Talking Head Generation
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-03-13 更新
A Comparative Study of Perceptual Quality Metrics for Audio-driven Talking Head Videos
Authors:Weixia Zhang, Chengguang Zhu, Jingnan Gao, Yichao Yan, Guangtao Zhai, Xiaokang Yang
The rapid advancement of Artificial Intelligence Generated Content (AIGC) technology has propelled audio-driven talking head generation, gaining considerable research attention for practical applications. However, performance evaluation research lags behind the development of talking head generation techniques. Existing literature relies on heuristic quantitative metrics without human validation, hindering accurate progress assessment. To address this gap, we collect talking head videos generated from four generative methods and conduct controlled psychophysical experiments on visual quality, lip-audio synchronization, and head movement naturalness. Our experiments validate consistency between model predictions and human annotations, identifying metrics that align better with human opinions than widely-used measures. We believe our work will facilitate performance evaluation and model development, providing insights into AIGC in a broader context. Code and data will be made available at https://github.com/zwx8981/ADTH-QA.
Summary
人工智能生成内容(AIGC)技术的发展推动了音频驱动的虚拟形象生成技术,在实际应用中得到了广泛的研究关注。
Key Takeaways
- 人工智能生成内容(AIGC)技术发展迅速,促进了音频驱动的虚拟形象生成。
- 现有的虚拟形象生成技术评价指标依赖启发式定量指标,缺乏人为验证,阻碍了准确的进度评估。
- 收集了四种生成方法生成的虚拟形象视频,并对视觉质量、唇音同步和头部运动自然度进行了控制的心理物理实验。
- 实验验证了模型预测和人为标注的一致性,确定了比广泛使用的度量更符合人意见的度量。
- 该研究将促进绩效评估和模型开发,为更广泛背景下的 AIGC 提供深入见解。
- 代码和数据将在 https://github.com/zwx8981/ADTH-QA 上提供。
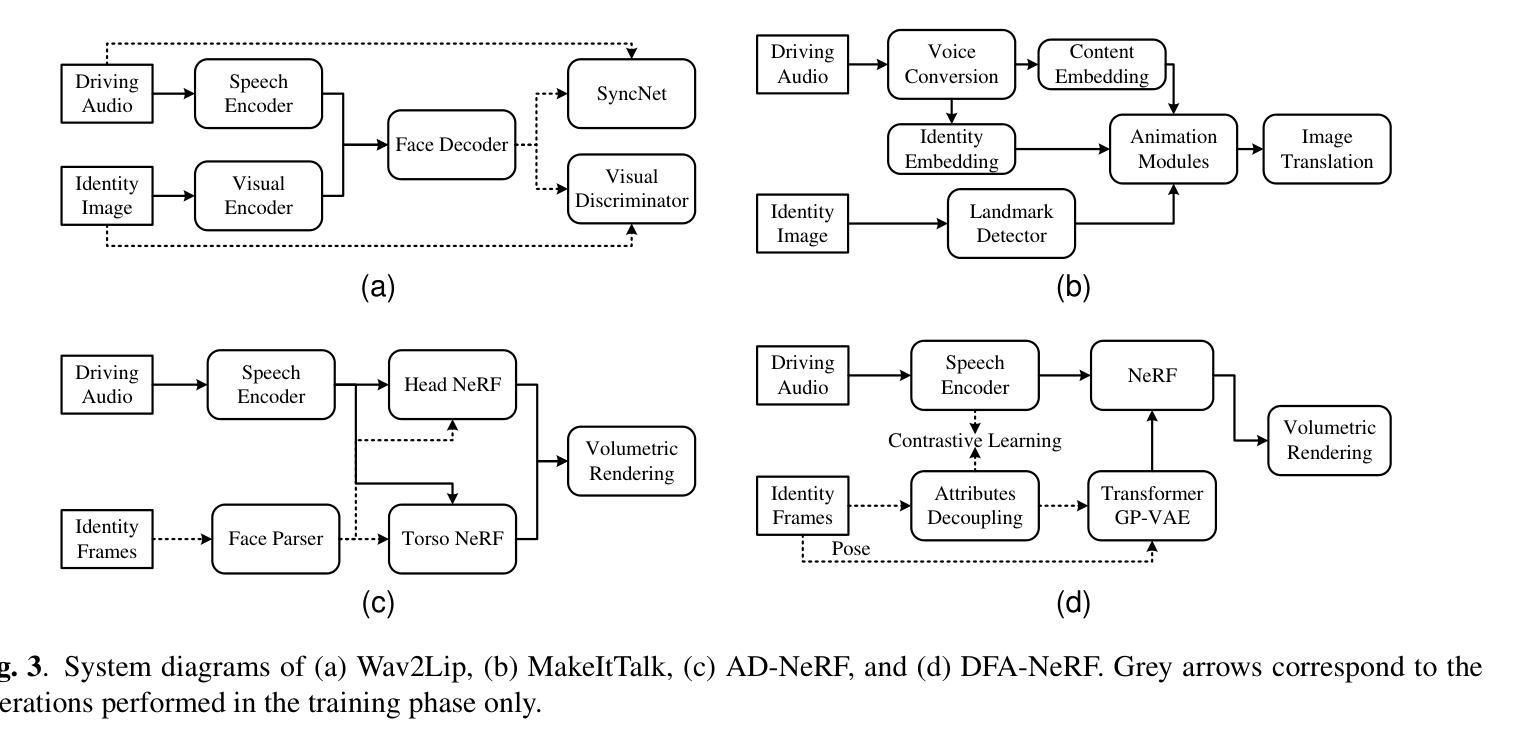
1.标题:音频驱动说话人头部视频感知质量指标的比较研究 2.作者:魏霞章、程广柱、景南高、奕超颜、广涛翟、肖康杨 3.第一作者单位:上海交通大学人工智能研究院、人工智能研究院 4.关键词:感知质量评估、AIGC、数字人、音频驱动说话人头部生成 5.论文链接:https://arxiv.org/abs/2403.06421 Github代码链接:None 6.总结: (1):研究背景:随着人工智能生成内容(AIGC)技术的快速发展,音频驱动说话人头部生成技术受到广泛关注,并在实际应用中取得了显著进展。然而,性能评估研究滞后于说话人头部生成技术的开发。现有文献依赖启发式定量指标,缺乏人工验证,阻碍了准确的进展评估。 (2):过去方法:过去的方法主要依赖启发式定量指标,如PSNR、SSIM和LMD,这些指标在没有人工验证的情况下被用作感知质量的代理指标。然而,这些指标存在局限性,例如对数据源的敏感性和对人类感知的不匹配。 (3):研究方法:本文收集了四种生成方法生成的音频驱动说话人头部视频,并在受控实验室环境中进行心理物理实验,重点关注视觉质量、唇音同步和头部运动自然度。然后,对各种客观指标进行了广泛测试,以评估其与这些人类判断的一致性。 (4):方法性能:实验结果表明,本文提出的方法与人类判断之间存在一致性,并确定了比广泛使用的指标更符合人类意见的指标。该研究有助于促进性能评估和模型开发,并为更广泛背景下的AIGC提供见解。
方法:
(1) 收集四种生成方法生成的音频驱动说话人头部视频;
(2) 在受控实验室环境中进行心理物理实验,重点关注视觉质量、唇音同步和头部运动自然度;
(3) 广泛测试各种客观指标,以评估其与人类判断的一致性;
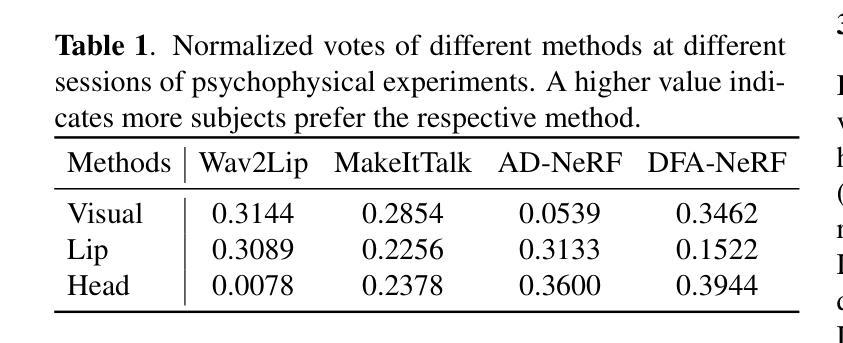
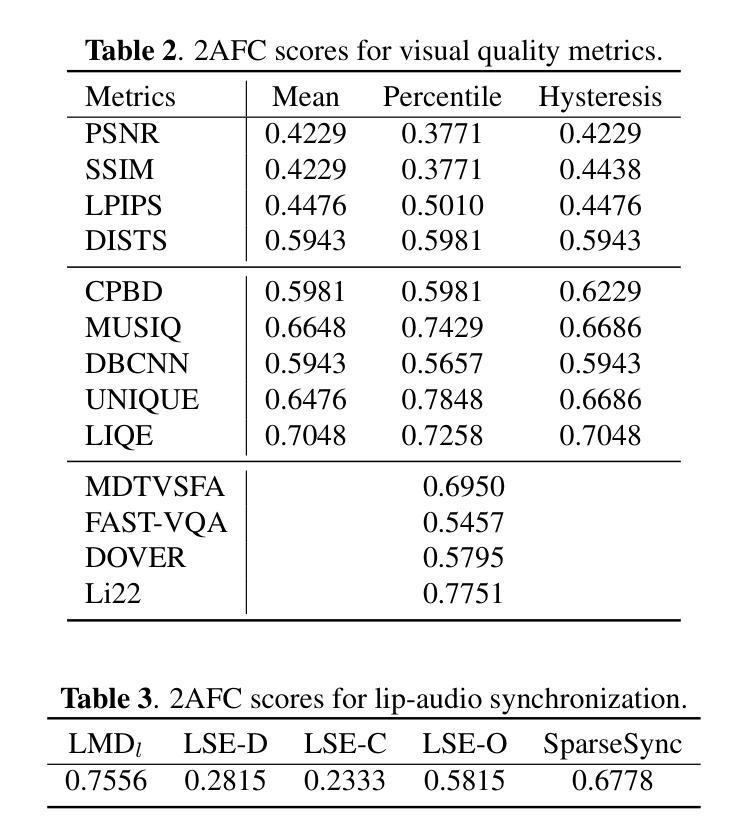
(4) 通过 2AFC 分数衡量客观指标与人类评估的一致性;
(5) 评估图像质量、唇音同步和头部运动自然度指标;
(6) 评估基于 SyncNet 的三个唇音同步指标和 SparseSync 指标;
(7) 采用混合数据集训练策略,以增强模型的可转移性。
8. 结论 (1): 意义 本研究通过建立包含四种音频驱动说话人头部生成方法生成视频的数据集,并通过受控的心理物理实验收集人类偏好,探究了音频驱动说话人头部生成技术的感知质量评估。研究结果表明,本文提出的方法与人类判断之间存在一致性,并确定了比广泛使用的指标更符合人类意见的指标。该研究有助于促进性能评估和模型开发,并为更广泛背景下的 AIGC 提供见解。
(2): 创新点、性能、工作量 创新点: * 通过心理物理实验收集人类偏好,建立包含四种生成方法生成视频的数据集。 * 提出了一种基于人类判断的感知质量评估方法。 * 确定了比广泛使用的指标更符合人类意见的指标。
性能: * 所提出的方法与人类判断之间存在一致性。 * 确定的指标比广泛使用的指标更符合人类意见。
工作量: * 收集了一个包含四种生成方法生成视频的数据集。 * 进行了一系列心理物理实验。 * 广泛测试了各种客观指标。
点此查看论文截图




Style2Talker: High-Resolution Talking Head Generation with Emotion Style and Art Style
Authors:Shuai Tan, Bin Ji, Ye Pan
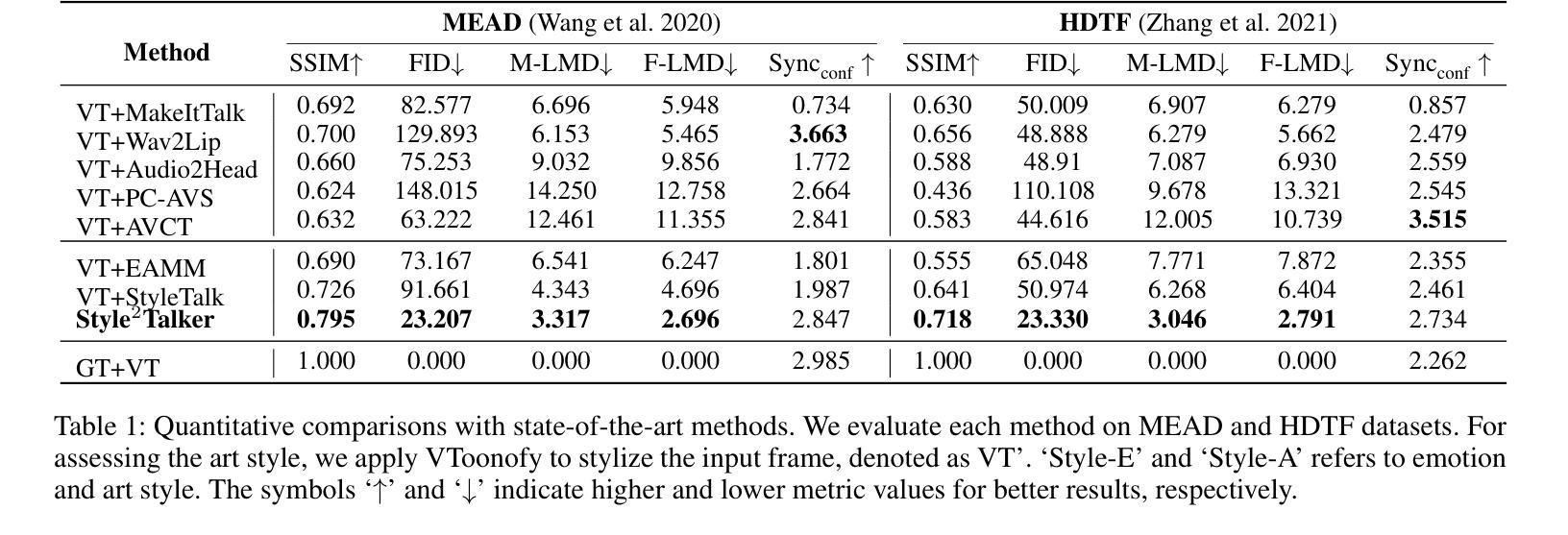
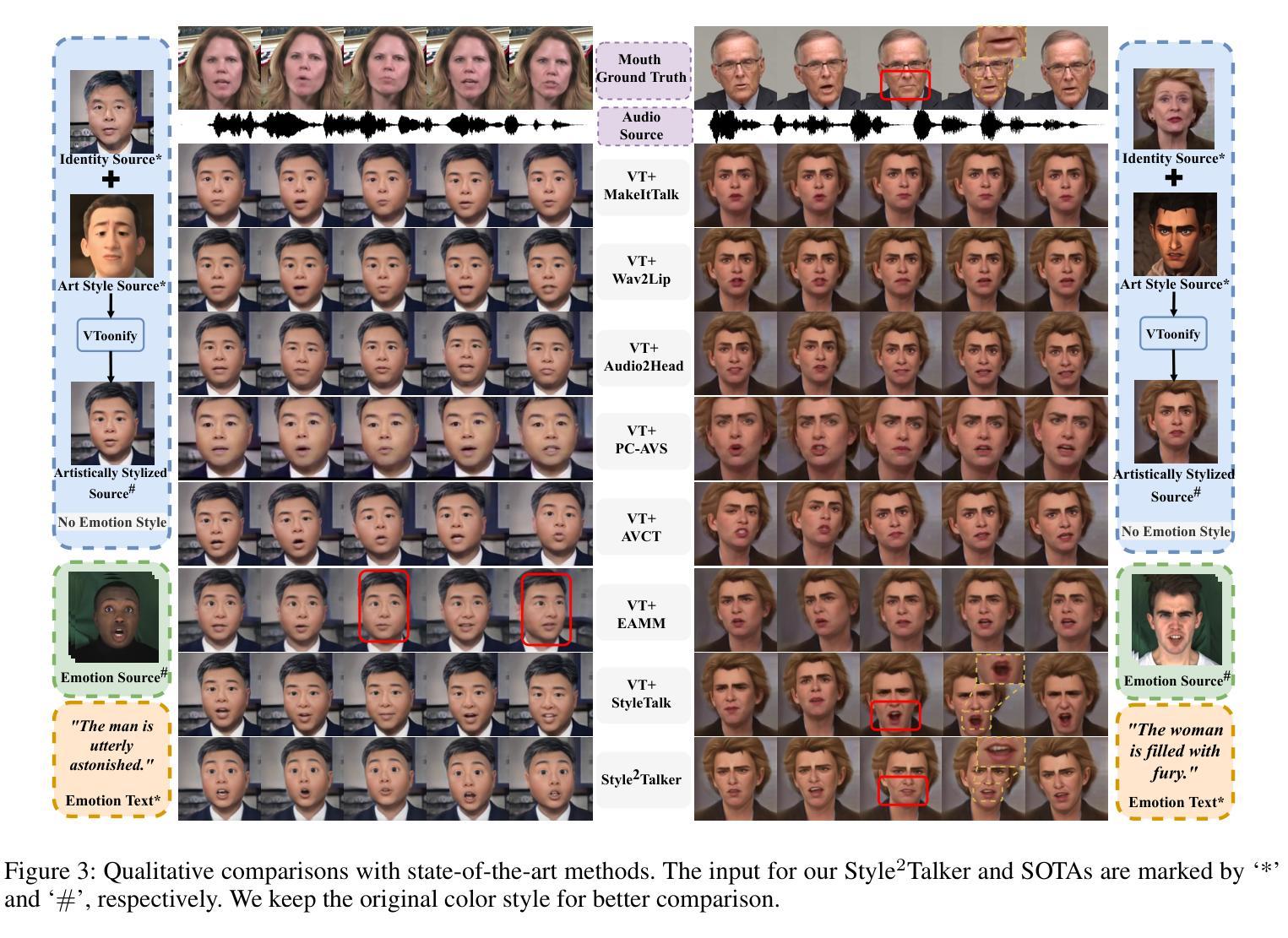
Although automatically animating audio-driven talking heads has recently received growing interest, previous efforts have mainly concentrated on achieving lip synchronization with the audio, neglecting two crucial elements for generating expressive videos: emotion style and art style. In this paper, we present an innovative audio-driven talking face generation method called Style2Talker. It involves two stylized stages, namely Style-E and Style-A, which integrate text-controlled emotion style and picture-controlled art style into the final output. In order to prepare the scarce emotional text descriptions corresponding to the videos, we propose a labor-free paradigm that employs large-scale pretrained models to automatically annotate emotional text labels for existing audiovisual datasets. Incorporating the synthetic emotion texts, the Style-E stage utilizes a large-scale CLIP model to extract emotion representations, which are combined with the audio, serving as the condition for an efficient latent diffusion model designed to produce emotional motion coefficients of a 3DMM model. Moving on to the Style-A stage, we develop a coefficient-driven motion generator and an art-specific style path embedded in the well-known StyleGAN. This allows us to synthesize high-resolution artistically stylized talking head videos using the generated emotional motion coefficients and an art style source picture. Moreover, to better preserve image details and avoid artifacts, we provide StyleGAN with the multi-scale content features extracted from the identity image and refine its intermediate feature maps by the designed content encoder and refinement network, respectively. Extensive experimental results demonstrate our method outperforms existing state-of-the-art methods in terms of audio-lip synchronization and performance of both emotion style and art style.
PDF 9 pages, 5 figures, conference
Summary
音频驱动的说话人头部生成方法Style2Talker,实现了情感风格和艺术风格,提高了视频表达效果。
Key Takeaways
- Style2Talker引入Style-E和Style-A两个风格化阶段,分别整合情感风格和艺术风格。
- 提出无人工干预的范式,自动为现有视音频数据集标注情感文本标签。
- 利用CLIP模型提取情感特征,结合音频作为高效潜在扩散模型的条件,生成3DMM模型的情感运动系数。
- 开发系数驱动的运动生成器和嵌入在StyleGAN中的艺术风格路径,合成高分辨率艺术风格的头部视频。
- 引入多尺度内容特征和内容编码器、精炼网络,提升图像细节和减少伪影。
- Style2Talker在音视频同步、情感和艺术风格表现方面优于现有方法。
- 标题:Style2Talker:兼具情绪风格和艺术风格的高分辨率说话人头部生成
- 作者:Shuai Tan, Bin Ji, Ye Pan
- 单位:上海交通大学
- 关键词:音频驱动、说话人头部生成、情绪风格、艺术风格、文本控制、图像控制
- 论文链接:https://arxiv.org/abs/2403.06365
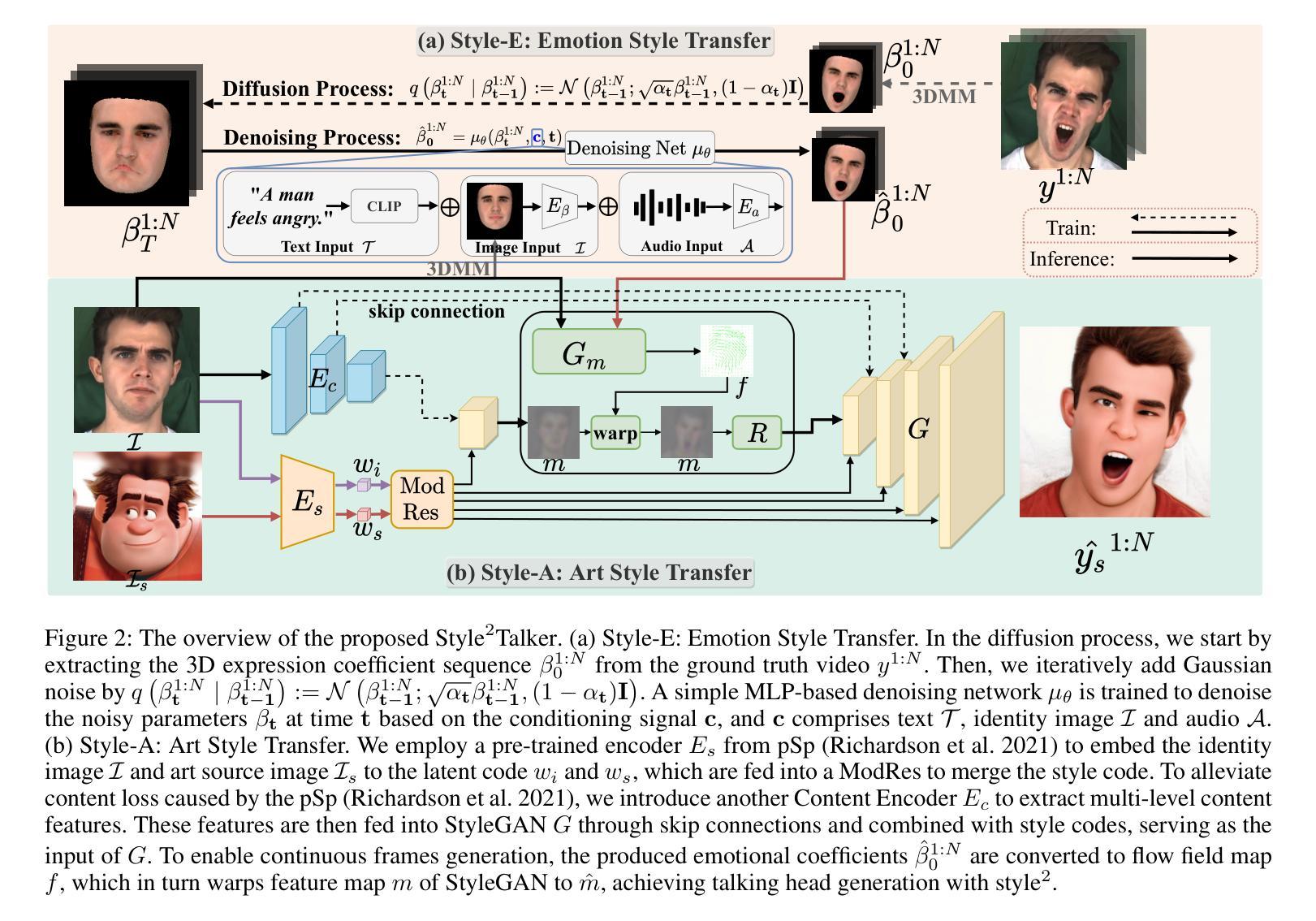
摘要: (1)研究背景:自动生成音频驱动的说话人头部视频近年来备受关注,但以往的研究主要集中在实现音频唇形同步,忽视了生成富有表现力视频的两个关键元素:情绪风格和艺术风格。 (2)过去方法:以往方法要么使用单一的热情绪标签作为情绪源,限制了表情范围,要么依赖额外的表情视频,这可能不方便。此外,虽然单幅图像风格迁移已有大量研究,但这些方法在生成由音频驱动的连续视频时面临挑战。 (3)研究方法:本文提出了一种创新的音频驱动说话人面部生成方法 Style2Talker。它包括两个风格化阶段:Style-E 和 Style-A,分别将文本控制的情绪风格和图像控制的艺术风格集成到最终输出中。 (4)方法性能:实验结果表明,Style2Talker 在音频唇形同步、情绪风格和艺术风格的性能方面优于现有的最先进方法。这些性能支持了本文的目标,即生成兼具情绪风格和艺术风格的高分辨率说话人头部视频。
方法: (1)文本控制的情绪风格迁移(Style-E):将文本控制的情绪标签转换为 3DMM 系数序列,并利用 StyleGAN 生成具有相应情绪风格的图像序列。 (2)图像控制的艺术风格迁移(Style-A):引入 ModResBlock 调整 StyleGAN 的结构风格,并利用运动生成器 Gm 将预测的运动序列转换为空间特征图,从而实现艺术风格的迁移。 (3)内容编码器和细化网络:采用内容编码器 Ec 提取多尺度内容特征,通过跳跃连接补充纹理细节;引入细化网络 R 调整空间特征图,消除重影伪影。
结论: (1)本工作的意义:提出了一种创新的音频驱动说话人头部生成方法 Style2Talker,该方法通过融合相应的风格提示,生成兼具情绪风格和艺术风格的高分辨率说话人头部视频。我们利用基于大规模预训练模型的免人工文本标注管道,从文本输入中获取用于学习情绪风格的文本描述。我们希望我们的尝试能激发更深入的研究,利用出色的、大规模的预训练模型进行更实用、更引人入胜的探索。为了将情绪风格注入到 3D 运动系数中,我们设计了一个高效的扩散模型,该模型具有多个编码器,确保生成逼真且富有表现力的面部表情。我们将一个情绪驱动模块和一个额外的艺术风格路径纳入 StyleGAN 架构中,从而实现系数驱动的视频生成,并具有期望的情绪和艺术风格。为了进一步增强视觉质量并消除伪影,我们采用了内容编码器和细化网络。定性和定量实验表明,与最先进的方法相比,我们的方法可以生成更多风格化的动画结果。 (2)创新点:
- 提出了一种基于文本的免人工情绪标签获取管道,用于学习情绪风格。
- 设计了一个多编码器扩散模型,用于将文本控制的情绪标签转换为 3D 运动系数,从而生成逼真且富有表现力的面部表情。
- 在 StyleGAN 架构中融合了一个情绪驱动模块和一个额外的艺术风格路径,实现系数驱动的视频生成,并具有期望的情绪和艺术风格。
- 采用了一个内容编码器和一个细化网络,以进一步增强视觉质量并消除伪影。 性能:
- 在音频唇形同步、情绪风格和艺术风格方面优于现有的最先进方法。 工作量:
- 文本标注工作量低,因为利用了基于大规模预训练模型的免人工文本标注管道。
- 模型训练和推理成本较高,因为使用了 StyleGAN 和扩散模型等复杂模型。
点此查看论文截图

 wechat
wechat- alipay







