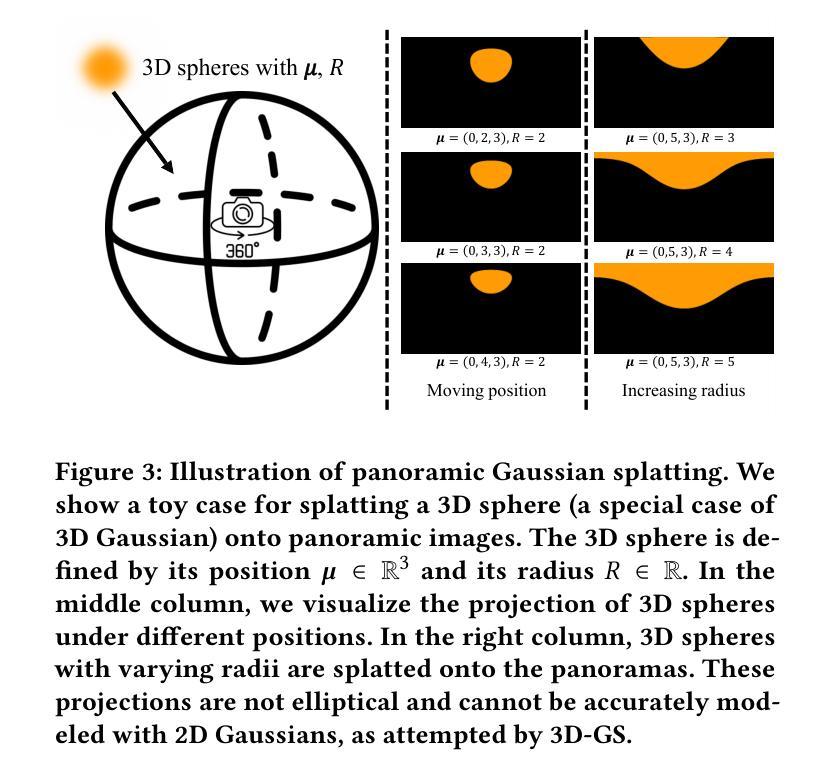
3DGS
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-03-28 更新
Modeling uncertainty for Gaussian Splatting
Authors:Luca Savant, Diego Valsesia, Enrico Magli
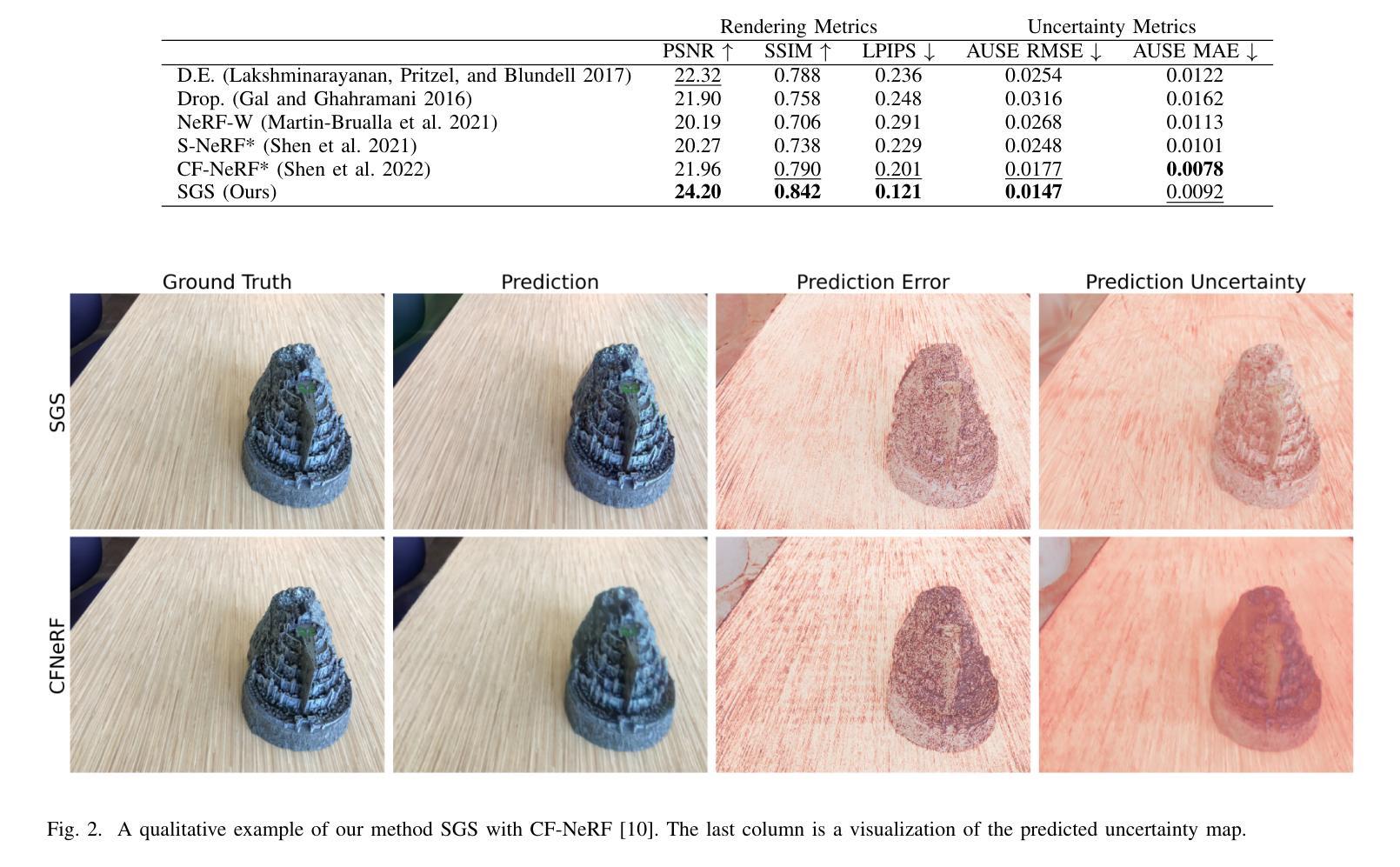
We present Stochastic Gaussian Splatting (SGS): the first framework for uncertainty estimation using Gaussian Splatting (GS). GS recently advanced the novel-view synthesis field by achieving impressive reconstruction quality at a fraction of the computational cost of Neural Radiance Fields (NeRF). However, contrary to the latter, it still lacks the ability to provide information about the confidence associated with their outputs. To address this limitation, in this paper, we introduce a Variational Inference-based approach that seamlessly integrates uncertainty prediction into the common rendering pipeline of GS. Additionally, we introduce the Area Under Sparsification Error (AUSE) as a new term in the loss function, enabling optimization of uncertainty estimation alongside image reconstruction. Experimental results on the LLFF dataset demonstrate that our method outperforms existing approaches in terms of both image rendering quality and uncertainty estimation accuracy. Overall, our framework equips practitioners with valuable insights into the reliability of synthesized views, facilitating safer decision-making in real-world applications.
Summary
高斯散射框架添加了不确定性评估,为图像重建带来了更可靠的决策。
Key Takeaways
- 提出使用高斯散射的不确定性估计框架,即随机高斯散射 (SGS)。
- 采用变分推理方法将不确定性预测无缝集成到高斯散射的渲染管线中。
- 引入稀疏化误差下表面积 (AUSE) 作为新的损失函数项。
- 通过优化不确定性估计和图像重建来提高总体性能。
- 在 LLFF 数据集上的实验表明 SGS 在图像渲染质量和不确定性估计准确性方面均优于现有方法。
- 该框架为从业者提供了对合成视图可靠性的宝贵见解,从而在实际应用中促进更安全的决策。
- 标题:高斯溅射的不确定性建模
- 作者:Luca Savant、Diego Valsesia、Enrico Magli
- 所属机构:意大利都灵理工大学电子与电信系
- 关键词:高斯溅射、不确定性估计、神经辐射场、计算机视觉
- 论文链接:None
摘要: (1)研究背景:神经辐射场(NeRF)在新型视图合成领域取得了巨大成功,但其计算复杂度和内存需求限制了其在实时应用中的实用性。高斯溅射(GS)技术作为一种更具计算效率的替代方案,在保持高质量新型视图合成的情况下,提高了渲染速度。 (2)过去方法和问题:NeRF 在新型视图合成中取得了令人印象深刻的结果,但缺乏提供与输出相关置信度信息的能力。GS 虽然在渲染速度上取得了优势,但同样缺乏不确定性估计机制。 (3)研究方法:本文提出了一个用于 GS 中不确定性估计的新框架,称为随机高斯溅射(SGS)。SGS 扩展了传统的确定性 GS 框架,引入了随机性,允许在合成视图的同时预测不确定性。该方法利用变分推理(VI)在贝叶斯框架中学习 GS 辐射场的参数,从而能够准确估计不确定性,同时不牺牲计算效率。此外,本文还通过在损失函数中引入稀疏化曲线下面积(AUSE)作为新项,创新了学习过程。 (4)方法性能:实验结果表明,SGS 在具有挑战性的 LLFF 数据集上取得了显著改进,在渲染质量和不确定性估计指标方面都优于最先进的方法。这些性能提升支持了本文提出的方法目标,即为从业者提供对合成视图可靠性的宝贵见解,从而促进在实际应用中更安全的决策制定。
方法: (1)扩展传统确定性高斯溅射框架,引入随机性,在合成视图的同时预测不确定性。 (2)利用变分推理(VI)在贝叶斯框架中学习高斯溅射辐射场的参数,准确估计不确定性。 (3)在损失函数中引入稀疏化曲线下面积(AUSE)作为新项,创新学习过程。
8.结论: (1): 本文提出了一种用于高斯溅射不确定性估计的新框架,称为随机高斯溅射(SGS)。SGS扩展了传统的确定性高斯溅射框架,引入了随机性,允许在合成视图的同时预测不确定性。该方法利用变分推理(VI)在贝叶斯框架中学习高斯溅射辐射场的参数,从而能够准确估计不确定性,同时不牺牲计算效率。此外,本文还通过在损失函数中引入稀疏化曲线下面积(AUSE)作为新项,创新了学习过程。实验结果表明,SGS在具有挑战性的LLFF数据集上取得了显著改进,在渲染质量和不确定性估计指标方面都优于最先进的方法。这些性能提升支持了本文提出的方法目标,即为从业者提供对合成视图可靠性的宝贵见解,从而促进在实际应用中更安全的决策制定。 (2): 创新点: - 提出了一种新的不确定性估计框架,称为随机高斯溅射(SGS)。 - 利用变分推理(VI)在贝叶斯框架中学习高斯溅射辐射场的参数。 - 在损失函数中引入稀疏化曲线下面积(AUSE)作为新项,创新学习过程。 性能: - 在具有挑战性的LLFF数据集上取得了显著改进。 - 在渲染质量和不确定性估计指标方面都优于最先进的方法。 工作量: - 引入了随机性,增加了计算复杂度。 - 利用变分推理(VI)学习参数,增加了训练时间。 - 在损失函数中引入稀疏化曲线下面积(AUSE)作为新项,增加了训练难度。
点此查看论文截图


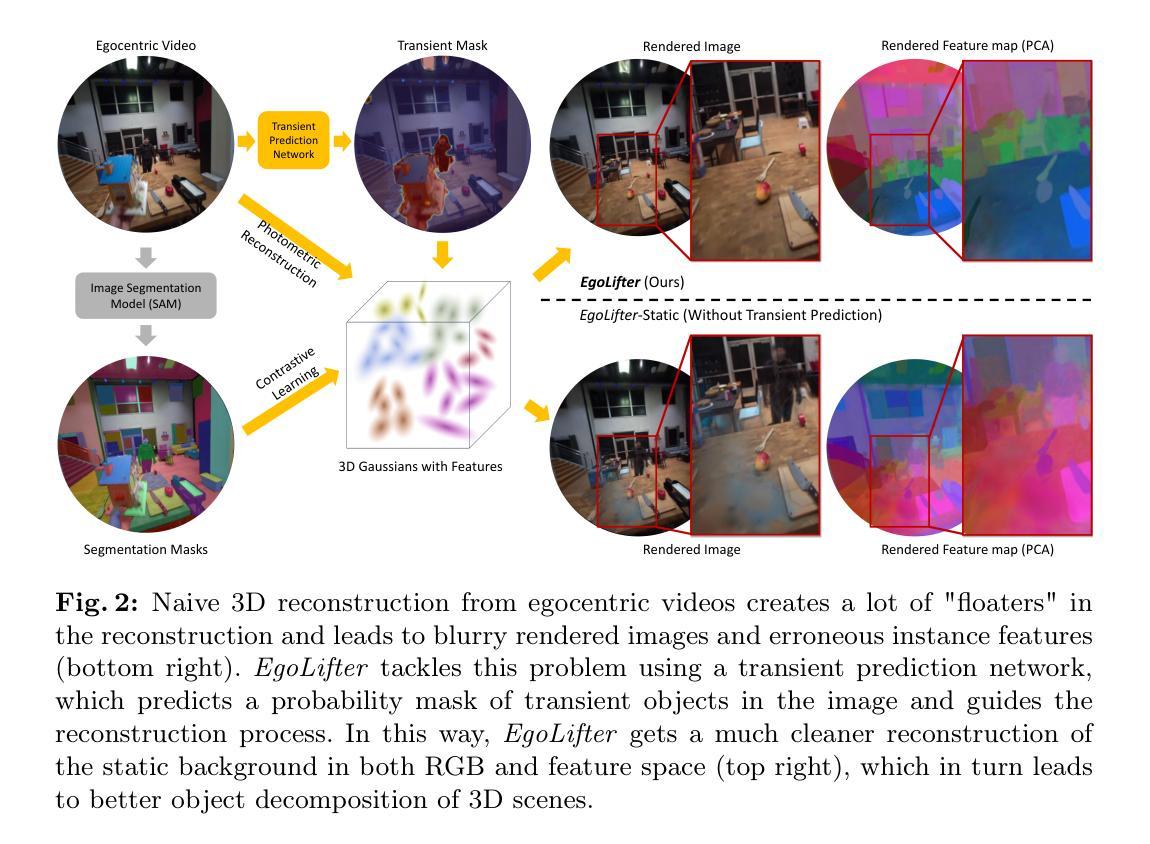
1.标题:EgoLifter 2.作者:Qiao Gu, Zhaoyang Lv, Duncan Frost, Simon Green, Julian Straub, Chris Sweeney 3.第一作者所属机构:多伦多大学 4.关键词:Egocentric Perception、Open-world Segmentation、3D Reconstruction 5.论文链接:https://arxiv.org/abs/2403.18118 Github 链接:None 6.摘要: (1)研究背景:随着可穿戴设备的普及,以自我为中心的机器感知算法变得越来越重要,这类算法能够理解用户周围的物理 3D 世界。自我为中心的视频直接反映了人类观察世界的方式,包含了关于物理环境以及人类用户如何与之交互的重要信息。然而,自我为中心运动的特定特征给 3D 计算机视觉和机器感知算法带来了挑战。与通过“扫描”运动捕捉的数据集不同,自我为中心的视频无法保证场景的完整覆盖。由于多视角观察有限或缺失,这使得重建过程极具挑战性。 (2)过去的方法及其问题:以往的方法通常依赖于特定的对象分类法,并且难以处理自我为中心视频中动态对象带来的挑战。 (3)提出的研究方法:本文提出 EgoLifter,这是一种新颖的系统,可以将从自我为中心传感器捕获的场景自动分割成各个 3D 对象的完整分解。该系统专门设计用于自我为中心数据,其中场景包含数百个从自然(非扫描)运动中捕获的对象。EgoLifter 采用 3D 高斯分布作为 3D 场景和对象的基础表示,并使用 Segment Anything Model (SAM) 的分割掩码作为弱监督,以学习灵活且可提示的对象实例定义,不受任何特定对象分类法的限制。为了应对自我为中心视频中动态对象带来的挑战,本文设计了一个瞬态预测模块,该模块能够学会在 3D 重建中滤除动态对象。最终的结果是一个全自动管道,能够将 3D 对象实例重建为 3D 高斯分布的集合,这些高斯分布共同构成整个场景。 (4)方法在任务和性能上的表现:在 Aria Digital Twin 数据集上创建了一个新的基准,该基准定量证明了该方法在基于自然自我为中心输入的开放世界 3D 分割中达到最先进的性能。在各种自我为中心活动数据集上运行 EgoLifter,展示了该方法在规模化 3D 自我为中心感知方面的前景。
方法: (1)EgoLifter系统采用3D高斯分布作为3D场景和对象的基础表示,并使用SegmentAnythingModel (SAM)的分割掩码作为弱监督,以学习灵活且可提示的对象实例定义,不受任何特定对象分类法的限制。 (2)为了应对自我为中心视频中动态对象带来的挑战,设计了一个瞬态预测模块,该模块能够学会在3D重建中滤除动态对象。 (3)EgoLifter系统最终的结果是一个全自动管道,能够将3D对象实例重建为3D高斯分布的集合,这些高斯分布共同构成整个场景。
结论: (1):EgoLifter 算法同时解决了野外以自我为中心的感知中的 3D 重建和开放世界分割问题。该算法通过将 2D 分割提升到 3D 高斯分布中,在没有 3D 数据注释的情况下实现了强大的开放世界 2D/3D 分割性能。为了处理以自我为中心的视频中快速且稀疏的动态变化,EgoLifter 采用瞬态预测网络来滤除瞬态对象并获得更准确的 3D 重建。EgoLifter 在几个具有挑战性的以自我为中心的的数据集上进行了评估,并优于其他现有的基准。EgoLifter 获得的表示还可以用于多种下游任务,如 3D 对象资产提取和场景编辑,显示出个人可穿戴设备和 AR/VR 应用的巨大潜力。 (2):创新点:EgoLifter 算法创新性地将 3D 高斯分布作为 3D 场景和对象的基础表示,并使用 SegmentAnythingModel (SAM) 的分割掩码作为弱监督,以学习灵活且可提示的对象实例定义。此外,EgoLifter 还设计了一个瞬态预测模块来处理以自我为中心的视频中动态对象带来的挑战。 性能:EgoLifter 在 AriaDigitalTwin 数据集上创建了一个新的基准,定量证明了该方法在基于自然自我为中心的输入的开放世界 3D 分割中达到最先进的性能。在各种以自我为中心的活动数据集上运行 EgoLifter,展示了该方法在规模化 3D 自我为中心感知方面的前景。 工作量:EgoLifter 算法的工作量相对较大,因为它需要使用 3D 高斯分布和瞬态预测网络来处理以自我为中心的视频中的复杂场景和动态对象。然而,EgoLifter 算法的性能优势证明了其工作量的合理性。
点此查看论文截图


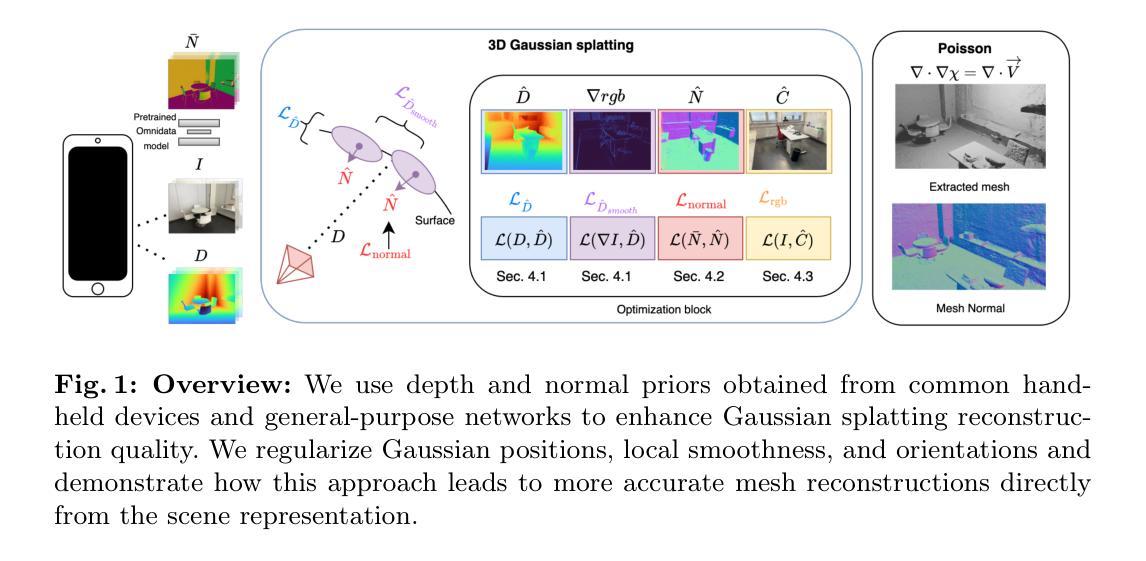
DN-Splatter: Depth and Normal Priors for Gaussian Splatting and Meshing
Authors:Matias Turkulainen, Xuqian Ren, Iaroslav Melekhov, Otto Seiskari, Esa Rahtu, Juho Kannala
3D Gaussian splatting, a novel differentiable rendering technique, has achieved state-of-the-art novel view synthesis results with high rendering speeds and relatively low training times. However, its performance on scenes commonly seen in indoor datasets is poor due to the lack of geometric constraints during optimization. We extend 3D Gaussian splatting with depth and normal cues to tackle challenging indoor datasets and showcase techniques for efficient mesh extraction, an important downstream application. Specifically, we regularize the optimization procedure with depth information, enforce local smoothness of nearby Gaussians, and use the geometry of the 3D Gaussians supervised by normal cues to achieve better alignment with the true scene geometry. We improve depth estimation and novel view synthesis results over baselines and show how this simple yet effective regularization technique can be used to directly extract meshes from the Gaussian representation yielding more physically accurate reconstructions on indoor scenes. Our code will be released in https://github.com/maturk/dn-splatter.
Summary
3D高斯斑点渲染技术通过深度和法线信息,增强了对室内数据集的几何约束,提升了深度估计和新视图合成性能。
Key Takeaways
- 3D高斯斑点渲染是一种新颖的可微渲染技术。
- 3D高斯斑点渲染在室内数据集上表现不佳,原因是优化过程中缺乏几何约束。
- 通过深度信息正则化优化过程,可以改善室内数据集的性能。
- 通过局部平滑和法线信息监督,可以增强3D高斯斑点的几何对齐。
- 改进后的3D高斯斑点渲染技术可直接从高斯表示中提取网格,生成更物理准确的室内场景重建。
- 该技术代码将在https://github.com/maturk/dn-splatter上发布。
- 标题:DN-Splatter:用于高斯散射和网格化的深度和法线先验
- 作者:Matias Turkulainen∗1, Xuqian Ren∗2, Iaroslav Melekhov3, Otto Seiskari4, Esa Rahtu2,4, Juho Kannala3,4
- 隶属:苏黎世联邦理工学院
- 关键词:高斯散射、室内重建、先验正则化
- 论文链接:None,Github 代码链接:https://github.com/maturk/dn-splatter
- 摘要: (1):三维高斯散射是一种新颖的可微渲染技术,已在高保真图像合成中取得了最先进的效果,具有较快的渲染速度和较短的训练时间。然而,由于优化过程中缺乏几何约束,它在室内数据集常见的场景中的性能较差。 (2):过去的方法包括 Nerfacto、Depth-Nerfacto、Neusfacto、MonoSDF、Splatfacto 和 SuGaR。这些方法存在的问题是缺乏几何约束,导致在室内场景中性能不佳。本文提出的方法动机明确,通过深度和法线信息来扩展三维高斯散射,以解决室内场景的挑战。 (3):本文提出的研究方法包括:利用深度信息对优化过程进行正则化、增强附近高斯分布的局部平滑度、利用法线信息监督三维高斯分布的几何形状,以更好地与真实场景几何形状对齐。 (4):本文方法在以下任务和性能方面取得了进展:在室内场景上提高了深度估计和新视图合成结果,表明该方法可以从高斯表示中直接提取网格,从而在室内场景中实现更物理准确的重建。这些性能支持了本文的目标。
7.方法:(1): 利用深度信息正则化优化过程;(2): 增强附近高斯分布的局部平滑度;(3): 利用法线信息监督三维高斯分布的几何形状;(4): 利用优化后的高斯场景直接提取网格,无需额外的优化或细化阶段。
- 结论: (1): 本文提出了一种用于深度和法线正则化的三维高斯散射方法,证明了这种简单但有效的方法可以通过提高常见的新视图 RGB 指标以及显著提高从高斯场景表示中提取的深度估计和表面质量来增强照片真实感。我们展示了先验正则化对于在具有挑战性的室内场景中实现更几何有效重建的必要性。 (2): 创新点:利用深度和法线信息扩展三维高斯散射,解决室内场景的几何约束问题; 性能:在室内场景上提高了深度估计和新视图合成结果,表明该方法可以从高斯表示中直接提取网格,从而在室内场景中实现更物理准确的重建; 工作量:利用优化后的高斯场景直接提取网格,无需额外的优化或细化阶段。
点此查看论文截图

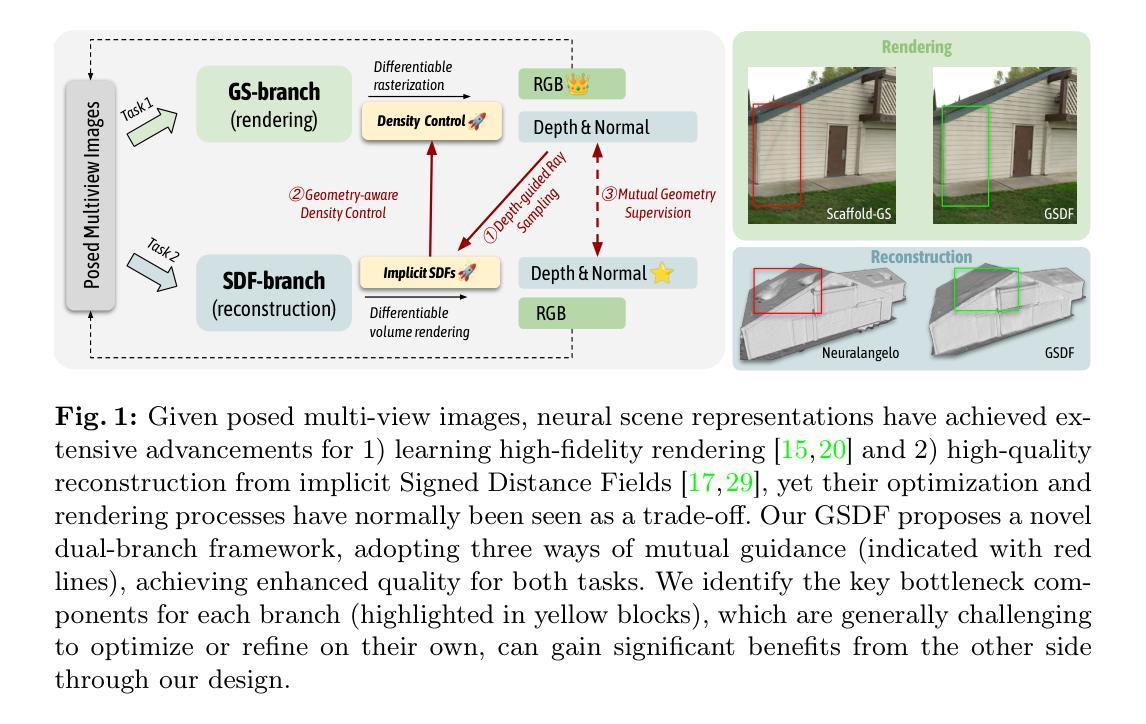
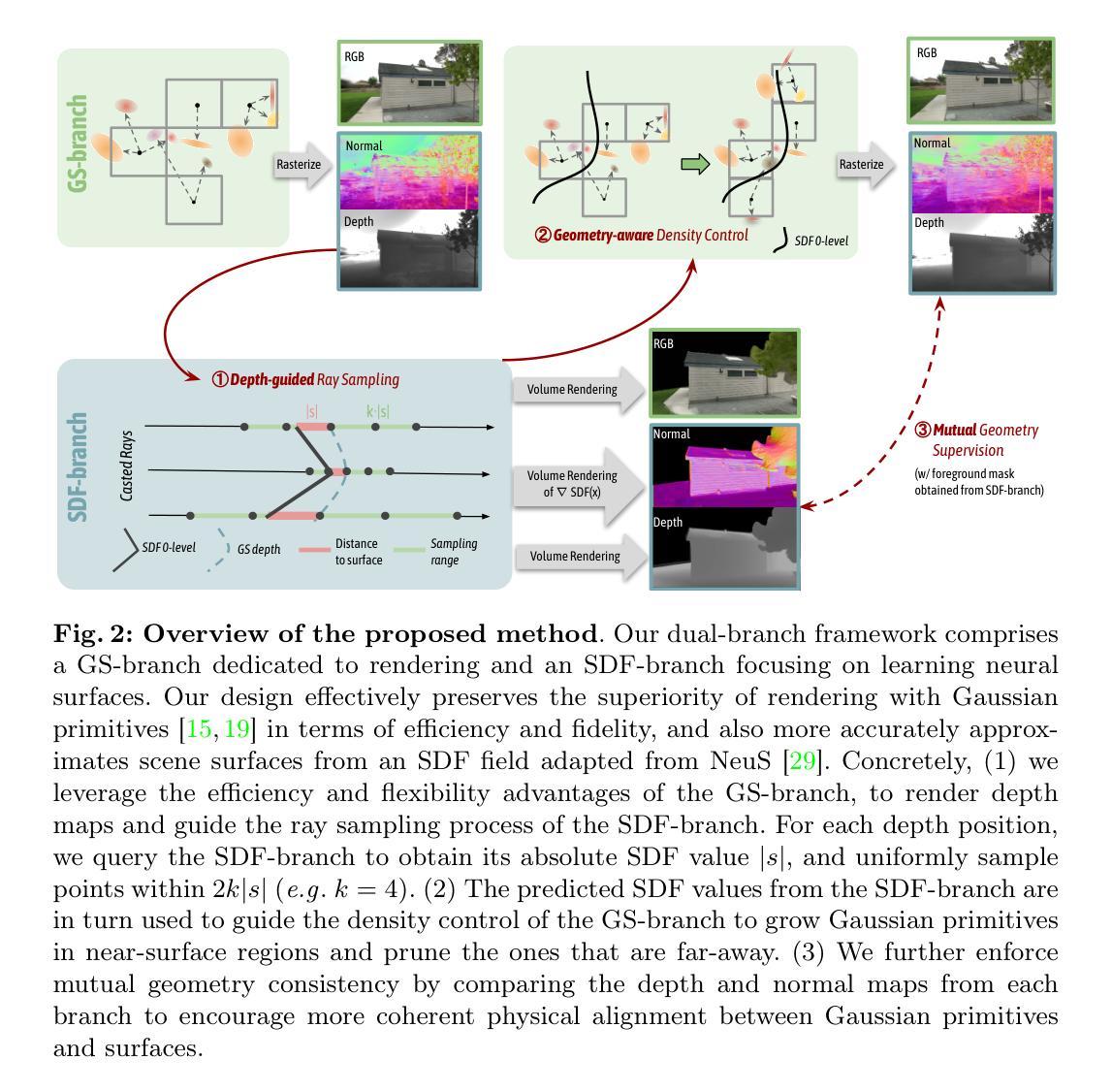
GSDF: 3DGS Meets SDF for Improved Rendering and Reconstruction
Authors:Mulin Yu, Tao Lu, Linning Xu, Lihan Jiang, Yuanbo Xiangli, Bo Dai
Presenting a 3D scene from multiview images remains a core and long-standing challenge in computer vision and computer graphics. Two main requirements lie in rendering and reconstruction. Notably, SOTA rendering quality is usually achieved with neural volumetric rendering techniques, which rely on aggregated point/primitive-wise color and neglect the underlying scene geometry. Learning of neural implicit surfaces is sparked from the success of neural rendering. Current works either constrain the distribution of density fields or the shape of primitives, resulting in degraded rendering quality and flaws on the learned scene surfaces. The efficacy of such methods is limited by the inherent constraints of the chosen neural representation, which struggles to capture fine surface details, especially for larger, more intricate scenes. To address these issues, we introduce GSDF, a novel dual-branch architecture that combines the benefits of a flexible and efficient 3D Gaussian Splatting (3DGS) representation with neural Signed Distance Fields (SDF). The core idea is to leverage and enhance the strengths of each branch while alleviating their limitation through mutual guidance and joint supervision. We show on diverse scenes that our design unlocks the potential for more accurate and detailed surface reconstructions, and at the meantime benefits 3DGS rendering with structures that are more aligned with the underlying geometry.
PDF Project page: https://city-super.github.io/GSDF
Summary
三维高斯泼溅 (3DGS) 与神经符号距离场 (SDF) 相结合,可用于呈现更准确、更精细的表面重建效果,并增强 3DGS 渲染的结构,使其更符合底层几何图形。
Key Takeaways
- 3DGS 和神经 SDF 的结合,可提升渲染和重建效果。
- 神经体积渲染技术,重点关注点/基元颜色,忽略了底层场景几何图形。
- 神经隐式表面学习, 受神经渲染成功启发。
- 当前工作,限制密度场的分布或基元的形状,导致渲染质量下降,学习场景表面存在缺陷。
- GSDF 架构,结合 3DGS 和神经 SDF 的优点,通过相互指导和联合监督,缓解其局限性。
- GSDF 设计,更准确、更精细的表面重建,同时提高 3DGS 渲染的结构,使其更符合底层几何图形。
- GSDF 在不同场景中,都展示了其潜力。
- 题目:GSDF:3DGS 融合 SDF,提升渲染和重建效果
- 作者:Mulin Yu1∗, Tao Lu1∗, Linning Xu2, Lihan Jiang3, Yuanbo Xiangli4�, Bo Dai1
- 第一作者单位:上海人工智能实验室
- 关键词:神经场景渲染·3D 高斯点云·神经曲面重建
- 论文地址:https://arxiv.org/abs/2403.16964,Github 代码:无
- 摘要: (1):从多视角图像呈现 3D 场景仍然是计算机视觉和计算机图形学中一项核心且长期的挑战。主要包含渲染和重建两个要求。值得注意的是,最先进的渲染质量通常通过神经体积渲染技术实现,该技术依赖于聚合的点/基元颜色,而忽略了底层场景几何。 (2):神经隐式曲面的学习源于神经渲染的成功。当前工作要么限制密度场的分布或基元的形状,导致渲染质量下降和学习场景曲面上的缺陷。此类方法的有效性受到所选神经表示的固有约束的限制,难以捕捉精细的曲面细节,特别是对于更大、更复杂的场景。 (3):为了解决这些问题,我们引入了 GSDF,这是一种新颖的双分支架构,它结合了灵活且高效的 3D 高斯点云(3DGS)表示与神经符号距离场(SDF)的优点。核心思想是利用和增强每个分支的优势,同时通过相互指导和联合监督来减轻它们的限制。我们在各种场景中展示了我们的设计释放了更准确和详细的曲面重建的潜力,同时使 3DGS 渲染受益于与底层几何更一致的结构。 (4):在不同的场景和任务上,该方法都取得了优异的性能,证明了其有效性。
7.Methods: (1): 我们提出了一种双分支框架,其中GS分支专注于高效、高质量的渲染,而SDF分支专注于学习神经隐式GSDF。 (2): 我们有效地保留了高斯基元渲染的效率和保真度优势,并从NeuS[29]改编的SDF场中更准确地逼近场景表面。 (3): 我们利用GS分支的效率和灵活性优势,渲染深度图并指导SDF分支的光线采样过程。 (4): 我们使用来自SDF分支的预测SDF值来指导GS分支的密度控制,在近表面区域生长高斯基元,并剪除远离表面的基元。 (5): 我们通过比较来自每个分支的深度图和法线图来进一步增强相互几何一致性,以鼓励高斯基元和表面之间更一致的物理对齐。
- 结论: (1):本工作提出了一种双分支框架,利用了 3D-GS 和 SDF 的优势,展示了其在保持训练和推理效率的同时,在渲染和重建质量上取得提升的潜力。两种隐式表示、渲染方法和监督损失的固有差异对两者无缝集成提出了挑战。因此,我们考虑了一种双向相互指导方法来规避这些限制。在我们的框架中引入了并验证了三种指导:1)深度引导采样(GS→SDF),2)几何感知高斯密度控制(SDF→GS);3)相互几何监督(GS↔SDF)。我们广泛的结果证明了在两个任务上的效率和联合性能改进。由于这两个分支保持了它们的原始架构,我们在推理期间保持了它们的效率,为将来通过更高级的模型替换每个分支留出了潜在的增强空间。我们设想我们的模型将有利于对高质量渲染和几何有要求的应用,包括具身环境、物理模拟和沉浸式 VR 体验。 (2):创新点:提出了一种双分支框架,结合了 3D-GS 和 SDF 的优点,提高了渲染和重建质量; 性能:在渲染和重建质量上取得了优异的性能,证明了该方法的有效性; 工作量:该方法具有较高的效率,在训练和推理阶段都保持了较低的计算成本。
点此查看论文截图

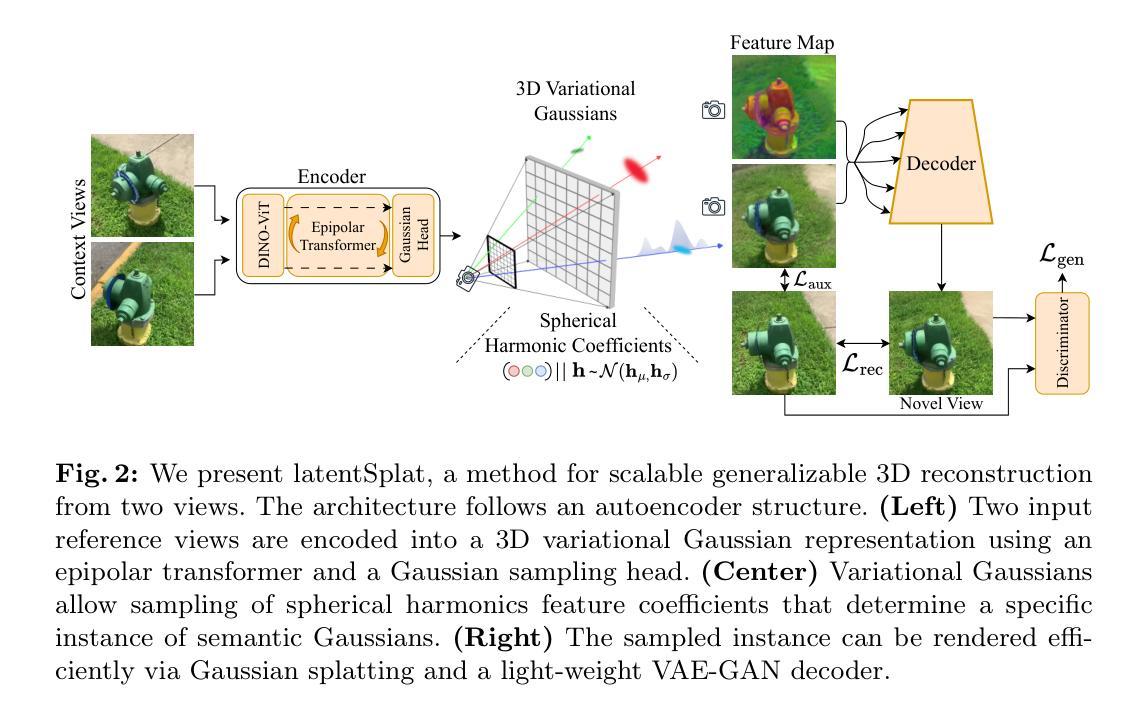
latentSplat: Autoencoding Variational Gaussians for Fast Generalizable 3D Reconstruction
Authors:Christopher Wewer, Kevin Raj, Eddy Ilg, Bernt Schiele, Jan Eric Lenssen
We present latentSplat, a method to predict semantic Gaussians in a 3D latent space that can be splatted and decoded by a light-weight generative 2D architecture. Existing methods for generalizable 3D reconstruction either do not enable fast inference of high resolution novel views due to slow volume rendering, or are limited to interpolation of close input views, even in simpler settings with a single central object, where 360-degree generalization is possible. In this work, we combine a regression-based approach with a generative model, moving towards both of these capabilities within the same method, trained purely on readily available real video data. The core of our method are variational 3D Gaussians, a representation that efficiently encodes varying uncertainty within a latent space consisting of 3D feature Gaussians. From these Gaussians, specific instances can be sampled and rendered via efficient Gaussian splatting and a fast, generative decoder network. We show that latentSplat outperforms previous works in reconstruction quality and generalization, while being fast and scalable to high-resolution data.
PDF Project website: https://geometric-rl.mpi-inf.mpg.de/latentsplat/
Summary
通过将回归模型与生成模型相结合,latentSplat 能够使用由 3D 特征高斯分布组成的潜在空间中的语义高斯分布预测快速推理高分辨率新视图。
Key Takeaways
- 提出了一种新的方法 latentSplat,可以预测 3D 潜在空间中的语义高斯分布,并通过轻量级生成 2D 架构进行 splatting 和解码。
- latentSplat 将回归方法与生成模型相结合,在同一个方法中实现了快速推理高分辨率新视图和 360 度泛化的能力。
- latentSplat 的核心是基于变分 3D 高斯分布,该表示有效地对潜在空间中包含 3D 特征高斯分布的不确定性进行编码。
- 可以从这些高斯分布中采样特定实例并通过高效的高斯 splatting 和快速的生成解码网络进行渲染。
- latentSplat 在重建质量和泛化方面优于以前的工作,同时对高分辨率数据快速且可扩展。
- latentSplat 不需要显式体积渲染,因此对于高分辨率场景具有效率优势。
- latentSplat仅使用现成的真实视频数据进行训练,无需 3D 扫描或重建数据。
- 题目:latentSplat:快速泛化 3D 重建的自动编码变分高斯
- 作者:Christopher Wewer、Kevin Raj、Eddy Ilg、Bernt Schiele、Jan Eric Lenssen
- 第一作者单位:马普学会信息学研究所
- 关键词:3D 重建、新视角合成、特征高斯体素化、高效 3D 表征学习
- 论文链接:None Github 链接:None
- 摘要: (1):研究背景:现有泛化 3D 重建方法要么由于体绘制图速度慢而无法快速推断高分辨率新视角,要么仅限于插值接近输入视角,即使在仅有单个中心物体的简单场景中,也无法进行 360 度泛化。 (2):过去方法:现有方法存在问题:要么无法快速推断高分辨率新视角,要么仅限于插值接近输入视角。 (3):研究方法:本文提出了一种方法,该方法结合回归方法和生成模型,在同一方法中朝着这两种能力迈进,完全在容易获取的真实视频数据上进行训练。该方法的核心是变分 3D 高斯,这是一种表征,可有效编码潜伏空间中不同特征高斯体素的不确定性。从这些高斯体素中,可以通过高效的高斯体素化和快速的生成解码器网络对特定实例进行采样和渲染。 (4):方法性能:实验表明,latentSplat 在重建质量和泛化方面优于以往工作,同时对高分辨率数据具有快速性和可扩展性。
7.Methods: (1):latentSplat方法结合了回归方法和生成模型,在同一方法中朝着快速推断高分辨率新视角和360度泛化两方面迈进; (2):方法的核心是变分3D高斯,它是一种表征,可有效编码潜伏空间中不同特征高斯体素的不确定性; (3):从这些高斯体素中,可以通过高效的高斯体素化和快速的生成解码器网络对特定实例进行采样和渲染。
- 结论 (1): latentSplat 是一种将回归方法和生成模型的优势成功结合起来的方法,以处理不确定性。我们的方法在新的视图合成中实现了最先进的图像质量,同时提供了与真实情况最高的感知相似性。与之前的生成方法相比,latentSplat 的速度更快,可扩展性更强,能够以更高的分辨率进行实时渲染。 (2): 创新点:
- 提出了一种新的表征——变分 3D 高斯,它可以有效地对潜伏空间中不同特征高斯体素的不确定性进行编码。
- 设计了一种高效的高斯体素化和快速的生成解码器网络,可以从高斯体素中对特定实例进行采样和渲染。 性能:
- 在重建质量和泛化方面优于以往的工作。
- 对高分辨率数据具有快速性和可扩展性。 工作量:
- 该方法完全在容易获取的真实视频数据上进行训练。
- 该方法的训练和推理速度都很快。
点此查看论文截图

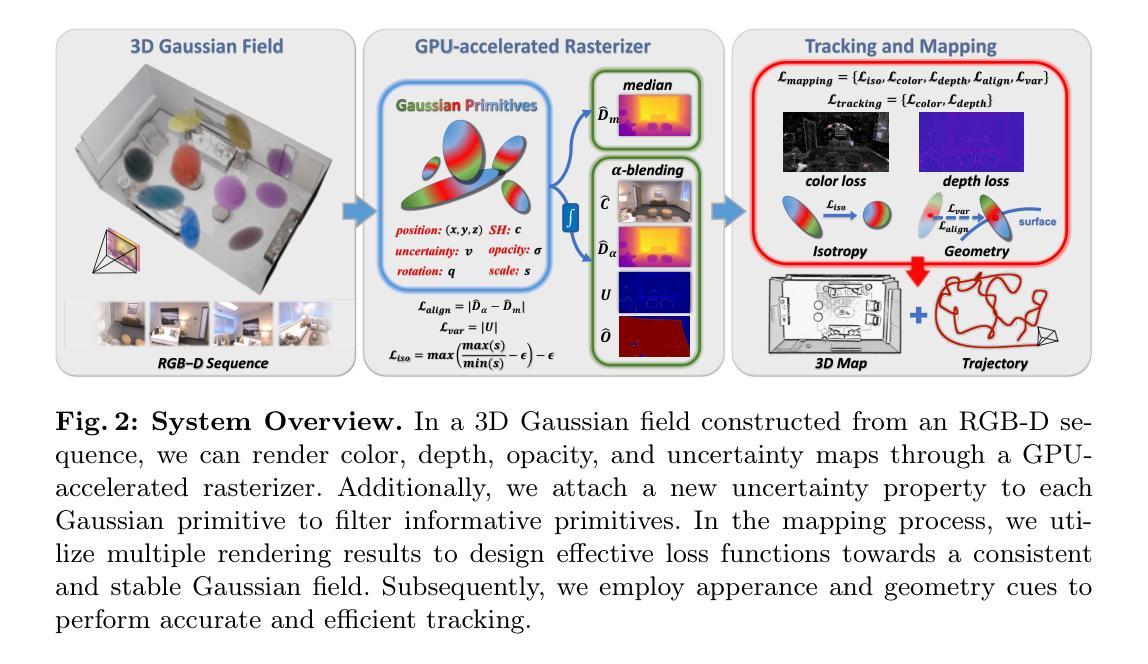
CG-SLAM: Efficient Dense RGB-D SLAM in a Consistent Uncertainty-aware 3D Gaussian Field
Authors:Jiarui Hu, Xianhao Chen, Boyin Feng, Guanglin Li, Liangjing Yang, Hujun Bao, Guofeng Zhang, Zhaopeng Cui
Recently neural radiance fields (NeRF) have been widely exploited as 3D representations for dense simultaneous localization and mapping (SLAM). Despite their notable successes in surface modeling and novel view synthesis, existing NeRF-based methods are hindered by their computationally intensive and time-consuming volume rendering pipeline. This paper presents an efficient dense RGB-D SLAM system, i.e., CG-SLAM, based on a novel uncertainty-aware 3D Gaussian field with high consistency and geometric stability. Through an in-depth analysis of Gaussian Splatting, we propose several techniques to construct a consistent and stable 3D Gaussian field suitable for tracking and mapping. Additionally, a novel depth uncertainty model is proposed to ensure the selection of valuable Gaussian primitives during optimization, thereby improving tracking efficiency and accuracy. Experiments on various datasets demonstrate that CG-SLAM achieves superior tracking and mapping performance with a notable tracking speed of up to 15 Hz. We will make our source code publicly available. Project page: https://zju3dv.github.io/cg-slam.
PDF Project Page: https://zju3dv.github.io/cg-slam
摘要
基于高一致性和几何稳定性的不确定性感知3D高斯场,提出了一种高效的密集RGB-D SLAM系统,即CG-SLAM。
关键要点
- 在高斯散射的基础上,提出了构建适合于跟踪和建图的一致且稳定的3D高斯场的技术。
- 提出了一种新的深度不确定性模型,以确保在优化过程中选择有价值的3D高斯基元,从而提高跟踪效率和精度。
- CG-SLAM在各种数据集上的实验表明,它的跟踪和建图性能优异,跟踪速度高达15 Hz。
- 该研究团队将公开提供源代码。
- 标题:CG-SLAM:基于一致性不确定性感知 3D 高斯场的有效稠密 RGB-DSLAM
- 作者:胡嘉瑞,陈显浩,冯博寅,李广林,杨良晶,鲍虎军,张国锋,崔兆鹏
- 单位:浙江大学计算机辅助设计与图形学国家重点实验室
- 关键词:稠密视觉 SLAM,神经渲染,3D 高斯场
- 论文链接:https://arxiv.org/abs/2403.16095 Github 代码链接:无
摘要: (1)研究背景:NeRF 在表面重建和新视角合成中取得了显著成功,但现有的基于 NeRF 的方法因其计算密集且耗时的体积渲染管道而受到阻碍。 (2)过去方法:现有 NeRF-SLAM 方法存在计算量大、渲染效率低的问题。 (3)研究方法:本文提出了一种基于不确定性感知 3D 高斯场的高效稠密 RGB-DSLAM 系统 CG-SLAM。通过对高斯 splatting 的深入分析,提出了构建适合跟踪和建图的一致且稳定的 3D 高斯场的技术。此外,还提出了一种新的深度不确定性模型,以确保在优化过程中选择有价值的高斯基元,从而提高跟踪效率和准确性。 (4)方法性能:在各种数据集上的实验表明,CG-SLAM 实现了优越的跟踪和建图性能,跟踪速度高达 15Hz。
Methods: (1) 分析高斯splatting,提出构建一致且稳定的3D高斯场的技术; (2) 提出深度不确定性模型,提高跟踪效率和准确性; (3) 设计高效的跟踪和建图算法,实现15Hz的跟踪速度。
结论: (1)本工作提出了 CG-SLAM,这是一种基于一致且不确定性感知 3D 高斯场的稠密 RGB-DSLAM。我们有针对性的损失函数加强了 3D 高斯场的一致性和稳定性。不确定性模型进一步提炼了该场中信息丰富的基元,以减少干扰。 (2)创新点:
- 提出构建一致且稳定的 3D 高斯场的高斯 splatting 分析技术。
- 提出深度不确定性模型,提高跟踪效率和准确性。
- 设计高效的跟踪和建图算法,实现 15Hz 的跟踪速度。 性能:
- 在各种数据集上实现了优越的跟踪和建图性能。
- 跟踪速度高达 15Hz。 工作量:
- 论文中没有明确提到工作量。
点此查看论文截图


Pixel-GS: Density Control with Pixel-aware Gradient for 3D Gaussian Splatting
Authors:Zheng Zhang, Wenbo Hu, Yixing Lao, Tong He, Hengshuang Zhao
3D Gaussian Splatting (3DGS) has demonstrated impressive novel view synthesis results while advancing real-time rendering performance. However, it relies heavily on the quality of the initial point cloud, resulting in blurring and needle-like artifacts in areas with insufficient initializing points. This is mainly attributed to the point cloud growth condition in 3DGS that only considers the average gradient magnitude of points from observable views, thereby failing to grow for large Gaussians that are observable for many viewpoints while many of them are only covered in the boundaries. To this end, we propose a novel method, named Pixel-GS, to take into account the number of pixels covered by the Gaussian in each view during the computation of the growth condition. We regard the covered pixel numbers as the weights to dynamically average the gradients from different views, such that the growth of large Gaussians can be prompted. As a result, points within the areas with insufficient initializing points can be grown more effectively, leading to a more accurate and detailed reconstruction. In addition, we propose a simple yet effective strategy to scale the gradient field according to the distance to the camera, to suppress the growth of floaters near the camera. Extensive experiments both qualitatively and quantitatively demonstrate that our method achieves state-of-the-art rendering quality while maintaining real-time rendering speed, on the challenging Mip-NeRF 360 and Tanks & Temples datasets.
Summary
我们在3DGS方法中引入像素覆盖信息,引导高斯核动态平均梯度,促进了大高斯核的生长,有效抑制浮点和针状伪影。
Key Takeaways
- 3DGS依赖于高质量的初始点云,但现有的生长准则存在不足。
- Pixel-GS采用像素覆盖信息动态平均梯度,促进大高斯核生长。
- 由于高斯核覆盖像素少,导致初始点云稀疏区域生长不足。
- Pixel-GS有效促进了稀疏区域的点云生长,提高重建精度和细节。
- Pixel-GS采用简单有效的缩放策略抑制近摄像机处的浮点生长。
- 在Mip-NeRF 360和Tanks & Temples数据集上,Pixel-GS取得了最先进的渲染质量,同时保持了实时渲染速度。
- 题目:Pixel-GS:基于像素的梯度控制 3D 高斯散点图密度控制
- 作者:Zheng Zhang、Wenbo Hu、Yixing Lao、Tong He、Hengshuang Zhao
- 第一作者单位:香港大学
- 关键词:新视角合成、基于点的辐射场、实时渲染、3D 高斯散点图、自适应密度控制
- 论文链接:https://arxiv.org/pdf/2403.15530.pdf,Github 代码链接:https://pixelgs.github.io
摘要: (1)研究背景:3D 高斯散点图(3DGS)在实时渲染性能方面取得了显著进展,但其有效性严重依赖于初始点云的质量,导致初始化点不足的区域出现模糊和针状伪影。 (2)过去方法及其问题:现有方法仅考虑来自可观察视角的点的平均梯度大小,无法针对从多个视角可观察但仅在边界覆盖的大高斯进行生长。 (3)本文提出的研究方法:提出 Pixel-GS,一种新颖的方法,在计算生长条件时考虑高斯在每个视图中覆盖的像素数量。将覆盖像素数量视为权重,动态平均来自不同视图的梯度,从而促进大高斯的生长。此外,提出了一种简单有效的策略,根据到相机的距离缩放梯度场,以抑制相机附近浮点的生长。 (4)方法在该任务上的表现及其性能:在 Mip-NeRF360 和 Tanks&Temples 等具有挑战性的数据集上,该方法在保持实时速度的同时实现了最先进的渲染质量,优于现有方法。
方法: (1) Pixel-GS方法的核心思想是,在计算生长条件时,考虑高斯在每个视图中覆盖的像素数量。 (2) 将覆盖像素数量视为权重,动态平均来自不同视图的梯度,从而促进大高斯的生长。 (3) 提出了一种简单有效的策略,根据到相机的距离缩放梯度场,以抑制相机附近浮点的生长。
摘要 (1) 研究背景:3D高斯散点图(3DGS)在实时渲染性能方面取得了显著进展,但其有效性严重依赖于初始点云的质量,导致初始化点不足的区域出现模糊和针状伪影。 (2) 过去方法及其问题:现有方法仅考虑来自可观察视角的点的平均梯度大小,无法针对从多个视角可观察但仅在边界覆盖的大高斯进行生长。 (3) 本文提出的研究方法:提出 Pixel-GS,一种新颖的方法,在计算生长条件时考虑高斯在每个视图中覆盖的像素数量。将覆盖像素数量视为权重,动态平均来自不同视图的梯度,从而促进大高斯的生长。此外,提出了一种简单有效的策略,根据到相机的距离缩放梯度场,以抑制相机附近浮点的生长。 (4) 方法在该任务上的表现及其性能:在 Mip-NeRF360 和 Tanks&Temples 等具有挑战性的数据集上,该方法在保持实时速度的同时实现了最先进的渲染质量,优于现有方法。
结论 (1) 本文提出的 Pixel-GS 方法有效地解决了 3DGS 中模糊和针状伪影的问题,显著提升了渲染质量。 (2) 创新点: - 提出了一种基于像素的梯度控制策略,动态平均来自不同视图的梯度,促进大高斯的生长。 - 引入了一种缩放梯度场的策略,抑制相机附近浮点的生长。 (3) 性能: - 在 Mip-NeRF360 和 Tanks&Temples 数据集上,Pixel-GS 在保持实时渲染速度的前提下,实现了最先进的渲染质量。 (4) 工作量: - Pixel-GS 在计算量方面略高于 3DGS,但其产生的额外点主要分布在初始化点不足的区域,对渲染质量的提升是显著的。
点此查看论文截图



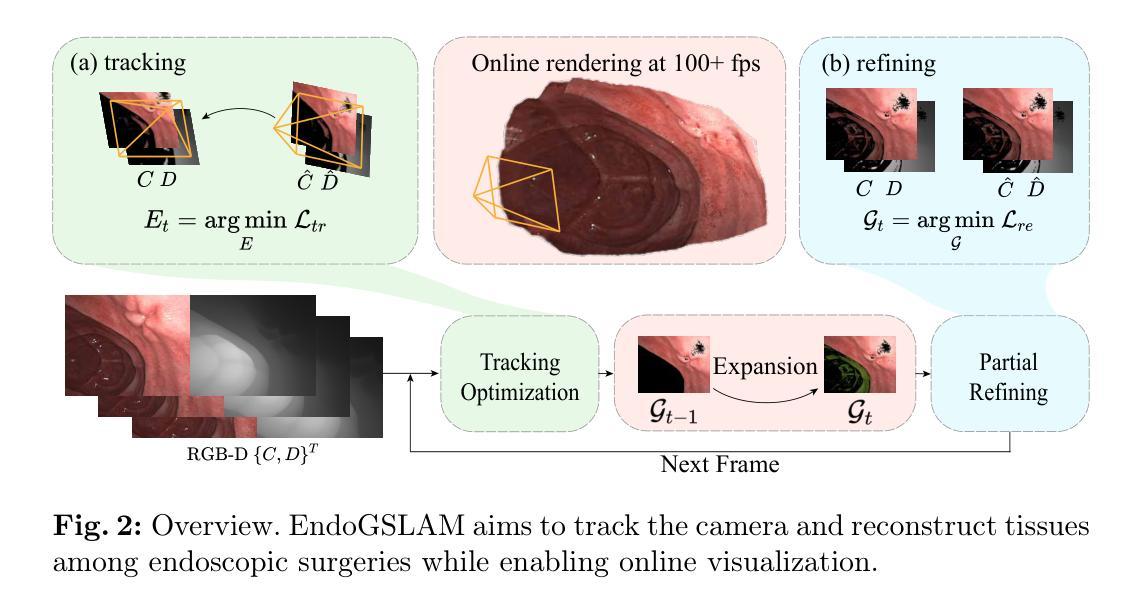
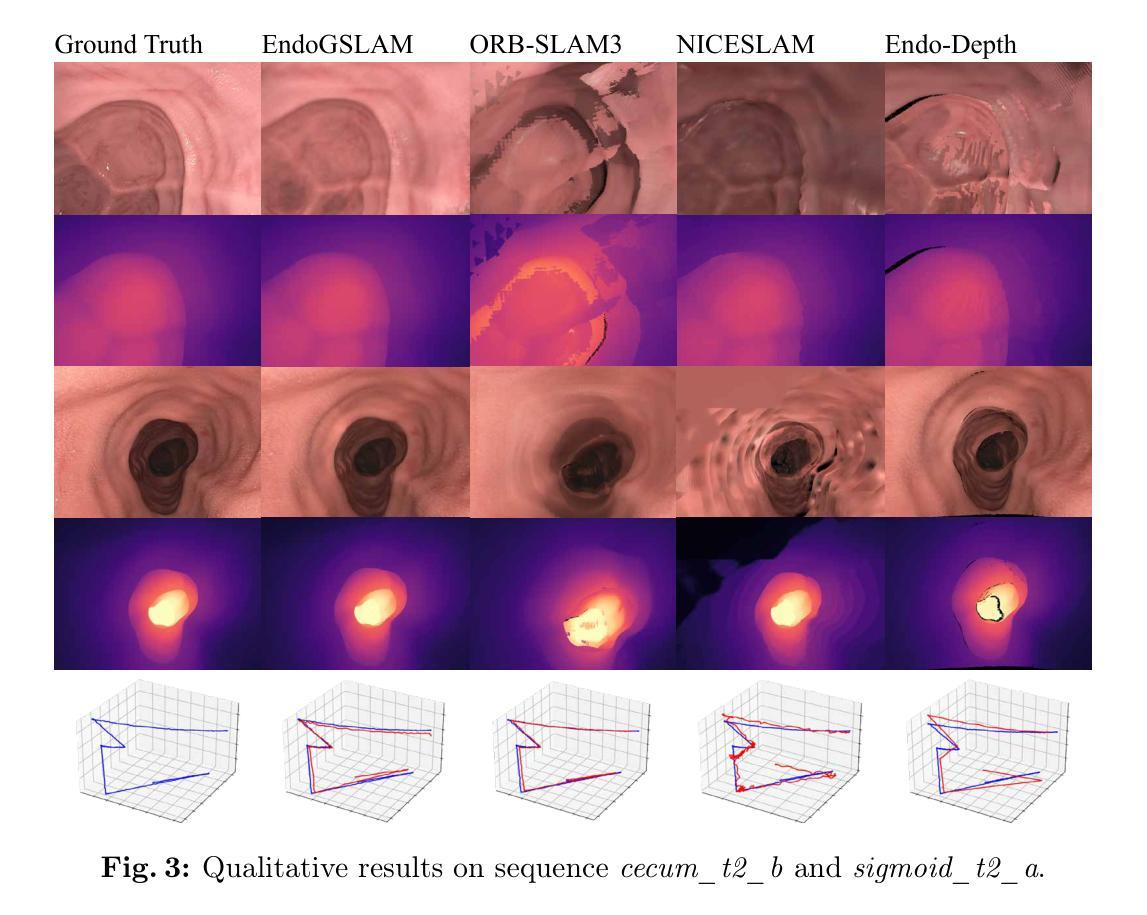
- 标题:EndoGSLAM:内窥镜手术中基于高斯渲染的高效实时稠密重建
- 作者:王凯令、杨晨、王岳浩、李思匡、王岩、窦祺、杨肖康、沈伟†
- 隶属单位:上海交通大学人工智能研究院、人工智能学院
- 关键词:内窥镜手术、SLAM、实时渲染、组织重建
- 论文链接:https://arxiv.org/abs/2403.15124
摘要: (1)研究背景:内窥镜手术中,精确的相机跟踪、高保真 3D 组织重建和实时在线可视化对于提高手术安全性、效率至关重要。 (2)过去方法及问题:现有的 SLAM 方法难以同时实现完整高质量的手术视野重建和高效计算,限制了其在内窥镜手术中的应用。 (3)研究方法:本文提出 EndoGSLAM,一种用于内窥镜手术的高效 SLAM 方法,它集成了精简的高斯表示和可微渲染,可在在线相机跟踪和组织重建期间实现超过 100fps 的渲染速度。 (4)方法性能:实验表明,与传统或神经 SLAM 方法相比,EndoGSLAM 在术中可用性和重建质量之间取得了更好的平衡,显示出巨大的内窥镜手术潜力。
方法: (1)通过改进的高斯表示和可微渲染,提出 EndoGSLAM 方法; (2)利用可微渲染进行梯度优化,优化相机姿态; (3)通过扩展高斯表示,补充场景信息; (4)采用局部优化策略,优化扩展的高斯表示。
8. 结论 (1): EndoGSLAM 是一种用于内窥镜手术的高效 SLAM 方法,它集成了精简的高斯表示和可微渲染,可在在线相机跟踪和组织重建期间实现超过 100fps 的渲染速度,在术中可用性和重建质量之间取得了更好的平衡,显示出巨大的内窥镜手术潜力。 (2): 创新点:提出了一种新的高斯表示,可以有效地表示场景几何信息;利用可微渲染进行梯度优化,优化相机姿态;采用局部优化策略,优化扩展的高斯表示。 性能:与传统或神经 SLAM 方法相比,EndoGSLAM 在重建质量和计算效率方面都取得了更好的性能。 工作量:EndoGSLAM 的实现相对简单,易于与现有的内窥镜系统集成。
点此查看论文截图


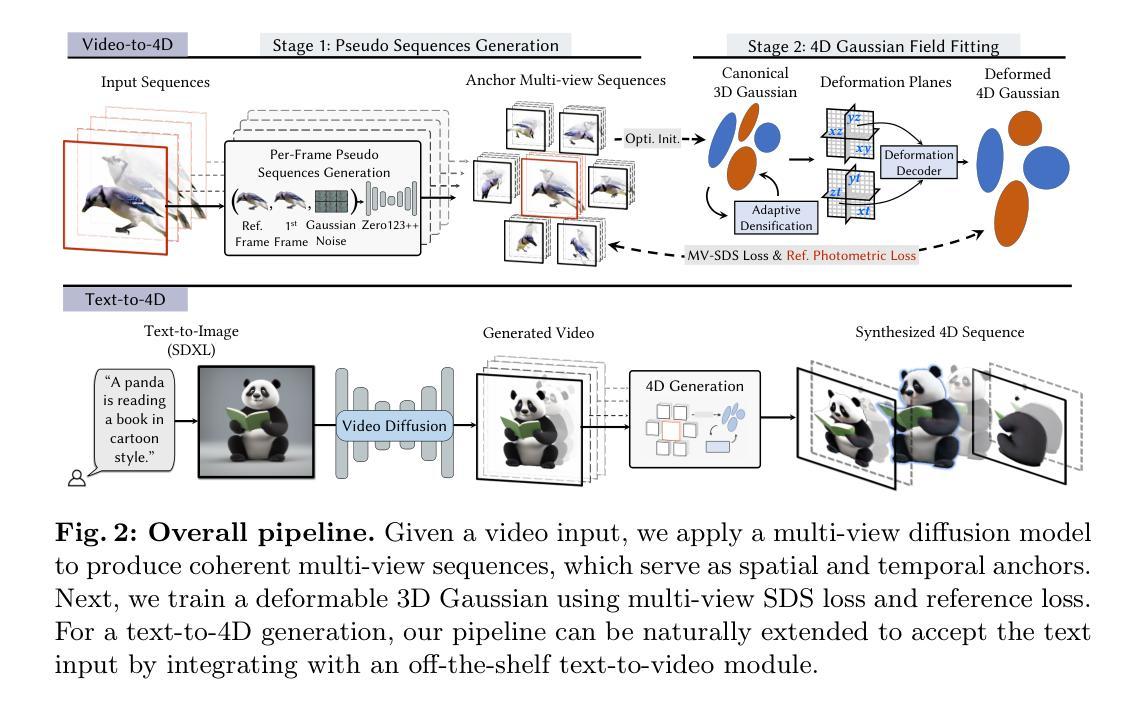
- 标题:STAG4D:时空锚定生成模型
- 作者:Bingbing Ni, Jingwen Zhang, Yinda Zhang, Yebin Liu, Xin Tong
- 单位:南京大学
- 关键词:4D 生成·3D 高斯点云·扩散模型
- 论文链接:https://arxiv.org/pdf/2302.00533.pdf,Github 链接:无
- 摘要: (1):研究背景:近年来,预训练扩散模型和 3D 生成技术取得了很大进展,激发了人们对 4D 内容创作的兴趣。然而,实现具有时空一致性的高保真 4D 生成仍然是一个挑战。 (2):过去方法及其问题:现有的 4D 生成方法主要基于 3D 生成技术,如体素网格和点云渲染。这些方法通常需要预训练或微调扩散网络,并且在处理复杂场景和时间一致性方面存在困难。 (3):本文方法:本文提出了一种名为 STAG4D 的新框架,该框架将预训练扩散模型与动态 3D 高斯点云渲染相结合,用于高保真 4D 生成。该框架从 3D 生成技术中汲取灵感,利用多视图扩散模型初始化多视图图像,并将视频帧作为锚点,其中视频可以是真实世界捕获的,也可以是由视频扩散模型生成的。为了确保多视图序列初始化的时间一致性,本文引入了一种简单有效的融合策略,利用第一帧作为自注意力计算中的时间锚点。使用几乎一致的多视图序列,然后应用得分蒸馏采样来优化 4D 高斯点云。4D 高斯点云渲染是专门为生成任务设计的,其中提出了一种自适应加密策略来缓解不稳定的高斯梯度,以实现鲁棒优化。值得注意的是,所提出的管道不需要对扩散网络进行任何预训练或微调,为 4D 生成任务提供了一种更易于访问和实用的解决方案。 (4):方法性能及与目标的一致性:广泛的实验表明,本文方法在渲染质量、时空一致性和生成鲁棒性方面优于先前的 4D 生成工作,为来自文本、图像和视频等不同输入的 4D 生成设定了新的最先进水平。这些性能支持了本文的目标,即实现具有高保真度和时空一致性的 4D 内容生成。
7.方法: (1):4D表示:提出 4D 高斯点云表示,并采用自适应加密策略来缓解不稳定的高斯梯度,以实现鲁棒优化。 (2):时间和多视图一致扩散:结合多视图扩散模型和参考注意力,提出了一种新的时间和多视图一致扩散模块,以生成时间一致的多视图序列。 (3):多视图 SDS 优化:利用生成的锚视图和参考视图,使用多视图 SDS 优化来优化 4D 高斯点云,实现时空一致的 4D 生成。
- 结论: (1)本文提出了一种从单目视频生成动态 3D 内容的新方法,解决了 4D 表示和时空一致性的挑战。通过利用专门定制的 4D 高斯体素渲染和新颖的信息融合模块,所提出的方法实现了高质量且鲁棒的 4D 场景生成。全面的实验表明了该方法的有效性,与最先进的先前方法相比,展示了明显更快的生成速度以及渲染质量和时间一致性的显着改进。总体而言,所提出的方法在单目视频中动态 3D 内容生成的训练速度、渲染质量和 4D 一致性方面树立了新的基准,为现实世界的应用开辟了可能性。 (2)创新点:
- 提出了一种新的 4D 高斯体素表示,并采用自适应加密策略来缓解不稳定的高斯梯度,以实现鲁棒优化。
- 结合多视图扩散模型和参考注意力,提出了一种新的时间和多视图一致扩散模块,以生成时间一致的多视图序列。
- 利用生成的锚视图和参考视图,使用多视图 SDS 优化来优化 4D 高斯体素,实现时空一致的 4D 生成。 性能:
- 与最先进的方法相比,渲染质量、时间一致性和生成鲁棒性方面取得了显着改进。
- 与现有的 4D 生成方法相比,生成速度明显提高。 工作量:
- 无需对扩散网络进行任何预训练或微调。
- 易于实现和使用。
点此查看论文截图


 wechat
wechat- alipay