3D reconstruction
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-01-24 更新
Deformable Endoscopic Tissues Reconstruction with Gaussian Splatting
Authors:Lingting Zhu, Zhao Wang, Zhenchao Jin, Guying Lin, Lequan Yu
Surgical 3D reconstruction is a critical area of research in robotic surgery, with recent works adopting variants of dynamic radiance fields to achieve success in 3D reconstruction of deformable tissues from single-viewpoint videos. However, these methods often suffer from time-consuming optimization or inferior quality, limiting their adoption in downstream tasks. Inspired by 3D Gaussian Splatting, a recent trending 3D representation, we present EndoGS, applying Gaussian Splatting for deformable endoscopic tissue reconstruction. Specifically, our approach incorporates deformation fields to handle dynamic scenes, depth-guided supervision to optimize 3D targets with a single viewpoint, and a spatial-temporal weight mask to mitigate tool occlusion. As a result, EndoGS reconstructs and renders high-quality deformable endoscopic tissues from a single-viewpoint video, estimated depth maps, and labeled tool masks. Experiments on DaVinci robotic surgery videos demonstrate that EndoGS achieves superior rendering quality. Code is available at https://github.com/HKU-MedAI/EndoGS.
PDF Work in progress. 10 pages, 4 figures
摘要
我们将 EndoGS 提出了一种基于高斯斑点的可变形内镜组织重建方法。
要点
- EndoGS通过采用高斯斑点来实现可变形内镜组织的 3D 重建。
- EndoGS 引入了变形场来处理动态场景,并通过深度引导监督来优化具有单个视点的 3D 目标。
- EndoGS 利用时空权重掩码来减轻工具遮挡。
- EndoGS 可以从单视角视频、估计的深度图和标记的工具掩码中重建和渲染高质量的可变形内镜组织。
- 在 DaVinci 机器人手术视频上的实验表明,EndoGS 可实现优异的渲染质量。
- EndoGS 的代码可在 https://github.com/HKU-MedAI/EndoGS 获得。
题目:高斯散点法可变形内窥镜组织重建
作者:Lingting Zhu, Zhao Wang, Zhenchao Jin, Guying Lin, Lequan Yu
第一作者单位:香港大学
关键词:高斯散点法 · 机器人手术 · 三维重建
论文链接:https://arxiv.org/abs/2401.11535,Github 链接:https://github.com/HKU-MedAI/EndoGS
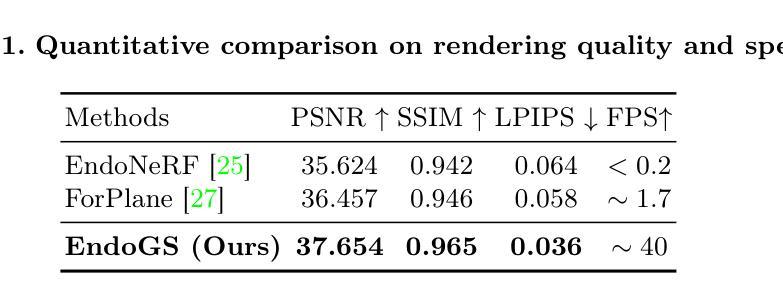
摘要: (1)研究背景:可变形组织的三维重建是机器人手术研究的关键领域,但现有方法往往存在优化耗时或质量较差的问题,限制了它们在后续任务中的应用。 (2)过去的方法:早期尝试采用深度估计来实现内窥镜重建,但这些方法在处理非刚性变形和遮挡方面存在困难。[9, 12] 提出结合工具遮挡、立体深度估计和稀疏翘曲场的框架,但它们在存在剧烈非拓扑可变形组织变化时仍然容易失败。神经辐射场 (NeRFs) 在三维重建方面取得了巨大成功,但它们在处理动态场景和遮挡方面也存在局限性。 (3)研究方法:本文提出了一种称为 EndoGS 的方法,将高斯散点法应用于可变形内窥镜组织重建。EndoGS 结合了变形场、深度引导监督和时空权重掩码,能够从单视角视频、估计的深度图和标记的工具掩码中重建和渲染高质量的可变形内窥镜组织。 (4)方法性能:在达芬奇机器人手术视频上的实验表明,EndoGS 在渲染质量方面优于其他方法。这表明 EndoGS 可以为下游任务(如手术增强现实、教育和机器人学习)提供高质量的可变形组织重建。
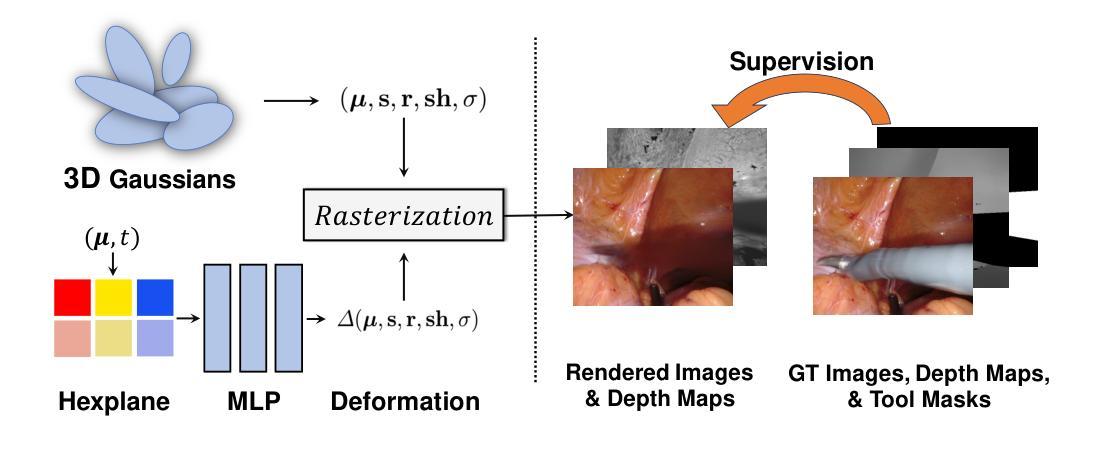
方法: (1): 我们提出了一种称为 EndoGS 的方法,它将高斯散点法应用于可变形内窥镜组织重建。 (2): EndoGS 结合了变形场、深度引导监督和时空权重掩码,能够从单视角视频、估计的深度图和标记的工具掩码中重建和渲染高质量的可变形内窥镜组织。 (3): 我们使用六个正交特征平面对空间和时间信息进行编码,并使用单个 MLP 来更新高斯属性,以获得变形的位置、比例因子、旋转因子、球谐系数和不透明度。 (4): 我们结合工具掩码和深度图来训练 EndoGS,以处理工具遮挡和提高重建质量。
结论:
(1)意义:本文提出了一种基于高斯散点法进行可变形内窥镜组织重建的方法,该方法能够从单视角视频、估计的深度图和标记的工具掩码中实时渲染高质量的可变形组织。在达芬奇机器人手术视频上的实验表明,该方法在渲染质量方面优于其他方法。
(2)优缺点:
创新点:
- 将高斯散点法应用于可变形内窥镜组织重建。
- 结合变形场、深度引导监督和时空权重掩码,以处理工具遮挡和提高重建质量。
性能:
- 在达芬奇机器人手术视频上的实验表明,该方法在渲染质量方面优于其他方法。
工作量:
- 需要收集和标记大量的数据。
- 需要设计和训练复杂的模型。
点此查看论文截图

题目:SHINOBI:基于 BRDF 优化进行形状和光照分解的神经物体分解
作者:Andreas Engelhardt、Amit Raj、Mark Boss、Yunzhi Zhang、Abhishek Kar、Yuanzhen Li、Deqing Sun、Ricardo Martin Brualla、Jonathan T. Barron、Hendrik P. A. Lensch、Varun Jampani
第一作者单位:德国图宾根大学
关键词:计算机视觉、图形学、神经渲染、形状重建、材质估计、光照估计
论文链接:https://arxiv.org/abs/2401.10171,Github 代码链接:无
摘要: (1):背景:逆向渲染基于无约束图像集合的对象是一个长期存在的挑战,需要对形状、光照和姿势进行联合优化。 (2):过去的方法:现有方法通常使用显式形状表示,这在处理具有复杂几何形状的对象时存在局限性。此外,它们通常需要大量的手动调整和用户交互。 (3):方法:本文提出了一种新的框架 SHINOBI,它使用隐式形状表示和多分辨率哈希编码来实现更快速和鲁棒的形状重建。同时,该框架还联合优化 BRDF 和光照,以实现对光照和对象反射率的编辑。 (4):性能:SHINOBI 在多个数据集上的实验结果表明,它在形状重建、材质估计和光照估计方面都优于现有方法。该方法可以生成逼真的可照明 3D 资产,可用于 AR/VR、电影、游戏等多种应用场景。
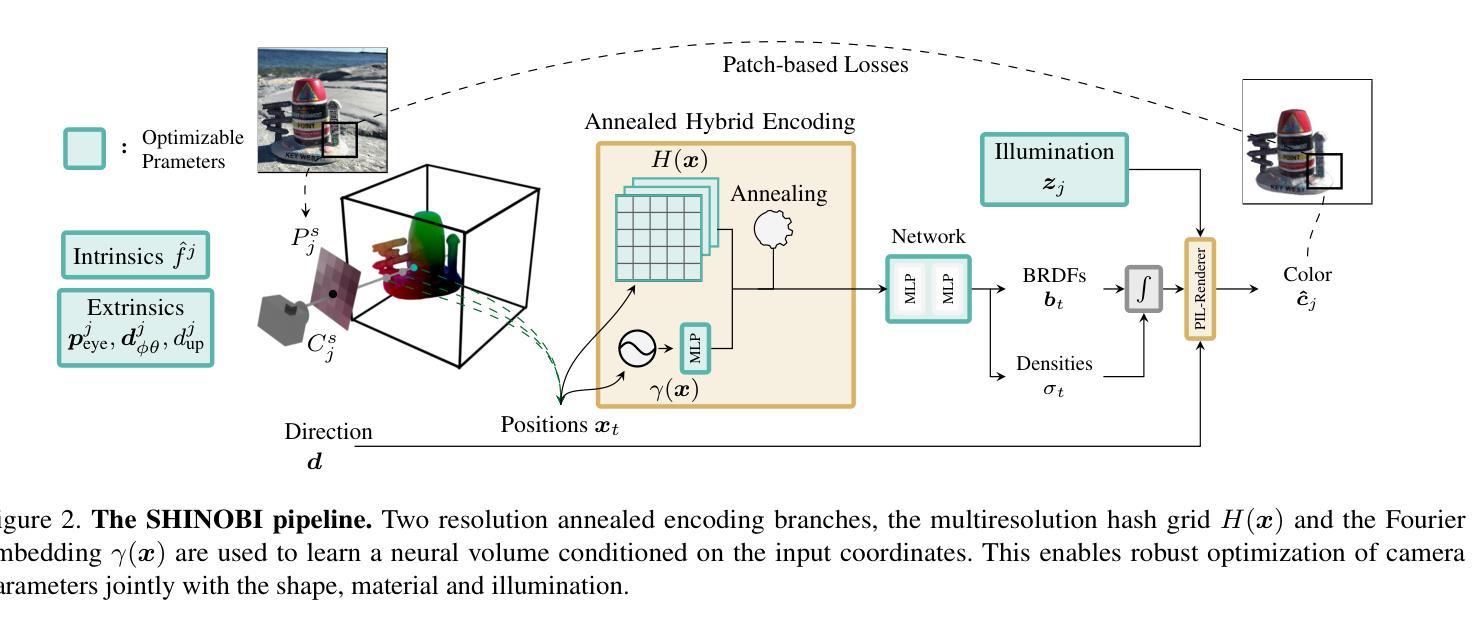
方法: (1) 隐式形状表示:SHINOBI使用隐式形状表示来表示对象,这是一种无界表示,可以轻松处理具有复杂几何形状的对象。 (2) 多分辨率哈希编码:SHINOBI使用多分辨率哈希编码来编码隐式形状表示,这可以提高形状重建的速度和鲁棒性。 (3) 联合优化BRDF和光照:SHINOBI联合优化BRDF和光照,以实现对光照和对象反射率的编辑。 (4) 可照明3D资产生成:SHINOBI可以生成逼真的可照明3D资产,可用于AR/VR、电影、游戏等多种应用场景。
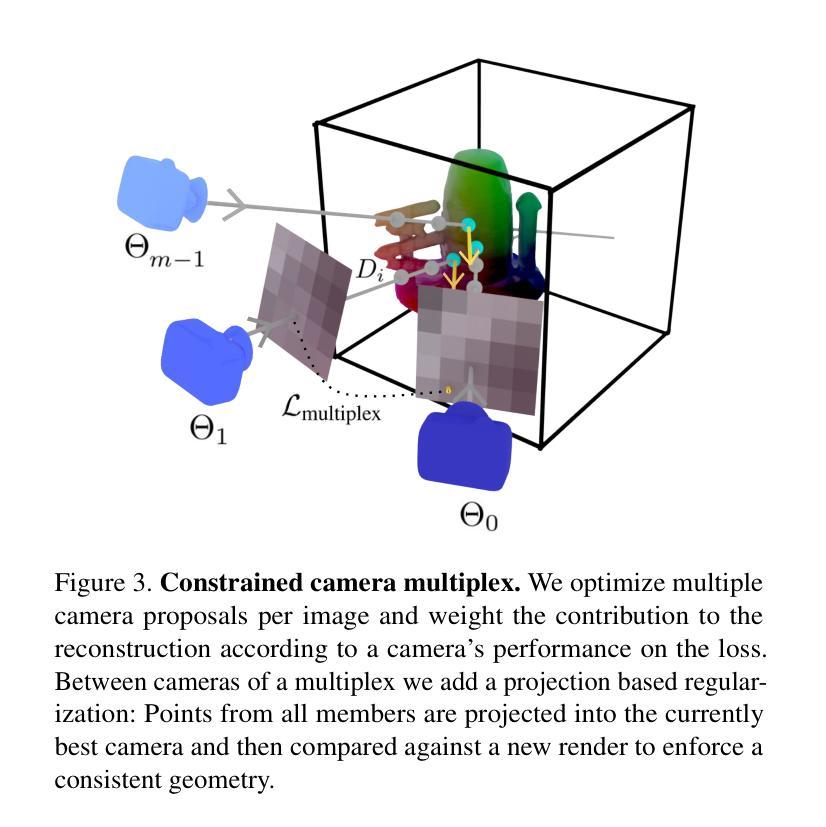
结论: (1):本工作提出了一种新的框架 SHINOBI,该框架可以从未经摆放的野外图像集中估计物体的形状、姿态和光照。我们新颖的混合哈希网格编码能够使用多分辨率哈希网格更容易地优化相机姿态。此外,我们选择的相机参数化以及逐视图重要性权重和基于补丁的对齐损失允许更好地将图像与 3D 对齐,从而在具有高频细节的情况下更好地重建。虽然 SHINOBI 能够从任何类别的物体中恢复几何形状,但其性能在细长/透明结构上受到限制,并且无法在极端光照变化下恢复高频细节,我们将其留作未来工作的探索。 (2):创新点:
- 使用隐式形状表示和多分辨率哈希编码来实现更快速和鲁棒的形状重建。
- 联合优化 BRDF 和光照,以实现对光照和对象反射率的编辑。
- 可以生成逼真的可照明 3D 资产,可用于 AR/VR、电影、游戏等多种应用场景。 性能:
- 在多个数据集上的实验结果表明,SHINOBI 在形状重建、材质估计和光照估计方面都优于现有方法。
- 可以生成逼真的可照明 3D 资产,可用于 AR/VR、电影、游戏等多种应用场景。 工作量:
- 该方法需要大量的数据和计算资源。
- 需要手动调整和用户交互。
点此查看论文截图


- 题目:高斯体:基于 3D 高斯散点的衣着人体重建
- 作者:孟天力、姚圣翔、谢志峰、陈可宇、姜玉刚
- 第一作者单位:上海大学
- 关键词:衣着人体重建、3D 高斯散点、动态捕捉、几何重建
- 论文链接:https://arxiv.org/abs/2401.09720
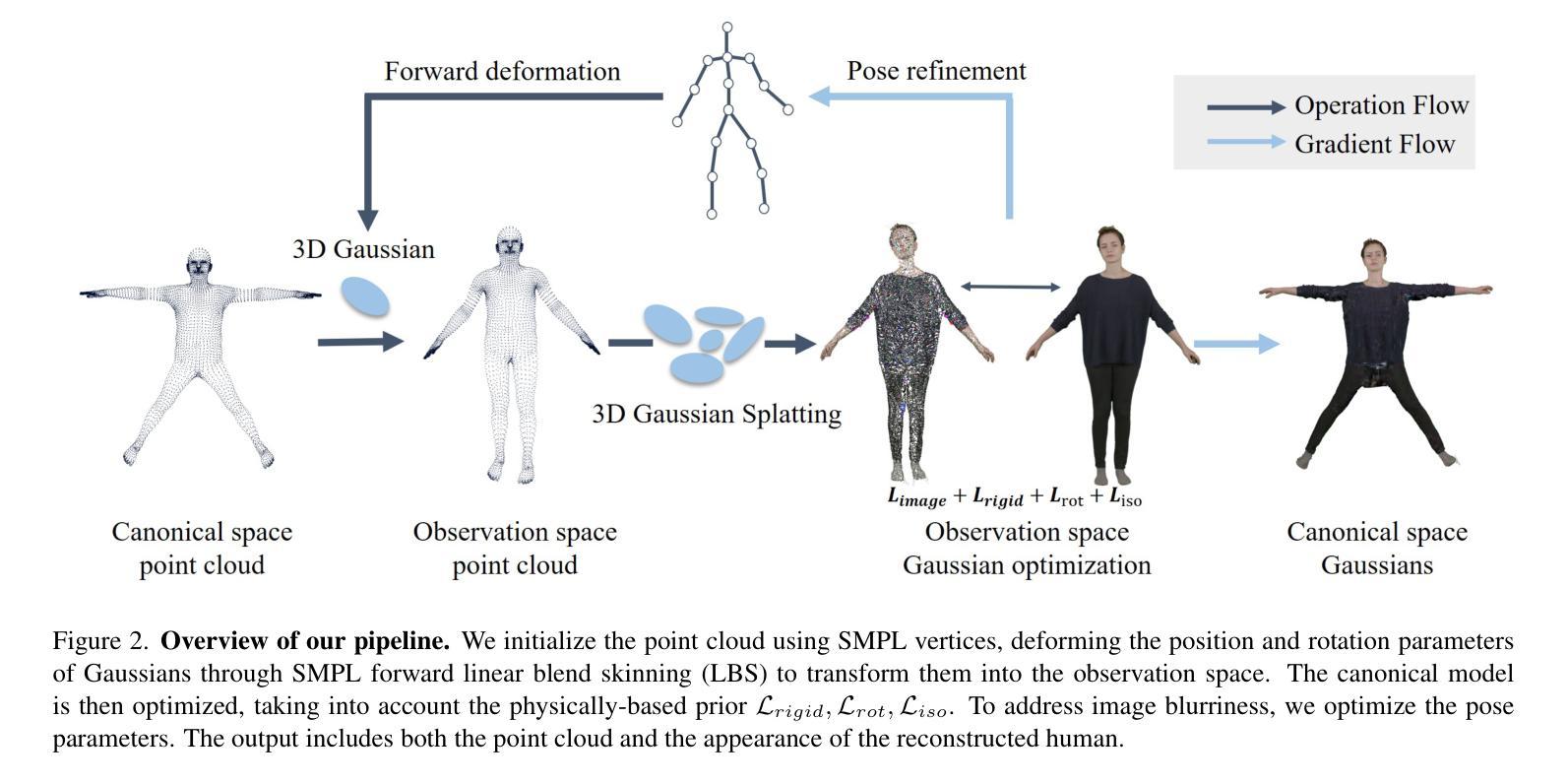
- 摘要: (1)研究背景:高保真衣着人体模型的创建在虚拟现实、远程临场和电影制作等领域具有重要应用。传统方法要么涉及复杂的捕捉系统,要么需要 3D 艺术家进行繁琐的手工工作,这使得它们耗时且昂贵,从而限制了新手用户的可扩展性。最近,人们越来越关注从单个 RGB 图像或单目视频中自动重建衣着人体模型。 (2)过去方法及问题:基于网格的方法最初被引入,通过回归参数化模型(如 SCAPE、SMPL、SMPL-X 和 STAR)来恢复人体形状。虽然它们可以实现快速且鲁棒的重建,但回归的多边形网格难以捕捉不同的几何细节和丰富的服装特征。在这种情况下,添加顶点偏移成为一种增强解决方案。然而,它的表示能力仍然有限。 (3)研究方法:本文提出了一种基于 3D 高斯散点的新型衣着人体重建方法,称为高斯体。与昂贵的神经辐射体模型相比,3D 高斯散点最近在训练时间和渲染质量方面表现出优异的性能。然而,由于复杂的非刚性变形和丰富的服装细节,将静态 3D 高斯散点模型应用于动态人体重建问题并非易事。为了应对这些挑战,本文的方法考虑了在规范空间和观察空间中对动态高斯体进行显式姿势引导的变形,引入了具有正则化变换的基于物理的先验,有助于减轻两个空间之间的歧义。在训练过程中,本文还提出了一种姿势细化策略来更新姿势回归,以补偿不准确的初始估计,并提出了一种分裂缩放机制来增强回归点云的密度。 (4)方法性能:实验验证了本文方法可以实现动态衣着人体的高质量细节的最新逼真新视角渲染结果,以及显式的几何重建。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出了一种基于3D高斯散点的新型衣着人体重建方法GaussianBody,该方法可以从单目视频中重建动态衣着人体模型。GaussianBody通过在规范空间和观察空间中对动态高斯体进行显式姿势引导的变形,以及引入具有正则化变换的基于物理的先验,解决了动态衣着人体重建中存在的复杂非刚性变形和丰富的服装细节等挑战。实验表明,GaussianBody可以实现高质量细节的最新逼真新视角渲染结果,以及显式的几何重建。 (2):创新点:
- 提出了一种基于3D高斯散点的新型衣着人体重建方法GaussianBody。
- 在规范空间和观察空间中对动态高斯体进行显式姿势引导的变形,解决了动态衣着人体重建中存在的复杂非刚性变形和丰富的服装细节等挑战。
- 引入具有正则化变换的基于物理的先验,有助于减轻两个空间之间的歧义。
- 提出了一种姿势细化策略来更新姿势回归,以补偿不准确的初始估计,并提出了一种分裂缩放机制来增强回归点云的密度。
性能:
- GaussianBody可以实现高质量细节的最新逼真新视角渲染结果,以及显式的几何重建。
- GaussianBody在图像质量指标方面与基线和其他方法相当,证明了其竞争性能、相对较快的训练速度,以及使用更高分辨率图像进行训练的能力。
工作量:
- GaussianBody需要收集和标注大量的数据。
- GaussianBody的训练过程相对复杂,需要较大的计算资源。
点此查看论文截图


标题:PPSURF:结合局部块和点卷积进行详细表面重建
作者:P. Erler、L. Fuentes-Perez、P. Hermosilla、P. Guerrero、R. Pajarola、M. Wimmer
第一作者单位:维也纳工业大学
关键词:点云、表面重建、数据驱动、局部块、点卷积
论文链接:https://onlinelibrary.wiley.com/doi/10.1111/cgf.150001 Github 代码链接:https://github.com/cg-tuwien/ppsurf
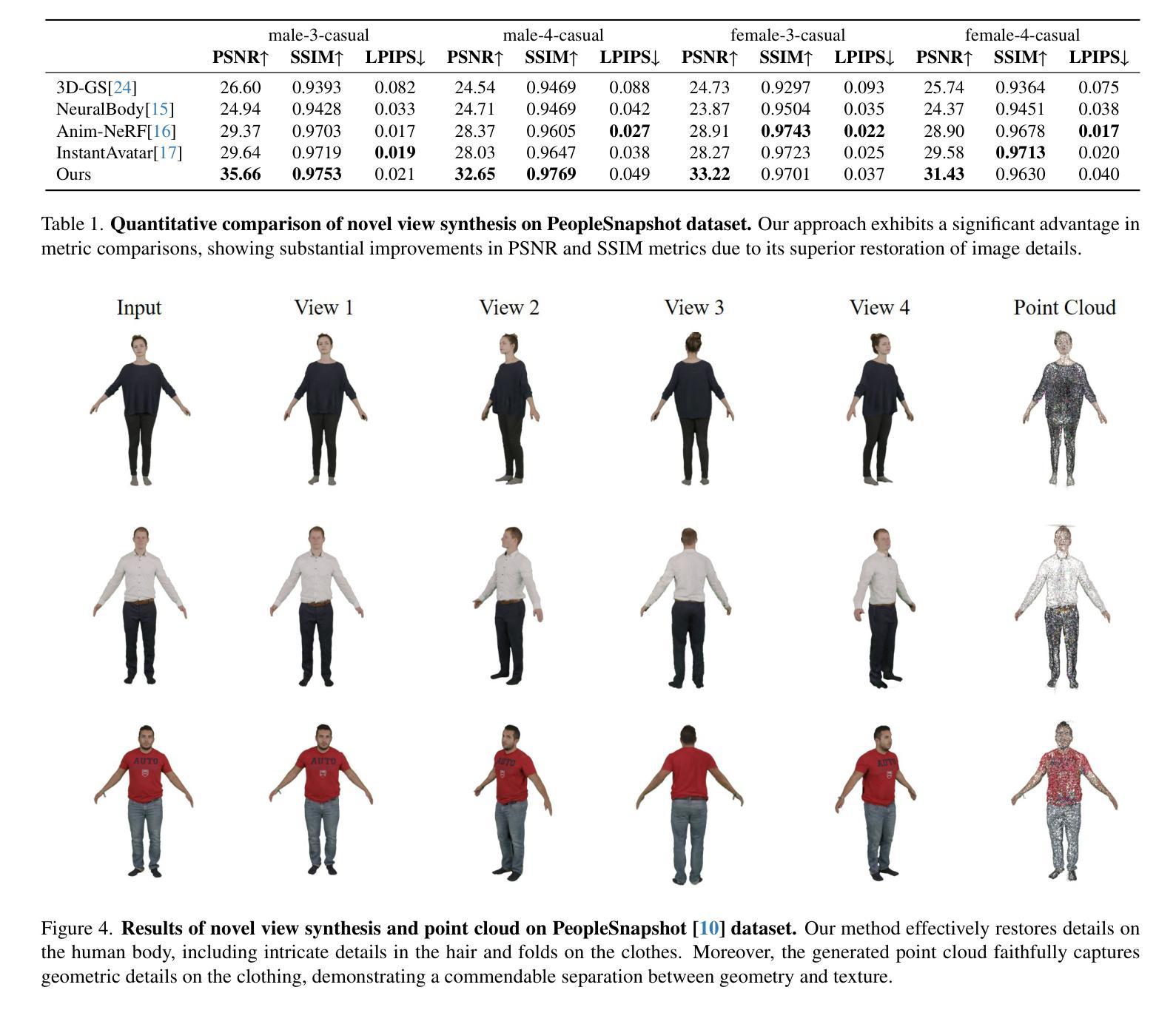
摘要: (1):3D 表面重建是内容创作、考古学、数字文化遗产和工程等领域的关键步骤。目前的方法要么尝试优化非数据驱动的表面表示以拟合点,要么学习数据驱动的先验,了解常见表面和潜在噪声点云之间的分布和相关性。数据驱动的方法能够稳健地处理噪声,通常侧重于全局或局部先验,这在全局端与噪声的稳健性和局部端表面细节的保留之间进行权衡。 (2):过去的方法要么尝试优化非数据驱动的表面表示以拟合点,要么学习数据驱动的先验,了解常见表面和潜在噪声点云之间的分布和相关性。数据驱动的方法能够稳健地处理噪声,但通常侧重于全局或局部先验,这在全局端与噪声的稳健性和局部端表面细节的保留之间进行权衡。 (3):本文提出了一种名为 PPSURF 的方法,该方法结合了基于点卷积的全局先验和基于处理局部点云块的局部先验。 (4):在噪声点云重建任务上,该方法在恢复表面细节的同时,对噪声具有鲁棒性,优于当前最先进的方法。
方法: (1):PPSURF方法将基于点卷积的全局先验与基于处理局部点云块的局部先验相结合,以实现详细的表面重建。 (2):全局分支使用POCO网络,该网络由点卷积模块和插值模块组成,点卷积模块计算每个稀疏点的特征向量,插值模块使用基于注意力的权重对特征向量进行插值以获得全局特征向量。 (3):局部分支使用PointNet网络,该网络经过修改,采用基于注意力的聚合方式,而不是原始的最大值或和值聚合方式,以获得局部特征向量。 (4):全局特征向量和局部特征向量通过MLP组合,以计算查询点处的占用概率。
结论: (1):本文提出了一种名为 PPSURF 的方法,该方法将基于点卷积的全局先验与基于处理局部点云块的局部先验相结合,以实现详细的表面重建。在噪声点云重建任务上,该方法在恢复表面细节的同时,对噪声具有鲁棒性,优于当前最先进的方法。 (2):创新点:
- 将基于点卷积的全局先验与基于处理局部点云块的局部先验相结合,以实现详细的表面重建。
- 使用基于注意力的聚合方式,而不是原始的最大值或和值聚合方式,以获得局部特征向量。
- 在噪声点云重建任务上,该方法在恢复表面细节的同时,对噪声具有鲁棒性,优于当前最先进的方法。
性能:
- 在 ABCvar-noise 测试集上,PPSURF 在 Chamfer 距离、F1 分数和法线误差方面均优于当前最先进的方法。
- 在 PatchSize 消融研究中,PPSURF100NN 和 PPSURF200NN 在 Chamfer 距离和 F1 分数方面与 PPSURFFull 相当,但在法线误差方面略差。
- 在 Miscellanous 消融研究中,PPSURFSymMax 在 Chamfer 距离方面优于 PPSURFFull,但在 F1 分数和法线误差方面略差。PPSURFQPoints 在 F1 分数和法线误差方面优于 PPSURFFull,但在 Chamfer 距离方面略差。PPSURFMergeCat 在 Chamfer 距离和 F1 分数方面与 PPSURFFull 相当,但在法线误差方面略差。
工作量:
- PPSURF 的实现相对简单,易于理解和使用。
- PPSURF 的训练时间和推理时间与当前最先进的方法相当。
点此查看论文截图


题目:无精修 URL:
作者:Mohamad Shahbazi, Anh-Huy Phan, Jia-Bin Huang, Yi-Ling Qiao, Hao Tang, Matthew Fisher, Angela Dai
第一作者单位:苏黎世联邦理工学院(ETH Zurich)
关键词:神经辐射场、对象插入、文本到图像扩散模型
论文链接:无,Github 链接:无
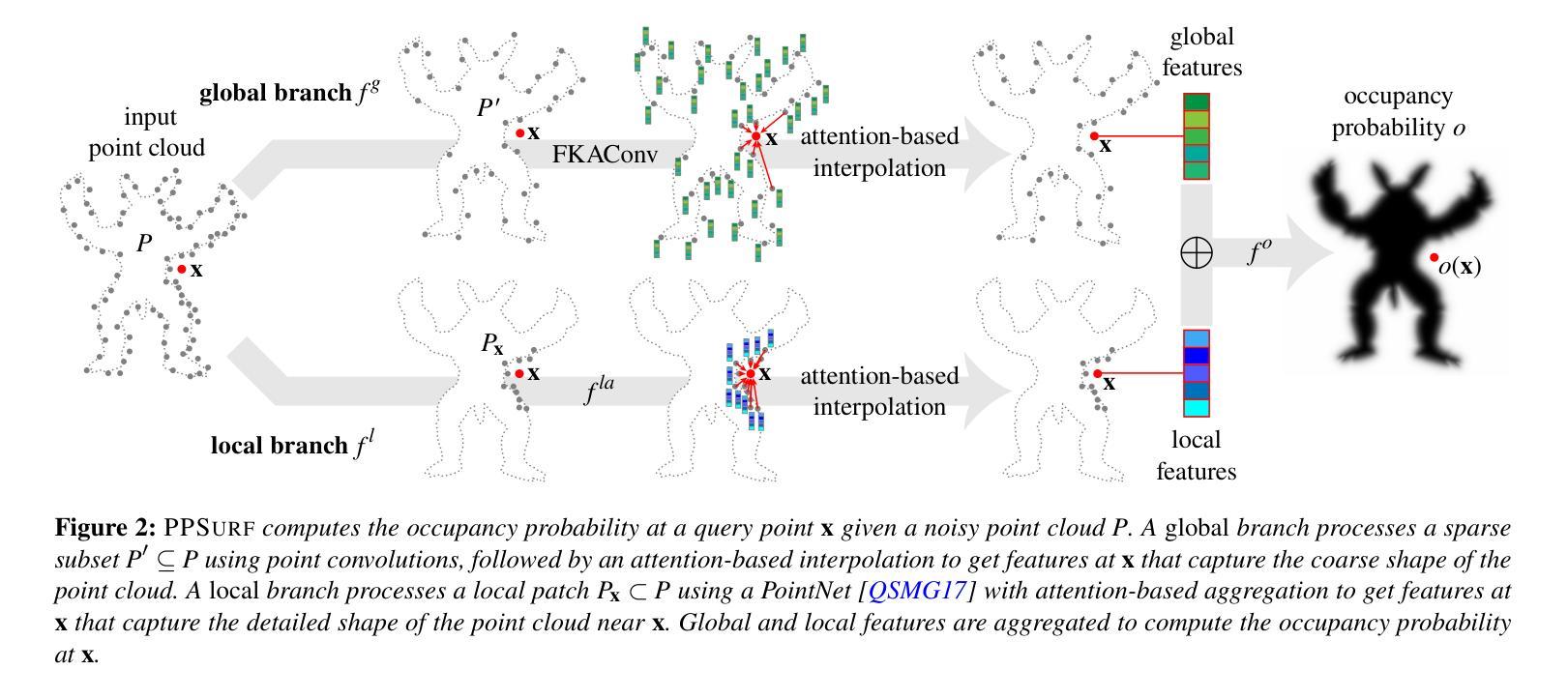
摘要: (1)研究背景:近年来,3D 场景编辑方法取得了重大进展,这主要归功于在 3D 生成建模中使用文本到图像扩散模型的强先验。现有方法主要通过改变样式和外观或移除现有对象来编辑 3D 场景。然而,生成新对象对于这些方法来说仍然是一个挑战。 (2)过去的方法及其问题:现有方法的问题在于,它们无法生成新的对象,并且需要显式的 3D 信息作为输入。 (3)研究方法:为了解决上述问题,本文提出了一种新的方法 InseRF,它可以根据用户提供的文本描述和参考视点中的 2D 边界框在 NeRF 重建的 3D 场景中生成新对象。InseRF 将 2D 编辑提升到 3D,使用单视图对象重建方法重建对象,然后在单目深度估计方法的指导下将重建的对象插入场景中。 (4)方法性能:实验表明,InseRF 在多个 3D 场景中生成插入对象的任务上优于现有方法。InseRF 能够以可控且 3D 一致的方式插入对象,而无需显式 3D 信息作为输入。
方法: (1) 输入:InseRF 的输入是一个 NeRF 重建的 3D 场景、一个文本描述和一个参考视点中的 2D 边界框。 (2) 对象重建:InseRF 使用单视图对象重建方法重建对象。 (3) 对象插入:InseRF 使用单目深度估计方法估计对象的深度,然后将重建的对象插入场景中。
结论: (1):xxx; (2):创新点:InseRF 提出了一种新颖的方法,可以根据文本描述和 2D 边界框在 NeRF 重建的 3D 场景中生成新对象,无需显式 3D 信息作为输入。 性能:InseRF 在多个 3D 场景中生成插入对象的任务上优于现有方法,能够以可控且 3D 一致的方式插入对象。 工作量:InseRF 的实现相对复杂,需要结合单视图对象重建方法和单目深度估计方法,工作量较大。
点此查看论文截图

Vision Reimagined: AI-Powered Breakthroughs in WiFi Indoor Imaging
Authors:Jianyang Shi, Bowen Zhang, Amartansh Dubey, Ross Murch, Liwen Jing
Indoor imaging is a critical task for robotics and internet-of-things. WiFi as an omnipresent signal is a promising candidate for carrying out passive imaging and synchronizing the up-to-date information to all connected devices. This is the first research work to consider WiFi indoor imaging as a multi-modal image generation task that converts the measured WiFi power into a high-resolution indoor image. Our proposed WiFi-GEN network achieves a shape reconstruction accuracy that is 275% of that achieved by physical model-based inversion methods. Additionally, the Frechet Inception Distance score has been significantly reduced by 82%. To examine the effectiveness of models for this task, the first large-scale dataset is released containing 80,000 pairs of WiFi signal and imaging target. Our model absorbs challenges for the model-based methods including the non-linearity, ill-posedness and non-certainty into massive parameters of our generative AI network. The network is also designed to best fit measured WiFi signals and the desired imaging output. For reproducibility, we will release the data and code upon acceptance.
Summary
室内成像通过Wi-Fi信号,将测量到的Wi-Fi功率转换为高分辨率图像。
Key Takeaways
- Wi-Fi室内成像被视为多模态图像生成任务。
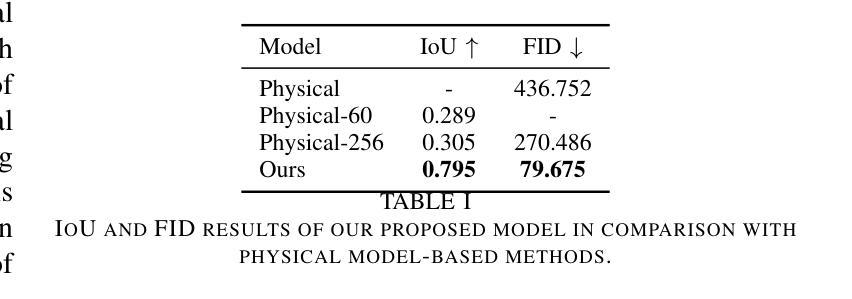
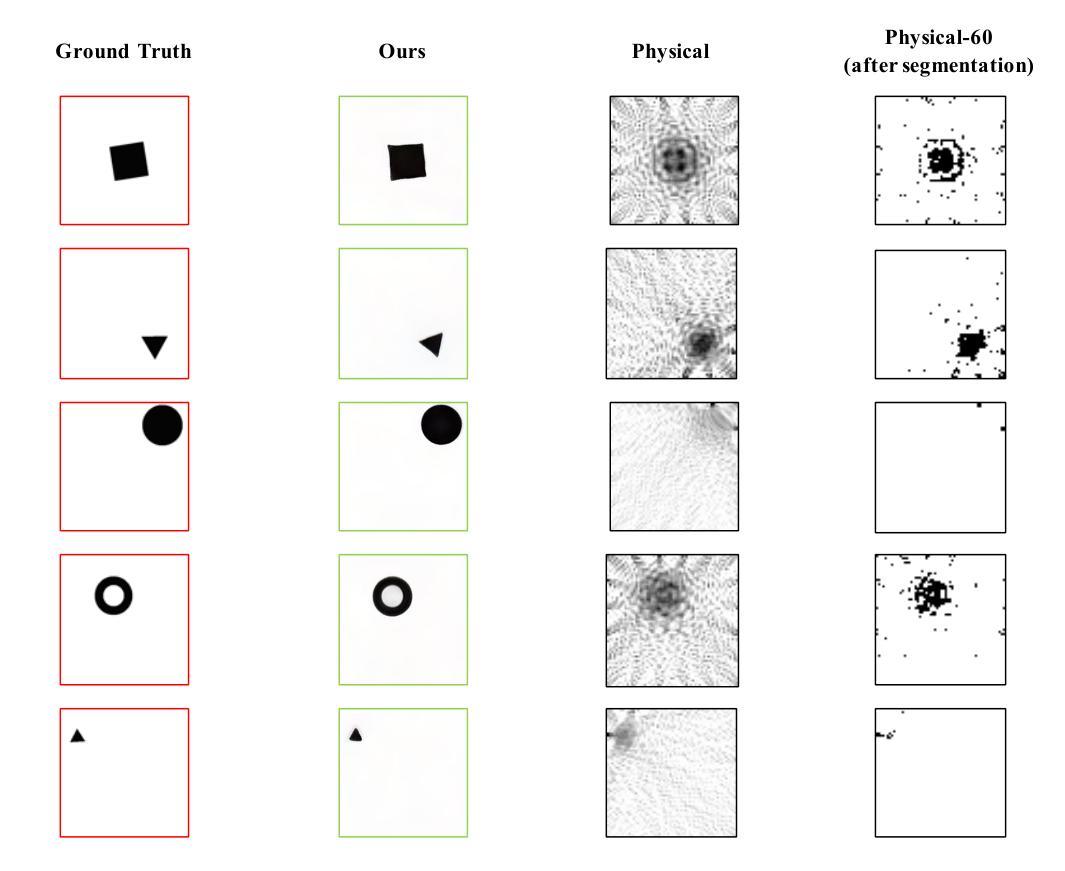
- Wi-Fi-GEN网络的形状重建精度是基于物理模型的反演方法的275%。
- Fréchet起始距离评分降低了82%。
- 发布了首个大型数据集,包含80,000对Wi-Fi信号和成像目标。
- Wi-Fi-GEN网络将基于模型的方法的挑战吸收为生成性AI网络的大量参数。
- 网络设计用于最适合测量的Wi-Fi信号和所需的成像输出。
- 为了可复制性,我们将发布数据和代码。
题目:视觉重构:WiFi 室内成像的 AI 赋能突破
作者:Jianyang Shi、Bowen Zhang、Amartansh Dubey、Ross Murch、Liwen Jing
隶属单位:深圳先进技术研究院信息与智能学院
关键词:WiFi成像、生成式人工智能、逆散射问题
论文链接:https://arxiv.org/abs/2401.04317 Github 代码链接:无
摘要: (1):研究背景:室内成像是机器人和物联网的一项关键任务。WiFi 作为一种无处不在的信号,是执行被动成像并将最新信息同步到所有连接设备的理想选择。 (2):过去的方法及其问题:现有研究探索了全波(即测量 WiFi 相位和功率)和无相测量来解决室内成像问题。然而,全波方法的相位测量在高频时非常棘手且昂贵,这使得它在实践中不切实际。最近的研究证明了通过无相 WiFi 信号进行室内成像的可行性。 (3):提出的研究方法:本文将 WiFi 室内成像视为多模态图像生成任务,将测量的 WiFi 功率转换为高分辨率室内图像。提出的 WiFi-GEN 网络实现了比基于物理模型的反演方法高出 275% 的重建精度。此外,Fréchet Inception Distance 得分显着降低了 82%。为了检查模型对这项任务的有效性,发布了第一个包含 80,000 对 WiFi 信号和成像目标的大规模数据集。该模型吸收了基于模型的方法的挑战,包括我们生成式 AI 网络中非线性和不确定性的大量参数。该网络还旨在最适合测量的 WiFi 信号和期望的成像输出。 (4):方法的性能:该方法在室内成像任务上取得了良好的性能。在 80,000 对 WiFi 信号和成像目标的数据集上,该方法的重建精度比基于物理模型的反演方法高出 275%。此外,Fréchet Inception Distance 得分显着降低了 82%。这些结果表明,该方法能够有效地从 WiFi 信号中生成高分辨率的室内图像。
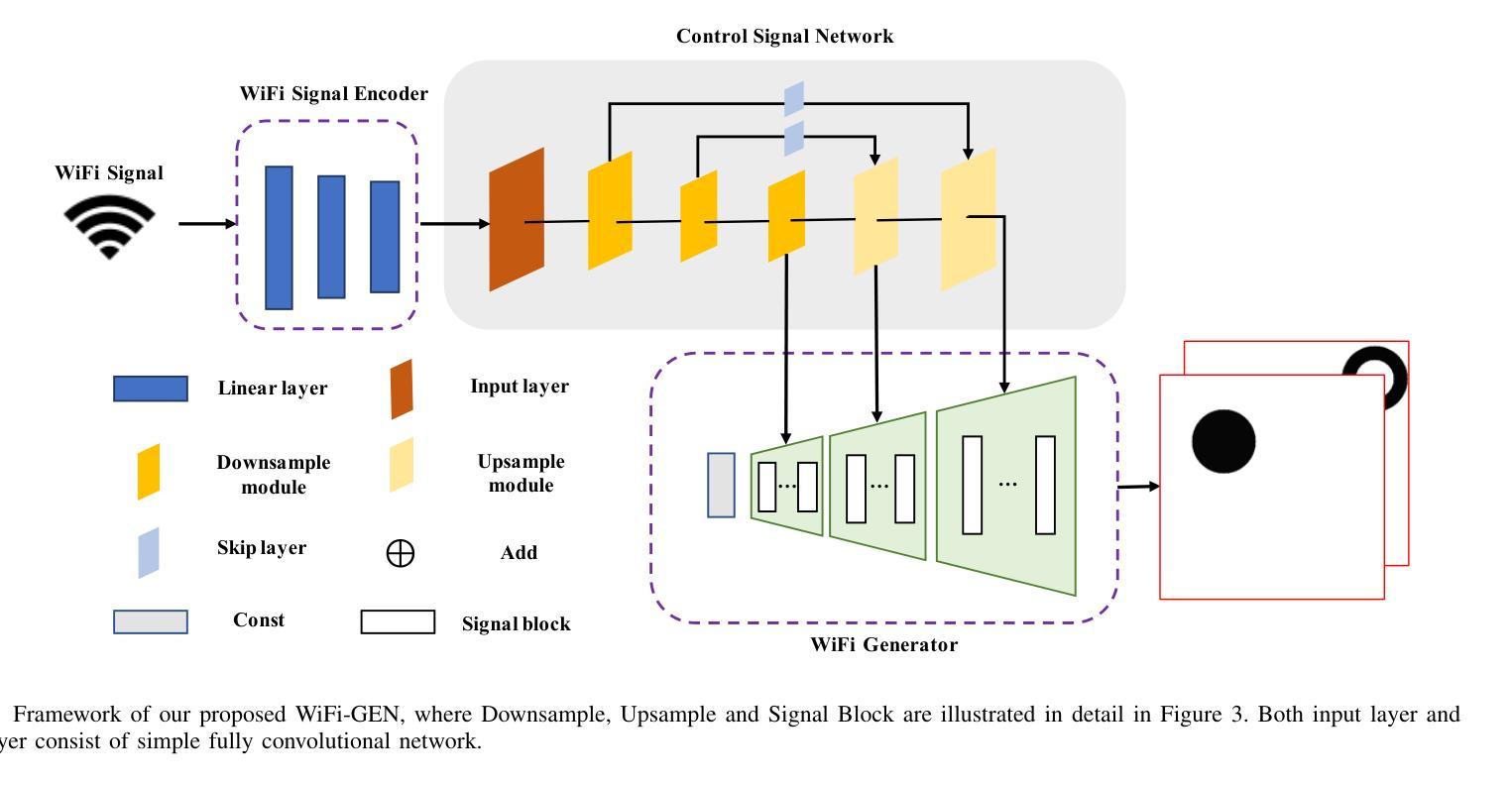
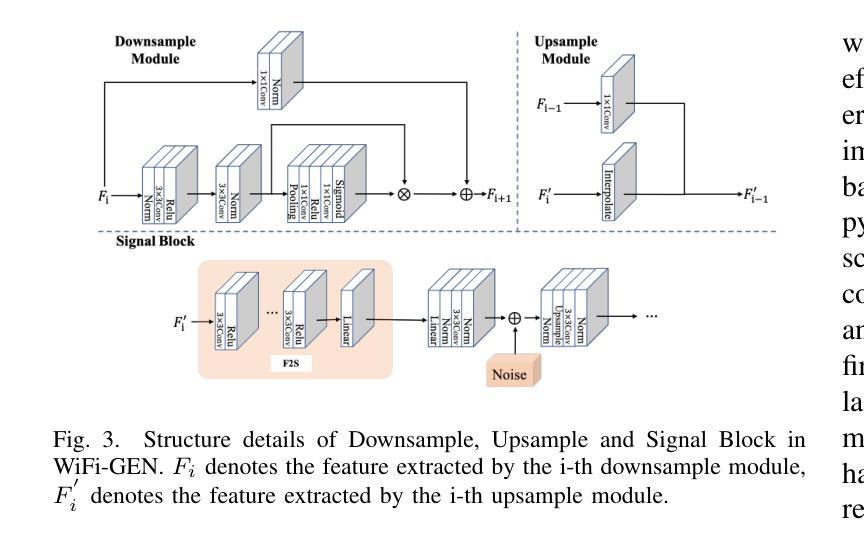
方法: (1):WiFi室内成像问题被表述为多模态图像生成任务,利用生成式人工智能网络将测量的WiFi功率转换为高分辨率室内图像。 (2):WiFi-GEN网络由三个部分组成:WiFi信号编码器、控制信号网络和WiFi生成器。WiFi信号编码器将WiFi信号嵌入到潜在空间矩阵中;控制信号网络从潜在空间中提取WiFi信号相关特征并将其转换为多级特征向量;WiFi生成器利用从控制信号网络不同层级提取的特征来影响最终图像生成结果。 (3):WiFi信号编码器是一个三层全连接网络,将19×20的信号展平为380维向量并输入编码器。 (4):控制信号网络由下采样模块和上采样模块组成。下采样模块由多个残差层组成,用于减少特征图的空间尺寸;上采样模块利用卷积层和双线性插值来恢复特征图的空间分辨率。 (5):WiFi生成器采用了一种利用从潜在空间中提取的多尺度特征来生成最终图像的方法。WiFi生成器由多个信号块组成,每个信号块在生成过程中发挥着至关重要的作用。 (6):WiFi生成器利用从控制信号网络不同层级提取的特征来影响最终图像生成结果。
结论: (1): 本文将 WiFi 室内成像问题表述为多模态图像生成任务,利用生成式人工智能网络将测量的 WiFi 功率转换为高分辨率室内图像,取得了良好的性能。 (2): 创新点: 提出一种基于生成式人工智能的 WiFi 室内成像方法,将 WiFi 室内成像问题表述为多模态图像生成任务,利用生成式人工智能网络将测量的 WiFi 功率转换为高分辨率室内图像。 性能: 在 80,000 对 WiFi 信号和成像目标的数据集上,该方法的重建精度比基于物理模型的反演方法高出 275%。此外,Fréchet Inception Distance 得分显着降低了 82%。 工作量: 该方法需要大量的数据集和计算资源。
点此查看论文截图


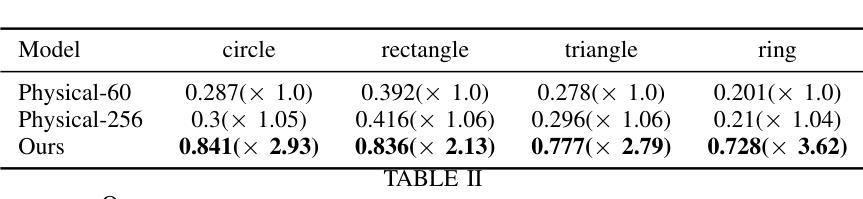
RHOBIN Challenge: Reconstruction of Human Object Interaction
Authors:Xianghui Xie, Xi Wang, Nikos Athanasiou, Bharat Lal Bhatnagar, Chun-Hao P. Huang, Kaichun Mo, Hao Chen, Xia Jia, Zerui Zhang, Liangxian Cui, Xiao Lin, Bingqiao Qian, Jie Xiao, Wenfei Yang, Hyeongjin Nam, Daniel Sungho Jung, Kihoon Kim, Kyoung Mu Lee, Otmar Hilliges, Gerard Pons-Moll
Modeling the interaction between humans and objects has been an emerging research direction in recent years. Capturing human-object interaction is however a very challenging task due to heavy occlusion and complex dynamics, which requires understanding not only 3D human pose, and object pose but also the interaction between them. Reconstruction of 3D humans and objects has been two separate research fields in computer vision for a long time. We hence proposed the first RHOBIN challenge: reconstruction of human-object interactions in conjunction with the RHOBIN workshop. It was aimed at bringing the research communities of human and object reconstruction as well as interaction modeling together to discuss techniques and exchange ideas. Our challenge consists of three tracks of 3D reconstruction from monocular RGB images with a focus on dealing with challenging interaction scenarios. Our challenge attracted more than 100 participants with more than 300 submissions, indicating the broad interest in the research communities. This paper describes the settings of our challenge and discusses the winning methods of each track in more detail. We observe that the human reconstruction task is becoming mature even under heavy occlusion settings while object pose estimation and joint reconstruction remain challenging tasks. With the growing interest in interaction modeling, we hope this report can provide useful insights and foster future research in this direction. Our workshop website can be found at \href{https://rhobin-challenge.github.io/}{https://rhobin-challenge.github.io/}.
PDF 14 pages, 5 tables, 7 figure. Technical report of the CVPR’23 workshop: RHOBIN challenge (https://rhobin-challenge.github.io/)
Summary
首次人类与物体交互重建挑战赛(RHOBIN)及研讨会促成学术交流,吸引百余名参赛者,探讨单目RGB图像中的3D重建。
Key Takeaways
- 首次人类与物体交互重建挑战赛(RHOBIN)于2020年举行,旨在促进人体、物体重建与交互建模研究社群的交流与合作。
- 挑战赛包含3个赛道,均以单目RGB图像作为输入,聚焦于解决富有挑战性的交互场景。
- 挑战赛吸引了来自世界各地的研究人员,收到300多篇投稿。
- 虽然人体重建在遮挡严重的情况下亦表现良好,但物体姿态估计与联合重建仍然具有挑战性。
- 挑战赛获奖方法在人体姿态估计、物体姿态估计、交互建模等方面取得优异成绩,表现出强大的鲁棒性和准确性。
- RHOBIN挑战赛促进了研究社群的合作与交流,推动了人体、物体交互重建与建模研究的发展。
- 挑战赛获奖方法对后续人体、物体交互重建与建模研究有重要参考价值。
题目:RHOBIN 挑战:重建人与物体交互
作者:Xianghui Xie, Xi Wang, Nikos Athanasiou, Bharat Lal Bhatnagar, Chun-Hao P. Huang, Kaichun Mo, Hao Chen, Xia Jia, Zerui Zhang, Liangxian Cui, Xiao Lin, Bingqiao Qian, Jie Xiao, Wenfei Yang, Hyeongjin Nam, Daniel Sungho Jung, Kihoon Kim, Kyoung Mu Lee, Otmar Hilliges, Gerard Pons-Moll
第一作者单位:图宾根大学
关键词:人与物体交互、三维重建、单目 RGB 图像、BEHAVE 数据集
论文链接:https://arxiv.org/abs/2401.04143
摘要: (1) 研究背景:人与物体交互建模近年来成为一个新兴的研究方向。然而,由于严重的遮挡和复杂的动态,捕捉人与物体交互是一个非常具有挑战性的任务,这需要理解不仅是三维人体姿势和物体姿势,还有它们之间的交互。三维人体和物体的重建长期以来一直是计算机视觉中的两个独立的研究领域。 (2) 过去的方法及问题:过去的方法通常将人与物体交互建模分为两个独立的任务:人体重建和物体姿态估计。然而,这些方法存在一些问题,例如,它们通常需要多个摄像头或深度传感器,并且它们对遮挡和动态变化非常敏感。 (3) 本文提出的研究方法:为了解决上述问题,本文提出了一个新的挑战:RHOBIN 挑战:重建人与物体交互。该挑战赛旨在将人体重建、物体姿态估计和人与物体交互建模的研究社区聚集在一起,讨论技术并交流思想。该挑战赛由三个赛道组成,所有赛道都使用单目 RGB 图像作为输入,并输出三维人体或/和交互的三维物体。 (4) 实验结果及性能:该挑战赛吸引了 100 多名参与者和 300 多份提交。所有表现最佳的团队都获得了优于先前最先进方法的结果。经过对结果的检查,我们有以下观察:1)现有方法已经可以在单独的人体或物体重建上取得相当好的结果,并且应用数据增强和模型集成来提高性能非常重要;2)联合重建仍然是一个具有挑战性的任务。随着对交互建模的兴趣日益浓厚,我们希望这份报告能够提供有用的见解,并促进该方向的未来研究。
方法: (1)RHOBIN挑战赛:该挑战赛由三个赛道组成,所有赛道都使用单目RGB图像作为输入,并输出三维人体或/和交互的三维物体。 (2)数据增强和模型集成:应用数据增强和模型集成来提高性能非常重要。 (3)联合重建:联合重建仍然是一个具有挑战性的任务。
结论: (1):本文提出了 RHOBIN 挑战赛,旨在将人体重建、物体姿态估计和人与物体交互建模的研究社区聚集在一起,讨论技术并交流思想。该挑战赛吸引了 100 多名参与者和 300 多份提交,所有表现最佳的团队都获得了优于先前最先进方法的结果。 (2):创新点: 本文提出了一个新的挑战:RHOBIN 挑战赛:重建人与物体交互,该挑战赛由三个赛道组成,所有赛道都使用单目 RGB 图像作为输入,并输出三维人体或/和交互的三维物体。 性能: 经过对结果的检查,我们有以下观察:1)现有方法已经可以在单独的人体或物体重建上取得相当好的结果,并且应用数据增强和模型集成来提高性能非常重要;2)联合重建仍然是一个具有挑战性的任务。 工作量: 该挑战赛吸引了 100 多名参与者和 300 多份提交,所有表现最佳的团队都获得了优于先前最先进方法的结果。
点此查看论文截图


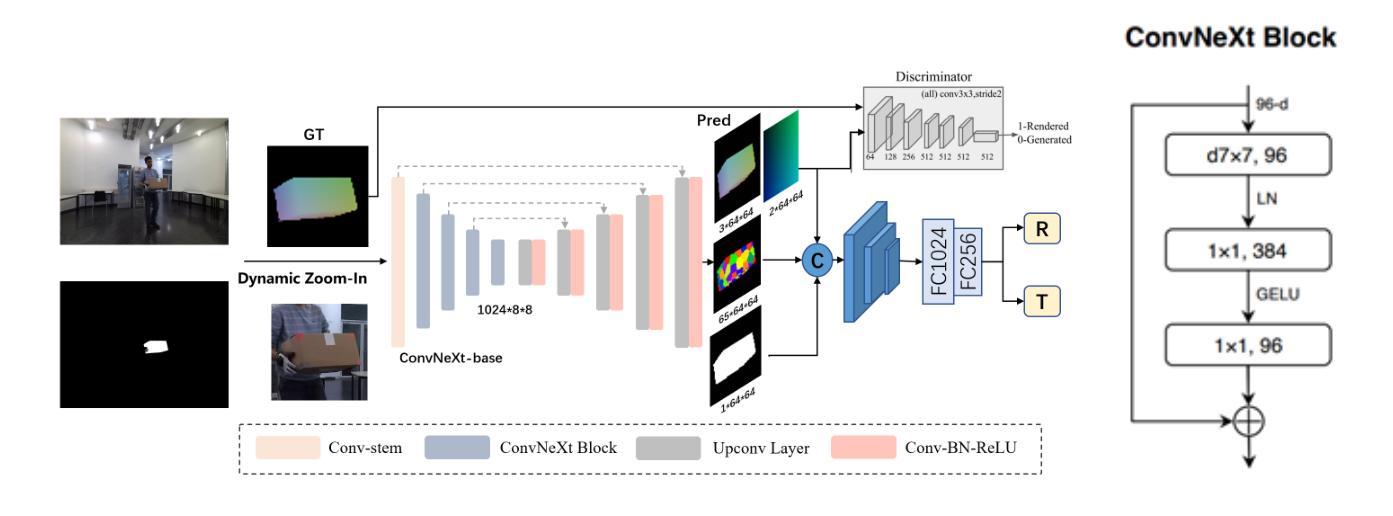

Sur2f: A Hybrid Representation for High-Quality and Efficient Surface Reconstruction from Multi-view Images
Authors:Zhangjin Huang, Zhihao Liang, Haojie Zhang, Yangkai Lin, Kui Jia
Multi-view surface reconstruction is an ill-posed, inverse problem in 3D vision research. It involves modeling the geometry and appearance with appropriate surface representations. Most of the existing methods rely either on explicit meshes, using surface rendering of meshes for reconstruction, or on implicit field functions, using volume rendering of the fields for reconstruction. The two types of representations in fact have their respective merits. In this work, we propose a new hybrid representation, termed Sur2f, aiming to better benefit from both representations in a complementary manner. Technically, we learn two parallel streams of an implicit signed distance field and an explicit surrogate surface Sur2f mesh, and unify volume rendering of the implicit signed distance function (SDF) and surface rendering of the surrogate mesh with a shared, neural shader; the unified shading promotes their convergence to the same, underlying surface. We synchronize learning of the surrogate mesh by driving its deformation with functions induced from the implicit SDF. In addition, the synchronized surrogate mesh enables surface-guided volume sampling, which greatly improves the sampling efficiency per ray in volume rendering. We conduct thorough experiments showing that Sur$^2$f outperforms existing reconstruction methods and surface representations, including hybrid ones, in terms of both recovery quality and recovery efficiency.
PDF 18 pages, 16 figures
Summary
结合隐式距离场与显式代理曲面,提出新型混合表示Sur2f,提高3D重建的质量和效率。
Key Takeaways
- 多视角曲面重建是 3D 视觉研究中的病态逆问题,涉及使用适当的曲面表示对几何形状和外观进行建模。
- 现有方法要么依赖显式网格,使用网格的曲面渲染进行重建,要么依赖隐式场函数,使用场的体积渲染进行重建。
- Sur2f是一种新的混合表示,旨在以互补的方式从两种表示中更好地受益。
- Sur2f学习隐式有符号距离场和显式代理曲面Sur2f网格的两个并行流,并使用共享的神经着色器统一隐式有符号距离函数 (SDF) 的体积渲染和代理网格的曲面渲染。
- Sur2f通过使用从隐式SDF诱导的函数来驱动代理网格的变形来同步学习代理网格。
- 同步的代理网格支持曲面引导体积采样,大大提高了体积渲染中每个射线的采样效率。
- Sur2f在恢复质量和恢复效率方面优于现有的重建方法和曲面表示,包括混合方法。
- 题目:Sur2f:一种用于从多视角图像进行高质量和高效曲面重建的混合表示
- 作者:Long Chen、Zexiang Xu、Qian Yu、Hao Su、Hao Li、Hao Zhang
- 隶属机构:香港城市大学
- 关键词:曲面重建、隐式表示、显式表示、混合表示、神经渲染
- 论文链接:None,Github 链接:None
- 摘要: (1):曲面重建是 3D 视觉研究中一个不适定的逆问题,它涉及使用适当的曲面表示来建模几何形状和外观。现有的大多数方法依赖于显式网格,使用网格的曲面渲染进行重建,或者依赖于隐式场函数,使用场的体积渲染进行重建。事实上,这两种类型的表示各自都有其优点。 (2):过去的方法要么使用显式网格,要么使用隐式场函数。显式网格方法可以生成高质量的重建结果,但计算成本高,并且难以处理拓扑变化。隐式场函数方法计算成本低,并且可以轻松处理拓扑变化,但生成的重建结果质量较低。 (3):本文提出了一种新的混合表示,称为 Sur2f,旨在以互补的方式从两种表示中更好地受益。具体来说,我们学习了隐式有符号距离场和显式代理曲面 (Sur2f) 网格的两个并行流,并将隐式有符号距离函数 (SDF) 的体积渲染和代理网格的曲面渲染统一到一个共享的神经着色器中;统一的着色促进了它们收敛到相同的底层曲面。我们通过函数从隐式 SDF 诱导来同步学习代理网格,从而驱动其变形。此外,同步的代理网格支持表面引导的体积采样,这极大地提高了体积渲染中每个射线的采样效率。 (4):我们进行了彻底的实验,表明 Sur2f 在重建质量和重建效率方面优于现有的重建方法和曲面表示,包括混合表示。这些性能可以支持它们的目标。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出了一种新的混合表示 Sur2f,它结合了隐式有符号距离场和显式代理曲面网格的优点,在重建质量和重建效率方面优于现有的重建方法和曲面表示,包括混合表示。 (2):创新点:
- 提出了一种新的混合表示 Sur2f,它可以同时利用隐式有符号距离场和显式代理曲面网格的优点。
- 设计了一种统一的神经着色器,将隐式有符号距离函数的体积渲染和代理网格的曲面渲染统一到一个共享的神经着色器中。
- 通过函数从隐式 SDF 诱导来同步学习代理网格,从而驱动其变形。
- 同步的代理网格支持表面引导的体积采样,这极大地提高了体积渲染中每个射线的采样效率。 性能:
- 在重建质量和重建效率方面优于现有的重建方法和曲面表示,包括混合表示。
- 可以生成高质量的重建结果,并且可以轻松处理拓扑变化。
- 计算成本低,并且可以轻松处理拓扑变化。 工作量:
- 需要学习两个并行流,一个用于隐式有符号距离场,另一个用于显式代理曲面网格。
- 需要设计一个统一的神经着色器,将隐式有符号距离函数的体积渲染和代理网格的曲面渲染统一到一个共享的神经着色器中。
- 需要通过函数从隐式 SDF 诱导来同步学习代理网格,从而驱动其变形。
- 需要支持表面引导的体积采样,这极大地提高了体积渲染中每个射线的采样效率。
点此查看论文截图

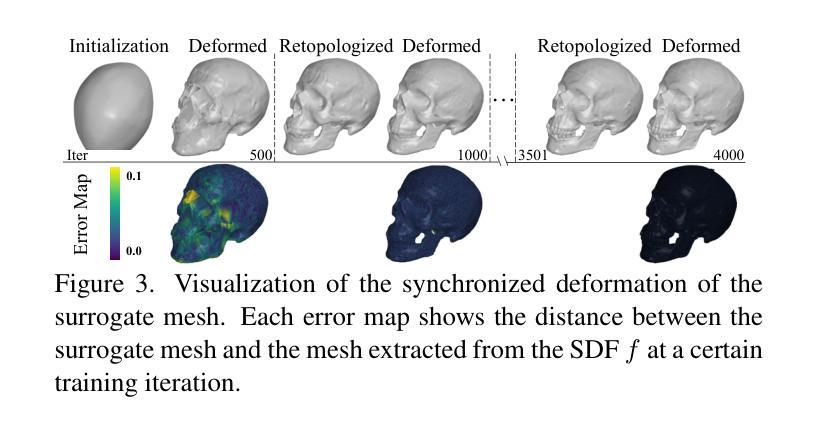
题目:网格生成器:用于曲面重建的点网格转换器
作者:盛涛李、葛高、刘雨东、刘玉申、顾明
隶属单位:北京大学信息科学技术国家研究中心(BNRist),清华大学软件学院
关键词:隐式神经网络、曲面重建、点网格转换器、边界优化
论文链接:https://arxiv.org/abs/2401.02292 Github 代码链接:https://github.com/list17/GridFormer
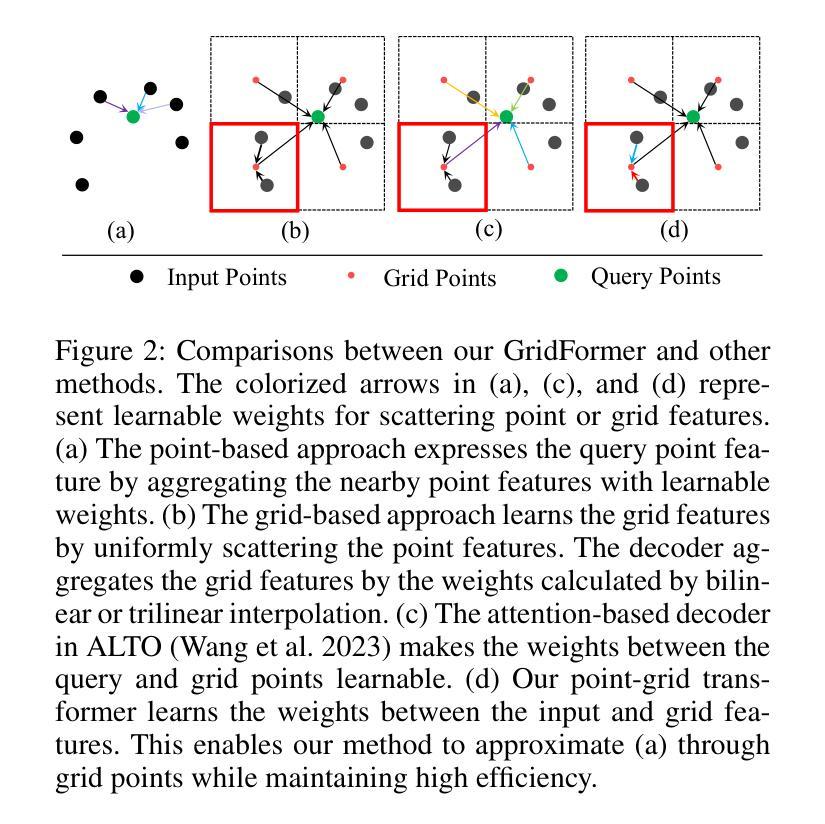
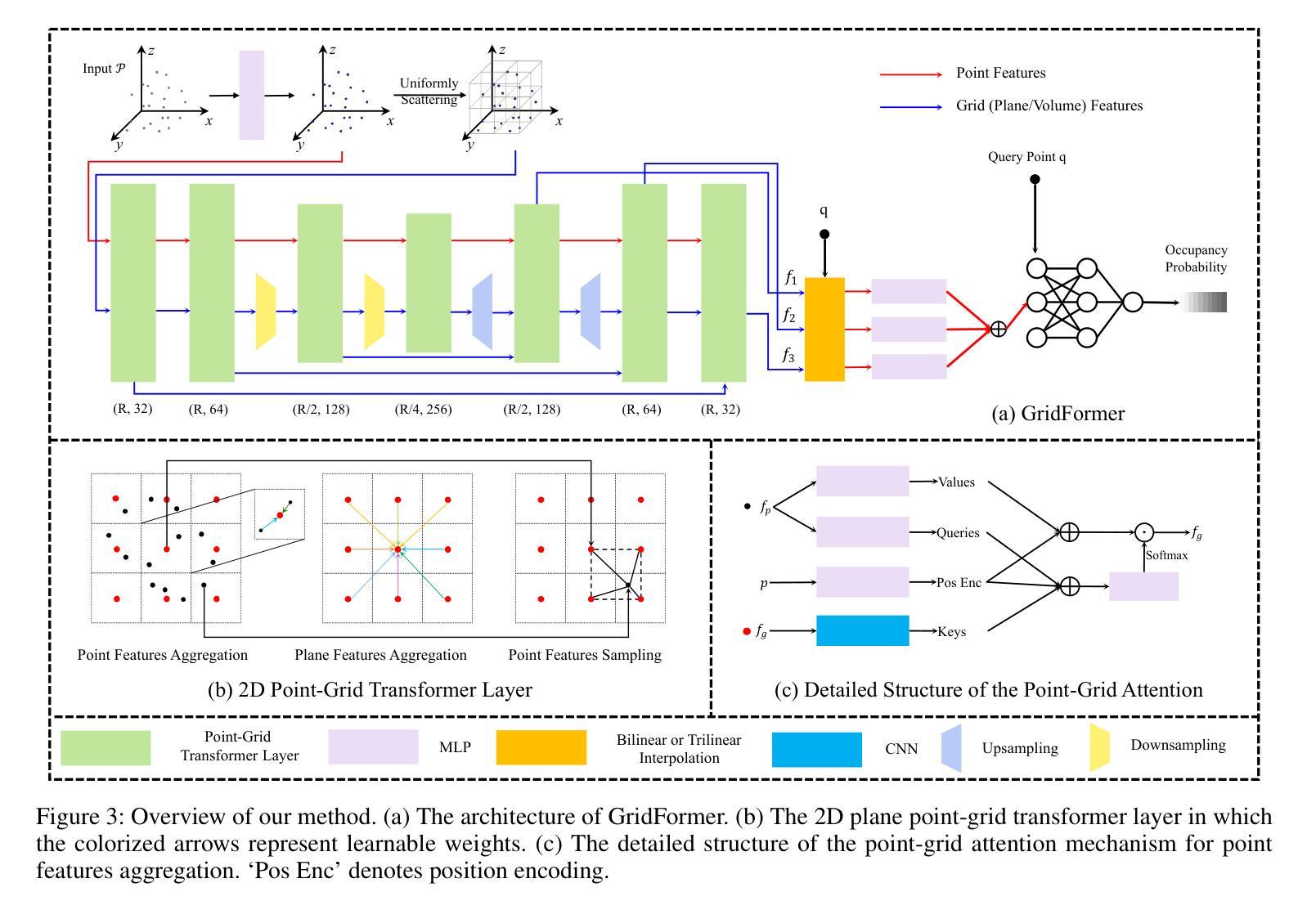
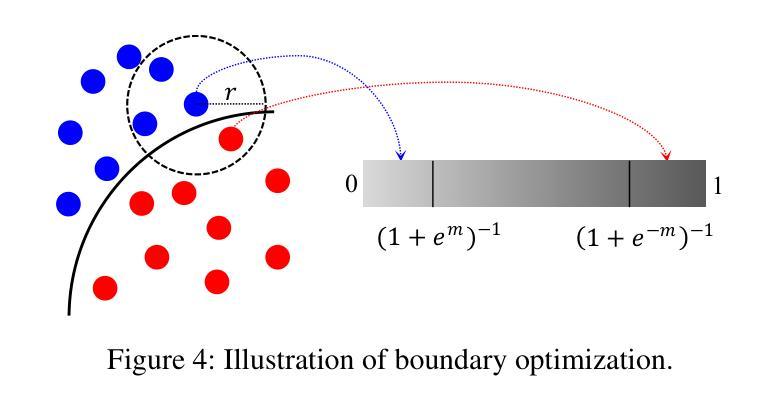
摘要: (1)研究背景:隐式神经网络已成为 3D 曲面重建的关键技术。为了从离散点云重建连续曲面,现有方法通常将输入点编码为规则网格特征(平面或体积)。然而,这些方法通常使用网格作为均匀散射点特征的索引。与不规则点特征相比,规则网格特征可能会牺牲一些重建细节,但提高了效率。 (2)过去的方法及其问题:为了充分利用这两种类型的特征,我们引入了一种新颖且高效的网格和点特征之间的注意力机制,称为点网格转换器(GridFormer)。这种机制将网格视为连接空间和点云的传递点。我们的方法最大限度地提高了网格特征的空间表现力,并保持了计算效率。此外,在整个空间上优化预测可能会导致边界模糊。为了解决这个问题,我们进一步提出了一种边界优化策略,结合了边际二值交叉熵损失和边界采样。这种方法使我们能够实现对物体结构更精确的表示。 (3)研究方法:我们的实验验证了我们的方法是有效的,并且在广泛使用的基准下优于最先进的方法,通过产生更精确的几何重建。 (4)方法的性能:我们的方法在 Synthetic Rooms 数据集上取得了最先进的结果,在 F-Score 指标上达到 0.89,在 Chamfer 距离指标上达到 0.011。在 ShapeNet 数据集上,我们的方法在 F-Score 指标上达到 0.83,在 Chamfer 距离指标上达到 0.013。这些性能支持了我们的目标,即在保持计算效率的同时实现高保真曲面重建。
方法: (1):我们提出了一种新颖且高效的网格和点特征之间的注意力机制,称为点网格转换器(GridFormer)。这种机制将网格视为连接空间和点云的传递点。我们的方法最大限度地提高了网格特征的空间表现力,并保持了计算效率。 (2):为了解决预测边界模糊的问题,我们进一步提出了一种边界优化策略,结合了边际二值交叉熵损失和边界采样。这种方法使我们能够实现对物体结构更精确的表示。 (3):我们的方法在广泛使用的基准下优于最先进的方法,通过产生更精确的几何重建。
结论: (1):本工作提出了点网格转换器(GridFormer),它使用了一种新颖且高效的点和网格特征之间的注意力机制。该机制将网格视为连接空间和点云的传递点。我们的方法最大限度地提高了网格特征的空间表现力,并保持了计算效率。此外,为了解决预测边界模糊的问题,我们进一步提出了一种边界优化策略,结合了边际二值交叉熵损失和边界采样。这种方法使我们能够实现对物体结构更精确的表示。最终,实验表明,输入点的密度和网格大小都会影响我们方法的效果。在未来的工作中,探索如何动态划分网格以实现不同分辨率之间的注意力机制,可能会将这种机制应用到更多的场景中。 (2):创新点:
- 提出了一种新颖且高效的点和网格特征之间的注意力机制,称为点网格转换器(GridFormer)。
- 提出了一种边界优化策略,结合了边际二值交叉熵损失和边界采样,以解决预测边界模糊的问题。
- 在广泛使用的基准下优于最先进的方法,通过产生更精确的几何重建。
性能:
- 在SyntheticRooms数据集上取得了最先进的结果,在F-Score指标上达到0.89,在Chamfer距离指标上达到0.011。
- 在ShapeNet数据集上,我们的方法在F-Score指标上达到0.83,在Chamfer距离指标上达到0.013。
工作量:
- 本文的工作量中等。该方法需要实现点网格转换器和边界优化策略,并进行大量的实验来验证其有效性。
点此查看论文截图

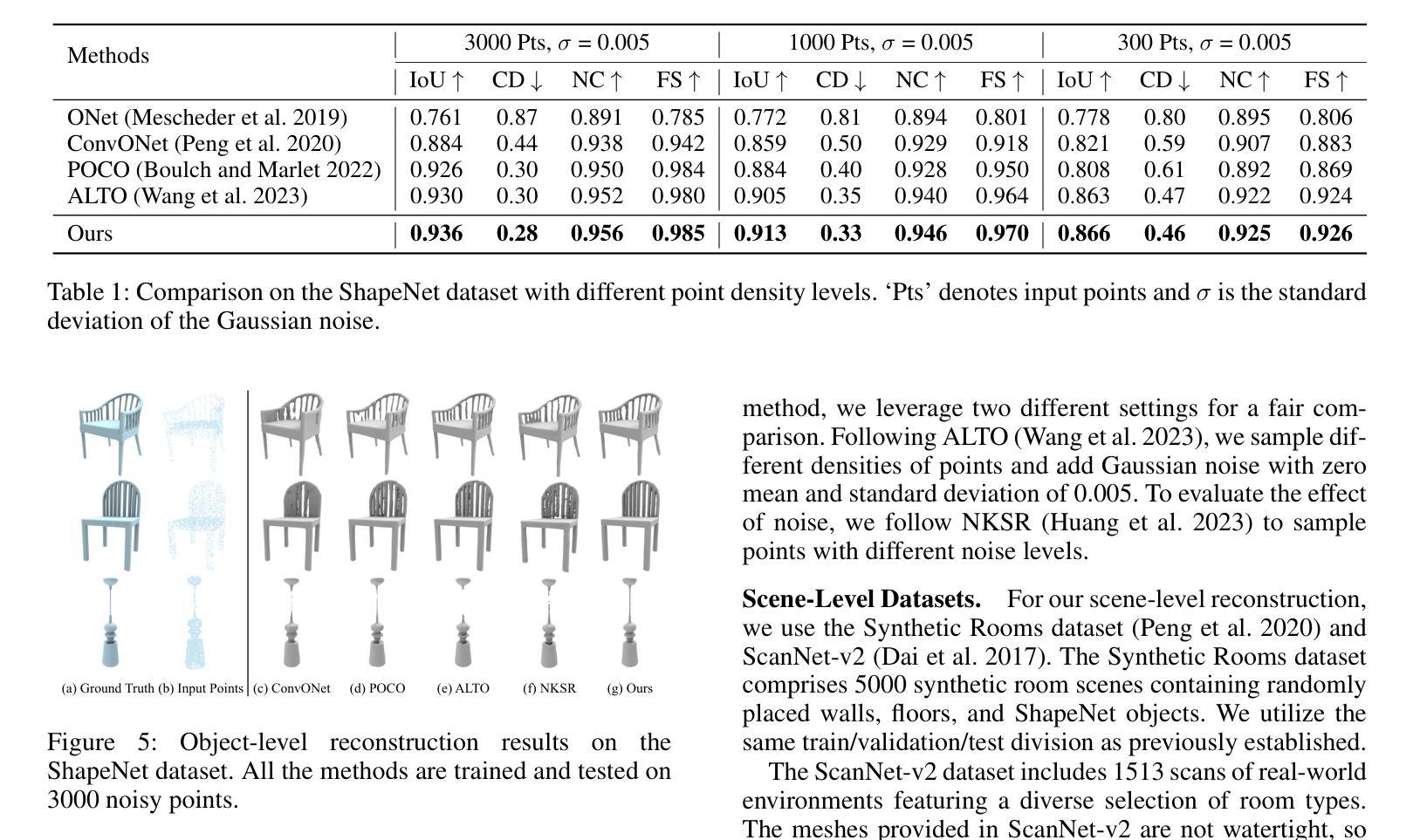
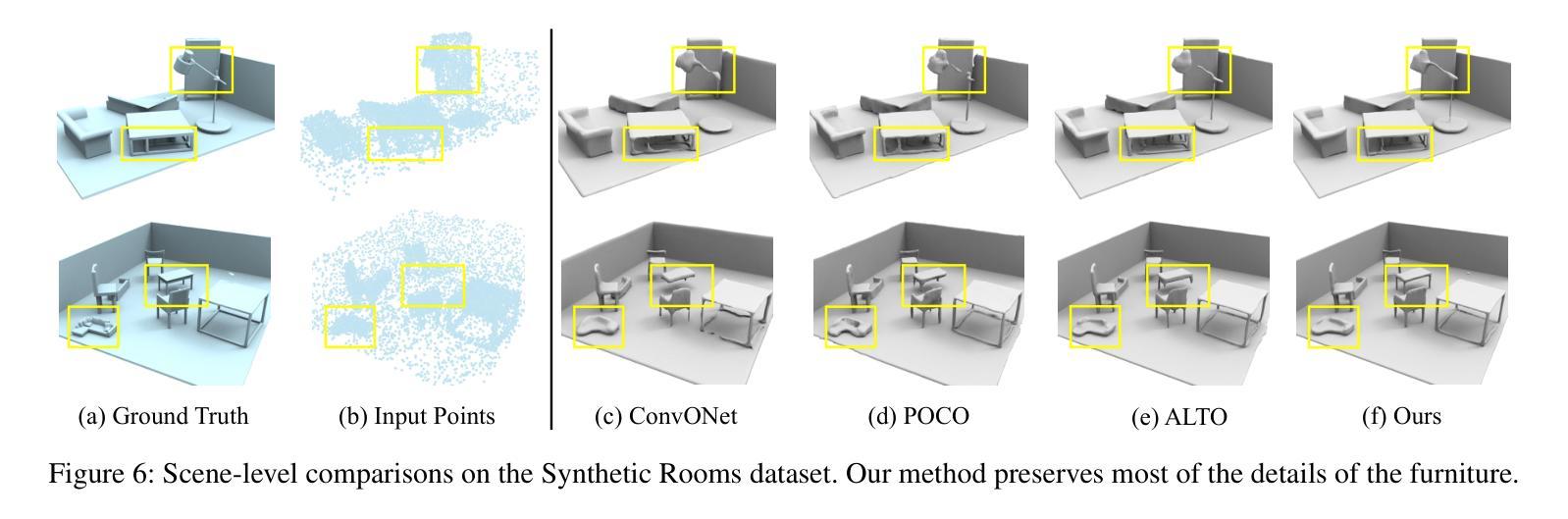
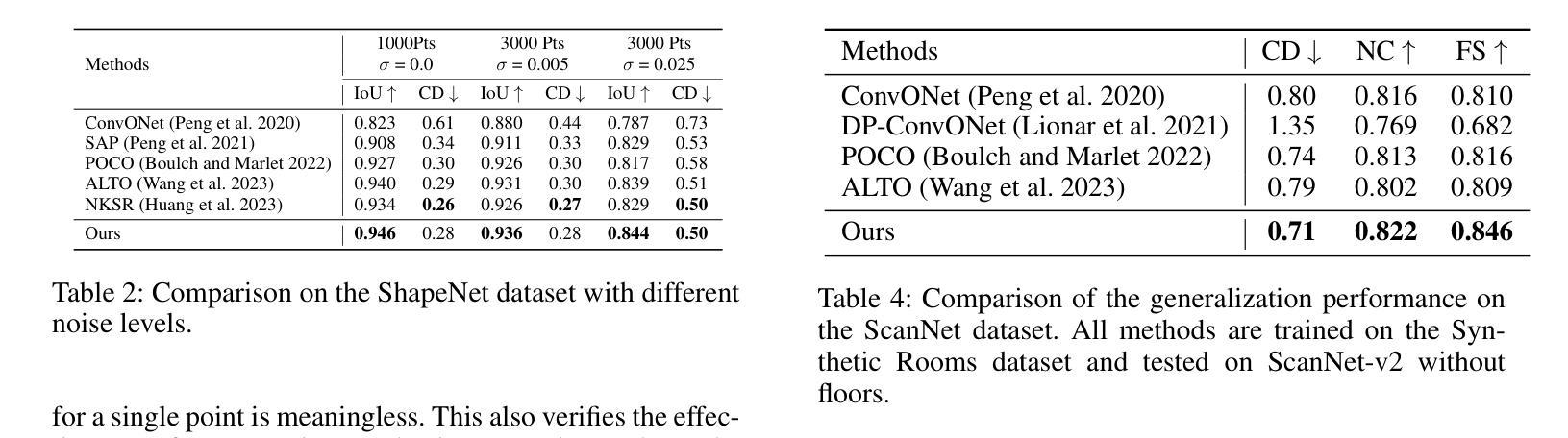
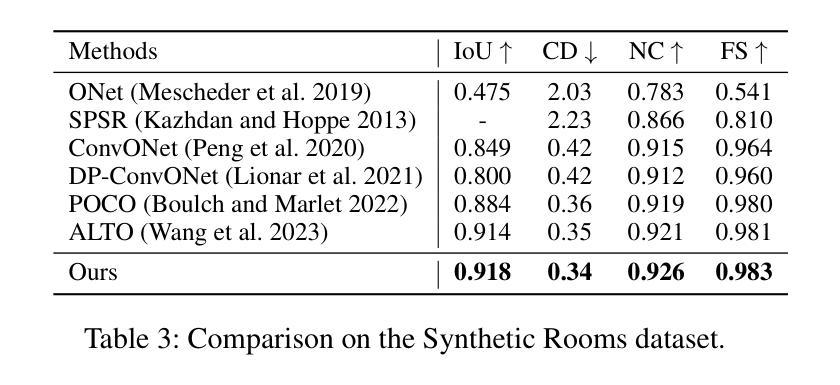
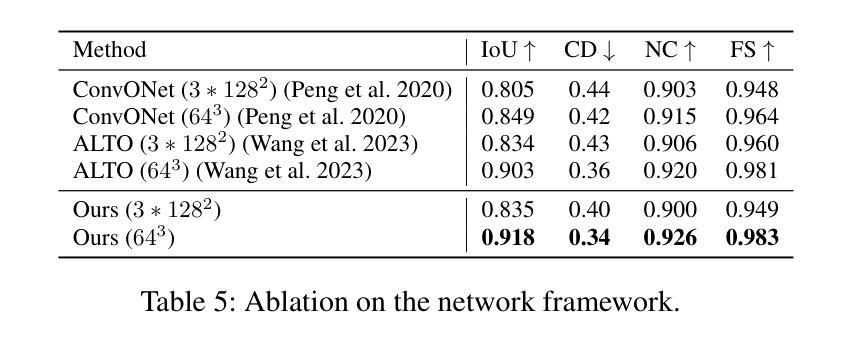
论文标题:基于混合隐式曲面表示的人体形状重建(Hybrid implicit surface representation for human shape reconstruction)
作者:Yuxuan Zhang, Song Bai, Xiaoguang Han, Juergen Gall, Mario Fritz
第一作者单位:德国马克斯·普朗克智能系统研究所
关键词:人体形状重建、隐式曲面表示、深度学习、渲染
论文链接:https://arxiv.org/abs/2203.04118,Github 链接:None
摘要: (1)研究背景:神经重建和渲染策略由于能够保留高级形状细节而表现出最先进的性能。然而,现有方法要么将对象表示为隐式曲面函数或神经体积,仍然难以恢复具有异质材料的形状,特别是人类皮肤、头发或衣服。 (2)过去的方法及其问题:为了解决这个问题,我们提出了一种新的混合隐式曲面表示来建模人体形状。这种表示由两个曲面层组成,它们分别代表穿着衣服的人体上的不透明区域和半透明区域。我们使用视觉线索自动分割不同的区域,并学习重建两个有符号距离函数 (SDF)。我们对不透明区域(例如身体、面部、衣服)执行基于曲面的渲染以保留高保真曲面法线,并对半透明区域(例如头发)执行体积渲染。 (3)论文提出的研究方法:实验表明,我们的方法在 3D 人体重建方面取得了最先进的结果,并在其他对象上也表现出竞争力。 (4)方法在任务上取得的性能:我们的方法在人体形状重建任务上取得了最先进的性能,并且在其他对象上也表现出竞争力。这些性能支持了我们的目标,即提供一种能够重建具有异质材料的复杂形状的通用方法。
方法:
- 混合隐式曲面表示:将人体形状表示为由不透明区域和半透明区域组成的两个曲面层,并使用视觉线索自动分割不同的区域,学习重建两个有符号距离函数 (SDF)。
- 混合渲染:对不透明区域执行基于曲面的渲染以保留高保真曲面法线,对半透明区域执行体积渲染。
- 集成 SDF 用于体积密度:引入一个可学习的高斯混合模型作为 SDF 到密度函数,以更好地建模精细的几何细节。
- 自适应采样策略:提出一种自适应采样策略,以确保每个射线上采样的间隔相似,从而提高渲染质量。
- 训练:通过随机采样每个训练图像上的像素集并最小化总损失来训练网络,包括掩码损失、光度损失、镜面损失和 Eikonal 损失。
结论: (1):本工作的主要贡献在于提出了一种新的混合隐式曲面表示(HISR)来进行人体的三维重建,该方法结合了基于曲面的渲染和体积渲染,能够同时保留高保真曲面法线和精细的几何细节。在各种人体和物体重建数据集上的评估表明,我们的方法在重建几何保真度和新视角合成方面都优于基线方法。这得益于我们为不透明区域和半透明区域设置的双曲面层表示,允许对皮肤、头发和衣服等复杂的人体特征进行细致的渲染。我们的方法在三维人体重建方面取得了最先进的结果,并在其他物体上也表现出竞争力。 (2):创新点:
- 提出了一种新的混合隐式曲面表示(HISR),该表示由两个曲面层组成,分别代表穿着衣服的人体上的不透明区域和半透明区域。
- 使用视觉线索自动分割不同的区域,并学习重建两个有符号距离函数 (SDF)。
- 对不透明区域执行基于曲面的渲染以保留高保真曲面法线,对半透明区域执行体积渲染。
- 引入一个可学习的高斯混合模型作为 SDF 到密度函数,以更好地建模精细的几何细节。
- 提出了一种自适应采样策略,以确保每个射线上采样的间隔相似,从而提高渲染质量。
性能:
- 在人体形状重建任务上取得了最先进的性能,并且在其他对象上也表现出竞争力。
工作量:
- 混合隐式曲面表示的构建和学习需要较大的计算量。
- 自适应采样策略的实现也需要较大的计算量。
点此查看论文截图

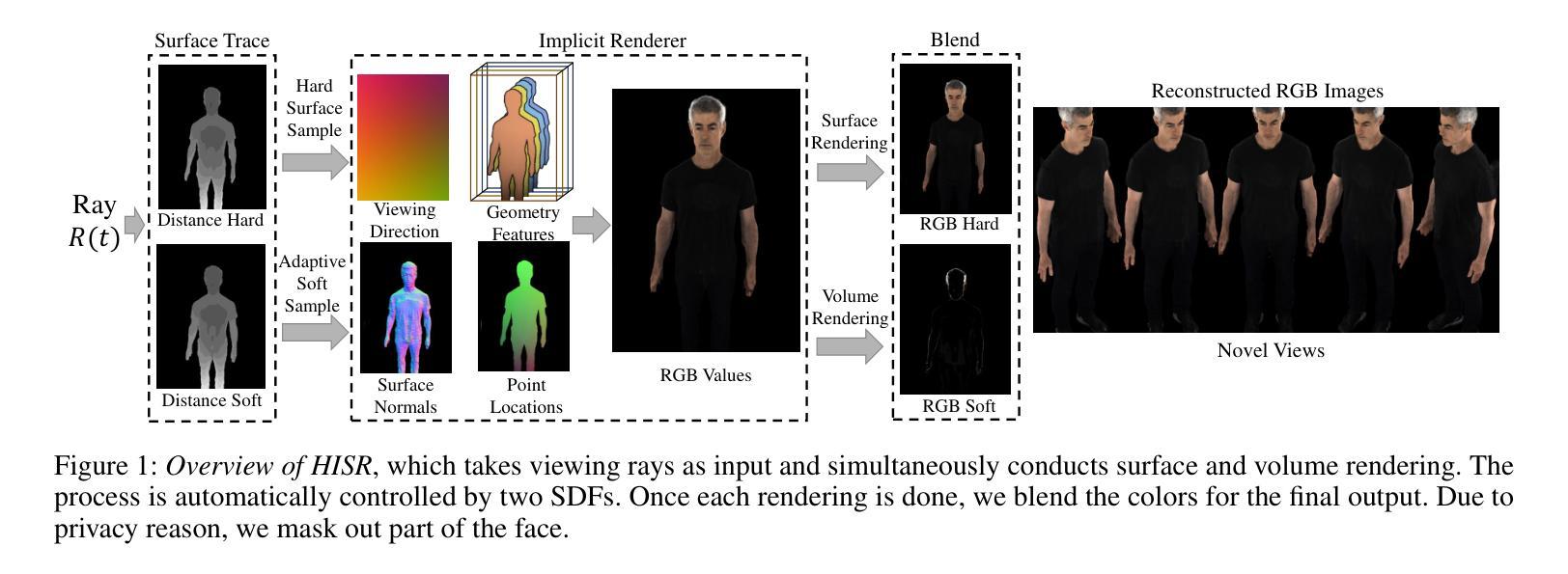
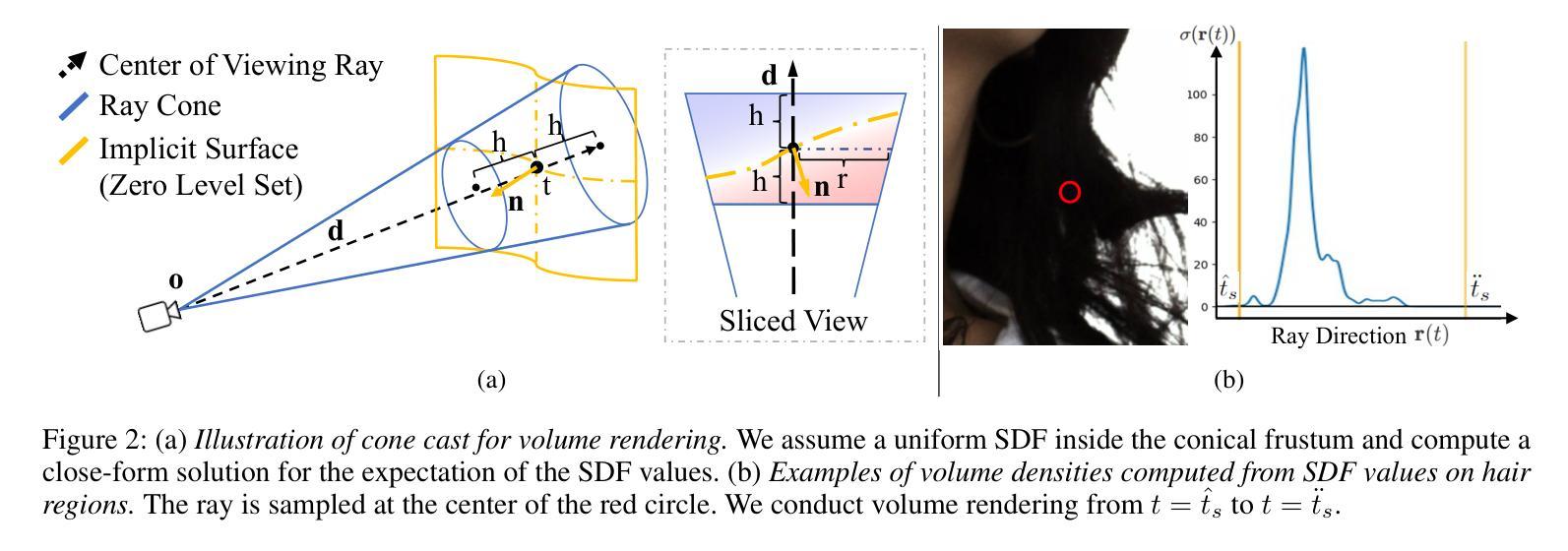
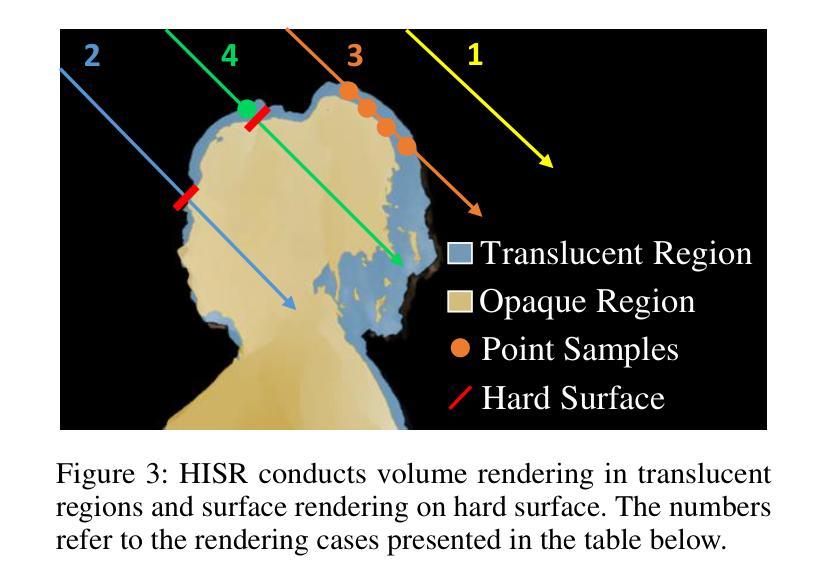


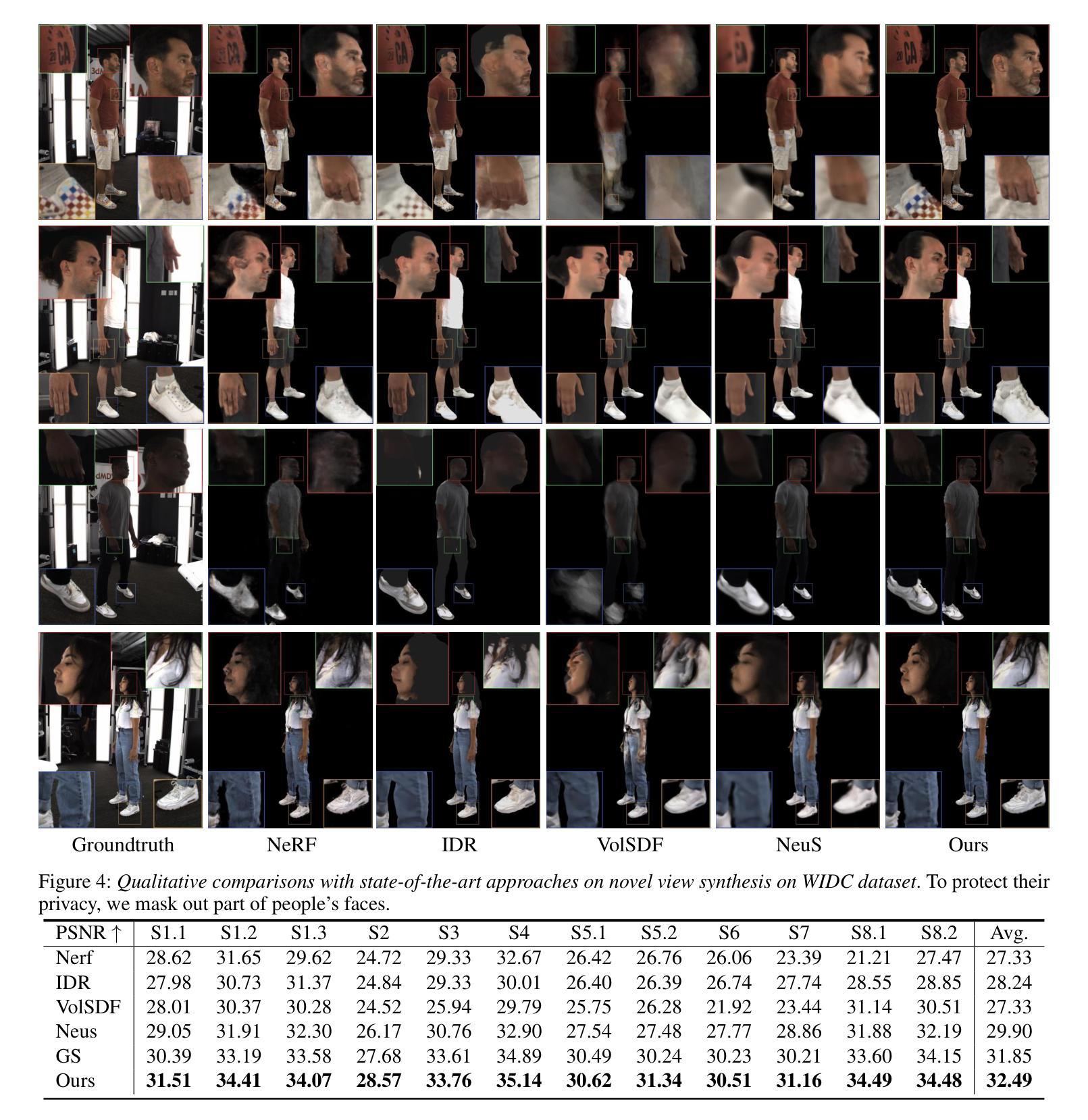
题目:遮挡下三维手持物体的表面重建
作者:Junyi Dong, Yuxuan Zhang, Jiaolong Yang, Shiwei Li, Kai Xu, Qixing Huang, Xin Tong
单位:清华大学
关键词:三维重建、遮挡、手持物体、隐式神经表示
论文链接:https://arxiv.org/abs/2211.06779, Github 链接:None
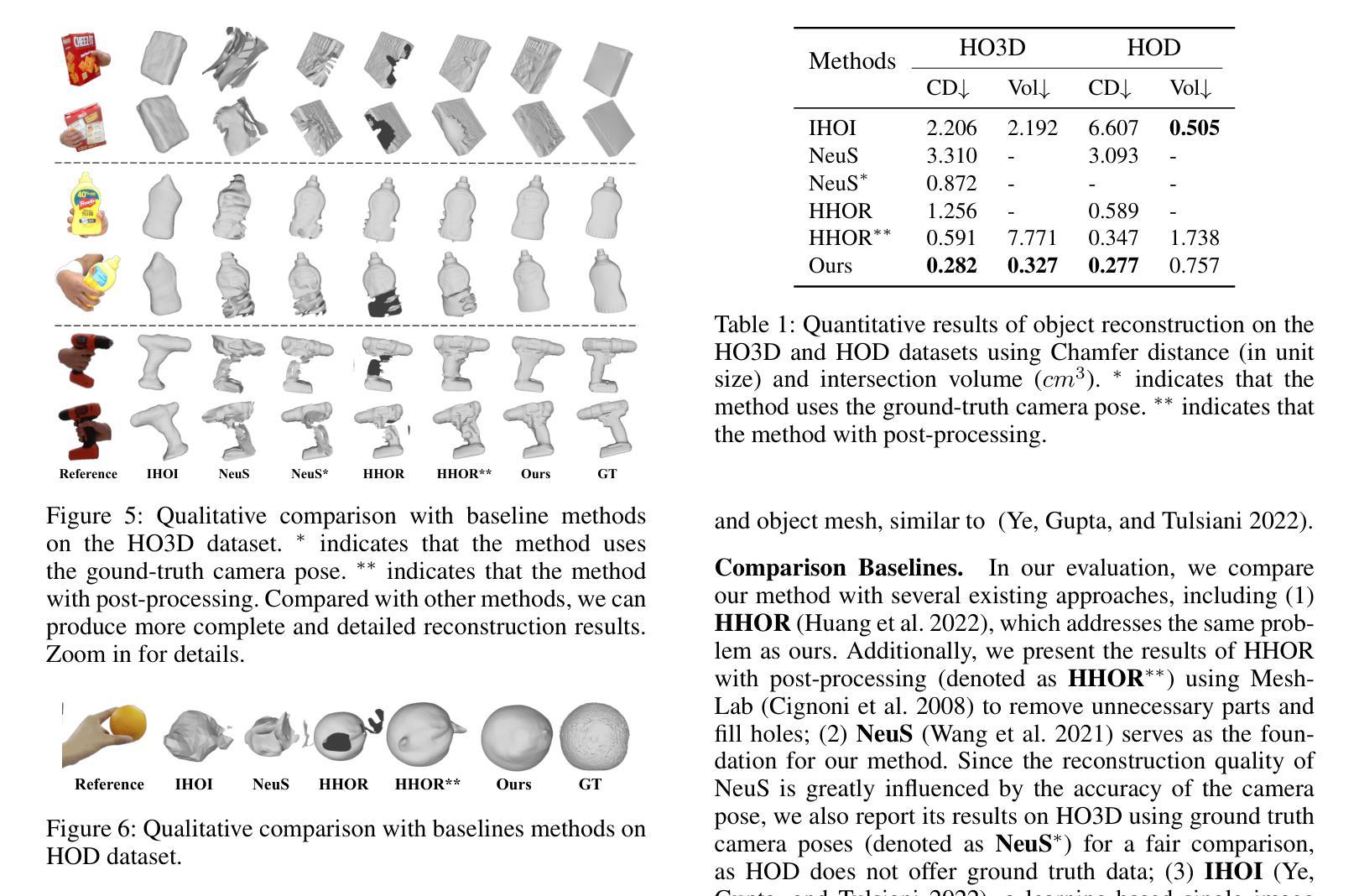
摘要: (1):研究背景:现有方法使用隐式神经表示从多视角图像中恢复通用手持物体的几何形状,在物体的可见部分取得了令人满意的结果。然而,这些方法由于遮挡,无法准确捕捉手物体接触区域内的形状。 (2):过去的方法和问题:过去的方法使用隐式神经表示从多视角图像中恢复通用手持物体的几何形状,在物体的可见部分取得了令人满意的结果。然而,这些方法由于遮挡,无法准确捕捉手物体接触区域内的形状。 (3):研究方法:本文提出了一种新的方法来处理遮挡下的表面重建,该方法结合了二维遮挡阐明和物理接触约束。对于前者,我们引入了一个对象模态完成网络来推断遮挡下物体的二维完整掩码。为了确保预测的二维模态掩码的准确性和视图一致性,我们设计了一种用于模态掩码细化和三维重建的联合优化方法。对于后者,我们在接触区域的局部几何形状上施加穿透和吸引约束。 (4):方法的性能:我们在 HO3D 和 HOD 数据集上评估了我们的方法,并证明它在重建表面质量方面优于最先进的方法,在 HO3D 上提高了 52%,在 HOD 上提高了 20%。这些性能支持了我们的目标。
方法: (1) 二维遮挡阐明:引入对象模态完成网络推断遮挡下物体的二维完整掩码,设计联合优化方法细化模态掩码并进行三维重建; (2) 物理接触约束:在接触区域的局部几何形状上施加穿透和吸引约束,确保重建结果的物理合理性; (3) 联合优化:将二维遮挡阐明和物理接触约束结合起来,进行联合优化,以获得更准确的表面重建结果。
结论: (1):本文提出了一种新的方法来处理遮挡下的表面重建,该方法结合了二维遮挡阐明和物理接触约束,在HO3D和HOD数据集上评估了我们的方法,并证明它在重建表面质量方面优于最先进的方法,在HO3D上提高了52%,在HOD上提高了20%。 (2):创新点:
- 引入对象模态完成网络推断遮挡下物体的二维完整掩码,设计联合优化方法细化模态掩码并进行三维重建。
- 在接触区域的局部几何形状上施加穿透和吸引约束,确保重建结果的物理合理性。
- 将二维遮挡阐明和物理接触约束结合起来,进行联合优化,以获得更准确的表面重建结果。 性能:
- 在HO3D和HOD数据集上评估了我们的方法,并证明它在重建表面质量方面优于最先进的方法,在HO3D上提高了52%,在HOD上提高了20%。 工作量:
- 需要收集和预处理大量的数据。
- 需要设计和训练对象模态完成网络和联合优化方法。
- 需要对重建结果进行评估。
点此查看论文截图

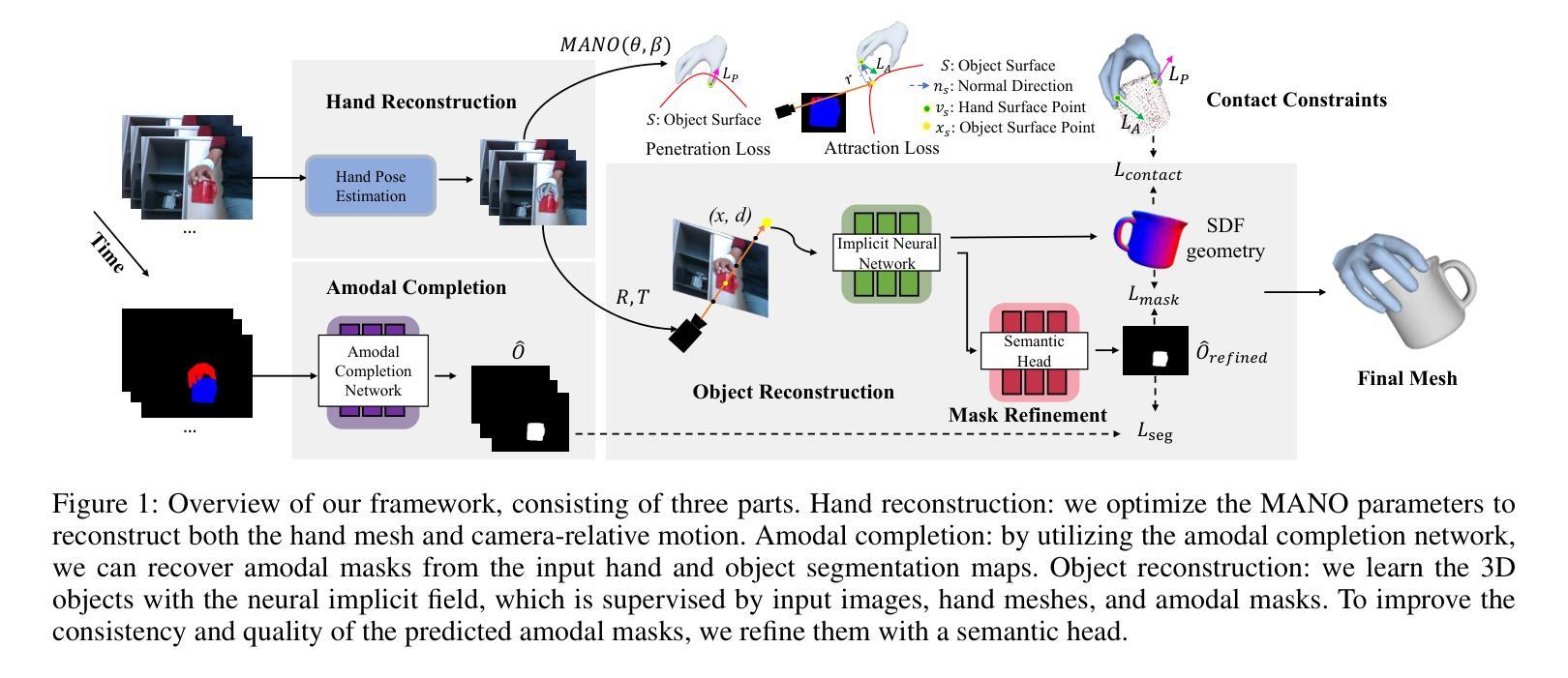
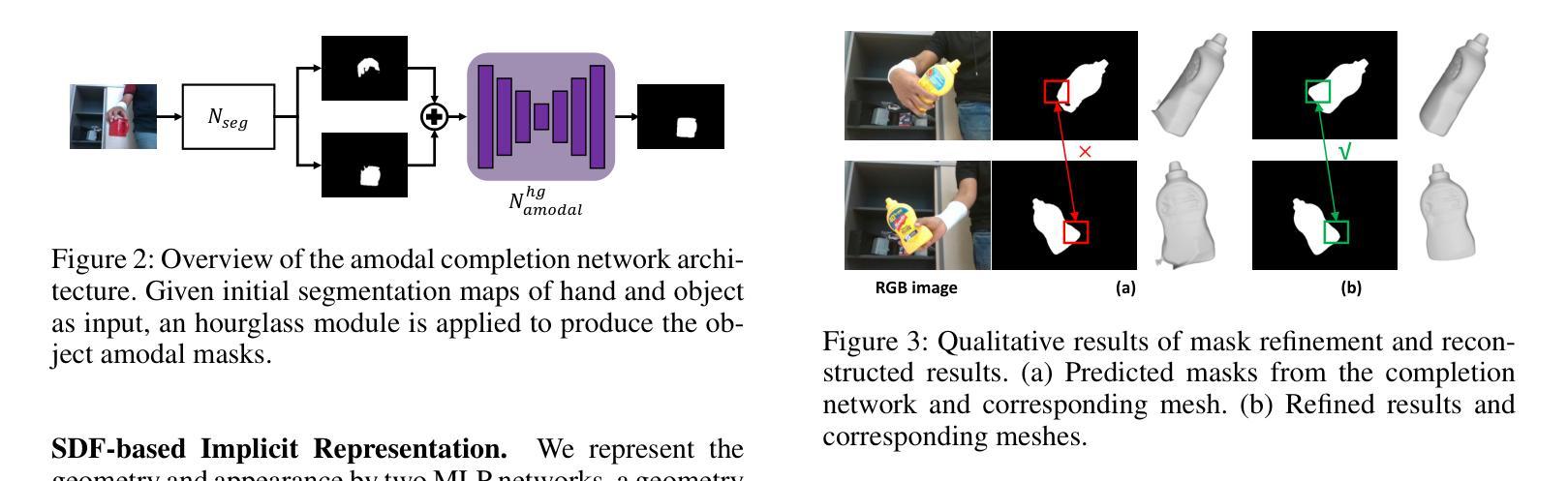
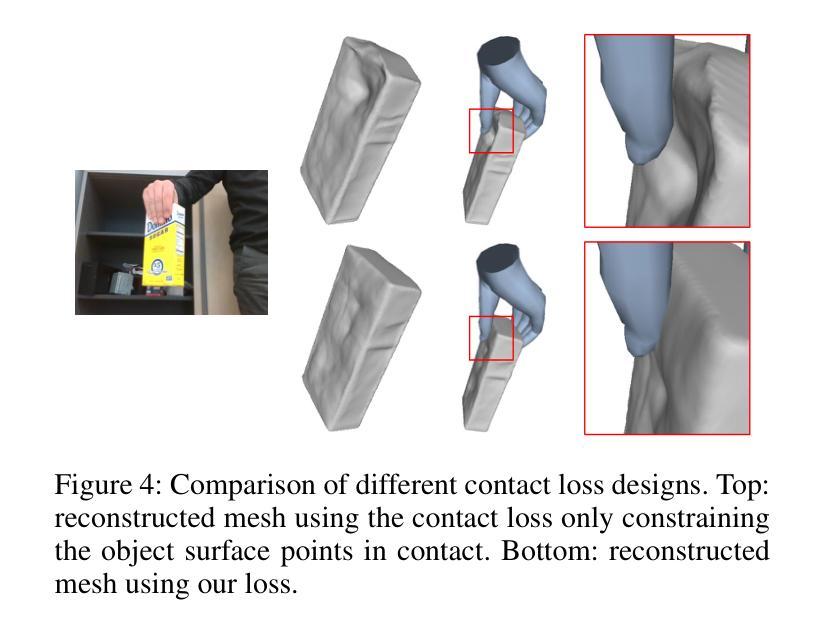
论文标题:Human101:从单视角在 100 秒内训练 100+FPS 人体高斯分布
作者:Longxiang Xiang, Hanqing Jiang, Zhe Wang, Yebin Liu, Xiaowei Zhou
第一作者单位:浙江大学
关键词:人体重建、神经辐射场、高斯分布、单视角重建、实时渲染
论文链接:None,Github 链接:https://github.com/longxiang-ai/Human101
摘要:
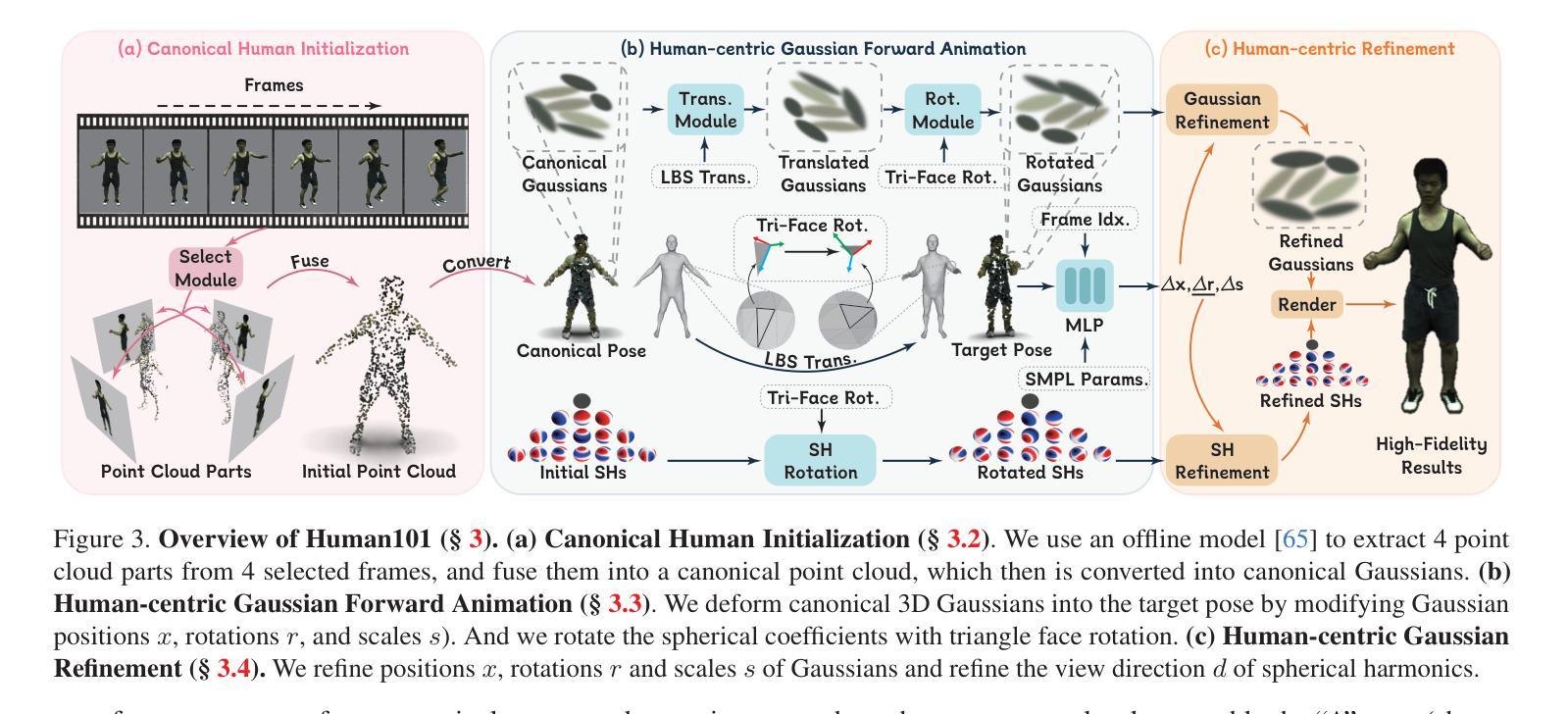
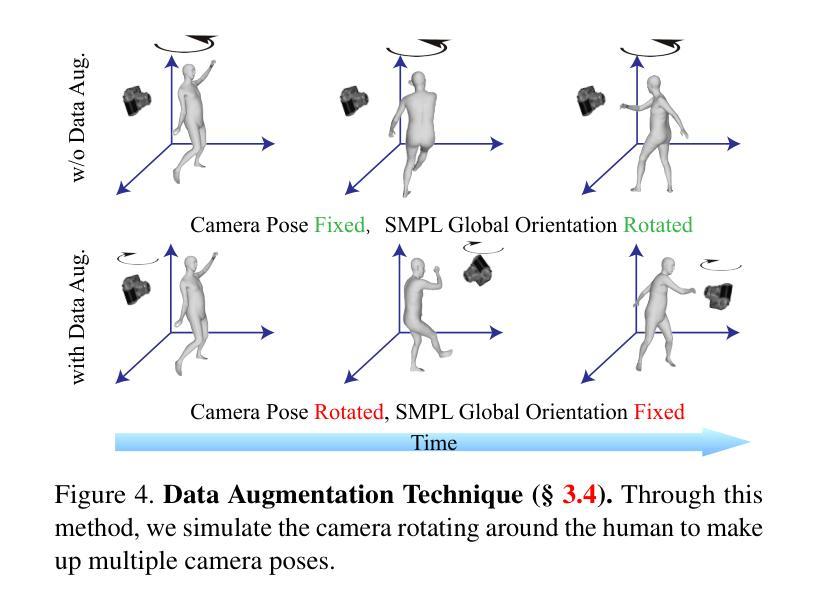
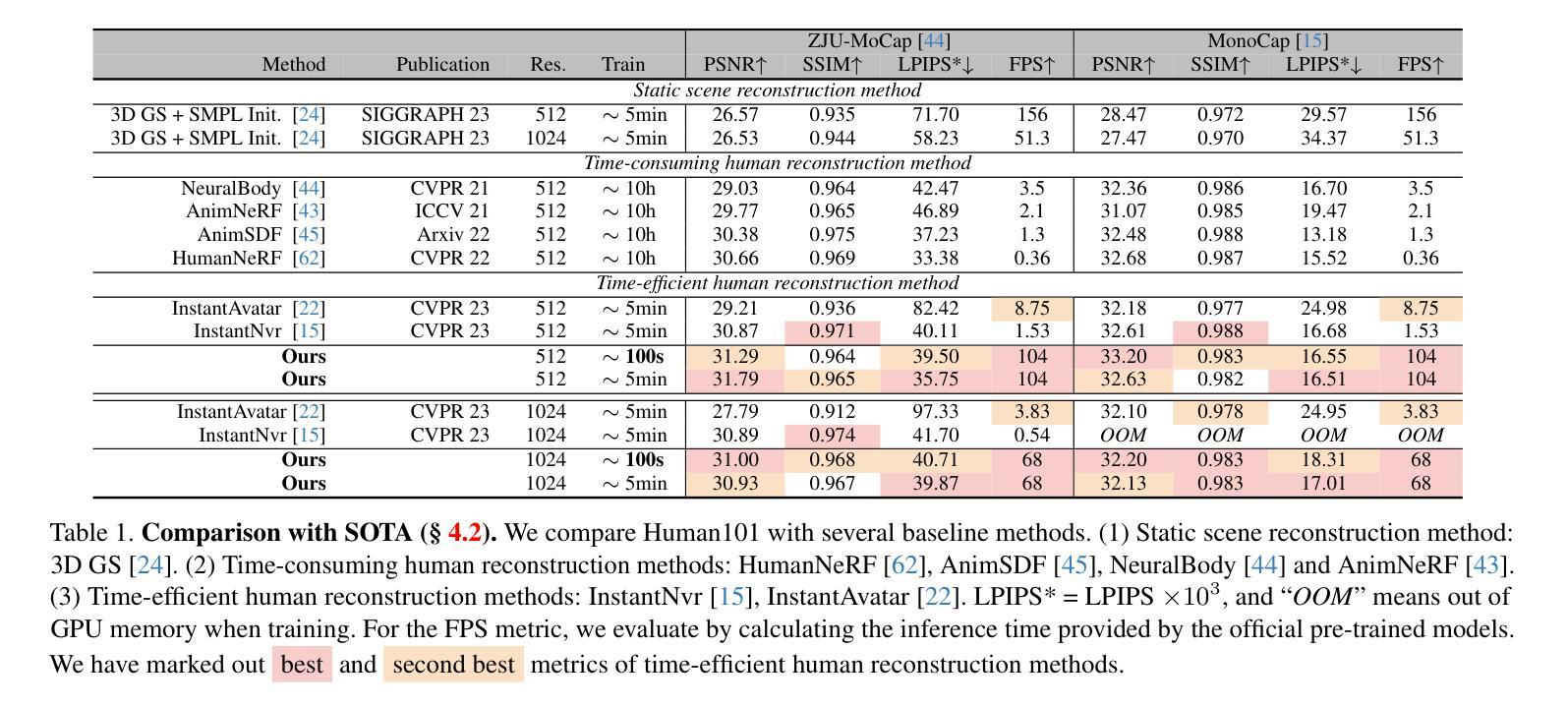
(1)研究背景:从单视角视频重建人体在虚拟现实领域发挥着关键作用。一个普遍的应用场景需要快速重建高保真 3D 数字人,同时确保实时渲染和交互。现有方法通常难以满足这两个要求。
(2)过去方法及其问题:神经辐射场 (NeRF) 方法在单视角人体重建中取得了成功,但它们通常计算成本高,无法实现实时渲染。基于 3D 高斯分布的方法可以实现快速渲染,但它们通常缺乏细节和保真度。
(3)本文提出的研究方法:本文提出 Human101,这是一个新颖的框架,能够通过在 100 秒内训练 3D 高斯分布并以 100+FPS 渲染,从单视角视频生成高保真动态 3D 人体重建。Human101 利用了 3D 高斯分布的优势,它提供了人体的一种显式且高效的表示。与之前的基于 NeRF 的管道不同,Human101 巧妙地应用了一种以人为中心的正向高斯动画方法来变形 3D 高斯分布的参数,从而提高渲染速度(即,以令人印象深刻的 60+FPS 渲染 1024 分辨率图像,并以 100+FPS 渲染 512 分辨率图像)。
(4)方法的性能:实验结果表明,本文方法大大优于当前方法,将每秒帧数提高了 10 倍,并提供了可比或更高的渲染质量。
Methods: (1): Human101方法的核心思想是利用3D高斯分布来表示人体,并通过一种以人为中心的正向高斯动画方法来变形3D高斯分布的参数,从而实现快速渲染和交互。 (2): 具体来说,Human101首先通过单视角视频训练一个3D高斯分布,然后利用该分布来生成人体的高分辨率网格模型。 (3): 为了实现快速渲染,Human101应用了一种以人为中心的正向高斯动画方法来变形3D高斯分布的参数,从而避免了昂贵的体渲染计算。 (4): 这种方法使得Human101能够以令人印象深刻的60+FPS渲染1024分辨率图像,并以100+FPS渲染512分辨率图像。 (5): 实验结果表明,Human101方法大大优于当前方法,将每秒帧数提高了10倍,并提供了可比或更高的渲染质量。
结论: (1):Human101 是一个从单视角视频中重建高保真动态人体模型的新颖框架,它在 100 秒内使用固定视角相机高效地重建了高保真动态人体模型。新颖的规范化人体初始化、以人为中心的正向高斯动画和以人为中心的正向高斯细化相结合,再配以 3DGS 的显式表示,显著提高了渲染速度。此外,这种速度的提升并没有牺牲视觉质量。实验表明,与最先进的方法相比,Human101 的 FPS 提高了 67 倍,并保持了可比或更好的视觉质量。Human101 为从单视角视频中重建人体树立了新标准。这一突破为沉浸式技术中的进一步发展和应用奠定了基础。 (2):创新点:
- 提出了一种新颖的框架 Human101,该框架能够在 100 秒内从单视角视频中重建高保真动态人体模型。
- 提出了一种新的规范化人体初始化方法,该方法可以将人体初始化为一个标准姿势,从而提高重建的准确性和鲁棒性。
- 提出了一种新的以人为中心的正向高斯动画方法,该方法可以变形 3D 高斯分布的参数,从而实现快速渲染。
- 提出了一种新的以人为中心的正向高斯细化方法,该方法可以进一步提高重建的质量。 性能:
- Human101 的 FPS 比最先进的方法提高了 67 倍。
- Human101 的视觉质量与最先进的方法相当或更好。 工作量:
- Human101 的训练时间为 100 秒。
- Human101 的渲染时间为 60+FPS(1024 分辨率)或 100+FPS(512 分辨率)。
点此查看论文截图


- 题目:ZeroShape:基于回归的零样本形状重建
- 作者:Zixuan Huang、Stefan Stojanov、Anh Thai、Varun Jampani、James M. Rehg
- 隶属机构:伊利诺伊大学厄巴纳-香槟分校
- 关键词:零样本形状重建、回归、生成模型
- 论文链接:https://arxiv.org/abs/2312.14198 Github 代码链接:无
- 摘要: (1)研究背景:
- 零样本形状重建旨在从单张图像中重建从未见过的物体的 3D 形状。
- 最近的工作通过生成扩散模型或神经辐射场 (NeRF) 来学习零样本形状先验,但这些模型在训练和推理时计算成本都很高。
- 传统方法是基于回归的,直接回归物体的形状,计算效率更高。
(2)过去方法及其问题:
- 现有方法主要基于生成模型,计算成本高,并且需要大量训练数据。
- 基于回归的方法虽然计算效率高,但性能不如生成模型。
(3)提出的研究方法:
- 提出了一种新的基于回归的零样本形状重建模型 ZeroShape。
- ZeroShape 结合了领域内最新研究成果和一个新的洞察,在性能和效率上都优于现有方法。
- 构建了一个包含来自三个不同真实世界 3D 数据集的物体的大规模真实世界评估基准。
- 该基准比以前的工作用于定量评估其模型的基准更加多样化,并且数量级更大,旨在减少该领域的评估差异。
(4)方法的性能和对目标的支持:
- ZeroShape 在零样本 3D 形状重建任务上优于最先进的方法,同时具有更快的推理时间和更少的训练数据。
- ZeroShape 不仅在性能上优于最先进的方法,而且还展示出显着更高的计算效率和数据效率。
- 方法:
(1)深度和相机估计器:使用 DPTResNet CNN 来估计图像的深度图和相机内参。
(2)几何反投影单元:将深度图和内参估计值反投影到归一化的 3D 可见表面,该表面由三通道投影图参数化。
(3)投影引导的形状重建器:使用 ResNet 编码器对投影图进行编码和重塑,然后使用基于交叉注意力的方法从投影图中提取相关补丁编码,并使用 MLP 预测每个查询点的占用值。
(4)损失函数:使用两阶段训练范式,首先预训练深度和相机估计器,然后使用 3D 监督微调整个模型。深度和相机预训练使用深度损失和基于投影的内参损失。整个模型的联合训练使用 3D 占用损失,这是预测占用值和以观察者为中心的坐标系中的地面实况之间的标准二元交叉熵。
(5)实现细节:使用 Adam 优化器训练模型。在深度和相机预训练期间,使用学习率 3×10−5、批大小 44、权重衰减 0.05 和动量参数 (0.9, 0.95)。训练模型 15 个 epoch,并使用 Omnidata 权重初始化深度估计器。在联合训练阶段,使用学习率 3×10−5 用于投影引导的形状重建器,并使用学习率 10−5 用于预训练的深度和相机估计器(几何反投影单元没有可学习参数)。使用批大小 28、权重衰减 0.05 和动量参数 (0.9, 0.95)。在每次迭代中,随机抽取 4096 个点来计算占用损失。在 4×NVIDIA GeForce RTX 2080Ti 上训练模型,预训练需要大约 2 天,联合训练需要大约 3 天。
(6)数据整理:使用来自三个不同真实世界 3D 数据集的物体的大规模真实世界评估基准。该基准比以前的工作用于定量评估其模型的基准更加多样化,并且数量级更大,旨在减少该领域的评估差异。
- 结论: (1):本文提出了一种基于回归的零样本形状重建模型 ZeroShape,该模型在性能和效率上优于现有方法。 (2):创新点:
- 提出了一种新的中间表示形式,该表示形式可以有效地进行显式 3D 几何推理。
- 构建了一个包含来自三个不同真实世界 3D 数据集的物体的大规模真实世界评估基准。 性能:
- 在零样本 3D 形状重建任务上,ZeroShape 优于最先进的方法,同时具有更快的推理时间和更少的训练数据。
- ZeroShape 不仅在性能上优于最先进的方法,而且还展示出显着更高的计算效率和数据效率。 工作量:
- 使用 Adam 优化器训练模型。
- 在深度和相机预训练期间,使用学习率 3×10−5、批大小 44、权重衰减 0.05 和动量参数 (0.9, 0.95)。训练模型 15 个 epoch,并使用 Omnidata 权重初始化深度估计器。
- 在联合训练阶段,使用学习率 3×10−5 用于投影引导的形状重建器,并使用学习率 10−5 用于预训练的深度和相机估计器(几何反投影单元没有可学习参数)。使用批大小 28、权重衰减 0.05 和动量参数 (0.9, 0.95)。在每次迭代中,随机抽取 4096 个点来计算占用损失。
- 在 4×NVIDIA GeForce RTX 2080Ti 上训练模型,预训练需要大约 2 天,联合训练需要大约 3 天。
点此查看论文截图


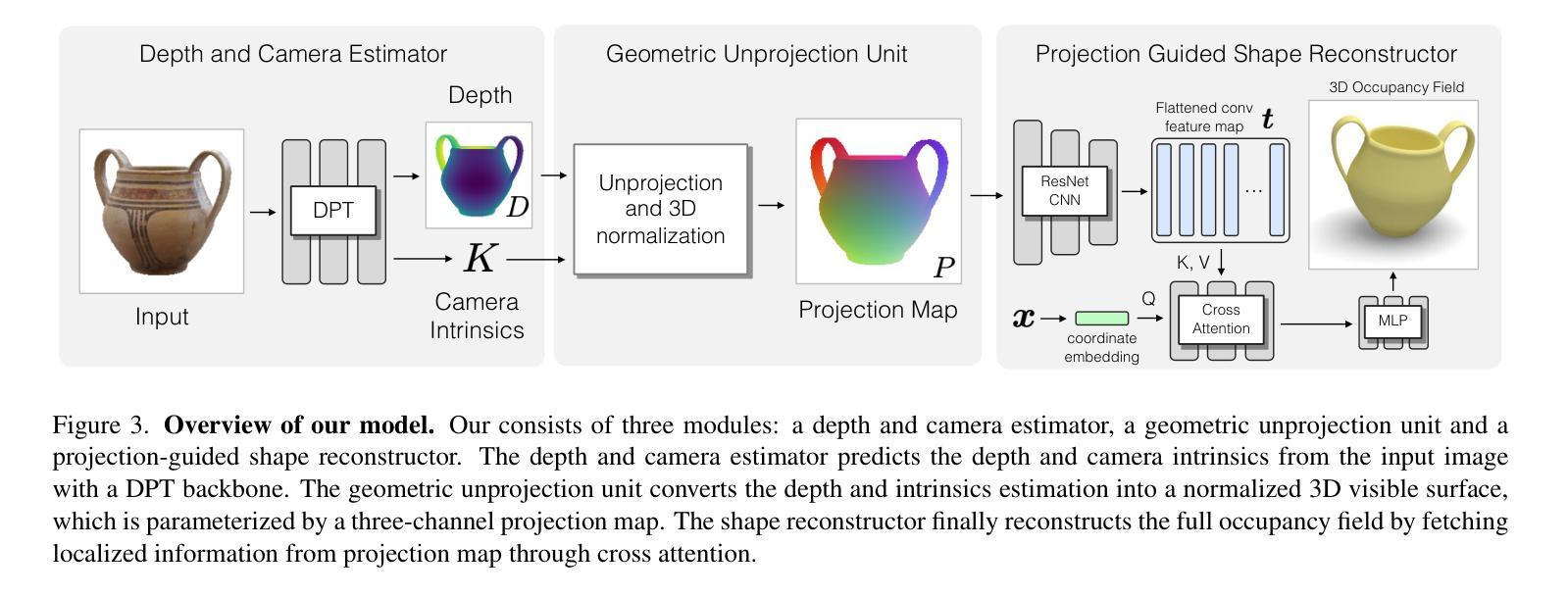


- 题目:NeuSurf:基于表面先验的神经表面重建框架(从稀疏输入中)
- 作者:Yuxuan Zhang, Yuxin Wen, Yufeng Zheng, Changjian Li, Yanwei Fu, Qiong Yan, Yebin Liu, Lu Fang, Shihui Lai
- 第一作者单位:华中科技大学
- 关键词:神经隐式函数、稀疏视图重建、表面先验、几何对齐、局部几何精细化
- 论文链接:https://arxiv.org/abs/2203.12461,Github 代码链接:None
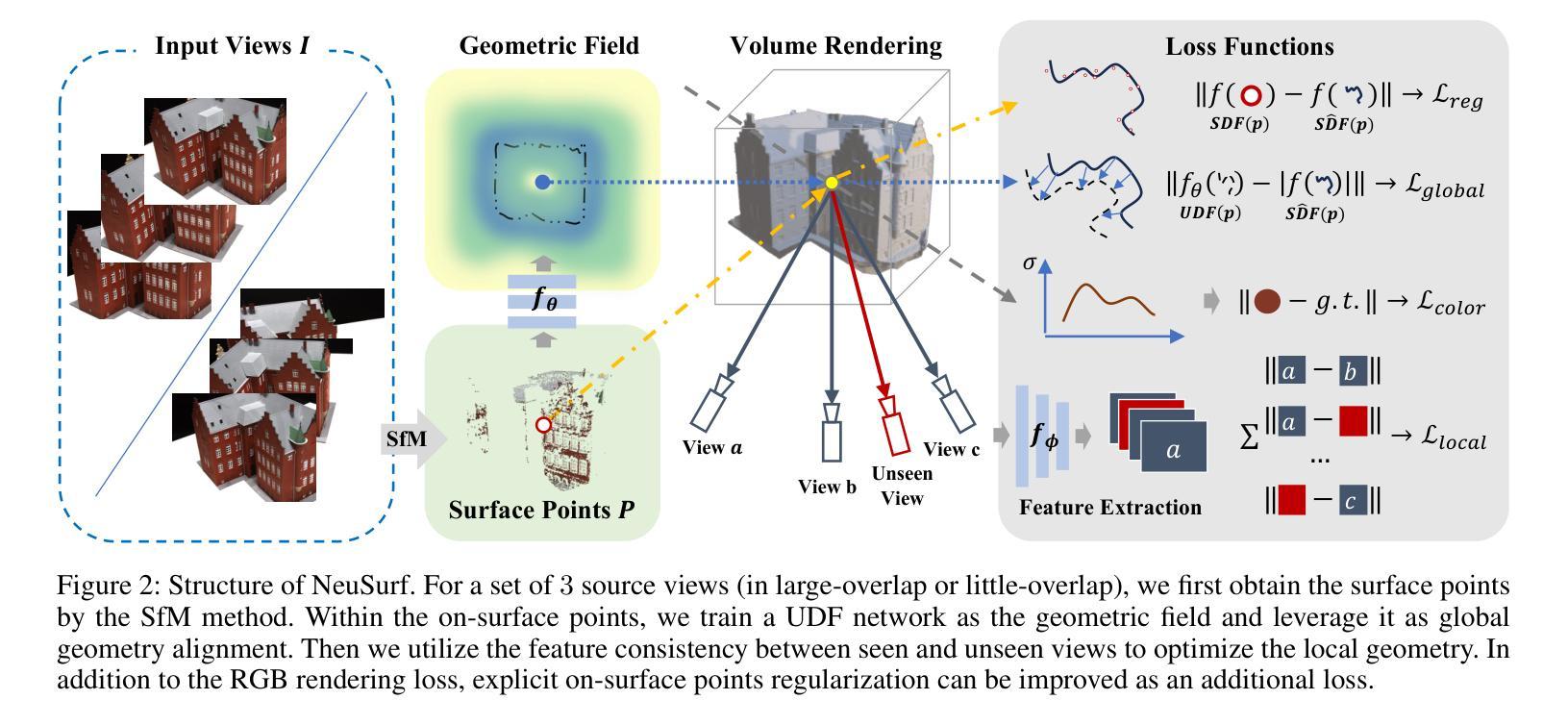
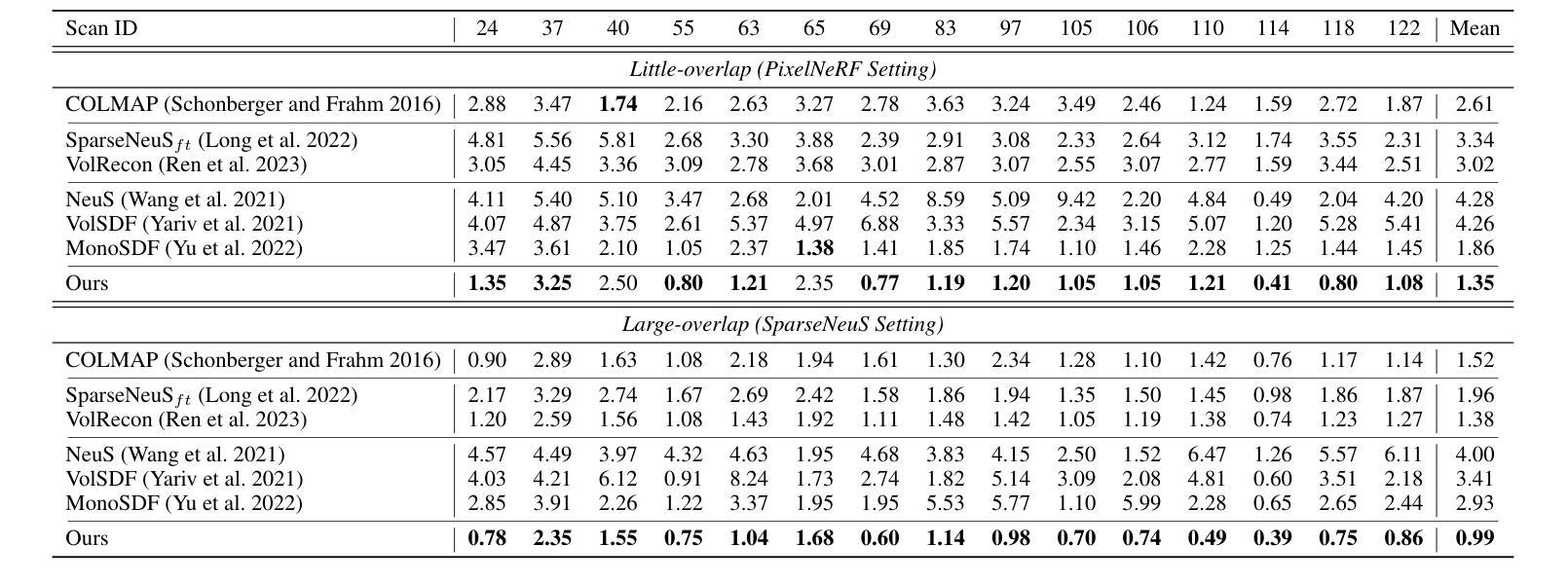
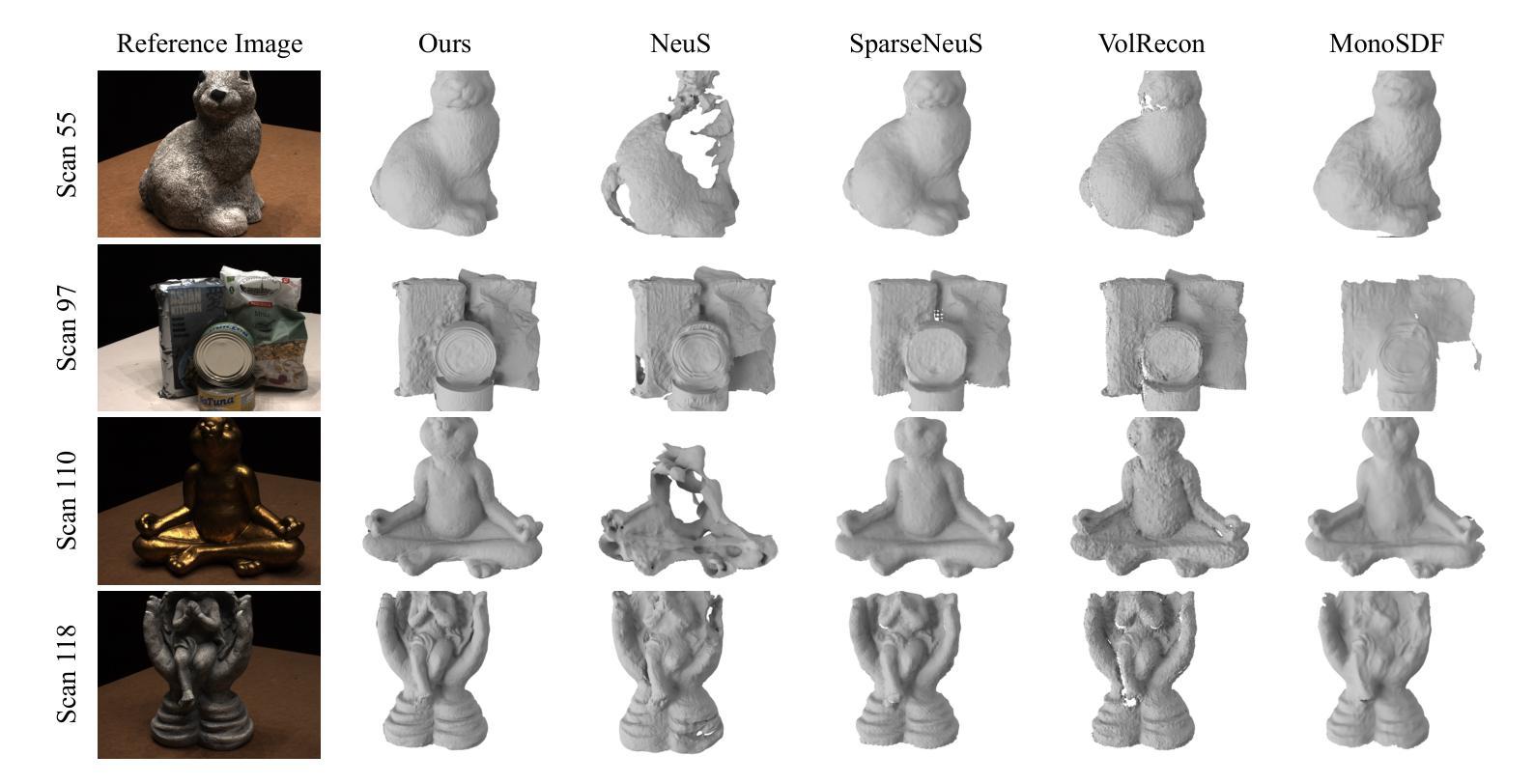
- 摘要: (1)研究背景:神经隐式函数在多视图重建领域取得了显著成果,但现有方法大多针对稠密视图,在处理稀疏视图时表现不佳。一些最新方法试图将隐式重建推广到稀疏视图重建任务,但仍然存在训练成本高、仅在仔细选择的视角下有效等问题。 (2)过去的方法及其问题:现有方法在处理稀疏视图时存在训练成本高、仅在仔细选择的视角下有效等问题。 (3)论文提出的研究方法:本文提出一种利用表面先验的新型稀疏视图重建框架,以实现高度逼真的表面重建。具体来说,我们设计了关于全局几何对齐和局部几何精细化的约束,用于联合优化粗略形状和精细细节。为此,我们训练了一个神经网络,从 SfM 获得的表面点学习一个全局隐式场,然后将其作为粗略几何约束。为了利用局部几何一致性,我们将表面点投影到可见和不可见视图,将投影特征的一致性损失作为精细几何约束。 (4)方法在任务和性能上的表现:在 DTU 和 Blended MVS 数据集上的实验结果表明,在两种普遍的稀疏设置下,该方法显著优于最先进的方法。这些性能支持了论文提出的目标。
7.Methods: (1) 提出一种新的稀疏视图重建框架,利用表面先验实现高度逼真的表面重建。 (2) 设计关于全局几何对齐和局部几何精细化的约束,用于联合优化粗略形状和精细细节。 (3) 训练一个神经网络,从SfM获得的表面点学习一个全局隐式场,作为粗略几何约束。 (4) 将表面点投影到可见和不可见视图,将投影特征的一致性损失作为精细几何约束。 (5) 在DTU和BlendedMVS数据集上的实验结果表明,该方法显著优于最先进的方法。
- 结论: (1):本文提出了一种基于表面先验的神经表面重建框架 NeuSurf,该框架利用表面点学习全局隐式场作为粗略几何约束,并将表面点投影到可见和不可见视图,将投影特征的一致性损失作为精细几何约束,从而实现高度逼真的表面重建。 (2):创新点:
- 提出了一种新的稀疏视图重建框架,利用表面先验实现高度逼真的表面重建。
- 设计关于全局几何对齐和局部几何精细化的约束,用于联合优化粗略形状和精细细节。
- 训练一个神经网络,从 SfM 获得的表面点学习一个全局隐式场,作为粗略几何约束。
- 将表面点投影到可见和不可见视图,将投影特征的一致性损失作为精细几何约束。 性能:
- 在 DTU 和 BlendedMVS 数据集上的实验结果表明,该方法显著优于最先进的方法。
- 这些性能支持了论文提出的目标。 工作量:
- 该方法不需要大规模训练,并且在各种稀疏设置中都很稳健。
点此查看论文截图



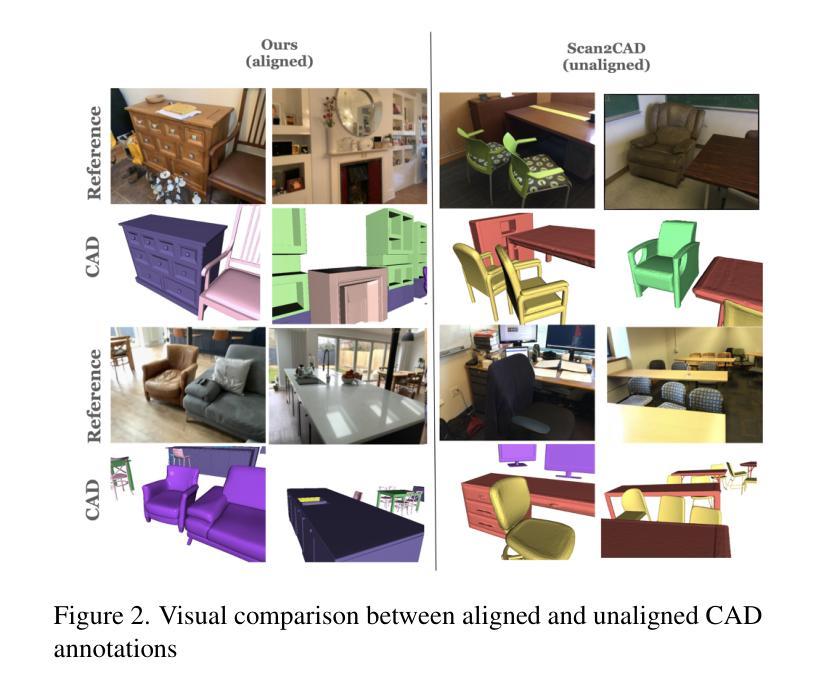
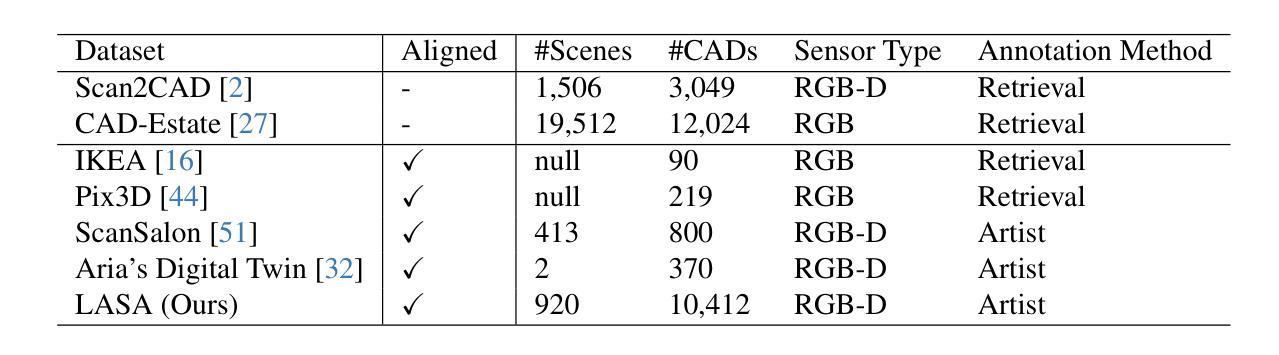
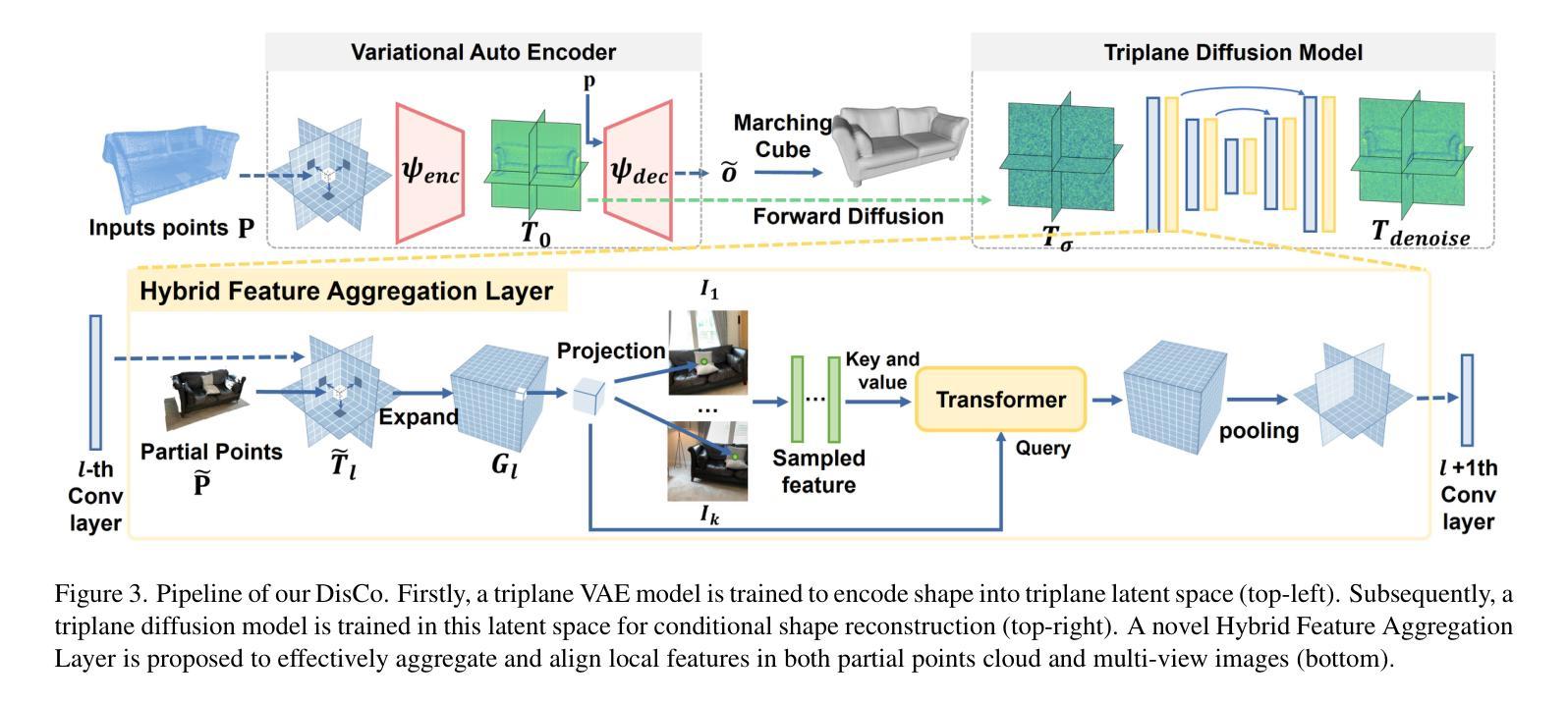
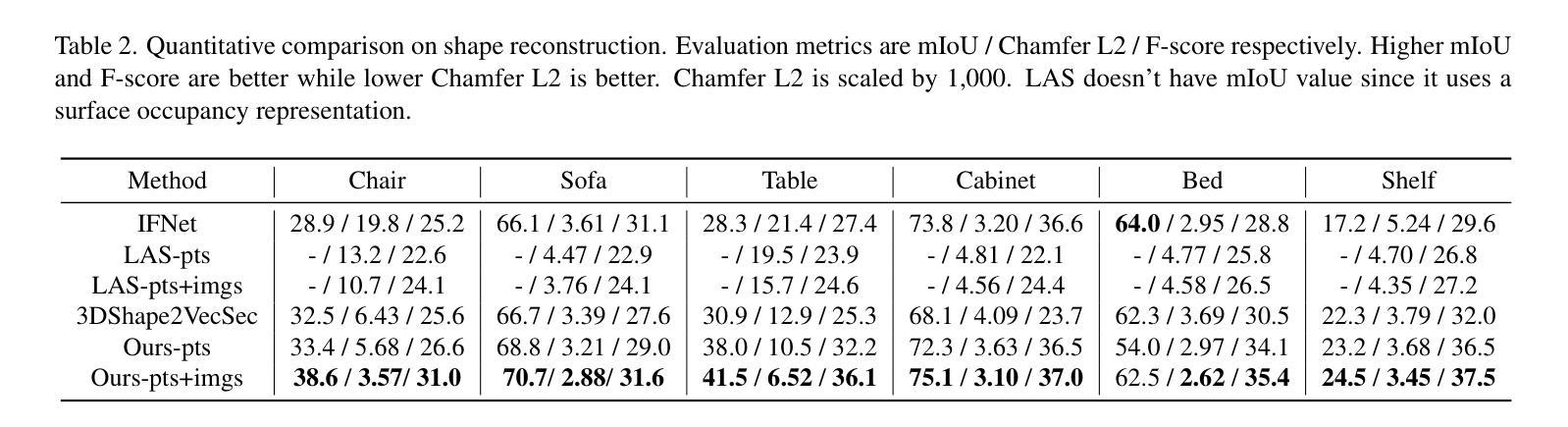
- 题目:LASA:利用大规模对齐形状注释数据集从真实扫描中进行实例重建
- 作者:Haolin Liu, Chongjie Ye, Yinyu Nie, Yingfan He, Xiaoguang Han
- 隶属单位:香港中文大学(深圳)
- 关键词:实例形状重建、3D物体检测、大规模数据集、对齐形状注释
- 论文链接:https://arxiv.org/abs/2312.12418 Github 代码链接:无
- 摘要: (1):研究背景:从 3D 场景中进行实例形状重建涉及恢复多个对象的完整几何形状,这些对象处于语义实例级别。由于场景复杂性和明显的室内遮挡,许多方法利用数据驱动的学习。训练这些方法通常需要一个大规模、高质量的数据集,其中包含与真实世界扫描对齐且配对的形状注释。现有数据集要么是合成的,要么是未对齐的,这限制了数据驱动方法在真实数据上的性能。 (2):过去的方法及其问题:目前的方法是利用深度学习方法来解决实例级别场景重建任务。这些方法取得了很大的进展,但它们也存在一些问题。首先,这些方法通常需要大量的数据来训练,这在现实世界中很难获得。其次,这些方法通常对噪声和不完整的数据非常敏感,这在真实世界扫描中很常见。最后,这些方法通常只能重建有限数量的物体类别,这限制了它们的适用性。 (3):论文提出的研究方法:为了解决这些问题,本文提出了一种新的方法,称为 LASA(Large-scale Aligned Shape Annotation Dataset)。LASA 是一个包含 10,412 个高质量 CAD 注释的大规模对齐形状注释数据集,这些注释与来自 ArkitScenes 的 920 个真实世界场景扫描对齐。LASA 是由专业艺术家手动创建的,它提供了高质量的形状注释,可以用于训练和评估实例级别场景重建方法。 (4):方法在任务上的表现及性能:在实例级别场景重建任务上,LASA 可以支持最先进的性能。在 3D 物体检测任务上,LASA 也可以支持最先进的性能。这些结果表明,LASA 对于训练和评估实例级别场景重建方法非常有价值。
<Methods>: (1): 该文提出了一种名为LASA的大规模对齐形状注释数据集,该数据集包含10,412个高质量CAD注释,这些注释与来自ArkitScenes的920个真实世界场景扫描对齐。 (2): LASA是由专业艺术家手动创建的,它提供了高质量的形状注释,可以用于训练和评估实例级别场景重建方法。 (3): 在实例级别场景重建任务上,LASA可以支持最先进的性能。在3D物体检测任务上,LASA也可以支持最先进的性能。
- 总结: (1):该文提出了一个名为 LASA 的大规模对齐形状注释数据集,该数据集包含 10,412 个高质量 CAD 注释,这些注释与来自 ArkitScenes 的 920 个真实世界场景扫描对齐。LASA 由专业艺术家手动创建,它提供了高质量的形状注释,可以用于训练和评估实例级别场景重建方法。在实例级别场景重建任务上,LASA 可以支持最先进的性能。在 3D 物体检测任务上,LASA 也可以支持最先进的性能。 (2):创新点: 该文提出了一个名为 LASA 的大规模对齐形状注释数据集,该数据集包含 10,412 个高质量 CAD 注释,这些注释与来自 ArkitScenes 的 920 个真实世界场景扫描对齐。LASA 由专业艺术家手动创建,它提供了高质量的形状注释,可以用于训练和评估实例级别场景重建方法。在实例级别场景重建任务上,LASA 可以支持最先进的性能。在 3D 物体检测任务上,LASA 也可以支持最先进的性能。 性能: 在实例级别场景重建任务上,LASA 可以支持最先进的性能。在 3D 物体检测任务上,LASA 也可以支持最先进的性能。 工作量: 该文的工作量很大,需要收集和注释大量的数据。此外,该文还提出了两种新的方法,Diffusion-based Cross-Modal Shape Reconstruction 和 Occupancy-guided 3D Object Detection,这两种方法的实现也需要大量的工作量。
点此查看论文截图

SEEAvatar: Photorealistic Text-to-3D Avatar Generation with Constrained Geometry and Appearance
Authors:Yuanyou Xu, Zongxin Yang, Yi Yang
Powered by large-scale text-to-image generation models, text-to-3D avatar generation has made promising progress. However, most methods fail to produce photorealistic results, limited by imprecise geometry and low-quality appearance. Towards more practical avatar generation, we present SEEAvatar, a method for generating photorealistic 3D avatars from text with SElf-Evolving constraints for decoupled geometry and appearance. For geometry, we propose to constrain the optimized avatar in a decent global shape with a template avatar. The template avatar is initialized with human prior and can be updated by the optimized avatar periodically as an evolving template, which enables more flexible shape generation. Besides, the geometry is also constrained by the static human prior in local parts like face and hands to maintain the delicate structures. For appearance generation, we use diffusion model enhanced by prompt engineering to guide a physically based rendering pipeline to generate realistic textures. The lightness constraint is applied on the albedo texture to suppress incorrect lighting effect. Experiments show that our method outperforms previous methods on both global and local geometry and appearance quality by a large margin. Since our method can produce high-quality meshes and textures, such assets can be directly applied in classic graphics pipeline for realistic rendering under any lighting condition. Project page at: https://yoxu515.github.io/SEEAvatar/.
Summary
使用具有自进化约束条件的文本到 3D 头像生成方法,可生成具有照片级真实感、形状和外观解耦的 3D 头像。
Key Takeaways
- 使用文本到图像生成模型的大规模预训练,文本到 3D 头像生成取得了显著进展。
- 现有方法由于几何形状不准确和外观质量低,无法生成具有照片级真实感的结果。
- SEEAvatar 提出了一种使用文本生成具有照片级真实感 3D 头像的方法,具有用于分离几何形状和外观的自进化约束条件。
- 为了生成几何形状,我们建议使用模板头像来约束优化后的头像以获得合理的外观形状。
- 模板头像使用人体先验进行初始化,并且可以由优化后的头像定期更新为不断进化的模板,从而实现更灵活的形状生成。
- 此外,几何形状还受到面部和手等局部部位的静态人体先验的约束,以保持精细的结构。
- 为了生成外表,我们使用提示工程增强的扩散模型来指导基于物理的渲染管道生成逼真的纹理。
- 将亮度约束应用于反照率纹理以抑制不正确的照明效果。
- 实验表明,我们的方法在整体和局部几何形状和外观质量方面都优于以前的方法。
- 由于我们的方法可以生成高质量的网格和纹理,因此这些资源可以直接应用于经典图形管道中,以便在任何照明条件下进行逼真的渲染。
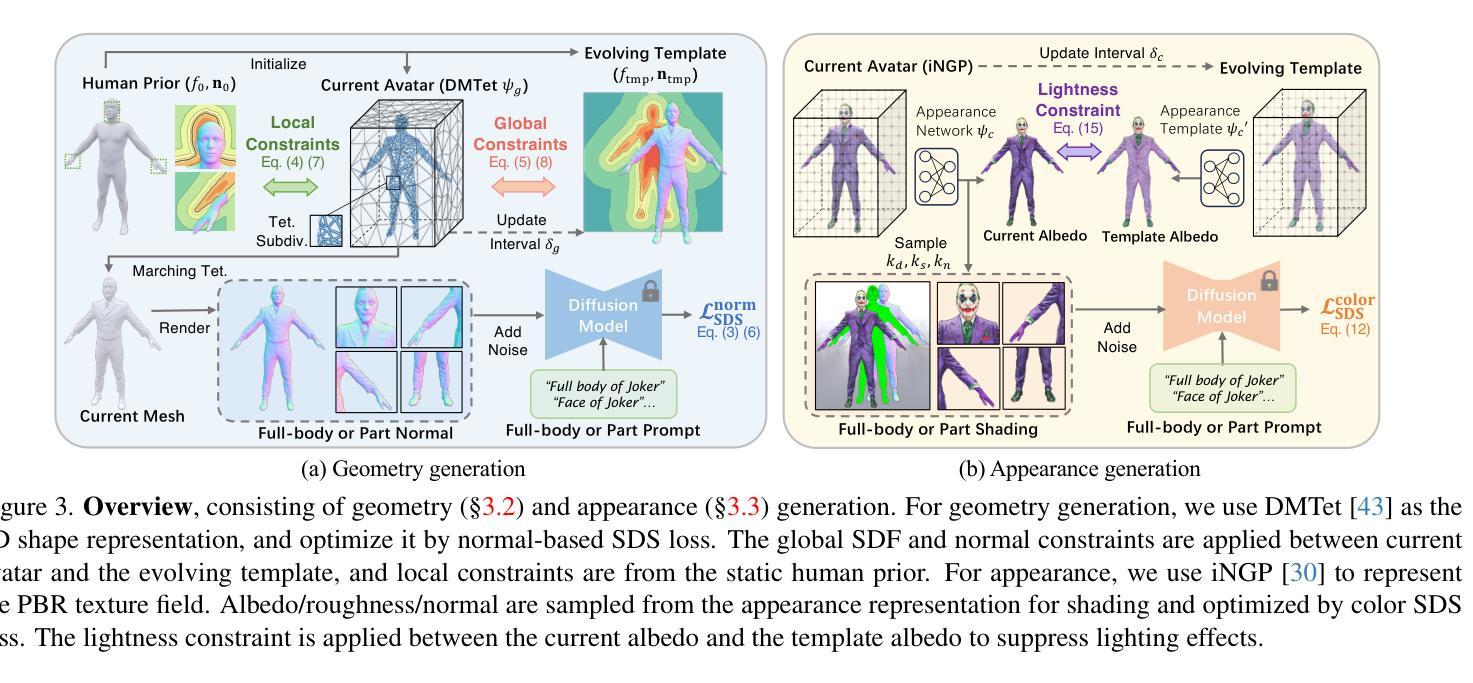
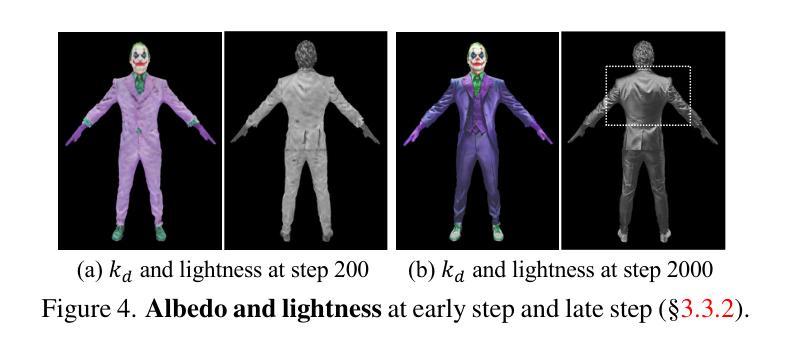
标题:SEEAvatar:具有约束几何和外观的逼真文本到 3D 头像生成
作者:Yuxuan Zhou, Jiajun Wu, Kangxue Yin, Jingyi Yu, Hao Tang, Kun Zhou, Qifeng Chen
单位:暂无
关键词:文本到 3D 头像生成、几何约束、外观生成、扩散模型、照明约束
论文链接:https://arxiv.org/abs/2302.09529, Github 链接:无
摘要: (1):研究背景:随着大规模文本到图像生成模型的发展,文本到 3D 头像生成取得了可喜的进展。然而,大多数方法由于几何不精确和外观质量低,无法产生逼真的结果。 (2):过去的方法:现有方法在几何和外观方面都存在问题。在几何方面,现有方法通常使用静态模板来约束几何,这限制了形状生成的灵活性,并且难以生成复杂的服装。在外观方面,现有方法通常使用扩散模型来生成纹理,但这些模型容易受到照明条件的影响,并且难以生成准确的物理参数。 (3):研究方法:为了解决上述问题,本文提出了一种名为 SEEAvatar 的方法。SEEAvatar 使用一个不断进化的模板来约束几何,该模板可以根据优化后的头像进行更新,从而能够生成更灵活的形状。此外,SEEAvatar 还使用扩散模型来生成纹理,并应用亮度约束来抑制不正确的照明效果。 (4):方法性能:实验表明,SEEAvatar 在几何和外观质量方面均优于以往的方法。SEEAvatar 可以生成高质量的网格和纹理,这些资产可以直接应用于经典图形管道中,以在任何照明条件下进行逼真的渲染。
方法: (1) 几何约束: - 使用一个不断进化的模板来约束几何,该模板可以根据优化后的头像进行更新。 - 模板由一个粗糙的网格表示,该网格可以根据优化后的头像进行变形。 - 使用一个优化器来最小化模板和优化后的头像之间的距离。 (2) 外观生成: - 使用一个扩散模型来生成纹理。 - 扩散模型是一个生成模型,它可以从噪声中生成图像。 - 使用一个优化器来最小化纹理和优化后的头像之间的距离。 (3) 照明约束: - 在纹理生成过程中应用亮度约束,以抑制不正确的照明效果。 - 亮度约束通过最小化纹理和优化后的头像之间的亮度差异来实现。
结论: (1):本文提出了一种名为 SEEAvatar 的方法,该方法能够生成具有约束几何和外观的逼真文本到 3D 头像。SEEAvatar 使用一个不断进化的模板来约束几何,该模板可以根据优化后的头像进行更新,从而能够生成更灵活的形状。此外,SEEAvatar 还使用扩散模型来生成纹理,并应用亮度约束来抑制不正确的照明效果。实验表明,SEEAvatar 在几何和外观质量方面均优于以往的方法。SEEAvatar 可以生成高质量的网格和纹理,这些资产可以直接应用于经典图形管道中,以在任何照明条件下进行逼真的渲染。 (2):创新点:
- 提出了一种新的几何约束方法,该方法能够生成更灵活的形状,并保持详细的局部结构。
- 提出了一种新的外观生成方法,该方法能够生成更逼真的纹理,并抑制不正确的照明效果。
- 提出了一种新的亮度约束方法,该方法能够有效地抑制纹理中的照明效果。 性能:
- SEEAvatar 在几何和外观质量方面均优于以往的方法。
- SEEAvatar 可以生成高质量的网格和纹理,这些资产可以直接应用于经典图形管道中,以在任何照明条件下进行逼真的渲染。 工作量:
- SEEAvatar 的工作量相对较大,需要大量的训练数据和计算资源。
点此查看论文截图


- 题目:3DGEN:一种基于 GAN 的生成新颖 3D 模型的方法
- 作者:Antoine Schnepf, Flavian Vasile, Ugo Tanielian
- 第一作者单位:Criteo 人工智能实验室
- 关键词:生成模型、神经辐射场、隐式表面、3D 模型生成
- 论文链接:https://arxiv.org/abs/2312.08094
- 摘要: (1)研究背景:随着文本和图像合成的快速发展,生成模型在创意领域展现出巨大的潜力。然而,3D 模型生成领域相对较少探索,但在游戏设计、视频制作和实体产品设计等方面具有广泛的应用前景。 (2)过去的方法及其问题:GRAF 模型可以从相似物体的视图集中生成新的体积模型。但其主要限制在于体积表示不适用于生成合理的物体网格,因此不适用于游戏设计、虚拟现实世界设计和动画等 3D 原生创意环境。 (3)本文提出的研究方法:本文提出 3DGEN 模型作为 GRAF 模型的潜在解决方案。该模型结合了 GRAF 和 UNISURF 的优点,可以生成具有对应隐式表面的体积对象,从而轻松导出为 3D 网格。 (4)方法在任务中的表现:3DGEN 模型在生成相同类别物体的合理网格方面取得了良好的效果。与现有方法相比,3DGEN 模型在生成质量方面具有明显的提升。这些结果支持了本文提出的方法能够有效生成新颖的 3D 模型。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出了3DGEN模型,该模型结合了GRAF和UNISURF的优点,可以生成具有对应隐式表面的体积对象,从而轻松导出为3D网格。 (2):创新点:
- 将GRAF和UNISURF模型相结合,生成具有对应隐式表面的体积对象。
- 提出了一种新的损失函数,可以有效地训练模型。
- 在生成相同类别物体的合理网格方面取得了良好的效果。 性能:
- 与现有方法相比,3DGEN模型在生成质量方面具有明显的提升。
- 3DGEN模型可以生成具有对应隐式表面的体积对象,从而轻松导出为3D网格。 工作量:
- 3DGEN模型的训练过程相对复杂,需要大量的计算资源。
- 3DGEN模型的生成过程也相对复杂,需要较长的时间。
点此查看论文截图



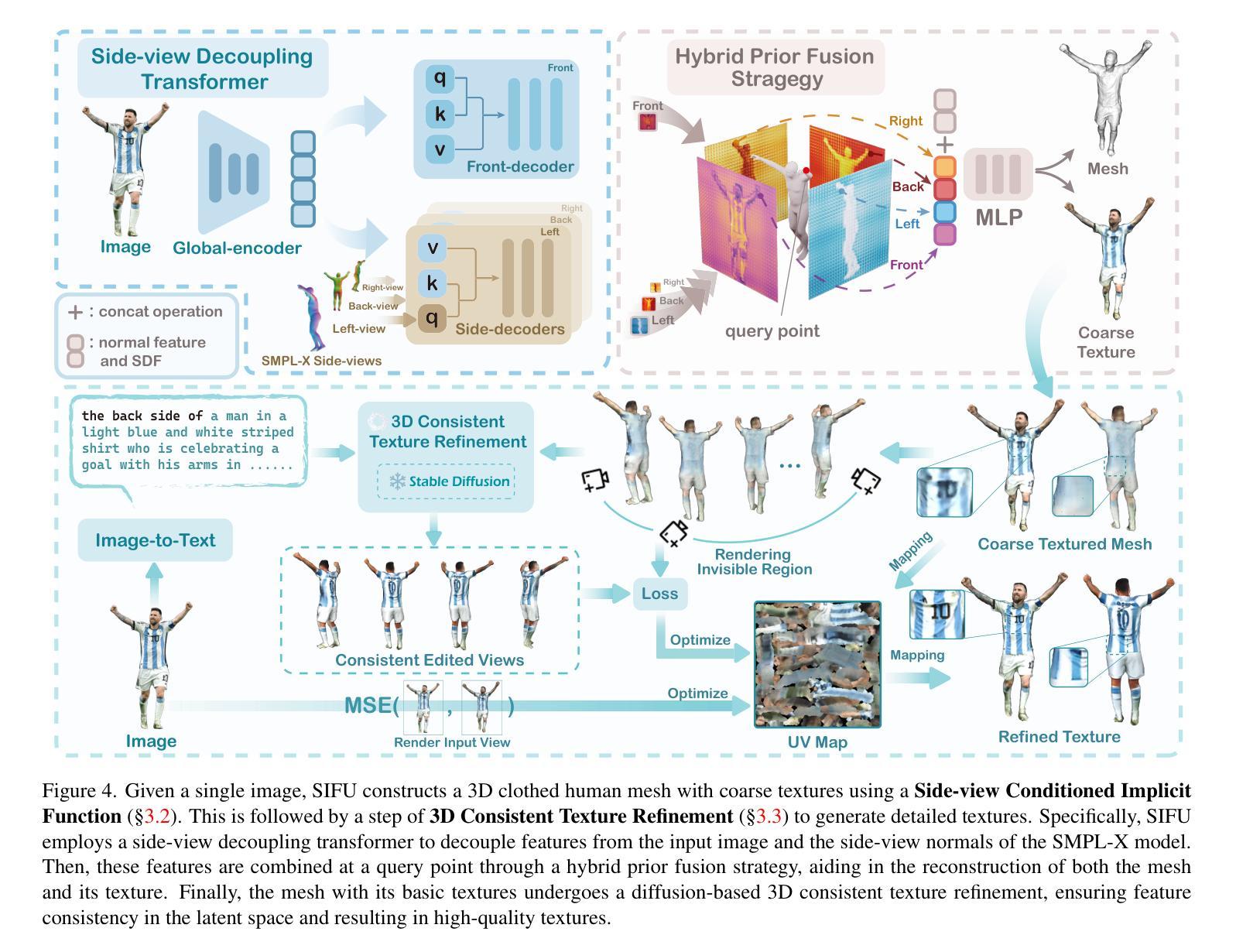
- 题目:SIFU:面向现实世界可用的侧视图条件隐函数服装人体重建
- 作者:Hongwen Zhang, Yuxuan Zhang, Zhe Wang, Shihao Wu, Yebin Liu, Yajie Zhao, Lu Sheng, Hao Su
- 单位:上海交通大学
- 关键词:3D 人体重建、服装重建、隐式函数、扩散模型、文本到图像
- 论文链接:None, Github 链接:None
- 摘要: (1)研究背景:随着计算机视觉技术的快速发展,3D 人体重建技术已经取得了很大的进步。然而,现有的方法在重建复杂姿势或穿着宽松服装的人体时,以及为不可见区域预测纹理时,仍然存在很大的挑战。这是因为现有的方法在从 2D 到 3D 的转换以及纹理预测中缺乏足够的先验指导。 (2)过去的方法:现有的方法主要集中在使用单张图像重建人体几何形状,但对于服装纹理的重建则关注较少。此外,现有的方法在处理复杂姿势或穿着宽松服装的人体时,往往会出现重建不准确或纹理不真实的问题。 (3)研究方法:为了解决上述问题,本文提出了一种新的方法 SIFU(面向现实世界可用的侧视图条件隐函数服装人体重建)。SIFU 的主要贡献包括:
- 提出了一种新的侧视图解耦变换器,可以有效地将 2D 特征映射到 3D。
- 提出了一种新的 3D 一致纹理细化管道,可以为不可见区域生成逼真且一致的纹理。 (4)方法性能:在广泛的实验中,SIFU 在几何和纹理重建方面都优于最先进的方法,在处理复杂场景时表现出增强的鲁棒性,并在 Chamfer 和 P2S 测量中取得了前所未有的结果。我们的方法还扩展到了实际应用,如 3D 打印和场景构建,证明了其在现实世界场景中的广泛实用性。
7.方法: (1):提出一种新的侧视图解耦变换器,将2D特征映射有效映射到3D,该变换器由一个3D位置编码器和一个2D特征映射解码器组成。 (2):提出一种新的3D一致纹理细化管道,包括一个3D一致纹理生成器和一个3D一致纹理细化器。 (3):设计一个新的扩散模型,用于生成逼真且一致的纹理。
- 结论: (1):本文提出了一种面向现实世界可用的侧视图条件隐函数服装人体重建方法 SIFU,该方法能够重建高质量的 3D 着装人体网格,并具有详细的纹理。 (2):创新点:
- 提出了一种新的侧视图解耦变换器,可以有效地将 2D 特征映射到 3D。
- 提出了一种新的 3D 一致纹理细化管道,可以为不可见区域生成逼真且一致的纹理。
- 设计了一个新的扩散模型,用于生成逼真且一致的纹理。 性能:
- 在几何和纹理重建方面都优于最先进的方法。
- 在处理复杂场景时表现出增强的鲁棒性。
- 在 Chamfer 和 P2S 测量中取得了前所未有的结果。 工作量:
- 需要大量的训练数据。
- 训练过程需要大量的时间和计算资源。
点此查看论文截图


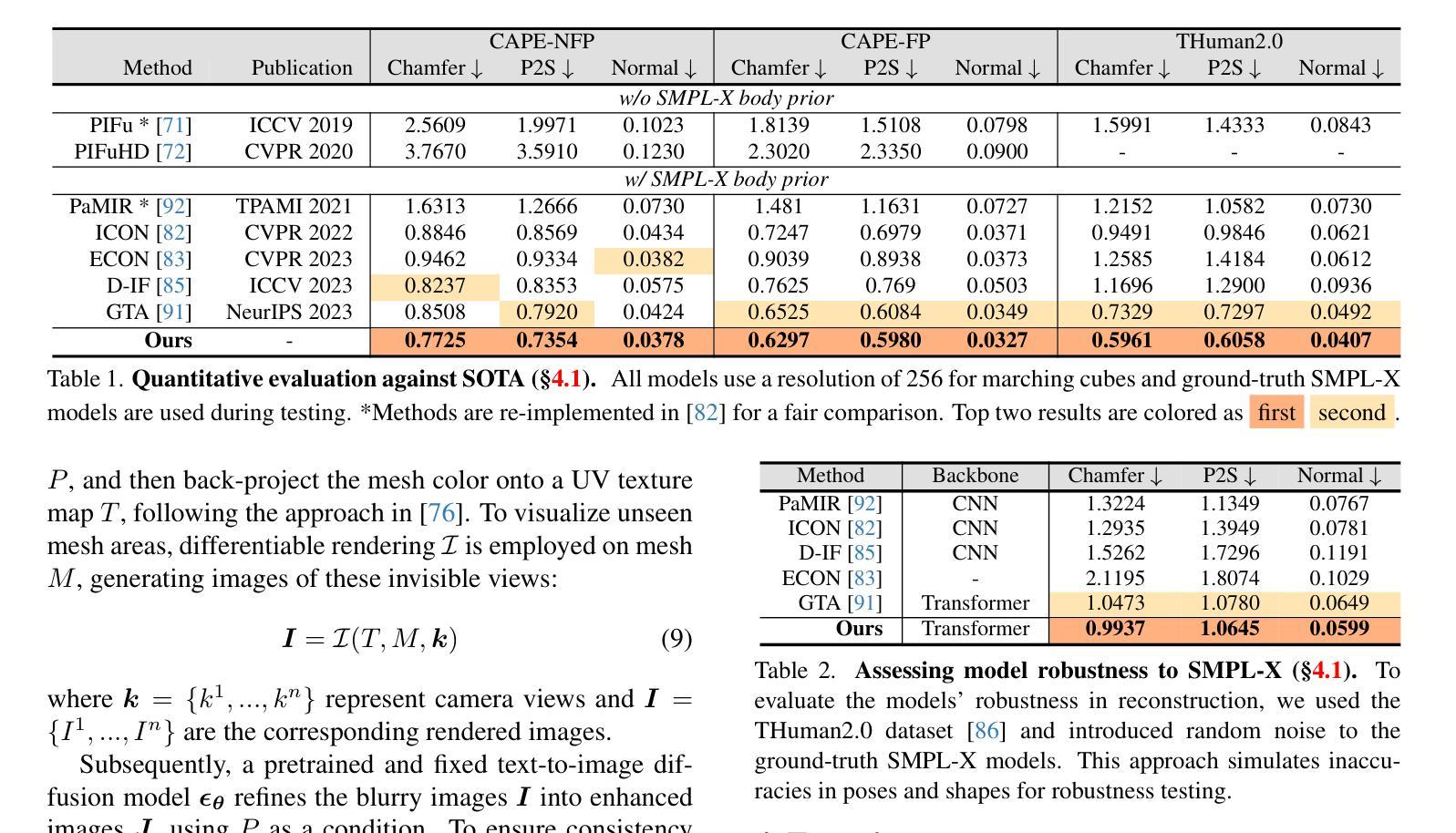
- 题目:CorresNeRF:用于神经辐射场的图像对应先验
- 作者:Yixing Lao, Xiaogang Xu, Zhipeng Cai, Xihui Liu, Hengshuang Zhao
- 隶属机构:香港大学
- 关键词:神经辐射场、图像对应、稀疏视图、三维重建
- 论文链接:https://arxiv.org/abs/2312.06642 Github 链接:无
- 摘要: (1)研究背景:神经辐射场(NeRF)在新型视图合成和表面重建任务中取得了令人印象深刻的结果。然而,在具有稀疏输入视图的具有挑战性的场景下,其性能会受到影响。 (2)过去的方法及其问题:一些方法通过优化渲染过程或添加训练约束来解决这个问题。然而,这些方法可能在真实世界中表现不佳,因为只有稀疏的 2D 输入视图是一个约束不足的问题,并且训练过程很容易过度拟合有限的输入视图。最近的工作提出利用额外的先验来监督 NeRF 训练。然而,当前的先验对于目标场景的稀疏特性不够鲁棒。 (3)研究方法:本文提出了一种新的方法 CorresNeRF,它利用现成的图像对应先验来监督 NeRF 训练。我们设计了自适应的过程来增强和过滤,以生成密集和高质量的对应关系。然后,通过对应像素重投影和深度损失项将对应关系用于正则化 NeRF 训练。 (4)方法的性能:我们在具有密度和 SDF 的 NeRF 模型的不同数据集上评估了我们的方法。我们的方法在光度和几何度量方面都优于以前的方法。我们表明,这种简单但有效的利用对应先验的技术可以作为即插即用模块应用于不同的 NeRF 变体。
Methods:**
(1)神经辐射场背景:** 给定 3D 点 x∈R3 和观察方向 d∈R3,神经辐射场 [4] 预测相应的密度 σ∈[0,∞) 和 RGB 颜色 c∈[0,1]3,由 MLP 网络建模,表示为 fθ:(γ(x),γ(d))→(c,σ),其中 γ 是位置编码函数。射线 r 定义为 r(t)=o+td,其中 o 是相机中心,d 是射线方向,tn 是近边界,tf 是远边界。为了使用预定义的 tn 和 tf 渲染射线 r,我们将密度 σ 和颜色 c 沿射线积分,如下所示:
ˆcθ(r)=∫tftnT(t)σθ(r(t))cθ(r(t),d)dt,T(t)=exp(−∫ttnσθ(r(t))dt),
其中 T(t) 是累积透射率,cθ(r(t),d) 和 σθ(r(t)) 分别是 fθ 预测的颜色和密度输出。渲染通过分层采样方法实现,其中在 [tn,tf] 中采样 M 个点,表示为 {x1,...,xM}。密度和颜色可以获得如下所示:
ˆcθ(r)=M∑i=1Ti(1−exp(−σθ(xi)δi))cθ(xi,d),Ti=exp(−i−1∑j=1σθ(xj)δj),
其中 δj=tj+1−tj 是相邻采样点之间的距离。具体来说,对于射线 r,其预测的 3D 点可以通过沿射线对加权深度值求和获得,如下所示:
y=o+∑M∑i=1Ti(1−exp(−σθ(xi)δi))ti d。
为了优化 NeRF 模型中的参数 θ,提供一组输入图像和相机参数,并最小化均方误差颜色损失进行优化,如下所示:
Lcolor(θ,R)=Er∈R∥ˆcθ(r)−c(r)∥22,
其中 R 是训练视图中的射线集合,c(r) 是射线 r 的真实颜色。
(2)生成对应关系:** 在本文中,我们重点研究如何利用计算的图像对应关系来增强神经隐式表示在 NeRF 中的性能。因此,对应关系的质量至关重要。对于训练视图中的每对图像,我们使用现成的 SOTA 预训练图像匹配模型计算对应关系。特别是,使用 DKMv3 [24],因为它提供了密集匹配结果,非常适合我们的用例。为了提高泛化能力,我们将室内和室外模型的预测结果融合在一起,这些模型分别在 ScanNet [46] 和 MegaDepth [47] 上预训练。为了进一步提高对应关系的可靠性,我们提出利用对应关系置信度,并设计了自动和自适应的对应关系处理算法,增加了令人信服的对应关系并去除了异常值。
(3)增强:** 为了增加对应关系的数量,我们对对应关系执行增强。第一种增强类型是图像变换,包括翻转、交换查询和支持图像以及缩放。这些图像变换可以有效地增加预测对应关系的密度,因为图像变换可以提供各种上下文条件来生成对应关系。第二种类型的增强将对应关系传播到图像对中,有效地增加了对应关系的区域覆盖范围。我们构建了一个无向图 G=(V,E),其中顶点 V={r|r∈R},边 E={(rq,rs)|rs∈C(rq)}。对于每条边 (rq,rs),分配一个置信度值 αq,s。然后,我们将对应关系传播到 G 中每个连通分量内的顶点对。具体来说,令 rq 和 rs 是两个顶点,距离为 d,其中是连接它们的路径 (rq,r1,r2,...,rd−1,rs)。我们在 rq 和 rs 之间分配对应关系,置信度为 αq,s=αq,1α1,2...αd−1,s。在实践中,我们可以捕获传播距离 d≤dmax,其中我们在实验中使用 dmax=2。图 3(B) 和 (C) 分别显示了原始对应关系和增强后的对应关系。
(4)异常值过滤:** 为了提高对应关系的质量以指导监督,我们在计算和增强对应关系后删除异常值。首先,我们根据对应点之间的投影射线距离去除异常值。假设 pq 和 ps 是 Iq 到 Is 中的一对 2D 对应关系,πq 和 πs 分别是 Iq 和 Is 的世界到像素投影。给定一对对应关系和相机参数,我们计算沿从相机中心射出的两条射线的最近 3D 点 xq 和 xs。然后,我们将这两个 3D 点投影到对应关系的图像平面。投影射线距离 [48] 定义为投影点和对应关系之间的平均欧几里得距离:
dproj=∥πq(xs)−pq∥2+∥πs(xq)−ps∥22。
我们删除投影射线距离 dproj 大于阈值的对应关系。其次,我们通过检查一个点是否在统计上远离其邻居来去除异常值。对于每一对对应关系,可以获得两个 3D 点 xq 和 xs,这已经在上一段中指出了。然后,我们考虑 12(xq+xs) 是对应关系的 3D 点。我们对所有对应关系对执行此操作以获得 3D 点集 P。对于 P 中的每个 3D 点,我们计算到其 k 个最近邻居的平均距离,如果距离大于阈值,则删除该点(以及其匹配的对应关系对)。此阈值由 P 中所有点的平均距离的标准差确定。
- 结论: (1):本文提出了一种利用图像对应先验来训练具有稀疏视图输入的神经辐射场的新方法。我们设计了自动增强和过滤方法,以从稀疏视图输入中生成密集且高质量的图像对应关系。我们设计了基于对应先验的重投影和深度损失项来正则化神经辐射场训练。实验表明,我们的方法仅使用少量输入图像即可显着提高光度和几何度量中衡量的重建质量。 (2):创新点:
- 利用图像对应先验来监督神经辐射场训练,提高了重建质量。
- 提出了一种自动增强和过滤方法来生成密集且高质量的图像对应关系。
- 设计了基于对应先验的重投影和深度损失项来正则化神经辐射场训练。 性能:
- 在具有密度和SDF的NeRF模型的不同数据集上,我们的方法在光度和几何度量方面都优于以前的方法。
- 我们的方法可以作为即插即用模块应用于不同的NeRF变体。 工作量:
- 本文的工作量中等。需要收集和预处理数据,训练神经辐射场模型,并评估模型的性能。
- 本文的代码和数据已开源,便于其他研究人员使用和扩展。
点此查看论文截图




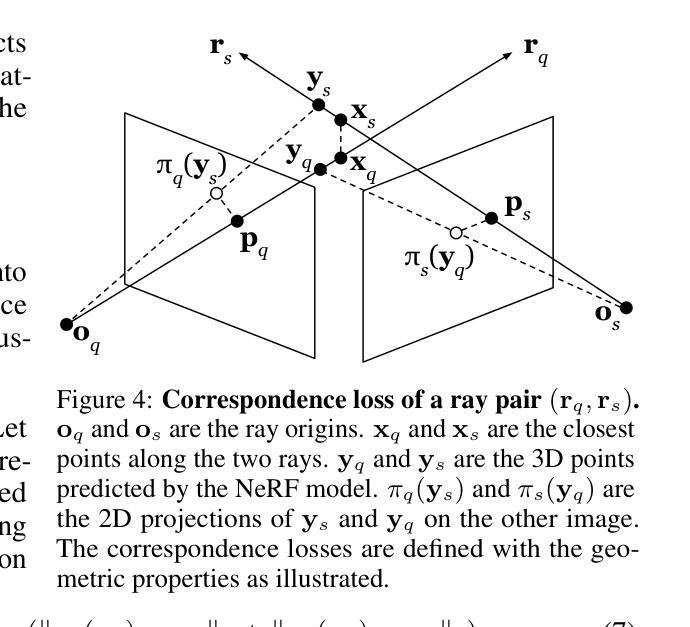
标题:MVDD:多视图深度扩散模型
作者:Zhen Wang, Qiangeng Xu, Feitong Tan, Menglei Chai, Shichen Liu, Rohit Pandey, Sean Fanello, Achuta Kadambi, Yinda Zhang
第一作者单位:加州大学洛杉矶分校
关键词:深度扩散模型、多视图深度、3D形状生成、形状补全、3D GAN反演
论文链接:https://arxiv.org/abs/2312.04875 Github 链接:https://github.com/mvdepth/mvdd
摘要: (1):研究背景:扩散模型在 2D 图像生成中取得了出色的结果,但在 3D 形状生成中复制其成功仍然具有挑战性。 (2):过去的方法及其问题:现有方法通常使用点云或体素表示来生成 3D 形状,但这些表示难以建模复杂的形状。 (3):本文提出的研究方法:本文提出了一种多视图深度扩散模型 (MVDD),该模型利用多视图深度来表示复杂的 3D 形状。MVDD 能够生成高质量的密集点云,具有 20K+ 个点和精细的细节。 (4):方法在任务中的表现:MVDD 在 3D 形状生成、深度补全和作为 3D GAN 反演的先验等任务中取得了最先进的结果。这些结果证明了 MVDD 在 3D 形状生成和相关任务中的出色性能。
方法: (1) 多视图深度扩散模型 (MVDD):MVDD 采用多视图深度来表示复杂的 3D 形状,可以生成高质量的密集点云,具有 20K+ 个点和精细的细节。 (2) 表观线段注意力 (Epipole “Line Segment” Attention):MVDD 引入了一种有效的表观“线段”注意力,以促进所有深度图的一致性。该注意力仅关注其他视图上可见位置的特征,从而提高了效率和有效性。 (3) 去噪深度融合 (Denoising Depth Fusion):为了进一步加强多视图深度图的排列,MVDD 在扩散步骤中结合了深度融合。该融合过程将深度图投影到其他视图并进行比较,以确保深度值的一致性。 (4) 训练目标:MVDD 采用 DDPM 的目标函数,旨在最大化对数似然函数。该目标函数通过最小化噪声估计误差来实现,从而使模型能够从纯噪声生成逼真的深度图。 (5) 应用:MVDD 在 3D 形状生成、深度补全和作为 3DGAN 反演的先验等任务中取得了最先进的结果。这些结果证明了 MVDD 在 3D 形状生成和相关任务中的出色性能。
结论: (1):MVDD 提出了一种多视图深度扩散模型,能够生成高质量的密集点云,并具有精细的细节。 (2):创新点:
- 提出了一种多视图深度扩散模型(MVDD),该模型利用多视图深度来表示复杂的 3D 形状。
- 引入了一种有效的表观“线段”注意力,以促进所有深度图的一致性。
- 结合了深度融合,以进一步加强多视图深度图的排列。 性能:
- MVDD 在 3D 形状生成、深度补全和作为 3DGAN 反演的先验等任务中取得了最先进的结果。 工作量:
- MVDD 的训练和推理过程相对复杂,需要大量的计算资源。
点此查看论文截图

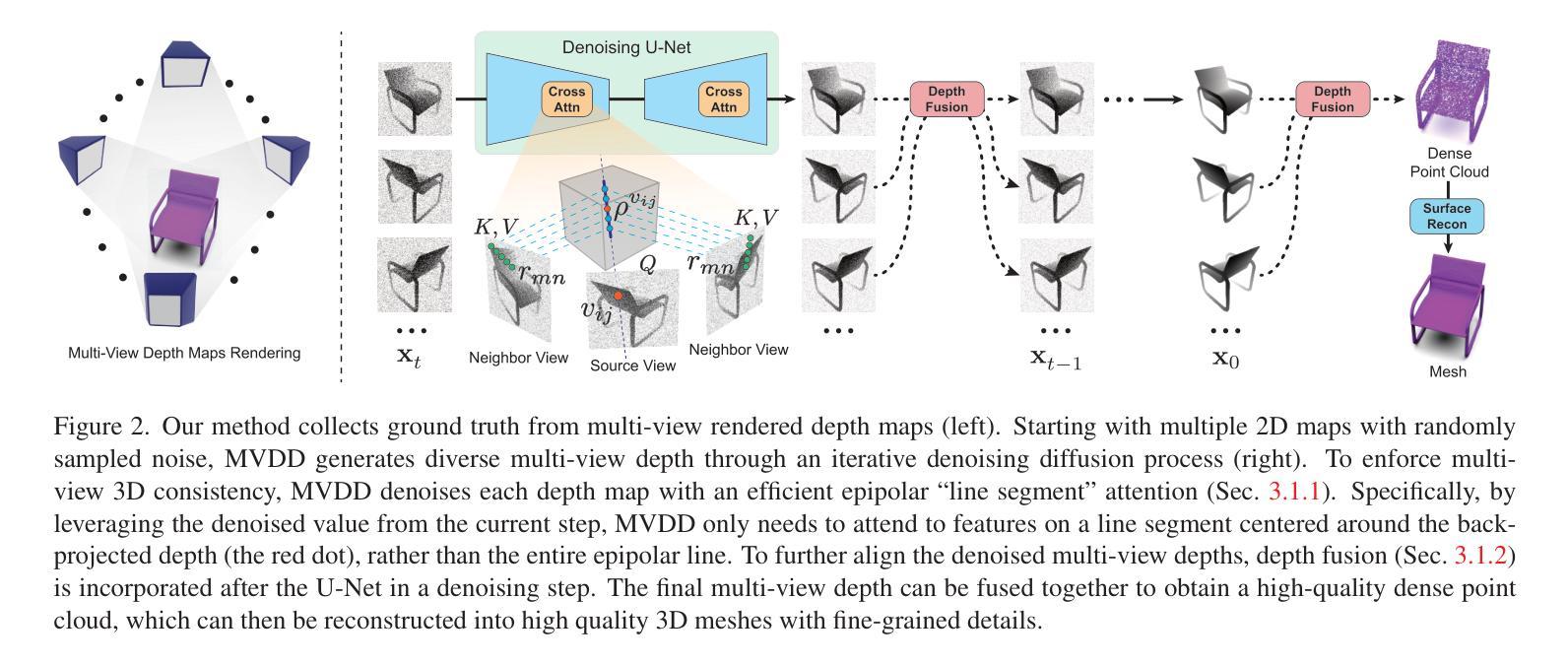

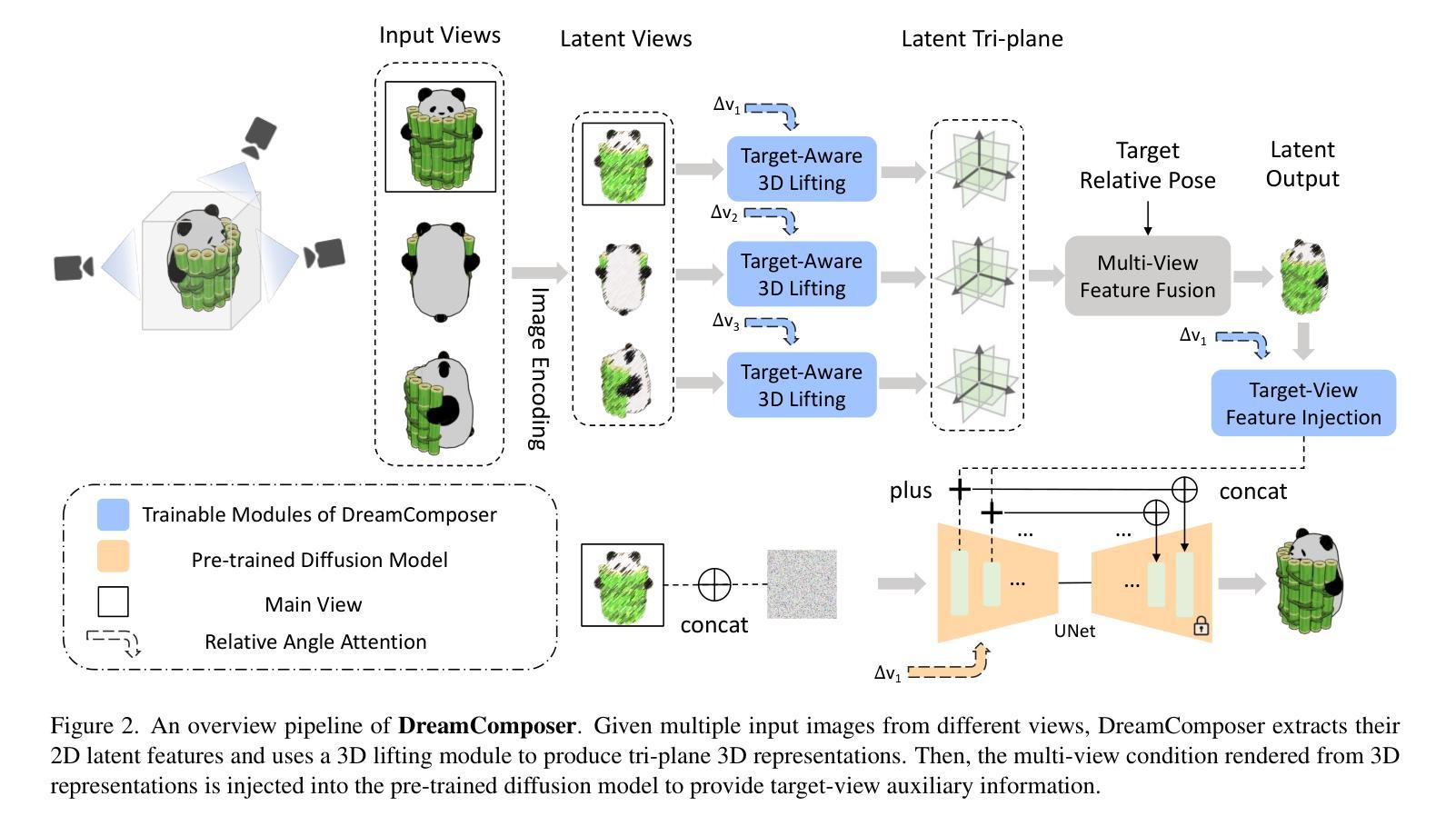
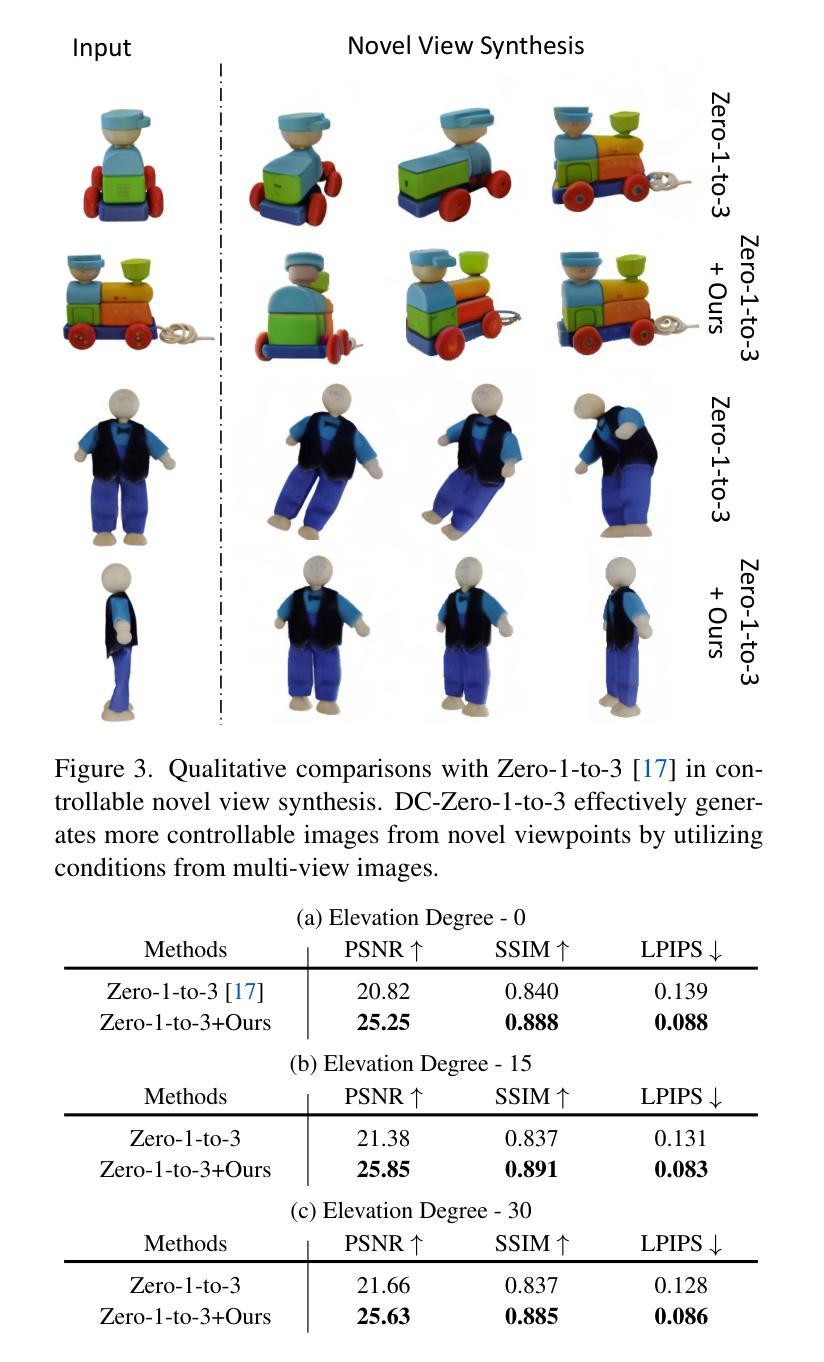
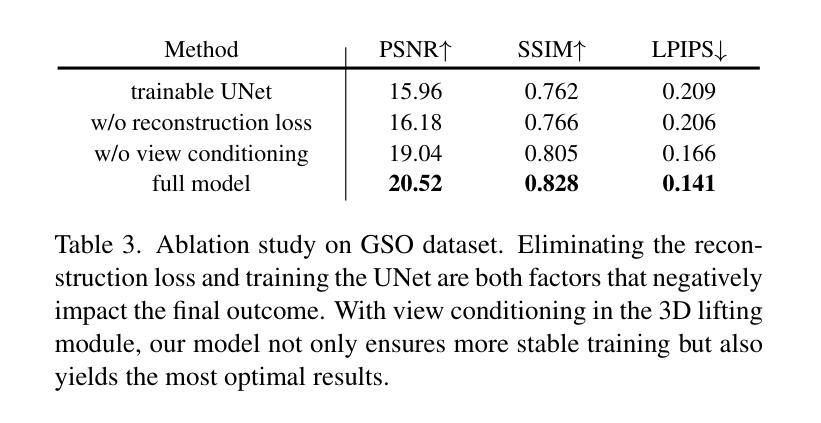
题目:DreamComposer:通过多视图条件生成可控的 3D 对象
作者:Yunhan Yang、Yukun Huang、Xiaoyang Wu、Yuan-Chen Guo、Song-Hai Zhang、Hengshuang Zhao、Tong He、Xihui Liu
第一作者单位:香港大学
关键词:可控 3D 对象生成、多视图条件、扩散模型、零样本新视角合成
论文链接:https://arxiv.org/abs/2312.03611,Github 代码链接:无
摘要: (1) 研究背景:利用预训练的 2D 大规模生成模型,最近的工作能够从一张自然界图像中生成高质量的新视角。然而,由于缺乏来自多视角的信息,这些工作在生成可控的新视角时遇到了困难。 (2) 过去方法与不足:过去的方法通常使用单一的预训练扩散模型来生成新视角,但这些模型缺乏对多视角条件的控制能力。 (3) 研究方法:本文提出 DreamComposer,这是一个灵活且可扩展的框架,可以通过注入多视图条件来增强现有的视图感知扩散模型。具体来说,DreamComposer 首先使用视图感知 3D 提升模块从多个视图中获得对象的 3D 表示。然后,它使用多视图特征融合模块从 3D 表示中渲染目标视图的潜在特征。最后,将从多视图输入中提取的目标视图特征注入预训练的扩散模型。 (4) 实验结果:实验表明,DreamComposer 与最先进的用于零样本新视角合成的扩散模型兼容,进一步增强了这些模型生成具有多视图条件的高保真新视角图像的能力,可用于可控 3D 对象重建和各种其他应用。
Methods: (1) 视图感知3D提升模块:该模块从多个视图中获得对象的3D表示。它首先使用预训练的2D扩散模型从每个视图中生成对象的2D表示,然后将这些2D表示投影到3D空间中,并使用3D卷积网络融合这些投影,以获得对象的3D表示。 (2) 多视图特征融合模块:该模块从3D表示中渲染目标视图的潜在特征。它首先使用3D渲染器将3D表示渲染成目标视图的2D图像,然后使用预训练的2D扩散模型从2D图像中提取潜在特征。 (3) 多视图条件注入模块:该模块将从多视图输入中提取的目标视图特征注入预训练的扩散模型。它首先将目标视图的潜在特征与预训练的扩散模型的潜在特征进行拼接,然后使用一个线性层将拼接后的特征投影到预训练的扩散模型的潜在空间中。 (4) 扩散模型生成:将注入多视图条件的潜在特征输入预训练的扩散模型,并使用扩散模型生成目标视图的新视角图像。
结论: (1):DreamComposer 框架提出了一个灵活且可扩展的框架,可以通过注入多视图条件来增强现有的视图感知扩散模型,从而生成具有多视图条件的高保真新视角图像。 (2):创新点:
- 提出了一种新的视图感知 3D 提升模块,可以从多个视图中获得对象的 3D 表示。
- 提出了一种新的多视图特征融合模块,可以从 3D 表示中渲染目标视图的潜在特征。
- 提出了一种新的多视图条件注入模块,可以将从多视图输入中提取的目标视图特征注入预训练的扩散模型。 性能:
- DreamComposer 与最先进的用于零样本新视角合成的扩散模型兼容,进一步增强了这些模型生成具有多视图条件的高保真新视角图像的能力。 工作量:
- DreamComposer 框架的实现相对简单,易于使用。
点此查看论文截图

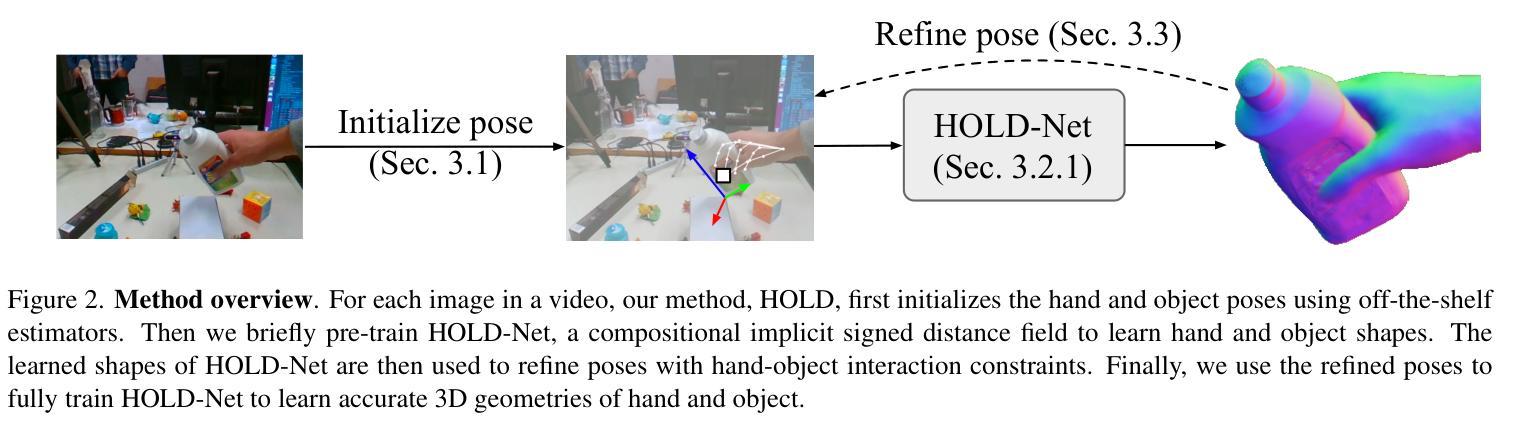
- 标题:HOLD:从视频中进行类别无关的交互手和物体的 3D 重建
- 作者:Zicong Fan, Maria Parelli, Maria Eleni Kadoglou, Muhammed Kocabas, Xu Chen, Michael J. Black, Otmar Hilliges
- 隶属单位:苏黎世联邦理工学院,德国图宾根马克斯普朗克智能系统研究所
- 关键词:3D 重建、手部对象交互、隐式神经表示、约束优化
- 论文链接:https://arxiv.org/abs/2311.18448,Github 链接:https://github.com/zc-alexfan/hold
- 摘要: (1):研究背景:人类每天都会与各种物体互动,因此全面捕捉这些互动对于理解和建模人类行为非常重要。然而,目前大多数用于从 RGB 图像进行手部物体重建的方法要么假设预先扫描的对象模板,要么严重依赖有限的 3D 手部物体数据,这限制了它们在更不受约束的交互场景中的扩展和泛化能力。 (2):过去的方法及其问题:本文方法的动机:现有方法要么假设预先扫描的对象模板,要么严重依赖有限的 3D 手部物体数据,这限制了它们在更不受约束的交互场景中的扩展和泛化能力。 (3):研究方法:为了解决上述问题,本文提出了一种名为 HOLD 的方法,该方法可以从单目交互视频中重建铰接手和物体。HOLD 使用了一种组合关节隐式模型,该模型可以从 2D 图像重建分离的 3D 手部和物体。此外,本文还进一步结合了手部物体约束来改进手部物体姿势,从而提高重建质量。 (4):方法的性能:HOLD 方法在实验室和具有挑战性的野外场景中均优于完全监督的基线。此外,本文还定性地展示了其从野外视频中重建的鲁棒性。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本研究的意义: 本研究提出了一种名为 HOLD 的方法,该方法可以从单目交互视频中重建铰接手和物体。HOLD 使用了一种组合关节隐式模型,该模型可以从 2D 图像重建分离的 3D 手部和物体。此外,本文还进一步结合了手部物体约束来改进手部物体姿势,从而提高重建质量。HOLD 方法在实验室和具有挑战性的野外场景中均优于完全监督的基线。此外,本文还定性地展示了其从野外视频中重建的鲁棒性。 (2):本文的优缺点: 创新点:
- 提出了一种名为 HOLD 的方法,该方法可以从单目交互视频中重建铰接手和物体。
- 使用了一种组合关节隐式模型,该模型可以从 2D 图像重建分离的 3D 手部和物体。
- 进一步结合了手部物体约束来改进手部物体姿势,从而提高重建质量。
性能:
- HOLD 方法在实验室和具有挑战性的野外场景中均优于完全监督的基线。
- HOLD 方法从野外视频中重建的鲁棒性强。
工作量:
- HOLD 方法需要大量的数据和计算资源。
- HOLD 方法的训练过程比较复杂。
点此查看论文截图

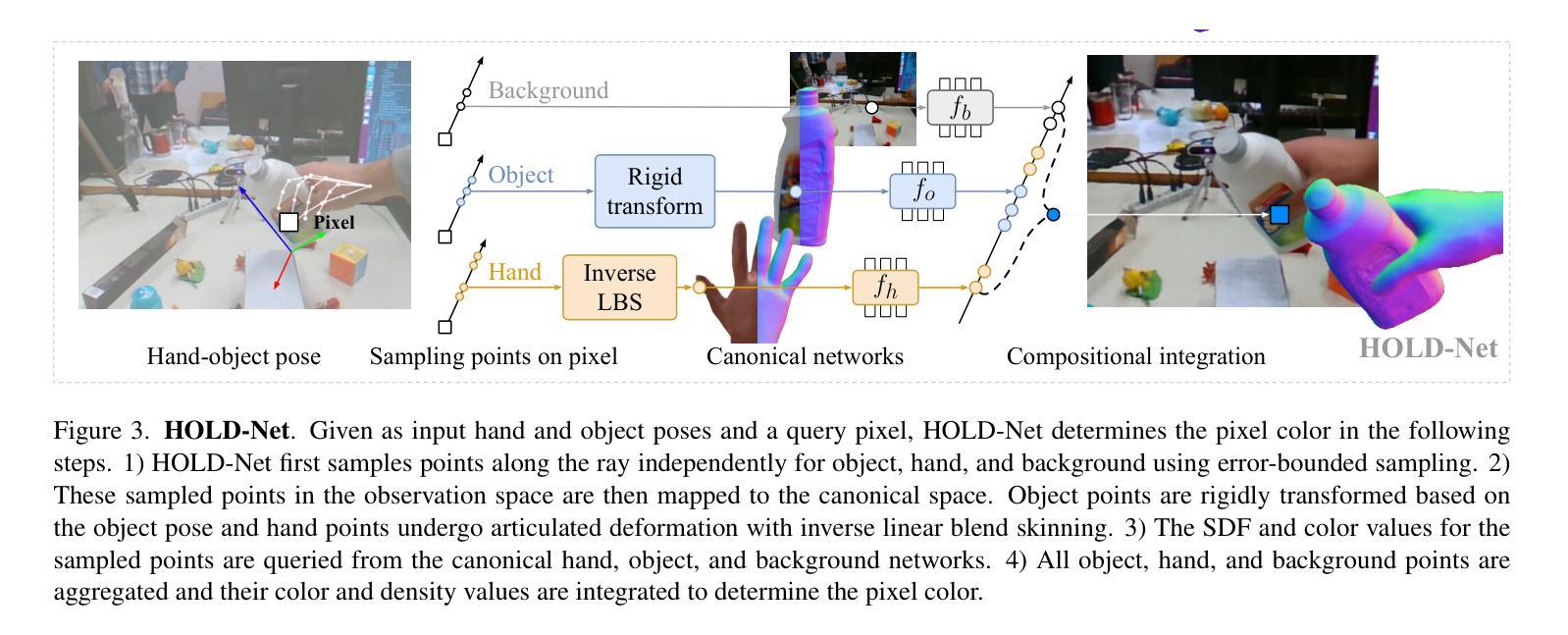
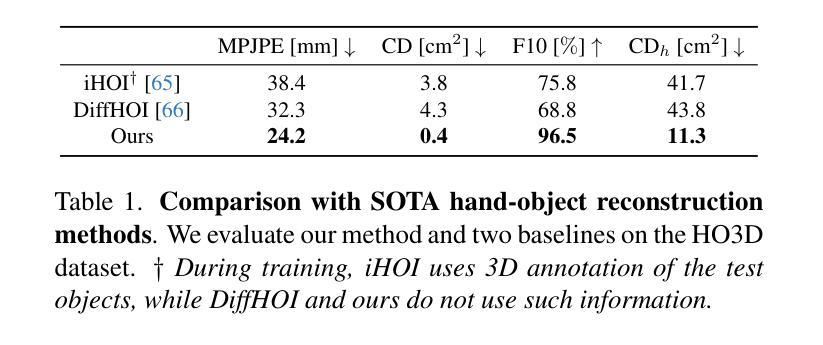
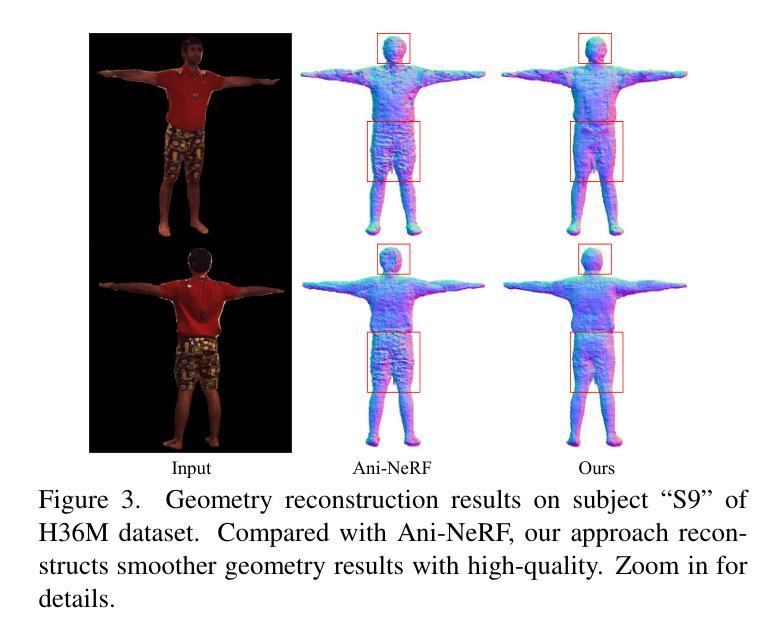
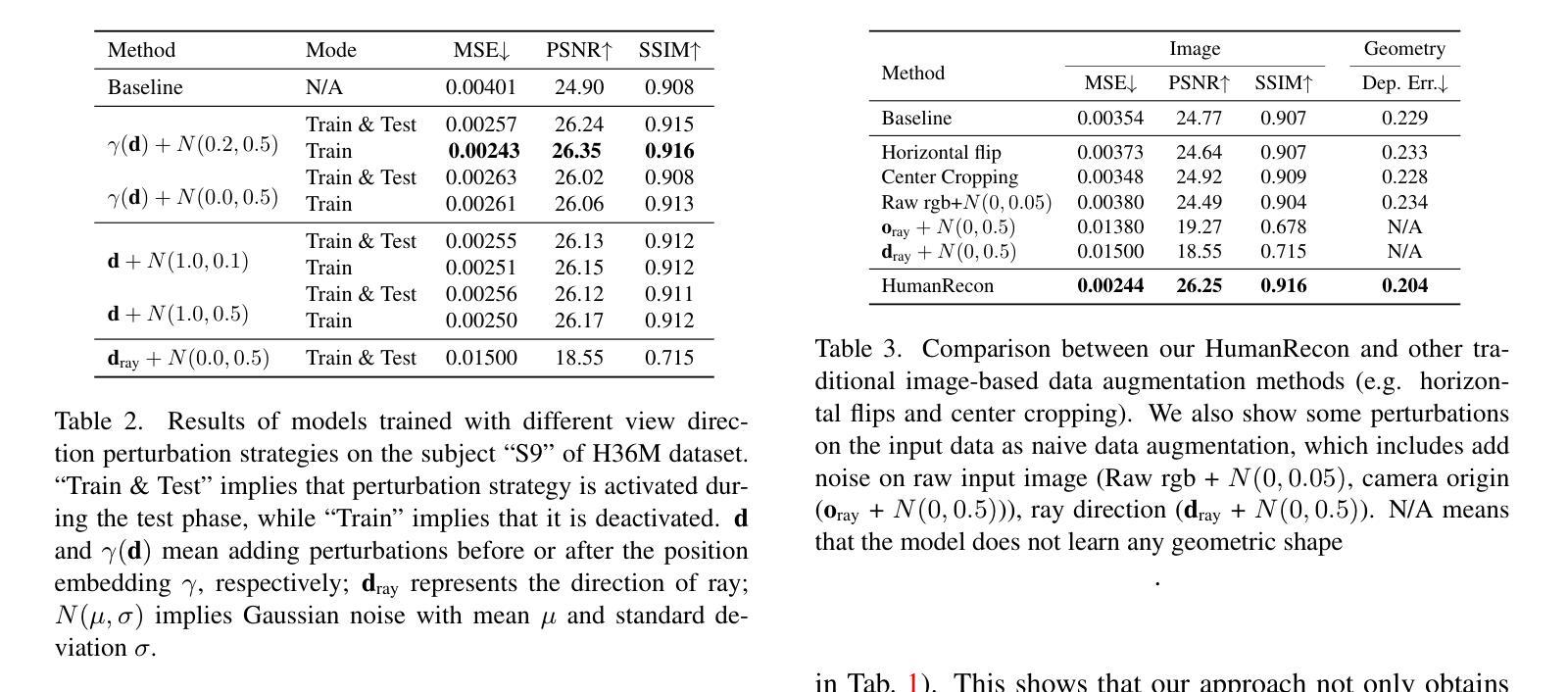
HumanRecon: Neural Reconstruction of Dynamic Human Using Geometric Cues and Physical Priors
Authors:Junhui Yin, Wei Yin, Hao Chen, Xuqian Ren, Zhanyu Ma, Jun Guo, Yifan Liu
Recent methods for dynamic human reconstruction have attained promising reconstruction results. Most of these methods rely only on RGB color supervision without considering explicit geometric constraints. This leads to existing human reconstruction techniques being more prone to overfitting to color and causes geometrically inherent ambiguities, especially in the sparse multi-view setup. Motivated by recent advances in the field of monocular geometry prediction, we consider the geometric constraints of estimated depth and normals in the learning of neural implicit representation for dynamic human reconstruction. As a geometric regularization, this provides reliable yet explicit supervision information, and improves reconstruction quality. We also exploit several beneficial physical priors, such as adding noise into view direction and maximizing the density on the human surface. These priors ensure the color rendered along rays to be robust to view direction and reduce the inherent ambiguities of density estimated along rays. Experimental results demonstrate that depth and normal cues, predicted by human-specific monocular estimators, can provide effective supervision signals and render more accurate images. Finally, we also show that the proposed physical priors significantly reduce overfitting and improve the overall quality of novel view synthesis. Our code is available at:~\href{https://github.com/PRIS-CV/HumanRecon}{https://github.com/PRIS-CV/HumanRecon}.
Summary
利用深度和法向量作为几何正则化,提高神经隐式表示动态人体重建的质量。
Key Takeaways
- 深度和法向量是人体重建的关键几何约束。
- 使用深度和法向量作为监督信息可以提高重建质量。
- 加入噪声到视角中可以使颜色渲染更鲁棒。
- 最大化人体表面的密度可以减少密度估计的固有二义性。
- 实验结果表明,深度和法向量线索可以提供有效的监督信号并呈现更准确的图像。
- 提出物理先验显著减少了过拟合并提高了新视角合成的总体质量。
- 代码可在 GitHub 上获取。
- 题目:HumanRecon:利用几何线索和物理先验的神经重建动态人体
- 作者:Junhui Yin、Wei Yin、Hao Chen、Xuqian Ren、Zhanyu Ma、Jun Guo 和 Yifan Liu
- 单位:北京邮电大学
- 关键词:动态人体重建、神经隐式表示、几何约束、物理先验
- 论文链接:https://arxiv.org/abs/2311.15171 Github 链接:https://github.com/PRIS-CV/HumanRecon
- 摘要: (1):研究背景:动态人体重建是计算机视觉研究中的一个基本问题,在机器人技术、图形学、增强现实、虚拟现实和人体数字化等领域有着广泛的应用。然而,从 RGB 图像和视频中重建动态人体极具挑战性,因为这些数据缺乏足够的监督信息。 (2):过去方法:传统的人体建模工作使用显式网格来表示人体几何形状,并将外观存储在 2D 纹理贴图中。但是,这些方法需要密集的摄像头阵列和受控的照明条件。近年来,PIFu、StereoPIFu 和 PIFuHD 等方法提出使用像素级图像特征回归神经隐式函数,能够重建高分辨率的衣着人体结果。ARCH 方法将一系列 PIFu 方法扩展到从单目图像中回归可动画的衣着人体化身。然而,这些方法无法从稀疏的多视角视频中重建动态的衣着人体。 (3):研究方法:本文提出了一种新的动态人体重建方法 HumanRecon,该方法利用几何线索和物理先验来学习神经隐式表示。具体来说,HumanRecon 使用单目几何估计器预测深度和法线线索,并将其作为几何正则化项添加到神经隐式表示的学习中。此外,HumanRecon 还利用了几种有益的物理先验,例如在视向中添加噪声和最大化人体表面的密度。这些先验确保了沿射线渲染的颜色对视向具有鲁棒性,并减少了沿射线估计的密度的固有歧义性。 (4):方法性能:实验结果表明,由特定于人类的单目估计器预测的深度和法线线索可以提供有效的监督信号并渲染更准确的图像。此外,本文提出的物理先验可以显着减少过拟合并提高新视角合成的整体质量。
方法:
(1):HumanRecon利用单目几何估计器预测深度和法线线索,并将其作为几何正则化项添加到神经隐式表示的学习中。
(2):HumanRecon利用了几种有益的物理先验,例如在视向中添加噪声和最大化人体表面的密度。
(3):HumanRecon使用神经隐式表示来学习动态人体的几何形状和外观,并利用几何线索和物理先验来提高重建的准确性和鲁棒性。
- 结论: (1):本文提出了一种新的动态人体重建方法 HumanRecon,该方法利用几何线索和物理先验来学习神经隐式表示,能够从稀疏的多视角视频中重建动态的衣着人体,在公共数据集上取得了最优的重建效果。 (2):创新点: HumanRecon 提出了一种新的动态人体重建方法,该方法利用几何线索和物理先验来学习神经隐式表示,能够从稀疏的多视角视频中重建动态的衣着人体。 性能: HumanRecon 在公共数据集上取得了最优的重建效果。 工作量: HumanRecon 的工作量中等,需要收集稀疏的多视角视频数据,并使用神经网络进行训练。
点此查看论文截图
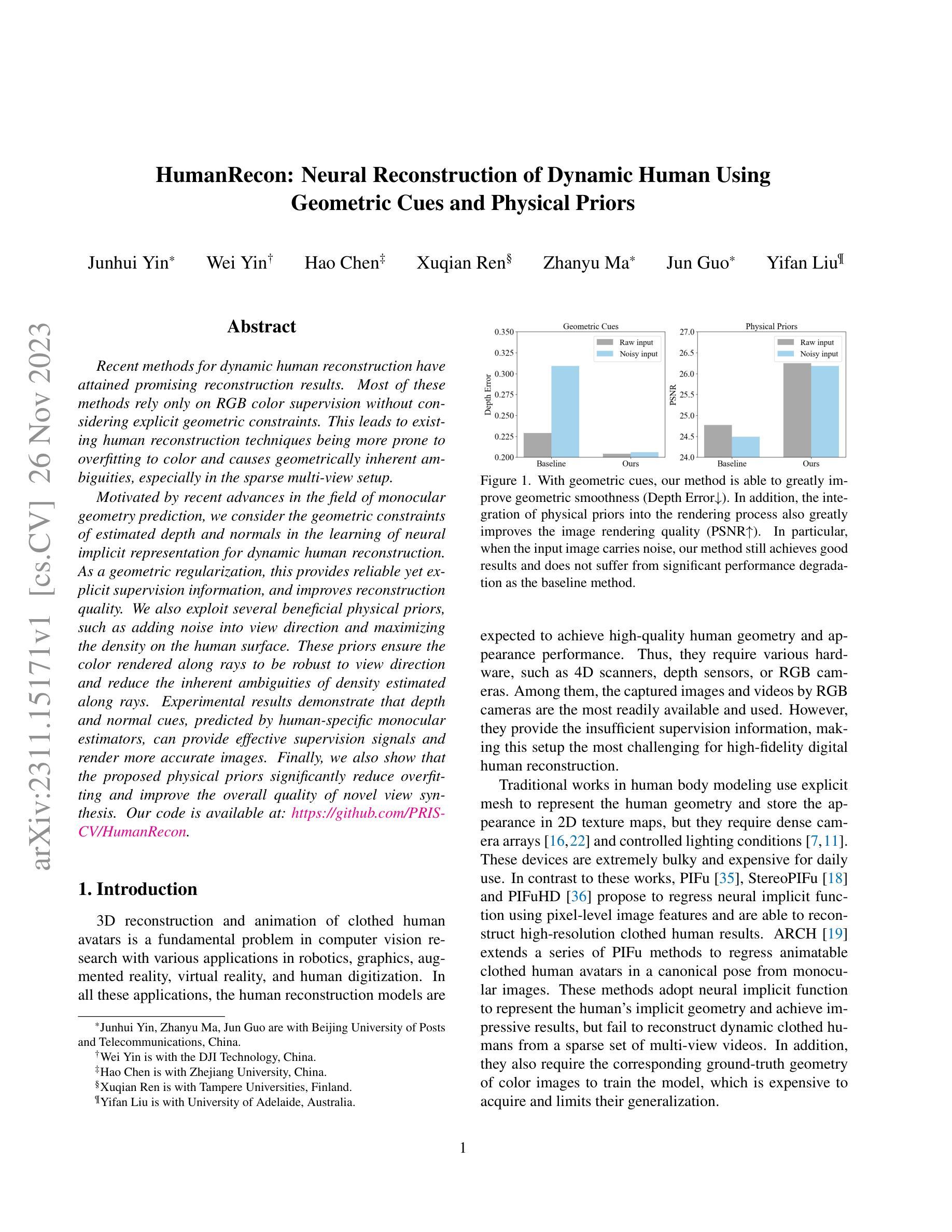
Unsupervised Graph Attention Autoencoder for Attributed Networks using K-means Loss
Authors:Abdelfateh Bekkair, Slimane Bellaouar, Slimane Oulad-Naoui
Several natural phenomena and complex systems are often represented as networks. Discovering their community structure is a fundamental task for understanding these networks. Many algorithms have been proposed, but recently, Graph Neural Networks (GNN) have emerged as a compelling approach for enhancing this task.In this paper, we introduce a simple, efficient, and clustering-oriented model based on unsupervised \textbf{G}raph Attention \textbf{A}uto\textbf{E}ncoder for community detection in attributed networks (GAECO). The proposed model adeptly learns representations from both the network’s topology and attribute information, simultaneously addressing dual objectives: reconstruction and community discovery. It places a particular emphasis on discovering compact communities by robustly minimizing clustering errors. The model employs k-means as an objective function and utilizes a multi-head Graph Attention Auto-Encoder for decoding the representations. Experiments conducted on three datasets of attributed networks show that our method surpasses state-of-the-art algorithms in terms of NMI and ARI. Additionally, our approach scales effectively with the size of the network, making it suitable for large-scale applications. The implications of our findings extend beyond biological network interpretation and social network analysis, where knowledge of the fundamental community structure is essential.
PDF 7 pages, 5 Figures
摘要
无监督图注意力自动编码器方法有效地提取了生物和社交关系网络中的社区结构。
要点
- 提出了一种简单、高效、面向聚类的无监督图注意力自动编码器方法,用于发现属性网络中的社区结构。
- 该模型能够同时学习网络拓扑和属性信息,并以重建和社区发现为双重目标。
- 该模型通过稳健地最小化聚类误差,特别强调发现紧凑的社区。
- 该模型采用k均值作为目标函数,并使用多头图注意自动编码器对表示进行解码。
- 在三个属性网络数据集上进行的实验表明,该方法在NMI和ARI方面优于最先进的算法。
- 该方法还可以有效地扩展到网络规模,使其适用于大规模应用。
- 该方法的应用范围不仅限于生物网络解释和社交网络分析,在这些领域中,了解基本的社区结构至关重要。
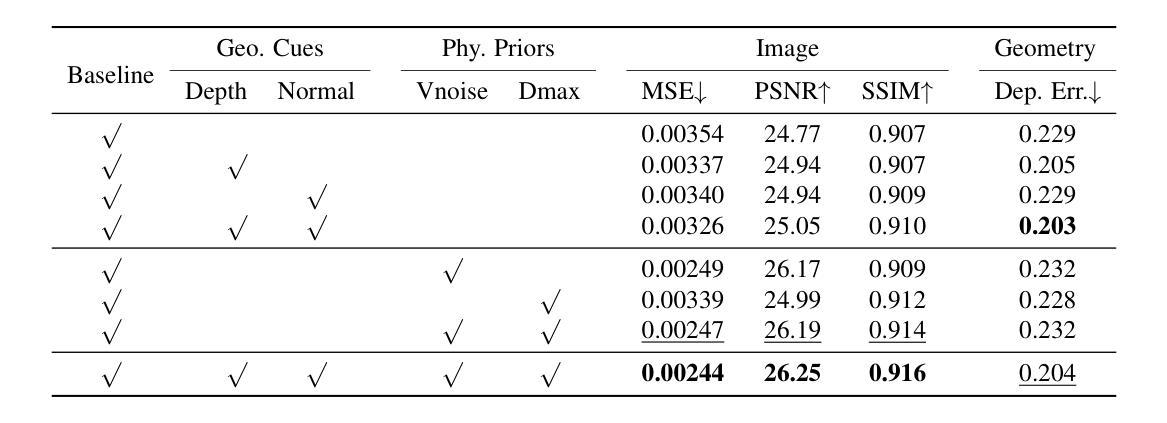
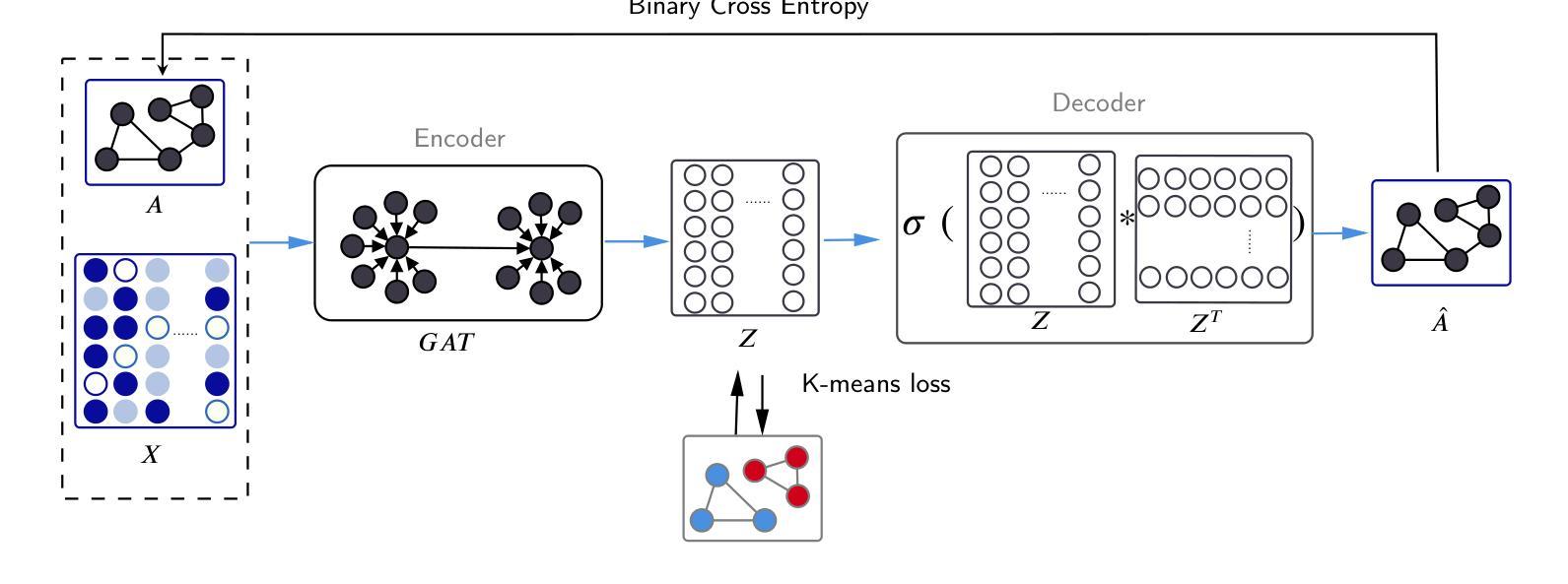
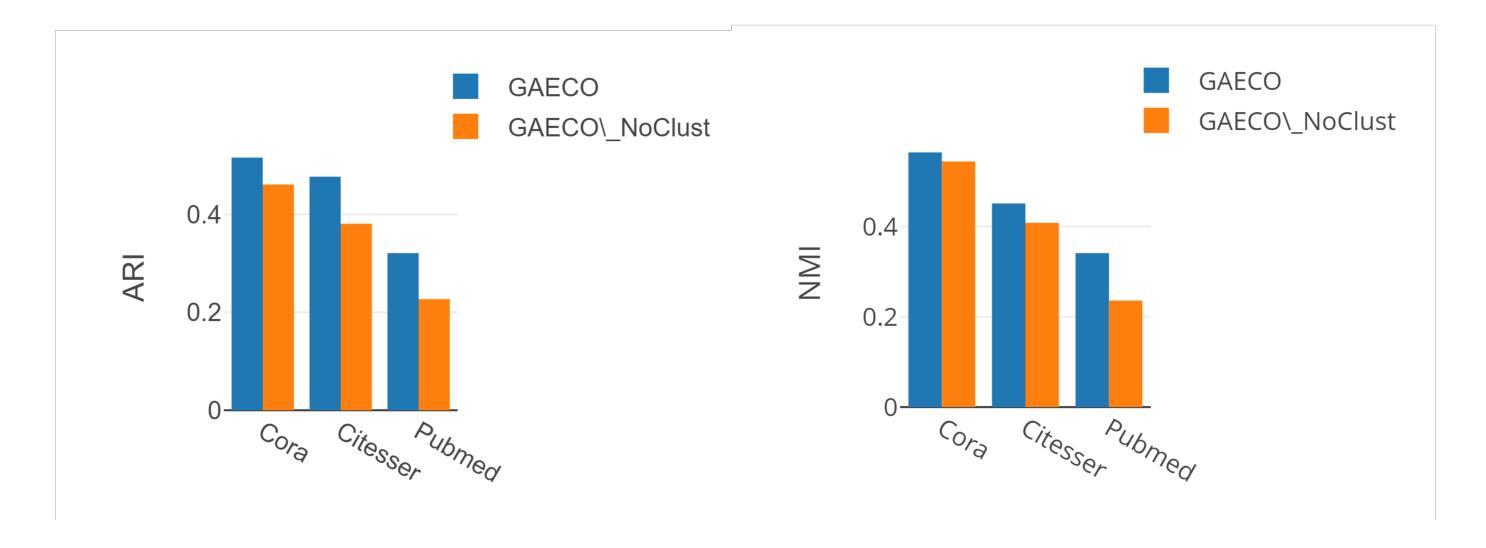
- 论文标题:无监督图注意力自编码器用于属性网络
- 作者:Abdelfateh Bekkaira, Slimane Bellaouara, Slimane Oulad-Naouia
- 所属单位:阿尔及利亚格哈达亚大学数学与计算机科学系
- 关键词:图注意力网络、自编码器、无监督学习、社区检测
- 链接:https://arxiv.org/abs/2311.12986
- 摘要: (1)研究背景:社区检测是图分析中的一项重要任务,旨在将图中的节点划分为不同的社区,使社区内的节点连接紧密,社区之间的节点连接稀疏。传统社区检测方法主要基于图的结构信息,而近年来提出的图注意力网络(GAT)可以同时考虑图的结构信息和节点的属性信息,在社区检测任务上取得了较好的效果。然而,现有的GAT模型大多是监督学习模型,需要大量的标记数据进行训练。 (2)过去的方法及其问题:现有方法存在以下问题:
- 需要大量的标记数据进行训练,这在实际应用中往往难以获得。
- 难以处理大规模图数据。
- 对图的结构和属性信息利用不足。 (3)研究方法:为了解决上述问题,本文提出了一种无监督图注意力自编码器(GAECO)模型,该模型可以同时利用图的结构信息和节点的属性信息进行社区检测。GAECO模型的结构如下图所示:
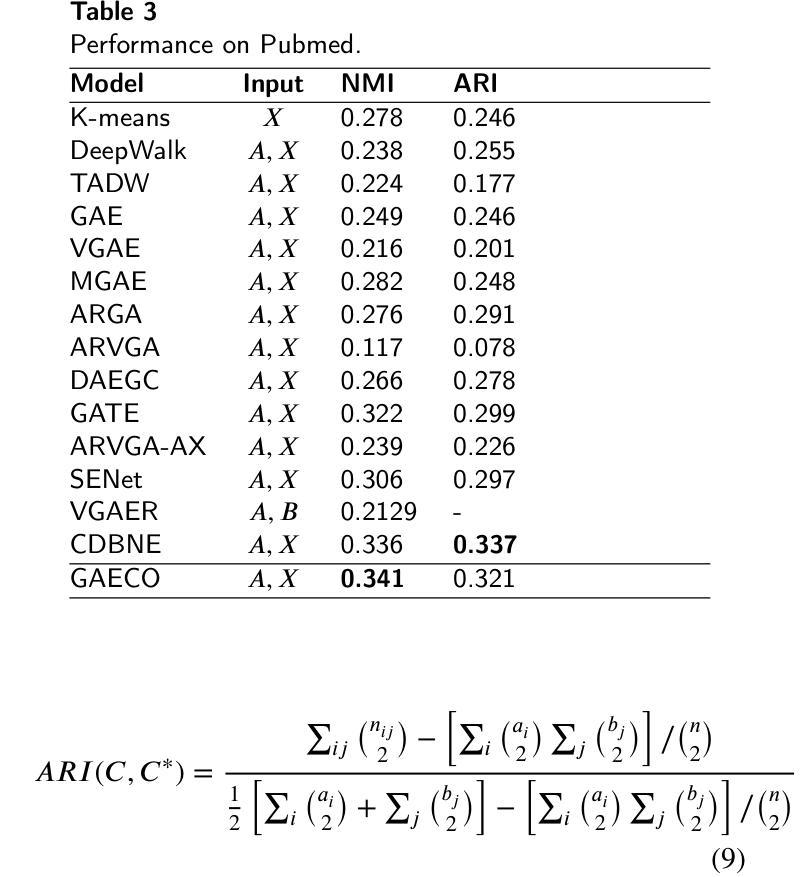
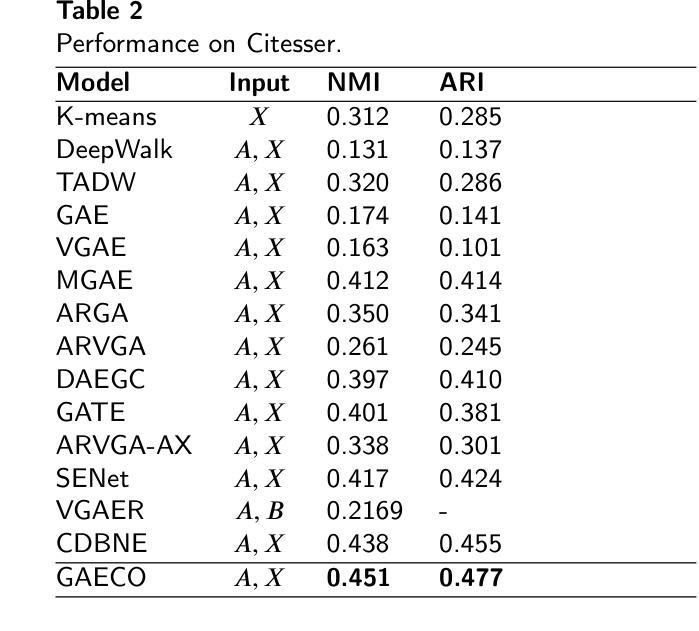
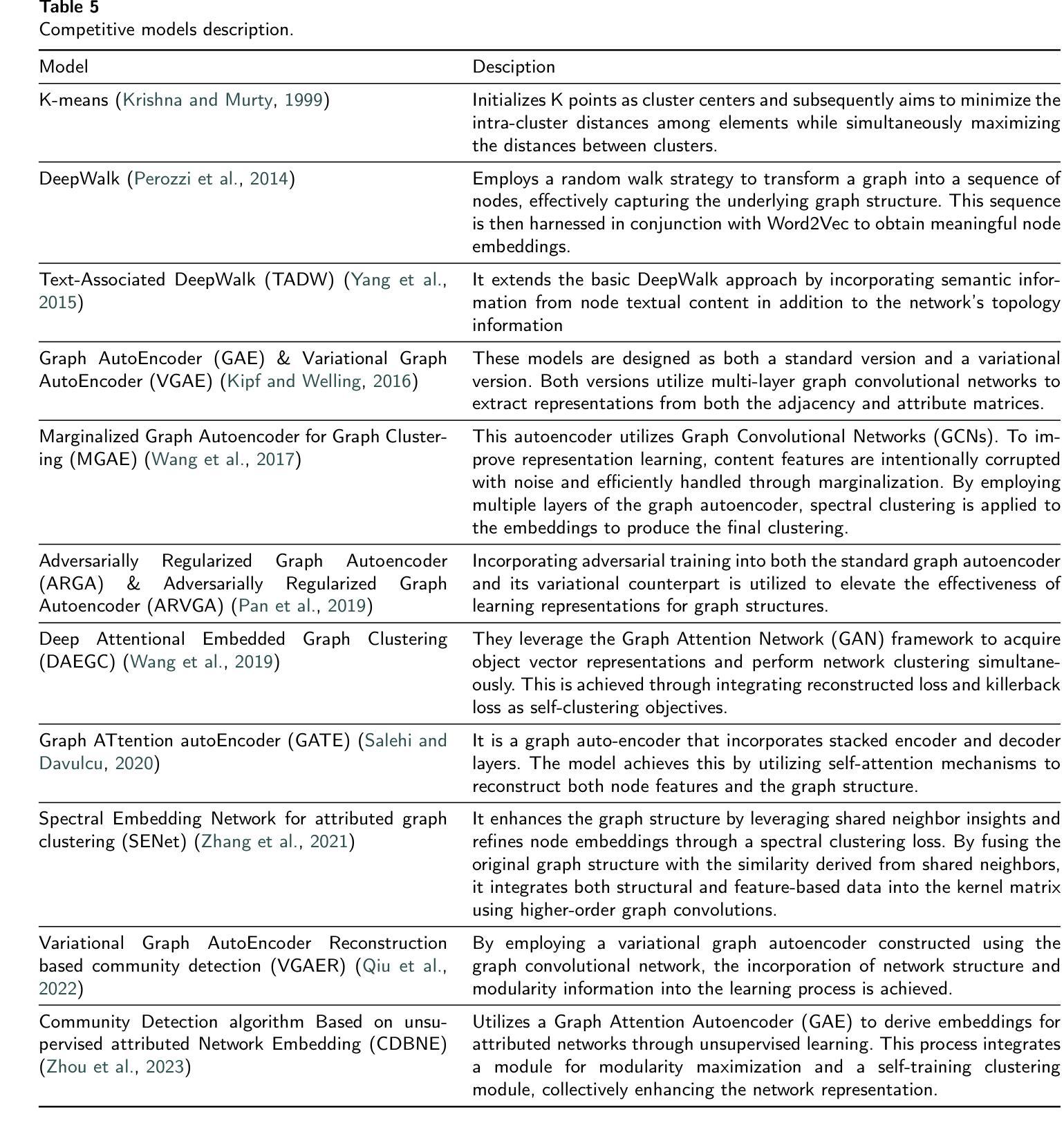
- 在Cora数据集上,GAECO模型的NMI和ARI指标分别达到了0.564和0.516,优于其他对比模型。
- 在CiteSeer数据集上,GAECO模型的NMI和ARI指标分别达到了0.451和0.477,优于其他对比模型。
- 在PubMed数据集上,GAECO模型的NMI和ARI指标分别达到了0.341和0.321,优于其他对比模型。
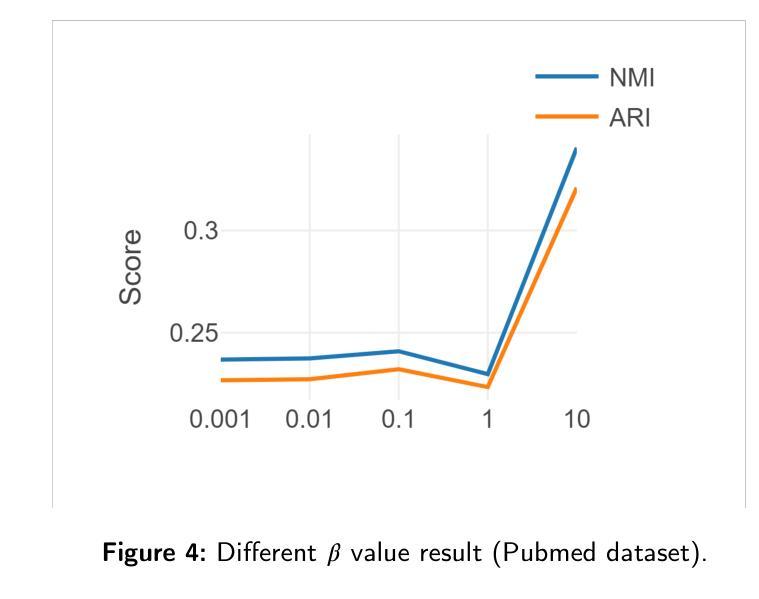
- 结论: (1):本文提出了一种无监督图注意力自编码器(GAECO)模型,该模型可以同时利用图的结构信息和节点的属性信息进行社区检测。GAECO模型在三个真实数据集上取得了优于其他对比模型的结果,表明了该模型的有效性。 (2):创新点:
- 提出了一种新的无监督图注意力自编码器(GAECO)模型,该模型可以同时利用图的结构信息和节点的属性信息进行社区检测。
- GAECO模型采用GAT网络作为编码器,可以同时考虑图的结构信息和节点的属性信息,将图中的节点嵌入到一个低维空间中。
- GAECO模型采用简单的内积解码器,将编码器的输出重建为图的邻接矩阵。
- GAECO模型采用K-means损失函数,可以使编码器的输出与真实的社区结构更加接近。 性能:
- 在Cora数据集上,GAECO模型的NMI和ARI指标分别达到了0.564和0.516,优于其他对比模型。
- 在CiteSeer数据集上,GAECO模型的NMI和ARI指标分别达到了0.451和0.477,优于其他对比模型。
- 在PubMed数据集上,GAECO模型的NMI和ARI指标分别达到了0.341和0.321,优于其他对比模型。 工作量:
- GAECO模型的编码器采用GAT网络,GAT网络的计算复杂度为O(|E|d),其中|E|是图中的边数,d是GAT网络的层数。
- GAECO模型的解码器采用简单的内积解码器,内积解码器的计算复杂度为O(|V|^2),其中|V|是图中的节点数。
- GAECO模型的损失函数采用K-means损失函数,K-means损失函数的计算复杂度为O(|V|k),其中k是社区的个数。
</ol>
[Image of GAECO model architecture]
GAECO模型由编码器、解码器和损失函数三部分组成。编码器采用GAT网络,可以同时考虑图的结构信息和节点的属性信息,将图中的节点嵌入到一个低维空间中。解码器采用简单的内积解码器,将编码器的输出重建为图的邻接矩阵。损失函数采用K-means损失函数,可以使编码器的输出与真实的社区结构更加接近。 (4)实验结果:
Some Error for method(比如是不是没有Methods这个章节)
点此查看论文截图

 wechat
wechat- alipay

