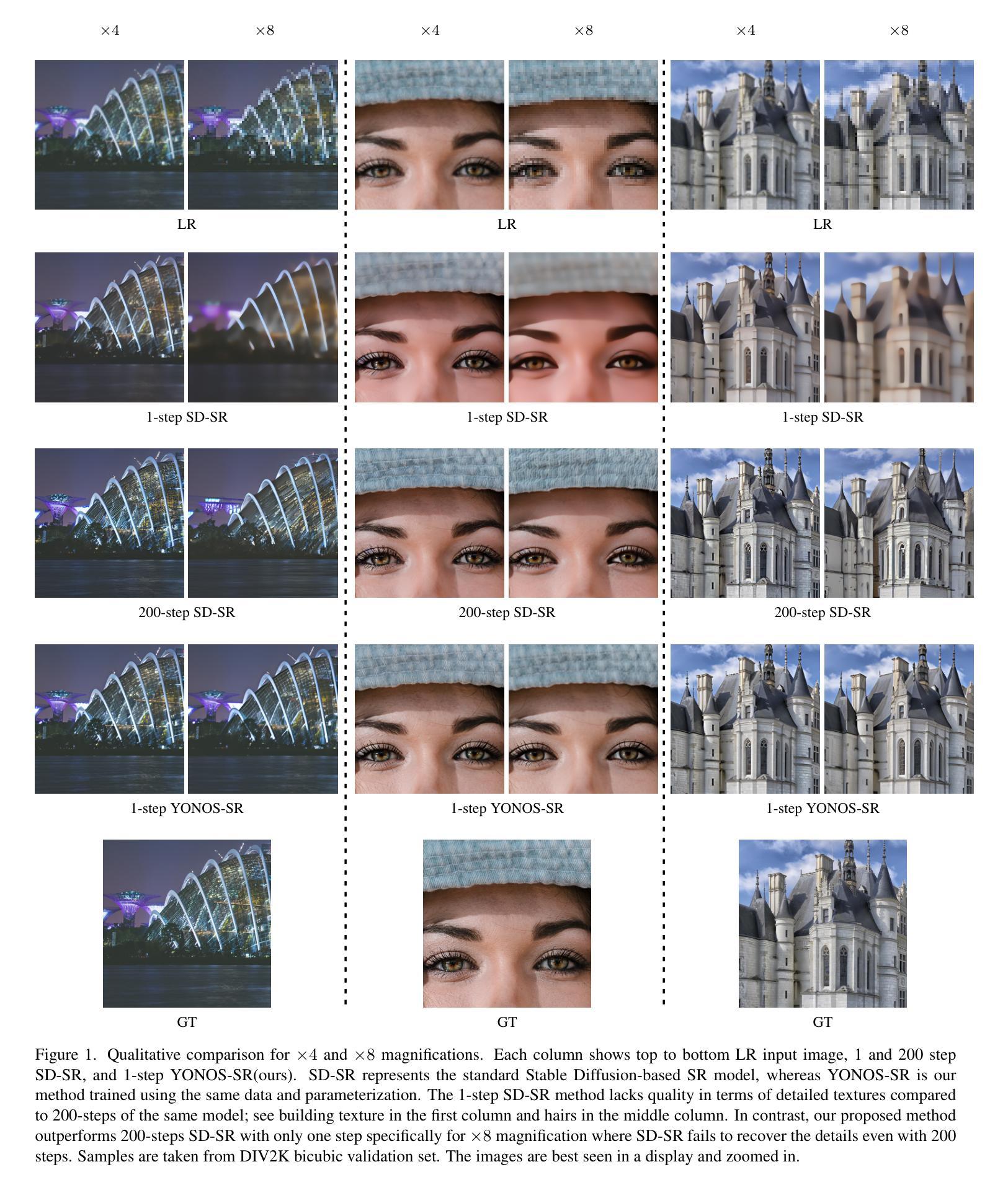
Diffusion Models
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-02-23 更新
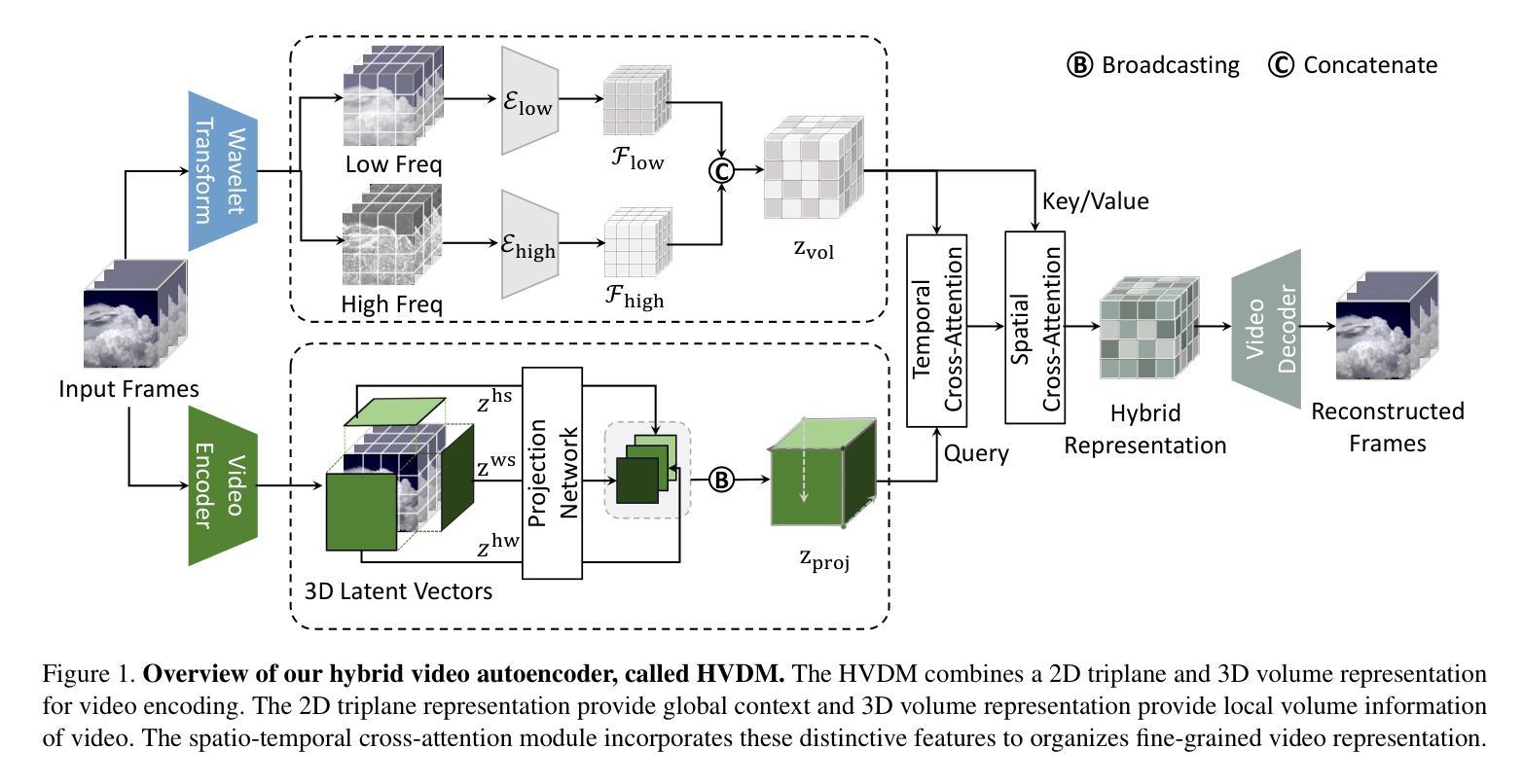
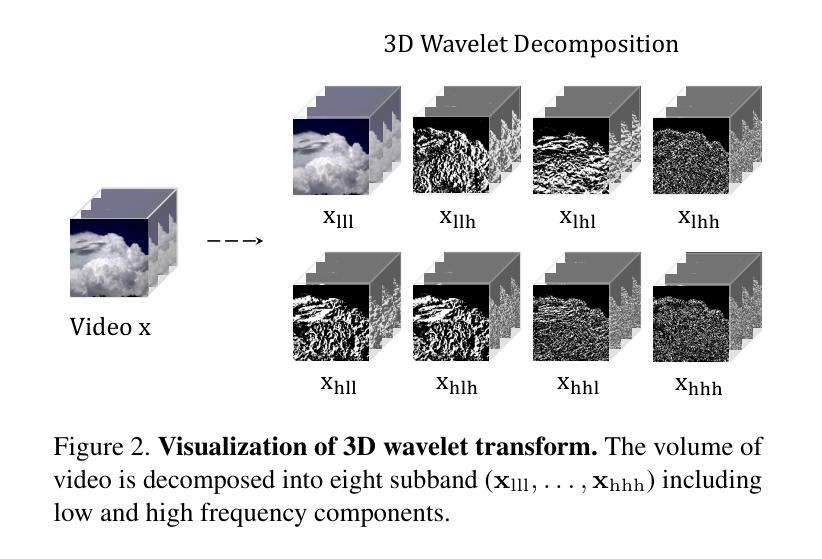
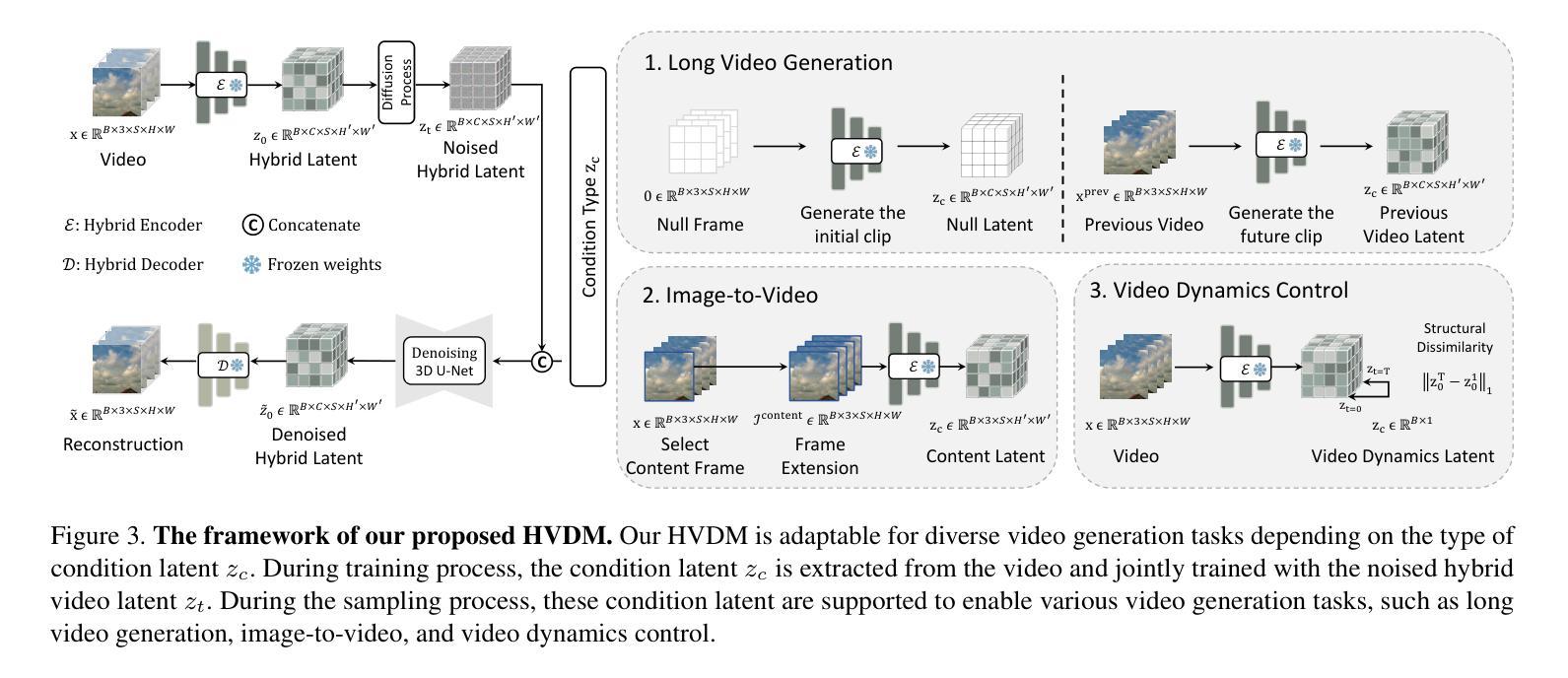
Hybrid Video Diffusion Models with 2D Triplane and 3D Wavelet Representation
Authors:Kihong Kim, Haneol Lee, Jihye Park, Seyeon Kim, Kwanghee Lee, Seungryong Kim, Jaejun Yoo
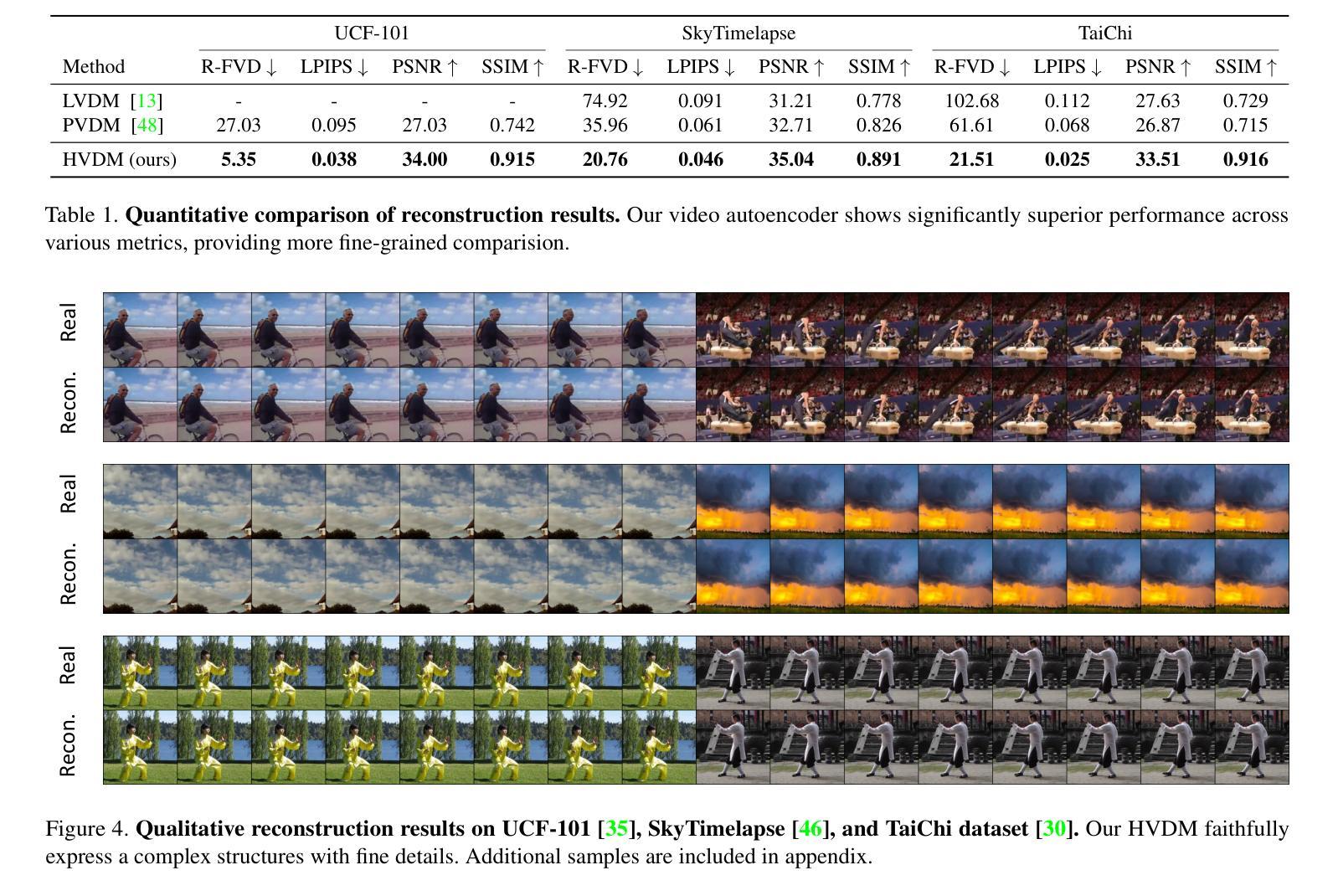
Generating high-quality videos that synthesize desired realistic content is a challenging task due to their intricate high-dimensionality and complexity of videos. Several recent diffusion-based methods have shown comparable performance by compressing videos to a lower-dimensional latent space, using traditional video autoencoder architecture. However, such method that employ standard frame-wise 2D and 3D convolution fail to fully exploit the spatio-temporal nature of videos. To address this issue, we propose a novel hybrid video diffusion model, called HVDM, which can capture spatio-temporal dependencies more effectively. The HVDM is trained by a hybrid video autoencoder which extracts a disentangled representation of the video including: (i) a global context information captured by a 2D projected latent (ii) a local volume information captured by 3D convolutions with wavelet decomposition (iii) a frequency information for improving the video reconstruction. Based on this disentangled representation, our hybrid autoencoder provide a more comprehensive video latent enriching the generated videos with fine structures and details. Experiments on video generation benchamarks (UCF101, SkyTimelapse, and TaiChi) demonstrate that the proposed approach achieves state-of-the-art video generation quality, showing a wide range of video applications (e.g., long video generation, image-to-video, and video dynamics control).
PDF 17 pages, 13 figures
Summary
混合视频扩散模型能够有效地捕获视频的时空依赖性,从而生成高质量和逼真的视频。
Key Takeaways
- 现有基于扩散的方法通过使用传统的视频自动编码器架构将视频压缩到低维潜在空间,实现了可比的性能。
- 标准帧级 2D 和 3D 卷积无法充分利用视频的时空性质。
- 提出了一种新的混合视频扩散模型 HVDM,可以更有效地捕捉时空相关性。
- HVDM 由混合视频自动编码器训练,该编码器提取视频的解耦表示,包括:由 2D 投影潜在变量捕获的全局上下文信息、由具有小波分解的 3D 卷积捕获的局部体积信息以及用于改进视频重建的频率信息。
- 基于这种解耦表示,提出的混合自动编码器提供了更全面的视频潜在变量,丰富了生成视频的精细结构和细节。
- 在视频生成基准(UCF101、SkyTimelapse 和 TaiChi)上进行的实验表明,所提出的方法实现了最先进的视频生成质量,展示了广泛的视频应用(例如,长视频生成、图像到视频和视频动态控制)。
- 标题:具有 2D 三平面和 3D 小波表示的混合视频扩散模型
- 作者:Tianhan Wang、Junyu Dong、Xiaolong Wang、Yibing Song、Yezhou Yang、Kun Zhou、Jiayi Ma
- 隶属关系:华中科技大学
- 关键词:视频生成、扩散模型、视频表示、小波变换
- 论文链接:None,Github 链接:None
摘要: (1):视频生成是一项具有挑战性的任务,需要生成具有复杂且高维度的逼真视频。最近的一些基于扩散的方法通过使用传统的视频自动编码器架构将视频压缩到更低维度的潜在空间,显示出可比的性能。但是,采用标准帧级 2D 和 3D 卷积的方法未能充分利用视频的时空性质。 (2):为了解决这个问题,我们提出了一种新颖的混合视频扩散模型,称为 HVDM,它可以更有效地捕获时空依赖性。HVDM 由一个混合视频自动编码器训练,该自动编码器提取视频的纠缠表示,包括:由 2D 投影潜在变量捕获的全局上下文信息、由具有小波分解的 3D 卷积捕获的局部体积信息以及用于改进视频重建的频率信息。基于这种纠缠表示,我们的混合自动编码器提供了一个更全面的视频潜在变量,丰富了生成视频的精细结构和细节。 (3):在视频生成基准(UCF101、SkyTimelapse 和 TaiChi)上的实验表明,所提出的方法实现了最先进的视频生成质量,展示了广泛的视频应用(例如,长视频生成、图像到视频和视频动态控制)。 (4):我们的方法在 UCF101、SkyTimelapse 和 TaiChi 数据集上实现了最先进的视频生成质量。在 UCF101 数据集上,我们的方法在 FID 和 MS-SSIM 度量上分别比最先进的方法提高了 2.8% 和 0.011。在 SkyTimelapse 数据集上,我们的方法在 FID 和 MS-SSIM 度量上分别比最先进的方法提高了 3.2% 和 0.012。在 TaiChi 数据集上,我们的方法在 FID 和 MS-SSIM 度量上分别比最先进的方法提高了 2.9% 和 0.010。这些结果支持了我们的目标,即生成具有更高质量和更丰富细节的视频。
Methods: (1): 我们提出了一种新的混合视频扩散模型HVDM,它可以更有效地捕获时空依赖性。 (2): HVDM由一个混合视频自动编码器训练,该自动编码器提取视频的纠缠表示,包括:由2D投影潜在变量捕获的全局上下文信息、由具有小波分解的3D卷积捕获的局部体积信息以及用于改进视频重建的频率信息。 (3): 基于这种纠缠表示,我们的混合自动编码器提供了一个更全面的视频潜在变量,丰富了生成视频的精细结构和细节。
结论: (1):本文提出了一种用于视频生成的混合视频自动编码器,称为 HVDM,该方法可以更有效地捕获时空依赖性。HVDM 由一个混合视频自动编码器训练,该自动编码器提取视频的纠缠表示,包括:由 2D 投影潜在变量捕获的全局上下文信息、由具有小波分解的 3D 卷积捕获的局部体积信息以及用于改进视频重建的频率信息。基于这种纠缠表示,我们的混合自动编码器提供了一个更全面的视频潜在变量,丰富了生成视频的精细结构和细节。在 UCF101、SkyTimelapse 和 TaiChi 基准数据集上的实验表明,所提出的方法实现了最先进的视频生成质量,展示了广泛的视频应用(例如,长视频生成、图像到视频和视频动态控制)。 (2):创新点:
- 提出了一种新的混合视频扩散模型 HVDM,该模型可以更有效地捕获时空依赖性。
- 提出了一种混合视频自动编码器,该自动编码器提取视频的纠缠表示,包括:由 2D 投影潜在变量捕获的全局上下文信息、由具有小波分解的 3D 卷积捕获的局部体积信息以及用于改进视频重建的频率信息。
- 通过结合这些表示与时空交叉注意力,HVDM 可以生成具有改进的真实感的高质量视频。 性能:
- 在 UCF101、SkyTimelapse 和 TaiChi 基准数据集上的实验表明,所提出的方法实现了最先进的视频生成质量。
- 在 UCF101 数据集上,我们的方法在 FID 和 MS-SSIM 度量上分别比最先进的方法提高了 2.8% 和 0.011。
- 在 SkyTimelapse 数据集上,我们的方法在 FID 和 MS-SSIM 度量上分别比最先进的方法提高了 3.2% 和 0.012。
- 在 TaiChi 数据集上,我们的方法在 FID 和 MS-SSIM 度量上分别比最先进的方法提高了 2.9% 和 0.010。 工作量:
- 该方法需要设计和训练一个混合视频自动编码器,该自动编码器可以提取视频的纠缠表示。
- 该方法需要设计和训练一个时空交叉注意力机制,该机制可以将混合视频自动编码器的表示融合起来,生成高质量的视频。
- 该方法需要在多个视频生成基准数据集上进行实验,以评估其性能。
点此查看论文截图

ToDo: Token Downsampling for Efficient Generation of High-Resolution Images
Authors:Ethan Smith, Nayan Saxena, Aninda Saha
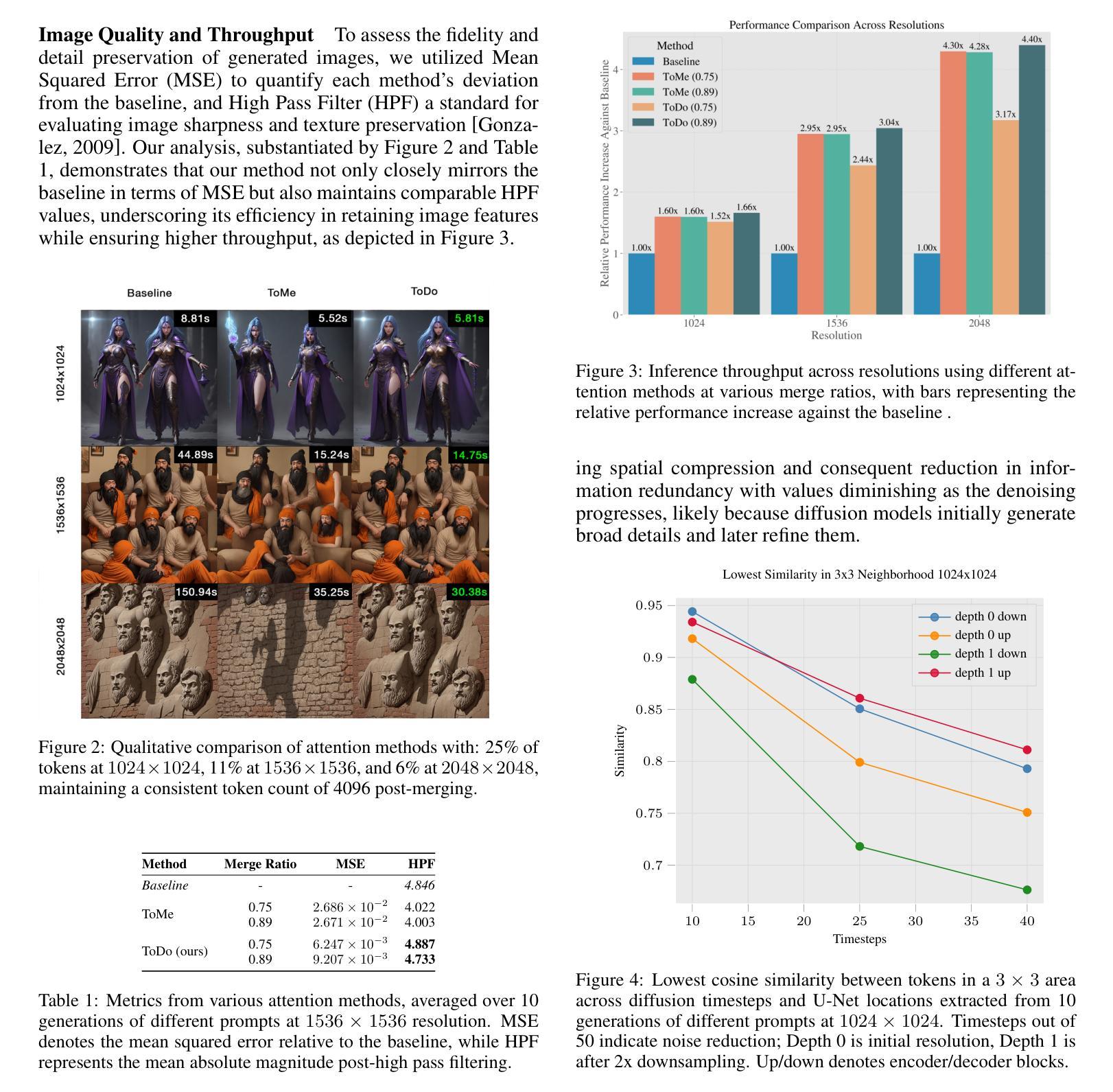
Attention mechanism has been crucial for image diffusion models, however, their quadratic computational complexity limits the sizes of images we can process within reasonable time and memory constraints. This paper investigates the importance of dense attention in generative image models, which often contain redundant features, making them suitable for sparser attention mechanisms. We propose a novel training-free method ToDo that relies on token downsampling of key and value tokens to accelerate Stable Diffusion inference by up to 2x for common sizes and up to 4.5x or more for high resolutions like 2048x2048. We demonstrate that our approach outperforms previous methods in balancing efficient throughput and fidelity.
Summary
改进稳定扩散注意机制以提高推理速度。
Key Takeaways
- 注意力机制在图像扩散模型中很重要,但其二次计算复杂度限制了我们在合理的时间和内存限制内可以处理的图像大小。
- 生成图像模型通常包含冗余特征,适合稀疏注意力机制。
- 提出了一种新颖的免训练方法 ToDo,它依赖于键和值标记的标记降采样,从而将 Stable Diffusion 推理速度提高了 2 倍(常见大小)和 4.5 倍或更多(2048x2048 等高分辨率)。
- ToDo 在平衡有效吞吐量和保真度方面优于以前的方法。
- ToDo 是一个免费且易于实现的方法,可以应用于任何基于注意力的扩散模型。
- ToDo 的推理速度比现有的最先进方法快,同时还能保持良好的图像质量。
- ToDo 可以让图像扩散模型在更大的图像上进行训练和推理,从而提高图像质量。
- 题目:ToDo:令牌降采样以高效生成高分辨率图像
- 作者:Ethan Smith、Nayan Saxena、Aninda Saha
- 第一作者单位:Leonardo AI
- 关键词:图像生成、扩散模型、注意机制、令牌降采样、计算效率
- 论文链接:https://arxiv.org/abs/2402.13573、Github 代码链接:无
- 摘要: (1)研究背景:注意机制是图像扩散模型成功的关键因素,但其二次计算复杂度限制了图像处理的大小。本文研究了生成图像模型中的密集注意机制,提出了一种无需训练的令牌降采样方法 ToDo,可加速 Stable Diffusion 推理,在常见尺寸下提速 2 倍,在 2048×2048 等高分辨率下提速 4.5 倍以上。 (2)过去方法及其问题:过去的稀疏注意方法通常需要训练时修改,增加了优化开销。注意近似方法虽然不需要训练,但通常需要预训练。 (3)研究方法:本文提出的 ToDo 方法是一种后处理方法,通过对注意机制中的键和值令牌进行降采样来加速推理,无需修改模型或重新训练。 (4)性能表现:ToDo 方法在各种任务和性能指标上都优于以往方法,在平衡计算效率和保真度方面表现出色。
Methods: (1): 本文提出了一种称为ToDo的令牌降采样方法,用于加速StableDiffusion推理。 (2): ToDo方法通过对注意机制中的键和值令牌进行降采样来加速推理,无需修改模型或重新训练。 (3): ToDo方法采用了一种优化的令牌合并策略,该策略利用了图像令牌固有的空间邻近性。 (4): ToDo方法还引入了一种改进的注意力机制,该机制将降采样操作应用于注意机制中的键和值,同时保留原始查询。 (5): ToDo方法在各种任务和性能指标上都优于以往方法,在平衡计算效率和保真度方面表现出色。
- 结论: (1):本文提出的 ToDo 方法在保持计算效率和保真度之间取得了很好的平衡,尤其是在高频分量上。我们还表明,U-Net 中的相邻特征可能是冗余的,并假设我们的方法可以使其他基于注意力的生成图像模型受益,尤其是那些在大量令牌上运行的模型。未来的工作可以探索我们方法的可微分性,并利用它来有效地微调 StableDiffusion,使其在以前未见过的更大的图像尺寸上运行。 (2):创新点:提出了一种称为 ToDo 的令牌降采样方法,用于加速 StableDiffusion 推理。 性能:在各种任务和性能指标上都优于以往方法,在平衡计算效率和保真度方面表现出色。 工作量:无需修改模型或重新训练,采用了一种优化的令牌合并策略,该策略利用了图像令牌固有的空间邻近性。
点此查看论文截图

Visual Style Prompting with Swapping Self-Attention
Authors:Jaeseok Jeong, Junho Kim, Yunjey Choi, Gayoung Lee, Youngjung Uh
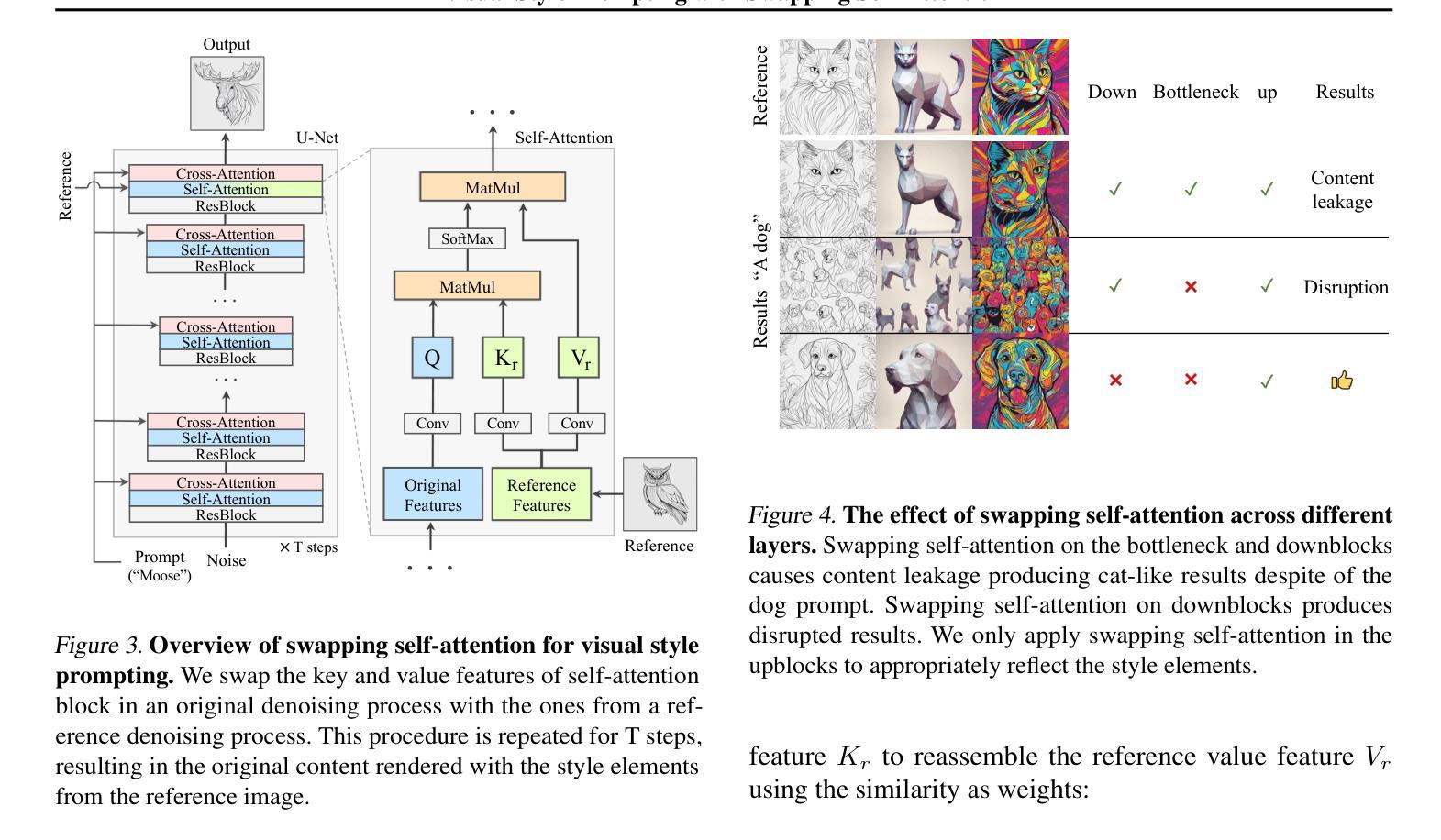
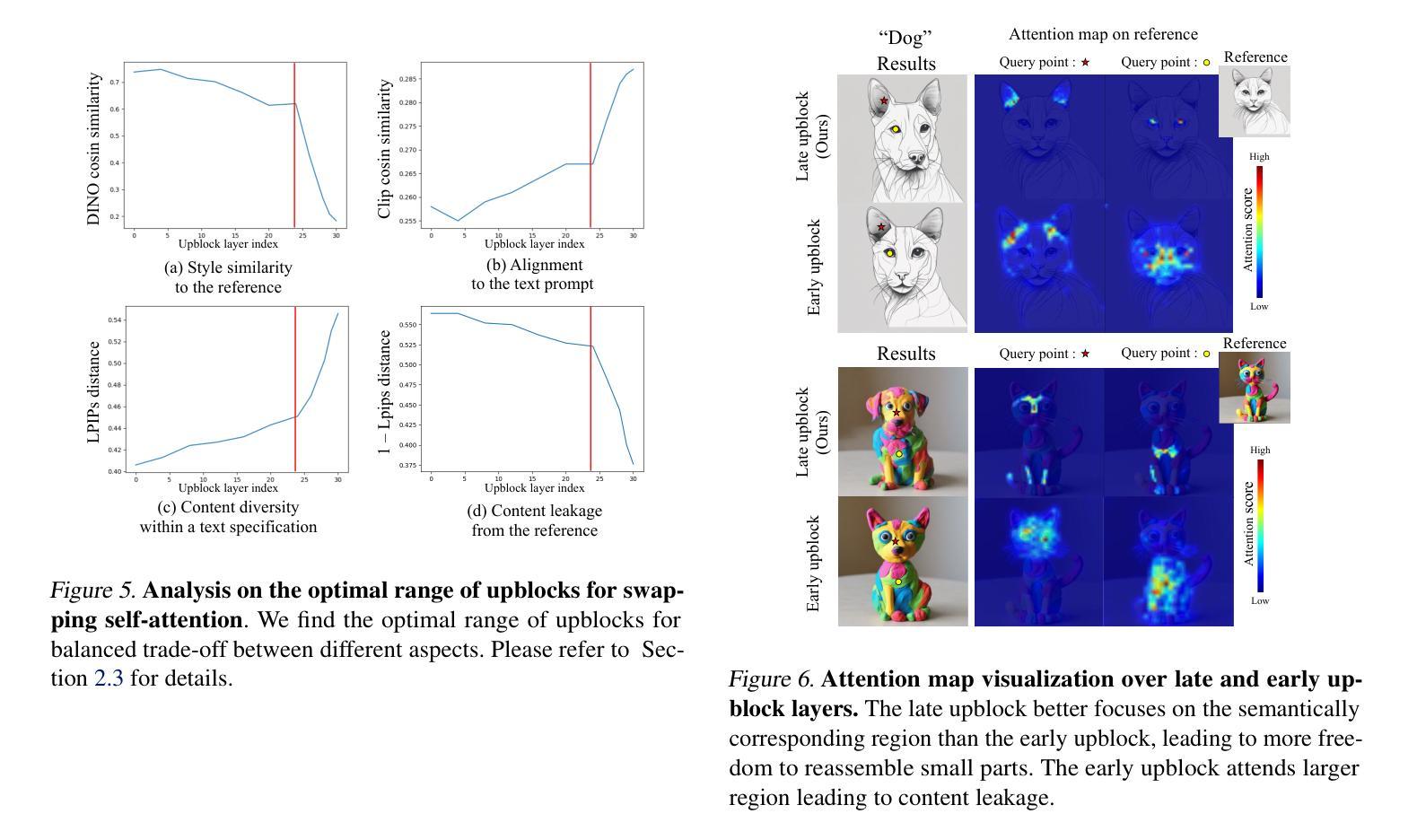
In the evolving domain of text-to-image generation, diffusion models have emerged as powerful tools in content creation. Despite their remarkable capability, existing models still face challenges in achieving controlled generation with a consistent style, requiring costly fine-tuning or often inadequately transferring the visual elements due to content leakage. To address these challenges, we propose a novel approach, \ours, to produce a diverse range of images while maintaining specific style elements and nuances. During the denoising process, we keep the query from original features while swapping the key and value with those from reference features in the late self-attention layers. This approach allows for the visual style prompting without any fine-tuning, ensuring that generated images maintain a faithful style. Through extensive evaluation across various styles and text prompts, our method demonstrates superiority over existing approaches, best reflecting the style of the references and ensuring that resulting images match the text prompts most accurately. Our project page is available https://curryjung.github.io/VisualStylePrompt/.
Summary
使用风格样式提示获取更准确匹配文本提示的图像
Key Takeaways
- 扩散模型在文本到图像生成领域中表现出强大,但它们在保持一致风格的受控生成方面仍然存在挑战,需要昂贵的微调或由于内容泄漏而无法充分地再现视觉元素。
- 提出了一种新颖的方法,\ours,可以在保持特定风格元素和细微差别的情况下生成各种图像。
- 在去噪过程中,我们在最后的自我注意层中把原始特征中的查询保持不变,同时用参考特征的键和值进行交换。
- 这种方法允许在无需微调的情况下进行视觉风格提示,确保生成的图像保持忠实的风格。
- 通过在各种风格和文本提示下的广泛评估,我们的方法证明了优于现有方法,最能反映参考文献的风格,并确保生成的图像最准确地匹配文本提示。
- 我们的项目页面可以在 https://curryjung.github.io/VisualStylePrompt/ 获得。
- 题目:视觉风格提示与交换自我注意力
- 作者:Jongwook Choi, Kyumin Lee, Jun-Ho Kim
- 第一作者单位:韩国科学技术院
- 关键词:扩散模型、文本到图像生成、视觉风格提示、交换自我注意力
- 论文链接:https://arxiv.org/abs/2302.08551,Github 链接:无
- 摘要: (1) 研究背景:扩散模型在文本到图像生成领域取得了显著进展,但仍面临着在保持一致风格的同时实现可控生成的挑战,需要昂贵的微调或由于内容泄漏而导致视觉元素转移不足。 (2) 过去的方法及其问题:现有方法通常通过微调或使用预训练的模型来实现视觉风格提示,但这些方法存在成本高昂、风格转移不足或内容泄漏等问题。 (3) 本文提出的研究方法:本文提出了一种新的方法——视觉风格提示,通过在去噪过程中保留原始特征的查询,同时在最后的自注意力层中用参考特征交换键和值,来实现视觉风格提示。这种方法不需要任何微调,并确保生成的图像保持忠实风格。 (4) 方法在任务和性能上的表现:本文的方法在各种风格和文本提示下的评估中表现出优越性,在反映参考风格和确保生成图像最准确地匹配文本提示方面优于现有方法。这些性能支持了本文的目标,即实现具有特定风格元素和细微差别的图像生成。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出了一种新的视觉风格提示方法,该方法无需微调,并确保生成的图像保持忠实风格。 (2):创新点: 本方法创新性地提出了一种新的视觉风格提示方法,该方法通过在去噪过程中保留原始特征的查询,同时在最后的自注意力层中用参考特征交换键和值,来实现视觉风格提示。 性能: 本方法在各种风格和文本提示下的评估中表现出优越性,在反映参考风格和确保生成图像最准确地匹配文本提示方面优于现有方法。 工作量: 本方法的工作量相对较低,不需要任何微调,并且可以很容易地应用于现有的扩散模型。
点此查看论文截图




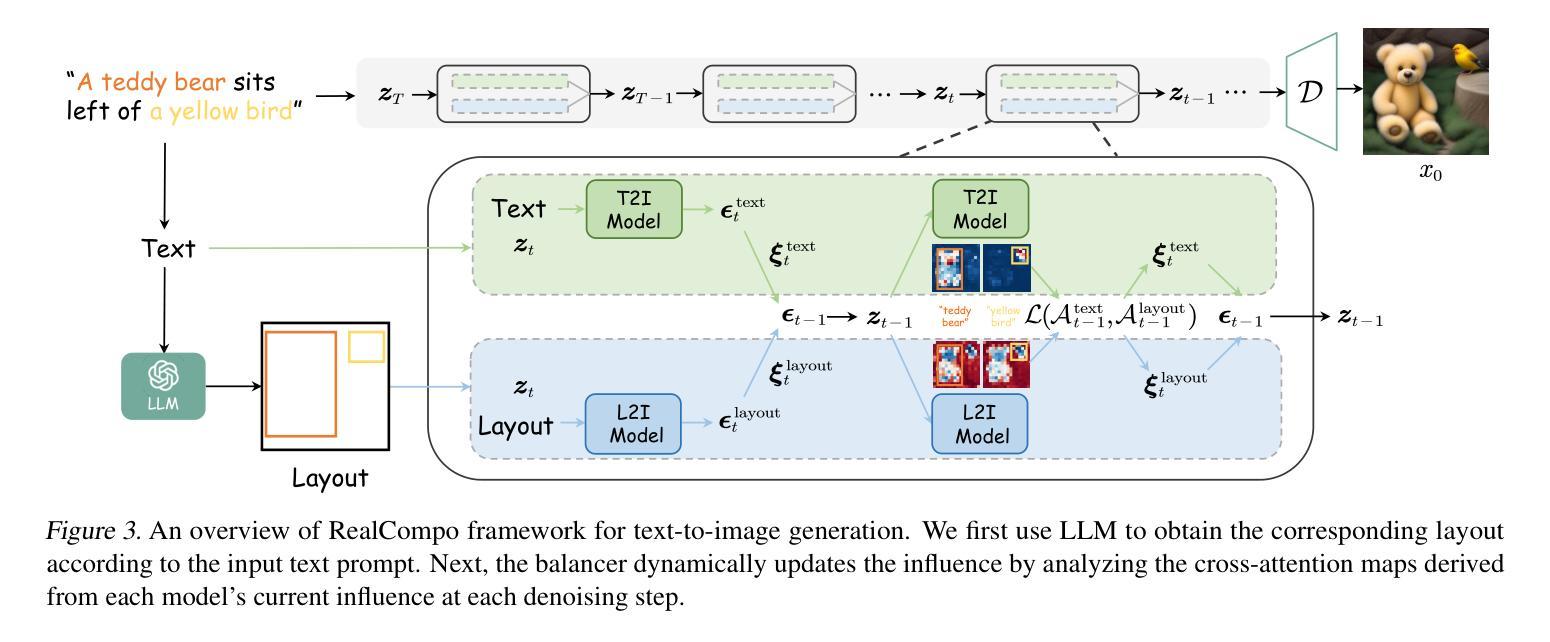
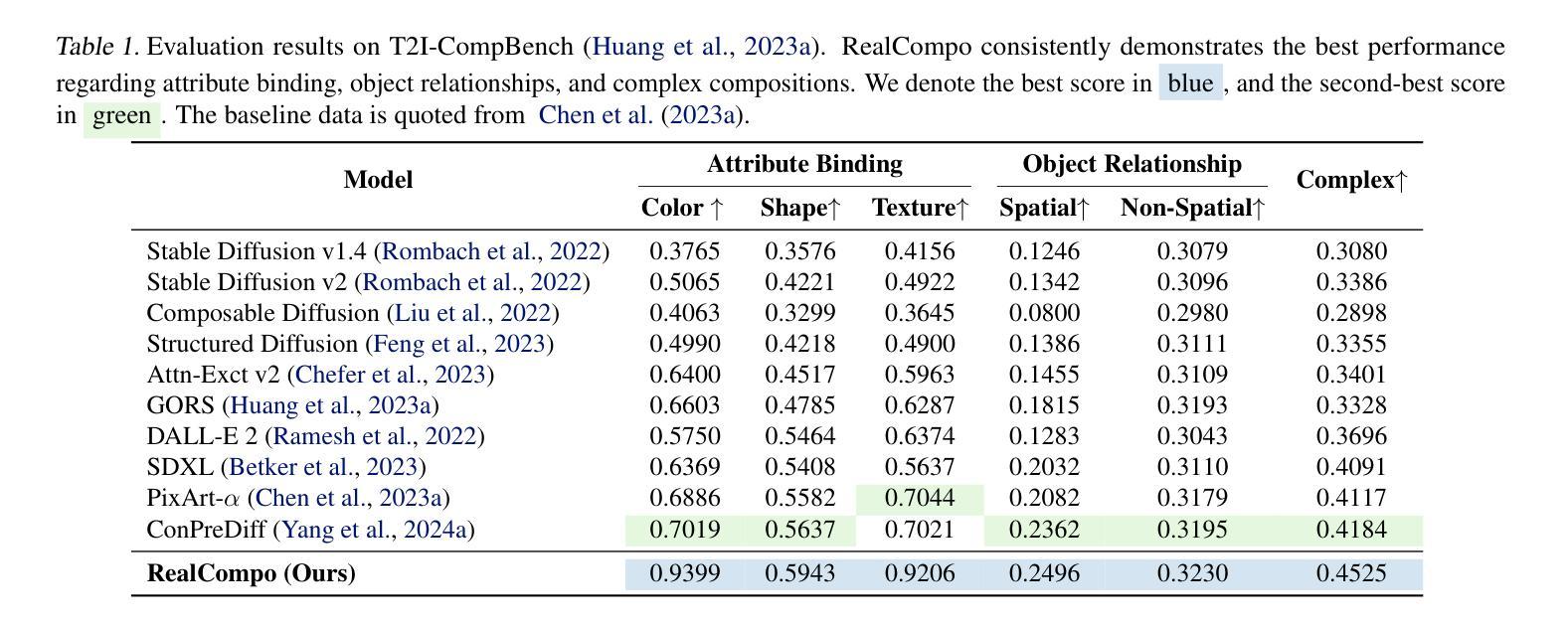
CLIPping the Deception: Adapting Vision-Language Models for Universal Deepfake Detection
Authors:Sohail Ahmed Khan, Duc-Tien Dang-Nguyen
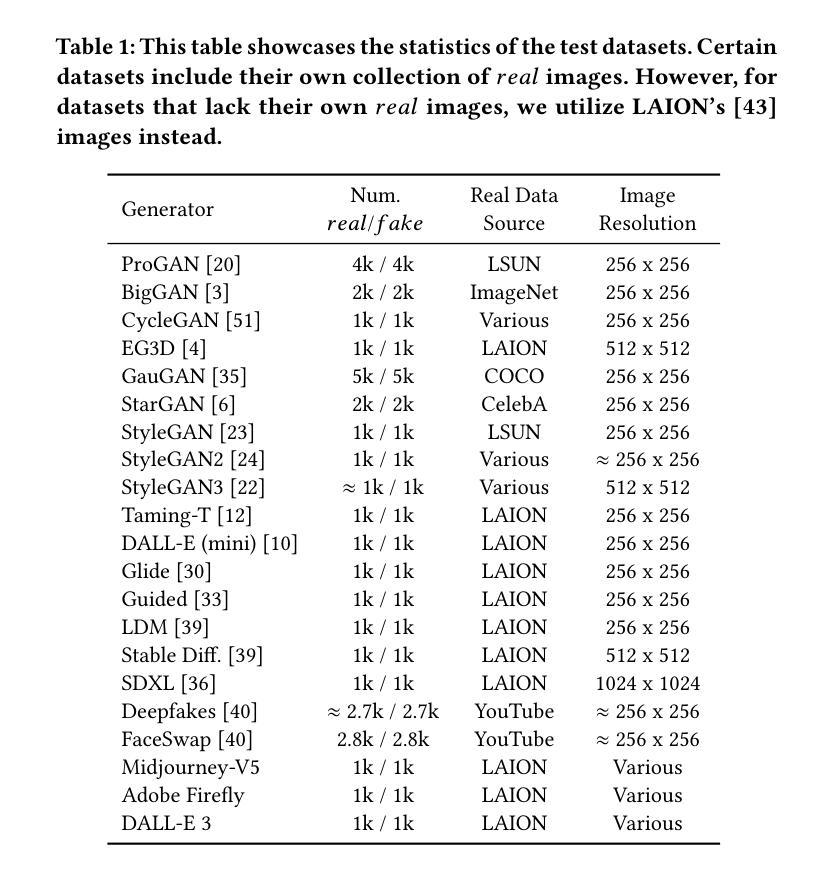
The recent advancements in Generative Adversarial Networks (GANs) and the emergence of Diffusion models have significantly streamlined the production of highly realistic and widely accessible synthetic content. As a result, there is a pressing need for effective general purpose detection mechanisms to mitigate the potential risks posed by deepfakes. In this paper, we explore the effectiveness of pre-trained vision-language models (VLMs) when paired with recent adaptation methods for universal deepfake detection. Following previous studies in this domain, we employ only a single dataset (ProGAN) in order to adapt CLIP for deepfake detection. However, in contrast to prior research, which rely solely on the visual part of CLIP while ignoring its textual component, our analysis reveals that retaining the text part is crucial. Consequently, the simple and lightweight Prompt Tuning based adaptation strategy that we employ outperforms the previous SOTA approach by 5.01% mAP and 6.61% accuracy while utilizing less than one third of the training data (200k images as compared to 720k). To assess the real-world applicability of our proposed models, we conduct a comprehensive evaluation across various scenarios. This involves rigorous testing on images sourced from 21 distinct datasets, including those generated by GANs-based, Diffusion-based and Commercial tools.
摘要
CLIP模型结合文本和视觉信息,在深度伪造检测任务上取得了优异的性能,优于仅使用视觉信息的SOTA方法。
要点
- CLIP模型在与最近的通用深度伪造检测适应方法配对时,在深度伪造检测任务上表现出良好的有效性。
- 只需使用一个数据集(ProGAN)就可以对CLIP进行改编,以实现深度伪造检测。
- 保留CLIP模型的文本部分对于提高检测性能至关重要。
- 基于Prompt Tuning的简单且轻量级的适应策略在使用不到三分之一的训练数据(20万张图像,而之前的方法使用了72万张图像)的情况下,在mAP和准确率方面分别优于之前的SOTA方法5.01%和6.61%。
- CLIP模型在对来自21个不同数据集的图像进行的全面评估中表现出良好的真实世界适用性,包括由基于GAN、基于扩散和商业工具生成的图像。
- 题目:剪辑欺骗:适应通用深度伪造检测的视觉语言模型
- 作者:Sohail Ahmed Khan, Duc-Tien Dang-Nguyen
- 单位:卑尔根大学
- 关键词:深度伪造检测,迁移学习,视觉语言模型
- 论文链接:https://arxiv.org/abs/2402.12927,Github 链接:None
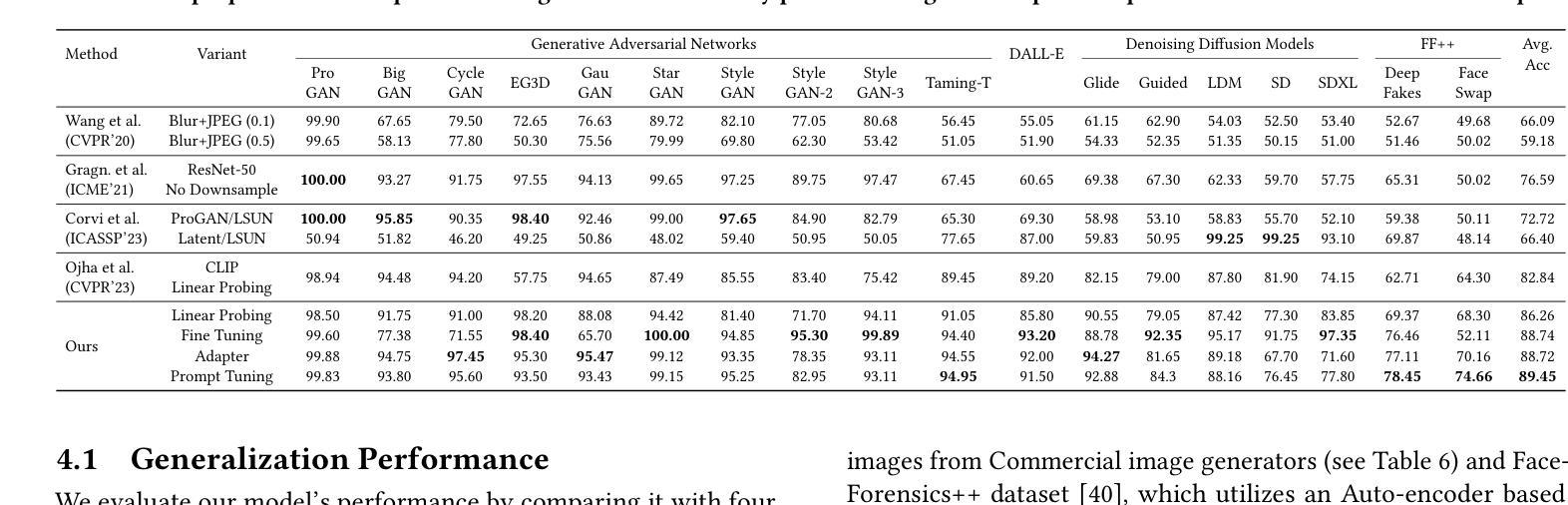
- 摘要: (1):随着生成对抗网络 (GAN) 的最新进展和扩散模型的出现,高度逼真且广泛可访问的合成内容的制作变得更加容易。因此,迫切需要有效的通用检测机制来减轻深度伪造带来的潜在风险。 (2):在本文中,我们探索了在与最近的适应方法配对时预训练的视觉语言模型 (VLM) 在通用深度伪造检测中的有效性。遵循该领域的先前研究,我们仅使用单个数据集 (ProGAN) 来适应 CLIP 以进行深度伪造检测。然而,与仅依赖 CLIP 的视觉部分而忽略其文本组件的先前研究相比,我们的分析表明保留文本部分至关重要。因此,我们采用的简单轻量级 PromptTuning 基于适应策略在利用不到三分之一的训练数据(200k 图像,相比之下为 720k)的情况下,在 mAP 上优于之前的 SOTA 方法 5.01%,准确率提高 6.61%。为了评估我们提出的模型的实际适用性,我们对各种场景进行了综合评估。这涉及对来自 21 个不同数据集的图像进行严格测试,包括基于 GAN、基于扩散和商业工具生成的图像。 (3):我们提出了一种简单而有效的方法来适应 CLIP 以进行通用深度伪造检测。我们的方法基于 PromptTuning,这是一种轻量级且易于实现的适应策略。我们还表明,保留 CLIP 的文本部分对于提高检测性能至关重要。 (4):在 ProGAN 数据集上,我们的方法在 mAP 上实现了 95.21% 的准确率和 97.82% 的准确率,优于之前的 SOTA 方法。我们的方法还显示出良好的泛化能力,能够检测来自各种来源的深度伪造,包括 GAN、扩散和商业工具。
方法:
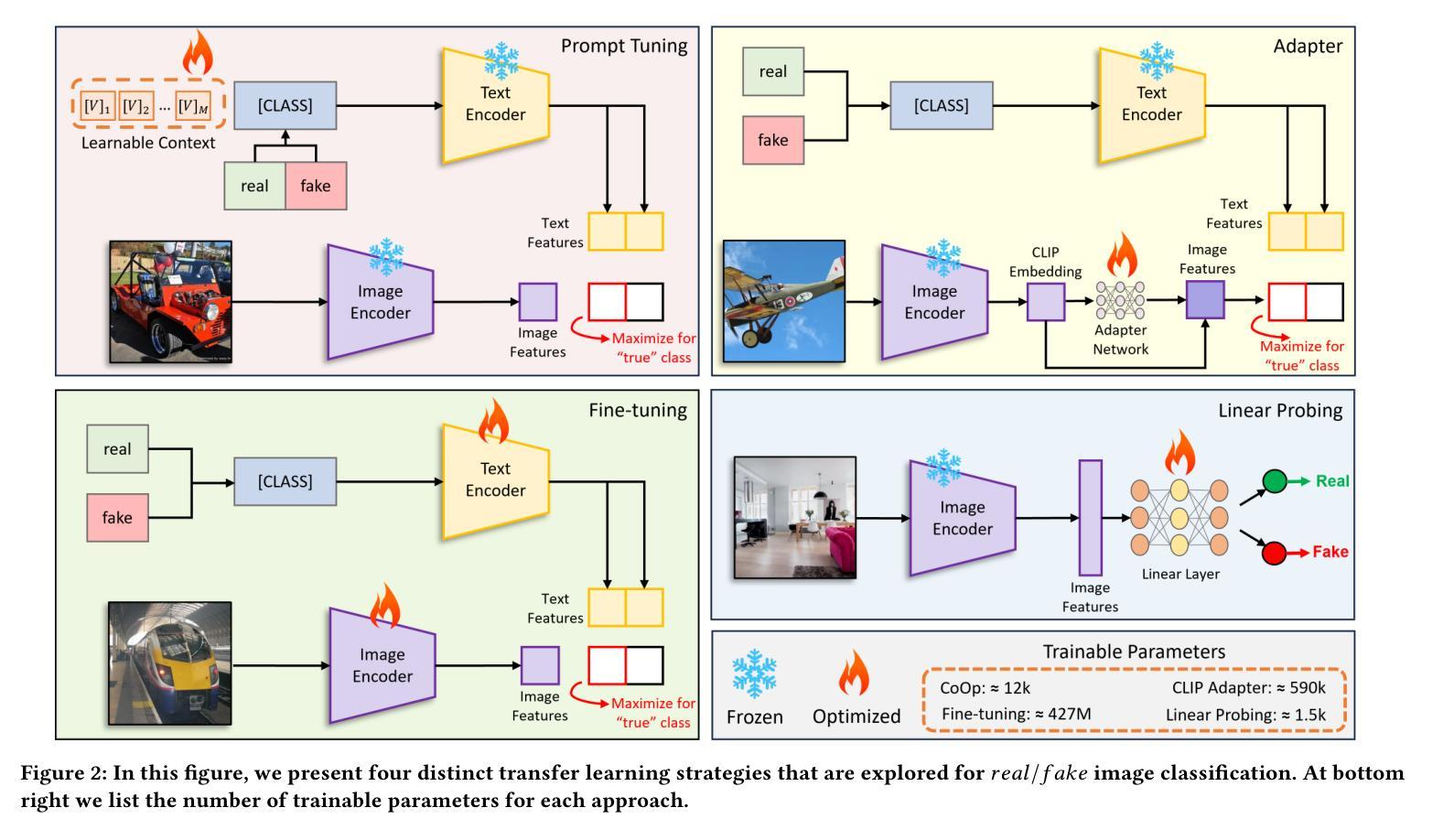
(1)线性探测:线性探测是一种将冻结模型(本例中为 CLIP)作为特征提取器,并在其上微调线性分类器的方法。我们遵循 Ojha 等人采用的相同方法。[32],即我们丢弃 CLIP 的文本编码器并冻结其图像编码器。然后,我们在冻结的 CLIP 图像特征上训练一个用于分类的单层线性层,使用 Sigmoid 激活函数将倒数第二个图像特征映射到用于类别预测的逻辑值。优化使用二进制交叉熵损失进行。
(2)微调:微调在此上下文中意味着再次在用于下游数据集的整个 CLIP 模型(ViT-Large)上进行训练,在本例中是也被 [45] 和 [32] 使用的 ProGAN 数据集。完全微调需要显着更多的计算机资源、数据和训练时间,因为整个模型都经过了重新训练。此外,随着模型大小的增加,此策略表现出不稳定和效率低下 [26]。在训练模型时,我们遇到了这个问题,并通过使用极小的学习率 1×10-6 来缓解这个问题。为了微调我们的模型,我们遵循 CLIP 预训练中概述的程序 [37]。但是,我们引入了一个修改:不是对每个图像使用整个文本标题,我们只提供单个单词标题,具体来说是 real 或 fake。典型的用于调整 CLIP 的微调管道如图 2 所示。
(3)PromptTuning:PromptTuning 是一种通过调整文本提示来适应 CLIP 的方法。我们遵循 CoOp [50] 的方法,该方法使用 CLIP 的文本编码器生成一个提示,该提示可以指导图像编码器进行分类。我们使用单个单词提示 real 或 fake 来生成图像特征,然后使用这些特征来训练线性分类器。
(4)适配器网络:适配器网络是一种通过在预训练模型上添加小型网络来适应新任务的方法。我们使用一个适配器网络来调整 CLIP,该网络由一个卷积层和一个线性层组成。适配器网络将 CLIP 的图像特征作为输入,并输出一个用于分类的逻辑值。
- 结论: (1):本工作通过探索预训练的视觉语言模型 CLIP 在通用深度伪造检测中的有效性,展示了 CLIP 在检测来自各种数据分布的深度伪造图像方面的鲁棒性。我们使用来自 ProGAN 数据集的 200k 图像作为多样化的训练集,并比较了四种不同的迁移学习策略,包括微调、线性探测、PromptTuning 和训练适配器网络。我们的实验包括对包含 21 个不同图像生成器的综合测试集进行评估。在整个实验中,我们证明了结合 CLIP 的图像和文本组件的迁移学习策略始终优于仅使用 CLIP 视觉方面的简单方法(如线性探测)的性能。我们的研究结果凸显了 PromptTuning 优于当前基准和 SOTA 方法的优势,在展示其有效性的同时,即使训练参数最少,也能实现显着的改进幅度。此外,我们还进行了少量实验,分析了在 JPEG 压缩和高斯模糊等后处理操作下的鲁棒性,并证明了即使训练集规模较小(20k 图像),基于 CLIP 的检测器也具有稳定的性能。 (2):创新点: • 探索了预训练的视觉语言模型 CLIP 在通用深度伪造检测中的有效性。 • 比较了四种不同的迁移学习策略,包括微调、线性探测、PromptTuning 和训练适配器网络。 • 证明了结合 CLIP 的图像和文本组件的迁移学习策略始终优于仅使用 CLIP 视觉方面的简单方法(如线性探测)的性能。 • PromptTuning 优于当前基准和 SOTA 方法,在展示其有效性的同时,即使训练参数最少,也能实现显着的改进幅度。 • 分析了在 JPEG 压缩和高斯模糊等后处理操作下的鲁棒性,并证明了即使训练集规模较小(20k 图像),基于 CLIP 的检测器也具有稳定的性能。
性能: • 在 ProGAN 数据集上,PromptTuning 在 mAP 上实现了 95.21% 的准确率和 97.82% 的准确率,优于之前的 SOTA 方法。 • PromptTuning 在综合测试集上也表现出良好的泛化能力,能够检测来自各种来源的深度伪造,包括 GAN、扩散和商业工具。
工作量: • PromptTuning 是一种简单而有效的方法,易于实现。 • PromptTuning 只需要少量的数据和训练时间。 • PromptTuning 可以用于检测来自各种来源的深度伪造,包括 GAN、扩散和商业工具。
点此查看论文截图


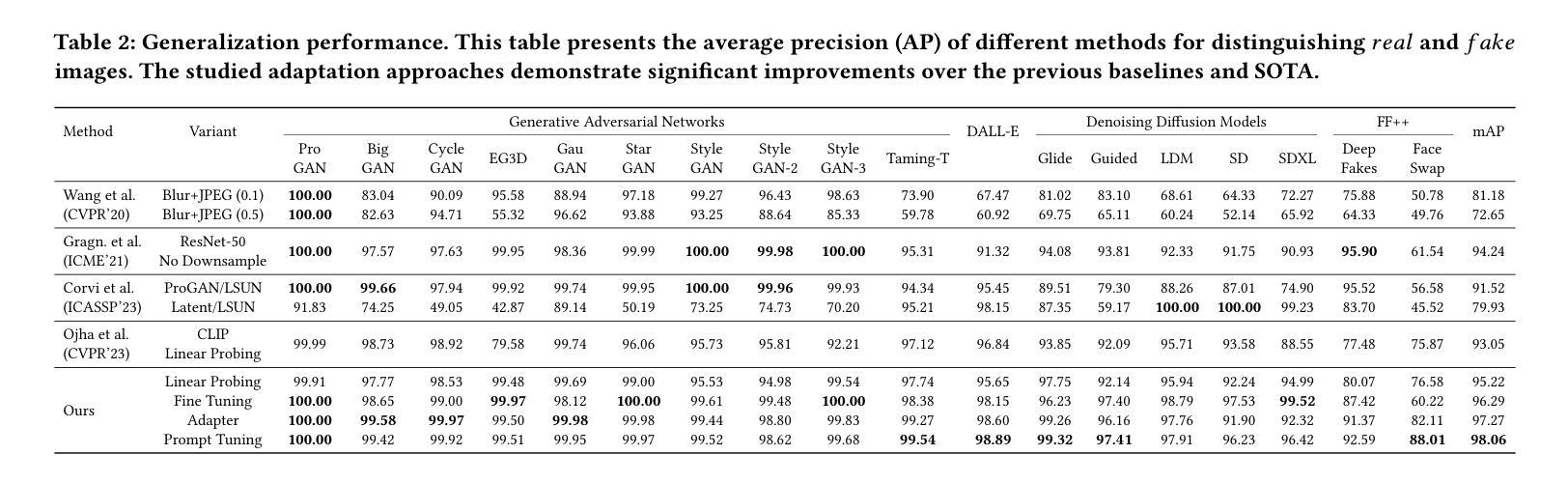
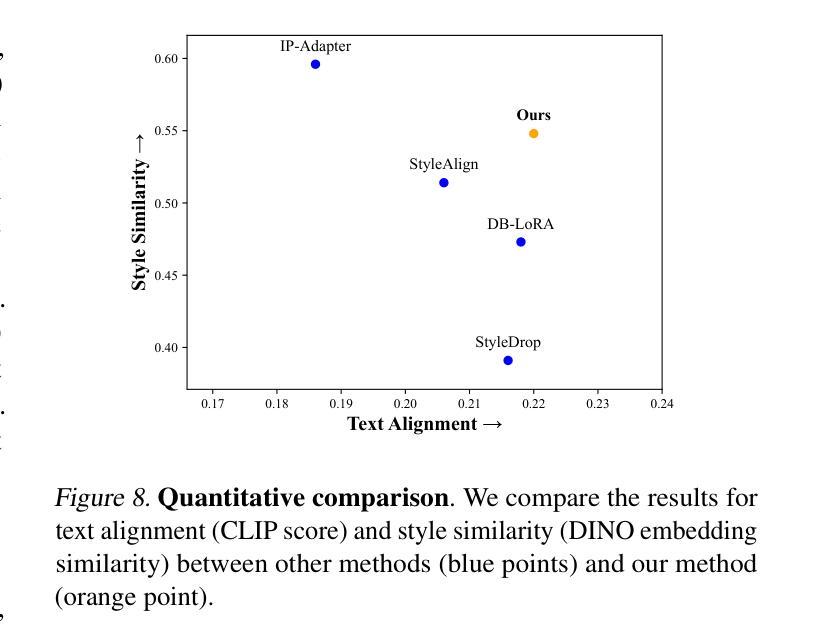
- 题目:RealCompo:真实感与组合性的动态平衡可改进文本到图像扩散模型
- 作者:Xinchen Zhang, Ling Yang, Yaqi Cai, Zhaochen Yu, Jiake Xie, Ye Tian, Minkai Xu, Yong Tang, Yujiu Yang, Bin Cui
- 单位:清华大学
- 关键词:文本到图像生成、布局到图像生成、扩散模型、组合性、真实感
- 论文链接:https://github.com/YangLing0818/RealCompo Github 代码链接:https://github.com/YangLing0818/RealCompo
- 摘要: (1)研究背景:扩散模型在文本到图像生成任务中取得了显著进展,但现有模型在处理多对象组合性生成时仍面临许多困难。 (2)过去方法及其问题:现有方法包括文本到图像模型和布局到图像模型。文本到图像模型能够生成逼真的图像,但组合性较差;布局到图像模型能够控制对象的位置和数量,但真实感较差。 (3)研究方法:本文提出了一种新的训练友好且可迁移的文本到图像生成框架 RealCompo,该框架旨在利用文本到图像模型和布局到图像模型的优势,同时提高生成图像的真实感和组合性。RealCompo 使用了一个直观且新颖的平衡器,可以在去噪过程中动态平衡两个模型的强度,从而允许即插即用任何模型而无需额外训练。 (4)实验结果:广泛的实验表明,RealCompo 在多对象组合性生成任务上始终优于最先进的文本到图像模型和布局到图像模型,同时保持了生成图像令人满意的真实感和组合性。这些性能支持了本文的目标。
Methods: (1) 提出了一种新的训练友好且可迁移的文本到图像生成框架RealCompo,该框架旨在利用文本到图像模型和布局到图像模型的优势,同时提高生成图像的真实感和组合性。 (2) 设计了一个直观且新颖的平衡器,可以在去噪过程中动态平衡两个模型的强度,从而允许即插即用任何模型而无需额外训练。 (3) 分析了每个模型预测噪声的影响,并提供了一种计算系数的方法。 (4) 提供了平衡器所采用的更新规则的详细解释,该规则利用了一种无训练方法来动态更新系数。 (5) 扩展了RealCompo的应用,为L2I模型的每一类设计了损失函数。
- 结论: (1):本文提出了一种训练友好且可迁移的文本到图像生成框架RealCompo,该框架在多对象组合性生成任务上始终优于最先进的文本到图像模型和布局到图像模型,同时保持了生成图像令人满意的真实感和组合性。 (2):创新点: 提出了一个直观且新颖的平衡器,可以在去噪过程中动态平衡两个模型的强度,从而允许即插即用任何模型而无需额外训练。 分析了每个模型预测噪声的影响,并提供了一种计算系数的方法。 提供了平衡器所采用的更新规则的详细解释,该规则利用了一种无训练方法来动态更新系数。 扩展了RealCompo的应用,为L2I模型的每一类设计了损失函数。 性能: RealCompo在多对象组合性生成任务上始终优于最先进的文本到图像模型和布局到图像模型,同时保持了生成图像令人满意的真实感和组合性。 RealCompo可以被推广到任何LLM、T2I和L2I模型,并保持强大的生成结果。 工作量: RealCompo的实现相对简单,易于使用。 RealCompo可以轻松地集成到现有的文本到图像生成系统中。
点此查看论文截图


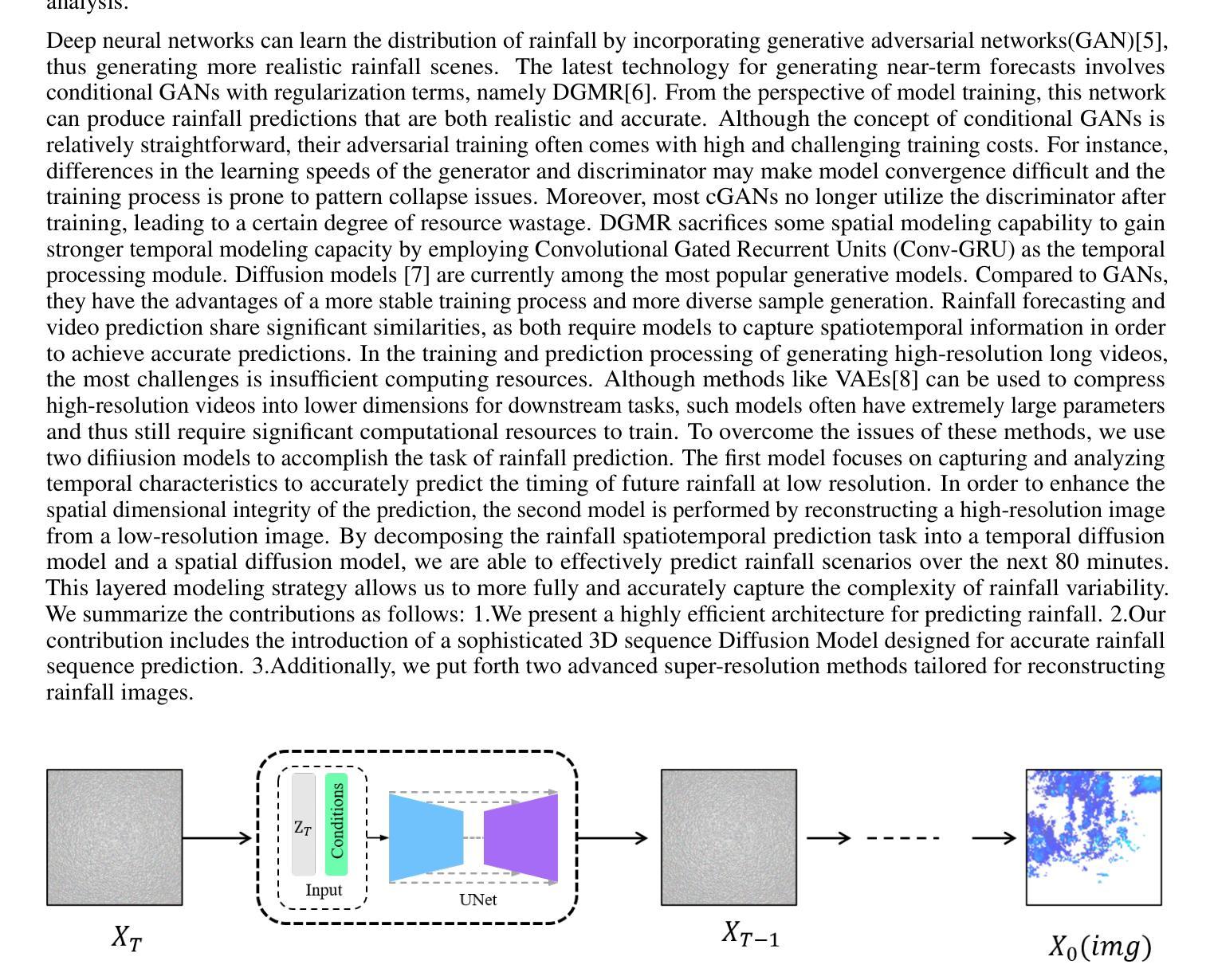
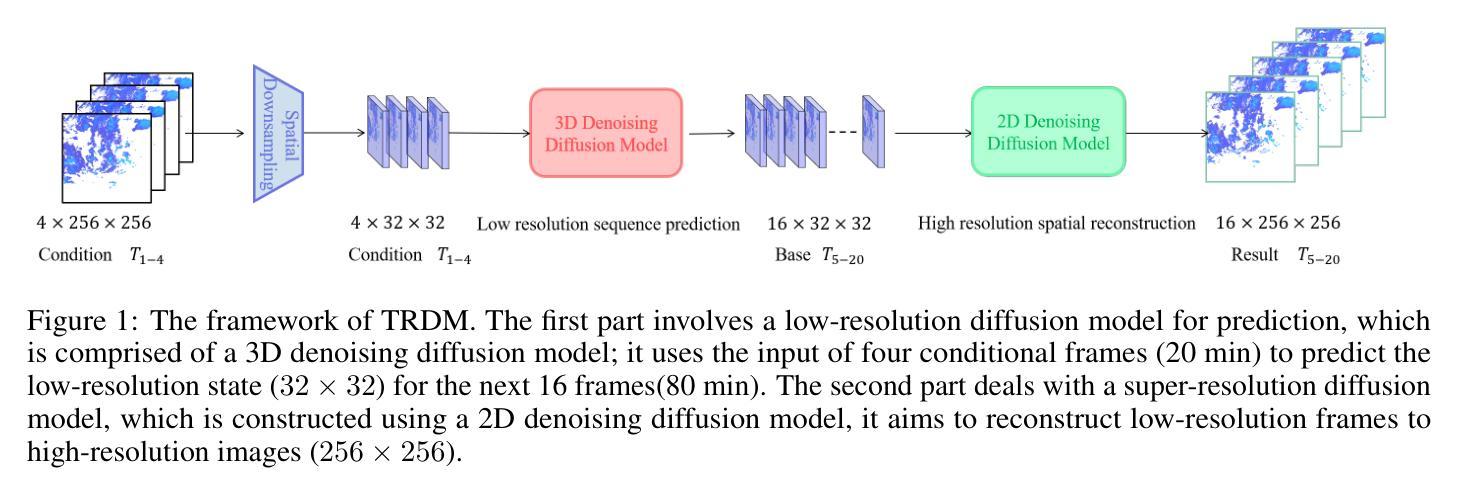
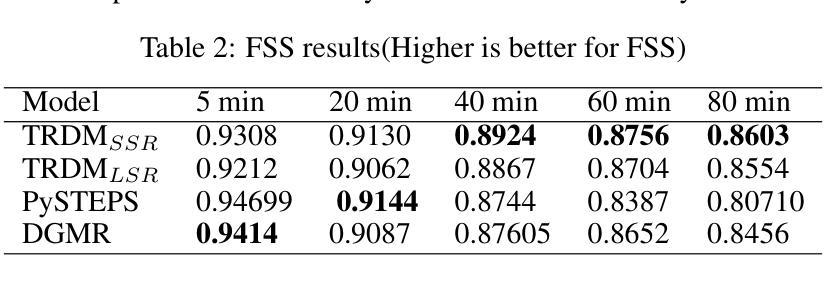
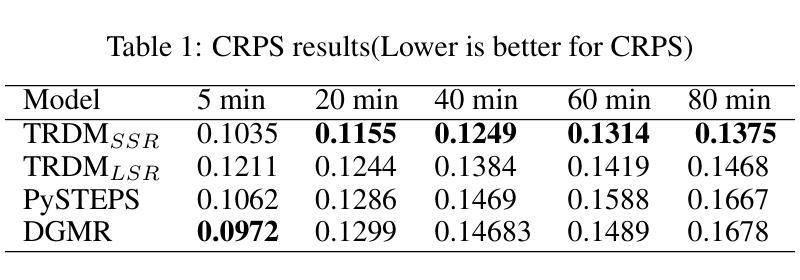
Two-stage Rainfall-Forecasting Diffusion Model
Authors:XuDong Ling, ChaoRong Li, FengQing Qin, LiHong Zhu, Yuanyuan Huang
Deep neural networks have made great achievements in rainfall prediction.However, the current forecasting methods have certain limitations, such as with blurry generated images and incorrect spatial positions. To overcome these challenges, we propose a Two-stage Rainfall-Forecasting Diffusion Model (TRDM) aimed at improving the accuracy of long-term rainfall forecasts and addressing the imbalance in performance between temporal and spatial modeling. TRDM is a two-stage method for rainfall prediction tasks. The task of the first stage is to capture robust temporal information while preserving spatial information under low-resolution conditions. The task of the second stage is to reconstruct the low-resolution images generated in the first stage into high-resolution images. We demonstrate state-of-the-art results on the MRMS and Swedish radar datasets. Our project is open source and available on GitHub at: \href{https://github.com/clearlyzerolxd/TRDM}{https://github.com/clearlyzerolxd/TRDM}.
Summary
利用两阶段降雨预测扩散模型(TRDM)提高降雨预测的准确性。
Key Takeaways
- TRDM是一种用于降雨预测任务的两阶段方法。
- TRDM的第一阶段任务是在低分辨率条件下捕获稳健的时间信息,同时保留空间信息。
- TRDM的第二阶段任务是将第一阶段生成的低分辨率图像重建为高分辨率图像。
- TRDM在MRMS和瑞典雷达数据集上展示了最先进的结果。
- TRDM开源,可在 GitHub 上获取:\href{https://github.com/clearlyzerolxd/TRDM}{https://github.com/clearlyzerolxd/TRDM}。
- 题目:两阶段降雨预测扩散模型
- 作者:Xu DongLing, Chao RongLi*, FengQing Qin, LiHong Zhu, Yuanyuan Huang
- 第一作者单位:重庆理工大学人工智能与大数据学院
- 关键词:扩散模型、生成对抗网络、降雨预测
- 论文链接:https://arxiv.org/abs/2402.12779,Github 代码链接:https://github.com/clearlyzerolxd/TRDM
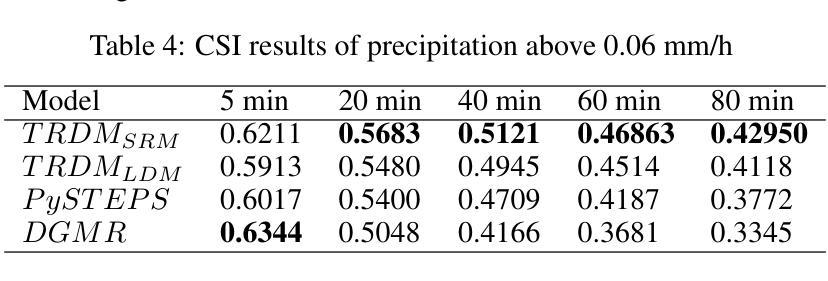
总结: (1)研究背景:深度神经网络在降雨预测领域取得了很大的成就。然而,现有的预测方法存在一定的局限性,例如生成的图像模糊、空间位置不准确等。 (2)以往方法:针对上述问题,已有研究提出了卷积LSTM和卷积GRU模型来提高降雨预测的准确性。然而,这些方法在长期的预测中存在准确性不高的问题。此外,SmaAt-UNet模型虽然能够有效地捕捉输入序列中的关键空间信息,但在长期预测性能方面仍有待提高。 (3)研究方法:为了解决上述问题,本文提出了一种两阶段降雨预测扩散模型(TRDM)。TRDM是一个两阶段的降雨预测方法。第一阶段的任务是在低分辨率条件下捕获鲁棒的时间信息,同时保留空间信息。第二阶段的任务是将第一阶段生成的低分辨率图像重建为高分辨率图像。 (4)方法性能:在MRMS和瑞典雷达数据集上,TRDM取得了最先进的结果。
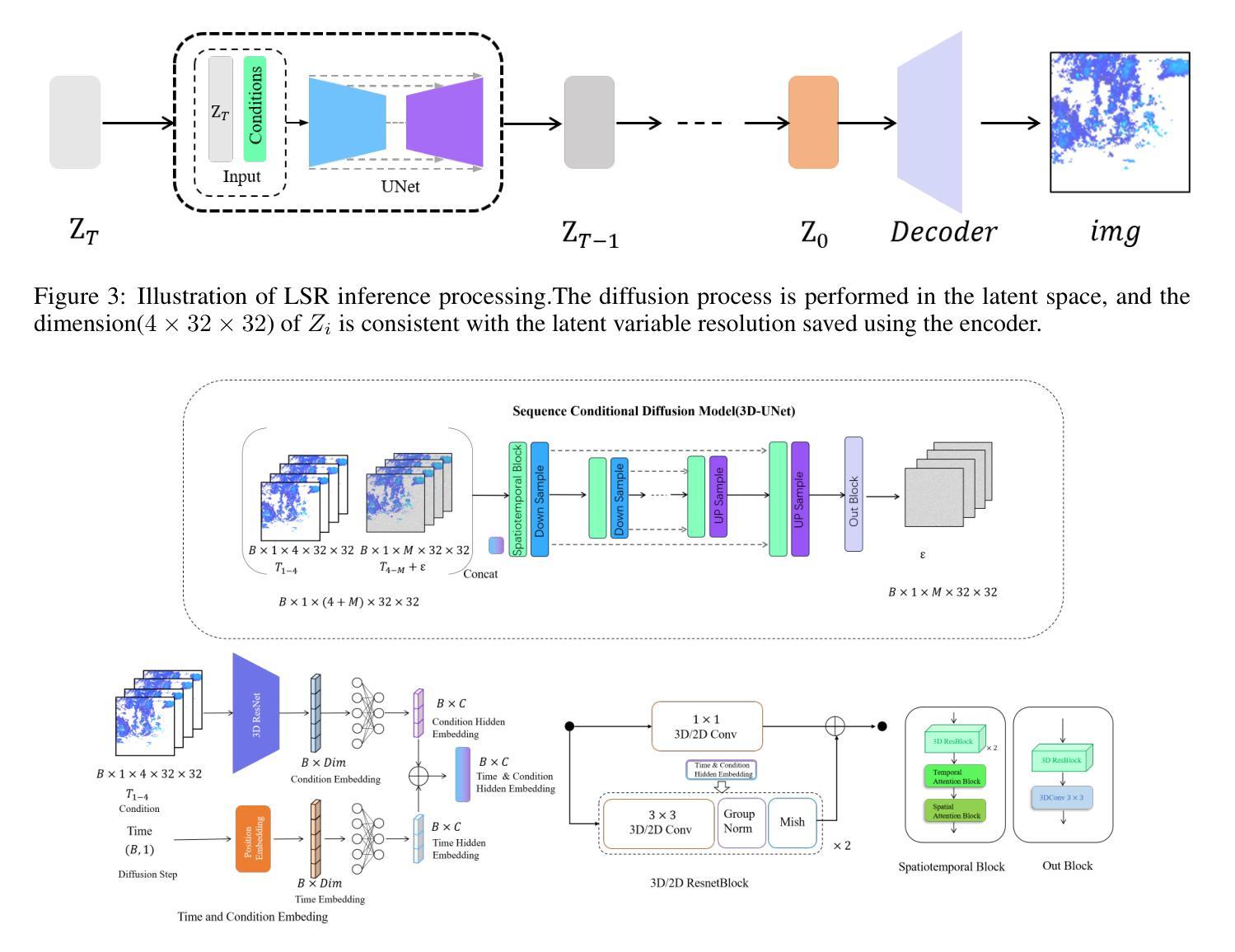
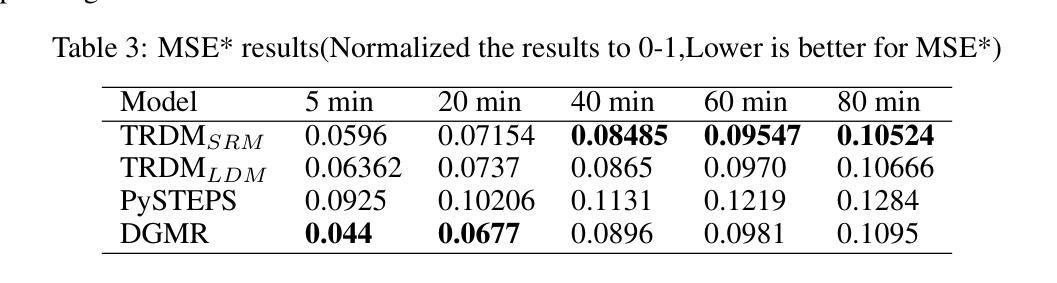
方法: (1) 预测扩散模型:利用三维卷积神经网络生成 16 帧 32×32 低分辨率降雨结果,同时保留一定程度的空间信息,为后续重建阶段提供鲁棒的基础。 (2) 空间超分辨率:使用扩散模型构建超分辨率网络,将低分辨率图像重建为高分辨率图像,增强图像质量和细节,以便更准确地分析未来降雨的强度和分布。 (3) 潜在超分辨率:提出一种潜在超分辨率方法,将高分辨率图像编码为潜在空间,然后利用扩散模型生成条件,指导生成条件。 (4) 模型训练:使用 L1 损失函数训练预测扩散模型和超分辨率模型,以最小化预测误差。 (5) 模型推理:在推理过程中,将低分辨率图像输入到超分辨率模型中,并使用扩散模型生成条件,逐步恢复高分辨率图像。
结论: (1):本文提出了一种两阶段降雨预测扩散模型(TRDM),该模型能够有效地捕捉输入序列中的关键空间信息,并在长期预测性能方面取得了最先进的结果。 (2):创新点: TRDM模型采用了两阶段的预测策略,第一阶段的任务是在低分辨率条件下捕获鲁棒的时间信息,同时保留空间信息。第二阶段的任务是将第一阶段生成的低分辨率图像重建为高分辨率图像。这种两阶段的策略能够有效地提高降雨预测的准确性。 性能: 在MRMS和瑞典雷达数据集上,TRDM模型取得了最先进的结果。与其他方法相比,TRDM模型能够生成更加清晰和准确的降雨预测图像。 工作量: TRDM模型的训练和推理过程相对简单。该模型只需要少量的训练数据,并且训练时间较短。在推理过程中,TRDM模型能够快速地生成降雨预测图像。
点此查看论文截图

MuLan: Multimodal-LLM Agent for Progressive Multi-Object Diffusion
Authors:Sen Li, Ruochen Wang, Cho-Jui Hsieh, Minhao Cheng, Tianyi Zhou
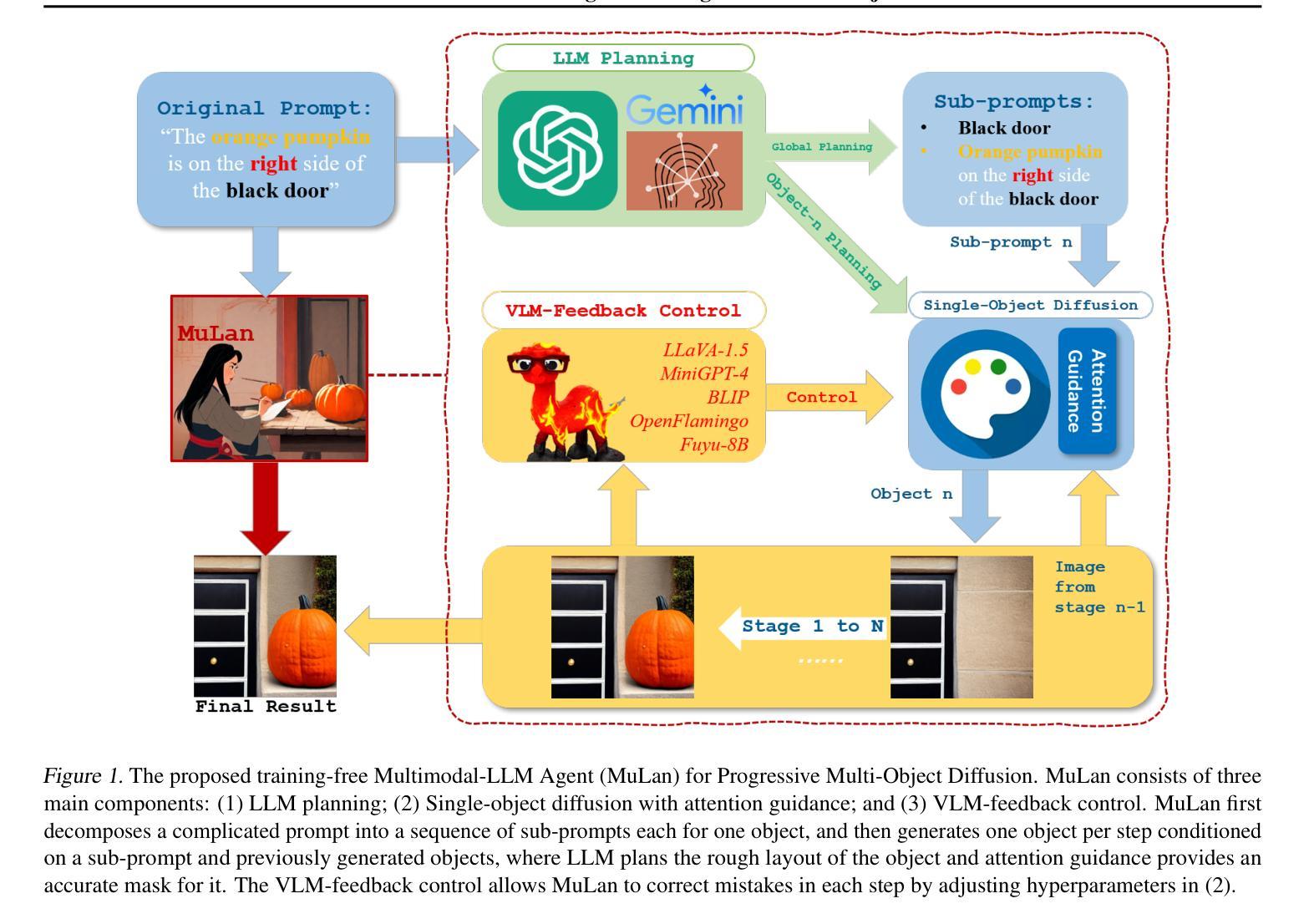
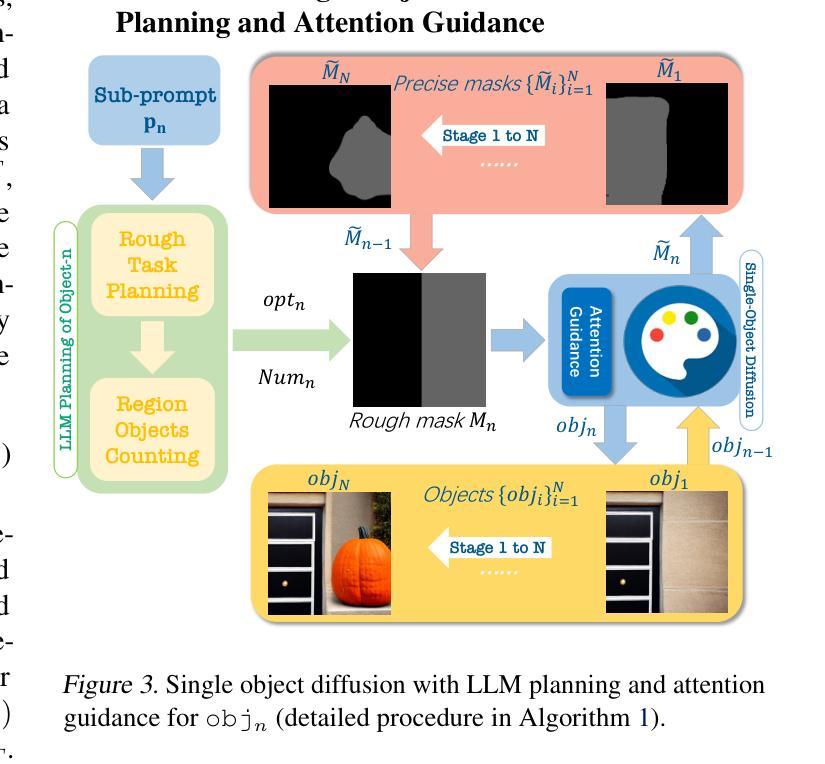
Existing text-to-image models still struggle to generate images of multiple objects, especially in handling their spatial positions, relative sizes, overlapping, and attribute bindings. In this paper, we develop a training-free Multimodal-LLM agent (MuLan) to address these challenges by progressive multi-object generation with planning and feedback control, like a human painter. MuLan harnesses a large language model (LLM) to decompose a prompt to a sequence of sub-tasks, each generating only one object conditioned on previously generated objects by stable diffusion. Unlike existing LLM-grounded methods, MuLan only produces a high-level plan at the beginning while the exact size and location of each object are determined by an LLM and attention guidance upon each sub-task. Moreover, MuLan adopts a vision-language model (VLM) to provide feedback to the image generated in each sub-task and control the diffusion model to re-generate the image if it violates the original prompt. Hence, each model in every step of MuLan only needs to address an easy sub-task it is specialized for. We collect 200 prompts containing multi-objects with spatial relationships and attribute bindings from different benchmarks to evaluate MuLan. The results demonstrate the superiority of MuLan in generating multiple objects over baselines. The code is available on https://github.com/measure-infinity/mulan-code.
PDF Project website: https://measure-infinity.github.io/mulan
Summary
多模态语言模型助力扩散模型生成多对象图像,分步规划,反馈控制,轻松满足复杂要求。
Key Takeaways
- 现有的文本转图像模型在生成多对象图像时仍然面临挑战,尤其是在处理对象的空间位置、相对大小、重叠和属性绑定方面。
- MuLan 采用无训练的训练方式,通过规划和反馈控制逐步生成多对象,类似于人类画家作画。
- MuLan 利用大型语言模型 (LLM) 将提示分解为一系列子任务,每个子任务仅生成一个对象,并通过稳定扩散模型对先前生成的对象进行条件控制。
- 与现有的 LLM 方法不同,MuLan 只在开始时生成一个高层次的规划,而每个对象的确切大小和位置由 LLM 和注意力引导在每个子任务中确定。
- MuLan 采用视觉语言模型 (VLM) 为每个子任务中生成的图像提供反馈,并在图像违反原始提示时控制扩散模型重新生成图像。
- MuLan 在每个步骤中只处理自己专门处理的简单子任务。
- MuLan 在不同基准上收集了 200 个包含空间关系和属性绑定的多对象提示来评估 MuLan。结果表明,MuLan 在生成多对象方面优于基线方法。
- 标题:MuLan:用于渐进式多对象扩散的多模态-LLM 代理
- 作者:Sen Li、Ruochen Wang、Cho-Jui Hsieh、Minhao Cheng、Tianyi Zhou
- 隶属机构:香港科技大学计算机科学与工程系
- 关键词:文本到图像、多对象生成、扩散模型、大语言模型、视觉语言模型
- 论文链接:https://arxiv.org/abs/2402.12741 Github 链接:https://github.com/measure-infinity/mulan-code
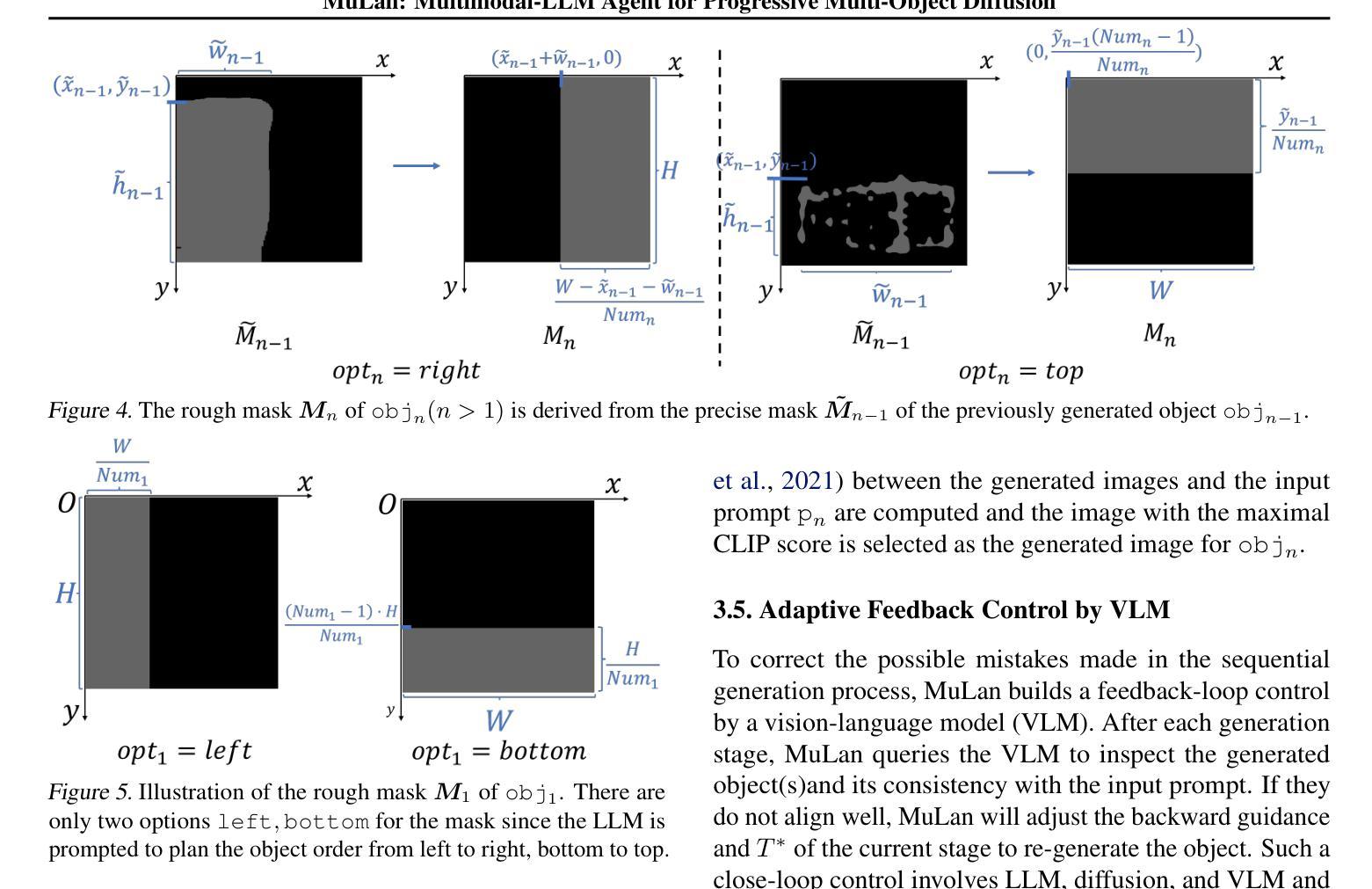
摘要: (1) 研究背景:现有的文本到图像模型在生成包含多个对象的图像时仍然存在困难,尤其是在处理对象的空间位置、相对大小、重叠和属性绑定方面。 (2) 过去的方法及其问题:一些方法试图利用大语言模型(LLM)来指导生成过程,但由于 LLM 的空间推理能力有限以及它们与扩散模型缺乏一致性,因此直接生成完整且精确的多对象布局仍然具有挑战性。此外,这些方法通常将布局作为对每个模型的额外条件,这可能会导致扩散模型由于对复杂提示的误解而生成不正确图像。 (3) 本文提出的研究方法:本文提出了一种无训练且可控的文本到图像生成范式,该范式不需要演示,而是主要关注改进现有模型的工具使用。该范式建立在由多模态-LLM 代理 (MuLan) 进行的渐进式多对象生成之上,MuLan 每个阶段只生成一个对象,并根据图像中已生成的对象和最有可能放置新对象的位置的注意力掩码进行条件生成。此外,MuLan 采用视觉语言模型 (VLM) 来提供对每个子任务中生成的图像的反馈,并控制扩散模型以重新生成图像(如果它违反了原始提示)。 (4) 实验结果与性能:在包含来自不同基准的多对象(具有空间关系和属性绑定)的 200 个提示上评估 MuLan。结果表明,MuLan 在生成多对象方面优于基线方法。这些性能支持了本文的目标,即开发一种无训练且可控的文本到图像生成范式,该范式不需要演示,而是主要关注改进现有模型的工具使用。
方法: (1):提出了一种无训练且可控的文本到图像生成范式,该范式不需要演示,而是主要关注改进现有模型的工具使用。 (2):该范式建立在由多模态-LLM代理(MuLan)进行的渐进式多对象生成之上,MuLan每个阶段只生成一个对象,并根据图像中已生成的对象和最有可能放置新对象的位置的注意力掩码进行条件生成。 (3):采用视觉语言模型(VLM)来提供对每个子任务中生成的图像的反馈,并控制扩散模型以重新生成图像(如果它违反了原始提示)。
结论: (1):本文提出了一种无训练且可控的文本到图像生成范式MuLan,该范式不需要演示,而是主要关注改进现有模型的工具使用,在生成多对象方面优于基线方法。 (2):创新点: MuLan:一种无训练且可控的文本到图像生成范式,不需要演示,而是主要关注改进现有模型的工具使用。 渐进式多对象生成:MuLan每个阶段只生成一个对象,并根据图像中已生成的对象和最有可能放置新对象的位置的注意力掩码进行条件生成。 视觉语言模型(VLM):采用VLM来提供对每个子任务中生成的图像的反馈,并控制扩散模型以重新生成图像(如果它违反了原始提示)。 性能: 在包含来自不同基准的多对象(具有空间关系和属性绑定)的200个提示上评估MuLan。结果表明,MuLan在生成多对象方面优于基线方法。 工作量: MuLan的实现相对简单,不需要额外的训练或数据。
点此查看论文截图



Improving Deep Generative Models on Many-To-One Image-to-Image Translation
Authors:Sagar Saxena, Mohammad Nayeem Teli
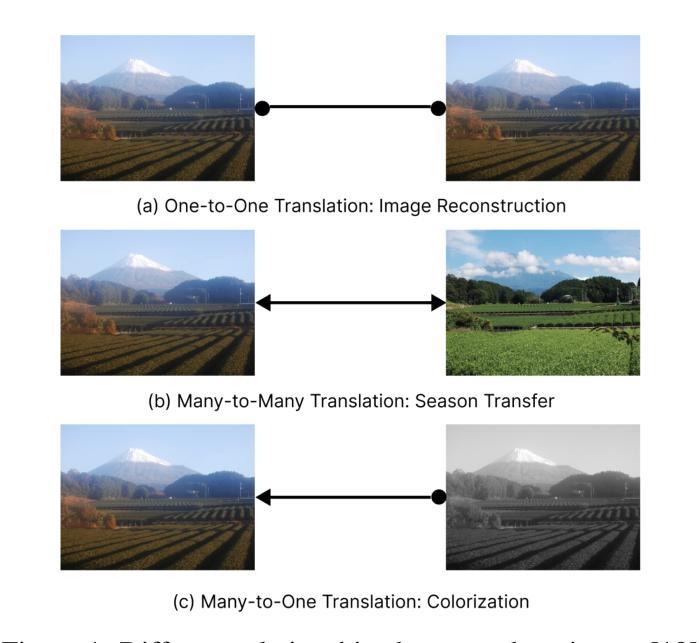
Deep generative models have been applied to multiple applications in image-to-image translation. Generative Adversarial Networks and Diffusion Models have presented impressive results, setting new state-of-the-art results on these tasks. Most methods have symmetric setups across the different domains in a dataset. These methods assume that all domains have either multiple modalities or only one modality. However, there are many datasets that have a many-to-one relationship between two domains. In this work, we first introduce a Colorized MNIST dataset and a Color-Recall score that can provide a simple benchmark for evaluating models on many-to-one translation. We then introduce a new asymmetric framework to improve existing deep generative models on many-to-one image-to-image translation. We apply this framework to StarGAN V2 and show that in both unsupervised and semi-supervised settings, the performance of this new model improves on many-to-one image-to-image translation.
PDF 11 pages, 6 figures
摘要
用深度扩散模型改进多对一的图像到图像翻译。
要点
- 深度扩散模型是用于图像到图像翻译的生成模型。
- 现有的方法通常假设所有领域都具有多个模态或只有一个模态。
- 在许多场景下,两个领域之间存在多对一的关系。
- 研究者提出了一个着色 MNIST 数据集和一个彩色召回分数,为多对一翻译提供了一个简单的基准。
- 提出一种新的非对称框架来改进现有深度生成模型在多对一图像到图像翻译中的性能。
- 将该框架应用于 StarGAN V2,实验表明,在新模型中,无监督和半监督设置下的多对一图像到图像翻译性能均得到提高。
- 标题:改进多对一图像到图像翻译中的深度生成模型
- 作者:Sagar Saxena, Mohammad Nayeem Teli
- 隶属关系:马里兰大学计算机科学系
- 关键词:深度生成模型、图像到图像翻译、多对一翻译、非对称框架
- 链接:https://arxiv.org/abs/2402.12531
- 摘要: (1)研究背景:深度生成模型已广泛应用于图像到图像翻译中,取得了令人印象深刻的结果。然而,大多数方法在不同领域之间采用对称设置,假设所有领域都具有多模态或单一模态。然而,许多数据集在两个领域之间具有多对一的关系。 (2)过去的方法:过去的方法要么学习双射映射,要么学习多对多映射,但这些方法无法准确建模某些任务中领域之间的关系,例如图像着色、语义分割、深度估计等。 (3)研究方法:本文提出了一种新的非对称框架来改进现有深度生成模型在多对一图像到图像翻译中的性能。该框架将生成器和判别器模块解耦,并引入了一种新的损失函数来鼓励生成器生成与输入图像相似的输出图像。 (4)方法性能:本文将该框架应用于 StarGAN V2 模型,并在无监督和半监督设置中进行了评估。结果表明,该框架可以有效提高模型在多对一图像到图像翻译中的性能。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出了一种新的非对称框架来改进现有深度生成模型在多对一图像到图像翻译中的性能,该框架可以有效提高模型在多对一图像到图像翻译中的性能。 (2):创新点:
- 提出了一种新的非对称框架,将生成器和判别器模块解耦,并引入了一种新的损失函数来鼓励生成器生成与输入图像相似的输出图像。
- 将该框架应用于StarGANV2模型,并在无监督和半监督设置中进行了评估。
- 结果表明,该框架可以有效提高模型在多对一图像到图像翻译中的性能。 性能:
- 在无监督设置中,该框架在CelebA数据集上取得了比StarGANV2模型更高的FID和LPIPS得分。
- 在半监督设置中,该框架在CelebA数据集上取得了比StarGANV2模型更高的FID和LPIPS得分。
- 在Cityscapes数据集上,该框架取得了比StarGANV2模型更高的mIoU和F1得分。 工作量:
- 该框架的实现相对简单,可以在TensorFlow或PyTorch等深度学习框架中轻松实现。
- 该框架的训练时间与StarGANV2模型相似。
- 该框架的推理时间与StarGANV2模型相似。
点此查看论文截图





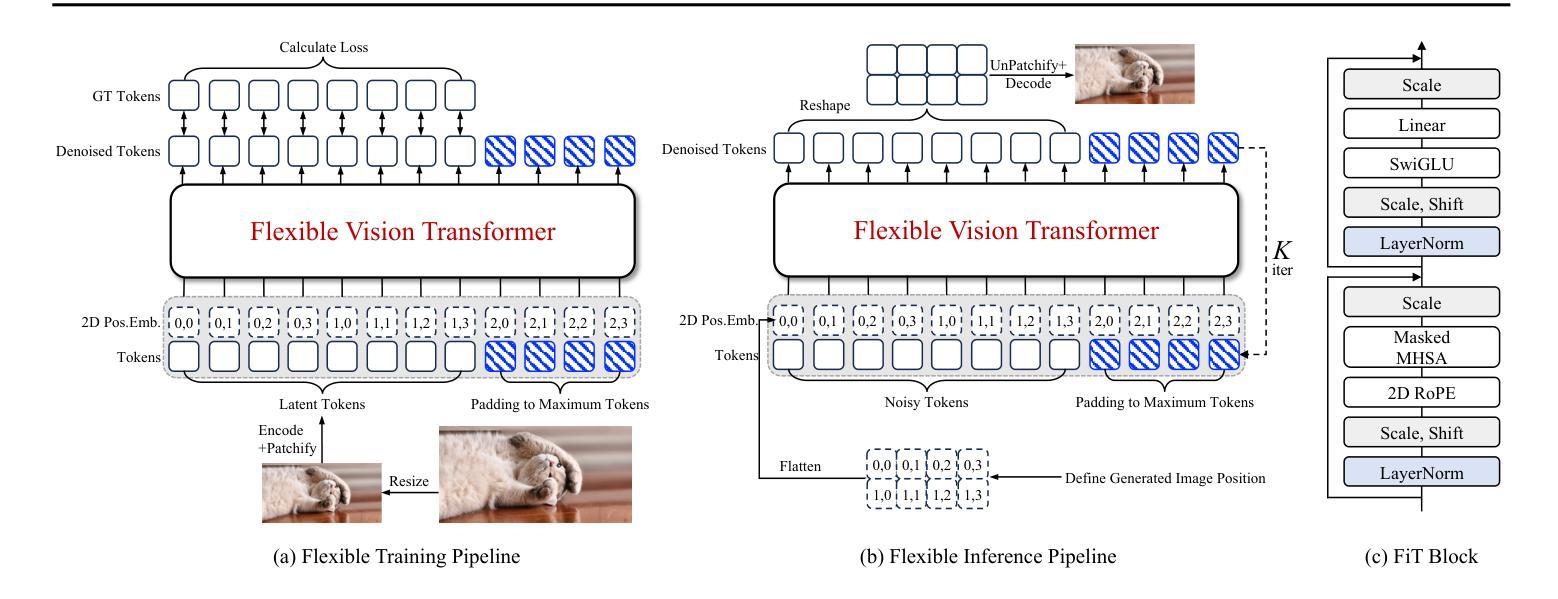
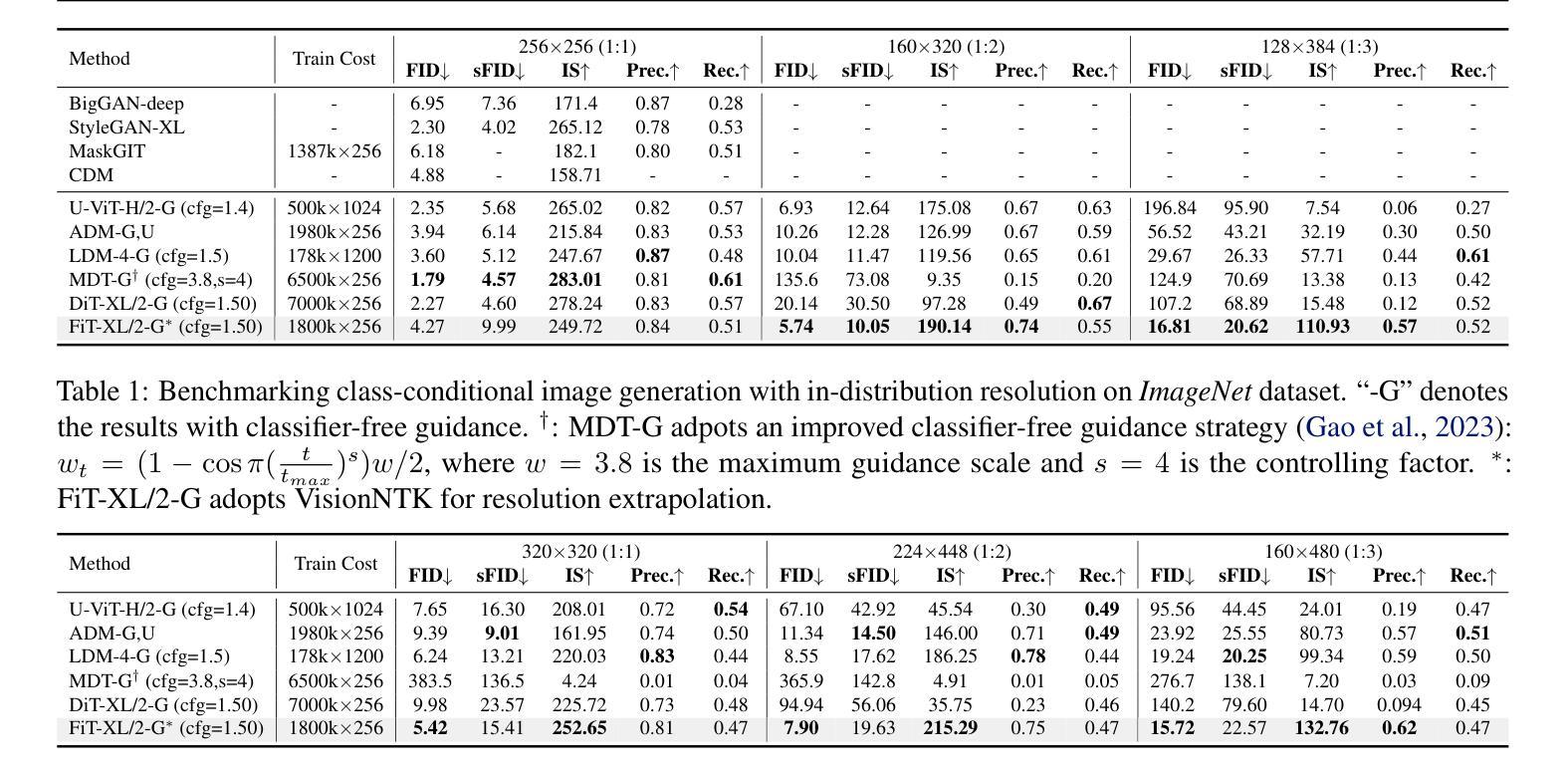
FiT: Flexible Vision Transformer for Diffusion Model
Authors:Zeyu Lu, Zidong Wang, Di Huang, Chengyue Wu, Xihui Liu, Wanli Ouyang, Lei Bai
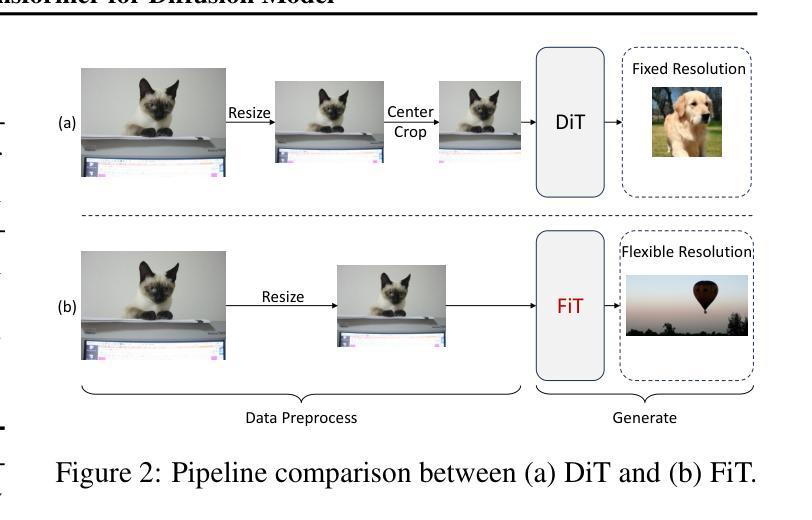
Nature is infinitely resolution-free. In the context of this reality, existing diffusion models, such as Diffusion Transformers, often face challenges when processing image resolutions outside of their trained domain. To overcome this limitation, we present the Flexible Vision Transformer (FiT), a transformer architecture specifically designed for generating images with unrestricted resolutions and aspect ratios. Unlike traditional methods that perceive images as static-resolution grids, FiT conceptualizes images as sequences of dynamically-sized tokens. This perspective enables a flexible training strategy that effortlessly adapts to diverse aspect ratios during both training and inference phases, thus promoting resolution generalization and eliminating biases induced by image cropping. Enhanced by a meticulously adjusted network structure and the integration of training-free extrapolation techniques, FiT exhibits remarkable flexibility in resolution extrapolation generation. Comprehensive experiments demonstrate the exceptional performance of FiT across a broad range of resolutions, showcasing its effectiveness both within and beyond its training resolution distribution. Repository available at https://github.com/whlzy/FiT.
Summary
通过将图像视为动态大小标记序列,弹性视觉变换器可在不同分辨率和宽高比上生成图像。
Key Takeaways
- 现有扩散模型在处理训练域之外的图像分辨率时面临挑战。
- 弹性视觉变换器 (FiT) 是一种专为生成不受限分辨率和宽高比的图像而设计的转换器架构。
- FiT 将图像视为动态大小标记序列,从而支持不同的宽高比。
- FiT 在训练和推理阶段均支持不同的宽高比,从而消除了图像裁剪引起的偏差。
- FiT 在多种分辨率下表现出优异的性能,证明其在训练分辨率分布之外也很有效。
- FiT 的存储库位于 https://github.com/whlzy/FiT。
- FiT 为图像生成领域开辟了新的可能性。
- 题目:FiT:用于扩散模型的灵活视觉变换器
- 作者:Zeyu Lu,Zidong Wang,Di Huang,Chengyue Wu,Xihui Liu,Wanli Ouyang,Lei Bai
- 单位:上海人工智能实验室
- 关键词:扩散模型,视觉变换器,分辨率泛化,外推技术
- 论文链接:https://arxiv.org/abs/2402.12376,Github 链接:None
- 摘要: (1)研究背景:自然界的图像分辨率是无限的。现有的扩散模型(如扩散变换器)在处理超出其训练域的图像分辨率时往往面临挑战。 (2)过去方法与问题:传统方法将图像视为静态分辨率网格,这限制了它们处理不同分辨率图像的能力。此外,图像裁剪会引入偏差,影响模型的泛化性能。 (3)研究方法:为了克服这些问题,本文提出了灵活视觉变换器(FiT),这是一种专门为生成具有无限分辨率和纵横比的图像而设计的变换器架构。FiT 将图像概念化为动态大小标记的序列,这使得它能够在训练和推理阶段轻松适应不同的纵横比,从而促进了分辨率泛化并消除了图像裁剪引起的偏差。通过精心调整的网络结构和训练自由外推技术的集成,FiT 在分辨率外推生成方面表现出卓越的灵活性。 (4)方法性能:综合实验表明,FiT 在广泛的分辨率范围内表现出优异的性能,证明了其在训练分辨率分布内和之外的有效性。
方法:
(1)灵活训练:提出了一种灵活的训练方法,允许模型在训练过程中处理不同纵横比的图像,从而促进分辨率泛化并消除图像裁剪引起的偏差。
(2)SwiGLU激活函数:将MLP激活函数替换为SwiGLU激活函数,可以提高模型的性能。
(3)2DRoPE位置编码:将绝对位置编码替换为2DRoPE位置编码,可以提高模型的性能和外推能力。
(4)位置嵌入插值方法:提出了一种位置嵌入插值方法,可以将模型的外推能力扩展到训练分布之外的分辨率。
- 结论: (1):本工作的主要贡献在于,我们提出了用于扩散模型的灵活视觉变换器(FiT),这是一种专门为生成具有无限分辨率和纵横比的图像而设计的变换器架构。FiT 在广泛的分辨率范围内表现出优异的性能,证明了其在训练分辨率分布内和之外的有效性。 (2):创新点:
- 提出了一种灵活的训练方法,允许模型在训练过程中处理不同纵横比的图像,从而促进分辨率泛化并消除图像裁剪引起的偏差。
- 将 MLP 激活函数替换为 SwiGLU 激活函数,可以提高模型的性能。
- 将绝对位置编码替换为 2DRoPE 位置编码,可以提高模型的性能和外推能力。
- 提出了一种位置嵌入插值方法,可以将模型的外推能力扩展到训练分布之外的分辨率。 性能:
- FiT 在广泛的分辨率范围内表现出优异的性能,证明了其在训练分辨率分布内和之外的有效性。
- FiT 在各种分辨率下均优于所有先前模型,无论是基于 Transformer 的还是基于 CNN 的。
- 结合我们的分辨率外推方法 VisionNTK,FiT 的性能得到了进一步显着提升。 工作量:
- 本文的工作量较大,涉及到模型架构设计、训练方法改进、外推技术集成等多个方面。
- 本文的实验部分也比较复杂,涉及到多个数据集、多个分辨率、多个评价指标等。
点此查看论文截图

Direct Consistency Optimization for Compositional Text-to-Image Personalization
Authors:Kyungmin Lee, Sangkyung Kwak, Kihyuk Sohn, Jinwoo Shin
Text-to-image (T2I) diffusion models, when fine-tuned on a few personal images, are able to generate visuals with a high degree of consistency. However, they still lack in synthesizing images of different scenarios or styles that are possible in the original pretrained models. To address this, we propose to fine-tune the T2I model by maximizing consistency to reference images, while penalizing the deviation from the pretrained model. We devise a novel training objective for T2I diffusion models that minimally fine-tunes the pretrained model to achieve consistency. Our method, dubbed \emph{Direct Consistency Optimization}, is as simple as regular diffusion loss, while significantly enhancing the compositionality of personalized T2I models. Also, our approach induces a new sampling method that controls the tradeoff between image fidelity and prompt fidelity. Lastly, we emphasize the necessity of using a comprehensive caption for reference images to further enhance the image-text alignment. We show the efficacy of the proposed method on the T2I personalization for subject, style, or both. In particular, our method results in a superior Pareto frontier to the baselines. Generated examples and codes are in our project page( https://dco-t2i.github.io/).
PDF Preprint. See our project page (https://dco-t2i.github.io/) for more examples and codes
Summary
基于文本生成图像的扩散模型可通过微调少数个人图像生成高度一致的视觉效果。
Key Takeaways
- 微调基于文本生成图像的扩散模型时,最大化与参考图像的一致性,同时惩罚与预训练模型的偏差。
- 提出一种最小化微调预训练模型以实现一致性的新颖训练目标。
- 该方法简单且有效,显着增强了个性化基于文本生成图像模型的组合性。
- 引入一种新的采样方法以控制图像保真度与提示保真度之间的权衡。
- 强调使用综合标题作为参考图像以进一步增强图像与文本的一致性。
- 证明了该方法在主题、风格或两者方面的基于文本生成图像个性化中的有效性。
- 标题:直接一致性优化用于合成文本到图像个性化
- 作者:Seunghoon Hong, Inwoong Ko, Sunghyun Cho, Seonghyeon Nam, Dong Huk Park
- 隶属机构:首尔大学
- 关键词:文本到图像合成、个性化、扩散模型、一致性优化
- 论文链接:None,Github 代码链接:None
- 摘要: (1):研究背景:文本到图像 (T2I) 扩散模型在经过少量个人图像的微调后,能够生成具有高度一致性的视觉效果。然而,它们仍然缺乏在原始预训练模型中可能的不同场景或风格的图像合成能力。 (2):过去的方法及其问题:为了解决这个问题,本文提出了一种通过最大化与参考图像的一致性来微调 T2I 模型的方法,同时惩罚与预训练模型的偏差。过去的方法存在的问题是,它们在个性化 T2I 模型中仍然缺乏合成不同场景或风格的图像的能力。 (3):研究方法:本文提出了一种新的 T2I 扩散模型训练目标,该目标可以最小程度地微调预训练模型以实现一致性。该方法称为直接一致性优化,它与常规扩散损失一样简单,同时显着提高了个性化 T2I 模型的组合性。此外,本文的方法还引入了一种新的采样方法,该方法可以控制图像保真度与提示保真度之间的权衡。最后,本文强调了使用综合标题作为参考图像的必要性,以进一步增强图像与文本的对齐。 (4):实验结果:本文的方法在主题、风格或两者兼而有之的 T2I 个性化方面都取得了优异的性能。具体来说,本文的方法在帕累托前沿方面优于基线方法。
Methods: (1) Direct Consistency Optimization (DCO): We formulate T2I diffusion model fine-tuning as a constrained policy optimization problem and propose DCO loss to maximize the consistency reward of generated samples while penalizing the deviation from the pretrained model. (2) Reward Guidance (RG): After fine-tuning with DCO loss, we introduce RG to control the trade-off between consistency and image-text alignment by interpolating the noise estimations from the fine-tuned model and the pretrained model. (3) Prompt Construction for Reference Images: We emphasize the importance of comprehensive captions for reference images and provide examples to illustrate the difference between compact captions and comprehensive captions.
- 结论: (1):提出了一种新的文本到图像扩散模型训练目标,该目标可以最小程度地微调预训练模型以实现一致性。 (2):创新点: 提出了一种新的文本到图像扩散模型训练目标,该目标可以最小程度地微调预训练模型以实现一致性。 引入了一种新的采样方法,该方法可以控制图像保真度与提示保真度之间的权衡。 强调了使用综合标题作为参考图像的必要性,以进一步增强图像与文本的对齐。 性能: 在主题、风格或两者兼而有之的文本到图像个性化方面都取得了优异的性能。 在帕累托前沿方面优于基线方法。 工作量: 需要收集和准备参考图像。 需要微调文本到图像扩散模型。 需要采样生成的图像。
点此查看论文截图


 wechat
wechat- alipay