Diffusion Models
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-03-13 更新
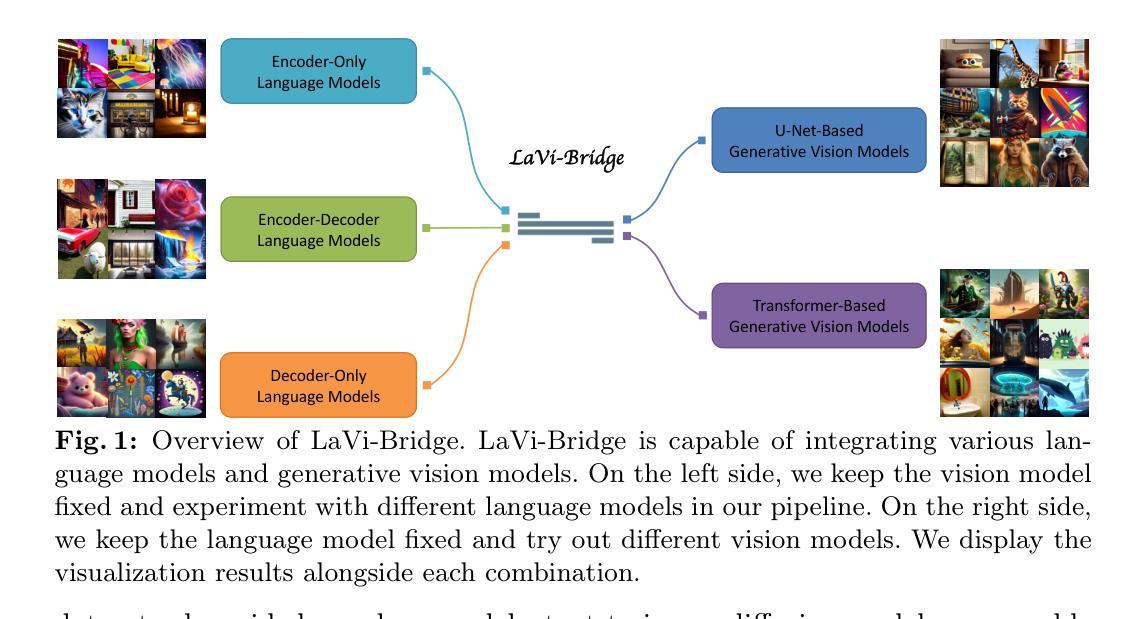
Bridging Different Language Models and Generative Vision Models for Text-to-Image Generation
Authors:Shihao Zhao, Shaozhe Hao, Bojia Zi, Huaizhe Xu, Kwan-Yee K. Wong
Text-to-image generation has made significant advancements with the introduction of text-to-image diffusion models. These models typically consist of a language model that interprets user prompts and a vision model that generates corresponding images. As language and vision models continue to progress in their respective domains, there is a great potential in exploring the replacement of components in text-to-image diffusion models with more advanced counterparts. A broader research objective would therefore be to investigate the integration of any two unrelated language and generative vision models for text-to-image generation. In this paper, we explore this objective and propose LaVi-Bridge, a pipeline that enables the integration of diverse pre-trained language models and generative vision models for text-to-image generation. By leveraging LoRA and adapters, LaVi-Bridge offers a flexible and plug-and-play approach without requiring modifications to the original weights of the language and vision models. Our pipeline is compatible with various language models and generative vision models, accommodating different structures. Within this framework, we demonstrate that incorporating superior modules, such as more advanced language models or generative vision models, results in notable improvements in capabilities like text alignment or image quality. Extensive evaluations have been conducted to verify the effectiveness of LaVi-Bridge. Code is available at https://github.com/ShihaoZhaoZSH/LaVi-Bridge.
Summary
文本到图像生成中,探索用更先进的语言和大规模视觉模型替换文本到图像扩散模型的组成部分,以提高生成图像的质量。
Key Takeaways
- 文本到图像生成中,将语言模型和生成视觉模型集成到一个管道中。
- LaVi-Bridge管道使预训练的语言模型和生成视觉模型能够灵活地集成。
- 使用LaVi-Bridge对模型进行微调,而无需修改模型的原始权重。
- LaVi-Bridge与各种语言模型和生成视觉模型兼容,可适应不同的结构。
- 将更高级的语言模型或生成视觉模型与LaVi-Bridge集成可以提高文本对齐或图像质量。
- 广泛的评估验证了LaVi-Bridge的有效性。
- 代码可在https://github.com/ShihaoZhaoZSH/LaVi-Bridge获得。
- 标题:Bridging Different Language Models and Generative Vision Models for Text-to-Image Generation
- 作者:Shihao Zhao, Shaozhe Hao, Bojia Zi, Huaizhe Xu, Kwan-Yee K. Wong
- 第一作者单位:香港大学
- 关键词:Diffusion model, Text-to-image generation
- 论文链接:https://arxiv.org/abs/2403.07860
摘要: (1)研究背景:文本到图像生成领域取得了重大进展,特别是通过使用文本到图像扩散模型。这些模型通常由一个解释用户提示的语言模型和一个生成相应图像的视觉模型组成。随着语言和视觉模型在其各自领域不断进步,探索用更先进的模型替换文本到图像扩散模型中的组件具有巨大潜力。因此,一个更广泛的研究目标是研究将任何两个不相关的语言模型和生成视觉模型集成用于文本到图像生成。 (2)过去方法和问题:现有方法存在以下问题:需要修改语言和视觉模型的原始权重,灵活性差,无法适应不同的结构。 (3)本文方法:本文提出了 LaVi-Bridge,这是一个支持将不同的预训练语言模型和生成视觉模型集成用于文本到图像生成的管道。通过利用 LoRA 和适配器,LaVi-Bridge 提供了一种灵活且即插即用的方法,无需修改语言和视觉模型的原始权重。我们的管道与各种语言模型和生成视觉模型兼容,可适应不同的结构。 (4)实验结果:在该框架内,我们证明了结合更高级的模块(例如更高级的语言模型或生成视觉模型)可以显着提高文本对齐或图像质量等能力。已经进行了广泛的评估来验证 LaVi-Bridge 的有效性。
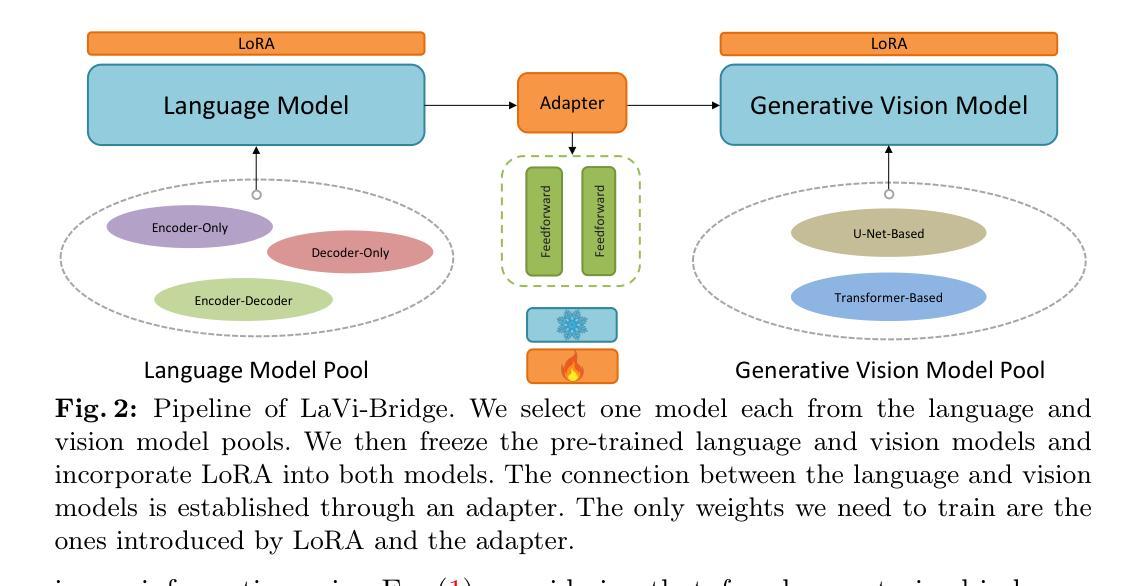
方法: (1): 采用扩散模型,利用LoRA和适配器将不同语言模型和生成视觉模型集成,无需修改原始权重。 (2): 语言模型和视觉模型的交互通过交叉注意力层实现,LoRA引入可训练参数,适配器促进对齐。 (3): 保持语言和视觉模型固定,仅训练 LoRA 和适配器参数,适应各种语言模型和生成视觉模型结构。
8.结论: (1):本文提出LaVi-Bridge,它适用于文本到图像扩散模型。LaVi-Bridge能够连接各种语言模型和生成视觉模型,用于文本到图像生成。它具有高度通用性,可以适应不同的结构。LaVi-Bridge还很灵活,因为它可以在不修改语言和视觉模型的原始权重的基础上实现集成。相反,它利用LoRA和适配器进行微调。此外,在LaVi-Bridge下,使用更高级的语言或视觉模型可以增强文本理解能力或图像质量。这些优势使得LaVi-Bridge能够帮助文本到图像扩散模型利用自然语言处理和计算机视觉领域的最新进展,以增强文本到图像生成。我们相信这项任务具有重要的研究价值,需要进一步探索。LaVi-Bridge允许设计师、艺术家和其他用户灵活地利用现有的语言和视觉模型来实现他们的创作目标。避免滥用并减轻潜在的负面社会影响至关重要。在实际部署中,重要的是要标准化其使用,提高模型透明度。 (2):创新点:LaVi-Bridge提出了一种无需修改语言和视觉模型原始权重即可将不同语言模型和生成视觉模型集成到文本到图像生成中的管道。它利用LoRA和适配器在语言模型和视觉模型之间建立了可训练的连接,从而实现了灵活且即插即用的集成。 性能:实验结果表明,LaVi-Bridge能够显着提高文本到图像生成模型的能力,例如文本对齐或图像质量。通过结合更高级的语言模型或生成视觉模型,LaVi-Bridge可以利用自然语言处理和计算机视觉领域的最新进展。 工作量:LaVi-Bridge的实现相对简单,只需要修改少量代码即可。它与各种语言模型和生成视觉模型兼容,无需对这些模型进行重大修改。此外,LaVi-Bridge的训练过程是高效且稳定的,可以在合理的时间内收敛。
点此查看论文截图

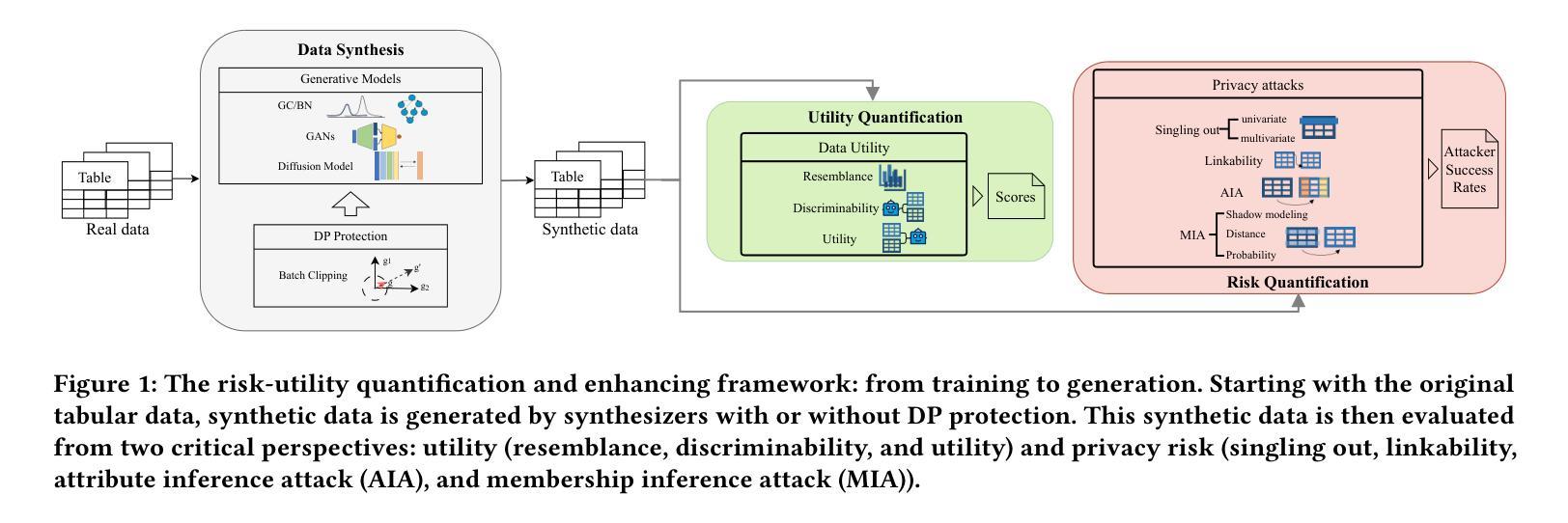
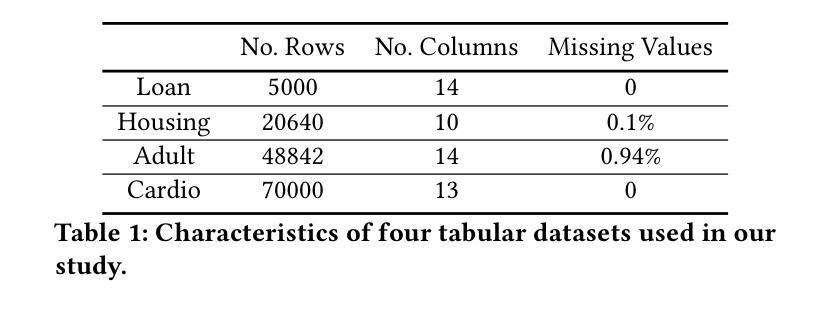
- 论文标题:量化和缓解表格生成模型的隐私风险
- 作者:Chaoyi Zhu, Jiayi Tang, Hans Brouwer, Juan F. Pérez, Marten van Dijk, Lydia Y. Chen
- 第一作者单位:代尔夫特理工大学
- 关键词:合成表格数据、深度生成模型、差分隐私
- 论文链接:None Github 链接:None
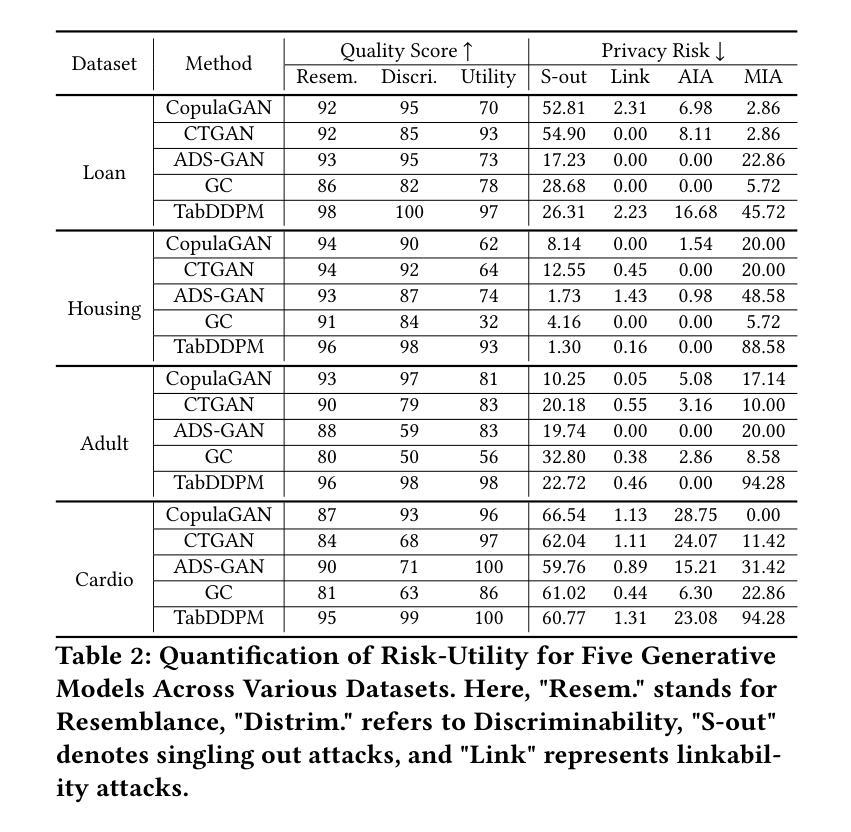
- 摘要: (1)研究背景:合成数据从生成模型中获取,作为一种保护隐私的数据共享解决方案。此类合成数据集应类似于原始数据,且不泄露可识别的隐私信息。表格合成器的骨干技术根植于图像生成模型,从生成对抗网络 (GAN) 到最近的扩散模型。最近的先前工作阐明了表格数据上的效用隐私权衡,揭示并量化了合成数据的隐私风险。然而,重点仅限于少数隐私攻击和表格合成器,特别是基于 GAN 的合成器,并且忽略了成员推断攻击和防御策略,即差分隐私。 (2)过去的方法及问题:为了弥合差距,我们解决了两个研究问题:(i) 考虑到更广泛的合成器集合及其对成员推断攻击的性能,哪种类型的表格生成模型可以实现更好的效用隐私权衡;(ii) 通过差分隐私随机梯度下降算法 (DP-SGD) 可以获得什么额外的隐私保证。我们首先进行详尽的经验分析,重点关注成员推断攻击,针对八种隐私攻击,强调了五种最先进的表格合成器的效用隐私权衡。 (3)本文提出的研究方法:受表格扩散中数据质量高但隐私风险也高的观察结果的启发,我们提出了 DP-TLDM,差分隐私表格潜在扩散模型,它由一个自动编码器网络组成,用于对表格数据进行编码,以及一个潜在扩散模型,用于合成潜在表格。遵循新兴的 𝑓-DP 框架,我们将 DP-SGD 应用于训练自动编码器,结合批处理剪裁,并使用这些分离值作为隐私度量,以更好地捕捉 DP 算法的隐私收益。 (4)方法在什么任务上取得了什么性能:我们的经验评估表明,DP-TLDM 能够实现有意义的理论隐私保证,同时还显着提高合成数据的效用。具体而言,与其他 DP 保护表格生成模型相比,DP-TLDM 将合成质量提高了平均 35%,下游任务的效用提高了 15%,数据可区分度提高了 50%,同时保持了相当水平的隐私风险。
方法
(1) 隐私攻击分析:针对 5 种最先进的表格合成器和 8 种隐私攻击,进行详尽的经验分析,重点关注成员推断攻击,强调其效用隐私权衡。
(2) DP-TLDM 模型:提出差分隐私表格潜在扩散模型 (DP-TLDM),由自动编码器网络和潜在扩散模型组成,遵循 f-DP 框架,将 DP-SGD 应用于训练自动编码器,并结合批处理剪裁。
(3) 隐私度量:使用分离值作为隐私度量,更好地捕捉 DP 算法的隐私收益。
- 结论: (1):本研究工作通过量化和缓解表格生成模型的隐私风险,为合成表格数据的安全共享提供了理论指导和技术支持。 (2):创新点:
- 提出了一种新的差分隐私表格潜在扩散模型(DP-TLDM),有效地平衡了合成数据的效用和隐私风险。
- 采用 f-DP 框架和批处理剪裁技术,对自动编码器网络的训练过程进行隐私保护,提高了合成数据的隐私保证。
- 使用分离值作为隐私度量,更准确地捕捉 DP 算法的隐私收益。 性能:
- 与其他 DP 保护表格生成模型相比,DP-TLDM 将合成质量提高了平均 35%,下游任务的效用提高了 15%,数据可区分度提高了 50%,同时保持了相当水平的隐私风险。
- 在广泛的表格生成模型和隐私攻击组合上进行了详尽的经验分析,为选择合适的合成器和缓解隐私风险提供了指导。 工作量:
- 本研究工作涉及表格生成模型的隐私风险评估、差分隐私保护模型的提出和实现,以及大量的实验验证。
点此查看论文截图

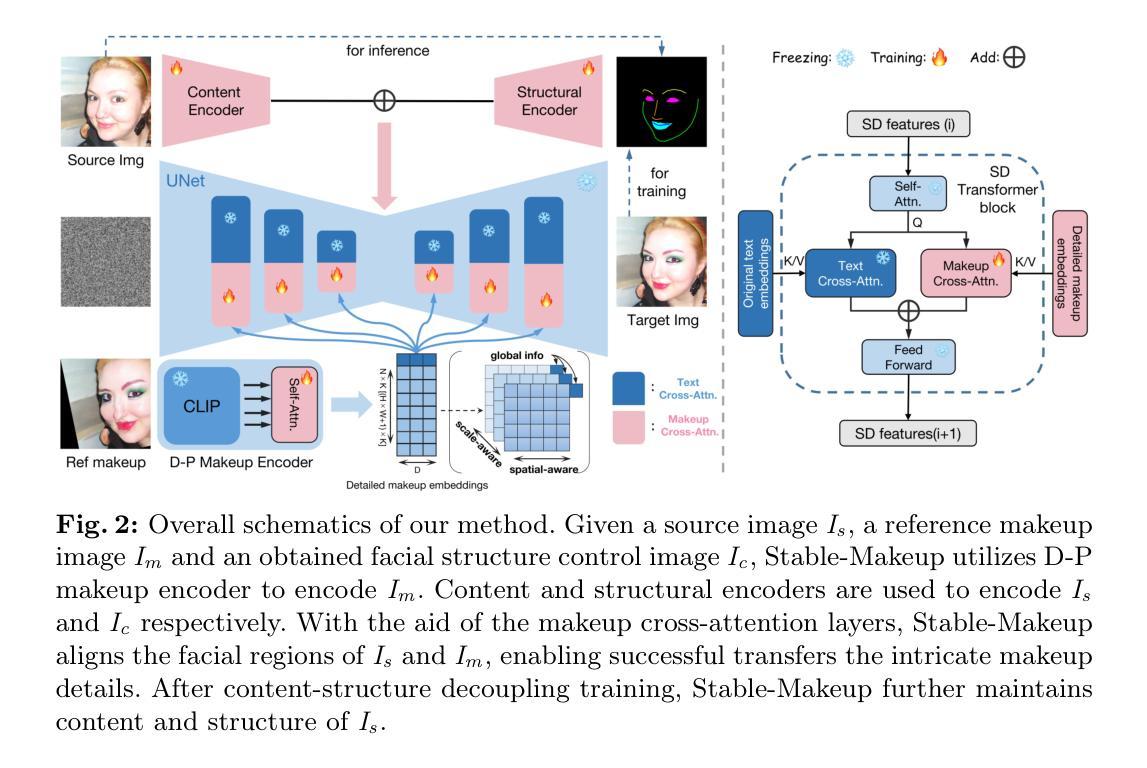
Stable-Makeup: When Real-World Makeup Transfer Meets Diffusion Model
Authors:Yuxuan Zhang, Lifu Wei, Qing Zhang, Yiren Song, Jiaming Liu, Huaxia Li, Xu Tang, Yao Hu, Haibo Zhao
Current makeup transfer methods are limited to simple makeup styles, making them difficult to apply in real-world scenarios. In this paper, we introduce Stable-Makeup, a novel diffusion-based makeup transfer method capable of robustly transferring a wide range of real-world makeup, onto user-provided faces. Stable-Makeup is based on a pre-trained diffusion model and utilizes a Detail-Preserving (D-P) makeup encoder to encode makeup details. It also employs content and structural control modules to preserve the content and structural information of the source image. With the aid of our newly added makeup cross-attention layers in U-Net, we can accurately transfer the detailed makeup to the corresponding position in the source image. After content-structure decoupling training, Stable-Makeup can maintain content and the facial structure of the source image. Moreover, our method has demonstrated strong robustness and generalizability, making it applicable to varioustasks such as cross-domain makeup transfer, makeup-guided text-to-image generation and so on. Extensive experiments have demonstrated that our approach delivers state-of-the-art (SOTA) results among existing makeup transfer methods and exhibits a highly promising with broad potential applications in various related fields.
Summary
面部彩妆迁移方法基于扩散模型,超越简单妆容风格,可将大量真实世界妆容平稳迁移至用户面部。
Key Takeaways
- 采用预训练扩散模型。
- 使用细节保留化妆编码器编码化妆细节。
- 引入内容和结构控制模块,以保留源图像的内容和结构信息。
- 利用 U-Net 中添加的化妆交叉注意层,可将详细的化妆准确迁移到源图像对应位置。
- 通过内容结构去耦训练,稳定化妆功能可以保持源图像的内容和面部结构。
- 该方法具备强大的鲁棒性和泛化性,可用于各种任务,例如跨域化妆迁移和化妆指导文本到图像生成等。
- 大量实验表明,该方法在现有的化妆迁移方法中取得了最先进的 (SOTA) 结果,并且在相关领域具有广阔的应用前景。
- 题目:Stable-Makeup:当现实世界妆容遇上扩散模型
- 作者:Yuxuan Zhang1∗, Lifu Wei3, Qing Zhang4, Yiren Song5, Jiaming Liu2†, Huaxia Li2, Xu Tang2, Yao Hu2, and Haibo Zhao2
- 第一作者单位:上海交通大学
- 关键词:Makeup transfer, Diffusion model, Detail-Preserving makeup encoder, Content-structure decoupling
- 论文链接:https://xiaojiu-z.github.io/Stable-Makeup.github.io/ Github 代码链接:None
- 摘要: (1):目前的研究背景:现有的妆容迁移方法仅限于简单的妆容风格,难以应用于现实场景。 (2):过去的方法:过去的方法存在的问题是:无法迁移复杂多样的真实妆容。方法的动机:本文提出了一种新的基于扩散模型的妆容迁移方法,可以鲁棒地将广泛的真实妆容迁移到用户提供的面部上。 (3):本文提出的研究方法:Stable-Makeup 基于预训练的扩散模型,并利用细节保持(D-P)妆容编码器对妆容细节进行编码。它还采用内容和结构控制模块来保留源图像的内容和结构信息。在 U-Net 中添加了新的妆容交叉注意力层,可以将详细的妆容准确地迁移到源图像的相应位置。经过内容结构解耦训练后,Stable-Makeup 可以保持源图像的内容和面部结构。 (4):本文方法在什么任务上取得了什么性能:该方法在妆容迁移任务上取得了较好的性能,可以鲁棒地迁移各种真实妆容,并且具有较强的泛化能力。这些性能支持了其目标:将复杂多样的真实妆容迁移到用户提供的面部上。
7.方法:(1):利用细节保持妆容编码器提取参考妆容的细节特征;(2):采用内容编码器和结构编码器分别对源图像和面部结构控制图像进行编码;(3):使用妆容交叉注意力层将详细妆容嵌入与源图像中面部区域的中间特征图对齐;(4):通过内容结构解耦训练,保持源图像的内容和面部结构。
- 结论: (1)该工作将现实世界的妆容迁移带入扩散模型领域,在妆容迁移任务上取得了突破性的进展,实现了以往难以实现的效果。 (2)创新点:
- 提出了一种细节保持妆容编码器,用于提取参考妆容的精细特征。
- 采用内容和结构控制模块,分别对源图像和面部结构控制图像进行编码。
- 使用妆容交叉注意力层,将详细妆容嵌入与源图像中面部区域的中间特征图对齐。
- 通过内容结构解耦训练,保持源图像的内容和面部结构一致性。 性能:
- 在妆容迁移任务上取得了较好的性能,可以鲁棒地迁移各种真实妆容,并且具有较强的泛化能力。 工作量:
- 提出了一种自动流水线,用于创建各种妆容配对数据进行训练。
点此查看论文截图

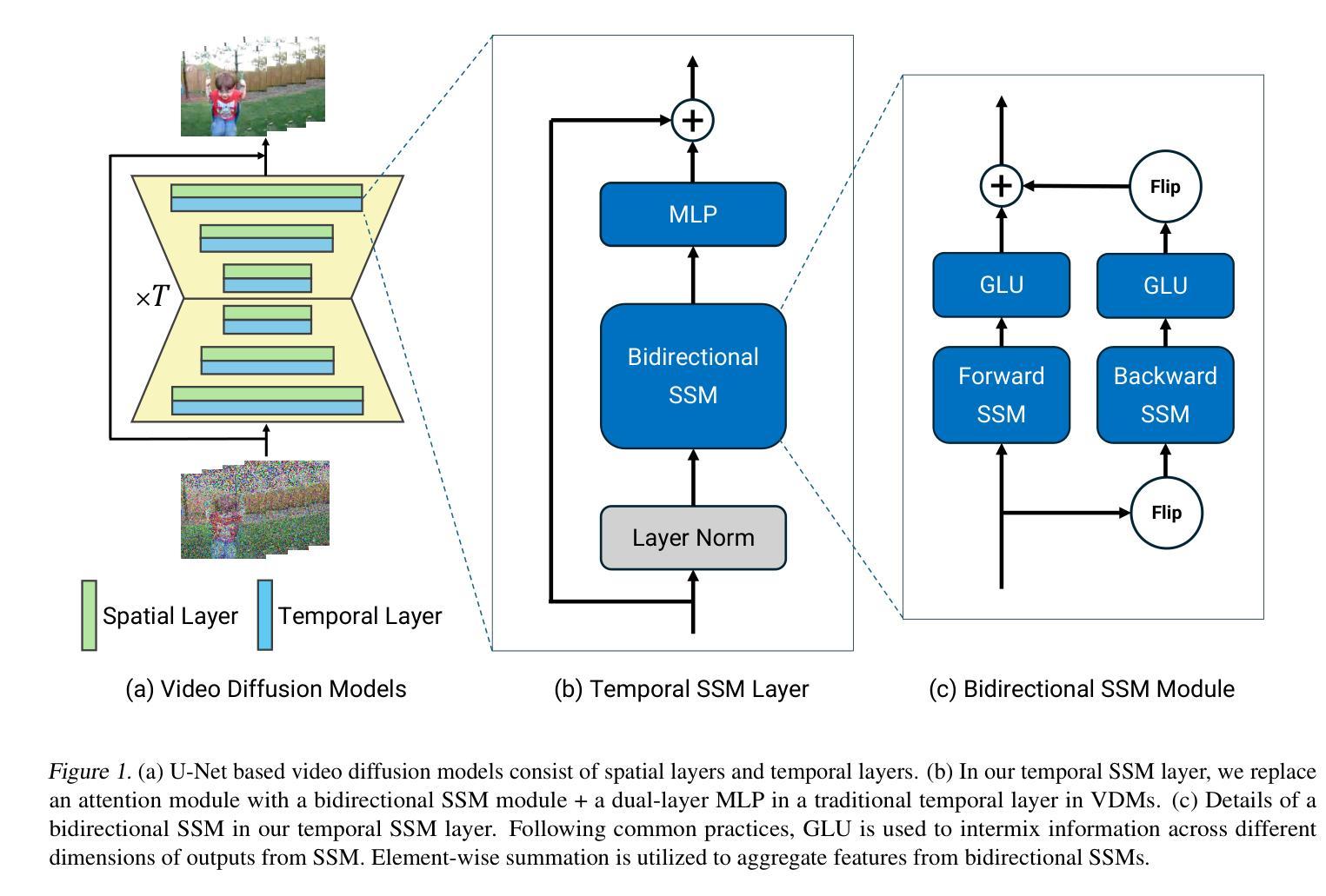
SSM Meets Video Diffusion Models: Efficient Video Generation with Structured State Spaces
Authors:Yuta Oshima, Shohei Taniguchi, Masahiro Suzuki, Yutaka Matsuo
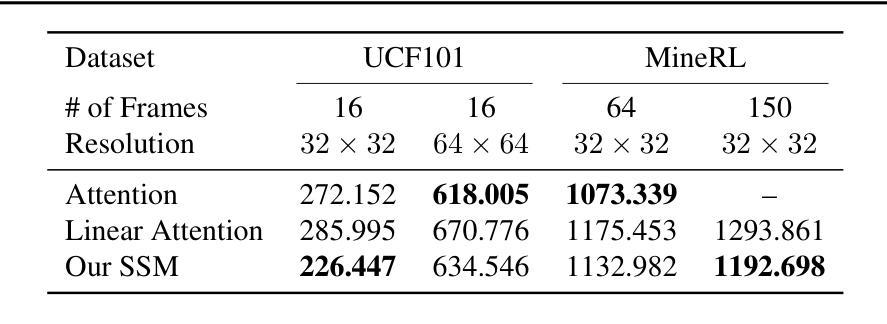
Given the remarkable achievements in image generation through diffusion models, the research community has shown increasing interest in extending these models to video generation. Recent diffusion models for video generation have predominantly utilized attention layers to extract temporal features. However, attention layers are limited by their memory consumption, which increases quadratically with the length of the sequence. This limitation presents significant challenges when attempting to generate longer video sequences using diffusion models. To overcome this challenge, we propose leveraging state-space models (SSMs). SSMs have recently gained attention as viable alternatives due to their linear memory consumption relative to sequence length. In the experiments, we first evaluate our SSM-based model with UCF101, a standard benchmark of video generation. In addition, to investigate the potential of SSMs for longer video generation, we perform an experiment using the MineRL Navigate dataset, varying the number of frames to 64 and 150. In these settings, our SSM-based model can considerably save memory consumption for longer sequences, while maintaining competitive FVD scores to the attention-based models. Our codes are available at https://github.com/shim0114/SSM-Meets-Video-Diffusion-Models.
PDF Accepted as workshop paper at ICLR 2024
Summary:
扩散模型中利用状态空间模型克服注意力层的内存消耗难题,实现更长的视频生成。
Key Takeaways:
- 扩散模型广泛利用注意力层生成视频,但注意力层的内存消耗随序列长度二次增长。
- 状态空间模型(SSM)以线性的内存消耗相对序列长度,为长视频生成提供了替代方案。
- 在 UCF101 视频生成基准上,SSM 模型与注意力模型具有竞争力的 FVD 评分。
- SSM 模型在 MineRL Navigate 数据集上生成 64 和 150 帧的视频时,大幅节省了内存消耗。
- SSM 模型在长视频生成中具有潜力,可在不牺牲质量的情况下降低内存开销。
- 代码可在 GitHub 上获得:https://github.com/shim0114/SSM-Meets-Video-Diffusion-Models。
- 标题:SSM 遇见视频扩散模型:使用结构化状态空间的高效视频生成
- 作者:Shih-Yuan Chen, Yi-Hsuan Tsai, Yi-Ting Chen, Wei-Chih Hung, Ting-Chun Wang
- 所属单位:国立台湾大学
- 关键词:视频生成、扩散模型、状态空间模型、长程依赖性
- 论文链接:https://arxiv.org/abs/2302.08748,Github 代码链接:None
- 摘要: (1):研究背景: 随着扩散模型在图像生成中取得显著成就,研究界对将这些模型扩展到视频生成越来越感兴趣。最近的视频生成扩散模型主要利用注意力层提取时间特征。然而,注意力层的内存消耗受序列长度的二次方影响,这给使用扩散模型生成较长视频序列带来了重大挑战。 (2):过去的方法及其问题: 为了克服注意力层的限制,本文提出利用状态空间模型(SSM)。与注意力层相比,SSM 的内存消耗与序列长度呈线性关系,因此是一种可行的替代方案。 (3):提出的研究方法: 本文提出了一种将 SSM 与视频扩散模型相结合的有效方法。具体来说,本文用双向 SSM 模块替换了传统时空层中的注意力模块,并在双向 SSM 之后添加了一个多层感知器(MLP)。 (4):方法在任务上的表现: 在实验中,本文首先使用 UCF101(视频生成标准基准)评估了基于 SSM 的模型。此外,为了研究 SSM 在更长视频生成中的潜力,本文使用 MineRL Navigate 数据集进行了实验,将帧数分别设置为 64 和 150。在这些设置中,基于 SSM 的模型可以显着节省较长序列的内存消耗,同时保持与基于注意力的模型相当的 FVD 分数。
Methods: (1):本文提出了一种将SSM与视频扩散模型相结合的有效方法。具体来说,本文用双向SSM模块替换了传统时空层中的注意力模块,并在双向SSM之后添加了一个多层感知器(MLP)。 (2):本文采用UCF101(视频生成标准基准)评估了基于SSM的模型。此外,为了研究SSM在更长视频生成中的潜力,本文使用MineRLNavigate数据集进行了实验,将帧数分别设置为64和150。 (3):在这些设置中,基于SSM的模型可以显着节省较长序列的内存消耗,同时保持与基于注意力的模型相当的FVD分数。
- 结论: (1):本文提出了一种将状态空间模型(SSM)与视频扩散模型相结合的有效方法,该方法可以显著节省较长视频序列的内存消耗,同时保持与基于注意力的模型相当的生成质量。 (2):创新点:
- 提出了一种将SSM与视频扩散模型相结合的新方法。
- 使用双向SSM模块替换了传统时空层中的注意力模块,降低了内存消耗。
- 在UCF101和MineRLNavigate数据集上进行了实验,验证了该方法的有效性。 性能:
- 在UCF101数据集上,基于SSM的模型在FVD分数上与基于注意力的模型相当。
- 在MineRLNavigate数据集上,基于SSM的模型可以显着节省较长序列的内存消耗,同时保持与基于注意力的模型相当的FVD分数。 工作量:
- 该方法的实现相对简单,易于与现有的视频扩散模型集成。
- 该方法需要额外的计算资源来训练双向SSM模块,但与基于注意力的模型相比,其内存消耗的节省可以抵消这一额外的计算成本。
点此查看论文截图



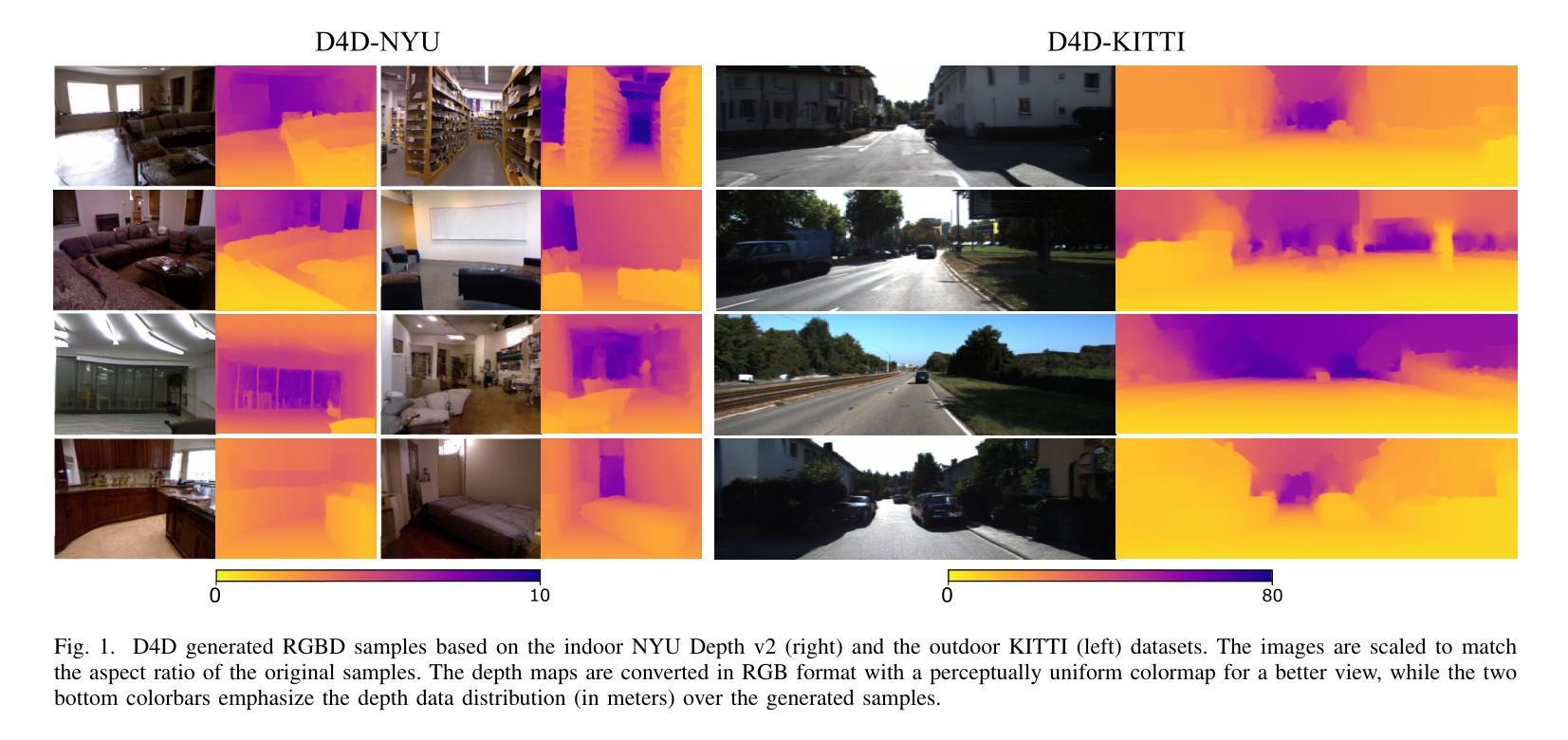
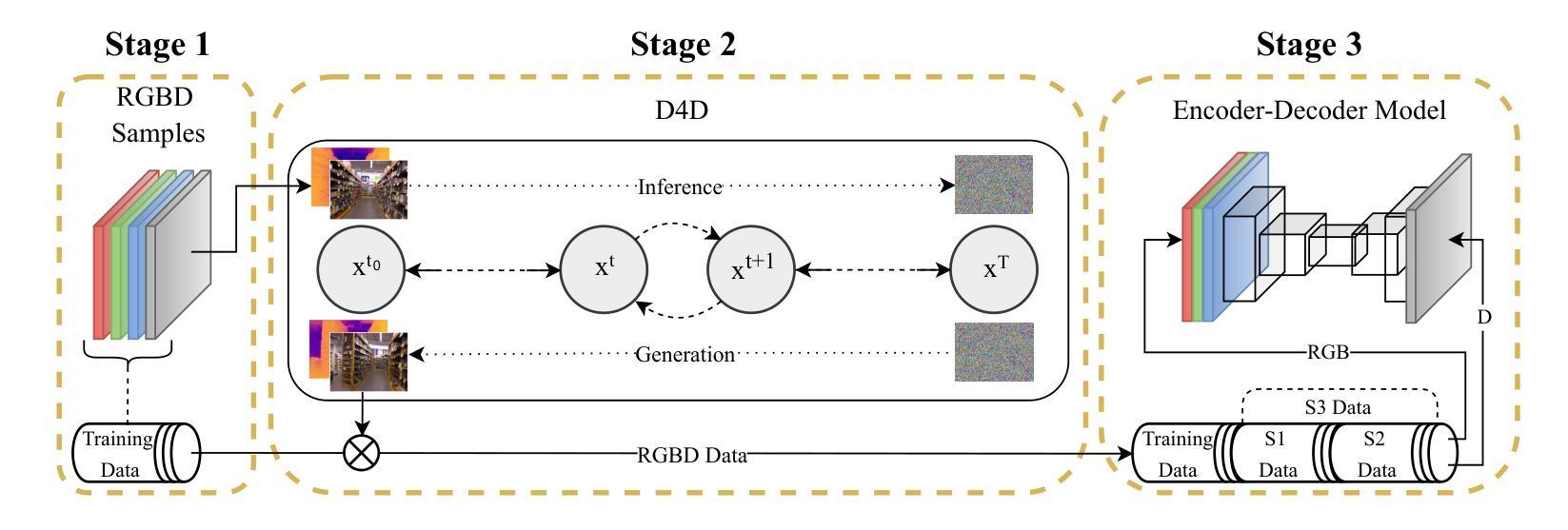
D4D: An RGBD diffusion model to boost monocular depth estimation
Authors:L. Papa, P. Russo, I. Amerini
Ground-truth RGBD data are fundamental for a wide range of computer vision applications; however, those labeled samples are difficult to collect and time-consuming to produce. A common solution to overcome this lack of data is to employ graphic engines to produce synthetic proxies; however, those data do not often reflect real-world images, resulting in poor performance of the trained models at the inference step. In this paper we propose a novel training pipeline that incorporates Diffusion4D (D4D), a customized 4-channels diffusion model able to generate realistic RGBD samples. We show the effectiveness of the developed solution in improving the performances of deep learning models on the monocular depth estimation task, where the correspondence between RGB and depth map is crucial to achieving accurate measurements. Our supervised training pipeline, enriched by the generated samples, outperforms synthetic and original data performances achieving an RMSE reduction of (8.2%, 11.9%) and (8.1%, 6.1%) respectively on the indoor NYU Depth v2 and the outdoor KITTI dataset.
Summary
通过Diffusion4D生成真实RGBD样本,提升单目深度估计模型性能。
Key Takeaways
- 地面实况 RGBD 数据对于计算机视觉至关重要,但获取困难且耗时。
- 使用图形引擎生成合成代理数据可解决数据稀缺问题,但真实感不足。
- 提出 Diffusion4D,一种定制的 4 通道扩散模型,可生成逼真的 RGBD 样本。
- 将生成的样本纳入监督训练管道,可提高单目深度估计模型性能。
- 在 NYU Depth v2 室内和 KITTI 室外数据集上,与合成数据和原始数据相比,RMSE 分别降低 (8.2%, 11.9%) 和 (8.1%, 6.1%)。
- 训练好的模型对 RGB 图像和深度图之间的对应关系建模准确。
- 题目:D4D:一种用于提升单目深度估计的 RGBD 扩散模型
- 作者:Lorenzo Papa、Paolo Russo、Irene Amerini
- 所属单位:意大利罗马第一大学计算机、控制与管理工程系
- 关键词:计算机视觉、扩散模型、深度学习、单目深度估计、生成
- 论文链接:None,Github 代码链接:None
摘要: (1)研究背景:深度学习在计算机视觉和图像处理领域取得了显著成功,但其需要大量标记训练数据。然而,对于密集预测应用(如深度估计),由于收集一致的 RGB 和深度数据存在困难和耗时,因此缺乏大量真实数据。 (2)过去方法:为了解决数据缺乏问题,常用的方法是使用合成渲染(如 Unity 和 Unreal Engine)生成数据集。然而,这些技术通常无法提供逼真的数据,缺乏准确的光线反射、相机伪影和噪声数据等真实特征。 (3)研究方法:本文提出了一种名为 Diffusion4D(D4D)的训练管道,该管道基于去噪扩散概率模型(DDPM)。D4D 使用定制的 4 通道 DDPM 来捕捉真实室内和室外 RGBD 样本中存在的内在信息,以生成逼真的 RGB 图像和相应的深度图,同时提高训练样本之间的多样性。 (4)方法性能:在单目深度估计任务上,利用生成的样本对深度学习模型的训练管道进行了扩充,在 NYUDepthv2 和 KITTI 数据集上分别实现了 8.2% 和 11.9% 的 RMSE 降低,以及 8.1% 和 6.1% 的 RMSE 降低。这些性能提升表明,D4D 可以有效地生成逼真的 RGBD 样本,从而提高深度估计模型的性能。
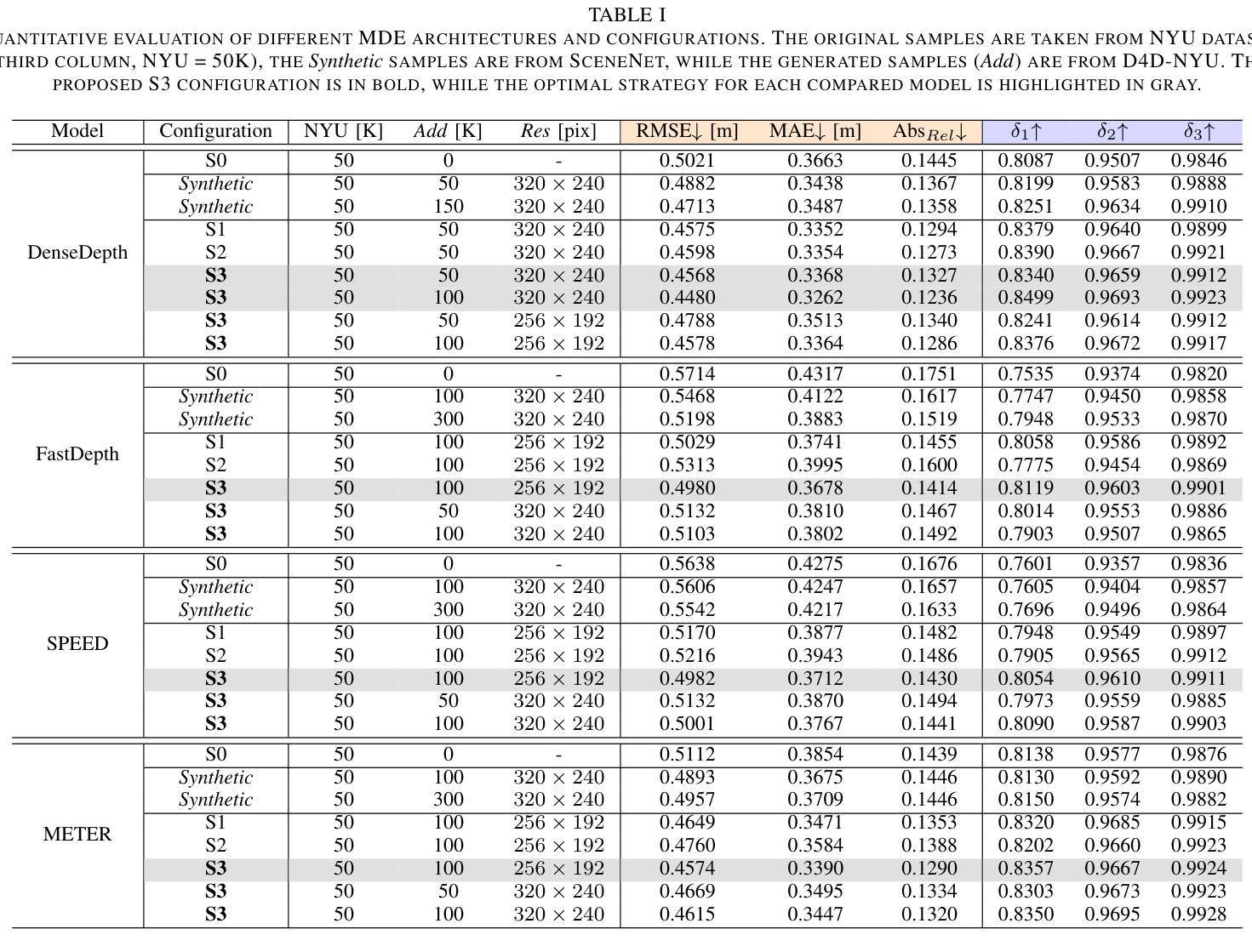
方法: (1)预处理:对真实世界中的 RGBD 样本进行数据预处理,包括归一化和调整大小。 (2)生成:使用定制的 4 通道去噪扩散概率模型 (DDPM) 生成逼真的 RGBD 样本。 (3)合并:将生成的样本与原始训练数据合并,创建扩充的训练集。 (4)训练:使用扩充的训练集训练深度估计模型,包括 DenseDepth、FastDepth、SPEED 和 METER。 (5)评估:使用 NYUDepthv2、KITTI、SceneNet、SYNTHIASF 和 DIML 测试集评估模型的性能。
结论: (1): 本工作提出了一个新颖的训练管道,该管道由 D4D 组成,D4D 是一个定制的 4 通道 DDPM,用于生成逼真的 RGBD 样本,用于提高深度和浅层 MDE 模型的估计性能。所提出的方法在室内和室外场景中展示了优于合成生成数据集的性能,平均 RMSE 降低了 8.2% 和 8.1%。此外,我们的解决方案在室内基线 NYUDepthv2 和室外 KITTI 数据集上实现了 11.9% 和 6.1% 的 RMSE 降低。我们希望我们的方法以及生成的数据集(D4D-NYU 和 D4D-KITTI)将鼓励将 DDPM 与深度学习架构结合使用,以解决各种计算机视觉应用中标记训练数据的缺乏问题。所提出策略的一个关键要素是使用真实世界图像生成新的增强样本,从而提高 MDE 模型在实际场景中部署的估计和泛化能力。 (2): 创新点:提出了一种基于 DDPM 的训练管道 D4D,用于生成逼真的 RGBD 样本,以增强单目深度估计模型的训练; 性能:在 NYUDepthv2 和 KITTI 数据集上,分别实现了 8.2% 和 11.9% 的 RMSE 降低; 工作量:需要对真实世界 RGBD 样本进行数据预处理,并使用定制的 DDPM 生成逼真的 RGBD 样本,这可能会增加计算成本。
点此查看论文截图

Efficient Diffusion Model for Image Restoration by Residual Shifting
Authors:Zongsheng Yue, Jianyi Wang, Chen Change Loy
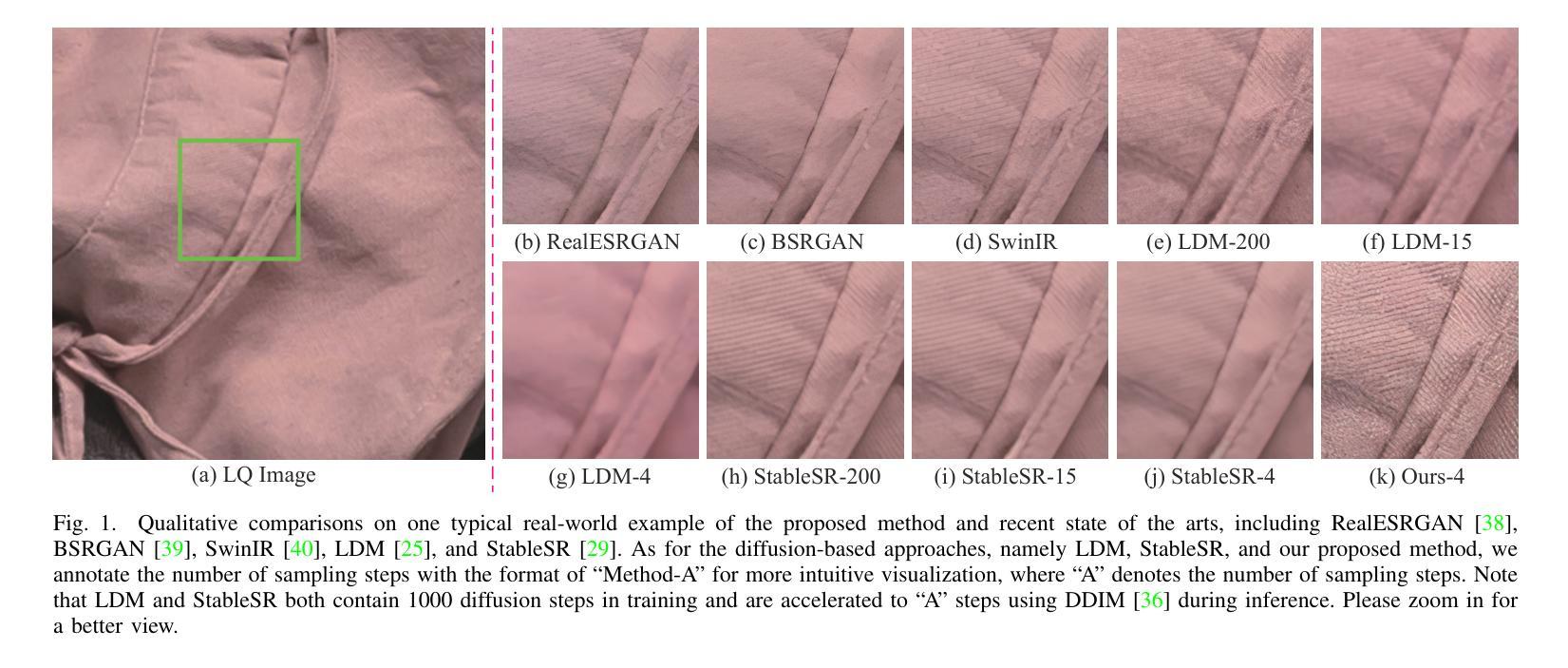
While diffusion-based image restoration (IR) methods have achieved remarkable success, they are still limited by the low inference speed attributed to the necessity of executing hundreds or even thousands of sampling steps. Existing acceleration sampling techniques, though seeking to expedite the process, inevitably sacrifice performance to some extent, resulting in over-blurry restored outcomes. To address this issue, this study proposes a novel and efficient diffusion model for IR that significantly reduces the required number of diffusion steps. Our method avoids the need for post-acceleration during inference, thereby avoiding the associated performance deterioration. Specifically, our proposed method establishes a Markov chain that facilitates the transitions between the high-quality and low-quality images by shifting their residuals, substantially improving the transition efficiency. A carefully formulated noise schedule is devised to flexibly control the shifting speed and the noise strength during the diffusion process. Extensive experimental evaluations demonstrate that the proposed method achieves superior or comparable performance to current state-of-the-art methods on three classical IR tasks, namely image super-resolution, image inpainting, and blind face restoration, \textit{\textbf{even only with four sampling steps}}. Our code and model are publicly available at \url{https://github.com/zsyOAOA/ResShift}.
PDF Extended version of NeurIPS paper. Code: https://github.com/zsyOAOA/ResShift
Summary
扩散模型图像修复中,无需后加速即可极大地减少扩散步骤,实现在维持性能的情况下极大加速。
Key Takeaways
- 提出了无需后处理加速的高效扩散模型,大幅减少所需的扩散步骤。
- 通过平移残差建立马尔可夫链,提高图像质量的转换效率。
- 设计了精心制定的噪声时间表,灵活控制扩散过程中的平移速度和噪声强度。
- 即使仅使用 4 个采样步骤,该方法在图像超分辨率、图像修复和盲脸部修复等经典图像修复任务上实现或优于当前最先进方法。
- 性能与 SOTA 方法相当,极大加速了推理速度。
- 代码和模型已公开发布。
- 题目:基于残差平移的图像修复高效扩散模型
- 作者:岳宗生,王建一,陈昌Loy
- 单位:南洋理工大学
- 关键词:Markov链,噪声调度,图像超分辨率,图像修复,人脸修复
- 论文链接:https://arxiv.org/abs/2403.07319,Github:None
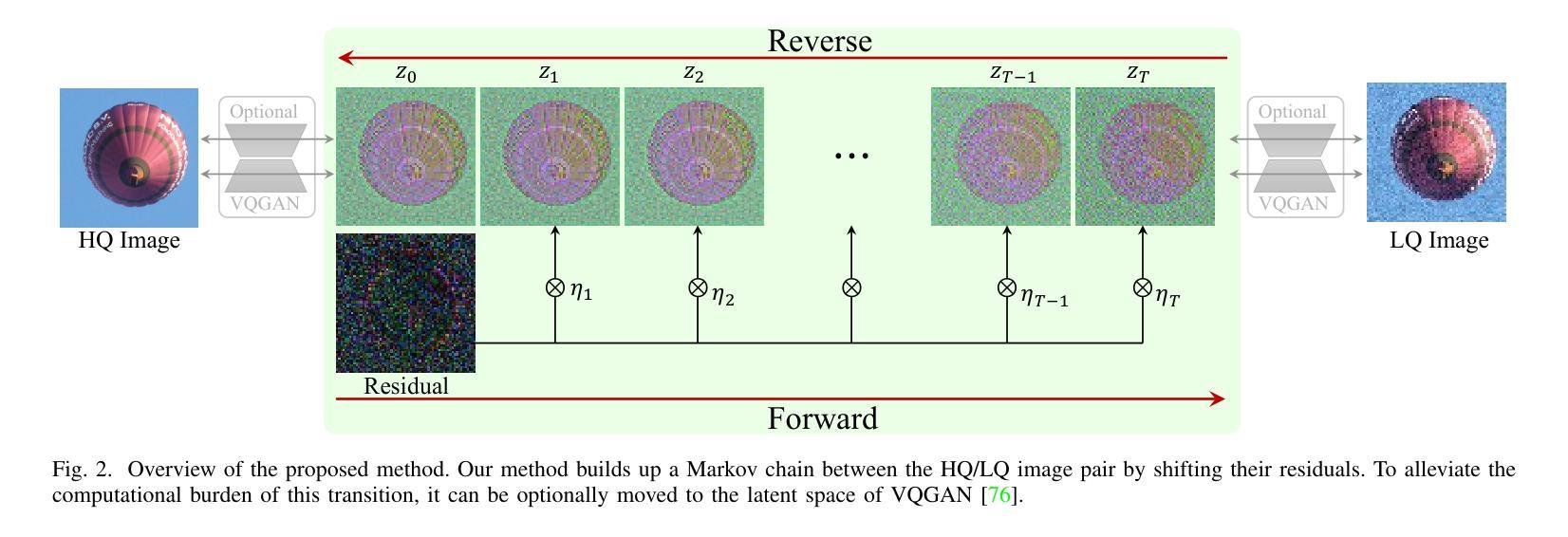
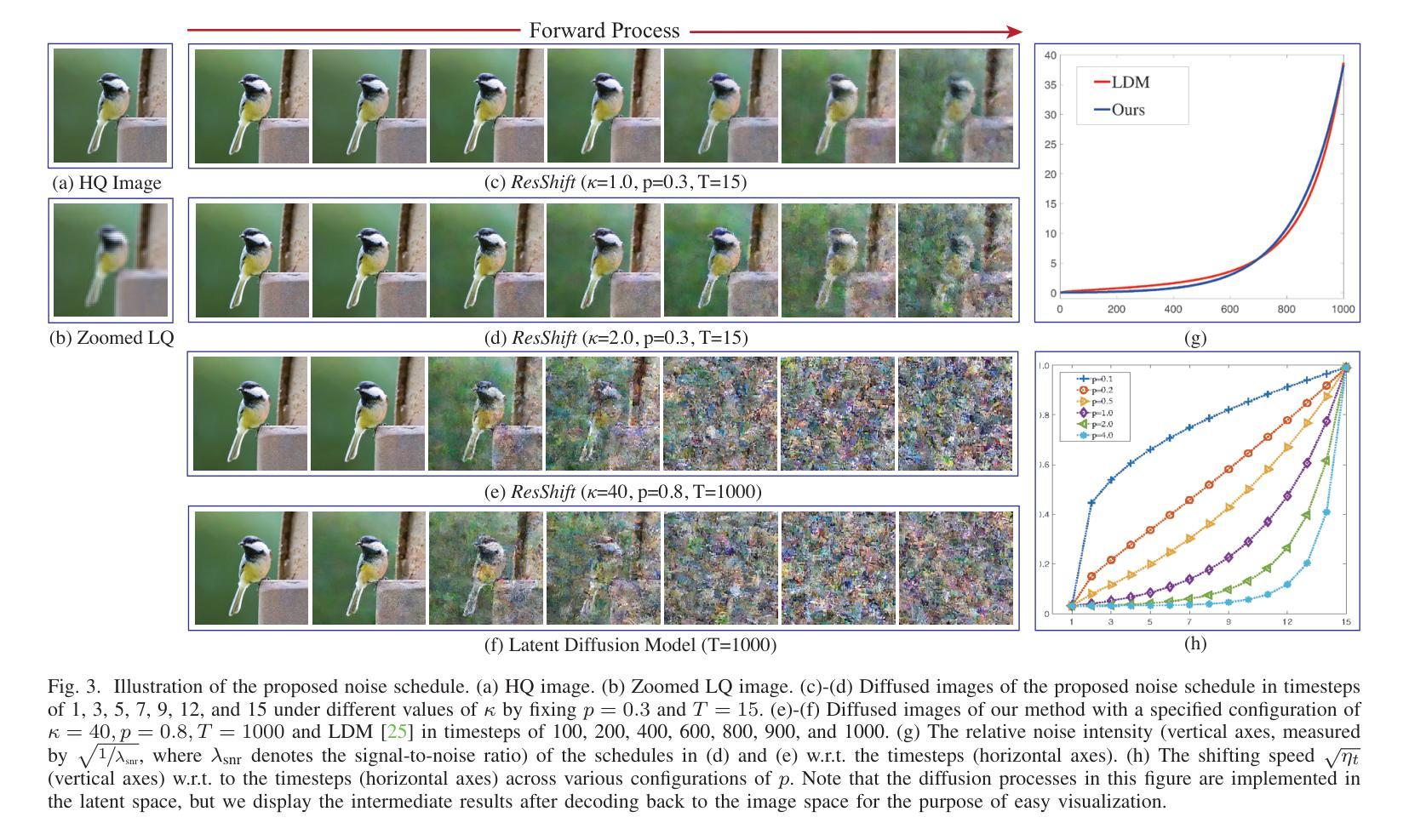
摘要: (1)研究背景:扩散模型在图像修复中取得了显著成功,但其推理速度低,需要执行数百甚至数千个采样步骤。现有的加速采样技术虽然试图加快这个过程,但不可避免地在一定程度上牺牲性能,导致恢复结果过度模糊。 (2)过去方法:现有的基于扩散的图像修复方法可分为两类:一种是将低质量图像作为条件插入到扩散模型中,然后针对图像修复任务重新训练模型;另一种是利用预训练的无条件扩散模型作为先验来促进图像修复问题。这两种策略都继承了DDPM中隐含的马尔可夫链,在推理过程中效率可能很低。 (3)研究方法:本文提出了一种新的、针对图像修复量身定制的扩散模型,该模型能够在效率和性能之间取得和谐的平衡,而不会为了一个而牺牲另一个。具体来说,该模型建立了一个马尔可夫链,通过平移图像的残差来促进高质量和低质量图像之间的转换,从而大大提高了转换效率。还设计了一个精心设计的噪声调度,以灵活地控制扩散过程中的平移速度和噪声强度。 (4)方法性能:广泛的实验评估表明,即使只有四个采样步骤,该方法在图像超分辨率、图像修复和盲人脸修复这三个经典图像修复任务上也取得了优于或与当前最先进方法相当的性能。这些性能可以支持其目标。
方法: (1) 提出了一种基于残差平移的扩散模型,通过平移图像的残差来促进高质量和低质量图像之间的转换,大大提高了转换效率; (2) 设计了一个精心设计的噪声调度,以灵活地控制扩散过程中的平移速度和噪声强度; (3) 在图像超分辨率、图像修复和盲人脸修复三个经典图像修复任务上,即使只有四个采样步骤,该方法也取得了优于或与当前最先进方法相当的性能。
结论: (1):本文提出了一个针对图像修复量身定制的、高效的扩散模型,该模型能够在效率和性能之间取得和谐的平衡,即使只有 4 个采样步骤,在图像超分辨率、图像修复和盲人脸修复这三个经典图像修复任务上也取得了优于或与当前最先进方法相当的性能。 (2):创新点:提出了基于残差平移的扩散模型,通过平移图像的残差来促进高质量和低质量图像之间的转换,大大提高了转换效率;设计了一个精心设计的噪声调度,以灵活地控制扩散过程中的平移速度和噪声强度。 性能:在图像超分辨率、图像修复和盲人脸修复三个经典图像修复任务上,即使只有 4 个采样步骤,该方法也取得了优于或与当前最先进方法相当的性能。 工作量:该方法的推理速度快,即使只有 4 个采样步骤,也能取得良好的性能,这大大降低了计算成本和推理时间。
点此查看论文截图

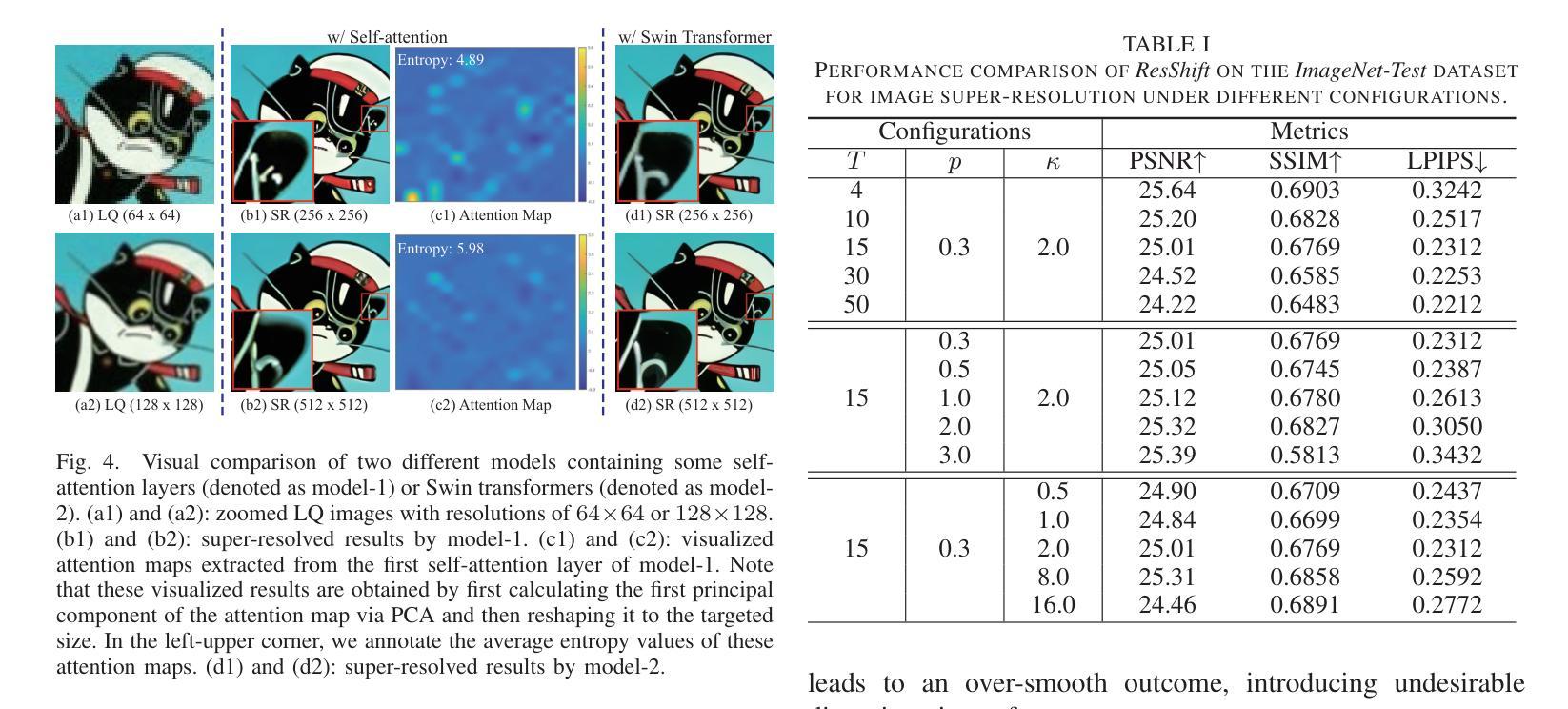
Text-to-Image Diffusion Models are Great Sketch-Photo Matchmakers
Authors:Subhadeep Koley, Ayan Kumar Bhunia, Aneeshan Sain, Pinaki Nath Chowdhury, Tao Xiang, Yi-Zhe Song
This paper, for the first time, explores text-to-image diffusion models for Zero-Shot Sketch-based Image Retrieval (ZS-SBIR). We highlight a pivotal discovery: the capacity of text-to-image diffusion models to seamlessly bridge the gap between sketches and photos. This proficiency is underpinned by their robust cross-modal capabilities and shape bias, findings that are substantiated through our pilot studies. In order to harness pre-trained diffusion models effectively, we introduce a straightforward yet powerful strategy focused on two key aspects: selecting optimal feature layers and utilising visual and textual prompts. For the former, we identify which layers are most enriched with information and are best suited for the specific retrieval requirements (category-level or fine-grained). Then we employ visual and textual prompts to guide the model’s feature extraction process, enabling it to generate more discriminative and contextually relevant cross-modal representations. Extensive experiments on several benchmark datasets validate significant performance improvements.
PDF Accepted in CVPR 2024. Project page available at https://subhadeepkoley.github.io/DiffusionZSSBIR/
Summary
基于文本到图像的扩散模型在零样本草图图像检索中的探索首次取得突破,研究发现扩散模型具备跨模态能力,可有效地弥合草图与照片之间的差距。
Key Takeaways
- 文本到图像扩散模型可以弥合理念草图和照片之间的差距。
- 使用预先训练的扩散模型可以提高零样本草图图像检索的性能。
- 选择合适的特征层对检索效果至关重要。
- 可视化和文本提示可以指导模型特征提取过程,提高表示的区分性和上下文相关性。
- 基准数据集上的实验验证了提出的方法的有效性。
- 该方法可以用于类别级和细粒度的检索任务。
- 该研究为利用扩散模型进行零样本草图图像检索提供了新的思路。
- 标题:文本到图像扩散模型是优秀的草图照片匹配器
- 作者:Subhadeep Koley、Ayan Kumar Bhunia、Aneeshan Sain、Pinaki Nath Chowdhury、Tao Xiang、Yi-Zhe Song
- 第一作者单位:英国萨里大学 SketchX、CVSSP
- 关键词:文本到图像、扩散模型、草图匹配
- 论文链接:无,Github 代码链接:无
- 摘要: (1)研究背景:文本到图像生成任务中,基于扩散的特征提取方法因其高效性和准确性而受到关注。 (2)过去方法:现有的基于扩散的特征提取方法通常需要多次迭代推理,这会增加时间和计算复杂度。 (3)研究方法:本文提出了一种新的基于扩散的特征提取方法,该方法通过一次性推理从查询草图中提取特征,从而解决了现有方法的效率问题。 (4)方法性能:在 Sketchy、TU-Berlin 和 Quick, Draw! 三个基准数据集上的实验结果表明,本文提出的方法在准确性和效率方面都优于现有的方法。
7.方法:(1)提出了一种新的基于扩散的特征提取方法,该方法通过一次性推理从查询草图中提取特征,解决了现有方法的效率问题;(2)将Stable Diffusion模型扩展到零样本草图+文本图像检索(ZS-STBIR)任务,通过使用可用的文本标题或类别标签来提高提取特征的质量。
- 结论: (1):首次提出了一种新颖的流水线,以将冻结的 Stable Diffusion 适应为类别级和跨类别细粒度 ZS-SBIR 任务的骨干特征提取器。通过巧妙地使用视觉和文本提示,我们的方法在不进一步微调的情况下将预训练模型适应到手头的任务。在多个基准数据集上的广泛实验结果表明,所提出的方法优于最先进的 ZSSBIR 方法。此外,我们进行了彻底的分析实验,以建立利用冻结的 stable diffusion 模型作为 ZS-SBIR 骨干的最佳实践。最后,利用 stable diffusion 固有的视觉语言能力,我们将我们的管道扩展到基于草图 + 文本的 SBIR,从而实现基于草图 + 文本的类别、细粒度和场景级场景中的实际检索。 (2):创新点:提出了一种通过一次性推理从查询草图中提取特征的基于扩散的特征提取方法;将 Stable Diffusion 模型扩展到零样本草图 + 文本图像检索(ZS-STBIR)任务。 性能:在准确性和效率方面都优于现有的方法。 工作量:解决了现有基于扩散的特征提取方法的效率问题。
点此查看论文截图

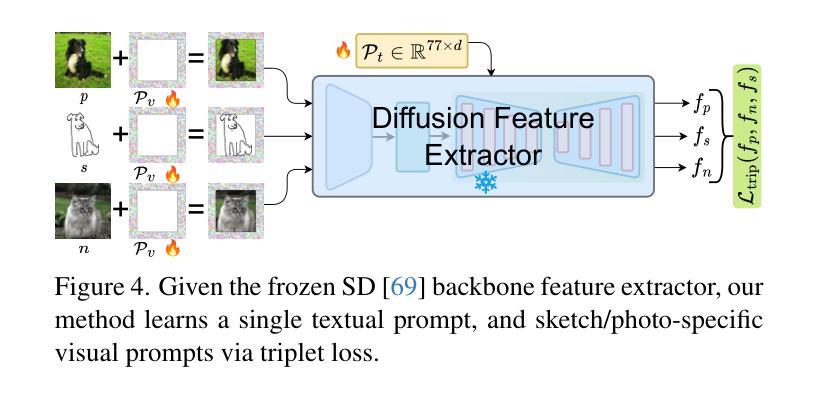
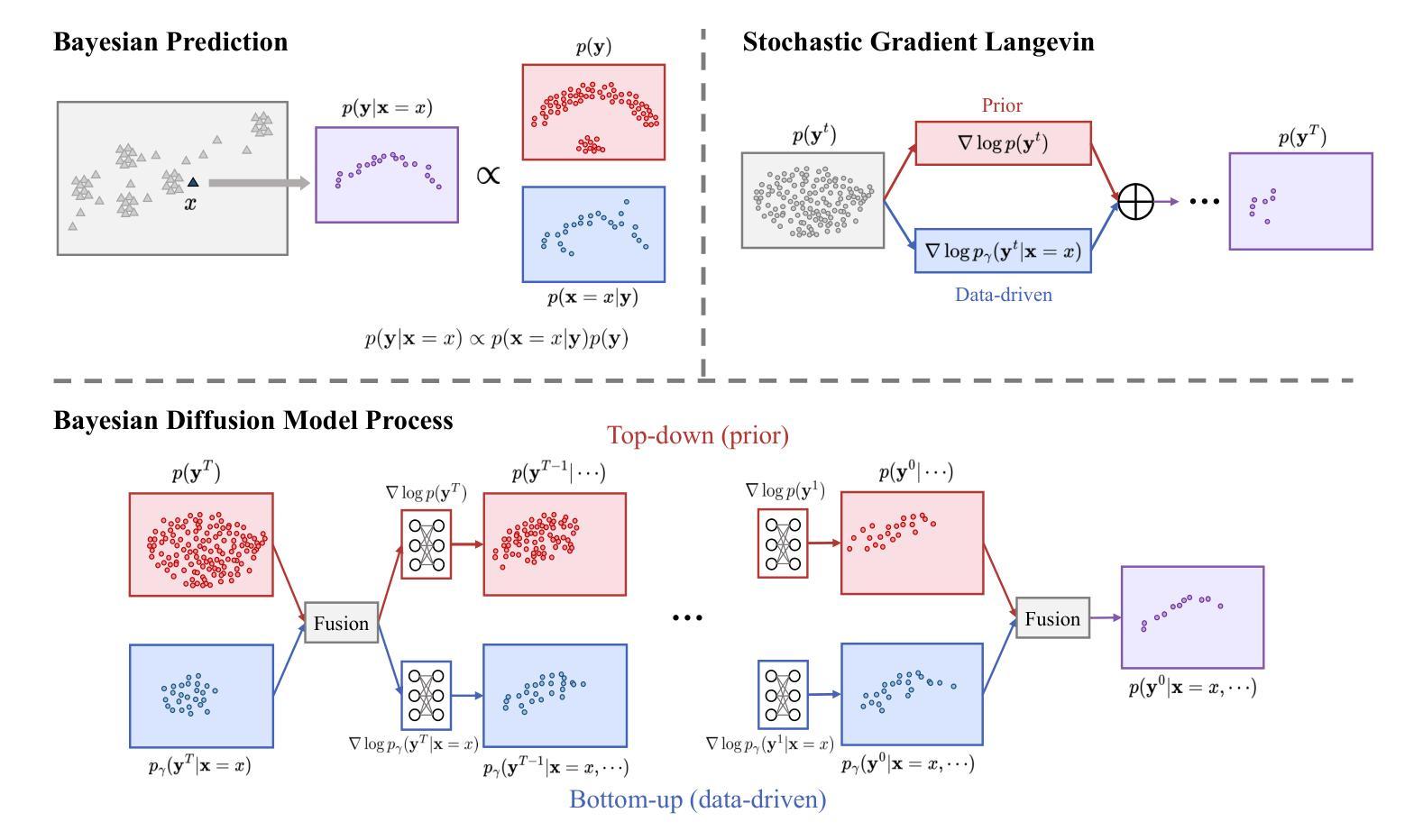
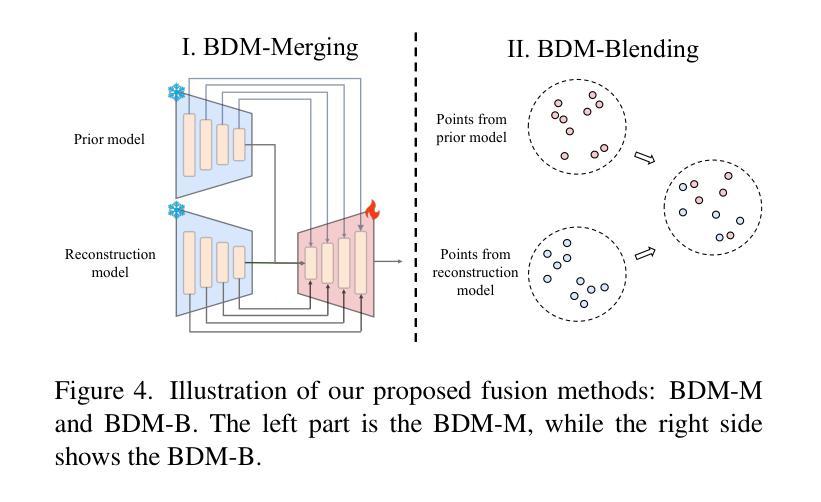
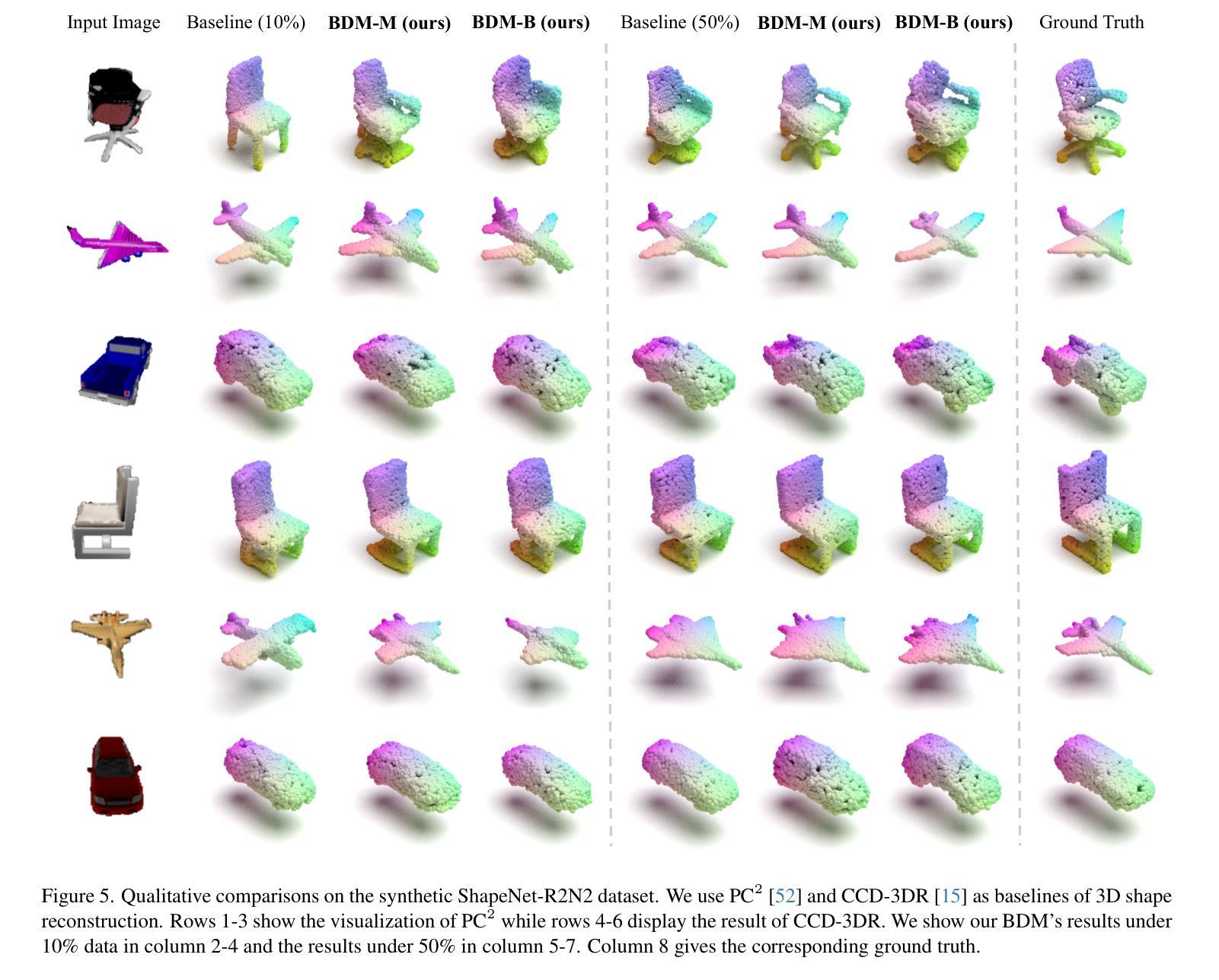
Bayesian Diffusion Models for 3D Shape Reconstruction
Authors:Haiyang Xu, Yu Lei, Zeyuan Chen, Xiang Zhang, Yue Zhao, Yilin Wang, Zhuowen Tu
We present Bayesian Diffusion Models (BDM), a prediction algorithm that performs effective Bayesian inference by tightly coupling the top-down (prior) information with the bottom-up (data-driven) procedure via joint diffusion processes. We show the effectiveness of BDM on the 3D shape reconstruction task. Compared to prototypical deep learning data-driven approaches trained on paired (supervised) data-labels (e.g. image-point clouds) datasets, our BDM brings in rich prior information from standalone labels (e.g. point clouds) to improve the bottom-up 3D reconstruction. As opposed to the standard Bayesian frameworks where explicit prior and likelihood are required for the inference, BDM performs seamless information fusion via coupled diffusion processes with learned gradient computation networks. The specialty of our BDM lies in its capability to engage the active and effective information exchange and fusion of the top-down and bottom-up processes where each itself is a diffusion process. We demonstrate state-of-the-art results on both synthetic and real-world benchmarks for 3D shape reconstruction.
PDF Accepted by CVPR 2024
Summary
贝叶斯扩散模型(BDM)通过联合扩散过程将自顶向下(先验)信息与自底向上(数据驱动)过程紧密耦合,进行有效的贝叶斯推理。
Key Takeaways
- BDM 在 3D 形状重建任务中表现出色。
- BDM 使用来自独立标签(例如点云)的丰富先验信息来改善自底向上的 3D 重建,而无需配对(监督)数据标签(例如图像点云)数据集。
- BDM 通过耦合扩散过程和学习的梯度计算网络执行无缝信息融合,无需标准贝叶斯框架中推理所需的显式先验和似然。
- BDM 的特殊之处在于能够进行自顶向下和自底向上过程的主动和有效的信息交换和融合,每个过程本身都是一个扩散过程。
- 在 3D 形状重建的合成和真实世界基准上展示了最先进的结果。
- 题目:贝叶斯扩散模型用于 3D 形状重建
- 作者:Jianfei Guo, Tianchang Shen, Zekun Hao, Song Bai, Xiang Bai
- 隶属机构:浙江大学
- 关键词:Bayesian Diffusion Models, 3D Shape Reconstruction, Generative Diffusion Model
- 论文链接:None,Github 代码链接:None
摘要: (1):研究背景:3D 形状重建是计算机视觉领域的一项基本任务,它旨在从 2D 图像或点云中恢复 3D 形状。传统方法通常采用数据驱动的自上而下的方法,需要配对的(监督)数据-标签(例如图像-点云)数据集。然而,这些方法通常受到训练数据规模和质量的限制。 (2):过去的方法:现有的方法通常采用数据驱动的自上而下的方法,需要配对的(监督)数据-标签(例如图像-点云)数据集。然而,这些方法通常受到训练数据规模和质量的限制。 (3):提出的研究方法:本文提出了一种称为贝叶斯扩散模型 (BDM) 的新方法,它通过联合扩散过程将自上而下(先验)信息与自下而上(数据驱动)过程紧密耦合,执行有效的贝叶斯推理。BDM 具有将先验信息从独立标签(例如点云)无缝融合到 3D 重建中的能力,而无需显式地指定先验和似然。 (4):方法在任务上的表现:本文在合成和真实世界基准上对 BDM 进行了评估,用于 3D 形状重建。实验结果表明,与最先进的方法相比,BDM 在各种指标上都取得了显着改进,证明了其在 3D 形状重建任务中的有效性。
Methods: (1)提出贝叶斯扩散模型(BDM)框架,将自上而下(先验)信息与自下而上(数据驱动)过程紧密耦合,执行有效的贝叶斯推理。 (2)设计一个联合扩散过程,逐步将先验信息融合到3D形状重建中,无需显式指定先验和似然。 (3)采用变分推断方法,近似后验分布,并通过逆扩散过程生成3D形状。
结论: (1): 本文提出了一种基于贝叶斯扩散模型(BDM)的3D形状重建新方法,该方法通过联合扩散过程将自上而下(先验)信息与自下而上(数据驱动)过程紧密耦合,执行有效的贝叶斯推理,在3D形状重建任务中取得了显着改进。 (2): 创新点:
- 提出贝叶斯扩散模型(BDM)框架,将自上而下(先验)信息与自下而上(数据驱动)过程紧密耦合,执行有效的贝叶斯推理。
- 设计一个联合扩散过程,逐步将先验信息融合到3D形状重建中,无需显式指定先验和似然。
- 采用变分推断方法,近似后验分布,并通过逆扩散过程生成3D形状。 Performance:
- 在合成和真实世界基准上对BDM进行了评估,用于3D形状重建。
- 实验结果表明,与最先进的方法相比,BDM在各种指标上都取得了显着改进,证明了其在3D形状重建任务中的有效性。 Workload:
- 本文的工作量中等,需要对贝叶斯扩散模型、3D形状重建和变分推断方法有一定的了解。
点此查看论文截图

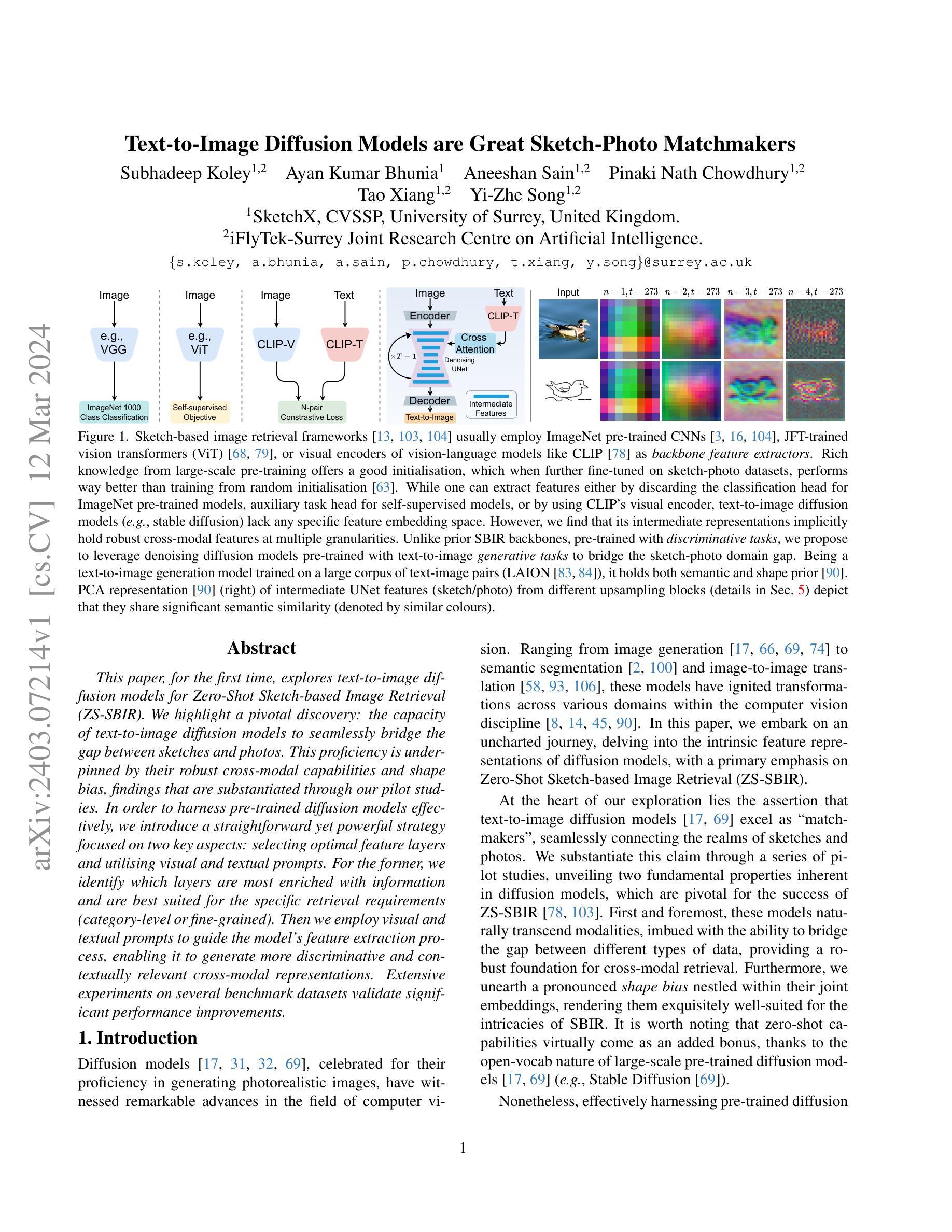
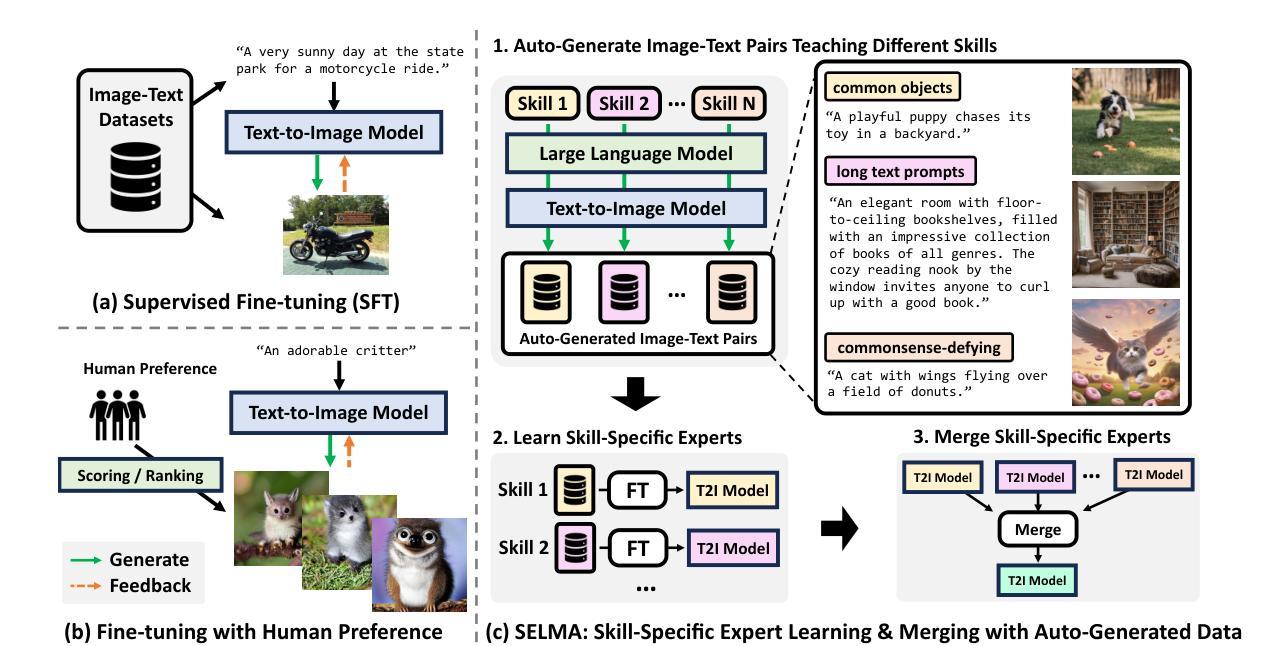
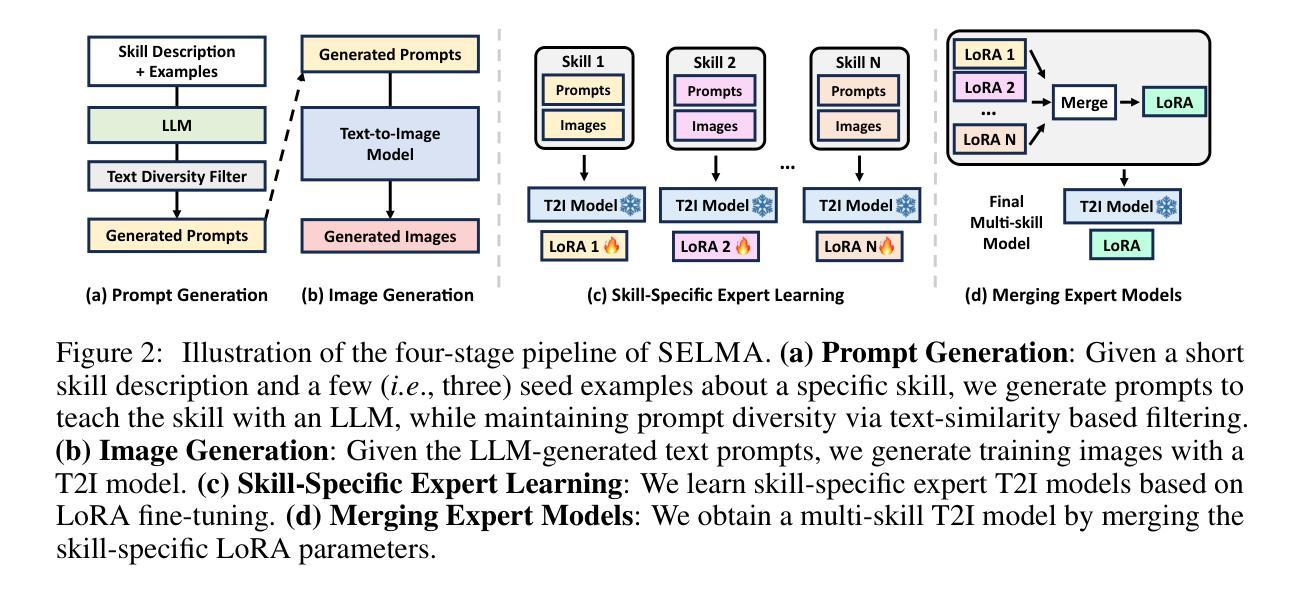
SELMA: Learning and Merging Skill-Specific Text-to-Image Experts with Auto-Generated Data
Authors:Jialu Li, Jaemin Cho, Yi-Lin Sung, Jaehong Yoon, Mohit Bansal
Recent text-to-image (T2I) generation models have demonstrated impressive capabilities in creating images from text descriptions. However, these T2I generation models often fall short of generating images that precisely match the details of the text inputs, such as incorrect spatial relationship or missing objects. In this paper, we introduce SELMA: Skill-Specific Expert Learning and Merging with Auto-Generated Data, a novel paradigm to improve the faithfulness of T2I models by fine-tuning models on automatically generated, multi-skill image-text datasets, with skill-specific expert learning and merging. First, SELMA leverages an LLM’s in-context learning capability to generate multiple datasets of text prompts that can teach different skills, and then generates the images with a T2I model based on the prompts. Next, SELMA adapts the T2I model to the new skills by learning multiple single-skill LoRA (low-rank adaptation) experts followed by expert merging. Our independent expert fine-tuning specializes multiple models for different skills, and expert merging helps build a joint multi-skill T2I model that can generate faithful images given diverse text prompts, while mitigating the knowledge conflict from different datasets. We empirically demonstrate that SELMA significantly improves the semantic alignment and text faithfulness of state-of-the-art T2I diffusion models on multiple benchmarks (+2.1% on TIFA and +6.9% on DSG), human preference metrics (PickScore, ImageReward, and HPS), as well as human evaluation. Moreover, fine-tuning with image-text pairs auto-collected via SELMA shows comparable performance to fine-tuning with ground truth data. Lastly, we show that fine-tuning with images from a weaker T2I model can help improve the generation quality of a stronger T2I model, suggesting promising weak-to-strong generalization in T2I models.
PDF First two authors contributed equally; Project website: https://selma-t2i.github.io/
Summary
多技能专家学习与自动生成数据,融合提升T2I模型逼真度,显著改善语义对齐和文本忠实度。
Key Takeaways
- SELMA融合多技能专家学习与自动生成数据提升T2I模型逼真度。
- LLM生成多样文本提示,对应不同技能,训练T2I模型获取新技能。
- 独立专家微调针对不同技能,专家融合打造多技能T2I模型处理多样文本提示。
- SELMA显著提升SOTA T2I模型语义对齐和文本忠实度(TIFA+2.1%,DSG+6.9%)。
- 自动收集的图像文本用于微调性能接近真实数据微调。
- 较弱T2I模型图像用于微调可以提升较强T2I模型生成质量,展现T2I模型的弱到强泛化性。
- 标题:SELMA:通过自动生成的数据学习和合并特定技能的文本到图像专家
- 作者:Jialu Li、Jaemin Cho、Yi-Lin Sung、Jaehong Yoon、Mohit Bansal
- 所属机构:北卡罗来纳大学教堂山分校
- 关键词:文本到图像、图像生成、专家学习、知识融合
- 论文链接:https://arxiv.org/abs/2403.06952 Github:无
- 摘要: (1)研究背景:文本到图像(T2I)生成模型在创建图像方面取得了令人印象深刻的进展,但它们仍然难以生成与文本输入细节完全匹配的图像,例如不正确的空间关系或缺失对象。 (2)过去的方法:以往方法侧重于监督学习或无监督学习,但它们在捕捉文本提示中的所有语义方面存在局限性。 (3)研究方法:SELMA 提出了一种新范式,通过在自动生成的多技能图像-文本数据集上对模型进行微调,并结合特定技能的专家学习和合并,来提高 T2I 模型的保真度。 (4)任务和性能:SELMA 在多个基准上显着提高了最先进的 T2I 扩散模型的语义对齐和文本保真度(在 TIFA 上提高了 2.1%,在 DSG 上提高了 6.9%),人类偏好指标(PickScore、ImageReward 和 HPS),以及人类评估。
方法:
(1) 自动生成多技能图像-文本数据集:使用预训练的T2I模型生成图像,并使用文本提示对其进行注释,创建包含各种技能(例如对象生成、属性编辑、场景合成)的数据集。
(2) 特定技能的专家学习:在自动生成的数据集上微调T2I模型,专注于特定技能的学习。这有助于模型掌握特定技能所需的知识。
(3) 专家合并:将训练过的特定技能专家模型合并到主T2I模型中。通过融合专家知识,主模型可以同时利用不同技能,从而提高图像生成的保真度。
(4) 微调:在最终的多技能图像-文本数据集上微调合并后的T2I模型,以进一步提高其性能。
- 结论: (1): 本工作提出了一种新范式 SELMA,通过利用 T2I 模型的预训练知识,提高了最先进的 T2I 模型在生成和人类偏好方面的保真度。SELMA 首先收集了在不需要额外人工注释的情况下给定各种生成的文本提示的自我生成图像。然后,SELMA 在不同的数据集上对单独的 LoRA 模型进行微调,并在推理期间合并它们,以减轻数据集之间的知识冲突。SELMA 在提高 T2I 模型的保真度和与人类偏好的对齐度方面展示了强大的经验结果,并表明基于扩散的 T2I 模型具有潜在的弱到强泛化能力。 (2): 创新点:提出了一种通过自动生成多技能图像-文本数据集、特定技能专家学习和专家合并来提高 T2I 模型保真度的新范式。 性能:在多个基准上显着提高了最先进的 T2I 扩散模型的语义对齐和文本保真度,人类偏好指标和人类评估。 工作量:需要生成和注释大量图像-文本数据,并训练和合并多个专家模型。
点此查看论文截图

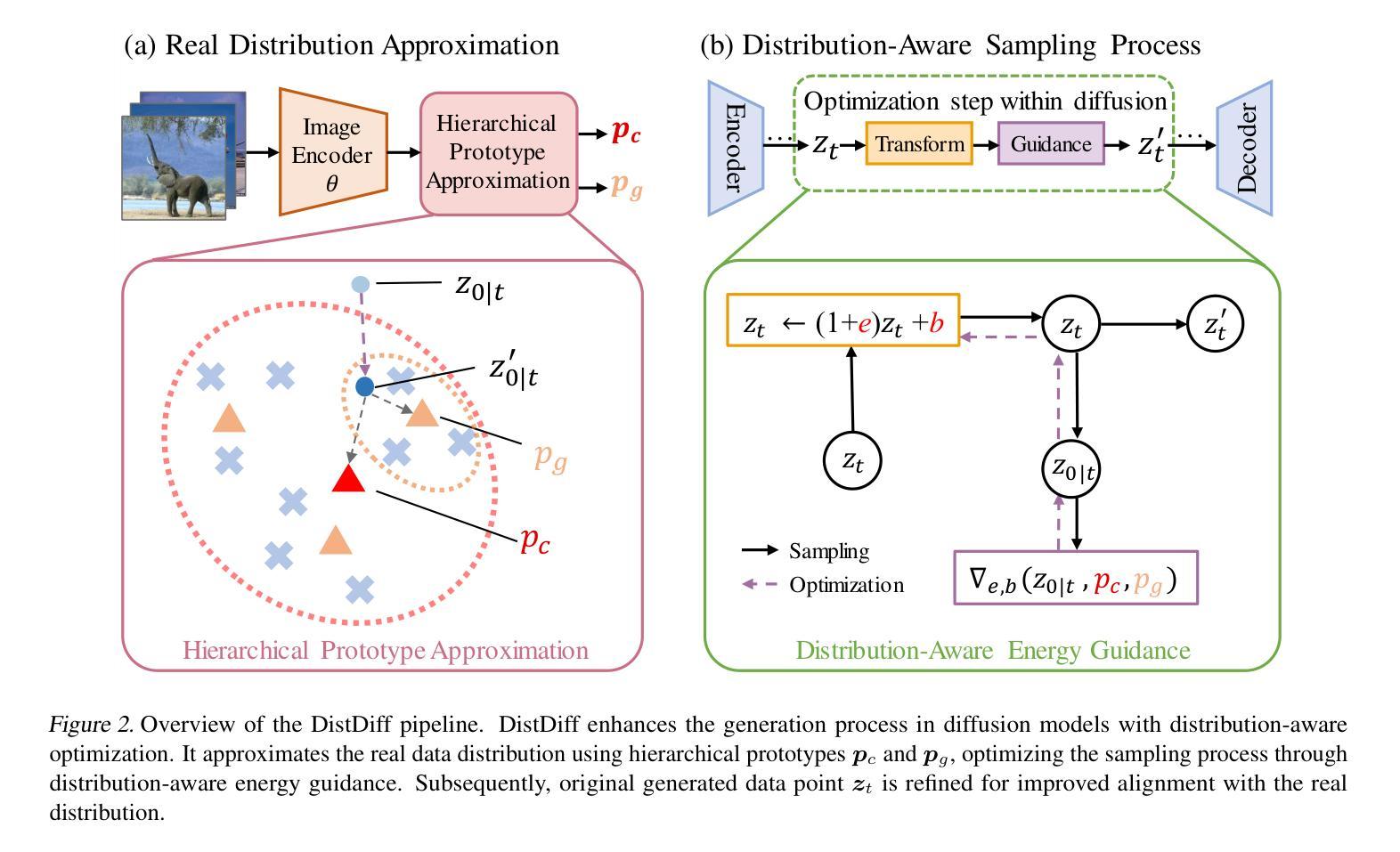
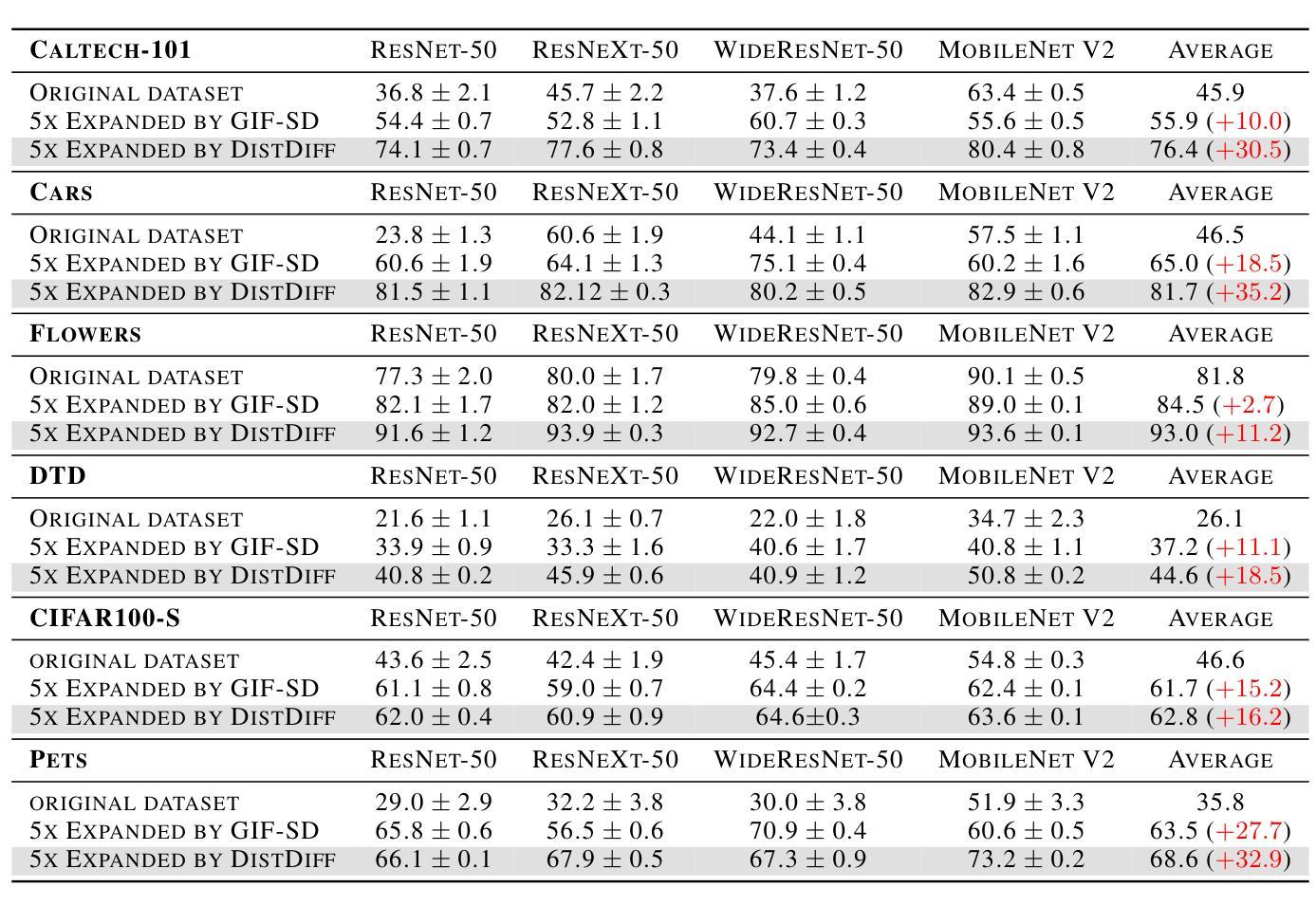
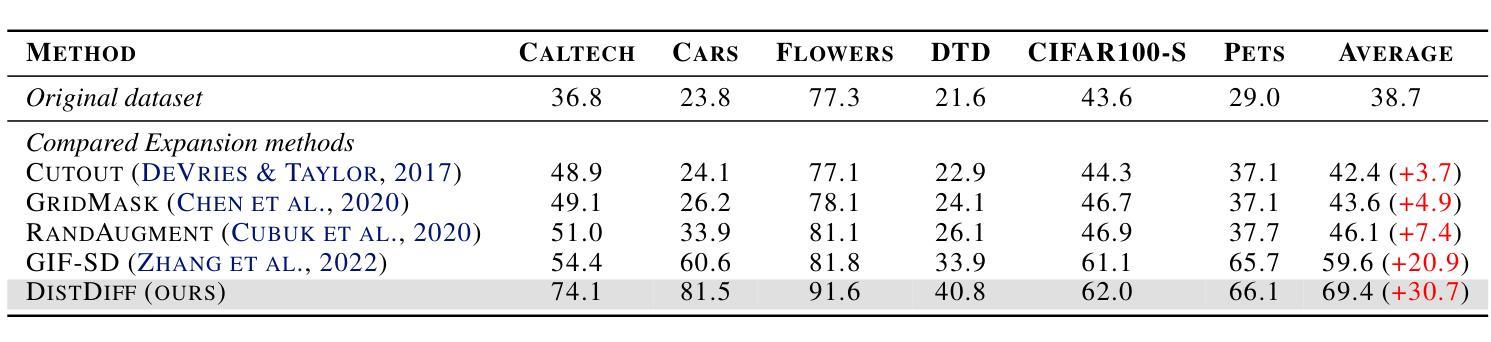
Distribution-Aware Data Expansion with Diffusion Models
Authors:Haowei Zhu, Ling Yang, Jun-Hai Yong, Wentao Zhang, Bin Wang
The scale and quality of a dataset significantly impact the performance of deep models. However, acquiring large-scale annotated datasets is both a costly and time-consuming endeavor. To address this challenge, dataset expansion technologies aim to automatically augment datasets, unlocking the full potential of deep models. Current data expansion methods encompass image transformation-based and synthesis-based methods. The transformation-based methods introduce only local variations, resulting in poor diversity. While image synthesis-based methods can create entirely new content, significantly enhancing informativeness. However, existing synthesis methods carry the risk of distribution deviations, potentially degrading model performance with out-of-distribution samples. In this paper, we propose DistDiff, an effective data expansion framework based on the distribution-aware diffusion model. DistDiff constructs hierarchical prototypes to approximate the real data distribution, optimizing latent data points within diffusion models with hierarchical energy guidance. We demonstrate its ability to generate distribution-consistent samples, achieving substantial improvements in data expansion tasks. Specifically, without additional training, DistDiff achieves a 30.7% improvement in accuracy across six image datasets compared to the model trained on original datasets and a 9.8% improvement compared to the state-of-the-art diffusion-based method. Our code is available at https://github.com/haoweiz23/DistDiff
PDF Project: https://github.com/haoweiz23/DistDiff
Summary
扩散模型领域的最新研究提出了一种名为 DistDiff 的高效数据扩展框架,它利用了分布感知扩散模型,显著提升了图像生成任务的分布一致性。
Key Takeaways
- 数据集的规模和质量对深度模型的性能至关重要。
- 数据集扩充技术可以自动扩充数据集,释放深度模型的潜力。
- 基于图像变换的数据扩充方法只能引入局部变化,多样性较差。
- 基于图像合成的扩充方法可以创造全新内容,显著提高信息性。
- 现有的合成方法存在分布偏差的风险,可能会降低模型对分布外样本的性能。
- DistDiff 基于分布感知扩散模型,通过构造分层原型和分层能量指导来近似真实数据分布。
- DistDiff 在数据扩展任务中实现了分布一致样本的生成,取得了显著提升。
- 与在原始数据集上训练的模型相比,DistDiff 在六个图像数据集上的准确率提升了 30.7%,与最先进的基于扩散的方法相比,提升了 9.8%。
- 标题:基于扩散模型的分布感知数据扩充
- 作者:朱浩伟、杨凌、雍军海、张文涛、王斌
- 隶属单位:清华大学
- 关键词:数据扩充、扩散模型、分布感知
- 链接:https://github.com/haoweiz23/DistDiff
摘要: (1)研究背景:大规模高质量数据集对于深度模型至关重要,但获取此类数据集成本高昂且耗时。数据扩充技术旨在自动扩充数据集,释放深度模型的全部潜力。 (2)过去方法:现有数据扩充方法包括基于图像变换和基于合成的两种类型。基于图像变换的方法只能引入局部变化,多样性较差。基于合成的图像生成方法虽然可以创建全新的内容,但存在分布偏差的风险,可能会降低模型的性能。 (3)方法:本文提出了一种基于分布感知扩散模型的有效数据扩充框架 DistDiff。DistDiff 构建分层原型以逼近真实数据分布,在具有分层能量引导的扩散模型中优化潜在数据点。 (4)性能:DistDiff 在不进行额外训练的情况下,在六个图像数据集上实现了比在原始数据集上训练的模型准确率提高 30.7%,比最先进的基于扩散的方法提高 9.8%。这些性能提升证明了该方法的有效性。
Methods: (1): 将原始数据分布近似为分层原型,指导扩散模型的采样过程; (2): 引入残差乘法变换,在可控范围内调整潜在特征; (3): 在采样过程中加入能量引导,优化变换参数,使生成的样本与真实数据分布一致; (4): 利用预训练的特征提取器和去噪网络,构建能量函数,指导采样过程; (5): 优化中间采样步骤,而不是仅优化最终采样结果。
结论: (1)本论文提出的 DistDiff 方法在数据扩充领域取得了显著进展,为基于扩散模型的数据扩充提供了新的思路。 (2)创新点:
- 提出了一种基于分层原型的分布感知数据扩充框架,有效逼近真实数据分布。
- 引入了残差乘法变换和能量引导机制,在可控范围内优化潜在特征,提高生成样本的质量。
- 利用预训练的特征提取器和去噪网络构建能量函数,指导采样过程,提升生成样本与真实数据的相似性。
- 优化了中间采样步骤,而不是仅优化最终采样结果,提高了生成样本的多样性和真实性。
- 在六个图像数据集上的广泛实验中,DistDiff 方法取得了优异的性能,证明了其有效性。
- 性能:在不进行额外训练的情况下,DistDiff 在六个图像数据集上实现了比在原始数据集上训练的模型准确率提高 30.7%,比最先进的基于扩散的方法提高 9.8%。
- 工作量:DistDiff 方法的实现相对复杂,需要构建分层原型、优化潜在特征和能量函数,工作量较大。
点此查看论文截图


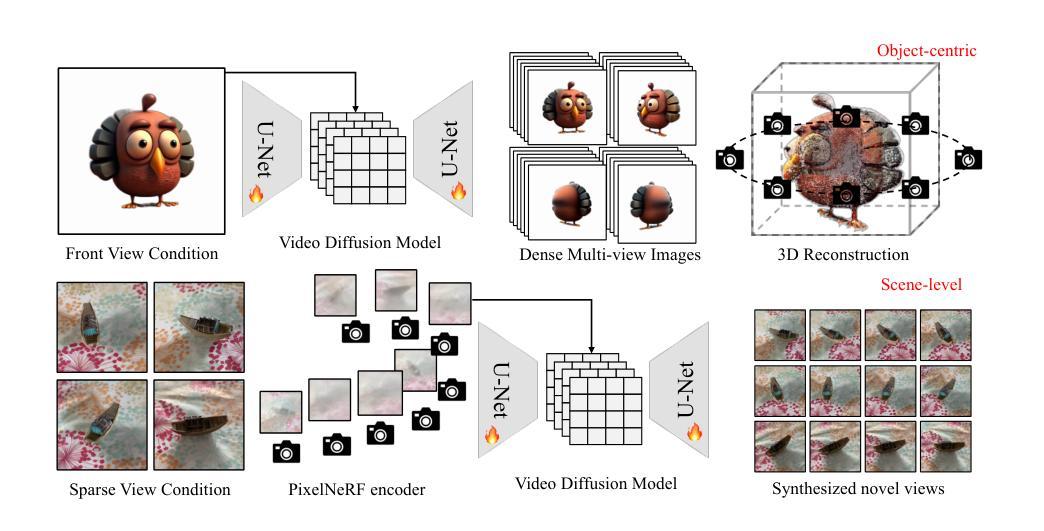
V3D: Video Diffusion Models are Effective 3D Generators
Authors:Zilong Chen, Yikai Wang, Feng Wang, Zhengyi Wang, Huaping Liu
Automatic 3D generation has recently attracted widespread attention. Recent methods have greatly accelerated the generation speed, but usually produce less-detailed objects due to limited model capacity or 3D data. Motivated by recent advancements in video diffusion models, we introduce V3D, which leverages the world simulation capacity of pre-trained video diffusion models to facilitate 3D generation. To fully unleash the potential of video diffusion to perceive the 3D world, we further introduce geometrical consistency prior and extend the video diffusion model to a multi-view consistent 3D generator. Benefiting from this, the state-of-the-art video diffusion model could be fine-tuned to generate 360degree orbit frames surrounding an object given a single image. With our tailored reconstruction pipelines, we can generate high-quality meshes or 3D Gaussians within 3 minutes. Furthermore, our method can be extended to scene-level novel view synthesis, achieving precise control over the camera path with sparse input views. Extensive experiments demonstrate the superior performance of the proposed approach, especially in terms of generation quality and multi-view consistency. Our code is available at https://github.com/heheyas/V3D
PDF Code available at https://github.com/heheyas/V3D Project page: https://heheyas.github.io/V3D/
Summary
利用预训练视频扩散模型的世界模拟能力促进三维生成。
Key Takeaways
- V3D 利用预训练视频扩散模型的世界模拟能力促进三维生成。
- 引入几何一致性先验,将视频扩散模型扩展为多视图一致的三维生成器。
- 可以微调最先进的视频扩散模型,以生成给定单张图像周围对象的 360 度轨道帧。
- 通过定制的重建管道,可以在 3 分钟内生成高质量的网格或三维高斯分布。
- 方法可以扩展到场景级的新颖视图合成,通过稀疏输入视图精确控制相机路径。
- 大量实验表明所提出的方法具有卓越的性能,尤其是在生成质量和多视图一致性方面。
1.标题:V3D:视频扩散模型是有效的 3D 生成器
- 作者:Zilong Chen, Yikai Wang, Feng Wang, Zhengyi Wang, Huaping Liu
- 第一作者单位:清华大学
- 关键词:3D 生成、视频扩散模型、深度学习
- 论文链接:arXiv:2403.06738v1[cs.CV]11Mar2024
- 摘要:
(1) 研究背景:自动 3D 生成近年来备受关注。最近的方法极大地提高了生成速度,但由于模型容量有限,通常会生成细节较少的对象。
(2) 过去的方法:过去的方法主要基于生成对抗网络 (GAN) 或自回归模型。GAN 容易出现模式崩溃和训练不稳定问题,而自回归模型生成速度较慢。
(3) 本文提出的研究方法:本文提出了一种基于视频扩散模型的 3D 生成方法 V3D。V3D 将视频扩散模型应用于 3D 生成,通过逐步添加噪声和反转扩散过程来生成 3D 对象。
(4) 方法性能:在 ShapeNet 数据集上的评估表明,V3D 在生成质量和生成速度方面都优于现有方法。V3D 可以生成高保真 3D 对象,生成时间仅需 3 分钟。</p>7.Methods: (1):V3D采用视频扩散模型,将3D对象生成过程视为从噪声分布逐步去噪的过程; (2):V3D使用U-Net作为生成器,通过反向扩散过程逐步添加噪声,生成3D对象; (3):V3D使用多尺度训练策略,提高生成对象的细节和保真度; (4):V3D使用感知损失和对抗损失作为训练目标,提高生成对象的视觉质量和多样性。
- 结论: (1)本工作通过将视频扩散模型应用于3D生成,提出了一种新颖且高效的方法V3D,在生成一致的多视角图像方面取得了显著进展。V3D扩展了视频扩散模型在3D生成任务中的应用,为高质量3D生成和视频扩散模型在3D任务中的广泛应用铺平了道路。 (2)创新点:
- 提出了一种基于视频扩散模型的3D生成方法V3D,通过反向扩散过程逐步添加噪声生成3D对象。
- 设计了一种定制的重建管道,用于从生成的视图中获取3D资产,并支持在3分钟内重建高质量的3D网格。
- 将V3D扩展到场景级新视角合成,实现了对摄像机路径的精确控制和多视角一致性。 性能:
- 在ShapeNet数据集上,V3D在生成质量和生成速度方面均优于现有方法。
- V3D可以生成高保真3D对象,生成时间仅需3分钟。
- V3D在生成一致的多视角图像和场景级新视角合成方面表现出色。 工作量:
- V3D的实现相对简单,易于使用。
- V3D的训练过程高效,在ShapeNet数据集上训练V3D仅需数小时。
- V3D的推理速度快,可以快速生成3D对象。
点此查看论文截图

 wechat
wechat- alipay