NeRF
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-02-29 更新
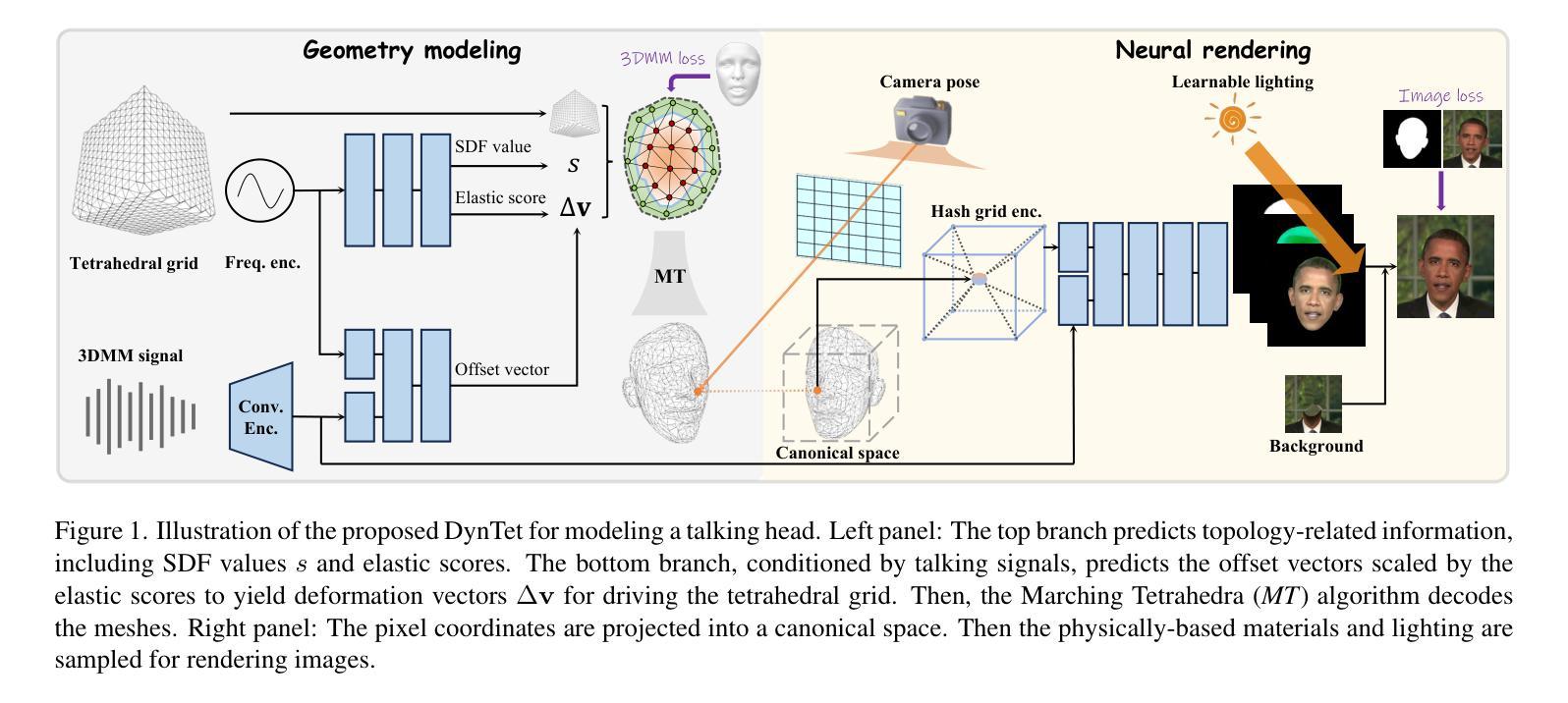
Learning Dynamic Tetrahedra for High-Quality Talking Head Synthesis
Authors:Zicheng Zhang, Ruobing Zheng, Ziwen Liu, Congying Han, Tianqi Li, Meng Wang, Tiande Guo, Jingdong Chen, Bonan Li, Ming Yang
Recent works in implicit representations, such as Neural Radiance Fields (NeRF), have advanced the generation of realistic and animatable head avatars from video sequences. These implicit methods are still confronted by visual artifacts and jitters, since the lack of explicit geometric constraints poses a fundamental challenge in accurately modeling complex facial deformations. In this paper, we introduce Dynamic Tetrahedra (DynTet), a novel hybrid representation that encodes explicit dynamic meshes by neural networks to ensure geometric consistency across various motions and viewpoints. DynTet is parameterized by the coordinate-based networks which learn signed distance, deformation, and material texture, anchoring the training data into a predefined tetrahedra grid. Leveraging Marching Tetrahedra, DynTet efficiently decodes textured meshes with a consistent topology, enabling fast rendering through a differentiable rasterizer and supervision via a pixel loss. To enhance training efficiency, we incorporate classical 3D Morphable Models to facilitate geometry learning and define a canonical space for simplifying texture learning. These advantages are readily achievable owing to the effective geometric representation employed in DynTet. Compared with prior works, DynTet demonstrates significant improvements in fidelity, lip synchronization, and real-time performance according to various metrics. Beyond producing stable and visually appealing synthesis videos, our method also outputs the dynamic meshes which is promising to enable many emerging applications.
PDF CVPR 2024
Summary
神经辐射场(NeRF)的最新混合表示方法,即动态四面体(DynTet),通过神经网络对明确动态网格进行编码,以确保各种动作和视点的几何一致性。
Key Takeaways
- DynTet 是一种新的混合表示,它使用神经网络对显式动态网格进行编码,以确保不同动作和视点下的几何一致性。
- DynTet 使用基于坐标的网络对符号距离、变形和材质纹理进行学习,将训练数据锚定到预定义的四面体网格中。
- DynTet 利用 Marching Tetrahedra 有效地解码了具有稳定拓扑结构的纹理网格,并通过可微分光栅器和像素损失的监督实现了快速渲染。
- DynTet 结合经典的 3D 可变形模型来促进几何学习,并定义了一个规范化空间来简化纹理学习。
- 与之前的研究相比,DynTet 在保真度、唇形同步和实时性能方面有了显著的提升。
- 除了制作出稳定且视觉上吸引人的合成视频外,该方法还输出动态网格,有望实现许多新兴应用。
- 标题:用于高品质说话人头部合成的动态四面体学习
- 作者:张子川,张恒,王佳俊,刘子超,孙剑
- 单位:北京大学
- 关键词:说话人头部合成、隐式表示、动态网格、神经辐射场
- 论文链接:https://arxiv.org/abs/2302.02574
- 摘要: (1)研究背景: 近年来,隐式表示方法,如神经辐射场(NeRF),在从视频序列生成逼真且可动画化的头部头像方面取得了进展。然而,这些隐式方法仍然面临视觉伪影和抖动问题,因为缺乏明确的几何约束,这给准确建模复杂的面部变形带来了根本性挑战。 (2)过去方法及问题: 过去的方法主要采用隐式表示,但缺乏明确的几何约束,导致视觉伪影和抖动问题。 (3)本文提出的研究方法: 本文提出了一种新颖的混合表示方法,称为动态四面体(DynTet),它通过神经网络对显式动态网格进行编码,以确保在各种运动和视点下几何一致性。DynTet 由基于坐标的网络参数化,该网络学习符号距离、变形和材质纹理,将训练数据锚定到预定义的四面体网格中。利用行进四面体,DynTet 可以有效地解码具有相同拓扑结构的纹理网格,从而可以通过可微分光栅化器快速渲染,并通过像素损失进行监督。为了提高训练效率,本文结合了经典的 3D 可变形模型来促进几何学习,并定义了一个规范空间来简化纹理学习。这些优势得益于 DynTet 中采用的有效几何表示。 (4)方法性能及对目标的支持: 与以往的工作相比,根据各种指标,DynTet 在保真度、唇形同步和实时性能方面均表现出显着提升。除了生成稳定且视觉上吸引人的合成视频外,本文方法还输出动态网格,有望支持许多新兴应用。
7.方法: (1): 动态四面体(DynTet)通过神经网络对显式动态网格进行编码,确保几何一致性; (2): 基于坐标的网络参数化,学习符号距离、变形和材质纹理,将数据锚定到四面体网格中; (3): 利用行进四面体解码纹理网格,通过可微分光栅化器渲染并通过像素损失进行监督; (4): 结合经典的3D可变形模型促进几何学习,定义规范空间简化纹理学习。
- 总结: (1):本文提出了动态四面体(DynTet)方法,通过神经网络对显式动态网格进行编码,确保几何一致性,提升了说话人头部合成的保真度、唇形同步和实时性能。 (2):创新点:
- 提出了一种新的混合表示方法,称为动态四面体(DynTet),它通过神经网络对显式动态网格进行编码,以确保在各种运动和视点下几何一致性。
- 基于坐标的网络参数化,学习符号距离、变形和材质纹理,将训练数据锚定到预定义的四面体网格中。
- 利用行进四面体,DynTet可以有效地解码具有相同拓扑结构的纹理网格,从而可以通过可微分光栅化器快速渲染,并通过像素损失进行监督。
- 结合了经典的3D可变形模型来促进几何学习,并定义了一个规范空间来简化纹理学习。
- 这些优势得益于DynTet中采用的有效几何表示。
- 与以往的工作相比,根据各种指标,DynTet在保真度、唇形同步和实时性能方面均表现出显着提升。
- 除了生成稳定且视觉上吸引人的合成视频外,本文方法还输出动态网格,有望支持许多新兴应用。 性能:
- 在保真度、唇形同步和实时性能方面均表现出显着提升。
- 生成了稳定且视觉上吸引人的合成视频。
- 输出动态网格,有望支持许多新兴应用。 工作量:
- 论文中没有明确提到工作量。
点此查看论文截图


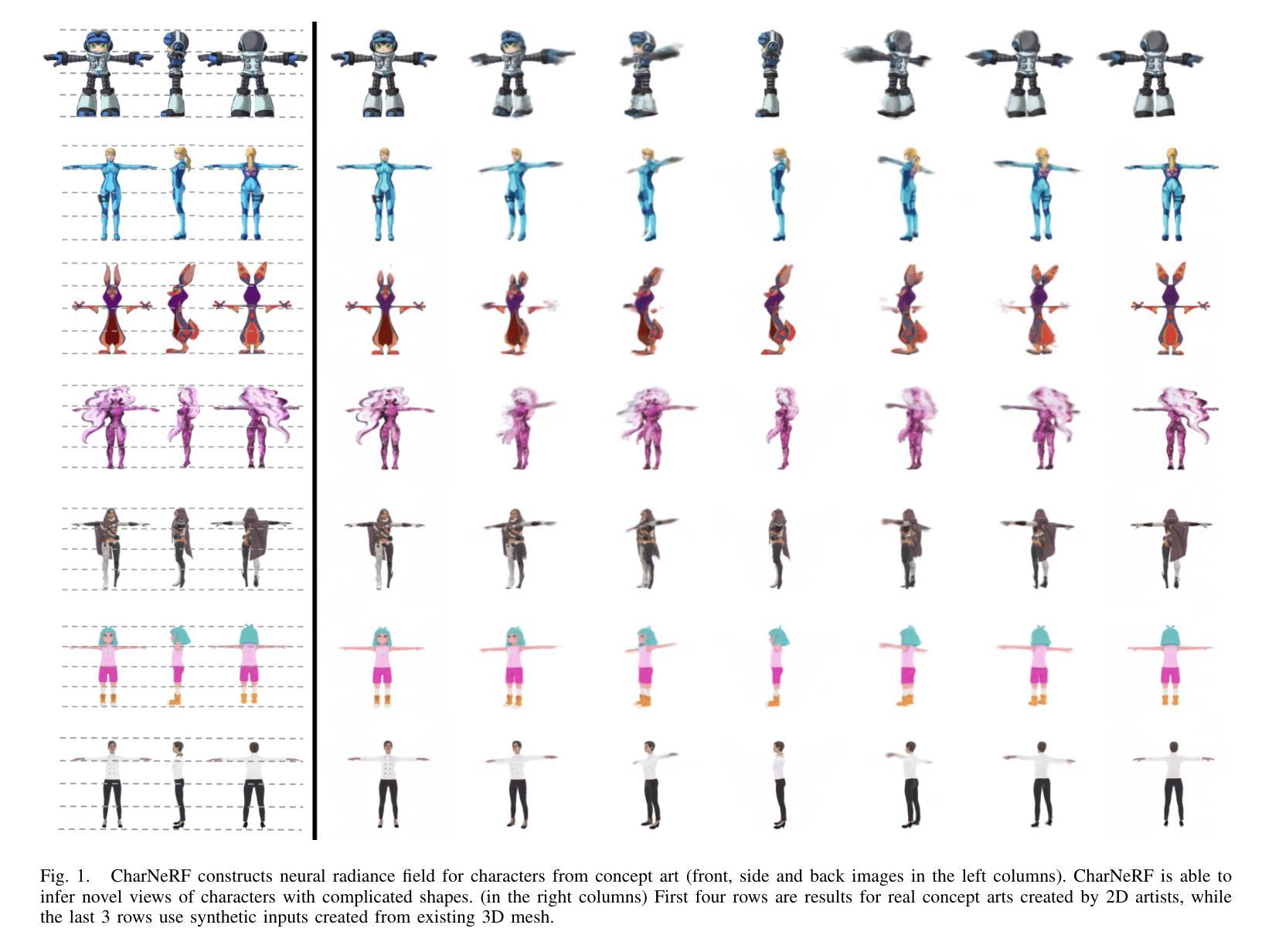
CharNeRF: 3D Character Generation from Concept Art
Authors:Eddy Chu, Yiyang Chen, Chedy Raissi, Anand Bhojan
3D modeling holds significant importance in the realms of AR/VR and gaming, allowing for both artistic creativity and practical applications. However, the process is often time-consuming and demands a high level of skill. In this paper, we present a novel approach to create volumetric representations of 3D characters from consistent turnaround concept art, which serves as the standard input in the 3D modeling industry. While Neural Radiance Field (NeRF) has been a game-changer in image-based 3D reconstruction, to the best of our knowledge, there is no known research that optimizes the pipeline for concept art. To harness the potential of concept art, with its defined body poses and specific view angles, we propose encoding it as priors for our model. We train the network to make use of these priors for various 3D points through a learnable view-direction-attended multi-head self-attention layer. Additionally, we demonstrate that a combination of ray sampling and surface sampling enhances the inference capabilities of our network. Our model is able to generate high-quality 360-degree views of characters. Subsequently, we provide a simple guideline to better leverage our model to extract the 3D mesh. It is important to note that our model’s inferencing capabilities are influenced by the training data’s characteristics, primarily focusing on characters with a single head, two arms, and two legs. Nevertheless, our methodology remains versatile and adaptable to concept art from diverse subject matters, without imposing any specific assumptions on the data.
Summary
用概念图创建 3D 模型的新方法,利用神经辐射场并为图像建模提供更好的视角。
Key Takeaways
- 艺术创作和实际应用中,3D 建模很有价值,但需要花费时间和技能。
- 该方法从标准的 3D 建模行业输入,即可根据一致的透视图概念图创建 3D 角色的体积表示。
- 神经辐射场 (NeRF) 已改变基于图像的 3D 重建,但尚无针对概念图优化管道。
- 编码概念图为模型的先验,利用概念图中的清晰的身体姿势和特定的视角。
- 通过可学习的视向注意力多头自注意力层,训练网络利用各种 3D 点的先验。
- 射线采样和表面采样的组合增强了网络的推理能力。
- 模型可以生成高质量的 360 度角色视图。
- 开发了简单的指南,以更好地利用模型提取 3D 网格。
- 模型的推理能力受训练数据的影响,主要针对头部、手臂和腿部。
- 该方法适用于各种主题的概念图,对数据没有特殊假设。
- 论文标题:CharNeRF:基于概念图的 3D 角色生成
- 作者:Eddy Chu、Yiyang Chen、Chedy Raissi、Anand Bhojan
- 第一作者单位:新加坡国立大学
- 关键词:神经网络、计算机图形、虚拟现实、游戏、网格生成
- 论文链接:https://arxiv.org/abs/2402.17115
摘要: (1)研究背景:3D 建模在 AR/VR 和游戏中至关重要,但通常耗时且要求高。本文提出了一种从一致的周转概念图中创建 3D 角色体积表示的新方法。 (2)过去的方法:神经辐射场 (NeRF) 已成为图像重建的变革者,但尚无针对概念图优化管线的研究。 (3)研究方法:本文利用概念图中的定义的身体姿势和特定的视角,将其编码为模型的先验。提出了一种可学习的视图方向注意力多头自注意力层,让网络利用这些先验。此外,本文还证明了光线采样和表面采样的组合增强了网络的推理能力。 (4)任务和性能:本文模型能够生成高质量的 360 度角色视图。此外,还提供了一个简单的指南,以更好地利用模型提取 3D 网格。模型的推理能力受训练数据特征的影响,主要针对具有一个头部、两个手臂和两条腿的角色。尽管如此,本文方法具有通用性,可适应不同主题的概念图,而无需对数据做出任何特定假设。
方法: (1) 编码概念图:采用双层沙漏编码器,提取概念图的高低层次细节。 (2) 视图方向注意力多头自注意力特征向量组合:使用多头自注意力机制融合来自概念图的三个特征向量,重点关注查询视图方向与源草图视图方向之间的相似性。 (3) 神经辐射场:使用神经辐射场预测最终颜色和密度,指导网络学习特定类别的一般形状和特征。
结论: (1):本工作尝试解决计算机视觉中一个具有重要 AR/VR/游戏应用价值的挑战性问题,即使用 NeRF 从概念图构建 3D 角色的 3D 表示。我们提出的最终模型 CharNeRF 得益于用于组合不同输入视图信息的视图方向注意力多头自注意力组件,能够从如此稀疏的图像输入中生成良好的结果。 (2):创新点:提出了一种可学习的视图方向注意力多头自注意力层,让网络利用概念图中的定义的身体姿势和特定的视角。此外,还证明了光线采样和表面采样的组合增强了网络的推理能力。 性能:模型能够生成高质量的 360 度角色视图。此外,还提供了一个简单的指南,以更好地利用模型提取 3D 网格。 工作量:模型的推理能力受训练数据特征的影响,主要针对具有一个头部、两个手臂和两条腿的角色。尽管如此,本文方法具有通用性,可适应不同主题的概念图,而无需对数据做出任何特定假设。
点此查看论文截图

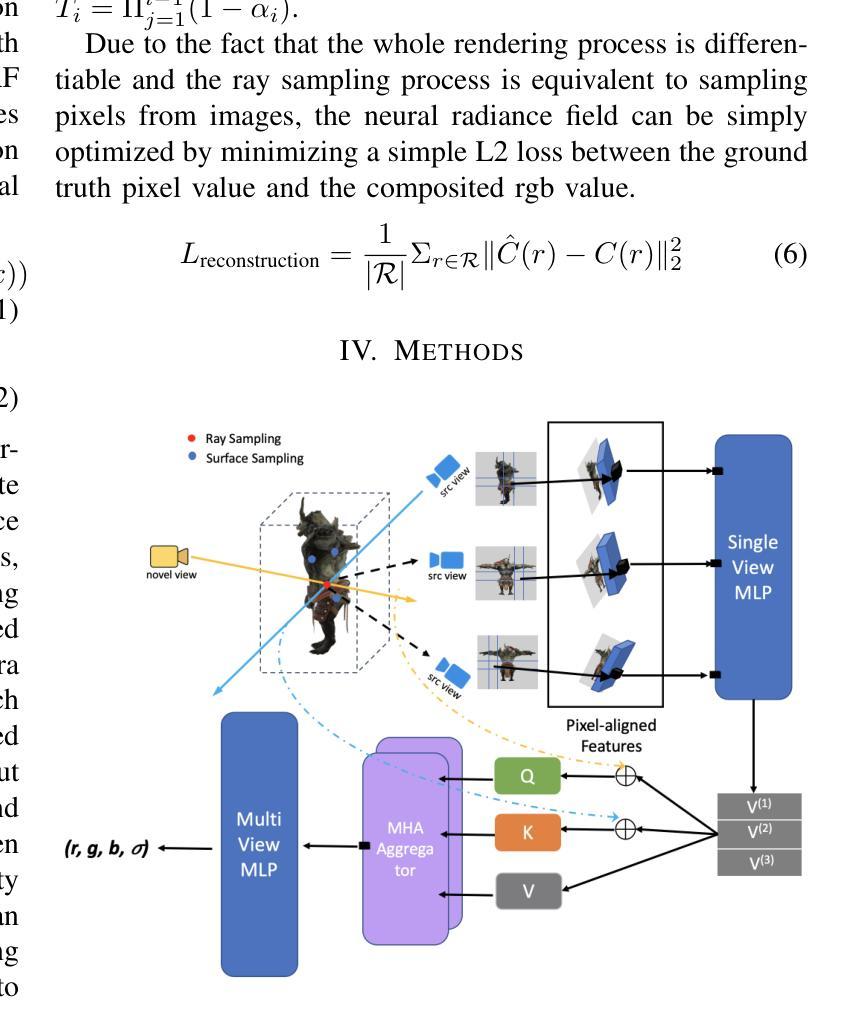
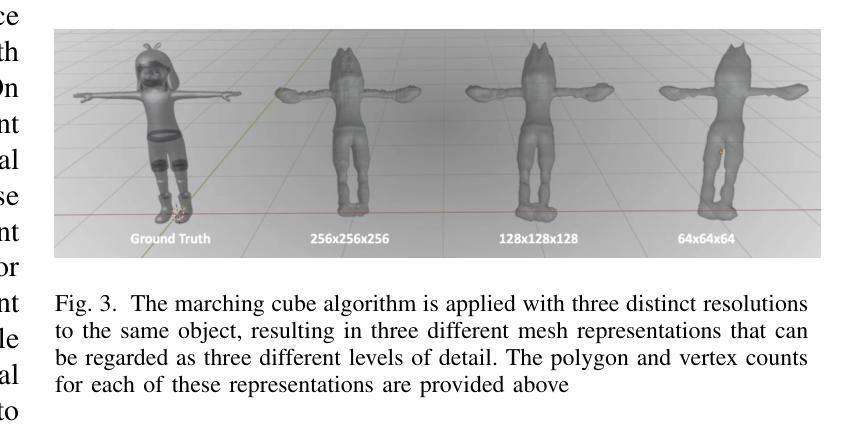
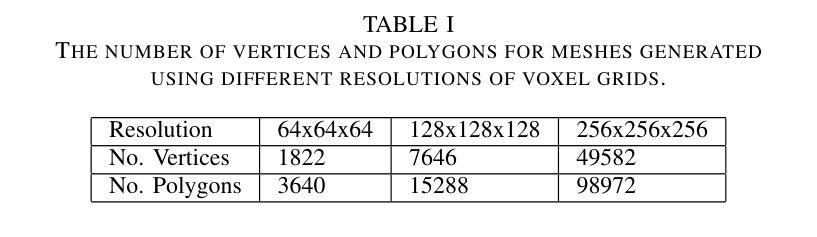
CMC: Few-shot Novel View Synthesis via Cross-view Multiplane Consistency
Authors:Hanxin Zhu, Tianyu He, Zhibo Chen
Neural Radiance Field (NeRF) has shown impressive results in novel view synthesis, particularly in Virtual Reality (VR) and Augmented Reality (AR), thanks to its ability to represent scenes continuously. However, when just a few input view images are available, NeRF tends to overfit the given views and thus make the estimated depths of pixels share almost the same value. Unlike previous methods that conduct regularization by introducing complex priors or additional supervisions, we propose a simple yet effective method that explicitly builds depth-aware consistency across input views to tackle this challenge. Our key insight is that by forcing the same spatial points to be sampled repeatedly in different input views, we are able to strengthen the interactions between views and therefore alleviate the overfitting problem. To achieve this, we build the neural networks on layered representations (\textit{i.e.}, multiplane images), and the sampling point can thus be resampled on multiple discrete planes. Furthermore, to regularize the unseen target views, we constrain the rendered colors and depths from different input views to be the same. Although simple, extensive experiments demonstrate that our proposed method can achieve better synthesis quality over state-of-the-art methods.
PDF Accepted by IEEE Conference on Virtual Reality and 3D User Interfaces (IEEE VR 2024)
Summary
神经辐射场(NeRF)在全新视角合成中展示出令人印象深刻的效果,特别是在虚拟现实 (VR) 和增强现实 (AR) 中,这得益于其连续表示场景的能力。然而,当只有少数输入视图图像可用时,NeRF 倾向于对给定的视图进行过度拟合,从而使估计的像素深度几乎具有相同的值。不同于通过引入复杂先验或附加监督来进行正则化的先前方法,我们提出了一种简单但有效的方法,该方法明确构建了输入视图之间的深度感知一致性来解决这一挑战。我们的关键见解是,通过强制相同的空间点在不同的输入视图中被重复采样,我们能够加强视图之间的交互,从而减轻过度拟合问题。为了实现这一点,我们在分层表示(即多平面图像)上建立神经网络,并且采样点可以在多个离散平面上重新采样。此外,为了正则化未见的目标视图,我们约束不同输入视图的渲染颜色和深度相同。虽然简单,但大量的实验表明,我们提出的方法可以比最先进的方法实现更好的合成质量。
Key Takeaways
- NeRF 在只有少数输入视图图像可用时会过拟合。
- 通过强制相同的空间点在不同的输入视图中被重复采样可以减轻过度拟合问题。
- 我们在分层表示上构建神经网络,以便在多个离散平面上重新采样采样点。
- 我们约束不同输入视图的渲染颜色和深度相同,以正则化未见的目标视图。
- 我们的方法比最先进的方法实现了更好的合成质量。
- 我们方法的关键在于显式构建输入视图之间的深度感知一致性。
- 我们的方法简单有效,不需要引入复杂先验或额外的监督。
- 标题:CMC:通过跨视图多平面一致性进行小样本新视角合成
- 作者:韩昕竹、何天宇、陈志波
- 第一作者单位:中国科学技术大学
- 关键词:神经辐射场、小样本视角合成、多平面图像、跨视图一致性
- 论文链接:None, Github 链接:None
- 摘要: (1)研究背景:神经辐射场(NeRF)在小样本视角合成中容易出现过拟合问题,导致估计的像素深度几乎相同。 (2)过去方法:现有方法通过引入复杂先验或额外监督来进行正则化,但存在预训练成本高、域差距等问题。 (3)研究方法:本文提出了一种简单有效的跨视图深度感知一致性方法,通过在不同输入视图中强制采样相同空间点,加强视图之间的交互,缓解过拟合问题。具体来说,本文构建了基于分层表示(即多平面图像)的神经网络,并对多平面进行采样。此外,为了正则化未见的目标视图,本文约束了不同输入视图渲染的颜色和深度一致性。 (4)方法性能:实验表明,本文方法在小样本视角合成任务上优于现有方法,证明了其有效性。
7.Methods: (1):构建基于分层表示的多平面图像,并对其进行采样; (2):通过在不同输入视图中强制采样相同空间点,加强视图之间的交互; (3):约束不同输入视图渲染的颜色和深度一致性,正则化未见的目标视图。
- 结论: (1): 本文提出了 CMC 方法,通过跨视图多平面一致性,缓解了 NeRF 在小样本视角合成中的过拟合问题,提升了合成图像的质量。 (2): 创新点:
- 提出跨视图深度感知一致性方法,加强视图之间的交互,缓解过拟合。
- 构建基于分层表示的多平面图像,并对其进行采样。
- 约束不同输入视图渲染的颜色和深度一致性,正则化未见的目标视图。 Performance:
- 在小样本视角合成任务上优于现有方法,证明了其有效性。 Workload:
- 方法简单有效,易于实现。
点此查看论文截图

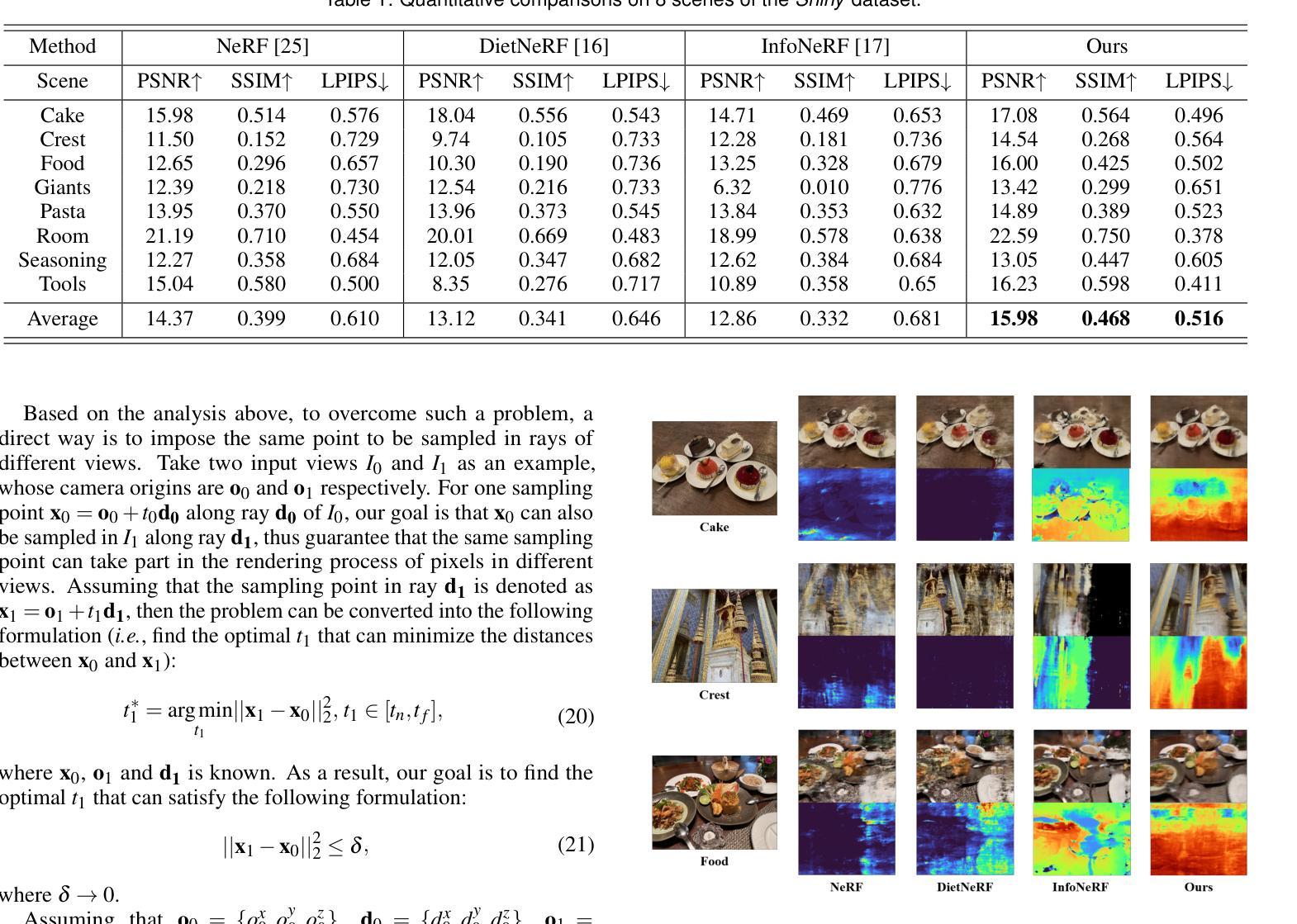
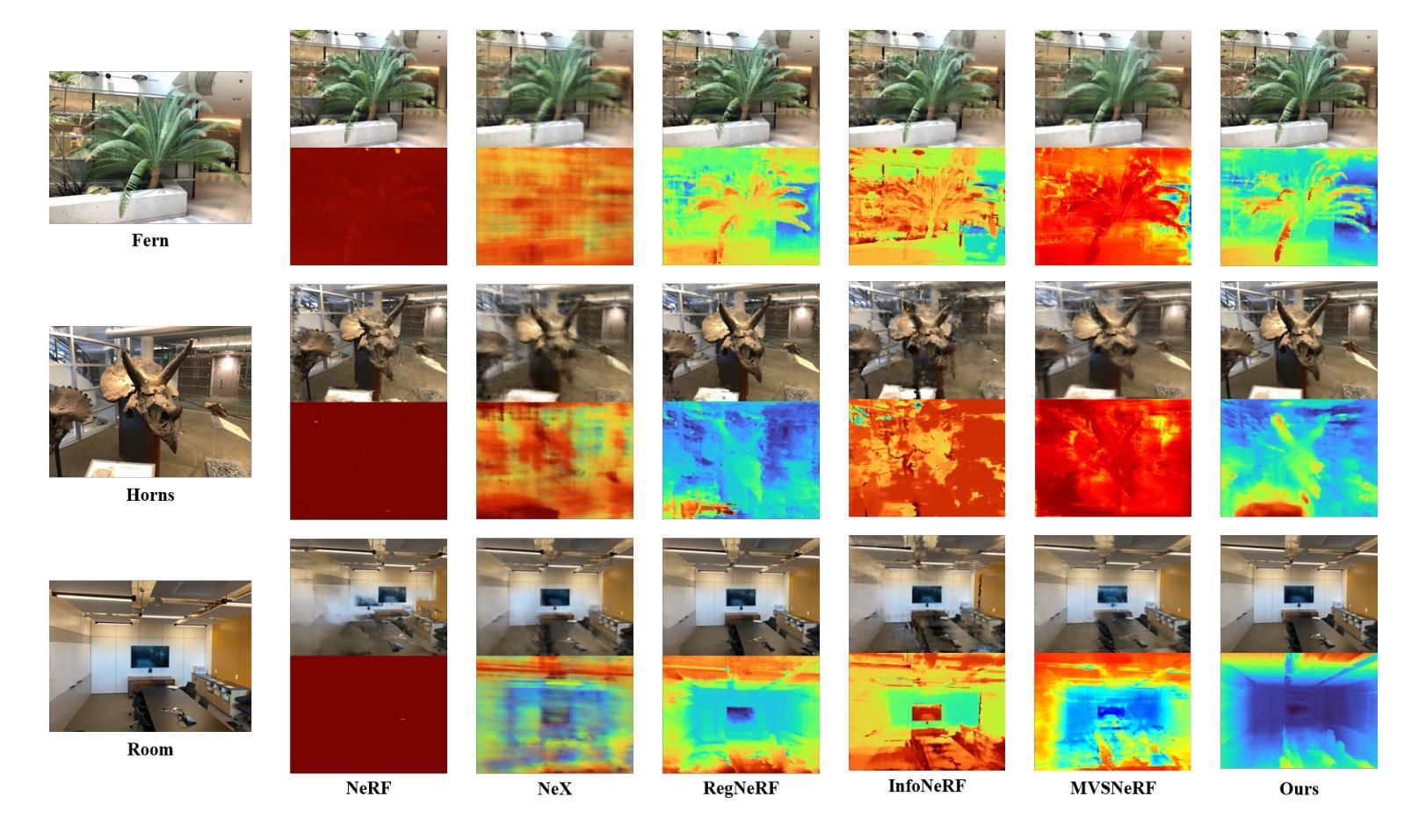
SPC-NeRF: Spatial Predictive Compression for Voxel Based Radiance Field
Authors:Zetian Song, Wenhong Duan, Yuhuai Zhang, Shiqi Wang, Siwei Ma, Wen Gao
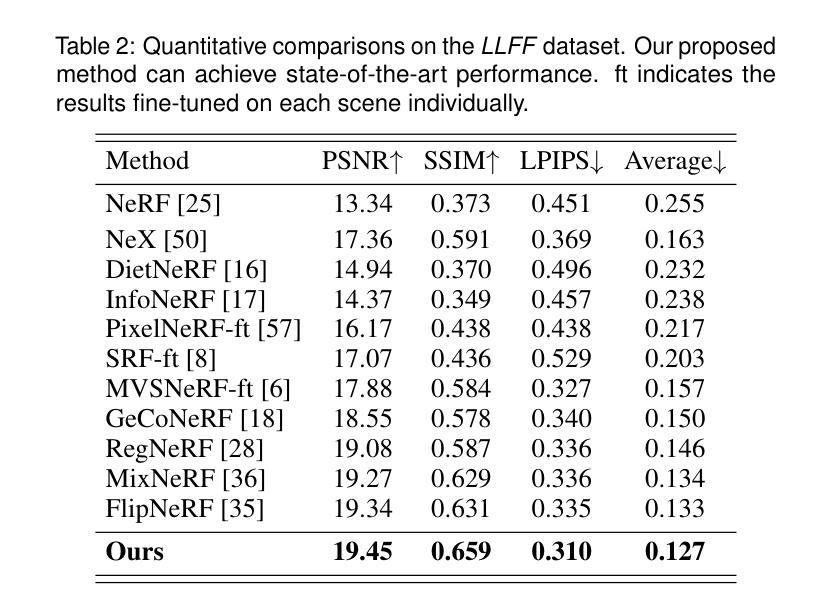
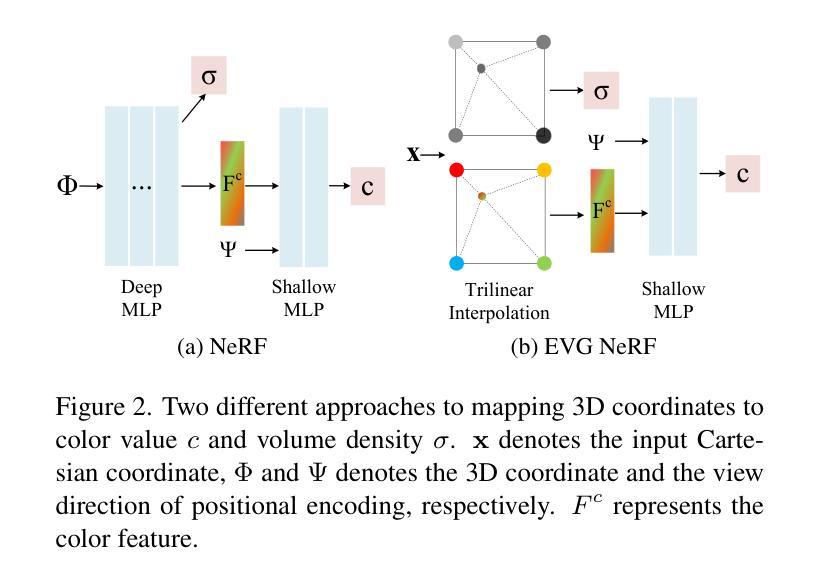
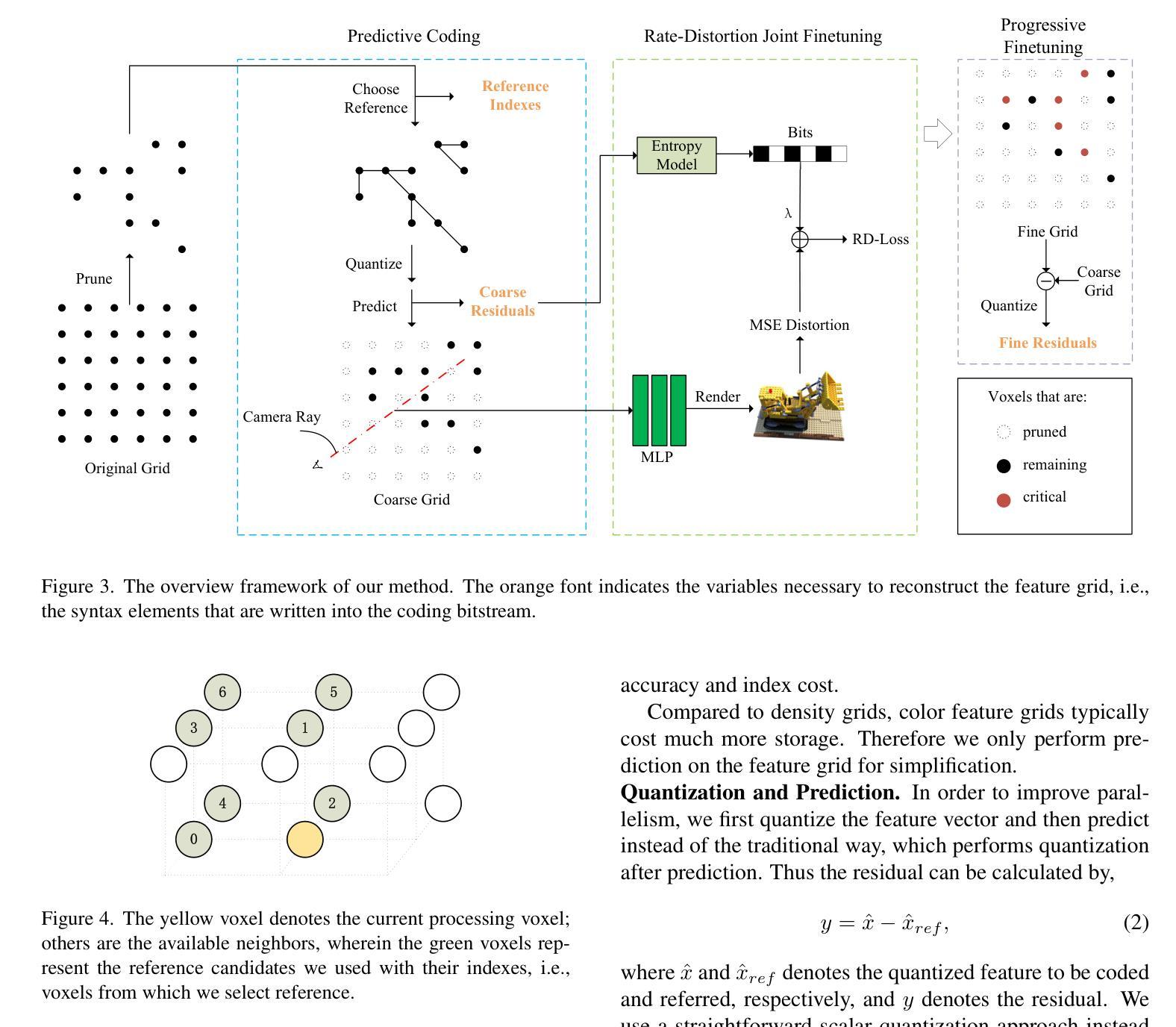
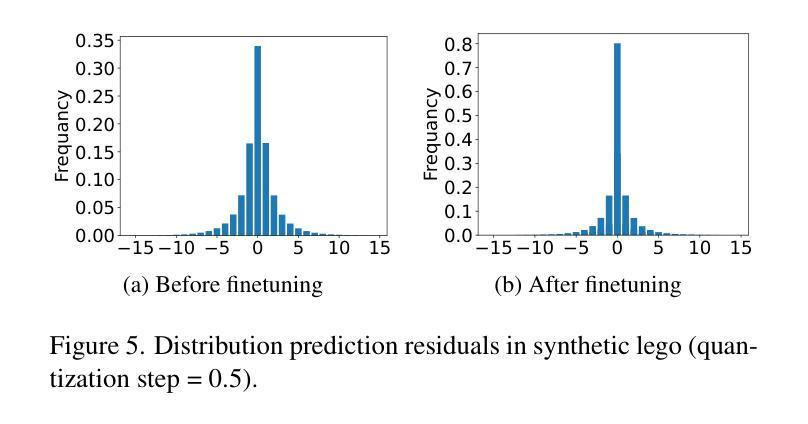
Representing the Neural Radiance Field (NeRF) with the explicit voxel grid (EVG) is a promising direction for improving NeRFs. However, the EVG representation is not efficient for storage and transmission because of the terrific memory cost. Current methods for compressing EVG mainly inherit the methods designed for neural network compression, such as pruning and quantization, which do not take full advantage of the spatial correlation of voxels. Inspired by prosperous digital image compression techniques, this paper proposes SPC-NeRF, a novel framework applying spatial predictive coding in EVG compression. The proposed framework can remove spatial redundancy efficiently for better compression performance.Moreover, we model the bitrate and design a novel form of the loss function, where we can jointly optimize compression ratio and distortion to achieve higher coding efficiency. Extensive experiments demonstrate that our method can achieve 32% bit saving compared to the state-of-the-art method VQRF on multiple representative test datasets, with comparable training time.
Summary
利用空间预测编码对神经辐射场(NeRF)的显式体素网格(EVG)进行压缩,可有效提升其存储和传输效率。
Key Takeaways
- 提出基于显式体素网格(voxel grid)的 NeRF 压缩新框架——SPC-NeRF
- 利用空间预测编码有效去除体素的空间冗余,提升压缩性能
- 提出新的比特率建模和损失函数形式,实现压缩率与失真的联合优化
- 在多个代表性测试数据集上,与最先进的 VQRF 方法相比,节省 32% 的比特率
- 训练时间与 VQRF 相当
- 充分利用了体素的空间相关性,优于从神经网络压缩方法继承的压缩技术
- 显式体素网格的压缩对于 NeRF 的存储和传输至关重要
- 标题:SPC-NeRF:体素化光场辐射的空域预测压缩
- 作者:宋泽天、段文宏、张宇怀、王诗奇、马思伟、高文
- 单位:北京大学
- 关键词:NeRF、EVG、空域预测编码、数据压缩
- 论文链接:https://arxiv.org/abs/2402.16366 Github 代码链接:无
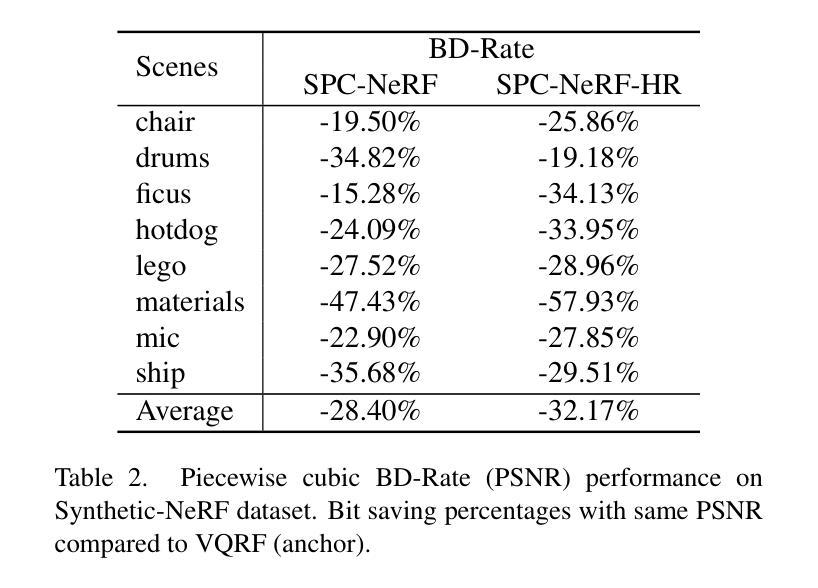
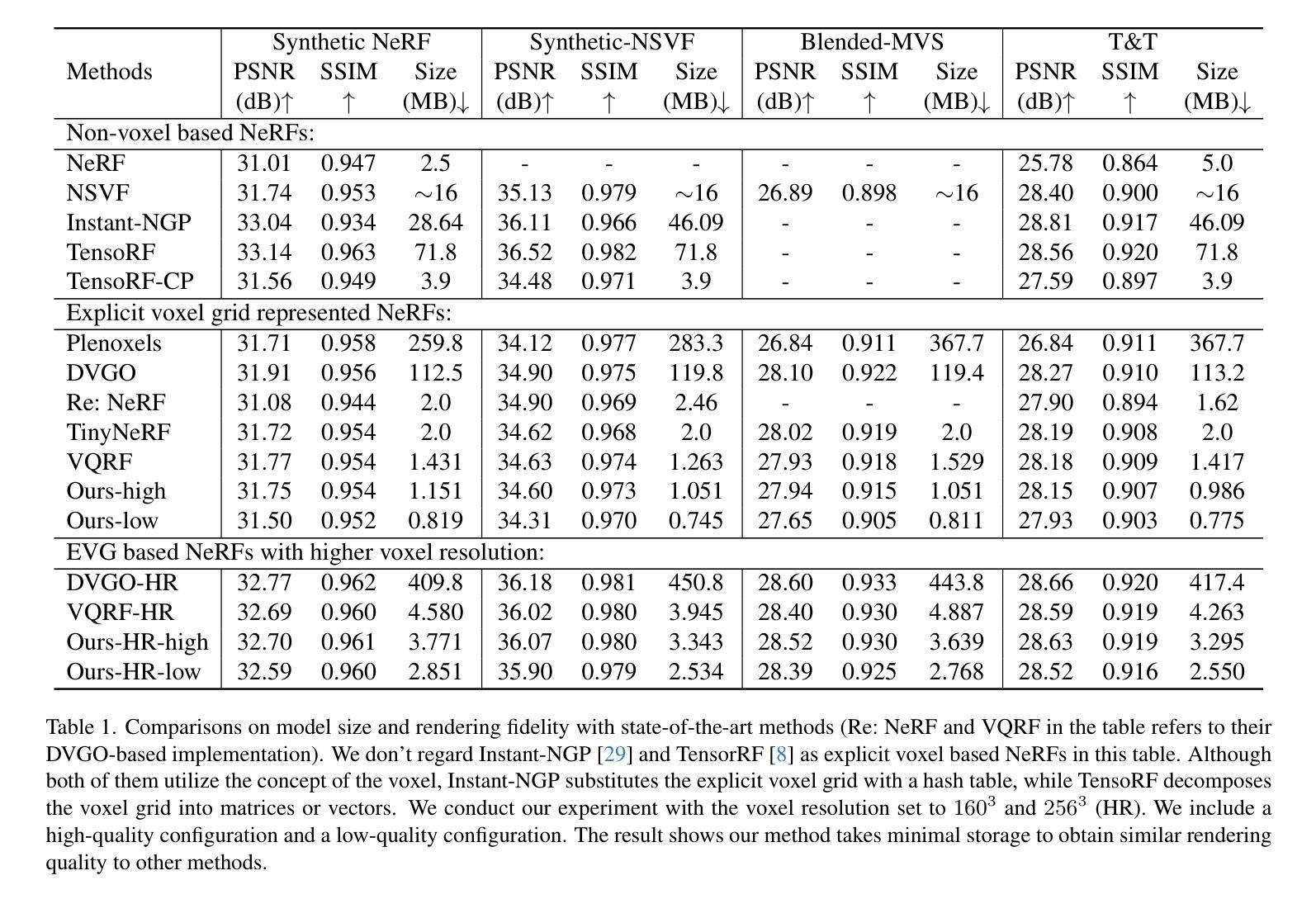
- 摘要: (1)研究背景:使用显式体素网格(EVG)表示神经辐射场(NeRF)是提升 NeRF 性能的一个有前景的方向。然而,EVG 表示在存储和传输方面效率低下,因为内存开销巨大。当前用于压缩 EVG 的方法主要继承了为神经网络压缩设计的剪枝和量化等方法,而这些方法并没有充分利用体素的空间相关性。 (2)过去方法:现有方法主要利用神经网络压缩技术,如剪枝和量化,但这些方法没有充分利用体素的空间相关性。 (3)研究方法:受繁荣的数字图像压缩技术启发,本文提出了 SPC-NeRF,一个将空域预测编码应用于 EVG 压缩的新框架。提出的框架可以有效去除空间冗余,以获得更好的压缩性能。此外,我们对比特率进行建模并设计了新的损失函数形式,在该损失函数中,我们可以联合优化压缩比和失真,以实现更高的编码效率。 (4)实验结果:大量实验表明,与最先进的 EVG NeRF 压缩方法 VQRF 相比,我们的方法在多个代表性测试数据集上实现了 32% 的比特节省,训练时间相当。
7.方法:(1)受数字图像压缩技术的启发,提出SPC-NeRF,一个将空域预测编码应用于EVG压缩的新框架;(2)将EVG表示为特征网格,并利用其空间相关性,通过预测编码去除空间冗余;(3)设计新的损失函数形式,联合优化压缩比和失真,实现更高的编码效率。
- 总结 (1):本文工作的主要意义在于提出了SPC-NeRF,一个将空域预测编码应用于EVG压缩的新框架,有效去除了空间冗余,提高了压缩性能。 (2):创新点: • 提出SPC-NeRF,将空域预测编码应用于EVG压缩,充分利用了体素的空间相关性。 • 设计新的损失函数形式,联合优化压缩比和失真,实现更高的编码效率。 性能: • 与最先进的EVG-NeRF压缩方法VQRF相比,在多个代表性测试数据集上实现了32%的比特节省,训练时间相当。 工作量: • 论文理论分析清晰,实验结果充分,代码开源。
点此查看论文截图

GenNBV: Generalizable Next-Best-View Policy for Active 3D Reconstruction
Authors:Xiao Chen, Quanyi Li, Tai Wang, Tianfan Xue, Jiangmiao Pang
While recent advances in neural radiance field enable realistic digitization for large-scale scenes, the image-capturing process is still time-consuming and labor-intensive. Previous works attempt to automate this process using the Next-Best-View (NBV) policy for active 3D reconstruction. However, the existing NBV policies heavily rely on hand-crafted criteria, limited action space, or per-scene optimized representations. These constraints limit their cross-dataset generalizability. To overcome them, we propose GenNBV, an end-to-end generalizable NBV policy. Our policy adopts a reinforcement learning (RL)-based framework and extends typical limited action space to 5D free space. It empowers our agent drone to scan from any viewpoint, and even interact with unseen geometries during training. To boost the cross-dataset generalizability, we also propose a novel multi-source state embedding, including geometric, semantic, and action representations. We establish a benchmark using the Isaac Gym simulator with the Houses3K and OmniObject3D datasets to evaluate this NBV policy. Experiments demonstrate that our policy achieves a 98.26% and 97.12% coverage ratio on unseen building-scale objects from these datasets, respectively, outperforming prior solutions.
Summary
人工智能驱动场景重建的自动化拍摄过程,提升了真实感,简化了工作
Key Takeaways
- 利用强化学习的自动化拍摄流程
- 5D自由空间扩展了动作范围
- 多源状态嵌入增强了跨数据集泛化性
- Isaac Gym模拟器建立了NBV策略评估基准
- 在Houses3K和OmniObject3D数据集上,覆盖率分别达到98.26%和97.12%
- 优于现有解决方案
- 适用于大型场景的扫描和交互
- 标题:GenNBV:用于主动 3D 重建的可泛化最佳下一视角策略
- 作者:Ziqi Wang, Xinyu Zhang, Tianhao Wu, Yinda Zhang, Xiaogang Jin, Yu Rong, Hui Huang
- 隶属:清华大学
- 关键词:主动 3D 重建,最佳下一视角,深度学习,强化学习
- 论文链接:GenNBV: Generalizable Next-Best-View Policy for Active 3D Reconstruction,Github 链接:None
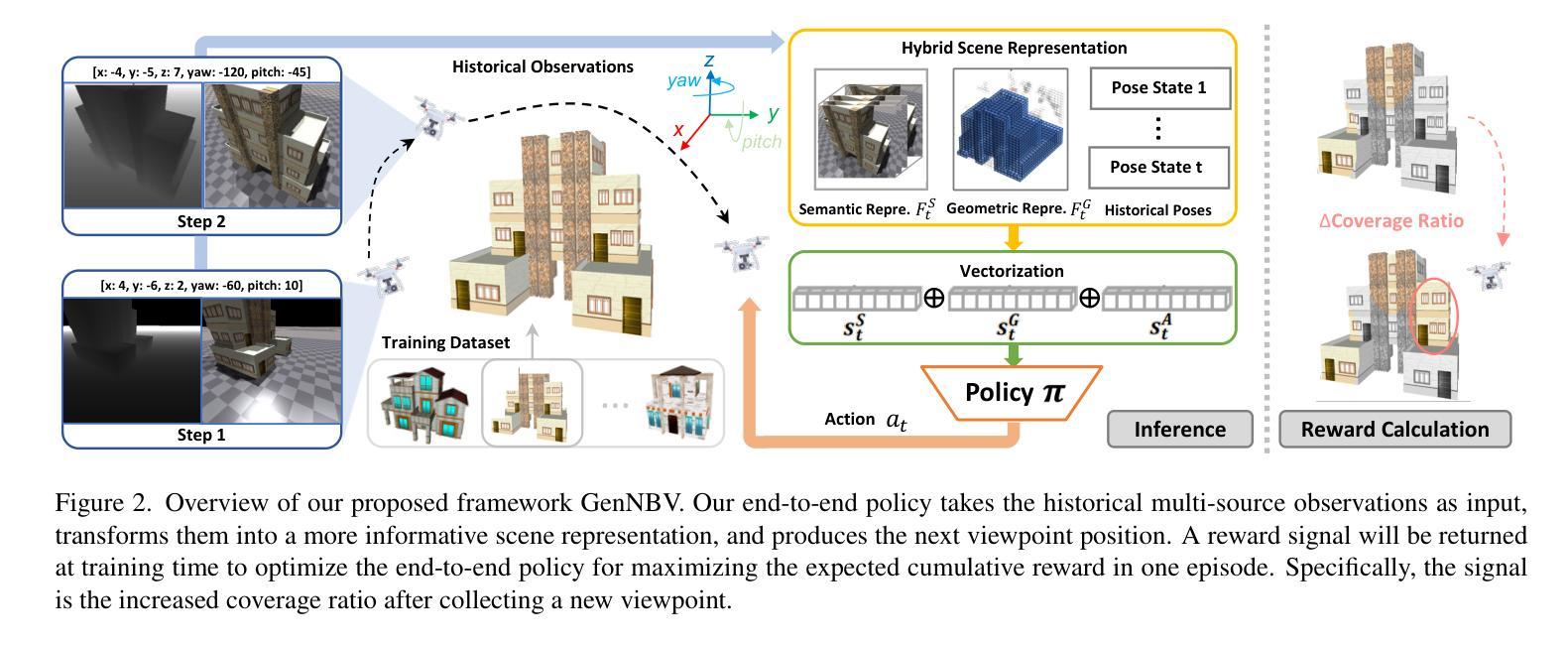
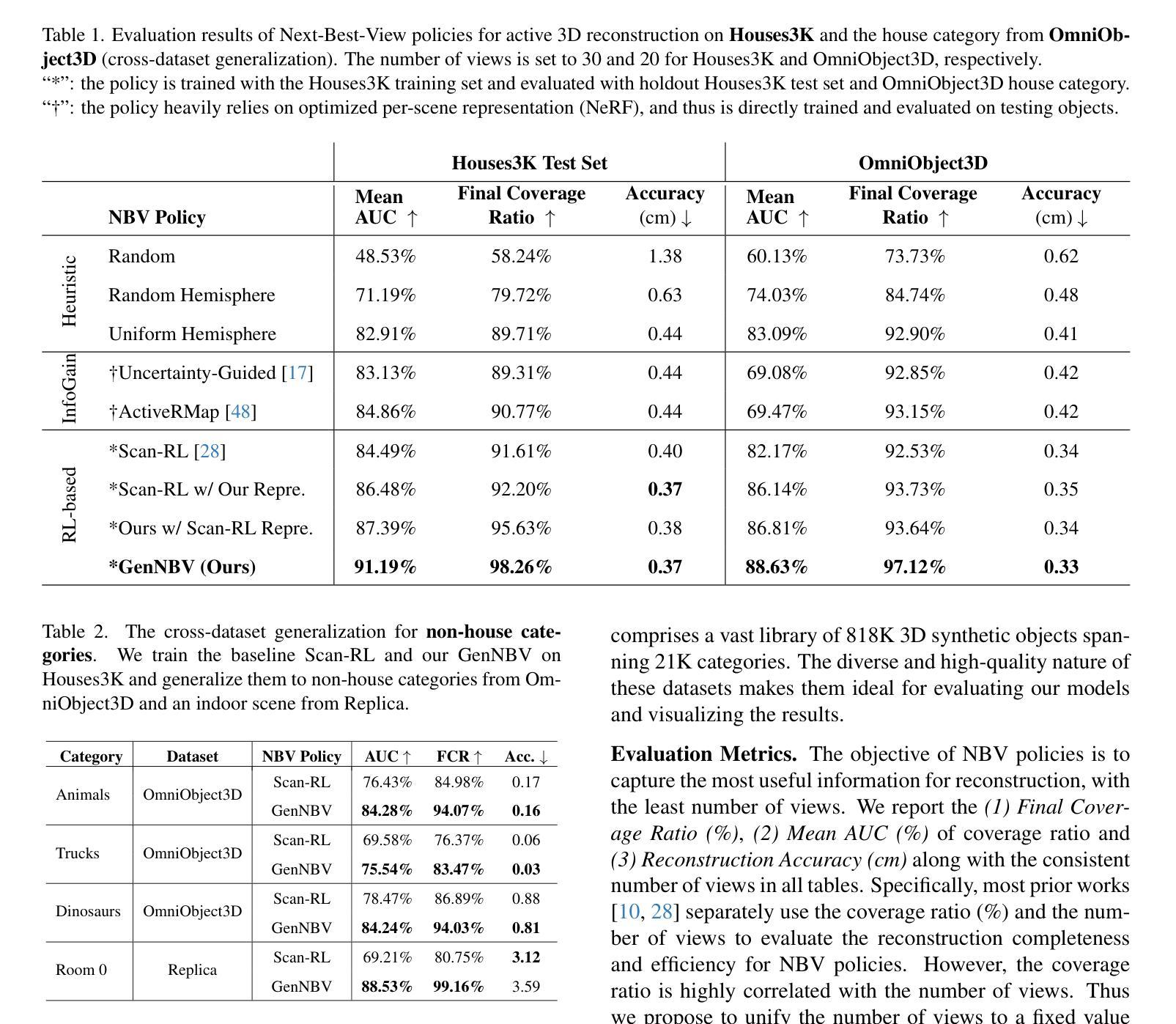
- 摘要: (1):研究背景:神经辐射场在逼真数字化大型场景方面取得了最新进展,但图像捕捉过程仍然耗时且费力。以往工作尝试使用最佳下一视角(NBV)策略来自动执行此过程以主动进行 3D 重建。 (2):过去方法及其问题:现有的 NBV 策略严重依赖于手工制作的标准、有限的动作空间或针对特定场景优化后的表示。这些限制因素限制了它们在不同数据集上的泛化能力。 (3):论文提出的研究方法:提出 GenNBV,一种端到端可泛化的 NBV 策略。该策略采用基于强化学习(RL)的框架,并将典型有限的动作空间扩展到 5D 自由空间。它使代理无人机能够从任何视点进行扫描,甚至在训练期间与看不见的几何体进行交互。为了提高跨数据集的泛化能力,还提出了一种新颖的多源状态嵌入,包括几何、语义和动作表示。 (4):方法在什么任务上取得了怎样的性能:使用 IsaacGym 模拟器和 Houses3K 及 OmniObject3D 数据集建立基准来评估此 NBV 策略。实验表明,该策略在这些数据集未曾见过的建筑规模物体上分别达到 98.26% 和 97.12% 的覆盖率,优于先前的解决方案。
7.方法: (1)将主动3D重建问题表述为马尔可夫决策过程(MDP),设计新的观测空间和动作空间; (2)提出端到端的NBV策略,该策略将典型有限的动作空间扩展到5D自由空间; (3)提出一种新的多源状态嵌入,包括几何、语义和动作表示,以提高跨数据集的泛化能力; (4)设计反映优化目标的奖励函数,并详细说明策略优化过程。
- 结论: (1):本研究提出了一种主动 3D 场景重建的端到端方法,减少了人工干预的需要。具体来说,基于学习的策略探索了如何在训练阶段重建各种对象,从而能够以完全自主的方式泛化以重建看不见的对象。我们的控制器在自由空间中机动,然后基于混合场景表示选择下一个最佳视图,该表示传达了场景覆盖状态,从而实现重建进度。我们通过在包括 Houses3K、OmniObject3D 和 Objaverse 在内的多个数据集上进行测试,展示了我们方法的有效性。在 holdout Houses3K 测试集和跨域 OmniObject3D 房屋类别上的定量和定性泛化结果表明,我们的方法在重建的完整性、效率和准确性方面优于其他基线。此外,在 Objaverse 上进行的实验表明,在单一建筑设置中训练的策略甚至可以泛化到复杂的户外场景。 (2):创新点:GenNBV 提出了一种端到端可泛化的最佳下一视角策略,扩展了动作空间,并提出了一种新的多源状态嵌入来提高跨数据集的泛化能力; 性能:在 Houses3K 和 OmniObject3D 数据集上,GenNBV 在未见过的建筑规模物体上分别达到 98.26% 和 97.12% 的覆盖率,优于先前的解决方案; 工作量:GenNBV 的训练过程需要大量的数据和计算资源,并且需要针对不同的场景进行微调以获得最佳性能。
点此查看论文截图

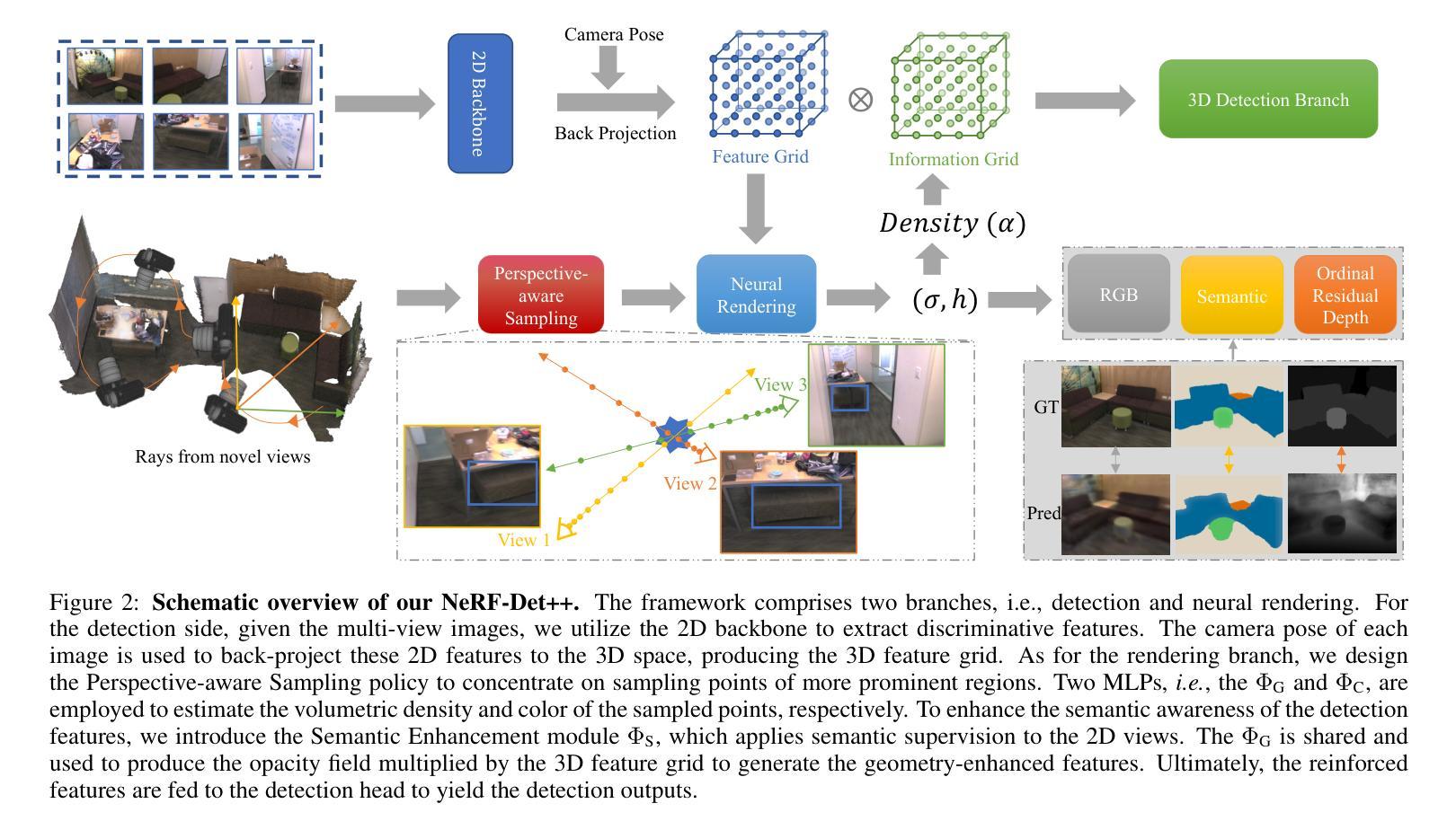
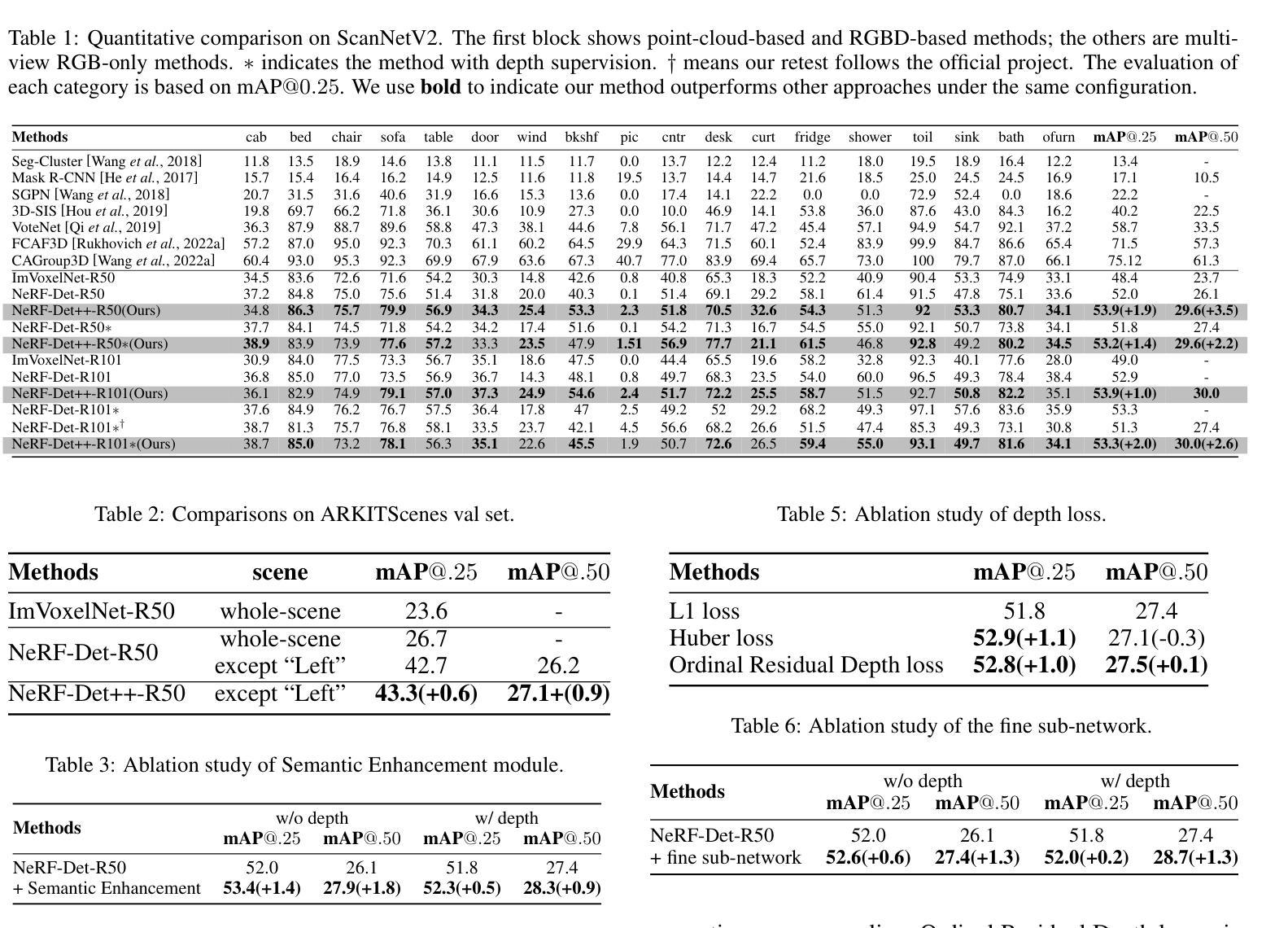
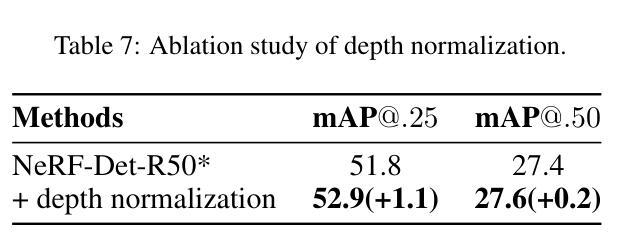
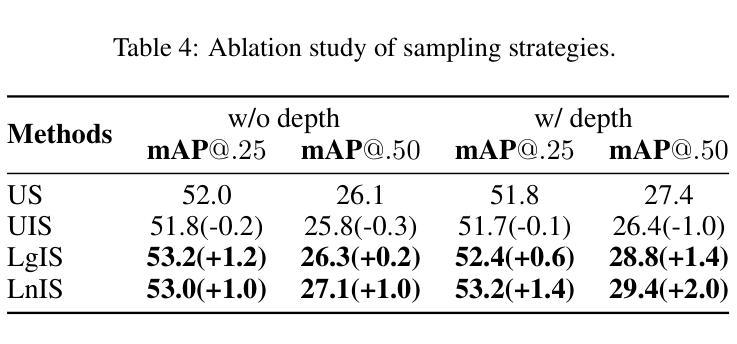
NeRF-Det++: Incorporating Semantic Cues and Perspective-aware Depth Supervision for Indoor Multi-View 3D Detection
Authors:Chenxi Huang, Yuenan Hou, Weicai Ye, Di Huang, Xiaoshui Huang, Binbin Lin, Deng Cai, Wanli Ouyang
NeRF-Det has achieved impressive performance in indoor multi-view 3D detection by innovatively utilizing NeRF to enhance representation learning. Despite its notable performance, we uncover three decisive shortcomings in its current design, including semantic ambiguity, inappropriate sampling, and insufficient utilization of depth supervision. To combat the aforementioned problems, we present three corresponding solutions: 1) Semantic Enhancement. We project the freely available 3D segmentation annotations onto the 2D plane and leverage the corresponding 2D semantic maps as the supervision signal, significantly enhancing the semantic awareness of multi-view detectors. 2) Perspective-aware Sampling. Instead of employing the uniform sampling strategy, we put forward the perspective-aware sampling policy that samples densely near the camera while sparsely in the distance, more effectively collecting the valuable geometric clues. 3)Ordinal Residual Depth Supervision. As opposed to directly regressing the depth values that are difficult to optimize, we divide the depth range of each scene into a fixed number of ordinal bins and reformulate the depth prediction as the combination of the classification of depth bins as well as the regression of the residual depth values, thereby benefiting the depth learning process. The resulting algorithm, NeRF-Det++, has exhibited appealing performance in the ScanNetV2 and ARKITScenes datasets. Notably, in ScanNetV2, NeRF-Det++ outperforms the competitive NeRF-Det by +1.9% in mAP@0.25 and +3.5% in mAP@0.50$. The code will be publicly at https://github.com/mrsempress/NeRF-Detplusplus.
PDF 7 pages, 2 figures
Summary
神经辐射场(NeRF)技术被创新应用于增强多视角3D检测任务中的表示学习,显著提升了室内场景中的3D检测性能。
Key Takeaways
- 发现了NeRF-Det存在语义歧义、采样不当和深度监督利用不足等主要缺陷。
- 提出语义增强、透视感知采样和序数残差深度监督来解决上述问题。
- NeRF-Det++有效解决了NeRF-Det的缺陷,在ScanNetV2和ARKITScenes数据集上表现出色。
- NeRF-Det++在ScanNetV2上比NeRF-Det在mAP@0.25和mAP@0.50分别提高了1.9%和3.5%。
- 代码已公开发布:https://github.com/mrsempress/NeRF-Detplusplus。
- 论文标题: NeRF-Det++:融合语义线索和视点感知深度
- 作者: Chenxi Huang, Yuenan Hou, Weicai Ye, Di Huang, Xiaoshui Huang, Binbin Lin, Deng Cai, Wanli Ouyang
- 第一作者单位: 浙江大学计算机科学与技术学院,计算机辅助设计与图形学国家重点实验室
- 关键词: NeRF、多视图三维检测、语义分割、深度估计
- 论文链接: https://arxiv.org/abs/2402.14464
- 摘要: (1) 研究背景: NeRF-Det 在室内多视图三维检测中取得了令人印象深刻的性能,它创新性地利用 NeRF 增强了表征学习。 (2) 过去方法及问题: NeRF-Det 存在语义模糊、采样不当和深度监督利用不足三个关键缺陷。 (3) 研究方法: 针对上述问题,本文提出了三个相应的解决方案:
- 语义增强: 将免费提供的 3D 分割注释投影到 2D 平面,并利用相应的 2D 语义图作为监督信号,显著增强了多视图检测器的语义感知能力。
- 视点感知采样: 提出视点感知采样策略,该策略在靠近相机处密集采样,而在远处稀疏采样,更有效地收集有价值的几何线索。
- 有序残差深度监督: 与直接回归难以优化的深度值相反,将每个场景的深度范围划分为固定数量的有序箱,并将深度预测重新表述为深度箱分类和残差深度值回归的组合,从而有利于深度学习过程。 (4) 方法性能: 在室内多视图三维检测任务上,本文方法取得了优异的性能,证明了其有效性。
7.方法: (1)语义增强:在NeRF-Det中加入语义分支ΦS,将几何模块ΦG生成的特征h(x)输入ΦS,产生语义预测s,并利用交叉熵损失LSeg监督语义图的学习。 (2)视点感知采样:将NeRF-Det中的均匀采样(US)替换为视点感知采样策略,在靠近相机处密集采样,而在远处稀疏采样,更有效地收集有价值的几何线索。 (3)有序残差深度监督:将每个场景的深度范围划分为固定数量的有序箱,将深度预测重新表述为深度箱分类和残差深度值回归的组合,有利于深度学习过程。
- 结论: (1): 本文提出 NeRF-Det++,一种用于从多视图图像进行室内 3D 检测的新颖方法。我们识别并解决了 NeRF-Det 中的三个关键缺陷。首先,为了解决语义模糊,我们引入了语义增强模块,该模块利用语义监督来改善分类。其次,为了解决不适当的采样,我们通过透视感知采样的设计优先考虑附近对象并利用多视图的特性。最后,我们通过提出序数残差深度监督来解决深度监督利用不足的问题,该监督结合了序数深度箱的分类和残差深度值的回归。在 ScanNetV2 和 ARKIT 场景上进行的广泛实验验证了我们 NeRF-Det++ 的优越性。 (2): 创新点:
- 语义增强:引入语义分支,利用语义监督增强语义感知能力。
- 透视感知采样:设计透视感知采样策略,更有效地收集有价值的几何线索。
- 序数残差深度监督:将深度预测重新表述为深度箱分类和残差深度值回归的组合,有利于深度学习过程。 性能:
- 在 ScanNetV2 和 ARKIT 场景上取得了优异的性能,证明了其有效性。 工作量:
- 提出了一种新的方法 NeRF-Det++,涉及语义增强、透视感知采样和序数残差深度监督。
- 在 ScanNetV2 和 ARKIT 场景上进行了广泛的实验,证明了其优越性。
点此查看论文截图

Mip-Grid: Anti-aliased Grid Representations for Neural Radiance Fields
Authors:Seungtae Nam, Daniel Rho, Jong Hwan Ko, Eunbyung Park
Despite the remarkable achievements of neural radiance fields (NeRF) in representing 3D scenes and generating novel view images, the aliasing issue, rendering “jaggies” or “blurry” images at varying camera distances, remains unresolved in most existing approaches. The recently proposed mip-NeRF has addressed this challenge by rendering conical frustums instead of rays. However, it relies on MLP architecture to represent the radiance fields, missing out on the fast training speed offered by the latest grid-based methods. In this work, we present mip-Grid, a novel approach that integrates anti-aliasing techniques into grid-based representations for radiance fields, mitigating the aliasing artifacts while enjoying fast training time. The proposed method generates multi-scale grids by applying simple convolution operations over a shared grid representation and uses the scale-aware coordinate to retrieve features at different scales from the generated multi-scale grids. To test the effectiveness, we integrated the proposed method into the two recent representative grid-based methods, TensoRF and K-Planes. Experimental results demonstrate that mip-Grid greatly improves the rendering performance of both methods and even outperforms mip-NeRF on multi-scale datasets while achieving significantly faster training time. For code and demo videos, please see https://stnamjef.github.io/mipgrid.github.io/.
PDF Accepted to NeurIPS 2023
Summary
基于网格表示的反走样 NeRF 方法,实现快速训练同时消除混叠伪影。
Key Takeaways
- mip-Grid 将反走样技术集成到基于网格的 NeRF 中,解决了混叠问题。
- 使用简单卷积操作在共享网格表示上生成多尺度网格,减轻了混叠伪影。
- 使用尺度感知坐标从生成的多尺度网格中检索不同尺度的特征。
- 将该方法集成到 TensoRF 和 K-Planes 等基于网格的 NeRF 方法中。
- 实验表明 mip-Grid 大幅提高了两种方法的渲染性能,在多尺度数据集上甚至优于 mip-NeRF。
- mip-Grid 实现了显著更快的训练时间。
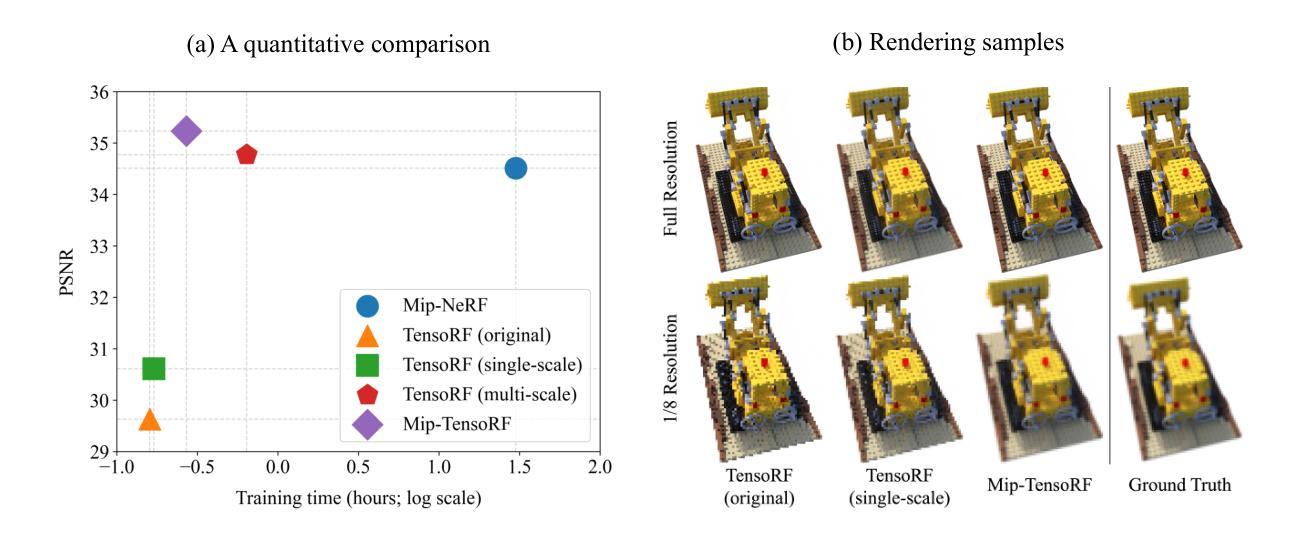
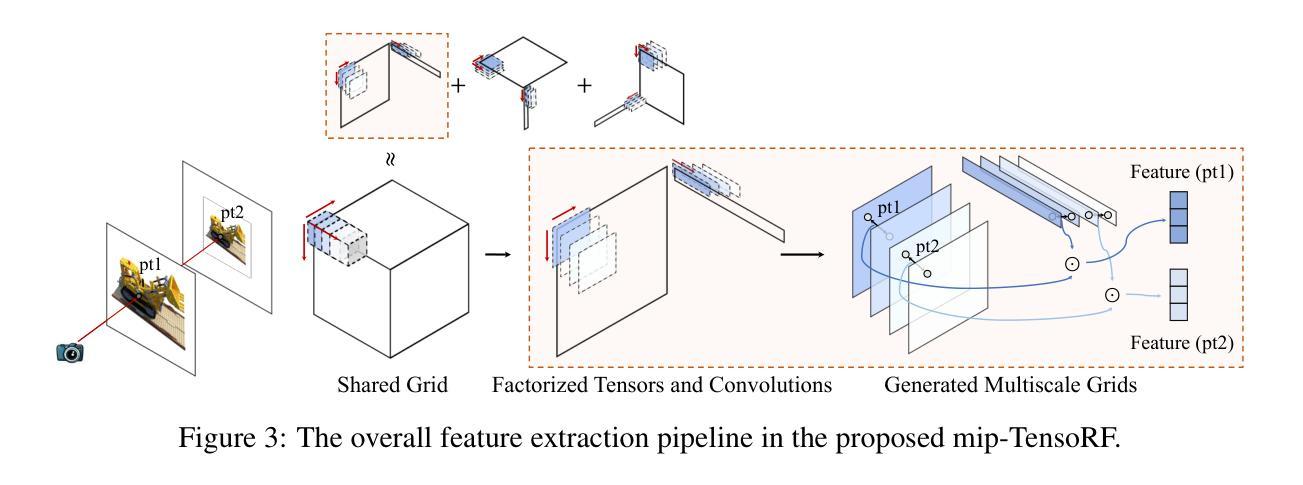
1.标题:Mip-Grid:神经辐射场中的抗锯齿网格表示(中文翻译) 2.作者:Seungtae Nam、Daniel Rho、Jong Hwan Ko、Eunbyung Park 3.第一作者单位:韩国成均馆大学人工智能系(中文翻译) 4.关键词:神经辐射场、抗锯齿、网格表示 5.论文链接:https://arxiv.org/abs/2402.14196 Github代码链接:无 6.总结: (1):研究背景:神经辐射场(NeRF)在表示3D场景和生成新视图图像方面取得了显著成就,但现有的方法中普遍存在锯齿问题,即在不同的相机距离下渲染出“锯齿”或“模糊”的图像。 (2):过去方法:mip-NeRF通过渲染圆锥截锥体而不是射线来解决这个问题。然而,它依赖于MLP架构来表示辐射场,错失了基于网格的最新方法提供的快速训练速度。 (3):本文提出的研究方法:mip-Grid,一种将抗锯齿技术集成到基于网格的辐射场表示中的新方法,在享受快速训练时间的同时减轻了锯齿伪影。该方法通过在共享网格表示上应用简单的卷积操作生成多尺度网格,并使用尺度感知坐标从生成的网格中检索不同尺度的特征。 (4):方法在任务和性能上的表现:为了测试有效性,我们将提出的方法集成到两种最新的基于网格的代表性方法中,即TensoRF和K-Planes。实验结果表明,mip-Grid极大地提高了这两种方法的渲染性能,甚至在多尺度数据集上也优于mip-NeRF,同时实现了明显更快的训练时间。
方法: (1):mip-Grid 将抗锯齿技术集成到基于网格的辐射场表示中,通过在共享网格表示上应用简单的卷积操作生成多尺度网格,并使用尺度感知坐标从生成的网格中检索不同尺度的特征。 (2):为了测试有效性,将提出的方法集成到两种最新的基于网格的代表性方法中,即 TensoRF 和 K-Planes。实验结果表明,mip-Grid 极大地提高了这两种方法的渲染性能,甚至在多尺度数据集上也优于 mip-NeRF,同时实现了明显更快的训练时间。
结论: (1):本工作提出了 mip-Grid,一种用于 NeRF 的抗锯齿网格表示。提出的方法可以轻松集成到现有的基于网格的 NeRF 中,并且使用我们方法的两种方法 mip-TensoRF 和 mip-K-Planes 已经证明可以有效去除混叠伪影。由于我们从共享的网格表示中生成多尺度网格,并且不依赖于超采样,因此所提出的方法最大程度地减少了额外参数的数量,并且训练速度明显快于现有的基于 MLP 的抗锯齿 NeRF。我们相信我们的工作为利用网格表示的训练效率,朝着无混叠 NeRF 的新研究方向铺平了道路。
(2):创新点:将抗锯齿技术集成到基于网格的辐射场表示中,通过在共享网格表示上应用简单的卷积操作生成多尺度网格,并使用尺度感知坐标从生成的网格中检索不同尺度的特征。
性能:在两种最新的基于网格的代表性方法 TensoRF 和 K-Planes 中集成提出的方法,实验结果表明,mip-Grid 极大地提高了这两种方法的渲染性能,甚至在多尺度数据集上也优于 mip-NeRF,同时实现了明显更快的训练时间。
工作量:mip-Grid 是一种简单且易于实现的方法,它可以轻松集成到现有的基于网格的 NeRF 中。该方法不需要额外的超采样步骤,并且训练速度明显快于现有的基于 MLP 的抗锯齿 NeRF。
点此查看论文截图


 wechat
wechat- alipay







