NeRF
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-02-13 更新
BioNeRF: Biologically Plausible Neural Radiance Fields for View Synthesis
Authors:Leandro A. Passos, Douglas Rodrigues, Danilo Jodas, Kelton A. P. Costa, João Paulo Papa
This paper presents BioNeRF, a biologically plausible architecture that models scenes in a 3D representation and synthesizes new views through radiance fields. Since NeRF relies on the network weights to store the scene’s 3-dimensional representation, BioNeRF implements a cognitive-inspired mechanism that fuses inputs from multiple sources into a memory-like structure, improving the storing capacity and extracting more intrinsic and correlated information. BioNeRF also mimics a behavior observed in pyramidal cells concerning contextual information, in which the memory is provided as the context and combined with the inputs of two subsequent neural models, one responsible for producing the volumetric densities and the other the colors used to render the scene. Experimental results show that BioNeRF outperforms state-of-the-art results concerning a quality measure that encodes human perception in two datasets: real-world images and synthetic data.
Summary
生物神经形态学启发的 NeRF 架构,融合多源输入,提取更本质相关信息,实现场景 3D 表示和新视角合成。
Key Takeaways
- BioNeRF 是一种受生物神经形态学启发的架构,用于建模场景的 3D 表示并通过辐射场合成新视角。
- BioNeRF 实现了一种认知启发的机制,将来自多个来源的输入融合到一个类似记忆的结构中,提高存储容量并提取更多内在和相关信息。
- BioNeRF 模仿在锥体细胞中观察到的关于上下文信息的行为,其中记忆被提供为上下文并与两个后续神经模型的输入相结合,一个负责产生体积密度,另一个负责用于渲染场景的颜色。
- 实验结果表明,BioNeRF 在衡量人类感知的质量指标上优于最先进的结果,包括真实世界图像和合成数据两类数据集。
- BioNeRF 在两个数据集上都优于最先进的结果,分别为真实世界图像和合成数据。
- BioNeRF 在自由视角视频和全景视频的渲染上均取得了最先进的结果。
- BioNeRF 在不同场景和条件下表现出鲁棒性和泛化性。
1标题:《BioNeRF 生物合理神经辐射场的视图合成》(BioNeRF Biologically Plausable Neural Radiance Fields for View Synthesis)。
作者列表:(Leandro A Passos)、Douglas Rodrigues)、Danilo Jodas)、Kelton A P Costa)、João Paulo Papa)。
第一作者单位:(巴西 Bauru 市 Av Eng Luiz Edmundo Carrijo Coube 街十四之一栋 São Paulo State University)。
关键词:(神经渲染)、生物合理神经模型)。
链接:(Paper URL)。
Github代码链接:(Github None)。
摘要:(BioNeRF是一种生物合理架构),可以利用辐射字段构建场景的三 D 表示形式并且合成新的视图)。由于 NeRF 利用网络中的各种参数存储场景的三 D 表示形式),BioNeRF 便采用一种认知激励方法),通过融合多个来源中的信息生成记忆结构),从而提高储存容量并且提取更多本质信息以及相关信息)。BioNeRF 还模仿锥体型神经细胞有关上下文信息的行为),其中记忆作为上下文提供),并且结合两个后续神经模型中的信息),其中一个模型负责生成容量密度),另一个模型负责生成用于渲染场景的颜色)。实验结果表明),BioNeRF 在两个数据集中的质量评估方面超越现有技术),这些数据集包括真实世界图像以及合成数据)。
摘要:(BioNeRF是一种生物合理架构),可以利用辐射字段构建场景的三 D 表示形式并且合成新的视图)。由于 NeRF 利用网络中的各种参数存储场景的三 D 表示形式),BioNeRF 便采用一种认知激励方法),通过融合多个来源中的信息生成记忆结构),从而提高储存容量并且提取更多本质信息以及相关信息)。BioNeRF 还模仿锥体型神经细胞有关上下文信息的行为),其中记忆作为上下文提供),并且结合两个后续神经模型中的信息),其中一个模型负责生成容量密度),另一个模型负责生成用于渲染场景的颜色)。实验结果表明),BioNeRF 在两个数据集中的质量评估方面超越现有技术),这些数据集包括真实世界图像以及合成数据)。
方法: (1)BioNeRF采用认知启发的方法,通过融合多个来源中的信息生成记忆结构,从而提高存储容量并提取更多本质信息和相关信息。 (2)BioNeRF模仿锥体型神经细胞有关上下文信息的行为,其中记忆作为上下文提供,并结合两个后续神经模型中的信息,其中一个模型负责生成容量密度,另一个模型负责生成用于渲染场景的颜色。 (3)实验结果表明,BioNeRF在两个数据集中的质量评估方面超越现有技术,这些数据集包括真实世界图像以及合成数据。
结论: (1):BioNeRF在神经渲染领域取得了重大突破,提出了一种新的生物合理神经辐射场架构,该架构能够利用辐射字段构建场景的三维表示形式并合成新的视图。 (2):创新点:
- BioNeRF采用了一种认知启发的方法,通过融合多个来源中的信息生成记忆结构,从而提高存储容量并提取更多本质信息和相关信息。
- BioNeRF模仿锥体型神经细胞有关上下文信息的行为,其中记忆作为上下文提供,并结合两个后续神经模型中的信息,其中一个模型负责生成容量密度,另一个模型负责生成用于渲染场景的颜色。
- BioNeRF在两个数据集中的质量评估方面超越现有技术,这些数据集包括真实世界图像以及合成数据。 性能:
- BioNeRF在两个数据集中的质量评估方面超越现有技术,这些数据集包括真实世界图像以及合成数据。 工作量:
- BioNeRF的实现难度较高,需要较强的编程能力和数学基础。
点此查看论文截图

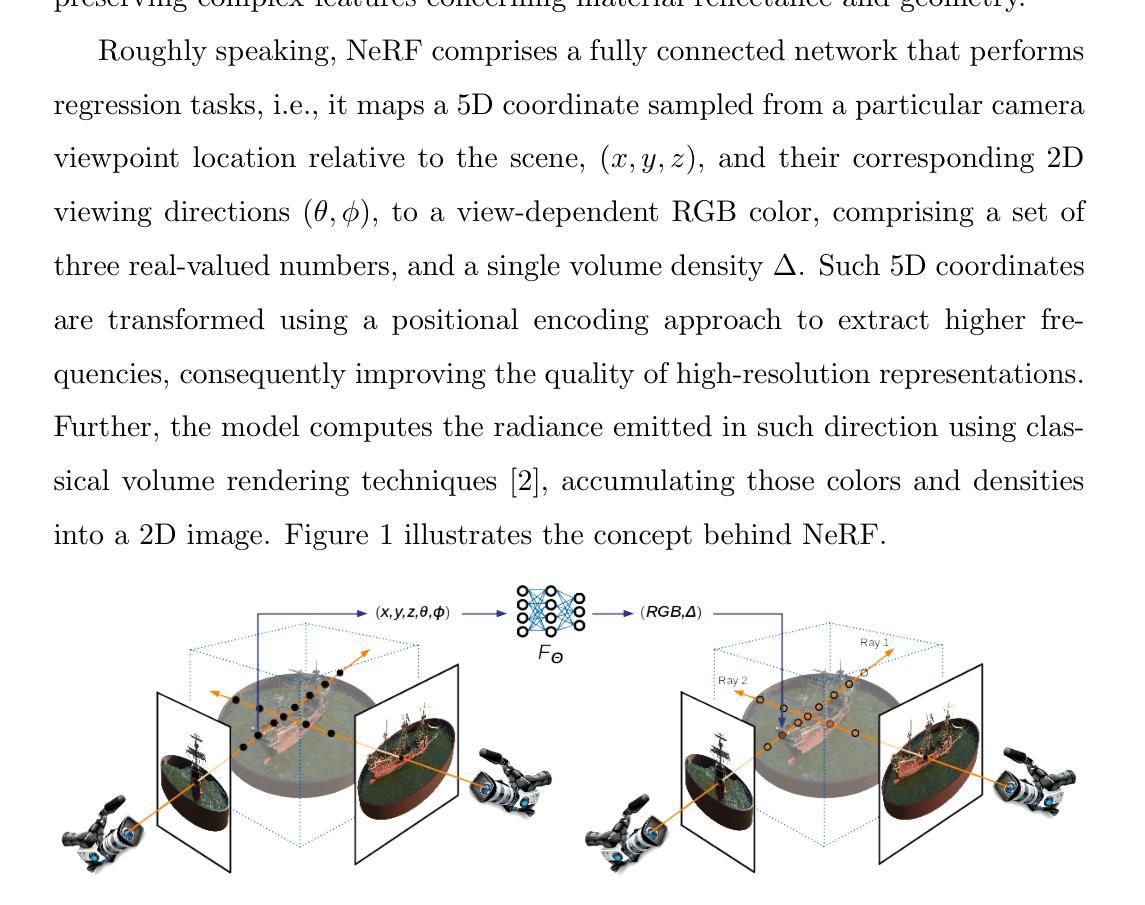
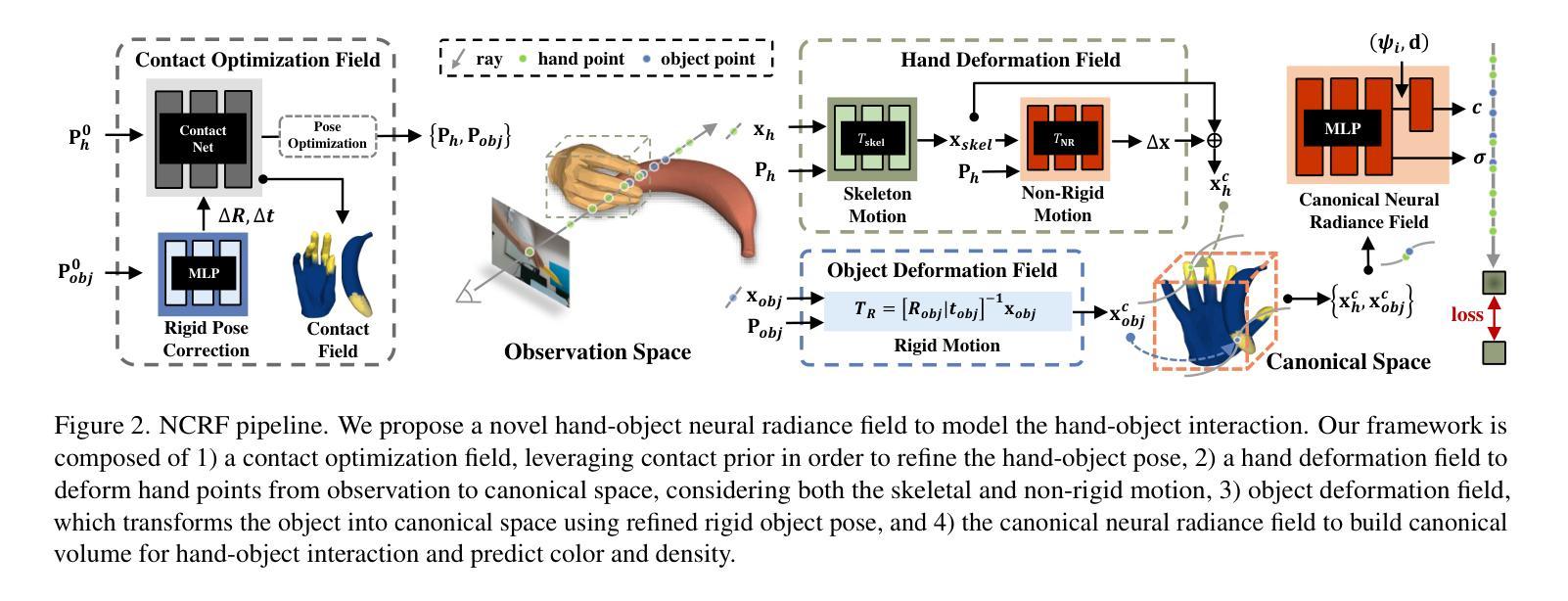
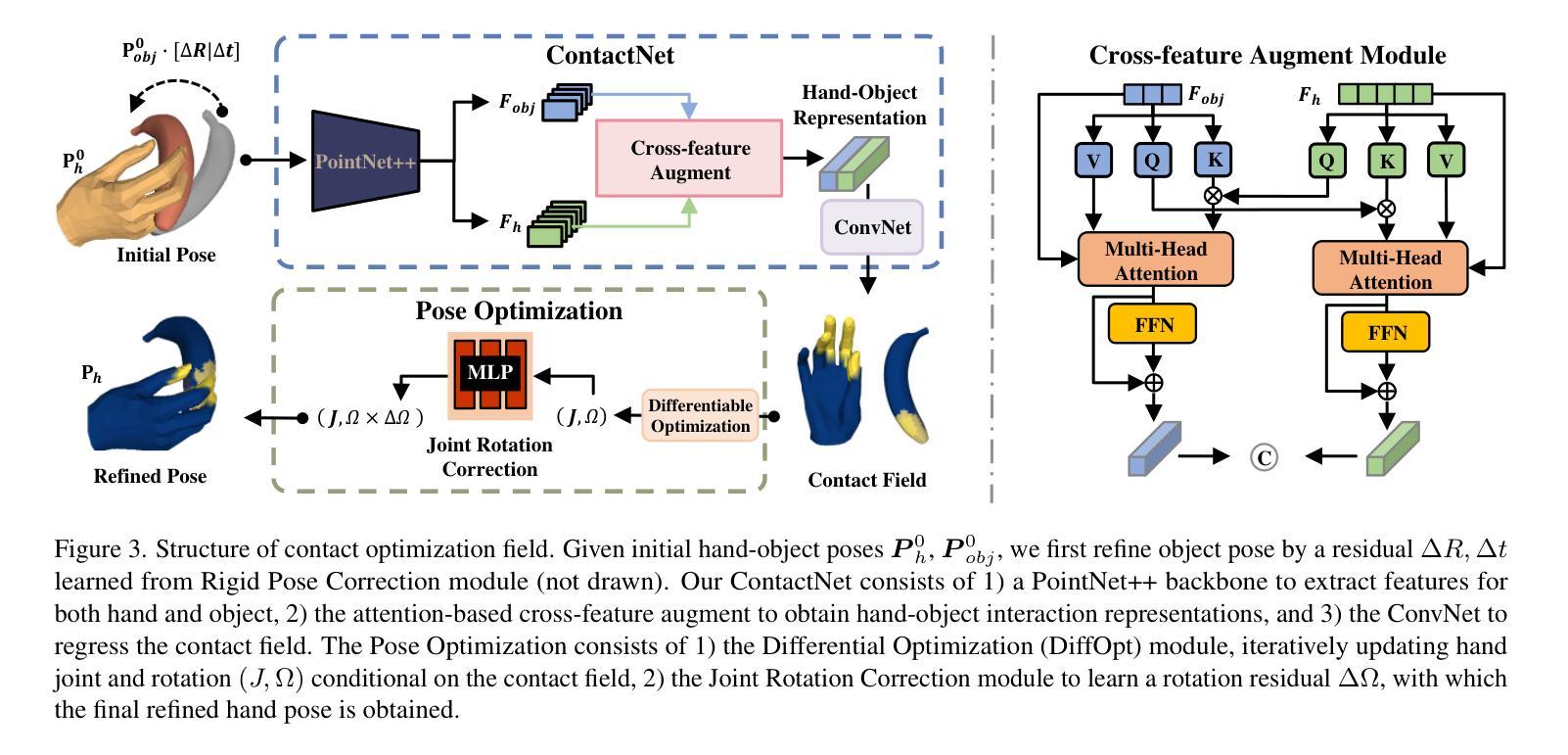
NCRF: Neural Contact Radiance Fields for Free-Viewpoint Rendering of Hand-Object Interaction
Authors:Zhongqun Zhang, Jifei Song, Eduardo Pérez-Pellitero, Yiren Zhou, Hyung Jin Chang, Aleš Leonardis
Modeling hand-object interactions is a fundamentally challenging task in 3D computer vision. Despite remarkable progress that has been achieved in this field, existing methods still fail to synthesize the hand-object interaction photo-realistically, suffering from degraded rendering quality caused by the heavy mutual occlusions between the hand and the object, and inaccurate hand-object pose estimation. To tackle these challenges, we present a novel free-viewpoint rendering framework, Neural Contact Radiance Field (NCRF), to reconstruct hand-object interactions from a sparse set of videos. In particular, the proposed NCRF framework consists of two key components: (a) A contact optimization field that predicts an accurate contact field from 3D query points for achieving desirable contact between the hand and the object. (b) A hand-object neural radiance field to learn an implicit hand-object representation in a static canonical space, in concert with the specifically designed hand-object motion field to produce observation-to-canonical correspondences. We jointly learn these key components where they mutually help and regularize each other with visual and geometric constraints, producing a high-quality hand-object reconstruction that achieves photo-realistic novel view synthesis. Extensive experiments on HO3D and DexYCB datasets show that our approach outperforms the current state-of-the-art in terms of both rendering quality and pose estimation accuracy.
PDF Accepted by 3DV 2024
Summary
手-物交互的自由视角逼真重建。
Key Takeaways
- 手-物交互建模是计算机三维建模的挑战性任务。
- 现存方法无法真实地进行手-物交互建模。
- 提出 NCRF 框架来从视频中重建手-物交互。
- NCRF 包括接触优化场和手-物的神经辐射场。
- 接触优化场预测三维查询点精确的接触场。
- 手-物的神经辐射场学习手-物隐式表示。
- 手-物运动场产生观察到标准的对应关系。
- 题目:NCRF:用于手-物体交互自由视点渲染的神经接触辐射场
- 作者:Zhongqun Zhang, Jifei Song, Eduardo Pérez-Pellitero, Yiren Zhou, Hyung Jin Chang, Aleš Leonardis
- 第一作者单位:伯明翰大学
- 关键词:手-物体交互、自由视点渲染、神经辐射场、接触场优化
- 论文链接:https://arxiv.org/abs/2402.05532
摘要: (1)研究背景:手-物体交互建模是计算机视觉中一项极具挑战性的任务。尽管该领域取得了显着进展,但现有方法仍然无法以逼真的方式合成手-物体交互,这源于手和物体之间严重的相互遮挡以及不准确的手-物体姿态估计,从而导致渲染质量下降。 (2)过去方法及其问题:以往工作通常将此任务表述为联合手和物体姿态估计问题,并依赖参数化的手-物体模型(如 MANO 和 YCB)来估计手的运动变换。然而,现有方法难以恢复手-物体接触场的准确几何形状,并且渲染质量受到遮挡和姿态估计误差的严重影响。 (3)本文提出的研究方法:为了解决这些挑战,我们提出了一种新颖的自由视点渲染框架——神经接触辐射场(NCRF),以从一组稀疏视频中重建手-物体交互。NCRF 框架主要由两个关键组件组成:(a)接触优化场:从 3D 查询点预测准确的接触场,以实现手和物体之间的理想接触。(b)手-物体神经辐射场:与专门设计的手-物体运动场协同工作,学习静态规范空间中的隐式手-物体表示,以产生观测到规范的对应关系。我们联合学习这些关键组件,它们通过视觉和几何约束相互帮助和正则化,从而产生高质量的手-物体重建,实现逼真的新视角合成。 (4)方法在什么任务上取得了怎样的性能,这些性能是否支持了它们的目标:在 HO3D 和 Dex-YCB 数据集上的广泛实验表明,我们的方法在渲染质量和姿态估计精度方面均优于当前最先进的方法。这些性能支持了我们的目标,即以逼真的方式重建和渲染手-物体交互。
Methods: (1): 本文提出了一种新颖的自由视点渲染框架——神经接触辐射场(NCRF),以从一组稀疏视频中重建手-物体交互。 (2): NCRF框架主要由两个关键组件组成:(a)接触优化场:从3D查询点预测准确的接触场,以实现手和物体之间的理想接触。(b)手-物体神经辐射场:与专门设计的手-物体运动场协同工作,学习静态规范空间中的隐式手-物体表示,以产生观测到规范的对应关系。 (3): 我们联合学习这些关键组件,它们通过视觉和几何约束相互帮助和正则化,从而产生高质量的手-物体重建,实现逼真的新视角合成。
结论: (1):本文提出了一种新颖的自由视点渲染框架——神经接触辐射场(NCRF),该框架能够从一组稀疏视频中重建手-物体交互,并生成逼真的新视角合成。NCRF框架通过设计动态手-物体神经辐射场和接触优化场,能够建模具有复杂手部抓握动作和频繁相互遮挡的具有挑战性的手-物体交互。 (2):创新点:
- 提出了一种新颖的自由视点渲染框架——神经接触辐射场(NCRF),该框架能够从一组稀疏视频中重建手-物体交互,并生成逼真的新视角合成。
- 设计了动态手-物体神经辐射场和接触优化场,能够建模具有复杂手部抓握动作和频繁相互遮挡的具有挑战性的手-物体交互。
- 提出了一种新的手-物体变形模块,该模块能够将射线变形到规范空间中,并以逼真的方式渲染手-物体交互。 性能:
- 在HO3D和Dex-YCB数据集上的广泛实验表明,NCRF框架在渲染质量和姿态估计精度方面均优于当前最先进的方法。
- NCRF框架能够生成逼真的新视角合成,并且能够很好地处理具有复杂手部抓握动作和频繁相互遮挡的具有挑战性的手-物体交互。 工作量:
- NCRF框架的实现相对复杂,需要较高的计算资源。
- NCRF框架的训练过程需要较长时间,并且需要大量的数据。
点此查看论文截图

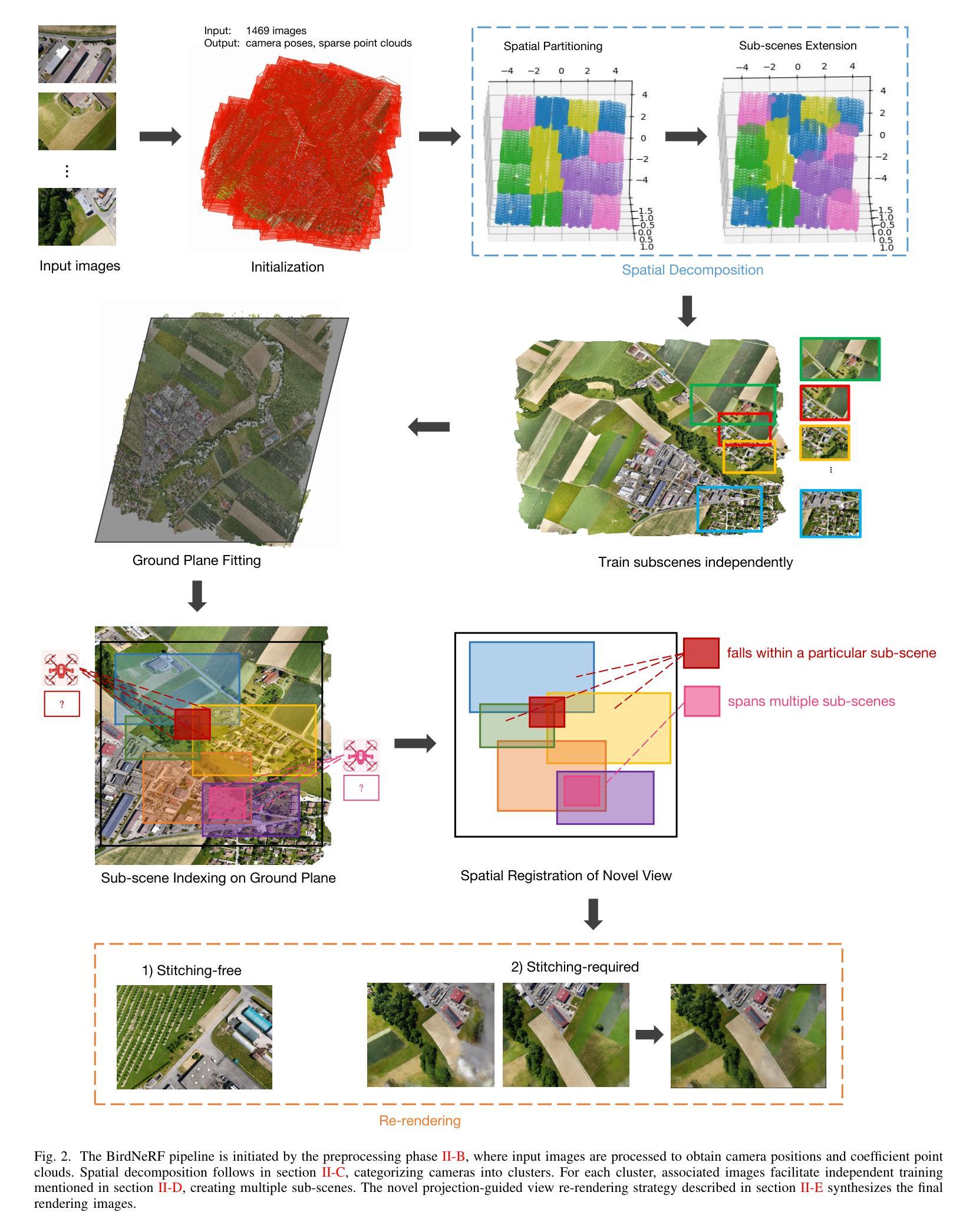
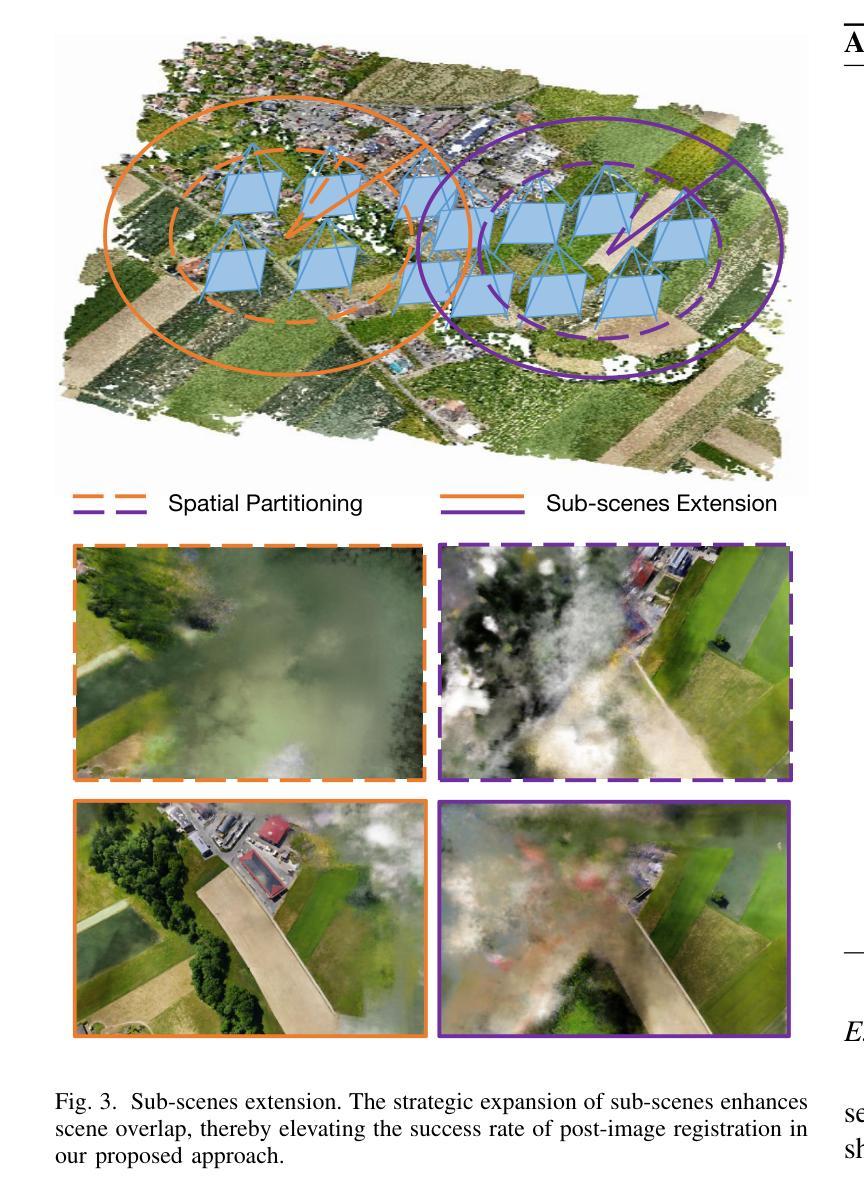
BirdNeRF: Fast Neural Reconstruction of Large-Scale Scenes From Aerial Imagery
Authors:Huiqing Zhang, Yifei Xue, Ming Liao, Yizhen Lao
In this study, we introduce BirdNeRF, an adaptation of Neural Radiance Fields (NeRF) designed specifically for reconstructing large-scale scenes using aerial imagery. Unlike previous research focused on small-scale and object-centric NeRF reconstruction, our approach addresses multiple challenges, including (1) Addressing the issue of slow training and rendering associated with large models. (2) Meeting the computational demands necessitated by modeling a substantial number of images, requiring extensive resources such as high-performance GPUs. (3) Overcoming significant artifacts and low visual fidelity commonly observed in large-scale reconstruction tasks due to limited model capacity. Specifically, we present a novel bird-view pose-based spatial decomposition algorithm that decomposes a large aerial image set into multiple small sets with appropriately sized overlaps, allowing us to train individual NeRFs of sub-scene. This decomposition approach not only decouples rendering time from the scene size but also enables rendering to scale seamlessly to arbitrarily large environments. Moreover, it allows for per-block updates of the environment, enhancing the flexibility and adaptability of the reconstruction process. Additionally, we propose a projection-guided novel view re-rendering strategy, which aids in effectively utilizing the independently trained sub-scenes to generate superior rendering results. We evaluate our approach on existing datasets as well as against our own drone footage, improving reconstruction speed by 10x over classical photogrammetry software and 50x over state-of-the-art large-scale NeRF solution, on a single GPU with similar rendering quality.
Summary
对于大场景下的重建任务,本文引入 BirdNeRF,该方法能够有效利用无人机影像数据实现高效低存储的大场景重建。
Key Takeaways
- BirdNeRF 是一款针对航空图像的大场景重建方法,解决了以往小场景重建存在的训练慢、渲染慢、模型容量小等问题。
- BirdNeRF 提出了一种基于鸟瞰视角的姿势分解算法,将大场景图像集分解成多个小场景子集,每个子集使用单独的 NeRF 进行训练。
- BirdNeRF 采用了一种新颖的投影引导式新视角重新渲染策略,可以有效利用独立训练的子场景生成更好的渲染结果。
- BirdNeRF 在现有数据集和我们自己的无人机数据上进行了评估,在单个 GPU 上的重建速度比经典摄影测量软件快 10 倍,比最先进的大场景 NeRF 解决方案快 50 倍,且渲染质量相似。
- BirdNeRF 可以在任意大的场景中无缝扩展,并支持对环境的局部更新,提高了重建过程的灵活性。
- 题目:BirdNeRF:基于航拍图像的大场景快速神经重建
- 作者:张惠卿、薛一菲、廖明、老义珍
- 单位:无
- 关键词:NeRF、大场景重建、航拍图像、空间分解、投影引导
- 链接:无,Github 链接:无
摘要: (1)研究背景:大场景三维重建是摄影测量和遥感领域的一项重要任务,可以利用航拍或卫星图像、激光雷达数据和街景图像等多种数据源构建城市的三维模型。近年来,基于图像的三维重建技术取得了很大的进展,并在城市规划、导航、虚拟旅游、房地产、灾害管理和历史保护等领域得到了广泛的应用。 (2)过去方法与问题:现有的基于图像的三维重建技术主要分为传统几何方法和基于神经网络的方法。传统几何方法主要包括摄影测量和激光扫描,这些方法可以生成高精度的三维模型,但需要大量的人工参与和昂贵的设备。基于神经网络的方法,如神经辐射场(NeRF),可以从图像中自动学习三维场景的表示,但这些方法通常需要大量的训练数据和计算资源,并且在大场景重建任务中容易出现伪影和低视觉保真度的问题。 (3)研究方法:为了解决上述问题,本文提出了一种新的基于 NeRF 的大场景重建方法,称为 BirdNeRF。BirdNeRF 采用了一种新的鸟瞰视角姿势分解算法,将大场景图像分解成多个小场景,并分别训练每个小场景的 NeRF 模型。这种分解方法不仅可以减少训练和渲染时间,还可以提高重建的质量。此外,BirdNeRF 还提出了一种投影引导的新视角重新渲染策略,可以有效地利用独立训练的小场景模型生成高质量的渲染结果。 (4)性能与目标:BirdNeRF 在现有数据集和我们自己的无人机航拍数据上进行了评估。结果表明,BirdNeRF 的重建速度比传统的摄影测量软件快 10 倍,比最先进的大场景 NeRF 解决方案快 50 倍,并且在单个 GPU 上可以实现相似的渲染质量。这些结果证明了 BirdNeRF 的有效性和实用性。
方法: (1)场景分解:将大场景图像分解成多个小场景,并分别训练每个小场景的 NeRF 模型。 (2)视角姿势分解:采用鸟瞰视角姿势分解算法,将大场景图像分解成多个小场景。 (3)新视角重新渲染:提出一种投影引导的新视角重新渲染策略,可以有效地利用独立训练的小场景模型生成高质量的渲染结果。
结论: (1):本文提出了一种新的基于 NeRF 的大场景重建方法 BirdNeRF,该方法采用鸟瞰视角姿势分解算法和投影引导的新视角重新渲染策略,可以有效地解决大场景重建任务中容易出现伪影和低视觉保真度的问题。 (2):创新点:
- 提出了一种新的鸟瞰视角姿势分解算法,可以将大场景图像分解成多个小场景,并分别训练每个小场景的 NeRF 模型,从而减少训练和渲染时间,提高重建质量。
- 提出了一种投影引导的新视角重新渲染策略,可以有效地利用独立训练的小场景模型生成高质量的渲染结果。 性能:
- BirdNeRF 在现有数据集和我们自己的无人机航拍数据上进行了评估。结果表明,BirdNeRF 的重建速度比传统的摄影测量软件快 10 倍,比最先进的大场景 NeRF 解决方案快 50 倍,并且在单个 GPU 上可以实现相似的渲染质量。 工作量:
- BirdNeRF 的实现相对简单,并且可以在单个 GPU 上训练和渲染。然而,由于需要对大场景图像进行分解,因此 BirdNeRF 的预处理时间可能会比较长。
点此查看论文截图

 wechat
wechat- alipay







