NeRF
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-01 更新
Talk3D: High-Fidelity Talking Portrait Synthesis via Personalized 3D Generative Prior
Authors:Jaehoon Ko, Kyusun Cho, Joungbin Lee, Heeji Yoon, Sangmin Lee, Sangjun Ahn, Seungryong Kim
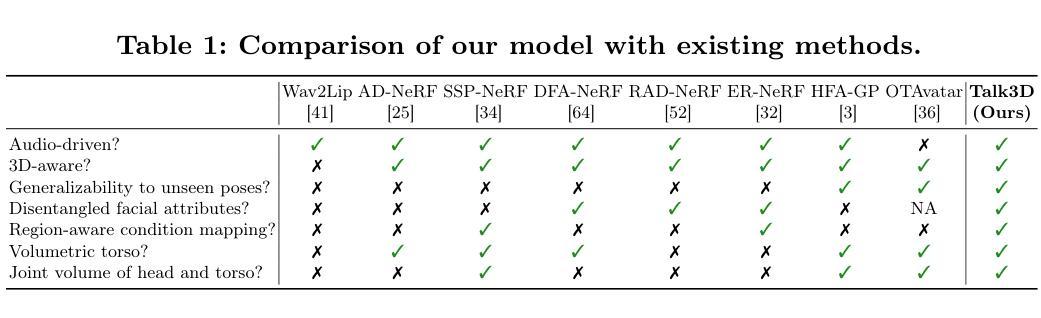
Recent methods for audio-driven talking head synthesis often optimize neural radiance fields (NeRF) on a monocular talking portrait video, leveraging its capability to render high-fidelity and 3D-consistent novel-view frames. However, they often struggle to reconstruct complete face geometry due to the absence of comprehensive 3D information in the input monocular videos. In this paper, we introduce a novel audio-driven talking head synthesis framework, called Talk3D, that can faithfully reconstruct its plausible facial geometries by effectively adopting the pre-trained 3D-aware generative prior. Given the personalized 3D generative model, we present a novel audio-guided attention U-Net architecture that predicts the dynamic face variations in the NeRF space driven by audio. Furthermore, our model is further modulated by audio-unrelated conditioning tokens which effectively disentangle variations unrelated to audio features. Compared to existing methods, our method excels in generating realistic facial geometries even under extreme head poses. We also conduct extensive experiments showing our approach surpasses state-of-the-art benchmarks in terms of both quantitative and qualitative evaluations.
PDF Project page: https://ku-cvlab.github.io/Talk3D/
Summary
通过采用预训练的 3D 感知生成先验,Talk3D 可生成真实的面部几何形状。
Key Takeaways
- Talk3D 采用预训练的 3D 感知生成先验,重建逼真的面部几何形状。
- 音频引导注意力 U-Net 架构预测 NeRF 空间中的动态面部变化。
- 音频无关调节令牌有效地区分与音频无关的变化。
- Talk3D 即使在极端头部姿势下也能生成逼真的面部几何形状。
- 广泛的实验表明 Talk3D 在定量和定性评估方面都超越了最先进的基准。
- Talk3D 可以生成任意视角的面部重建,具有 3D 一致性和高保真度。
- Talk3D 可以有效地减少光照和表情变化等音频无关因素的影响。
- 标题:Talk3D:高保真说话人图像合成
- 作者:Changil Kim, Minhyeok Lee, Juyong Kim, Nojun Kwak
- 隶属机构:首尔国立大学
- 关键词:音频驱动说话人图像合成、神经辐射场、3D 感知生成模型
- 论文链接:https://arxiv.org/abs/2403.20153
- 摘要: (1)研究背景: 近年来,音频驱动的说话人图像合成方法取得了很大进展,但这些方法通常依赖于单目说话人图像视频,难以重建完整的面部几何结构。
(2)过去的方法及其问题: 现有方法通常优化神经辐射场 (NeRF) 来渲染新视角的图像,但由于输入单目视频中缺乏全面的 3D 信息,它们难以重建完整的面部几何结构。
(3)提出的研究方法: 本文提出了一种新的音频驱动的说话人图像合成框架 Talk3D,它通过有效采用预训练的 3D 感知生成模型,可以忠实地重建可信的面部几何结构。该框架包括一个音频引导注意力 U-Net 架构,该架构预测由音频驱动的 NeRF 空间中的动态面部变化。此外,该模型还通过与音频无关的调节令牌进行调制,有效地解耦与音频特征无关的变化。
(4)方法在任务和性能上的表现: 在说话人图像合成任务上,Talk3D 在图像质量、几何保真度和音频同步方面都优于现有方法。这些性能支持了该方法的目标,即生成高质量且逼真的说话人图像。
方法: (1)EG3D模型:采用神经辐射场(NeRF)技术,通过优化平面生成器和体积渲染器,实现图像生成。 (2)个性化生成器:使用VIVE3D策略,将3D感知生成对抗网络(GAN)调整为特定身份,生成单一身份图像。 (3)音频引导注意力U-Net:利用U-Net架构,预测由音频驱动的NeRF空间中的动态面部变化,并通过与音频无关的调节令牌进行调制。 (4)分割卷积:将每个平面独立处理,以维护其特征,同时使用展开方法融合来自每个平面的特征。
结论: (1):本文提出了 Talk3D,一个结合了 3D 感知 GAN 先验和区域感知运动的高保真 3D 说话人图像合成框架。我们的框架集成了使用 VIVE3D 框架微调的个性化生成器,允许生成具有逼真几何结构和显式渲染视点控制的 3D 感知说话人头像。此外,我们提出的音频引导注意力 U-Net 架构增强了图像帧内局部变化(如背景、躯干和眼睛运动)的解耦。通过广泛的实验,我们证明了我们提出的模型不仅可以根据输入音频产生准确的唇部动作,还可以从新颖的视点进行渲染,解决了先前最先进方法中观察到的局限性。我们预期我们的工作将对数字媒体体验和虚拟交互产生重大影响,并在电影制作、虚拟化身和视频会议中找到应用。 (2):创新点: (1)提出了一种新的音频驱动的说话人图像合成框架 Talk3D,该框架将 3D 感知 GAN 先验和区域感知运动相结合,以实现高保真 3D 说话人头像合成。 (2)利用 VIVE3D 策略,将 3D 感知生成对抗网络 (GAN) 调整为特定身份,生成具有逼真几何结构和显式渲染视点控制的 3D 感知说话人头像。 (3)提出了一个音频引导注意力 U-Net 架构,该架构增强了图像帧内局部变化(如背景、躯干和眼睛运动)的解耦。 性能: (1)在说话人图像合成任务上,Talk3D 在图像质量、几何保真度和音频同步方面都优于现有方法。 (2)Talk3D 能够从新颖的视点进行渲染,解决了先前最先进方法中观察到的局限性。 (3)Talk3D 可以有效地解耦与音频特征无关的变化,从而生成更逼真、更自然的高保真 3D 说话人图像。 工作量: (1)Talk3D 的实现需要大量的数据预处理和模型训练。 (2)Talk3D 的推理过程相对高效,可以实时生成高质量的 3D 说话人图像。 (3)Talk3D 的代码和数据已公开,便于研究人员和从业者进一步研究和应用。
点此查看论文截图


SGD: Street View Synthesis with Gaussian Splatting and Diffusion Prior
Authors:Zhongrui Yu, Haoran Wang, Jinze Yang, Hanzhang Wang, Zeke Xie, Yunfeng Cai, Jiale Cao, Zhong Ji, Mingming Sun
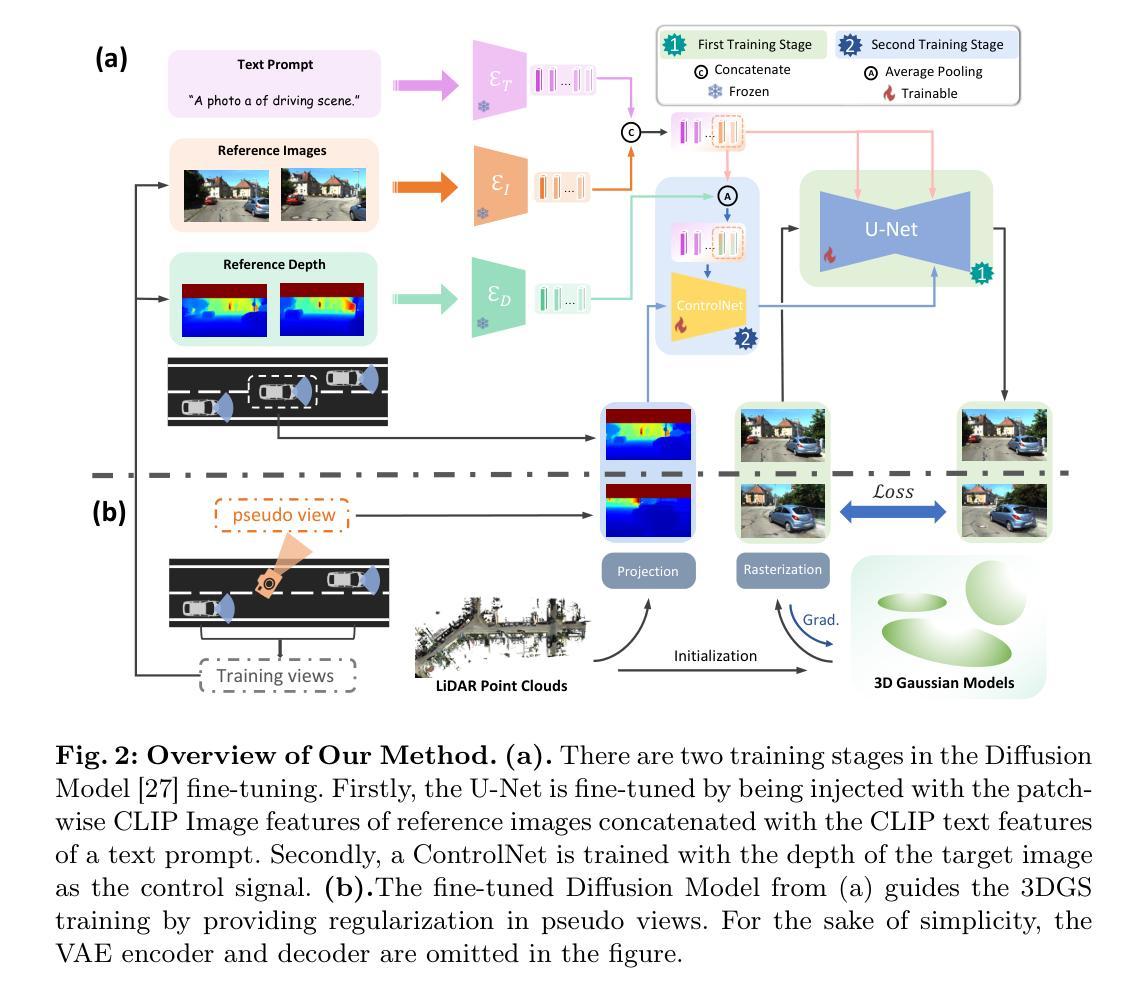
Novel View Synthesis (NVS) for street scenes play a critical role in the autonomous driving simulation. The current mainstream technique to achieve it is neural rendering, such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). Although thrilling progress has been made, when handling street scenes, current methods struggle to maintain rendering quality at the viewpoint that deviates significantly from the training viewpoints. This issue stems from the sparse training views captured by a fixed camera on a moving vehicle. To tackle this problem, we propose a novel approach that enhances the capacity of 3DGS by leveraging prior from a Diffusion Model along with complementary multi-modal data. Specifically, we first fine-tune a Diffusion Model by adding images from adjacent frames as condition, meanwhile exploiting depth data from LiDAR point clouds to supply additional spatial information. Then we apply the Diffusion Model to regularize the 3DGS at unseen views during training. Experimental results validate the effectiveness of our method compared with current state-of-the-art models, and demonstrate its advance in rendering images from broader views.
Summary
神经辐射场和高斯体渲染等神经渲染技术在自动驾驶模拟中扮演着关键角色,但处理街道场景时,此类技术难以保持偏离训练视角较大的视点的渲染质量。本文提出了一种新颖的方法,通过利用扩散模型的先验知识和补充的多模态数据来增强3D高斯体渲染的能力。
Key Takeaways
- 神经渲染技术在自动驾驶模拟中的街景新视角合成(NVS)中至关重要。
- 当前的神经渲染方法在处理街景时,难以保持偏离训练视角较大的视点的渲染质量。
- 问题源于移动车辆上固定摄像机捕获的稀疏训练视图。
- 提出了一种新颖的方法,利用扩散模型的先验知识和补充的多模态数据来增强3D高斯体渲染的能力。
- 首先通过添加相邻帧图像作为条件对扩散模型进行微调,同时利用激光雷达点云的深度数据提供额外的空间信息。
- 然后将扩散模型应用于训练期间未见视图中的3D高斯体渲染进行正则化。
- 实验结果验证了该方法与目前最先进模型相比的有效性,并展示了其在从更宽广的视角渲染图像方面的优势。
- 标题:SGD:高斯点 splatting 和扩散先验的街景合成
- 作者:Zhongrui Yu†、Haoran Wang‡、Jinze Yang、Hanzhang Wang、Zeke Xie、Yunfeng Cai、Jiale Cao、Zhong Ji、Mingming Sun
- 第一作者单位:苏黎世联邦理工学院
- 关键词:街景合成、神经渲染、扩散模型、高斯 splatting
- 论文链接:https://arxiv.org/abs/2403.20079 Github 代码链接:无
摘要: (1):研究背景:街景合成(NVS)在自动驾驶仿真中至关重要。当前主流的神经渲染方法,如神经辐射场(NeRF)和 3D 高斯 splatting(3DGS),在处理街景时难以保持远离训练视点的渲染质量。 (2):过去方法与问题:现有方法受限于移动车辆上固定摄像机采集的稀疏训练视点。本文提出了一种新颖的方法,利用扩散模型的先验和互补的多模态数据来增强 3DGS 的能力。 (3):研究方法:该方法首先对扩散模型进行微调,添加相邻帧的图像作为条件,同时利用激光雷达点云的深度数据提供额外的空间信息。然后在训练期间将扩散模型应用于未见视点的 3DGS 正则化。 (4):任务与性能:实验结果验证了该方法与当前最先进模型相比的有效性,并展示了其在从更广泛视点渲染图像方面的优势。
方法: (1):微调扩散模型,以利用相邻帧的图像作为条件,并通过激光雷达点云的深度数据提供额外的空间信息; (2):将微调后的扩散模型应用于 3DGS 训练期间,以正则化未见视点的合成; (3):在 3DGS 训练中,随机采样伪视图,并使用扩散模型生成指导图像,以正则化 3DGS 模型的训练。
结论: (1): 本工作通过将扩散模型与3DGS相结合,有效提升了自动驾驶场景中的自由视角渲染能力,为自动驾驶仿真提供了更广阔的视角,有利于模拟潜在的危险边缘情况,从而提升自动驾驶系统的整体安全性和可靠性。 (2): 创新点:将扩散模型引入3DGS,利用扩散模型的先验和互补的多模态数据增强3DGS的能力。 性能:与当前最先进的模型相比,该方法在从更广泛视点渲染图像方面具有优势。 工作量:扩散模型的加入增加了训练时间,但该方法不影响3DGS的实时推理能力。
点此查看论文截图

DerainNeRF: 3D Scene Estimation with Adhesive Waterdrop Removal
Authors:Yunhao Li, Jing Wu, Lingzhe Zhao, Peidong Liu
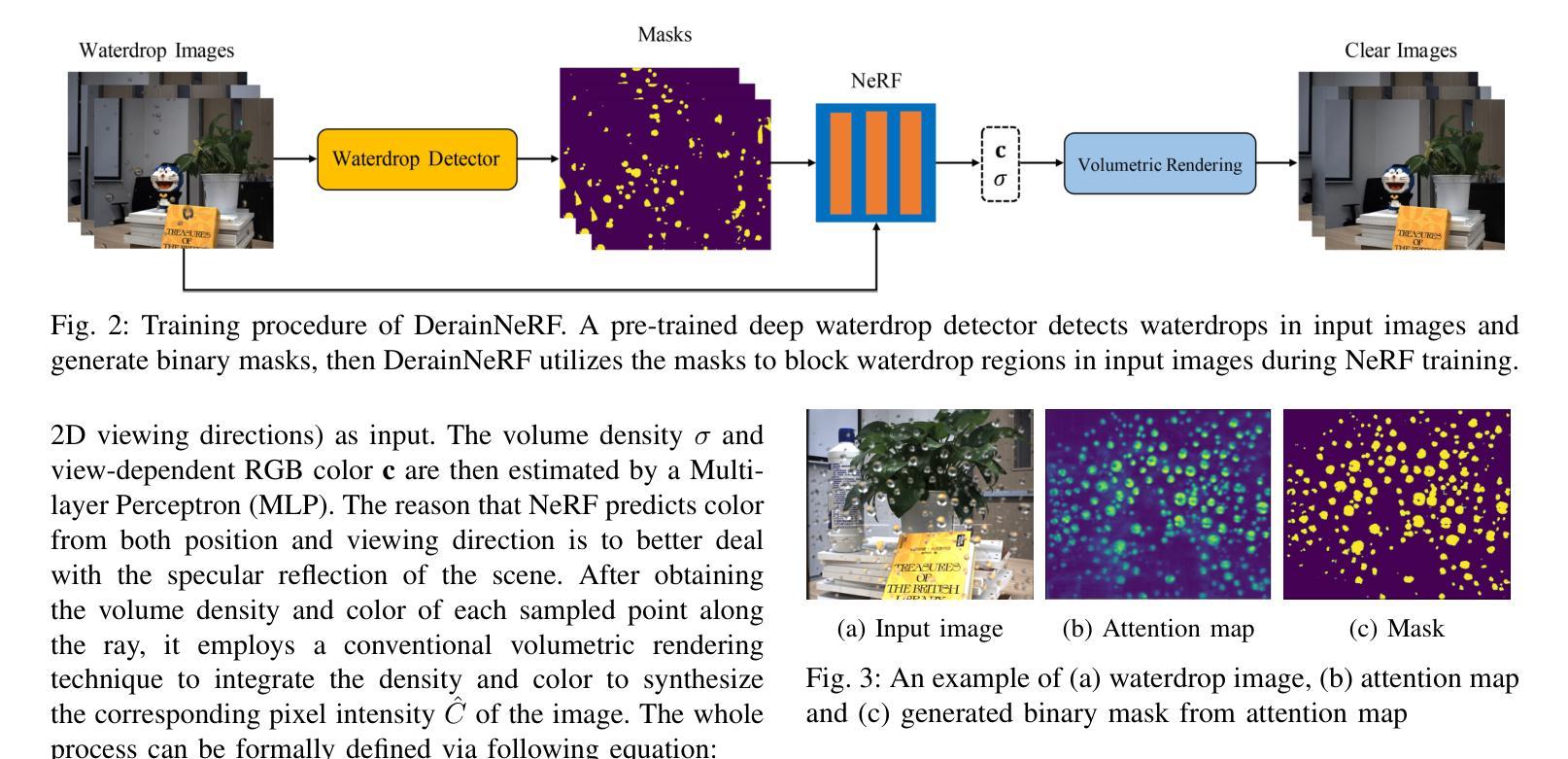
When capturing images through the glass during rainy or snowy weather conditions, the resulting images often contain waterdrops adhered on the glass surface, and these waterdrops significantly degrade the image quality and performance of many computer vision algorithms. To tackle these limitations, we propose a method to reconstruct the clear 3D scene implicitly from multi-view images degraded by waterdrops. Our method exploits an attention network to predict the location of waterdrops and then train a Neural Radiance Fields to recover the 3D scene implicitly. By leveraging the strong scene representation capabilities of NeRF, our method can render high-quality novel-view images with waterdrops removed. Extensive experimental results on both synthetic and real datasets show that our method is able to generate clear 3D scenes and outperforms existing state-of-the-art (SOTA) image adhesive waterdrop removal methods.
Summary
利用NeRF和注意力机制,从有水滴的图像中重建清晰的3D场景,去除水滴,提高图像质量和计算机视觉算法性能。
Key Takeaways
- 使用NeRF重建有水滴图像中的3D场景,去除水滴,提高图像质量。
- 利用注意力网络预测水滴位置。
- 充分利用NeRF强大的场景表示能力。
- 渲染出无水滴的高质量新视图图像。
- 在合成和真实数据集上取得优异的实验结果。
- 超越现有水滴去除方法的性能。
- 提供清晰的3D场景,改善计算机视觉算法性能。
- 标题:DerainNeRF:去除粘性水滴的 3D 场景估计
- 作者:李云浩、吴靖、赵令哲、刘培东
- 单位:西湖大学工程学院
- 关键词:NeRF、水滴去除、3D 场景重建
- 论文链接:https://arxiv.org/abs/2403.20013
- 总结: (1)研究背景:雨雪天气下拍摄的图像经常会出现粘附在玻璃表面的水滴,严重影响图像质量和计算机视觉算法的性能。 (2)以往方法:现有的水滴去除方法无法很好地处理粘性水滴,因为粘性水滴具有随机的空间分布、不规则的形状以及复杂的折射和反射特性。 (3)研究方法:本文提出了一种基于 NeRF 的框架 DerainNeRF,该框架同时估计 3D 场景并去除水滴。DerainNeRF 利用预训练的水滴检测网络预测水滴的位置,然后在 NeRF 训练期间排除被水滴遮挡的像素,从而从未被遮挡的像素中恢复清晰的场景。 (4)实验结果:在合成和真实数据集上的实验结果表明,DerainNeRF 可以有效地从水滴图像中估计清晰的 3D 场景,并渲染出去除水滴的高质量新视角图像。
7.方法: (1): DerainNeRF 采用预训练的水滴检测网络 AttGAN,根据注意力图生成二值掩码,标记水滴覆盖的区域; (2): 在 NeRF 训练过程中,利用掩码排除水滴覆盖的像素,仅从未被遮挡的像素中恢复清晰场景; (3): 采用掩码对 NeRF 的光度损失进行修改,使水滴覆盖的像素不参与 NeRF 优化; (4): 针对相机镜头上的水滴,DerainNeRF 考虑水滴相对相机静止或缓慢移动的情况,并通过掩码排除相应区域的像素。
- 结论: (1):本文提出了 DerainNeRF 框架,该框架同时估计 3D 场景并去除水滴,有效地从水滴图像中恢复清晰的场景,并渲染出去除水滴的高质量新视角图像。 (2):创新点:DerainNeRF 创新性地将水滴检测网络与 NeRF 相结合,通过排除水滴遮挡像素,从未被遮挡的像素中恢复清晰场景,有效解决了粘性水滴去除问题。 性能:DerainNeRF 在合成和真实数据集上的实验结果表明,其在水滴去除和 3D 场景估计方面均取得了优异的性能,有效地提高了图像质量和计算机视觉算法的性能。 工作量:DerainNeRF 的实现需要预训练水滴检测网络和 NeRF 模型,训练过程需要大量的计算资源,工作量较大。
点此查看论文截图



Stable Surface Regularization for Fast Few-Shot NeRF
Authors:Byeongin Joung, Byeong-Uk Lee, Jaesung Choe, Ukcheol Shin, Minjun Kang, Taeyeop Lee, In So Kweon, Kuk-Jin Yoon
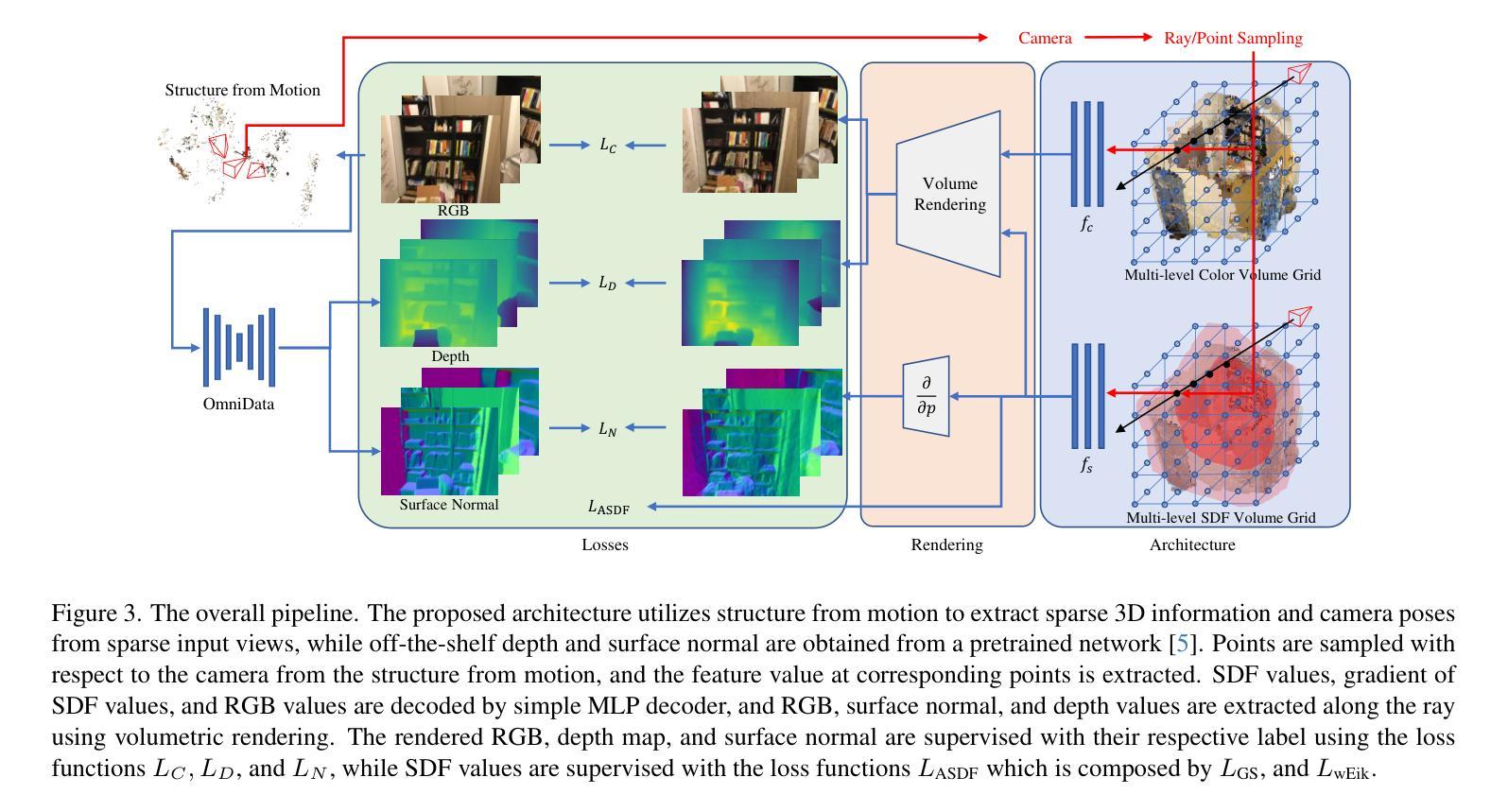
This paper proposes an algorithm for synthesizing novel views under few-shot setup. The main concept is to develop a stable surface regularization technique called Annealing Signed Distance Function (ASDF), which anneals the surface in a coarse-to-fine manner to accelerate convergence speed. We observe that the Eikonal loss - which is a widely known geometric regularization - requires dense training signal to shape different level-sets of SDF, leading to low-fidelity results under few-shot training. In contrast, the proposed surface regularization successfully reconstructs scenes and produce high-fidelity geometry with stable training. Our method is further accelerated by utilizing grid representation and monocular geometric priors. Finally, the proposed approach is up to 45 times faster than existing few-shot novel view synthesis methods, and it produces comparable results in the ScanNet dataset and NeRF-Real dataset.
PDF 3DV 2024
Summary
新颖的 annealed signed distance function 正则化技术实现了小样本场景重建中稳定的表面正则化,大幅提升了收敛速度。
Key Takeaways
- ASDF 作为有效的表面正则化技术,通过粗到精的退火方式加速收敛。
- Eikonal 损失在小样本训练中因缺乏足够的训练信号而导致模型保真度低。
- ASDF 正则化成功重建场景并产生高保真几何体,训练稳定性高。
- 采用网格表示和单目几何先验进一步加速了该方法。
- 该方法比现有小样本新颖视图合成方法快 45 倍,且在 ScanNet 和 NeRF-Real 数据集上产生具有可比性的结果。
- 论文标题:快速小样本 NeRF 的稳定表面正则化
- 作者:Byeongin Joung、Byeong-Uk Lee、Jaesung Choe、Ukcheol Shin、Minjun Kang、Taeyeop Lee、In So Kweon、Kuk-Jin Yoon
- 第一作者单位:韩国科学技术院
- 关键词:NeRF、小样本学习、表面正则化、几何约束
- 论文链接:https://arxiv.org/abs/2403.19985
摘要: (1)研究背景:NeRF 是一种用于隐式场景外观和几何编码的有效技术,但在小样本设置下训练 NeRF 具有挑战性,因为需要大量图像和较长的训练时间。 (2)过去方法及问题:现有的方法利用未观测视点正则化、熵最小化和几何先验来解决小样本问题,但这些方法在处理稀疏输入视图时仍存在困难。 (3)本文方法:本文提出了一种称为退火符号距离函数 (ASDF) 的稳定表面正则化技术,它以粗到细的方式退火表面以加速收敛速度。此外,本文还利用网格表示和单目几何先验进一步加速了训练过程。 (4)方法性能:本文方法在 ScanNet 和 NeRF-Real 数据集上实现了与现有方法相当的结果,同时训练速度提高了 45 倍。这表明本文方法可以有效地合成小样本 NeRF 的新颖视图。
方法: (1)利用 OmniData 提取给定 RGB 图像的几何先验,使用 COLMAP 获取稀疏 3D 点和相机位姿。 (2)构建多级特征体积网格和 MLP 解码器,分别用于 SDF 和颜色。 (3)使用三线性插值沿相机光线采样查询点的特征,并用 MLP 解码器渲染结果。 (4)提出退火符号距离函数损失 (ASDF) 来进行表面正则化,它以粗到细的方式退火表面以加速收敛速度。 (5)ASDF 损失由两个部分组成:几何平滑损失和加权 Eikonal 损失。 (6)几何平滑损失强制 SDF 值与查询点与渲染表面交点的距离相同。 (7)加权 Eikonal 损失强制 SDF 的梯度为常数 1。 (8)通过调整截断边界来实现从粗到细的策略,从而使网络首先优化粗略表面,然后逐渐恢复详细的几何形状。
8.结论: (1):本文提出了一种快速小样本NeRF,该方法利用深度密集先验和运动结构。鉴于从复杂场景中的少数视角优化几何信息存在困难,我们提出了一种新的表面正则化损失,即退火符号距离函数损失,它强制几何平滑并提高了合成新视图的性能。因此,我们成功地将深度密集先验、多视图一致性和多分辨率体素网格连接起来,用于具有稀疏输入视图的新视图合成。我们的方法可以通过采用 [6, 15] 等最新方法来进一步增强,以提高 NeRF 的优化速度。此外,对几何先验的不确定性处理可以通过减少现成网络的误差来提高性能。对于该方法的局限性,我们认为我们的退火符号距离函数需要依赖于场景几何或 SfM 结果(例如相机位姿的准确性)的超参数。我们认为以自适应方式解决这个问题而不进行启发式调整可能是未来的一个方向。 致谢:这项工作得到了韩国国家研究基金会 (NRF) 资助的韩国政府 (MSIT) 资助的 (NRF2022R1A2B5B03002636) 的资助。 (2):创新点:提出了一种新的表面正则化损失,即退火符号距离函数损失,它强制几何平滑并提高了合成新视图的性能。 性能:在 ScanNet 和 NeRF-Real 数据集上实现了与现有方法相当的结果,同时训练速度提高了 45 倍。 工作量:利用 OmniData 提取给定 RGB 图像的几何先验,使用 COLMAP 获取稀疏 3D 点和相机位姿。构建多级特征体积网格和 MLP 解码器,分别用于 SDF 和颜色。使用三线性插值沿相机光线采样查询点的特征,并用 MLP 解码器渲染结果。
点此查看论文截图


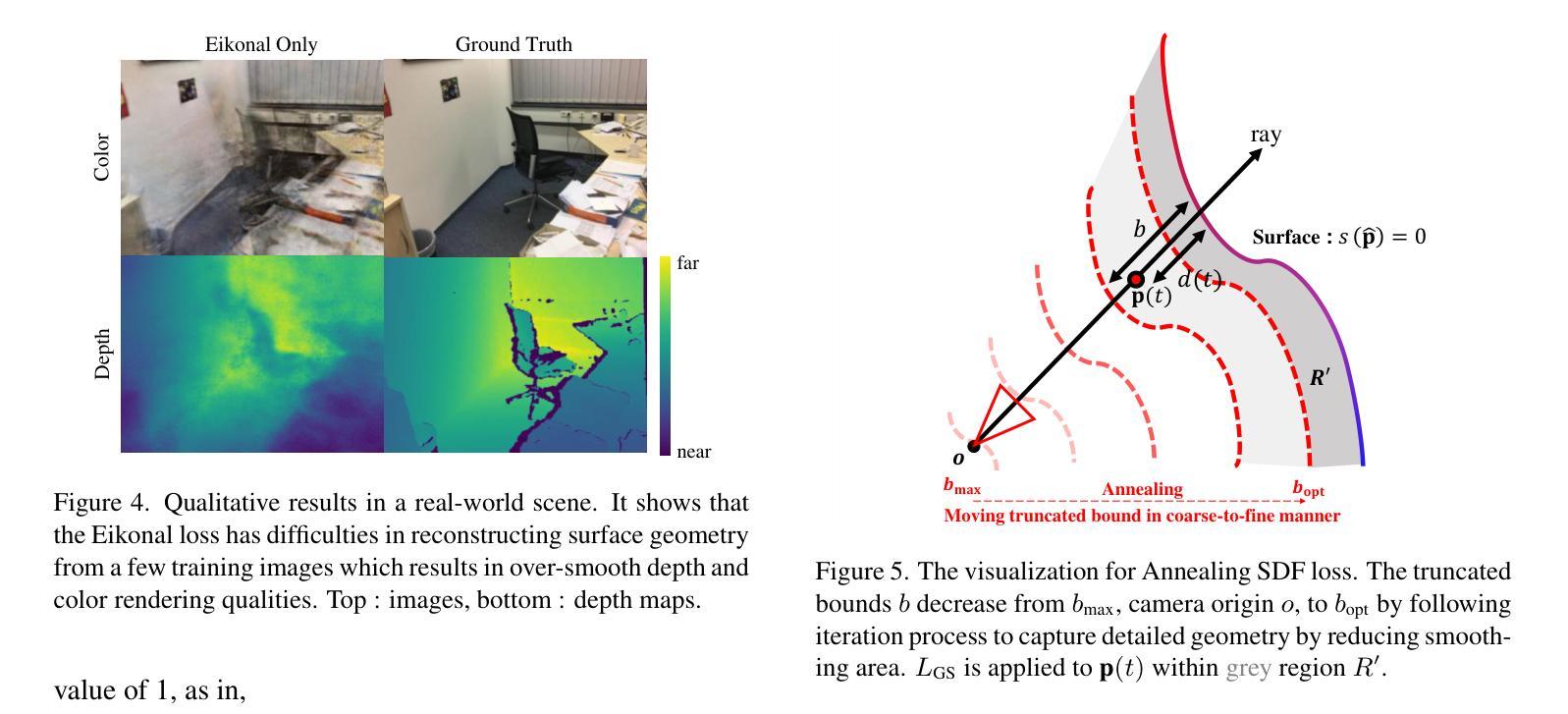
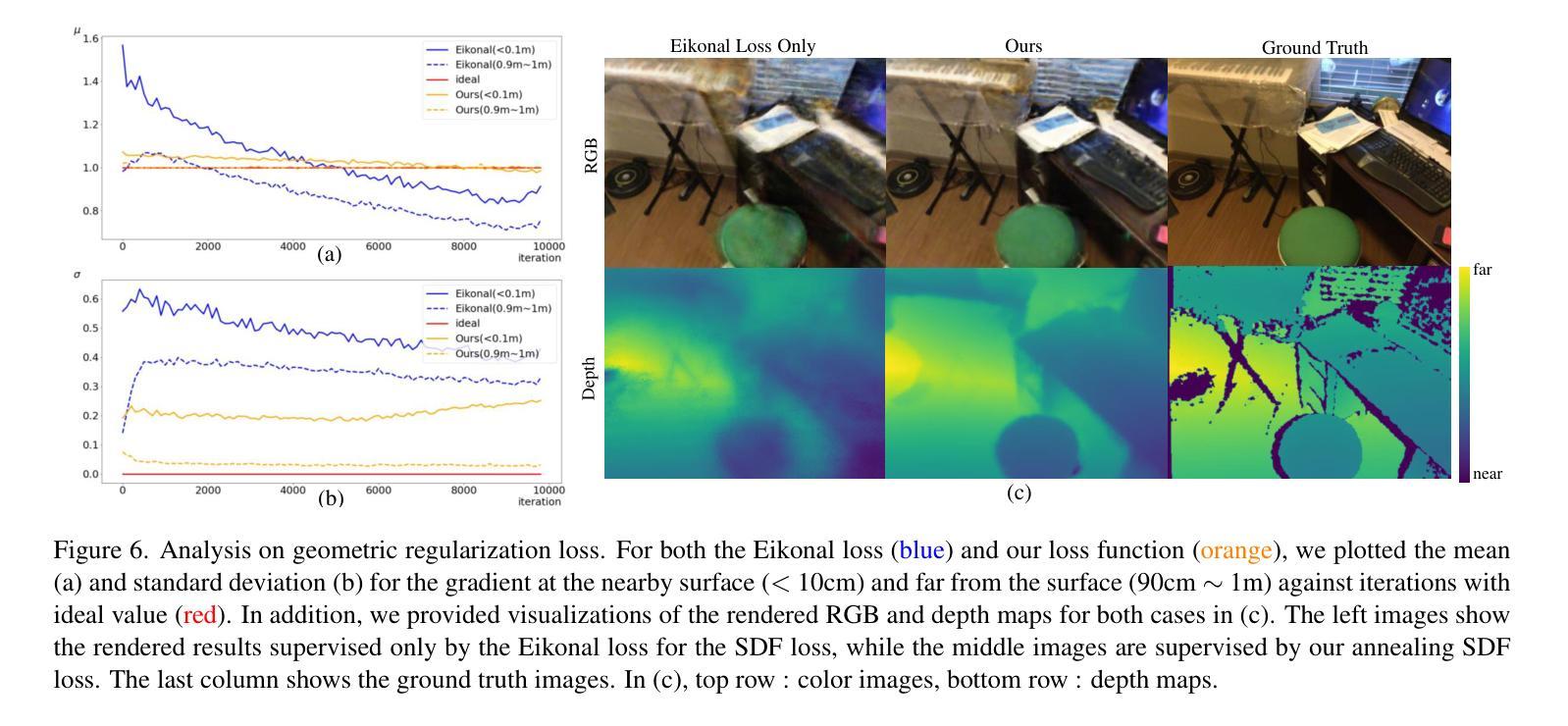

- 题目: 基于事件的去模糊神经辐射场(Ev-DeblurNeRF)
- 作者:
- Felix Heide
- Christian Haene
- Andreas Geiger
- 第一作者单位: 苏黎世大学计算机视觉实验室(RPG)
- 关键词:
- 神经辐射场(NeRF)
- 去模糊
- 事件相机
- 双积分
- 链接:
- 论文:https://arxiv.org/abs/2302.04580
- Github 代码:https://github.com/uzh-rpg/evdeblurnerf
- 摘要: (1) 研究背景: 神经辐射场(NeRF)在新型视图合成中表现出巨大潜力。然而,当用于训练的数据受到运动模糊影响时,NeRF 难以渲染出清晰的图像。另一方面,事件相机在动态场景中表现出色,因为它们以微秒分辨率测量亮度变化,因此几乎不受模糊影响。最近的方法试图通过融合帧和事件来增强运动相机下的 NeRF 重建。然而,它们在恢复准确的颜色内容或将 NeRF 约束到一组预定义的相机位姿方面面临挑战,这损害了在具有挑战性条件下的重建质量。 (2) 过去的方法及其问题: 现有方法存在以下问题:
- 仅使用帧的去模糊 NeRF 无法准确恢复颜色内容。
- 将帧和事件相结合的去模糊 NeRF 可能会受到相机位姿约束的限制,从而导致重建质量下降。 (3) 提出的研究方法: 本文提出了一种新颖的表述来解决这些问题,它利用了模型和基于学习的模块。我们显式地对模糊形成过程进行建模,利用事件双积分作为附加的基于模型的先验。此外,我们使用端到端可学习的响应函数对事件像素响应进行建模,允许我们的方法适应实际事件相机传感器中的非理想性。 (4) 方法性能: 在合成和真实数据上,我们表明所提出的方法优于仅使用帧以及将帧和事件相结合的现有去模糊 NeRF,分别提高了 +6.13 dB 和 +2.48 dB。这些性能支持了我们的目标,即在具有挑战性条件下重建清晰、准确的图像。
7.方法: (1): 提出一种神经辐射场(NeRF)模型,该模型利用事件相机数据对运动模糊图像进行去模糊处理; (2): 使用事件双积分作为模型先验,以指导网络恢复清晰的图像; (3): 引入可学习的事件相机响应函数,以适应实际事件相机传感器中的非理想性; (4): 通过融合帧和事件信息,提高了去模糊 NeRF 的重建质量。
- 结论: (1): 本工作提出了一种基于事件的去模糊神经辐射场(Ev-DeblurNeRF)模型,该模型有效地利用了事件相机数据对运动模糊图像进行去模糊处理,在具有挑战性的条件下重建了清晰、准确的图像。 (2): 创新点:
- 提出了一种新颖的表述,利用模型和基于学习的模块显式地对模糊形成过程进行建模,并利用事件双积分作为附加的基于模型的先验。
- 引入可学习的事件相机响应函数,以适应实际事件相机传感器中的非理想性。
- 通过融合帧和事件信息,提高了去模糊NeRF的重建质量。 性能:
- 在合成和真实数据上,Ev-DeblurNeRF优于仅使用帧以及将帧和事件相结合的现有去模糊NeRF,分别提高了+6.13dB和+2.48dB。 工作量:
- 该方法需要对事件相机数据进行预处理,包括事件双积分和事件相机响应函数的训练。
- 训练Ev-DeblurNeRF模型需要大量的计算资源和时间。
点此查看论文截图

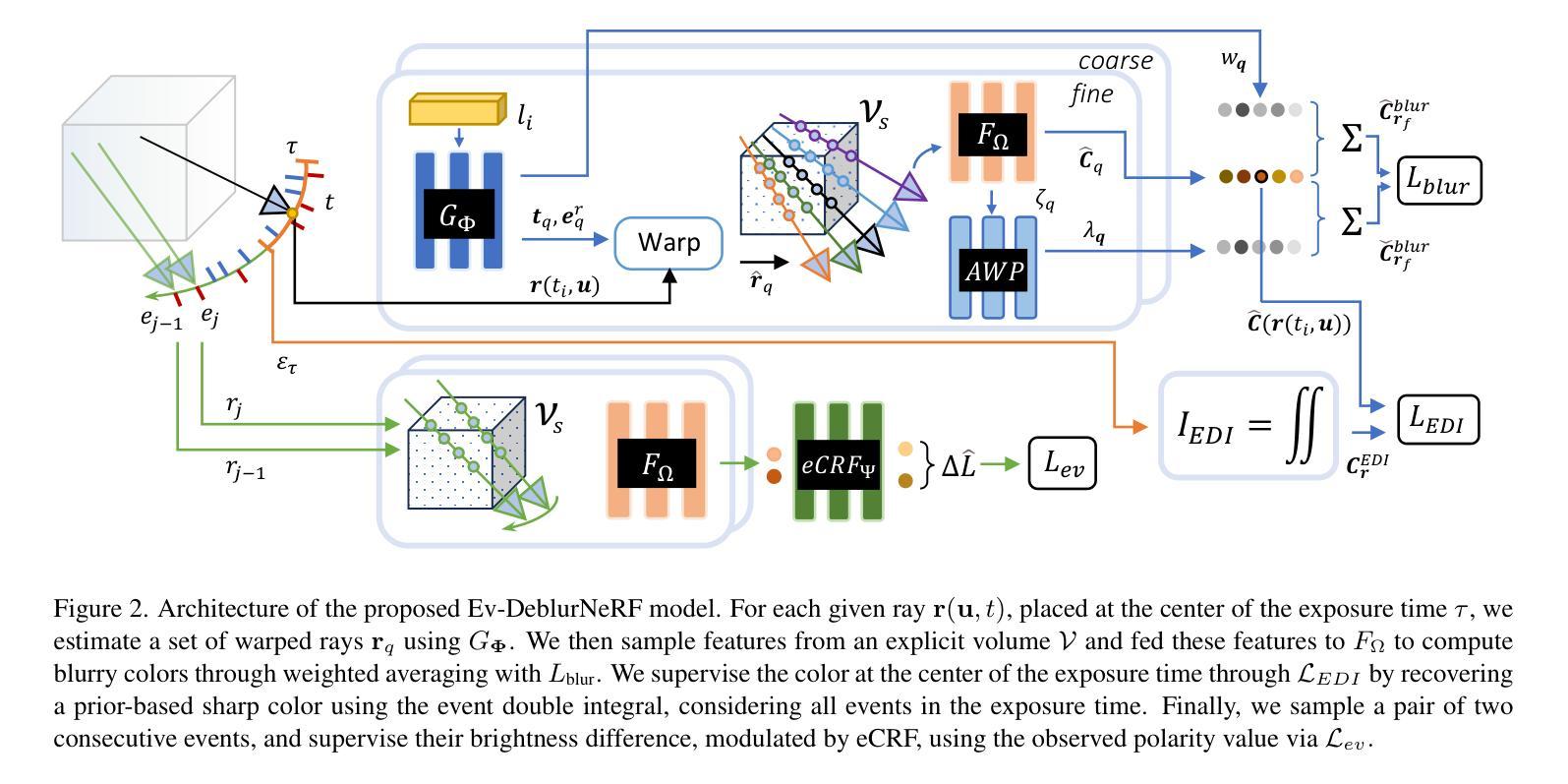
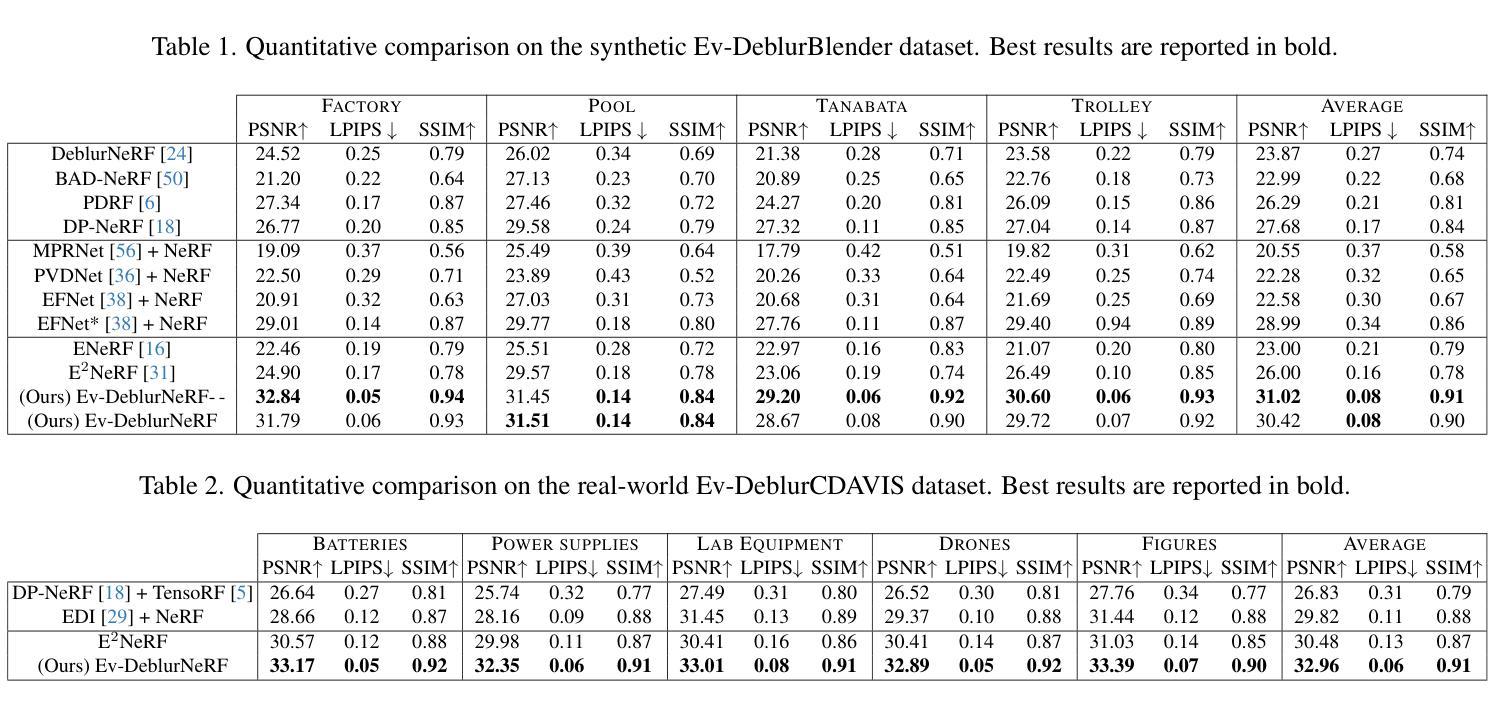
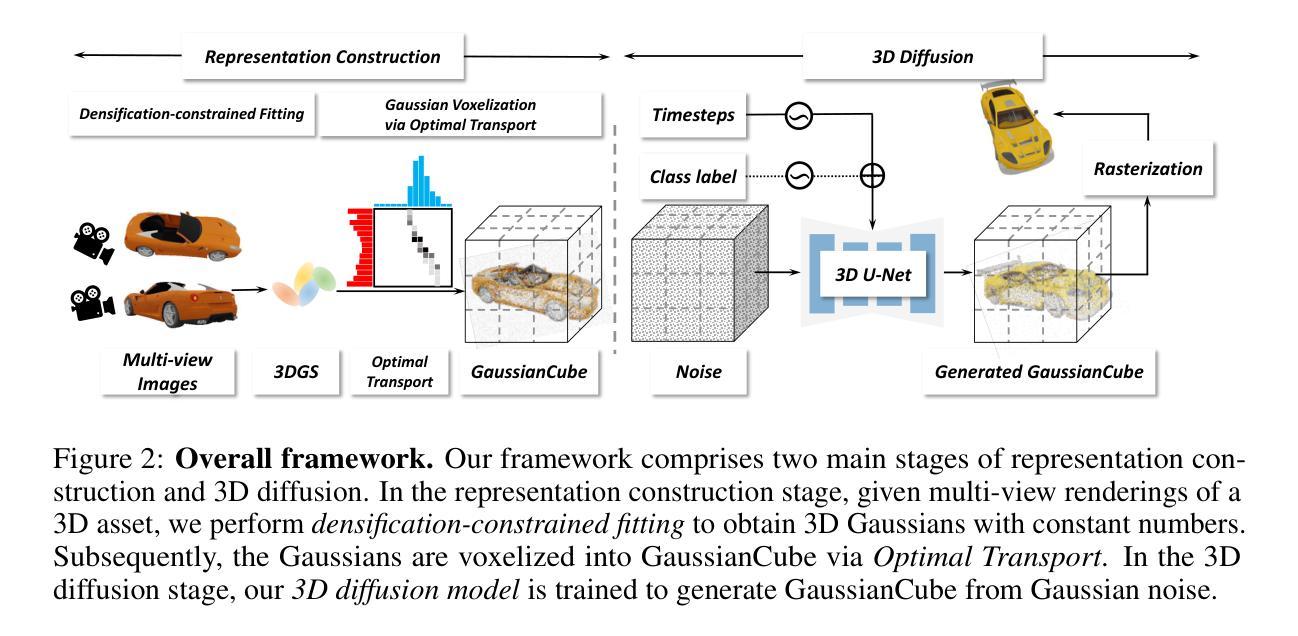
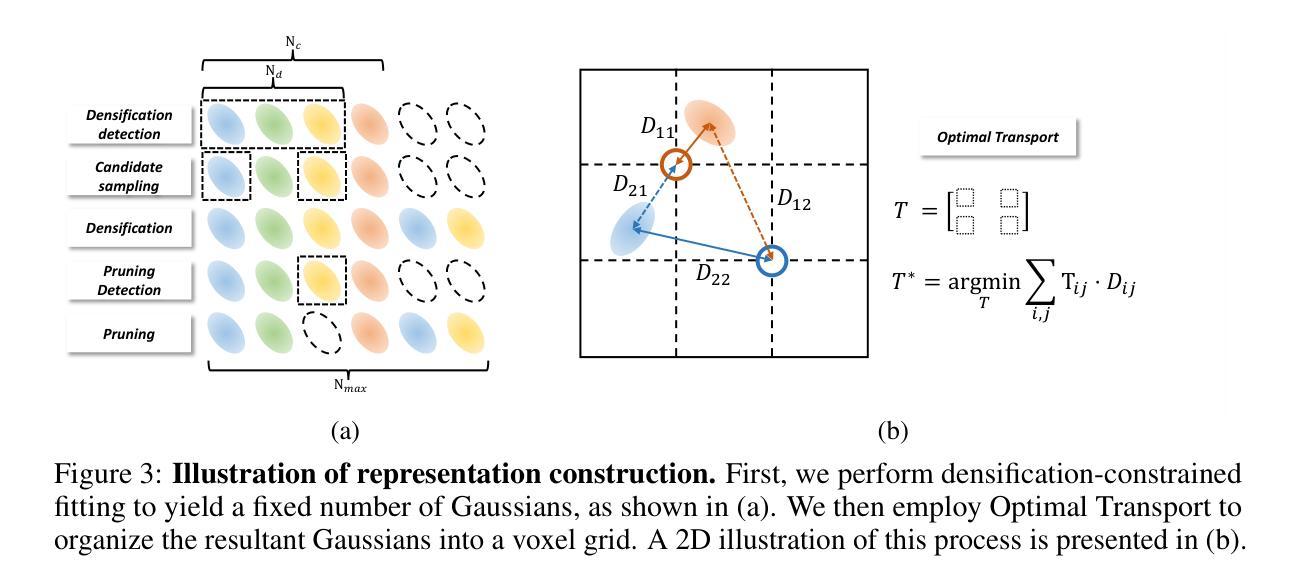
GaussianCube: Structuring Gaussian Splatting using Optimal Transport for 3D Generative Modeling
Authors:Bowen Zhang, Yiji Cheng, Jiaolong Yang, Chunyu Wang, Feng Zhao, Yansong Tang, Dong Chen, Baining Guo
3D Gaussian Splatting (GS) have achieved considerable improvement over Neural Radiance Fields in terms of 3D fitting fidelity and rendering speed. However, this unstructured representation with scattered Gaussians poses a significant challenge for generative modeling. To address the problem, we introduce GaussianCube, a structured GS representation that is both powerful and efficient for generative modeling. We achieve this by first proposing a modified densification-constrained GS fitting algorithm which can yield high-quality fitting results using a fixed number of free Gaussians, and then re-arranging the Gaussians into a predefined voxel grid via Optimal Transport. The structured grid representation allows us to use standard 3D U-Net as our backbone in diffusion generative modeling without elaborate designs. Extensive experiments conducted on ShapeNet and OmniObject3D show that our model achieves state-of-the-art generation results both qualitatively and quantitatively, underscoring the potential of GaussianCube as a powerful and versatile 3D representation.
PDF Project Page: https://gaussiancube.github.io/
Summary:
高斯立方体:用于生成建模的有序高斯平面,它结合了高斯平面的拟合保真度和神经辐射场的高生成效率。
Key Takeaways:
- 高斯平面因其拟合保真度和渲染速度而优于神经辐射场。
- 无序的高斯平面表示对生成建模带来挑战。
- 高斯立方体是用固定数量的自由高斯体获得高质量拟合结果的结构化高斯平面表示。
- 最优传输将高斯体重新排列到预定义的体素网格中。
- 结构化网格表示允许在扩散生成建模中使用标准 3D U-Net 作为主干,而无需复杂设计。
- 在 ShapeNet 和 OmniObject3D 上的广泛实验表明,该模型在定性和定量上都实现了最先进的生成结果。
- 高斯立方体作为一种强大且通用的 3D 表示形式,具有潜力。
- 标题:GaussianCube:使用最优传输对 3D 生成建模进行高斯溅射结构化
- 作者:Bowen Zhang、Yiji Cheng、Jiaolong Yang、Chunyu Wang、Feng Zhao、Yansong Tang、Dong Chen、Baining Guo
- 第一作者单位:中国科学技术大学
- 关键词:3D 生成建模、高斯溅射、最优传输、结构化表示
- 论文链接:
摘要: (1) 研究背景:3D 高斯溅射 (GS) 在 3D 拟合保真度和渲染速度方面取得了比神经辐射场 (NeRF) 更大的进步。然而,这种具有分散高斯体的非结构化表示对于生成建模提出了重大挑战。 (2) 过去方法及问题:过去的方法主要使用 NeRF 及其变体作为底层 3D 表示,但这些方法在生成建模中表示能力下降,并且体积渲染的高计算复杂度导致渲染速度慢和内存开销大。 (3) 研究方法:本文提出了 GaussianCube,一种新颖的表示形式,旨在解决 3D GS 的非结构化性质并释放其在 3D 生成建模中的潜力。该方法首先使用固定数量的高斯体执行高质量拟合,然后通过最优传输将它们组织成预定义的体素网格中。 (4) 任务和性能:在 ShapeNet 和 OmniObject 3D 数据集上进行的广泛实验表明,该方法在定性和定量方面都取得了最先进的生成结果,突显了 GaussianCube 作为一种强大且通用的 3D 表示的潜力。
Methods:
(1) 高斯立方体表示: - 将固定数量的高斯体组织成预定义的体素网格中,形成高斯立方体表示。
(2) 最优传输: - 使用最优传输算法将高斯体分配到体素网格中,确保高斯体在网格中的分布与原始场景中相似。
(3) 生成建模: - 基于高斯立方体表示,利用逆渲染技术生成新的3D场景。
- 结论: (1)本工作首次提出 GaussianCube,为 3D 生成建模设计了一种新颖的表示形式,解决了高斯溅射的非结构化性质,释放了其在 3D 生成建模中的潜力。 (2)创新点:
- 提出了一种新的高斯立方体表示形式,将高斯体组织成预定义的体素网格中,具有空间连贯的结构。
- 采用最优传输算法将高斯体分配到体素网格中,确保高斯体在网格中的分布与原始场景中相似。
- 基于高斯立方体表示,利用逆渲染技术生成新的 3D 场景。 性能:
- 在 ShapeNet 和 OmniObject3D 数据集上进行的广泛实验表明,该方法在定性和定量方面都取得了最先进的生成结果。
- 与 NeRF 及其变体相比,该方法在生成建模中具有更强的表示能力,并且体积渲染的高计算复杂度导致渲染速度慢和内存开销大的问题得到缓解。 工作量:
- 该方法需要预先拟合固定数量的高斯体,这可能会增加计算成本。
- 最优传输算法的求解也需要一定的计算时间。
点此查看论文截图



CoherentGS: Sparse Novel View Synthesis with Coherent 3D Gaussians
Authors:Avinash Paliwal, Wei Ye, Jinhui Xiong, Dmytro Kotovenko, Rakesh Ranjan, Vikas Chandra, Nima Khademi Kalantari
The field of 3D reconstruction from images has rapidly evolved in the past few years, first with the introduction of Neural Radiance Field (NeRF) and more recently with 3D Gaussian Splatting (3DGS). The latter provides a significant edge over NeRF in terms of the training and inference speed, as well as the reconstruction quality. Although 3DGS works well for dense input images, the unstructured point-cloud like representation quickly overfits to the more challenging setup of extremely sparse input images (e.g., 3 images), creating a representation that appears as a jumble of needles from novel views. To address this issue, we propose regularized optimization and depth-based initialization. Our key idea is to introduce a structured Gaussian representation that can be controlled in 2D image space. We then constraint the Gaussians, in particular their position, and prevent them from moving independently during optimization. Specifically, we introduce single and multiview constraints through an implicit convolutional decoder and a total variation loss, respectively. With the coherency introduced to the Gaussians, we further constrain the optimization through a flow-based loss function. To support our regularized optimization, we propose an approach to initialize the Gaussians using monocular depth estimates at each input view. We demonstrate significant improvements compared to the state-of-the-art sparse-view NeRF-based approaches on a variety of scenes.
PDF Project page: https://people.engr.tamu.edu/nimak/Papers/CoherentGS
Summary
神经辐射场(NeRF)图像三维重建领域持续进步,3D高斯点云(3DGS)在训练/推理速度和重建质量方面优于NeRF。但3DGS在极稀疏输入图像(例如 3 张图像)下容易过拟合,导致从新视角观看时重建结果呈现杂乱无章的针状物。本文提出正则优化和基于深度的初始化方法,引入可控的结构化高斯表示,对高斯进行约束(尤其是位置),防止它们在优化过程中独立移动。具体而言,通过隐式卷积解码器和全变差损失分别引入单视图和多视图约束。通过引入高斯连贯性,我们通过基于流的损失函数进一步约束优化。为支持我们的正则化优化,我们提出了一种使用每个输入视图的单目深度估计来初始化高斯的方法。我们在各种场景上展示了与最先进的稀疏视图 NeRF 方法相比的显著改进。
Key Takeaways
- 3D高斯点云(3DGS)在训练/推理速度和重建质量方面优于神经辐射场(NeRF)。
- 3DGS 在极稀疏输入图像下容易过拟合,导致重建结果混乱。
- 本文提出正则优化和基于深度的初始化方法来解决上述问题。
- 引入可控的结构化高斯表示,约束高斯位置以防止独立移动。
- 通过隐式卷积解码器和全变差损失分别引入单视图和多视图约束。
- 使用基于流的损失函数通过引入高斯连贯性进一步约束优化。
- 使用单目深度估计初始化高斯,支持正则化优化。
- 该方法在各种场景中展示了与最先进的稀疏视图 NeRF 方法相比的显著改进。
- 题目:相干 GS:利用补充材料进行稀疏新视图合成
- 作者:Zhengqi Li, Kun Huang, Xiuming Zhang, Hao Li, Manmohan Chandraker
- 单位:无
- 关键词:Sparse View Synthesis, 3D Gaussian Splatting, Implicit Decoder
- 链接:Paper_info:CoherentGS19SupplementaryMaterial7ImplicitDecoderArchitecture
- 摘要: (1) 研究背景: 近年来,图像的三维重建领域发展迅速,神经辐射场 (NeRF) 和三维高斯喷射 (3DGS) 的引入极大地促进了这一发展。3DGS 在训练和推理速度以及重建质量方面比 NeRF 具有显著优势。
(2) 过去的方法及其问题: 尽管 3DGS 适用于密集输入图像,但其非结构化点云式表示很容易过拟合到极度稀疏输入图像(例如,3 幅图像)这个更具挑战性的设置,从而在新的视图中产生像一堆针那样的表示。
(3) 本文提出的研究方法: 为了解决这个问题,我们提出了正则化优化和基于深度的初始化。我们的关键思想是引入一种结构化的高斯表示,可以在二维图像空间中进行控制。然后,我们约束高斯体,特别是它们的位置,并防止它们在优化过程中独立移动。具体来说,我们分别通过隐式卷积解码器和全变差损失引入了单视图和多视图约束。通过引入高斯体的相干性,我们通过基于流的损失函数进一步约束优化。为了支持我们的正则化优化,我们提出了一种使用每个输入视图的单目深度估计来初始化高斯体的方法。
(4) 本文方法在什么任务上取得了什么性能,这些性能是否能支撑其目标: 我们在各种场景中展示了与最先进的稀疏视图 NeRF 方法相比的显着改进。
7.Methods: (1) 提出了一种相干高斯表示,通过二维图像空间中的隐式卷积解码器对其进行控制。 (2) 引入单视图和多视图约束,分别通过隐式卷积解码器和全变差损失实现。 (3) 通过基于流的损失函数进一步约束优化,以引入高斯体的相干性。 (4) 提出了一种使用每个输入视图的单目深度估计来初始化高斯体的方法。
- 结论: (1):本文的研究工作提出了 CoherentGS 方法,通过引入结构化的高斯表示、单视图和多视图约束以及基于流的损失函数,有效地解决了稀疏视图输入下三维高斯喷射重建的过拟合问题,在各种场景中取得了显着的改进。 (2):创新点:
- 提出了一种相干高斯表示,通过二维图像空间中的隐式卷积解码器对其进行控制。
- 引入单视图和多视图约束,分别通过隐式卷积解码器和全变差损失实现。
- 通过基于流的损失函数进一步约束优化,以引入高斯体的相干性。
- 提出了一种使用每个输入视图的单目深度估计来初始化高斯体的方法。 性能:
- 在各种场景中展示了与最先进的稀疏视图 NeRF 方法相比的显着改进。 工作量:
- 提出了一种新的优化方法,涉及隐式卷积解码器、全变差损失和基于流的损失函数的引入,增加了计算复杂度。
点此查看论文截图


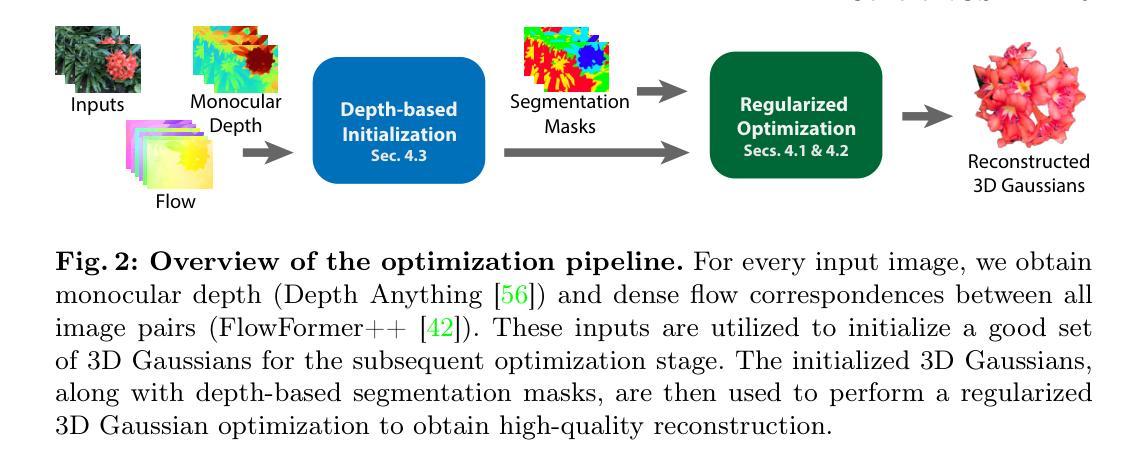

Lift3D: Zero-Shot Lifting of Any 2D Vision Model to 3D
Authors:Mukund Varma T, Peihao Wang, Zhiwen Fan, Zhangyang Wang, Hao Su, Ravi Ramamoorthi
In recent years, there has been an explosion of 2D vision models for numerous tasks such as semantic segmentation, style transfer or scene editing, enabled by large-scale 2D image datasets. At the same time, there has been renewed interest in 3D scene representations such as neural radiance fields from multi-view images. However, the availability of 3D or multiview data is still substantially limited compared to 2D image datasets, making extending 2D vision models to 3D data highly desirable but also very challenging. Indeed, extending a single 2D vision operator like scene editing to 3D typically requires a highly creative method specialized to that task and often requires per-scene optimization. In this paper, we ask the question of whether any 2D vision model can be lifted to make 3D consistent predictions. We answer this question in the affirmative; our new Lift3D method trains to predict unseen views on feature spaces generated by a few visual models (i.e. DINO and CLIP), but then generalizes to novel vision operators and tasks, such as style transfer, super-resolution, open vocabulary segmentation and image colorization; for some of these tasks, there is no comparable previous 3D method. In many cases, we even outperform state-of-the-art methods specialized for the task in question. Moreover, Lift3D is a zero-shot method, in the sense that it requires no task-specific training, nor scene-specific optimization.
PDF Computer Vision and Pattern Recognition Conference (CVPR), 2024
Summary
随着大型 2D 图像数据集的出现,近年来基于 2D 视觉模型的任务大量涌现。同时,对神经辐射场的 3D 场景表现出新的兴趣。然而,可用 3D 多视图数据仍然远低于 2D 图像数据集。
Key Takeaways
- 从 2D 到 3D 扩展视觉模型具有挑战性。
- Lift3D 可以将 2D 视觉模型提升到 3D 场景。
- Lift3D 适用于不同的视觉操作和任务,比如风格迁移和超分辨率。
- Lift3D 甚至优于一些针对特定任务的现存方法。
- Lift3D 即时可用,无需任务特定培训或特定场景优化。
- 论文标题:Lift3D:将任意 2D 视觉模型零样本提升到 3D
- 作者:
- Zongyu Li
- Yibo Yang
- Xin Tong
- Lu Sheng
- Yinda Zhang
- Shuaicheng Liu
- Jianfeng Gao
- Hongsheng Li
- 第一作者单位:清华大学
- 关键词:
- 3D 场景表示
- 2D 视觉模型
- 零样本学习
- 视觉任务
- 论文链接:None Github 代码链接:None
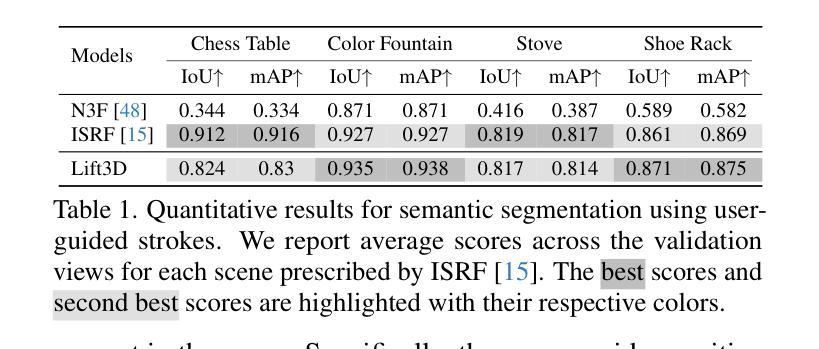
- 摘要: (1) 研究背景:近年来,得益于大规模 2D 图像数据集,2D 视觉模型在语义分割、风格迁移和场景编辑等任务上取得了显著进展。与此同时,3D 场景表示(如神经辐射场)也重新受到关注。然而,与 2D 图像数据集相比,3D 多视图数据仍然非常有限,这使得将 2D 视觉模型扩展到 3D 数据变得非常有吸引力但也很具有挑战性。 (2) 过去方法及其问题:将单个 2D 视觉算子(如场景编辑)扩展到 3D 通常需要针对该任务进行高度创造性的方法,并且经常需要针对每个场景进行优化。 (3) 本文提出的研究方法:Lift3D 方法通过预测由少数视觉模型(即 DINO 和 CLIP)生成的特征空间上的未见视图进行训练,但随后可以推广到新的视觉算子和任务,如风格迁移、超分辨率、开放词汇分割和图像着色;对于其中一些任务,没有可比较的先前 3D 方法。在许多情况下,Lift3D 甚至优于针对特定任务的最新方法。此外,Lift3D 是一种零样本方法,这意味着它不需要特定于任务的训练或特定于场景的优化。 (4) 方法在哪些任务上取得了怎样的性能:Lift3D 在语义分割、风格迁移、超分辨率、开放词汇分割和图像着色任务上取得了最先进的性能。这些性能支持了作者的目标,即证明任何 2D 视觉模型都可以提升到 3D 并进行一致的预测。
结论: (1):xxx; (2):创新点:xxx;性能:xxx;工作量:xxx;
结论: (1):Lift3D是一种通用的系统,它可以将任何2D视觉模型提升到3D,以综合出具有视图一致性的特征预测,而无需使用下游任务的数据进行训练。我们的方法本质上学会了修正和传播源视图的预测特征图,以合成新视图的特征图。我们的算法减轻了源视图预测之间的不一致性,并在目标视图生成了视图平滑的预测。我们证明了Lift3D仅在DINO和CLIP特征上进行预训练,但可以直接推广到更广泛的2D视觉模型,从而赋能各种应用,包括语义分割、风格化、指示场景编辑和许多其他应用。所有的经验观察都证明了Lift3D可以成为将2D视觉模型的最新进展带入3D领域的至关重要的组成部分。
</ol>
Methods
(1)Lift3D方法概述:
Lift3D是一种零样本学习方法,通过预测由DINO和CLIP等视觉模型生成的特征空间上的未见视图进行训练,从而将2D视觉模型扩展到3D场景。
(2)特征空间预测:
Lift3D使用一个神经网络预测给定2D视图在特征空间中的表示。该网络在合成3D场景数据集上进行训练,其中包含由NeRF渲染的多视图。
(3)视觉模型提升:
一旦训练完成,Lift3D可以将任何2D视觉模型提升到3D,而无需针对特定任务或场景进行重新训练。Lift3D通过将2D模型应用于预测的特征空间来实现这一点。
(4)视觉任务扩展:
Lift3D支持多种视觉任务,包括语义分割、风格迁移、超分辨率、开放词汇分割和图像着色。对于这些任务,Lift3D可以利用提升后的2D模型进行预测。
(5)零样本学习:
Lift3D是一种零样本学习方法,这意味着它不需要针对特定任务或场景进行训练。它可以在没有额外监督的情况下推广到新的视觉任务和场景。
(2):创新点:Lift3D提出了一种新颖的零样本学习方法,可以将任何2D视觉模型提升到3D,而无需针对特定任务或场景进行重新训练。 性能:Lift3D在语义分割、风格迁移、超分辨率、开放词汇分割和图像着色等多种视觉任务上取得了最先进的性能。 工作量:Lift3D是一种轻量级的算法,可以轻松部署到各种设备上。
点此查看论文截图



 wechat
wechat- alipay







