Diffusion Models
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-02-29 更新
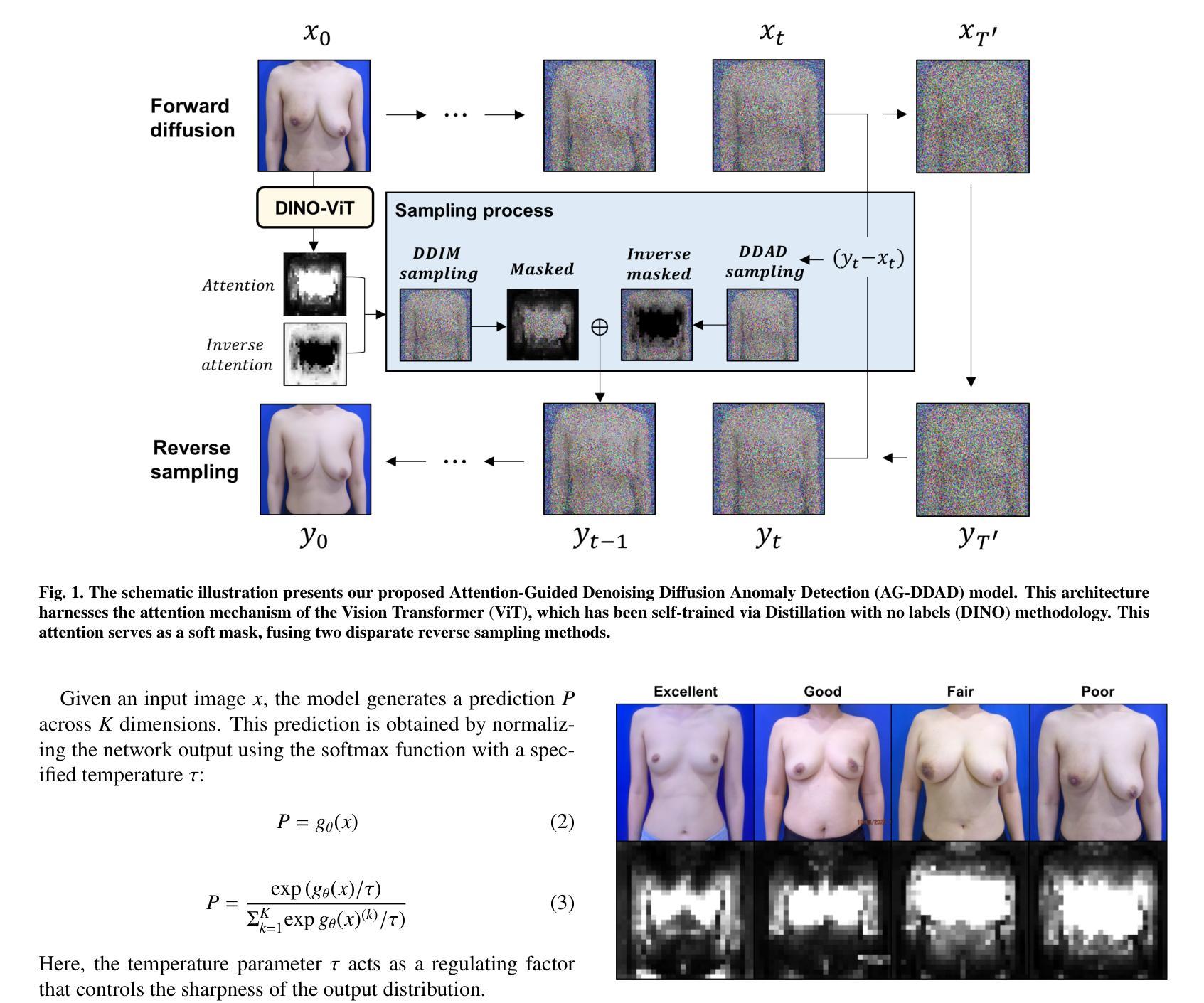
Objective and Interpretable Breast Cosmesis Evaluation with Attention Guided Denoising Diffusion Anomaly Detection Model
Authors:Sangjoon Park, Yong Bae Kim, Jee Suk Chang, Seo Hee Choi, Hyungjin Chung, Ik Jae Lee, Hwa Kyung Byun
As advancements in the field of breast cancer treatment continue to progress, the assessment of post-surgical cosmetic outcomes has gained increasing significance due to its substantial impact on patients’ quality of life. However, evaluating breast cosmesis presents challenges due to the inherently subjective nature of expert labeling. In this study, we present a novel automated approach, Attention-Guided Denoising Diffusion Anomaly Detection (AG-DDAD), designed to assess breast cosmesis following surgery, addressing the limitations of conventional supervised learning and existing anomaly detection models. Our approach leverages the attention mechanism of the distillation with no label (DINO) self-supervised Vision Transformer (ViT) in combination with a diffusion model to achieve high-quality image reconstruction and precise transformation of discriminative regions. By training the diffusion model on unlabeled data predominantly with normal cosmesis, we adopt an unsupervised anomaly detection perspective to automatically score the cosmesis. Real-world data experiments demonstrate the effectiveness of our method, providing visually appealing representations and quantifiable scores for cosmesis evaluation. Compared to commonly used rule-based programs, our fully automated approach eliminates the need for manual annotations and offers objective evaluation. Moreover, our anomaly detection model exhibits state-of-the-art performance, surpassing existing models in accuracy. Going beyond the scope of breast cosmesis, our research represents a significant advancement in unsupervised anomaly detection within the medical domain, thereby paving the way for future investigations.
Summary
利用无人监督方法,自动评估乳腺癌术后外观,为提高患者生活质量提供新途径。
Key Takeaways
- 采用无监督异常检测视角,无需标记即可评估外观。
- 使用蒸馏无标签 (DINO) 自监督视觉 Transformer (ViT) 的注意力机制,实现高质量图像重建和判别区域的精确转换。
- 在以正常外观为主的未标记数据上训练扩散模型。
- 提供视觉上吸引人的表示和可量化的分数,用于外观评估。
- 消除人工标注的需要,提供客观评估。
- 在准确性方面超过现有模型,展现出最先进的性能。
- 为医学领域的无监督异常检测提供了重大进展。
- 探索无监督外观评估在其他医疗领域的潜力。
- Title: 基于注意力引导去噪扩散的客观可解释乳房美观评估
- Authors: Sangjoon Park, YongBae Kim, JeeSuk Chang, SeoHee Choi, Hyungjin Chung, IkJae Lee, HwaKyung Byun
- Affiliation: 韩国首尔延世大学医学院放射肿瘤科
- Keywords: 扩散模型、异常检测、视觉 Transformer、乳房美观
- Urls: Paper, Github: None
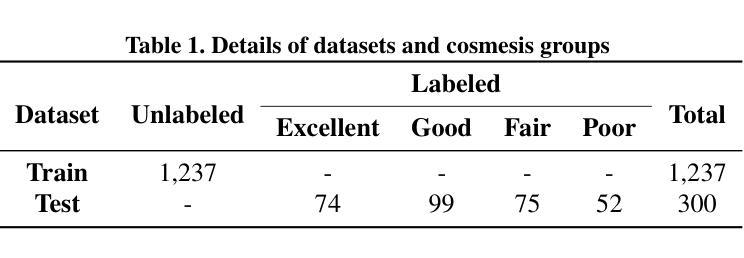
Summary: (1): 乳房癌术后美观评估对患者生活质量影响很大,但传统方法存在主观性强、依赖人工标注等问题。 (2): 现有方法依赖专家标注,存在成本高、标注偏差、模型过拟合、可解释性差等问题。 (3): 本文提出一种名为 AG-DDAD 的创新架构,利用扩散模型的高质量生成能力和 DINO 视觉 Transformer 注意力的显著特征识别能力。该模型可以在无监督的方式下训练,利用来自 1,237 名主要为正常美观(优秀到良好)患者的未标记数据,无需专家标注和人工勾勒。AG-DDAD 通过比较正常美观情况下预期的恢复结果,提供直接且出色的可视化结果,为不良美观成因提供有价值的见解。 (4): 在一个经过精心整理的包含 300 名接受乳腺癌保乳手术患者的数据集上进行的实验表明,本文模型优于传统的基于规则的方法和其他最先进的异常检测方法。
方法: (1):提出一种名为 AG-DDAD 的创新架构,该架构利用扩散模型的高质量生成能力和 DINO 视觉 Transformer 注意力的显著特征识别能力; (2):AG-DDAD 在无监督的方式下训练,利用来自主要为正常美观(优秀到良好)患者的未标记数据,无需专家标注和人工勾勒; (3):AG-DDAD 通过比较正常美观情况下预期的恢复结果,提供直接且出色的可视化结果,为不良美观成因提供有价值的见解。
结论: (1):本文提出了一种基于注意力引导去噪扩散的客观可解释乳房美观评估方法,该方法利用了扩散模型的高质量生成能力和DINO视觉Transformer注意力的显著特征识别能力,在无监督的方式下训练,无需专家标注和人工勾勒,通过比较正常美观情况下预期的恢复结果,提供直接且出色的可视化结果,为不良美观成因提供有价值的见解。 (2):创新点:
- 提出了一种基于注意力引导去噪扩散的客观可解释乳房美观评估方法,该方法利用了扩散模型的高质量生成能力和DINO视觉Transformer注意力的显著特征识别能力。
- 该方法在无监督的方式下训练,无需专家标注和人工勾勒,通过比较正常美观情况下预期的恢复结果,提供直接且出色的可视化结果,为不良美观成因提供有价值的见解。 性能:
- 在一个经过精心整理的包含300名接受乳腺癌保乳手术患者的数据集上进行的实验表明,本文模型优于传统的基于规则的方法和其他最先进的异常检测方法。 工作量:
- 该方法需要比传统的分类器模型略多的时间,评估单个患者的美观大约需要15秒,而简单的分类器模型可以在1秒内产生结果。
点此查看论文截图

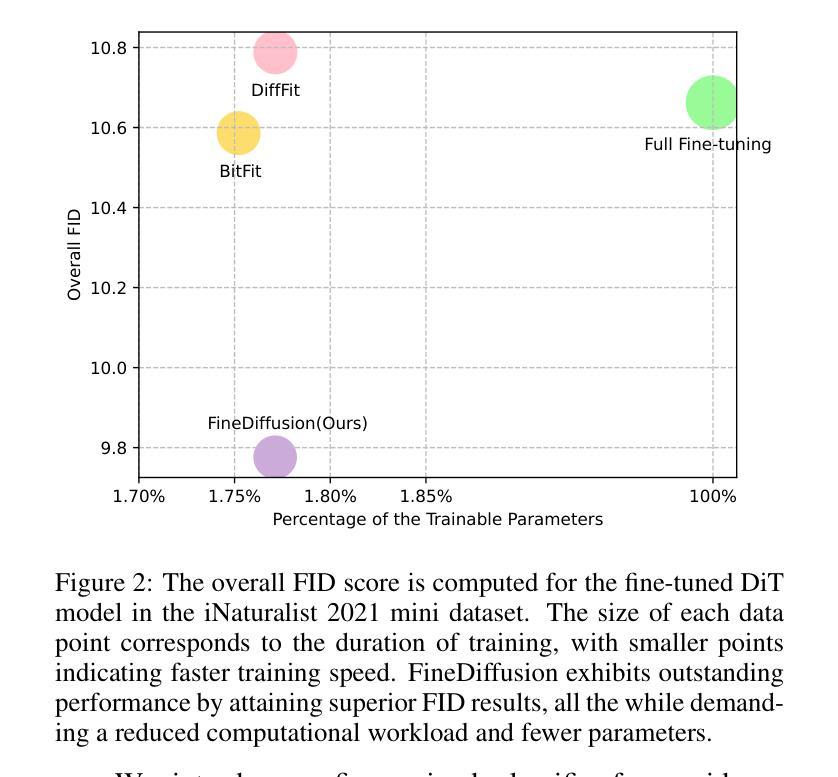
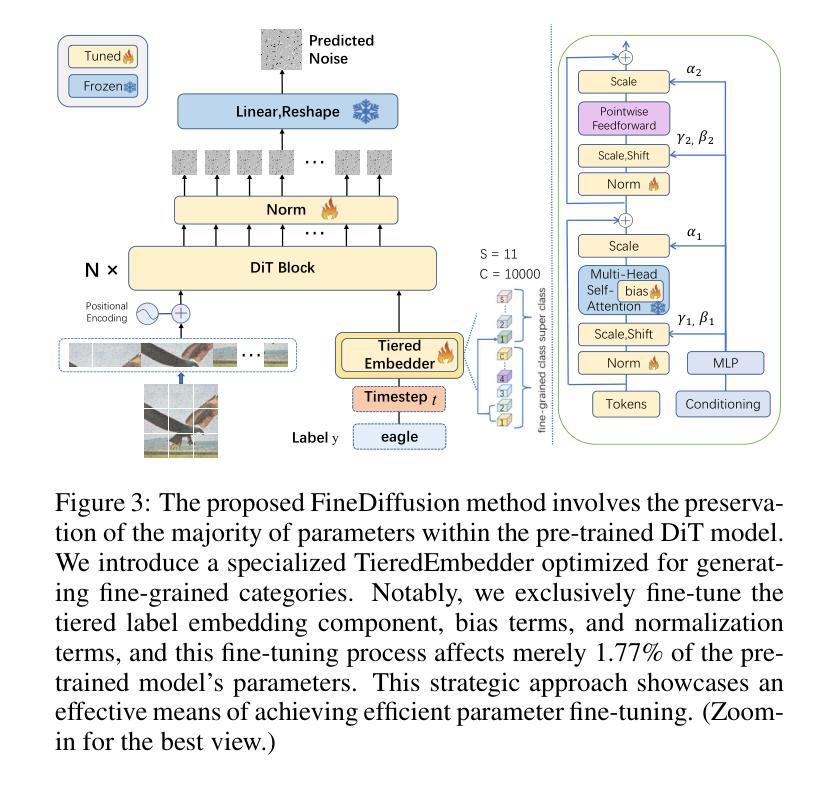
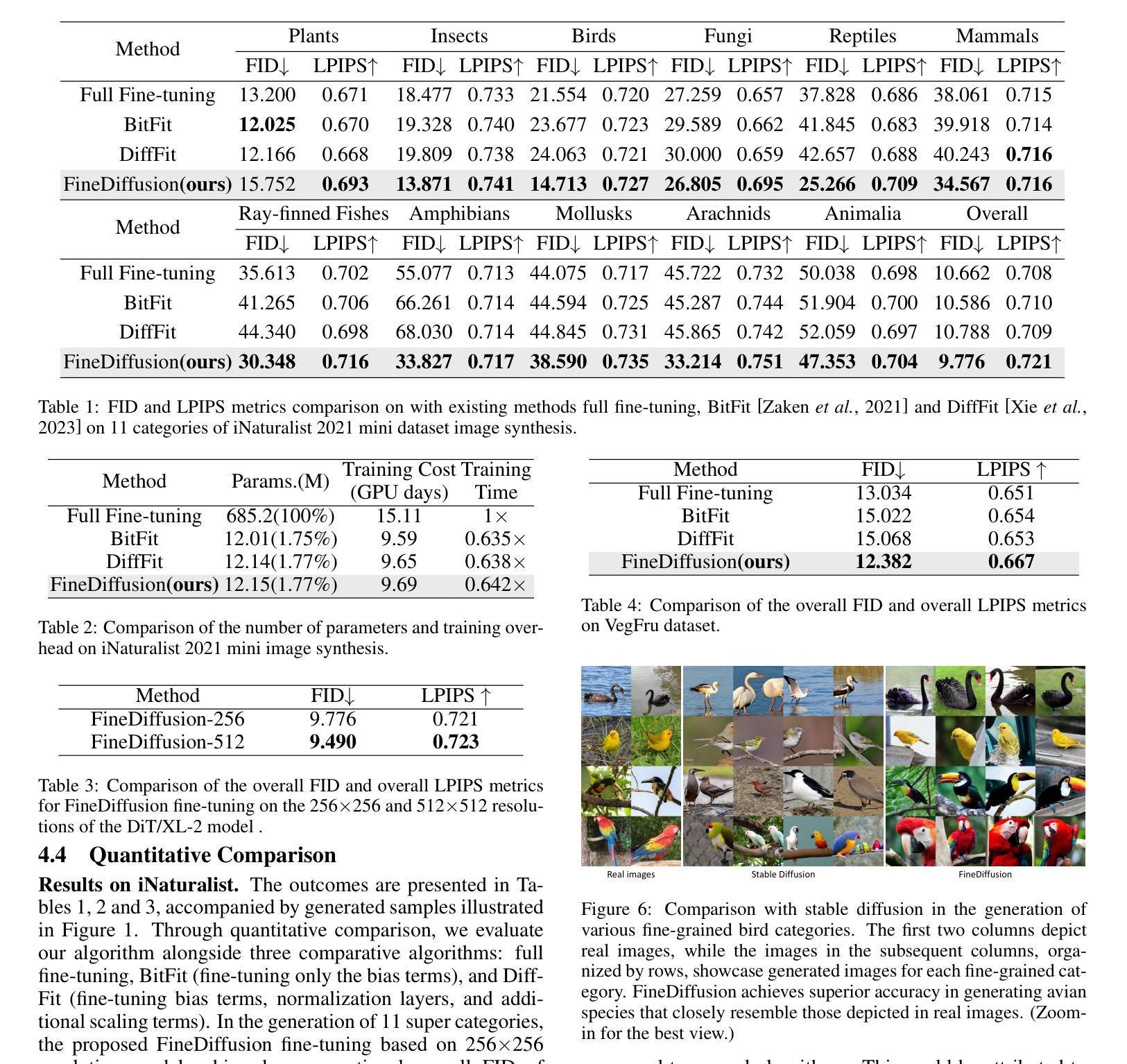
FineDiffusion: Scaling up Diffusion Models for Fine-grained Image Generation with 10,000 Classes
Authors:Ziying Pan, Kun Wang, Gang Li, Feihong He, Xiwang Li, Yongxuan Lai
The class-conditional image generation based on diffusion models is renowned for generating high-quality and diverse images. However, most prior efforts focus on generating images for general categories, e.g., 1000 classes in ImageNet-1k. A more challenging task, large-scale fine-grained image generation, remains the boundary to explore. In this work, we present a parameter-efficient strategy, called FineDiffusion, to fine-tune large pre-trained diffusion models scaling to large-scale fine-grained image generation with 10,000 categories. FineDiffusion significantly accelerates training and reduces storage overhead by only fine-tuning tiered class embedder, bias terms, and normalization layers’ parameters. To further improve the image generation quality of fine-grained categories, we propose a novel sampling method for fine-grained image generation, which utilizes superclass-conditioned guidance, specifically tailored for fine-grained categories, to replace the conventional classifier-free guidance sampling. Compared to full fine-tuning, FineDiffusion achieves a remarkable 1.56x training speed-up and requires storing merely 1.77% of the total model parameters, while achieving state-of-the-art FID of 9.776 on image generation of 10,000 classes. Extensive qualitative and quantitative experiments demonstrate the superiority of our method compared to other parameter-efficient fine-tuning methods. The code and more generated results are available at our project website: https://finediffusion.github.io/.
Summary
通过微调预训练扩散模型,以参数高效策略实现针对 10,000 个细粒度类别的大规模图像生成
Key Takeaways
- 提出 FineDiffusion,将大规模扩散模型缩小到细粒度图像生成中
- 只微调分类嵌入、偏置项和归一化层的参数,大幅提升训练速度和存储效率
- 提出针对细粒度类别的超类条件引导采样方法,提升图像生成质量
- 与完全微调相比,FineDiffusion 训练速度提升 1.56 倍,所需存储参数仅为原模型的 1.77%
- 在 10,000 个类别的图像生成上取得最先进的 FID 为 9.776
- 大量定性和定量实验验证了该方法的优越性
- 标题:FineDiffusion:将扩散模型扩展到 10,000 类别的细粒度图像生成
- 作者:Ziying Pan, Kun Wang, Gang Li, Feihong He, Xiwang Li, Yongxuan Lai
- 第一作者单位:厦门大学
- 关键词:Diffusion Models, Fine-grained Image Generation, Parameter-efficient Fine-tuning
- 论文链接:https://arxiv.org/abs/2402.18331 Github 代码链接:None
- 摘要: (1):研究背景:基于扩散模型的图像生成以产生高质量和多样化的图像而闻名。然而,大多数先前的努力都集中在为一般类别生成图像,例如 ImageNet-1k 中的 1000 个类别。一个更具挑战性的任务,即大规模细粒度图像生成,仍然是需要探索的边界。 (2):过去的方法:过去的方法主要集中在一般类别的图像生成,而对于细粒度图像生成,需要模型对高度相似的细粒度类别中的细微差异(例如鸟类的羽毛纹理)进行复杂的建模。从头开始训练用于大规模细粒度图像生成的扩散模型需要更大的计算资源和训练迭代。 (3):研究方法:本文提出了一种新的微调方法 FineDiffusion,它可以通过微调预训练模型的一小部分参数,有效地微调大型预训练图像生成扩散模型,以进行大规模细粒度图像生成。 (4):方法性能:与完全微调相比,FineDiffusion 实现了显着的 1.56 倍训练加速,并且只需要存储 1.77% 的总模型参数,同时在 10,000 个类别的图像生成上实现了 9.776 的最先进 FID。广泛的定性和定量实验表明,与其他参数有效的微调方法相比,本文方法具有优越性。
7.方法:(1)提出了一种新的微调方法FineDiffusion,该方法通过微调预训练模型的一小部分参数,有效地微调大型预训练图像生成扩散模型,以进行大规模细粒度图像生成;(2)提出了一种分层类标签编码策略,该策略同时对超类和子类标签进行编码;(3)同时微调偏差和归一化项以及分层嵌入器,以学习全局数据集的分布特征;(4)引入了一种分层无分类器引导采样方法,该方法利用超类条件信息来增强对生成图像的控制。
- 结论: (1):本文首次尝试将扩散模型扩展到 10,000 类的细粒度图像生成。我们引入了 FineDiffusion,这是一种高效的参数微调方法,可以微调预训练模型的关键组件,包括分层标签嵌入、偏差项和归一化项。我们的方法大幅减少了训练和存储开销。此外,我们引入了一种细粒度无分类器引导采样技术,利用分层数据标签信息来有效增强细粒度图像生成的性能。充分的定性和定量结果证明了我们方法与其他方法相比的优越性。 (2):创新点:提出了一种新的微调方法 FineDiffusion,该方法通过微调预训练模型的一小部分参数,有效地微调大型预训练图像生成扩散模型,以进行大规模细粒度图像生成;提出了分层类标签编码策略,该策略同时对超类和子类标签进行编码;同时微调偏差和归一化项以及分层嵌入器,以学习全局数据集的分布特征;引入了一种分层无分类器引导采样方法,该方法利用超类条件信息来增强对生成图像的控制。 性能:与完全微调相比,FineDiffusion 实现了显着的 1.56 倍训练加速,并且只需要存储 1.77% 的总模型参数,同时在 10,000 个类别的图像生成上实现了 9.776 的最先进 FID。广泛的定性和定量实验表明,与其他参数有效的微调方法相比,本文方法具有优越性。 工作量:与从头开始训练用于大规模细粒度图像生成的扩散模型相比,FineDiffusion 可以显着减少计算资源和训练迭代。
点此查看论文截图



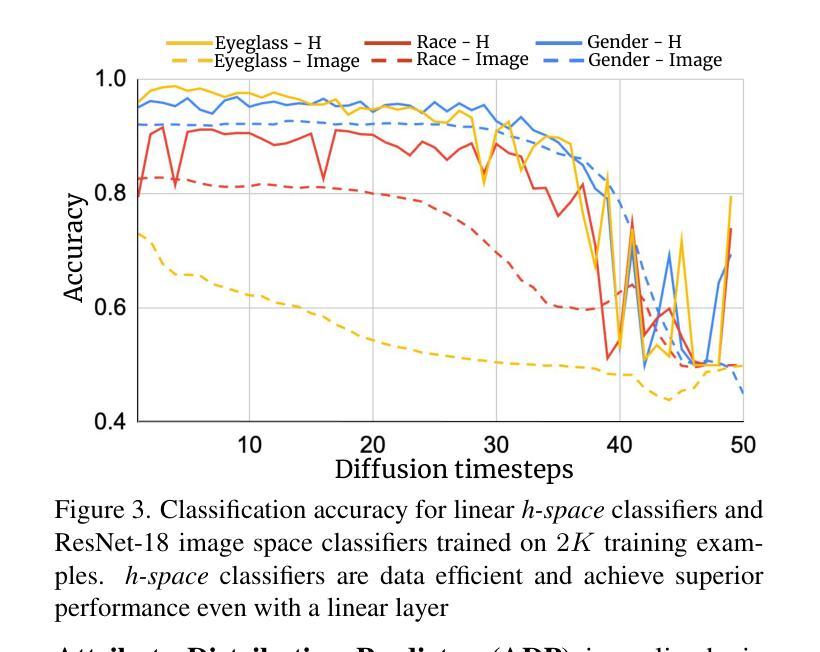
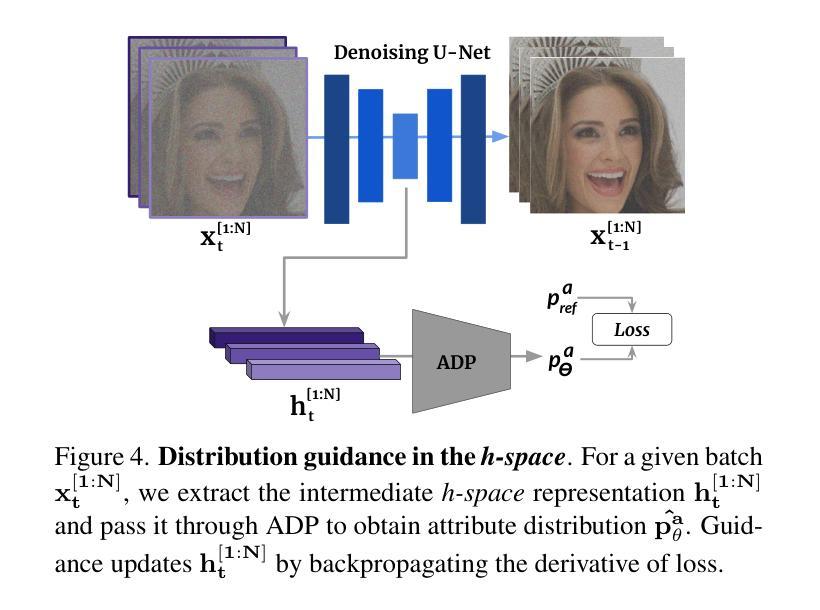
Balancing Act: Distribution-Guided Debiasing in Diffusion Models
Authors:Rishubh Parihar, Abhijnya Bhat, Saswat Mallick, Abhipsa Basu, Jogendra Nath Kundu, R. Venkatesh Babu
Diffusion Models (DMs) have emerged as powerful generative models with unprecedented image generation capability. These models are widely used for data augmentation and creative applications. However, DMs reflect the biases present in the training datasets. This is especially concerning in the context of faces, where the DM prefers one demographic subgroup vs others (eg. female vs male). In this work, we present a method for debiasing DMs without relying on additional data or model retraining. Specifically, we propose Distribution Guidance, which enforces the generated images to follow the prescribed attribute distribution. To realize this, we build on the key insight that the latent features of denoising UNet hold rich demographic semantics, and the same can be leveraged to guide debiased generation. We train Attribute Distribution Predictor (ADP) - a small mlp that maps the latent features to the distribution of attributes. ADP is trained with pseudo labels generated from existing attribute classifiers. The proposed Distribution Guidance with ADP enables us to do fair generation. Our method reduces bias across single/multiple attributes and outperforms the baseline by a significant margin for unconditional and text-conditional diffusion models. Further, we present a downstream task of training a fair attribute classifier by rebalancing the training set with our generated data.
PDF CVPR 2024. Project Page : https://ab-34.github.io/balancing_act/
Summary
去除扩散模型中的偏见,无需额外数据或模型重新训练。
Key Takeaways
- 扩散模型(DM)存在偏见,表现为对特定人口亚组(如女性)的偏好。
- 分布引导是一种无偏 DM 的方法,无需额外数据或重新训练。
- 分布引导利用去噪 UNet 的潜在特征中丰富的语义信息。
- 属性分布预测器 (ADP) 将潜在特征映射到属性分布。
- ADP 使用现有属性分类器生成的伪标签进行训练。
- 分布引导和 ADP 实现了公平生成,显著优于基线。
- 通过使用生成的数据重新平衡训练集,可以训练公平的属性分类器。
- 标题:平衡行为:扩散模型中的分布引导去偏
- 作者:Rishubh Parihar*, Abhijnya Bhat∗, Saswat Mallick, Abhipsa Basu, Jogendra Nath Kundu, R. Venkatesh Babu
- 隶属:印度科学院,班加罗尔
- 关键词:Diffusion Models, Debiasing, Distribution Guidance, Attribute Distribution Predictor, Fair Generation
- 链接:https://arxiv.org/abs/2402.18206
摘要: (1)研究背景:扩散模型(DM)作为强大的生成模型,在图像生成方面表现出色,但它们会反映训练数据集中的偏见,特别是对于人脸,DM 偏好某些人口统计学亚组(例如女性比男性)。 (2)过去方法:现有去偏方法需要额外数据或模型重新训练。 (3)研究方法:本文提出分布引导,通过强制生成图像遵循规定的属性分布来对 DM 进行去偏。通过训练属性分布预测器 (ADP) 来映射潜在特征到属性分布,ADP 使用现有属性分类器生成的伪标签进行训练。 (4)方法性能:该方法在无条件和文本条件扩散模型上减少了单一/多属性的偏差,并且优于基线方法。此外,本文还提出了一种通过使用生成数据重新平衡训练集来训练公平属性分类器的下游任务。
方法: (1): 提出分布引导方法,通过强制生成图像遵循规定的属性分布来对扩散模型(DM)进行去偏。 (2): 训练属性分布预测器(ADP)来映射潜在特征到属性分布,ADP使用现有属性分类器生成的伪标签进行训练。 (3): 在无条件和文本条件扩散模型上评估该方法,减少了单一/多属性的偏差,并优于基线方法。 (4): 提出了一种通过使用生成数据重新平衡训练集来训练公平属性分类器的下游任务。
结论: (1)本文的意义:本文提出了一种无需重新训练即可减轻预训练扩散模型偏差的方法,仅给定所需的参考属性分布。我们提出了一种新颖的方法,利用分布引导,联合引导一批图像遵循参考属性分布。所提出的方法是有效的,并且在 (2)创新点:本文的创新点在于提出了一种新的分布引导方法,通过强制生成图像遵循规定的属性分布来对扩散模型进行去偏。 性能:本文的方法在无条件和文本条件扩散模型上减少了单一/多属性的偏差,并且优于基线方法。 工作量:本文的方法需要训练一个属性分布预测器,该预测器使用现有属性分类器生成的伪标签进行训练。训练属性分布预测器的工作量取决于训练数据的规模和属性的数量。
点此查看论文截图



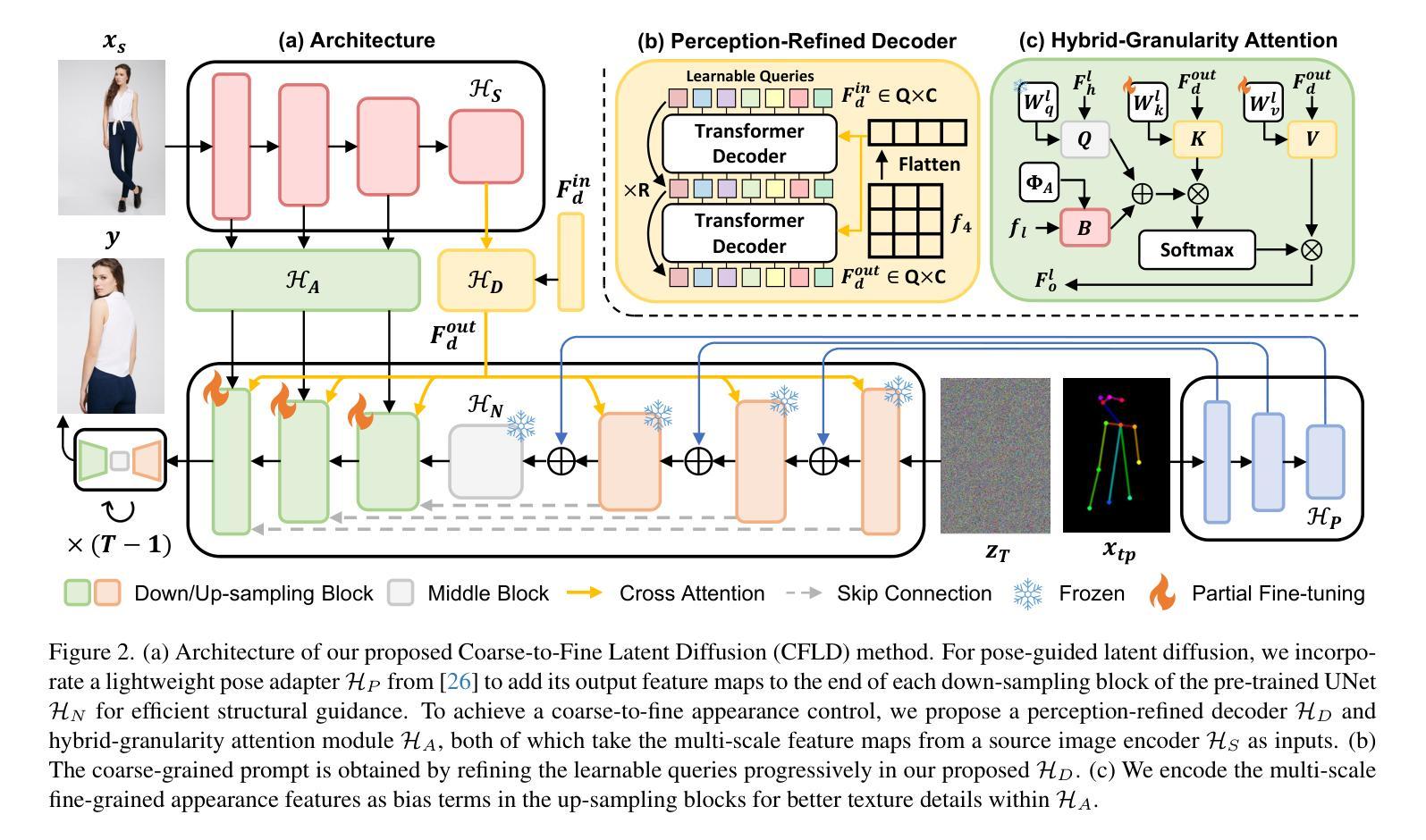
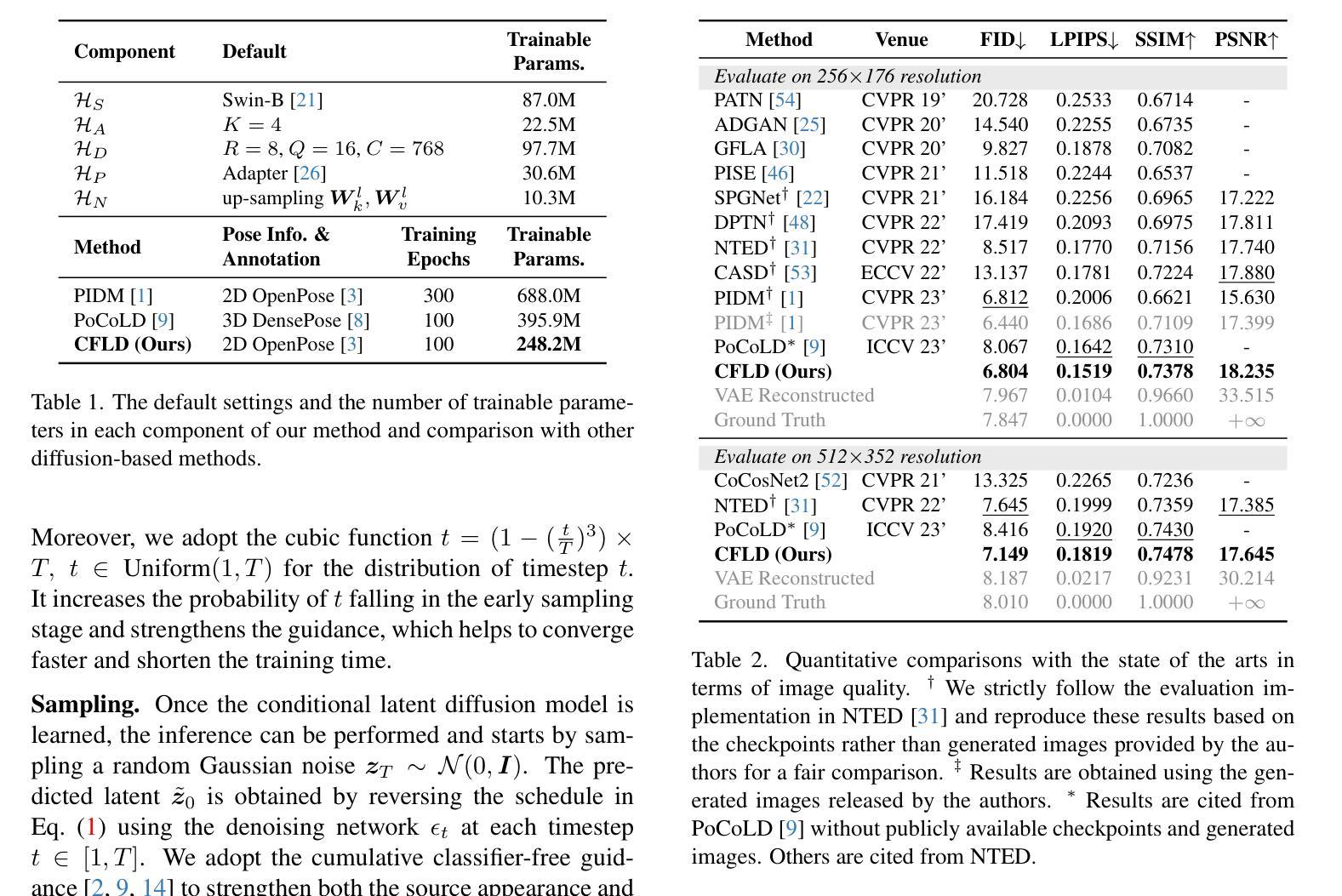
Coarse-to-Fine Latent Diffusion for Pose-Guided Person Image Synthesis
Authors:Yanzuo Lu, Manlin Zhang, Andy J Ma, Xiaohua Xie, Jian-Huang Lai
Diffusion model is a promising approach to image generation and has been employed for Pose-Guided Person Image Synthesis (PGPIS) with competitive performance. While existing methods simply align the person appearance to the target pose, they are prone to overfitting due to the lack of a high-level semantic understanding on the source person image. In this paper, we propose a novel Coarse-to-Fine Latent Diffusion (CFLD) method for PGPIS. In the absence of image-caption pairs and textual prompts, we develop a novel training paradigm purely based on images to control the generation process of the pre-trained text-to-image diffusion model. A perception-refined decoder is designed to progressively refine a set of learnable queries and extract semantic understanding of person images as a coarse-grained prompt. This allows for the decoupling of fine-grained appearance and pose information controls at different stages, and thus circumventing the potential overfitting problem. To generate more realistic texture details, a hybrid-granularity attention module is proposed to encode multi-scale fine-grained appearance features as bias terms to augment the coarse-grained prompt. Both quantitative and qualitative experimental results on the DeepFashion benchmark demonstrate the superiority of our method over the state of the arts for PGPIS. Code is available at https://github.com/YanzuoLu/CFLD.
PDF Accepted by CVPR 2024
Summary
提出了一种粗到细的潜在扩散(CFLD)方法,利用图像而非文本提示,控制预训练文本到图像扩散模型,实现姿势引导的图像合成。
Key Takeaways
- 提出 CFLD 方法,改善了 PGPIS 中姿势引导图像合成的效果。
- 使用纯图像训练范式,无需图像字幕或文本提示。
- 设计了一个感知精炼解码器,逐步优化查询并提取人物图像的语义理解。
- 将外貌和姿势信息控制解耦,避免过度拟合。
- 提出混合粒度注意力模块,对多尺度外观特征进行编码,增强粗粒度提示。
- 在 DeepFashion 数据集上,定量和定性实验结果证明了 CFLD 的优越性。
- 代码已开源。
- 题目:粗到细的潜在扩散用于姿态引导的人物图像合成
- 作者:Lu Yanzuo, Zhang Manlin, Ma Andy J, Xie Xiaohua, Lai Jianhuang
- 单位:中山大学计算机科学与工程学院
- 关键词:姿态引导、人物图像合成、潜在扩散模型、粗到细、语义理解
- 论文链接:https://arxiv.org/abs/2402.18078 Github 代码链接:https://github.com/YanzuoLu/CFLD
- 摘要: (1) 研究背景:姿态引导的人物图像合成旨在将源人物图像转换为特定的目标姿态,同时尽可能保留外观。它在电影制作、虚拟现实和时尚电子商务等领域有广泛的应用。 (2) 过去的方法:现有基于生成对抗网络 (GAN) 的方法容易出现极小极大训练目标的不稳定性和难以在一次前向传递中生成高质量图像的问题。作为 GAN 在图像生成中的一种有前途的替代方案,扩散模型通过一系列去噪步骤逐渐合成更逼真的图像。 (3) 本文方法:本文提出了一种新颖的粗到细潜在扩散 (CFLD) 方法用于姿态引导的人物图像合成。在没有图像-标题对和文本提示的情况下,我们开发了一种纯粹基于图像的新颖训练范式来控制预训练文本到图像扩散模型的生成过程。我们设计了一个感知精炼解码器来渐进地细化一组可学习查询并提取人物图像的语义理解作为粗粒度提示。这允许在不同的阶段解耦细粒度外观和姿态信息控制,从而规避了潜在的过拟合问题。为了生成更逼真的纹理细节,我们提出了一种混合粒度注意力模块,将多尺度细粒度外观特征编码为偏差项以增强粗粒度提示。 (4) 性能:在 DeepFashion 基准上的定量和定性实验结果证明了我们方法在姿态引导的人物图像合成任务上的优越性。这些性能支持了他们的目标,即生成具有更好泛化性能的高质量图像。
7.Methods: (1) 提出粗到细潜在扩散(CFLD)方法,用于姿态引导的人物图像合成; (2) 开发基于图像的新训练范式,控制预训练文本到图像扩散模型的生成过程; (3) 设计感知精炼解码器,渐进细化可学习查询,提取人物图像语义理解作为粗粒度提示; (4) 提出混合粒度注意力模块,将多尺度细粒度外观特征编码为偏差项,增强粗粒度提示; (5) 通过在DeepFashion基准上的定量和定性实验,验证了CFLD方法的优越性。
结论: (1)xxx; (2)创新点:xxx;性能:xxx;工作量:xxx;
总结: (1)本工作的重要意义是什么? (2)从创新点、性能、工作量三个维度总结本文的优缺点: 创新点:本文提出了一种新颖的粗到细潜在扩散(CFLD)方法,用于姿态引导的人物图像合成。该方法通过渐进细化可学习查询,提取人物图像的语义理解作为粗粒度提示,并提出混合粒度注意力模块,将多尺度细粒度外观特征编码为偏差项,增强粗粒度提示。 性能:在 DeepFashion 基准上的定量和定性实验结果证明了 CFLD 方法在姿态引导的人物图像合成任务上的优越性。这些性能支持了他们的目标,即生成具有更好泛化性能的高质量图像。 工作量:本文的工作量适中。该方法的实现需要对文本到图像扩散模型进行预训练,这可能需要大量的计算资源。此外,该方法需要设计感知精炼解码器和混合粒度注意力模块,这需要额外的开发和实验工作。
点此查看论文截图


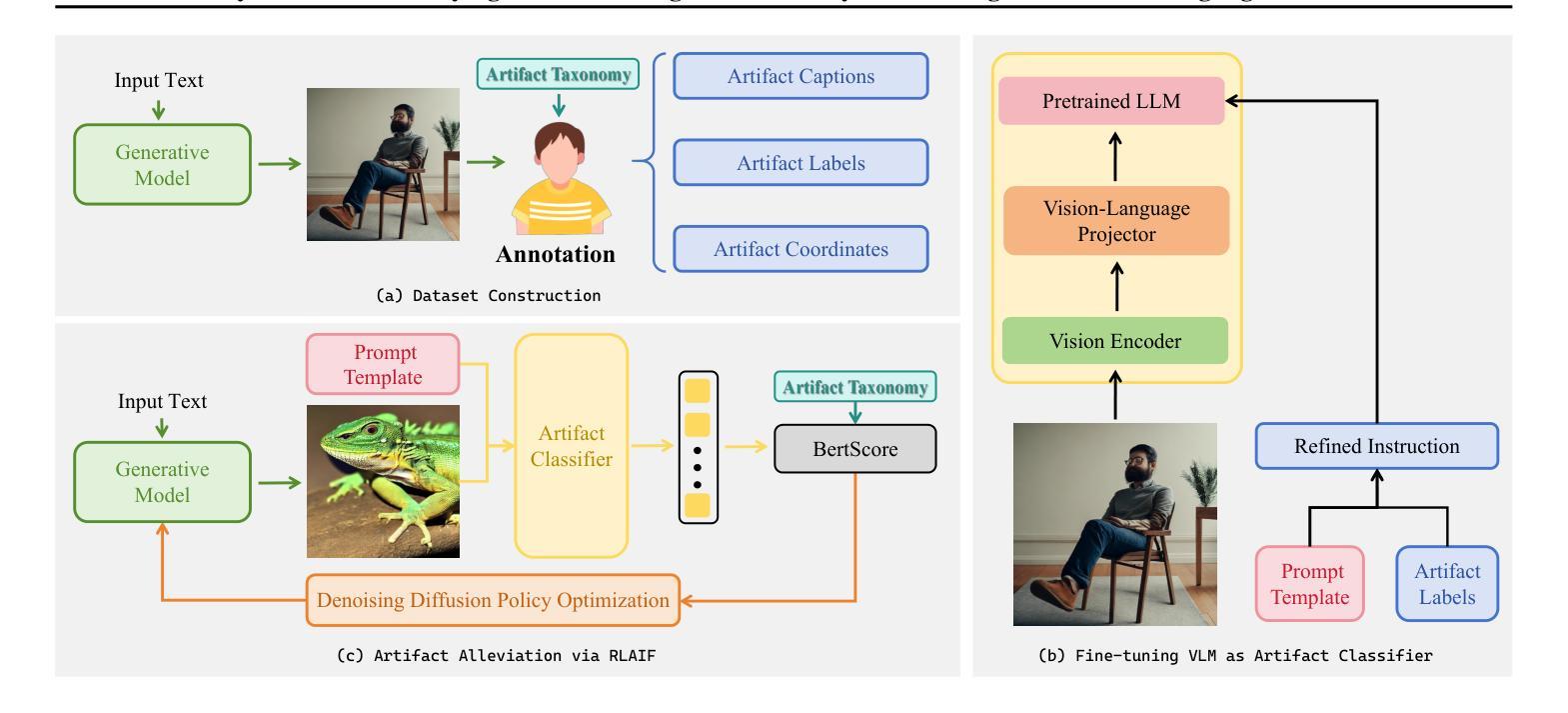
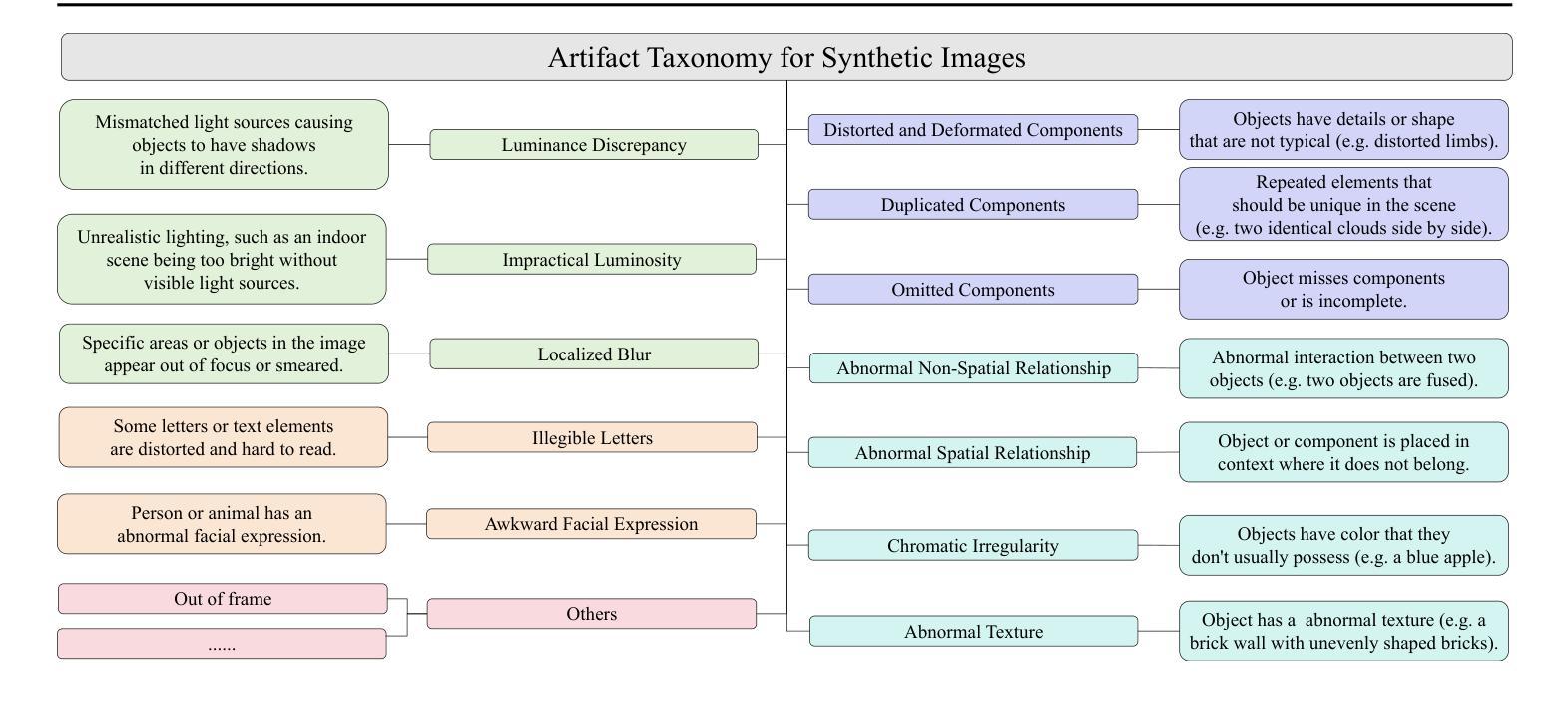
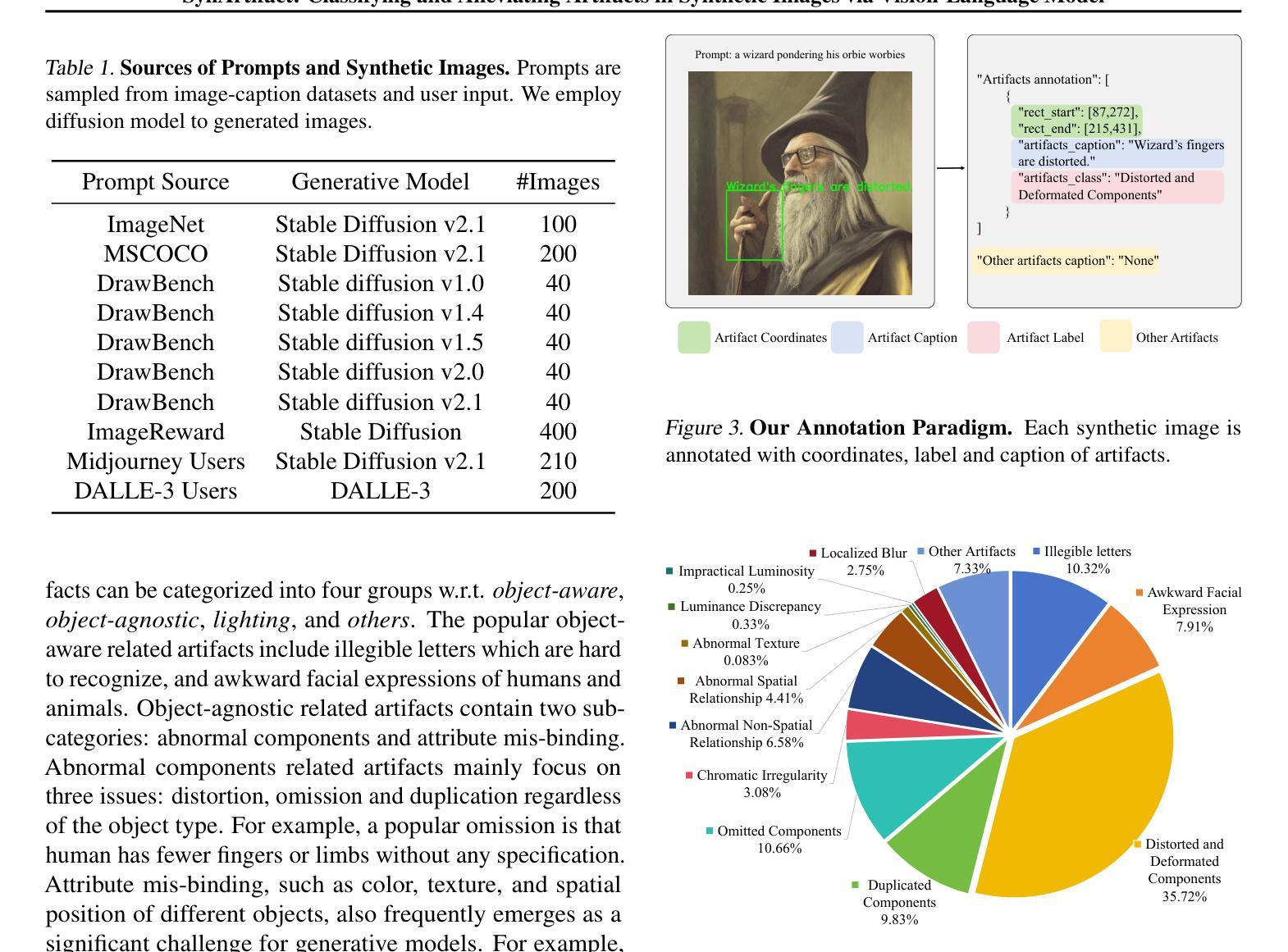
SynArtifact: Classifying and Alleviating Artifacts in Synthetic Images via Vision-Language Model
Authors:Bin Cao, Jianhao Yuan, Yexin Liu, Jian Li, Shuyang Sun, Jing Liu, Bo Zhao
In the rapidly evolving area of image synthesis, a serious challenge is the presence of complex artifacts that compromise perceptual realism of synthetic images. To alleviate artifacts and improve quality of synthetic images, we fine-tune Vision-Language Model (VLM) as artifact classifier to automatically identify and classify a wide range of artifacts and provide supervision for further optimizing generative models. Specifically, we develop a comprehensive artifact taxonomy and construct a dataset of synthetic images with artifact annotations for fine-tuning VLM, named SynArtifact-1K. The fine-tuned VLM exhibits superior ability of identifying artifacts and outperforms the baseline by 25.66%. To our knowledge, this is the first time such end-to-end artifact classification task and solution have been proposed. Finally, we leverage the output of VLM as feedback to refine the generative model for alleviating artifacts. Visualization results and user study demonstrate that the quality of images synthesized by the refined diffusion model has been obviously improved.
Summary
利用预训练的视觉语言模型对图像合成中的伪影进行自动分类,为生成模型的进一步优化提供监管,从而提高合成图像的质量。
Key Takeaways
- 合成图像中复杂伪影的存在构成了一项重大挑战,对感知真实性产生了负面影响。
- 研究人员提出将视觉语言模型(VLM)微调为伪影分类器,以便自动识别和分类各种伪影。
- 开发了一个全面的伪影分类体系,并构建了一个具有伪影注释的合成图像数据集(SynArtifact-1K)。
- 微调后的 VLM 在识别伪影方面表现出优异的能力,比基线高出 25.66%。
- 这是首次提出此类端到端伪影分类任务和解决方案。
- 利用 VLM 的输出作为反馈来优化生成模型,以减轻伪影。
- 视觉化结果和用户研究表明,优化后的扩散模型合成的图像质量得到了明显改善。
- 论文题目:SynArtifact:通过视觉语言模型对合成图像中的伪影进行分类和消除
- 作者:Bin Cao, Jianhao Yuan, Yexin Liu, Jian Li, Shuyang Sun, Jing Liu, Bo Zhao
- 第一作者单位:中国科学院自动化研究所
- 关键词:合成图像、伪影、视觉语言模型、生成模型
- 论文链接:https://arxiv.org/abs/2402.18068
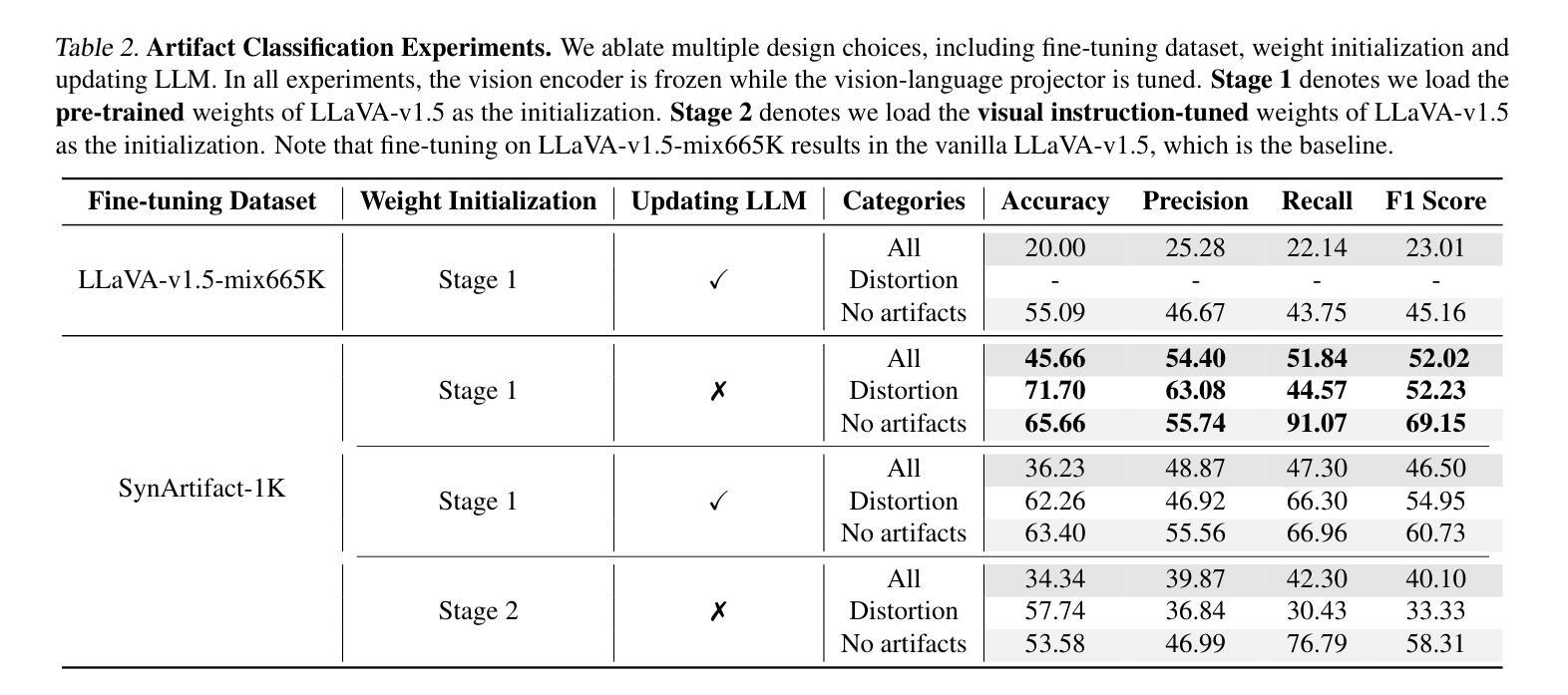
摘要: (1) 研究背景:合成图像中存在复杂伪影,影响图像的感知真实性。 (2) 过往方法:现有方法主要依赖单一评分指标优化生成模型,无法有效反映伪影的多样性和复杂性。 (3) 本文方法:提出一个综合伪影分类法,构建了一个带有伪影注释的合成图像数据集 SynArtifact-1K,并微调视觉语言模型 (VLM) 对伪影进行分类。利用 VLM 的输出作为 AI 反馈来改进生成模型,以减轻伪影。 (4) 实验结果:微调后的 VLM 在伪影分类任务上比基线方法提高了 25.66% 的准确率和 29.01% 的 F1 分数。通过利用伪影分类器的输出作为 AI 反馈,可以有效减轻生成模型中的伪影。
方法: (1)构建综合伪影分类法,建立包含伪影注释的合成图像数据集 SynArtifact-1K; (2)微调视觉语言模型 VLM,将其作为伪影分类器; (3)利用 VLM 输出作为 AI 反馈,计算生成模型输出与每种伪影之间的 BertScore,作为伪影分类奖励; (4)通过最大化伪影分类奖励,优化扩散模型,以减轻伪影。
结论: (1):本文针对合成图像中的伪影问题,提出了一个综合的伪影分类法,构建了包含伪影注释的合成图像数据集 SynArtifact-1K,并利用视觉语言模型对伪影进行分类,有效地减轻了生成模型中的伪影,提升了合成图像的感知真实性。 (2):创新点:
- 构建了包含 13 种常见伪影的综合伪影分类法。
- 创建了首个带有伪影类别、描述和坐标注释的图像数据集 SynArtifact-1K。
- 微调视觉语言模型用于自动分类伪影,并利用其输出作为 AI 反馈来优化生成模型。 性能:
- 微调后的视觉语言模型在伪影分类任务上比基线方法提高了 25.66% 的准确率和 29.01% 的 F1 分数。
- 利用伪影分类器的输出作为 AI 反馈,可以有效减轻生成模型中的伪影。 工作量:
- 构建了包含 1000 张合成图像的 SynArtifact-1K 数据集。
- 微调了视觉语言模型用于伪影分类。
- 通过最大化伪影分类奖励,优化了扩散模型以减轻伪影。
点此查看论文截图


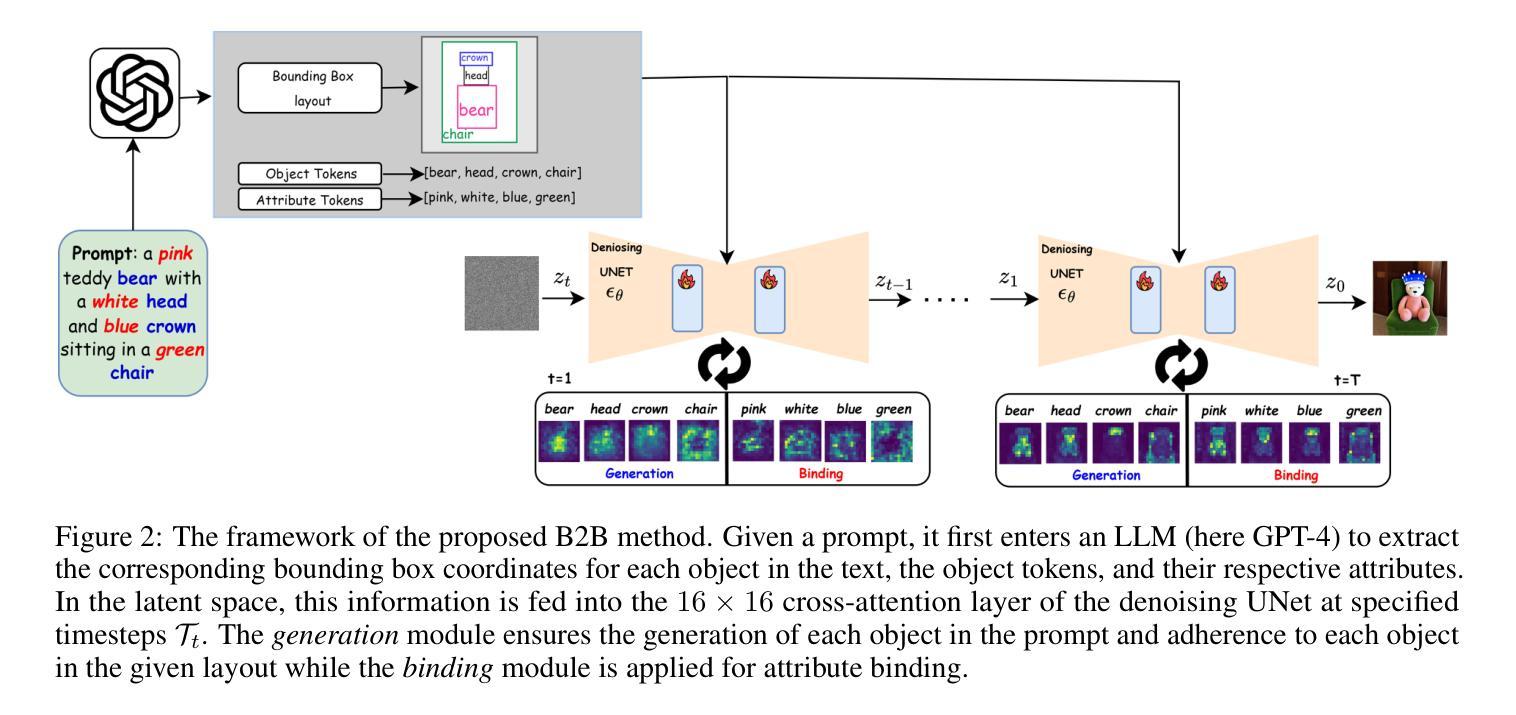
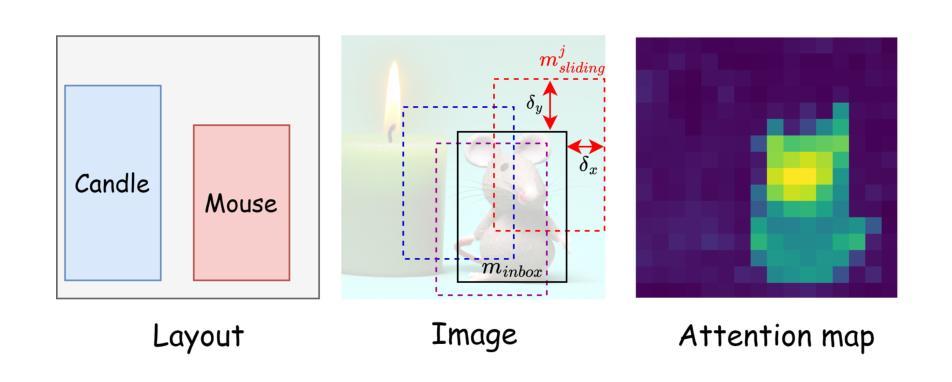
Box It to Bind It: Unified Layout Control and Attribute Binding in T2I Diffusion Models
Authors:Ashkan Taghipour, Morteza Ghahremani, Mohammed Bennamoun, Aref Miri Rekavandi, Hamid Laga, Farid Boussaid
While latent diffusion models (LDMs) excel at creating imaginative images, they often lack precision in semantic fidelity and spatial control over where objects are generated. To address these deficiencies, we introduce the Box-it-to-Bind-it (B2B) module - a novel, training-free approach for improving spatial control and semantic accuracy in text-to-image (T2I) diffusion models. B2B targets three key challenges in T2I: catastrophic neglect, attribute binding, and layout guidance. The process encompasses two main steps: i) Object generation, which adjusts the latent encoding to guarantee object generation and directs it within specified bounding boxes, and ii) attribute binding, guaranteeing that generated objects adhere to their specified attributes in the prompt. B2B is designed as a compatible plug-and-play module for existing T2I models, markedly enhancing model performance in addressing the key challenges. We evaluate our technique using the established CompBench and TIFA score benchmarks, demonstrating significant performance improvements compared to existing methods. The source code will be made publicly available at https://github.com/nextaistudio/BoxIt2BindIt.
Summary
Box-it-to-Bind-it(B2B)是一种无需训练的新模块,可提高文本到图像(T2I)扩散模型中图像的生成质量、语义准确度和空间控制能力。
Key Takeaways
- B2B 模块可改善 T2I 中的三个关键挑战:灾难性遗漏、属性绑定和布局指导。
- B2B 包括生成对象和属性绑定的两个主要步骤。
- B2B 可作为现有的 T2I 模型的即插即用模块,无需训练。
- B2B 在 CompBench 和 TIFA 评分基准上表现出显著的性能提升。
- B2B 的源代码将在 https://github.com/nextaistudio/BoxIt2BindIt 上公开。
- B2B 提高了 LDM 在生成图像时的空间控制和语义准确性。
- B2B 适用于不同的 T2I 模型,易于集成。
- 题目:Box-it-to-Bind-it:统一布局控制和属性绑定到 T2I 扩散模型中
- 作者:Ashkan Taghipour, Morteza Ghahremani, Mohammed Bennamoun, Aref Miri Rekavandi, Hamid Laga, Farid Boussaid
- 第一作者单位:西澳大利亚大学
- 关键词:文本到图像、扩散模型、空间控制、属性绑定、布局引导
- 论文链接:https://arxiv.org/abs/2402.17910
- 摘要: (1)研究背景: 现有扩散模型在生成图像时缺乏语义保真度和空间控制,难以忠实地遵循给定的提示,尤其是在对象属性和对象放置方面。
(2)过去的方法和问题: 现有方法要么从头开始训练模型,要么微调现有模型,但需要大量计算资源和时间。此外,利用预训练模型并集成特征的方法虽然不需要大量训练,但效果有限。
(3)提出的研究方法: 本文提出了一种免训练的方法 Box-it-to-Bind-it (B2B),解决文本到图像生成中的三个关键挑战:灾难性遗漏、属性绑定和布局引导。B2B 在推理阶段通过两步引导扩散模型的潜在编码:对象生成和属性绑定。
(4)方法在任务和性能上的表现: 在 CompBench 和 TIFA 得分基准上,与现有方法相比,B2B 在解决关键挑战方面显着提高了模型性能。这些性能提升支持了本文的目标,即提高文本到图像生成中的空间控制和语义准确性。
方法: (1) B2B是一种奖励引导扩散模型,它在推理阶段通过两步引导扩散模型的潜在编码:对象生成和属性绑定。 (2) 对象生成:基于IoU,增加对象生成概率,将注意力权重集中在给定边界框内,同时抑制边界框外的注意力权重。 (3) 属性绑定:使用KL散度测量属性概率分布与对应对象概率分布的差异,减少差异,将属性分布强制收敛到各自的对象。
- 结论: (1):本研究针对文本到图像生成中的关键挑战,特别是属性绑定和空间控制,提出了 B2B 模型。B2B 采用生成和绑定双模块系统,有效解决了灾难性遗漏、提高属性绑定精度和确保准确对象放置的问题。它作为现有 T2I 框架的即插即用模块的兼容性通过其在 CompBench 和 TIFA 基准中的出色表现得到证明,标志着生成建模的重大飞跃。B2B 的突破凸显了其作为未来研究潜在标准的作用,为数字成像和生成式 AI 的创新发展铺平了道路。 (2):创新点:
- 提出了一种免训练的方法 B2B,通过两步引导扩散模型的潜在编码来解决文本到图像生成中的关键挑战。
- 设计了对象生成和属性绑定两个模块,有效解决了灾难性遗漏、属性绑定和布局引导问题。
- B2B 作为现有 T2I 框架的即插即用模块,易于集成和使用。 性能:
- 在 CompBench 和 TIFA 基准上,与现有方法相比,B2B 在解决关键挑战方面显着提高了模型性能。
- 消融研究验证了对象生成和属性绑定奖励组件的有效性,表明 B2B 的各个组件对整体性能至关重要。 工作量:
- B2B 是一种免训练的方法,不需要从头开始训练模型或微调现有模型,从而节省了大量的计算资源和时间。
- B2B 易于集成到现有 T2I 框架中,无需进行复杂的修改或重新训练,降低了工作量。
点此查看论文截图


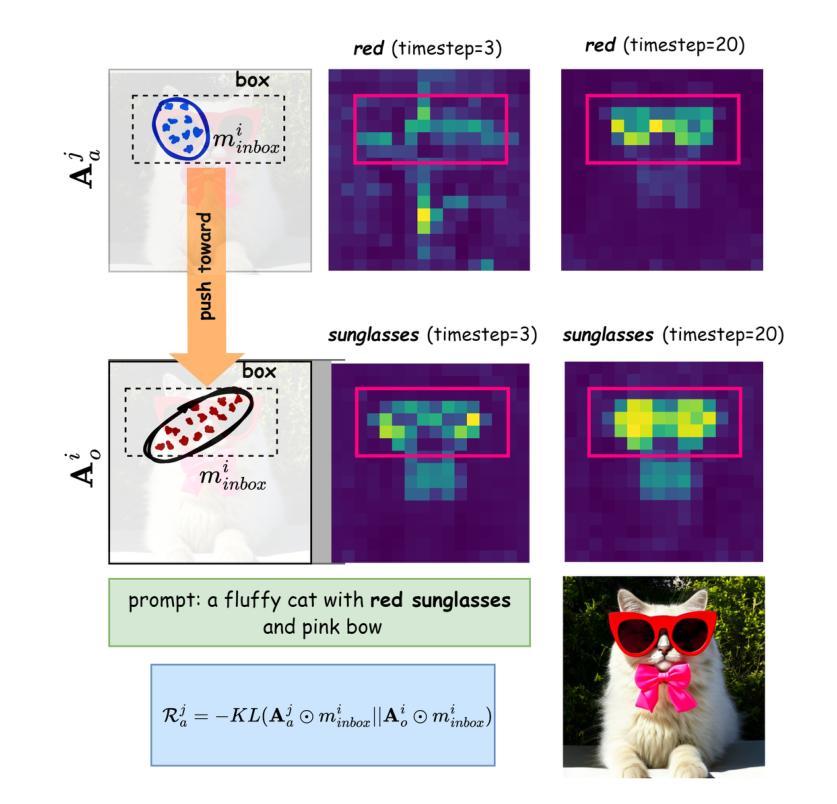
Structure-Guided Adversarial Training of Diffusion Models
Authors:Ling Yang, Haotian Qian, Zhilong Zhang, Jingwei Liu, Bin Cui
Diffusion models have demonstrated exceptional efficacy in various generative applications. While existing models focus on minimizing a weighted sum of denoising score matching losses for data distribution modeling, their training primarily emphasizes instance-level optimization, overlooking valuable structural information within each mini-batch, indicative of pair-wise relationships among samples. To address this limitation, we introduce Structure-guided Adversarial training of Diffusion Models (SADM). In this pioneering approach, we compel the model to learn manifold structures between samples in each training batch. To ensure the model captures authentic manifold structures in the data distribution, we advocate adversarial training of the diffusion generator against a novel structure discriminator in a minimax game, distinguishing real manifold structures from the generated ones. SADM substantially improves existing diffusion transformers (DiT) and outperforms existing methods in image generation and cross-domain fine-tuning tasks across 12 datasets, establishing a new state-of-the-art FID of 1.58 and 2.11 on ImageNet for class-conditional image generation at resolutions of 256x256 and 512x512, respectively.
PDF Accepted by CVPR 2024
Summary
扩散模型通过结构对抗训练,学习批内样本流形结构,提升图像生成和跨域微调任务的性能。
Key Takeaways
- 现有扩散模型专注于单个样本的去噪得分匹配损失优化,忽视批内样本之间的成对关系。
- 结构对抗训练 (SADM) 引入结构鉴别器来区分真实和生成的流形结构。
- SADM 迫使模型学习训练批次中样本之间的流形结构。
- SADM 与扩散变压器 (DiT) 相结合,在图像生成和跨域微调任务上优于现有方法。
- SADM 在 12 个数据集上实现了图像生成和跨域微调任务的最新 FID 分别为 1.58 和 2.11。
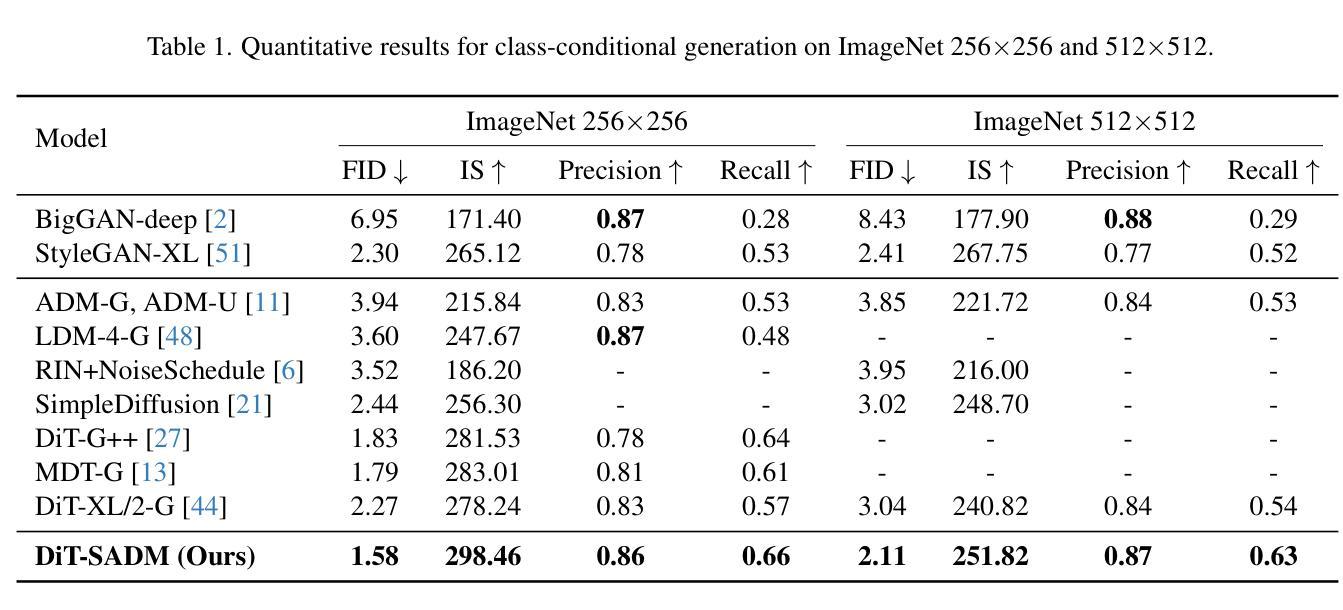
- SADM 在 256x256 和 512x512 分辨率下,在 ImageNet 上实现了类条件图像生成的最新 FID 分别为 1.58 和 2.11。
- SADM 证明了流形结构学习对于扩散模型在生成任务中的重要性。
- 题目:结构引导扩散模型对抗性训练
- 作者:杨凌、钱浩天、张智龙、刘景伟、崔斌
- 第一作者单位:北京大学
- 关键词:扩散模型、结构引导、对抗训练
- 论文链接:https://arxiv.org/abs/2402.17563 Github 链接:无
- 摘要: (1)研究背景: 扩散模型在生成任务中表现出色,但现有方法主要关注最小化去噪得分匹配损失的加权和,训练过程侧重于实例级优化,忽略了小批量样本之间的宝贵结构信息。
(2)过去的方法及其问题: 现有方法主要集中在实例级优化,忽略了小批量样本之间的结构信息,导致无法充分建模数据分布。
(3)提出的研究方法: 提出结构引导扩散模型对抗性训练(SADM),通过对抗训练指导扩散生成器学习小批量样本之间的流形结构。引入结构判别器来区分真实流形结构和生成流形结构,确保模型捕获数据分布中的真实流形结构。
(4)方法在任务和性能上的表现: SADM 显著提升了现有扩散 Transformer,在 12 个数据集上的图像生成和跨域微调任务中优于现有方法,在 ImageNet 上分别以 256×256 和 512×512 的分辨率实现了 1.58 和 2.11 的新 SOTA FID,验证了方法的有效性。
7.Methods: (1)提出结构引导扩散模型对抗性训练(SADM),通过对抗训练指导扩散生成器学习小批量样本之间的流形结构; (2)引入结构判别器来区分真实流形结构和生成流形结构,确保模型捕获数据分布中的真实流形结构; (3)采用Wasserstein GAN损失函数,指导生成器生成与真实流形结构相似的样本; (4)在训练过程中交替更新生成器和判别器,直至达到纳什均衡; (5)将SADM与扩散Transformer相结合,形成更强大的图像生成模型。
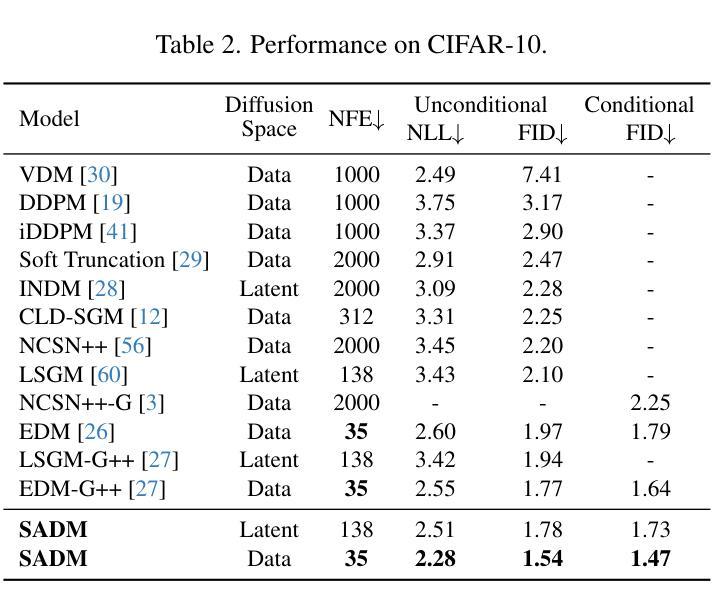
- 总结 (1): 本文提出了从结构角度优化扩散模型的结构引导对抗性训练方法,该训练算法可以轻松推广到图像和潜在扩散模型,并通过理论推导和实验结果一致地改进了现有的扩散模型。我们在 12 个图像数据集上的图像生成和跨域微调任务中取得了新的 SOTA 性能。对于未来的工作,我们将把我们的方法扩展到更具挑战性的基于扩散的应用程序(例如,文本到图像/视频生成)。 (2): 创新点: 提出结构引导对抗性训练方法,通过对抗训练指导扩散生成器学习小批量样本之间的流形结构,从而提升扩散模型的生成质量。 性能: 在 12 个图像数据集上的图像生成和跨域微调任务中取得了新的 SOTA 性能,在 ImageNet 上分别以 256×256 和 512×512 的分辨率实现了 1.58 和 2.11 的新 SOTAFID。 工作量: 该方法易于实现,可以轻松推广到图像和潜在扩散模型,工作量较小。
点此查看论文截图


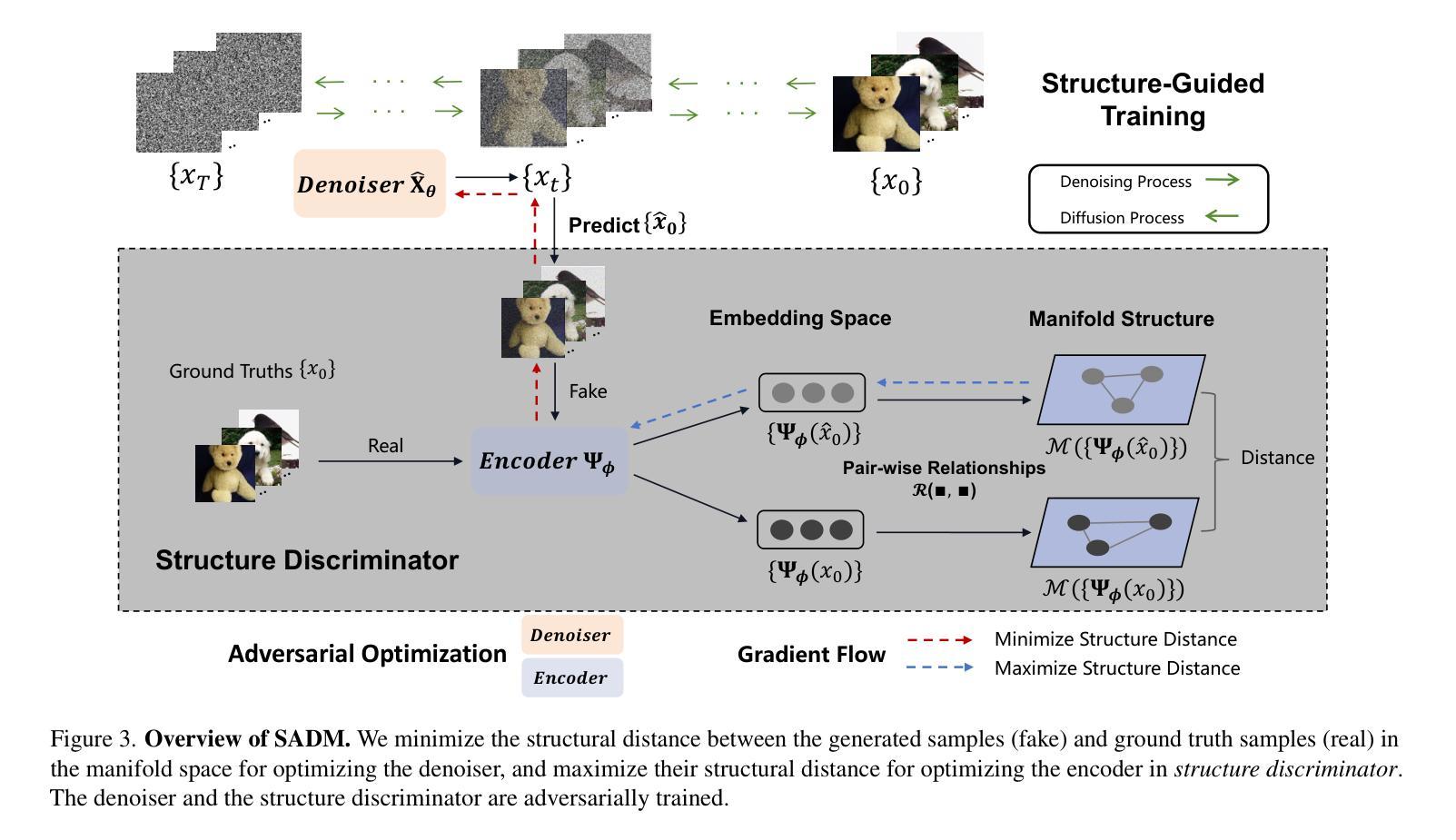
Diffusion Model-Based Image Editing: A Survey
Authors:Yi Huang, Jiancheng Huang, Yifan Liu, Mingfu Yan, Jiaxi Lv, Jianzhuang Liu, Wei Xiong, He Zhang, Shifeng Chen, Liangliang Cao
Denoising diffusion models have emerged as a powerful tool for various image generation and editing tasks, facilitating the synthesis of visual content in an unconditional or input-conditional manner. The core idea behind them is learning to reverse the process of gradually adding noise to images, allowing them to generate high-quality samples from a complex distribution. In this survey, we provide an exhaustive overview of existing methods using diffusion models for image editing, covering both theoretical and practical aspects in the field. We delve into a thorough analysis and categorization of these works from multiple perspectives, including learning strategies, user-input conditions, and the array of specific editing tasks that can be accomplished. In addition, we pay special attention to image inpainting and outpainting, and explore both earlier traditional context-driven and current multimodal conditional methods, offering a comprehensive analysis of their methodologies. To further evaluate the performance of text-guided image editing algorithms, we propose a systematic benchmark, EditEval, featuring an innovative metric, LMM Score. Finally, we address current limitations and envision some potential directions for future research. The accompanying repository is released at https://github.com/SiatMMLab/Awesome-Diffusion-Model-Based-Image-Editing-Methods.
Summary
扩散模型在图像生成和编辑任务中应用广泛,可从复杂分布中生成高质量样本,且支持无条件和输入条件下的图像编辑。
Key Takeaways
- 扩散模型通过学习逆转图像加噪过程,生成高质量样本。
- 扩散模型图像编辑方法可分为不同学习策略、用户输入条件和编辑任务。
- 图像修复和外延可使用传统上下文驱动方法或多模态条件方法。
- 提出 EditEval 基准和 LMM 评分用于评估文本指导图像编辑算法。
- 目前存在限制,未来研究方向包括多模态、3D 和编辑元数据。
- 可在 https://github.com/SiatMMLab/Awesome-Diffusion-Model-Based-Image-Editing-Methods 获取相关代码。
- 标题:基于扩散模型的图像编辑:综述
- 作者:Yi Huang、Jiancheng Huang、Yifan Liu、Mingfu Yan、Jiaxi Lv、Jianzhuang Liu、Wei Xiong、He Zhang、Shifeng Chen、Liangliang Cao
- 单位:深圳先进技术研究院
- 关键词:Diffusion Model、Image Editing、AIGC
- 链接:https://arxiv.org/abs/2402.17525 Github:无
- 摘要: (1):随着人工智能(AI)技术的发展,AI 生成的内容(AIGC)领域蓬勃发展,图像编辑作为其中一项重要任务,在数字媒体、广告和科学研究等领域有着广泛的应用。 (2):基于扩散模型的图像编辑方法近年来取得了显著进展,该方法通过学习逐步给图像添加噪声并逆转这一过程,可以从复杂分布中生成高质量的样本。 (3):本文对基于扩散模型的图像编辑方法进行了全面的综述,从学习策略、用户输入条件和具体编辑任务等多个角度对现有工作进行了深入分析和分类。 (4):基于扩散模型的图像编辑方法在图像修复、图像外延等任务上取得了很好的效果,本文还提出了一个系统性的基准 EditEval 和一个创新的指标 LMMScore 来进一步评估文本引导图像编辑算法的性能。
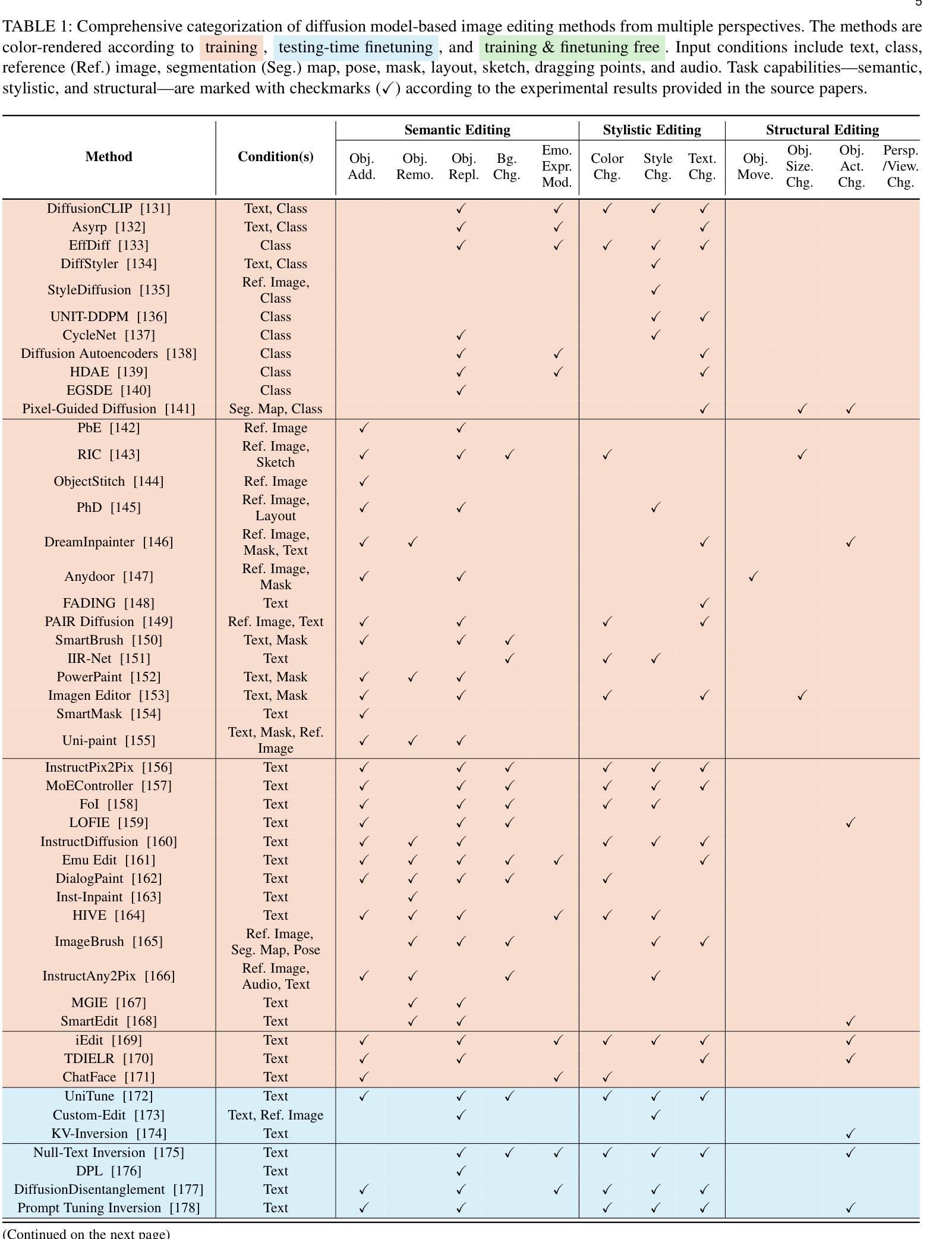
7.Methods: (1): 基于CLIP指导的图像编辑:DiffusionCLIP、Asyrp、EffDiff、DiffStyler、StyleDiffusion、UNIT-DDPM、CycleNet、DiffusionAutoencoders、HDAE、EGSDE、Pixel-GuidedDiffusion; (2): 基于参考和属性指导的图像编辑:PbE、RIC、ObjectStitch、PhD、DreamInpainter、Anydoor、FADING、PAIRDiffusion、SmartBrush、IIR-Net; (3): 基于指令指导的图像编辑:InstructPix2Pix、MoEController、FoI、LOFIE、InstructDiffusion、EmuEdit、DialogPaint、Inst-Inpaint、HIVE、ImageBrush、InstructAny2Pix、MGIE、SmartEdit。
- 结论: (1)本工作对基于扩散模型的图像编辑方法进行了全面的综述,从多个角度对现有工作进行了深入分析和分类,并提出了一个系统性的基准 EditEval 和一个创新的指标 LMMScore 来进一步评估文本引导图像编辑算法的性能。 (2)创新点:
- 提出了一种新的图像编辑基准 EditEval 和一个创新的指标 LMMScore,用于评估文本引导图像编辑算法的性能。
- 对基于扩散模型的图像编辑方法进行了全面的综述和分类,从学习策略、用户输入条件和具体编辑任务等多个角度对现有工作进行了深入分析。
- 探索了这些方法在增强编辑性能方面的贡献。
- 在我们的图像编辑基准 EditEval 中对 7 项任务进行了评估,以及最新最先进的方法。
- 总结了图像编辑领域的广泛潜力,并提出了未来研究的方向。
- 性能:在 EditEval 基准上,基于扩散模型的图像编辑方法在图像修复、图像外延等任务上取得了很好的效果。
- 工作量:本文对超过 100 种基于扩散模型的图像编辑方法进行了综述和分类,并对 7 项任务进行了评估,工作量较大。
点此查看论文截图

Enhancing Hyperspectral Images via Diffusion Model and Group-Autoencoder Super-resolution Network
Authors:Zhaoyang Wang, Dongyang Li, Mingyang Zhang, Hao Luo, Maoguo Gong
Existing hyperspectral image (HSI) super-resolution (SR) methods struggle to effectively capture the complex spectral-spatial relationships and low-level details, while diffusion models represent a promising generative model known for their exceptional performance in modeling complex relations and learning high and low-level visual features. The direct application of diffusion models to HSI SR is hampered by challenges such as difficulties in model convergence and protracted inference time. In this work, we introduce a novel Group-Autoencoder (GAE) framework that synergistically combines with the diffusion model to construct a highly effective HSI SR model (DMGASR). Our proposed GAE framework encodes high-dimensional HSI data into low-dimensional latent space where the diffusion model works, thereby alleviating the difficulty of training the diffusion model while maintaining band correlation and considerably reducing inference time. Experimental results on both natural and remote sensing hyperspectral datasets demonstrate that the proposed method is superior to other state-of-the-art methods both visually and metrically.
PDF Accepted by AAAI2024
Summary
扩散模型与群组自编码器相结合的创新框架,有效提升高光谱图像超分辨率,显著改善谱空关系建模和低层细节恢复。
Key Takeaways
- 扩散模型擅长建模复杂关系和学习视觉特征,在高光谱图像超分辨率中潜力巨大。
- 训练扩散模型面临收敛困难和推理时间长挑战。
- 群组自编码器框架通过将高维高光谱数据编码到低维潜在空间,缓解了扩散模型训练难度,并保持了波段相关性。
- 扩散模型与群组自编码器相结合,有效解决了推理时间问题。
- 在自然和遥感高光谱数据集上,该方法在视觉和度量上均优于现有技术。
- 标题:基于扩散模型和组自编码器的超分辨率高光谱图像增强
- 作者:王兆阳,李东阳,张明阳,罗浩,巩茂国
- 隶属单位:西安电子科技大学协同智能系统教育部重点实验室
- 关键词:高光谱图像,超分辨率,扩散模型,组自编码器
- 论文链接:https://arxiv.org/abs/2402.17285
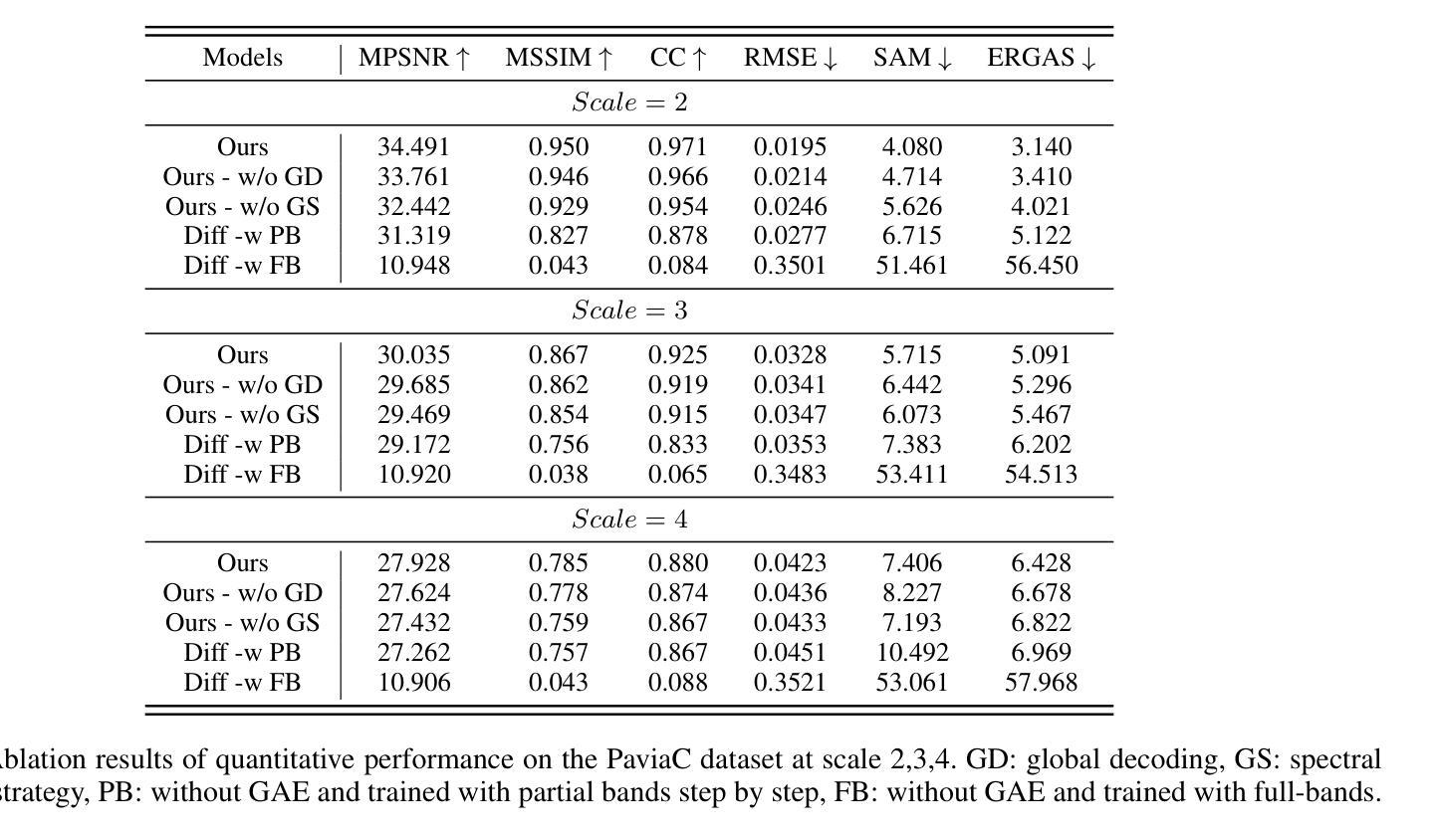
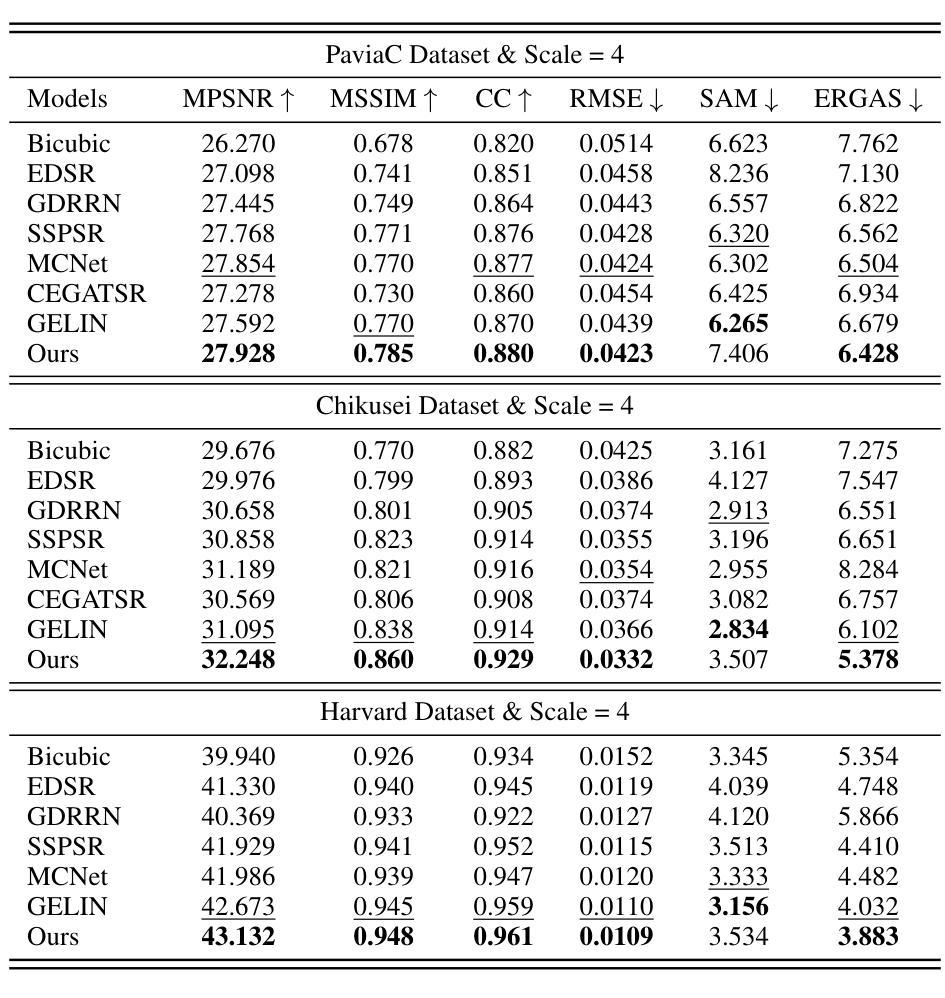
摘要: (1)研究背景:现有高光谱图像超分辨率方法难以有效捕捉复杂的光谱-空间关系和低级细节,而扩散模型是一种有前途的生成模型,以其在建模复杂关系和学习高低级视觉特征方面的出色性能而闻名。 (2)过去方法及问题:将扩散模型直接应用于高光谱图像超分辨率面临着模型收敛困难和推理时间长的挑战。 (3)研究方法:提出了一种新的组自编码器(GAE)框架,该框架与扩散模型协同结合,构建了一个高效的高光谱图像超分辨率模型(DMGASR)。提出的 GAE 框架将高维高光谱数据编码为低维潜在空间,扩散模型在此空间中工作,从而缓解了训练扩散模型的难度,同时保持了波段相关性并大大减少了推理时间。 (4)任务和性能:在自然和遥感高光谱数据集上的实验结果表明,所提出的方法在视觉和度量上都优于其他最先进的方法。
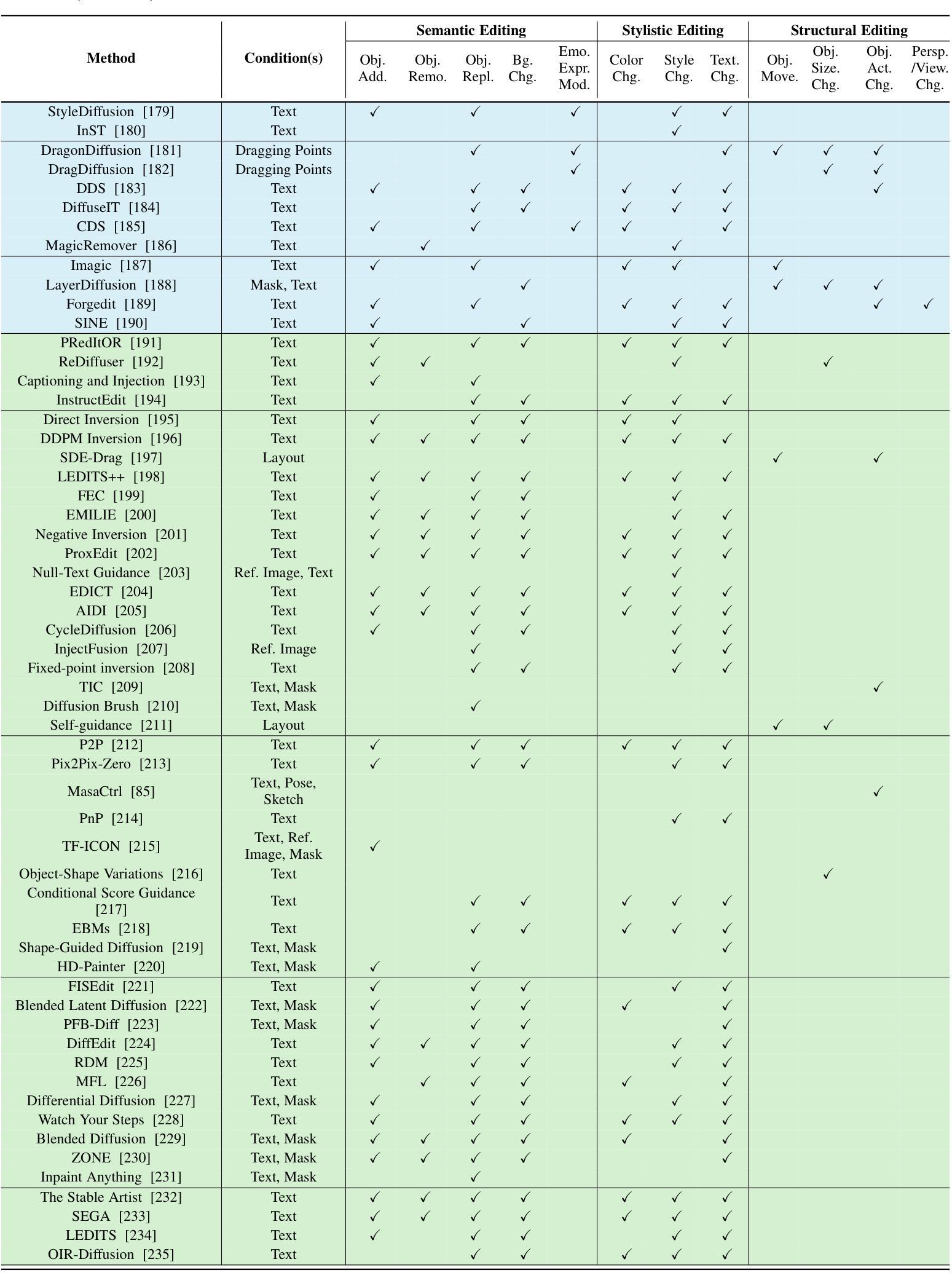
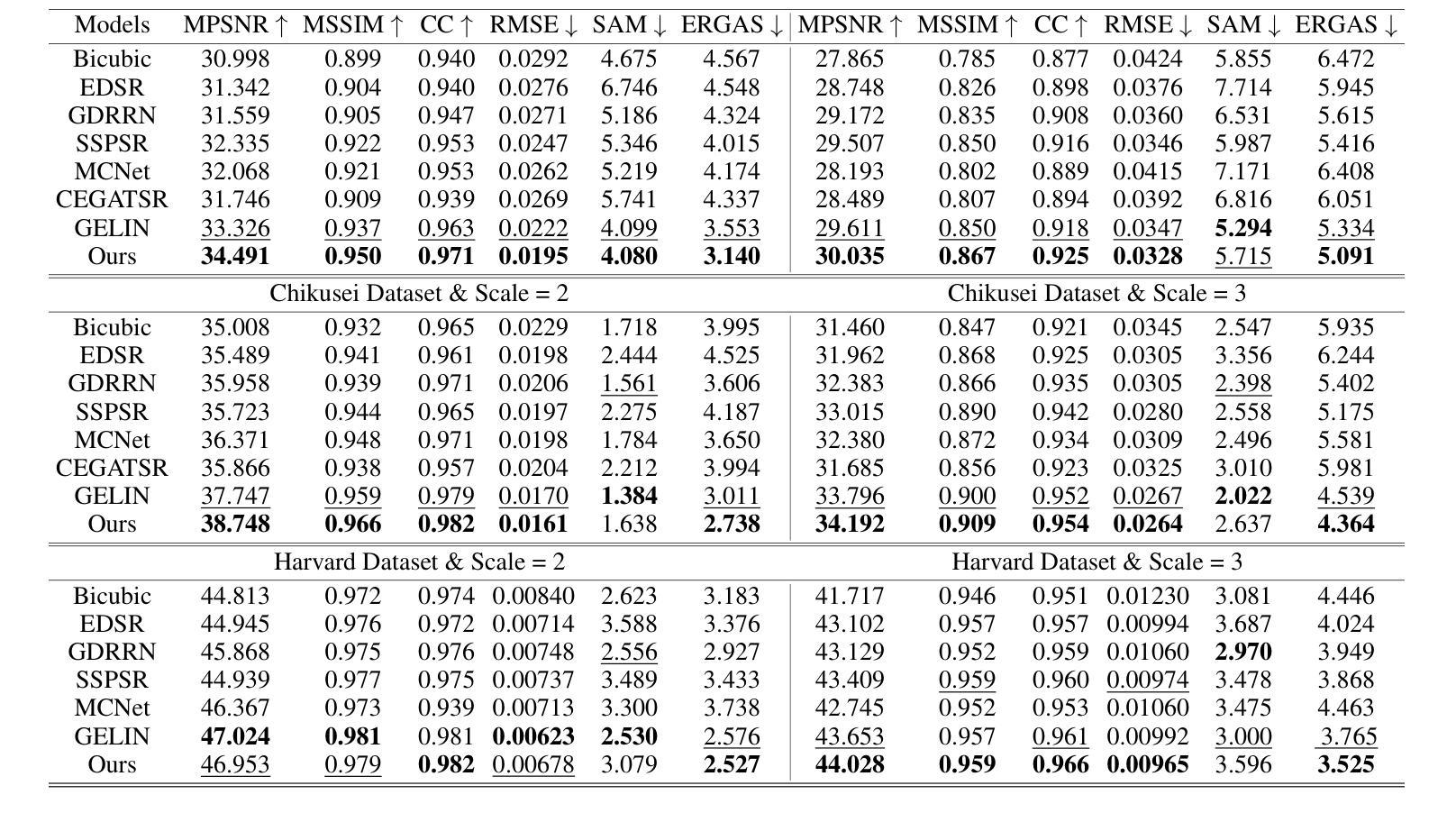
方法: (1): 提出了一种基于扩散模型和组自编码器的超分辨率高光谱图像增强模型(DMGASR); (2): 该模型采用两阶段训练方式,包括自动编码器和扩散超分辨率模型; (3): 采用谱分组策略和非对称解码器设计,有效地将高维高光谱数据编码为低维潜在空间; (4): 训练扩散模型在潜在空间中工作,缓解了训练扩散模型的难度,同时保持了波段相关性并大大减少了推理时间; (5): 训练自动编码器重构输入数据,生成一系列隐藏变量; (6): 将低分辨率隐藏变量作为条件信息,与高分辨率隐藏变量串联,在去噪过程中加入到扩散模型中; (7): 采用 U-Net 作为去噪模型,迭代去除噪声,生成超分辨率潜在变量列表; (8): 将超分辨率潜在变量列表传递给解码器,生成超分辨率图像。
结论: (1):本文提出了一种基于扩散模型和组自编码器的高光谱图像超分辨率增强模型(DMGASR),该模型将扩散模型与自动编码器相结合,有效解决了扩散模型在高维数据上收敛困难的问题,并通过在低维潜在空间中训练扩散模型,大大减少了推理时间。该方法在自然和遥感高光谱数据集上均取得了优异的性能,在视觉和度量上均优于其他最先进的方法。 (2):创新点:
- 提出了一种基于扩散模型和组自编码器的超分辨率高光谱图像增强模型(DMGASR)。
- 采用两阶段训练方式,包括自动编码器和扩散超分辨率模型。
- 采用谱分组策略和非对称解码器设计,有效地将高维高光谱数据编码为低维潜在空间。
- 训练扩散模型在潜在空间中工作,缓解了训练扩散模型的难度,同时保持了波段相关性并大大减少了推理时间。 性能:
- 在自然和遥感高光谱数据集上均取得了优异的性能。
- 在视觉和度量上均优于其他最先进的方法。 工作量:
- 算法设计和实现。
- 数据集的收集和预处理。
- 实验的进行和结果分析。
点此查看论文截图

One-Shot Structure-Aware Stylized Image Synthesis
Authors:Hansam Cho, Jonghyun Lee, Seunggyu Chang, Yonghyun Jeong
While GAN-based models have been successful in image stylization tasks, they often struggle with structure preservation while stylizing a wide range of input images. Recently, diffusion models have been adopted for image stylization but still lack the capability to maintain the original quality of input images. Building on this, we propose OSASIS: a novel one-shot stylization method that is robust in structure preservation. We show that OSASIS is able to effectively disentangle the semantics from the structure of an image, allowing it to control the level of content and style implemented to a given input. We apply OSASIS to various experimental settings, including stylization with out-of-domain reference images and stylization with text-driven manipulation. Results show that OSASIS outperforms other stylization methods, especially for input images that were rarely encountered during training, providing a promising solution to stylization via diffusion models.
PDF CVPR 2024
Summary
基于扩散模型的 OSASIS 实现了图像风格化,同时保持了结构完整性,即使是对训练中很少遇到的输入图像。
Key Takeaways
- OSASIS 采用扩散模型进行图像风格化,解决了 GAN 模型在保持结构方面的不足。
- OSASIS 能够有效分离图像语义和结构,可控地调整给定输入的内容和风格级别。
- OSASIS 在各种实验设置中表现出色,包括使用域外参考图像进行风格化和使用文本驱动的操作进行风格化。
- 与其他风格化方法相比,OSASIS 在训练中很少遇到的输入图像上表现得尤为出色,为通过扩散模型进行风格化提供了有前景的解决方案。
- OSASIS 采用了渐进式训练策略,通过从添加噪声到恢复图像,逐步将风格应用于输入。
- OSASIS 使用预训练的扩散模型,提高了效率和泛化性。
- OSASIS 在图像风格化领域展现出了广泛的应用前景,包括图像编辑、艺术创作和视频处理。
- 标题:单次结构感知风格化图像合成
- 作者:Jongmin Lee*, Jaeyeon Kang, Sangwoo Mo, Seongwon Lee†, Kyoung Mu Lee†
- 隶属单位:NAVER Cloud
- 关键词:图像风格化、扩散模型、结构保持
- 论文链接:https://arxiv.org/abs/2302.05447, Github 代码链接:无
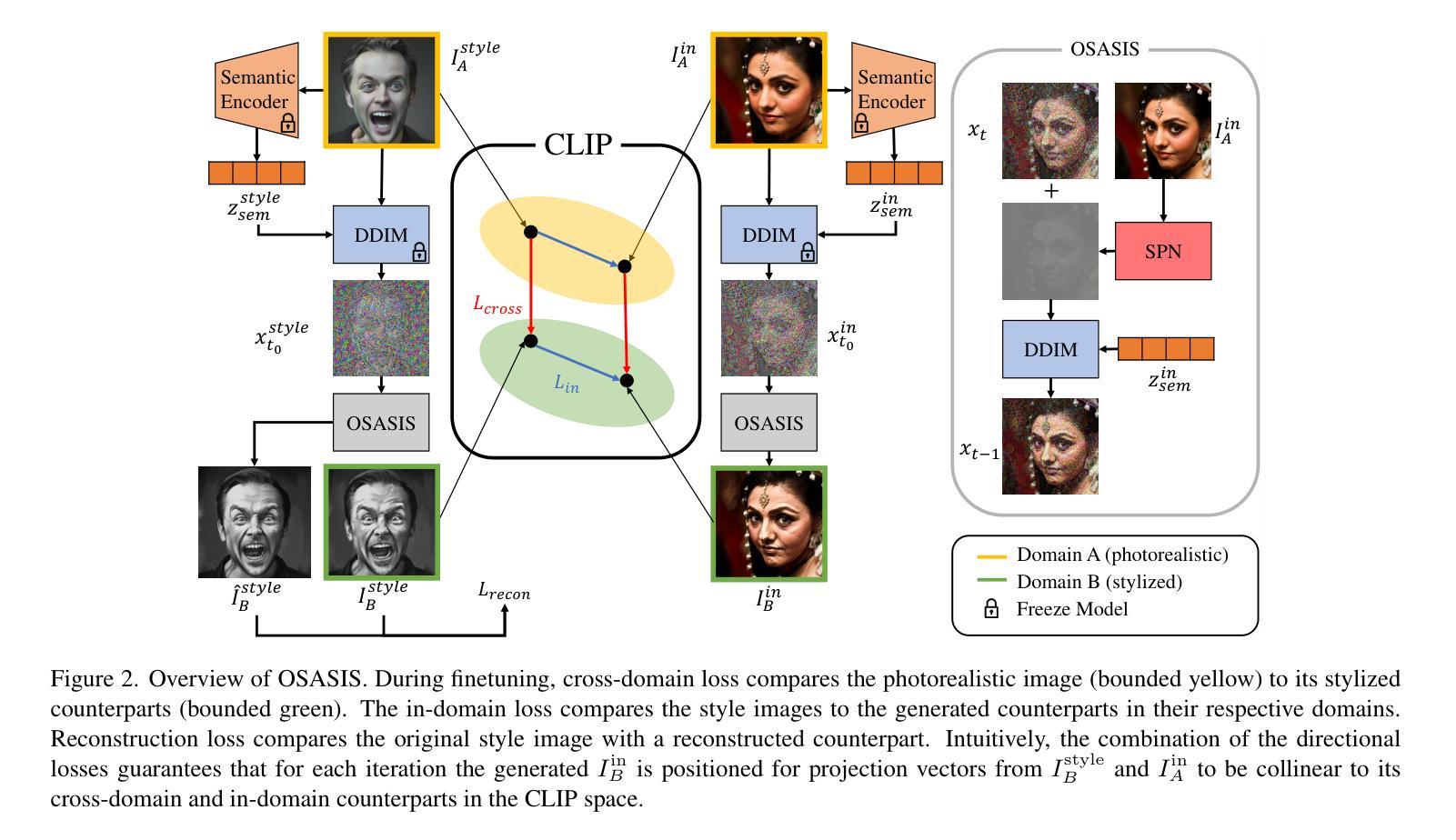
- 摘要: (1) 研究背景:GAN 模型在图像风格化任务中取得成功,但难以在风格化各种输入图像时保持结构。最近,扩散模型被用于图像风格化,但仍缺乏保持输入图像原始质量的能力。 (2) 过去方法及问题:过去方法包括基于 GAN 的模型和基于扩散模型的方法。GAN 模型难以保持结构,而基于扩散模型的方法缺乏控制内容和风格的能力。 (3) 本文提出的研究方法:本文提出了一种新的单次风格化方法 OSASIS,该方法在结构保持方面具有鲁棒性。OSASIS 通过将语义从图像的结构中解耦,从而有效地控制应用于给定输入的内容和风格的级别。 (4) 任务和性能:OSASIS 在各种实验设置中得到应用,包括使用域外参考图像的风格化和使用文本驱动的操作的风格化。结果表明,OSASIS 优于其他风格化方法,特别是对于在训练期间很少遇到的输入图像,为通过扩散模型进行风格化提供了一种有前景的解决方案。
Methods:
- 图像分解:将输入图像分解为内容和结构特征,其中内容特征表示图像的语义信息,而结构特征表示图像的几何形状和纹理。
- 风格嵌入:将参考风格图像嵌入到一个潜在空间中,该空间由扩散模型训练。
- 风格传输:将输入图像的内容特征与参考风格的风格嵌入相结合,生成一个新的图像,该图像具有输入图像的结构和参考风格的风格。
结构保持:通过使用一个额外的损失函数,将输入图像的结构特征与生成图像的结构特征进行匹配,从而保持输入图像的原始质量。
结论: (1): 本工作提出了一种基于扩散模型的新型单次图像风格化方法 OSASIS,该方法在结构保持方面具有鲁棒性。与基于 GAN 和其他基于扩散的风格化方法相比,OSASIS 展示了在风格化中对结构的强大感知,有效地将图像的结构和语义解耦。尽管 OSASIS 在结构感知风格化方面取得了重大进展,但仍存在一些局限性。OSASIS 的一个显着限制是其训练时间,比比较方法更长。这种延长的训练持续时间是为了换取该方法增强了保持结构完整性和适应各种风格的能力。此外,OSASIS 需要针对每张风格图像进行训练。在需要跨多种风格快速部署的场景中,这一要求可以被视为一种限制。尽管存在这些挑战,但 OSASIS 在保持输入图像结构完整性方面的稳健性、其在域外参考风格化中的有效性以及其在文本驱动操作中的适应性使其成为风格化图像合成领域中一种很有前景的方法。未来的工作将解决这些限制,特别是在优化训练效率和减少对单个风格图像训练的必要性方面,以增强 OSASIS 在各种实际场景中的实用性和适用性。 (2): 创新点:
- 提出了一种新的图像风格化方法 OSASIS,该方法基于扩散模型,在结构保持方面具有鲁棒性。
- OSASIS 通过将图像的结构和语义解耦,有效地控制应用于给定输入的内容和风格的级别。
- OSASIS 在各种实验设置中得到应用,包括使用域外参考图像的风格化和使用文本驱动的操作的风格化。 性能:
- OSASIS 在结构保持方面优于其他风格化方法,特别是对于在训练期间很少遇到的输入图像。
- OSASIS 为通过扩散模型进行风格化提供了一种有前景的解决方案。 工作量:
- OSASIS 的训练时间比比较方法更长。
- OSASIS 需要针对每张风格图像进行训练。
点此查看论文截图



Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation
Authors:Daiqing Li, Aleks Kamko, Ehsan Akhgari, Ali Sabet, Linmiao Xu, Suhail Doshi
In this work, we share three insights for achieving state-of-the-art aesthetic quality in text-to-image generative models. We focus on three critical aspects for model improvement: enhancing color and contrast, improving generation across multiple aspect ratios, and improving human-centric fine details. First, we delve into the significance of the noise schedule in training a diffusion model, demonstrating its profound impact on realism and visual fidelity. Second, we address the challenge of accommodating various aspect ratios in image generation, emphasizing the importance of preparing a balanced bucketed dataset. Lastly, we investigate the crucial role of aligning model outputs with human preferences, ensuring that generated images resonate with human perceptual expectations. Through extensive analysis and experiments, Playground v2.5 demonstrates state-of-the-art performance in terms of aesthetic quality under various conditions and aspect ratios, outperforming both widely-used open-source models like SDXL and Playground v2, and closed-source commercial systems such as DALLE 3 and Midjourney v5.2. Our model is open-source, and we hope the development of Playground v2.5 provides valuable guidelines for researchers aiming to elevate the aesthetic quality of diffusion-based image generation models.
PDF Model weights: https://huggingface.co/playgroundai/playground-v2.5-1024px-aesthetic
Summary
通过对噪声时间表、宽高比准备和面向人类的微调的研究,Playground v2.5 diffusion 模型可产生极佳的美学质量。
Key Takeaways
- 噪音时间表对模型真实性和视觉保真度至关重要。
- 平衡的分区数据集可改善不同宽高比的图像生成。
- 将模型输出与人类偏好相结合可提升图像的共鸣效果。
- Playground v2.5 在各种条件和宽高比下表现出最先进的审美质量。
- Playground v2.5 模型开源,为提升基于扩散的图像生成模型的审美质量提供了有价值的指导。
- Playground v2.5 优于 SDXL、Playground v2、DALLE 3 和 Midjourney v5.2。
- 研究有助于提高基于扩散的图像生成模型的审美质量。
- 标题:Playground v2.5:提升文本到图像生成审美质量的三点见解
- 作者:Daiqing Li、Aleks Kamko、Ehsan Akhgari、Ali Sabet、Linmiao Xu、Suhail Doshi
- 第一作者单位:Playground Research
- 关键词:文本到图像生成、扩散模型、审美质量
- 论文链接:arXiv:2402.17245v1[cs.CV]
- 摘要: (1)研究背景:文本到图像生成模型在生成图像的审美质量方面取得了显著进展,但仍存在一些挑战,如颜色和对比度不足、不同宽高比生成质量不佳、缺乏对人类偏好的对齐。 (2)过去方法:以往方法主要集中在改进扩散模型的训练过程,如优化噪声调度或使用更大的数据集。然而,这些方法在提升审美质量方面效果有限。 (3)研究方法:本文提出了三点见解来提升审美质量:改进噪声调度以增强颜色和对比度,构建平衡的分桶数据集以支持不同宽高比的生成,以及利用人类反馈来对齐模型输出与人类偏好。 (4)方法性能:在广泛的分析和实验中,Playground v2.5 在各种条件和宽高比下展示了最先进的审美质量,优于 SDXL、Playground v2 等开源模型和 DALL·E 3、Midjourney v5.2 等闭源商业系统。
方法: (1)改进噪声调度:采用 EDM 框架和更噪声的调度方式,增强图像色彩和对比度。 (2)平衡分桶数据集:构建包含不同宽高比图像的分桶数据集,支持多种宽高比的生成。 (3)利用人类反馈:使用人类评级系统自动筛选高质量数据集,并采用迭代训练方法,根据人类偏好对齐模型输出。
- 总结: (1):本文提出 Playground v2.5,该模型通过改进噪声调度、构建平衡的分桶数据集和利用人类反馈等三点见解,提升了文本到图像生成模型的审美质量。 (2): 创新点:
- 提出了一种新的噪声调度框架,增强了图像的色彩和对比度。
- 构建了一个包含不同宽高比图像的分桶数据集,支持多种宽高比的生成。
- 利用人类评级系统自动筛选高质量数据集,并采用迭代训练方法,根据人类偏好对齐模型输出。 性能:
- 在广泛的分析和实验中,Playground v2.5 在各种条件和宽高比下展示了最先进的审美质量,优于其他开源和闭源模型。
- Playground v2.5 在增强图像色彩和对比度、生成不同宽高比的高质量图像以及对齐模型输出与人类偏好方面表现出色,尤其是在生成人物图像的精细细节方面。 工作量:
- 该模型已开源,用户可以在 Playground 产品网站上使用。
- Playground v2.5 的权重已在 Hugging Face 上开源。
- Playground 将继续提供扩展,以便在 A1111 和 ComfyUI 等流行社区工具中使用 Playground v2.5。
点此查看论文截图





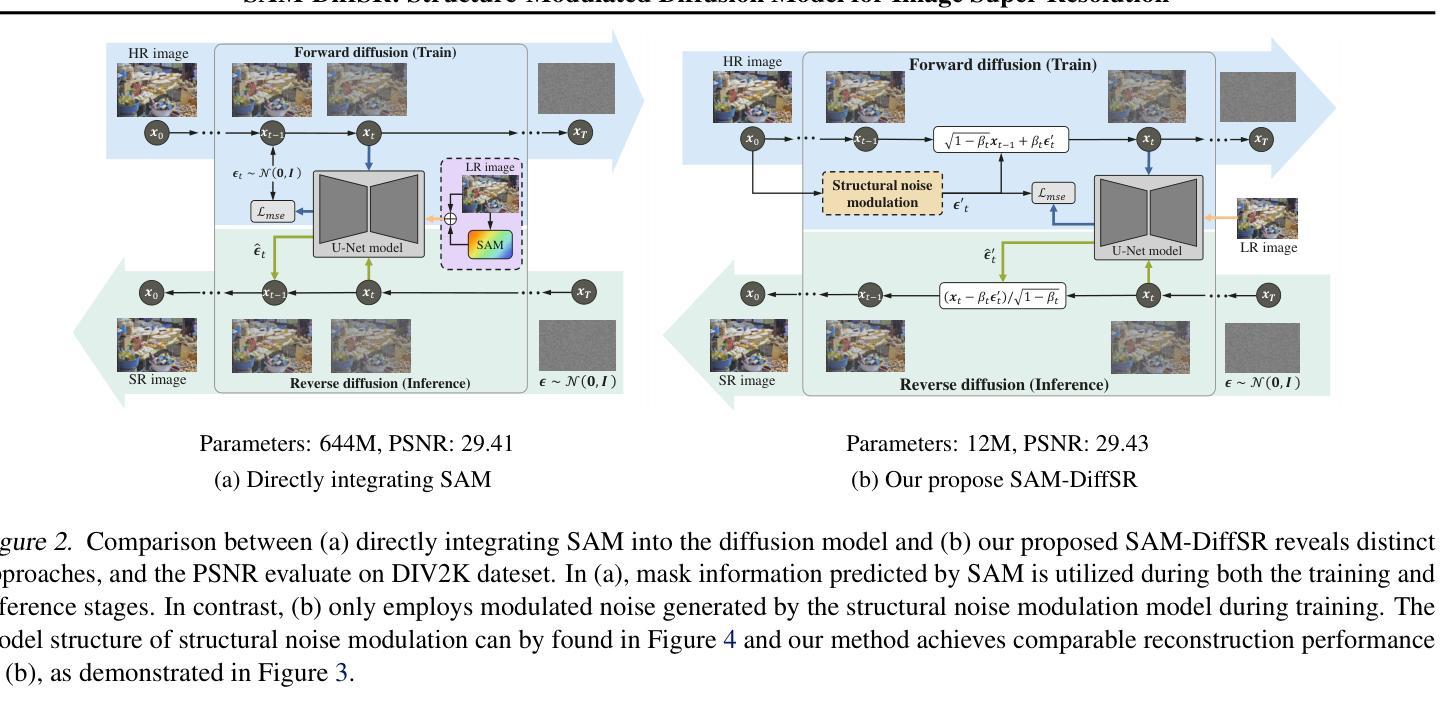
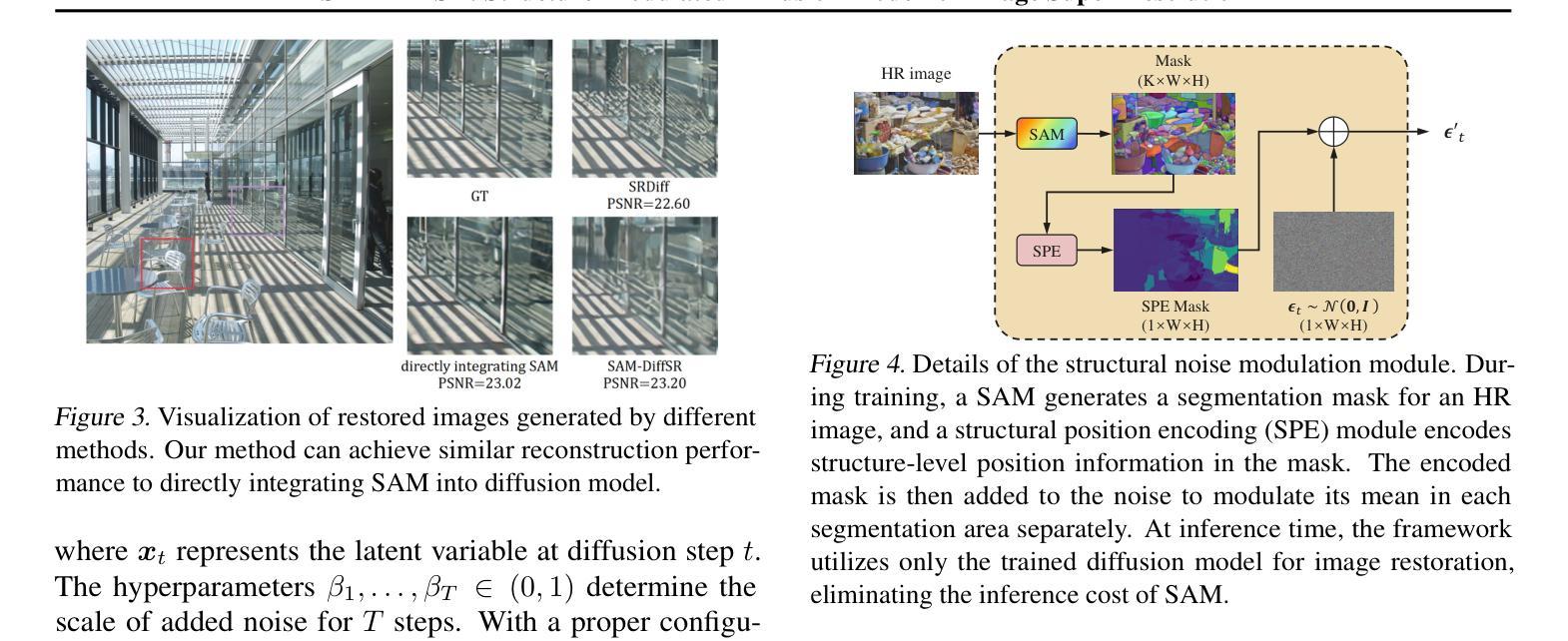
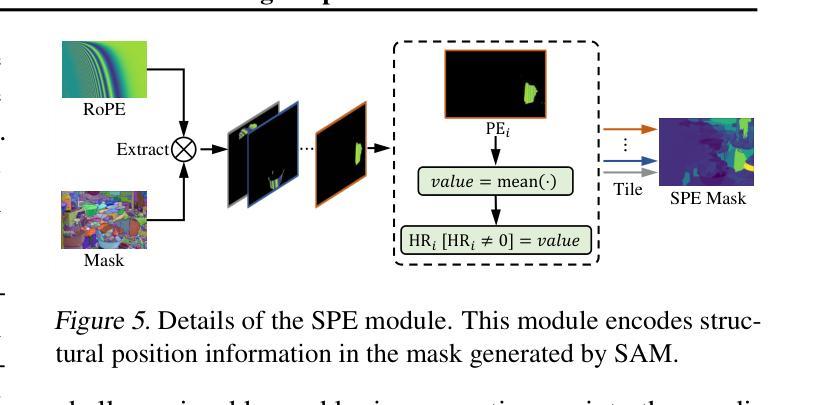
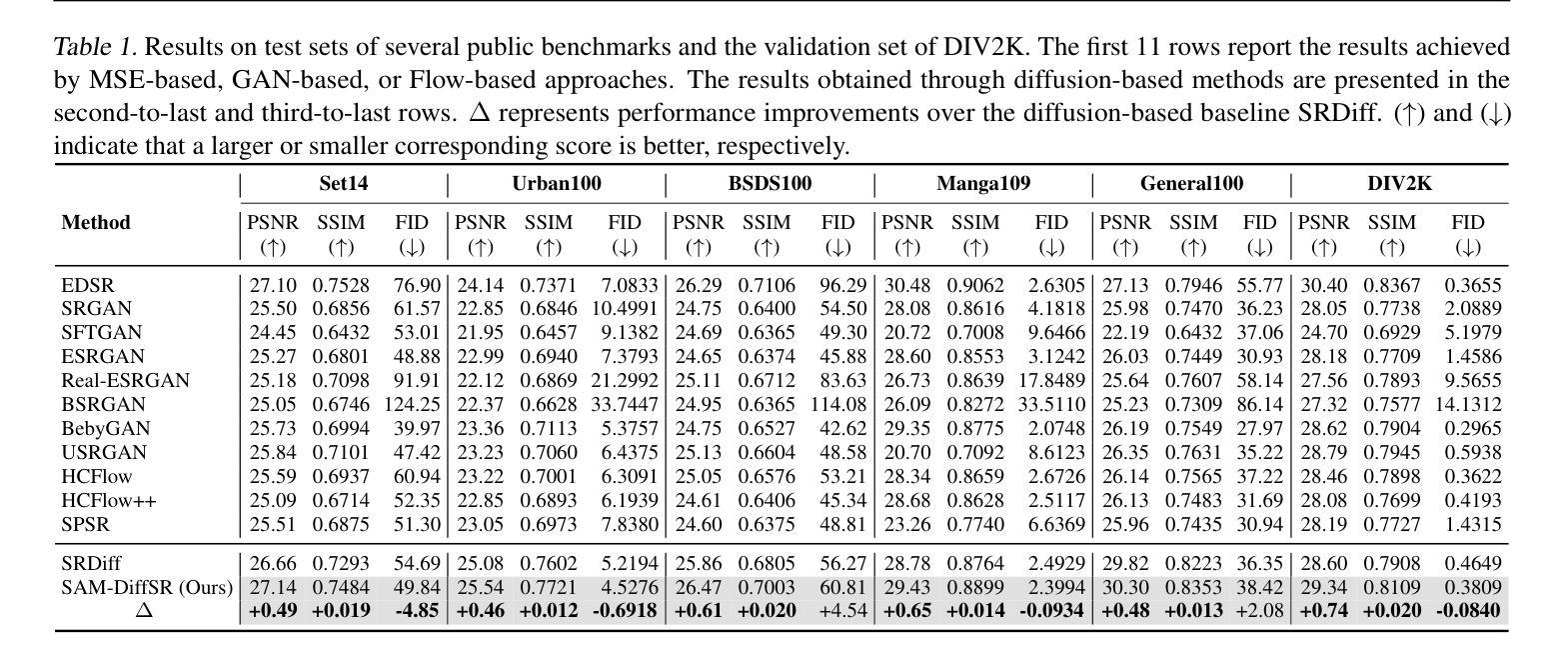
SAM-DiffSR: Structure-Modulated Diffusion Model for Image Super-Resolution
Authors:Chengcheng Wang, Zhiwei Hao, Yehui Tang, Jianyuan Guo, Yujie Yang, Kai Han, Yunhe Wang
Diffusion-based super-resolution (SR) models have recently garnered significant attention due to their potent restoration capabilities. But conventional diffusion models perform noise sampling from a single distribution, constraining their ability to handle real-world scenes and complex textures across semantic regions. With the success of segment anything model (SAM), generating sufficiently fine-grained region masks can enhance the detail recovery of diffusion-based SR model. However, directly integrating SAM into SR models will result in much higher computational cost. In this paper, we propose the SAM-DiffSR model, which can utilize the fine-grained structure information from SAM in the process of sampling noise to improve the image quality without additional computational cost during inference. In the process of training, we encode structural position information into the segmentation mask from SAM. Then the encoded mask is integrated into the forward diffusion process by modulating it to the sampled noise. This adjustment allows us to independently adapt the noise mean within each corresponding segmentation area. The diffusion model is trained to estimate this modulated noise. Crucially, our proposed framework does NOT change the reverse diffusion process and does NOT require SAM at inference. Experimental results demonstrate the effectiveness of our proposed method, showcasing superior performance in suppressing artifacts, and surpassing existing diffusion-based methods by 0.74 dB at the maximum in terms of PSNR on DIV2K dataset. The code and dataset are available at https://github.com/lose4578/SAM-DiffSR.
Summary
基于扩散的超分辨率模型中,本文提出了一种新颖的SAM-DiffSR方法,该方法利用SAM的精细结构信息在采样噪声的过程中来改善最终图像质量,而推理过程中不需要SAM,有效降低了计算成本。
Key Takeaways
- 提出了一种SAM-DiffSR模型,可以利用SAM的精细结构信息来改善图像质量。
- SAM-DiffSR模型通过将编码的掩码整合到前向扩散过程中,在采样噪声之前进行调整。
- 该调整允许独立调整每个对应分割区域内的噪声均值。
- 扩散模型被训练来估计这种调制的噪声。
- 所提出的方法不改变反向扩散过程,并且在推理过程中不需要SAM。
- 实验结果表明,该方法有效地抑制了伪影,在DIV2K数据集上以PSNR指标超越了现有的基于扩散的方法0.74 dB。
- 代码和数据集可在https://github.com/lose4578/SAM-DiffSR获得。
- 标题:SAM-DiffSR:用于图像超分辨率的结构调制扩散模型
- 作者:Chengcheng Wang、Zhiwei Hao、Yehui Tang、Jianyuan Guo、Yujie Yang、Kai Han、Yunhe Wang
- 单位:华为诺亚方舟实验室
- 关键词:图像超分辨率、扩散模型、结构调制
- 链接:https://arxiv.org/abs/2402.17133 Github:https://github.com/lose4578/SAM-DiffSR
- 摘要: (1)研究背景: 扩散模型在图像超分辨率领域取得了显著进展,但传统扩散模型从单一分布中进行噪声采样,限制了其处理真实场景和跨语义区域复杂纹理的能力。
(2)过去方法及问题: Segment Anything Model(SAM)能生成足够精细的区域掩码,增强扩散模型的细节恢复能力。但直接将 SAM 集成到 SR 模型中会大幅增加计算成本。
(3)研究方法: 提出 SAM-DiffSR 模型,在噪声采样过程中利用 SAM 的精细结构信息,在不增加推理计算成本的情况下提高图像质量。在训练过程中,将结构位置信息编码到 SAM 的分割掩码中。然后将编码后的掩码集成到前向扩散过程中,将其调制到采样的噪声中。这种调整允许在每个对应的分割区域内独立调整噪声均值。扩散模型被训练来估计这种调制的噪声。
(4)方法性能: 实验结果表明,所提出的方法有效,在抑制伪影方面表现出优异的性能,在 DIV2K 数据集上以 PSNR 衡量,比现有的基于扩散的方法提高了 0.74dB。该方法的性能支持其目标。
Methods:
(1) 利用 SegmentAnythingModel(SAM)生成精细的区域掩码,编码结构位置信息。
(2) 将编码后的掩码集成到前向扩散过程中,调制采样的噪声。
(3) 训练扩散模型估计调制的噪声,从而在每个分割区域内独立调整噪声均值。
- 结论: (1):本文重点通过集成 SAM,增强基于扩散的图像超分辨率模型的结构层次信息恢复能力。具体来说,我们引入了一个名为 SAM-DiffSR 的框架,它涉及将结构位置信息纳入 SAM 生成的掩码,然后在正向扩散过程中将其添加到采样的噪声中。此操作单独调节每个相应分割区域中噪声的均值,从而将结构层次知识注入扩散模型。通过采用这种方法,训练后的模型在恢复结构细节和抑制图像伪影方面表现出改进,而无需产生任何额外的推理成本。我们的方法的有效性通过在常用的图像超分辨率基准上进行的广泛实验得到证实。 (2):创新点:利用 SAM 注入结构信息,增强扩散模型的结构恢复能力; 性能:在抑制伪影和恢复结构细节方面优于现有方法; 工作量:推理成本与基线模型相当。
点此查看论文截图

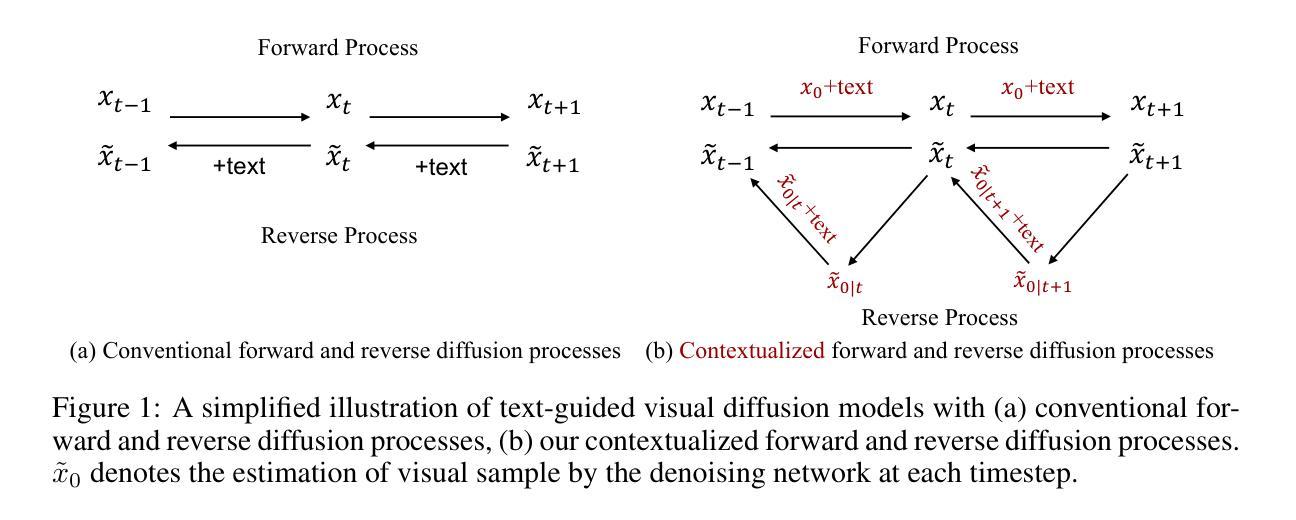
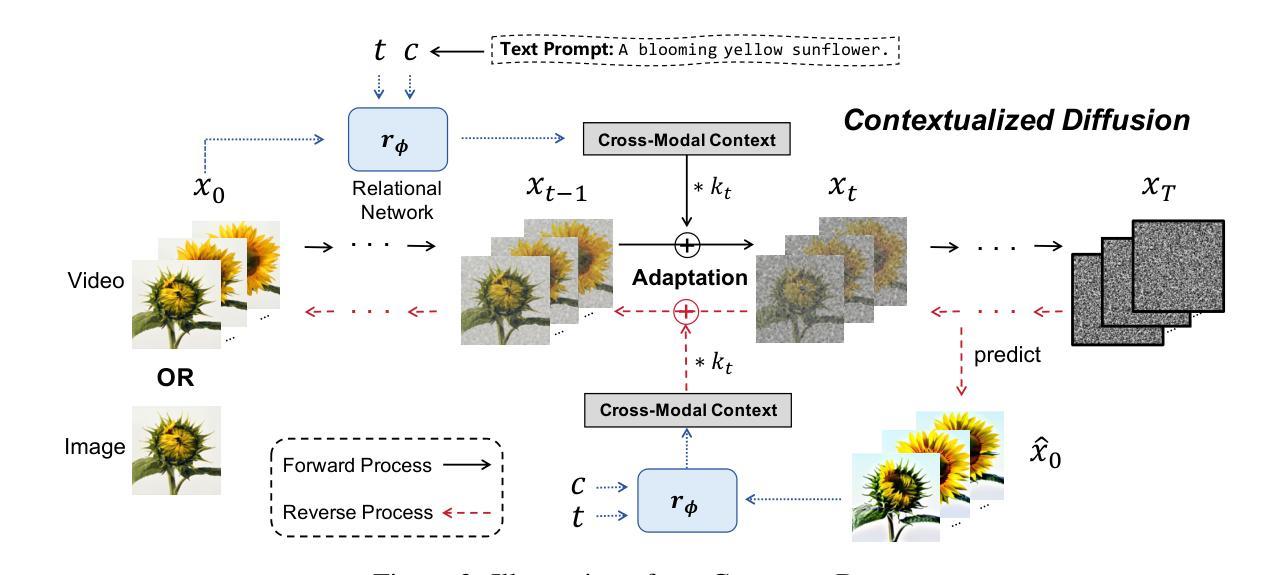
Cross-Modal Contextualized Diffusion Models for Text-Guided Visual Generation and Editing
Authors:Ling Yang, Zhilong Zhang, Zhaochen Yu, Jingwei Liu, Minkai Xu, Stefano Ermon, Bin Cui
Conditional diffusion models have exhibited superior performance in high-fidelity text-guided visual generation and editing. Nevertheless, prevailing text-guided visual diffusion models primarily focus on incorporating text-visual relationships exclusively into the reverse process, often disregarding their relevance in the forward process. This inconsistency between forward and reverse processes may limit the precise conveyance of textual semantics in visual synthesis results. To address this issue, we propose a novel and general contextualized diffusion model (ContextDiff) by incorporating the cross-modal context encompassing interactions and alignments between text condition and visual sample into forward and reverse processes. We propagate this context to all timesteps in the two processes to adapt their trajectories, thereby facilitating cross-modal conditional modeling. We generalize our contextualized diffusion to both DDPMs and DDIMs with theoretical derivations, and demonstrate the effectiveness of our model in evaluations with two challenging tasks: text-to-image generation, and text-to-video editing. In each task, our ContextDiff achieves new state-of-the-art performance, significantly enhancing the semantic alignment between text condition and generated samples, as evidenced by quantitative and qualitative evaluations. Our code is available at https://github.com/YangLing0818/ContextDiff
PDF ICLR 2024. Project: https://github.com/YangLing0818/ContextDiff
Summary
上下文扩散模型通过在扩散正反过程中加入文本可视关系,提升了文本引导可视化生成和编辑的语义对齐。
Key Takeaways
- 扩散模型在文本引导可视化生成和编辑中表现优越。
- 传统模型只将文本可视关系融入反向过程,忽略了正向过程的关联性。
- 正反过程的不一致性限制了文本语义在可视化合成结果中的传递精度。
- 语义扩散模型通过将文本条件和可视样本之间的交互和对齐纳入正反过程,改善了这种不一致性。
- 改进适用于 DDPM 和 DDIM,并通过理论推理得到证明。
- 在文本到图像生成和文本到视频编辑任务中,语义扩散模型均达到新的最佳性能。
- 定量和定性评估表明语义扩散模型显著提升了文本条件和生成样本之间的语义对齐。
- 标题:跨模态语境化扩散模型用于文本引导的视觉生成和编辑
- 作者:杨凌、张志龙、于兆宸、刘景伟、徐明凯、Stefano Ermon、崔斌
- 隶属:北京大学
- 关键词:文本引导视觉生成、文本引导视频编辑、扩散模型、语境化
- 论文链接:https://arxiv.org/abs/2402.16627 Github 代码链接:None
摘要: (1):研究背景:扩散模型在文本引导视觉生成和编辑领域表现优异,但现有方法主要关注将文本-视觉关系融入逆过程,忽视了其在前向过程中的相关性,导致文本语义在视觉合成结果中的精确传达受到限制。 (2):过去方法及问题:现有方法存在以下问题:
- 忽略了文本-视觉关系在前向过程中的作用,导致文本语义在视觉合成结果中的精确传达受限。
- 缺乏一种通用的语境化扩散模型,无法同时处理文本引导图像和视频生成/编辑任务。 (3):研究方法:本文提出了一种新颖且通用的语境化扩散模型(CONTEXTDIFF),通过将跨模态语境(包含文本条件和视觉样本之间的交互和对齐)融入前向和逆过程来解决上述问题。具体来说,将该语境传播到两个过程中的所有时间步,以适应它们的轨迹,从而促进跨模态条件建模。同时,将语境化扩散模型推广到 DDPM 和 DDIM,并通过理论推导证明了其有效性。 (4):任务和性能:在文本到图像生成和文本到视频编辑两个具有挑战性的任务上,CONTEXTDIFF 均取得了新的 SOTA 性能,显著增强了文本条件与生成样本之间的语义对齐,定量和定性评估均证明了这一点。
Methods: (1): 提出跨模态语境化扩散模型(CONTEXTDIFF),将跨模态语境(包含文本条件和视觉样本之间的交互和对齐)融入前向和逆过程,促进跨模态条件建模; (2): 将语境化扩散模型推广到DDPM和DDIM,并通过理论推导证明了其有效性; (3): 在文本到图像生成和文本到视频编辑两个任务上,CONTEXTDIFF均取得了新的SOTA性能,显著增强了文本条件与生成样本之间的语义对齐。
结论: (1)本工作提出了一种新颖且通用的条件扩散模型(CONTEXTDIFF),通过将跨模态语境传播到扩散和逆过程中的所有时间步,并适应它们的轨迹,从而促进跨模态条件建模。我们将上下文化轨迹适配器推广到 DDPM 和 DDIM,并通过理论推导证明了其有效性。在文本到图像生成和文本到视频编辑这两个具有挑战性的任务上,CONTEXTDIFF 始终达到最先进的性能。两项任务的广泛定量和定性结果证明了我们提出的跨模态语境化扩散模型的有效性和优越性。 (2)创新点:提出了一种新颖的跨模态语境化扩散模型,通过将跨模态语境融入扩散和逆过程,促进跨模态条件建模。 性能:在文本到图像生成和文本到视频编辑两个任务上达到最先进的性能,显著增强了文本条件与生成样本之间的语义对齐。 工作量:工作量较大,需要对扩散模型和跨模态语境化进行深入理解。
点此查看论文截图



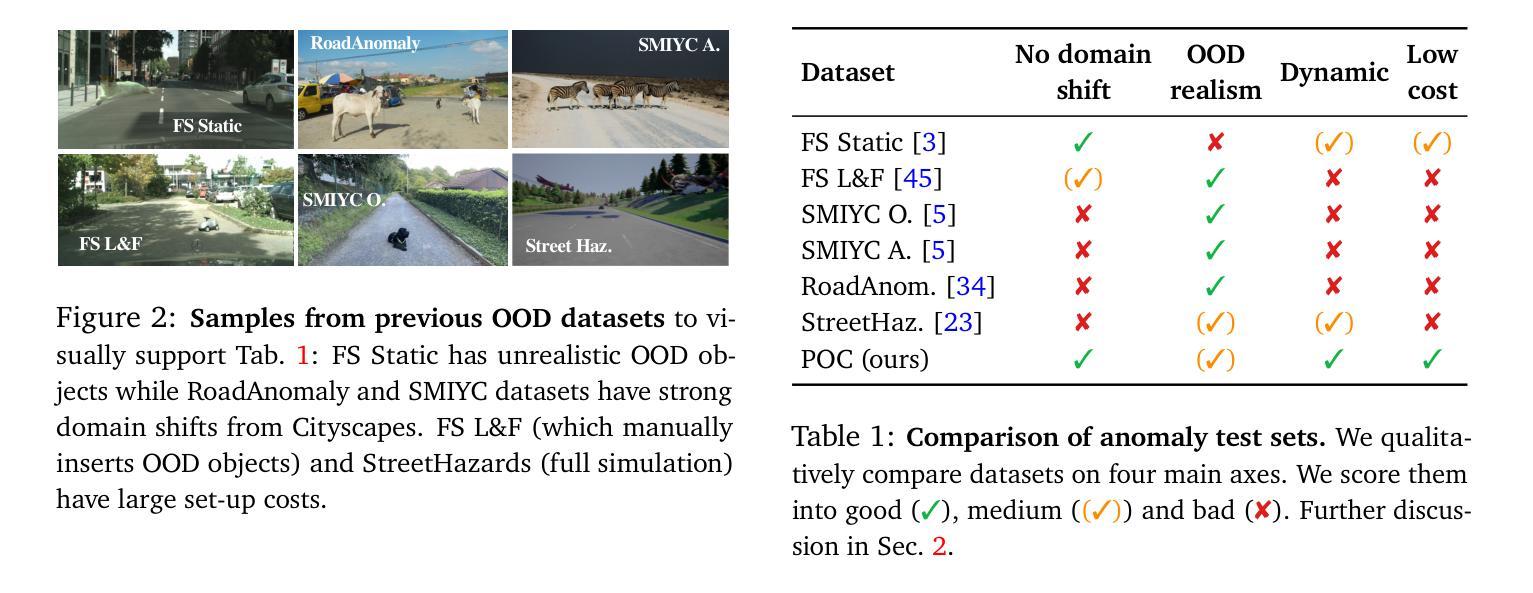
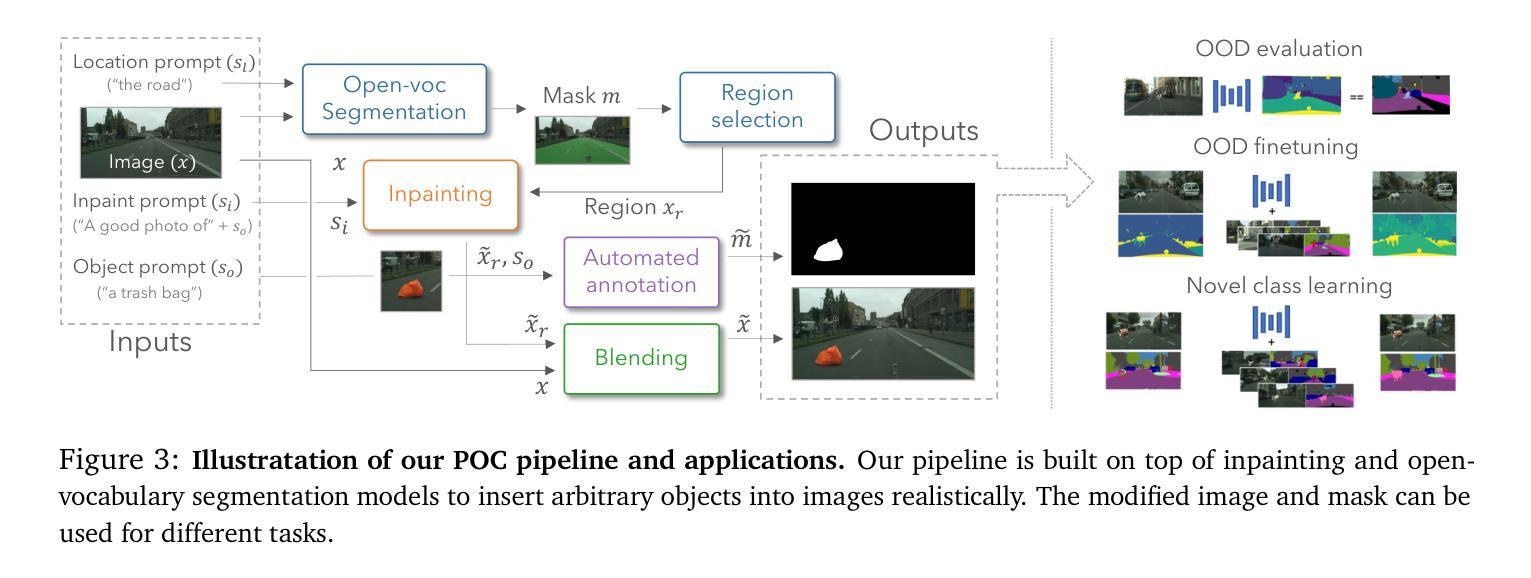
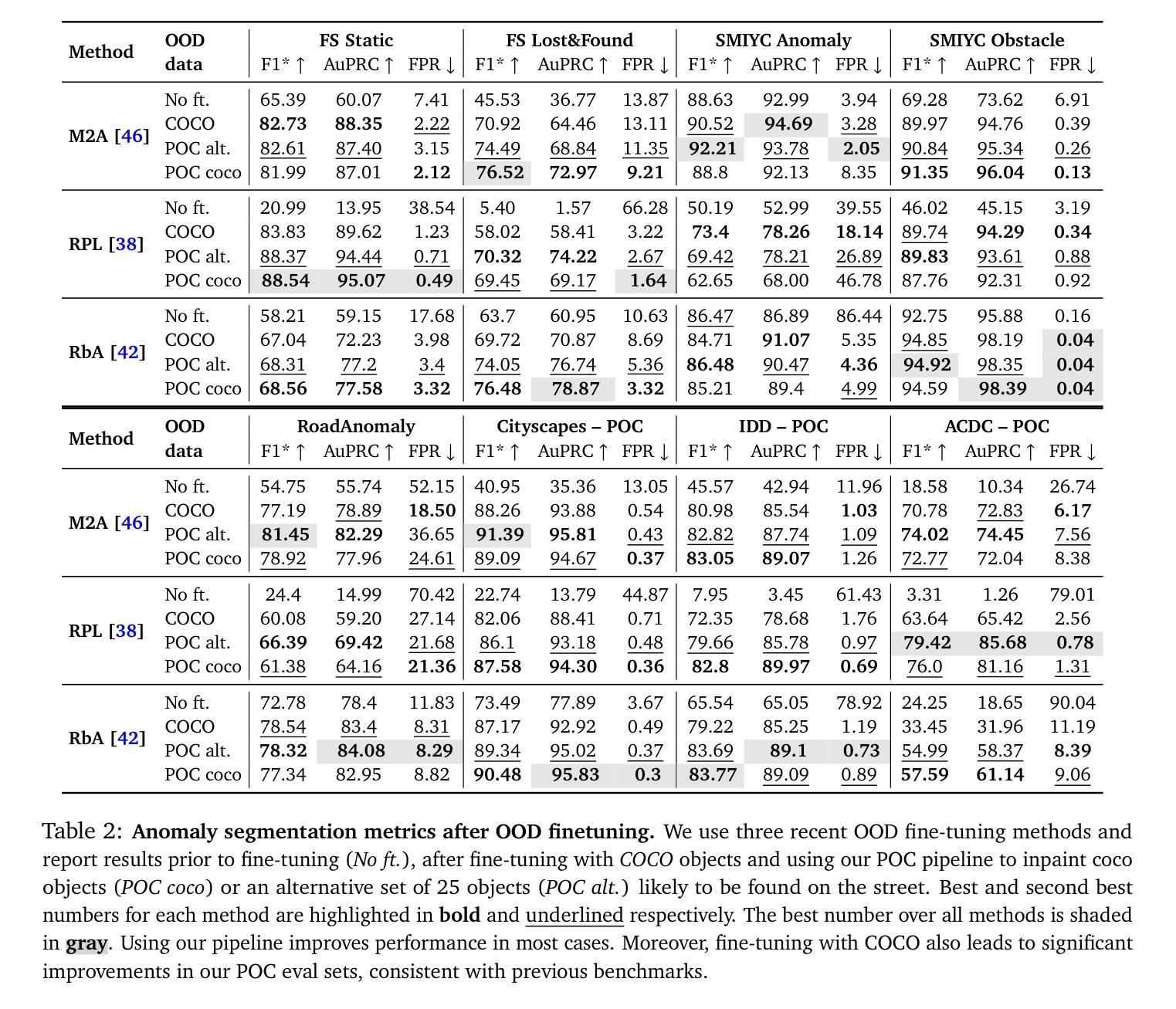
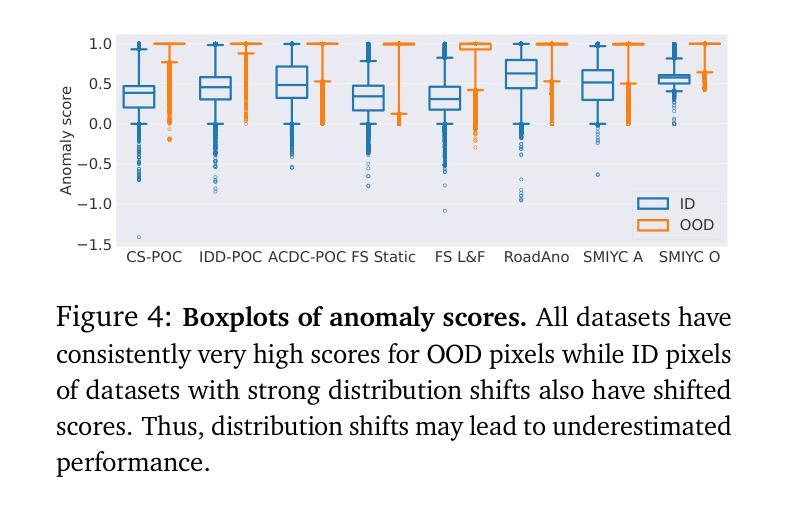
Placing Objects in Context via Inpainting for Out-of-distribution Segmentation
Authors:Pau de Jorge, Riccardo Volpi, Puneet K. Dokania, Philip H. S. Torr, Gregory Rogez
When deploying a semantic segmentation model into the real world, it will inevitably be confronted with semantic classes unseen during training. Thus, to safely deploy such systems, it is crucial to accurately evaluate and improve their anomaly segmentation capabilities. However, acquiring and labelling semantic segmentation data is expensive and unanticipated conditions are long-tail and potentially hazardous. Indeed, existing anomaly segmentation datasets capture a limited number of anomalies, lack realism or have strong domain shifts. In this paper, we propose the Placing Objects in Context (POC) pipeline to realistically add any object into any image via diffusion models. POC can be used to easily extend any dataset with an arbitrary number of objects. In our experiments, we present different anomaly segmentation datasets based on POC-generated data and show that POC can improve the performance of recent state-of-the-art anomaly fine-tuning methods in several standardized benchmarks. POC is also effective to learn new classes. For example, we use it to edit Cityscapes samples by adding a subset of Pascal classes and show that models trained on such data achieve comparable performance to the Pascal-trained baseline. This corroborates the low sim-to-real gap of models trained on POC-generated images.
Summary
使用扩散模型将对象插入上下文(POC)管道,可真实地向图像中添加任何对象,有效扩展数据集和改善异常分割性能。
Key Takeaways
- 利用扩散模型构建POC管道,可向图像中真实地添加任意对象。
- POC能轻松扩展数据集,添加任意数量的对象。
- POC生成的异常分割数据集比现有数据集更真实、全面。
- POC能提升最新异常精调方法在基准测试中的性能。
- POC可用于学习新类别,如将Pascal类别添加到Cityscapes。
- 基于POC生成图像训练的模型,其仿真到真实差距低。
- POC管道能够提高模型应对未见语义类别的能力,增强异常分割性能。
1.标题:通过图像修复将对象置于上下文中以进行分布外分割 2.作者:Paude Jorge†, Riccardo Volpi†, Puneet K. Dokania‡, Philip H.S. Torr‡, Grégory Rogez† 3.所属机构:NAVERLABS 欧洲,牛津大学 4.关键词:异常分割、分布外检测、图像修复、语义分割、开放词汇分割 5.链接:https://github.com/naver/poc 6.摘要: (1):研究背景:在现实世界中部署语义分割模型时,模型不可避免地会遇到训练期间未见过的语义类别。因此,为了安全地部署此类系统,准确评估和提高其异常分割能力至关重要。然而,获取和标记语义分割数据代价高昂,而且意外情况是长尾且可能具有危险性。实际上,现有的异常分割数据集捕获的异常数量有限,缺乏真实性或具有很强的域偏移。 (2):过去的方法及其问题:本文提出了一种放置对象在上下文(POC)管道,通过扩散模型将任何对象现实地添加到任何图像中。POC 可用于轻松地使用任意数量的对象扩展任何数据集。在我们的实验中,我们展示了基于 POC 生成的不同异常分割数据集,并表明 POC 可以提高几种标准基准中最近的异常精细调整方法的性能。POC 还可以有效地学习新类别。例如,我们使用它通过添加 Pascal 类别的子集来编辑 Cityscapes 样本,并表明在这些数据上训练的模型与 Pascal 训练的基线实现了相当的性能。这证实了在 POC 生成的图像上训练的模型的低模拟到真实差距。 (3):提出的研究方法:POC 管道建立在图像修复和开放词汇分割模型之上,将任意对象现实地插入图像中。修改后的图像和掩码可用于不同的任务。 (4):方法在什么任务上取得了什么性能,该性能是否能支撑其目标:在我们的实验中,我们表明在 POC 生成的图像上进行微调可以显着提高最先进的异常分割方法的性能——优于通过标准做法(拼接 COCO 对象)进行微调的模型。我们还展示了三个基于 Cityscapes 和其他两个自动驾驶数据集的 POC 生成的评估集,并在其上对不同的异常分割方法进行了基准测试(有关结果的第一眼,请参见图 1)。最后,由于 POC 可以添加任意对象,我们展示了它可用于学习新类别。例如,使用动物类别增强 Cityscapes 图像导致 Pascal 测试集上的 93.14mIoU(考虑相同的类别),而直接在 Pascal 上训练产生 94.75——也就是说,在 POC 编辑的图像上训练的模型产生了相当小的模拟到真实差距。
- 方法: (1) POC管道:POC管道由图像修复模型和开放词汇分割模型组成。图像修复模型用于将对象现实地插入图像中,而开放词汇分割模型用于为插入的对象生成掩码。修改后的图像和掩码可用于不同的任务,例如异常分割。 (2) 异常分割微调:POC管道可用于生成异常分割数据集。在这些数据集上微调异常分割模型可以提高模型的性能,优于通过标准做法(拼接COCO对象)进行微调的模型。 (3) 学习新类别:POC管道还可以用于学习新类别。例如,使用动物类别增强Cityscapes图像导致Pascal测试集上的93.14mIoU(考虑相同的类别),而直接在Pascal上训练产生94.75——也就是说,在POC编辑的图像上训练的模型产生了相当小的模拟到真实差距。
8.结论: (1):xxx; (2):创新点:xxx;性能:xxx;工作量:xxx; 8. 结论: (1):本文提出了一种放置对象在上下文(POC)管道,通过扩散模型将任意对象现实地添加到任何图像中。POC可用于轻松地使用任意数量的对象扩展任何数据集。在我们的实验中,我们展示了基于POC生成的不同异常分割数据集,并表明POC可以提高几种标准基准中最近的异常精细调整方法的性能。POC还可以有效地学习新类别。例如,我们使用它通过添加Pascal类别的子集来编辑Cityscapes样本,并表明在这些数据上训练的模型与Pascal训练的基线实现了相当的性能。这证实了在POC生成的图像上训练的模型的低模拟到真实差距。 (2):创新点: - 提出了一种放置对象在上下文(POC)管道,通过扩散模型将任意对象现实地添加到任何图像中。 - POC可用于轻松地使用任意数量的对象扩展任何数据集。 - POC可以提高几种标准基准中最近的异常精细调整方法的性能。 - POC还可以有效地学习新类别。 性能: - 在我们的实验中,我们展示了基于POC生成的不同异常分割数据集,并表明POC可以提高几种标准基准中最近的异常精细调整方法的性能。 - POC还可以有效地学习新类别。例如,我们使用它通过添加Pascal类别的子集来编辑Cityscapes样本,并表明在这些数据上训练的模型与Pascal训练的基线实现了相当的性能。这证实了在POC生成的图像上训练的模型的低模拟到真实差距。 工作量: - POC管道由图像修复模型和开放词汇分割模型组成。图像修复模型用于将对象现实地插入图像中,而开放词汇分割模型用于为插入的对象生成掩码。 - POC管道可用于生成异常分割数据集。在这些数据集上微调异常分割模型可以提高模型的性能,优于通过标准做法(拼接COCO对象)进行微调的模型。 - POC管道还可以用于学习新类别。例如,使用动物类别增强Cityscapes图像导致Pascal测试集上的93.14mIoU(考虑相同的类别),而直接在Pascal上训练产生94.75——也就是说,在POC编辑的图像上训练的模型产生了相当小的模拟到真实差距。
点此查看论文截图

 wechat
wechat- alipay