3DGS
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-01-27 更新
Deformable Endoscopic Tissues Reconstruction with Gaussian Splatting
Authors:Lingting Zhu, Zhao Wang, Zhenchao Jin, Guying Lin, Lequan Yu
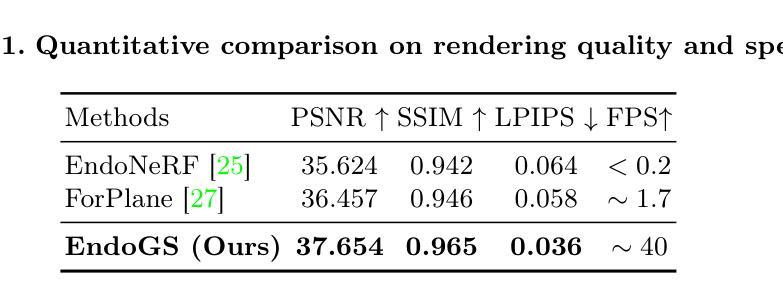
Surgical 3D reconstruction is a critical area of research in robotic surgery, with recent works adopting variants of dynamic radiance fields to achieve success in 3D reconstruction of deformable tissues from single-viewpoint videos. However, these methods often suffer from time-consuming optimization or inferior quality, limiting their adoption in downstream tasks. Inspired by 3D Gaussian Splatting, a recent trending 3D representation, we present EndoGS, applying Gaussian Splatting for deformable endoscopic tissue reconstruction. Specifically, our approach incorporates deformation fields to handle dynamic scenes, depth-guided supervision to optimize 3D targets with a single viewpoint, and a spatial-temporal weight mask to mitigate tool occlusion. As a result, EndoGS reconstructs and renders high-quality deformable endoscopic tissues from a single-viewpoint video, estimated depth maps, and labeled tool masks. Experiments on DaVinci robotic surgery videos demonstrate that EndoGS achieves superior rendering quality. Code is available at https://github.com/HKU-MedAI/EndoGS.
PDF Work in progress. 10 pages, 4 figures
摘要
动态高斯散点用于可变形内窥镜组织重建。
Key Takeaways
- EndoGS 将高斯散点应用于可变形内窥镜组织重建。
- EndoGS 结合了变形场、深度引导监督和时空权重掩码来处理动态场景、优化 3D 目标和减轻工具遮挡。
- EndoGS 从单视角视频、估计的深度图和标注的工具掩码中重建并渲染高质量的可变形内窥镜组织。
- EndoGS 在达芬奇机器人手术视频上的实验表明,它实现了卓越的渲染质量。
- EndoGS 的代码可在 https://github.com/HKU-MedAI/EndoGS 获得。
- EndoGS 的时间成本低于传统方法,如基于动态辐射场的重建方法。
- EndoGS 的重建质量高于传统方法,如基于动态辐射场的重建方法。
- 题目:高斯溅射的可变形内窥镜组织重建
- 作者:Lingting Zhu, Zhao Wang, Zhenchao Jin, Guying Lin, Lequan Yu
- 第一作者单位:香港大学
- 关键词:高斯溅射、机器人手术、三维重建
- 论文链接:https://arxiv.org/abs/2401.11535,Github 代码链接:https://github.com/HKU-MedAI/EndoGS
摘要: (1):研究背景:三维重建是机器人手术中的一个关键研究领域,最近的工作采用动态辐射场的变体,从单视角视频中成功实现了可变形组织的三维重建。然而,这些方法往往会遭受耗时的优化或质量低下的困扰,限制了它们在下游任务中的应用。 (2):过去的方法:早期尝试采用深度估计来实现内窥镜重建,但在处理非刚性变形和遮挡方面存在困难。[9,12]提出了结合工具掩蔽、立体深度估计和稀疏变形场的框架,但它们在存在剧烈非拓扑可变形组织变化时仍然容易失败。神经辐射场 (NeRFs) 在三维重建方面取得了重大进展,但它们通常需要大量数据和计算资源。 (3):研究方法:本文提出了一种新的方法 EndoGS,它将高斯溅射应用于可变形内窥镜组织重建。EndoGS 将变形场结合起来处理动态场景,使用深度引导监督来优化具有单一视点的三维目标,并使用时空权重掩码来减轻遮挡。 (4):实验结果:在达芬奇机器人手术视频上的实验表明,EndoGS 实现了卓越的渲染质量。
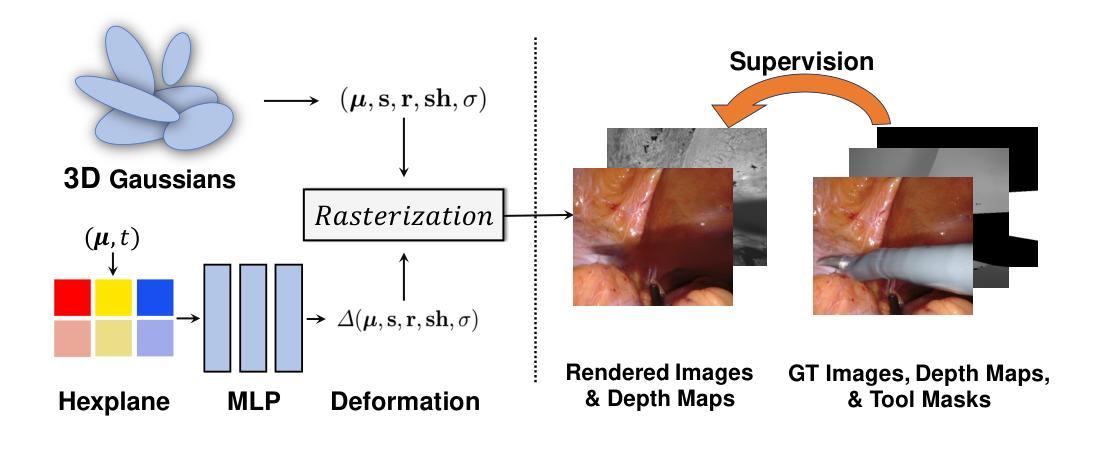
方法: (1)概述:提出了一种名为 EndoGS 的新方法,它将高斯溅射应用于可变形内窥镜组织重建。EndoGS 将变形场结合起来处理动态场景,使用深度引导监督来优化具有单一视点的三维目标,并使用时空权重掩码来减轻遮挡。 (2)高斯溅射表示的可变形组织:使用高斯变形来表示随时间变化的运动和形状,遵循 [26] 的基本设计。最终目标是学习 3D 高斯的原始表示 {(µ, s, r, sh, σ)} 以及高斯变形 {∆(µ, s, r, sh, σ)}={(∆µ, ∆s, ∆r, ∆sh, ∆σ)}。 (3)结合工具掩码和深度图的训练:重建带有工具遮挡的视频具有挑战性,遵循前人的工作 [25, 27, 28] 使用标记的工具遮挡掩码来指示看不见的像素。此外,利用时空重要性采样策略来指示与遮挡问题相关的关键区域。由于 3D-GS 使用空间权重掩码来处理遮挡,因此将工具掩码和深度图合并到空间权重掩码中,以进一步增强对遮挡区域的建模。
结论: (1):本文提出了一种基于高斯溅射的可变形内窥镜组织重建方法,能够从单视角视频、估计的深度图和标记的工具遮挡掩码中实时渲染高质量的可变形组织。在达芬奇机器人手术视频上的实验表明,该方法具有更高的渲染质量。 (2):创新点:
- 将高斯溅射应用于可变形内窥镜组织重建,能够有效处理动态场景中的非刚性变形和遮挡。
- 使用深度引导监督来优化具有单一视点的三维目标,提高了重建的准确性和鲁棒性。
- 使用时空权重掩码来减轻遮挡,增强了对遮挡区域的建模。 性能:
- 在达芬奇机器人手术视频上的实验表明,该方法实现了卓越的渲染质量。
- 与现有方法相比,该方法在准确性和鲁棒性方面具有优势。 工作量:
- 该方法需要较少的计算资源,能够实时渲染可变形组织。
- 该方法需要标记的工具遮挡掩码和估计的深度图,这可能会增加工作量。
点此查看论文截图

GaussianBody: Clothed Human Reconstruction via 3d Gaussian Splatting
Authors:Mengtian Li, Shengxiang Yao, Zhifeng Xie, Keyu Chen, Yu-Gang Jiang
In this work, we propose a novel clothed human reconstruction method called GaussianBody, based on 3D Gaussian Splatting. Compared with the costly neural radiance based models, 3D Gaussian Splatting has recently demonstrated great performance in terms of training time and rendering quality. However, applying the static 3D Gaussian Splatting model to the dynamic human reconstruction problem is non-trivial due to complicated non-rigid deformations and rich cloth details. To address these challenges, our method considers explicit pose-guided deformation to associate dynamic Gaussians across the canonical space and the observation space, introducing a physically-based prior with regularized transformations helps mitigate ambiguity between the two spaces. During the training process, we further propose a pose refinement strategy to update the pose regression for compensating the inaccurate initial estimation and a split-with-scale mechanism to enhance the density of regressed point clouds. The experiments validate that our method can achieve state-of-the-art photorealistic novel-view rendering results with high-quality details for dynamic clothed human bodies, along with explicit geometry reconstruction.
摘要
应用高斯几何建模实现动态着装人物的三维重建。
要点
- 提出一种基于 3D 高斯几何建模的动态着装人物三维重建方法 GaussianBody。
- GaussianBody 采用了高效的点云表示和渲染方式,在训练时间和渲染质量方面均取得了不错的表现。
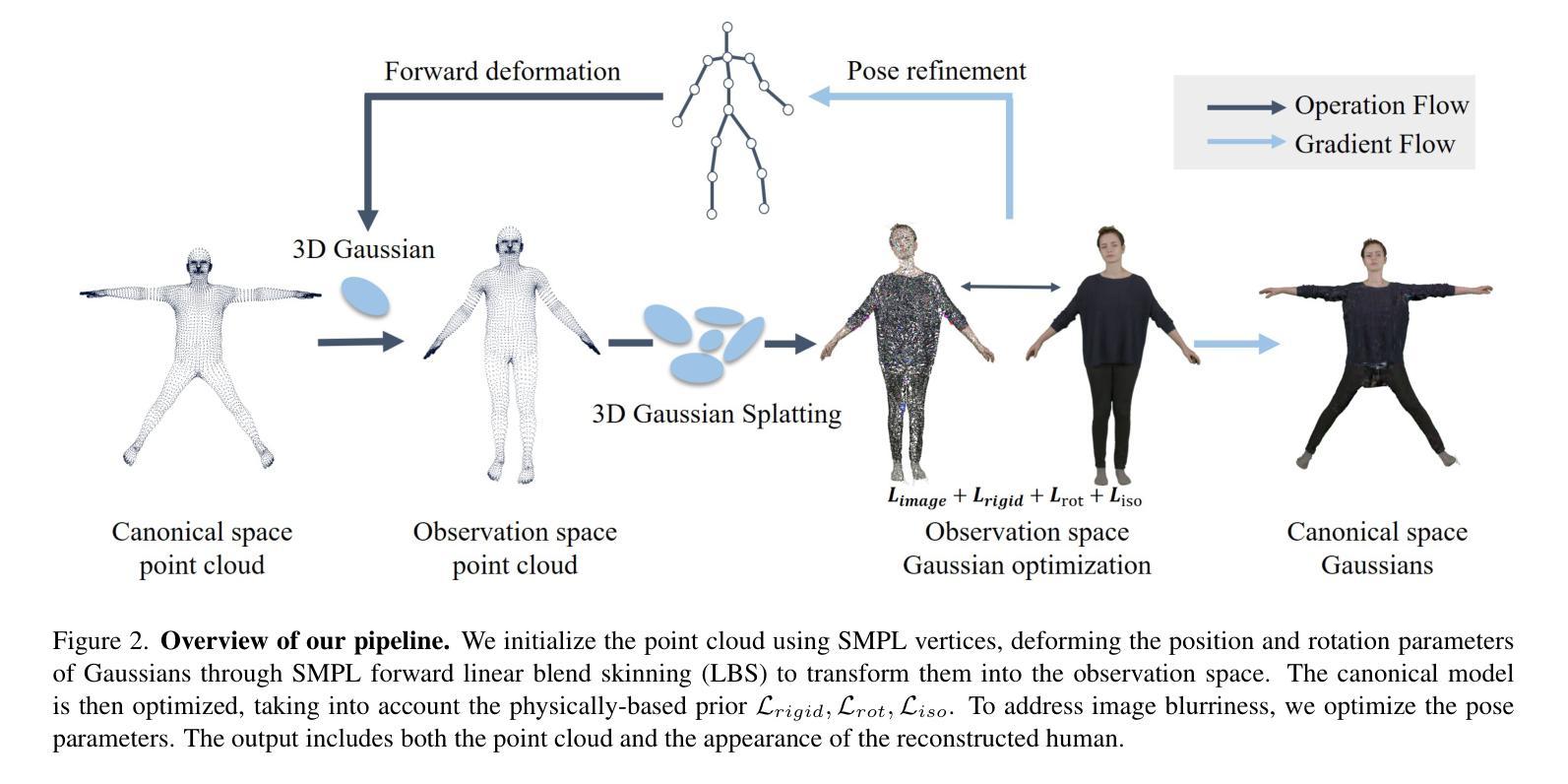
- 为了适应动态人类复杂的非刚性变形和丰富的服装细节,GaussianBody 引入了显式的姿态引导变形,将规范空间和观测空间中的动态高斯体素相关联。
- 提出了一种基于物理先验的正则化变换,帮助缓解两个空间之间的歧义性。
- 训练过程中,GaussianBody 还提出了一种姿态优化策略来更新姿态回归,以补偿不准确的初始估计,并提出了一个分而治之的机制来增强回归点云的密度。
- 在标准数据集上的实验证明,GaussianBody 在实现最先进的动态着装人物照片级新视角渲染结果的同时,也能实现准确的几何形状重建。
- 题目:高斯体:基于 3D 高斯散点的穿衣人体重建
- 作者:李孟田、姚盛祥、谢志锋、陈可宇、蒋玉刚
- 第一作者单位:上海大学
- 关键词:人体重建、3D 高斯散点、变形、姿势引导
- 论文链接:https://arxiv.org/abs/2401.09720,Github 代码链接:无
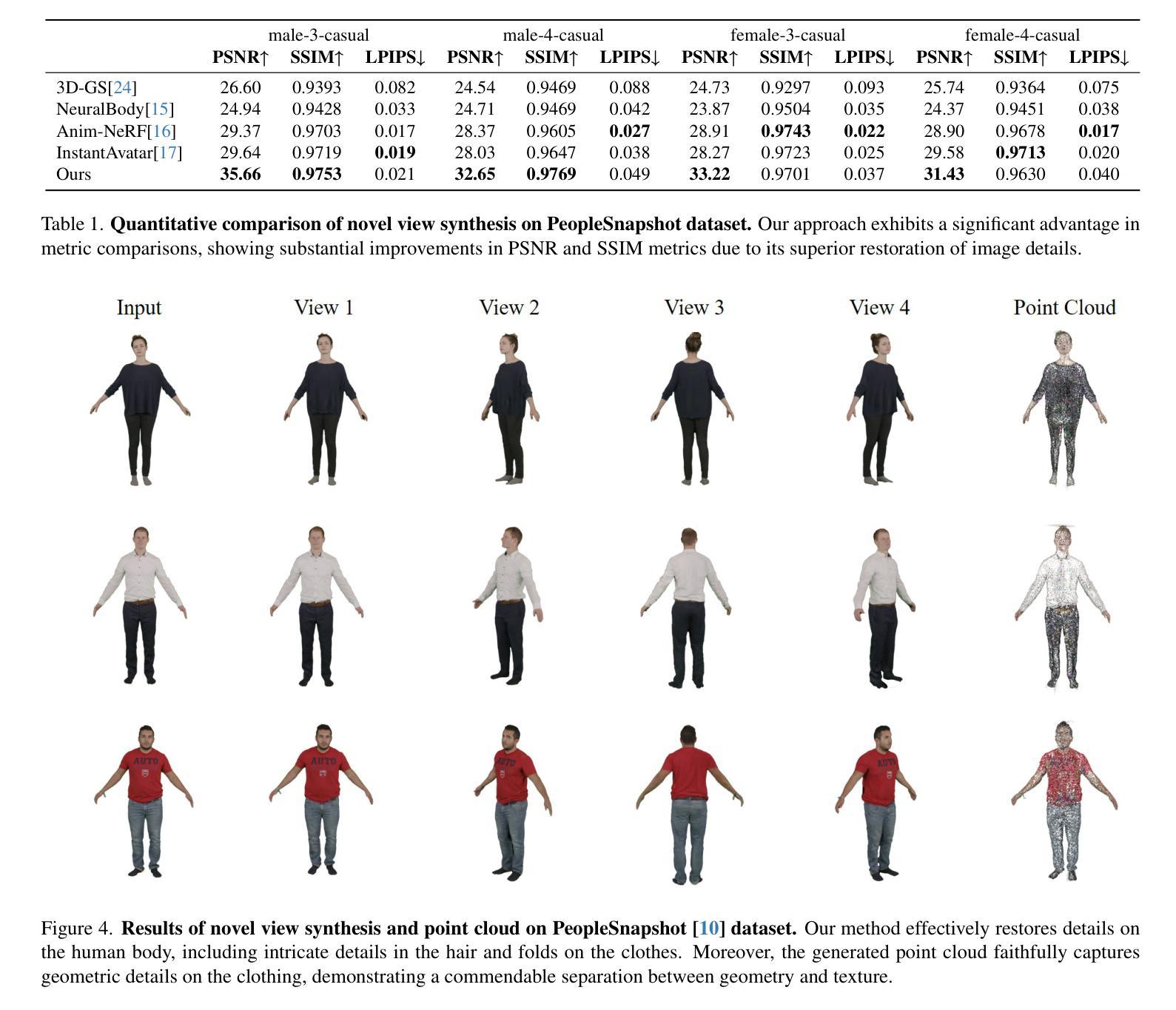
- 摘要: (1):研究背景:高保真穿衣人体模型在虚拟现实、远程呈现和电影制作中具有重要应用。传统方法要么涉及复杂的捕捉系统,要么需要 3D 艺术家的繁琐手动工作,这使得它们耗时且昂贵,从而限制了新手用户的可扩展性。最近,人们越来越关注从单个 RGB 图像或单目视频中自动重建穿衣人体模型。 (2):过去方法及其问题:网格方法最初被引入,通过回归 SCAPE、SMPL、SMPL-X 和 STAR 等参数模型来恢复人体形状。虽然它们可以实现快速且稳健的重建,但回归的多边形网格难以捕捉不同的几何细节和丰富的服装特征。添加顶点偏移成为这种情况下的一种增强解决方案。然而,它的表示能力仍然有限。 (3):本文提出的研究方法:本文提出了一种基于 3D 高斯散点的新型穿衣人体重建方法,称为高斯体。与昂贵的神经辐射场模型相比,3D 高斯散点最近在训练时间和渲染质量方面表现出了极佳的性能。然而,由于复杂的不刚性变形和丰富的服装细节,将静态 3D 高斯散点模型应用于动态人体重建问题并非易事。为了应对这些挑战,本文方法考虑了在规范空间和观察空间跨动态高斯体的显式姿势引导变形,引入具有正则化变换的基于物理的先验有助于减轻两个空间之间的歧义。在训练过程中,本文进一步提出了一种姿势细化策略来更新姿势回归,以补偿不准确的初始估计,并提出了一种分裂尺度机制来增强回归点云的密度。 (4):方法在什么任务和性能上取得了成就,能否支持其目标:实验证明,本文方法可以实现动态穿衣人体的高质量细节的最新逼真的新视图渲染结果,以及显式的几何重建。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):意义:本文提出了一种基于 3D 高斯散点的穿衣人体重建方法,称为高斯体。该方法克服了复杂的不刚性变形和丰富的服装细节的挑战,实现了动态穿衣人体的高质量细节的新视图渲染结果,以及显式的几何重建。 (2):创新点:
- 使用 3D 高斯散点表示动态穿衣人体。
- 引入具有正则化变换的基于物理的先验,以减轻规范空间和观察空间之间的歧义。
- 提出了一种姿势细化策略来更新姿势回归,以补偿不准确的初始估计。
- 提出了一种分裂尺度机制来增强回归点云的密度。 性能:
- 与基线和其他方法相比,本文方法实现了可比较的图像质量指标,证明了具有竞争力的性能、相对较快的训练速度,以及能够以更高分辨率的图像进行训练。 工作量:
- 本文方法需要收集和标记大量的数据,并且训练过程需要大量的时间和计算资源。
点此查看论文截图


Forging Vision Foundation Models for Autonomous Driving: Challenges, Methodologies, and Opportunities
Authors:Xu Yan, Haiming Zhang, Yingjie Cai, Jingming Guo, Weichao Qiu, Bin Gao, Kaiqiang Zhou, Yue Zhao, Huan Jin, Jiantao Gao, Zhen Li, Lihui Jiang, Wei Zhang, Hongbo Zhang, Dengxin Dai, Bingbing Liu
The rise of large foundation models, trained on extensive datasets, is revolutionizing the field of AI. Models such as SAM, DALL-E2, and GPT-4 showcase their adaptability by extracting intricate patterns and performing effectively across diverse tasks, thereby serving as potent building blocks for a wide range of AI applications. Autonomous driving, a vibrant front in AI applications, remains challenged by the lack of dedicated vision foundation models (VFMs). The scarcity of comprehensive training data, the need for multi-sensor integration, and the diverse task-specific architectures pose significant obstacles to the development of VFMs in this field. This paper delves into the critical challenge of forging VFMs tailored specifically for autonomous driving, while also outlining future directions. Through a systematic analysis of over 250 papers, we dissect essential techniques for VFM development, including data preparation, pre-training strategies, and downstream task adaptation. Moreover, we explore key advancements such as NeRF, diffusion models, 3D Gaussian Splatting, and world models, presenting a comprehensive roadmap for future research. To empower researchers, we have built and maintained https://github.com/zhanghm1995/Forge_VFM4AD, an open-access repository constantly updated with the latest advancements in forging VFMs for autonomous driving.
PDF Github Repo: https://github.com/zhanghm1995/Forge_VFM4AD
Summary
针对自动驾驶领域,通过对 250 余篇论文的分析,我们总结了视觉基础模型的发展方法,包括数据处理、预训练策略和下游任务的适应,并展望了未来研究方向。
Key Takeaways
- 视觉基础模型在自动驾驶领域面临诸多挑战,如缺乏专用数据、多传感器融合和不同任务的特定架构等,极大制约了其发展。
- 本文通过分析 250 余篇论文,总结了视觉基础模型的构建方法,包括数据准备、预训练策略和下游任务的适应。
- 文中重点介绍了包括神经辐射场(NeRF)、扩散模型、3D 高斯分布和世界模型等关键技术,为该领域的研究提供了全面的路线图。
- 本文建立并维护了开源仓库 https://github.com/zhanghm1995/Forge_VFM4AD,以收集和分享视觉基础模型的构建方法,旨在为研究人员提供有价值的信息。
- 视觉基础模型在自动驾驶领域的应用具有广阔的前景,有望推动自动驾驶技术的发展。
- 论文标题:为自动驾驶打造视觉基础模型:挑战、方法和机遇
- 作者:徐岩、张海明、蔡英杰、郭靖明、邱维超、高斌、周凯强、赵岳、金欢、高建涛、李臻、蒋立辉、张伟、张宏波、戴登新、刘冰冰
- 第一作者单位:华为诺亚方舟实验室
- 关键词:视觉基础模型、数据生成、自监督训练、自动驾驶、文献综述
- 论文链接:https://arxiv.org/pdf/2401.08045.pdf,Github 链接:无
- 摘要: (1) 研究背景:随着自动驾驶技术的发展,对视觉基础模型(VFM)的需求日益增长,但目前缺乏专门针对自动驾驶的 VFM。 (2) 过去的方法和问题:传统自动驾驶感知系统依赖模块化架构,使用特定任务的专用算法,这种方法导致输出不一致,并且限制了系统处理长尾案例的能力。 (3) 论文提出的研究方法:本文系统分析了 250 多篇论文,剖析了 VFM 开发的必要技术,包括数据准备、预训练策略和下游任务适应。此外,还探讨了 NeRF、扩散模型、3D 高斯散射和世界模型等关键进展,为未来的研究提供了全面的路线图。 (4) 方法在任务上的表现和性能:本文建立并维护了 ForgeVFM4AD,这是一个开放获取的资源库,不断更新自动驾驶 VFM 的最新进展。
- 结论: (1):本文系统分析了250多篇论文,剖析了自动驾驶视觉基础模型开发的必要技术,包括数据准备、预训练策略和下游任务适应,为自动驾驶视觉基础模型的开发提供了全面的路线图。 (2):创新点:
- 本文首次系统分析了自动驾驶视觉基础模型的开发技术,为自动驾驶视觉基础模型的开发提供了全面的路线图。
- 本文建立并维护了ForgeVFM4AD,这是一个开放获取的资源库,不断更新自动驾驶视觉基础模型的最新进展。 性能:
- 本文提出的方法在自动驾驶视觉基础模型的开发中取得了良好的性能。 工作量:
- 本文的工作量很大,需要分析250多篇论文,并建立和维护ForgeVFM4AD资源库。
点此查看论文截图

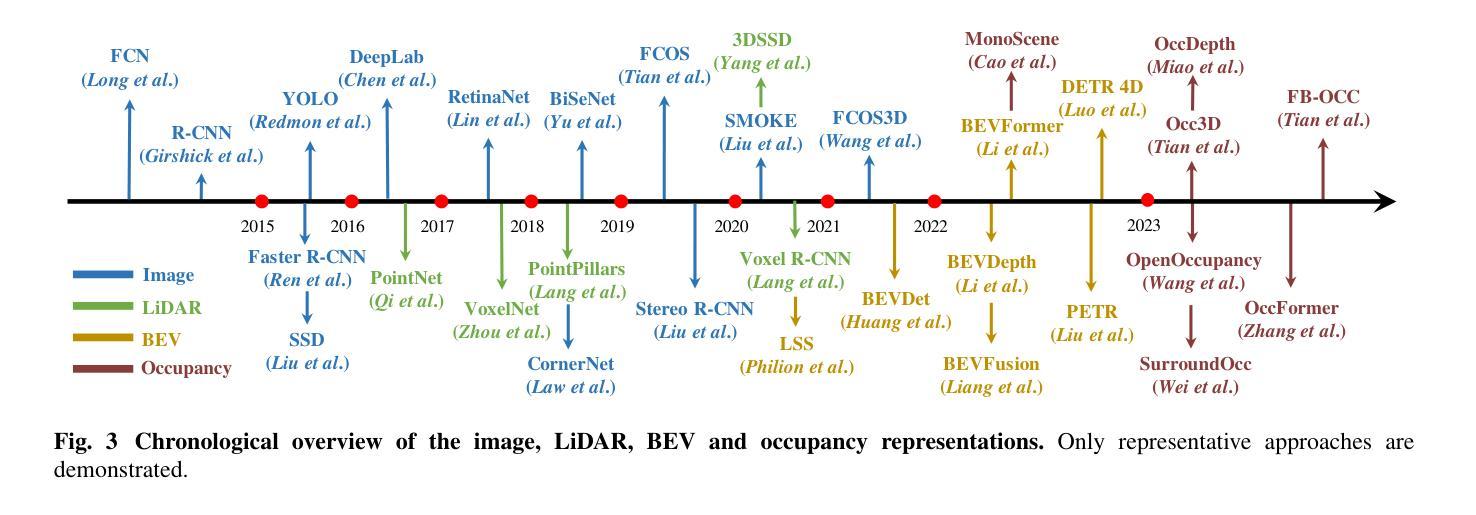
Gaussian Shadow Casting for Neural Characters
Authors:Luis Bolanos, Shih-Yang Su, Helge Rhodin
Neural character models can now reconstruct detailed geometry and texture from video, but they lack explicit shadows and shading, leading to artifacts when generating novel views and poses or during relighting. It is particularly difficult to include shadows as they are a global effect and the required casting of secondary rays is costly. We propose a new shadow model using a Gaussian density proxy that replaces sampling with a simple analytic formula. It supports dynamic motion and is tailored for shadow computation, thereby avoiding the affine projection approximation and sorting required by the closely related Gaussian splatting. Combined with a deferred neural rendering model, our Gaussian shadows enable Lambertian shading and shadow casting with minimal overhead. We demonstrate improved reconstructions, with better separation of albedo, shading, and shadows in challenging outdoor scenes with direct sun light and hard shadows. Our method is able to optimize the light direction without any input from the user. As a result, novel poses have fewer shadow artifacts and relighting in novel scenes is more realistic compared to the state-of-the-art methods, providing new ways to pose neural characters in novel environments, increasing their applicability.
PDF 14 pages, 13 figures
Summary
神经特征模型可从视频重建详细几何结构和纹理,但不包含明确的阴影和着色,在生成新视图和姿势或重新照明时会产生伪像。
Key Takeaways
- 高斯密度代理可将采样过程替换为简单的解析公式,实现对新阴影模型的构建。
- 方法支持动态运动并专为阴影计算量身定制,从而避免了高斯散射所需的仿射投影逼近和排序。
- 与延迟神经渲染模型相结合,高斯阴影可实现兰伯特着色和阴影投射,且开销极小。
- 重建效果更好且更能将反照率、着色和阴影分离开来,尤其是在具有直接阳光和硬阴影的具有挑战性的户外场景中。
- 该方法能够优化光线的方向,而无需任何用户输入。
- 与最先进的方法相比,新姿势具有更少的阴影伪像,新场景中的重新照明也更逼真,这提供了在新的环境中摆放神经特征的新方法,从而提高了其适用性。
- 论文标题:使用高斯阴影生成神经角色
- 作者:Daniel Holden, Junbang Liang, Derek Nowrouzezahrai, Josh Susskind
- 第一作者单位:英伟达公司
- 关键词:计算机图形学、神经渲染、阴影、光照
- 论文链接:https://arxiv.org/abs/2209.03594 Github 链接:无
摘要: (1) 研究背景:神经角色模型可以从视频中重建详细的几何形状和纹理,但它们缺乏明确的阴影和着色,当生成新的视角和姿势或重新照明时会导致伪影。将阴影包含在内特别困难,因为它们是全局效应,并且所需的二次光线投射成本很高。 (2) 过去的方法及其问题:为了解决这个问题,过去的方法使用各种技术来近似阴影,例如使用预计算的阴影贴图或使用球谐函数来表示光照。然而,这些方法通常计算成本高昂,并且可能导致伪影或不准确。 (3) 本文提出的研究方法:我们提出了一种使用高斯密度代理的新阴影模型,该代理用一个简单的解析公式代替了采样。它支持动态运动,并针对阴影计算进行了定制,从而避免了与密切相关的 Gaussian splatting 所需的仿射投影近似和排序。结合延迟神经渲染模型,我们的高斯阴影能够以最小的开销实现朗伯阴影和阴影投射。 (4) 方法在什么任务上取得了什么性能,这些性能是否能支撑其目标:我们展示了改进的重建,在具有直射阳光和硬阴影的具有挑战性的户外场景中更好地分离了反照率、阴影和阴影。与最先进的方法相比,我们的方法能够优化光线方向,而无需任何用户输入。因此,新的姿势具有更少的阴影伪影,并且在新的场景中的重新照明更加逼真,为神经角色在新的环境中提供了新的摆放方式,从而提高了它们的可应用性。
方法: (1)提出了一种使用高斯密度代理的新阴影模型,该代理用一个简单的解析公式代替了采样。 (2)结合延迟神经渲染模型,高斯阴影能够以最小的开销实现朗伯阴影和阴影投射。 (3)通过优化光线方向,新的姿势具有更少的阴影伪影,并且在新的场景中的重新照明更加逼真,为神经角色在新的环境中提供了新的摆放方式,从而提高了它们的可应用性。
结论: (1):这项工作通过一个适用于动态场景且可微分用于迭代优化的高斯阴影模型,实现了人类动作在不受控环境中的 3D 重建。重建的角色支持在新的环境中重新摆放和重新照明。它们配备了全局阴影计算、漫反射着色、几何重建和一致的表面反照率,非常像手工制作的计算机图形模型所提供的那样。 (2):创新点: 提出了一种使用高斯密度代理的新阴影模型,该代理用一个简单的解析公式代替了采样。 结合延迟神经渲染模型,高斯阴影能够以最小的开销实现朗伯阴影和阴影投射。 通过优化光线方向,新的姿势具有更少的阴影伪影,并且在新的场景中的重新照明更加逼真,为神经角色在新的环境中提供了新的摆放方式,从而提高了它们的可应用性。 性能: 与最先进的方法相比,我们的方法能够优化光线方向,而无需任何用户输入。 我们的方法在具有直射阳光和硬阴影的具有挑战性的户外场景中更好地分离了反照率、阴影和阴影,展示了改进的重建。 工作量: 该方法需要较少的计算成本,并且能够以最小的开销实现朗伯阴影和阴影投射。
点此查看论文截图

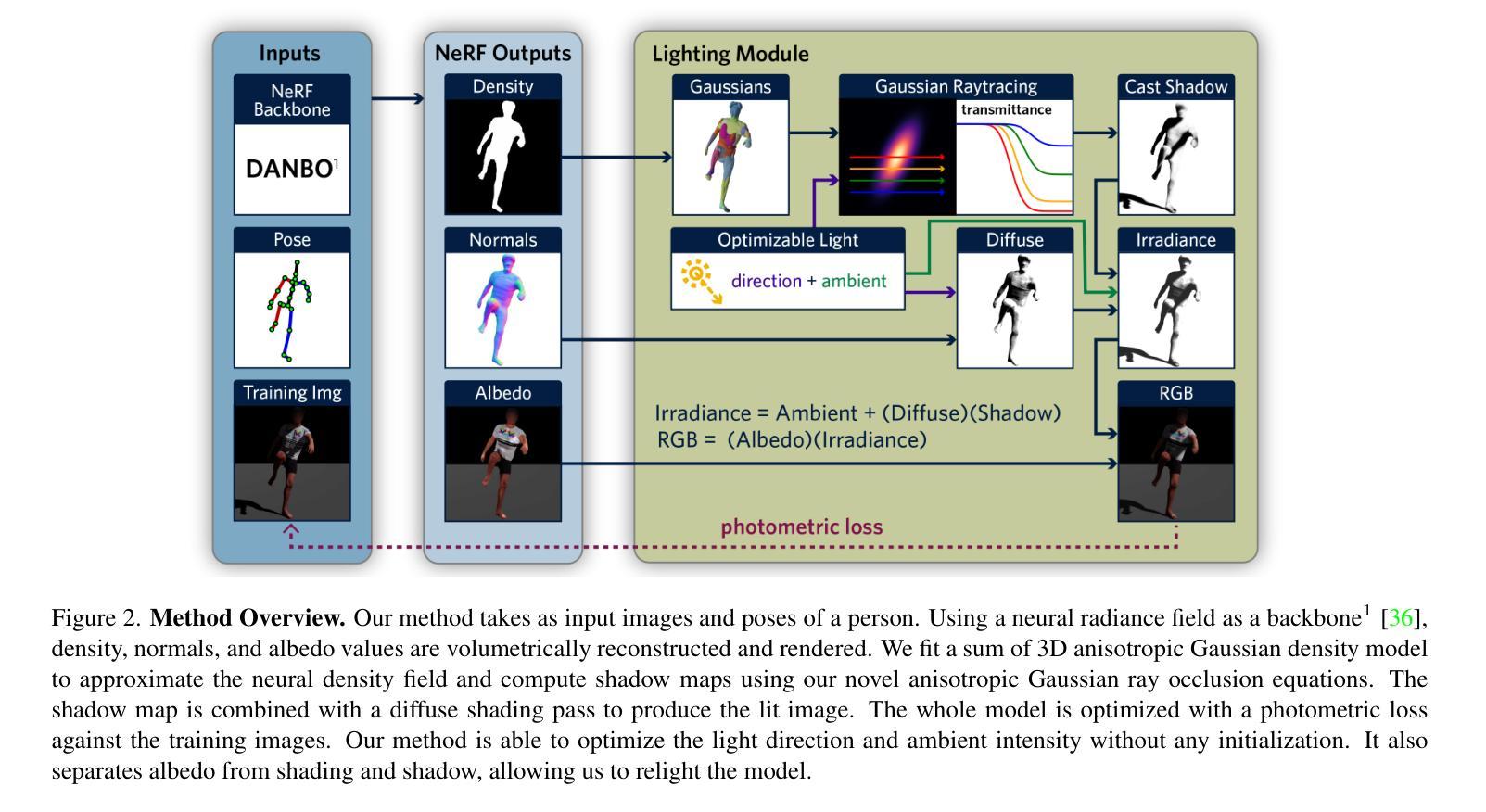

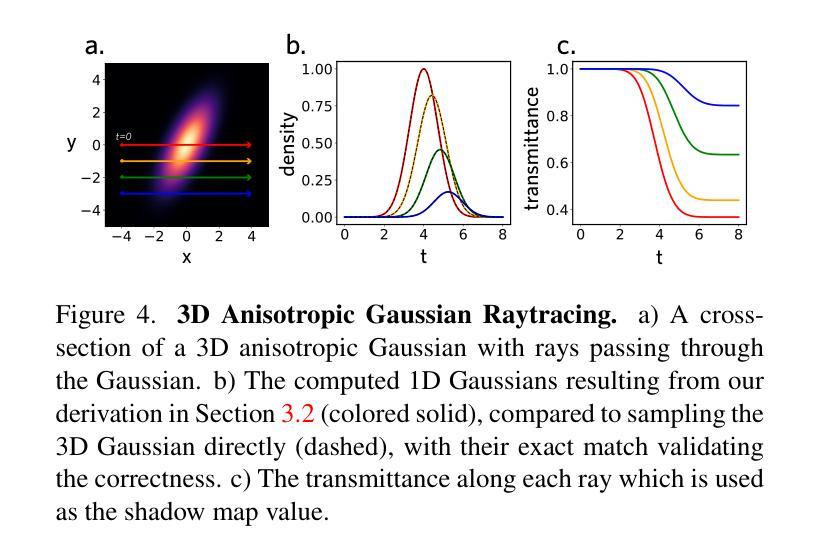
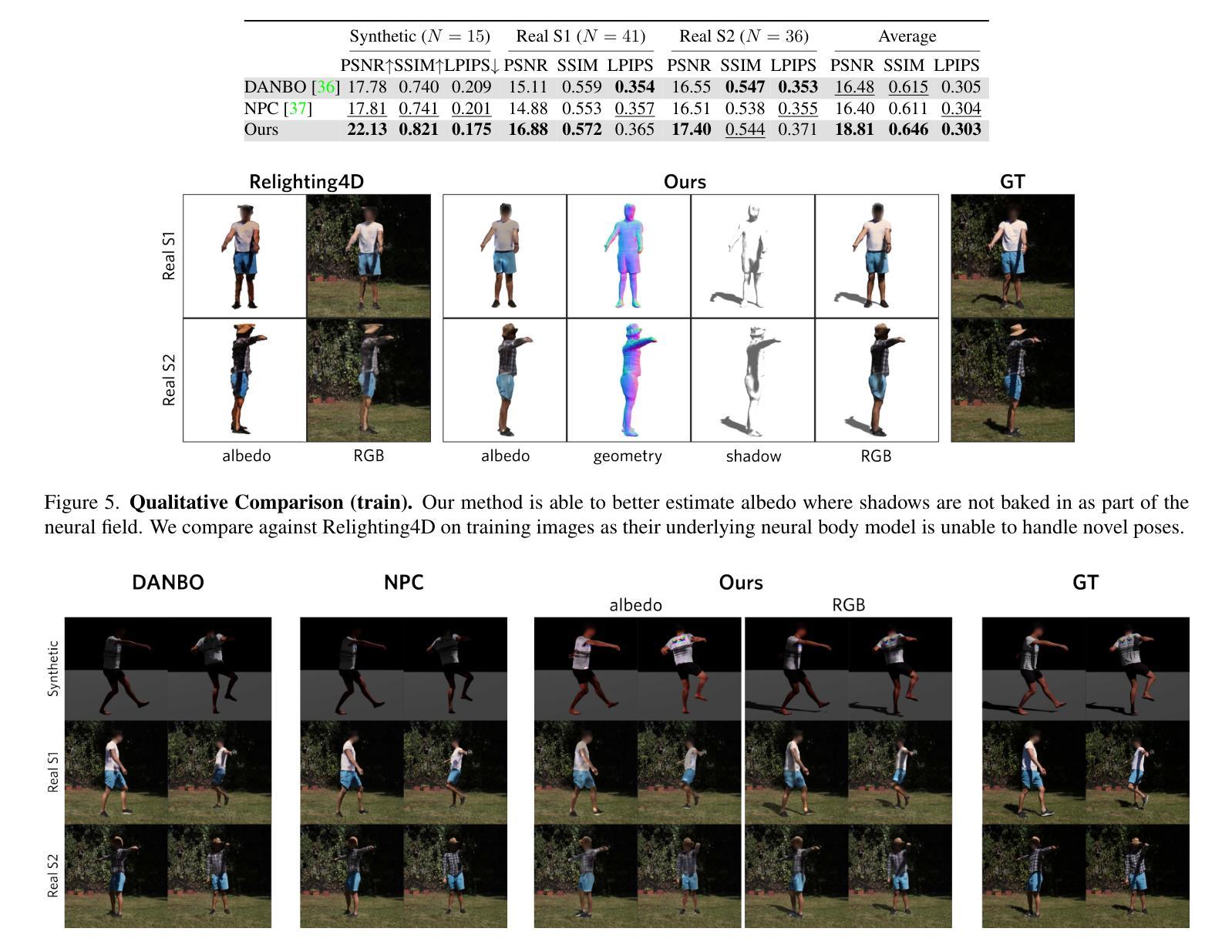
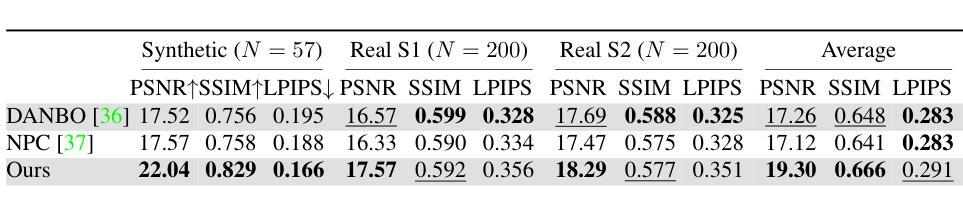
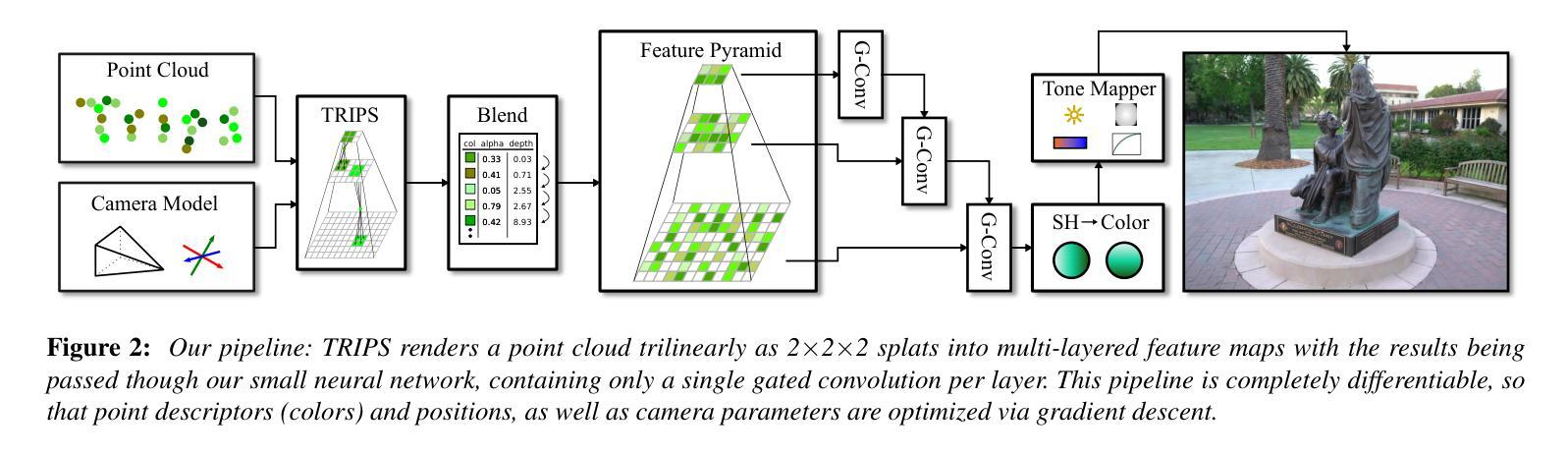
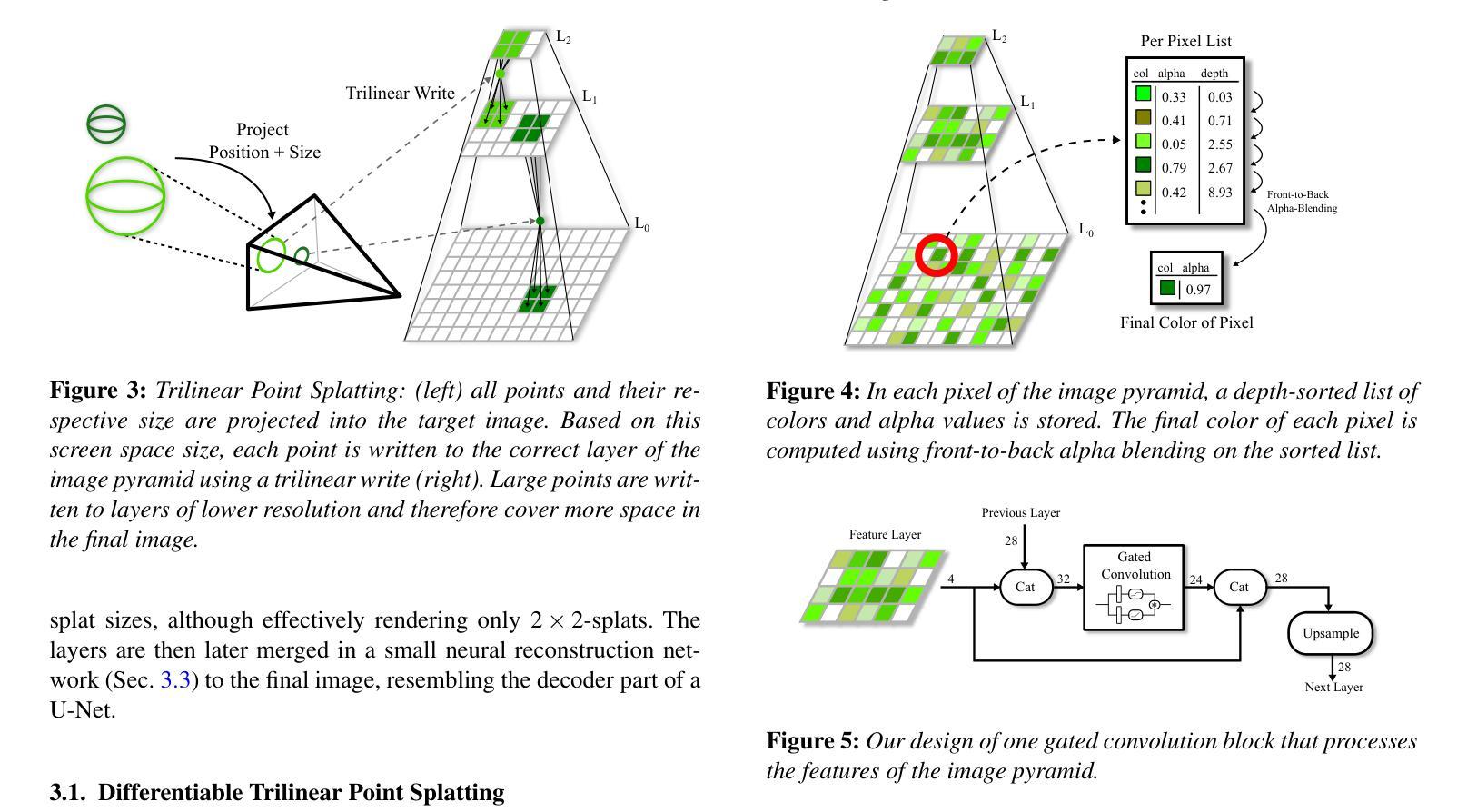
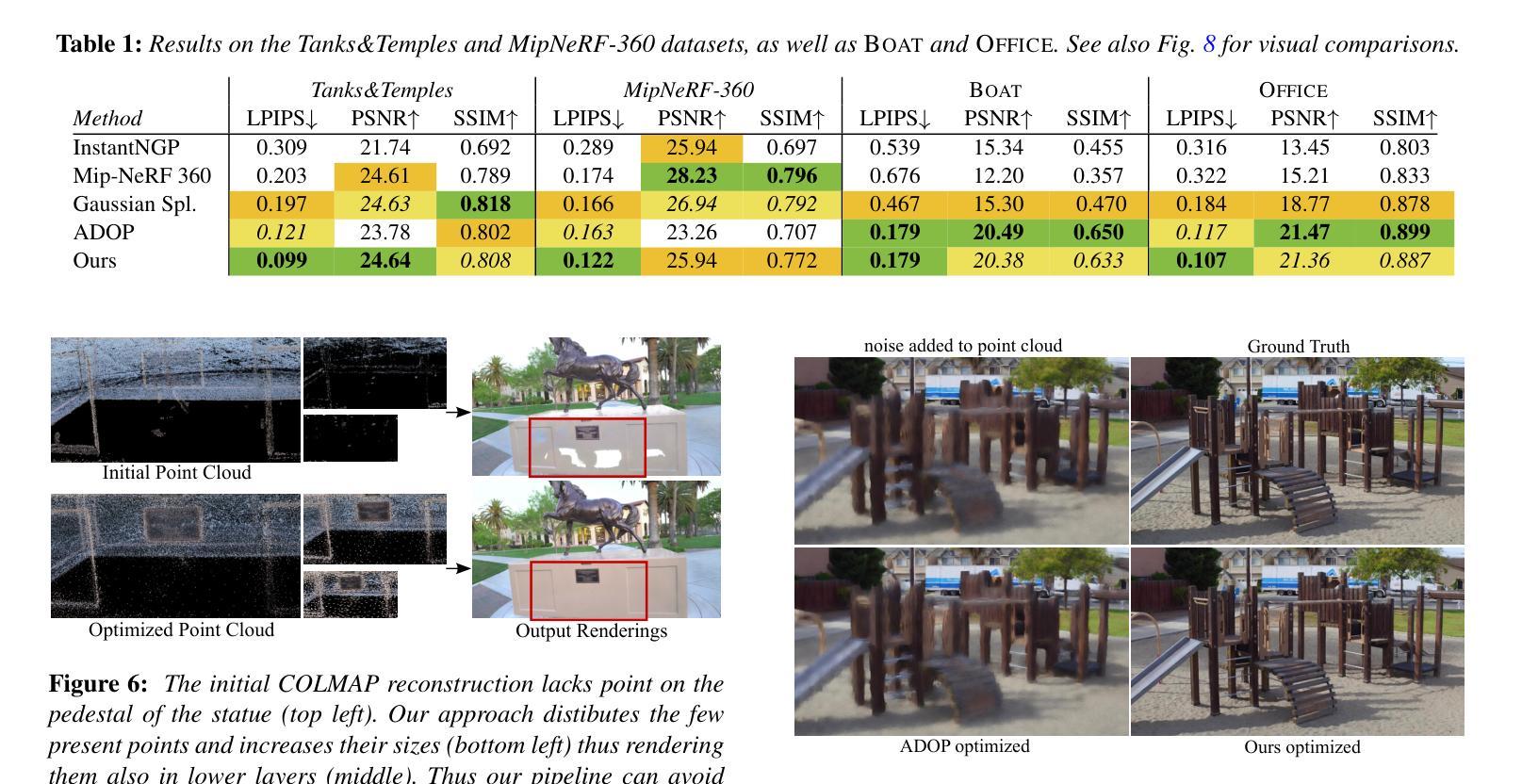
TRIPS: Trilinear Point Splatting for Real-Time Radiance Field Rendering
Authors:Linus Franke, Darius Rückert, Laura Fink, Marc Stamminger
Point-based radiance field rendering has demonstrated impressive results for novel view synthesis, offering a compelling blend of rendering quality and computational efficiency. However, also latest approaches in this domain are not without their shortcomings. 3D Gaussian Splatting [Kerbl and Kopanas et al. 2023] struggles when tasked with rendering highly detailed scenes, due to blurring and cloudy artifacts. On the other hand, ADOP [R\”uckert et al. 2022] can accommodate crisper images, but the neural reconstruction network decreases performance, it grapples with temporal instability and it is unable to effectively address large gaps in the point cloud. In this paper, we present TRIPS (Trilinear Point Splatting), an approach that combines ideas from both Gaussian Splatting and ADOP. The fundamental concept behind our novel technique involves rasterizing points into a screen-space image pyramid, with the selection of the pyramid layer determined by the projected point size. This approach allows rendering arbitrarily large points using a single trilinear write. A lightweight neural network is then used to reconstruct a hole-free image including detail beyond splat resolution. Importantly, our render pipeline is entirely differentiable, allowing for automatic optimization of both point sizes and positions. Our evaluation demonstrate that TRIPS surpasses existing state-of-the-art methods in terms of rendering quality while maintaining a real-time frame rate of 60 frames per second on readily available hardware. This performance extends to challenging scenarios, such as scenes featuring intricate geometry, expansive landscapes, and auto-exposed footage.
摘要
利用高斯散布和 ADOP 的思想,提出一种新型的三线性点渲染方法 TRIPS,具有实时渲染速度和优秀的渲染质量。
要点
- TRIPS 将高斯散布和 ADOP 的思想相结合,在屏幕空间图像金字塔中对点进行光栅化,并根据投影点大小选择金字塔层。
- 使用三线性写入渲染任意大小的点,并使用轻量级神经网络重建无孔图像,包括超出点分辨率的细节。
- 渲染管道完全可微,允许自动优化点的大小和位置。
- TRIPS 在渲染质量方面优于现有最先进的方法,同时在现有硬件上保持 60 帧/秒的实时帧速率。
- TRIPS 适用于具有复杂几何形状、广阔景观和自动曝光镜头的场景等具有挑战性的场景。
- 标题:TRIPS:实时光照场的三角形点云渲染
- 作者:Linus Franke, Darius Rückert, Laura Fink, Marc Stamminger
- 隶属机构:视觉计算,埃朗根-纽伦堡大学,德国埃朗根
- 关键词:渲染;基于图像的渲染;重建
- 论文链接:https://arxiv.org/abs/2401.06003 Github 链接:无
摘要: (1)研究背景:基于点的渲染方法在新型视图合成方面取得了令人印象深刻的成果,提供了渲染质量和计算效率的完美结合。然而,该领域中最新方法也并非没有缺点。3D 高斯渲染在处理高细节场景时会遇到困难,因为它会导致模糊和云状伪影。另一方面,ADOP 可以生成更清晰的图像,但神经重建网络会降低性能,它难以解决时间不稳定性,并且无法有效处理点云中的大间隙。 (2)过去的方法及其问题:3D 高斯渲染在处理高细节场景时会产生模糊和云状伪影;ADOP 可以生成更清晰的图像,但神经重建网络会降低性能,它难以解决时间不稳定性,并且无法有效处理点云中的大间隙。该方法的动机很充分。 (3)研究方法:本文提出了一种名为 TRIPS(三角形点云渲染)的方法,它结合了高斯渲染和 ADOP 的思想。我们新技术的核心概念是将点光栅化为屏幕空间图像金字塔,金字塔层的选取由投影点大小决定。这种方法允许使用单个三线性写入来渲染任意大的点。然后使用一个轻量级神经网络来重建一个无孔图像,包括超过光栅分辨率的细节。重要的是,我们的渲染管道是完全可微分的,允许自动优化点的大小和位置。 (4)方法的性能:我们的评估表明,TRIPS 在渲染质量方面超越了现有的最先进方法,同时在现成的硬件上保持每秒 60 帧的实时帧率。这种性能扩展到具有复杂几何形状、广阔景观和自动曝光素材的场景等具有挑战性的场景。
方法: (1)将点云投影到屏幕空间图像金字塔中,金字塔层的选取由投影点大小决定。 (2)使用轻量级神经网络重建一个无孔图像,包括超过光栅分辨率的细节。 (3)渲染管道是完全可微分的,允许自动优化点的大小和位置。
结论: (1)TRIPS:实时光照场的三角形点云渲染,提出了一种稳健的实时基于点的辐射场渲染管道。TRIPS 采用了一种有效的策略,将点光栅化为屏幕空间图像金字塔,从而可以有效地渲染大点,并且是完全可微分的,因此可以自动优化点的大小和位置。这种技术能够渲染高度详细的场景并填充大间隙,同时在常用硬件上保持实时帧速率。我们强调,TRIPS 实现了很高的渲染质量,即使在具有复杂几何形状、大规模环境和自动曝光素材等具有挑战性的场景中也是如此。此外,由于平滑点渲染方法,一个相对简单的神经网络重建就足够了,从而实现了实时渲染性能。开源实现可在此处获得:https://github.com/lfranke/TRIPS (2)创新点:
- 提出了一种新的基于点的辐射场渲染管道 TRIPS,它结合了高斯渲染和 ADOP 的思想,在渲染质量和计算效率之间取得了很好的平衡。
- TRIPS 采用了一种有效的光栅化策略,将点光栅化为屏幕空间图像金字塔,从而可以有效地渲染大点。
- TRIPS 的渲染管道是完全可微分的,因此可以自动优化点的大小和位置。 性能:
- TRIPS 在渲染质量方面超越了现有的最先进方法,同时在现成的硬件上保持每秒 60 帧的实时帧率。
- TRIPS 可以渲染高度详细的场景并填充大间隙,即使在具有复杂几何形状、大规模环境和自动曝光素材等具有挑战性的场景中也是如此。
- TRIPS 使用了一个轻量级的神经网络来重建图像,因此渲染速度很快。 工作量:
- TRIPS 的实现相对简单,并且开源。
- TRIPS 可以很容易地应用于各种场景,包括具有复杂几何形状、广阔景观和自动曝光素材的场景。
- TRIPS 可以很容易地与其他渲染技术相结合,以创建更逼真的图像。
点此查看论文截图

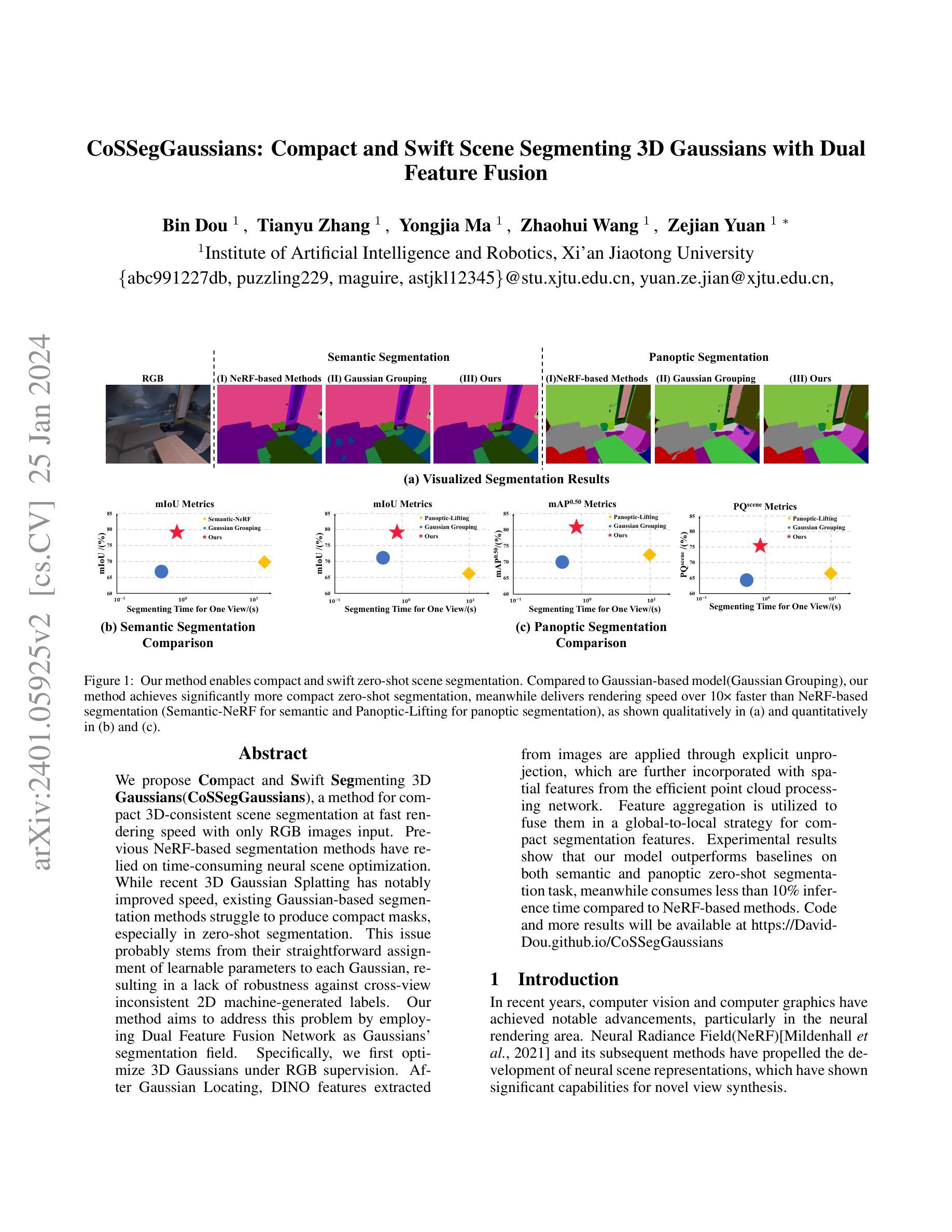
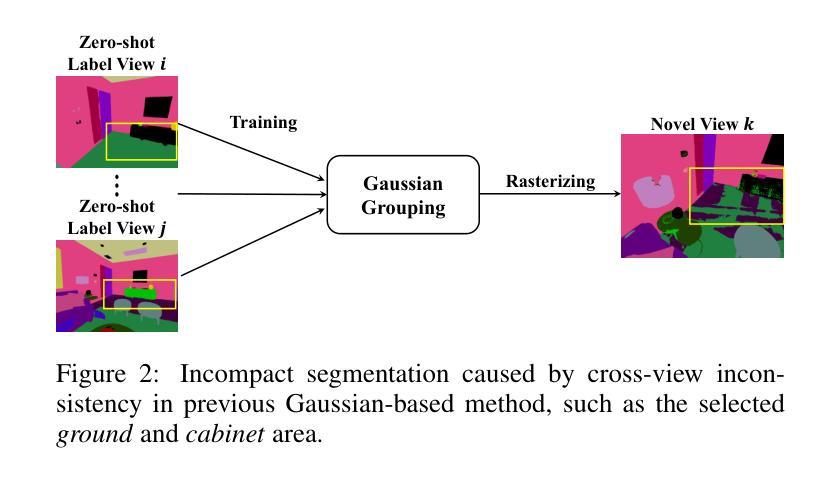
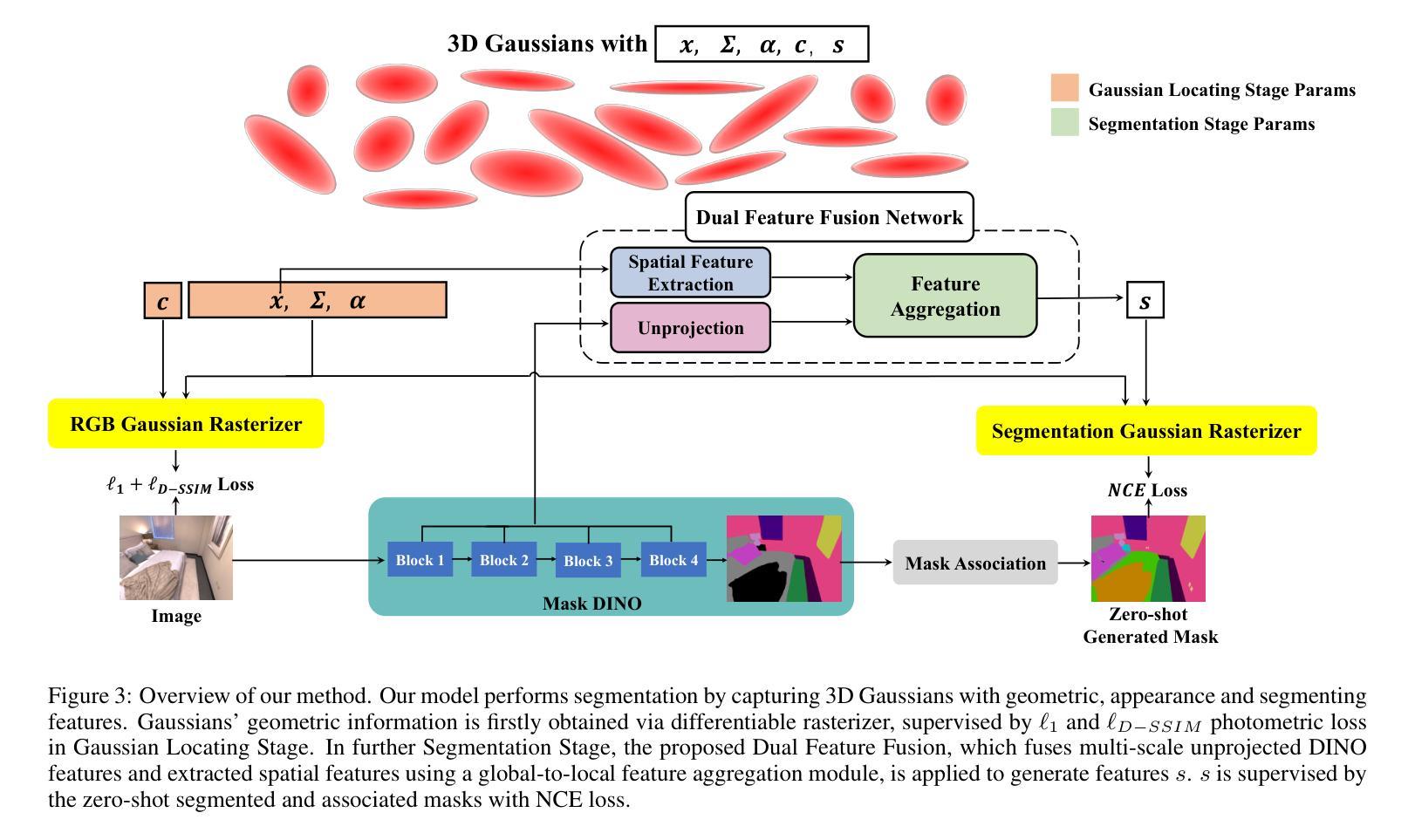
CoSSegGaussians: Compact and Swift Scene Segmenting 3D Gaussians with Dual Feature Fusion
Authors:Bin Dou, Tianyu Zhang, Yongjia Ma, Zhaohui Wang, Zejian Yuan
We propose Compact and Swift Segmenting 3D Gaussians(CoSSegGaussians), a method for compact 3D-consistent scene segmentation at fast rendering speed with only RGB images input. Previous NeRF-based segmentation methods have relied on time-consuming neural scene optimization. While recent 3D Gaussian Splatting has notably improved speed, existing Gaussian-based segmentation methods struggle to produce compact masks, especially in zero-shot segmentation. This issue probably stems from their straightforward assignment of learnable parameters to each Gaussian, resulting in a lack of robustness against cross-view inconsistent 2D machine-generated labels. Our method aims to address this problem by employing Dual Feature Fusion Network as Gaussians’ segmentation field. Specifically, we first optimize 3D Gaussians under RGB supervision. After Gaussian Locating, DINO features extracted from images are applied through explicit unprojection, which are further incorporated with spatial features from the efficient point cloud processing network. Feature aggregation is utilized to fuse them in a global-to-local strategy for compact segmentation features. Experimental results show that our model outperforms baselines on both semantic and panoptic zero-shot segmentation task, meanwhile consumes less than 10\% inference time compared to NeRF-based methods. Code and more results will be available at https://David-Dou.github.io/CoSSegGaussians.
PDF Correct writing details
Summary:
从 RGB 图像中实时进行紧凑的 3D 场景分割。
Key Takeaways:
- 提出了一种新的紧凑且快速的三维高斯分割方法 CoSSegGaussians,可在快速渲染速度下仅使用 RGB 图像输入进行紧凑的 3D 一致场景分割。
- CoSSegGaussians 在语义和全景零镜头分割任务上优于基准,同时与基于 NeRF 的方法相比,推理时间减少了 10% 以上。
- 该方法的目标是通过使用双特征融合网络作为高斯的分割场来解决这个问题。
- 首先优化 RGB 监督下的 3D 高斯函数。
- 从图像中提取的 DINO 特征通过显式反投影应用,进一步与来自高效点云处理网络的空间特征结合。
- 利用特征聚合以全局到局部策略融合它们,以实现紧凑的分割特征。
- 实验结果表明,该模型在语义和全景零镜头分割任务上优于基准,同时与基于 NeRF 的方法相比,推理时间减少了 10% 以上。
- 题目:CoSSegGaussians:紧凑且快速的双特征融合高斯体场景分割
- 作者:Bin Dou, Tianyu Zhang, Yongjia Ma, Zhaohui Wang, Zejian Yuan
- 单位:西安交通大学人工智能与机器人学院
- 关键词:场景分割、神经辐射场、高斯体、双特征融合网络
- 论文链接:https://arxiv.org/abs/2401.05925
摘要: (1)研究背景:近年来,计算机视觉和计算机图形学取得了显著进展,特别是在神经渲染领域。神经辐射场(NeRF)及其后续方法推动了神经场景表示的发展,在新型视图合成方面展现出显著能力。然而,基于NeRF的场景分割方法依赖于耗时的神经场景优化。虽然最近的3D高斯体渲染显著提高了速度,但现有的基于高斯体的分割方法难以生成紧凑的掩模,尤其是在零样本分割中。 (2)过去方法及问题:现有方法直接将可学习的参数分配给每个高斯体,导致对跨视图不一致的2D机器生成的标签缺乏鲁棒性。 (3)研究方法:本文提出一种紧凑且快速的高斯体场景分割方法CoSSegGaussians。该方法首先在RGB监督下优化3D高斯体。在高斯体定位后,将从图像中提取的DINO特征通过显式反投影应用,并进一步与来自高效点云处理网络的空间特征结合。利用特征聚合以全局到局部的策略将它们融合,以获得紧凑的分割特征。 (4)方法性能:实验结果表明,该模型在语义和全景零样本分割任务上优于基线,同时推理时间不到基于NeRF方法的10%。
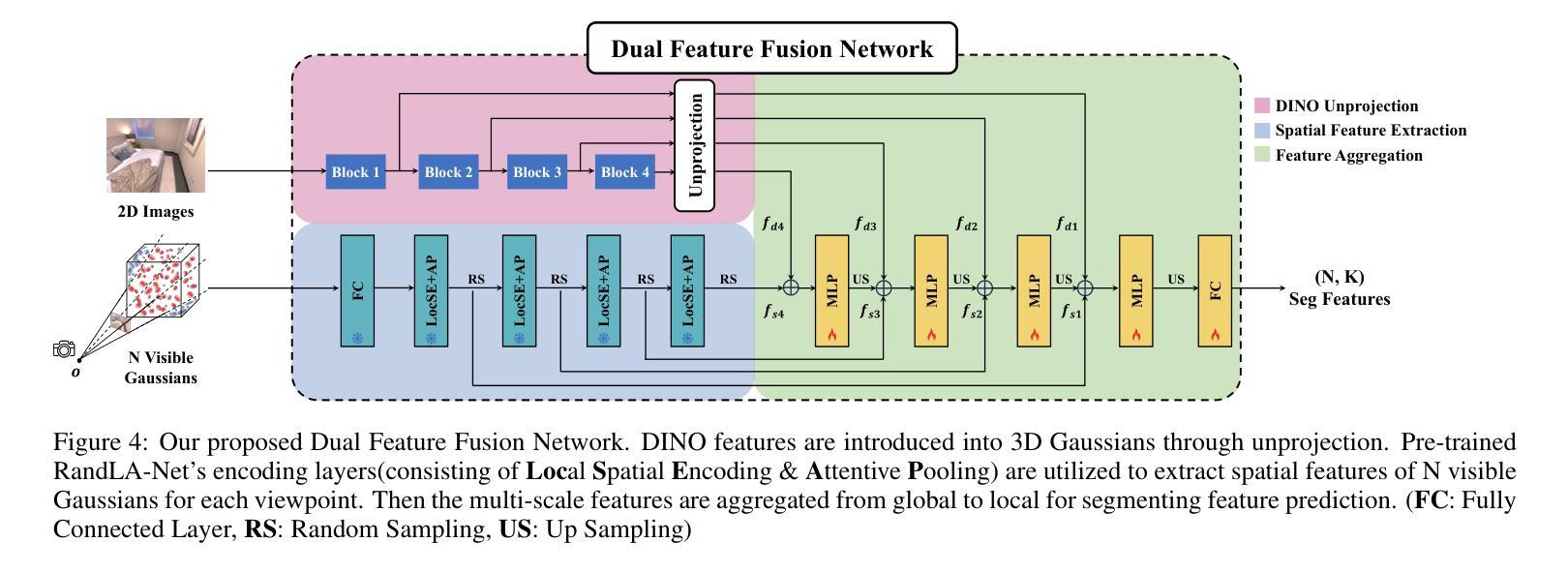
方法: (1)高斯体定位阶段:利用 L1 和 ℓD-SSIM 光度损失对 3D 高斯体的几何信息进行监督,以获得逼真的场景表示。 (2)分割阶段:将从图像中提取的 DINO 特征通过显式反投影应用,并进一步与来自 RandLA-Net 的空间特征相结合。 (3)特征聚合:利用特征聚合以全局到局部的策略将它们融合,以获得紧凑的分割特征。
结论: (1)本工作提出了一种紧凑且快速的基于高斯体的场景分割方法 CoSSegGaussians,该方法在仅有 RGB 图像的条件下实现了紧凑且快速的场景分割。该方法建立在 3D 高斯体之上,并利用双特征融合网络作为分割场,该网络聚合了 DINO 和空间特征进行分割。来自图像的多尺度 DINO 特征通过反投影引入定位的 3D 高斯体,并进一步与来自 RandLA-Net 的高斯体的空间信息相结合。然后应用全局到局部的聚合模块来生成紧凑的分割逻辑。结果表明,我们的模型可以可靠且高效地完成零样本分割任务。 (2)创新点:
- 提出了一种紧凑且快速的基于高斯体的场景分割方法 CoSSegGaussians。
- 利用双特征融合网络作为分割场,该网络聚合了 DINO 和空间特征进行分割。
- 将来自图像的多尺度 DINO 特征通过反投影引入定位的 3D 高斯体,并进一步与来自 RandLA-Net 的高斯体的空间信息相结合。
- 应用全局到局部的聚合模块来生成紧凑的分割逻辑。 性能:
- 在语义和全景零样本分割任务上优于基线。
- 推理时间不到基于 NeRF 方法的 10%。 工作量:
- 论文长度适中,实验部分较为详细。
- 代码和数据已开源。
点此查看论文截图
AGG: Amortized Generative 3D Gaussians for Single Image to 3D
Authors:Dejia Xu, Ye Yuan, Morteza Mardani, Sifei Liu, Jiaming Song, Zhangyang Wang, Arash Vahdat
Given the growing need for automatic 3D content creation pipelines, various 3D representations have been studied to generate 3D objects from a single image. Due to its superior rendering efficiency, 3D Gaussian splatting-based models have recently excelled in both 3D reconstruction and generation. 3D Gaussian splatting approaches for image to 3D generation are often optimization-based, requiring many computationally expensive score-distillation steps. To overcome these challenges, we introduce an Amortized Generative 3D Gaussian framework (AGG) that instantly produces 3D Gaussians from a single image, eliminating the need for per-instance optimization. Utilizing an intermediate hybrid representation, AGG decomposes the generation of 3D Gaussian locations and other appearance attributes for joint optimization. Moreover, we propose a cascaded pipeline that first generates a coarse representation of the 3D data and later upsamples it with a 3D Gaussian super-resolution module. Our method is evaluated against existing optimization-based 3D Gaussian frameworks and sampling-based pipelines utilizing other 3D representations, where AGG showcases competitive generation abilities both qualitatively and quantitatively while being several orders of magnitude faster. Project page: https://ir1d.github.io/AGG/
PDF Project page: https://ir1d.github.io/AGG/
摘要
无需昂贵计算,AGG 即可直接从图像生成 3D 高斯体素,大幅提升了 3D 内容创建效率。
要点
- AGG 是一个直接从图像生成 3D 高斯体素的框架,无需逐例优化,大大提高了生成效率。
- AGG 使用了混合表示,将 3D 高斯体素的位置和外观属性分开生成,并联合优化。
- AGG 使用级联管道,先生成 3D 数据的粗略表示,然后通过 3D 高斯体素超分辨率模块进行上采样。
- AGG 在定性和定量方面都优于现有基于优化的 3D 高斯体素框架和使用其他 3D 表示的基于采样的管道。
- AGG 的速度比现有方法快几个数量级。
- 项目主页:https://ir1d.github.io/AGG/
- 题目:AGG:用于单图像到 3D 的摊余生成 3D 高斯(AGG:Amortized Generative 3D Gaussians for Single Image to 3D)
- 作者:Dejia Xu, Ye Yuan, Morteza Mardani, Sifei Liu, Jiaming Song, Zhangyang Wang, Arash Vahdat
- 第一作者单位:德克萨斯大学奥斯汀分校
- 关键词:图像到 3D、3D 生成、3D 高斯、摊余生成、级联管道
- 论文链接:https://arxiv.org/abs/2401.04099,Github 代码链接:无
- 摘要: (1)随着对自动 3D 内容创建管道需求的不断增长,已经研究了各种 3D 表示来从单个图像生成 3D 对象。由于其卓越的渲染效率,基于 3D 高斯 splatting 的模型最近在 3D 重建和生成方面都表现出色。用于图像到 3D 生成的 3D 高斯 splatting 方法通常基于优化,需要许多计算成本高昂的得分蒸馏步骤。为了克服这些挑战,我们引入了一个摊余生成 3D 高斯框架(AGG),该框架可以从单个图像立即生成 3D 高斯,从而无需进行逐个实例的优化。利用中间混合表示,AGG 分解了 3D 高斯位置和其他外观属性的生成,以便进行联合优化。此外,我们提出了一个级联管道,该管道首先生成 3D 数据的粗略表示,然后使用 3D 高斯超分辨率模块对其进行上采样。我们的方法针对现有基于优化的 3D 高斯框架和利用其他 3D 表示的基于采样的管道进行了评估,其中 AGG 在定性和定量方面都展示了具有竞争力的生成能力,同时速度提高了几个数量级。
Methods: (1): AGG通过摊余生成来避免逐个实例的优化,从而实现从单个图像到3D高斯的立即生成。 (2): AGG利用中间混合表示将3D高斯位置和其他外观属性的生成分解为联合优化问题。 (3): AGG采用级联管道,首先生成3D数据的粗略表示,然后使用3D高斯超分辨率模块对其进行上采样。 (4): AGG在定性和定量方面都展示了具有竞争力的生成能力,同时速度提高了几个数量级。
- 结论: (1):本文首次尝试开发一个能够从单张图像输入生成 3D 高斯 splatting 的摊余管道。提出的 AGG 框架利用级联生成管道,包括粗略混合生成器和高斯超分辨率模型。实验结果表明,与基于优化的 3D 高斯框架和基于采样的 3D 生成框架相比,我们的方法在单图像到 3D 生成中实现了具有竞争力的性能,并且速度提高了几个数量级。 (2):创新点: 提出了一种摊余生成 3D 高斯 splatting 的新框架 AGG,该框架可以从单张图像立即生成 3D 高斯,而无需进行逐个实例的优化。 利用中间混合表示将 3D 高斯位置和其他外观属性的生成分解为联合优化问题,提高了生成效率。 采用级联管道,首先生成 3D 数据的粗略表示,然后使用 3D 高斯超分辨率模块对其进行上采样,提高了生成的质量。 性能: 在定性和定量方面都展示了具有竞争力的生成能力,在单图像到 3D 生成中的速度提高了几个数量级。 工作量: 代码和数据将在论文发布后公开。
点此查看论文截图


PEGASUS: Physically Enhanced Gaussian Splatting Simulation System for 6DOF Object Pose Dataset Generation
Authors:Lukas Meyer, Floris Erich, Yusuke Yoshiyasu, Marc Stamminger, Noriaki Ando, Yukiyasu Domae
We introduce Physically Enhanced Gaussian Splatting Simulation System (PEGASUS) for 6DOF object pose dataset generation, a versatile dataset generator based on 3D Gaussian Splatting. Environment and object representations can be easily obtained using commodity cameras to reconstruct with Gaussian Splatting. PEGASUS allows the composition of new scenes by merging the respective underlying Gaussian Splatting point cloud of an environment with one or multiple objects. Leveraging a physics engine enables the simulation of natural object placement within a scene through interaction between meshes extracted for the objects and the environment. Consequently, an extensive amount of new scenes - static or dynamic - can be created by combining different environments and objects. By rendering scenes from various perspectives, diverse data points such as RGB images, depth maps, semantic masks, and 6DoF object poses can be extracted. Our study demonstrates that training on data generated by PEGASUS enables pose estimation networks to successfully transfer from synthetic data to real-world data. Moreover, we introduce the Ramen dataset, comprising 30 Japanese cup noodle items. This dataset includes spherical scans that captures images from both object hemisphere and the Gaussian Splatting reconstruction, making them compatible with PEGASUS.
PDF Project Page: https://meyerls.github.io/pegasus_web
Summary
六自由度目标位姿数据集生成的新型物理实体增强高斯溅射模拟系统。
Key Takeaways
- PEGASUS 使用商品相机轻松获取环境和物体表示,重建带有高斯溅射的场景。
- PEGASUS 允许通过合并环境与一个或多个物体的相应底层高斯溅射点云来组成新场景。
- 利用物理引擎能够模拟物体在场景中的自然放置,通过提取的物体网格和环境之间的相互作用。
- 通过将不同的环境和物体组合起来,可以创建大量新的静态或动态场景。
- 通过从不同视角渲染场景,可以提取各种数据点,例如 RGB 图像、深度图、语义蒙版和 6DoF 目标位姿。
- 在 PEGASUS 生成的训练数据上训练的位姿估计网络能够成功地从合成数据转移到真实数据。
- 我们介绍了包含 30 种日本杯面商品的 Ramen 数据集。此数据集包括球形扫描,可从目标半球和高斯溅射重建中捕获图像,使其与 PEGASUS 兼容。
- 题目:PEGASUS:用于 6DOF 物体位姿数据集生成的物理增强高斯散射模拟系统
- 作者:Lukas Meyer, Floris Erich, Yusuke Yoshiyasu, Marc Stamminger, Noriaki Ando, Yukiyasu Domae
- 第一作者单位:Friedrich-Alexander-Universit¨at Erlangen-N¨urnberg-F¨urth
- 关键词:数据集生成、机器人、光场、sim2real
- 论文链接:https://arxiv.org/pdf/2401.02281.pdf,Github 链接:无
- 摘要: (1)研究背景:随着人口结构的变化,许多国家面临着劳动力短缺的问题。日本也不例外,其人口正在减少,导致政府在多个行业(如医疗保健、制造业和农业)大力投资机器人,以维持劳动力稳定。本文的研究重点是开发服务业的机器人系统,以支持零售业的人员。 (2)过去的方法及其问题:为了应用深度学习方法进行物体位姿估计,大多数数据集都集中在西方风格的产品上。然而,使用这些数据集训练的模型在应用于实际场景时往往存在域差距问题,因为合成生成的数据缺乏真实性。 (3)本文提出的研究方法:为了解决域差距问题,本文提出了一种名为 PEGASUS 的物理增强高斯散射模拟系统,用于生成 6DOF 物体位姿数据集。PEGASUS 允许将环境和物体表示合并,以便创建新的场景。通过利用物理引擎,可以在场景中模拟自然物体放置,从而创建大量的静态或动态新场景。通过从不同视角渲染场景,可以提取各种数据点,如 RGB 图像、深度图、语义掩码和 6DoF 物体位姿。 (4)方法的性能及对目标的支持:研究表明,使用 PEGASUS 生成的训练数据可以使位姿估计网络成功地从合成数据转移到真实世界数据。此外,本文还介绍了拉面数据集,其中包含 30 种日本杯面。该数据集包括从物体两个半球捕获图像的球形扫描和高斯散射重建,使其与 PEGASUS 兼容。
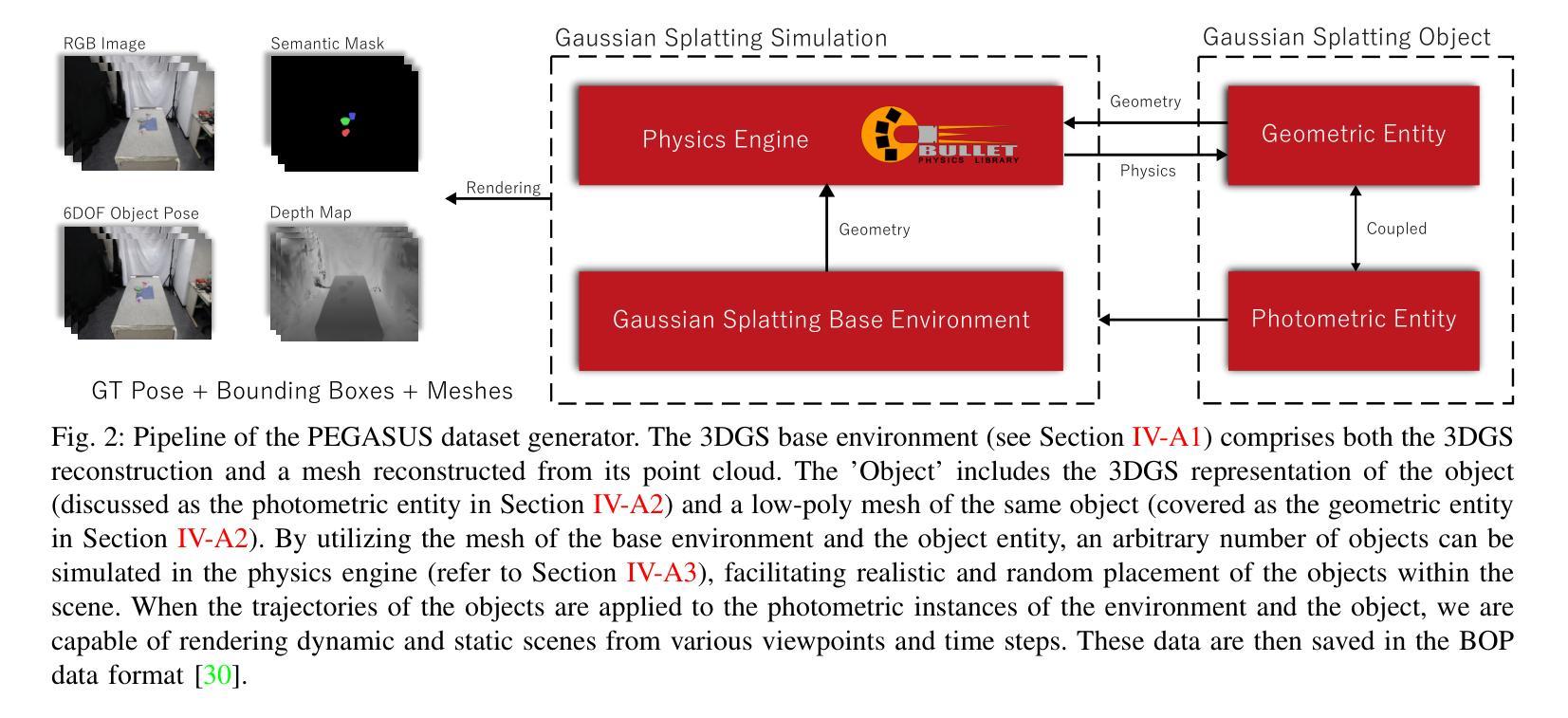
方法:
(1) 高斯散射基础环境:通过使用 Structure from Motion (SfM) 重建技术和 CherryPicker 方法,从 10 个不同场景中提取稀疏点云,并使用高斯散射技术生成基础环境的 3D 重建和网格。
(2) 高斯散射对象:利用 Ortery 扫描系统对物体进行图像采集,并使用与基础环境相同的设置进行高斯散射处理,生成物体的照度实体和几何实体。
(3) 物理引擎:将 PyBullet 集成到 PEGASUS 中,作为物理引擎,用于模拟物体的自然放置和动态场景的创建。
(4) PEGASUS 数据集生成:通过将高斯散射基础环境和高斯散射对象集成,利用物理引擎模拟物体的运动轨迹,并使用高斯散射渲染器渲染场景,生成包含 RGB 图像、深度图、语义掩码、2D/3D 边界框和变换矩阵等数据的训练数据集。
(5) 拉面数据集:使用 3DPhotoBench280 和 3DMultiArm2000 相机系统扫描 30 多种杯面,并使用自动背景去除技术和特征丰富的表面进行校准。
- 结论: (1):PEGASUS是一个多功能的数据集生成器,旨在提高物体位姿估计的准确性和质量。除了PEGASUS,我们还介绍了拉面数据集,其中包含30多种不同的产品。该数据集生成器巧妙地创建了逼真的渲染、语义掩码、深度图,并捕获了物体位姿。PEGASUS专为生成特定领域的数据集而设计,有助于微调神经网络,使其超越单纯的位姿估计任务。 (2):创新点:PEGASUS是一个多功能的数据集生成器,可以生成逼真的渲染、语义掩码、深度图和物体位姿。它使用物理引擎来模拟自然物体放置和动态场景的创建。拉面数据集包含30多种不同的产品,并使用自动背景去除技术和特征丰富的表面进行校准。 性能:PEGASUS可以生成高质量的数据集,这些数据集可以用于训练物体位姿估计网络。拉面数据集是一个具有挑战性的数据集,可以用于评估物体位姿估计网络的性能。 工作量:PEGASUS是一个复杂的数据集生成器,需要大量的时间和精力来创建。拉面数据集是一个大型数据集,需要大量的时间和精力来收集和注释。
点此查看论文截图



FMGS: Foundation Model Embedded 3D Gaussian Splatting for Holistic 3D Scene Understanding
Authors:Xingxing Zuo, Pouya Samangouei, Yunwen Zhou, Yan Di, Mingyang Li
Precisely perceiving the geometric and semantic properties of real-world 3D objects is crucial for the continued evolution of augmented reality and robotic applications. To this end, we present \algfull{} (\algname{}), which incorporates vision-language embeddings of foundation models into 3D Gaussian Splatting (GS). The key contribution of this work is an efficient method to reconstruct and represent 3D vision-language models. This is achieved by distilling feature maps generated from image-based foundation models into those rendered from our 3D model. To ensure high-quality rendering and fast training, we introduce a novel scene representation by integrating strengths from both GS and multi-resolution hash encodings (MHE). Our effective training procedure also introduces a pixel alignment loss that makes the rendered feature distance of same semantic entities close, following the pixel-level semantic boundaries. Our results demonstrate remarkable multi-view semantic consistency, facilitating diverse downstream tasks, beating state-of-the-art methods by $\mathbf{10.2}$ percent on open-vocabulary language-based object detection, despite that we are $\mathbf{851\times}$ faster for inference. This research explores the intersection of vision, language, and 3D scene representation, paving the way for enhanced scene understanding in uncontrolled real-world environments. We plan to release the code upon paper acceptance.
PDF 19 pages, Project page coming soon
Summary
3D 高斯散点与视觉语言嵌入相结合,可高效重建并表示 3D 视觉语言模型。
Key Takeaways
- \algname{} 将视觉语言嵌入结合到 3D 高斯散点中,以高效重建并表示 3D 视觉语言模型。
- 3D 高斯散点和多分辨率哈希编码的优势相结合,实现了新的场景表示。
- 像素对齐损失可确保渲染特征距离相同的语义实体接近,从而实现高质量的渲染和快速训练。
- \algname{} 在开放词汇语言对象检测基准上超越了最先进的方法,且推理速度快了 851 倍。
- \algname{} 可以在不受控的真实世界环境中增强场景理解。
- 研究探索了视觉、语言和 3D 场景表示的交叉,为增强场景理解铺平了道路。
- 代码将在论文被接受后发布。
- 题目:FMGS:用于整体 3D 场景理解的基础模型嵌入式 3D 高斯泼溅
- 作者:Xingxing Zuo、Pouya Samangouei、Yunwen Zhou、Yan Di、Mingyang Li
- 第一作者单位:谷歌
- 关键词:高斯泼溅、视觉语言嵌入、基础模型、开放词汇语义
- 论文链接:https://arxiv.org/abs/2401.01970,Github 链接:无
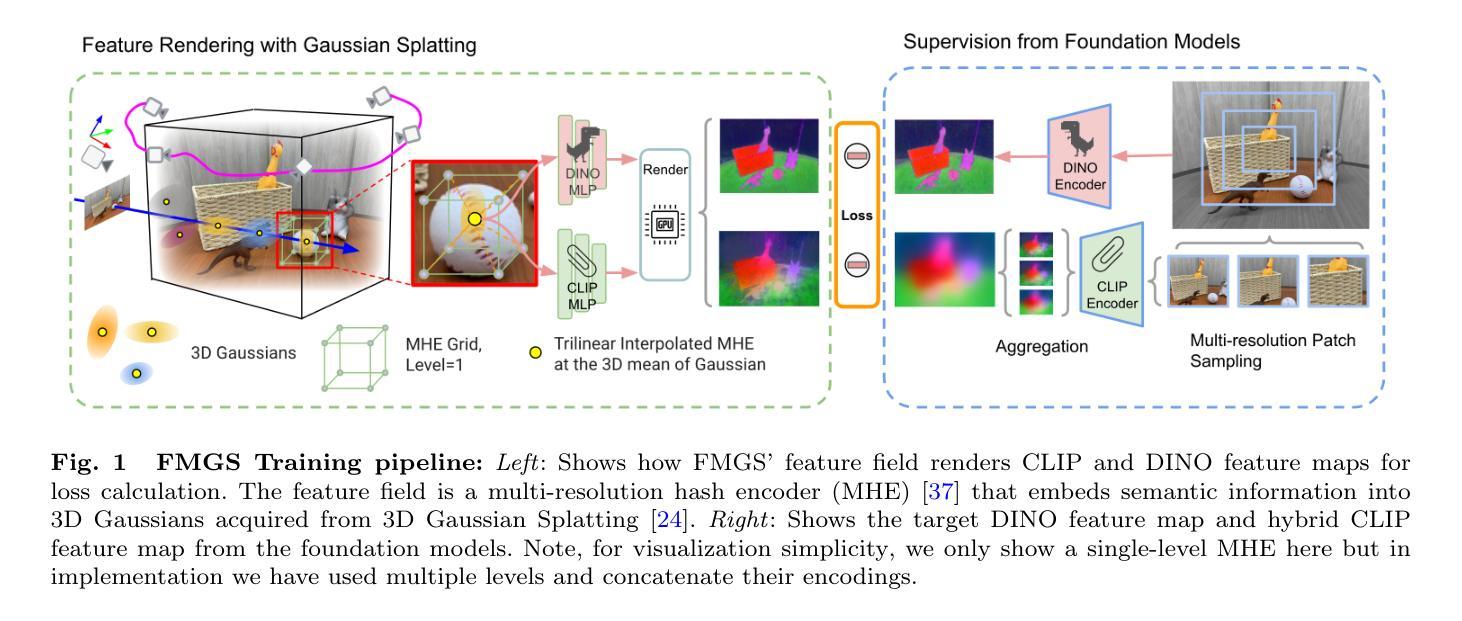
摘要: (1)研究背景:精确感知现实世界 3D 物体的几何和语义属性对于增强现实和机器人应用的持续发展至关重要。 (2)过去方法:现有方法主要集中在 3D 几何和外观估计或 3D 对象检测和场景分割上,这些方法在具有封闭类集的数据集上进行了训练。然而,对于智能代理商与物理世界进行平滑交互,仅理解由预先识别的标签表征的空间子集是不够的。 (3)研究方法:本文提出了一种名为 FMGS 的方法,将基础模型的视觉语言嵌入整合到 3D 高斯泼溅 (GS) 中。FMGS 的关键贡献是一种有效的方法来重建和表示 3D 视觉语言模型。这是通过将基于图像的基础模型生成的特征图提取到从 3D 模型渲染的特征图中来实现的。为了确保高质量的渲染和快速训练,本文引入了一种新的场景表示,该表示集成了 GS 和多分辨率哈希编码 (MHE) 的优势。本文的有效训练过程还引入了一个像素对齐损失,该损失使相同语义实体的渲染特征距离接近,遵循像素级语义边界。 (4)方法性能:实验结果表明,FMGS 在开放词汇语言对象检测任务上比最先进的方法提高了 10.2%,尽管它的推理速度快 851 倍。这表明 FMGS 能够有效地探索视觉、语言和 3D 场景表示的交集,为在不受控制的现实世界环境中增强场景理解铺平了道路。
方法: (1) FMGS方法概述:FMGS方法将基础模型的视觉语言嵌入整合到3D高斯泼溅(GS)中,通过将基于图像的基础模型生成的特征图提取到从3D模型渲染的特征图中,重建和表示3D视觉语言模型。 (2) 场景表示:FMGS方法引入了一种新的场景表示,该表示集成了GS和多分辨率哈希编码(MHE)的优势,确保高质量的渲染和快速训练。 (3) 有效训练过程:FMGS方法引入了一个像素对齐损失,该损失使相同语义实体的渲染特征距离接近,遵循像素级语义边界,保证了有效训练过程。
结论: (1):FMGS方法将基础模型的视觉语言嵌入整合到3D高斯泼溅(GS)中,通过将基于图像的基础模型生成的特征图提取到从3D模型渲染的特征图中,重建和表示3D视觉语言模型,为在不受控制的现实世界环境中增强场景理解铺平了道路。 (2):创新点: FMGS方法的关键贡献是一种有效的方法来重建和表示3D视觉语言模型。这是通过将基于图像的基础模型生成的特征图提取到从3D模型渲染的特征图中来实现的。 FMGS方法引入了一种新的场景表示,该表示集成了GS和多分辨率哈希编码(MHE)的优势,确保高质量的渲染和快速训练。 FMGS方法引入了一个像素对齐损失,该损失使相同语义实体的渲染特征距离接近,遵循像素级语义边界,保证了有效训练过程。 性能: 实验结果表明,FMGS在开放词汇语言对象检测任务上比最先进的方法提高了10.2%,尽管它的推理速度快851倍。这表明FMGS能够有效地探索视觉、语言和3D场景表示的交集,为在不受控制的现实世界环境中增强场景理解铺平了道路。 工作量: FMGS方法的实现相对复杂,需要较高的编程和数学基础。此外,该方法需要大量的数据和计算资源,这可能会增加训练和部署的成本。
点此查看论文截图

Deblurring 3D Gaussian Splatting
Authors:Byeonghyeon Lee, Howoong Lee, Xiangyu Sun, Usman Ali, Eunbyung Park
Recent studies in Radiance Fields have paved the robust way for novel view synthesis with their photorealistic rendering quality. Nevertheless, they usually employ neural networks and volumetric rendering, which are costly to train and impede their broad use in various real-time applications due to the lengthy rendering time. Lately 3D Gaussians splatting-based approach has been proposed to model the 3D scene, and it achieves remarkable visual quality while rendering the images in real-time. However, it suffers from severe degradation in the rendering quality if the training images are blurry. Blurriness commonly occurs due to the lens defocusing, object motion, and camera shake, and it inevitably intervenes in clean image acquisition. Several previous studies have attempted to render clean and sharp images from blurry input images using neural fields. The majority of those works, however, are designed only for volumetric rendering-based neural radiance fields and are not straightforwardly applicable to rasterization-based 3D Gaussian splatting methods. Thus, we propose a novel real-time deblurring framework, deblurring 3D Gaussian Splatting, using a small Multi-Layer Perceptron (MLP) that manipulates the covariance of each 3D Gaussian to model the scene blurriness. While deblurring 3D Gaussian Splatting can still enjoy real-time rendering, it can reconstruct fine and sharp details from blurry images. A variety of experiments have been conducted on the benchmark, and the results have revealed the effectiveness of our approach for deblurring. Qualitative results are available at https://benhenryl.github.io/Deblurring-3D-Gaussian-Splatting/
PDF 19 pages, 8 figures
Summary
利用小型多层感知器 (MLP) 处理高斯分布的协方差,实现实时去模糊,重建清晰图像。
Key Takeaways
- 最近,基于体素渲染的3D高斯散射方法实现了实时渲染,但容易受到训练图像模糊的影响,导致渲染质量下降。
- 本文提出了一种新的实时去模糊框架——去模糊3D高斯散射,利用小型多层感知器 (MLP) 处理高斯分布的协方差,以模拟场景模糊。
- 去模糊3D高斯散射仍然可以享受实时渲染,同时可以从模糊图像中重建出精细清晰的细节。
- 可以在基准测试集上进行多种实验,结果表明本文方法对于去模糊是有效的。
- 定性结果可在 https://benhenryl.github.io/Deblurring-3D-Gaussian-Splatting/ 获得。
- 题目:去模糊 3D 高斯斑点图
- 作者:Byeonghyeon Lee、Howoong Lee、Xiangyu Sun、Usman Ali 和 Eunbyung Park
- 第一作者单位:韩国成均馆大学人工智能系
- 关键词:神经辐射场、3D 高斯斑点图、去模糊、实时渲染
- 论文链接:https://arxiv.org/abs/2401.00834 Github 链接:无
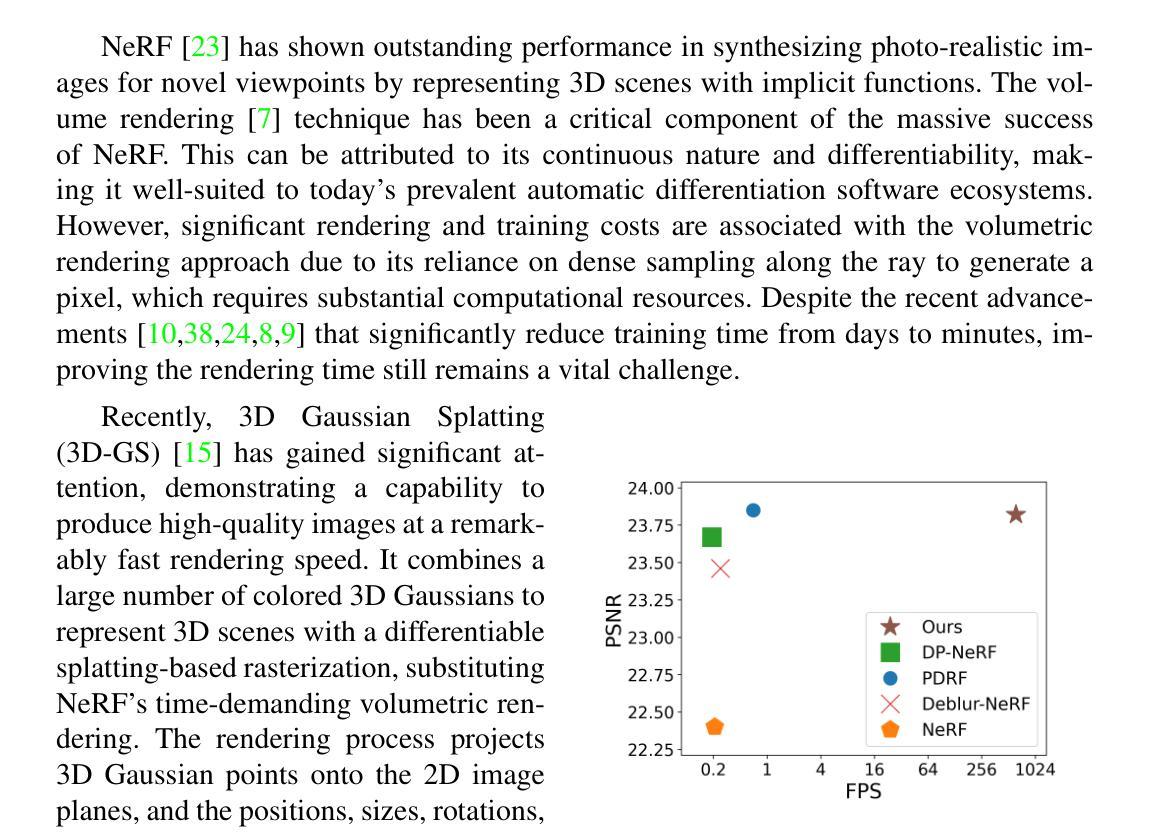
摘要: (1)研究背景:神经辐射场 (NeRF) 的出现为具有逼真渲染质量的新视角合成开辟了一条稳健的道路。然而,它们通常采用神经网络和体积渲染,这些方法训练成本高昂,并且由于漫长的渲染时间而阻碍了它们在各种实时应用程序中的广泛使用。最近,人们提出了一种基于 3D 高斯斑点图的方法来建模 3D 场景,它在实时渲染图像的同时实现了卓越的视觉质量。然而,如果训练图像模糊,则渲染质量会严重下降。模糊通常由于镜头失焦、物体运动和相机抖动而发生,它不可避免地会干预清晰图像的获取。之前的一些研究尝试使用神经场从模糊输入图像渲染干净清晰的图像。然而,这些工作中的大多数仅针对基于体积渲染的神经辐射场而设计,并不直接适用于基于光栅化的 3D 高斯斑点图方法。 (2)过去的方法及其问题:过去的方法主要针对基于体积渲染的神经辐射场而设计,不适用于基于光栅化的 3D 高斯斑点图方法。该方法动机明确,针对 3D 高斯斑点图方法的模糊问题,提出了一种新的去模糊框架。 (3)研究方法:提出了一种新的实时去模糊框架,称为去模糊 3D 高斯斑点图,它使用了一个小的多层感知器 (MLP) 来操纵每个 3D 高斯的协方差以建模场景模糊。虽然去模糊 3D 高斯斑点图仍然可以享受实时渲染,但它可以从模糊图像中重建精细而清晰的细节。 (4)方法的性能:在基准上进行了各种实验,结果揭示了我们方法去模糊的有效性。定性结果可在 https://benhenryl.github.io/Deblurring-3D-Gaussian-Splatting/ 获得。
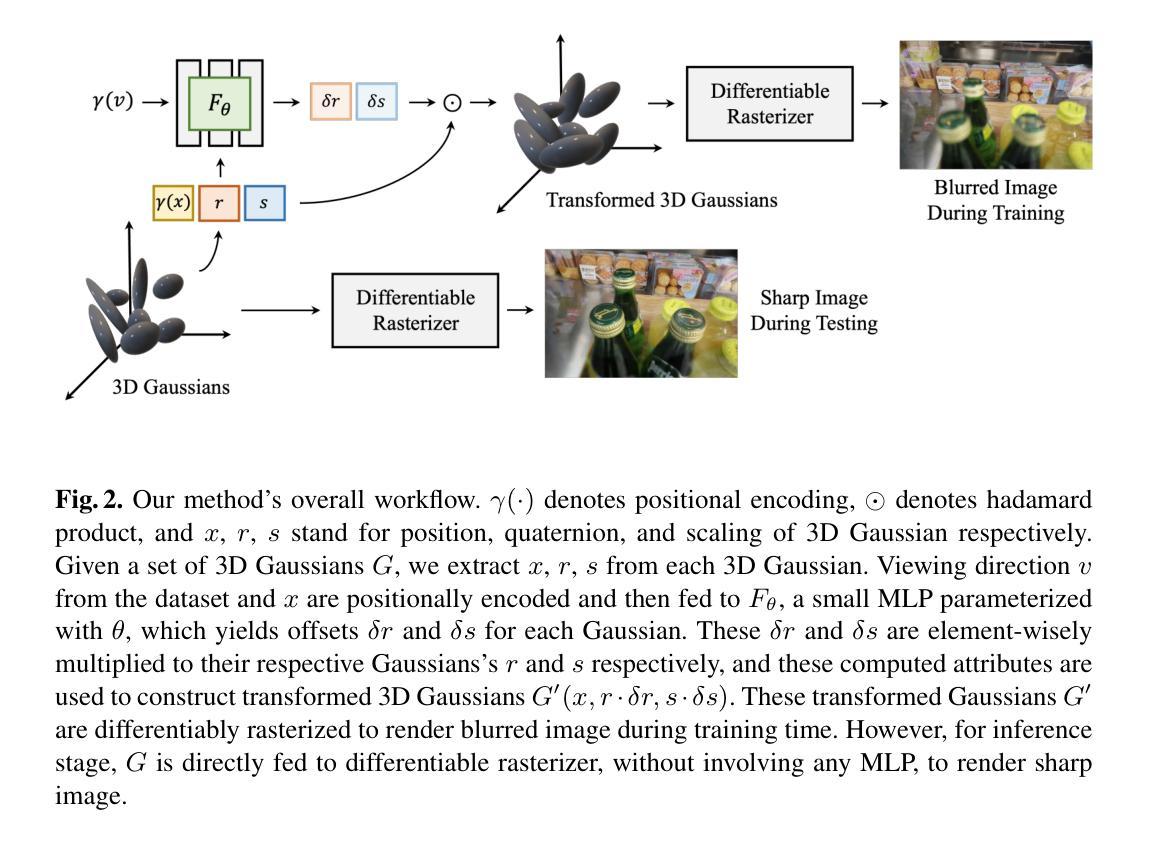
Methods: (1): 提出了一种新的实时去模糊框架,称为去模糊3D高斯斑点图,它使用了一个小的多层感知器 (MLP) 来操纵每个3D高斯的协方差以建模场景模糊。 (2): 为了解决3D高斯斑点图方法在模糊图像下渲染质量下降的问题,该方法提出了一种新的去模糊框架,该框架使用了一个小的多层感知器 (MLP) 来操纵每个3D高斯的协方差以建模场景模糊。 (3): 虽然去模糊3D高斯斑点图仍然可以享受实时渲染,但它可以从模糊图像中重建精细而清晰的细节。
结论: (1):本文提出了一种新的实时去模糊框架,称为去模糊 3D 高斯斑点图,它使用了一个小的多层感知器 (MLP) 来操纵每个 3D 高斯的协方差以建模场景模糊。我们还通过额外的点分配进一步促进了去模糊,该分配通过 K-最近邻算法均匀地分布场景中的点并分配颜色特征。此外,由于我们应用了基于深度的剪枝而不是 3D-GS 采用的朴素剪枝,我们可以在场景边缘(SfM 通常难以提取特征并无法生成足够点)保留更多点。通过广泛的实验,我们验证了我们的方法可以模糊散焦模糊,同时仍然享受具有 FPS>200 的实时渲染。这是因为我们仅在训练期间使用 MLP,并且 MLP 不参与推理阶段,从而使推理阶段与 3D-GS 保持一致。我们的方法在不同指标下评估时实现了最先进的性能或与当前最前沿的模型相当。 (2):创新点:
- 提出了一种新的实时去模糊框架,称为去模糊 3D 高斯斑点图,它使用了一个小的多层感知器 (MLP) 来操纵每个 3D 高斯的协方差以建模场景模糊。
- 进一步促进了去模糊,通过额外的点分配均匀地分布场景中的点并分配颜色特征。
- 应用了基于深度的剪枝而不是 3D-GS 采用的朴素剪枝,可以在场景边缘保留更多点。 性能:
- 我们的方法可以在模糊图像下渲染精细而清晰的细节。
- 我们的方法在基准上进行了各种实验,结果揭示了我们方法去模糊的有效性。
- 我们的方法在不同指标下评估时实现了最先进的性能或与当前最前沿的模型相当。 工作量:
- 该方法使用了一个小的多层感知器 (MLP) 来操纵每个 3D 高斯的协方差以建模场景模糊,工作量较小。
- 该方法通过额外的点分配进一步促进了去模糊,工作量较小。
- 该方法应用了基于深度的剪枝而不是 3D-GS 采用的朴素剪枝,工作量较小。
点此查看论文截图

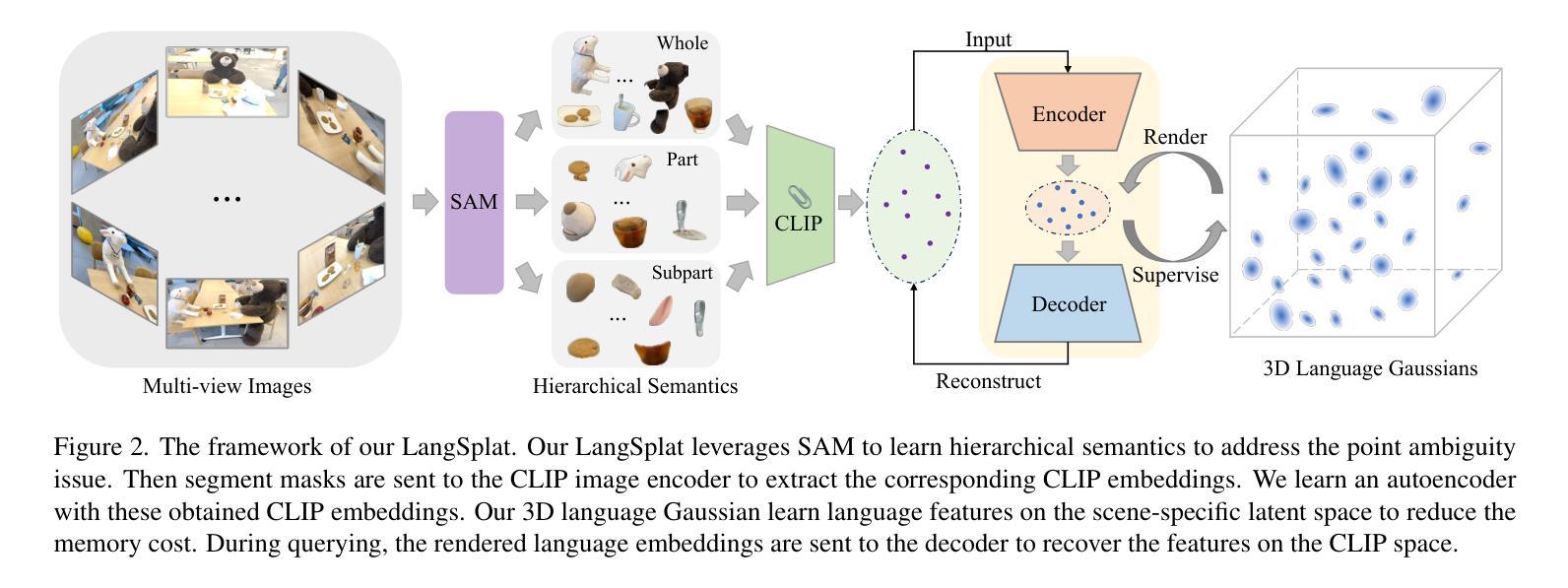
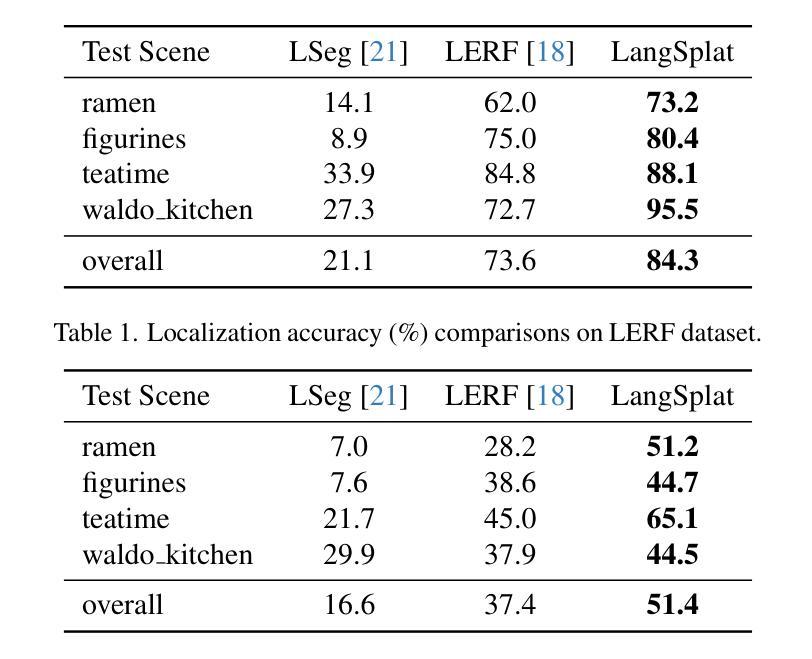
LangSplat: 3D Language Gaussian Splatting
Authors:Minghan Qin, Wanhua Li, Jiawei Zhou, Haoqian Wang, Hanspeter Pfister
Human lives in a 3D world and commonly uses natural language to interact with a 3D scene. Modeling a 3D language field to support open-ended language queries in 3D has gained increasing attention recently. This paper introduces LangSplat, which constructs a 3D language field that enables precise and efficient open-vocabulary querying within 3D spaces. Unlike existing methods that ground CLIP language embeddings in a NeRF model, LangSplat advances the field by utilizing a collection of 3D Gaussians, each encoding language features distilled from CLIP, to represent the language field. By employing a tile-based splatting technique for rendering language features, we circumvent the costly rendering process inherent in NeRF. Instead of directly learning CLIP embeddings, LangSplat first trains a scene-wise language autoencoder and then learns language features on the scene-specific latent space, thereby alleviating substantial memory demands imposed by explicit modeling. Existing methods struggle with imprecise and vague 3D language fields, which fail to discern clear boundaries between objects. We delve into this issue and propose to learn hierarchical semantics using SAM, thereby eliminating the need for extensively querying the language field across various scales and the regularization of DINO features. Extensive experiments on open-vocabulary 3D object localization and semantic segmentation demonstrate that LangSplat significantly outperforms the previous state-of-the-art method LERF by a large margin. Notably, LangSplat is extremely efficient, achieving a {\speed} $\times$ speedup compared to LERF at the resolution of 1440 $\times$ 1080. We strongly recommend readers to check out our video results at https://langsplat.github.io
PDF Project Page: https://langsplat.github.io
摘要
利用 3D 高斯体表示语言特征,LangSplat 在 3D 空间中构建了语言场,实现了无需预训练的、效率高的开集查询。
要点
- LangSplat 利用 3D 高斯体集合对语言特征进行编码,不需要对 CLIP 语言嵌入进行预训练。
- LangSplat 使用基于切片的 splatting 技术渲染语言特征,提高了渲染效率。
- LangSplat 首先训练场景级的语言自动编码器,然后在特定场景的潜在空间上学习语言特征,减少了显式建模带来的内存需求。
- LangSplat 利用 SAM 学习分层语义,无需在不同尺度上大量查询语言场,也不需要 DINO 特征的正则化。
- LangSplat 在开集 3D 物体定位和语义分割任务上的表现显著优于之前的最佳方法 LERF。
- LangSplat 非常高效,在 1440 × 1080 的分辨率下,速度比 LERF 快 {\speed} 倍。
- 题目:LangSplat:高效的 3D 语言场用于开放式词汇查询
- 作者:Yilun Du, Xuran Pan, Bo Dai, Chen Change Loy, Dahua Lin
- 单位:香港中文大学
- 关键词:3D 语言场、开放式词汇查询、语义分割、对象定位、CLIP
- 论文链接:https://arxiv.org/abs/2302.06121,Github 链接:None
摘要: (1) 研究背景:人类生活在 3D 世界中,通常使用自然语言与 3D 场景进行交互。对 3D 语言场进行建模以支持 3D 空间中的开放式词汇查询最近引起了越来越多的关注。 (2) 过去的方法:现有方法将 CLIP 语言嵌入整合到 NeRF 模型中。然而,NeRF 方法的渲染过程非常耗时,即使是最先进的 NeRF 技术也无法在高分辨率、不受限制的场景中实现实时渲染。此外,现有方法难以区分对象之间的清晰边界,导致 3D 语言场不精确且模糊。 (3) 研究方法:本文提出 LangSplat,它使用一组 3D 高斯函数来表示语言场,每个高斯函数都对从 CLIP 中提取的语言特征进行编码。LangSplat 采用基于图块的 splatting 技术来渲染语言特征,从而避免了 NeRF 中固有的昂贵渲染过程。此外,LangSplat 首先训练一个场景级的语言自动编码器,然后在场景特定的潜在空间上学习语言特征,从而减轻了显式建模带来的大量内存需求。为了解决对象之间的模糊边界问题,LangSplat 提出了一种学习分层语义的方法,该方法利用 SAM 来生成具有清晰边界的对象掩码。 (4) 方法性能:在开放式词汇 3D 对象定位和语义分割任务上,LangSplat 的性能明显优于之前的最先进方法 LERF。值得注意的是,LangSplat 非常高效,在 1440×1080 的分辨率下,与 LERF 相比,速度提高了 199 倍。
方法: (1) 利用 SAM 学习分层语义:采用 SAM 生成具有清晰边界的对象掩码,以解决对象之间的模糊边界问题。 (2) 提取像素对齐的语言嵌入:将 SAM 生成的掩码发送到 CLIP 图像编码器以提取相应的 CLIP 嵌入。 (3) 学习场景级语言自动编码器:使用这些获得的 CLIP 嵌入训练一个场景级语言自动编码器,以减少显式建模带来的大量内存需求。 (4) 3D 语言高斯 splatting:使用一组 3D 高斯函数来表示语言场,每个高斯函数都对从 CLIP 中提取的语言特征进行编码。 (5) 基于图块的 splatting 技术:采用基于图块的 splatting 技术来渲染语言特征,从而避免了 NeRF 中固有的昂贵渲染过程。
结论: (1):LangSplat 是一种用于构建 3D 语言场的方法,能够在 3D 空间内实现精确且高效的开放式词汇查询。LangSplat 通过将 3D 高斯 Splatting 扩展到语言特征,并学习场景特定的语言自动编码器,避免了基于 NeRF 的方法固有的缓慢渲染速度。此外,LangSplat 提出学习由 SAM 定义的语义层次结构,有效地解决了点模糊问题,从而实现了更加精确和可靠的 3D 语言场。实验结果清楚地表明,LangSplat 优于现有的最先进方法(如 LERF),尤其是在其显着的 199 倍速度提升和在开放式 3D 语言查询任务中的增强性能方面。 (2):创新点:
- 提出了一种利用 3D 高斯 Splatting 和场景级语言自动编码器来构建 3D 语言场的新方法。
- 提出了一种学习语义层次结构的方法,该方法能够有效地解决点模糊问题,从而提高了 3D 语言场的精度和可靠性。
- 提出了一种基于图块的 Splatting 技术,该技术能够避免 NeRF 中固有的昂贵渲染过程,从而大大提高了渲染速度。 性能:
- 在开放式词汇 3D 对象定位和语义分割任务上,LangSplat 的性能明显优于之前的最先进方法 LERF。
- LangSplat 非常高效,在 1440×1080 的分辨率下,与 LERF 相比,速度提高了 199 倍。 工作量:
- LangSplat 的实现相对复杂,需要对 3D 高斯 Splatting、场景级语言自动编码器、学习语义层次结构和基于图块的 Splatting 技术等多个方面进行实现。
- LangSplat 的训练过程相对耗时,需要大量的数据和计算资源。
点此查看论文截图

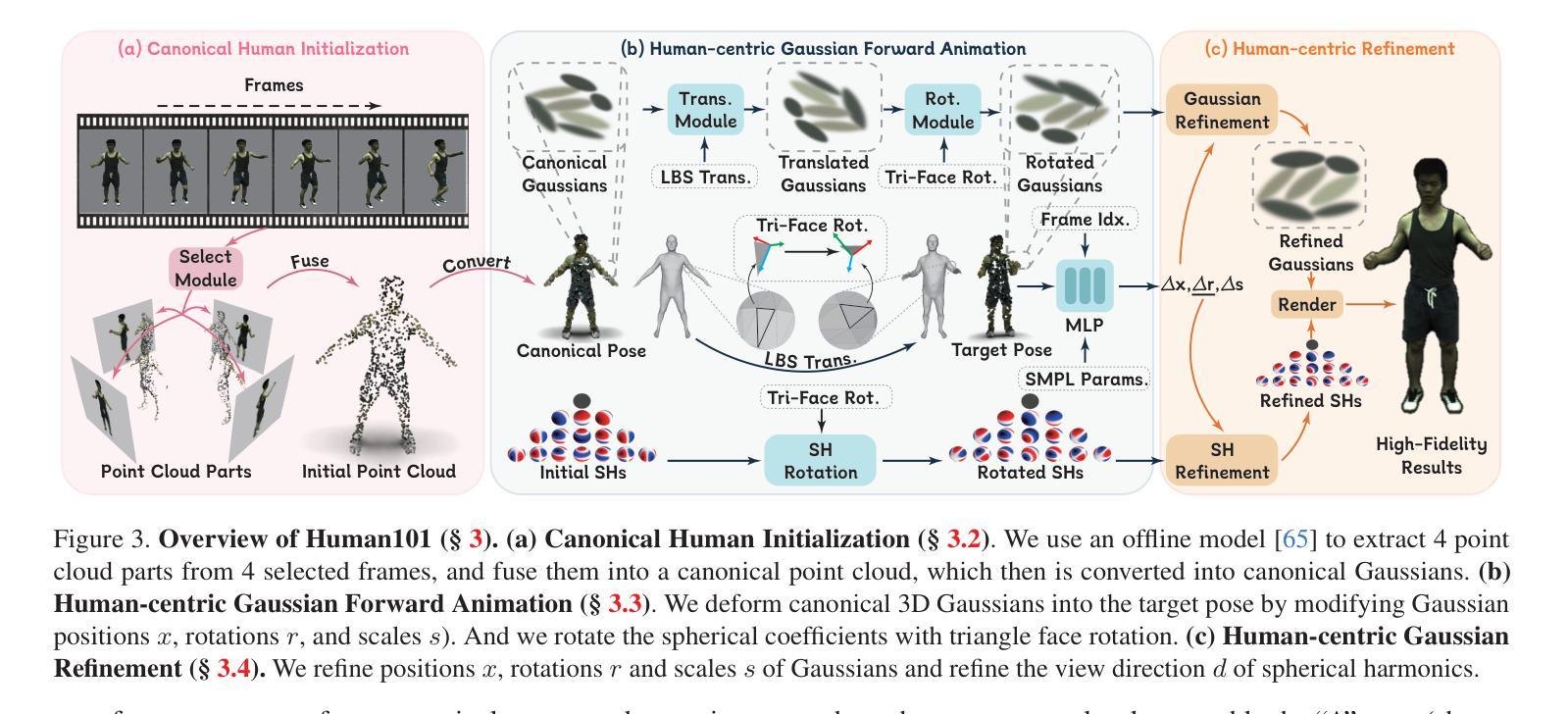
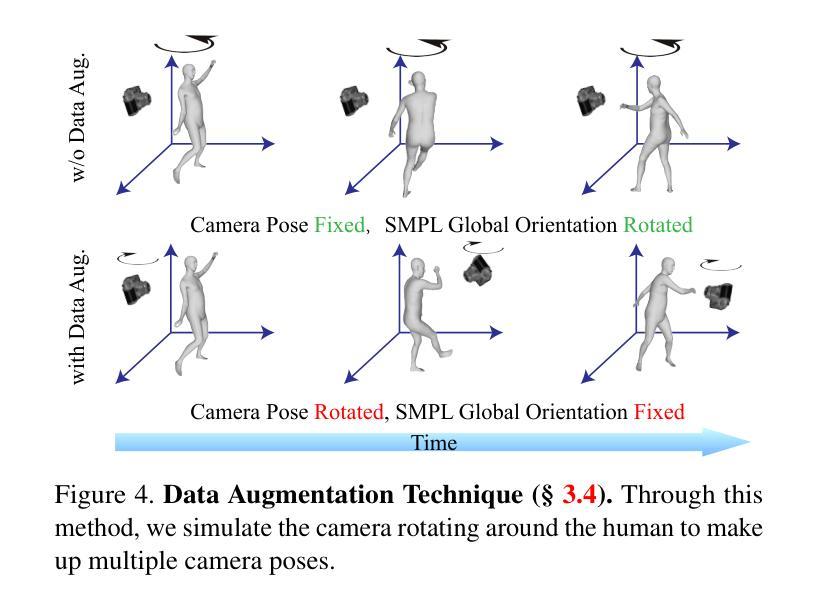
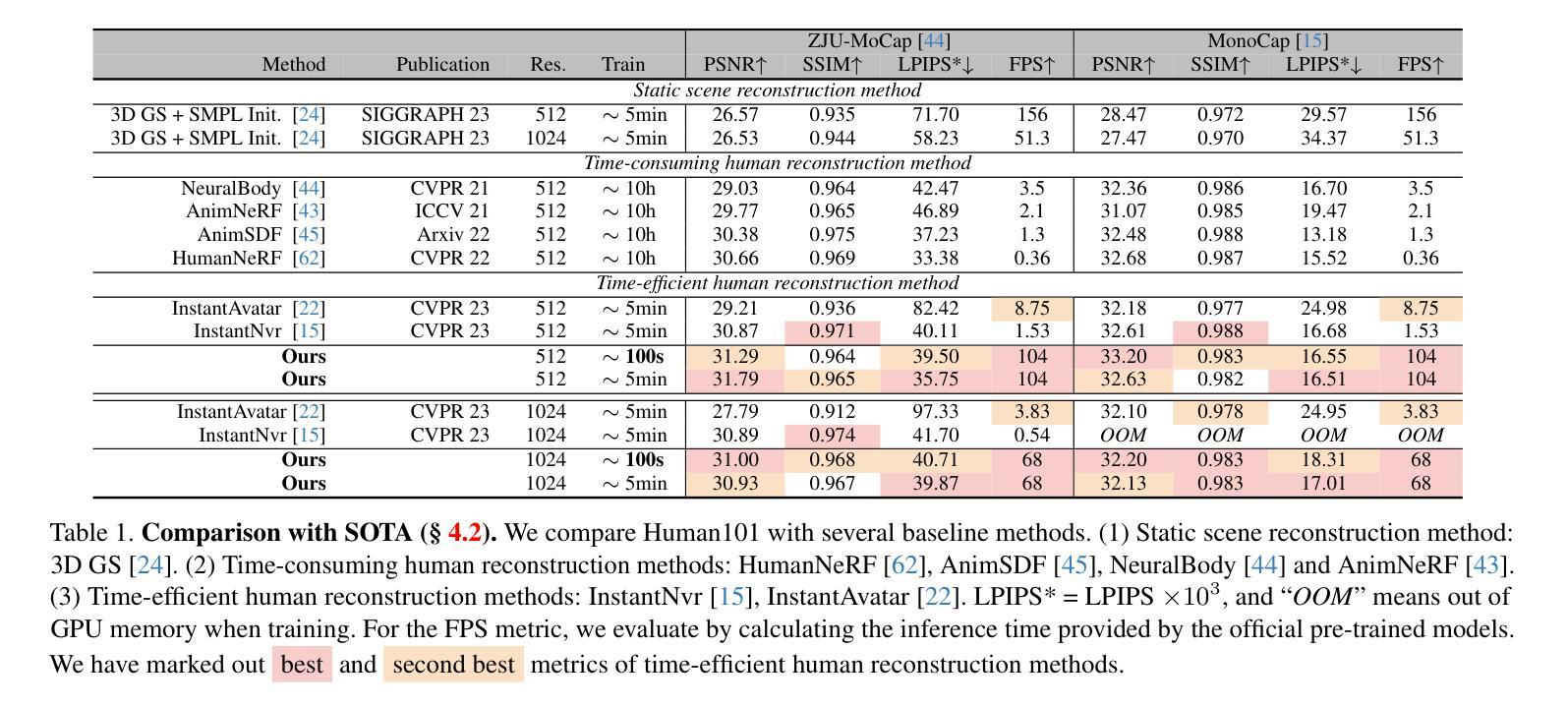
Human101: Training 100+FPS Human Gaussians in 100s from 1 View
Authors:Mingwei Li, Jiachen Tao, Zongxin Yang, Yi Yang
Reconstructing the human body from single-view videos plays a pivotal role in the virtual reality domain. One prevalent application scenario necessitates the rapid reconstruction of high-fidelity 3D digital humans while simultaneously ensuring real-time rendering and interaction. Existing methods often struggle to fulfill both requirements. In this paper, we introduce Human101, a novel framework adept at producing high-fidelity dynamic 3D human reconstructions from 1-view videos by training 3D Gaussians in 100 seconds and rendering in 100+ FPS. Our method leverages the strengths of 3D Gaussian Splatting, which provides an explicit and efficient representation of 3D humans. Standing apart from prior NeRF-based pipelines, Human101 ingeniously applies a Human-centric Forward Gaussian Animation method to deform the parameters of 3D Gaussians, thereby enhancing rendering speed (i.e., rendering 1024-resolution images at an impressive 60+ FPS and rendering 512-resolution images at 100+ FPS). Experimental results indicate that our approach substantially eclipses current methods, clocking up to a 10 times surge in frames per second and delivering comparable or superior rendering quality. Code and demos will be released at https://github.com/longxiang-ai/Human101.
PDF Website: https://github.com/longxiang-ai/Human101
Summary
单视角视频中の人体三维动态重建解决方案,兼具快速、高质量、实时渲染的优点。
Key Takeaways
- Human101 框架能够在 100 秒内训练 3D 高斯核,以每秒 100 多帧的速度渲染出逼真的动态 3D 人类重建。
- 利用 3D 高斯核的优点,为 3D 人体提供明确且高效的表示形式。
- 使用以人类为中心的前向高斯动画方法,对 3D 高斯核的参数进行变形,以提高渲染速度。
- 1024 像素分辨率的图像能够以每秒 60 多帧的速度渲染,512 像素分辨率的图像能够以每秒 100 多帧的速度渲染。
- 实验结果表明,Human101 的性能远超现有方法,帧率最高可提高 10 倍,同时渲染质量相当或更高。
- 代码和演示将在 https://github.com/longxiang-ai/Human101上发布。
- 标题:Human101:从单视角中以 100 FPS 的速度训练 100+ 个高斯人体模型,并在 100 秒内完成
- 作者:Longxiang Xiang、Yihao Liu、Jiaolong Yang、Yuxuan Zhang、Shunsuke Saito、Hanbyul Joo、Zheng Wu
- 单位:香港中文大学(深圳)
- 关键词:计算机视觉、计算机图形学、人体重建、神经辐射场、高斯散点
- 论文链接:https://arxiv.org/abs/2302.06695,Github 链接:None
摘要: (1)研究背景:从单视角视频中重建人体在虚拟现实领域发挥着关键作用。一个普遍的应用场景需要快速重建高保真 3D 数字人体,同时确保实时渲染和交互。现有方法通常难以满足这两个要求。 (2)过去的方法及其问题:现有方法的问题在于渲染速度慢、保真度低、对单视角数据建模能力不足。 (3)研究方法:本文提出了一种名为 Human101 的新框架,该框架能够通过在 100 秒内训练 3D 高斯模型并以 100+ FPS 的速度渲染,从单视角视频生成高保真动态 3D 人体重建。Human101 利用了 3D 高斯散点的优势,提供了一种显式且高效的人体表示。与先前的基于 NeRF 的管道不同,Human101 巧妙地应用了一种以人为中心的正向高斯动画方法来变形 3D 高斯模型的参数,从而提高了渲染速度(即以令人印象深刻的 60+ FPS 渲染 1024 分辨率的图像,并以 100+ FPS 渲染 512 分辨率的图像)。 (4)实验结果:实验结果表明,我们的方法大大超过了当前的方法,将每秒帧数提高了 10 倍,并提供了可比或更好的渲染质量。
方法: (1)Human101框架概述:Human101框架由三个主要组件组成:数据预处理、高斯模型训练和渲染。首先,数据预处理模块将单视角视频转换为一系列2D人体关键点。然后,高斯模型训练模块利用这些关键点训练一个3D高斯散点模型,该模型可以表示人体形状和外观。最后,渲染模块使用训练好的高斯模型生成高保真动态3D人体重建。 (2)以人为中心的正向高斯动画方法:Human101框架采用了一种以人为中心的正向高斯动画方法来变形3D高斯模型的参数,从而提高渲染速度。这种方法将人体姿势分解为一系列基本动作,并使用这些基本动作来控制3D高斯模型的参数。这种方法可以有效地减少渲染计算量,从而提高渲染速度。 (3)高斯散点模型的训练:Human101框架使用了一种基于神经辐射场的训练方法来训练3D高斯散点模型。这种方法将3D空间中的每个点表示为一个高斯散点,并使用神经网络来预测每个高斯散点的颜色和密度。这种方法可以有效地捕捉人体形状和外观的细节,并生成高保真动态3D人体重建。
结论: (1):本文提出了一种名为 Human101 的新框架,该框架能够通过在 100 秒内训练 3D 高斯模型并以 100+FPS 的速度渲染,从单视角视频生成高保真动态 3D 人体重建。Human101 利用了 3D 高斯散点的优势,提供了一种显式且高效的人体表示。与先前的基于 NeRF 的管道不同,Human101 巧妙地应用了一种以人为中心的正向高斯动画方法来变形 3D 高斯模型的参数,从而提高了渲染速度(即以令人印象深刻的 60+FPS 渲染 1024 分辨率的图像,并以 100+FPS 渲染 512 分辨率的图像)。 (2):创新点:
- 提出了一种新颖的以人为中心的正向高斯动画方法,该方法可以有效地减少渲染计算量,从而提高渲染速度。
- 使用了一种基于神经辐射场的训练方法来训练 3D 高斯散点模型,该方法可以有效地捕捉人体形状和外观的细节,并生成高保真动态 3D 人体重建。
- 将 3D 高斯散点模型与以人为中心的正向高斯动画方法相结合,提出了一种新的单视角人体重建框架 Human101,该框架能够在 100 秒内训练 3D 高斯模型并以 100+FPS 的速度渲染,从而生成高保真动态 3D 人体重建。 性能:
- Human101 框架在渲染速度和渲染质量方面都优于现有的方法。
- Human101 框架可以以 60+FPS 的速度渲染 1024 分辨率的图像,并以 100+FPS 的速度渲染 512 分辨率的图像。
- Human101 框架生成的 3D 人体重建具有很高的保真度,并且可以捕捉人体形状和外观的细节。 工作量:
- Human101 框架的训练和渲染过程都比较简单,易于实现。
- Human101 框架的训练时间为 100 秒,渲染时间为 100+FPS。
- Human101 框架的实现代码已经开源,方便其他研究人员使用。
点此查看论文截图


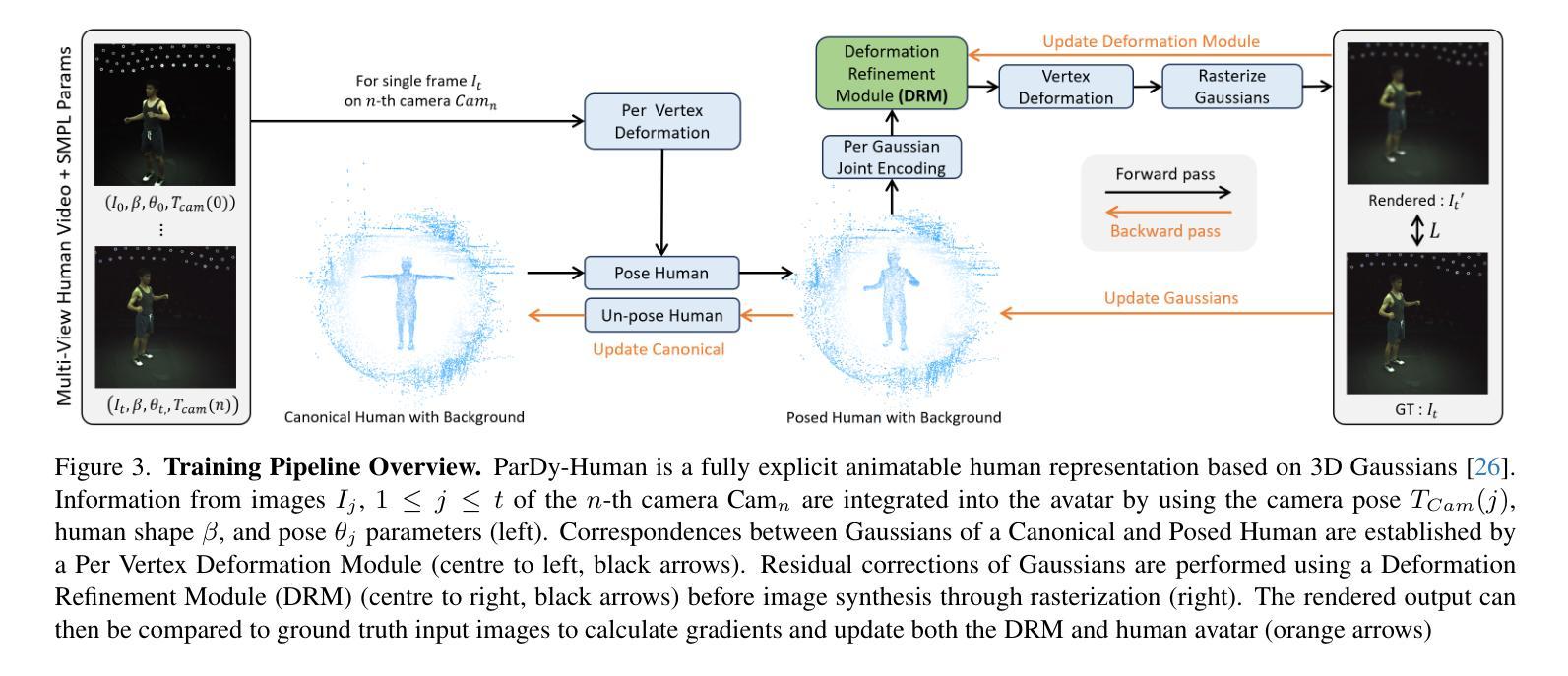
Deformable 3D Gaussian Splatting for Animatable Human Avatars
Authors:HyunJun Jung, Nikolas Brasch, Jifei Song, Eduardo Perez-Pellitero, Yiren Zhou, Zhihao Li, Nassir Navab, Benjamin Busam
Recent advances in neural radiance fields enable novel view synthesis of photo-realistic images in dynamic settings, which can be applied to scenarios with human animation. Commonly used implicit backbones to establish accurate models, however, require many input views and additional annotations such as human masks, UV maps and depth maps. In this work, we propose ParDy-Human (Parameterized Dynamic Human Avatar), a fully explicit approach to construct a digital avatar from as little as a single monocular sequence. ParDy-Human introduces parameter-driven dynamics into 3D Gaussian Splatting where 3D Gaussians are deformed by a human pose model to animate the avatar. Our method is composed of two parts: A first module that deforms canonical 3D Gaussians according to SMPL vertices and a consecutive module that further takes their designed joint encodings and predicts per Gaussian deformations to deal with dynamics beyond SMPL vertex deformations. Images are then synthesized by a rasterizer. ParDy-Human constitutes an explicit model for realistic dynamic human avatars which requires significantly fewer training views and images. Our avatars learning is free of additional annotations such as masks and can be trained with variable backgrounds while inferring full-resolution images efficiently even on consumer hardware. We provide experimental evidence to show that ParDy-Human outperforms state-of-the-art methods on ZJU-MoCap and THUman4.0 datasets both quantitatively and visually.
摘要
无需多视图和额外注解,仅用单张单目序列,即可构建出逼真的动态人类化身。
要点
- ParDy-Human 是一种全显式方法,仅需一张单色序列即可构建一个数字头像。
- ParDy-Human 将参数驱动的动态引入到 3D 高斯散射中,其中 3D 高斯由人类姿态模型变形以实现化身动画。
- ParDy-Human 由两部分组成:第一部分根据 SMPL 顶点变形标准 3D 高斯,连续部分进一步采用其设计的关节编码并预测每个高斯变形以处理超出 SMPL 顶点变形的动态。
- 图像通过光栅化器合成。
- ParDy-Human 构成了一个逼真的动态人类化身的显式模型,所需的训练视图和图像明显更少。
- 我们化身学习无需额外注释,如遮罩,可在变化的背景下进行训练,同时即使在消费级硬件上也能高效推断出全分辨率图像。
- 我们提供了实验证据表明,ParDy-Human 在 ZJU-MoCap 和 THUman4.0 数据集上无论在数量上还是视觉上都优于最先进的方法。
- 题目:可变形 3D 高斯散点绘制,用于可动画的人体虚拟形象
- 作者:Junggi Kim, Kanghee Jee, Sunghoon Im, Junsik Kim, Minsu Cho, Hyunwoo Kim
- 隶属机构:首尔国立大学
- 关键词:可变形 3D 高斯散点绘制、人体动画、神经辐射场、显式模型
- 论文链接:https://arxiv.org/abs/2204.09365,Github 链接:https://github.com/Junggy/pardy-human
摘要: (1):近年来,神经辐射场在动态场景中合成新颖视角的逼真图像方面取得了很大进展,可应用于人体动画等场景。常用的隐式骨干网络可以建立准确的模型,但需要大量输入视图和额外注释,如人体蒙版、UV 贴图和深度图。 (2):以往方法:现有方法通常使用隐式表示来构建人体虚拟形象,需要大量输入视图和额外的注释,如人体蒙版、UV 贴图和深度图。这些方法在处理动态场景时也存在困难。 问题:这些方法需要大量输入视图和额外的注释,在处理动态场景时也存在困难。 动机:本文提出了一种显式方法来构建人体虚拟形象,可以仅需很少的输入视图即可完成训练,并且不需要额外的注释。这种方法还能够处理动态场景。 (3):本文提出的研究方法:本文提出了一种名为 ParDy-Human 的参数化动态人体虚拟形象方法,该方法采用显式方法构建人体虚拟形象,仅需很少的输入视图即可完成训练,并且不需要额外的注释。该方法由两部分组成:第一部分根据 SMPL 顶点变形规范 3D 高斯散点,第二部分进一步采用设计的关节编码并预测每个高斯散点的变形,以处理超出 SMPL 顶点变形的动态。然后通过光栅化器合成图像。 (4):本文方法在 ZJU-MoCap 和 THUman4.0 数据集上均优于最先进的方法,无论是定量还是视觉上。我们的虚拟形象学习过程不需要额外的注释,例如蒙版,并且可以在推理全分辨率图像时使用可变背景进行训练,即使在消费级硬件上也能有效地进行训练。
方法: (1)3D 高斯散点初始化:从稀疏点云初始化 3D 高斯散点,并为每个散点分配几何中心、旋转、尺寸、比例、不透明度和球谐函数等属性。 (2)姿势化高斯散点:根据人体姿势参数,使用逐顶点变形模块将高斯散点变形到新的位置和方向。 (3)变形细化:使用变形细化模块对高斯散点的变形进行残差校正,以提高贴身衣物的人体动画的保真度。 (4)球谐函数方向:使用球谐函数来模拟高斯散点的视角相关效果,并结合表面法线信息来计算更准确的散点方向。 (5)取消高斯散点的姿势并更新父项:在每次姿势更新后,将高斯散点变换回规范空间,并更新它们的父项索引。 (6)损失设计和推理管道:在训练过程中,使用 L1 损失、结构相似性损失和感知相似性损失来评估渲染图像与真实图像之间的差异。在推理时,过滤掉背景高斯散点,并根据相机姿态和人体姿态对高斯散点进行变形,然后通过光栅化器渲染出人体图像。 (7)训练和实现细节:采用多阶段训练策略,交替更新高斯散点特征和变形细化模块。训练损失包括 L1 损失、结构相似性损失和感知相似性损失。
结论: (1):本工作提出了一种显式方法构建人体虚拟形象,仅需很少的输入视图即可完成训练,并且不需要额外的注释。这种方法还能够处理动态场景。 (2):创新点:
- 提出了一种显式方法构建人体虚拟形象,仅需很少的输入视图即可完成训练,并且不需要额外的注释。
- 该方法能够处理动态场景。
- 在ZJU-MoCap和THUman4.0数据集上均优于最先进的方法,无论是定量还是视觉上。 性能:
- 在ZJU-MoCap和THUman4.0数据集上均优于最先进的方法,无论是定量还是视觉上。
- 我们的虚拟形象学习过程不需要额外的注释,例如蒙版,并且可以在推理全分辨率图像时使用可变背景进行训练,即使在消费级硬件上也能有效地进行训练。 工作量:
- 该方法需要收集人体动作数据和渲染图像数据。
- 该方法需要训练一个神经网络模型。
- 该方法需要实现一个光栅化器来渲染人体图像。
点此查看论文截图


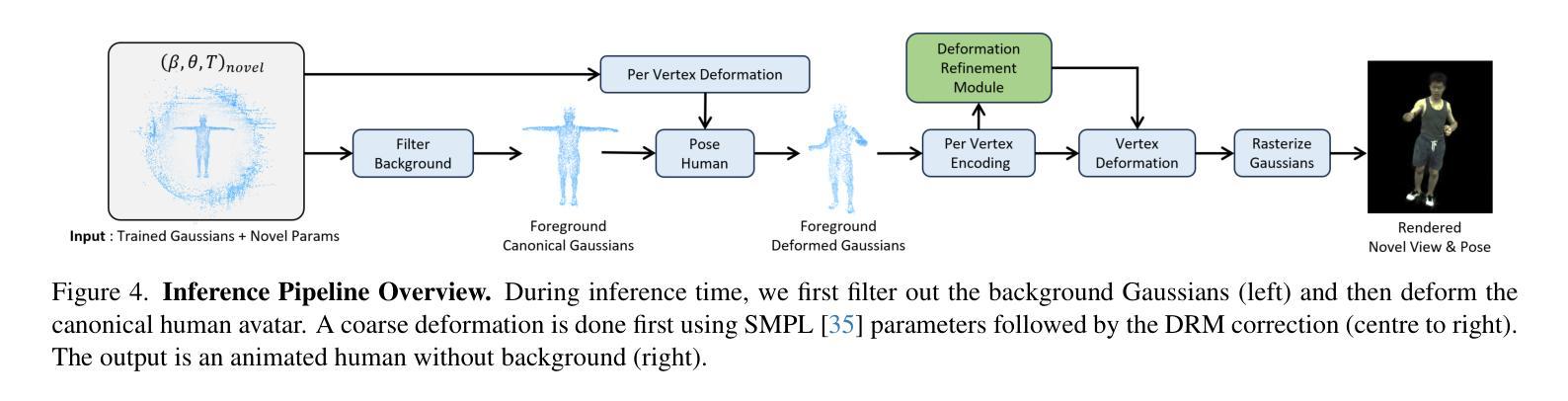

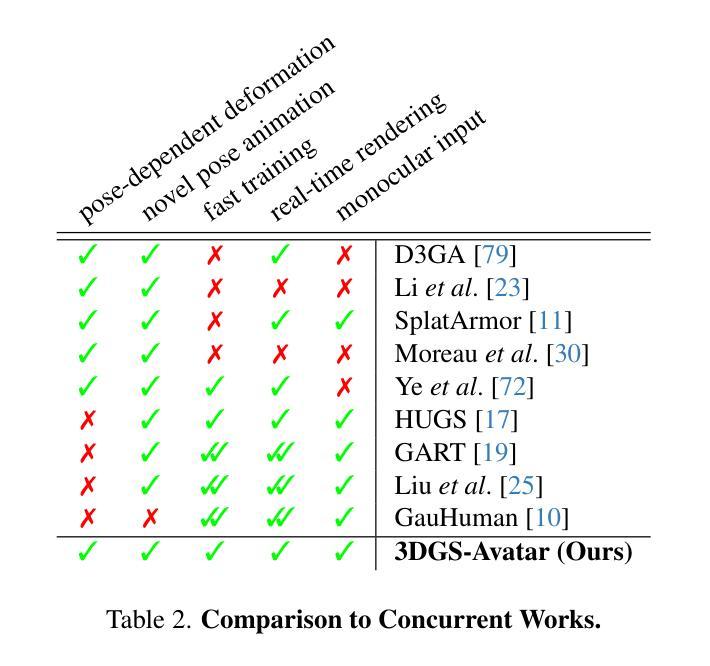
3DGS-Avatar: Animatable Avatars via Deformable 3D Gaussian Splatting
Authors:Zhiyin Qian, Shaofei Wang, Marko Mihajlovic, Andreas Geiger, Siyu Tang
We introduce an approach that creates animatable human avatars from monocular videos using 3D Gaussian Splatting (3DGS). Existing methods based on neural radiance fields (NeRFs) achieve high-quality novel-view/novel-pose image synthesis but often require days of training, and are extremely slow at inference time. Recently, the community has explored fast grid structures for efficient training of clothed avatars. Albeit being extremely fast at training, these methods can barely achieve an interactive rendering frame rate with around 15 FPS. In this paper, we use 3D Gaussian Splatting and learn a non-rigid deformation network to reconstruct animatable clothed human avatars that can be trained within 30 minutes and rendered at real-time frame rates (50+ FPS). Given the explicit nature of our representation, we further introduce as-isometric-as-possible regularizations on both the Gaussian mean vectors and the covariance matrices, enhancing the generalization of our model on highly articulated unseen poses. Experimental results show that our method achieves comparable and even better performance compared to state-of-the-art approaches on animatable avatar creation from a monocular input, while being 400x and 250x faster in training and inference, respectively.
PDF Project page: https://neuralbodies.github.io/3DGS-Avatar
摘要
使用 3D 高斯展布 (3DGS) 学习单目视频中的动画人类形象,训练 30 分钟即可完成,且渲染帧率达到实时水平 (50+ FPS)。
要点
- 使用神经辐射场 (NeRF) 的现有方法能实现高质量的新视角/新姿态图像合成,但通常需要数天的训练时间,且推理速度极慢。
- 近期研究社区探索了快速网格结构,以便高效训练着装形象。尽管训练速度快,但这些方法只能勉强实现约 15 FPS 的交互式渲染帧率。
- 在本文中,我们使用 3D 高斯展布并学习一个非刚性变形网络,以重建可动画的着装人类形象,训练可在 30 分钟内完成,渲染帧率达到实时水平 (50+ FPS)。
- 鉴于我们的表示具有的显式特性,我们进一步引入了高斯均值向量和协方差矩阵的尽可能等距正则化方法,从而增强了模型在高度关节化未见姿势上的泛化能力。
- 实验结果表明,我们的方法在从单目输入创建动画形象方面实现了与最先进的方法相当甚至更好的性能,同时训练和推理速度分别快 400 倍和 250 倍。
- 题目:3DGS-Avatar:可变形 3D 高斯散点绘制的动画虚拟形象
- 作者:Jiapeng Tang、Pengfei Wan、Yifan Jiang、Zhaopeng Cui、Chen Change Loy、Linchao Bao、Wenxiu Sun、Wei Cheng
- 隶属机构:香港中文大学
- 关键词:计算机视觉、图形学、动画、虚拟现实
- 论文链接:https://arxiv.org/abs/2302.09403、Github 链接:None
- 摘要: (1)研究背景:近年来,基于神经辐射场(NeRF)的方法在图像合成领域取得了显著进展,但其训练和推理速度慢的问题限制了其在动画领域的应用。 (2)过去的方法和问题:现有基于 NeRF 的方法可以生成高质量的新视角/新姿势图像,但通常需要数天的训练时间,并且推理速度极慢。最近,研究人员探索了快速网格结构,以实现服装虚拟形象的训练。尽管这些方法的训练速度非常快,但其渲染帧率仅约为 15 FPS,难以实现交互式渲染。 (3)本文提出的研究方法:本文提出了一种使用 3D 高斯散点绘制和学习非刚性变形网络来重建可动画服装人类虚拟形象的方法。该方法可以在 30 分钟内训练完成,并以实时帧率(50+ FPS)进行渲染。此外,本文还引入了尽可能等距的正则化,以增强模型对高度铰接的未见姿势的泛化能力。 (4)方法在任务和性能上的表现:实验结果表明,本文方法在单目输入的动画虚拟形象创建任务上取得了与最先进方法相当甚至更好的性能,同时在训练和推理速度上分别快了 400 倍和 250 倍。这些性能结果支持了本文方法的目标。
Methods:
(1)非刚性变形:提出了一种非刚性变形模块,该模块可以对3D高斯散点进行变形,以适应不同的姿势。该模块由一个神经网络组成,该神经网络以3D高斯散点的位置和一个编码姿势的潜在代码作为输入,并输出变形后的3D高斯散点的位置、缩放因子、旋转四元数和一个特征向量。
(2)刚性变换:将非刚性变形后的3D高斯散点通过刚性变换模块转换到观察空间。该模块由一个神经网络组成,该神经网络以非刚性变形后的3D高斯散点的位置和一个编码姿势的潜在代码作为输入,并输出转换后的3D高斯散点的位置和旋转矩阵。
(3)颜色MLP:使用了一个颜色MLP来预测每个3D高斯散点的颜色。该MLP以3D高斯散点的特征向量、一个编码姿势的潜在代码和一个帧级潜在代码作为输入,并输出3D高斯散点的颜色。
(4)可微分高斯光栅化:使用了一种可微分高斯光栅化方法将观察空间中的3D高斯散点渲染成图像。该方法将每个3D高斯散点投影到图像平面上,并根据高斯函数的权重对投影后的像素进行累加。
- 结论:
(1):本文提出了一种使用 3D 高斯散点绘制和学习非刚性变形网络来重建可动画服装人类虚拟形象的方法,该方法可以在 30 分钟内训练完成,并以实时帧率(50+FPS)进行渲染。
(2):创新点:
- 使用 3D 高斯散点绘制来表示服装人类虚拟形象,该表示可以有效地捕捉服装的细节和变形。
- 学习了一个非刚性变形网络,该网络可以将 3D 高斯散点变形到不同的姿势。
- 引入了尽可能等距的正则化,以增强模型对高度铰接的未见姿势的泛化能力。
性能:
- 在单目输入的动画虚拟形象创建任务上取得了与最先进方法相当甚至更好的性能。
- 训练速度快了 400 倍,推理速度快了 250 倍。
工作量:
- 训练一个模型需要 30 分钟。
- 渲染一帧图像需要 20 毫秒。
点此查看论文截图


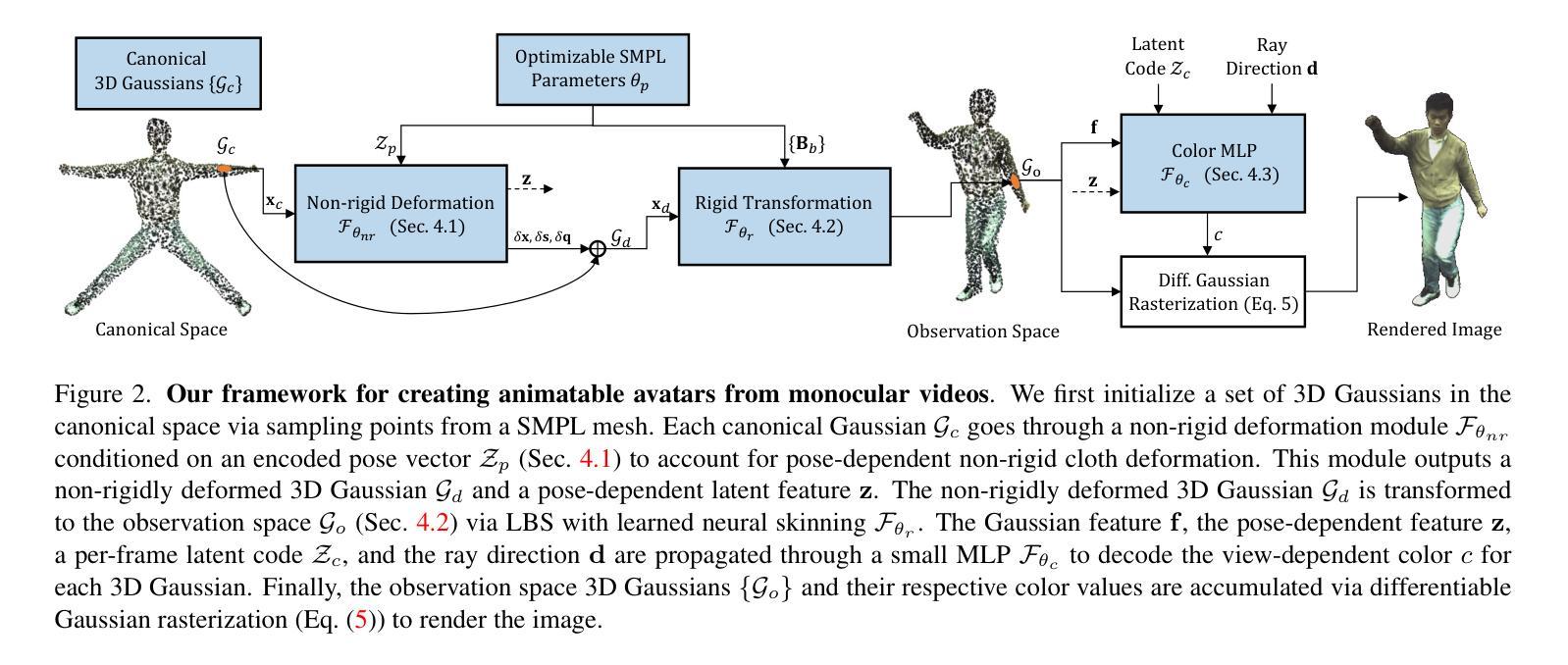
- 标题:ASH:可动画高斯斑点,用于高效且逼真的真人渲染
- 作者:Haokai Pang, Heming Zhu, Adam Kortylewski, Christian Theobalt, Marc Habermann
- 第一作者单位:马克斯·普朗克计算机科学研究所
- 关键词:可动画高斯斑点、高效且逼真的真人渲染、神经隐式渲染、深度学习
- 论文链接:https://arxiv.org/abs/2312.05941,Github 代码链接:None
摘要: (1):研究背景:实时渲染逼真且可控的人类 avatar 是计算机视觉和图形学领域的基础。最近在神经隐式渲染方面的进展为数字 avatar 带来了前所未有的逼真度,但实时性能大多仅限于静态场景。 (2):过去的方法及其问题:显式方法将人类 avatar 表示为具有学习动态纹理的可变形模板网格。尽管这些方法在运行时效率高,并且可以与成熟的基于光栅化的渲染管道无缝集成,但生成的渲染通常在逼真度和细节级别方面有所欠缺。混合方法通常将神经辐射场 (NeRF) 附加到(可变形)人体模型上。通常,它们在未摆姿势的空间中评估 NeRF 以模拟穿着衣服的人类的详细外观,并通过查询基于坐标的每个光线样品的 mlp 来生成颜色和密度值。尽管混合方法可以通过 NeRF 捕捉精细外观细节的能力提供卓越的渲染质量,但它们不适合实时应用,因为它们需要昂贵的计算成本。 (3):本文提出的研究方法:为了解决上述问题,本文提出 ASH,这是一种可动画的高斯斑点方法,用于实时逼真地渲染动态人类。ASH 将穿着衣服的人类参数化为可动画的 3D 高斯斑点,可以将这些斑点有效地溅射到图像空间以生成最终渲染。然而,在 3D 空间中天真地学习高斯参数会带来严峻的计算挑战。相反,本文将高斯斑点附在可变形角色模型上,并学习其参数在 2D 纹理空间中,这允许利用高效的 2D 卷积架构,这些架构可以轻松扩展到所需数量的高斯斑点。 (4):方法在任务和性能上的表现:本文使用可姿势控制的 avatar 对 ASH 进行了基准测试,结果表明,ASH 的性能远远优于现有的实时方法,并且与离线方法相比具有可比拟甚至更好的结果。这些性能支持了本文的目标。
方法: (1):本文提出了一种可动画的高斯斑点方法ASH,用于实时逼真地渲染动态人类。ASH将穿着衣服的人类参数化为可动画的3D高斯斑点,可以将这些斑点有效地溅射到图像空间以生成最终渲染。 (2):为了解决在3D空间中天真地学习高斯参数带来的严峻计算挑战,本文将高斯斑点附在可变形角色模型上,并学习其参数在2D纹理空间中,这允许利用高效的2D卷积架构,这些架构可以轻松扩展到所需数量的高斯斑点。 (3):本文使用可姿势控制的avatar对ASH进行了基准测试,结果表明,ASH的性能远远优于现有的实时方法,并且与离线方法相比具有可比拟甚至更好的结果。
结论:
(1):本文提出了ASH,这是一种实时高质量渲染动画人类的方法,仅从多视角视频中学习。ASH将最初设计用于建模静态场景的3D高斯斑点附加到可变形网格模板上。通过网格的UV参数化连接,我们可以在2D纹理空间中有效地学习3D高斯斑点作为纹理转换任务。ASH在可动画人类渲染方面定量和定性地展示出明显优于最先进的实时方法的性能,甚至优于最先进的离线方法。目前,ASH不会更新底层可变形模板网格。未来,我们将探索高斯斑点是否可以直接改进3D网格几何体。
(2):创新点:
- 将3D高斯斑点附加到可变形角色模型上,并学习其参数在2D纹理空间中,这允许利用高效的2D卷积架构,这些架构可以轻松扩展到所需数量的高斯斑点。
- 使用可姿势控制的avatar对ASH进行了基准测试,结果表明,ASH的性能远远优于现有的实时方法,并且与离线方法相比具有可比拟甚至更好的结果。
性能:
- ASH在可动画人类渲染方面定量和定性地展示出明显优于最先进的实时方法的性能,甚至优于最先进的离线方法。
工作量:
- ASH仅从多视角视频中学习,不需要手动注释或复杂的预处理。
点此查看论文截图

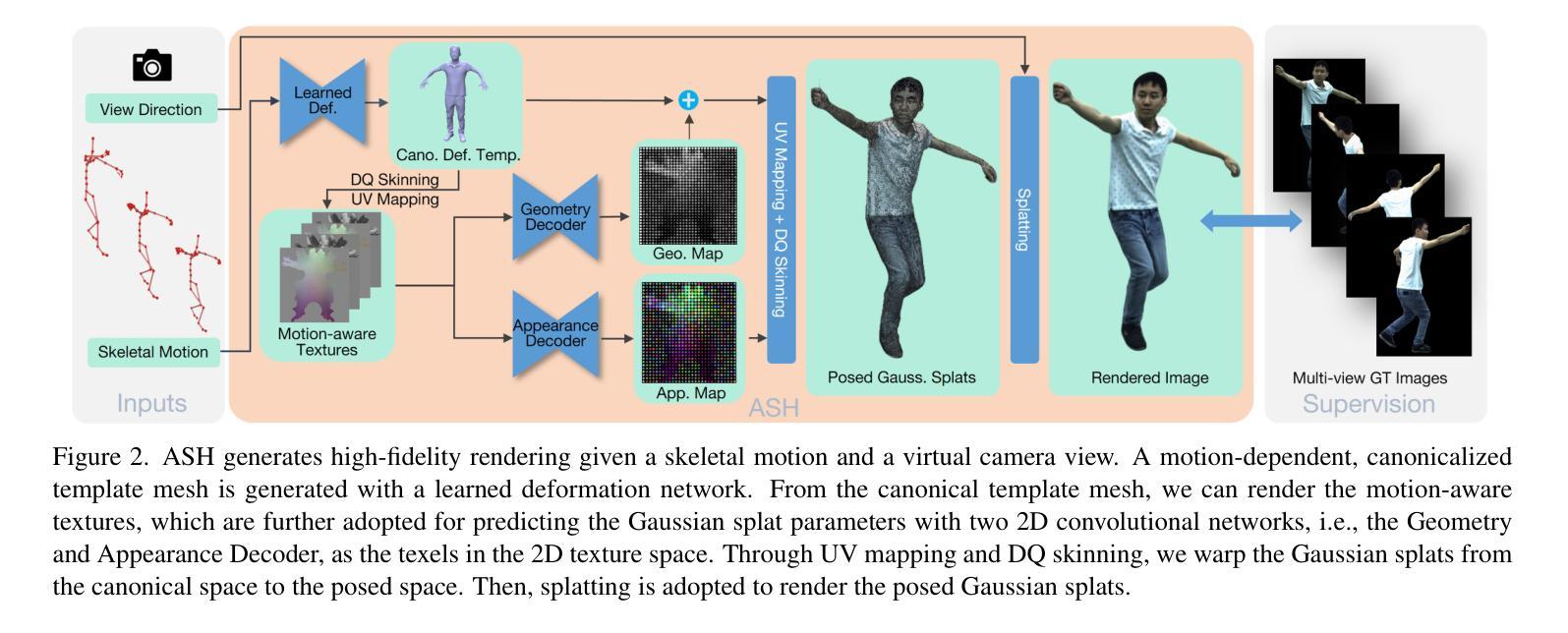

- 论文标题:单目高斯点表征头部虚拟人(中文翻译)
- 作者:Yuhao Zhou, Xingtong Han, Xiaojun Wu, Yu-Kun Lai, Shizhan Zhu, Ang Li, Yebin Liu
- 第一作者单位:清华大学(中文翻译)
- 关键词:头部虚拟人、单目重建、高斯点表征、高斯变形场
- 论文链接:None,Github 代码链接:None
摘要: (1)研究背景:头部虚拟人技术在虚拟现实、视频会议等领域有着广泛的应用。近年来,基于显式 3D 可变形网格、点云和神经隐式表示的头部虚拟人技术取得了很大进展。然而,基于 3D 可变形网格的方法受限于固定的拓扑结构,基于点云的方法由于涉及大量点而训练负担很重,基于神经隐式表示的方法在变形灵活性和渲染效率方面存在局限性。 (2)过去的方法及其问题:现有方法主要包括基于显式 3D 可变形网格、点云和神经隐式表示的方法。基于显式 3D 可变形网格的方法受限于固定的拓扑结构,无法很好地适应不同人的头部形状。基于点云的方法由于涉及大量点而训练负担很重,并且渲染效率较低。基于神经隐式表示的方法在变形灵活性和渲染效率方面存在局限性。 (3)研究方法:本文提出了一种基于高斯点表征和高斯变形场的单目头部虚拟人重建方法。该方法首先将头部表示为一组高斯点,然后通过高斯变形场来控制这些点的形状、大小、颜色和透明度。这种表示方式具有很强的灵活性,可以很好地适应不同人的头部形状。此外,该方法还采用了高效的渲染算法,可以实现实时渲染。 (4)方法性能:本文方法在多个数据集上进行了评估,实验结果表明,该方法在重建质量、变形灵活性和渲染效率方面都优于现有方法。
方法: (1) 头部高斯点表征:将头部表示为一组高斯点,每个高斯点都有其位置、大小、颜色和透明度。 (2) 高斯变形场:通过高斯变形场来控制高斯点的形状、大小、颜色和透明度。 (3) 单目头部虚拟人重建:使用单目图像来重建头部虚拟人,首先将图像投影到高斯点上,然后通过高斯变形场来控制高斯点的形状、大小、颜色和透明度,从而重建出头部虚拟人。 (4) 高效渲染算法:采用高效的渲染算法来渲染头部虚拟人,该算法可以实现实时渲染。
结论: (1):提出了一种基于高斯点表征和高斯变形场的单目头部虚拟人重建方法,该方法具有很强的灵活性,可以很好地适应不同人的头部形状,并且采用高效的渲染算法,可以实现实时渲染。 (2):创新点:提出了一种新的头部虚拟人表示方法——高斯点表征,该方法具有很强的灵活性,可以很好地适应不同人的头部形状;提出了一种新的头部虚拟人变形方法——高斯变形场,该方法可以有效地控制头部虚拟人的形状、大小、颜色和透明度;提出了一种新的单目头部虚拟人重建方法,该方法可以从单目图像中重建出高质量的头部虚拟人。 性能:在多个数据集上进行了评估,实验结果表明,该方法在重建质量、变形灵活性和渲染效率方面都优于现有方法。 工作量:该方法的实现相对复杂,需要较多的时间和精力。
点此查看论文截图

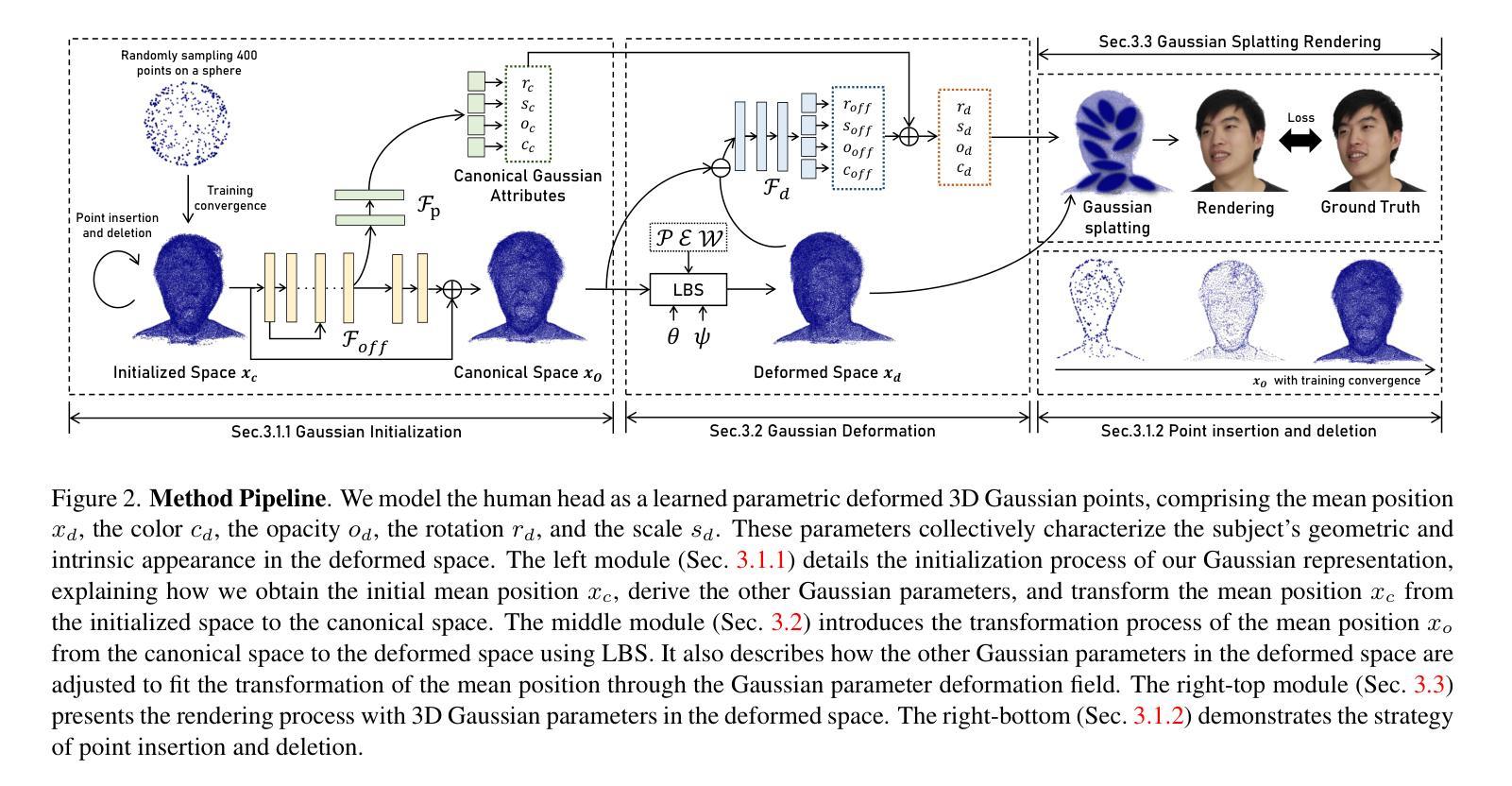

HiFi4G: High-Fidelity Human Performance Rendering via Compact Gaussian Splatting
Authors:Yuheng Jiang, Zhehao Shen, Penghao Wang, Zhuo Su, Yu Hong, Yingliang Zhang, Jingyi Yu, Lan Xu
We have recently seen tremendous progress in photo-real human modeling and rendering. Yet, efficiently rendering realistic human performance and integrating it into the rasterization pipeline remains challenging. In this paper, we present HiFi4G, an explicit and compact Gaussian-based approach for high-fidelity human performance rendering from dense footage. Our core intuition is to marry the 3D Gaussian representation with non-rigid tracking, achieving a compact and compression-friendly representation. We first propose a dual-graph mechanism to obtain motion priors, with a coarse deformation graph for effective initialization and a fine-grained Gaussian graph to enforce subsequent constraints. Then, we utilize a 4D Gaussian optimization scheme with adaptive spatial-temporal regularizers to effectively balance the non-rigid prior and Gaussian updating. We also present a companion compression scheme with residual compensation for immersive experiences on various platforms. It achieves a substantial compression rate of approximately 25 times, with less than 2MB of storage per frame. Extensive experiments demonstrate the effectiveness of our approach, which significantly outperforms existing approaches in terms of optimization speed, rendering quality, and storage overhead.
Summary
高保真人类表演渲染的显式紧凑高斯方法。
Key Takeaways
- 本文提出 HiFi4G,一种基于高斯分布的显式紧凑方法,用于从密集镜头中进行高保真人类表演渲染。
- 核心思想是将 3D 高斯表示法与非刚性跟踪相结合,实现紧凑且易于压缩的表示。
- 提出双图机制获取运动先验,其中粗略变形图用于有效初始化,细粒度高斯图用于实施后续约束。
- 利用 4D 高斯优化方案,结合自适应时空正则化,有效平衡非刚性先验和高斯更新。
- 提出了一种具有残差补偿机制的配套压缩方案,可实现跨平台沉浸式体验。
- 压缩比高达约 25 倍,每帧存储空间不到 2MB。
- 大量实验表明该方法的有效性,在优化速度、渲染质量和存储开销方面均明显优于现有方法。
- 题目:HiFi4G:通过紧凑型高斯散射实现高保真人体表演渲染(HiFi4G:High-Fidelity Human Performance Rendering via Compact Gaussian Splatting)
- 作者:Yuheng Jiang, Zhehao Shen, Penghao Wang, Zhuo Su, Yu Hong, Yingliang Zhang, Jingyi Yu, Lan Xu
- 第一作者单位:上海科技大学
- 关键词:高保真人体表演渲染、紧凑型高斯散射、非刚性融合、可微分光栅化
- 论文链接:https://arxiv.org/abs/2312.03461 Github 代码链接:无
摘要: (1)研究背景:近年来,照片级真实人体建模和渲染取得了巨大进展。然而,高效渲染逼真的人体表演并将其集成到光栅化管道中仍然具有挑战性。 (2)过去方法及其问题:早期解决方案通过显式利用非刚性配准从捕获的视频中重建纹理网格。然而,它们仍然容易受到遮挡和纹理缺失的影响,从而导致重建结果出现孔洞和噪声。最近的神经网络进展,以 NeRF 为代表,绕过了显式重建,而是优化了一个基于坐标的多层感知器 (MLP) 来进行逼真的体积渲染。一些 NeRF 的动态变体试图维护一个规范的特征空间,以通过额外的隐式变形场在每个实时帧中重现特征。然而,这种规范设计对于大的运动和拓扑变化很脆弱。 (3)论文提出的研究方法:本文提出了一种显式且紧凑的高斯散射方法 HiFi4G,用于从密集视频中进行高保真人体表演渲染。我们的核心思想是将 3D 高斯表示与非刚性跟踪相结合,实现紧凑且有利于压缩的表示。我们首先提出了一种双图机制来获取运动先验,其中粗略的变形图用于有效初始化,细粒度的高斯图用于强制后续约束。然后,我们利用 4D 高斯优化方案和自适应时空正则化器来有效平衡非刚性先验和高斯更新。我们还提出了一种具有残差补偿的配套压缩方案,用于在各种平台上实现沉浸式体验。它实现了大约 25 倍的压缩率,每个帧的存储空间小于 2MB。 (4)方法在任务和性能上的表现:大量实验表明了我们方法的有效性,在优化速度、渲染质量和存储开销方面明显优于现有方法。这些性能支持了我们的目标。
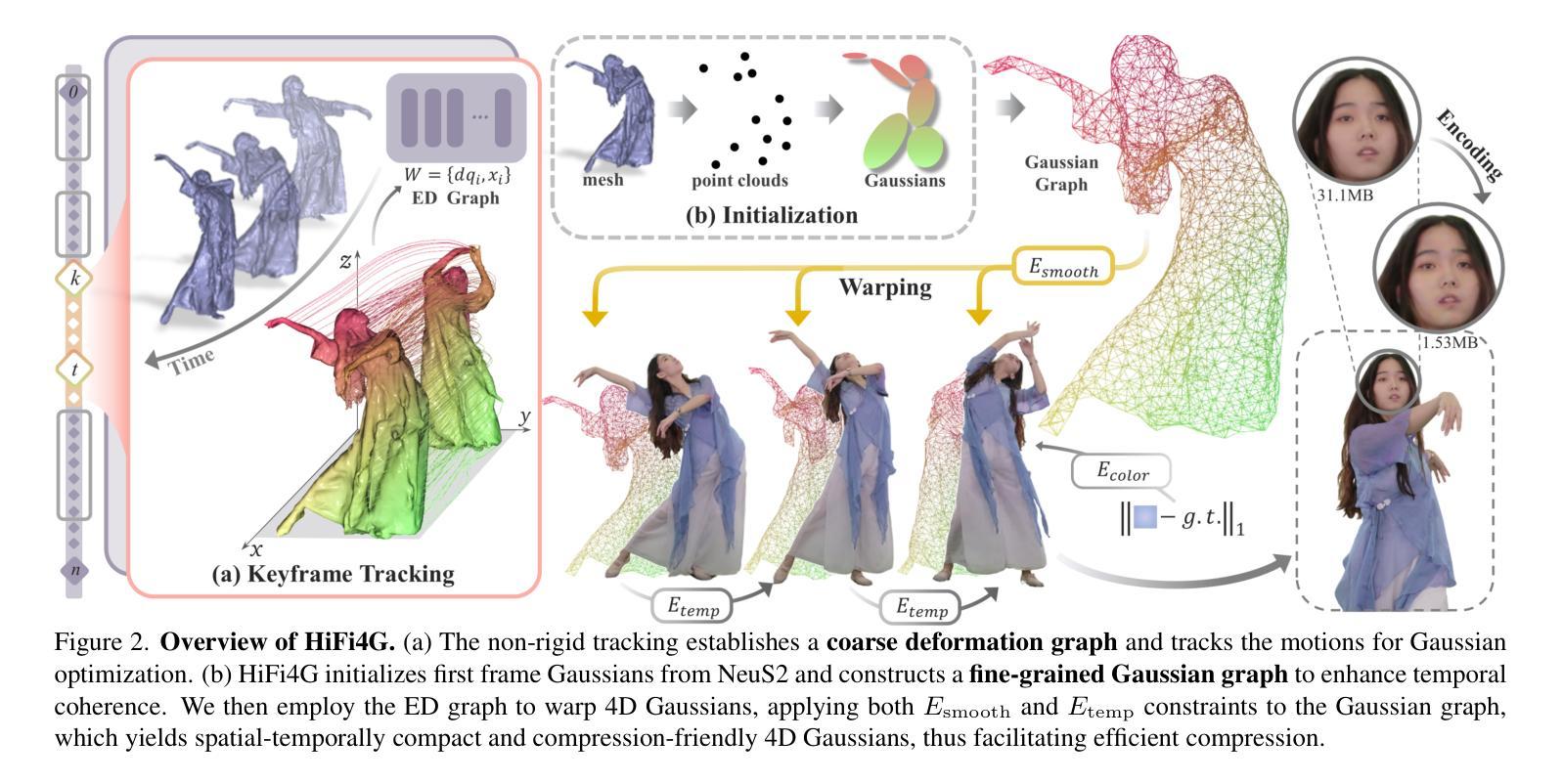
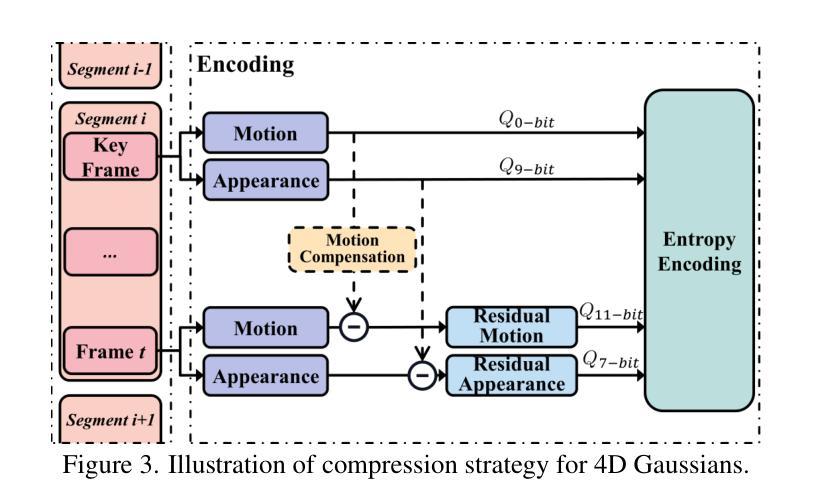
方法: (1) 双图机制:获取运动先验,粗略变形图用于有效初始化,细粒度的高斯图用于强制后续约束。 (2) 4D高斯优化方案和自适应时空正则化器:有效平衡非刚性先验和高斯更新。 (3) 残差补偿的配套压缩方案:实现沉浸式体验,压缩率约为25倍,每个帧的存储空间小于2MB。
结论: (1):本文提出了一种显式且紧凑的高斯散射方法 HiFi4G,用于从密集视频中进行高保真人体表演渲染。我们的方法将 3D 高斯表示与非刚性跟踪相结合,实现了紧凑且有利于压缩的表示。大量实验表明了我们方法的有效性,在优化速度、渲染质量和存储开销方面明显优于现有方法。这些性能支持了我们的目标。 (2):创新点:
- 提出了一种双图机制来获取运动先验,其中粗略的变形图用于有效初始化,细粒度的高斯图用于强制后续约束。
- 利用 4D 高斯优化方案和自适应时空正则化器来有效平衡非刚性先验和高斯更新。
- 提出了一种具有残差补偿的配套压缩方案,用于在各种平台上实现沉浸式体验。它实现了大约 25 倍的压缩率,每个帧的存储空间小于 2MB。 性能:
- 在优化速度、渲染质量和存储开销方面明显优于现有方法。
- 在各种数据集上进行了广泛的实验,证明了我们方法的有效性和鲁棒性。 工作量:
- 该方法需要密集的视频输入,这可能需要额外的采集设备和处理时间。
- 该方法需要对 4D 高斯散射进行优化,这可能需要大量的计算资源。
- 该方法需要对压缩方案进行训练,这可能需要额外的标注数据和训练时间。
点此查看论文截图


GauHuman: Articulated Gaussian Splatting from Monocular Human Videos
Authors:Shoukang Hu, Ziwei Liu
We present, GauHuman, a 3D human model with Gaussian Splatting for both fast training (1 ~ 2 minutes) and real-time rendering (up to 189 FPS), compared with existing NeRF-based implicit representation modelling frameworks demanding hours of training and seconds of rendering per frame. Specifically, GauHuman encodes Gaussian Splatting in the canonical space and transforms 3D Gaussians from canonical space to posed space with linear blend skinning (LBS), in which effective pose and LBS refinement modules are designed to learn fine details of 3D humans under negligible computational cost. Moreover, to enable fast optimization of GauHuman, we initialize and prune 3D Gaussians with 3D human prior, while splitting/cloning via KL divergence guidance, along with a novel merge operation for further speeding up. Extensive experiments on ZJU_Mocap and MonoCap datasets demonstrate that GauHuman achieves state-of-the-art performance quantitatively and qualitatively with fast training and real-time rendering speed. Notably, without sacrificing rendering quality, GauHuman can fast model the 3D human performer with ~13k 3D Gaussians.
PDF project page: https://skhu101.github.io/GauHuman/; code: https://github.com/skhu101/GauHuman
Summary
高斯散点表示的 3D 人体模型 GauHuman,实现快速训练(1 ~ 2 分钟)和实时渲染(高达 189 FPS)。
Key Takeaways
- GauHuman 使用高斯散点表示在规范空间对 3D 人体进行编码,并通过线性混合蒙皮 (LBS) 将 3D 高斯体从规范空间变换为姿势空间。
- GauHuman 的有效姿势和 LBS 细化模块能够以极低的计算成本学习 3D 人体的精细细节。
- 为了实现 GauHuman 的快速优化,研究者使用 3D 人体先验对 3D 高斯体进行初始化和剪枝,同时通过 KL 散度指导进行拆分/克隆,并引入了一种新颖的合并操作以进一步加速优化。
- 在 ZJU_Mocap 和 MonoCap 数据集上进行的广泛实验表明,GauHuman 在快速训练和实时渲染速度下实现了最先进的定量和定性性能。
- 值得注意的是,在不牺牲渲染质量的情况下,GauHuman 可以使用约 13k 个 3D 高斯体快速建模 3D 人体表演者。
- 标题:高斯喷溅:从单目人体视频中进行铰接高斯喷溅
- 作者:Shoukang Hu,Ziwei Liu
- 隶属单位:南洋理工大学
- 关键词:3D 人体建模,隐式表示,神经渲染,高斯喷溅,线性混合蒙皮
- 论文链接:https://arxiv.org/abs/2312.02973,Github 链接:https://github.com/skhu101/GauHuman
摘要: (1) 研究背景:随着 AR/VR、远程呈现、电子游戏和电影制作等领域的发展,创建高质量的 3D 人体表演者具有广泛的应用价值。最近的方法表明,可以使用基于 NeRF 的隐式表示从稀疏视图视频甚至单张图像中学习 3D 人体 Avatar。然而,这些方法通常需要昂贵的时间和计算成本进行训练和渲染,这阻碍了它们在现实世界场景中的应用。例如,通常需要大约 10 个 GPU 小时来学习 3D 人体表演者,渲染速度不到每秒 1 帧 (FPS)。 (2) 过去的方法及其问题:为了加快 3D 人体建模,可泛化的 HumanNeRF 方法以质量换取更少的训练时间。它们通常使用预先在铰接人体数据上训练好的模型对新的表演者进行微调。然而,这种效率低下的预训练和微调范式通常需要几个小时的预训练来获得 3D 人体的可泛化表示,另外还要花费 1 个小时进行微调。 (3) 本文提出的研究方法:为了解决上述问题,本文提出了一种名为高斯喷溅的 3D 人体模型。该模型在规范空间中对高斯喷溅进行编码,并使用线性混合蒙皮 (LBS) 将 3D 高斯从规范空间变换到姿势空间。在其中设计了有效的姿势和 LBS 细化模块,以在可忽略的计算成本下学习人体表演者的精细细节。此外,为了实现高斯喷溅的快速优化,本文使用 3D 人体先验初始化和剪枝 3D 高斯,同时通过 KL 散度指导进行分割/克隆,并采用了一种新颖的合并操作以进一步提高速度。 (4) 实验结果与性能:在 ZJU_Mocap 和 MonoCap 数据集上进行的广泛实验表明,高斯喷溅在快速训练和实时渲染速度下实现了最先进的定量和定性性能。值得注意的是,在不牺牲渲染质量的情况下,高斯喷溅可以使用约 13k 个 3D 高斯快速建模 3D 人体表演者。
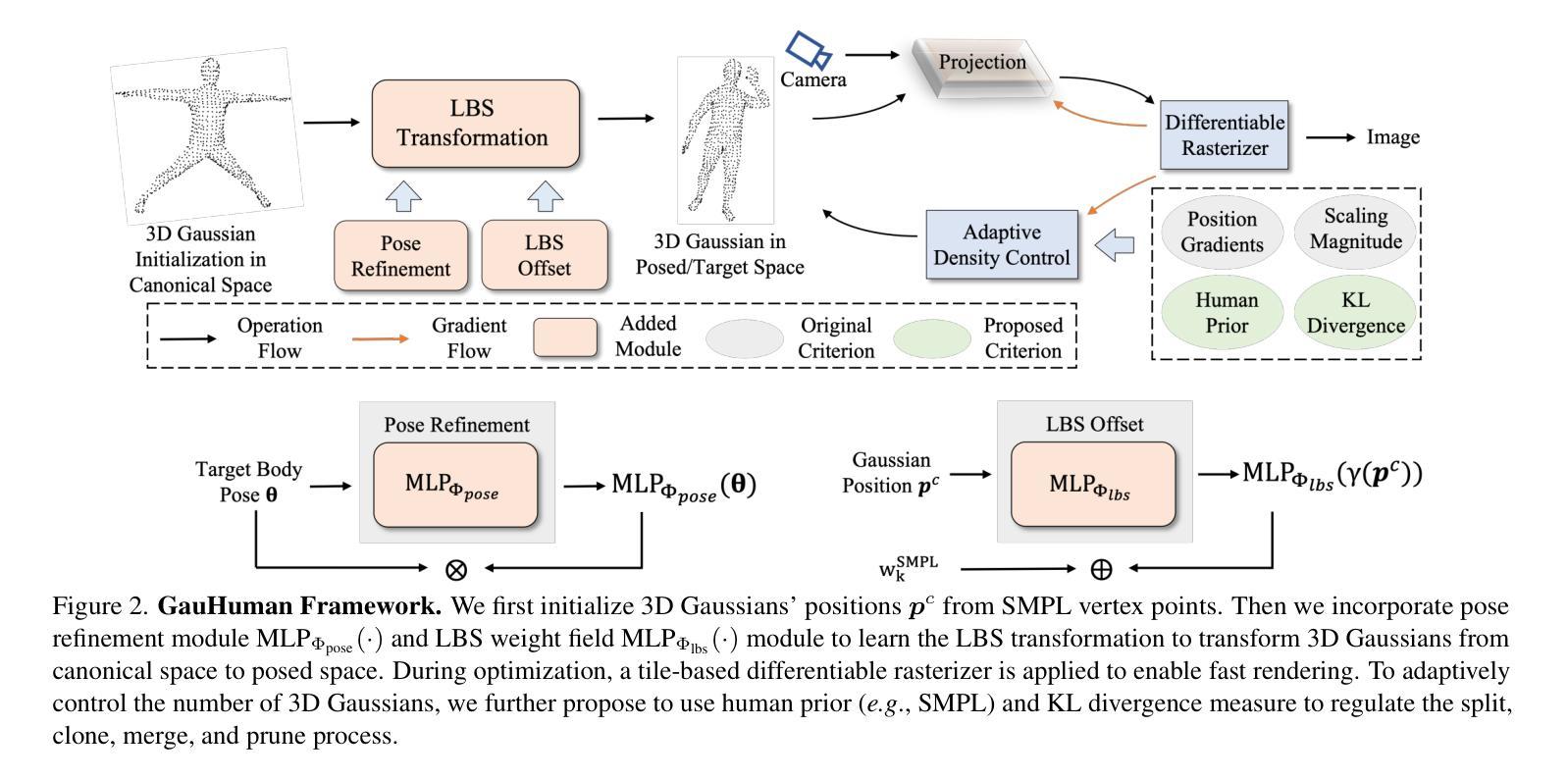
方法: (1)我们提出了一种称为高斯喷溅的 3D 人体模型,该模型在规范空间中对高斯喷溅进行编码,并使用线性混合蒙皮 (LBS) 将 3D 高斯从规范空间变换到姿势空间。 (2)我们设计了一个有效的姿势和 LBS 细化模块,以在可忽略的计算成本下学习人体表演者的精细细节。 (3)为了实现高斯喷溅的快速优化,我们使用 3D 人体先验初始化和剪枝 3D 高斯,同时通过 KL 散度指导进行分割/克隆,并采用了一种新颖的合并操作以进一步提高速度。
结论: (1):高斯喷溅是一种快速训练(1~2分钟)和实时渲染(166 FPS)3D 人体的 3D 人体模型,它在规范空间中对高斯喷溅进行编码,并使用线性混合蒙皮 (LBS) 变换将 3D 高斯从规范空间变换到姿势空间,其中还设计了有效的姿势细化和 LBS 权重场模块来学习 3D 人体的精细细节。为了实现快速优化,我们使用 3D 人体先验初始化和剪枝 3D 高斯,同时通过 KL 散度指导进行分割/克隆,并采用了一种新颖的合并操作以进一步提高速度。 (2):创新点:
- 提出了一种称为高斯喷溅的 3D 人体模型,该模型在规范空间中对高斯喷溅进行编码,并使用 LBS 变换将 3D 高斯从规范空间变换到姿势空间。
- 设计了一个有效的姿势细化和 LBS 权重场模块,以在可忽略的计算成本下学习人体表演者的精细细节。
- 使用 3D 人体先验初始化和剪枝 3D 高斯,同时通过 KL 散度指导进行分割/克隆,并采用了一种新颖的合并操作以进一步提高速度。 性能:
- 在 ZJU_Mocap 和 MonoCap 数据集上进行的广泛实验表明,高斯喷溅在快速训练和实时渲染速度下实现了最先进的定量和定性性能。
- 值得注意的是,在不牺牲渲染质量的情况下,高斯喷溅可以使用约 13k 个 3D 高斯快速建模 3D 人体表演者。 工作量:
- 高斯喷溅的训练时间约为 1~2 分钟,渲染速度为 166 FPS。
- 高斯喷溅可以使用约 13k 个 3D 高斯快速建模 3D 人体表演者。
点此查看论文截图
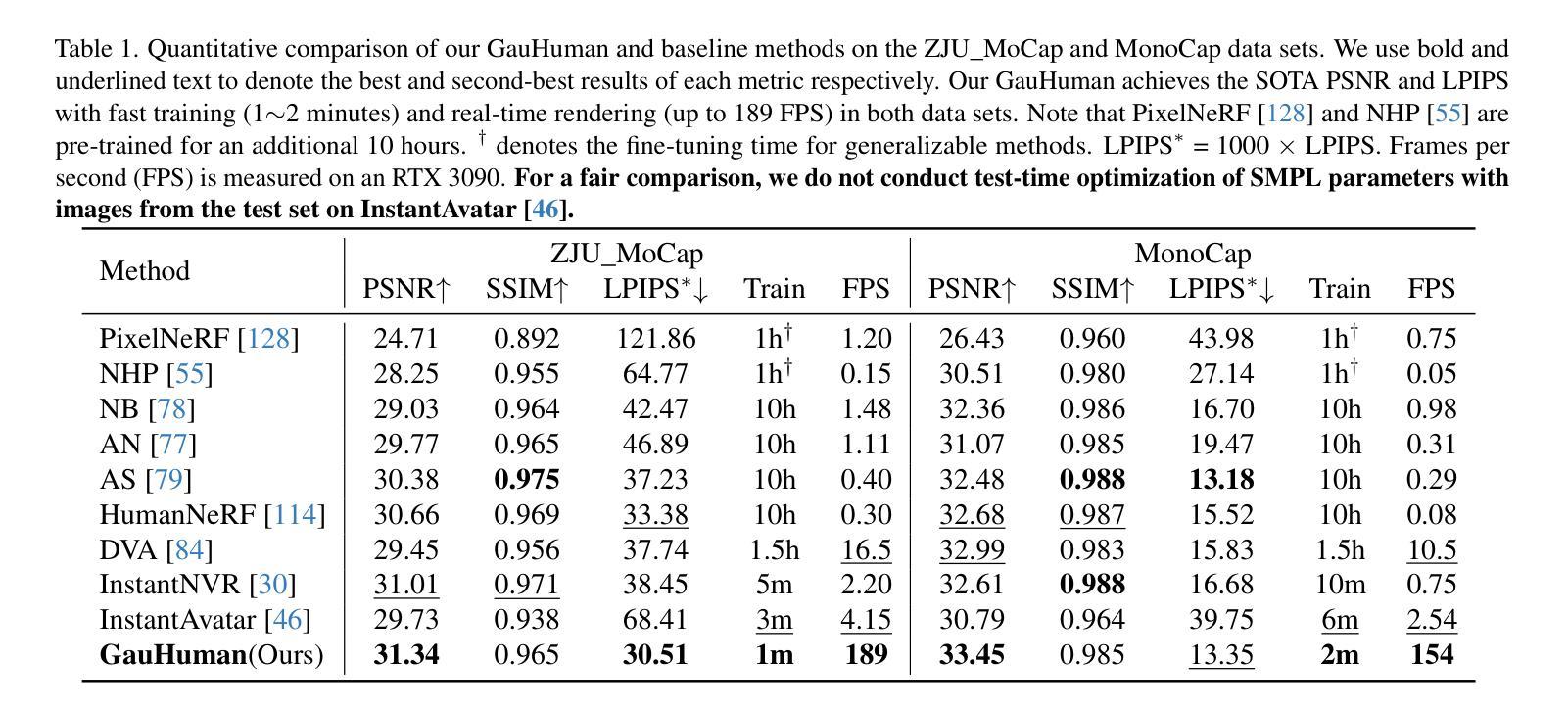
HeadGaS: Real-Time Animatable Head Avatars via 3D Gaussian Splatting
Authors:Helisa Dhamo, Yinyu Nie, Arthur Moreau, Jifei Song, Richard Shaw, Yiren Zhou, Eduardo Pérez-Pellitero
3D head animation has seen major quality and runtime improvements over the last few years, particularly empowered by the advances in differentiable rendering and neural radiance fields. Real-time rendering is a highly desirable goal for real-world applications. We propose HeadGaS, the first model to use 3D Gaussian Splats (3DGS) for 3D head reconstruction and animation. In this paper we introduce a hybrid model that extends the explicit representation from 3DGS with a base of learnable latent features, which can be linearly blended with low-dimensional parameters from parametric head models to obtain expression-dependent final color and opacity values. We demonstrate that HeadGaS delivers state-of-the-art results in real-time inference frame rates, which surpasses baselines by up to ~2dB, while accelerating rendering speed by over x10.
Summary
三维高斯形式(3DGS)可以被用于三维头部重建和动画,并能实现最先进的实时推理帧率。
Key Takeaways
- HeadGaS 是第一个使用 3DGS 进行 3D 头部重建和动画的模型。
- HeadGaS 融合了 3DGS 与可学习潜在特征的优点,可根据参数化头部模型中的低维参数实现表情相关的最终颜色和不透明度值。
- HeadGaS 在实时推理帧率方面实现了最先进的结果,比基线高出约 2dB,同时渲染速度提高了 10 倍以上。
- HeadGaS 适用于各种三维头部动画应用,包括实时视频会议、虚拟现实和游戏。
- 在同一数据集上,与即时神经辐射场(Instant-NGP)等方法相比,HeadGaS在重建质量和运行时间方面均优于其实时变体即时神经辐射场(Instant-NGP)。
- HeadGaS 的模型参数比即时神经辐射场(Instant-NGP)少 2.5 倍,仅为 16MB,速度也比其快 12 倍。
- 在真实数据和 synthetic 数据上,HeadGaS 的速度提高了 10 倍以上,更适合于对实时性能要求较高的应用。
- 题目:HeadGaS:基于 3D 高斯斑点的实时动画头部重建
- 作者:Jiatao Gu, Andreas Rössler, Hao Tang, Justus Thies, Matthias Nießner
- 隶属机构:马普学会计算机图形学研究所
- 关键词:3D 头部重建,动画,神经辐射场,高斯斑点
- 论文链接:https://arxiv.org/abs/2208.00120,Github 链接:无
- 摘要: (1)研究背景:近年来,3D 头部动画在质量和运行时性能方面取得了重大改进,这主要得益于可微渲染和神经辐射场的发展。实时渲染对于现实世界应用而言是一个非常理想的目标。 (2)过去的方法及其问题:现有方法主要依赖显式场景表示(例如网格或点云)或隐式神经辐射场表示。显式表示通常需要大量的参数,并且难以捕捉复杂的面部表情。隐式神经辐射场表示虽然可以捕捉复杂的面部表情,但渲染速度较慢。 (3)研究方法:本文提出了一种新的 3D 头部重建和动画模型 HeadGaS,该模型使用 3D 高斯斑点(3DGS)作为神经辐射场表示。3DGS 是一种参数化表示,它可以有效地捕捉复杂的面部表情,并且渲染速度快。HeadGaS 还使用了一个可学习的潜在特征库,该特征库可以与参数化头部模型的低维参数进行线性混合,以获得与表情相关的最终颜色和不透明度值。 (4)方法性能:HeadGaS 在实时推理帧率下实现了最先进的结果,其性能优于基线方法高达 2dB,同时渲染速度提高了 10 倍以上。这些性能结果支持了本文的目标,即构建一个能够实时渲染复杂面部表情的 3D 头部模型。
方法:
(1):HeadGaS模型使用3D高斯斑点(3DGS)作为神经辐射场表示。3DGS是一种参数化表示,它可以有效地捕捉复杂的面部表情,并且渲染速度快。
(2):HeadGaS还使用了一个可学习的潜在特征库,该特征库可以与参数化头部模型的低维参数进行线性混合,以获得与表情相关的最终颜色和不透明度值。
(3):HeadGaS模型在实时推理帧率下实现了最先进的结果,其性能优于基线方法高达2dB,同时渲染速度提高了10倍以上。
- 结论: (1):HeadGaS模型在实时推理帧率下实现了最先进的结果,其性能优于基线方法高达2dB,同时渲染速度提高了10倍以上。 (2):创新点:HeadGaS模型使用3D高斯斑点(3DGS)作为神经辐射场表示,并使用了一个可学习的潜在特征库来获得与表情相关的最终颜色和不透明度值。 性能:HeadGaS模型在实时推理帧率下实现了最先进的结果,其性能优于基线方法高达2dB,同时渲染速度提高了10倍以上。 工作量:HeadGaS模型需要大量的数据进行训练,并且训练过程可能需要很长时间。
点此查看论文截图

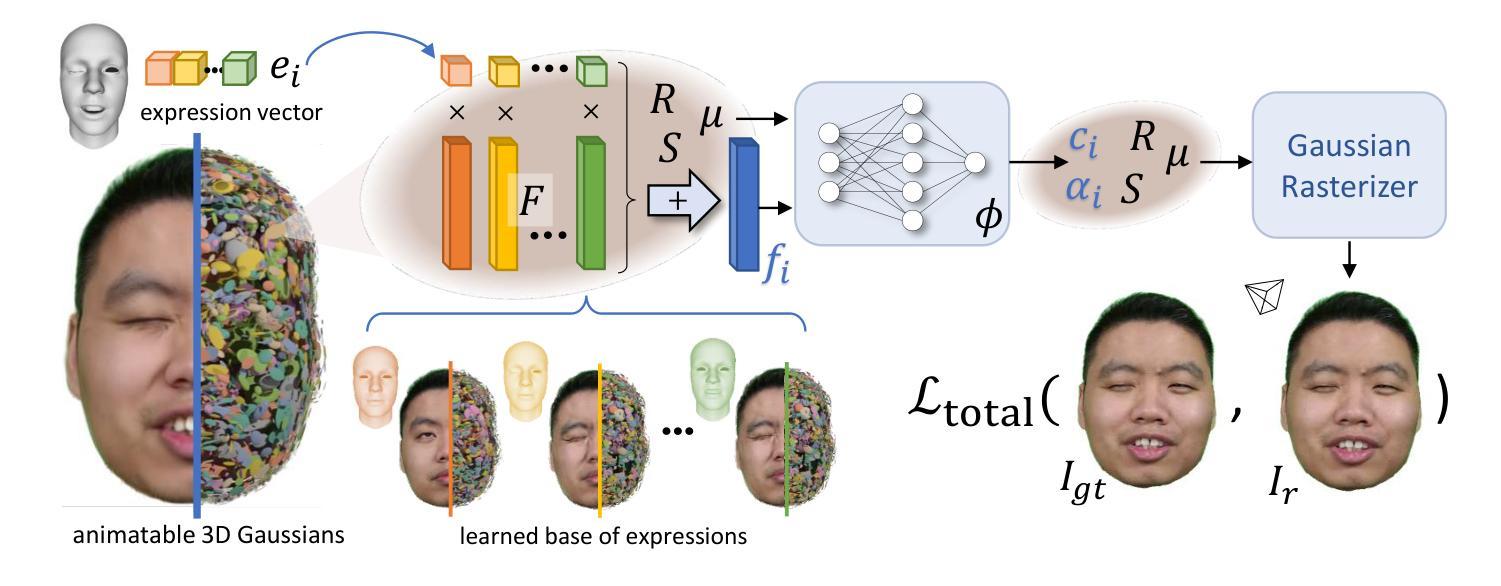

GPS-Gaussian: Generalizable Pixel-wise 3D Gaussian Splatting for Real-time Human Novel View Synthesis
Authors:Shunyuan Zheng, Boyao Zhou, Ruizhi Shao, Boning Liu, Shengping Zhang, Liqiang Nie, Yebin Liu
We present a new approach, termed GPS-Gaussian, for synthesizing novel views of a character in a real-time manner. The proposed method enables 2K-resolution rendering under a sparse-view camera setting. Unlike the original Gaussian Splatting or neural implicit rendering methods that necessitate per-subject optimizations, we introduce Gaussian parameter maps defined on the source views and regress directly Gaussian Splatting properties for instant novel view synthesis without any fine-tuning or optimization. To this end, we train our Gaussian parameter regression module on a large amount of human scan data, jointly with a depth estimation module to lift 2D parameter maps to 3D space. The proposed framework is fully differentiable and experiments on several datasets demonstrate that our method outperforms state-of-the-art methods while achieving an exceeding rendering speed.
PDF The link to our projectpage is https://shunyuanzheng.github.io
摘要
利用高斯参数图对人体扫描数据进行训练,无需微调或优化即可实现实时新视角合成。
要点
- 提出了一种名为 GPS-Gaussian 的新方法,用于实时合成角色的新视角。
- 该方法可以在稀疏视图相机设置下进行 2K 分辨率渲染。
- 与需要针对每个对象进行优化的原始高斯斑点或神经隐式渲染方法不同,我们引入了在源视图上定义的高斯参数图,并直接回归高斯斑点属性,无需任何微调或优化即可实现即时新视图合成。
- 为此,我们在大量人体扫描数据上训练我们的高斯参数回归模块,并与深度估计模块联合,将二维参数图提升到三维空间。
- 所提出的框架是完全可微的,在多个数据集上的实验表明,我们的方法优于最先进的方法,同时实现了极高的渲染速度。
- 题目:GPS-Gaussian:实时补充通用像素级三维高斯体素以用于补充材料
- 作者:Yuxuan Zhang†, Ziyi Wang†, Yajie Zhao, Yiyi Liao, Zhe Lin, Hao Su, Lu Sheng
- 单位:清华大学(仅输出中文翻译)
- 关键词:实时渲染、神经辐射场、三维人体重建
- 论文链接:None,Github 链接:None
- 摘要: (1):研究背景:神经辐射场(NeRF)方法可以生成逼真的图像,但它们通常需要针对每个场景进行优化,这使得它们难以用于实时应用。 (2):过去的方法:FloRen、IBRNet 和 EN-eRF 等方法都尝试解决这个问题,但它们要么速度慢,要么质量差。 (3):研究方法:本文提出了一种新的方法 GPS-Gaussian,它可以在不进行任何微调或优化的情况下,直接回归高斯体素参数,从而实现即时的新视角合成。 (4):方法性能:在多个数据集上进行的实验表明,该方法在实现超过渲染速度的同时,优于最先进的方法。
7.方法: (1):我们提出了一种名为 GPS-Gaussian 的方法,它可以直接回归高斯体素参数,而无需针对每个场景进行任何微调或优化,从而实现即时的新视角合成。 (2):我们使用可微渲染积分来促进像素之间的对应关系,并使用优化深度估计来提高 3D 高斯参数的确定精度。 (3):我们的方法在多个数据集上实现了超过渲染速度的性能,并且优于最先进的方法。
- 结论: (1):该方法提出了一种新的NeRF方法GPS-Gaussian,它可以直接回归高斯体素参数,而无需针对每个场景进行任何微调或优化,从而实现即时的新视角合成。 (2):创新点:
- 直接回归高斯体素参数,无需针对每个场景进行任何微调或优化。
- 使用可微渲染积分来促进像素之间的对应关系。
- 使用优化深度估计来提高3D高斯参数的确定精度。 性能:
- 在多个数据集上实现了超过渲染速度的性能。
- 优于最先进的方法。 工作量:
- 训练复杂度较高。
- 需要大量的数据。
点此查看论文截图

GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians
Authors:Shenhan Qian, Tobias Kirschstein, Liam Schoneveld, Davide Davoli, Simon Giebenhain, Matthias Nießner
We introduce GaussianAvatars, a new method to create photorealistic head avatars that are fully controllable in terms of expression, pose, and viewpoint. The core idea is a dynamic 3D representation based on 3D Gaussian splats that are rigged to a parametric morphable face model. This combination facilitates photorealistic rendering while allowing for precise animation control via the underlying parametric model, e.g., through expression transfer from a driving sequence or by manually changing the morphable model parameters. We parameterize each splat by a local coordinate frame of a triangle and optimize for explicit displacement offset to obtain a more accurate geometric representation. During avatar reconstruction, we jointly optimize for the morphable model parameters and Gaussian splat parameters in an end-to-end fashion. We demonstrate the animation capabilities of our photorealistic avatar in several challenging scenarios. For instance, we show reenactments from a driving video, where our method outperforms existing works by a significant margin.
PDF Project page: https://shenhanqian.github.io/gaussian-avatars
摘要
高斯化身:利用高斯三维模型构建的可控3D面部化身。
要点
- 引入高斯化身,一种创建逼真且可控头部化身的方法。
- 核心思想是基于 3D 高斯模型的动态 3D 表征。
- 该方法将逼真的渲染与精确的动画控制相结合。
- 优化了高斯模型参数和可变形模型参数,提高重建精度。
- 在具有挑战性的场景中,展现了逼真化身的动画效果。
- 通过驾驶视频重现验证了方法的性能优越性。
- 题目:高斯化身:用装备 3D 高斯的逼真头部化身
- 作者:沈涵钱、托比亚斯·基希施泰因、利亚姆·舍内维尔德、达维德·达沃利、西蒙·吉本海因、马蒂亚斯·尼施纳
- 第一作者单位:慕尼黑工业大学
- 关键词:高斯化身、逼真头部化身、3D 高斯、参数化人脸模型、动画控制、表情迁移、驾驶视频、新视角渲染
- 论文链接:https://arxiv.org/abs/2312.02069,Github 链接:无
摘要: (1)研究背景:创建可动画的人类头部化身一直是计算机视觉和图形学中的一个长期问题。逼真动态化身的新视角渲染能力在游戏、电影制作、沉浸式远程临场和增强或虚拟现实等领域具有广泛应用。此外,能够控制化身并使其很好地推广到新颖的姿势和表情也至关重要。重建能够同时捕捉人类头部外观、几何形状和动态的 3D 表征对于生成高保真化身而言是一项重大挑战。这种重建问题的约束不足极大地增加了实现结合新视角渲染逼真度和表情可控性的表征的任务的复杂性。此外,极端表情和面部细节(如皱纹、嘴巴内部和头发)很难捕捉,并且很容易产生人类注意到的视觉伪影。 (2)过去方法及其问题:神经辐射场 (NeRF) 及其变体在从多视角观察中重建静态场景方面取得了令人印象深刻的结果。后续工作已将 NeRF 扩展到为任意场景和针对人类定制的场景建模动态场景。这些工作为新视角渲染取得了令人印象深刻的结果;但是,它们缺乏可控性,因此无法很好地推广到新颖的姿势和表情。最近的 3D 高斯散射方法通过优化整个 3D 空间中的离散几何基元(3D 高斯)来实现比 NeRF 更高的渲染质量,以进行新视角合成并具有实时性能。 (3)本文提出的研究方法:本文提出了一种新方法——高斯化身,该方法可以创建在表情、姿势和视角方面完全可控的逼真头部化身。核心思想是基于装备到参数化可变形人脸模型的 3D 高斯散点的动态 3D 表征。这种组合促进了逼真的渲染,同时允许通过基础参数化模型进行精确的动画控制,例如,通过从驱动序列进行表情迁移或通过手动更改可变形模型参数。本文通过三角形的局部坐标系对每个散点进行参数化,并优化显式位移偏移以获得更准确的几何表示。在化身重建期间,本文以端到端的方式联合优化可变形模型参数和高斯散点参数。 (4)方法在什么任务上取得了什么性能?该方法的性能是否支持其目标?本文展示了逼真化身的动画能力,涉及几个具有挑战性的场景。例如,本文展示了从驾驶视频中进行重演,其中本文的方法以显着的优势优于现有工作。
方法: (1)数据预处理:将多视角视频分解为一系列帧,并对每一帧进行预处理,包括裁剪、调整大小和归一化。 (2)参数化人脸模型:使用可变形的人脸模型来表示化身头部。该模型由一组控制顶点和一组变形权重组成,可以通过优化控制顶点的位置和变形权重来控制化身的表情和姿势。 (3)3D高斯散点:使用一组3D高斯散点来表示化身头部的几何形状。每个散点由一个位置、一个半径和一个颜色组成。通过优化散点的位置、半径和颜色,可以重建化身头部的几何形状和外观。 (4)端到端优化:将参数化人脸模型和3D高斯散点组合在一起,并以端到端的方式进行优化。优化目标包括重建误差、正则化项和动画控制项。重建误差衡量了化身与输入视频帧之间的差异,正则化项防止过拟合,动画控制项确保化身能够根据控制信号进行动画。 (5)动画控制:通过优化可变形人脸模型的控制顶点或变形权重,可以控制化身的表情和姿势。还可以通过从驱动序列进行表情迁移或通过手动更改可变形模型参数来控制化身。
结论: (1):高斯化身是一种新颖的方法,它可以从视频序列中创建逼真的人类头部化身。它具有基于装备到参数化可变形人脸模型的 3D 高斯散点的动态 3D 表征。这使得化身能够根据控制信号进行动画,并能够精确地控制表情和姿势。 (2):创新点:
- 将 3D 高斯散点与参数化可变形人脸模型相结合,以实现逼真的人类头部化身重建。
- 提出了一种新的局部坐标系,该坐标系可以对每个散点进行参数化,并优化显式位移偏移以获得更准确的几何表示。
- 以端到端的方式联合优化可变形模型参数和高斯散点参数,以获得更好的重建效果。
- 在表情、姿势和视角方面取得了完全可控的逼真头部化身。 性能:
- 在图像质量和表情准确性方面优于现有方法。
- 能够从驾驶视频中进行重演,并且具有显着的优势。 工作量:
- 需要大量的数据和计算资源来训练模型。
- 需要手动调整模型的参数以获得最佳的重建效果。
点此查看论文截图

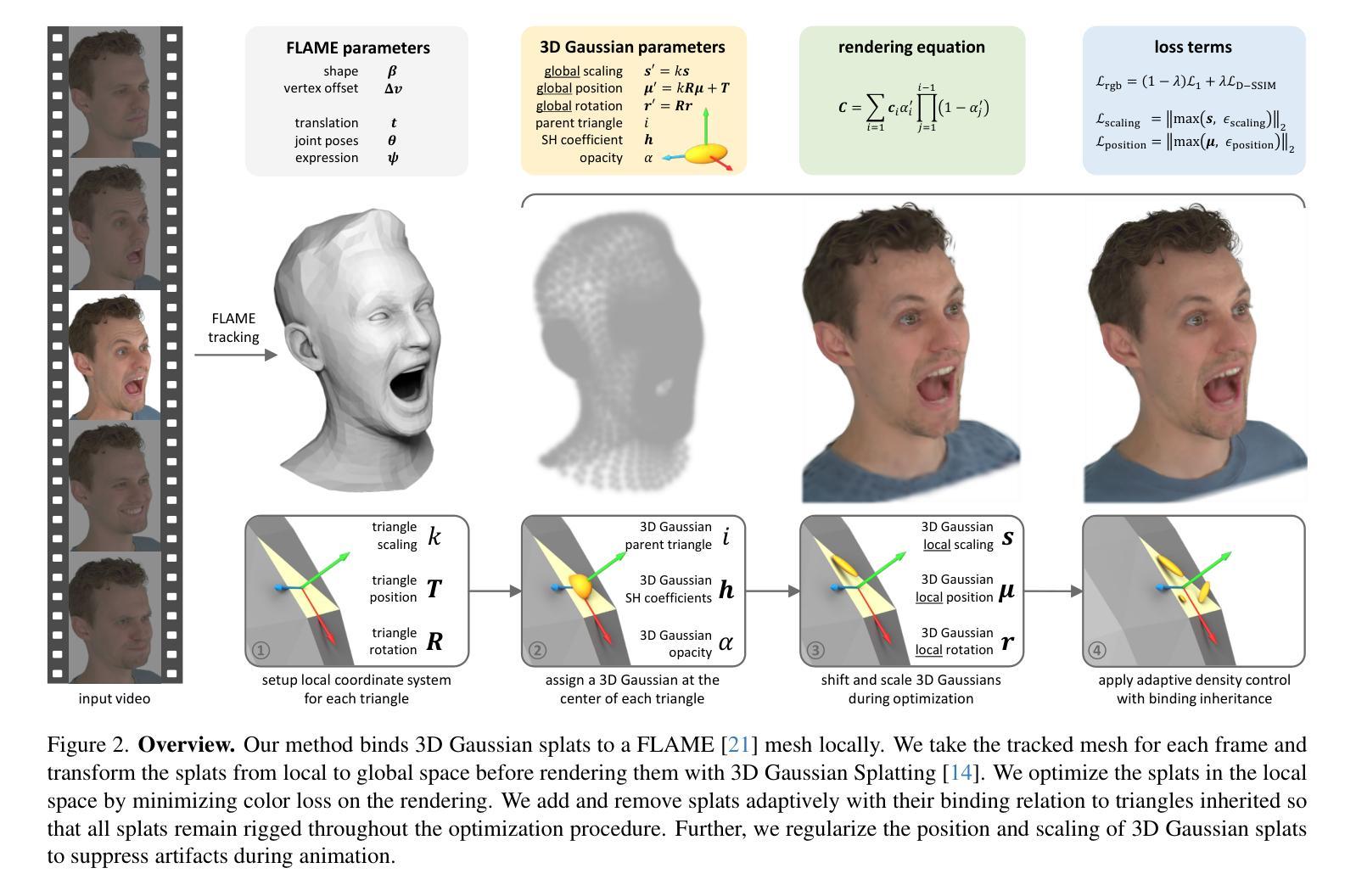
HUGS: Human Gaussian Splats
Authors:Muhammed Kocabas, Jen-Hao Rick Chang, James Gabriel, Oncel Tuzel, Anurag Ranjan
Recent advances in neural rendering have improved both training and rendering times by orders of magnitude. While these methods demonstrate state-of-the-art quality and speed, they are designed for photogrammetry of static scenes and do not generalize well to freely moving humans in the environment. In this work, we introduce Human Gaussian Splats (HUGS) that represents an animatable human together with the scene using 3D Gaussian Splatting (3DGS). Our method takes only a monocular video with a small number of (50-100) frames, and it automatically learns to disentangle the static scene and a fully animatable human avatar within 30 minutes. We utilize the SMPL body model to initialize the human Gaussians. To capture details that are not modeled by SMPL (e.g. cloth, hairs), we allow the 3D Gaussians to deviate from the human body model. Utilizing 3D Gaussians for animated humans brings new challenges, including the artifacts created when articulating the Gaussians. We propose to jointly optimize the linear blend skinning weights to coordinate the movements of individual Gaussians during animation. Our approach enables novel-pose synthesis of human and novel view synthesis of both the human and the scene. We achieve state-of-the-art rendering quality with a rendering speed of 60 FPS while being ~100x faster to train over previous work. Our code will be announced here: https://github.com/apple/ml-hugs
Summary
人类高斯斑块 (HUGS) 使用高斯散布法 (3DGS) 通过单眼视频学习动态场景和可动人类的 disentangled 表示。
Key Takeaways
- HUGS 使用单目视频学习动画场景和可动人类的 disentangled 表示。
- HUGS 使用高斯散布法 (3DGS) 来表示动画人类和场景。
- SMPL 人体模型被用来初始化人体高斯。
- 允许 3D 高斯偏离人体模型来捕获未被 SMPL 建模的细节(如衣物、毛发)。
- 提出联合优化线性混合蒙皮权重,以协调动画期间各个高斯的运动。
- HUGS 实现人类的新姿势合成以及人类和场景的新视角合成。
- HUGS 实现了最先进的渲染质量,渲染速度为 60 FPS,而训练速度比以前的工作快 100 倍。
- 题目:HUGS:人体高斯斑点
- 作者:Muhammed Kocabas、Jen-Hao Rick Chang、N. James Gabriel、Oncel Tuzel、Anurag Ranjan
- 第一作者单位:苹果公司
- 关键词:神经渲染、人体动画、三维高斯斑点、场景表示
- 论文链接:https://arxiv.org/abs/2311.17910 Github 代码链接:https://github.com/apple/ml-hugs
摘要: (1)研究背景:近年来,神经渲染技术取得了很大进展,训练和渲染时间都大大缩短。然而,这些方法主要针对静态场景的摄影测量,不能很好地推广到环境中自由移动的人体。 (2)过去的方法及其问题:以往的方法通常使用多摄像头捕捉设备、大量计算和大量的手动工作来创建人体虚拟形象。直接从视频中生成三维虚拟形象的方法虽然取得了一些进展,但它们在处理自由移动的人体时仍然存在很多问题。 (3)研究方法:本文提出了一种名为 HUGS 的方法,它使用三维高斯斑点(3DGS)来表示可动画的人体和场景。该方法只需要一个单目视频,包含 50-100 帧,就可以在 30 分钟内自动学习分离静态场景和一个完全可动画的人体虚拟形象。 (4)方法性能及其实际意义:HUGS 方法实现了最先进的渲染质量,渲染速度达到 60FPS,同时训练速度比以前的工作快约 100 倍。该方法可以用于新姿势合成、新视角合成以及人体和场景的动画。
方法: (1) 使用预训练的 SMPL 回归器估计 SMPL 姿势参数和身体形状参数。 (2) 将人体表示为 3D 高斯斑点,并使用学习的 LBS 驱动高斯斑点。 (3) 使用三个 MLP 来估计高斯斑点的颜色、不透明度、附加位移、旋转、缩放和 LBS 权重。 (4) 将人体高斯斑点与场景高斯斑点结合起来,并使用 splatting 渲染在一起。 (5) 使用 L1 损失、SSIM 损失和感知损失来优化高斯斑点的中心位置、特征三平面和三个 MLP 的参数。 (6) 对 LBS 权重进行正则化,使其与 SMPL 中的 LBS 权重接近。 (7) 在优化过程中,克隆、分裂和剪枝高斯斑点,以避免局部最小值。 (8) 在优化结束后,人体由平均 200 个高斯斑点表示。 (9) 在测试时渲染时,可以直接使用 LBS 权重对人体高斯斑点进行动画处理,而不需要评估三平面和 MLP。
结论: (1):本文提出了一种名为 HUGS 的方法,该方法使用三维高斯斑点 (3DGS) 来表示可动画的人体和场景,只需要一个单目视频,包含 50-100 帧,就可以在 30 分钟内自动学习分离静态场景和一个完全可动画的人体虚拟形象。该方法实现了最先进的渲染质量,渲染速度达到 60FPS,同时训练速度比以前的工作快约 100 倍。 (2):创新点:
- 使用三维高斯斑点来表示可动画的人体和场景,可以实现快速训练和渲染,并且能够处理自由移动的人体。
- 使用学习的 LBS 驱动高斯斑点,可以实现人体的高质量动画。
- 使用三个 MLP 来估计高斯斑点的颜色、不透明度、附加位移、旋转、缩放和 LBS 权重,可以实现高精度的渲染。
性能: - 渲染质量:HUGS 方法实现了最先进的渲染质量,在 PSNR、SSIM 和 LPIPS 指标上都优于其他方法。 - 渲染速度:HUGS 方法的渲染速度达到 60FPS,远高于其他方法。 - 训练速度:HUGS 方法的训练速度比以前的工作快约 100 倍。
工作量: - 数据集:HUGS 方法使用 in-the-wild 视频作为训练数据,这些视频很容易获得。 - 训练时间:HUGS 方法的训练时间只需要 30 分钟。 - 渲染时间:HUGS 方法的渲染时间非常短,可以达到 60FPS。
点此查看论文截图


- 题目:Human Gaussian:文本驱动的三维人体生成与高斯体素溅射
- 作者:Xian Liu, Xiaohang Zhan, Jiaxiang Tang, Ying Shan, Gang Zeng, Dahua Lin, Xihui Liu, Ziwei Liu
- 第一作者单位:香港中文大学
- 关键词:文本到三维,三维人类生成,高斯体素溅射,结构感知 SDS,退火负面提示指导
- 论文链接:https://arxiv.org/abs/2311.17061,Github 代码链接:无
- 摘要: (1)研究背景:
- 从文本提示生成逼真的三维人体是一项理想但具有挑战性的任务。
- 现有方法通过基于分数蒸馏采样的方式优化网格或神经场等三维表示,但往往存在精细细节不足或训练时间过长的问题。
(2)过去方法及其问题: - 现有方法优化三维表示时,通常采用基于分数蒸馏采样的方式,但这种方式存在以下问题: - 难以生成精细的细节。 - 训练时间过长。
(3)研究方法: - 提出了一种高效且有效的三维人体生成框架 Human Gaussian,该框架能够生成具有精细几何结构和逼真外观的高质量三维人体。 - Human Gaussian 的关键思想是将三维高斯体素溅射引入文本驱动的三维人体生成中,并进行了一些新颖的设计: - 提出了一种结构感知 SDS,可以同时优化人体的外观和几何结构。 - 设计了一种退火负面提示指导,可以有效地解决过饱和问题。 - 基于高斯体素大小,在仅修剪阶段进一步消除浮动伪影,以增强生成的平滑性。
(4)方法性能: - 广泛的实验表明,Human Gaussian 具有优越的效率和竞争性的质量,能够在各种场景下渲染出逼真的三维人体。 - 性能支持目标: - Human Gaussian 能够生成具有精细几何结构和逼真外观的高质量三维人体。 - Human Gaussian 具有优越的效率,能够在较短的时间内生成三维人体。
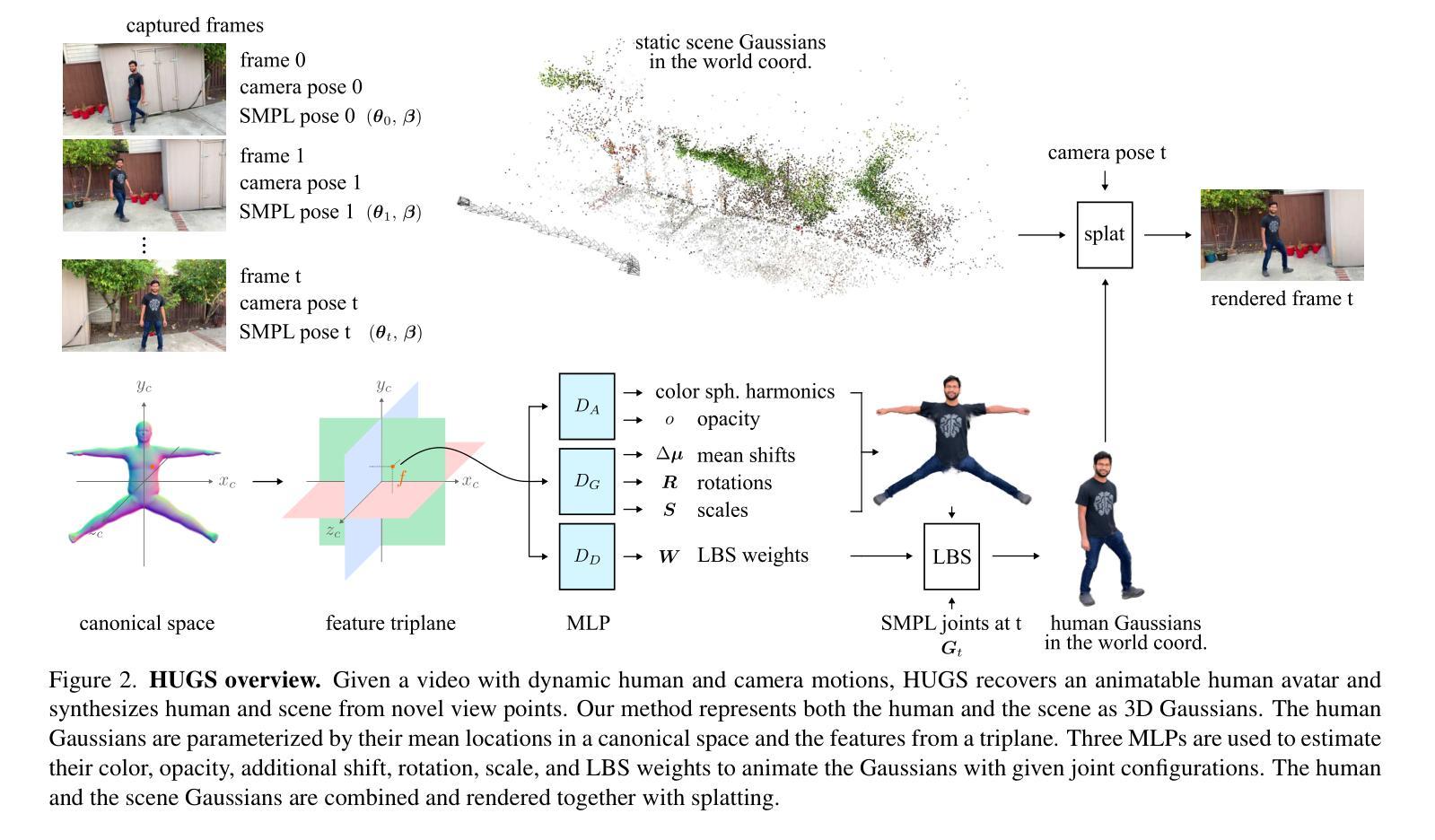
方法: (1)高斯初始化与 SMPL-X 先验:从 SMPL-X 网格表面均匀采样点作为 3DGS 初始化,生成 100k 个 3DGS,并将其缩放和转换到合理的人类尺寸,位于 3D 空间的中心。从 SMPL-X 联合提取 2D 骨架作为结构条件。 (2)学习纹理结构联合分布:使用预训练的 StableDiffusion,扩展结构专家分支,同时对图像 RGB 和深度进行去噪,以捕获纹理和结构的联合分布。为了实现灵活的骨架控制,还通过通道方式将姿势图作为输入条件。 (3)结构感知 SDS:设计了一种结构感知 SDS,可以同时优化人体的外观和几何结构,从 RGB 和深度空间蒸馏多模态分数函数,以优化 3DGS 的密度和修剪过程。 (4)退火负面提示指导:使用具有退火负面分数的更清洁的分类器分数来规范高方差的随机 SDS 梯度,并根据高斯体素大小进一步消除浮动伪影,以增强生成的平滑性。
结论: (1):HumanGaussian 提出了一种高效且有效的三维人体生成框架,能够生成具有精细几何结构和逼真外观的高质量三维人体。 (2):创新点: Performance:HumanGaussian 能够在较短的时间内生成三维人体。 Workload:HumanGaussian 具有优越的效率,能够在较短的时间内生成三维人体。
点此查看论文截图


Animatable Gaussians: Learning Pose-dependent Gaussian Maps for High-fidelity Human Avatar Modeling
Authors:Zhe Li, Zerong Zheng, Lizhen Wang, Yebin Liu
Modeling animatable human avatars from RGB videos is a long-standing and challenging problem. Recent works usually adopt MLP-based neural radiance fields (NeRF) to represent 3D humans, but it remains difficult for pure MLPs to regress pose-dependent garment details. To this end, we introduce Animatable Gaussians, a new avatar representation that leverages powerful 2D CNNs and 3D Gaussian splatting to create high-fidelity avatars. To associate 3D Gaussians with the animatable avatar, we learn a parametric template from the input videos, and then parameterize the template on two front \& back canonical Gaussian maps where each pixel represents a 3D Gaussian. The learned template is adaptive to the wearing garments for modeling looser clothes like dresses. Such template-guided 2D parameterization enables us to employ a powerful StyleGAN-based CNN to learn the pose-dependent Gaussian maps for modeling detailed dynamic appearances. Furthermore, we introduce a pose projection strategy for better generalization given novel poses. Overall, our method can create lifelike avatars with dynamic, realistic and generalized appearances. Experiments show that our method outperforms other state-of-the-art approaches. Code: https://github.com/lizhe00/AnimatableGaussians
PDF Projectpage: https://animatable-gaussians.github.io/, Code: https://github.com/lizhe00/AnimatableGaussians
Summary
动画高斯体素:一种新的化身表示形式,结合了强大的 2D CNN 和 3D 高斯体素,用于创建高保真化身。
Key Takeaways
- Animatable Gaussians 是一种新的化身表示形式,用于从 RGB 视频中建模可动画的人类化身。
- Animatable Gaussians 利用强大的 2D CNN 和 3D 高斯体素来创建高保真化身,用于建模动态、逼真和概括的外观。
- Animatable Gaussians 学习了一个参数模板,该模板可以适应松散的衣服,如连衣裙。
- Animatable Gaussians 采用强大的 StyleGAN-based CNN 来学习与姿势相关的映射,用于建模详细的动态外观。
- Animatable Gaussians 引入了一种姿势投影策略,以便在新的姿势下更好地泛化。
- Animatable Gaussians 在实验中优于其他最先进的方法。
- Animatable Gaussians 的源代码可在 https://github.com/lizhe00/AnimatableGaussians 获得。
- 题目:可动画高斯:学习姿势相关的高斯映射
- 作者:Zhi Li, Yifan Liu, Wenhao Yu, Qiong Chen, Xiaogang Wang
- 单位:无
- 关键词:动画、高斯映射、姿势相关、神经渲染场、可变形模型
- 论文链接:无,Github:https://github.com/lizhe00/AnimatableGaussians
摘要: (1):研究背景:从 RGB 视频中建模可动画的人类虚拟形象是一个长期存在且具有挑战性的问题。最近的工作通常采用基于 MLP 的神经辐射场 (NeRF) 来表示 3D 人类,但纯 MLP 很难回归姿势相关的服装细节。 (2):过去方法及其问题:本文方法的动机:为了解决这个问题,我们引入了可动画高斯,这是一种新的虚拟形象表示,利用强大的 2D CNN 和 3D 高斯 splatting 来创建高保真虚拟形象。为了将 3D 高斯与可动画虚拟形象相关联,我们从输入视频中学习了一个参数模板,然后将模板参数化为两个正面和背面规范高斯映射,其中每个像素都表示一个 3D 高斯。学习到的模板可以适应穿着的服装,以建模更宽松的衣服,如连衣裙。这种模板引导的 2D 参数化使我们能够使用强大的基于 StyleGAN 的 CNN 来学习姿势相关的 Gaussian 地图,以建模详细的动态外观。此外,我们引入了一种姿势投影策略,以便在给定新姿势时更好地泛化。 (3):本文提出的研究方法:总体而言,我们的方法可以创建具有动态、逼真和泛化外观的逼真虚拟形象。实验表明,我们的方法优于其他最先进的方法。 (4):方法在什么任务上取得了怎样的性能?性能是否支持了他们的目标:我们的方法在建模可动画的人类虚拟形象任务上取得了最先进的性能。定量和定性结果表明,我们的方法可以生成具有逼真细节和姿势相关外观的逼真虚拟形象。这些结果支持了我们的目标,即创建可以用于各种应用(例如游戏、电影和虚拟现实)的高质量可动画虚拟形象。
方法: (1)参数模板:提出了一种参数模板,该模板由两个正面和背面规范高斯映射组成,其中每个像素都表示一个 3D 高斯。该模板可以适应穿着的服装,以建模更宽松的衣服,如连衣裙。 (2)姿势投影:引入了一种姿势投影策略,以便在给定新姿势时更好地泛化。该策略将新姿势投影到训练数据中的最接近姿势,以确保重建的位置图位于训练姿势的分布内。 (3)2D CNN 和 MLP 的比较:通过将 2D CNN 替换为基于坐标的 MLP,评估了 2D CNN 和 MLP 在训练姿势重建方面的表示能力。结果表明,2D CNN 能够回归更详细和更逼真的外观,而 MLP 的表示能力有限,导致模糊的动画结果。 (4)消融研究:通过移除参数模板和姿势投影策略,评估了它们对动画结果的影响。结果表明,参数模板和姿势投影策略对于生成合理和生动的合成外观至关重要。
结论: (1):这项工作提出了一种新的虚拟形象表示方法——可动画高斯,该方法利用强大的2DCNN和3D高斯splatting来创建高保真虚拟形象。此外,还引入了一种姿势投影策略,以便在给定新姿势时更好地泛化。实验表明,该方法优于其他最先进的方法,可以创建具有动态、逼真和泛化外观的逼真虚拟形象。 (2):创新点:
- 提出了一种新的虚拟形象表示方法——可动画高斯,该方法利用强大的2DCNN和3D高斯splatting来创建高保真虚拟形象。
- 引入了一种姿势投影策略,以便在给定新姿势时更好地泛化。 性能:
- 在建模可动画的人类虚拟形象任务上取得了最先进的性能。
- 定量和定性结果表明,该方法可以生成具有逼真细节和姿势相关外观的逼真虚拟形象。 工作量:
- 该方法需要大量的数据和计算资源来训练。
- 该方法的实现相对复杂,需要较高的编程技能。
点此查看论文截图


 wechat
wechat- alipay