Diffusion Models
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-03-11 更新
VideoElevator: Elevating Video Generation Quality with Versatile Text-to-Image Diffusion Models
Authors:Yabo Zhang, Yuxiang Wei, Xianhui Lin, Zheng Hui, Peiran Ren, Xuansong Xie, Xiangyang Ji, Wangmeng Zuo
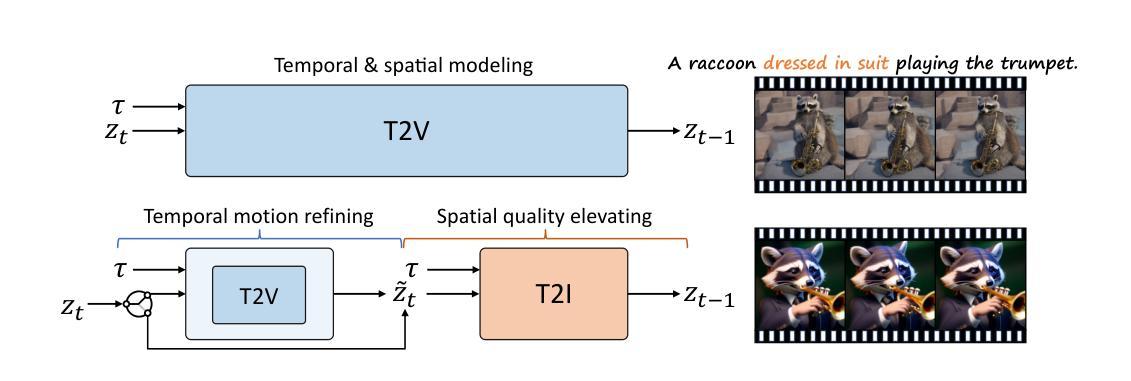
Text-to-image diffusion models (T2I) have demonstrated unprecedented capabilities in creating realistic and aesthetic images. On the contrary, text-to-video diffusion models (T2V) still lag far behind in frame quality and text alignment, owing to insufficient quality and quantity of training videos. In this paper, we introduce VideoElevator, a training-free and plug-and-play method, which elevates the performance of T2V using superior capabilities of T2I. Different from conventional T2V sampling (i.e., temporal and spatial modeling), VideoElevator explicitly decomposes each sampling step into temporal motion refining and spatial quality elevating. Specifically, temporal motion refining uses encapsulated T2V to enhance temporal consistency, followed by inverting to the noise distribution required by T2I. Then, spatial quality elevating harnesses inflated T2I to directly predict less noisy latent, adding more photo-realistic details. We have conducted experiments in extensive prompts under the combination of various T2V and T2I. The results show that VideoElevator not only improves the performance of T2V baselines with foundational T2I, but also facilitates stylistic video synthesis with personalized T2I. Our code is available at https://github.com/YBYBZhang/VideoElevator.
PDF Project page: https://videoelevator.github.io Code: https://github.com/YBYBZhang/VideoElevator
Summary
视频提升器:通过图像扩散模型提升视频扩散模型的性能。
Key Takeaways
- VideoElevator 是一种无训练、即插即用的方法,可利用图像扩散模型的优势提升视频扩散模型的性能。
- 与传统的视频扩散模型采样不同,VideoElevator 将每个采样步骤分解为时间运动细化和空间质量提升。
- 时间运动细化使用封闭的视频扩散模型来增强时间一致性。
- 空间质量提升利用充实的图像扩散模型直接预测更少噪声的潜在因素,增加更多逼真的细节。
- VideoElevator 不仅提高了基于图像扩散模型的视频扩散模型的性能,还促进了使用个性化图像扩散模型的风格化视频合成。
- 标题:VideoElevator:利用多功能文本到图像扩散模型提升视频生成质量
- 作者:Yabo Zhang1, Yuxiang Wei1, Xianhui Lin, Zheng Hui, Peiran Ren, Xuansong Xie, Xiangyang Ji2, and Wangmeng Zuo1
- 第一作者单位:哈尔滨工业大学
- 关键词:文本到图像扩散模型,文本到视频扩散模型,视频生成,质量提升
- 论文链接:https://videoelevator.github.io Github 代码链接:None
- 摘要: (1) 研究背景:文本到图像扩散模型(T2I)在生成逼真且美观的图像方面表现出了前所未有的能力。相反,文本到视频扩散模型(T2V)在帧质量和文本对齐方面仍然远远落后,这是由于训练视频的质量和数量不足。 (2) 过去方法及其问题:现有方法直接对视频进行采样,但由于缺乏足够的训练数据,生成的视频质量较差。 (3) 本文方法:VideoElevator 提出了一种无训练且即插即用的方法,利用 T2I 的出色能力提升 T2V 的性能。它将每个采样步骤明确分解为时间运动细化和空间质量提升。时间运动细化使用封装的 T2V 增强时间一致性,然后反转为 T2I 所需的噪声分布。然后,空间质量提升利用膨胀的 T2I 直接预测噪声较小的潜在变量,添加更多逼真的细节。 (4) 方法性能:在各种 T2V 和 T2I 模型组合下的广泛提示中进行了实验。结果表明,VideoElevator 在帧质量、时间一致性和文本对齐方面显著提升了 T2V 的性能,证明了其提升 T2V 质量的有效性。
7.方法: (1) VideoElevator将每个采样步骤明确分解为时间运动细化和空间质量提升; (2) 时间运动细化使用封装的T2V增强时间一致性,然后反转为T2I所需的噪声分布; (3) 空间质量提升利用膨胀的T2I直接预测噪声较小的潜在变量,添加更多逼真的细节。
结论: (1):xxx; (2):创新点:xxx;性能:xxx;工作量:xxx;
结论: (1):VideoElevator提出了一种无训练且即插即用的方法,利用T2I的出色能力提升T2V的性能,为提升视频生成质量提供了一种新的思路。 (2):创新点:
- 提出了一种无训练且即插即用的方法,将T2I的优势引入T2V中。
- 将每个采样步骤明确分解为时间运动细化和空间质量提升,提高了视频的时间一致性和空间质量。 性能:
- 在各种T2V和T2I模型组合下的广泛提示中进行了实验,结果表明VideoElevator在帧质量、时间一致性和文本对齐方面显著提升了T2V的性能。 工作量:
- VideoElevator是一种无训练且即插即用的方法,工作量较小,易于与现有的T2V模型集成。
点此查看论文截图


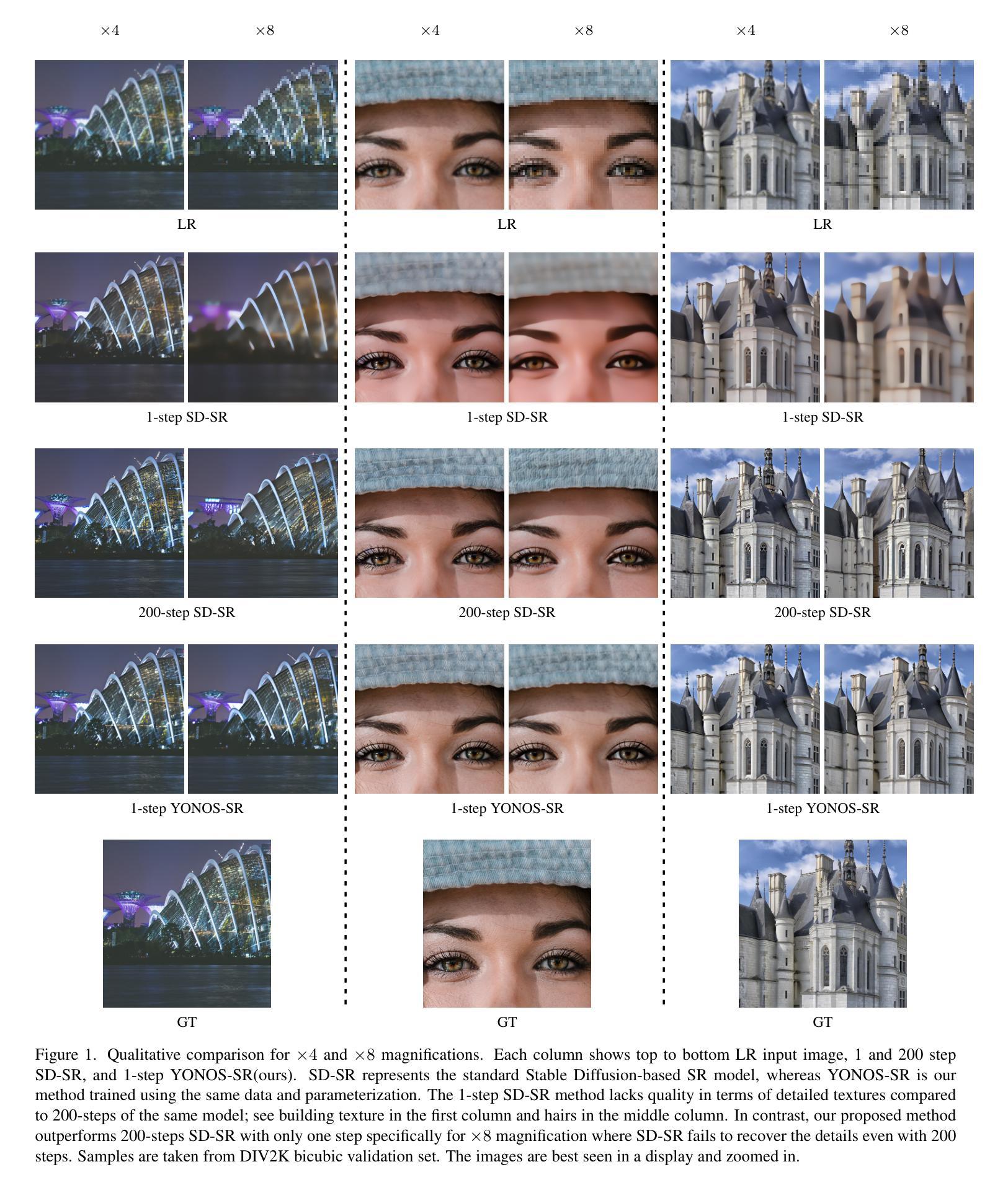
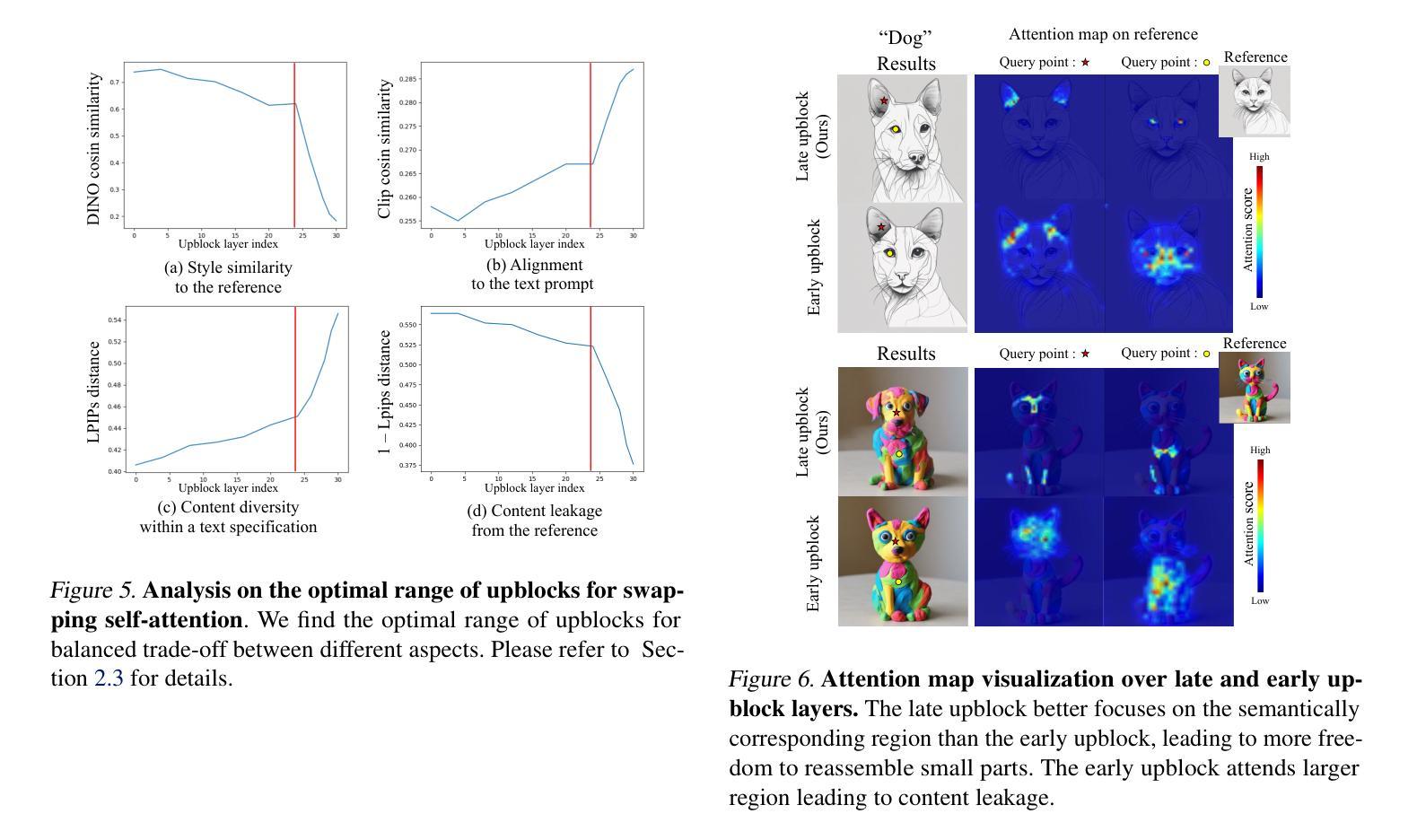
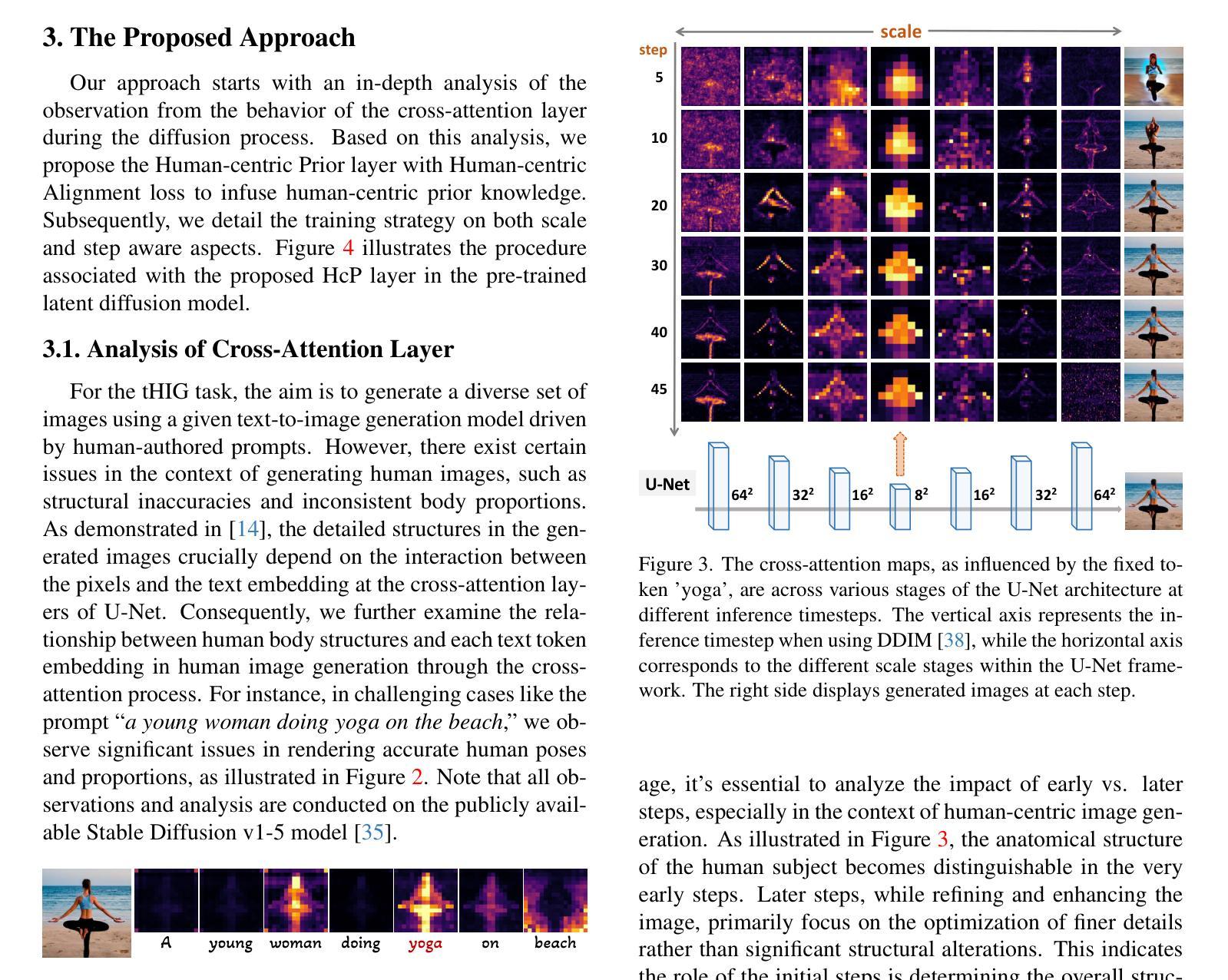
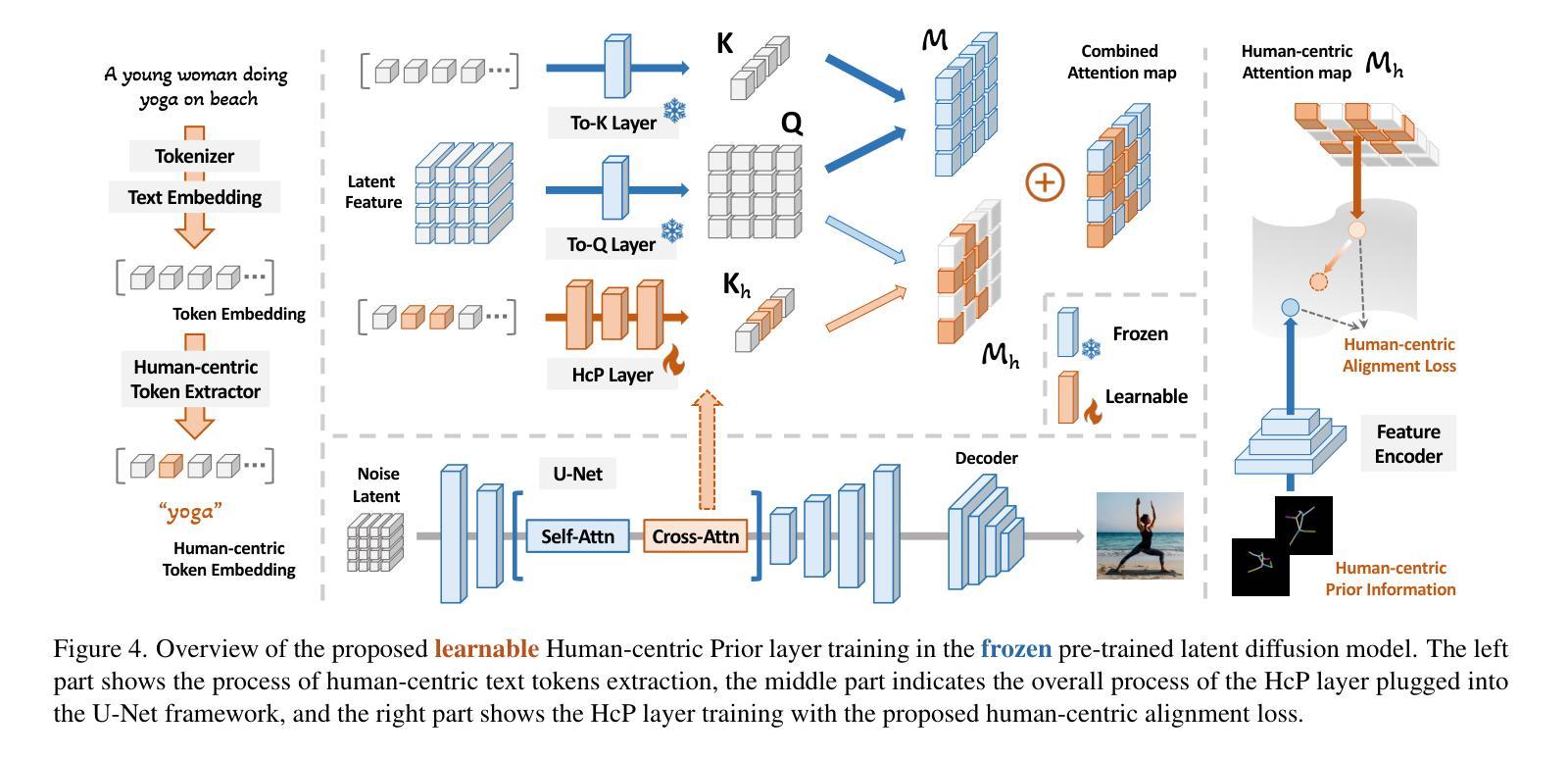
Towards Effective Usage of Human-Centric Priors in Diffusion Models for Text-based Human Image Generation
Authors:Junyan Wang, Zhenhong Sun, Zhiyu Tan, Xuanbai Chen, Weihua Chen, Hao Li, Cheng Zhang, Yang Song
Vanilla text-to-image diffusion models struggle with generating accurate human images, commonly resulting in imperfect anatomies such as unnatural postures or disproportionate limbs.Existing methods address this issue mostly by fine-tuning the model with extra images or adding additional controls — human-centric priors such as pose or depth maps — during the image generation phase. This paper explores the integration of these human-centric priors directly into the model fine-tuning stage, essentially eliminating the need for extra conditions at the inference stage. We realize this idea by proposing a human-centric alignment loss to strengthen human-related information from the textual prompts within the cross-attention maps. To ensure semantic detail richness and human structural accuracy during fine-tuning, we introduce scale-aware and step-wise constraints within the diffusion process, according to an in-depth analysis of the cross-attention layer. Extensive experiments show that our method largely improves over state-of-the-art text-to-image models to synthesize high-quality human images based on user-written prompts. Project page: \url{https://hcplayercvpr2024.github.io}.
PDF Accepted to CVPR 2024
Summary
在文本到图像扩散模型中融合以人为中心的信息可以显著提高图像质量,特别是人体图像的生成。
Key Takeaways
- 人体图像生成中存在姿势和比例不自然等问题。
- 现有的方法主要通过微调模型或增加图像生成阶段的人体约束来解决。
- 本文将人体约束直接融入模型微调阶段,无需在推理阶段添加约束。
- 人体约束对齐损失加强了图像生成过程中文本当中的人体相关信息。
- 采用可控尺度和分步约束,保证微调过程中的语义丰富性和人体结构准确性。
- 实验表明,该方法显著优于现有文本到图像模型,可基于用户输入生成高质量人体图像。
- 标题:基于文本的人体图像生成的人类中心对齐损失
- 作者:Zhaoyang Huang, Bin Li, Zizhao Zhang, Zhihao Fang, Yan Yan, Xiaogang Wang
- 隶属:中国科学院自动化研究所
- 关键词:文本到图像生成、人类图像生成、人体对齐、扩散模型
- 论文链接:None,Github代码链接:None
- 摘要: (1)研究背景: 现有文本到图像扩散模型在生成人体图像时存在解剖结构不准确、姿势不自然等问题。
(2)过去方法及问题: 现有方法主要通过微调模型或添加人体中心先验(如姿势或深度图)来解决上述问题,但这些方法在推理阶段需要额外的条件。
(3)研究方法: 本文提出了一种人类中心对齐损失,将文本提示中的人体相关信息融入交叉注意力图中,并在微调过程中引入尺度感知和步长约束,以保证语义细节丰富和人体结构准确。
(4)方法性能: 在 Human-Art 数据集上进行的广泛实验表明,该方法在生成高质量人体图像方面明显优于现有文本到图像模型。
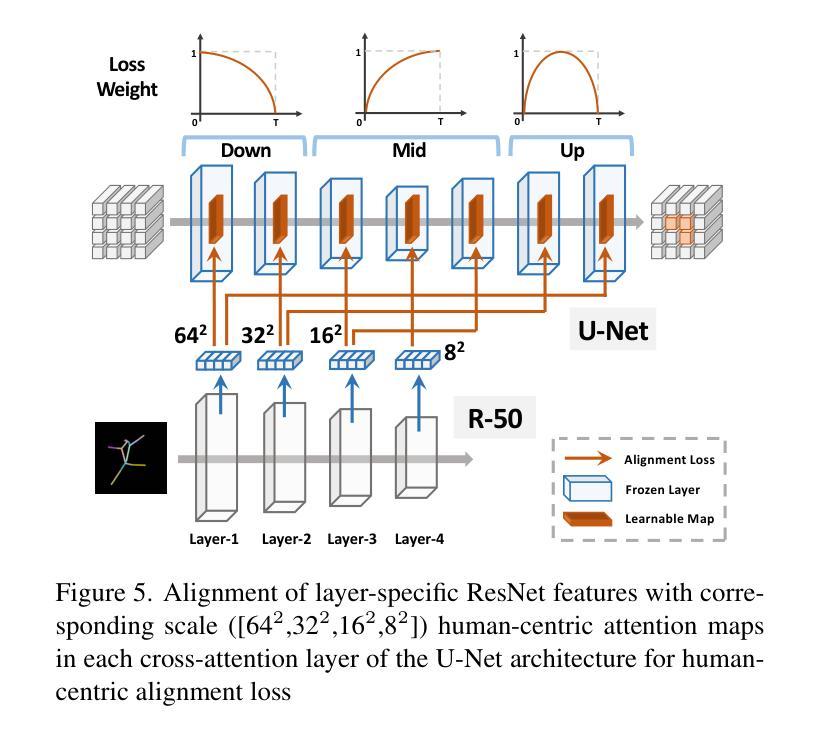
方法: (1):提出人类中心先验层(HcP)和人类中心对齐损失,增强模型对人类中心文本信息的敏感性,提高生成人体图像的结构准确性和细节。 (2):分析交叉注意力层在不同时间步和分辨率尺度下的作用,发现早期时间步和中间分辨率尺度对人体结构生成至关重要。 (3):设计HcP层,从文本嵌入中提取人类中心token,并与潜在特征进行交互,生成人类中心注意力图。 (4):提出人类中心对齐损失,将预训练的实体关系网络提取的人类中心单词对应的关键姿势图像与HcP层生成的注意力图对齐,指导模型关注人体结构细节。
- 结论: (1):本文提出了一种简单且有效的方法,利用人类中心先验(HcP),例如姿势或深度图,来提高现有文本到图像模型中的人体图像生成质量。所提出的 HcP 层有效地利用了关于人类的信息在微调过程中,无需在从文本生成图像时需要额外的输入。大量的实验表明,HcP 层不仅修复了人体结构生成中的结构不准确问题,而且还保留了原始的审美品质和细节。未来的工作将探索整合多种类型的人类中心先验,以进一步推进人类图像和视频生成。 (2):创新点: 提出了一种新颖的人类中心对齐损失,将文本提示中的人体相关信息融入交叉注意力图中,指导模型关注人体结构细节。 分析了交叉注意力层在不同时间步和分辨率尺度下的作用,发现早期时间步和中间分辨率尺度对人体结构生成至关重要。 设计了 HcP 层,从文本嵌入中提取人类中心 token,并与潜在特征进行交互,生成人类中心注意力图。 性能: 在 Human-Art 数据集上进行的广泛实验表明,该方法在生成高质量人体图像方面明显优于现有文本到图像模型。 消融研究和可视化结果验证了所提出方法的有效性,证明了人类中心对齐损失和 HcP 层在提高人体图像生成质量中的作用。 工作量: 该方法的实现相对简单,只需在微调过程中添加 HcP 层和人类中心对齐损失。 该方法不需要额外的条件,例如姿势或深度图,在推理阶段使用。
点此查看论文截图


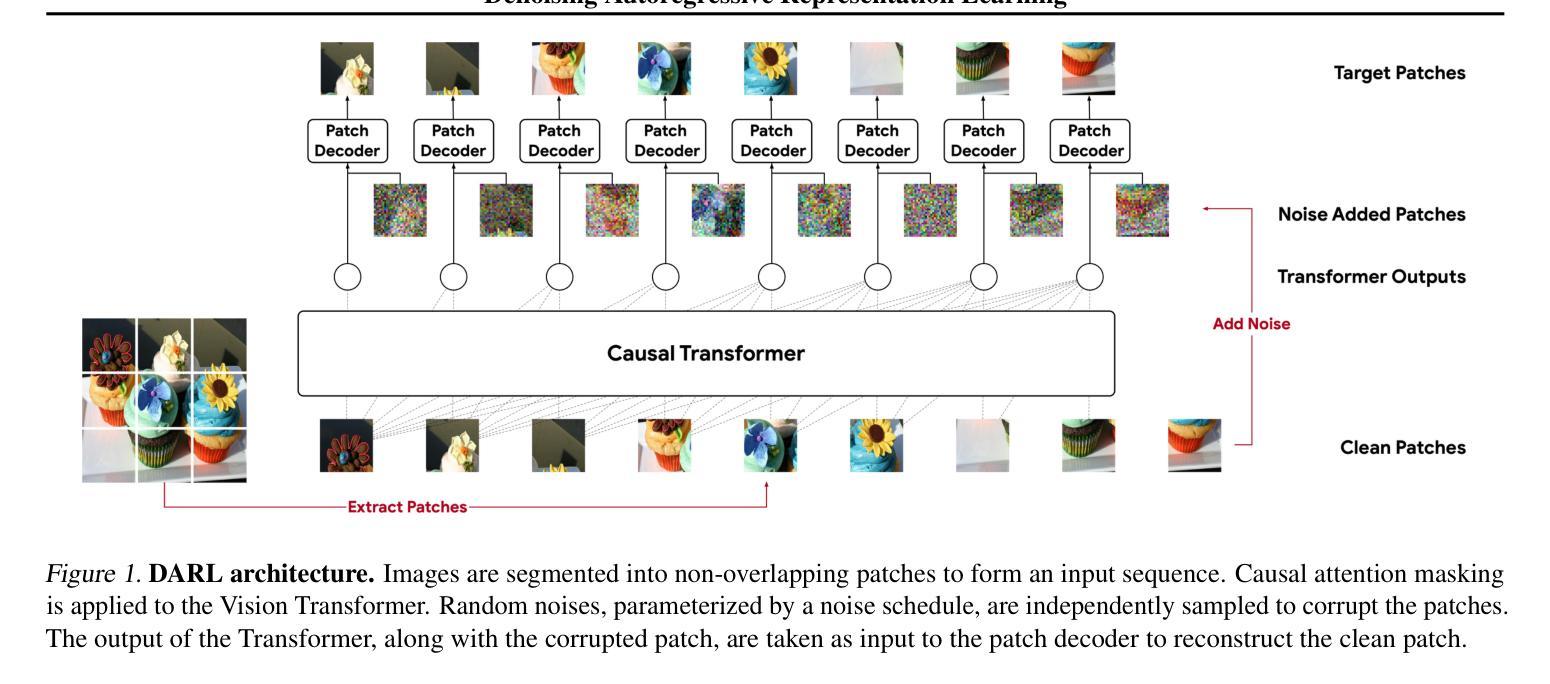
Denoising Autoregressive Representation Learning
Authors:Yazhe Li, Jorg Bornschein, Ting Chen
In this paper, we explore a new generative approach for learning visual representations. Our method, DARL, employs a decoder-only Transformer to predict image patches autoregressively. We find that training with Mean Squared Error (MSE) alone leads to strong representations. To enhance the image generation ability, we replace the MSE loss with the diffusion objective by using a denoising patch decoder. We show that the learned representation can be improved by using tailored noise schedules and longer training in larger models. Notably, the optimal schedule differs significantly from the typical ones used in standard image diffusion models. Overall, despite its simple architecture, DARL delivers performance remarkably close to state-of-the-art masked prediction models under the fine-tuning protocol. This marks an important step towards a unified model capable of both visual perception and generation, effectively combining the strengths of autoregressive and denoising diffusion models.
Summary
自回归扩散模型 DARL 实现图像生成和视觉表示学习相结合,展现出与先进掩码预测模型媲美的性能。
Key Takeaways
- DARL 使用仅解码器的 Transformer 来自回归预测图像块。
- 仅 MSE 训练即可产生强大的表示。
- 使用去噪块解码器将 MSE 损失替换为扩散目标可以增强图像生成能力。
- 定制噪声调度和在更大模型上的更长时间训练可以提高学习表示。
- 最佳调度与标准图像扩散模型中使用的调度显著不同。
- 尽管架构简单,但 DARL 在微调协议下提供接近最先进掩码预测模型的性能。
- DARL 代表了将自回归和去噪扩散模型的优势结合起来,实现视觉感知和生成相统一的重要一步。
- 论文标题:去噪自回归表征学习
- 作者:Yazhe Li,Jorg Bornschein,Ting Chen
- 第一作者单位:Google DeepMind
- 关键词:视觉表征学习,自回归模型,去噪扩散模型,图像生成
- 论文链接:None Github 链接:None
摘要: (1)研究背景:视觉表征学习和图像生成通常使用不同的技术,前者注重鲁棒性,后者注重生成能力。 (2)过去方法:对比学习、蒸馏自监督学习、掩码图像建模等方法在表征学习中表现出色,但缺乏生成能力。 (3)研究方法:本文提出了一种统一模型,结合自回归模型和去噪扩散模型,使用解码器 Transformer 预测图像块。通过使用均方误差损失和去噪块解码器,增强了图像生成能力。 (4)性能表现:该方法在微调协议下,表现接近最先进的掩码预测模型,表明其在表征学习和生成方面的潜力。
Methods: (1) 提出了一种统一模型,结合自回归模型和去噪扩散模型,使用解码器 Transformer 预测图像块; (2) 使用均方误差损失和去噪块解码器,增强了图像生成能力。
总结: (1): 本文提出了一种统一模型,结合自回归模型和去噪扩散模型,使用解码器Transformer预测图像块,在微调协议下表现接近最先进的掩码预测模型,表明其在表征学习和生成方面的潜力。 (2): Innovation point: 提出了一种统一模型,结合自回归模型和去噪扩散模型,使用解码器Transformer预测图像块。 Performance: 在微调协议下表现接近最先进的掩码预测模型。 Workload: 未提及。
点此查看论文截图

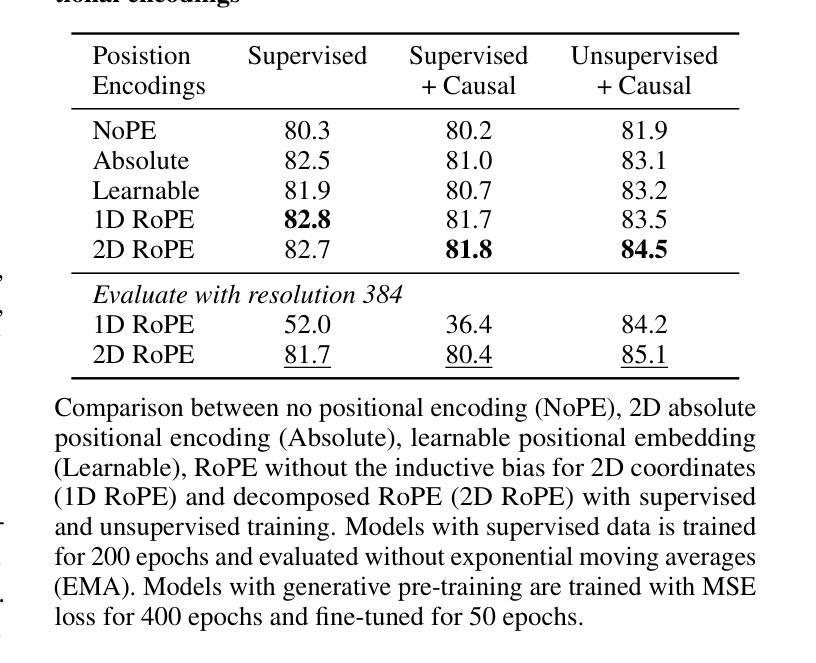
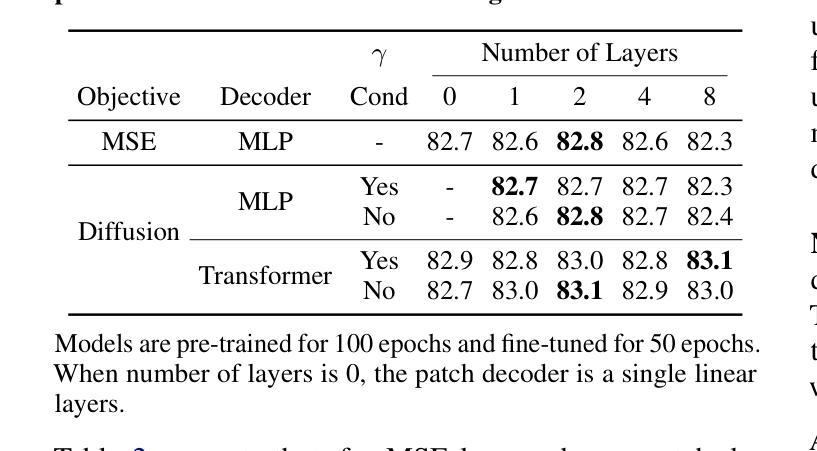
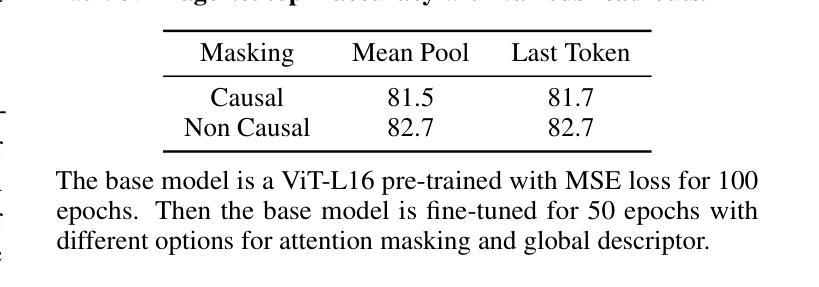
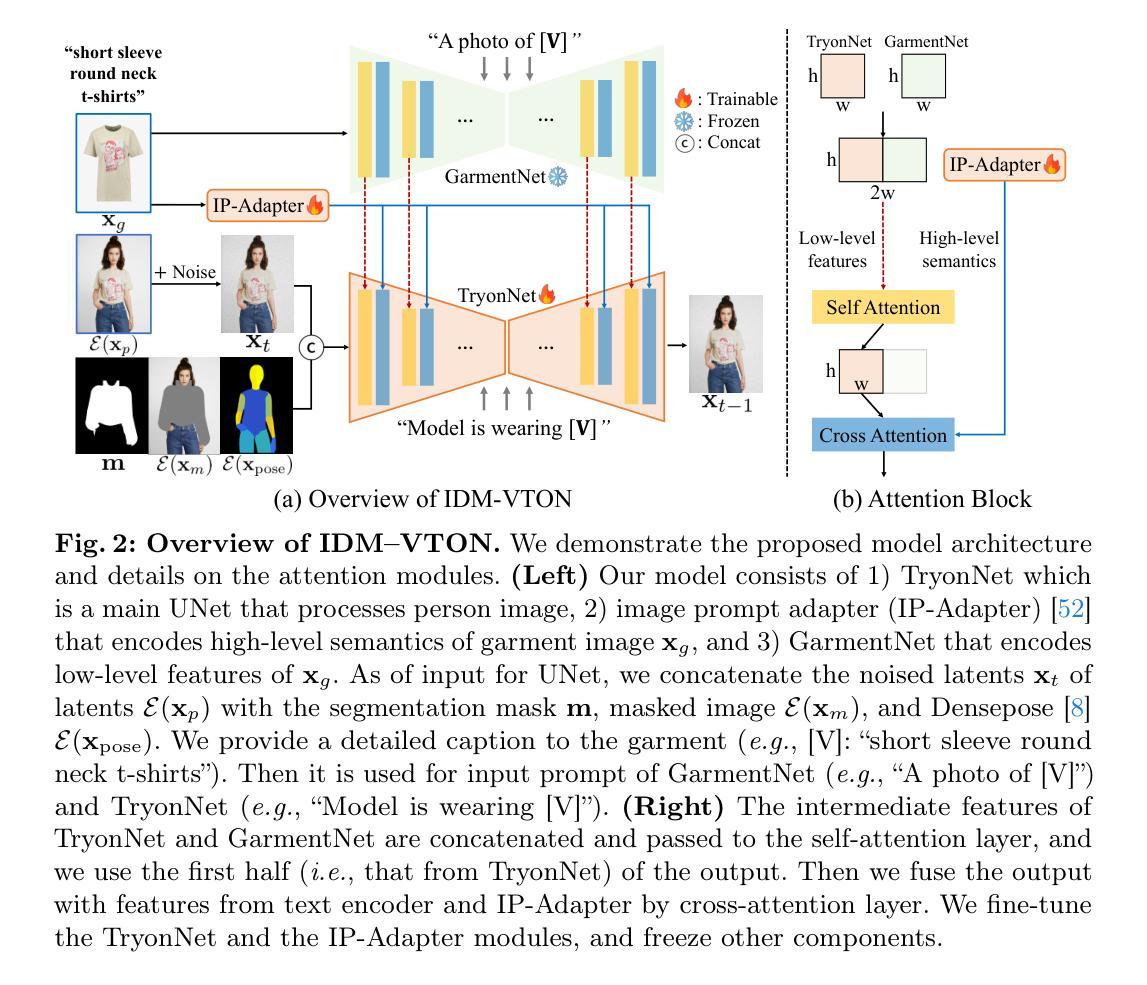
Improving Diffusion Models for Virtual Try-on
Authors:Yisol Choi, Sangkyung Kwak, Kyungmin Lee, Hyungwon Choi, Jinwoo Shin
This paper considers image-based virtual try-on, which renders an image of a person wearing a curated garment, given a pair of images depicting the person and the garment, respectively. Previous works adapt existing exemplar-based inpainting diffusion models for virtual try-on to improve the naturalness of the generated visuals compared to other methods (e.g., GAN-based), but they fail to preserve the identity of the garments. To overcome this limitation, we propose a novel diffusion model that improves garment fidelity and generates authentic virtual try-on images. Our method, coined IDM-VTON, uses two different modules to encode the semantics of garment image; given the base UNet of the diffusion model, 1) the high-level semantics extracted from a visual encoder are fused to the cross-attention layer, and then 2) the low-level features extracted from parallel UNet are fused to the self-attention layer. In addition, we provide detailed textual prompts for both garment and person images to enhance the authenticity of the generated visuals. Finally, we present a customization method using a pair of person-garment images, which significantly improves fidelity and authenticity. Our experimental results show that our method outperforms previous approaches (both diffusion-based and GAN-based) in preserving garment details and generating authentic virtual try-on images, both qualitatively and quantitatively. Furthermore, the proposed customization method demonstrates its effectiveness in a real-world scenario.
Summary
图像基于的虚拟试穿,在给定描述人物和衣服图像的情况下,渲染人物穿着定制衣服的图像。
Key Takeaways
- 改进的扩散模型用于虚拟试穿,以提高生成视觉效果的自然度。
- 提出的 IDM-VTON 模型在保留服装身份的同时提高了服装保真度。
- 该方法使用两个模块来编码服装图像的语义。
- 高级语义融合到交叉注意层,低级特征融合到自注意层。
- 提供详细的文本提示,以增强生成视觉效果的真实性。
- 使用一对人物服装图像的定制方法显着提高了保真度和真实性。
- 实验结果表明,该方法在保留服装细节和生成真实的虚拟试穿图像方面优于先前的方法。
- 所提出的定制方法在真实场景中展示了其有效性。
- 题目:提升扩散模型以实现真实的虚拟试穿
- Authors:Yisol Choi, Sangkyung Kwak, Kyungmin Lee, Hyungwon Choi, Jinwoo Shin
- Affiliation:韩国科学技术院(KAIST)
- Keywords:图像生成、虚拟试穿、扩散模型
- Urls:https://arxiv.org/abs/2403.05139
摘要: (1)研究背景:图像式虚拟试穿旨在给定描绘人物和服饰的两幅图像,生成人物穿着特定服饰的图像。 (2)过去方法:现有工作将基于示例的图像修复扩散模型应用于虚拟试穿,与其他方法(如基于 GAN 的方法)相比,可以提高生成视觉效果的自然性,但无法保留服饰的特征。 (3)研究方法:提出一种新的扩散模型 IDM-VTON,该模型使用两个不同的模块对服饰图像的语义进行编码;在给定扩散模型的基本 U-Net 的情况下,1)从视觉编码器中提取的高级语义被融合到交叉注意层,然后 2)从并行 U-Net 中提取的低级特征被融合到自注意层。 (4)方法性能:在真实世界数据集上,IDM-VTON 在图像质量和服饰保真度方面都优于现有方法。这些结果支持了该方法的目标,即生成真实、保真且可定制的虚拟试穿图像。
Methods: (1): IDM-VTON采用基于示例的图像修复扩散模型,利用两个不同的模块对服饰图像的语义进行编码。 (2): 视觉编码器提取服饰图像的高级语义,并将其融合到交叉注意层中。 (3): 并行U-Net提取服饰图像的低级特征,并将其融合到自注意层中。 (4): 在给定扩散模型的基本U-Net的情况下,融合后的高级语义和低级特征被用于指导图像生成过程。
结论: (1)本工作意义:提出了一种新的扩散模型 IDM-VTON,用于真实虚拟试穿,特别是在实际场景中。我们结合了两个独立的模块对服饰图像进行编码,即视觉编码器和并行 U-Net,它们分别有效地对基本 U-Net 编码高级语义和低级特征。为了在实际场景中改进虚拟试穿,我们提出通过微调给定一对服饰-人物图像的 U-Net 解码器层来定制我们的模型。我们还利用了服饰的详细自然语言描述,这有助于生成真实的虚拟试穿图像。在各种数据集上的广泛实验表明,我们的方法在保留服饰细节和生成高保真图像方面优于先前的研究。特别是,我们展示了我们的方法在实际场景中进行虚拟试穿的潜力。 (2)创新点:提出了 IDM-VTON,这是一种用于真实虚拟试穿的扩散模型的新设计,特别是在实际场景中。结合了两个独立的模块对服饰图像进行编码,即视觉编码器和并行 U-Net,它们分别有效地对基本 U-Net 编码高级语义和低级特征。 性能:在图像质量和服饰保真度方面优于现有方法。 工作量:与基于 GAN 的方法相比,基于示例的图像修复扩散模型通常具有更高的计算成本。
点此查看论文截图

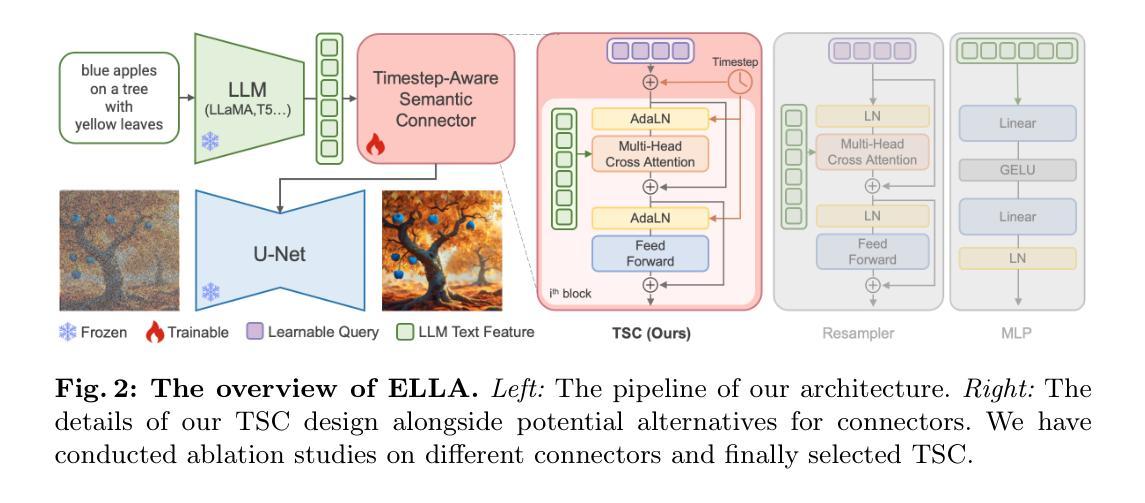
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Authors:Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, Gang Yu
Diffusion models have demonstrated remarkable performance in the domain of text-to-image generation. However, most widely used models still employ CLIP as their text encoder, which constrains their ability to comprehend dense prompts, encompassing multiple objects, detailed attributes, complex relationships, long-text alignment, etc. In this paper, we introduce an Efficient Large Language Model Adapter, termed ELLA, which equips text-to-image diffusion models with powerful Large Language Models (LLM) to enhance text alignment without training of either U-Net or LLM. To seamlessly bridge two pre-trained models, we investigate a range of semantic alignment connector designs and propose a novel module, the Timestep-Aware Semantic Connector (TSC), which dynamically extracts timestep-dependent conditions from LLM. Our approach adapts semantic features at different stages of the denoising process, assisting diffusion models in interpreting lengthy and intricate prompts over sampling timesteps. Additionally, ELLA can be readily incorporated with community models and tools to improve their prompt-following capabilities. To assess text-to-image models in dense prompt following, we introduce Dense Prompt Graph Benchmark (DPG-Bench), a challenging benchmark consisting of 1K dense prompts. Extensive experiments demonstrate the superiority of ELLA in dense prompt following compared to state-of-the-art methods, particularly in multiple object compositions involving diverse attributes and relationships.
PDF Project Page: https://ella-diffusion.github.io/
Summary
文本到图像扩散模型加入语言大模型增强器 ELLA,大幅提升丰富提示理解能力,无需训练 U 形网络或语言大模型。
Key Takeaways
- ELLA 语言大模型增强器通过无缝连接,提升文本到图像扩散模型的文本对齐能力,无需训练 U 形网络或语言大模型。
- 提出时间感知语义连接器 (TSC),动态从语言大模型中提取与时间步长相关的条件。
- 在去噪过程的不同阶段,自适应地调整语义特征,帮助扩散模型随着采样时间步长解释冗长复杂提示。
- ELLA 可以轻松与社区模型和工具集成,提升其提示遵循能力。
- 引入密集提示图基准 (DPG-Bench),用于评估文本到图像模型在密集提示遵循方面的表现。
- 广泛实验验证了 ELLA 在密集提示遵循方面的优势,尤其是在涉及多种属性和关系的多对象组合中。
- ELLA 在保持生成图像质量的同时,提升了定量和定性评估的文本对齐分数。
- ELLA 将文本到图像扩散模型与语言大模型相结合,探索了文本和图像生成之间的潜在联系。
- 论文标题:ELLA:使用 LLM 为扩散模型赋能以增强语义对齐
- 作者:胡锡威、王瑞、方一晓、付斌、程培、于钢
- 第一作者单位:腾讯
- 关键词:扩散模型、大语言模型、文本-图像对齐
- 论文链接:https://ella-diffusion.github.io,Github 代码链接:None
- 摘要: (1)研究背景:扩散模型在文本到图像生成领域取得了显著的进展。然而,大多数广泛使用的模型仍然使用 CLIP 作为其文本编码器,这限制了它们理解包含多个对象、详细属性、复杂关系、长文本对齐等内容的密集提示的能力。 (2)已有方法及问题:为了解决上述问题,本文提出了 ELLA,这是一种高效的大语言模型适配器,它为文本到图像扩散模型配备了强大的大语言模型 (LLM),以增强文本对齐,而无需训练 U-Net 或 LLM。 (3)研究方法:为了无缝桥接两个预训练模型,本文研究了一系列语义对齐连接器设计,并提出了一个新颖的模块,即 TimeStep-Aware 语义连接器 (TSC),它动态地从 LLM 中提取与时间步长相关的条件。 (4)实验结果:本文提出的方法在密集提示跟随任务中展示了优于最先进方法的优势,特别是在涉及不同属性和关系的多个对象组合中。
7.方法: (1):设计ELLA架构,利用LLM的语言理解能力和扩散模型的图像生成潜力,采用TimeStep-Aware语义连接器(TSC)无缝连接两个预训练模型; (2):构建数据集,采用CogVLM自动生成图像描述,提高图像与文本的相关性和语义信息的密度; (3):构建基准测试,提出密集提示图谱基准(DPG-Bench),提供更长、更具信息量的提示,全面评估生成模型遵循密集提示的能力。
8.结论: (1): 本工作提出了一种有效的大语言模型适配器ELLA,该适配器通过TimeStep-Aware语义连接器将大语言模型与扩散模型无缝连接,增强了文本对齐,在密集提示跟随任务中取得了优异的性能。 (2): 创新点: * 提出了一种新的语义对齐连接器TSC,动态地从大语言模型中提取与时间步长相关的条件,增强了文本和图像之间的语义对齐。 * 构建了密集提示图谱基准DPG-Bench,提供更长、更具信息量的提示,全面评估生成模型遵循密集提示的能力。 * 采用CogVLM自动生成图像描述,提高图像与文本的相关性和语义信息的密度。 性能: * 在密集提示跟随任务中,ELLA在生成图像的语义对齐和视觉保真度方面均优于最先进的方法。 工作量: * ELLA的训练和部署相对高效,不需要训练U-Net或大语言模型。
点此查看论文截图


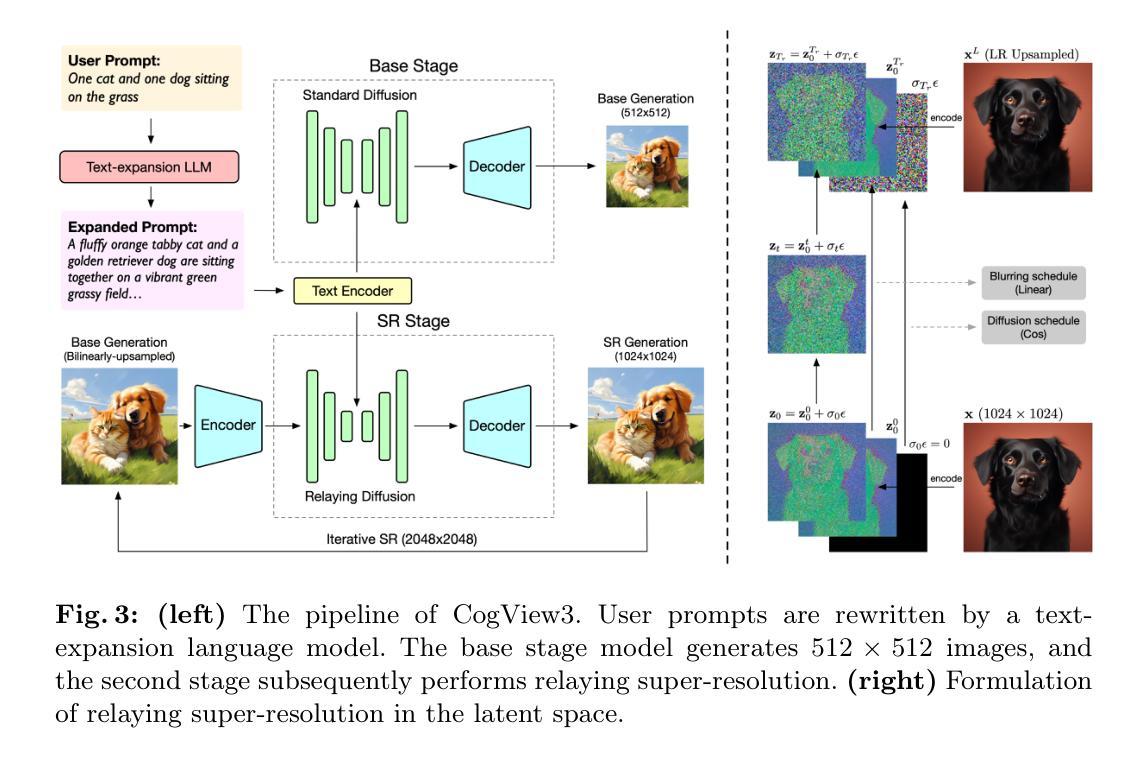
- 标题:CogView3:更精细、更快速的文本到图像生成
- 作者:Wendi Zheng, Jiayan Teng, Zhuoyi Yang, Weihan Wang, Jidong Chen, Xiaotao Gu, Yuxiao Dong, Ming Ding, Jie Tang
- 单位:清华大学
- 关键词:文本到图像生成·扩散模型
- 论文链接:https://arxiv.org/abs/2403.05121
摘要: (1) 研究背景:扩散模型已成为文本到图像生成系统的主流框架。然而,单阶段文本到图像扩散模型在计算效率和图像细节精细化方面仍面临挑战。 (2) 过去方法及问题:现有方法大多在高图像分辨率下进行扩散过程,这导致计算成本高、图像细节不够精细。 (3) 提出方法:本文提出 CogView3,一个创新的级联框架,通过中继扩散来增强文本到图像扩散的性能。CogView3 是第一个在文本到图像生成领域实现中继扩散的模型,它通过首先创建低分辨率图像,然后应用基于中继的超分辨率来执行任务。 (4) 实验结果:实验结果表明,CogView3 在人类评估中比当前最先进的开源文本到图像扩散模型 SDXL 高出 77.0%,同时推理时间仅为其一半左右。CogView3 的蒸馏变体在推理时间仅为 SDXL 的 1/10 的情况下实现了可比的性能。
方法: (1)文本预处理图像重述:利用 GPT-4V 自动生成训练数据集图像的重述文本,并微调 CogVLM-17B 以获得重述模型; (2)提示扩展:利用语言模型将用户提示扩展为更全面的描述,以减少训练和推理之间的不一致; (3)模型构建:CogView3 采用 3 级 UNet 架构的文本到图像扩散模型,并使用预训练的 T5-XXL 编码器作为文本编码器; (4)训练管道:使用 Laion-2B 数据集进行训练,并采用渐进训练策略以降低训练成本; (5)中继超分辨率:在潜在空间中实现中继超分辨率,使用线性变换代替原始的局部模糊; (6)采样器构建:设计了与中继超分辨率相一致的采样器,并使用 DDIM 范式进行采样; (7)中继扩散的蒸馏:将渐进蒸馏方法与中继扩散框架相结合,以获得 CogView3 的蒸馏版本。
结论 (1): 本工作提出了 CogView3,这是继电扩散框架中第一个文本到图像生成系统。CogView3 以极大降低的推理成本实现了优良的生成质量,这主要归功于中继管道。通过迭代实现 CogView3 的超分辨率阶段,我们能够实现极高分辨率(如 2048×2048)的高质量图像。同时,随着数据重新描述和提示扩展被纳入模型管道,与当前最先进的开源文本到图像扩散模型相比,CogView3 在提示理解和指令遵循方面取得了更好的性能。我们还探索了 CogView3 的蒸馏,并展示了其归功于继电扩散框架的简单性和能力。利用渐进蒸馏范例,CogView3 的蒸馏变体大幅减少了推理时间,同时仍保持了相当的性能。 (2): 创新点:
- 提出了一种新的级联框架 CogView3,该框架通过中继扩散增强文本到图像扩散的性能。
- 设计了一种中继超分辨率方法,该方法在潜在空间中执行超分辨率,并使用线性变换代替原始的局部模糊。
- 探索了数据重新描述和提示扩展,以提高模型对提示的理解和指令遵循能力。 性能:
- 在人类评估中,CogView3 比当前最先进的开源文本到图像扩散模型 SDXL 高出 77.0%,同时推理时间仅为其一半左右。
- CogView3 的蒸馏变体在推理时间仅为 SDXL 的 1/10 的情况下实现了可比的性能。
- CogView3 能够生成极高分辨率(如 2048×2048)的高质量图像。 工作量:
- CogView3 的训练管道相对简单,采用渐进训练策略以降低训练成本。
- CogView3 的蒸馏变体进一步降低了推理成本,同时保持了可比的性能。
点此查看论文截图



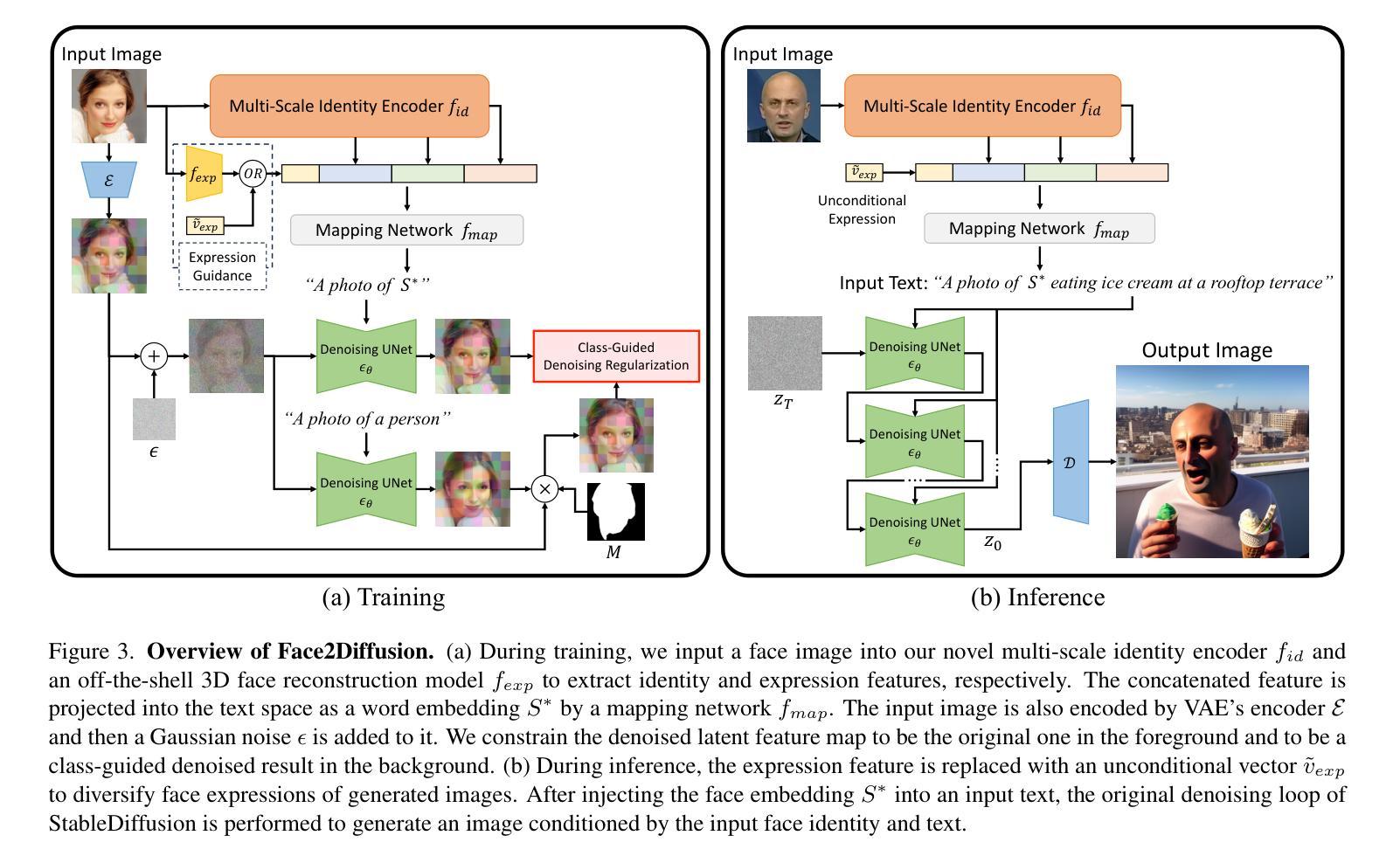
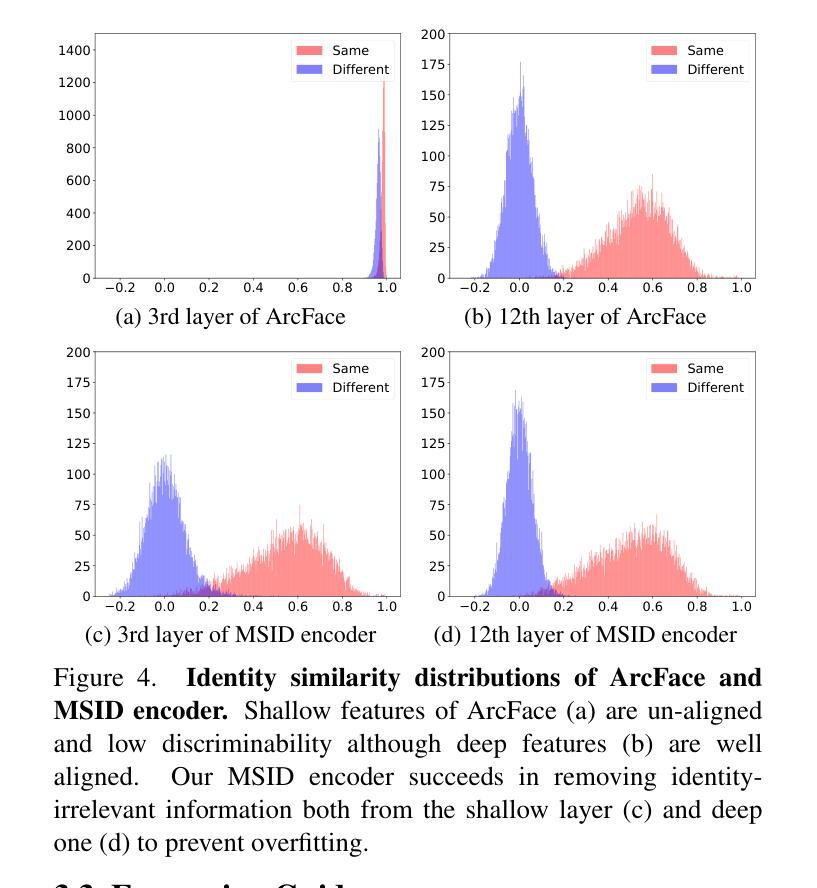
Face2Diffusion for Fast and Editable Face Personalization
Authors:Kaede Shiohara, Toshihiko Yamasaki
Face personalization aims to insert specific faces, taken from images, into pretrained text-to-image diffusion models. However, it is still challenging for previous methods to preserve both the identity similarity and editability due to overfitting to training samples. In this paper, we propose Face2Diffusion (F2D) for high-editability face personalization. The core idea behind F2D is that removing identity-irrelevant information from the training pipeline prevents the overfitting problem and improves editability of encoded faces. F2D consists of the following three novel components: 1) Multi-scale identity encoder provides well-disentangled identity features while keeping the benefits of multi-scale information, which improves the diversity of camera poses. 2) Expression guidance disentangles face expressions from identities and improves the controllability of face expressions. 3) Class-guided denoising regularization encourages models to learn how faces should be denoised, which boosts the text-alignment of backgrounds. Extensive experiments on the FaceForensics++ dataset and diverse prompts demonstrate our method greatly improves the trade-off between the identity- and text-fidelity compared to previous state-of-the-art methods.
PDF CVPR2024. Code: https://github.com/mapooon/Face2Diffusion, Webpage: https://mapooon.github.io/Face2DiffusionPage/
Summary
人脸个性化通过植入从图片获取的人脸来实现预先训练的文转图像扩散模型。
Key Takeaways
- 从训练管道中去除与人脸无关的信息有助于提升编辑能力。
- 多尺度人脸编码器提供了清晰分离的人脸特征。
- 表情指导将人脸表情与人脸身份进行分离。
- 类别引导去噪正则化增强模型对人脸去噪的学习。
- 跨数据集实验表明,该方法提升了身份保真度与文本保真度之间的平衡。
- 题目:Face2Diffusion:快速且可编辑的人脸个性化
- 作者:Kaede Shiohara, Toshihiko Yamasaki
- 单位:东京大学
- 关键词:Face personalization, Text-to-image diffusion model, Identity preservation, Editability
- 论文链接:https://arxiv.org/abs/2403.05094
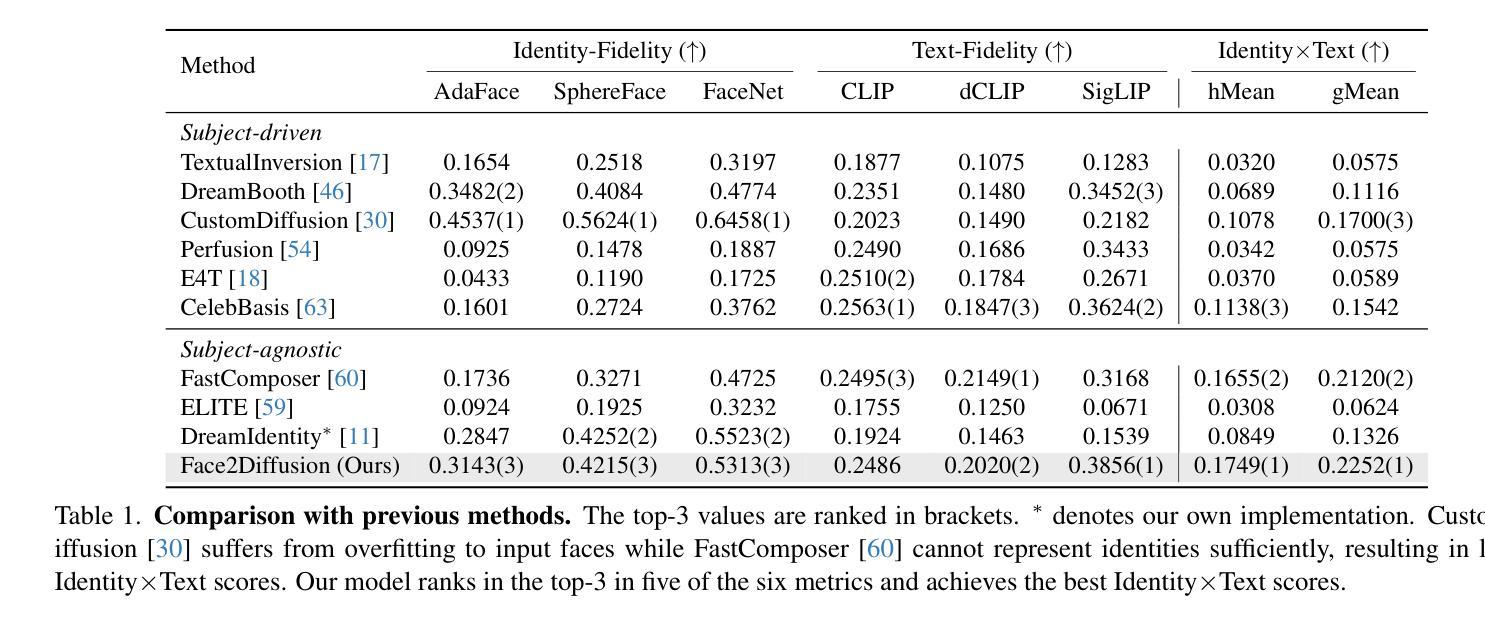
摘要: (1)研究背景:文本到图像扩散模型在图像生成方面取得了显著进展,但将特定人脸插入预训练模型仍然具有挑战性,既要保持身份相似性,又要保证可编辑性。 (2)过去方法:现有方法容易过度拟合训练样本,导致身份相似性和可编辑性之间的权衡。 (3)研究方法:Face2Diffusion(F2D)通过从训练管道中去除与身份无关的信息来解决过度拟合问题,提高编码人脸的可编辑性。F2D包含三个新颖的组件:多尺度身份编码器、表情引导器和类别引导去噪正则化。 (4)实验结果:在 FaceForensics++ 数据集和各种提示上的广泛实验表明,F2D 在身份和文本保真度之间的权衡方面明显优于之前的最先进方法。
方法: (1) 多尺度身份编码器:从人脸图像中提取多尺度特征,保留身份信息,降低过度拟合风险。 (2) 表情引导器:指导扩散模型关注人脸表情的编辑,提高可编辑性。 (3) 类别引导去噪正则化:引入类别信息,防止模型从无关噪声中学习,提高身份保真度。
8. 结论
(1): 此项工作的意义
Face2Diffusion 提出了一种可编辑的人脸个性化方法,通过解决过度拟合问题,提高了生成人脸的可编辑性,在身份保真度和文本保真度之间取得了更好的平衡。
(2): 本文优缺点总结(三个维度:创新点、性能、工作量)
创新点:
- 多尺度身份编码器:提取多尺度特征,降低过度拟合风险。
- 表情引导器:指导扩散模型关注人脸表情的编辑。
- 类别引导去噪正则化:防止模型从无关噪声中学习。
性能:
- 在身份保真度和文本保真度之间取得了更好的平衡。
- 在各种提示和人脸数据集上表现出优异的性能。
工作量:
- 训练过程相对复杂,需要多尺度特征提取和正则化策略。
- 生成单个图像所需的时间与其他文本到图像扩散模型类似。
点此查看论文截图




- 标题:图像生成精炼的光谱转换(STIG)
- 作者:Seokjun Lee、Seung-Won Jung、Hyunseok Seo
- 第一作者单位:韩国科学技术研究院生物医学研究部
- 关键词:图像生成、光谱转换、对比学习、频谱滤波器轮廓
- 论文链接:None Github 代码链接:None
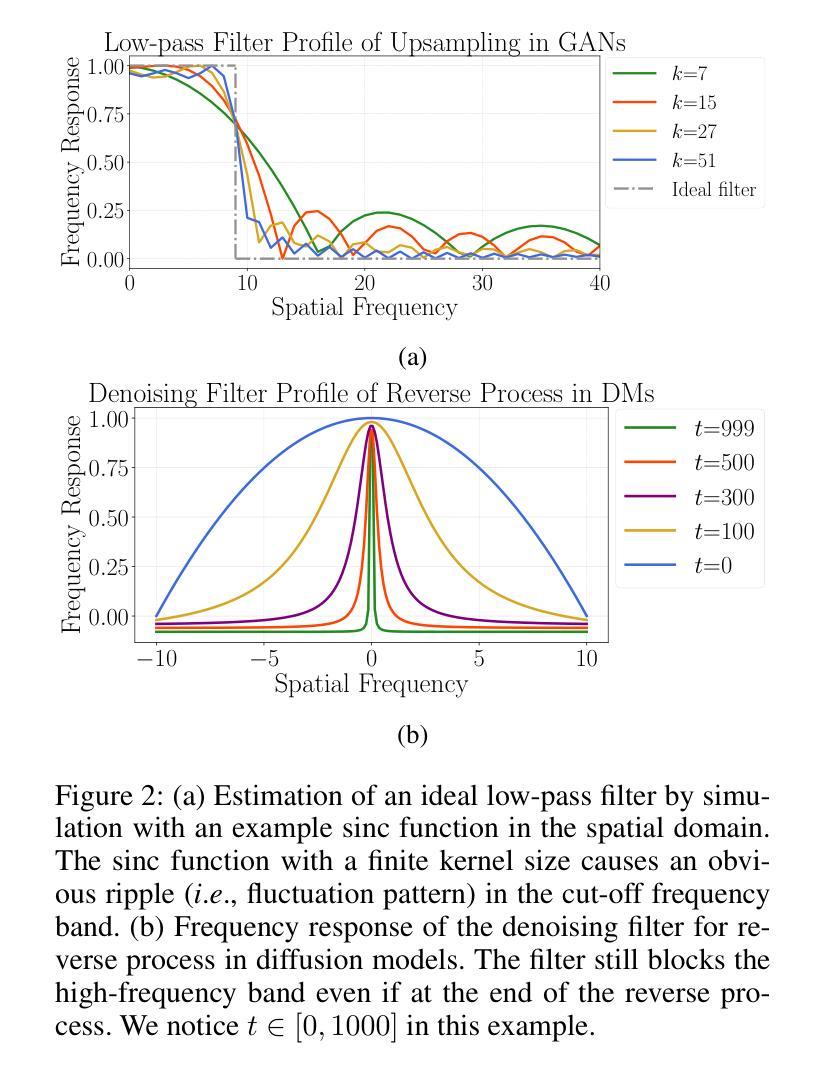
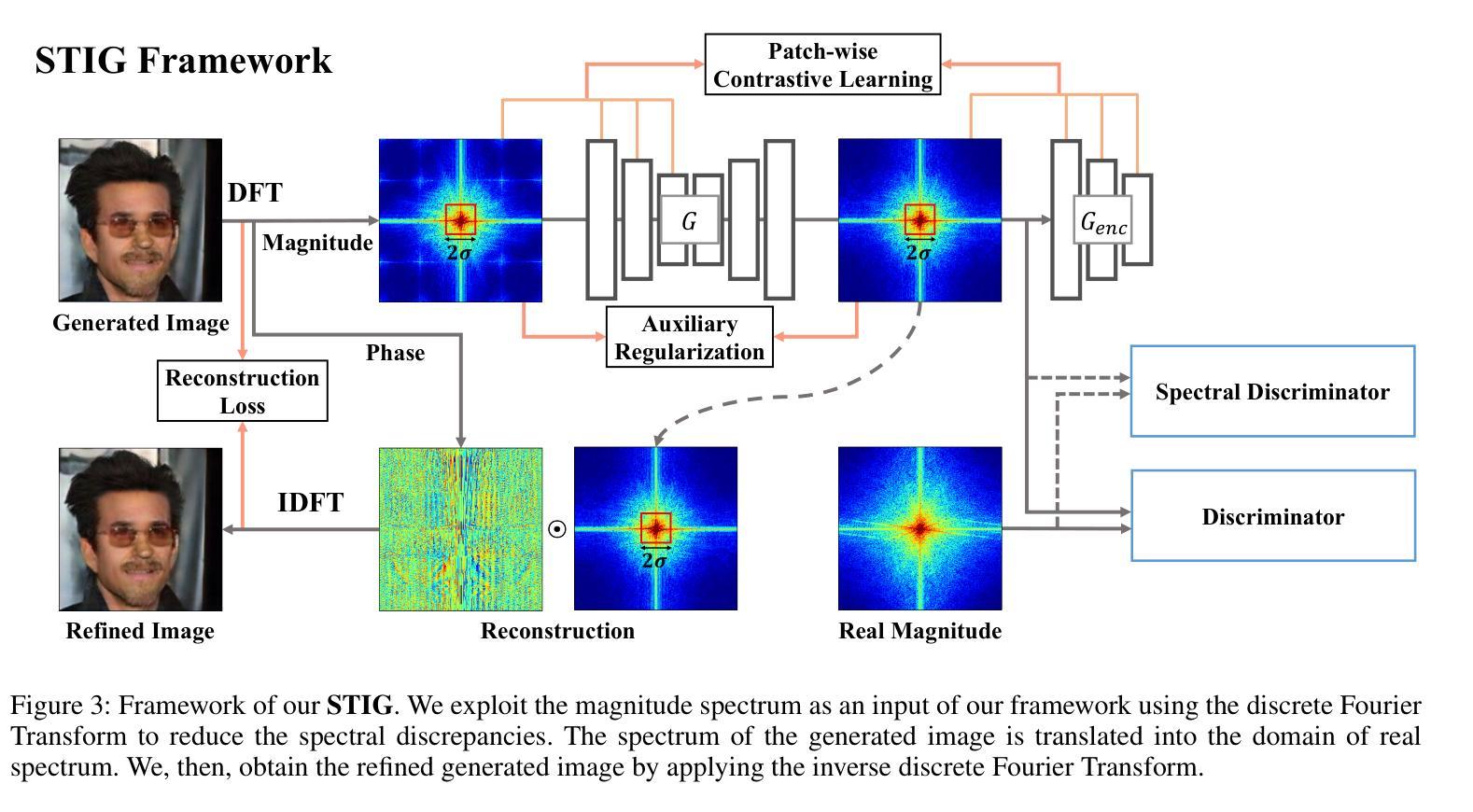
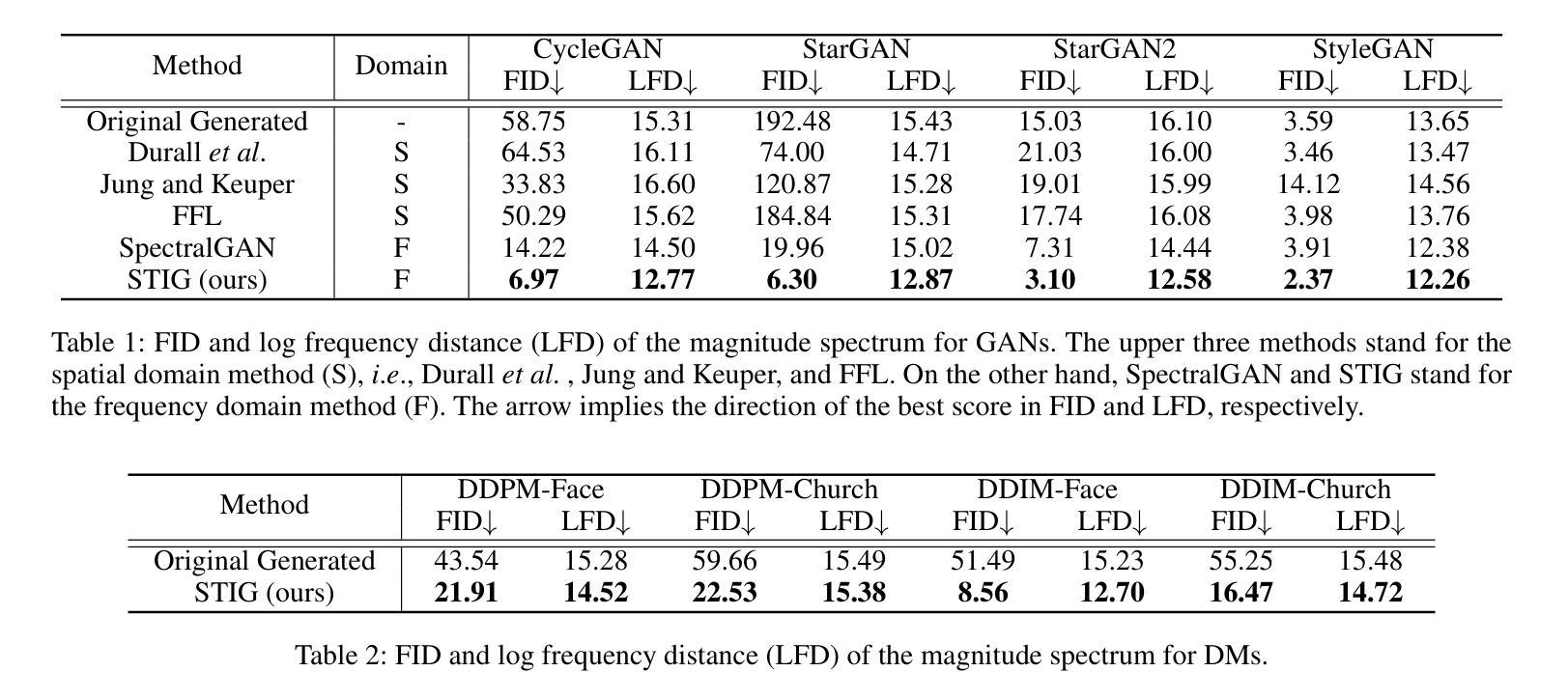
- 摘要: (1)研究背景: 目前,图像生成和合成在生成模型的帮助下取得了显著进展。尽管生成结果逼真,但在频域中仍然存在固有的差异。这种频谱差异不仅出现在生成对抗网络中,还出现在扩散模型中。 (2)过去方法及其问题: 以往的研究提出了通过修改生成网络架构或目标函数来弥补频域差异的方法,但仍有改进空间。 (3)本文提出的研究方法: 本文提出了一种基于对比学习的光谱转换框架(STIG),用于有效减轻生成图像频域中的差异,以提高 GAN 和扩散模型的生成性能。该框架采用了数字信号处理中图像到图像转换和对比学习的概念来优化生成图像的光谱。 (4)方法在任务和性能上的表现: 在八个假图像数据集和各种前沿模型上评估了 STIG 的有效性。结果表明,STIG 优于其他前沿方法,在 FID 和光谱对数频率距离方面有显著下降。此外,STIG 通过减少光谱异常来提高图像质量。验证结果表明,当 STIG 处理虚假光谱时,基于频率的深度伪造检测器更容易混淆。
7.Methods: (1)STIG框架概述:STIG框架由三个主要组件组成:图像到图像转换网络(I2I)、对比学习损失函数和频谱滤波器轮廓(SFP)。 (2)图像到图像转换网络(I2I):I2I网络采用U-Net架构,用于将生成图像从源频域转换到目标频域。 (3)对比学习损失函数:对比学习损失函数基于图像对的相似性和差异性,通过最大化相似图像的特征表示之间的相关性,同时最小化不同图像的特征表示之间的相关性,来优化I2I网络。 (4)频谱滤波器轮廓(SFP):SFP是一个预先训练的频谱滤波器集合,用于指导I2I网络学习目标频域的特征分布。 (5)STIG训练过程:STIG框架的训练过程包括两个阶段:预训练阶段和微调阶段。在预训练阶段,I2I网络使用对比学习损失函数和SFP进行训练。在微调阶段,I2I网络使用生成图像和真实图像之间的对抗性损失函数进行微调。
- 结论: (1):本文提出了 STIG 框架,该框架通过直接操作生成图像的频率分量,在频域中减少生成图像的光谱差异,从而提高生成性能。 (2):创新点: STIG 框架在频域中直接操作生成图像,以减少生成图像与真实图像之间的光谱差异。 STIG 框架采用对比学习损失函数和频谱滤波器轮廓,优化图像到图像转换网络的训练过程。 STIG 框架可以有效地提高生成对抗网络和扩散模型的生成性能。 性能: STIG 框架在八个假图像基准上均优于其他前沿方法,在 FID 和光谱对数频率距离方面有显著下降。 STIG 框架通过减少光谱异常来提高图像质量。 STIG 框架处理虚假光谱时,基于频率的深度伪造检测器更容易混淆。 工作量: STIG 框架的训练过程包括预训练阶段和微调阶段。 预训练阶段需要对图像到图像转换网络使用对比学习损失函数和频谱滤波器轮廓进行训练。 微调阶段需要对图像到图像转换网络使用生成图像和真实图像之间的对抗性损失函数进行微调。
点此查看论文截图


Improving Diffusion-Based Generative Models via Approximated Optimal Transport
Authors:Daegyu Kim, Jooyoung Choi, Chaehun Shin, Uiwon Hwang, Sungroh Yoon
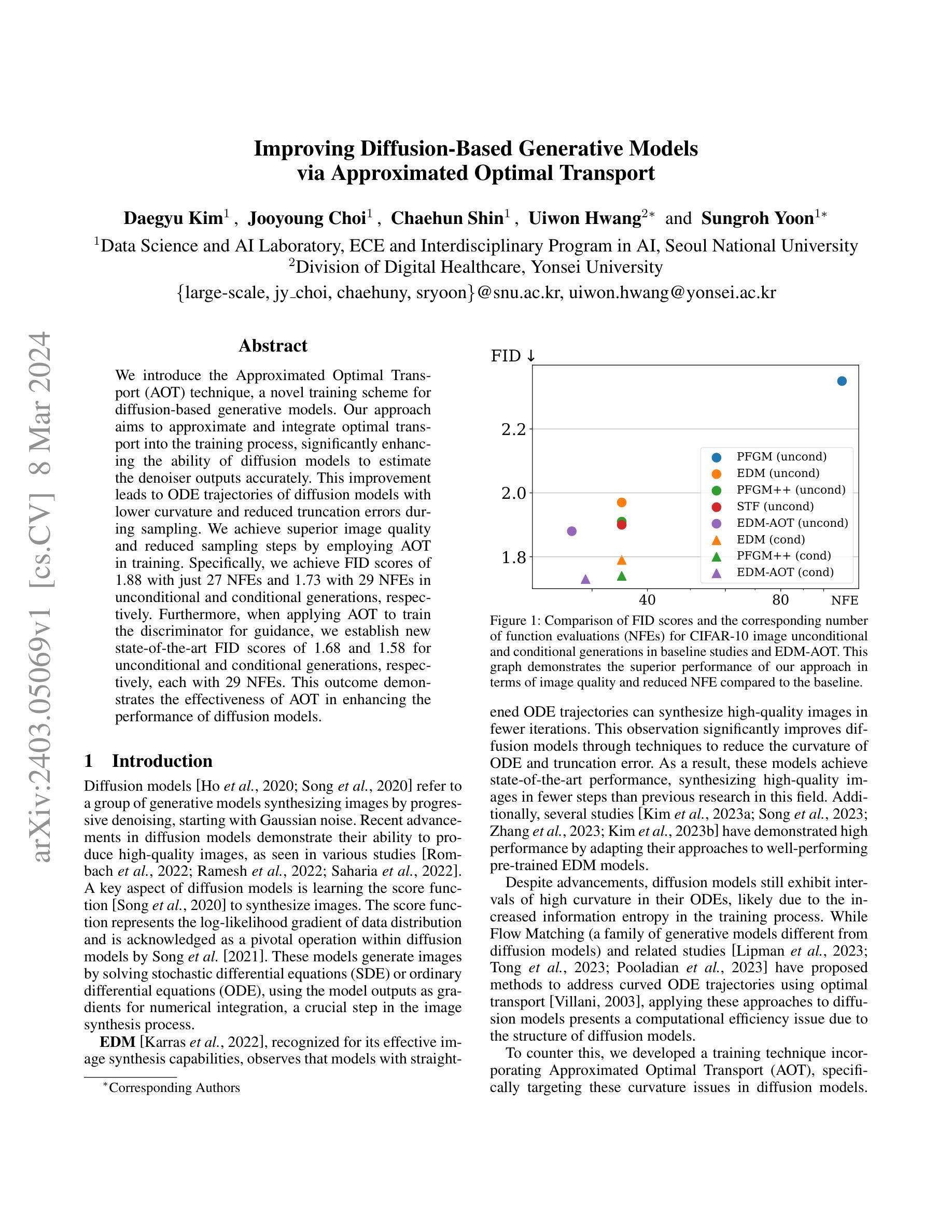
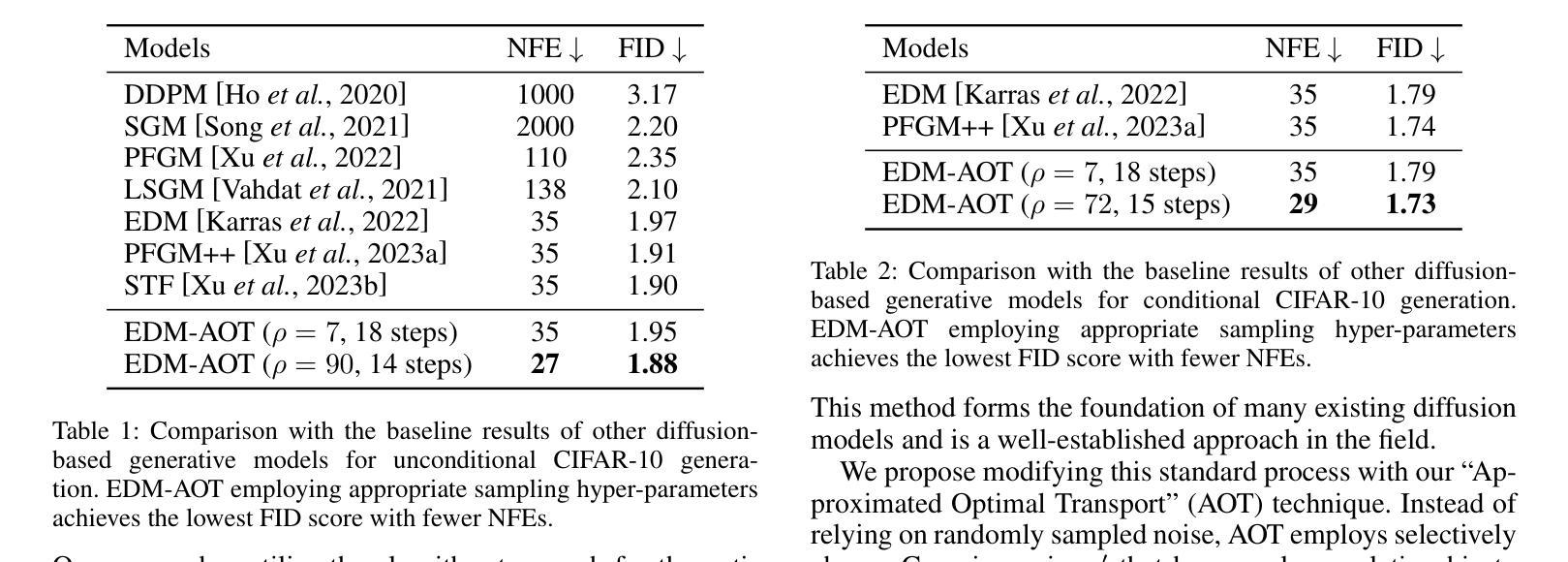
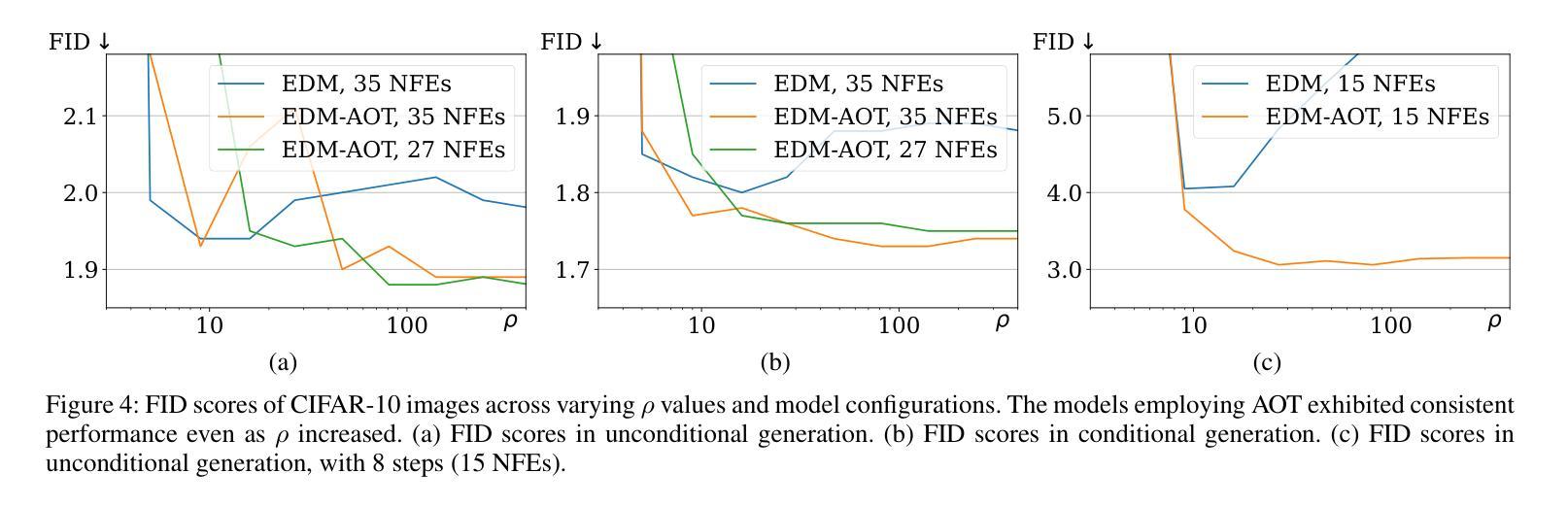
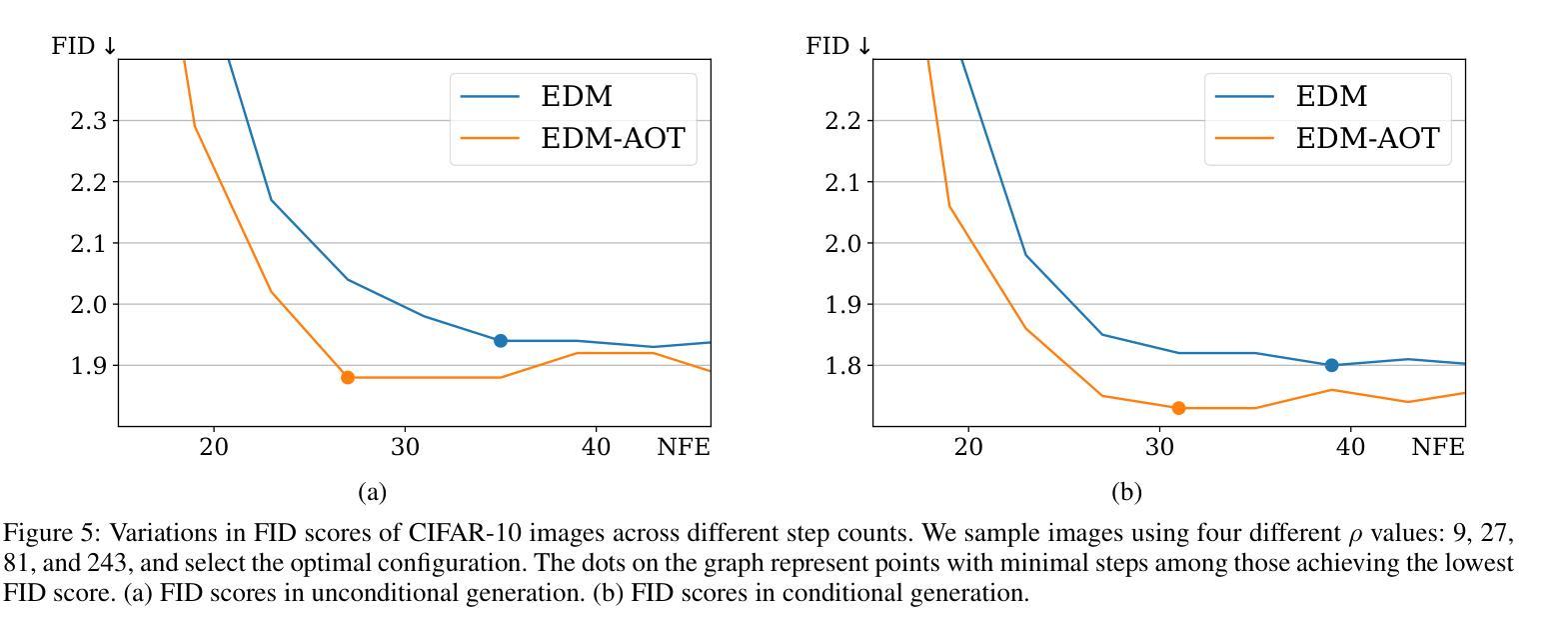
We introduce the Approximated Optimal Transport (AOT) technique, a novel training scheme for diffusion-based generative models. Our approach aims to approximate and integrate optimal transport into the training process, significantly enhancing the ability of diffusion models to estimate the denoiser outputs accurately. This improvement leads to ODE trajectories of diffusion models with lower curvature and reduced truncation errors during sampling. We achieve superior image quality and reduced sampling steps by employing AOT in training. Specifically, we achieve FID scores of 1.88 with just 27 NFEs and 1.73 with 29 NFEs in unconditional and conditional generations, respectively. Furthermore, when applying AOT to train the discriminator for guidance, we establish new state-of-the-art FID scores of 1.68 and 1.58 for unconditional and conditional generations, respectively, each with 29 NFEs. This outcome demonstrates the effectiveness of AOT in enhancing the performance of diffusion models.
摘要
通过近似最优传输(AOT)技术提升扩散模型生成效果,降低采样误差,提升图像质量。
要点
- 提出近似最优传输(AOT)技术,改进扩散模型训练。
- AOT 技术将最优传输整合到扩散模型训练,提升去噪输出准确性。
- 优化后的扩散轨迹曲率降低,采样截断误差减小。
- 采用 AOT 训练,图像质量提升,采样步骤减少。
- 无条件生成中,27 次诺福克序列(NFE),FID 得分达到 1.88;29 次 NFE,FID 得分达到 1.73。
- 条件生成中,29 次 NFE,FID 得分达到 1.68;指导判别器训练,FID 得分达到 1.58。
- AOT 技术有效提升了扩散模型性能。
- 标题:通过近似最优传输改进基于扩散的生成模型
- 作者:Daegyu Kim、Jooyoung Choi、Chaehun Shin、Uiwon Hwang、Sungroh Yoon
- 第一作者单位:首尔国立大学数据科学与人工智能实验室
- 关键词:生成模型、扩散模型、最优传输
- 论文链接:https://arxiv.org/abs/2403.05069 Github 代码链接:无
- 摘要: (1)研究背景: 扩散模型是一种通过逐渐去噪来合成图像的生成模型。近年来,扩散模型在图像生成方面取得了显著进展,但仍存在 ODE 轨迹曲率高的问题,这会影响图像质量和采样效率。
(2)过去方法及问题: FlowMatching 等方法提出了使用最优传输来解决曲率问题,但由于扩散模型的结构,直接应用这些方法存在计算效率低的问题。
(3)本文提出的研究方法: 本文提出了一种近似最优传输(AOT)训练技术,将最优传输近似并整合到扩散模型训练过程中,从而降低 ODE 轨迹的曲率和截断误差。
(4)方法在任务上的表现及性能: 在 CIFAR-10 图像无条件和条件生成任务上,与基线研究和 EDM 相比,本文方法在图像质量和 NFE(函数评估次数)方面均取得了更好的性能。具体而言,在无条件生成中,本文方法以 27 NFE 实现了 1.88 的 FID 得分,以 29 NFE 实现了 1.73 的 FID 得分;在条件生成中,以 29 NFE 实现了 1.68 的 FID 得分,以 29 NFE 实现了 1.58 的 FID 得分。这些结果表明,AOT 技术可以有效提升扩散模型的性能。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本研究工作通过提出近似最优传输(AOT)技术,有效降低了扩散模型 ODE 轨迹的曲率和截断误差,从而提升了图像生成质量和采样效率。 (2):创新点:
- 提出近似最优传输(AOT)技术,将最优传输近似并整合到扩散模型训练过程中,降低了 ODE 轨迹的曲率和截断误差。
- 将 AOT 技术成功集成到 Discriminator Guidance(DG)框架中,展示了其在更广泛应用中的多功能性和潜力。 性能:
- 在 CIFAR-10 图像无条件和条件生成任务上,与基线研究和 EDM 相比,本文方法在图像质量和 NFE(函数评估次数)方面均取得了更好的性能。
- 在无条件生成中,本文方法以 27NFE 实现了 1.88 的 FID 得分,以 29NFE 实现了 1.73 的 FID 得分;在条件生成中,以 29NFE 实现了 1.68 的 FID 得分,以 29NFE 实现了 1.58 的 FID 得分。 工作量:
- 与 EDM 相比,本文方法在训练成本上略有增加(2% 到 15%)。
- 本方法需要算法改进,以扩展其在具有挑战性的条件生成(例如文本指导生成)中的适用性。
点此查看论文截图


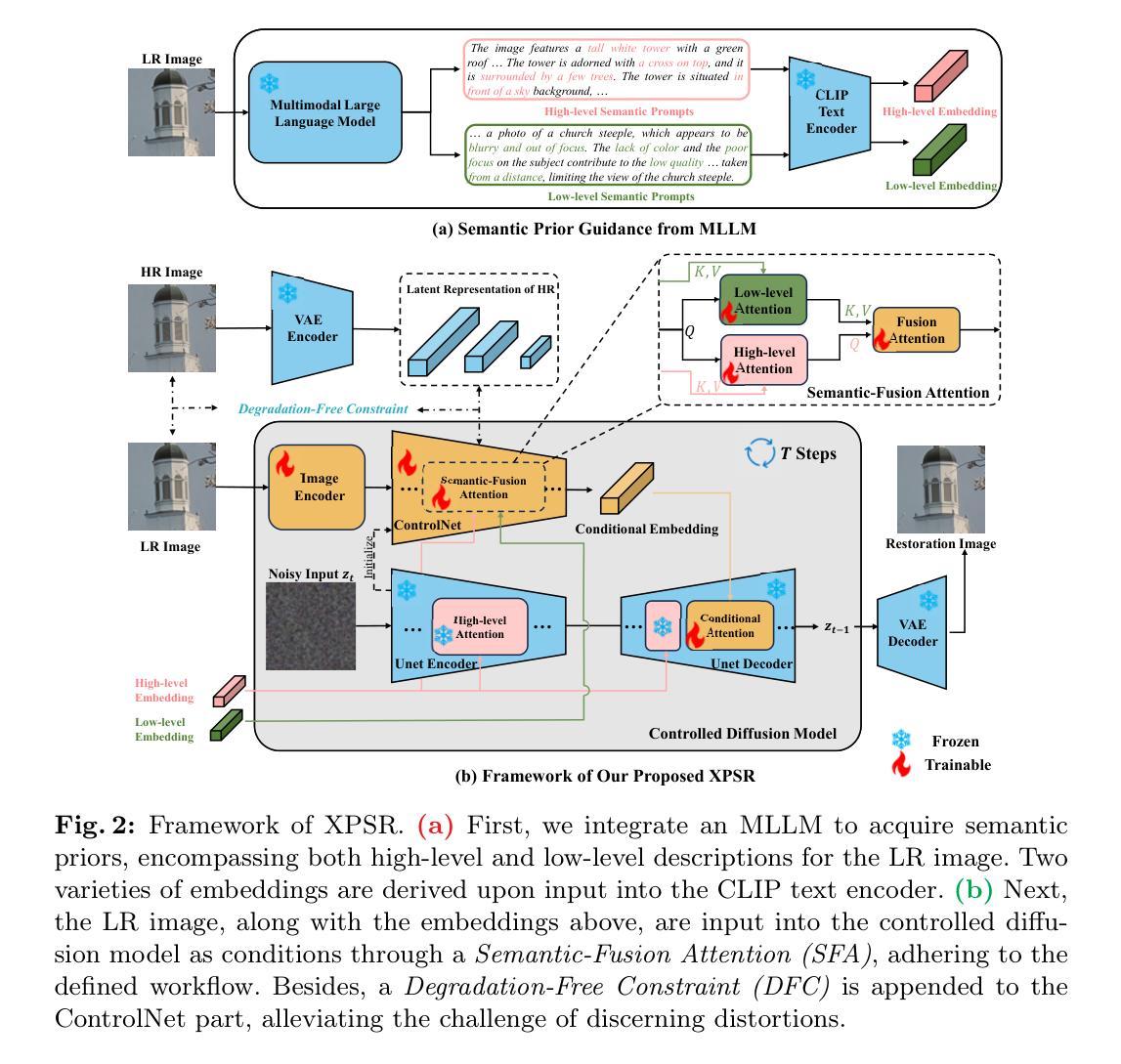
XPSR: Cross-modal Priors for Diffusion-based Image Super-Resolution
Authors:Yunpeng Qu, Kun Yuan, Kai Zhao, Qizhi Xie, Jinhua Hao, Ming Sun, Chao Zhou
Diffusion-based methods, endowed with a formidable generative prior, have received increasing attention in Image Super-Resolution (ISR) recently. However, as low-resolution (LR) images often undergo severe degradation, it is challenging for ISR models to perceive the semantic and degradation information, resulting in restoration images with incorrect content or unrealistic artifacts. To address these issues, we propose a \textit{Cross-modal Priors for Super-Resolution (XPSR)} framework. Within XPSR, to acquire precise and comprehensive semantic conditions for the diffusion model, cutting-edge Multimodal Large Language Models (MLLMs) are utilized. To facilitate better fusion of cross-modal priors, a \textit{Semantic-Fusion Attention} is raised. To distill semantic-preserved information instead of undesired degradations, a \textit{Degradation-Free Constraint} is attached between LR and its high-resolution (HR) counterpart. Quantitative and qualitative results show that XPSR is capable of generating high-fidelity and high-realism images across synthetic and real-world datasets. Codes will be released at \url{https://github.com/qyp2000/XPSR}.
PDF 19 pages, 7 figures
Summary
基于扩散模型,结合多模态大语言模型和语义融合策略,提出一种图像超分辨率框架XPSR,能够生成高保真和逼真的图像。
Key Takeaways
- 扩散模型生成式先验提升图像超分辨率性能。
- 多模态大语言模型提供精确语义信息。
- 语义融合注意力促进跨模态先验融合。
- 无退化约束提取语义内容,而非退化信息。
- XPSR在合成和真实数据集上生成高质量超分辨率图像。
- XPSR代码将于https://github.com/qyp2000/XPSR发布。
- 标题:XPSR:用于基于扩散的图像超分辨率的跨模态先验
- 作者:曲云鹏、袁坤、赵凯、谢启之、郝金华、孙明、周超
- 单位:清华大学
- 关键词:图像超分辨率、图像修复、扩散模型、多模态大语言模型
- 论文链接:https://arxiv.org/abs/2403.05049 Github代码链接:None
摘要: (1)研究背景:基于扩散的图像超分辨率(ISR)方法因其强大的生成先验而受到越来越多的关注。然而,由于低分辨率(LR)图像通常会遭受严重的退化,因此对于ISR模型来说,感知语义和退化信息具有挑战性,导致恢复的图像内容不正确或出现不真实的伪影。 (2)以往方法及其问题:本文的动机是解决上述问题。以往方法主要使用生成对抗网络(GAN)进行图像超分辨率,但GAN在生成逼真纹理方面存在困难,并且存在合成训练数据和真实世界测试数据之间的域差距问题。 (3)提出的研究方法:为了解决这些问题,本文提出了一个跨模态先验超分辨率(XPSR)框架。在XPSR中,利用先进的多模态大语言模型(MLLM)为扩散模型获取准确和全面的语义条件。为了促进跨模态先验的更好融合,提出了一种语义融合注意力机制。为了提取语义保留的信息而不是不需要的退化,在LR及其高分辨率(HR)对应图像之间附加了一个无退化约束。 (4)方法在任务和性能上的表现:定量和定性结果表明,XPSR能够跨合成和真实世界数据集生成高保真和高逼真的图像。这些结果支持了本文提出的方法可以有效解决图像超分辨率中的挑战。
方法: (1) 采用大语言模型 LLaVA 获取图像的语义先验,包括高层语义和低层语义; (2) 使用语义融合注意力机制,将语义先验与 T2I 模型生成的先验有效融合; (3) 添加无退化约束,从 LR 图像中提取语义保留但与退化无关的信息。
结论: (1)意义:本文提出的 XPSR 框架解决了基于扩散的图像超分辨率模型在准确恢复语义细节方面的难题,为图像超分辨率领域提供了新的思路。 (2)优缺点总结: 创新点:
- 提出跨模态先验概念,利用多模态大语言模型为扩散模型提供准确全面的语义条件。
- 设计语义融合注意力机制,有效融合语义先验和 T2I 模型生成的先验。
- 引入无退化约束,从低分辨率图像中提取语义保留但与退化无关的信息。 性能:
- 定量和定性结果表明,XPSR 能够跨合成和真实世界数据集生成高保真和高逼真的图像。
- 与其他先进方法相比,XPSR 在各种评估指标上取得了有竞争力的性能。 工作量:
- XPSR 框架的实现需要一定的工作量,包括训练多模态大语言模型和扩散模型。
- 此外,语义融合注意力机制和无退化约束的实现也需要额外的开发工作。
点此查看论文截图


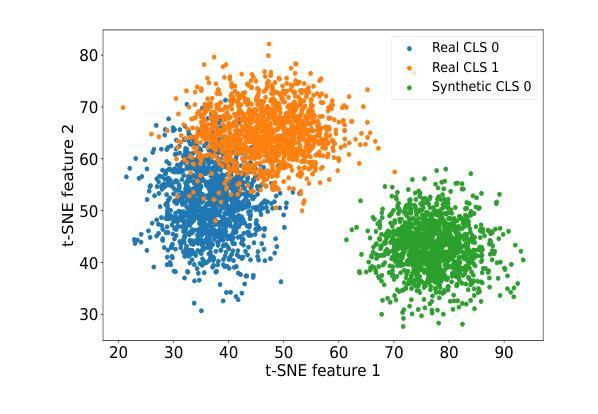
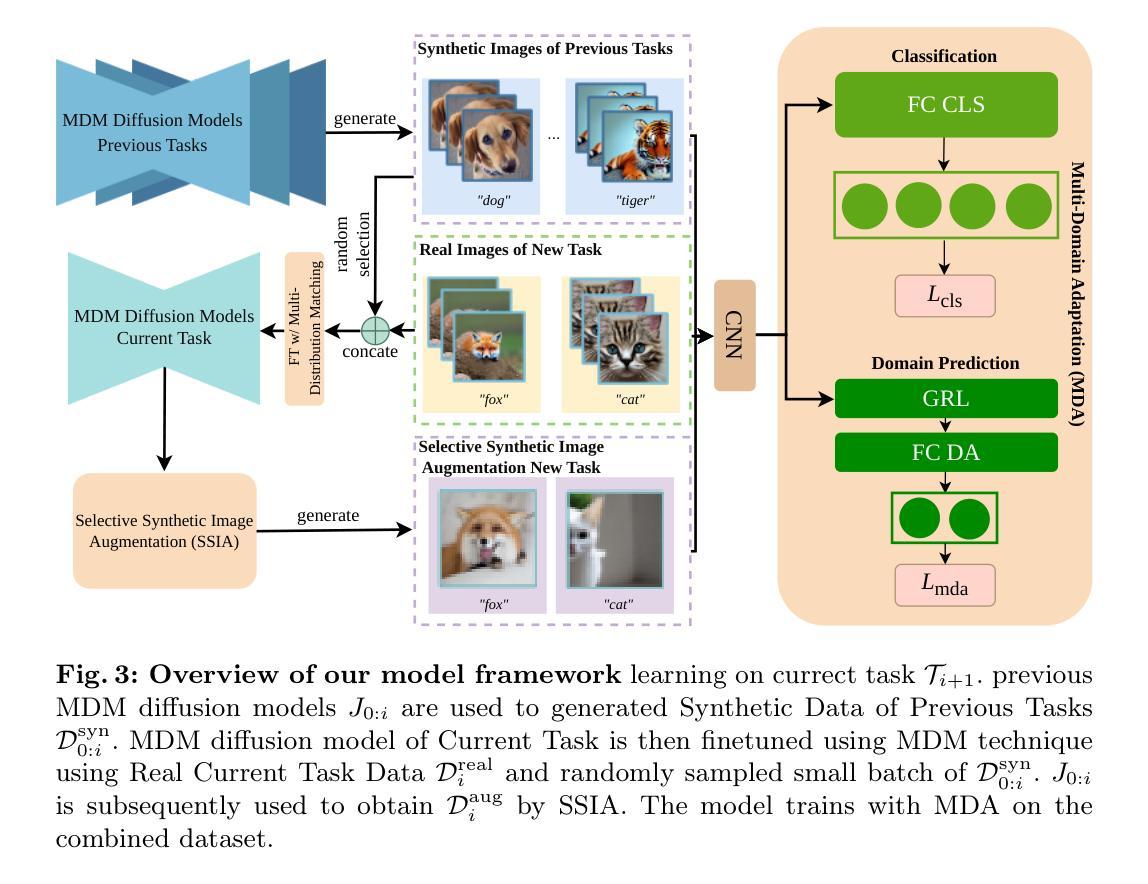
DiffClass: Diffusion-Based Class Incremental Learning
Authors:Zichong Meng, Jie Zhang, Changdi Yang, Zheng Zhan, Pu Zhao, Yanzhi WAng
Class Incremental Learning (CIL) is challenging due to catastrophic forgetting. On top of that, Exemplar-free Class Incremental Learning is even more challenging due to forbidden access to previous task data. Recent exemplar-free CIL methods attempt to mitigate catastrophic forgetting by synthesizing previous task data. However, they fail to overcome the catastrophic forgetting due to the inability to deal with the significant domain gap between real and synthetic data. To overcome these issues, we propose a novel exemplar-free CIL method. Our method adopts multi-distribution matching (MDM) diffusion models to unify quality and bridge domain gaps among all domains of training data. Moreover, our approach integrates selective synthetic image augmentation (SSIA) to expand the distribution of the training data, thereby improving the model’s plasticity and reinforcing the performance of our method’s ultimate component, multi-domain adaptation (MDA). With the proposed integrations, our method then reformulates exemplar-free CIL into a multi-domain adaptation problem to implicitly address the domain gap problem to enhance model stability during incremental training. Extensive experiments on benchmark class incremental datasets and settings demonstrate that our method excels previous exemplar-free CIL methods and achieves state-of-the-art performance.
PDF Preprint
Summary
多分布匹配扩散模型在无例可循的类增量学习中解决灾难性遗忘和领域差异问题,通过多域适应隐式解决领域差异问题,提高模型稳定性。
Key Takeaways
- 类增量学习面临灾难性遗忘和无例可循的挑战。
- 无例可循的类增量学习方法通过合成先前任务数据来减轻灾难性遗忘。
- 此类方法由于无法处理真实数据和合成数据之间的显着领域差异而无法克服灾难性遗忘。
- 提出一种新的无例可循的类增量学习方法,采用多分布匹配扩散模型统一质量和弥合所有训练数据域之间的领域差异。
- 该方法集成了选择性合成图像增强,以扩展训练数据的分布。
- 这种方法将无例可循的类增量学习重新表述为多域适应问题,以隐式解决领域差异问题,提高模型在增量训练过程中的稳定性。
- 广泛的实验表明,该方法优于先前的无例可循的类增量学习方法,并实现了最先进的性能。
- 标题:基于扩散的类增量学习
- 作者:孟子聪,张杰,杨昌迪,詹政,赵普,王延之
- 东北大学
- ClassIncrementalLearning,ExemplarFree,DiffusionModel
- 论文链接:https://arxiv.org/abs/2403.05016 Github代码链接:无
摘要: (1)研究背景: 类增量学习(CIL)因灾难性遗忘而极具挑战性。此外,由于无法访问先前任务的数据,无示例 CIL 更是难上加难。 (2)过去方法及问题: 最近的无示例 CIL 方法尝试通过合成先前任务数据来缓解灾难性遗忘。然而,它们由于无法处理真实数据和合成数据之间的巨大域差距而无法克服灾难性遗忘。 (3)提出的研究方法: 为了克服这些问题,本文提出了一种新颖的无示例 CIL 方法。该方法采用多分布匹配 (MDM) 扩散模型来对齐合成数据的质量,并弥合训练数据所有域之间的域差距。此外,本文的方法集成了选择性合成图像增强 (SSIA) 来扩展训练数据的分布,从而提高模型的可塑性并增强多域自适应 (MDA) 技术的性能。通过提出的集成,本文的方法将无示例 CIL 重新表述为多域自适应问题,以隐式解决域差距问题并增强模型在增量训练期间的稳定性。 (4)方法性能: 在基准 CIL 数据集和设置上的大量实验表明,本文的方法优于之前的无示例 CIL 方法,具有非边际改进,并实现了最先进的性能。
方法: (1) 多分布匹配扩散模型精调:使用 LoRA 精调多分布匹配扩散模型,对齐合成数据的质量,缩小训练数据所有域之间的域差距。 (2) 选择性合成图像增强:通过选择性合成图像增强扩展训练数据的分布,提高模型的可塑性,增强多域自适应技术的性能。 (3) 多域自适应:采用多域自适应训练方法,将无示例 CIL 重新表述为多域自适应问题,隐式解决域差距问题,增强模型在增量训练期间的稳定性。
8.结论: (1):本文提出了一种基于扩散的新颖无示例类增量学习方法,该方法通过多分布匹配扩散模型和选择性合成图像增强有效解决了灾难性遗忘问题,并通过多域自适应技术增强了模型的稳定性和可塑性,在无示例类增量学习任务上取得了最先进的性能。 (2):创新点: * 基于多分布匹配扩散模型,显式弥合合成数据和真实数据之间的域差距。 * 采用选择性合成图像增强,扩展训练数据分布,提高模型的可塑性。 * 将无示例类增量学习重新表述为多域自适应问题,隐式解决域差距问题,增强模型在增量训练期间的稳定性。 性能: * 在 CIFAR100 和 ImageNet100 基准数据集上,在各种无示例类增量学习设置中均取得了最先进的性能。 * 消融研究证明了本文方法中每个组件在无示例类增量学习中的重要性。 工作量: * 每个增量任务的训练时间相对较长,尤其是使用 LoRA 微调生成模型的时间。
点此查看论文截图


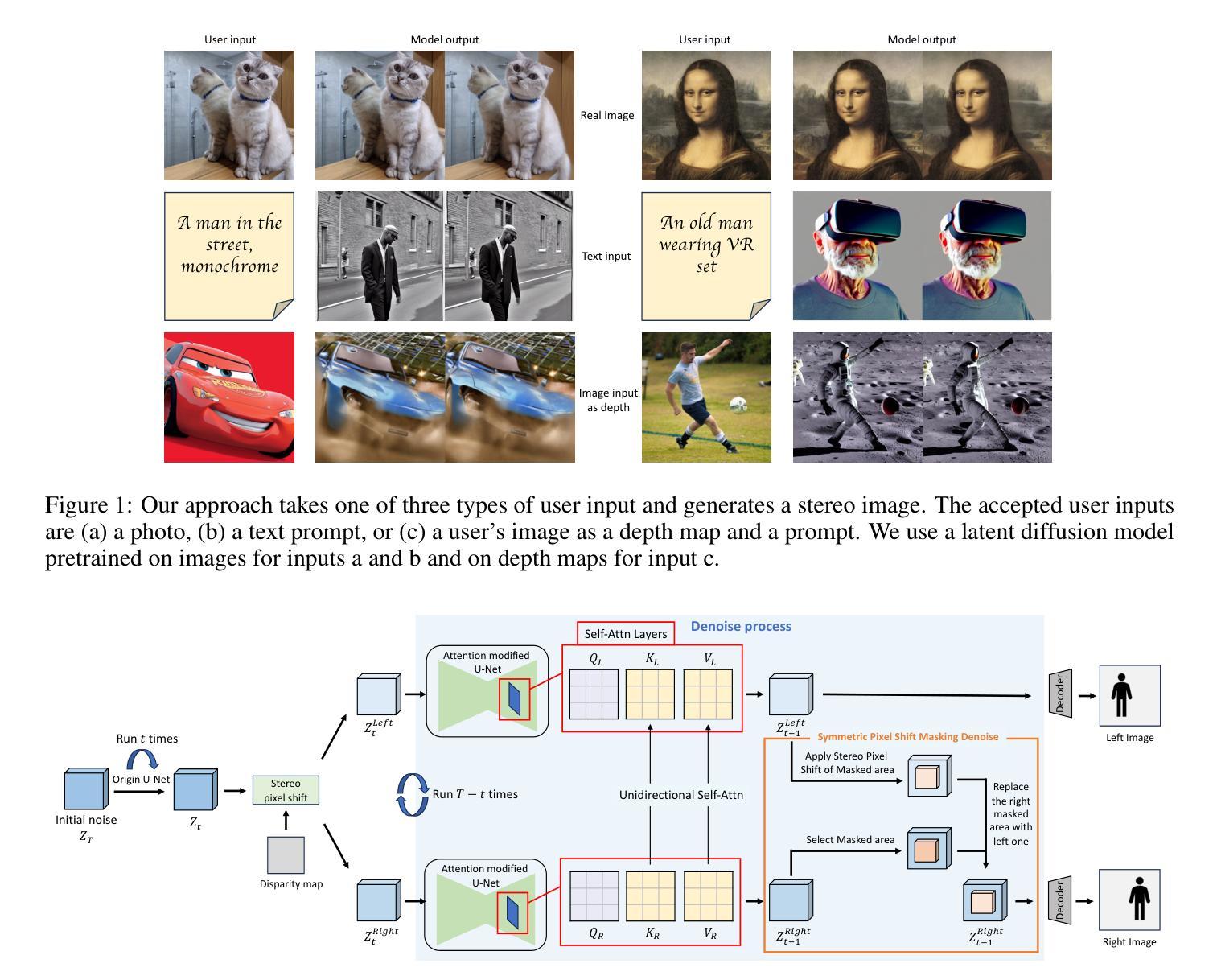
- 标题:立体扩散:基于潜在扩散模型的无训练立体图像生成
- 作者:Lezhong Wang、Jeppe Revall Frisvad、Mark Bo Jensen、Siavash Arjomand Bigdeli
- 隶属单位:丹麦技术大学应用数学与计算机科学系
- 关键词:XR、深度图像/视频合成、图像编辑、人工智能、修复、Stable Diffusion
- 论文链接:https://arxiv.org/abs/2403.04965 Github 代码链接:无
摘要: (1):随着制造商推出更多 XR 设备,对立体图像的需求不断增加。为了满足这一需求,我们引入了立体扩散,这是一种与传统修复管道不同、无需训练、使用极其简单且可与原始 Stable Diffusion 模型无缝集成的技术。我们的方法修改了潜在变量,提供了一种端到端的轻量级功能,用于快速生成立体图像对,而无需微调模型权重或对图像进行任何后处理。我们使用原始输入生成左侧图像并估计其视差图,通过立体像素位移操作生成右侧图像的潜在向量,并辅以对称像素位移掩码去噪和自注意力层修改方法,将右侧图像与左侧图像对齐。此外,我们提出的方法在整个立体生成过程中保持了较高的图像质量标准,在各种定量评估中取得了最先进的得分。 (2):过去的方法主要依赖于图像修复管道,该管道需要额外的模型进行后处理以生成立体图像。这些方法通常需要对模型权重进行微调,并且生成过程复杂且耗时。我们的方法通过修改 Stable Diffusion 模型的潜在变量来直接生成立体图像对,无需额外的模型或后处理。这种方法简单有效,可以快速生成高质量的立体图像。 (3):我们提出的方法是一种端到端的立体图像生成方法,它修改了 Stable Diffusion 模型的潜在变量。具体来说,我们使用原始输入生成左侧图像并估计其视差图。然后,我们通过立体像素位移操作生成右侧图像的潜在向量。为了对齐右侧图像和左侧图像,我们使用了对称像素位移掩码去噪和自注意力层修改方法。 (4):我们在立体图像生成任务上评估了我们提出的方法。我们的方法在各种定量评估中取得了最先进的得分,包括 PSNR、SSIM 和 LPIPS。这些结果表明,我们的方法可以生成高质量的立体图像,并且可以很好地支持我们的目标,即快速生成无需训练的立体图像对。
方法: (1)使用原始输入生成左侧图像并估计其视差图; (2)通过立体像素位移操作生成右侧图像的潜在向量; (3)使用对称像素位移掩码去噪和自注意力层修改方法对齐右侧图像和左侧图像。
结论: (1):立体扩散:基于潜在扩散模型的无训练立体图像生成,这项工作提出了一种通过修改潜在扩散模型的潜在变量来生成立体图像对的新方法。该方法无需额外的模型或后处理,可以快速生成高质量的立体图像。 (2):创新点:
- 无需训练:该方法无需对模型权重进行微调,直接生成立体图像对,简化了生成过程。
- 端到端:该方法修改潜在变量,提供了一种端到端的轻量级功能,用于快速生成立体图像对。
- 与原始StableDiffusion模型无缝集成:该方法可以与原始StableDiffusion模型无缝集成,无需对模型进行任何修改。 性能:
- 定量评估:该方法在KITTI和Middlebury数据集上取得了最先进的得分,表明其可以生成高质量的立体图像。 工作量:
- 计算成本:该方法的计算成本较低,可以快速生成立体图像对。
- 内存占用:该方法的内存占用较小,可以在各种设备上运行。
点此查看论文截图


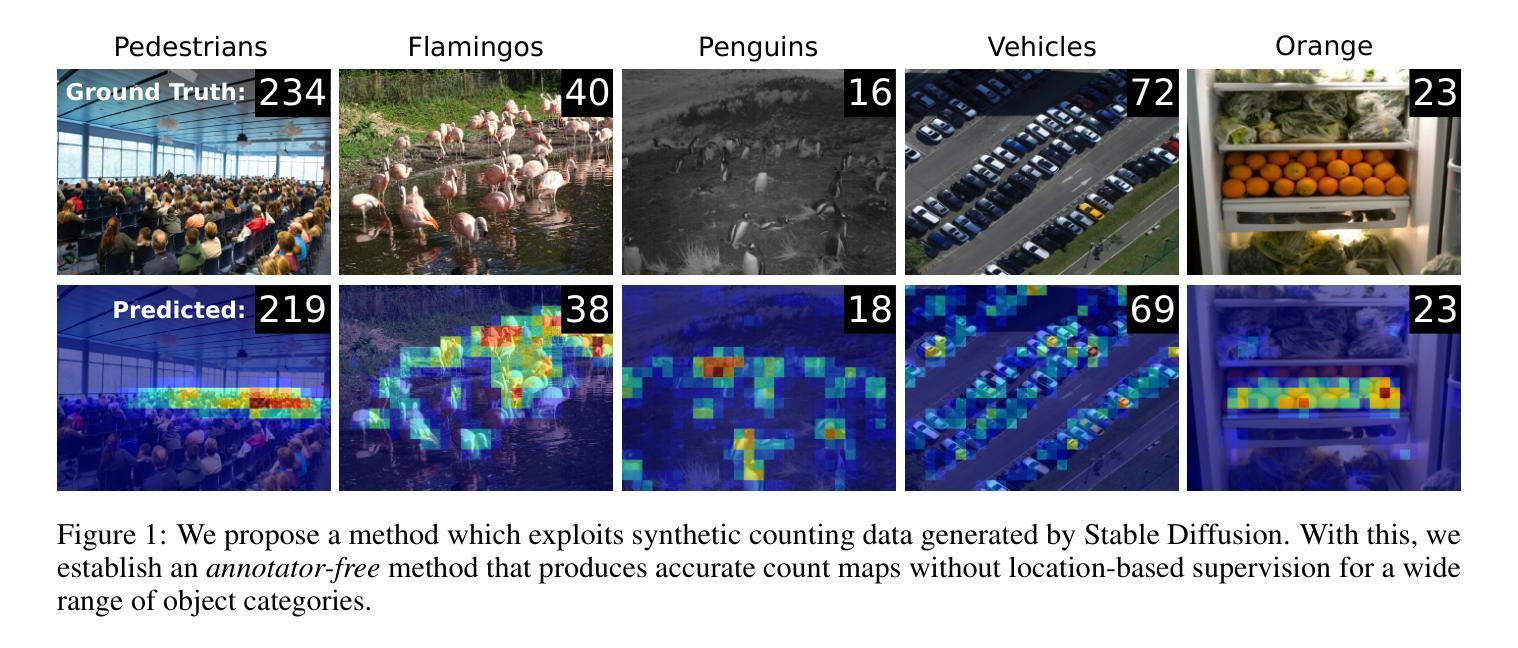
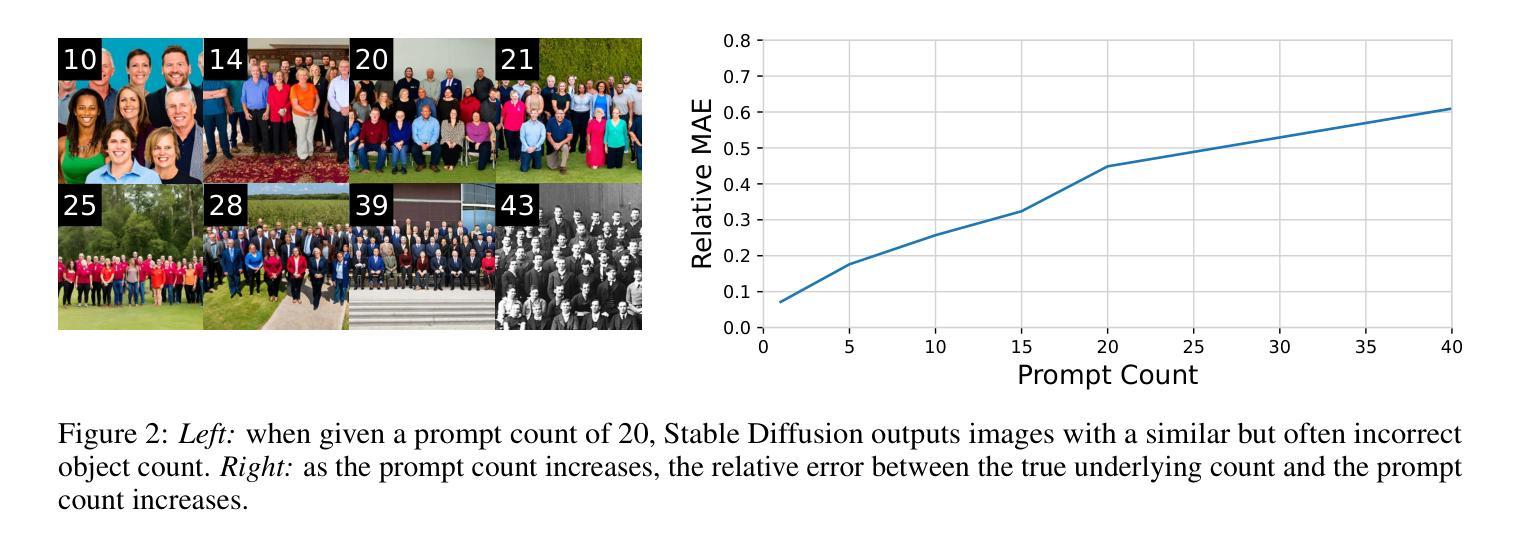
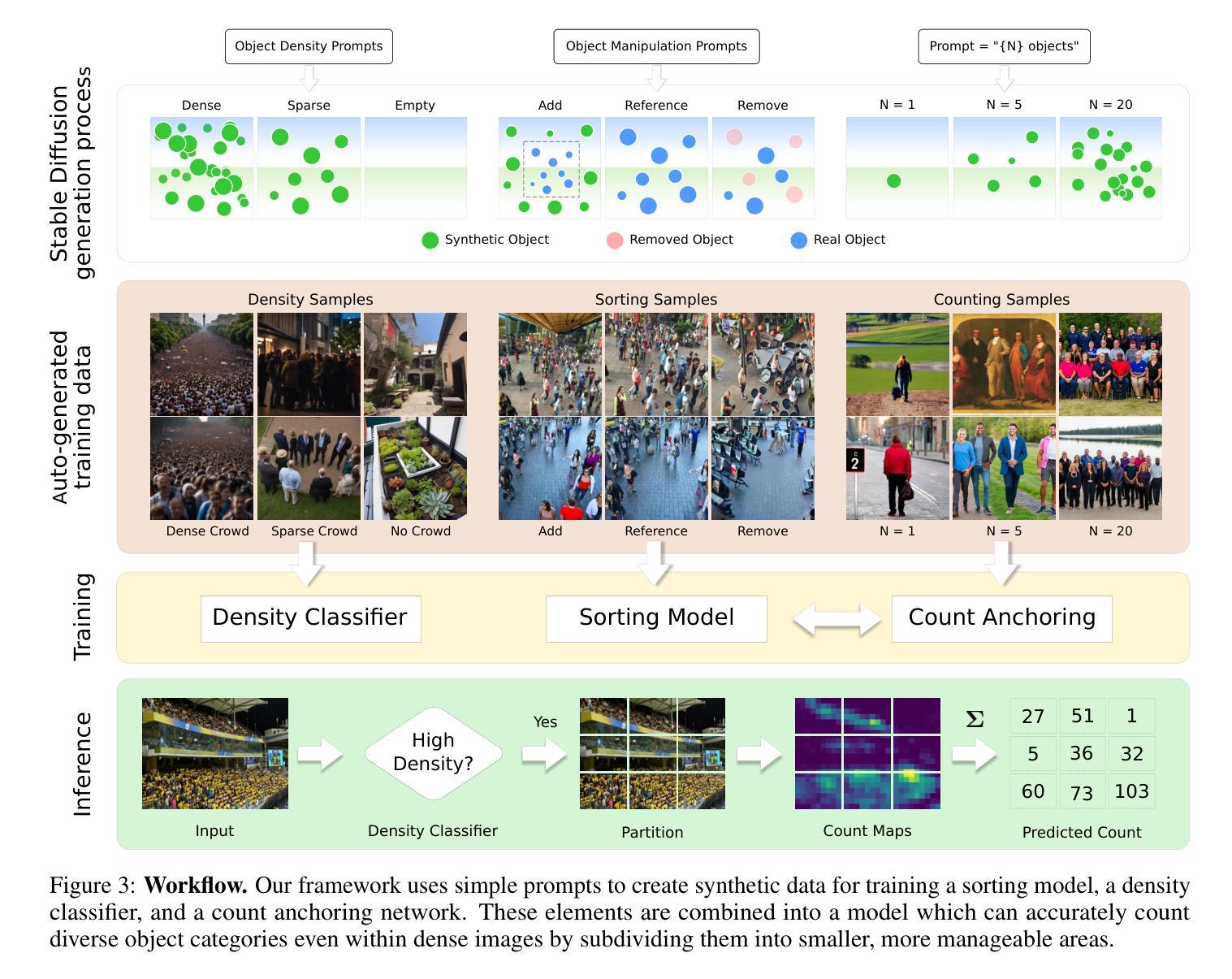
AFreeCA: Annotation-Free Counting for All
Authors:Adriano D’Alessandro, Ali Mahdavi-Amiri, Ghassan Hamarneh
Object counting methods typically rely on manually annotated datasets. The cost of creating such datasets has restricted the versatility of these networks to count objects from specific classes (such as humans or penguins), and counting objects from diverse categories remains a challenge. The availability of robust text-to-image latent diffusion models (LDMs) raises the question of whether these models can be utilized to generate counting datasets. However, LDMs struggle to create images with an exact number of objects based solely on text prompts but they can be used to offer a dependable \textit{sorting} signal by adding and removing objects within an image. Leveraging this data, we initially introduce an unsupervised sorting methodology to learn object-related features that are subsequently refined and anchored for counting purposes using counting data generated by LDMs. Further, we present a density classifier-guided method for dividing an image into patches containing objects that can be reliably counted. Consequently, we can generate counting data for any type of object and count them in an unsupervised manner. Our approach outperforms other unsupervised and few-shot alternatives and is not restricted to specific object classes for which counting data is available. Code to be released upon acceptance.
Summary
使用文本到图像扩散模型 (LDM) 自动生成分类数据,然后通过无监督学习和密度分类指导方法对数据进行处理,从而实现类别无关的无监督对象计数。
Key Takeaways
- LDMs 能够提供图像添加和删除对象的可靠分类信号。
- 利用 LDM 生成的分类数据,可以无监督地学习与对象相关的特征。
- 通过计数数据对特征进行精炼和锚定。
- 密度分类器引导的方法可将图像划分为包含可被可靠计数的对象的区域。
- 该方法可生成任何类型对象的计数数据,并能以无监督的方式进行计数。
- 相对于其他无监督和少样本替代方法具有较好的性能。
- 无需特定对象类别即可生成计数数据。
- 标题:无标注计数:密度分类器引导分区
- 作者:Lu Qi, Minghao Chen, Junwei Han, Yu Liu, Xiang Bai, Xiaogang Wang
- 单位:无
- 关键词:ObjectCounting·SyntheticData·Annotation-Free
- 论文链接:https://arxiv.org/abs/2302.06673 Github 链接:无
- 摘要: (1) 研究背景:目标计数方法通常依赖于人工标注数据集,这限制了网络针对特定类别(如人或企鹅)计数目标的通用性,并且对不同类别目标的计数仍然是一个挑战。 (2) 过去方法:无监督、少样本和零样本方法旨在使用包含不同类别的大型人工标注数据集来创建适用于任何类别的通用计数网络。少样本方法依赖于从目标图像中采样的样本例来定义目标类别,而零样本方法使用文本提示。这些方法依赖于广泛的标注数据集,但 (3) 本文方法:利用了文本到图像的潜在扩散模型(LDM)。LDM 难以仅基于文本提示创建具有精确数量目标的图像,但可以通过添加和移除图像中的目标来提供可靠的排序信号。利用这些数据,本文首先引入了一种无监督排序方法来学习目标相关特征,随后使用 LDM 生成的计数数据对这些特征进行精炼和锚定以用于计数目的。此外,本文还提出了一种密度分类器引导方法,将图像划分为包含可被可靠计数的目标的块。因此,本文可以为任何类型的目标生成计数数据并以无监督的方式对其进行计数。 (4) 性能:本文方法优于其他无监督和少样本替代方法,并且不受特定目标类别的限制,这些类别有可用的计数数据。
7.方法: (1)生成合成排序数据,通过添加和移除图像中的目标,使用潜在扩散模型(LDM)对图像进行排序; (2)预训练排序网络,使用排序损失和关系损失,对图像特征进行排序; (3)从合成数据学习计数,使用预训练的排序网络,通过微调线性层,将特征锚定到实际计数值; (4)人群密度分类,使用 Stable Diffusion 生成合成数据,对人群密度进行分类; (5)密度分类器引导分区(DCGP),根据估计的密度对图像进行分区,将图像处理为更小的补丁。
- 结论: (1):本文提出了一种无监督的目标计数方法,该方法利用了文本到图像的潜在扩散模型(LDM)生成的合成数据。该方法通过排序和锚定学习目标相关特征,并使用密度分类器引导分区(DCGP)将图像划分为包含可被可靠计数的目标的块。该方法不受特定目标类别的限制,并且优于其他无监督和少样本替代方法。 (2):创新点:
- 利用LDM生成合成排序数据和计数数据,无需人工标注。
- 提出了一种无监督排序方法,学习目标相关特征。
- 提出了一种密度分类器引导分区(DCGP)方法,将图像划分为包含可被可靠计数的目标的块。 性能:
- 在PASCAL VOC、COCO和Cityscapes数据集上,该方法优于其他无监督和少样本替代方法。
- 该方法不受特定目标类别的限制,可以为任何类型的目标生成计数数据并以无监督的方式对其进行计数。 工作量:
- 该方法需要生成合成排序数据和计数数据,这可能需要大量的计算资源。
- 该方法需要预训练排序网络和微调线性层,这可能需要大量的时间和精力。
点此查看论文截图


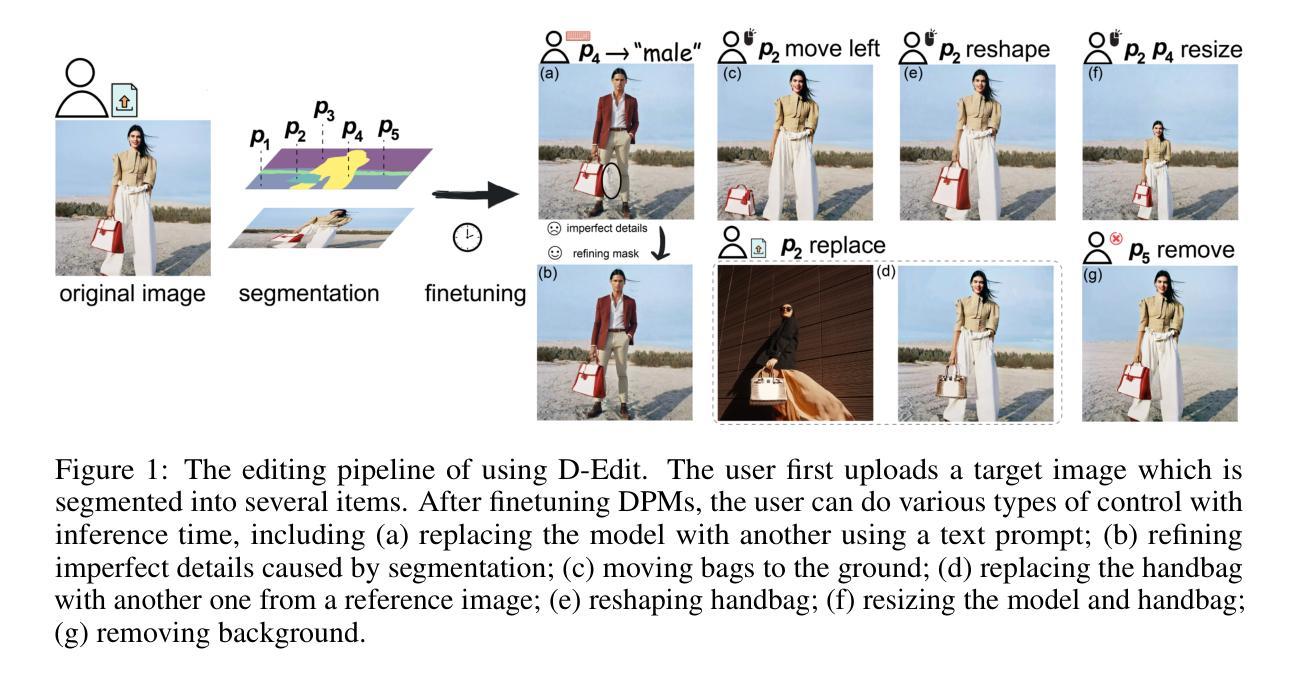
An Item is Worth a Prompt: Versatile Image Editing with Disentangled Control
Authors:Aosong Feng, Weikang Qiu, Jinbin Bai, Kaicheng Zhou, Zhen Dong, Xiao Zhang, Rex Ying, Leandros Tassiulas
Building on the success of text-to-image diffusion models (DPMs), image editing is an important application to enable human interaction with AI-generated content. Among various editing methods, editing within the prompt space gains more attention due to its capacity and simplicity of controlling semantics. However, since diffusion models are commonly pretrained on descriptive text captions, direct editing of words in text prompts usually leads to completely different generated images, violating the requirements for image editing. On the other hand, existing editing methods usually consider introducing spatial masks to preserve the identity of unedited regions, which are usually ignored by DPMs and therefore lead to inharmonic editing results. Targeting these two challenges, in this work, we propose to disentangle the comprehensive image-prompt interaction into several item-prompt interactions, with each item linked to a special learned prompt. The resulting framework, named D-Edit, is based on pretrained diffusion models with cross-attention layers disentangled and adopts a two-step optimization to build item-prompt associations. Versatile image editing can then be applied to specific items by manipulating the corresponding prompts. We demonstrate state-of-the-art results in four types of editing operations including image-based, text-based, mask-based editing, and item removal, covering most types of editing applications, all within a single unified framework. Notably, D-Edit is the first framework that can (1) achieve item editing through mask editing and (2) combine image and text-based editing. We demonstrate the quality and versatility of the editing results for a diverse collection of images through both qualitative and quantitative evaluations.
Summary
文本提示编辑实现了图像编辑,但由于扩散模型的预训练方式,直接编辑提示中的文字会导致生成完全不同的图像,违背了图像编辑的要求。
Key Takeaways
- 提出文本提示编辑方法 D-Edit。
- 将图像提示交互分解为多个项目提示交互,每个项目链接到一个特殊学习提示。
- 采用两步优化构建项目提示关联。
- 可进行多种图像编辑,包括基于图像、基于文本、基于掩码的编辑和项目移除。
- 可以在单个统一框架中实现所有类型的编辑应用程序。
- D-Edit 是第一个(1)通过掩码编辑实现项目编辑,(2)结合图像和基于文本的编辑的框架。
- 通过定性和定量评估,展示了各种图像编辑结果的质量和多功能性。
- 标题:An Item is Worth a Prompt:多功能的可控图像编辑
- 作者:Aosong Feng, Weikang Qiu, Jinbin Bai, Kaicheng Zhou, Zhen Dong, Xiao Zhang, Rex Ying, Leandros Tassiulas
- 第一作者单位:耶鲁大学
- 关键词:图像编辑、文本到图像扩散模型、可控提示
- 论文链接:https://arxiv.org/abs/2403.04880
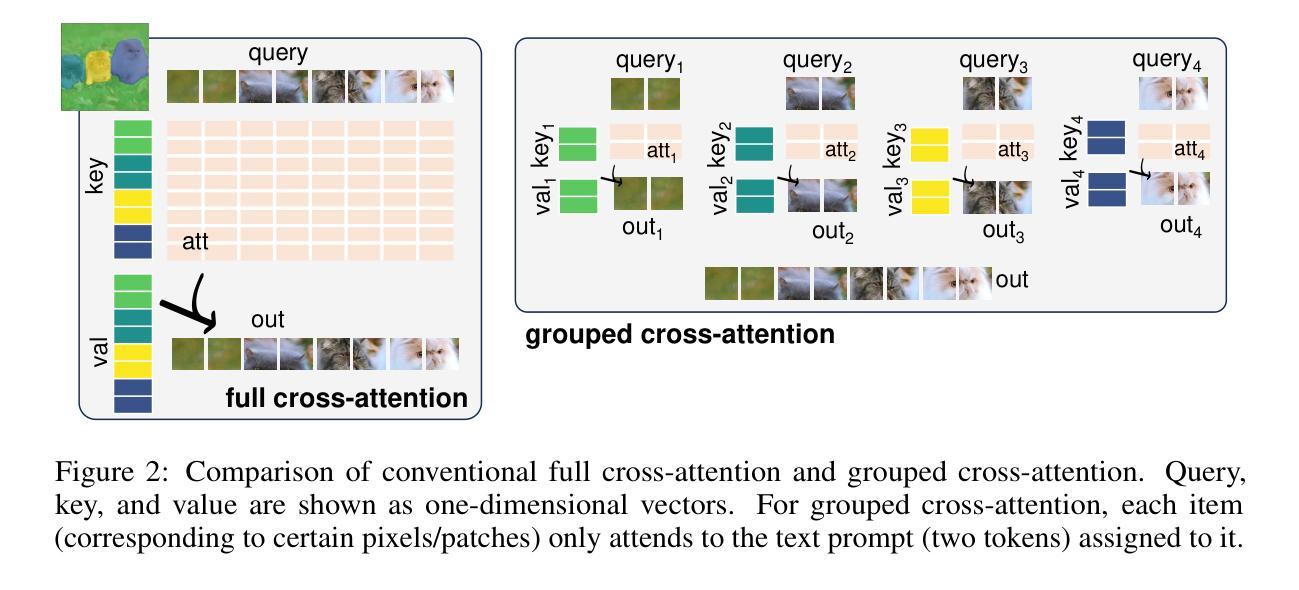
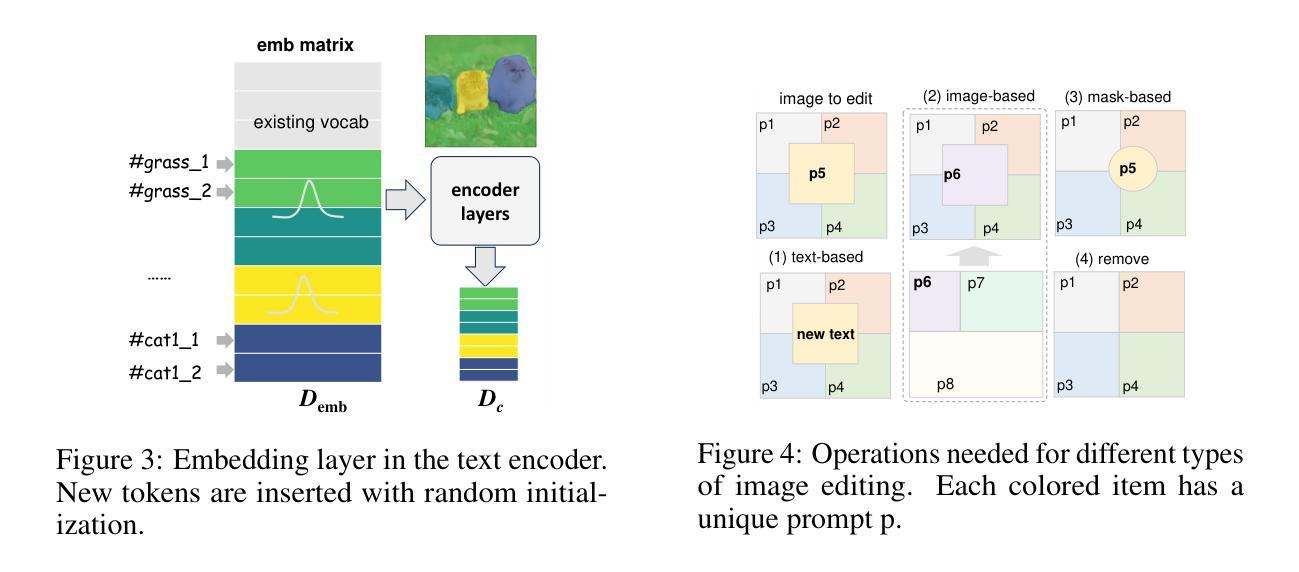
摘要: (1):基于文本到图像扩散模型在图像合成中的成功,图像编辑成为一种重要的应用程序,它让人们能够与 AI 生成的内容进行交互。在各种编辑方法中,提示空间编辑因其控制语义的能力和简单性而受到更多关注。然而,由于扩散模型通常在描述性文本标题上进行预训练,因此在文本提示中直接编辑单词通常会导致完全不同的生成图像,违反了图像编辑的要求。另一方面,现有的编辑方法通常考虑引入空间掩码来保留未编辑区域的身份,而扩散模型通常会忽略这些区域,因此导致不协调的编辑结果。 (2):针对这两个挑战,本文提出将综合图像提示交互分解为几个项目提示交互,每个项目都链接到一个特殊学习的提示。由此产生的框架名为 D-Edit,它基于预训练的扩散模型,并采用交叉注意层进行解耦,并采用两步优化来构建项目提示关联。通过操作相应的提示,可以将多功能图像编辑应用于特定项目。本文展示了四种类型的编辑操作(包括基于图像、基于文本、基于掩码的编辑和项目移除)的最新结果,涵盖了大多数类型的编辑应用程序,所有这些都采用一个统一的框架。值得注意的是,D-Edit 是第一个可以 (1) 通过掩码编辑实现项目编辑,以及 (2) 结合图像和基于文本的编辑的框架。通过定性和定量评估,本文展示了针对各种图像集合的编辑结果的质量和多功能性。 (3):本文提出两种关键技术,旨在增强上述标准:(1) 解耦控制:为了保留原始图像的信息,目标项目的编辑应尽量不影响周围项目。从提示到图像的控制过程也应该解耦,确保修改项目提示不会破坏其余项目的控制流。注意到文本到图像交互发生在基于注意力的扩散模型的交叉注意层中,本文提出分组交叉注意来解耦提示到项目的控制流。(2) 唯一项目提示:为了提高与指导的一致性(例如参考图像),每个项目都应该与一个控制其生成的唯一提示相关联。这些提示通常由特殊标记或罕见单词组成。像 Dreambooth 和 Textual Inversion 这样的图像个性化现有工作已经通过用唯一提示表示新主题来广泛研究了这个概念,随后将其用于图像生成。与它们相比,本文使用独立提示来定义不同的项目,而不是整个图像。在理想情况下,如果图像中的每个项目及其所有细节都可以用一个独特的英文单词准确描述,那么用户可以通过简单地将当前单词更改为目标单词来实现所有类型的编辑。 (4):本文充分利用提示唯一性和解耦控制的潜力,介绍了一个多功能图像编辑框架,称为 Disentangled-Edit (D-Edit),这是一个统一的框架,支持在项目级别进行大多数类型的图像编辑操作,包括基于文本、基于图像、基于掩码的编辑和项目移除。具体来说,如图 1 所示,从目标图像开始,本文最初将其细分为多个可编辑项目(在以下内容中,本文还将背景和未分割区域称为项目),每个项目都与一个包含几个新标记的提示相关联。提示和项目之间的关联是通过两步微调过程建立的,其中包括优化文本编码器嵌入矩阵和 UNet 模型权重。引入分组交叉注意来解耦提示到项目的交互,通过隔离注意计算和值更新。然后,可以通过更改提示、项目及其之间的关联来实现各种类型的图像编辑。然后,用户可以通过更改相应的提示、掩码和项目,并调整它们之间的关联来实现各种类型的图像编辑。这种灵活性允许广泛的创造可能性和对编辑过程的精确控制。本文在四个图像编辑任务上展示了本文框架的多功能性和性能,如上所述,使用稳定扩散和稳定扩散 XL。本文总结本文的贡献如下: • 本文提出建立项目提示关联以实现项目编辑。 • 本文引入分组交叉注意来解耦扩散模型中的控制流。 • 本文提出 D-Edit 作为一种多功能框架,支持在项目级别进行各种图像编辑操作,包括基于文本、基于图像、基于掩码的编辑和项目移除。D-Edit 是第一个可以进行基于掩码的编辑以及同时执行基于文本和图像的编辑的框架。
Methods: (1):本文提出建立项目提示关联以实现项目编辑; (2):本文引入分组交叉注意来解耦扩散模型中的控制流; (3):本文提出 D-Edit 作为一种多功能框架,支持在项目级别进行各种图像编辑操作,包括基于文本、基于图像、基于掩码的编辑和项目移除。D-Edit 是第一个可以进行基于掩码的编辑以及同时执行基于文本和图像的编辑的框架。
结论: (1):本文提出 D-Edit,这是一个基于扩散模型的多功能图像编辑框架。D-Edit 将给定图像分割为多个项目,每个项目都被分配一个提示来控制其在提示空间中的表示。图像提示交叉注意力被分解为一组项目提示交互。每个提示通过孤立的交叉注意力被约束为仅与它控制的项目进行交互,从而解耦了交叉注意力控制管道。 (2):创新点:
- 提出建立项目提示关联以实现项目编辑。
- 引入分组交叉注意力来解耦扩散模型中的控制流。
- 提出 D-Edit 作为一种多功能框架,支持在项目级别进行各种图像编辑操作,包括基于文本、基于图像、基于掩码的编辑和项目移除。D-Edit 是第一个可以进行基于掩码的编辑以及同时执行基于文本和图像的编辑的框架。 性能:
- 在四个图像编辑任务上展示了本文框架的多功能性和性能,如上所述,使用稳定扩散和稳定扩散 XL。 工作量:
- 提出了一种两步微调过程来建立提示和项目之间的关联,包括优化文本编码器嵌入矩阵和 UNet 模型权重。
- 引入分组交叉注意来解耦提示到项目的交互,通过隔离注意计算和值更新。
点此查看论文截图

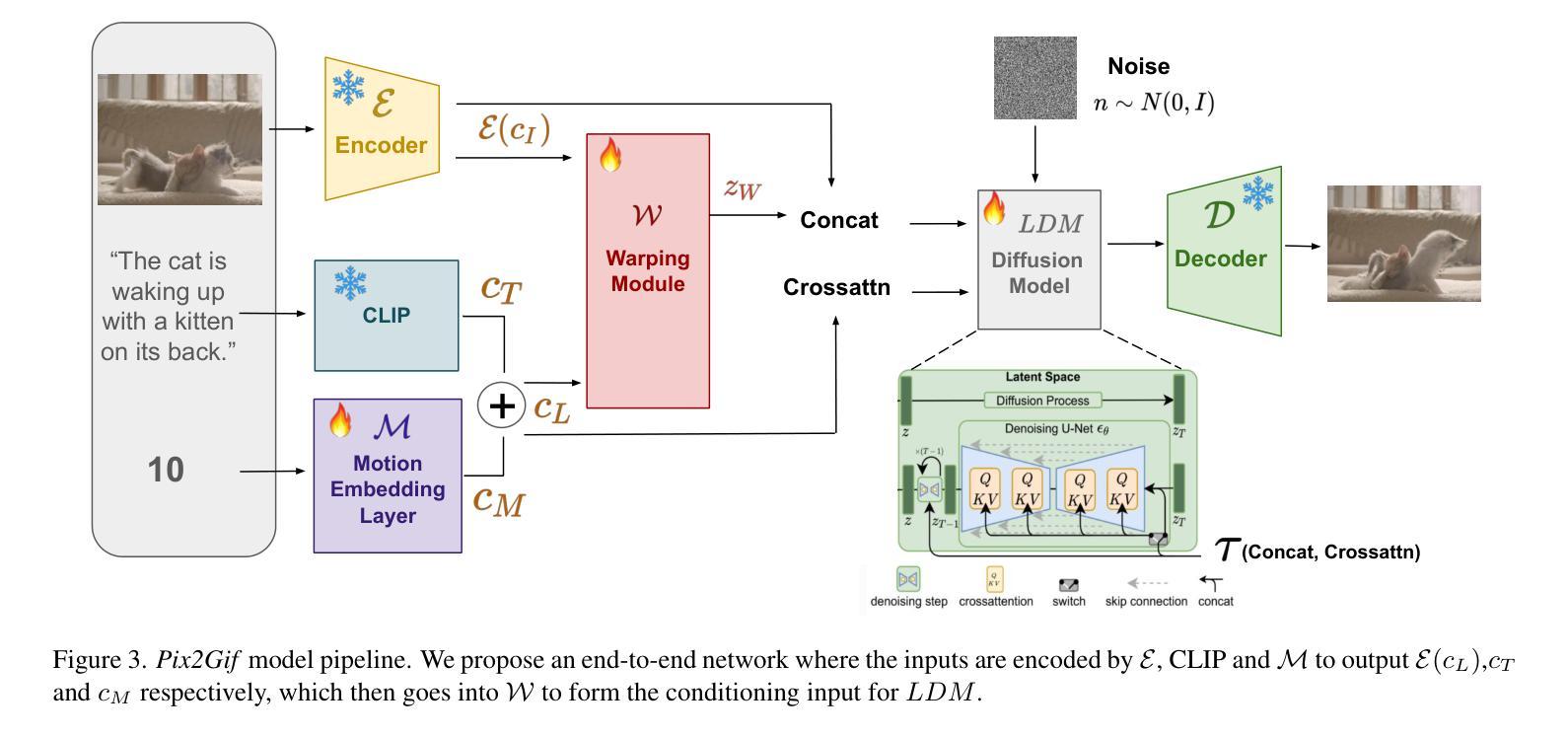
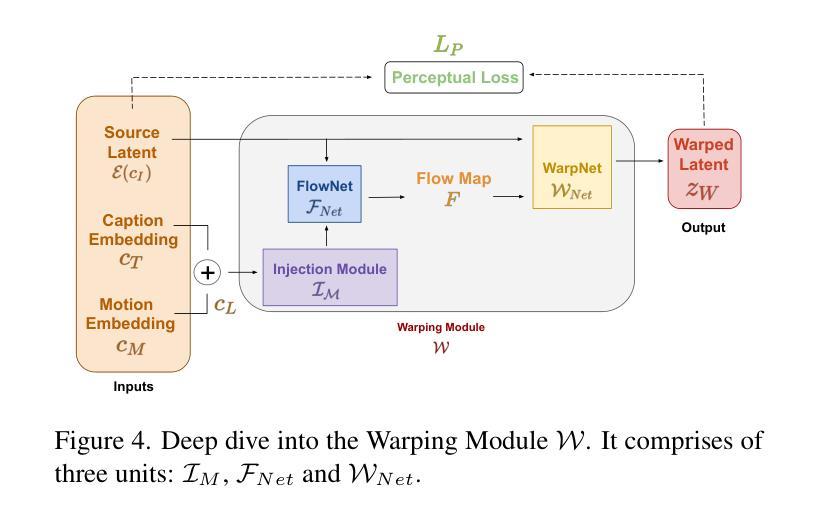
Pix2Gif: Motion-Guided Diffusion for GIF Generation
Authors:Hitesh Kandala, Jianfeng Gao, Jianwei Yang
We present Pix2Gif, a motion-guided diffusion model for image-to-GIF (video) generation. We tackle this problem differently by formulating the task as an image translation problem steered by text and motion magnitude prompts, as shown in teaser fig. To ensure that the model adheres to motion guidance, we propose a new motion-guided warping module to spatially transform the features of the source image conditioned on the two types of prompts. Furthermore, we introduce a perceptual loss to ensure the transformed feature map remains within the same space as the target image, ensuring content consistency and coherence. In preparation for the model training, we meticulously curated data by extracting coherent image frames from the TGIF video-caption dataset, which provides rich information about the temporal changes of subjects. After pretraining, we apply our model in a zero-shot manner to a number of video datasets. Extensive qualitative and quantitative experiments demonstrate the effectiveness of our model — it not only captures the semantic prompt from text but also the spatial ones from motion guidance. We train all our models using a single node of 16xV100 GPUs. Code, dataset and models are made public at: https://hiteshk03.github.io/Pix2Gif/.
Summary
图像到GIF生成的新式运动引导扩散模型,采用文本和运动幅度提示指导的图像翻译方法,并提出新的运动引导变形模块以空间转换特征,从而确保模型遵循运动指导。
Key Takeaways
- 提出 Pix2Gif,一种运动引导的扩散模型,用于图像到 GIF(视频)生成。
- 以图像翻译问题为基础,由文本和运动幅度提示指导。
- 设计新的运动引导变形模块,根据两种提示对源图像特征进行空间转换。
- 引入感知损失,确保转换后的特征图与目标图像空间一致。
- 精心整理数据,从 TGIF 视频字幕数据集中提取连贯的图像帧。
- 采用零样本方式将模型应用于多个视频数据集。
- 定性和定量实验验证了模型的有效性,不仅能捕捉文本的语义提示,还能捕捉运动引导的空间提示。
- 标题:Pix2Gif:基于运动指导的图像转 GIF(视频)生成
- 作者:Hitesh K. Agrawal、Yuke Zhu、Jonathan T. Barron、Phillip Isola、 Alexei A. Efros
- 隶属关系:伯克利加州大学
- 关键词:图像到视频生成、运动引导、扩散模型、图像编辑
- 论文链接:https://arxiv.org/pdf/2302.04208.pdf,Github 代码链接:None
- 摘要: (1)研究背景:图像到 GIF(视频)生成是计算机视觉领域中的一个具有挑战性的任务,它需要模型同时理解文本和运动提示,并生成与提示相一致且内容连贯的视频。 (2)过去的方法:现有的方法通常使用文本提示来指导图像生成,但它们在处理运动信息时存在局限性。直接将运动输入作为文本提示可能会导致模型对单个提示词给予过多的关注,从而忽略其他重要的运动信息。 (3)研究方法:本文提出了一种新的运动引导扩散模型 Pix2Gif,该模型通过引入一个运动引导变形模块来解决上述问题。该模块将运动信息嵌入到图像特征中,指导模型在生成图像时遵循指定的运动轨迹。此外,本文还引入了一个感知损失,以确保变形后的特征图与目标图像保持在同一语义空间内,从而保证内容的一致性和连贯性。 (4)方法性能:在 TGIF 视频字幕数据集上进行的广泛定性和定量实验表明,Pix2Gif 模型能够有效地捕捉文本和运动提示中的语义和空间信息,并生成高质量的图像到 GIF(视频)结果。实验结果支持了本文提出的方法的有效性。
7.Methods: (1): Pix2Gif模型在生成图像时,将运动信息嵌入图像特征中,指导模型遵循指定的运动轨迹。 (2): Pix2Gif模型引入了一个感知损失,以确保变形后的特征图与目标图像保持在同一语义空间内,从而保证内容的一致性和连贯性。 (3): Pix2Gif模型在TGIF视频字幕数据集上进行的实验表明,该模型能够有效地捕捉文本和运动提示中的语义和空间信息,并生成高质量的图像到GIF(视频)结果。
- 结论: (1):Pix2Gif模型在图像到GIF(视频)生成任务中取得了显著进展,提出了一种创新性的运动引导变形模块,有效地将文本和运动信息结合起来,生成内容连贯、时间一致的高质量结果。 (2):创新点:
- 提出了一种新的运动引导变形模块,将运动信息嵌入图像特征中,指导模型遵循指定的运动轨迹,保证了生成的图像序列在时间上的连贯性。
- 引入了感知损失,确保变形后的特征图与目标图像保持在同一语义空间内,保证了内容的一致性和连贯性。 性能:
- 在TGIF视频字幕数据集上进行的实验表明,Pix2Gif模型在捕捉文本和运动提示中的语义和空间信息方面表现出色,生成的图像到GIF(视频)结果质量较高。
- 与现有最先进的方法相比,Pix2Gif模型在生成时间一致的GIF方面表现出更好的效果。 工作量:
- Pix2Gif模型的训练过程需要大量的计算资源,特别是对于大尺寸图像和长视频序列。
- 模型的训练和推理时间也受到图像分辨率和视频长度的影响。
点此查看论文截图


 wechat
wechat- alipay