Blendshape学习笔记
Blendshape(Morph Target动画)
Blendshapes泛指3D定点动画的制作方式 (Maya里面称之为 blend shapes ,而3DS Max里称之为morph targets) ,在3D动画中用的比较多,尤其是人脸动画的制作,通过blendshape来驱动角色的面部表情。
用在脸部动画制作时,blendshape可以被称之为脸部特征,表情基准,定位符等等。这里要引入一个FACS的概念,可以简单理解为将脸部进行合理化的分区标准。
“表情这个东西看起来是一个无限多可能的东西,怎么能够计算expression呢?
这就带来了Blendshapes——一组组成整体表情的基准(数量可以有十几个、50个、100+、 200+,越多就越细腻)。我们可以使用这一组基准通过线性组合来计算出整体的expression,用公式来说就是 ,其中e是expression,B是一组表情基准,d是对应的系数(在这一组里面的权重),b是neutral。”
BlendShape系数介绍
在ARKit中,对表情特征位置定义了52组运动blendshape系数(
https://developer.apple.com/documentation/arkit/arfaceanchor/blendshapelocation ),每个blendshape系数代表一种表情定位符,表情定位符定义了特定表情属性,如mouthSmileLeft、mouthSmileRight等,与其对应的blendshape系数则表示表情运动范围。这52组blendshape系数极其描述如下表所示。

每一个blendshape系数的取值范围为0~1的浮点数。以jawOpen为例,当认为用户的嘴巴完全闭紧时,返回的jawOpen系数为0。当认为用户的嘴巴张开至最大时,返回的jawOpen系数为1。
在用户完全闭嘴与嘴张到最大之间的过渡状态,jawOpen会根据用户嘴张大的幅度返回一个0~1的插值。
脸部动捕的使用
ARKit 脸部与Vive脸部blendshape基准对比
| ARKit(52) | Extra | VIVE(52) | Extra | |
|---|---|---|---|---|
| Brow | 5 | 0 | ||
| Eye | 13 | 14 | Eye Frown + 1 | |
| Cheek | 3 | 3 | ||
| Nose | 2 | 0 | ||
| Jaw | 4 | 4 | ||
| Mouth | 24 | 20 | O shape - 1 | |
| Tongue | 1 | Tongue + 7 | 11 | |
| Sum | 52 | 59 | 52 | 52 |
ARKit的52个Blendshape表情基准组
可以看ARKit Face Blendshapes的照片和3D模型示例:https://arkit-face-blendshapes.com/
| CC3 | ARKit Name 表情基准/定位符 | ARKit Picture | CC3 Picture |
|---|---|---|---|
| A01 | browInnerUp |  |  |
| A02 | browDownLeft |  |  |
| A03 | browDownRight | 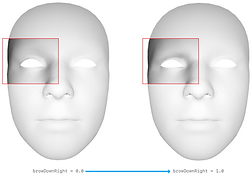 |  |
| A04 | browOuterUpLeft |  |  |
| A05 | browOuterUpRight |  |  |
| A06 | eyeLookUpLeft |  |  |
| A07 | eyeLookUpRight |  |  |
| A08 | eyeLookDownLeft |  |  |
| A09 | eyeLookDownRight |  |  |
| A10 | eyeLookOutLeft |  |  |
| A11 | eyeLookInLeft |  |  |
| A12 | eyeLookInRight |  |  |
| A13 | eyeLookOutRight |  |  |
| A14 | eyeBlinkLeft |  |  |
| A15 | eyeBlinkRight |  |  |
| A16 | eyeSquintLeft |  |  |
| A17 | eyeSquintRight |  |  |
| A18 | eyeWideLeft |  |  |
| A19 | eyeWideRight |  |  |
| A20 | cheekPuff |  |  |
| A21 | cheekSquintLeft |  |  |
| A22 | cheekSquintRight |  |  |
| A23 | noseSneerLeft |  |  |
| A24 | noseSneerRight |  |  |
| A25 | jawOpen |  |  |
| A26 | jawForward |  |  |
| A27 | jawLeft |  |  |
| A28 | jawRight | 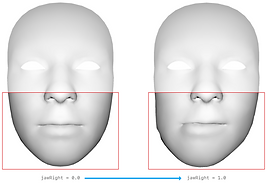 |  |
| A29 | mouthFunnel |  |  |
| A30 | mouthPucker |  |  |
| A31 | mouthLeft |  |  |
| A32 | mouthRight |  |  |
| A33 | mouthRollUpper |  |  |
| A34 | mouthRollLower |  |  |
| A35 | mouthShrugUpper |  |  |
| A36 | mouthShrugLower |  |  |
| A37 | mouthClose |  |  |
| A38 | mouthSmileLeft |  |  |
| A39 | mouthSmileRight |  |  |
| A40 | mouthFrownLeft |  |  |
| A41 | mouthFrownRight |  |  |
| A42 | mouthDimpleLeft |  |  |
| A43 | mouthDimpleRight |  |  |
| A44 | mouthUpperUpLeft |  |  |
| A45 | mouthUpperUpRight |  |  |
| A46 | mouthLowerDownLeft |  |  |
| A47 | mouthLowerDownRight |  |  |
| A48 | mouthPressLeft |  |  |
| A49 | mouthPressRight |  |  |
| A50 | mouthStretchLeft |  |  |
| A51 | mouthStretchRight |  |  |
| A52 | tongueOut |  |
- CC3 额外的舌头Blendshape(with open month):
| T01 | Tongue_Up |  | |
|---|---|---|---|
| T02 | Tongue_Down |  | |
| T03 | Tongue_Left |  | |
| T04 | Tongue_Right |  | |
| T05 | Tongue_Roll |  | |
| T06 | Tongue_Tip_Up |  | |
| T07 | Tongue_Tip_Down |  |
Vive面部的表情基准组
Vive这一套脸部追踪也是52个blendshapes,但是和苹果的基准有很大区别。
- 区别一:舌头
苹果其实是52+7,因为舌头在52个里只有一个伸舌头的blendshape,但vive其实是42 + 10,整体来讲Vive表情记住能tracking到的表情细节还是更少一些。
- 区别二:眉毛
ARKit的52个blendshapes,是根据硬件分区一对一tracking的,然而Vive眉毛不分是没有单独另设blendshapes,而是与眼睛的动作blended在一起作为一个blendshape的,并不是精准的一对一分区tracking。
我下面编号的排序是按照VIVE Eye and Facial Tracking SDK unity 里inspector里的顺序,方便我加表情。
这里是整理的用ARKit制作Vive基准的对应编号:
https://docs.google.com/spreadsheets/d/1kWXnqtiVbXRb1FrD5NLlxxuxbYmS0Z6YBLuIE1WwqD4/edit?usp=sharing
- Eye Blendshapes (14 = 12 + 2)
| Vive编号 | Vive表情基准 | Vive Picture | Create by CC3 blendshapes |
|---|---|---|---|
| V01 | Eye_Left_Blink |  |  |
| V02 | Eye_Left_Wide |  |  |
| V03 | Eye_Left_Right |  |  |
| V04 | Eye_Left_Left |  |  |
| V05 | Eye_Left_Up | 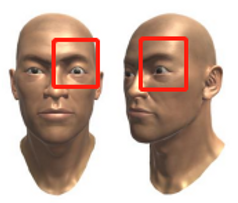 |  |
| V06 | Eye_Left_Down |  |  |
| V07 | Eye_Right_Blink |  | |
| V08 | Eye_Right_Wide |  | |
| V09 | Eye_Right_Right |  | |
| V10 | Eye_Right_Left |  | |
| V11 | Eye_Right_Up |  | |
| V12 | Eye_Right_Down |  | |
| V13 | Eye_Left_squeeze: The blendShape close eye tightly when Eye_Left_Blink value is 100. | 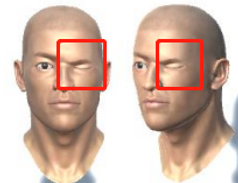 |  |
| V14 | Eye_Right_squeeze |  |
- Lip Blendshapes (38 = 37 + 1)
| Vive编号 | Vive表情基准 | Vive Picture | Create by CC3 blendshapes |
|---|---|---|---|
| V15 | Jaw_Right |  |  |
| V16 | Jaw_Left |  |  |
| V17 | Jaw_Forward |  |  |
| V18 | Jaw_Open |  |  |
| V19 | Mouth_Ape_Shape |  |  |
| V20 | Mouth_Upper_Right |  |  |
| V21 | Mouth_Upper_Left |  |  |
| V22 | Mouth_Lower_Right |  |  |
| V23 | Mouth_Lower_Left |  |  |
| V24 | *Mouth_Upper_Overturn | 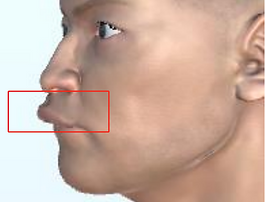 |  |
| V25 | *Mouth_Lower_Overturn |  |  |
| V26 | Mouth_Pout |  |  |
| V27 | Mouth_Smile_Right |  |  |
| V28 | Mouth_Smile_Left |  |  |
| V29 | Mouth_Sad_Right |  |  |
| V30 | Mouth_Sad_Left |  |  |
| V31 | Cheek_Puff_Right |  |  |
| V32 | Cheek_Puff_Left |  |  |
| V33 | Cheek_Suck |  |  |
| V34 | Mouth_Upper_UpRight | 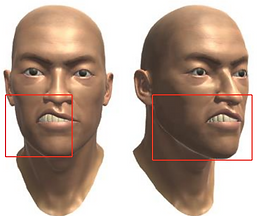 |  |
| V35 | MouthUpper UpLeft |  |  |
| V36 | Mouth_Lower_DownRight |  |  |
| V37 | Mouth_Lower_DownLeft |  |  |
| V38 | Mouth_Upper_Inside |  |  |
| V39 | Mouth_Lower_Inside |  |  |
| V40 | Mouth_Lower_Overlay |  |  |
| V41 | Tongue_LongStep1 |  |  |
| V42 | Tongue_LongStep2 |  |  |
| V43 | *Tongue_Down |  |  |
| V44 | *Tongue_Up |  |  |
| V45 | *Tongue_Right |  |  |
| V46 | *Tongue_Left |  |  |
| V47 | *Tongue_Roll |  |  |
| V48 | *Tongue_UpLeft_Morph |   | |
| V49 | *Tongue_UpRight_Morph |   | |
| V50 | *Tongue_DownLeft_Morph |   | |
| V51 | *Tongue_DownRight_Morph |   | |
| V52 | *O-shaped mouth |  |   |
MediaPipe提取BlendShape
MediaPipe Face Landmarker解决方案最初于5月的Google I/O 2023发布。它可以检测面部landmark并输出blendshape score,以渲染与用户匹配的3D面部模型。通过MediaPipe Face Landmarker解决方案,KDDI和谷歌成功地为虚拟主播带来了真实感。
技术实现
使用Mediapipe强大而高效的Python包,KDDI开发人员能够检测表演者的面部特征并实时提取52个混合形状。
1 | import mediapipe as mp |
参考
- wechat
- alipay







