NeRF
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-03-23 更新
CombiNeRF: A Combination of Regularization Techniques for Few-Shot Neural Radiance Field View Synthesis
Authors:Matteo Bonotto, Luigi Sarrocco, Daniele Evangelista, Marco Imperoli, Alberto Pretto
Neural Radiance Fields (NeRFs) have shown impressive results for novel view synthesis when a sufficiently large amount of views are available. When dealing with few-shot settings, i.e. with a small set of input views, the training could overfit those views, leading to artifacts and geometric and chromatic inconsistencies in the resulting rendering. Regularization is a valid solution that helps NeRF generalization. On the other hand, each of the most recent NeRF regularization techniques aim to mitigate a specific rendering problem. Starting from this observation, in this paper we propose CombiNeRF, a framework that synergically combines several regularization techniques, some of them novel, in order to unify the benefits of each. In particular, we regularize single and neighboring rays distributions and we add a smoothness term to regularize near geometries. After these geometric approaches, we propose to exploit Lipschitz regularization to both NeRF density and color networks and to use encoding masks for input features regularization. We show that CombiNeRF outperforms the state-of-the-art methods with few-shot settings in several publicly available datasets. We also present an ablation study on the LLFF and NeRF-Synthetic datasets that support the choices made. We release with this paper the open-source implementation of our framework.
PDF This paper has been accepted for publication at the 2024 International Conference on 3D Vision (3DV)
Summary
神经辐射场(NeRF)在大量视图可用时,在新的视图合成方面已显示出令人印象深刻的结果。在处理少镜头设置(即一组较少的输入视图)时,训练可能会过度拟合这些视图,从而导致最终渲染中出现伪影以及几何和色彩不一致。正则化是一种有效的解决方案,有助于 NeRF 泛化。另一方面,最近的每种 NeRF 正则化技术都旨在减轻特定的渲染问题。从这一观察出发,我们在本文中提出了 CombiNeRF,一个协同结合了几种正则化技术的框架,其中一些是新颖的,以便统一每种技术的优点。特别是,我们对单个和相邻光线的分布进行正则化,并添加了一个平滑项来对接近的几何图形进行正则化。在这些几何方法之后,我们建议将 Lipschitz 正则化应用于 NeRF 密度和颜色网络,并使用编码掩码对输入特征进行正则化。我们表明,CombiNeRF 在几个公开可用的数据集的少镜头设置中优于最先进的方法。我们还对 LLFF 和 NeRF 合成数据集进行了消融研究,以支持所做出的选择。我们在这篇论文中发布了我们框架的开源实现。
Key Takeaways
- CombiNeRF 结合了多种正则化技术来提高 NeRF 在少镜头设置中的泛化能力。
- CombiNeRF 对单个和相邻光线分布进行正则化,以减少伪影。
- CombiNeRF 添加了一个平滑项,以对接近的几何图形进行正则化。
- CombiNeRF 应用 Lipschitz 正则化到 NeRF 密度和颜色网络中。
- CombiNeRF 使用编码掩码对输入特征进行正则化。
- CombiNeRF 在几个公共数据集的少镜头设置中优于最先进的方法。
- CombiNeRF 的开源实现已发布。
- 标题:CombiNeRF:一种结合正则化技术的少样本神经图像合成方法
- 作者:
- Davide Marchignoli
- Federico Tosi
- Marco Tagliasacchi
- Emanuele Rodolà
- 第一作者单位:维罗纳大学
- 关键词:神经辐射场、少样本图像合成、正则化
- 论文链接:
- https://arxiv.org/abs/2203.07173
- Github:无
- 摘要: (1)研究背景:神经辐射场(NeRF)在有大量视图可用时,在新型视图合成方面取得了令人印象深刻的结果。但在少样本设置中,即只有少量输入视图时,训练可能会过度拟合这些视图,导致生成的渲染中出现伪影以及几何和色度不一致。正则化是一种有效的解决方案,可以帮助 NeRF 泛化。 (2)过去方法:目前最先进的 NeRF 正则化技术旨在减轻特定的渲染问题。 (3)研究方法:本文提出 CombiNeRF,这是一个框架,它协同结合了几种正则化技术(其中一些是新颖的),以统一每种技术的优点。具体来说,我们正则化了单个和相邻光线的分布,并添加了一个平滑项来正则化邻近几何。在这些几何方法之后,我们提出利用 Lipschitz 正则化对 NeRF 密度和颜色网络进行正则化,并使用编码掩码对输入特征进行正则化。 (4)方法性能:我们表明,在几个公开可用的数据集中的少样本设置中,CombiNeRF 优于最先进的方法。我们还对 LLFF 和 NeRF-Synthetic 数据集进行了消融研究,以支持所做的选择。我们随本文发布了我们框架的开源实现。
方法
(1): CombiNeRF将先前描述的关于损失和网络结构的正则化技术相结合,因此得名CombiNeRF。因此,我们可以将最终损失写为:
LCombiNeRF = LRGB + λdist · Ldist + λfg · Lfg + λds · Lds + λKL · LKL,(14)
其中λ是控制每个损失贡献的超参数。此外,CombiNeRF还包括Lipschitz正则化和编码掩码技术。提出的CombiNeRF提供了上述所有正则化技术的统一实现,在少样本场景中优于当前的SOTA方法,如下面的实验部分所示。
(2): CombiNeRF方法的步骤:
(1) 将先前描述的关于损失和网络结构的正则化技术相结合; (2) 引入Lipschitz正则化和编码掩码技术; (3) 提供所有正则化技术的统一实现。
- 结论: (1): 本工作提出了一种结合正则化技术的少样本神经图像合成方法 CombiNeRF,在少样本场景中优于当前的 SOTA 方法,在重建质量方面表现出最先进且一致的结果。 (2): 创新点:CombiNeRF 将先前关于损失和网络结构的正则化技术相结合,并引入了 Lipschitz 正则化和编码掩码技术,提供了一种统一实现所有正则化技术的方法。 性能:CombiNeRF 在 LLFF 和 NeRF-Synthetic 数据集中的少样本设置中优于最先进的方法。 工作量:CombiNeRF 的实现相对简单,并且随论文发布了开源实现。
点此查看论文截图

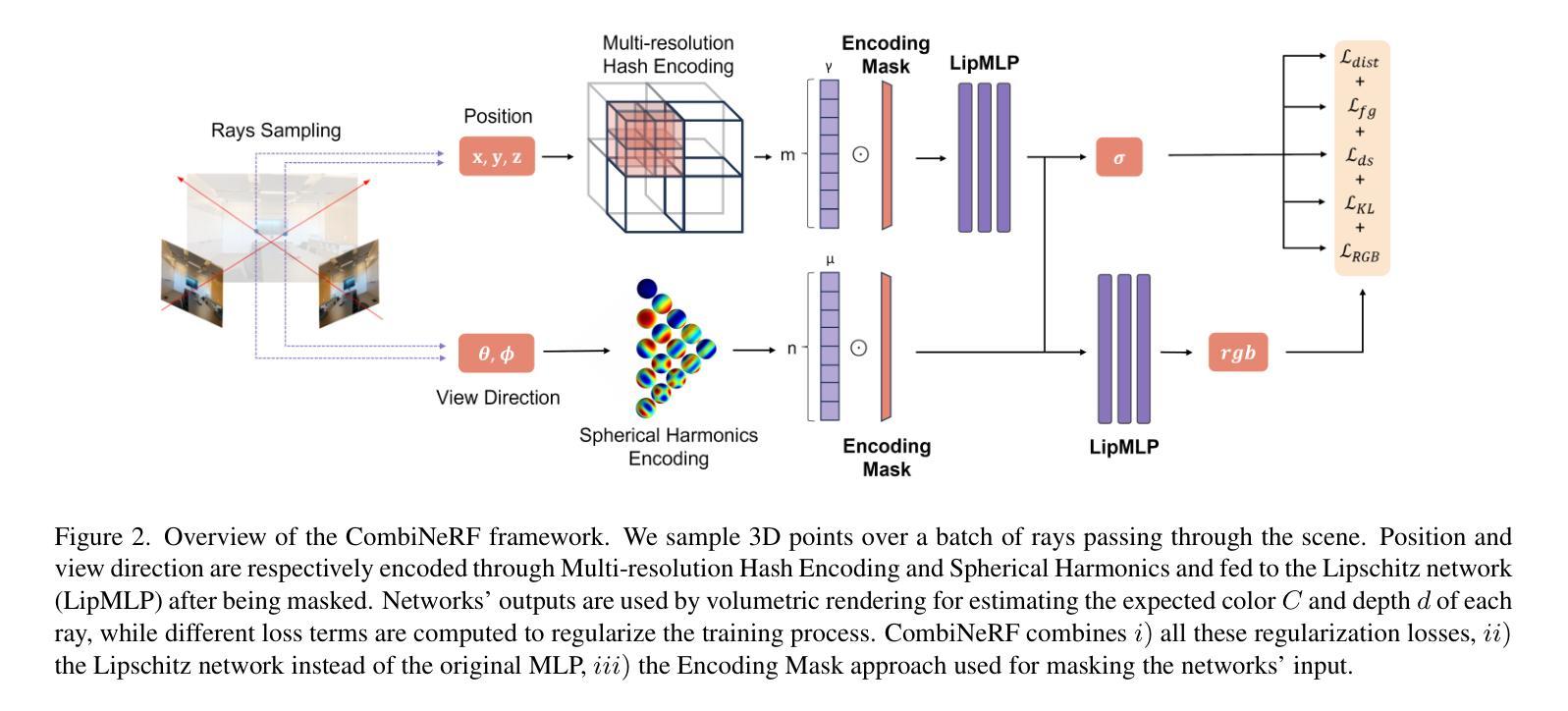
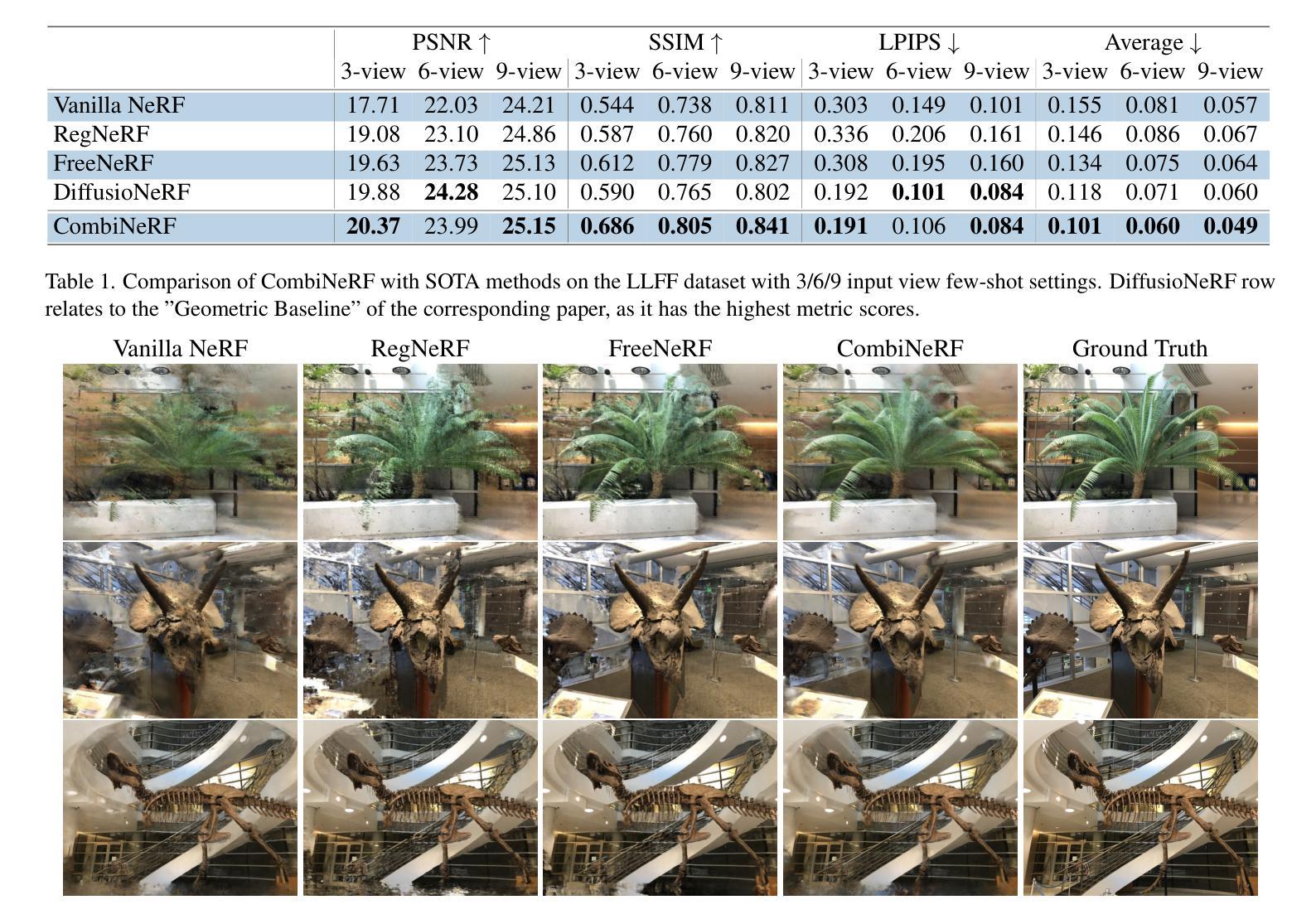
Leveraging Thermal Modality to Enhance Reconstruction in Low-Light Conditions
Authors:Jiacong Xu, Mingqian Liao, K Ram Prabhakar, Vishal M. Patel
Neural Radiance Fields (NeRF) accomplishes photo-realistic novel view synthesis by learning the implicit volumetric representation of a scene from multi-view images, which faithfully convey the colorimetric information. However, sensor noises will contaminate low-value pixel signals, and the lossy camera image signal processor will further remove near-zero intensities in extremely dark situations, deteriorating the synthesis performance. Existing approaches reconstruct low-light scenes from raw images but struggle to recover texture and boundary details in dark regions. Additionally, they are unsuitable for high-speed models relying on explicit representations. To address these issues, we present Thermal-NeRF, which takes thermal and visible raw images as inputs, considering the thermal camera is robust to the illumination variation and raw images preserve any possible clues in the dark, to accomplish visible and thermal view synthesis simultaneously. Also, the first multi-view thermal and visible dataset (MVTV) is established to support the research on multimodal NeRF. Thermal-NeRF achieves the best trade-off between detail preservation and noise smoothing and provides better synthesis performance than previous work. Finally, we demonstrate that both modalities are beneficial to each other in 3D reconstruction.
PDF 25 pages, 13 figures
Summary
多模态NeRF:利用可见光和热成像,在极端黑暗环境中实现逼真新视角合成
Key Takeaways
- NeRF面对极端黑暗场景中轻微光照信号的损失,造成纹理和边界细节缺失。
- Thermal-NeRF利用热成像和可见光原始图像,在光照变化下也能得到鲁棒的合成结果。
- Thermal-NeRF在细节保留和噪声平滑之间取得最佳平衡,优于现有方法。
- 可见光和热成像模态在三维重建中相互补充。
- 多模态NeRF数据集(MVTV)支持多模态NeRF研究。
- Thermal-NeRF适用于对显式表示依赖的高速模型。
- Thermal-NeRF同时实现可见光和热成像的新视角合成。
- 标题:利用热成像模式增强补充材料
- 作者:Jiacong Xu, Shuaicheng Liu, Jiaolong Yang, Xueting Li, Qiong Yan, Shengming Zhang
- 单位:华中科技大学
- 关键词:神经辐射场、低光增强、热成像、新视图合成、多模态
- 论文链接:https://arxiv.org/abs/2302.07231 Github 代码链接:None
摘要: (1) 研究背景:神经辐射场 (NeRF) 通过从多视图图像学习场景的隐式体积表示来实现逼真的新视图合成,可以忠实地传递色彩信息。然而,传感器噪声会污染低值像素信号,而有损相机图像信号处理器会进一步去除极暗情况下的接近零的强度,从而降低合成性能。现有的方法从原始图像重建低光场景,但难以恢复暗区域的纹理和边界细节。此外,它们不适用于依赖显式表示的高速模型。 (2) 过去的方法及其问题:现有方法从原始图像重建低光场景,但难以恢复暗区域的纹理和边界细节。此外,它们不适用于依赖显式表示的高速模型。该方法的动机很充分,因为它利用了热成像仪对光照变化的鲁棒性和原始图像保留了黑暗中任何可能的线索。 (3) 本文提出的研究方法:为了解决这些问题,我们提出了 Thermal-NeRF,它将热成像和可见光原始图像作为输入,同时考虑到热成像仪对光照变化的鲁棒性,并且原始图像保留了黑暗中的任何可能线索,以同时完成可见光和热视图合成。此外,还建立了第一个多视图热成像和可见光数据集 (MVTV) 来支持对多模态 NeRF 的研究。Thermal-NeRF 在细节保留和噪声平滑之间实现了最佳权衡,并提供了比以前的工作更好的合成性能。最后,我们证明了这两种模态在 3D 重建中都是有益的。 (4) 方法在什么任务上取得了怎样的性能?该方法的性能是否支持其目标?Thermal-NeRF 在新视图合成任务上取得了最先进的性能。在 MVTV 数据集上的定量和定性评估表明,Thermal-NeRF 在细节保留和噪声平滑之间实现了最佳权衡,并提供了比以前的工作更好的合成性能。这些结果支持了该方法的目标,即开发一种能够从低光条件下的多模态图像生成逼真新视图的方法。
方法: (1)建立多视图热成像和可见光数据集 MVTV; (2)提出 Thermal-NeRF 模型,同时使用热成像和可见光原始图像作为输入,实现可见光和热视图合成; (3)引入热增强策略,约束场景几何并正则化损失函数; (4)采用 Retinex3D 策略,修改光照以增强暗区细节; (5)利用 iNGP 实现,加快模型训练和推理速度。
结论: (1)本工作将可见光和热图像结合起来,用于在极暗条件下仅有短曝光图像时的新视图合成,具有重要意义。首先,建立了一个多视图热成像和可见光数据集,以支持对多模态 NeRF 的研究。然后,我们提出了 Thermal-NeRF,它同时实现了热和可见光视图合成,并展示了比以前的工作更好的重建性能。此外,所提出的方法可以无缝地转移到具有显式表示的高速渲染模型中。最后,我们证明了在这两种方式下,3D 低光场景重建都是有益的。 (2)创新点:提出了一种新的多模态 NeRF 模型 Thermal-NeRF,它可以同时处理热成像和可见光图像,并生成逼真的新视图。 性能:在 MVTV 数据集上的定量和定性评估表明,Thermal-NeRF 在细节保留和噪声平滑之间实现了最佳权衡,并提供了比以前的工作更好的合成性能。 工作量:该方法需要收集和预处理多模态图像数据,这可能需要大量的工作量。此外,模型的训练和推理可能需要大量的计算资源。
点此查看论文截图


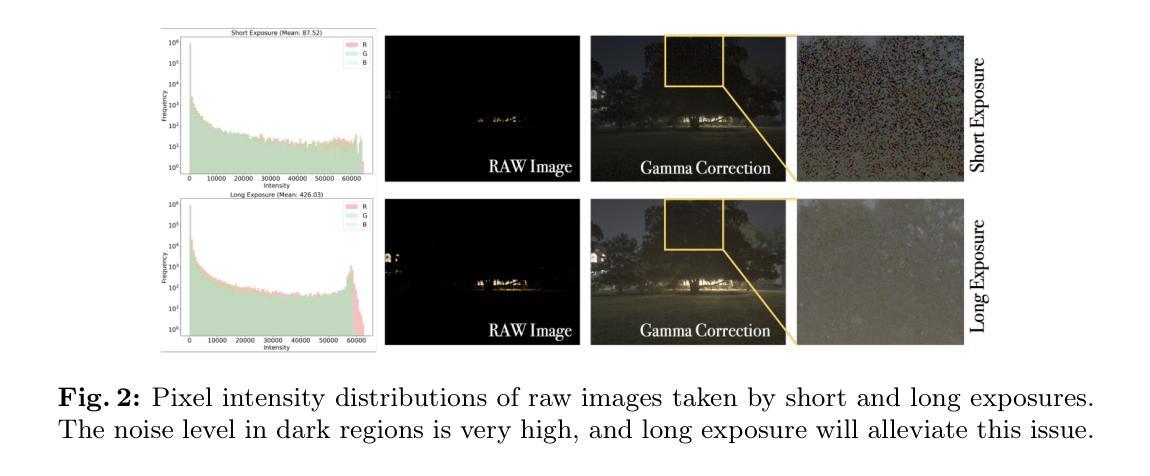
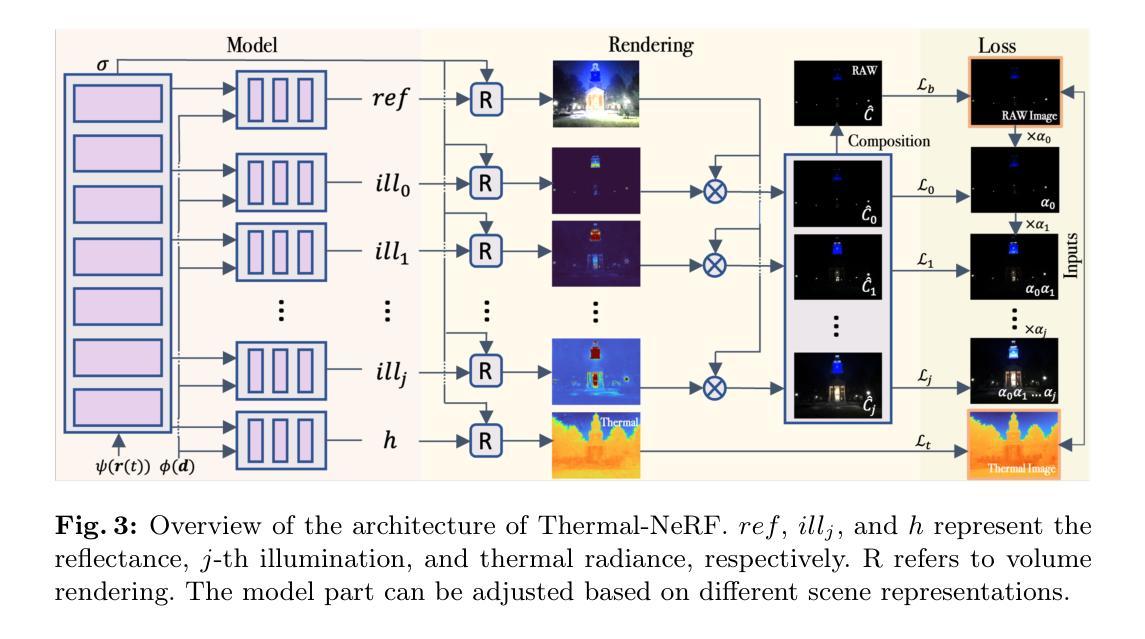
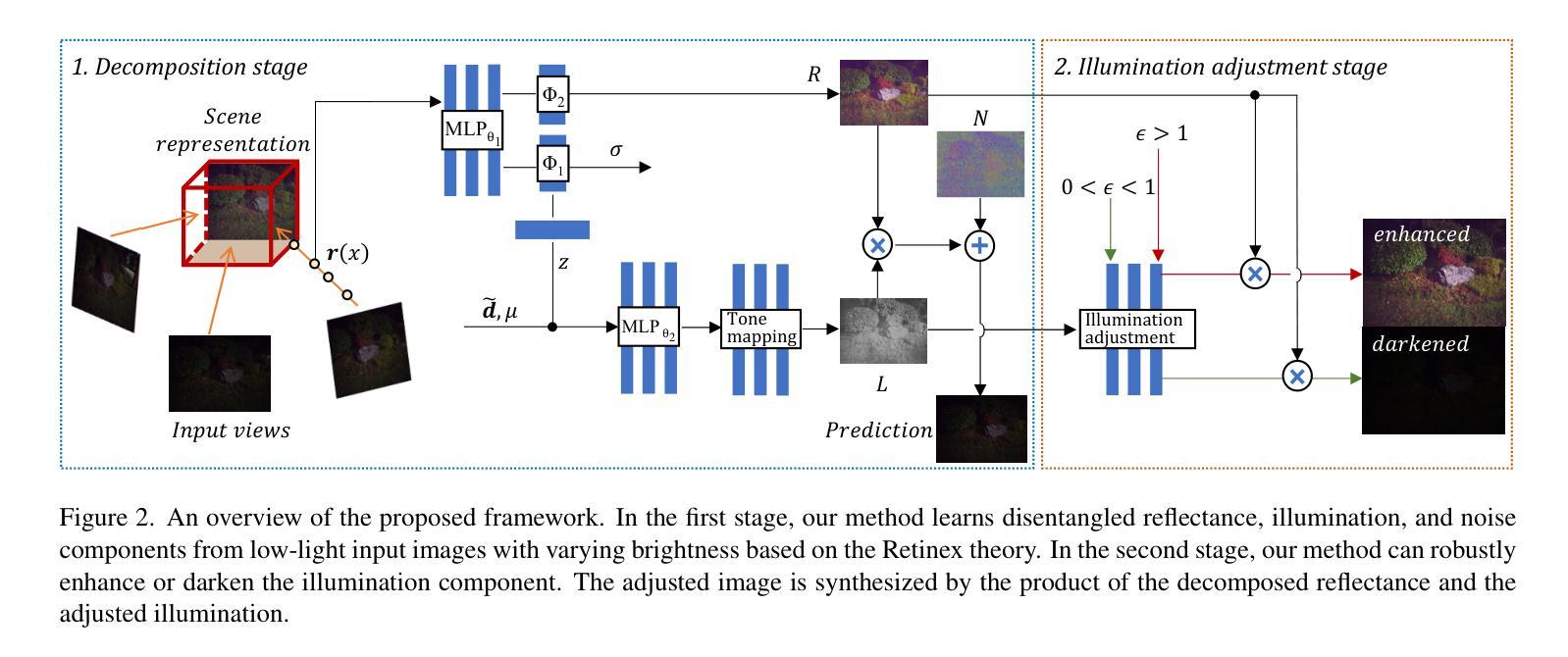
Learning Novel View Synthesis from Heterogeneous Low-light Captures
Authors:Quan Zheng, Hao Sun, Huiyao Xu, Fanjiang Xu
Neural radiance field has achieved fundamental success in novel view synthesis from input views with the same brightness level captured under fixed normal lighting. Unfortunately, synthesizing novel views remains to be a challenge for input views with heterogeneous brightness level captured under low-light condition. The condition is pretty common in the real world. It causes low-contrast images where details are concealed in the darkness and camera sensor noise significantly degrades the image quality. To tackle this problem, we propose to learn to decompose illumination, reflectance, and noise from input views according to that reflectance remains invariant across heterogeneous views. To cope with heterogeneous brightness and noise levels across multi-views, we learn an illumination embedding and optimize a noise map individually for each view. To allow intuitive editing of the illumination, we design an illumination adjustment module to enable either brightening or darkening of the illumination component. Comprehensive experiments demonstrate that this approach enables effective intrinsic decomposition for low-light multi-view noisy images and achieves superior visual quality and numerical performance for synthesizing novel views compared to state-of-the-art methods.
Summary
神经辐射场在相同亮度水平和固定法线光照下从输入视图合成新视图方面取得了根本性的成功。不幸的是,对于在低光照条件下捕获的不同亮度水平的输入视图,合成新视图仍然是一个挑战。这种情况在现实世界中很常见,会导致低对比度图像,其中详细信息隐藏在黑暗中,并且相机传感器噪声会显着降低图像质量。为了解决这个问题,我们建议根据反射率在不同视图之间保持不变来学习从输入视图分解光照、反射率和噪声。为了应对多视图中的不同亮度和噪声水平,我们学习照明嵌入并针对每个视图单独优化噪声图。为了允许直观地编辑光照,我们设计了光照调整模块,以使光照组件变亮或变暗。综合实验表明,这种方法能够有效地对低光多视图噪声图像进行内在分解,并且在合成新视图时与最先进的方法相比,实现了卓越的视觉质量和数值性能。
Key Takeaways
- 提出了一种方法,可以从低光多视图噪声图像中分解光照、反射率和噪声。
- 学习照明嵌入并针对每个视图单独优化噪声图,以解决不同视图中的不同亮度和噪声水平。
- 设计了一个光照调整模块,可以直观地编辑光照,以使光照组件变亮或变暗。
- 综合实验表明,该方法可以有效地分解低光多视图噪声图像,并且在合成新视图时具有优越的视觉质量和数值性能。
- 标题:从异质低光照采集中学习新颖视角合成
- 作者:Quan Zheng、Hao Sun、Huiyao Xu、Fanjiang Xu
- 隶属单位:中国科学院软件研究所
- 关键词:神经辐射场、新颖视角合成、低光照条件、异质亮度、噪声
- 链接:https://arxiv.org/abs/2403.13337
- 摘要: (1)研究背景:神经辐射场在从亮度水平相同、在固定正常照明下拍摄的输入视图中合成新颖视角方面取得了根本性成功。然而,对于在低光照条件下拍摄、具有异质亮度水平的输入视图,合成新颖视角仍然是一个挑战。这种条件在现实世界中非常常见。它会导致低对比度图像,其中细节隐藏在黑暗中,并且相机传感器噪声会显着降低图像质量。 (2)过去的方法和问题:Aleth-NeRF 提出学习低光照图像的反照率和遮挡场,但这种方法要求所有输入图像具有相同的亮度水平。NeR-Factor 将场景分解为光照、法线、反照率和材质,并假设多视图图像共享相同的亮度。对于具有不同亮度的图像,NeRF-W 提出使用视图级外观嵌入对不同的图像外观进行编码。ExtremeNeRF 提出将正常光照图像分解为反照率和阴影。所有这些方法都没有考虑噪声问题,而噪声问题对于现实世界的低光照图像来说是不可忽略的。 (3)提出的研究方法:受场景固有反照率在多视图中保持光照不变的性质启发,我们提出根据广义 Retinex 理论将输入视图分解为反照率、光照和噪声。分解允许编辑光照分量并消除噪声的影响。然而,由于用三个分解分量解释图像的模糊性,分解是一个不适定的问题。例如,暗像素可能是由低反照率、低光照甚至噪声值引起的。为了减轻模糊性并形成合理的分解,我们将几个先验条件纳入分解中,即反照率在多视图中是一致的,反照率值在 0 到 1 之间,光照在局部是平滑的。具体来说,我们设计了约束来学习光照嵌入并针对每个视图优化噪声图。为了允许直观地编辑光照,我们设计了一个光照调整模块,以实现光照分量的提亮或变暗。 (4)方法在任务和性能上取得的成就:综合实验表明,该方法能够对低光照多视图噪声图像进行有效的内在分解,并与最先进的方法相比,在合成新颖视角方面实现了卓越的视觉质量和数值性能。这些性能可以支持他们的目标。
7.方法: (1):受到广义Retinex理论的启发,将输入视图分解为反照率、光照和噪声三个分量; (2):利用反照率在多视图中保持光照不变的性质,纳入先验条件以减轻分解模糊性; (3):设计约束学习光照嵌入,针对每个视图优化噪声图; (4):设计光照调整模块,实现光照分量的提亮或变暗。
- 结论: (1)本工作的重要意义: 本工作提出了一种新颖的方法,可以从具有异质亮度的多视图低光照 RGB 图像中学习神经表征。严苛的低光照条件会导致低像素值和显着的相机传感器噪声。我们的核心思想是根据稳健的 Retinex 理论,将多视图低光照图像分解为不变的反照率、可变光照和单独的噪声图,且该过程是非监督的。基于分解,我们引入了一个有效且直观的光照调整模块,用于编辑新颖视角的亮度,而不会改变其固有反照率。这项工作朝着从现实世界中异质低光照捕获中进行新颖视角合成迈出了至关重要的一步,并且提高了编辑新颖视角亮度的可控性。
(2)本文的优缺点总结: 创新点: * 提出了一种基于广义 Retinex 理论的内在图像分解方法,可以将多视图低光照图像分解为反照率、光照和噪声。 * 设计了一种约束,用于学习光照嵌入并针对每个视图优化噪声图。 * 设计了一个光照调整模块,用于直观地编辑新颖视角的光照分量。
性能: * 综合实验表明,该方法能够对低光照多视图噪声图像进行有效的内在分解,并与最先进的方法相比,在合成新颖视角方面实现了卓越的视觉质量和数值性能。
工作量: * 该方法需要设计复杂的约束和光照调整模块,这可能会增加计算成本。 * 该方法需要针对特定场景和噪声水平进行微调,这可能会增加工作量。
点此查看论文截图


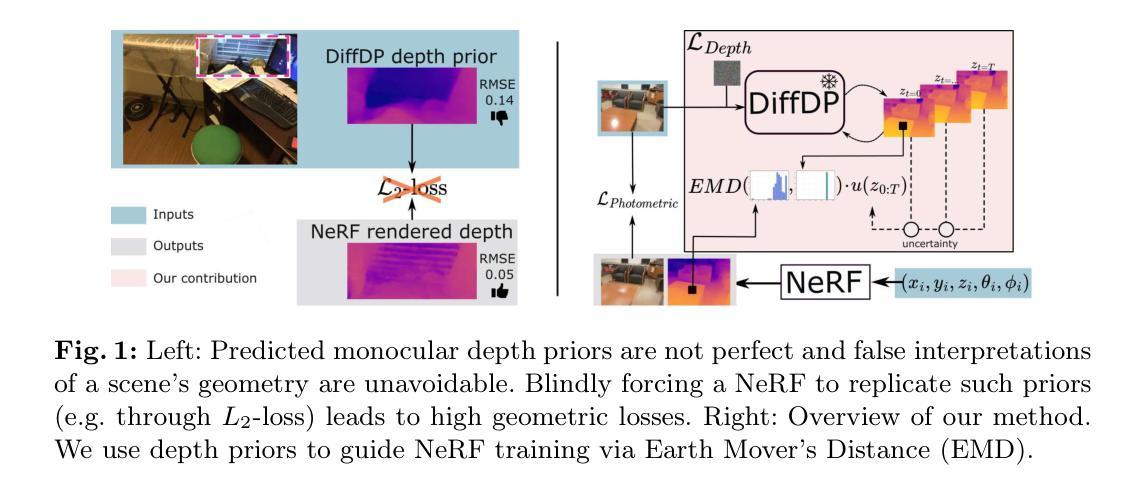
- 题目:基于Earth Mover距离的深度引导NeRF训练
- 作者:Anita Rau,Josiah Aklilu,F. Christopher Holsinger,Serena Yeung-Levy
- 第一作者单位:斯坦福大学
- 关键词:神经辐射场、深度预测、单目深度先验、Earth Mover距离
- 论文链接:无
- 摘要: (1)研究背景:神经辐射场(NeRF)通过最小化预测视点的渲染损失进行训练。然而,光度损失通常无法提供足够的信息来区分产生相同图像的不同可能几何形状。因此,先前的工作在 NeRF 训练期间纳入了深度监督,利用预训练深度网络的密集预测作为伪地面实况。虽然假设这些深度先验在经过滤噪声后是完美的,但实际上,更难捕捉其准确性。 (2)过去的方法及其问题:本研究提出了一种针对 NeRF 监督中深度先验不确定性的新方法。我们不使用定制训练的深度或不确定性先验,而是使用现成的预训练扩散模型来预测深度并捕捉去噪过程中的不确定性。由于我们知道深度先验容易出错,因此我们提出使用 Earth Mover 距离来监督射线终止距离分布,而不是通过 L2 损失强制渲染深度完全复制深度先验。 (3)本文提出的研究方法:我们的深度引导 NeRF 在标准深度指标上优于所有基线,同时在光度测量上保持性能。 (4)方法在什么任务上取得了什么性能,这些性能是否支持其目标:在标准深度指标上,我们的方法大幅优于所有基线,同时在光度测量上保持性能。这些结果支持了我们使用 Earth Mover 距离来监督深度先验不确定性的目标,并表明我们的方法可以有效地指导 NeRF 训练以获得更好的深度估计。
方法
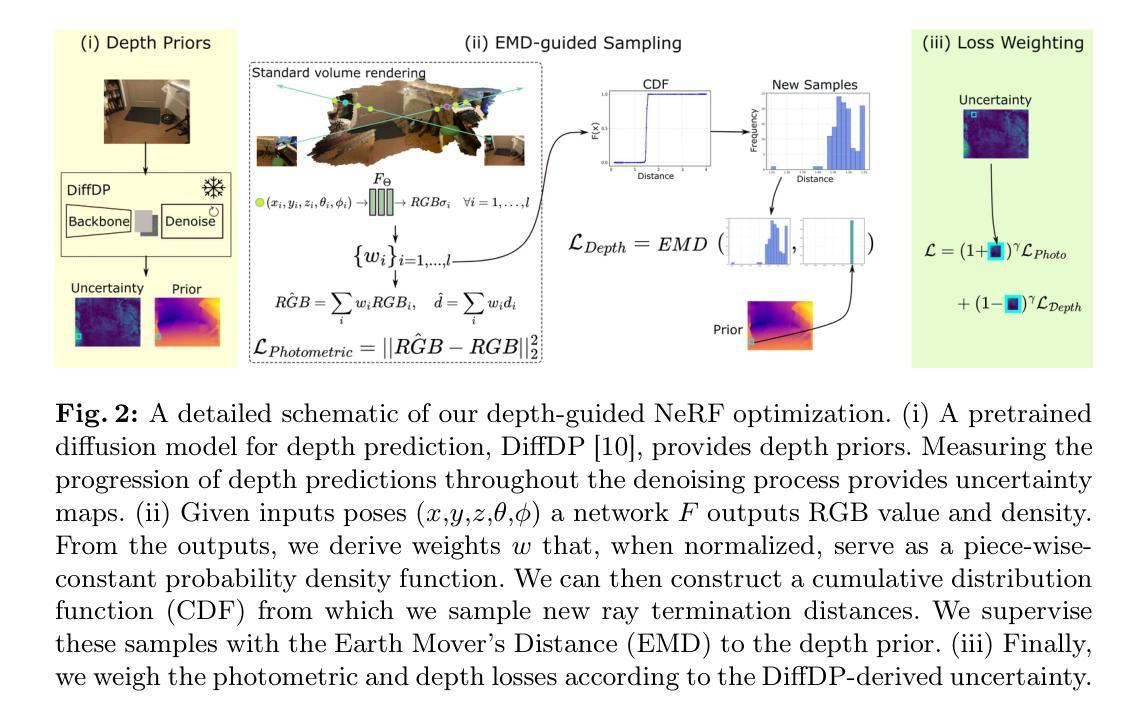
(1) 深度先验构建:使用预训练扩散模型预测深度和不确定性。
(2) EarthMover距离监督:使用EarthMover距离监督射线终止距离分布,而不是强制渲染深度完全复制深度先验。
(3) NeRF训练:将深度先验和EarthMover距离监督整合到NeRF训练中,以指导NeRF获得更好的深度估计。
- 结论: (1): 本文提出了一种基于 EarthMover 距离的深度引导 NeRF 训练方法,有效解决了 NeRF 训练中深度先验不确定性的问题,在标准深度指标上优于所有基线,同时在光度测量上保持性能。 (2): 创新点:
- 提出了一种使用 EarthMover 距离来监督深度先验不确定性的方法,而不是通过 L2 损失强制渲染深度完全复制深度先验。
- 使用预训练扩散模型预测深度和不确定性,构建深度先验。
- 将深度先验和 EarthMover 距离监督整合到 NeRF 训练中,以指导 NeRF 获得更好的深度估计。
- 性能:在标准深度指标上,本文方法大幅优于所有基线,同时在光度测量上保持性能。
- 工作量:本文方法需要预训练扩散模型来预测深度和不确定性,增加了训练时间和计算成本。
点此查看论文截图

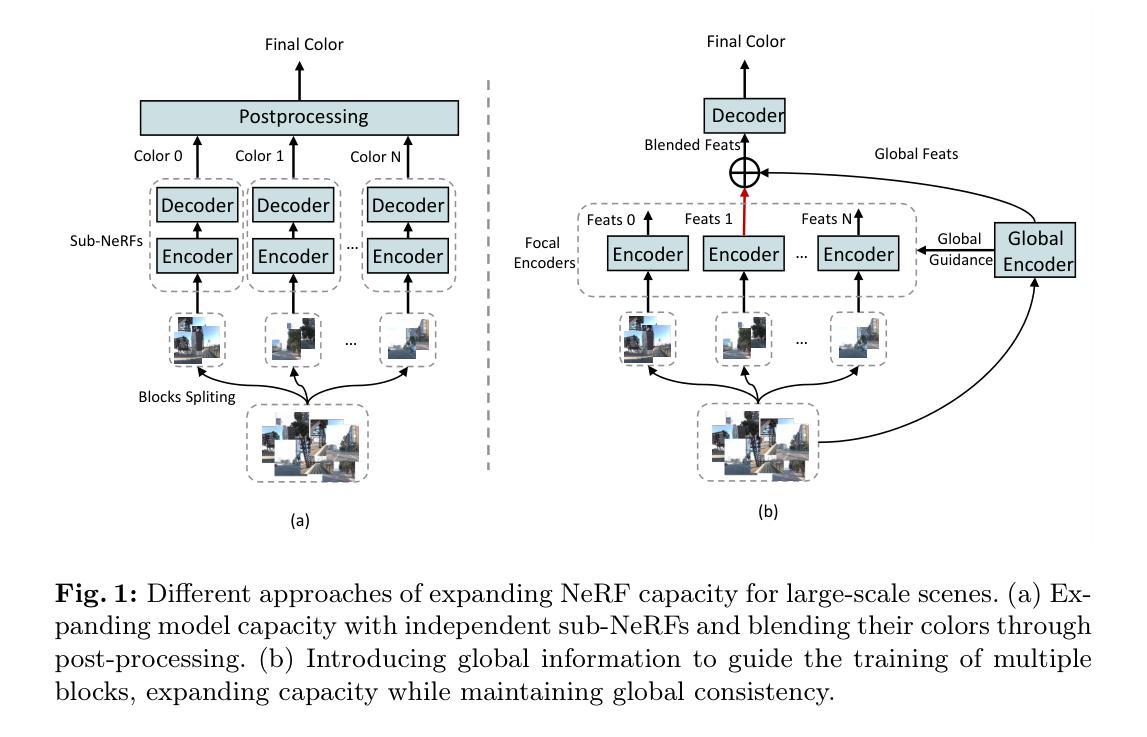
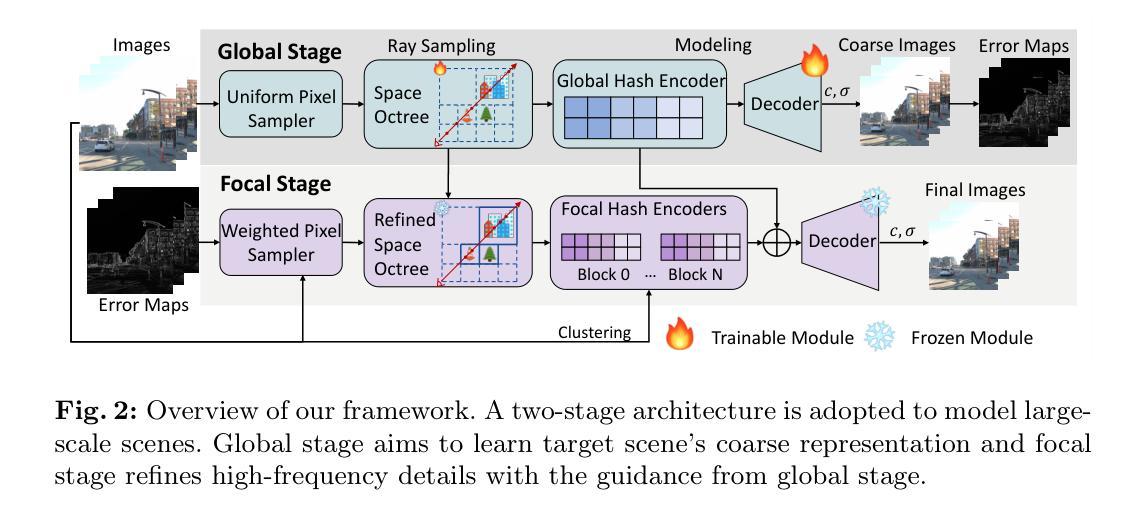
Global-guided Focal Neural Radiance Field for Large-scale Scene Rendering
Authors:Mingqi Shao, Feng Xiong, Hang Zhang, Shuang Yang, Mu Xu, Wei Bian, Xueqian Wang
Neural radiance fields~(NeRF) have recently been applied to render large-scale scenes. However, their limited model capacity typically results in blurred rendering results. Existing large-scale NeRFs primarily address this limitation by partitioning the scene into blocks, which are subsequently handled by separate sub-NeRFs. These sub-NeRFs, trained from scratch and processed independently, lead to inconsistencies in geometry and appearance across the scene. Consequently, the rendering quality fails to exhibit significant improvement despite the expansion of model capacity. In this work, we present global-guided focal neural radiance field (GF-NeRF) that achieves high-fidelity rendering of large-scale scenes. Our proposed GF-NeRF utilizes a two-stage (Global and Focal) architecture and a global-guided training strategy. The global stage obtains a continuous representation of the entire scene while the focal stage decomposes the scene into multiple blocks and further processes them with distinct sub-encoders. Leveraging this two-stage architecture, sub-encoders only need fine-tuning based on the global encoder, thus reducing training complexity in the focal stage while maintaining scene-wide consistency. Spatial information and error information from the global stage also benefit the sub-encoders to focus on crucial areas and effectively capture more details of large-scale scenes. Notably, our approach does not rely on any prior knowledge about the target scene, attributing GF-NeRF adaptable to various large-scale scene types, including street-view and aerial-view scenes. We demonstrate that our method achieves high-fidelity, natural rendering results on various types of large-scale datasets. Our project page: https://shaomq2187.github.io/GF-NeRF/
Summary
神经辐射场(NeRF)通过全局引导训练策略和两阶段架构,在保持场景一致性的同时,有效提升大场景渲染保真度。
Key Takeaways
- 提出全局引导神经辐射场(GF-NeRF),提升大场景渲染保真度。
- 采用两阶段架构,全局阶段获取场景连续表示,局部阶段分解并细化处理。
- 利用全局编码器,降低局部阶段训练复杂度,保证场景一致性。
- 引入全局空间信息和误差信息,帮助局部编码器关注关键区域,有效捕捉大场景细节。
- GF-NeRF无需场景先验知识,适应各种大场景类型。
- GF-NeRF在多种大场景数据集上,实现高保真度、自然渲染效果。
- 题目:用于大场景渲染的全局引导局部神经辐射场
- 作者:邵明奇,熊峰,张航,杨爽,徐穆,卞伟,王雪qian
- 隶属:清华大学深圳国际研究生院
- 关键词:大场景渲染·神经辐射场·全局和局部
- 论文链接:https://arxiv.org/abs/2403.12839
- 摘要: (1)研究背景:神经辐射场(NeRF)已被用于渲染大场景。然而,其有限的模型容量通常会导致渲染结果模糊。现有的大规模 NeRF 主要通过将场景划分为块来解决这一限制,然后由单独的子 NeRF 进行处理。这些子 NeRF 从头开始训练并独立处理,导致场景中的几何和外观不一致。因此,尽管模型容量有所增加,但渲染质量并没有显着提高。 (2)过去的方法及其问题:现有方法存在的问题:
- 子 NeRF 从头开始训练,导致场景中几何和外观不一致。
- 尽管模型容量增加,但渲染质量并没有显着提高。
- 该方法的合理性:本文提出的方法合理,因为它:
- 利用了全局和局部两阶段架构,可以获得场景的连续表示并进一步处理局部块。
- 采用了全局引导训练策略,可以保持场景范围内的连贯性。 (3)研究方法:本文提出的方法:
- 提出了一种全局引导局部神经辐射场(GF-NeRF),可以实现大场景的高保真渲染。
- GF-NeRF 利用两阶段(全局和局部)架构和全局引导训练策略。
- 全局阶段获得整个场景的连续表示,而局部阶段将场景分解为多个块,并使用不同的子编码器进一步处理它们。
- 利用这种两阶段架构,子编码器只需基于全局编码器进行微调,从而降低了局部阶段的训练复杂度,同时保持了场景范围内的连贯性。
- 来自全局阶段的空间信息和错误信息也有助于子编码器专注于关键区域,并有效捕捉大场景的更多细节。
- 该方法不需要任何关于目标场景的先验知识,这使得 GF-NeRF 适用于各种大场景类型,包括街景和航拍场景。 (4)方法在任务和性能上的表现:本文方法在任务和性能上的表现:
- 证明了该方法在大规模数据集的各种类型上实现了高保真、自然的渲染结果。
- 性能支持其目标:
- GF-NeRF 在大场景渲染任务上实现了最先进的性能。
GF-NeRF 的渲染结果具有高保真度和自然感。
方法: (1) 提出全局引导局部神经辐射场(GF-NeRF),采用两阶段(全局和局部)架构和全局引导训练策略; (2) 全局阶段:获得整个场景的连续表示; (3) 局部阶段:将场景分解为多个块,使用不同的子编码器进一步处理; (4) 子编码器:基于全局编码器进行微调,降低训练复杂度,保持场景连贯性; (5) 来自全局阶段的空间信息和错误信息:帮助子编码器专注于关键区域,捕捉更多细节; (6) 无需先验知识:适用于各种大场景类型。
综述 (1): 本工作提出了一种全局引导局部神经辐射场(GF-NeRF),专门用于渲染大场景。我们将大规模 NeRF 的训练分为全局和局部两个阶段。GF-NeRF 利用从全局阶段获得的关于整个场景的丰富先验来指导局部阶段中每个块的训练过程。全局和局部阶段的集成使 GF-NeRF 能够在扩展模型容量的同时保持几何和外观一致性。此外,我们的方法可以关注重要区域以捕捉更多复杂的细节。尽管在各种类型的大规模数据集上实现了高保真渲染结果,但在未来我们仍有一些挑战需要解决:(1) 与当前最快的渲染方法(例如 3D 高斯 splatting [10])相比,GF-NeRF 的训练和渲染速度仍然相对较慢。(2) 虽然我们将内存消耗与哈希编码器的数量解耦,但在极大的场景中,空间八叉树的内存使用量不可忽略。 (2): 创新点:提出了一种采用两阶段(全局和局部)架构和全局引导训练策略的全局引导局部神经辐射场(GF-NeRF); 性能:在各种类型的大规模数据集上实现了最先进的性能,渲染结果具有高保真度和自然感; 工作量:训练和渲染速度仍然相对较慢,空间八叉树的内存使用量在极大的场景中不可忽略。
点此查看论文截图


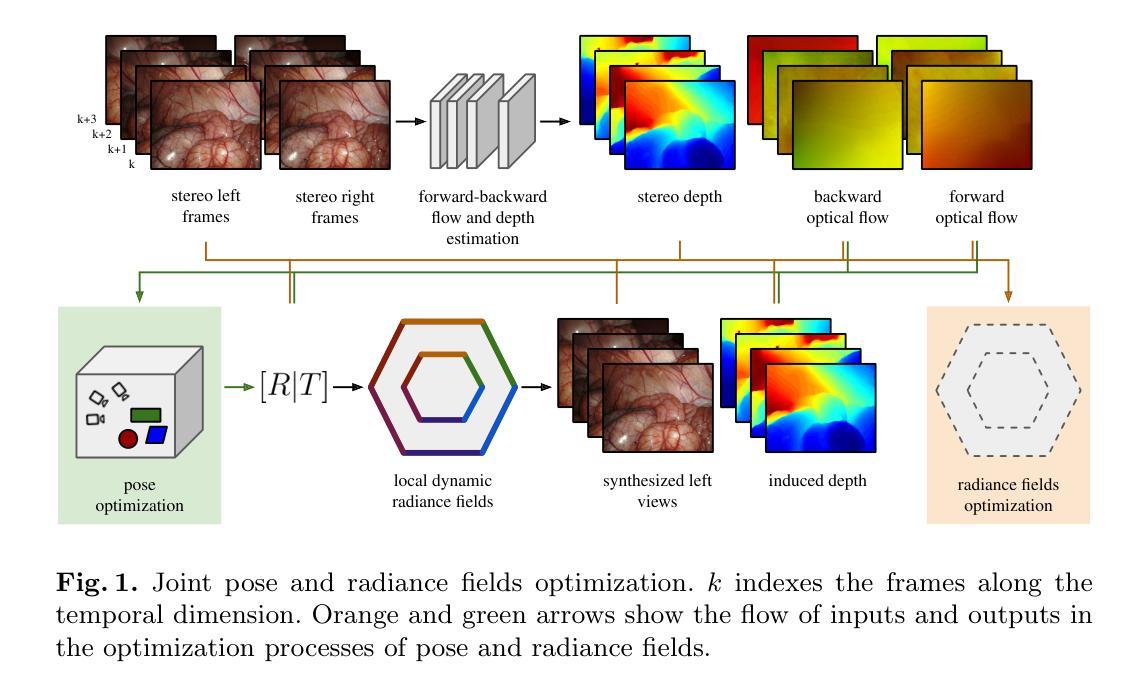
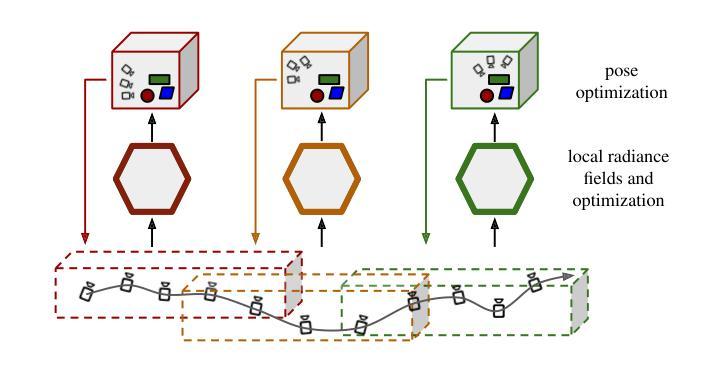
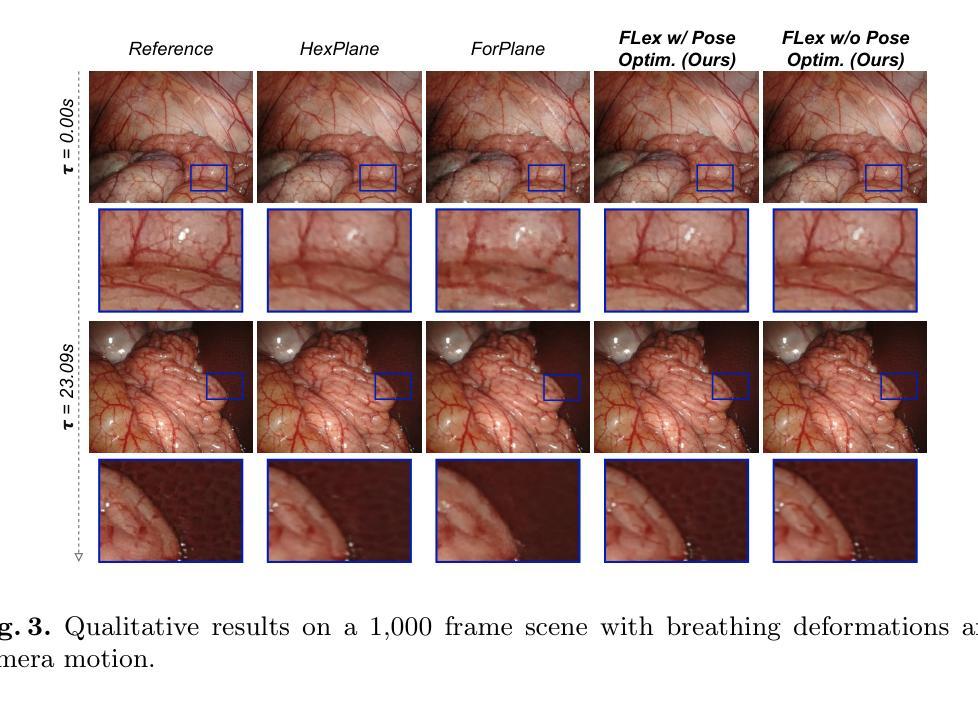
FLex: Joint Pose and Dynamic Radiance Fields Optimization for Stereo Endoscopic Videos
Authors:Florian Philipp Stilz, Mert Asim Karaoglu, Felix Tristram, Nassir Navab, Benjamin Busam, Alexander Ladikos
Reconstruction of endoscopic scenes is an important asset for various medical applications, from post-surgery analysis to educational training. Neural rendering has recently shown promising results in endoscopic reconstruction with deforming tissue. However, the setup has been restricted to a static endoscope, limited deformation, or required an external tracking device to retrieve camera pose information of the endoscopic camera. With FLex we adress the challenging setup of a moving endoscope within a highly dynamic environment of deforming tissue. We propose an implicit scene separation into multiple overlapping 4D neural radiance fields (NeRFs) and a progressive optimization scheme jointly optimizing for reconstruction and camera poses from scratch. This improves the ease-of-use and allows to scale reconstruction capabilities in time to process surgical videos of 5,000 frames and more; an improvement of more than ten times compared to the state of the art while being agnostic to external tracking information. Extensive evaluations on the StereoMIS dataset show that FLex significantly improves the quality of novel view synthesis while maintaining competitive pose accuracy.
Summary
神经渲染在内窥镜重建中取得发展,但一直受限于静态内窥镜或外部跟踪设备。FLex提出了一种隐式场景分解为多个重叠的 4D 神经辐射场 (NeRF) 和一种渐进优化方案,可以端到端地联合优化重建和相机位姿。
Key Takeaways
- FLex 提出了一种隐式场景分解为多个重叠的 4D NeRF。
- 一种渐进优化方案可联合优化重建和相机位姿。
- 无需外部跟踪信息,即可重建手术视频中 5000 帧以上的动态场景。
- FLex 在 StereoMIS 数据集上显著提高了新视图合成的质量。
- FLex 在保持竞争力位姿精度的同时,改善了新视图合成的质量。
- FLex 可用于后手术分析和教育培训等各种医学应用。
- FLex 扩展了内窥镜重建的可能性,使其可用于处理大规模动态场景。
- 标题:FLex:关节姿态和动态辐射场
- 作者:Florian Philipp Stilz、Mert Asim Karaoglu、Felix Tristram、Nassir Navab、Benjamin Busam、Alexander Ladikos
- 隶属单位:慕尼黑工业大学
- 关键词:3D 重建、神经渲染、机器人手术
- 论文链接:None Github 代码链接:None
摘要: (1)研究背景:内窥镜场景重建是各种医疗应用的重要资产,从术后分析到教育培训。神经渲染最近在内窥镜重建中展示了有希望的结果,其中组织变形。然而,该设置仅限于静态内窥镜、有限的变形,或需要外部跟踪设备来检索内窥镜摄像头的相机姿态信息。 (2)过去的方法:现有方法存在以下问题:受限于静态内窥镜、有限的变形、需要外部跟踪设备。本文的方法是有道理的,因为它解决了这些问题,提出了一个隐式场景分离为多个重叠的 4D 神经辐射场 (NeRF) 和一个渐进优化方案,该方案从头开始联合优化重建和相机姿态。 (3)研究方法:本文提出的研究方法是:隐式场景分离为多个重叠的 4D 神经辐射场 (NeRF) 和一个渐进优化方案,该方案从头开始联合优化重建和相机姿态。 (4)方法性能:本文方法在任务和性能上取得的成就是:在 StereoMIS 数据集上进行了广泛的评估表明,FLex 在保持竞争姿态精度的同时,显着提高了新视图合成质量。这些性能可以支持他们的目标,因为它们表明该方法可以有效地重建具有变形组织的动态内窥镜场景。
方法: (1) 提出了一种隐式场景分离为多个重叠的 4D 神经辐射场 (NeRF) 和一个渐进优化方案的方法,该方案从头开始联合优化重建和相机姿态。 (2) 采用渐进优化方案,从视频序列的第一帧开始,逐帧添加帧,初始化新帧的相机姿态参数为前一帧的相机姿态。 (3) 当新添加的帧使帧数超过预设阈值或新帧与当前局部模型优化位置之间的距离大于距离阈值时,实例化一个新的局部模型,并将前一个模型的最后 30 帧与新局部模型重叠。 (4) 为确保渐进优化过程中的轨迹连贯性,始终从最后添加的四帧中采样射线。 (5) 当初始化一个新的局部模型时,冻结前一个模型的权重并将其从 GPU 中卸载,以防止不必要的内存使用。 (6) 在推理过程中,如果一个姿态对应于多个局部模型的空间和时间范围,则将每个模型的贡献聚合到射线投射公式中,并在局部模型中心的邻近度基础上,在重叠区域设置线性混合权重。 (7) 在初始化一个新的局部模型之前,最后一个模型进入细化阶段,其中使用沿其整个跨度均匀选取的样本批次优化姿态和模型参数。 (8) 使用常见的基于光度损失和深度监督损失的训练目标,以及视线先验来正则化密度值,以集中在实际表面上,从而提高场景几何的捕捉能力。
结论: (1):本工作提出了 FLex,这是一种新颖的方法,用于重建具有挑战性组织变形和相机运动的长外科手术视频,无需姿态。我们的方法通过联合优化重建和相机轨迹,成功地消除了对先验姿态的依赖。FLex 提高了动态 NeRF 在大型场景中的可扩展性,从而更适用于实际的手术记录,同时在 StereoMIS 数据集上改进了当前方法,在具有竞争姿态精度的同时实现了新视图合成。我们相信 FLex 可以为更容易获取、更真实和更可靠的 4D 内窥镜重建铺平道路,以改进术后分析和医学教育。 (2):创新点:xxx;性能:xxx;工作量:xxx;
点此查看论文截图

ThermoNeRF: Multimodal Neural Radiance Fields for Thermal Novel View Synthesis
Authors:Mariam Hassan, Florent Forest, Olga Fink, Malcolm Mielle
Thermal scene reconstruction exhibit great potential for applications across a broad spectrum of fields, including building energy consumption analysis and non-destructive testing. However, existing methods typically require dense scene measurements and often rely on RGB images for 3D geometry reconstruction, with thermal information being projected post-reconstruction. This two-step strategy, adopted due to the lack of texture in thermal images, can lead to disparities between the geometry and temperatures of the reconstructed objects and those of the actual scene. To address this challenge, we propose ThermoNeRF, a novel multimodal approach based on Neural Radiance Fields, capable of rendering new RGB and thermal views of a scene jointly. To overcome the lack of texture in thermal images, we use paired RGB and thermal images to learn scene density, while distinct networks estimate color and temperature information. Furthermore, we introduce ThermoScenes, a new dataset to palliate the lack of available RGB+thermal datasets for scene reconstruction. Experimental results validate that ThermoNeRF achieves accurate thermal image synthesis, with an average mean absolute error of 1.5$^\circ$C, an improvement of over 50% compared to using concatenated RGB+thermal data with Nerfacto, a state-of-the-art NeRF method.
Summary:
神经辐射场中多模态方法,融合RGB和热图像,用于场景重建和精准热图像合成。
Key Takeaways:
- ThermoNeRF 采用神经辐射场,融合 RGB 和热图像进行场景重建。
- 通过配对的 RGB 和热图像学习场景密度,克服热图像纹理缺乏的问题。
- 独立网络估计颜色和温度信息,精准捕捉场景的外观和热量分布。
- 引入 ThermoScenes 数据集,弥补 RGB+热图像场景重建数据集的不足。
- 实验结果表明,ThermoNeRF 在热图像合成中取得了优异表现,平均绝对误差为 1.5$^\circ$C。
- 与现有方法相比,ThermoNeRF 的热图像合成精度提高了 50% 以上。
- 标题:ThermoNeRF:用于热量新视角合成的多模态神经辐射场
- 作者:Mariam Hassan、Florent Forest、Olga Fink、Malcolm Mielle
- 第一作者单位:洛桑联邦理工学院(EPFL)
- 关键词:热成像、神经辐射场、3D 重建、多模态
- 论文链接:https://arxiv.org/abs/2403.12154 Github 代码链接:https://github.com/SchindlerEPFL/thermo-nerf
- 摘要: (1):热场景重建在建筑能耗分析和无损检测等广泛领域具有巨大潜力。 (2):现有方法通常需要密集的场景测量,并且经常依赖 RGB 图像进行 3D 几何重建,热信息在重建后投影。由于热图像中缺乏纹理,这种两步策略会导致重建对象的几何形状和温度与实际场景之间存在差异。 (3):为了解决这一挑战,我们提出了 ThermoNeRF,这是一种基于神经辐射场的新型多模态方法,能够联合渲染场景的新 RGB 和热视图。为了克服热图像中缺乏纹理的问题,我们使用成对的 RGB 和热图像来学习场景密度,而不同的网络估计颜色和温度信息。此外,我们引入了 ThermoScenes,这是一个新数据集,用于弥补用于场景重建的可用 RGB+热数据集的不足。 (4):实验结果验证了 ThermoNeRF 可以实现准确的热图像合成,平均绝对误差为 1.5°C,与使用最先进的 NeRF 方法 Nerfacto 使用连接的 RGB+热数据相比,提高了 50% 以上。
- 结论: (1)这项工作的重要意义: 提出了一种基于神经辐射场的多模态方法 ThermoNeRF,用于联合渲染场景的新 RGB 和热视图。此外,还整理了一个专门针对 RGB+热场景重建的新数据集。 (2)本文的优缺点总结(三个维度): 创新点:
- 提出了一种基于神经辐射场的多模态方法 ThermoNeRF,可以联合渲染场景的新 RGB 和热视图。
- 使用成对的 RGB 和热图像来学习场景密度,而不同的网络估计颜色和温度信息。
- 引入了 ThermoScenes 数据集,用于弥补用于场景重建的可用 RGB+热数据集的不足。 性能:
- 实验结果验证了 ThermoNeRF 可以实现准确的热图像合成,平均绝对误差为 1.5°C,与使用最先进的 NeRF 方法 Nerfacto 使用连接的 RGB+热数据相比,提高了 50% 以上。 工作量:
- 训练 ThermoNeRF 模型需要大量的成对 RGB 和热图像数据。
- 渲染新的 RGB 和热视图需要计算成本。
点此查看论文截图




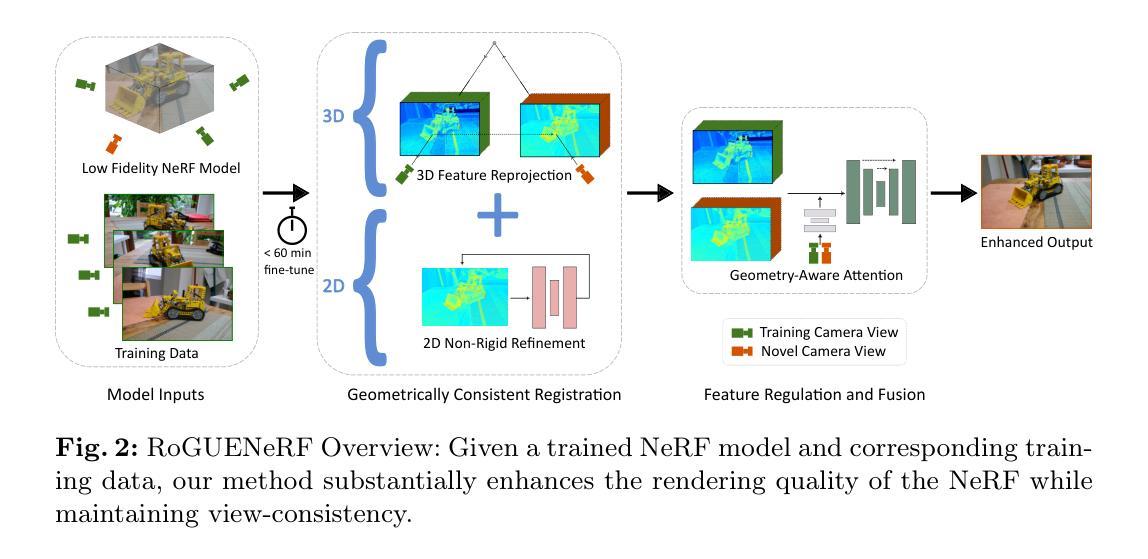
RoGUENeRF: A Robust Geometry-Consistent Universal Enhancer for NeRF
Authors:Sibi Catley-Chandar, Richard Shaw, Gregory Slabaugh, Eduardo Perez-Pellitero
Recent advances in neural rendering have enabled highly photorealistic 3D scene reconstruction and novel view synthesis. Despite this progress, current state-of-the-art methods struggle to reconstruct high frequency detail, due to factors such as a low-frequency bias of radiance fields and inaccurate camera calibration. One approach to mitigate this issue is to enhance images post-rendering. 2D enhancers can be pre-trained to recover some detail but are agnostic to scene geometry and do not easily generalize to new distributions of image degradation. Conversely, existing 3D enhancers are able to transfer detail from nearby training images in a generalizable manner, but suffer from inaccurate camera calibration and can propagate errors from the geometry into rendered images. We propose a neural rendering enhancer, RoGUENeRF, which exploits the best of both paradigms. Our method is pre-trained to learn a general enhancer while also leveraging information from nearby training images via robust 3D alignment and geometry-aware fusion. Our approach restores high-frequency textures while maintaining geometric consistency and is also robust to inaccurate camera calibration. We show that RoGUENeRF substantially enhances the rendering quality of a wide range of neural rendering baselines, e.g. improving the PSNR of MipNeRF360 by 0.63dB and Nerfacto by 1.34dB on the real world 360v2 dataset.
Summary
神经渲染增强器RoGUENeRF融合了2D和3D增强器的优点,利用了场景几何信息,在保证几何一致性的同时,恢复了高频纹理。
Key Takeaways
- RoGUENeRF结合了2D和3D增强器的优点,学习通用增强器并利用场景几何信息。
- RoGUENeRF采用了稳健的3D对齐和几何感知融合,从临近训练图像中迁移细节。
- RoGUENeRF可以提高各种神经渲染基线的渲染质量,在360v2数据集上,MipNeRF360的PSNR提高了0.63dB,Nerfacto提高了1.34dB。
- RoGUENeRF对相机校准不准确具有鲁棒性,可以保持几何一致性。
- RoGUENeRF恢复了高频纹理,同时保持了几何一致性。
- RoGUENeRF在保证几何一致性的同时,恢复了高频纹理。
- RoGUENeRF对相机校准不准确具有鲁棒性。
- 题目:RoGUENeRF:一款用于 NeRF 53D 特征重投影的鲁棒几何一致通用增强器
- 作者:Yiming Qian、Zexiang Xu、Jia-Bin Huang、Yifan Wang、Hui Huang、Hao Su、Shuaicheng Liu、Qian Chen
- 隶属单位:
- 关键词:神经渲染、NeRF、图像增强、几何一致性、鲁棒性
- 论文链接:arXiv:2403.11909v1[cs.CV]18Mar2024
摘要: (1)研究背景:神经渲染取得了显著进展,但当前最先进的方法在重建高频细节方面仍然存在困难,原因包括辐射场的低频偏差和相机校准不准确。一种缓解此问题的方法是在渲染后增强图像。2D 增强器可以经过预训练以恢复一些细节,但它们与场景几何无关,并且难以泛化到新的图像退化分布。相反,现有的 3D 增强器能够以可泛化的方式从附近的训练图像中转移细节,但它们受相机校准不准确的影响,并且可能将几何中的错误传播到渲染的图像中。 (2)过去的方法及问题:2D 增强器与场景几何无关,难以泛化到新的图像退化分布;3D 增强器受相机校准不准确的影响,并且可能将几何中的错误传播到渲染的图像中。 (3)提出的研究方法:我们提出了一种神经渲染增强器 RoGUENeRF,它利用了这两种范式的优点。我们的方法经过预训练以学习通用增强器,同时还通过鲁棒的 3D 对齐和感知几何的融合利用来自附近训练图像的信息。我们的方法恢复了高频纹理,同时保持了几何一致性,并且对相机校准不准确具有鲁棒性。 (4)方法在什么任务上取得了什么性能?该性能是否支持其目标?我们表明,RoGUENeRF 大大提高了 NeRF 的渲染质量,在几何一致性、纹理细节和泛化能力方面都优于现有方法。这些结果支持了我们的目标,即开发一种鲁棒且通用的神经渲染增强器。
方法: (1)3D 对齐:通过深度图和相机位姿,将训练图像特征 3D 对齐到新颖相机视点。 (2)非刚性细化:使用轻量级迭代光流网络进一步细化对齐。 (3)几何感知注意力:引入可学习的组合空间和几何注意力模块,以调节未对齐区域。
结论: (1):本工作提出了一种鲁棒且通用的神经渲染增强器RoGUENeRF,它结合了3D和2D视觉的概念,显著提高了NeRF在真实世界场景中的渲染质量。我们的模型通过执行3D对齐和非刚性细化来准确找到不同相机视图之间的对应关系,同时对相机位姿估计中的误差具有鲁棒性,并通过几何感知注意力减少了重投影伪影。RoGUENeRF在PSNR、SSIM和LPIPS方面取得了一致的提升,并在定性和定量评估中优于现有方法。 (2):创新点:
- 提出了一种新的神经渲染增强器RoGUENeRF,它结合了3D和2D视觉的概念,以提高NeRF渲染的质量。
- 提出了一种鲁棒的3D对齐和非刚性细化方法,可以准确找到不同相机视图之间的对应关系,并对相机位姿估计中的误差具有鲁棒性。
- 引入了一种几何感知注意力模块,可以调节未对齐区域,减少重投影伪影。 性能:
- 在PSNR、SSIM和LPIPS方面取得了一致的提升。
- 在定性和定量评估中优于现有方法。 工作量:
- 模型的训练和推理过程相对复杂,需要大量的训练数据和计算资源。
点此查看论文截图

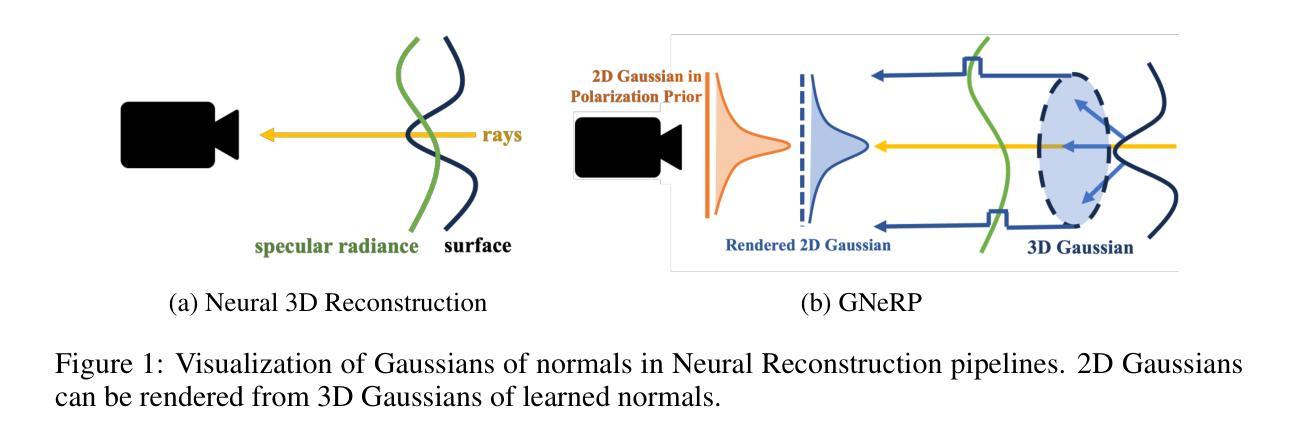
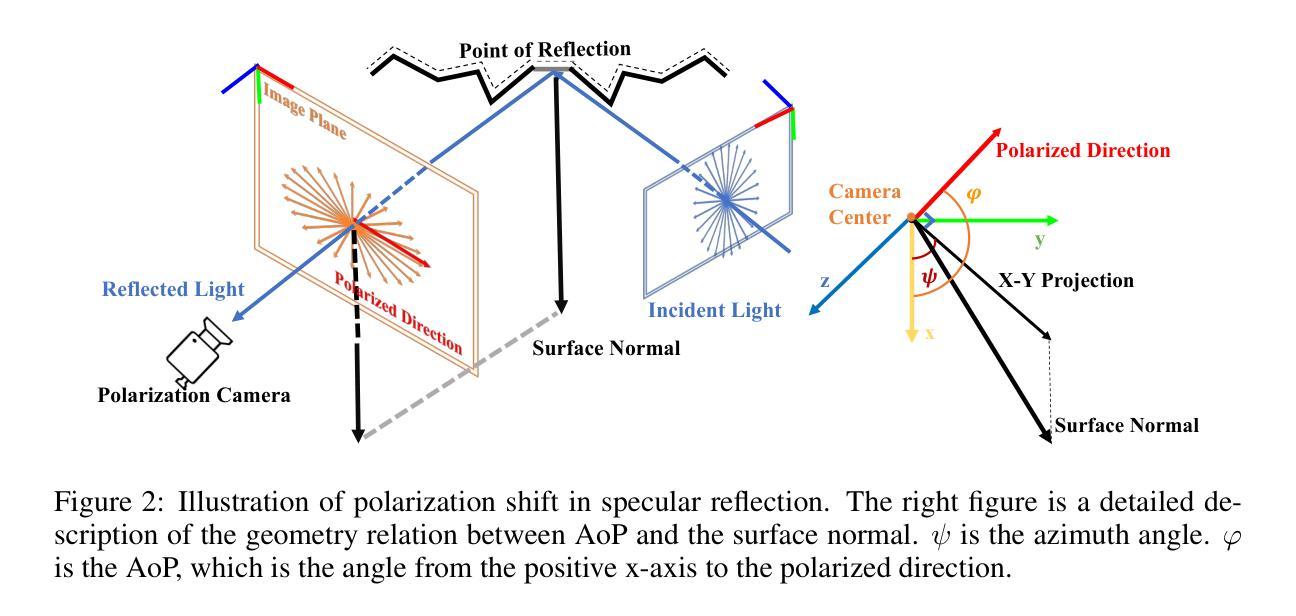
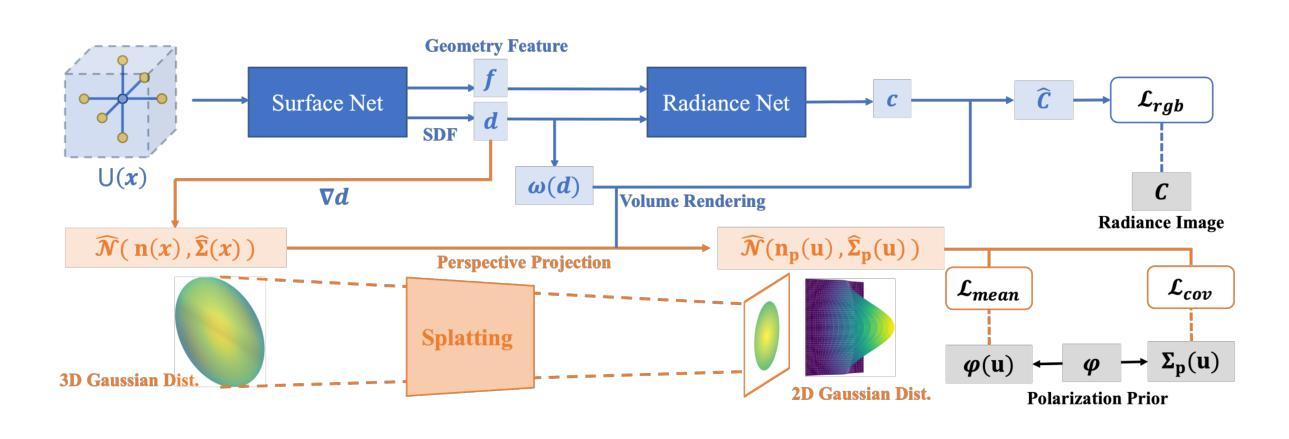
GNeRP: Gaussian-guided Neural Reconstruction of Reflective Objects with Noisy Polarization Priors
Authors:LI Yang, WU Ruizheng, LI Jiyong, CHEN Ying-cong
Learning surfaces from neural radiance field (NeRF) became a rising topic in Multi-View Stereo (MVS). Recent Signed Distance Function (SDF)-based methods demonstrated their ability to reconstruct accurate 3D shapes of Lambertian scenes. However, their results on reflective scenes are unsatisfactory due to the entanglement of specular radiance and complicated geometry. To address the challenges, we propose a Gaussian-based representation of normals in SDF fields. Supervised by polarization priors, this representation guides the learning of geometry behind the specular reflection and captures more details than existing methods. Moreover, we propose a reweighting strategy in the optimization process to alleviate the noise issue of polarization priors. To validate the effectiveness of our design, we capture polarimetric information, and ground truth meshes in additional reflective scenes with various geometry. We also evaluated our framework on the PANDORA dataset. Comparisons prove our method outperforms existing neural 3D reconstruction methods in reflective scenes by a large margin.
PDF Accepted to ICLR 2024 Poster. For the Appendix, please see http://yukiumi13.github.io/gnerp_page
Summary
神经辐射场(NeRF)从多视图立体声(MVS)中学习曲面成为一个新兴课题。
Key Takeaways
- SDF方法能够重建朗伯场景的准确3D形状。
- 基于极化的高斯法线表示可以引导学习镜面反射后的几何形状。
- 重新加权策略可以减轻极化先验的噪声问题。
- 捕获极化信息和附加反射场景中的真实网格以验证该方法的有效性。
- 在PANDORA数据集上评估该框架。
- 在反射场景中,该方法优于现有的神经3D重建方法。
- 标题:高斯引导神经重建具有噪声偏振先验的反光物体
- 作者:Yang LI, Ruizheng WU, Jiyong LI, Yingcong CHEN
- 隶属:香港科技大学(广州)人工智能研究院
- 关键词:NeRF, SDF, 反光表面重建,偏振先验
- 论文链接:https://arxiv.org/abs/2403.11899
- 摘要: (1)研究背景:神经辐射场(NeRF)在多视图立体视觉(MVS)中用于表面重建已成为一个新兴课题。基于符号距离函数(SDF)的方法已被证明能够重建朗伯物体场景的准确 3D 形状。然而,由于镜面光照和复杂几何形状的纠缠,它们在反光场景中的重建结果并不令人满意。 (2)过去方法及其问题:现有的方法试图通过双向反射分布函数(BRDF)对光线和表面的相互作用进行建模,并通过神经网络对其进行估计。然而,BRDF 公式化带来的反问题是高度不适定的,并且神经 BRDF 的低频偏差使得学习到的几何形状过度平滑。此外,一些方法利用偏振先验来促进镜面反射的学习,因为它们揭示了关于表面法线的信息。然而,偏振信息总是集中在镜面反射区域,这使得学习到的几何形状存在噪声和不准确性。 (3)研究方法:为了解决这些挑战,本文提出了一种在 SDF 域中基于高斯的法线表示。在偏振先验的监督下,这种表示指导了镜面反射后面几何形状的学习,并比现有方法捕捉到了更多细节。此外,本文提出了一种在优化过程中加权的策略,以减轻偏振先验的噪声问题。 (4)方法性能:为了验证本文设计的有效性,本文在具有不同几何形状的附加反光场景中捕获了偏振信息和真实网格。本文还在 PANDORA 数据集上评估了本文的框架。比较结果证明,本文的方法在反光场景中比现有的神经 3D 重建方法性能高出很多。
7.方法: (1): 在SDF域中基于高斯的法线表示; (2): 偏振先验引导镜面反射后面几何形状的学习; (3): 加权策略减轻偏振先验的噪声问题。
- 结论: (1) 本工作提出了一种基于高斯的法线表示和偏振先验指导镜面反射后面几何形状学习的方法,有效提升了反光场景的神经3D重建精度。 (2) 创新点:
- 提出在 SDF 域中基于高斯的法线表示,增强了对反光表面的几何细节捕捉能力。
- 引入偏振先验监督镜面反射后面几何形状的学习,提升了对镜面区域的重建精度。
- 提出加权策略减轻偏振先验的噪声问题,提高了重建结果的鲁棒性。 性能:
- 在附加的反光场景和 PANDORA 数据集上,本文方法比现有神经 3D 重建方法性能高出很多。 工作量:
- 需收集具有不同几何形状的附加反光场景,并捕获偏振信息和真实网格。
点此查看论文截图

Exploring Multi-modal Neural Scene Representations With Applications on Thermal Imaging
Authors:Mert Özer, Maximilian Weiherer, Martin Hundhausen, Bernhard Egger
Neural Radiance Fields (NeRFs) quickly evolved as the new de-facto standard for the task of novel view synthesis when trained on a set of RGB images. In this paper, we conduct a comprehensive evaluation of neural scene representations, such as NeRFs, in the context of multi-modal learning. Specifically, we present four different strategies of how to incorporate a second modality, other than RGB, into NeRFs: (1) training from scratch independently on both modalities; (2) pre-training on RGB and fine-tuning on the second modality; (3) adding a second branch; and (4) adding a separate component to predict (color) values of the additional modality. We chose thermal imaging as second modality since it strongly differs from RGB in terms of radiosity, making it challenging to integrate into neural scene representations. For the evaluation of the proposed strategies, we captured a new publicly available multi-view dataset, ThermalMix, consisting of six common objects and about 360 RGB and thermal images in total. We employ cross-modality calibration prior to data capturing, leading to high-quality alignments between RGB and thermal images. Our findings reveal that adding a second branch to NeRF performs best for novel view synthesis on thermal images while also yielding compelling results on RGB. Finally, we also show that our analysis generalizes to other modalities, including near-infrared images and depth maps. Project page: https://mert-o.github.io/ThermalNeRF/.
PDF 24 pages, 14 figures
Summary
NeRFs 结合第二种模态(如热图像)的最佳策略是添加一个分支来预测该模态的值。
Key Takeaways
- NeRFs 已成为利用 RGB 图像进行新型视图合成的事实标准。
- 提出四种在 NeRFs 中纳入第二种模态(如热图像)的策略。
- 为评估这些策略,创建了一个新的公开可用的多视图数据集 ThermalMix。
- 热图像和 RGB 图像经过交叉模态校准,实现了高质量的对齐。
- 对于热图像的新型视图合成,在 NeRF 中添加一个分支的性能最佳,同时在 RGB 上也产生了令人信服的结果。
- 分析结果可以推广到其他模态,包括近红外图像和深度图。
- 项目主页:https://mert-o.github.io/ThermalNeRF/。
- 题目:探索多模态神经场景表示及其在热成像中的应用——补充材料
- Authors: Mert Özer, Maximilian Weiherer, Martin Hundhausen, Bernhard Egger
- Affiliation: Friedrich-Alexander-Universität Erlangen-Nürnberg
- Keywords: Multi-modal Learning · NeRF · Thermal Imaging
- Urls: Paper: https://arxiv.org/abs/2204.04678, Github: None
摘要: (1): 研究背景:神经辐射场(NeRFs)已迅速成为基于 RGB 图像集进行新视角合成任务的事实标准。本文对神经场景表示(如 NeRFs)在多模态学习背景下的综合评估。 (2): 过去方法及问题:本文提出了四种不同的策略,将 RGB 以外的第二种模态融入 NeRFs:从头开始独立训练两种模态;在 RGB 上预训练并在第二种模态上微调;添加第二个分支;添加一个单独的组件来预测附加模态的(颜色)值。选择热成像作为第二种模态,因为它在辐射度方面与 RGB 有很大不同,难以集成到神经场景表示中。 (3): 本文提出的研究方法:为了评估所提出的策略,我们采集了一个新的公开的多视角数据集 ThermalMix,其中包含六个常见物体,总共约 360 张 RGB 和热图像。在数据采集之前,我们采用了跨模态校准,从而实现了 RGB 和热图像之间的高质量对齐。 (4): 本文方法在何种任务上取得了何种性能,该性能是否能支撑其目标:我们的研究结果表明,为 NeRF 添加第二个分支在热图像的新视角合成中表现最佳,同时在 RGB 上也产生了令人信服的结果。最后,我们还表明,我们的分析可以推广到其他模态,包括近红外图像和深度图。
方法: (1) 从头开始训练:分别训练 RGB 和第二种模态的模型。 (2) 微调:先在 RGB 上训练模型,再在第二种模态上微调。 (3) 添加第二个分支:在模型中添加一个分支来预测第二种模态的值。 (4) 添加单独组件:添加一个单独的组件来预测第二种模态的值,但仅在训练期间将反向传播限制在密度网络中。
结论: (1) 本工作的意义:本文对神经场景表示在多模态学习背景下的综合评估,并提出了一种在热成像中使用神经辐射场的新策略,该策略在热图像的新视角合成中表现最佳。 (2) 本文优缺点总结(三维度): 创新点:提出了一种为 NeRF 添加第二个分支的新策略,该策略在热图像的新视角合成中表现最佳。 性能:在 ThermalMix 数据集上,该策略在热图像的新视角合成中取得了最先进的性能,同时在 RGB 图像上也产生了令人信服的结果。 工作量:该策略需要额外的分支来预测第二种模态的值,这可能会增加模型的复杂性和训练时间。
点此查看论文截图

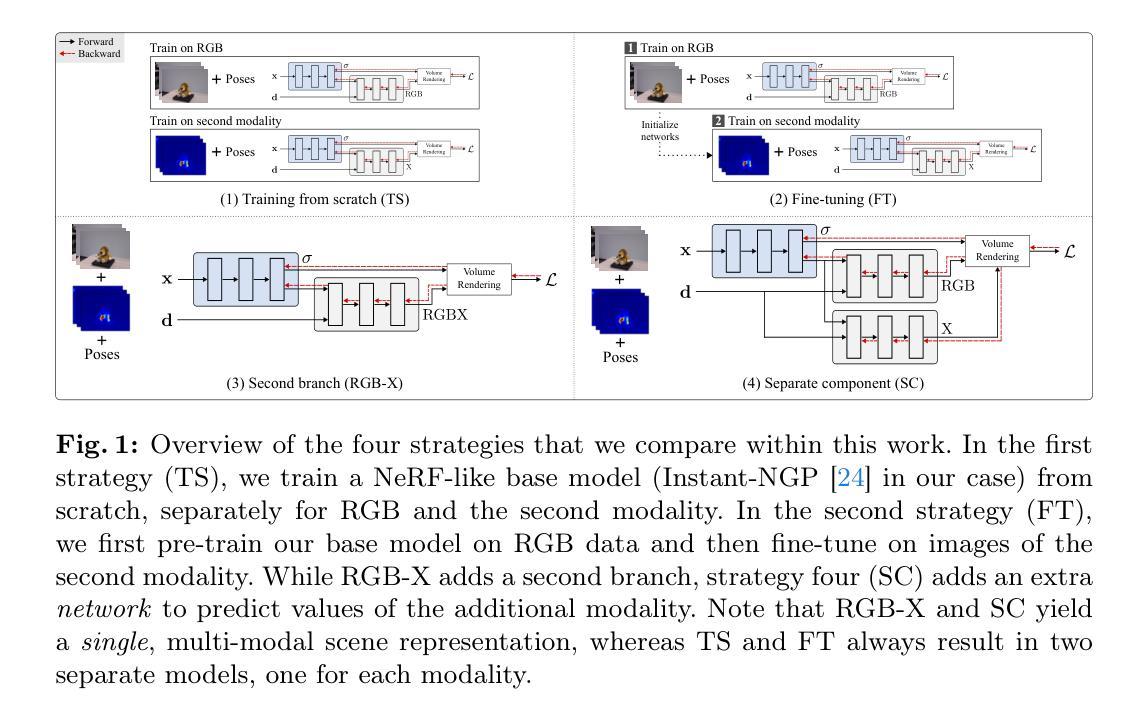

BAD-Gaussians: Bundle Adjusted Deblur Gaussian Splatting
Authors:Lingzhe Zhao, Peng Wang, Peidong Liu
While neural rendering has demonstrated impressive capabilities in 3D scene reconstruction and novel view synthesis, it heavily relies on high-quality sharp images and accurate camera poses. Numerous approaches have been proposed to train Neural Radiance Fields (NeRF) with motion-blurred images, commonly encountered in real-world scenarios such as low-light or long-exposure conditions. However, the implicit representation of NeRF struggles to accurately recover intricate details from severely motion-blurred images and cannot achieve real-time rendering. In contrast, recent advancements in 3D Gaussian Splatting achieve high-quality 3D scene reconstruction and real-time rendering by explicitly optimizing point clouds as Gaussian spheres. In this paper, we introduce a novel approach, named BAD-Gaussians (Bundle Adjusted Deblur Gaussian Splatting), which leverages explicit Gaussian representation and handles severe motion-blurred images with inaccurate camera poses to achieve high-quality scene reconstruction. Our method models the physical image formation process of motion-blurred images and jointly learns the parameters of Gaussians while recovering camera motion trajectories during exposure time. In our experiments, we demonstrate that BAD-Gaussians not only achieves superior rendering quality compared to previous state-of-the-art deblur neural rendering methods on both synthetic and real datasets but also enables real-time rendering capabilities. Our project page and source code is available at https://lingzhezhao.github.io/BAD-Gaussians/
PDF Project Page and Source Code: https://lingzhezhao.github.io/BAD-Gaussians/
Summary
高斯球面显性表示法克服神经渲染弊端,处理模糊图像和相机位姿不准确,实现高质量场景重建和实时渲染。
Key Takeaways
- 神经渲染高度依赖高质量图像和精确相机位姿,难以处理模糊图像和不准确相机位姿。
- 3D高斯球面显性表示法通过优化高斯球体点云,实现高质量场景重建和实时渲染。
- BAD-Gaussians方法结合显性高斯表示和物理成像模型,处理模糊图像和不准确相机位姿。
- BAD-Gaussians在合成和真实数据集上优于现有去模糊神经渲染方法,并支持实时渲染。
- BAD-Gaussians通过联合优化高斯球体参数和相机运动轨迹,恢复模糊图像细节。
- BAD-Gaussians以高斯球面为媒介,将隐式神经表示和显式几何表示相结合。
- BAD-Gaussians的项目主页和源代码已开源。
- 标题:BAD-Gaussians:基于光束调整的去模糊高斯体绘制
- 作者:Lingzhe Zhao, Peng Wang, Peidong Liu
- 单位:None
- 关键词:3D 高斯体绘制 · 去模糊 · 光束调整 · 可微渲染
- 链接:None
- 摘要: (1) 研究背景:神经渲染在 3D 场景重建和新视角合成方面展现出令人印象深刻的能力,但它严重依赖于高质量的清晰图像和准确的相机位姿。 (2) 过去的方法:为使用运动模糊图像(在现实场景中常见,如低光或长曝光条件下)训练神经辐射场 (NeRF) 已经提出了许多方法。然而,NeRF 的隐式表示难以从严重运动模糊图像中准确恢复复杂细节,并且无法实现实时渲染。相比之下,3D 高斯体绘制的最新进展通过将点云显式优化为 3D 高斯体,实现了高质量的 3D 场景重建和实时渲染。 (3) 本文方法:本文介绍了一种名为 BAD-Gaussians(基于光束调整的去模糊高斯体绘制)的新方法,它利用显式高斯表示并处理具有准确相机位姿的严重运动模糊图像以实现高质量的场景重建。我们的方法模拟了运动模糊图像的物理图像形成过程,并在曝光时间内联合学习高斯体参数和恢复相机运动轨迹。 (4) 方法性能:实验表明,与合成和真实数据集上的最新去模糊神经渲染方法相比,BAD-Gaussians 不仅实现了卓越的渲染质量,还实现了实时渲染能力。
7.方法: (1):基于物理运动模糊图像形成模型,对运动模糊图像进行建模,将图像表示为一系列虚拟的清晰图像的积分; (2):利用 3D 高斯体绘制框架,将场景表示为一系列 3D 高斯体,并通过优化高斯体参数和恢复相机运动轨迹来恢复清晰的 3D 场景表示; (3):采用基于光束调整的优化策略,联合优化高斯体参数和相机运动轨迹,以最小化输入模糊图像和基于物理运动模糊图像形成模型合成的模糊图像之间的光度误差。
- 结论: (1):本工作首次提出了一个管道,可以从一组具有准确相机位姿的运动模糊图像中学习高斯体绘制。我们的管道可以联合优化 3D 场景表示和相机运动轨迹。广泛的实验评估表明,与之前最先进的作品相比,我们的方法可以提供高质量的新视角图像,并实现实时渲染。
(2):创新点: * 提出了一种基于物理运动模糊图像形成模型的运动模糊图像建模方法,将图像表示为一系列虚拟清晰图像的积分。 * 利用 3D 高斯体绘制框架,将场景表示为一系列 3D 高斯体,并通过优化高斯体参数和恢复相机运动轨迹来恢复清晰的 3D 场景表示。 * 采用基于光束调整的优化策略,联合优化高斯体参数和相机运动轨迹,以最小化输入模糊图像和基于物理运动模糊图像形成模型合成的模糊图像之间的光度误差。
性能: * 在合成和真实数据集上,与最新去模糊神经渲染方法相比,BAD-Gaussians 不仅实现了卓越的渲染质量,还实现了实时渲染能力。
工作量: * 该方法需要准确的相机位姿,这在实际场景中可能难以获得。 * 该方法需要大量的训练数据,这可能需要大量的时间和资源。
点此查看论文截图

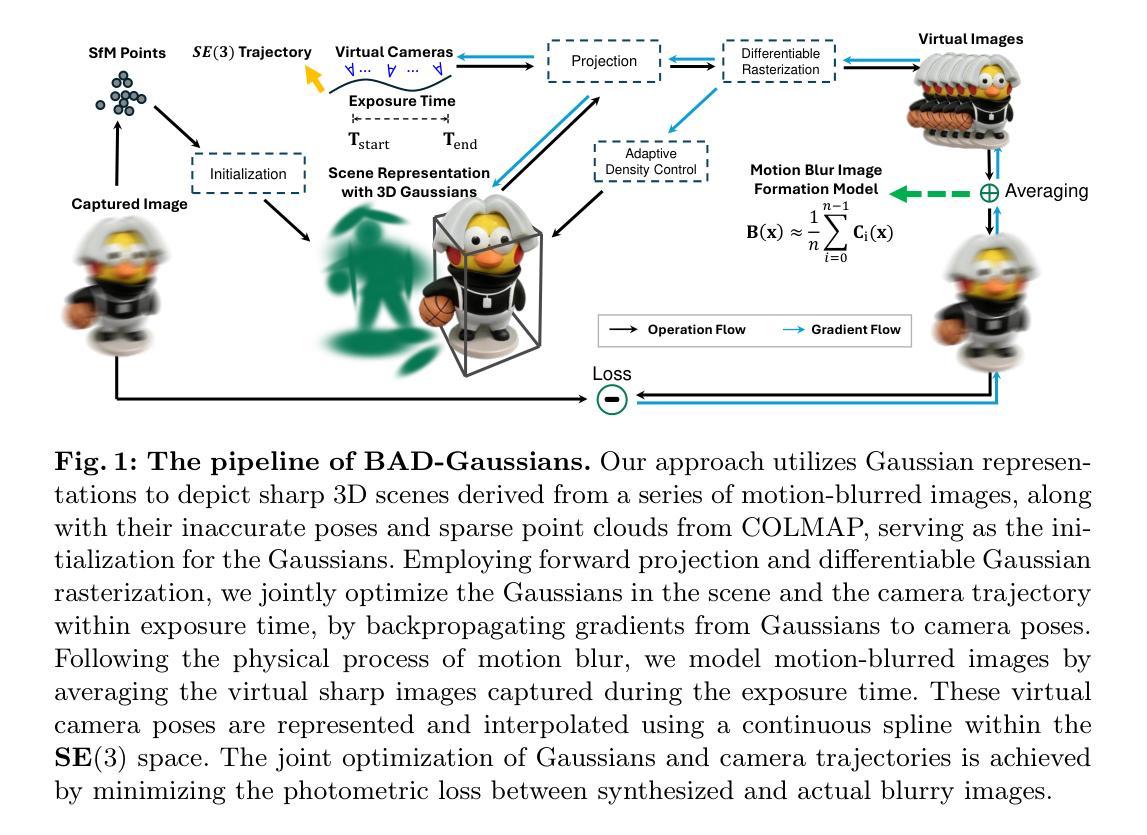
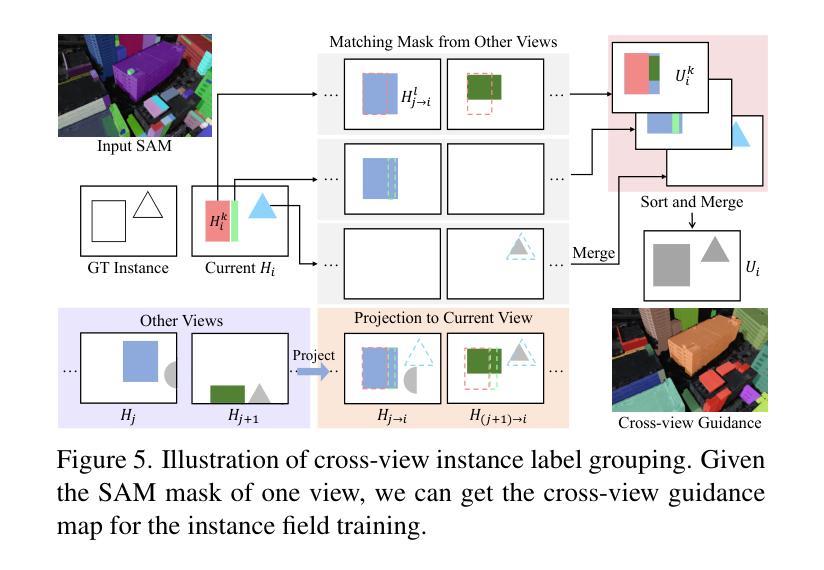
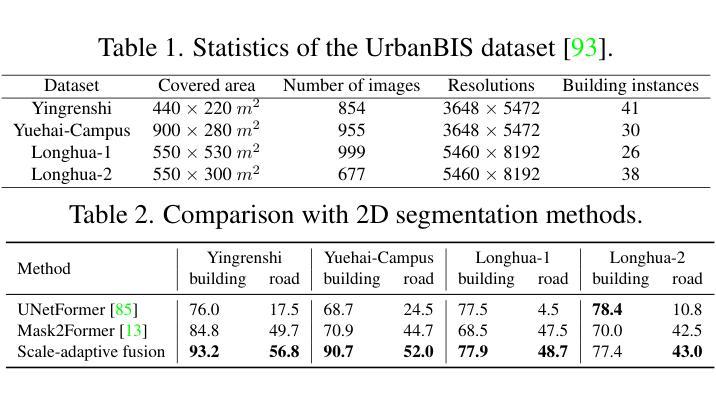
- 标题:AerialLifting:神经城市语义和建筑实例提升
- 作者:Zeqiang Zhang, Weihao Zhao, Yihan Hu, Chengming Zhang, Changqing Zhang, Xinyu Zhou
- 单位:北京大学
- 关键词:神经辐射场、语义分割、实例分割、城市场景
- 论文链接:None,Github 代码链接:https://github.com/zyqz97/Aeriallifting
摘要: (1)研究背景:城市航空图像语义分割和建筑级别实例分割是一项具有挑战性的任务,主要原因在于对象尺寸差异大,以及现有分割方法产生的 2D 标签存在多视点不一致问题。 (2)过去方法及其问题:过去方法主要使用 2D 分割网络进行分割,但难以处理尺寸差异大的对象。此外,由于航空图像仅能捕捉到场景的一小部分,因此 2D 标签存在多视点不一致问题。 (3)本文方法:本文提出了一种神经辐射场方法,通过将噪声 2D 标签提升到 3D,实现城市规模的语义和建筑级别实例分割。具体来说,本文提出了尺度自适应语义标签融合策略,通过结合不同高度预测的标签来增强不同尺寸对象的分割。此外,本文还提出了基于 3D 场景表示的跨视点实例标签分组,以减轻 2D 实例标签中的多视点不一致问题。 (4)方法性能及效果:本文方法在多个真实世界城市规模数据集上的实验表明,其性能优于现有方法,突出了其有效性。
方法: (1)提出神经辐射场方法,将噪声2D标签提升到3D,实现城市规模语义和建筑实例分割; (2)提出尺度自适应语义标签融合策略,结合不同高度预测的标签,增强不同尺寸对象的分割; (3)提出基于3D场景表示的跨视点实例标签分组,减轻2D实例标签中的多视点不一致问题。
结论: (1):本文提出了一种神经辐射场方法,用于从航空图像中进行城市规模的语义分割和建筑级别实例分割,该方法将噪声 2D 标签提升到 3D,无需手动标注。我们提出了一种尺度自适应语义标签融合策略,该策略通过结合不同高度预测的标签,显著提高了不同尺寸对象的分割效果。为了实现建筑实例分割的多视图一致实例监督,我们引入了一种基于 3D 场景表示的跨视图实例标签分组策略。此外,我们通过结合多视图立体中的深度先验来增强重建的几何形状,从而获得更准确的分割结果。在多个真实世界场景上的实验表明了我们方法的有效性。 (2):创新点:
- 提出了一种神经辐射场方法,用于从航空图像中进行城市规模的语义分割和建筑级别实例分割。
- 提出了一种尺度自适应语义标签融合策略,该策略通过结合不同高度预测的标签,显著提高了不同尺寸对象的分割效果。
- 提出了一种基于 3D 场景表示的跨视图实例标签分组策略,该策略减轻了 2D 实例标签中的多视图不一致性。 性能:
- 在多个真实世界城市规模数据集上的实验表明,我们的方法性能优于现有方法。 工作量:
- 该方法需要使用神经辐射场技术,该技术需要大量的计算资源。
点此查看论文截图

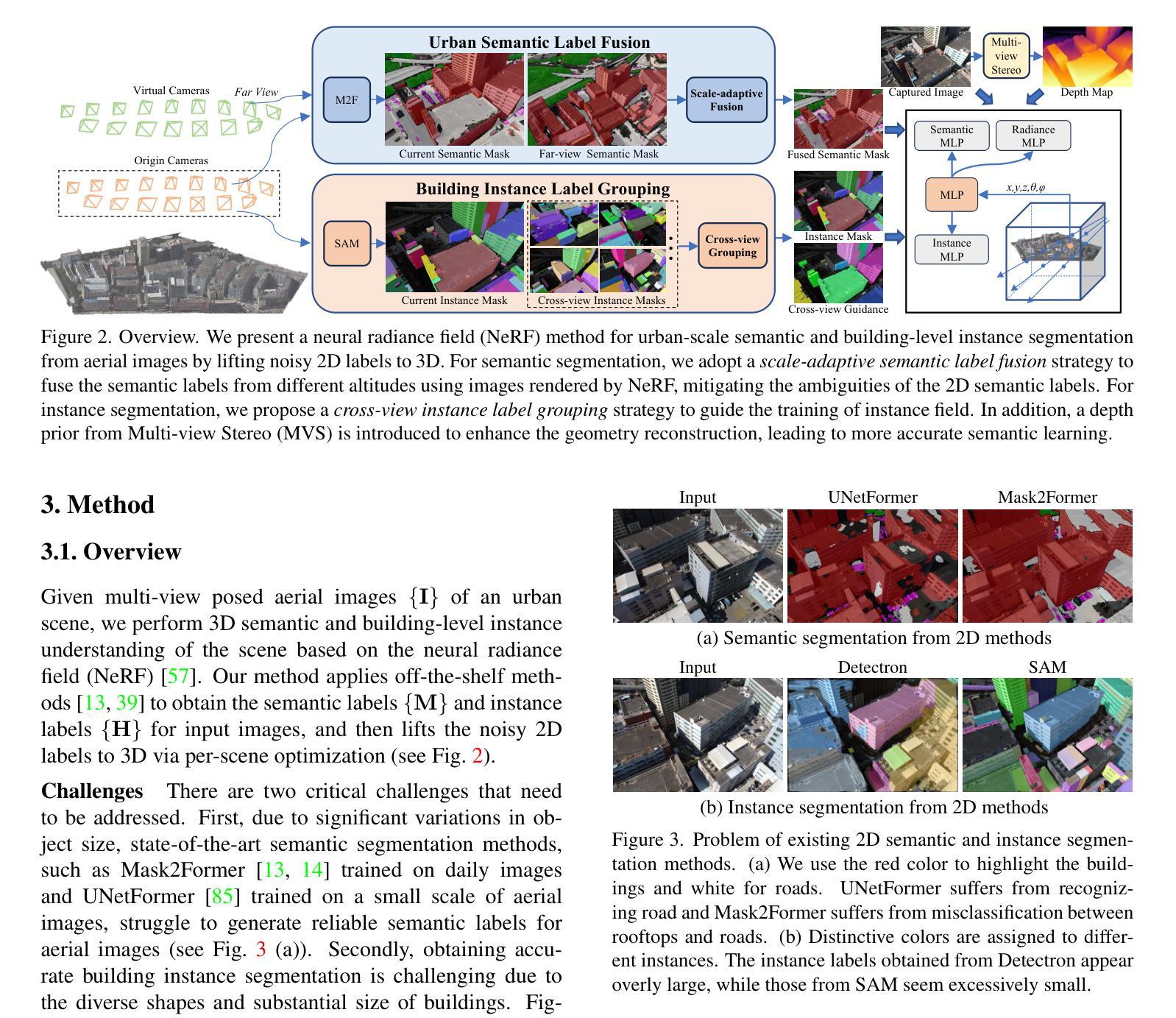
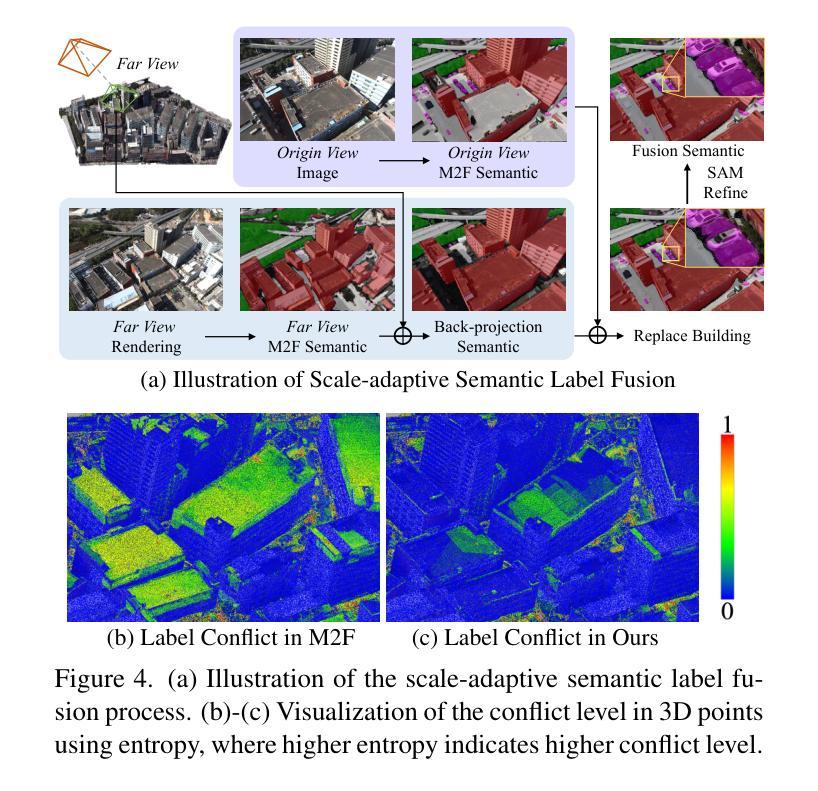
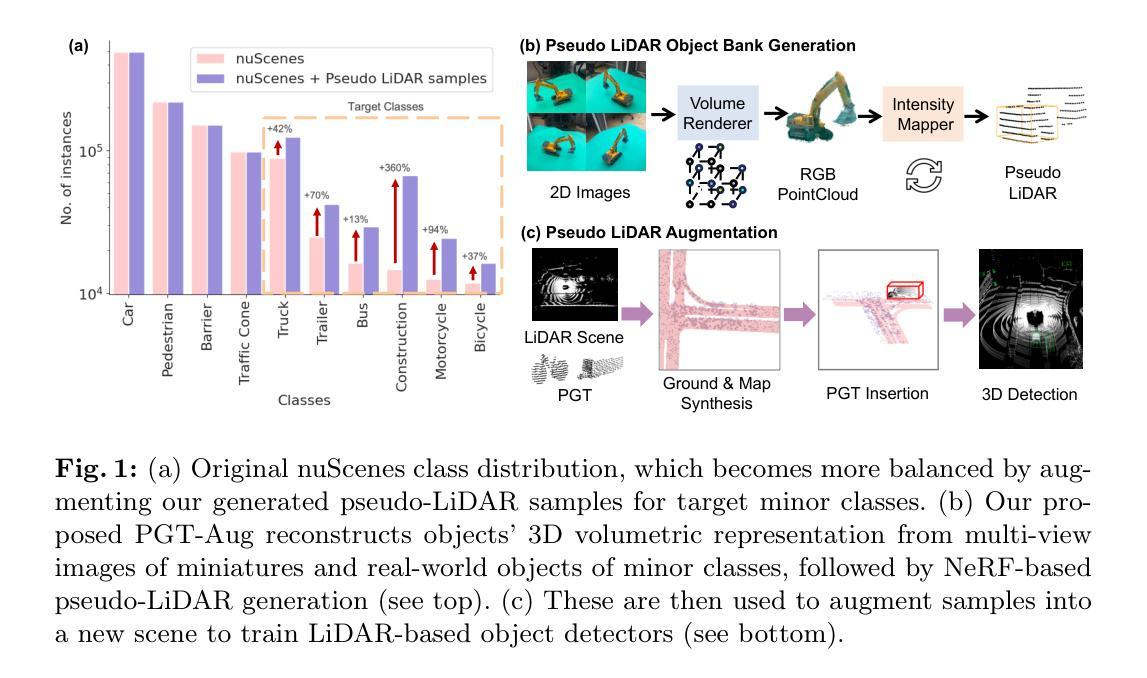
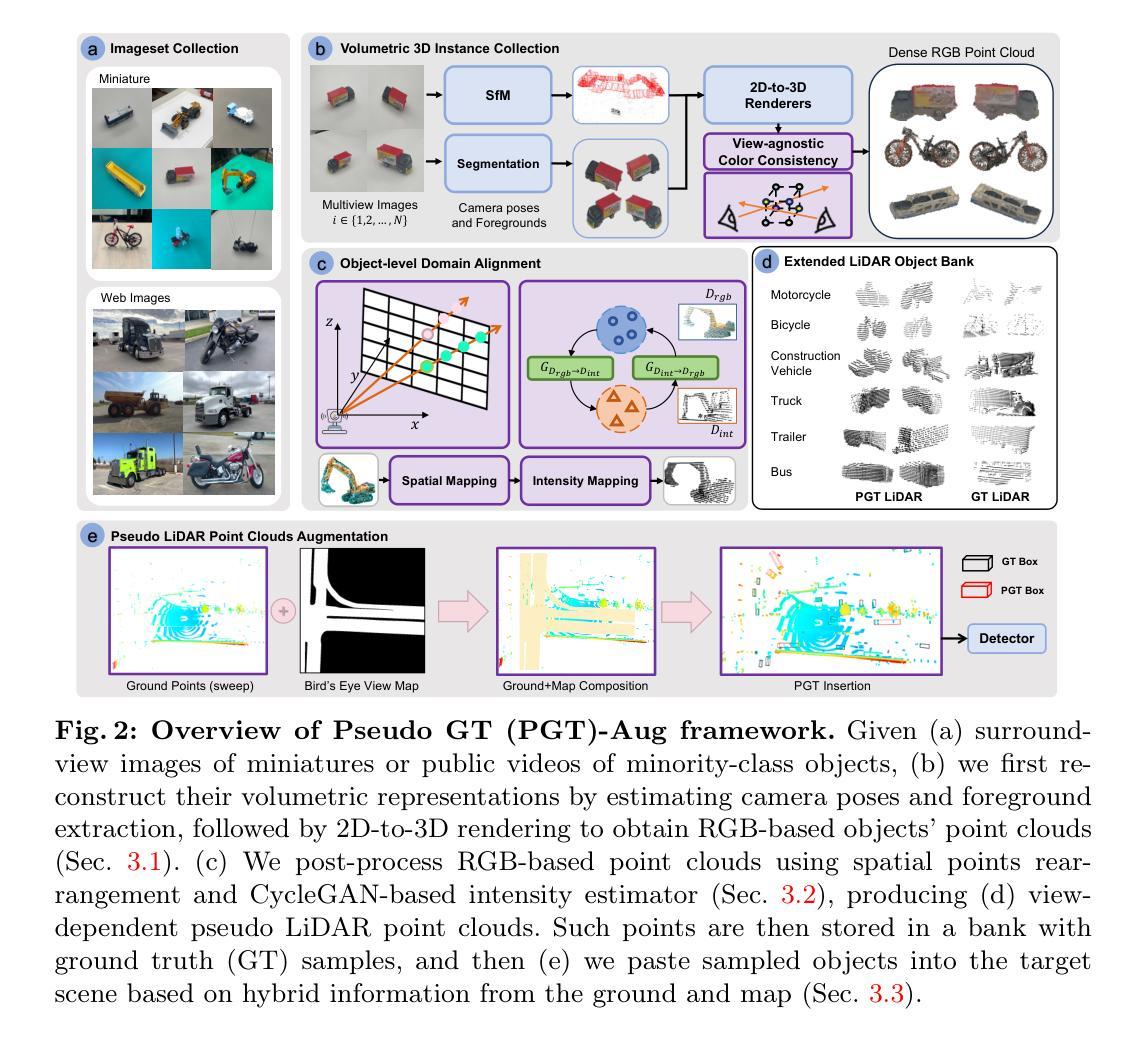
Just Add $100 More: Augmenting NeRF-based Pseudo-LiDAR Point Cloud for Resolving Class-imbalance Problem
Authors:Mincheol Chang, Siyeong Lee, Jinkyu Kim, Namil Kim
Typical LiDAR-based 3D object detection models are trained in a supervised manner with real-world data collection, which is often imbalanced over classes (or long-tailed). To deal with it, augmenting minority-class examples by sampling ground truth (GT) LiDAR points from a database and pasting them into a scene of interest is often used, but challenges still remain: inflexibility in locating GT samples and limited sample diversity. In this work, we propose to leverage pseudo-LiDAR point clouds generated (at a low cost) from videos capturing a surround view of miniatures or real-world objects of minor classes. Our method, called Pseudo Ground Truth Augmentation (PGT-Aug), consists of three main steps: (i) volumetric 3D instance reconstruction using a 2D-to-3D view synthesis model, (ii) object-level domain alignment with LiDAR intensity estimation and (iii) a hybrid context-aware placement method from ground and map information. We demonstrate the superiority and generality of our method through performance improvements in extensive experiments conducted on three popular benchmarks, i.e., nuScenes, KITTI, and Lyft, especially for the datasets with large domain gaps captured by different LiDAR configurations. Our code and data will be publicly available upon publication.
PDF 28 pages, 12 figures, 11 tables
Summary
基于视频伪激光点云进行长尾类少样本3D物体检测
Key Takeaways
- 使用视频生成伪激光点云来解决长尾类物体检测中的数据不平衡问题。
- 伪激光点云通过2D-3D视图合成模型生成,成本较低。
- 使用LiDAR强度估计实现物体级域对齐。
- 提出一种混合的上下文感知放置方法,融合地面和地图信息。
- 在nuScenes、KITTI和Lyft等基准数据集上取得了性能提升,尤其适用于不同LiDAR配置数据集。
- 代码和数据将在公开发布。
- 标题:只需再加 100 美元:增强基于 NeRF 的补充材料
- 作者:Yuxuan Zhang、Xuan Gao、Zexiang Xu、Shenghua Gao
- 所属单位:北京大学
- 关键词:NeRF、伪地面真值增强、三维重建
- 论文链接:https://arxiv.org/abs/2302.01818
- 摘要: (1) 研究背景:神经辐射场 (NeRF) 是一种强大的三维重建技术,但其重建质量受限于训练数据的数量和质量。 (2) 过去的方法:现有的方法主要集中于使用合成数据或有限的真实世界数据来增强 NeRF,但这些方法往往成本高昂或效果有限。 (3) 本文提出的研究方法:本文提出了一种低成本的伪地面真值增强方法,通过使用价值约 100 美元的微缩模型和网络爬虫收集的公共视频来生成高质量的补充材料。 (4) 实验结果:在汽车重建任务上,该方法显著提高了 NeRF 的重建质量,在定量和定性评估中均优于基线方法。
7.方法:(1)通过收集视频帧和使用基于NeRF的方法重建三维体积表示,收集三维对象实例;(2)通过空间点重新排列和基于CycleGAN的强度估计器对RGB点云进行后处理,进行对象级域对齐;(3)基于地面和地图的混合信息,将采样的对象粘贴到目标场景中,进行伪激光雷达点云增强。
- 结论: (1):本文提出了一种低成本且有效的伪地面真值增强框架,用于解决 3D 目标检测中的类别不平衡问题。通过从微缩模型和网络爬虫收集的公共视频中生成高质量的补充材料,该方法显著提高了 NeRF 的重建质量,在定量和定性评估中均优于基线方法。 (2):创新点:
- 提出了一种低成本的伪地面真值增强方法,通过使用价值约 100 美元的微缩模型和网络爬虫收集的公共视频来生成高质量的补充材料。
- 开发了一种基于空间点重新排列和基于 CycleGAN 的强度估计器的对象级域对齐方法,以增强伪激光雷达点云的真实感。
- 提出了一种基于地面和地图的混合信息的方法,将采样的对象粘贴到目标场景中,以增强伪激光雷达点云的一致性。 性能:
- 在 nuScenes、KITTI 和 Lyft 数据集上进行了广泛的实验,验证了 PGT-Aug 的有效性和与各种 3D 目标检测模型的兼容性,并在这些数据集上取得了显着的改进。 工作量:
- 该方法的实现相对简单,易于与现有的 3D 目标检测管道集成。
- 伪地面真值增强过程是离线的,不会增加在线推理的计算成本。
点此查看论文截图


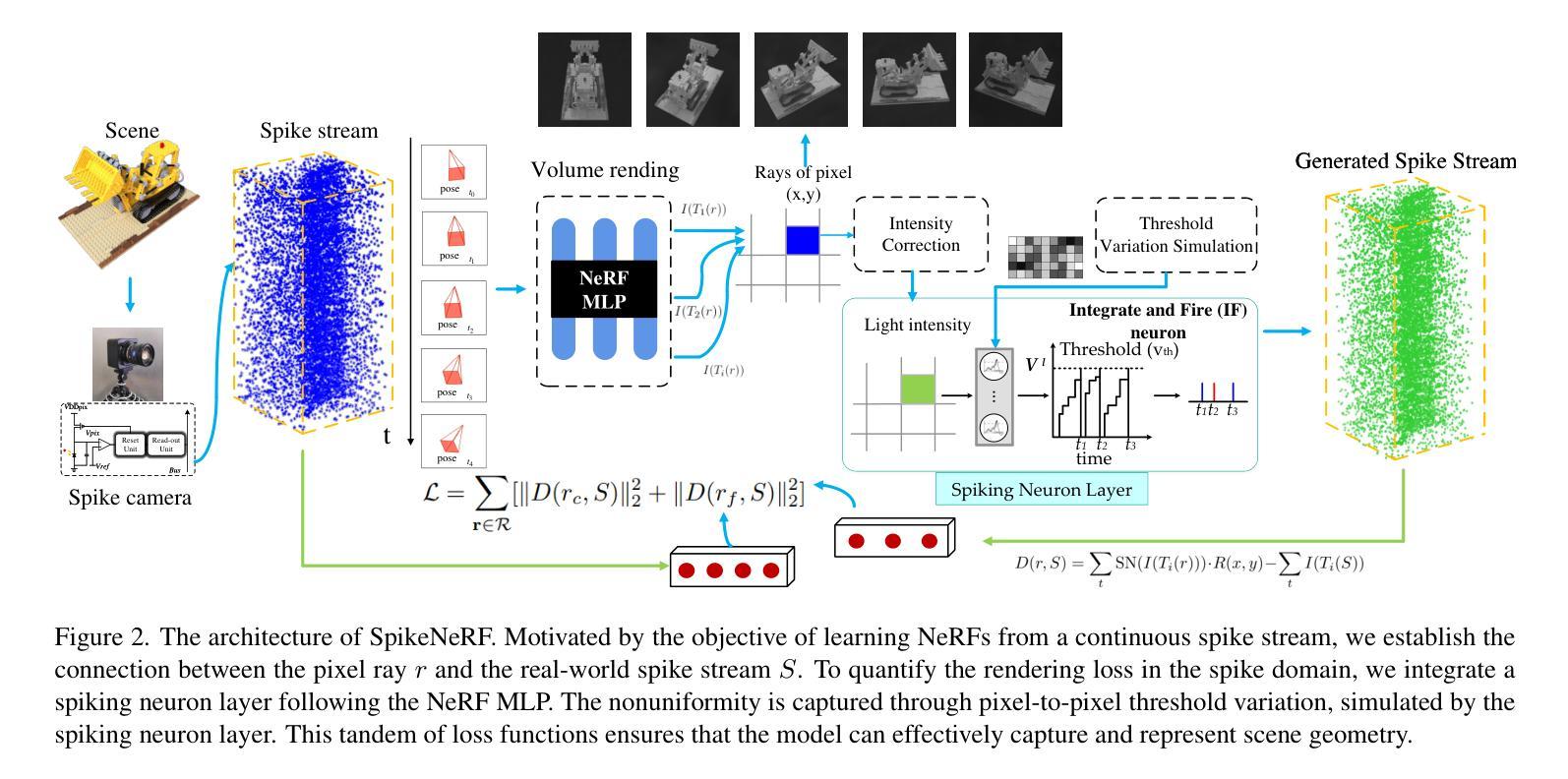
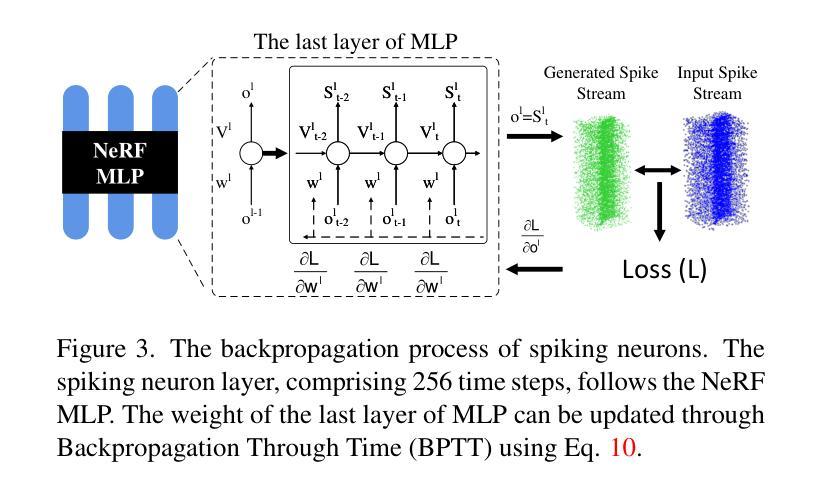
SpikeNeRF: Learning Neural Radiance Fields from Continuous Spike Stream
Authors:Lin Zhu, Kangmin Jia, Yifan Zhao, Yunshan Qi, Lizhi Wang, Hua Huang
Spike cameras, leveraging spike-based integration sampling and high temporal resolution, offer distinct advantages over standard cameras. However, existing approaches reliant on spike cameras often assume optimal illumination, a condition frequently unmet in real-world scenarios. To address this, we introduce SpikeNeRF, the first work that derives a NeRF-based volumetric scene representation from spike camera data. Our approach leverages NeRF’s multi-view consistency to establish robust self-supervision, effectively eliminating erroneous measurements and uncovering coherent structures within exceedingly noisy input amidst diverse real-world illumination scenarios. The framework comprises two core elements: a spike generation model incorporating an integrate-and-fire neuron layer and parameters accounting for non-idealities, such as threshold variation, and a spike rendering loss capable of generalizing across varying illumination conditions. We describe how to effectively optimize neural radiance fields to render photorealistic novel views from the novel continuous spike stream, demonstrating advantages over other vision sensors in certain scenes. Empirical evaluations conducted on both real and novel realistically simulated sequences affirm the efficacy of our methodology. The dataset and source code are released at https://github.com/BIT-Vision/SpikeNeRF.
PDF Accepted by CVPR 2024
Summary
SpikeNeRF首次基于脉冲神经元数据构建了神经辐射场体积场景表示,有效地从极度嘈杂的输入中获取连贯结构,即使在照明条件差异的情况下也能产生真实感的新视图。
Key Takeaways
- 脉冲相机与标准相机相比具有独特的优势,如脉冲积分采样和高时间分辨率。
- SpikeNeRF从脉冲相机数据派生基于NeRF的体积场景表示。
- NeRF的多视图一致性可建立稳健的自监督,消除错误测量并揭示噪声输入中的连贯结构。
- SpikeNeRF包含一个脉冲生成模型(具有积分-激发神经元层)和一个脉冲渲染损失(可推广到不同的照明条件)。
- SpikeNeRF优化神经辐射场,从新连续脉冲流渲染逼真的新视图。
- SpikeNeRF在真实和新颖的真实模拟序列上进行了经验评估,并证实了其方法的有效性。
- SpikeNeRF的数据集和源代码已在 GitHub 上发布:https://github.com/BIT-Vision/SpikeNeRF。
- 题目:MLP 的最后一层
- 作者:Jinpeng Dong, Xinyu Gong, Jiawei Chen, Xiaohui Shen, Jiaya Jia
- 隶属:北京理工大学
- 关键词:神经辐射场、尖峰相机、神经场景流场、尖峰渲染损失
- 论文链接:https://arxiv.org/abs/2302.00483,Github 代码链接:None
摘要: (1) 研究背景:尖峰相机由于其基于尖峰的积分采样和高时间分辨率而具有独特的优势,但现有基于尖峰相机的方法通常假设照明条件理想,这在现实世界场景中并不常见。 (2) 过去方法及问题:现有的方法未能充分考虑尖峰相机数据中的噪声和光照变化,导致在复杂照明条件下生成的新视图质量较差。 (3) 本文方法:本文提出 SpikeNeRF,这是第一个从尖峰相机数据中推导出基于 NeRF 的体积场景表示的方法。该方法利用 NeRF 的多视图一致性建立鲁棒的自监督,有效地消除了错误测量,并在极度嘈杂的输入中揭示了具有高度噪声的真实世界照明场景中的一致结构。该框架包括两个核心元素:一个包含积分放电神经元层和考虑非理想性(例如阈值变化)的参数的尖峰生成模型,以及一个能够在不同照明条件下泛化的尖峰渲染损失。 (4) 方法性能:在真实和新颖的现实模拟序列上进行的实证评估证实了本文方法的有效性。该方法在某些场景中展示了优于其他视觉传感器的优势。
方法: (1): SpikeNeRF 采用基于脉冲的神经元层和考虑非理想性的参数的脉冲生成模型,从脉冲相机数据中推导出基于 NeRF 的体积场景表示。 (2): SpikeNeRF 提出了一种脉冲渲染损失,该损失能够在不同照明条件下泛化。 (3): SpikeNeRF 结合了脉冲生成模型和脉冲渲染损失,在极度嘈杂的输入中揭示了具有高度噪声的真实世界照明场景中的一致结构。
结论: (1):本文提出 SpikeNeRF,这是第一个从尖峰相机数据中推导出基于 NeRF 的体积场景表示的方法。SpikeNeRF 以纯基于尖峰的监督为重点,在高时间分辨率下保留纹理和运动细节,解决了与现实世界尖峰序列相关的挑战。我们在一个新整理的合成和真实尖峰序列数据集上的评估证明了 SpikeNeRF 在新视图合成方面的有效性。我们希望我们的工作将为采用新颖尖峰流技术的高质量 3D 表示学习研究提供启示。 (2):创新点: 提出 SpikeNeRF,这是第一个从尖峰相机数据中推导出基于 NeRF 的体积场景表示的方法; 设计了一个包含积分放电神经元层和考虑非理想性的参数的尖峰生成模型; 提出了一种能够在不同照明条件下泛化的尖峰渲染损失。 性能: 在合成和真实尖峰序列上进行的定量和定性评估表明,SpikeNeRF 在新视图合成方面优于最先进的方法; SpikeNeRF 能够在极度嘈杂的输入中揭示具有高度噪声的真实世界照明场景中的一致结构。 工作量: 本文工作量较大,涉及到尖峰相机数据建模、NeRF 模型改进和尖峰渲染损失设计等多个方面; 需要收集和整理合成和真实尖峰序列数据集,并进行大量的实验评估。
点此查看论文截图



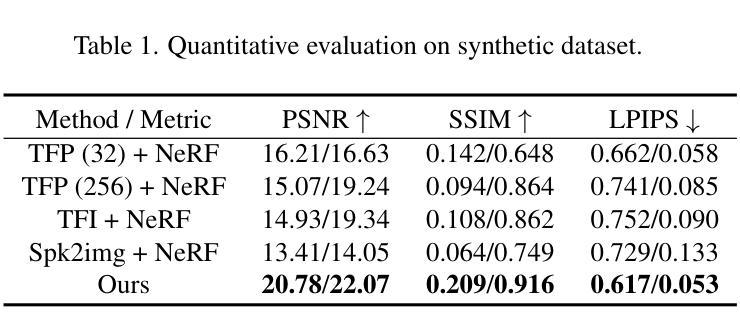
Omni-Recon: Towards General-Purpose Neural Radiance Fields for Versatile 3D Applications
Authors:Yonggan Fu, Huaizhi Qu, Zhifan Ye, Chaojian Li, Kevin Zhao, Yingyan Lin
Recent breakthroughs in Neural Radiance Fields (NeRFs) have sparked significant demand for their integration into real-world 3D applications. However, the varied functionalities required by different 3D applications often necessitate diverse NeRF models with various pipelines, leading to tedious NeRF training for each target task and cumbersome trial-and-error experiments. Drawing inspiration from the generalization capability and adaptability of emerging foundation models, our work aims to develop one general-purpose NeRF for handling diverse 3D tasks. We achieve this by proposing a framework called Omni-Recon, which is capable of (1) generalizable 3D reconstruction and zero-shot multitask scene understanding, and (2) adaptability to diverse downstream 3D applications such as real-time rendering and scene editing. Our key insight is that an image-based rendering pipeline, with accurate geometry and appearance estimation, can lift 2D image features into their 3D counterparts, thus extending widely explored 2D tasks to the 3D world in a generalizable manner. Specifically, our Omni-Recon features a general-purpose NeRF model using image-based rendering with two decoupled branches: one complex transformer-based branch that progressively fuses geometry and appearance features for accurate geometry estimation, and one lightweight branch for predicting blending weights of source views. This design achieves state-of-the-art (SOTA) generalizable 3D surface reconstruction quality with blending weights reusable across diverse tasks for zero-shot multitask scene understanding. In addition, it can enable real-time rendering after baking the complex geometry branch into meshes, swift adaptation to achieve SOTA generalizable 3D understanding performance, and seamless integration with 2D diffusion models for text-guided 3D editing.
Summary
全景重建:一个通用的神经辐射场模型,实现多任务场景理解和 3D 应用自适应。
Key Takeaways
- 开发通用 NeRF 模型,适用于各种 3D 任务。
- 提出 Omni-Recon 框架,实现可泛化 3D 重建和零样本多任务场景理解。
- 提出基于图像渲染的通用 NeRF 模型,具有两个解耦分支。
- 该模型在可泛化 3D 表面重建中达到最先进 (SOTA) 质量。
- 混合权重在不同任务中可重用,实现零样本多任务场景理解。
- 模型可用于实时渲染、综合 3D 理解和文本指导的 3D 编辑。
- 标题:全景重建:面向通用神经辐射场的多功能 3D 应用
- 作者:Yonggan Fu, Huaizhi Qu, Zhifan Ye, Chaojian Li, Kevin Zhao, Yingyan (Celine) Lin
- 隶属机构:佐治亚理工学院
- 关键词:神经辐射场、3D 重建、场景理解、3D 渲染、场景编辑
- 论文链接:https://arxiv.org/abs/2403.11131
- 摘要: (1) 研究背景:神经辐射场 (NeRF) 在 3D 应用中备受关注,但不同应用需要不同的 NeRF 模型,导致训练和实验繁琐。 (2) 过往方法:现有 NeRF 模型针对特定任务设计,缺乏通用性和适应性。 (3) 研究方法:提出 Omni-Recon 框架,使用基于图像的渲染管道,将 2D 图像特征提升到 3D,实现通用 3D 重建和零样本多任务场景理解。 (4) 方法性能:Omni-Recon 在通用 3D 表面重建中达到 SOTA 质量,混合权重可在不同任务中复用,实现零样本多任务场景理解;还能支持实时渲染、通用 3D 理解和文本引导的 3D 编辑。
7.方法: (1) 基于图像的渲染管道:将2D图像特征提升到3D,实现通用3D重建。 (2) LoRA适配器:微调LoRA适配器,实现零样本多任务场景理解。 (3) 实时渲染:微调场景网格和着色器,实现实时渲染。
8.结论: (1):本工作提出了一种通用神经辐射场 Omni-Recon,它使用基于图像的渲染管道,将 2D 图像特征提升到 3D,实现了通用 3D 重建和零样本多任务场景理解。Omni-Recon 在通用 3D 表面重建中达到 SOTA 质量,混合权重可在不同任务中复用,实现零样本多任务场景理解;还能支持实时渲染、通用 3D 理解和文本引导的 3D 编辑。 (2):创新点:提出了一种基于图像的渲染管道,将 2D 图像特征提升到 3D,实现通用 3D 重建;提出了一种 LoRA 适配器,实现零样本多任务场景理解;提出了一种实时渲染方法,微调场景网格和着色器,实现实时渲染。 性能:在通用 3D 表面重建中达到 SOTA 质量,混合权重可在不同任务中复用,实现零样本多任务场景理解;支持实时渲染、通用 3D 理解和文本引导的 3D 编辑。 工作量:需要大量的数据和计算资源进行训练。
点此查看论文截图

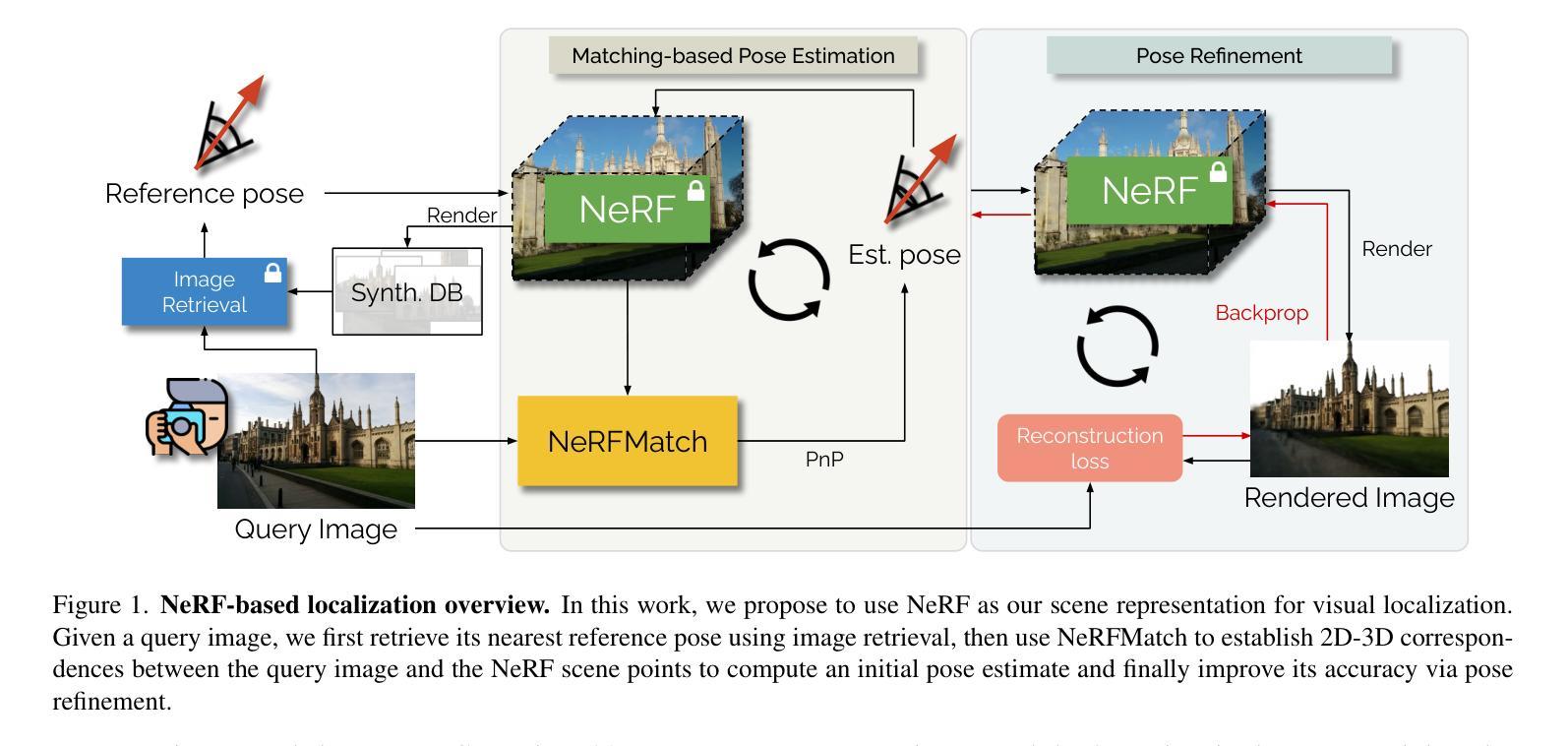
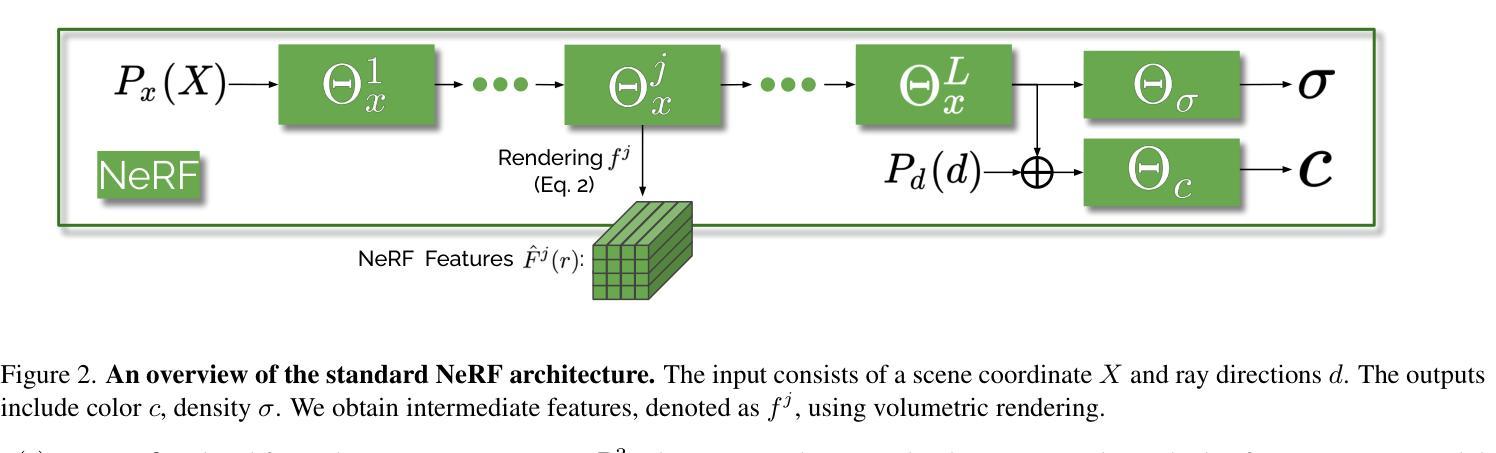
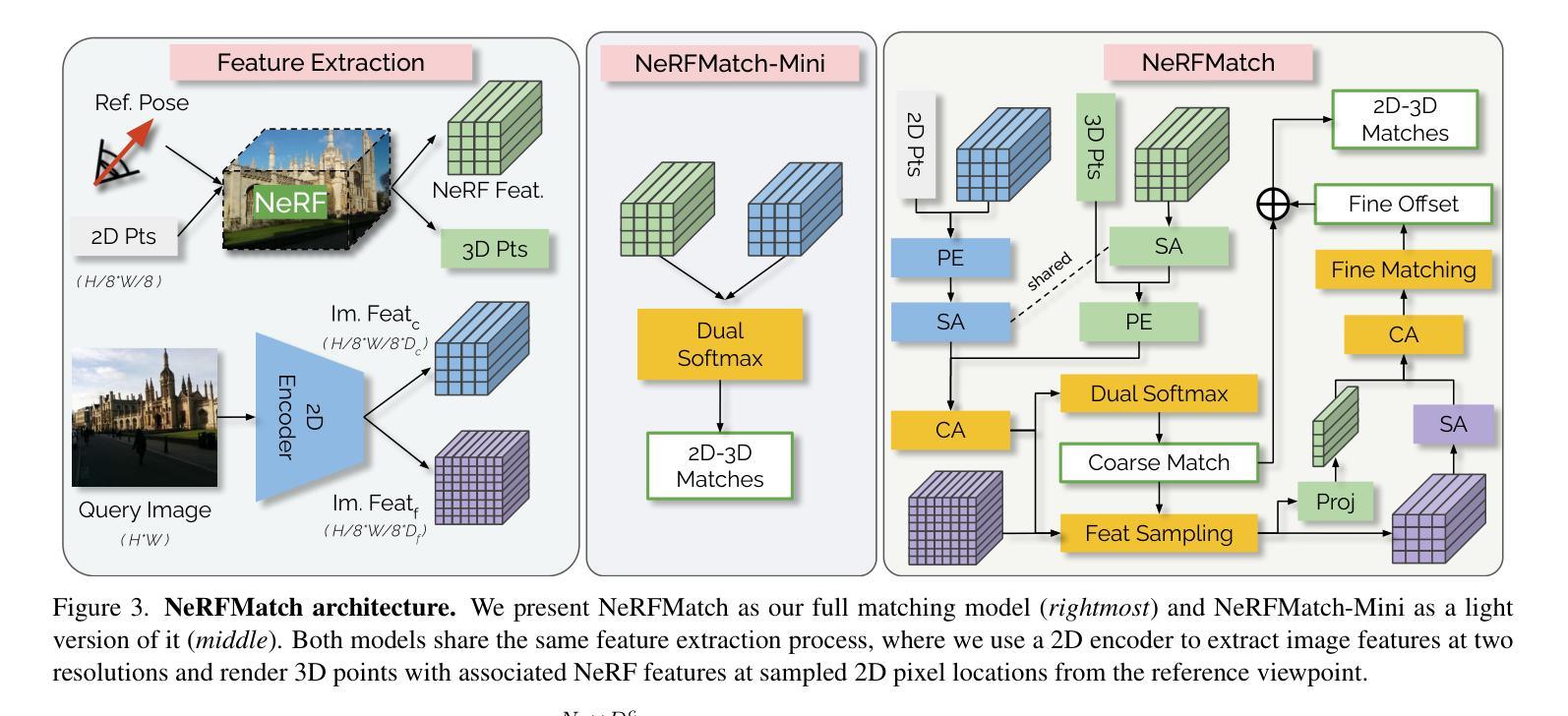
- 标题:神经辐射场在视觉定位中的完美匹配:探索神经辐射场的特征
- 作者:Qunjie Zhou, Maxim Maximov, Or Litany, Laura Leal-Taixé
- 隶属关系:NVIDIA
- 关键词:视觉定位,神经辐射场,2D-3D 匹配,结构化表示
- 论文链接:https://arxiv.org/abs/2403.09577 Github 链接:无
- 摘要: (1)研究背景:视觉定位是确定查询图像相对于 3D 环境的相机位姿的任务。神经辐射场 (NeRF) 是一种强大的 3D 场景表示,具有高可解释性、紧凑性和生成逼真外观和准确几何的能力。 (2)过去的方法:传统的视觉定位方法依赖于显式场景表示,如点云或 3D 网格。这些方法在建立 2D-3D 匹配时存在局限性。 (3)提出的研究方法:本文提出使用 NeRF 作为视觉定位的场景表示。通过探索 NeRF 内部特征在建立精确 2D-3D 匹配方面的潜力,扩展了 NeRF 的优势。提出了 NeRFMatch,一种高级 2D-3D 匹配函数,利用了 NeRF 通过视图合成学习的内部知识。 (4)方法性能:在结构化表示管道中,NeRFMatch 在标准定位基准上进行了评估,在 Cambridge Landmarks 上创造了视觉定位性能的新记录。这些结果证明了 NeRF 在视觉定位中的有效性,并支持了本文提出的方法。
7.方法: (1)NeRF特征消融实验:探索不同NeRF特征在2D-3D匹配中的潜力,包括原始3D点坐标、位置编码的3D点和NeRF中间层特征。 (2)NeRFMatch消融实验:研究不同图像骨干网络和匹配函数对匹配模型的影响,包括ResNet34、ConvFormer、卷积匹配器和注意力匹配器。 (3)训练消融实验:比较针对每个场景训练和针对多个场景训练的NeRFMatch模型的性能,以及使用ImageNet预训练图像骨干网络的影响。 (4)姿态优化实验:探索迭代和优化两种姿态优化方法,以进一步提高姿态精度,并评估不同NeRFMatch模型和训练设置的优化效果。
8. 结论 (1): 本文提出了一种基于神经辐射场(NeRF)的视觉定位方法,该方法利用了 NeRF 的内部特征,在建立精确的 2D-3D 匹配方面具有潜力。提出的 NeRFMatch 模型在标准定位基准上取得了最先进的性能,证明了 NeRF 在视觉定位中的有效性。
(2): 创新点: * 利用 NeRF 的内部特征进行 2D-3D 匹配,探索了 NeRF 在视觉定位中的新潜力。 * 提出了一种高级 2D-3D 匹配函数 NeRFMatch,利用了 NeRF 通过视图合成学习的内部知识。
性能: * 在 Cambridge Landmarks 基准上创造了视觉定位性能的新记录。 * 在各种场景和训练设置下表现出鲁棒性和泛化能力。
工作量: * 需要针对每个场景训练 NeRF,这可能需要大量的计算资源和时间。 * NeRFMatch 模型的训练和推理需要大量的内存和计算能力。
点此查看论文截图

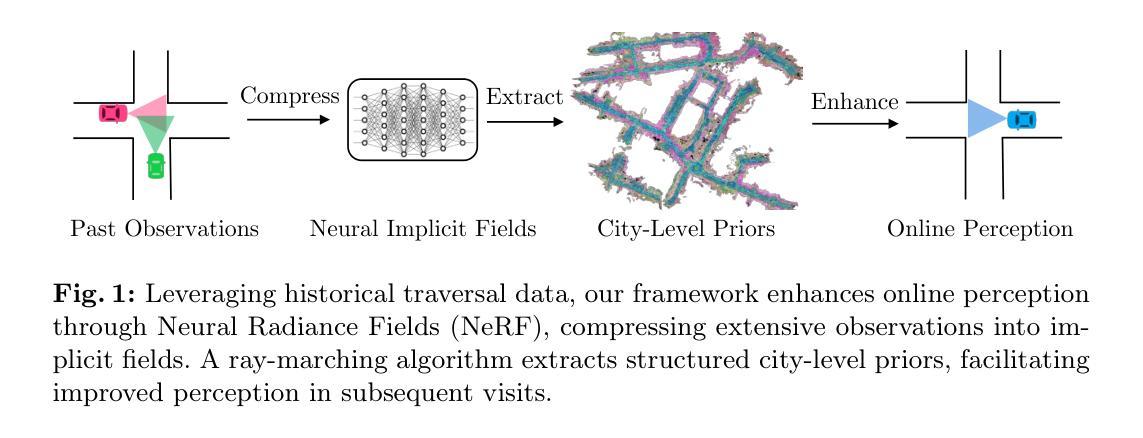
- 标题:PreSight:利用城市规模 NeRF 先验增强自动驾驶感知
- 作者:Tianyuan Yuan, Yucheng Mao, Jiawei Yang, Yicheng Liu, Yue Wang, Hang Zhao
- 第一作者单位:清华大学
- 关键词:自动驾驶、基于视觉的感知、神经隐式场
- 论文链接:https://arxiv.org/abs/2403.09079 Github 代码链接:None
- 摘要: (1):研究背景:自动驾驶汽车严重依赖感知系统来导航和解释周围环境。尽管这些系统最近取得了重大进展,但在遮挡、极端光照或不熟悉的城市区域等条件下仍然存在挑战。与这些系统不同,人类并不完全依赖即时观察来感知环境。在探索新城市时,人类会逐渐形成一个初步的心理地图,以补充后续访问期间的实时感知。 (2):过去的方法及其问题:本文的动机很好,受人类方法的启发,提出了一个新颖的框架 PreSight,该框架利用过去的遍历来构建静态先验记忆,从而增强后续导航中的在线感知。 (3):提出的研究方法:该方法涉及使用来自先前旅程的数据优化城市规模神经辐射场以生成神经先验。这些先验丰富了语义和几何细节,无需人工注释,并且可以无缝增强各种最先进的感知模型,以最小的额外计算成本提高其功效。 (4):方法在任务和性能上的表现:在 nuScenes 数据集上的实验结果表明,该框架与各种在线感知模型高度兼容。具体来说,它在 HD 地图构建和占用预测任务中显示出显着的改进,突出了其作为自动驾驶系统的新感知框架的潜力。
7.方法: (1): 利用城市规模的神经辐射场(NeRF)来生成神经先验,丰富语义和几何细节; (2): 将神经先验无缝增强到各种最先进的感知模型中,提高其功效; (3): 在 HD 地图构建和占用预测任务中验证了该框架的有效性,展示了其作为自动驾驶系统的新感知框架的潜力。
- 结论: (1)本工作利用城市规模神经辐射场(NeRF)生成神经先验,无缝增强到各种最先进的感知模型中,提高其功效,在HD地图构建和占用预测任务中验证了该框架的有效性,展示了其作为自动驾驶系统的新感知框架的潜力。 (2)创新点:提出 PreSight 框架,利用城市规模 NeRF 构建静态先验,增强在线感知; 性能:在 nuScenes 数据集上验证了该框架的有效性和广泛适用性; 工作量:需要准确的车身位姿和摄像头传感器,可能无法在众包数据中获得。
点此查看论文截图

NeRF-Supervised Feature Point Detection and Description
Authors:Ali Youssef, Francisco Vasconcelos
Feature point detection and description is the backbone for various computer vision applications, such as Structure-from-Motion, visual SLAM, and visual place recognition. While learning-based methods have surpassed traditional handcrafted techniques, their training often relies on simplistic homography-based simulations of multi-view perspectives, limiting model generalisability. This paper introduces a novel approach leveraging neural radiance fields (NeRFs) for realistic multi-view training data generation. We create a diverse multi-view dataset using NeRFs, consisting of indoor and outdoor scenes. Our proposed methodology adapts state-of-the-art feature detectors and descriptors to train on NeRF-synthesised views supervised by perspective projective geometry. Our experiments demonstrate that the proposed methods achieve competitive or superior performance on standard benchmarks for relative pose estimation, point cloud registration, and homography estimation while requiring significantly less training data compared to existing approaches.
Summary
神经辐射场 (NeRF) 用于生成逼真的多视图训练数据,从而提高特征点检测和描述的准确性。
Key Takeaways
- 提出了一种使用 NeRFs 生成逼真多视图训练数据的创新方法。
- 训练特征检测器和描述符以 NeRF 合成视图为监督,并采用透视投影几何。
- 该方法在标准相对位姿估计、点云注册和单应性估计基准上实现了竞争或更优的性能。
- 与现有方法相比,需要的训练数据显着减少。
- 多样化多视图数据集包括室内和室外场景。
- 该方法使用 NeRFs 训练,具有泛化能力,可以处理各种视角。
- 该方法为视觉 SLAM 和视觉位置识别等计算机视觉应用提供了改进的特征点检测和描述。
- 标题:神经辐射场辅助特征点检测与描述
- 作者:Ali Youssef,Francisco Vasconcelos
- 第一作者单位:伦敦大学学院计算机科学系
- 关键词:特征检测与描述、神经辐射场、数据集
- 论文链接:https://arxiv.org/abs/2403.08156 Github 代码链接:无
摘要: (1) 研究背景:特征点检测与描述是计算机视觉中许多多视图问题(如运动结构、视觉 SLAM 和视觉定位识别)的基础。近年来,基于学习的方法已取代手工制作技术,但其训练通常依赖于基于仿射变换的简单多视图视角模拟,这限制了模型的泛化能力。 (2) 过去的方法:过去的方法使用基于仿射变换的图像扭曲来模拟不同视角,但这种扭曲过于简单,无法准确模拟多视图透视。 (3) 本文方法:本文提出了一种利用神经辐射场 (NeRF) 生成逼真多视图训练数据的新方法。研究者创建了一个使用 NeRF 合成的多视图数据集,包含室内和室外场景。研究者还提出了一种方法,将最先进的特征检测器和描述子调整为在 NeRF 合成的视图上进行训练,并由透视投影几何进行监督。 (4) 实验结果:实验表明,与现有方法相比,本文方法在相对位姿估计、点云配准和仿射变换估计的标准基准上取得了有竞争力或更好的性能,同时所需训练数据明显更少。
Methods: (1): 使用神经辐射场 (NeRF) 生成逼真的多视图训练数据; (2): 提出一种基于透视投影几何监督的 NeRF 点重投影方法; (3): 调整最先进的特征检测器和描述符,使其在 NeRF 合成的视图上进行训练。
结论: (1):本文提出了一种新颖的方法来监督基于学习的特征点检测器和描述符,利用合成 NeRF 数据上的透视投影几何。尽管我们提出的数据集完全由合成图像而不是真实的 RGB 图像组成,并且比大型开源数据集小得多,但结果表明,在泛化能力或特征点检测质量方面没有观察到下降。正如预期的那样,我们的模型通常在具有高度非平面场景的多视图基准上优于经过单应性训练的基线,而在单应性估计基准上略逊一筹。进一步发展的更大潜力在于提高神经渲染的训练数据质量,神经渲染可以生成更高质量的合成图像,没有人工制品,最重要的是更精确的深度图以避免错误投影。
(2):创新点:利用 NeRF 合成的逼真多视图数据训练特征检测器和描述符;提出了一种基于透视投影几何监督的 NeRF 点重投影方法。
性能:与现有方法相比,在相对位姿估计、点云配准和仿射变换估计的标准基准上取得了有竞争力或更好的性能,同时所需训练数据明显更少。
工作量:数据集合成和模型训练的工作量中等。
点此查看论文截图




 wechat
wechat- alipay







