NeRF
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-02-23 更新
Identifying Unnecessary 3D Gaussians using Clustering for Fast Rendering of 3D Gaussian Splatting
Authors:Joongho Jo, Hyeongwon Kim, Jongsun Park
3D Gaussian splatting (3D-GS) is a new rendering approach that outperforms the neural radiance field (NeRF) in terms of both speed and image quality. 3D-GS represents 3D scenes by utilizing millions of 3D Gaussians and projects these Gaussians onto the 2D image plane for rendering. However, during the rendering process, a substantial number of unnecessary 3D Gaussians exist for the current view direction, resulting in significant computation costs associated with their identification. In this paper, we propose a computational reduction technique that quickly identifies unnecessary 3D Gaussians in real-time for rendering the current view without compromising image quality. This is accomplished through the offline clustering of 3D Gaussians that are close in distance, followed by the projection of these clusters onto a 2D image plane during runtime. Additionally, we analyze the bottleneck associated with the proposed technique when executed on GPUs and propose an efficient hardware architecture that seamlessly supports the proposed scheme. For the Mip-NeRF360 dataset, the proposed technique excludes 63% of 3D Gaussians on average before the 2D image projection, which reduces the overall rendering computation by almost 38.3% without sacrificing peak-signal-to-noise-ratio (PSNR). The proposed accelerator also achieves a speedup of 10.7x compared to a GPU.
摘要
NeurRF 加速:一种新的计算方法,通过快速识别不必要的 3D 高斯体在实时渲染当前视图,从而提高渲染速度和图像质量。
要点
- NeurRF 是一种新的渲染方法,利用数百万个 3D 高斯体来表示 3D 场景,并将其投影到 2D 图像平面上进行渲染。
- 在渲染过程中,存在大量对于当前视图方向来说不必要的 3D 高斯体,导致识别这些高斯体的计算成本很高。
- 提出了一种计算简化技术,能够在实时快速识别不必要的 3D 高斯体,从而在不影响图像质量的情况下渲染当前视图。
- 该技术通过对距离相近的 3D 高斯体进行离线聚类来实现,然后在运行时将这些簇投影到 2D 图像平面上。
- 分析了该技术在 GPU 上执行时遇到的瓶颈,并提出了一种高效的硬件架构来无缝支持该方案。
- 对于 Mip-NeRF360 数据集,该技术在 2D 图像投影前平均排除 63% 的 3D 高斯体,从而将整体渲染计算量减少了近 38.3%,而峰值信噪比 (PSNR) 却不会下降。
- 所提出的加速器与 GPU 相比,速度提高了 10.7 倍。
- 题目:使用聚类识别不必要的 3D 高斯体,实现 3D 高斯斑点渲染的快速渲染
- 作者:Joongho Jo, Hyeongwon Kim, Jongsun Park
- 单位:韩国大学电气工程学院(仅翻译单位名称)
- 关键词:3D 高斯斑点渲染、渲染、NeRF、神经辐射场、硬件加速器
- 链接:Paper_info:Identifying Unnecessary 3D Gaussians using Clustering for Fast Rendering of 3D Gaussian Splatting,Github:无
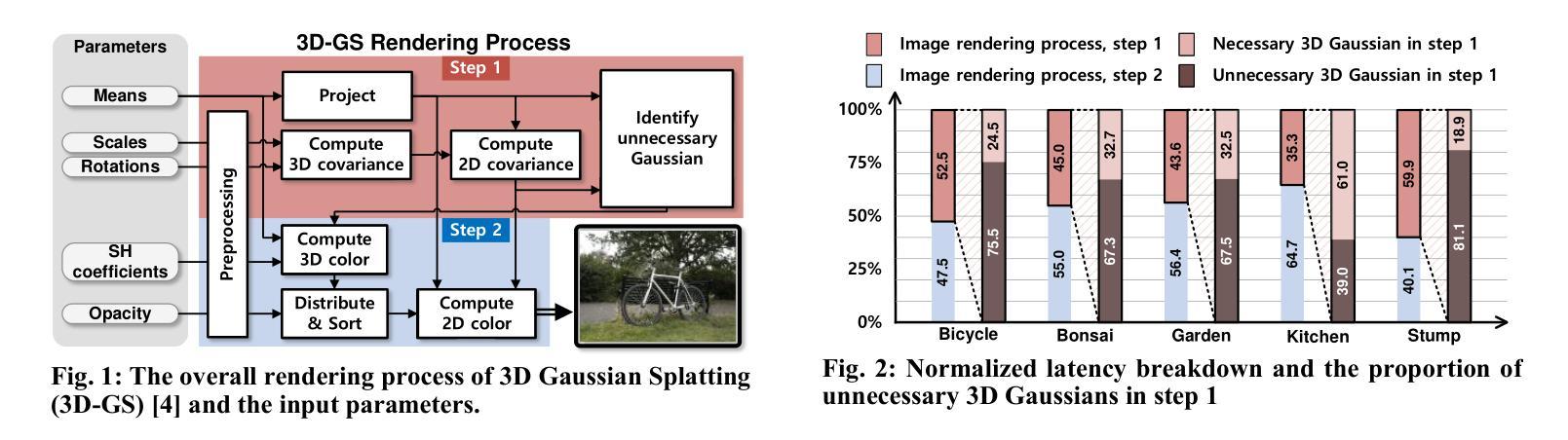
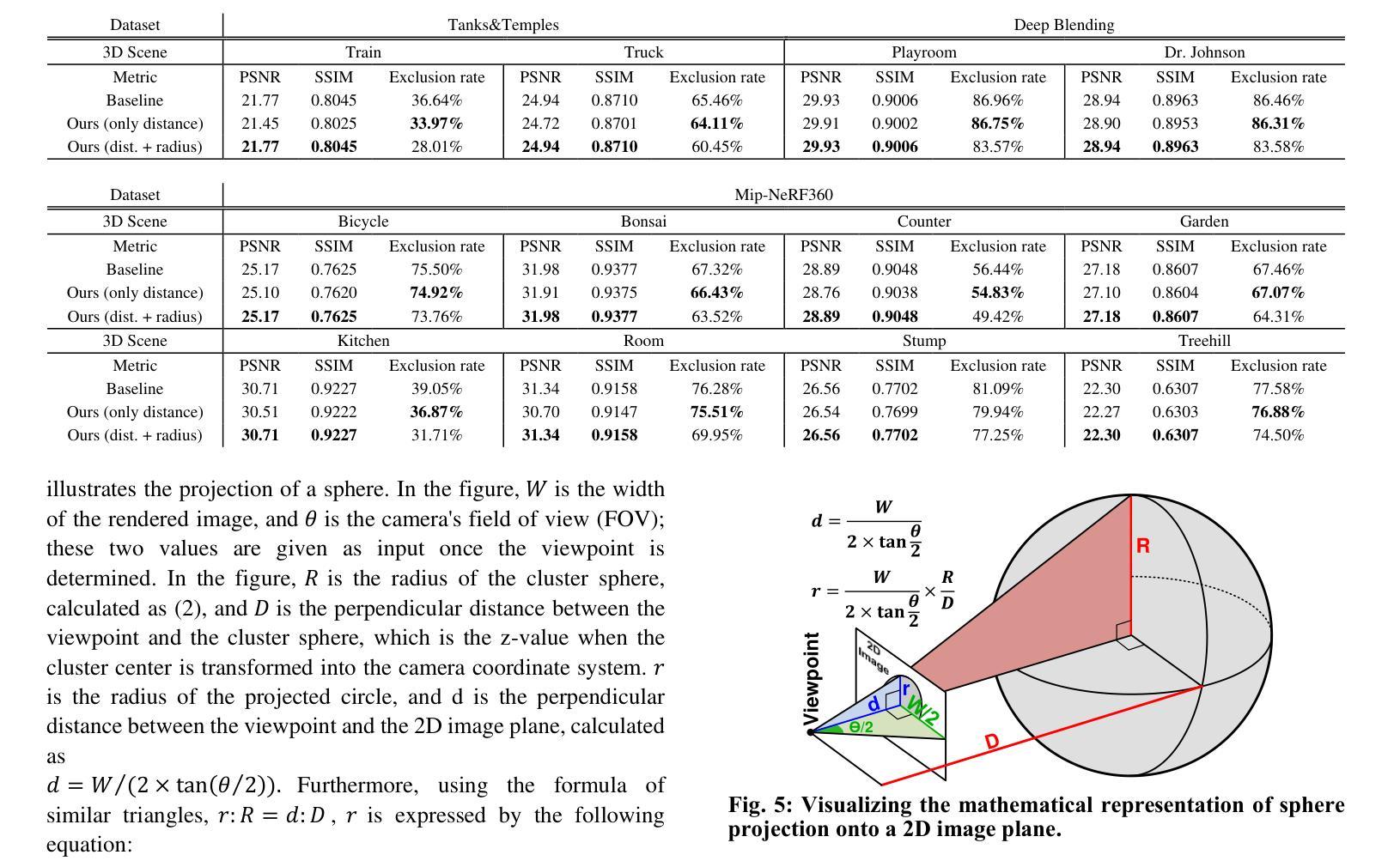
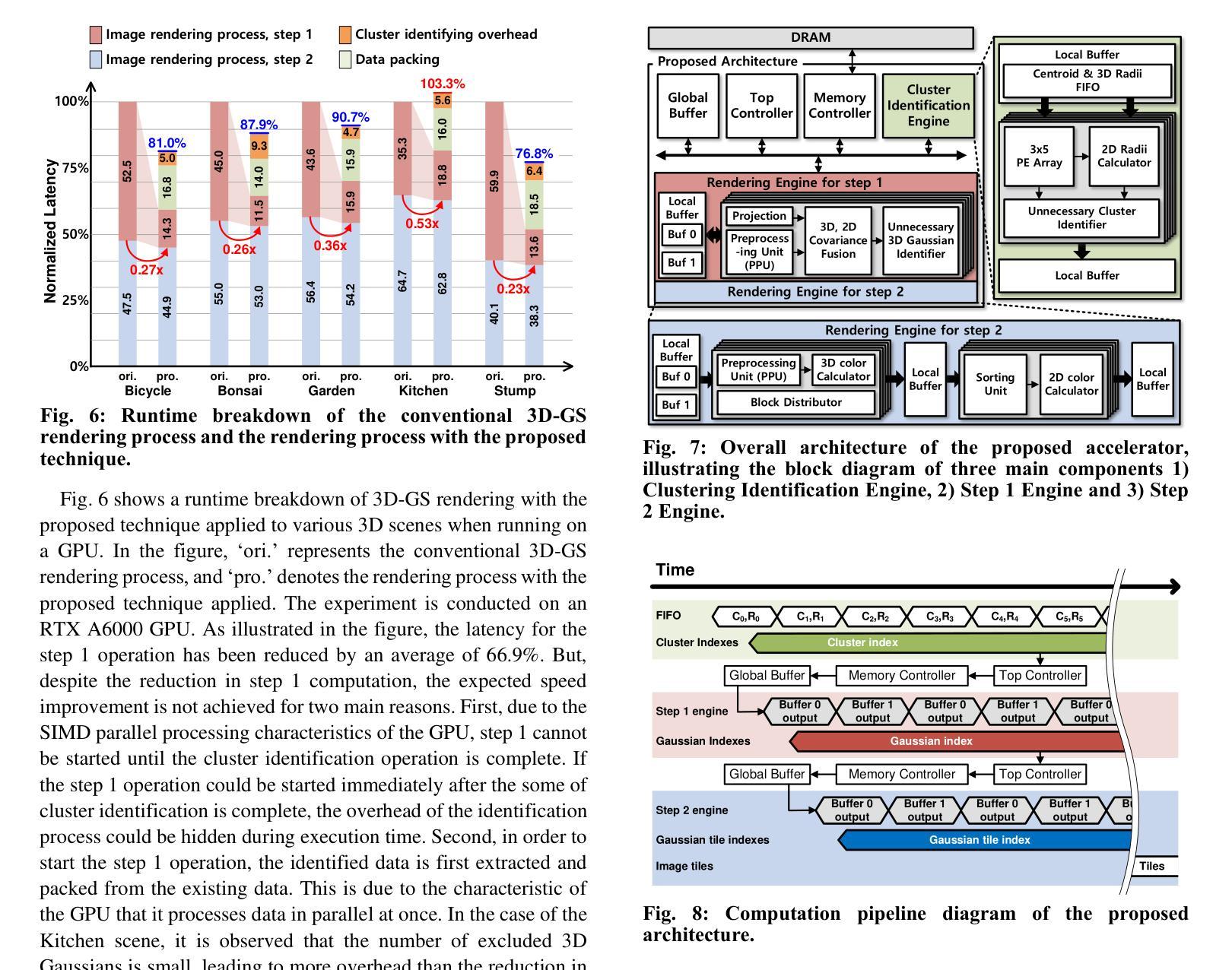
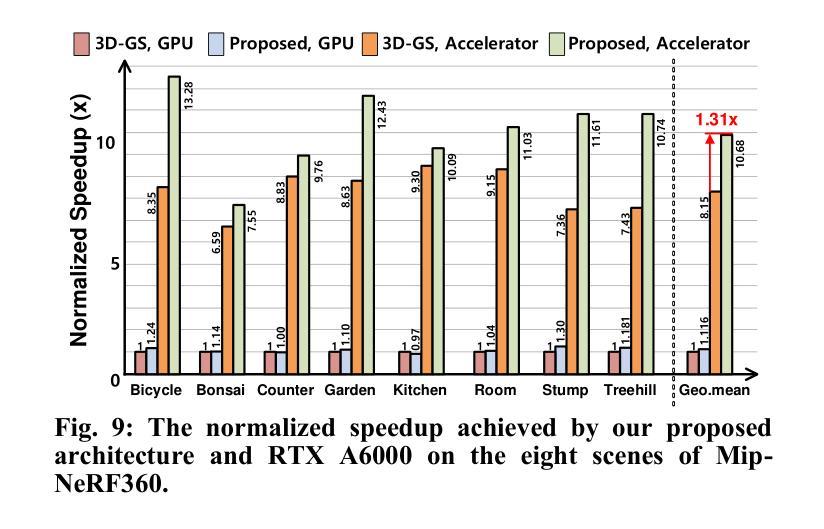
- 摘要: (1)研究背景:在 3D 计算机视觉应用中,例如增强现实 (AR)、虚拟现实 (VR) 和元宇宙,快速且高质量的图像渲染非常重要。虽然使用深度神经网络的渲染技术,例如神经辐射场 (NeRF),已经得到了广泛的研究,但 3D 高斯斑点渲染 (3D-GS) 作为一种新的渲染方法,因其与传统 NeRF 相比能够快速渲染高质量图像而备受关注。3D-GS 利用数百万个 3D 高斯体来表示复杂的 3D 场景,并通过将 3D 高斯体投影到 2D 图像平面上来渲染 3D 场景。 (2)过去的方法及其问题:3D-GS 渲染过程主要分为两步:1)将所有 3D 高斯体投影到 2D 图像平面上,并识别出影响 2D 图像颜色的 3D 高斯体。2)然后使用影响颜色的已识别 3D 高斯体计算 2D 图像中每个像素的颜色。在渲染过程的第一步中,高斯体投影到 2D 图像上,但被识别为不影响 2D 图像的颜色,投影就变成了计算浪费。在 Mip-NeRF360 数据集中,平均约有 67.6% 的 3D 高斯体不影响 2D 图像的颜色。因此,这些高斯体可以从当前视图渲染过程中排除。然而,由于影响 2D 图像颜色的 3D 高斯体可能会随着渲染视点的位置和方向而改变,因此在将它们投影到 2D 图像平面前识别出不必要的 3D 高斯体仍然具有挑战性。因此,这些不必要的 3D 高斯体仍然会进行投影计算。因此,如果能够开发一种简单而有效的方法来预测不影响 2D 图像颜色的 3D 高斯体,并在渲染过程开始前将它们排除,则可以显着降低整个 3D-GS 过程的总体计算复杂度。 (3)本文提出的研究方法:本文提出了一种基于聚类的方法,通过识别不影响 2D 图像颜色的簇来排除当前视图渲染过程中的不必要 3D 高斯体。聚类的目的是将位置相近的 3D 高斯体分组在一起,并且簇的形状应该是球形的,以便于投影到 2D 图像上。因此,我们采用了 K-means 聚类算法,它满足这两个标准。鉴于 3D 高斯体具有由其协方差定义的大小或影响,簇球体的半径不仅由到簇质心的距离决定,还考虑了高斯体的大小。然后将这些定义的簇球体投影到 2D 图像平面上,以确定它们对 2D 图像颜色的影响。不影响图像颜色的簇可以从渲染过程中排除。在我们的方法中,聚类和计算簇的半径可以在线下执行,只有将簇投影到 2D 图像平面上是在实时进行的,这仅需要 6.2% 的计算开销。在 3D-GS 渲染过程中,在当前视图渲染之前应用所提出的方法时,平均可以排除 63% 的 3D 高斯体,从而将整体渲染计算减少了近 38.3%,而不会牺牲峰值信噪比 (PSNR)。所提出的加速器还实现了比 GPU 快 10.7 倍的速度。 (4)方法在什么任务上取得了什么性能?性能是否支持其目标?本文提出的方法在 Mip-NeRF360 数据集上进行了评估。结果表明,该方法能够有效地排除不必要的 3D 高斯体,从而减少渲染计算量并提高渲染速度。具体来说,该方法可以排除平均 63% 的 3D 高斯体,从而将整体渲染计算减少了近 38.3%,而不会牺牲峰值信噪比 (PSNR)。此外,所提出的加速器还实现了比 GPU 快 10.7 倍的速度。这些结果表明,该方法能够有效地实现其目标,即快速渲染高质量的 3D 图像。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出了一种基于聚类的方法,通过识别不影响2D图像颜色的簇来排除当前视图渲染过程中的不必要3D高斯体。该方法能够有效地减少渲染计算量并提高渲染速度,在Mip-NeRF360数据集上,该方法可以排除平均63%的3D高斯体,从而将整体渲染计算减少了近38.3%,而不会牺牲峰值信噪比(PSNR)。此外,所提出的加速器还实现了比GPU快10.7倍的速度。 (2):创新点:本文提出了一种基于聚类的方法来识别不必要的3D高斯体,该方法简单有效,能够显着降低3D-GS渲染过程的总体计算复杂度。 性能:该方法能够有效地排除不必要的3D高斯体,从而减少渲染计算量并提高渲染速度。在Mip-NeRF360数据集上,该方法可以排除平均63%的3D高斯体,从而将整体渲染计算减少了近38.3%,而不会牺牲峰值信噪比(PSNR)。此外,所提出的加速器还实现了比GPU快10.7倍的速度。 工作量:该方法的实现相对简单,并且可以在线下执行聚类和计算簇的半径,只有将簇投影到2D图像平面上是在实时进行的,这仅需要6.2%的计算开销。
点此查看论文截图


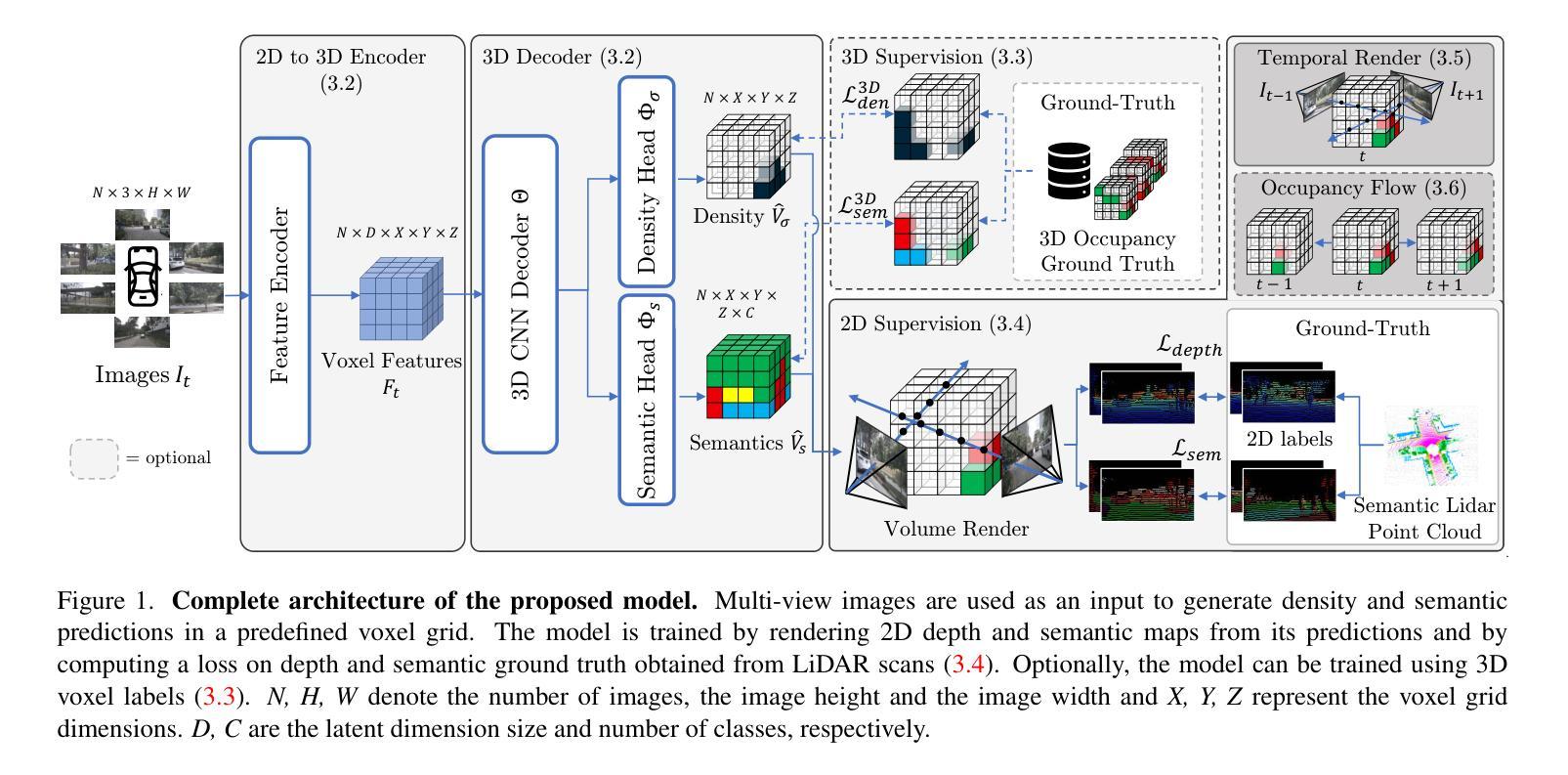
OccFlowNet: Towards Self-supervised Occupancy Estimation via Differentiable Rendering and Occupancy Flow
Authors:Simon Boeder, Fabian Gigengack, Benjamin Risse
Semantic occupancy has recently gained significant traction as a prominent 3D scene representation. However, most existing methods rely on large and costly datasets with fine-grained 3D voxel labels for training, which limits their practicality and scalability, increasing the need for self-monitored learning in this domain. In this work, we present a novel approach to occupancy estimation inspired by neural radiance field (NeRF) using only 2D labels, which are considerably easier to acquire. In particular, we employ differentiable volumetric rendering to predict depth and semantic maps and train a 3D network based on 2D supervision only. To enhance geometric accuracy and increase the supervisory signal, we introduce temporal rendering of adjacent time steps. Additionally, we introduce occupancy flow as a mechanism to handle dynamic objects in the scene and ensure their temporal consistency. Through extensive experimentation we demonstrate that 2D supervision only is sufficient to achieve state-of-the-art performance compared to methods using 3D labels, while outperforming concurrent 2D approaches. When combining 2D supervision with 3D labels, temporal rendering and occupancy flow we outperform all previous occupancy estimation models significantly. We conclude that the proposed rendering supervision and occupancy flow advances occupancy estimation and further bridges the gap towards self-supervised learning in this domain.
Summary
神经辐射场可从仅使用二维标签中估计语义占用。
Key Takeaways
- 利用神经辐射场(NeRF)提出了一种仅使用二维标签估计占用率的新方法。
- 采用可微体积渲染来预测深度和语义图,并仅基于二维监督训练三维网络。
- 为了增强几何精度并增加监督信号,引入了相邻时间步长的时序渲染。
- 引入占用流作为处理场景中动态对象并确保其时间一致性的机制。
- 与使用三维标签的方法相比,实验表明仅二维监督就足以实现最先进的性能,同时优于同时期的二维方法。
- 当将二维监督与三维标签、时态渲染和占用流相结合时,大大优于所有以前的占有估计模型。
- 渲染监督和占用流的进步促进了占用估计,并进一步缩小了该领域中自监督学习的差距。
- 题目:OccFlowNet:基于可微渲染和占用流的自监督占用估计
- 作者:Simon Boeder, Fabian Gigengack, Benjamin Risse
- 作者单位:博世公司、明斯特大学
- 关键词:占用估计、神经辐射场、可微渲染、占用流、自监督学习
- 论文链接:https://arxiv.org/abs/2402.12792
摘要: (1) 研究背景:语义占用最近作为一种突出的 3D 场景表示形式而受到广泛关注。然而,大多数现有方法依赖于具有细粒度 3D 体素标签的大型且昂贵的训练数据集,这限制了它们的实用性和可扩展性,增加了该领域中自监督学习的需求。 (2) 过去方法及其问题:本文提出了受神经辐射场 (NeRF) 启发的新型占用估计方法,仅使用更易获取的 2D 标签。具体来说,我们采用可微体积渲染来预测深度和语义图,并仅基于 2D 监督训练 3D 网络。为了提高几何精度并增加监督信号,我们引入了相邻时间步的长时渲染。此外,我们引入了占用流作为处理场景中动态对象并确保其时间一致性的机制。 (3) 研究方法:我们通过广泛的实验表明,仅使用 2D 监督就足以与使用 3D 标签的方法相比实现最先进的性能,同时优于同时期的 2D 方法。当将 2D 监督与 3D 标签、时序渲染和占用流相结合时,我们明显优于所有以前的占用估计模型。我们得出结论,所提出的渲染监督和占用流促进了占用估计,并进一步缩小了该领域中自监督学习的差距。 (4) 性能和结论:在广泛使用的数据集上进行的实验表明,所提出的方法在占用估计任务上取得了最先进的性能。这些结果支持了我们的目标,即仅使用 2D 监督就可以实现准确的占用估计,从而使该方法更易于训练和部署。
方法: (1):我们提出了一种新的占用估计方法 OccFlowNet,仅使用更易获取的 2D 标签,无需昂贵的 3D 体素标签。 (2):我们采用可微体积渲染来预测深度和语义图,并仅基于 2D 监督训练 3D 网络。 (3):为了提高几何精度并增加监督信号,我们引入了相邻时间步的长时渲染。 (4):我们引入了占用流作为处理场景中动态对象并确保其时间一致性的机制。 (5):我们通过广泛的实验表明,仅使用 2D 监督就足以与使用 3D 标签的方法相比实现最先进的性能,同时优于同时期的 2D 方法。 (6):当将 2D 监督与 3D 标签、时序渲染和占用流相结合时,我们明显优于所有以前的占用估计模型。
结论: (1):本工作首次提出了一种仅使用易于获取的 2D 标签即可进行占用估计的方法,无需昂贵的 3D 体素标签,为占用估计任务提供了一种新的思路。 (2):创新点: 创新点 1:提出了一种新的占用估计方法 OccFlowNet,仅使用更易获取的 2D 标签,无需昂贵的 3D 体素标签。 创新点 2:采用可微体积渲染来预测深度和语义图,并仅基于 2D 监督训练 3D 网络。 创新点 3:为了提高几何精度并增加监督信号,引入了相邻时间步的长时渲染。 创新点 4:引入了占用流作为处理场景中动态对象并确保其时间一致性的机制。 性能: 在广泛使用的数据集上进行的实验表明,所提出的方法在占用估计任务上取得了最先进的性能。 工作量: 本工作需要解决的问题是,如何仅使用 2D 标签进行占用估计。为了解决这个问题,作者提出了 OccFlowNet 方法,该方法采用可微体积渲染来预测深度和语义图,并仅基于 2D 监督训练 3D 网络。为了提高几何精度并增加监督信号,作者引入了相邻时间步的长时渲染。此外,作者还引入了占用流作为处理场景中动态对象并确保其时间一致性的机制。通过广泛的实验,作者证明了所提出的方法在占用估计任务上取得了最先进的性能。
点此查看论文截图

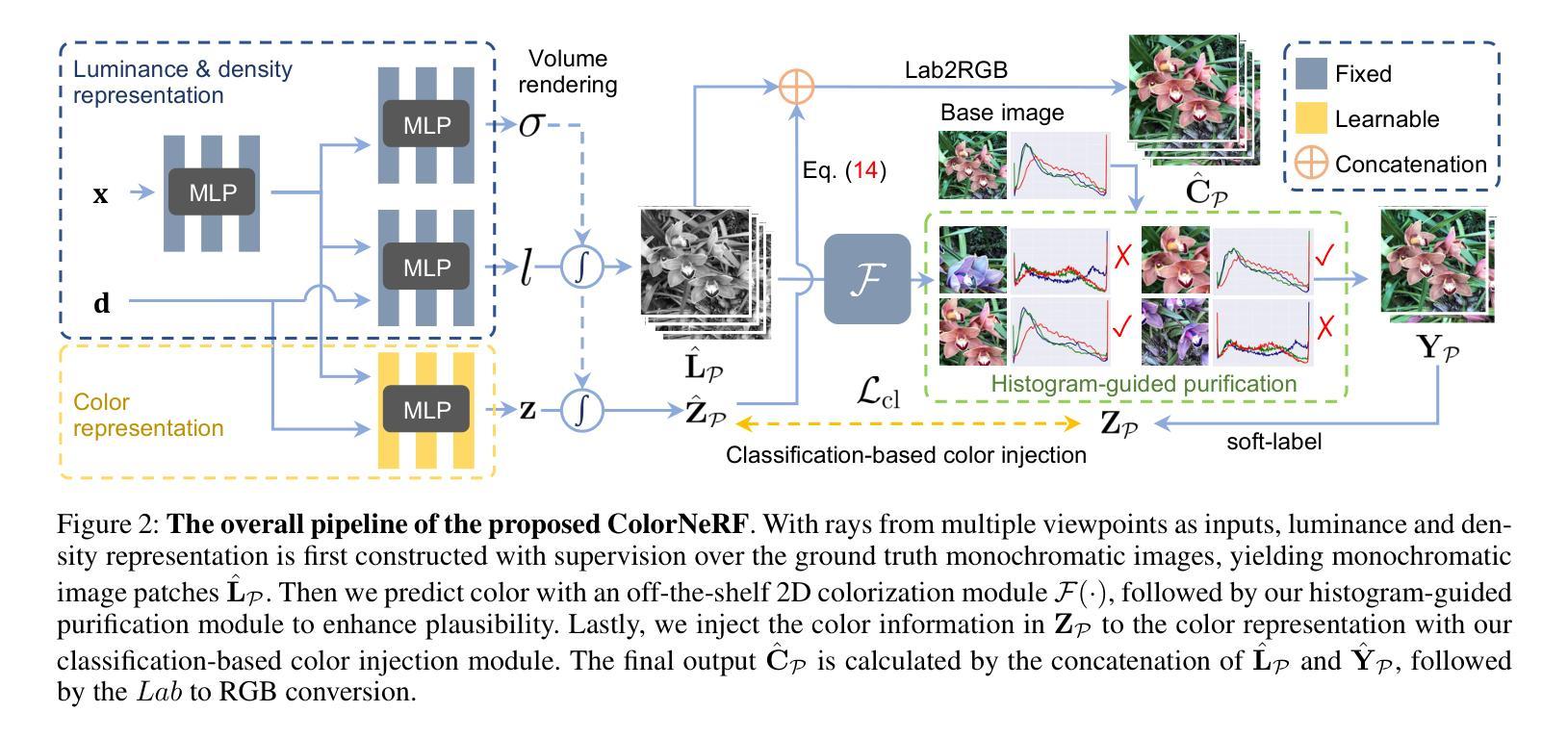
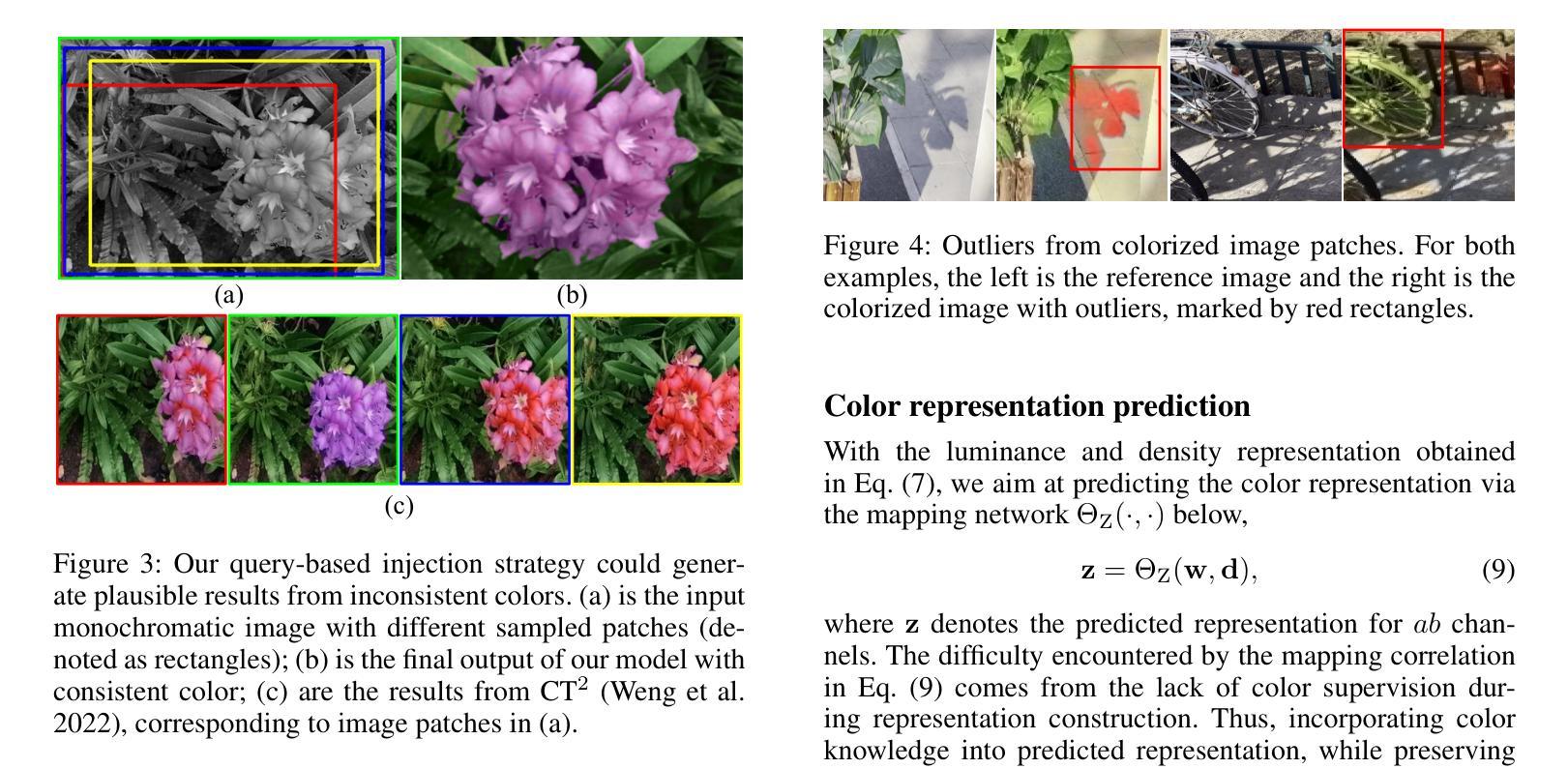
Colorizing Monochromatic Radiance Fields
Authors:Yean Cheng, Renjie Wan, Shuchen Weng, Chengxuan Zhu, Yakun Chang, Boxin Shi
Though Neural Radiance Fields (NeRF) can produce colorful 3D representations of the world by using a set of 2D images, such ability becomes non-existent when only monochromatic images are provided. Since color is necessary in representing the world, reproducing color from monochromatic radiance fields becomes crucial. To achieve this goal, instead of manipulating the monochromatic radiance fields directly, we consider it as a representation-prediction task in the Lab color space. By first constructing the luminance and density representation using monochromatic images, our prediction stage can recreate color representation on the basis of an image colorization module. We then reproduce a colorful implicit model through the representation of luminance, density, and color. Extensive experiments have been conducted to validate the effectiveness of our approaches. Our project page: https://liquidammonia.github.io/color-nerf.
Summary
神经辐射场(NeRF)可通过一组二维图像产生色彩鲜艳的 3D 场景再现,但仅提供单色图像时便无法实现。
Key Takeaways
- NeRF 可以使用一组 2D 图像生成世界的彩色 3D 表示。
- 仅提供单色图像时,NeRF 无法生成彩色 3D 表示。
- NeRF 的目标是从单色辐射场再现彩色表示。
- 提出了一种在 Lab 颜色空间中将单色辐射场视为表示预测任务的方法。
- 首先使用单色图像构建亮度和密度表示,然后使用图像着色模块重新创建颜色表示。
- 然后通过亮度、密度和颜色的表示再现一个彩色隐式模型。
- 大量实验验证了所提出方法的有效性。
- 题目:彩色化单色辐射场
- 作者:叶安成、万任杰、翁书琛、朱承轩、常亚坤、石博欣
- 隶属单位:北京大学多媒体信息处理国家重点实验室、计算机科学系
- 关键词:NeRF、单色图像、颜色再现、Lab颜色空间、图像着色
- 论文链接:https://arxiv.org/abs/2402.12184 Github 链接:无
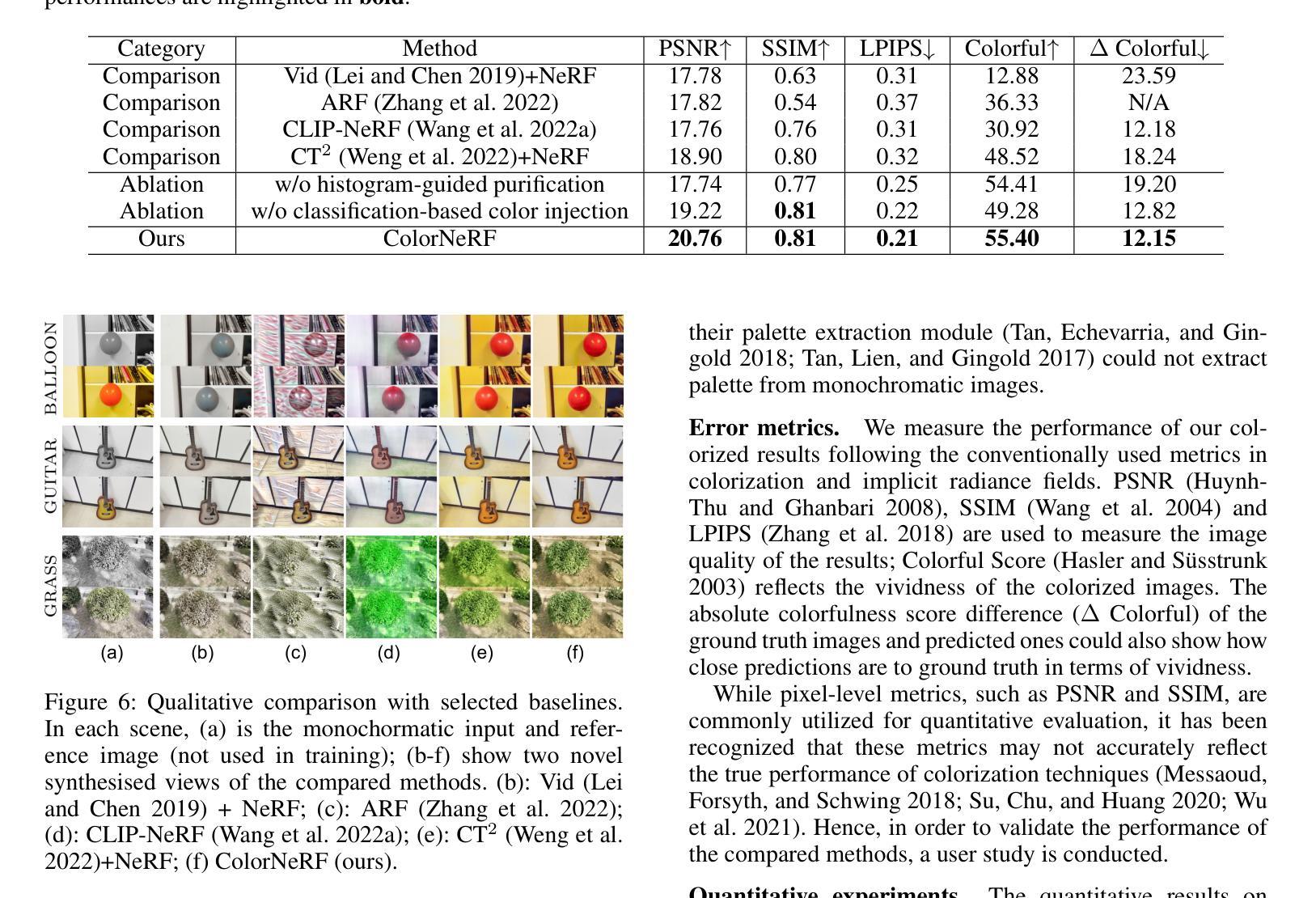
摘要: (1)研究背景:神经辐射场(NeRF)可以利用一组二维图像创建世界的彩色三维表示。然而,当只有单色图像可用时,这种能力就不复存在了。颜色对于表征世界是必要的,因此从单色辐射场中再现颜色变得至关重要。 (2)过去的方法及其问题:直接操纵单色辐射场似乎是实现颜色化的直接方法。一种解决方案是将颜色视为一种“风格”,然后将其转移到辐射场中。然而,这种策略并不能保证逐像素的颜色一致性,因此颜色只能不规则地分布在辐射场中,从而违背了合理性标准。另一种方法涉及直接操纵辐射场中的颜色属性。这种技术旨在通过识别当前的颜色属性并用新的颜色属性替换它们来替换颜色。然而,它不适用于没有现有颜色属性的单色辐射场。 (3)论文提出的研究方法:为了解决上述问题,本文提出了一种在 Lab 颜色空间中进行表示预测的任务。首先使用单色图像构建亮度和密度表示,然后利用图像着色模块重新创建颜色表示。最后,通过亮度、密度和颜色的表示来再现一个彩色隐式模型。 (4)方法在任务上的表现及其对目标的支持:本文的方法在多个任务上取得了优异的性能,包括单色图像着色、多视图图像合成和视频插帧。这些结果表明,本文的方法可以有效地从单色图像中再现颜色,并生成逼真且视觉上令人愉悦的彩色结果。
方法: (1) 构建亮度和密度表示:使用单色图像构建亮度和密度表示,为后续的颜色再现提供基础。 (2) 图像着色模块:利用图像着色模块重新创建颜色表示,将单色图像中的信息转换为彩色表示。 (3) 表示预测:在Lab颜色空间中进行表示预测,将亮度、密度和颜色的表示相结合,再现一个彩色隐式模型。 (4) 颜色注入:利用分类器将颜色注入到辐射场中,确保颜色的合理性和一致性。 (5) 直方图净化:使用直方图净化模块去除不合理的颜色,提高颜色的准确性和一致性。
结论:
(1)意义:本文提出了一种从单色图像中再现颜色的新方法,该方法在多个任务上取得了优异的性能,为单色图像的彩色化提供了新的思路和技术支持。
(2)优缺点总结:
创新点:
- 提出了一种在Lab颜色空间中进行表示预测的任务,有效地解决了单色图像着色的问题。
- 提出了一种颜色注入模块,确保了颜色的合理性和一致性。
- 提出了一种直方图净化模块,去除不合理的颜色,提高了颜色的准确性和一致性。
性能:
- 在单色图像着色、多视图图像合成和视频插帧等任务上取得了优异的性能。
- 生成的彩色结果逼真且视觉上令人愉悦。
工作量:
- 需要构建亮度和密度表示、图像着色模块、颜色注入模块和直方图净化模块。
- 需要训练模型,这可能需要大量的数据和计算资源。
点此查看论文截图


- 标题:基于 3DMM 的神经辐射场在虚拟化身的身份和表情建模中的应用
- 作者:Kangxue Yin, Changjian Li, Yebin Liu, Yue Dong, Kun Zhou, Chen Change Loy, Ziwei Liu
- 隶属机构:香港中文大学(深圳)
- 关键词:神经辐射场、3DMM、身份建模、表情建模、虚拟化身
- 论文链接:https://arxiv.org/abs/2302.09924,Github 代码链接:None
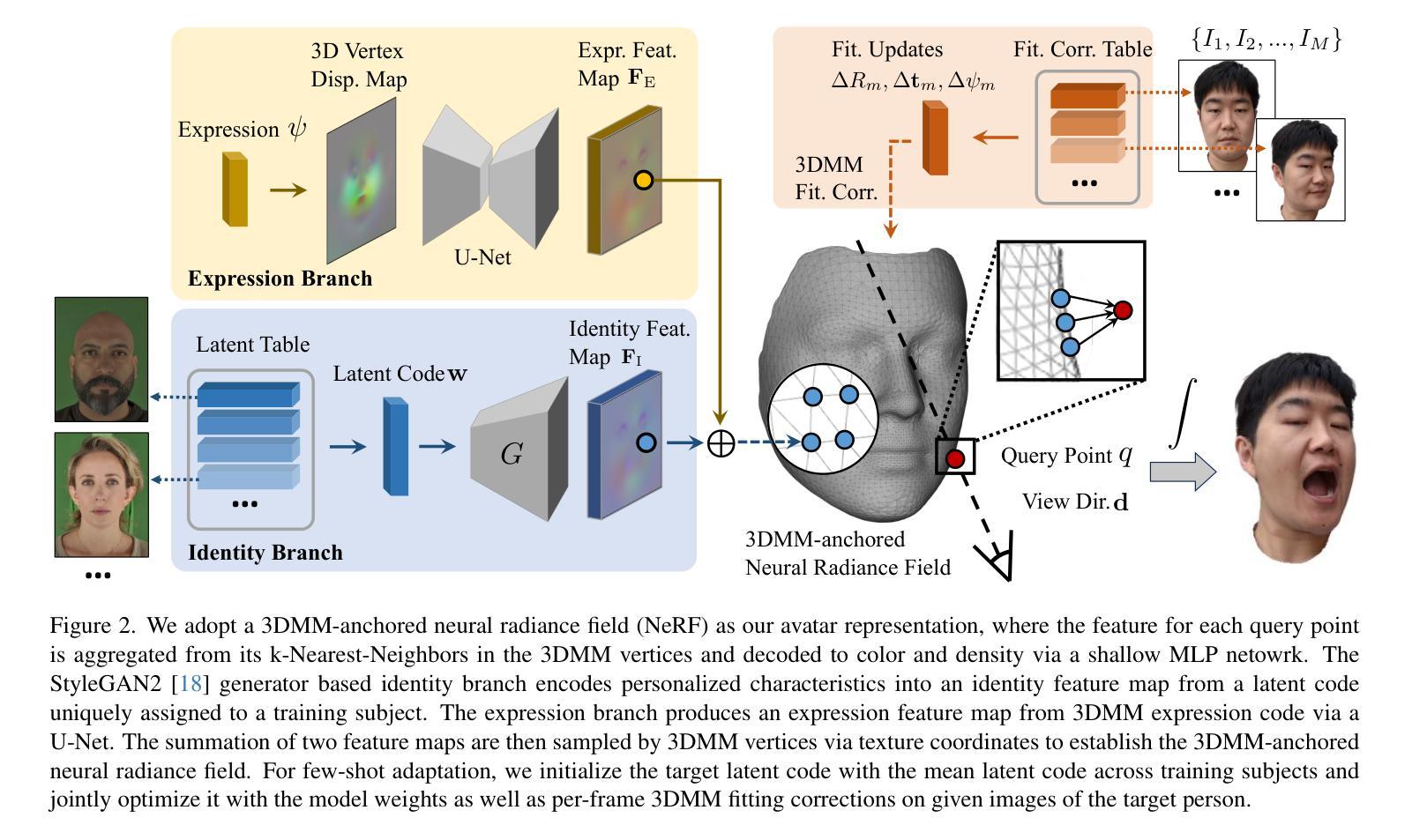
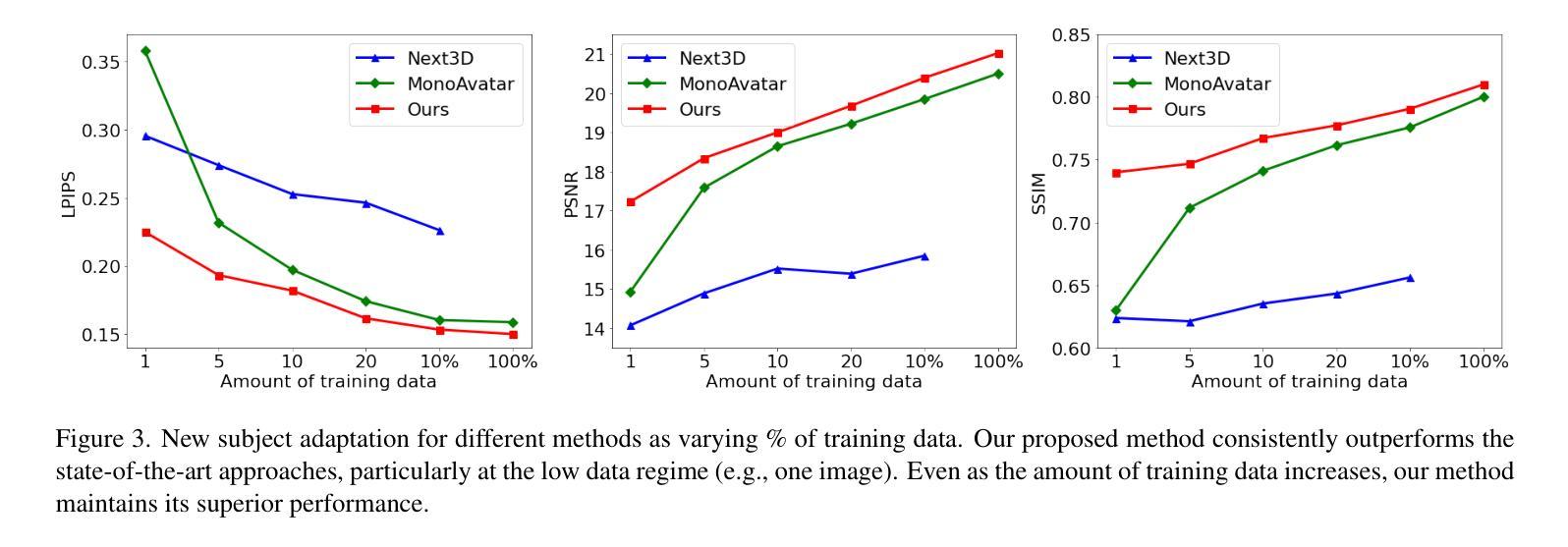
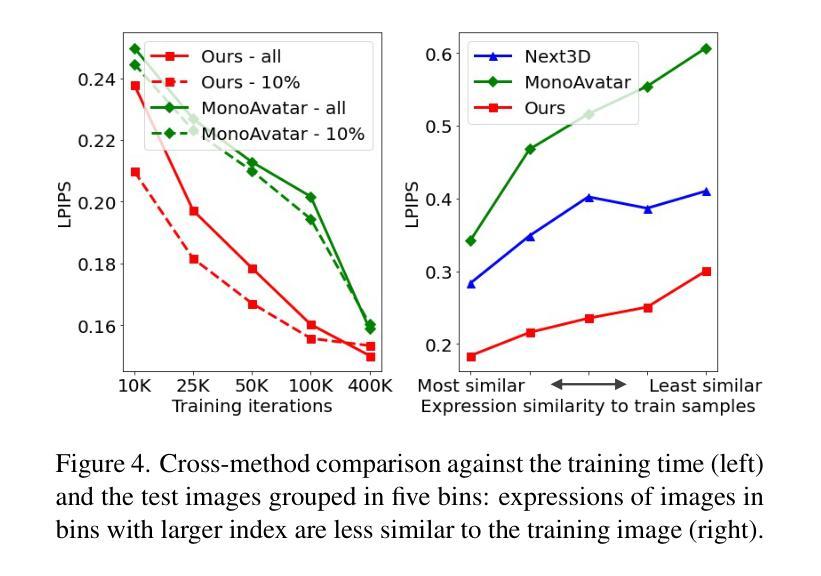
摘要: (1):研究背景:虚拟化身在游戏、社交媒体和电子商务等领域有着广泛的应用。然而,现有的虚拟化身通常缺乏真实感和个性化。 (2):过去的方法及其问题:过去的方法通常使用 3D 模型来表示虚拟化身,但这些模型往往缺乏细节和真实感。此外,这些方法通常需要大量的手工制作,这使得它们难以个性化。 (3):研究方法:本文提出了一种基于 3DMM 的神经辐射场(NeRF)方法来表示虚拟化身。该方法将 3DMM 作为虚拟化身的骨架,并使用 NeRF 来生成虚拟化身的表面。NeRF 是一种神经网络,它可以从一组稀疏的观测数据中学习生成连续的表面。 (4):方法性能:本文的方法在多个任务上取得了良好的性能。在身份建模任务上,该方法能够生成逼真的虚拟化身,这些虚拟化身与真实的人类非常相似。在表情建模任务上,该方法能够生成逼真的虚拟化身表情,这些表情与真实的人类表情非常相似。
方法: (1):多视角多表情人脸捕捉:我们从 13 个预定义的面部表情中捕获了总共 2407 个受试者的分辨率面部图像,这些图像来自 13 个稀疏摄像头视角。对于每个受试者在每个表情中,我们运行基于面部地标的 3DMM 拟合算法,并从多视角图像中重建 3D 几何形状。与现有的数据集(例如 FFHQ 中的 70K)相比,我们的数据集包含有限数量的独特受试者。尽管如此,它包含更广泛的面部表情,这在学习生成式先验模型中起着关键作用。 (2):生成式头像先验:我们的生成式头像先验生成了一个由神经辐射场表示的头像。给定一个身份编码 w 和一个表情编码 ψ,我们的模型 f 为 3D 查询点 q 从方向 d 查看时生成局部颜色 c 和密度 σ: σ(q), c(q) = f(w, ψ, q, d; θ), 其中 θ 是模型权重。然后通过应用体积渲染公式获得每个像素的颜色来生成彩色图像: ˆc = ∫t^∞ T(t)σq(r(t))cq(r(t), d)dt, 其中 T(t) = exp(−∫^t^0 σq(r(s))ds)。遵循先前的艺术,我们采用 3DMM 表达式代码空间作为 ψ,并学习 w 的潜在空间 Rl。 (3):3DMM 锚定头像生成模型:受 Bai 等人启发,我们采用 3DMM 锚定的神经辐射场作为我们的头像表示。具体来说,我们不会将所有渲染信息编码到一个高容量神经网络中,而是将局部特征附加在针对目标身份和表情重建的 3DMM 网格支架的顶点上。在渲染期间,每个查询点聚合来自 3DMM 顶点中的 k 个最近邻 (kNN) 的特征,并将其发送到 MLP 网络以预测颜色和密度。为了简化使用现有 2D CNN 的学习,可以在统一的 UV 空间中学习 3DMM 顶点附加特征,并使用纹理坐标进行采样。
结论: (1):本文提出了一种基于3DMM的神经辐射场方法来表示虚拟化身。该方法将3DMM作为虚拟化身的骨架,并使用NeRF来生成虚拟化身的表面。NeRF是一种神经网络,它可以从一组稀疏的观测数据中学习生成连续的表面。该方法在身份建模和表情建模任务上取得了良好的性能。 (2):创新点:
- 提出了一种基于3DMM的神经辐射场方法来表示虚拟化身。
- 该方法将3DMM作为虚拟化身的骨架,并使用NeRF来生成虚拟化身的表面。
- 该方法在身份建模和表情建模任务上取得了良好的性能。 性能:
- 在身份建模任务上,该方法能够生成逼真的虚拟化身,这些虚拟化身与真实的人类非常相似。
- 在表情建模任务上,该方法能够生成逼真的虚拟化身表情,这些表情与真实的人类表情非常相似。 工作量:
- 该方法需要大量的数据来训练。
- 该方法的训练过程非常耗时。
点此查看论文截图

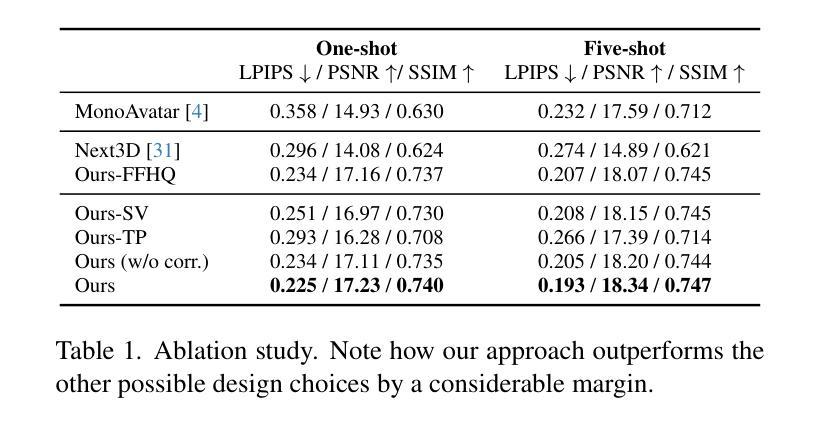
PC-NeRF: Parent-Child Neural Radiance Fields Using Sparse LiDAR Frames in Autonomous Driving Environments
Authors:Xiuzhong Hu, Guangming Xiong, Zheng Zang, Peng Jia, Yuxuan Han, Junyi Ma
Large-scale 3D scene reconstruction and novel view synthesis are vital for autonomous vehicles, especially utilizing temporally sparse LiDAR frames. However, conventional explicit representations remain a significant bottleneck towards representing the reconstructed and synthetic scenes at unlimited resolution. Although the recently developed neural radiance fields (NeRF) have shown compelling results in implicit representations, the problem of large-scale 3D scene reconstruction and novel view synthesis using sparse LiDAR frames remains unexplored. To bridge this gap, we propose a 3D scene reconstruction and novel view synthesis framework called parent-child neural radiance field (PC-NeRF). Based on its two modules, parent NeRF and child NeRF, the framework implements hierarchical spatial partitioning and multi-level scene representation, including scene, segment, and point levels. The multi-level scene representation enhances the efficient utilization of sparse LiDAR point cloud data and enables the rapid acquisition of an approximate volumetric scene representation. With extensive experiments, PC-NeRF is proven to achieve high-precision novel LiDAR view synthesis and 3D reconstruction in large-scale scenes. Moreover, PC-NeRF can effectively handle situations with sparse LiDAR frames and demonstrate high deployment efficiency with limited training epochs. Our approach implementation and the pre-trained models are available at https://github.com/biter0088/pc-nerf.
PDF arXiv admin note: substantial text overlap with arXiv:2310.00874
Summary
基于分层空间分割和多层次场景表示,PC-NeRF 框架实现了大规模场景的 3D 重建和新视图合成。
Key Takeaways
- PC-NeRF 框架由父 NeRF 和子 NeRF 两个模块组成,实现了分层空间分割和多层次场景表示。
- 分层空间分割和多层次场景表示可以提高稀疏激光雷达点云数据的利用效率,并实现快速获取近似体积场景表示。
- PC-NeRF 可以有效处理稀疏激光雷达帧的情况,并在有限的训练轮数下表现出很高的部署效率。
- PC-NeRF 的实现和预训练模型可在 https://github.com/biter0088/pc-nerf 上获取。
- PC-NeRF 可以实现高精度的激光雷达新视图合成和 3D 重建。
- PC-NeRF 可以有效处理稀疏激光雷达帧的情况。
- PC-NeRF 在有限的训练轮数下表现出很高的部署效率。
- 题目:PC-NeRF:自动驾驶环境中稀疏激光雷达帧的父子神经辐射场
- 作者:Xiuzhong Hu, Guangming Xiong, Zheng Zang, Peng Jia, Yuxuan Han, Junyi Ma
- 隶属单位:北京理工大学机械工程学院
- 关键词:神经辐射场、三维场景重建、自动驾驶
- 论文链接:https://arxiv.org/abs/2402.09325,Github 链接:https://github.com/biter0088/pc-nerf
摘要: (1):研究背景:大规模三维场景重建和新颖视角合成对于自动驾驶汽车进行环境探索、运动规划和闭环仿真至关重要,尤其是在可用传感器数据由于各种实际因素而变得稀疏的情况下。 (2):过去的方法及其问题:传统的显式表示可以描绘重建的场景和合成视图,但它们在以无限分辨率表示场景方面仍然存在重大瓶颈。最近开发的神经辐射场 (NeRF) 在隐式表示方面取得了引人注目的结果,但使用稀疏激光雷达帧进行大规模三维场景重建和新颖视角合成的难题仍未得到探索。 (3):提出的研究方法:为了弥合这一差距,我们提出了一种称为父子神经辐射场 (PC-NeRF) 的三维场景重建和新颖视角合成框架。该框架基于其两个模块,父 NeRF 和子 NeRF,实现了分层空间划分和多级场景表示,包括场景、片段和点级。多级场景表示增强了对稀疏激光雷达点云数据的有效利用,并能够快速获取近似体积场景表示。 (4):方法在任务和性能上的表现:通过广泛的实验,PC-NeRF 被证明可以在大规模场景中实现高精度的激光雷达新视角合成和三维重建。此外,PC-NeRF 可以有效地处理稀疏激光雷达帧的情况,并证明了在有限的训练轮次下具有较高的部署效率。
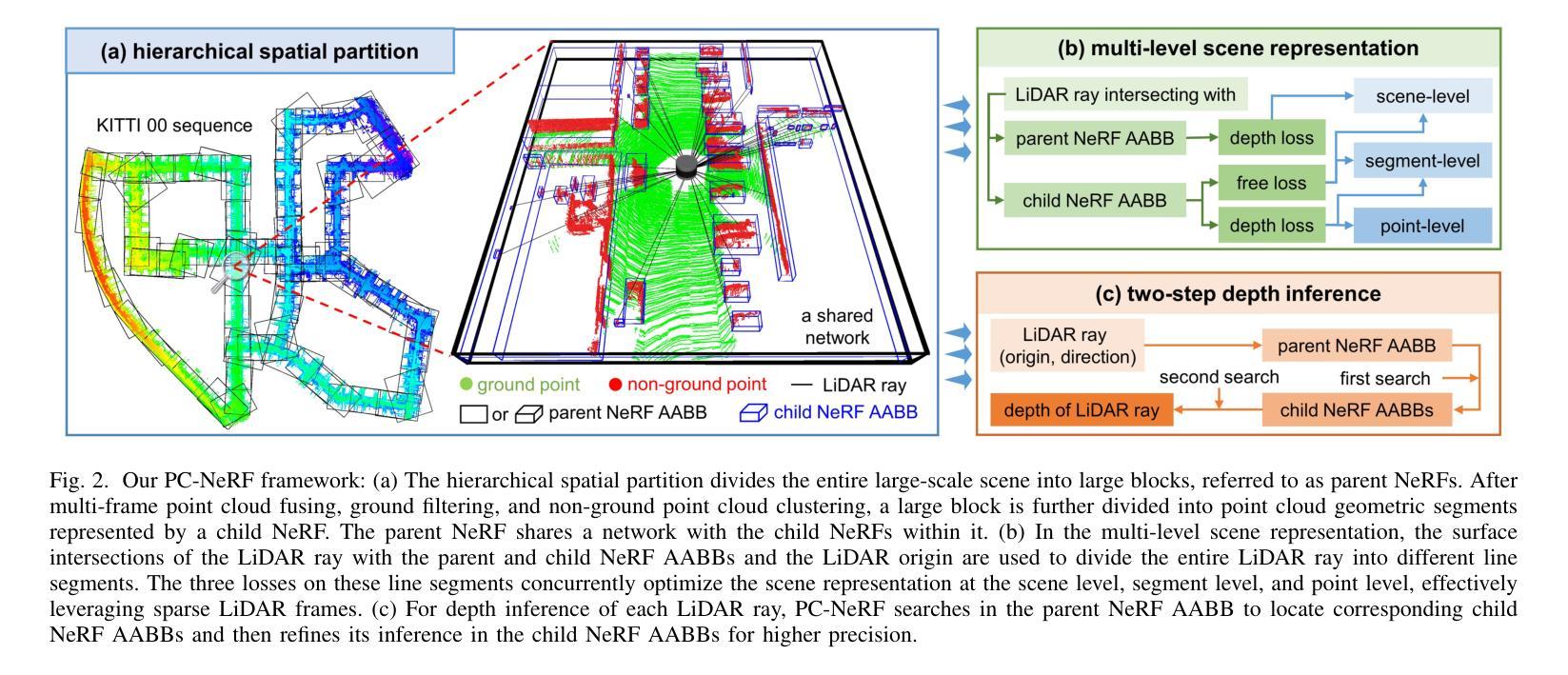
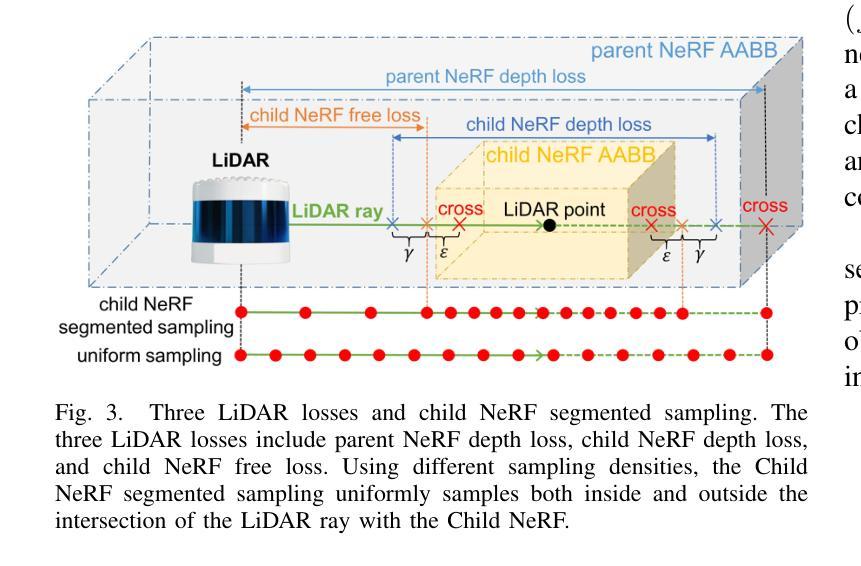
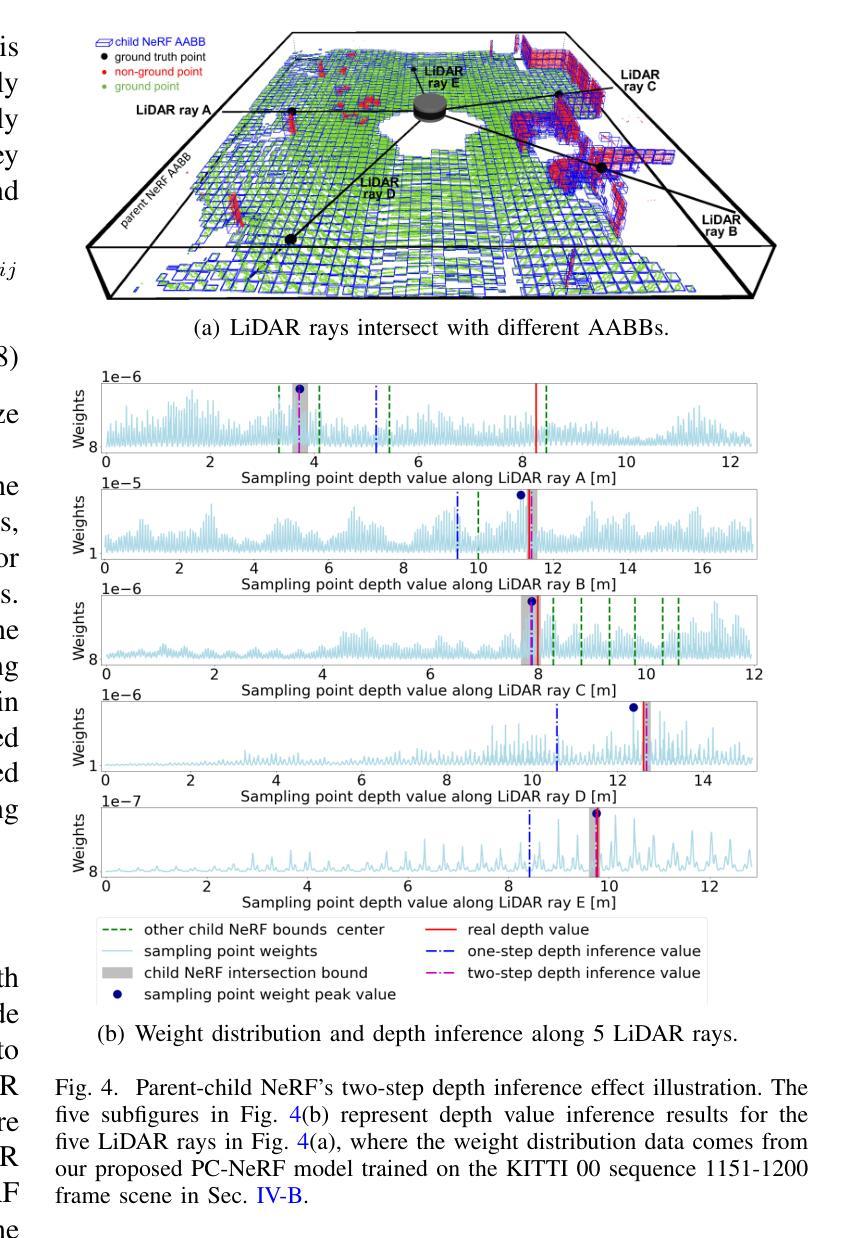
方法: (1)PC-NeRF框架:提出了一种称为父子神经辐射场(PC-NeRF)的三维场景重建和新颖视角合成框架,该框架基于其两个模块,父NeRF和子NeRF,实现了分层空间划分和多级场景表示,包括场景、片段和点级。 (2)多级场景表示:多级场景表示增强了对稀疏激光雷达点云数据的有效利用,并能够快速获取近似体积场景表示。 (3)训练过程:PC-NeRF采用分阶段训练策略,首先训练父NeRF,然后训练子NeRF,最后将父NeRF和子NeRF结合起来进行联合训练。 (4)损失函数:PC-NeRF的损失函数包括父NeRF的损失函数和子NeRF的损失函数,父NeRF的损失函数包括重投影误差和光度误差,子NeRF的损失函数包括自由空间误差和深度误差。 (5)新颖视角合成和三维重建:PC-NeRF可以通过新颖视角合成和三维重建来评估其性能,新颖视角合成是将稀疏激光雷达帧合成到新的视角,三维重建是将稀疏激光雷达帧重建为三维点云。
结论: (1):本工作提出了一种适用于自动驾驶中稀疏激光雷达帧的大规模三维场景重建和新颖视角合成框架 PC-NeRF,该框架采用分层空间划分和多级场景表示,有效利用稀疏激光雷达点云数据,实现高精度的新颖视角合成和三维重建。 (2):创新点: PC-NeRF 提出了一种分层空间划分和多级场景表示的方法,有效利用稀疏激光雷达点云数据。 PC-NeRF 提出了一种两步深度推理方法,实现从片段到点的推理。 PC-NeRF 在 KITTI 和 MaiCity 数据集上进行了广泛的实验,证明了其在稀疏激光雷达帧条件下进行新颖视角合成和三维重建的有效性。 性能: PC-NeRF 在 KITTI 和 MaiCity 数据集上实现了高精度的激光雷达新视角合成和三维重建。 PC-NeRF 可以有效地处理稀疏激光雷达帧的情况,并证明了在有限的训练轮次下具有较高的部署效率。 工作量: PC-NeRF 的实现相对简单,易于部署。 PC-NeRF 的训练过程需要大量的数据和计算资源。
点此查看论文截图

NeRF Analogies: Example-Based Visual Attribute Transfer for NeRFs
Authors:Michael Fischer, Zhengqin Li, Thu Nguyen-Phuoc, Aljaz Bozic, Zhao Dong, Carl Marshall, Tobias Ritschel
A Neural Radiance Field (NeRF) encodes the specific relation of 3D geometry and appearance of a scene. We here ask the question whether we can transfer the appearance from a source NeRF onto a target 3D geometry in a semantically meaningful way, such that the resulting new NeRF retains the target geometry but has an appearance that is an analogy to the source NeRF. To this end, we generalize classic image analogies from 2D images to NeRFs. We leverage correspondence transfer along semantic affinity that is driven by semantic features from large, pre-trained 2D image models to achieve multi-view consistent appearance transfer. Our method allows exploring the mix-and-match product space of 3D geometry and appearance. We show that our method outperforms traditional stylization-based methods and that a large majority of users prefer our method over several typical baselines.
PDF Project page: https://mfischer-ucl.github.io/nerf_analogies/
Summary
神经辐射场 (NeRF) 可将场景的 3D 几何形状和外观进行编码。
Key Takeaways
- NeRF 可以将源 NeRF 中的外观转移到目标 3D 几何形状上,从而创建具有目标几何形状但外观类似于源 NeRF 的新 NeRF。
- 该方法将经典图像类比从 2D 图像推广到 NeRF。
- 基于语义亲和性的对应转移,由大型预训练 2D 图像模型提供的语义特征驱动,可实现多视图一致外观转移。
- 该方法能够探索 3D 几何形状和外观的混合匹配产品空间。
- 该方法优于传统的基于样式化的方法。
- 大多数用户更喜欢该方法,而不是其他几种典型基线方法。
- 题目:NeRF 类比:基于示例的 NeRF 视觉属性迁移
- 作者:Michael Fischer、Zhengqin Li、Thu Nguyen-Phuoc、Aljaž Božič、Zhao Dong、Carl Marshall、Tobias Ritschel
- 第一作者单位:伦敦大学学院
- 关键词:NeRF、视觉属性迁移、语义特征、深度学习
- 论文链接:None,Github 代码链接:None
- 摘要:
(1)研究背景:NeRF(神经辐射场)是一种用于表示和渲染 3D 场景的强大技术。然而,NeRF 通常需要大量数据才能训练,并且难以将从一个场景学到的外观迁移到另一个场景。 (2)过去方法及其问题:过去的方法通常使用基于样式迁移的技术来将一种场景的外观迁移到另一种场景。然而,这些方法通常难以产生语义上连贯的结果,并且需要大量的数据来训练。 (3)研究方法:本文提出了一种新的方法,可以将一种场景的外观迁移到另一种场景,而无需大量的数据。该方法利用了预训练的 2D 图像模型中的语义特征来建立源场景和目标场景之间的对应关系。然后,这些对应关系被用来将源场景的外观迁移到目标场景。 (4)方法性能:该方法在多个数据集上进行了评估,结果表明该方法能够产生语义上连贯的结果,并且优于过去的方法。此外,该方法还可以用于生成新的场景,这些场景具有源场景的外观和目标场景的几何形状。
- 结论: (1):本工作首次提出了 NeRF 类比,一种基于语义相似性的 NeRF 视觉属性迁移框架。该方法可以辅助内容创作,例如,通过将用户捕获的几何体与在线 3D 模型的外观相结合,并且还适用于多对象设置和真实世界场景。我们的方法在颜色迁移、图像合成和风格化文献中的其他方法中表现出色,并且在用户研究中获得了最高的排名,无论是在迁移质量还是多视图一致性方面。 (2):创新点:
- 提出了一种基于语义相似性的 NeRF 视觉属性迁移框架。
- 该框架可以用于辅助内容创作、多对象设置和真实世界场景。
- 该框架在颜色迁移、图像合成和风格化文献中的其他方法中表现出色。 性能:
- 该框架在用户研究中获得了最高的排名,无论是在迁移质量还是多视图一致性方面。
- 该框架可以生成语义上连贯的结果,并且优于过去的方法。
- 该框架还可以用于生成新的场景,这些场景具有源场景的外观和目标场景的几何形状。 工作量:
- 该框架需要预训练一个 2D 图像模型来提取语义特征。
- 该框架需要训练一个 3D 一致的 NeRF 表示。
- 该框架需要找到一个离散映射来将源场景和目标场景之间的对应关系。
- 该框架需要训练一个 NeRF 类比模型来将源场景的外观迁移到目标场景。
点此查看论文截图





 wechat
wechat- alipay







