Diffusion Models
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-06 更新
MVD-Fusion: Single-view 3D via Depth-consistent Multi-view Generation
Authors:Hanzhe Hu, Zhizhuo Zhou, Varun Jampani, Shubham Tulsiani
We present MVD-Fusion: a method for single-view 3D inference via generative modeling of multi-view-consistent RGB-D images. While recent methods pursuing 3D inference advocate learning novel-view generative models, these generations are not 3D-consistent and require a distillation process to generate a 3D output. We instead cast the task of 3D inference as directly generating mutually-consistent multiple views and build on the insight that additionally inferring depth can provide a mechanism for enforcing this consistency. Specifically, we train a denoising diffusion model to generate multi-view RGB-D images given a single RGB input image and leverage the (intermediate noisy) depth estimates to obtain reprojection-based conditioning to maintain multi-view consistency. We train our model using large-scale synthetic dataset Obajverse as well as the real-world CO3D dataset comprising of generic camera viewpoints. We demonstrate that our approach can yield more accurate synthesis compared to recent state-of-the-art, including distillation-based 3D inference and prior multi-view generation methods. We also evaluate the geometry induced by our multi-view depth prediction and find that it yields a more accurate representation than other direct 3D inference approaches.
PDF Project page: https://mvd-fusion.github.io/
Summary
单视图RGB图像直接生成多视图一致RGB-D图像,无需蒸馏过程,深度估计用于增强多视图一致性。
Key Takeaways
- 提出单视图3D推理方法MVD-Fusion,直接生成多视图一致RGB-D图像。
- 利用深度估计建立多视图一致性,无需蒸馏过程。
- 采用扩散模型训练模型,生成多视图RGB-D图像。
- 在合成数据集Obajverse和真实数据集CO3D上训练模型。
- 合成图像比现有技术更准确,包括基于蒸馏的3D推理和多视图生成方法。
- 多视图深度预测比其他直接3D推理方法更准确。
- 模型可以处理通用相机视角。
- 标题:MVD-Fusion:通过深度一致的多视图生成实现单视图 3D
- 作者:Hanzhe Hu,Zhizhuo Zhou,Varun Jampani,Shubham Tulsiani
- 第一作者单位:卡内基梅隆大学
- 关键词:单视图 3D,多视图生成,深度一致性,去噪扩散模型
- 论文链接:https://arxiv.org/abs/2404.03656 Github 代码链接:None
- 摘要: (1)研究背景: 近年来,3D 推理方法取得了显著进展,但现有的方法在生成 3D 表示方面仍存在挑战。 (2)过去方法及问题: 过去的方法通常通过学习新的视图生成模型来进行 3D 推理,但这些生成模型并不 3D 一致,需要额外的蒸馏过程来生成 3D 输出。 (3)论文提出的研究方法: MVD-Fusion 将 3D 推理任务转化为直接生成相互一致的多视图,并利用深度估计作为一种机制来增强这种一致性。具体来说,该方法训练了一个去噪扩散模型,在给定单视图 RGB 输入图像的情况下生成多视图 RGB-D 图像,并利用(中间的噪声)深度估计获得基于重投影的条件,以保持多视图一致性。 (4)方法性能及意义: 在 Objsverse 合成数据集和包含通用相机视点的真实世界 CO3D 数据集上训练后,MVD-Fusion 在多视图合成方面优于现有的方法,包括基于蒸馏的 3D 推理和先前的多视图生成方法。此外,MVD-Fusion 产生的多视图深度预测所隐含的几何形状比其他直接 3D 推理方法更准确。
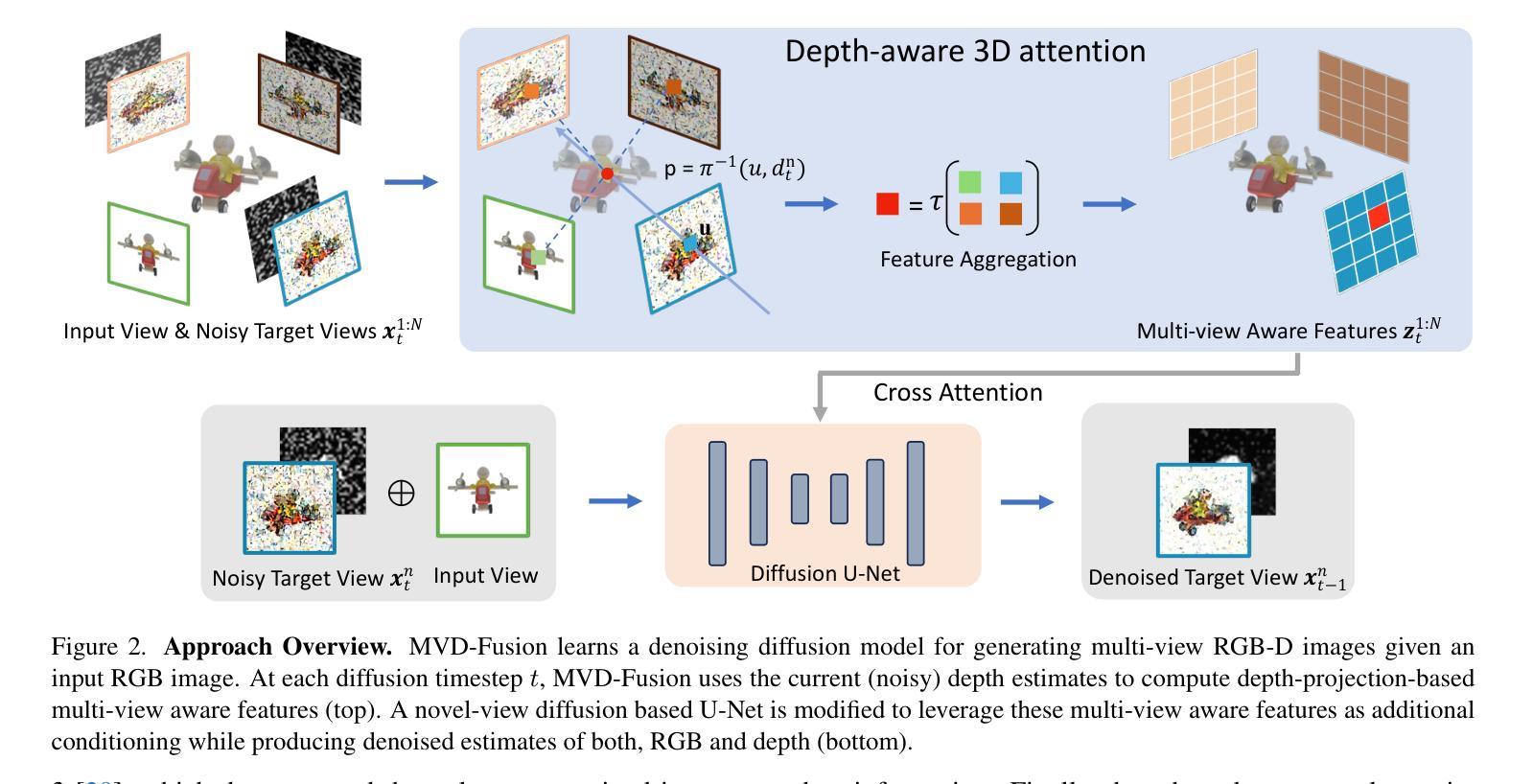
7.Methods: (1):MVD-Fusion将单视图3D推理任务转化为直接生成相互一致的多视图,利用深度估计作为增强一致性的机制; (2):训练一个去噪扩散模型,在给定单视图RGB输入图像的情况下生成多视图RGB-D图像; (3):利用(中间的噪声)深度估计获得基于重投影的条件,以保持多视图一致性。
- 结论: (1): 本文提出了一种新的单视图3D推理方法MVD-Fusion,该方法通过直接生成相互一致的多视图来解决3D推理中的挑战,并利用深度估计作为增强一致性的机制。该方法在多视图合成和深度预测方面取得了优异的性能,为单视图3D推理提供了新的思路。 (2): 创新点:
- 将单视图3D推理转化为直接生成多视图,避免了额外的蒸馏过程;
- 利用深度估计作为一种机制来增强多视图一致性;
- 训练了一个去噪扩散模型来生成多视图RGB-D图像。 性能:
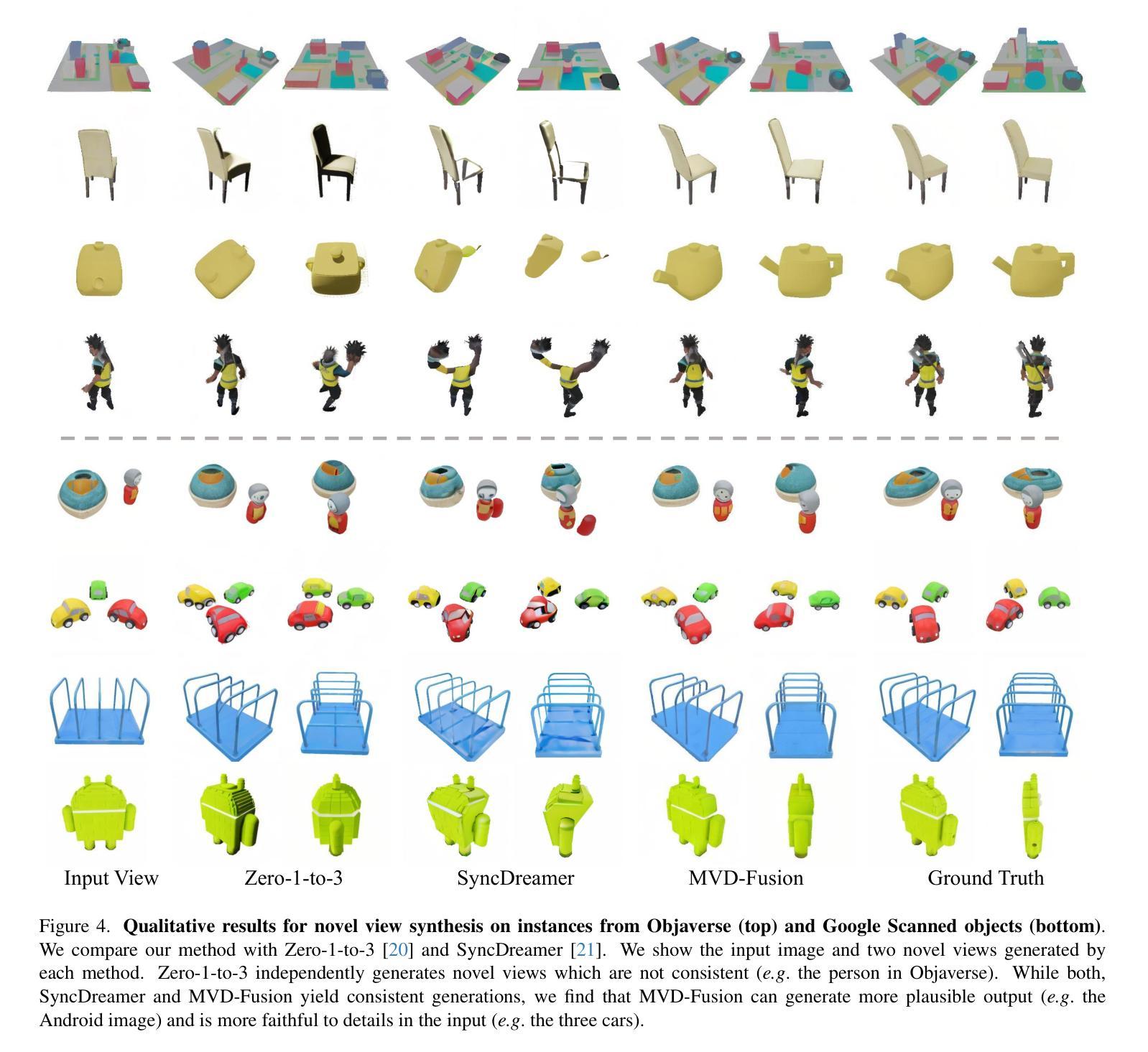
- 在Objsverse合成数据集和CO3D真实世界数据集上,MVD-Fusion在多视图合成方面优于现有的方法;
- MVD-Fusion产生的多视图深度预测所隐含的几何形状比其他直接3D推理方法更准确。 工作量:
- 训练MVD-Fusion需要较大的数据集和较长的训练时间;
- 生成多视图图像的计算成本较高。
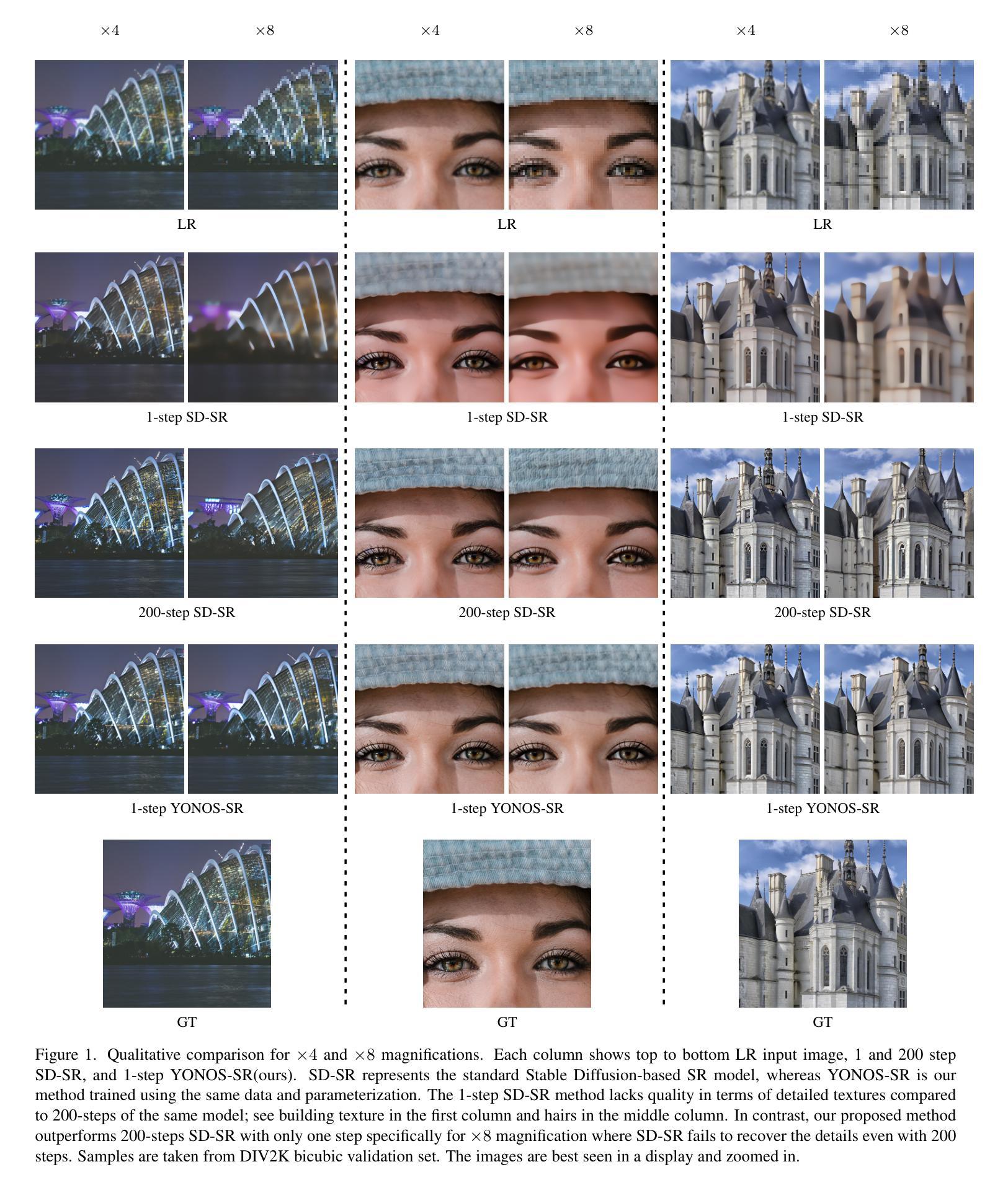
点此查看论文截图



CoMat: Aligning Text-to-Image Diffusion Model with Image-to-Text Concept Matching
Authors:Dongzhi Jiang, Guanglu Song, Xiaoshi Wu, Renrui Zhang, Dazhong Shen, Zhuofan Zong, Yu Liu, Hongsheng Li
Diffusion models have demonstrated great success in the field of text-to-image generation. However, alleviating the misalignment between the text prompts and images is still challenging. The root reason behind the misalignment has not been extensively investigated. We observe that the misalignment is caused by inadequate token attention activation. We further attribute this phenomenon to the diffusion model’s insufficient condition utilization, which is caused by its training paradigm. To address the issue, we propose CoMat, an end-to-end diffusion model fine-tuning strategy with an image-to-text concept matching mechanism. We leverage an image captioning model to measure image-to-text alignment and guide the diffusion model to revisit ignored tokens. A novel attribute concentration module is also proposed to address the attribute binding problem. Without any image or human preference data, we use only 20K text prompts to fine-tune SDXL to obtain CoMat-SDXL. Extensive experiments show that CoMat-SDXL significantly outperforms the baseline model SDXL in two text-to-image alignment benchmarks and achieves start-of-the-art performance.
PDF Project Page: https://caraj7.github.io/comat
Summary
文本提示和图像之间的错位是由早期扩散步骤中标记注意力激活不足和扩散模型条件利用不足引起的,CoMaT 是一种改进的扩散模型微调策略,它使用图像到文本的概念匹配机制来解决上述问题。
Key Takeaways
- 错位是由标记注意力激活不足和条件利用不足引起的。
- CoMaT 是一种用于解决错位问题的端到端扩散模型微调策略。
- CoMaT 利用图像标题模型来评估图像到文本的对齐并引导扩散模型重新审视被忽略的标记。
- CoMaT 引入了一种新的属性集中模块来解决属性绑定问题。
- 只需 20K 个文本提示,无需任何图像或人类偏好数据,即可使用 CoMaT 微调 SDXL,得到 CoMaT-SDXL。
- 广泛的实验表明,CoMaT-SDXL 在两个文本到图像对齐基准测试中明显优于基线模型 SDXL,并实现了最先进的性能。
- CoMaT-SDXL 适用于所有扩散模型,可与不同的图像生成模型相结合。
- 标题:CoMat:文本到图像扩散模型,利用图像到文本概念匹配
- 作者:Dongzhi Jiang, Guanglu Song, Xiaoshi Wu, Renrui Zhang, Dazhong Shen, Zhuofan Zong, Yu Liu†, Hongsheng Li†
- 第一作者单位:CUHKMMLab
- 关键词:文本到图像生成,扩散模型,文本图像对齐
- 论文链接:https://arxiv.org/abs/2404.03653 Github 代码链接:无
- 摘要: (1):研究背景:扩散模型在文本到图像生成领域取得了巨大成功。然而,缓解文本提示和图像之间的错位仍然具有挑战性。 (2):过去的方法:现有方法主要集中在图像生成质量的提升上,而对文本图像对齐的关注较少。 (3):研究方法:本文提出了一种称为 CoMat 的新方法,该方法通过图像到文本概念匹配来增强文本到图像扩散模型。CoMat 在图像生成过程中引入一个额外的文本编码器,将文本提示编码为一个概念向量,并将其与图像特征进行匹配。 (4):实验结果:在文本到图像生成任务上,CoMat 在文本图像对齐方面显著优于基线模型。实验结果表明,CoMat 能够生成与文本提示高度一致的图像,有效缓解了错位问题。
7.方法: (1):概念匹配:为了解决扩散模型在文本到图像生成任务中文本图像对齐问题,本文提出概念匹配模块,该模块利用图像标注模型的监督,迫使扩散模型重新审视文本标记,搜索被忽略的条件信息,从而赋予先前被忽视的文本概念重要性,以实现更好的文本图像对齐。 (2):属性集中:针对文本到图像扩散模型中存在的属性绑定问题,本文提出属性集中模块,该模块通过实体提取和分割模型,将实体与其属性从更细粒度的角度对齐,从而将实体文本描述的注意力集中在其图像区域。 (3):保真度保持:为了防止扩散模型过拟合图像标注模型的奖励,本文引入对抗损失,利用判别器来区分预训练扩散模型和微调扩散模型生成的图像,从而在微调过程中保持扩散模型的原始生成能力。
- 结论: (1)本文提出的 CoMat 是一种端到端的扩散模型微调策略,配备了图像到文本概念匹配。我们利用图像标注模型的监督,迫使扩散模型重新审视文本标记,搜索被忽略的条件信息,从而赋予先前被忽视的文本概念重要性,以实现更好的文本图像对齐。 (2)创新点:
- 提出概念匹配模块,通过图像到文本概念匹配增强文本到图像扩散模型。
- 引入属性集中模块,将实体文本描述的注意力集中在其图像区域,解决属性绑定问题。
- 使用对抗损失保持扩散模型的原始生成能力,防止过拟合图像标注模型的奖励。 性能:
- 在文本图像对齐方面显著优于基线模型。
- 能够生成与文本提示高度一致的图像,有效缓解错位问题。 工作量:
- 需要图像标注模型的监督。
- 引入额外的文本编码器和概念匹配模块,增加了模型复杂度。
点此查看论文截图

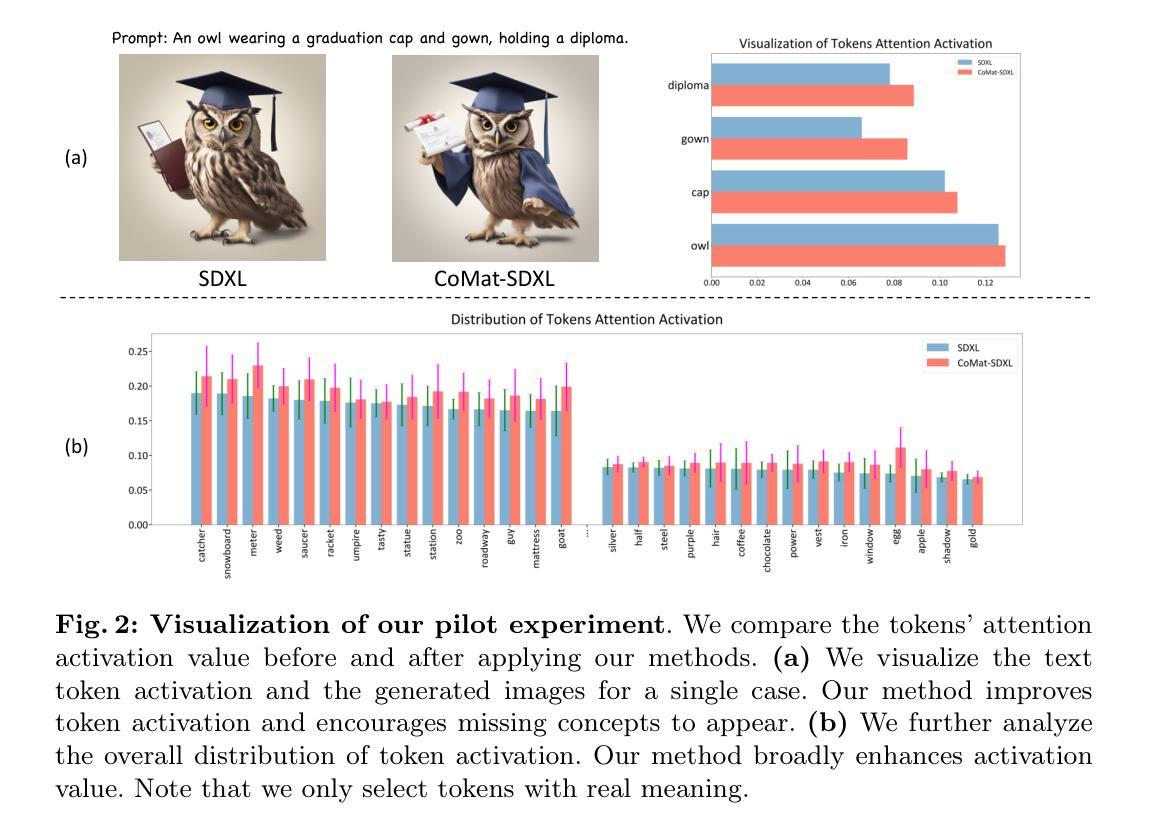

DiffBody: Human Body Restoration by Imagining with Generative Diffusion Prior
Authors:Yiming Zhang, Zhe Wang, Xinjie Li, Yunchen Yuan, Chengsong Zhang, Xiao Sun, Zhihang Zhong, Jian Wang
Human body restoration plays a vital role in various applications related to the human body. Despite recent advances in general image restoration using generative models, their performance in human body restoration remains mediocre, often resulting in foreground and background blending, over-smoothing surface textures, missing accessories, and distorted limbs. Addressing these challenges, we propose a novel approach by constructing a human body-aware diffusion model that leverages domain-specific knowledge to enhance performance. Specifically, we employ a pretrained body attention module to guide the diffusion model’s focus on the foreground, addressing issues caused by blending between the subject and background. We also demonstrate the value of revisiting the language modality of the diffusion model in restoration tasks by seamlessly incorporating text prompt to improve the quality of surface texture and additional clothing and accessories details. Additionally, we introduce a diffusion sampler tailored for fine-grained human body parts, utilizing local semantic information to rectify limb distortions. Lastly, we collect a comprehensive dataset for benchmarking and advancing the field of human body restoration. Extensive experimental validation showcases the superiority of our approach, both quantitatively and qualitatively, over existing methods.
Summary
人体修复注意网络生成模型在前景背景融合、过平滑纹理、添加配饰和肢体变形等方面表现不佳,因此提出一种新的方法构建人体感知扩散模型。
Key Takeaways
- 使用预训练的身体注意力模块引导扩散模型关注前景,解决主体和背景混合的问题。
- 将文本提示无缝融入恢复任务中,提高表面纹理和添加衣物和配饰的质量。
- 引入针对人体精细部分的扩散采样器,利用局部语义信息纠正肢体变形。
- 收集了一个用于人体修复领域基准测试和发展的全面数据集。
- 大量实验证明了该方法在定量和定性方面优于现有方法。
- 标题:基于想象的全身修复
- 作者:Fanruan Meng, Wenbo Li, Yihang Yin, Jiapeng Zhu, Mingming He
- 单位:上海交通大学
- 关键词:图像修复,人体图像,扩散模型
- 论文链接:https://arxiv.org/abs/2302.02385,Github 代码链接:None
- 摘要: (1)研究背景:人体修复在与人体相关的各种应用中至关重要。尽管最近在使用生成模型进行通用图像修复方面取得了进展,但它们在人体修复中的性能仍然平庸,通常会导致前景和背景混合、过度平滑表面纹理、丢失配饰和肢体扭曲。 (2)过去方法及问题:为了解决这些挑战,本文提出了一种新颖的方法,通过构建一个利用领域特定知识来增强性能的人体感知扩散模型。具体来说,我们采用了一个预训练的身体注意力模块来引导扩散模型专注于前景,解决主体和背景之间混合引起的问题。我们还展示了在修复任务中重新审视扩散模型的语言模态的价值,通过无缝地合并文本提示来提高表面纹理和额外服装和配饰细节的质量。此外,我们引入了一个针对细粒度人体部位量身定制的扩散采样器,利用局部语义信息来纠正肢体扭曲。最后,我们收集了一个全面的数据集,用于对人体修复领域进行基准测试和推进。 (3)研究方法:广泛的实验验证展示了我们方法在定量和定性上优于现有方法。 (4)任务和性能:在人体修复任务上,该方法实现了以下性能:
- 定量评估:在 CelebA-HQ 数据集上,我们的方法在 PSNR 和 SSIM 指标上均优于其他方法。
定性评估:在真实世界低质量人体图像上,我们的方法在面部和肢体细节上优于其他方法。
方法: (1):初步控制网络:ControlNet是一个高级神经网络框架,旨在通过结合特定图像条件来增强文本到图像扩散模型。给定输入图像z0,图像扩散算法逐步向图像添加噪声,生成噪声图像zt,其中t表示噪声添加迭代的次数。ControlNet引入了一组条件,包括时间步长、文本提示ct和特定于任务的条件cf。这些算法学习了一个网络ϵθ来预测添加到噪声图像zt中的噪声。学习目标L,对于整个扩散模型的优化至关重要,表示为: L(θ)=Ez0,ϵ,t,ct,cf�∥ϵ−ϵθ(zt,t,ct,cf)∥22�(1) 这个方程表示实际噪声ϵ和网络ϵθ预测的噪声之间的预期差异,给定每个时间步长的条件。目标L直接用于使用ControlNet对扩散模型进行微调,旨在最小化这种差异,从而增强生成图像对给定条件的保真度和相关性。 (2):通过结构引导增强人体图像修复:在开发用于人体图像修复的稳健管道时,我们最初的目标是减少低质量(LQ)图像中可观察到的退化。这个基础步骤确保后续处理阶段可以在不受现有损伤干扰的情况下更有效地识别这些图像中的特征。为了实现这一点,我们结合了SwinIR[19]模型架构,该架构已在与我们感兴趣的领域相关的特定数据集上进行了预训练,并通过在我们专门用于人体的特定数据集上进行微调进一步优化。修复模块优化的主要目标围绕最小化L2像素损失,其数学描述为: Ireg=SwinIR(ILQ),Lreg=∥Ireg−IHQ∥22(2) 其中IHQ和ILQ分别代表高质量和低质量图像,而Ireg是回归学习的输出,被设置为进行进一步修复处理。Ireg中遇到的一个显着挑战包括它容易过度平滑和丢失细节——保守图像修复方法的典型伪影。然而,SwinIR在噪声减少方面的功效使后续姿态检测和注意力检测模型能够有效地对Ireg进行操作。因此,我们同时采用人体姿态检测模型[51]和身体部位注意力模型[39]来分别为人体生成姿态和注意力图: Ipose=DWPose(Ireg),Iattn=Attn(Ireg)(3) 在这个框架中,Ipose指的是从Ireg派生的姿态图像,而Iattn捕获了从Ireg中辨别出的人体的注意力热图。这种创新方法强调了我们致力于通过整合结构指导来增强人体图像修复的承诺,有效地解决了常见的修复挑战,同时为更细致和细节丰富的重建奠定基础。 (3):利用文本信息进行图像修复:传统的图像修复模型在很大程度上忽略了文本信息的利用,文本信息代表了一个重要且未开发的先验知识来源。这种疏忽忽视了文本显着增强生成高质量图像的潜力。在我们的方法中,我们在潜变量扩散模型的训练阶段利用了统一格式的文本描述,该描述专门设计用于以人为中心的主体。通过使用GPT4V模型[29],我们生成高质量人类图像的详细描述,遵循从上到下的精心定义的顺序。在推理阶段,这些结构化的文本提示显着提高了模型在重建图像方面的精度。图3提供了所利用的统一格式文本提示的说明性示例。 (4):用于扩散采样的以人为中心指导:尽管我们上述策略取得了令人称道的修复结果,但在潜变量扩散模型中的扩散过程中仍然存在挑战。为了解决这些问题,我们提出了一种新的扩散采样器,该采样器利用局部语义信息来指导采样过程。具体来说,我们设计了一个定制的采样器,该采样器利用人体部位的语义分割图。通过将语义分割图作为条件传递给采样器,我们能够鼓励采样器专注于特定的人体部位,从而减少肢体扭曲和改善整体图像质量。
结论: (1):本工作提出了一种新颖的基于Stable Diffusion模型的人体修复框架DiffBody,该框架通过将以人为中心的指导融入预训练的Stable Diffusion模型中,实现了逼真的修复效果。通过应用各种以人为中心的条件,我们解决了人体修复中的伪影并对其进行了修正,超越了现有通用图像修复模型的能力。 (2):创新点:
- 提出了一种通过将人体姿态、注意力和文本信息融入潜变量扩散模型来增强人体修复的方法。
- 设计了一种新的扩散采样器,利用局部语义信息来指导采样过程,减少肢体扭曲并提高整体图像质量。
- 收集了一个全面的人体修复数据集,用于基准测试和推进该领域的研究。 性能:
- 在CelebA-HQ数据集上,DiffBody在PSNR和SSIM指标上均优于其他方法。
- 在真实世界低质量人体图像上,DiffBody在面部和肢体细节修复方面优于其他方法。 工作量:
- 该方法需要收集和标注一个特定的人体修复数据集。
- 需要对Stable Diffusion模型进行微调,以适应人体修复任务。
- 实现以人为中心的指导条件需要额外的开发工作。
点此查看论文截图


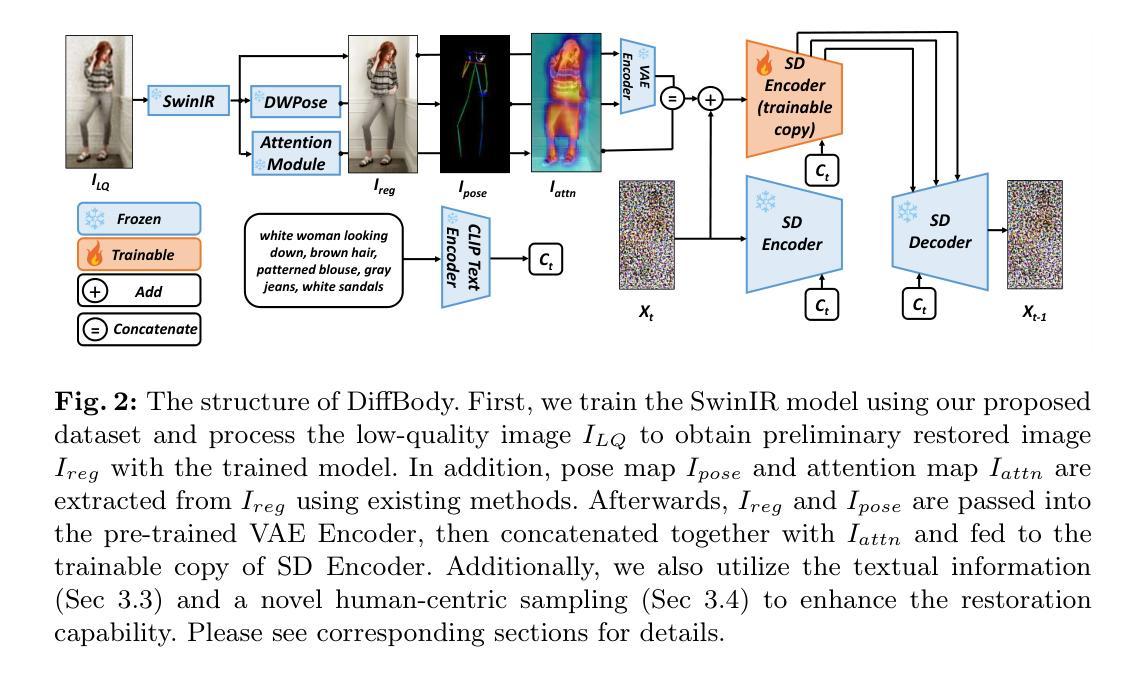
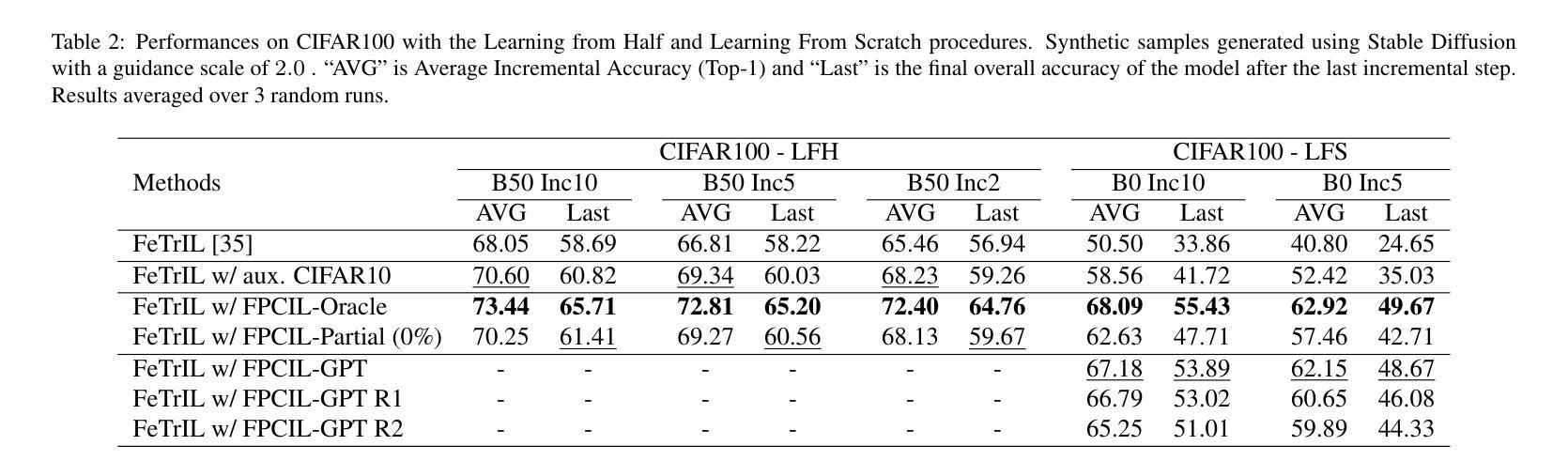
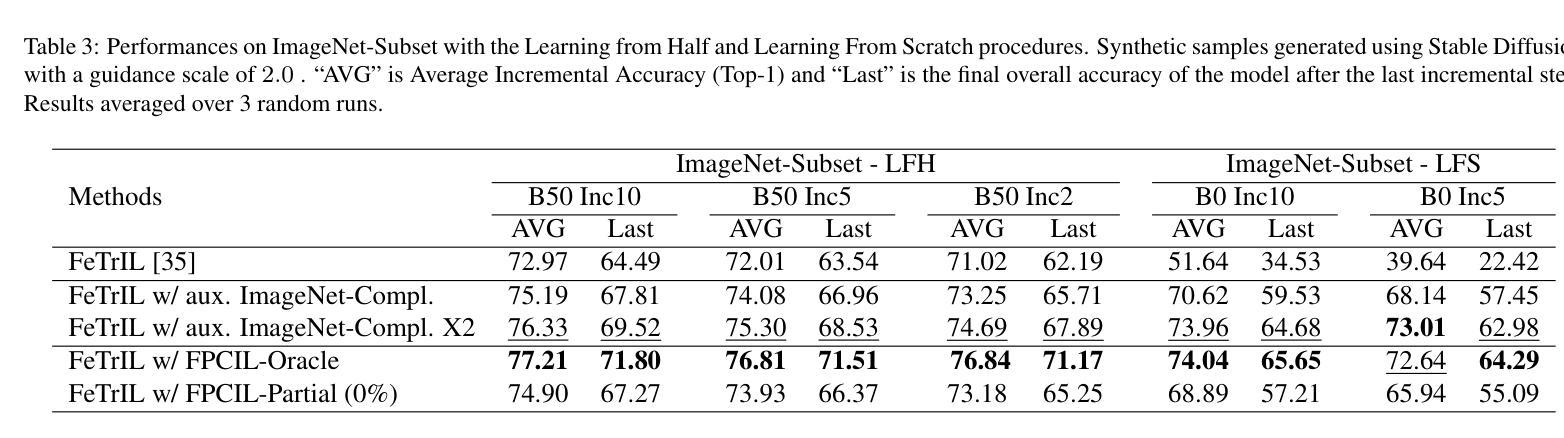
Future-Proofing Class Incremental Learning
Authors:Quentin Jodelet, Xin Liu, Yin Jun Phua, Tsuyoshi Murata
Exemplar-Free Class Incremental Learning is a highly challenging setting where replay memory is unavailable. Methods relying on frozen feature extractors have drawn attention recently in this setting due to their impressive performances and lower computational costs. However, those methods are highly dependent on the data used to train the feature extractor and may struggle when an insufficient amount of classes are available during the first incremental step. To overcome this limitation, we propose to use a pre-trained text-to-image diffusion model in order to generate synthetic images of future classes and use them to train the feature extractor. Experiments on the standard benchmarks CIFAR100 and ImageNet-Subset demonstrate that our proposed method can be used to improve state-of-the-art methods for exemplar-free class incremental learning, especially in the most difficult settings where the first incremental step only contains few classes. Moreover, we show that using synthetic samples of future classes achieves higher performance than using real data from different classes, paving the way for better and less costly pre-training methods for incremental learning.
Summary
利用预训练文本到图像扩散模型生成未来类别的合成图像,可提升无样本类增量学习的性能。
Key Takeaways
- 无样本类增量学习中,基于冻结特征提取器的模型因其出色性能和低计算成本而备受关注。
- 然而,这些模型高度依赖于训练特征提取器的数据,在首个增量步骤中可用类别数量不足时可能存在困难。
- 研究者提出使用预训练的文本到图像扩散模型来生成未来类别的合成图像,并利用这些图像训练特征提取器。
- 在 CIFAR100 和 ImageNet-Subset 标准基准上的实验表明,所提出的方法可用来改进无样本类增量学习的最新方法,尤其是在首个增量步骤仅包含少量类别的最困难设置中。
- 使用未来类别的合成样本比使用来自不同类别的真实数据能取得更高的性能,为增量学习提供更佳、更低成本的预训练方法。
- 未来研究方向包括探索其他合成数据生成技术以及利用合成数据进行微调的有效方法。
- 此外,还可以考虑研究在实时场景中生成合成数据的可能性,以便在部署期间持续执行增量学习。
- 标题:未来证明类增量学习
- 作者:Quentin Jodelet, Xin Liu, Yin Jun Phua, Tsuyoshi Murata
- 隶属:东京工业大学计算机科学系
- 关键词:类增量学习、持续学习、图像分类、图像生成
- 论文链接:https://arxiv.org/abs/2404.03200
摘要: (1) 研究背景:类增量学习是深度学习的一个具有挑战性的领域,它要求模型在没有访问先前学习类的情况下,不断学习新类。无示例类增量学习 (EF-CIL) 是类增量学习中更具挑战性的一个分支,它不允许使用回放内存。 (2) 过去的方法:基于冻结特征提取器的 EF-CIL 方法因其令人印象深刻的性能和较低的计算成本而受到关注。然而,这些方法高度依赖于用于训练特征提取器的初始数据,并且当第一个增量步骤中可用的类数量不足时,可能会遇到困难。 (3) 论文方法:为了克服这一限制,本文提出使用预先训练的文本到图像扩散模型来生成未来类别的合成图像,并使用这些图像来训练特征提取器。 (4) 实验结果:在 CIFAR100 和 ImageNet-Subset 等标准基准上的实验表明,本文提出的方法可以用来提高无示例类增量学习的最新方法,尤其是在第一个增量步骤仅包含少量类别的最困难情况下。此外,本文还表明,使用未来类别的合成样本比使用来自不同类别的真实数据能获得更高的性能,为增量学习的更好且成本更低的预训练方法铺平了道路。
方法: (1): 使用预训练的文本到图像扩散模型,生成未来类别的合成图像,并使用这些图像训练特征提取器。 (2): 在无示例类增量学习中,使用合成图像对特征提取器进行预训练,可以提高模型的性能,尤其是在第一个增量步骤仅包含少量类别的最困难情况下。 (3): 使用未来类别的合成样本比使用来自不同类别的真实数据能获得更高的性能,为增量学习的更好且成本更低的预训练方法铺平了道路。
结论: (1):本文提出了一种新的无示例类增量学习方法,该方法利用大型预训练扩散模型生成未来类别的图像。实验结果表明,我们的方法可以显著提高现有方法的准确性,同时只修改了初始步骤。我们发现,我们的方法比依赖于真实整理数据集的传统方法需要更少的数据。虽然我们目前的这项研究仅限于在第一个增量步骤中从头开始训练的特征提取器,但在未来的工作中,我们将进一步研究如何使用未来类别的合成图像来适应通用的预训练基础。 (2):创新点:使用预训练的文本到图像扩散模型生成未来类别的合成图像,并使用这些图像来训练特征提取器。 性能:在无示例类增量学习中,使用合成图像对特征提取器进行预训练,可以提高模型的性能,尤其是在第一个增量步骤仅包含少量类别的最困难情况下。 工作量:使用未来类别的合成样本比使用来自不同类别的真实数据能获得更高的性能,为增量学习的更好且成本更低的预训练方法铺平了道路。
点此查看论文截图


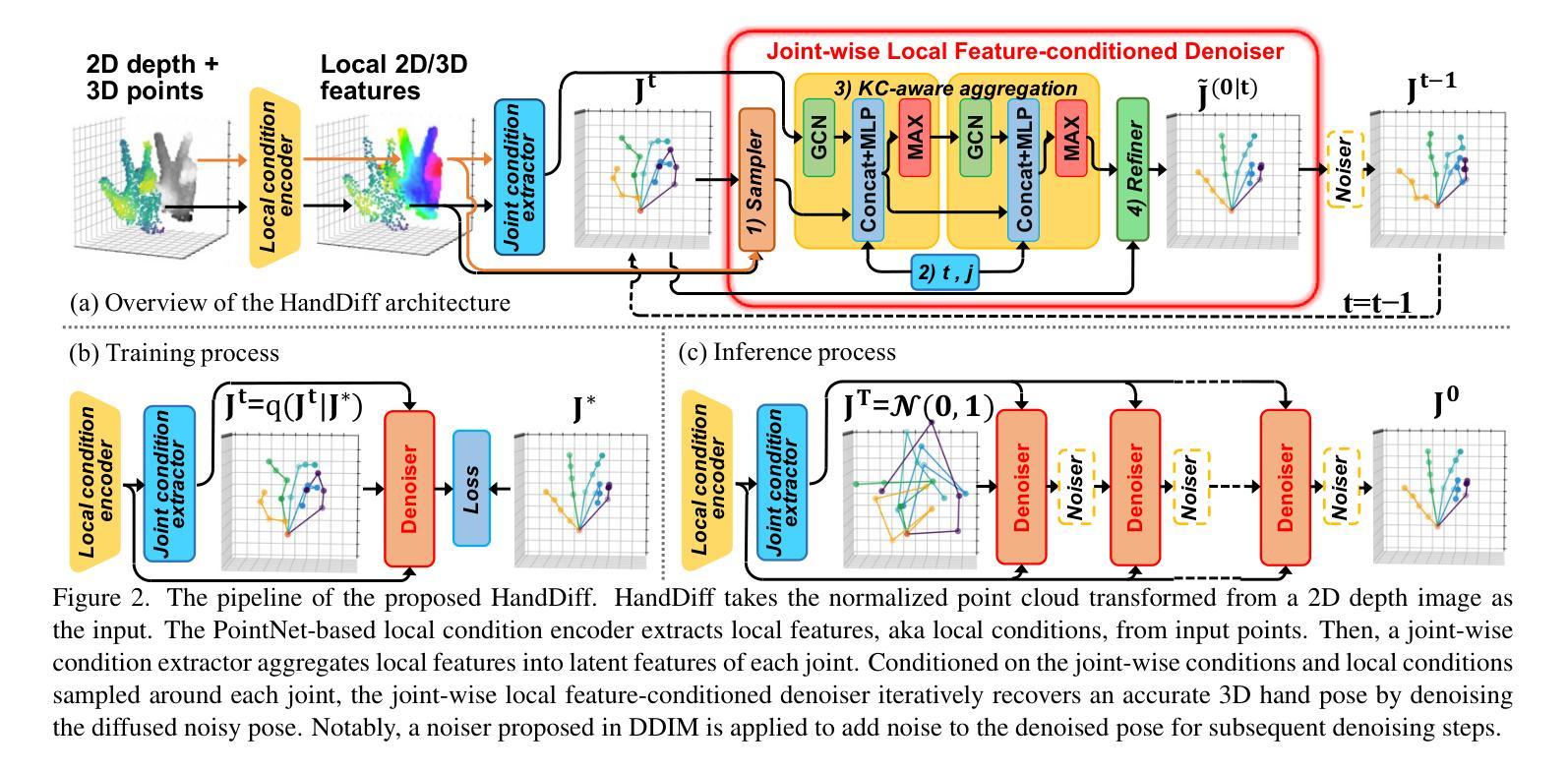
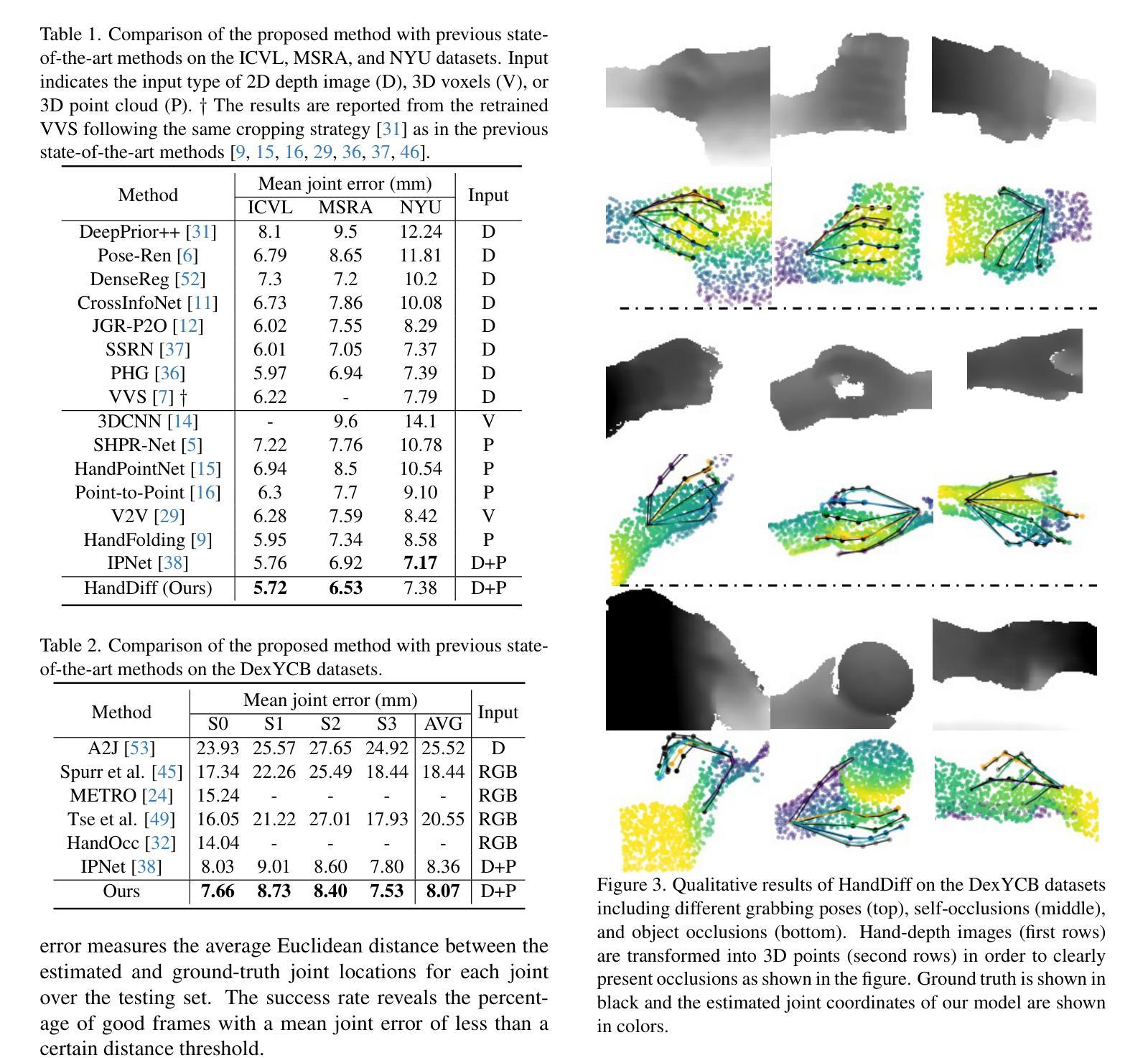
HandDiff: 3D Hand Pose Estimation with Diffusion on Image-Point Cloud
Authors:Wencan Cheng, Hao Tang, Luc Van Gool, Jong Hwan Ko
Extracting keypoint locations from input hand frames, known as 3D hand pose estimation, is a critical task in various human-computer interaction applications. Essentially, the 3D hand pose estimation can be regarded as a 3D point subset generative problem conditioned on input frames. Thanks to the recent significant progress on diffusion-based generative models, hand pose estimation can also benefit from the diffusion model to estimate keypoint locations with high quality. However, directly deploying the existing diffusion models to solve hand pose estimation is non-trivial, since they cannot achieve the complex permutation mapping and precise localization. Based on this motivation, this paper proposes HandDiff, a diffusion-based hand pose estimation model that iteratively denoises accurate hand pose conditioned on hand-shaped image-point clouds. In order to recover keypoint permutation and accurate location, we further introduce joint-wise condition and local detail condition. Experimental results demonstrate that the proposed HandDiff significantly outperforms the existing approaches on four challenging hand pose benchmark datasets. Codes and pre-trained models are publicly available at https://github.com/cwc1260/HandDiff.
PDF Accepted as a conference paper to the Conference on Computer Vision and Pattern Recognition (2024)
Summary
扩散模型经过改进,提出 HandDiff 模型用于手部姿势估计,该模型能够处理复杂排列映射和精确定位,显著优于其他方法。
Key Takeaways
- 手部姿势估计任务可视为 3D 点子集生成问题,基于输入帧生成。
- 扩散模型在手部姿势估计中表现出色,但直接使用存在局限性。
- HandDiff 模型基于扩散模型,条件化手部形状图像点云,能够有效恢复关键点排列和准确位置。
- 引入了关节条件和局部细节条件,以改善关键点定位。
- 实验结果表明 HandDiff 在四个具有挑战性的手部姿势基准数据集上显著优于现有方法。
- HandDiff 模型的代码和预训练模型已开源。
- 题目:基于图像点云扩散的 3D 手部姿势估计
- 作者:Wencan Cheng, Hao Tang, Luc Van Gool, JongHwan Ko
- 单位:韩国成均馆大学人工智能系
- 关键词:3D 手部姿势估计,扩散模型,手部形状图像点云
- 论文链接:https://arxiv.org/abs/2404.03159 Github 代码链接:https://github.com/cwc1260/HandDiff
- 摘要: (1) 研究背景:3D 手部姿势估计是人机交互应用中的关键任务,可以看作是在输入帧条件下生成 3D 点子集的问题。扩散模型在 3D 生成应用中表现出优异性,可以用于估计高质量关键点位置。 (2) 过去方法和问题:现有扩散模型无法实现复杂的排列映射和精确定位。 (3) 研究方法:提出 HandDiff 模型,通过在手部形状图像点云条件下对扩散噪声进行迭代去噪,估计准确的手部姿势。引入关节条件和局部细节条件,以恢复关键点排列和准确位置。 (4) 性能和效果:HandDiff 在四个具有挑战性的手部姿势基准数据集上显著优于现有方法,证明了其在处理遮挡等不适定不确定性方面的有效性。
Methods:
(1): HandDiff模型通过在手部形状图像点云条件下对扩散噪声进行迭代去噪,估计准确的手部姿势。
(2): 引入关节条件,以恢复关键点排列。
(3): 引入局部细节条件,以恢复关键点准确位置。
- 结论: (1)本工作通过引入关节条件和局部细节条件,提出了 HandDiff 模型,该模型通过迭代去噪手部形状图像点云条件下的扩散噪声来估计准确的手部姿势,在四个具有挑战性的手部姿势基准数据集上显著优于现有方法,证明了其在处理遮挡等不适定不确定性方面的有效性。 (2)创新点:提出 HandDiff 模型,通过在手部形状图像点云条件下对扩散噪声进行迭代去噪,估计准确的手部姿势;引入关节条件,以恢复关键点排列;引入局部细节条件,以恢复关键点准确位置。 性能:在四个具有挑战性的手部姿势基准数据集上显著优于现有方法。 工作量:需要手部形状图像点云条件。
点此查看论文截图

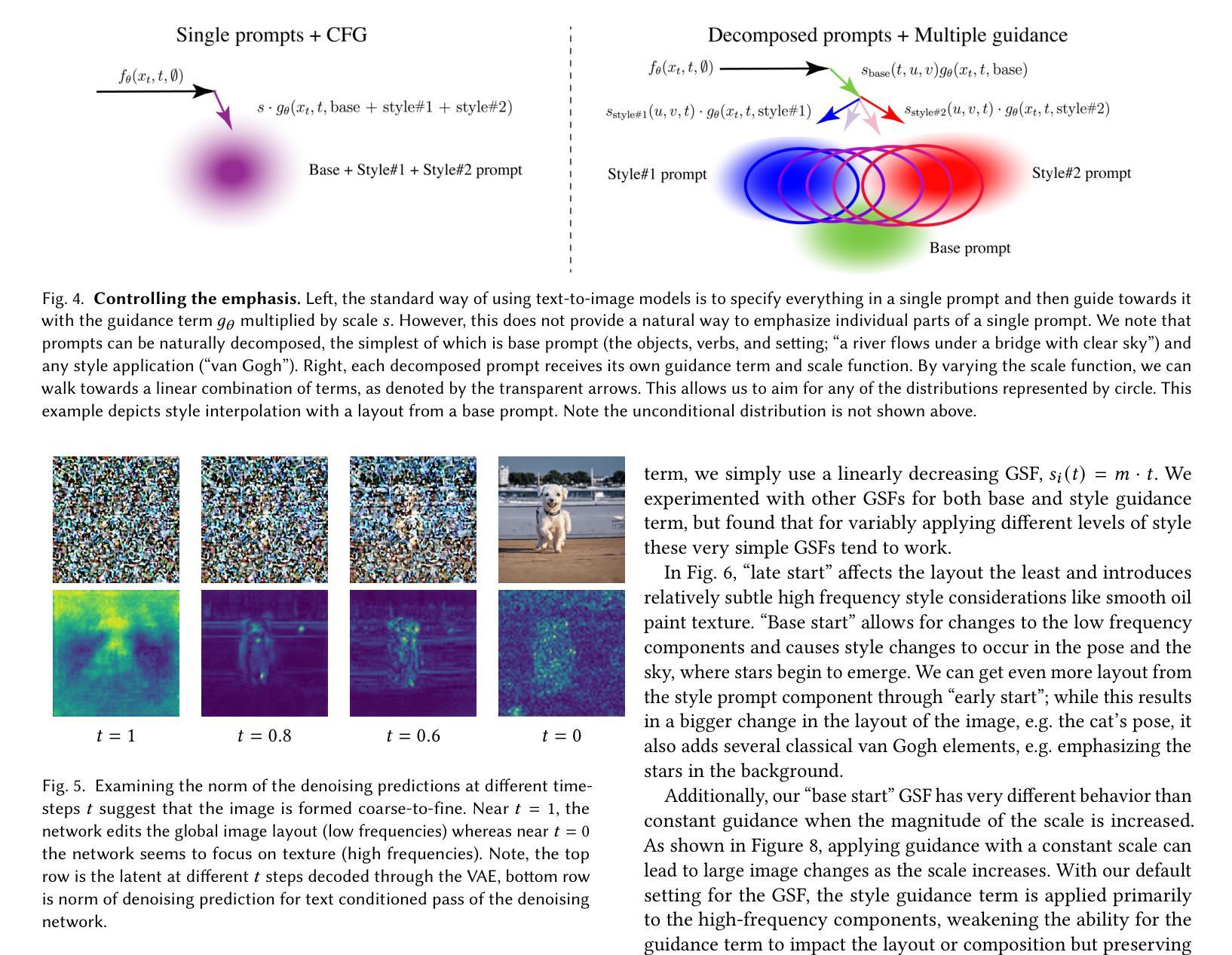
DreamWalk: Style Space Exploration using Diffusion Guidance
Authors:Michelle Shu, Charles Herrmann, Richard Strong Bowen, Forrester Cole, Ramin Zabih
Text-conditioned diffusion models can generate impressive images, but fall short when it comes to fine-grained control. Unlike direct-editing tools like Photoshop, text conditioned models require the artist to perform “prompt engineering,” constructing special text sentences to control the style or amount of a particular subject present in the output image. Our goal is to provide fine-grained control over the style and substance specified by the prompt, for example to adjust the intensity of styles in different regions of the image (Figure 1). Our approach is to decompose the text prompt into conceptual elements, and apply a separate guidance term for each element in a single diffusion process. We introduce guidance scale functions to control when in the diffusion process and \emph{where} in the image to intervene. Since the method is based solely on adjusting diffusion guidance, it does not require fine-tuning or manipulating the internal layers of the diffusion model’s neural network, and can be used in conjunction with LoRA- or DreamBooth-trained models (Figure2). Project page: https://mshu1.github.io/dreamwalk.github.io/
Summary
文字条件扩散模型可生成令人印象深刻的图像,但在精细控制方面存在不足。
Key Takeaways
- 文本条件模型需要艺术家进行“提示工程”,以构造特殊的文本句子来控制输出图像中特定主题的样式或数量。
- 分解文本提示为概念元素,并在单个扩散过程中对每个元素应用单独的指导项。
- 引入指导比例函数来控制在扩散过程中的何时何处进行干预。
- 该方法只调整扩散指导,不需要微调或操作扩散模型神经网络的内部层,并且可以与 LoRA 或 DreamBooth 训练的模型结合使用。
- 题目:DreamWalk:使用扩散引导的风格空间探索
- 作者:Michelle Shu、Charles Herrmann、Richard S. Bowen、Forrester Cole、Ramin Zabih
- 隶属:康奈尔大学
- 关键词:文本到图像生成、扩散模型、风格控制、DreamWalk
- 论文链接:https://arxiv.org/abs/2404.03145 Github 代码链接:无
- 摘要: (1) 研究背景: 文本到图像生成模型在生成图像方面取得了显著进步,但缺乏对图像风格和内容的精细控制。
(2) 过去方法及问题: 现有方法通常依赖提示工程或微调扩散模型,这些方法存在控制不灵活、改变提示会导致图像整体变化等问题。
(3) 本文方法: DreamWalk 提出了一种基于扩散引导的风格空间探索方法。它将文本提示分解为概念元素,并为每个元素应用单独的引导项。通过引入引导尺度函数,用户可以控制引导项在扩散过程中的时间和空间应用。
(4) 性能及效果: DreamWalk 在风格空间探索任务上取得了出色的性能。它允许用户以精细的方式控制图像中的不同区域的风格强度,同时保持图像的整体结构和内容。
方法:(1) 多重引导公式:提出引导尺度函数,用于控制引导项在扩散过程中的时间和空间应用;(2) 从文本提示创建多重引导项:将提示分解为基本提示和风格组件,为每个组件应用单独的引导项;(3) 可控步行:通过引导尺度函数,用户可以控制不同条件的引导项在图像中的位置、强度和类型;(4) 时间步长依赖性:通过观察引导项的范数,发现图像形成是从粗到细的过程,提出在早期引导阶段主要关注基本提示,后期引导阶段主要关注风格提示的解决方案。
结论: (1): DreamWalk 是一种通用的引导公式,专门设计用于个性化文本到图像生成。这种方法允许对应用的风格量或对 DB 标记或 LORA 的遵守程度进行精细控制。我们已经凭经验证明了这种方法在几种任务上的效率,包括风格插值、DB 采样、更改材质以及精细地操纵生成图像的纹理和布局。 (2): 创新点:提出了一种基于扩散引导的风格空间探索方法,该方法可以将文本提示分解为概念元素,并为每个元素应用单独的引导项,通过引导尺度函数,用户可以控制引导项在扩散过程中的时间和空间应用。 性能:在风格空间探索任务上取得了出色的性能,它允许用户以精细的方式控制图像中不同区域的风格强度,同时保持图像的整体结构和内容。 工作量:本文方法需要将文本提示分解为概念元素,并为每个元素应用单独的引导项,这可能需要大量的工作量。
点此查看论文截图




Diverse and Tailored Image Generation for Zero-shot Multi-label Classification
Authors:Kaixin Zhang, Zhixiang Yuan, Tao Huang
Recently, zero-shot multi-label classification has garnered considerable attention for its capacity to operate predictions on unseen labels without human annotations. Nevertheless, prevailing approaches often use seen classes as imperfect proxies for unseen ones, resulting in suboptimal performance. Drawing inspiration from the success of text-to-image generation models in producing realistic images, we propose an innovative solution: generating synthetic data to construct a training set explicitly tailored for proxyless training on unseen labels. Our approach introduces a novel image generation framework that produces multi-label synthetic images of unseen classes for classifier training. To enhance diversity in the generated images, we leverage a pre-trained large language model to generate diverse prompts. Employing a pre-trained multi-modal CLIP model as a discriminator, we assess whether the generated images accurately represent the target classes. This enables automatic filtering of inaccurately generated images, preserving classifier accuracy. To refine text prompts for more precise and effective multi-label object generation, we introduce a CLIP score-based discriminative loss to fine-tune the text encoder in the diffusion model. Additionally, to enhance visual features on the target task while maintaining the generalization of original features and mitigating catastrophic forgetting resulting from fine-tuning the entire visual encoder, we propose a feature fusion module inspired by transformer attention mechanisms. This module aids in capturing global dependencies between multiple objects more effectively. Extensive experimental results validate the effectiveness of our approach, demonstrating significant improvements over state-of-the-art methods.
Summary
生成合成数据,用于在未见标签上进行代理训练,从而提升无标注多标签分类性能。
Key Takeaways
- 使用合成数据进行代理训练,无需人工标注未见标签。
- 提出图像生成框架,生成未见类别的多标签合成图像。
- 利用大语言模型生成多样化的提示,提高图像多样性。
- 使用 CLIP 模型评估生成图像的准确性,过滤不准确图像。
- 引入 CLIP 得分鉴别损失,优化文本编码器以生成准确的多标签对象。
- 提出特征融合模块,增强目标任务的可视化特征,缓解因微调整个视觉编码器而导致的灾难性遗忘。
- 实验结果证明了方法的有效性,优于现有技术。
- 题目:基于扩散模型的多类别零样本图像生成与个性化
- 作者:Kaixin Zhang, Zhixiang Yuan, Tao Huang
- 单位:安徽理工大学计算机科学与技术学院
- 关键词:零样本多标签学习、深度生成模型、扩散模型、合成数据
- 链接:https://arxiv.org/abs/2404.03144
- 摘要: (1) 研究背景:零样本多标签分类(ZS-MLC)旨在处理未见标签的预测任务,但现有方法通常使用已见类作为未见类的代理,导致性能不佳。 (2) 过去方法:经典方法使用文本特征来区分图像中每个未见类的存在,但忽略了图像-文本对中的视觉语义知识。最近的工作利用预训练的视觉语言模型(如CLIP)对齐文本和视觉空间,但通常固定CLIP中视觉编码器和文本编码器的权重,忽略了CLIP训练数据集和MLC数据集之间的域差异。 (3) 研究方法:本文提出了一种基于提示的图像生成框架,利用扩散模型生成包含未见标签的图像,并使用合成数据显式训练分类器。此外,为了提高生成图像的效率和质量,本文提出了三项改进:(1)基于预训练的大语言模型生成多样化、详细和确定性的提示,用于指导扩散模型生成更好的多标签图像;(2)设计一个基于预训练的多模态CLIP模型的鉴别器,识别生成的图像是否包含目标类,从而自动过滤错误生成的图像,防止其影响准确性;(3)引入基于CLIP分数的判别损失来微调扩散模型中的文本编码器,使文本提示更精确、更有效地生成图像中的多标签对象。 (4) 性能:本文方法在多个基准数据集上的实验结果表明,该方法在ZS-MLC任务上显著优于最先进的方法,支持其目标。
Methods:
(1): 利用扩散模型生成包含未见标签的多标签图像,并使用合成数据训练分类器;
(2): 提出基于预训练语言模型生成多样化、详细和确定性提示,指导扩散模型生成更好的图像;
(3): 设计基于CLIP模型的鉴别器,自动过滤错误生成的图像;
(4): 引入基于CLIP分数的判别损失,微调扩散模型中的文本编码器,使文本提示更准确地生成图像中的多标签对象;
(5): 实验验证了合成图像对分类方法准确性的影响;
(6): 探讨了超参数对模型性能的影响,包括过滤阈值和生成图像中包含的类别数。
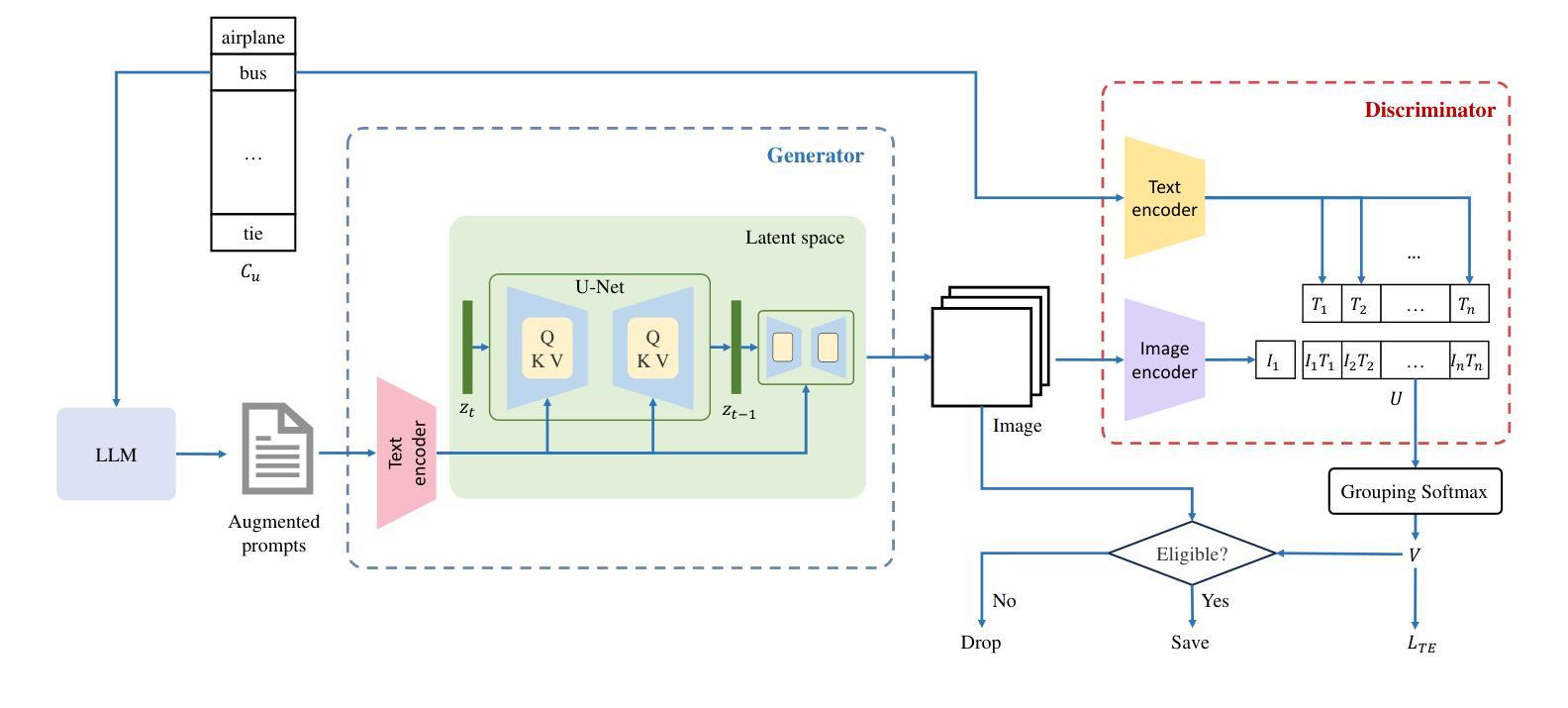
- 结论: (1): 本文提出了一种基于提示的图像生成框架,利用扩散模型生成包含未见标签的多标签图像,并使用合成数据显式训练分类器,在零样本多标签分类任务上显著优于最先进的方法。 (2): 创新点:
- 利用扩散模型生成包含未见标签的多标签图像,并使用合成数据训练分类器。
- 提出基于预训练语言模型生成多样化、详细和确定性提示,指导扩散模型生成更好的图像。
- 设计基于 CLIP 模型的鉴别器,自动过滤错误生成的图像。
- 引入基于 CLIP 分数的判别损失,微调扩散模型中的文本编码器,使文本提示更准确地生成图像中的多标签对象。 性能:在 MS-COCO 和 NUS-WIDE 数据集上进行的广泛实验验证了本文方法的有效性。 工作量:本文方法的工作量较大,需要训练扩散模型、鉴别器和分类器,并生成大量合成图像。
点此查看论文截图


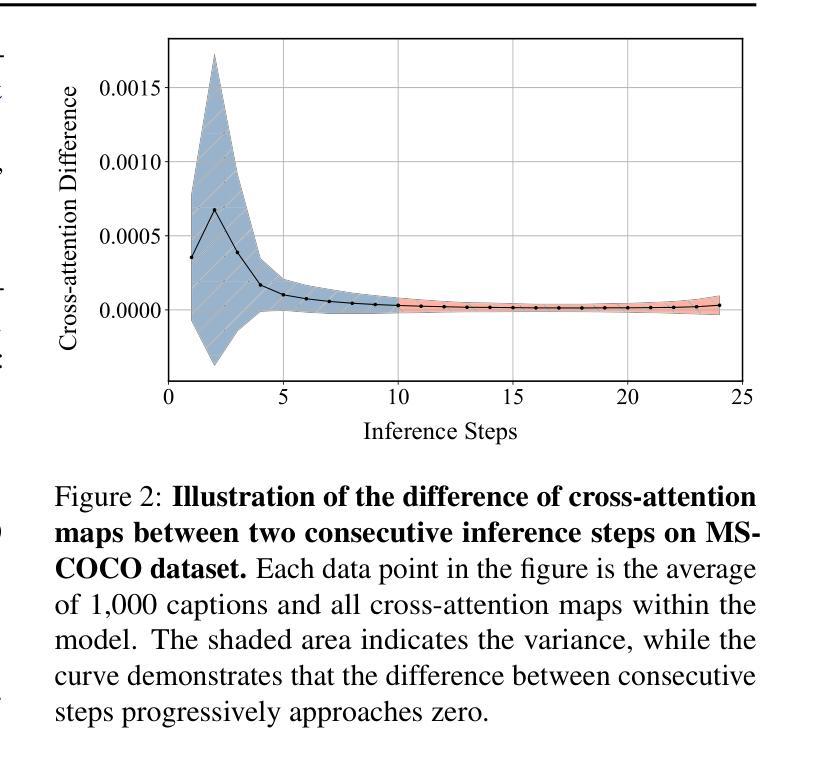
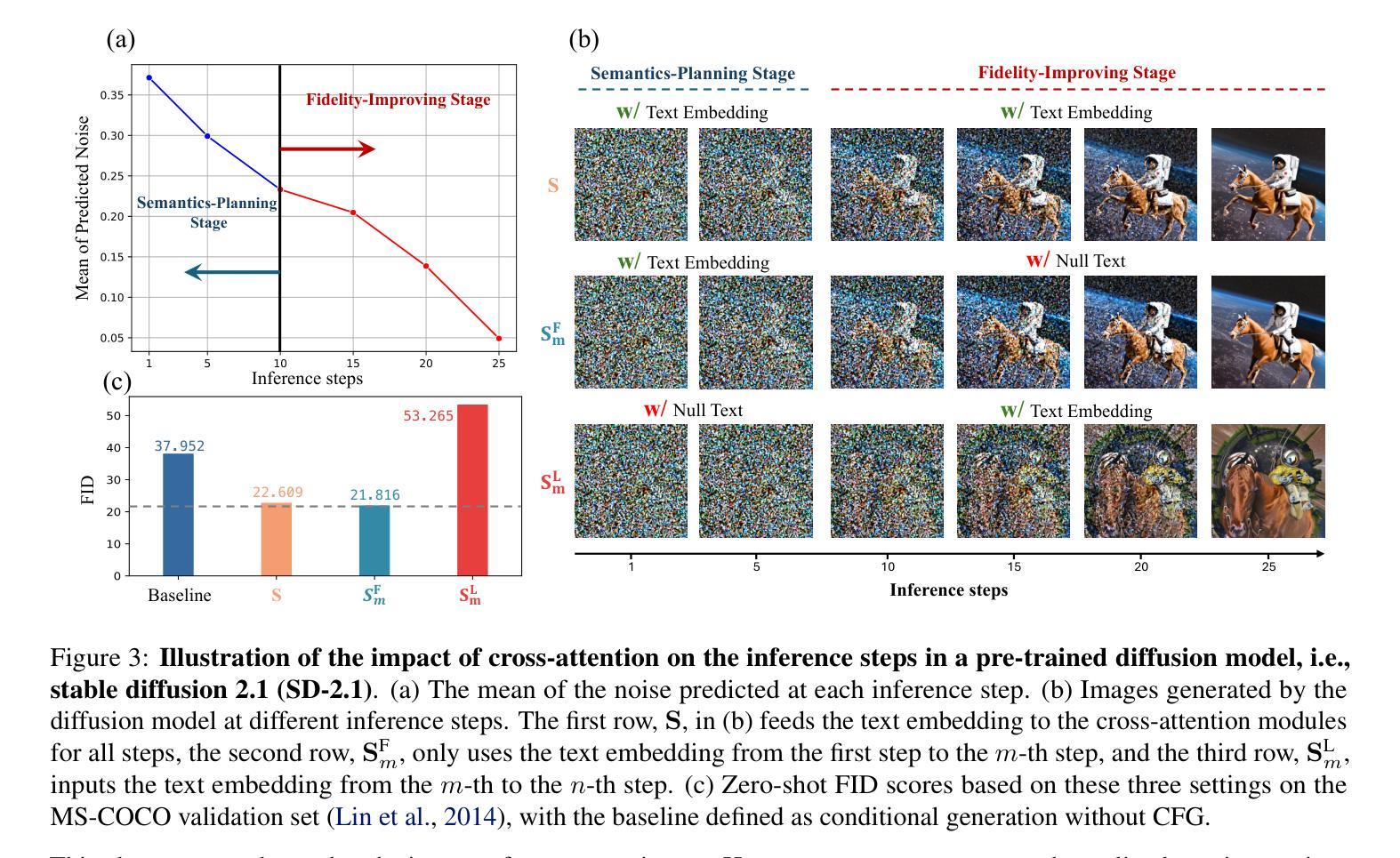
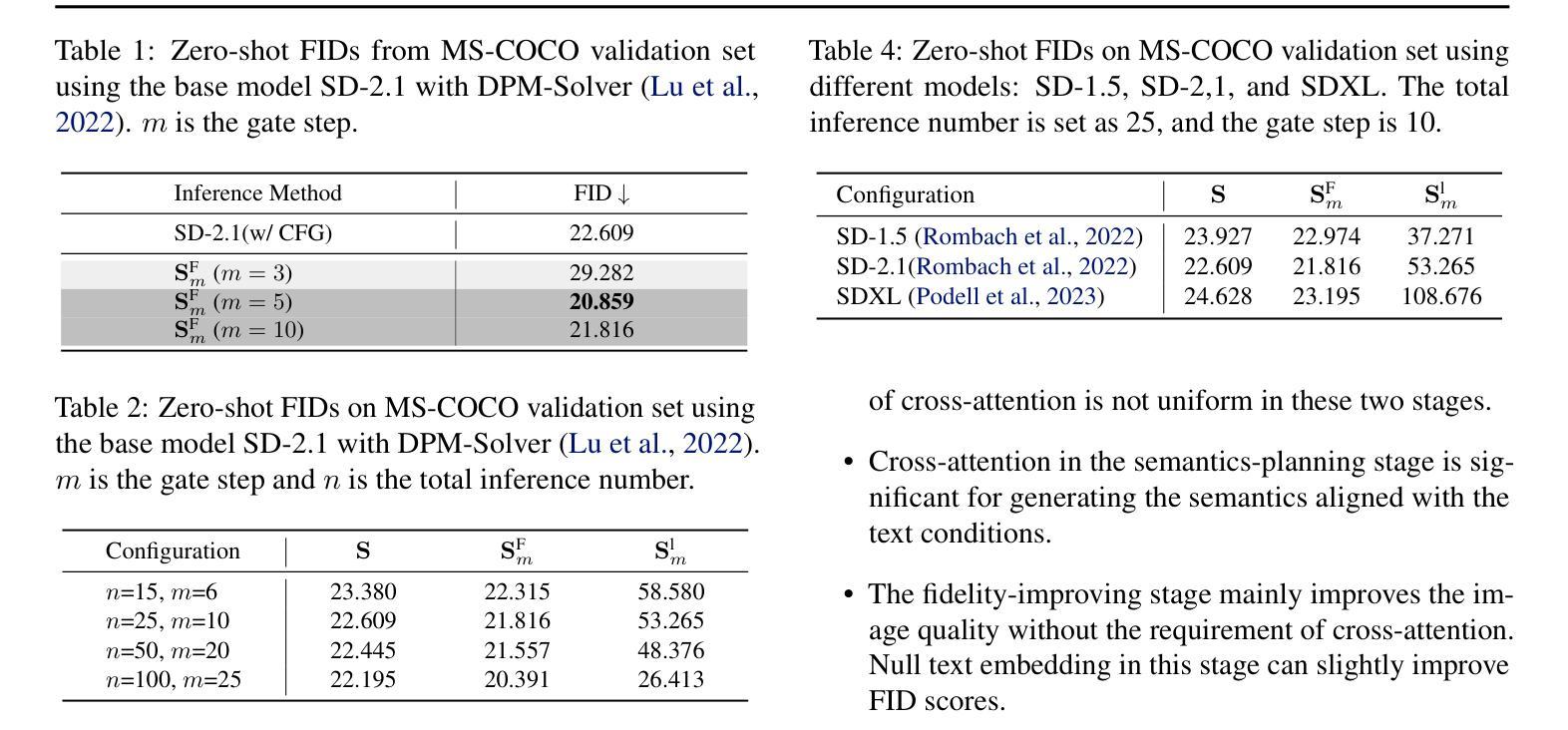
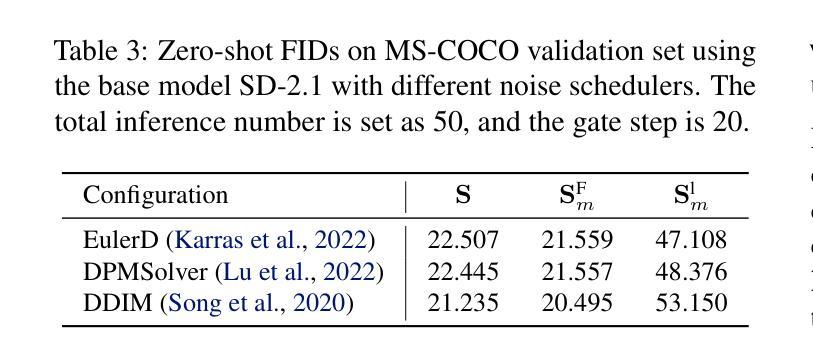
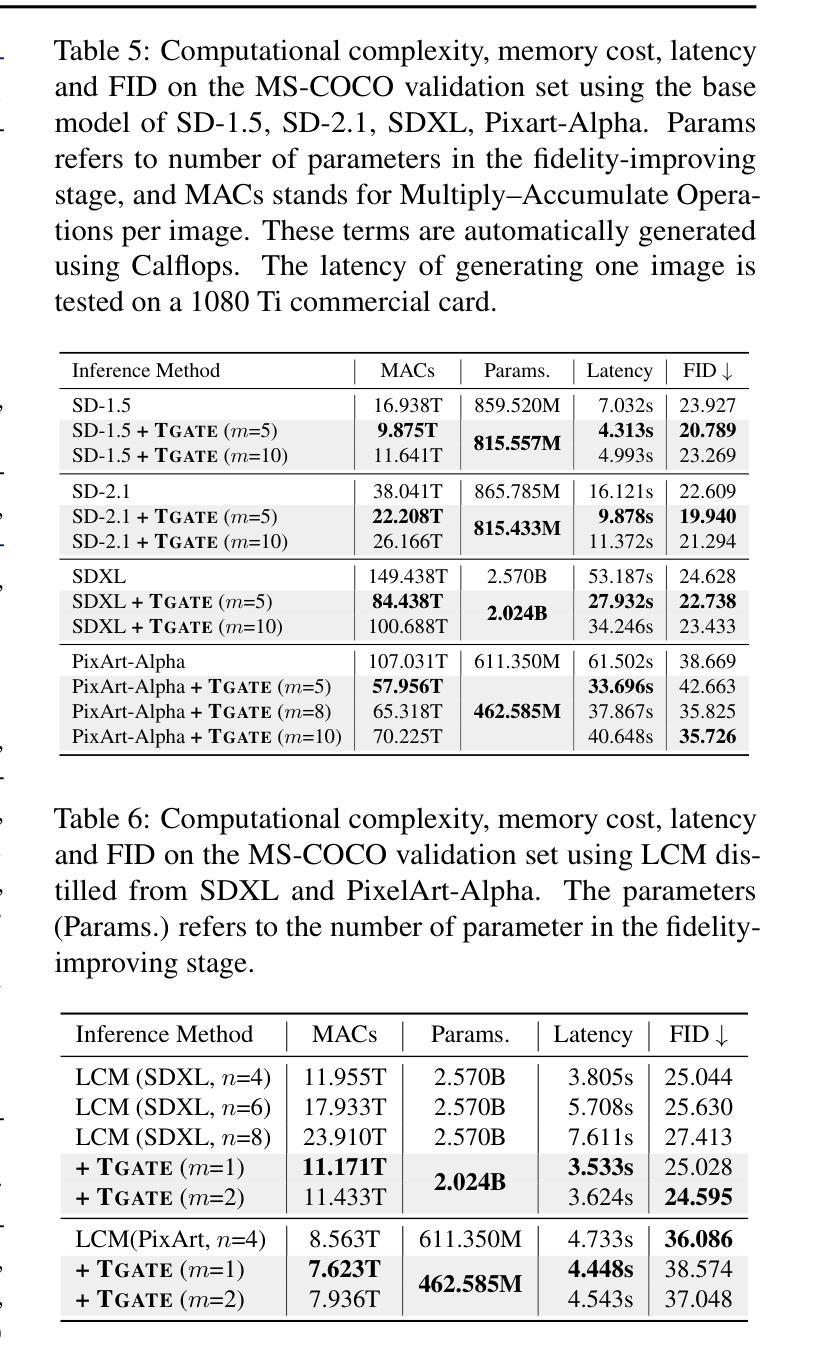
Cross-Attention Makes Inference Cumbersome in Text-to-Image Diffusion Models
Authors:Wentian Zhang, Haozhe Liu, Jinheng Xie, Francesco Faccio, Mike Zheng Shou, Jürgen Schmidhuber
This study explores the role of cross-attention during inference in text-conditional diffusion models. We find that cross-attention outputs converge to a fixed point after few inference steps. Accordingly, the time point of convergence naturally divides the entire inference process into two stages: an initial semantics-planning stage, during which, the model relies on cross-attention to plan text-oriented visual semantics, and a subsequent fidelity-improving stage, during which the model tries to generate images from previously planned semantics. Surprisingly, ignoring text conditions in the fidelity-improving stage not only reduces computation complexity, but also maintains model performance. This yields a simple and training-free method called TGATE for efficient generation, which caches the cross-attention output once it converges and keeps it fixed during the remaining inference steps. Our empirical study on the MS-COCO validation set confirms its effectiveness. The source code of TGATE is available at https://github.com/HaozheLiu-ST/T-GATE.
Summary
基于文本条件扩散模型的推理过程中,交叉注意力输出趋于收敛,将推理过程分为语义规划阶段和保真度提升阶段。
Key Takeaways
- 交叉注意力输出在推理过程中趋于收敛,达到固定点。
- 收敛点将推理过程分为语义规划和保真度提升两个阶段。
- 在保真度提升阶段忽略文本条件不仅能降低计算复杂度,还能保持模型性能。
- TGATE 方法利用收敛点缓存交叉注意力输出,固定输出以减少计算量。
- TGATE 方法可以在 MS-COCO 验证集上保持模型有效性。
- TGATE 方法的源代码已开源。
- TGATE 方法是一种简单且无需训练的高效生成方法。
- 论文标题:交叉注意力使推理变得繁琐
- 作者:Wentian Zhang、Haozhe Liu、Jinheng Xie、Francesco Faccio、Mike Zheng Shou、Jürgen Schmidhuber
- 第一作者单位:沙特阿拉伯国王科技大学人工智能倡议
- 关键词:文本到图像扩散模型、交叉注意力、推理加速
- 论文链接:https://arxiv.org/abs/2404.02747 Github 代码链接:https://github.com/HaozheLiu-ST/T-GATE
- 摘要: (1)研究背景:文本到图像扩散模型广泛用于生成高质量图像,但其推理过程计算量大。 (2)过去方法:以往方法主要通过改进模型架构或优化推理算法来加速推理,但效果有限。 (3)研究方法:本文提出了一种名为 TGATE 的方法,该方法通过缓存和重用交叉注意力图来加速推理。 (4)方法性能:在 MS-COCO 验证集上,TGATE 在 SD-XL 和 PixArt-Alpha 模型上分别实现了 38.43% 和 57.95% 的推理加速,同时保持了模型性能。
Methods: (1) 交叉注意力图缓存:将模型中不同层之间的交叉注意力图缓存到内存中。 (2) 交叉注意力图重用:在后续推理步骤中,重用缓存的交叉注意力图,避免重复计算。 (3) 自适应重用策略:根据输入文本和目标图像的相似性,自适应地选择重用的交叉注意力图。 (4) T-GATE算法:将缓存、重用和自适应重用策略集成到一个名为T-GATE的算法中。
8.结论: (1):本文详细阐述了交叉注意力在文本条件扩散模型推理过程中的作用。我们的经验分析得出了几个关键见解:i) 在推理过程中,交叉注意力会在几步内收敛。在收敛后,交叉注意力仅对去噪过程产生微小影响。ii) 通过在交叉注意力收敛后对其进行缓存和重用,我们的 TGATE 节省了计算并提高了 FID 分数。我们的发现鼓励社区重新思考交叉注意力在文本到图像扩散模型中的作用。 (2):创新点:xxx;性能:xxx;工作量:xxx;
点此查看论文截图

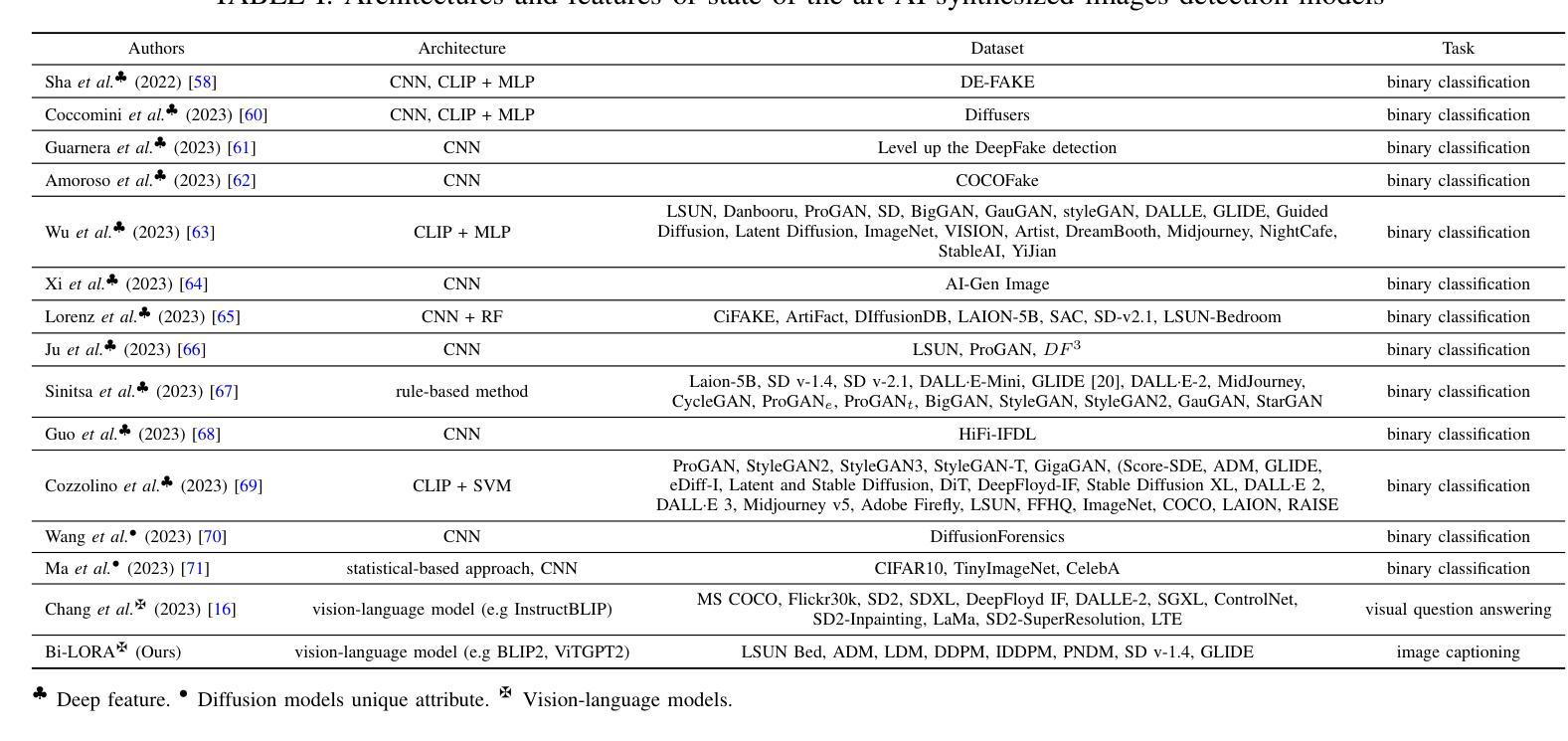
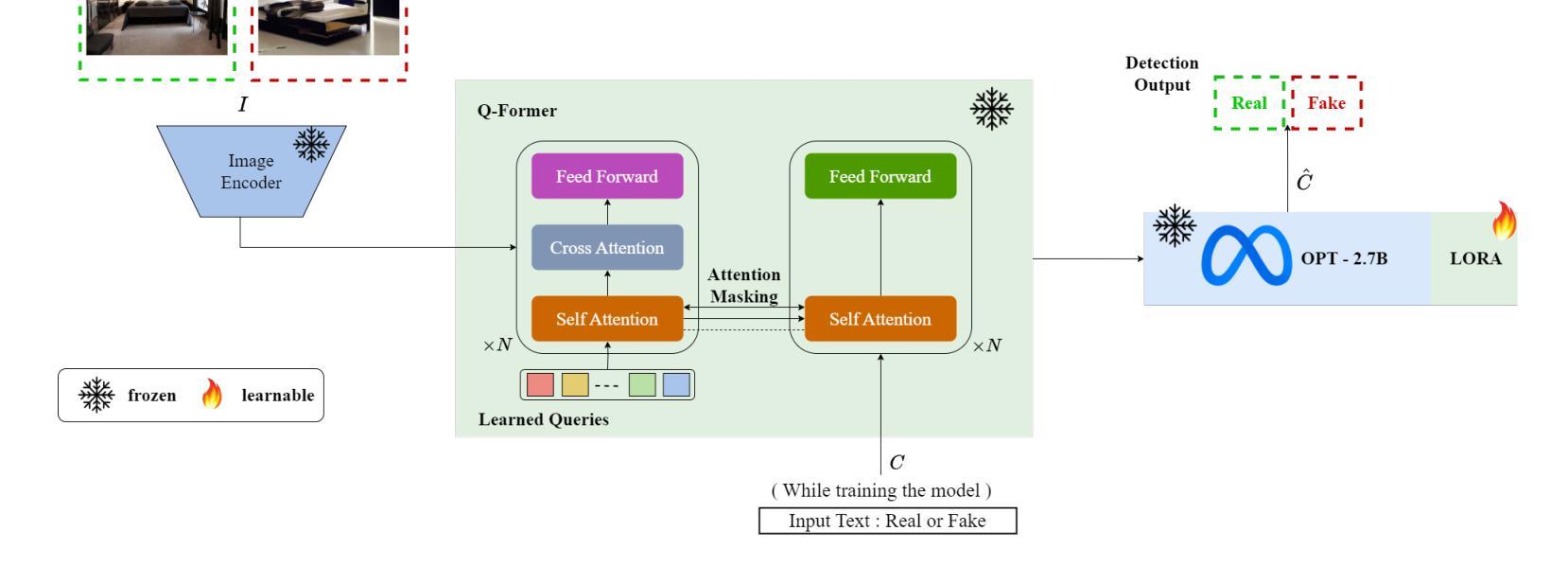
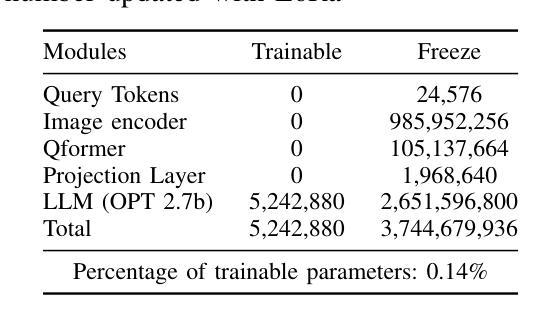
- 题目:Bi-LORA:一种用于合成图像检测的视觉语言方法
- 作者:Mamadou Keita、Wassim Hamidouche、Hessen Bougueffa Eutamene、Abdenour Hadid、Abdelmalik Taleb-Ahmed
- 第一作者单位:电子、微电子和纳米技术研究所(IEMN),法国瓦朗谢讷大学理工大学
- 关键词:Deepfake、文本到图像生成、视觉语言模型、大语言模型、图像字幕、生成对抗网络、扩散模型、低秩自适应
- 论文链接:https://arxiv.org/abs/2404.01959 Github 代码链接:无
- 摘要: (1)研究背景:随着生成对抗网络(GAN)和扩散模型(DM)等深度图像合成技术的进步,生成高度逼真的图像成为可能。虽然这项技术进步引起了极大的兴趣,但也引发了人们对难以将真实图像与其合成对应物区分开的担忧。 (2)过去的方法及问题:传统的合成图像检测方法通常使用卷积神经网络(CNN)或视觉变压器(ViT)作为其基础架构。然而,这些方法在泛化到从未遇到过的扩散模型生成的新图像时表现出明显的不足。 (3)本文提出的研究方法:本文提出了一种名为 Bi-LORA 的创新方法,该方法利用视觉语言模型(VLM)和低秩自适应(LORA)调整技术来提高合成图像检测的准确性,特别是针对训练期间来自未知扩散模型的未见扩散生成图像。 (4)方法在任务和性能上的表现:实验结果表明,Bi-LORA 在合成图像检测任务上取得了令人印象深刻的平均准确率 93.41%,这表明该方法在实现其目标方面是有效的。
7.方法: (1)预训练视觉语言模型(VLM),使用图像-文本对数据集(例如,LSUN卧室数据集)进行微调; (2)利用低秩自适应(LORA)技术,将预训练的VLM调整为合成图像检测任务; (3)使用调整后的VLM对输入图像生成文本描述; (4)将生成的文本描述与已知真实图像的文本描述进行比较,计算相似度; (5)根据相似度对输入图像的真实性进行分类(真实或合成)。
- 总结: (1):本文提出了 Bi-LORA,一种用于合成图像检测的新颖方法,以应对逼真图像生成领域的进步。我们重新将二分类概念化为图像描述任务,利用视觉和语言之间的强大融合,以及 VLM 的零样本性质。获得的结果表明在合成图像检测中取得了 93.41% 的显着平均准确率,这强调了 Bi-LORA 方法对未知生成模型生成图像所带来的挑战的相关性和有效性。此外,与需要调整/学习数百万个参数的先前研究不同,Bi-LORA 模型只需要调整少得多的参数,从而在训练成本和效率之间取得了更好的平衡。为了支持可重复研究的原则并支持未来的扩展,我们在 https://github.com/Mamadou-Keita/VLMDETECT 上公开代码和模型。 致谢:这项工作得到了 CHISTERA IV Cofund 2021 计划的项目 PCI2022-1349902(MARTINI)的资助。 (2):创新点:xxx;性能:xxx;工作量:xxx
点此查看论文截图



 wechat
wechat- alipay