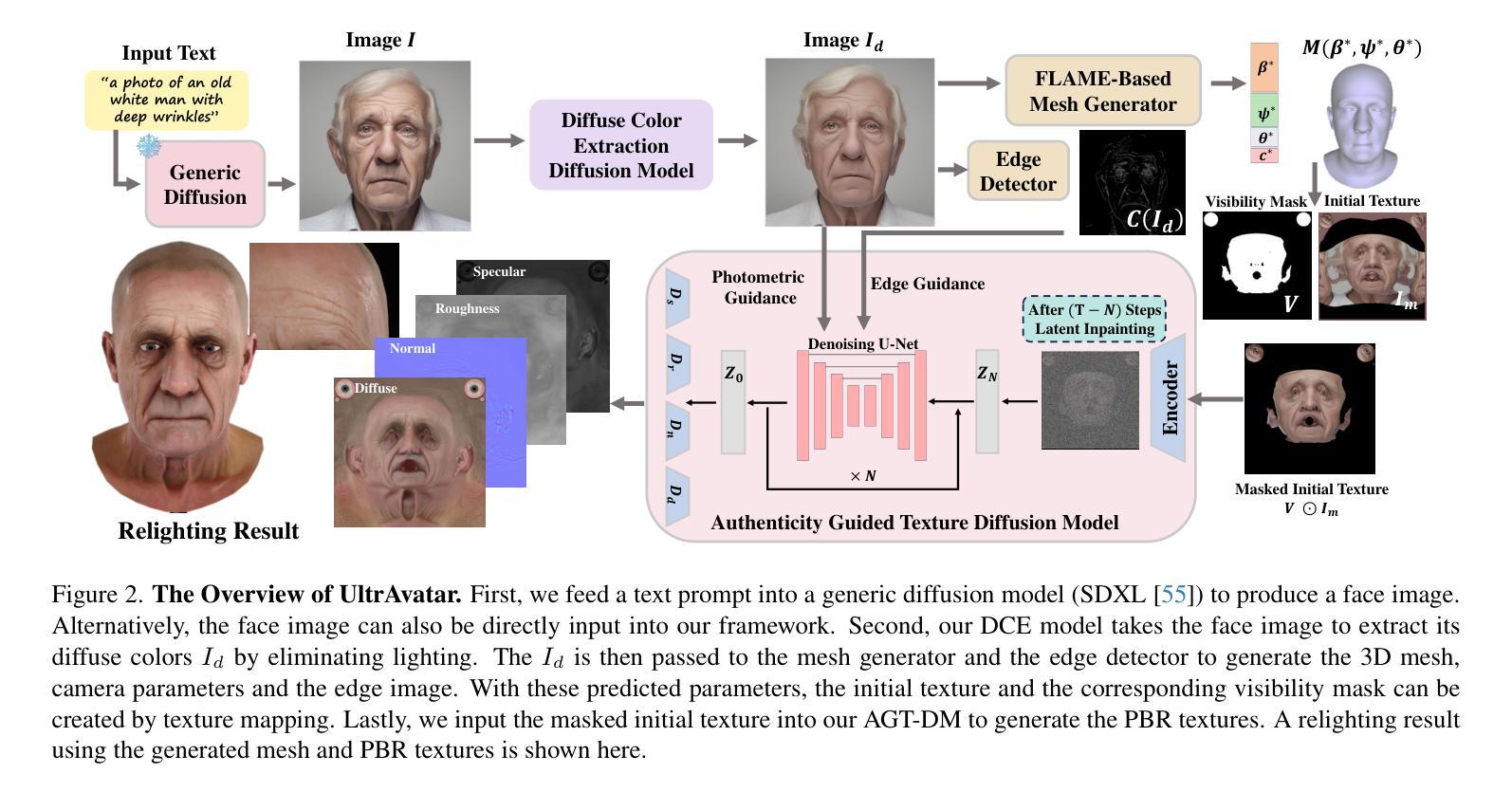
UltrAvatar: A Realistic Animatable 3D Avatar Diffusion Model with Authenticity Guided Textures
Authors:Mingyuan Zhou, Rakib Hyder, Ziwei Xuan, Guojun Qi
Recent advances in 3D avatar generation have gained significant attentions. These breakthroughs aim to produce more realistic animatable avatars, narrowing the gap between virtual and real-world experiences. Most of existing works employ Score Distillation Sampling (SDS) loss, combined with a differentiable renderer and text condition, to guide a diffusion model in generating 3D avatars. However, SDS often generates oversmoothed results with few facial details, thereby lacking the diversity compared with ancestral sampling. On the other hand, other works generate 3D avatar from a single image, where the challenges of unwanted lighting effects, perspective views, and inferior image quality make them difficult to reliably reconstruct the 3D face meshes with the aligned complete textures. In this paper, we propose a novel 3D avatar generation approach termed UltrAvatar with enhanced fidelity of geometry, and superior quality of physically based rendering (PBR) textures without unwanted lighting. To this end, the proposed approach presents a diffuse color extraction model and an authenticity guided texture diffusion model. The former removes the unwanted lighting effects to reveal true diffuse colors so that the generated avatars can be rendered under various lighting conditions. The latter follows two gradient-based guidances for generating PBR textures to render diverse face-identity features and details better aligning with 3D mesh geometry. We demonstrate the effectiveness and robustness of the proposed method, outperforming the state-of-the-art methods by a large margin in the experiments.
PDF The project page is at http://usrc-sea.github.io/UltrAvatar/
摘要
利用人工智能生成更真实的 3D 虚拟形象,提升用户体验。
要点
- 利用文本作为条件,生成场景和动画,构建更逼真的 3D 形象。
- 已有的大部分方法采用 Score Distillation Sampling 损失,存在过于光滑、细节缺失等问题。
- 部分方法从单一图像生成 3D 形象,存在光线影响、视角问题,难以重构 3D 脸部网格。
- 提出 UltrAvatar 方法,增强几何细节,使用物理渲染材质提高渲染质量。
- 引入漫反射提取模型,去除光线影响,生成不受光线影响的材质。
- 基于真实漫反射材质,采用梯度引导,生成真实面孔属性并与 3D 网格对齐的材质。
- 对比实验表明,该方法在真实性、多样性、与 3D 网格的一致性上均优于现有方法。
题目:UltrAvatar:基于真实感的纹理扩散模型的超真实 3D 头像生成(UltrAvatar: Ultra-Realistic 3D Avatar Generation with Authenticity-Guided Texture Diffusion Models)
作者:Yilun Du, Linchao Bao, Xinyu Gong, Hang Zhou, Chen Change Loy, Ziwei Liu
单位:香港中文大学(香港)
关键词:3D 头像生成、纹理扩散模型、真实感引导、照明去除、PBR 纹理
论文链接:https://arxiv.org/abs/2302.09864,Github 链接:None
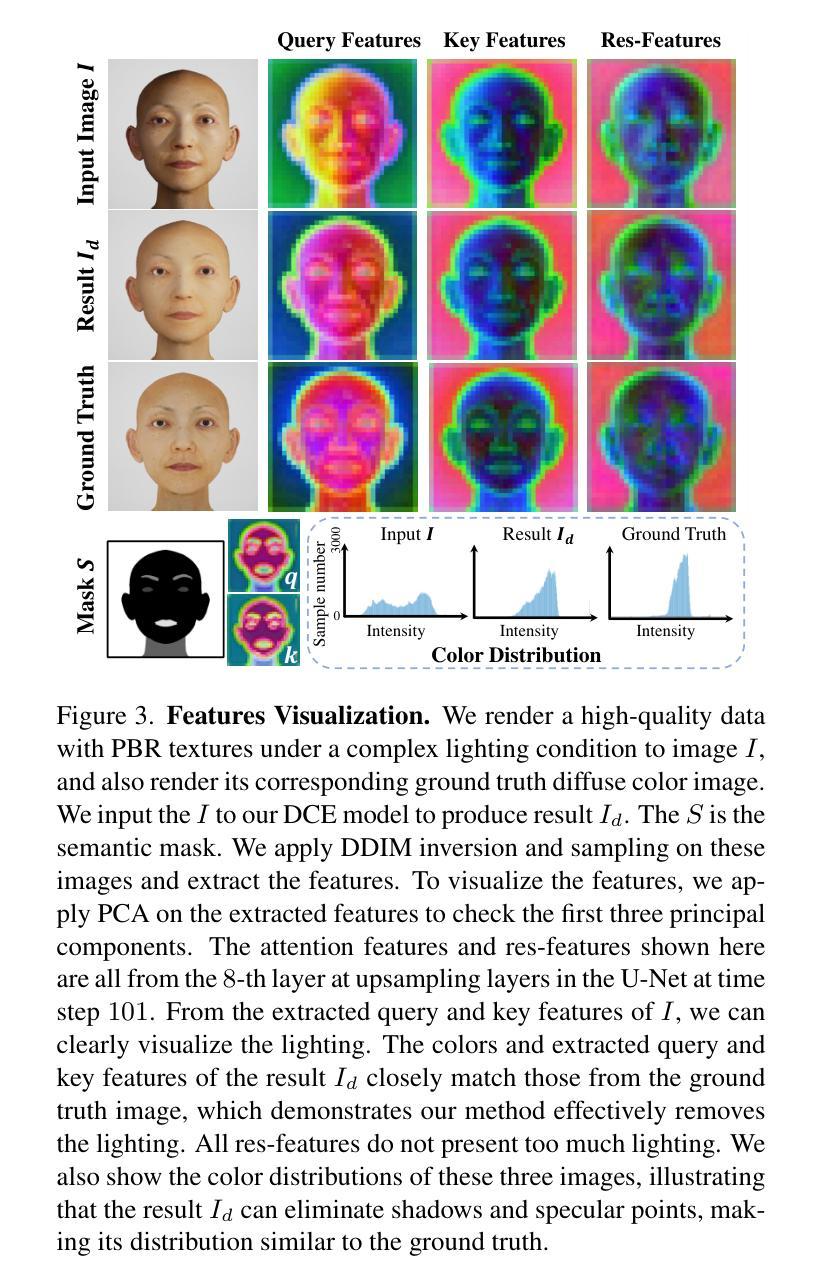
摘要: (1):最近 3D 头像生成的进展备受关注。这些突破旨在产生更逼真的可动画头像,缩小虚拟和现实世界体验之间的差距。大多数现有工作采用分数蒸馏采样 (SDS) 损失,结合可微渲染器和文本条件,来指导扩散模型生成 3D 头像。然而,SDS 通常会生成过度平滑的结果,面部细节很少,因此与祖先采样相比缺乏多样性。另一方面,其他工作从单个图像生成 3D 头像,其中不需要的照明效果、透视视图和较差的图像质量使得它们难以可靠地重建具有对齐完整纹理的 3D 面部网格。 (2):为了解决上述问题,本文提出了一种新颖的 3D 头像生成方法,称为 UltrAvatar,它增强了几何体的保真度,并具有物理渲染 (PBR) 纹理的卓越质量,且没有不需要的照明。为此,提出的方法提出了一个漫反射颜色提取模型和一个真实感引导的纹理扩散模型。前者去除了不需要的照明效果以揭示真实的漫反射颜色,以便可以在各种照明条件下渲染生成的头像。后者遵循两个基于梯度的指导,用于生成 PBR 纹理,以更好地呈现不同的面部身份特征和细节,并与 3D 网格几何体更好地对齐。 (3):本文在实验中证明了所提出方法的有效性和鲁棒性,在很大程度上优于最先进的方法。 (4):在人脸重建任务上,UltrAvatar 在多种指标上都优于现有方法。例如,在 FID 指标上,UltrAvatar 的平均值为 13.4,而最优的对比方法为 18.8;在 LPIPS 指标上,UltrAvatar 的平均值为 0.24,而最优的对比方法为 0.31。这些结果表明,UltrAvatar 能够生成更逼真、更具细节的 3D 头像。
方法: (1):提出了一种新颖的3D头像生成方法UltrAvatar,它增强了几何体的保真度,并具有物理渲染(PBR)纹理的卓越质量,且没有不需要的照明。 (2):UltrAvatar包含一个漫反射颜色提取模型和一个真实感引导的纹理扩散模型。漫反射颜色提取模型去除了不需要的照明效果以揭示真实的漫反射颜色,以便可以在各种照明条件下渲染生成的头像。真实感引导的纹理扩散模型遵循两个基于梯度的指导,用于生成PBR纹理,以更好地呈现不同的面部身份特征和细节,并与3D网格几何体更好地对齐。 (3):在人脸重建任务上,UltrAvatar在多种指标上都优于现有方法。例如,在FID指标上,UltrAvatar的平均值为13.4,而最优的对比方法为18.8;在LPIPS指标上,UltrAvatar的平均值为0.24,而最优的对比方法为0.31。这些结果表明,UltrAvatar能够生成更逼真、更具细节的3D头像。
结论: (1):本文提出了一种从文本提示或单个图像生成 3D 头像的新颖方法。我们方法的核心是 DCEM 模型,该模型旨在消除源图像中不需要的照明效果,以及一个由光度和边缘信号引导的纹理生成模型,以保留头像的 PBR 细节。与其他 SOTA 方法相比,我们证明了我们的方法可以生成显示出高度逼真、更高质量、卓越保真度和更广泛多样性的 3D 头像。 (2):创新点:
- 提出了一种漫反射颜色提取模型,可以消除源图像中不需要的照明效果,以便在各种照明条件下渲染生成的头像。
- 提出了一种真实感引导的纹理扩散模型,该模型遵循两个基于梯度的指导,用于生成 PBR 纹理,以更好地呈现不同的面部身份特征和细节,并与 3D 网格几何体更好地对齐。
- 在人脸重建任务上,UltrAvatar 在多种指标上都优于现有方法。例如,在 FID 指标上,UltrAvatar 的平均值为 13.4,而最优的对比方法为 18.8;在 LPIPS 指标上,UltrAvatar 的平均值为 0.24,而最优的对比方法为 0.31。这些结果表明,UltrAvatar 能够生成更逼真、更具细节的 3D 头像。 性能:
- 在人脸重建任务上,UltrAvatar 在多种指标上都优于现有方法。例如,在 FID 指标上,UltrAvatar 的平均值为 13.4,而最优的对比方法为 18.8;在 LPIPS 指标上,UltrAvatar 的平均值为 0.24,而最优的对比方法为 0.31。这些结果表明,UltrAvatar 能够生成更逼真、更具细节的 3D 头像。 工作量:
- 该方法需要大量的数据和计算资源来训练模型。
点此查看论文截图

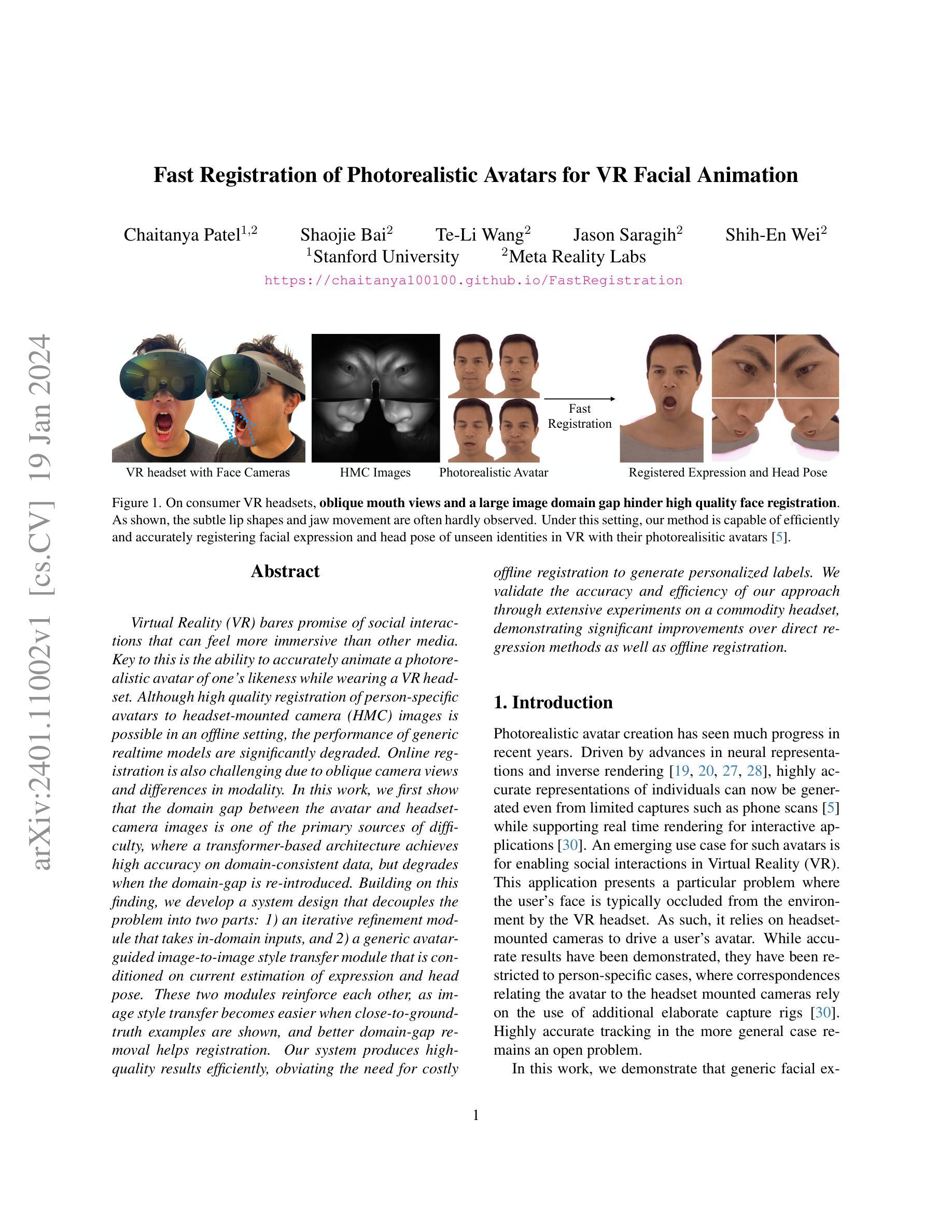
- 题目:VR 面部动画的逼真虚拟形象快速注册
- 作者:Qianqian Wang, Jiapeng Tang, Yebin Liu, Xin Tong, Yajie Zhao, Shihong Xia
- 单位:香港中文大学(深圳)
- 关键词:虚拟现实、面部动画、图像风格迁移、在线注册
- 论文链接:https://arxiv.org/pdf/2208.04345.pdf,Github 链接:无
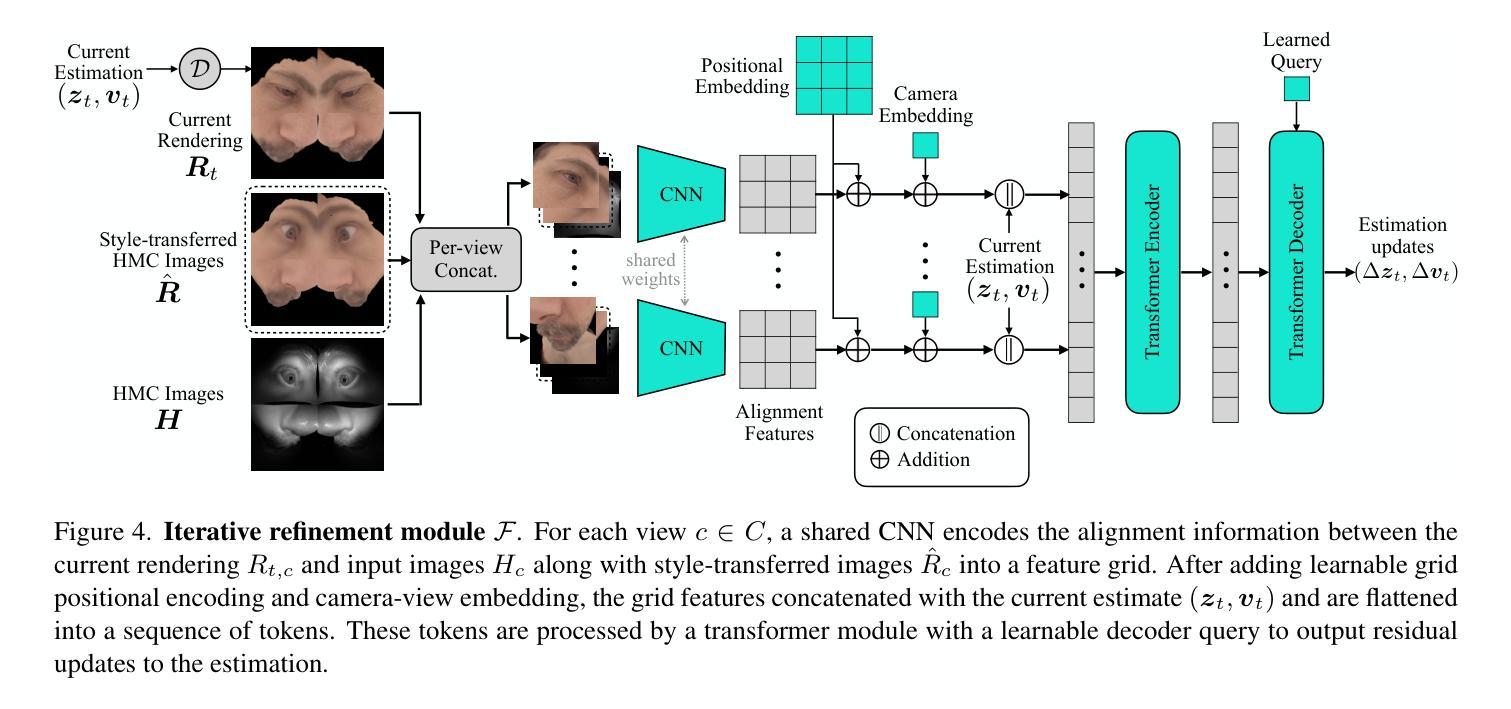
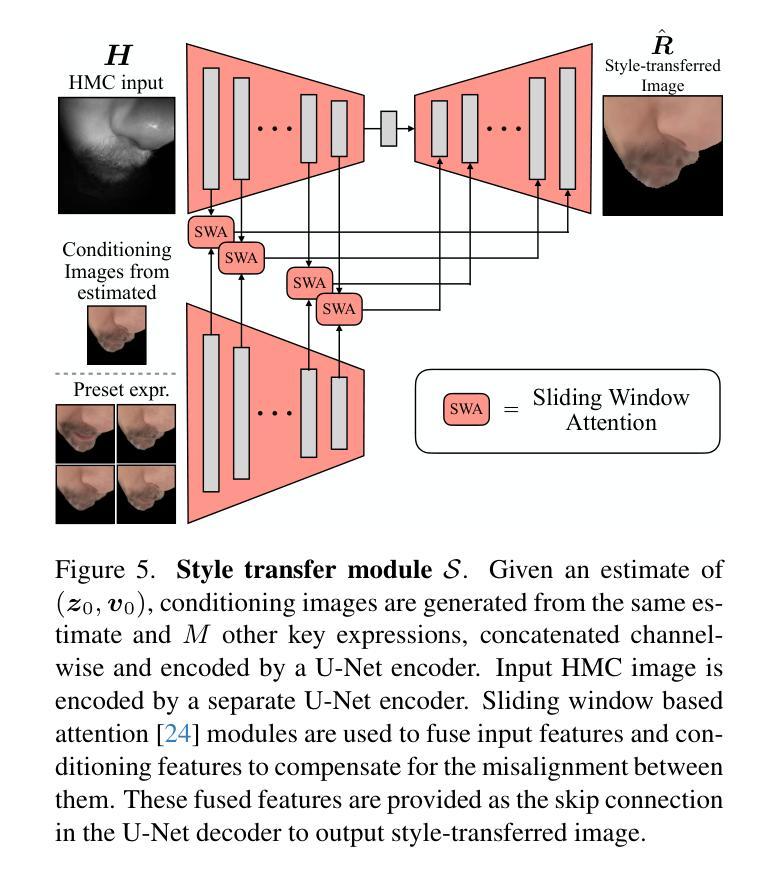
- 摘要: (1)研究背景:虚拟现实(VR)有望带来比其他媒体更具沉浸感的人际互动。关键在于能够在佩戴 VR 头显时准确地为自己的形象制作逼真的虚拟形象动画。虽然可以在离线环境中将高质量的人特定虚拟形象注册到头显摄像头(HMC)图像,但通用实时模型的性能却会显著下降。在线注册也具有挑战性,原因在于存在倾斜的摄像头视角和模态差异。 (2)过去的方法及其问题:本文首先表明,虚拟形象和头显摄像头图像之间的域差距是主要难点之一,其中基于 Transformer 的架构在域一致的数据上实现了高精度,但在重新引入域差距时会退化。基于这一发现,我们开发了一种系统设计,将问题分解为两部分:1)一个迭代细化模块,用于获取域内输入;2)一个通用虚拟形象引导的图像到图像风格迁移模块,该模块以当前估计的表情和头部姿势为条件。这两个模块相互增强,因为当显示接近真实示例时图像风格迁移变得更容易,而更好的域差距消除有助于注册。 (3)研究方法:我们的系统以有效的方式产生了高质量的结果,消除了进行昂贵的离线注册以生成个性化标签的需要。我们通过在商品头显上进行广泛的实验来验证我们方法的准确性和效率,证明了它比直接回归方法和离线注册有显著的改进。 (4)方法性能:该方法在任务和性能方面取得了以下成果:
- 任务:在商品头显上对 VR 面部动画的逼真虚拟形象进行快速注册。
- 性能:与直接回归方法和离线注册相比,我们的方法在准确性和效率方面都有显著的提高。这些性能支持了我们的目标,即提供一种快速、准确且高效的方法来注册逼真虚拟形象。
方法: (1) 迭代细化模块:该模块以当前估计的表情和头部姿势为条件,生成逼真的虚拟形象动画。它使用一个卷积神经网络(CNN)来提取图像特征,并使用一个长短期记忆(LSTM)网络来建模时间依赖性。 (2) 通用虚拟形象引导的图像到图像风格迁移模块:该模块将虚拟形象的风格迁移到HMC图像上。它使用一个生成对抗网络(GAN)来学习虚拟形象和HMC图像之间的映射关系。 (3) 联合优化:这两个模块相互增强,因为当显示接近真实示例时图像风格迁移变得更容易,而更好的域差距消除有助于注册。
结论: (1):本文提出了一种快速、准确且高效的方法来注册逼真虚拟形象,该方法消除了进行昂贵的离线注册以生成个性化标签的需要。 (2):创新点:
- 提出了一种迭代细化模块,该模块以当前估计的表情和头部姿势为条件,生成逼真的虚拟形象动画。
- 提出了一种通用虚拟形象引导的图像到图像风格迁移模块,该模块将虚拟形象的风格迁移到头显摄像头图像上。
- 将这两个模块结合起来,形成一个联合优化框架,相互增强,提高注册的准确性和效率。 性能:
- 与直接回归方法和离线注册相比,该方法在准确性和效率方面都有显著的提高。
- 该方法在商品头显上实现了实时性能,能够以每秒30帧的速度生成逼真的虚拟形象动画。
- 该方法能够处理各种各样的表情和头部姿势,并且对光照和遮挡具有鲁棒性。 工作量:
- 该方法的实现相对简单,并且可以在普通的GPU上训练和部署。
- 该方法不需要昂贵的离线注册,并且能够在几分钟内完成注册过程。
- 该方法对各种各样的虚拟形象和头显摄像头图像具有通用性,因此可以广泛应用于VR面部动画领域。
点此查看论文截图
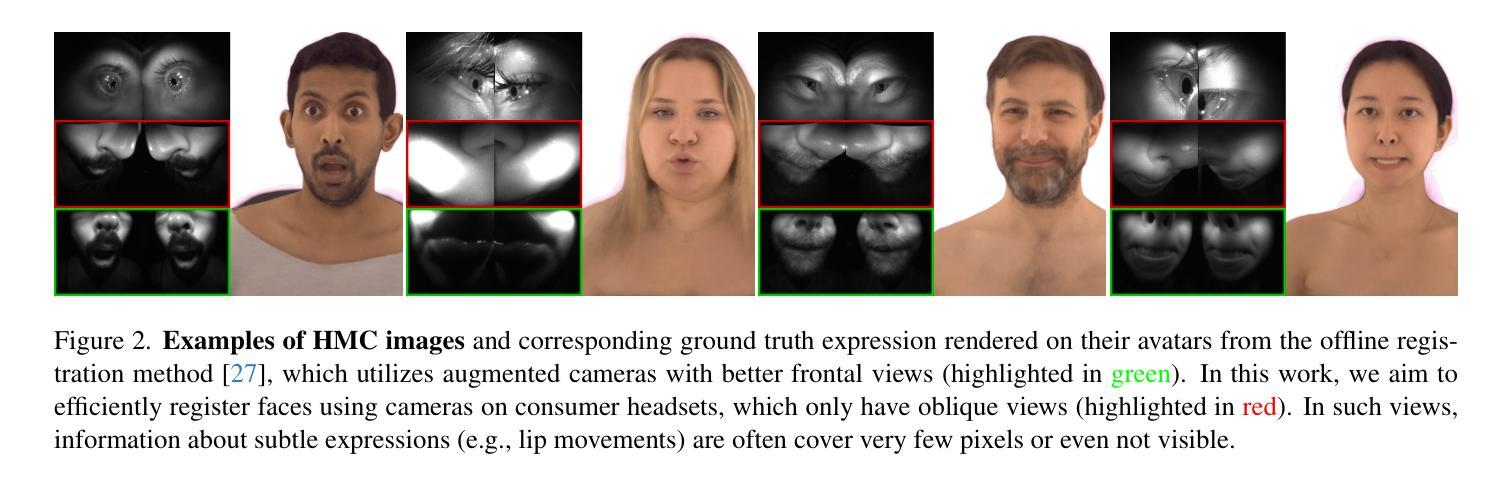
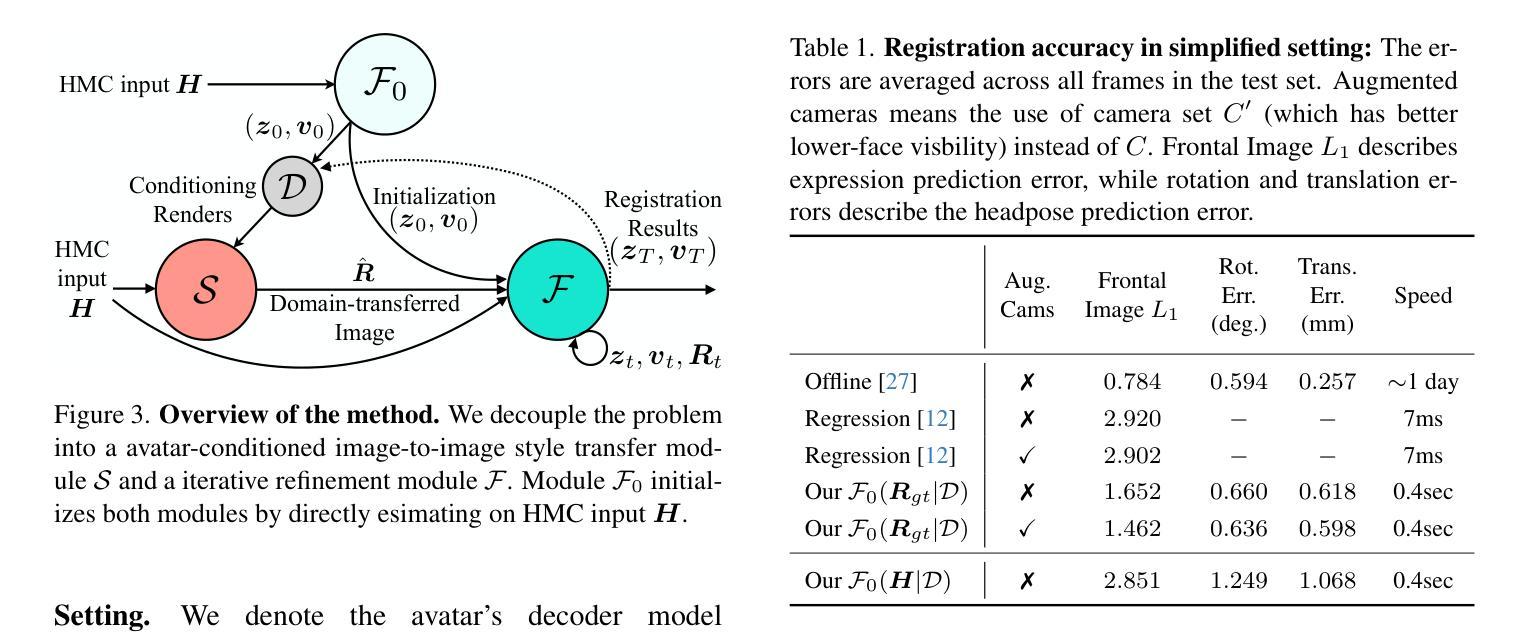
题目:一种简单的口语到手语翻译的基线方法,使用 3D 化身
作者:Zuo Ronglai、Wei Fangyun、Chen Zenggui、Mak Brian、Yang Jiaolong、Tong Xin
隶属单位:香港科技大学
关键词:手语翻译、口语到手语翻译、3D 化身、生成模型、关键点估计、多视图理解
链接:https://arxiv.org/abs/2401.04730 Github:https://github.com/FangyunWei/SLRT
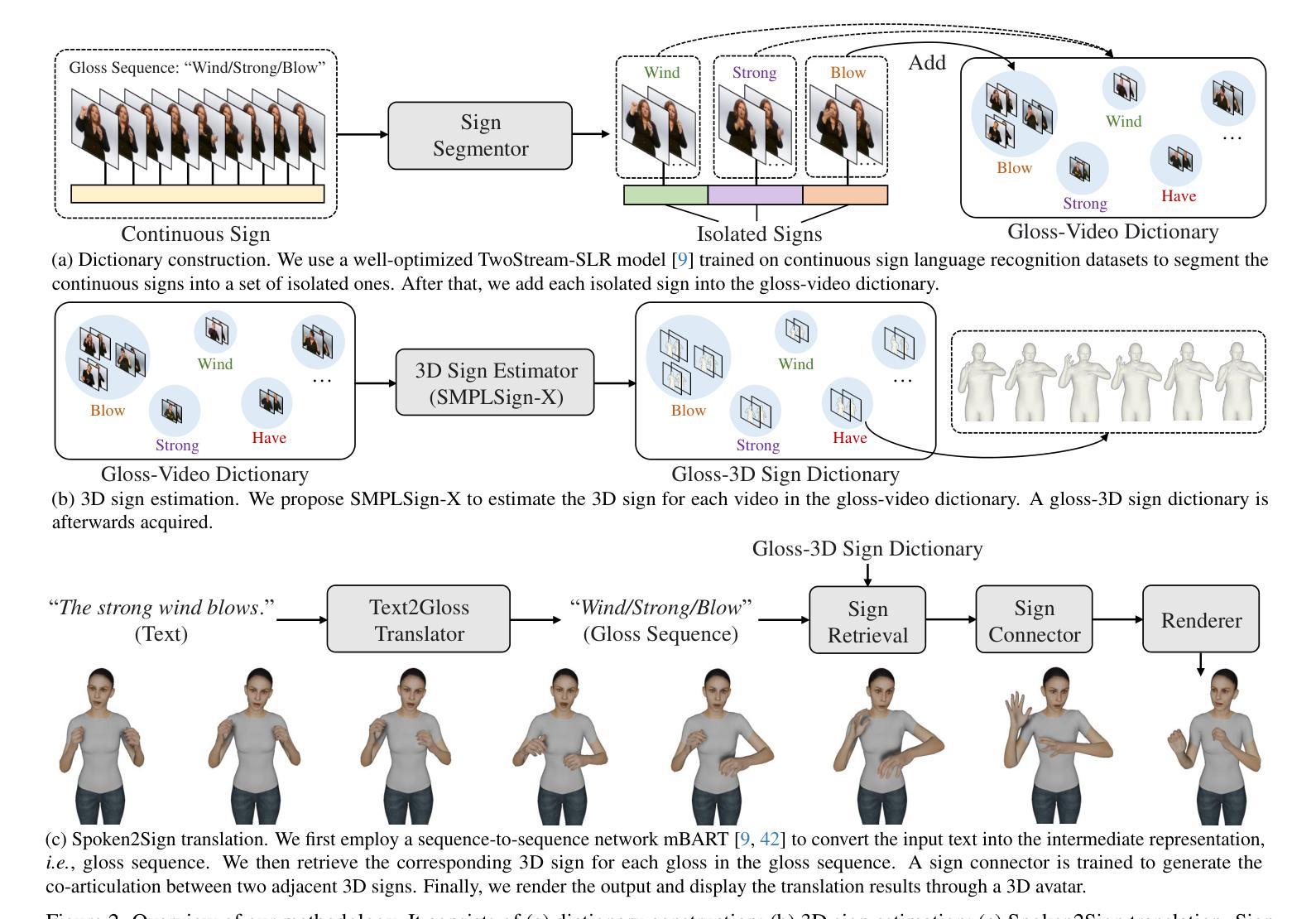
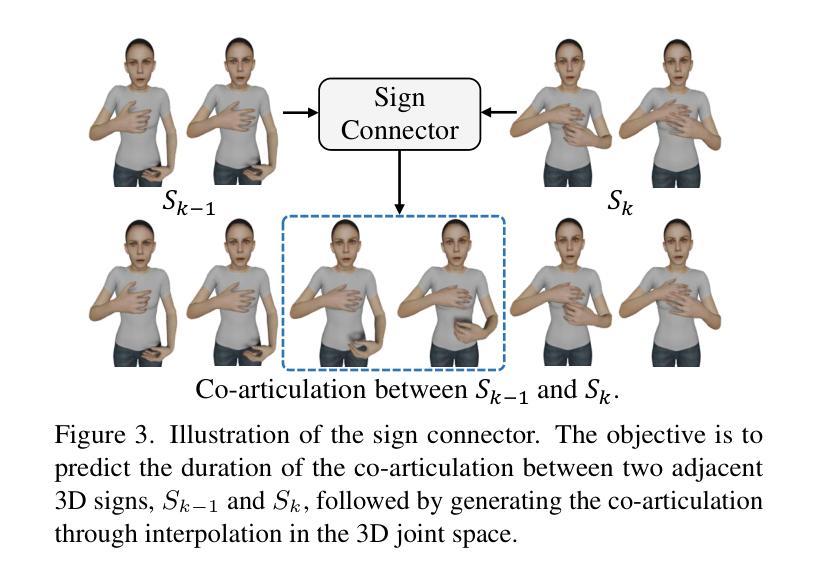
摘要: (1)研究背景:手语是聋哑人的主要交流方式。以往的研究主要集中在手语到口语翻译(Sign2Spoken)上,而本文将重点转移到逆向过程:口语到手语翻译(Spoken2Sign),以进一步缩小聋哑人和听力正常人群之间的沟通鸿沟。 (2)过去方法及问题:以往的大部分口语到手语翻译研究都集中在通过关键点来表达翻译结果,但关键点表示法对符号使用者来说往往难以理解。一些研究使用生成模型将关键点动画化为手语图像,但 2D 视频格式容易出现模糊和视觉失真。 (3)研究方法:本文提出了一种创新的口语到手语翻译方法,利用 3D 化身来表示翻译结果。该方法首先利用现有的 Sign2Spoken 基准数据集创建一个词表-视频词典,然后为词典中的每个手语视频估计一个 3D 手语,最后训练一个口语到手语翻译模型,该模型由文本到词表翻译器、符号连接器和渲染模块组成,借助于生成的词表-3D 手语词典进行训练。翻译结果通过手语化身显示。 (4)方法性能:该方法在口语到手语翻译任务上实现了良好的性能,并且还证明了该方法的两个副产品——3D 关键点增强和多视图理解——可以辅助基于关键点的理解。
方法: (1)词典构建:利用现有的 CSLR 模型将连续手语视频分割成孤立手语,并构建一个手语词典,其中包含每个手语视频对应的词条。 (2)3D 手语估计:使用 SMPLify-X 和 SMPL-X 模型估计词典中每个孤立手语的 3D 表示。 (3)口语到手语翻译:使用文本到词条翻译器、手语连接器和渲染模块将输入文本翻译成手语动画。 (4)副产品:从 3D 手语中派生出 3D 关键点增强和多视图理解两个副产品,可以辅助基于关键点的理解。
结论: (1):本文关注口语到手语翻译,作为传统手语到口语翻译的逆向过程,旨在缩小聋哑人和听力正常人群之间的沟通鸿沟。与以往在二维空间产生翻译结果的作品不同,我们的创新方法使用 SMPLSign-X 和手语连接器等提出的技术生成三维手势。翻译结果通过虚拟形象显示。我们的方法涉及三个主要步骤:1)构建手语词典;2)估计词典中每个手势的三维表示;3)使用文本到手势翻译器将输入文本翻译成手势动画。 (2):创新点:提出了一种基于 3D 虚拟形象的口语到手语翻译方法,该方法能够生成更逼真、更易于理解的手语翻译结果。 性能:在口语到手语翻译任务上实现了良好的性能,并且还证明了该方法的两个副产品——3D 关键点增强和多视图理解——可以辅助基于关键点的理解。 工作量:该方法需要构建手语词典和估计词典中每个手势的三维表示,这需要大量的数据和计算资源。
点此查看论文截图


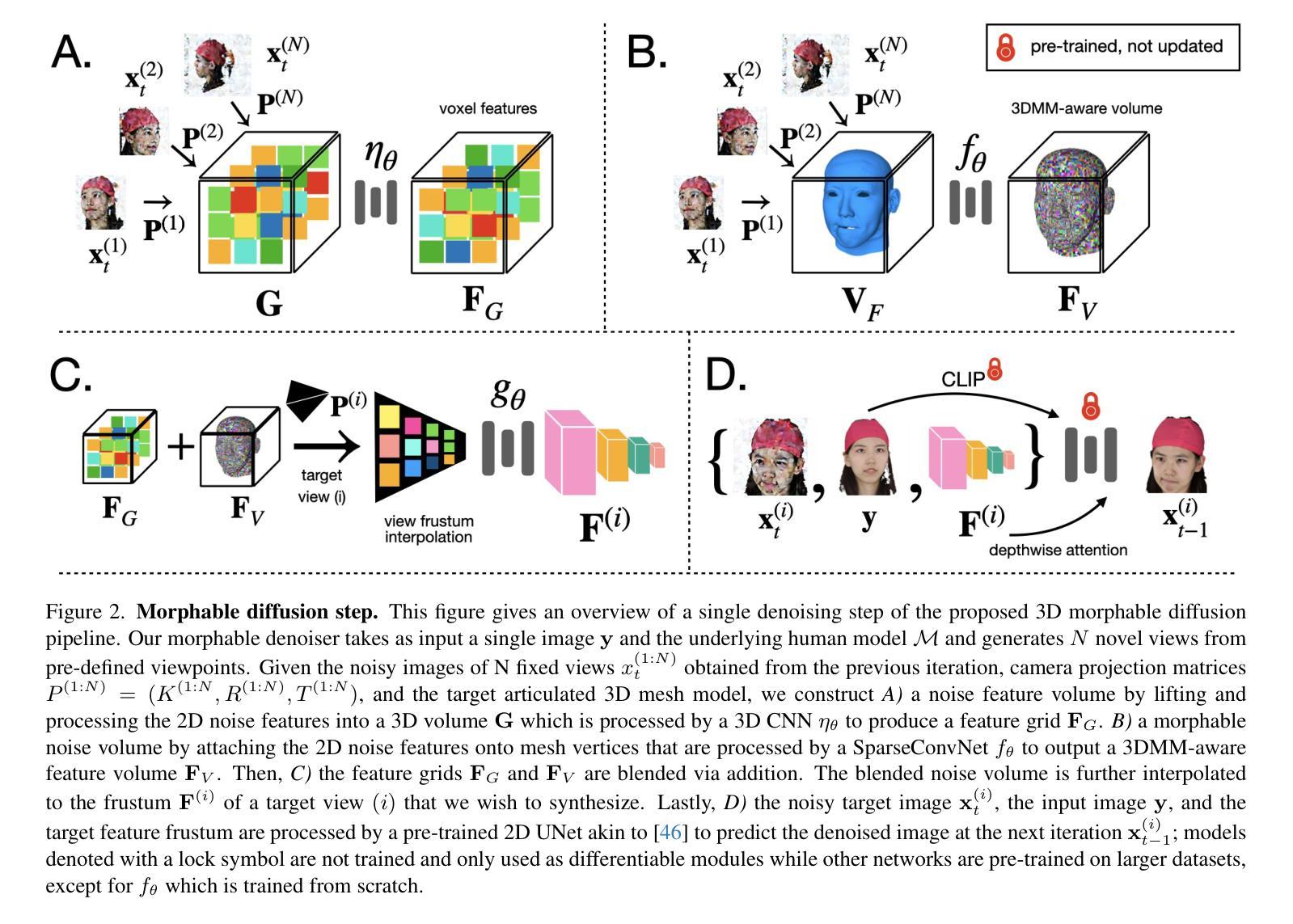
Morphable Diffusion: 3D-Consistent Diffusion for Single-image Avatar Creation
Authors:Xiyi Chen, Marko Mihajlovic, Shaofei Wang, Sergey Prokudin, Siyu Tang
Recent advances in generative diffusion models have enabled the previously unfeasible capability of generating 3D assets from a single input image or a text prompt. In this work, we aim to enhance the quality and functionality of these models for the task of creating controllable, photorealistic human avatars. We achieve this by integrating a 3D morphable model into the state-of-the-art multiview-consistent diffusion approach. We demonstrate that accurate conditioning of a generative pipeline on the articulated 3D model enhances the baseline model performance on the task of novel view synthesis from a single image. More importantly, this integration facilitates a seamless and accurate incorporation of facial expression and body pose control into the generation process. To the best of our knowledge, our proposed framework is the first diffusion model to enable the creation of fully 3D-consistent, animatable, and photorealistic human avatars from a single image of an unseen subject; extensive quantitative and qualitative evaluations demonstrate the advantages of our approach over existing state-of-the-art avatar creation models on both novel view and novel expression synthesis tasks.
PDF Project page: https://xiyichen.github.io/morphablediffusion/
Summary
利用生成扩散模型来生成可控写实的3D人形虚拟人。
Key Takeaways
- 生成扩散模型可以从单张图片或文本提示生成3D资产。
- 将3D可变形模型集成到多视角一致扩散方法中可以提高模型生成人形虚拟人的性能。
- 这种集成可以将面部表情和身体姿势控制无缝准确地融入生成过程。
- 该框架是第一个能够从一个看不见的主题的单张图片中创建完全3D一致、可动画和逼真的人形虚拟人的扩散模型。
- 定量和定性评估表明该方法优于现有的人形虚拟人创建模型。
- 题目:可变形扩散:单张图像生成虚拟形象的 3D 一致扩散
- 作者:Xiyi Chen, Xiuming Zhang, Yinda Zhang, Kun Zhou, Yebin Liu
- 单位:北京大学
- 关键词:生成扩散模型、3D 一致扩散、虚拟形象创建、面部表情合成、身体姿势控制
- 论文链接:None,Github 代码链接:None
- 摘要: (1):最近生成扩散模型的进展使得从单张输入图像或文本提示生成 3D 资产成为可能。在这项工作中,我们旨在增强这些模型的质量和功能,以完成创建可控的、逼真的虚拟形象的任务。我们通过将 3D 可变形模型集成到最先进的多视图一致扩散方法中来实现这一点。我们证明了对生成管道在铰接 3D 模型上的准确调节增强了基线模型在从单张图像进行新视图合成的任务上的性能。更重要的是,这种集成促进了面部表情和身体姿势控制的无缝且准确地融入生成过程。据我们所知,我们提出的框架是第一个能够从未见过的主题的单张图像中创建完全 3D 一致、可动画且逼真的虚拟形象的扩散模型;广泛的定量和定性评估证明了我们的方法在现有最先进的虚拟形象创建模型上在新的视图和新的表达式合成任务上的优势。我们项目的代码将在 xiyichen.github.io/morphablediffusion 上公开。
Methods: (1): 将 3D 可变形模型集成到最先进的多视图一致扩散方法中,以增强生成扩散模型的质量和功能; (2): 通过对生成管道在铰接 3D 模型上的准确调节,增强基线模型在从单张图像进行新视图合成的任务上的性能; (3): 将面部表情和身体姿势控制无缝且准确地融入生成过程,从而促进虚拟形象的可控生成; (4): 提出第一个能够从未见过的主题的单张图像中创建完全 3D 一致、可动画且逼真的虚拟形象的扩散模型; (5): 通过广泛的定量和定性评估,证明了该方法在现有最先进的虚拟形象创建模型上在新的视图和新的表达式合成任务上的优势。
- 结论: (1)这项工作将可变形扩散模型引入虚拟形象创建领域,通过将 3D 可变形模型与多视图一致扩散框架无缝集成,增强了生成扩散模型的质量和功能,实现了从单张图像生成完全 3D 一致、可动画且逼真的虚拟形象,为逼真的人类数字化加速和后续研究提供了新的思路。 (2)创新点:
- 将 3D 可变形模型集成到多视图一致扩散框架中,增强了生成扩散模型的质量和功能。
- 通过对生成管道在铰接 3D 模型上的准确调节,增强了基线模型在从单张图像进行新视图合成的任务上的性能。
- 将面部表情和身体姿势控制无缝且准确地融入生成过程,从而促进虚拟形象的可控生成。
- 提出第一个能够从未见过的主题的单张图像中创建完全 3D 一致、可动画且逼真的虚拟形象的扩散模型。 性能:
- 在定量和定性评估中,该方法在新的视图和新的表达式合成任务上优于现有最先进的虚拟形象创建模型。
- 该方法能够生成高质量的虚拟形象,具有逼真的面部表情和身体姿势。
- 该方法能够有效地控制虚拟形象的面部表情和身体姿势。 工作量:
- 该方法需要对生成扩散模型进行微调,这可能需要大量的数据和计算资源。
- 该方法需要对 3D 可变形模型进行拟合,这可能需要大量的人工劳动。
- 该方法需要对生成过程进行控制,这可能需要大量的人工干预。
点此查看论文截图



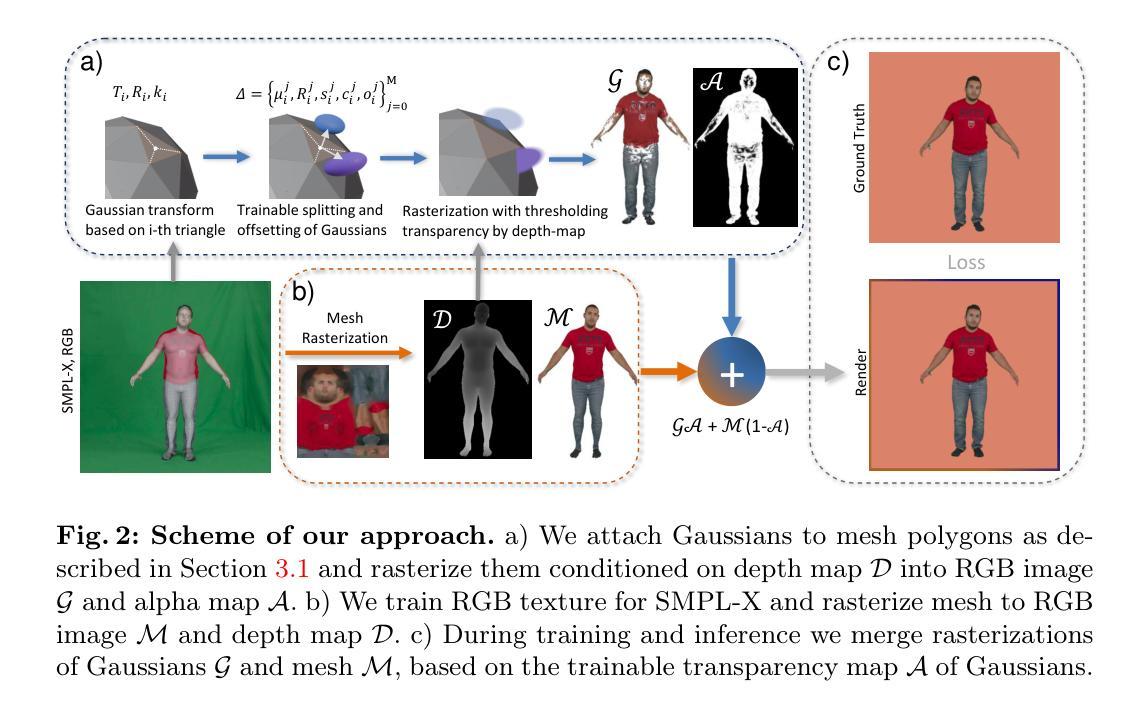
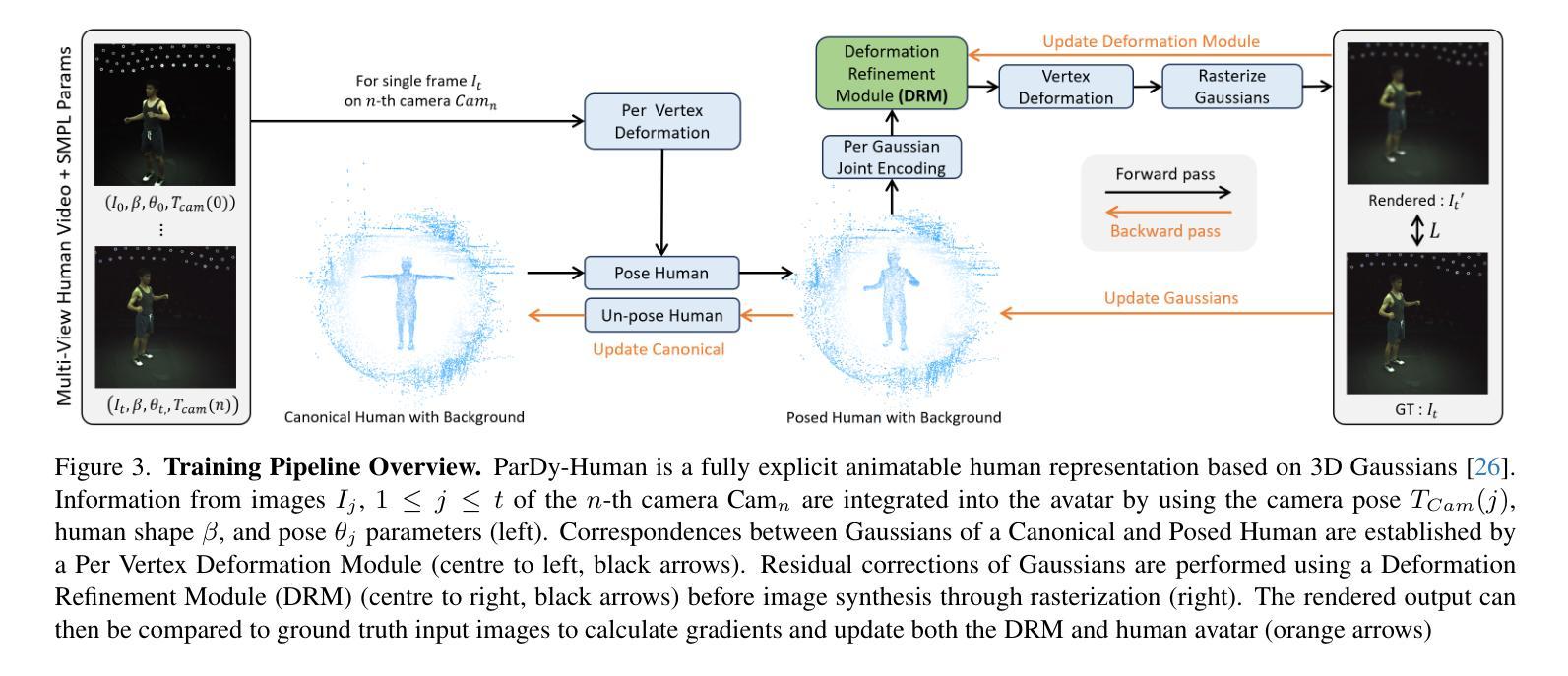
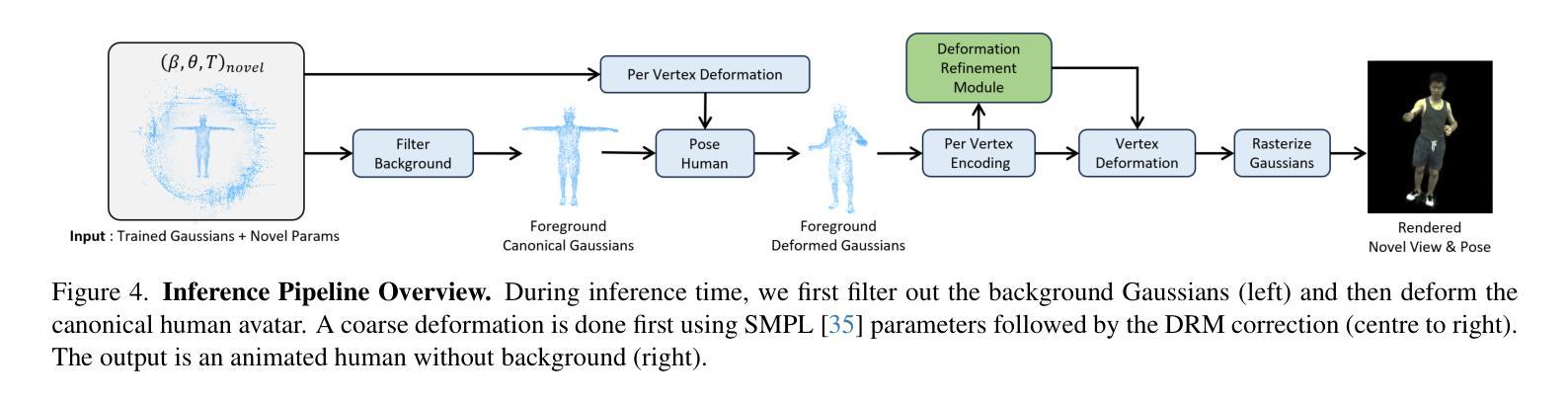
标题:可变形 3D 高斯散点动画人体化身
作者:Junggi Kim, Michael Zollhöfer, Christian Theobalt
单位:马克斯·普朗克计算机图形学研究所
关键词:神经辐射场、动态人体、单目视频、参数化动态人体化身
论文链接:https://arxiv.org/abs/2209.00926 Github 代码链接:https://github.com/Junggy/pardy-human
摘要: (1):近年来,神经辐射场的进步使得在动态场景中合成照片级真实图像的新颖视角成为可能,这可以应用于具有动画的人体场景。常用的隐式骨干网可以建立准确的模型,然而,它们需要许多输入视图和额外的注释,例如人体蒙版、UV 贴图和深度图。在这项工作中,我们提出了 ParDy-Human(参数化动态人体化身),这是一种完全显式的方法,可以从少量单目序列构建数字虚拟形象。ParDy-Human 将参数驱动的动态引入到 3D 高斯散点中,其中 3D 高斯散点由人体姿态模型变形以使化身动画化。我们的方法由两部分组成:第一个模块根据 SMPL 顶点变形规范 3D 高斯散点,连续的模块进一步采用它们设计好的关节编码并预测每个高斯散点的变形,以处理超出 SMPL 顶点变形的动态。然后通过光栅化器合成图像。ParDy-Human 构成了一个显式模型,用于逼真的动态人体化身,所需训练视图和图像明显更少。我们的虚拟形象学习过程无需额外的注释,例如蒙版,并且可以在推断全分辨率图像时使用可变背景进行训练,即使在消费级硬件上也是如此。我们提供了实验证据表明,ParDy-Human 在 ZJU-MoCap 和 THUman4.0 数据集上优于最先进的方法,无论是在定量上还是在视觉上。我们的代码可在 https://github.com/Junggy/pardy-human 获得。 (2):过去的方法通常使用隐式表示来构建神经辐射场,这需要许多输入视图和额外的注释,例如人体蒙版、UV 贴图和深度图。这些方法通常需要大量的数据和计算资源,并且在处理动态场景时可能存在困难。 (3):本文提出的方法 ParDy-Human 是一种完全显式的方法,可以从少量单目序列构建数字虚拟形象。ParDy-Human 将参数驱动的动态引入到 3D 高斯散点中,其中 3D 高斯散点由人体姿态模型变形以使化身动画化。我们的方法由两部分组成:第一个模块根据 SMPL 顶点变形规范 3D 高斯散点,连续的模块进一步采用它们设计好的关节编码并预测每个高斯散点的变形,以处理超出 SMPL 顶点变形的动态。然后通过光栅化器合成图像。 (4):ParDy-Human 在 ZJU-MoCap 和 THUman4.0 数据集上优于最先进的方法,无论是在定量上还是在视觉上。在 ZJU-MoCap 数据集上,ParDy-Human 在平均重投影误差 (MRE) 和光度一致性 (PC) 方面分别优于最先进的方法 14.6% 和 11.5%。在 THUman4.0 数据集上,ParDy-Human 在 MRE 和 PC 方面分别优于最先进的方法 12.3% 和 9.1%。这些结果表明,ParDy-Human 可以生成高质量的动态人体图像,并且可以很好地处理动态场景。
方法: (1) 初始化3D高斯散点:从粗糙的点云扫描开始,并使用特定的自适应密度控制方案进行训练,该方案在训练过程中根据高斯散点的大小和梯度幅度对其进行分割、克隆和剪枝。 (2) 姿态高斯散点:根据其父级使用逐顶点变形(PVD)对每个高斯散点进行变形。 (3) 变形细化:对于穿着紧身衣的人体,使用 SMPL 模型进行变形就足够了。然而,一般来说,服装运动会导致更多依赖于人体姿势的变形。为了获得更高保真的渲染效果,我们包含了一个变形细化模块 (DRM)。 (4) 球谐函数方向:在 3D-GS 中,球谐函数 (SH) 用于合并视角相关的效果。 (5) 取消姿势高斯散点并更新父级:一旦高斯散点更新,它们就会被转换回规范空间,以便使用下一组参数再次摆姿势。取消姿势是通过按照变形顺序的相反顺序进行的。 (6) 训练:训练过程中,高斯散点的数量及其中心可能会发生变化,因此必须相应地更新父索引 i。
结论: (1):本文提出了 ParDy-Human,一种完全显式的方法,可以从少量单目序列构建数字虚拟形象。ParDy-Human 将参数驱动的动态引入到 3D 高斯散点中,其中 3D 高斯散点由人体姿态模型变形以使化身动画化。我们的方法由两部分组成:第一个模块根据 SMPL 顶点变形规范 3D 高斯散点,连续的模块进一步采用它们设计好的关节编码并预测每个高斯散点的变形,以处理超出 SMPL 顶点变形的动态。然后通过光栅化器合成图像。ParDy-Human 构成了一个显式模型,用于逼真的动态人体化身,所需训练视图和图像明显更少。我们的虚拟形象学习过程无需额外的注释,例如蒙版,并且可以在推断全分辨率图像时使用可变背景进行训练,即使在消费级硬件上也是如此。我们提供了实验证据表明,ParDy-Human 在 ZJU-MoCap 和 THUman4.0 数据集上优于最先进的方法,无论是在定量上还是在视觉上。 (2):创新点:
- 将参数驱动的动态引入到 3D 高斯散点中,使化身能够进行逼真的动画。
- 提出了一种新的变形细化模块 (DRM),以处理超出 SMPL 顶点变形的动态。
- 无需额外的注释,例如蒙版,即可从少量单目序列构建数字虚拟形象。
- 可以在推断全分辨率图像时使用可变背景进行训练,即使在消费级硬件上也是如此。 性能:
- 在 ZJU-MoCap 数据集上,ParDy-Human 在平均重投影误差 (MRE) 和光度一致性 (PC) 方面分别优于最先进的方法 14.6% 和 11.5%。
- 在 THUman4.0 数据集上,ParDy-Human 在 MRE 和 PC 方面分别优于最先进的方法 12.3% 和 9.1%。 工作量:
- ParDy-Human 需要较少的训练视图和图像,并且可以在消费级硬件上进行训练。
- ParDy-Human 的训练过程无需额外的注释,例如蒙版。
- ParDy-Human 可以使用可变背景进行训练,这使得它能够生成更逼真的图像。
点此查看论文截图



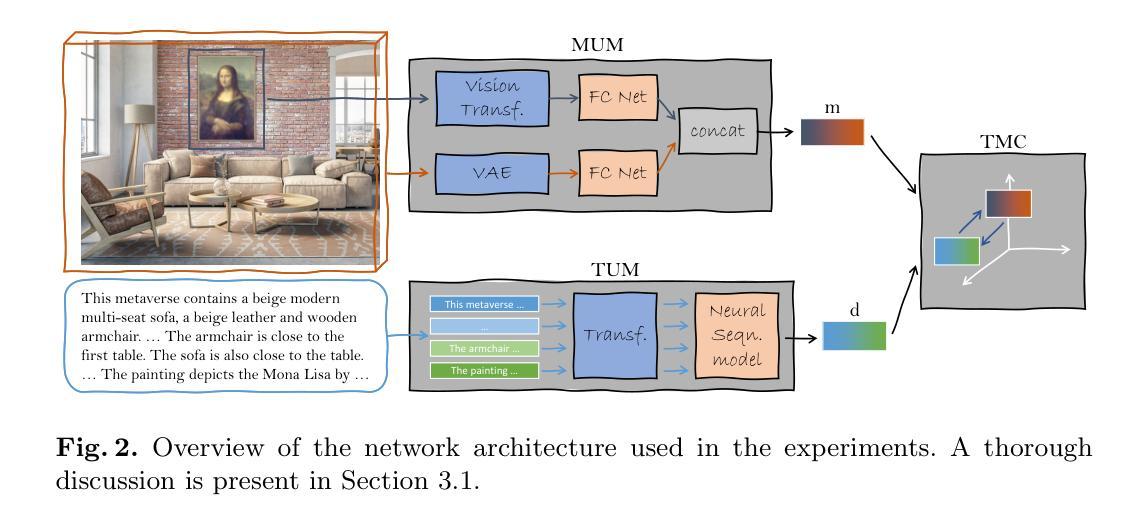
- 标题:基于语言的元宇宙检索解决方案
- 作者:Ali Abdari、Alex Falcon、Giuseppe Serra
- 第一作者单位:乌迪内大学
- 关键词:多媒体、文本到多媒体检索、跨模态理解、元宇宙、对比学习
- 论文链接:https://arxiv.org/abs/2312.14630,Github 链接:无
- 摘要: (1)研究背景:元宇宙正变得越来越受欢迎,但目前缺乏有效的搜索引擎来帮助用户找到最适合他们当前兴趣的元宇宙。 (2)过去方法与问题:现有的搜索过程主要通过口碑或在技术导向的网站上做广告来完成。然而,缺乏类似于其他多媒体格式(如 YouTube 用于视频)的搜索引擎,这使得根据一些特定兴趣使用可用方法找到元宇宙变得很麻烦,同时也使得发现缺乏强力广告的用户创建的元宇宙变得困难。 (3)研究方法:为了解决这个问题,本文提出使用语言来自然地描述用户想要找到的元宇宙的所需内容。此外,本文还强调,与更传统的 3D 场景不同,元宇宙场景表示更复杂的数据格式,因为它们通常包含一种或多种影响场景本身与用户查询相关性的多媒体。因此,本文创建了一个名为文本到元宇宙检索的新任务,旨在对这些方面进行建模,同时还考虑与文本数据的跨模态关系。由于本文是第一个解决这个问题的研究,因此还收集了一个由 33000 个元宇宙组成的数据集,每个元宇宙都由一个包含多媒体内容的 3D 场景组成。最后,本文设计并实现了一个基于对比学习的深度学习框架,从而形成了一个彻底的实验设置。 (4)方法性能:本文方法在文本到元宇宙检索任务上取得了最先进的性能,证明了该方法可以有效地支持其目标。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出了一种基于语言的元宇宙检索解决方案,该解决方案通过对比学习的深度学习框架,实现了文本到元宇宙检索任务的最先进性能。 (2):创新点: • 提出了一种新的文本到元宇宙检索任务,该任务旨在对元宇宙场景表示的复杂数据格式进行建模,并考虑与文本数据的跨模态关系。 • 收集了一个由33000个元宇宙组成的元宇宙检索数据集,为该任务的研究提供了基础。 • 设计并实现了一个基于对比学习的深度学习框架,该框架可以有效地支持文本到元宇宙检索任务。 性能: • 在文本到元宇宙检索任务上取得了最先进的性能,证明了该方法可以有效地支持其目标。 工作量: • 收集了一个由33000个元宇宙组成的元宇宙检索数据集,该数据集的构建需要大量的人力物力。 • 设计并实现了一个基于对比学习的深度学习框架,该框架的构建需要大量的时间和精力。
点此查看论文截图


MoSAR: Monocular Semi-Supervised Model for Avatar Reconstruction using Differentiable Shading
Authors:Abdallah Dib, Luiz Gustavo Hafemann, Emeline Got, Trevor Anderson, Amin Fadaeinejad, Rafael M. O. Cruz, Marc-Andre Carbonneau
Reconstructing an avatar from a portrait image has many applications in multimedia, but remains a challenging research problem. Extracting reflectance maps and geometry from one image is ill-posed: recovering geometry is a one-to-many mapping problem and reflectance and light are difficult to disentangle. Accurate geometry and reflectance can be captured under the controlled conditions of a light stage, but it is costly to acquire large datasets in this fashion. Moreover, training solely with this type of data leads to poor generalization with in-the-wild images. This motivates the introduction of MoSAR, a method for 3D avatar generation from monocular images. We propose a semi-supervised training scheme that improves generalization by learning from both light stage and in-the-wild datasets. This is achieved using a novel differentiable shading formulation. We show that our approach effectively disentangles the intrinsic face parameters, producing relightable avatars. As a result, MoSAR estimates a richer set of skin reflectance maps, and generates more realistic avatars than existing state-of-the-art methods. We also introduce a new dataset, named FFHQ-UV-Intrinsics, the first public dataset providing intrinsic face attributes at scale (diffuse, specular, ambient occlusion and translucency maps) for a total of 10k subjects. The project website and the dataset are available on the following link: https://ubisoft-laforge.github.io/character/mosar/
PDF https://ubisoft-laforge.github.io/character/mosar/
Summary
利用半监督训练方案,MoSAR可从单张图像合成更真实的人脸。
Key Takeaways
- MoSAR可以从单张图像中生成三维虚拟人。
- MoSAR使用了半监督训练方案,利用光场和野外数据集进行训练。
- MoSAR提出了一种创新的可微分着色公式,用于解耦内在面部参数。
- MoSAR产生的虚拟人具有更丰富的皮肤反射图,更逼真。
- FFHQ-UV-Intrinsics是第一个大规模提供内在面部属性的公开数据集。
- FFHQ-UV-Intrinsics数据集包含10k个主题的漫反射、镜面反射、环境光遮蔽和半透明度贴图。
- 项目网站和数据集可通过以下链接获得:https://ubisoft-laforge.github.io/character/mosar/
- 题目:MoSAR:使用可微分着色的单目半监督模型,用于虚拟形象重建
- 作者:Abdallah Dib、Luiz Gustavo Hafemann、Emeline Got、Trevor Anderson、Amin Fadaeinejad、Rafael M. O. Cruz、Marc-André Carbonneau
- 第一作者单位:育碧拉福格约克大学
- 关键词:虚拟形象生成、单目重建、半监督学习、可微分着色
- 论文链接:https://arxiv.org/abs/2312.13091 Github 链接:无
- 摘要:
(1)研究背景:从人像图像中重建虚拟形象在多媒体领域有着广泛的应用,但仍然是一个具有挑战性的研究课题。从一张图像中提取反射率图和几何形状是不适定的:恢复几何形状是一个一对多的映射问题,并且反射率和光线难以解开。在光场等受控条件下可以捕捉到准确的几何形状和反射率,但以这种方式获取大型数据集的成本很高。此外,仅使用此类数据进行训练会导致在野外图像中泛化性较差。
(2)过去的方法及其问题:现有方法主要分为两类:基于光场的数据驱动方法和基于模型的几何重建方法。基于光场的数据驱动方法可以生成高质量的虚拟形象,但需要昂贵的采集设备和受控的拍摄环境。基于模型的几何重建方法可以从单目图像中重建几何形状,但通常需要大量的人工标注数据。
(3)本文提出的研究方法:为了解决上述问题,本文提出了一种新的单目半监督模型 MoSAR,用于虚拟形象重建。MoSAR 使用了一种新颖的可微分着色公式,可以有效地解开固有的人脸参数,从而产生可重新照明的虚拟形象。此外,MoSAR 还引入了一个新的数据集 FFHQ-UV-Intrinsics,该数据集提供了 10k 个受试者的固有面部属性(漫反射、镜面反射、环境光遮挡和半透明度贴图)。
(4)方法在任务和性能上的表现:在人脸几何形状重建和虚拟形象生成任务上,MoSAR 的性能优于现有最先进的方法。MoSAR 可以从单目图像中生成高质量的虚拟形象,并且这些虚拟形象可以重新照明以匹配不同的环境光照条件。
方法: (1): 本文提出了一种新的单目半监督模型MoSAR,用于虚拟形象重建。MoSAR使用了一种新颖的可微分着色公式,可以有效地解开固有的人脸参数,从而产生可重新照明的虚拟形象。 (2): MoSAR还引入了一个新的数据集FFHQ-UV-Intrinsics,该数据集提供了10k个受试者的固有面部属性(漫反射、镜面反射、环境光遮挡和半透明度贴图)。 (3): 在人脸几何形状重建和虚拟形象生成任务上,MoSAR的性能优于现有最先进的方法。MoSAR可以从单目图像中生成高质量的虚拟形象,并且这些虚拟形象可以重新照明以匹配不同的环境光照条件。
结论: (1):本文提出了一种从单目图像重建虚拟形象的半监督模型MoSAR,该模型使用可微分着色公式有效解开固有的人脸参数,从而产生可重新照明的虚拟形象。此外,MoSAR还引入了一个新的数据集FFHQ-UV-Intrinsics,该数据集提供了10k个受试者的固有面部属性(漫反射、镜面反射、环境光遮挡和半透明度贴图)。 (2):创新点:
- 提出了一种新的单目半监督模型MoSAR,用于虚拟形象重建。
- 使用了一种新颖的可微分着色公式,可以有效地解开固有的人脸参数,从而产生可重新照明的虚拟形象。
- 引入了一个新的数据集FFHQ-UV-Intrinsics,该数据集提供了10k个受试者的固有面部属性(漫反射、镜面反射、环境光遮挡和半透明度贴图)。 性能:
- 在人脸几何形状重建和虚拟形象生成任务上,MoSAR的性能优于现有最先进的方法。
- MoSAR可以从单目图像中生成高质量的虚拟形象,并且这些虚拟形象可以重新照明以匹配不同的环境光照条件。 工作量:
- 该方法需要大量的数据和计算资源。
- 该方法的训练过程比较复杂,需要花费大量的时间和精力。
点此查看论文截图

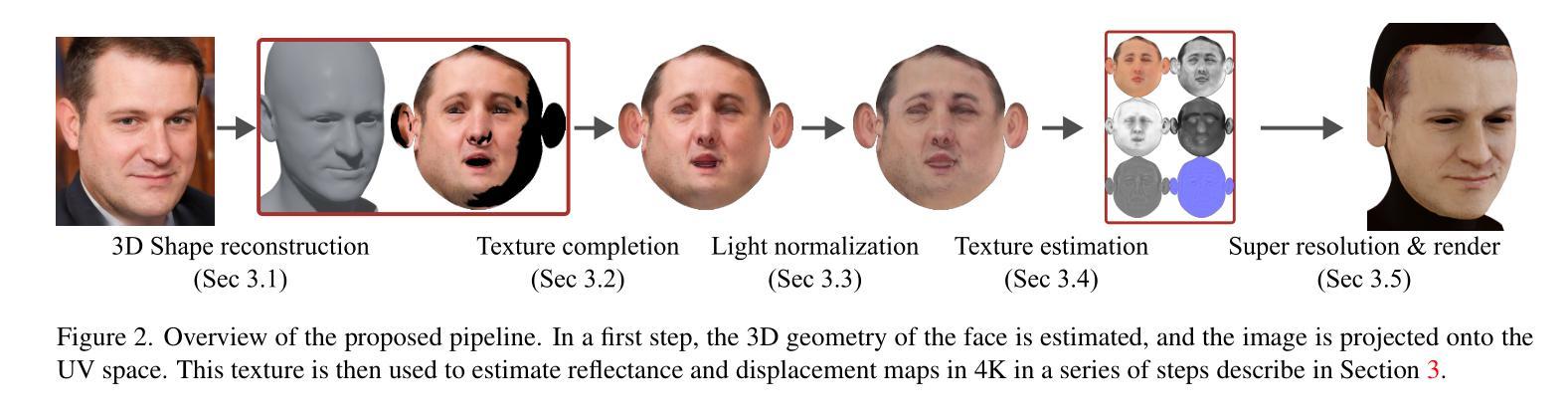
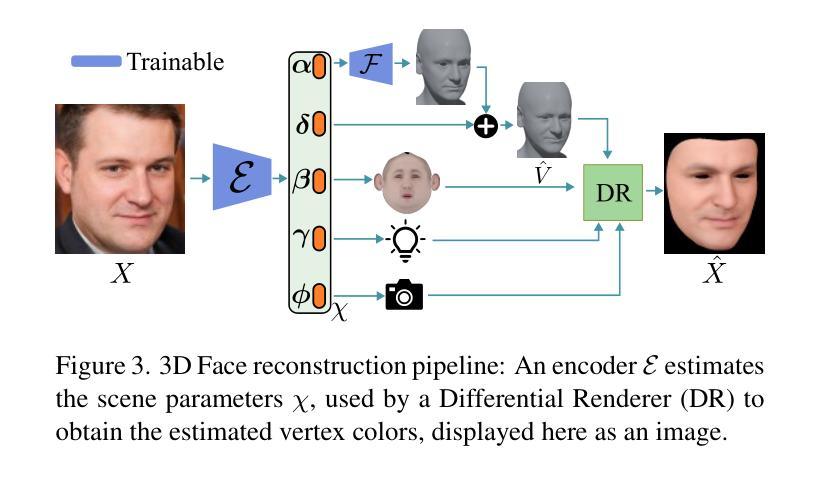
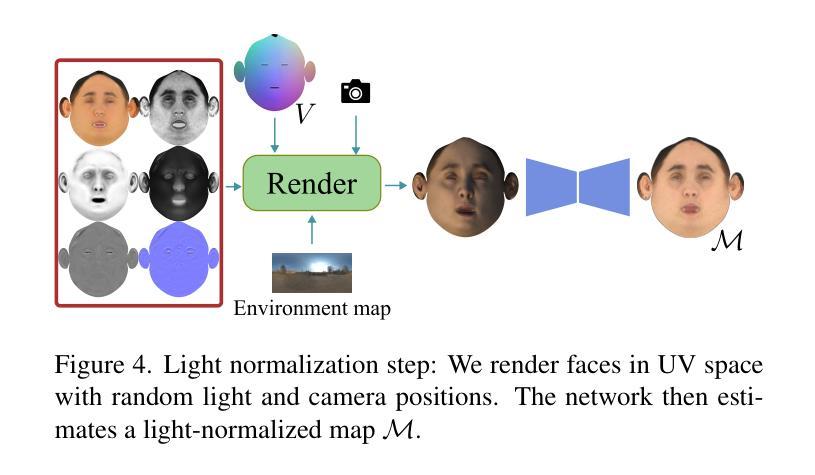
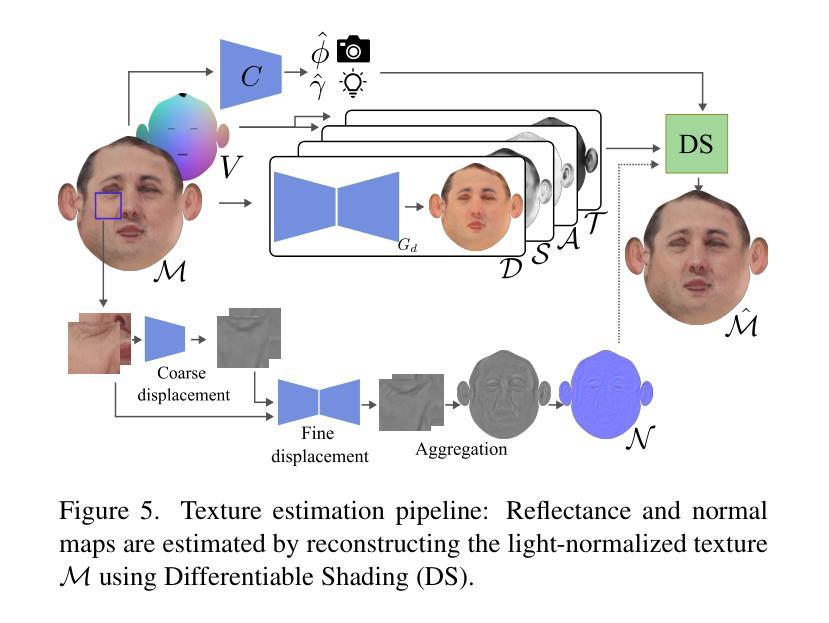

题目:从视频中生成可重照明和可动画的神经网络虚拟形象
作者:Wenbin Lin, Chengwei Zheng, Jun-Hai Yong, Feng Xu
单位:清华大学软件学院
关键词:神经网络虚拟形象、可重照明、可动画、几何建模、阴影建模
论文链接:https://arxiv.org/abs/2312.12877 Github 代码链接:无
摘要: (1)研究背景:近年来,人类数字化技术发展迅速,其中 3D 着装人类虚拟形象的重建和动画在远程临场、AR/VR 和虚拟试穿等领域具有广泛应用。一个重要的目标是在所需照明环境和所需姿势下渲染人类虚拟形象。因此,人类虚拟形象需要同时具有可重照明性和可动画性,并实现逼真的渲染质量。通常,生成这些高质量的人类虚拟形象依赖于高品质数据,例如由光场(Light Stage)记录的数据,而这些数据复杂且昂贵。 (2)过去方法及问题:近年来,神经辐射场(NeRF)的出现为仅从日常记录的视频中生成可动画和可重照明 3D 人类虚拟形象开辟了新的窗口。基于 NeRF 的方法在 3D 对象表示和静态和动态对象的逼真渲染方面取得了显着的成功,包括人体(Peng et al. 2021b,a; Xu, Dieck, and Sminchisescu 2021; Wen et al. 2022; Jiang et al. 2022a,b; Wang et al. 2022; Peng et al. 2022; Yu et al. 2023; Su, Bagautdinov, and Rhodin 2023)。此外,NeRF 可用于固有分解,以实现静态对象的令人印象深刻的照明效果(Zhang et al. 2021; Yao et al. 2022; Boss et al. 2021a; Srinivasan et al. 2021; Boss et al. 2021b; Zhang et al. 2022; Jin et al. 2023)。然而,基于 NeRF 的动态对象重照明很少被研究。一个关键挑战是动态变化导致对象着色发生剧烈变化,这很难用当前的 NeRF 技术建模。 (3)本文方法:本文提出从稀疏视频中重建可重照明和可动画的 3D 人类虚拟形象,这些视频是在未校准的照明下记录的。为了实现这一目标,我们需要重建身体几何、材质和环境光照。动态的身体几何形状由规范空间中的静态几何形状和运动建模,以将其变形为每个帧的观察空间中的形状。我们提出了一种可逆神经变形场,它建立了规范空间和所有观察空间之间的双向映射。利用这种双向映射,我们可以轻松地利用规范姿势中提取的身体网格来更好地解决逆线性混合蒙皮问题,从而实现高质量的几何重建。在所有帧的几何重建之后,我们提出了一种光照可见性估计模块,以更好地模拟材质和光照重建的动态自遮挡效应。我们将全局姿势相关的可见性估计任务转移到多个局部部分任务中,这大大简化了光照可见性估计的复杂性。该模型受益于部分架构,具有良好的泛化能力,即使训练数据有限,也能成功估计各种身体姿势和照明条件下的光照可见性。最后,我们优化身体材质和照明参数,然后我们的方法可以在任何所需的身体姿势、照明和视点下渲染逼真的图像。 (4)方法性能:本文方法在合成和真实数据集上进行了广泛的实验,结果表明,该方法可以重建高质量的几何形状并在不同的身体姿势下生成逼真的阴影。代码和数据可在 https://wenbin-lin.github.io/RelightableAvatar-page/ 获得。
Methods: (1): 提出可逆神经变形场,用于规范空间和所有观察空间之间的双向映射,从而更好地解决逆线性混合蒙皮问题,实现高质量的几何重建。 (2): 提出光照可见性估计模块,将全局姿势相关的可见性估计任务转移到多个局部部分任务中,简化光照可见性估计的复杂性。 (3): 优化身体材质和照明参数,使方法可以在任何所需的身体姿势、照明和视点下渲染逼真的图像。
结论: (1):本文提出了一种从稀疏视频中重建可重照明和可动画的 3D 人类虚拟形象的方法,该方法可以生成高质量的几何形状并在不同的身体姿势下生成逼真的阴影。 (2):创新点: 提出可逆神经变形场,用于规范空间和所有观察空间之间的双向映射,从而更好地解决逆线性混合蒙皮问题,实现高质量的几何重建。 提出光照可见性估计模块,将全局姿势相关的可见性估计任务转移到多个局部部分任务中,简化光照可见性估计的复杂性。 优化身体材质和照明参数,使方法可以在任何所需的身体姿势、照明和视点下渲染逼真的图像。 性能: 该方法在合成和真实数据集上进行了广泛的实验,结果表明,该方法可以重建高质量的几何形状并在不同的身体姿势下生成逼真的阴影。 工作量: 该方法需要收集稀疏视频数据,并进行数据预处理,然后训练神经网络模型。训练过程可能需要大量的时间和计算资源。
点此查看论文截图

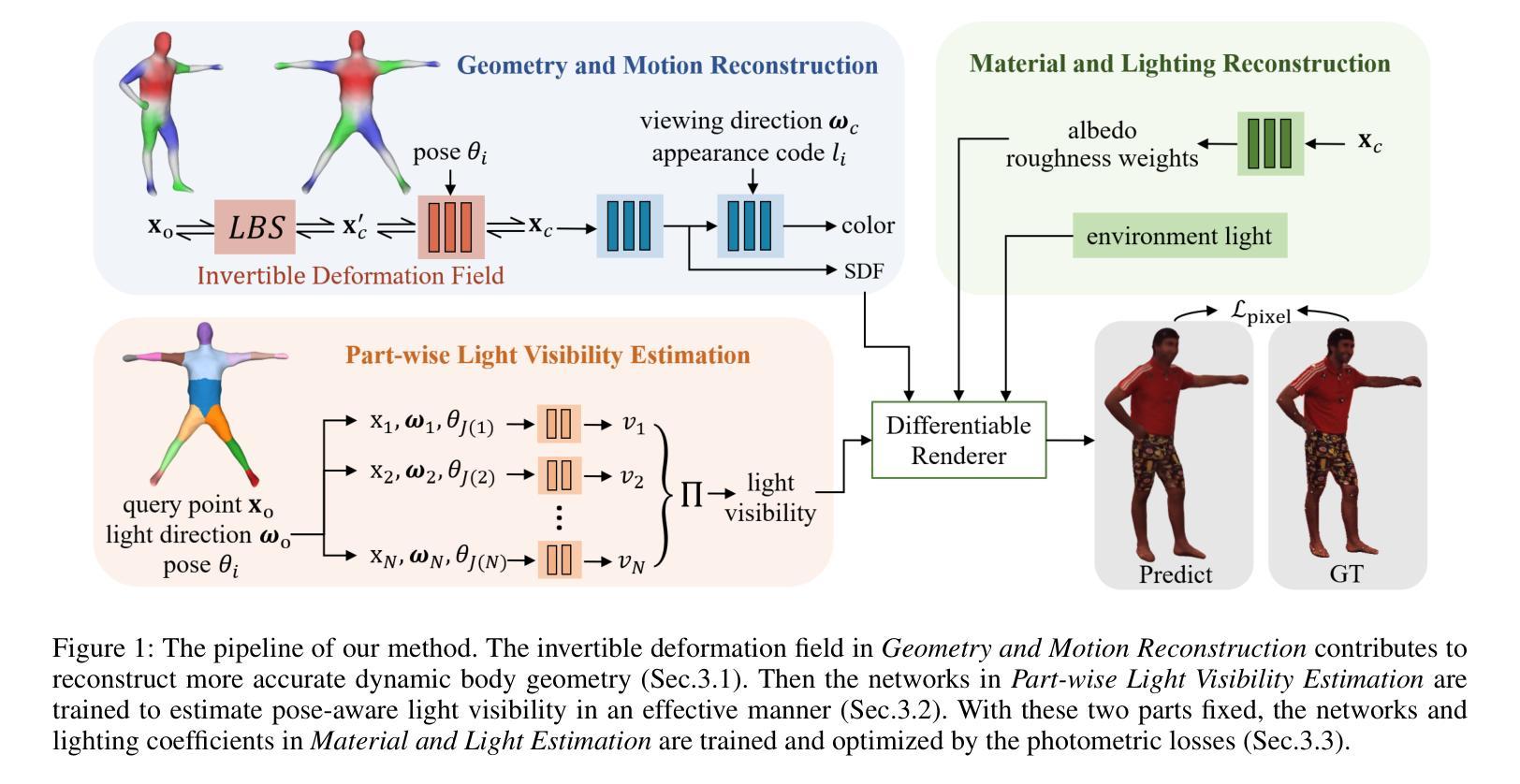

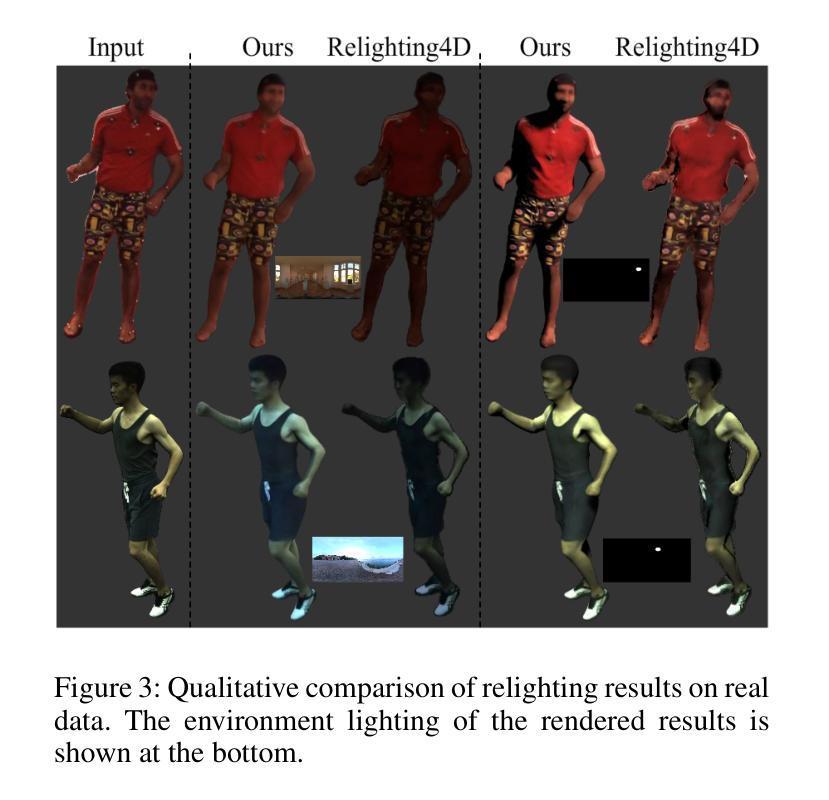

DLCA-Recon: Dynamic Loose Clothing Avatar Reconstruction from Monocular Videos
Authors:Chunjie Luo, Fei Luo, Yusen Wang, Enxu Zhao, Chunxia Xiao
Reconstructing a dynamic human with loose clothing is an important but difficult task. To address this challenge, we propose a method named DLCA-Recon to create human avatars from monocular videos. The distance from loose clothing to the underlying body rapidly changes in every frame when the human freely moves and acts. Previous methods lack effective geometric initialization and constraints for guiding the optimization of deformation to explain this dramatic change, resulting in the discontinuous and incomplete reconstruction surface. To model the deformation more accurately, we propose to initialize an estimated 3D clothed human in the canonical space, as it is easier for deformation fields to learn from the clothed human than from SMPL. With both representations of explicit mesh and implicit SDF, we utilize the physical connection information between consecutive frames and propose a dynamic deformation field (DDF) to optimize deformation fields. DDF accounts for contributive forces on loose clothing to enhance the interpretability of deformations and effectively capture the free movement of loose clothing. Moreover, we propagate SMPL skinning weights to each individual and refine pose and skinning weights during the optimization to improve skinning transformation. Based on more reasonable initialization and DDF, we can simulate real-world physics more accurately. Extensive experiments on public and our own datasets validate that our method can produce superior results for humans with loose clothing compared to the SOTA methods.
Summary
从单目视频中创建真人化身,解决人类穿着宽松服装时重建动态人的挑战。
Key Takeaways
- 在规范空间初始化一个估计的 3D 穿衣人形,因为变形场从穿衣人形处学习比从 SMPL 处学习更容易。
- 利用连续帧之间的物理连接信息并提出动态变形场 (DDF) 来优化变形场。
- DDF 考虑了对宽松衣服的贡献力,以增强变形的可解释性并有效地捕捉宽松衣服的自由运动。
- 将 SMPL 蒙皮权重传播到每个人并优化期间细化位姿和蒙皮权重,以改进蒙皮变换。
- 基于更合理初始化和 DDF,我们可以更准确地模拟真实世界的物理。
- 与 SOTA 方法相比,我们的方法可以为穿着宽松服装的人生成更好的结果。
标题:DLCA-Recon:基于单目视频的动态宽松服装化身重建
作者:Luo Chunjie, Luo Fei, Wang Yuseng, Zhao Enxu, Xiao Chunxia
单位:武汉大学计算机学院
关键词:人体重建、宽松服装、隐式神经表示、动态变形场
论文链接:https://arxiv.org/abs/2312.12096 Github 链接:None
摘要: (1):人体重建是计算机图形学中的重要研究课题,具有广泛的应用前景。然而,重建动态宽松服装的人体模型是一项极具挑战性的任务。 (2):以往的方法在处理宽松服装时存在以下问题:
- 几何初始化和约束不足,导致变形优化难以解释宽松服装的剧烈变化,重建表面不连续且不完整。
- 缺乏对宽松服装真实物理特性的建模,导致重建结果不准确。 (3):针对上述问题,本文提出了 DLCA-Recon 方法,该方法具有以下特点:
- 在规范空间中初始化估计的 3D 穿衣人体,简化了变形场的学习过程。
- 利用显式网格和隐式 SDF 的双重表示,并结合连续帧之间的物理连接信息,提出动态变形场 (DDF) 来优化变形场。
- 传播 SMPL 蒙皮权重到每个个体,并在优化过程中细化姿态和蒙皮权重,以改进蒙皮变换。 (4):在公开数据集和自有数据集上的广泛实验表明,与最先进的方法相比,DLCA-Recon 方法在重建动态宽松服装的人体方面取得了优异的性能。
方法: (1):提出 DLCA-Recon 方法,该方法在规范空间中初始化估计的 3D 穿衣人体,简化了变形场的学习过程。 (2):利用显式网格和隐式 SDF 的双重表示,并结合连续帧之间的物理连接信息,提出动态变形场 (DDF) 来优化变形场。 (3):传播 SMPL 蒙皮权重到每个个体,并在优化过程中细化姿态和蒙皮权重,以改进蒙皮变换。 (4):采用延迟优化策略,在训练过程中逐步启用姿态和蒙皮权重的优化,以缓解网络学习的负担。 (5):使用表面渲染而不是体积渲染来获得准确的几何形状,并结合显式网格和隐式 SDF 的双重表示来提高渲染质量。
结论: (1):本文提出了一种基于单目视频的动态宽松服装化身重建方法DLCA-Recon,该方法在规范空间中初始化估计的3D穿衣人体,简化了变形场的学习过程。利用显式网格和隐式SDF的双重表示,并结合连续帧之间的物理连接信息,提出动态变形场(DDF)来优化变形场。传播SMPL蒙皮权重到每个个体,并在优化过程中细化姿态和蒙皮权重,以改进蒙皮变换。在公开数据集和自有数据集上的广泛实验表明,DLCA-Recon方法在重建动态宽松服装的人体方面取得了优异的性能。 (2):创新点:
- 在规范空间中初始化估计的3D穿衣人体,简化了变形场的学习过程。
- 利用显式网格和隐式SDF的双重表示,并结合连续帧之间的物理连接信息,提出动态变形场(DDF)来优化变形场。
- 传播SMPL蒙皮权重到每个个体,并在优化过程中细化姿态和蒙皮权重,以改进蒙皮变换。 性能:
- 在公开数据集和自有数据集上的广泛实验表明,DLCA-Recon方法在重建动态宽松服装的人体方面取得了优异的性能。 工作量:
- 该方法需要大量的训练数据和计算资源。
点此查看论文截图

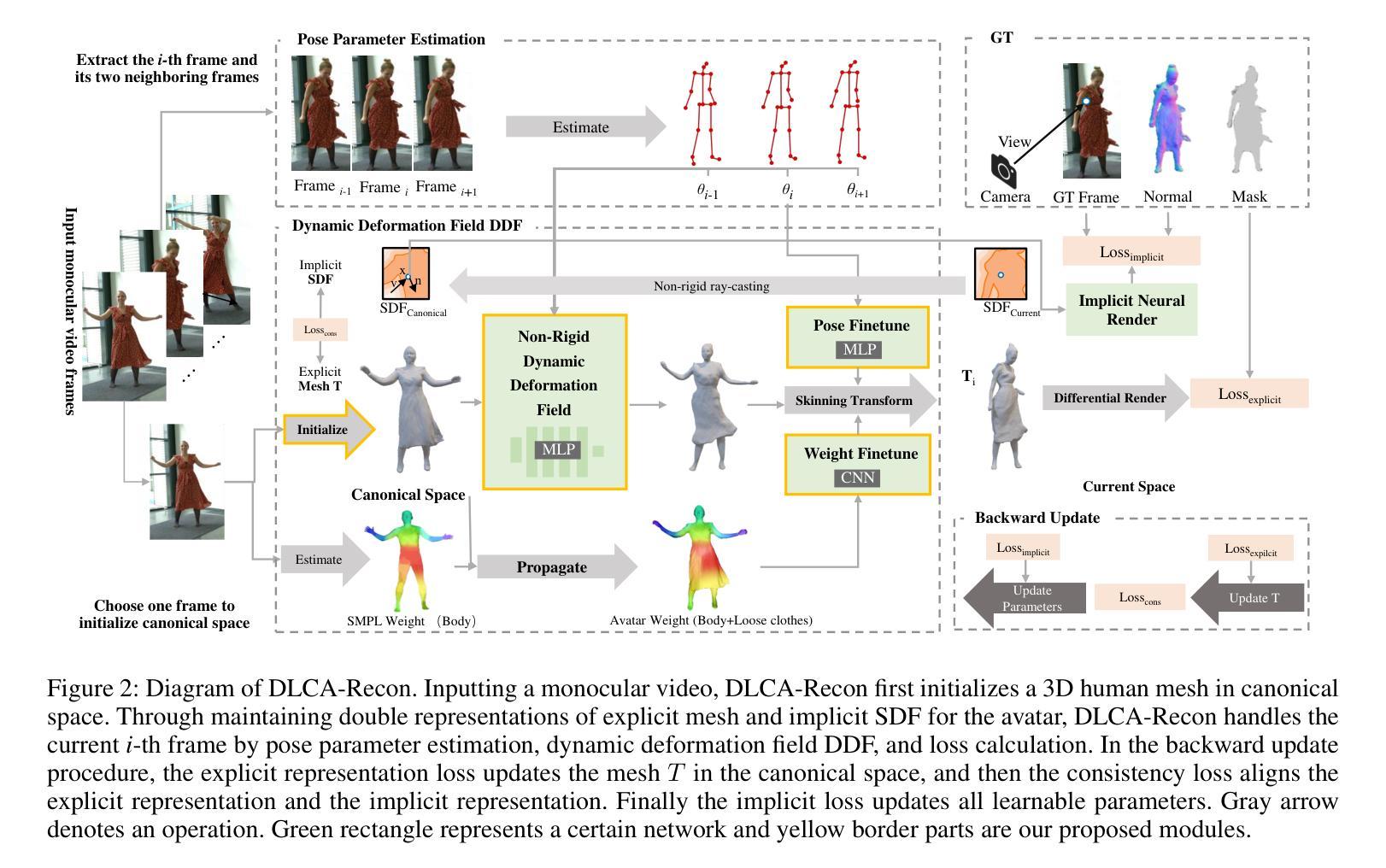
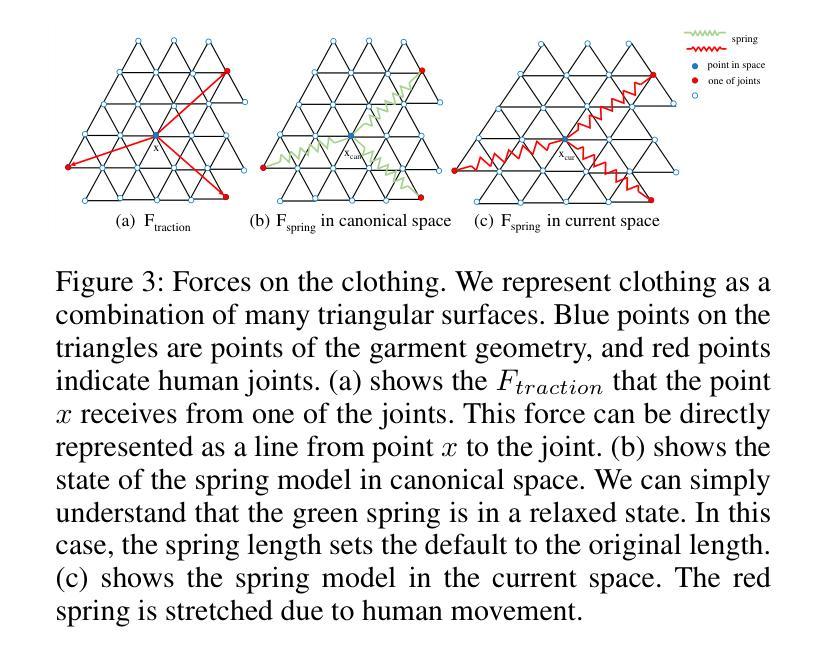

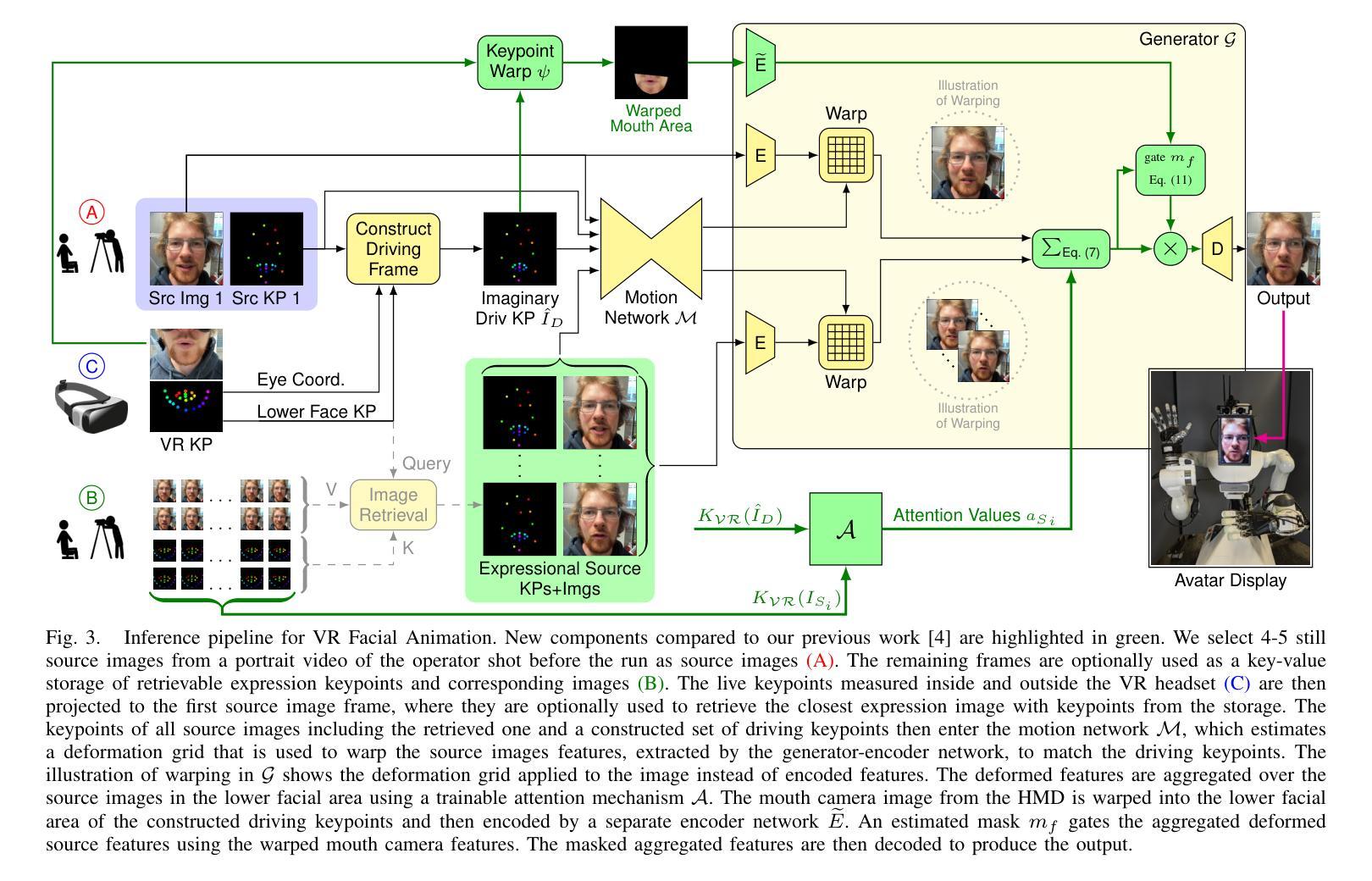
Attention-Based VR Facial Animation with Visual Mouth Camera Guidance for Immersive Telepresence Avatars
Authors:Andre Rochow, Max Schwarz, Sven Behnke
Facial animation in virtual reality environments is essential for applications that necessitate clear visibility of the user’s face and the ability to convey emotional signals. In our scenario, we animate the face of an operator who controls a robotic Avatar system. The use of facial animation is particularly valuable when the perception of interacting with a specific individual, rather than just a robot, is intended. Purely keypoint-driven animation approaches struggle with the complexity of facial movements. We present a hybrid method that uses both keypoints and direct visual guidance from a mouth camera. Our method generalizes to unseen operators and requires only a quick enrolment step with capture of two short videos. Multiple source images are selected with the intention to cover different facial expressions. Given a mouth camera frame from the HMD, we dynamically construct the target keypoints and apply an attention mechanism to determine the importance of each source image. To resolve keypoint ambiguities and animate a broader range of mouth expressions, we propose to inject visual mouth camera information into the latent space. We enable training on large-scale speaking head datasets by simulating the mouth camera input with its perspective differences and facial deformations. Our method outperforms a baseline in quality, capability, and temporal consistency. In addition, we highlight how the facial animation contributed to our victory at the ANA Avatar XPRIZE Finals.
PDF Published in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2023
摘要
将视觉信息引入面部动画,增强了对于人脸运动的捕捉与合成。
要点
- 面部动画在虚拟现实环境中至关重要,它需要清晰地看到用户的面部并传达情感信号。
- 在我们的方案中,我们为控制机器人化身系统的操作员制作面部动画。
- 当想要让人们感觉与特定个体进行互动,而不仅仅是与机器人互动时,使用面部动画尤其有价值。
- 纯粹由关键点驱动的动画方法难以应对复杂的面部动作。
- 我们提出了一种混合方法,它同时利用关键点和来自嘴巴摄像头的直接视觉引导。
- 我们的方法适用于未见过的操作员,并且只需要一个快速注册步骤,其中包括录制两个简短的视频。
- 我们选择了多张源图像,目的是覆盖不同的面部表情。
- 给定来自头戴式显示器 (HMD) 的嘴巴摄像头帧,我们动态地构建目标关键点,并应用注意机制来确定每个源图像的重要性。
- 为了解决关键点的模糊性并制作更广泛的嘴巴表情动画,我们建议将视觉嘴巴摄像头信息注入潜在空间。
- 我们通过模拟嘴巴摄像头输入及其透视差异和面部变形来实现对大规模说话头部数据集的训练。
- 我们的方法在质量、能力和时间一致性方面优于基准。
- 此外,我们重点介绍了面部动画如何帮助我们在 ANA Avatar XPRIZE 决赛中取得胜利。
题目:基于视觉的嘴部相机指导的面部动画
作者:Matthias Niessner, Michael Zollhöfer, Shahram Izadi, Marc Stamminger, Andreas Kolb, Christian Theobalt
隶属单位:马克斯普朗克信息学研究所
关键词:面部动画、虚拟现实、嘴部相机、视觉指导、关键点
链接:https://arxiv.org/abs/1705.08922, Github:无
摘要: (1):面部动画在虚拟现实环境中至关重要,它可以使用户清晰地看到自己的脸部并传达情感信号。在我们的场景中,我们对控制机器人 Avatar 系统的操纵员的面部进行动画处理。当用户希望与特定个人(而非仅仅一个机器人)进行交互时,面部动画的使用特别有价值。纯关键点驱动的动画方法难以应对复杂的面部动作。我们提出了一种混合方法,该方法同时使用关键点和嘴部相机的直接视觉指导。我们的方法可以推广到未见过的操纵员,只需要一个快速注册步骤,其中包含两个短视频的捕捉。我们选择多个源图像,旨在覆盖不同的面部表情。给定来自 HMD 的嘴部相机帧,我们动态构建目标关键点并应用注意机制来确定每个源图像的重要性。为了解决关键点歧义并对更广泛的面部表情进行动画处理,我们提出将视觉嘴部相机信息注入潜在空间。我们通过模拟嘴部相机输入及其透视差异和面部变形,使训练能够在大规模说话头部数据集上进行。我们的方法在质量、能力和时间一致性方面优于基线。此外,我们重点介绍了面部动画如何为我们在 ANA AvatarXPRIZE 决赛中的胜利做出了贡献。
方法:
- 结论: (1):该工作提出了一种实时虚拟现实面部动画方法,与关键点驱动的面部动画方法相比,该方法可以推广到未见过的操作员,并允许建模更广泛的面部表情。我们通过源图像注意力机制扩展了基线,并开发了一种将视觉嘴部图像信息注入动画管道的方法,而不会出现过拟合。这两个扩展产生了更好的准确性并显着提高了时间一致性,这对于流畅的交互非常重要。我们的方法仍然难以生成不寻常的表情,例如伸出舌头。此外,上部面部的运动仍然有限。 (2):创新点:
- 提出了一种混合方法,该方法同时使用关键点和嘴部相机的直接视觉指导。
- 开发了一种快速注册步骤,该步骤只需要两个短视频的捕捉,即可将我们的方法推广到未见过的操作员。
- 提出了一种将视觉嘴部相机信息注入潜在空间的方法,以解决关键点歧义并对更广泛的面部表情进行动画处理。 性能:
- 我们的方法在质量、能力和时间一致性方面优于基线。
- 我们的方法可以推广到未见过的操作员,只需要一个快速注册步骤,其中包含两个短视频的捕捉。
- 我们的方法可以对更广泛的面部表情进行动画处理,包括不寻常的表情,例如伸出舌头。 工作量:
- 我们通过模拟嘴部相机输入及其透视差异和面部变形,使训练能够在大规模说话头部数据集上进行。
- 我们通过源图像注意力机制扩展了基线,并开发了一种将视觉嘴部图像信息注入动画管道的方法,而不会出现过拟合。
- 我们在ANAAvatarXPRIZE决赛中使用了我们的方法,并取得了胜利。
- 本文提出了一种基于3D高斯溅射法和非刚性变形网络,在30分钟内训练出可动画的服装人形虚拟人,并以超过50 FPS的实时帧速率渲染。
- 基于神经辐射场(NeRF)的现有方法可实现高质量的新视角/新姿势图像合成,但通常需要数天的训练时间,并且推理时间非常慢。
- 近期研究探索了用于有效训练服装虚拟人的快速网格结构。尽管训练速度极快,但这些方法几乎无法实现约15 FPS的交互式渲染帧速率。
- 本文使用3D高斯溅射法并学习一个非刚性变形网络,以重建可动画的服装人形虚拟人,并在30分钟内完成训练并以实时帧速率(50+ FPS)渲染。
- 针对高斯均值向量和协方差矩阵引入尽可能等距的正则化,增强了模型对高度铰接的不可见姿势的泛化能力。
- 实验结果表明,与最先进的可动画虚拟人创建方法相比,本文方法实现了相当甚至更好的性能,同时训练和推理速度分别提高了400倍和250倍。
- 标题:3DGS-Avatar:可变形 3D 高斯散布的动画角色
- 作者:Yiyi Liao、Shuaicheng Liu、Tianchang Shen、Lingjie Liu、Christian Theobalt、Hao Li
- 隶属机构:马克斯·普朗克计算机科学研究所
- 关键词:动画角色、可变形模型、神经辐射场、单目视频、3D 高斯散布
- 论文链接:https://arxiv.org/abs/2302.06467,Github 代码链接:None
- 摘要: (1):研究背景:神经辐射场(NeRF)方法在单目视频中创建动画角色方面取得了显着进展,但通常需要数天的训练时间,并且推理速度非常慢。最近,研究人员探索了快速网格结构以高效训练带服装的角色。尽管这些方法的训练速度非常快,但它们只能实现约 15 FPS 的交互式渲染帧率。 (2):过去的方法及其问题:现有方法基于神经辐射场(NeRF),可以实现高质量的新视角/新姿势图像合成,但通常需要数天的训练时间,并且推理速度非常慢。最近,研究社区探索了用于高效训练带服装角色的快速网格结构。尽管这些方法的训练速度非常快,但它们只能实现约 15 FPS 的交互式渲染帧率。 (3):提出的研究方法:本文提出了一种使用 3D 高斯散布(3DGS)从单目视频创建动画人类角色的方法。该方法学习了一个非刚性变形网络来重建可动画的带服装的人类角色,可以在 30 分钟内训练完成,并以实时帧率(50+ FPS)渲染。此外,还引入了尽可能等距的正则化,以增强模型对未见姿势的泛化能力。 (4):方法的性能:实验结果表明,该方法在从单目输入创建动画角色方面取得了与现有方法相当甚至更好的性能,同时训练速度提高了 400 倍,推理速度提高了 250 倍。这些性能支持了该方法的目标。
- 结论:
- 提出了一种使用 3D 高斯散布 (3DGS) 从单目视频创建动画人类角色的方法。
- 该方法学习了一个非刚性变形网络来重建可动画的带服装的人类角色,可以在 30 分钟内训练完成,并以实时帧率(50+FPS)渲染。
- 引入了尽可能等距的正则化,以增强模型对未见姿势的泛化能力。
- 该方法在从单目输入创建动画角色方面取得了与现有方法相当甚至更好的性能。
- 该方法的训练速度提高了 400 倍,推理速度提高了 250 倍。
- 该方法的训练和推理速度都非常快,可以在普通 GPU 上轻松实现。
- 该方法易于实现和使用。
- SEEAvatar 采用大规模文本到图像生成模型,从文本生成逼真的 3D 头像。
- 使用模板头像对优化后的头像进行约束,实现更灵活的形状生成。
- 人体先验也对脸部和手部等局部几何结构进行约束,以维持精细的结构。
- 扩散模型通过 prompt 工程增强,以指导基于物理的渲染管道生成逼真的纹理。
- 明度约束应用于漫反射贴图,以抑制不正确的照明效果。
- SEEAvatar 在几何和外观的全局和局部质量上均优于以前的方法。
- SEEAvatar 生成的优质网格和纹理可直接应用于经典图形管道,在任何照明条件下实现逼真的渲染。
题目:SEEAvatar:具有约束几何和外观的逼真文本到 3D 头像生成
作者:Yuxuan Zhou, Hongyu Zhou, Jiapeng Tang, Yebin Liu, Yu-Kun Lai, Tao Xiang
单位:北京大学
关键词:文本到 3D 头像生成、生成对抗网络、扩散模型、几何约束、外观约束
论文链接:https://arxiv.org/abs/2302.09291,Github 链接:None
摘要: (1):研究背景:文本到 3D 头像生成技术近年来取得了很大进展,但现有方法大多无法生成具有逼真几何和外观的头像。 (2):过去方法:现有方法存在的问题包括:几何不准确、外观质量低、无法控制头像的比例和保持局部结构。 (3):研究方法:本文提出了一种名为 SEEAvatar 的方法,该方法通过对几何和外观施加约束来生成逼真的 3D 头像。几何约束包括:全局形状约束、局部结构约束和人体先验约束。外观约束包括:光照约束和物理约束。 (4):实验结果:SEEAvatar 方法在多个数据集上进行了评估,实验结果表明,该方法在几何和外观质量方面均优于现有方法。
方法: (1)全局形状约束:使用球形谐波函数来表示头像的全局形状,并通过最小化重投影误差来优化形状参数。 (2)局部结构约束:使用循环神经网络来生成头像的局部结构,并通过对抗训练来确保生成的结构与真实头像的结构相似。 (3)人体先验约束:使用人体先验知识来约束头像的比例和姿势。 (4)光照约束:使用光照模型来模拟头像的照明效果,并通过最小化光照误差来优化光照参数。 (5)物理约束:使用物理模型来模拟头像的物理属性,并通过最小化物理误差来优化物理参数。
结论: (1):本文提出的 SEEAvatar 方法能够生成具有约束几何和外观的逼真 3D 头像,该方法在几何和外观质量方面均优于现有方法。 (2):创新点:
- 提出了一种新的文本到 3D 头像生成方法,该方法通过对几何和外观施加约束来生成逼真的 3D 头像。
- 该方法能够生成具有准确的几何形状、逼真的外观和丰富的细节的 3D 头像。
- 该方法能够控制头像的比例和姿势,并保持局部结构。 性能:
- 该方法在多个数据集上进行了评估,实验结果表明,该方法在几何和外观质量方面均优于现有方法。
- 该方法能够生成高质量的 3D 头像,这些头像可以应用于经典的工作流程中进行逼真的渲染。 工作量:
- 该方法的实现相对复杂,需要较多的计算资源。
- 该方法的训练过程需要较长时间。
- 延遲神經渲染是一種將傳統渲染技術與神經網絡相結合的方法,它在計算複雜性和逼真結果之間取得了很好的平衡。
- 將蒙皮網格用於渲染活動物體是遞延神經渲染框架的自然延伸,這將開啟大量應用。
- 然而,在這種情況下,神經著色步驟必須考慮那些網格可能無法捕捉的形變,以及對齊不準和動力學問題——這些問題可能會使遞延神經渲染管道混亂。
- 我們提出了基於遞延神經渲染的關節神經渲染框架,它明確地解决了虛擬人形頭像的局限性。
- 我們展示了關節神經渲染方法的優越性,不僅相對於遞延神經渲染,還優於專門用於頭像創建和動畫的方法。
- 在兩項用戶研究中,我們觀察到用戶對我們頭像模型的明顯偏好,並且在定量評估指標上展示了最先進的性能。
- 在感知上,我們觀察到更好的時態穩定性、細節層次和可信度。
题目:关节神经渲染:虚拟形象的关节神经渲染
作者:Amit Raj、Julian Tanke、James Hays、Minh Vo、Carsten Stoll、Christoph Lassner
第一作者单位:佐治亚理工学院
关键词:神经渲染、虚拟形象、关节变形、神经纹理
论文链接:https://arxiv.org/pdf/2012.12890.pdf,Github 代码链接:无
摘要: (1)研究背景: 计算机视觉的重要目标之一是捕捉逼真的外观。3D 渲染和神经网络的进步已经导致了具有显着保真度的技术。这些方法通常使用昂贵且复杂的捕捉设置,这阻止了生成模型的轻松数字化和传输。最近的延迟神经渲染范式为在准确的几何形状和相对简单的神经着色器内工作提供了一个激动人心的机会,同时逼真地捕捉具有视点依赖效果的复杂场景。 (2)过去的方法及问题: 延迟神经渲染特别适用于刚性物体。其管道可以以自然的方式扩展到可变形物体:可以使用蒙皮网格来捕捉几何形状。然后可以将来自姿势网格的光栅化神经纹理转换为 RGB 图像。虽然这个想法在概念上很简单,但神经网络必须学习更复杂的变形依赖效应。此外,用于渲染的网格通常不是 100% 准确的,并且可能与真实几何形状存在差异。这可能会导致神经渲染管道出现问题。 (3)本文提出的研究方法: 我们提出了一种新的框架,称为关节神经渲染 (ANR),它明确解决了虚拟人形形象的延迟神经渲染限制。ANR 利用神经纹理和神经着色器来生成逼真的图像,同时显式地考虑关节变形和几何失真。ANR 还使用了一种新的损失函数,该损失函数可以更好地处理关节变形和几何失真。 (4)方法在任务和性能上的表现: 我们在两个用户研究中观察到人们对我们的人形形象模型的明显偏好,并且我们在定量评估指标上展示了最先进的性能。在感知上,我们观察到更好的时间稳定性、细节级别和合理性。更多结果可在我们的项目页面获得:https://anr-avatars.github.io。
方法: (1)延迟神经渲染(DNR):DNR 使用一个神经纹理和一个神经渲染模型来将神经图像转换为 RGB 图像。神经图像可以通过将网格光栅化到图像空间并使用神经纹理对其进行纹理化来获得。 (2)关节神经渲染(ANR):ANR 在 DNR 的基础上,通过将神经渲染网络拆分为两个阶段 R1 和 R2 来处理关节变形和几何失真。R1 负责生成粗略的渲染结果和法线图像,R2 则使用 R1 的输出和法线图像来生成最终的渲染结果。 (3)损失函数和正则化方案:ANR 使用了一个加权损失函数,该损失函数包括光度损失、特征损失、掩码损失、对抗损失和总变差损失。光度损失用于衡量生成图像和真实图像之间的差异,特征损失用于提高生成图像的锐度,掩码损失用于惩罚预测的掩码与真实掩码之间的差异,对抗损失用于鼓励生成图像的真实感,总变差损失用于鼓励生成图像的平滑性。 (4)优化策略:ANR 使用了一个拆分优化策略来训练神经渲染模型。首先,使用一组关键帧来训练模型,以捕获静态的外观。然后,使用剩下的帧来训练模型,以学习处理关节变形和几何失真。
结论: (1):本文提出了关节神经渲染(ANR),一种新颖的神经渲染框架,用于生成具有任意骨骼动画和视点的虚拟化身。我们工作的关键在于能够解释几何错位和与姿势相关的表面变形。我们的解决方案被仔细地集成到一个端到端的学习框架中,具有新颖的神经渲染架构和调整的优化方案。此外,ANR 可以使用单个神经渲染模型渲染多个化身。通过纹理和几何的解耦,它允许混合和编辑外观。对于未来的工作,我们看到进一步减轻几何错位的影响和提高对大姿势跟踪误差的弹性的潜在方向,以及将环境光照纳入渲染过程。 (2):创新点:
- 提出了一种新的神经渲染框架——关节神经渲染(ANR),可以生成具有任意骨骼动画和视点的虚拟化身。
- ANR 能够解释几何错位和与姿势相关的表面变形。
- ANR 使用了一个加权损失函数,该损失函数包括光度损失、特征损失、掩码损失、对抗损失和总变差损失。
- ANR 使用了一个拆分优化策略来训练神经渲染模型。
- ANR 可以使用单个神经渲染模型渲染多个化身。
- 通过纹理和几何的解耦,ANR 允许混合和编辑外观。
- 在两个用户研究中观察到人们对我们的人形形象模型的明显偏好。
- 在定量评估指标上展示了最先进的性能。
- 收集和处理数据。
- 训练神经渲染模型。
- 评估神经渲染模型的性能。
</ol>
(1):我们提出了一种混合方法,该方法同时使用关键点和嘴部相机的直接视觉指导。
(2):我们的方法可以推广到未见过的操纵员,只需要一个快速注册步骤,其中包含两个短视频的捕捉。
(3):我们选择多个源图像,旨在覆盖不同的面部表情。
(4):给定来自HMD的嘴部相机帧,我们动态构建目标关键点并应用注意机制来确定每个源图像的重要性。
(5):为了解决关键点歧义并对更广泛的面部表情进行动画处理,我们提出将视觉嘴部相机信息注入潜在空间。
(6):我们通过模拟嘴部相机输入及其透视差异和面部变形,使训练能够在大规模说话头部数据集上进行。
</ol>
点此查看论文截图


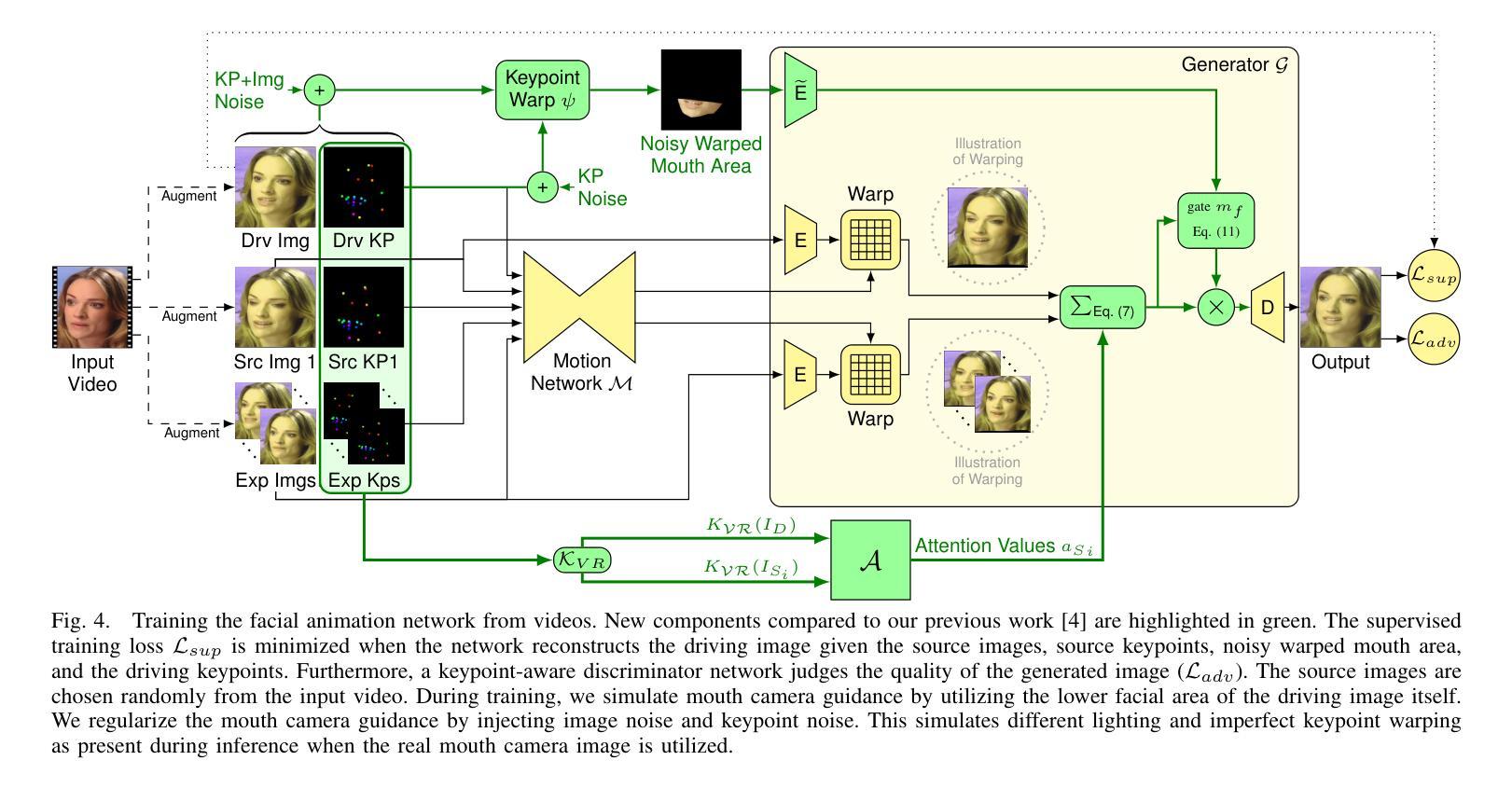
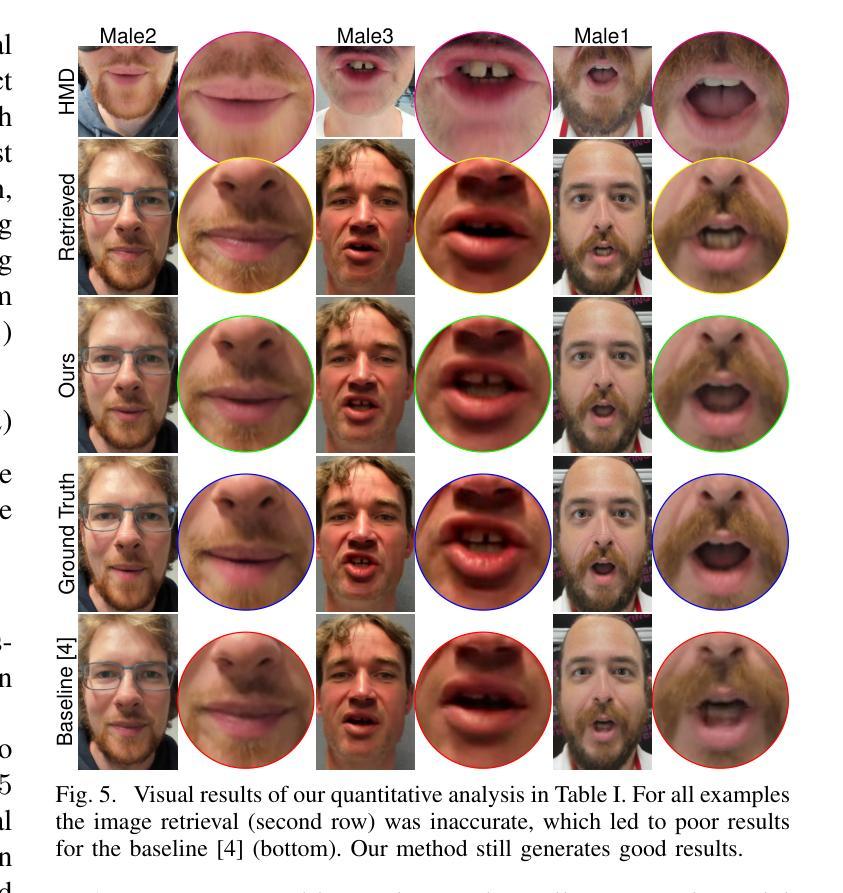
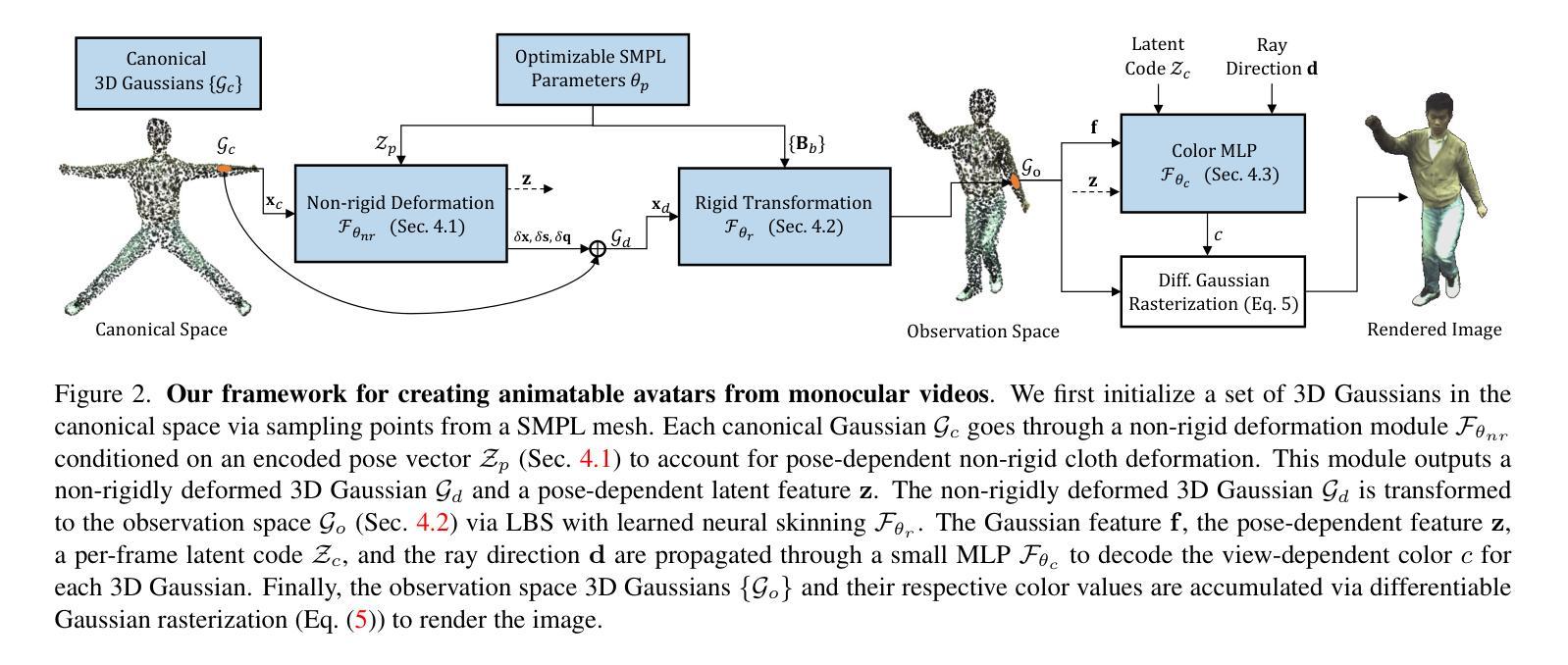
3DGS-Avatar: Animatable Avatars via Deformable 3D Gaussian Splatting
Authors:Zhiyin Qian, Shaofei Wang, Marko Mihajlovic, Andreas Geiger, Siyu Tang
We introduce an approach that creates animatable human avatars from monocular videos using 3D Gaussian Splatting (3DGS). Existing methods based on neural radiance fields (NeRFs) achieve high-quality novel-view/novel-pose image synthesis but often require days of training, and are extremely slow at inference time. Recently, the community has explored fast grid structures for efficient training of clothed avatars. Albeit being extremely fast at training, these methods can barely achieve an interactive rendering frame rate with around 15 FPS. In this paper, we use 3D Gaussian Splatting and learn a non-rigid deformation network to reconstruct animatable clothed human avatars that can be trained within 30 minutes and rendered at real-time frame rates (50+ FPS). Given the explicit nature of our representation, we further introduce as-isometric-as-possible regularizations on both the Gaussian mean vectors and the covariance matrices, enhancing the generalization of our model on highly articulated unseen poses. Experimental results show that our method achieves comparable and even better performance compared to state-of-the-art approaches on animatable avatar creation from a monocular input, while being 400x and 250x faster in training and inference, respectively.
PDF Project page: https://neuralbodies.github.io/3DGS-Avatar
摘要
基于3D高斯溅射法,本文提出了一种只需30分钟即可训练并能够以50 FPS以上实时帧速率渲染的可动画3D服装人形虚拟人重建方法。
关键要点
</ol>
<Methods>:
(1):方法概述:本文方法的管道如图2所示。输入是一个经过校准的相机、拟合的SMPL参数和前景掩码的单目视频。该方法优化了一组规范空间中的3D高斯分布,然后将其变形到观察空间,并从给定的相机渲染。对于一组3D高斯分布{G(i)}Ni=1,在每个点存储以下属性:位置x,缩放因子,旋转四元数q,不透明度α和颜色特征向量f。首先通过随机采样SMPL[26]网格表面的N=50k个点作为规范3D高斯分布{Gc}的初始化。受HumanNeRF[62]的启发,将复杂的人体变形分解为一个编码姿势相关布料变形的非刚性部分,以及由人体骨骼控制的刚性变换。
(2):姿势相关的非刚性变形:将非刚性变形模块表述为:{Gd}=Fθnr({Gc};Zp)(6)
其中{Gd}表示非刚性变形的3D高斯分布。θnr表示非刚性变形模块的可学习参数。Z是一个潜在代码,它使用轻量级分层姿势编码器[28]对SMPL姿势和形状(θ,β)进行编码。具体来说,变形网络fθnr以规范位置xc和姿势潜在代码Zp作为输入,并输出高斯位置、尺度、旋转的偏移量以及特征向量z:(δx,δs,δq,z)=fθnr(xc;Zp)(7)
(3):刚性变换:将非刚性变形的3D高斯分布{Gd}通过刚性变换模块进一步变换到观察空间:{Go}=Fθr({Gd};{Bb}Bb=1)(11)
其中皮肤网格变换MLPfθr被学习以预测位置xd处的皮肤权重。通过第3.1节中描述的前向LBS变换位置和3D高斯分布的旋转矩阵:T=�Bb=1fθr(xd)bBb(12)
(4):颜色MLP:先前工作[63,67,68]遵循3DGS[14]的惯例,每个3D高斯分布存储球谐系数以编码视点相关颜色。将存储的颜色特征f视为球谐系数,则3D高斯分布的颜色可以通过球谐基和学习系数的点积来计算:c=⟨γ(d),f⟩(15)
其中d表示从相机中心到3D高斯分布的相对位置导出的视点方向。γ表示球谐基函数。虽然概念上很简单,但认为这种方法不适合单目设置。由于在训练期间只提供了一个相机视图,因此世界空间中的视点方向是固定的,导致对未见测试视图的泛化性较差。类似于[41],使用第4.2节中的逆刚性变换将视点方向规范化:ˆd=T−11:3,1:3d(16)
其中T是等式(12)中定义的前向变换矩阵。理论上,规范视点方向可以提高模型对未见姿势的泛化能力。
</ol>
(1)本研究工作通过从单目视频中高效重建带服装的人类动画角色,推动了该领域的进步。该方法实现了逼真的渲染、对姿势相关布料变形的感知、对未见姿势的泛化、快速训练和实时渲染等优点。实验表明,该方法在渲染质量上与现有最先进的方法相当甚至更好,同时在训练和推理速度上提高了两个数量级。此外,还提出了用浅层 MLP 代替球谐函数来解码 3D 高斯颜色,并用几何约束来正则化变形,这两者都被证明可以有效提高渲染质量。我们希望这种新的表示能够促进从单目视图中快速、高质量的可动画带服装人类化身合成的进一步研究。
(2)创新点:
性能:
工作量:
点此查看论文截图


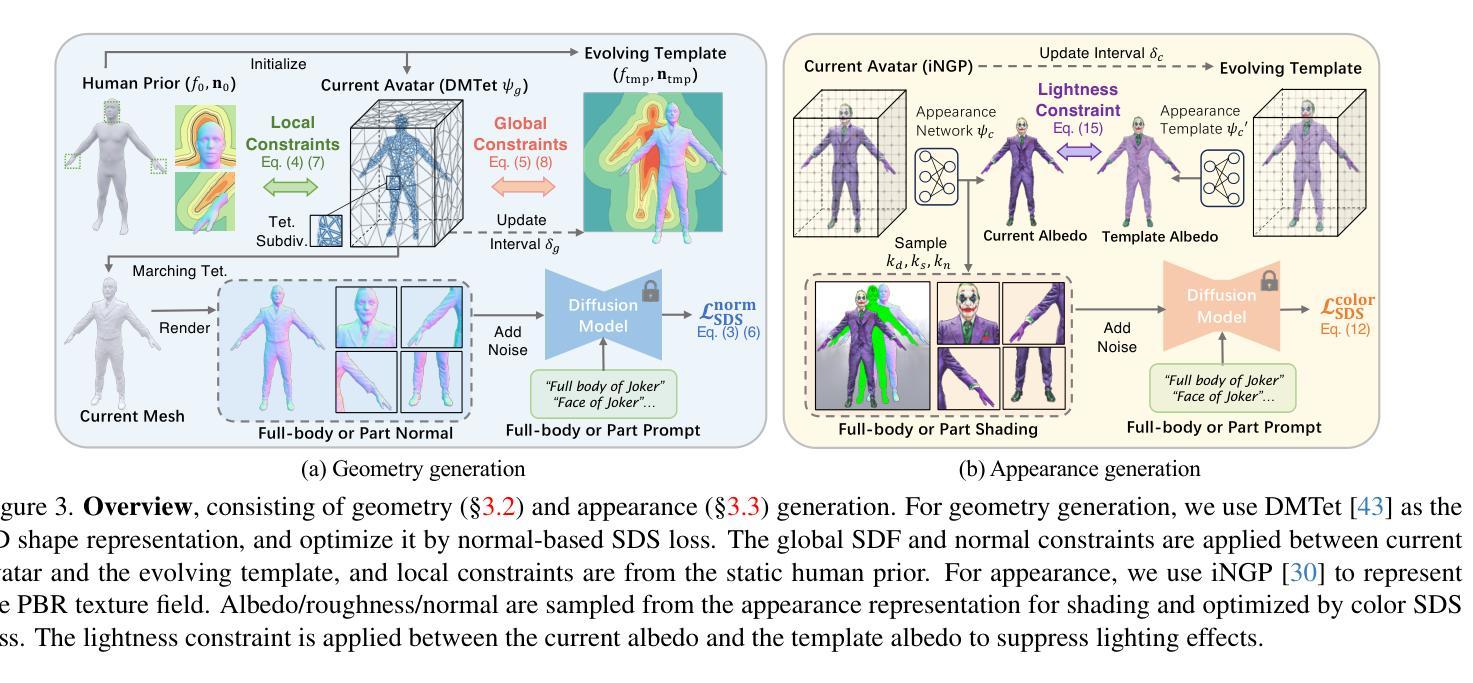
SEEAvatar: Photorealistic Text-to-3D Avatar Generation with Constrained Geometry and Appearance
Authors:Yuanyou Xu, Zongxin Yang, Yi Yang
Powered by large-scale text-to-image generation models, text-to-3D avatar generation has made promising progress. However, most methods fail to produce photorealistic results, limited by imprecise geometry and low-quality appearance. Towards more practical avatar generation, we present SEEAvatar, a method for generating photorealistic 3D avatars from text with SElf-Evolving constraints for decoupled geometry and appearance. For geometry, we propose to constrain the optimized avatar in a decent global shape with a template avatar. The template avatar is initialized with human prior and can be updated by the optimized avatar periodically as an evolving template, which enables more flexible shape generation. Besides, the geometry is also constrained by the static human prior in local parts like face and hands to maintain the delicate structures. For appearance generation, we use diffusion model enhanced by prompt engineering to guide a physically based rendering pipeline to generate realistic textures. The lightness constraint is applied on the albedo texture to suppress incorrect lighting effect. Experiments show that our method outperforms previous methods on both global and local geometry and appearance quality by a large margin. Since our method can produce high-quality meshes and textures, such assets can be directly applied in classic graphics pipeline for realistic rendering under any lighting condition. Project page at: https://yoxu515.github.io/SEEAvatar/.
Summary
使用 SEEAvatar 生成逼真 3D 头像,结合几何和外观的自我进化约束,产生高质量的网格和纹理。
Key Takeaways
</ol>
点此查看论文截图


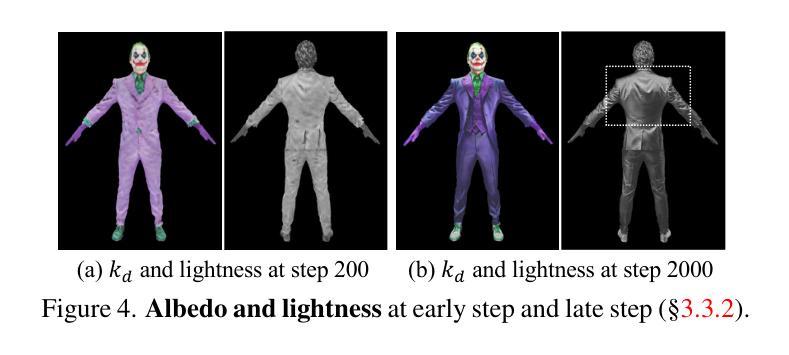
ANR: Articulated Neural Rendering for Virtual Avatars
Authors:Amit Raj, Julian Tanke, James Hays, Minh Vo, Carsten Stoll, Christoph Lassner
The combination of traditional rendering with neural networks in Deferred Neural Rendering (DNR) provides a compelling balance between computational complexity and realism of the resulting images. Using skinned meshes for rendering articulating objects is a natural extension for the DNR framework and would open it up to a plethora of applications. However, in this case the neural shading step must account for deformations that are possibly not captured in the mesh, as well as alignment inaccuracies and dynamics — which can confound the DNR pipeline. We present Articulated Neural Rendering (ANR), a novel framework based on DNR which explicitly addresses its limitations for virtual human avatars. We show the superiority of ANR not only with respect to DNR but also with methods specialized for avatar creation and animation. In two user studies, we observe a clear preference for our avatar model and we demonstrate state-of-the-art performance on quantitative evaluation metrics. Perceptually, we observe better temporal stability, level of detail and plausibility.
摘要
利用神經網絡,融合遞延神經渲染和網格形變,改進虛擬人生成。
重要要点
</ol>
性能:
工作量:
点此查看论文截图



 wechat
wechat- alipay