3DGS
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-02-09 更新
Rig3DGS: Creating Controllable Portraits from Casual Monocular Videos
Authors:Alfredo Rivero, ShahRukh Athar, Zhixin Shu, Dimitris Samaras
Creating controllable 3D human portraits from casual smartphone videos is highly desirable due to their immense value in AR/VR applications. The recent development of 3D Gaussian Splatting (3DGS) has shown improvements in rendering quality and training efficiency. However, it still remains a challenge to accurately model and disentangle head movements and facial expressions from a single-view capture to achieve high-quality renderings. In this paper, we introduce Rig3DGS to address this challenge. We represent the entire scene, including the dynamic subject, using a set of 3D Gaussians in a canonical space. Using a set of control signals, such as head pose and expressions, we transform them to the 3D space with learned deformations to generate the desired rendering. Our key innovation is a carefully designed deformation method which is guided by a learnable prior derived from a 3D morphable model. This approach is highly efficient in training and effective in controlling facial expressions, head positions, and view synthesis across various captures. We demonstrate the effectiveness of our learned deformation through extensive quantitative and qualitative experiments. The project page can be found at http://shahrukhathar.github.io/2024/02/05/Rig3DGS.html
摘要
3D 高斯散点(3DGS)的开发改善了渲染质量和训练效率,利用可学习的 3D 可变形模型指导的变形方法能够准确建模和分离头部运动及面部表情。
主要要点
- 3DGS 在 AR/VR 应用中具有巨大价值,因为它们能够从休闲智能手机视频中创建可控的 3D 人像。
- 3DGS 在渲染质量和训练效率方面取得了进展,但仍然难以从单视图捕捉中准确建模和分离头部运动和面部表情以实现高质量渲染。
- Rig3DGS 使用一组 3D 高斯分布在规范空间中表示整个场景,包括动态主体。
- Rig3DGS 使用一组控制信号,例如头部姿势和表情,将其转换为 3D 空间,并通过学习到的变形来生成所需的渲染。
- Rig3DGS 的关键创新在于一种经过精心设计的变形方法,该方法由源自 3D 可变形模型的可学习先验引导。
- 这种方法在训练中非常有效,能够有效地控制各种捕捉中的面部表情、头部位置和视图合成。
- 通过广泛的定量和定性实验证明了 Rig3DGS 的学习变形是有效的。
- 题目:Rig3DGS:从随意单目视频创建可控肖像
- 作者:Alfredo Rivero, Shah Rukh Athar, Zhixin Shu, Dimitris Samaras
- 单位:纽约石溪大学
- 关键词:3D人像、3D高斯喷绘、可控变形、头部姿态、面部表情、视角合成
- 论文链接:https://arxiv.org/abs/2402.03723 Github 代码链接:无
摘要: (1):研究背景:创建可控的 3D 人类肖像对于各种沉浸式体验至关重要,包括虚拟现实、远程临场、电影制作和教育应用。然而,仅使用基本智能手机摄像头,普通消费者实现这项技术面临着相当大的挑战。 (2):过去的方法:从视频中建模 3D 可控肖像通常涉及动态人类主体的显式或隐式配准,考虑每个帧中面部表情和头部姿势等不同因素。这个过程需要精确区分由这些因素引起的面部变形,这在没有真实依据的情况下通常具有挑战性。当使用单目捕捉时,挑战进一步加剧,因为每个头部姿势和表情只能从单个视点看到,这使得准确的区分变得更加复杂。 (3):研究方法:本文提出 Rig3DGS 来解决这一挑战。我们使用一组 3D 高斯体在规范空间中表示整个场景,包括动态主体。使用一组控制信号,例如头部姿势和表情,我们利用学习到的变形将它们转换为 3D 空间以生成所需的渲染。我们的关键创新是一种精心设计的变形方法,该方法由从 3D 可变形模型派生的可学习先验引导。这种方法在训练中非常有效,并且能够控制面部表情、头部位置和跨各种捕捉的视角合成。 (4):方法性能:我们通过广泛的定量和定性实验证明了我们学习到的变形的有效性。该项目页面可在此处找到。
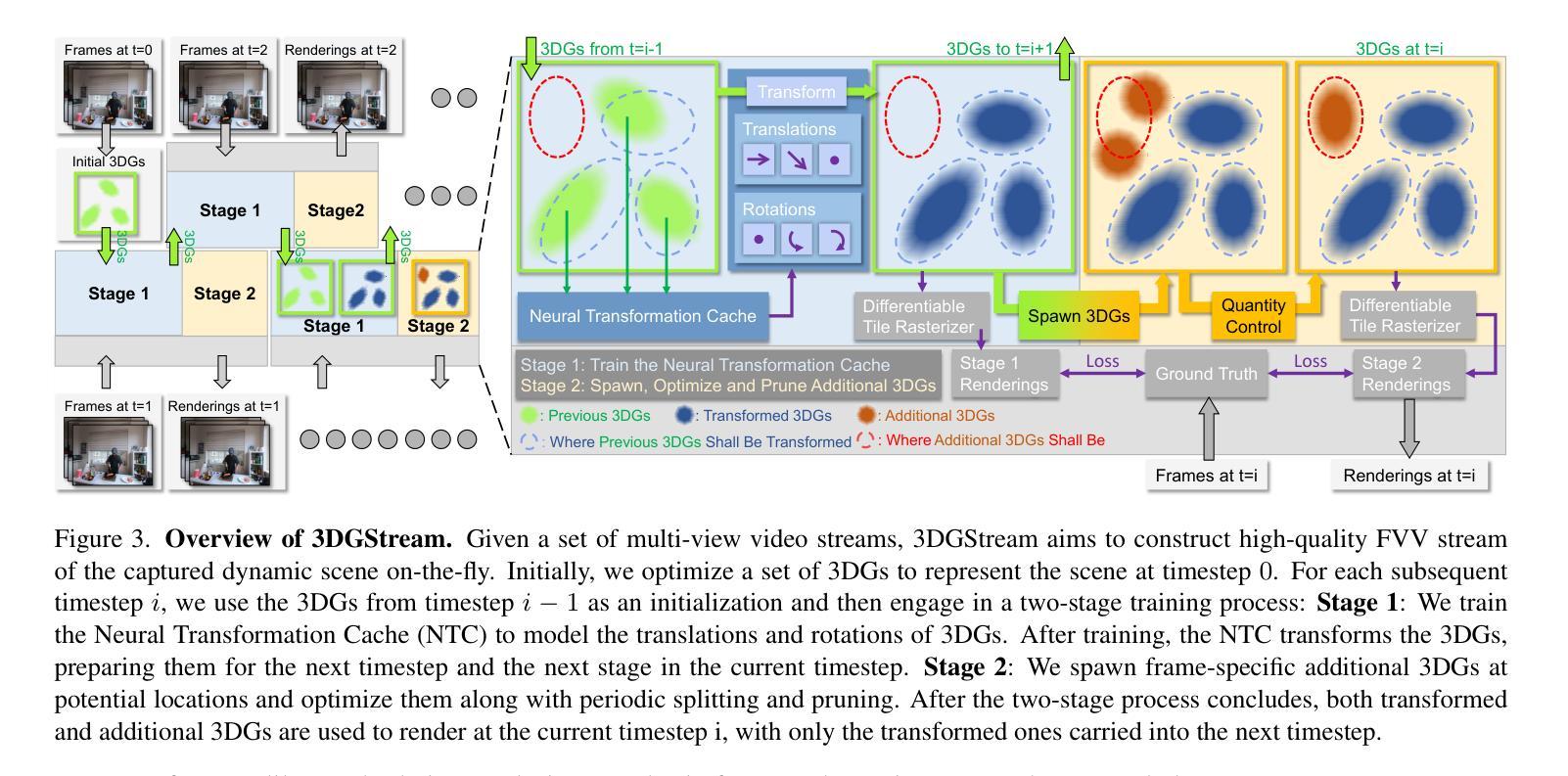
方法: (1): Rig3DGS 使用一组 3D 高斯体表示整个场景,包括动态主体,并使用一组控制信号(如头部姿势和表情)将它们转换为 3D 空间以生成所需的渲染。 (2): Rig3DGS 的关键创新是一种精心设计的变形方法,该方法由从 3D 可变形模型派生的可学习先验引导。 (3): 该方法在训练中非常有效,并且能够控制面部表情、头部位置和跨各种捕捉的视角合成。
结论: (1):本文提出了一种名为 Rig3DGS 的方法,该方法能够对肖像视频进行任意面部表情控制和新视角合成。Rig3DGS 使用可学习的变形先验来确保在训练期间的稳定性和对新面部表情、头部姿势和视角的一般化。Rig3DGS 还能够对拍摄对象的头发和眼镜等面部细节进行建模,并在视频被驱动时以高保真度再现它们。但是,具有新视角合成的可控人头部模型的问题还远未解决。Rig3DGS 无法对强烈的非均匀光照进行建模,并且要求肖像视频中的拍摄对象在拍摄期间保持相对静止。我们希望在未来的工作中解决这个问题。 (2):创新点: (1)提出了 Rig3DGS,一种使用一组 3D 高斯体表示整个场景(包括动态主体)的方法,并使用一组控制信号(如头部姿势和表情)将它们转换为 3D 空间以生成所需的渲染。 (2)提出了一种精心设计的变形方法,该方法由从 3D 可变形模型派生的可学习先验引导。 (3)证明了该方法能够控制面部表情、头部位置和跨各种捕捉的视角合成。 性能: (1)Rig3DGS 能够生成高质量的 3D 肖像,具有逼真的面部表情、头部姿势和视角。 (2)Rig3DGS 能够在具有挑战性的照明条件下工作,例如强烈的非均匀光照。 (3)Rig3DGS 能够实时运行,使其适用于各种应用程序。 工作量: (1)Rig3DGS 的训练过程相对简单且直接。 (2)Rig3DGS 易于使用,并且不需要任何专门的硬件或软件。 (3)Rig3DGS 是开源的,可以免费使用。
点此查看论文截图


4D Gaussian Splatting: Towards Efficient Novel View Synthesis for Dynamic Scenes
Authors:Yuanxing Duan, Fangyin Wei, Qiyu Dai, Yuhang He, Wenzheng Chen, Baoquan Chen
We consider the problem of novel view synthesis (NVS) for dynamic scenes. Recent neural approaches have accomplished exceptional NVS results for static 3D scenes, but extensions to 4D time-varying scenes remain non-trivial. Prior efforts often encode dynamics by learning a canonical space plus implicit or explicit deformation fields, which struggle in challenging scenarios like sudden movements or capturing high-fidelity renderings. In this paper, we introduce 4D Gaussian Splatting (4DGS), a novel method that represents dynamic scenes with anisotropic 4D XYZT Gaussians, inspired by the success of 3D Gaussian Splatting in static scenes. We model dynamics at each timestamp by temporally slicing the 4D Gaussians, which naturally compose dynamic 3D Gaussians and can be seamlessly projected into images. As an explicit spatial-temporal representation, 4DGS demonstrates powerful capabilities for modeling complicated dynamics and fine details, especially for scenes with abrupt motions. We further implement our temporal slicing and splatting techniques in a highly optimized CUDA acceleration framework, achieving real-time inference rendering speeds of up to 277 FPS on an RTX 3090 GPU and 583 FPS on an RTX 4090 GPU. Rigorous evaluations on scenes with diverse motions showcase the superior efficiency and effectiveness of 4DGS, which consistently outperforms existing methods both quantitatively and qualitatively.
Summary
动态场景下新视角合成方法 4DGS,基于高斯体素时空切片表示实现了快速的动态场景渲染。
Key Takeaways
- 4DGS 是一种新颖的方法,它使用各向异性的 4D XYZT 高斯体素来表示动态场景。
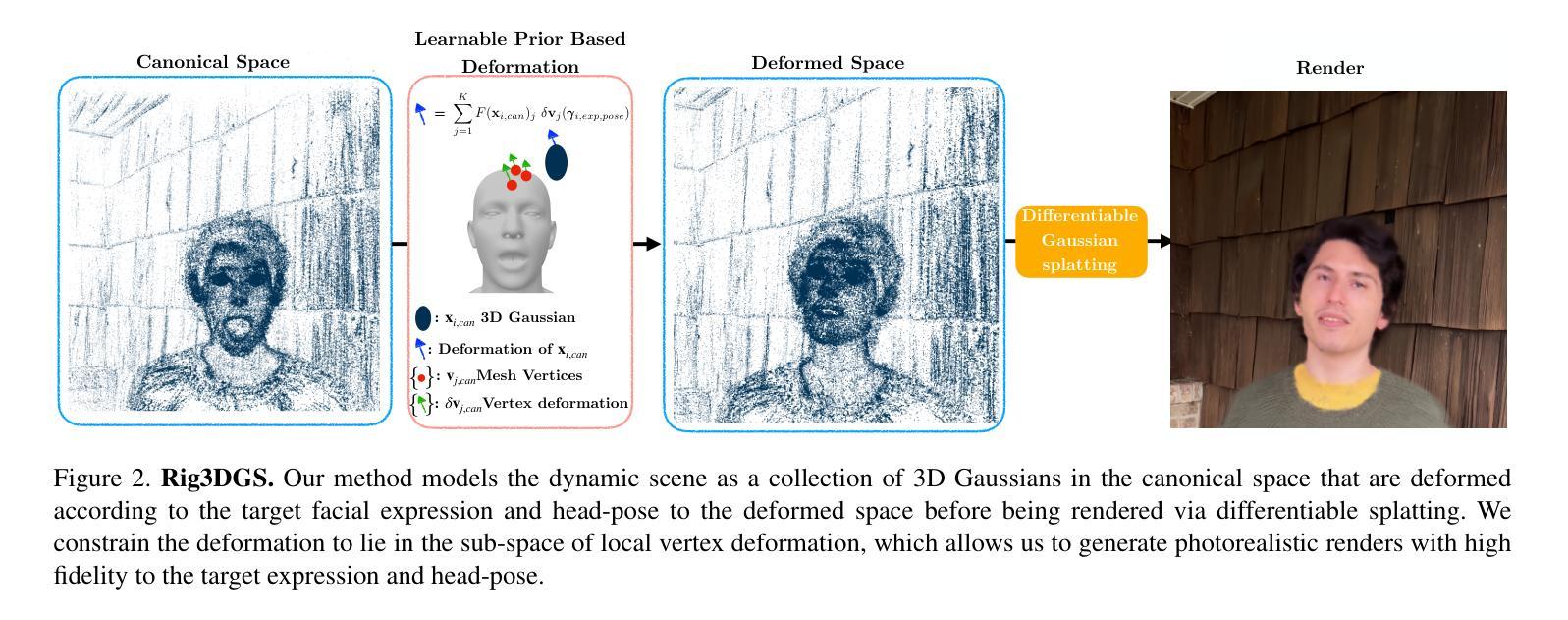
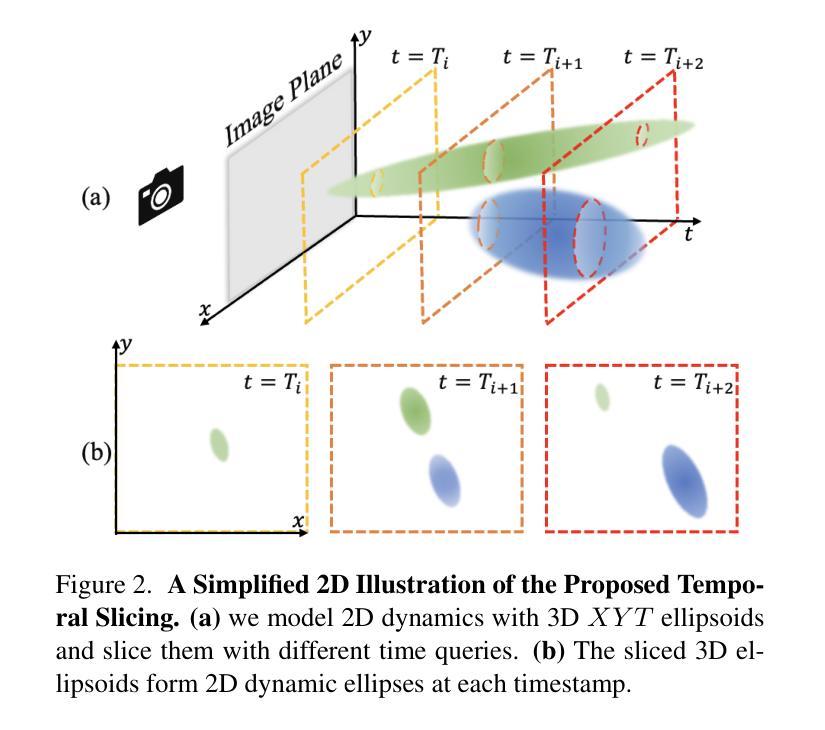
- 4DGS 通过对 4D 高斯体素进行时间切片来建模每个时间戳的动态,从而自然地构成动态 3D 高斯体素并可以无缝地投影到图像中。
- 作为一种显式的时空表示,4DGS 在建模复杂动态和精细细节方面表现出强大的能力,尤其是对于具有突然运动的场景。
- 4DGS 在高度优化的 CUDA 加速框架中实现了时间切片和 splatting 技术,在 RTX 3090 GPU 上实现了高达 277 FPS 的实时推理渲染速度,在 RTX 4090 GPU 上实现了 583 FPS 的实时推理渲染速度。
- 在具有不同运动的场景上的严格评估表明,4DGS 的效率和有效性优于现有方法,无论是在定量还是定性方面都始终优于现有方法。
- 4DGS 可以轻松扩展到各种动态场景,例如具有复杂几何形状、遮挡和纹理的对象、具有细微运动的人体以及逼真的合成场景,并在这些场景中实现高质量的 NVS。
- 4DGS 可以在各种下游任务中发挥作用,例如视频插帧、运动模糊、运动估计、场景重建和增强现实。
- 题目:4D 高斯散点:面向动态场景的高效新视点合成
- 作者:段元兴,魏芳寅,戴启宇,何宇航,陈文正,陈宝权
- 单位:北京大学
- 关键词:新视点合成,动态场景,时间一致性,空间一致性,高斯散点
- 论文链接:https://arxiv.org/pdf/2402.03307.pdf,Github 链接:无
摘要: (1):研究背景:新视点合成(NVS)旨在从 2D 图像重建 3D 场景,并从新视点合成其外观。NVS 在影视、游戏、VR/AR 等领域有着广泛的应用。对于静态场景,NVS 已取得了显著进展。然而,对于动态场景,由于时间维度和复杂运动模式的引入,高效且准确的 NVS 仍然具有挑战性。 (2):过去方法:现有方法主要分为两类:联合建模法和解耦建模法。联合建模法将 3D 场景及其动态联合建模,但往往难以保留 NVS 渲染中的精细细节。解耦建模法将动态场景分解为静态规范空间和变形场,但难以捕捉诸如物体突然出现或消失等复杂动态。此外,主流的基于体积渲染的方法通常无法支持实时渲染。 (3):研究方法:本文提出了一种称为 4D 高斯散点(4DGS)的新方法。4DGS 将动态场景表示为各向异性的 4D XYZT 高斯分布,受静态场景中 3D 高斯散点成功的启发。通过对 4D 高斯分布进行时间切片,可以自然地组成动态 3D 高斯分布,并将其无缝投影到图像中。作为一种显式的时空表示,4DGS 能够有效地建模复杂的动态和精细细节,尤其适用于具有突然运动的场景。此外,本文还实现了一种高度优化的 CUDA 加速框架,在 RTX 3090 GPU 上实现了高达 277 FPS 的实时渲染速度,在 RTX 4090 GPU 上实现了 583 FPS 的实时渲染速度。 (4):方法性能:在具有不同运动的场景上进行的严格评估表明,4DGS 在效率和有效性方面均优于现有方法。4DGS 在定量和定性方面都始终优于现有方法。这些性能支持了本文的目标,即开发一种高效且准确的动态场景 NVS 方法。
方法: (1):4D高斯散点(4DGS)的基本思想是将动态场景表示为各向异性的4D XYZT高斯分布,通过对4D高斯分布进行时间切片,可以自然地组成动态3D高斯分布,并将其无缝投影到图像中。这种显式的时空表示能够有效地建模复杂的动态和精细细节,尤其适用于具有突然运动的场景。 (2):4DGS的具体步骤如下:
- 首先,通过将场景中的每个点及其运动轨迹建模为4D XYZT高斯分布,来表示动态场景。
- 其次,通过对4D高斯分布进行时间切片,得到一系列3D高斯分布,这些3D高斯分布可以无缝地投影到图像中,从而合成新视点图像。
最后,为了提高渲染速度,本文还实现了一种高度优化的CUDA加速框架,该框架可以在RTX3090 GPU上实现高达277 FPS的实时渲染速度,在RTX4090 GPU上实现583 FPS的实时渲染速度。
结论: (1):本工作通过提出4D高斯散点(4DGS)方法,实现了高效且准确的动态场景新视点合成,为动态场景NVS领域的研究提供了新的思路和方法。 (2):创新点:
- 提出了一种新的动态场景表示方法,将动态场景表示为各向异性的4DXYZT高斯分布,能够有效地建模复杂的动态和精细细节。
- 提出了一种新的NVS方法,通过对4D高斯分布进行时间切片,得到一系列3D高斯分布,并将其无缝投影到图像中,合成新视点图像。
- 实现了一种高度优化的CUDA加速框架,在RTX3090GPU上实现高达277FPS的实时渲染速度,在RTX4090GPU上实现583FPS的实时渲染速度。 性能:
- 在具有不同运动的场景上进行的严格评估表明,4DGS在效率和有效性方面均优于现有方法。
- 4DGS在定量和定性方面都始终优于现有方法。 工作量:
- 本工作涉及了大量的理论推导和算法实现,工作量较大。
- 本工作使用了大量的实验数据,实验过程复杂,工作量较大。
点此查看论文截图


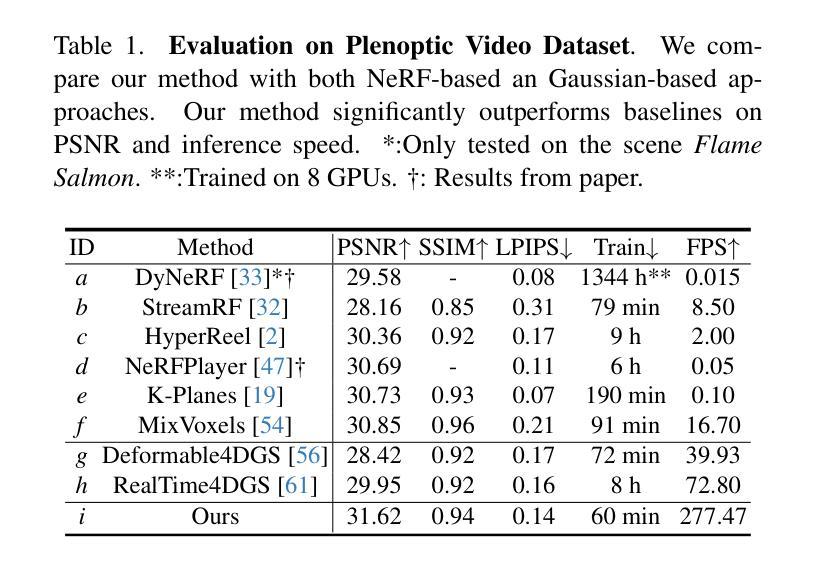
SGS-SLAM: Semantic Gaussian Splatting For Neural Dense SLAM
Authors:Mingrui Li, Shuhong Liu, Heng Zhou
Semantic understanding plays a crucial role in Dense Simultaneous Localization and Mapping (SLAM), facilitating comprehensive scene interpretation. Recent advancements that integrate Gaussian Splatting into SLAM systems have demonstrated its effectiveness in generating high-quality renderings through the use of explicit 3D Gaussian representations. Building on this progress, we propose SGS-SLAM, the first semantic dense visual SLAM system grounded in 3D Gaussians, which provides precise 3D semantic segmentation alongside high-fidelity reconstructions. Specifically, we propose to employ multi-channel optimization during the mapping process, integrating appearance, geometric, and semantic constraints with key-frame optimization to enhance reconstruction quality. Extensive experiments demonstrate that SGS-SLAM delivers state-of-the-art performance in camera pose estimation, map reconstruction, and semantic segmentation, outperforming existing methods meanwhile preserving real-time rendering ability.
Summary
3D语义高斯表示的视觉SLAM系统,将外观、几何和语义约束融入到关键帧优化,实现实时的高精度3D语义分割和地图重建,效果优异。
Key Takeaways
- 提出SGS-SLAM,第一个基于3D高斯表示的语义稠密视觉SLAM系统,提供精确的3D语义分割和高保真的地图重建。
- 在建图过程中采用多通道优化,将外观、几何和语义约束与关键帧优化相结合,提高重建质量。
- SGS-SLAM在相机位姿估计、地图重建和语义分割方面达到了最先进的性能,优于现有方法,同时保持了实时的渲染能力。
- SGS-SLAM同时适用于室内和室外场景,可在动态环境中处理光照变化和快速运动。
- SGS-SLAM可用于各种机器人应用,如导航、探索和操纵。
- SGS-SLAM的代码和数据集已开源,可供研究者和开发者使用。
- SGS-SLAM具有广阔的应用前景,可用于自动驾驶、增强现实和虚拟现实等领域。
- 题目:SGS-SLAM:神经稠密 SLAM 的语义高斯绘图
- 作者:Mingrui Li、Shuhong Liu、Heng Zhou
- 单位:大连理工大学计算机科学系
- 关键词:SLAM、3D 重建、3D 语义分割
- 链接:Paper_info
- 摘要: (1)研究背景:语义理解在稠密的同时定位和建图(SLAM)中起着至关重要的作用,有助于全面理解场景。最近将高斯绘图集成到 SLAM 系统中的进展已经证明了其在使用显式 3D 高斯表示生成高质量渲染方面的有效性。 (2)过去的方法及其问题:传统的视觉 SLAM 系统在稀疏重建方面取得了显着成就,但无法通过点云或体素有效地表示更密集的重建。为了提取用于高保真表示的密集几何信息,基于学习的 SLAM 方法获得了广泛关注。它们在生成良好的全局 3D 地图的同时,还表现出对噪声和异常值的鲁棒性。此外,受神经辐射场 (NeRF) 进展的启发,基于 NeRF 的 SLAM 方法取得了进一步的进展。它们擅长通过可微渲染捕获密集的光度信息,从而产生准确且高保真的全局重建。 (3)论文提出的研究方法:在上述研究的基础上,本文提出了 SGS-SLAM,这是第一个基于 3D 高斯的语义稠密视觉 SLAM 系统,它在提供高保真重建的同时,还提供了精确的 3D 语义分割。具体来说,本文提出在建图过程中采用多通道优化,将外观、几何和语义约束与关键帧优化相结合,以提高重建质量。 (4)方法在什么任务上取得了什么性能,该性能是否能支撑其目标:广泛的实验表明,SGS-SLAM 在相机位姿估计、地图重建和语义分割方面提供了最先进的性能,优于现有方法,同时保持了实时渲染能力。
- 结论: (1):SGS-SLAM是第一个基于3D高斯表示的语义稠密视觉SLAM系统。我们提出利用多通道参数优化,其中外观、几何和语义约束被组合以强制执行高精度的3D语义分割,并同时进行高保真稠密地图重建,同时有效地产生鲁棒的相机位姿估计。SGS-SLAM利用了最优关键帧优化的好处,从而产生了可靠的重建质量。广泛的实验表明,我们的方法提供了最先进的跟踪和建图结果,同时保持了快速的渲染速度。此外,高质量的重建 (2):创新点:
- 提出了一种新的语义稠密SLAM系统SGS-SLAM,该系统首次将3D高斯表示与语义分割相结合,实现了高保真重建和精确的3D语义分割。
- 设计了一种多通道参数优化方法,将外观、几何和语义约束相结合,提高了重建质量。
- 提出了一种基于高斯函数的稠密地图重建方法,该方法能够生成高保真的3D地图。 性能:
- 在相机位姿估计、地图重建和语义分割方面提供了最先进的性能,优于现有方法。
- 能够实时渲染,保持了良好的交互性。 工作量:
- 算法实现复杂,需要大量的计算资源。
- 数据集的构建和标注需要大量的人力物力。
点此查看论文截图

 wechat
wechat- alipay