SyncTalk实验笔记
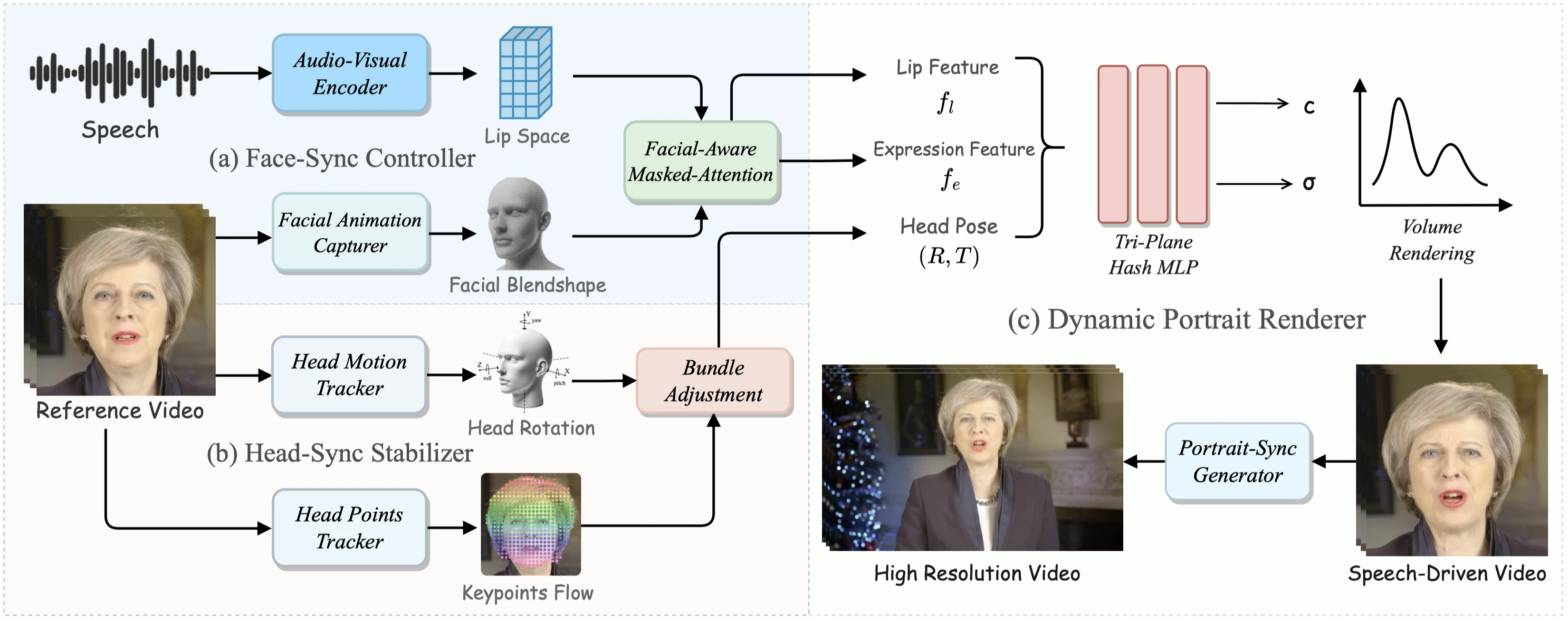
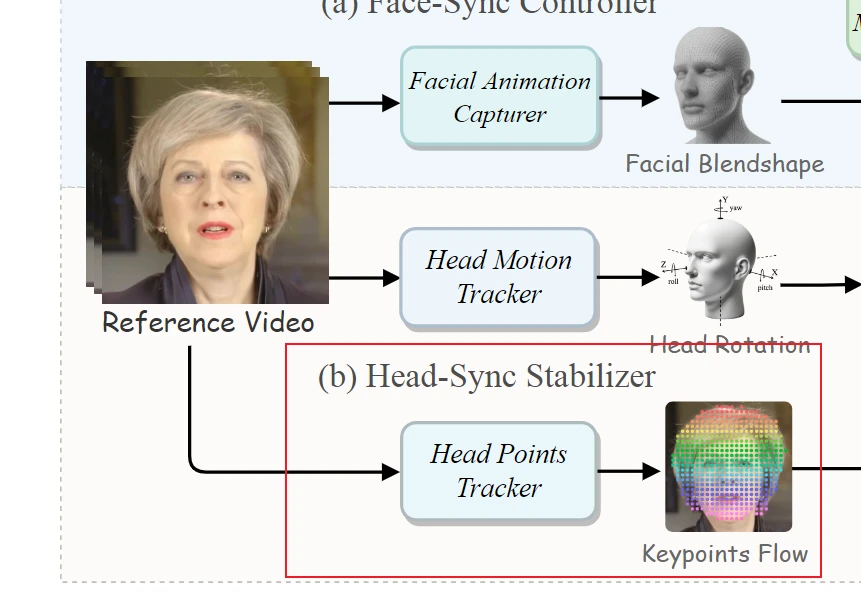
Face-Sync Controller
Facial Animation Capturer
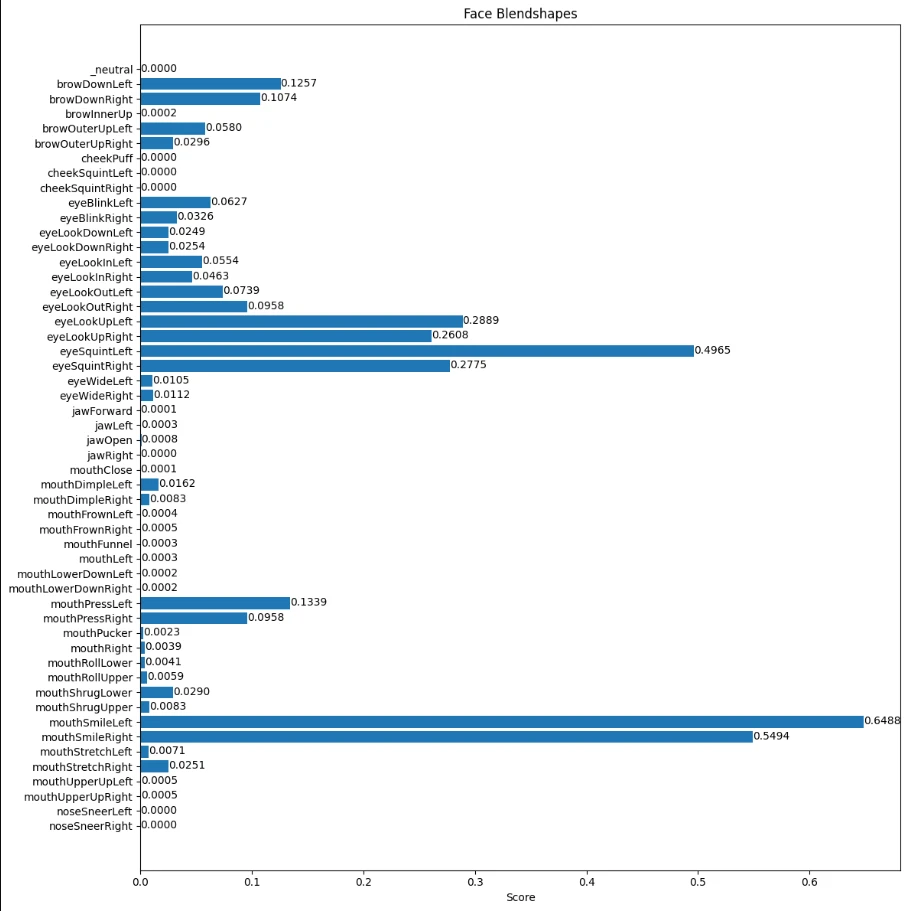
Blendshape的提取可参考

Head-Sync Stabilizer
Head Motion Tracker
头部姿势,表示为 p,是指人的头部在 3D 空间中的旋转角度,由旋转 R 和平移 T 定义。
不稳定的头部姿势会导致头部抖动,所以为了获得头部姿势的粗略估计。首先,通过在预定范围内迭代 i 次来确定最佳焦距,对于每个焦距候选 fi,重新初始化旋转和平移值,目标是最小化 3D 可变形模型 (3DMM) 的投影地标与视频帧中的实际地标之间的误差。
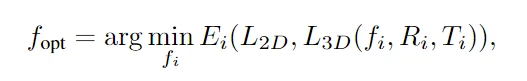
其中 $E_i$ 表示的就是 MSE,这样能够以更好地将模型的投影 lmk 与实际视频 lmk 对齐,然后得到最优的旋转和平移矩阵,也是用 MSE 来最小化,这是对每一帧进行操作的,在对应视频帧的最优值。
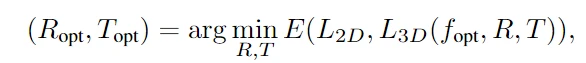
这一部分实际上和原来的代码差别不大,可以调整一下所有帧和对应的优化部分,比如600~1500的步长可以设置为50,原本是100,因为结果也发现是1350

Head Points Tracker
对于之前基于 NeRF 的方法来说,先前的方法利用基于 3DMM 的技术来提取头部姿势并生成不准确的结果。为了提高 R 和 T 的精度,我们使用像 Co- tracker 这样的光流估计模型来跟踪面部关键点 K。

接下来,使用预训练的光流估计模型,在获取面部运动光流后,我们使用拉普拉斯滤波器选择位于最显著流变化位置的关键点,并在流序列中跟踪这些关键点的运动轨迹。通过这个模块确保了所有帧上的面部关键点对齐更加精确和一致,从而增强了头部姿势参数的准确性。
Bundle Adjustment
根据关键点和粗略的头部姿势,引入了一个两阶段优化框架来提高关键点和头部姿势估计的准确性。
- 第一阶段,随机初始化 j 个关键点的 3D 坐标并优化它们的位置,以便与图像平面上跟踪的关键点对齐。这一部分最小化损失函数 $L_{init}$,捕获投影关键点 P 和跟踪关键点 K 之间的差异:
- 第二阶段,开始进行更全面的优化,以细化 3D 关键点和相关的头部联合姿势参数,通过 Adam 优化器优化算法,调整空间坐标、旋转角度 R 和平移 T 以最小化对齐误差 $L_{sec}$,表示为:
经过这些优化后,观察到所得的头部姿势和平移参数平滑且稳定。
现在的面部跟踪技术(Face Tracking)通常结合了多种算法和技术,以实现对视频中人脸的实时和准确跟踪。以下是一些关键的技术和方法,它们被广泛应用于现代面部跟踪系统中:
合成分析法(Analysis-by-Synthesis):
这种方法通过创建一个人脸模型,并将其拟合到视频中的每一帧,以实现跟踪。初始化阶段通常通过最小化人脸关键点的重投影误差来获得初始人脸参数。这种方法可以处理光照变化和遮挡问题,提高跟踪的鲁棒性和准确性。基于模型跟踪:
这种方法依赖于预先定义的人脸模型,通过调整模型参数来适应视频中的人脸。这包括使用形状模型(如Active Shape Models)和外观模型来捕捉人脸的几何和外观变化。基于运动信息跟踪:
利用视频中的运动信息来预测和跟踪人脸的移动。这种方法通常结合了光流算法或其他运动估计技术。基于人脸局部特征跟踪:
通过检测和跟踪人脸的局部特征(如眼睛、鼻子、嘴巴等)来实现跟踪。这些特征点可以提供关于人脸姿态和表情变化的详细信息。基于神经网络跟踪:
利用深度学习模型,尤其是卷积神经网络(CNN),来识别和跟踪人脸。这些模型可以学习从大量数据中提取复杂的面部特征,并在各种条件下保持高准确度。实时人脸跟踪算法:
为了在实时视频流中实现人脸跟踪,算法需要高效且能够快速处理连续帧。一些成熟的SDK,如OpenCV,提供了实时人脸检测和跟踪的功能。多人脸跟踪(Multi-face tracking):
在多人场景中,跟踪技术需要能够同时识别和跟踪多个面部。这通常涉及到更复杂的算法,如FairMOT,它是一种单类多目标跟踪算法,可以根据需求修改为多类多目标跟踪。非刚性人脸跟踪:
考虑到人脸的非刚性特性,一些跟踪算法会使用非刚性模型来更好地适应面部表情和头部动作的变化。在实际应用中,面部跟踪系统可能会结合以上多种方法,以提高在不同环境和条件下的跟踪性能。例如,一个系统可能会首先使用基于模型的方法来初始化跟踪,然后切换到基于特征的方法来处理面部表情变化,同时利用神经网络来提高在复杂背景下的跟踪准确性。
AD-NeRF
(2)我们应用多帧光流估计方法[18]来获得前额、耳朵和头发等近刚性区域中视频帧的密集对应关系,然后使用束调整来估计姿势参数[2]。 值得注意的是,估计的姿势仅对面部部分有效,而对颈部和肩部等身体其他区域无效,即面部姿势不能代表上半身的全部运动;

Portrait-Sync Generator
代码改进一共只有几部分
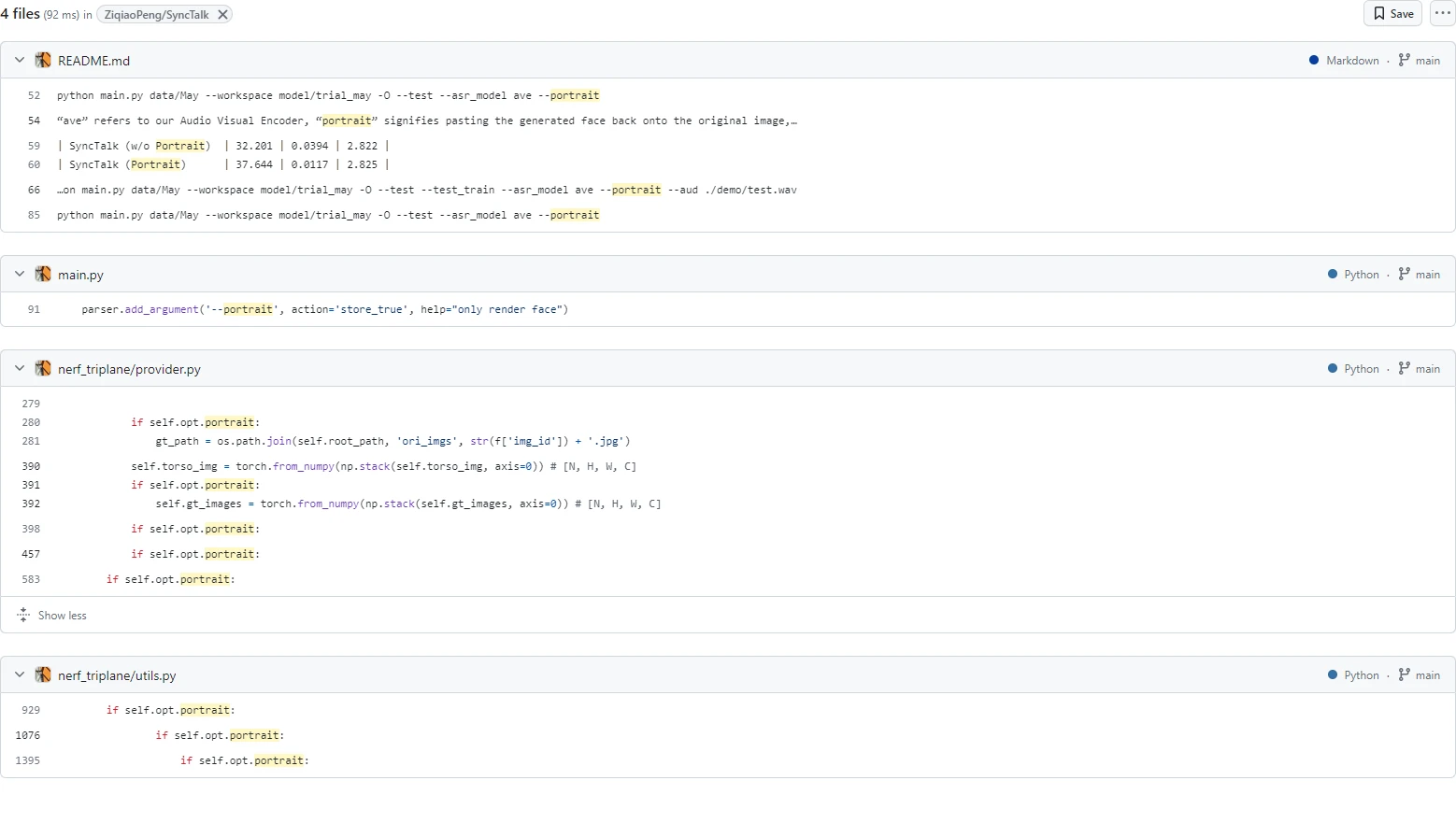
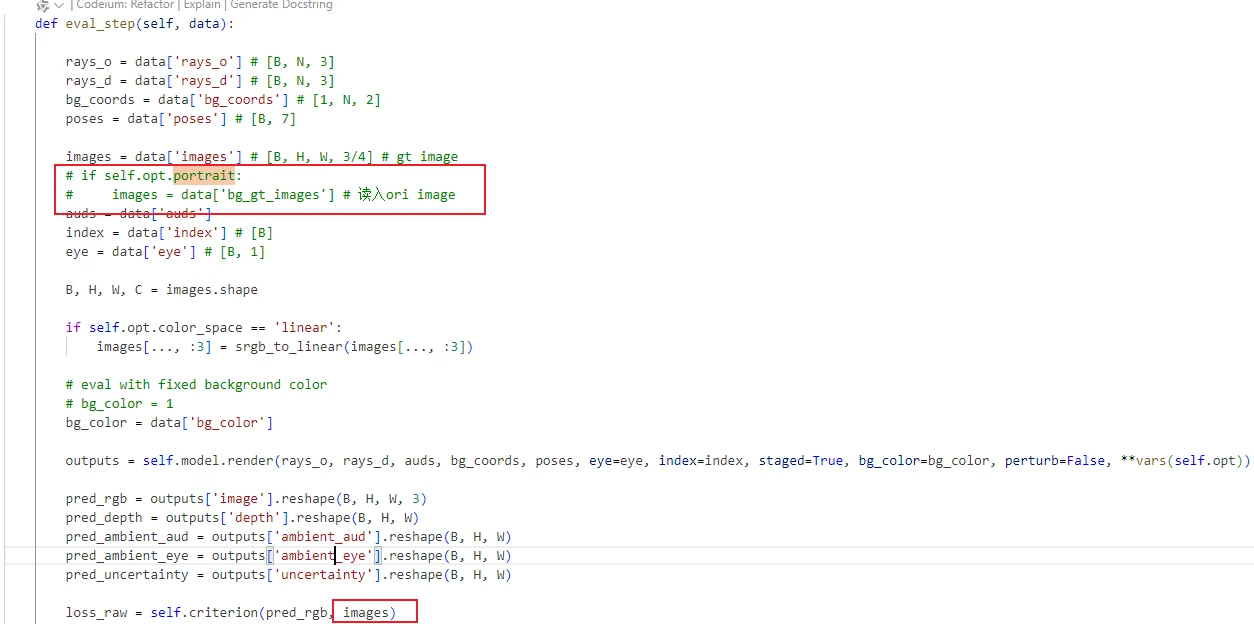
在数据读取的时候,加了face_mask的读取,以及bg_image的读取,也就是GT Image的读取,对于GT Image来说,是通过parsing去出对应部分来进行操作的,从下图也可以看出区别,也就是有无头发丝的细节部分

指标可能有两个GT,因为两种模式下,对应的计算指标是不同的
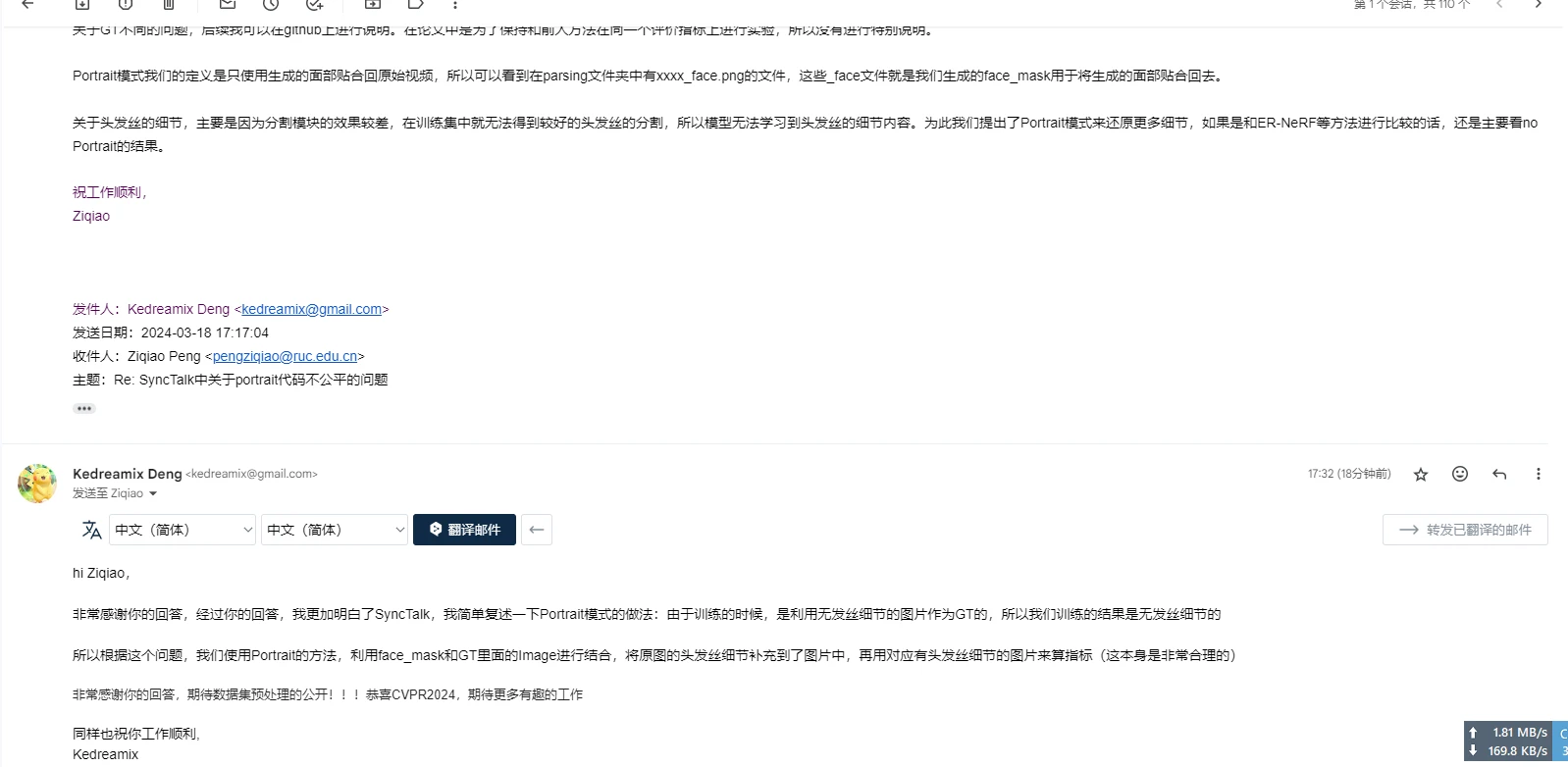
问了一下作者,大概更明白了这个的意思,其实本质上是使用了原图的头发丝的细节加入到图像中,使得图像能够得到更好的结果,然后再进行结合得到更好的效果。
实验结果

 wechat
wechat- alipay






