Diffusion Models
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-03-04 更新
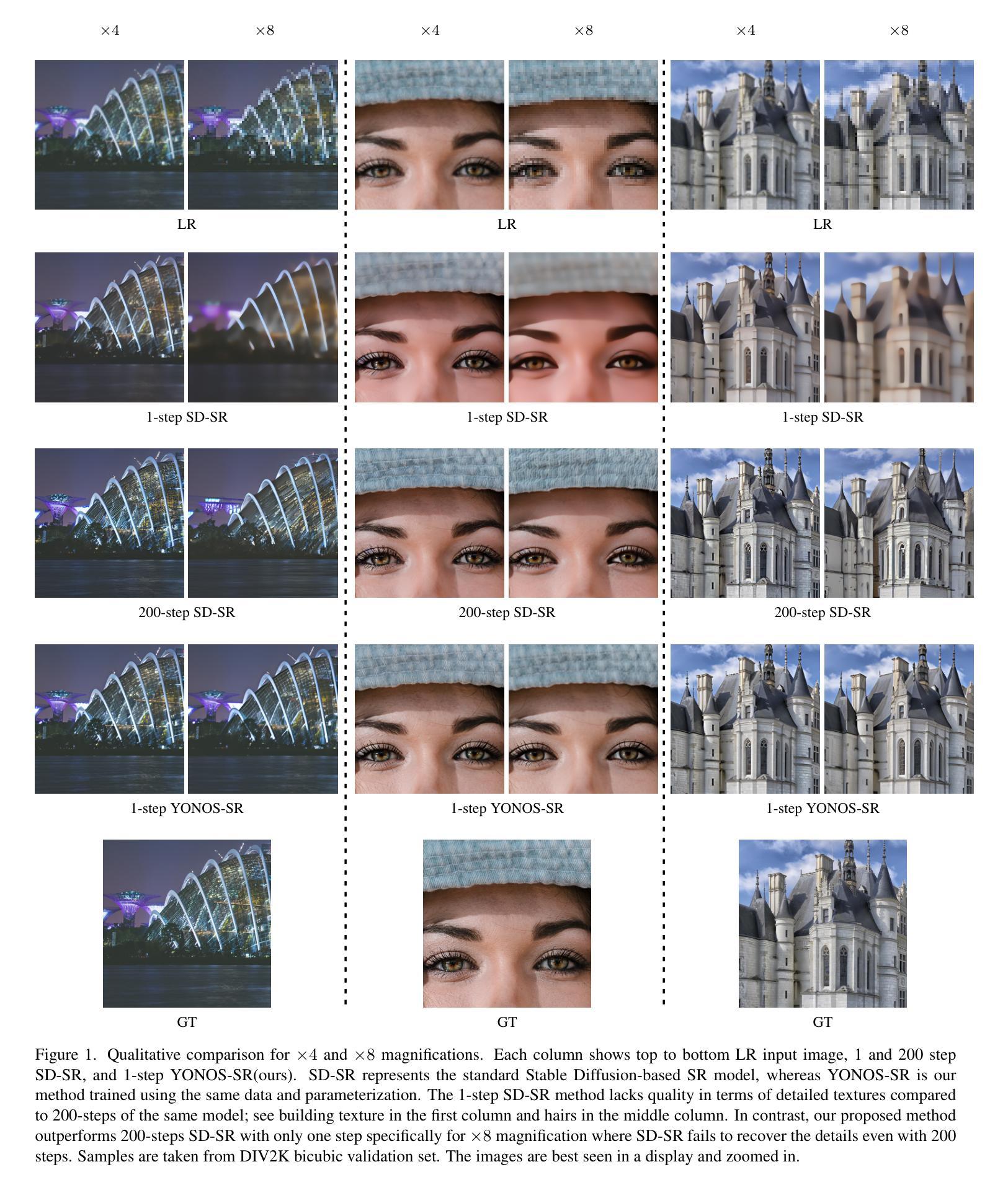
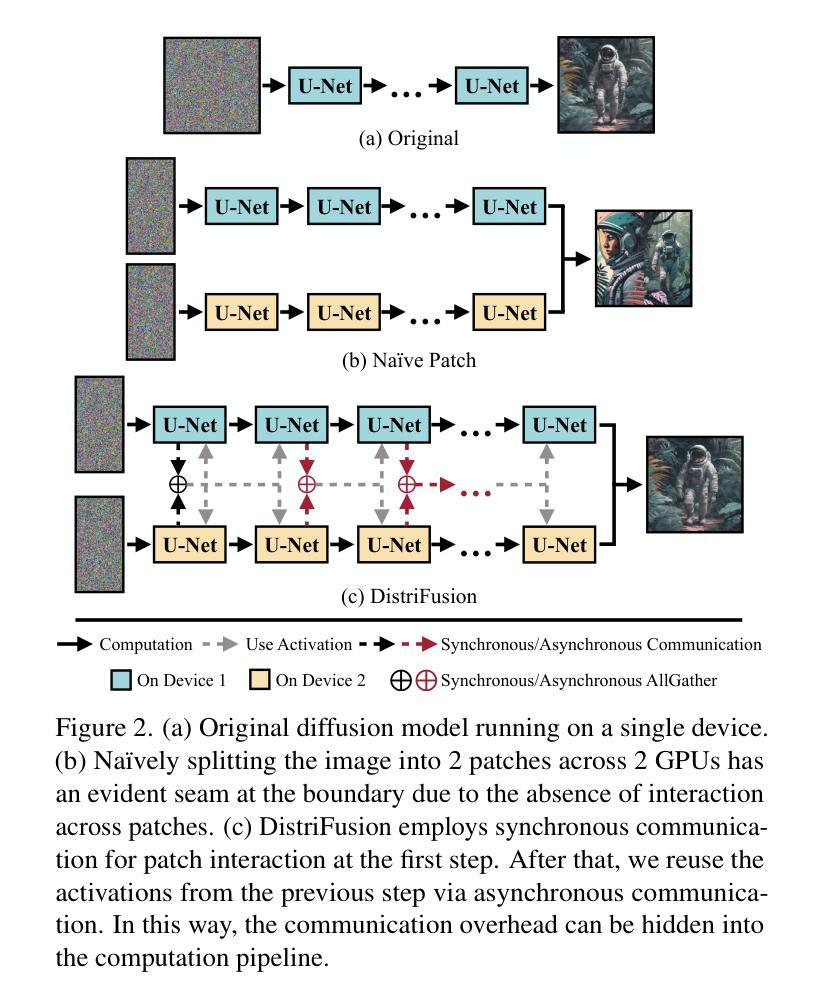
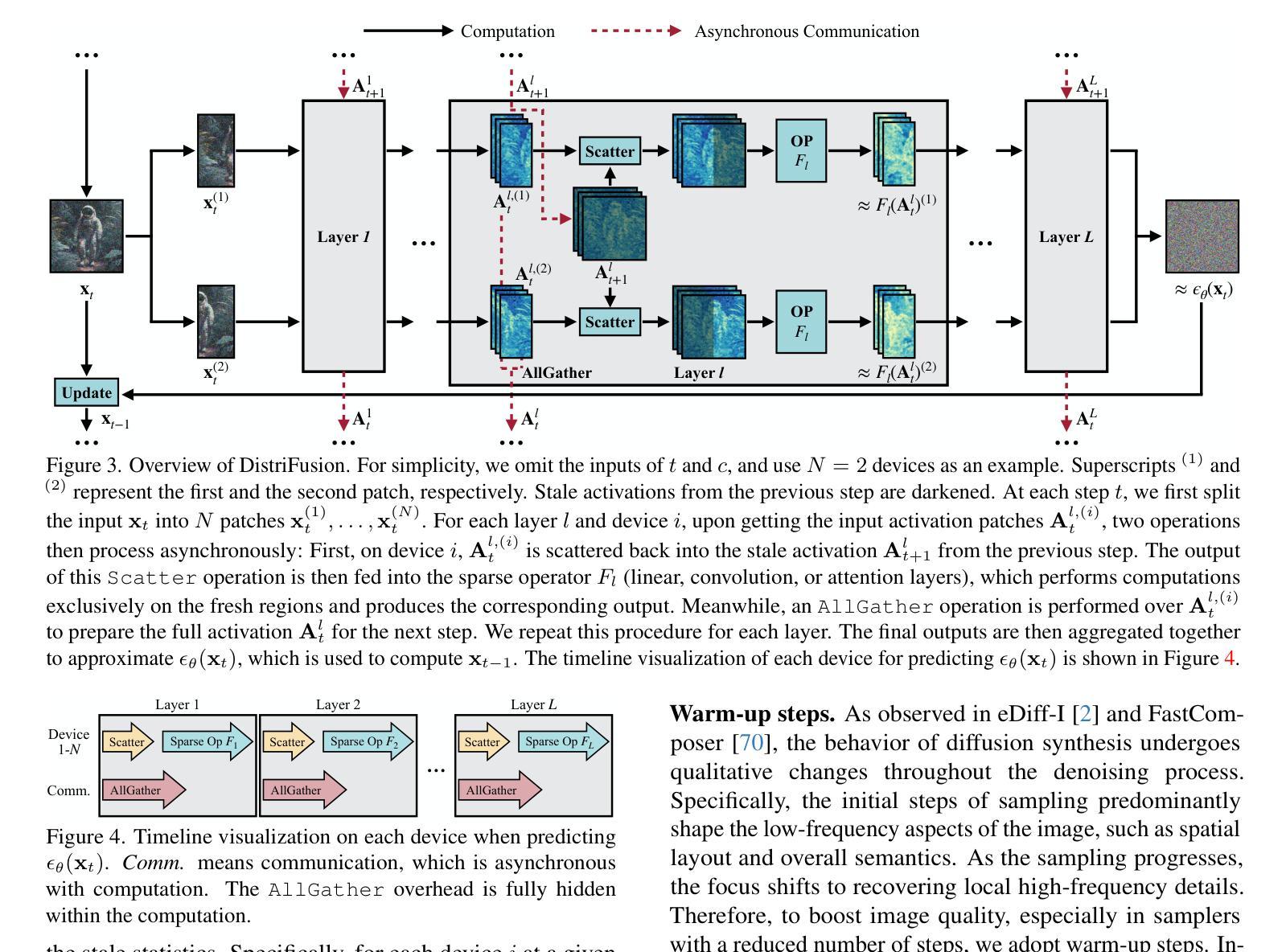
DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models
Authors:Muyang Li, Tianle Cai, Jiaxin Cao, Qinsheng Zhang, Han Cai, Junjie Bai, Yangqing Jia, Ming-Yu Liu, Kai Li, Song Han
Diffusion models have achieved great success in synthesizing high-quality images. However, generating high-resolution images with diffusion models is still challenging due to the enormous computational costs, resulting in a prohibitive latency for interactive applications. In this paper, we propose DistriFusion to tackle this problem by leveraging parallelism across multiple GPUs. Our method splits the model input into multiple patches and assigns each patch to a GPU. However, na\”{\i}vely implementing such an algorithm breaks the interaction between patches and loses fidelity, while incorporating such an interaction will incur tremendous communication overhead. To overcome this dilemma, we observe the high similarity between the input from adjacent diffusion steps and propose displaced patch parallelism, which takes advantage of the sequential nature of the diffusion process by reusing the pre-computed feature maps from the previous timestep to provide context for the current step. Therefore, our method supports asynchronous communication, which can be pipelined by computation. Extensive experiments show that our method can be applied to recent Stable Diffusion XL with no quality degradation and achieve up to a 6.1$\times$ speedup on eight NVIDIA A100s compared to one. Our code is publicly available at https://github.com/mit-han-lab/distrifuser.
PDF CVPR 2024 Code: https://github.com/mit-han-lab/distrifuser Website: https://hanlab.mit.edu/projects/distrifusion Blog: https://hanlab.mit.edu/blog/distrifusion
Summary
利用多GPU实现并行处理,提升高分辨率图像生成效率,并通过复用特征图降低通信开销,显著加速扩散模型推理。
Key Takeaways
- 多GPU并行处理可大幅提升扩散模型推理速度。
- 将模型输入拆分为多个patch,分配给不同GPU处理。
- 位移patch并行机制,利用相邻扩散步长的相似性,复用特征图减少通信开销。
- 支持异步通信,可与计算流水线化。
- 在Stable Diffusion XL模型上验证有效性,无质量损失且加速6.1倍。
- 已开源代码:https://github.com/mit-han-lab/distrifuser.
- 标题:DistriFusion:用于高分辨率扩散模型的分布式并行推理
- 作者:Muyang Li、Tianle Cai、Jiaxin Cao、Qinsheng Zhang、Han Cai、Junjie Bai、Yangqing Jia、Ming-Yu Liu、Kai Li、Song Han
- 第一作者单位:麻省理工学院
- 关键词:Diffusion Models、Parallel Inference、High-Resolution Images
- 论文链接:https://arxiv.org/abs/2402.19481 Github 代码链接:https://github.com/mit-han-lab/distrifuser
- 摘要: (1)研究背景:扩散模型在合成高质量图像方面取得了巨大成功。然而,使用扩散模型生成高分辨率图像仍然具有挑战性,因为计算成本巨大,导致交互式应用程序的延迟很高。 (2)过去方法及问题:过去的方法将模型输入拆分为多个块,并将其分配给不同的 GPU。然而,这种朴素的实现会破坏块之间的交互,从而降低保真度。而引入交互又会导致巨大的通信开销。 (3)研究方法:本文提出了 DistriFusion,通过利用多 GPU 的并行性来解决这个问题。该方法利用扩散过程的顺序性质,重用来自前一时间步的预计算特征图,为当前时间步提供上下文。 (4)任务和性能:DistriFusion 可以应用于最新的 Stable Diffusion XL,且不降低质量。与单个 GPU 相比,在八个 NVIDIA A100 上,该方法实现了高达 6.1 倍的加速。这些性能支持了他们的目标,即以较低的延迟生成高质量的高分辨率图像。
7. 方法 (1): DistriFusion通过利用扩散过程的顺序性质,重用来自前一时间步的预计算特征图,为当前时间步提供上下文,从而解决多GPU并行推理中块之间交互破坏保真度的问题。 (2): 该方法将模型输入拆分为多个块,并将其分配给不同的GPU,在每个GPU上独立执行扩散过程。 (3): 为了维护块之间的交互,DistriFusion利用了预计算特征图,这些特征图包含了前一时间步的上下文信息。 (4): 通过重用这些预计算特征图,DistriFusion避免了在块之间传输中间特征图的需要,从而减少了通信开销。 (5): 此外,DistriFusion还采用了异步执行机制,允许不同GPU在不同的时间步上工作,进一步提高了并行效率。
- 结论: (1)本工作通过提出 DistriFusion 方法,解决了高分辨率扩散模型分布式并行推理中块之间交互破坏保真度的难题,为交互式应用程序生成高质量高分辨率图像提供了支持。 (2)创新点:
- 利用扩散过程的顺序性质,重用预计算特征图,为当前时间步提供上下文,避免了块之间传输中间特征图的需要,减少了通信开销。
- 采用异步执行机制,允许不同 GPU 在不同的时间步上工作,进一步提高了并行效率。 性能:
- 在八个 NVIDIA A100 上,与单个 GPU 相比,实现了高达 6.1 倍的加速。 工作量:
- 该方法可以应用于最新的 StableDiffusionXL,且不降低质量。
点此查看论文截图


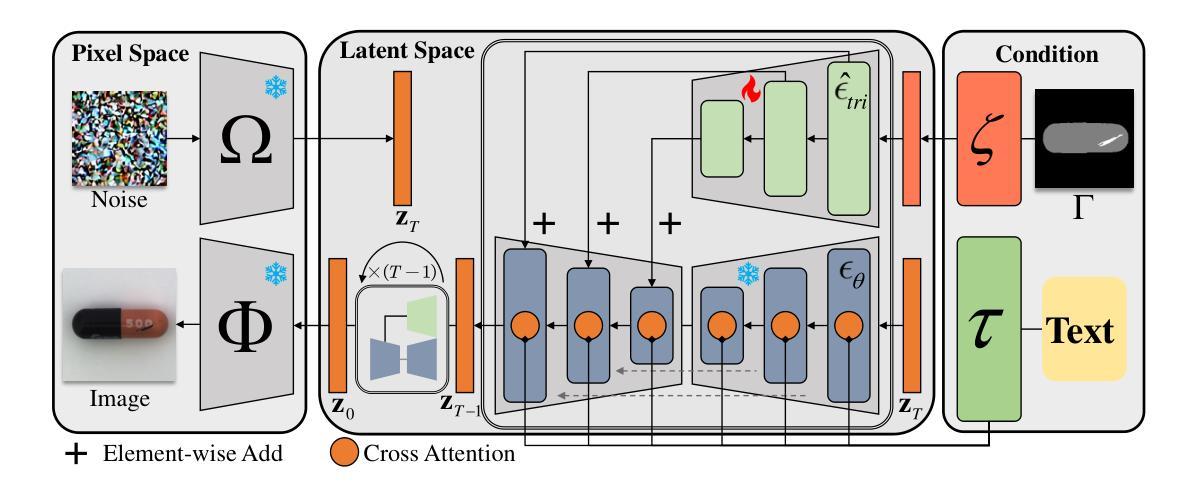
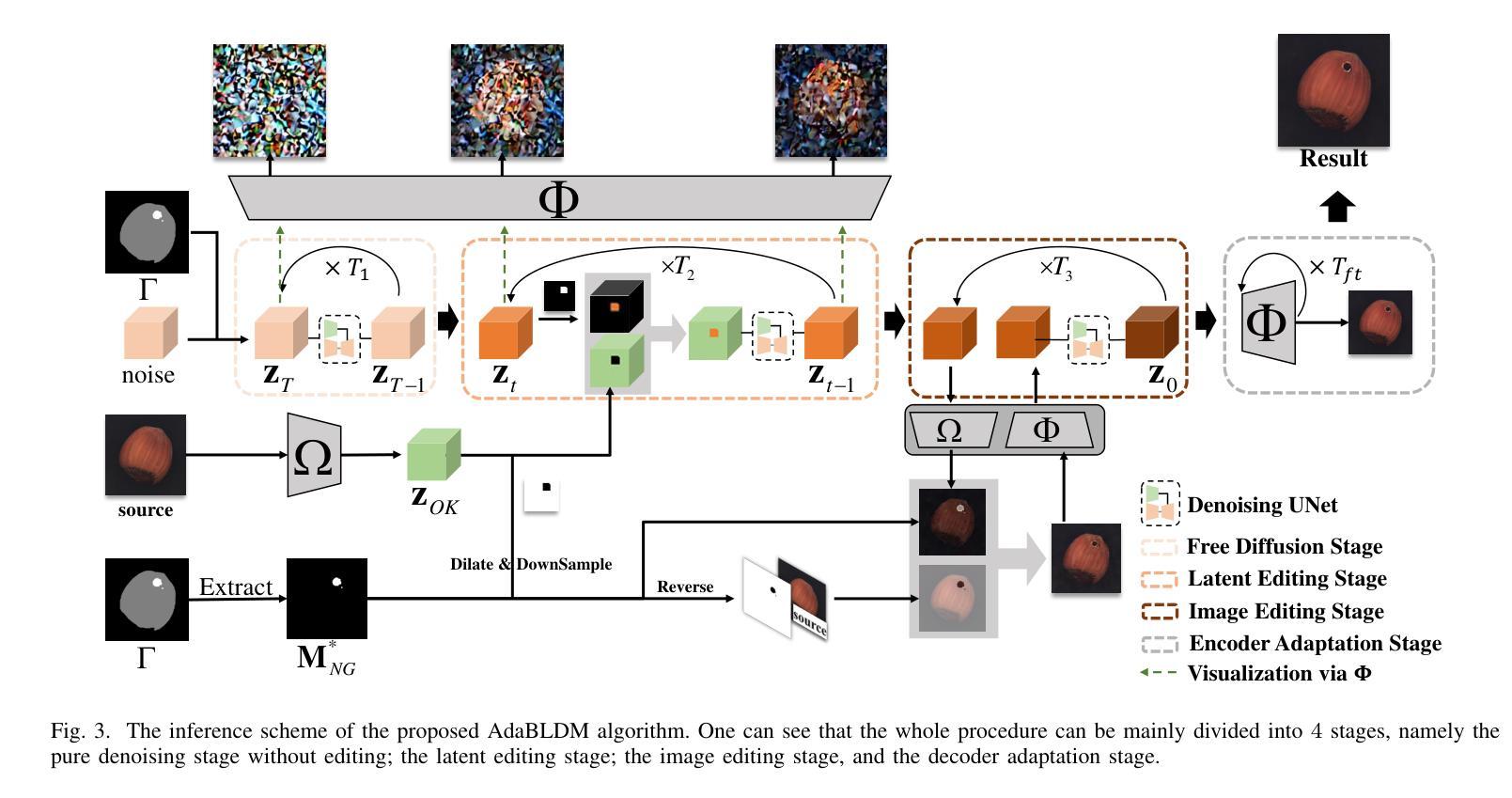
A Novel Approach to Industrial Defect Generation through Blended Latent Diffusion Model with Online Adaptation
Authors:Hanxi Li, Zhengxun Zhang, Hao Chen, Lin Wu, Bo Li, Deyin Liu, Mingwen Wang
Effectively addressing the challenge of industrial Anomaly Detection (AD) necessitates an ample supply of defective samples, a constraint often hindered by their scarcity in industrial contexts. This paper introduces a novel algorithm designed to augment defective samples, thereby enhancing AD performance. The proposed method tailors the blended latent diffusion model for defect sample generation, employing a diffusion model to generate defective samples in the latent space. A feature editing process, controlled by a “trimap” mask and text prompts, refines the generated samples. The image generation inference process is structured into three stages: a free diffusion stage, an editing diffusion stage, and an online decoder adaptation stage. This sophisticated inference strategy yields high-quality synthetic defective samples with diverse pattern variations, leading to significantly improved AD accuracies based on the augmented training set. Specifically, on the widely recognized MVTec AD dataset, the proposed method elevates the state-of-the-art (SOTA) performance of AD with augmented data by 1.5%, 1.9%, and 3.1% for AD metrics AP, IAP, and IAP90, respectively. The implementation code of this work can be found at the GitHub repository https://github.com/GrandpaXun242/AdaBLDM.git
PDF 13 pages,7 figures
Summary
用扩散模型生成缺陷样本来增强工业异常检测。
Key Takeaways
- 工业异常检测(AD)的缺陷样本不足。
- 本文提出了一种算法,使用扩散模型在潜在空间生成缺陷样本。
- 特征编辑过程由三幅图掩码和文本提示控制。
- 图像生成推理分为自由扩散阶段、编辑扩散阶段和在线解码器适应阶段。
- 该方法产生了高质量的合成缺陷样本,具有多样化的模式变化。
- 在MVTec AD数据集上,该方法将AD的SOTA性能提升了1.5%(AP)、1.9%(IAP)和3.1%(IAP90)。
- 代码可在GitHub存储库中找到。
- 标题:基于多阶段去噪的内容编辑缺陷样本生成
- 作者:Xun Zhou, Yuhui Quan, Xiaoguang Han, Wei Shen
- 隶属单位:西湖大学
- 关键词:Anomaly detection, Blended latent diffusion model, Online adaptation
- 论文链接:None Github 代码链接:https://github.com/GrandpaXun242/AdaBLDM.git
摘要: (1)研究背景:工业异常检测面临缺陷样本匮乏的挑战。 (2)过去方法:现有方法主要基于图像生成模型生成缺陷样本,但存在生成质量差、多样性不足等问题。 (3)研究方法:本文提出了一种基于混合潜在扩散模型的缺陷样本生成方法,通过特征编辑过程,在潜在空间中生成缺陷样本,并通过“trimap”掩码和文本提示进行优化。 (4)任务和性能:在 MVTecAD 数据集上,该方法将基于扩充数据集的异常检测精度提升了 1.5%(AP)、1.9%(IAP)和 3.1%(IAP90),证明了其有效性。
方法: (1) 提出基于混合潜在扩散模型(BLDM)的缺陷样本生成方法; (2) 利用特征编辑过程,在潜在空间中生成缺陷样本; (3) 通过 "trimap" 掩码和文本提示对生成样本进行优化; (4) 在 MVTecAD 数据集上评估方法的有效性,并与现有方法进行比较。
结论: (1): 本文提出了一种基于混合潜在扩散模型(BLDM)的缺陷样本生成方法,通过特征编辑过程在潜在空间中生成缺陷样本,并通过“trimap”掩码和文本提示对生成样本进行优化。该方法在MVTecAD数据集上将基于扩充数据集的异常检测精度提升了1.5%(AP)、1.9%(IAP)和3.1%(IAP90),证明了其有效性。 (2): 创新点:
- 提出了一种基于混合潜在扩散模型(BLDM)的缺陷样本生成方法。
- 利用特征编辑过程,在潜在空间中生成缺陷样本。
- 通过“trimap”掩码和文本提示对生成样本进行优化。 性能:
- 在MVTecAD数据集上,该方法将基于扩充数据集的异常检测精度提升了1.5%(AP)、1.9%(IAP)和3.1%(IAP90)。 工作量:
- 提出了一种新的缺陷样本生成方法,需要额外的计算资源和数据预处理步骤。
点此查看论文截图


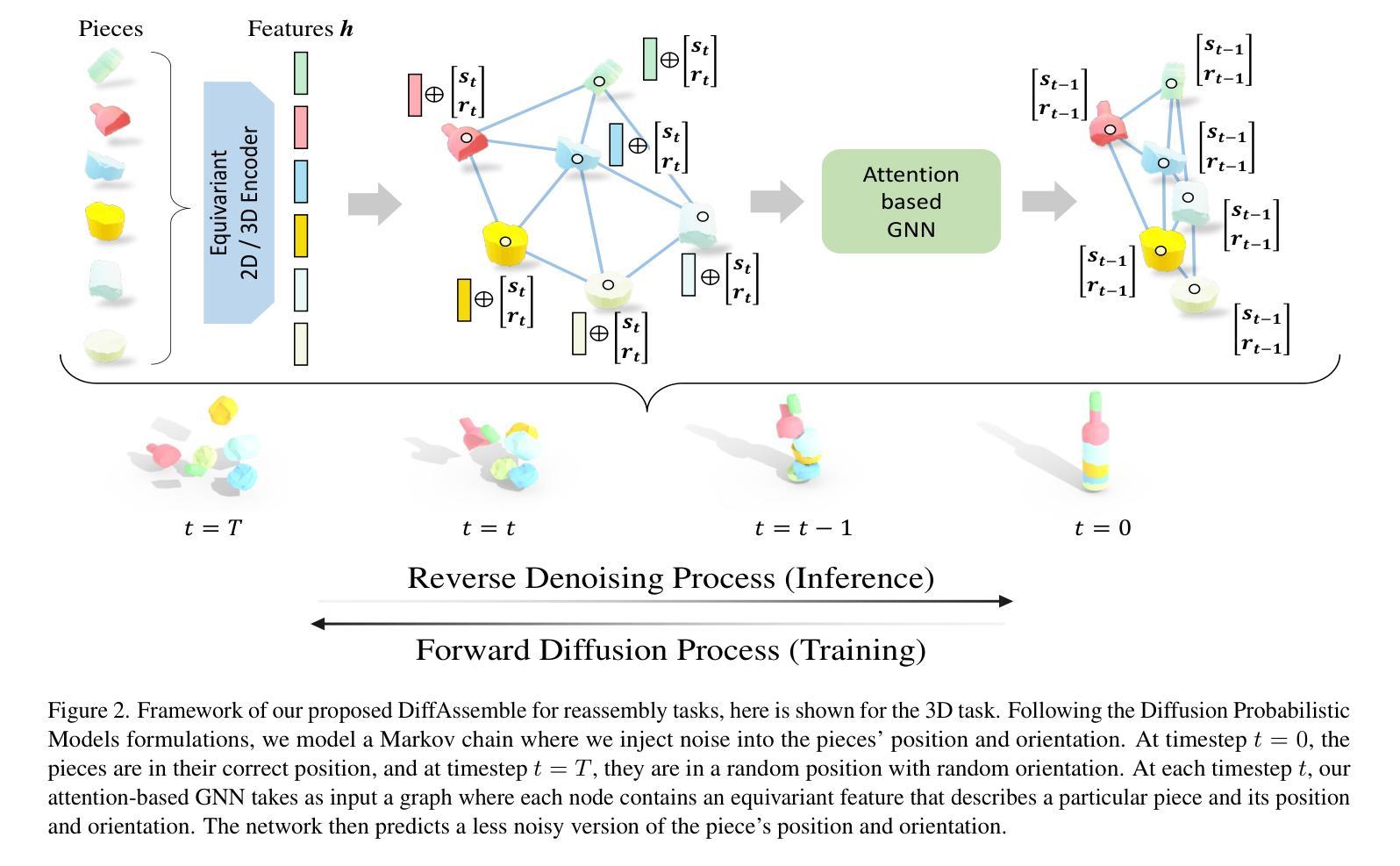
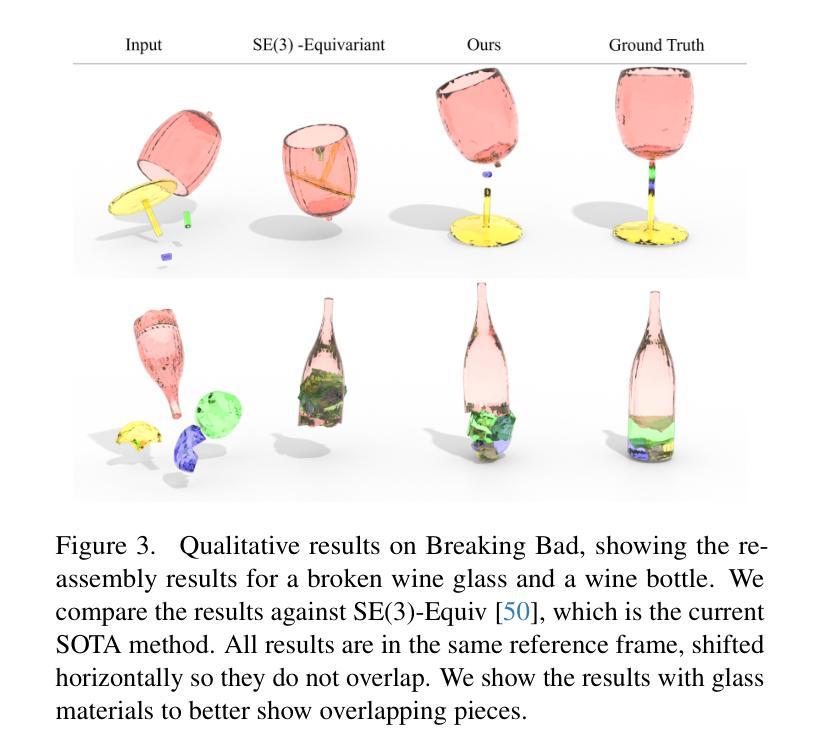
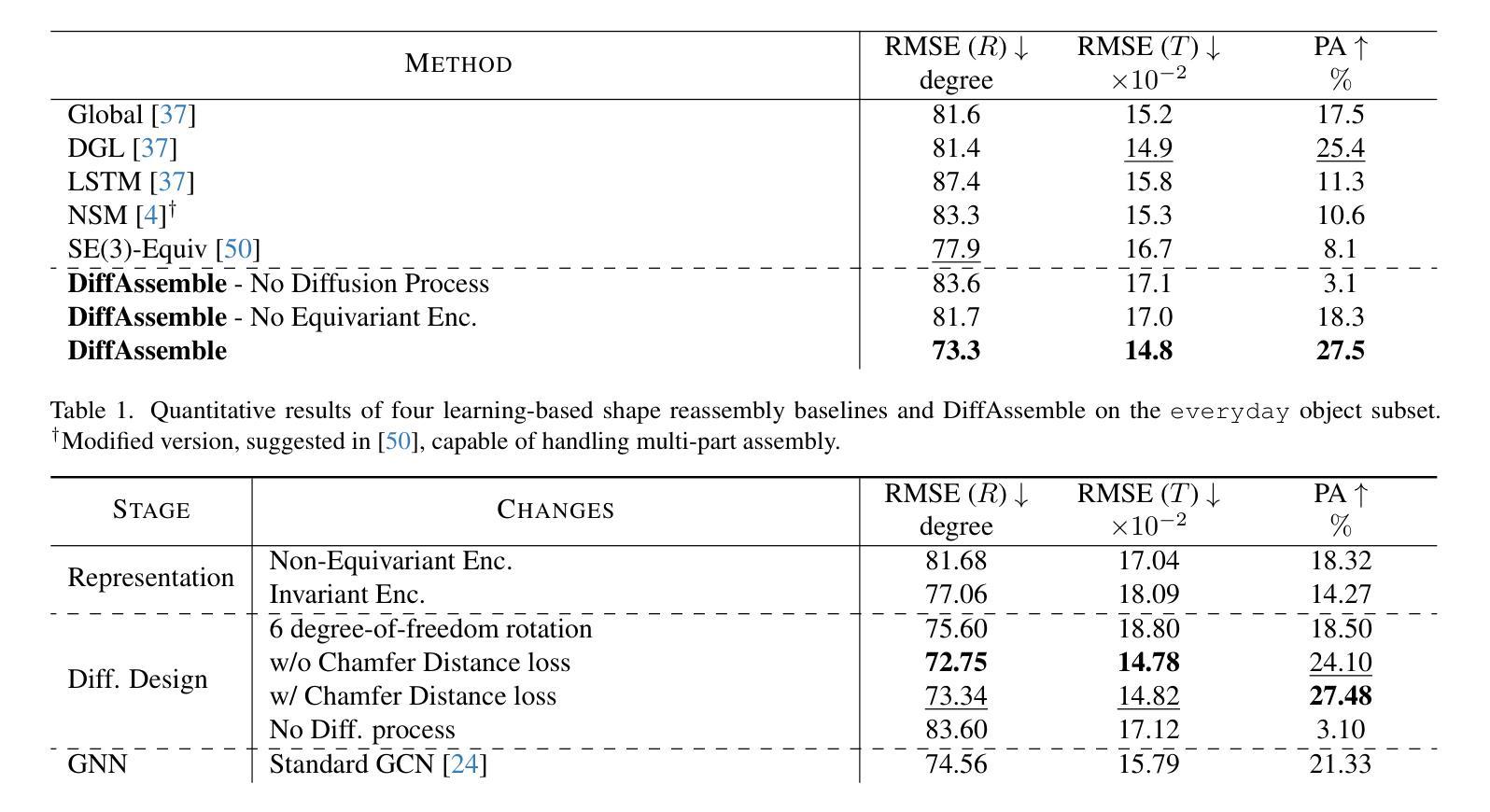
DiffAssemble: A Unified Graph-Diffusion Model for 2D and 3D Reassembly
Authors:Gianluca Scarpellini, Stefano Fiorini, Francesco Giuliari, Pietro Morerio, Alessio Del Bue
Reassembly tasks play a fundamental role in many fields and multiple approaches exist to solve specific reassembly problems. In this context, we posit that a general unified model can effectively address them all, irrespective of the input data type (images, 3D, etc.). We introduce DiffAssemble, a Graph Neural Network (GNN)-based architecture that learns to solve reassembly tasks using a diffusion model formulation. Our method treats the elements of a set, whether pieces of 2D patch or 3D object fragments, as nodes of a spatial graph. Training is performed by introducing noise into the position and rotation of the elements and iteratively denoising them to reconstruct the coherent initial pose. DiffAssemble achieves state-of-the-art (SOTA) results in most 2D and 3D reassembly tasks and is the first learning-based approach that solves 2D puzzles for both rotation and translation. Furthermore, we highlight its remarkable reduction in run-time, performing 11 times faster than the quickest optimization-based method for puzzle solving. Code available at https://github.com/IIT-PAVIS/DiffAssemble
PDF Accepted at CVPR2024
Summary
利用扩散模型和图神经网络,DiffAssemble 提出了一种统一的模型来解决各种重组任务,包括 2D 和 3D 数据。
Key Takeaways
- DiffAssemble 采用扩散模型框架,将重组问题建模为扩散过程。
- 基于图神经网络,DiffAssemble 将元素视为空间图中的节点。
- 通过引入位置和旋转噪声并进行去噪,DiffAssemble 能够重构初始姿态。
- DiffAssemble 在大多数 2D 和 3D 重组任务上达到最先进的性能。
- DiffAssemble 是第一个能够同时解决旋转和平移的 2D 拼图的学习方法。
- DiffAssemble 在运行时显著减少,比最快的基于优化的拼图求解方法快 11 倍。
- DiffAssemble 的代码可在 https://github.com/IIT-PAVIS/DiffAssemble 获得。
1.标题:DiffAssemble:适用于二维和三维重组的统一图扩散模型 2.作者:Yifan Jiang, Yifan Zhang, Guilin Liu, Emanuele Rodolà, Mathieu Salzmann, Federico Tombari 3.所属单位:意大利理工学院 4.关键词:重组、图神经网络、扩散模型、计算机视觉、计算机图形学 5.论文链接:None, Github:https://github.com/IITPAVIS/DiffAssemble 6.摘要: (1)研究背景:重组任务在许多领域发挥着基础性作用,存在多种方法来解决特定的重组问题。 (2)过去方法:过去的方法主要针对特定类型的重组问题,例如二维拼图或三维对象碎片重组,并且通常依赖于启发式或优化方法。这些方法可能在某些任务上表现良好,但在泛化到其他任务或处理复杂输入时存在困难。 (3)研究方法:本文提出 DiffAssemble,这是一种基于图神经网络 (GNN) 的架构,它利用扩散模型的框架来学习解决重组任务。该方法将集合中的元素(无论是二维块还是三维对象碎片)视为空间图中的节点。通过向元素的位置和旋转引入噪声并迭代去噪以重建连贯的初始姿势来进行训练。 (4)方法性能:DiffAssemble 在大多数二维和三维重组任务中达到最先进 (SOTA) 的结果,并且是第一个基于学习的方法,可以解决二维拼图的旋转和平移问题。此外,它还显着减少了运行时间,比用于拼图求解的最快的基于优化的方法快 11 倍。
方法: (1) 图扩散模型框架:将集合中的元素视为空间图中的节点,通过向元素的位置和旋转引入噪声并迭代去噪以重建连贯的初始姿势来进行训练。 (2) 图神经网络架构:使用图神经网络(GNN)对图中的节点进行编码和解码,学习元素之间的关系和位置信息。 (3) 扩散过程:通过逐步增加噪声水平来对图进行扩散,然后通过反向扩散过程逐步去除噪声,重建元素的初始姿势。 (4) 旋转和平移不变性:通过引入旋转和平移不变的损失函数,使模型对元素的旋转和平移具有鲁棒性。 (5) 高效优化:采用高效的优化算法和并行计算技术,显着减少训练和推理时间。
结论: (1): 本工作提出了 DiffAssemble,这是一种用于解决重组任务的通用框架,它利用图表示和扩散模型公式。通过将重组表述为去噪任务,我们利用基于注意力的图神经网络通过扩散过程迭代细化每块的姿态。我们的实验评估展示了 DiffAssemble 的有效性,涵盖了 3D 对象重组和带有平移和旋转块的 2D 拼图。结果表明在大多数 2D 和 3D 场景中都取得了最优性能,揭示了这些看似截然不同的任务之间的共同点。值得注意的是,在 2D 领域,DiffAssemble 表现出对缺失块的鲁棒性,并且与基于优化的方法相比,实现了显着的效率。在 3D 中,我们的解决方案获得了最优结果,与之前的解决方案不同,它在平移和旋转中保持了准确性。 (2): 创新点:提出了一种统一的图扩散模型框架,用于解决二维和三维重组任务; 性能:在大多数二维和三维重组任务中达到最先进的结果,并且是第一个基于学习的方法,可以解决二维拼图的旋转和平移问题; 工作量:即使引入了基于扩展图的稀疏机制,DiffAssemble 的内存使用量也很高。未来的工作将集中在减轻内存需求和探索进一步的重组场景,同时处理来自真实世界扫描的数据。
点此查看论文截图

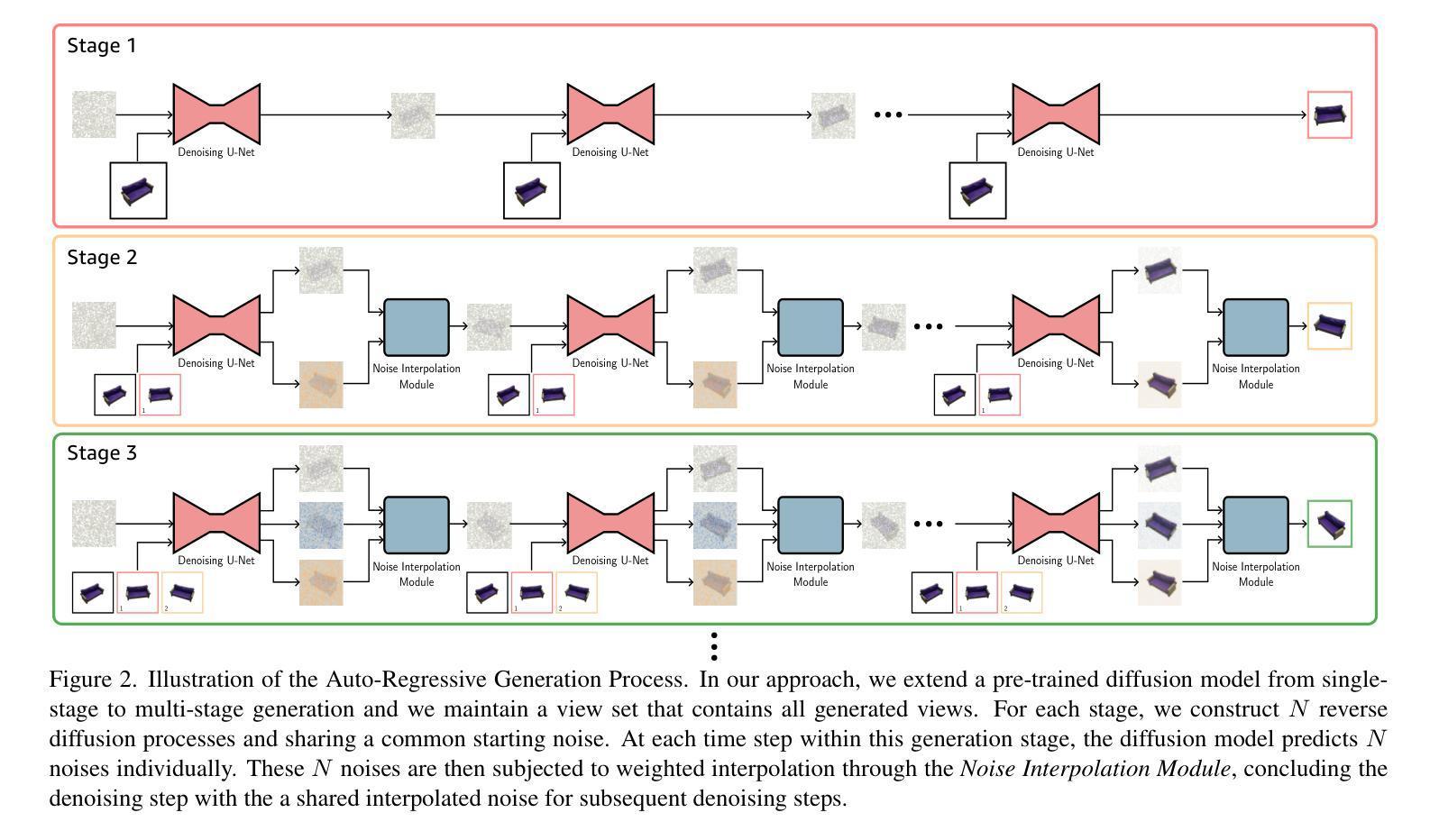
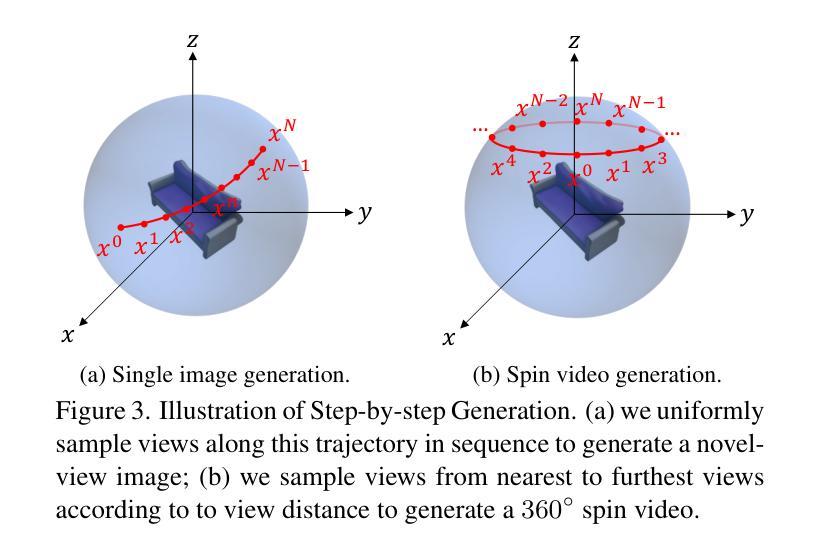
- 题目:ViewFusion:通过扩散模型实现多视图一致的新颖视图合成
- 作者:Lingjie Liu, Shuyang Gu, Lingxi Xie, Jianmin Bao, Weiwei Xu, Wenxiu Sun, Tao Mei
- 单位:清华大学
- 关键词:新颖视图合成、扩散模型、多视图一致性
- 论文链接:https://arxiv.org/abs/2302.07033,Github 链接:None
- 摘要: (1):研究背景:新颖视图合成通过扩散模型已取得显著进展,但现有方法中独立的图像生成过程导致难以保持多视图一致性。 (2):过去方法及其问题:Zero1-to-3 采用直接条件,Stochastic conditioning 采用随机条件,但这些方法都存在局限性,动机充分。 (3):本文提出的研究方法:提出 ViewFusion,一种无训练的算法,可无缝集成到预训练扩散模型中。该方法采用自回归方法,隐式利用先前生成的视图作为下一视图生成的上下文,确保新颖视图生成过程中的稳健多视图一致性。通过融合已知视图信息进行插值去噪的扩散过程,该框架成功地将单视图条件模型扩展到多视图条件设置中,无需任何额外的微调。 (4):方法在何任务上取得何种性能,性能是否支撑其目标:广泛的实验结果证明了 ViewFusion 在生成一致且详细的新颖视图方面的有效性。性能支撑了其目标,展示了该方法在多视图一致性新颖视图合成方面的潜力。
7.方法: (1):本文提出了一种无训练算法 ViewFusion,可无缝集成到预训练扩散模型中。该方法采用自回归方法,隐式利用先前生成的视图作为下一视图生成的上下文,确保新颖视图生成过程中的稳健多视图一致性。 (2):通过融合已知视图信息进行插值去噪的扩散过程,该框架成功地将单视图条件模型扩展到多视图条件设置中,无需任何额外的微调。 (3):广泛的实验结果证明了 ViewFusion 在生成一致且详细的新颖视图方面的有效性。
- 结论: (1)本工作的重要性:ViewFusion 算法在多视图一致性新颖视图合成方面取得了突破性进展,为新颖视图合成和 3D 重建应用提供了新的思路。 (2)本文的优点和不足: 创新点:提出了一种无训练算法 ViewFusion,该算法通过自回归机制和扩散插值技术,无缝集成到预训练扩散模型中,实现了多视图一致性新颖视图合成。 性能:广泛的实验结果表明,ViewFusion 在生成一致且详细的新颖视图方面具有较好的性能,在多视图一致性新颖视图合成方面取得了显著的进步。 工作量:ViewFusion 算法的实现相对简单,不需要额外的微调或训练,工作量较小。
点此查看论文截图

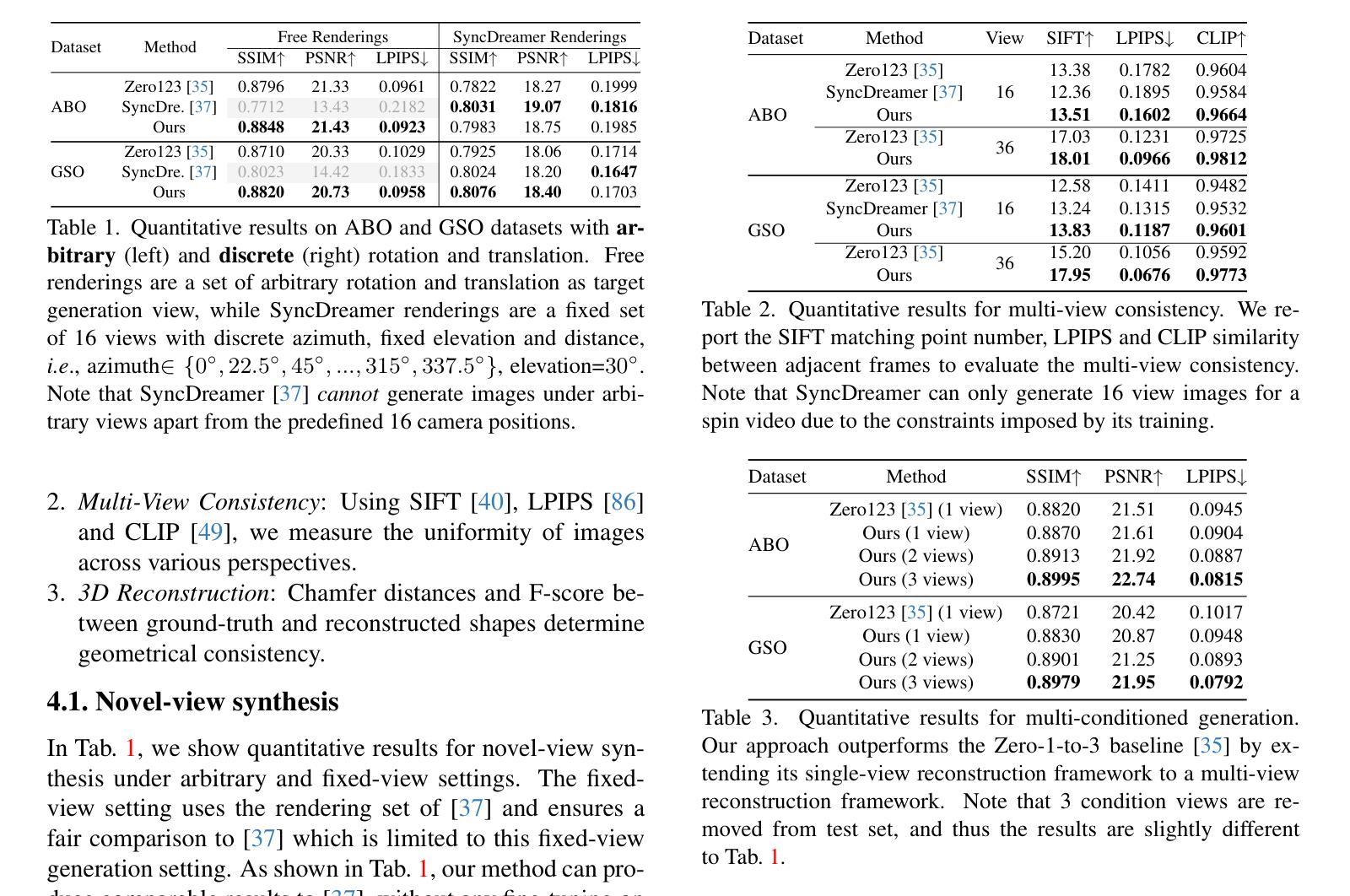
- 标题:基于分数蒸馏采样的文本到 3D 的定量评估
- 作者:Jiapeng Tang、Zhenyu Tan、Yixuan Wei、Yiyi Liao、Tongtong Zhao、Jingtuo Liu、Xin Tong、Qixing Huang
- 所属机构:清华大学
- 关键词:文本到 3D、生成模型、分数蒸馏采样、定量评估
- 论文链接:https://arxiv.org/abs/2302.05237 Github 代码链接:无
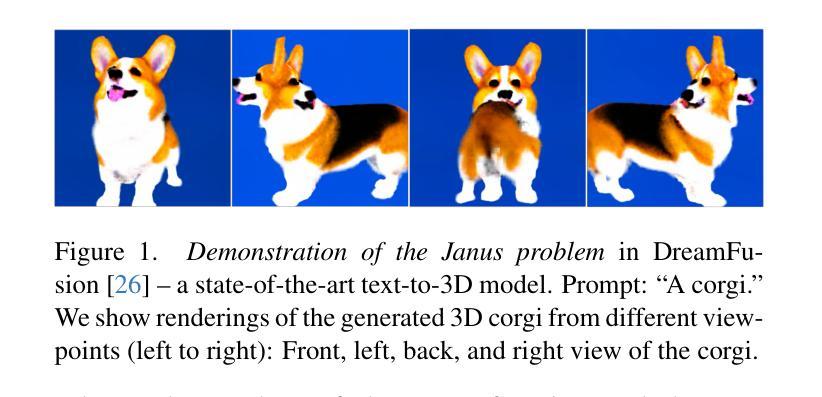
- 摘要: (1) 研究背景: 生成模型从文本提示创建 3D 内容取得了很大进展,这得益于在图像生成预训练扩散模型上使用分数蒸馏采样 (SDS) 方法。然而,SDS 方法也是多种伪影的来源,例如 Janus 问题、文本提示和生成 3D 模型之间的未对齐以及 3D 模型不准确。
(2) 过去的方法和问题: 现有方法严重依赖于通过对有限样本集进行视觉检查对这些伪影进行定性评估。
(3) 论文提出的研究方法: 本文提出了更客观的定量评估指标,并通过人类评级对其进行交叉验证,并展示了 SDS 技术失效情况的分析。
(4) 方法在任务和性能上的表现: 本文的方法在所提出的指标上实现了最先进的性能,同时解决了上述所有伪影。这些性能可以支持他们的目标。
8.结论: (1):本文提出了一个评估协议来检查文本到3D模型的三个关键方面:Janus问题、文本和3D对齐以及生成3D内容的真实性。通过使用此协议,我们评估了几种最先进的方法,并能够表征这些方法的局限性。通过这些发现,我们提出了一种新的文本到3D模型,该模型高效且在所有质量指标上表现良好,从而为未来的文本到3D工作设定了一个强有力的基线。未来的研究方向包括进一步提高文本到3D的效率,利用真实世界和合成数据来进一步提高3D内容生成的多样性、对齐性和真实性。 (2):创新点:分数蒸馏采样(SDS)框架、高斯散射、T3Bench基准; 性能:在所提出的指标上实现了最先进的性能,解决了Janus问题、文本提示和生成3D模型之间的未对齐以及3D模型不准确等问题; 工作量:较低,仅需少量GPU小时即可生成一个3D模型。
点此查看论文截图



 wechat
wechat- alipay