3DGS
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-06 更新
Per-Gaussian Embedding-Based Deformation for Deformable 3D Gaussian Splatting
Authors:Jeongmin Bae, Seoha Kim, Youngsik Yun, Hahyun Lee, Gun Bang, Youngjung Uh
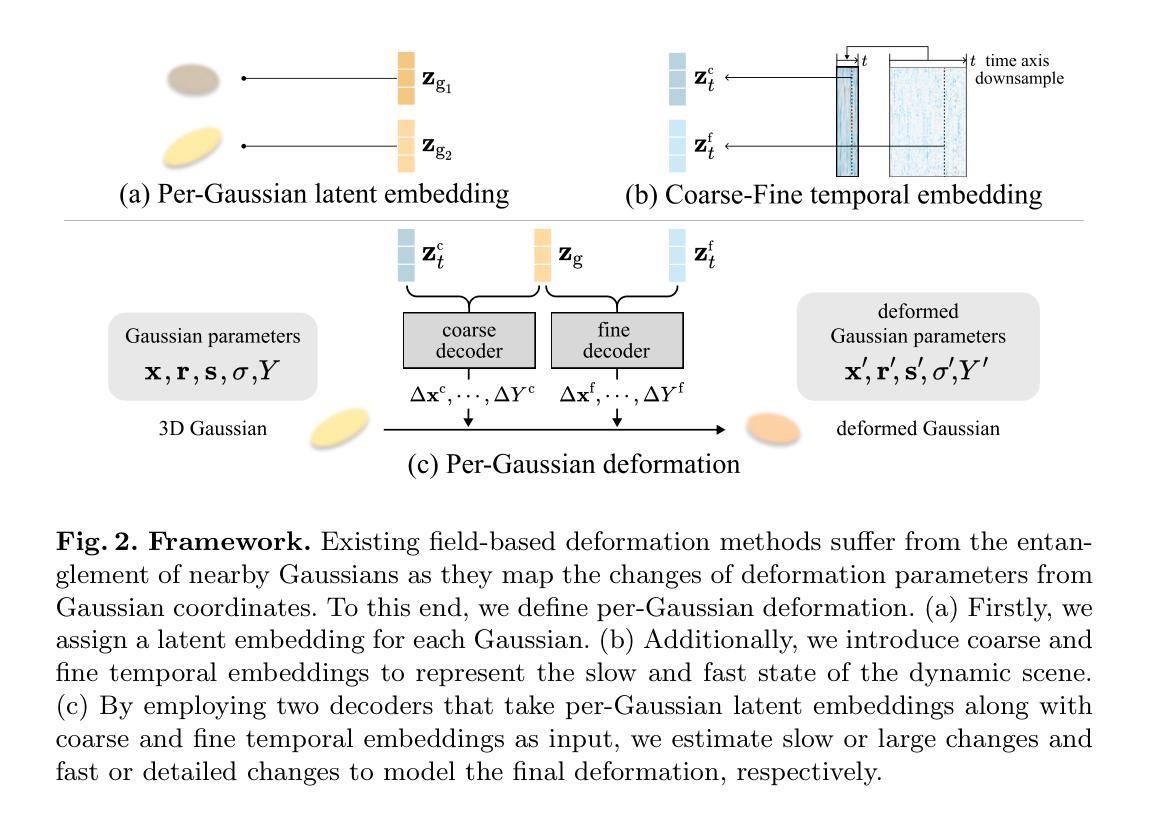
As 3D Gaussian Splatting (3DGS) provides fast and high-quality novel view synthesis, it is a natural extension to deform a canonical 3DGS to multiple frames. However, previous works fail to accurately reconstruct dynamic scenes, especially 1) static parts moving along nearby dynamic parts, and 2) some dynamic areas are blurry. We attribute the failure to the wrong design of the deformation field, which is built as a coordinate-based function. This approach is problematic because 3DGS is a mixture of multiple fields centered at the Gaussians, not just a single coordinate-based framework. To resolve this problem, we define the deformation as a function of per-Gaussian embeddings and temporal embeddings. Moreover, we decompose deformations as coarse and fine deformations to model slow and fast movements, respectively. Also, we introduce an efficient training strategy for faster convergence and higher quality. Project page: https://jeongminb.github.io/e-d3dgs/
PDF Preprint
Summary
3D 高斯斑点采样通过变形网格来实现动态场景的精确重建,解决了以往作品的局限性,包括静态部件沿着动态部件移动和动态区域模糊的问题。
Key Takeaways
- 动态场景变形重建存在问题,包括静态部件沿动态部件移动和动态区域模糊。
- 问题的根源在于变形场的错误设计,需采用基于混合高斯核的函数。
- 变形定义为基于高斯嵌入和时间嵌入的函数,可分解为粗略和精细变形。
- 引入高效训练策略,加速收敛并提升质量。
- 该研究通过变形网格实现了动态场景的精确重建。
- 提出了一种新的变形场设计,基于每个高斯核的嵌入和时间嵌入。
- 采用粗略和精细变形相结合的方式,分别建模缓慢和快速运动。
- 标题:基于高斯嵌入的变形
- 作者:Jeongmin Bae、Seoha Kim、Youngsik Yun、Hahyun Lee、Gun Bang、Youngjung Uh
- 所属单位:延世大学
- 关键词:高斯散布、动态场景重建、新颖视图合成
- 论文链接:https://arxiv.org/abs/2404.03613 Github 链接:无
摘要: (1) 研究背景: 3D 高斯散布(3DGS)提供快速且高质量的新颖视图合成,将正则 3DGS 变形到多个帧是其自然延伸。然而,以往的研究无法准确重建动态场景,特别是:1)静止部分沿着附近的动态部分移动;2)一些动态区域模糊。 (2) 过去的方法及其问题: 将变形场设计为基于坐标的函数,这是导致上述问题的原因。这种方法存在问题,因为 3DGS 是以高斯为中心的多个场的混合,而不仅仅是一个基于坐标的框架。 (3) 本文提出的研究方法: 将变形定义为每个高斯嵌入和时间嵌入的函数。此外,将变形分解为粗略变形和精细变形,分别对慢速运动和快速运动进行建模。还引入了一种有效的训练策略,以实现更快的收敛和更高的质量。 (4) 方法在任务和性能上的表现: 该方法在动态场景重建任务上实现了先进的性能。它可以准确地重建动态场景,同时避免静止部分沿附近动态部分移动和动态区域模糊的问题。这些性能支持了本文的目标,即准确重建动态场景。
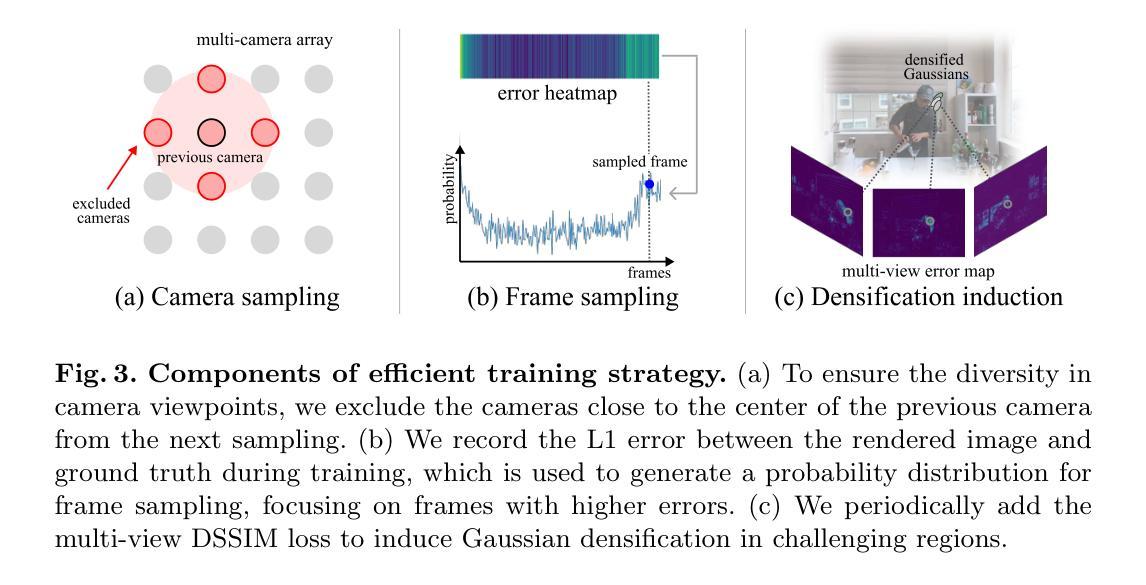
Methods: (1): 将变形定义为每个高斯嵌入和时间嵌入的函数,以解决以往基于坐标的变形函数的局限性。 (2): 将变形分解为粗略变形和精细变形,分别建模慢速运动和快速运动,从而提高重建精度。 (3): 提出了一种有效的训练策略,包括预训练、联合训练和细化训练,以实现更快的收敛和更高的质量。
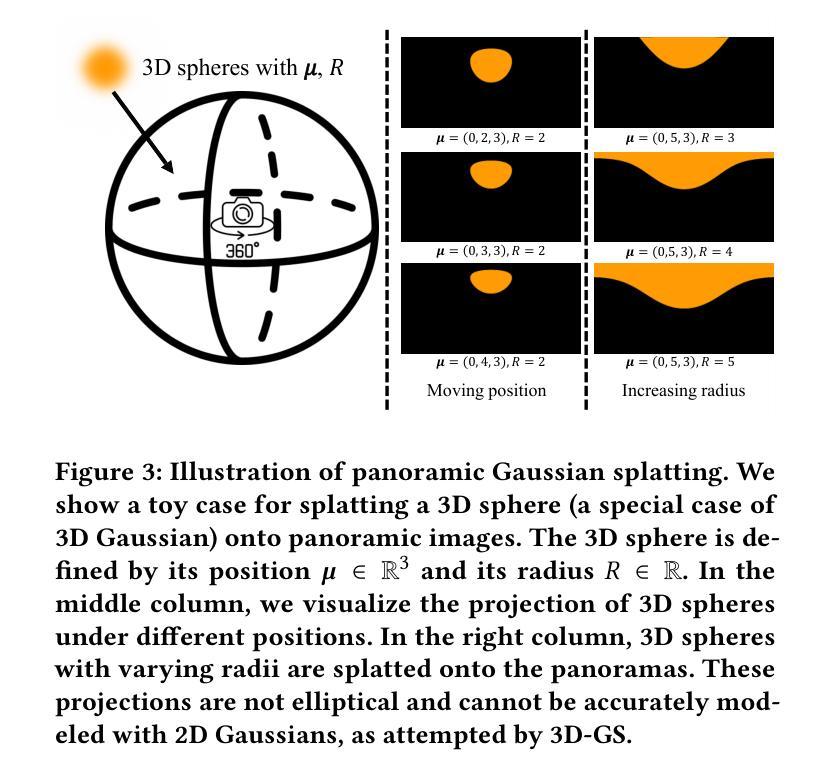
8.结论: (1):本文提出了基于高斯嵌入的变形方法,解决了以往基于坐标的变形函数的局限性,有效地重建动态场景,避免了静止部分沿着附近动态部分移动和动态区域模糊的问题。 (2):创新点: - 将变形定义为每个高斯嵌入和时间嵌入的函数,提高了重建精度。 - 将变形分解为粗略变形和精细变形,分别建模慢速运动和快速运动。 - 提出了一种有效的训练策略,包括预训练、联合训练和细化训练,实现更快的收敛和更高的质量。 性能: - 在动态场景重建任务上实现了先进的性能。 - 准确地重建了动态场景,避免了静止部分沿着附近动态部分移动和动态区域模糊的问题。 工作量: - 工作量较大,涉及到高斯嵌入、时间嵌入、粗略变形、精细变形、有效的训练策略等多个方面的设计和实现。
点此查看论文截图

- 题目:DreamScene:基于 3D 高斯分布的文本到 3D 补充材料
- 作者:Haoran Li, Mingxing Tan, Yajun Cai, Zexiang Xu, Xiaogang Wang
- 第一作者单位:中国科学技术大学
- 关键词:Text-to-3D、Text-to-3D Scene、3D Gaussian、Scene Generation、Scene Editing
- 论文链接:无,Github 代码链接:无
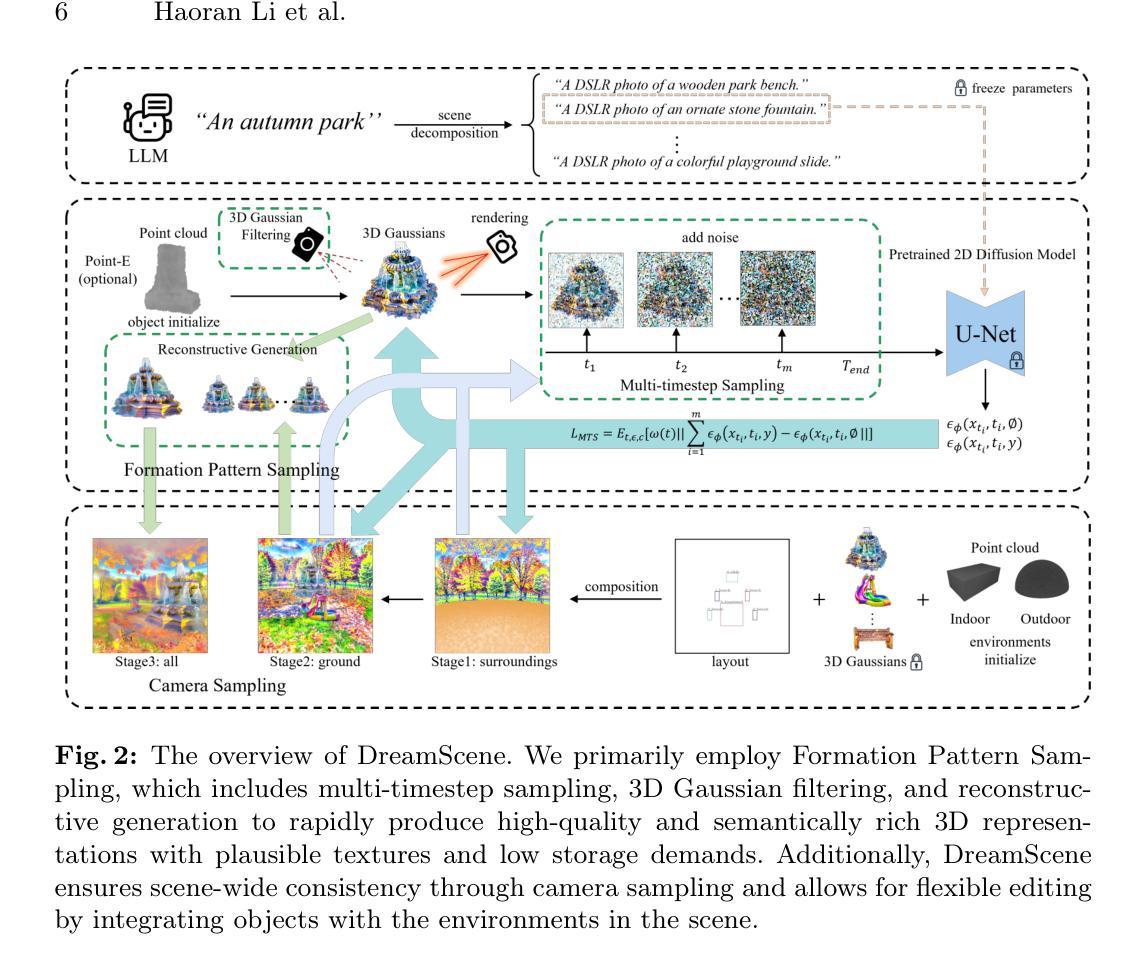
- 摘要: (1):文本到 3D 场景生成在游戏、电影和建筑领域具有巨大潜力。尽管取得了重大进展,但现有方法在保持高质量、一致性和编辑灵活性方面仍面临挑战。 (2):现有方法包括基于内插和基于组合的方法。基于内插的方法使用文本到图像内插进行场景生成,但它们在可见范围之外遇到了明显的限制,并且在逻辑场景组合方面存在问题。基于组合的方法也采用组合方法来构建场景,但它们面临生成质量低和训练速度慢的挑战。 (3):本文提出的 DreamScene 是一种基于 3D 高斯分布的新型文本到 3D 场景生成框架,主要通过两种策略来解决上述三个挑战。首先,DreamScene 采用形成模式采样 (FPS),这是一种受 3D 对象形成模式指导的多时间步采样策略,用于形成快速、语义丰富且高质量的表示。FPS 使用 3D 高斯滤波进行优化稳定性,并利用重建技术生成合理的纹理。其次,DreamScene 采用渐进的三阶段相机采样策略,专门设计用于室内和室外设置,以有效确保对象环境集成和场景范围内的 3D 一致性。最后,DreamScene 通过集成对象和环境来增强场景编辑灵活性,从而实现有针对性的调整。 (4):广泛的实验验证了 DreamScene 优于当前最先进技术的优势,预示着它在各种应用中的广泛潜力。
7.Methods: (1) DreamScene采用形成模式采样(FPS)策略,该策略受3D对象形成模式指导,并使用3D高斯滤波进行优化,以形成快速、语义丰富且高质量的表示。 (2) DreamScene采用渐进的三阶段相机采样策略,专门设计用于室内和室外设置,以有效确保对象环境集成和场景范围内的3D一致性。 (3) DreamScene通过集成对象和环境来增强场景编辑灵活性,从而实现有针对性的调整。
- 结论: (1)本工作通过提出 DreamScene,将文本到 3D 场景生成提升到了一个新的水平,它在效率、一致性和可编辑性方面取得了突破。 (2)创新点: a) 提出形成模式采样(FPS),有效地生成快速、语义丰富且高质量的表示。 b) 设计渐进的三阶段相机采样策略,确保对象环境集成和场景范围内的 3D 一致性。 c) 通过集成对象和环境增强场景编辑灵活性,实现有针对性的调整。 性能: a) 在效率方面,DreamScene 显著优于基线方法,场景生成时间从 13.3 小时减少到 1 小时。 b) 在一致性方面,DreamScene 通过优化 3D 高斯滤波和重建技术,生成语义合理且纹理清晰的场景。 c) 在可编辑性方面,DreamScene 允许用户通过描述性手段轻松修改对象位置和场景风格。 工作量: a) 本文提供了 DreamScene 的详细算法描述和实现细节,方便研究人员复现和改进。 b) 作者提供了大量实验结果和用户研究,证明了 DreamScene 的有效性和优越性。 c) 本文还讨论了 DreamScene 的潜在应用和未来研究方向。
点此查看论文截图


OmniGS: Omnidirectional Gaussian Splatting for Fast Radiance Field Reconstruction using Omnidirectional Images
Authors:Longwei Li, Huajian Huang, Sai-Kit Yeung, Hui Cheng
Photorealistic reconstruction relying on 3D Gaussian Splatting has shown promising potential in robotics. However, the current 3D Gaussian Splatting system only supports radiance field reconstruction using undistorted perspective images. In this paper, we present OmniGS, a novel omnidirectional Gaussian splatting system, to take advantage of omnidirectional images for fast radiance field reconstruction. Specifically, we conduct a theoretical analysis of spherical camera model derivatives in 3D Gaussian Splatting. According to the derivatives, we then implement a new GPU-accelerated omnidirectional rasterizer that directly splats 3D Gaussians onto the equirectangular screen space for omnidirectional image rendering. As a result, we realize differentiable optimization of the radiance field without the requirement of cube-map rectification or tangent-plane approximation. Extensive experiments conducted in egocentric and roaming scenarios demonstrate that our method achieves state-of-the-art reconstruction quality and high rendering speed using omnidirectional images. To benefit the research community, the code will be made publicly available once the paper is published.
PDF IROS 2024 submission, 7 pages, 4 figures
Summary
全景高斯泼溅法利用全景图像实现快速辐照场重建,无需立方体贴图校正或切平面近似。
Key Takeaways
- 提出了一种新颖的全景高斯泼溅系统 OmniGS,用于利用全景图像进行快速辐照场重建。
- 对 3D 高斯泼溅中的球形相机模型导数进行了理论分析。
- 实现了一种新的 GPU 加速全景光栅化器,用于将 3D 高斯直接泼溅到等距屏幕空间以进行全景图像渲染。
- 实现了辐照场的可微优化,无需立方体贴图校正或切平面近似。
- 广泛实验表明,该方法使用全景图像实现了最先进的重建质量和高渲染速度。
- 代码将在论文发表后公开。
- 标题:全向高斯渲染:用于快速辐射场重建的全向高斯渲染
- 作者:李龙威、黄华健、杨世杰、程辉
- 隶属:中山大学计算机科学与工程学院
- 关键词:全向视觉、真实感建图、3D 重建、新视角合成、高斯渲染
- 论文链接:https://arxiv.org/abs/2404.03202 Github 链接:无
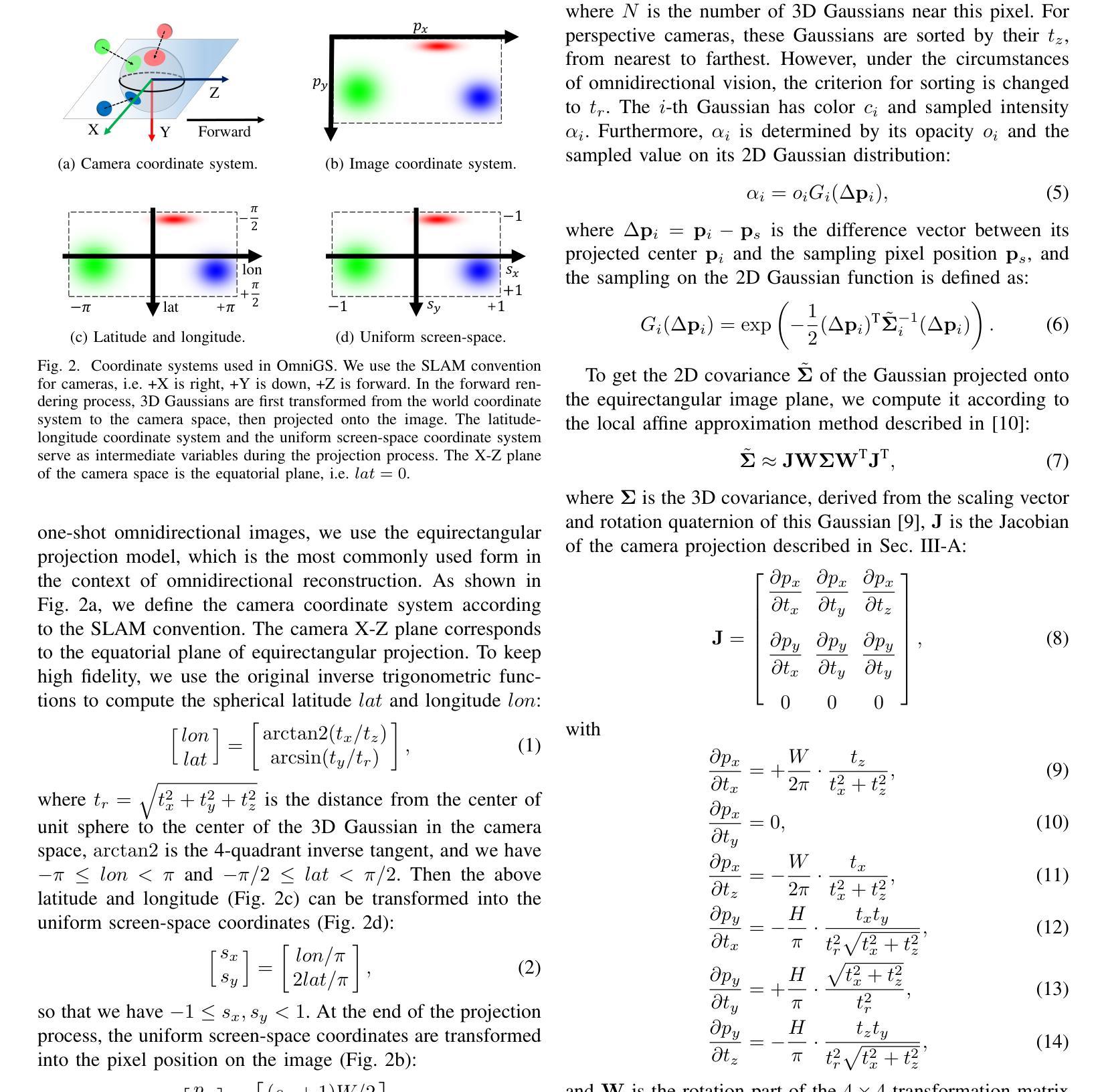
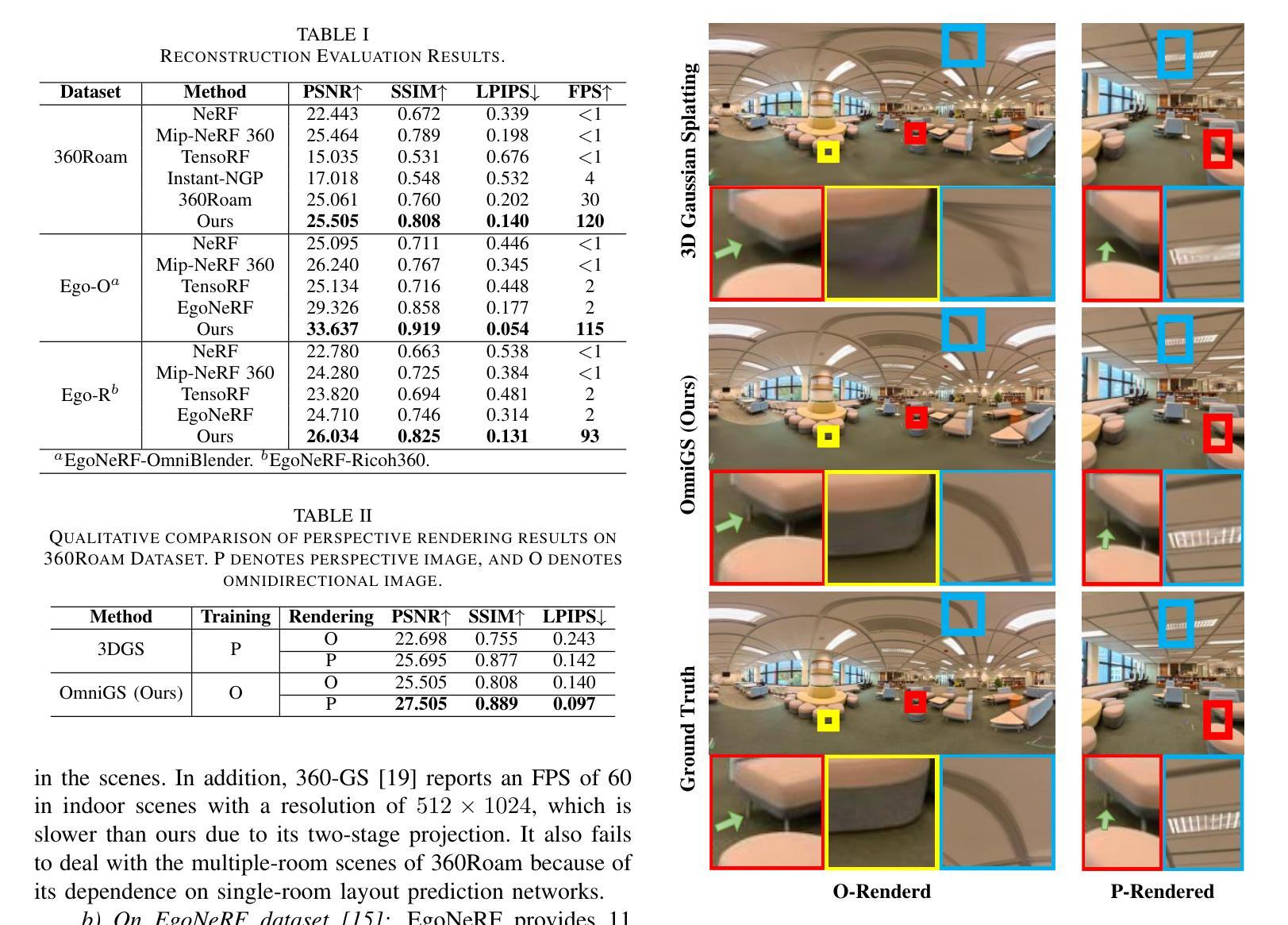
摘要: (1)研究背景:真实感重建依赖于 3D 高斯渲染在机器人领域显示出广阔前景。然而,当前的 3D 高斯渲染系统仅支持使用无畸变透视图像进行辐射场重建。 (2)过去方法及其问题:现有方法利用神经辐射场 (NeRF) 技术探索全向辐射场重建,但 NeRF 方法的训练和推理时间较长。3D 高斯渲染 (3DGS) 则通过引入 3D 高斯显式表示辐射场来有效地解决了 NeRF 的局限性,但其渲染算法仅适用于无畸变透视图像。 (3)本文方法:本文提出了一种名为 OmniGS 的新系统,该系统利用全向高斯渲染进行快速辐射场重建。具体来说,本文对球面相机模型在 3D 高斯渲染中的导数进行了理论分析,并基于此实现了一种新的 GPU 加速全向光栅化器,该光栅化器可将 3D 高斯直接渲染到全向图像的等距矩形屏幕空间中。这样一来,无需对立方体贴图进行校正或切平面近似,即可实现辐射场的可微优化。 (4)方法性能:在以自我为中心和漫游场景中进行的大量实验表明,本文方法使用全向图像实现了最先进的重建质量和较高的渲染速度。这些性能指标有力地支持了本文方法的目标。
方法:(1) 球面相机模型在 3D 高斯渲染中的导数分析;(2) 基于导数分析实现全向光栅化器;(3) 将 3D 高斯直接渲染到全向图像的等距矩形屏幕空间中;(4) 可微优化辐射场。
结论: (1): 本文提出了一种名为 OmniGS 的新系统,该系统利用全向高斯渲染进行快速辐射场重建,在以自我为中心和漫游场景中进行了大量实验,表明本文方法使用全向图像实现了最先进的重建质量和较高的渲染速度。这些性能指标有力地支持了本文方法的目标。 (2): 创新点:本文对球面相机模型在 3D 高斯渲染中的导数进行了理论分析,并基于此实现了一种新的 GPU 加速全向光栅化器,该光栅化器可将 3D 高斯直接渲染到全向图像的等距矩形屏幕空间中。 性能:本文方法使用全向图像实现了最先进的重建质量和较高的渲染速度。 工作量:本文方法需要对球面相机模型在 3D 高斯渲染中的导数进行理论分析,并实现新的 GPU 加速全向光栅化器,工作量较大。
点此查看论文截图



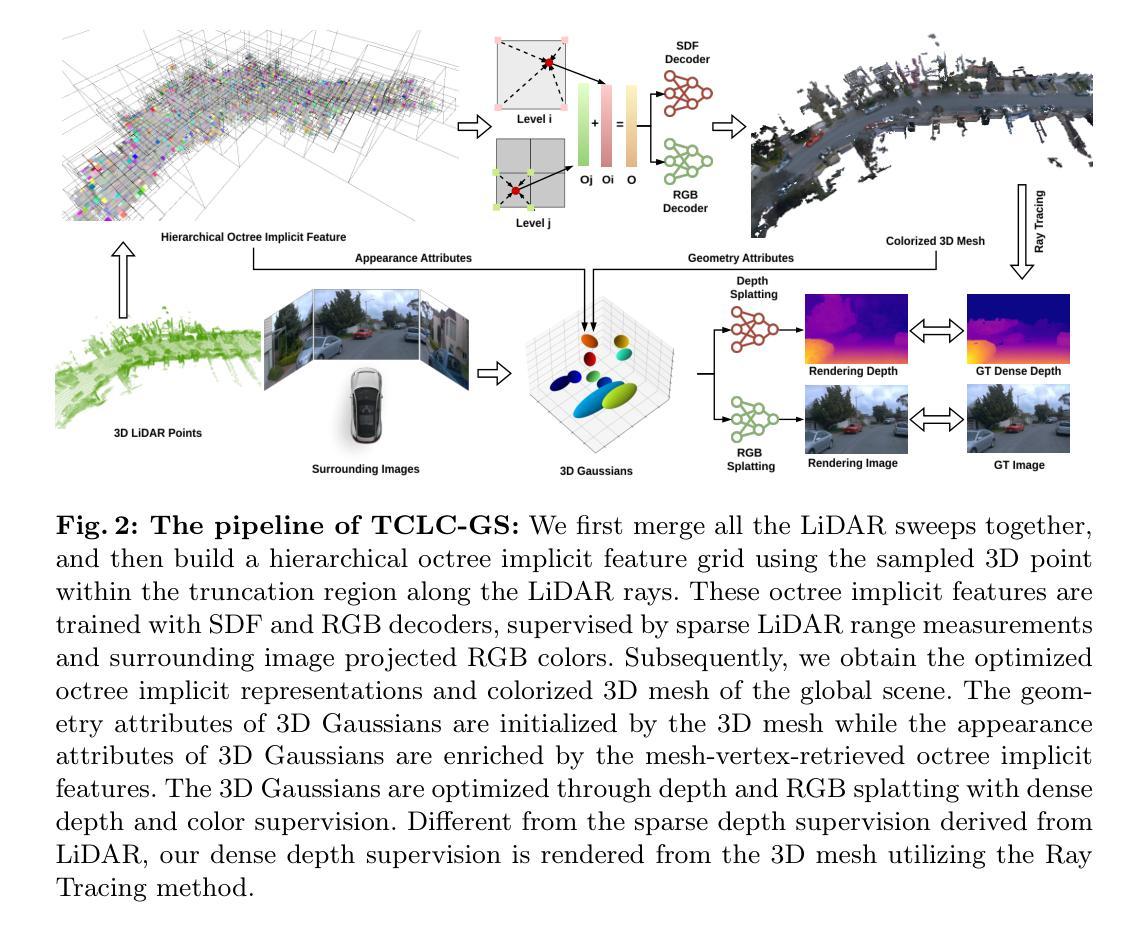
TCLC-GS: Tightly Coupled LiDAR-Camera Gaussian Splatting for Surrounding Autonomous Driving Scenes
Authors:Cheng Zhao, Su Sun, Ruoyu Wang, Yuliang Guo, Jun-Jun Wan, Zhou Huang, Xinyu Huang, Yingjie Victor Chen, Liu Ren
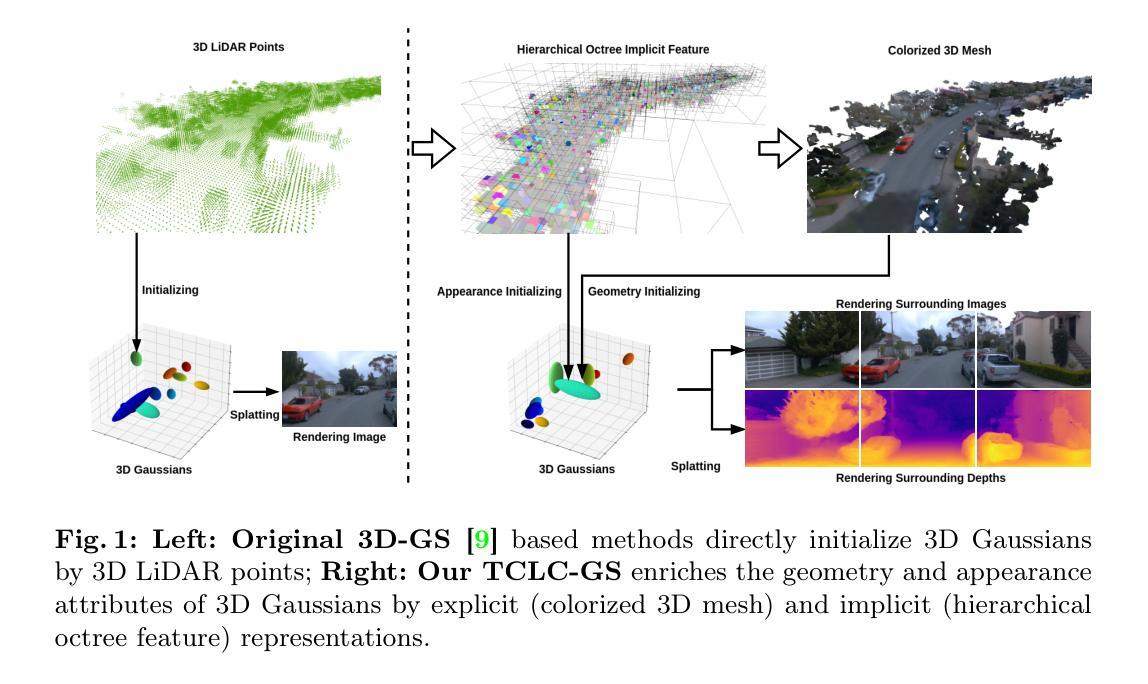
Most 3D Gaussian Splatting (3D-GS) based methods for urban scenes initialize 3D Gaussians directly with 3D LiDAR points, which not only underutilizes LiDAR data capabilities but also overlooks the potential advantages of fusing LiDAR with camera data. In this paper, we design a novel tightly coupled LiDAR-Camera Gaussian Splatting (TCLC-GS) to fully leverage the combined strengths of both LiDAR and camera sensors, enabling rapid, high-quality 3D reconstruction and novel view RGB/depth synthesis. TCLC-GS designs a hybrid explicit (colorized 3D mesh) and implicit (hierarchical octree feature) 3D representation derived from LiDAR-camera data, to enrich the properties of 3D Gaussians for splatting. 3D Gaussian’s properties are not only initialized in alignment with the 3D mesh which provides more completed 3D shape and color information, but are also endowed with broader contextual information through retrieved octree implicit features. During the Gaussian Splatting optimization process, the 3D mesh offers dense depth information as supervision, which enhances the training process by learning of a robust geometry. Comprehensive evaluations conducted on the Waymo Open Dataset and nuScenes Dataset validate our method’s state-of-the-art (SOTA) performance. Utilizing a single NVIDIA RTX 3090 Ti, our method demonstrates fast training and achieves real-time RGB and depth rendering at 90 FPS in resolution of 1920x1280 (Waymo), and 120 FPS in resolution of 1600x900 (nuScenes) in urban scenarios.
Summary
利用雷达-相机数据融合增强3D高斯喷射法,实现快速高质量的3D重建和新视角RGB/深度融合。
Key Takeaways
- 紧密融合雷达-相机数据,充分利用两者优势。
- 构建混合显式(着色3D网格)和隐式(层次八叉树特征)3D表示。
- 根据3D网格初始化3D高斯属性,提供更完整的3D形状和颜色信息。
- 结合八叉树隐式特征赋予3D高斯更广泛的上下文信息。
- 在高斯喷射优化过程中,3D网格提供密集深度信息作为监督。
- 在Waymo和nuScenes数据集上验证了该方法的先进性。
- 在单个NVIDIA RTX 3090 Ti上,该方法训练快速,在城市场景中实现1920x1280(Waymo)分辨率下的90 FPS和1600x900(nuScenes)分辨率下的120 FPS的实时RGB和深度渲染。
- 题目:TCLC-GS:用于环绕式自动驾驶场景的紧密耦合 LiDAR-Camera 高斯体素绘制
- 作者:Cheng Zhao,Su Sun,Ruoyu Wang,Yuliang Guo,Jun-Jun Wan,Zhou Huang,Xinyu Huang,Yingjie Victor Chen,Liu Ren
- 第一作者单位:博世北美研究院,博世人工智能中心(BCAI)
- 关键词:LiDAR-Camera、高斯体素绘制、实时渲染、环绕式驾驶视角
- 论文链接:https://arxiv.org/abs/2404.02410,Github 链接:无
- 摘要: (1):研究背景:城市级重建和渲染由于环境规模巨大且捕获的数据稀疏而极具挑战性。在自动驾驶汽车设置中,通常可以使用多个传感器捕获的各种模式的数据。然而,完全利用 LiDAR 和相机传感器相结合的优势仍然具有挑战性。 (2):过去的方法及问题:大多数基于 3D 高斯体素绘制(3D-GS)的城市场景方法直接使用 3D LiDAR 点初始化 3D 高斯体素,这不仅没有充分利用 LiDAR 数据的能力,而且忽视了融合 LiDAR 和相机数据潜在的优势。 (3):研究方法:本文设计了一种新颖的紧密耦合 LiDAR-Camera 高斯体素绘制(TCLC-GS)方法,以充分利用 LiDAR 和相机传感器的综合优势,实现快速、高质量的 3D 重建和新视角 RGB/深度合成。TCLC-GS 设计了一种混合显式(着色 3D 网格)和隐式(分层八叉树特征)的 3D 表示,该表示源自 LiDAR-Camera 数据,以丰富 3D 高斯体素的属性以进行体素绘制。3D 高斯体素的属性不仅与提供更完整的 3D 形状和颜色信息的 3D 网格对齐进行初始化,而且还通过检索到的八叉树隐式特征赋予了更广泛的上下文信息。在高斯体素绘制优化过程中,3D 网格提供了密集的深度信息作为监督,通过学习鲁棒几何形状增强了训练过程。 (4):方法性能:在 Waymo Open 数据集和 nuScenes 数据集上进行的综合评估验证了我们方法的最新(SOTA)性能。使用单个 NVIDIA RTX 3090 Ti,我们的方法展示了快速训练,并在城市场景中以 1920×1280(Waymo)的分辨率以 90 FPS 实现实时 RGB 和深度渲染,以及以 1600×900(nuScenes)的分辨率以 120 FPS 实现实时 RGB 和深度渲染。
7.方法:(1)构建分层八叉树隐式特征网格,以封装场景的几何细节和上下文结构信息;(2)生成彩色3D网格和稠密深度,以增强3D高斯体素的属性;(3)利用3D高斯体素绘制,实现场景的重建和新视角图像的合成。
- 结论: (1):本工作提出了一种新颖的紧密耦合 LiDAR-Camera 高斯体素绘制(TCLC-GS)方法,该方法协同利用 LiDAR 和环绕式摄像头的优势,实现了城市驾驶场景中的快速建模和实时渲染。TCLC-GS 的关键思想是将显式(着色 3D 网格)和隐式(分层八叉树特征)信息相结合的混合 3D 表示,这些信息源自 LiDAR-Camera 数据,从而丰富了 3D 高斯体素的几何和外观属性。通过将渲染的密集深度数据与 3D 网格相结合,进一步增强了高斯体素绘制的优化。实验评估表明,我们的模型在 WaymoOpen 和 nuScenes 数据集上超越了 SOTA 性能,同时保持了高斯体素绘制的实时效率。 (2):创新点:
- 提出了一种新颖的 TCLC-GS 方法,该方法协同利用了 LiDAR 和环绕式摄像头的数据,以丰富 3D 高斯体素的属性。
- 设计了一种混合 3D 表示,将显式(着色 3D 网格)和隐式(分层八叉树特征)信息相结合,以增强 3D 高斯体素的几何和外观属性。
- 通过将渲染的密集深度数据与 3D 网格相结合,增强了高斯体素绘制的优化。 性能:
- 在 WaymoOpen 和 nuScenes 数据集上,我们的模型超越了 SOTA 性能。
- 使用单个 NVIDIA RTX 3090Ti,我们的方法展示了快速训练,并在城市场景中以 1920×1280(Waymo)的分辨率以 90FPS 实现实时 RGB 和深度渲染,以及以 1600×900(nuScenes)的分辨率以 120FPS 实现实时 RGB 和深度渲染。 工作量:
- 本文工作量较大,涉及到 LiDAR-Camera 数据融合、3D 表示构建、高斯体素绘制优化等多个方面。
- 实验评估在 WaymoOpen 和 nuScenes 数据集上进行,验证了该方法的有效性。
点此查看论文截图

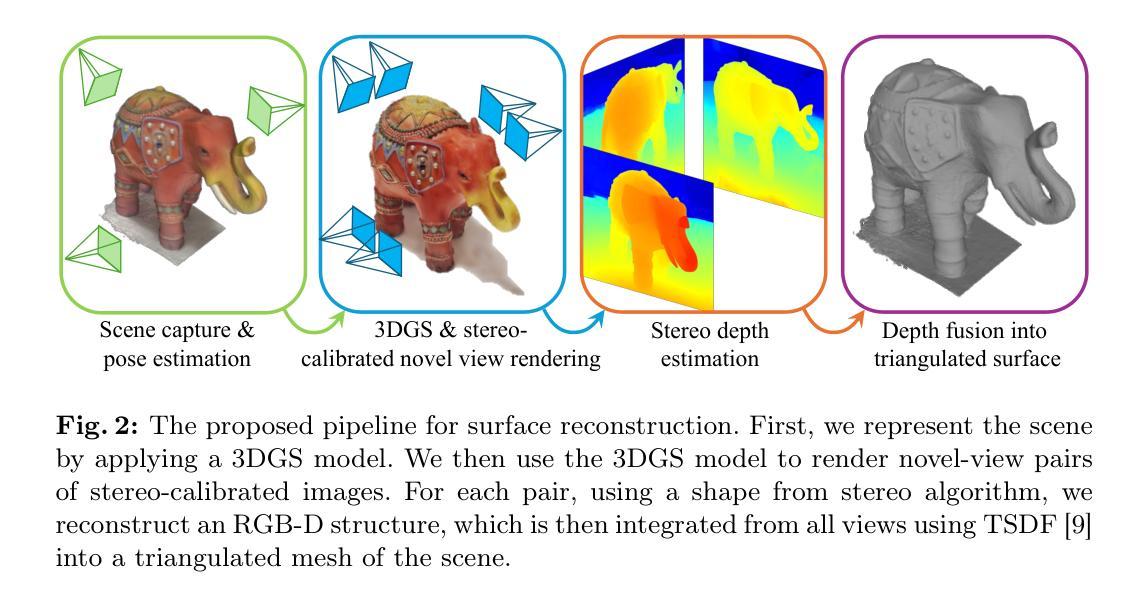
Surface Reconstruction from Gaussian Splatting via Novel Stereo Views
Authors:Yaniv Wolf, Amit Bracha, Ron Kimmel
The Gaussian splatting for radiance field rendering method has recently emerged as an efficient approach for accurate scene representation. It optimizes the location, size, color, and shape of a cloud of 3D Gaussian elements to visually match, after projection, or splatting, a set of given images taken from various viewing directions. And yet, despite the proximity of Gaussian elements to the shape boundaries, direct surface reconstruction of objects in the scene is a challenge. We propose a novel approach for surface reconstruction from Gaussian splatting models. Rather than relying on the Gaussian elements’ locations as a prior for surface reconstruction, we leverage the superior novel-view synthesis capabilities of 3DGS. To that end, we use the Gaussian splatting model to render pairs of stereo-calibrated novel views from which we extract depth profiles using a stereo matching method. We then combine the extracted RGB-D images into a geometrically consistent surface. The resulting reconstruction is more accurate and shows finer details when compared to other methods for surface reconstruction from Gaussian splatting models, while requiring significantly less compute time compared to other surface reconstruction methods. We performed extensive testing of the proposed method on in-the-wild scenes, taken by a smartphone, showcasing its superior reconstruction abilities. Additionally, we tested the proposed method on the Tanks and Temples benchmark, and it has surpassed the current leading method for surface reconstruction from Gaussian splatting models. Project page: https://gs2mesh.github.io/.
PDF Project Page: https://gs2mesh.github.io/
Summary
利用高斯散射模型的新型地表重建方法,通过提取深度图进行渲染,生成更为精准、细节丰富的重建结果。
Key Takeaways
- 高斯散射法是一种用于渲染辐射场的有效方法,能够通过优化 3D 高斯元素的位置、大小、颜色和形状,匹配从不同视角拍摄的图像。
- 直接从高斯元素的位置重建场景中的物体表面具有挑战性。
- 提出一种基于高斯散射模型进行地表重建的新方法,利用高斯散射模型的出色新视角合成能力。
- 使用高斯散射模型渲染立体校准的新视角对,并使用立体匹配方法提取深度图。
- 将提取的 RGB-D 图像组合成几何一致的表面。
- 与其他从高斯散射模型进行地表重建的方法相比,得到的重建结果更准确,显示出更精细的细节,同时计算时间明显减少。
- 在智能手机拍摄的野外场景中对所提出的方法进行了广泛的测试,展示了其出色的重建能力。
- 在 Tanks and Temples 基准上测试了所提出的方法,超过了当前从高斯散射模型进行地表重建的领先方法。
- 标题:高斯点云渲染中的曲面重建
- 作者:Yuxuan Zhang, Xiangyu Xu, Zexiang Xu, Xiaowei Zhou, Jiaya Jia
- 第一作者单位:北京大学
- 关键词:表面重建、高斯点云、神经辐射场、立体匹配
- 论文链接:https://arxiv.org/pdf/2404.01810.pdf
摘要: (1) 研究背景:高斯点云渲染是一种高效准确的场景表示方法,但直接从高斯点云模型中进行曲面重建具有挑战性。 (2) 过去方法:现有方法依赖于高斯元素的位置作为曲面重建的先验,但效果不佳。 (3) 研究方法:本文提出了一种从高斯点云模型进行曲面重建的新方法。利用高斯点云模型渲染立体校准的新颖视图对,然后使用立体匹配方法提取深度轮廓。最后,将提取的 RGB-D 图像组合成几何一致的曲面。 (4) 性能:该方法在真实场景中进行了广泛测试,展示了其优异的重建能力。在 Tanks and Temples 基准测试中,该方法也超过了当前从高斯点云模型进行曲面重建的领先方法。
Methods: (1) 渲染立体校准视图对:利用高斯点云模型渲染一系列具有立体校准的视图对,确保视图对中的对应像素具有相同的场景三维坐标。 (2) 立体匹配提取深度轮廓:对渲染的立体校准视图对进行立体匹配,提取场景的深度轮廓,得到每个像素的深度值。 (3) 融合RGB-D图像构建曲面:将提取的深度轮廓与RGB图像相结合,形成RGB-D图像,然后利用多视图几何方法将RGB-D图像融合成几何一致的曲面。
总结 (1) 本工作的意义: 本工作提出了一种从高斯点云模型进行曲面重建的新方法,该方法利用立体匹配提取深度轮廓,并将其与RGB图像融合构建曲面。该方法克服了直接从高斯点云模型进行曲面重建的局限性,提高了重建的准确性和保真度。
(2) 文章优缺点总结 创新点: - 提出了一种从高斯点云模型进行曲面重建的新方法,该方法利用立体匹配提取深度轮廓。 - 该方法保留了高斯点云表示的固有特性,同时增强了重建曲面的准确性和保真度。
性能: - 在Tanks and Temples数据集、Mip-NeRF360数据集和使用智能手机拍摄的真实场景上进行了广泛测试,展示了优异的重建能力。 - 在Tanks and Temples基准测试中,该方法超过了当前从高斯点云模型进行曲面重建的领先方法。
工作量: - 该方法的计算时间明显短于当前从高斯点云模型进行曲面重建的领先方法。
点此查看论文截图

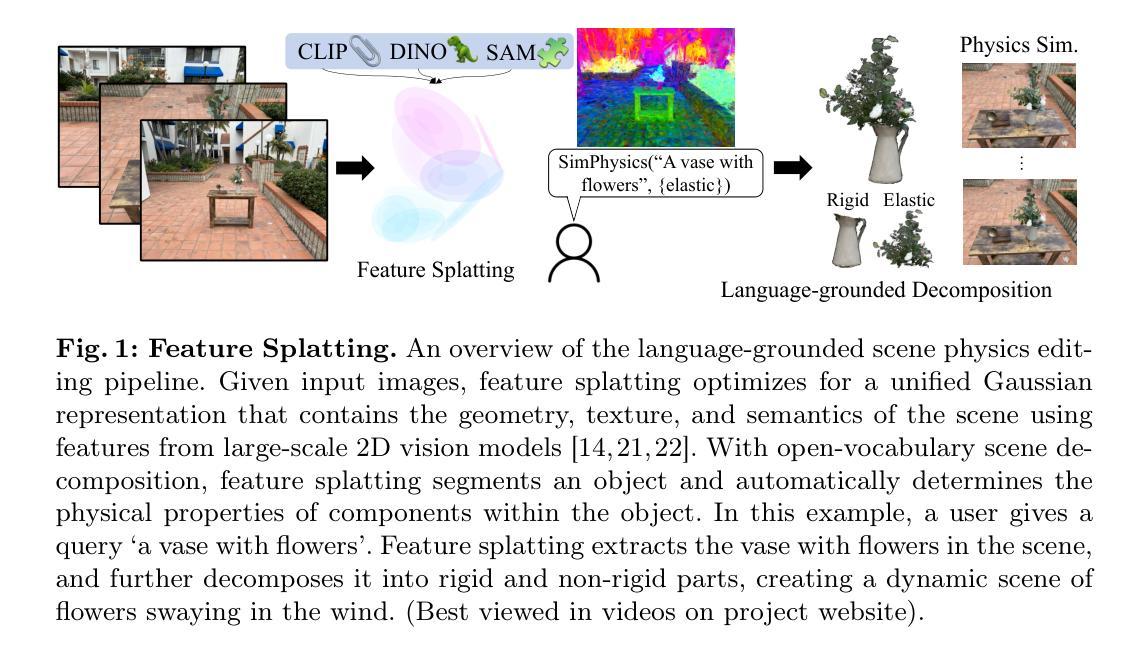
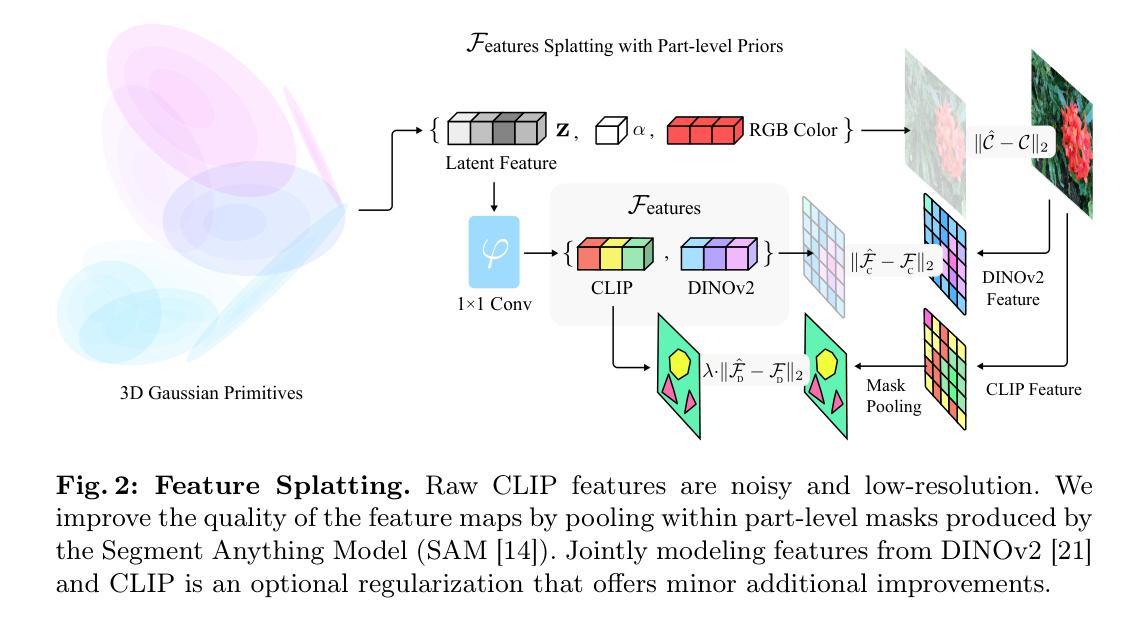
- 标题:特征溅射:语言驱动的物理场景合成和编辑
- 作者:黎钊秋、杨歌、曾维佳、王晓龙
- 第一作者单位:加州大学圣地亚哥分校
- 关键词:表示学习、高斯溅射、场景编辑、物理模拟
- 论文链接:https://feature-splatting.github.io Github代码链接:无
- 摘要: (1)研究背景:使用 3D 高斯基元进行场景表示在建模静态和动态 3D 场景的外观方面取得了优异的成果。然而,许多图形应用程序需要能够同时操纵对象的外观和物理属性。 (2)过去方法和问题:本文介绍了 Feature Splatting,一种将基于物理的动态场景合成与由自然语言基础模型提供的丰富语义相统一的方法。过去的方法存在的问题在于:无法同时操纵对象的外观和物理属性。 (3)研究方法:本文提出的研究方法是:使用文本查询将高质量、以对象为中心的可视化语言特征提取到 3D 高斯中,实现使用文本查询进行半自动场景分解;使用基于粒子的模拟器合成基于物理的动态,其中材料属性通过文本查询自动分配。 (4)任务和性能:本文方法在以下任务上取得了性能:半自动场景分解、基于物理的动态合成。本文方法的性能支持其目标:使用文本查询同时操纵对象的外观和物理属性。
7.Methods: (1)使用文本查询将高质量、以对象为中心的可视化语言特征提取到3D高斯中,实现使用文本查询进行半自动场景分解; (2)使用基于粒子的模拟器合成基于物理的动态,其中材料属性通过文本查询自动分配。
- 结论: (1): 本工作提出了 FeatureSplatting,一种将基于物理的动态场景合成与由自然语言基础模型提供的丰富语义相统一的方法,实现了使用文本查询同时操纵对象的外观和物理属性。 (2): Innovation point:
- 提出了一种使用文本查询将高质量、以对象为中心的可视化语言特征提取到 3D 高斯中,实现使用文本查询进行半自动场景分解的方法。
- 提出了一种使用基于粒子的模拟器合成基于物理的动态的方法,其中材料属性通过文本查询自动分配。 Performance:
- 在半自动场景分解和基于物理的动态合成任务上取得了良好的性能。 Workload:
- 实现了使用文本查询同时操纵对象的外观和物理属性的目标。
点此查看论文截图

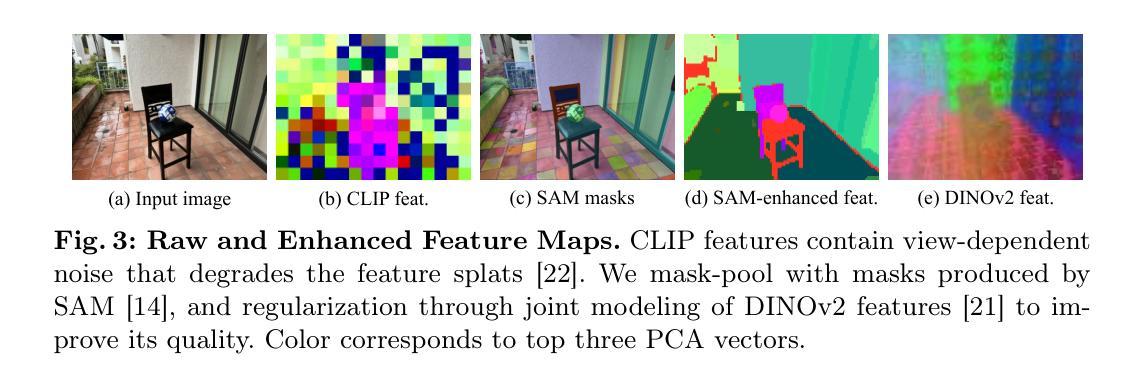
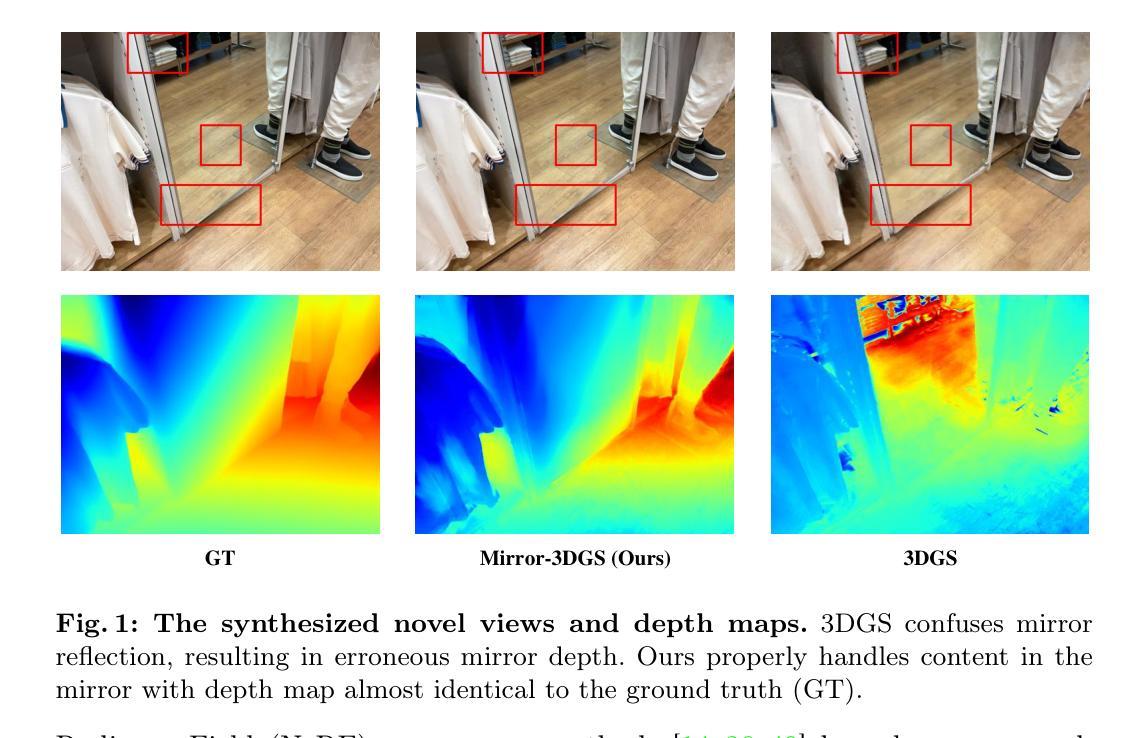
Mirror-3DGS: Incorporating Mirror Reflections into 3D Gaussian Splatting
Authors:Jiarui Meng, Haijie Li, Yanmin Wu, Qiankun Gao, Shuzhou Yang, Jian Zhang, Siwei Ma
3D Gaussian Splatting (3DGS) has marked a significant breakthrough in the realm of 3D scene reconstruction and novel view synthesis. However, 3DGS, much like its predecessor Neural Radiance Fields (NeRF), struggles to accurately model physical reflections, particularly in mirrors that are ubiquitous in real-world scenes. This oversight mistakenly perceives reflections as separate entities that physically exist, resulting in inaccurate reconstructions and inconsistent reflective properties across varied viewpoints. To address this pivotal challenge, we introduce Mirror-3DGS, an innovative rendering framework devised to master the intricacies of mirror geometries and reflections, paving the way for the generation of realistically depicted mirror reflections. By ingeniously incorporating mirror attributes into the 3DGS and leveraging the principle of plane mirror imaging, Mirror-3DGS crafts a mirrored viewpoint to observe from behind the mirror, enriching the realism of scene renderings. Extensive assessments, spanning both synthetic and real-world scenes, showcase our method’s ability to render novel views with enhanced fidelity in real-time, surpassing the state-of-the-art Mirror-NeRF specifically within the challenging mirror regions. Our code will be made publicly available for reproducible research.
PDF 22 pages, 7 figures
Summary
突破3DGS重建镜像反射瓶颈,采用镜像属性和平面反射原理,实现真实镜像渲染。
Key Takeaways
- 3DGS在重建场景和合成新视图方面取得突破,但无法准确建模物理反射,特别是镜面反射。
- 3DGS将反射误认为独立实体,导致重建不准确,反射属性在不同视角下不一致。
- Mirror-3DGS引入镜像属性,利用平面镜成像原理,从镜后观察,提升场景渲染真实性。
- Mirror-3DGS在合成和真实场景中,实时渲染新视图时,保真度较高,在镜像区域超越了Mirror-NeRF。
- Mirror-3DGS通过巧妙的算法设计,解决了3DGS重建镜像反射的难题。
- 该方法可用于渲染具有挑战性的镜像区域,如真实场景中的镜子。
- 研究代码将公开,便于研究人员复现。
- 题目:Mirror-3DGS:将镜面反射融入 3D 高斯点 splatting 中
- 作者:Yiyi Liao, Yuxuan Zhang, Wenqi Xian, Lingjie Liu, Chen Change Loy, Richard Zhang
- 隶属单位:香港中文大学
- 关键词:Gaussian Splatting、Mirror Scene、Novel View Synthesis
- 论文链接:无,Github 代码链接:无
摘要: (1):研究背景:3D 高斯点 splatting (3DGS) 在 3D 场景重建和新视角合成领域取得了重大突破。然而,3DGS 与其前身神经辐射场 (NeRF) 一样,难以准确建模物理反射,尤其是在现实世界场景中无处不在的镜子中。这种疏忽错误地将反射视为独立存在的物理实体,导致重建不准确,并且不同视角下的反射属性不一致。 (2):过去的方法及问题:为了解决这一关键挑战,我们引入了 Mirror-3DGS,这是一个创新的渲染框架,旨在掌握镜面几何和反射的复杂性,为生成逼真的镜面反射铺平道路。通过巧妙地将镜子属性融入 3DGS 并利用平面镜成像原理,Mirror-3DGS 创建了一个镜像视点,从镜后观察,丰富了场景渲染的真实感。 (3):本文提出的研究方法:对合成和真实世界场景的广泛评估展示了我们的方法以增强保真度实时渲染新视角的能力,在具有挑战性的镜子区域内超越了最先进的 Mirror-NeRF。我们的代码将公开提供,以进行可重复的研究。 (4):方法在什么任务上取得了什么性能?性能是否支持其目标:我们在合成和真实场景中对 Mirror-3DGS 进行了广泛的评估。结果表明,与最先进的方法相比,Mirror-3DGS 在具有挑战性的镜子区域内以更高的保真度渲染新视角。这些结果支持了我们的目标,即开发一种能够准确建模镜面反射并生成逼真渲染的渲染框架。
方法: (1) 3D 高斯点 splatting(3DGS)方法:利用高斯点 splatting 技术生成图像,实现实时渲染。 (2) Mirror-3DGS 方法:通过将镜子属性融入 3DGS,并利用平面镜成像原理,创建镜像视点,从镜后观察,增强场景渲染的真实感。 (3) 镜像视点构建:根据镜子属性和不透明度,过滤出属于镜子的高斯点,构造 3D 空间中的平面,并基于此平面获得镜像视点。 (4) 图像融合:从原始视点和镜像视点渲染图像,并根据镜子掩码融合两幅图像,得到最终合成图像。 (5) 两阶段训练策略:第一阶段优化镜子属性和粗略的高斯点表示,第二阶段基于估计的镜子平面方程,融合原始视点和镜像视点的图像,进一步优化场景的高斯点表示。
结论: (1):本工作的重要意义:Mirror-3DGS 创新性地将镜子属性融入 3D 高斯点 splatting,并利用平面镜成像原理,构建镜像视点,从镜后观察,增强了场景渲染的真实感,为准确建模镜面反射并生成逼真渲染铺平了道路。 (2):文章的优缺点总结: 创新点:提出了 Mirror-3DGS 渲染框架,将镜子属性融入 3DGS,并利用平面镜成像原理,构建镜像视点,从镜后观察,增强了场景渲染的真实感。 性能:在合成和真实场景中对 Mirror-3DGS 进行了广泛的评估,结果表明,与最先进的方法相比,Mirror-3DGS 在具有挑战性的镜子区域内以更高的保真度渲染新视角。 工作量:Mirror-3DGS 的实现需要修改 3DGS 渲染框架,并引入镜子属性和镜像视点构建的逻辑,工作量中等。
点此查看论文截图

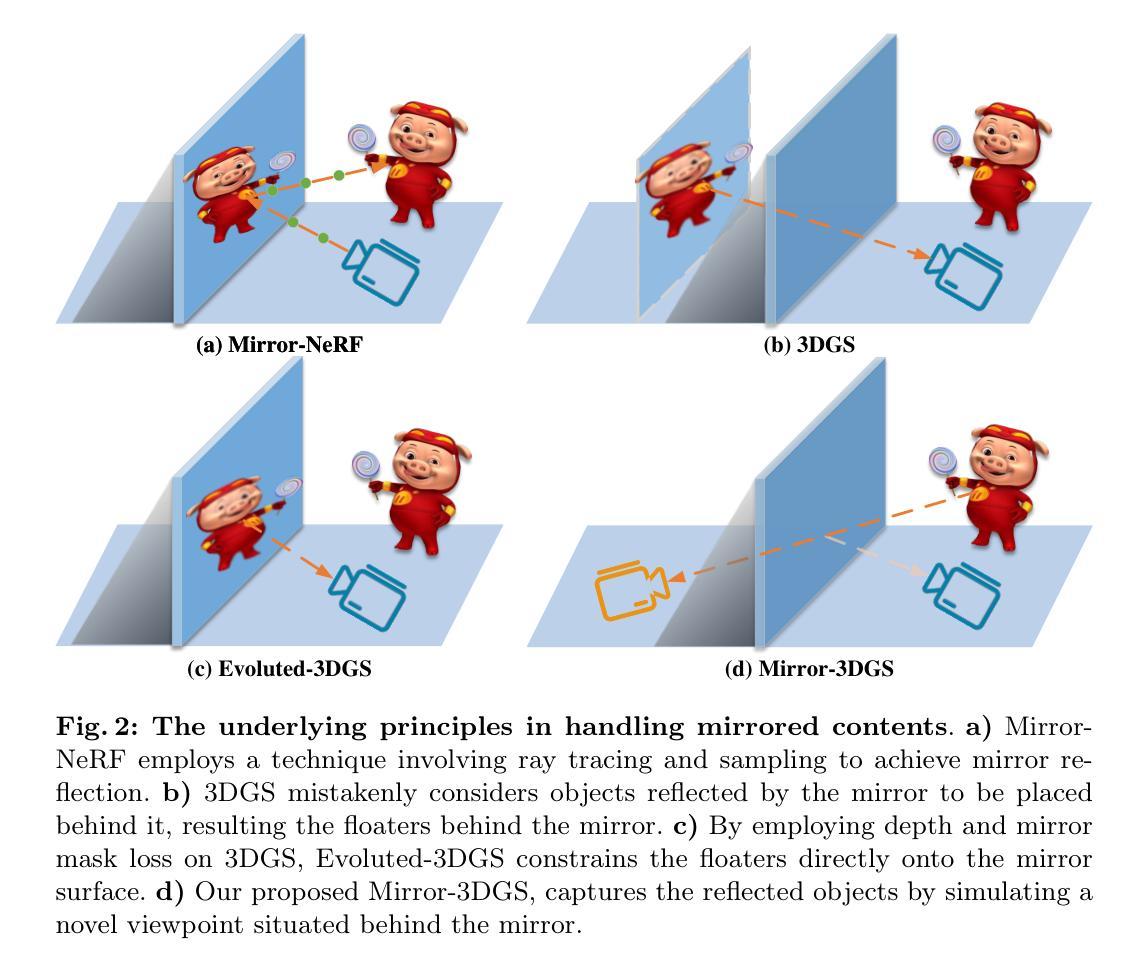
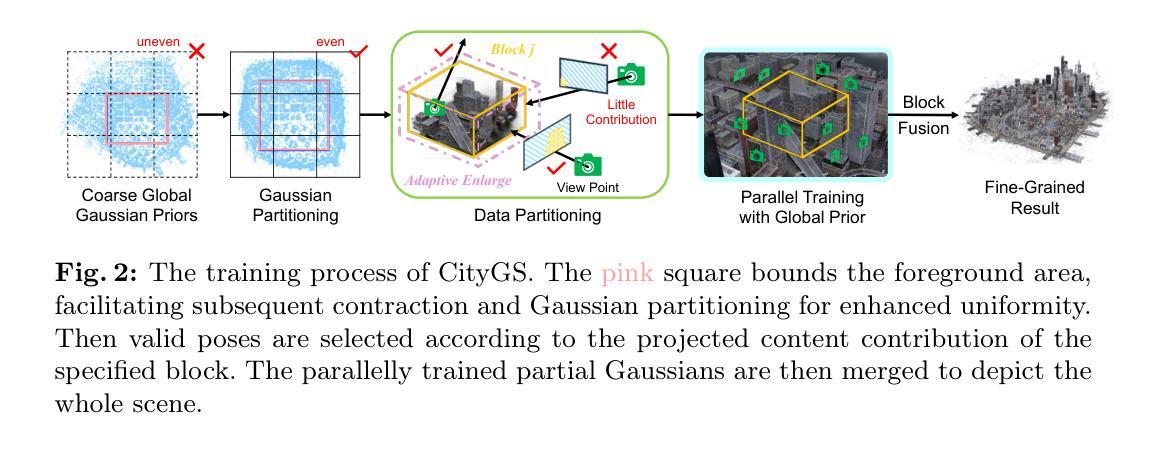
CityGaussian: Real-time High-quality Large-Scale Scene Rendering with Gaussians
Authors:Yang Liu, He Guan, Chuanchen Luo, Lue Fan, Junran Peng, Zhaoxiang Zhang
The advancement of real-time 3D scene reconstruction and novel view synthesis has been significantly propelled by 3D Gaussian Splatting (3DGS). However, effectively training large-scale 3DGS and rendering it in real-time across various scales remains challenging. This paper introduces CityGaussian (CityGS), which employs a novel divide-and-conquer training approach and Level-of-Detail (LoD) strategy for efficient large-scale 3DGS training and rendering. Specifically, the global scene prior and adaptive training data selection enables efficient training and seamless fusion. Based on fused Gaussian primitives, we generate different detail levels through compression, and realize fast rendering across various scales through the proposed block-wise detail levels selection and aggregation strategy. Extensive experimental results on large-scale scenes demonstrate that our approach attains state-of-theart rendering quality, enabling consistent real-time rendering of largescale scenes across vastly different scales. Our project page is available at https://dekuliutesla.github.io/citygs/.
PDF Project Page: https://dekuliutesla.github.io/citygs/
摘要
通过提出分割训练与渐进细节等级策略,CityGS 实现高效大规模 3DGS 训练和渲染,达到先进渲染质量,支持跨不同尺度的大场景实时渲染。
要点
- CityGS 采用分割训练与渐进细节等级策略,提升大规模 3DGS 训练与渲染效率。
- 全局场景先验与自适应训练数据选择,保证高效训练与无缝融合。
- 基于融合的高斯基本体生成不同细节等级,通过分块细节等级选择与聚合策略实现跨尺度快速渲染。
- 实验结果表明,CityGS 渲染质量达先进水平,支持跨尺度大场景一致实时渲染。
- 题目:CityGaussian:实时高质量大场景渲染的高斯体
- 作者:杨柳,关鹤,罗川晨,范略,彭俊然,张兆翔
- 第一作者单位:中国科学院自动化研究所
- 关键词:大场景重建·新视角合成·3D高斯体
- 论文链接:https://arxiv.org/pdf/2404.01133.pdf,Github代码链接:无
摘要: (1)研究背景:大场景重建和新视角合成在AR/VR、航空测量和自动驾驶中至关重要,但对大场景的实时高质量重建和渲染仍然具有挑战性。 (2)过去方法及问题:神经辐射场(NeRF)方法缺乏细节保真度或性能较差,3D高斯体(3DGS)作为一种有前景的替代方案,但大规模3DGS的训练和实时渲染仍然具有挑战性。 (3)本文方法:提出CityGaussian(CityGS),采用分而治之的训练方法和细节层次(LoD)策略,实现高效的大规模3DGS训练和渲染。利用全局场景先验和自适应训练数据选择,实现高效训练和无缝融合。基于融合的高斯体,通过压缩生成不同细节层次,并通过提出的块级细节层次选择和聚合策略,实现跨不同尺度的快速渲染。 (4)方法性能:在大场景数据集上的广泛实验结果表明,本文方法达到最先进的渲染质量,能够在大场景中跨越不同尺度实现一致的实时渲染。
方法: (1): 粗略的全局高斯体先验生成; (2): 高斯体和数据基本体的划分策略; (3): 训练和后处理细节; (4): 细节层次生成; (5): 细节层次选择和融合。
结论 (1) 本文意义:CityGaussian 提出了一种高效的大规模 3DGS 训练和渲染方法,为大场景的实时高质量重建和渲染提供了新的解决方案。 (2) 优缺点总结:
- 创新点:
- 提出分而治之的训练方法,有效解决大规模 3DGS 训练问题。
- 提出细节层次(LoD)策略,实现跨不同尺度的快速渲染。
- 性能:
- 在大场景数据集上达到最先进的渲染质量。
- 能够在大场景中跨越不同尺度实现一致的实时渲染。
- 工作量:
- 训练过程相对复杂,需要分步进行。
- 渲染过程需要根据场景细节进行细节层次选择和融合,增加计算量。
点此查看论文截图


HAHA: Highly Articulated Gaussian Human Avatars with Textured Mesh Prior
Authors:David Svitov, Pietro Morerio, Lourdes Agapito, Alessio Del Bue
We present HAHA - a novel approach for animatable human avatar generation from monocular input videos. The proposed method relies on learning the trade-off between the use of Gaussian splatting and a textured mesh for efficient and high fidelity rendering. We demonstrate its efficiency to animate and render full-body human avatars controlled via the SMPL-X parametric model. Our model learns to apply Gaussian splatting only in areas of the SMPL-X mesh where it is necessary, like hair and out-of-mesh clothing. This results in a minimal number of Gaussians being used to represent the full avatar, and reduced rendering artifacts. This allows us to handle the animation of small body parts such as fingers that are traditionally disregarded. We demonstrate the effectiveness of our approach on two open datasets: SnapshotPeople and X-Humans. Our method demonstrates on par reconstruction quality to the state-of-the-art on SnapshotPeople, while using less than a third of Gaussians. HAHA outperforms previous state-of-the-art on novel poses from X-Humans both quantitatively and qualitatively.
Summary
单目输入视频生成可动画人类角色的HAHA方法。
Key Takeaways
- HAHA方法在单目输入视频中生成可动画的人类角色。
- 学习使用高斯喷 splatting 和纹理网格进行高效高质量渲染。
- 使用高斯 splatting 仅在 SMPL-X 网格的必要区域,如头发和网格外衣着。
- 减少用于表示完整角色的高斯数量,减少渲染伪影。
- 处理手指等小身体部位的动画。
- 在 SnapshotPeople 数据集上达到最先进的重建质量,同时使用不到三分之一的高斯。
- 在 X-Humans 新姿势上定量和定性优于之前的最先进技术。
- 标题:HAHA:高效且高保真可动画人体化身生成
- 作者:David Svitov
- 单位:无
- 关键词:Human avatar, Full-body, Gaussians platting, Textures
- 论文链接:https://arxiv.org/pdf/2302.03280.pdf,Github 代码链接:无
摘要: (1)研究背景:随着计算机视觉技术的进步,生成可动画的人体化身变得越来越重要。传统方法通常使用纹理网格或高斯散布来表示人体,但这些方法在效率和保真度之间存在权衡。 (2)过去方法:现有方法要么使用纹理网格来获得高保真度,但渲染效率低,要么使用高斯散布来提高效率,但保真度较低。 (3)研究方法:本文提出了一种名为 HAHA 的新方法,该方法结合了高斯散布和纹理网格的优点。HAHA 学习在人体 SMPL-X 网格中需要的地方(例如头发和非网格服装)应用高斯散布,从而最大限度地减少高斯散布的使用数量并减少渲染伪影。 (4)方法性能:在 SnapshotPeople 和 X-Humans 两个公开数据集上,HAHA 在重建质量上与最先进的方法相当,同时使用的高斯散布数量不到三分之一。在 X-Humans 数据集上,HAHA 在新姿势上的表现优于之前的最先进方法。
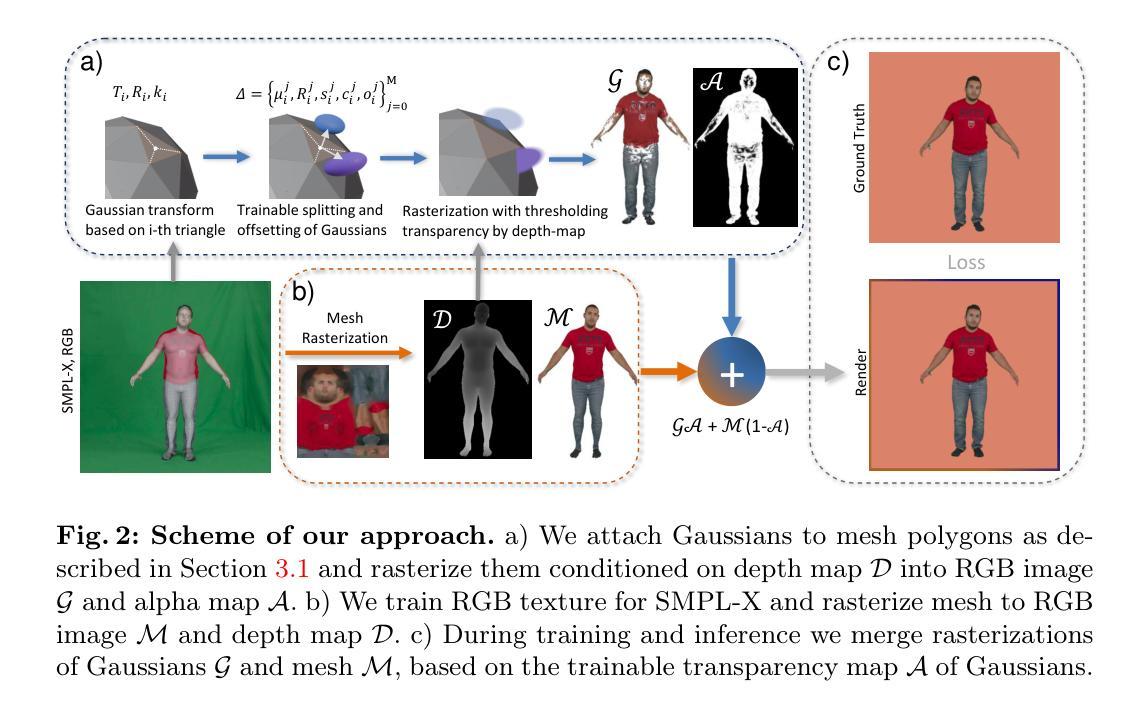
方法: (1)学习全身高斯表示,并微调 SMPL-X 的姿态和形状以进行训练帧。 (2)使用结果的 SMPL-X 网格和提供的 UV 映射来学习 RGB 纹理。 (3)合并两个化身,并学习删除一些高斯而不会降低质量。
结论: (1)本工作通过提出一种新的方法HAHA,在高效且高保真可动画人体化身生成方面取得了显著进展。 (2)创新点:HAHA将高斯散布和纹理网格相结合,学习在需要的地方应用高斯散布,最大限度地减少高斯散布的使用数量,同时保持高保真度。 性能:在公开数据集上,HAHA在重建质量上与最先进的方法相当,同时使用的高斯散布数量不到三分之一。 工作量:HAHA的方法涉及学习全身高斯表示、微调SMPL-X姿态和形状、学习RGB纹理以及合并两个化身。
点此查看论文截图


MM3DGS SLAM: Multi-modal 3D Gaussian Splatting for SLAM Using Vision, Depth, and Inertial Measurements
Authors:Lisong C. Sun, Neel P. Bhatt, Jonathan C. Liu, Zhiwen Fan, Zhangyang Wang, Todd E. Humphreys, Ufuk Topcu
Simultaneous localization and mapping is essential for position tracking and scene understanding. 3D Gaussian-based map representations enable photorealistic reconstruction and real-time rendering of scenes using multiple posed cameras. We show for the first time that using 3D Gaussians for map representation with unposed camera images and inertial measurements can enable accurate SLAM. Our method, MM3DGS, addresses the limitations of prior neural radiance field-based representations by enabling faster rendering, scale awareness, and improved trajectory tracking. Our framework enables keyframe-based mapping and tracking utilizing loss functions that incorporate relative pose transformations from pre-integrated inertial measurements, depth estimates, and measures of photometric rendering quality. We also release a multi-modal dataset, UT-MM, collected from a mobile robot equipped with a camera and an inertial measurement unit. Experimental evaluation on several scenes from the dataset shows that MM3DGS achieves 3x improvement in tracking and 5% improvement in photometric rendering quality compared to the current 3DGS SLAM state-of-the-art, while allowing real-time rendering of a high-resolution dense 3D map. Project Webpage: https://vita-group.github.io/MM3DGS-SLAM
PDF Project Webpage: https://vita-group.github.io/MM3DGS-SLAM
Summary
实时3D建图与定位系统3D Gaussians首次与相机图像和惯性测量相结合,可实现高精度的SLAM。
Key Takeaways
- 利用3D Gaussians进行地图表示,可实现更快的渲染、尺度感知和更佳的轨迹跟踪。
- 提出了一种将预积分惯性测量、深度估计和光度渲染质量度量纳入损失函数的框架。
- 发布了一个由配备相机和惯性测量单元的移动机器人收集的多模态数据集。
- 实验评估表明,MM3DGS在跟踪方面实现了3倍的提升,在光度渲染质量方面实现了5%的提升。
- MM3DGS允许实时渲染高分辨率稠密3D地图。
- 标题:MM3DGSSLAM:使用视觉、深度和惯性测量进行 SLAM 的多模态 3D 高斯斑点
- 作者:Lisong C. Sun, Neel P. Bhatt, Jonathan C. Liu, Zhiwen Fan, Zhangyang Wang, Todd E. Humphreys, Ufuk Topcu
- 隶属:德克萨斯大学奥斯汀分校
- 关键词:SLAM、3D 重建、神经辐射场、高斯斑点
- 论文链接:https://vita-group.github.io/MM3DGS-SLAM Github 代码链接:无
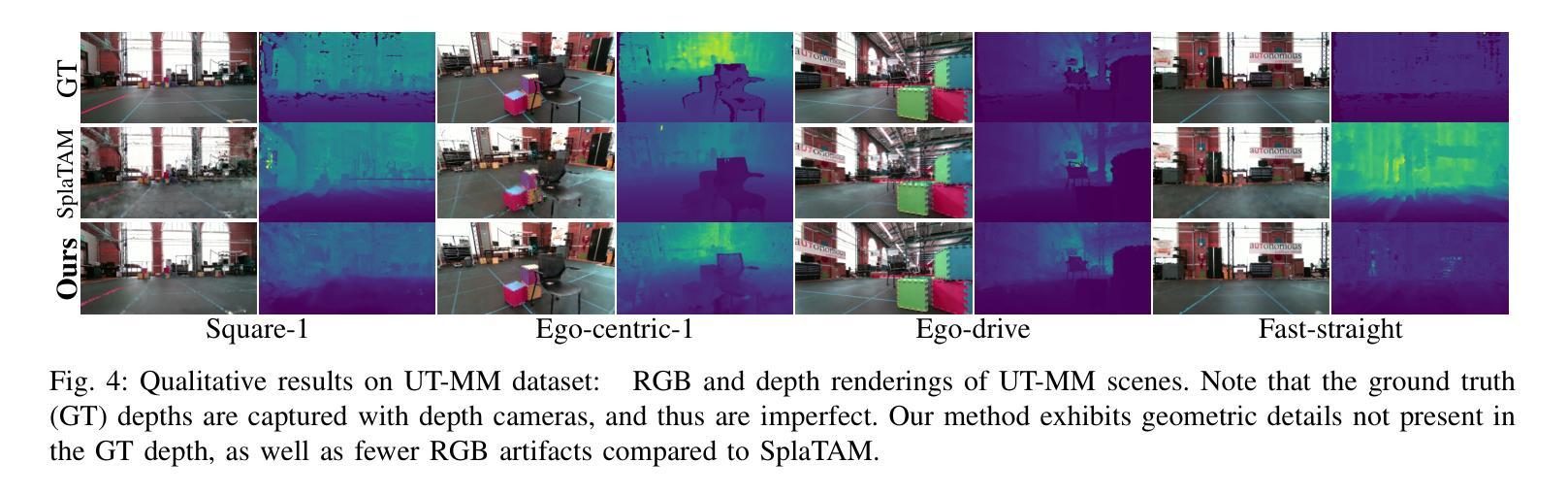
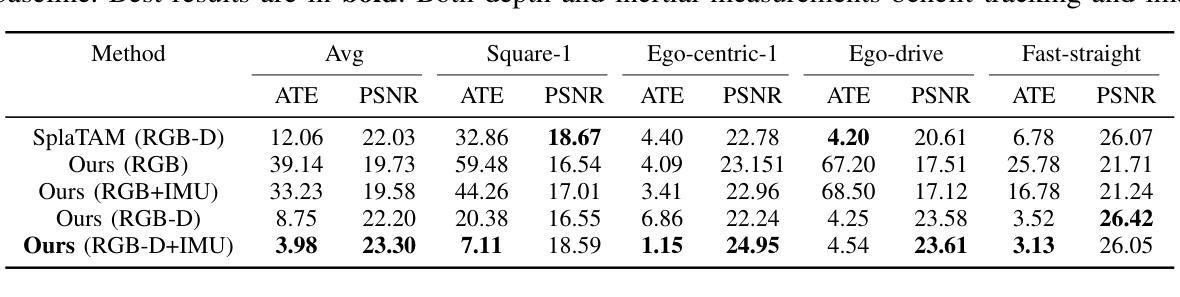
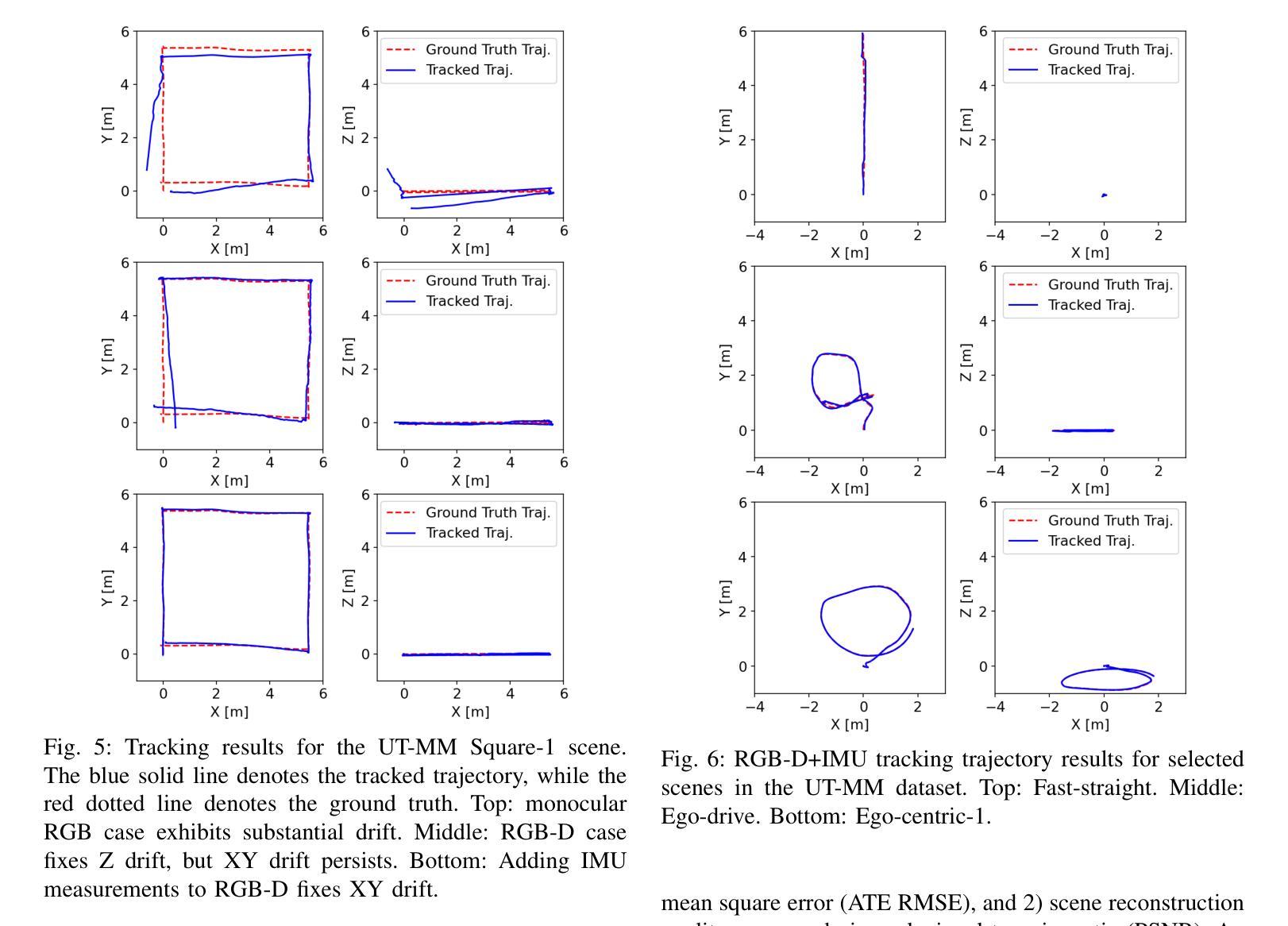
摘要: (1)研究背景:SLAM 在自主系统中至关重要,3D 场景重建和传感器定位是其核心能力。神经辐射场是用于 3D 重建的新兴技术,但其在 SLAM 中的应用受到渲染速度、尺度感知和轨迹跟踪准确性方面的限制。 (2)过去的方法:神经辐射场方法在 SLAM 中存在上述限制。 (3)研究方法:MM3DGS 提出了一种基于 3D 高斯斑点的 SLAM 方法,利用预积分惯性测量、深度估计和光度渲染质量度量来优化跟踪和建图。 (4)方法性能:在 UT-MM 数据集上进行评估,MM3DGS 在跟踪方面比最先进的 3DGSSLAM 方法提高了 3 倍,在光度渲染质量方面提高了 5%,同时允许实时渲染高分辨率密集 3D 地图。这些性能支持了其在 SLAM 中实现准确定位和逼真重建的目标。
方法: (1) MM3DGS采用预积分惯性测量(Pre-integrated Inertial Measurements,PIM)来估计相机位姿和速度,减少噪声影响; (2) 使用深度估计模块从RGB图像中提取深度信息,用于神经辐射场渲染和场景重建; (3) 引入光度渲染质量度量(Photometric Rendering Quality,PRQ),通过优化渲染质量来提高跟踪和建图的准确性; (4) 将3D高斯斑点(3D Gaussian Splat,3DGS)应用于神经辐射场,提高渲染速度和尺度感知能力; (5) 提出一种基于3DGS的轨迹跟踪算法,通过优化PRQ和PIM来实现准确定位; (6) 采用分块渲染技术,允许实时渲染高分辨率密集3D地图。
8.结论: (1):本文提出了一种多模态3D高斯斑点SLAM方法MM3DGS,该方法利用预积分惯性测量、深度估计和光度渲染质量度量来优化跟踪和建图,在跟踪方面比最先进的3DGSSLAM方法提高了3倍,在光度渲染质量方面提高了5%,同时允许实时渲染高分辨率密集3D地图,为SLAM中实现准确定位和逼真重建提供了新的解决方案。 (2):创新点: - 提出了一种基于3D高斯斑点的SLAM方法,提高了渲染速度和尺度感知能力。 - 引入光度渲染质量度量,通过优化渲染质量来提高跟踪和建图的准确性。 - 采用分块渲染技术,允许实时渲染高分辨率密集3D地图。 性能: - 在UT-MM数据集上进行评估,在跟踪方面比最先进的3DGSSLAM方法提高了3倍,在光度渲染质量方面提高了5%。 - 允许实时渲染高分辨率密集3D地图。 工作量: - 该方法需要预积分惯性测量、深度估计和光度渲染质量度量等模块,工作量较大。
点此查看论文截图


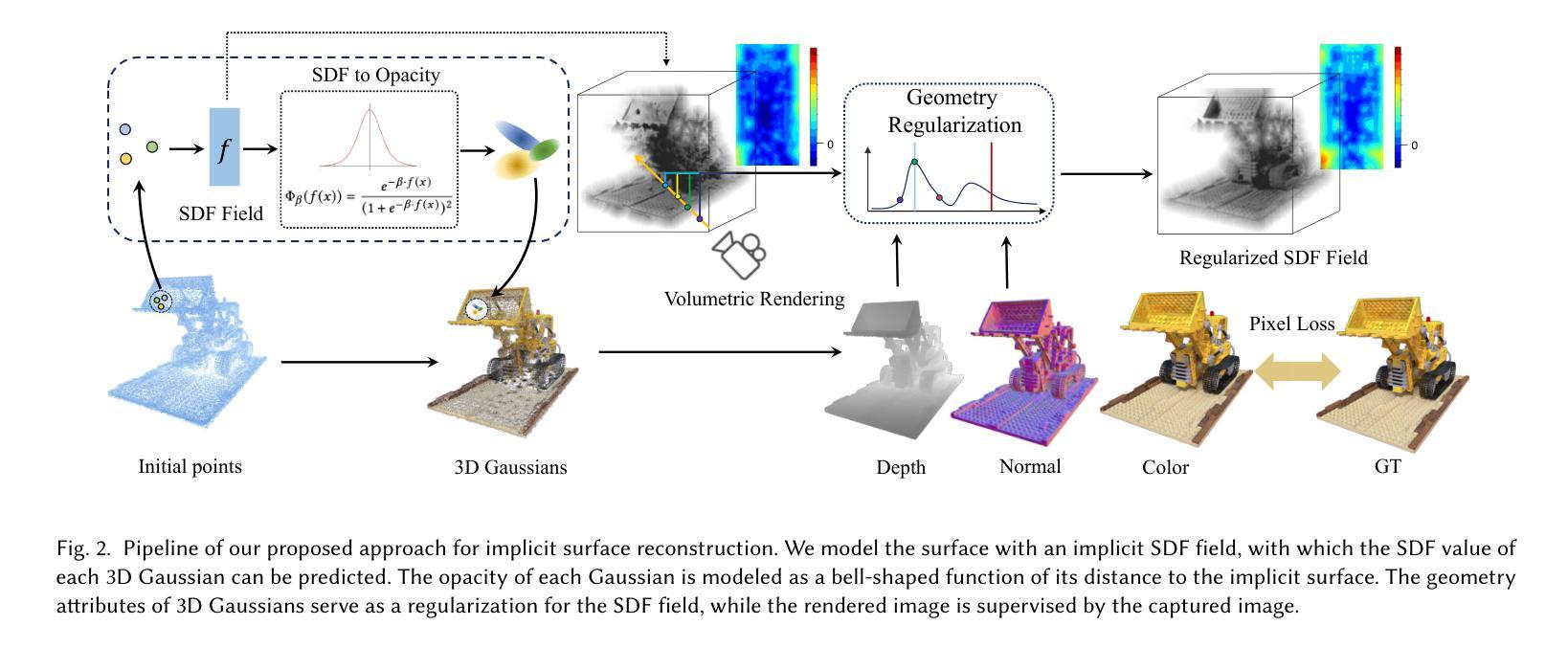
- 题目:3DGSR:基于 3D 高斯溅射的隐式曲面重建
- 作者:Xiaoyang Lyu, Yang-Tian Sun, Yi-Hua Huang, Xiuzhe Wu, Ziyi Yang, Yilun Chen, Jiangmiao Pang, Xiaojuan Qi
- 隶属:香港大学
- 关键词:Gaussian Splatting、隐式函数、符号距离函数、体积渲染
- 论文链接:https://doi.org/10.1145/nnnnnnn.nnnnnnn Github 代码链接:None
摘要: (1)研究背景:3D 高斯溅射(3DGS)是一种用于高质量新视角合成的新型技术,但它只能生成嘈杂且不完整的 3D 几何点,无法准确重建场景的 3D 曲面。 (2)过去方法:3DGS 无法忠实地表示 3D 曲面,因为它采用非结构化的基于点的几何表示。 (3)研究方法:本文提出了一种隐式曲面重建方法,称为 3DGS 的 3D 高斯溅射(3DGSR),它允许准确重建具有复杂细节的 3D,同时继承了 3DGS 的高效率和渲染质量。关键思想是将隐式符号距离场(SDF)合并到 3D 高斯中,使它们能够对齐并共同优化。 (4)方法性能:实验结果表明,3DGSR 方法能够实现高质量的 3D 曲面重建,同时保持 3DGS 的效率和渲染质量。该方法在与领先的曲面重建技术竞争时表现出色,同时提供了更高效的学习过程和更好的渲染质量。
方法: (1) 将隐式符号距离场(SDF)与 3D 高斯溅射(3DGS)相结合,使它们能够对齐并共同优化。 (2) 使用 SDF 来指导 3DGS 的优化过程,从而生成更准确和完整的 3D 曲面。 (3) 采用分层优化策略,从粗糙的曲面逐步细化到精细的曲面,以提高重建效率。 (4) 引入正则化项,以促进重建曲面的光滑性和连贯性。 (5) 使用基于梯度的优化算法,以实现高效和稳定的曲面重建。
结论: (1):本工作提出了一种高效的隐式曲面重建方法,该方法基于 3D 高斯溅射,能够重建具有复杂细节的高质量 3D 曲面。 (2):创新点:
- 将神经隐式符号距离场(SDF)与 3D 高斯溅射(3DGS)相结合,通过可微分 SDF 到不透明度转换函数实现 SDF 和 3D 高斯的对齐和联合优化。
- 利用体积渲染和 SDF 与高斯几何一致性正则化进行 SDF 优化。 性能:
- 在不影响 3D 高斯渲染能力和效率的情况下,3DGSR 在重建高质量曲面方面优于最先进的重建管道。 工作量:
- 由于渲染质量和曲面平滑度之间的权衡,本研究确实存在一定的局限性。
点此查看论文截图


 wechat
wechat- alipay