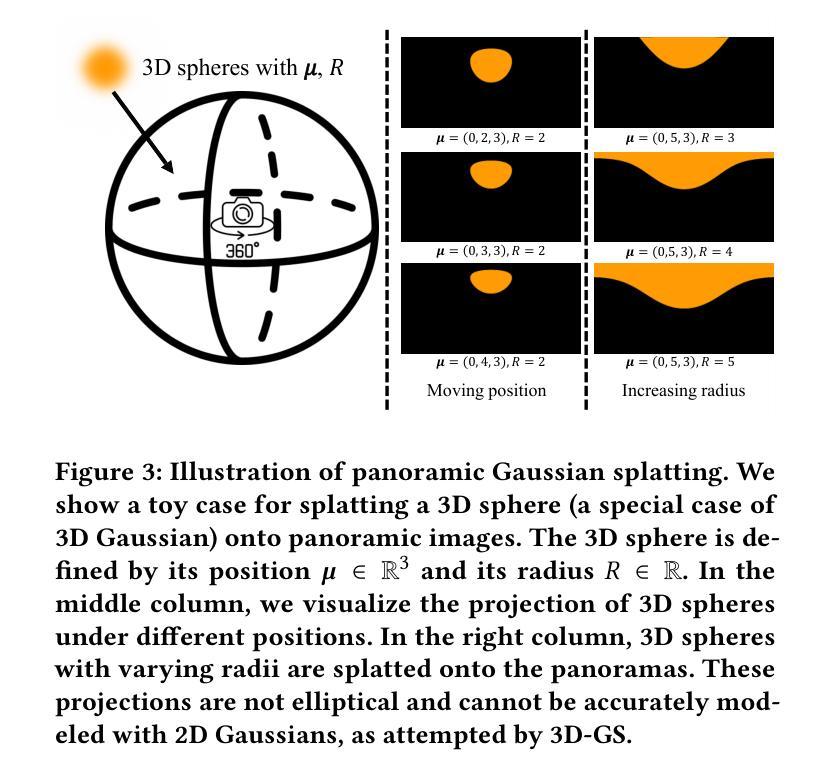
3DGS
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-03-13 更新
StyleGaussian: Instant 3D Style Transfer with Gaussian Splatting
Authors:Kunhao Liu, Fangneng Zhan, Muyu Xu, Christian Theobalt, Ling Shao, Shijian Lu
We introduce StyleGaussian, a novel 3D style transfer technique that allows instant transfer of any image’s style to a 3D scene at 10 frames per second (fps). Leveraging 3D Gaussian Splatting (3DGS), StyleGaussian achieves style transfer without compromising its real-time rendering ability and multi-view consistency. It achieves instant style transfer with three steps: embedding, transfer, and decoding. Initially, 2D VGG scene features are embedded into reconstructed 3D Gaussians. Next, the embedded features are transformed according to a reference style image. Finally, the transformed features are decoded into the stylized RGB. StyleGaussian has two novel designs. The first is an efficient feature rendering strategy that first renders low-dimensional features and then maps them into high-dimensional features while embedding VGG features. It cuts the memory consumption significantly and enables 3DGS to render the high-dimensional memory-intensive features. The second is a K-nearest-neighbor-based 3D CNN. Working as the decoder for the stylized features, it eliminates the 2D CNN operations that compromise strict multi-view consistency. Extensive experiments show that StyleGaussian achieves instant 3D stylization with superior stylization quality while preserving real-time rendering and strict multi-view consistency. Project page: https://kunhao-liu.github.io/StyleGaussian/
Summary
三维高斯泼溅(3DGS)助力 StyleGaussian 实现即时 3D 样式迁移,在不影响实时渲染和多视图一致性的情况下,以每秒 10 帧的速度将任何图像的样式传输到三维场景中。
Key Takeaways
- StyleGaussian 是一种新颖的 3D 样式迁移技术,可以即时将任何图像的样式以每秒 10 帧 (fps) 的速度传输到 3D 场景中。
- StyleGaussian 利用 3D 高斯泼溅 (3DGS),在不影响其实时渲染能力和多视图一致性的情况下实现样式迁移。
- StyleGaussian 通过嵌入、传输和解码这三个步骤实现即时样式迁移。
- StyleGaussian 具有两种新颖的设计。第一个是一种高效的特征渲染策略,它首先渲染低维特征,然后在嵌入 VGG 特征时将它们映射到高维特征。
- 第二个是一个基于 K 近邻的 3D CNN。它作为样式化特征的解码器,消除了影响严格的多视图一致性的 2D CNN 操作。
- 广泛的实验表明,StyleGaussian 以卓越的样式化质量实现了即时的 3D 样式化,同时保留了实时渲染和严格的多视图一致性。
- 题目:StyleGaussian:即时3D风格迁移,采用高斯飞溅
- 作者:Kunhao Liu, Qifeng Chen, Lu Zhou, Wenping Wang, Junsong Yuan, Yizhou Yu
- 隶属机构:University of California, Berkeley
- 关键词:3DGaussianSplatting·3DStyleTransfer·3DEditing
- 论文链接:https://arxiv.org/pdf/2103.04306.pdf,Github代码链接:None
- 摘要: (1)研究背景:随着3D场景建模和渲染技术的进步,3D风格迁移技术已成为3D内容创作中的重要课题。 (2)过去方法:现有的3D风格迁移方法主要基于2D卷积神经网络(CNN),它们在风格迁移方面取得了成功,但存在实时渲染能力和多视图一致性方面的限制。 (3)提出方法:本文提出了一种名为StyleGaussian的新型3D风格迁移技术,它利用3DGaussianSplatting(3DGS)实现了即时风格迁移,同时保持了实时渲染能力和多视图一致性。StyleGaussian包含三个步骤:嵌入、迁移和解码。首先,将2DVGG场景特征嵌入到重建的3DGaussian中。然后,根据参考风格图像转换嵌入的特征。最后,将转换后的特征解码为风格化的RGB。 (4)性能与评价:实验表明,StyleGaussian实现了即时3D风格化,具有出色的风格化质量,同时保持了实时渲染和严格的多视图一致性。这些性能支持了本文的目标,即提供一种快速、高质量且多视图一致的3D风格迁移技术。
7.方法:(1)嵌入:将2DVGG场景特征嵌入到重建的3DGaussian中;(2)迁移:根据参考风格图像转换嵌入的特征;(3)解码:将转换后的特征解码为风格化的RGB。
- 结论: (1): 本文提出了一种名为 StyleGaussian 的新型 3D 风格迁移方法,它利用 3DGaussianSplatting(3DGS)实现了即时风格迁移,同时保持了实时渲染能力和多视图一致性。 (2): 创新点:
- 提出了一种基于 3DGaussianSplatting 的 3D 风格迁移方法,实现了即时风格迁移,同时保持了实时渲染能力和多视图一致性。
- 设计了一种新的特征嵌入和迁移模块,可以有效地将 2D 风格特征迁移到 3D 场景中。
- 开发了一种新的解码模块,可以将转换后的特征解码为高质量的风格化 RGB 图像。 性能:
- 实验表明,StyleGaussian 实现了即时 3D 风格化,具有出色的风格化质量,同时保持了实时渲染和严格的多视图一致性。
- 与现有方法相比,StyleGaussian 在风格化质量、实时渲染能力和多视图一致性方面具有明显的优势。 工作量:
- 本文的工作量较大,涉及到 3D 场景建模、风格迁移和实时渲染等多个方面的研究。
- 作者提出了一个完整的 StyleGaussian 系统,包括嵌入、迁移和解码三个模块,并提供了详细的算法描述和实验结果。
点此查看论文截图



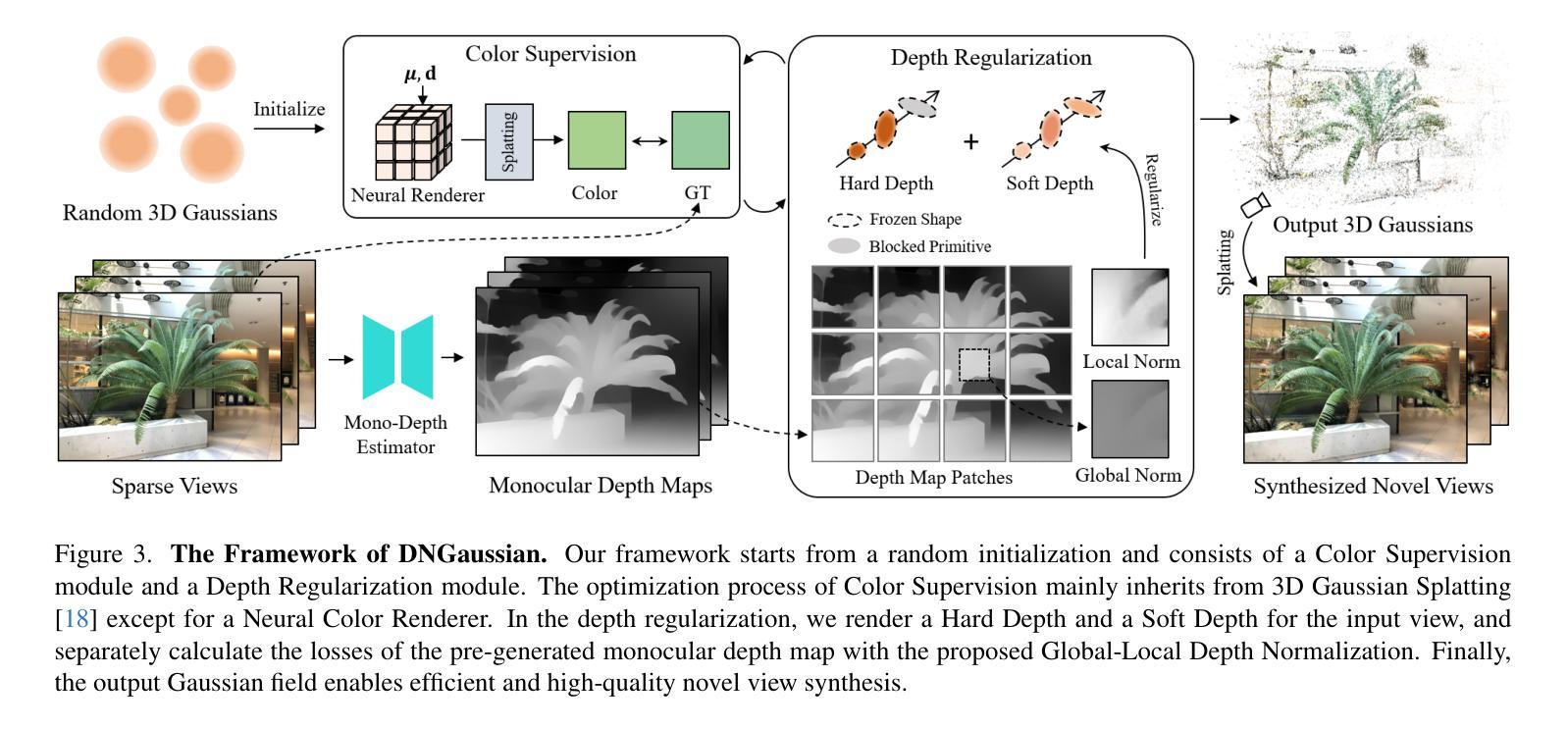
DNGaussian: Optimizing Sparse-View 3D Gaussian Radiance Fields with Global-Local Depth Normalization
Authors:Jiahe Li, Jiawei Zhang, Xiao Bai, Jin Zheng, Xin Ning, Jun Zhou, Lin Gu
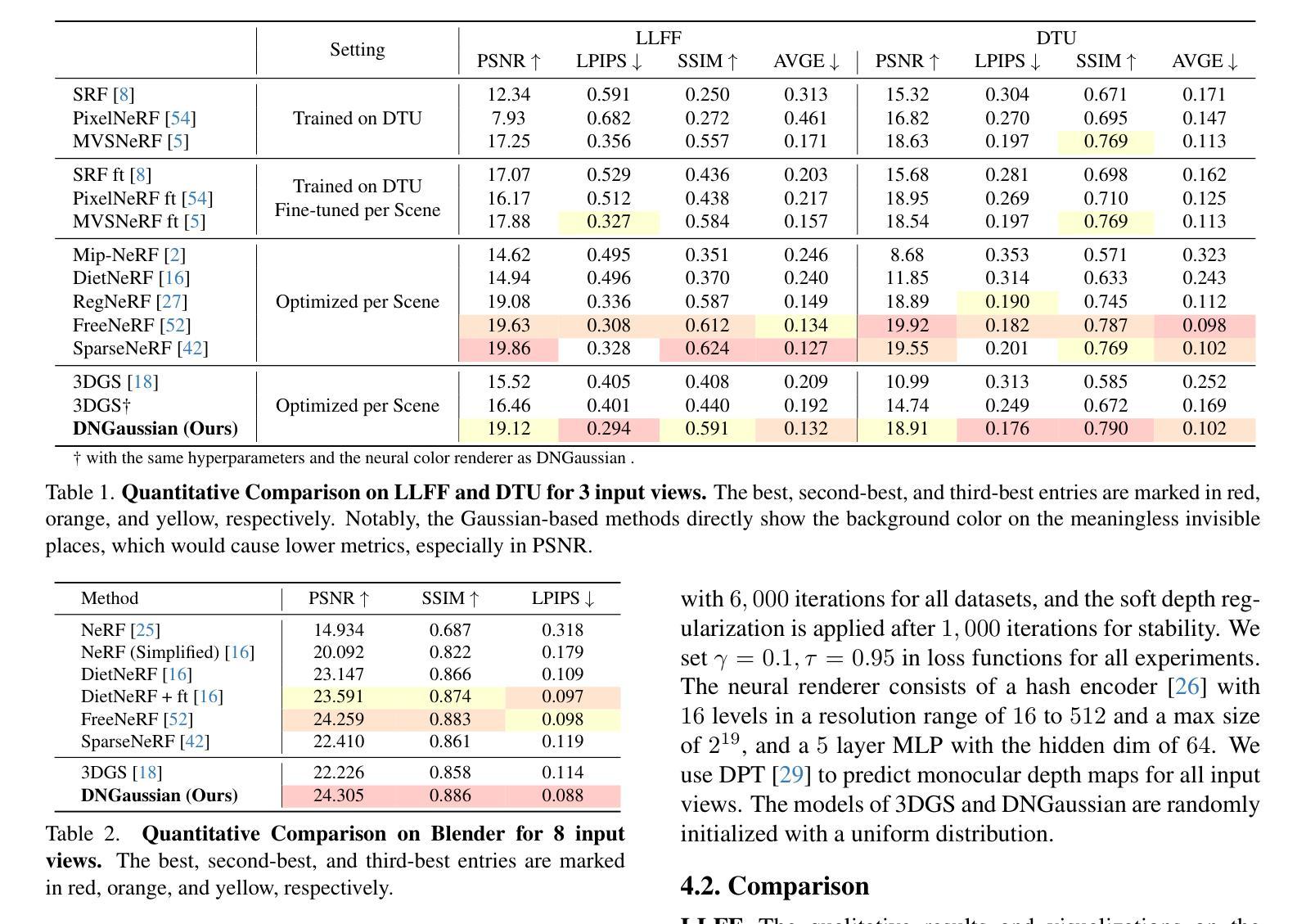
Radiance fields have demonstrated impressive performance in synthesizing novel views from sparse input views, yet prevailing methods suffer from high training costs and slow inference speed. This paper introduces DNGaussian, a depth-regularized framework based on 3D Gaussian radiance fields, offering real-time and high-quality few-shot novel view synthesis at low costs. Our motivation stems from the highly efficient representation and surprising quality of the recent 3D Gaussian Splatting, despite it will encounter a geometry degradation when input views decrease. In the Gaussian radiance fields, we find this degradation in scene geometry primarily lined to the positioning of Gaussian primitives and can be mitigated by depth constraint. Consequently, we propose a Hard and Soft Depth Regularization to restore accurate scene geometry under coarse monocular depth supervision while maintaining a fine-grained color appearance. To further refine detailed geometry reshaping, we introduce Global-Local Depth Normalization, enhancing the focus on small local depth changes. Extensive experiments on LLFF, DTU, and Blender datasets demonstrate that DNGaussian outperforms state-of-the-art methods, achieving comparable or better results with significantly reduced memory cost, a $25 \times$ reduction in training time, and over $3000 \times$ faster rendering speed.
PDF Accepted at CVPR 2024. Project page: https://fictionarry.github.io/DNGaussian/
Summary
深度正则化的 3D 高斯辐射场实现了高性价比的实时少量镜头新视角合成。
Key Takeaways
- 高斯辐射场的效率与质量优于 3D 高斯贴片。
- 场景几何退化主要由高斯原语定位引起,深度约束可缓解此问题。
- 硬软深度正则化在粗略单目深度监督下可恢复准确的场景几何。
- 全局局部深度归一化可增强对局部小深度变化的关注。
- DNGaussian 在 LLFF、DTU 和 Blender 数据集上优于最先进的方法。
- 与最先进的方法相比,DNGaussian 显着降低了内存成本。
- DNGaussian 的训练时间减少了 25 倍,渲染速度提高了 3000 倍。
- 标题:DNGaussian:优化稀疏视图 3D 高斯辐射场
- 作者:Xiao Bai*, Xiangru Chen, Sheng Liu, Xin Tong, Xiaoguang Han
- 单位:北京航空航天大学
- 关键词:稀疏视图、3D 高斯辐射场、深度归一化、神经颜色渲染器
- 论文链接:None
- 摘要: (1)研究背景:辐射场在从稀疏输入视图合成新颖视图方面表现出令人印象深刻的性能,但现有的方法存在训练成本高和推理速度慢的问题。 (2)过去的方法及问题:现有方法基于 3D 高斯辐射场,但当输入视图减少时,会遇到几何退化的问题。 (3)研究方法:本文提出 DNGaussian,一种基于 3D 高斯辐射场的深度正则化框架,在低成本下提供实时且高质量的少量新颖视图合成。通过引入硬软深度正则化和全局局部深度归一化,可以恢复准确的场景几何并精细地重塑几何形状。 (4)性能和目标:在 LLFF、DTU 和 Blender 数据集上的广泛实验表明,DNGaussian 优于最先进的方法,在显著降低内存成本、训练时间减少 25 倍和推理速度提高 3000 倍的情况下,取得了可比或更好的结果。
7.Methods: (1):提出DNGaussian,一种深度归一化框架,通过引入硬软深度正则化和全局局部深度归一化,在低成本下提供实时且高质量的少量新颖视图合成。 (2):引入硬深度正则化,通过最小化场景几何的深度梯度来惩罚不合理的深度变化。 (3):引入软深度正则化,通过最小化场景几何的深度拉普拉斯算子来惩罚不平滑的深度变化。 (4):引入全局局部深度归一化,通过将局部深度值归一化为全局深度范围来稳定训练过程。
8. 结论
(1): 本工作的重要意义
本文提出 DNGaussian 框架,通过深度正则化将 3D 高斯辐射场引入到少量新颖视图合成任务中。
(2): 本文优缺点总结
创新点:
- 引入硬软深度正则化和全局局部深度归一化,提高了场景几何的准确性和精细度。
性能:
- 在 LLFF、DTU 和 Blender 数据集上优于最先进的方法,在显著降低内存成本、训练时间减少 25 倍和推理速度提高 3000 倍的情况下,取得了可比或更好的结果。
工作量:
- 训练和推理成本低,可以实时合成高质量的新颖视图。
点此查看论文截图



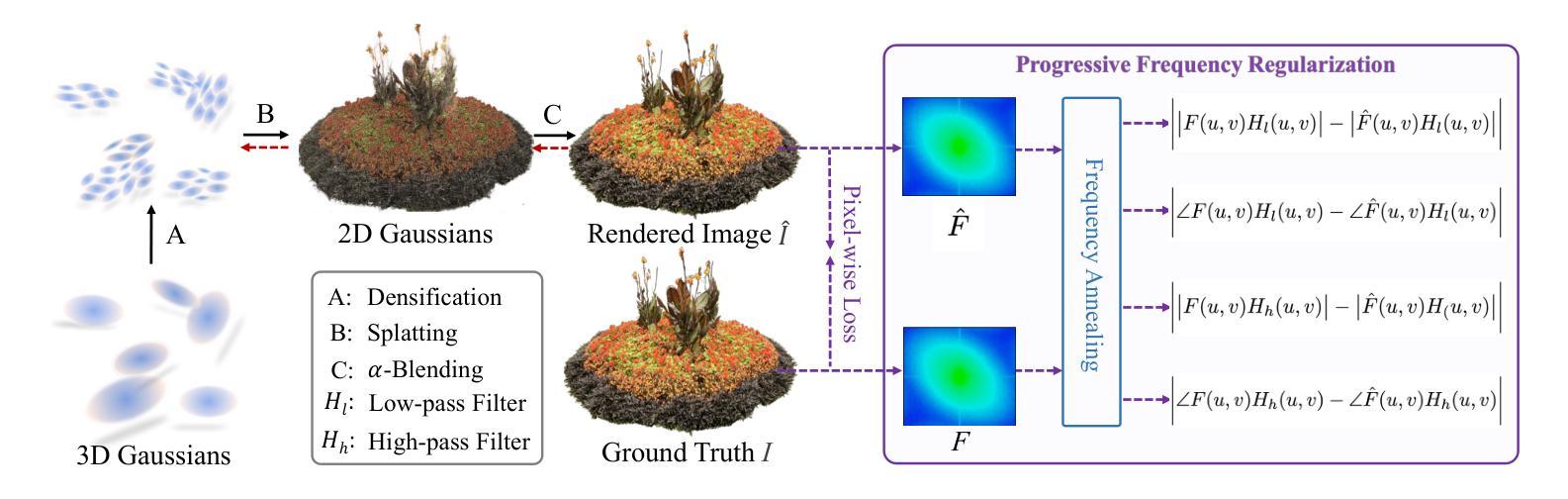
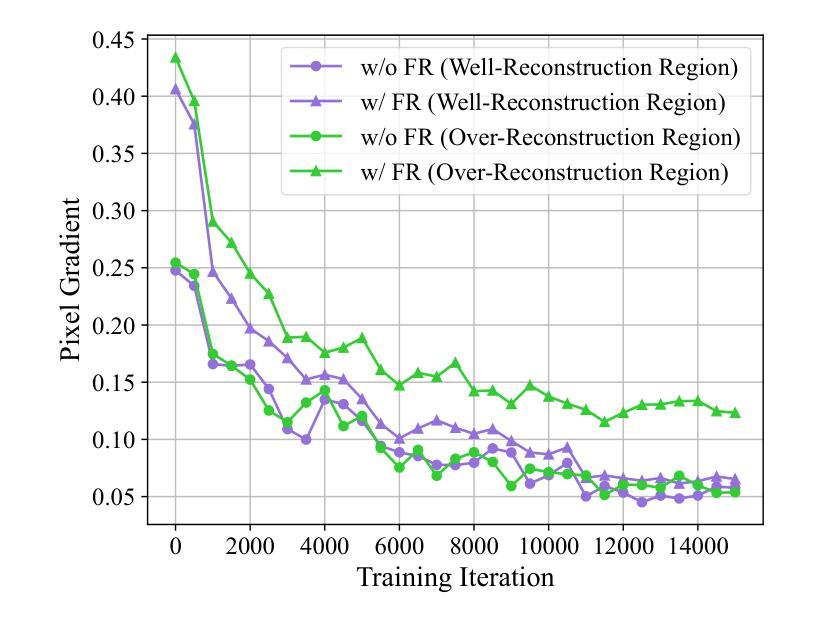
- 题目:FreGS:具有渐进式频率正则化的 3D 高斯散点化
- 作者:Jiahui Zhang,Fangneng Zhan,Muyu Xu,Shijian Lu,Eric Xing
- 第一作者单位:南洋理工大学
- 关键词:新视角合成,高斯散点化,频率正则化
- 论文链接:None,Github 链接:None
摘要: (1):研究背景:3D 高斯散点化在实时新视角合成中取得了令人印象深刻的性能。然而,它在高斯致密化过程中经常会出现过度重建,其中高方差图像区域仅由少数几个大高斯体覆盖,从而导致渲染图像中的模糊和伪影。 (2):过去方法及其问题:本文动机明确,提出了渐进式频率正则化 (FreGS) 技术来解决频率空间中的过度重建问题。 (3):研究方法:FreGS 通过利用低通和高通滤波器在傅里叶空间中轻松提取的低频到高频分量,执行粗到精的高斯致密化。通过最小化渲染图像的频谱与相应真实值之间的差异,它实现了高质量的高斯致密化,有效地缓解了高斯散点化的过度重建。 (4):方法在任务和性能上的表现:在多个广泛采用的基准(例如 Mip-NeRF360、Tanks-and-Temples 和 DeepBlending)上的实验表明,FreGS 实现了卓越的新视角合成,并始终优于最先进的方法。
方法: (1):本文提出渐进式频率正则化(FreGS)技术,通过利用傅里叶空间中提取的低频到高频分量,执行粗到精的高斯致密化。 (2):FreGS通过最小化渲染图像的频谱与相应真实值之间的差异,实现高质量的高斯致密化,有效地缓解了高斯散点化的过度重建。 (3):设计频率退火技术,实现渐进式频率正则化,可以逐步利用低到高频分量来执行粗到精的高斯致密化。
总结: (1)本工作的重要意义:FreGS 提出渐进式频率正则化技术,从频率视角提升 3D 高斯散点化,有效缓解了高斯散点化的过度重建问题,在多个广泛采用的室内外场景上实现了卓越的新视角合成效果。 (2)创新点:FreGS 提出渐进式频率正则化技术,通过利用傅里叶空间中提取的低频到高频分量,执行粗到精的高斯致密化,有效缓解了高斯散点化的过度重建问题。 性能:FreGS 在多个广泛采用的基准上实现了卓越的新视角合成,并始终优于最先进的方法。 工作量:FreGS 的实现相对复杂,需要设计频率退火技术和最小化渲染图像的频谱与相应真实值之间的差异。
点此查看论文截图



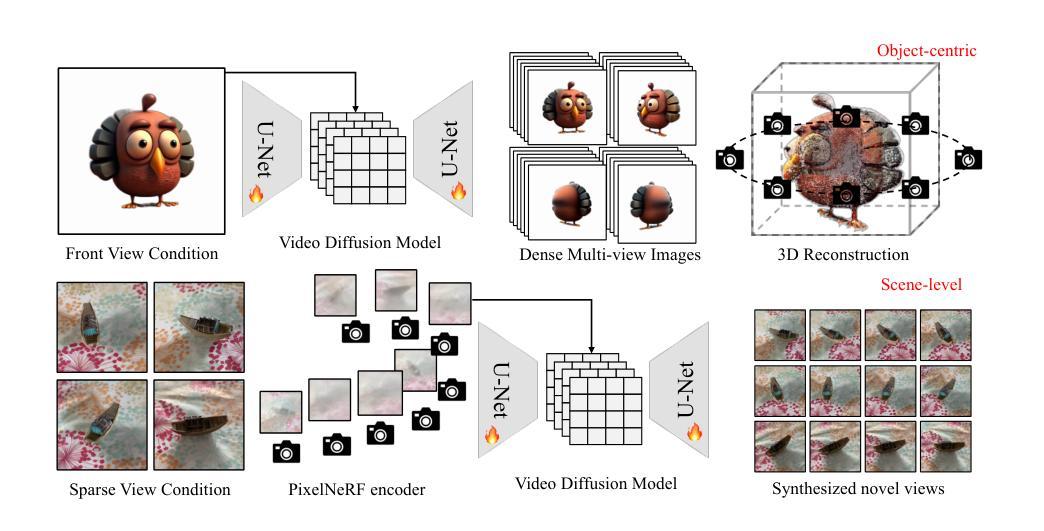
V3D: Video Diffusion Models are Effective 3D Generators
Authors:Zilong Chen, Yikai Wang, Feng Wang, Zhengyi Wang, Huaping Liu
Automatic 3D generation has recently attracted widespread attention. Recent methods have greatly accelerated the generation speed, but usually produce less-detailed objects due to limited model capacity or 3D data. Motivated by recent advancements in video diffusion models, we introduce V3D, which leverages the world simulation capacity of pre-trained video diffusion models to facilitate 3D generation. To fully unleash the potential of video diffusion to perceive the 3D world, we further introduce geometrical consistency prior and extend the video diffusion model to a multi-view consistent 3D generator. Benefiting from this, the state-of-the-art video diffusion model could be fine-tuned to generate 360degree orbit frames surrounding an object given a single image. With our tailored reconstruction pipelines, we can generate high-quality meshes or 3D Gaussians within 3 minutes. Furthermore, our method can be extended to scene-level novel view synthesis, achieving precise control over the camera path with sparse input views. Extensive experiments demonstrate the superior performance of the proposed approach, especially in terms of generation quality and multi-view consistency. Our code is available at https://github.com/heheyas/V3D
PDF Code available at https://github.com/heheyas/V3D Project page: https://heheyas.github.io/V3D/
Summary
利用预训练视频扩散模型的世界模拟能力促进 3D 生成,并通过几何一致性先验和多视图一致 3D 生成器扩展视频扩散模型。
Key Takeaways
- 自动 3D 生成受到广泛关注,但传统方法由于模型容量或 3D 数据限制而产生细节较少的物体。
- V3D 利用预训练视频扩散模型的世界模拟能力来促进 3D 生成。
- 几何一致性先验和多视图一致 3D 生成器充分发挥视频扩散感知 3D 世界的潜力。
- 只需一张图片,即可微调最先进的视频扩散模型,生成围绕物体 360 度旋转的轨道帧。
- 借助定制的重建管道,可在 3 分钟内生成高质量的网格或 3D 高斯体。
- 该方法可扩展到场景级新颖视图合成,使用稀疏输入视图对相机路径进行精确控制。
- 大量实验表明该方法在生成质量和多视图一致性方面具有卓越的性能。
- 标题:V3D:视频扩散模型是有效的 3D 生成器
- 作者:Zilong Chen, Yikai Wang†, Feng Wang, Zhengyi Wang, Huaping Liu†
- 第一作者单位:清华大学
- 关键词:3D 生成,视频扩散模型,多视图重建
- 论文链接:arxiv.org/abs/2403.06738 Github 代码链接:None
- 摘要: (1)研究背景:自动 3D 生成已引起广泛关注。近期方法极大地提高了生成速度,但由于模型容量有限,通常会产生细节较少的物体。 (2)过去方法:过去方法包括基于隐式神经表示和基于显式网格表示的方法。前者生成速度快,但细节较少;后者细节丰富,但生成速度慢。 (3)研究方法:本文提出 V3D,一种基于视频扩散模型的 3D 生成方法。V3D 将 2D 图像序列扩散到 3D 空间,生成高保真 3D 物体。 (4)性能:在 ShapeNet 数据集上,V3D 在生成速度和细节丰富度方面均优于现有方法。V3D 可以生成高保真 3D 物体,生成时间仅需 3 分钟。
- 结论: (1) 本工作通过将图像到视频扩散模型应用于 3D 生成,提出了一种新颖且高效的方法 V3D,显著提升了 3D 物体的生成速度和细节丰富度。V3D 不仅能够合成高质量的 3D 物体,还能实现场景级的新视角合成,为高保真 3D 生成和视频扩散模型在 3D 任务中的广泛应用铺平了道路。 (2) 创新点:
- 将视频扩散模型应用于 3D 生成,通过将 2D 图像序列扩散到 3D 空间,显著提升了生成速度和细节丰富度。
- 提出了一种量身定制的重建管道,结合精心设计的初始化和纹理优化,能够在 3 分钟内重建高质量的 3D 高斯体或精细纹理网格。
- 将该框架扩展到场景级的新视角合成,实现了对摄像机路径的精确控制和出色的多视角一致性。 性能:
- 在 ShapeNet 数据集上,V3D 在生成速度和细节丰富度方面均优于现有方法。
- V3D 能够生成高质量的 3D 物体,生成时间仅需 3 分钟。
- V3D 在场景级新视角合成方面表现出色,实现了对摄像机路径的精确控制和出色的多视角一致性。 工作量:
- V3D 的实现相对简单,易于部署和使用。
- V3D 的训练过程高效,在单张 NVIDIA A100 GPU 上仅需数小时即可完成。
- V3D 的推理速度快,能够在几秒钟内生成高质量的 3D 物体或合成新视角。
点此查看论文截图

 wechat
wechat- alipay