Talking Head Generation
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-02-09 更新
EmoSpeaker: One-shot Fine-grained Emotion-Controlled Talking Face Generation
Authors:Guanwen Feng, Haoran Cheng, Yunan Li, Zhiyuan Ma, Chaoneng Li, Zhihao Qian, Qiguang Miao, Chi-Man Pun
Implementing fine-grained emotion control is crucial for emotion generation tasks because it enhances the expressive capability of the generative model, allowing it to accurately and comprehensively capture and express various nuanced emotional states, thereby improving the emotional quality and personalization of generated content. Generating fine-grained facial animations that accurately portray emotional expressions using only a portrait and an audio recording presents a challenge. In order to address this challenge, we propose a visual attribute-guided audio decoupler. This enables the obtention of content vectors solely related to the audio content, enhancing the stability of subsequent lip movement coefficient predictions. To achieve more precise emotional expression, we introduce a fine-grained emotion coefficient prediction module. Additionally, we propose an emotion intensity control method using a fine-grained emotion matrix. Through these, effective control over emotional expression in the generated videos and finer classification of emotion intensity are accomplished. Subsequently, a series of 3DMM coefficient generation networks are designed to predict 3D coefficients, followed by the utilization of a rendering network to generate the final video. Our experimental results demonstrate that our proposed method, EmoSpeaker, outperforms existing emotional talking face generation methods in terms of expression variation and lip synchronization. Project page: https://peterfanfan.github.io/EmoSpeaker/
摘要
利用视觉属性引导音频解耦器和细粒度情绪系数预测模块,精细控制谈话头生成中的情绪表达,提升生成的视频的自然性和真实性。
要点
- 提出视觉属性引导音频解耦器,仅与音频内容相关的表征向量,增强后续口型系数预测的稳定性。
- 引入细粒度情绪系数预测模块,实现更准确的情绪表达。
- 提出使用细粒度情绪矩阵的情绪强度控制方法,对生成的视频中的情绪表达进行有效控制,并对情绪强度进行更精细的分类。
- 3DMM 系数生成网络用于预测 3D 系数,然后利用渲染网络生成最终视频。
- EmoSpeaker 方法在表情变化和唇形同步方面优于现有情感谈话人脸生成方法。
- 项目主页:https://peterfanfan.github.io/EmoSpeaker/
- 标题:EmoSpeaker:单次学习细粒度情感控制的说话人面部生成
- 作者:Guanwen Feng, Haoran Cheng, Yunan Li, Zhiyuan Ma, Chaoneng Li, Zhihao Qian, Qiguang Miao
- 第一作者单位:西安电子科技大学计算机科学与技术学院
- 关键词:说话人面部、三维可变形模型、视觉属性引导的解耦过程、细粒度情感控制
- 论文链接:https://arxiv.org/abs/2402.01422 Github 链接:https://github.com/peterfanfan/EmoSpeaker
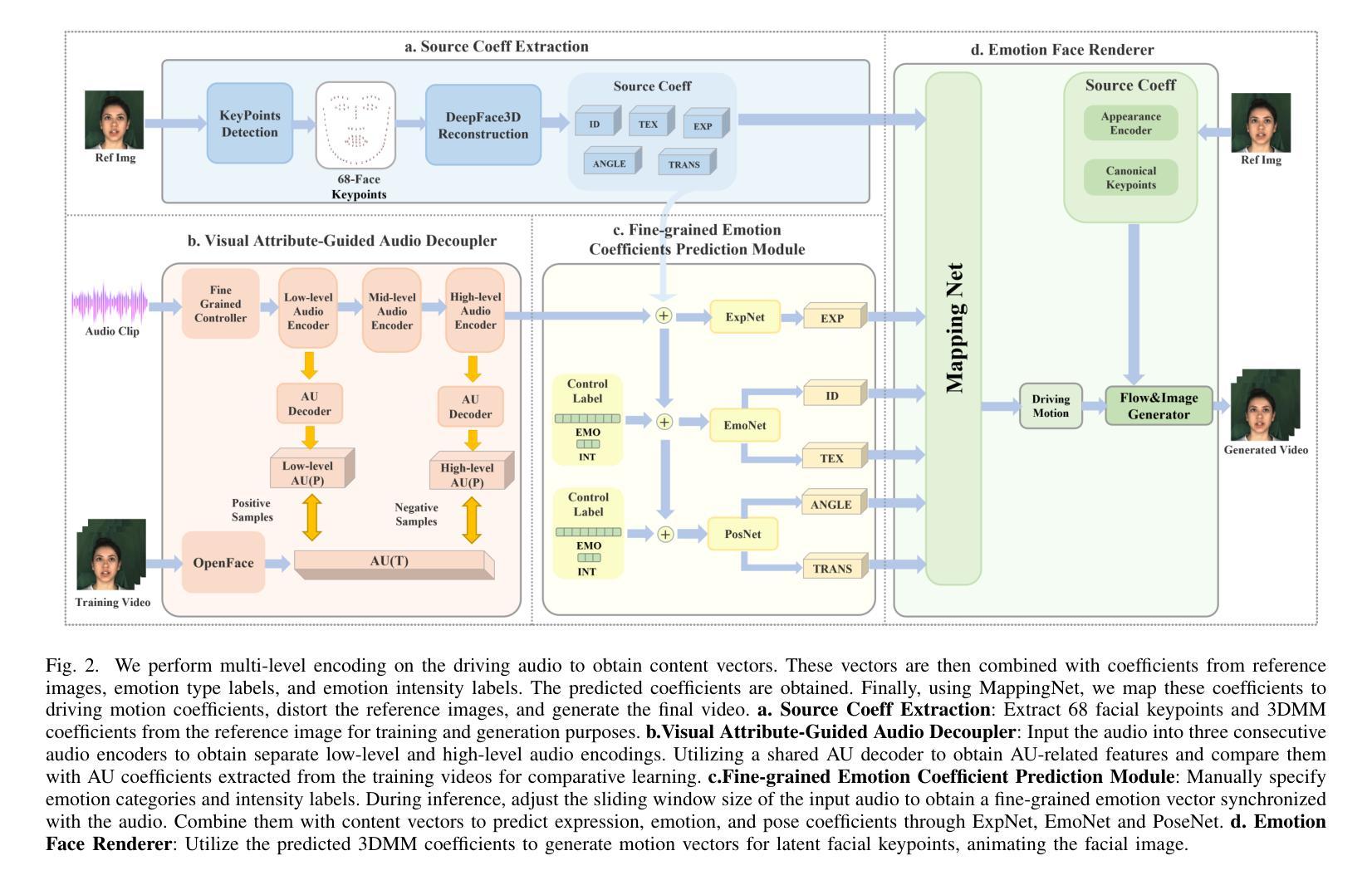
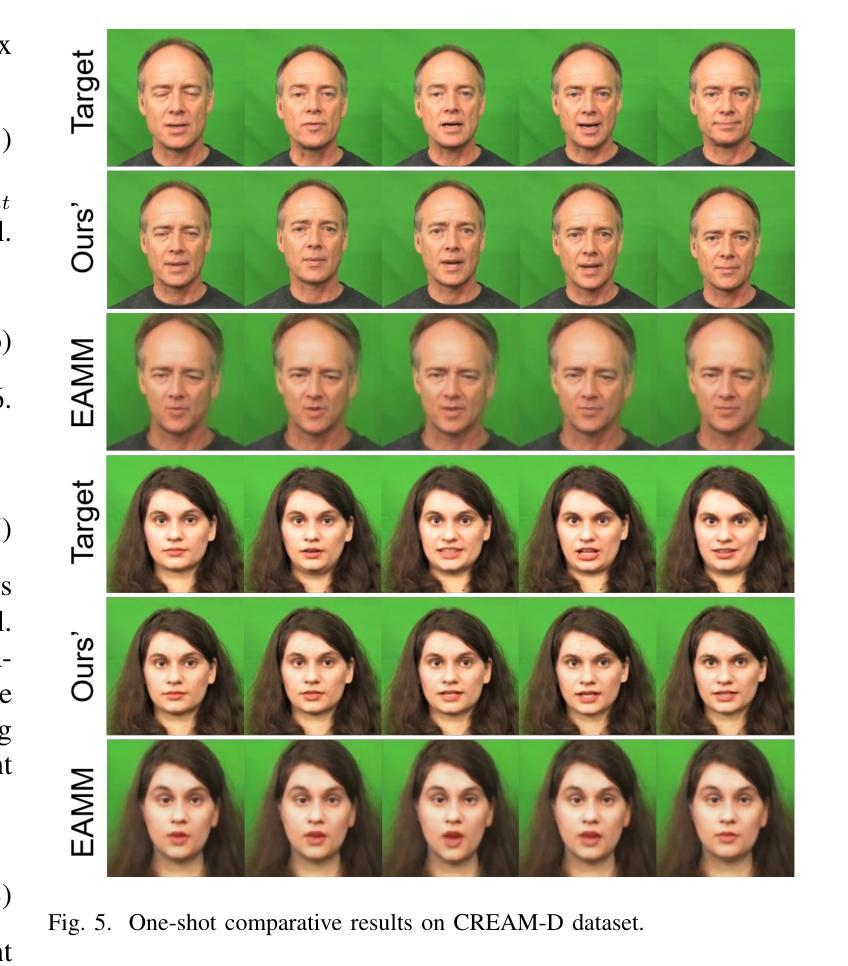
摘要: (1) 研究背景:说话人面部生成技术已成为近年来研究的热点,其在虚拟数字人生成、虚拟现实和电影特效等领域具有广泛的应用场景。然而,现有方法主要关注唇形同步和视频生成质量,对生成视频的情感表达关注较少。 (2) 过去方法及其问题:一些现有方法解决了情感面部动画生成的问题,但它们通常受限于长视频或短视频的驱动。此外,使用标签控制的方法难以生成具有不同强度和不同情感中间状态的情感视频。单次学习生成方法通常只考虑唇形同步,而没有考虑情感因素。 (3) 本文方法:本文提出了一种名为 EmoSpeaker 的方法,该方法通过 3D 系数作为中间表示来连接说话人面部生成过程的不同部分。为了实现这一目标,首先引入视觉属性引导的音频解耦器,从音频中提取与内容向量相关的内容向量,增强后续唇部动作系数预测的稳定性。其次,在细粒度情感系数预测模块中,将内容向量与情感标签聚合,预测细粒度的面部动作系数。此外,本文提出了一种使用细粒度情感矩阵的情感强度控制方法。通过这些方法,实现了对生成视频中的情感表达的有效控制和对情感强度的更精细分类。最后,设计了一系列 3DMM 系数生成网络来预测 3D 系数,然后利用渲染网络生成最终视频。 (4) 方法性能:实验结果表明,本文提出的 EmoSpeaker 方法在表情表达和唇形同步方面优于现有情感说话人面部生成方法。该方法可以支持其目标,生成具有任意强度的任意情感面部视频。
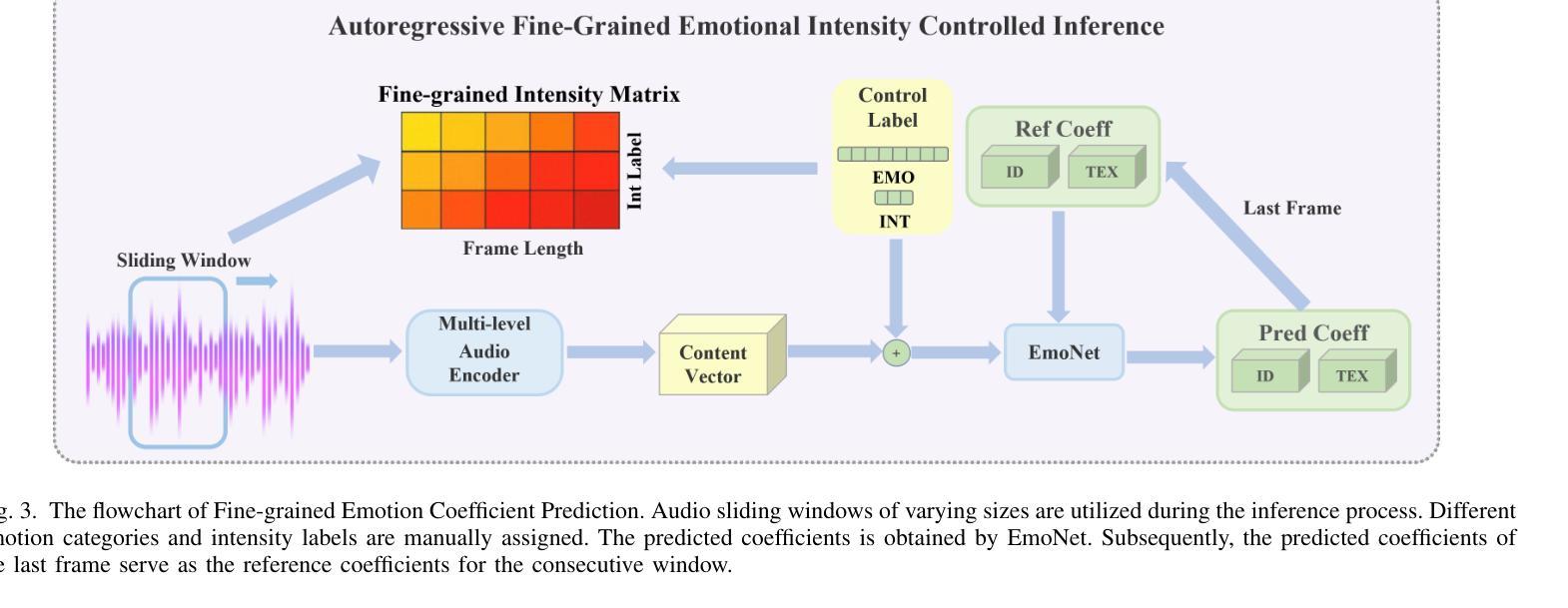
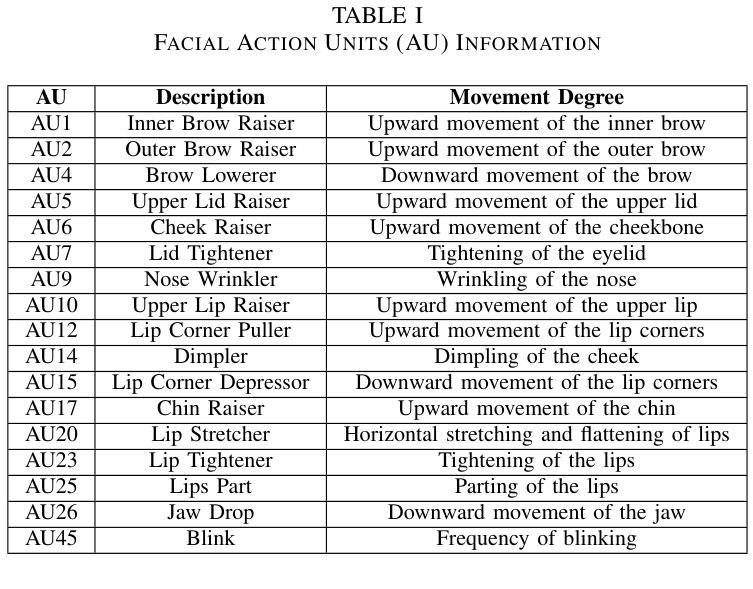
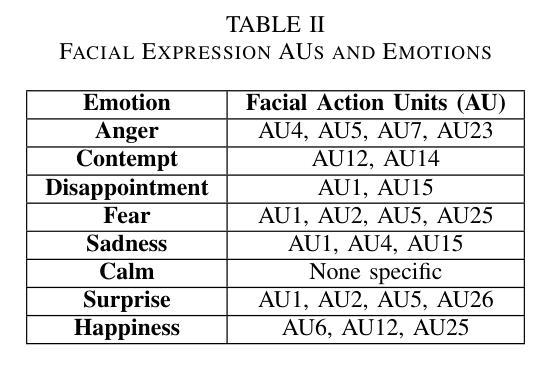
方法: (1)视觉属性引导的音频解耦器:为了准确预测唇部信息,提出了一种视觉属性引导的音频解耦器。该解耦器利用面部动作单元(AU)作为视觉信息,指导音频的情感解耦过程,增强解耦的精度和可控性。 (2)细粒度情感系数预测模块:将内容向量与情感标签聚合,预测细粒度的面部动作系数。同时,提出了一种使用细粒度情感矩阵的情感强度控制方法,实现对生成视频中情感表达的有效控制和对情感强度的更精细分类。 (3)情感面部渲染器:设计了一系列三维可变形模型系数生成网络来预测三维系数,然后利用渲染网络生成最终视频。
结论: (1):本文提出了一种名为 EmoSpeaker 的算法,该算法仅需音频剪辑、肖像、特定情绪和强度粒度,即可生成具有细粒度强度的表情面部。该方法使用面部情绪解耦模块提取内容特征,并结合细粒度强度控制模块来实现任意情绪强度。这在电子游戏、虚拟现实、电影特效和人机界面交互等领域展示了有希望的应用。主观和客观评估表明,与最先进的方法相比,我们的方法在生成更丰富的面部动画方面具有优越性。未来的研究将集中于在细粒度强度控制领域进行深入研究,以增强更具表现力和细微差别的面部动画的生成。 (2):创新点:
- 提出了一种视觉属性引导的音频解耦器,该解耦器利用面部动作单元作为视觉信息,指导音频的情感解耦过程,增强解耦的精度和可控性。
- 提出了一种细粒度情感系数预测模块,将内容向量与情感标签聚合,预测细粒度的面部动作系数。同时,提出了一种使用细粒度情感矩阵的情感强度控制方法,实现对生成视频中情感表达的有效控制和对情感强度的更精细分类。
- 设计了一系列三维可变形模型系数生成网络来预测三维系数,然后利用渲染网络生成最终视频。 性能:
- 在表情表达和唇形同步方面优于现有情感说话人面部生成方法。
- 可以支持其目标,生成具有任意强度的任意情感面部视频。 工作量:
- 需要收集大量的数据集来训练模型。
- 模型的训练过程比较耗时。
- 需要对模型进行微调以适应不同的数据集。
点此查看论文截图


 wechat
wechat- alipay






