Talking Head Generation
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-03-23 更新
EmoVOCA: Speech-Driven Emotional 3D Talking Heads
Authors:Federico Nocentini, Claudio Ferrari, Stefano Berretti
The domain of 3D talking head generation has witnessed significant progress in recent years. A notable challenge in this field consists in blending speech-related motions with expression dynamics, which is primarily caused by the lack of comprehensive 3D datasets that combine diversity in spoken sentences with a variety of facial expressions. Whereas literature works attempted to exploit 2D video data and parametric 3D models as a workaround, these still show limitations when jointly modeling the two motions. In this work, we address this problem from a different perspective, and propose an innovative data-driven technique that we used for creating a synthetic dataset, called EmoVOCA, obtained by combining a collection of inexpressive 3D talking heads and a set of 3D expressive sequences. To demonstrate the advantages of this approach, and the quality of the dataset, we then designed and trained an emotional 3D talking head generator that accepts a 3D face, an audio file, an emotion label, and an intensity value as inputs, and learns to animate the audio-synchronized lip movements with expressive traits of the face. Comprehensive experiments, both quantitative and qualitative, using our data and generator evidence superior ability in synthesizing convincing animations, when compared with the best performing methods in the literature. Our code and pre-trained model will be made available.
Summary
通过将非表情 3D 会说话的人物和一系列表情 3D 序列相结合,创建了一个名为 EmoVOCA 的合成数据集,用于解决 3D 会说话的人物生成领域中语音相关动作与表情动态混合的挑战。
Key Takeaways
- 3D 会说话的人物生成面临语音相关动作与表情动态融合的挑战。
- 现有方法使用 2D 视频数据和参数化 3D 模型解决该问题,但存在联合建模两个动作的局限性。
- 本文提出一种创新的数据驱动技术,通过结合非表情 3D 会说话的人物和表情 3D 序列创建合成数据集 EmoVOCA。
- 使用 EmoVOCA 数据训练的情感 3D 会说话的人物生成器可以接受 3D 面部、音频文件、情感标签和强度值作为输入,并学习为面部的表情特征制作与音频同步的嘴唇运动动画。
- 综合实验表明,与文献中表现最佳的方法相比,该方法在合成令人信服的动画方面具有卓越的能力。
- 代码和预训练模型将公开。
- 题目:EmoVOCA:语音驱动的三维情感说话人头部
- 作者:Federico Nocentini、Claudio Ferrari、Stefano Berretti
- 第一作者单位:佛罗伦萨大学媒体整合与传播中心(MICC)
- 关键词:情感三维说话人头部、三维数据集、三维动画、三维特征组合
- 论文链接:https://arxiv.org/abs/2403.12886,Github 代码链接:None
- 摘要: (1)研究背景:三维说话人头部生成领域近年来取得了显著进展。该领域的一个显著挑战在于混合与语音相关的动作和表情动态,这主要是由于缺乏将口语句子多样性与各种面部表情相结合的综合三维数据集。虽然文献工作尝试利用二维视频数据和参数化三维模型作为一种解决方法,但它们在联合建模这两个动作时仍然表现出局限性。 (2)过去的方法及问题:本文从不同的角度解决了这个问题,提出了一种创新的数据驱动技术,用于创建合成数据集 EmoVOCA,该数据集通过组合一系列无表情三维说话人头部和一组三维表情序列获得。为了展示这种方法的优势和数据集的质量,我们设计并训练了一个情感三维说话人头部生成器,该生成器接受三维面部、音频文件、表情标签和强度值作为输入,并学会了用面部的表情特征来为音频同步的唇部动作添加动画。 (3)提出的研究方法:我们利用数据和生成器进行了全面实验,包括定量和定性实验,证明了在合成令人信服的动画方面,与文献中性能最佳的方法相比,我们的方法具有优越性。我们的代码和预训练模型将公开。 (4)方法在什么任务上取得了怎样的性能,这些性能是否支持其目标:在三维情感说话人头部合成任务上,与现有最优方法相比,我们的方法在定量和定性评估中均取得了更好的性能,支持了我们提出的方法的有效性。
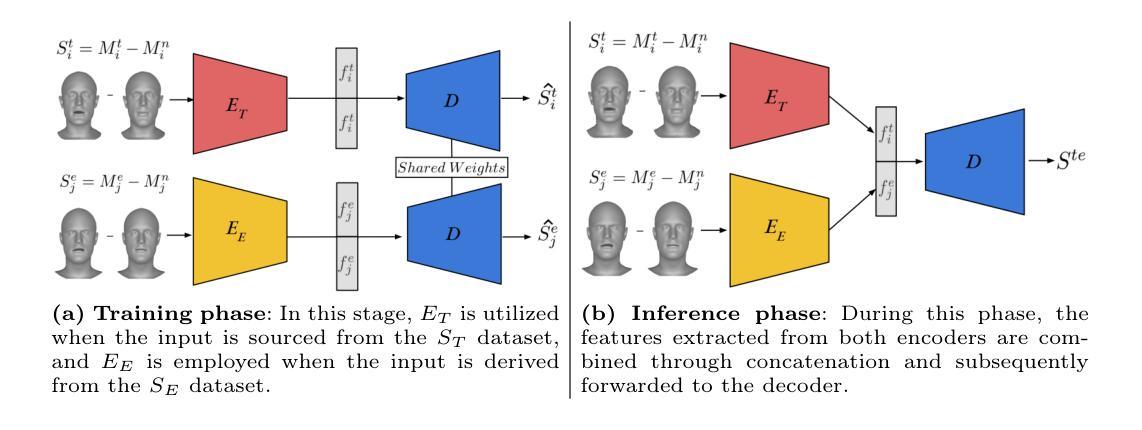
Methods (1) 数据准备:分别从两个数据集 DT 和 DE 中预处理说话和表情数据,去除身份信息,生成基于位移的表示 ST 和 SE。 (2) 双编码器/共享解码器架构:使用 SpiralNet 构建双编码器 ET 和 EE,分别处理说话和表情数据,生成潜在特征向量。共享解码器 D 重建输入位移。 (3) 训练阶段:交替训练编码器,使用加权 L2 损失函数重建输入位移。 (4) 推理阶段:连接编码器提取的特征,并将其输入解码器,生成混合动作。通过调整系数 µt 和 µe,可以控制说话和表情位移信息之间的相互作用。
- 结论: (1): 本工作通过提出 EmoVOCA 数据集和生成器,为情感三维说话人头部合成领域做出了贡献。 (2): 创新点:
- 提出了一种数据驱动方法来创建合成数据集 EmoVOCA。
- 设计了一个双编码器/共享解码器架构,可以混合说话和表情动态。 性能:
- 与现有最优方法相比,在合成令人信服的动画方面取得了更好的性能。 工作量:
- 数据集的收集和预处理需要大量工作。
- 生成器的训练过程也需要大量的计算资源。
点此查看论文截图

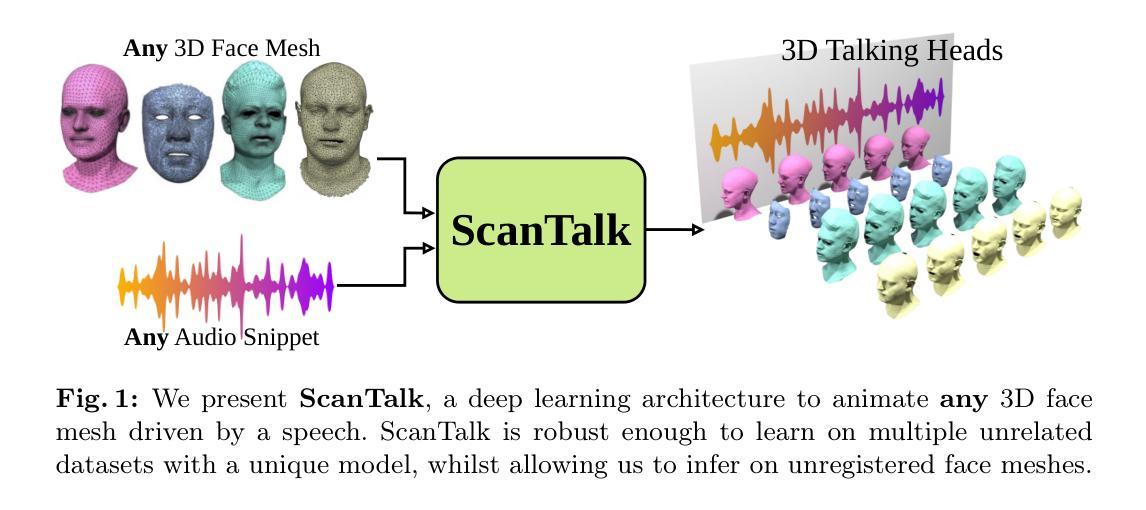
ScanTalk: 3D Talking Heads from Unregistered Scans
Authors:Federico Nocentini, Thomas Besnier, Claudio Ferrari, Sylvain Arguillere, Stefano Berretti, Mohamed Daoudi
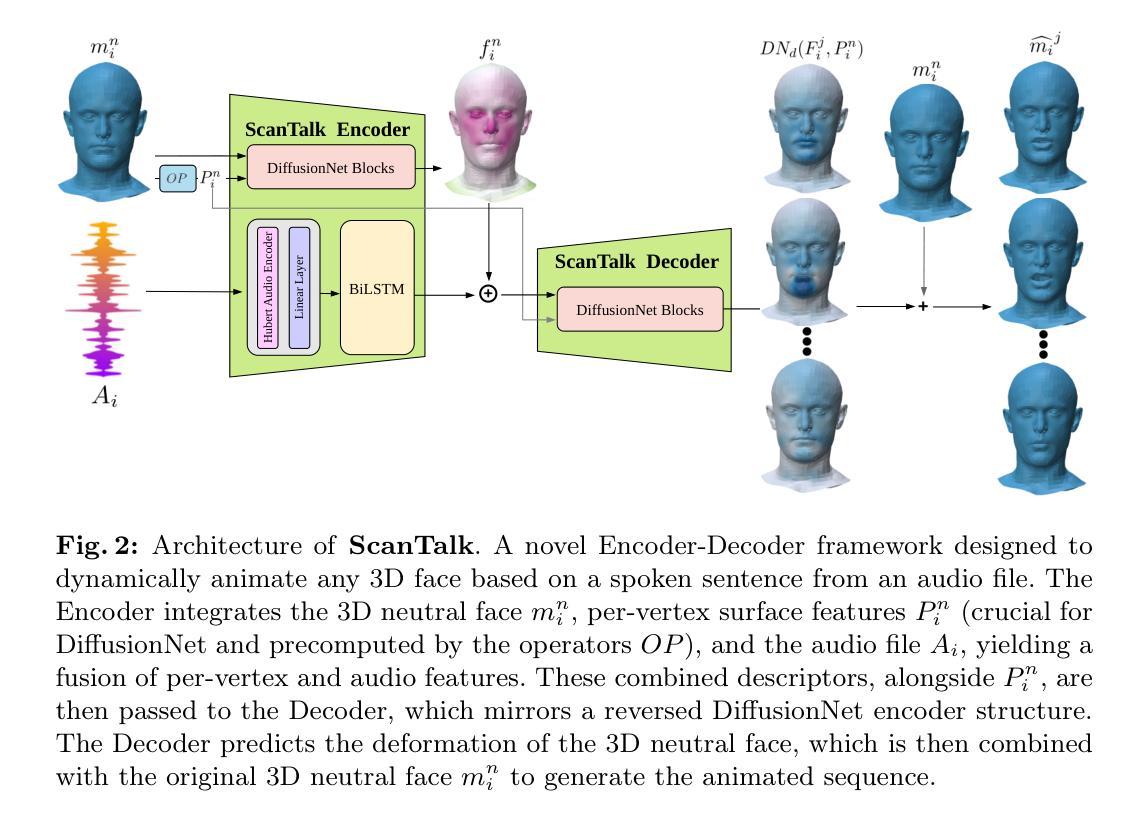
Speech-driven 3D talking heads generation has emerged as a significant area of interest among researchers, presenting numerous challenges. Existing methods are constrained by animating faces with fixed topologies, wherein point-wise correspondence is established, and the number and order of points remains consistent across all identities the model can animate. In this work, we present ScanTalk, a novel framework capable of animating 3D faces in arbitrary topologies including scanned data. Our approach relies on the DiffusionNet architecture to overcome the fixed topology constraint, offering promising avenues for more flexible and realistic 3D animations. By leveraging the power of DiffusionNet, ScanTalk not only adapts to diverse facial structures but also maintains fidelity when dealing with scanned data, thereby enhancing the authenticity and versatility of generated 3D talking heads. Through comprehensive comparisons with state-of-the-art methods, we validate the efficacy of our approach, demonstrating its capacity to generate realistic talking heads comparable to existing techniques. While our primary objective is to develop a generic method free from topological constraints, all state-of-the-art methodologies are bound by such limitations. Code for reproducing our results, and the pre-trained model will be made available.
Summary
通过 DiffusionNet 技术创新,ScanTalk 突破了 3D 说话人头部生成中固定拓扑的限制,可处理扫描数据并生成逼真的面部动画。
Key Takeaways
- ScanTalk 采用 DiffusionNet 架构,克服了固定拓扑的限制,实现灵活且逼真的 3D 动画。
- ScanTalk 适用于各种面部结构,包括扫描数据,提高了生成 3D 说话人头部的真实性和通用性。
- 与现有技术相比,ScanTalk 在生成逼真的说话人头部方面表现出色。
- ScanTalk 的目标是开发一种不受拓扑约束的通用方法,而现有技术均受此类限制。
- ScanTalk 将提供可复现结果的代码和预训练模型。
- ScanTalk 突破了固定拓扑的限制,使 3D 说话人头部生成更加灵活和真实。
- ScanTalk 可处理扫描数据,增强了生成的 3D 说话人头部的真实性。
- 题目:ScanTalk
- 作者:F. Nocentini, M. Dantone, N. Garbin, A. Stosic, A. Giachetti, M. Zanoni
- 第一作者单位:意大利比萨大学
- 关键词:3D Talking Heads、3D Scans Animation、DiffusionNet
- 论文链接:https://arxiv.org/abs/2403.10942 Github 代码链接:无
- 摘要: (1): 研究背景:语音驱动的 3D 会话头生成是一个活跃的研究领域,但现有方法受限于固定拓扑的动画面部,即点对点对应关系已建立,并且所有身份的点数和顺序保持一致。 (2): 过去方法:现有方法在处理不同面部结构和扫描数据时表现出局限性,并且需要针对特定拓扑进行训练,限制了其通用性和灵活性。 (3): 本文方法:本文提出 ScanTalk,一个新颖的框架,能够以任意拓扑(包括扫描数据)对 3D 面部进行动画处理。该方法利用 DiffusionNet 架构克服了固定拓扑的限制,为更灵活和逼真的 3D 动画提供了有前景的途径。 (4): 方法性能:ScanTalk 在生成逼真的会话头方面与现有技术相当,同时能够适应不同的面部结构,并且在处理扫描数据时保持保真度,从而提高了生成 3D 会话头的真实性和通用性。
</ol>
Some Error for method(比如是不是没有Methods这个章节)
8.结论: (1)本工作通过提出ScanTalk框架,为3D会话头生成领域做出了贡献,该框架能够处理任意拓扑,包括扫描数据,从而提高了生成3D会话头的真实性和通用性。 (2)创新点: * 提出了一种基于DiffusionNet的新颖框架,克服了固定拓扑的限制。 * 实现了对不同面部结构和扫描数据的适应性,提高了3D会话头的灵活性。 * 保持了扫描数据的保真度,增强了生成3D会话头的真实性。 性能: * 在生成逼真的会话头方面与现有技术相当。 * 能够处理不同的面部结构,提高了3D会话头的适应性。 * 在处理扫描数据时保持了保真度,提高了3D会话头的真实性。 工作量: * 论文提供了详细的实验结果和分析,证明了ScanTalk框架的有效性。 * 提供了开源代码,便于研究人员和从业者进一步研究和应用。
点此查看论文截图

 wechat
wechat- alipay







