VividTalk One-Shot Audio-Driven Talking Head Generation Based on 3D Hybrid Prior
VividTalk: One-Shot Audio-Driven Talking Head Generation Based on 3D Hybrid Prior
Paper : https://arxiv.org/pdf/2312.01841.pdf
Project : https://humanaigc.github.io/vivid-talk/
Video : https://www.youtube.com/watch?v=lJVzt7JCe_4
Code : https://github.com/HumanAIGC/VividTalk (Maybe Comming Soon)
摘要
创新的两阶段框架 VividTalk 可生成高质量视觉效果的说话人头部视频,包括唇形同步、丰富的面部表情、自然的头部姿势等。
(1)音频驱动的说话头生成已经引起广泛关注,在唇形同步、面部表情、头部姿势生成和视频质量方面取得了进展。然而,由于音频和动作之间的一对多映射,还没有模型能够在所有这些指标上达到最优SOTA。
(2)以往的方法通常使用混合形状Blendshape或顶点偏移vertex来表示面部表情,但这些方法在捕捉精细的表情细节方面存在局限性。此外,头部姿势的生成通常是通过直接从音频中学习来实现的,这可能会导致不合理和不连续的结果。
(3)本文提出了一种名为 VividTalk 的两阶段通用框架,支持生成具有所有上述属性的高视觉质量说话头视频。在第一阶段,通过学习非刚性表情运动和刚性头部运动将音频映射到网格。对于表情运动,采用混合形状和顶点作为中间表示,以最大限度地提高模型的表示能力。对于自然头部运动,提出了一种新颖的可学习头部姿势codebook,并采用两阶段训练机制。在第二阶段,提出了一种双分支运动-VAE 和生成器,将网格转换为密集运动并逐帧合成高质量视频。
(4)广泛的实验表明,所提出的 VividTalk 可以生成具有唇形同步和逼真头部姿势的高视觉质量说话头视频,并且在客观和主观比较中优于以往的最新作品。
要点
- VividTalk 采用双阶段通用框架,可以生成高质量视觉效果的说话人头部视频。
- VividTalk 在第一阶段通过学习非刚性表情运动和刚性头部运动,将音频映射到网格。
- VividTalk 在第二阶段使用双分支运动-VAE 和生成器将网格转换为密集运动并逐帧合成高质量视频。
- 广泛的实验表明,与目前最先进的作品相比,VividTalk 可以生成高质量视觉效果的说话人头部视频,并将唇形同步和逼真的增强效果提高很大幅度。

相关工作
音频驱动人脸生成
主要是利用音频驱动人脸,生成相匹配的图像,最近的一些工作如SadTalker,是用3DMM作为中间表示,再使用3DMM渲染得到对应的视频;也有利用人脸面部关键点的,这都是比较类似的。同时加入生成mask的嘴唇部份,但是由于中间的表示限制,所有这些方法都不足以生成口型同步和逼真的头部说话视频。
这个VIvidTalker是使用blendshape和vertex来作为中间表示,分别对粗粒度和细粒度进行建模。
视频驱动人脸生成
视频驱动可以认为是表情迁移,也就是将参考视频的动作迁移到目标人脸上,比如FOMM这样的方式,用无监督的关键点作为中间的表示,以及有利用depth深度作为信息的。
主要方法
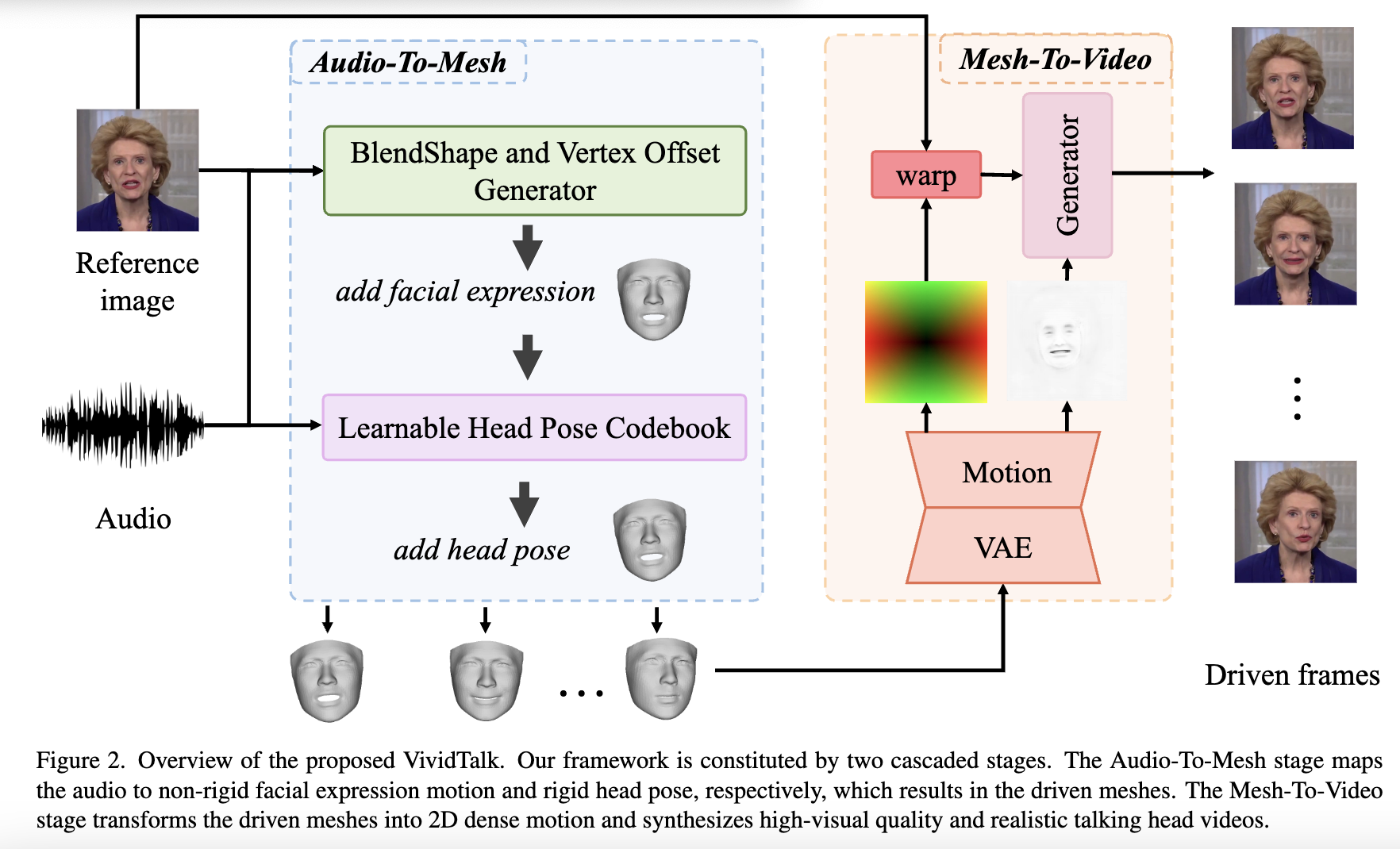
VividTalk主要的框架由两个级联阶段组成,分别是
- Audio-To-Mesh 音频到网格生成
- Mesh-To-VIdeo 网格到视频生成
前馈知识
3DMM
3D Morphable Model(3DMM)是一种用于建模和分析人脸形状和外观的计算机图形技术。它是基于数学模型的方法,用于描述和生成人脸的三维几何形状和表面纹理。3DMM的基本原理是利用统计学方法从大量的三维人脸数据中学习人脸形状和纹理的变化规律,并将这些信息编码到一个数学模型中。
这个模型包括两个主要的部分:形状模型和纹理模型。
- 形状模型:形状模型描述了人脸的几何形状的变化。通常采用的方法是使用主成分分析(PCA)对人脸的形状数据进行降维和建模。通过分析大量的人脸形状数据,可以得到一组主成分,它们描述了人脸形状变化的主要模式。形状模型可以用来生成新的人脸形状,或者对现有的人脸形状进行编辑和变形。
- 纹理模型:纹理模型描述了人脸表面的颜色和纹理的变化。与形状模型类似,纹理模型也可以利用主成分分析等方法来建模人脸的表面纹理。通过分析大量的人脸纹理数据,可以得到一组主成分,它们描述了人脸表面颜色和纹理的变化模式。纹理模型可以用来生成新的人脸纹理,或者对现有的人脸纹理进行编辑和变换。

数据处理
除此之外,首先还需要对数据集进行预处理,使用FOMM对方式对视听数据集进行预处理,并且裁剪面部区域为256x256。同时也是用FaceVerse来提取表情系数和网格顶点序列。
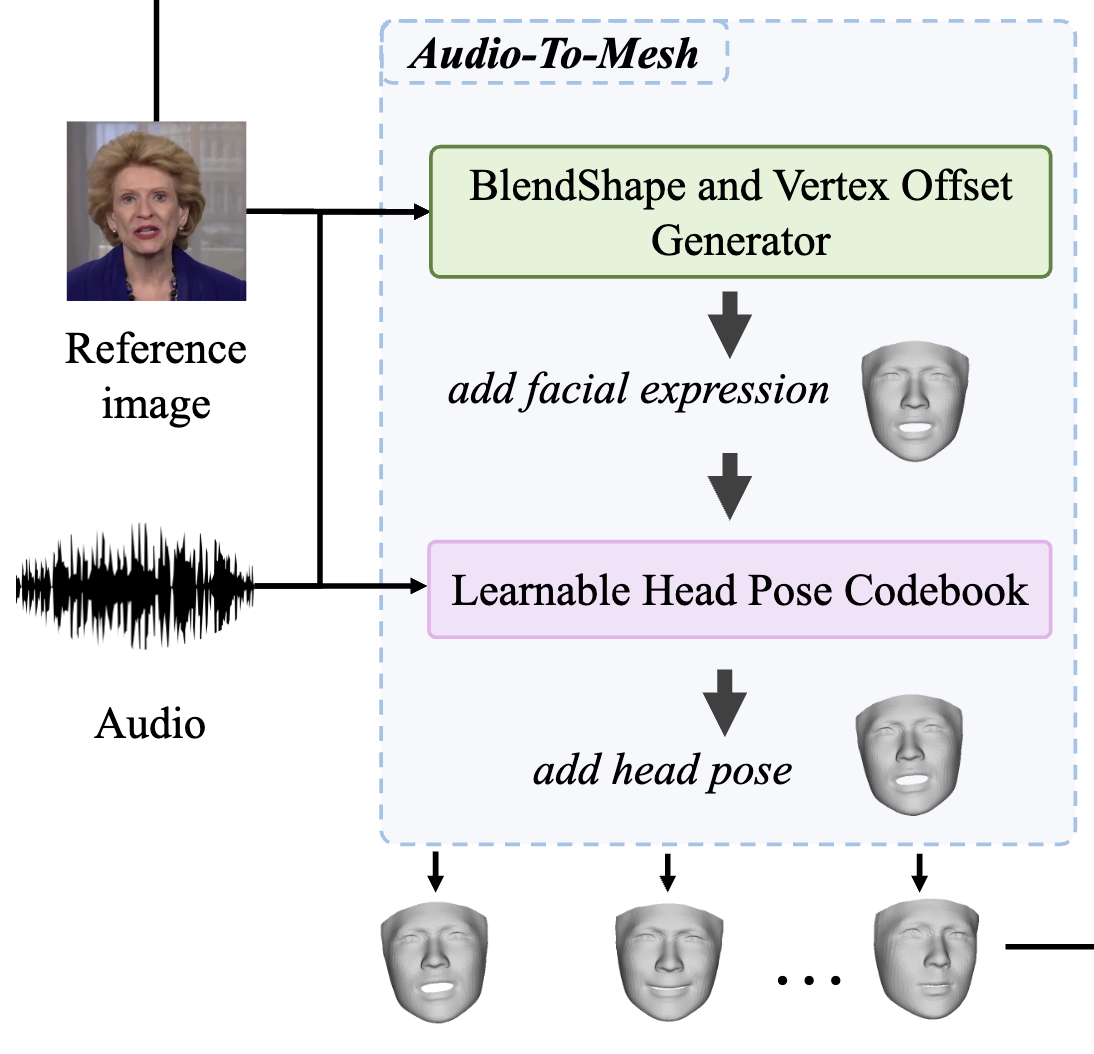
Audio-To-Mesh
在数据预处理的时候,使用Faceverse重建我们的参考图像,从音频中学习非刚性面部表情运动和刚性头部运动来驱动重建的网格。为此,提出了一个多分支的Blendshape和Vertex偏移生成器以及学习头部姿势的codebook,具体如下图所示。
BlendShape and Vertex Offset Generator
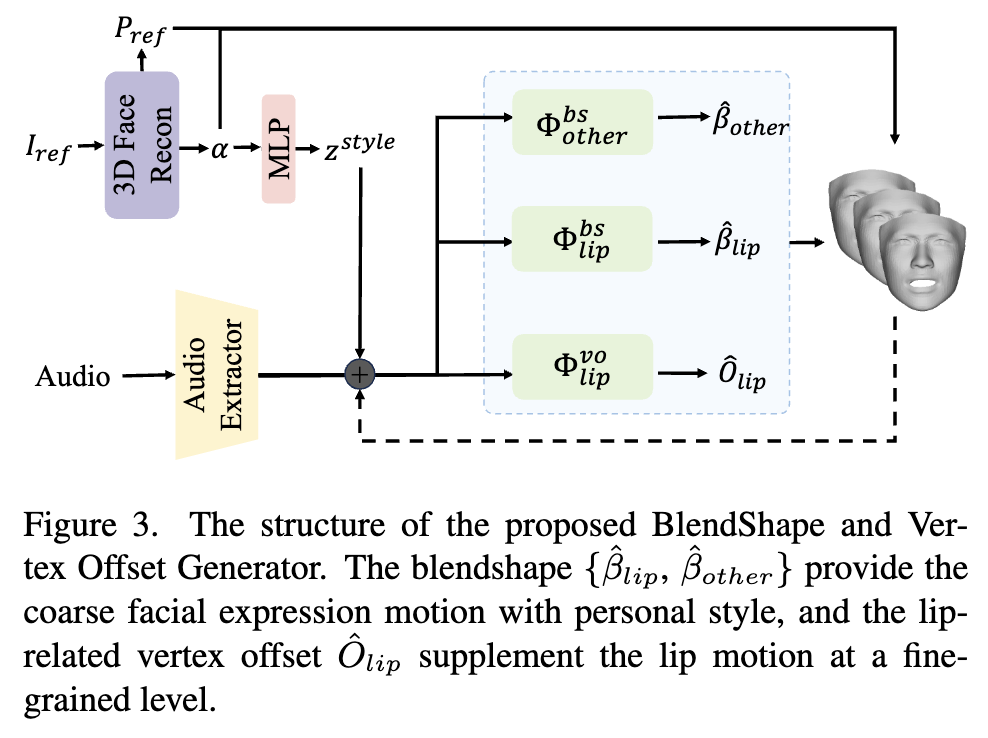
对于BlendShape and Vertex Offset Generator来说,首先会使用一个预训练的音频模型来提取音频特征,然后从参考图像中提取身份信息$\alpha$,并且编码为风格信息$z_{style}$,然后在音频特征中嵌入个人风格信息,再结合送到基于多分支的Transformer架构中,一共有三个分支,两个分支生成粗粒度的blendshape,第三个分支生成细粒度的与嘴唇相关的vertex偏移对嘴唇运动进行补充。
训练完成后,就可以通过以下方式来进行驱动
这里面的$P_{ref}$为参考图像的head pose,$\otimes$是对应的仿射变化。
Learnable Head Pose Codebook
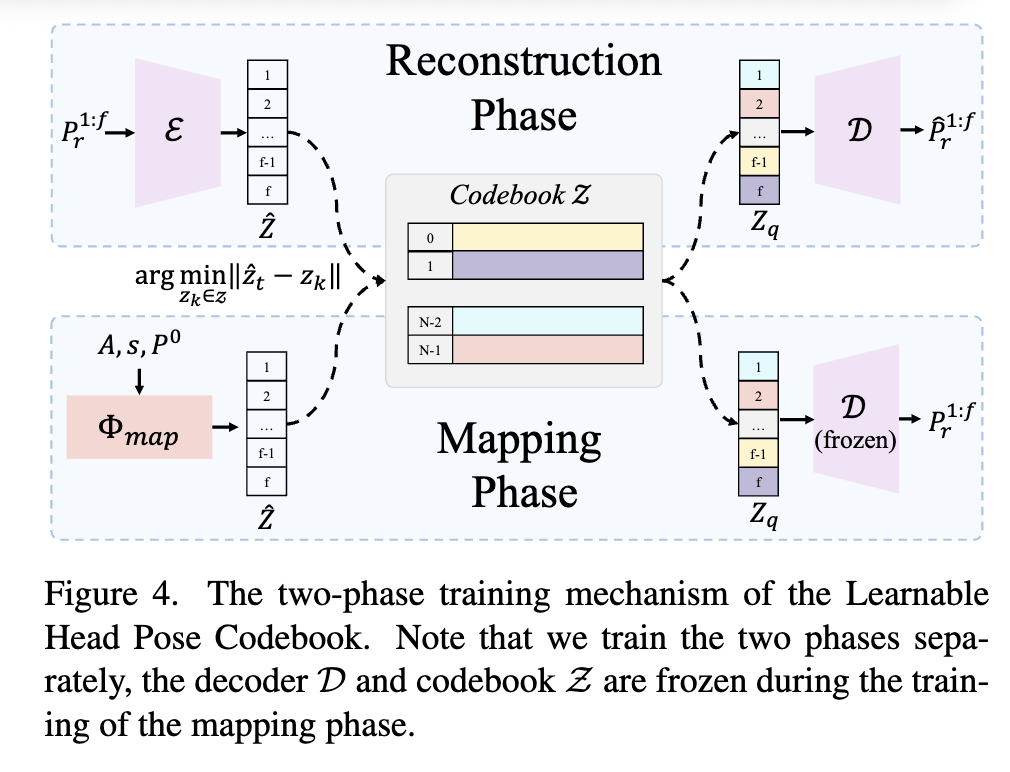
头部姿势是非常重要的一环,直接从音频中学习还是比较困难的,因为这里面的关系是比较微弱的,因此,使用离散的codebook的,将生成的问题转化为在离散和且有限的姿势空间中查询codebook的任务,设计了两阶段的训练机制。
第一阶段是重建阶段,利用VQ-VAE来构建丰富的头部姿势codebook,是一个编码解码结构。
第二阶段是映射阶段,将输入音频映射到codebook生成最终结果,具体来说,$\Phi_{map}$以音频序列A、特定于人的风格嵌入$z^{style}$和初始头部姿势$P^0$ 作为输入,输出中间特征$\hat Z$,该中间特征将从codebook$Z$量化为$Z_q$,然后由预训练的解码器$D$解码
从目前为止,非刚性面部表情运动和刚性头部姿势都已学习。现在我们就可以运用学习到的刚性头部姿势应用于Mesh $\hat{M}{nr}$来获得最最终的驱动网格Mesh $\hat{M}{d}$。
Mesh-To-Video
这一部份是为了将驱动的Mesh转成视频,提出了一个双分支的Motion-VAE对这些2D密集运动进行建模,最后合成最终的视频。
如果要建模2D与3D之间的关系比较难,为了更好的学习,使用投影纹理表示来实现2D的转换。
并且为了更好的学习3D Mesh的纹理,首先在x,y,z三个轴的进行归一化的处理,归一化到0,得到纹理的新表示NCC:
然后,使用了Z-Buffer方式和NCC的颜色去渲染3D面度的纹理$PT{in}$,由于3DMM的限制,外表的区域是无法被建模的,所以使用Deep Learning Face Attributes in the Wild 方法解析图像并获得外部面部区域纹理$PT{out}$,例如躯干和背景,将其与$PT_{in}$ 组合如下:
其中$M$是内部人脸的Mask,为了进一步增强嘴唇运动并更准确地建模,我们还选择与嘴唇相关的标志并将其转换为高斯图,这是一种更紧凑、更有效的表示。然后,Hourglass网络将减去的高斯图作为输入并输出 2D 嘴唇运动,该运动将与面部运动连接并解码为密集运动和遮挡图。
最后,根据之前预测的密集运动图对参考图像进行变形,获得变形图像,该变形图像将与遮挡图一起作为生成器的输入,逐帧合成最终视频。
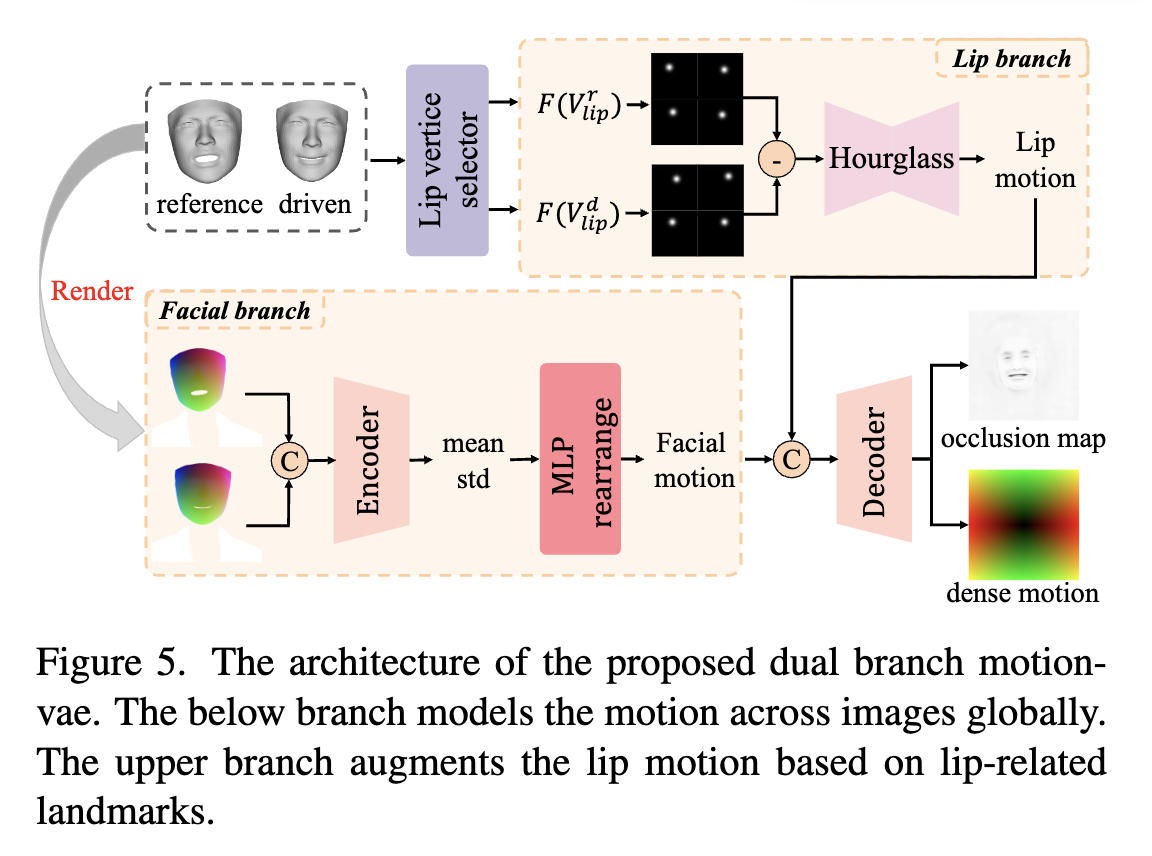
训练策略
这几部分实际上都是分开训练的,不过训练后可以通过端到端的方式生成结果。
BlendShape and Vertex Offset Generator由Blendshape和Mesh重建损失来进行监督
Learnable Head Pose Codebook部分中,由于量化函数是不可微分的,所以使用straight-through gradient estimator将梯度从解码器复制到编码器,然后对两阶段训练进行如下监督:
sg表示停止梯度操作,也就是 stop gradient
Mesh-To-Video阶段中,基于预训练的VGG-19 网络的感知损失$L{perc}$被用作主要驱动损失。特征匹配损失 $L{fm}$还用于稳定训练产生更真实的结果。
实验结果
接下来总结一下实验的结果方法的对比,该模型使用了HDTF和VoxCeleb数据集,使用Adam优化器,在两个阶段中学习率分别为1e-4和1e-5,最后用8个V100训练了2天得到最终的结果。
| 方法 | 优点 | 缺点 |
|---|---|---|
| SadTalker | 无法生成精确的细节唇部动作 | 视频质量不佳 |
| TalkLip | 生成模糊结果,皮肤色调稍微偏黄,失去了一定程度的身份信息 | 质量较差 |
| MakeItTalk | 在交叉身份配音设置中不能生成准确的嘴部形状 | 嘴部形状不准确 |
| Wav2Lip | 容易合成模糊的口部区域,单一参考图像时输出视频头部姿势和眼部运动静止 | 视频输出质量较低 |
| PC-AVS | 需要一个驱动视频作为输入,身份保存困难 | 身份保存困难 |
| VividTalker | 可以生成高质量的说话头像视频,具有准确的唇同步和丰富的面部运动 | 视频质量高,唇同步准确,面部运动丰富 |
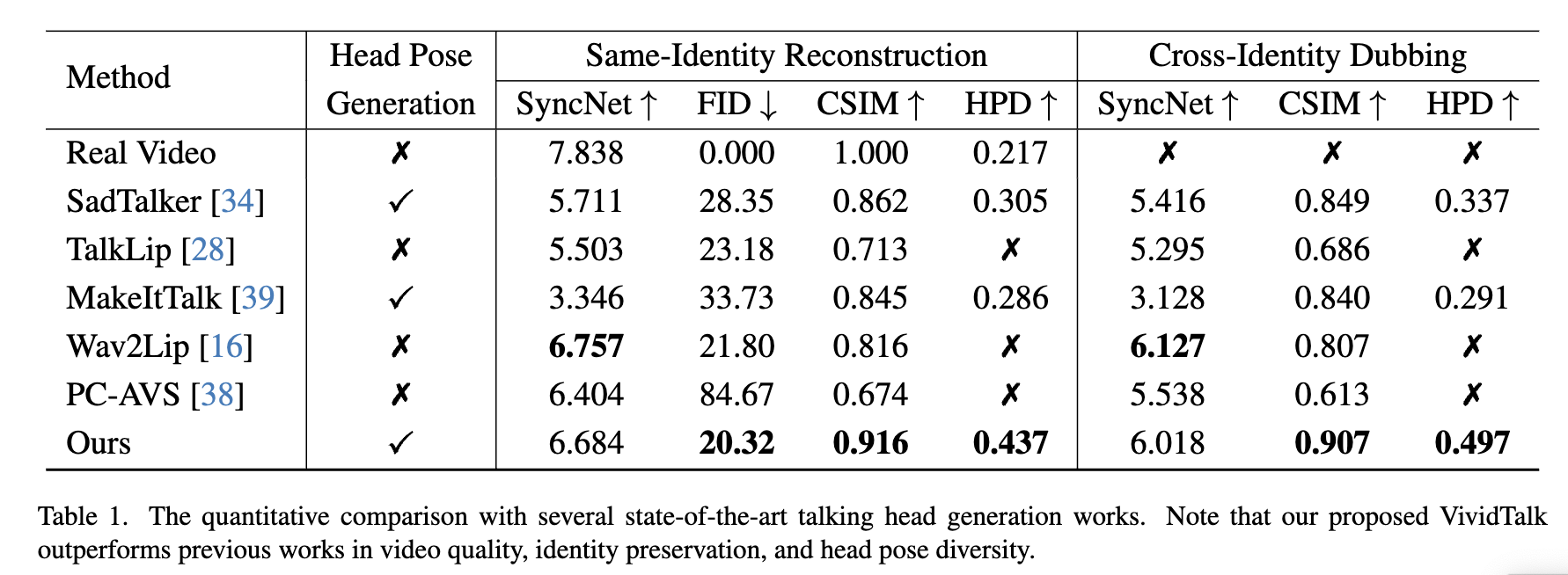
总结
VividTalk框架的优点包括:
高质量的生成视频:VividTalk能够生成高质量的说话头像视频,具有清晰的面部表情和自然的头部姿势,为用户提供更具沉浸感和真实感的体验。
丰富的表达能力:通过将混合形状和顶点映射为中间表示,VividTalk能够最大化模型的表达能力,从而呈现出丰富的面部表情,包括细微的细节运动。
灵活的模型设计:采用多分支生成器,VividTalk能够灵活地对全局和局部面部运动进行建模,使得生成的视频更加生动和自然。
自然的头部姿势合成:通过引入新颖的可学习的头部姿势码本和两阶段训练机制,VividTalk能够合成更加自然的头部姿势,使得生成的视频更加逼真。
创新的双分支机制:利用双分支运动-VAE和生成器,VividTalk能够有效地转化驱动网格为密集运动,并用于合成最终视频,提高了生成视频的质量和真实感。
超越性能:实验证明,VividTalk优于以往的最先进方法,为数字人类创建、视频会议等应用开辟了新的可能性。
 wechat
wechat- alipay







