NeRF
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-01-30 更新
Divide and Conquer: Rethinking the Training Paradigm of Neural Radiance Fields
Authors:Rongkai Ma, Leo Lebrat, Rodrigo Santa Cruz, Gil Avraham, Yan Zuo, Clinton Fookes, Olivier Salvado
Neural radiance fields (NeRFs) have exhibited potential in synthesizing high-fidelity views of 3D scenes but the standard training paradigm of NeRF presupposes an equal importance for each image in the training set. This assumption poses a significant challenge for rendering specific views presenting intricate geometries, thereby resulting in suboptimal performance. In this paper, we take a closer look at the implications of the current training paradigm and redesign this for more superior rendering quality by NeRFs. Dividing input views into multiple groups based on their visual similarities and training individual models on each of these groups enables each model to specialize on specific regions without sacrificing speed or efficiency. Subsequently, the knowledge of these specialized models is aggregated into a single entity via a teacher-student distillation paradigm, enabling spatial efficiency for online render-ing. Empirically, we evaluate our novel training framework on two publicly available datasets, namely NeRF synthetic and Tanks&Temples. Our evaluation demonstrates that our DaC training pipeline enhances the rendering quality of a state-of-the-art baseline model while exhibiting convergence to a superior minimum.
Summary
利用教师-学生知识蒸馏范式,提升 NeRF 模型的渲染质量。
Key Takeaways
- 传统 NeRF 模型的训练范式对训练集中每个图像赋予同等重要性,这导致在渲染具有复杂几何结构的特定视图时表现不佳。
- 将输入视图根据其视觉相似性划分为多个组,并在每个组上训练单独的模型,使每个模型专注于特定区域,从而提高渲染质量。
- 通过教师-学生知识蒸馏范式将这些专门模型的知识聚合到一个实体中,实现在线渲染的空间效率。
- 在 NeRF 合成和 Tanks&Temples 两个公开数据集上对提出的训练框架进行评估,结果表明该框架优于最先进的基线模型,并且收敛到更好的最小值。
- 提出了一种名为 DaC 的分而治之训练框架。
- DaC 将训练集划分为多个子集,并在每个子集上训练一个单独的神经辐射场 (NeRF) 模型。
- 然后将这些子模型通过知识蒸馏聚合成一个最终模型。
- DaC 在 NeRF 合成和 Tanks&Temples 数据集上的实验表明,它优于最先进的 NeRF 模型。
- 题目:分而治之:重新思考神经辐射场的训练范式
- 作者:Rongkai Ma、Leo Lebrat、Rodrigo SantaCruz、Gil Avraham、Yan Zuo、Clinton Fookes、Olivier Salvado
- 第一作者单位:英伟达
- 关键词:神经辐射场、分而治之、教师-学生蒸馏、空间效率
- 链接:https://arxiv.org/abs/2401.16144 Github:无
摘要: (1)研究背景:神经辐射场(NeRF)在合成 3D 场景的高保真视图方面表现出潜力,但 NeRF 的标准训练范式预设了训练集中每个图像具有同等重要性。这种假设对渲染呈现复杂几何体的特定视图提出了重大挑战,从而导致性能不佳。 (2)过去的方法及其问题:以往的方法通常将所有场景视角的几何和光度信息统一压缩到神经网络权重中。这种方法往往忽略了复杂场景不同视角中存在的细节的自然不对称性,导致渲染质量下降。 (3)本文提出的研究方法:本文重新审视了当前训练范式的含义,并重新设计了该范式,以提高 NeRF 的渲染质量。将输入视图根据它们的视觉相似性划分为多个组,并在每个组上训练单独的模型,使每个模型能够专门针对特定区域,而不会牺牲速度或效率。随后,通过教师-学生蒸馏范式将这些专门化模型的知识聚集到一个单一实体中,从而实现在线渲染的空间效率。 (4)方法在任务和性能上的表现:在两个公开可用的数据集 NeRF 合成和 Tanks&Temples 上对新颖的训练框架进行了评估。评估表明,本文提出的分而治之训练管道提高了最先进的基准模型的渲染质量,同时收敛到一个更好的最小值。
方法: (1)场景划分:将输入视图根据视觉相似性划分为多个组,每个组训练一个专门的模型,称为专家模型。 (2)专家训练:在每个组上训练专家模型,使每个专家模型能够专门针对特定区域,而不会牺牲速度或效率。 (3)教师-学生蒸馏:通过教师-学生蒸馏范式将这些专门化模型的知识聚集到一个单一实体中,从而实现在线渲染的空间效率。
结论: (1):本文提出了一种新的NeRF训练框架,该框架通过将输入视图划分为多个组并训练专门的专家模型,提高了NeRF的渲染质量。 (2):创新点:
- 提出了一种新的NeRF训练框架,该框架通过将输入视图划分为多个组并训练专门的专家模型,提高了NeRF的渲染质量。
- 使用教师-学生蒸馏范式将这些专门化模型的知识聚集到一个单一实体中,从而实现在线渲染的空间效率。 性能:
- 在两个公开可用的数据集NeRF合成和Tanks&Temples上对新颖的训练框架进行了评估。
- 评估表明,本文提出的分而治之训练管道提高了最先进的基准模型的渲染质量,同时收敛到一个更好的最小值。 工作量:
- 提出了一种新的NeRF训练框架,该框架通过将输入视图划分为多个组并训练专门的专家模型,提高了NeRF的渲染质量。
- 使用教师-学生蒸馏范式将这些专门化模型的知识聚集到一个单一实体中,从而实现在线渲染的空间效率。
点此查看论文截图


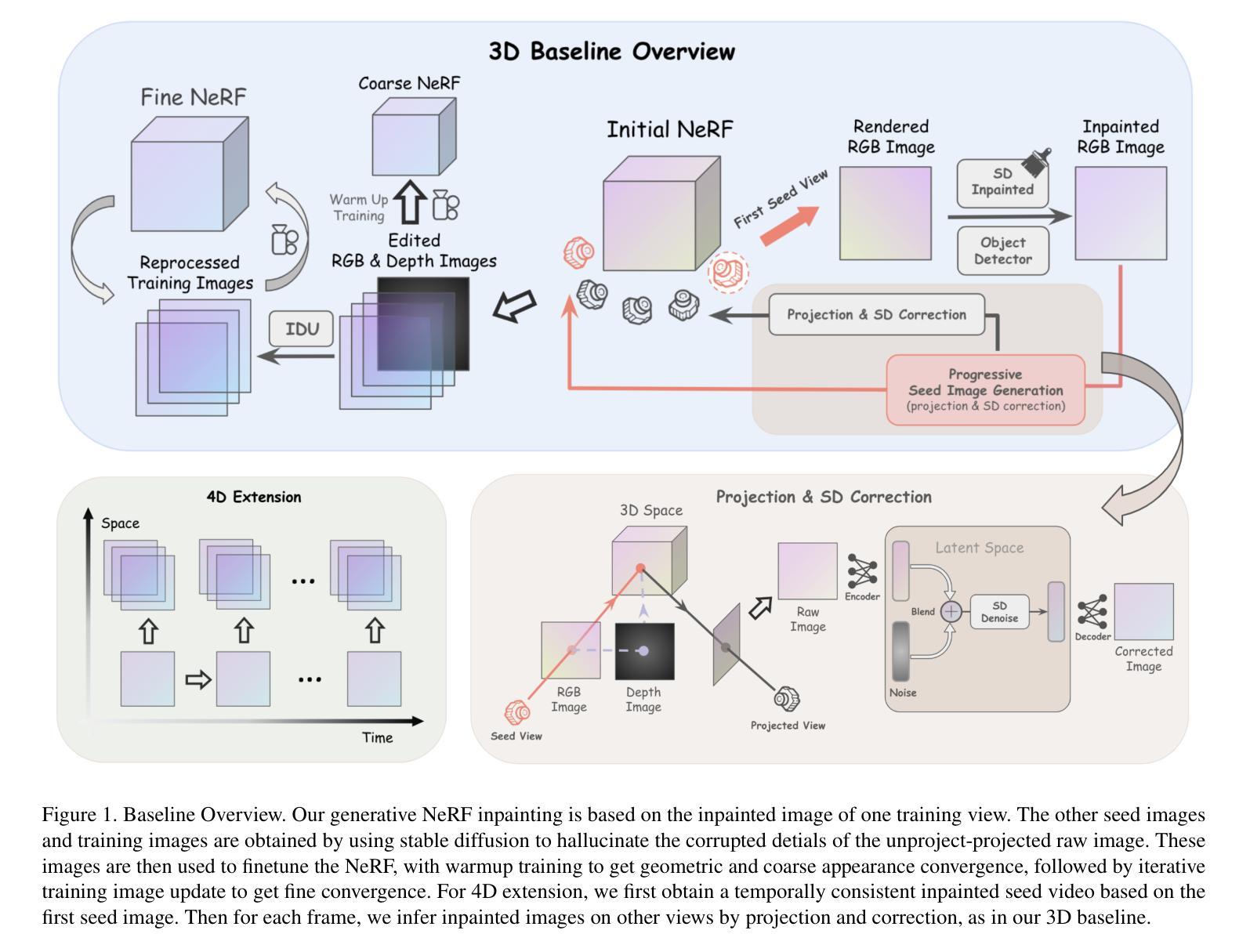
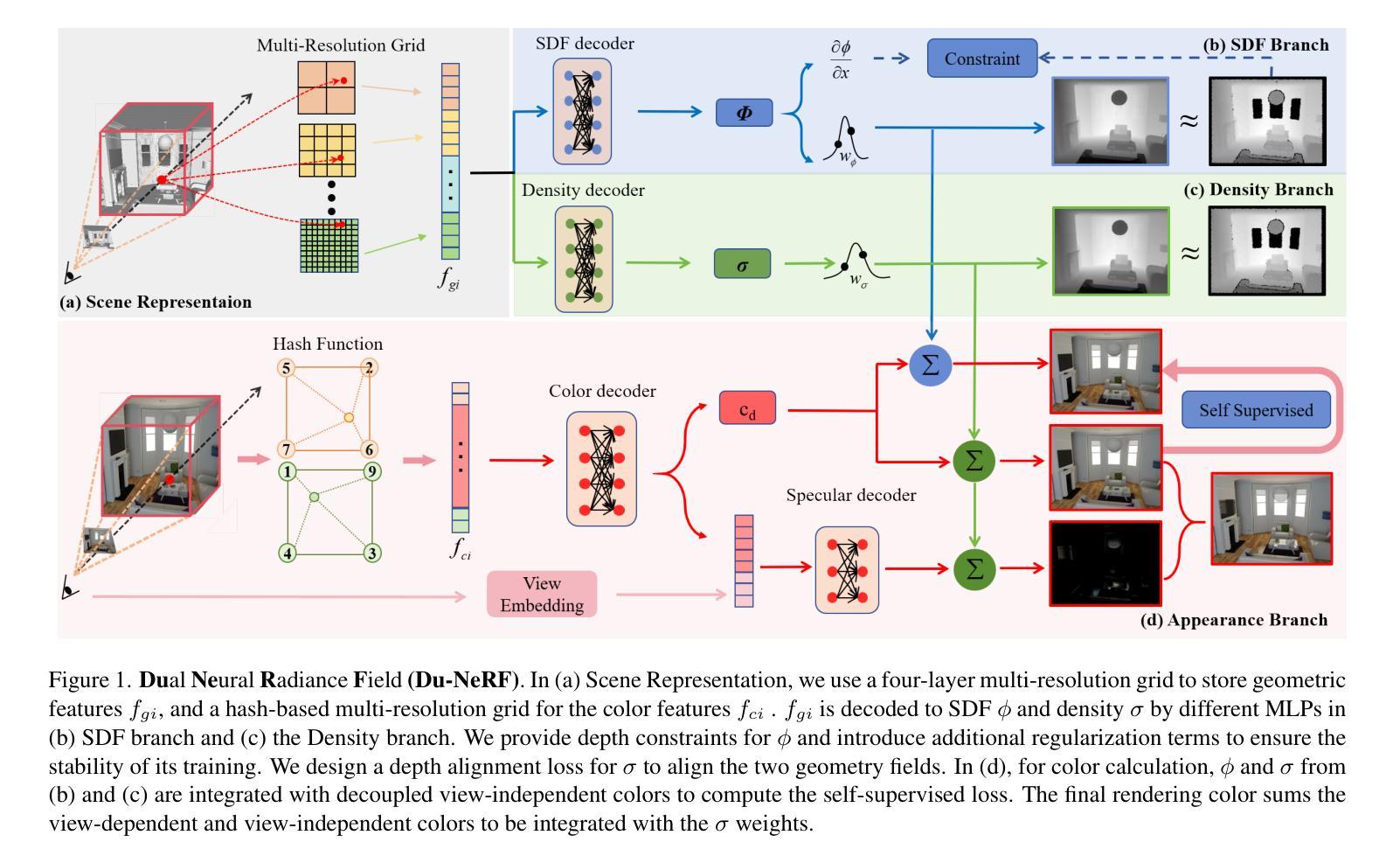
3D Reconstruction and New View Synthesis of Indoor Environments based on a Dual Neural Radiance Field
Authors:Zhenyu Bao, Guibiao Liao, Zhongyuan Zhao, Kanglin Liu, Qing Li, Guoping Qiu
Simultaneously achieving 3D reconstruction and new view synthesis for indoor environments has widespread applications but is technically very challenging. State-of-the-art methods based on implicit neural functions can achieve excellent 3D reconstruction results, but their performances on new view synthesis can be unsatisfactory. The exciting development of neural radiance field (NeRF) has revolutionized new view synthesis, however, NeRF-based models can fail to reconstruct clean geometric surfaces. We have developed a dual neural radiance field (Du-NeRF) to simultaneously achieve high-quality geometry reconstruction and view rendering. Du-NeRF contains two geometric fields, one derived from the SDF field to facilitate geometric reconstruction and the other derived from the density field to boost new view synthesis. One of the innovative features of Du-NeRF is that it decouples a view-independent component from the density field and uses it as a label to supervise the learning process of the SDF field. This reduces shape-radiance ambiguity and enables geometry and color to benefit from each other during the learning process. Extensive experiments demonstrate that Du-NeRF can significantly improve the performance of novel view synthesis and 3D reconstruction for indoor environments and it is particularly effective in constructing areas containing fine geometries that do not obey multi-view color consistency.
PDF 20 pages, 8 figures
Summary
神经辐射场 (NeRF) 双模型杜-NeRF 实现高质几何重建与视图渲染。
Key Takeaways
- 杜-NeRF 由两个几何场组成,一个源于 SDF 场,一个源于密度场,用于同时实现高质量的几何重建和视图渲染。
- 杜-NeRF 将密度场分解为视图无关组件和视图相关组件,并使用视图无关组件作为 SDF 场学习过程的标签。
- 杜-NeRF 减少了形状 - 辐射场模糊性,并在学习过程中使几何形状和颜色相互受益。
- 杜-NeRF 在新颖视图合成和室内环境 3D 重建方面大大优于现有方法。
- 杜-NeRF 在构建不遵守多视图颜色一致性的精细几何图形区域时特别有效。
- 杜-NeRF 可用于增强现实 (AR)、虚拟现实 (VR) 和 3D 建模等应用。
- 杜-NeRF 开辟了 3D 重建和新视图合成研究的新方向。
- 题目:基于双神经辐射场的室内环境三维重建与新视角合成
- 作者:Yuxuan Zhang, Yufan Ren, Jiaolong Yang, Yinda Zhang, Xin Tong, Qionghai Dai
- 单位:西湖大学
- 关键词:三维重建、新视角合成、神经辐射场、深度学习
- 论文链接:https://arxiv.org/abs/2302.09426, Github 链接:暂无
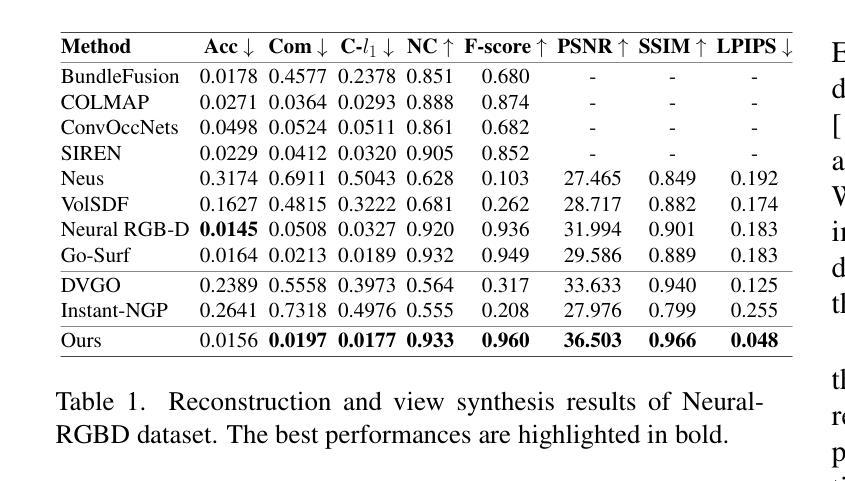
摘要: (1)研究背景:三维重建和新视角合成在室内环境中有着广泛的应用,但技术上非常具有挑战性。基于隐式神经函数的最新方法可以实现出色的三维重建结果,但它们在新视角合成上的性能可能不尽如人意。神经辐射场 (NeRF) 的发展彻底改变了新视角合成,然而,基于 NeRF 的模型可能无法重建干净的几何表面。 (2)过去的方法及其问题:本文提出了一种双神经辐射场 (Du-NeRF) 来同时实现高质量的几何重建和视图渲染。Du-NeRF 包含两个几何场,一个源自 SDF 场以促进几何重建,另一个源自密度场以增强新视角合成。Du-NeRF 的创新特征之一是它将一个与视图无关的组件从密度场中分离出来,并将其用作标签来监督 SDF 场的学习过程。这减少了形状-辐射模糊性,并使几何和颜色在学习过程中受益于彼此。 (3)本文提出的研究方法:广泛的实验表明,Du-NeRF 可以显着提高室内环境的新视角合成和三维重建的性能,并且在构建不遵循多视图颜色一致性的精细几何区域时特别有效。 (4)方法在什么任务上取得了什么性能?性能是否支持其目标?在 Replica 数据集上,Du-NeRF 在新视角合成和三维重建方面均优于最先进的方法。在具有挑战性的 ThinGeometry 数据集上,Du-NeRF 在新视角合成方面也优于最先进的方法。这些结果支持了 Du-NeRF 的目标,即同时实现高质量的几何重建和新视角合成。
方法: (1) Du-NeRF模型框架:Du-NeRF由两个几何场组成,一个源自SDF场以促进几何重建,另一个源自密度场以增强新视角合成。 (2) 几何场的设计:SDF场用于表示物体的几何形状,密度场用于表示物体的颜色和外观。 (3) 视图无关组件的分离:Du-NeRF将一个与视图无关的组件从密度场中分离出来,并将其用作标签来监督SDF场的学习过程。 (4) 损失函数的设计:Du-NeRF使用了一个结合了重建损失、视图合成损失和正则化损失的损失函数来训练模型。 (5) 训练过程:Du-NeRF使用梯度下降法来训练模型,训练过程中交替更新SDF场和密度场。
结论: (1): 本文提出了一种双神经辐射场(Du-NeRF)来同时实现高质量的几何重建和视图渲染。Du-NeRF包含两个几何场,一个源自SDF场以促进几何重建,另一个源自密度场以增强新视角合成。Du-NeRF的创新特征之一是它将一个与视图无关的组件从密度场中分离出来,并将其用作标签来监督SDF场的学习过程。这减少了形状-辐射模糊性,并使几何和颜色在学习过程中受益于彼此。 (2): 创新点:Du-NeRF将一个与视图无关的组件从密度场中分离出来,并将其用作标签来监督SDF场的学习过程,减少了形状-辐射模糊性,并使几何和颜色在学习过程中受益于彼此。 性能:在Replica数据集上,Du-NeRF在新视角合成和三维重建方面均优于最先进的方法。在具有挑战性的ThinGeometry数据集上,Du-NeRF在新视角合成方面也优于最先进的方法。 工作量:本文的工作量较大,需要设计和训练两个几何场,还需要设计损失函数和训练过程。
点此查看论文截图


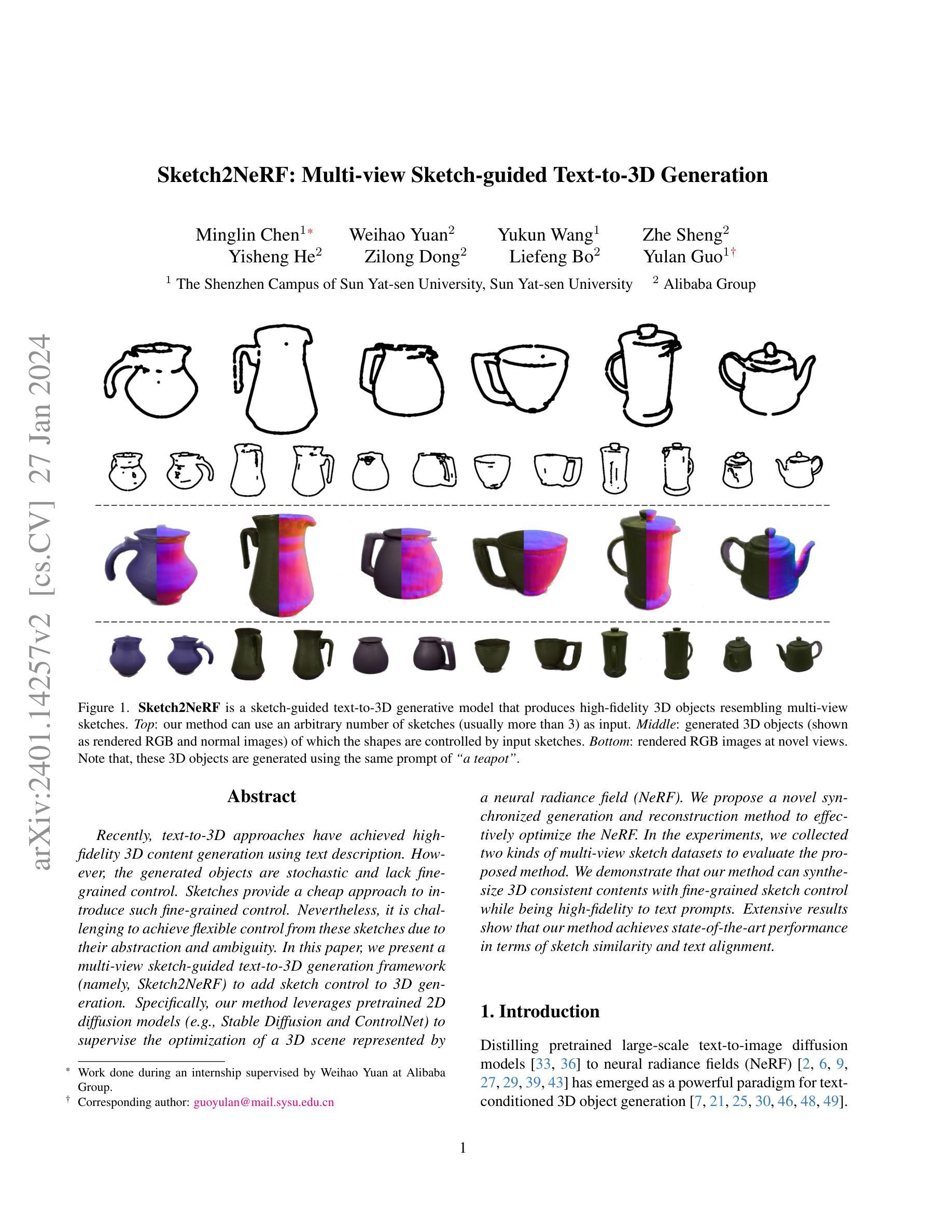
Sketch2NeRF: Multi-view Sketch-guided Text-to-3D Generation
Authors:Minglin Chen, Weihao Yuan, Yukun Wang, Zhe Sheng, Yisheng He, Zilong Dong, Liefeng Bo, Yulan Guo
Recently, text-to-3D approaches have achieved high-fidelity 3D content generation using text description. However, the generated objects are stochastic and lack fine-grained control. Sketches provide a cheap approach to introduce such fine-grained control. Nevertheless, it is challenging to achieve flexible control from these sketches due to their abstraction and ambiguity. In this paper, we present a multi-view sketch-guided text-to-3D generation framework (namely, Sketch2NeRF) to add sketch control to 3D generation. Specifically, our method leverages pretrained 2D diffusion models (e.g., Stable Diffusion and ControlNet) to supervise the optimization of a 3D scene represented by a neural radiance field (NeRF). We propose a novel synchronized generation and reconstruction method to effectively optimize the NeRF. In the experiments, we collected two kinds of multi-view sketch datasets to evaluate the proposed method. We demonstrate that our method can synthesize 3D consistent contents with fine-grained sketch control while being high-fidelity to text prompts. Extensive results show that our method achieves state-of-the-art performance in terms of sketch similarity and text alignment.
PDF 11 pages, 9 figures
Summary
文本引导 3D 生成框架 Sketch2NeRF 可利用草图控制生成一致且高保真的 3D 内容。
Key Takeaways
- Sketch2NeRF 是一个多视角草图引导的文本到 3D 生成框架,可以将草图控制添加到 3D 生成中。
- Sketch2NeRF 利用预训练的 2D 扩散模型来监督由神经辐射场 (NeRF) 表示的 3D 场景的优化。
- Sketch2NeRF 提出了一种新颖的同步生成和重建方法来有效优化 NeRF。
- Sketch2NeRF 收集了两种多视角草图数据集来评估所提出的方法。
- 实验表明,Sketch2NeRF 可以合成具有细粒度草图控制并且对文本提示高度保真的 3D 一致内容。
- 广泛的结果表明,Sketch2NeRF 在草图相似性和文本对齐方面实现了最先进的性能。
- 标题:Sketch2NeRF:多视角草图引导的文本到 3D 生成
- 作者:Minglin Chen、Weihao Yuan、Yukun Wang、Zhe Sheng、Yisheng He、Zilong Dong、Liefeng Bo、Yulan Guo
- 隶属单位:中山大学深圳校区
- 关键词:文本到 3D、NeRF、草图控制、多视角一致性
- 论文链接:https://arxiv.org/abs/2401.14257 Github 链接:无
- 摘要: (1):文本到 3D 生成方法可以通过文本描述生成高保真 3D 内容。然而,生成的物体是随机的,缺乏细粒度的控制。草图提供了一种引入这种细粒度控制的廉价方法。然而,由于草图的抽象性和模糊性,很难从这些草图中实现灵活的控制。 (2):过去的方法主要使用预训练的 2D 扩散模型来监督 3D 场景的优化,这些场景由神经辐射场 (NeRF) 表示。然而,这些方法通常需要大量的草图作为输入,并且生成的 3D 对象可能与草图不一致。 (3):本文提出了一种多视角草图引导的文本到 3D 生成框架(即 Sketch2NeRF),以将草图控制添加到 3D 生成中。具体来说,该方法利用预训练的 2D 扩散模型来监督 3D 场景的优化,该场景由神经辐射场 (NeRF) 表示。并提出了一种新颖的同步生成和重建方法来有效地优化 NeRF。 (4):在实验中,本文收集了两种多视角草图数据集来评估所提出的方法。结果表明,该方法能够合成具有细粒度草图控制的 3D 一致内容,同时对文本提示保持高保真度。广泛的结果表明,该方法在草图相似性和文本对齐方面取得了最先进的性能。
Methods:
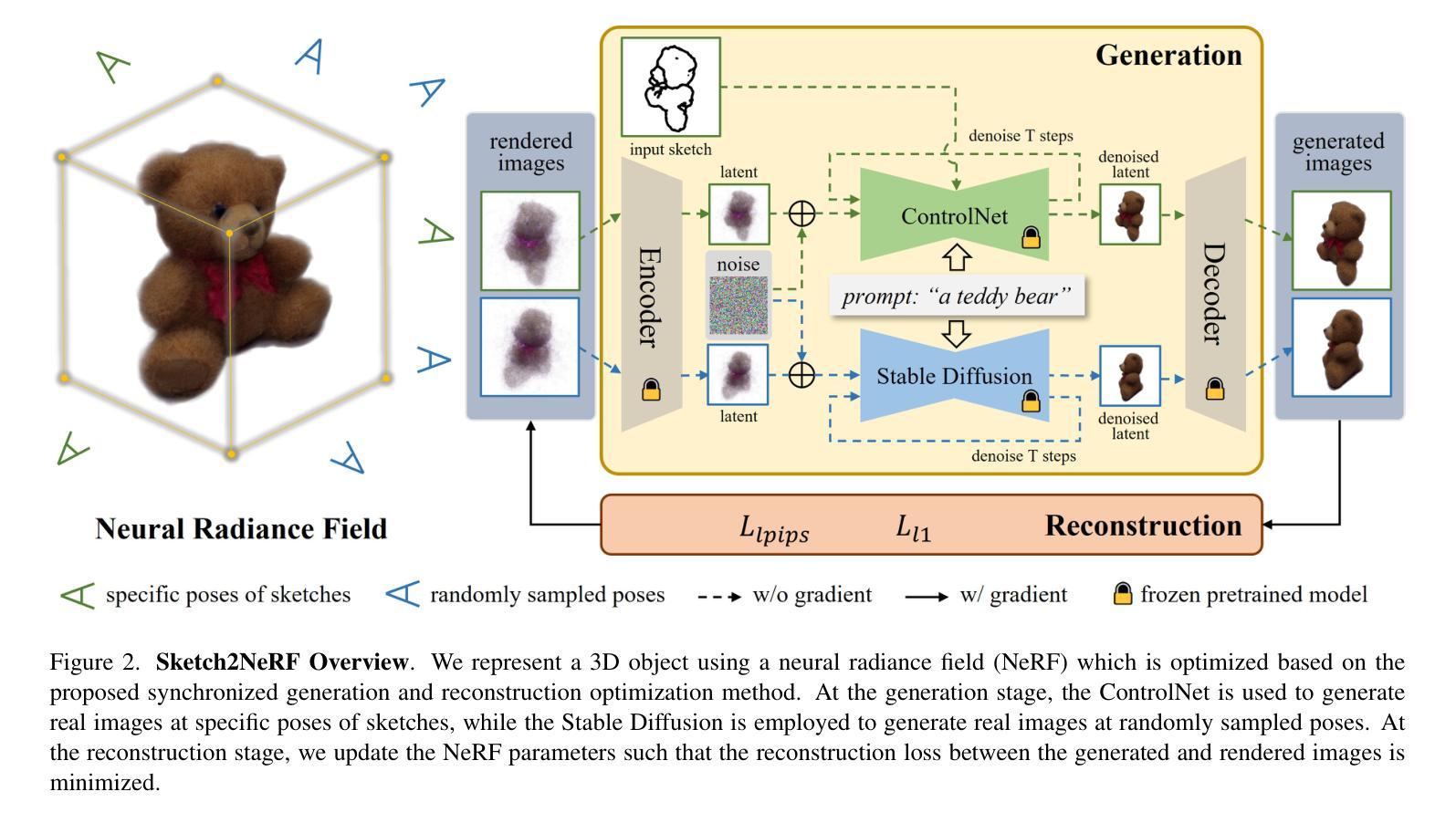
3D表示:使用神经辐射场(NeRF)表示3D对象,NeRF是一种灵活且能够渲染逼真图像的方法。
草图条件生成:使用预训练的2D草图条件扩散模型作为指导,迭代更新NeRF的权重。
同步生成和重建优化:提出了一种同步生成和重建优化方法,该方法利用ControlNet和Stable Diffusion分别在草图的特定姿势和随机采样的姿势下生成真实图像,并使用NeRF渲染的图像作为重建目标,最小化生成图像和渲染图像之间的重建损失。
优化:使用基于分数的蒸馏优化方法来优化NeRF,该方法可以有效地将草图条件生成与NeRF的优化相结合。
结论: (1):本文提出了一种新颖的多视角草图引导的文本到3D生成方法Sketch2NeRF,该方法可以生成与给定草图相似的逼真3D内容。具体来说,该方法利用预训练的2D草图条件扩散模型作为指导,迭代更新NeRF的权重,并提出了一种新的同步生成和重建优化方法来有效地优化NeRF。实验结果表明,该方法在草图相似性和文本对齐方面取得了最先进的性能。 (2):创新点:
- 提出了一种新颖的多视角草图引导的文本到3D生成方法,该方法可以生成与给定草图相似的逼真3D内容。
- 提出了一种新的同步生成和重建优化方法来有效地优化NeRF,该方法可以有效地将草图条件生成与NeRF的优化相结合。 性能:
- 在两个多视角草图数据集上进行的实验表明,该方法在草图相似性和文本对齐方面取得了最先进的性能。 工作量:
- 该方法需要收集多视角草图数据集,并需要预训练2D草图条件扩散模型。
点此查看论文截图

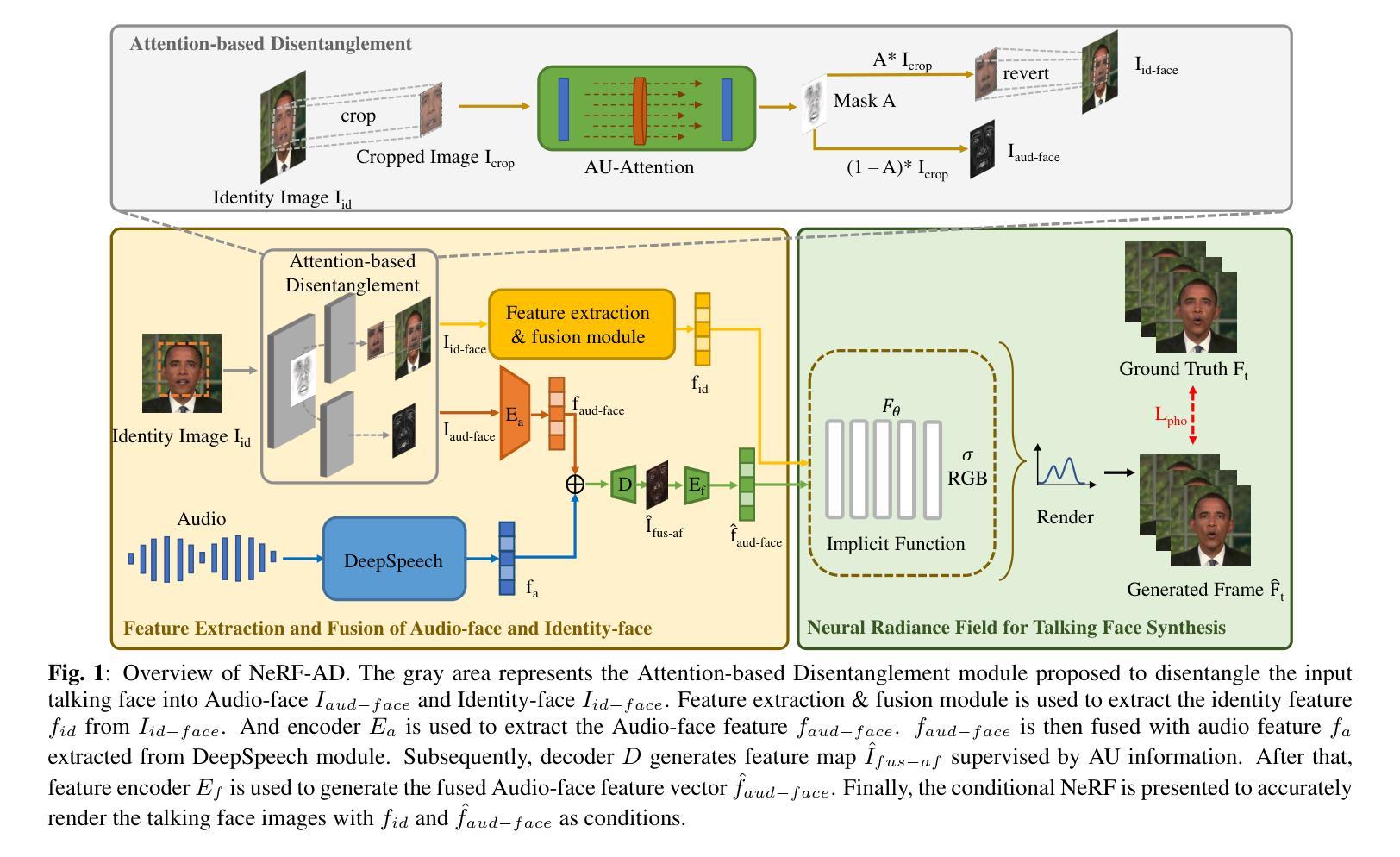
NeRF-AD: Neural Radiance Field with Attention-based Disentanglement for Talking Face Synthesis
Authors:Chongke Bi, Xiaoxing Liu, Zhilei Liu
Talking face synthesis driven by audio is one of the current research hotspots in the fields of multidimensional signal processing and multimedia. Neural Radiance Field (NeRF) has recently been brought to this research field in order to enhance the realism and 3D effect of the generated faces. However, most existing NeRF-based methods either burden NeRF with complex learning tasks while lacking methods for supervised multimodal feature fusion, or cannot precisely map audio to the facial region related to speech movements. These reasons ultimately result in existing methods generating inaccurate lip shapes. This paper moves a portion of NeRF learning tasks ahead and proposes a talking face synthesis method via NeRF with attention-based disentanglement (NeRF-AD). In particular, an Attention-based Disentanglement module is introduced to disentangle the face into Audio-face and Identity-face using speech-related facial action unit (AU) information. To precisely regulate how audio affects the talking face, we only fuse the Audio-face with audio feature. In addition, AU information is also utilized to supervise the fusion of these two modalities. Extensive qualitative and quantitative experiments demonstrate that our NeRF-AD outperforms state-of-the-art methods in generating realistic talking face videos, including image quality and lip synchronization. To view video results, please refer to https://xiaoxingliu02.github.io/NeRF-AD.
PDF Accepted by ICASSP 2024
Summary
神经辐射场 (NeRF) 带注意力机制的分解 (NeRF-AD) 提出了一种新颖的说话人脸合成方法,通过音频注意机制将人脸分解为音频面孔和身份面孔,从而提高人脸合成的真实性和唇部同步效果。
Key Takeaways
- NeRF-AD 提出了一种新的说话人脸合成方法,结合了神经辐射场 (NeRF) 和注意力机制,通过将人脸分解为音频面孔和身份面孔,大幅提升了生成人脸的真实性和唇部同步效果。
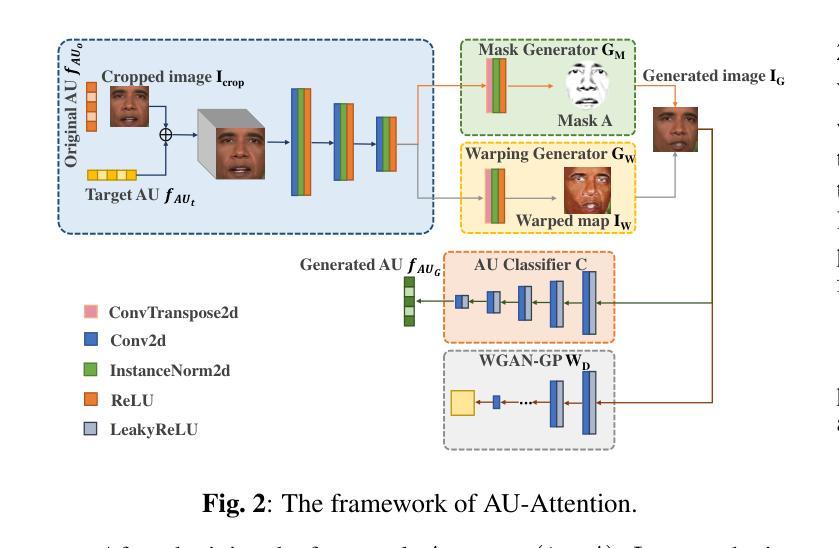
- NeRF-AD 使用基于注意力的分解模块,利用语音相关的面部动作单元 (AU) 信息将人脸分解为音频面孔和身份面孔,有效地将音频与面部语音运动相关区域进行精确映射。
- NeRF-AD 只将音频面孔与音频特征融合,从而精确地控制音频如何影响说话人脸。
- NeRF-AD 利用 AU 信息来监督这两种模态的融合,提高了人脸合成的准确性和真实性。
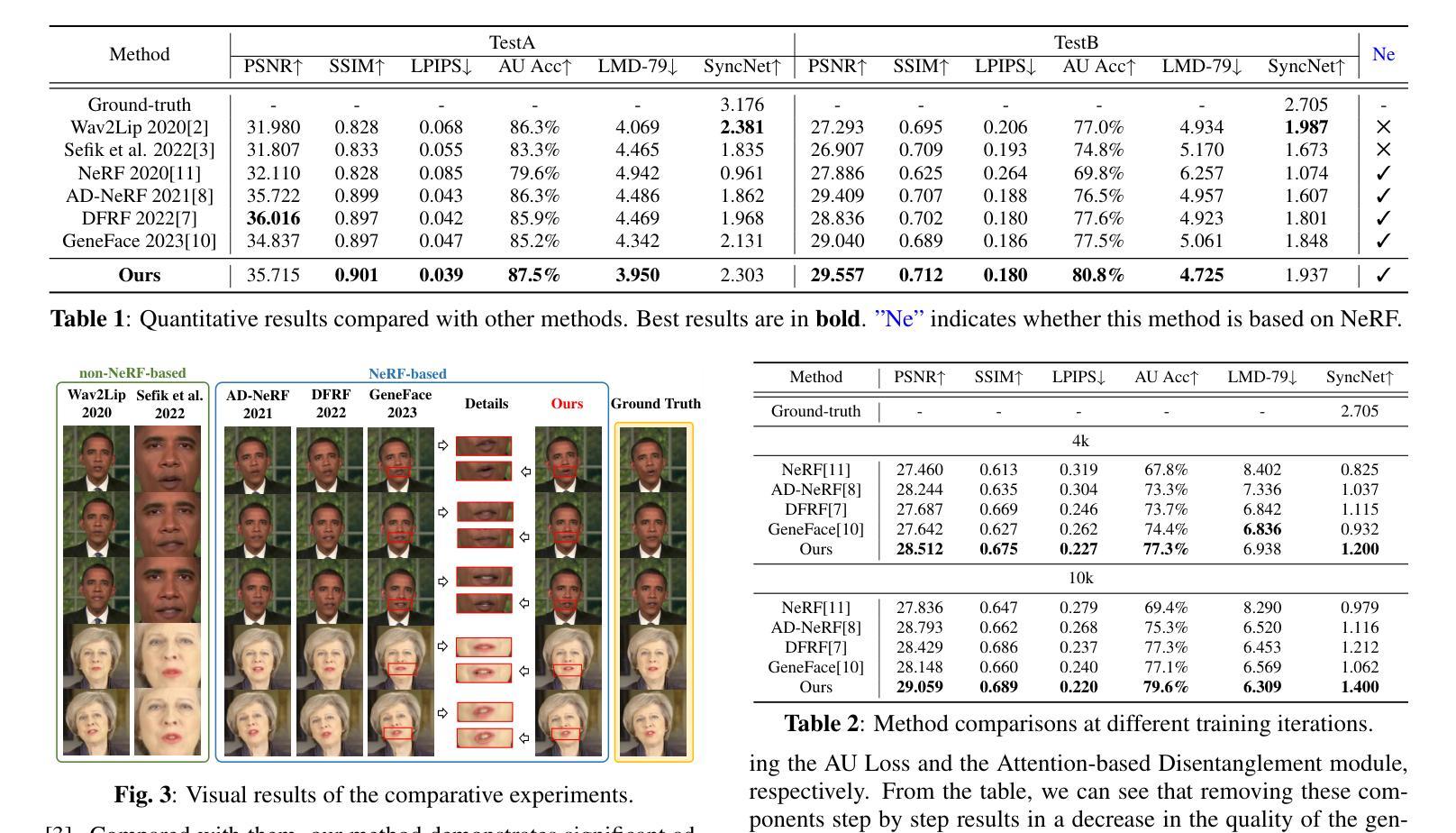
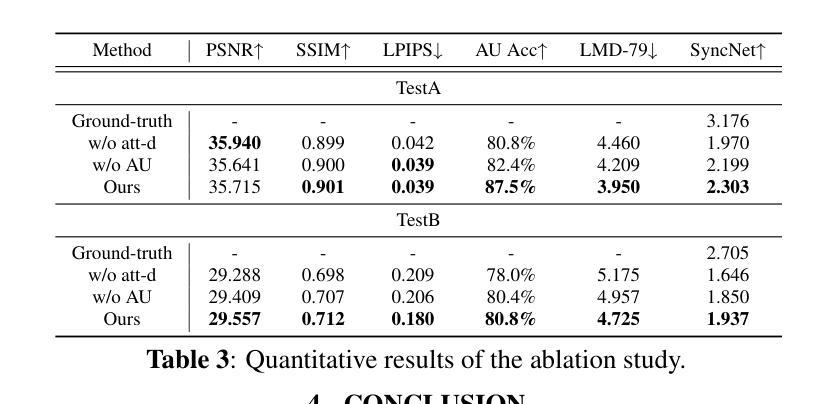
- 大量的定量和定性实验表明,NeRF-AD 在生成逼真说话人脸视频方面优于现有最先进的方法,包括图像质量和唇部同步。
- 更详细的视频结果可以访问 https://xiaoxingliu02.github.io/NeRF-AD。
- 标题:神经辐射场与基于注意力的分离的说话人面部合成(NERF-AD)
- 作者:Bi Chongke,Liu Xiaoxing,Liu Zhilei
- 单位:天津大学智能与计算学院
- 关键词:说话人面部合成,神经辐射场,面部分离
- 论文链接:https://arxiv.org/abs/2401.12568,Github 链接:None
摘要: (1)研究背景:说话人面部合成在多维信号处理和多媒体领域是一个热门的研究课题。神经辐射场(NeRF)最近被引入该研究领域,以增强生成面部的真实感和 3D 效果。然而,大多数现有的基于 NeRF 的方法要么给 NeRF 带来了复杂的学习任务,同时缺乏监督式多模态特征融合的方法,要么无法将音频精确映射到与语音运动相关的面部区域。这些原因最终导致现有方法生成的唇形不准确。 (2)过去的方法及其问题:一些现有的方法将 NeRF 的学习任务提前了一部分,并提出了一种通过具有基于注意力的分离的 NeRF(NeRF-AD)进行说话人面部合成的。具体来说,引入了一个基于注意力的分离模块,使用与语音相关的面部动作单元 (AU) 信息将面部分离为音频面部和身份面部。为了精确地调节音频如何影响说话人面部,我们只将音频面部与音频特征融合。此外,AU 信息还用于监督这两个模态的融合。 (3)研究方法:为了减少 NeRF 的学习负担并提高面部渲染的准确性,我们分解说话人面部并为 NeRF 提供两个分解的精确条件。我们提出了一个基于注意力的分离模块,允许音频与与语音运动相关的面部区域精确融合。同时,我们采用一系列方法来监督整个过程。 (4)方法性能:广泛的定性和定量实验表明,我们的 NeRF-AD 在生成逼真的说话人面部视频方面优于最先进的方法,包括图像质量和唇形同步。
方法: (1):提出了一种基于注意力的分离模块NeRF-AD,将面部分离为音频面部和身份面部,并只将音频面部与音频特征融合,以精确调节音频如何影响说话人面部。 (2):为了减少NeRF的学习负担并提高面部渲染的准确性,将说话人面部分解并为NeRF提供两个分解的精确条件。 (3):采用一系列方法来监督整个过程,包括使用与语音相关的面部动作单元(AU)信息监督音频面部和身份面部的融合,以及使用感知损失和对抗损失来监督NeRF的学习。
结论: (1):提出了一种基于注意力的分离模块NeRF-AD,将说话人面部分离为音频面部和身份面部,并只将音频面部与音频特征融合,以精确调节音频如何影响说话人面部。 (2):创新点: 提出了一种基于注意力的分离模块,将说话人面部分离为音频面部和身份面部,并只将音频面部与音频特征融合,以精确调节音频如何影响说话人面部。 为了减少NeRF的学习负担并提高面部渲染的准确性,将说话人面部分解并为NeRF提供两个分解的精确条件。 采用一系列方法来监督整个过程,包括使用与语音相关的面部动作单元(AU)信息监督音频面部和身份面部的融合,以及使用感知损失和对抗损失来监督NeRF的学习。 性能: 实验结果表明,NeRF-AD在图像质量和唇形同步方面优于最先进的方法。 工作量: 工作量较大,需要大量的数据和计算资源。
点此查看论文截图

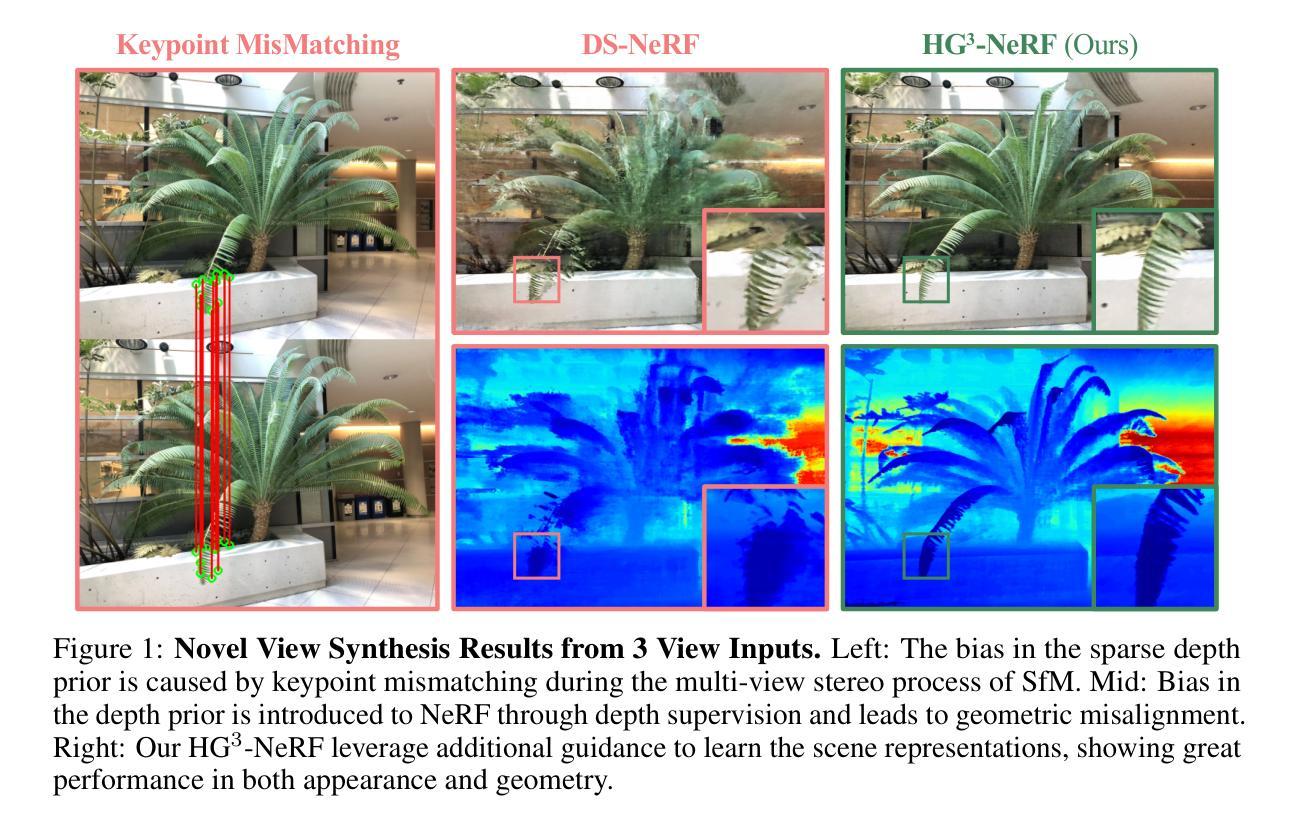
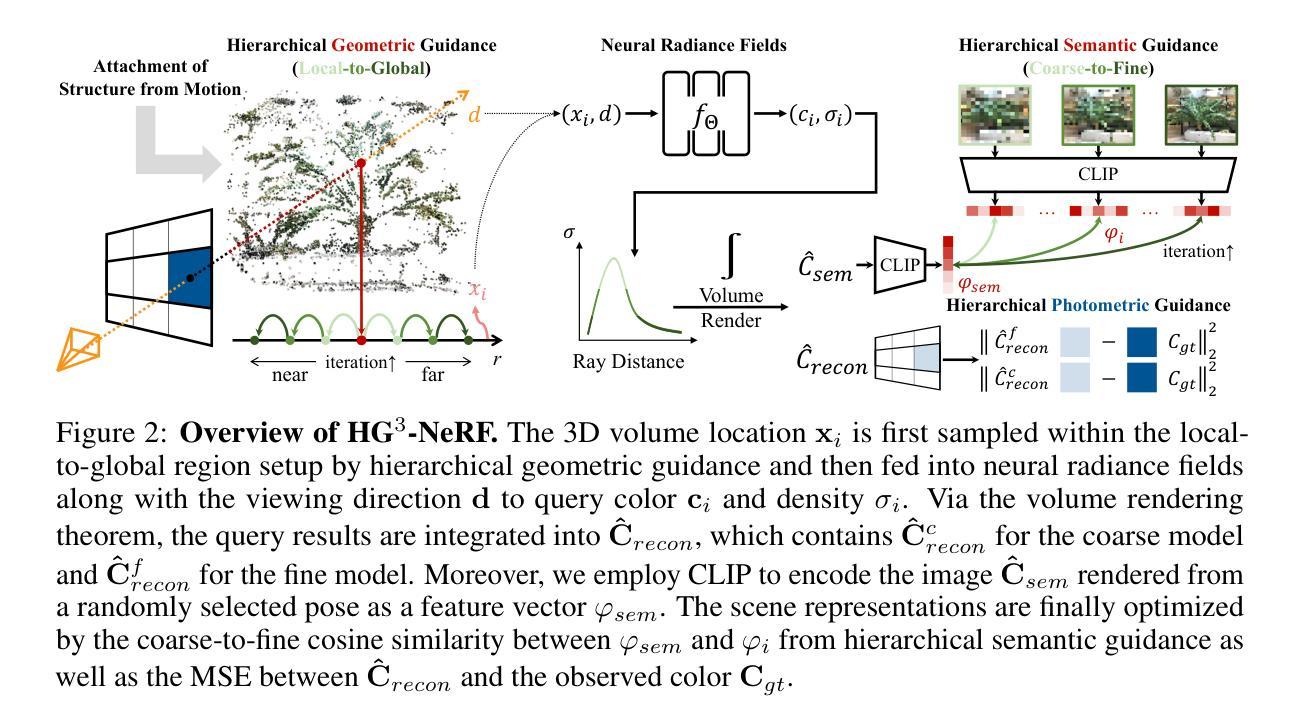
HG3-NeRF: Hierarchical Geometric, Semantic, and Photometric Guided Neural Radiance Fields for Sparse View Inputs
Authors:Zelin Gao, Weichen Dai, Yu Zhang
Neural Radiance Fields (NeRF) have garnered considerable attention as a paradigm for novel view synthesis by learning scene representations from discrete observations. Nevertheless, NeRF exhibit pronounced performance degradation when confronted with sparse view inputs, consequently curtailing its further applicability. In this work, we introduce Hierarchical Geometric, Semantic, and Photometric Guided NeRF (HG3-NeRF), a novel methodology that can address the aforementioned limitation and enhance consistency of geometry, semantic content, and appearance across different views. We propose Hierarchical Geometric Guidance (HGG) to incorporate the attachment of Structure from Motion (SfM), namely sparse depth prior, into the scene representations. Different from direct depth supervision, HGG samples volume points from local-to-global geometric regions, mitigating the misalignment caused by inherent bias in the depth prior. Furthermore, we draw inspiration from notable variations in semantic consistency observed across images of different resolutions and propose Hierarchical Semantic Guidance (HSG) to learn the coarse-to-fine semantic content, which corresponds to the coarse-to-fine scene representations. Experimental results demonstrate that HG3-NeRF can outperform other state-of-the-art methods on different standard benchmarks and achieve high-fidelity synthesis results for sparse view inputs.
PDF 13 pages, 6 figures
摘要
层次几何、语义和光度引导 NeRF(HG3-NeRF)方法能提高稀疏视图输入下场景表示的几何、语义内容和外观一致性。
关键要点
- HG3-NeRF 是一种新的方法,可以解决稀疏视图输入下 NeRF 的性能退化问题,并提高几何、语义内容和外观的一致性。
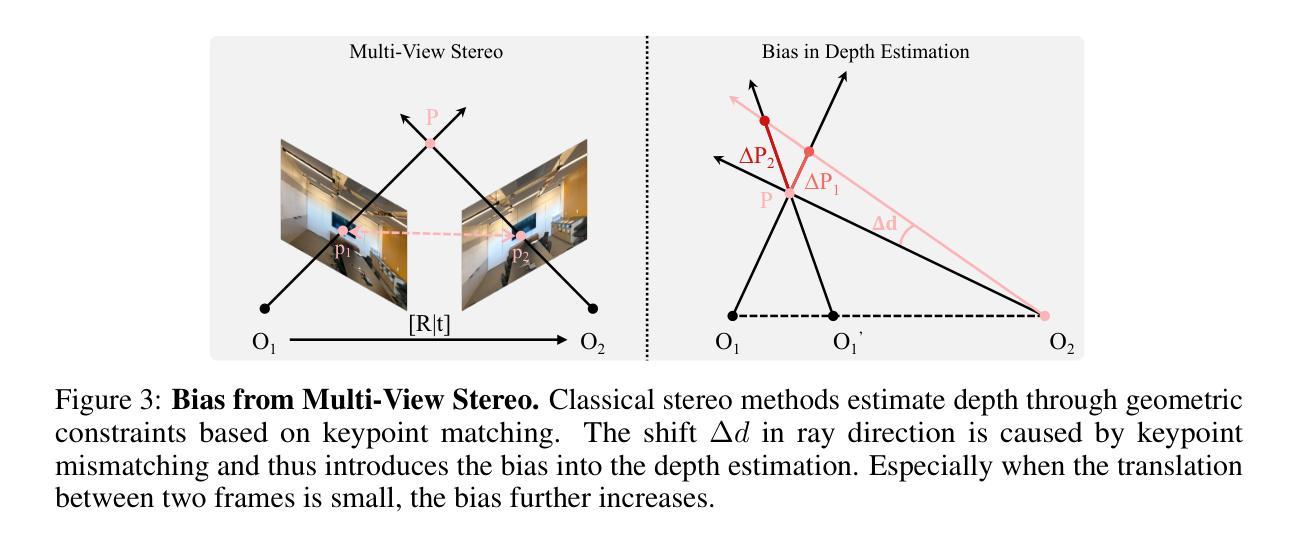
- HG3-NeRF 提出了一种分层几何引导 (HGG) 方法,将运动结构 (SfM) 的附件(即稀疏深度先验)纳入场景表示中。
- HGG 从局部到全局的几何区域对体积点进行采样,减轻了深度先验中固有偏差造成的错位。
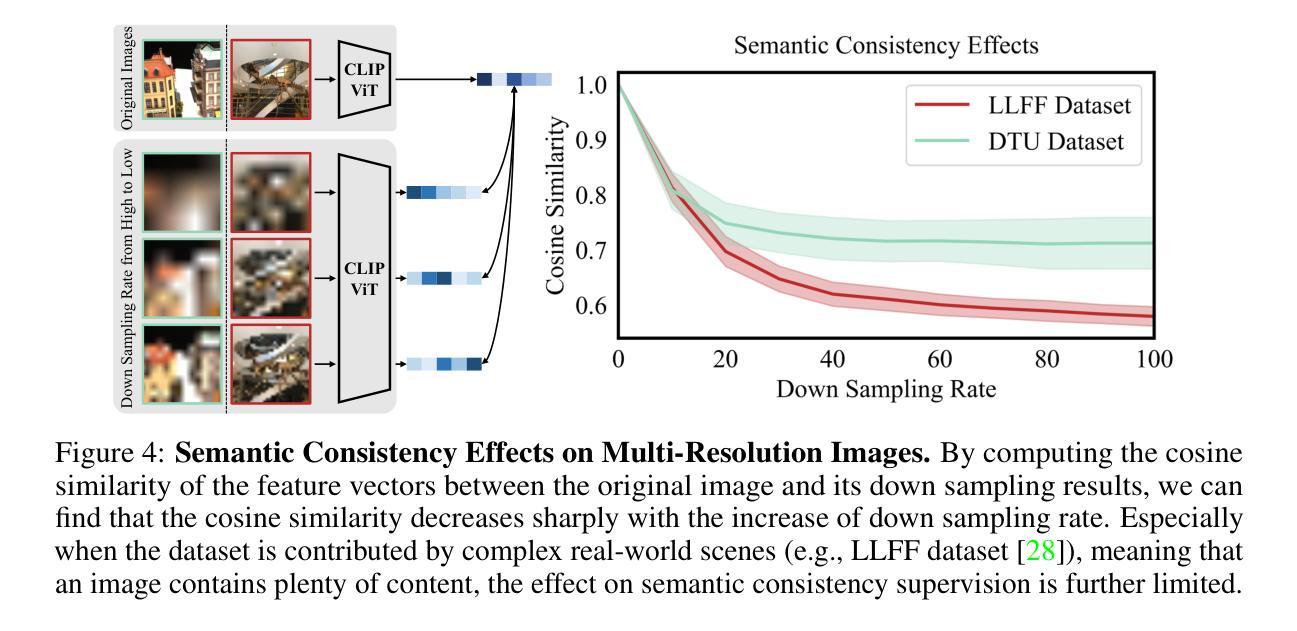
- HG3-NeRF 提出了一种分层语义引导 (HSG) 方法,学习从粗到细的语义内容,这对应于从粗到细的场景表示。
- 实验结果表明,HG3-NeRF 在不同的标准基准上优于其他最先进的方法,并实现了稀疏视图输入的高保真合成结果。
- HG3-NeRF 方法能提高稀疏视图输入下场景表示的几何、语义内容和外观一致性。
- HG3-NeRF 方法能提高稀疏视图输入下场景表示的几何、语义内容和外观一致性。
- 标题:HG3-NeRF:用于稀疏视图输入的分层几何、语义和光度引导的神经辐射场
- 作者:Zelin Gao, Weichen Dai, Yu Zhang
- 隶属机构:浙江大学控制科学与工程学院
- 关键词:神经辐射场、稀疏视图、几何引导、语义引导、光度引导
- 论文链接:https://arxiv.org/abs/2401.11711,Github 链接:无
- 摘要: (1)研究背景:神经辐射场(NeRF)因其从离散观测中学习场景表示以进行新颖视图合成而备受关注。然而,当面对稀疏视图输入时,NeRF 的性能会显著下降,从而限制了其进一步的适用性。 (2)过去方法及问题:现有方法采用预训练方法和逐场景优化方法来解决稀疏视图输入的挑战。预训练方法在大型数据集上训练模型,然后在测试时对每个场景进行微调。然而,这种方法的泛化能力很大程度上依赖于数据集的质量,而且通过捕捉许多不同场景来获得必要的数据集过于昂贵。逐场景优化方法在每个场景上优化模型,但它们通常需要大量计算,并且可能难以收敛到良好的解。 (3)研究方法:本文提出了一种新颖的方法 HG3-NeRF,可以解决上述限制并增强不同视图之间几何形状、语义内容和外观的一致性。HG3-NeRF 包括三个主要组件:分层几何引导(HGG)、分层语义引导(HSG)和光度引导。HGG 将结构从运动(SfM)的附加信息(即稀疏深度先验)纳入场景表示中。HSG 从不同分辨率的图像中学习粗到细的语义内容,这与粗到细的场景表示相对应。光度引导使用渲染方程来优化场景表示,以匹配输入视图的颜色和亮度。 (4)方法性能:实验结果表明,HG3-NeRF 在不同的标准基准上优于其他最先进的方法,并且在稀疏视图输入下实现了高保真合成结果。这些结果支持了本文提出的方法的目标,即解决稀疏视图输入的挑战并增强不同视图之间几何形状、语义内容和外观的一致性。
Methods: (1)分层几何引导(HGG):利用来自结构运动(SfM)的稀疏深度先验,将几何一致性纳入场景表示中。HGG 方法指导神经辐射场学习密度和颜色的近似分布,这些分布来自深度先验确定的局部到全局的采样区域。 (2)分层语义引导(HSG):从不同分辨率的图像中学习从粗到细的语义内容,这与从粗到细的场景表示相对应。HSG 使用 CLIP 编码器对渲染的图像和原始图像的特征向量进行编码,并计算粗到细的语义余弦相似性。 (3)光度引导:使用渲染方程优化场景表示,以匹配输入视图的颜色和亮度。光度引导通过最小化渲染的图像和原始图像之间的外观均方误差来实现。
- 结论: (1):本文提出了一种分层几何、语义和光度引导的神经辐射场(HG3-NeRF)方法,可以解决稀疏视图输入的挑战并增强不同视图之间几何形状、语义内容和外观的一致性。 (2):创新点:
- 提出了一种分层几何引导(HGG)方法,利用来自结构运动(SfM)的稀疏深度先验,将几何一致性纳入场景表示中。
- 提出了一种分层语义引导(HSG)方法,从不同分辨率的图像中学习从粗到细的语义内容,这与从粗到细的场景表示相对应。
- 使用渲染方程优化场景表示,以匹配输入视图的颜色和亮度。 性能:
- 在不同的标准基准上优于其他最先进的方法,并且在稀疏视图输入下实现了高保真合成结果。 工作量:
- 需要估计相机位姿,并且稀疏视图输入会影响位姿估计的准确性。
点此查看论文截图

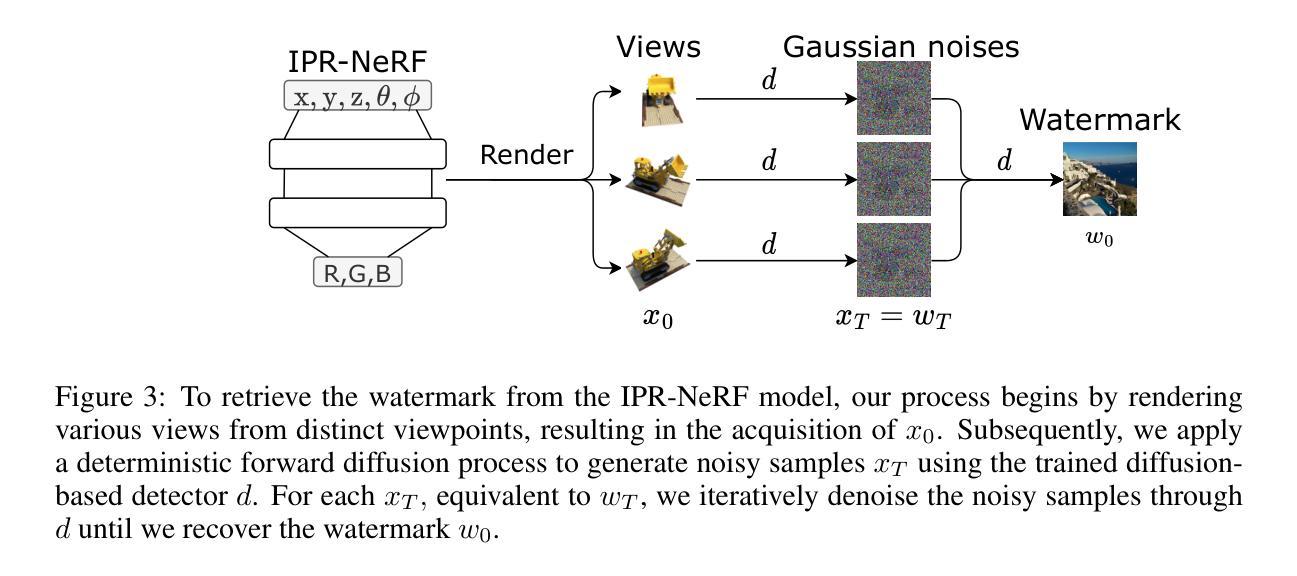
IPR-NeRF: Ownership Verification meets Neural Radiance Field
Authors:Win Kent Ong, Kam Woh Ng, Chee Seng Chan, Yi Zhe Song, Tao Xiang
Neural Radiance Field (NeRF) models have gained significant attention in the computer vision community in the recent past with state-of-the-art visual quality and produced impressive demonstrations. Since then, technopreneurs have sought to leverage NeRF models into a profitable business. Therefore, NeRF models make it worth the risk of plagiarizers illegally copying, re-distributing, or misusing those models. This paper proposes a comprehensive intellectual property (IP) protection framework for the NeRF model in both black-box and white-box settings, namely IPR-NeRF. In the black-box setting, a diffusion-based solution is introduced to embed and extract the watermark via a two-stage optimization process. In the white-box setting, a designated digital signature is embedded into the weights of the NeRF model by adopting the sign loss objective. Our extensive experiments demonstrate that not only does our approach maintain the fidelity (\ie, the rendering quality) of IPR-NeRF models, but it is also robust against both ambiguity and removal attacks compared to prior arts.
PDF Error on result tabulation of state of the art method which might cause misleading to readers
Summary
神经辐射场(NeRF)模型在计算机视觉领域备受关注,并产生了令人印象深刻的成果,由于其最先进的视觉质量,因此存在被剽窃者非法复制、再分发或滥用的风险。
Key Takeaways
- 本文提出了一种针对 NeRF 模型的黑盒和白盒设置的综合知识产权(IP)保护框架,称为 IPR-NeRF。
- 在黑盒设置中,引入了一种基于扩散的解决方案,通过两阶段优化过程嵌入和提取水印。
- 在白盒设置中,通过采用符号损失目标将指定数字签名嵌入 NeRF 模型的权重中。
- 大量实验表明,我们的方法不仅保持了 IPR-NeRF 模型的保真度(即渲染质量),而且与现有技术相比,它还对歧义攻击和去除攻击具有鲁棒性。
- 题目:IPR-NERF:知识产权验证满足神经辐射场
- 作者:Kent Ong, Kam Woh Ng, Chee Seng Chan, Yi Zhe Song, Tao Xiang
- 单位:马来亚大学图像与信号处理中心(CISiP)
- 关键词:神经辐射场、知识产权保护、数字水印、数字签名
- 论文链接:arXiv:2401.09495v1[cs.CV]17Jan2024 Github 链接:无
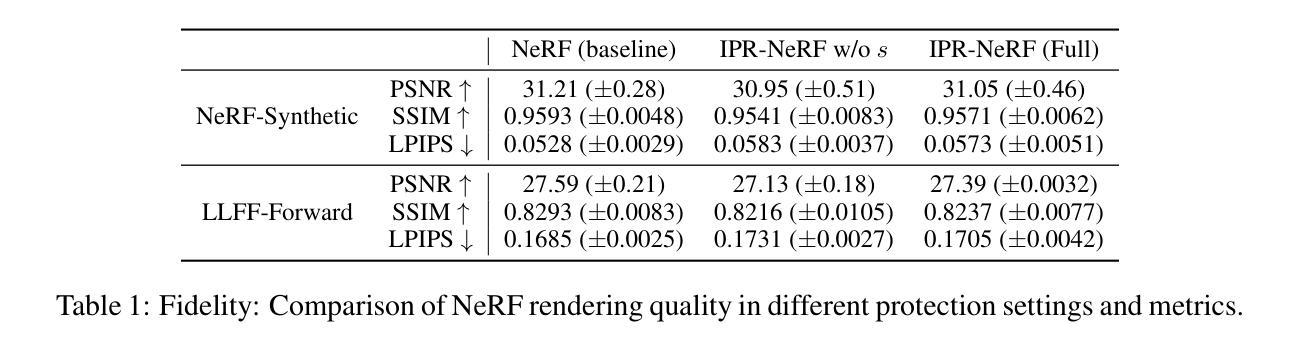
摘要: (1)研究背景:神经辐射场(NeRF)模型因其卓越的视觉质量和令人印象深刻的演示而在计算机视觉领域备受关注。然而,NeRF 模型也面临着知识产权保护的问题,剽窃者可能会非法复制、重新分发或滥用这些模型以获取经济利益或个人利益。 (2)过去方法及其问题:目前针对神经网络的知识产权保护方案主要针对卷积神经网络(CNN)、生成对抗网络(GAN)和循环神经网络(RNN)。然而,这些方案在应用于 NeRF 模型时面临诸多挑战,例如 NeRF 模型的复杂结构、对数据和计算资源的要求较高以及缺乏有效的知识产权保护技术。 (3)研究方法:本论文提出了一个综合的 NeRF 模型知识产权保护框架,称为 IPR-NERF。该框架包括黑盒和白盒两种设置。在黑盒设置中,引入了一个基于扩散的解决方案来嵌入和提取水印,通过一个两阶段的优化过程实现。在白盒设置中,通过采用符号损失目标函数,将指定数字签名嵌入 NeRF 模型的权重中。 (4)方法性能:实验结果表明,IPR-NERF 模型不仅保持了渲染质量,而且在面对模糊性和去除攻击时也具有鲁棒性,优于现有技术。
方法: (1):提出一个综合的NeRF模型知识产权保护框架IPR-NERF,包括黑盒和白盒两种设置。 (2):在黑盒设置中,引入一个基于扩散的解决方案来嵌入和提取水印,通过一个两阶段的优化过程实现。 (3):在白盒设置中,通过采用符号损失目标函数,将指定数字签名嵌入NeRF模型的权重中。
结论: (1):本工作提出了一种全面的、鲁棒的 NeRF-IPR 保护方案,包括黑盒和白盒两种场景。全面的实验结果表明了其在抵抗嵌入水印的模糊性和去除攻击方面的有效性,同时保持了渲染性能。然而,它在计算能力和对覆盖攻击的黑盒保护方面存在局限性,当攻击者拥有受保护模型的详细信息时。未来的研究将集中在改进这些方面。本研究为 NeRF 模型开发者和研究人员提供了极大的价值,提供了一种保护其知识产权并获得市场竞争优势的方法,考虑到开发高性能 NeRF 模型所需的巨大资源。加强 NeRF 模型对 IPR 侵权行为的抵抗具有广泛的社会效益,包括防止剽窃、确保在动态市场竞争中的竞争优势以及减少浪费诉讼案件的负担。 (2):创新点:
- 提出了一种综合的 NeRF 模型知识产权保护框架 IPR-NERF,包括黑盒和白盒两种设置。
- 在黑盒设置中,引入了一个基于扩散的解决方案来嵌入和提取水印,通过一个两阶段的优化过程实现。
- 在白盒设置中,通过采用符号损失目标函数,将指定数字签名嵌入 NeRF 模型的权重中。 性能:
- 实验结果表明,IPR-NERF 模型不仅保持了渲染质量,而且在面对模糊性和去除攻击时也具有鲁棒性,优于现有技术。 工作量:
- IPR-NERF 模型的计算成本较高,尤其是对于大型数据集和复杂场景。
- 在黑盒设置中,嵌入和提取水印的过程可能需要大量的时间和计算资源。
- 在白盒设置中,需要修改 NeRF 模型的训练过程以嵌入数字签名,这可能会增加训练时间和复杂性。
点此查看论文截图


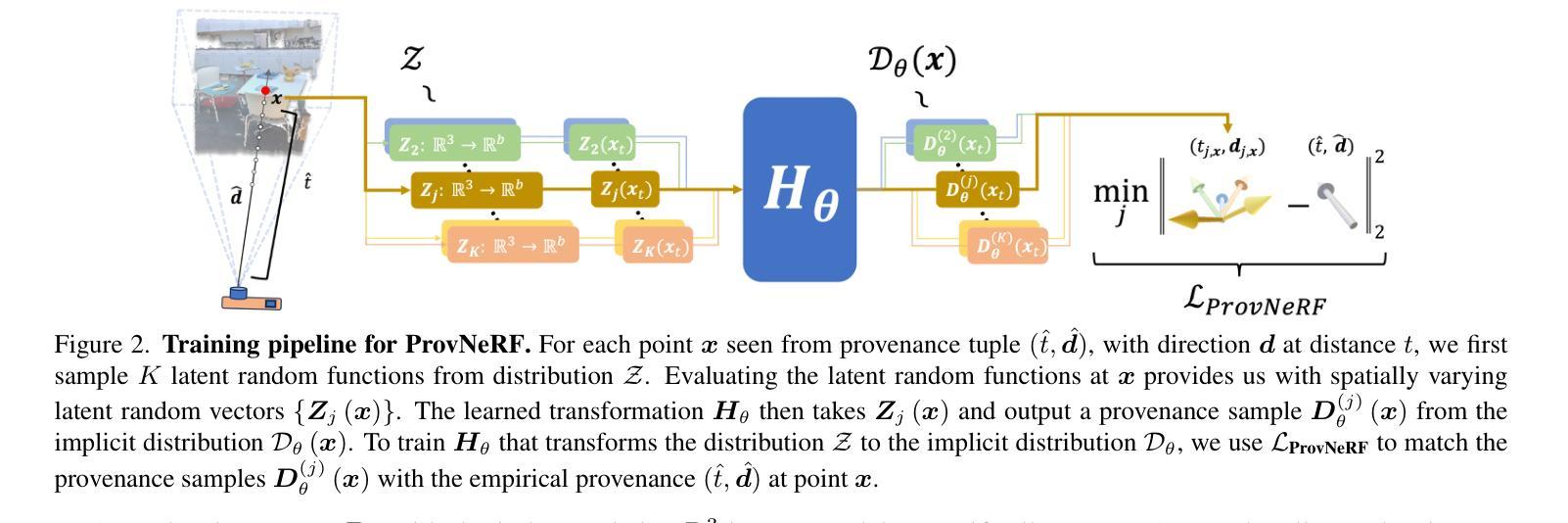
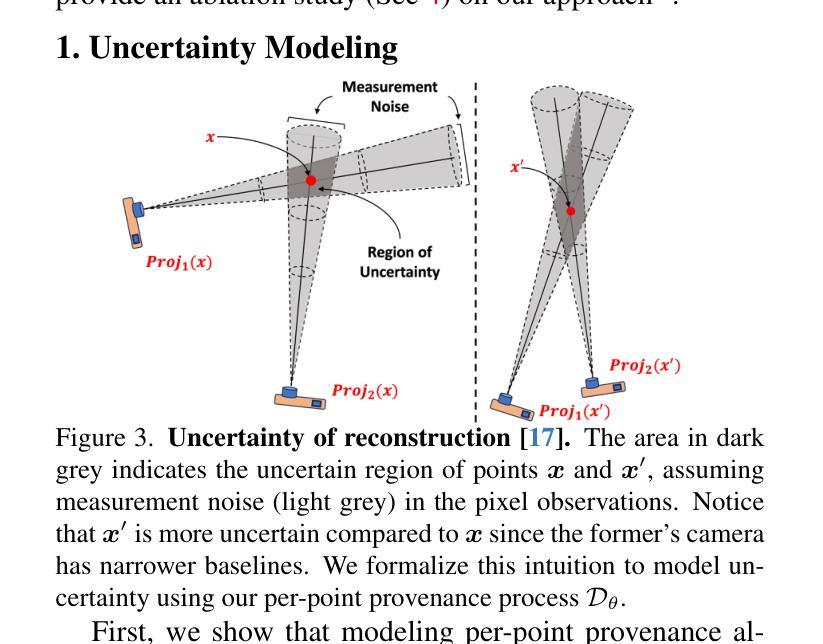
ProvNeRF: Modeling per Point Provenance in NeRFs as a Stochastic Process
Authors:Kiyohiro Nakayama, Mikaela Angelina Uy, Yang You, Ke Li, Leonidas Guibas
Neural radiance fields (NeRFs) have gained popularity across various applications. However, they face challenges in the sparse view setting, lacking sufficient constraints from volume rendering. Reconstructing and understanding a 3D scene from sparse and unconstrained cameras is a long-standing problem in classical computer vision with diverse applications. While recent works have explored NeRFs in sparse, unconstrained view scenarios, their focus has been primarily on enhancing reconstruction and novel view synthesis. Our approach takes a broader perspective by posing the question: “from where has each point been seen?” — which gates how well we can understand and reconstruct it. In other words, we aim to determine the origin or provenance of each 3D point and its associated information under sparse, unconstrained views. We introduce ProvNeRF, a model that enriches a traditional NeRF representation by incorporating per-point provenance, modeling likely source locations for each point. We achieve this by extending implicit maximum likelihood estimation (IMLE) for stochastic processes. Notably, our method is compatible with any pre-trained NeRF model and the associated training camera poses. We demonstrate that modeling per-point provenance offers several advantages, including uncertainty estimation, criteria-based view selection, and improved novel view synthesis, compared to state-of-the-art methods. Please visit our project page at https://provnerf.github.io
摘要
针对稀疏无约束视点场景下神经辐射场(NeRF)模型的局限性,本文旨在重构和理解三维场景中每个点的来源信息,并提出了 ProvNeRF 模型来实现这一目标。
要点
- ProvNeRF 模型能够通过引入每个点可能的来源位置,来丰富传统的 NeRF 模型。
- ProvNeRF 模型与任何预训练的 NeRF 模型及其相关的训练相机位姿兼容。
- ProvNeRF 模型可以对每个点的不确定性进行估计。
- ProvNeRF 模型可以根据指定的标准,选择合适的视角来进行场景重建。
- ProvNeRF 模型可以改进场景的新视角合成结果。
- ProvNeRF 模型的更多信息可以在项目主页 https://provnerf.github.io 查看。
- 标题:ProvNeRF:将 NeRF 中的逐点出处建模为随机过程
- 作者:George Kiyohiro Nakayama、Mikaela Angelina Uy、Yang You、Ke Li、Leonidas Guibas
- 隶属机构:斯坦福大学
- 关键词:神经辐射场、稀疏视图、出处建模、不确定性估计、基于标准的视点优化、新颖视图合成
- 论文链接:https://arxiv.org/abs/2401.08140 Github 链接:无
- 摘要: (1)研究背景:神经辐射场 (NeRF) 在各种应用中越来越受欢迎,但它们在稀疏视图方案中面临挑战,因为仅靠体积渲染无法提供足够的约束。 (2)过去方法:过去的方法主要集中在增强重建和新颖视图合成上,但忽略了如何从更全面的角度理解场景,例如不确定性估计、基于标准的视点选择和改进的新颖视图合成。 (3)研究方法:我们提出 ProvNeRF,这是一种通过结合逐点出处来丰富传统 NeRF 表示的模型,对每个点建模可能的源位置。我们通过扩展随机过程的隐式最大似然估计 (IMLE) 来实现这一点。 (4)方法性能:我们的方法在不确定性估计、基于标准的视点选择和改进的新颖视图合成方面优于最先进的方法,这表明建模逐点出处可以提供几个优势。
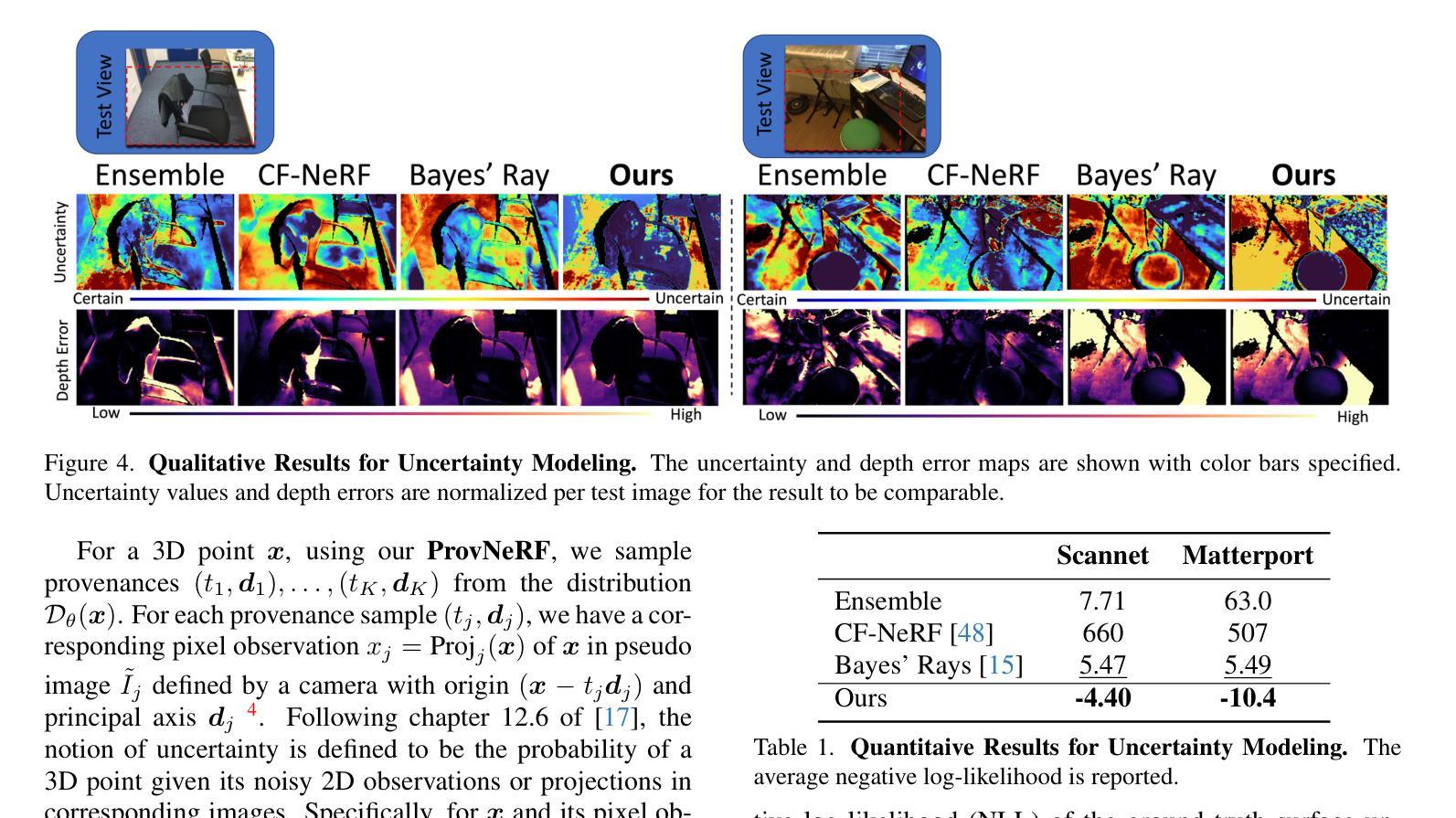
- 结论: (1):本工作提出 ProvNeRF,通过扩展随机过程的 IMLE 来增强传统 NeRF 表示,从而将每个点的出处建模为随机过程。ProvNeRF 可轻松应用于任何预训练的 NeRF 模型以及相关的训练相机位姿。我们展示了在各种下游应用中建模逐点出处的优势,包括不确定性建模、基于标准的视点选择以及与现有最先进方法相比改进的新颖视图合成。 (2):创新点:
- 提出 ProvNeRF,一种通过扩展随机过程的 IMLE 来增强传统 NeRF 表示的模型,从而将每个点的出处建模为随机过程。
- 证明了 ProvNeRF 可以轻松应用于任何预训练的 NeRF 模型以及相关的训练相机位姿。
- 展示了在各种下游应用中建模逐点出处的优势,包括不确定性建模、基于标准的视点选择以及与现有最先进方法相比改进的新颖视图合成。
</ol>
Methods:**
(1):我们将神经辐射场 (NeRF) 表示扩展为包含每个点的出处,即每个点的来源或从何处看到它。
(2):我们使用随机过程对每个点的出处进行建模,该随机过程由坐标 x∈R3 索引,其在 x 处的边际分布编码了 x 处的出处。
(3):我们通过扩展随机过程的隐式最大似然估计 (IMLE) 来实现这一点,该估计将潜在随机变量的变换学习为数据分布,其中每个数据样本都是一个标量或向量。
(4):我们提出 ProvNeRF,它通过扩展隐式概率模型(特别是 IMLE)来处理随机过程,从而将每个点的出处建模为随机过程。
(5):ProvNeRF 学习一个确定性变换 Hθ:Rb→R+×D3,该变换将每个潜在随机函数样本 Z∼Z 映射到一个函数 Dθ∼Dθ。
(6):为了优化 Dθ,我们扩展 IMLE 来对随机过程的分布进行建模。我们将 Eq.3 调整到函数空间,并证明它等价于在每个点 x 处对经验样本 ˆD(x)∼ˆD(x) 和模型样本 Dθ(x)∼Dθ(x) 进行逐点匹配。
性能: - 在不确定性估计、基于标准的视点选择和改进的新颖视图合成方面优于最先进的方法。
工作量: - 需要扩展随机过程的 IMLE 来对随机过程的分布进行建模。 - 需要调整 Eq.3 到函数空间,并证明它等价于在每个点 x 处对经验样本 ˆD(x)∼ˆD(x) 和模型样本 Dθ(x)∼Dθ(x) 进行逐点匹配。
点此查看论文截图

 wechat
wechat- alipay