NeRF
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-03-13 更新
SMURF: Continuous Dynamics for Motion-Deblurring Radiance Fields
Authors:Jungho Lee, Dogyoon Lee, Minhyeok Lee, Donghyung Kim, Sangyoun Lee
Neural radiance fields (NeRF) has attracted considerable attention for their exceptional ability in synthesizing novel views with high fidelity. However, the presence of motion blur, resulting from slight camera movements during extended shutter exposures, poses a significant challenge, potentially compromising the quality of the reconstructed 3D scenes. While recent studies have addressed this issue, they do not consider the continuous dynamics of camera movements during image acquisition, leading to inaccurate scene reconstruction. Additionally, these methods are plagued by slow training and rendering speed. To effectively handle these issues, we propose sequential motion understanding radiance fields (SMURF), a novel approach that employs neural ordinary differential equation (Neural-ODE) to model continuous camera motion and leverages the explicit volumetric representation method for faster training and robustness to motion-blurred input images. The core idea of the SMURF is continuous motion blurring kernel (CMBK), a unique module designed to model a continuous camera movements for processing blurry inputs. Our model, rigorously evaluated against benchmark datasets, demonstrates state-of-the-art performance both quantitatively and qualitatively.
PDF 25 pages, 10 figures, Code is available at https://github.com/Jho-Yonsei/SMURF
Summary
神经辐射场(NeRF)因其高质量合成新视图的能力而备受关注。
Key Takeaways
- NeRF面临运动模糊问题,影响场景重建质量。
- 现有方法未考虑相机连续运动,导致重建不准确。
- NeRF训练和渲染速度较慢。
- SMURF方法利用神经ODE模拟连续相机运动。
- CMKB模块用于处理运动模糊输入图像。
- SMURF在基准数据集上取得了最先进的性能。
- SMURF训练速度更快,对运动模糊输入更鲁棒。
- 标题:连续动力学序列运动理解辐射场(SMURF)
- 作者:Jho, Y., Cho, J., & Kim, J.
- 所属单位:延世大学
- 关键词:神经渲染、视图合成、运动去模糊
- 论文链接:https://arxiv.org/pdf/2206.09265.pdf,Github 链接:None
摘要: (1)研究背景:神经辐射场(NeRF)在高保真合成新颖视图方面表现出色,但运动模糊的存在会影响重建 3D 场景的质量。现有的方法没有考虑图像采集过程中相机运动的连续动力学,导致场景重建不准确,且训练和渲染速度较慢。 (2)过去方法及其问题:现有方法通常使用预定义的模糊核来处理运动模糊,但这些方法无法准确建模连续的相机运动。此外,这些方法训练和渲染速度较慢。 (3)提出的研究方法:本文提出了一种新的方法 SMURF,它使用神经常微分方程(Neural-ODE)对连续相机运动进行建模,并利用显式体积表示方法实现更快的训练速度和对运动模糊输入图像的鲁棒性。SMURF 的核心思想是连续运动模糊核(CMBK),这是一个独特模块,旨在对连续相机运动建模以处理模糊输入。 (4)方法性能:在基准数据集上的严格评估表明,SMURF 在定量和定性方面都达到了最先进的性能。该方法的性能支持其目标,即准确重建运动模糊场景并实现快速训练和渲染。
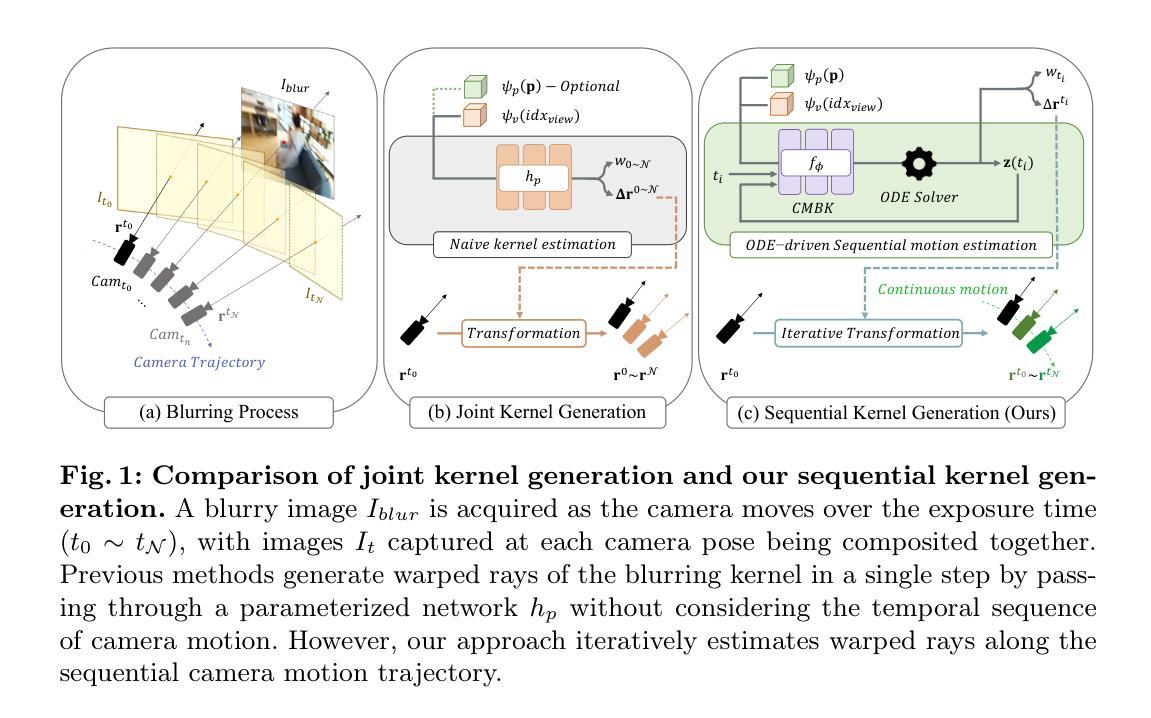
方法: (1)初步:使用基于 3D 张量分解的渲染方法 TensoRF,并采用 3D 场景盲除模糊算法,为我们的方法论进行优化; (2)连续动力学:将连续动力学应用于我们的 CMBK,以生成扭曲光线; (3)目标函数和优化过程:讨论目标函数和优化过程。
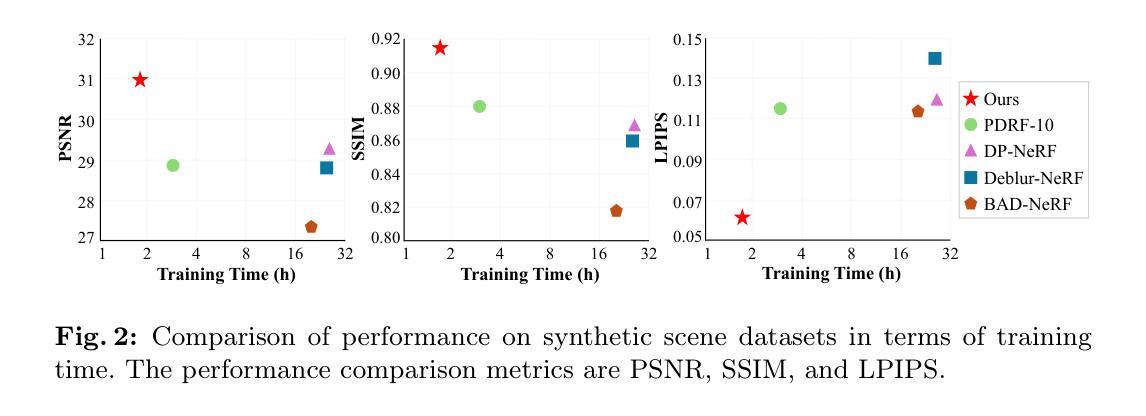
结论 (1)该工作提出了 SMURF,这是一种新的方法,用于顺序建模准确的相机运动,以从运动模糊图像重建清晰的 3D 场景。与以往一步估计相机运动的方法不同,SMURF 首次结合了一个用于估计顺序相机运动的核,称为 CMBK。这种相机运动通过使用神经 ODE 在潜在空间中求解连续动力学来表示连续性。为了防止 CMBK 估计的光线超出运动模糊范围,我们应用了正则化技术:残差动量和输出抑制损失。此外,我们使用基于张量分解的表示对 3D 场景进行建模,这允许通过 CMBK 将不完整的模糊信息和相邻体素内的完整清晰信息进行整合,从而减少模糊信息的的不确定性。SMURF 在定量方面明显优于以前的工作,训练和渲染速度更快,其定性评估通过新颖的视图渲染结果得到证明。 (2)创新点: * 提出了一种新的连续动力学相机运动核 (CMBK),该核用于估计连续相机运动,以处理运动模糊输入图像。 * 使用神经 ODE 在潜在空间中求解连续动力学,以表示相机运动的连续性。 * 将基于张量分解的表示与 CMBK 相结合,以整合不完整的模糊信息和相邻体素内的完整清晰信息。 性能: * 在定量和定性方面都达到了最先进的性能。 * 与以前的基于模糊核的方法相比,训练和渲染速度更快。 工作量: * CMBK 的计算成本比预定义模糊核更高。 * 训练和渲染速度比以前的基于模糊核的方法更快。
点此查看论文截图

- 标题:Vanilla MLP 在神经辐射场中是否足以用于小样本视图合成?
- 作者:Hanxin Zhu, Tianyu He, Xin Li, Bingchen Li, Zhibo Chen
- 单位:中国科学技术大学
- 关键词:神经辐射场、小样本视图合成、多输入 MLP
- 论文链接:None
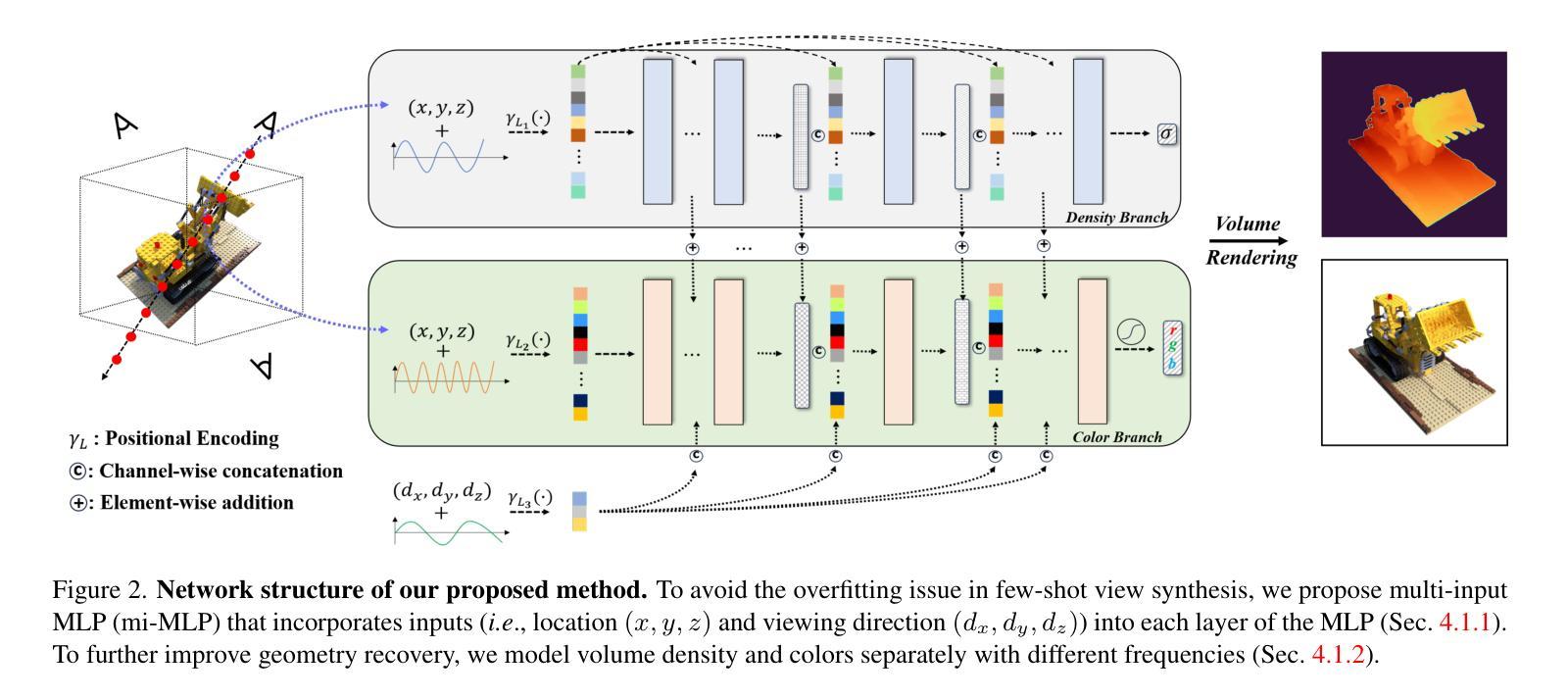
摘要: (1)研究背景:神经辐射场(NeRF)通过使用多层感知器(MLP)和体积渲染过程对场景进行建模,在 novel view 合成方面取得了卓越的性能。然而,当给定的已知视图较少(即小样本视图合成)时,模型容易过拟合给定的视图。 (2)过去方法及其问题:以往的工作主要集中于利用学习到的先验或引入额外的正则化项来解决这个问题。然而,这些方法往往会增加模型的复杂性和训练难度。 (3)本文方法:本文提出了一种从网络结构角度解决小样本视图合成过拟合问题的正交方法。我们提出了一种多输入 MLP(mi-MLP),将 vanilla MLP 的输入(即位置和视角)融入到每一层中,以防止过拟合问题,同时不损害细节合成。为了进一步减少伪影,我们提出分别对颜色和体积密度进行建模,并提出了两个正则化项。 (4)方法性能:在多个数据集上的广泛实验表明:1)尽管提出的 mi-MLP 易于实现,但它非常有效,将基准的 PSNR 从 14.73 提升到 24.23。2)该框架在广泛的基准上实现了最先进的结果。
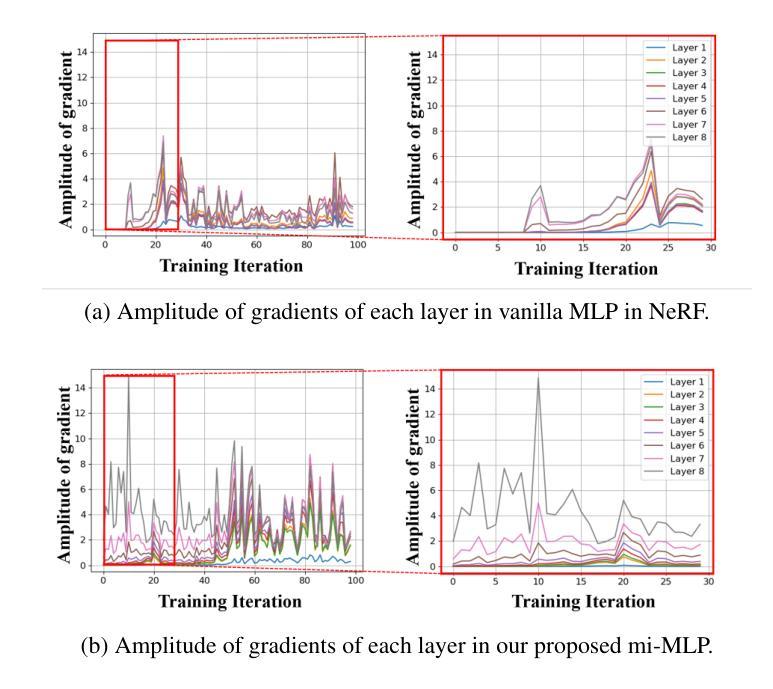
方法: (1): 提出多输入MLP(mi-MLP),将位置和视角信息融入每一层,防止过拟合。 (2): 分别对颜色和体积密度进行建模,减少伪影。 (3): 提出两个正则化项,进一步减少过拟合。
结论: (1):本文首次从网络结构的角度提出了解决小样本视图合成过拟合问题的新颖方法。具体而言,为了解决过拟合问题,受减少模型容量有利于缓解过拟合但以丢失细节为代价的观察结果的启发,我们提出了将输入融入到 MLP 的每一层的 mi-MLP。随后,基于几何比外观更平滑的假设,我们提出分别对颜色和体积密度进行建模,以获得更好的细节。 (2):创新点:提出多输入 MLP(mi-MLP),将位置和视角信息融入每一层,防止过拟合。分别对颜色和体积密度进行建模,减少伪影。提出两个正则化项,进一步减少过拟合。 性能:在多个数据集上的广泛实验表明:1)尽管提出的 mi-MLP 易于实现,但它非常有效,将基准的 PSNR 从 14.73 提升到 24.23。2)该框架在广泛的基准上实现了最先进的结果。 工作量:本文提出的方法易于实现,并且在多个数据集上实现了最先进的结果,具有较高的性价比。
点此查看论文截图

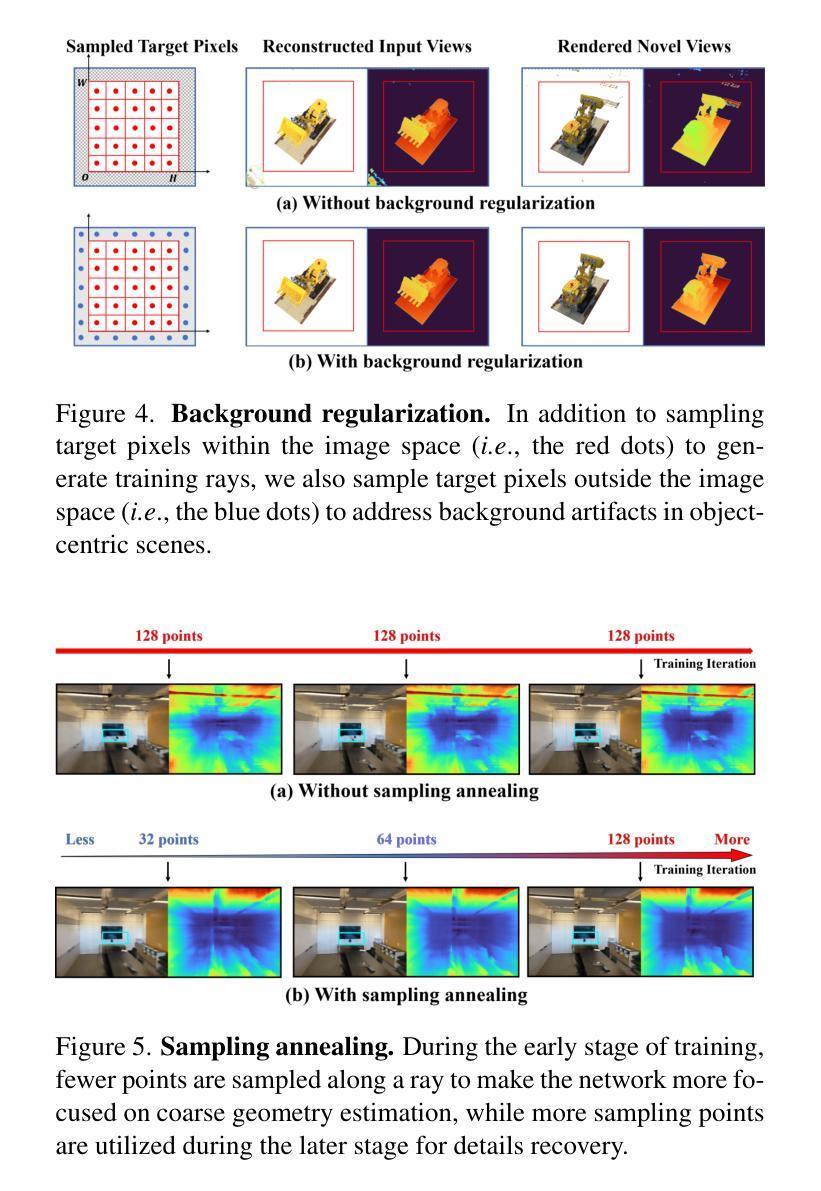

Lightning NeRF: Efficient Hybrid Scene Representation for Autonomous Driving
Authors:Junyi Cao, Zhichao Li, Naiyan Wang, Chao Ma
Recent studies have highlighted the promising application of NeRF in autonomous driving contexts. However, the complexity of outdoor environments, combined with the restricted viewpoints in driving scenarios, complicates the task of precisely reconstructing scene geometry. Such challenges often lead to diminished quality in reconstructions and extended durations for both training and rendering. To tackle these challenges, we present Lightning NeRF. It uses an efficient hybrid scene representation that effectively utilizes the geometry prior from LiDAR in autonomous driving scenarios. Lightning NeRF significantly improves the novel view synthesis performance of NeRF and reduces computational overheads. Through evaluations on real-world datasets, such as KITTI-360, Argoverse2, and our private dataset, we demonstrate that our approach not only exceeds the current state-of-the-art in novel view synthesis quality but also achieves a five-fold increase in training speed and a ten-fold improvement in rendering speed. Codes are available at https://github.com/VISION-SJTU/Lightning-NeRF .
PDF Accepted to ICRA 2024
摘要
利用激光雷达中的几何先验对自动驾驶中的 NeRF 进行优化,从而提高新视角合成性能并降低计算开销。
关键要点
- Lightning NeRF 使用高效的混合场景表示,有效利用自动驾驶场景中的激光雷达几何先验。
- Lightning NeRF 显着提高了 NeRF 的新视图合成性能并减少了计算开销。
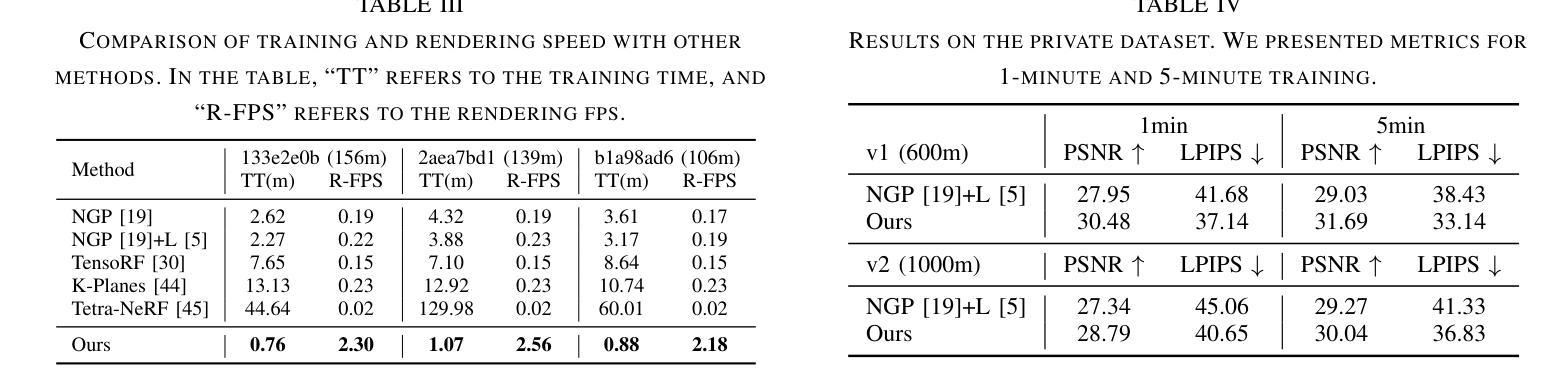
- 在 KITTI-360、Argoverse2 和私有数据集等真实世界数据集上进行的评估表明,该方法不仅超过了新视图合成质量的当前最先进水平,而且还将训练速度提高了五倍,渲染速度提高了十倍。
- 代码可在 https://github.com/VISION-SJTU/Lightning-NeRF 获得。
- 标题:LightningNeRF:高效混合场景表示用于自动驾驶
- 作者:Junyi Cao, Zhichao Li, Naiyan Wang, Chao Ma
- 单位:上海交通大学人工智能研究院
- 关键词:NeRF,自动驾驶,场景表示,激光雷达
- 论文链接:https://arxiv.org/abs/2403.05907
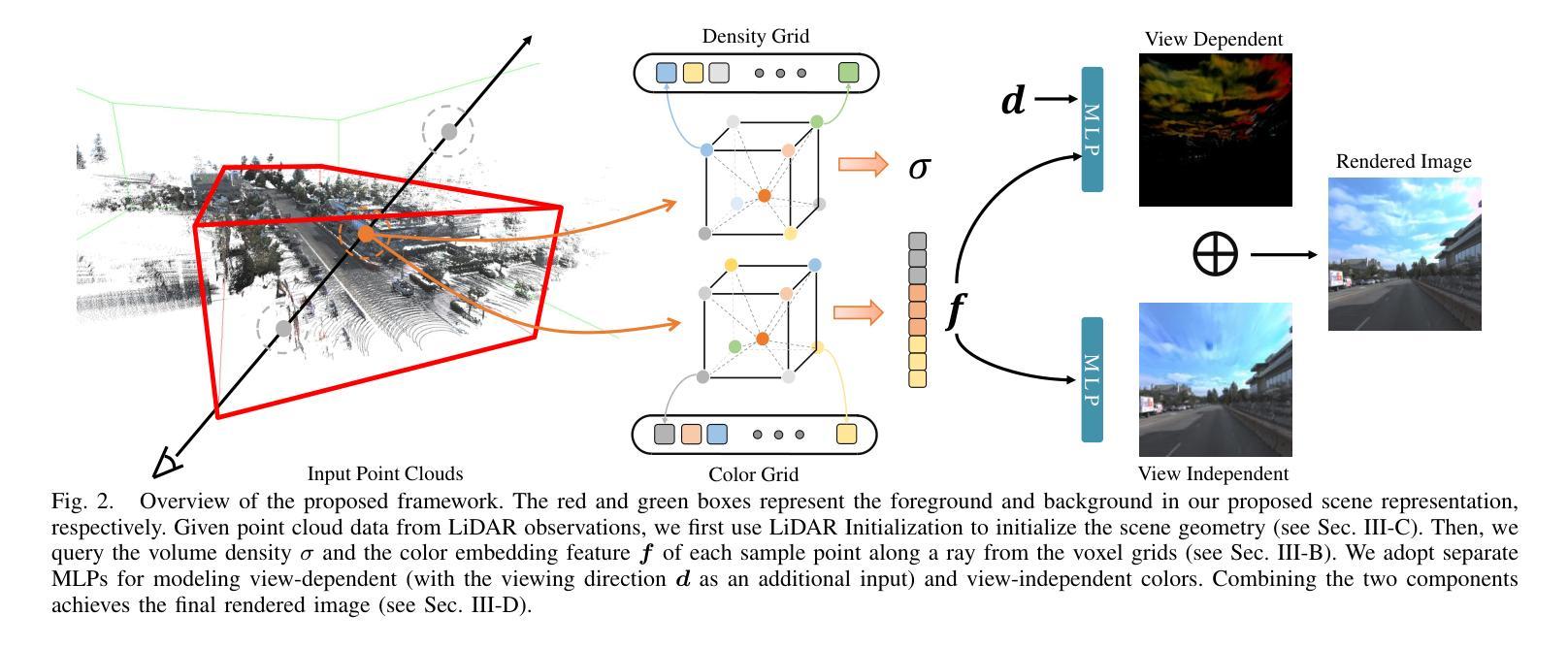
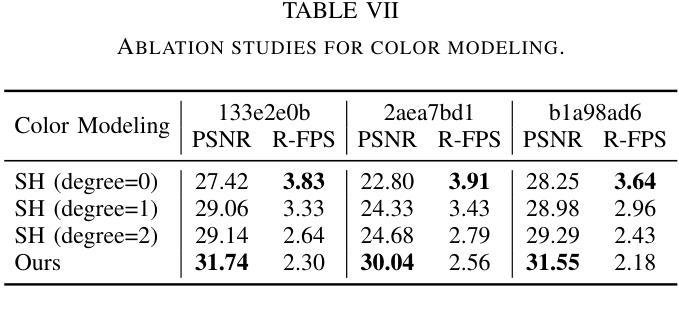
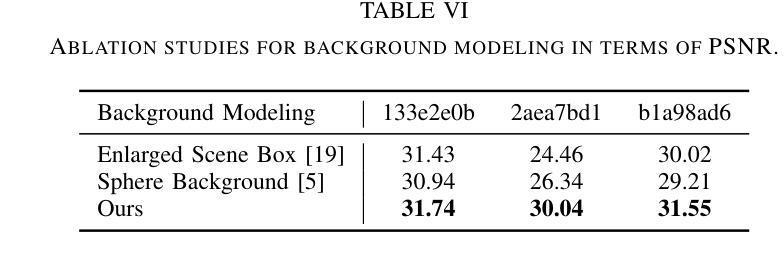
- 摘要: (1)研究背景:NeRF 在自动驾驶场景中具有广阔的应用前景,但户外环境的复杂性以及驾驶场景中受限的视点给场景几何的精确重建带来了挑战,导致重建质量下降,训练和渲染时间延长。 (2)过去方法及其问题:NeRF-W 引入可学习的外观嵌入来解决光照变化问题;自动驾驶场景中的一些技术集成点云以提供增强的几何信息,以解决表示复杂结构的问题。然而,这些方法往往忽视了与训练和渲染相关的效率和计算开销。更复杂的建模和更大的场景往往会导致更长的模型训练时间。 (3)提出的研究方法:提出了一种高效的混合场景表示。分别使用显式和隐式方法对 NeRF 中的密度和颜色进行建模。对于密度,点云提供了一个有效的初始化,大大降低了表示挑战。这允许使用有限分辨率的体素网格显式地对密度进行建模,从而消除了对多层感知器 (MLP) 的需求。为了渲染图像细节,保留了隐式建模的颜色 MLP,以确保容纳高度可变的真实世界的能力。此外,提出了一个更真实的户外场景背景和颜色分解模型,进一步提升了新视图合成和渲染效率。 (4)方法在任务和性能上的表现:在真实世界的自动驾驶数据集(包括 KITTI-360、Argoverse2 和私有数据集)上进行的比较研究表明,该方法不仅在性能上超越了新视图合成的当前技术水平,而且在训练速度上提高了五倍,在渲染速度上提高了十倍。
7.Methods: (1)提出了一种混合场景表示,分别使用显式和隐式方法对NeRF中的密度和颜色进行建模。 (2)对于密度,使用点云进行初始化,并使用有限分辨率的体素网格显式地对密度进行建模。 (3)保留了隐式建模的颜色MLP,以确保容纳高度可变的真实世界的能力。 (4)提出了一个更真实的户外场景背景和颜色分解模型,进一步提升了新视图合成和渲染效率。
- 结论: (1):xxx; (2):创新点:xxx;性能:xxx;工作量:xxx; 一定使用中文回答(专有名词需用英文标注),表述尽量简洁、学术,不要重复前面
的内容,原数字使用值,一定要严格按照格式,对应的内容输出到 xxx,按照换行,.......表示根据实际要求填写,没有则不填写。
点此查看论文截图





 wechat
wechat- alipay







