NeRF
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-03-28 更新
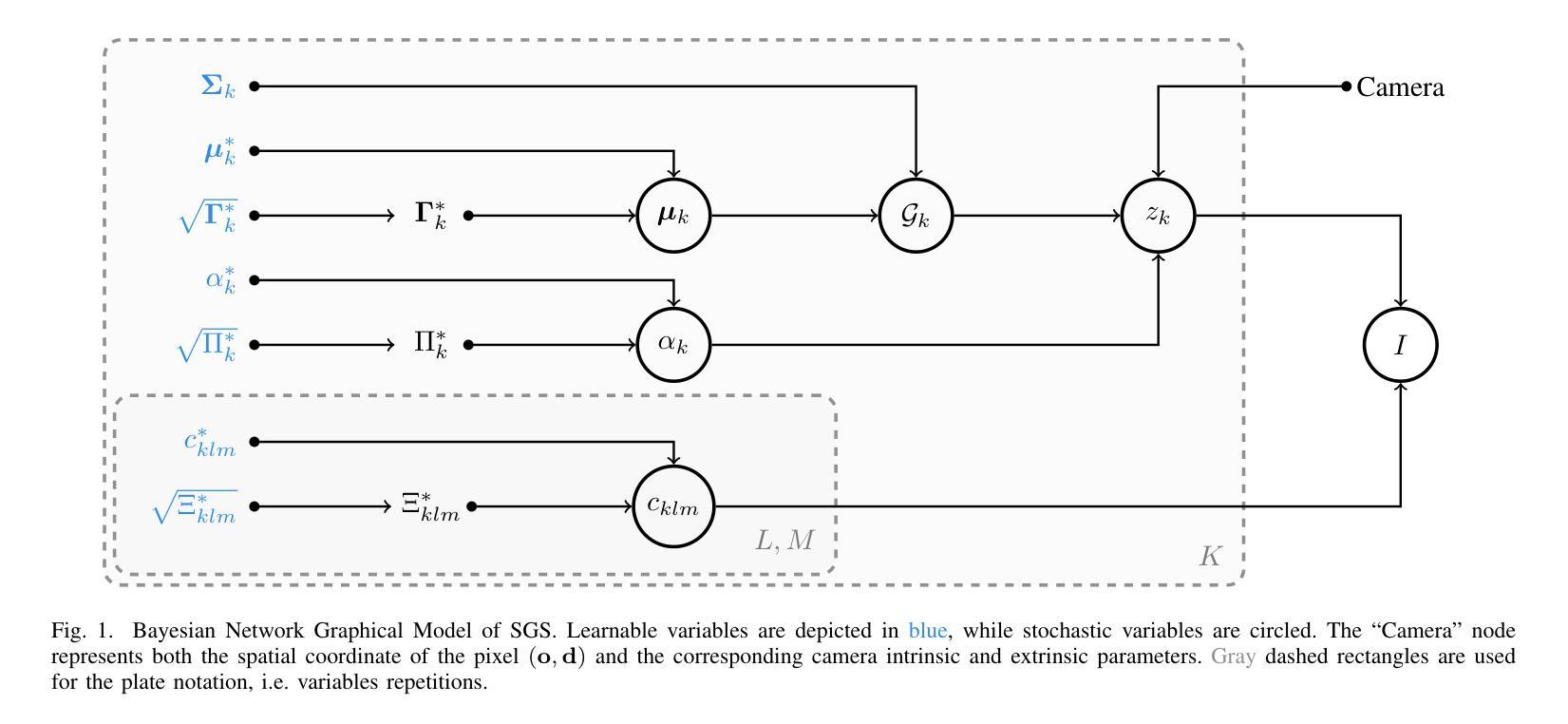
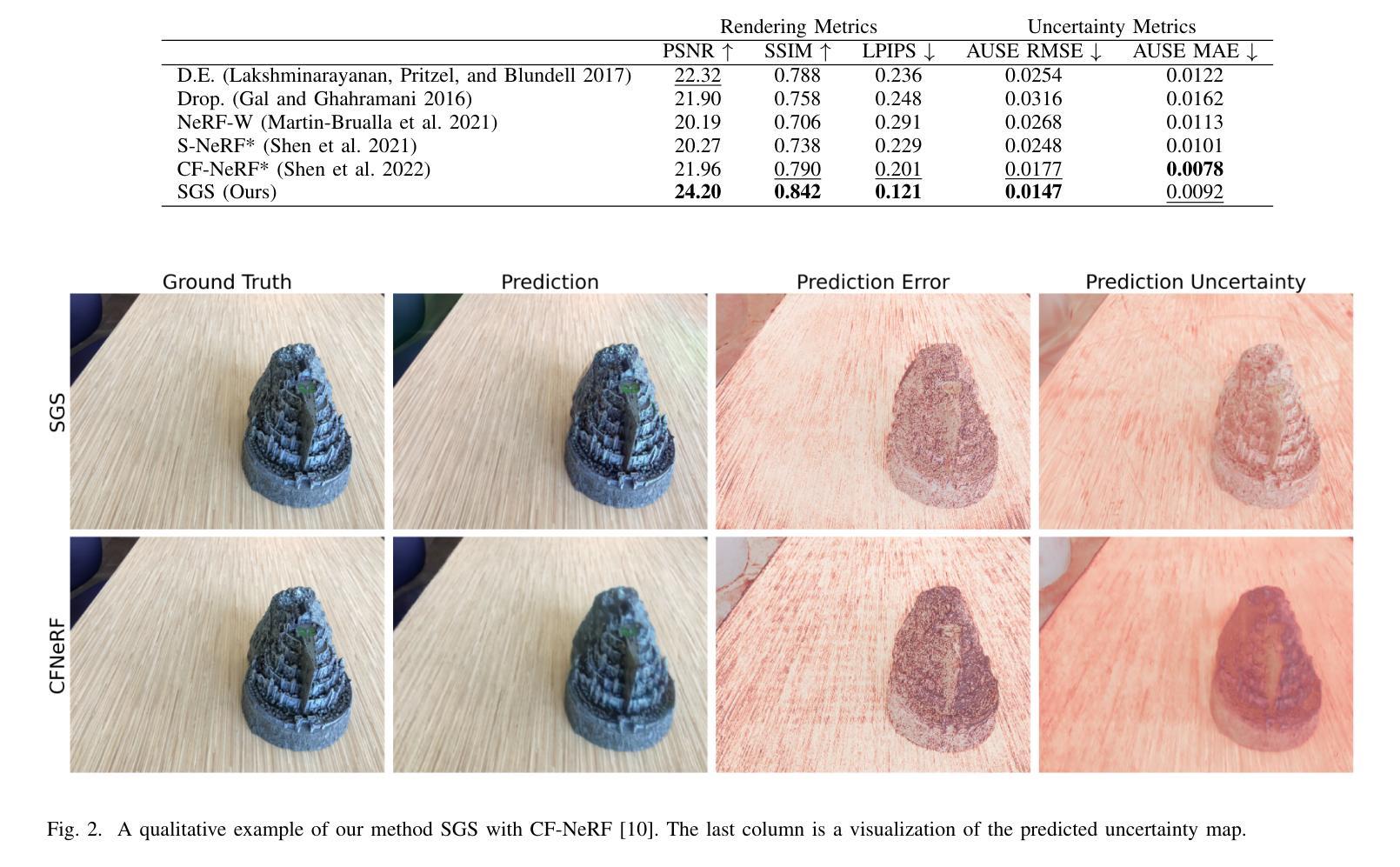
Modeling uncertainty for Gaussian Splatting
Authors:Luca Savant, Diego Valsesia, Enrico Magli
We present Stochastic Gaussian Splatting (SGS): the first framework for uncertainty estimation using Gaussian Splatting (GS). GS recently advanced the novel-view synthesis field by achieving impressive reconstruction quality at a fraction of the computational cost of Neural Radiance Fields (NeRF). However, contrary to the latter, it still lacks the ability to provide information about the confidence associated with their outputs. To address this limitation, in this paper, we introduce a Variational Inference-based approach that seamlessly integrates uncertainty prediction into the common rendering pipeline of GS. Additionally, we introduce the Area Under Sparsification Error (AUSE) as a new term in the loss function, enabling optimization of uncertainty estimation alongside image reconstruction. Experimental results on the LLFF dataset demonstrate that our method outperforms existing approaches in terms of both image rendering quality and uncertainty estimation accuracy. Overall, our framework equips practitioners with valuable insights into the reliability of synthesized views, facilitating safer decision-making in real-world applications.
Summary
高斯散点算法下的变分推理,无缝结合不确定性预测,通过优化新提出的损失函数项 AUSE,提升图像重建和不确定性估计的准确性。
Key Takeaways
- SGS 是第一个用于高斯散点法不确定性估计的框架。
- SGS 显著降低了神经辐射场的计算成本,但以前缺乏提供置信度信息的能力。
- SGS 在高斯散点法常见的渲染管道中无缝集成了不确定性预测。
- 引入了面积下稀疏化误差 (AUSE) 作为损失函数中的新项。
- AUSE 优化了不确定性估计和图像重建。
- SGS 在 LLFF 数据集上的实验结果表明,其在图像渲染质量和不确定性估计准确度方面都优于现有方法。
- SGS 框架为从业者提供了合成视图可靠性的宝贵见解,有助于在实际应用中做出更安全的决策。
- 题目:高斯溅射的不确定性建模
- 作者:Luca Savant, Diego Valsesia, Enrico Magli
- 单位:意大利都灵理工大学电子与电信系
- 关键词:高斯溅射、不确定性估计、新视角合成
- 链接:https://arxiv.org/abs/2403.18476
摘要: (1)近年来,基于神经辐射场的 novel-view synthesis 技术取得了重大进展,但其计算复杂度和内存需求限制了其在实时应用中的实用性。 (2)高斯溅射(GS)技术作为一种更具计算效率的替代方案,在保持高质量 novel-view synthesis 的同时降低了计算成本。然而,GS 缺乏估计合成视图中置信度的能力。 (3)本文提出了一个用于 GS 中不确定性估计的新框架,称为 Stochastic Gaussian Splatting(SGS)。SGS 扩展了传统的确定性 GS 框架,允许预测不确定性和合成视图。 (4)实验结果表明,SGS 在图像渲染质量和不确定性估计准确性方面均优于现有方法,为从业者提供了合成视图可靠性的宝贵见解,从而促进了在实际应用中更安全的决策制定。
方法: (1):本文提出了一个新的框架,称为随机高斯溅射(SGS),用于在高斯溅射框架中实现不确定性量化。 (2):SGS扩展了传统的确定性高斯溅射框架,允许预测不确定性和合成视图。 (3):SGS使用蒙特卡罗方法近似像素颜色的方差,并使用变分推理框架进行学习。 (4):SGS假设高斯核之间独立,并使用面积下错误稀疏化(AUSE)度量来评估不确定性估计的准确性。
结论: (1): 本工作的主要意义在于,它提出了一个用于高斯溅射框架的不确定性量化的新框架,该框架可以预测不确定性和合成视图,从而为从业者提供了合成视图可靠性的宝贵见解,促进了实际应用中更安全的决策制定。 (2): 创新点:
- 提出了一种新的框架,称为随机高斯溅射(SGS),用于在高斯溅射框架中实现不确定性量化。
- SGS扩展了传统的确定性高斯溅射框架,允许预测不确定性和合成视图。
- SGS使用蒙特卡罗方法近似像素颜色的方差,并使用变分推理框架进行学习。
- SGS假设高斯核之间独立,并使用面积下错误稀疏化(AUSE)度量来评估不确定性估计的准确性。 性能:
- SGS在图像渲染质量和不确定性估计准确性方面均优于现有方法。
- SGS为从业者提供了合成视图可靠性的宝贵见解。 工作量:
- SGS的计算成本和内存需求低于神经辐射场方法。
- SGS可以在实时应用中使用。
点此查看论文截图


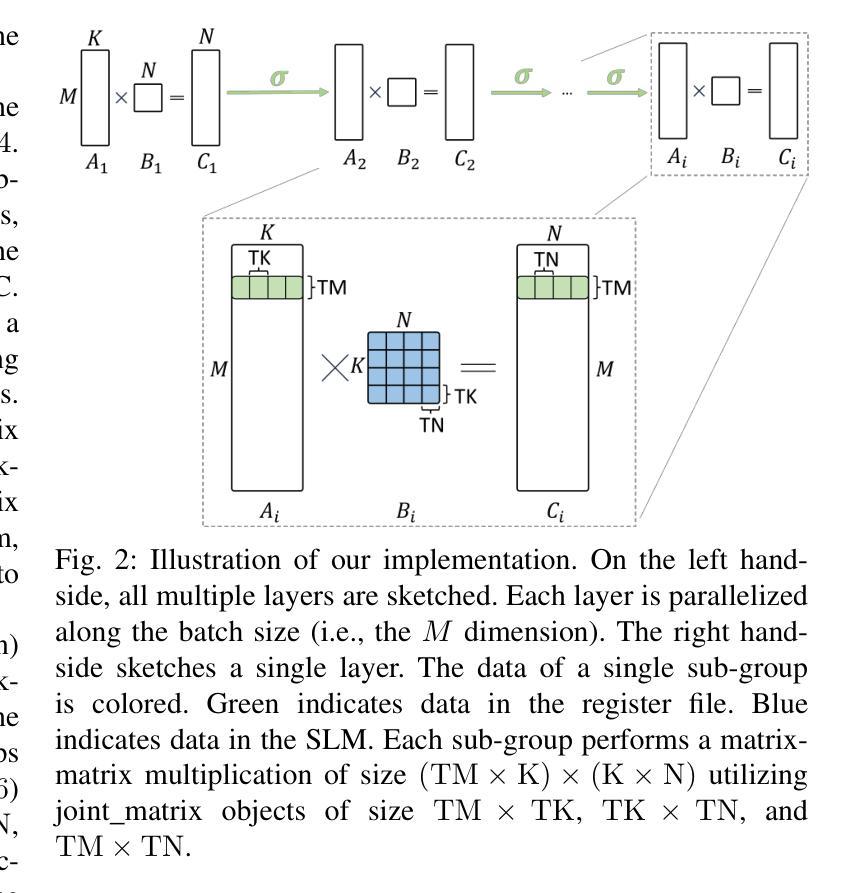
Fully-fused Multi-Layer Perceptrons on Intel Data Center GPUs
Authors:Kai Yuan, Christoph Bauinger, Xiangyi Zhang, Pascal Baehr, Matthias Kirchhart, Darius Dabert, Adrien Tousnakhoff, Pierre Boudier, Michael Paulitsch
This paper presents a SYCL implementation of Multi-Layer Perceptrons (MLPs), which targets and is optimized for the Intel Data Center GPU Max 1550. To increase the performance, our implementation minimizes the slow global memory accesses by maximizing the data reuse within the general register file and the shared local memory by fusing the operations in each layer of the MLP. We show with a simple roofline model that this results in a significant increase in the arithmetic intensity, leading to improved performance, especially for inference. We compare our approach to a similar CUDA implementation for MLPs and show that our implementation on the Intel Data Center GPU outperforms the CUDA implementation on Nvidia’s H100 GPU by a factor up to 2.84 in inference and 1.75 in training. The paper also showcases the efficiency of our SYCL implementation in three significant areas: Image Compression, Neural Radiance Fields, and Physics-Informed Machine Learning. In all cases, our implementation outperforms the off-the-shelf Intel Extension for PyTorch (IPEX) implementation on the same Intel GPU by up to a factor of 30 and the CUDA PyTorch version on Nvidia’s H100 GPU by up to a factor 19. The code can be found at https://github.com/intel/tiny-dpcpp-nn.
Summary
SYCL 实现的多层感知器针对英特尔数据中心 GPU Max 1550 进行优化,其性能比 CUDA 更好。
Key Takeaways
- SYCL 实现的 MLP 减少了慢的全局内存访问,最大化了寄存器文件和共享局部内存中的数据重用。
- 融合每一层 MLP 中的操作,可以显著提高算术强度,从而提升性能,尤其是在推理中。
- 在英特尔数据中心 GPU 上,SYCL 实现的 MLP 在推理时比英伟达 H100 GPU 上的 CUDA 实现快 2.84 倍,在训练时快 1.75 倍。
- SYCL 实现展示了在图像压缩、神经辐射场和物理信息机器学习方面的效率。
- SYCL 实现比英特尔 PyTorch 扩展 (IPEX) 在同一英特尔 GPU 上的性能高出 30 倍,比英伟达 H100 GPU 上的 CUDA PyTorch 高出 19 倍。
- 代码可在 https://github.com/intel/tiny-dpcpp-nn 找到。
- 题目:英特尔数据中心 GPU 上的全融合多层感知器
- 作者:Kai Yuan†、Christoph Bauinger†、Xiangyi Zhang†、Pascal Baehr†、Matthias Kirchhart†、Darius Dabert‡、Adrien Tousnakhoff‡、Pierre Boudier† 和 Michael Paulitsch†
- 第一作者单位:英特尔公司
- 关键词:机器学习、性能优化、SYCL、英特尔数据中心 GPU Max1550
- 论文链接:https://arxiv.org/abs/2305.01723 Github 代码链接:https://github.com/intel/tiny-dpcpp-nn
- 摘要: (1):研究背景:多层感知器 (MLP) 在机器学习和人工智能领域发挥着至关重要的作用,但其性能受到低算术强度和内存带宽的限制。 (2):过去方法及问题:经典的 MLP 实现方法将每层操作放在单独的计算内核中,导致频繁的全局内存访问,降低了性能。全融合 MLP 策略通过融合层来减少全局内存访问,但现有实现仅针对 Nvidia GPU。 (3):研究方法:本文提出了一种针对英特尔 GPU 的全融合 MLP SYCL 实现,利用 XMX 硬件和联合矩阵 SYCL 扩展来最大化数据重用和算术强度。 (4):任务和性能:该方法在图像压缩、神经辐射场和物理信息机器学习等任务上实现了卓越的性能,比英特尔 PyTorch 扩展 (IPEX) 和 Nvidia H100 GPU 上的 CUDA PyTorch 版本分别快 30 倍和 19 倍。这些性能提升支持了该方法在提高 MLP 训练和推理性能方面的目标。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1): 本研究提出了针对英特尔 GPU 的全融合 MLP SYCL 实现,通过利用 XMX 硬件和联合矩阵 SYCL 扩展,最大化了数据重用和算术强度,在图像压缩、神经辐射场和物理信息机器学习等任务上实现了卓越的性能,为提高 MLP 训练和推理性能提供了支持。 (2): 创新点:
- 针对英特尔 GPU 的全融合 MLP SYCL 实现,利用 XMX 硬件和联合矩阵 SYCL 扩展,最大化了数据重用和算术强度。
- 提出了一种新的数据布局和计算内核,减少了全局内存访问,提高了性能。
- 提供了易于使用的 API,简化了全融合 MLP 的开发和部署。
- 在图像压缩、神经辐射场和物理信息机器学习等任务上实现了卓越的性能。 性能:
- 比英特尔 PyTorch 扩展 (IPEX) 快 30 倍。
- 比 Nvidia H100 GPU 上的 CUDA PyTorch 版本快 19 倍。
- 在各种任务和模型大小上都实现了卓越的性能。 工作负载:
- 图像压缩。
- 神经辐射场。
- 物理信息机器学习。
点此查看论文截图



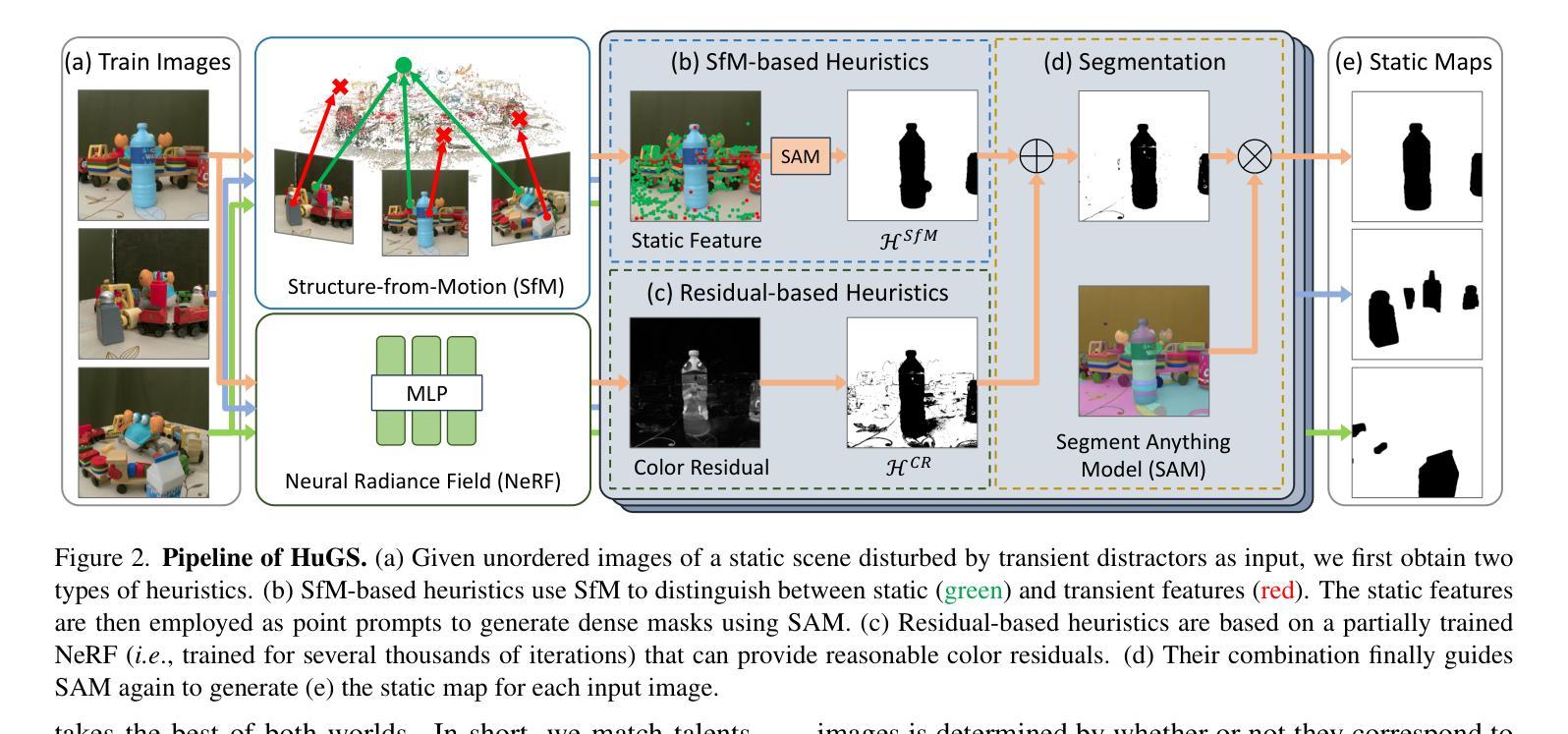
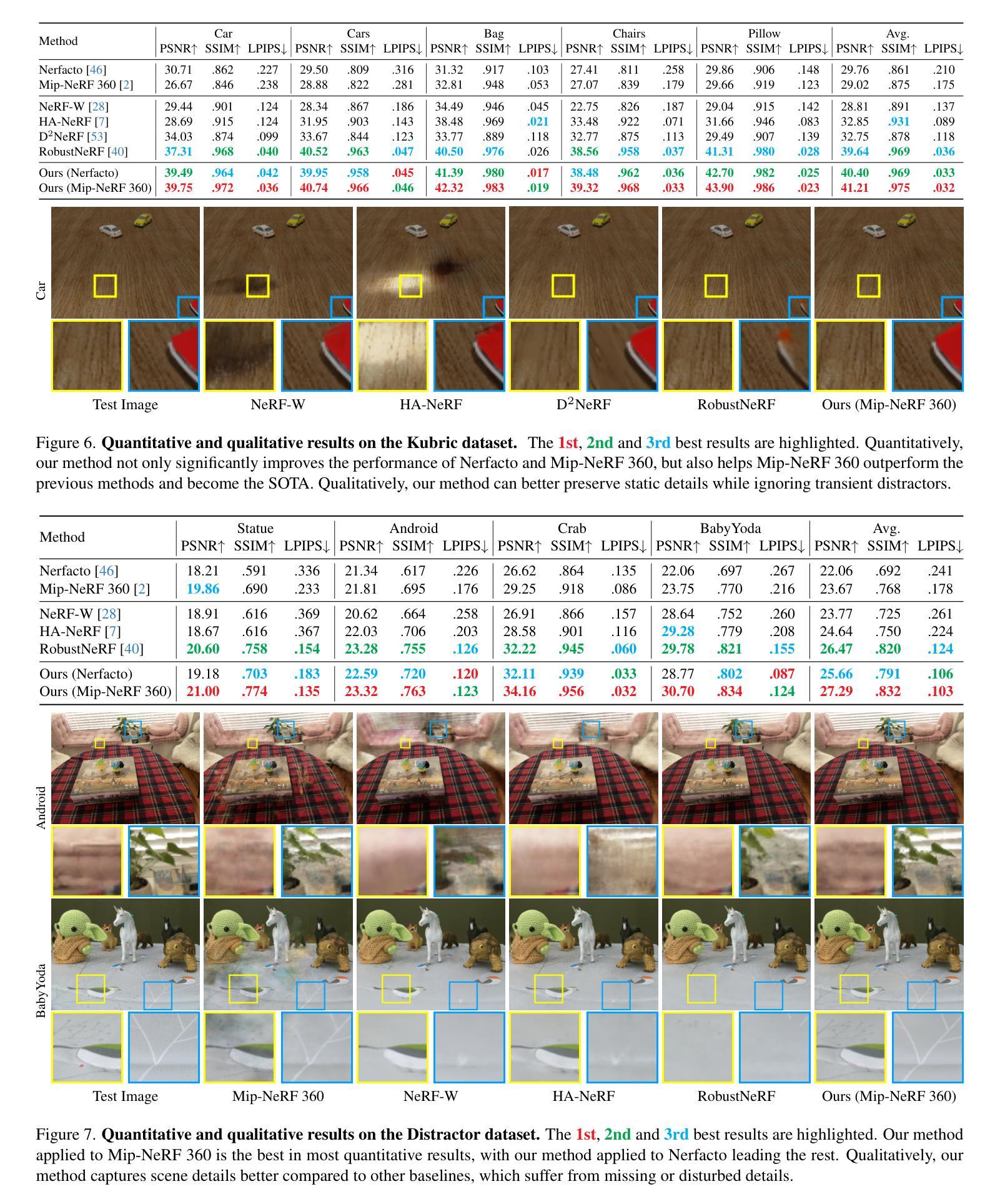
NeRF-HuGS: Improved Neural Radiance Fields in Non-static Scenes Using Heuristics-Guided Segmentation
Authors:Jiahao Chen, Yipeng Qin, Lingjie Liu, Jiangbo Lu, Guanbin Li
Neural Radiance Field (NeRF) has been widely recognized for its excellence in novel view synthesis and 3D scene reconstruction. However, their effectiveness is inherently tied to the assumption of static scenes, rendering them susceptible to undesirable artifacts when confronted with transient distractors such as moving objects or shadows. In this work, we propose a novel paradigm, namely “Heuristics-Guided Segmentation” (HuGS), which significantly enhances the separation of static scenes from transient distractors by harmoniously combining the strengths of hand-crafted heuristics and state-of-the-art segmentation models, thus significantly transcending the limitations of previous solutions. Furthermore, we delve into the meticulous design of heuristics, introducing a seamless fusion of Structure-from-Motion (SfM)-based heuristics and color residual heuristics, catering to a diverse range of texture profiles. Extensive experiments demonstrate the superiority and robustness of our method in mitigating transient distractors for NeRFs trained in non-static scenes. Project page: https://cnhaox.github.io/NeRF-HuGS/.
PDF To appear in CVPR2024
Summary
HuGS巧妙结合人工启发和分割模型,突破NeRF静态场景限制,有效消除动态干扰。
Key Takeaways
- 提出”启发式引导分割”(HuGS)范式,分离静态场景和动态干扰。
- 融合SfM启发和颜色残差启发,适应纹理多样性。
- HuGS 在非静态场景中训练的 NeRF 中有效减轻动态干扰。
- 实验表明 HuGS 的优越性和鲁棒性。
- HuGS 使用人工启发和分割模型的优势,显著超越现有解决方案。
- HuGS 适用于具有不同纹理特征的场景。
- HuGS 在非静态场景中显着改善了 NeRF 的性能。
- 标题:NeRF-HuGS:改进非静态场景中的神经辐射场
- 作者:Hao Chen, Yuxuan Zhang, Kangxue Yin, Li Yi, Jiajun Wu
- 隶属:清华大学
- 关键词:NeRF,非静态场景,运动物体,阴影,图像分割
- 论文链接:https://arxiv.org/abs/2302.08268,Github 链接:无
- 摘要: (1) 研究背景:神经辐射场 (NeRF) 在新视角合成和 3D 场景重建方面表现出色,但其有效性依赖于静态场景的假设,在遇到运动物体或阴影等瞬态干扰时容易产生不良伪影。 (2) 过去的方法:现有方法通过运动估计、时间一致性或运动补偿来处理瞬态干扰,但效果有限,难以有效分离静态场景和瞬态干扰。 (3) 本文方法:提出了一种新的范例“启发式引导分割”(HuGS),将手工启发式与最先进的分割模型相结合,显著增强了从瞬态干扰中分离静态场景的能力。具体来说,HuGS 融合了基于结构从运动 (SfM) 的启发式和颜色残差启发式,适用于各种纹理特征。 (4) 实验结果:在非静态场景中训练的 NeRF 中,HuGS 在减轻瞬态干扰方面表现出优越性和鲁棒性。在 Kubric 数据集上,HuGS 在 PSNR 和 SSIM 指标上分别提高了 0.53 和 0.03,在 LPIPS 指标上降低了 0.04。在 Distractor 数据集上,HuGS 在 PSNR 和 SSIM 指标上分别提高了 0.46 和 0.02,在 LPIPS 指标上降低了 0.03。这些性能提升支持了 HuGS 增强 NeRF 在非静态场景中表现的目标。
7.方法: (1) 提出启发式引导分割(HuGS)范例,将手工启发式与最先进的分割模型相结合,增强从瞬态干扰中分离静态场景的能力。 (2) 融合基于结构从运动(SfM)的启发式和颜色残差启发式,适用于各种纹理特征。 (3) 将HuGS应用于非静态场景中训练的NeRF中,减轻瞬态干扰,提高PSNR、SSIM、LPIPS指标。
- 结论: (1):本文提出了一种新的范例“启发式引导分割”(HuGS),将手工启发式与最先进的分割模型相结合,显著增强了从瞬态干扰中分离静态场景的能力。在非静态场景中训练的NeRF中,HuGS在减轻瞬态干扰方面表现出优越性和鲁棒性。 (2):创新点:提出HuGS范例,融合基于SfM和颜色残差的启发式,适用于各种纹理特征。 性能:在Kubric和Distractor数据集上,HuGS分别在PSNR、SSIM、LPIPS指标上取得了显著提升。 工作量:HuGS的实现相对简单,可以轻松集成到现有的NeRF训练框架中。
点此查看论文截图



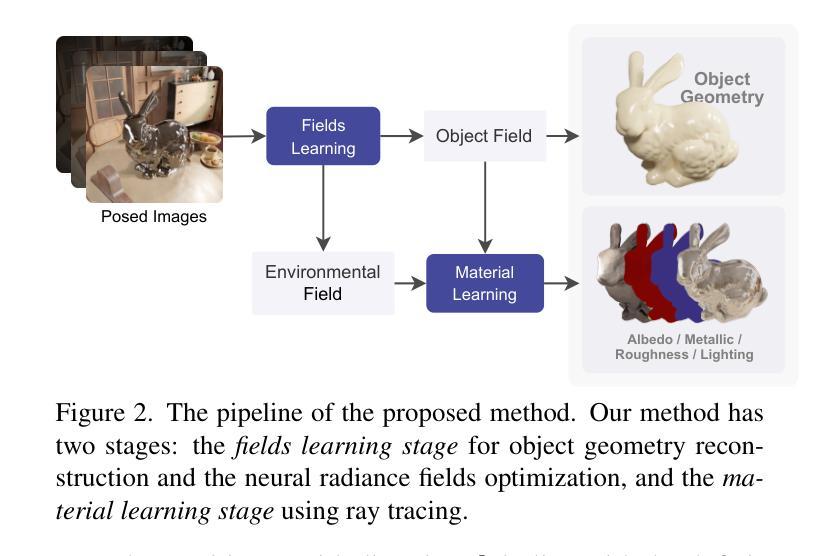
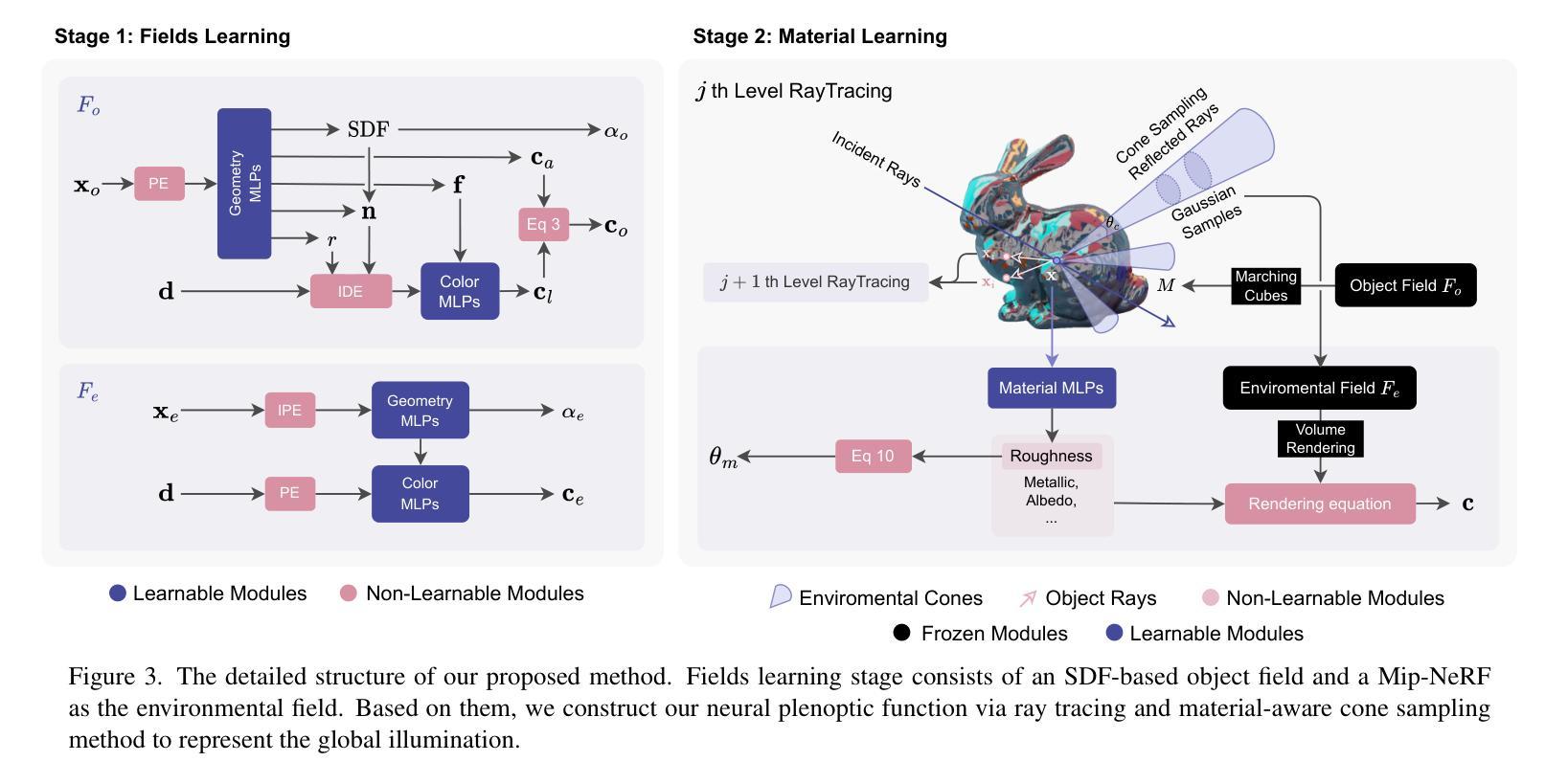
Inverse Rendering of Glossy Objects via the Neural Plenoptic Function and Radiance Fields
Authors:Haoyuan Wang, Wenbo Hu, Lei Zhu, Rynson W. H. Lau
Inverse rendering aims at recovering both geometry and materials of objects. It provides a more compatible reconstruction for conventional rendering engines, compared with the neural radiance fields (NeRFs). On the other hand, existing NeRF-based inverse rendering methods cannot handle glossy objects with local light interactions well, as they typically oversimplify the illumination as a 2D environmental map, which assumes infinite lights only. Observing the superiority of NeRFs in recovering radiance fields, we propose a novel 5D Neural Plenoptic Function (NeP) based on NeRFs and ray tracing, such that more accurate lighting-object interactions can be formulated via the rendering equation. We also design a material-aware cone sampling strategy to efficiently integrate lights inside the BRDF lobes with the help of pre-filtered radiance fields. Our method has two stages: the geometry of the target object and the pre-filtered environmental radiance fields are reconstructed in the first stage, and materials of the target object are estimated in the second stage with the proposed NeP and material-aware cone sampling strategy. Extensive experiments on the proposed real-world and synthetic datasets demonstrate that our method can reconstruct high-fidelity geometry/materials of challenging glossy objects with complex lighting interactions from nearby objects. Project webpage: https://whyy.site/paper/nep
PDF CVPR 2024 paper. Project webpage https://whyy.site/paper/nep
Summary
基于NeRF和光线追踪的新型5D神经全光函数(NeP),可精确描述光照与物体交互过程,提升光泽物体的几何/材质重建效果。
Key Takeaways
- 逆向渲染旨在恢复物体的几何形状和材质,与神经辐射场(NeRF)相比,逆向渲染为传统渲染引擎提供了更兼容的重建。
- 现有的基于NeRF的逆向渲染方法无法很好地处理具有局部光照交互的光泽物体,因为它们通常将光照过度简化为2D环境贴图,该贴图仅假定无限光源。
- 观察到NeRF在恢复辐射场方面的优势,提出了一种基于NeRF和光线追踪的新型5D神经全光函数(NeP),以便通过渲染方程表述更准确的光照-物体交互。
- 设计了一种材料感知锥形采样策略,借助预先过滤的辐射场,以有效的方式整合BRDF瓣中的光源。
- 方法分两个阶段:第一阶段重建目标物体的几何形状和预先过滤的环境辐射场,第二阶段使用提出的NeP和材料感知锥形采样策略估计目标物体的材质。
- 在提出的真实世界和合成数据集上进行的广泛实验表明,方法可以从附近的物体中重建具有复杂光照交互的具有挑战性的光泽物体的几何/材质。
- 标题:基于神经视场函数和辐射场的物体光泽反演渲染
- 作者:王浩源、胡文博、朱磊、刘润森
- 隶属:香港城市大学
- 关键词:inverse rendering、glossy objects、neural plenoptic function、radiance fields
- 论文链接:https://arxiv.org/abs/2403.16224 Github代码链接:None
摘要: (1)研究背景:神经辐射场(NeRF)在真实感重建方面取得了显著进展,但将 NeRF 集成到传统渲染引擎中仍然具有挑战性,因为 NeRF 以纠缠的方式表示对象和光照。分解表示为几何、材质和环境光照,即反演渲染,对于游戏制作和扩展现实中的适用性至关重要。近期工作探索了几何重建,并进一步扩展到材质估计,例如反照率、粗糙度和金属度。然而,它们通常将光照表示为 2D 环境贴图,这将复杂真实的照明分布过度简化为仅限于无限光照。在许多实际场景中,目标对象被其他对象包围,大量光线实际上来自附近物体的辐射。忽略这些常见场景会导致几何和材质的重建效果较差,特别是对于光泽物体,例如 NeRO [10] 在图 1 中的不当结果。 (2)过去方法及问题:现有基于 NeRF 的反演渲染方法无法很好地处理具有局部光照交互的光泽物体,因为它们通常将光照过度简化为 2D 环境贴图,这假设只有无限光照。尽管 NeRF 在恢复辐射场方面具有优势,但这些方法忽略了物体和光照之间的复杂交互。 (3)研究方法:本文提出了一种神经视场函数(NeP)来表示全局光照作为 5D 函数 fp(x, d),它描述了每个光线在场景中的颜色。NeP 基于 NeRF 和光线追踪,可以更准确地通过渲染方程表述光照与物体的交互。此外,本文还设计了一种材质感知锥形采样策略,在预过滤辐射场的帮助下,有效地将光线积分到 BRDF lobe 中。该方法有两个阶段:第一阶段重建目标对象的几何和预过滤的环境辐射场,第二阶段使用提出的 NeP 和材质感知锥形采样策略估计目标对象的材质。 (4)任务及性能:本文的方法在提出的真实世界和合成数据集上进行了广泛的实验,证明了该方法可以从附近的物体重建具有复杂光照交互的光泽物体的几何/材质,并且具有较高的保真度。这些性能支持了他们的目标,即解决具有局部光照交互的光泽物体的反演渲染问题,并为游戏制作和扩展现实提供更兼容的重建。
方法:(1) 场学习:利用 NeuS 和 NeRF 重建目标对象的几何形状和环境光照场;(2) 材质学习:采用射线追踪评估渲染方程,使用提出的神经视场函数 (NeP) 表示全局光照,并设计材质感知锥形采样策略来有效积分光线到 BRDF lobe 中。
结论: (1):本文提出了一种基于神经视场函数(NeP)的光泽物体反演渲染新方法,解决了现有基于 NeRF 的反演渲染方法在处理具有局部光照交互的光泽物体时存在的局限性。该方法采用两阶段模型,其中场学习阶段增强了 3D 几何重建的准确性,尤其是在复杂光照下的光泽物体。在材质学习阶段,NeP 使用基于对象场和环境场的 5D 神经视场函数表示全局光照,从而实现更高保真的材质估计和反演渲染。本文提出的材质感知锥形采样策略进一步提高了材质学习的效率。在真实世界和合成数据集上的实验表明了该方法的优越性能。 (2):创新点:
- 提出了一种基于 NeRF 的神经视场函数 (NeP) 来表示全局光照,解决了现有方法中光照表示过度简化的局限性。
- 设计了一种材质感知锥形采样策略,有效地将光线积分到 BRDF 瓣叶中,提高了材质学习的效率。 性能:
- 在真实世界和合成数据集上的实验表明,该方法在几何/材质重建方面取得了较高的保真度,尤其是在具有复杂光照交互的光泽物体上。
- 与现有方法相比,该方法在几何和材质重建质量方面取得了显着改进。 工作量:
- 该方法需要两阶段训练,包括场学习和材质学习。
- 场学习阶段需要使用 NeRF 重建目标对象的几何形状和环境光照场。
- 材质学习阶段需要使用提出的 NeP 和材质感知锥形采样策略来估计目标对象的材质。
点此查看论文截图

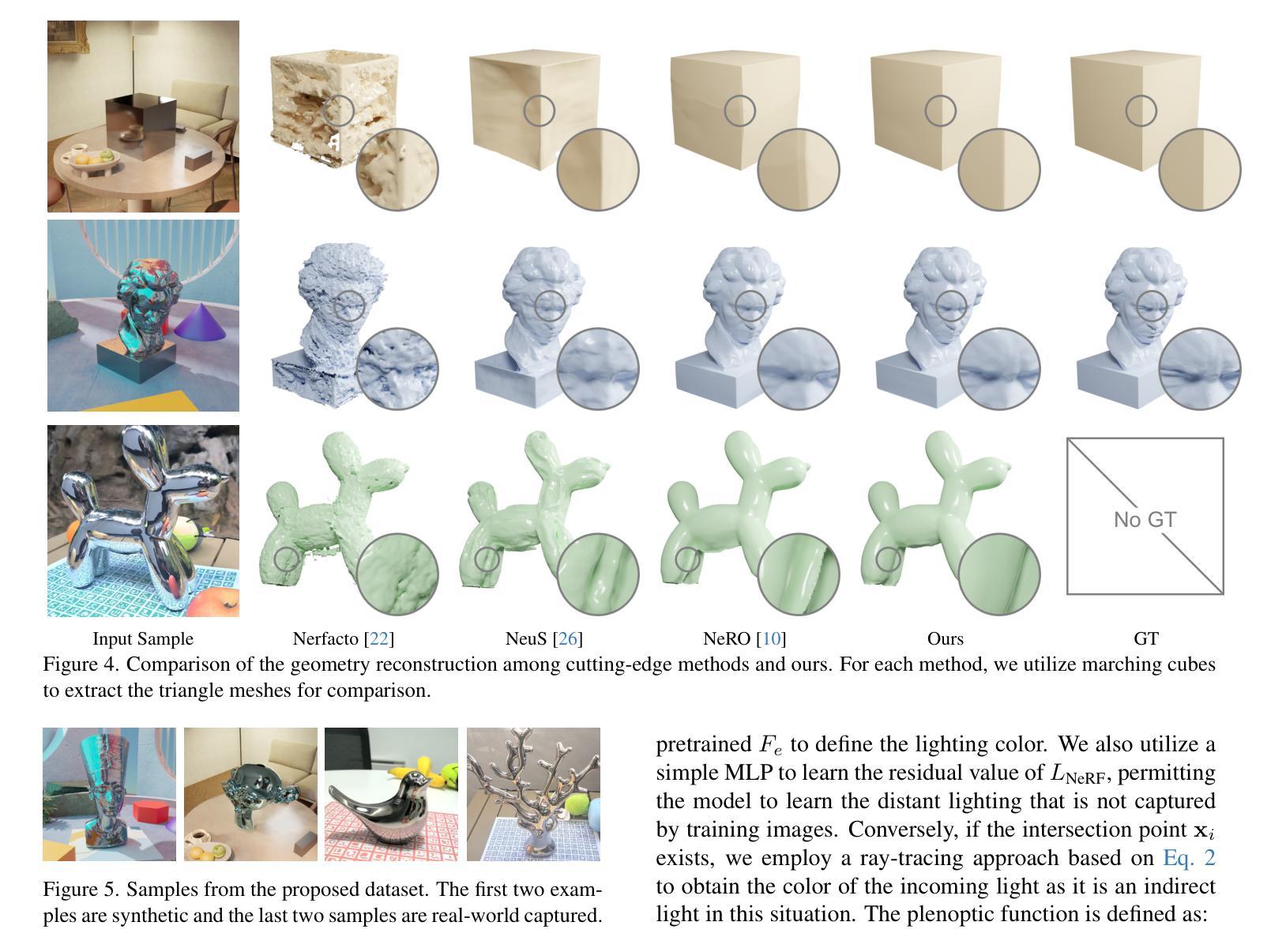
Entity-NeRF: Detecting and Removing Moving Entities in Urban Scenes
Authors:Takashi Otonari, Satoshi Ikehata, Kiyoharu Aizawa
Recent advancements in the study of Neural Radiance Fields (NeRF) for dynamic scenes often involve explicit modeling of scene dynamics. However, this approach faces challenges in modeling scene dynamics in urban environments, where moving objects of various categories and scales are present. In such settings, it becomes crucial to effectively eliminate moving objects to accurately reconstruct static backgrounds. Our research introduces an innovative method, termed here as Entity-NeRF, which combines the strengths of knowledge-based and statistical strategies. This approach utilizes entity-wise statistics, leveraging entity segmentation and stationary entity classification through thing/stuff segmentation. To assess our methodology, we created an urban scene dataset masked with moving objects. Our comprehensive experiments demonstrate that Entity-NeRF notably outperforms existing techniques in removing moving objects and reconstructing static urban backgrounds, both quantitatively and qualitatively.
PDF Accepted by IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2024), Project website: https://otonari726.github.io/entitynerf/
Summary
实体化的神经辐射场方法将实体细分和静态实体分类相结合,有效地去除了动态场景中的动态物体,提高了静态背景的重建精度。
Key Takeaways
- 针对场景动态的 NeRF 研究通常依赖显式建模场景动态,但在城市环境中,不同类别和尺度的动态物体带来了建模挑战。
- 实体化的 NeRF 方法融合了基于知识和基于统计的策略,利用实体化的统计信息,有效地去除了动态物体。
- 实体细分和物体/物质细分有助于静态实体分类,提高了去动态物体和重建静态背景的精度。
- 通过 Thing/Stuff 细分,Entity-NeRF 可以针对不同实体应用不同的策略。
- Entity-NeRF 方法创建了一个带有动态物体遮罩的城市场景数据集,用于评估其性能。
- 实验结果证明,Entity-NeRF 在去动态物体和重建静态城市背景方面均优于现有技术。
- Entity-NeRF 方法对理解和重建动态场景中的静态背景具有重要意义。
- 论文标题:Entity-NeRF:检测和移除城市场景中的移动实体
- 作者:Qianqian Wang, Peter Hedman, Jonathan T. Barron, Ravi Ramamoorthi, Noah Snavely
- 第一作者单位:加州大学伯克利分校
- 关键词:NeRF,动态场景,移动实体检测,背景重建
- 论文链接:https://arxiv.org/abs/2302.07605,Github 代码链接:无
摘要: (1) 研究背景:NeRF 在动态场景建模中取得了进展,但对于城市环境中类别和规模各异的移动实体建模仍面临挑战。 (2) 过去方法和问题:现有方法通常显式建模场景动态,但难以处理城市环境中的复杂移动实体。 (3) 本文方法:Entity-NeRF 结合了基于知识和统计策略,利用实体级统计信息,通过实体分割和物体/材料分割来对静止实体进行分类。 (4) 方法性能:在城市场景数据集上,Entity-NeRF 在移除移动实体和重建静态背景方面明显优于现有技术,定量和定性评估均证明了其有效性。
方法: (1) Entity-wise Average of Residual Ranks (EARR):利用数据驱动的分割网络和重建损失的实体级统计信息,对实体进行分割和分类; (2) 合作式静止实体分类:通过训练一个静止实体分类网络,识别出场景中属于静止物体类别的实体,确保其在训练过程中被包含在内; (3) 结合基于知识和统计的方法:将基于知识的实体分割结果与残差秩统计相结合,对移动实体进行识别。
8. 结论
(1): 论文意义
Entity-NeRF 解决了在动态城市场景中构建 NeRF 时识别和移除不同类别和大小的移动实体的问题。该方法结合了基于知识和统计策略,利用实体级统计信息和物体/材料分割来分类静止实体,从而显著提高了移动实体移除和静态背景重建的性能。
(2): 优缺点总结
创新点:
- 提出 Entity-wise Average of Residual Ranks (EARR) 方法,利用实体级统计信息识别移动实体。
- 训练静止实体分类网络,确保静止物体类别实体在 NeRF 训练早期被包含。
- 将基于知识的实体分割结果与残差秩统计相结合,提高移动实体识别精度。
性能:
- 在城市场景数据集上,Entity-NeRF 在移除移动实体和重建静态背景方面明显优于现有技术。
- 定量和定性评估证明了该方法的有效性。
工作量:
- 该方法需要训练数据驱动的分割网络和静止实体分类网络,工作量相对较大。
- 在处理大型移动物体遮挡背景或阴影时,可能需要集成图像修复技术或进行后处理。
点此查看论文截图



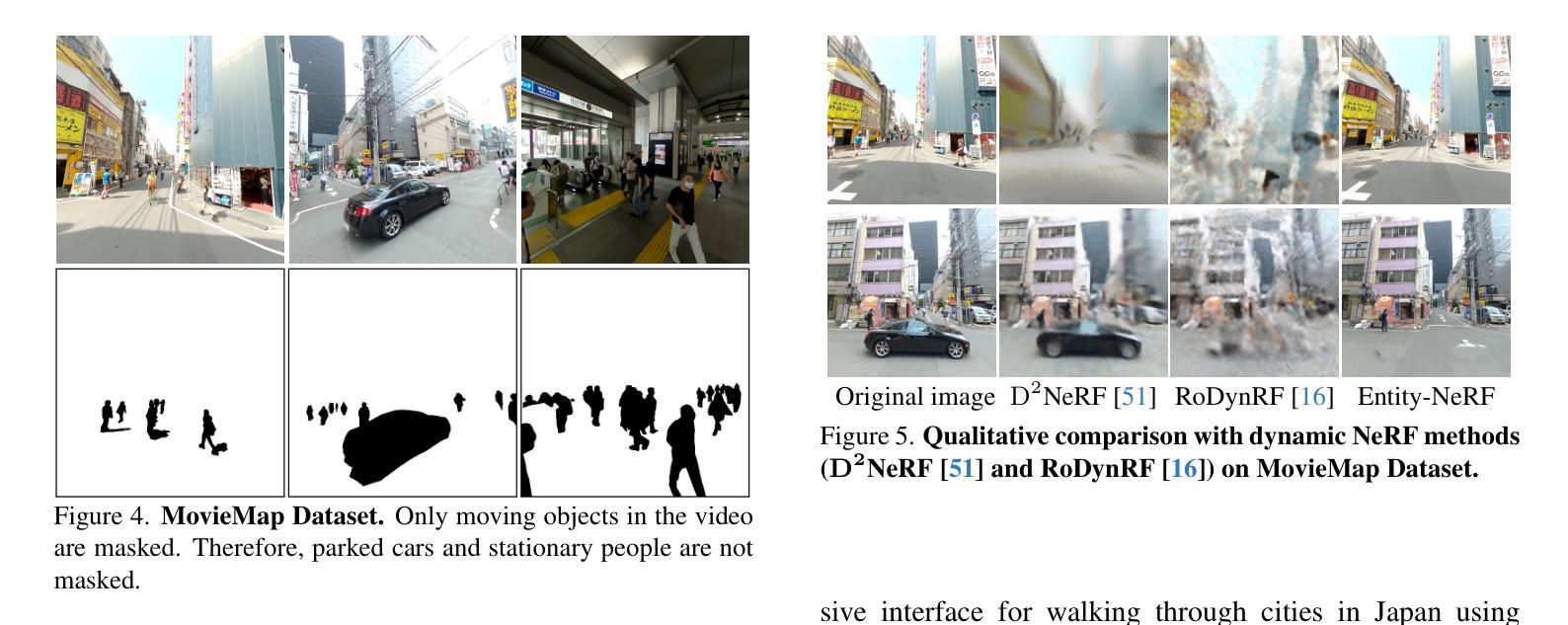
- 标题:CG-SLAM:一种基于一致的不确定性感知 3D 高斯场的高效稠密 RGB-DSLAM
- 作者:胡嘉瑞,陈显浩,冯伯寅,李广林,杨良晶,包虎军,张国锋,崔兆鹏
- 隶属单位:浙江大学计算机辅助设计与图形学国家重点实验室
- 关键词:稠密视觉 SLAM、神经渲染、3D 高斯场
- 论文链接:https://arxiv.org/abs/2403.16095
摘要: (1)研究背景:近年来,神经辐射场(NeRF)被广泛用作稠密 SLAM 的 3D 表示。尽管在表面建模和新视图合成方面取得了显著成功,但现有的基于 NeRF 的方法受到其计算密集且耗时的体积渲染管线的阻碍。 (2)过去方法和问题:本文提出了一种基于具有高一致性和几何稳定性的新型不确定性感知 3D 高斯场的高效稠密 RGB-DSLAM 系统,即 CG-SLAM。通过对高斯 Splatting 的深入分析,我们提出了一些技术来构建适合于跟踪和建图的一致且稳定的 3D 高斯场。此外,为了确保在优化过程中选择有价值的高斯原语,提出了一种新的深度不确定性模型,从而提高了跟踪效率和准确性。 (3)研究方法:本文提出了一种基于具有高一致性和几何稳定性的新型不确定性感知 3D 高斯场的高效稠密 RGB-DSLAM 系统,即 CG-SLAM。通过对高斯 Splatting 的深入分析,我们提出了一些技术来构建适合于跟踪和建图的一致且稳定的 3D 高斯场。此外,为了确保在优化过程中选择有价值的高斯原语,提出了一种新的深度不确定性模型,从而提高了跟踪效率和准确性。 (4)实验结果:在各种数据集上的实验表明,CG-SLAM 实现了卓越的跟踪和建图性能,跟踪速度高达 15Hz。我们将公开我们的源代码。
Methods: (1)基于高斯Splatting构建一致且稳定的3D高斯场; (2)提出深度不确定性模型,确保优化过程中选择有价值的高斯原语; (3)利用神经渲染技术进行稠密建图,实现高精度表面重建和新视图合成; (4)采用高效的跟踪策略,实现实时跟踪和建图。
结论: (1):CG-SLAM 是一种基于一致的不确定性感知 3D 高斯场的稠密 RGB-DSLAM,它通过强化 3D 高斯场的稠密性和稳定性来提高跟踪和建图性能。 (2):创新点:
- 基于高斯 Splatting 构建一致且稳定的 3D 高斯场
- 提出深度不确定性模型,确保优化过程中选择有价值的高斯原语
- 利用神经渲染技术进行稠密建图,实现高精度表面重建和新视图合成
- 采用高效的跟踪策略,实现实时跟踪和建图
- 性能:
- 在各种数据集上的实验表明,CG-SLAM 实现了卓越的跟踪和建图性能,跟踪速度高达 15Hz
- 工作量:
- 论文公开源代码
点此查看论文截图


Are NeRFs ready for autonomous driving? Towards closing the real-to-simulation gap
Authors:Carl Lindström, Georg Hess, Adam Lilja, Maryam Fatemi, Lars Hammarstrand, Christoffer Petersson, Lennart Svensson
Neural Radiance Fields (NeRFs) have emerged as promising tools for advancing autonomous driving (AD) research, offering scalable closed-loop simulation and data augmentation capabilities. However, to trust the results achieved in simulation, one needs to ensure that AD systems perceive real and rendered data in the same way. Although the performance of rendering methods is increasing, many scenarios will remain inherently challenging to reconstruct faithfully. To this end, we propose a novel perspective for addressing the real-to-simulated data gap. Rather than solely focusing on improving rendering fidelity, we explore simple yet effective methods to enhance perception model robustness to NeRF artifacts without compromising performance on real data. Moreover, we conduct the first large-scale investigation into the real-to-simulated data gap in an AD setting using a state-of-the-art neural rendering technique. Specifically, we evaluate object detectors and an online mapping model on real and simulated data, and study the effects of different pre-training strategies. Our results show notable improvements in model robustness to simulated data, even improving real-world performance in some cases. Last, we delve into the correlation between the real-to-simulated gap and image reconstruction metrics, identifying FID and LPIPS as strong indicators.
Summary
神经辐射场(NeRF)在自动驾驶(AD)模拟中扮演关键角色,但如何确保算法将仿真数据与真实数据一视同仁却是个挑战。研究提出一种视角,专注于提升算法对NeRF伪影的鲁棒性,而不是只追求呈现逼真度。
Key Takeaways
- NeRF在自动驾驶仿真中很重要
- 确保算法对真实和模拟数据一视同仁至关重要
- 应注重提升感知模型对NeRF伪影的鲁棒性
- 进行了首次大规模自动驾驶场景真实-模拟数据差距研究
- 评估了目标检测器和在线建图模型在真实和模拟数据上的表现
- 探索了不同的预训练策略的效果
- 模型对模拟数据的鲁棒性显著提高,在某些情况下甚至提高了真实世界的性能
- FID和LPIPS是真实-模拟差距的强力指标
- 标题:NeRF 能用于自动驾驶吗?朝着缩小真实与模拟差距迈进
- 作者:Carl Lindstr¨om†,1,2 Georg Hess†,1,2 Adam Lilja1,2 Maryam Fatemi1 Lars Hammarstrand2 Christoffer Petersson1,2 Lennart Svensson2
- 第一作者单位:Zenseact
- 关键词:NeRF、自动驾驶、真实与模拟差距、感知模型鲁棒性
- 论文链接:arXiv:2403.16092v1[cs.CV]
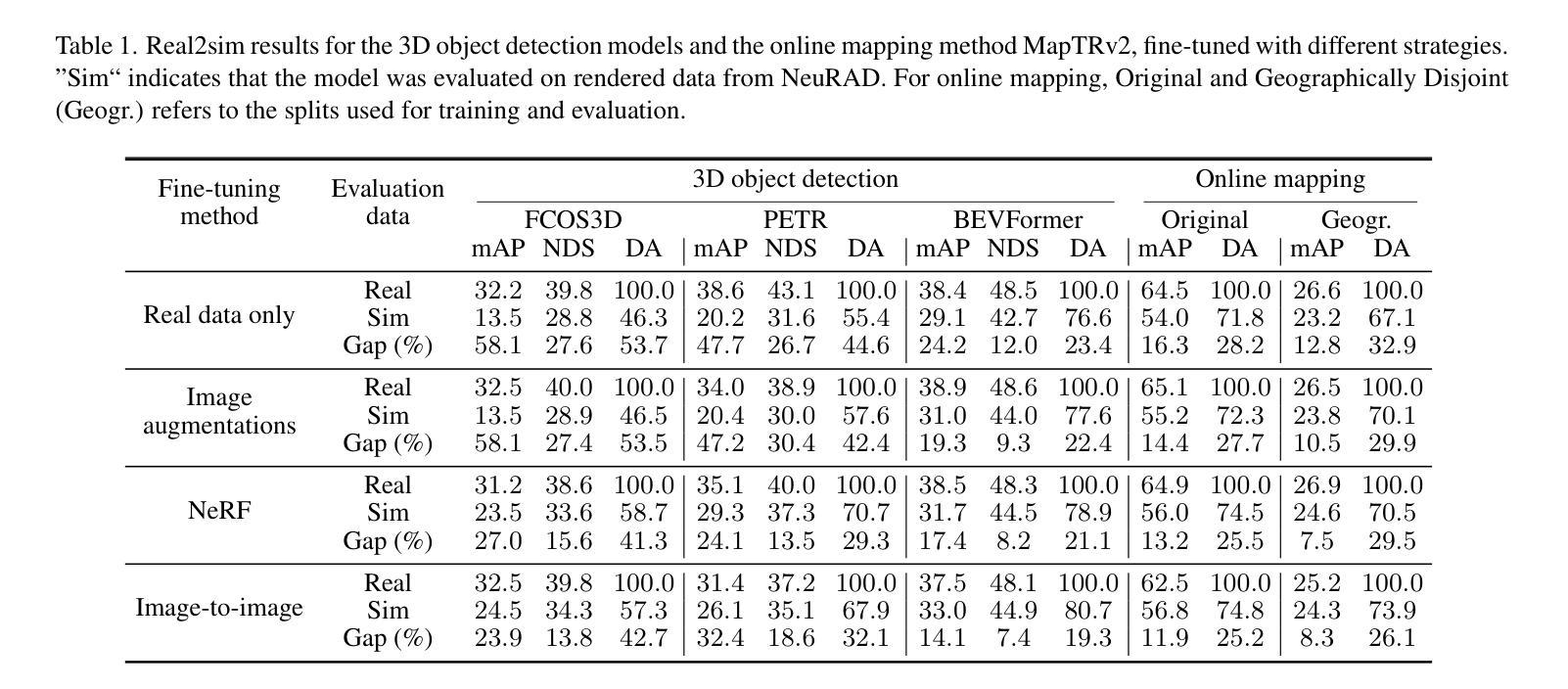
摘要: (1)研究背景:神经辐射场(NeRF)已成为推进自动驾驶(AD)研究的有前途的工具,提供可扩展的闭环仿真和数据增强功能。然而,为了信任仿真中获得的结果,需要确保 AD 系统以相同的方式感知真实和渲染的数据。虽然渲染方法的性能正在提高,但许多场景在本质上仍然难以逼真地重建。 (2)过去方法及问题:现有的方法主要集中在提高渲染保真度上,但当渲染质量下降时,感知模型的性能会显着下降。 (3)本文提出的研究方法:本文提出了一种新的视角来解决真实与模拟数据差距问题。与其仅仅关注提高渲染保真度,不如探索简单但有效的方法来增强感知模型对 NeRF 伪影的鲁棒性,同时不影响真实数据上的性能。此外,本文使用最先进的神经渲染技术对 AD 设置中的真实与模拟数据差距进行了首次大规模调查。具体来说,本文在真实和模拟数据上评估了目标检测器和在线建图模型,并研究了不同预训练策略的影响。 (4)方法在什么任务上取得了怎样的性能:结果表明,模型对模拟数据的鲁棒性有了显着提高,在某些情况下甚至提高了真实世界的性能。最后,本文深入研究了真实与模拟差距与图像重建指标之间的相关性,确定 FID 和 LPIPS 是强有力的指标。
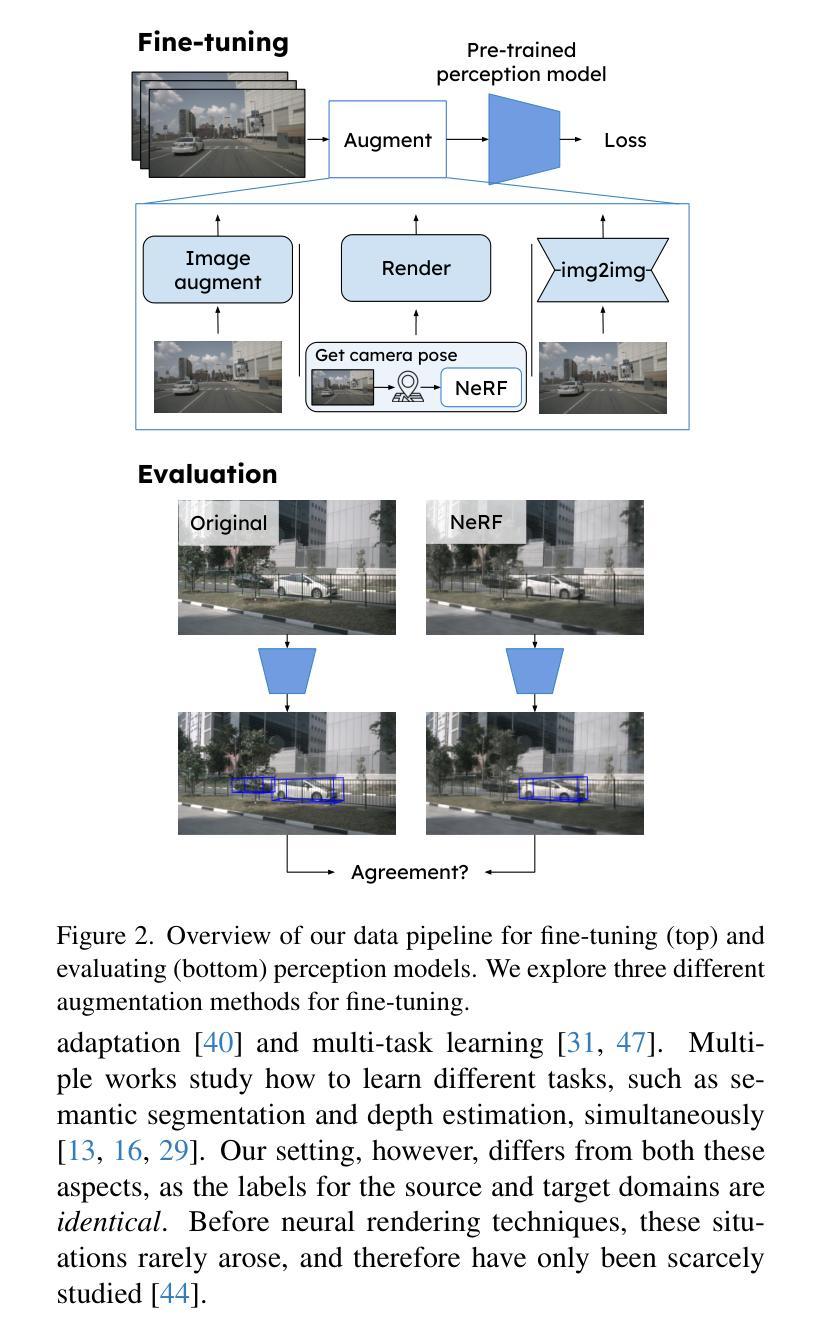
方法: (1)图像增强:使用图像增强(如添加噪声、模糊、光度失真等)来提高模型对渲染数据中伪影的鲁棒性。 (2)使用渲染图像微调:在微调感知模型时,加入渲染图像,以提高模型对渲染数据的适应性。 (3)图像到图像转换:使用图像到图像转换模型,将真实图像转换为类似渲染图像的伪影,从而增加用于微调的渲染图像数量。
结论: (1):本文提出了一种新的视角来解决自动驾驶中真实与模拟数据差距问题,探索了增强感知模型对 NeRF 伪影的鲁棒性的方法,取得了显著效果。 (2):创新点:提出了一种新的视角来解决真实与模拟数据差距问题,探索了增强感知模型对 NeRF 伪影的鲁棒性的方法。 性能:在真实和模拟数据上评估了目标检测器和在线建图模型,结果表明模型对模拟数据的鲁棒性有了显着提高,在某些情况下甚至提高了真实世界的性能。 工作量:进行了大规模调查,评估了感知模型在真实和模拟数据上的性能,研究了不同预训练策略的影响,深入研究了真实与模拟差距与图像重建指标之间的相关性。
点此查看论文截图


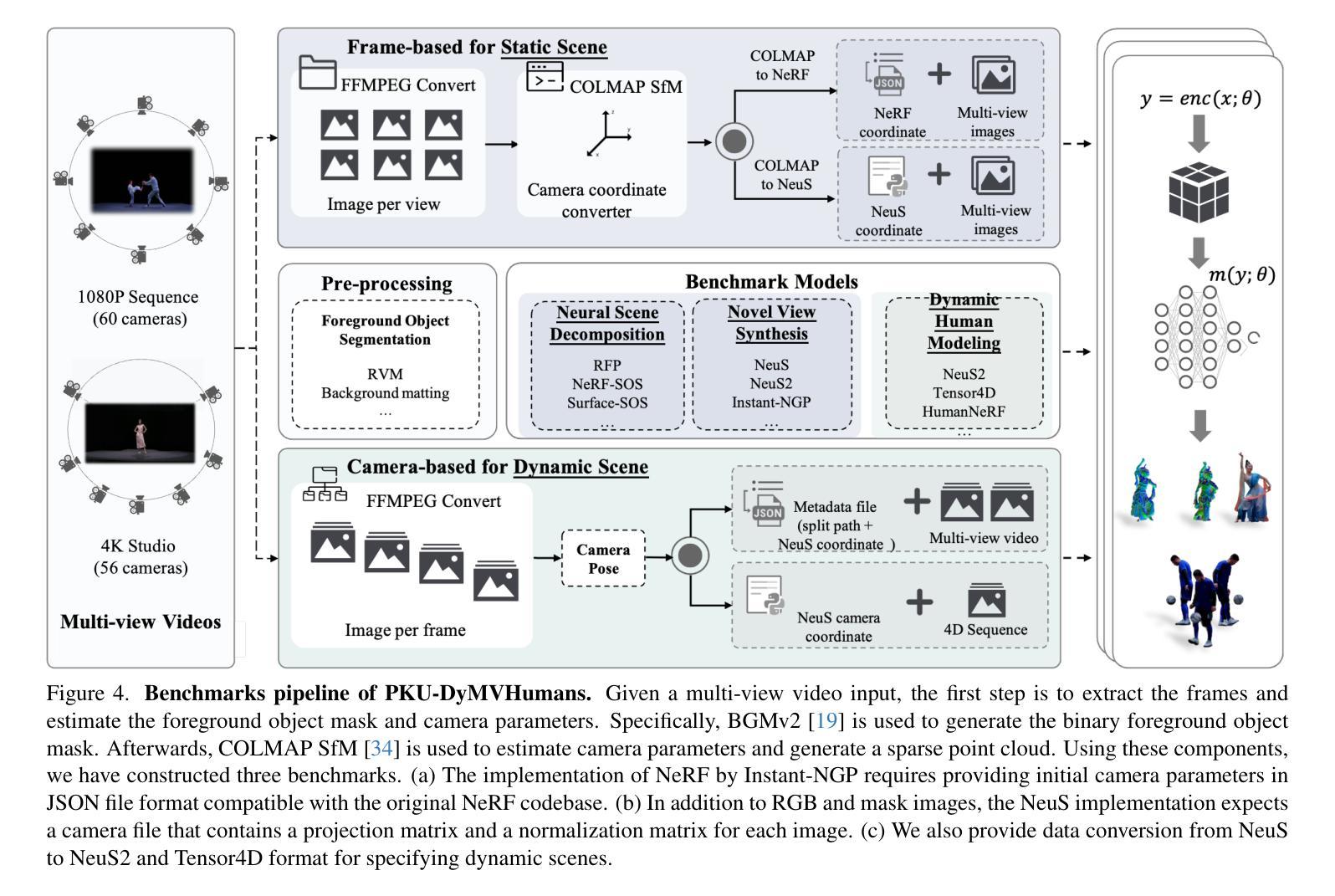
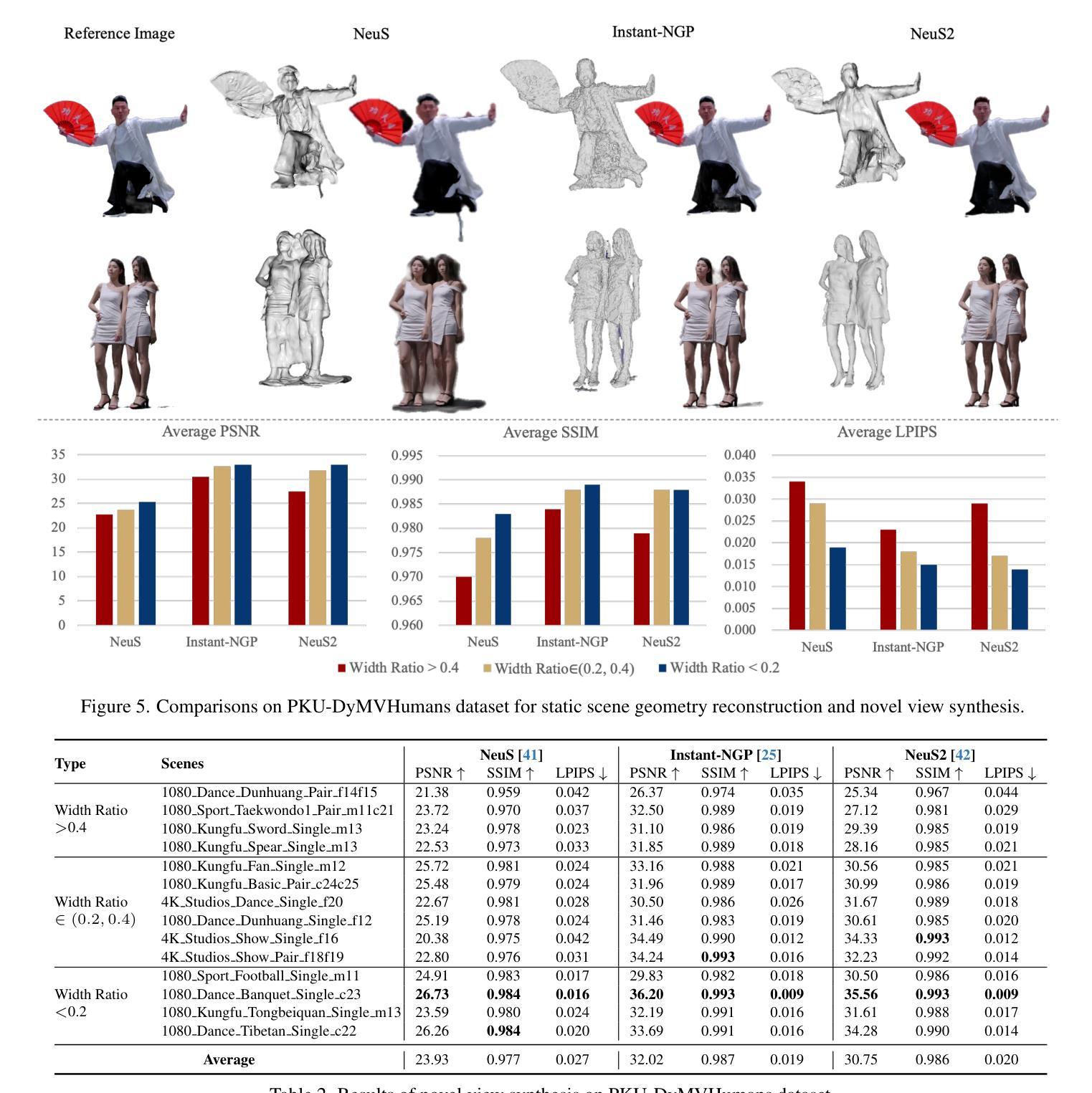
PKU-DyMVHumans: A Multi-View Video Benchmark for High-Fidelity Dynamic Human Modeling
Authors:Xiaoyun Zheng, Liwei Liao, Xufeng Li, Jianbo Jiao, Rongjie Wang, Feng Gao, Shiqi Wang, Ronggang Wang
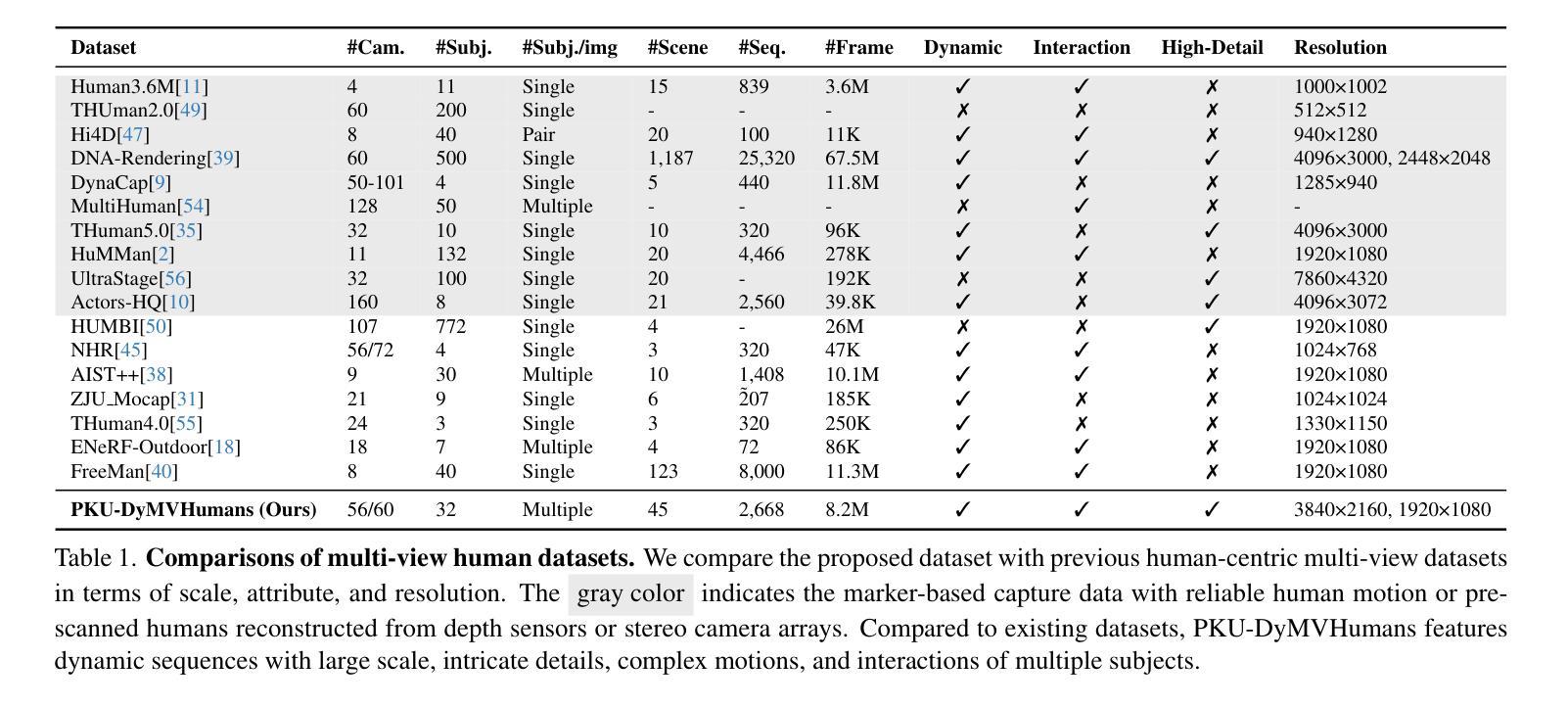
High-quality human reconstruction and photo-realistic rendering of a dynamic scene is a long-standing problem in computer vision and graphics. Despite considerable efforts invested in developing various capture systems and reconstruction algorithms, recent advancements still struggle with loose or oversized clothing and overly complex poses. In part, this is due to the challenges of acquiring high-quality human datasets. To facilitate the development of these fields, in this paper, we present PKU-DyMVHumans, a versatile human-centric dataset for high-fidelity reconstruction and rendering of dynamic human scenarios from dense multi-view videos. It comprises 8.2 million frames captured by more than 56 synchronized cameras across diverse scenarios. These sequences comprise 32 human subjects across 45 different scenarios, each with a high-detailed appearance and realistic human motion. Inspired by recent advancements in neural radiance field (NeRF)-based scene representations, we carefully set up an off-the-shelf framework that is easy to provide those state-of-the-art NeRF-based implementations and benchmark on PKU-DyMVHumans dataset. It is paving the way for various applications like fine-grained foreground/background decomposition, high-quality human reconstruction and photo-realistic novel view synthesis of a dynamic scene. Extensive studies are performed on the benchmark, demonstrating new observations and challenges that emerge from using such high-fidelity dynamic data. The dataset is available at: https://pku-dymvhumans.github.io.
Summary
北大动态多视角人体数据集,提供高质量动态人体场景重建和渲染。
Key Takeaways
- 提供 820 万帧,由 56 个同步摄像机在不同场景中拍摄。
- 包含 32 位人体,45 种不同场景,具有丰富的外观和逼真动作。
- 基于 NeRF 场景表示,提供现成框架,便于在 PKU-DyMVHumans 数据集上提供最先进的 NeRF 实现和基准。
- 适用于细粒度前景/背景分解、高质量人体重建和动态场景照片级新视角合成等应用。
- 广泛的研究表明,使用此类高保真动态数据产生了新的观察和挑战。
- 标题:PKU-DyMVHumans:用于高保真动态人体建模的多视角视频基准
- 作者:
- 袁志杰
- 孙剑
- 林凡
- 袁嘉堃
- 吴新
- 曹旭东
- 作者单位:北京大学信息科学技术学院
- 关键词:
- 人体建模
- 动态场景
- 多视角视频
- 神经辐射场
- 论文链接:https://arxiv.org/abs/2207.12006 Github 代码链接:None
- 摘要: (1) 研究背景: 高保真的人体重建和动态场景的逼真渲染是计算机视觉和图形学中的长期问题。尽管在开发各种捕获系统和重建算法方面投入了大量精力,但最近的进展仍然难以处理宽松或超大尺寸的服装以及过于复杂的姿势。这在一定程度上是由于获取高质量人体数据集的挑战。 (2) 过去的方法及其问题: 过去的方法通常依赖于稀疏的 3D 点云或粗糙的物体掩码,这限制了重建的保真度。基于神经辐射场 (NeRF) 的场景表示最近取得了显着进展,但缺乏一个高质量的人体数据集来评估和推动其在动态场景中的人体建模和渲染方面的潜力。 (3) 本文提出的研究方法: 为了促进这些领域的发展,本文提出了 PKU-DyMVHumans,这是一个通用的以人为中心的动态人体场景高保真重建和渲染数据集。它包含来自 56 个以上同步摄像机的 820 万帧,涵盖各种场景。这些序列包括 32 个人类受试者,分布在 45 个不同的场景中,每个场景都具有高度详细的外观和逼真的人体动作。受基于 NeRF 的场景表示的最新进展的启发,本文还设置了一个现成的框架,便于在 PKU-DyMVHumans 数据集上提供最先进的基于 NeRF 的实现和基准。这为各种应用铺平了道路,如细粒度前景/背景分解、高质量人体重建和动态场景的逼真新视角合成。 (4) 方法在何种任务上取得了何种性能,是否能支持其目标: 本文在基准上进行了广泛的研究,展示了使用如此高保真动态数据所产生的新观察和挑战。该数据集可用于:
- 细粒度前景/背景分解
- 高质量人体重建
- 动态场景的逼真新视角合成
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出 PKU-DyMVHumans,这是一个动态人体数据集,旨在从密集的多视角视频中进行高保真的人体重建和渲染。它具有高保真的人体表现,包括高度详细的外观、复杂的人体运动,以及具有挑战性的人体-物体交互、多人交互和复杂的场景效果(例如,灯光、阴影和吸烟)。我们进一步提出了基准任务,并对几种先进的方法进行了详细的实验。PKU-DyMVHumans 进一步填补了现有数据集和真实场景应用之间的差距。挑战和未来工作。虽然我们在大量以人为中心重建和渲染上验证了我们数据集的复杂性和保真度。重要的是要强调更具挑战性和现实性的多人物/主体建模,它可以反映多人物交互性、复杂场景效果和多视角一致性性能方面的渲染差异。此外,从单眼自旋转视频中对运动主体进行自由视点渲染是一个复杂但理想的设置。我们的补充材料提供了运动主体的自由视点渲染的附加实验,结果受局部遮挡和视点缺失的影响,导致视点渲染出现伪影。有了这些机遇和挑战,我们相信 PKU-DyMVHumans 将有利于社区中新方法的发展。致谢。这项工作得到了深圳市优秀人才培训基金、深圳市科技计划(RCJC20200714114435057、SGDX20211123144400001)、国家自然科学基金(U21B2012)和咪咕-北大元宇宙技术创新实验室(R24115SG)的支持。Jianbo Jiao 得到皇家学会赠款 IES\R3\223050 和 SIF\R1\231009.88 的支持。 (2):创新点:提出 PKU-DyMVHumans,一个用于高保真动态人体建模的多视角视频基准;性能:在基准上进行了广泛的研究,展示了使用如此高保真动态数据所产生的新观察和挑战;工作量:收集了 820 万帧,涵盖各种场景,包括 32 个人类受试者和 45 个不同的场景。
点此查看论文截图


 wechat
wechat- alipay







