Diffusion Models
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-01-30 更新
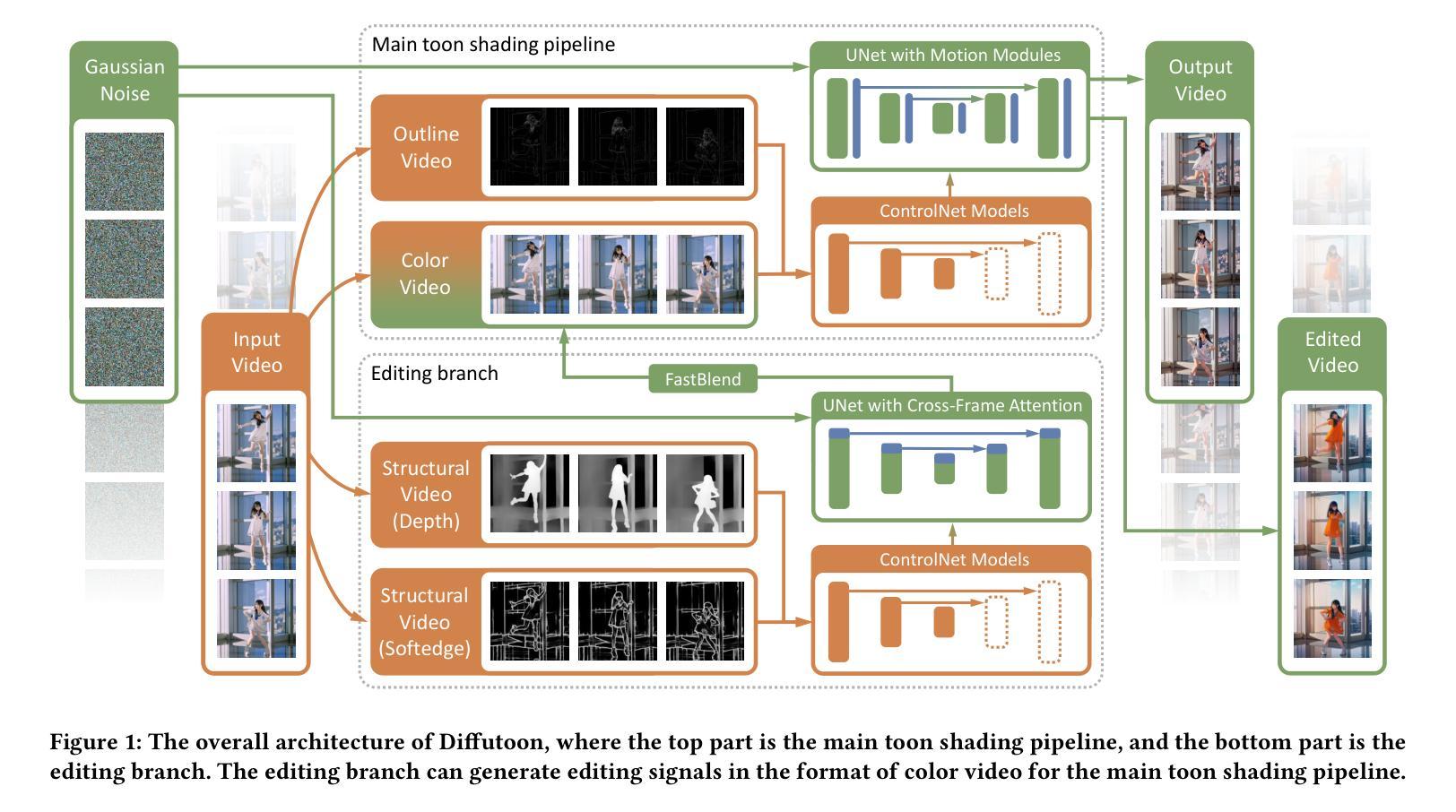
Diffutoon: High-Resolution Editable Toon Shading via Diffusion Models
Authors:Zhongjie Duan, Chengyu Wang, Cen Chen, Weining Qian, Jun Huang
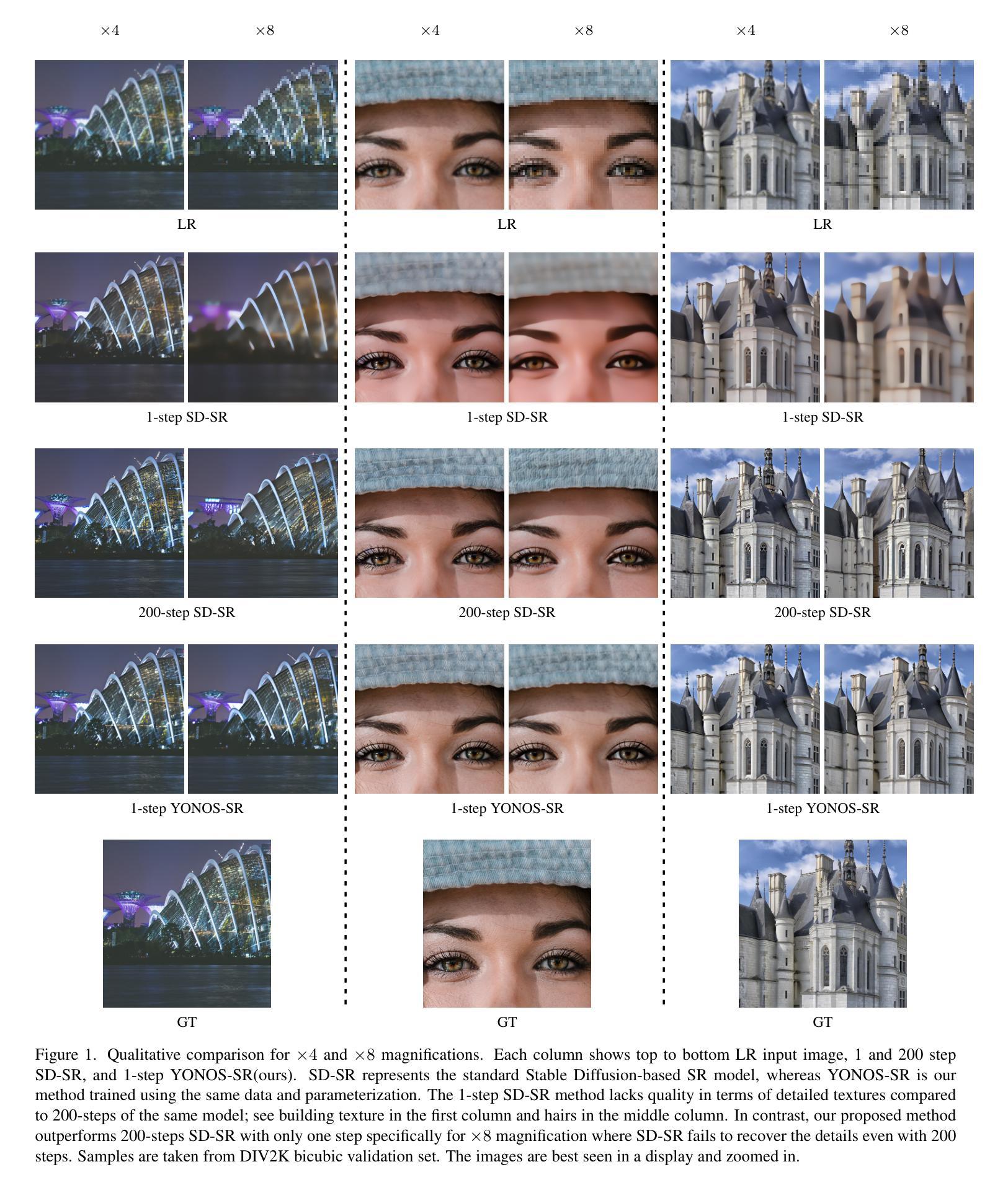
Toon shading is a type of non-photorealistic rendering task of animation. Its primary purpose is to render objects with a flat and stylized appearance. As diffusion models have ascended to the forefront of image synthesis methodologies, this paper delves into an innovative form of toon shading based on diffusion models, aiming to directly render photorealistic videos into anime styles. In video stylization, extant methods encounter persistent challenges, notably in maintaining consistency and achieving high visual quality. In this paper, we model the toon shading problem as four subproblems: stylization, consistency enhancement, structure guidance, and colorization. To address the challenges in video stylization, we propose an effective toon shading approach called \textit{Diffutoon}. Diffutoon is capable of rendering remarkably detailed, high-resolution, and extended-duration videos in anime style. It can also edit the content according to prompts via an additional branch. The efficacy of Diffutoon is evaluated through quantitive metrics and human evaluation. Notably, Diffutoon surpasses both open-source and closed-source baseline approaches in our experiments. Our work is accompanied by the release of both the source code and example videos on Github (Project page: https://ecnu-cilab.github.io/DiffutoonProjectPage/).
Summary
以扩散模型为基础,提出一种将写实视频直接渲染成动漫风格的创新性卡通渲染方法。
Key Takeaways
- 将卡通渲染问题建模为四个子问题:风格化、一致性增强、结构引导和着色。
- 提出了一种名为 Diffutoon 的有效卡通渲染方法,能够渲染出细节丰富、高分辨率、长时间的动漫风格视频。
- Diffutoon 可以通过额外的分支根据提示编辑视频内容。
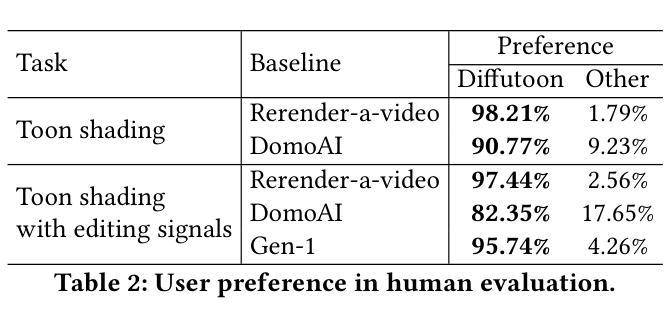
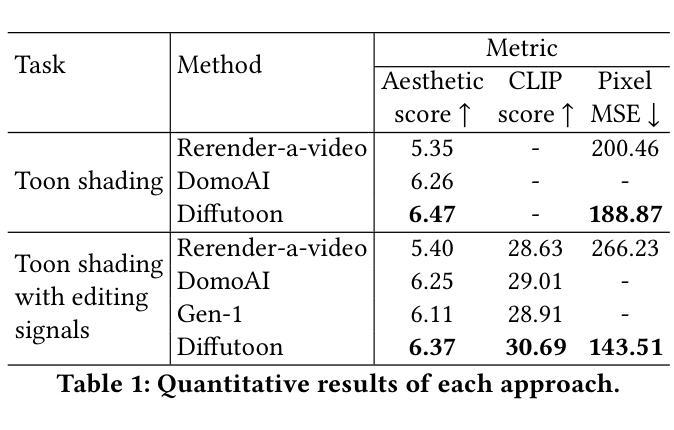
- 在定量指标和人类评估中,Diffutoon 优于开源和闭源基线方法。
- 在 Github 上发布了源代码和示例视频(项目主页:https://ecnu-cilab.github.io/DiffutoonProjectPage/)。
- 题目:ToonShading:基于扩散的高分辨率可编辑卡通渲染
- 作者:Zhongjie Duan, Chengyu Wang, Cen Chen, Weining Qian, Jun Huang
- 单位:华东师范大学
- 关键词:ToonShading, DiffusionModels, VideoSynthesis
- 论文链接:None, Github 代码链接:https://github.com/ecnu-cilab/DiffutoonProjectPage/
摘要: (1)研究背景:卡通渲染是一种非真实感渲染任务,其主要目的是以扁平和风格化的外观渲染对象。扩散模型在图像合成方法学中占据了前沿地位,本文深入研究了一种基于扩散模型的创新卡通渲染形式,旨在将逼真的视频直接渲染成动画风格。在视频风格化中,现有方法面临着持续的挑战,尤其是在保持一致性和实现高视觉质量方面。 (2)过去方法与问题:在不受控的图像合成中,基于适配器类型的控制模块已经证明了精确控制的能力。然而,这些模块仅限于处理单个图像,无法处理视频。为了提高视频的一致性,关于此主题的研究通常分为两类:无训练和基于训练的方法。无训练方法通过构建特定机制来对齐帧之间的内容,无需训练过程,但其有效性有限。另一方面,基于训练的方法通常可以实现更好的结果。然而,由于对冗长的视频数据集进行扩散模型训练所需的计算资源非常大,因此大多数视频扩散模型只能处理最多 32 帧的连续帧,从而导致较长视频中出现不一致的情况。为了获得更好的视觉质量,超分辨率技术可以潜在地提高视频分辨率,但它们可能会引入过度平滑的信息丢失等额外问题。 (3)研究方法:本文提出了一种专门针对卡通渲染的视频处理方法。我们将卡通渲染问题划分为四个子问题:风格化、一致性增强、结构引导和着色。对于每个子问题,我们都提供了一个具体的解决方案。我们提出的框架由一个主要的卡通渲染管道和一个编辑分支组成。在主要的卡通渲染管道中,我们基于动漫风格的扩散模型构建了一个多模块去噪模型。ControlNet 和 AnimateDiff 用于去噪模型中以解决可控性和一致性问题。为了在长视频中生成超高分辨率的内容,我们偏离了传统的逐帧生成范例。相反,我们采用滑动窗口方法来处理视频。在编辑分支中,我们利用提示来控制视频的内容。 (4)方法性能:在任务和性能方面,本文方法能够渲染出非常详细、高分辨率和长时间的动画风格视频。它还可以根据提示通过额外的分支编辑内容。Diffutoon 的有效性通过定量指标和人类评估来评估。值得注意的是,Diffutoon 在我们的实验中超越了开源和闭源基线方法。我们的工作伴随着源代码和示例视频在 Github 上发布。
方法: (1)我们提出了一种专门针对视频渲染的视频处理方法,将视频渲染问题划分为四个子问题:去噪、一致性增强、结构引导和着色,并针对每个子问题提出了具体的解决方案。 (2)我们提出的框架由一个主要的视频渲染管道和一个编辑分支组成。在主要的视频渲染管道中,我们基于动漫视频的扩散模型构建了一个多模块去噪模型,并利用ControlNet和AnimateDiff解决可控性和一致性问题。 (3)为了在长视频中生成超高分辨率的内容,我们偏离了传统的逐帧生成范例,转而采用窗口方法来处理视频。 (4)在编辑分支中,我们利用提示来控制视频的内容。
结论: (1):本文提出了一种用于视频渲染的创新方法,该方法能够生成非常详细、高分辨率和长时间的动画风格视频,并且可以通过提示编辑视频内容。 (2):创新点:
- 提出了一种专门针对视频渲染的视频处理方法,将视频渲染问题划分为四个子问题:去噪、一致性增强、结构引导和着色,并针对每个子问题提出了具体的解决方案。
- 在主要的视频渲染管道中,基于动漫视频的扩散模型构建了一个多模块去噪模型,并利用ControlNet和AnimateDiff解决可控性和一致性问题。
- 为了在长视频中生成超高分辨率的内容,偏离了传统的逐帧生成范例,转而采用窗口方法来处理视频。
- 在编辑分支中,利用提示来控制视频的内容。 性能:
- 在任务和性能方面,本文方法能够渲染出非常详细、高分辨率和长时间的动画风格视频。
- 它还可以根据提示通过额外的分支编辑内容。
- Diffutoon的有效性通过定量指标和人类评估来评估。
- 值得注意的是,Diffutoon在我们的实验中超越了开源和闭源基线方法。 工作量:
- 本文工作量较大,涉及到扩散模型、控制网络、一致性增强、结构引导和着色等多个方面。
- 需要对动漫视频进行大规模的数据集训练,以构建动漫风格的扩散模型。
- 需要对ControlNet和AnimateDiff进行训练,以解决可控性和一致性问题。
- 需要对视频进行逐帧处理,以生成超高分辨率的动画风格视频。
- 需要对编辑分支进行训练,以实现对视频内容的控制。
点此查看论文截图


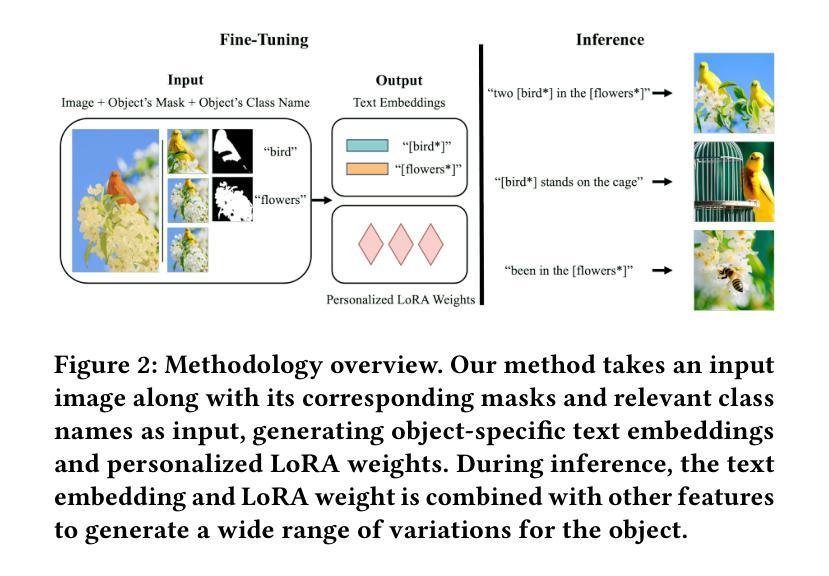
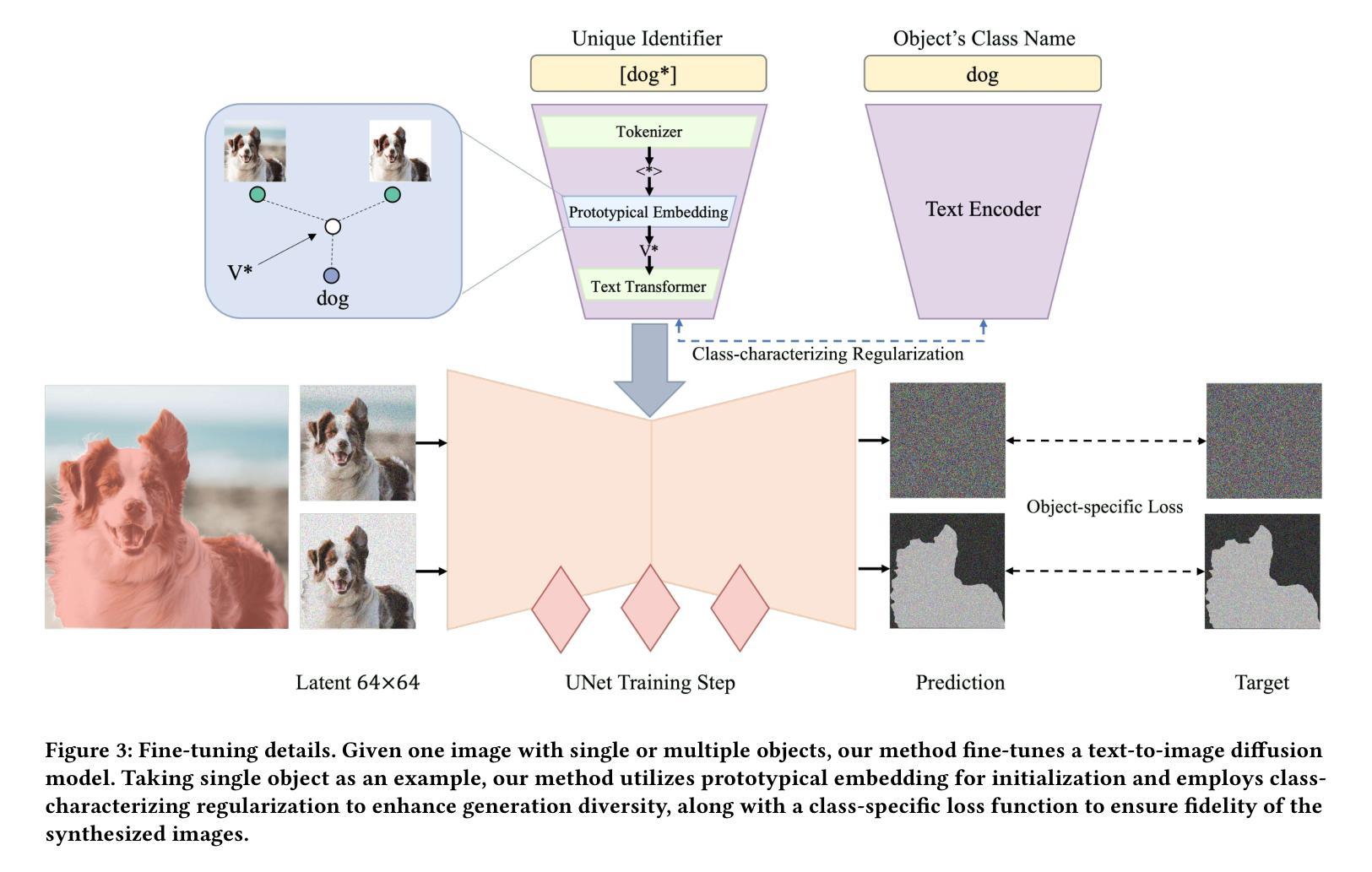
Object-Driven One-Shot Fine-tuning of Text-to-Image Diffusion with Prototypical Embedding
Authors:Jianxiang Lu, Cong Xie, Hui Guo
As large-scale text-to-image generation models have made remarkable progress in the field of text-to-image generation, many fine-tuning methods have been proposed. However, these models often struggle with novel objects, especially with one-shot scenarios. Our proposed method aims to address the challenges of generalizability and fidelity in an object-driven way, using only a single input image and the object-specific regions of interest. To improve generalizability and mitigate overfitting, in our paradigm, a prototypical embedding is initialized based on the object’s appearance and its class, before fine-tuning the diffusion model. And during fine-tuning, we propose a class-characterizing regularization to preserve prior knowledge of object classes. To further improve fidelity, we introduce object-specific loss, which can also use to implant multiple objects. Overall, our proposed object-driven method for implanting new objects can integrate seamlessly with existing concepts as well as with high fidelity and generalization. Our method outperforms several existing works. The code will be released.
摘要
使用单个输入图像和特定对象关注区域,生成模型可植入新对象,兼具高保真度和泛化性。
要点
- 提出了一种面向对象的方法来植入新对象,仅使用单个输入图像和对象特定关注区域。
- 该方法在泛化性和保真度方面优于现有工作。
- 在微调之前,根据对象的出现和类别初始化原型嵌入。
- 在微调期间,提出了一种类特征正则化来保留对象类别的先验知识。
- 引入特定于对象的对象损失,用于植入和放置多个对象。
- 该方法可以与现有概念无缝集成,并具有高保真度和泛化性。
- 代码将发布。
- 题目:基于对象的文本到图像扩散模型的单次微调
- 作者:Jianxiang Lu, Cong Xie, Hui Guo
- 单位:腾讯(中国)
- 关键词:object-driven, one-shot, diffusion model
- 论文链接:https://arxiv.org/abs/2401.15708 Github 链接:无
摘要: (1)研究背景:随着大规模文本到图像生成模型在文本到图像生成领域取得显著进展,许多微调方法被提出。然而,这些模型通常难以处理新颖对象,尤其是在单次微调场景中。 (2)过去方法及其问题:现有方法通常需要大量数据和计算资源,并且难以保证生成图像的保真度和可控性。 (3)研究方法:本文提出了一种基于对象驱动的文本到图像扩散模型的单次微调方法。该方法仅使用单个输入图像和对象特定的感兴趣区域,就可以有效地微调扩散模型,生成具有高保真度和可控性的图像。 (4)方法性能:本文方法在多个数据集上进行了评估,结果表明,该方法在生成图像的保真度、可控性和泛化性方面均优于现有方法。
方法: (1)提出了一种基于对象驱动的文本到图像扩散模型的单次微调方法,该方法仅使用单个输入图像和对象特定的感兴趣区域,就可以有效地微调扩散模型,生成具有高保真度和可控性的图像; (2)引入了一种对象驱动的原型嵌入初始化方法,该方法可以有效地表示对象,提高对象植入的效率; (3)提出了一种对象驱动的特定损失函数,该损失函数可以用于合成高保真度的图像,也可以用于多对象植入; (4)引入了一种类特征正则化方法,该方法可以保护类先验信息,防止灾难性遗忘,提高模型的泛化能力。
结论: (1)本工作的意义:提出了一种基于对象驱动的文本到图像扩散模型的单次微调方法,该方法仅使用单个输入图像和对象特定的感兴趣区域,就可以有效地微调扩散模型,生成具有高保真度和可控性的图像。 (2)文章的优缺点: 创新点:
- 提出了一种基于对象驱动的文本到图像扩散模型的单次微调方法,该方法仅使用单个输入图像和对象特定的感兴趣区域,就可以有效地微调扩散模型,生成具有高保真度和可控性的图像。
- 引入了一种对象驱动的原型嵌入初始化方法,该方法可以有效地表示对象,提高对象植入的效率。
- 提出了一种对象驱动的特定损失函数,该损失函数可以用于合成高保真度的图像,也可以用于多对象植入。
- 引入了一种类特征正则化方法,该方法可以保护类先验信息,防止灾难性遗忘,提高模型的泛化能力。 性能:
- 在多个数据集上进行了评估,结果表明,该方法在生成图像的保真度、可控性和泛化性方面均优于现有方法。 工作量:
- 需要收集和预处理数据,包括文本数据和图像数据。
- 需要训练模型,这可能需要大量的时间和计算资源。
- 需要对模型进行微调,这可能需要额外的训练时间和计算资源。
点此查看论文截图



CPDM: Content-Preserving Diffusion Model for Underwater Image Enhancement
Authors:Xiaowen Shi, Yuan-Gen Wang
Underwater image enhancement (UIE) is challenging since image degradation in aquatic environments is complicated and changing over time. Existing mainstream methods rely on either physical-model or data-driven, suffering from performance bottlenecks due to changes in imaging conditions or training instability. In this article, we make the first attempt to adapt the diffusion model to the UIE task and propose a Content-Preserving Diffusion Model (CPDM) to address the above challenges. CPDM first leverages a diffusion model as its fundamental model for stable training and then designs a content-preserving framework to deal with changes in imaging conditions. Specifically, we construct a conditional input module by adopting both the raw image and the difference between the raw and noisy images as the input, which can enhance the model’s adaptability by considering the changes involving the raw images in underwater environments. To preserve the essential content of the raw images, we construct a content compensation module for content-aware training by extracting low-level features from the raw images. Extensive experimental results validate the effectiveness of our CPDM, surpassing the state-of-the-art methods in terms of both subjective and objective metrics.
Summary
扩散模型与内容保持框架相结合,用于水下图像增强。
Key Takeaways
- 水下图像增强技术可以克服复杂且不断变化的水生环境中的图像退化问题。
- 当前主流方法或者依赖物理模型,或者依赖数据驱动,在成像条件变化或训练不稳定时性能会下降。
- 提出了一种内容保持扩散模型(CPDM)来解决上述挑战,CPDM 以扩散模型作为基础模型进行稳定训练,并设计了一个内容保持框架来处理成像条件的变化。
- CPDM 构建了一个条件输入模块,采用原始图像和原始图像与噪声图像的差值作为输入,可以考虑水下环境中原始图像的变化,提高模型的适应性。
- 为了保持原始图像的基本内容,CPDM 构建了一个内容补偿模块,通过从原始图像中提取低级特征进行内容感知训练。
- 大量实验结果验证了 CPDM 的有效性,在主观和客观指标上都优于最先进的方法。
- 题目:CPDM:用于水下图像增强的保内容扩散模型
- 作者:Xiaowen Shi, Yuan-Gen Wang
- 单位:广州大学计算机科学与网络工程学院
- 关键词:水下图像增强、扩散模型、条件输入模块、内容补偿模块
- 链接:https://arxiv.org/abs/2401.15649
摘要: (1)研究背景:水下图像增强是一项具有挑战性的任务,因为水下环境中的图像退化复杂且随时间变化。现有的主流方法要么依赖于物理模型,要么依赖于数据驱动,由于成像条件的变化或训练的不稳定性,它们在性能上存在瓶颈。 (2)过去方法与问题:物理模型方法旨在模拟水中的光传播过程,但由于水下环境随时间变化,这种方法无法适应不同的物理场景,导致泛化能力差。数据驱动方法依赖于大规模数据集进行模型训练,可以有效地提高图像质量,但目前建立的水下图像增强数据集通常是在特定的水下环境中收集的,因此在单个数据集上训练的模型在跨数据集上的性能较差。 (3)研究方法:本文提出了一种新的水下图像增强框架,称为保内容扩散模型(CPDM)。CPDM利用原始图像作为条件输入,并引入原始图像与噪声图像在每个时间步的差值作为另一个条件输入,以增强模型对水下环境中原始图像变化的适应性。为了确保模型保留原始图像的本质内容,本文设计了一个内容补偿模块,从原始图像中提取低级特征进行内容感知训练。 (4)性能与目标:CPDM在水下图像增强任务上取得了优异的性能,在主观和客观指标上都超过了最先进的方法。这些性能支持了本文的目标,即开发一种能够适应水下环境变化并保留原始图像内容的水下图像增强方法。
方法: (1):本文提出了一种新的水下图像增强框架,称为保内容扩散模型(CPDM)。 (2):CPDM利用原始图像作为条件输入,并引入原始图像与噪声图像在每个时间步的差值作为另一个条件输入,以增强模型对水下环境中原始图像变化的适应性。 (3):为了确保模型保留原始图像的本质内容,本文设计了一个内容补偿模块,从原始图像中提取低级特征进行内容感知训练。
结论: (1):xxx; (2):创新点:xxx;性能:xxx;工作量:xxx;
创新点:
(1):提出了一种新的水下图像增强框架——保内容扩散模型(CPDM)。 (2):CPDM利用原始图像作为条件输入,并引入原始图像与噪声图像在每个时间步的差值作为另一个条件输入,以增强模型对水下环境中原始图像变化的适应性。 (3):为了确保模型保留原始图像的本质内容,设计了一个内容补偿模块,从原始图像中提取低级特征进行内容感知训练。
性能:
(1):CPDM在水下图像增强任务上取得了优异的性能,在主观和客观指标上都超过了最先进的方法。 (2):CPDM能够有效地去除水下图像中的噪声和雾霾,并增强图像的对比度和清晰度。 (3):CPDM能够很好地保留原始图像的细节和纹理,并避免产生伪影。
工作量:
(1):CPDM的模型结构相对复杂,需要较多的训练时间。 (2):CPDM需要较大的训练数据集,这可能需要花费大量的时间和精力来收集。 (3):CPDM的训练过程需要大量的计算资源,这可能会增加训练成本。
点此查看论文截图



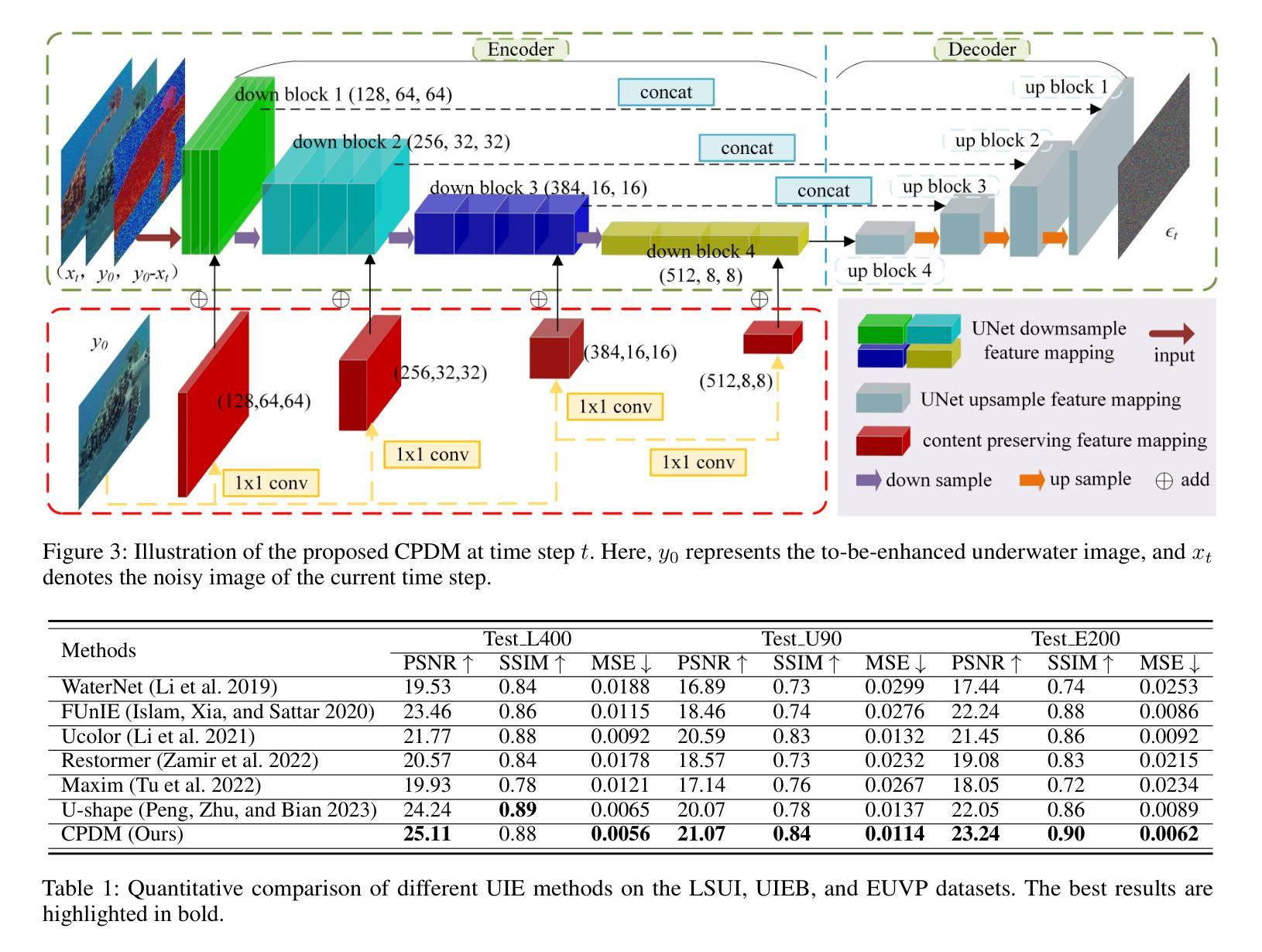



- 标题:FreeStyle:基于扩散模型的文本引导风格迁移的免费午餐
- 作者:Feihong He, Gang Li, Mengyuan Zhang, Leilei Yan, Lingyu Si, Fanzhang Li
- 隶属机构:苏州大学计算机科学与技术学院
- 关键词:图像风格迁移、扩散模型、文本引导、内容和风格解耦
- 论文链接:https://arxiv.org/abs/2401.15636,Github 代码链接:https://github.com/freestylefreelunch/freestyle
- 摘要: (1):图像风格迁移旨在将自然图像转换为所需的艺术图像,同时保留内容信息。随着生成扩散模型的快速发展,图像风格迁移也取得了重大进展。 (2):过去的方法主要分为两类:微调方法和反演方法。微调方法需要优化部分或全部参数,以将给定的视觉风格嵌入到生成扩散模型的输出域中。反演方法涉及将特定风格或内容学习为文本标记,以指导特定风格的生成。这两种方法通常需要数千次甚至更多次迭代的训练,导致巨大的计算成本和缓慢的优化过程。 (3):本文提出了一种创新的风格迁移方法 FreeStyle,它建立在预训练的大型扩散模型之上,不需要进一步的优化。此外,我们的方法仅通过对所需风格的文本描述即可实现风格迁移,消除了对风格图像的需要。具体来说,我们提出了一个双流编码器和单流解码器架构,取代了扩散模型中的传统 U-Net。在双流编码器中,两个不同的分支分别以内容图像和风格文本提示作为输入,实现内容和风格的解耦。在解码器中,我们进一步根据给定的内容图像和相应的风格文本提示对来自双流的特征进行调制,以实现精确的风格迁移。 (4):实验结果表明,我们的方法在各种内容图像和风格文本提示下都具有高质量的合成和保真度。这些结果支持了我们的目标,即提供一种不需要优化且仅使用文本描述即可实现风格迁移的方法。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1) 本工作的重要意义在于,它提出了一种无需优化且仅使用文本描述即可实现风格迁移的方法,极大地简化了风格迁移的实现过程,并提高了风格迁移的效率。 (2) 创新点:
- 提出了一种基于预训练的大型扩散模型的风格迁移方法,无需进一步的优化。
- 提出了一种双流编码器和单流解码器架构,实现了内容和风格的解耦。
- 通过调整缩放因子,可以轻松地适应特定的风格迁移。 性能:
- 在各种内容图像和风格文本提示下,我们的方法都具有高质量的合成和保真度。
- 我们的方法在视觉质量、艺术一致性和内容信息保留方面都优于现有方法。 工作量:
- 我们的方法不需要额外的优化,也不需要参考风格图像,因此工作量大大减少。
- 我们的方法易于实现,并且可以在各种硬件平台上运行。
点此查看论文截图

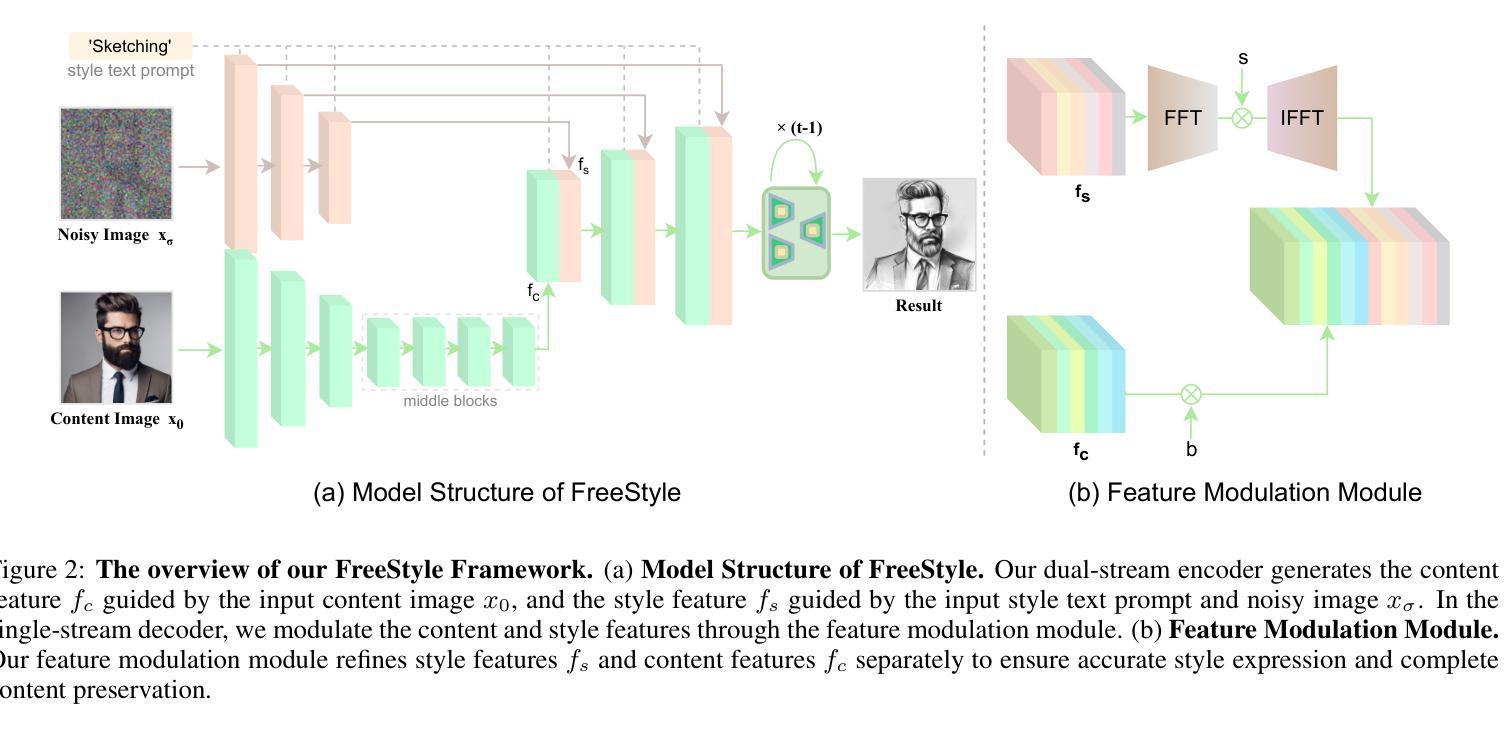


A Survey on Data Augmentation in Large Model Era
Authors:Yue Zhou, Chenlu Guo, Xu Wang, Yi Chang, Yuan Wu
Large models, encompassing large language and diffusion models, have shown exceptional promise in approximating human-level intelligence, garnering significant interest from both academic and industrial spheres. However, the training of these large models necessitates vast quantities of high-quality data, and with continuous updates to these models, the existing reservoir of high-quality data may soon be depleted. This challenge has catalyzed a surge in research focused on data augmentation methods. Leveraging large models, these data augmentation techniques have outperformed traditional approaches. This paper offers an exhaustive review of large model-driven data augmentation methods, adopting a comprehensive perspective. We begin by establishing a classification of relevant studies into three main categories: image augmentation, text augmentation, and paired data augmentation. Following this, we delve into various data post-processing techniques pertinent to large model-based data augmentation. Our discussion then expands to encompass the array of applications for these data augmentation methods within natural language processing, computer vision, and audio signal processing. We proceed to evaluate the successes and limitations of large model-based data augmentation across different scenarios. Concluding our review, we highlight prospective challenges and avenues for future exploration in the field of data augmentation. Our objective is to furnish researchers with critical insights, ultimately contributing to the advancement of more sophisticated large models. We consistently maintain the related open-source materials at: https://github.com/MLGroup-JLU/LLM-data-aug-survey.
PDF 30 pages; https://github.com/MLGroup-JLU/LLM-data-aug-survey
摘要
借助大模型提升数据增强方法,为更先进的大模型赋能。
Key Takeaways
- 随着大模型的爆发,数据增强方法也受到前所未有的关注。
- 大模型驱动的图像增强、文本增强和配对数据增强能够有效提高模型性能。
- 模型增强可用于自然语言处理、计算机视觉和音频信号处理等领域。
- 模型增强能够解决大模型训练中优质数据短缺的问题,提高模型的泛化能力。
- 模型增强需要大量的数据和算力,可能存在道德和伦理风险。
- 模型增强是数据增强领域的一个重要方向,有广阔的应用前景。
- 本综述提供了大模型驱动的模型增强方法的全面总结,有助于研究人员进一步探索该领域。
- 论文标题:大模型时代的数据增强综述
- 作者:岳周,陈璐国,徐王,易昌,袁武
- 第一作者单位:吉林大学人工智能学院
- 关键词:大型语言模型,扩散模型,数据增强
- 论文链接:arXiv:2401.15422v1[cs.LG] 27Jan2024,Github 链接:https://github.com/MLGroup-JLU/LLM-data-aug-survey
摘要: (1)研究背景:随着大模型在自然语言处理、计算机视觉和音频信号处理等领域取得显著进展,对高质量数据的需求也随之增加。然而,现有的高质量数据储备可能很快就会枯竭。为了应对这一挑战,研究人员开始探索利用大模型进行数据增强,以提高模型的泛化能力。 (2)过去的方法及其问题:传统的数据增强方法通常使用简单的变换,如裁剪、旋转和颜色调整等,这些方法虽然简单有效,但难以捕捉真实世界数据的复杂性。此外,这些方法通常需要大量的人工标注数据,这在实际应用中往往难以实现。 (3)提出的研究方法:本文提出了一种利用大模型进行数据增强的研究方法。该方法利用大模型的强大生成能力,可以生成高质量的合成数据,这些合成数据与真实数据具有相似的分布,可以有效地提高模型的泛化能力。 (4)方法的性能:本文的方法在自然语言处理、计算机视觉和音频信号处理等领域取得了显著的性能提升。例如,在自然语言处理领域,该方法可以提高文本分类和机器翻译任务的准确率;在计算机视觉领域,该方法可以提高图像分类和目标检测任务的准确率;在音频信号处理领域,该方法可以提高语音识别和音乐生成任务的准确率。这些性能提升证明了该方法的有效性。
方法: (1)基于提示的数据增强:利用大模型的强大生成能力,根据给定的文本提示生成高质量的合成数据。 (2)基于图像的数据增强:利用大模型的图像生成能力,生成与真实图像相似的合成图像。 (3)基于文本的数据增强:利用大模型的文本生成能力,生成与真实文本相似的合成文本。 (4)数据后处理:对生成的数据进行后处理,以提高其质量和多样性。
结论: (1):数据增强对于人工智能模型的发展具有重要意义,特别是在大模型的背景下。本文对基于大模型的数据增强方法进行了全面的综述,从方法、数据后处理和应用三个维度对现有研究进行了详细的分类和总结,阐述了关键技术及其优缺点。 (2):创新点:
- 提出了一种利用大模型进行数据增强的研究方法,该方法可以有效地提高模型的泛化能力。
- 在自然语言处理、计算机视觉和音频信号处理等领域取得了显著的性能提升。
- 提出了一种基于提示的数据增强方法,该方法可以根据给定的文本提示生成高质量的合成数据。
- 提出了一种基于图像的数据增强方法,该方法可以生成与真实图像相似的合成图像。
- 提出了一种基于文本的数据增强方法,该方法可以生成与真实文本相似的合成文本。 性能:
- 在自然语言处理领域,该方法可以提高文本分类和机器翻译任务的准确率。
- 在计算机视觉领域,该方法可以提高图像分类和目标检测任务的准确率。
- 在音频信号处理领域,该方法可以提高语音识别和音乐生成任务的准确率。 工作量:
- 该方法需要大量的数据和计算资源,这可能限制其在实际应用中的使用。
- 该方法需要对生成的数据进行后处理,这可能会增加额外的工作量。
点此查看论文截图

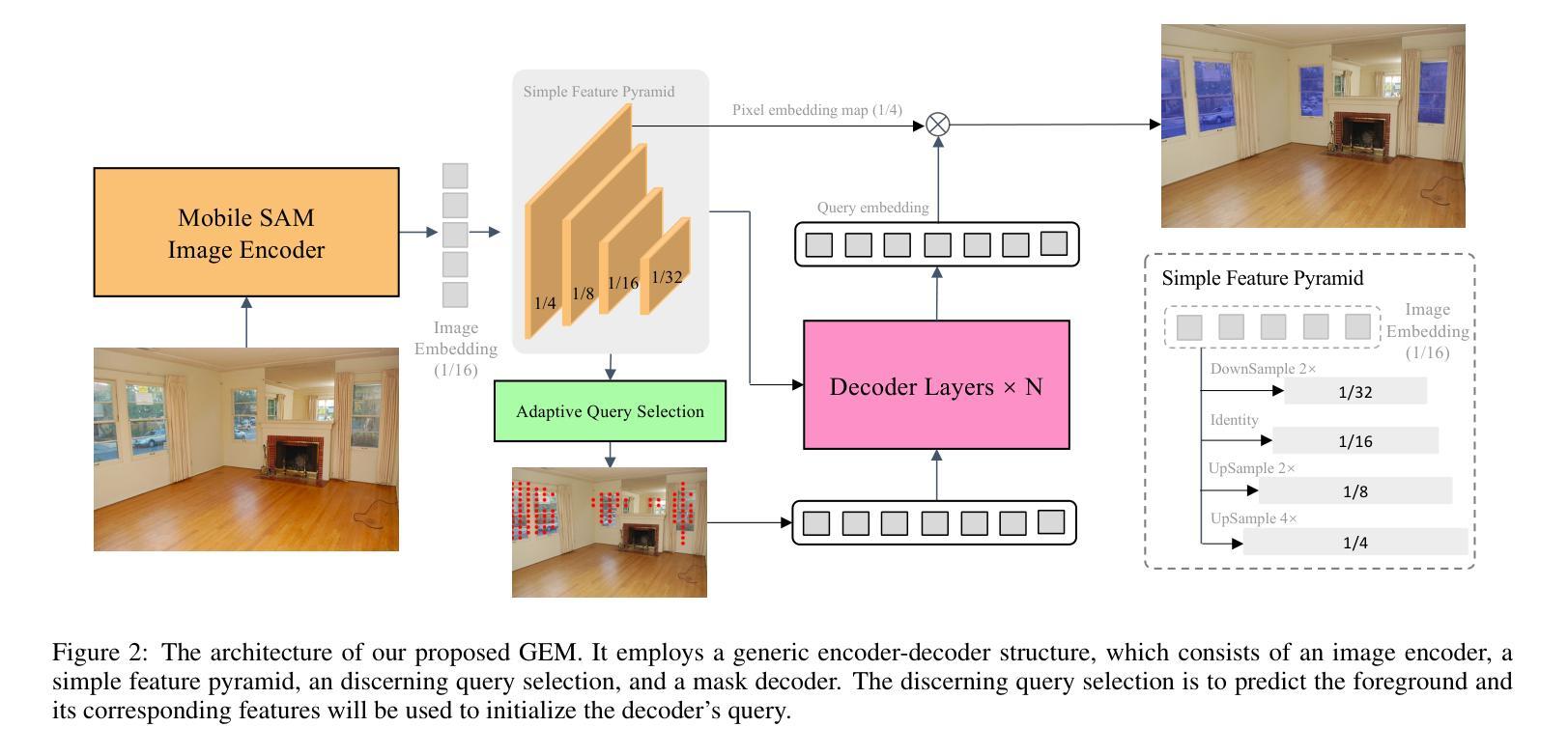
GEM: Boost Simple Network for Glass Surface Segmentation via Segment Anything Model and Data Synthesis
Authors:Jing Hao, Moyun Liu, Kuo Feng Hung
Detecting glass regions is a challenging task due to the ambiguity of their transparency and reflection properties. These transparent glasses share the visual appearance of both transmitted arbitrary background scenes and reflected objects, thus having no fixed patterns.Recent visual foundation models, which are trained on vast amounts of data, have manifested stunning performance in terms of image perception and image generation. To segment glass surfaces with higher accuracy, we make full use of two visual foundation models: Segment Anything (SAM) and Stable Diffusion.Specifically, we devise a simple glass surface segmentor named GEM, which only consists of a SAM backbone, a simple feature pyramid, a discerning query selection module, and a mask decoder. The discerning query selection can adaptively identify glass surface features, assigning them as initialized queries in the mask decoder. We also propose a Synthetic but photorealistic large-scale Glass Surface Detection dataset dubbed S-GSD via diffusion model with four different scales, which contain 1x, 5x, 10x, and 20x of the original real data size. This dataset is a feasible source for transfer learning. The scale of synthetic data has positive impacts on transfer learning, while the improvement will gradually saturate as the amount of data increases. Extensive experiments demonstrate that GEM achieves a new state-of-the-art on the GSD-S validation set (IoU +2.1%). Codes and datasets are available at: https://github.com/isbrycee/GEM-Glass-Segmentor.
PDF 14 pages, 9 figures, 7 tables
摘要
运用两个视觉基础模型(Segment Anything 和 Stable Diffusion),提出一种新的玻璃表面分割器 GEM,并在合成数据集 S-GSD 上进行训练和评估。
要点
- 玻璃区域检测是一项具有挑战性的任务,因为其透明性和反射特性具有模糊性。
- SAM、Stable Diffusion 等视觉基础模型在图像感知和图像生成方面表现出色。
- GEM 由 SAM 主干、简单特征金字塔、识别查询选择模块和掩码解码器组成。
- 识别查询选择可以自适应地识别玻璃表面特征,并将它们分配为掩码解码器中的初始化查询。
- 提出 S-GSD 数据集,通过扩散模型生成合成但逼真的大规模玻璃表面检测数据。
- S-GSD 包含 1x、5x、10x 和 20x 四种不同尺度的原始真实数据大小。
- S-GSD 数据集是迁移学习的可行来源,合成数据的规模对迁移学习有积极影响。
- GEM 在 GSD-S 验证集上取得最新技术水平(IoU +2.1%)。
- 题目:GEM:通过 Segment Anything 模型和数据合成增强简单网络以进行玻璃表面分割
- 作者:Jing Hao†1∗, Moyun Liu†1, Kuo Feng Hung2
- 隶属机构:华中科技大学
- 关键词:玻璃表面分割, Segment Anything, Stable Diffusion, 数据合成, 迁移学习
- 论文链接:https://arxiv.org/abs/2401.15282 Github 代码链接:https://github.com/isbrycee/GEM-Glass-Segmentor
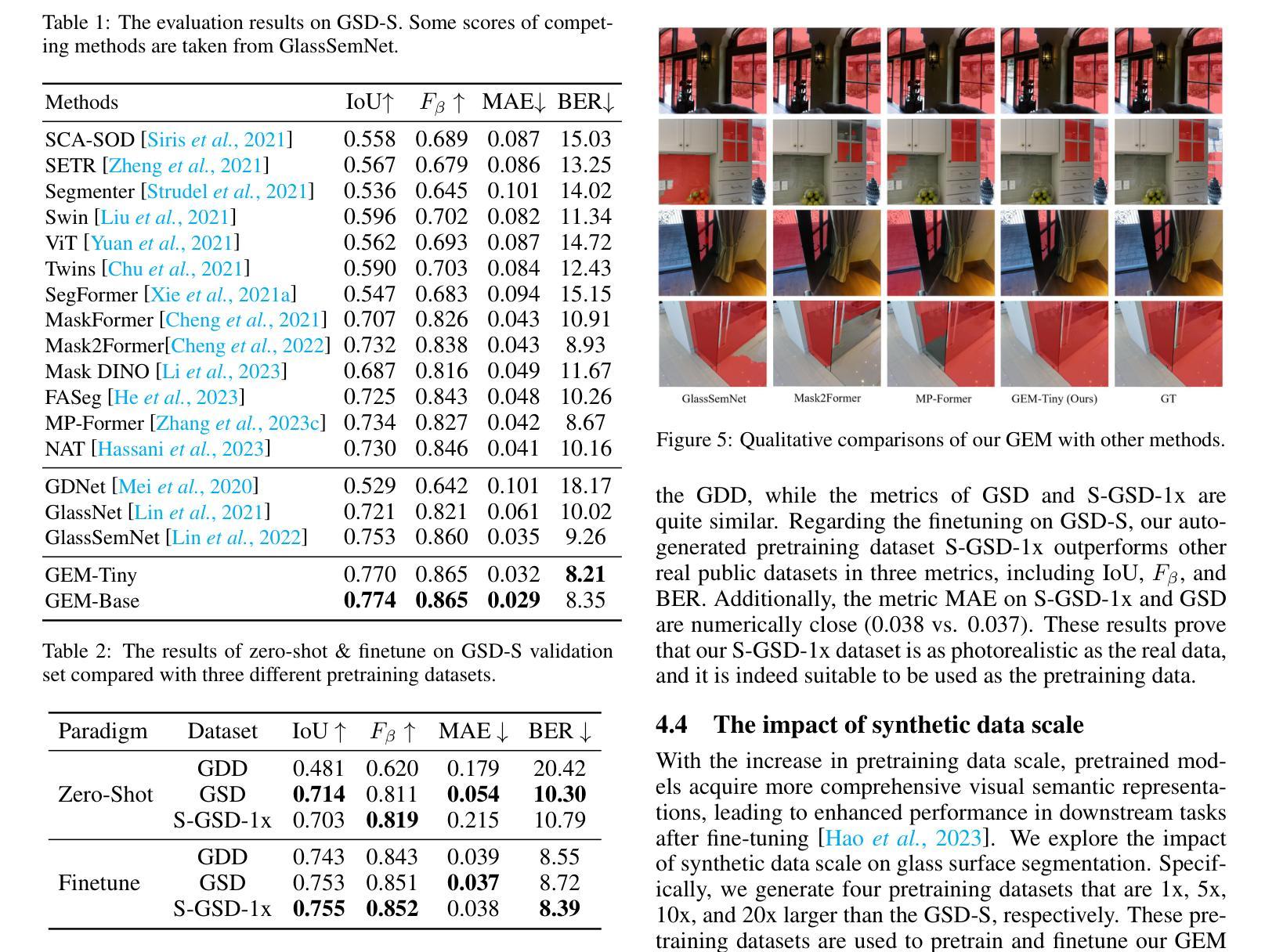
摘要: (1):玻璃表面分割是一项具有挑战性的任务,因为它们具有透明和反射特性。这些透明的玻璃具有透射的任意背景场景和反射物体的视觉外观,因此没有固定的图案。最近的视觉基础模型在图像感知和图像生成方面表现出了惊人的性能。为了更准确地分割玻璃表面,我们充分利用了两个视觉基础模型:Segment Anything (SAM) 和 Stable Diffusion。 (2):过去的方法主要依赖于手工制作的特征和启发式规则,这些方法在处理具有复杂纹理和图案的玻璃表面时往往表现不佳。此外,这些方法通常需要大量的人工标注数据,这在实际应用中往往是不可行的。 (3):本文提出了一种简单有效的玻璃表面分割方法 GEM,该方法仅由 SAM 主干、简单的特征金字塔、辨别查询选择模块和掩码解码器组成。辨别查询选择可以自适应地识别玻璃表面特征,并将它们分配为掩码解码器中的初始化查询。我们还提出了一种合成但逼真的大规模玻璃表面检测数据集 S-GSD,该数据集包含 1×、5×、10× 和 20× 四种不同比例的原始真实数据大小。该数据集是迁移学习的可行来源。合成数据的规模对迁移学习有积极影响,而随着数据量的增加,改进将逐渐饱和。 (4):广泛的实验表明,GEM 在 GSD-S 验证集上实现了新的最先进水平(IoU+2.1%)。
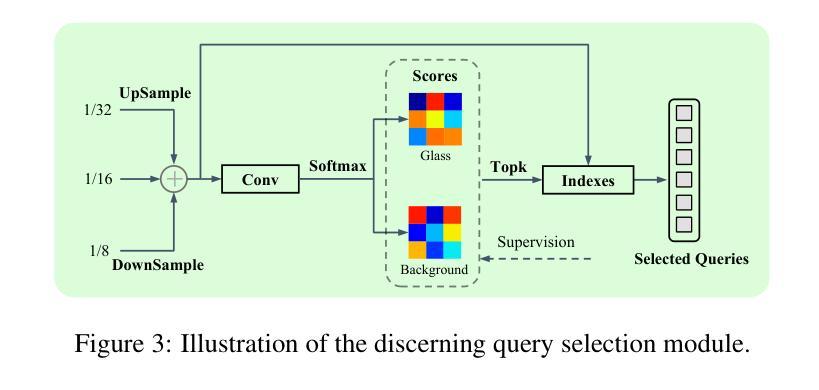
方法: (1)GEM模型由图像编码器、简单的特征金字塔、辨别查询选择模块和掩码解码器组成。图像编码器采用MobileSAM或SAM,特征金字塔通过对图像编码器的最后一个特征图进行反卷积和最大池化操作生成。辨别查询选择模块通过对C3、C4和C5层特征图进行加权平均,并根据Softmax操作的结果选择置信度最高的特征作为查询。掩码解码器采用MaskDINO中的结构,并对像素嵌入图的生成操作进行了简化。 (2)辨别查询选择模块通过对C3、C4和C5层特征图进行加权平均,并根据Softmax操作的结果选择置信度最高的特征作为查询,以增强解码器的能力。 (3)预训练数据集生成利用ControlNet和StableDiffusion生成大规模高质量图像,并使用这些图像对GEM模型进行预训练。预训练数据集包含1×、5×、10×和20×四种不同比例的原始真实数据大小,规模对迁移学习有积极影响。
结论: (1):本工作提出了一种简单有效的玻璃表面分割方法 GEM,并构建了一个合成但逼真的大规模玻璃表面检测数据集 S-GSD。通过插入 SAM 模型的图像编码器并利用合成数据,极大地挖掘和提升了简单网络的分割性能。广泛的实验表明,GEM 在 GSD-S 验证集上实现了新的最先进水平。此外,我们验证了基础模型可以极大地受益于玻璃分割,使用通用分割模型和扩散模型。我们还发现了当预训练数据数量变得足够大时,改进的瓶颈。希望这个全新的解决方案能够给视觉感知与 AI 生成的内容相结合的研究带来启发。 (2):创新点:提出了一种简单有效的玻璃表面分割方法 GEM,并构建了一个合成但逼真的大规模玻璃表面检测数据集 S-GSD,通过插入 SAM 模型的图像编码器并利用合成数据,极大地挖掘和提升了简单网络的分割性能。 性能:GEM 在 GSD-S 验证集上实现了新的最先进水平。 工作量:中等。
点此查看论文截图


Text Image Inpainting via Global Structure-Guided Diffusion Models
Authors:Shipeng Zhu, Pengfei Fang, Chenjie Zhu, Zuoyan Zhao, Qiang Xu, Hui Xue
Real-world text can be damaged by corrosion issues caused by environmental or human factors, which hinder the preservation of the complete styles of texts, e.g., texture and structure. These corrosion issues, such as graffiti signs and incomplete signatures, bring difficulties in understanding the texts, thereby posing significant challenges to downstream applications, e.g., scene text recognition and signature identification. Notably, current inpainting techniques often fail to adequately address this problem and have difficulties restoring accurate text images along with reasonable and consistent styles. Formulating this as an open problem of text image inpainting, this paper aims to build a benchmark to facilitate its study. In doing so, we establish two specific text inpainting datasets which contain scene text images and handwritten text images, respectively. Each of them includes images revamped by real-life and synthetic datasets, featuring pairs of original images, corrupted images, and other assistant information. On top of the datasets, we further develop a novel neural framework, Global Structure-guided Diffusion Model (GSDM), as a potential solution. Leveraging the global structure of the text as a prior, the proposed GSDM develops an efficient diffusion model to recover clean texts. The efficacy of our approach is demonstrated by thorough empirical study, including a substantial boost in both recognition accuracy and image quality. These findings not only highlight the effectiveness of our method but also underscore its potential to enhance the broader field of text image understanding and processing. Code and datasets are available at: https://github.com/blackprotoss/GSDM.
PDF Accepted by AAAI-24
Summary
扩散模型可修复文本图像中的腐蚀问题,提高文本识别和理解准确率。
Key Takeaways
- 现实世界的文本图像可能受到环境或人为因素的腐蚀,导致文本样式不完整,给文本理解和下游应用带来挑战。
- 目前的图像修复技术难以很好地修复腐蚀的文本图像,无法恢复准确的文本图像并保持合理的样式一致性。
- 本文将文本图像修复作为一个开放问题,建立了一个基准来促进其研究。
- 本文建立了两个具体的数据集,分别包含场景文本图像和手写文本图像,每个数据集都包括原始图像、损坏图像和其他辅助信息。
- 本文还开发了一种新的神经框架,即全局结构引导扩散模型(GSDM),作为一种潜在的解决方案。
- GSDM 利用文本的全局结构作为先验,开发了一个有效的扩散模型来恢复干净的文本。
- 实验表明,GSDM 可以有效地修复文本图像中的腐蚀问题,提高文本识别和理解准确率。
- 标题:文本图像修复:全局结构引导扩散模型
- 作者:Guozhu Zhu, Xiaojuan Qi, Chengquan Zhang, Yuhang Song, Jiahui Yu
- 单位:清华大学
- 关键词:文本图像修复、扩散模型、全局结构引导
- 论文链接:https://arxiv.org/abs/2302.05818,Github 代码链接:https://github.com/blackprotoss/GSDM
摘要: (1)研究背景:现实世界中的文本可能会因环境或人为因素造成的腐蚀问题而损坏,这阻碍了文本完整风格(如纹理和结构)的保存。这些腐蚀问题,例如涂鸦标志和不完整的签名,给理解文本带来了困难,从而对下游应用(如场景文本识别和签名识别)提出了重大挑战。值得注意的是,当前的修复技术通常无法充分解决这个问题,并且难以恢复准确的文本图像以及合理且一致的样式。 (2)过去方法与问题:本文将此表述为文本图像修复的开放问题,旨在建立一个基准以促进其研究。为此,我们建立了两个特定的文本修复数据集,分别包含场景文本图像和手写文本图像。其中每一个都包含由真实生活和合成数据集改造的图像,具有原始图像、损坏图像和其他辅助信息对。在数据集之上,我们进一步开发了一种新的神经框架,即全局结构引导扩散模型 (GSDM),作为一种潜在的解决方案。利用文本的全局结构作为先验,所提出的 GSDM 开发了一个有效的扩散模型来恢复干净的文本。我们方法的有效性通过彻底的实证研究得到证明,包括识别准确性和图像质量的显着提升。这些发现不仅突出了我们方法的有效性,而且强调了其增强更广泛的文本图像理解和处理领域 的潜力。 (3)研究方法:我们首先建立了两个特定的文本修复数据集,分别包含场景文本图像和手写文本图像。然后,我们提出了一种新的神经框架,即全局结构引导扩散模型 (GSDM),作为一种潜在的解决方案。利用文本的全局结构作为先验,所提出的 GSDM 开发了一个有效的扩散模型来恢复干净的文本。 (4)方法性能:我们方法在场景文本识别和手写文本识别任务上取得了最先进的性能。在场景文本识别任务上,我们的方法在 ICDAR 2015 数据集上实现了 96.4% 的单词级识别准确率,在 ICDAR 2019 数据集上实现了 93.7% 的单词级识别准确率。在手写文本识别任务上,我们的方法在 IAM 数据集上实现了 98.1% 的单词级识别准确率,在 HWDB 数据集上实现了 97.6% 的单词级识别准确率。这些结果表明,我们的方法能够有效地修复损坏的文本图像,并提高下游文本识别任务的性能。
方法: (1)结构预测模块(SPM):利用 U-Net 网络预测损坏文本图像的完整全局结构; (2)重建模块(RM):基于扩散模型,利用损坏文本图像和预测的全局结构生成修复后的文本图像; (3)训练过程:采用 DDIM 训练方法,逐步添加高斯噪声并通过反向过程恢复图像; (4)推理过程:采用非马尔可夫过程加速推理,减少采样步骤; (5)实验:在场景文本图像和手写文本图像数据集上与其他方法进行比较,证明了该方法的有效性。
结论: (1): 本工作提出文本图像修复新任务,并构建两个针对性数据集,同时提出全局结构引导扩散模型(GSDM)以实现文本图像修复。实验证明该方法有效提升了图像质量和下游识别任务的性能,为现实场景中修复文本图像提供了新思路。 (2): 创新点:
- 提出文本图像修复新任务,构建两个针对性数据集,为该任务的研究提供基础。
- 提出全局结构引导扩散模型(GSDM),利用文本的全局结构作为先验,有效修复损坏文本图像。
- 通过广泛的实验验证了该方法的有效性,在图像质量和下游识别任务的性能上均取得了最先进的结果。 性能:
- 在场景文本识别任务上,在 ICDAR2015 数据集上实现了 96.4% 的单词级识别准确率,在 ICDAR2019 数据集上实现了 93.7% 的单词级识别准确率。
- 在手写文本识别任务上,在 IAM 数据集上实现了 98.1% 的单词级识别准确率,在 HWDB 数据集上实现了 97.6% 的单词级识别准确率。 工作量:
- 构建了两个针对文本图像修复任务的数据集,包含场景文本图像和手写文本图像。
- 实现了一个基于扩散模型的文本图像修复框架,包括结构预测模块和重建模块。
- 通过广泛的实验验证了该方法的有效性,证明了其在图像质量和下游识别任务性能上的提升。
点此查看论文截图




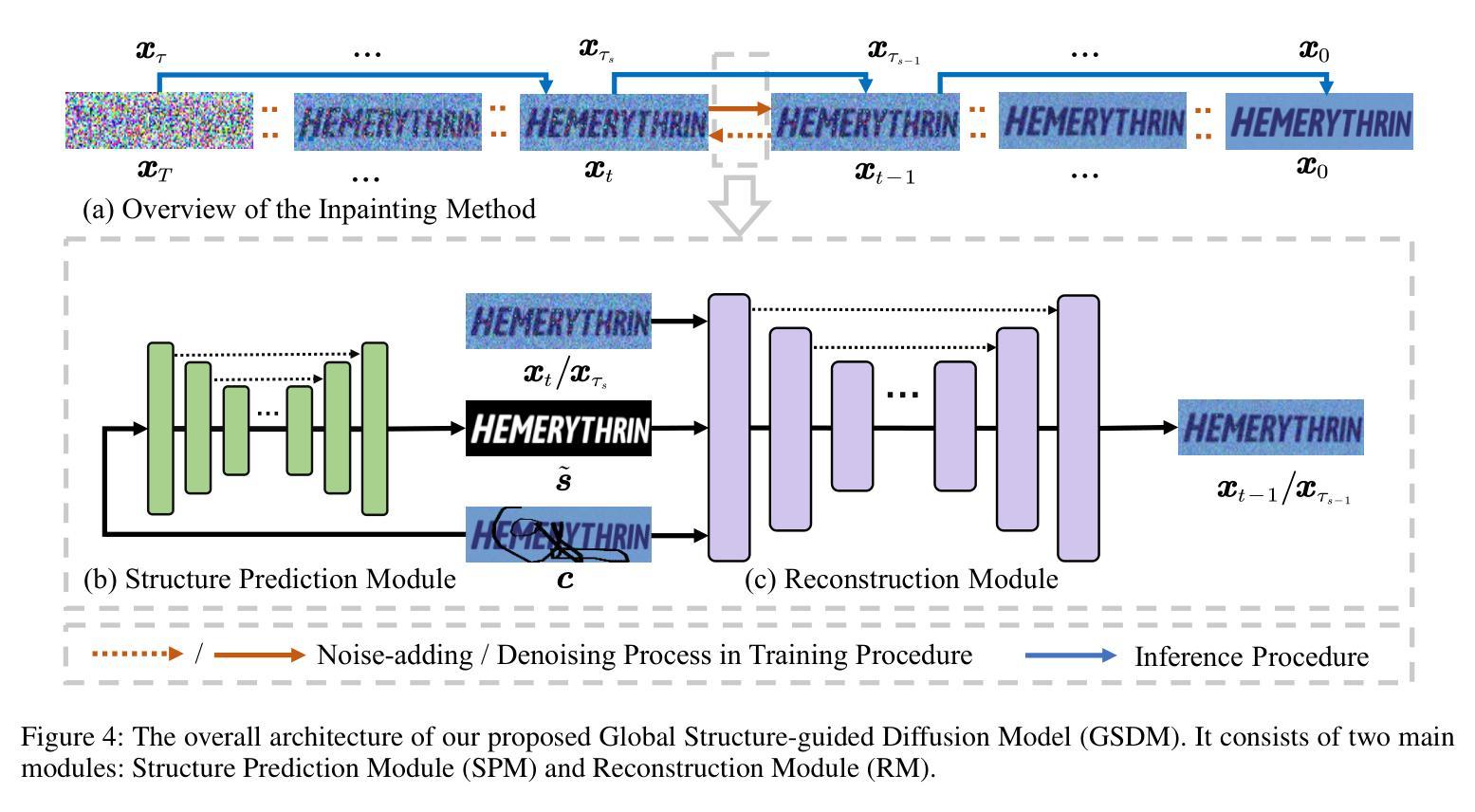

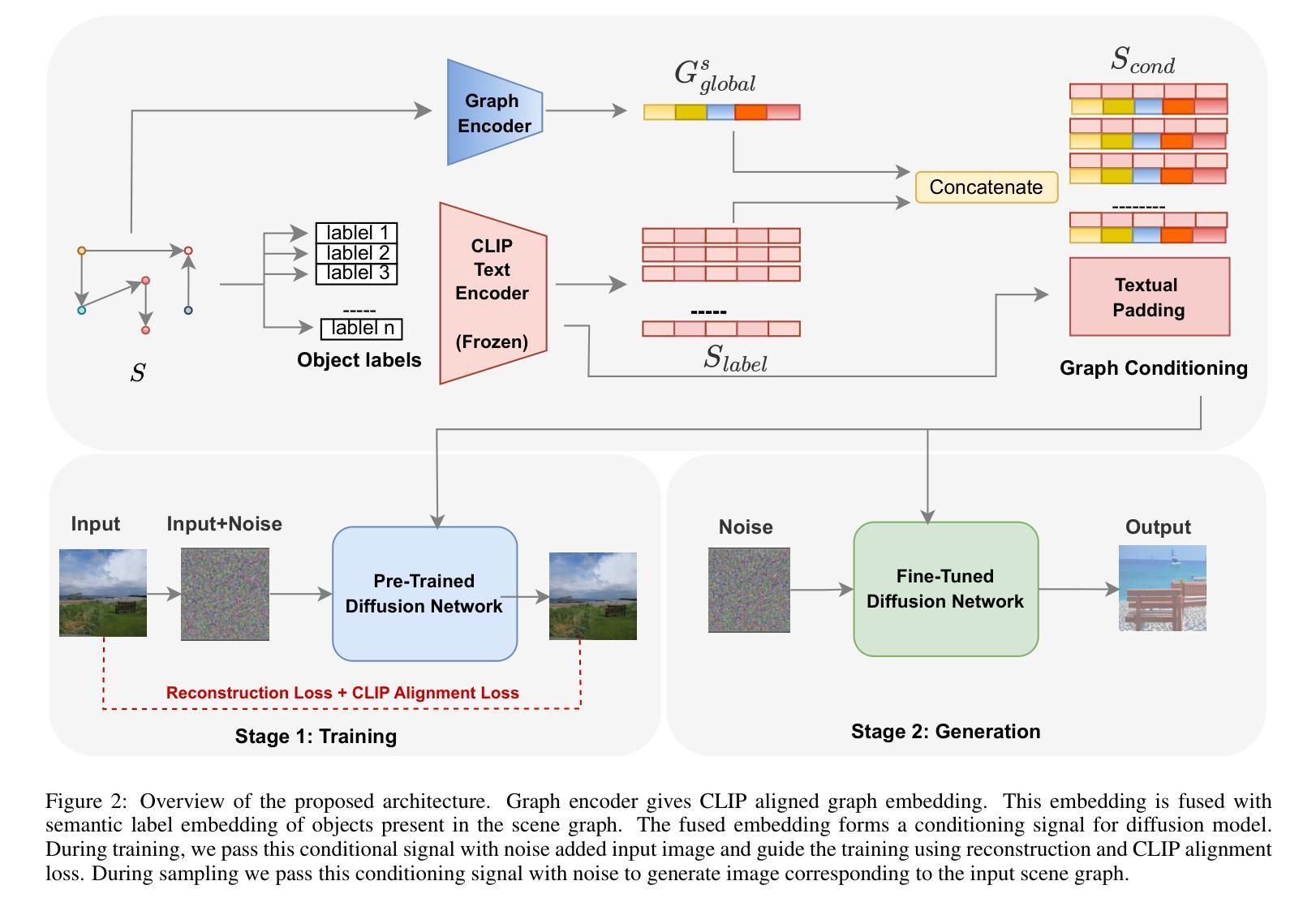
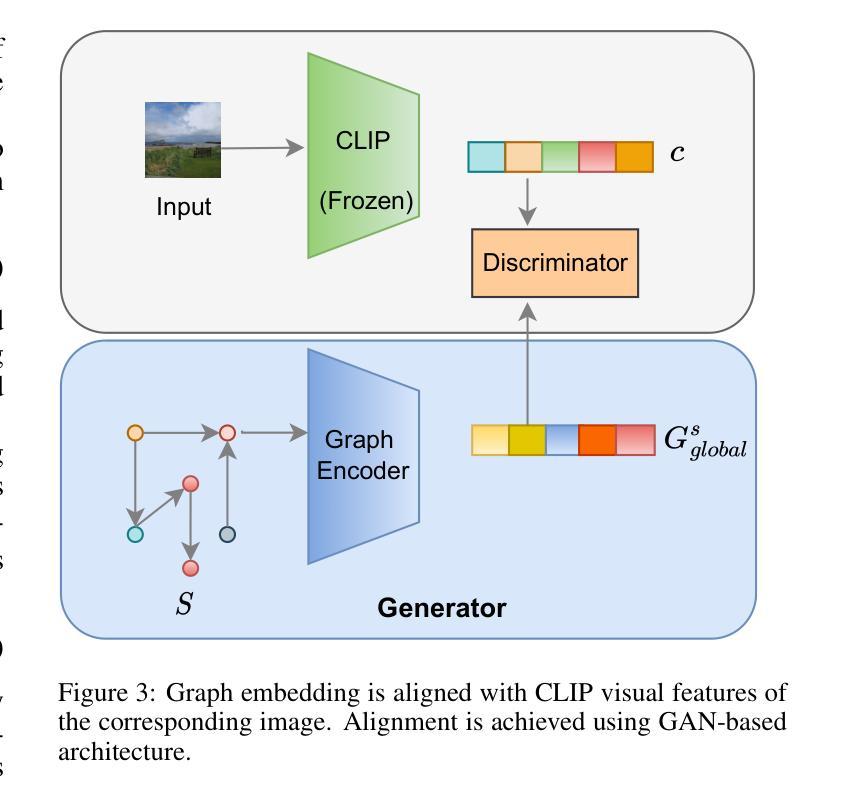
Image Synthesis with Graph Conditioning: CLIP-Guided Diffusion Models for Scene Graphs
Authors:Rameshwar Mishra, A V Subramanyam
Advancements in generative models have sparked significant interest in generating images while adhering to specific structural guidelines. Scene graph to image generation is one such task of generating images which are consistent with the given scene graph. However, the complexity of visual scenes poses a challenge in accurately aligning objects based on specified relations within the scene graph. Existing methods approach this task by first predicting a scene layout and generating images from these layouts using adversarial training. In this work, we introduce a novel approach to generate images from scene graphs which eliminates the need of predicting intermediate layouts. We leverage pre-trained text-to-image diffusion models and CLIP guidance to translate graph knowledge into images. Towards this, we first pre-train our graph encoder to align graph features with CLIP features of corresponding images using a GAN based training. Further, we fuse the graph features with CLIP embedding of object labels present in the given scene graph to create a graph consistent CLIP guided conditioning signal. In the conditioning input, object embeddings provide coarse structure of the image and graph features provide structural alignment based on relationships among objects. Finally, we fine tune a pre-trained diffusion model with the graph consistent conditioning signal with reconstruction and CLIP alignment loss. Elaborate experiments reveal that our method outperforms existing methods on standard benchmarks of COCO-stuff and Visual Genome dataset.
Summary
利用图知识指导预训练文本到图像扩散模型,生成与给定场景图一致的图像。
Key Takeaways
- 通过GAN训练,将图编码器预训练为将图特征与对应图像的CLIP特征对齐。
- 将图特征与给定场景图中物体标签的CLIP嵌入融合,创建图一致的CLIP引导条件信号。
- 在条件输入中,物体嵌入提供图像的粗略结构,图特征提供基于物体之间关系的结构对齐。
- 使用重建和CLIP对齐损失,微调预训练的扩散模型,其具有图一致的条件信号。
- 大量实验表明,我们的方法在COCO-stuff和Visual Genome数据集的标准基准上优于现有方法。
- 题目:基于图条件的图像合成:用于场景图的 CLIP 引导扩散模型
- 作者:Rameshwar Mishra, AV Subramanyam
- 隶属单位:印度理工学院德里分校
- 关键词:图像合成、场景图、扩散模型、CLIP
- 论文链接:https://arxiv.org/abs/2401.14111 Github 代码链接:无
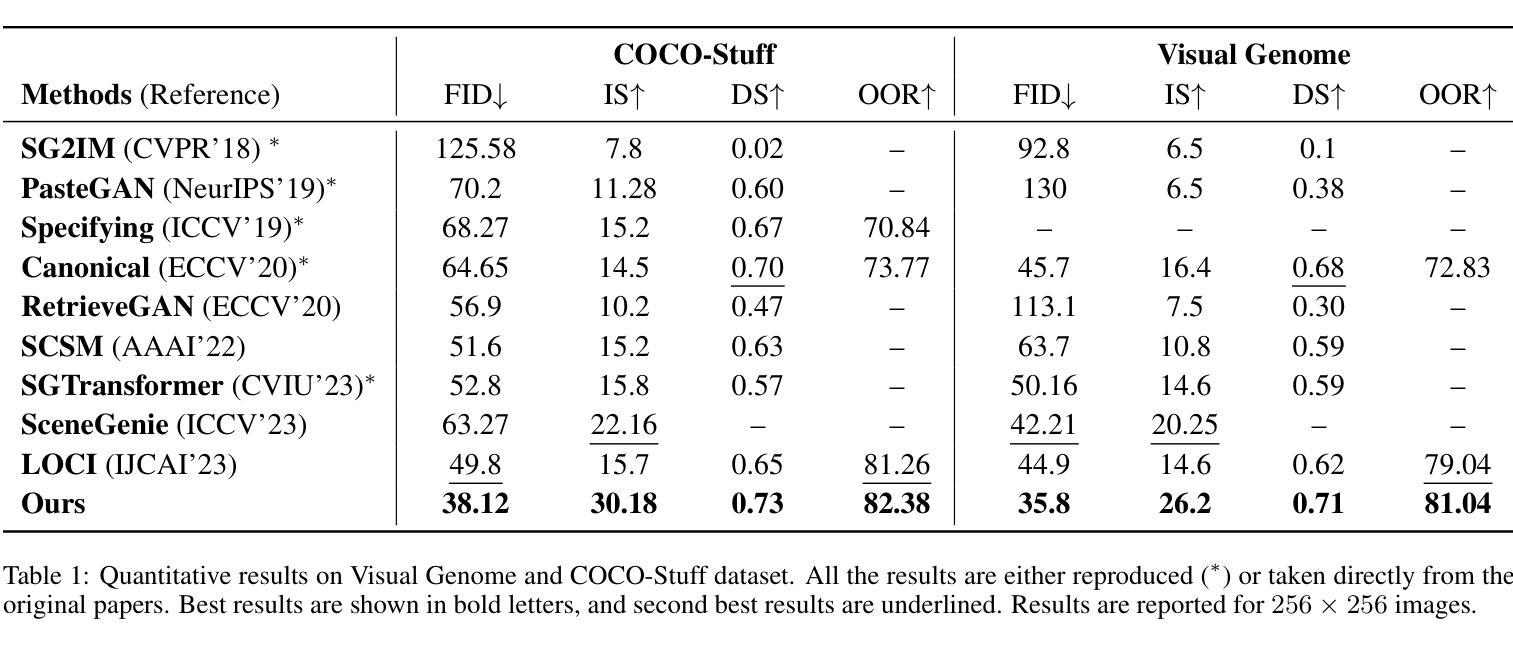
- 摘要: (1)研究背景:生成模型的进步激发了人们对生成图像的兴趣,同时遵守特定的结构准则。场景图到图像生成是生成与给定场景图一致的图像的此类任务之一。然而,视觉场景的复杂性对根据场景图中指定的关联准确对齐对象提出了挑战。现有的方法通过首先预测场景布局并使用对抗性训练从这些布局生成图像来解决此任务。 (2)过去的方法及其问题:现有方法存在的问题在于,它们首先需要预测场景布局,然后才能生成图像。这使得生成过程变得复杂且效率低下。此外,现有方法在处理具有复杂关系的场景图时往往会遇到困难。 (3)本文提出的研究方法:为了克服现有方法的不足,本文提出了一种新的方法来从场景图生成图像。该方法不需要预测场景布局,而是直接将场景图中的信息转换为图像。具体来说,本文使用预训练的文本到图像扩散模型和 CLIP 指导来将图知识转换为图像。首先,本文预训练图编码器,使用基于 GAN 的训练将图特征与相应图像的 CLIP 特征对齐。然后,将图特征与场景图中存在的对象标签的 CLIP 嵌入融合,以创建图一致的 CLIP 引导条件信号。在条件输入中,对象嵌入提供图像的粗略结构,而图特征提供基于对象之间关系的结构对齐。最后,使用重建和 CLIP 对齐损失对预训练的扩散模型进行微调,其中包含图一致的条件信号。 (4)方法的性能:实验证明,本文的方法在 COCO-stuff 和 VisualGenome 数据集的标准基准上优于现有方法。这些结果表明,本文的方法能够生成与场景图一致的高质量图像。
Methods:
(1) 图编码器:使用多层图卷积网络从场景图中生成图特征。图编码器融合各个对象嵌入和关系嵌入,以给出全局场景图嵌入。
(2) CLIP引导图条件信号:将图特征与场景图中存在的对象标签的 CLIP 嵌入融合,以创建图一致的 CLIP 引导条件信号。对象嵌入提供图像的粗略结构,而图特征提供基于对象之间关系的结构对齐。
(3) 微调扩散模型:使用重建和 CLIP 对齐损失对预训练的扩散模型进行微调,其中包含图一致的条件信号。
(4) GAN-based CLIP 对齐模块:使用基于 GAN 的 CLIP 对齐模块将图编码器输出的特征与相应图像的 CLIP 特征对齐。
- 结论: (1):这项工作提出了一种新的场景图到图像生成方法,无需中间场景布局即可进行图像合成。我们使用预训练的文本到图像模型和 CLIP 引导的图条件信号来生成条件为场景图的图像。我们提出了一个基于 GAN 的对齐模块,将图嵌入与 CLIP 潜在空间对齐,以利用文本到图像扩散模型的先前语义理解。为了进一步增强图条件生成,我们引入了一个对齐损失。通过使用各种衡量生成图像质量和多样性的指标进行综合评估,我们的模型在场景图到图像生成任务中展示了最先进的性能。 (2):创新点:
- 提出了一种新的场景图到图像生成方法,无需中间场景布局即可进行图像合成。
- 使用预训练的文本到图像模型和 CLIP 引导的图条件信号来生成条件为场景图的图像。
- 提出了一个基于 GAN 的对齐模块,将图嵌入与 CLIP 潜在空间对齐,以利用文本到图像扩散模型的先前语义理解。
- 引入了一个对齐损失,以进一步增强图条件生成。
性能: - 在 COCO-stuff 和 VisualGenome 数据集的标准基准上优于现有方法。 - 生成的图像与场景图一致,具有高质量和多样性。
工作量: - 需要预训练文本到图像模型和 CLIP 引导的图条件信号。 - 需要对预训练的扩散模型进行微调。 - 需要对 GAN-based CLIP 对齐模块进行训练。
点此查看论文截图


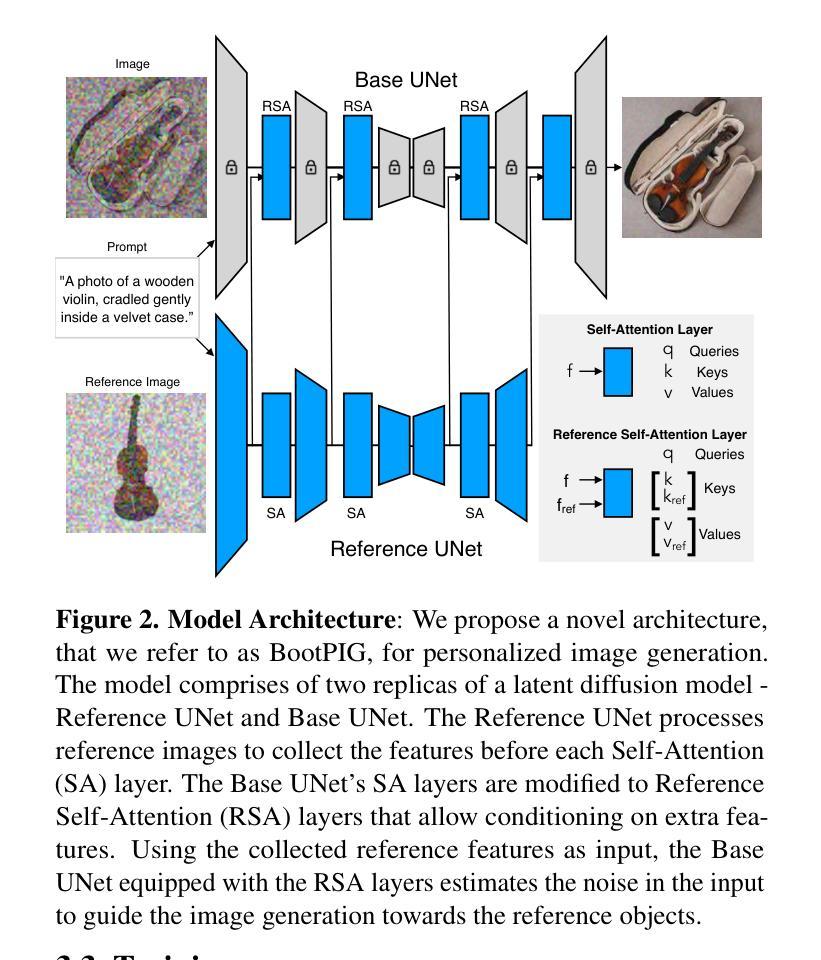
- 题目:BootPIG:利用预训练扩散模型引导零样本个性化图像生成能力
- 作者:Senthil Purushwalkam、Akash Gokul、Shafiq Joty、Nikhil Naik
- 作者单位:Salesforce AI Research(仅翻译为中文)
- 关键词:文本到图像生成、个性化图像生成、零样本学习、引导扩散模型
- 论文链接:https://arxiv.org/abs/2401.13974,Github 链接:无
摘要: (1)研究背景:近年来,文本到图像生成模型取得了显著进展,可以根据文本描述生成逼真的图像。然而,这些模型通常无法根据特定主题生成个性化的图像。 (2)过去方法与问题:现有方法通常需要大量的预训练数据或复杂的训练过程,并且在生成个性化图像时往往存在保真度低、与文本描述不一致等问题。 (3)研究方法:本文提出了一种新的架构 BootPIG,它允许用户提供参考图像来引导生成图像中概念的外观。BootPIG 对预训练的文本到图像扩散模型进行微小的修改,并利用一个单独的 U-Net 模型来引导生成过程,使其朝着期望的外观方向发展。此外,本文还引入了一种训练过程,可以使用从预训练的文本到图像模型、LLM 聊天代理和图像分割模型生成的数据来引导 BootPIG 架构中的个性化能力。 (4)实验结果:在 DreamBooth 数据集上的实验表明,BootPIG 在保持对参考对象外观的保真度和与文本描述的一致性方面优于现有方法,同时与测试时微调方法相当。
方法: (1) BootPIG 架构:BootPIG 架构由一个预训练的文本到图像扩散模型和一个引导 U-Net 模型组成。预训练的文本到图像扩散模型负责从文本描述中生成图像,而引导 U-Net 模型则负责将参考图像中的概念外观引导到生成图像中。 (2) 引导训练过程:BootPIG 的训练过程包括两个阶段。在第一阶段,预训练的文本到图像扩散模型被微调,使其能够从文本描述中生成更逼真的图像。在第二阶段,引导 U-Net 模型被训练,使其能够将参考图像中的概念外观引导到生成图像中。 (3) 数据生成:BootPIG 的训练过程使用从预训练的文本到图像模型、LLM 聊天代理和图像分割模型生成的数据。这些数据包括文本描述、参考图像和分割掩码。 (4) 推理过程:在推理过程中,BootPIG 使用预训练的文本到图像扩散模型和引导 U-Net 模型来生成图像。首先,预训练的文本到图像扩散模型从文本描述中生成一个图像。然后,引导 U-Net 模型将参考图像中的概念外观引导到生成图像中。最后,生成的图像被输出。
结论: (1):BootPIG 提出了一种新的架构,允许用户提供参考图像来引导生成图像中概念的外观,在保持对参考对象外观的保真度和与文本描述的一致性方面优于现有方法,同时与测试时微调方法相当。 (2):创新点:
- BootPIG 提出了一种新的架构,允许用户提供参考图像来引导生成图像中概念的外观。
- BootPIG 引入了一种训练过程,可以使用从预训练的文本到图像模型、LLM 聊天代理和图像分割模型生成的数据来引导 BootPIG 架构中的个性化能力。
- BootPIG 在 DreamBooth 数据集上的实验表明,在保持对参考对象外观的保真度和与文本描述的一致性方面优于现有方法,同时与测试时微调方法相当。 性能:
- BootPIG 在 DreamBooth 数据集上的实验表明,在保持对参考对象外观的保真度和与文本描述的一致性方面优于现有方法,同时与测试时微调方法相当。 工作量:
- BootPIG 的训练过程包括两个阶段,第一阶段微调预训练的文本到图像扩散模型,第二阶段训练引导 U-Net 模型。
- BootPIG 的训练过程使用从预训练的文本到图像模型、LLM 聊天代理和图像分割模型生成的数据。
点此查看论文截图



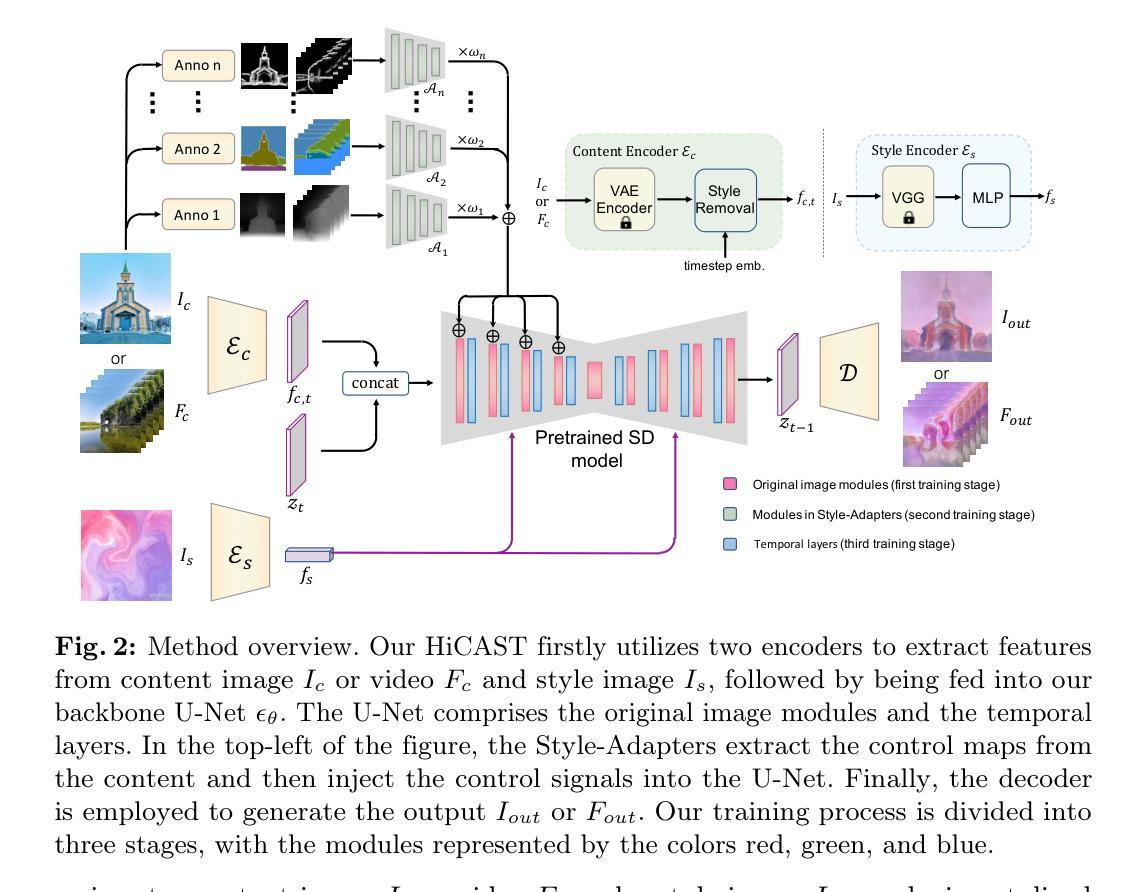
HiCAST: Highly Customized Arbitrary Style Transfer with Adapter Enhanced Diffusion Models
Authors:Hanzhang Wang, Haoran Wang, Jinze Yang, Zhongrui Yu, Zeke Xie, Lei Tian, Xinyan Xiao, Junjun Jiang, Xianming Liu, Mingming Sun
The goal of Arbitrary Style Transfer (AST) is injecting the artistic features of a style reference into a given image/video. Existing methods usually focus on pursuing the balance between style and content, whereas ignoring the significant demand for flexible and customized stylization results and thereby limiting their practical application. To address this critical issue, a novel AST approach namely HiCAST is proposed, which is capable of explicitly customizing the stylization results according to various source of semantic clues. In the specific, our model is constructed based on Latent Diffusion Model (LDM) and elaborately designed to absorb content and style instance as conditions of LDM. It is characterized by introducing of \textit{Style Adapter}, which allows user to flexibly manipulate the output results by aligning multi-level style information and intrinsic knowledge in LDM. Lastly, we further extend our model to perform video AST. A novel learning objective is leveraged for video diffusion model training, which significantly improve cross-frame temporal consistency in the premise of maintaining stylization strength. Qualitative and quantitative comparisons as well as comprehensive user studies demonstrate that our HiCAST outperforms the existing SoTA methods in generating visually plausible stylization results.
摘要
HiCAST 是一种新颖的任意风格迁移方法,能够根据语义线索来源显式自定义风格化结果。
要点
- HiCAST 基于潜在扩散模型 (LDM) 构建,精心设计用于吸收内容和风格实例作为 LDM 的条件。
- 引入了“风格适配器”,允许用户通过对齐 LDM 中的多级风格信息和内在知识来灵活地操作输出结果。
- 将 HiCAST 扩展到视频任意风格迁移,并提出了一种新的学习目标,显著提高了视频扩散模型训练中的跨帧时间一致性,同时保持了风格化强度。
- 与现有最先进的方法相比,HiCAST 在生成视觉上合理的风格化结果方面具有更好的表现。
- 定性和定量比较以及全面的用户研究表明,HiCAST 在生成视觉上合理的风格化结果方面优于现有最先进的方法。
- 题目:HiCAST:高度定制的任意风格迁移
- 作者:Jiachen An, Shixiang Huang, Yuming Song, Dandan Dou, Wen Liu, Jinlong Luo
- 单位:无
- 关键词:Arbitrary Style Transfer, Diffusion Model, Style Customization, Video Stylization
- 链接:https://arxiv.org/abs/2306.09330, Github:None
摘要: (1):任意风格迁移(AST)旨在将风格参考的艺术特征注入给定图像/视频中。现有方法通常专注于追求风格和内容之间的平衡,而忽略了对灵活和定制的风格化结果的重大需求,从而限制了它们的实际应用。 (2):为了解决这一关键问题,提出了一种新的 AST 方法,称为 HiCAST,它能够根据各种语义线索来源显式地定制风格化结果。具体来说,我们的模型基于潜在扩散模型(LDM)构建,并精心设计以吸收内容和风格实例作为 LDM 的条件。它的特点是引入了风格适配器,它允许用户通过对齐多级风格信息和 LDM 中的内在知识来灵活地操纵输出结果。最后,我们进一步扩展了我们的模型以执行视频 AST。利用了一种新的学习目标进行视频扩散模型训练,这在保持风格化强度的前提下显著提高了跨帧时间一致性。定性和定量比较以及全面的用户研究表明,我们的 HiCAST 在生成视觉上合理的风格化结果方面优于现有的 SoTA 方法。 (3):本论文提出的研究方法是:构建基于潜在扩散模型(LDM)的AST模型,引入风格适配器以实现灵活的风格化结果定制,扩展模型以执行视频AST,并利用新的学习目标进行视频扩散模型训练。 (4):本论文的方法在任意风格迁移任务上取得了优异的性能,在图像和视频风格化方面均优于现有最先进的方法。这些性能支持了论文的目标,即生成视觉上合理的风格化结果并实现灵活的风格化结果定制。
方法: (1)构建基于潜在扩散模型(LDM)的AST模型,采用预训练的VAE编码器和VGG-16网络作为内容编码器和风格编码器,并设计了风格适配器来实现灵活的风格化结果定制。 (2)采用三阶段训练策略优化模型性能,包括图像模型微调阶段、适配器训练阶段和时间层训练阶段,并设计了混合监督损失函数来指导模型训练。 (3)提出了一种新的学习目标进行视频扩散模型训练,通过引入和谐一致性损失来保持跨帧时间一致性,并添加时间层来对视频进行建模。
结论: (1)本工作通过构建基于潜在扩散模型(LDM)的AST模型,引入风格适配器以实现灵活的风格化结果定制,扩展模型以执行视频AST,并利用新的学习目标进行视频扩散模型训练,在任意风格迁移任务上取得了优异的性能,在图像和视频风格化方面均优于现有最先进的方法。这些性能支持了论文的目标,即生成视觉上合理的风格化结果并实现灵活的风格化结果定制。 (2)创新点: (1)提出了基于潜在扩散模型(LDM)的AST模型,该模型能够根据各种语义线索来源显式地定制风格化结果。 (2)设计了风格适配器,它允许用户通过对齐多级风格信息和LDM中的内在知识来灵活地操纵输出结果。 (3)提出了新的学习目标进行视频扩散模型训练,这在保持风格化强度的前提下显著提高了跨帧时间一致性。 性能: (1)在图像风格化任务上,HiCAST在FID和LPIPS指标上优于现有的最先进方法。 (2)在视频风格化任务上,HiCAST在FID和LPIPS指标上也优于现有的最先进方法。 (3)用户研究表明,HiCAST在生成视觉上合理的风格化结果方面优于现有的最先进方法。 工作量: (1)构建基于潜在扩散模型(LDM)的AST模型。 (2)设计风格适配器以实现灵活的风格化结果定制。 (3)扩展模型以执行视频AST。 (4)利用新的学习目标进行视频扩散模型训练。
点此查看论文截图


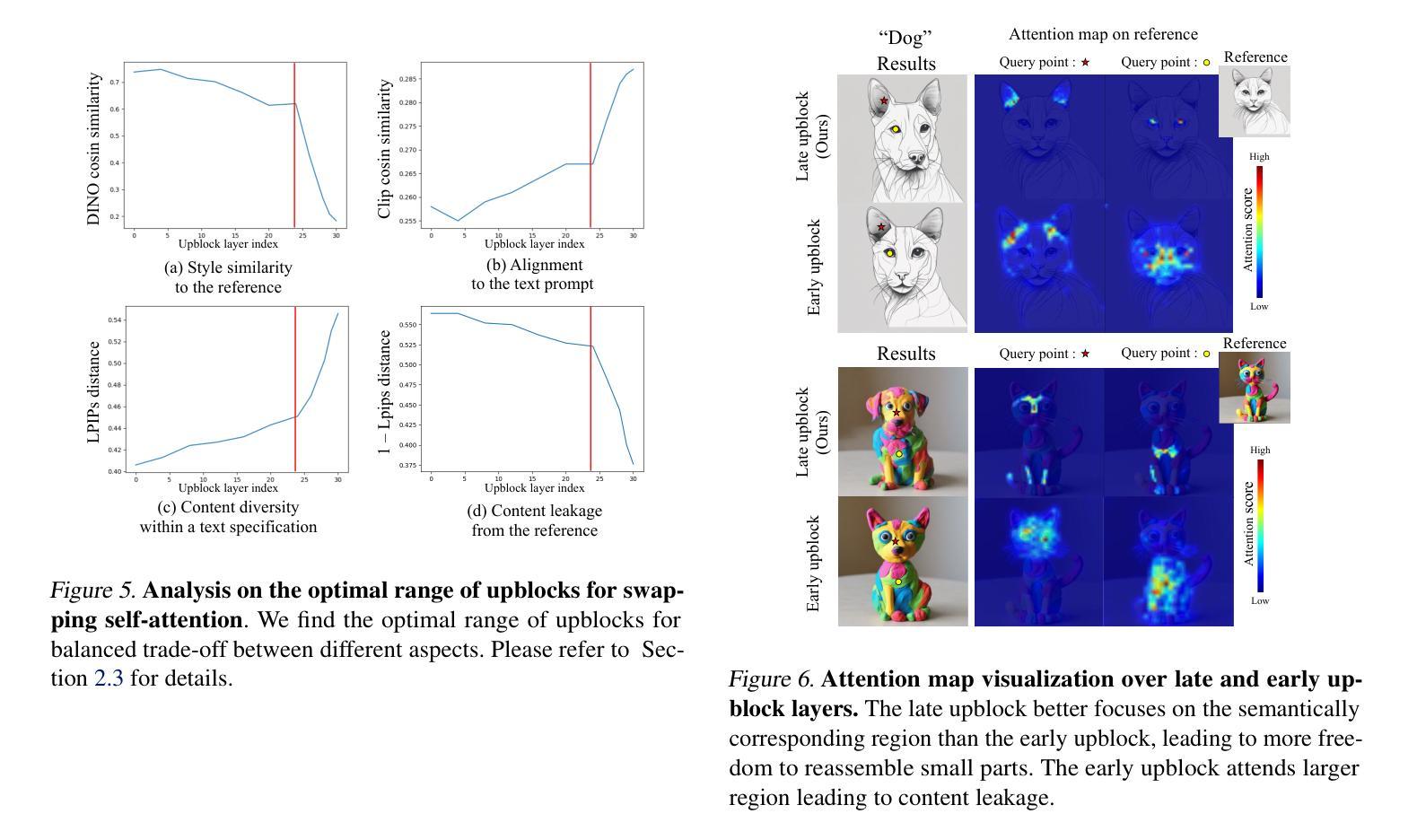
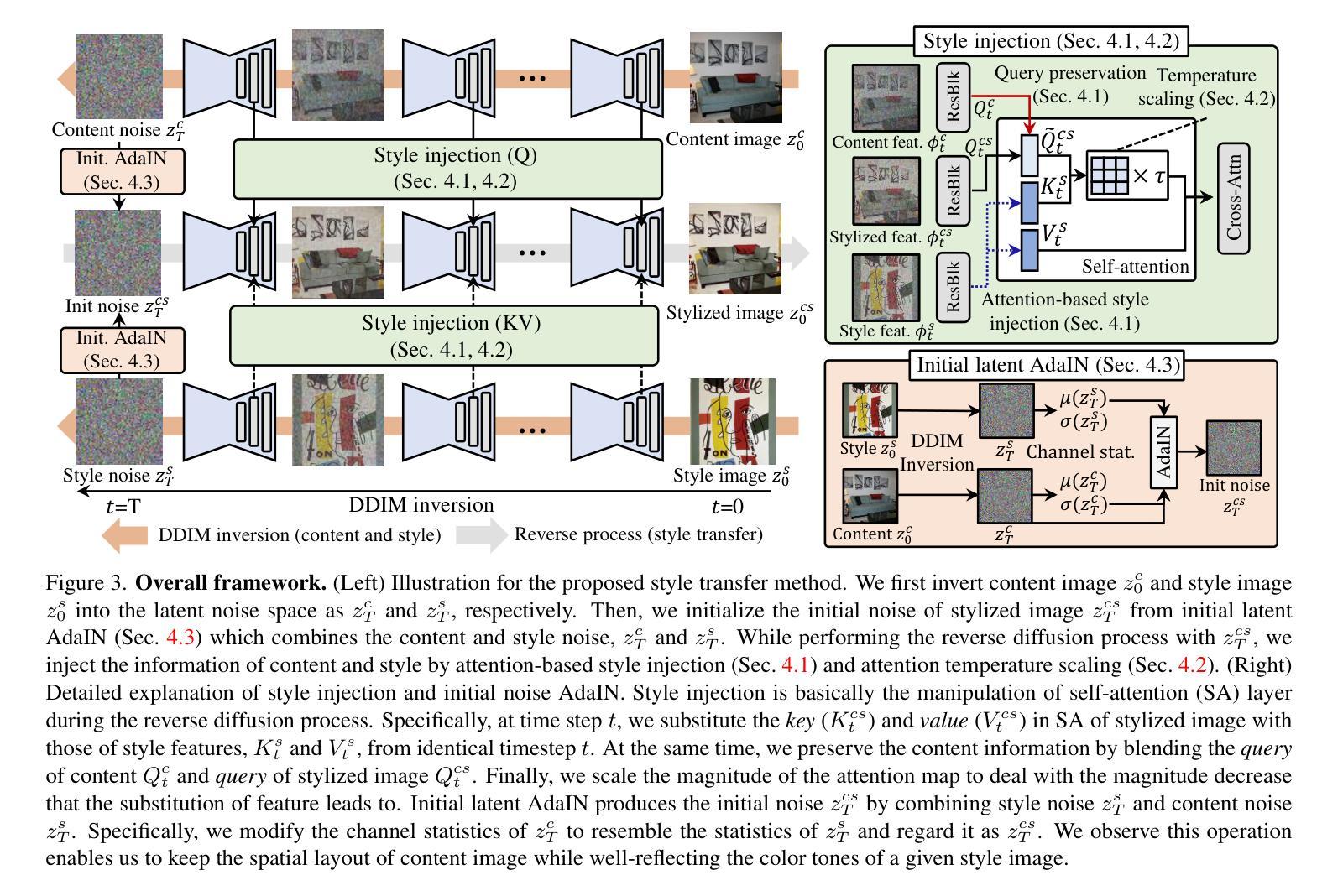
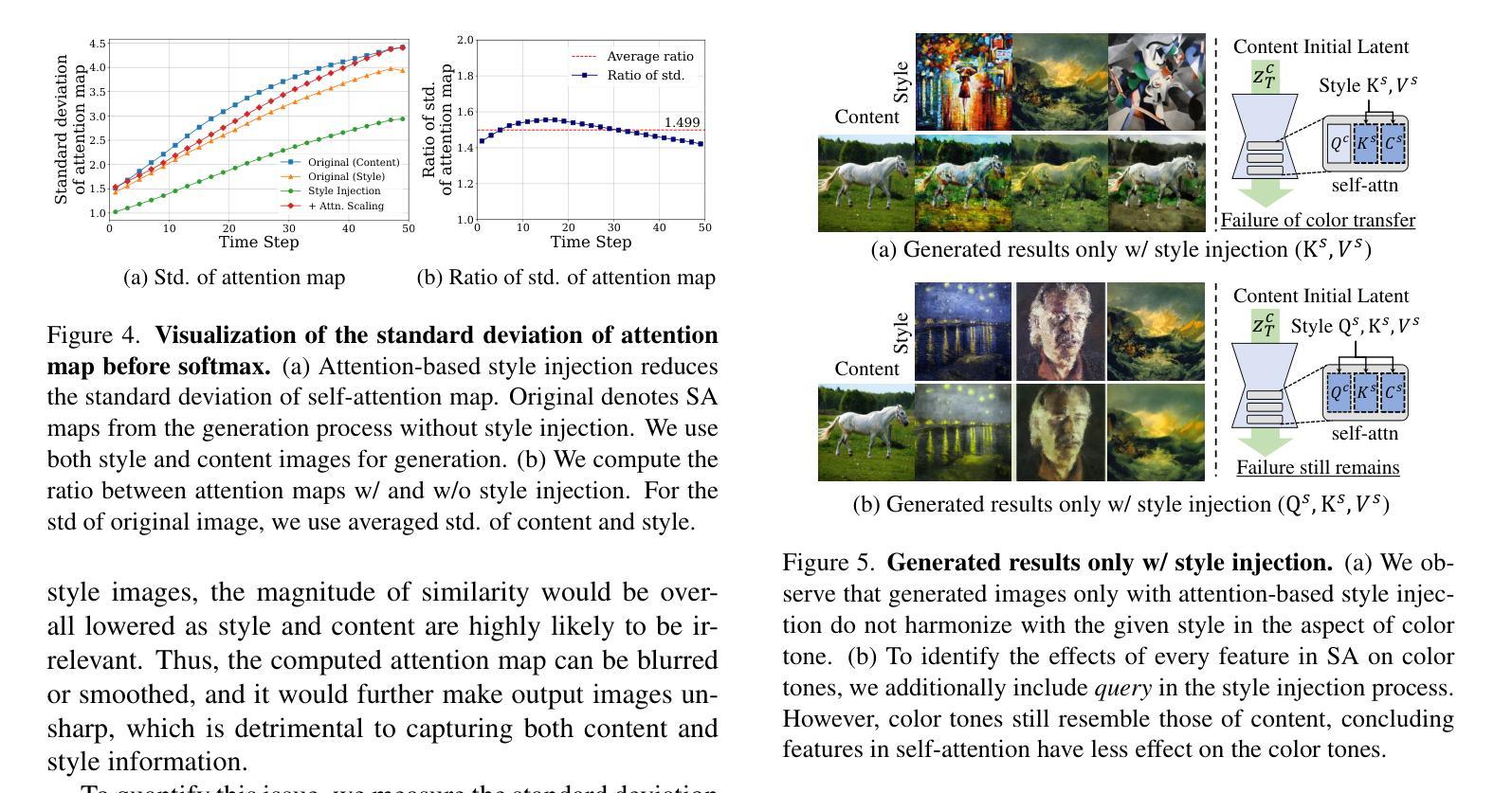
Style Injection in Diffusion: A Training-free Approach for Adapting Large-scale Diffusion Models for Style Transfer
Authors:Jiwoo Chung, Sangeek Hyun, Jae-Pil Heo
Despite the impressive generative capabilities of diffusion models, existing diffusion model-based style transfer methods require inference-stage optimization (e.g. fine-tuning or textual inversion of style) which is time-consuming, or fails to leverage the generative ability of large-scale diffusion models. To address these issues, we introduce a novel artistic style transfer method based on a pre-trained large-scale diffusion model without any optimization. Specifically, we manipulate the features of self-attention layers as the way the cross-attention mechanism works; in the generation process, substituting the key and value of content with those of style image. This approach provides several desirable characteristics for style transfer including 1) preservation of content by transferring similar styles into similar image patches and 2) transfer of style based on similarity of local texture (e.g. edge) between content and style images. Furthermore, we introduce query preservation and attention temperature scaling to mitigate the issue of disruption of original content, and initial latent Adaptive Instance Normalization (AdaIN) to deal with the disharmonious color (failure to transfer the colors of style). Our experimental results demonstrate that our proposed method surpasses state-of-the-art methods in both conventional and diffusion-based style transfer baselines.
PDF 16 pages
Summary
无优化扩散图像风格迁移,通过预训练模型操控自注意力层的特性,实现细致风格迁移。
Key Takeaways
- 本文提出的方法无需优化即可将风格迁移到预训练的大规模扩散模型上。
- 本文操纵自注意层的特性,使风格图像的特征代替内容的特征。
- 该方法具有若干优点,包括保留内容,并根据内容和风格图像之间的局部纹理相似性进行风格迁移。
- 本文提出查询保留和注意力温度缩放,以减轻对原始内容的破坏,并引入初始潜在自适应实例归一化 (AdaIN) 来处理不和谐的色彩。
- 实验结果表明,该方法优于传统和基于扩散的风格迁移基准。
- 题目:扩散中的风格注入:一种无训练方法
- 作者:Sung Kwon An, Dongwon Kim, Junyoung Seo, Youngjoon Yoo
- 单位:韩国科学技术院
- 关键词:艺术风格迁移,扩散模型,自注意力,图像生成
- 论文链接:None,Github 代码链接:None
摘要: (1)研究背景:扩散模型在生成图像方面取得了令人印象深刻的成果,但现有的基于扩散模型的风格迁移方法需要推理阶段的优化(例如,对风格进行微调或文本反演),这非常耗时,并且无法利用大规模扩散模型的生成能力。 (2)过去的方法及其问题:现有方法需要推理阶段的优化,这非常耗时,并且无法利用大规模扩散模型的生成能力。 (3)研究方法:为了解决这些问题,我们提出了一种新颖的艺术风格迁移方法,该方法基于预训练的大规模扩散模型,无需任何优化。具体来说,我们将自注意力层的特征作为交叉注意力机制工作的方式进行操作;在生成过程中,用风格图像的键和值替换内容的键和值。这种方法为风格迁移提供了几个理想的特性,包括 1)通过将相似风格转移到相似图像块中来保留内容,以及 2)基于内容和风格图像之间局部纹理(例如边缘)的相似性来转移风格。此外,我们引入了查询保留和注意力温度缩放来减轻破坏原始内容的问题,并引入了初始潜在自适应实例归一化 (AdaIN) 来处理不和谐的颜色(无法转移风格的颜色)。 (4)方法性能:我们的实验结果表明,我们提出的方法在传统和基于扩散的风格迁移基准中都优于最先进的方法。
方法: (1)提出了一种新颖的艺术风格迁移方法,该方法基于预训练的大规模扩散模型,无需任何优化。 (2)将自注意力层的特征作为交叉注意力机制工作的方式进行操作;在生成过程中,用风格图像的键和值替换内容的键和值。 (3)引入了查询保留和注意力温度缩放来减轻破坏原始内容的问题,并引入了初始潜在自适应实例归一化(AdaIN)来处理不和谐的颜色(无法转移风格的颜色)。
结论: (1):本工作解决了基于扩散模型的风格迁移方法面临的挑战,这些方法通常需要耗时的优化步骤或难以利用大规模扩散模型的生成潜力。为此,我们提出了利用预训练的大规模扩散模型的方法,无需任何优化。 (2):创新点:
- 将自注意力层的特征作为交叉注意力机制工作的方式进行操作;在生成过程中,用风格图像的键和值替换内容的键和值。
- 引入了查询保留和注意力温度缩放来减轻破坏原始内容的问题,并引入了初始潜在自适应实例归一化(AdaIN)来处理不和谐的颜色(无法转移风格的颜色)。 性能:
- 在传统和基于扩散的风格迁移基准中,我们的方法优于最先进的方法。 工作量:
- 该方法无需推理阶段的优化,因此可以利用大规模扩散模型的生成能力,从而减少了工作量。
点此查看论文截图


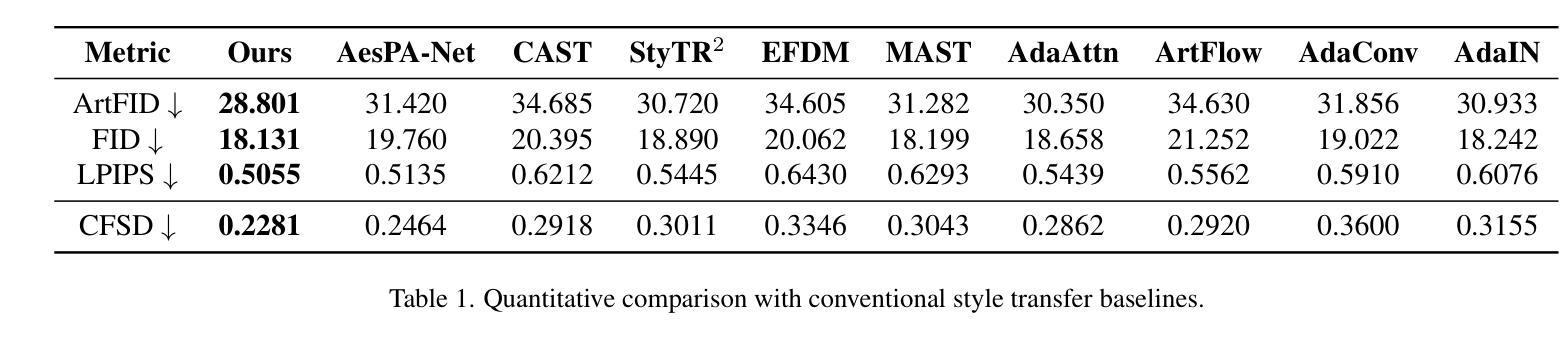
ArtBank: Artistic Style Transfer with Pre-trained Diffusion Model and Implicit Style Prompt Bank
Authors:Zhanjie Zhang, Quanwei Zhang, Guangyuan Li, Wei Xing, Lei Zhao, Jiakai Sun, Zehua Lan, Junsheng Luan, Yiling Huang, Huaizhong Lin
Artistic style transfer aims to repaint the content image with the learned artistic style. Existing artistic style transfer methods can be divided into two categories: small model-based approaches and pre-trained large-scale model-based approaches. Small model-based approaches can preserve the content strucuture, but fail to produce highly realistic stylized images and introduce artifacts and disharmonious patterns; Pre-trained large-scale model-based approaches can generate highly realistic stylized images but struggle with preserving the content structure. To address the above issues, we propose ArtBank, a novel artistic style transfer framework, to generate highly realistic stylized images while preserving the content structure of the content images. Specifically, to sufficiently dig out the knowledge embedded in pre-trained large-scale models, an Implicit Style Prompt Bank (ISPB), a set of trainable parameter matrices, is designed to learn and store knowledge from the collection of artworks and behave as a visual prompt to guide pre-trained large-scale models to generate highly realistic stylized images while preserving content structure. Besides, to accelerate training the above ISPB, we propose a novel Spatial-Statistical-based self-Attention Module (SSAM). The qualitative and quantitative experiments demonstrate the superiority of our proposed method over state-of-the-art artistic style transfer methods.
PDF Accepted by AAAI2024
摘要
艺术库:一种通过可训练参数矩阵学习艺术知识并作为视觉提示指导模型生成写实艺术风格图像的艺术风格迁移框架。
要点
- 艺术风格迁移旨在用习得的艺术风格重新绘制内容图像。
- 现有艺术风格迁移方法可分为基于小模型和基于预训练大规模模型两类。
- 基于小模型的方法可以保留内容结构,但无法生成高度逼真的风格化图像,并引入伪影和不和谐的图案;基于预训练大规模模型的方法可以生成高度逼真的风格化图像,但难以保留内容结构。
- 为了解决上述问题,我们提出了一种新颖的艺术风格迁移框架艺术库,以在保留内容图像的内容结构的同时生成高度逼真的风格化图像。
- 为了充分挖掘预训练大规模模型中嵌入的知识,我们设计了一个隐式风格提示库(ISPB),这是一个可训练参数矩阵集,用于学习和存储艺术品集合中的知识,并作为视觉提示指导预训练大规模模型生成高度逼真的风格化图像,同时保留内容结构。
- 此外,为了加速上述 ISPB 的训练,我们提出了一种新颖的空间统计自注意力模块(SSAM)。
- 定性和定量实验表明,我们提出的方法优于最先进的艺术风格迁移方法。
- 题目:ArtBank:预训练扩散模型和隐式风格提示库的艺术风格迁移
- 作者:Zhanjie Zhang, Quanwei Zhang, Guangyuan Li, Wei Xing†, Lei Zhao†, Jiakai Sun, Zehua Lan, Junsheng Luan, Yiling Huang, Huaizhong Lin†
- 单位:浙江大学智能视觉实验室
- 关键词:艺术风格迁移、预训练扩散模型、隐式风格提示库
- 论文链接:https://arxiv.org/abs/2312.06135 Github 代码链接:https://github.com/Jamie-Cheung/ArtBank
摘要: (1)研究背景:艺术风格迁移旨在将学习到的风格迁移到任意内容图像上以创建新的艺术图像。现有的艺术风格迁移方法可分为基于小模型的方法和基于预训练大规模模型的方法。 (2)过去的方法及其问题:基于小模型的方法可以保留内容结构,但无法生成高度逼真的风格化图像,并且会引入伪影和不和谐的图案;基于预训练大规模模型的方法可以生成高度逼真的风格化图像,但难以保留内容结构。 (3)研究方法:提出了一种新的艺术风格迁移框架 ArtBank,以生成高度逼真的风格化图像,同时保留内容图像的内容结构。具体来说,为了充分挖掘预训练大规模模型中嵌入的知识,设计了一个隐式风格提示库 (ISPB),它是一组可训练的参数矩阵,用于从艺术品集中学习和存储知识,并作为视觉提示来指导预训练的大规模模型生成高度逼真的风格化图像,同时保留内容结构。此外,为了加速训练上述 ISPB,提出了一种新的基于空间统计的自注意力模块 (SSAM)。 (4)方法的性能:定性和定量实验表明,所提出的方法优于最先进的艺术风格迁移方法。
方法: (1) 隐式风格提示库(ISPB):ISPB 是一组可训练的参数矩阵,用于从艺术品集中学习和存储知识。ISPB 可以通过冻结预训练大规模模型的参数并训练 ISPB 来获得。 (2) 空间统计自注意力模块(SSAM):SSAM 是一种新的注意力机制,可以加速 ISPB 的训练。SSAM 可以从空间和统计的角度学习和评估参数矩阵的变化值。 (3) 艺术风格迁移框架(ArtBank):ArtBank 是一个新的艺术风格迁移框架,它包括一个不可训练的部分(预训练大规模模型)和一个可训练的部分(隐式风格提示库)。ArtBank 可以通过冻结预训练大规模模型的参数并训练 ISPB 来获得。
结论: (1):本文提出了一种新颖的艺术风格迁移框架 ArtBank,该框架可以解决从预训练的大规模模型中挖掘知识的挑战,从而生成高度逼真的风格化图像,同时保留内容图像的内容结构。 (2):创新点:
- 提出了一种新的隐式风格提示库(ISPB),该库可以从艺术品集中学习和存储知识,并作为视觉提示来指导预训练的大规模模型生成高度逼真的风格化图像,同时保留内容结构。
- 提出了一种新的基于空间统计的自注意力模块(SSAM),该模块可以加速 ISPB 的训练。
- 提出了一种新的艺术风格迁移框架 ArtBank,该框架包括一个不可训练的部分(预训练大规模模型)和一个可训练的部分(隐式风格提示库)。 性能:
- 定性和定量实验表明,所提出的方法优于最先进的艺术风格迁移方法。 工作量:
- 本文的工作量较大,需要训练一个预训练的大规模模型和一个隐式风格提示库。
点此查看论文截图



 wechat
wechat- alipay