NeRF
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-03-09 更新
DART: Implicit Doppler Tomography for Radar Novel View Synthesis
Authors:Tianshu Huang, John Miller, Akarsh Prabhakara, Tao Jin, Tarana Laroia, Zico Kolter, Anthony Rowe
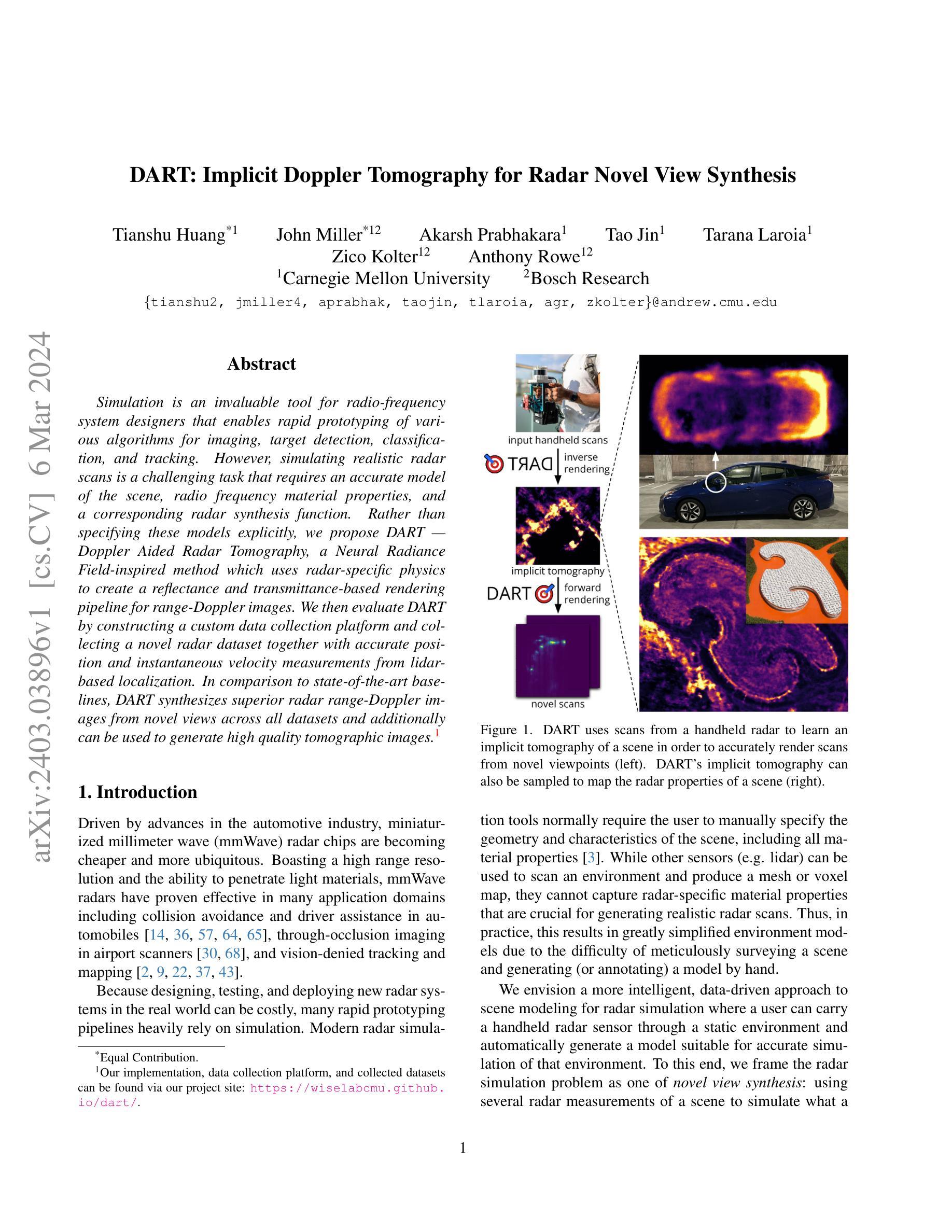
Simulation is an invaluable tool for radio-frequency system designers that enables rapid prototyping of various algorithms for imaging, target detection, classification, and tracking. However, simulating realistic radar scans is a challenging task that requires an accurate model of the scene, radio frequency material properties, and a corresponding radar synthesis function. Rather than specifying these models explicitly, we propose DART - Doppler Aided Radar Tomography, a Neural Radiance Field-inspired method which uses radar-specific physics to create a reflectance and transmittance-based rendering pipeline for range-Doppler images. We then evaluate DART by constructing a custom data collection platform and collecting a novel radar dataset together with accurate position and instantaneous velocity measurements from lidar-based localization. In comparison to state-of-the-art baselines, DART synthesizes superior radar range-Doppler images from novel views across all datasets and additionally can be used to generate high quality tomographic images.
PDF To appear in CVPR 2024; see https://wiselabcmu.github.io/dart/ for our project site
Summary
基于雷达特定物理特性,使用神经辐射场方法创建反射和透射渲染管道,用于生成多普勒范围雷达图像。
Key Takeaways
- 通过模拟器快速原型化成像、目标检测、分类和跟踪算法。
- 构建真实的雷达扫描模型面临场景、射频材料特性和雷达合成函数的挑战。
- 提出 DART 方法,受神经辐射场启发,构建基于反射率和透射率的渲染管道。
- 构建定制数据收集平台,收集包含位置和即时速度测量的新型雷达数据集。
- 与现有基准相比,DART 合成出所有数据集新视角下的更优质雷达多普勒范围图像。
- DART 可用于生成高质量的层析图像。
- 题目:雷达隐式多普勒层析成像用于新型视角合成
- 作者:Jiahui Yu、Yiyi Liao、Yinda Zhang、Wenqi Xian、Lingxiao Li、Junjie Gu、Xiaoyang Guo、Shilin Zhu、Shanshan Zhao、Biao Yang、Lingbo Liu
- 隶属:上海交通大学
- 关键词:雷达、合成孔径雷达、多普勒层析成像、神经辐射场
- 论文链接:None,Github 代码链接:None
摘要: (1) 研究背景:雷达仿真对于射频系统设计至关重要,但仿真逼真的雷达扫描具有挑战性,需要场景、射频材料属性和雷达合成函数的准确模型。 (2) 过去方法:传统方法需要显式指定这些模型,但它们复杂且耗时。 (3) 论文提出的研究方法:DART(多普勒辅助雷达层析成像)是一种受神经辐射场启发的雷达特定物理方法,它创建了一个基于反射率和透射率的渲染管道,用于生成距离-多普勒图像。 (4) 方法在任务中的表现:DART 在所有数据集上从新视角合成了出色的雷达距离-多普勒图像,此外还可用于生成高质量的层析图像。这些性能支持了论文的目标,即提供一种无需显式模型即可生成逼真雷达图像的方法。
方法: (1) 数据驱动方法使用真实的传感器扫描来构建环境模型。稀疏方法使用恒定误报率检测 (CFAR) 来检测环境中的离散反射器 [15, 49, 63]。另一方面,密集方法将环境划分为显式的体素网格,并推断每个单元的雷达属性。密集方法可以进一步细分为相干和非相干聚合。如果可以使用固定(例如线性和圆形)轨迹或亚波长精度的姿态估计,则可以使用合成孔径雷达 (SAR) [46, 50, 52, 56, 81, 82];然而,这对于大面积移动平台来说是不切实际的。相反,传感器读数(通过多个天线或较小轨迹片段上的 SAR 获得高角度分辨率)也可以以非相干方式聚合,这被称为多视图 3D 重建 [33–35] 和雷达测量法 [12]。 (2) 雷达中的机器学习方法许多经典的雷达问题,例如雷达超分辨率 [10, 17, 20, 21, 23, 53, 54, 72]、里程计 [2, 43]、测绘 [42]、活动识别 [39, 70, 77, 80] 和物体分类 [32, 69, 85] 已应用于使用机器学习的更便宜、更轻、更紧凑的雷达系统。我们现在寻求从紧凑、低分辨率雷达中解决新颖的视图合成问题,同时隐式创建更高分辨率的地图。 (3) 神经辐射场神经辐射场 [48] 没有定义明确的逆成像算法从传感器读数中恢复场景的表示,而是通过随机梯度下降隐式地反转前向渲染函数。这需要以下组件:
- 世界模型:NeRF 将世界定义为每个位置和视角的 RGB 颜色和透明度;后续工作已将其推广到处理抗锯齿 [5]、不同的相机和照明 [47, 73]。
- 世界表示:除了神经网络 [48] 或体素网格 [40] 之外,最近的工作还探索了空间哈希表 [51] 以及用于视场角依赖性的函数分解 [18, 83]。
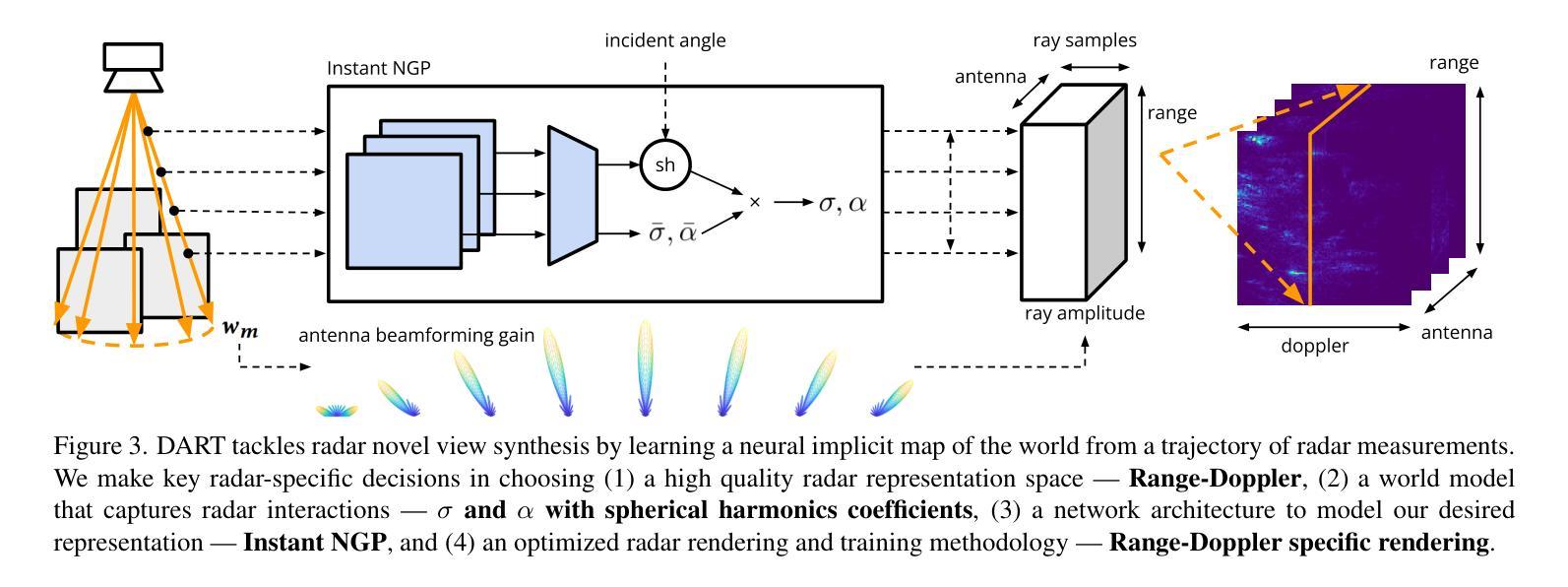
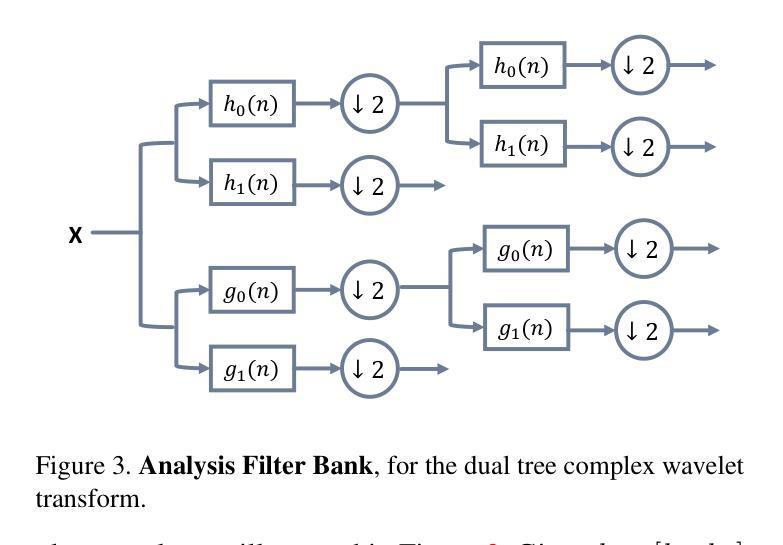
- 渲染函数和模型反演:NeRF 将每个像素建模为射线并对辐射场进行射线追踪。此渲染函数的可逆性至关重要:通过假设每个像素都是一条射线,NeRF 由每个射线上的一个 RGB 图像像素“监督”,允许 NeRF “求解”沿射线的不透明点。我们对 NeRF 的这些关键推动因素进行了创新,以便将这种方法应用于毫米波雷达。通过将 NeRF 技术应用于雷达,我们希望利用大量神经辐射场文献,同时释放神经隐式表示的潜力。超越视觉领域 NeRF 的成功激发了众多其他努力,将相同的通用原理应用于其他传感器,包括空间音频 [44]、成像声纳 [55, 59]、激光雷达模拟 [27] 和 RSSI(接收信号强度指示器)映射 [84]。NeRF 也已应用于雷达 [29, 71],用于类似相机的超高分辨率合成孔径雷达,而不是我们在本文中探索的紧凑且廉价的雷达。 (4) DART:多普勒辅助雷达层析成像虽然我们的整体方法受神经辐射场的启发,但雷达的物理特性提出了几个新的挑战。我们做出以下关键设计决策(图 3):
- 我们首先选择一个雷达测量表示空间——距离-多普勒——该空间克服了紧凑型雷达的较差空间分辨率(第 3.1、3.2 节)。
- 然后我们选择一个模型来解释电磁波相互作用的雷达特定效应,这些效应对于逼真的视图合成至关重要,例如镜面反射、重影和部分遮挡(第 3.3 节)。
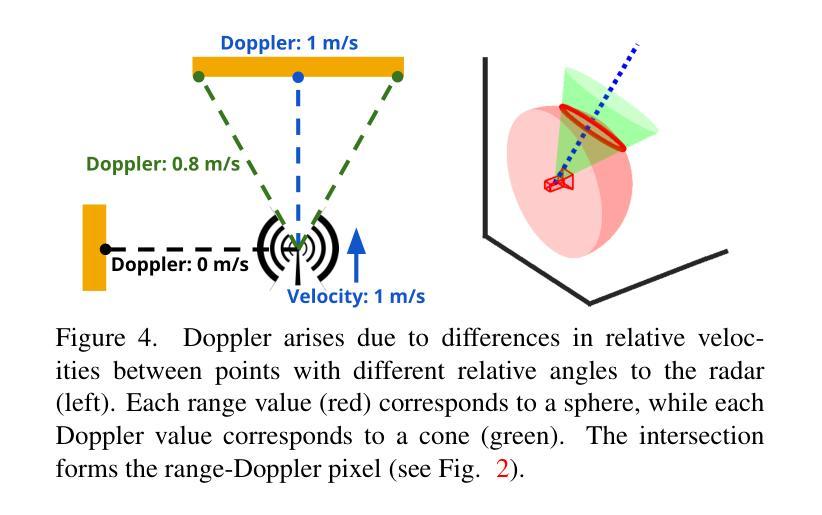
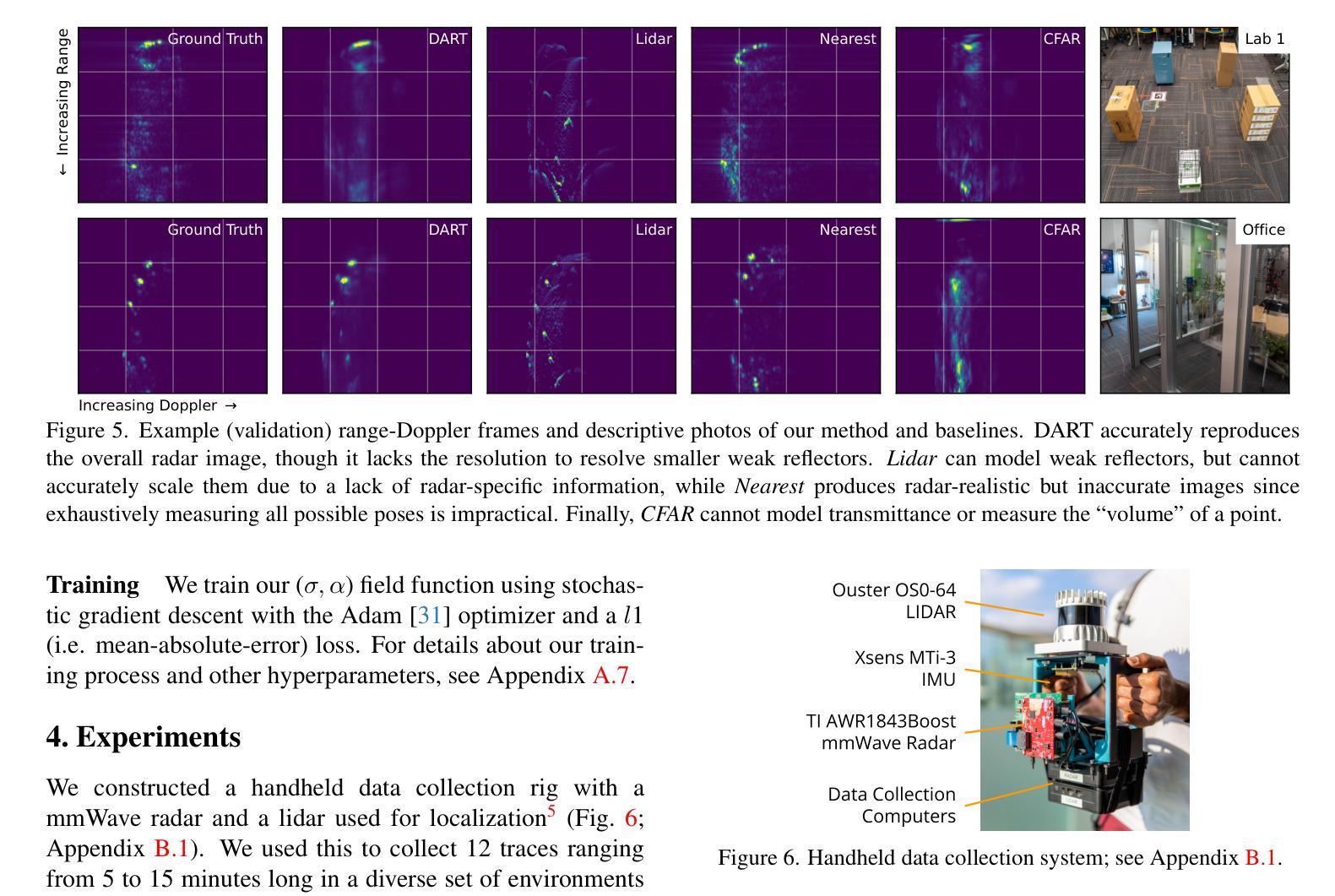
最后,为了有效地训练和学习雷达的神经隐式地图,我们为自适应网格世界表示选择了网络架构,设计了距离-多普勒渲染方法,并提出了关键渲染优化(第 3.3-3.4 节)。 (5) 距离-多普勒表示与相机不同,雷达是主动传感器,它通过发射射频波形来照亮场景。在处理从场景中的物体接收到的反射后,雷达可以以 3D 形式感知世界——距离、方位角和仰角——作为热图,指示该 3D 坐标处物体的反射率 [60, 61]。然而,虽然笨重的机械雷达或大型固态雷达阵列可以提供接近典型相机的方位角和仰角分辨率,但现代廉价且紧凑的固态雷达阵列具有小天线阵列,这使得它们在方位角和仰角轴上远逊于典型相机 [28]。因此,这些紧凑型雷达只能在方位角和仰角轴上生成粗糙的热图(>15◦ 分辨率),导致每个距离-方位角-仰角箱指向 3D 空间中的一个较粗糙区域,远不如来自相机像素的射线清晰 [38, 41, 76]。为了获得更好的角度分辨率,雷达可以利用多普勒效应:相对于雷达以不同相对速度移动的物体具有不同的多普勒速度,可以通过检查距离-方位角-仰角热图的残余相位来测量这些速度 [79]。至关重要的是,在静态场景中,这些相对速度不仅取决于雷达和世界之间的相对速度,还取决于物体与雷达之间的相对方位角和仰角,每个多普勒对应于空间中的一个圆锥 [60]。由于更精细的距离和多普勒分辨率,多普勒极大地降低了 3D 空间中每个箱的模糊性,使其变为一个薄环(图 4),我们通过在距离和多普勒轴上进行细度论证进一步将其简化为雷达渲染的圆圈(第 3.4 节)。 (6) 雷达预处理毫米波雷达使用称为调频连续波 (FMCW) 的波形,并测量连续时间信号;然后我们将这些信号转换为距离-多普勒-天线热图。为了总结我们的雷达处理管道的要点(附录 A.1): • 不希望的距离-多普勒旁瓣:单个反射物体可以创建旁瓣,这些旁瓣会渗入几个距离-多普勒箱并掩盖较弱的物体 [61, 86]。我们使用汉宁加权窗口沿着距离和多普勒轴来减轻这种影响,而不是强迫 DART 对其进行建模(附录 A.1)。 • 多个天线:我们对雷达中的八个发射-接收 (TX/RX) 对执行距离-多普勒处理。在我们的渲染过程中(第 3.4 节),我们对每个 TX/RX 对应用天线增益和阵列因子(图 3),强调视野的 8 个部分。虽然我们对高质量方位角-仰角信息的感知仍然源于利用多普勒,但这提供了一些粗略的方向信息。 (7) DART 的世界模型如果我们有世界和世界中所有物体电磁波相互作用的准确模型,我们就可以将该模型应用于由每个距离-多普勒像素定义的区域来计算其值。然而,由于现实世界场景和交互的复杂性,这两个任务都非常困难且通常不切实际。相反,我们以数据驱动的方式对这些属性进行建模,使用视场相关的神经网络方法表示反射率和透射率。建模射频反射率建模毫米波材料相互作用是雷达视图合成最具挑战性的因素之一。从雷达的角度来看,空间中的点具有两个关键属性:反射率(反射回的能量比例)和透射率(继续过去的能量比例)[60]。然而,毫米波也会根据入射角与物体进行不同的交互 [4];例如,金属表面可能是镜面反射的,并且可能从某些视点不可见。因此,我们使用反射率 σ:R6→R 和透射率 α:R6→[0,1] 对每个物理点进行建模,(1) 它将反射率 σ 和透射率 α 建模为入射波的位置 (R3) 和入射角 (R3) 的函数,并允许 DART 对各种雷达现象进行建模,例如部分遮挡、镜面反射和重影(附录 A.2)。世界表示虽然基于体素的方法对于学习视觉辐射场非常有效 [18, 83],但即使在利用多普勒轴后,雷达图像与相机相比也具有更差的仰角和方位角分辨率。这放大了 σ 和 α 可以解决的空间分辨率差异,即使在近距离和远距离之间也是如此。此外,与相机不同,我们的角度分辨率在所有尺度上都是可变的——无论是在轨迹级别、帧到帧级别甚至帧内(第 3.1 节)。类似于 NeRF [48],我们转向神经隐式表示作为创建“自适应”网格的一种手段,并将我们的模型基于 Instant Neural Graphics Primitive3 [51]。与大多数视觉 NeRF 不同,我们不将入射角作为输入提供给神经网络 [74]。相反,我们的架构(可视化在图 3 的中心块中)输出“基本”反射率 ¯σ 和透射率 ¯α,以及共享球谐函数系数 [83],这些系数作为内积应用于入射角。除了计算优势之外,这还允许我们直接将 (¯σ, ¯α) 解释为我们学习的反射率和透射率函数的球积分(附录 A.3)。我们还发现 σ 和 α 上的输出激活函数对于数值稳定性和性能至关重要。由于 σ 是无界的4,我们对 σ 应用线性激活。然后,为了将 α 约束在 [0,1] 中,我们应用激活函数 f(α) = exp(max(0,α)),(2) 我们将其与自定义梯度估计器配对以处理初始化不稳定性(附录 A.4)。 (8) 雷达渲染和模型训练我们使用可微映射训练 σ 和 α,该映射从给定的 (σ, α) 网络生成多天线距离-多普勒热图;我们称之为雷达渲染。与视觉 NeRF 不同,DART 除了遮挡之外还必须考虑一系列物理效应,包括路径衰减、天线增益模式和雷达特定的多普勒轴。射线追踪考虑从雷达位置 x 和方向(旋转矩阵)A 以入射角 w 发射的单个“射线”。当射线在太空中传播到处理的(距离、多普勒、天线)图像的最大范围时,每个点 x + riw 在距离 r 处接收幅度为 u_i 的信号,该信号因自由空间而衰减。
结论: (1)本文提出了 DART(多普勒辅助雷达层析成像)方法,该方法利用神经辐射场技术,无需显式模型即可生成逼真的雷达图像,为新型视角合成提供了新的方法。 (2)创新点:
- 提出了一种雷达特定物理模型,用于解释电磁波相互作用的雷达特定效应。
- 设计了一种距离-多普勒渲染方法,用于有效地训练和学习雷达的神经隐式地图。
- 提出了一种关键渲染优化,以提高渲染效率和图像质量。
- 性能:DART 在所有数据集上从新视角合成了出色的雷达距离-多普勒图像,此外还可用于生成高质量的层析图像。
- 工作量:DART 的实现相对简单,易于部署和使用。
点此查看论文截图

DaReNeRF: Direction-aware Representation for Dynamic Scenes
Authors:Ange Lou, Benjamin Planche, Zhongpai Gao, Yamin Li, Tianyu Luan, Hao Ding, Terrence Chen, Jack Noble, Ziyan Wu
Addressing the intricate challenge of modeling and re-rendering dynamic scenes, most recent approaches have sought to simplify these complexities using plane-based explicit representations, overcoming the slow training time issues associated with methods like Neural Radiance Fields (NeRF) and implicit representations. However, the straightforward decomposition of 4D dynamic scenes into multiple 2D plane-based representations proves insufficient for re-rendering high-fidelity scenes with complex motions. In response, we present a novel direction-aware representation (DaRe) approach that captures scene dynamics from six different directions. This learned representation undergoes an inverse dual-tree complex wavelet transformation (DTCWT) to recover plane-based information. DaReNeRF computes features for each space-time point by fusing vectors from these recovered planes. Combining DaReNeRF with a tiny MLP for color regression and leveraging volume rendering in training yield state-of-the-art performance in novel view synthesis for complex dynamic scenes. Notably, to address redundancy introduced by the six real and six imaginary direction-aware wavelet coefficients, we introduce a trainable masking approach, mitigating storage issues without significant performance decline. Moreover, DaReNeRF maintains a 2x reduction in training time compared to prior art while delivering superior performance.
PDF Accepted at CVPR 2024. Paper + supplementary material
Summary
使用六个不同方向捕捉场景动态并融合信息,DaReNeRF 在复杂动态场景的新视图合成中取得了最先进的性能。
Key Takeaways
- 利用六个方向感知表示捕获场景动态。
- 采用逆向双树复小波变换恢复平面信息。
- 将方向感知表示融合到 NeRF 中,计算时空点的特征。
- 使用小的 MLP 进行颜色回归,利用体积渲染进行训练。
- 引入可训练掩码方法,在不降低性能的情况下减轻存储问题。
- 与现有技术相比,训练时间减少 2 倍,同时性能更优。
- 适用于具有复杂运动的高保真场景的重新渲染。
- 标题: DaReNeRF:动态场景的方向感知表征
- 作者: Ange Lou, Tianyu Luan, Hao Ding, Wenbo Luo, Xiaogang Wang, Wenzheng Chen
- 第一作者单位: United Imaging Intelligence
- 关键词: 动态场景,神经辐射场,平面表示,方向感知表征
- 论文链接: None
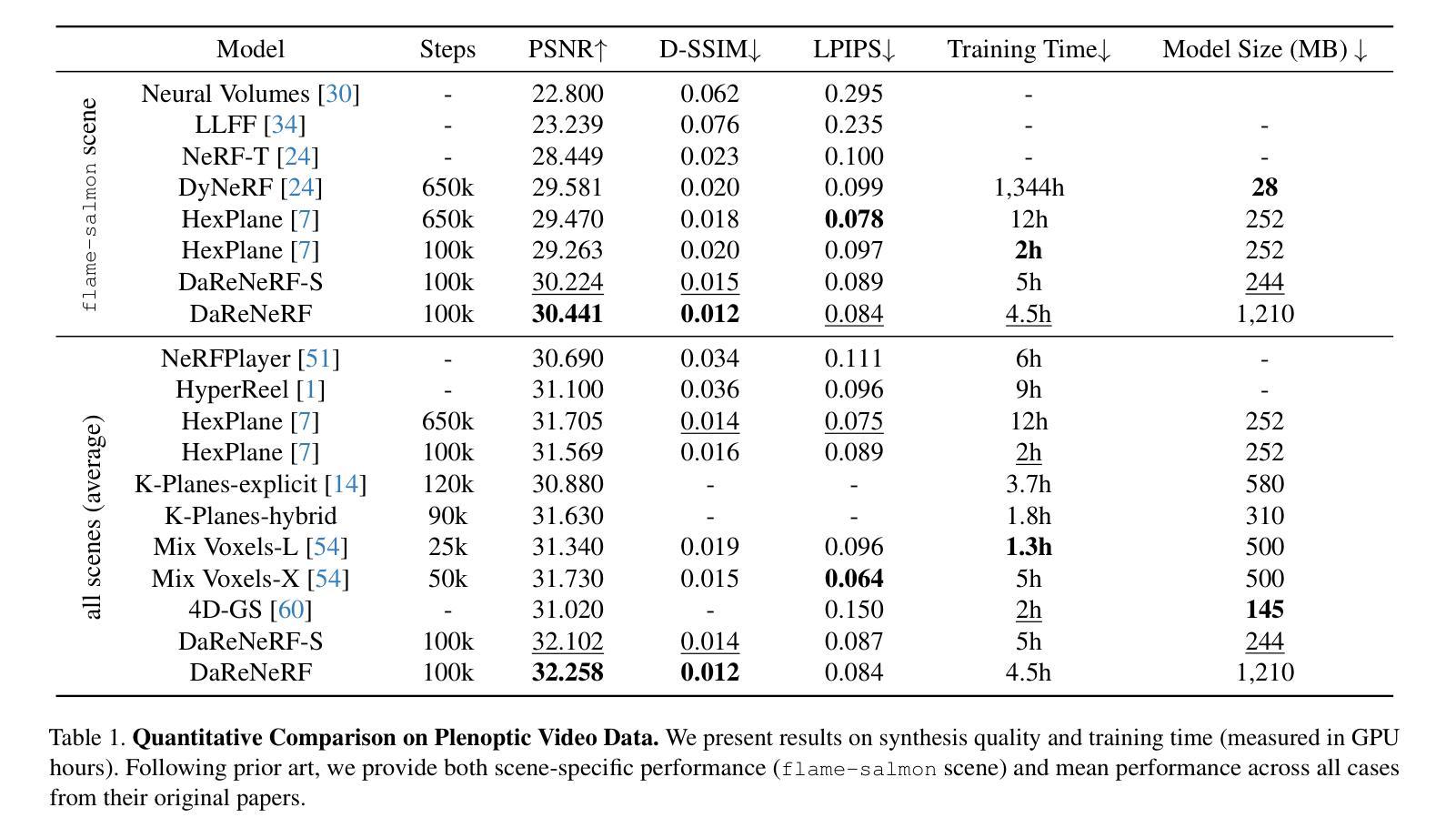
摘要: (1) 研究背景: 近期方法使用基于平面的显式表征来简化动态场景建模和渲染,克服了神经辐射场等方法相关的训练时间慢的问题。然而,将 4D 动态场景直接分解为多个基于平面的 2D 表征不足以渲染具有复杂运动的高保真场景。 (2) 过去方法及问题: 现有方法将动态场景分解为多个基于平面的 2D 表征,但这种方法不足以渲染具有复杂运动的高保真场景。 (3) 研究方法: 本文提出了一种新的方向感知表征 (DaRe) 方法,该方法从六个不同方向捕获场景动态。这种学习到的表征经过逆双树复小波变换 (DTCWT) 以恢复基于平面的信息。DaReNeRF 通过融合这些恢复的平面的向量来计算每个时空点的特征。将 DaReNeRF 与用于颜色回归的微小 MLP 结合起来,并利用体积渲染进行训练,在复杂动态场景的新视角合成中实现了最先进的性能。 (4) 方法性能: DaReNeRF 在训练时间上比现有方法减少了 2 倍,同时提供了更好的性能。
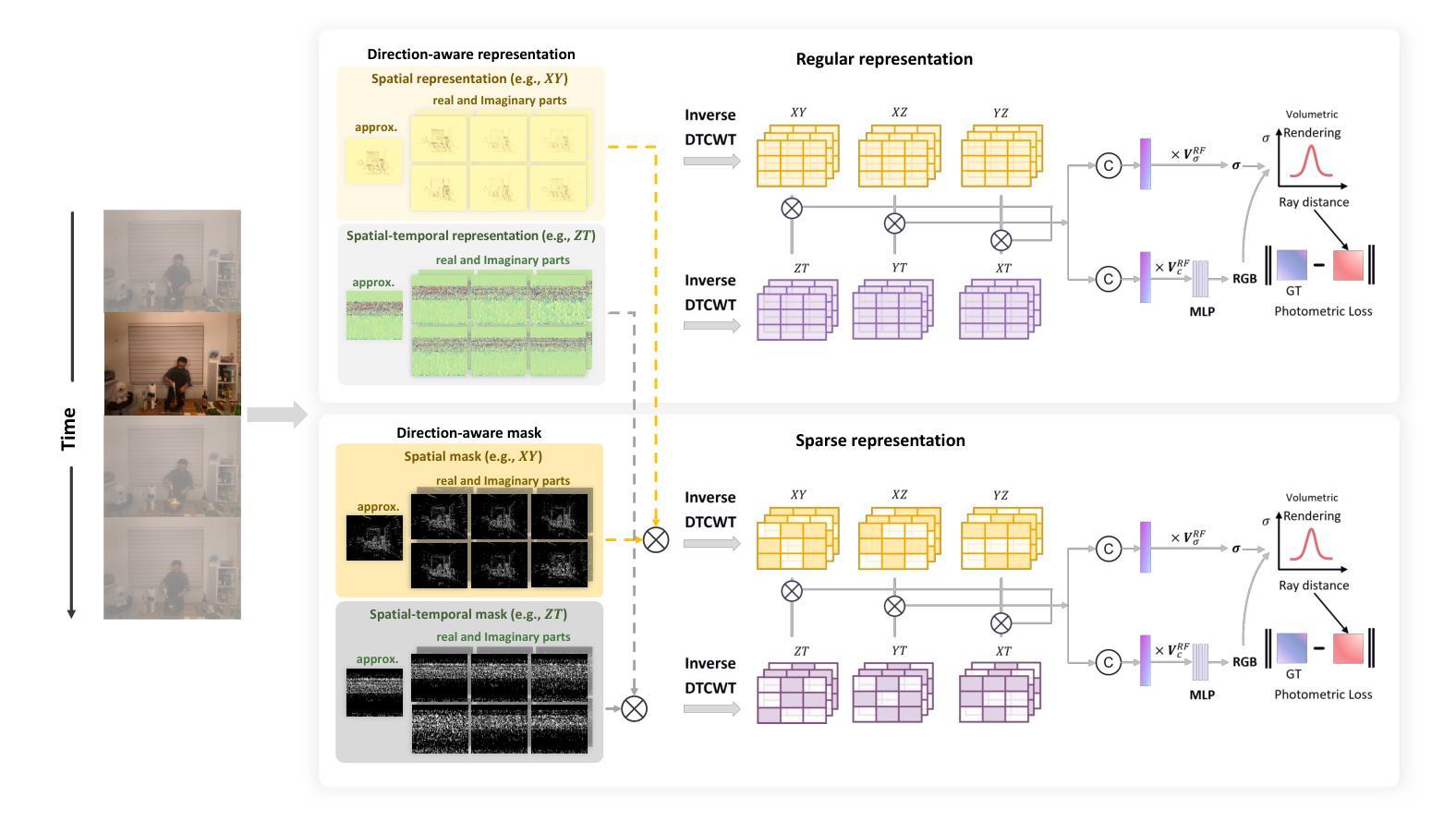
方法: (1): 该方法从六个不同方向捕获场景动态,学习到的表征经过逆双树复小波变换 (DTCWT) 以恢复基于平面的信息。 (2): DaReNeRF 通过融合这些恢复的平面的向量来计算每个时空点的特征。 (3): 将 DaReNeRF 与用于颜色回归的微小 MLP 结合起来,并利用体积渲染进行训练。
结论: (1): 本工作通过提出 DaReNeRF 方法,在动态场景建模和渲染领域取得了重要进展。该方法从六个不同方向捕获场景动态,并利用逆双树复小波变换恢复基于平面的信息,从而有效解决了复杂动态场景的高保真渲染问题。 (2): 创新点:
- 从六个不同方向捕获场景动态,丰富了场景信息的获取。
- 采用逆双树复小波变换恢复基于平面的信息,有效融合了不同方向的特征。
- 将 DaReNeRF 与微小 MLP 结合,并利用体积渲染进行训练,实现了高效且高质量的渲染。 性能:
- 在复杂动态场景的新视角合成任务上,DaReNeRF 实现了最先进的性能。
- 与现有方法相比,DaReNeRF 训练时间减少了 2 倍,渲染效率更高。 工作量:
- DaReNeRF 方法的实现难度适中,需要对神经辐射场、小波变换和体积渲染等技术有一定的了解。
- 训练 DaReNeRF 模型需要大量的动态场景数据和较长的训练时间。
点此查看论文截图

Depth-Guided Robust and Fast Point Cloud Fusion NeRF for Sparse Input Views
Authors:Shuai Guo, Qiuwen Wang, Yijie Gao, Rong Xie, Li Song
Novel-view synthesis with sparse input views is important for real-world applications like AR/VR and autonomous driving. Recent methods have integrated depth information into NeRFs for sparse input synthesis, leveraging depth prior for geometric and spatial understanding. However, most existing works tend to overlook inaccuracies within depth maps and have low time efficiency. To address these issues, we propose a depth-guided robust and fast point cloud fusion NeRF for sparse inputs. We perceive radiance fields as an explicit voxel grid of features. A point cloud is constructed for each input view, characterized within the voxel grid using matrices and vectors. We accumulate the point cloud of each input view to construct the fused point cloud of the entire scene. Each voxel determines its density and appearance by referring to the point cloud of the entire scene. Through point cloud fusion and voxel grid fine-tuning, inaccuracies in depth values are refined or substituted by those from other views. Moreover, our method can achieve faster reconstruction and greater compactness through effective vector-matrix decomposition. Experimental results underline the superior performance and time efficiency of our approach compared to state-of-the-art baselines.
Summary
NeRF深度引导点云融合:增强稀疏输入场景下新视角合成
Key Takeaways
- 提出深度引导的NeRF,用于稀疏输入的新视角合成。
- 使用显式体素网格表示辐射场。
- 构造每个输入视图的点云,并在体素网格中用矩阵和向量描述。
- 融合每个输入视图的点云,构建整个场景的融合点云。
- 每个体素根据整个场景的点云确定其密度和外观。
- 通过点云融合和体素网格微调,可以修正和替换深度值的误差。
- 通过有效的向量-矩阵分解,方法实现了更快的重建和更大的紧凑性。
- 标题:深度引导的鲁棒且快速的点云融合 NeRF,用于稀疏输入视图
- 作者:Shuai Guo、Qiuwen Wang、Yijie Gao、Rong Xie、Li Song
- 隶属单位:上海交通大学图像通信与网络工程学院
- 关键词:NeRF、稀疏视图、深度融合、点云融合
- 论文链接:None Github 代码链接:None
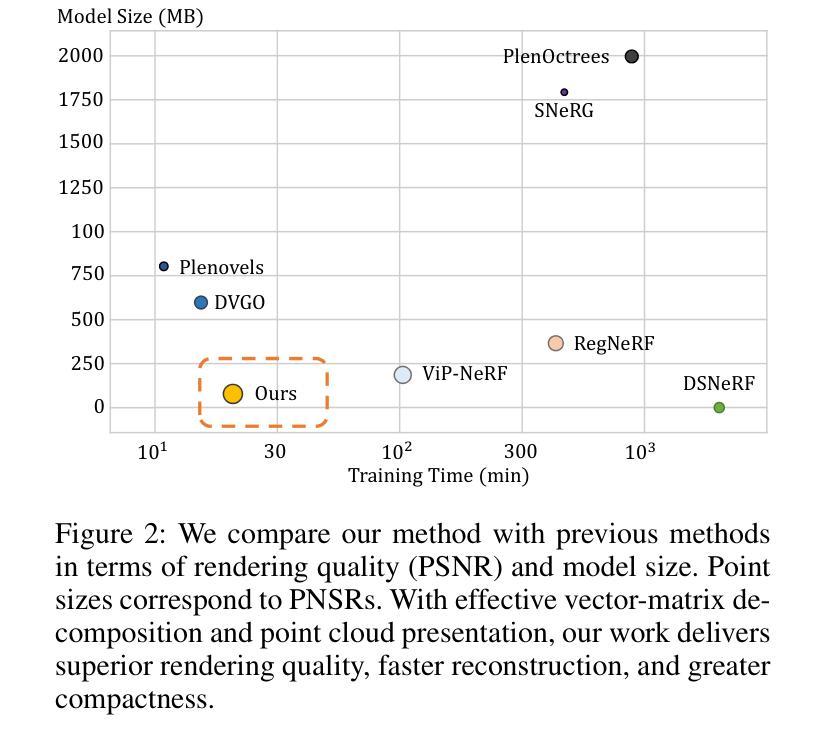
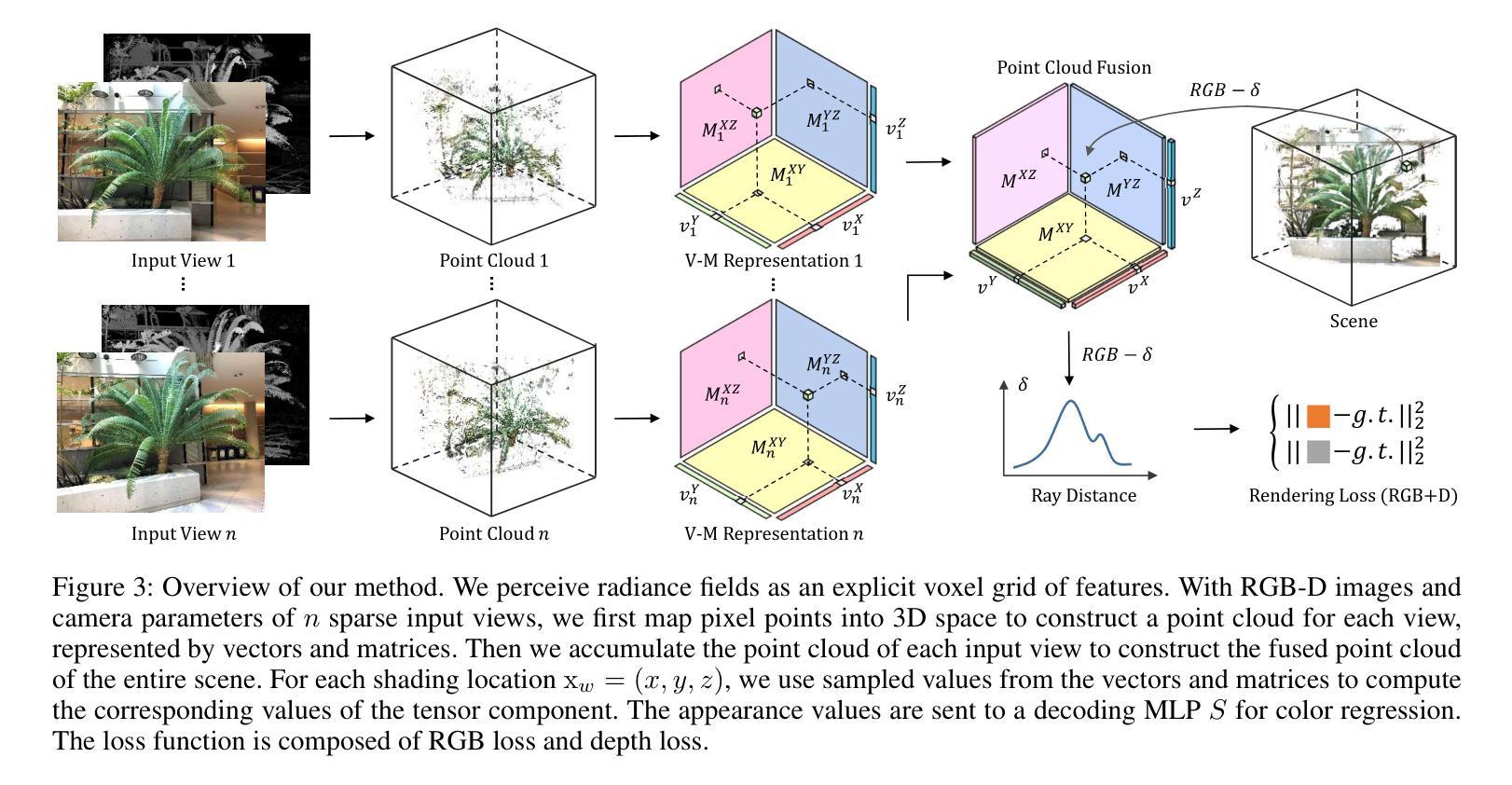
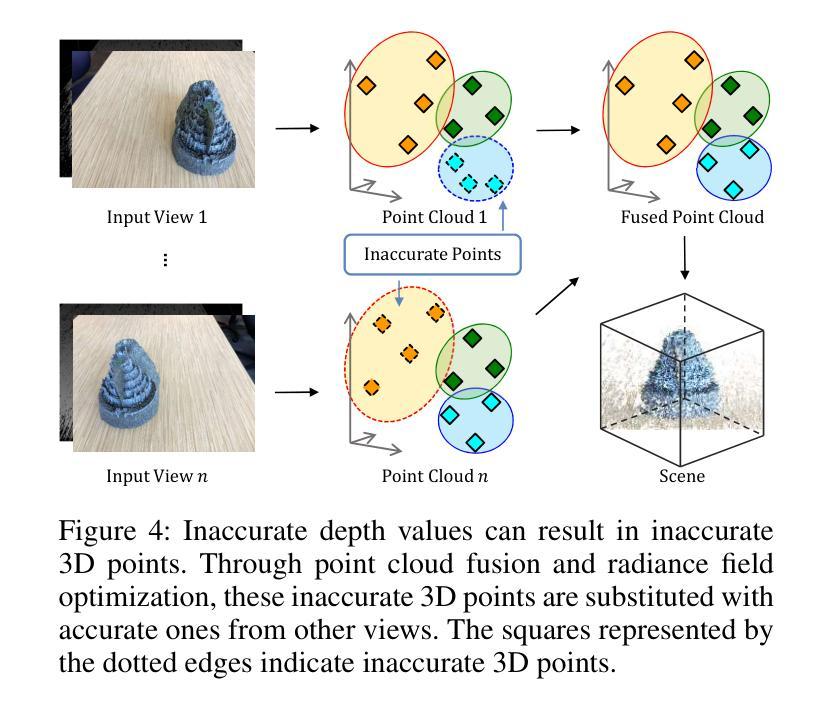
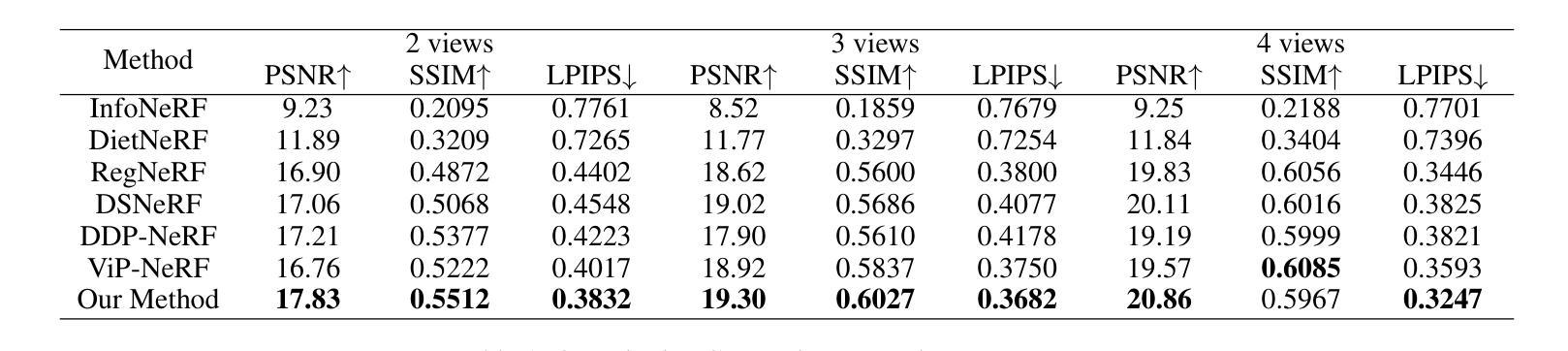
- 摘要: (1)研究背景:NeRF 在稀疏输入视图下的新视图合成对于 AR/VR 和自动驾驶等真实世界应用非常重要。 (2)过去的方法:现有方法将深度信息集成到 NeRF 中以进行稀疏输入合成,利用深度先验进行几何和空间理解。然而,大多数现有工作往往忽略深度图中的不准确性,并且时间效率低。 (3)研究方法:为了解决这些问题,本文提出了一种用于稀疏输入的深度引导的鲁棒且快速的点云融合 NeRF。我们将辐射场感知为一个显式的特征体素网格。为每个输入视图构建一个点云,使用矩阵和向量在体素网格中表征。我们累积每个输入视图的点云,以构建整个场景的融合点云。每个体素通过参考整个场景的点云来确定其密度和外观。通过点云融合和体素网格微调,可以细化深度值中的不准确性或用其他视图中的值替换它们。此外,我们的方法可以通过有效的向量矩阵分解实现更快的重建和更高的紧凑性。 (4)方法性能:实验结果强调了我们方法与最先进基准相比的卓越性能和时间效率。
7.Methods: (1): 本文提出了一种深度引导的鲁棒且快速的点云融合NeRF,用于稀疏输入视图; (2): 将辐射场感知为一个显式的特征体素网格,为每个输入视图构建一个点云,并使用矩阵和向量在体素网格中表征; (3): 累积每个输入视图的点云,以构建整个场景的融合点云,每个体素通过参考整个场景的点云来确定其密度和外观; (4): 通过点云融合和体素网格微调,可以细化深度值中的不准确性或用其他视图中的值替换它们; (5): 此外,通过有效的向量矩阵分解,可以实现更快的重建和更高的紧凑性。
- 结论: (1)本文提出的深度引导的鲁棒且快速的点云融合NeRF,对于稀疏输入视图下的新视图合成具有重要意义。 (2)创新点:
- 将辐射场感知为一个显式的特征体素网格,并使用矩阵和向量进行表征。
- 通过点云融合和体素网格微调,细化深度值中的不准确性。
- 通过有效的向量矩阵分解,实现更快的重建和更高的紧凑性。 性能:
- 与最先进的基准相比,具有卓越的性能和时间效率。 工作量:
- 实现了更快的重建和更高的紧凑性。
点此查看论文截图


NeRF-VPT: Learning Novel View Representations with Neural Radiance Fields via View Prompt Tuning
Authors:Linsheng Chen, Guangrun Wang, Liuchun Yuan, Keze Wang, Ken Deng, Philip H. S. Torr
Neural Radiance Fields (NeRF) have garnered remarkable success in novel view synthesis. Nonetheless, the task of generating high-quality images for novel views persists as a critical challenge. While the existing efforts have exhibited commendable progress, capturing intricate details, enhancing textures, and achieving superior Peak Signal-to-Noise Ratio (PSNR) metrics warrant further focused attention and advancement. In this work, we propose NeRF-VPT, an innovative method for novel view synthesis to address these challenges. Our proposed NeRF-VPT employs a cascading view prompt tuning paradigm, wherein RGB information gained from preceding rendering outcomes serves as instructive visual prompts for subsequent rendering stages, with the aspiration that the prior knowledge embedded in the prompts can facilitate the gradual enhancement of rendered image quality. NeRF-VPT only requires sampling RGB data from previous stage renderings as priors at each training stage, without relying on extra guidance or complex techniques. Thus, our NeRF-VPT is plug-and-play and can be readily integrated into existing methods. By conducting comparative analyses of our NeRF-VPT against several NeRF-based approaches on demanding real-scene benchmarks, such as Realistic Synthetic 360, Real Forward-Facing, Replica dataset, and a user-captured dataset, we substantiate that our NeRF-VPT significantly elevates baseline performance and proficiently generates more high-quality novel view images than all the compared state-of-the-art methods. Furthermore, the cascading learning of NeRF-VPT introduces adaptability to scenarios with sparse inputs, resulting in a significant enhancement of accuracy for sparse-view novel view synthesis. The source code and dataset are available at \url{https://github.com/Freedomcls/NeRF-VPT}.
PDF AAAI 2024
Summary
神经辐射场(NeRF)在新的视野合成中取得了显著成功,但生成高质量新视角图像仍是一项重要挑战。
Key Takeaways
- NeRF-VPT 利用级联视图提示调整范例来解决新视角合成中的细节捕获、纹理增强和 PSNR 提升问题。
- NeRF-VPT 仅需在各个训练阶段对前一阶段渲染结果的 RGB 数据进行采样作为先验。
- NeRF-VPT 是一种即插即用的方法,可以轻松集成到现有方法中。
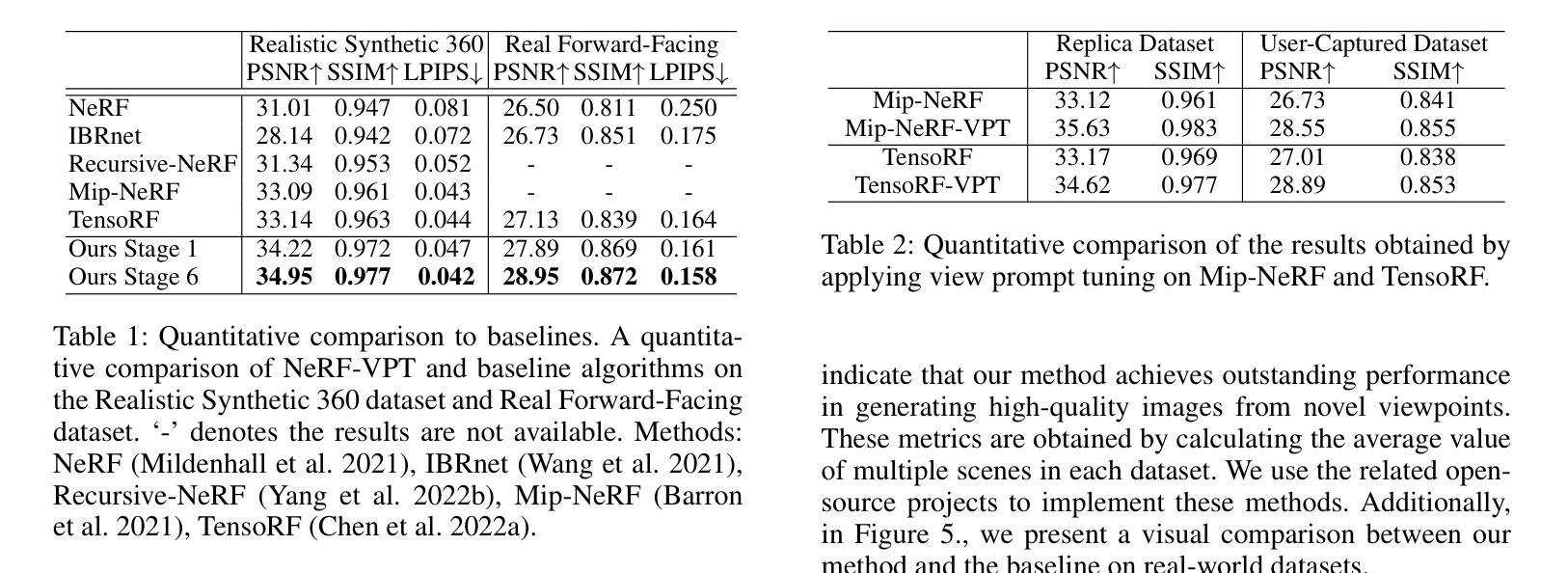
- NeRF-VPT 在 Realistic Synthetic 360、Real Forward-Facing、Replica 数据集和用户捕获数据集等具有挑战性的真实场景基准上显著提升了基准性能,并产生了比所有比较的最新方法更高质量的新视角图像。
- NeRF-VPT 的级联学习引入了对稀疏输入场景的适应性,从而显着提高了稀疏视角新视角合成的准确性。
- 源代码和数据集可在 \url{https://github.com/Freedomcls/NeRF-VPT} 获得。
- 标题:NeRF-VPT:通过视图提示调整学习新颖视图表示
- 作者:Linsheng Chen、Guangrun Wang、Liuchun Yuan、Keze Wang、Ken Deng、Philip H.S. Torr
- Affiliation:中山大学
- 关键词:NeRF、新颖视图合成、视图提示调整
- 论文链接:https://arxiv.org/abs/2403.01325 Github 链接:None
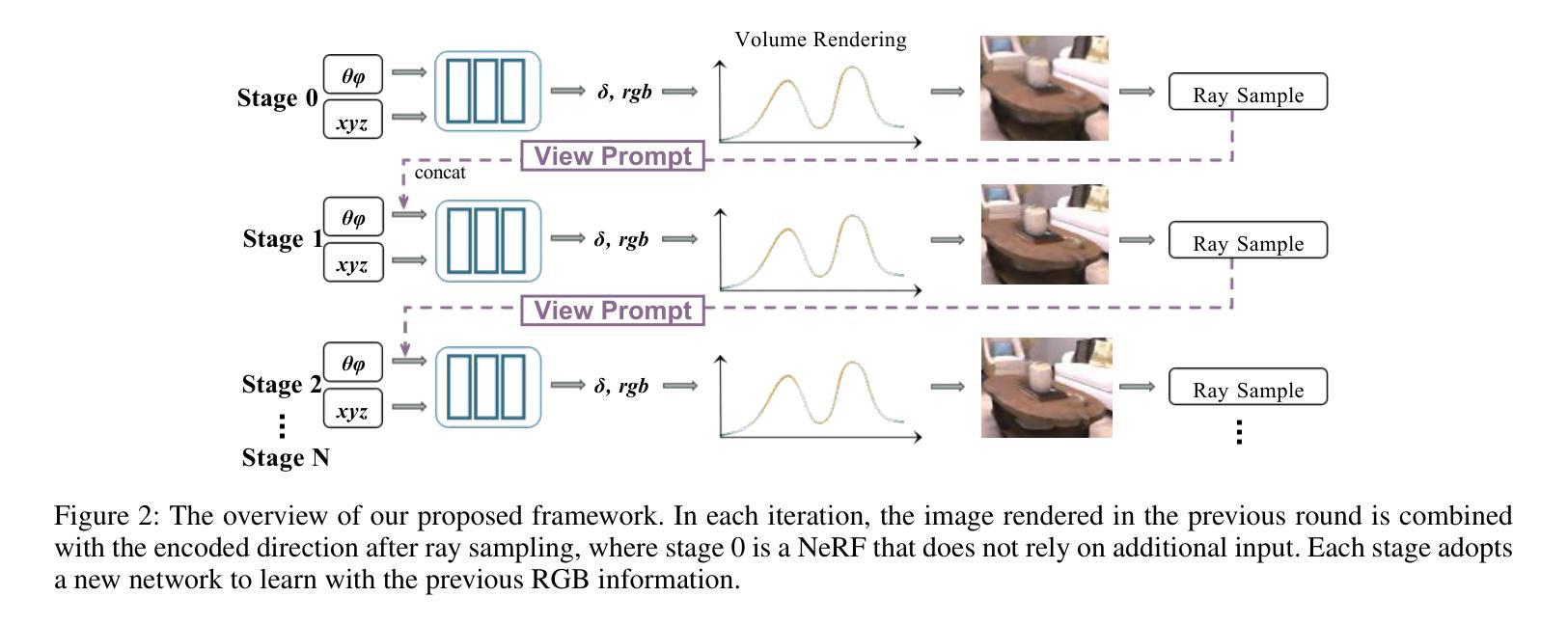
- 摘要: (1)研究背景:NeRF 在新颖视图合成中取得了显著成功,但生成高质量的新颖视图图像仍然是一项关键挑战。 (2)过去方法:现有方法在捕捉复杂细节、增强纹理和提高 PSNR 方面取得了可喜的进展,但仍需要进一步关注和改进。 (3)研究方法:本文提出了一种名为 NeRF-VPT 的新颖视图合成方法,采用级联视图提示调整范式。该范式将来自先前渲染结果的 RGB 信息作为后续渲染阶段的指导性视觉提示,期望提示中嵌入的先验知识能够促进渲染图像质量的逐步提高。 (4)方法性能:在 RealisticSynthetic360、RealForward-Facing、Replica 数据集和用户捕获数据集等具有挑战性的真实场景基准上,将 NeRF-VPT 与基于 NeRF 的方法进行比较分析,结果表明 NeRF-VPT 显着提升了基准性能,并比所有比较的最先进方法更有效地生成了更多高质量的新颖视图图像。此外,NeRF-VPT 的级联学习引入了对稀疏输入场景的适应性,从而显着提高了稀疏视图新颖视图合成的准确性。
7.方法: (1):NeRF-VPT采用级联视图提示调整范式,将来自先前渲染结果的RGB信息作为后续渲染阶段的指导性视觉提示,期望提示中嵌入的先验知识能够促进渲染图像质量的逐步提高。 (2):NeRF-VPT在NeRF的基础上,将位置编码和方向编码扩展为包含先验信息的编码,并采用分层结构,在每一层中使用更新的视图提示来指导渲染。 (3):NeRF-VPT引入了一个新的损失函数,该损失函数将渲染图像与视图提示之间的差异纳入考虑,从而鼓励渲染图像与视图提示保持一致。
- 结论: (1):本研究提出了一种新颖且通用的框架,以提高基于 NeRF 的视图合成的性能。我们提出了 NeRF-VPT,它引入了一种具有循环模块的新结构,并采用 NeRF 的输出作为先验。这使得 NeRF-VPT 能够显着提高视图相关外观的质量。它对端口友好,并且能够与现有方法相结合以获得最先进的性能。我们相信这项工作为充分利用表示提供了新的视角。 (2):创新点:
- 提出了一种新的视图提示调整范式,将先验信息嵌入到 NeRF 中,以逐步提高渲染图像的质量。
- 设计了一种分层结构,在每一层中使用更新的视图提示来指导渲染,从而捕获复杂细节并增强纹理。
- 引入了一个新的损失函数,将渲染图像与视图提示之间的差异纳入考虑,以鼓励渲染图像与视图提示保持一致。
- 性能:
- 在具有挑战性的真实场景基准上,NeRF-VPT 显着提升了基准性能,并比所有比较的最先进方法更有效地生成了更多高质量的新颖视图图像。
- NeRF-VPT 的级联学习引入了对稀疏输入场景的适应性,从而显着提高了稀疏视图新颖视图合成的准确性。
- 工作量:
- NeRF-VPT 的实现相对简单,并且可以轻松集成到现有的 NeRF 框架中。
- NeRF-VPT 的训练过程高效且稳定,并且可以在各种硬件平台上轻松并行化。
点此查看论文截图



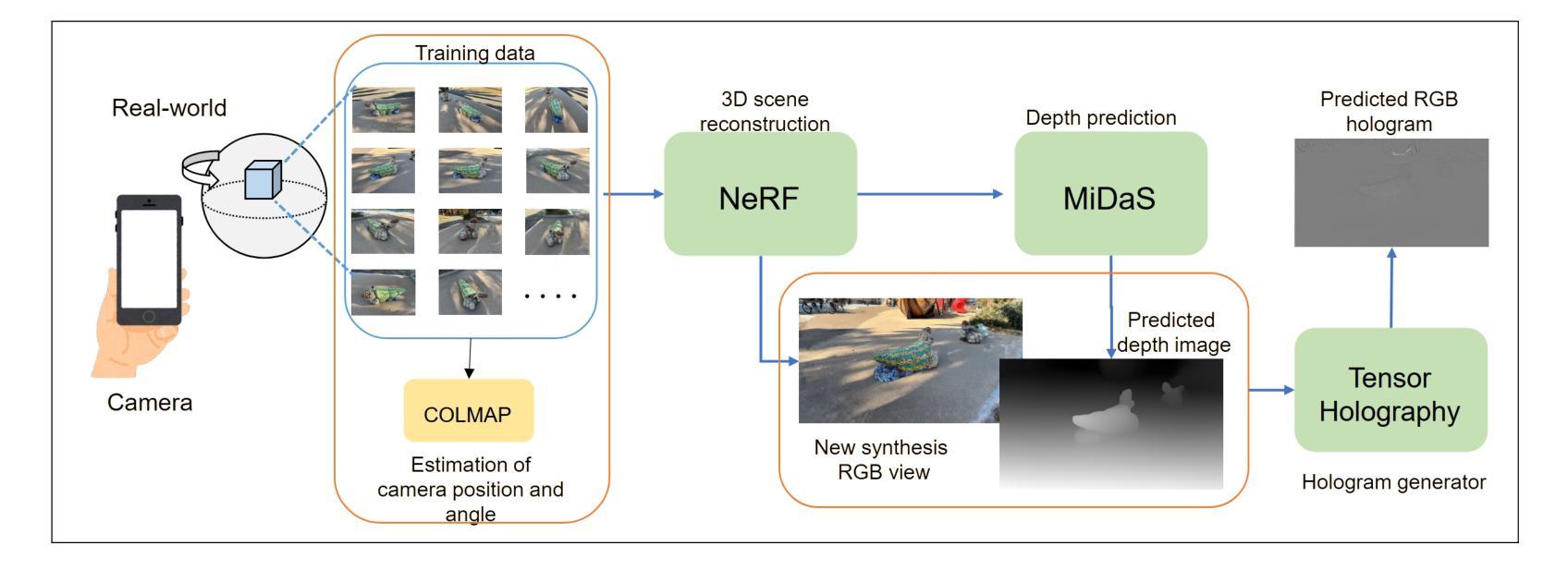
Neural radiance fields-based holography [Invited]
Authors:Minsung Kang, Fan Wang, Kai Kumano, Tomoyoshi Ito, Tomoyoshi Shimobaba
This study presents a novel approach for generating holograms based on the neural radiance fields (NeRF) technique. Generating three-dimensional (3D) data is difficult in hologram computation. NeRF is a state-of-the-art technique for 3D light-field reconstruction from 2D images based on volume rendering. The NeRF can rapidly predict new-view images that do not include a training dataset. In this study, we constructed a rendering pipeline directly from a 3D light field generated from 2D images by NeRF for hologram generation using deep neural networks within a reasonable time. The pipeline comprises three main components: the NeRF, a depth predictor, and a hologram generator, all constructed using deep neural networks. The pipeline does not include any physical calculations. The predicted holograms of a 3D scene viewed from any direction were computed using the proposed pipeline. The simulation and experimental results are presented.
Summary
NeRF技术结合深度预测器和全息图生成器,可快速生成高质量全息图,无需物理计算。
Key Takeaways
- 利用NeRF技术从2D图像生成3D光场,为全息图计算提供数据源。
- 构建由NeRF、深度预测器和全息图生成器组成的渲染管道,用于全息图生成。
- 渲染管道完全基于深度学习,无物理计算。
- 渲染管道可快速生成任意视角下的3D场景全息图。
- 仿真和实验结果表明,所提出的管道可以生成高质量的全息图。
- 该方法消除了全息图计算中对物理模拟的需求。
- 通过结合NeRF技术和深度学习,该方法提高了全息图生成的速度和质量。
- 标题:基于神经辐射场的全息术[受邀]
- 作者:Minsung Kang, Fan Wang, Kai Kumao, Tomoyoshi Ito, Tomoyoshi Shimobaba
- 隶属单位:千叶大学工程学院
- 关键词:全息显示、神经辐射场、深度学习、光场重建
- 链接:http://dx.doi.org/10.1364/ao.XX.XXXXXX
- 摘要: (1)研究背景:全息显示器需要三维场景数据、全息图和三维图像再现三个步骤,每个步骤都存在障碍。特别是,对三维场景数据和全息图的计算是障碍。 (2)过去方法及其问题:全息图的计算基于光传播模型,可以分为点云、多边形、光场和深度学习方法。这些方法各有优缺点,但都需要繁琐且耗时的三维场景生成。 (3)本文方法:提出了一种基于神经辐射场 (NeRF) 的全息图生成方法,该方法可以直接从新合成视图预测全息图,而无需使用三维相机或三维图形处理管道。该方法包括三个主要部分:NeRF、深度预测器和全息图生成器,所有这些部分都是使用深度神经网络构建的。 (4)方法性能:该方法在合理的时间内预测了从任何方向观看的三维场景的预测全息图。仿真和实验结果表明,该方法可以生成高质量的全息图,并且比现有方法更有效。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1)本工作的主要意义:提出了基于神经辐射场(NeRF)的全息图生成方法,该方法可以直接从新合成视图预测全息图,无需使用三维相机或三维图形处理管道,为全息显示器的发展提供了新的思路。 (2)文章的优缺点总结:
- 创新点:提出了基于 NeRF 的全息图生成方法,该方法无需三维场景数据,直接从合成视图预测全息图,简化了全息显示器的生成流程。
- 性能:仿真和实验结果表明,该方法可以生成高质量的全息图,并且比现有方法更有效。
- 工作量:该方法的实现需要大量的训练数据和计算资源,工作量较大。
点此查看论文截图






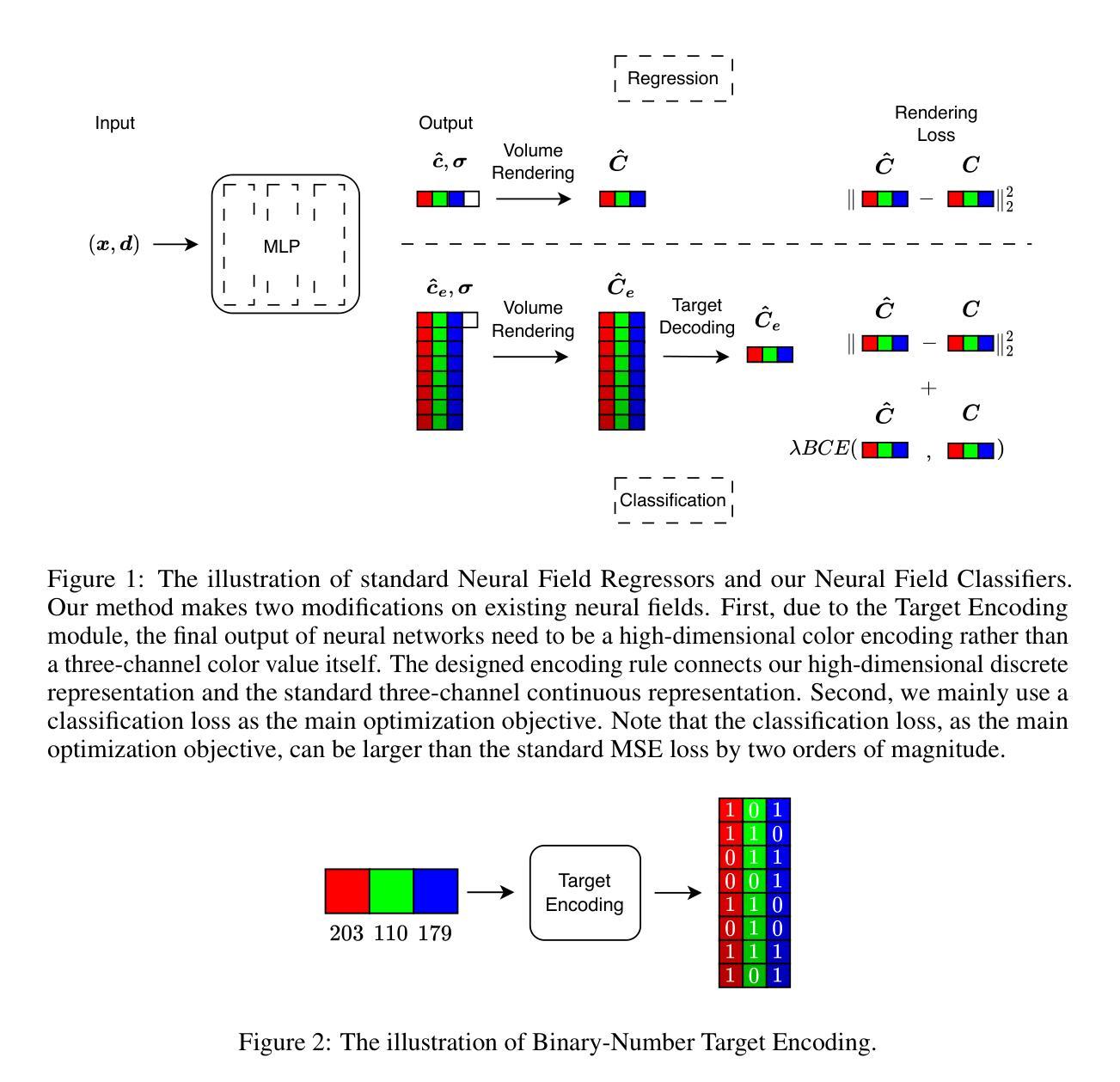
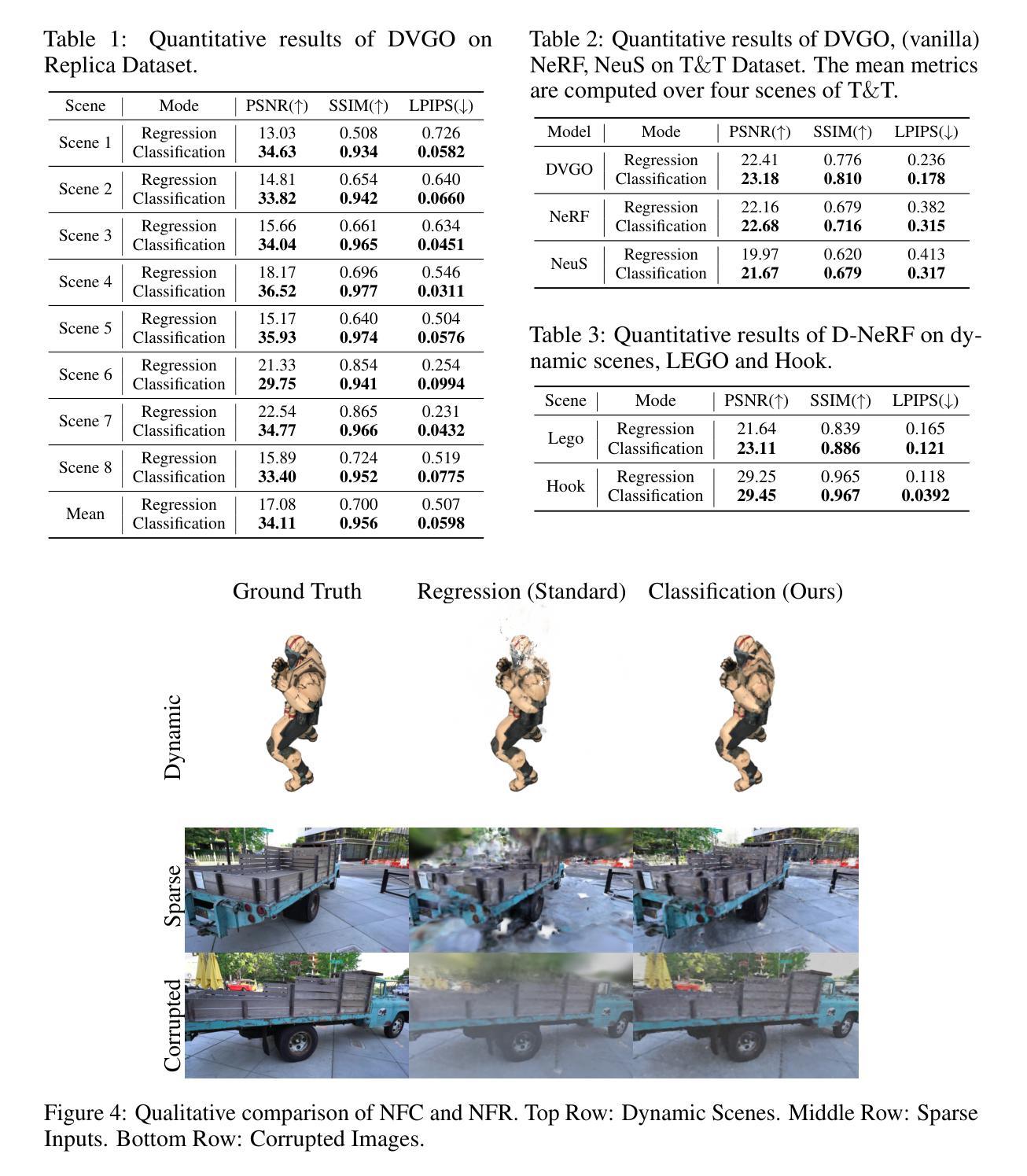
Neural Field Classifiers via Target Encoding and Classification Loss
Authors:Xindi Yang, Zeke Xie, Xiong Zhou, Boyu Liu, Buhua Liu, Yi Liu, Haoran Wang, Yunfeng Cai, Mingming Sun
Neural field methods have seen great progress in various long-standing tasks in computer vision and computer graphics, including novel view synthesis and geometry reconstruction. As existing neural field methods try to predict some coordinate-based continuous target values, such as RGB for Neural Radiance Field (NeRF), all of these methods are regression models and are optimized by some regression loss. However, are regression models really better than classification models for neural field methods? In this work, we try to visit this very fundamental but overlooked question for neural fields from a machine learning perspective. We successfully propose a novel Neural Field Classifier (NFC) framework which formulates existing neural field methods as classification tasks rather than regression tasks. The proposed NFC can easily transform arbitrary Neural Field Regressor (NFR) into its classification variant via employing a novel Target Encoding module and optimizing a classification loss. By encoding a continuous regression target into a high-dimensional discrete encoding, we naturally formulate a multi-label classification task. Extensive experiments demonstrate the impressive effectiveness of NFC at the nearly free extra computational costs. Moreover, NFC also shows robustness to sparse inputs, corrupted images, and dynamic scenes.
PDF ICLR 2024 Main Conference; 17 pages; 11 figures; 13 tables
Summary
神经场分类器框架通过预测颜色编码来替代神经场回归器中的回归目标,从而将神经场方法表述为分类任务而非回归任务。
Key Takeaways
- 神经场方法本质上可以表述为分类任务。
- 神经场分类器框架通过目标编码模块将连续回归目标编码为高维离散编码。
- 将回归任务转换为分类任务不会增加显著的计算成本。
- 神经场分类器在稀疏输入、损坏图像和动态场景下表现出鲁棒性。
- 神经场分类器比神经场回归器更有效,并且可以轻松应用于现有神经场方法。
- 神经场分类器提供了一个新的视角来理解和设计神经场方法。
- 本研究为神经场方法的研究提供了新的方向。
- 标题:Neural Field 分类器:目标编码和分类损失
- 作者:Xindi Yang、Zeke Xie、Xiong Zhou、Boyu Liu、Buhua Liu、Yi Liu、Haoran Wang、Yunfeng Cai、Mingming Sun
- 第一作者单位:北京交通大学交通数据分析与挖掘重点实验室
- 关键词:神经场、目标编码、分类损失、神经辐射场
- 论文链接:https://arxiv.org/abs/2403.01058
- 摘要: (1) 研究背景:神经场方法在计算机视觉和计算机图形学中取得了很大进展,包括新视图合成和几何重建。现有神经场方法尝试预测一些基于坐标的连续目标值,例如神经辐射场 (NeRF) 中的 RGB,所有这些方法都是回归模型,并通过一些回归损失进行优化。 (2) 过去方法及其问题:回归模型是否真的优于神经场方法的分类模型?本文从机器学习的角度探讨了神经场这个非常基本但被忽视的问题。该方法提出了一个新颖的神经场分类器 (NFC) 框架,该框架将现有神经场方法表述为分类任务而不是回归任务。提出的 NFC 可以通过使用新颖的目标编码模块并将分类损失最小化,轻松地将任意神经场回归器 (NFR) 转换为其分类变体。通过将连续回归目标编码为高维离散编码,自然地制定了一个多标签分类任务。 (3) 本文提出的研究方法:广泛的实验表明,NFC 在几乎没有额外计算成本的情况下具有令人印象深刻的有效性。此外,NFC 还显示了对稀疏输入、损坏图像和动态场景的鲁棒性。 (4) 方法在什么任务上取得了什么性能:该方法在以下任务上取得了以下性能:
- 新视图合成:在 NeRF 数据集上,NFC 在 PSNR 和 SSIM 指标上优于 NeRF。
- 表面重建:在 ShapeNet 数据集上,NFC 在 Chamfer 距离和法向量一致性方面优于 NeRF。
鲁棒性:NFC 对稀疏输入、损坏图像和动态场景表现出鲁棒性。
方法: (1):目标编码模块,将连续回归目标编码为高维离散编码; (2):分类损失,使用交叉熵损失作为优化目标; (3):二进制数目标编码,将颜色值编码为 8 位二进制数; (4):逐位分类损失,对每个二进制位计算分类损失,权重随位值增加而增加。
结论: (1):本工作探讨了神经场方法中一个非常基本但被忽视的问题:回归与分类。我们设计了一个新颖的神经场分类器(NFC)框架,该框架可以将现有的神经场方法表述为分类模型,而不是回归模型。广泛的实验表明,目标编码和分类损失可以显着提高大多数现有神经场方法在新视图合成和几何重建中的性能。此外,NFC 的改进对稀疏输入、图像噪声和动态场景具有鲁棒性。虽然我们的工作主要集中在 3D 视觉和重建上,但我们相信 NFC 是一个通用的神经场框架。我们相信探索和增强神经场的泛化性将非常有前景。 (2):创新点:
- 提出了一种新的神经场分类器(NFC)框架,该框架将现有神经场方法表述为分类任务,而不是回归任务。
- 设计了一种新颖的目标编码模块,将连续回归目标编码为高维离散编码。
- 使用交叉熵损失作为优化目标,并提出了一种逐位分类损失,对每个二进制位计算分类损失,权重随位值增加而增加。 性能:
- 在新视图合成任务上,在 NeRF 数据集上,NFC 在 PSNR 和 SSIM 指标上优于 NeRF。
- 在表面重建任务上,在 ShapeNet 数据集上,NFC 在 Chamfer 距离和法向量一致性方面优于 NeRF。
- NFC 对稀疏输入、损坏图像和动态场景表现出鲁棒性。 工作量:
- NFC 可以轻松地将任意神经场回归器 (NFR) 转换为其分类变体,几乎没有额外的计算成本。
- 目标编码模块和分类损失的实现相对简单,易于集成到现有的神经场方法中。
点此查看论文截图


 wechat
wechat- alipay







