NeRF
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-02-09 更新
NeRF as Non-Distant Environment Emitter in Physics-based Inverse Rendering
Authors:Jingwang Ling, Ruihan Yu, Feng Xu, Chun Du, Shuang Zhao
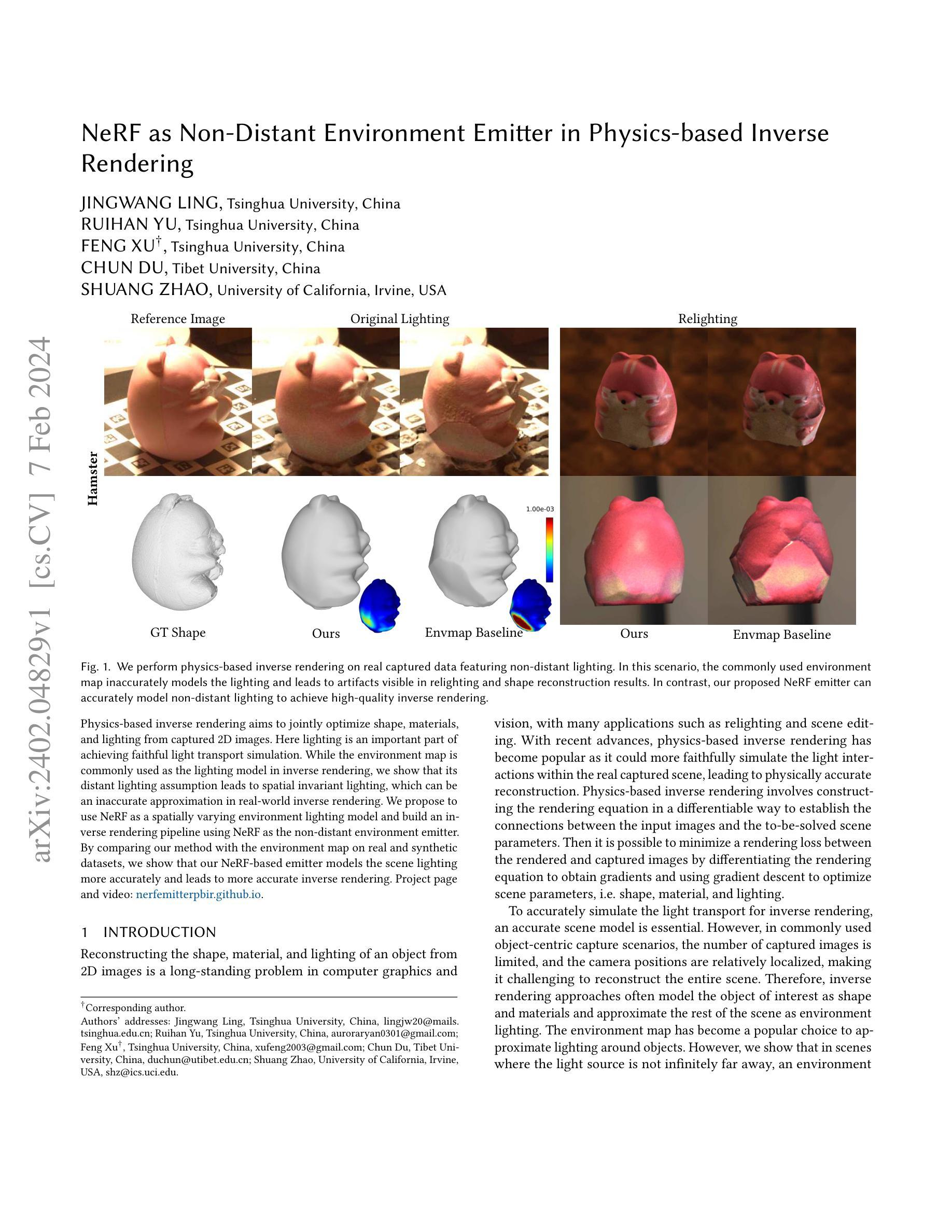
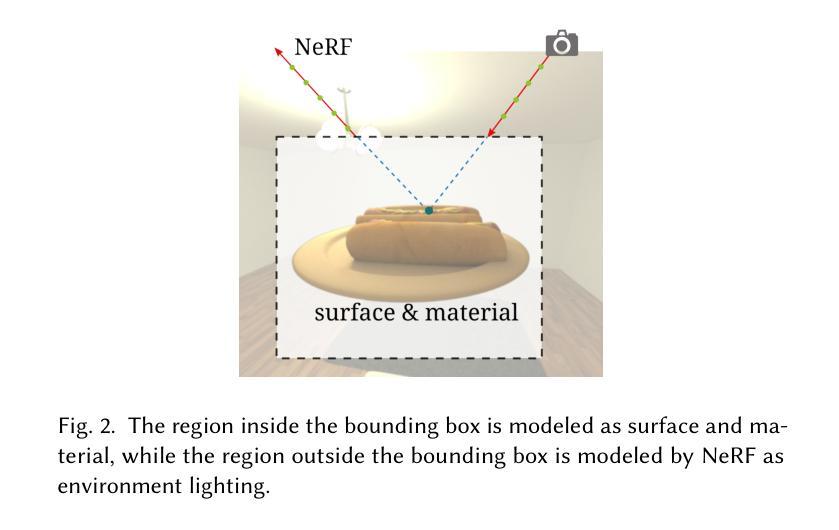
Physics-based inverse rendering aims to jointly optimize shape, materials, and lighting from captured 2D images. Here lighting is an important part of achieving faithful light transport simulation. While the environment map is commonly used as the lighting model in inverse rendering, we show that its distant lighting assumption leads to spatial invariant lighting, which can be an inaccurate approximation in real-world inverse rendering. We propose to use NeRF as a spatially varying environment lighting model and build an inverse rendering pipeline using NeRF as the non-distant environment emitter. By comparing our method with the environment map on real and synthetic datasets, we show that our NeRF-based emitter models the scene lighting more accurately and leads to more accurate inverse rendering. Project page and video: https://nerfemitterpbir.github.io/.
PDF Project page and video: https://nerfemitterpbir.github.io/
摘要
神经辐射场可以作为空间非距离环境光源,用于物理逆渲染,使逆渲染更加真实准确。
主要要点
- 基于物理的逆渲染旨在联合优化从捕获的 2D 图像中提取的形状、材质和光照。
- 在逆渲染中,通常使用环境贴图作为光照模型,但这种假设会导致空间不变的光照,这在真实世界的逆渲染中可能是不准确的近似。
- 提出使用神经辐射场作为空间可变的环境光照模型,并构建了一个以神经辐射场作为非距离环境光源的逆渲染管道。
- 将方法与环境贴图在真实和合成数据集上进行比较,结果表明,基于神经辐射场的光源可以更准确地模拟场景光照,并实现更准确的逆渲染。
- 项目页面和视频:https://nerfemitterpbir.github.io/。
- 题目:基于物理的反演渲染中,NeRF 作为非远处环境发射器
- 作者:Jingwang Ling、Ruihan Yu、Feng Xu、Chun Du、Shuang Zhao
- 单位:清华大学
- 关键词:NeRF、物理反演渲染、环境光照、形状重建
- 论文链接:https://arxiv.org/pdf/2402.04829.pdf,Github 链接:None
摘要: (1)研究背景:基于物理的反演渲染旨在从捕获的 2D 图像中联合优化形状、材质和光照。其中,光照是实现真实光照传输模拟的重要组成部分。环境贴图是反演渲染中常用的光照模型,但我们发现,在光源不是无限远处的场景中,环境贴图的空间不变光照假设会导致空间不变的光照,这在现实世界中的反演渲染中可能是不准确的近似。 (2)过去方法及问题:过去的方法通常使用环境贴图来近似物体周围的光照,但这种方法在光源不是无限远处的场景中会导致不准确的结果。 (3)研究方法:我们提出使用 NeRF 作为空间变化的环境光照模型,并构建了一个以 NeRF 作为非远处环境发射器的反演渲染管道。通过在真实和合成数据集上与环境贴图进行比较,我们证明了我们的 NeRF 模型可以更准确地模拟场景光照,并实现更准确的反演渲染。 (4)方法性能:我们的方法在真实和合成数据集上都取得了比环境贴图更好的结果。在真实数据集上,我们的方法在重照明和形状重建任务上都取得了更好的性能。在合成数据集上,我们的方法在重照明、形状重建和材质估计任务上都取得了更好的性能。这些结果证明了我们的方法可以更准确地模拟场景光照,并实现更准确的反演渲染。
方法: (1)提出使用 NeRF 作为空间变化的环境光照模型,构建以 NeRF 作为非远处环境发射器的反演渲染管道。 (2)利用真实和合成数据集,与环境贴图进行比较,证明 NeRF 模型可以更准确地模拟场景光照,实现更准确的反演渲染。 (3)在真实和合成数据集上,与环境贴图相比,在重照明、形状重建和材质估计任务上都取得了更好的性能。
结论: (1):本文提出了一种基于 NeRF 的反演渲染管道,该管道将 NeRF 用作非远处环境发射器,可以更准确地模拟场景光照,并实现更准确的反演渲染。 (2):创新点:
- 使用 NeRF 作为空间变化的环境光照模型,可以更准确地模拟场景光照。
- 构建了一个以 NeRF 作为非远处环境发射器的反演渲染管道,可以实现更准确的反演渲染。
- 在真实和合成数据集上,与环境贴图相比,在重照明、形状重建和材质估计任务上都取得了更好的性能。 性能:
- 在真实数据集上,在重照明和形状重建任务上都取得了更好的性能。
- 在合成数据集上,在重照明、形状重建和材质估计任务上都取得了更好的性能。 工作量:
- 需要训练 NeRF 模型,这可能需要大量的数据和计算资源。
- 需要构建反演渲染管道,这可能需要大量的编程工作。
点此查看论文截图
OV-NeRF: Open-vocabulary Neural Radiance Fields with Vision and Language Foundation Models for 3D Semantic Understanding
Authors:Guibiao Liao, Kaichen Zhou, Zhenyu Bao, Kanglin Liu, Qing Li
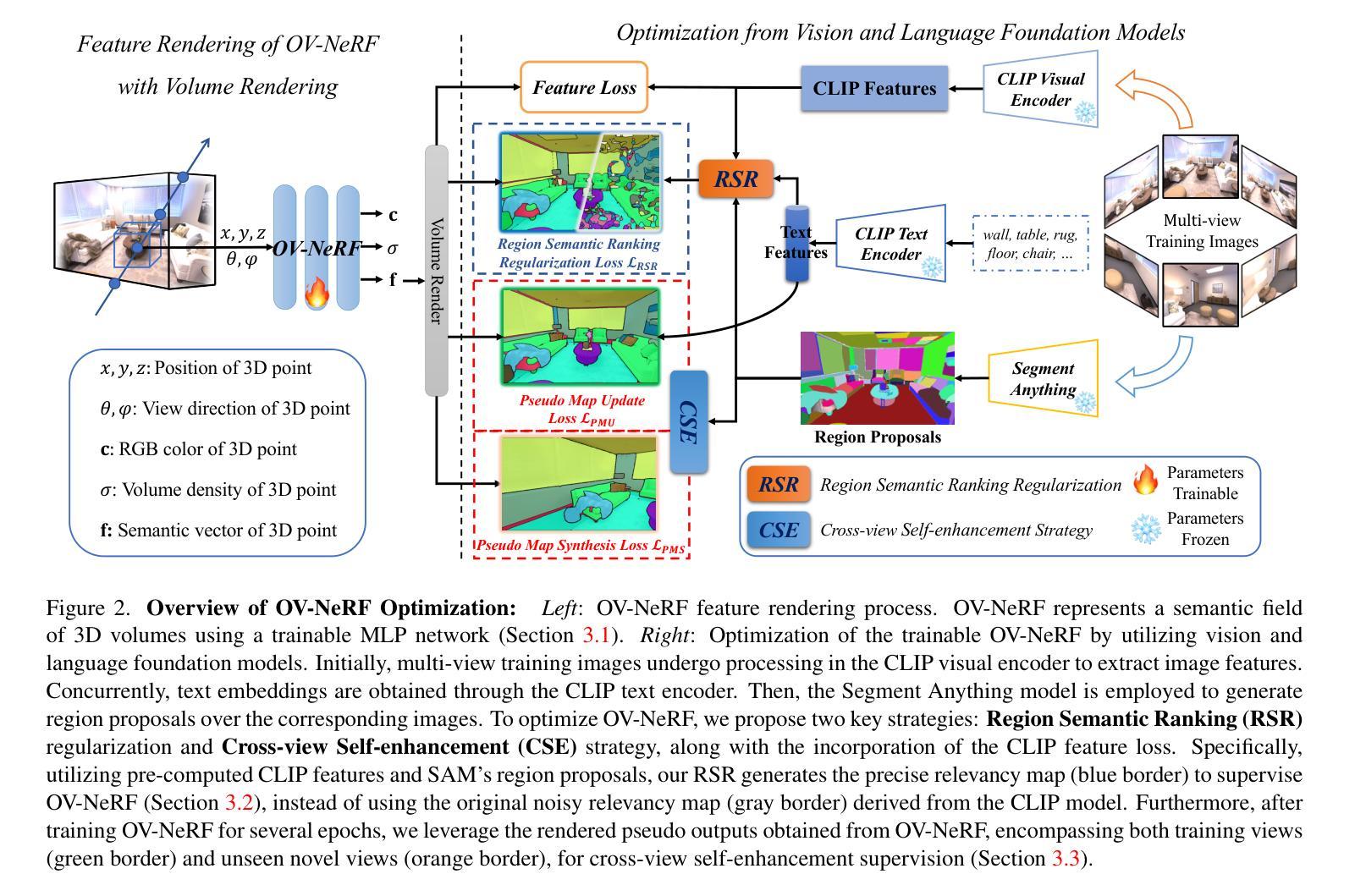
The development of Neural Radiance Fields (NeRFs) has provided a potent representation for encapsulating the geometric and appearance characteristics of 3D scenes. Enhancing the capabilities of NeRFs in open-vocabulary 3D semantic perception tasks has been a recent focus. However, current methods that extract semantics directly from Contrastive Language-Image Pretraining (CLIP) for semantic field learning encounter difficulties due to noisy and view-inconsistent semantics provided by CLIP. To tackle these limitations, we propose OV-NeRF, which exploits the potential of pre-trained vision and language foundation models to enhance semantic field learning through proposed single-view and cross-view strategies. First, from the single-view perspective, we introduce Region Semantic Ranking (RSR) regularization by leveraging 2D mask proposals derived from SAM to rectify the noisy semantics of each training view, facilitating accurate semantic field learning. Second, from the cross-view perspective, we propose a Cross-view Self-enhancement (CSE) strategy to address the challenge raised by view-inconsistent semantics. Rather than invariably utilizing the 2D inconsistent semantics from CLIP, CSE leverages the 3D consistent semantics generated from the well-trained semantic field itself for semantic field training, aiming to reduce ambiguity and enhance overall semantic consistency across different views. Extensive experiments validate our OV-NeRF outperforms current state-of-the-art methods, achieving a significant improvement of 20.31% and 18.42% in mIoU metric on Replica and Scannet, respectively. Furthermore, our approach exhibits consistent superior results across various CLIP configurations, further verifying its robustness.
Summary
神经辐射场(NeRF)技术通过结合视觉和语言基础模型,提升了NeRF在开放词汇表3D语义感知中的表现。
Key Takeaways
- OV-NeRF 提出了一种单视图和跨视图策略,将NeRF用于开放词汇表3D语义感知。
- 利用 SAM 提取的 2D 掩模建议,引入区域语义排序 (RSR) 正则化,以纠正每个训练视图的语义噪声。
- 提出跨视图自增强 (CSE) 策略,利用训练语义场本身生成的 3D 一致语义,减少语义模糊性和增强语义一致性。
- OV-NeRF 在 Replica 和 Scannet 数据集上分别实现了 20.31% 和 18.42% 的 mIoU 指标提升,优于现有最优方法。
- OV-NeRF 在各种 CLIP 配置下均表现出优异的性能,验证了其鲁棒性。
- 题目:OV-NeRF:具有视觉和语言的开放词汇神经辐射场
- 作者:廖桂标,周凯晨,鲍振宇,刘康林,李庆
- 单位:北京大学
- 关键词:神经辐射场,开放词汇,语义理解,视觉语言模型
- 链接:https://arxiv.org/abs/2402.04648
摘要: (1) 研究背景:神经辐射场(NeRF)是一种强大的表示方法,可以捕捉复杂真实世界的 3D 场景。然而,在开放词汇 3D 语义感知任务中实现全面的 3D 语义理解仍然是一个具有挑战性的问题。 (2) 过去的方法:过去的方法直接从对比视觉语言预训练(CLIP)中提取语义,用于语义场学习,但遇到了来自 CLIP 的嘈杂和视图不一致语义的困难。 (3) 研究方法:为了解决这些限制,本文提出了 OV-NeRF,它利用预训练的视觉语言基础模型的潜力,通过提出的单视图和跨视图策略来增强语义场学习。 (4) 性能表现:OV-NeRF 在 Replica 和 Scannet 上分别在 mIoU 度量中取得了 20.31% 和 18.42% 的显着改进。此外,该方法在各种 CLIP 配置中表现出一致的优异结果,进一步验证了其鲁棒性。
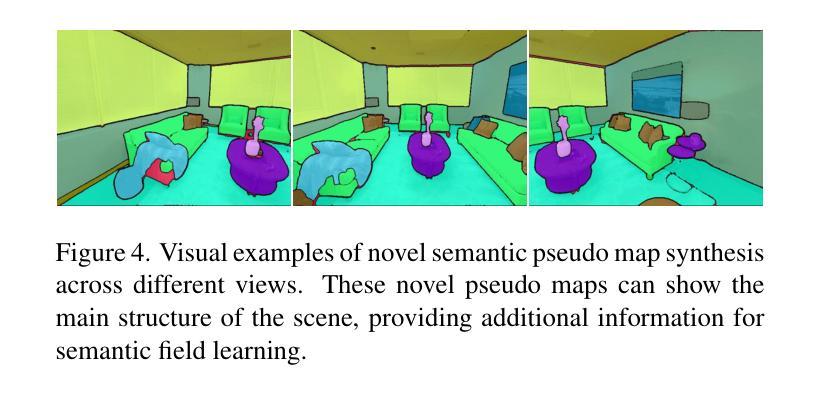
方法: (1) 提出 OV-NeRF,利用预训练的视觉语言基础模型的潜力,通过提出的单视图和跨视图策略来增强语义场学习。 (2) 利用预先计算的 CLIP 特征和 SAM 的区域提议来生成精确的相关性图,以监督 OV-NeRF,而不是使用源自 CLIP 模型的原始噪声相关性图。 (3) 在训练 OV-NeRF 数个 epoch 后,利用从 OV-NeRF 获得的渲染伪输出,包括训练视图和未见新颖视图,用于跨视图自我增强监督。
结论: (1):本工作通过利用视觉语言基础模型的能力,提出 OV-NeRF 来解决基于 NeRF 的 3D 语义理解挑战。在 OV-NeRF 中,提出的区域语义排序(RSR)正则化产生精确的单视图相关性图来训练 OV-NeRF,跨视图自我增强确保视图一致的分割结果。实验结果表明,我们的方法在合成和真实世界基准数据集上以很大优势优于 SOTA 方法,显示了我们方法的优越性。此外,我们的方法在不同的 CLIP 配置中始终表现出优异的性能,肯定了其通用性。 (2):创新点: 提出了一种新的 NeRF 模型 OV-NeRF,该模型利用预训练的视觉语言基础模型的潜力,通过提出的单视图和跨视图策略来增强语义场学习。 提出了一种新的区域语义排序(RSR)正则化,该正则化产生精确的单视图相关性图来训练 OV-NeRF。 提出了一种新的跨视图自我增强方法,该方法利用从 OV-NeRF 获得的渲染伪输出,包括训练视图和未见新颖视图,用于跨视图自我增强监督。 性能: OV-NeRF 在 Replica 和 Scannet 上分别在 mIoU 度量中取得了 20.31% 和 18.42% 的显着改进。 该方法在各种 CLIP 配置中表现出一致的优异结果,进一步验证了其鲁棒性。 工作量: 该方法需要预先计算 CLIP 特征和 SAM 的区域提议,这可能会增加计算成本。 该方法需要训练多个 epoch,这可能会增加训练时间。
点此查看论文截图



GSN: Generalisable Segmentation in Neural Radiance Field
Authors:Vinayak Gupta, Rahul Goel, Sirikonda Dhawal, P. J. Narayanan
Traditional Radiance Field (RF) representations capture details of a specific scene and must be trained afresh on each scene. Semantic feature fields have been added to RFs to facilitate several segmentation tasks. Generalised RF representations learn the principles of view interpolation. A generalised RF can render new views of an unknown and untrained scene, given a few views. We present a way to distil feature fields into the generalised GNT representation. Our GSN representation generates new views of unseen scenes on the fly along with consistent, per-pixel semantic features. This enables multi-view segmentation of arbitrary new scenes. We show different semantic features being distilled into generalised RFs. Our multi-view segmentation results are on par with methods that use traditional RFs. GSN closes the gap between standard and generalisable RF methods significantly. Project Page: https://vinayak-vg.github.io/GSN/
PDF Accepted at the Main Technical Track of AAAI 2024
Summary
利用几个视图就可以渲染未知且未训练场景的新视图,并提供一致的逐像素语义特征。
Key Takeaways
- 传统辐射场表示捕获特定场景的细节,必须在每个场景上重新训练。
- 语义特征字段已添加到射频中以促进多项分割任务。
- 广义射频表示学习了视图插值原理。
- 给定几个视图,广义射频可以渲染未知且未训练场景的新视图。
- 我们提供了一种将特征字段提炼成广义 GNT 表示的方法。
- 我们的 GSN 表示可以快速生成未见场景的新视图,并提供一致的逐像素语义特征。
- 这允许对任意新场景进行多视图分割。
- 题目:GSN:神经辐射场中的可泛化分割
- 作者:Vinayak Gupta,Rahul Goel,Sirikonda Dhawal,P.J. Narayanan
- 隶属机构:印度理工学院马德拉斯分校
- 关键词:神经辐射场、可泛化分割、语义特征场
- 论文链接:https://arxiv.org/abs/2402.04632 Github 链接:无
摘要: (1)研究背景:传统的神经辐射场(RF)表示可以捕捉特定场景的细节,但必须针对每个场景重新训练。语义特征场已被添加到 RF 中以促进多项分割任务。泛化的 RF 表示学习视图插值原理。给定几个视图,泛化的 RF 可以渲染未知且未训练场景的新视图。 (2)过去的方法及其问题:本文提出了一种将特征场提炼到泛化的 GNT 表示中的方法。我们的 GSN 表示可以即时生成未见场景的新视图,同时提供一致的逐像素语义特征。这使得任意新场景的多视图分割成为可能。我们展示了将不同语义特征提取到泛化的 RF 中。我们的多视图分割结果与使用传统 RF 的方法相当。GSN 显着缩小了标准 RF 方法和可泛化 RF 方法之间的差距。 (3)研究方法:过去的 RF 表示学习特定场景的细节,必须针对每个场景重新训练。语义特征场已被添加到 RF 中以促进多项分割任务。泛化的 RF 表示学习视图插值原理。给定几个视图,泛化的 RF 可以渲染未知且未训练场景的新视图。我们提出了一种将特征场提炼到泛化的 GNT 表示中的方法。我们的 GSN 表示可以即时生成未见场景的新视图,同时提供一致的逐像素语义特征。这使得任意新场景的多视图分割成为可能。我们展示了将不同语义特征提取到泛化的 RF 中。我们的多视图分割结果与使用传统 RF 的方法相当。GSN 显着缩小了标准 RF 方法和可泛化 RF 方法之间的差距。 (4)方法的性能:我们的多视图分割结果与使用传统 RF 的方法相当。GSN 显着缩小了标准 RF 方法和可泛化 RF 方法之间的差距。这些性能支持了我们的目标。
方法: (1)首先,我们修改 GNT 架构以帮助语义特征提取。 (2)然后,我们描述了我们的两阶段训练蒸馏过程。 (3)最后,我们描述了如何使用蒸馏特征执行多视图分割。
结论: (1):本文提出了一种新的多视图分割方法,其主要优势在于其泛化性,即它可以在任意新场景上执行分割而无需任何训练。这使其区别于以前的方法。我们将我们的结果与早期方法进行了比较,并表明我们的性能与它们相当,同时可以泛化到未见场景。这是将泛化神经辐射场的应用拉近到特定场景辐射场的一大步。我们方法预测的特征可用于多种下游任务。 (2):创新点:提出了将特征场提炼到泛化的 GNT 表示中的方法,该表示可以即时生成未见场景的新视图,同时提供一致的逐像素语义特征。 性能:我们的多视图分割结果与使用传统 RF 的方法相当。GSN 显着缩小了标准 RF 方法和可泛化 RF 方法之间的差距。 工作量:我们的方法依赖于基于 transformer 的架构,因此渲染过程与几种特定场景的辐射场方法相比固有地缓慢。提高渲染速度可以显着改善我们基于笔划的分割方法所需的人机交互体验。我们将泛化辐射场的渲染速度改进留作未来的工作。目前,我们的方法执行多视图分割,因为它使用基于图像的渲染。某些应用程序需要 3D 分割而不是多视图分割。因此,可泛化的 3D 分割框架有望成为未来的工作。
点此查看论文截图




BirdNeRF: Fast Neural Reconstruction of Large-Scale Scenes From Aerial Imagery
Authors:Huiqing Zhang, Yifei Xue, Ming Liao, Yizhen Lao
In this study, we introduce BirdNeRF, an adaptation of Neural Radiance Fields (NeRF) designed specifically for reconstructing large-scale scenes using aerial imagery. Unlike previous research focused on small-scale and object-centric NeRF reconstruction, our approach addresses multiple challenges, including (1) Addressing the issue of slow training and rendering associated with large models. (2) Meeting the computational demands necessitated by modeling a substantial number of images, requiring extensive resources such as high-performance GPUs. (3) Overcoming significant artifacts and low visual fidelity commonly observed in large-scale reconstruction tasks due to limited model capacity. Specifically, we present a novel bird-view pose-based spatial decomposition algorithm that decomposes a large aerial image set into multiple small sets with appropriately sized overlaps, allowing us to train individual NeRFs of sub-scene. This decomposition approach not only decouples rendering time from the scene size but also enables rendering to scale seamlessly to arbitrarily large environments. Moreover, it allows for per-block updates of the environment, enhancing the flexibility and adaptability of the reconstruction process. Additionally, we propose a projection-guided novel view re-rendering strategy, which aids in effectively utilizing the independently trained sub-scenes to generate superior rendering results. We evaluate our approach on existing datasets as well as against our own drone footage, improving reconstruction speed by 10x over classical photogrammetry software and 50x over state-of-the-art large-scale NeRF solution, on a single GPU with similar rendering quality.
摘要
鸟瞰 NeRF:基于神经辐射场的大规模场景重建。
要点
- 针对大规模场景重建,提出了基于神经辐射场的 BirdNeRF 算法。
- BirdNeRF 将大场景图像集分解为多个小集合,每个小集合训练单独的 NeRF 模型。
- 这种分解方法将渲染时间与场景大小解耦,并使渲染能够无缝扩展到任意大的环境。
- 此外,它允许对环境进行逐块更新,从而提高重建过程的灵活性和适应性。
- 提出了一种基于投影的新颖视角重新渲染策略,有助于有效利用独立训练的子场景生成更好的渲染结果。
- 在现有数据集以及我们自己的无人机航拍视频上评估了我们的方法,在单个 GPU 上将重建速度提高了 10 倍(相对于经典摄影测量软件)和 50 倍(相对于最先进的大规模 NeRF 解决方案),同时渲染质量相似。
- 题目:鸟瞰神经辐射场:使用航拍图像快速神经重建大场景
- 作者:张慧清、薛一飞、廖明、老一真
- 单位:无
- 关键词:神经辐射场、大规模重建、航拍图像、空间分解、投影引导
- 链接:https://arxiv.org/abs/2402.04554 Github:无
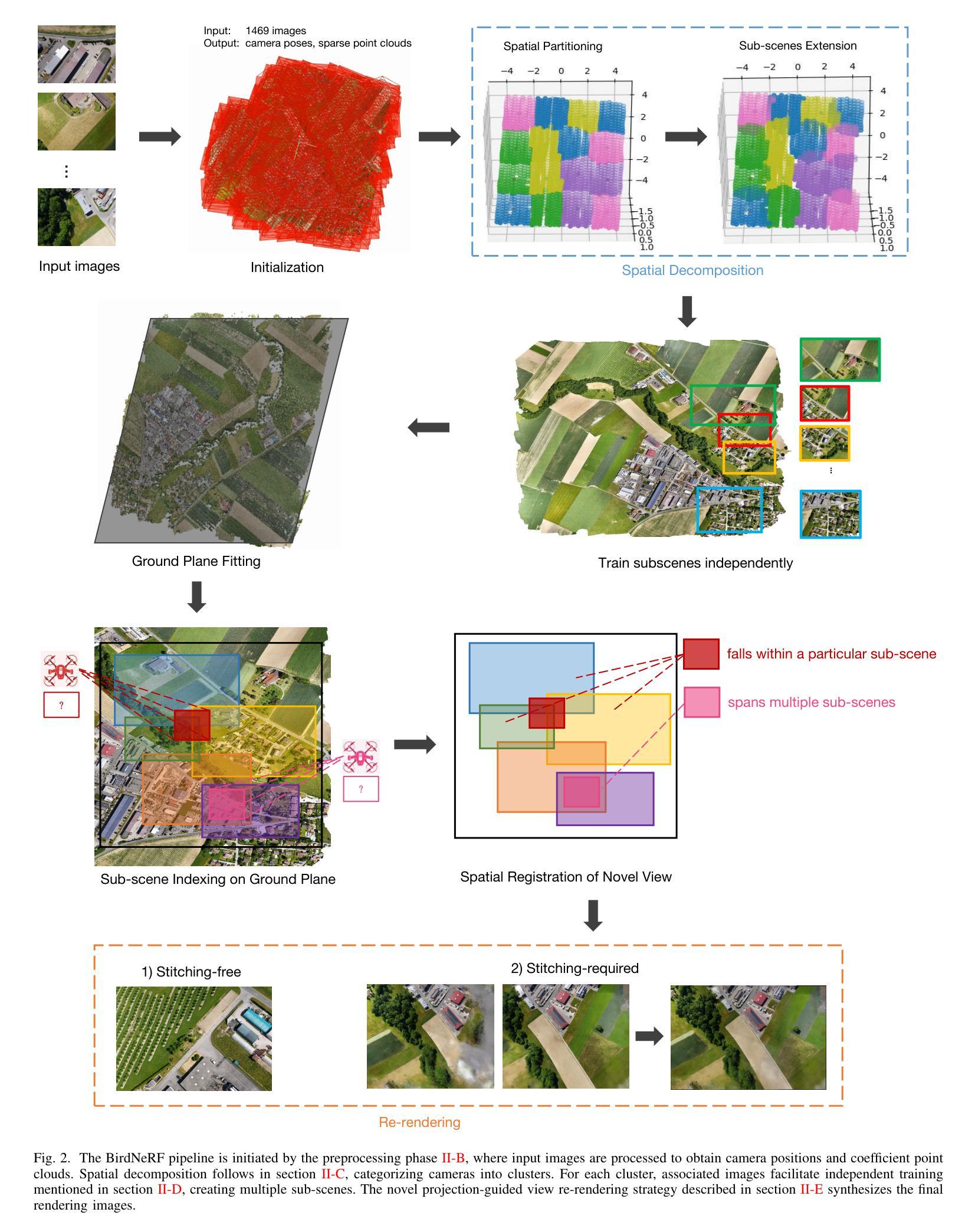
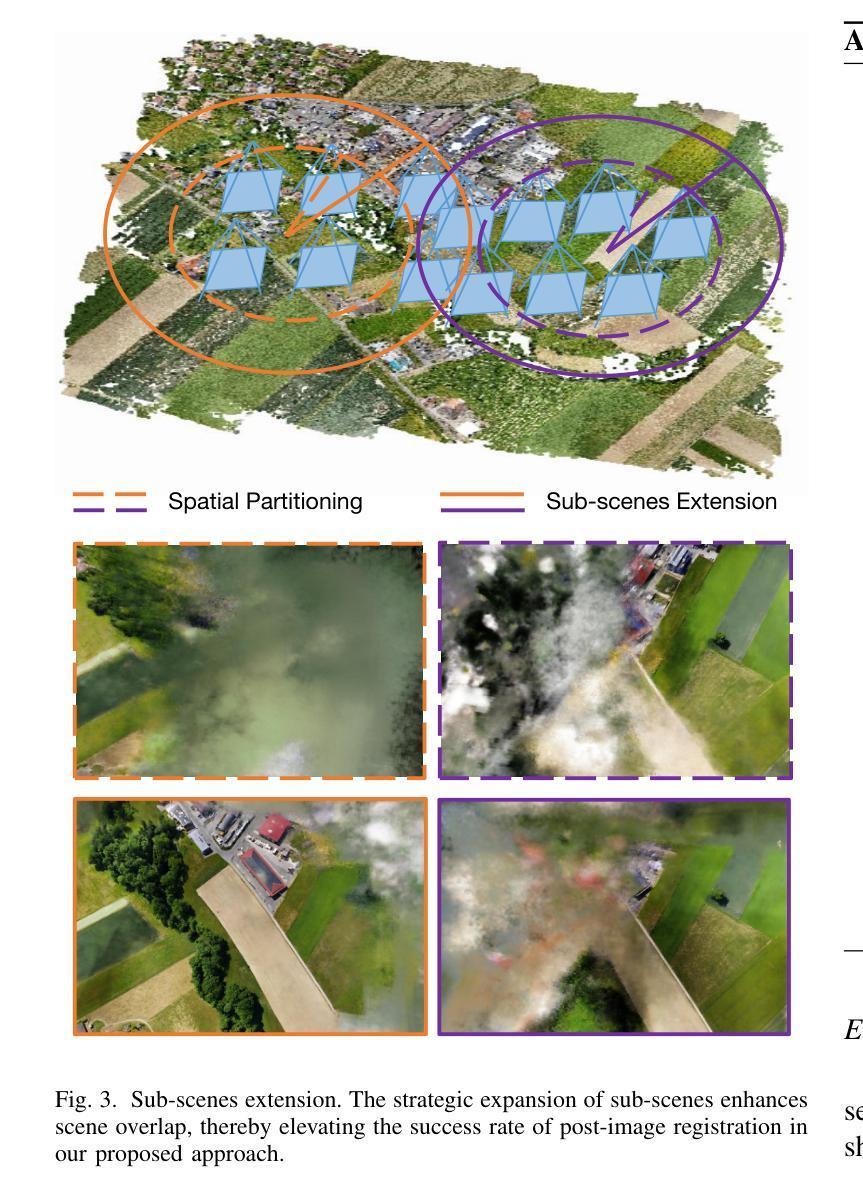
摘要: (1):随着航空测量技术的进步,获取高分辨率图像变得更加容易和经济实惠,基于图像的 3D 重建已成为一个活跃的研究领域,并在城市规划、导航、虚拟旅游、房地产和灾害管理等领域有着广泛的应用。 (2):现有的基于图像的 3D 重建技术主要分为传统的基于几何的方法和基于神经网络的方法。基于几何的方法通常需要大量的人工干预,并且对图像的质量和数量非常敏感。基于神经网络的方法,例如神经辐射场 (NeRF),可以自动从图像中学习场景的 3D 表示,并且对图像的质量和数量不太敏感。然而,NeRF 在处理大规模场景时面临着训练速度慢、渲染时间长和容易产生伪影等挑战。 (3):为了解决这些挑战,本文提出了一种新的 NeRF 变体,称为鸟瞰神经辐射场 (BirdNeRF)。BirdNeRF 使用了一种新的空间分解算法,将大规模航拍图像集分解成多个较小的子集,并分别训练每个子集的 NeRF 模型。这种分解方法不仅可以减少训练时间和渲染时间,还可以提高重建的质量。此外,BirdNeRF 还提出了一种新的投影引导的新视图重新渲染策略,可以有效地利用独立训练的子场景来生成高质量的渲染结果。 (4):在多个数据集上的实验结果表明,BirdNeRF 在重建速度和质量方面都优于现有的方法。在单个 GPU 上,BirdNeRF 的重建速度比传统的摄影测量软件快 10 倍,比最先进的大规模 NeRF 解决方案快 50 倍,同时具有相似的渲染质量。
方法: (1) 将大场景分解为多个较小的子场景,分别训练每个子场景的 NeRF 模型。 (2) 使用一种新的投影引导的新视图重新渲染策略,有效地利用独立训练的子场景来生成高质量的渲染结果。
结论: (1):本文提出了一种新的NeRF变体,称为鸟瞰神经辐射场(BirdNeRF),可以快速重建大规模场景。BirdNeRF使用了一种新的空间分解算法,将大规模航拍图像集分解成多个较小的子集,并分别训练每个子集的NeRF模型。这种分解方法不仅可以减少训练时间和渲染时间,还可以提高重建的质量。此外,BirdNeRF还提出了一种新的投影引导的新视图重新渲染策略,可以有效地利用独立训练的子场景来生成高质量的渲染结果。 (2):创新点:
- 提出了一种新的NeRF变体,称为鸟瞰神经辐射场(BirdNeRF),可以快速重建大规模场景。
- 提出了一种新的空间分解算法,将大规模航拍图像集分解成多个较小的子集,并分别训练每个子集的NeRF模型。
- 提出了一种新的投影引导的新视图重新渲染策略,可以有效地利用独立训练的子场景来生成高质量的渲染结果。
性能: - 在单个GPU上,BirdNeRF的重建速度比传统的摄影测量软件快10倍,比最先进的大规模NeRF解决方案快50倍,同时具有相似的渲染质量。 - BirdNeRF可以重建包含数百万个三角形的场景,而不会出现明显的伪影。
工作量: - BirdNeRF的实现相对简单,易于使用。 - BirdNeRF的训练时间和渲染时间都比较短,可以满足实际应用的需求。
点此查看论文截图

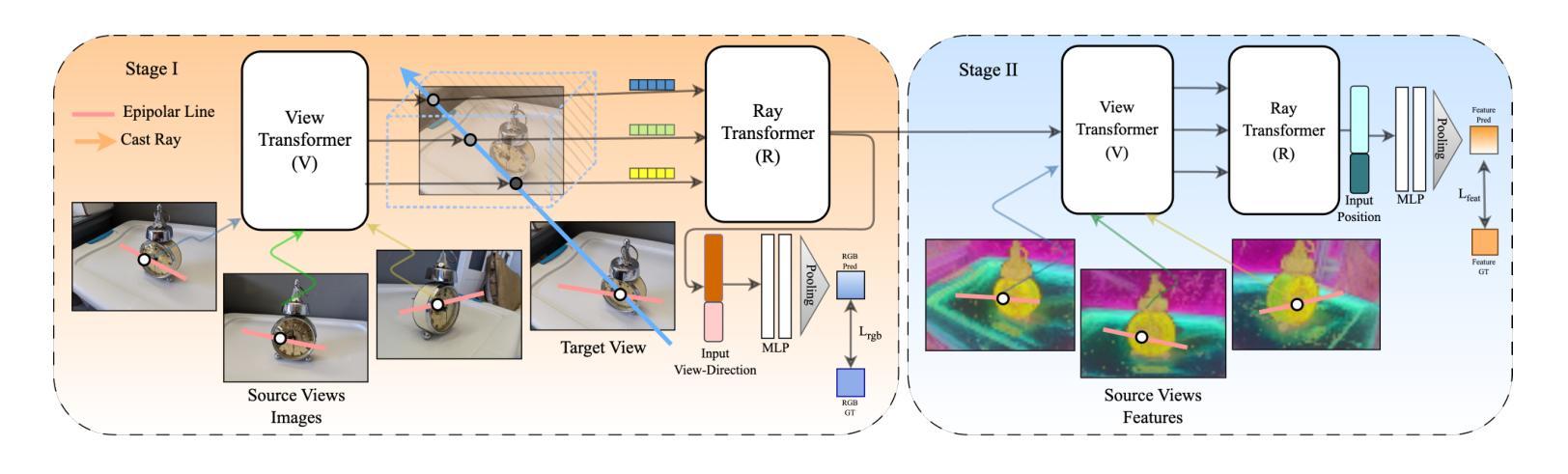
- 题目:ViewFusion:用于新颖视图合成的可组合扩散模型的学习
- 作者:Bernard Spiegl、Andrea Perin、St´ephane Deny、Alexander Ilin
- 第一作者单位:阿尔托大学计算机科学系(仅翻译中文)
- 关键词:新颖视图合成、扩散模型、可组合性、自适应输入视图、鲁棒性
- 论文链接:https://arxiv.org/abs/2402.02906,Github 代码链接:None
摘要: (1)研究背景:新颖视图合成是一个计算机视觉领域的长期研究课题。传统方法通常使用显式建模 3D 空间的方法,如体素、点云或网格。近年来,基于神经辐射场 (NeRF) 的方法也取得了很大进展。然而,这些方法通常存在需要昂贵的逐场景重新训练、无法在没有输入视图的姿态信息的情况下操作或无法适应测试时输入视图数量的可变性等缺点。 (2)过去方法及问题:过去的方法通常存在需要昂贵的逐场景重新训练、无法在没有输入视图的姿态信息的情况下操作或无法适应测试时输入视图数量的可变性等缺点。因此,本文旨在提出一种直观的端到端架构,用于执行新颖视图合成,同时解决先前工作中提到的缺点。 (3)研究方法:本文提出的 ViewFusion 方法通过一系列针对特定问题的设计选择,一次性解决了上述缺点。首先,使用在大量场景和类别上同时训练的扩散概率框架,使其能够在无需重新训练的情况下进行泛化。此外,由于扩散过程的随机性质,该模型即使在不确定性设置(例如,对象的严重遮挡或有限数量的输入视图)中也能表现良好,因为它提供了多种合理的视图。此外,本文提出的解决方案不需要输入视图的顺序或任何显式姿态信息。最后,与之前的对应方法不同,一旦训练完成,本文的方法就可以有效地处理任意长度的输入。这要归功于一种新的加权解决方案,与去噪骨干网络的组合一起,该解决方案允许模型根据视图的信息量对视图进行加权,同时扩展到任意数量的视图。 (4)方法性能:本文在包含各种类别和输入视图姿势的数据集上评估了所提出的方法。此外,本文通过对中间模型输出的分析验证了该方法,证明了该模型能够推断和自适应地调整每个输入视图的重要性。加权不仅对输出的质量有影响,而且推断的加权方案也与直观的人类感知一致。
方法: (1) 提出了一种基于扩散概率框架的新颖视图合成方法 ViewFusion,该方法能够同时处理多个输入视图,并根据每个视图的重要性对视图进行加权,从而生成高质量的新颖视图。 (2) ViewFusion 模型由多个 U-Net 组成,每个 U-Net 负责处理一个输入视图。U-Net 的输出包括噪声预测和权重,权重用于对噪声进行加权,从而生成最终的新颖视图。 (3) ViewFusion 模型的训练过程包括两个阶段:预训练和微调。在预训练阶段,模型在大量场景和类别上进行训练,以学习一般化的特征表示。在微调阶段,模型在特定场景或类别上进行微调,以提高模型的性能。 (4) ViewFusion 模型的推理过程包括两个阶段:噪声采样和扩散过程。在噪声采样阶段,模型从正态分布中采样噪声。在扩散过程中,模型通过逐渐降低噪声的强度来生成新颖视图。
结论: (1):ViewFusion 是一种灵活、无需姿态的生成方法,可使用可组合扩散模型执行新颖视图合成。我们提出了一种新颖的加权方案,用于组合扩散模型,确保仅将信息量最大的输入视图用于预测目标视图,并使 ViewFusion 能够自适应地处理任意长且无序的输入视图集合,而无需重新训练。此外,ViewFusion 的生成性质使其即使在严重欠定条件下也能生成合理视图。我们认为,我们的方法在进行新颖视图合成时是一个有价值的贡献,并且有可能应用于其他问题。 (2):创新点: ViewFusion 引入了一种新颖的加权方案,用于组合扩散模型,确保仅将信息量最大的输入视图用于预测目标视图,并使 ViewFusion 能够自适应地处理任意长且无序的输入视图集合,而无需重新训练。此外,ViewFusion 的生成性质使其即使在严重欠定条件下也能生成合理视图。 性能: ViewFusion 在各种类别和输入视图姿势的数据集上均取得了最先进的性能。此外,ViewFusion 能够有效地处理任意数量的输入视图,并且对输入视图的顺序和姿态信息不敏感。 工作量: ViewFusion 的训练过程包括两个阶段:预训练和微调。预训练阶段需要大量的数据和计算资源,但微调阶段可以相对快速地完成。ViewFusion 的推理过程也非常有效,可以在几秒钟内生成新颖视图。
点此查看论文截图

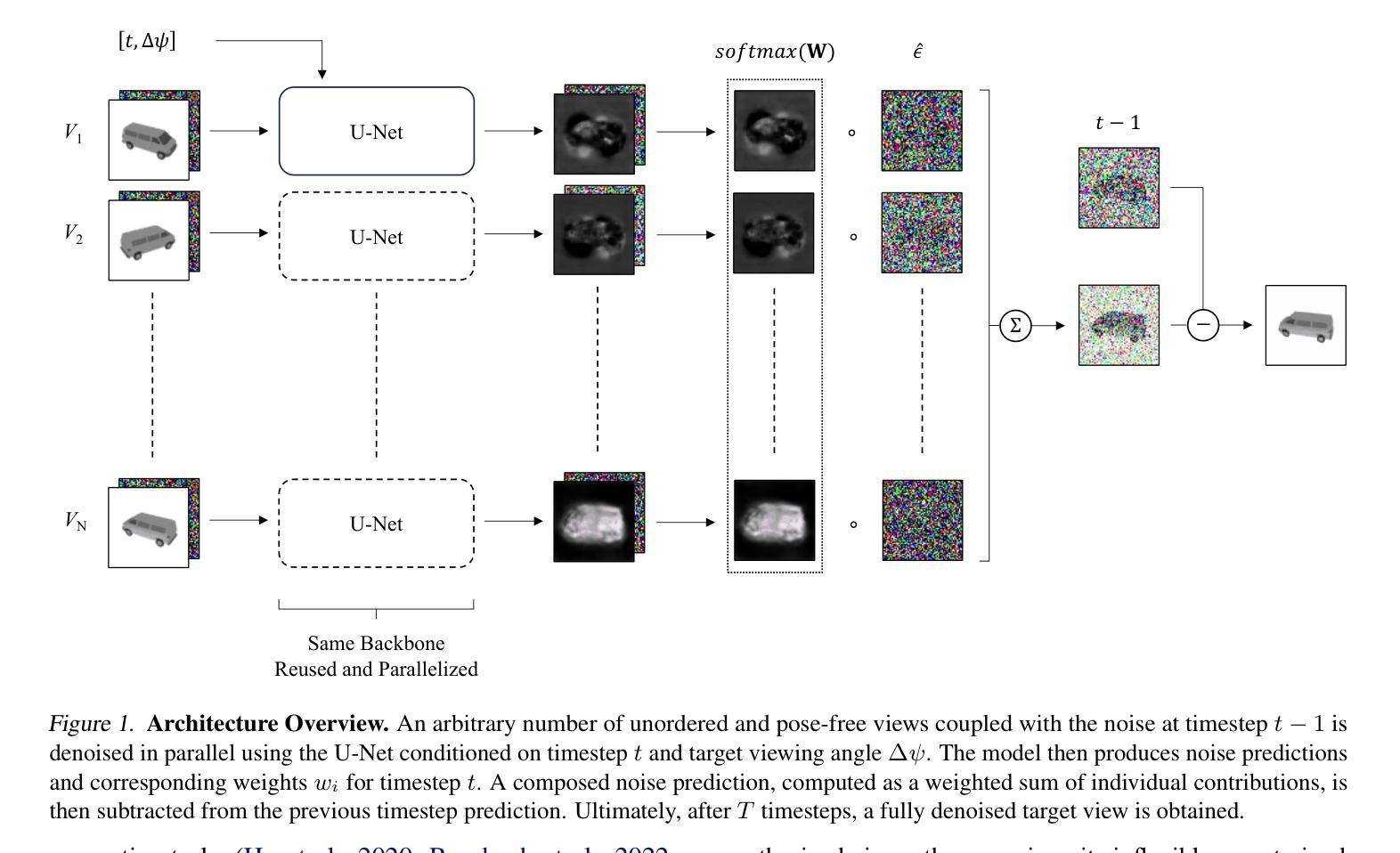




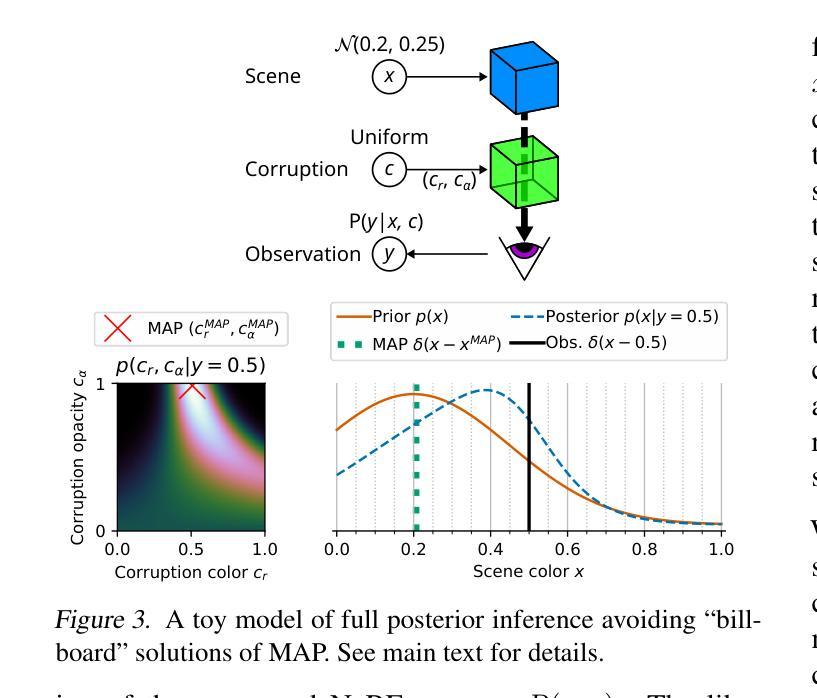
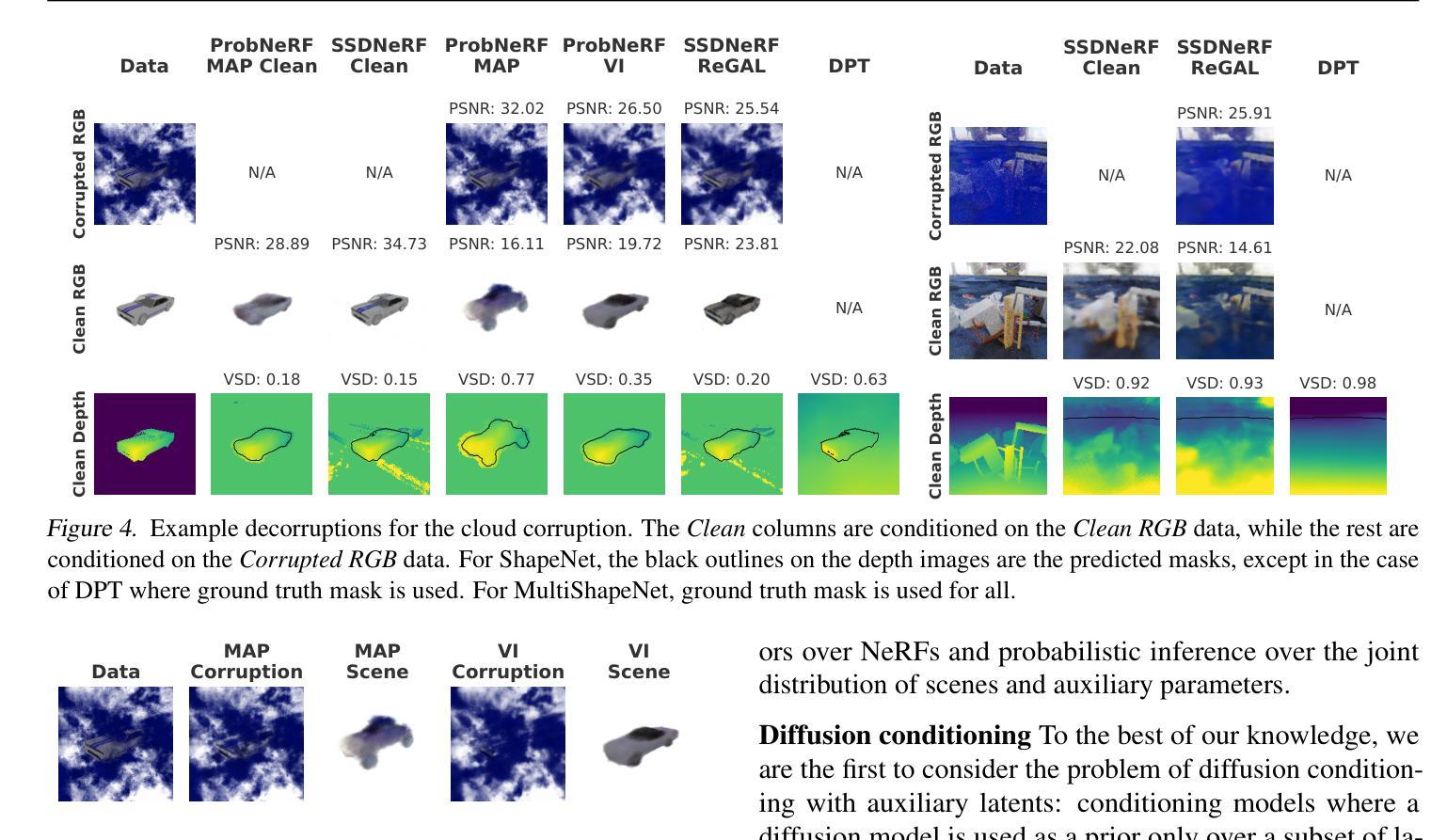
Robust Inverse Graphics via Probabilistic Inference
Authors:Tuan Anh Le, Pavel Sountsov, Matthew D. Hoffman, Ben Lee, Brian Patton, Rif A. Saurous
How do we infer a 3D scene from a single image in the presence of corruptions like rain, snow or fog? Straightforward domain randomization relies on knowing the family of corruptions ahead of time. Here, we propose a Bayesian approach-dubbed robust inverse graphics (RIG)-that relies on a strong scene prior and an uninformative uniform corruption prior, making it applicable to a wide range of corruptions. Given a single image, RIG performs posterior inference jointly over the scene and the corruption. We demonstrate this idea by training a neural radiance field (NeRF) scene prior and using a secondary NeRF to represent the corruptions over which we place an uninformative prior. RIG, trained only on clean data, outperforms depth estimators and alternative NeRF approaches that perform point estimation instead of full inference. The results hold for a number of scene prior architectures based on normalizing flows and diffusion models. For the latter, we develop reconstruction-guidance with auxiliary latents (ReGAL)-a diffusion conditioning algorithm that is applicable in the presence of auxiliary latent variables such as the corruption. RIG demonstrates how scene priors can be used beyond generation tasks.
Summary
新颖的贝叶斯方法 RIG 可同时对场景和破坏进行推理,以克服各种场景损坏。
Key Takeaways
- RIG 是一种新的贝叶斯方法,可同时对场景和破坏进行推理。
- RIG 仅使用干净的数据进行训练,优于深度估计器和替代的 NeRF 方法。
- RIG 可与多种基于正则化流和扩散模型的场景先验架构一起使用。
- 对于后者,我们开发了具有辅助潜变量的重建指导(ReGAL)——一种扩散调节算法,适用于具有辅助潜变量(如破坏)的情况。
- RIG 演示了场景先验如何用于生成任务之外。
- RIG 利用强大的场景先验和无信息的均匀破坏先验,使其适用于广泛的破坏。
- 在给定单一图像的情况下,RIG 对场景和破坏进行后验推理。
- 题目:鲁棒逆向图形生成:基于概率推理
- 作者:Tuan Anh Le、Pavel Sountsov、Matthew D. Hoffman、Ben Lee、Brian Patton、Rif A. Saurous
- 单位:谷歌(Google)
- 关键词:鲁棒逆向图形生成、神经辐射场、概率推理、域随机化、数据增强
- 论文链接:https://arxiv.org/abs/2402.01915
- 摘要:
(1)研究背景: * 在存在雨、雪、雾等干扰的情况下,如何从单张图像中推断出 3D 场景? * 直接的域随机化依赖于提前知道干扰的种类。
(2)过去的方法及其问题: * 域随机化:通过在数据生成过程中选择一系列干扰来实现鲁棒性,但这种方法需要提前知道干扰的种类。 * 正则化训练:通过在重建损失中添加额外的损失项来实现鲁棒性,但这种方法难以扩展到更极端的情况。
(3)本文提出的研究方法: * 鲁棒逆向图形生成(RIG):将问题视为概率推理问题,利用预训练的场景先验(在本例中是神经辐射场先验)和一个关于干扰的弱先验(在本例中是具有均匀先验权重的另一个神经辐射场)来进行推理。 * RIG 在场景和干扰神经辐射场中执行完整的概率推理,而不是像最大后验概率推理那样寻找最可能的解。
(4)方法的性能表现: * RIG 在具有各种场景先验架构(基于正则化流和扩散模型)的情况下都优于深度估计器和执行点估计而不是完整推理的替代神经辐射场方法。 * RIG 仅在干净数据上训练,但它在具有各种干扰(雨、雪、雾、噪声)的图像上都优于其他方法。
方法: (1)场景表示:我们使用神经辐射场 (NeRF) 表示,因为它易于进行基于梯度的推理。 (2)场景先验:我们假设我们有一个预训练的 NeRF 先验 p(x),我们可以从中对场景潜在变量 x 进行采样,并从不同的视点 ζ 渲染图像 y。 (3)损坏表示和先验:我们关注的是对 3D 场景的损坏,例如漂浮物或天气伪影(如雨、雪或雾),尽管我们的方法可以泛化到传感器损坏,如相机内部噪声(第 6.1 节)。我们将 3D 损坏表示为另一个 NeRF 的参数。与场景 x 不同,我们不需要对 c 有一个强先验。在我们的实验中,我们假设一个不适当的先验 p(c)∝1。这意味着我们不需要预先知道损坏的种类;损坏可以是任何 3D 实体,从天气伪影和漂浮物到不需要的对象。 (4)似然:为了给定场景潜在变量 x 和损坏 c 渲染图像 y,我们组合各自的 NeRF 输出。对于光线位置和方向 (xr, dr),我们将场景 NeRF (γz, σz) 和损坏 NeRF (γc, σc) 的输出组合为 σ = σz + σc,γ = (γzσz + γcσc)/σ(Niemeyer & Geiger,2021)。我们将组合的 NeRF 的渲染表示为 y = R(x, c)。似然是一个逐像素和逐通道的高斯分布 p(y|x, c) = ∏像素和通道j N(yij|R(x, c)ij, σ2y),其中 σ2y 是观测噪声方差。 (5)MAP 推理不够:推断场景 x 的一种直接方法是找到最大化 p(x)p(c)p(y|x, c) 的 MAP 估计 (x, c)。然而,这种方法会导致“广告牌”解决方案,其中损坏最终解释了场景,就像一个放置在相机前面的广告牌。 (6)完全后验推理就足够了:在 RIG 中,我们执行完全后验推理以获得潜在场景 x, c∼p(x, c|y) ∝ p(x)p(c)p(y|x, c),这在经验上可以避免广告牌解决方案(第 6.1 节)。直观地说,这可以看作是模式与典型集不同的一个实例。损坏完全覆盖场景的模式周围区域具有高密度但低体积——没有许多损坏可以精确地渲染到观测图像。另一方面,后验同时考虑密度和体积,集中在具有高概率质量的区域——有许多非广告牌损坏与正确的场景一起渲染到观测图像,尽管每个这样的解决方案可能具有低密度。 (7)变分推理:我们使用变分推理,其中我们优化证据下界 (ELBO) 关于引导分布 q(x, c):ELBO(q) = Eq(x, c)[logp(y, x|c) - logq(x, c)]。 (8)扩散场景先验:去噪扩散已成为正则化流的有力替代方案。虽然可以直接用基于扩散的先验替换 ProbNeRF 中使用的 RealNVP(例如 Dupontet al.,2022),但扩散模型允许我们可追踪地增加我们的潜在表示的维数。高维潜在空间能够进行高保真采样和重建。我们构建了单级扩散 NeRF (SSDNeRF) 框架(Chen et al.,2023)来训练场景先验。SSDNeRF 优化了一组针对每个训练示例的潜在变量 {xn},也称为 GLO 潜在变量(Bojanowski et al.,2018),由 ϕ 参数化的扩散先验 pϕ(x) 和由 ψ 参数化的似然 pψ(y|x)。有关更多详细信息,请参见附录 D。 (9)扩散模型:扩散模型是一个潜在变量生成模型,包含正向和反向过程。正向扩散过程 q(z|x) 从数据 x 开始。
结论: (1):本文提出了一种鲁棒逆向图形生成(RIG)方法,该方法将问题视为概率推理问题,利用预训练的场景先验和一个关于干扰的弱先验来进行推理。RIG在各种场景先验架构下都优于深度估计器和执行点估计而不是完整推理的替代神经辐射场方法。RIG仅在干净数据上训练,但它在具有各种干扰(雨、雪、雾、噪声)的图像上都优于其他方法。 (2):创新点:
- 将逆向图形生成问题视为概率推理问题,利用预训练的场景先验和一个关于干扰的弱先验来进行推理。
- 提出了一种鲁棒逆向图形生成(RIG)方法,该方法在各种场景先验架构下都优于深度估计器和执行点估计而不是完整推理的替代神经辐射场方法。
- RIG仅在干净数据上训练,但它在具有各种干扰(雨、雪、雾、噪声)的图像上都优于其他方法。 性能:
- RIG在各种场景先验架构下都优于深度估计器和执行点估计而不是完整推理的替代神经辐射场方法。
- RIG仅在干净数据上训练,但它在具有各种干扰(雨、雪、雾、噪声)的图像上都优于其他方法。 工作量:
- RIG需要预训练一个场景先验和一个关于干扰的弱先验。
- RIG需要执行完整的概率推理,这比执行点估计或最大后验概率推理更耗时。
点此查看论文截图


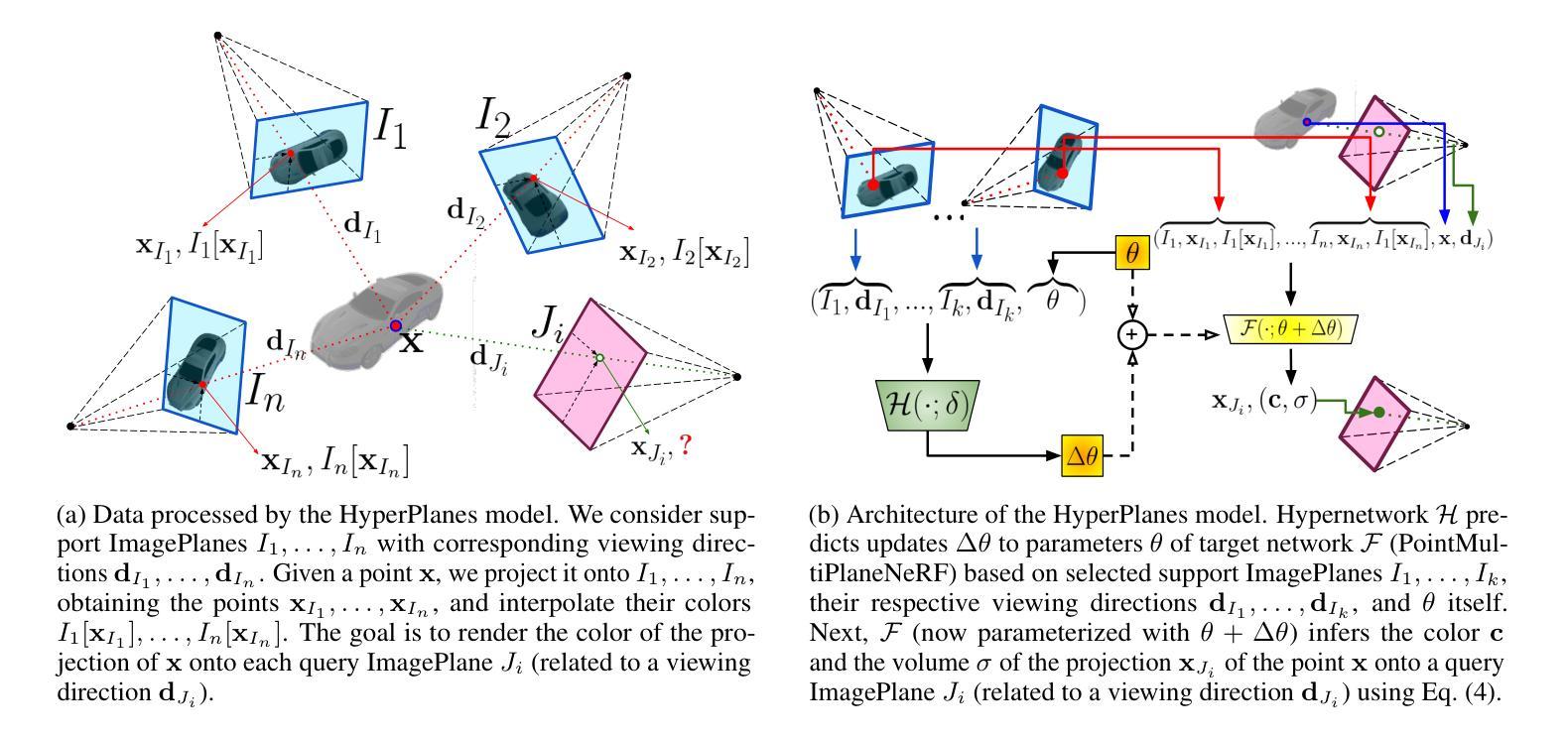
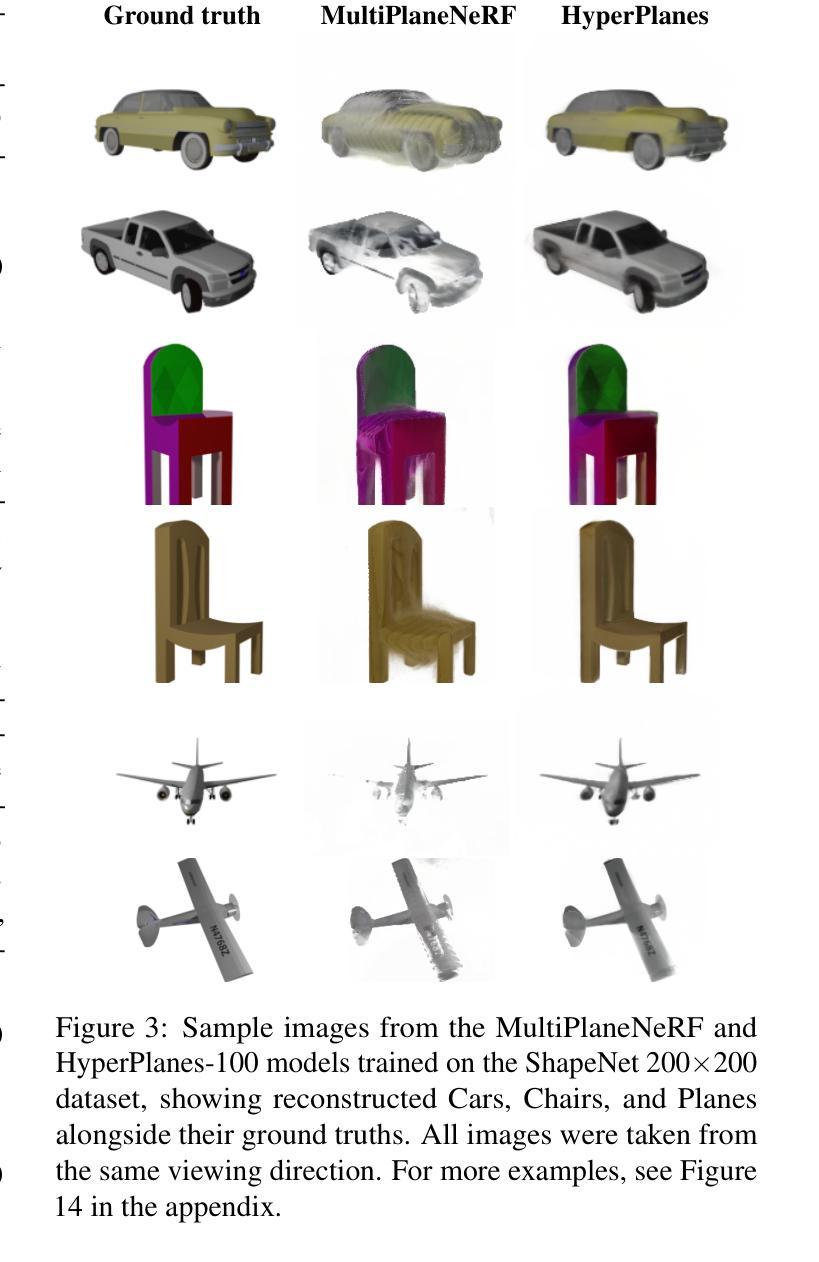
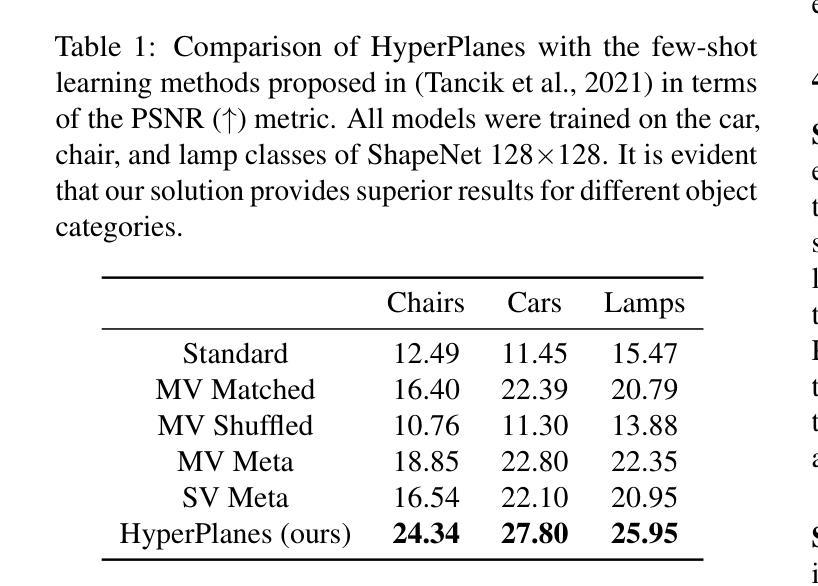
HyperPlanes: Hypernetwork Approach to Rapid NeRF Adaptation
Authors:Paweł Batorski, Dawid Malarz, Marcin Przewięźlikowski, Marcin Mazur, Sławomir Tadeja, Przemysław Spurek
Neural radiance fields (NeRFs) are a widely accepted standard for synthesizing new 3D object views from a small number of base images. However, NeRFs have limited generalization properties, which means that we need to use significant computational resources to train individual architectures for each item we want to represent. To address this issue, we propose a few-shot learning approach based on the hypernetwork paradigm that does not require gradient optimization during inference. The hypernetwork gathers information from the training data and generates an update for universal weights. As a result, we have developed an efficient method for generating a high-quality 3D object representation from a small number of images in a single step. This has been confirmed by direct comparison with the state-of-the-art solutions and a comprehensive ablation study.
Summary
神经辐射场方法对于少数基础图像合成新奇3D物体视图有着广泛的认可,却存在泛化性质有限的问题,不妨碍我们利用显著计算资源为我们要展示的每个对象训练独立体系结构。
Key Takeaways
- 神经辐射场方法是一种用于从少数基础图像合成新 3D 物体视图的标准方法。
- 这种方法存在泛化性质有限的弊端,导致为我们要展示的每个对象训练独立体系结构时需要显著的计算资源。
- 作者针对此问题提出了一个基于超网络范式的 few-shot 学习方法,该方法在推理过程中无需梯度优化。
- 超网络从训练数据中收集信息,并为通用权重生成更新。
- 上述方式打造了一种有效的方法,可从少量图像中生成高质量的 3D 对象表示,只需一个步骤即可完成。
- 我们已通过直接比较最先进的解决方案和全面的消融研究来证实这一点。
- 该方法已被直接比较最先进的解决方案和全面的消融研究证实。
- 标题:HyperPlanes:快速 NeRF 适应的超网络方法
- 作者:Paweł Batorski, Dawid Malarz, Marcin Przewi˛e´zlikowski, Marcin Mazur, Slawomir Tadeja, Przemysław Spurek
- 第一作者单位:雅盖隆大学,数学与计算机科学学院,克拉科夫,波兰
- 关键词:NeRF,Few-Shot 学习,超网络,快速适应
- 论文链接:https://arxiv.org/abs/2402.01524 Github 链接:无
- 摘要: (1):NeRF 是一种可以从少量基本图像合成新的逼真 3D 对象视图的深度学习方法,但它缺乏泛化性,需要针对每个对象训练单独的架构。 (2):过去的方法通常需要大量的计算资源和训练时间,并且泛化性能有限。 (3):本文提出了一种基于超网络范式的 few-shot 学习方法,该方法不需要在推理期间进行梯度优化。超网络从训练数据中收集信息并生成对通用权重的更新。 (4):实验结果表明,该方法可以在单个步骤中从少量图像生成高质量的 3D 对象表示,并且在速度和质量方面都优于现有技术。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出了一种基于超网络范式的few-shot学习方法HyperPlanes,该方法不需要在推理期间进行梯度优化,可以在单个步骤中从少量图像生成高质量的3D对象表示,并且在速度和质量方面都优于现有技术。 (2):创新点:
- 提出了一种基于超网络范式的few-shot学习方法,该方法不需要在推理期间进行梯度优化。
- 该方法可以从训练数据中收集信息并生成对通用权重的更新。
- 该方法可以在单个步骤中从少量图像生成高质量的3D对象表示。 性能:
- 该方法在速度和质量方面都优于现有技术。
- 该方法可以在单个步骤中从少量图像生成高质量的3D对象表示。 工作量:
- 该方法不需要在推理期间进行梯度优化,因此可以减少计算资源和训练时间。
- 该方法可以从训练数据中收集信息并生成对通用权重的更新,因此可以减少训练时间。
点此查看论文截图

 wechat
wechat- alipay







