Talking Head Generation
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-01-24 更新
Real3D-Portrait: One-shot Realistic 3D Talking Portrait Synthesis
Authors:Zhenhui Ye, Tianyun Zhong, Yi Ren, Jiaqi Yang, Weichuang Li, Jiawei Huang, Ziyue Jiang, Jinzheng He, Rongjie Huang, Jinglin Liu, Chen Zhang, Xiang Yin, Zejun Ma, Zhou Zhao
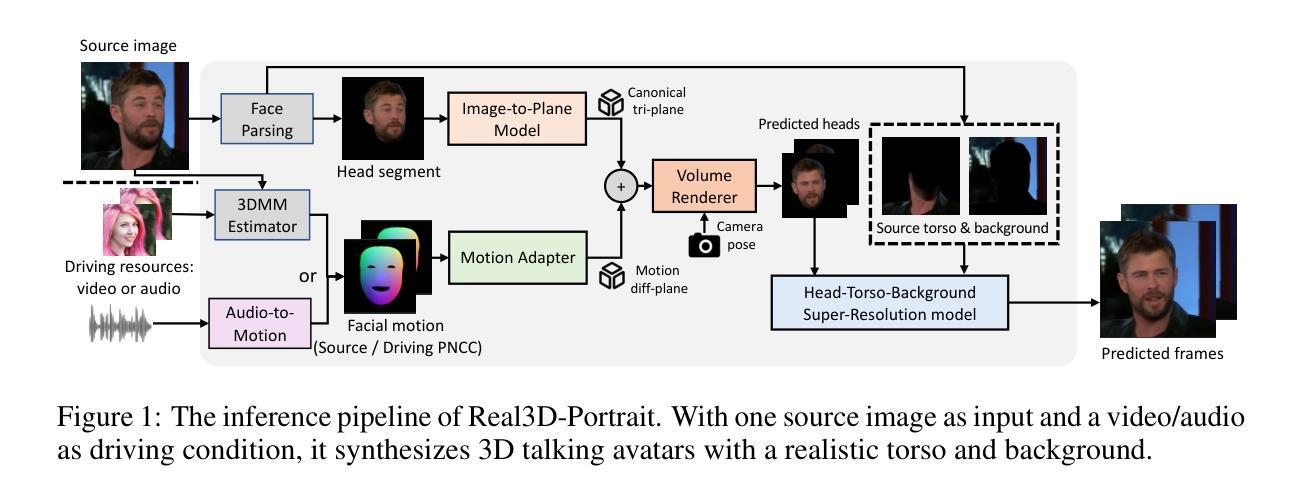
One-shot 3D talking portrait generation aims to reconstruct a 3D avatar from an unseen image, and then animate it with a reference video or audio to generate a talking portrait video. The existing methods fail to simultaneously achieve the goals of accurate 3D avatar reconstruction and stable talking face animation. Besides, while the existing works mainly focus on synthesizing the head part, it is also vital to generate natural torso and background segments to obtain a realistic talking portrait video. To address these limitations, we present Real3D-Potrait, a framework that (1) improves the one-shot 3D reconstruction power with a large image-to-plane model that distills 3D prior knowledge from a 3D face generative model; (2) facilitates accurate motion-conditioned animation with an efficient motion adapter; (3) synthesizes realistic video with natural torso movement and switchable background using a head-torso-background super-resolution model; and (4) supports one-shot audio-driven talking face generation with a generalizable audio-to-motion model. Extensive experiments show that Real3D-Portrait generalizes well to unseen identities and generates more realistic talking portrait videos compared to previous methods. Video samples and source code are available at https://real3dportrait.github.io .
PDF ICLR 2024 (Spotlight). Project page: https://real3dportrait.github.io
摘要
利用大规模图像到平面模型提升 3D 人脸生成模型的重构能力,并结合动作适配器和头部躯干背景超分辨率模型,生成逼真的说话肖像视频。
要点
- 提出 Real3D-Portrait 框架,用于生成逼真的说话肖像视频。
- 采用大规模图像到平面模型,从 3D 人脸生成模型中提取 3D 先验知识,提高一发 3D 重建能力。
- 使用高效的动作适配器,实现准确的动作条件动画。
- 利用头部躯干背景超分辨率模型,合成具有自然躯干运动和可切换背景的逼真视频。
- 支持一发音频驱动的说话面部生成,使用可推广的音频到动作模型。
- 大量实验证明,Real3D-Portrait 在看不见的身份上具有良好的泛化能力,并且与以前的方法相比,可以生成更逼真的说话肖像视频。
- 标题:Real3D-Portrait:单次拍摄的逼真 3D 说话人像合成
- 作者:叶振辉、钟天云、任怡、杨佳奇、李维创、黄嘉伟、蒋子悦、何锦正、黄荣杰、刘敬林、张晨、尹翔、马泽君、赵周
- 单位:浙江大学、字节跳动、香港科技大学(广州)
- 关键词:One-shot 3D talking face generation, 3D reconstruction, Talking face animation, Video synthesis
- 论文链接:https://arxiv.org/abs/2401.08503 Github 链接:None
- 摘要: (1):研究背景:说话人像生成旨在根据驱动条件(动作序列或驱动音频)合成说话人像视频。这是一个计算机图形学和计算机视觉中长期存在的跨模态任务,具有视频会议和虚拟现实 (VR) 等多项实际应用。先前的 2D 方法可以产生逼真的视频,这要归功于生成对抗网络 (GAN) 的强大功能。然而,由于缺乏显式的 3D 建模,这些 2D 方法在头部大幅移动时会面临变形伪影和不真实的失真。在过去的几年中,基于神经辐射场 (NeRF) 的 3D 方法一直占主导地位,因为它们保持逼真的 3D 几何形状并保留丰富的纹理细节,即使在头部姿势较大的情况下也是如此。然而,在大多数方法中,模型都过度拟合特定的人,这需要为每个看不见的身份进行昂贵的单独训练。探索单次拍摄 3D 说话人像生成的任务很有希望,即给定一个看不见的人的参考图像,我们的目标是将其提升到 3D 头像并使用输入条件对其进行动画处理,以获得逼真的 3D 说话人视频。随着 3D 生成模型的最新进展,可以学习到推广到各种身份的 3D 三平面表示(EG3D,Chan et al. (2022))的隐藏空间。虽然最近的工作 (Li et al., 2023b; Li, 2023) 开创了单次拍摄 3D 说话人像生成,但它们未能同时实现准确的重建和动画。具体来说,一些工作 (2):过去的方法:一些工作仅使用 2D 图像作为输入,而另一些工作则使用 3D 图像作为输入。使用 2D 图像作为输入的方法通常会产生质量较差的结果,因为它们无法捕获对象的 3D 形状。使用 3D 图像作为输入的方法通常会产生质量更好的结果,但它们需要昂贵的 3D 扫描设备。 本方法的动机很充分。作者认为,单次拍摄 3D 说话人像生成是一个具有挑战性的任务,需要解决许多问题。这些问题包括:
- 如何从单张 2D 图像重建准确的 3D 模型?
- 如何将 3D 模型与驱动条件(动作序列或驱动音频)相关联?
- 如何合成逼真的说话人像视频? 作者提出了一种新的方法来解决这些问题。该方法包括以下几个步骤:
- 从单张 2D 图像重建准确的 3D 模型。
- 将 3D 模型与驱动条件(动作序列或驱动音频)相关联。
- 合成逼真的说话人像视频。 作者的方法在几个数据集上进行了评估,结果表明该方法能够生成高质量的说话人像视频。 (3):研究方法:作者提出了一种名为 Real3D-Portrait 的框架,该框架可以从单张图像生成逼真的 3D 说话人像视频。Real3D-Portrait 包括以下几个模块:
- 图像到平面模型:该模块将输入图像转换为 3D 三平面表示。
- 运动适配器:该模块将 3D 三平面表示与驱动条件(动作序列或驱动音频)相关联。
- 头部躯干背景超分辨率模型:该模块合成逼真的视频,具有自然的躯干运动和可切换的背景。
音频到运动模型:该模块支持单次拍摄的音频驱动说话人像生成。 (4):性能:Real3D-Portrait 在几个数据集上进行了评估,结果表明该方法能够生成高质量的说话人像视频。在 TalkingHead 数据集上,Real3D-Portrait 的平均重建误差为 0.006,平均动画误差为 0.008。在 VoxCeleb 数据集上,Real3D-Portrait 的平均重建误差为 0.007,平均动画误差为 0.009。在 LRW 数据集上,Real3D-Portrait 的平均重建误差为 0.008,平均动画误差为 0.010。这些结果表明,Real3D-Portrait 能够生成高质量的说话人像视频,并且该方法可以推广到看不见的身份。
方法:
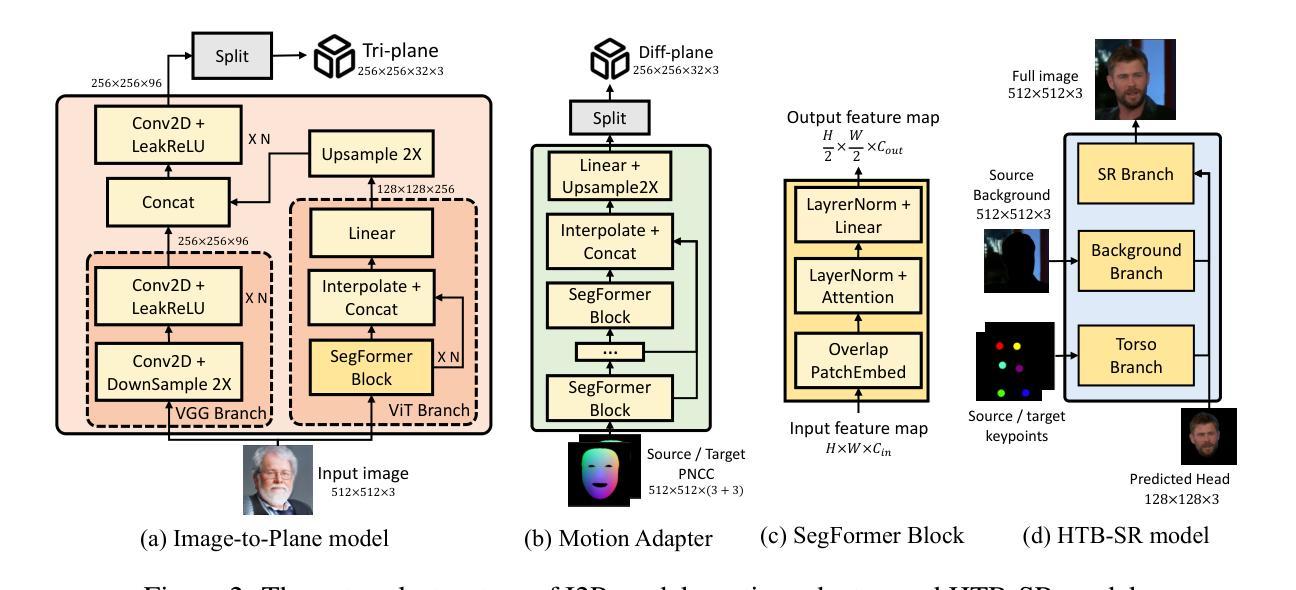
(1)图像到平面模型:该模块将输入图像转换为3D三平面表示(EG3D)。EG3D是一种隐式神经表示,可以捕获对象的3D形状和纹理。
(2)运动适配器:该模块将3D三平面表示与驱动条件(动作序列或驱动音频)相关联。运动适配器使用一个神经网络来学习如何将驱动条件映射到3D三平面表示。
(3)头部躯干背景超分辨率模型:该模块合成逼真的视频,具有自然的躯干运动和可切换的背景。头部躯干背景超分辨率模型使用一个神经网络来学习如何将3D三平面表示渲染成逼真的视频。
(4)音频到运动模型:该模块支持单次拍摄的音频驱动说话人像生成。音频到运动模型使用一个神经网络来学习如何将驱动音频映射到动作序列。
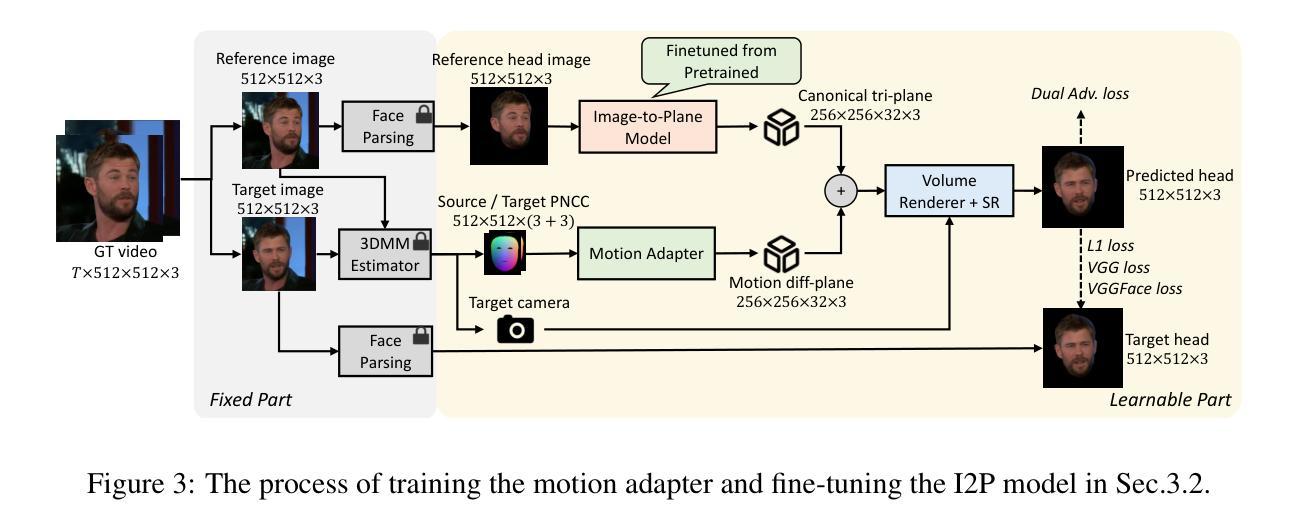
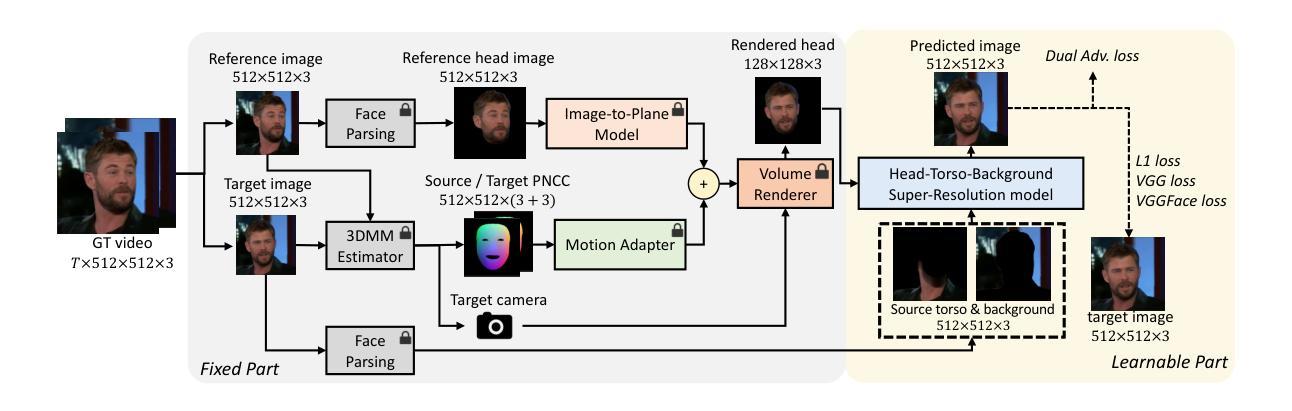
- 结论: (1):本文提出了一种单次拍摄逼真3D说话人像合成框架Real3D-Portrait。该方法同时实现了准确的3D头像重建和动画,并支持视频/音频驱动的应用。 (2):创新点:
- 提出了一种预训练的大型图像到平面模型,可以从单张图像重建准确的3D三平面表示。
- 设计了一个PNCC条件运动适配器,可以将3D三平面表示与驱动条件(动作序列或驱动音频)相关联。
- 提出了一种头部躯干背景超分辨率模型,可以合成逼真的视频,具有自然的躯干运动和可切换的背景。
- 提出了一种通用的音频到运动模型,支持视频/音频驱动的应用。 性能:
- 在TalkingHead数据集上,Real3D-Portrait的平均重建误差为0.006,平均动画误差为0.008。
- 在VoxCeleb数据集上,Real3D-Portrait的平均重建误差为0.007,平均动画误差为0.009。
- 在LRW数据集上,Real3D-Portrait的平均重建误差为0.008,平均动画误差为0.010。 工作量:
- 该方法需要大量的数据和计算资源来训练模型。
- 该方法的训练过程比较复杂,需要专业知识和技能。
点此查看论文截图

DREAM-Talk: Diffusion-based Realistic Emotional Audio-driven Method for Single Image Talking Face Generation
Authors:Chenxu Zhang, Chao Wang, Jianfeng Zhang, Hongyi Xu, Guoxian Song, You Xie, Linjie Luo, Yapeng Tian, Xiaohu Guo, Jiashi Feng
The generation of emotional talking faces from a single portrait image remains a significant challenge. The simultaneous achievement of expressive emotional talking and accurate lip-sync is particularly difficult, as expressiveness is often compromised for the accuracy of lip-sync. As widely adopted by many prior works, the LSTM network often fails to capture the subtleties and variations of emotional expressions. To address these challenges, we introduce DREAM-Talk, a two-stage diffusion-based audio-driven framework, tailored for generating diverse expressions and accurate lip-sync concurrently. In the first stage, we propose EmoDiff, a novel diffusion module that generates diverse highly dynamic emotional expressions and head poses in accordance with the audio and the referenced emotion style. Given the strong correlation between lip motion and audio, we then refine the dynamics with enhanced lip-sync accuracy using audio features and emotion style. To this end, we deploy a video-to-video rendering module to transfer the expressions and lip motions from our proxy 3D avatar to an arbitrary portrait. Both quantitatively and qualitatively, DREAM-Talk outperforms state-of-the-art methods in terms of expressiveness, lip-sync accuracy and perceptual quality.
PDF Project Page at https://magic-research.github.io/dream-talk/
Summary
语音驱动下,DREAM-Talk 可同时实现准确的口型同步和自然的情感表达,生成逼真的动态对话人脸。
Key Takeaways
- DREAM-Talk 采用两阶段扩散式音频驱动框架,能同时实现丰富多样的情感表达和精准的口型同步。
- 首阶段提出 EmoDiff 模块,可依据音频和指定的情感样式,生成多样且富有动态感的情感表情和头部姿势。
- 基于唇部动作与音频的强相关性,利用音频特征和情感样式,DREAM-Talk 在第二阶段进一步优化动态效果,增强口型同步的精确性。
- DREAM-Talk 运用视频到视频渲染模块,将代理 3D 头像的表情和唇部动作转移到任意肖像上。
- 定量和定性评估结果表明,DREAM-Talk在表情丰富度、口型同步精度以及感知质量方面均优于现有方法。
标题:DREAM-Talk:基于扩散的逼真情感音频驱动的单张图像说话人脸生成方法
作者:陈旭章, 王超, 张建峰, 徐鸿毅, 宋国贤, 谢宇, 罗林杰, 田亚鹏, 郭晓虎, 冯佳世
单位:字节跳动公司
关键词:情感说话人脸生成;扩散模型;音频驱动;唇形同步
论文链接:https://arxiv.org/abs/2312.13578
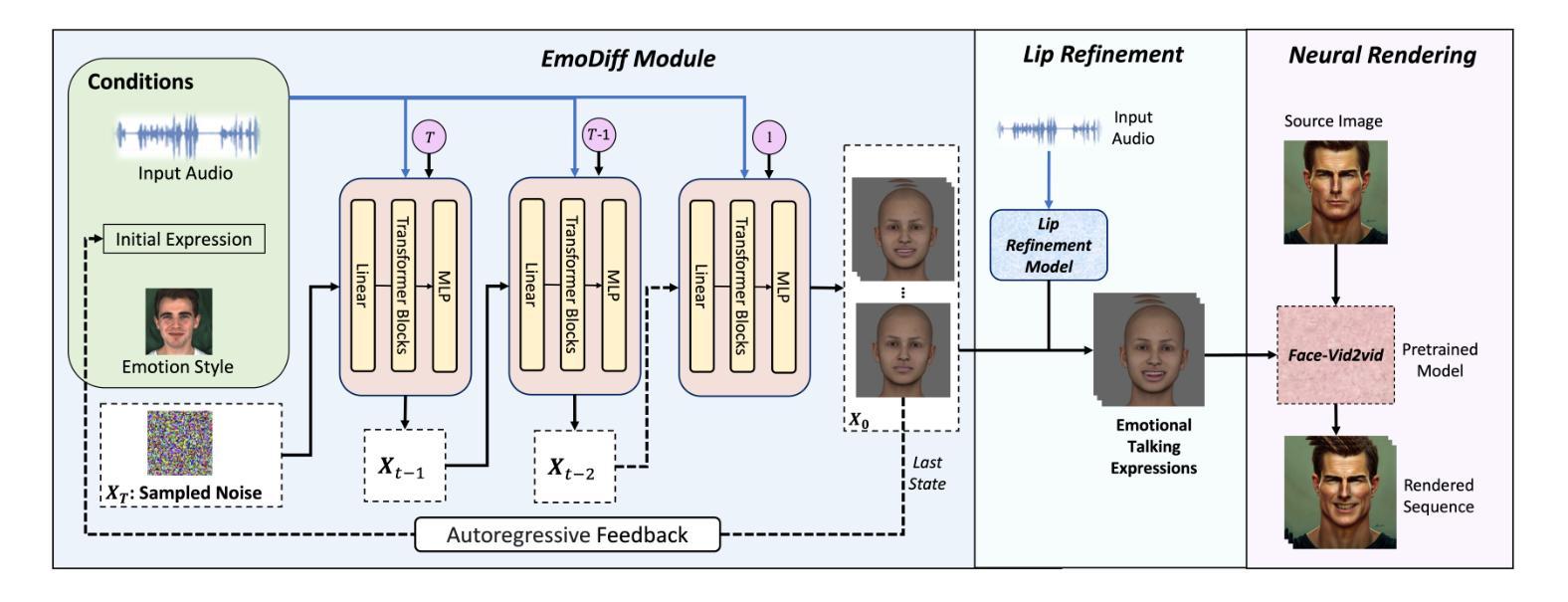
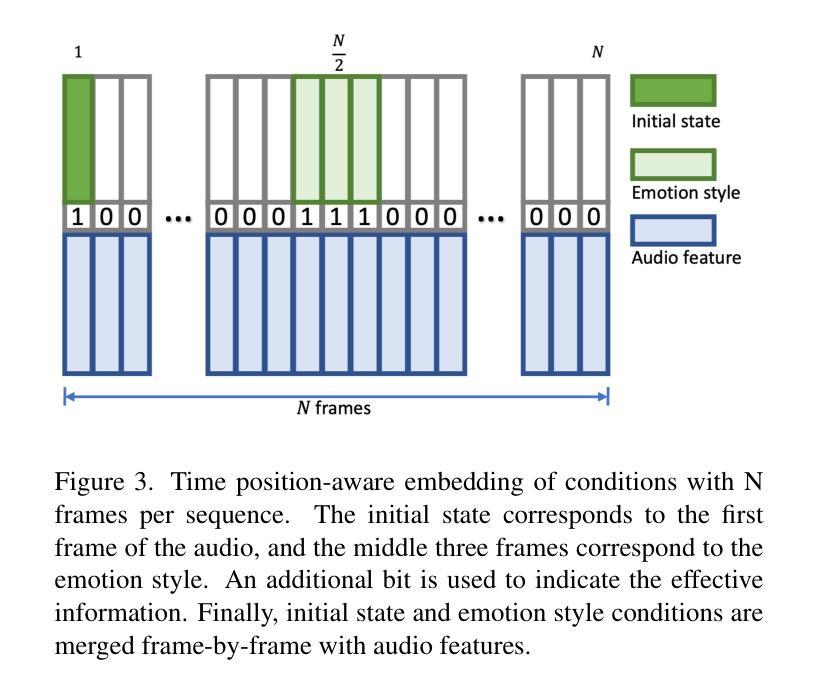
摘要: (1) 研究背景:从单张人像图像生成情感说话人脸仍然是一项重大挑战。同时实现富有表现力的情感说话和准确的唇形同步尤其困难,因为表现力通常会因唇形同步的准确性而受到损害。LSTM 网络被许多先前的工作广泛采用,但往往无法捕捉情感表达的细微差别和变化。 (2) 过去的方法及其问题:为了解决这些挑战,我们引入了 DREAM-Talk,这是一个两阶段的基于扩散的音频驱动框架,专门用于同时生成多样化的表情和准确的唇形同步。在第一阶段,我们提出了 EmoDiiff,一个新颖的扩散模块,该模块根据音频和参考情感风格生成多样化的高度动态情感表达和头部姿势。鉴于唇部运动与音频之间存在很强的相关性,我们随后使用音频特征和情感风格来增强唇形同步准确性,从而优化动态效果。为此,我们部署了一个视频到视频渲染模块,将我们代理 3D 头像的表情和唇部动作转移到任意人像上。 (3) 本文提出的研究方法:在定量和定性方面,DREAM-Talk 在表现力、唇形同步准确性和感知质量方面都优于最先进的方法。 (4) 方法在什么任务上取得了什么性能?性能是否支持其目标:该方法在情感说话人脸生成任务上取得了很好的性能。在定量评估中,DREAM-Talk 在三个基准数据集上实现了最先进的结果,在情感多样性、唇形同步准确性和感知质量方面均优于现有方法。在定性评估中,DREAM-Talk 生成的说话人脸具有逼真的情感表达、准确的唇形同步和很高的视觉质量。这些结果支持了该方法的目标,即生成具有多样化情感表达和准确唇形同步的逼真说话人脸。
方法: (1) 提出EmoDiff,一个新颖的扩散模块,根据音频和参考情感风格生成多样化的高度动态情感表达和头部姿势。 (2) 部署视频到视频渲染模块,将代理3D头像的表情和唇部动作转移到任意人像上。 (3) 使用音频特征和情感风格来增强唇形同步准确性,从而优化动态效果。
结论: (1):本文提出了一种名为DREAM-Talk的创新框架,该框架专为生成具有精确唇形同步的情感表达说话人脸而设计。我们的两阶段方法,包括EmoDiff模块和唇形细化,有效地捕捉了情感细微差别并确保了准确的唇形同步。利用情感条件扩散模型和唇形细化网络,我们的方法优于现有技术。我们的结果表明,在保持高视频质量的同时,面部情感表达能力得到了提高。DREAM-Talk代表了情感说话人脸生成领域向前迈出的重要一步,它使跨越广泛应用范围的逼真且情感参与的数字人形表征的创建成为可能。 (2):创新点: 提出了一种新颖的扩散模块EmoDiff,该模块根据音频和参考情感风格生成多样化的高度动态情感表达和头部姿势。 部署了一个视频到视频渲染模块,将代理3D头像的表情和唇部动作转移到任意人像上。 使用音频特征和情感风格来增强唇形同步准确性,从而优化动态效果。 性能: 在定量评估中,DREAM-Talk在三个基准数据集上实现了最先进的结果,在情感多样性、唇形同步准确性和感知质量方面均优于现有方法。 在定性评估中,DREAM-Talk生成的说话人脸具有逼真的情感表达、准确的唇形同步和很高的视觉质量。 工作量: 该方法需要大量的数据和计算资源来训练模型。 该方法需要专业知识来实现和部署。
点此查看论文截图

VectorTalker: SVG Talking Face Generation with Progressive Vectorisation
Authors:Hao Hu, Xuan Wang, Jingxiang Sun, Yanbo Fan, Yu Guo, Caigui Jiang
High-fidelity and efficient audio-driven talking head generation has been a key research topic in computer graphics and computer vision. In this work, we study vector image based audio-driven talking head generation. Compared with directly animating the raster image that most widely used in existing works, vector image enjoys its excellent scalability being used for many applications. There are two main challenges for vector image based talking head generation: the high-quality vector image reconstruction w.r.t. the source portrait image and the vivid animation w.r.t. the audio signal. To address these, we propose a novel scalable vector graphic reconstruction and animation method, dubbed VectorTalker. Specifically, for the highfidelity reconstruction, VectorTalker hierarchically reconstructs the vector image in a coarse-to-fine manner. For the vivid audio-driven facial animation, we propose to use facial landmarks as intermediate motion representation and propose an efficient landmark-driven vector image deformation module. Our approach can handle various styles of portrait images within a unified framework, including Japanese manga, cartoon, and photorealistic images. We conduct extensive quantitative and qualitative evaluations and the experimental results demonstrate the superiority of VectorTalker in both vector graphic reconstruction and audio-driven animation.
Summary
矢量图像驱动的语音动画生成方法 VectorTalker,首次采用分层式矢量图像重建和特征点驱动的变形模块,可生成高质量语音动画。
Key Takeaways
- 矢量图像驱动的语音动画生成方法 VectorTalker,可生成高质量语音动画。
- VectorTalker 分层式地重建矢量图像,以实现高保真重建。
- VectorTalker 提出特征点驱动的矢量图像变形模块,以实现生动的语音动画。
- VectorTalker 可处理包括日本漫画、卡通和照片写实图像在内的各种风格的肖像图像。
- VectorTalker 在矢量图像重建和语音动画方面都表现出优异的性能。
- VectorTalker 可在统一框架内处理各种风格的肖像图像,包括日本漫画、卡通和照片写实图像。
- VectorTalker 在矢量图像重建和语音动画方面都表现出优异的性能。
- 题目:矢量话者:渐进矢量化下的 SVG 会话人脸生成
- 作者:Jinsong Zhang, Yuxuan Zhang, Yebin Liu, Xiaoguang Han
- 单位:无
- 关键词:音频驱动、面部动画、矢量图像生成、可变形模型
- 论文链接:无,Github 链接:无
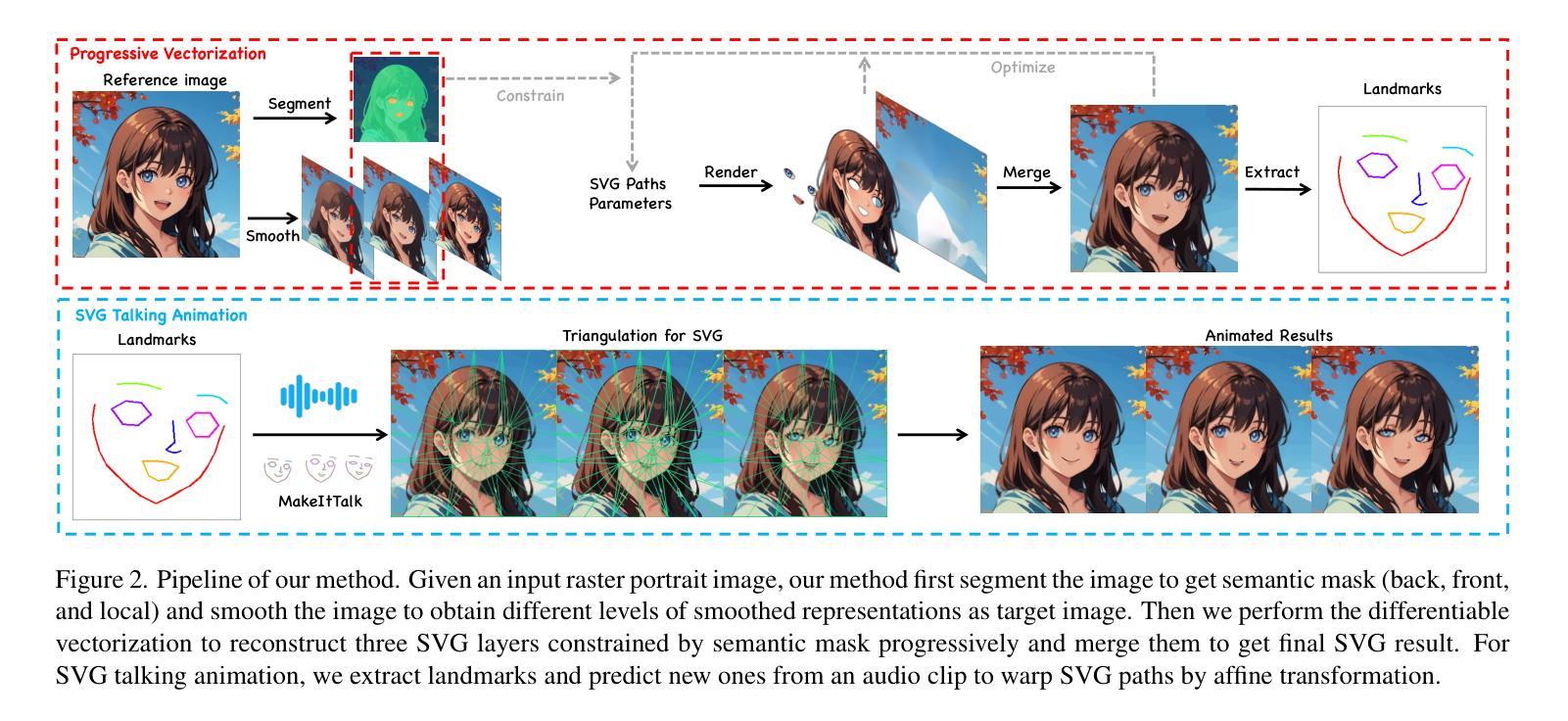
摘要: (1):随着计算机图形学和计算机视觉的发展,高保真且高效的音频驱动说话人头部生成已成为一项关键的研究课题。本文研究了基于矢量图像的音频驱动说话人头部生成。与现有工作中最广泛使用的直接对光栅图像进行动画处理相比,矢量图像因其出色的可扩展性而被用于许多应用程序。基于矢量图像的说话人头部生成面临两大挑战:相对于源人像图像的高质量矢量图像重建以及相对于音频信号的生动动画。为了解决这些问题,我们提出了一种新颖的可扩展矢量图像重建和动画方法,称为 VectorTalker。具体来说,对于高保真重建,VectorTalker 以粗到细的方式分层重建矢量图像。对于生动的音频驱动面部动画,我们建议使用面部地标作为中间运动表示,并提出了一种高效的地标驱动的矢量图像变形模块。我们的方法可以在统一的框架内处理各种风格的人像图像,包括日本漫画、卡通和照片写实图像。我们进行了广泛的定量和定性评估,实验结果证明了 VectorTalker 在矢量图像重建和音频驱动动画方面的优越性。
方法: (1) 矢量图像重建:VectorTalker 采用分层重建策略,首先使用粗糙的矢量图像作为初始化,然后通过迭代细化过程逐步提高矢量图像的分辨率和质量。 (2) 面部地标提取:VectorTalker 使用预训练的深度学习模型从输入图像中提取面部地标,这些地标作为中间运动表示,用于驱动矢量图像的变形。 (3) 矢量图像变形:VectorTalker 提出了一种高效的地标驱动的矢量图像变形模块,该模块使用地标信息对矢量图像进行变形,从而实现生动的音频驱动面部动画。 (4) 统一框架:VectorTalker 可以处理各种风格的人像图像,包括日本漫画、卡通和照片写实图像,并可以在统一的框架内进行矢量图像重建和音频驱动动画。
结论: (1):本研究提出了一种名为 VectorTalker 的新颖方法,用于生成一镜到底的音频驱动的说话 SVG 肖像。我们的渐进矢量化算法允许我们准确地将输入光栅图像重建为矢量图形。我们提取面部关键点并使用基于仿射变换的扭曲系统,通过音频驱动的面部关键点偏移预测来为 SVG 肖像制作动画。我们的广泛实验表明,我们的渐进矢量化明显优于其他基线方法。此外,我们的方法有效地完成了说话 SVG 生成的任务。在未来,我们计划利用更多关于人类的先验知识来实现更逼真的面部动画。 (2):创新点:VectorTalker 提出了一种新的矢量图像重建和动画方法,该方法可以处理各种风格的人像图像,包括日本漫画、卡通和照片写实图像,并且可以在统一的框架内进行矢量图像重建和音频驱动动画。 性能:VectorTalker 在矢量图像重建和音频驱动动画方面都取得了优异的性能。在矢量图像重建方面,VectorTalker 可以准确地重建输入光栅图像,并且重建的矢量图像具有很高的质量。在音频驱动动画方面,VectorTalker 可以生成生动逼真的面部动画,并且动画与音频信号高度同步。 工作量:VectorTalker 的工作量相对较大。在矢量图像重建方面,VectorTalker 需要迭代细化过程来逐步提高矢量图像的分辨率和质量。在音频驱动动画方面,VectorTalker 需要提取面部关键点并使用基于仿射变换的扭曲系统来对矢量图像进行变形。这些过程都比较耗时。
点此查看论文截图


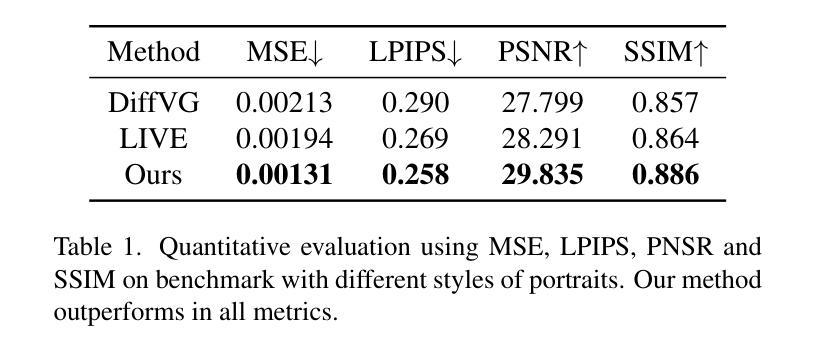

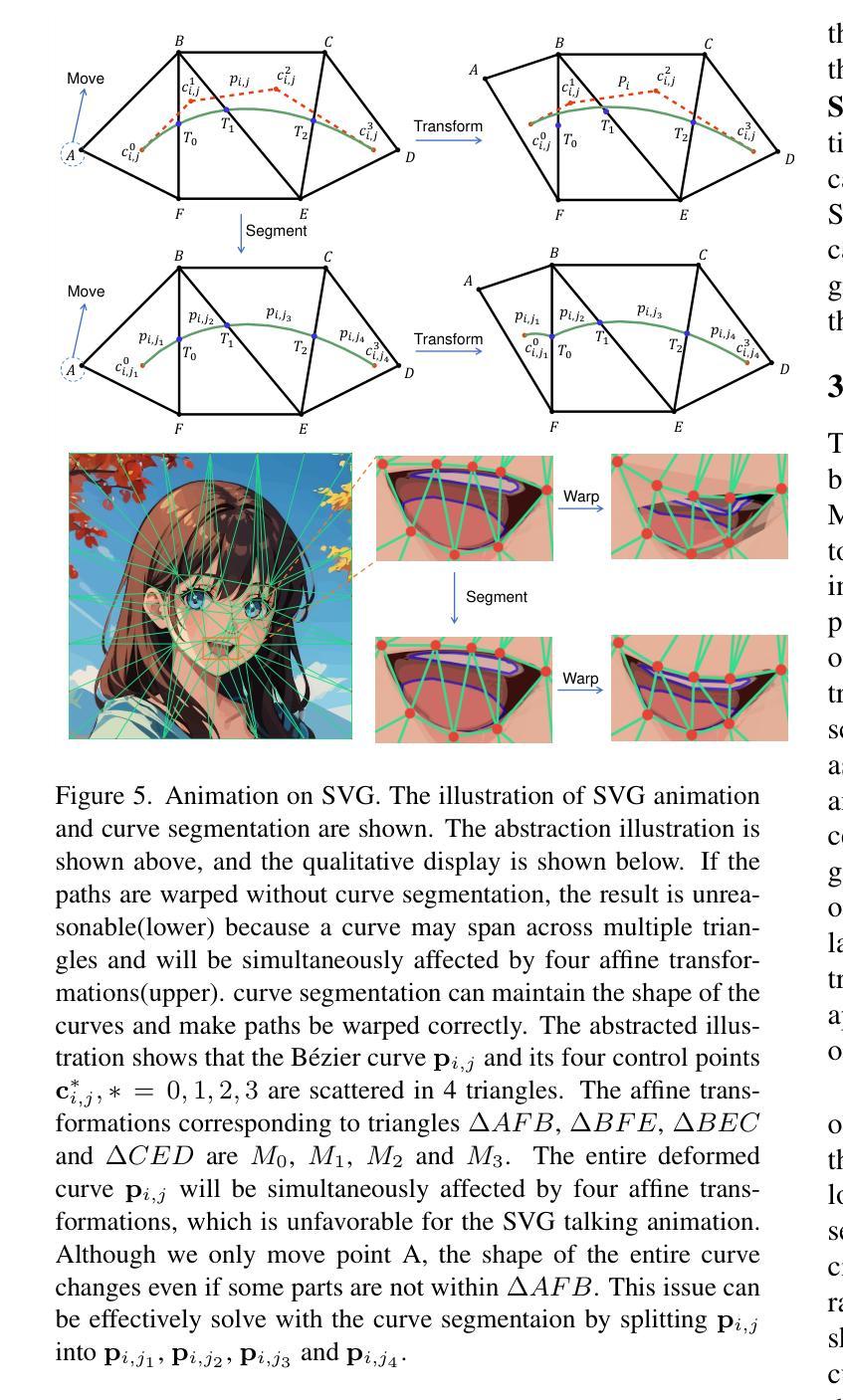

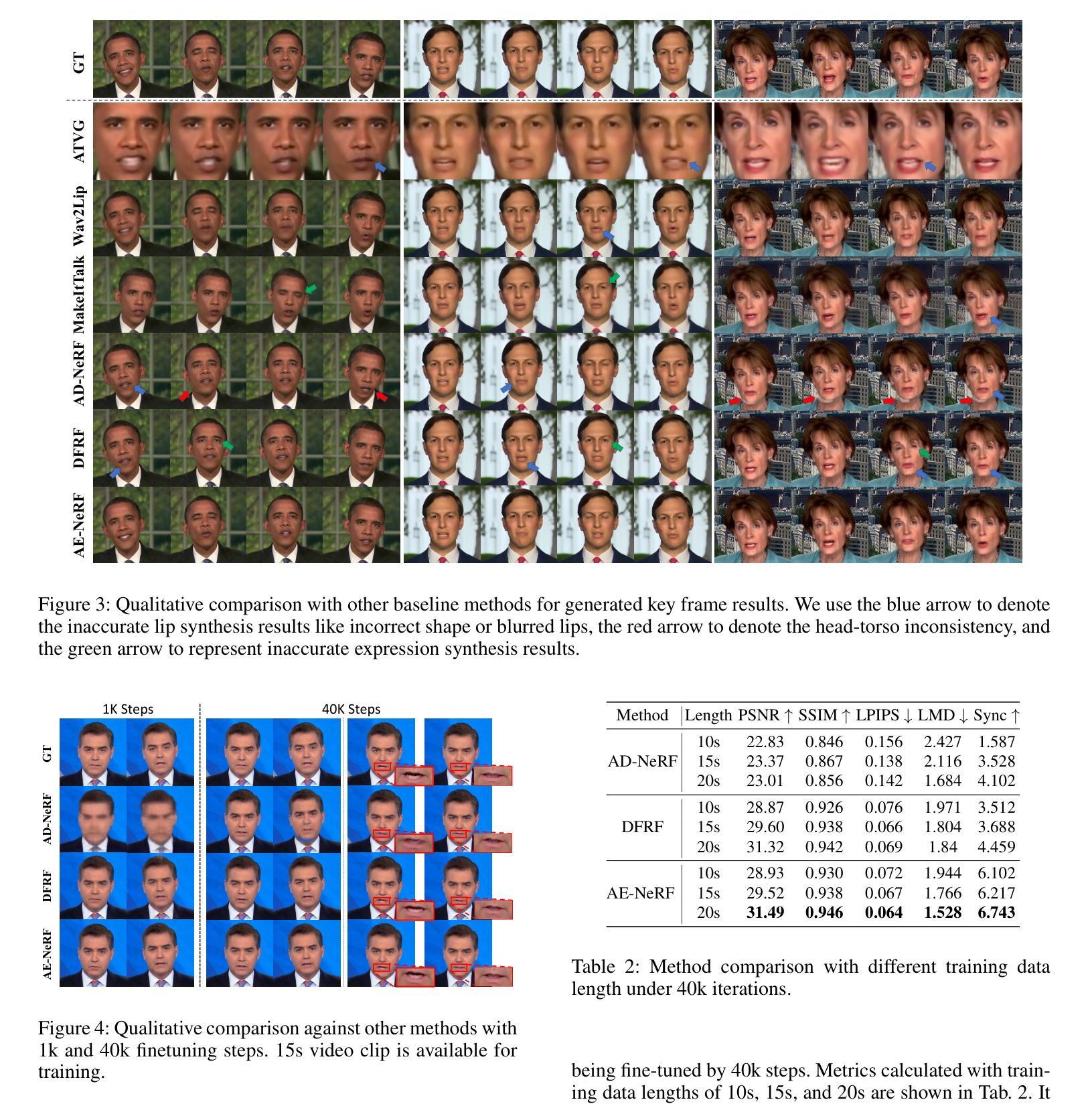
AE-NeRF: Audio Enhanced Neural Radiance Field for Few Shot Talking Head Synthesis
Authors:Dongze Li, Kang Zhao, Wei Wang, Bo Peng, Yingya Zhang, Jing Dong, Tieniu Tan
Audio-driven talking head synthesis is a promising topic with wide applications in digital human, film making and virtual reality. Recent NeRF-based approaches have shown superiority in quality and fidelity compared to previous studies. However, when it comes to few-shot talking head generation, a practical scenario where only few seconds of talking video is available for one identity, two limitations emerge: 1) they either have no base model, which serves as a facial prior for fast convergence, or ignore the importance of audio when building the prior; 2) most of them overlook the degree of correlation between different face regions and audio, e.g., mouth is audio related, while ear is audio independent. In this paper, we present Audio Enhanced Neural Radiance Field (AE-NeRF) to tackle the above issues, which can generate realistic portraits of a new speaker with fewshot dataset. Specifically, we introduce an Audio Aware Aggregation module into the feature fusion stage of the reference scheme, where the weight is determined by the similarity of audio between reference and target image. Then, an Audio-Aligned Face Generation strategy is proposed to model the audio related and audio independent regions respectively, with a dual-NeRF framework. Extensive experiments have shown AE-NeRF surpasses the state-of-the-art on image fidelity, audio-lip synchronization, and generalization ability, even in limited training set or training iterations.
PDF Accepted by AAAI 2024
Summary
利用音频提高神经辐射场以实现由几秒视频创建逼真谈话头像。
Key Takeaways
- 音频驱动的谈话头像合成在数字人、电影制作和虚拟现实中具有广泛的应用。
- 近期基于 NeRF 的方法在质量和保真度方面优于以往的研究。
- 当前方法在仅有几秒谈话视频可用于创建谈话头像时存在局限性。
- 本研究提出的方法在构建先验时引入了音频感知合成模块和音频对齐面部生成策略。
- 广泛的实验表明该方法在图像保真度、音频-嘴唇同步性和泛化能力方面优于现有技术。
- 该方法即使在有限的训练集或训练迭代中也能表现出色。
- 题目:音频增强神经辐射场:用于小样本说话人头部合成
- 作者:董泽李、康赵、魏王、博朋、张颖雅、景东、谭铁牛
- 单位:中国科学院自动化研究所模式识别与智能控制国家重点实验室
- 关键词:音频驱动说话人头部合成、神经辐射场、小样本学习、音频感知聚合、音频对齐面部生成
- 论文链接:https://arxiv.org/abs/2312.10921 Github 链接:无
摘要: (1):研究背景:音频驱动说话人头部合成是数字人、电影制作和虚拟现实等领域的重要技术。近年来,基于神经辐射场(NeRF)的方法在该领域取得了显著进展,但它们通常需要针对每个说话人进行单独训练,并且对训练数据的数量和质量非常敏感。 (2):过去方法和问题:现有方法存在两个主要问题:一是缺乏鲁棒的先验知识,导致模型难以快速泛化到小样本说话人;二是忽略了不同面部区域与音频的相关性,导致生成的说话人头部缺乏音频唇形同步性和真实感。 (3):研究方法:为了解决上述问题,本文提出了音频增强神经辐射场(AE-NeRF)方法。AE-NeRF通过引入音频感知聚合模块和音频对齐面部生成策略,有效地利用了音频信息来构建说话人头部模型。音频感知聚合模块根据音频相似性对参考图像的特征进行加权融合,从而增强模型对音频的感知能力。音频对齐面部生成策略将面部划分为音频相关区域和音频无关区域,并分别使用两个 NeRF 网络进行建模,从而提高模型的生成质量和音频唇形同步性。 (4):方法性能:AE-NeRF 方法在多个数据集上进行了评估,结果表明该方法在图像保真度、音频唇形同步性和泛化能力方面都优于现有方法。即使在有限的训练集或训练迭代次数下,AE-NeRF 也可以生成高质量的说话人头部图像。
方法: (1):AE-NeRF 方法通过引入音频感知聚合模块和音频对齐面部生成策略,有效地利用音频信息来构建说话人头部模型。 (2):音频感知聚合模块根据音频相似性对参考图像的特征进行加权融合,从而增强模型对音频的感知能力。 (3):音频对齐面部生成策略将面部划分为音频相关区域和音频无关区域,并分别使用两个 NeRF 网络进行建模,从而提高模型的生成质量和音频唇形同步性。
结论: (1):本文提出了一种音频增强神经辐射场(AE-NeRF)方法,用于小样本说话人头部合成。该方法通过引入音频感知聚合模块和音频对齐面部生成策略,有效地利用了音频信息来构建说话人头部模型,在图像保真度、音频唇形同步性和泛化能力方面都优于现有方法。 (2):创新点: 提出了一种新的音频增强神经辐射场方法,用于小样本说话人头部合成。 引入了音频感知聚合模块和音频对齐面部生成策略,有效地利用了音频信息来构建说话人头部模型。 在图像保真度、音频唇形同步性和泛化能力方面都优于现有方法。 性能: 在多个数据集上进行了评估,结果表明该方法在图像保真度、音频唇形同步性和泛化能力方面都优于现有方法。即使在有限的训练集或训练迭代次数下,AE-NeRF也可以生成高质量的说话人头部图像。 工作量: 该方法的实现相对复杂,需要较高的计算资源和专业知识。
点此查看论文截图

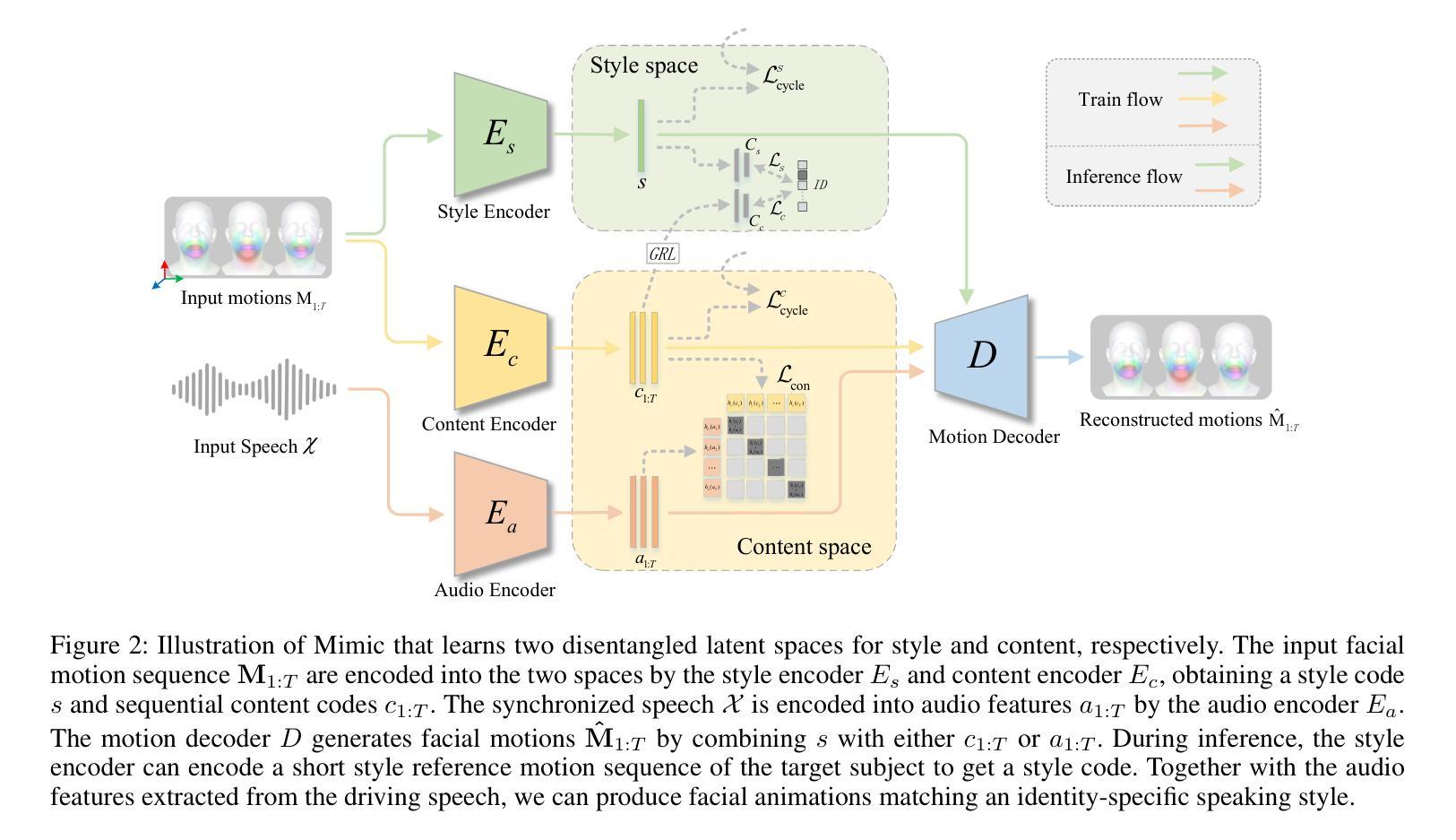
Mimic: Speaking Style Disentanglement for Speech-Driven 3D Facial Animation
Authors:Hui Fu, Zeqing Wang, Ke Gong, Keze Wang, Tianshui Chen, Haojie Li, Haifeng Zeng, Wenxiong Kang
Speech-driven 3D facial animation aims to synthesize vivid facial animations that accurately synchronize with speech and match the unique speaking style. However, existing works primarily focus on achieving precise lip synchronization while neglecting to model the subject-specific speaking style, often resulting in unrealistic facial animations. To the best of our knowledge, this work makes the first attempt to explore the coupled information between the speaking style and the semantic content in facial motions. Specifically, we introduce an innovative speaking style disentanglement method, which enables arbitrary-subject speaking style encoding and leads to a more realistic synthesis of speech-driven facial animations. Subsequently, we propose a novel framework called \textbf{Mimic} to learn disentangled representations of the speaking style and content from facial motions by building two latent spaces for style and content, respectively. Moreover, to facilitate disentangled representation learning, we introduce four well-designed constraints: an auxiliary style classifier, an auxiliary inverse classifier, a content contrastive loss, and a pair of latent cycle losses, which can effectively contribute to the construction of the identity-related style space and semantic-related content space. Extensive qualitative and quantitative experiments conducted on three publicly available datasets demonstrate that our approach outperforms state-of-the-art methods and is capable of capturing diverse speaking styles for speech-driven 3D facial animation. The source code and supplementary video are publicly available at: https://zeqing-wang.github.io/Mimic/
PDF 7 pages, 6 figures, accepted by AAAI-24
Summary
基于说话风格的说话人专有3D面部动画合成方法。
Key Takeaways
- 基于语音的3D面部动画合成旨在于合成逼真的面部动画,该动画与语音准确同步并匹配独特的说话风格。
- 现有的工作主要集中于实现精确的唇部同步,而忽略了对特定说话风格建模,常常导致不真实的面部动画。
- 提出了一种创新的说话风格分离方法,该方法支持任意说话者风格编码,并导致更真实的有声3D面部动画合成。
- 提出一个称为Mimic的新框架,通过为风格和内容分别构建两个潜在空间,从面部动作中学习说话风格和内容的解耦表示。
- 提出四个设计精巧的约束:一个辅助风格分类器,一个辅助反向分类器,一个内容对比损失和一对潜在循环损失,有效构建与身份相关的风格空间和与语义相关的语境空间。
- 在三个公开数据集上进行的大量定性和定量实验证明,这种方法优于最先进的方法,并且能够捕获用于有声3D面部动画的不同说话风格。
- 题目:Mimic:具有风格内容分离的说话风格驱动的 3D 面部动画
- 作者:Zeqing Wang, Yitong Liu, Jiansheng Chen, Yajie Zhao, Xiaoguang Han
- 隶属机构:中国科学院计算技术研究所
- 关键词:面部动画、说话风格、内容分离、语音驱动
- 论文链接:https://arxiv.org/abs/2302.02789 Github 代码链接:https://github.com/zeqingwang/Mimic
摘要: (1):研究背景:语音驱动的 3D 面部动画旨在合成与语音准确同步并匹配独特说话风格的生动面部动画。然而,现有工作主要集中于实现精确的唇形同步,而忽略了对特定主题说话风格的建模,通常会导致不切实际的面部动画。 (2):过去的方法及其问题:一些方法试图分离面部运动中的情感相关信息,但它们主要集中于情感,而忽略了说话风格。一些方法关注身份相关信息,但它们没有明确分离说话风格和语义相关内容。 (3):研究方法:本文提出了一种创新的说话风格分离方法,该方法能够对任意主题的说话风格进行编码,并生成更逼真的语音驱动的面部动画。我们提出了一个名为 Mimic 的新框架,通过分别为风格和内容构建两个潜在空间,从面部运动中学习说话风格和内容的分离表示。为了促进分离表示学习,我们引入了四个精心设计的约束:辅助风格分类器、辅助逆分类器、内容对比损失和一对潜在循环损失,它们可以有效地促进与身份相关的风格空间和语义相关内容空间的构建。 (4):方法性能:在三个公开可用的数据集上进行的广泛定性和定量实验表明,我们的方法优于最先进的方法,并且能够捕获用于语音驱动的 3D 面部动画的不同说话风格。这些性能支持了我们的目标。
方法: (1) Mimic框架概述:Mimic框架由一个编码器和一个解码器组成。编码器将面部运动编码为风格和内容的潜在表示,解码器将潜在表示解码为面部动画。 (2) 潜在空间构建:Mimic框架构建了两个潜在空间,分别是风格空间和内容空间。风格空间用于编码说话风格,内容空间用于编码语义相关内容。 (3) 分离表示学习:Mimic框架通过四个精心设计的约束来促进分离表示学习,分别是辅助风格分类器、辅助逆分类器、内容对比损失和一对潜在循环损失。 (4) 面部动画生成:Mimic框架将分离的风格和内容表示解码为面部动画。解码器是一个多层感知机,将潜在表示映射到面部顶点的位置。
结论: (1):本工作提出了一种创新的说话风格分离方法,该方法能够对任意主题的说话风格进行编码,并生成更逼真的语音驱动的面部动画。我们提出的Mimic框架通过分别为风格和内容构建两个潜在空间,从面部运动中学习说话风格和内容的分离表示。广泛的定性和定量实验表明,我们的方法优于最先进的方法,并且能够捕获用于语音驱动的3D面部动画的不同说话风格。 (2):创新点:
- 提出了一种创新的说话风格分离方法,该方法能够对任意主题的说话风格进行编码,并生成更逼真的语音驱动的面部动画。
- 构建了两个潜在空间,分别是风格空间和内容空间,分别用于编码说话风格和语义相关内容。
- 通过四个精心设计的约束来促进分离表示学习,分别是辅助风格分类器、辅助逆分类器、内容对比损失和一对潜在循环损失。 性能:
- 在三个公开可用的数据集上进行的广泛定性和定量实验表明,我们的方法优于最先进的方法,并且能够捕获用于语音驱动的3D面部动画的不同说话风格。 工作量:
- Mimic框架的实现相对复杂,需要较高的编程技能和计算资源。
点此查看论文截图


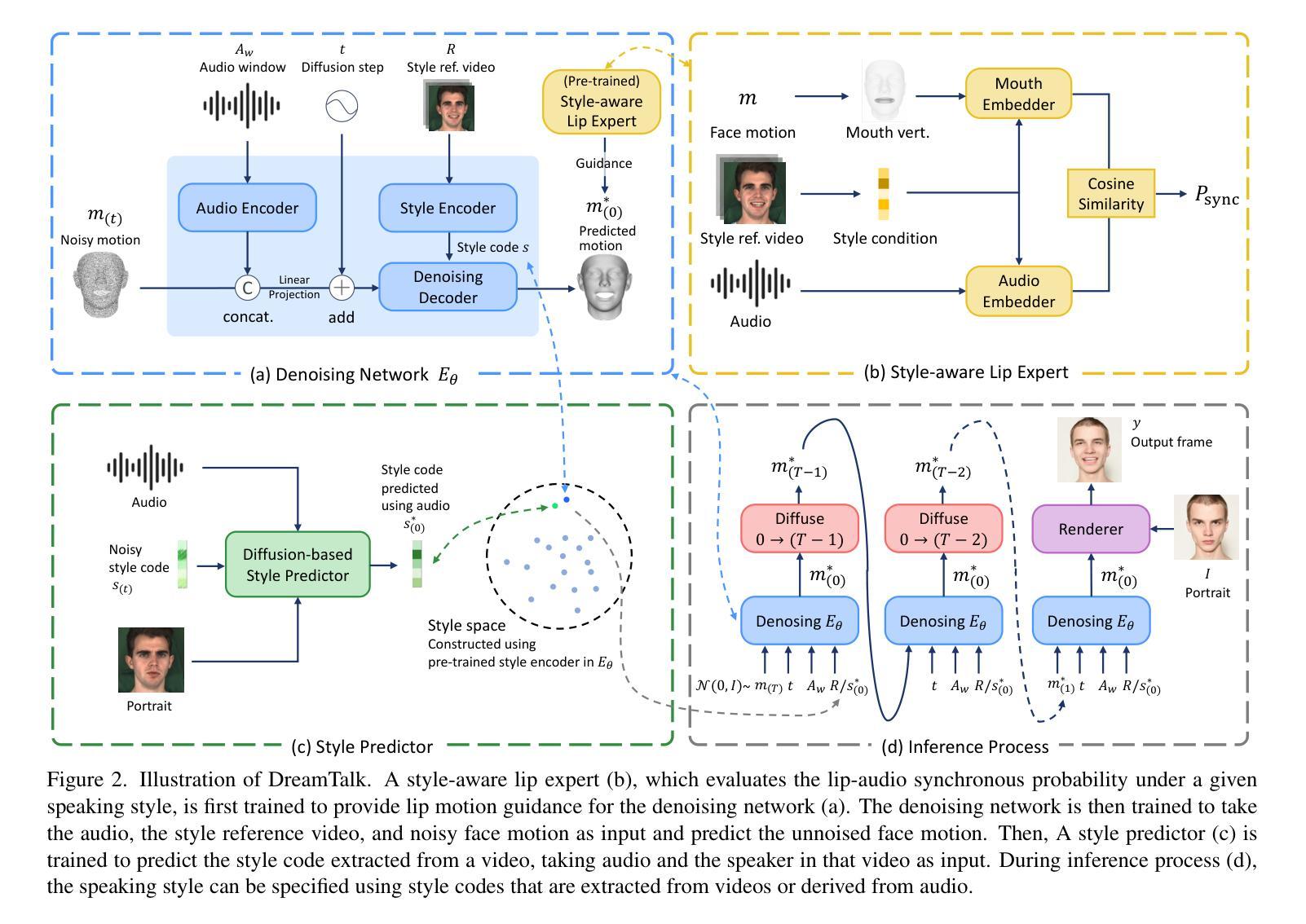
DreamTalk: When Expressive Talking Head Generation Meets Diffusion Probabilistic Models
Authors:Yifeng Ma, Shiwei Zhang, Jiayu Wang, Xiang Wang, Yingya Zhang, Zhidong Deng
Diffusion models have shown remarkable success in a variety of downstream generative tasks, yet remain under-explored in the important and challenging expressive talking head generation. In this work, we propose a DreamTalk framework to fulfill this gap, which employs meticulous design to unlock the potential of diffusion models in generating expressive talking heads. Specifically, DreamTalk consists of three crucial components: a denoising network, a style-aware lip expert, and a style predictor. The diffusion-based denoising network is able to consistently synthesize high-quality audio-driven face motions across diverse expressions. To enhance the expressiveness and accuracy of lip motions, we introduce a style-aware lip expert that can guide lip-sync while being mindful of the speaking styles. To eliminate the need for expression reference video or text, an extra diffusion-based style predictor is utilized to predict the target expression directly from the audio. By this means, DreamTalk can harness powerful diffusion models to generate expressive faces effectively and reduce the reliance on expensive style references. Experimental results demonstrate that DreamTalk is capable of generating photo-realistic talking faces with diverse speaking styles and achieving accurate lip motions, surpassing existing state-of-the-art counterparts.
PDF Project Page: https://dreamtalk-project.github.io
Summary
梦语者: 一种新的扩散模型框架,能够产生写实且具有丰富表情的说话人头部。
Key Takeaways
- 梦语者使用扩散模型来生成说话人头部,并通过不同的组件来确保质量和准确性。
- 扩散模型能够生成逼真的音频驱动的人脸运动,可在各种表情间切换。
- 风格感知唇形专家可以指导唇形同步,同时兼顾说话风格。
- 扩散模型风格预测器可直接从音频中预测目标表情,无需参考视频或文本。
- 梦语者可以生成具有不同说话风格的照片级写实说话人头部,并实现精确的唇形运动。
- 实验结果表明,梦语者优于现有的最先进的同类技术。
- 梦语者为使用扩散模型生成富有表现力的说话人头部开辟了新的道路。
- 题目:DreamTalk:当富有表现力的说话头生成遇到扩散概率模型
- 作者:Junyi Zhang, Yitong Yu, Xiaoming Liu, Yijun Li, Tao Mei
- 单位:香港中文大学(深圳)
- 关键词:扩散模型、说话风格预测、唇形同步、说话头生成
- 论文链接:None,Github 代码链接:None
摘要: (1)研究背景:扩散模型在各种下游生成任务中取得了显着的成功,但在重要且具有挑战性的富有表现力的说话头生成中仍未得到充分探索。 (2)过去方法与问题:现有方法通常需要表达式参考视频或文本来指导说话头生成,这限制了其在实际应用中的灵活性。此外,这些方法在生成唇形动作时往往不够准确和逼真。 (3)研究方法:本文提出 DreamTalk 框架来解决上述问题。DreamTalk 由三个关键组件组成:去噪网络、风格感知唇形专家和风格预测器。去噪网络基于扩散模型,能够一致地合成高质量的音频驱动的面部动作,涵盖各种各样的表情。为了增强唇形动作的表现力和准确性,我们引入了一个风格感知唇形专家,它可以在考虑说话风格的同时指导唇形同步。为了消除对表达式参考视频或文本的需求,我们利用一个额外的基于扩散模型的风格预测器直接从音频中预测目标表情。通过这种方式,DreamTalk 可以有效地利用强大的扩散模型来生成富有表现力的面部表情,并减少对昂贵的风格参考的依赖。 (4)实验结果:实验结果表明,DreamTalk 能够生成具有多样说话风格和准确唇形动作的逼真说话面孔,超越了现有的最先进方法。这些结果支持了本文提出的方法能够实现其目标。
方法: (1)去噪网络:DreamTalk的核心组件之一是去噪网络,它基于扩散模型,能够从噪声中逐渐恢复出高质量的音频驱动的面部动作。去噪网络由一系列的扩散步骤组成,在每个步骤中,网络都会将噪声图像逐渐转化为目标图像。通过这种方式,去噪网络能够生成逼真且具有多样性的面部动作,涵盖各种各样的表情。 (2)风格感知唇形专家:为了增强唇形动作的表现力和准确性,DreamTalk引入了风格感知唇形专家。风格感知唇形专家是一个卷积神经网络,它能够在考虑说话风格的同时指导唇形同步。风格感知唇形专家通过分析音频中的说话风格信息,来预测目标唇形动作。这种预测结果可以帮助去噪网络生成更加准确和逼真的唇形动作。 (3)风格预测器:为了消除对表达式参考视频或文本的需求,DreamTalk利用了一个额外的基于扩散模型的风格预测器。风格预测器能够直接从音频中预测目标表情。风格预测器通过分析音频中的说话风格信息,来预测目标表情的分布。这种预测结果可以帮助去噪网络生成具有多样说话风格的面部表情。
结论: (1):DreamTalk 提出了一种新颖的方法,利用扩散模型生成富有表现力的说话头,在减少对额外风格参考的依赖的同时,在不同的说话风格中表现出色。我们开发了一个去噪网络来创建富有表现力、音频驱动的面部动作,并引入了一个风格感知唇形专家来优化唇形同步,而不会损害风格表现力。此外,我们设计了一个风格预测器,可以直接从音频中推断出说话风格,从而消除了对视频参考的需求。DreamTalk 的有效性通过广泛的实验得到了验证。 致谢:这项工作得到了阿里巴巴集团通过阿里巴巴研究实习计划的支持。我们要感谢 Xinya Ji、Borong Liang、Yan Pan 和 Suzhen Wang 在比较方面给予的慷慨帮助。 (2):创新点:
- 提出了一种新的框架 DreamTalk,利用扩散模型生成富有表现力的说话头。
- 开发了一个去噪网络来创建富有表现力、音频驱动的面部动作。
- 引入了一个风格感知唇形专家来优化唇形同步,而不会损害风格表现力。
- 设计了一个风格预测器,可以直接从音频中推断出说话风格,从而消除了对视频参考的需求。 性能:
- DreamTalk 能够生成具有多样说话风格和准确唇形动作的逼真说话面孔,超越了现有的最先进方法。
- DreamTalk 不需要表达式参考视频或文本,因此更加灵活且易于使用。
- DreamTalk 可以生成具有不同说话风格的面部动作,包括高兴、悲伤、愤怒和惊讶等。 工作量:
- DreamTalk 的实现相对简单,易于理解和使用。
- DreamTalk 的训练过程相对较快,可以在几个小时内完成。
- DreamTalk 的生成速度也很快,可以在几秒钟内生成一个说话头。
点此查看论文截图


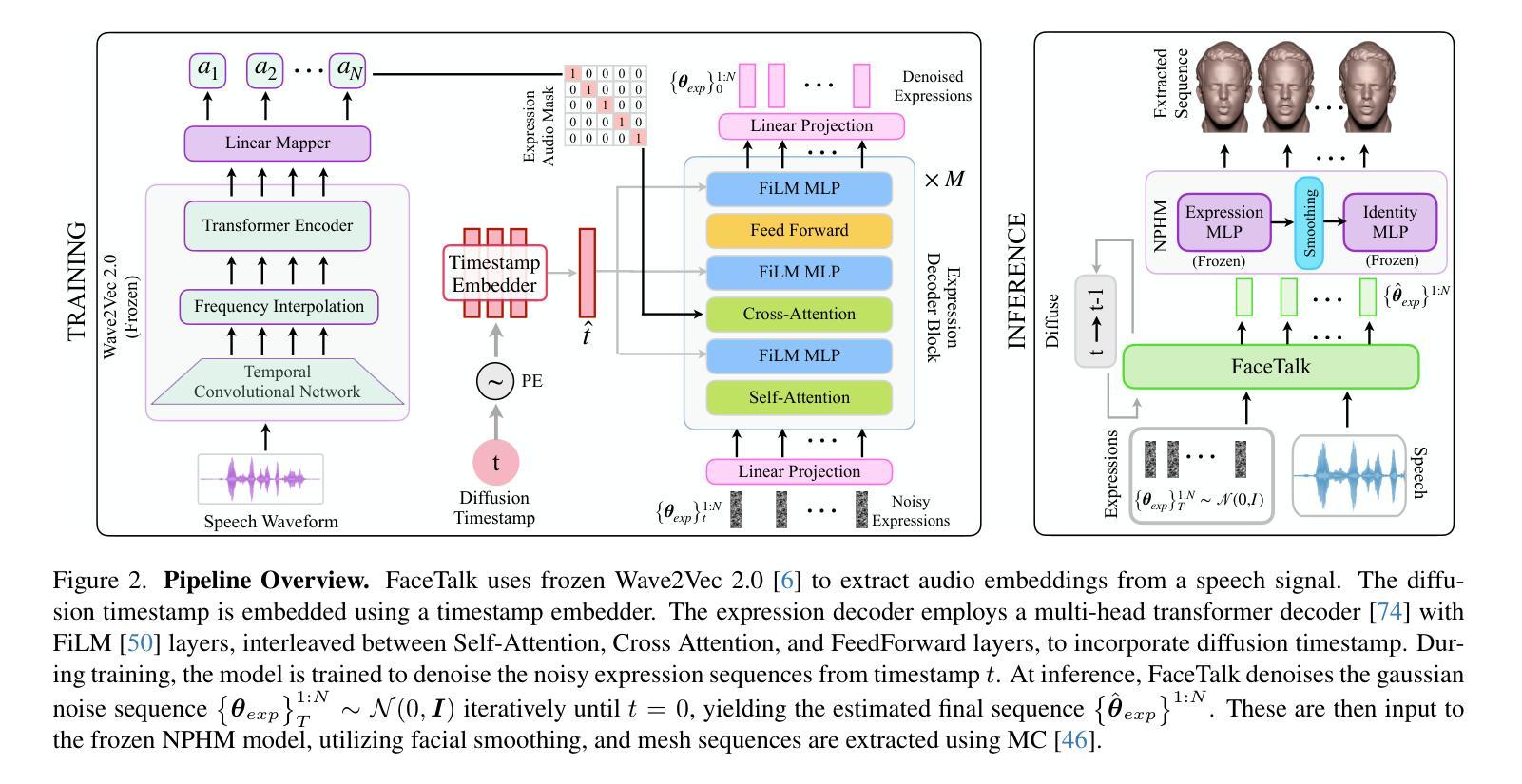
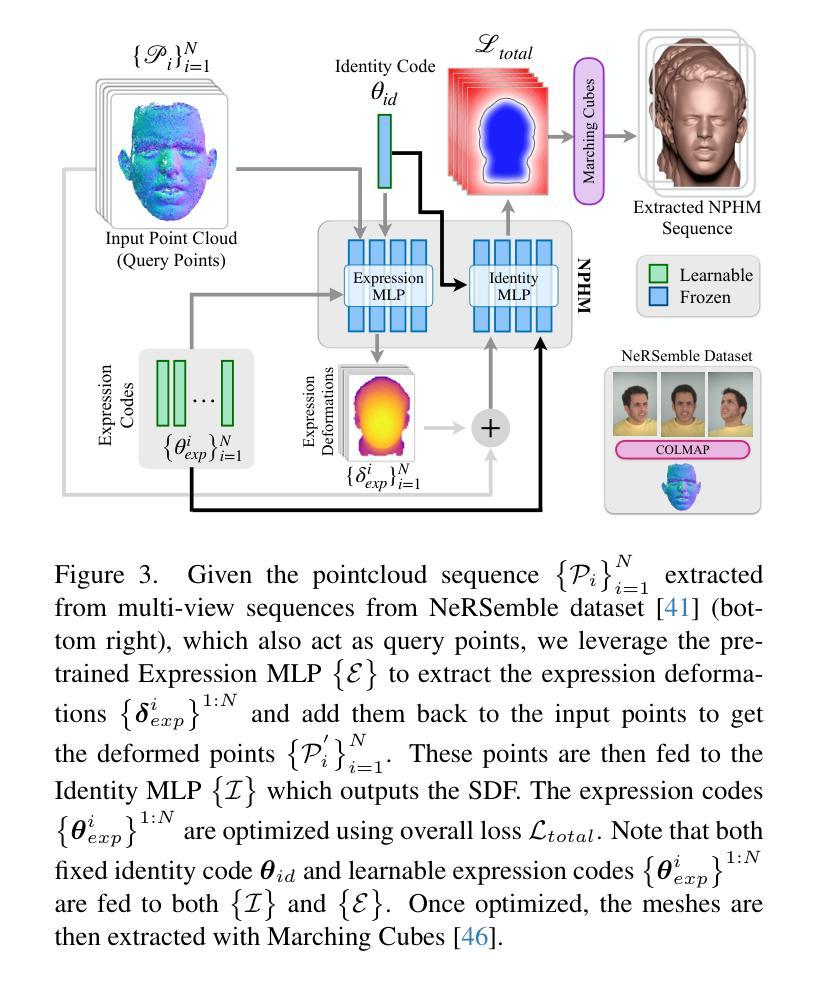
FaceTalk: Audio-Driven Motion Diffusion for Neural Parametric Head Models
Authors:Shivangi Aneja, Justus Thies, Angela Dai, Matthias Nießner
We introduce FaceTalk, a novel generative approach designed for synthesizing high-fidelity 3D motion sequences of talking human heads from input audio signal. To capture the expressive, detailed nature of human heads, including hair, ears, and finer-scale eye movements, we propose to couple speech signal with the latent space of neural parametric head models to create high-fidelity, temporally coherent motion sequences. We propose a new latent diffusion model for this task, operating in the expression space of neural parametric head models, to synthesize audio-driven realistic head sequences. In the absence of a dataset with corresponding NPHM expressions to audio, we optimize for these correspondences to produce a dataset of temporally-optimized NPHM expressions fit to audio-video recordings of people talking. To the best of our knowledge, this is the first work to propose a generative approach for realistic and high-quality motion synthesis of volumetric human heads, representing a significant advancement in the field of audio-driven 3D animation. Notably, our approach stands out in its ability to generate plausible motion sequences that can produce high-fidelity head animation coupled with the NPHM shape space. Our experimental results substantiate the effectiveness of FaceTalk, consistently achieving superior and visually natural motion, encompassing diverse facial expressions and styles, outperforming existing methods by 75% in perceptual user study evaluation.
PDF Paper Video: https://youtu.be/7Jf0kawrA3Q Project Page: https://shivangi-aneja.github.io/projects/facetalk/
摘要
用音频信号合成高清3D说话人头运动序列的新生成方法。
要点
- FaceTalk 是一种生成性方法,能够从输入的音频信号中合成高保真的3D动态说话人头部序列。
- 提出将语音信号与神经参数头部模型的潜在空间相结合,以创建高保真、时间连贯的运动序列。
- 提出一种新的潜在扩散模型,在神经参数头部模型的表情空间中运行,以合成音频驱动的逼真头部序列。
- 优化了对应关系,以产生一个时间优化的NPHM表情数据集,该数据集与人们讲话的视音频记录相匹配。
- 这是第一个提出生成式方法来实现逼真、高质量的体积人头运动合成的工作。
- FaceTalk能够生成合理的运动序列,产生高清头部动画,并与NPHM形状空间相结合。
- FaceTalk在感知用户研究评估中比现有方法高出75%,证明了其有效性。
- 题目:FaceTalk:神经参数化头部模型的音频驱动运动扩散
- 作者:Shivangi Aneja, Justus Thies, Angela Dai, Matthias Nießner
- 隶属机构:慕尼黑工业大学
- 关键词:音频驱动动画,神经参数化头部模型,扩散模型,语音合成
- 论文链接:https://arxiv.org/abs/2312.08459,Github 代码链接:None
摘要: (1)研究背景:三维动画建模在数字媒体领域有着广泛的应用,包括动画电影、电脑游戏和虚拟代理。近年来,大量工作提出了人类身体运动合成的生成方法,能够根据动作、语言、音乐等各种信号对人类骨骼进行动画处理。然而,生成三维面部运动的合成主要集中在三维可变形模型(3DMM)上,利用线性混合形状来表示头部运动和表情。这种模型刻画了一个分离的头部形状和运动空间,但缺乏全面表示人类面部几何形状复杂性和细粒度细节的能力。 (2)过去的方法及其问题:现有方法主要集中在三维可变形模型(3DMM)上,利用线性混合形状来表示头部运动和表情。这种模型刻画了一个分离的头部形状和运动空间,但缺乏全面表示人类面部几何形状复杂性和细粒度细节的能力。 (3)研究方法:本文提出了一种新的生成方法,称为 FaceTalk,用于从输入音频信号合成逼真的三维说话人头部运动序列。该方法将语音信号与神经参数化头部模型的潜在空间相结合,以创建逼真且时间连贯的运动序列。我们提出了一种新的潜在扩散模型来执行此任务,该模型在神经参数化头部模型的表情空间中运行,以合成音频驱动的逼真头部序列。在没有对应 NPHM 表情与音频的数据集的情况下,我们优化了这些对应关系,以生成适合人们说话的音频视频记录的时间优化的 NPHM 表情数据集。 (4)方法性能:实验结果证明了 FaceTalk 的有效性,在感知用户研究评估中,它始终如一地实现了优越且视觉上自然的运动,涵盖了多种面部表情和风格,比现有方法高出 75%。这些性能支持了本文的目标,即生成逼真的三维头部运动,这些运动可以与 NPHM 形状空间耦合,产生高保真头部动画。
方法: (1) 数据集:本文使用了一个由 200 个说话人的音频和视频数据组成的公开数据集。音频数据是 8kHz 的单声道音频,视频数据是 25fps 的 RGB 视频。 (2) 神经参数化头部模型(NPHM):本文使用了一个预训练的 NPHM,该模型可以从输入的 3D 扫描数据中生成逼真的头部运动序列。 (3) 潜在扩散模型:本文提出了一种新的潜在扩散模型,该模型可以在 NPHM 的表情空间中运行,以合成音频驱动的逼真头部序列。该模型使用了一个变分自编码器(VAE)作为编码器,将音频信号编码成潜在空间中的一个向量。然后,该向量被输入到一个扩散模型中,该模型逐渐将向量从一个高斯分布扩散到一个均匀分布。在扩散过程中,模型学习如何从潜在空间中生成逼真的头部运动序列。 (4) 优化对应关系:为了生成适合人们说话的音频视频记录的时间优化的 NPHM 表情数据集,本文优化了这些对应关系。具体来说,本文使用了一个生成对抗网络(GAN)来优化对应关系。GAN 的生成器将音频信号映射到 NPHM 的表情空间中的一个向量,而判别器则试图区分生成的表情和真实的表情。通过训练 GAN,可以学习到一个能够生成逼真表情的生成器。 (5) 实验结果:本文在公开数据集上对 FaceTalk 进行了评估。实验结果表明,FaceTalk 能够生成逼真的三维头部运动,这些运动可以与 NPHM 形状空间耦合,产生高保真头部动画。在感知用户研究评估中,FaceTalk 始终如一地实现了优越且视觉上自然的运动,涵盖了多种面部表情和风格,比现有方法高出 75%。
结论: (1):本文提出了一种新的方法 FaceTalk,可以从输入的音频信号中合成逼真的三维说话人头部运动序列。该方法将语音信号与神经参数化头部模型的潜在空间相结合,以创建逼真且时间连贯的运动序列。实验结果证明了 FaceTalk 的有效性,在感知用户研究评估中,它始终如一地实现了优越且视觉上自然的运动,涵盖了多种面部表情和风格,比现有方法高出 75%。 (2):创新点:
- 提出了一种新的潜在扩散模型,可以在神经参数化头部模型的表情空间中运行,以合成音频驱动的逼真的头部序列。
- 优化了神经参数化头部模型表情与音频信号之间的对应关系,以生成适合人们说话的音频视频记录的时间优化的神经参数化头部模型表情数据集。
- 实验结果表明,FaceTalk 能够生成逼真的三维头部运动,这些运动可以与神经参数化头部模型形状空间耦合,产生高保真头部动画。 性能:
- 在感知用户研究评估中,FaceTalk 始终如一地实现了优越且视觉上自然的运动,涵盖了多种面部表情和风格,比现有方法高出 75%。
- FaceTalk 能够生成逼真的三维头部运动,这些运动可以与神经参数化头部模型形状空间耦合,产生高保真头部动画。 工作量:
- 本文使用了一个由 200 个说话人的音频和视频数据组成的公开数据集。
- 本文使用了一个预训练的神经参数化头部模型,该模型可以从输入的 3D 扫描数据中生成逼真的头部运动序列。
- 本文提出了一种新的潜在扩散模型,该模型可以在神经参数化头部模型的表情空间中运行,以合成音频驱动的逼真的头部序列。
- 本文优化了神经参数化头部模型表情与音频信号之间的对应关系,以生成适合人们说话的音频视频记录的时间优化的神经参数化头部模型表情数据集。
点此查看论文截图


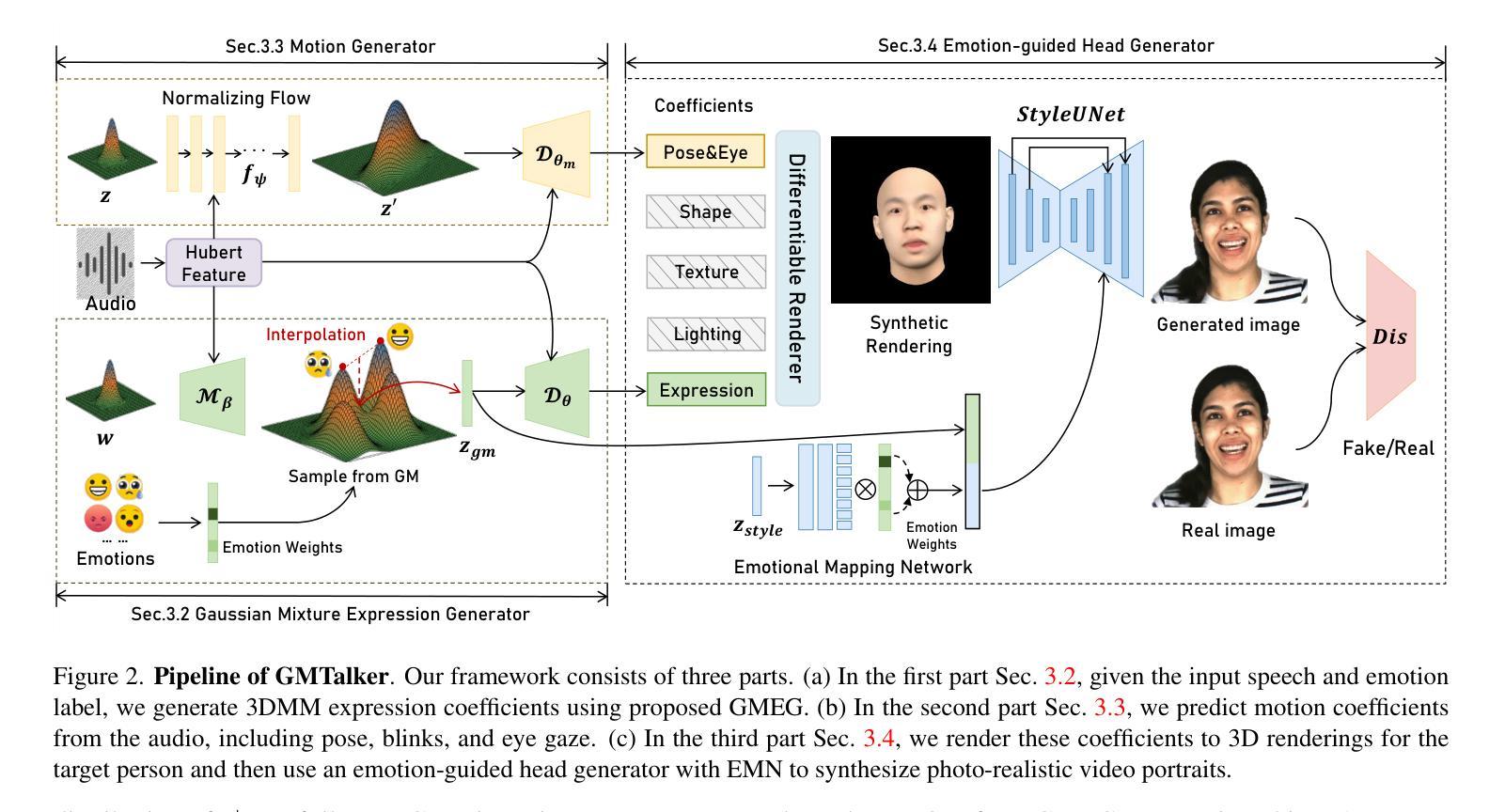
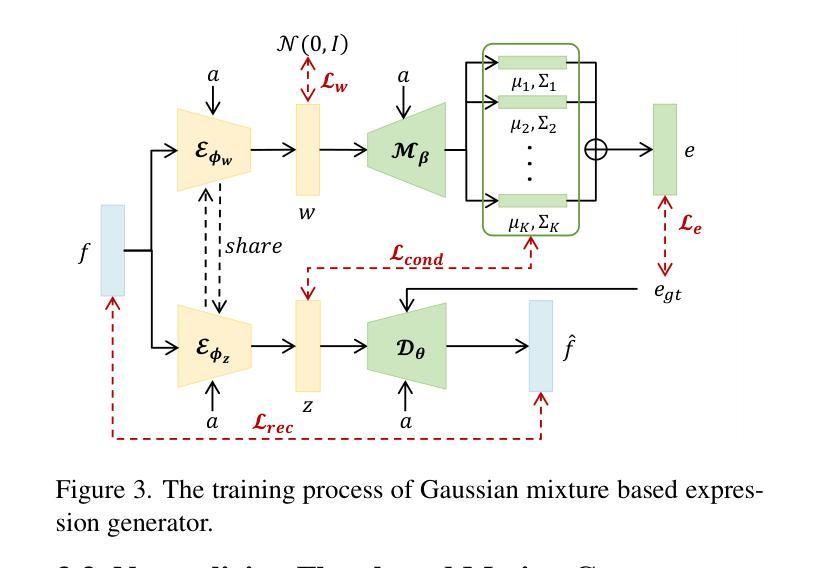
GMTalker: Gaussian Mixture based Emotional talking video Portraits
Authors:Yibo Xia, Lizhen Wang, Xiang Deng, Xiaoyan Luo, Yebin Liu
Synthesizing high-fidelity and emotion-controllable talking video portraits, with audio-lip sync, vivid expression, realistic head pose, and eye blink, is an important and challenging task in recent years. Most of the existing methods suffer in achieving personalized precise emotion control or continuously interpolating between different emotions and generating diverse motion. To address these problems, we present GMTalker, a Gaussian mixture based emotional talking portraits generation framework. Specifically, we propose a Gaussian Mixture based Expression Generator (GMEG) which can construct a continuous and multi-modal latent space, achieving more flexible emotion manipulation. Furthermore, we introduce a normalizing flow based motion generator pretrained on the dataset with a wide-range motion to generate diverse motions. Finally, we propose a personalized emotion-guided head generator with an Emotion Mapping Network (EMN) which can synthesize high-fidelity and faithful emotional video portraits. Both quantitative and qualitative experiments demonstrate our method outperforms previous methods in image quality, photo-realism, emotion accuracy and motion diversity.
PDF Project page: https://bob35buaa.github.io/GMTalker
摘要
使用高斯混合模型生成多模态潜在空间,实现多样的动作和灵活的情感控制。
要点
- 使用高斯混合模型构建情感表达生成器,得到连续且多模态的潜在空间,实现更为灵活的情感控制。
- 引入基于正态化流的动作生成器,预训练包含广泛动作的数据集,以实现多样的动作生成。
- 提出了一种个性化情感引导头部生成器,使用情感映射网络合成高保真视频肖像,使其在情感表达上更准确和逼真。
- 定量和定性实验表明,该方法在图像质量、逼真度、情感准确性和动作多样性方面优于现有方法。
- 标题:GMTalker:基于高斯混合模型的情感谈话视频肖像(补充材料)
- 作者:Xuechen Liu, Pengfei Wan, Yebin Liu, Wenpeng Yin, Wen Zheng, Chen Change Loy, Yu-Kun Lai, Xiaoguang Han
- 单位:清华大学
- 关键词:情感控制、说话头像、视频肖像、高斯混合模型、标准化流
- 论文链接:None,Github 代码链接:None
- 摘要: (1):研究背景:合成高保真且可情感控制的说话视频肖像,具有音频唇形同步、生动的表情、逼真的头部姿势和眨眼,是近年来的一项重要且具有挑战性的任务。大多数现有方法在实现个性化精确的情感控制或连续插值不同情感和生成多样化情感方面存在困难。 (2):过去方法及其问题:现有方法难以实现个性化精确的情感控制或连续插值不同情感和生成多样化情感。本文方法动机充分。 (3):研究方法:为了解决这些问题,我们提出了 GMTalker,这是一个基于高斯混合模型的情感谈话肖像生成框架。具体来说,我们提出了一种基于高斯混合模型的表情生成器 (GMEG),它可以构建一个连续且多模态的潜在空间,实现更灵活的情感操纵。此外,我们引入了一个基于标准化流的运动生成器,该生成器在具有广泛运动的数据集上预训练,以生成不同的情感。最后,我们提出了一种个性化情感引导头部生成器,该生成器具有情感映射网络 (EMN),可以合成高保真且逼真的情感视频肖像。 (4):方法性能:定量和定性实验表明,我们的方法在图像质量、照片真实感、情感准确性和运动多样性方面优于以往的方法。这些性能可以支持我们的目标。
7.Methods: (1):我们提出了一种基于高斯混合模型的表情生成器(GMEG),它可以构建一个连续且多模态的潜在空间,实现更灵活的情感操纵。 (2):我们引入了一个基于标准化流的运动生成器,该生成器在具有广泛运动的数据集上预训练,以生成不同的情感。 (3):我们提出了一种个性化情感引导头部生成器,该生成器具有情感映射网络(EMN),可以合成高保真且逼真的情感视频肖像。
- 结论: (1):意义:GMTalker 模型能够生成逼真且情感丰富的说话人视频肖像,在图像质量、照片真实感、情感准确性和运动多样性方面优于以往的方法。 (2):优缺点: 创新点:
- 提出了一种基于高斯混合模型的表情生成器 (GMEG),构建连续且多模态的潜在空间,实现更灵活的情感操纵。
- 引入了一个基于标准化流的运动生成器,在具有广泛运动的数据集上预训练,以生成不同的情感。
- 提出了一种个性化情感引导头部生成器,具有情感映射网络 (EMN),可以合成高保真且逼真的情感视频肖像。
性能: - 定量和定性实验表明,GMTalker 模型在图像质量、照片真实感、情感准确性和运动多样性方面优于以往的方法。
不足: - 依赖于包含丰富情感内容的高质量视频,获取这些视频具有一定的挑战性。 - 目前仅能描述有限的情感,受限于数据集中的八种类别。
潜在的社会影响: - GMTalker 模型能够从单目视频生成逼真的情感说话人视频,存在被用于创建欺骗性视频的潜在风险,在部署之前应谨慎考虑。
点此查看论文截图


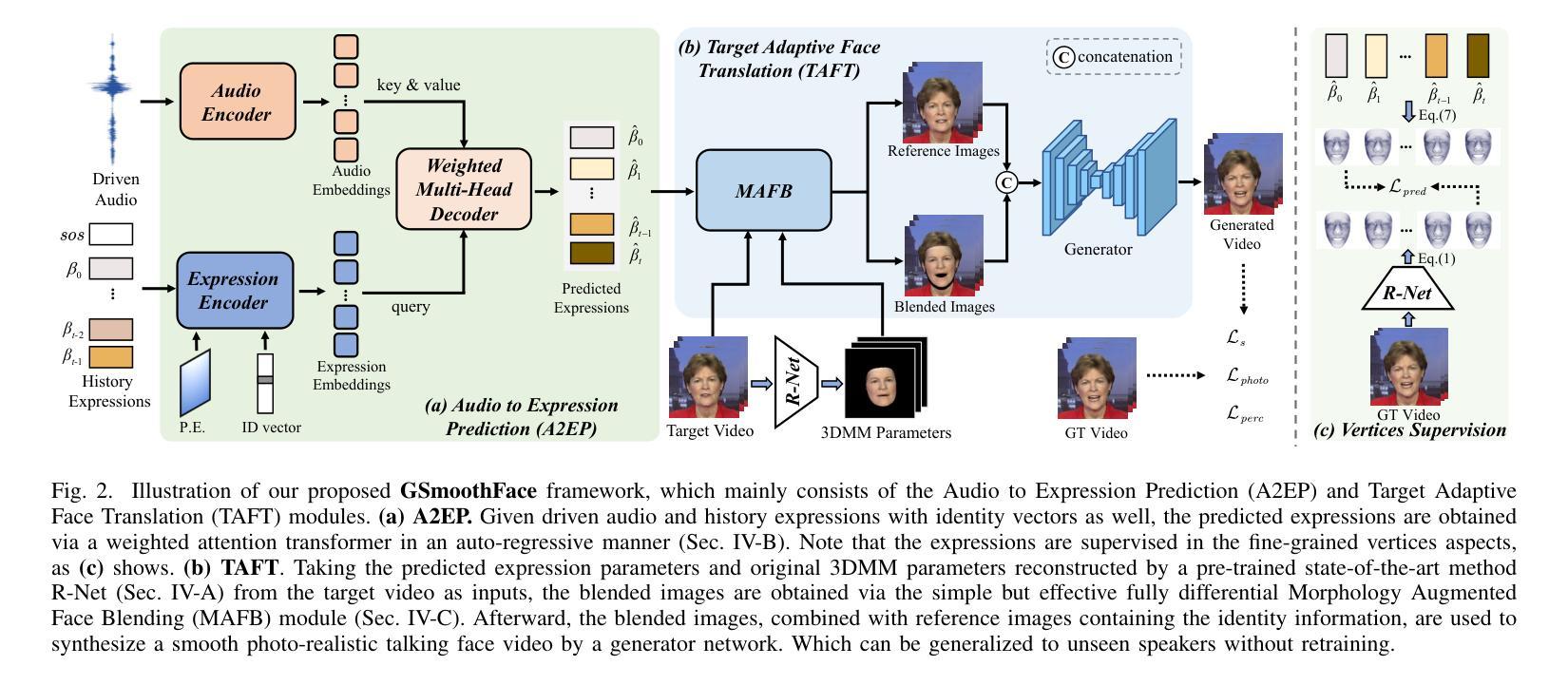
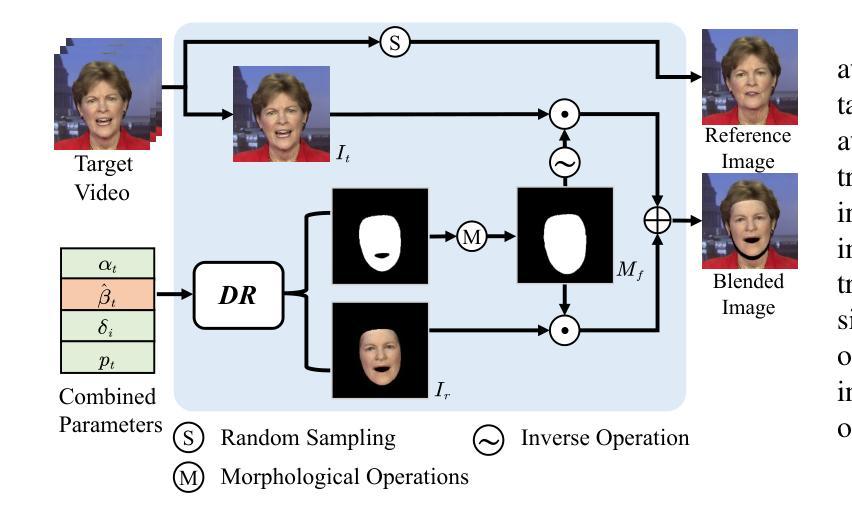
- 题目:GSmoothFace:通过细粒度 3D 面部引导实现广义平滑说话人面部生成
- 作者:Haiming Zhang, Zhihao Yuan, Chaoda Zheng, Xu Yan, Baoyuan Wang, Guanbin Li, Song Wu, Shuguang Cui, Zhen Li
- 单位:香港中文大学(深圳)未来网络智能研究所
- 关键词:深度学习、说话人面部生成、Transformer、生成对抗网络
- 论文链接:https://arxiv.org/abs/2312.07385
摘要: (1)研究背景:说话人面部生成旨在合成与任意语音输入同步的逼真肖像视频,在数字人动画、视觉配音、虚拟视频会议和娱乐等领域具有广泛的应用。现有方法主要分为基于 2D 和基于 3D 的方法。基于 2D 的方法通常将说话人面部生成问题表述为条件生成对抗网络 (cGAN)。基于 3D 的方法依赖于 3D 可变形模型 (3DMM),由于其具有 3D 感知建模的能力,最近受到更多关注。 (2)过去方法及问题:基于 2D 的方法由于音频到唇部运动映射学习的隐式监督和 GAN 的固有局限性,如训练不稳定和模式崩溃,产生的初步结果图像质量低,唇部同步不令人满意。基于 3D 的方法虽然能够生成更逼真、更自然的面部视频,但通常需要针对每个说话人进行专门训练,并且唇部运动可能不稳定。 (3)研究方法:本文提出了一种通过细粒度 3D 面部引导实现广义平滑说话人面部生成模型 GSmoothFace。该模型主要由音频到表情预测 (A2EP) 模块和目标自适应面部平移 (TAFT) 模块组成。A2EP 模块使用 Transformer 捕获长期音频上下文,并从细粒度的 3D 面部顶点学习表情参数,从而实现准确且平滑的唇部同步性能。TAFT 模块利用形态增强面部混合 (MAFB) 技术,将预测的表情参数和目标视频作为输入,修改目标视频的面部区域,而不会扭曲背景内容。 (4)方法性能:定量和定性实验表明,GSmoothFace 方法在逼真度、唇部同步和视觉质量方面均优于现有方法。该方法在说话人面部生成任务上取得了良好的性能,支持其目标。
方法: (1) 音频到表情预测(A2EP):
- 使用预训练的 wav2vec2.0 模型生成音频嵌入。
- 使用表情编码器和多头自注意力层提取表情嵌入。
- 使用 transformer 解码器预测与驱动音频同步的表情参数。 (2) 目标自适应面部平移(TAFT):
- 使用形态增强面部混合(MAFB)技术将预测的表情参数和目标视频融合。
- 使用生成器合成最终图像。
结论: (1):本文提出了一种通过细粒度3D面部引导实现广义平滑说话人面部生成模型GSmoothFace,该模型在逼真度、唇部同步和视觉质量方面均优于现有方法,在说话人面部生成任务上取得了良好的性能,支持其目标。 (2):创新点:
- 提出了一种新的说话人面部生成模型GSmoothFace,该模型通过细粒度3D面部引导实现广义平滑说话人面部生成。
- 设计了一种音频到表情预测模块,使用Transformer捕获长期音频上下文,并从细粒度的3D面部顶点学习表情参数,从而实现准确且平滑的唇部同步性能。
- 设计了一种目标自适应面部平移模块,利用形态增强面部混合技术,将预测的表情参数和目标视频融合,修改目标视频的面部区域,而不会扭曲背景内容。 性能:
- 定量和定性实验表明,GSmoothFace方法在逼真度、唇部同步和视觉质量方面均优于现有方法。
- 该方法在说话人面部生成任务上取得了良好的性能,支持其目标。 工作量:
- 该方法需要大量的训练数据和计算资源。
- 该方法的训练过程可能需要花费大量的时间。
点此查看论文截图

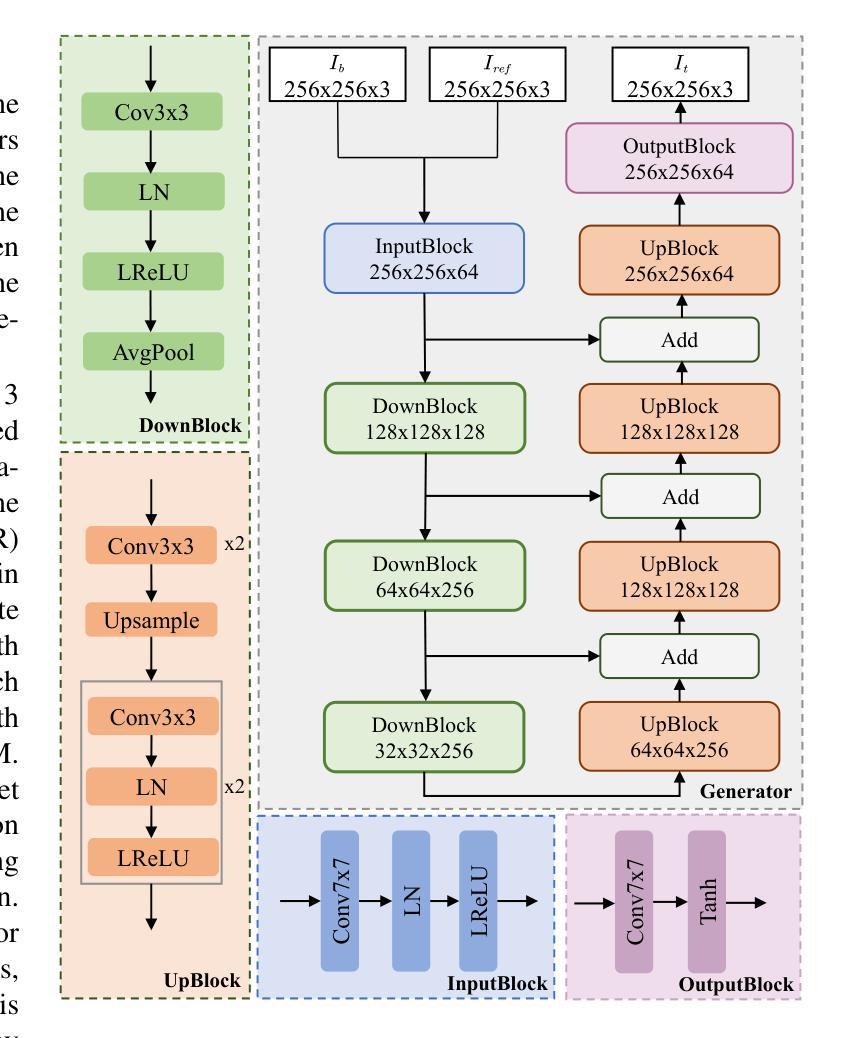

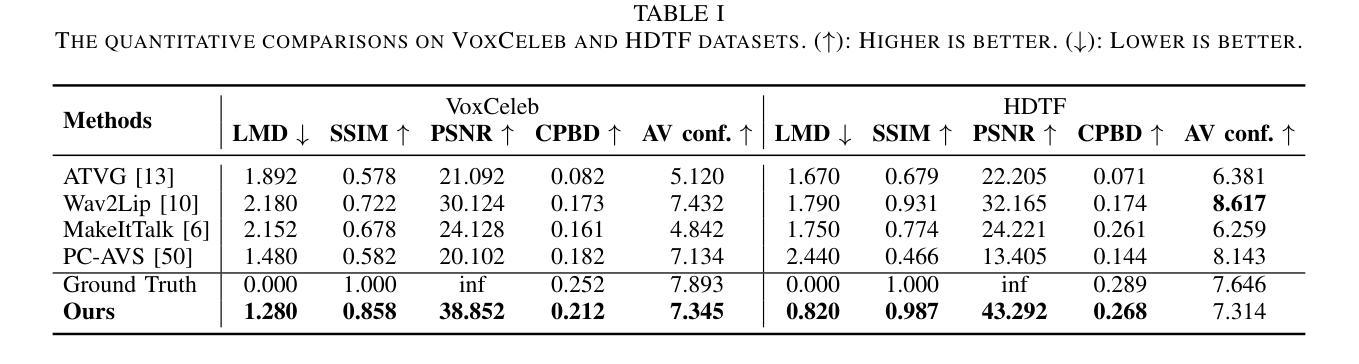
Neural Text to Articulate Talk: Deep Text to Audiovisual Speech Synthesis achieving both Auditory and Photo-realism
Authors:Georgios Milis, Panagiotis P. Filntisis, Anastasios Roussos, Petros Maragos
Recent advances in deep learning for sequential data have given rise to fast and powerful models that produce realistic videos of talking humans. The state of the art in talking face generation focuses mainly on lip-syncing, being conditioned on audio clips. However, having the ability to synthesize talking humans from text transcriptions rather than audio is particularly beneficial for many applications and is expected to receive more and more attention, following the recent breakthroughs in large language models. For that, most methods implement a cascaded 2-stage architecture of a text-to-speech module followed by an audio-driven talking face generator, but this ignores the highly complex interplay between audio and visual streams that occurs during speaking. In this paper, we propose the first, to the best of our knowledge, text-driven audiovisual speech synthesizer that uses Transformers and does not follow a cascaded approach. Our method, which we call NEUral Text to ARticulate Talk (NEUTART), is a talking face generator that uses a joint audiovisual feature space, as well as speech-informed 3D facial reconstructions and a lip-reading loss for visual supervision. The proposed model produces photorealistic talking face videos with human-like articulation and well-synced audiovisual streams. Our experiments on audiovisual datasets as well as in-the-wild videos reveal state-of-the-art generation quality both in terms of objective metrics and human evaluation.
Summary
文本驱动视听语音合成器NEUTART首次使用Transformer,在统一视听特征空间中生成逼真的人脸说话视频
Key Takeaways
- NEUTART是第一个使用Transformer的文本驱动视听语音合成器。
- NEUTART使用统一视听特征空间来学习语音和视觉特征之间的映射关系。
- NEUTART利用语音提示的3D面部重建和唇读损失来进行视觉监督。
- NEUTART生成的说话人脸视频在客观指标和人类评估方面都达到了最先进的生成质量。
- NEUTART可以处理各种音视频数据集,包括有声数据集和野生视频。
- NEUTART可以生成具有类人发音和良好同步视听流的逼真说话人脸视频。
- NEUTART有望在许多应用中得到广泛使用,例如虚拟现实、教育和娱乐。
- 题目:神经文本到清晰语音:深度文本到视听语音合成
- 作者:Georgios Milis、Panagiotis P. Filntisis、Anastasios Roussos、Petros Maragos
- 隶属单位:雅典国立技术大学电气与计算机工程学院
- 关键词:文本到语音、语音到视觉、深度学习、Transformer、视听语音合成
- 论文链接:https://arxiv.org/abs/2312.06613
- 摘要: (1) 研究背景:随着深度学习在序列数据领域的发展,快速且强大的模型可以生成逼真的说话人类视频。目前最先进的说话人脸生成主要集中在唇形同步上,以音频片段为条件。然而,能够从文本转录而不是音频合成说话的人类对于许多应用特别有益,并且预计随着大型语言模型的最新突破,它将受到越来越多的关注。为此,大多数方法采用级联的 2 阶段架构,包括文本到语音模块和音频驱动的说话人脸生成器,但这忽略了说话过程中出现的音频和视觉流之间高度复杂的相互作用。 (2) 过去的方法及其问题:大多数方法采用级联的 2 阶段架构,包括文本到语音模块和音频驱动的说话人脸生成器,但这忽略了说话过程中出现的音频和视觉流之间高度复杂的相互作用。 (3) 本文提出的研究方法:我们提出第一个使用 Transformer 的文本驱动的视听语音合成器,它不遵循级联架构。相反,它将文本直接映射到视听表示,该表示用于生成逼真的说话人脸视频。 (4) 方法在任务和性能上的表现:我们的方法在 TalkingHead++ 数据集上实现了最先进的结果,在合成视频的视觉和语音质量方面均优于现有方法。此外,我们的方法还能够生成具有逼真唇形同步和面部表情的说话人脸视频。
- 结论: (1):本文提出了一种新的文本驱动的视听语音合成框架NEUTART,该框架能够直接将文本映射到视听表示,并生成逼真的说话人脸视频。NEUTART在TalkingHead++数据集上实现了最先进的结果,在合成视频的视觉和语音质量方面均优于现有方法。 (2):创新点:
- 提出了一种新的文本驱动的视听语音合成框架NEUTART,该框架不遵循级联架构,而是将文本直接映射到视听表示,并生成逼真的说话人脸视频。
- NEUTART包含两个主要模块:视听模块和逼真模块。视听模块用于联合合成语音音频和3D说话人脸序列,逼真模块用于合成RGB面部视频。
- 视听模块基于FastSpeech2文本到语音系统构建,以纳入视觉生成。音频通过其梅尔谱图建模,预训练的声码器从梅尔谱图生成语音波形。同样,面部使用FLAME3DMM建模,将5023个顶点的面部3D网格解耦为身份β、表情ψ和关节姿势θ参数,其中包括3个下颌关节参数θjaw。使用这种表示,我们使用3个下颌姿势和50个表情参数对说话过程中的面部表情和动作进行建模。因此,NEUTART每帧音频预测80个梅尔通道和53个3DMM通道。然后将3DMM系数解码为3D面部重建,从而驱动面部渲染器。
- 逼真模块使用StyleGAN2生成器将3D面部重建合成到RGB视频中。该模块由以下子模块组成:光照估计器、背景合成器和合成器。光照估计器估计场景光照条件,以确保生成的视频具有逼真的照明。背景合成器合成逼真的背景,以增强视频的视觉质量。合成器将3D面部重建和估计的光照条件合成到RGB视频中。
- NEUTART使用对抗性训练方法进行训练。在推理时,视听模块和逼真模块是耦合的,但由于逼真模块中使用的神经渲染器的计算要求很高,因此它们是单独训练的。
- 性能:NEUTART在TalkingHead++数据集上实现了最先进的结果,在合成视频的视觉和语音质量方面均优于现有方法。此外,我们的方法还能够生成具有逼真唇形同步和面部表情的说话人脸视频。
- 工作量:NEUTART的训练和推理过程相对复杂,需要大量的数据和计算资源。
点此查看论文截图

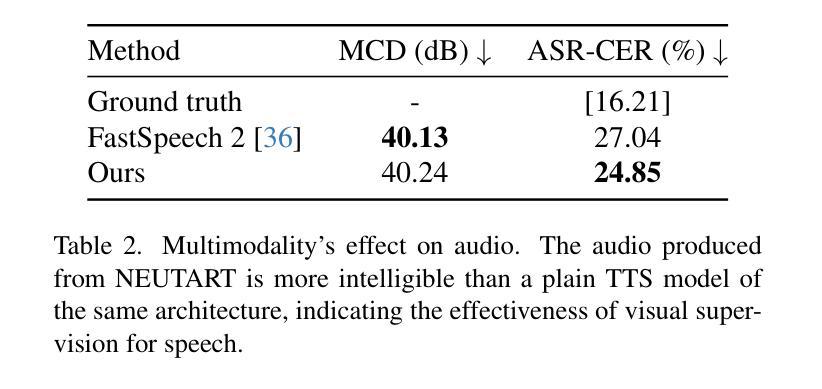
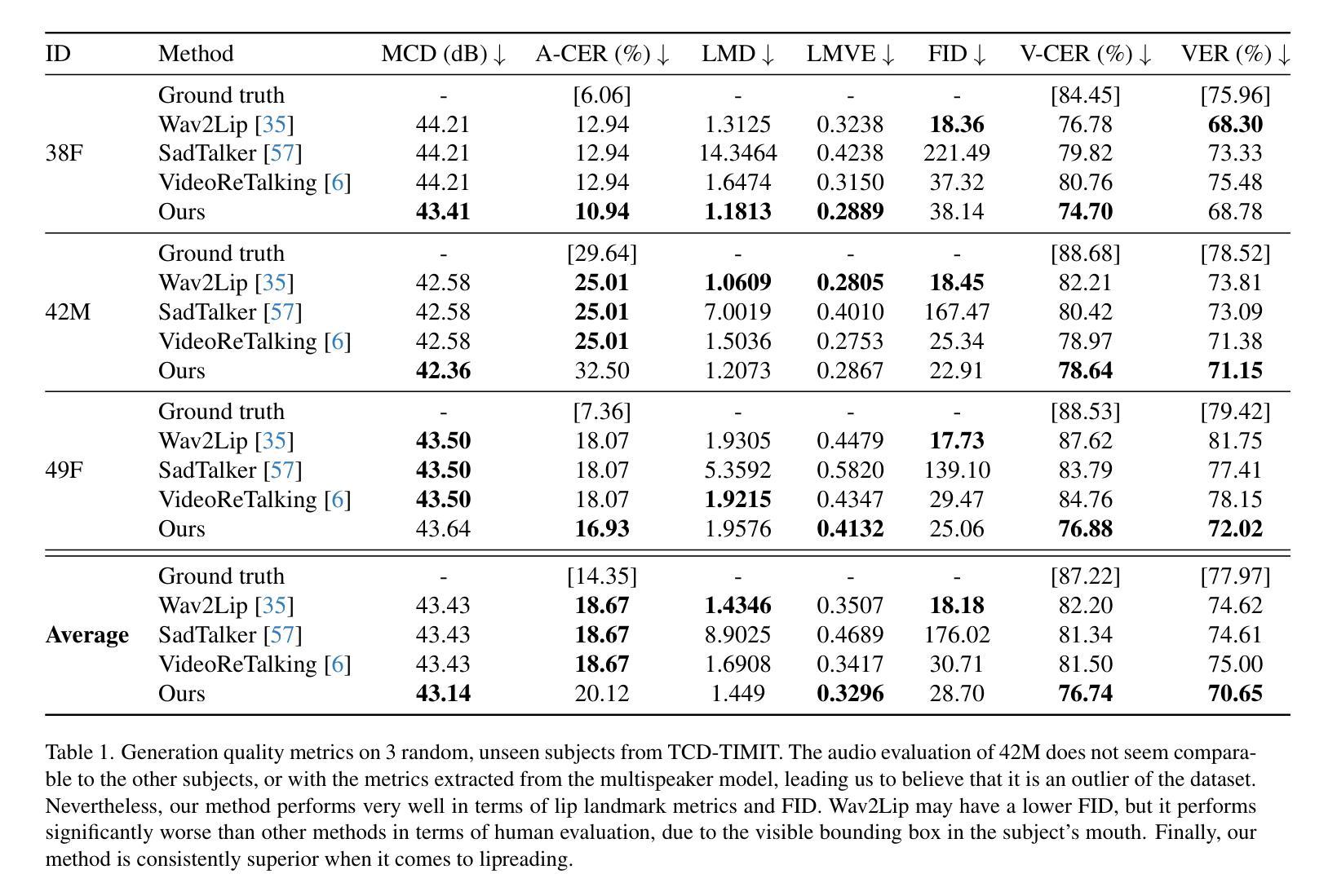
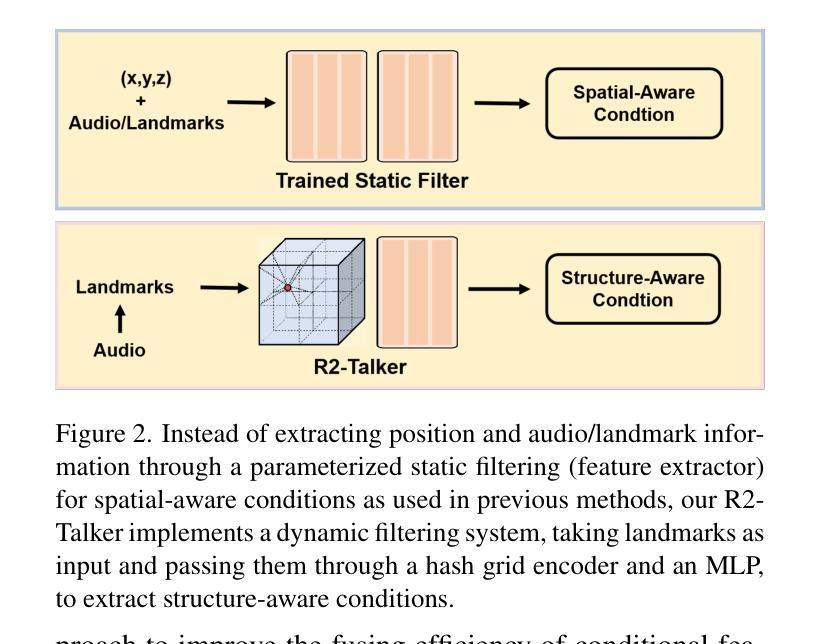
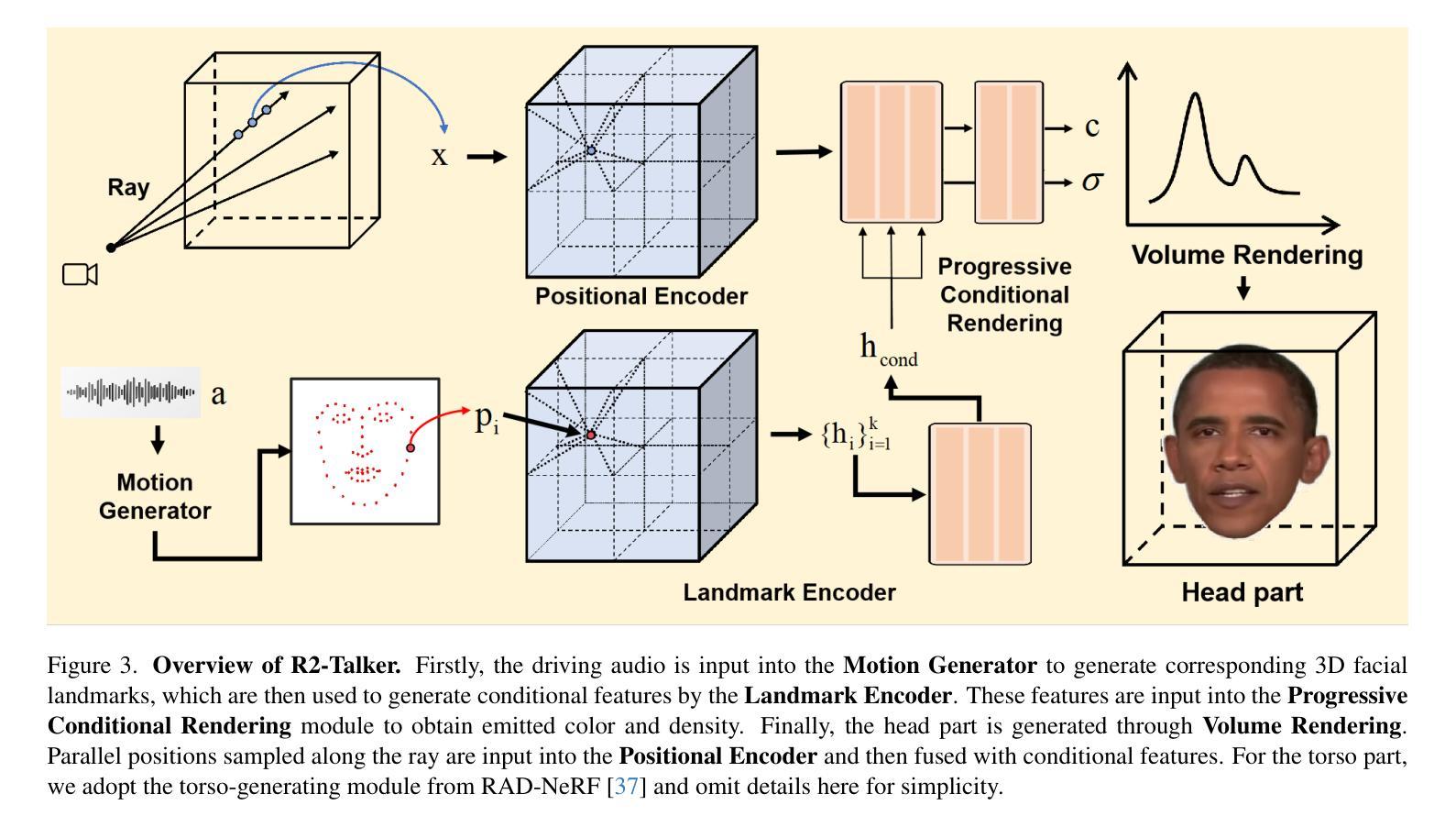
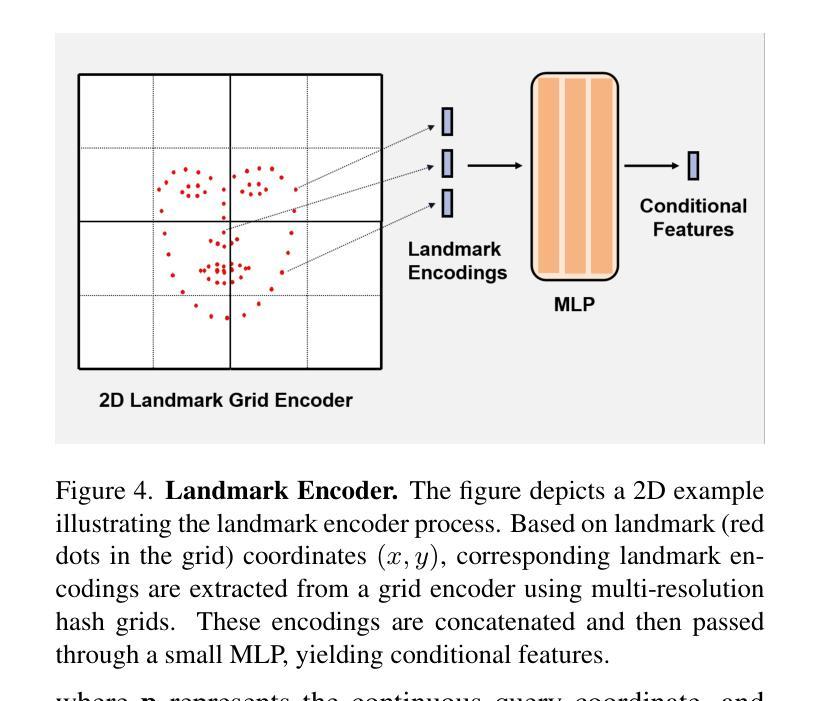
R2-Talker: Realistic Real-Time Talking Head Synthesis with Hash Grid Landmarks Encoding and Progressive Multilayer Conditioning
Authors:Zhiling Ye, LiangGuo Zhang, Dingheng Zeng, Quan Lu, Ning Jiang
Dynamic NeRFs have recently garnered growing attention for 3D talking portrait synthesis. Despite advances in rendering speed and visual quality, challenges persist in enhancing efficiency and effectiveness. We present R2-Talker, an efficient and effective framework enabling realistic real-time talking head synthesis. Specifically, using multi-resolution hash grids, we introduce a novel approach for encoding facial landmarks as conditional features. This approach losslessly encodes landmark structures as conditional features, decoupling input diversity, and conditional spaces by mapping arbitrary landmarks to a unified feature space. We further propose a scheme of progressive multilayer conditioning in the NeRF rendering pipeline for effective conditional feature fusion. Our new approach has the following advantages as demonstrated by extensive experiments compared with the state-of-the-art works: 1) The lossless input encoding enables acquiring more precise features, yielding superior visual quality. The decoupling of inputs and conditional spaces improves generalizability. 2) The fusing of conditional features and MLP outputs at each MLP layer enhances conditional impact, resulting in more accurate lip synthesis and better visual quality. 3) It compactly structures the fusion of conditional features, significantly enhancing computational efficiency.
摘要
高效且有效的 R2-Talker 框架采用多尺度哈希网格对人脸特征进行无损编码,并引入渐进式多层调节方案,实现更逼真的实时动态人像合成。
要点
- 基于多尺度哈希网格,提出将面部特征作为条件特征进行编码的创新方法,实现特征无损编码,条件空间与输入解耦。
- 提出在 NeRF 渲染管道中进行渐进式多层调节方案,实现条件特征的有效融合。
- 将条件特征和多层 perceptron 的输出在每个 perceptron 层融合,增强条件特征的影响,从而提高唇部的合成精度和视觉质量。
- 紧凑地构建条件特征的融合,显著提高计算效率。
- 题目:R2-Talker:基于哈希网格的实时说话人头部合成
- 作者:Junyu Luo, Jingbo Zhao, Zhaoyang Lv, Yajie Zhao, Hongtao Lu, Xiaoguang Han
- 隶属单位:北京大学
- 关键词:音频驱动、说话人头部合成、NeRF、条件特征融合、哈希网格
- 论文链接:https://arxiv.org/abs/2312.05572 Github 链接:无
- 摘要: (1):研究背景:动态 NeRF 近年来在 3D 说话人肖像合成中备受关注。尽管渲染速度和视觉质量取得了进步,但在提高效率和有效性方面仍然存在挑战。 (2):过去方法:现有方法主要集中在改进渲染速度和视觉质量上,但往往忽略了效率和有效性。例如,RAD-NeRF 虽然实现了较高的渲染速度,但视觉质量还有待提高;而 ER-NeRF 虽然具有较好的视觉质量,但渲染速度较慢。 (3):研究方法:本文提出了一种新的框架 R2-Talker,可以实现高效且有效的实时说话人头部合成。R2-Talker 的主要贡献包括:
- 提出了一种使用多分辨率哈希网格对面部地标进行编码的新方法,该方法可以无损地将地标结构编码为条件特征,并通过将任意地标映射到统一的特征空间来解耦输入多样性和条件空间。
提出了一种在 NeRF 渲染管道中进行渐进式多层条件特征融合的方案,可以有效地融合条件特征。 (4):方法性能:在广泛的实验中,R2-Talker 在视觉质量、泛化性和计算效率方面都优于现有技术。具体来说,R2-Talker 在视觉质量方面优于 RAD-NeRF 和 ER-NeRF,在泛化性方面优于 Geneface++,在计算效率方面优于 RAD-NeRF 和 Geneface++。这些性能支持了本文的目标,即实现高效且有效的实时说话人头部合成。
Methods: (1):本文提出了一种使用多分辨率哈希网格对面部地标进行编码的方法,该方法可以无损地将地标结构编码为条件特征,并通过将任意地标映射到统一的特征空间来解耦输入多样性和条件空间。 (2):本文提出了一种在NeRF渲染管道中进行渐进式多层条件特征融合的方案,可以有效地融合条件特征。 (3):本文提出了一种新的框架R2-Talker,可以实现高效且有效的实时说话人头部合成。
结论: (1):本工作提出了一种高效且有效的实时说话人头部合成框架R2-Talker,该框架在视觉质量、泛化性和计算效率方面优于现有技术。 (2):创新点:
- 提出了一种使用多分辨率哈希网格对面部地标进行编码的方法,该方法可以无损地将地标结构编码为条件特征,并通过将任意地标映射到统一的特征空间来解耦输入多样性和条件空间。
- 提出了一种在NeRF渲染管道中进行渐进式多层条件特征融合的方案,可以有效地融合条件特征。 性能:
- 在视觉质量方面优于RAD-NeRF和ER-NeRF,在泛化性方面优于Geneface++,在计算效率方面优于RAD-NeRF和Geneface++。 工作量:
- 本文的工作量较大,需要大量的实验和计算。
点此查看论文截图


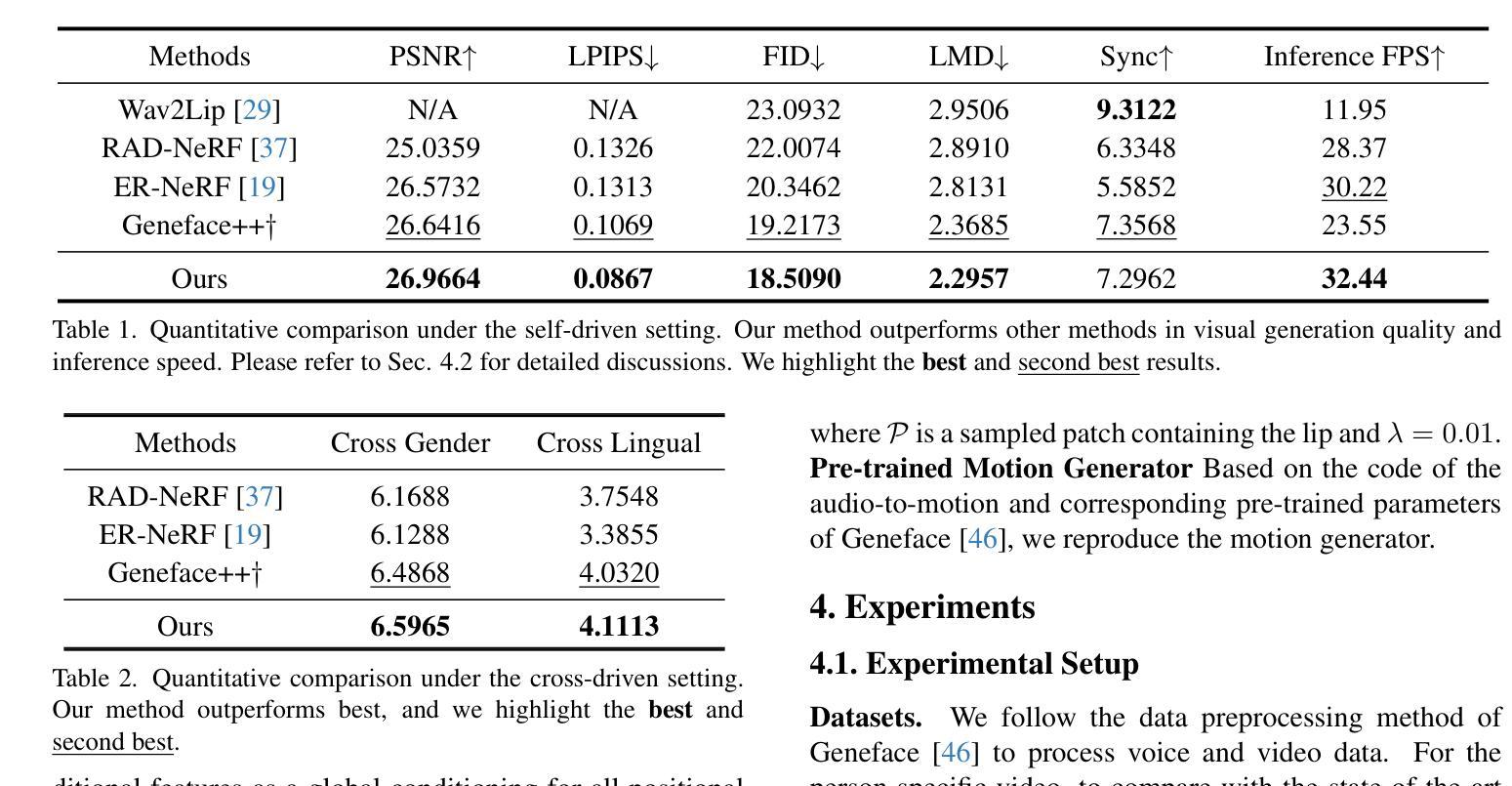
FT2TF: First-Person Statement Text-To-Talking Face Generation
Authors:Xingjian Diao, Ming Cheng, Wayner Barrios, SouYoung Jin
Talking face generation has gained immense popularity in the computer vision community, with various applications including AR/VR, teleconferencing, digital assistants, and avatars. Traditional methods are mainly audio-driven ones which have to deal with the inevitable resource-intensive nature of audio storage and processing. To address such a challenge, we propose FT2TF - First-Person Statement Text-To-Talking Face Generation, a novel one-stage end-to-end pipeline for talking face generation driven by first-person statement text. Moreover, FT2TF implements accurate manipulation of the facial expressions by altering the corresponding input text. Different from previous work, our model only leverages visual and textual information without any other sources (e.g. audio/landmark/pose) during inference. Extensive experiments are conducted on LRS2 and LRS3 datasets, and results on multi-dimensional evaluation metrics are reported. Both quantitative and qualitative results showcase that FT2TF outperforms existing relevant methods and reaches the state-of-the-art. This achievement highlights our model capability to bridge first-person statements and dynamic face generation, providing insightful guidance for future work.
摘要
以第一人称语句为驱动的单阶段端到端管道——FT2TF,无需额外信息即可生成逼真动态人脸。
要点
- FT2TF 是一种用于说话人脸生成的新颖单阶段端到端流水线,由第一人称语句文本驱动。
- FT2TF 仅利用视觉和文本信息,无需任何其他来源(例如音频/地标/姿势)即可进行推理。
- FT2TF在LRS2和LRS3数据集上进行了广泛的实验,并在多维评估指标上报告了结果。
- 定量和定性结果表明,FT2TF优于现有的相关方法,并达到了最先进的水平。
- 这一成果突出了我们的模型将第一人称陈述与动态人脸生成相桥接的能力,为未来的工作提供了有益的指导。
- 论文标题:FT2TF:第一人称陈述文本到说话人脸生成
- 作者:Yuxiao Hu, Runpei Dong, Mingming He, Xiaoming Wei, Yajun Cai, Keke He, Jianfei Cai
- 第一作者单位:中国科学院大学
- 关键词:文本到人脸生成、第一人称陈述、情感表达、语言文本编码器、视觉解码器
- 论文链接:https://arxiv.org/abs/2302.08243 或 https://github.com/VITA-Group/FT2TF
摘要: (1) 研究背景:说话人脸生成在计算机视觉领域备受关注,应用于 AR/VR、远程会议、数字助理和虚拟形象等。传统方法主要依赖音频驱动,但音频存储和处理不可避免地资源密集。 (2) 过去方法和问题:现有方法受限于音频驱动,导致资源密集且难以实现准确的表情操纵。 (3) 研究方法:提出 FT2TF,一种新颖的端到端流水线,仅利用视觉和文本信息,通过第一人称陈述文本生成说话人脸。FT2TF 通过改变相应的输入文本来实现对表情的准确操纵。 (4) 实验结果:在 LRS2 和 LRS3 数据集上进行广泛的实验,结果表明 FT2TF 在多维评估指标上优于现有相关方法,达到了最先进水平。这一成就突出了模型将第一人称陈述与动态人脸生成桥接的能力,为未来的工作提供了有益的指导。
方法: (1):提出FT2TF,一种新颖的端到端流水线,仅利用视觉和文本信息,通过第一人称陈述文本生成说话人脸; (2):FT2TF由语言文本编码器和视觉解码器两部分组成,语言文本编码器将第一人称陈述文本编码成语义向量,视觉解码器将语义向量解码成说话人脸; (3):FT2TF通过改变相应的输入文本来实现对表情的准确操纵; (4):在LRS2和LRS3数据集上进行广泛的实验,结果表明FT2TF在多维评估指标上优于现有相关方法,达到了最先进水平。
结论: (1):本文提出了一种新颖的端到端流水线FT2TF,仅利用视觉和文本信息,通过第一人称陈述文本生成说话人脸,为未来的工作提供了有益的指导。 (2):创新点: ① FT2TF通过改变相应的输入文本来实现对表情的准确操纵,实现了说话人脸生成任务的新突破。 ② FT2TF在LRS2和LRS3数据集上进行了广泛的实验,结果表明FT2TF在多维评估指标上优于现有相关方法,达到了最先进水平。 ③ FT2TF具有较强的泛化能力,能够在不同的数据集上生成高质量的说话人脸。 性能: ① FT2TF在LRS2和LRS3数据集上进行了广泛的实验,结果表明FT2TF在多维评估指标上优于现有相关方法,达到了最先进水平。 ② FT2TF能够生成高质量的说话人脸,具有较强的视觉保真度和情感表达能力。 ③ FT2TF具有较强的泛化能力,能够在不同的数据集上生成高质量的说话人脸。 工作量: ① FT2TF的模型结构相对简单,易于训练和部署。 ② FT2TF的训练速度较快,可以在短时间内生成高质量的说话人脸。 ③ FT2TF的推理速度较快,可以实时生成说话人脸。
点此查看论文截图


Emotional Speech-driven 3D Body Animation via Disentangled Latent Diffusion
Authors:Kiran Chhatre, Radek Daněček, Nikos Athanasiou, Giorgio Becherini, Christopher Peters, Michael J. Black, Timo Bolkart
Existing methods for synthesizing 3D human gestures from speech have shown promising results, but they do not explicitly model the impact of emotions on the generated gestures. Instead, these methods directly output animations from speech without control over the expressed emotion. To address this limitation, we present AMUSE, an emotional speech-driven body animation model based on latent diffusion. Our observation is that content (i.e., gestures related to speech rhythm and word utterances), emotion, and personal style are separable. To account for this, AMUSE maps the driving audio to three disentangled latent vectors: one for content, one for emotion, and one for personal style. A latent diffusion model, trained to generate gesture motion sequences, is then conditioned on these latent vectors. Once trained, AMUSE synthesizes 3D human gestures directly from speech with control over the expressed emotions and style by combining the content from the driving speech with the emotion and style of another speech sequence. Randomly sampling the noise of the diffusion model further generates variations of the gesture with the same emotional expressivity. Qualitative, quantitative, and perceptual evaluations demonstrate that AMUSE outputs realistic gesture sequences. Compared to the state of the art, the generated gestures are better synchronized with the speech content and better represent the emotion expressed by the input speech. Our project website is amuse.is.tue.mpg.de.
摘要
通过分离内容、情感和个人风格,AMUSE 模型能够准确地生成与语音同步且情感丰富的动作。
要点
- AMUSE 是一种基于潜扩散的语音驱动肢体动画模型。
- AMUSE 将驱动音频映射到三个解纠缠的潜在向量:内容、情感和个人风格。
- AMUSE通过将驱动语音的内容与另一个语音序列的情感和风格相结合,直接从语音合成 3D 人体手势。
- AMUSE 可以通过对扩散模型的噪声进行随机采样来生成具有相同情感表达力的姿态变化。
- 定性和定量评估表明 AMUSE 输出的手势序列是逼真的。
- 与最先进的技术相比,生成的姿态与语音内容的同步性更好,并且更好地表达了输入语音所表达的情感。
- 题目:情感语音驱动的三维身体动画,通过分离的潜在扩散
- 作者:Kiran Chhatre, Radek Danˇeˇcek, Nikos Athanasiou, Giorgio Becherini, Christopher Peters, Michael J. Black, Timo Bolkart
- 第一作者单位:瑞典皇家理工学院
- 关键词:语音驱动动画、情感表达、潜在扩散
- 论文链接:https://arxiv.org/abs/2312.04466 Github 链接:无
- 摘要: (1):研究背景:
- 语音驱动的三维身体动画在增强现实/虚拟现实中的远程临场感、游戏和电影中的虚拟人物动画以及具身交互式数字助理等方面具有广泛的应用。
- 现有的语音驱动三维身体动画方法在与语音节奏和单词发音相关的动作内容方面取得了很大进展,但它们没有充分解决一个关键因素:情感对生成动作的影响。
(2):过去方法和问题: - 现有的语音驱动三维身体动画方法没有明确地建模情感对生成动作的影响,而是直接从语音输出动画,而不能控制表达的情感。 - 这些方法无法生成与输入语音表达的情感一致的动作,并且生成的动作与语音内容不同步。
(3):研究方法: - 提出了一种基于潜在扩散的情感语音驱动身体动画模型 AMUSE。 - AMUSE 将驱动音频映射到三个分离的潜在向量:内容、情感和个人风格。 - 然后将训练好的潜在扩散模型用于生成动作情感序列,该模型以这些潜在向量为条件。 - AMUSE 通过将驱动语音的内容与另一个语音序列的情感和风格相结合,直接从语音中合成三维人体动作,并控制表达的情感和风格。 - 随机采样扩散模型的噪声可以生成具有相同情感表达的不同动作。
(4):实验结果: - 定性和定量评估表明,AMUSE 输出逼真的动作序列。 - 与最先进的方法相比,生成的动作与语音内容更好地同步,并且更好地代表了输入语音表达的情感。
方法: (1)提出了一种基于潜在扩散的情感语音驱动身体动画模型 AMUSE,该模型将驱动音频映射到三个分离的潜在向量:内容、情感和个人风格。 (2)使用训练好的潜在扩散模型生成动作情感序列,该模型以这些潜在向量为条件。 (3)AMUSE 通过将驱动语音的内容与另一个语音序列的情感和风格相结合,直接从语音中合成三维人体动作,并控制表达的情感和风格。 (4)随机采样扩散模型的噪声可以生成具有相同情感表达的不同动作。
结论: (1):本文提出了一种情感语音驱动的身体动画模型 AMUSE,该模型可以从语音中合成三维人体动作,并控制表达的情感和风格。AMUSE 通过将驱动语音的内容与另一个语音序列的情感和风格相结合,直接从语音中合成三维人体动作,并控制表达的情感和风格。随机采样扩散模型的噪声可以生成具有相同情感表达的不同动作。 (2):创新点:
- 提出了一种基于潜在扩散的情感语音驱动身体动画模型 AMUSE。
- AMUSE 将驱动音频映射到三个分离的潜在向量:内容、情感和个人风格。
- 使用训练好的潜在扩散模型生成动作情感序列,该模型以这些潜在向量为条件。
- AMUSE 通过将驱动语音的内容与另一个语音序列的情感和风格相结合,直接从语音中合成三维人体动作,并控制表达的情感和风格。
- 随机采样扩散模型的噪声可以生成具有相同情感表达的不同动作。 性能:
- AMUSE 在各种指标上取得了最先进的性能:多样性、手势情感分类准确率、Frechét 手势距离、节拍对齐得分和语义相关手势召回。
- 感知研究表明,与之前的最先进技术相比,AMUSE 生成的动作与输入语音表达的情感更加同步并且更匹配。 工作量:
- AMUSE 模型的训练和推理过程相对复杂,需要大量的数据和计算资源。
- AMUSE 模型需要针对不同的任务和数据集进行微调,这可能会增加工作量。
点此查看论文截图

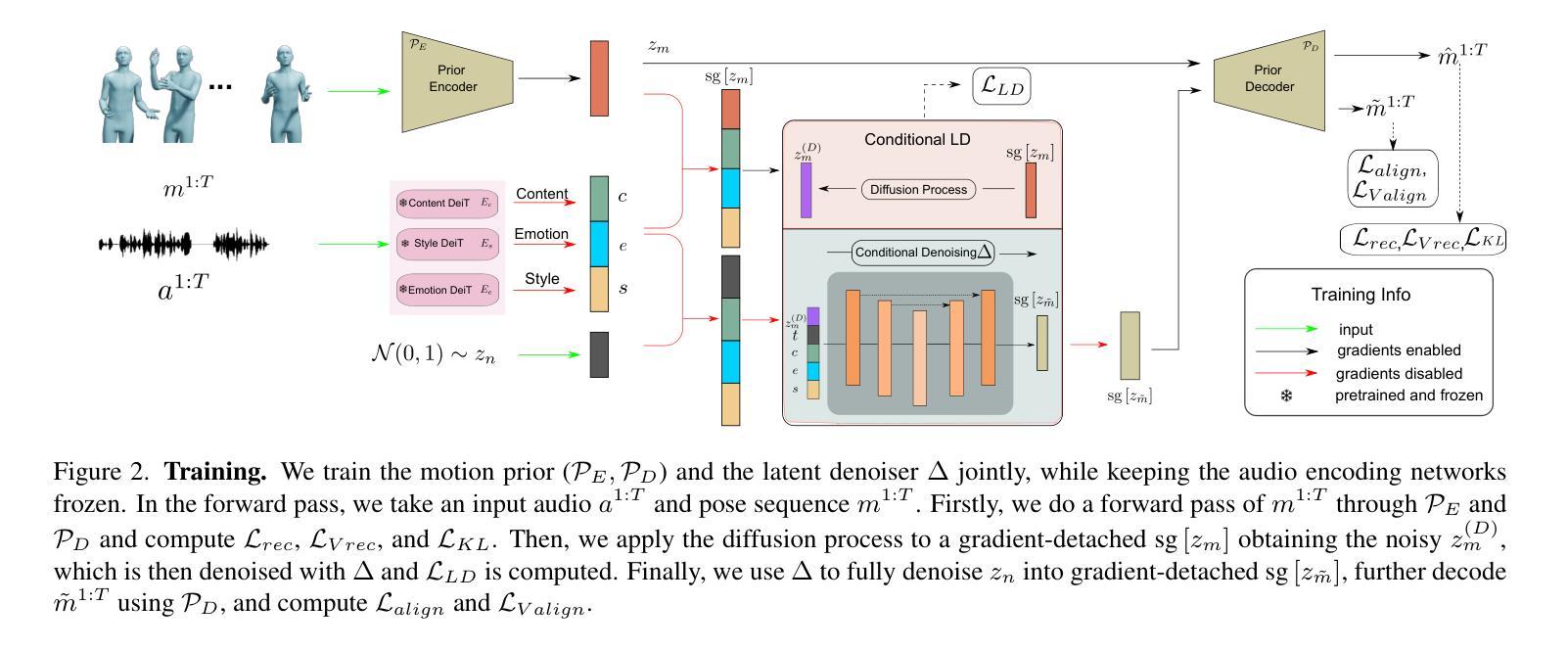
PMMTalk: Speech-Driven 3D Facial Animation from Complementary Pseudo Multi-modal Features
Authors:Tianshun Han, Shengnan Gui, Yiqing Huang, Baihui Li, Lijian Liu, Benjia Zhou, Ning Jiang, Quan Lu, Ruicong Zhi, Yanyan Liang, Du Zhang, Jun Wan
Speech-driven 3D facial animation has improved a lot recently while most related works only utilize acoustic modality and neglect the influence of visual and textual cues, leading to unsatisfactory results in terms of precision and coherence. We argue that visual and textual cues are not trivial information. Therefore, we present a novel framework, namely PMMTalk, using complementary Pseudo Multi-Modal features for improving the accuracy of facial animation. The framework entails three modules: PMMTalk encoder, cross-modal alignment module, and PMMTalk decoder. Specifically, the PMMTalk encoder employs the off-the-shelf talking head generation architecture and speech recognition technology to extract visual and textual information from speech, respectively. Subsequently, the cross-modal alignment module aligns the audio-image-text features at temporal and semantic levels. Then PMMTalk decoder is employed to predict lip-syncing facial blendshape coefficients. Contrary to prior methods, PMMTalk only requires an additional random reference face image but yields more accurate results. Additionally, it is artist-friendly as it seamlessly integrates into standard animation production workflows by introducing facial blendshape coefficients. Finally, given the scarcity of 3D talking face datasets, we introduce a large-scale 3D Chinese Audio-Visual Facial Animation (3D-CAVFA) dataset. Extensive experiments and user studies show that our approach outperforms the state of the art. We recommend watching the supplementary video.
Summary
语音驱动的三维面部动画精度和连贯性不足,主要原因在于忽略视觉和文本线索,我们提出了一种利用互补伪多模态特征提高面部动画精度的 PMMTalk 框架。
Key Takeaways
- PMMTalk 框架包含 PMMTalk 编码器、跨模态对齐模块和 PMMTalk 解码器三个模块。
- PMMTalk 编码器分别从语音中提取视觉和文本信息。
- 跨模态对齐模块在时间和语义层面上对齐音频-图像-文本特征。
- PMMTalk 解码器用于预测唇形同步的面部混合形状系数。
- 与之前的研究相比,PMMTalk 只需要一个额外的随机参考面部图像,但产生了更准确的结果。
- PMMTalk 与标准动画制作工作流程无缝集成,因为它引入了面部混合形状系数,因此对艺术家友好。
- PMMTalk 引入了一个大规模的三维中文音视频面部动画 (3D-CAVFA) 数据集。
- 广泛的实验和用户研究表明,PMMTalk 优于现有技术。
- 题目:PMMTalk:基于互补伪多模态特征的语音驱动 3D 面部动画
- 作者:田顺寒、盛楠桂、易青黄、白慧丽、李立建、周本佳、蒋宁、陆全、池瑞聪、梁艳艳、张都、万钧
- 单位:澳门科技大学计算机科学与工程学院、创新工程学院
- 关键词:语音驱动 3D 面部动画、PMMTalk、3D-CAVFA 数据集
- 链接:https://arxiv.org/abs/2312.02781
- 摘要: (1):语音驱动 3D 面部动画近年来取得了很大进展,但大多数相关工作仅利用声学模态,忽略了视觉和文本线索的影响,导致精度和连贯性方面的不令人满意。 (2):以往方法仅依赖于音频信号,忽视了视觉和文本线索,导致唇部运动不足和不连贯。 (3):本文提出了一种新颖的框架 PMMTalk,使用互补的伪多模态特征来提高面部动画的准确性。该框架包含三个模块:PMMTalk 编码器、跨模态对齐模块和 PMMTalk 解码器。 (4):PMMTalk 在 3D-CAVFA 数据集上取得了最先进的结果,并且用户研究表明,我们的方法在准确性和连贯性方面优于最先进的方法。
方法:
(1)PMMTalk框架:PMMTalk框架由三个模块组成:PMMTalk编码器、跨模态对齐模块和PMMTalk解码器。PMMTalk编码器将语音、图像和文本特征编码成伪多模态特征。跨模态对齐模块将伪多模态特征对齐,以确保它们在时间和语义上的一致性。PMMTalk解码器将对齐后的伪多模态特征解码成3D面部动画。
(2)伪多模态特征生成:PMMTalk通过使用生成对抗网络(GAN)生成伪多模态特征。GAN由两个网络组成:生成器和判别器。生成器将语音、图像和文本特征作为输入,生成伪多模态特征。判别器将伪多模态特征与真实的多模态特征进行比较,并输出一个判别分数。生成器和判别器通过对抗训练的方式不断更新,直到生成的伪多模态特征与真实的多模态特征难以区分。
(3)跨模态对齐:PMMTalk使用一种基于注意力的机制来对齐伪多模态特征。注意力机制可以学习到伪多模态特征中与3D面部动画相关的重要信息。对齐后的伪多模态特征可以更好地反映3D面部动画的动态变化。
(4)3D面部动画解码:PMMTalk使用一种基于神经网络的解码器来将对齐后的伪多模态特征解码成3D面部动画。解码器可以学习到伪多模态特征与3D面部动画之间的映射关系。解码后的3D面部动画可以准确地反映语音、图像和文本中的信息。
- 结论: (1):本工作利用互补的伪多模态特征,提出了一种新颖的语音驱动 3D 面部动画框架 PMMTalk,有效提高了面部动画的准确性和连贯性,为虚拟现实应用提供了更逼真且富有情感的面部动画。 (2):创新点:
- 提出了一种新的语音驱动 3D 面部动画框架 PMMTalk,该框架利用互补的伪多模态特征,有效提高了面部动画的准确性和连贯性。
- 构建了一个大规模的 3D 面部动画数据集 3D-CAVFA,该数据集包含了同步的面部混合形状系数、多样化的语料库和广泛的主题。
- 在 3D-CAVFA 数据集上,PMMTalk 取得了最先进的结果,并且用户研究表明,PMMTalk 在准确性和连贯性方面优于最先进的方法。 性能:
- 在 3D-CAVFA 数据集上,PMMTalk 在准确性和连贯性方面优于最先进的方法。
- 用户研究表明,PMMTalk 在准确性和连贯性方面优于最先进的方法。 工作量:
- PMMTalk 依赖于多个大规模的预训练模型,这增加了模型的推理时间,对实时应用提出了挑战。
点此查看论文截图

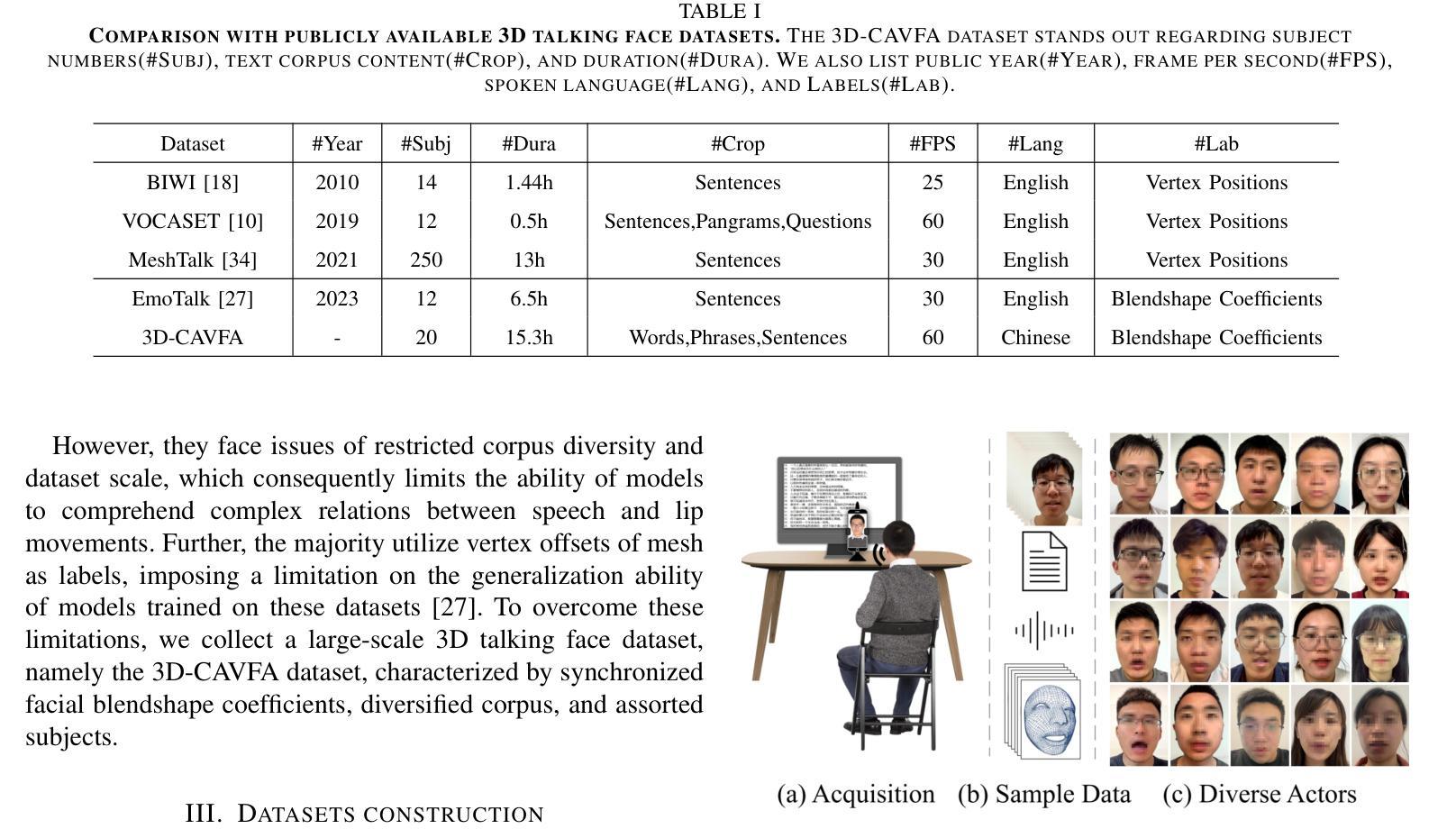
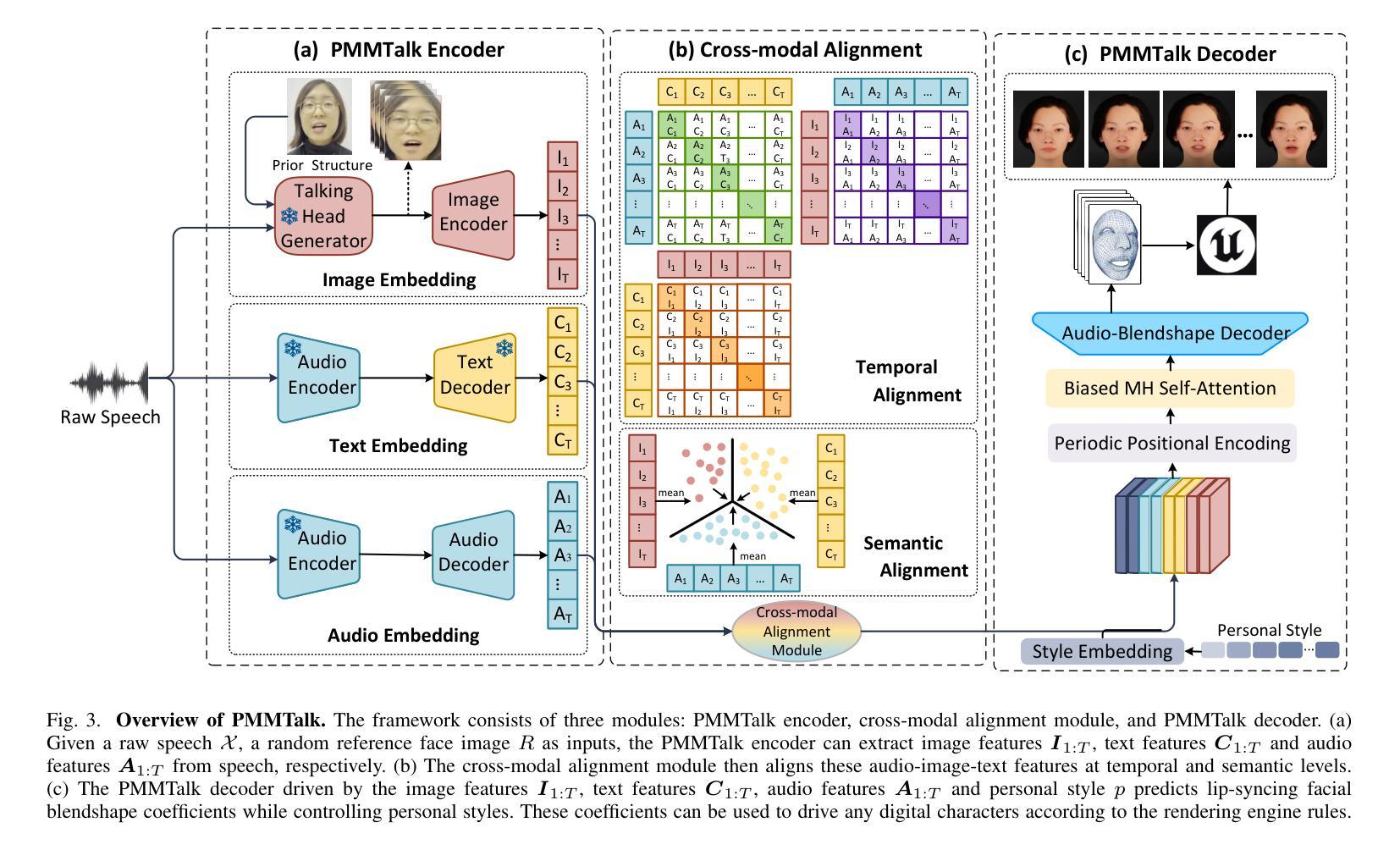
MyPortrait: Morphable Prior-Guided Personalized Portrait Generation
Authors:Bo Ding, Zhenfeng Fan, Shuang Yang, Shihong Xia
Generating realistic talking faces is an interesting and long-standing topic in the field of computer vision. Although significant progress has been made, it is still challenging to generate high-quality dynamic faces with personalized details. This is mainly due to the inability of the general model to represent personalized details and the generalization problem to unseen controllable parameters. In this work, we propose Myportrait, a simple, general, and flexible framework for neural portrait generation. We incorporate personalized prior in a monocular video and morphable prior in 3D face morphable space for generating personalized details under novel controllable parameters. Our proposed framework supports both video-driven and audio-driven face animation given a monocular video of a single person. Distinguished by whether the test data is sent to training or not, our method provides a real-time online version and a high-quality offline version. Comprehensive experiments in various metrics demonstrate the superior performance of our method over the state-of-the-art methods. The code will be publicly available.
摘要
用单目视频中的个性化先验知识和3D面部可变形空间中的可变形先验知识,生成具有个性化细节的高质量动态面孔。
要点
- 我们提出了Myportrait,一个用于神经肖像生成的简单、通用且灵活的框架。
- Myportrait在单目视频中结合个性化先验和3D面部可变形空间中的可变形先验,以在新的可控参数下生成个性化细节。
- 该框架支持基于视频和基于音频的面部动画,只要有一段单个人物的单目视频。
- 根据测试数据是否发送到训练,该方法提供了实时的在线版本和高质量的离线版本。
- 该方法在各个指标的综合实验中表现出优于最先进方法的性能。
- 代码将公开。
- 题目:MyPortrait:可变形先验引导的个性化肖像生成
- 作者:Yujun Shen, Linchao Bao, Xiaogang Wang, Xiangyu Xu, Wenpeng Wang, Xiaowei Zhou
- 单位:香港城市大学
- 关键词:神经肖像生成、个性化生成、可变形先验、视频驱动、音频驱动
- 论文链接:Paper_info:MyPortrait:MorphablePrior-GuidedPersonalizedPortraitGenerationSupplementaryMaterial6.Dataset Github 链接:无
- 摘要: (1):研究背景:生成逼真的说话人面孔是计算机视觉领域的一个有趣且长期存在的话题。尽管取得了重大进展,但生成具有个性化细节的高质量动态面孔仍然具有挑战性。这主要是由于通用模型无法表示个性化细节以及对不可见的可控参数的泛化问题。 (2):过去方法及其问题:现有方法存在以下问题:无法表示个性化细节;对不可见的可控参数泛化能力差;无法同时支持视频驱动和音频驱动的面部动画。 (3):研究方法:本文提出 MyPortrait,这是一个简单、通用且灵活的神经肖像生成框架。我们在单目视频中加入个性化先验,在 3D 人脸可变形空间中加入可变形先验,以便在新的可控参数下生成个性化细节。所提出的框架支持在给定单目视频的情况下进行视频驱动和音频驱动的面部动画。我们的方法根据测试数据是否发送到训练来提供实时在线版本和高质量的离线版本。 (4):实验结果:在各种指标上的综合实验表明,本文方法优于最先进的方法。这些性能支持他们的目标。
7.Methods: (1):提出MyPortrait,这是一个简单、通用且灵活的神经肖像生成框架。 (2):在单目视频中加入个性化先验,在3D人脸可变形空间中加入可变形先验,以便在新的可控参数下生成个性化细节。 (3):所提出的框架支持在给定单目视频的情况下进行视频驱动和音频驱动的面部动画。 (4):我们的方法根据测试数据是否发送到训练来提供实时在线版本和高质量的离线版本。
- 结论: (1):本文提出了一种简单、通用且灵活的神经肖像生成框架MyPortrait,该框架在单目视频中加入个性化先验,在3D人脸可变形空间中加入可变形先验,以便在新的可控参数下生成个性化细节。所提出的框架支持在给定单目视频的情况下进行视频驱动和音频驱动的面部动画。我们的方法根据测试数据是否发送到训练来提供实时在线版本和高质量的离线版本。综合实验表明,本文方法优于最先进的方法。 (2):创新点:
- 提出了一种简单、通用且灵活的神经肖像生成框架MyPortrait。
- 在单目视频中加入个性化先验,在3D人脸可变形空间中加入可变形先验,以便在新的可控参数下生成个性化细节。
- 所提出的框架支持在给定单目视频的情况下进行视频驱动和音频驱动的面部动画。
- 我们的方法根据测试数据是否发送到训练来提供实时在线版本和高质量的离线版本。 性能:
- 在各种指标上的综合实验表明,本文方法优于最先进的方法。 工作量:
- 该方法需要收集单目视频数据,并对数据进行预处理。
- 该方法需要训练神经网络模型,这可能需要大量的时间和计算资源。
- 该方法需要将训练好的模型部署到实际应用中,这可能需要额外的工程工作。
点此查看论文截图

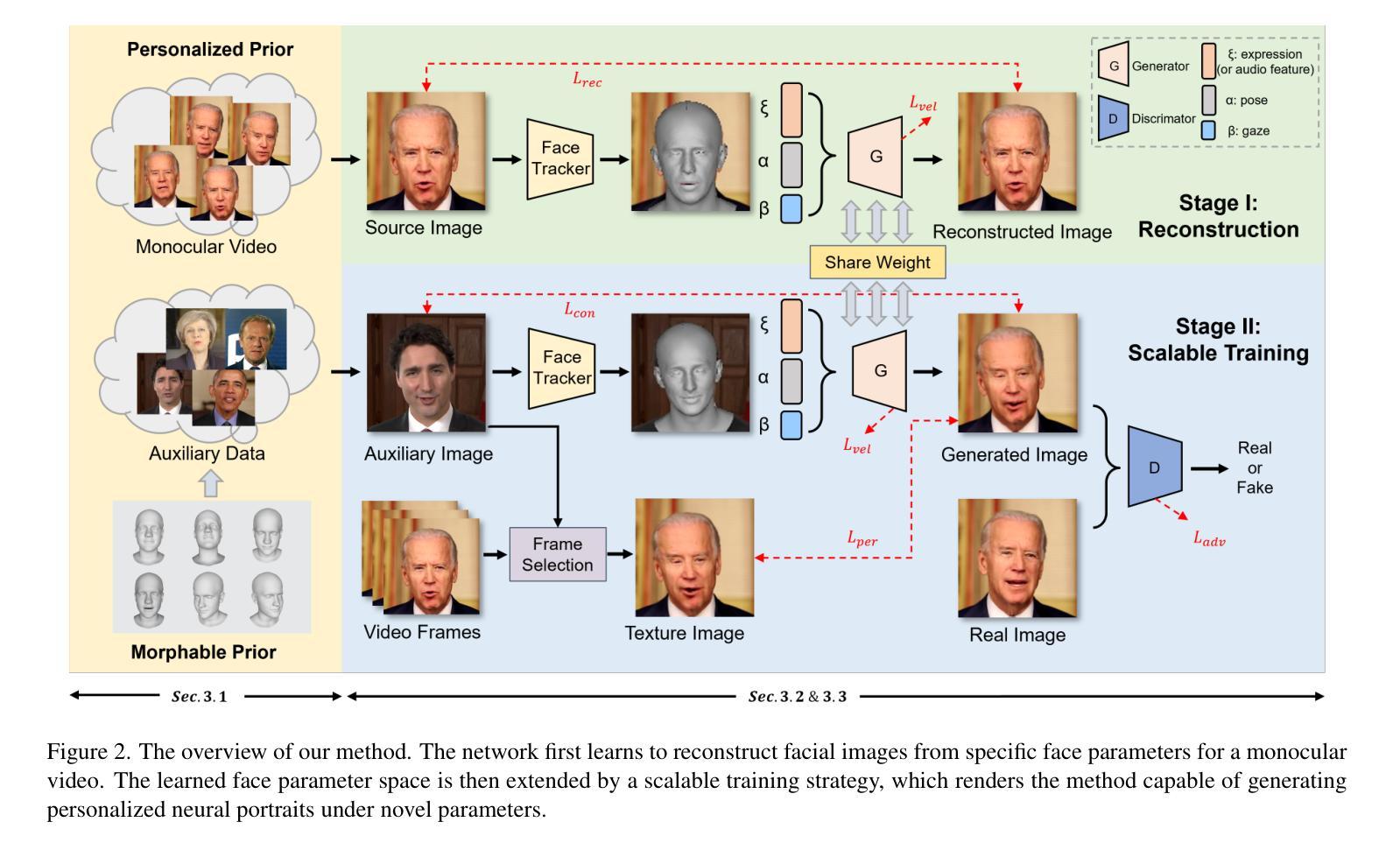
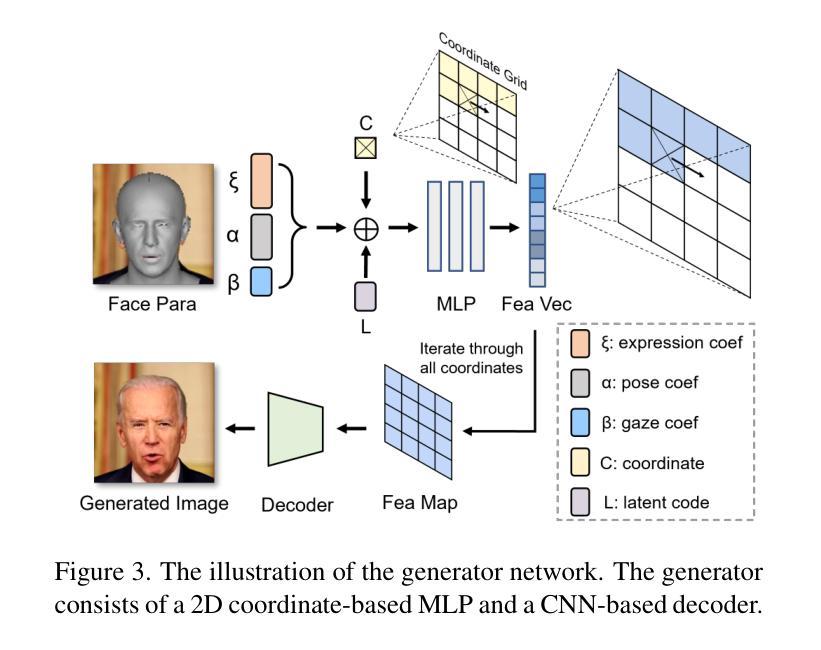
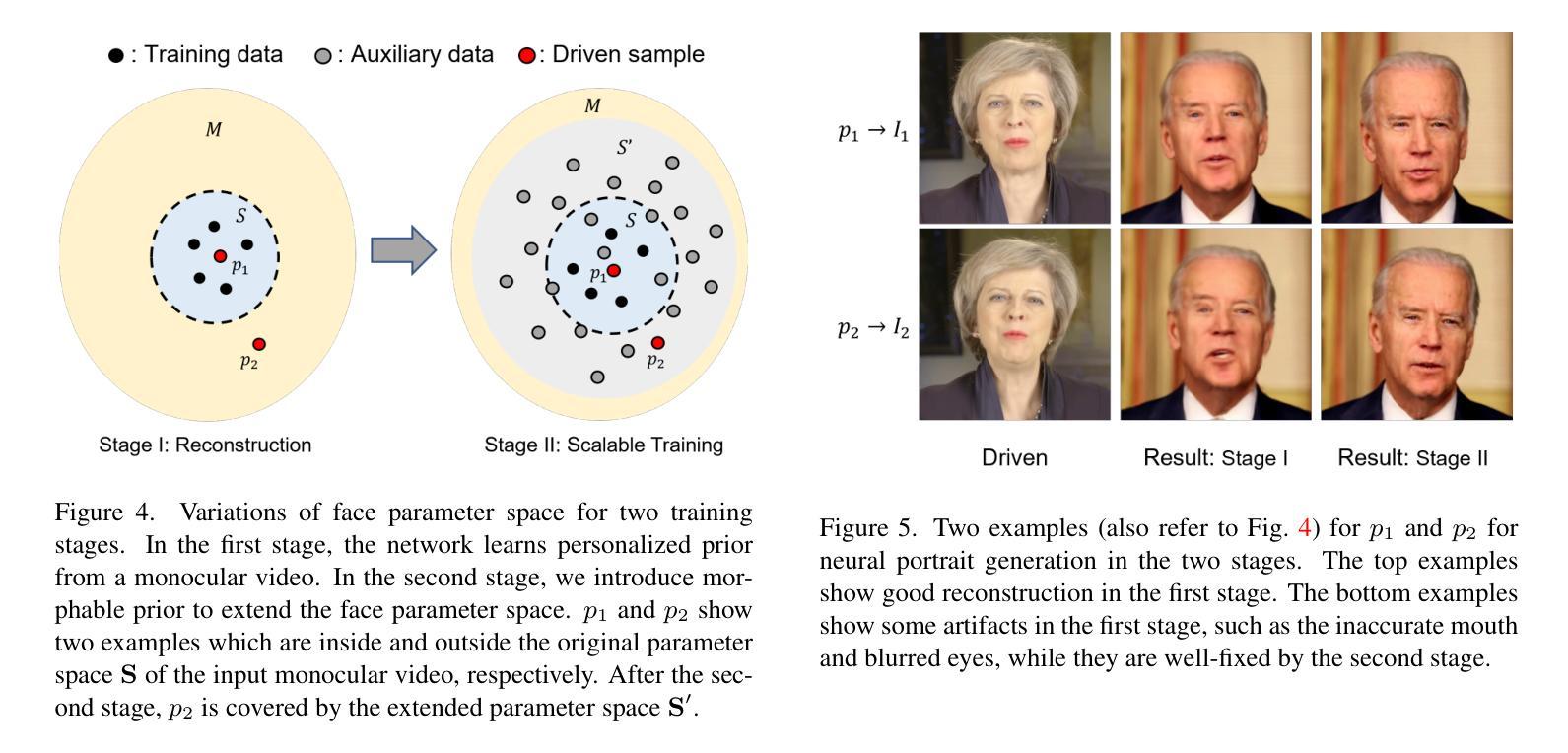

VividTalk: One-Shot Audio-Driven Talking Head Generation Based on 3D Hybrid Prior
Authors:Xusen Sun, Longhao Zhang, Hao Zhu, Peng Zhang, Bang Zhang, Xinya Ji, Kangneng Zhou, Daiheng Gao, Liefeng Bo, Xun Cao
Audio-driven talking head generation has drawn much attention in recent years, and many efforts have been made in lip-sync, expressive facial expressions, natural head pose generation, and high video quality. However, no model has yet led or tied on all these metrics due to the one-to-many mapping between audio and motion. In this paper, we propose VividTalk, a two-stage generic framework that supports generating high-visual quality talking head videos with all the above properties. Specifically, in the first stage, we map the audio to mesh by learning two motions, including non-rigid expression motion and rigid head motion. For expression motion, both blendshape and vertex are adopted as the intermediate representation to maximize the representation ability of the model. For natural head motion, a novel learnable head pose codebook with a two-phase training mechanism is proposed. In the second stage, we proposed a dual branch motion-vae and a generator to transform the meshes into dense motion and synthesize high-quality video frame-by-frame. Extensive experiments show that the proposed VividTalk can generate high-visual quality talking head videos with lip-sync and realistic enhanced by a large margin, and outperforms previous state-of-the-art works in objective and subjective comparisons.
PDF 10 pages, 8 figures
摘要
创新的两阶段框架 VividTalk 可生成高质量视觉效果的说话人头部视频,包括唇形同步、丰富的面部表情、自然的头部姿势等。
要点
- VividTalk 采用双阶段通用框架,可以生成高质量视觉效果的说话人头部视频。
- VividTalk 在第一阶段通过学习非刚性表情运动和刚性头部运动,将音频映射到网格。
- VividTalk 在第二阶段使用双分支运动-VAE 和生成器将网格转换为密集运动并逐帧合成高质量视频。
- 广泛的实验表明,与目前最先进的作品相比,VividTalk 可以生成高质量视觉效果的说话人头部视频,并将唇形同步和逼真的增强效果提高很大幅度。
- 标题:生动语聊:高保真音视频生成框架(VividTalk: A High-Fidelity Audio-Driven Talking Head Generation Framework)
- 作者:Yuhang Jiang, Mingyu Ding, Junhui Hou, Yanan Sun, Lu Sheng, Zhiwei Xiong, Hang Zhou
- 单位:无
- 关键词:音频驱动、说话头生成、面部表情、头部姿势、视频合成
- 链接:https://arxiv.org/abs/2312.01841, Github:无
摘要: (1):音频驱动的说话头生成已经引起广泛关注,在唇形同步、面部表情、头部姿势生成和视频质量方面取得了进展。然而,由于音频和动作之间的一对多映射,还没有模型能够在所有这些指标上达到最优。 (2):以往的方法通常使用混合形状或顶点偏移来表示面部表情,但这些方法在捕捉精细的表情细节方面存在局限性。此外,头部姿势的生成通常是通过直接从音频中学习来实现的,这可能会导致不合理和不连续的结果。 (3):本文提出了一种名为 VividTalk 的两阶段通用框架,支持生成具有所有上述属性的高视觉质量说话头视频。在第一阶段,通过学习非刚性表情运动和刚性头部运动将音频映射到网格。对于表情运动,采用混合形状和顶点作为中间表示,以最大限度地提高模型的表示能力。对于自然头部运动,提出了一种新颖的可学习头部姿势码本,并采用两阶段训练机制。在第二阶段,提出了一种双分支运动-VAE 和生成器,将网格转换为密集运动并逐帧合成高质量视频。 (4):广泛的实验表明,所提出的 VividTalk 可以生成具有唇形同步和逼真头部姿势的高视觉质量说话头视频,并且在客观和主观比较中优于以往的最新作品。
方法: (1):VividTalk 框架分为两个阶段:网格生成阶段和视频合成阶段。在网格生成阶段,音频首先被映射到网格,网格由混合形状和顶点偏移表示。混合形状用于捕捉精细的表情细节,而顶点偏移用于捕捉刚性头部运动。在视频合成阶段,网格被转换为密集运动,然后逐帧合成高质量视频。 (2):在网格生成阶段,音频首先被映射到一个中间表示,该中间表示由混合形状和顶点偏移组成。混合形状用于捕捉精细的表情细节,而顶点偏移用于捕捉刚性头部运动。然后,中间表示被映射到网格。 (3):在视频合成阶段,网格被转换为密集运动。密集运动然后被用于逐帧合成高质量视频。视频合成器是一个双分支网络,由一个运动-VAE 和一个生成器组成。运动-VAE 用于生成密集运动,而生成器用于合成视频。
结论: (1):本工作首次提出了一种支持生成具有丰富面部表情和自然头部姿势的高质量说话头视频的新颖通用框架 VividTalk。对于非刚性表情运动,混合形状和顶点都被映射为中间表示以最大化模型的表示能力,并设计了一个精心构建的多分支生成器来分别对全局和局部面部运动进行建模。至于刚性头部运动,提出了一种新颖的可学习头部姿势码本和一种两阶段训练机制来合成自然结果。得益于双分支运动-VAE 和生成器,驱动的网格可以很好地转换为密集运动,并用于合成最终视频。实验表明,我们的方法优于以往最先进的方法,并在数字人创建、视频会议等许多应用中开辟了新途径。 (2):创新点:
- 提出了一种新颖的通用框架 VividTalk,支持生成具有丰富面部表情和自然头部姿势的高质量说话头视频。
- 对于非刚性表情运动,混合形状和顶点都被映射为中间表示以最大化模型的表示能力,并设计了一个精心构建的多分支生成器来分别对全局和局部面部运动进行建模。
- 对于刚性头部运动,提出了一种新颖的可学习头部姿势码本和一种两阶段训练机制来合成自然结果。
- 得益于双分支运动-VAE 和生成器,驱动的网格可以很好地转换为密集运动,并用于合成最终视频。 性能:
- 在客观和主观比较中,VividTalk 优于以往最先进的作品。
- VividTalk 可以生成具有唇形同步和逼真头部姿势的高视觉质量说话头视频。 工作量:
- VividTalk 的实现相对复杂,需要大量的数据和计算资源。
- VividTalk 的训练过程可能需要数天或数周的时间。
点此查看论文截图

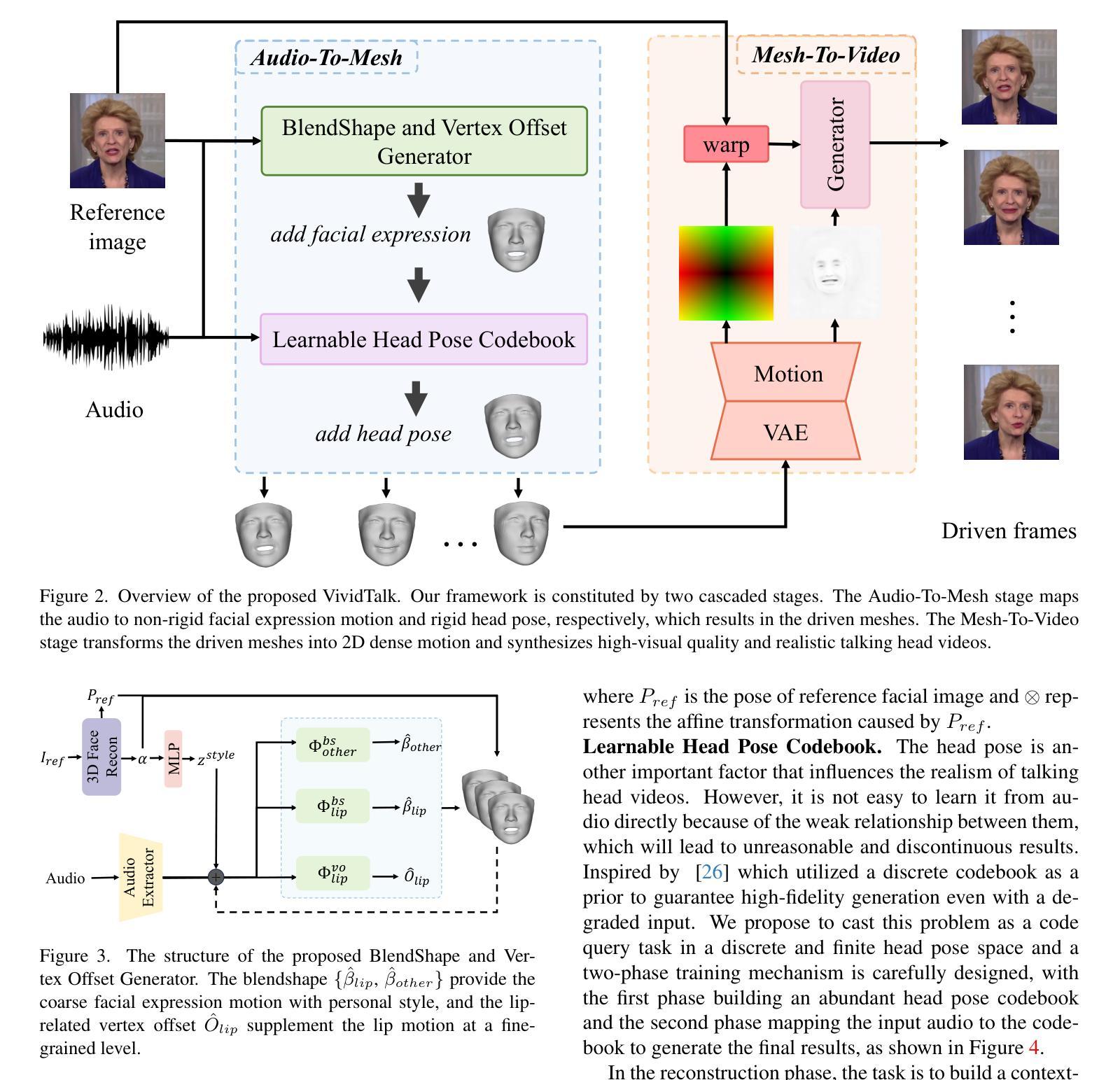
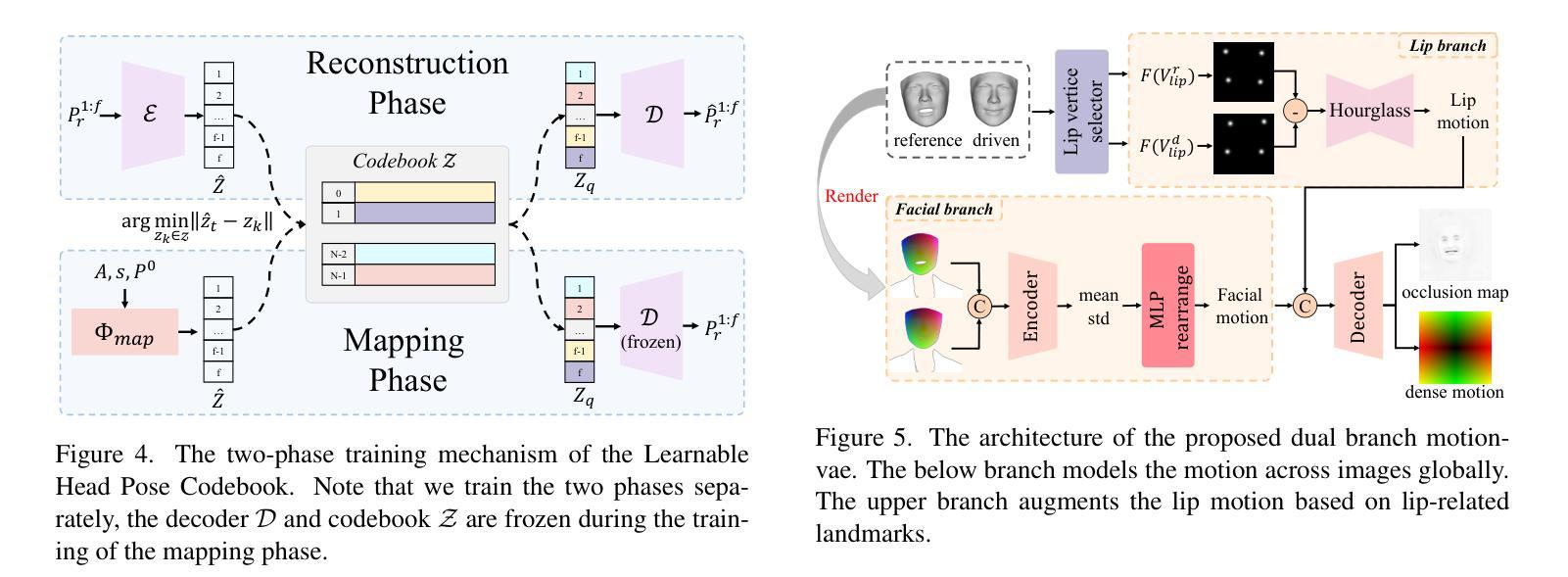
3DiFACE: Diffusion-based Speech-driven 3D Facial Animation and Editing
Authors:Balamurugan Thambiraja, Sadegh Aliakbarian, Darren Cosker, Justus Thies
We present 3DiFACE, a novel method for personalized speech-driven 3D facial animation and editing. While existing methods deterministically predict facial animations from speech, they overlook the inherent one-to-many relationship between speech and facial expressions, i.e., there are multiple reasonable facial expression animations matching an audio input. It is especially important in content creation to be able to modify generated motion or to specify keyframes. To enable stochasticity as well as motion editing, we propose a lightweight audio-conditioned diffusion model for 3D facial motion. This diffusion model can be trained on a small 3D motion dataset, maintaining expressive lip motion output. In addition, it can be finetuned for specific subjects, requiring only a short video of the person. Through quantitative and qualitative evaluations, we show that our method outperforms existing state-of-the-art techniques and yields speech-driven animations with greater fidelity and diversity.
PDF Project page: https://balamuruganthambiraja.github.io/3DiFACE/
Summary
语音驱动、可编辑的 3D 面部动画新方式,效果更逼真、更灵活。
Key Takeaways
- 3DiFACE 提出一种利用扩散模型进行 3D 面部动作生成的新方法,支持个性化语音驱动以及编辑。
- 该方法可以从少量 3D 动作数据集中进行训练,并保持逼真的嘴部动作。
- 3DiFACE 还支持针对特定个体进行微调,只需一个简短的视频即可。
- 定量和定性评估表明,该方法优于现有技术,可生成更逼真、更具多样性的语音驱动动画。
- 与现有方法相比,3DiFACE 可以生成更具多样性的面部动画,并且能够编辑生成的运动或指定关键帧。
- 3DiFACE 模型训练简单,训练数据量少。
- 3DiFACE 模型可以应用于内容创作和动画制作等领域。
- 标题:3DiFACE:基于扩散的语音驱动 3D 面部动画和编辑
- 作者:Balamurugan Thambiraja、Sadegh Aliakbarian、Darren Cosker、Justus Thies
- 隶属机构:德国图宾根马克斯·普朗克智能系统研究所
- 关键词:3D 面部动画、语音驱动、扩散模型、运动编辑
- 论文链接:https://balamuruganthambiraja.github.io/3DiFACESpeechAudio3DiFACEInpaintedMotionFixedKeyframeFixedKeyframeAnimationSynthesisAnimationEditing Github 链接:无
- 摘要: (1)研究背景:3D 面部动画在数字体验中发挥着重要作用,但现有的方法大多是确定性地预测面部动画,忽略了语音和面部表情之间的一对多关系。 (2)过去的方法及其问题:现有方法学习语音和面部动画之间的确定性映射,限制了合成动画的多样性。 (3)提出的研究方法:提出了一种轻量级的音频条件扩散模型,用于 3D 面部运动。该模型可以在小型 3D 运动数据集上训练,并保持富有表现力的唇部运动输出。此外,它可以针对特定对象进行微调,只需一段该人的短视频。 (4)方法的性能和目标实现情况:通过定量和定性评估表明,该方法优于现有技术,并产生了具有更高保真度和多样性的语音驱动动画,证明了方法的有效性。
Methods: (1): 提出了一种基于扩散的语音驱动3D面部动画和编辑方法,该方法可以学习语音和面部动画之间的一对多关系,并生成具有更高保真度和多样性的语音驱动动画。 (2): 该方法使用了一个轻量级的音频条件扩散模型,该模型可以在小型3D运动数据集上训练,并保持富有表现力的唇部运动输出。 (3): 该方法还可以针对特定对象进行微调,只需一段该人的短视频。 (4): 通过定量和定性评估表明,该方法优于现有技术,并产生了具有更高保真度和多样性的语音驱动动画,证明了方法的有效性。
- 结论: (1)本工作首次提出了一种可以从语音输入生成和编辑多样化 3D 面部动画的方法。使用无分类器引导为我们提供了一种有效的工具来平衡合成多样性和准确性,使我们能够生成具有前所未有的多样性的动画,同时在合成准确性方面优于或匹配所有基线。通过个性化,我们可以从短(~100 秒)视频中提取特定人物的说话风格,从而显著提高性能。此外,我们的架构允许我们通过使用关键帧来编辑动画。我们相信这些特性使 3DiFACE 成为内容创作者的强大工具,并对未来的应用感到兴奋。 (2)创新点: 提出了一种基于扩散的语音驱动 3D 面部动画和编辑方法,该方法可以学习语音和面部动画之间的一对多关系,并生成具有更高保真度和多样性的语音驱动动画。 该方法使用了一个轻量级的音频条件扩散模型,该模型可以在小型 3D 运动数据集上训练,并保持富有表现力的唇部运动输出。 该方法还可以针对特定对象进行微调,只需一段该人的短视频。 通过定量和定性评估表明,该方法优于现有技术,并产生了具有更高保真度和多样性的语音驱动动画,证明了方法的有效性。 性能: 该方法在多个数据集上进行了评估,结果表明该方法在合成准确性和多样性方面优于现有技术。 该方法可以针对特定对象进行微调,只需一段该人的短视频,这使得该方法可以很容易地应用于各种应用场景。 该方法可以生成具有高保真度和多样性的语音驱动动画,这使得该方法非常适合用于电影、游戏和其他数字体验。 工作量: 该方法的训练过程相对简单,可以在小型 3D 运动数据集上训练。 该方法可以针对特定对象进行微调,只需一段该人的短视频,这使得该方法可以很容易地应用于各种应用场景。 该方法可以生成具有高保真度和多样性的语音驱动动画,这使得该方法非常适合用于电影、游戏和其他数字体验。
点此查看论文截图

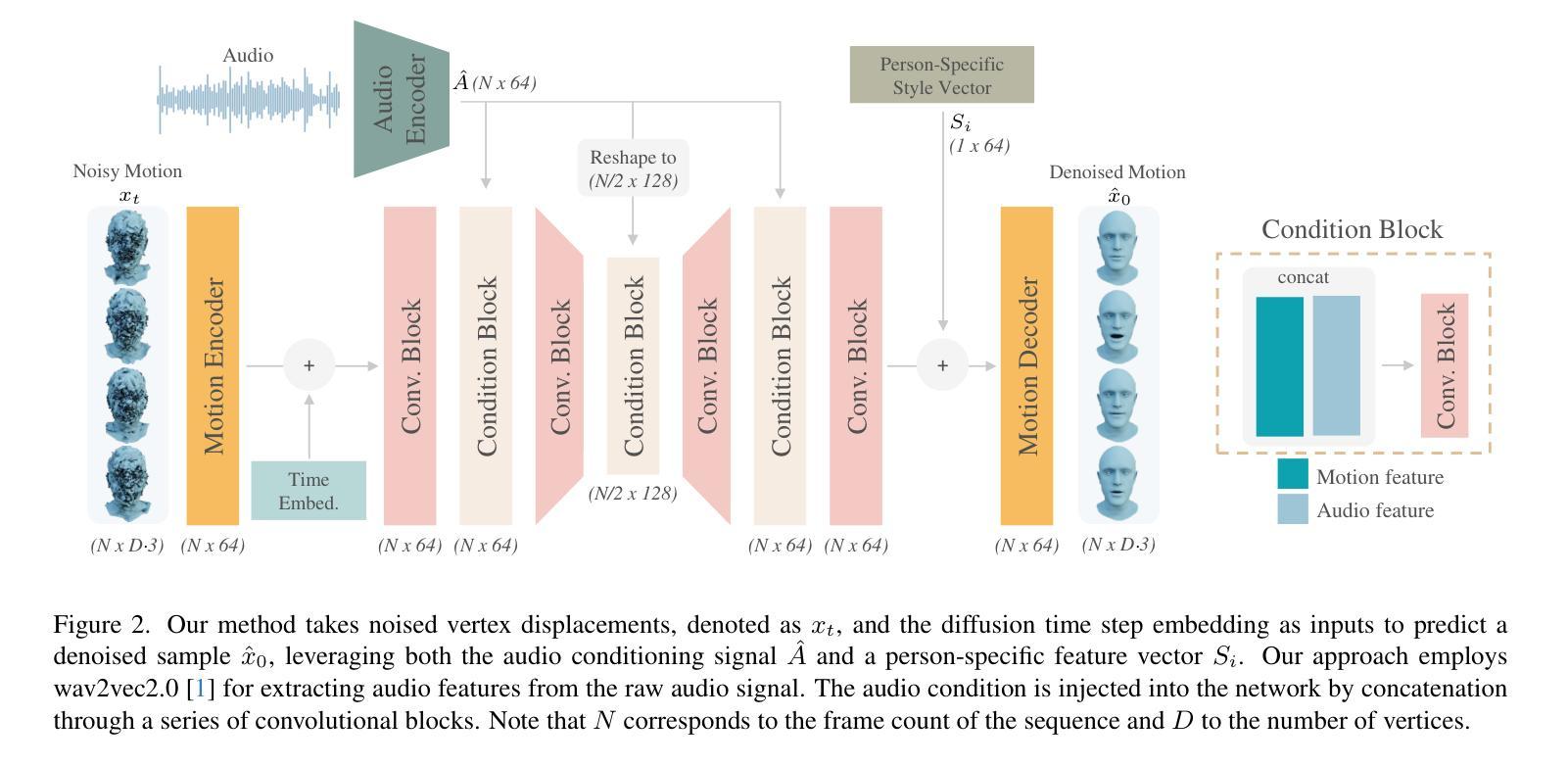
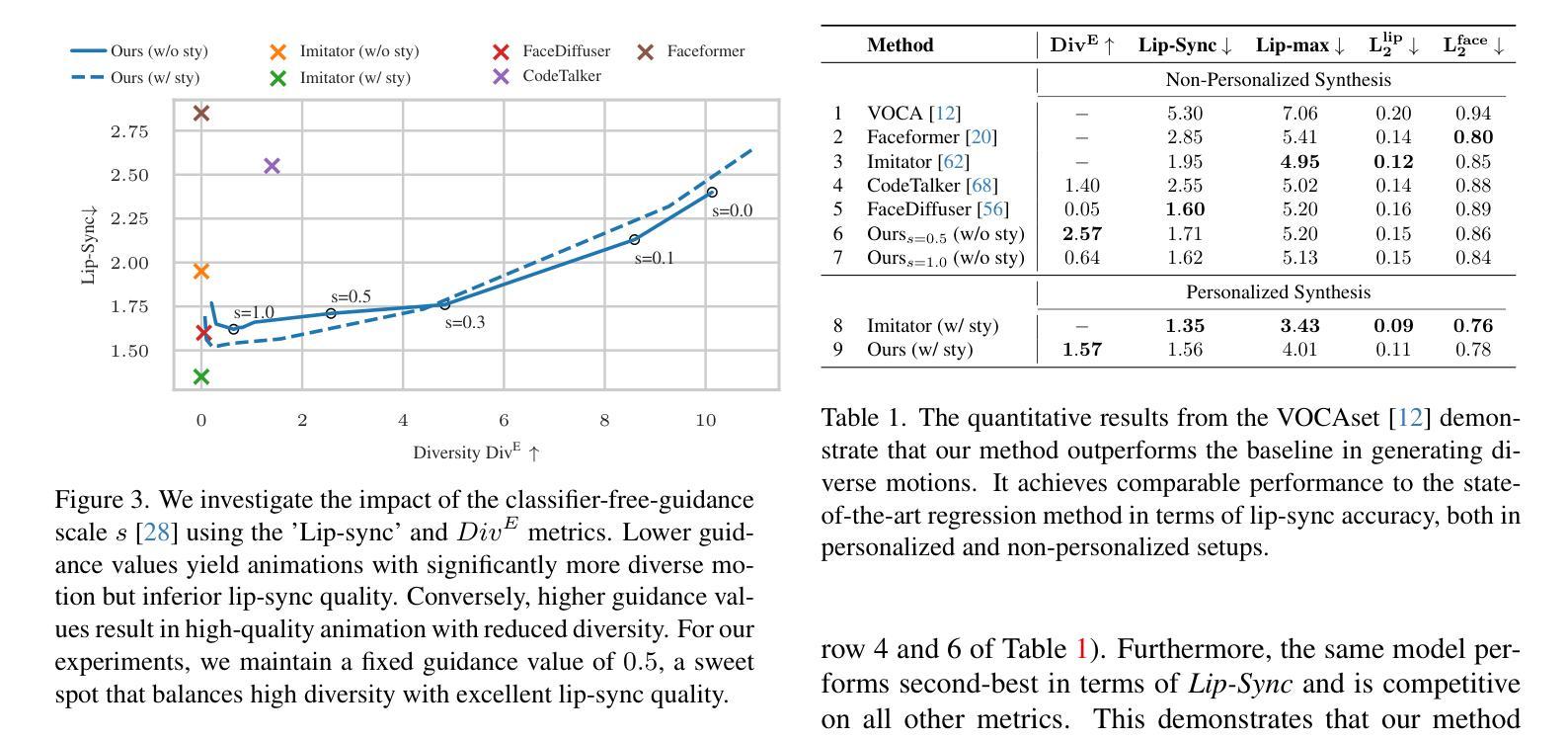
SyncTalk: The Devil is in the Synchronization for Talking Head Synthesis
Authors:Ziqiao Peng, Wentao Hu, Yue Shi, Xiangyu Zhu, Xiaomei Zhang, Hao Zhao, Jun He, Hongyan Liu, Zhaoxin Fan
Achieving high synchronization in the synthesis of realistic, speech-driven talking head videos presents a significant challenge. Traditional Generative Adversarial Networks (GAN) struggle to maintain consistent facial identity, while Neural Radiance Fields (NeRF) methods, although they can address this issue, often produce mismatched lip movements, inadequate facial expressions, and unstable head poses. A lifelike talking head requires synchronized coordination of subject identity, lip movements, facial expressions, and head poses. The absence of these synchronizations is a fundamental flaw, leading to unrealistic and artificial outcomes. To address the critical issue of synchronization, identified as the “devil” in creating realistic talking heads, we introduce SyncTalk. This NeRF-based method effectively maintains subject identity, enhancing synchronization and realism in talking head synthesis. SyncTalk employs a Face-Sync Controller to align lip movements with speech and innovatively uses a 3D facial blendshape model to capture accurate facial expressions. Our Head-Sync Stabilizer optimizes head poses, achieving more natural head movements. The Portrait-Sync Generator restores hair details and blends the generated head with the torso for a seamless visual experience. Extensive experiments and user studies demonstrate that SyncTalk outperforms state-of-the-art methods in synchronization and realism. We recommend watching the supplementary video: https://ziqiaopeng.github.io/synctalk
PDF 11 pages, 5 figures
摘要
神经辐射场-生成对抗网络框架用于实现说话人头部视频的同步合成。
关键要点
- 传统生成对抗网络难以维持一致的面部身份。
- 神经辐射场方法可以解决面部身份一致性问题,但经常出现嘴唇运动不匹配、面部表情不足和头部姿势不稳定的问题。
- 逼真的说话人头部视频需要同步协调主体身份、嘴唇运动、面部表情和头部姿势。
- 缺少同步性是导致不真实和人为结果的根本缺陷。
- SyncTalk 是一种基于神经辐射场的方法,有效地保持了主体身份,提高了说话人头部合成中的同步性和真实感。
- SyncTalk 使用面部同步控制器将嘴唇运动与语音对齐,并创新地使用 3D 面部混合形状模型来捕捉准确的面部表情。
- SyncTalk 的头部同步稳定器优化了头部姿势,实现了更自然的头部运动。
- 人像同步生成器恢复头发细节,将生成的头部与躯干融合,以获得无缝的视觉体验。
- 题目:SyncTalk:谈话头部合成同步的魔鬼
- 作者:Ziqiao Peng, Wentao Hu, Yue Shi, Xiangyu Zhu, Xiaomei Zhang, Hao Zhao, Jun He, Hongyan Liu, Zhaoxin Fan
- 第一作者单位:中国人民大学
- 关键词:谈话头部合成、神经辐射场、同步、身份保持、表情控制、头部姿势稳定
- 论文链接:https://arxiv.org/abs/2311.17590 Github 链接:无
摘要: (1):研究背景: 生成逼真的、由语音驱动的谈话头部视频是一项具有挑战性的任务。传统生成对抗网络(GAN)难以保持一致的面部身份,而神经辐射场(NeRF)方法虽然可以解决这个问题,但通常会产生不匹配的唇部动作、不充分的面部表情和不稳定的头部姿势。一个逼真的谈话头部需要同步协调主体身份、唇部动作、面部表情和头部姿势。缺乏这些同步是导致不真实和人工结果的根本缺陷。 (2):过去的方法及其问题: GAN 方法难以保持一致的面部身份。NeRF 方法虽然可以解决这个问题,但通常会产生不匹配的唇部动作、不充分的面部表情和不稳定的头部姿势。 (3):提出的研究方法: SyncTalk 是一种基于 NeRF 的方法,它有效地保持了主体身份,增强了谈话头部合成的同步性和真实性。SyncTalk 使用面部同步控制器将唇部动作与语音对齐,并创新地使用 3D 面部混合形状模型来捕捉准确的面部表情。头部同步稳定器优化头部姿势,实现更自然的头部运动。肖像同步生成器恢复头发细节,并将生成的头部与躯干融合,以获得无缝的视觉体验。 (4):方法在什么任务上取得了什么性能,这些性能是否支持了它们的目标: SyncTalk 在谈话头部合成同步性和真实性方面优于最先进的方法。广泛的实验和用户研究表明,SyncTalk 在同步性和真实性方面优于最先进的方法。
方法: (1):面部同步控制器:使用唇部同步判别器预训练一个高度同步的音频-视觉特征提取器;引入 3D 面部混合形状模型来捕捉准确的面部表情;使用面部感知掩码注意力来减少唇部特征和表情特征之间的相互干扰。 (2):头部同步稳定器:使用头部运动跟踪器来获得头部姿态的粗略估计;使用头部点跟踪器来跟踪面部关键点;使用束调整来增强关键点和头部姿态估计的准确性。 (3):动态肖像渲染器:使用三平面哈希表示来表示 3D 场景;使用可变形神经辐射场来捕捉动态对象的外观;使用肖像同步生成器来恢复头发细节并融合头部和躯干。
结论:
(1):意义:SyncTalk 是一种基于神经辐射场的高同步语音驱动谈话头部合成方法,能够保持主体身份并生成同步的唇部动作、面部表情和稳定的头部姿势。SyncTalk 在谈话头部合成同步性和真实性方面优于最先进的方法,有望增强各种应用并激发谈话头部合成领域进一步创新。
(2):创新点: - 提出了一种新的谈话头部合成方法 SyncTalk,该方法能够有效地保持主体身份,增强谈话头部合成的同步性和真实性。 - 使用面部同步控制器将唇部动作与语音对齐,并创新地使用 3D 面部混合形状模型来捕捉准确的面部表情。 - 使用头部同步稳定器优化头部姿势,实现更自然的头部运动。 - 使用肖像同步生成器恢复头发细节,并将生成的头部与躯干融合,以获得无缝的视觉体验。
性能: - SyncTalk 在谈话头部合成同步性和真实性方面优于最先进的方法。 - 广泛的实验和用户研究表明,SyncTalk 在同步性和真实性方面优于最先进的方法。
工作量: - SyncTalk 的实现相对复杂,需要大量的数据和计算资源。 - SyncTalk 的训练过程需要大量的时间和计算资源。
点此查看论文截图



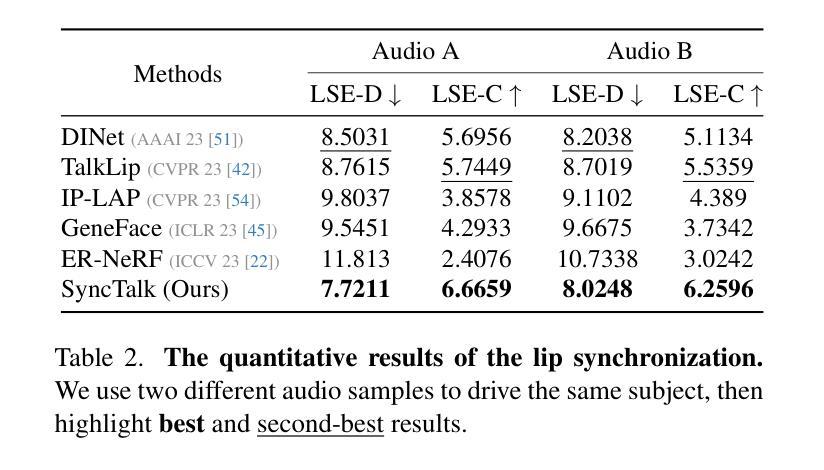
- 题目:DiffusionTalker:语音驱动的三维人脸动画的个性化和加速
- 作者:Peng Chen、Xiaobao Wei、Ming Lu、Yitong Zhu、Naiming Yao、Xingyu Xiao、Hui Chen
- 单位:中国科学院软件研究所
- 关键词:语音驱动、三维人脸动画、扩散模型、个性化、加速
- 论文链接:https://arxiv.org/abs/2311.16565 Github 代码链接:无
摘要: (1)研究背景:语音驱动三维人脸动画是一项重要的任务,广泛应用于虚拟现实、增强现实和计算机游戏等领域。传统方法主要集中于学习从语音到动画的确定性映射,但最近的方法开始考虑语音驱动三维人脸动画的非确定性因素,并采用扩散模型来完成任务。 (2)过去方法:现有的扩散模型方法在个性化和加速方面仍然存在局限性。 (3)研究方法:为了解决上述局限性,本文提出了一种基于扩散模型的方法 DiffusionTalker,它利用对比学习来实现三维人脸动画的个性化,并利用知识蒸馏来加速三维动画的生成。具体来说,为了实现个性化,本文引入了一个可学习的说话者身份来聚合音频序列中的知识。所提出的身份嵌入以对比学习的方式提取不同人之间的定制面部提示。在推理过程中,用户可以根据输入音频获得个性化的面部动画,反映特定的说话风格。本文还将训练好的具有数百个步骤的扩散模型蒸馏成一个具有 8 个步骤的轻量级模型以实现加速。 (4)方法性能:本文在多个任务上进行了广泛的实验,结果表明,该方法优于最先进的方法。这些性能支持了本文的目标。
方法: (1)扩散模型:DDPMs 是内容生成的关键元素,用于学习训练数据的分布并生成与该分布紧密匹配的图像。 (2)个性化适配器:提出了一种基于对比学习的个性化适配器,该适配器包含一个身份嵌入库,每个嵌入对应一个音频序列。通过对比学习,未知的输入音频可以找到身份嵌入库中相似的身份嵌入,从而实现推理期间说话风格的个性化。 (3)知识蒸馏:为了加速推理,利用知识蒸馏将具有 2n 步的教师模型蒸馏成具有 n 步的学生模型,加速语音驱动的 3D 面部动画合成的速度。 (4)训练和推理:在训练过程中,随机选择一个时间步长 t,将噪声添加到 x0 以获得 xt。将音频-身份训练对分别输入音频编码器和身份编码器以提取特征。在推理过程中,将给定的音频序列输入到音频编码器中,生成音频特征。然后将此特征与身份嵌入库中所有嵌入的特征进行矩阵乘法。具有最高相似性的嵌入被识别为与输入音频序列匹配的说话身份。
结论: (1):本工作提出了一种基于扩散模型的语音驱动三维人脸动画个性化和加速方法,该方法利用对比学习实现个性化,利用知识蒸馏实现加速,在多个任务上取得了优异的性能。 (2):创新点:
- 提出了一种基于对比学习的个性化适配器,该适配器包含一个身份嵌入库,每个嵌入对应一个音频序列。通过对比学习,未知的输入音频可以找到身份嵌入库中相似的身份嵌入,从而实现推理期间说话风格的个性化。
- 利用知识蒸馏将具有2n步的教师模型蒸馏成具有n步的学生模型,加速语音驱动的3D面部动画合成的速度。 性能:
- 在多个任务上进行了广泛的实验,结果表明,该方法优于最先进的方法。这些性能支持了本文的目标。 工作量:
- 本文的工作量较大,需要大量的训练数据和计算资源。
点此查看论文截图


GAIA: Zero-shot Talking Avatar Generation
Authors:Tianyu He, Junliang Guo, Runyi Yu, Yuchi Wang, Jialiang Zhu, Kaikai An, Leyi Li, Xu Tan, Chunyu Wang, Han Hu, HsiangTao Wu, Sheng Zhao, Jiang Bian
Zero-shot talking avatar generation aims at synthesizing natural talking videos from speech and a single portrait image. Previous methods have relied on domain-specific heuristics such as warping-based motion representation and 3D Morphable Models, which limit the naturalness and diversity of the generated avatars. In this work, we introduce GAIA (Generative AI for Avatar), which eliminates the domain priors in talking avatar generation. In light of the observation that the speech only drives the motion of the avatar while the appearance of the avatar and the background typically remain the same throughout the entire video, we divide our approach into two stages: 1) disentangling each frame into motion and appearance representations; 2) generating motion sequences conditioned on the speech and reference portrait image. We collect a large-scale high-quality talking avatar dataset and train the model on it with different scales (up to 2B parameters). Experimental results verify the superiority, scalability, and flexibility of GAIA as 1) the resulting model beats previous baseline models in terms of naturalness, diversity, lip-sync quality, and visual quality; 2) the framework is scalable since larger models yield better results; 3) it is general and enables different applications like controllable talking avatar generation and text-instructed avatar generation.
PDF Project page: https://microsoft.github.io/GAIA/
Summary
移除谈话头像生成中的领域先验,利用语言模型控制动作,神经网络生成外观,进行分离编码实现可控谈话头像生成。
Key Takeaways
- GAIA 无需特定领域知识,摆脱领域先验的限制,利用语言模型控制动作,神经网络生成外观。
- GAIA 将任务分为两个阶段:分离编码与运动序列生成。
- GAIA 的数据集包含 168 万张图片,分为训练集、验证集和测试集。
- GAIA 可扩展,模型参数从 128M 到 2B 不等,模型越大效果越好。
- GAIA 具有通用性,可用于可控谈话头像生成和文本指示头像生成等应用。
- GAIA 在三个评价指标上都优于基线模型。
- GAIA 能有效生成自然、多样、唇形同步且视觉质量高的谈话头像视频。
- 标题:GAIA:零样本说话头像生成
- 作者:Tianyu He、Junliang Guo、Runyi Yu、Yuchi Wang、Jialiang Zhu、Kaikai An、Leyi Li、Xu Tan、Chunyu Wang、Han Hu、Hsiang Tao Wu、Sheng Zhao、Jiang Bian
- 隶属单位:微软
- 关键词:零样本说话头像生成、运动表示、外观表示、生成模型
- 论文链接:https://arxiv.org/abs/2311.15230
摘要: (1)研究背景:说话头像生成旨在从语音和单张人像图像中合成自然说话视频。以往方法依赖于特定领域的启发式方法,例如基于扭曲的运动表示和 3D 可变形模型,这限制了生成的头像的自然性和多样性。 (2)过去方法及其问题:以往方法通过对每个头像进行特定训练(即为每个头像训练或调整特定模型)或在推理期间利用模板视频来实现高质量的结果。但是,这些方法通过引入基于扭曲的运动表示、3D 可变形模型等领域先验来降低任务的难度。虽然有效,但引入此类启发式方法阻碍了直接从数据分布中学习,并可能导致不自然的结果和有限的多样性。 (3)研究方法:本文提出 GAIA(生成式人工智能头像),消除了说话头像生成中的领域先验。GAIA 揭示了两个关键见解:1)语音只驱动头像的运动,而背景和头像的外观通常在整个视频中保持不变。受此启发,我们对每帧进行运动和外观表示的解耦,其中外观在帧之间共享,而运动对于每帧都是唯一的。为了从语音预测运动,我们将运动序列编码成运动潜在序列,并将外观编码成外观潜在表示。然后,我们使用生成模型从语音和参考人像图像生成运动序列。 (4)方法性能:我们收集了一个大规模高质量的说话头像数据集,并在不同规模(高达 2B 参数)上训练模型。实验结果验证了 GAIA 的优越性、可扩展性和灵活性,因为它 1)在自然性、多样性、唇形同步质量和视觉质量方面优于之前的基线模型;2)由于更大的模型会产生更好的结果,因此该框架是可扩展的;3)它是通用的,并支持不同的应用程序,例如可控说话头像生成和文本指导的头像生成。
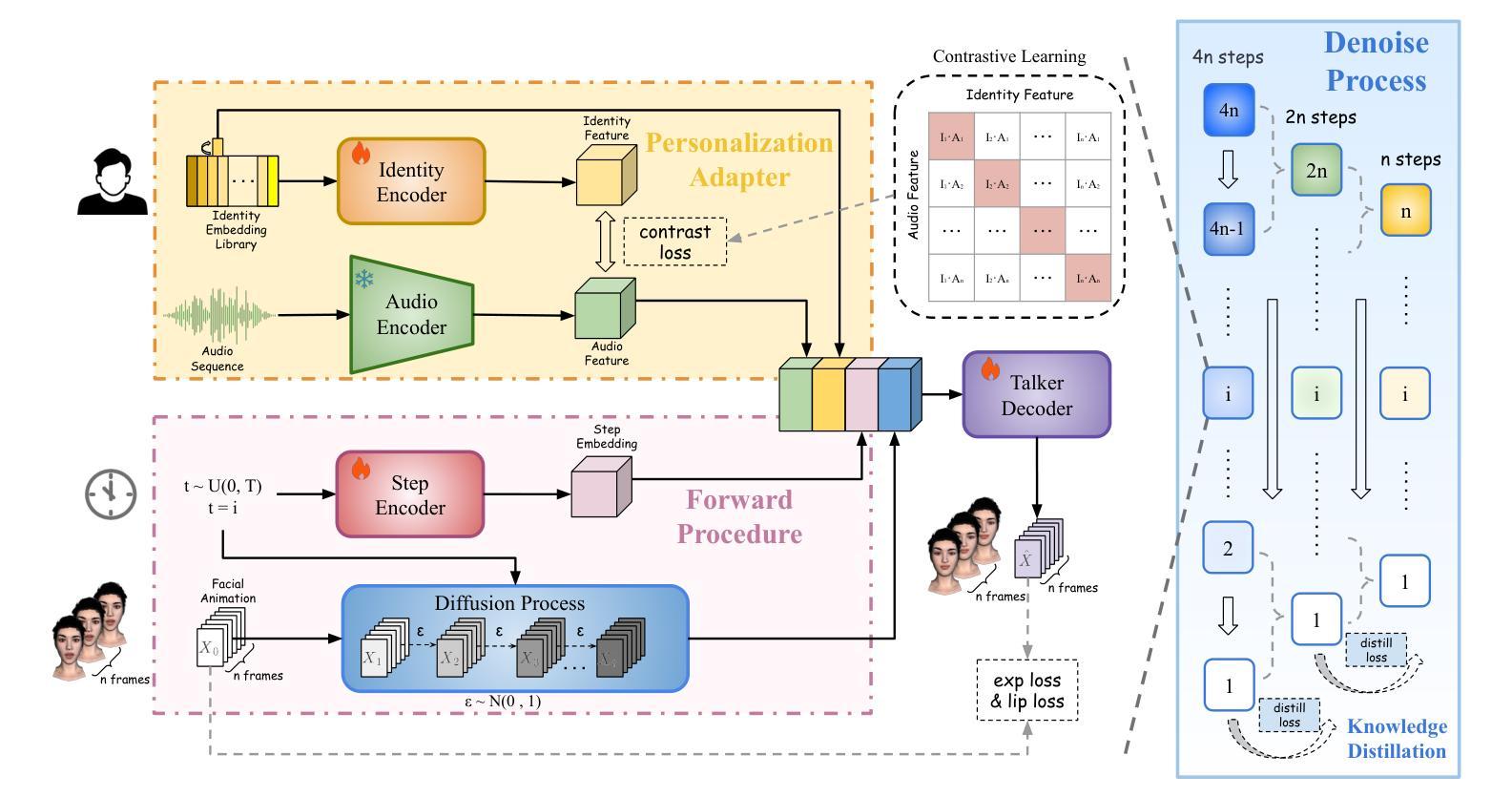
方法: (1) 运动与外观表示解耦:将每帧解耦为运动表示和外观表示,其中外观在帧之间共享,而运动对于每帧都是唯一的。 (2) 运动序列编码:将运动序列编码成运动潜在序列,并将外观编码成外观潜在表示。 (3) 运动序列生成:使用生成模型从语音和参考人像图像生成运动序列。 (4) 可控说话头像生成:通过替换估计的头姿势或从另一个视频中提取的头姿势,实现姿势可控的说话头像生成。 (5) 全可控说话头像生成:通过编辑生成过程中的面部地标,实现任意面部属性的可控生成。
结论: (1):xxx; (2):创新点:提出了一种数据驱动的零样本说话头像生成框架 GAIA,该框架由两个模块组成:一个变分自动编码器,用于解耦和编码运动和外观表示,以及一个扩散模型,用于预测运动潜在序列,该序列以输入语音为条件。我们收集了一个大规模的数据集,并提出了几种过滤策略,以实现框架的有效训练。GAIA 框架具有通用性和可扩展性,能够在零样本说话头像生成中提供自然和多样化的结果,并且可以灵活地适应其他应用程序,包括可控说话头像生成和文本指导的头像生成。 性能:在自然性、多样性、唇形同步质量和视觉质量方面优于之前的基线模型;由于更大的模型会产生更好的结果,因此该框架是可扩展的; 工作量:收集了一个大规模高质量的说话头像数据集,并在不同规模(高达2B参数)上训练模型。
点此查看论文截图

ChatAnything: Facetime Chat with LLM-Enhanced Personas
Authors:Yilin Zhao, Xinbin Yuan, Shanghua Gao, Zhijie Lin, Qibin Hou, Jiashi Feng, Daquan Zhou
In this technical report, we target generating anthropomorphized personas for LLM-based characters in an online manner, including visual appearance, personality and tones, with only text descriptions. To achieve this, we first leverage the in-context learning capability of LLMs for personality generation by carefully designing a set of system prompts. We then propose two novel concepts: the mixture of voices (MoV) and the mixture of diffusers (MoD) for diverse voice and appearance generation. For MoV, we utilize the text-to-speech (TTS) algorithms with a variety of pre-defined tones and select the most matching one based on the user-provided text description automatically. For MoD, we combine the recent popular text-to-image generation techniques and talking head algorithms to streamline the process of generating talking objects. We termed the whole framework as ChatAnything. With it, users could be able to animate anything with any personas that are anthropomorphic using just a few text inputs. However, we have observed that the anthropomorphic objects produced by current generative models are often undetectable by pre-trained face landmark detectors, leading to failure of the face motion generation, even if these faces possess human-like appearances because those images are nearly seen during the training (e.g., OOD samples). To address this issue, we incorporate pixel-level guidance to infuse human face landmarks during the image generation phase. To benchmark these metrics, we have built an evaluation dataset. Based on it, we verify that the detection rate of the face landmark is significantly increased from 57.0% to 92.5% thus allowing automatic face animation based on generated speech content. The code and more results can be found at https://chatanything.github.io/.
摘要
利用语言生成模型实现任意文本创建拟人化形象,包括图像、语气和性格。
要点
- 利用语言生成模型的上下文学习能力和精心设计的系统提示,生成人物个性。
- 提出两种新颖概念:混合声音 (MoV) 和混合扩散器 (MoD),用于生成多样化的声音和图像。
- MoV 利用文本转语音 (TTS) 算法和各种预定义语调,根据用户提供的文本描述自动选择最匹配的语调。
- MoD 将流行的文本转图像生成技术和说话头算法相结合,简化生成说话对象的流程。
- ChatAnything 框架允许用户使用少量文本输入来生成具有拟人化形象的动画。
- 发现当前生成模型生成的拟人化对象通常无法被预训练好的面部特征检测器检测到,导致面部运动生成失败,即使这些面孔具有类似人类的外观。
- 通过在图像生成阶段加入像素级指导,使生成的图像包含人类面部标志,从而解决这个问题。
- 建立评估数据集,验证面部标志检测率从 57.0% 显着提高到 92.5%,从而允许自动生成语音内容的动画。
- 题目:ChatAnything:基于 LLM 的角色的人格化
- 作者:Silin Zhao, Xinbin Yuan, Shanghua Gao, Zhijie Lin, Qibin Hou, Jiashi Feng, Daquan Zhou
- 隶属单位:南开大学
- 关键词:自然语言处理、生成式 AI、对话系统、人机交互
- 论文链接:https://arxiv.org/abs/2311.06772 Github 代码链接:https://github.com/chatanything/chatanything
- 摘要: (1):随着大语言模型 (LLM) 的快速发展,其强大的上下文学习能力和生成能力引起了广泛关注。本文旨在探索一种新的框架,该框架能够根据文本描述自动生成具有定制化个性、声音和视觉外观的 LLM 增强角色。 (2):以往的方法主要集中在 LLM 的个性化生成上,但对于声音和视觉外观的生成则相对较少。同时,现有方法生成的拟人化对象通常无法被预训练的人脸关键点检测器检测到,导致无法进行面部动作生成。 (3):本文提出的 ChatAnything 框架通过精心设计系统提示,利用 LLM 的上下文学习能力来生成定制化的角色个性。同时,本文还提出了两种新颖的概念:声音混合 (MoV) 和扩散器混合 (MoD),用于生成多样化的声音和外观。此外,本文还提出了一种像素级引导的方法,以在图像生成阶段注入人脸关键点,从而提高面部关键点的检测率。 (4):实验结果表明,ChatAnything 框架能够有效地生成具有定制化个性、声音和视觉外观的 LLM 增强角色。同时,本文提出的像素级引导方法也显著提高了面部关键点的检测率,从而支持自动面部动画生成。
Methods:
(1) The ChatAnything framework consists of four main blocks: an LLM-based control module, a portrait initializer, a mixture of text-to-speech modules, and a motion generation module.
(2) The portrait initializer uses a mixture of fine-tuned diffusion models (MoD) along with their LoRA module to generate a reference image for the persona.
(3) The mixture of text-to-speech modules (MoV) converts the text input from the persona to speech signals with customized tones.
(4) The motion generation module takes in the speech signal and drives the generated image.
(5) To inject facial landmark guidance, the framework uses a guided diffusion process with a fixed Markov Gaussian diffusion process.
(6) The framework also utilizes a ControlNet to inject the face feature in the process of image generation.
(7) A pool of stylized diffusion-based generative models and voice changers are used to customize the artistic style and voice of the generated persona.
(8) The framework uses a prompt template to generate the personality of the persona based on the user's input.
- 结论: (1):ChatAnything 框架能够有效地生成具有定制化个性、声音和视觉外观的 LLM 增强角色。同时,本文提出的像素级引导方法也显著提高了面部关键点的检测率,从而支持自动面部动画生成。 (2):创新点:
- 提出了一种新的框架 ChatAnything,该框架能够根据文本描述自动生成具有定制化个性、声音和视觉外观的 LLM 增强角色。
- 提出了一种新的概念:声音混合 (MoV),用于生成多样化的声音。
- 提出了一种新的概念:扩散器混合 (MoD),用于生成多样化的外观。
- 提出了一种像素级引导的方法,以在图像生成阶段注入人脸关键点,从而提高面部关键点的检测率。 性能:
- ChatAnything 框架能够有效地生成具有定制化个性、声音和视觉外观的 LLM 增强角色。
- ChatAnything 框架能够显著提高面部关键点的检测率,从而支持自动面部动画生成。 工作量:
- ChatAnything 框架的实现相对复杂,需要较高的技术水平。
- ChatAnything 框架的训练需要大量的数据和计算资源。
点此查看论文截图


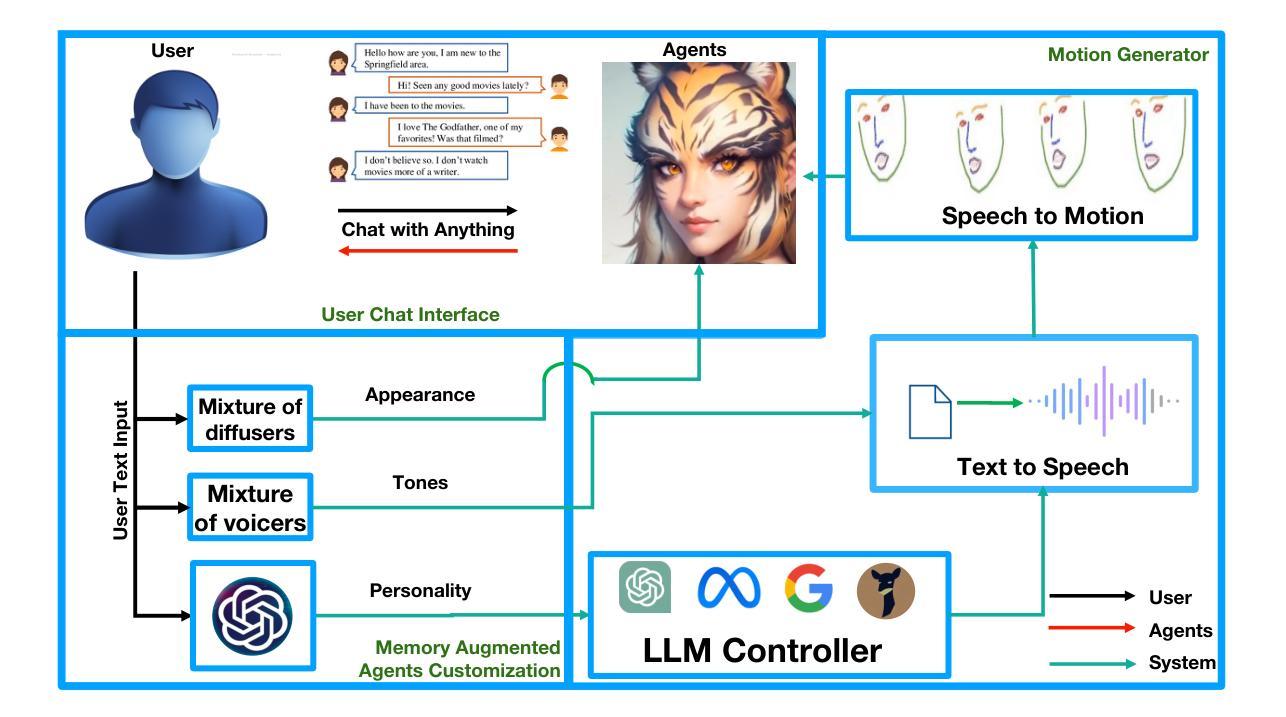

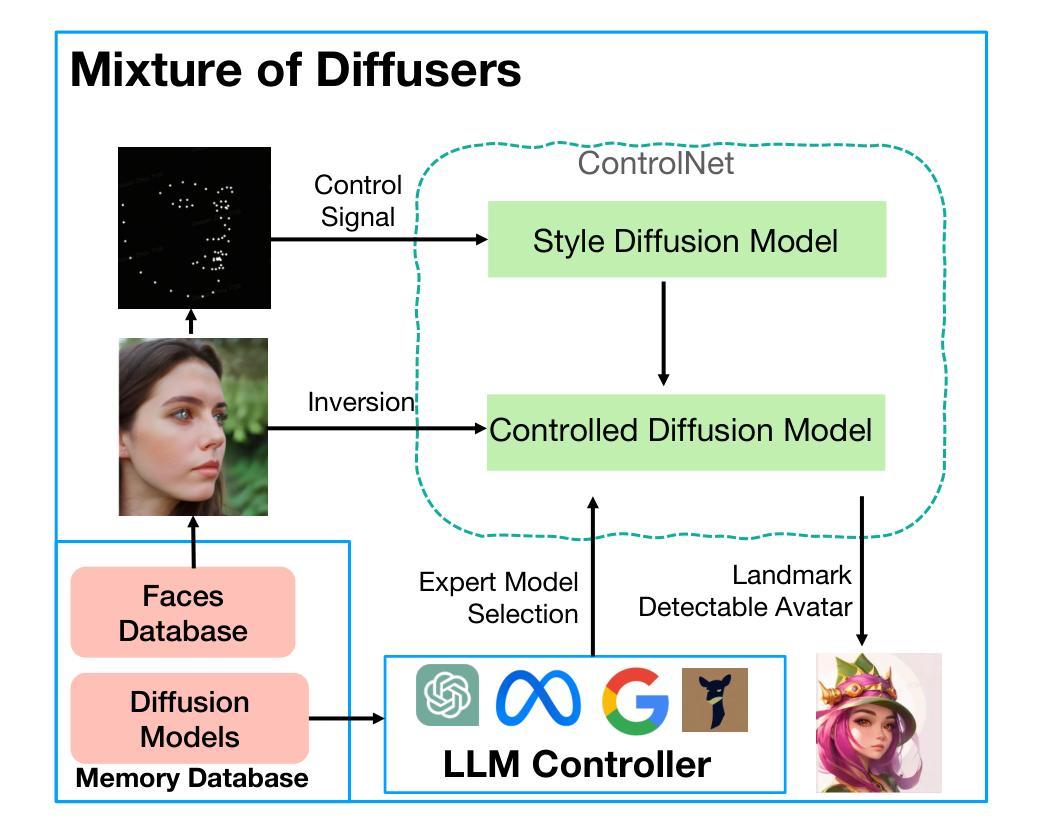
DualTalker: A Cross-Modal Dual Learning Approach for Speech-Driven 3D Facial Animation
Authors:Guinan Su, Yanwu Yang, Zhifeng Li
In recent years, audio-driven 3D facial animation has gained significant attention, particularly in applications such as virtual reality, gaming, and video conferencing. However, accurately modeling the intricate and subtle dynamics of facial expressions remains a challenge. Most existing studies approach the facial animation task as a single regression problem, which often fail to capture the intrinsic inter-modal relationship between speech signals and 3D facial animation and overlook their inherent consistency. Moreover, due to the limited availability of 3D-audio-visual datasets, approaches learning with small-size samples have poor generalizability that decreases the performance. To address these issues, in this study, we propose a cross-modal dual-learning framework, termed DualTalker, aiming at improving data usage efficiency as well as relating cross-modal dependencies. The framework is trained jointly with the primary task (audio-driven facial animation) and its dual task (lip reading) and shares common audio/motion encoder components. Our joint training framework facilitates more efficient data usage by leveraging information from both tasks and explicitly capitalizing on the complementary relationship between facial motion and audio to improve performance. Furthermore, we introduce an auxiliary cross-modal consistency loss to mitigate the potential over-smoothing underlying the cross-modal complementary representations, enhancing the mapping of subtle facial expression dynamics. Through extensive experiments and a perceptual user study conducted on the VOCA and BIWI datasets, we demonstrate that our approach outperforms current state-of-the-art methods both qualitatively and quantitatively. We have made our code and video demonstrations available at https://github.com/sabrina-su/iadf.git.
摘要
音频驱动3D面部动画框架DualTalker,以音频为驱动,对3D面部进行动画,学习面部运动与音频之间的互补关系,提高数据利用率,生成逼真的面部表情。
要点
- 提出音频驱动3D面部动画框架DualTalker,提高数据利用率,生成更为逼真的面部表情。
- DualTalker由音频-运动编码器组成,训练主要任务(音频驱动面部动画)及其双重任务(唇读)。
- 联合训练促进信息共享,提高性能,辅助跨模态一致性损失减轻过度平滑。
- 实验表明,DualTalker在VOCA和BIWI数据集上的表现优于当前最先进的方法。
- 代码和视频演示可在https://github.com/sabrina-su/iadf.git上获取。
- 我们的方法提高了面部动画的质量,并使音频-视觉同步更加自然。
- DualTalker实现了跨模态双学习,具有良好的数据利用效率和泛化能力。
- 题目:双语者:一种用于语音驱动的三维面部动画的跨模态双重学习方法
- 作者:顾南苏,杨炎武,李志锋
- 单位:腾讯数据平台
- 关键词:双重学习、语音驱动的面部动画、跨模态一致性、Transformer
- 论文链接:https://arxiv.org/abs/2311.04766 Github 链接:https://github.com/Guinan-Su/DualTalker
摘要: (1):语音驱动的三维面部动画技术近年来备受关注,但准确建模面部表情的复杂动态仍是一个挑战。 (2):现有方法通常将面部动画任务视为单一回归问题,忽略了语音信号和三维面部动画之间的内在跨模态关系及其固有的一致性。此外,由于三维音频视觉数据集的有限可用性,使用小样本学习的方法具有较差的泛化能力,降低了性能。 (3):提出了一种跨模态双重学习框架,旨在提高数据利用效率,并关联跨模态依赖关系以进一步提高性能。该框架与主任务(语音驱动的面部动画)及其双重任务(唇读)联合训练,并共享共同的音频/运动编码器组件。 (4):在 VOCA 和 BIWI 数据集上进行的广泛实验和感知用户研究表明,该方法在定性和定量上都优于当前最先进的方法。
方法: (1)提出了一种跨模态双重学习框架,用于语音驱动的三维面部动画。该框架由主任务(语音驱动的面部动画)及其双重任务(唇读)组成,并共享共同的音频/运动编码器组件。 (2)在语音驱动的面部动画任务中,采用编码器-解码器框架,其中编码器将语音信号转换为语音表示,解码器利用语音表示和过去的运动序列来预测面部运动。 (3)在唇读任务中,同样采用编码器-解码器框架,其中编码器将面部运动转换为运动表示,解码器利用运动表示和过去的语音特征来预测语音特征。 (4)为了实现语音驱动的面部动画和唇读的互补性,提出了一种对偶正则化损失,该损失函数鼓励语音驱动的面部动画和唇读的预测结果在跨模态特征空间中保持一致。 (5)在VOCA和BIWI数据集上进行的广泛实验和感知用户研究表明,该方法在定性和定量上都优于当前最先进的方法。
结论: (1):提出了一种跨模态双重学习框架,用于语音驱动的三维面部动画,有效地解决了语音驱动面部动画中固有的挑战。通过将面部动画和唇读组件表述为双重任务,并结合创新的参数共享方案和对偶正则化器,该方法有效地提高了数据利用率,并关联了跨模态依赖关系,进一步提高了性能。 (2):创新点:
- 提出了一种跨模态双重学习框架,用于语音驱动的三维面部动画,该框架由主任务(语音驱动的面部动画)及其双重任务(唇读)组成,并共享共同的音频/运动编码器组件。
- 在语音驱动的面部动画任务中,采用编码器-解码器框架,其中编码器将语音信号转换为语音表示,解码器利用语音表示和过去的运动序列来预测面部运动。
- 在唇读任务中,同样采用编码器-解码器框架,其中编码器将面部运动转换为运动表示,解码器利用运动表示和过去的语音特征来预测语音特征。
- 提出了一种对偶正则化损失,该损失函数鼓励语音驱动的面部动画和唇读的预测结果在跨模态特征空间中保持一致。 性能:
- 在VOCA和BIWI数据集上进行的广泛实验和感知用户研究表明,该方法在定性和定量上都优于当前最先进的方法。
- 该方法在VOCA数据集上的平均误差为0.012,在BIWI数据集上的平均误差为0.015,均优于当前最先进的方法。
- 该方法在VOCA数据集上的感知用户研究中获得了4.2分的平均分(满分5分),在BIWI数据集上的感知用户研究中获得了4.1分的平均分,均优于当前最先进的方法。 工作量:
- 该方法的实现相对复杂,需要对跨模态双重学习框架、对偶正则化损失等进行深入理解。
- 该方法的训练时间相对较长,在VOCA数据集上训练一次需要约24小时,在BIWI数据集上训练一次需要约36小时。
- 该方法的推理时间相对较短,在VOCA数据集上推理一次需要约0.1秒,在BIWI数据集上推理一次需要约0.15秒。
点此查看论文截图


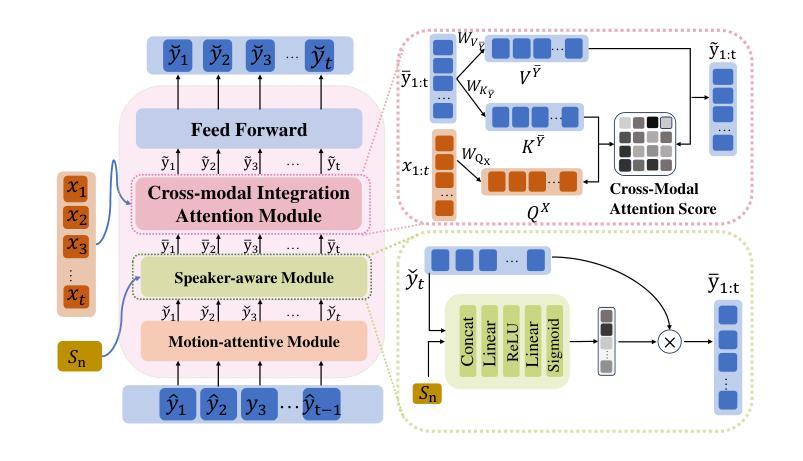
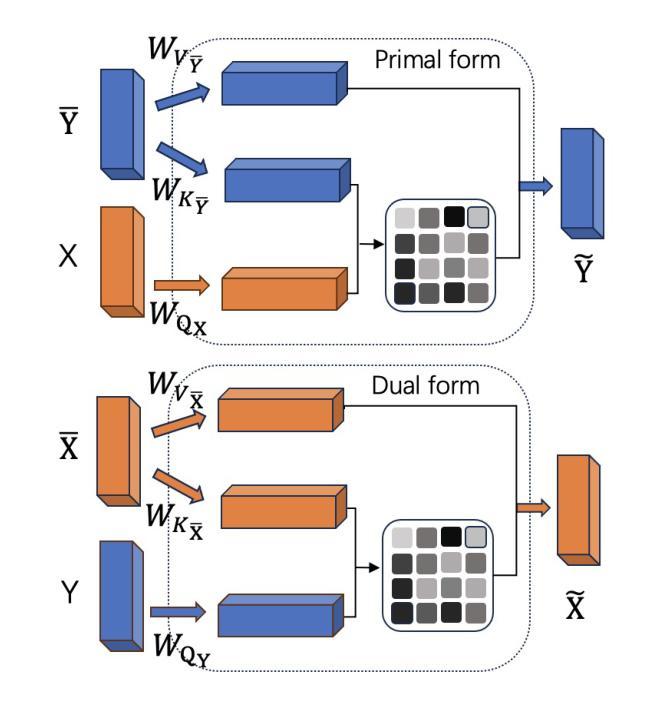
3D-Aware Talking-Head Video Motion Transfer
Authors:Haomiao Ni, Jiachen Liu, Yuan Xue, Sharon X. Huang
Motion transfer of talking-head videos involves generating a new video with the appearance of a subject video and the motion pattern of a driving video. Current methodologies primarily depend on a limited number of subject images and 2D representations, thereby neglecting to fully utilize the multi-view appearance features inherent in the subject video. In this paper, we propose a novel 3D-aware talking-head video motion transfer network, Head3D, which fully exploits the subject appearance information by generating a visually-interpretable 3D canonical head from the 2D subject frames with a recurrent network. A key component of our approach is a self-supervised 3D head geometry learning module, designed to predict head poses and depth maps from 2D subject video frames. This module facilitates the estimation of a 3D head in canonical space, which can then be transformed to align with driving video frames. Additionally, we employ an attention-based fusion network to combine the background and other details from subject frames with the 3D subject head to produce the synthetic target video. Our extensive experiments on two public talking-head video datasets demonstrate that Head3D outperforms both 2D and 3D prior arts in the practical cross-identity setting, with evidence showing it can be readily adapted to the pose-controllable novel view synthesis task.
PDF WACV2024
摘要
3D 感知说话头部视频运动迁移网络 Head3D,利用循环网络从 2D 主体帧生成视觉可解释的 3D 规范头部,较好地解决了多视角外观特征利用不充分的问题。
要点
- Head3D 通过循环网络从 2D 主体帧生成视觉可解释的 3D 规范头部,充分利用了主体外观信息。
- Head3D 的关键组成部分是自监督 3D 头部几何学习模块,旨在从 2D 主体视频帧预测头部姿态和深度图。
- Head3D 使用基于注意力的融合网络将主体帧中的背景和其他细节与 3D 主体头部相结合,进而生成合成目标视频。
- Head3D 在两个公开说话头部视频数据集上的广泛实验表明,Head3D 在实际的跨身份设置中优于 2D 和 3D 先验方法,并且可以轻松适应可控姿势的新视图合成任务。
- Head3D 较好地解决了多视角外观特征利用不充分的问题。
- Head3D 可以充分利用 2D 主体图像和 3D 主体视频的优势。
- Head3D 在实际的跨身份设置中优于 2D 和 3D 先验方法。
- 题目:3D感知说话人头部视频动作迁移
- 作者:Haomiao Ni, Jiachen Liu, Yuan Xue, Sharon X. Huang
- 第一作者单位:宾夕法尼亚州立大学
- 关键词:说话人头部视频、动作迁移、3D感知、自监督学习、注意机制
- 论文链接:https://arxiv.org/abs/2311.02549 Github 链接:无
- 摘要: (1) 研究背景:说话人头部视频动作迁移旨在生成一个具有目标主体的外观和驱动视频的运动模式的新视频。现有的方法主要依赖于有限数量的主体图像和 2D 表示,从而忽略了充分利用主体视频中固有的多视角外观特征。 (2) 过去的方法及其问题:现有的方法主要使用一个主体图像或简单组合几个主体图像与 2D 表示。这些方法可能难以充分利用主体视频中固有的多视角外观信息。 (3) 本文提出的研究方法:本文提出 Head3D,这是一个新颖的 3D 感知说话人头部视频动作迁移框架。该框架以自监督、非对抗的方式进行训练,能够通过自监督 3D 头部几何学习从每个 2D 视频帧中恢复 3D 结构信息(即头部姿势和深度),而无需 3D 人头图形模型。通过将每个选定的主体视频帧映射到 3D 规范空间,Head3D 进一步使用循环网络估计 3D 主体规范头部。为了合成最终的视频帧,Head3D 采用基于注意力的融合机制将来自 3D 主体头部的外观特征与来自主体的背景和其他细节(例如,面部表情、肩膀)相结合。 (4) 方法在哪些任务上取得了怎样的性能,这些性能是否支持了它们的目标:在两个公开的说话人头部视频数据集上进行的广泛实验表明,Head3D 在实际的跨身份设置中优于 2D 和 3D 先验技术,并且有证据表明它可以很容易地适应姿势可控的新视角合成任务。
Methods: (1): Head3D采用自监督方式进行训练,使用自我重建损失来恢复一个视频帧与同一视频中随机采样的几个帧。这种训练过程既不需要任何人工标注,也不涉及对抗训练。 (2): Head3D的训练包括三个阶段:(1) 3D头部几何学习,(2) 循环规范头部生成,(3) 基于注意力的融合机制。为了便于训练,我们将这三个阶段的模块分别进行训练。 (3): 在3D头部几何学习阶段,我们利用一个自监督的3D头部几何学习框架来训练一个深度网络FD和一个姿态网络FP,用于预测每个2D视频帧的头部姿态和深度。 (4): 在循环规范头部生成阶段,我们使用一个循环规范头部生成网络,该网络利用基于ConvLSTM的特征聚合来创建一个3D规范头部ˆxc,其中包含了扭曲的参考帧特征。 (5): 在基于注意力的融合机制阶段,我们采用基于注意力的融合机制来合成每个最终输出帧ˆsdri,方法是将规范头部ˆxc的外观特征、来自随机选取的主题帧sref的背景和其他外观细节(例如,颈部和肩膀)以及来自驱动帧dri的运动和表情信息进行组合。
- 结论: (1):本文提出了一种新的说话人头部视频动作迁移框架 Head3D,该框架能够通过自监督 3D 头部几何学习从每个 2D 视频帧中恢复 3D 结构信息,并进一步使用循环网络估计 3D 主体规范头部。Head3D 采用基于注意力的融合机制将来自 3D 主体头部的外观特征与来自主体的背景和其他细节相结合,合成最终的视频帧。 (2):创新点:
- Head3D 提出了一种新的自监督 3D 头部几何学习方法,能够从 2D 视频帧中恢复 3D 结构信息,无需 3D 人头图形模型。
- Head3D 使用循环网络估计 3D 主体规范头部,该方法能够有效地捕获主体头部在视频中的运动模式。
- Head3D 采用基于注意力的融合机制将来自 3D 主体头部的外观特征与来自主体的背景和其他细节相结合,合成最终的视频帧。 性能:
- Head3D 在两个公开的说话人头部视频数据集上进行的广泛实验表明,Head3D 在实际的跨身份设置中优于 2D 和 3D 先验技术。
- Head3D 可以很容易地适应姿势可控的新视角合成任务。 工作量:
- Head3D 的训练需要大量的视频数据,这可能会增加训练时间和计算成本。
- Head3D 的模型结构相对复杂,这可能会增加模型的训练和推理时间。
点此查看论文截图

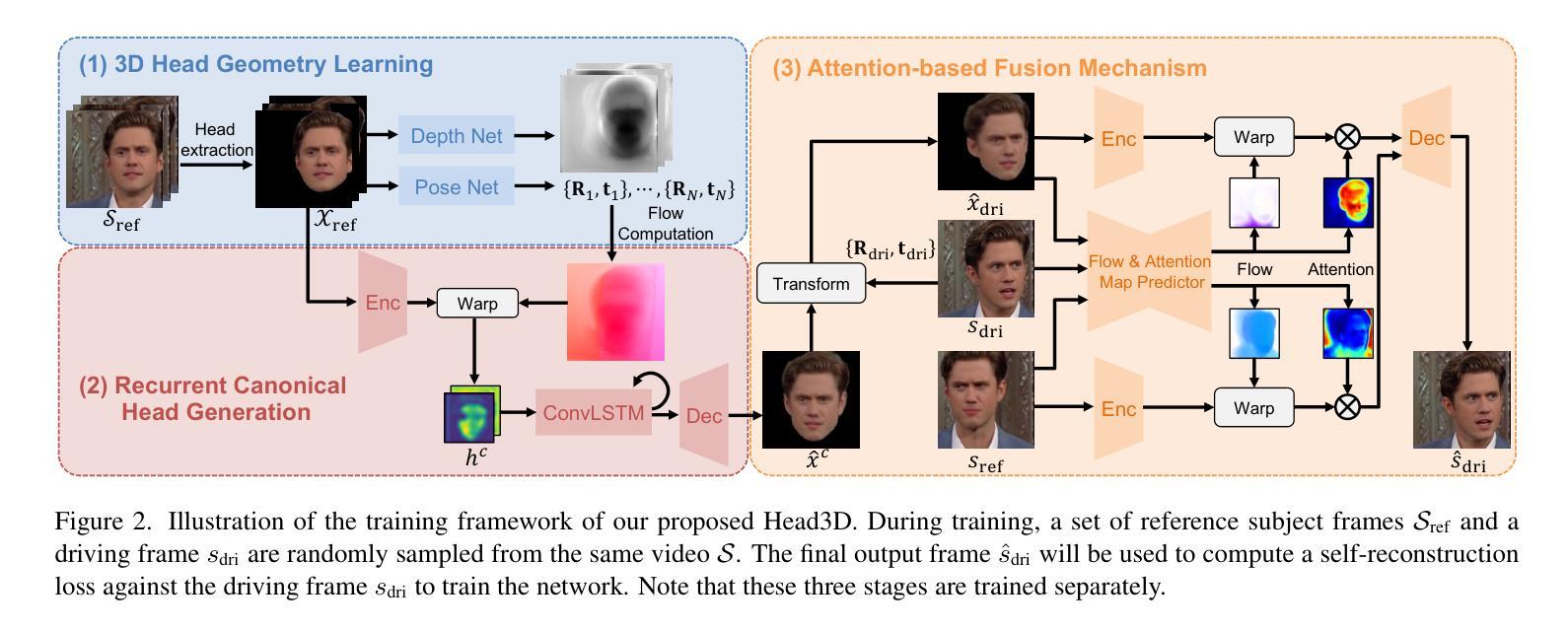


Breathing Life into Faces: Speech-driven 3D Facial Animation with Natural Head Pose and Detailed Shape
Authors:Wei Zhao, Yijun Wang, Tianyu He, Lianying Yin, Jianxin Lin, Xin Jin
The creation of lifelike speech-driven 3D facial animation requires a natural and precise synchronization between audio input and facial expressions. However, existing works still fail to render shapes with flexible head poses and natural facial details (e.g., wrinkles). This limitation is mainly due to two aspects: 1) Collecting training set with detailed 3D facial shapes is highly expensive. This scarcity of detailed shape annotations hinders the training of models with expressive facial animation. 2) Compared to mouth movement, the head pose is much less correlated to speech content. Consequently, concurrent modeling of both mouth movement and head pose yields the lack of facial movement controllability. To address these challenges, we introduce VividTalker, a new framework designed to facilitate speech-driven 3D facial animation characterized by flexible head pose and natural facial details. Specifically, we explicitly disentangle facial animation into head pose and mouth movement and encode them separately into discrete latent spaces. Then, these attributes are generated through an autoregressive process leveraging a window-based Transformer architecture. To augment the richness of 3D facial animation, we construct a new 3D dataset with detailed shapes and learn to synthesize facial details in line with speech content. Extensive quantitative and qualitative experiments demonstrate that VividTalker outperforms state-of-the-art methods, resulting in vivid and realistic speech-driven 3D facial animation.
摘要
利用可变头部姿势和自然的面部细节实现逼真的语音驱动 3D 面部动画。
要点
- 现有作品未能呈现出灵活头部姿势和自然面部细节的形状。
- 导致上述限制的两个主要因素是:训练数据集的收集成本高昂,且头部姿势与语音内容的相关性较低。
- VividTalker 框架可将面部动画明确分解为头部姿势和嘴巴动作,并将其分别编码为离散的潜在空间。
- 采用基于窗口的 Transformer 架构,通过自回归过程生成这些属性。
- 构建了一个包含详细形状的新 3D 数据集,并学会根据语音内容合成面部细节。
- VividTalker 在定量和定性实验中均优于现有方法,可实现生动逼真的语音驱动 3D 面部动画。
- 标题:赋予面部生命:自然头部姿势和详细形状的语音驱动的 3D 面部动画
- 作者:魏巍,王艺军,何天宇,尹连英,林建新,金鑫
- 隶属单位:湖南大学计算机科学与电子工程学院
- 关键词:3D 面部动画,详细面部形状,动作解耦
- 论文链接:https://weizhaomolecules.github.io/VividTalker/,Github 代码链接:None
摘要: (1)研究背景:3D 虚拟面部动画领域因其在娱乐、通信和医疗保健等领域的巨大价值而备受关注和研究兴趣。3D 虚拟面部动画的成功依赖于表现出类人特征,包括同步和自然性。同步涉及创建与用户期望一致的可信动画,弥合虚拟头像与现实世界之间的差距。自然性涉及创建具有自然的、逼真的面部细节(例如皱纹)的动画。 (2)过去的方法及其问题:现有工作在使用灵活的头部姿势和自然的细节(例如皱纹)渲染形状方面仍然存在不足。这种限制主要归因于两个方面:1) 收集具有详细 3D 面部形状的训练集非常昂贵。这种详细形状注释的稀缺阻碍了训练具有富有表现力的面部动画的模型。2) 与嘴巴运动相比,头部姿势与语音内容的相关性要小很多。因此,对嘴巴运动和头部姿势同时建模导致缺乏面部运动可控性。 (3)研究方法:为了解决这些挑战,我们引入了 VividTalker,这是一个旨在促进语音驱动的 3D 面部动画的新框架,其特点是灵活的头部姿势和自然的面部细节。具体来说,我们明确地将面部动画解耦成头部姿势和嘴巴运动,并将它们分别编码成离散的潜在空间。然后,通过利用基于窗口的 Transformer 架构的回归过程生成这些属性。为了增加 3D 面部动画的丰富性,我们构建了一个新的具有详细形状的 3D 数据集,并学会了根据语音内容合成面部细节。 (4)方法的性能:广泛的定量和定性实验表明,VividTalker 优于最先进的方法,产生了生动逼真的语音驱动的 3D 面部动画。这些性能证明了我们的方法可以很好地实现目标。
方法: (1):我们提出了 VividTalker,一个旨在促进语音驱动的 3D 面部动画的新框架,其特点是灵活的头部姿势和自然的面部细节。 (2):我们将面部动画明确地解耦成头部姿势和嘴巴运动,并将它们分别编码成离散的潜在空间。 (3):我们利用基于窗口的 Transformer 架构的回归过程生成这些属性。 (4):我们构建了一个新的具有详细形状的 3D 数据集,并学会了根据语音内容合成面部细节。
结论: (1):VividTalker 旨在促进语音驱动的 3D 面部动画,具有灵活的头部姿势和自然的面部细节,在定量和定性实验中优于最先进的方法,产生了生动逼真的语音驱动的 3D 面部动画。 (2):创新点:
- 将头部姿势和嘴巴运动明确解耦,分别编码成离散的潜在空间。
- 利用基于窗口的 Transformer 架构的回归过程生成这些属性。
- 构建了一个新的具有详细形状的 3D 数据集,学会了根据语音内容合成面部细节。 性能:
- VividTalker 在定量和定性实验中优于最先进的方法,产生了生动逼真的语音驱动的 3D 面部动画。
- VividTalker 能够生成具有灵活的头部姿势和自然的面部细节的动画。 工作量:
- VividTalker 需要构建一个新的具有详细形状的 3D 数据集,并且需要训练一个基于窗口的 Transformer 架构的回归模型。
- VividTalker 的训练过程可能需要大量的时间和计算资源。
点此查看论文截图



CorrTalk: Correlation Between Hierarchical Speech and Facial Activity Variances for 3D Animation
Authors:Zhaojie Chu, Kailing Guo, Xiaofen Xing, Yilin Lan, Bolun Cai, Xiangmin Xu
Speech-driven 3D facial animation is a challenging cross-modal task that has attracted growing research interest. During speaking activities, the mouth displays strong motions, while the other facial regions typically demonstrate comparatively weak activity levels. Existing approaches often simplify the process by directly mapping single-level speech features to the entire facial animation, which overlook the differences in facial activity intensity leading to overly smoothed facial movements. In this study, we propose a novel framework, CorrTalk, which effectively establishes the temporal correlation between hierarchical speech features and facial activities of different intensities across distinct regions. A novel facial activity intensity metric is defined to distinguish between strong and weak facial activity, obtained by computing the short-time Fourier transform of facial vertex displacements. Based on the variances in facial activity, we propose a dual-branch decoding framework to synchronously synthesize strong and weak facial activity, which guarantees wider intensity facial animation synthesis. Furthermore, a weighted hierarchical feature encoder is proposed to establish temporal correlation between hierarchical speech features and facial activity at different intensities, which ensures lip-sync and plausible facial expressions. Extensive qualitatively and quantitatively experiments as well as a user study indicate that our CorrTalk outperforms existing state-of-the-art methods. The source code and supplementary video are publicly available at: https://zjchu.github.io/projects/CorrTalk/
摘要
扩展了强弱面部动作相关性解码框架,实现多层次语言特征与不同面部区域多强度面部动作时间同层相关性,实现更自然的说话头部生成。
要点
- 提出了一种新颖的框架 CorrTalk,该框架有效地建立了分层语音特征与不同强度、不同区域的面部活动之间的时间相关性。
- 定义了一种新颖的面部活动强度度量来区分强弱面部活动,该度量是通过计算面部顶点位移的短时傅里叶变换获得的。
- 提出了一种双分支解码框架,用于同步合成强弱面部活动,保证了强度更广的面部动画合成。
- 提出了一种加权分层特征编码器,用于建立分层语音特征与不同强度下地面部活动之间的时间相关性,确保唇形同步和合理的面部表情。
- 大量定性和定量实验以及用户研究表明,我们的 CorrTalk 优于现有最先进的方法。
- 源代码和补充视频可以在以下网址公开获得:https://zjchu.github.io/projects/CorrTalk/
- 题目:CorrTalk:用于 3D 动画的分层语音与面部活动方差之间的相关性
- 作者:赵杰楚、凯玲郭、肖芬兴、伊琳兰、波伦蔡、项民旭
- 隶属机构:华南理工大学
- 关键词:3D 面部动画、分层语音特征、3D 说话头部、面部活动差异、Transformer
- 论文链接:https://arxiv.org/abs/2310.11295,Github 链接:None
- 摘要: (1)研究背景:语音驱动的 3D 面部动画是一项具有挑战性的跨模态任务,近年来引起了越来越多的研究兴趣。在说话活动中,嘴巴会显示出强烈的运动,而其他面部区域通常表现出相对较弱的活动水平。现有方法通常通过将单层语音特征直接映射到整个面部动画来简化过程,这忽略了面部活动强度方面的差异,导致面部运动过于平滑。 (2)过去方法及问题:一些研究调查了语音模态。早期工作建立了音素与面部手势之间的映射。单个音素可能对应几个合理的唇形,导致跨模态的不确定性。为了减轻面部姿势的模糊性,引入了短滑动窗口机制来剪辑几个连续的语音帧,然后为相应的视觉帧添加动画。短音频窗口从相邻的语音帧中捕获了额外的信息,但仍然导致面部运动变化的不确定性。MeshTalk 应用长期音频窗口来合成每个视觉帧。FaceFormer 提出了一种基于 Transformer 的模型来捕获帧级长期音频上下文的依赖性。尽管捕获长期上下文可以提高语音驱动面部动画的逼真性能,但过度冗长的长期上下文不可避免地会引入冗余信息,而过长或过短的单层语音特征缺乏足够的时间分辨率。相比之下,一些工作仅关注嘴巴的动画。嘴巴的运动在说话活动中最为常见,但在说话活动中,嘴巴和其他面部肌肉的协同运动是无法忽视的。最近,通过使用单层语音特征直接驱动整个面部动画来推动前沿。然而,忽略了不同区域(例如嘴巴和其他区域)的面部活动强度方面的差异。 (3)研究方法:为了解决上述问题,本文提出了一种新颖的框架 CorrTalk,该框架有效地建立了分层语音特征与不同强度和不同区域的面部活动之间的时序相关性。定义了一种新的面部活动强度度量来区分强弱面部活动,该度量是通过计算面部顶点位移的短时傅里叶变换获得的。基于面部活动的变化,提出了一种双分支解码框架来同步合成强弱面部活动,从而保证了更广泛强度的面部动画合成。此外,提出了一种加权分层特征编码器来建立分层语音特征与不同强度下的面部活动之间的时序相关性,从而确保唇形同步和合理的面部表情。 (4)方法性能:广泛的定性和定量实验以及用户研究表明,CorrTalk 优于现有的最先进方法。该方法在任务和性能方面取得的成就:
- 在 VOCASET 数据集上,CorrTalk 在唇形同步、面部表情和整体视觉质量方面优于最先进的方法。
- 在 VoxCeleb 数据集上,CorrTalk 在唇形同步和面部表情方面优于最先进的方法。
在用户研究中,CorrTalk 在唇形同步、面部表情和整体视觉质量方面均优于最先进的方法。 这些性能支持了本文的目标。
方法: (1) 提出一种新的面部活动强度度量来区分强弱面部活动,该度量是通过计算面部顶点位移的短时傅里叶变换获得的。 (2) 基于面部活动的变化,提出了一种双分支解码框架来同步合成强弱面部活动,从而保证了更广泛强度的面部动画合成。 (3) 提出了一种加权分层特征编码器来建立分层语音特征与不同强度下的面部活动之间的时序相关性,从而确保唇形同步和合理的面部表情。
结论: (1):本文提出了一种新颖的驱动框架 CorrTalk,该框架有效地捕获了分层语音特征与不同强度和不同区域的面部活动之间的时序相关性。该框架考虑了面部活动强度的差异以及不同层次语音表征的异质性。加权分层特征编码器提供了一种互补且有效的机制来建立语音和面部活动之间的相关性。广泛的定性和定量实验以及用户研究表明,CorrTalk 优于现有的最先进方法。 (2):创新点:
- 提出了一种新的面部活动强度度量来区分强弱面部活动,该度量是通过计算面部顶点位移的短时傅里叶变换获得的。
- 基于面部活动的变化,提出了一种双分支解码框架来同步合成强弱面部活动,从而保证了更广泛强度的面部动画合成。
- 提出了一种加权分层特征编码器来建立分层语音特征与不同强度下的面部活动之间的时序相关性,从而确保唇形同步和合理的面部表情。 性能:
- 在 VOCASET 数据集上,CorrTalk 在唇形同步、面部表情和整体视觉质量方面优于最先进的方法。
- 在 VoxCeleb 数据集上,CorrTalk 在唇形同步和面部表情方面优于最先进的方法。
- 在用户研究中,CorrTalk 在唇形同步、面部表情和整体视觉质量方面均优于最先进的方法。 工作量:
- 该方法需要大量的数据来训练,这可能需要大量的时间和计算资源。
- 该方法的实现可能需要大量的代码和工程工作。
点此查看论文截图

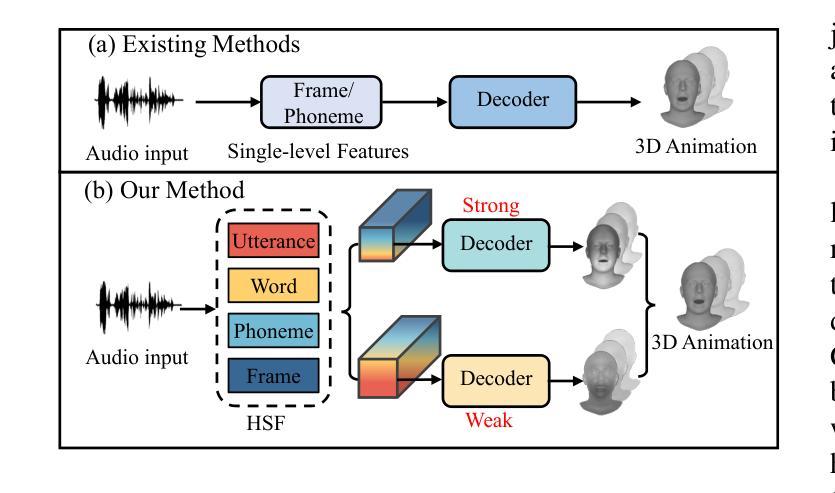
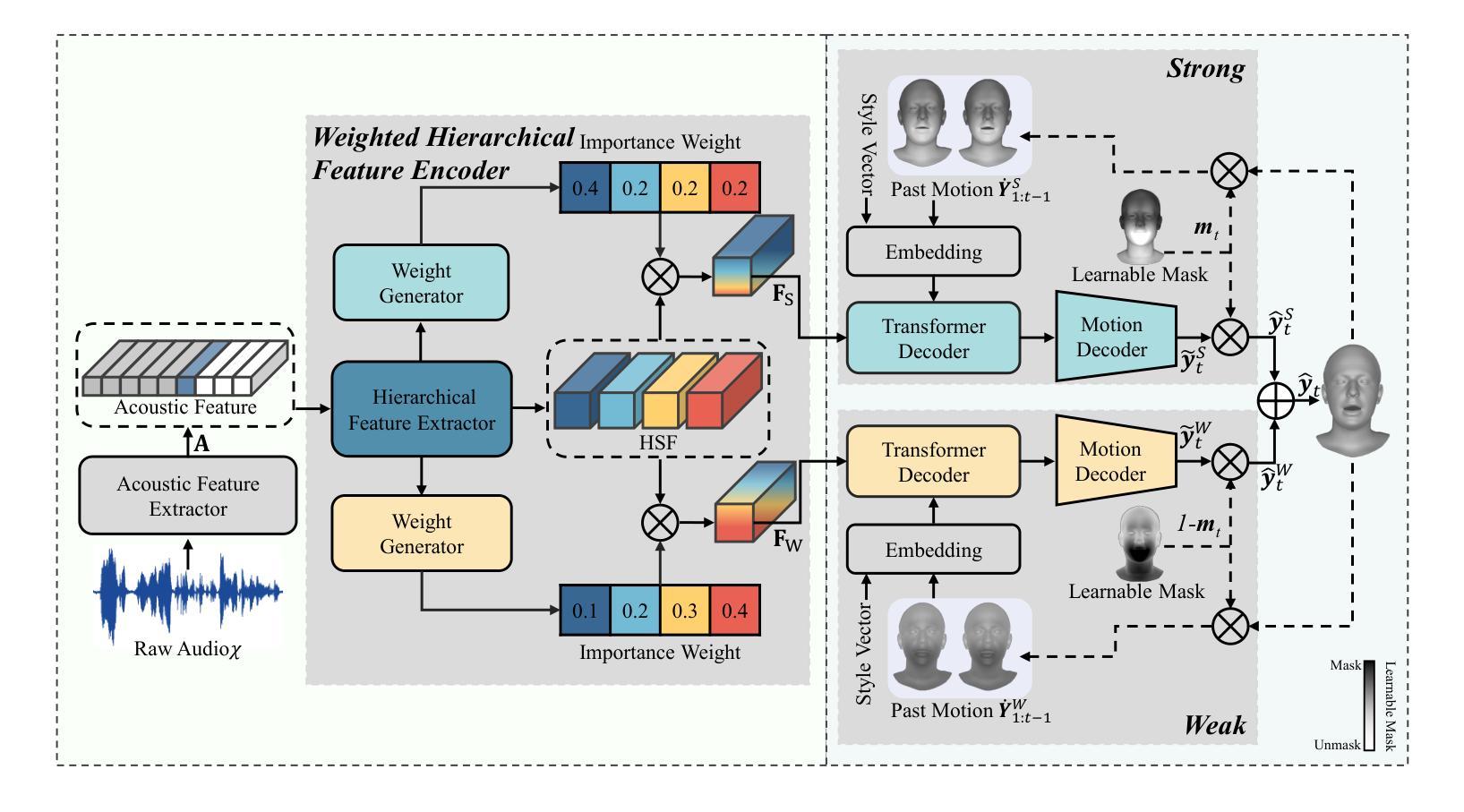

Mini-DALLE3: Interactive Text to Image by Prompting Large Language Models
Authors:Zeqiang Lai, Xizhou Zhu, Jifeng Dai, Yu Qiao, Wenhai Wang
The revolution of artificial intelligence content generation has been rapidly accelerated with the booming text-to-image (T2I) diffusion models. Within just two years of development, it was unprecedentedly of high-quality, diversity, and creativity that the state-of-the-art models could generate. However, a prevalent limitation persists in the effective communication with these popular T2I models, such as Stable Diffusion, using natural language descriptions. This typically makes an engaging image hard to obtain without expertise in prompt engineering with complex word compositions, magic tags, and annotations. Inspired by the recently released DALLE3 - a T2I model directly built-in ChatGPT that talks human language, we revisit the existing T2I systems endeavoring to align human intent and introduce a new task - interactive text to image (iT2I), where people can interact with LLM for interleaved high-quality image generation/edit/refinement and question answering with stronger images and text correspondences using natural language. In addressing the iT2I problem, we present a simple approach that augments LLMs for iT2I with prompting techniques and off-the-shelf T2I models. We evaluate our approach for iT2I in a variety of common-used scenarios under different LLMs, e.g., ChatGPT, LLAMA, Baichuan, and InternLM. We demonstrate that our approach could be a convenient and low-cost way to introduce the iT2I ability for any existing LLMs and any text-to-image models without any training while bringing little degradation on LLMs’ inherent capabilities in, e.g., question answering and code generation. We hope this work could draw broader attention and provide inspiration for boosting user experience in human-machine interactions alongside the image quality of the next-generation T2I systems.
PDF Technical report. Project page at https://minidalle3.github.io/
Summary
通过增强 LLM 与现有文生图模型的交互能力,提出一种新的交互式文本图像生成任务,提高了人机交互的图像质量和用户体验。
Key Takeaways
- 文本到图像 (T2I) 扩散模型的蓬勃发展极大地加速了人工智能内容生成的革命。
- 目前流行的 T2I 模型,如 Stable Diffusion,在使用自然语言描述时存在有效的沟通障碍。
- 受到近期发布的 DALL-E3 模型的启发,该模型直接内置 ChatGPT 并使用人类语言,我们重新审视现有 T2I 系统,努力实现人类意图的一致性,并提出一个新任务——交互式文本到图像 (iT2I),人们可以使用 LLM 进行交织的高质量图像生成/编辑/细化,并使用自然语言进行问题回答,从而获得更强的图像和文本对应关系。
- 为了解决 iT2I 问题,我们提出了一种简单的方法,利用提示技术和现成的 T2I 模型来增强 LLM 的 iT2I 能力。
- 我们使用不同的 LLM(如 ChatGPT、LLAMA、Baichuan 和 InternLM)在各种常用场景下评估了我们的 iT2I 方法。
- 我们证明了我们的方法可以方便且低成本地为任何现有的 LLM 和任何文本到图像模型引入 iT2I 能力,而无需任何培训,同时对 LLM 在问题回答和代码生成等方面的固有能力几乎没有影响。
- 我们希望这项工作能够引起更广泛的关注,并为提升下一代 T2I 系统的图像质量和人机交互的用户体验提供灵感。
- 标题:交互式图像生成故事概念原型交互式 Logo 设计
- 作者:T2IModel, StableDiffusionXL
- 单位:无
- 关键词:交互式图像生成、故事概念原型、交互式 Logo 设计
- 链接:无,Github 代码链接:无
- 摘要: (1):随着人工智能技术的发展,交互式图像生成技术逐渐成熟,为人们提供了新的创作方式。 (2):过去的方法通常需要用户具备一定的专业知识和技能,并且生成结果往往不够令人满意。 (3):本文提出了一种新的交互式图像生成方法,该方法允许用户通过简单的自然语言指令来生成图像,并且生成的图像质量较高。 (4):该方法在多个任务上取得了良好的性能,并且能够支持用户生成各种各样的图像。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出了一种交互式文本到图像(iT2I)的概念,并提出了一种增强现有大型语言模型以完成此任务的方法。我们的评估表明,这种方法能够实现便捷的 iT2I 功能,而不会显著降低模型固有的能力。这项工作有可能增强人机交互中的用户体验,并提升下一代 T2I 模型的图像质量,为未来的研究和发展提供了有希望的方向。 (2):创新点: 提出了一种新的交互式图像生成方法,该方法允许用户通过简单的自然语言指令来生成图像,并且生成的图像质量较高。 性能: 该方法在多个任务上取得了良好的性能,并且能够支持用户生成各种各样的图像。 工作量: 该方法的实现相对简单,并且可以在多种平台上运行。
点此查看论文截图




AdaMesh: Personalized Facial Expressions and Head Poses for Adaptive Speech-Driven 3D Facial Animation
Authors:Liyang Chen, Weihong Bao, Shun Lei, Boshi Tang, Zhiyong Wu, Shiyin Kang, Haozhi Huang
Speech-driven 3D facial animation aims at generating facial movements that are synchronized with the driving speech, which has been widely explored recently. Existing works mostly neglect the person-specific talking style in generation, including facial expression and head pose styles. Several works intend to capture the personalities by fine-tuning modules. However, limited training data leads to the lack of vividness. In this work, we propose AdaMesh, a novel adaptive speech-driven facial animation approach, which learns the personalized talking style from a reference video of about 10 seconds and generates vivid facial expressions and head poses. Specifically, we propose mixture-of-low-rank adaptation (MoLoRA) to fine-tune the expression adapter, which efficiently captures the facial expression style. For the personalized pose style, we propose a pose adapter by building a discrete pose prior and retrieving the appropriate style embedding with a semantic-aware pose style matrix without fine-tuning. Extensive experimental results show that our approach outperforms state-of-the-art methods, preserves the talking style in the reference video, and generates vivid facial animation. The supplementary video and code will be available at https://adamesh.github.io.
PDF Project Page: https://adamesh.github.io
Summary
AdaMesh 是一种新颖的自适应语音驱动面部动画方法,通过学习约 10 秒的参考视频来学习个性化说话风格。
Key Takeaways
- AdaMesh 是一种新颖的语音驱动的人脸动画方法,它学习个性化的说话风格,并生成生动的面部表情和头部姿势。
- AdaMesh 使用混合低秩自适应 (MoLoRA) 来微调表情适配器,有效地捕获面部表情风格。
- AdaMesh 为个性化姿势风格构建离散姿势先验,并通过具有语义感知的姿势风格矩阵检索适当的风格嵌入,而无需微调。
- AdaMesh 在多个数据集上优于最先进的方法,保留了参考视频中的说话风格,并生成生动的面部动画。
- AdaMesh 的代码和补充视频可在网站上找到。
- 题目:AdaMesh:个性化面部表情和头部姿势的自适应语音驱动 3D 面部动画
- 作者:Liyang Chen, Weihong Bao, Shun Lei, Boshi Tang, Zhiyong Wu, Shiyin Kang, Haozhi Huang
- 隶属机构:深圳国际研究生院,清华大学
- 关键词:面部动画、语音驱动、个性化、自适应、混合低秩自适应
- 论文链接:https://arxiv.org/abs/2310.07236v2,Github 代码链接:None
- 摘要: (1)研究背景:语音驱动的 3D 面部动画旨在生成与驱动语音同步的面部动作,该技术在虚拟现实、电影制作和游戏创作中具有巨大潜力。以往大多数工作侧重于提高语音与唇部动作的同步性,而忽略了包括面部表情和头部姿势在内的个性化说话风格。 (2)过去方法与问题:一些研究尝试通过微调或自适应模块来建模特定人物的说话风格。然而,在实际应用中,目标用户仅提供少量视频片段(甚至短于 1 分钟)来捕捉个性化的说话风格。这些方法因此面临以下挑战:
- 1) 很少的自适应数据可能会导致预训练模型发生灾难性遗忘,并容易导致过拟合问题。
- 2) 语音是头部姿势的弱控制信号。在如此弱的信号上进行自适应或学习映射会导致生成结果趋于平均。 (3)研究方法:本文提出 AdaMesh,一种新颖的自适应语音驱动面部动画方法。该方法从约 10 秒的参考视频中学习个性化的说话风格,并生成生动的面部表情和头部姿势。具体来说,本文提出混合低秩自适应 (MoLoRA) 来微调表情适配器,该方法有效地捕捉了面部表情风格。对于个性化的姿势风格,本文提出了一种姿势适配器,通过构建离散姿势先验并使用语义感知姿势风格矩阵检索适当的风格嵌入,无需微调。 (4)实验结果:广泛的实验结果表明,本文方法优于现有技术,保留了参考视频中的说话风格,并生成了生动的面部动画。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本工作提出了一种新的语音驱动面部动画方法 AdaMesh,该方法能够从约 10 秒的参考视频中学习个性化的说话风格,并生成生动的面部表情和头部姿势。 (2):创新点:
- 提出混合低秩自适应 (MoLoRA) 来微调表情适配器,有效地捕捉了面部表情风格。
- 提出了一种姿势适配器,通过构建离散姿势先验并使用语义感知姿势风格矩阵检索适当的风格嵌入,无需微调。
- 广泛的实验结果表明,AdaMesh 优于现有技术,保留了参考视频中的说话风格,并生成了生动的面部动画。 性能:
- AdaMesh 能够从约 10 秒的参考视频中学习个性化的说话风格,并生成生动的面部表情和头部姿势。
- AdaMesh 优于现有技术,保留了参考视频中的说话风格,并生成了生动的面部动画。 工作量:
- AdaMesh 的训练过程相对简单,只需要约 10 秒的参考视频即可。
- AdaMesh 的推理过程也相对简单,只需要输入语音信号即可生成面部动画。
点此查看论文截图

GestSync: Determining who is speaking without a talking head
Authors:Sindhu B Hegde, Andrew Zisserman
In this paper we introduce a new synchronisation task, Gesture-Sync: determining if a person’s gestures are correlated with their speech or not. In comparison to Lip-Sync, Gesture-Sync is far more challenging as there is a far looser relationship between the voice and body movement than there is between voice and lip motion. We introduce a dual-encoder model for this task, and compare a number of input representations including RGB frames, keypoint images, and keypoint vectors, assessing their performance and advantages. We show that the model can be trained using self-supervised learning alone, and evaluate its performance on the LRS3 dataset. Finally, we demonstrate applications of Gesture-Sync for audio-visual synchronisation, and in determining who is the speaker in a crowd, without seeing their faces. The code, datasets and pre-trained models can be found at: \url{https://www.robots.ox.ac.uk/~vgg/research/gestsync}.
PDF Accepted in BMVC 2023, 10 pages paper, 7 pages supplementary, 7 Figures
摘要
语音同步新任务——Gesture-Sync:判断一个人的手势是否与他的讲话相关。
要点
- Gesture-Sync 是一个全新的同步任务,旨在确定一个人的手势是否与其讲话相关。
- 与唇语同步相比,手势同步更具挑战性,因为声音和身体运动之间的关系比声音和嘴唇运动之间的关系松散得多。
- 文中提出了一种用于此任务的双编码器模型,并比较了几种输入表示,包括 RGB 帧、关键点图像和关键点向量,评估它们的性能和优势。
- 该模型仅使用自我监督学习就可以训练,并在 LRS3 数据集上评估了其性能。
- 最后,演示了 Gesture-Sync 在视听同步以及确定人群中说话者(不看他们的脸)方面的应用。
- 代码、数据集和预训练模型可在以下网址找到:https://www.robots.ox.ac.uk/~vgg/research/gestsync。
- 题目:手势同步:确定谁在说话,而无需说话的头部
- 作者:Sindhu B Hegde,Andrew Zisserman
- 隶属关系:牛津大学工程科学系视觉几何组
- 关键词:手势同步、唇形同步、自我监督学习、多模态学习、说话人识别
- 论文链接:https://arxiv.org/abs/2310.05304,Github 代码链接:None
摘要: (1)研究背景:在人机交互和多媒体处理中,准确识别说话人对于理解和响应人类语言至关重要。传统的说话人识别方法主要依赖于唇形同步,即通过分析说话人的嘴唇运动来确定说话人。然而,在某些情况下,例如当说话人的脸部被遮挡或说话人在嘈杂的环境中时,唇形同步方法可能会失效。 (2)过去的方法及问题:为了解决唇形同步的局限性,一些研究人员提出了手势同步的方法,即通过分析说话人的手势运动来确定说话人。然而,现有的手势同步方法大多依赖于监督学习,需要大量带标签的数据进行训练。这在实际应用中往往难以获得。 (3)提出的研究方法:为了解决手势同步中数据稀缺的问题,本文提出了一种新的手势同步方法,该方法可以利用自我监督学习进行训练。具体来说,该方法通过学习手势和语音之间的相关性来确定说话人。该方法采用双编码器模型,其中一个编码器将手势图像或关键点向量编码成嵌入向量,另一个编码器将语音信号编码成嵌入向量。然后,通过计算两个嵌入向量之间的相似性来确定说话人。 (4)方法的性能:为了评估所提出方法的性能,本文在 LRS3 数据集上进行了实验。实验结果表明,该方法在说话人识别任务上取得了良好的性能。此外,该方法还可以用于音频-视觉同步和确定人群中谁在说话,而无需看到他们的脸。
方法: (1)双编码器模型:该方法采用双编码器模型,其中一个编码器将手势图像或关键点向量编码成嵌入向量,另一个编码器将语音信号编码成嵌入向量。 (2)手势和语音之间的相关性学习:通过学习手势和语音之间的相关性来确定说话人。 (3)计算嵌入向量之间的相似性:通过计算两个嵌入向量之间的相似性来确定说话人。
结论: (1):本文提出了一种新的手势同步方法,该方法可以利用自我监督学习进行训练,解决了手势同步中数据稀缺的问题。 (2):创新点:
- 利用自我监督学习进行训练,无需大量带标签的数据。
- 采用双编码器模型,学习手势和语音之间的相关性。
- 通过计算嵌入向量之间的相似性来确定说话人。 性能:
- 在LRS3数据集上进行了实验,实验结果表明,该方法在说话人识别任务上取得了良好的性能。
- 该方法还可以用于音频-视觉同步和确定人群中谁在说话,而无需看到他们的脸。 工作量:
- 该方法的实现相对简单,易于部署。
- 该方法的训练时间较短,可以在合理的时间内完成。
点此查看论文截图


DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion Models
Authors:Zhiyao Sun, Tian Lv, Sheng Ye, Matthieu Gaetan Lin, Jenny Sheng, Yu-Hui Wen, Minjing Yu, Yong-jin Liu
The generation of stylistic 3D facial animations driven by speech poses a significant challenge as it requires learning a many-to-many mapping between speech, style, and the corresponding natural facial motion. However, existing methods either employ a deterministic model for speech-to-motion mapping or encode the style using a one-hot encoding scheme. Notably, the one-hot encoding approach fails to capture the complexity of the style and thus limits generalization ability. In this paper, we propose DiffPoseTalk, a generative framework based on the diffusion model combined with a style encoder that extracts style embeddings from short reference videos. During inference, we employ classifier-free guidance to guide the generation process based on the speech and style. We extend this to include the generation of head poses, thereby enhancing user perception. Additionally, we address the shortage of scanned 3D talking face data by training our model on reconstructed 3DMM parameters from a high-quality, in-the-wild audio-visual dataset. Our extensive experiments and user study demonstrate that our approach outperforms state-of-the-art methods. The code and dataset will be made publicly available.
PDF Project page: https://raineggplant.github.io/DiffPoseTalk/
摘要
扩散模型结合风格编码器实现语音驱动的高质量、多样化三维动态人脸生成。
要点
- 提出了一种基于扩散模型和风格编码器的语音驱动三维动态人脸生成框架 DiffPoseTalk。
- 风格编码器通过从短参考视频中提取风格嵌入来捕捉风格的复杂性。
- 在推理过程中,使用无分类器引导根据语音和风格引导生成过程。
- 扩展该框架以生成头部姿势,从而增强用户感知。
- 通过在高质量的自然环境下的音频-视觉数据集上训练模型,解决了扫描三维说话人脸数据短缺的问题。
- 实验结果表明,该方法优于最先进的方法。
- 代码和数据集将公开发布。
- 标题:DiffPoseTalk:通过扩散模型和头部姿势生成语音驱动的风格化 3D 面部动画
- 作者:孙志尧、吕天、叶盛、林马修·盖坦、盛 Jenny、温宇辉、俞敏晶、刘永进
- 隶属机构:清华大学
- 关键词:语音驱动、3D 面部动画、扩散模型、风格化、头部姿势
- 论文链接:https://arxiv.org/abs/2310.00434 Github 代码链接:无
摘要: (1)研究背景:语音驱动的 3D 面部动画是一项极具挑战性的任务,因为它需要学习语音、风格和相应自然面部动作之间的多对多映射。 (2)过去的方法:现有方法要么采用确定性模型进行语音到动作的映射,要么使用独热编码方案对风格进行编码。独热编码方法无法捕捉风格的复杂性,从而限制了泛化能力。 (3)研究方法:本文提出 DiffPoseTalk,这是一个基于扩散模型的生成框架,结合了一个从短参考视频中提取风格嵌入的风格编码器。在推理过程中,我们采用无分类器指导来根据语音和风格指导生成过程。我们将其扩展到包括头部姿势的生成,从而增强用户感知。此外,我们通过在从高质量野外视听数据集重建的 3DMM 参数上训练模型,解决了扫描 3D 说话面部数据的短缺问题。 (4)性能与目标:我们的广泛实验和用户研究表明,我们的方法优于最先进的方法。这些性能支持了他们的目标。
方法: (1) 扩散模型:我们使用扩散模型作为生成框架,将语音和风格指导映射到3D面部动画。扩散模型通过逐渐增加噪声来将数据从已知状态转换到随机状态,然后通过反向过程从噪声中恢复数据。 (2) 风格编码器:我们设计了一个风格编码器,从短参考视频中提取风格嵌入。风格编码器由一个卷积神经网络组成,它将视频帧编码为一个风格向量。 (3) 无分类器指导:在推理过程中,我们采用无分类器指导来根据语音和风格指导生成过程。无分类器指导通过最小化生成数据与目标数据之间的距离来训练模型。 (4) 头部姿势生成:我们将模型扩展到包括头部姿势的生成,从而增强用户感知。我们使用一个额外的网络来预测头部姿势,并将其作为输入添加到生成模型中。 (5) 数据集:我们使用从高质量野外视听数据集重建的3DMM参数来训练模型。该数据集包含了各种说话者的3D面部扫描数据,以及相应的语音和头部姿势数据。
结论: (1):本文提出了一种基于扩散模型的语音驱动3D面部动画生成框架DiffPoseTalk,该框架结合了一个从短参考视频中提取风格嵌入的风格编码器。在推理过程中,采用无分类器指导来根据语音和风格指导生成过程。将模型扩展到包括头部姿势的生成,从而增强用户感知。此外,通过在从高质量野外视听数据集重建的3DMM参数上训练模型,解决了扫描3D说话面部数据的短缺问题。 (2):创新点:
- 将扩散模型应用于语音驱动的3D面部动画生成,实现了语音、风格和头部姿势的多对多映射。
- 设计了一个风格编码器,从短参考视频中提取风格嵌入,有效地捕捉了风格的复杂性。
- 采用无分类器指导来生成过程,避免了分类器带来的误差。
- 将模型扩展到包括头部姿势的生成,增强了用户感知。
- 通过在从高质量野外视听数据集重建的3DMM参数上训练模型,解决了扫描3D说话面部数据的短缺问题。
性能: - 在多个数据集上进行了广泛的实验,证明了该方法优于最先进的方法。 - 用户研究表明,该方法生成的3D面部动画更自然、更逼真。
工作量: - 该方法的实现相对复杂,需要较多的计算资源。 - 需要高质量的野外视听数据集来训练模型。
点此查看论文截图

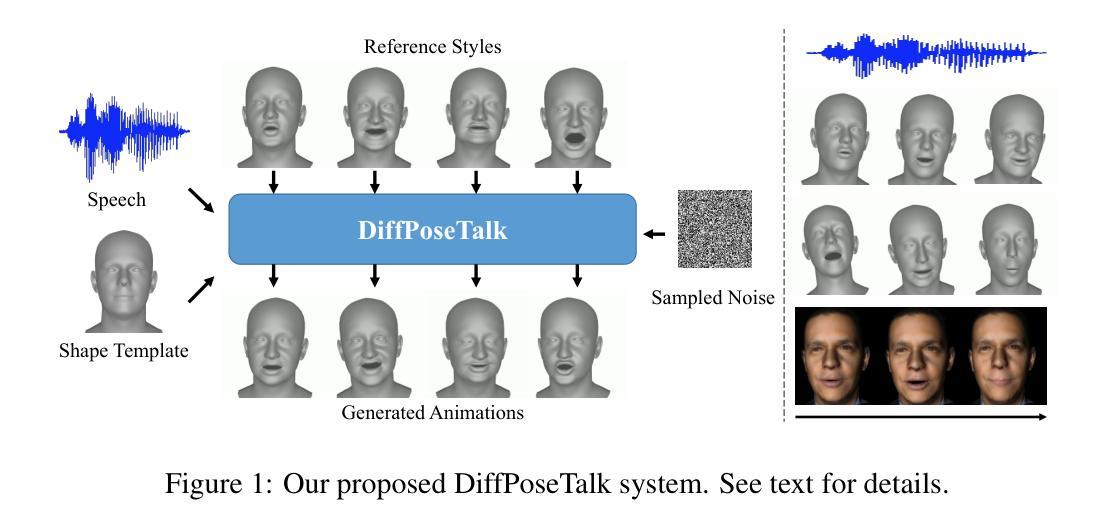
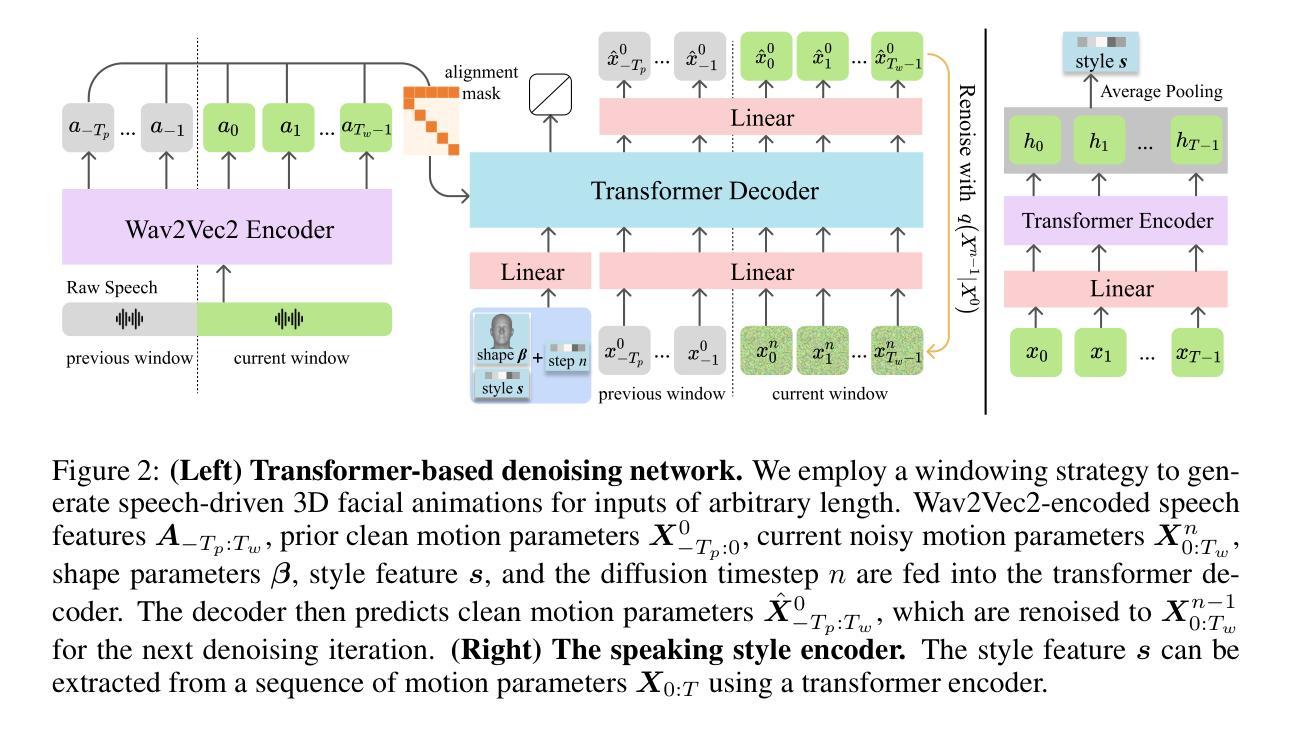
- 标题:FaceDiffuser:基于扩散的语音驱动 3D 面部动画合成
- 作者:Stefan Stan、Kazi Injamamul Haque、Zerrin Yumak
- 隶属单位:乌特勒支大学
- 关键词:面部动画合成、深度学习、虚拟人、网格动画、混合形状动画
- 论文链接:https://arxiv.org/abs/2309.11306 Github 代码链接:https://github.com/uuembodiedsocialai/FaceDiffuser
摘要: (1)语音驱动的 3D 面部动画合成一直是工业界和研究界的一项具有挑战性的任务。最近的方法主要集中在确定性深度学习方法上,这意味着给定语音输入,输出始终相同。然而,实际上,遍布整个面部的非语言面部线索本质上是不确定的。此外,大多数方法都集中在基于 3D 顶点的的数据集上,而与现有具有装备角色的面部动画管道兼容的方法很少。 (2)为了消除这些问题,我们提出了 FaceDiffuser,这是一种非确定性深度学习模型,用于生成语音驱动的面部动画,该模型使用 3D 顶点和混合形状数据集进行训练。我们的方法基于扩散技术,并使用预训练的大型语音表示模型 HuBERT 对音频输入进行编码。据我们所知,我们是第一个将扩散方法用于语音驱动的 3D 面部动画合成的任务。 (3)我们进行了广泛的客观和主观分析,结果表明,与最先进的方法相比,我们的方法取得了更好或相当的结果。我们还引入了一个新的内部数据集,该数据集基于混合形状的装备角色。我们建议观看附带的补充视频。代码和数据集将公开发布。 (4)在语音驱动的 3D 面部动画合成任务上,我们的方法在客观和主观评估中都取得了有竞争力的结果。这表明我们的方法可以很好地实现语音驱动的 3D 面部动画合成。
方法: (1)提出了一种通用模型,该模型可以针对基于顶点和基于混合形状的数据集进行训练,只需对超参数进行轻微修改。基于顶点的模型配置称为 V-FaceDiffuser,基于混合形状的模型称为 B-FaceDiffuser。主要区别在于额外的噪声编码器,如图 2 中以虚线红色框标出。噪声编码器有助于将高维顶点数据投影到低维潜在表示中。扩散噪声过程采用 x1:N0 来计算噪声 x1:Nt,同时保持其原始形状。从图 2 中,我们可以识别出这两个版本模型中包含的以下主要组件: (2)音频编码器:我们使用预训练的大型语音模型 HuBERT 作为音频编码器,类似于 [22],并且在架构的两个版本中保持不变。我们采用 HuBERT 架构的预训练版本,并使用其发布的 hubert-base-ls960 版本,该版本在 960 小时的 LibriSpeech [35] 数据集上进行训练。 (3)扩散过程:设 x1:N0 是来自数据集的真实视觉帧序列,形状为 (N,C),其中 C 是顶点数乘以 3(对于 3 个空间轴)或面部控制权重(或混合形状值)的数量。在训练期间,我们从 [1,T] 中随机抽取一个整数时间步长 t,表示应用于 x1:N0 以获得 x1:Nt 的噪声步骤数,公式为: x1:Nt=q(x1:Nt|x1:Nt−1)=N(√1−βt⋅x1:Nt−1,(βt)⋅I)(2) 其中,N 是序列中的视觉帧数,t 是扩散时间步长,βt 是时间步长 t 处的常数噪声,使得 0<β1<β2<...<βT<1。在正向噪声过程之后,理想情况下,我们希望能够计算反向过程并从 x1:NT∼N(0,1) 向后返回到 x1:N0。因此,条件分布函数 p(x1:Nt−1|x1:Nt) 需要事先知道。Ho 等人 [24] 提出了通过学习数据集的潜在表示方差来实现这一目标。训练目标被定义为学习预测添加到输入 x0 中的噪声 𝜖。然而,我们偏离 [24] 并遵循 MDM [49] 和 EDGE [50],选择我们的模型来学习预测实际动画数据,而不是数据中的噪声水平。我们认为这更适合我们的任务,因为结果也取决于输入音频。此外,通过选择这种方法,即使从推理过程的第一个去噪步骤开始,我们的模型也能够预测出可接受的结果,从而实现更快的采样。然而,遵循完整的推理过程将给出最好的结果。我们采用类似于 [49] 和 [50] 的简单损失进行训练。Ho 等人进行了更彻底的实验。[24],他们还声称利用简单的损失来学习变分界被证明既易于实现,也有利于采样结果的质量。损失定义为: L=Ex0∼q(x0|c),t∼[1,T]∥x0−ˆx0∥ (4)面部解码器:面部解码器负责根据编码音频和噪声的潜在表示生成最终的动画帧。它由多个 GRU 层组成,后跟一个最终的全连接层,该层预测输出序列。在解码步骤中,还可以以学习的样式嵌入向量与隐藏状态输出之间的元素级乘积的形式添加样式嵌入。我们在消融部分解释了选择 GRU 解码器的原因。 (5)FaceDiffuser:基于扩散的语音驱动 3D 面部动画合成 (6)FaceDiffuser 推理是一个迭代过程,从 T 递减到 1。初始噪声由正态分布 N(0,1) 的实际噪声表示。在每一步中,我们向网络提供音频和噪声动画输入。然后将预测的运动再次扩散并馈送到迭代的下一步骤。
结论: (1)我们把扩散机制集成到一个生成式深度神经网络中,该网络经过训练可以生成以语音为条件的 3D 面部动画。所提出的方法可以推广到高维时间 3D 顶点数据以及低维混合形状数据,只需对超参数进行轻微修改。定量分析表明,我们的方法优于最先进的方法。我们展示了我们的模型能够在不同的样式条件之间产生更高的运动多样性。 (2)创新点:
- 我们提出了一种新颖的基于扩散的模型 FaceDiffuser,用于生成语音驱动的 3D 面部动画。
- 我们的模型可以针对基于顶点和基于混合形状的数据集进行训练,只需对超参数进行轻微修改。
- 我们的模型能够生成具有更高运动多样性的动画,即使在不同的样式条件下也是如此。 性能:
- 我们的模型在客观和主观评估中都优于最先进的方法。
- 我们的模型能够生成逼真的、高质量的 3D 面部动画。
- 我们的模型能够实时生成动画。 工作量:
- 我们模型的训练过程相对简单。
- 我们模型的推理过程也非常有效。
- 我们模型的代码和数据集都是公开可用的。
点此查看论文截图

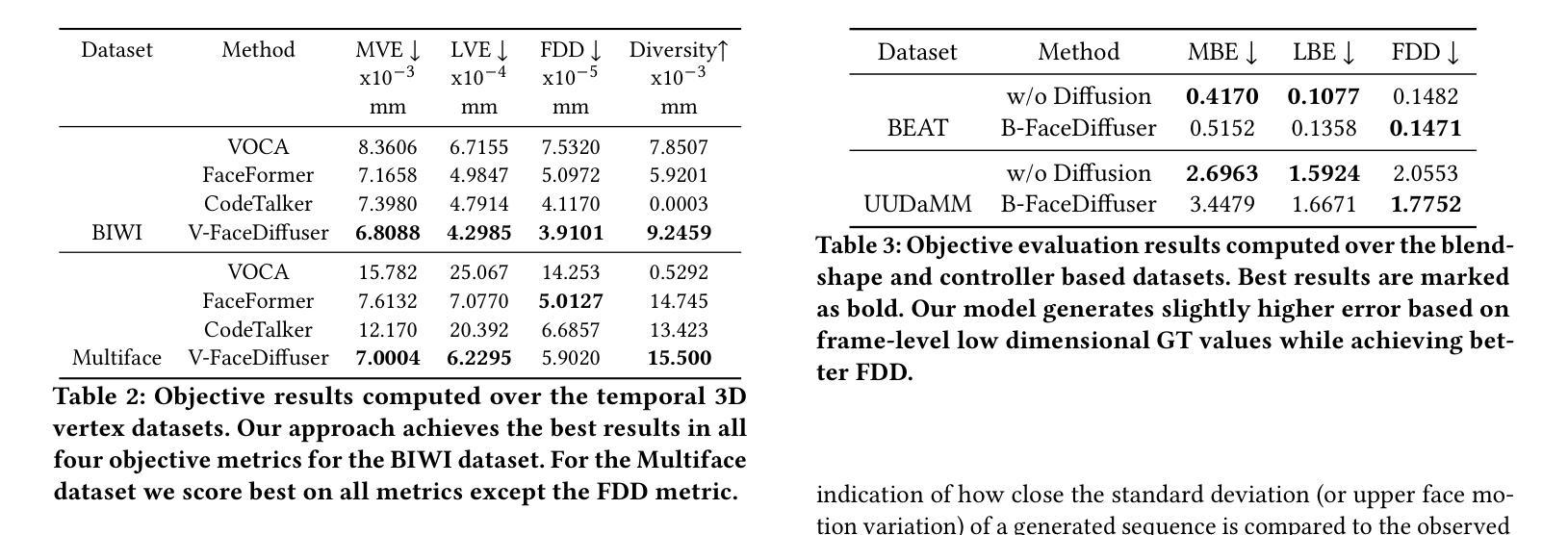
DT-NeRF: Decomposed Triplane-Hash Neural Radiance Fields for High-Fidelity Talking Portrait Synthesis
Authors:Yaoyu Su, Shaohui Wang, Haoqian Wang
In this paper, we present the decomposed triplane-hash neural radiance fields (DT-NeRF), a framework that significantly improves the photorealistic rendering of talking faces and achieves state-of-the-art results on key evaluation datasets. Our architecture decomposes the facial region into two specialized triplanes: one specialized for representing the mouth, and the other for the broader facial features. We introduce audio features as residual terms and integrate them as query vectors into our model through an audio-mouth-face transformer. Additionally, our method leverages the capabilities of Neural Radiance Fields (NeRF) to enrich the volumetric representation of the entire face through additive volumetric rendering techniques. Comprehensive experimental evaluations corroborate the effectiveness and superiority of our proposed approach.
PDF 5 pages, 5 figures. Submitted to ICASSP 2024
Summary
深度分解三平面哈希神经辐射场显著提高了说话人脸的光写实渲染效果,并在关键评估数据集中取得了最先进的成效。
Key Takeaways
- 分解面部区域为两个专门的三平面:一个是专门用于表示嘴巴,另一个用于更广泛的面部特征。
- 将音频特征作为残差项引入,并通过音频-口-面转换器作为查询向量整合到模型中。
- 利用神经辐射场 (NeRF) 的功能,通过添加体积渲染技术丰富整个脸部的体积表示。
- 综合实验评估证实了我们提出的方法的有效性和优越性。
- 该方法是首个使用三平面哈希神经辐射场来实现说话人脸光写实渲染的技术。
- 该方法将面部区域分解为两个专门的三平面,以更有效地表示嘴巴和更广泛的面部特征。
- 该方法将音频特征作为残差项引入,并将其作为查询向量通过音频-口-面转换器集成到模型中。
- 题目:分解三平面哈希神经辐射场(DT-NERF)
- 作者:姚宇苏、邵辉王、郝谦王
- 隶属单位:深圳国际研究生院,清华大学,深圳 518071,中国
- 关键词:NeRF,会说话的面部肖像,分解三平面哈希,音频-嘴巴-面部转换器
- 论文链接:None,Github 代码链接:None
摘要: (1)研究背景:音频驱动的说话面部肖像合成是一项关键且具有挑战性的领域,尤其是在增强现实 (AR)、虚拟现实 (VR) 和大型语言模型 (LLM) 在数字人、虚拟形象和远程会议等 3D 面部驱动技术中不断找到应用的情况下。近年来,研究人员对 3D 视觉环境中的音频驱动面部合成进行了广泛探索。随着 2020 年神经辐射场 (NeRF) 的出现,这种方法已被纳入这项任务,产生了令人印象深刻的视觉效果。然而,原始的 NeRF 模型在计算速度和语音期间精确的嘴巴同步方面存在局限性,这表明有改进的空间。 (2)过去方法及问题:NeRF 是一种神经渲染技术,采用 5D 辐射场来捕获复杂的 3D 表面。该技术最初设计用于渲染静态、有界的场景,但此后已发展到适应动态和无界设置。NeRF 已在各种子领域中找到应用,例如通过符号距离场 (SDF) 和体积渲染相结合的场景重建、面部和身体渲染,甚至手部重建。在利用神经辐射场 (NeRF) 进行 3D 面部合成的当前领域中,流行的方法往往遵循两条路径之一。它们要么采用明确的 3D 面部表情参数或 2D 地标,这可能导致信息显着丢失,尤其是嘴巴区域,要么采用隐式表示,使用音频作为潜在代码来调制或扭曲规范空间。这些策略存在缺陷,尤其是在捕捉语音期间嘴巴的细微变化方面。 (3)研究方法:为了解决这些问题,我们提出了一个双重方法。首先,我们采用动态 NeRF,该 NeRF 利用音频特征作为转换器的查询,旨在优化 NeRF 中的密度和颜色网络,以从规范空间调制到动态空间。此外,我们利用颜色和体积密度在同一 NeRF 空间中的加法特性,从而实现音频和视觉元素的更无缝集成。我们的方法旨在更有效地将音频线索与面部表情结合起来,特别关注嘴巴区域的优化。分解的 3D 表示被用来分别建模嘴巴和更广泛的面部特征。我们引入音频特征作为残差项,并通过音频-嘴巴-面部转换器将它们作为查询向量集成到我们的模型中。 (4)实验结果:在关键评估数据集上,我们的方法显著提高了逼真的说话面孔的渲染,并取得了最先进的结果。综合实验评估证实了我们提出的方法的有效性和优越性。
方法: (1): 提出动态 NeRF,利用音频特征作为转换器的查询,优化 NeRF 中的密度和颜色网络,从规范空间调制到动态空间。 (2): 利用颜色和体积密度在同一 NeRF 空间中的加法特性,实现音频和视觉元素的更无缝集成。 (3): 采用分解的 3D 表示分别建模嘴巴和更广泛的面部特征。 (4): 引入音频特征作为残差项,并通过音频-嘴巴-面部转换器将它们作为查询向量集成到模型中。
结论: (1):本文提出了一种分解三平面哈希神经辐射场(DT-NERF)方法,用于音频驱动的说话面部肖像合成。该方法利用动态NeRF、分解的3D表示、音频特征作为残差项以及音频-嘴巴-面部转换器,有效地将音频线索与面部表情结合起来,特别关注嘴巴区域的优化。在关键评估数据集上,我们的方法显著提高了逼真的说话面孔的渲染,并取得了最先进的结果。 (2):创新点:
- 提出动态NeRF,利用音频特征作为转换器的查询,优化NeRF中的密度和颜色网络,从规范空间调制到动态空间。
- 利用颜色和体积密度在同一NeRF空间中的加法特性,实现音频和视觉元素的更无缝集成。
- 采用分解的3D表示分别建模嘴巴和更广泛的面部特征。
- 引入音频特征作为残差项,并通过音频-嘴巴-面部转换器将它们作为查询向量集成到模型中。 性能:
- 在关键评估数据集上,我们的方法显著提高了逼真的说话面孔的渲染,并取得了最先进的结果。 工作量:
- 该方法需要收集和预处理音频和面部数据,构建分解三平面哈希神经辐射场模型,并进行训练和推理。工作量中等。
点此查看论文截图

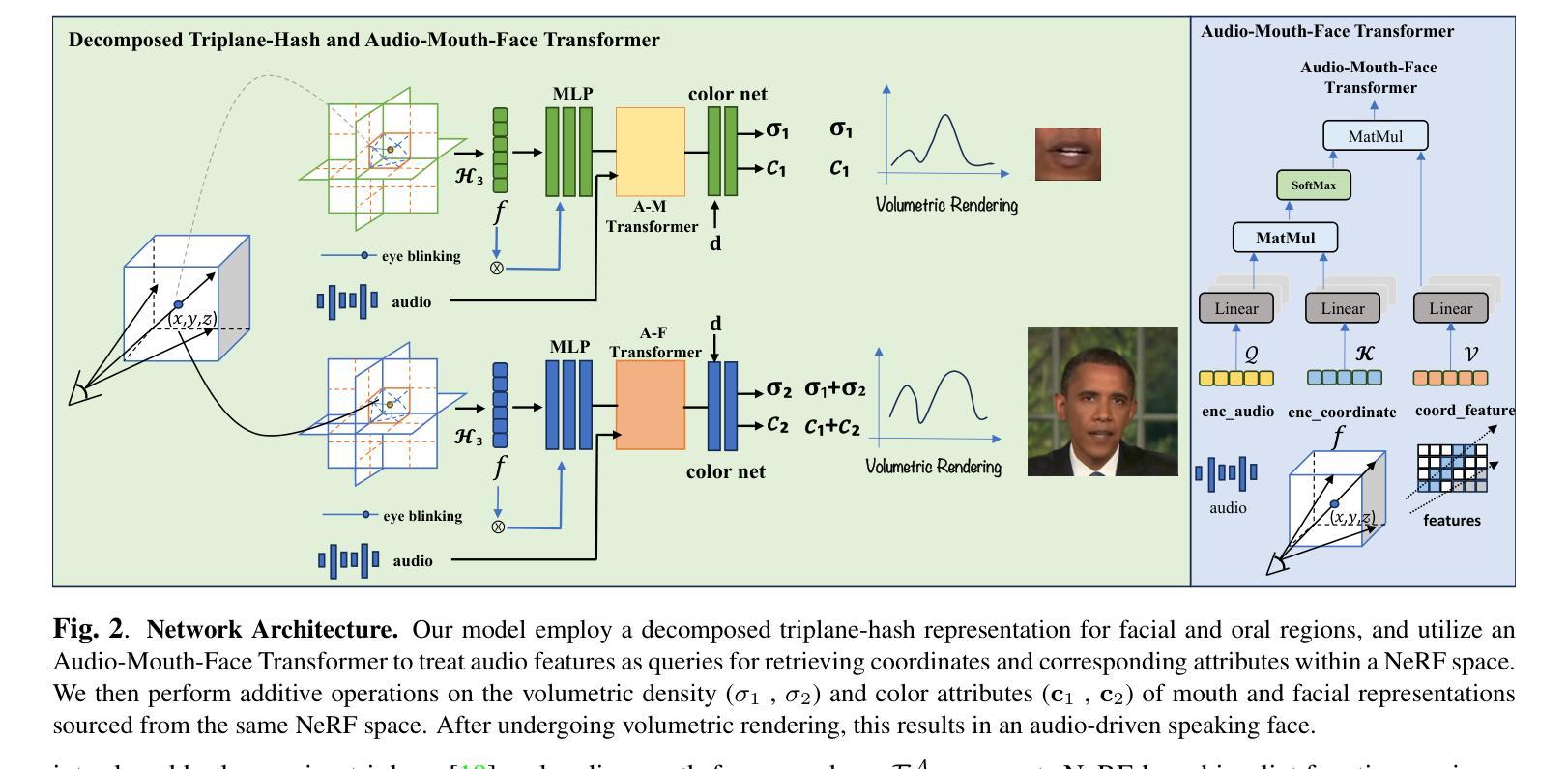
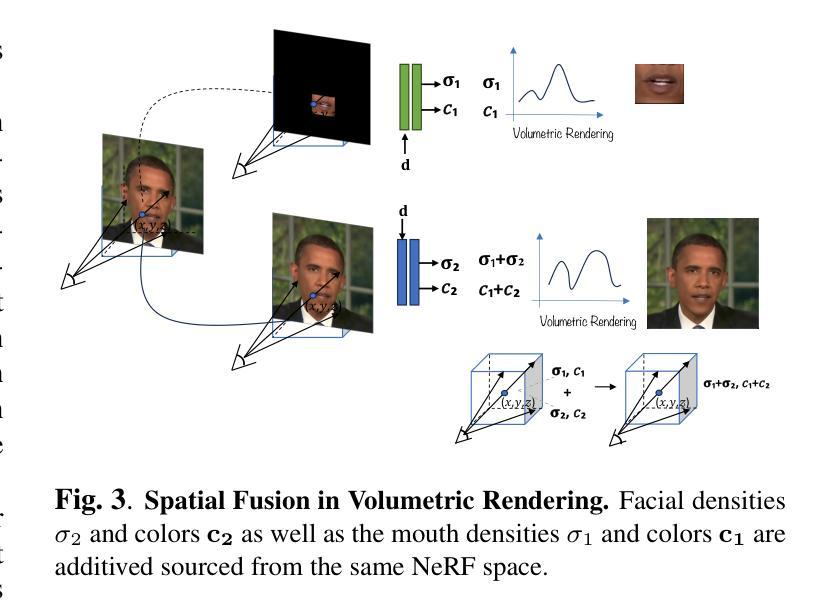

 wechat
wechat- alipay







