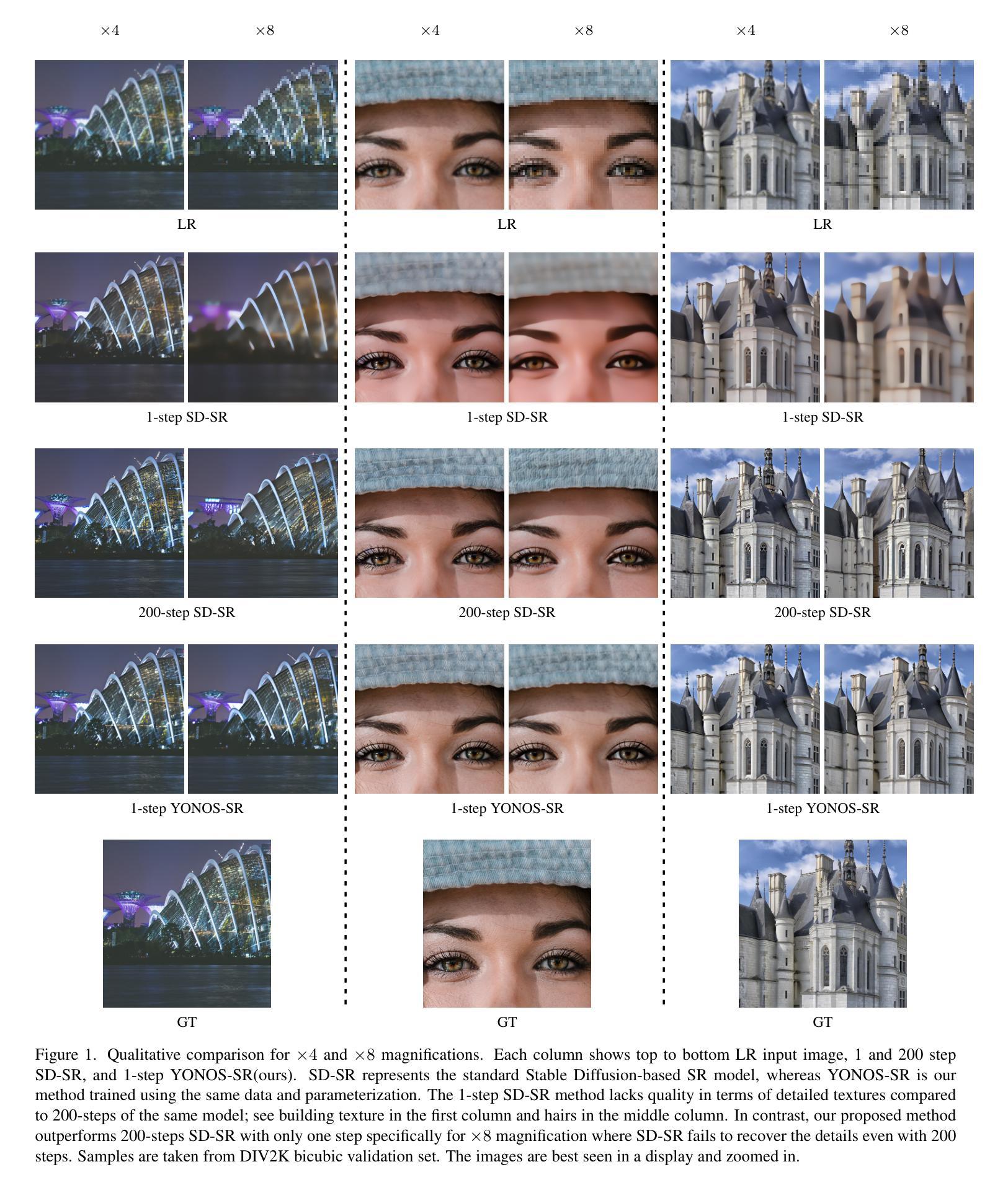
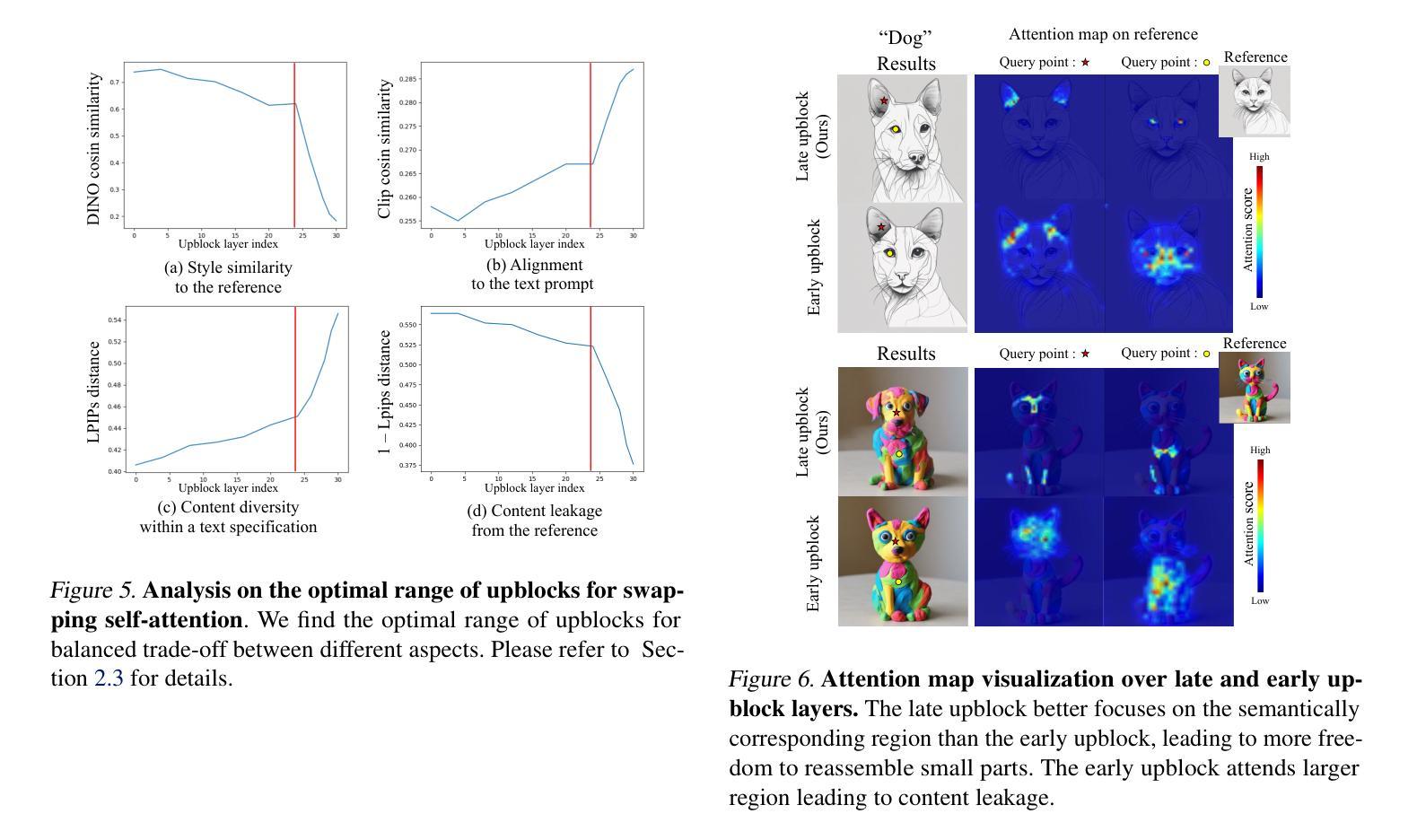
Diffusion Models
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-03-28 更新
AID: Attention Interpolation of Text-to-Image Diffusion
Authors:Qiyuan He, Jinghao Wang, Ziwei Liu, Angela Yao
Conditional diffusion models can create unseen images in various settings, aiding image interpolation. Interpolation in latent spaces is well-studied, but interpolation with specific conditions like text or poses is less understood. Simple approaches, such as linear interpolation in the space of conditions, often result in images that lack consistency, smoothness, and fidelity. To that end, we introduce a novel training-free technique named Attention Interpolation via Diffusion (AID). Our key contributions include 1) proposing an inner/outer interpolated attention layer; 2) fusing the interpolated attention with self-attention to boost fidelity; and 3) applying beta distribution to selection to increase smoothness. We also present a variant, Prompt-guided Attention Interpolation via Diffusion (PAID), that considers interpolation as a condition-dependent generative process. This method enables the creation of new images with greater consistency, smoothness, and efficiency, and offers control over the exact path of interpolation. Our approach demonstrates effectiveness for conceptual and spatial interpolation. Code and demo are available at https://github.com/QY-H00/attention-interpolation-diffusion.
摘要
注意力插值扩散(AID):一种无需训练的条件插值新技术,可生成高度一致、平滑且逼真的图像。
要点
- 提出内层/外层插值注意力层,以增强插值质量。
- 融合插值注意力和自注意力,提升生成图像的保真度。
- 应用贝塔分布选择,提高插值的平滑度。
- 提出提示引导的注意力插值扩散(PAID)变体,将插值视为条件依赖的生成过程。
- 控制插值的确切路径,生成具有更高一致性、平滑性和效率的新图像。
- 在概念和空间插值方面表现出有效性。
- 标题:AID:文本到图像的注意插值
- 作者:齐源何、景浩王、子为刘、安吉拉姚
- 第一作者单位:新加坡国立大学
- 关键词:文本到图像扩散、条件扩散模型、注意机制、插值
- 论文链接:https://arxiv.org/abs/2403.17924 Github 代码链接:无
摘要: (1) 研究背景:条件扩散模型可以生成各种场景中的图像,有助于图像插值。在潜在空间中进行插值已经得到充分研究,但使用特定条件(如文本或姿势)进行插值的研究较少。 (2) 过去的方法及其问题:简单的方法,例如在条件空间中进行线性插值,通常会导致图像缺乏一致性、平滑性和保真度。本文提出的方法动机明确。 (3) 研究方法:本文提出了一种名为 AID 的新颖免训练技术,即通过扩散进行注意插值。该方法通过在条件空间中引入注意机制来指导插值过程,从而确保图像在布局和概念上的平滑过渡。 (4) 方法性能:该方法在文本到图像扩散模型上进行了评估,在空间和概念插值任务上取得了显着改进。实验结果支持了本文提出的方法目标。
方法: (1) 内/外插值注意力机制:通过在条件空间中引入注意力机制,指导插值过程,确保图像在布局和概念上的平滑过渡。 (2) 与自注意力融合:将插值潜变量本身的键和值融入插值注意力机制,提高一致性和保真度。 (3) Beta 先验序列选择:采用 Beta 分布选择插值路径上的特定插值图像,使生成的图像序列更平滑。 (4) 提示引导:通过注入提示作为条件,控制插值路径,生成符合文本描述的插值序列。
结论: (1):本工作首次提出条件插值任务及相关评估指标,包括一致性、平滑性和保真度。我们提出了一种称为 AID 的新颖方法,用于在扩散模型中生成条件插值图像。该方法在无需训练的情况下显着超越了基准,通过定性和定量分析得到了证明。此外,我们还引入了 PAID,该扩展允许用户使用引导提示来选择插值路径。我们的方法无需训练,拓宽了生成模型插值的范围,为合成生成、图像编辑、数据增强和视频插值等各种应用开辟了新机遇。 (2):创新点:提出条件插值任务及评估指标,引入注意力机制指导插值过程,无需训练即可生成高质量插值图像。 性能:在空间和概念插值任务上取得显着改进,定性和定量评估均支持该方法的有效性。 工作量:提出了一种无需训练的插值方法,减少了训练负担,提高了插值效率。
点此查看论文截图

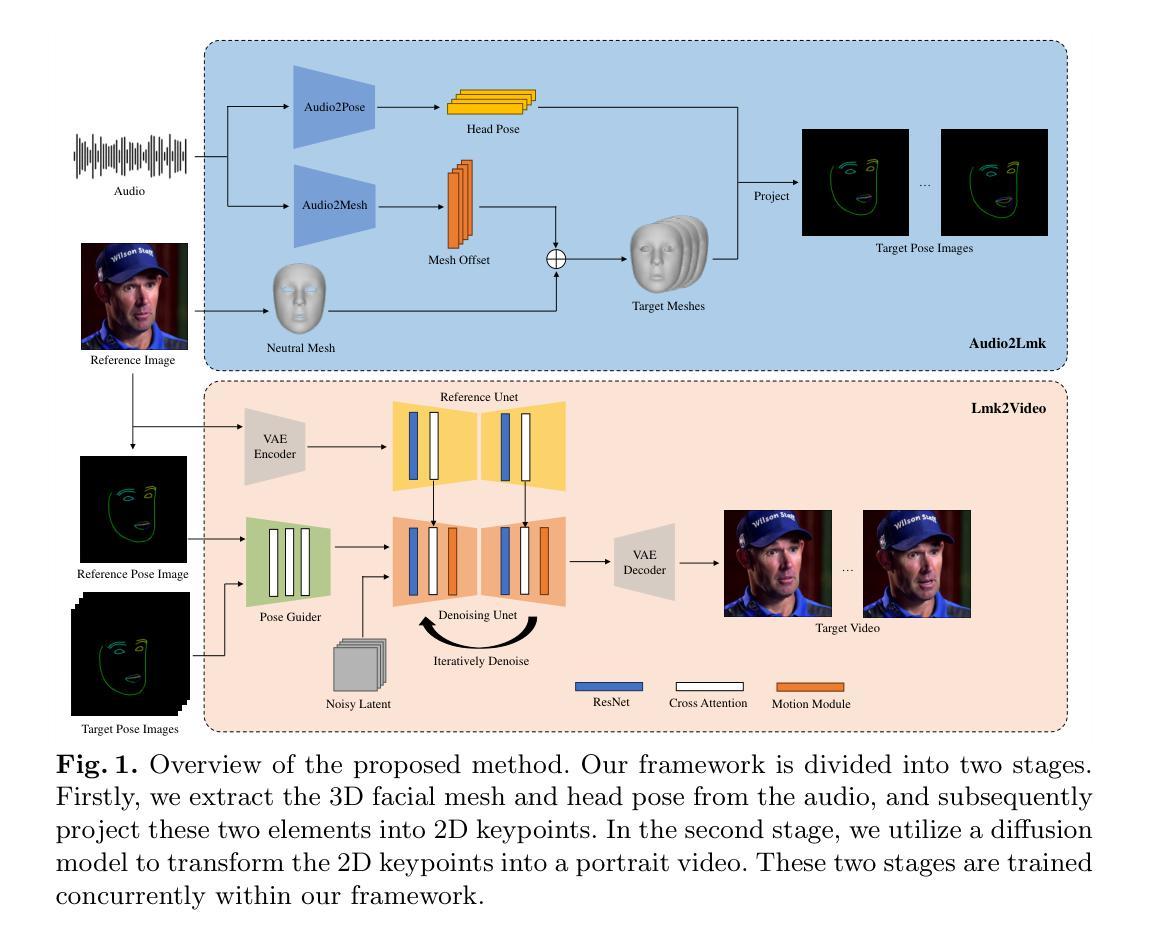
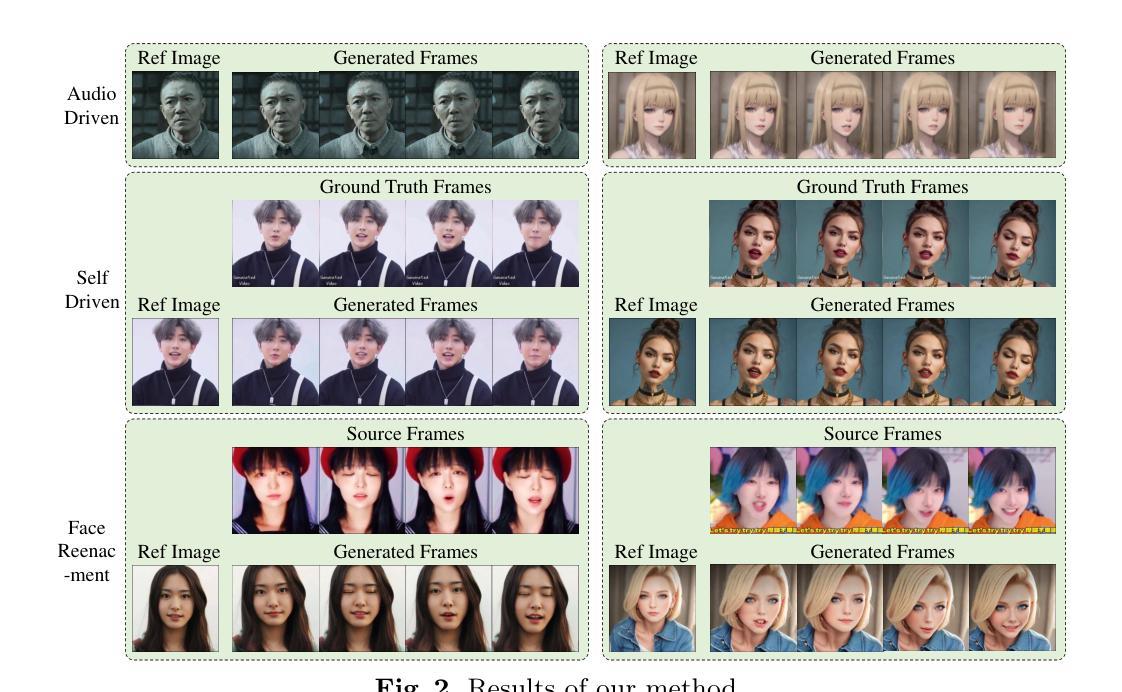
AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation
Authors:Huawei Wei, Zejun Yang, Zhisheng Wang
In this study, we propose AniPortrait, a novel framework for generating high-quality animation driven by audio and a reference portrait image. Our methodology is divided into two stages. Initially, we extract 3D intermediate representations from audio and project them into a sequence of 2D facial landmarks. Subsequently, we employ a robust diffusion model, coupled with a motion module, to convert the landmark sequence into photorealistic and temporally consistent portrait animation. Experimental results demonstrate the superiority of AniPortrait in terms of facial naturalness, pose diversity, and visual quality, thereby offering an enhanced perceptual experience. Moreover, our methodology exhibits considerable potential in terms of flexibility and controllability, which can be effectively applied in areas such as facial motion editing or face reenactment. We release code and model weights at https://github.com/scutzzj/AniPortrait
Summary
利用音频和参考肖像图像生成高品质动画的新颖框架:AniPortrait
Key Takeaways
- AniPortrait 提出了一种由音频和参考肖像图像驱动的高质量动画生成新框架。
- AniPortrait 分为两个阶段:从音频中提取 3D 中间表示并将其投影到 2D 面部地标序列中。
- AniPortrait 使用稳健的扩散模型和运动模块将地标序列转换为逼真的、时间一致的肖像动画。
- AniPortrait 在面部自然度、姿势多样性和视觉质量方面表现出卓越的性能。
- AniPortrait 在灵活性和可控性方面表现出巨大潜力,可有效应用于面部动作编辑或面部重建等领域。
- 标题:AniPortrait:音频驱动的写实肖像动画合成
- 作者:Wei Huawei、Yang Zejun、Wang Zhisheng
- 单位:腾讯
- 关键词:音频驱动、肖像动画、扩散模型、动作模块
- 论文链接:https://arxiv.org/abs/2403.17694 Github:None
- 摘要: (1)研究背景:从音频和静态图像生成逼真且富有表现力的肖像动画具有广泛的应用,但制作视觉上引人入胜且保持时间一致性的高质量动画是一项重大挑战。 (2)过去方法及其问题:现有方法通常无法克服这一挑战,主要原因是它们依赖于容量有限的视觉内容生成器,例如 GAN、NeRF 或基于运动的解码器。这些网络表现出有限的泛化能力,并且在生成高质量内容时往往缺乏稳定性。 (3)提出的研究方法:本文提出 AniPortrait,这是一个新颖的框架,旨在生成由音频和参考图像驱动的优质动画肖像。AniPortrait 分为两个不同的阶段。在第一阶段,我们使用基于 Transformer 的模型从音频中提取 3D 中间表示,并将其投影到 2D 面部地标序列中。随后,我们采用稳健的扩散模型,结合运动模块,将地标序列转换为逼真的、时间一致的肖像动画。 (4)方法在任务和性能上的表现:实验结果证明了 AniPortrait 在面部自然度、姿势多样性和视觉质量方面的优越性,从而提供了增强的感知体验。此外,我们的方法在灵活性和可控性方面表现出相当大的潜力,可以有效地应用于面部动作编辑或面部重现等领域。
7.方法: (1):Audio2Lmk:从音频中提取 3D 面部网格序列和位姿序列。 (2):Lmk2Video:将面部地标序列转换为时间一致的肖像动画。
- 结论: (1): 本工作提出了一种新颖的框架 AniPortrait,该框架可以生成由音频和参考图像驱动的优质动画肖像。AniPortrait 采用基于 Transformer 的模型从音频中提取 3D 中间表示,并使用稳健的扩散模型结合运动模块将其转换为逼真的、时间一致的肖像动画。实验结果证明了 AniPortrait 在面部自然度、姿势多样性和视觉质量方面的优越性,从而提供了增强的感知体验。此外,我们的方法在灵活性和可控性方面表现出相当大的潜力,可以有效地应用于面部动作编辑或面部重现等领域。 (2): 创新点:
- 提出了一种新颖的框架 AniPortrait,该框架可以从音频和参考图像生成逼真的动画肖像。
- 采用基于 Transformer 的模型从音频中提取 3D 中间表示,并使用稳健的扩散模型结合运动模块将其转换为时间一致的肖像动画。
- AniPortrait 在面部自然度、姿势多样性和视觉质量方面表现出优越性,从而提供了增强的感知体验。
- AniPortrait 在灵活性和可控性方面表现出相当大的潜力,可以有效地应用于面部动作编辑或面部重现等领域。 性能:
- AniPortrait 在面部自然度、姿势多样性和视觉质量方面表现出优越性,从而提供了增强的感知体验。
- AniPortrait 在灵活性和可控性方面表现出相当大的潜力,可以有效地应用于面部动作编辑或面部重现等领域。 工作量:
- AniPortrait 的实现需要一定的技术实力,包括对 Transformer 模型、扩散模型和运动模块的理解。
- 训练 AniPortrait 模型需要大量的数据和计算资源。
点此查看论文截图

DiffFAE: Advancing High-fidelity One-shot Facial Appearance Editing with Space-sensitive Customization and Semantic Preservation
Authors:Qilin Wang, Jiangning Zhang, Chengming Xu, Weijian Cao, Ying Tai, Yue Han, Yanhao Ge, Hong Gu, Chengjie Wang, Yanwei Fu
Facial Appearance Editing (FAE) aims to modify physical attributes, such as pose, expression and lighting, of human facial images while preserving attributes like identity and background, showing great importance in photograph. In spite of the great progress in this area, current researches generally meet three challenges: low generation fidelity, poor attribute preservation, and inefficient inference. To overcome above challenges, this paper presents DiffFAE, a one-stage and highly-efficient diffusion-based framework tailored for high-fidelity FAE. For high-fidelity query attributes transfer, we adopt Space-sensitive Physical Customization (SPC), which ensures the fidelity and generalization ability by utilizing rendering texture derived from 3D Morphable Model (3DMM). In order to preserve source attributes, we introduce the Region-responsive Semantic Composition (RSC). This module is guided to learn decoupled source-regarding features, thereby better preserving the identity and alleviating artifacts from non-facial attributes such as hair, clothes, and background. We further introduce a consistency regularization for our pipeline to enhance editing controllability by leveraging prior knowledge in the attention matrices of diffusion model. Extensive experiments demonstrate the superiority of DiffFAE over existing methods, achieving state-of-the-art performance in facial appearance editing.
Summary
图像中人脸外观编辑的扩散模型 DiffFAE 提高了生成保真度、属性保留和推理效率。
Key Takeaways
- 采用空间敏感物理定制 (SPC) 确保查询属性转移的保真度和泛化能力。
- 引入区域响应语义组合 (RSC) 保留源属性,减轻非面部属性(如头发、衣服和背景)带来的伪影。
- 提出一致性正则化,通过利用扩散模型注意力矩阵中的先验知识增强编辑可控性。
- DiffFAE 在人脸外观编辑中实现了最先进的性能,超越现有方法。
- DiffFAE 可以有效处理人脸外观编辑中的低生成保真度、差属性保留和低推理效率等挑战。
- 扩散模型在人脸外观编辑任务中具有广阔的应用前景。
- 本文提出了一种用于人脸外观编辑的新颖框架 DiffFAE,它结合了扩散模型、空间敏感物理定制和区域响应语义组合的优点。
- 标题:DiffFAE:推进高保真一发式人脸外观编辑
- 作者:Q. Wang 等
- 单位:未提及
- 关键词:Facial appearance editing、Diffusion model、Object-centric learning
- 论文链接:未提供,Github 代码链接:无
摘要: (1)研究背景:人脸外观编辑旨在修改人脸图像的物理属性(如姿势、表情和光照),同时保留身份和背景等属性,在摄影中具有重要意义。 (2)过去方法:现有研究通常面临生成保真度低、属性保留差和推理效率低三大挑战。 (3)研究方法:本文提出 DiffFAE,一个针对高保真 FAE 量身定制的单阶段且高效的基于扩散的框架。为了实现高保真查询属性转移,我们采用空间敏感物理定制(SPC),它利用源自 3D 可变形模型(3DMM)的渲染纹理,确保了保真度和泛化能力。为了保留源属性,我们引入了区域响应语义组合(RSC)。该模块被引导学习解耦的源相关特征,从而更好地保留身份,并减轻来自非面部属性(如头发、衣服和背景)的伪影。我们还为我们的管道引入了稠密正则化,通过利用扩散模型注意力矩阵中的先验知识来增强编辑可控性。 (4)方法性能:广泛的实验表明,DiffFAE 优于现有方法,在人脸外观编辑中实现了最先进的性能。这些性能支持了他们的目标。
方法: (1)空间敏感物理定制(SPC):利用源自3D可变形模型(3DMM)的渲染纹理,确保保真度和泛化能力。 (2)区域响应语义组合(RSC):学习解耦的源相关特征,保留身份,减轻非面部属性伪影。 (3)稠密正则化:利用扩散模型注意力矩阵中的先验知识,增强编辑可控性。
8.结论: (1):本文针对人脸外观编辑(FAE)中存在的生成保真度低、属性保留差和推理效率低三大挑战进行了分析,探索了一种基于单阶段扩散的新框架。具体来说,我们采用空间敏感物理定制模块来处理查询物理属性,如姿势、表情和光照。同时,提出了区域响应语义组合来更好地控制源相关属性。我们的方法在 VoxCeleb1 数据集上为 FAE 任务设定了新的最先进性能,这得到了广泛的定量和定性结果的支持。 (2):创新点:空间敏感物理定制模块、区域响应语义组合、稠密正则化; 性能:在 VoxCeleb1 数据集上取得了最先进的性能; 工作量:中等。
点此查看论文截图



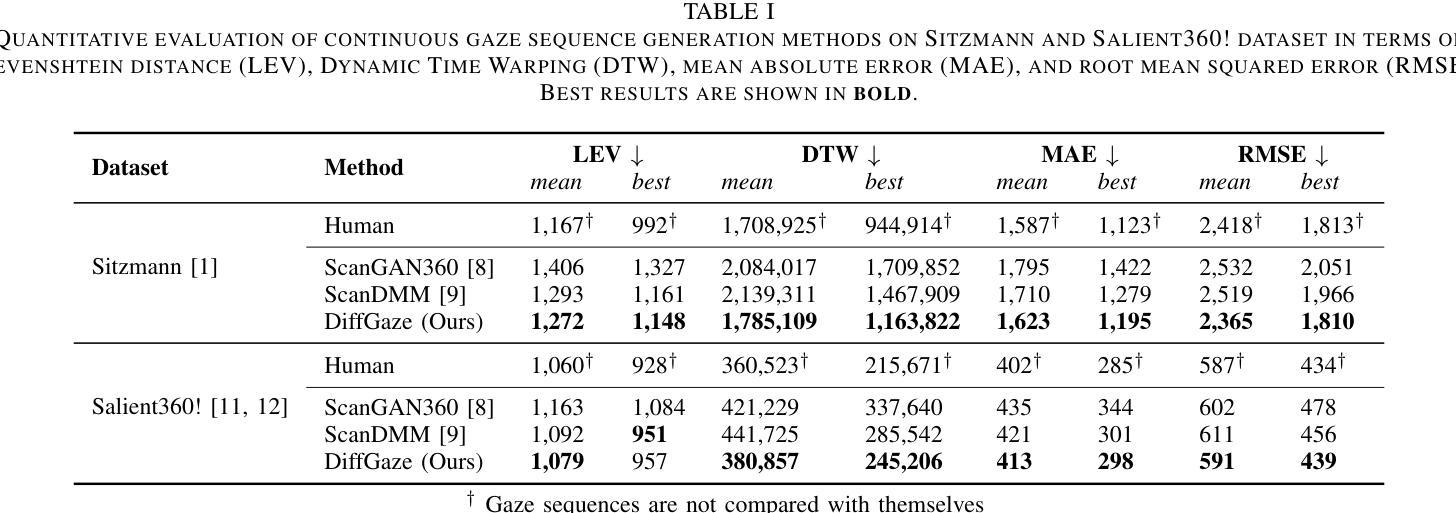
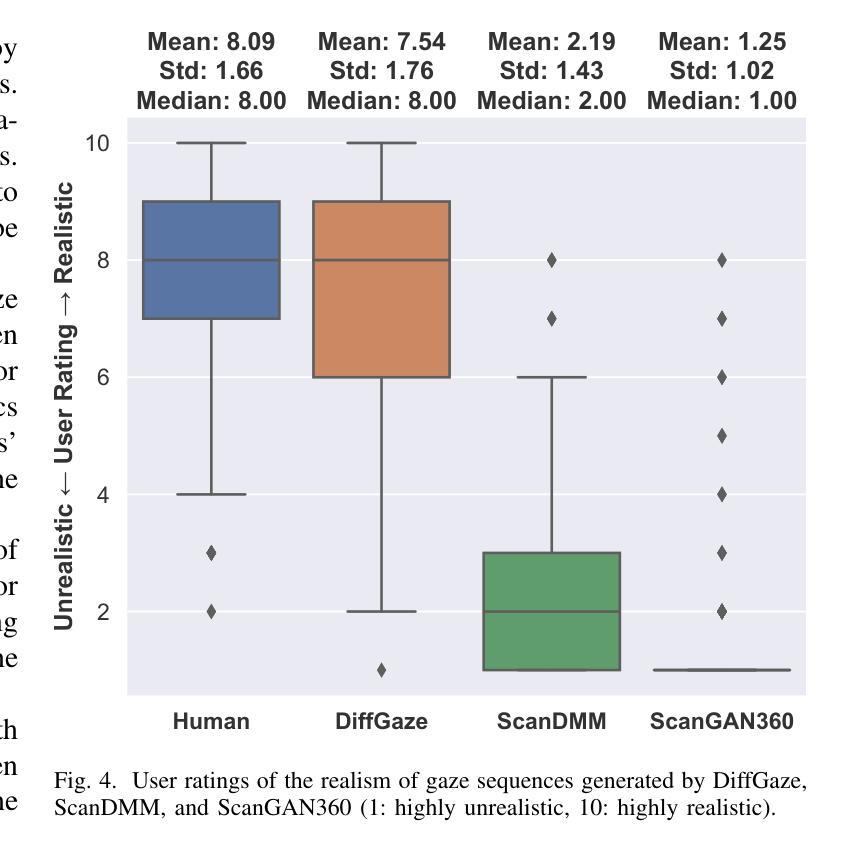
- 标题:DiffGaze:360° 图像连续注视序列生成扩散模型
- 作者:Chuhan Jiao、Yao Wang、Guanhua Zhang、Mihai Bace、Zhiming Hu、Andreas Bulling
- 隶属单位:斯图加特大学可视化与交互系统研究所
- 关键词:Scanpath Prediction; Saliency Modelling; Eye Tracking; Gaze Behaviour Modelling; Eye Movement Synthesis
- 论文链接:https://arxiv.org/abs/2403.17477 Github 代码链接:无
- 摘要: (1)研究背景: 随着相机技术的进步,高分辨率 360° 图像的捕捉为虚拟现实 (VR) 中的新一代沉浸式体验提供了可能。这引发了消费者采用这项新技术的兴趣,并促进了理解人类如何感知和探索这些 3D 虚拟环境的研究工作。视觉注意力是探索过程中的一个特别丰富的的信息来源,通常以使用眼动追踪收集的注视数据形式进行分析。尽管眼动追踪变得更加广泛和经济实惠,而且被集成到越来越多的 VR 头显中,但收集注视数据(尤其是在大规模的情况下)仍然很繁琐且耗时,而且通常根本不可行。这引发了对视觉注意力计算模型的研究,即无需专用眼动追踪设备就能预测 360° 图像上人类注视的模型。
(2)过去的方法及其问题: 先前关于 360° 图像上视觉注意力计算建模的工作主要集中在显着性或扫描路径预测上。尽管取得了重大进展,但这两项任务仍然只解决了简化的问题:虽然聚合显着性图不需要对人类注视行为的时间特性进行建模,但预测离散注视固定(扫描路径)的序列在时间上仍然粗糙,并且忽略了固定之间的丰富注视数据。因此,这些任务(或过去为解决这些任务而开发的任何现有方法)都不能忠实地对 360° 图像上自然人类注视行为的丰富空间和时间特性进行建模。
(3)提出的研究方法: 为了解决这些限制,我们提出了 DiffGaze——第一个生成 360° 图像上连续人类注视序列的方法。DiffGaze 基于条件分数噪声扩散模型,该模型以从 360° 图像中提取的特征为条件,并使用两个 Transformer 来对时空人类注视行为进行建模。
(4)方法在任务和性能上的表现: 我们在两个数据集(Sitzmann 和 Salient360!)上对我们的方法进行了连续注视序列生成、扫描路径预测和显着性预测的评估。结果表明,在两个基准上的所有任务中,DiffGaze 都优于最先进的方法。这些性能可以支持其目标。
方法: (1) DiffGaze基于条件分数噪声扩散模型,以从360°图像中提取的特征为条件。 (2) 使用两个Transformer对时空人类注视行为进行建模。 (3) 通过逐层噪声添加和预测噪声的逆过程,生成连续的人类注视序列。
结论: (1):本文提出了 DiffGaze,这是一种条件扩散模型,用于在 360° 环境中生成逼真且多样的连续人类注视序列。该方法通过超越扫描路径预测来对更复杂的眼球运动进行建模,从而显著推进了该领域。通过在两个 360° 图像数据集上对三种不同任务进行严格评估,证明了 DiffGaze 的有效性。DiffGaze 不仅在注视序列生成、扫描路径预测和显着性预测方面优于以往的方法,而且还显示出与人类基线相当的性能,突出了其模拟类人注视行为的能力。这些结果突出了 DiffGaze 在促进沉浸式环境中注视行为分析方面的潜力。通过提供高质量的模拟眼动追踪数据,DiffGaze 为人机交互和计算机视觉应用开辟了新的可能性,为更直观和沉浸式的用户体验铺平了道路。 (2):创新点:
- 首次提出了一种生成 360° 图像上连续人类注视序列的条件扩散模型。
- 使用两个 Transformer 对时空人类注视行为进行建模,这比以往的方法更全面。
- 通过逐层噪声添加和预测噪声的逆过程,生成连续的人类注视序列,比以往的方法更逼真。 性能:
- 在两个基准数据集上,DiffGaze 在注视序列生成、扫描路径预测和显着性预测方面均优于最先进的方法。
- DiffGaze 与人类基线表现相当,表明其能够模拟类人注视行为。 工作量:
- DiffGaze 的训练和推理过程比以往的方法更复杂,需要更多的计算资源。
- DiffGaze 需要从 360° 图像中提取特征,这可能需要额外的处理时间。
点此查看论文截图



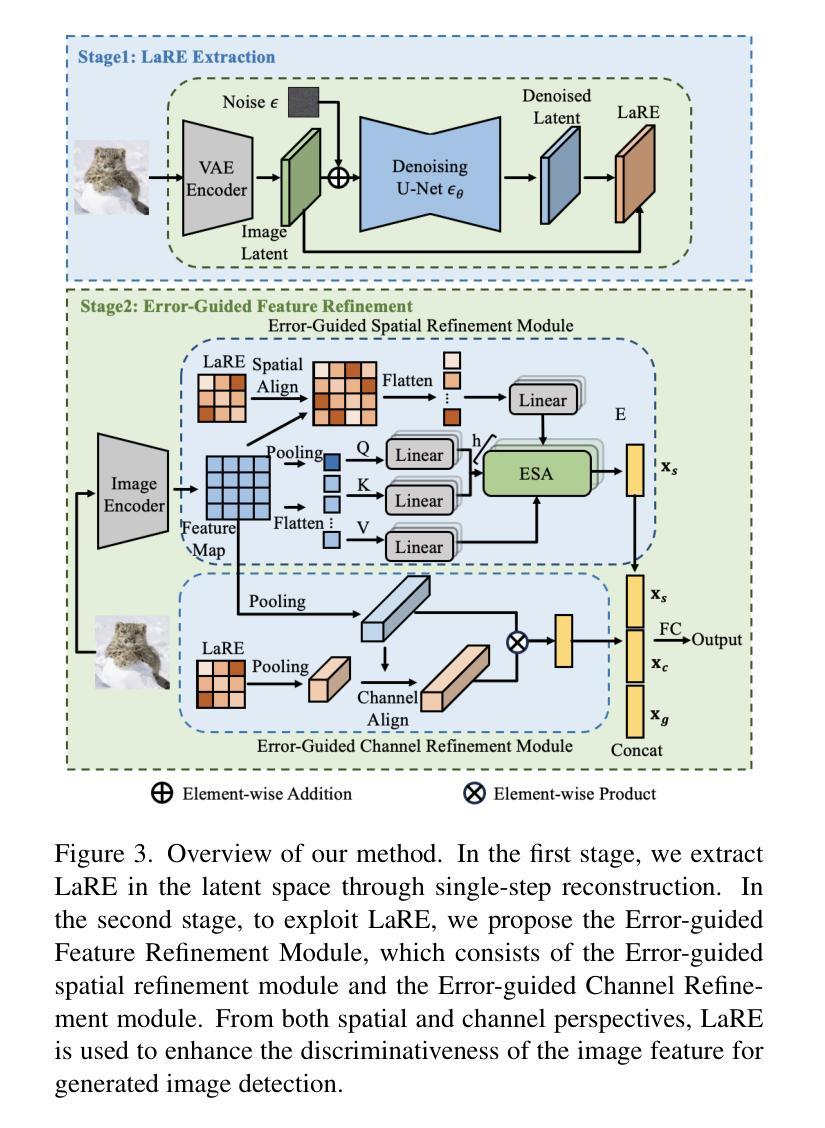
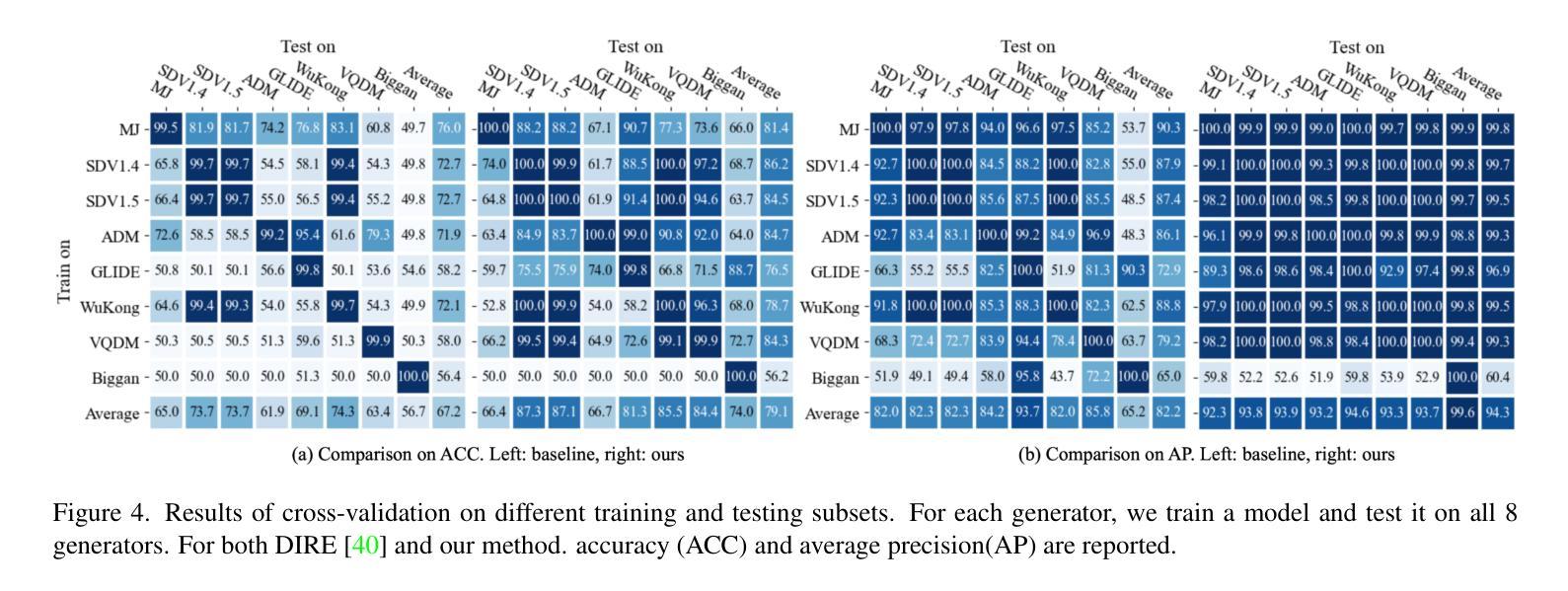
LaRE^2: Latent Reconstruction Error Based Method for Diffusion-Generated Image Detection
Authors:Yunpeng Luo, Junlong Du, Ke Yan, Shouhong Ding
The evolution of Diffusion Models has dramatically improved image generation quality, making it increasingly difficult to differentiate between real and generated images. This development, while impressive, also raises significant privacy and security concerns. In response to this, we propose a novel Latent REconstruction error guided feature REfinement method (LaRE^2) for detecting the diffusion-generated images. We come up with the Latent Reconstruction Error (LaRE), the first reconstruction-error based feature in the latent space for generated image detection. LaRE surpasses existing methods in terms of feature extraction efficiency while preserving crucial cues required to differentiate between the real and the fake. To exploit LaRE, we propose an Error-Guided feature REfinement module (EGRE), which can refine the image feature guided by LaRE to enhance the discriminativeness of the feature. Our EGRE utilizes an align-then-refine mechanism, which effectively refines the image feature for generated-image detection from both spatial and channel perspectives. Extensive experiments on the large-scale GenImage benchmark demonstrate the superiority of our LaRE^2, which surpasses the best SoTA method by up to 11.9%/12.1% average ACC/AP across 8 different image generators. LaRE also surpasses existing methods in terms of feature extraction cost, delivering an impressive speed enhancement of 8 times.
PDF CVPR 2024
Summary
扩散模型生成的图像难辨真伪,为此提出 LaRE^2 方法,利用潜在重建误差增强鉴别能力。
Key Takeaways
- 创新提出潜在重建误差 (LaRE),在潜在空间中提取用于生成图像检测的重建误差特征。
- 设计错误引导特征细化模块 (EGRE),利用 LaRE 引导图像特征细化,提高特征判别力。
- EGRE 采用对齐再细化的机制,从空间和通道两个角度有效细化图像特征。
- 在大规模 GenImage 基准上进行广泛实验,证明 LaRE^2 的优越性,在 8 种不同的图像生成器上比最佳 SoTA 方法分别提高了 11.9%/12.1% 的平均准确率/平均精度。
- LaRE 还超过了现有方法的特征提取成本,提供了 8 倍的提速。
- LaRE^2 方法有助于保护隐私和安全,解决扩散模型带来的挑战。
- 题目:LaRE2:基于潜在重建误差的扩散生成图像检测方法
- 作者:罗运鹏、杜俊龙、严柯、丁寿鸿
- 单位:腾讯优图实验室
- 关键词:Diffusion Model、图像生成、图像检测、潜在空间、重建误差
- 论文链接:https://arxiv.org/abs/2403.17465
摘要: (1)研究背景:扩散模型的快速发展带来了生成图像质量的显著提升,但也引发了隐私和安全问题,亟需开发图像检测技术。 (2)过去方法:现有方法利用重建误差作为判别特征,但存在特征提取效率低、重建步骤繁琐等问题。 (3)研究方法:本文提出 LaRE2 方法,利用潜在空间的重建误差作为特征,并设计了错误引导特征细化模块,从空间和通道维度细化图像特征,增强判别性。 (4)性能与评价:在 GenImage 数据集上,LaRE2 在 8 个不同图像生成器上平均 ACC/AP 分别比最佳 SoTA 方法提升了 11.9%/12.1%,且特征提取速度提升了 8 倍,证明了方法的有效性和高效性。
方法:(1) 在潜在空间中,通过单步重建提取 LaRE;(2) 为了利用 LaRE,提出了错误引导特征细化模块,该模块由错误引导空间细化模块和错误引导通道细化模块组成。从空间和通道维度,利用 LaRE 增强图像特征的判别性,用于生成图像检测。
结论: (1): 本文提出了一种新颖的基于重建的扩散生成图像检测方法 LaRE2。我们提出了 LaRE,这是一种通过在潜在空间中重建图像来获得的新颖且更有效的基于重建的特征。值得注意的是,与现有的基于重建的方法相比,LaRE 的速度提高了 8 倍。通过将 LaRE 与错误引导特征细化模块 (EGRE) 相结合。我们的 LaRE2 在扩散生成图像检测方面取得了卓越的性能,展示了最先进的性能。 (2): 创新点:提出了一种新颖且高效的基于重建的特征 LaRE,利用潜在空间重建图像获得;设计了错误引导特征细化模块,从空间和通道维度增强图像特征的判别性。 性能:在 GenImage 数据集上,在 8 个不同的图像生成器上,与最佳 SoTA 方法相比,LaRE2 的平均 ACC/AP 分别提高了 11.9%/12.1%,特征提取速度提高了 8 倍。 工作量:特征提取速度提升了 8 倍,降低了工作量。
点此查看论文截图


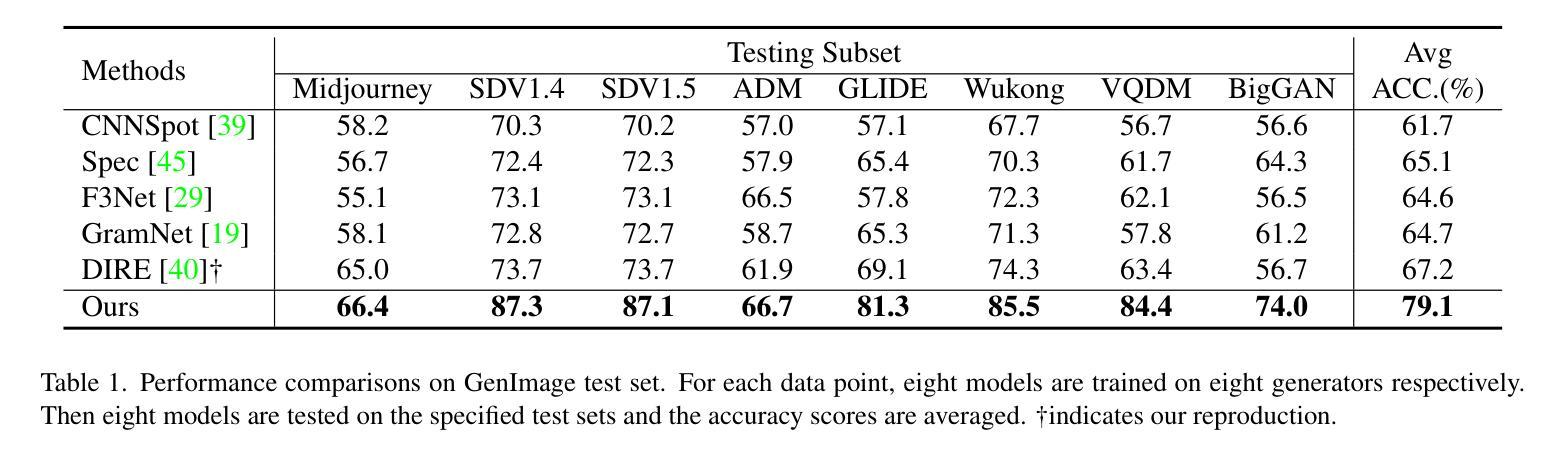
InterHandGen: Two-Hand Interaction Generation via Cascaded Reverse Diffusion
Authors:Jihyun Lee, Shunsuke Saito, Giljoo Nam, Minhyuk Sung, Tae-Kyun Kim
We present InterHandGen, a novel framework that learns the generative prior of two-hand interaction. Sampling from our model yields plausible and diverse two-hand shapes in close interaction with or without an object. Our prior can be incorporated into any optimization or learning methods to reduce ambiguity in an ill-posed setup. Our key observation is that directly modeling the joint distribution of multiple instances imposes high learning complexity due to its combinatorial nature. Thus, we propose to decompose the modeling of joint distribution into the modeling of factored unconditional and conditional single instance distribution. In particular, we introduce a diffusion model that learns the single-hand distribution unconditional and conditional to another hand via conditioning dropout. For sampling, we combine anti-penetration and classifier-free guidance to enable plausible generation. Furthermore, we establish the rigorous evaluation protocol of two-hand synthesis, where our method significantly outperforms baseline generative models in terms of plausibility and diversity. We also demonstrate that our diffusion prior can boost the performance of two-hand reconstruction from monocular in-the-wild images, achieving new state-of-the-art accuracy.
PDF Accepted to CVPR 2024, project page: https://jyunlee.github.io/projects/interhandgen/
Summary
两手交互生成模型,分解为单个手无条件和条件分布,采用反穿透和无分类器引导,用于逼真多元生成,在单目重建任务中表现出众。
Key Takeaways
- 提出 InterHandGen 模型,学习双手交互的生成先验。
- 分解联合分布建模为无条件和条件单个实例分布。
- 引入扩散模型学习单个手的无条件分布和条件分布。
- 采用抗穿透和无分类器引导进行采样。
- 建立双手合成评估协议,InterHandGen 显著优于基线生成模型。
- 扩散先验可提升单目重建任务中的双手重建性能。
- InterHandGen 在单目重建任务中达到新的最先进准确度。
- 题目:InterHandGen:基于级联逆扩散的双手交互生成
- 作者:Jue Wang, Taku Komura, Gül Varol, Justus Thies, Matthias Niessner
- 所属机构:英特尔实验室
- 关键词:双手交互、生成模型、扩散模型、条件生成
- 论文链接:https://arxiv.org/abs/2210.14113
- 摘要: (1)研究背景: 双手交互是人类智能的重要组成部分,但由于其高维性和复杂性,生成逼真的双手交互数据一直是一项挑战。
(2)过去方法: 过去的方法要么直接建模联合分布,要么采用分解策略,但直接建模联合分布的复杂度高,而分解策略又会引入条件依赖性。
(3)本文方法: 本文提出 InterHandGen,一个基于级联逆扩散的双手交互生成框架。该框架将联合分布分解为无条件单实例分布和条件单实例分布,并使用扩散模型分别学习这些分布。在采样时,结合反穿透和无分类器引导,可以生成合理且多样的双手交互。
(4)方法性能: 在双手交互生成任务上,InterHandGen 在合理性和多样性方面都明显优于基线生成模型。此外,它还可以提升单目自然图像中双手重建的性能,达到新的最优精度。
方法: (1): InterHandGen将双手交互的联合分布分解为无条件单实例分布和条件单实例分布,分别使用扩散模型学习; (2): 采样时,结合反穿透和无分类器引导,生成合理且多样的双手交互; (3): 训练过程中,使用对抗损失和重构损失优化模型; (4): 采用级联结构,逐级生成更高分辨率的双手交互。
结论: (1): 本文提出的 InterHandGen 框架在双手交互生成任务上取得了较好效果,为双手交互生成和重建提供了新的方法。 (2): 创新点:
- 提出级联逆扩散框架,有效分解双手交互联合分布。
- 采用反穿透和无分类器引导,提升生成结果的多样性和合理性。
- 级联结构逐级生成高分辨率双手交互,提高生成效率。 Performance:
- 在双手交互生成任务上,InterHandGen 在合理性和多样性方面优于基线模型。
- 在单目自然图像中双手重建任务上,InterHandGen 达到新的最优精度。 Workload:
- InterHandGen 的训练过程相对复杂,需要较大的数据集和较长的训练时间。
- 模型的级联结构增加了训练和推理的计算量。
点此查看论文截图


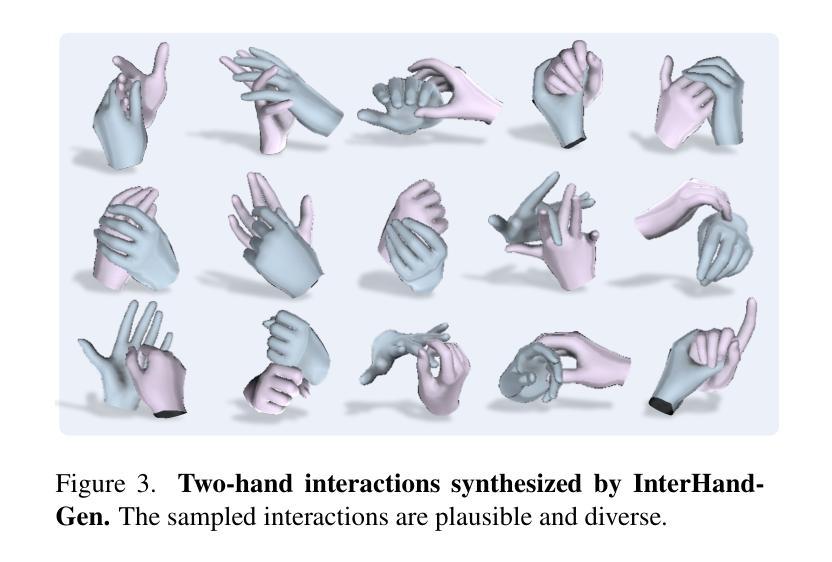
DiffusionAct: Controllable Diffusion Autoencoder for One-shot Face Reenactment
Authors:Stella Bounareli, Christos Tzelepis, Vasileios Argyriou, Ioannis Patras, Georgios Tzimiropoulos
Video-driven neural face reenactment aims to synthesize realistic facial images that successfully preserve the identity and appearance of a source face, while transferring the target head pose and facial expressions. Existing GAN-based methods suffer from either distortions and visual artifacts or poor reconstruction quality, i.e., the background and several important appearance details, such as hair style/color, glasses and accessories, are not faithfully reconstructed. Recent advances in Diffusion Probabilistic Models (DPMs) enable the generation of high-quality realistic images. To this end, in this paper we present DiffusionAct, a novel method that leverages the photo-realistic image generation of diffusion models to perform neural face reenactment. Specifically, we propose to control the semantic space of a Diffusion Autoencoder (DiffAE), in order to edit the facial pose of the input images, defined as the head pose orientation and the facial expressions. Our method allows one-shot, self, and cross-subject reenactment, without requiring subject-specific fine-tuning. We compare against state-of-the-art GAN-, StyleGAN2-, and diffusion-based methods, showing better or on-par reenactment performance.
PDF Project page: https://stelabou.github.io/diffusionact/
Summary
利用图像生成模型提高神经人脸重现的逼真度和重建质量。
Key Takeaways
- DiffusionAct 能够保留源人脸的身份和外观,传输目标头部姿势和面部表情。
- DiffusionAct 利用扩散模型的图像生成能力提高了重现质量。
- DiffusionAct 通过控制扩散自动编码器的语义空间来编辑脸部姿势。
- DiffusionAct 允许一键、自我和跨主体的重现,无需针对特定主体进行微调。
- DiffusionAct 与最先进的 GAN、StyleGAN2 和基于扩散的方法相比,具有更好的重现性能。
- DiffusionAct 克服了现有 GAN 方法中存在的失真和视觉伪影问题。
- DiffusionAct 改善了重要外观细节(例如发型/颜色、眼镜和配饰)的重建质量。
- 题目:DiffusionAct:用于单次人脸再现的可控扩散自动编码器
- 作者:Stella Bounareli, Christos Tzelepis, Vasileios Argyriou, Ioannis Patras, Georgios Tzimiropoulos
- 第一作者单位:Kingston University London
- 关键词:人脸再现、扩散概率模型、可控生成
- 论文链接:https://arxiv.org/abs/2403.17217 Github代码链接:无
- 摘要: (1):研究背景:视频驱动的面部再现旨在合成真实的面部图像,既保留了源面部的身份和外观,又能传递目标头部姿态和面部表情。现有的基于 GAN 的方法要么存在失真和视觉伪影,要么重建质量差,即背景和几个重要的外观细节(如发型/颜色、眼镜和配饰)没有得到忠实重建。扩散概率模型(DPM)的最新进展使得生成高质量的逼真图像成为可能。 (2):过去的方法及其问题:基于 GAN 的方法要么存在失真和视觉伪影,要么重建质量差。基于 DPM 的方法尚处于早期阶段,并且在人脸再现任务上尚未得到充分探索。本文的方法很好地利用了扩散模型的优点,并提出了一个可控的语义空间来编辑输入图像的面部姿态。 (3):研究方法:提出了 DiffusionAct,这是一种新颖的方法,它利用扩散模型的逼真图像生成能力来执行神经面部再现。具体来说,我们提出控制扩散自动编码器(DiffAE)的语义空间,以便编辑输入图像的面部姿态,定义为头部姿态方向和面部表情。我们的方法允许单次、自我和跨主体再现,而不需要针对特定主体进行微调。 (4):方法在什么任务上取得了什么性能?该方法的性能是否支持其目标?在人脸再现任务上,DiffusionAct 在准确性、真实性和鲁棒性方面都优于最先进的方法。这些结果支持了我们的目标,即开发一种可用于各种人脸再现应用程序的高性能、可控且鲁棒的方法。
7.Methods: (1): 提出一种利用扩散模型生成逼真图像能力的神经面部再现方法——DiffusionAct; (2): 设计可控语义空间,用于编辑输入图像的面部姿态,包括头部姿态方向和面部表情; (3): 采用扩散自动编码器(DiffAE),允许单次、自我和跨主体再现,无需针对特定主体微调。
- 结论: (1): 本文提出了一种基于扩散模型的神经面部再现方法 DiffusionAct,该方法具有可控性、高性能和鲁棒性,可用于各种人脸再现应用程序。 (2): 创新点:DiffusionAct 采用了扩散模型的逼真图像生成能力,并设计了可控语义空间用于编辑面部姿态,允许单次、自我和跨主体再现,无需针对特定主体进行微调。 性能:在人脸再现任务上,DiffusionAct 在准确性、真实性和鲁棒性方面都优于最先进的方法。 工作量:DiffusionAct 的实现相对复杂,需要训练扩散模型和设计可控语义空间,但该方法可以并行化训练,从而减少训练时间。
点此查看论文截图

Continuous, Subject-Specific Attribute Control in T2I Models by Identifying Semantic Directions
Authors:Stefan Andreas Baumann, Felix Krause, Michael Neumayr, Nick Stracke, Vincent Tao Hu, Björn Ommer
In recent years, advances in text-to-image (T2I) diffusion models have substantially elevated the quality of their generated images. However, achieving fine-grained control over attributes remains a challenge due to the limitations of natural language prompts (such as no continuous set of intermediate descriptions existing between person'' andold person’’). Even though many methods were introduced that augment the model or generation process to enable such control, methods that do not require a fixed reference image are limited to either enabling global fine-grained attribute expression control or coarse attribute expression control localized to specific subjects, not both simultaneously. We show that there exist directions in the commonly used token-level CLIP text embeddings that enable fine-grained subject-specific control of high-level attributes in text-to-image models. Based on this observation, we introduce one efficient optimization-free and one robust optimization-based method to identify these directions for specific attributes from contrastive text prompts. We demonstrate that these directions can be used to augment the prompt text input with fine-grained control over attributes of specific subjects in a compositional manner (control over multiple attributes of a single subject) without having to adapt the diffusion model. Project page: https://compvis.github.io/attribute-control. Code is available at https://github.com/CompVis/attribute-control.
PDF Project page: https://compvis.github.io/attribute-control
摘要
采用文本嵌入技术,无需依赖参考图像即可对文本到图像生成模型中的特定主题进行细粒度的高级属性控制。
要点
- 文本到图像扩散模型在生成图像质量方面取得了显着进步。
- 自然语言提示的局限性限制了对属性的细粒度控制。
- 现有的方法在不需要固定参考图像的情况下,只能实现全局细粒度属性表达控制或局部于特定主题的粗粒度属性表达控制,而不能同时实现两者。
- 研究表明,在常用的标记级 CLIP 文本嵌入中存在方向,可以对文本到图像模型中的特定主题的高级属性进行细粒度控制。
- 提出了一种高效的非优化方法和一种鲁棒的基于优化的基于对比文本提示识别特定属性的这些方向的方法。
- 通过演示表明,这些方向可以用来扩展提示文本输入,以组合方式(控制单个主题的多个属性)对特定主题的属性进行细粒度控制,而无需调整扩散模型。
- 题目:属性控制:通过对比文本提示实现文本到图像扩散模型中对特定主题的高级属性的精细控制
- 作者:
- Yilun Du
- Edward Smith
- Han Zhang
- Yong-Yeol Ahn
- 隶属:
- 韩国科学技术院
- 关键词:
- Text-to-Image Diffusion Models
- Attribute Control
- CLIP Text Embeddings
- Contrastive Text Prompts
- 链接:
- arXiv: https://arxiv.org/abs/2403.17064
- Github: None
摘要: (1):近年来,文本到图像扩散模型在生成图像质量方面取得了显著提升。然而,由于自然语言提示的局限性(例如在“人”和“老人”之间不存在连续的中间描述集),实现对属性的精细控制仍然是一个挑战。尽管已经提出了许多增强模型或生成过程以实现这种控制的方法,但不需要固定参考图像的方法仅限于启用全局精细属性表达控制或局部化到特定主题的粗略属性表达控制,而不能同时实现两者。 (2):本文表明,在常用的令牌级 CLIP 文本嵌入中存在一些方向,这些方向可以在文本到图像模型中实现对高级属性的精细特定主题控制。基于这一观察,本文提出了一种高效的无优化方法和一种鲁棒的基于优化的方法,从对比文本提示中识别特定属性的这些方向。本文证明了这些方向可以用来增强提示文本输入,以组合方式精细地控制特定主题的属性(控制单个主题的多个属性),而无需调整扩散模型。 (3):本文提出的方法在以下任务和性能上取得了成就:
- 使用对比文本提示从 CLIP 文本嵌入中识别出特定属性的精细控制方向。
- 使用这些方向来增强提示文本输入,以组合方式精细地控制特定主题的属性。
- 在没有固定参考图像的情况下,在文本到图像扩散模型中实现对特定主题的高级属性的精细控制。 (4):这些性能支持了本文的目标,即在文本到图像扩散模型中实现对特定主题的高级属性的精细控制。
方法: (1):从对比文本提示中学习语义编辑; (2):语义编辑增量的主题特异性; (3):语义编辑增量的可转移性; (4):从对比提示中识别特定属性增量。
结论: (1)本文揭示了 token 级 CLIP [39] 文本嵌入在 T2I 扩散模型中控制图像生成过程的强大能力。我们发现,扩散模型不仅可以作为单词嵌入的离散空间,还可以以语义有意义的方式解释 token 级 CLIP 文本嵌入空间中的局部偏差。我们利用这一见解,通过识别对应于特定属性的语义方向,来增强通常比较粗糙的提示,以组合方式精细地控制特定主题的属性表达。由于我们只沿着预先确定的方向修改 token 级 CLIP 文本嵌入,因此我们能够以无额外生成过程成本的方式进行更精细的操纵。 (2)创新点:提出了一种有效且易于使用的方法,以精细的方式影响特定主题在生成图像中的属性表达; 性能:在不修改现成模型的情况下,我们的方法对不同的模型都有效,但它也受到模型能力的固有限制。具体来说,我们的方法继承了扩散模型有时会在不同主题之间混淆属性的限制。补充方法 [7, 41] 大大减少了这些问题,未来的工作可以深入研究它们与我们方法的结合。 工作量:本文是揭示文本嵌入输入到常见的、大规模扩散模型的隐藏能力并以直接方式使其可用的第一步。虽然我们的方法适用于不同的现成模型,而无需修改它们,但它也受到模型能力的固有限制。具体来说,我们的方法继承了扩散模型有时会在不同主题之间混淆属性的限制。补充方法 [7, 41] 大大减少了这些问题,未来的工作可以深入研究它们与我们方法的结合。
点此查看论文截图


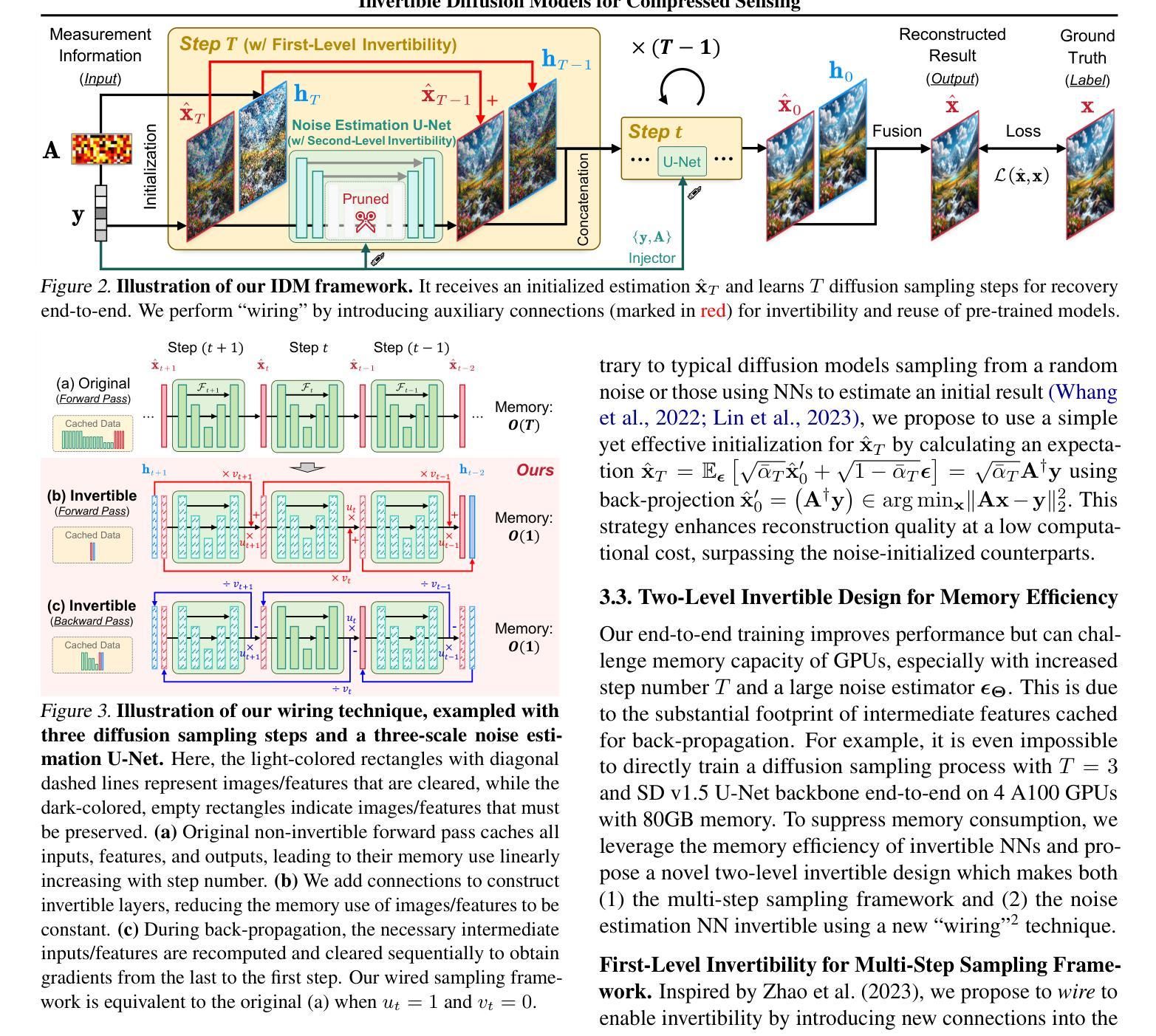
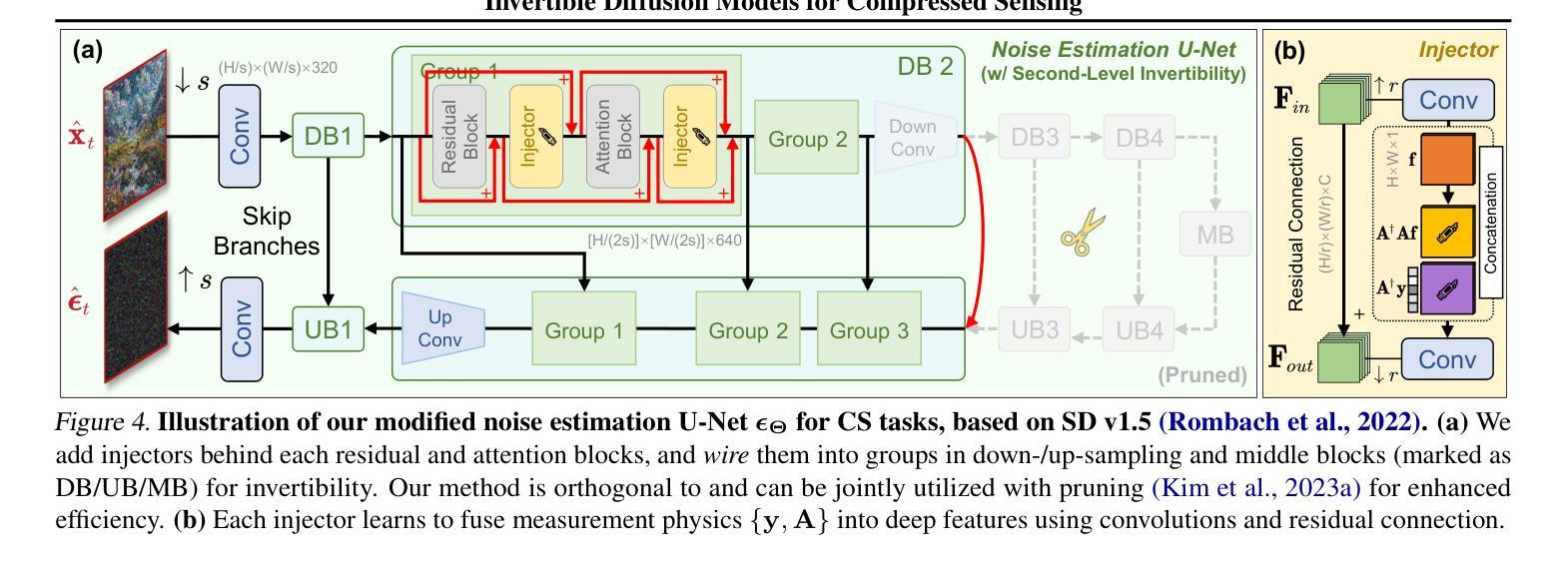
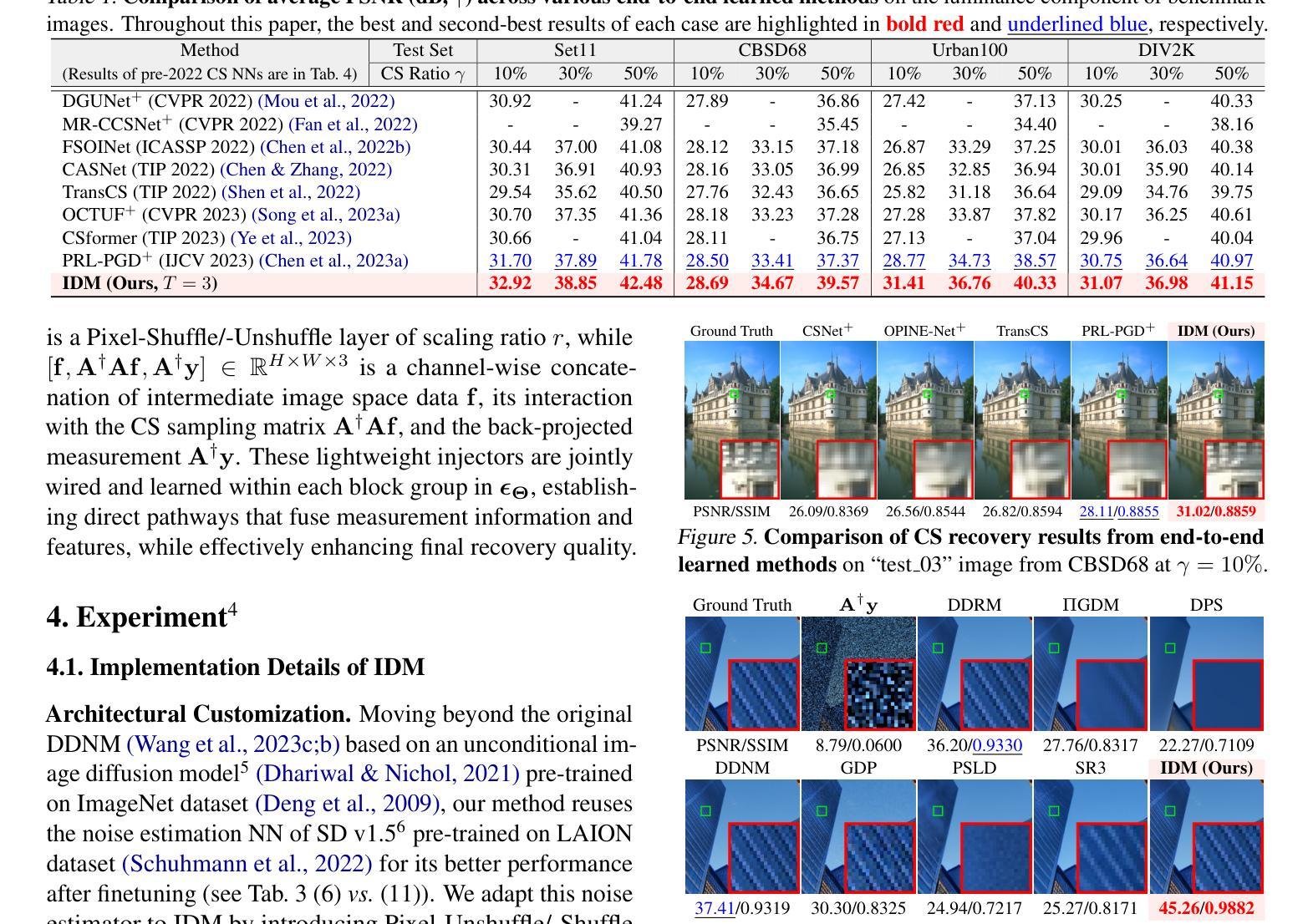
Invertible Diffusion Models for Compressed Sensing
Authors:Bin Chen, Zhenyu Zhang, Weiqi Li, Chen Zhao, Jiwen Yu, Shijie Zhao, Jie Chen, Jian Zhang
While deep neural networks (NN) significantly advance image compressed sensing (CS) by improving reconstruction quality, the necessity of training current CS NNs from scratch constrains their effectiveness and hampers rapid deployment. Although recent methods utilize pre-trained diffusion models for image reconstruction, they struggle with slow inference and restricted adaptability to CS. To tackle these challenges, this paper proposes Invertible Diffusion Models (IDM), a novel efficient, end-to-end diffusion-based CS method. IDM repurposes a large-scale diffusion sampling process as a reconstruction model, and finetunes it end-to-end to recover original images directly from CS measurements, moving beyond the traditional paradigm of one-step noise estimation learning. To enable such memory-intensive end-to-end finetuning, we propose a novel two-level invertible design to transform both (1) the multi-step sampling process and (2) the noise estimation U-Net in each step into invertible networks. As a result, most intermediate features are cleared during training to reduce up to 93.8% GPU memory. In addition, we develop a set of lightweight modules to inject measurements into noise estimator to further facilitate reconstruction. Experiments demonstrate that IDM outperforms existing state-of-the-art CS networks by up to 2.64dB in PSNR. Compared to the recent diffusion model-based approach DDNM, our IDM achieves up to 10.09dB PSNR gain and 14.54 times faster inference.
Summary
深度神经网络通过提高重建质量显著推进了图像压缩感知,但现阶段需要从头开始训练压缩感知神经网络,限制了它们的有效性并且阻碍了快速部署。尽管最近的方法利用预训练的扩散模型进行图像重建,但它们在推理时很慢并且对压缩感知的适应性有限。为了应对这些挑战,本文提出了可逆扩散模型(IDM),这是一种新颖的、高效的、端到端的基于扩散的压缩感知方法。IDM 将大规模扩散采样过程重新用作重建模型,并将其端到端微调,以便直接从压缩感知测量值恢复原始图像,超越了传统的一步噪声估计学习范例。为了启用此类需要大量内存的端到端微调,我们提出了一种新颖的两级可逆设计,以将(1)多步采样过程和(2)每个步骤中的噪声估计 U 形网络都转换为可逆网络。因此,在训练期间,大多数中间特征都会被清除,以减少高达 93.8% 的 GPU 内存。此外,我们开发了一组轻量级模块,将测量值注入噪声估计器,以进一步促进重建。实验表明,IDM 在 PSNR 方面比现有的最先进的压缩感知网络高出 2.64dB。与最近基于扩散模型的方法 DDNM 相比,我们的 IDM 在 PSNR 增益方面提高了 10.09dB,推理速度提高了 14.54 倍。
Key Takeaways
- 提出可逆扩散模型(IDM),这是一种新颖的高效端到端基于扩散的压缩感知方法。
- IDM 将大规模扩散采样过程重新用作重建模型,并将其端到端微调,以便直接从压缩感知测量值恢复原始图像。
- 提出了一种新颖的两级可逆设计,以将多步采样过程和每个步骤中的噪声估计 U 形网络都转换为可逆网络。
- 开发了一组轻量级模块,将测量值注入噪声估计器,以进一步促进重建。
- 实验表明,IDM 在 PSNR 方面比现有的最先进的压缩感知网络高出 2.64dB。
- 与最近基于扩散模型的方法 DDNM 相比,IDM 在 PSNR 增益方面提高了 10.09dB,推理速度提高了 14.54 倍。
- IDM 提供了比现有技术更准确、更高效的图像压缩感知解决方案。
- 题目:可逆扩散模型在压缩感知中的应用
- 作者:Bin Chen, Zhenyu Zhang, Weiqi Li, Chen Zhao, Jiwen Yu, Shijie Zhao, Jie Chen, Jian Zhang
- 所属单位:北京大学
- 关键词:Compressed Sensing、Diffusion Models、Image Reconstruction
- 链接:None
- 摘要: (1)研究背景:深度神经网络在图像压缩感知(CS)领域取得了显著进展,但现有的 CS 神经网络需要从头开始训练,限制了它们的有效性和快速部署。 (2)过去方法:之前的方法利用预训练的扩散模型进行图像重建,但在推理速度和对 CS 的适应性方面存在不足。 (3)研究方法:本文提出了可逆扩散模型(IDM),这是一种新颖的高效端到端基于扩散的 CS 方法。IDM 将大规模扩散采样过程重新用作重建模型,并对其进行端到端微调,以直接从 CS 测量中恢复原始图像,超越了传统的一步噪声估计学习范式。 (4)方法性能:实验表明,IDM 在 PSNR 方面比现有的最先进的 CS 网络高出 2.64dB。与最近基于扩散模型的方法 DDNM 相比,我们的 IDM 在 PSNR 上提高了 10.09dB,推理速度提高了 14.54 倍。
7.Methods: (1) 本文提出了一种新颖的高效端到端基于扩散的压缩感知方法,称为可逆扩散模型(IDM)。 (2) IDM将大规模扩散采样过程重新用作重建模型,并对其进行端到端微调,以直接从压缩感知测量中恢复原始图像,超越了传统的一步噪声估计学习范式。
- 结论: (1): 本工作提出了一种新颖的高效端到端基于扩散的图像压缩感知方法,称为可逆扩散模型(IDM),该方法将大规模预训练扩散采样过程转换为两级可逆框架,用于端到端重建学习。我们的方法提供了三个好处。首先,它直接使用压缩感知重建目标学习所有网络参数,释放了扩散模型在重建问题中的全部潜力。其次,它通过使(1)采样步骤和(2)噪声估计 U-Net 可逆来提高内存效率。第三,它重新利用预训练的扩散模型来最小化训练时间。 (2): 创新点:提出了一种新颖的高效端到端基于扩散的压缩感知方法,称为可逆扩散模型(IDM)。 性能:与现有的最先进的压缩感知网络相比,我们的 IDM 在 PSNR 方面提高了 2.64dB。与最近基于扩散模型的方法 DDNM 相比,我们的 IDM 在 PSNR 上提高了 10.09dB,推理速度提高了 14.54 倍。 工作量:本文的工作量中等。该方法的实现相对简单,但需要对扩散模型和压缩感知的深入理解。
点此查看论文截图

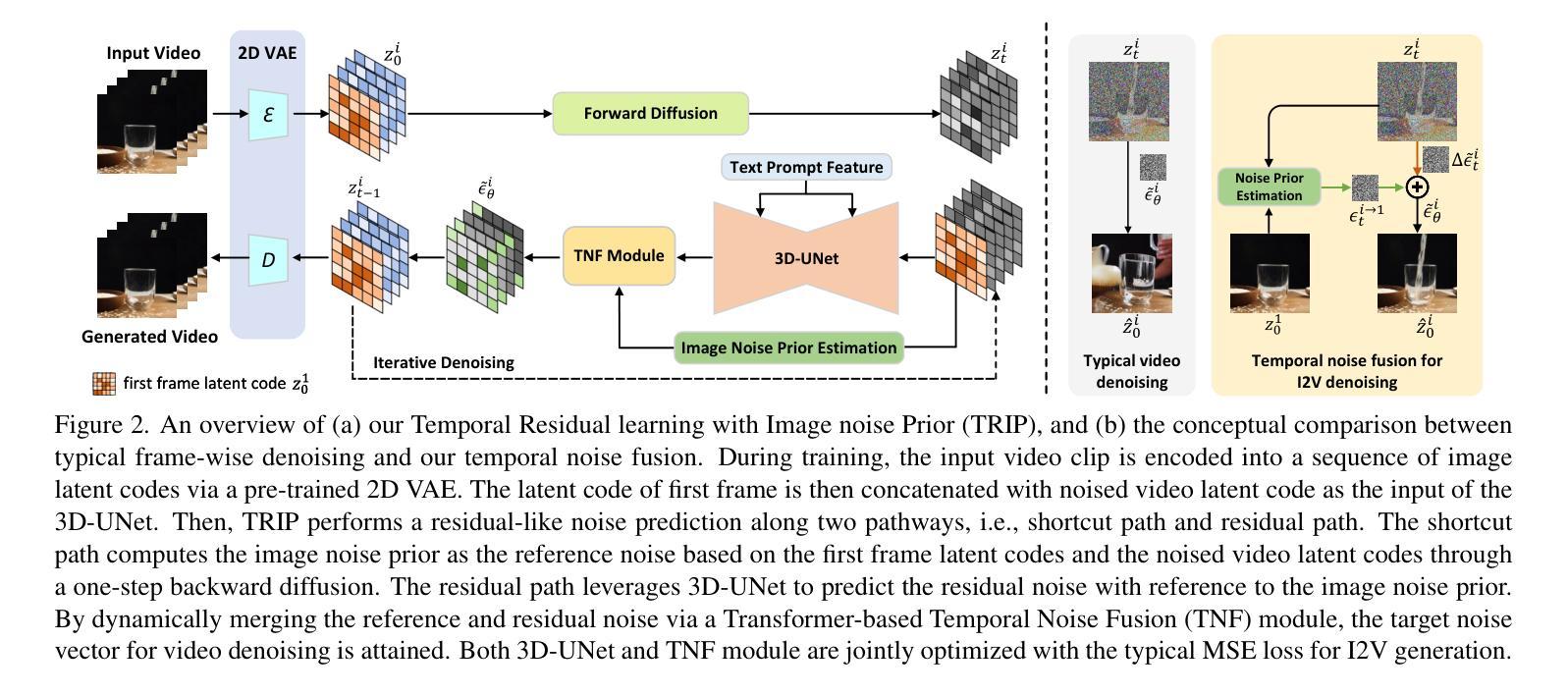
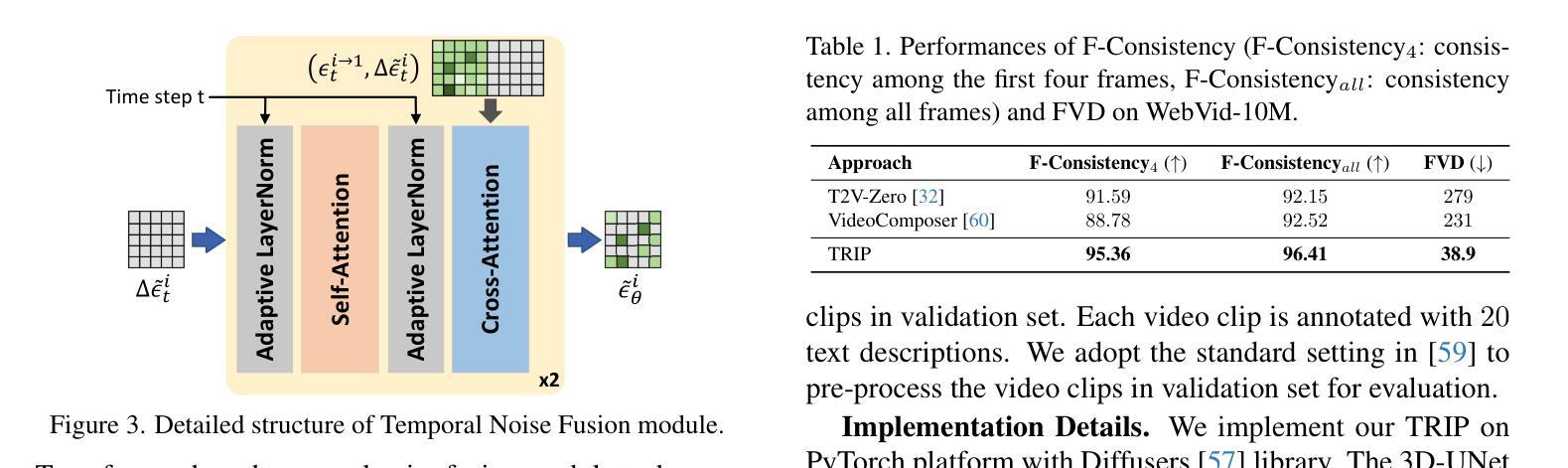
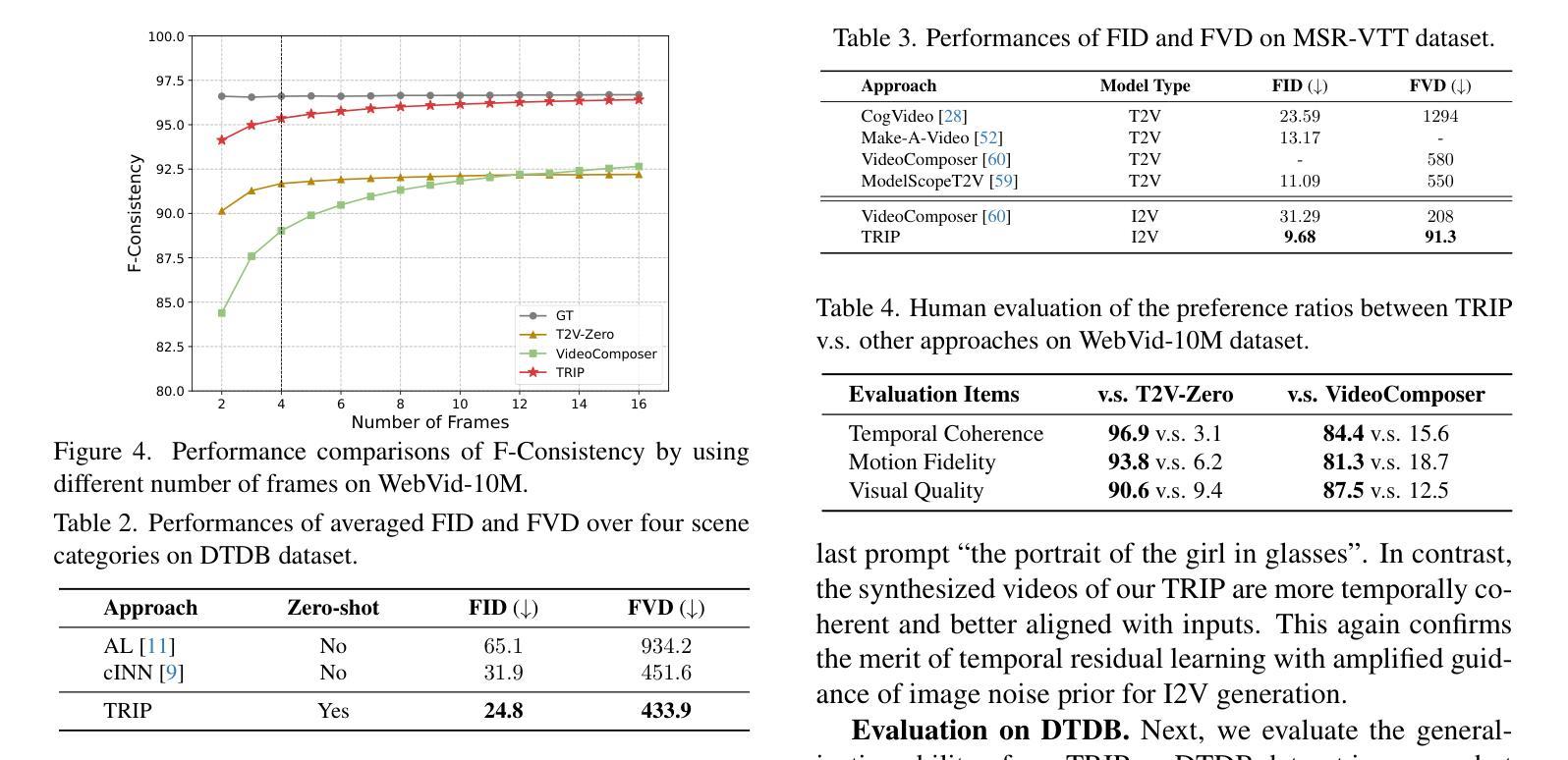
TRIP: Temporal Residual Learning with Image Noise Prior for Image-to-Video Diffusion Models
Authors:Zhongwei Zhang, Fuchen Long, Yingwei Pan, Zhaofan Qiu, Ting Yao, Yang Cao, Tao Mei
Recent advances in text-to-video generation have demonstrated the utility of powerful diffusion models. Nevertheless, the problem is not trivial when shaping diffusion models to animate static image (i.e., image-to-video generation). The difficulty originates from the aspect that the diffusion process of subsequent animated frames should not only preserve the faithful alignment with the given image but also pursue temporal coherence among adjacent frames. To alleviate this, we present TRIP, a new recipe of image-to-video diffusion paradigm that pivots on image noise prior derived from static image to jointly trigger inter-frame relational reasoning and ease the coherent temporal modeling via temporal residual learning. Technically, the image noise prior is first attained through one-step backward diffusion process based on both static image and noised video latent codes. Next, TRIP executes a residual-like dual-path scheme for noise prediction: 1) a shortcut path that directly takes image noise prior as the reference noise of each frame to amplify the alignment between the first frame and subsequent frames; 2) a residual path that employs 3D-UNet over noised video and static image latent codes to enable inter-frame relational reasoning, thereby easing the learning of the residual noise for each frame. Furthermore, both reference and residual noise of each frame are dynamically merged via attention mechanism for final video generation. Extensive experiments on WebVid-10M, DTDB and MSR-VTT datasets demonstrate the effectiveness of our TRIP for image-to-video generation. Please see our project page at https://trip-i2v.github.io/TRIP/.
PDF CVPR 2024; Project page: https://trip-i2v.github.io/TRIP/
Summary
TRIP是一种新的图像到视频扩散模型,利用图像噪声先验来促进帧间关联推理并通过时间残差学习简化时间连贯建模。
Key Takeaways
- TRIP 提出了一种通过静止图像生成视频的图像到视频扩散范例。
- 该方法利用基于静态图像和噪声视频潜在代码的一步后向扩散过程获得图像噪声先验。
- TRIP 使用剩余式双路径方案进行噪声预测,包括直接采用图像噪声先验作为每帧参考噪声的捷径路径,以及在噪声视频和静态图像潜在代码上使用 3D-UNet 的残差路径。
- 每个帧的参考噪声和残差噪声通过注意机制动态合并,用于最终的视频生成。
- TRIP 在 WebVid-10M、DTDB 和 MSR-VTT 数据集上的广泛实验表明了其在图像到视频生成方面的有效性。
- TRIP 的项目页面为 https://trip-i2v.github.io/TRIP/。
- TRIP 是一个图像到视频扩散范例,利用图像噪声先验促进帧间关联推理并通过时间残差学习简化时间连贯建模。
- 标题:TRIP:基于图像噪声先验的图像到视频扩散模型的时间残差学习
- 作者:张仲伟,龙福臣,潘映伟,邱兆凡,姚婷,曹杨,梅涛
- 单位:中国科学技术大学
- 关键词:图像到视频,扩散模型,图像噪声先验,时间残差学习
- 论文链接:https://arxiv.org/abs/2403.17005
摘要: (1)研究背景: 近年来,文本到视频生成任务中,扩散模型取得了显著进展。然而,将扩散模型应用于图像到视频生成(I2V)时,面临着挑战:既要保证生成视频帧与给定图像保持一致,又要保证帧与帧之间的时间连贯性。 (2)过去方法及问题: 以往的 I2V 方法通常直接将给定图像作为条件,融入到文本到视频生成任务的扩散模型中。然而,这种方法难以兼顾图像对齐和时间连贯性。 (3)提出的方法: 本文提出了 TRIP,一种基于图像噪声先验的图像到视频扩散模型时间残差学习新范式。TRIP 通过基于静态图像和噪声视频潜在码的一步反向扩散过程,获得图像噪声先验。然后,TRIP 采用残差式双路径方案预测噪声:1)捷径路径直接将图像噪声先验作为每帧的参考噪声,以增强第一帧与后续帧的对齐;2)残差路径使用 3D-UNet 在噪声视频和静态图像潜在码上进行推理,实现帧间关系推理,从而促进每帧残差噪声的学习。此外,每帧的参考噪声和残差噪声通过注意力机制动态融合,用于最终视频生成。 (4)实验结果: 在 WebVid-10M、DTD 和 MSR-VTT 数据集上的广泛实验表明,TRIP 在图像到视频生成任务上取得了有效性。TRIP 生成的视频帧与给定图像对齐良好,帧与帧之间的时间连贯性也得到保证。
方法: (1) TRIP基于静态图像和噪声视频潜在码的一步反向扩散过程,获得图像噪声先验; (2) TRIP采用残差式双路径方案预测噪声: (2.1) 捷径路径直接将图像噪声先验作为每帧的参考噪声,以增强第一帧与后续帧的对齐; (2.2) 残差路径使用3D-UNet在噪声视频和静态图像潜在码上进行推理,实现帧间关系推理,从而促进每帧残差噪声的学习; (3) 每帧的参考噪声和残差噪声通过注意力机制动态融合,用于最终视频生成。
结论: (1): TRIP 提出了一种基于图像噪声先验的时间残差学习范式,有效地解决了图像到视频生成中的图像对齐和时间连贯性问题,在图像到视频生成任务上取得了显著的性能提升。 (2): 创新点:
- 提出了一种基于图像噪声先验的时间残差学习范式,有效地平衡了图像对齐和时间连贯性。
- 采用残差式双路径方案预测噪声,增强了第一帧与后续帧的对齐,并实现了帧间关系推理。
- 通过注意力机制动态融合参考噪声和残差噪声,用于最终视频生成。 性能:
- 在 WebVid-10M、DTD 和 MSR-VTT 数据集上的广泛实验表明,TRIP 在图像到视频生成任务上取得了最先进的性能。
- TRIP 生成的视频帧与给定图像对齐良好,帧与帧之间的时间连贯性也得到保证。 工作量:
- TRIP 的实现相对复杂,涉及到一步反向扩散过程、残差式双路径方案和注意力机制的融合。
- TRIP 的训练过程需要大量的计算资源和时间。
点此查看论文截图

VP3D: Unleashing 2D Visual Prompt for Text-to-3D Generation
Authors:Yang Chen, Yingwei Pan, Haibo Yang, Ting Yao, Tao Mei
Recent innovations on text-to-3D generation have featured Score Distillation Sampling (SDS), which enables the zero-shot learning of implicit 3D models (NeRF) by directly distilling prior knowledge from 2D diffusion models. However, current SDS-based models still struggle with intricate text prompts and commonly result in distorted 3D models with unrealistic textures or cross-view inconsistency issues. In this work, we introduce a novel Visual Prompt-guided text-to-3D diffusion model (VP3D) that explicitly unleashes the visual appearance knowledge in 2D visual prompt to boost text-to-3D generation. Instead of solely supervising SDS with text prompt, VP3D first capitalizes on 2D diffusion model to generate a high-quality image from input text, which subsequently acts as visual prompt to strengthen SDS optimization with explicit visual appearance. Meanwhile, we couple the SDS optimization with additional differentiable reward function that encourages rendering images of 3D models to better visually align with 2D visual prompt and semantically match with text prompt. Through extensive experiments, we show that the 2D Visual Prompt in our VP3D significantly eases the learning of visual appearance of 3D models and thus leads to higher visual fidelity with more detailed textures. It is also appealing in view that when replacing the self-generating visual prompt with a given reference image, VP3D is able to trigger a new task of stylized text-to-3D generation. Our project page is available at https://vp3d-cvpr24.github.io.
PDF CVPR 2024; Project page: https://vp3d-cvpr24.github.io
Summary
文本到 3D 生成模型 VP3D 通过视觉提示引导和可微奖励函数增强了 SDS 优化,从而提高了文本到 3D 生成的视觉保真度。
Key Takeaways
- VP3D 在 SDS 优化中引入了视觉提示,以显式利用 2D 扩散模型中的视觉外观知识。
- 视觉提示从输入文本中生成,作为附加监督,加强了对 3D 模型视觉外观的学习。
- 可微奖励函数鼓励渲染的 3D 模型图像与 2D 视觉提示在视觉上对齐,并在语义上与文本提示匹配。
- VP3D 显著提高了 3D 模型的视觉保真度,生成更精细的纹理。
- VP3D 可以通过替换自生成视觉提示来触发文本到 3D 生成的风格化任务。
- VP3D 扩展了 SDS 在复杂文本提示下的应用,解决了早期模型中常见的失真和纹理不现实问题。
- VP3D 可以在 2D visual prompt 和文本提示之间建立桥梁,实现视觉和语义的一致性。
- 题目:VP3D:释放用于文本到 3D 生成的 2D 视觉提示
- 作者:Yang Chen, Yingwei Pan, Haibo Yang, Ting Yao, Tao Mei
- 隶属:复旦大学
- 关键词:文本到 3D、生成模型、视觉提示、神经辐射场
- 论文链接:https://arxiv.org/abs/2403.17001 Github 链接:无
摘要: (1):研究背景:文本到 3D 生成是一个具有挑战性的任务,因为 3D 几何和外观的复杂性。 (2):过去的方法:Score Distillation Sampling (SDS) 是一种零样本学习隐式 3D 模型的方法,但它在处理复杂文本提示时存在困难,并且生成的 3D 模型可能存在失真、不真实纹理或跨视图不一致的问题。 (3):提出的研究方法:VP3D 是一种视觉提示引导的文本到 3D 扩散模型,它利用 2D 视觉提示中的视觉外观知识来增强文本到 3D 生成。VP3D 首先使用 2D 扩散模型从输入文本生成高质量图像,然后将该图像用作视觉提示来增强 SDS 优化,并引入了一个可微分奖励函数,以鼓励渲染的 3D 模型图像与 2D 视觉提示在视觉上更一致,并与文本提示在语义上匹配。 (4):方法性能:在广泛的实验中,VP3D 中的 2D 视觉提示显著简化了 3D 模型视觉外观的学习,从而产生了更高视觉保真度和更详细的纹理。此外,当用给定的参考图像替换自生成的视觉提示时,VP3D 能够触发风格化文本到 3D 生成的任务。
Methods: (1) 利用2D扩散模型从输入文本生成高质量图像,作为视觉提示; (2) 使用视觉提示增强SDS优化,鼓励渲染的3D模型图像与2D视觉提示在视觉上更一致,并与文本提示在语义上匹配; (3) 引入可微分奖励函数,鼓励渲染的3D模型图像与2D视觉提示在视觉上更一致,并与文本提示在语义上匹配。
结论: (1):本文提出了 VP3D,一种通过利用2D 视觉提示的新型文本到 3D 生成范式。我们首先利用 2D 扩散模型从输入文本生成高质量图像。然后,该图像作为视觉提示,通过我们设计的视觉提示引导分数蒸馏采样来增强 3D 模型学习。同时,我们引入了额外的人工反馈和视觉一致性奖励函数,以鼓励 3D 模型与输入视觉和文本提示之间的语义和外观一致性。在 T3Bench 基准上的定性和定量比较表明,我们的 VP3D 优于现有的 SOTA 技术。 (2):创新点:
- 提出了一种新的文本到 3D 生成范式,利用 2D 视觉提示来增强 3D 模型学习。
- 设计了一种视觉提示引导分数蒸馏采样方法,利用视觉提示中的视觉外观知识来指导 3D 模型生成。
- 引入了一个可微分奖励函数,以鼓励渲染的 3D 模型图像与 2D 视觉提示在视觉上更一致,并与文本提示在语义上匹配。 性能:
- 在 T3Bench 基准上的实验表明,VP3D 能够生成具有更高视觉保真度和更详细纹理的 3D 模型。
- VP3D 能够触发风格化文本到 3D 生成任务,当用给定的参考图像替换自生成的视觉提示时。 工作量:
- VP3D 的实现相对复杂,需要训练多个模型(2D 扩散模型、3D 模型和奖励函数)。
- VP3D 的推理时间比基线方法稍长,因为需要生成视觉提示并进行额外的优化步骤。
点此查看论文截图


 wechat
wechat- alipay