SyncTalk The Devil is in the Synchronization for Talking Head Synthesis
SyncTalk: The Devil is in the Synchronization for Talking Head Synthesis
Paper : https://arxiv.org/abs/2311.17590
Project : https://ziqiaopeng.github.io/synctalk/
Video : https://ziqiaopeng.github.io/synctalk/#teaser
Code : https://github.com/ziqiaopeng/SyncTalk
摘要
神经辐射场 - 生成对抗网络框架用于实现说话人头部视频的同步合成。
(1)研究背景: 生成逼真的、由语音驱动的谈话头部视频是一项具有挑战性的任务。传统生成对抗网络(GAN)难以保持一致的面部身份,而神经辐射场(NeRF)方法虽然可以解决这个问题,但通常会产生不匹配的唇部动作、不充分的面部表情和不稳定的头部姿势。一个逼真的谈话头部需要同步协调主体身份、唇部动作、面部表情和头部姿势。缺乏这些同步是导致不真实和人工结果的根本缺陷。
(2)过去的方法及其问题: GAN 方法难以保持一致的面部身份。NeRF 方法虽然可以解决这个问题,但通常会产生不匹配的唇部动作、不充分的面部表情和不稳定的头部姿势。
(3)提出的研究方法: SyncTalk 是一种基于 NeRF 的方法,它有效地保持了主体身份,增强了谈话头部合成的同步性和真实性。SyncTalk 使用面部同步控制器将唇部动作与语音对齐,并创新地使用 3D 面部混合形状模型来捕捉准确的面部表情。头部同步稳定器优化头部姿势,实现更自然的头部运动。肖像同步生成器恢复头发细节,并将生成的头部与躯干融合,以获得无缝的视觉体验。
(4)方法在什么任务上取得了什么性能,这些性能是否支持了它们的目标: SyncTalk 在谈话头部合成同步性和真实性方面优于最先进的方法。广泛的实验和用户研究表明,SyncTalk 在同步性和真实性方面优于最先进的方法。
关键要点
- 传统生成对抗网络难以维持一致的面部身份。
- 神经辐射场方法可以解决面部身份一致性问题,但经常出现嘴唇运动不匹配、面部表情不足和头部姿势不稳定的问题。
- 逼真的说话人头部视频需要同步协调主体身份、嘴唇运动、面部表情和头部姿势。
- 缺少同步性是导致不真实和人为结果的根本缺陷。
- SyncTalk 是一种基于神经辐射场的方法,有效地保持了主体身份,提高了说话人头部合成中的同步性和真实感。
- SyncTalk 使用面部同步控制器将嘴唇运动与语音对齐,并创新地使用 3D 面部混合形状模型来捕捉准确的面部表情。
- SyncTalk 的头部同步稳定器优化了头部姿势,实现了更自然的头部运动。
- 人像同步生成器恢复头发细节,将生成的头部与躯干融合,以获得无缝的视觉体验。

介绍
这篇论文中,解决最好的就是同步的问题,所以也称为同步的Devil 魔鬼😈。现有方法在四个关键领域需要更多的同步:主体身份、唇部运动、面部表情和头部姿势。
首先,在基于GAN的方法中,由于连续帧中特征的不稳定性以及仅使用少量帧作为面部重建参考,保持视频中主体的身份是具有挑战性的。
其次,唇部运动与语音不同步。在基于NeRF的方法中,仅基于5分钟语音数据集训练的音频特征难以泛化到不同的语音输入。
第三,缺乏面部表情控制,大多数方法只能产生唇部运动或控制眨眼,导致面部动作不自然。
第四,头部姿势不同步。
先前的方法依赖于稀疏的landmarks来计算投影误差,但这些landmarks的抖动和不准确性导致头部姿势不稳定。这些同步问题会引入伪影,并显著降低真实感。
为了解决这些同步挑战,引入了SyncTalk,这是一种基于NeRF的方法,专注于高度同步、逼真的、语音驱动的说话头部合成,采用三平面哈希表示来维护主体身份。通过面部同步控制器和头部同步稳定器,SyncTalk显著提高了合成视频的同步性和视觉质量。PortraitSync Generator进一步改善了视觉质量,精心细化了视觉细节。整个渲染过程可以实现50 FPS,并输出高分辨率视频。
| 模块 | 描述 |
|---|---|
| Face-Sync Controller | 在Face-Sync控制器中,预先在2D音频视听数据集上对音频视觉编码器进行预训练,得到了一种通用表示,确保了不同语音样本之间的唇部同步运动。对于控制面部表情,采用了一个语义丰富的3D面部混合形状模型,该模型通过52个参数控制特定的面部表情区域。 |
| Head-Sync Stabilizer | 在Head-Sync稳定器中,使用AD-NeRF中的头部运动跟踪器来推断头部的粗略旋转和平移参数。由于粗略参数的不稳定性,借鉴了同步定位与地图(SLAM)的思想,结合头部关键点跟踪器跟踪稠密关键点,并采用bundle adjustment method 束调整方法来优化头部姿势,从而实现稳定连续的头部运动。 |
| Portrait-Sync Generator | 为了进一步提高SyncTalk的视觉保真度,设计了一个Portrait-Sync生成器。这个模块修复了NeRF建模中的伪影,特别是头发和背景等细节,输出高分辨率视频。 |
主要贡献
- 提出了一个Face-Sync控制器,结合音频视觉编码器和面部动画捕捉器,确保准确的唇部同步和动态面部表情渲染。
- 引入了一个Head-Sync稳定器,跟踪头部旋转和面部运动关键点。利用束调整方法,该稳定器保证了平滑同步的头部运动。
- 设计了一个Portrait-Sync生成器,通过修复NeRF建模中的伪影和细化头发和背景等细节,提高了视觉保真度。
相关工作
GAN-based Method
近来,基于GAN的说话头合成成为了计算机视觉中的一个重要研究领域。然而,它们在保持视频中主体的身份一致性方面存在挑战。
例如,Wav2Lip引入了一个唇部同步专家来监督唇部运动。然而,由于使用了来自参考帧的五帧来重建唇部,它难以保持主体的身份。另一些方法尝试进行全脸合成,但往往难以确保面部表情和头部姿势之间的同步。除了视频流技术外,还有一些方法试图通过语音使单张图像“说话”,如SadTalker可以从单张图像生成一个人说话的视频。然而,这些方法无法生成自然的头部姿势和面部表情,难以保持主体的身份,影响了同步效果,导致视觉感知不真实。
与这些方法相比,SyncTalk使用NeRF对人脸进行三维建模。其能够在规范空间中表示连续的3D场景的能力,使其在保持主体身份一致性和保留细节方面表现出色。
NeRF-based Method
近来,随着NeRF的崛起,许多领域已开始利用它来解决相关挑战。先前的工作已将NeRF整合到合成说话头像的任务中,并将音频作为驱动信号,但这些方法都是基于普通的NeRF模型。
例如,AD-NeRF需要大约10秒来渲染单个图像。RADNeRF旨在实现实时视频生成,并使用了基于Instant-NGP的NeRF。ER-NeRF通过引入三平面哈希编码器来修剪空白空间区域,提倡紧凑且加速的渲染方法。GeneFace试图通过将语音特征转换为面部标志来减少NeRF的伪影,但这往往导致唇部运动不准确。尝试使用基于NeRF的方法创建角色头像,例如,不能直接由语音驱动。这些方法仅将音频作为条件,没有清晰的同步概念,并且通常导致唇部运动平均。
此外,先前的方法缺乏对面部表情的控制,仅限于控制眨眼,并且无法对抬眉毛或皱眉等动作进行建模。此外,这些方法在头部姿势不稳定方面存在显着问题,导致头部和躯干分离。相比之下,使用Face-Sync控制器来建模音频和唇部运动之间的关系,从而增强唇部运动和表情的同步性,使用Head-Sync稳定器来稳定头部姿势,通过解决这些同步问题,提高了视觉质量。
主要方法
SyncTalk主要由三部分组成,接下来会一一介绍
- Face-Sync Controller 控制嘴唇运动和面部表情
- Head-Sync Stabilizer 稳定头部姿势
- Portrait-Sync Generator 渲染的高同步面部帧
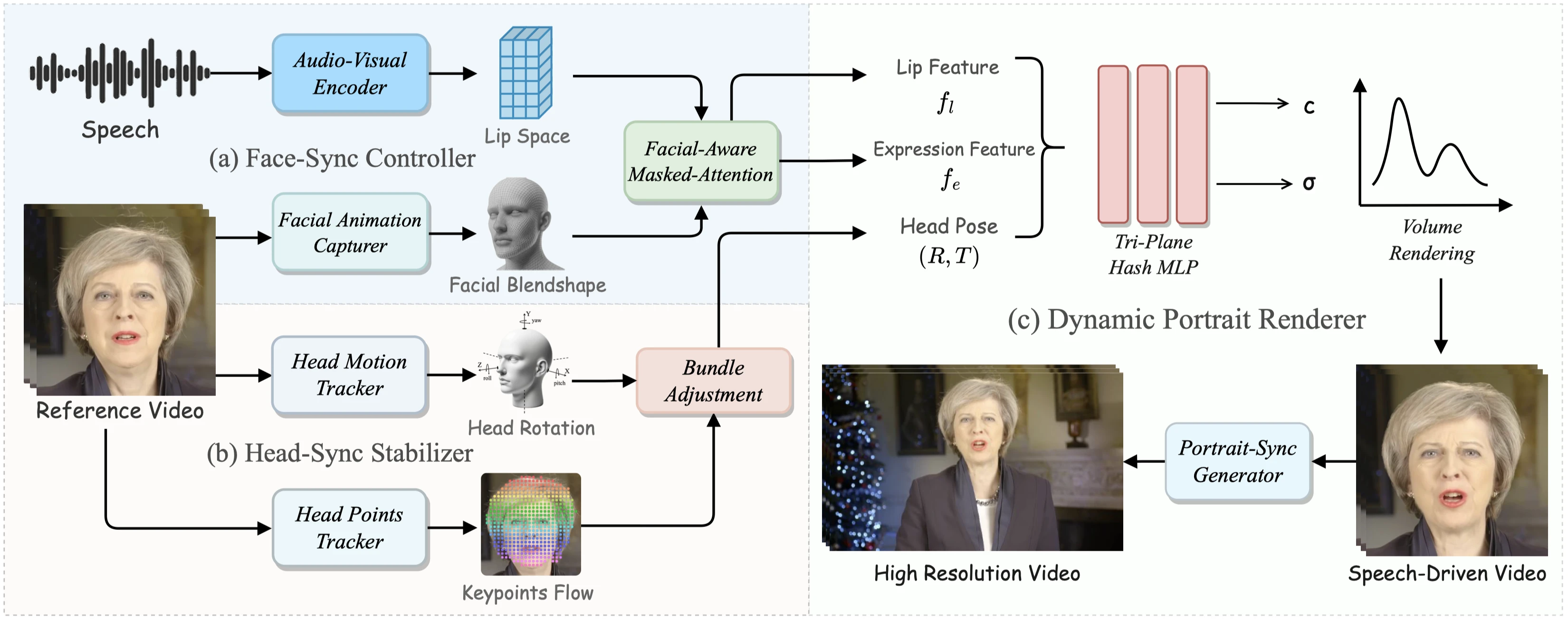
Face-Sync Controller
Audio-Visual Encoder
在现有的方法中,大部分的音频特征提取器是用类似于 DeepSpeech,Wav2Vec 2.0 和 HuBERT 等ASR模型,但是这些事专门为Automatic Speech Recognition ASR任务设计的,这种设计的音频编码器并不能真正反映嘴唇运动。这是因为预训练的模型是基于从音频到文本的特征分布,而需要从音频到嘴唇运动的特征分布。
针对这种情况,使用在LRS2上训练的deep avsr来做音频特征提取器,使用预训练的唇形同步鉴别器 SyncNet来监督视频的同步效果,这是使用连续的面部窗口F和相对应的音频帧A输入,同时分为正负样本进行训练,利用余弦相似度和交叉熵损失来最小化同步样本的距离并最大化非同步样本的距离。
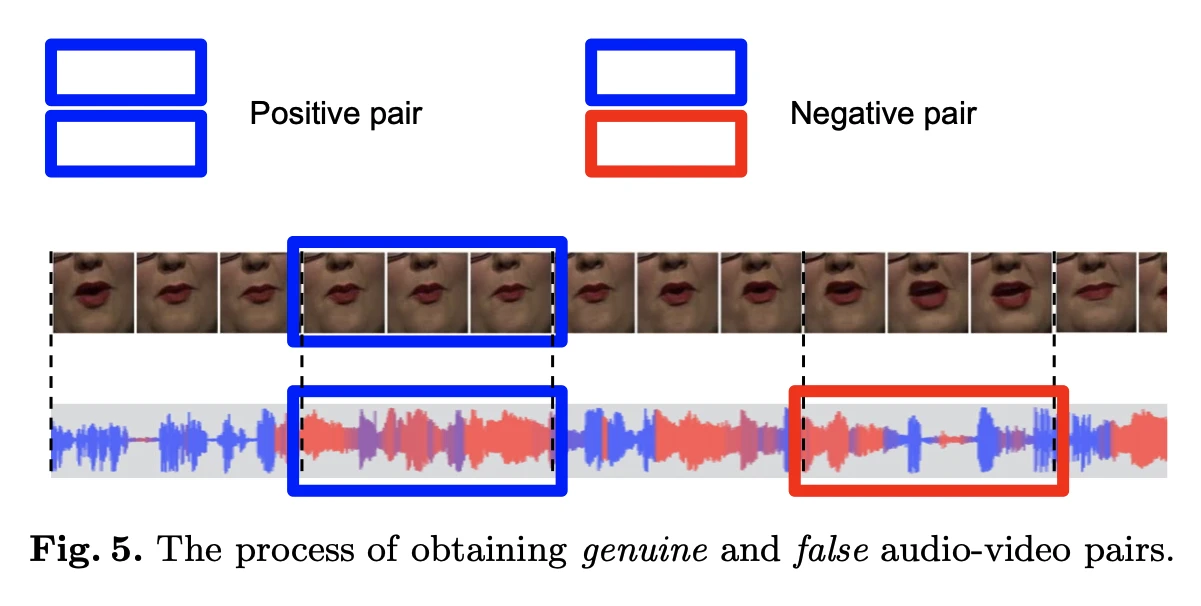
同时在同步鉴别器的监督下,预训练对应的视听特征提取器,这里面堆叠卷积网络进行编码解码,最后用重建损失来进行监督。训练后,我们使用 Conv(A) 作为从音频中提取的唇部空间。
Facial Animation Capturer
在之前的研究中发现,基于NeRF的方法只能改变眨眼,无法准确地建模面部表情。这导致训练出的角色表情僵硬,面部细节不准确,特别是对于有明显面部动作的角色,如眨眼、抬眉毛或皱眉等。考虑到需要更加同步和逼真的面部表情,添加了一个表情同步控制模块。
具体而言,引入了一个基于52个语义面部混合形状系数 B 的3D面部先验模型来建模面部,也就是3D blendshape 系数来控制面部,这一部分类似于 EmoTalk。因为3D面部模型能够保留面部运动的结构信息,所以它能够很好地反映面部动作的内容,同时又不会引起面部结构的失真。
在训练过程中,首先使用一个复杂的面部混合形状捕捉模块将面部表情捕捉为E(B),然后选择七个核心面部表情控制系数来控制眉毛、额头和眼睛区域。这些系数与表情高度相关,且独立于嘴唇的运动。因为面部系数具有语义信息,所以我们可以在推理过程中同步演讲者的面部表情。

Facial-Aware Masked-Attention
为了减少训练过程中嘴唇特征和表情特征之间的相互干扰,引入了Facial-Aware Disentangle Attention模块。基于区域注意力向量 V,这类似于ER-NeRF,我们分别将Mask $M{lip}$ 和 $M{exp}$ 添加到嘴唇和表情的注意力区域。
通过这样设计的注意力机制,能够有效解耦嘴唇运动和眨眼运动等,从而减少耦合带来的伪影,最后利用解耦的嘴唇特征 $fl = F{lip} ⊙ V{lip}$ 和表情特征$f_e = f{exp} ⊙ V_{exp}$。

Head-Sync Stabilizer
Head Motion Tracker
头部姿势,表示为 p,是指人的头部在 3D 空间中的旋转角度,由旋转 R 和平移 T 定义。
不稳定的头部姿势会导致头部抖动。为了获得头部姿势的粗略估计,首先,通过在预定范围内迭代 i 次来确定最佳焦距。对于每个焦距候选 fi,重新初始化旋转和平移值。目标是最小化 3D 可变形模型 (3DMM) 的投影地标与视频帧中的实际地标之间的误差。
其中 $E_i$表示的就是MSE,这样能够以更好地将模型的投影lmk与实际视频lmk对齐,然后得到最优的旋转和平移矩阵,也是用MSE来最小化,这是对每一帧进行操作的,在对应视频帧的最优值。
Head Points Tracker
对于之前基于NeRF的方法来说,先前的方法利用基于 3DMM 的技术来提取头部姿势并生成不准确的结果。为了提高R和T的精度,我们使用像Co- tracker这样的光流估计模型来跟踪面部关键点K。
接下来,使用预训练的光流估计模型,在获取面部运动光流后,我们使用拉普拉斯滤波器选择位于最显著流变化位置的关键点,并在流序列中跟踪这些关键点的运动轨迹。通过这个模块确保了所有帧上的面部关键点对齐更加精确和一致,从而增强了头部姿势参数的准确性。
Bundle Adjustment
根据关键点和粗略的头部姿势,引入了一个两阶段优化框架来提高关键点和头部姿势估计的准确性。
第一阶段,随机初始化 j 个关键点的 3D 坐标并优化它们的位置,以便与图像平面上跟踪的关键点对齐。这一部分最小化损失函数 $L_{init}$,捕获投影关键点 P 和跟踪关键点 K 之间的差异:
第二阶段,开始进行更全面的优化,以细化 3D 关键点和相关的头部联合姿势参数,通过Adam优化器优化算法,调整空间坐标、旋转角度R和平移T以最小化对齐误差$L_{sec}$,表示为:
经过这些优化后,观察到所得的头部姿势和平移参数平滑且稳定。
Dynamic Portrait Renderer
Tri-Plane Hash Representation
这一部分实际上就是NeRF的体渲染的方式,都是一些定义的部分。
类似于ER-NeRF的方式,解决哈希冲突和优化音频特征处理的问题,结合了三个独特定向xyz的 2D 哈希网格,也就是 Tri-Plane Hash,作为hash的编码器。
其中输出 $f^{AB}{ab} ∈ R{LD}$,具有层数 $L$ 和每个方向的特征维度 $D$,表示与投影坐标$ (a, b)$ 相对应的平面几何特征,$H^{AB}$ 表示平面 $R^{AB}$ 的多分辨率哈希编码器。得到每个方向的向量以后,产生 $3 × LD$ 通道向量。采用$fx$、视角方向$d$、嘴唇特征$f_l$和表情特征$f_e$,三平面哈希的隐式函数定义为:
类似于ER-NeRF,训练采用了一个两步粗到细的策略。首先,使用MSE损失评估预测的 $\hat{C(r)}$与实际图像颜色$C(r)$之间的差异。鉴于MSE在细节捕捉方面的局限性。接下来进入一个细化阶段,引入LPIPS损失以增强细节,类似于ER-NeRF。我们从图像中提取随机补丁Patch $P$,并将LPIPS(由λ加权)与MSE结合起来以改善细节表示。
Portrait-Sync Generator
在训练过程中,为了解决 NeRF 在捕捉发丝和动态背景等精细细节方面的局限性,引入了一个包含两个关键部分的 PortraitSync 生成器。
首先,NeRF 渲染面部区域 ($Fr$),通过高斯模糊创建 $G(Fr)$,然后使用我们同步的头部姿势能够与原始图像 ($F_o$) 合并,以增强头发细节保真度。
其次,当头部和躯干结合在一起时,如果源视频中的角色说话而生成的面部保持沉默,则可能会出现暗间隙区域,如下图(b)所示。 所以用平均颈部颜色 ($Cn$) 填充这些区域。
这种方法通过肖像同步生成器产生更真实的细节并提高视觉质量。
实验结果
数据集
为了进行公平比较,我们使用了来自AD-NeRF,GeneFace和ER-NeRF中相同的视频序列,其中包括英语和法语。这些视频的平均长度约为8,843帧,每个视频以25 FPS录制。除了来自AD-NeRF的视频分辨率为450 × 450外,所有其他视频的分辨率均为512 × 512,并以角色为中心。
比较基线
- GAN-based 方法 :Wav2Lip,VideoReTalking,DINet,TalkLip and IP-LAP。
- NeRF-based 方法 : AD-NeRF,RADNeRF,GeneFace and ER-NeRF。
实验细节
- 在粗略阶段,肖像头部经过100,000次迭代训练,在精细阶段训练25,000次迭代。
- 每次迭代使用2D哈希编码器(L=14,F=1)采样$256^2$条光线。
- 采用AdamW优化器[24],哈希编码器的学习率为0.01,其他模块的学习率为0.001。
- 在NVIDIA RTX 3090 GPU上,总训练时间约为2小时。
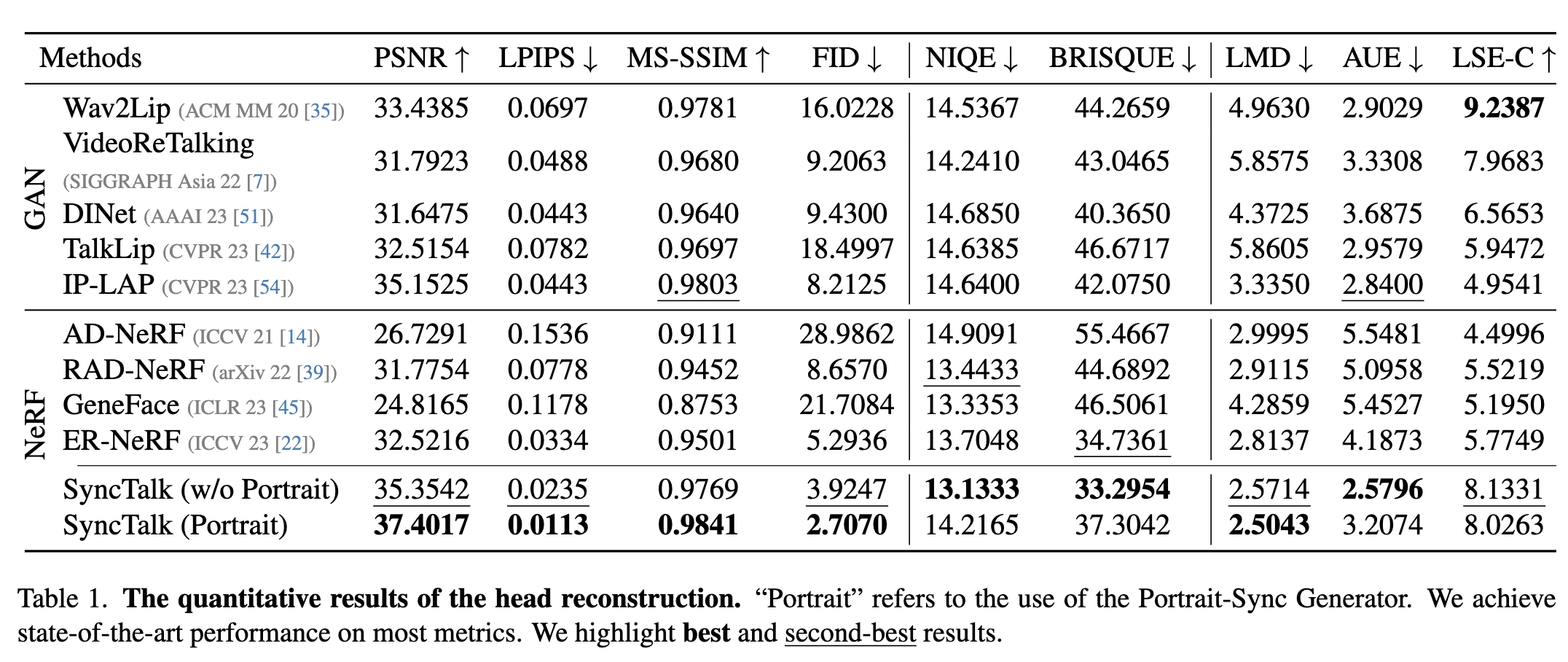
定量评价
| 评估指标 | 描述 |
|---|---|
| 全参考质量评估 | 使用峰值信噪比(PSNR)、学习感知图像补丁相似性(LPIPS)、多尺度结构相似性(MS-SSIM)和Frechet Inception Distance(FID)作为评估指标。 |
| 无参考质量评估 | 在高PSNR图像中,纹理细节可能与人类视觉感知不一致。为了更精确地定义和比较输出,使用两种无参考方法:自然图像质量评估器(NIQE)和无参考图像空间质量评估器(BRISQUE)。 |
| 同步评估 | 对于同步性,使用地标距离(LMD)来衡量面部运动的同步性,动作单位误差(AUE)来评估面部运动的准确性,并引入唇同步误差置信度(LSE-C),与Wav2Lip一致,以评估唇部运动与音频之间的同步性。 |
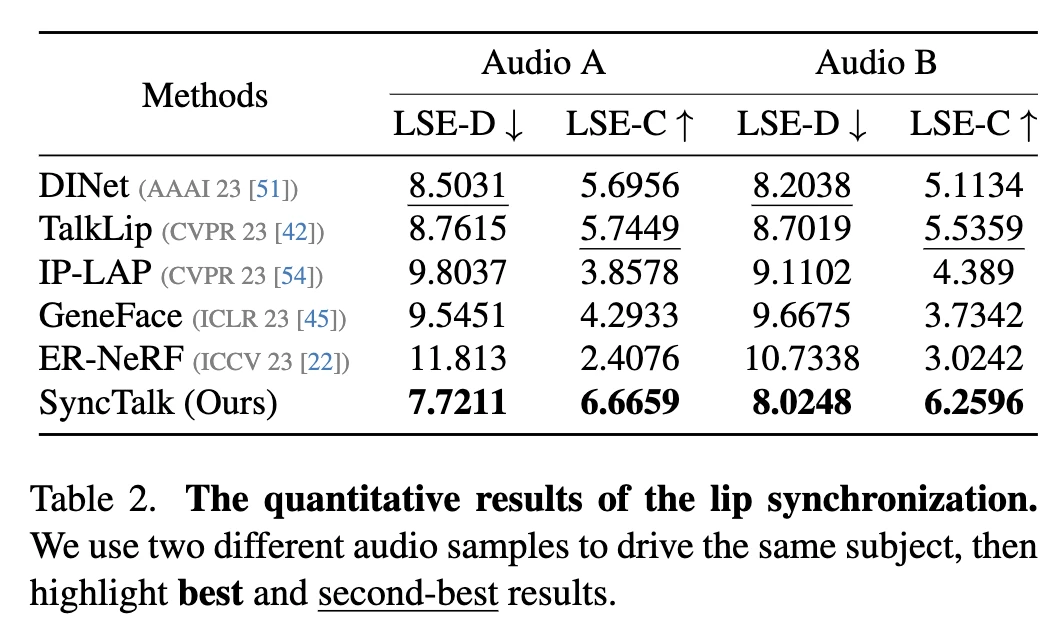
定量评估结果
- 头部重建方法在图像质量和同步性方面均优于基于GAN和NeRF的最新方法。
- 经过
Portrait-Sync Generator处理后,图像质量得到了显著改善,头发细节得到了恢复。 - 方法在维持主体身份、唇部、表情和姿势的同步性方面表现出色。
- 使用分布外音频的最新SOTA方法的驱动器结果表明,方法在唇音同步评估方面领先。
- 渲染速度远远超过视频输入速度,可以实现实时生成视频流。
定性评价
| 评估结果 | 描述 |
|---|---|
| 图像质量比较 | 在图中,我们展示了我们的方法与其他方法的比较。可以观察到,SyncTalk展示了更精确、更准确的面部细节。 |
| 与Wav2Lip的比较 | 与Wav2Lip相比,我们的方法在保持主体身份的同时提供了更高的保真度和分辨率。 |
| 与IP-LAP的比较 | 与IP-LAP相比,我们的方法在唇形同步方面表现出色,主要归功于音频-视觉编码器带来的音频-视觉一致性。 |
| 与GeneFace的比较 | 与GeneFace相比,我们的方法可以通过表情同步精确地重现眨眼和抬眉等动作。 |
| 与ER-NeRF的比较 | 与ER-NeRF相比,我们的方法通过姿势同步稳定器避免了头部和身体的分离,并生成了更准确的唇形。 |

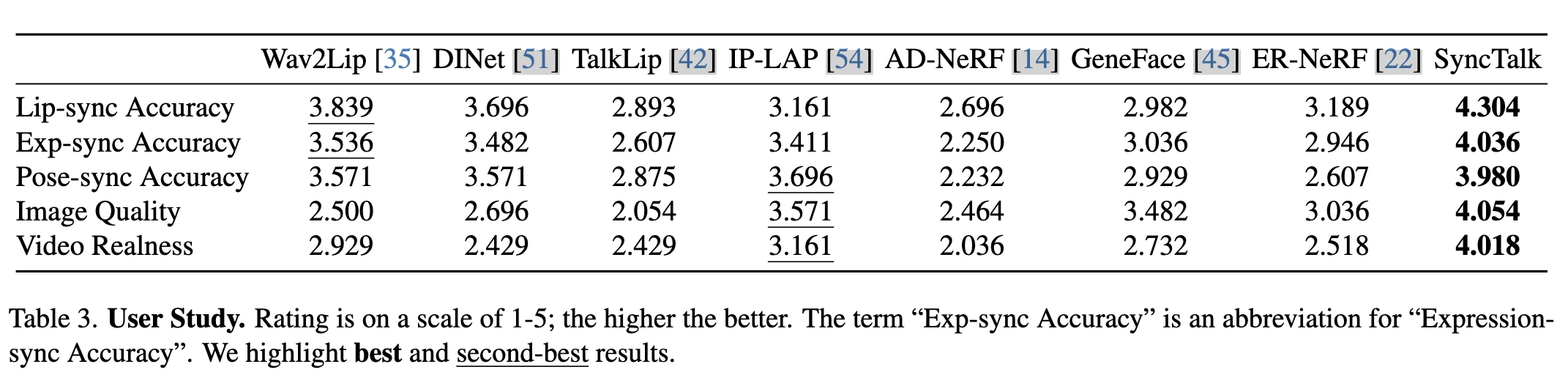
User Study
我们设计了一个详尽的用户研究问卷,35名参与者进行评分。问卷设计了五个方面的评分:唇同步准确性、表情同步准确性、姿势同步准确性、图像质量和视频真实性。
参与者平均完成问卷时间为19分钟,标准化的Cronbach α系数为0.96。用户研究结果显示,SyncTalk在所有评估中均超过以前的方法,特别是在视频真实性方面。
Ablation Study
接下来进行了消融研究,以检验我们模型中不同部分的贡献,选择了三个核心指标进行评估:PSNR、LPIPS和LMD。
我们选择了一个名为“May”的主体进行测试,结果如表所示。
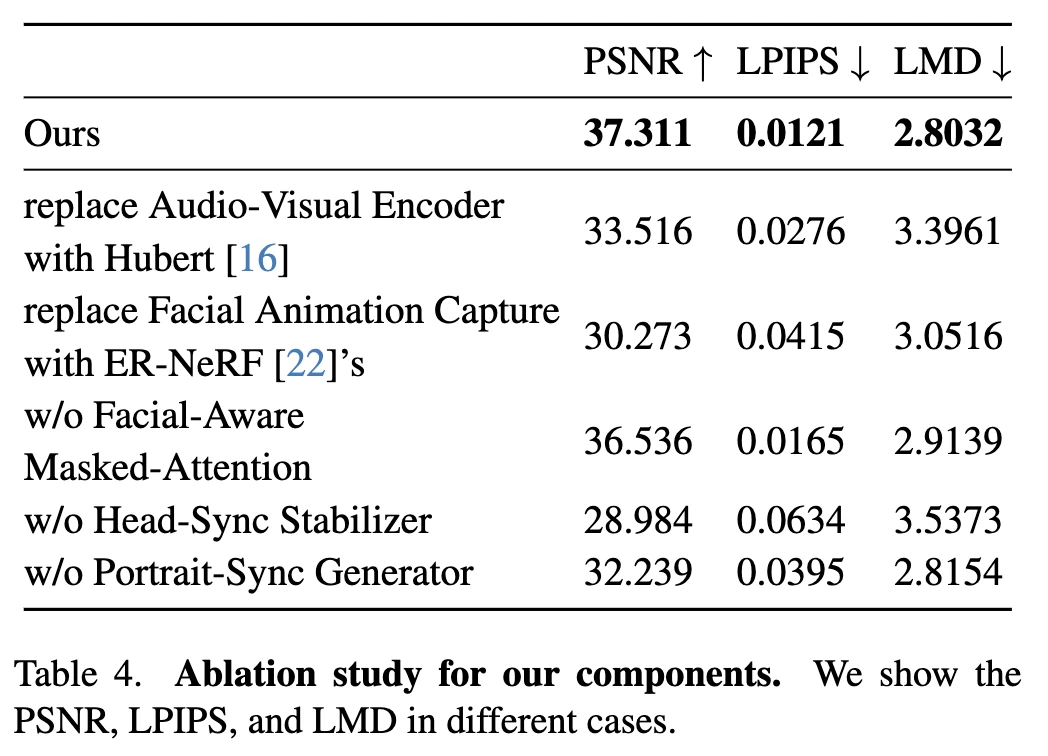
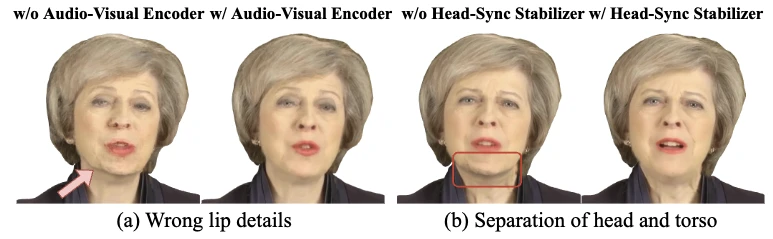
音频-视觉编码器提供了主要的唇部同步信息,当替换此模块时,所有三个指标都变差,其中特别是LMD错误增加了21.15%,表明唇部动作同步减少,如图5(a)所示,显示出我们的音频-视觉编码器可以提取准确的唇部特征。

用ER-NeRF 的眨眼模块替换Facial Animation Capture模块,这一部分会影响眉毛的运动和图像质量。
Facial-Aware Masked-Attention主要解耦了唇部和面部其他部位之间的运动,在移除后略微影响图像质量。
若没有头部同步稳定器,所有指标都显著下降,特别是LPIPS,导致头部姿势抖动和头部与躯干分离,如图5(b)所示。
Portrait-Sync Generator恢复了像头发这样的细节,移除此模块会影响头发等细节的恢复,导致明显的分割边界。
总结
- 本文介绍了SyncTalk,这是一种基于高度同步的NeRF方法,用于实现逼真的语音驱动的说话头部合成。
- 框架包括面部同步控制器、头部同步稳定器和肖像同步生成器,能够保持主体身份,并生成同步的唇部动作、面部表情和稳定的头部姿势。
- 通过广泛的评估,SyncTalk在创建逼真和同步的说话头部视频方面表现出优异的性能,相较于现有方法。
- 期望SyncTalk不仅能增强各种应用程序的功能,还能在说话头部合成领域激发进一步的创新。
 wechat
wechat- alipay







