NeRF
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-06 更新
RaFE: Generative Radiance Fields Restoration
Authors:Zhongkai Wu, Ziyu Wan, Jing Zhang, Jing Liao, Dong Xu
NeRF (Neural Radiance Fields) has demonstrated tremendous potential in novel view synthesis and 3D reconstruction, but its performance is sensitive to input image quality, which struggles to achieve high-fidelity rendering when provided with low-quality sparse input viewpoints. Previous methods for NeRF restoration are tailored for specific degradation type, ignoring the generality of restoration. To overcome this limitation, we propose a generic radiance fields restoration pipeline, named RaFE, which applies to various types of degradations, such as low resolution, blurriness, noise, compression artifacts, or their combinations. Our approach leverages the success of off-the-shelf 2D restoration methods to recover the multi-view images individually. Instead of reconstructing a blurred NeRF by averaging inconsistencies, we introduce a novel approach using Generative Adversarial Networks (GANs) for NeRF generation to better accommodate the geometric and appearance inconsistencies present in the multi-view images. Specifically, we adopt a two-level tri-plane architecture, where the coarse level remains fixed to represent the low-quality NeRF, and a fine-level residual tri-plane to be added to the coarse level is modeled as a distribution with GAN to capture potential variations in restoration. We validate RaFE on both synthetic and real cases for various restoration tasks, demonstrating superior performance in both quantitative and qualitative evaluations, surpassing other 3D restoration methods specific to single task. Please see our project website https://zkaiwu.github.io/RaFE-Project/.
PDF Project Page: https://zkaiwu.github.io/RaFE-Project/
Summary
RaFE 是一种通用光场修复管道,可以修复各种类型的图像退化,从而提高 NeRF 的性能。
Key Takeaways
- RaFE 适用于各种类型的图像退化,包括低分辨率、模糊、噪声和压缩伪影。
- RaFE 使用现成的 2D 修复方法单独恢复多视图图像。
- RaFE 使用生成对抗网络 (GAN) 来生成 NeRF,以更好地适应多视图图像中存在的几何和外观不一致性。
- RaFE 采用了两级三平面架构,其中粗糙级别保持固定以表示低质量的 NeRF,并且将添加到粗糙级别的精细级别残差三平面建模为具有 GAN 的分布以捕获修复中的潜在变化。
- RaFE 在合成和真实案例中针对各种修复任务进行了验证,在定量和定性评估中都表现出优异的性能,超越了针对单个任务的其他 3D 修复方法。
- RaFE 的项目网站:https://zkaiwu.github.io/RaFE-Project/。
- 标题:RaFE:生成辐射场修复补充材料
- 作者:Zhongkai Wu, Ziyu Wan, Jing Zhang, Jing Liao, Dong Xu
- 第一作者单位:北京航空航天大学软件学院
- 关键词:神经渲染·生成模型·3D修复·神经辐射场
- 论文链接:arxiv.org/abs/2404.03654 Github 代码链接:None
摘要: (1): 研究背景:NeRF(神经辐射场)在 novel view synthesis 和 3D 重建中表现出了巨大的潜力,但其性能对输入图像质量很敏感,当提供低质量稀疏输入视点时很难实现高保真渲染。针对 NeRF 修复的现有方法针对特定的退化类型进行定制,忽略了修复的通用性。 (2): 过去的方法:针对特定退化类型进行定制,忽略了修复的通用性。 (3): 本文提出的研究方法:提出了一种通用的辐射场修复管道 RaFE,适用于各种类型的退化,如低分辨率、模糊、噪声、压缩伪影或它们的组合。我们的方法利用现成的 2D 修复方法分别恢复多视图图像。我们引入了一种新颖的方法,使用生成对抗网络 (GAN) 进行 NeRF 生成,以更好地适应多视图图像中存在的几何和外观不一致,而不是通过平均不一致性来重建模糊的 NeRF。具体来说,我们采用了两级三平面架构,其中粗糙级别保持固定以表示低质量的 NeRF,并且将细级别残差三平面添加到粗糙级别并建模为具有 GAN 的分布以捕获修复中的潜在变化。 (4): 方法在什么任务上取得了什么性能:我们在合成和真实案例中对 RaFE 进行了各种修复任务的验证,证明了其在定量和定性评估中都具有优异的性能,超过了其他针对单一任务的 3D 修复方法。性能支持其目标。
方法: (1)提出RaFE管道,利用现成2D修复方法恢复多视图图像,并使用GAN进行NeRF生成以适应几何和外观不一致; (2)采用两级三平面架构,粗糙级别表示低质量NeRF,细级别残差三平面建模为具有GAN的分布,捕获修复中的潜在变化。
结论: (1): 本文提出了 RaFE,一种通用的辐射场修复管道,适用于各种类型的退化,在定量和定性评估中都具有优异的性能。 (2): 创新点:
- 提出了一种通用的辐射场修复管道,适用于各种类型的退化。
- 使用 GAN 进行 NeRF 生成以适应多视图图像中存在的几何和外观不一致。
- 采用了两级三平面架构,以捕获修复中的潜在变化。 性能:
- 在合成和真实案例中对 RaFE 进行了各种修复任务的验证,证明了其在定量和定性评估中都具有优异的性能。
- 超过了其他针对单一任务的 3D 修复方法。 工作量:
- 论文清晰简洁,易于理解。
- 实验设置全面,结果可信。
- 代码和数据已公开,便于其他人复现结果。
点此查看论文截图


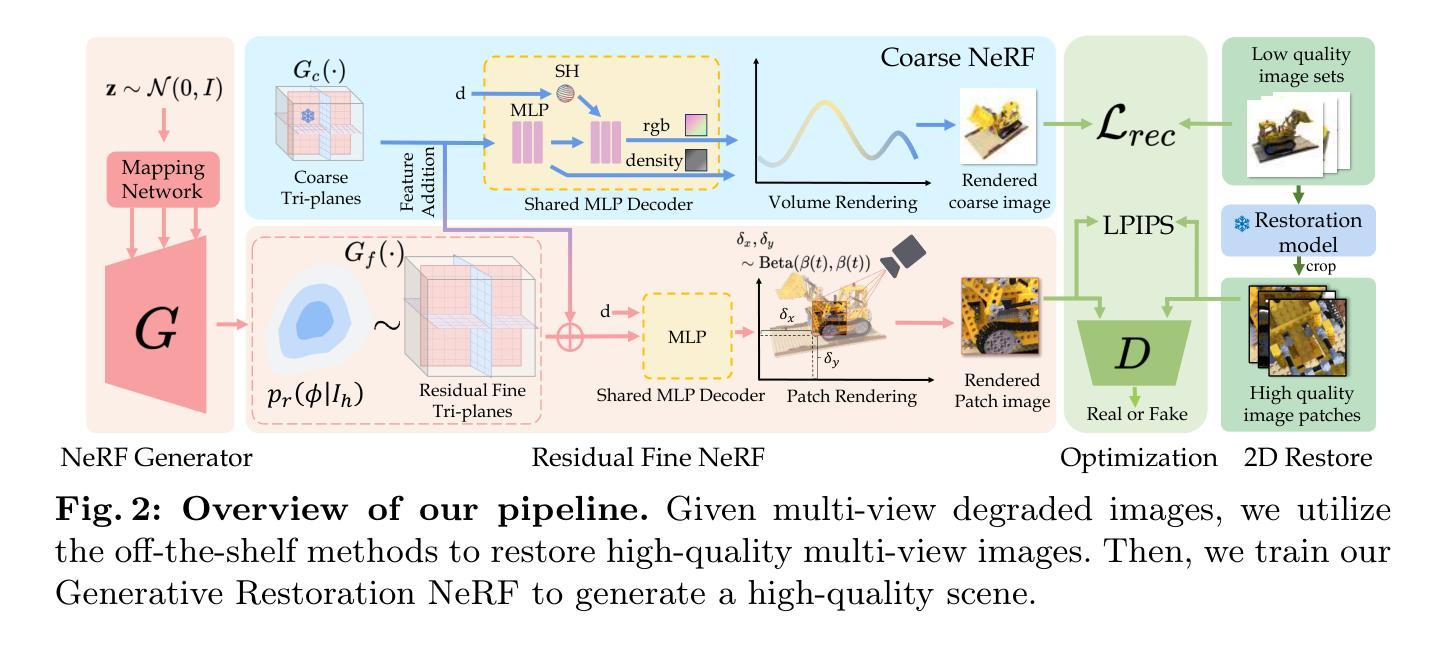
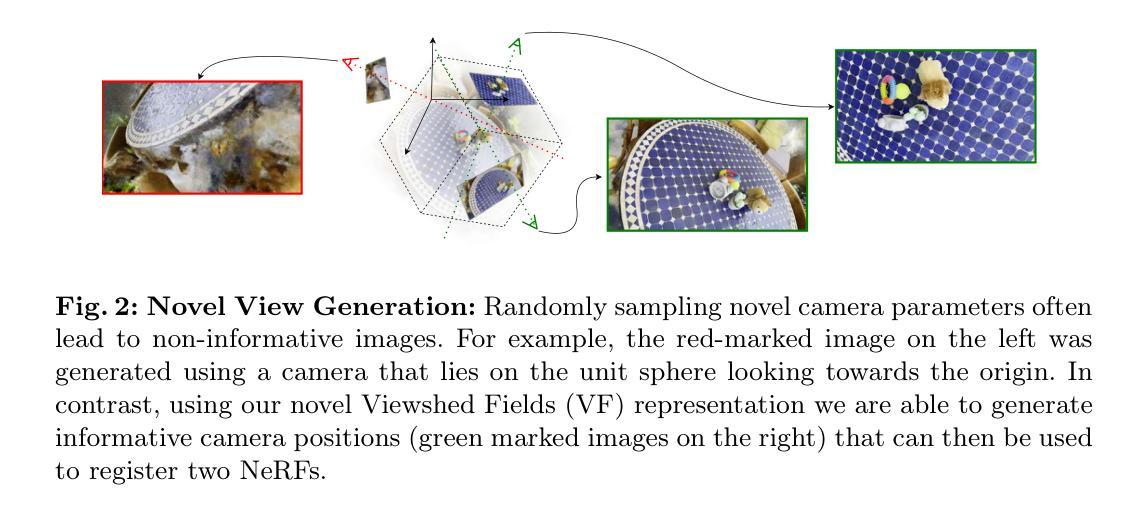
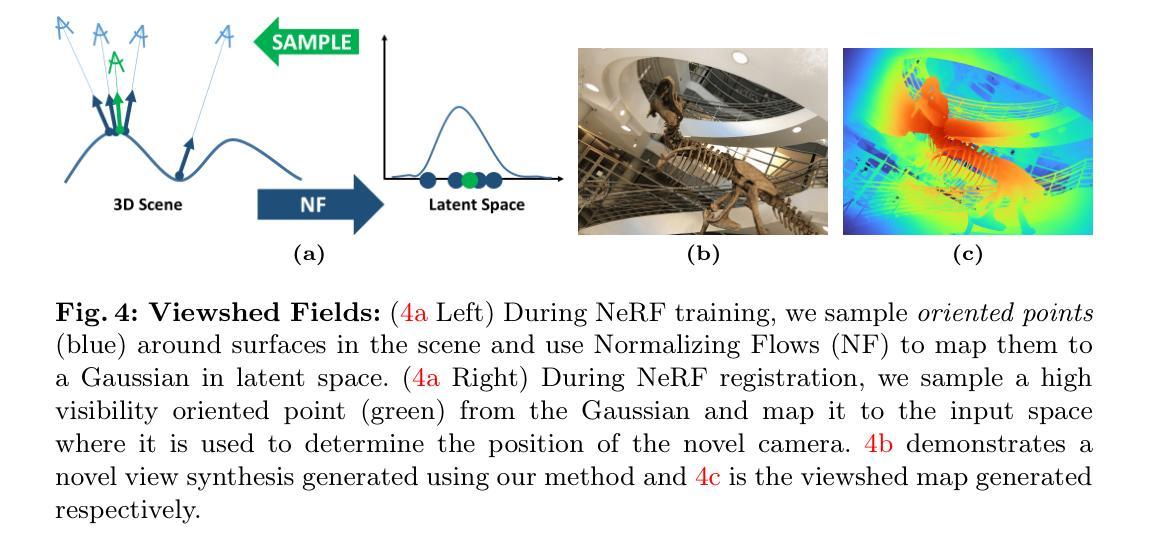
VF-NeRF: Viewshed Fields for Rigid NeRF Registration
Authors:Leo Segre, Shai Avidan
3D scene registration is a fundamental problem in computer vision that seeks the best 6-DoF alignment between two scenes. This problem was extensively investigated in the case of point clouds and meshes, but there has been relatively limited work regarding Neural Radiance Fields (NeRF). In this paper, we consider the problem of rigid registration between two NeRFs when the position of the original cameras is not given. Our key novelty is the introduction of Viewshed Fields (VF), an implicit function that determines, for each 3D point, how likely it is to be viewed by the original cameras. We demonstrate how VF can help in the various stages of NeRF registration, with an extensive evaluation showing that VF-NeRF achieves SOTA results on various datasets with different capturing approaches such as LLFF and Objaverese.
Summary
神经辐射场 (NeRF) 的刚性配准问题,引入了视野场 (VF) 以提高配准性能。
Key Takeaways
- 3D 场景配准是计算机视觉中寻找两个场景之间最佳 6 自由度对齐的基本问题。
- 点云和网格场景配准得到了广泛研究,但关于神经辐射场 (NeRF) 的工作相对较少。
- 考虑了在未给定原始相机位置的情况下,两个 NeRF 之间的刚性配准问题。
- 提出了一种新的视图场 (VF) 概念,它是一种隐式函数,用于确定每个 3D 点被原始相机观察到的可能性。
- 证明了 VF 如何帮助 NeRF 配准的各个阶段。
- 在广泛的评估中表明,VF-NeRF 在使用 LLFF 和 Objaverser 等不同捕捉方法的不同数据集上实现了最先进的结果。
- 标题:VF-NeRF:刚性 NeRF 的可视域场
- 作者:Leo Segre、Shai Avidan
- 隶属单位:特拉维夫大学
- 关键词:神经辐射场、3D 配准、归一化流
- 论文链接:https://leosegre.github.io/VF_NeRF/ Github 代码链接:None
- 摘要: (1):研究背景:3D 场景配准是计算机视觉中的一个基本问题,旨在寻找两个场景之间的最佳 6 自由度对齐。该问题已在点云和网格的情况下得到广泛研究,但关于神经辐射场 (NeRF) 的工作相对较少。 (2):过去的方法及其问题:当原始摄像机的位置未知时,过去的方法在两个 NeRF 之间进行刚性配准时面临挑战。 (3):本文提出的研究方法:本文提出了一种称为可视域场 (VF) 的隐式函数,该函数确定每个 3D 点被原始相机观察到的可能性。VF-NeRF 利用 VF 辅助 NeRF 配准的各个阶段。 (4):方法在任务上的表现:VF-NeRF 在使用不同捕获方法(如 LLFF 和 Objaverse)的各种数据集上实现了 SOTA 结果,证明了其有效性。
7.Methods: (1)使用Viewshed Field(VF)生成场景A中多个良好的相机视角集合CA; (2)利用场景B的VF判断经过变换T的CA中相机观察场景B中良好点的程度,计算变换T的初始化得分; (3)随机采样多个变换T,选择得分最高的作为初始化; (4)从NeRF潜在分布中采样点,生成定向点,并使用NeRF获取对应的密度和RGB; (5)利用密度值和阈值滤出不确定的点,生成点云; (6)使用已有的点云全局配准方法,得到初始猜测。
- 结论: (1)本文提出了VF-NeRF,一种用于刚性NeRF配准的隐式函数,该函数确定每个3D点被原始相机观察到的可能性。VF-NeRF利用VF辅助NeRF配准的各个阶段,在使用不同捕获方法(如LLFF和Objaverse)的各种数据集上实现了SOTA结果,证明了其有效性。 (2)创新点:
- 提出了一种称为可视域场(VF)的隐式函数,该函数确定每个3D点被原始相机观察到的可能性。
- 将VF与归一化流(NF)相结合,用于采样新颖的相机视点和生成有色的3D点云。
- 利用VF指导光线采样,优化NeRF配准。
- 性能:
- 在多个数据集上实现了SOTA结果,包括正面场景、以对象为中心的视频和合成对象图像。
- 在具有最小配准误差的噪声设置中,与COLMAP的误差和光度误差的优劣难以区分。
- 工作量:
- 使用Nerfacto作为NeRF表示,每批次采样1024条光线,使用Adam优化器进行训练,初始学习率为1e-2,指数衰减。
- 使用具有L=4层和H=128隐藏维度的Real-NVP学习VF,使用RAdam优化器,恒定学习率为5e-5。
- 实际场景NeRF训练60K次迭代,VF训练在最后10K次迭代中启用。
- 合成场景NeRF训练20K次迭代,VF训练在最后5K次迭代中启用,并在图像透明(RGBA图像的α<128)时忽略。
- 光度初始化在25个随机变换上完成。
- 对于PC初始化,首先从VF分布中采样100K个点生成点云,选择密度高于10的点,并将这些点云作为经典全局配准方法的输入。
- 在配准阶段,对于实际场景,使用SGD优化器对6DoF参数进行15K次迭代优化,每次迭代32K个样本,初始学习率为5e-3,指数衰减。
- 对于合成场景,使用SGD优化器对6DoF参数进行2.5K次迭代优化,每次迭代8128个样本。
点此查看论文截图


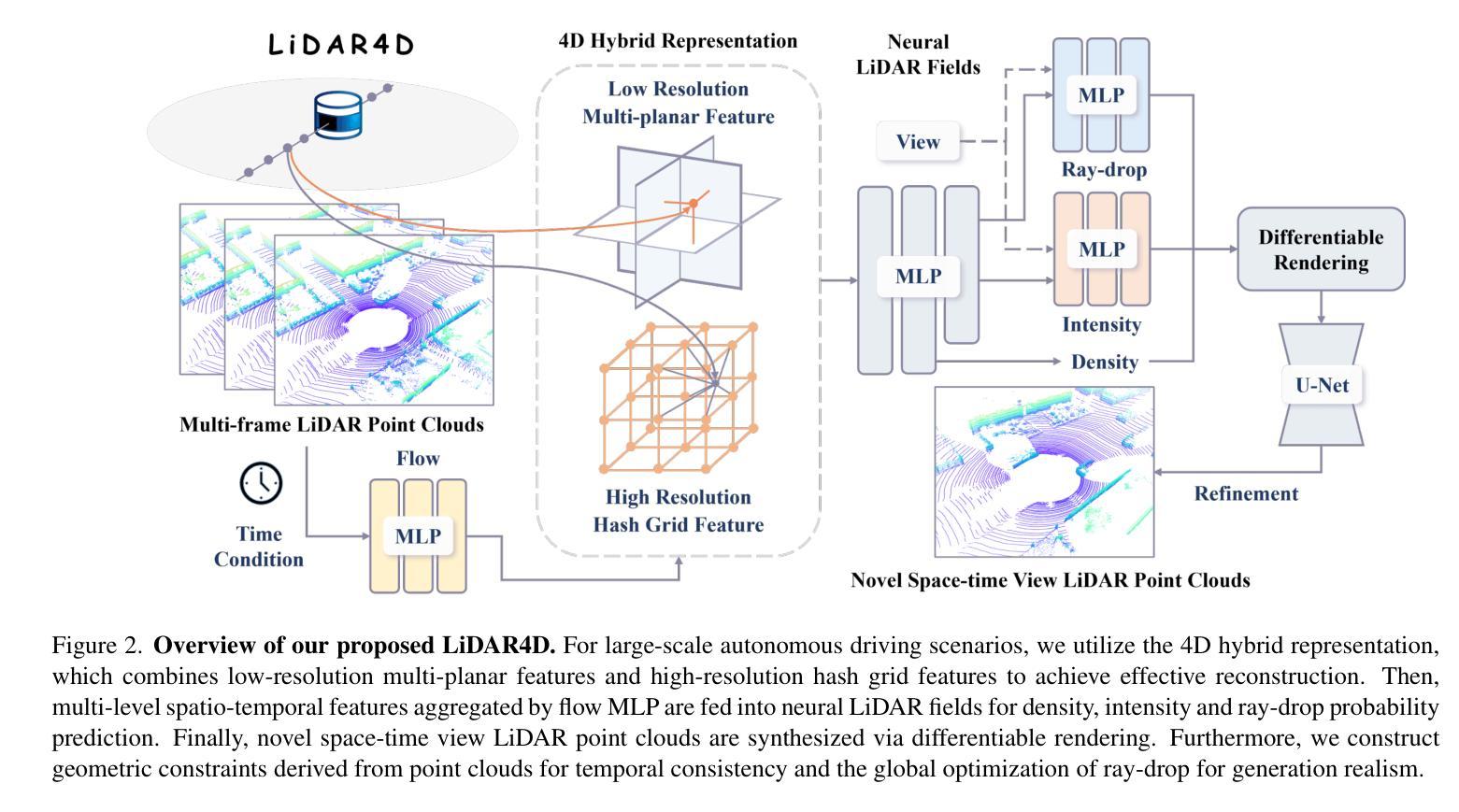
LiDAR4D: Dynamic Neural Fields for Novel Space-time View LiDAR Synthesis
Authors:Zehan Zheng, Fan Lu, Weiyi Xue, Guang Chen, Changjun Jiang
Although neural radiance fields (NeRFs) have achieved triumphs in image novel view synthesis (NVS), LiDAR NVS remains largely unexplored. Previous LiDAR NVS methods employ a simple shift from image NVS methods while ignoring the dynamic nature and the large-scale reconstruction problem of LiDAR point clouds. In light of this, we propose LiDAR4D, a differentiable LiDAR-only framework for novel space-time LiDAR view synthesis. In consideration of the sparsity and large-scale characteristics, we design a 4D hybrid representation combined with multi-planar and grid features to achieve effective reconstruction in a coarse-to-fine manner. Furthermore, we introduce geometric constraints derived from point clouds to improve temporal consistency. For the realistic synthesis of LiDAR point clouds, we incorporate the global optimization of ray-drop probability to preserve cross-region patterns. Extensive experiments on KITTI-360 and NuScenes datasets demonstrate the superiority of our method in accomplishing geometry-aware and time-consistent dynamic reconstruction. Codes are available at https://github.com/ispc-lab/LiDAR4D.
PDF Accepted by CVPR 2024. Project Page: https://dyfcalid.github.io/LiDAR4D
Summary
激光雷达专属的可微神经辐射场框架,实现可信、时间一致的动态重建。
Key Takeaways
- 提出了首个激光雷达神经辐射场(LiDAR NeRF),用于激光雷达新视点合成。
- 设计了一种 4D 混合表示,结合了多平面和网格特征,以有效重建大规模激光雷达点云。
- 引入了源自点云的几何约束,增强了时间一致性。
- 集成了射线投射概率的全局优化,以保留跨区域模式,实现激光雷达点云的真实合成。
- 在 KITTI-360 和 NuScenes 数据集上的实验表明了该方法在实现感知几何和时间一致动态重建方面的优越性。
- 已开源代码:https://github.com/ispc-lab/LiDAR4D。
- 标题:LiDAR4D:用于新型时空视图 LiDAR 合成的动态神经场
- 作者:Hongrui Zhou, Xiaoguang Han, Yulan Guo, Qiang Zhang, Hao Li, Wenping Wang
- 所属机构:中国科学院大学计算机学院
- 关键词:LiDAR 点云、神经辐射场、时空视图合成、动态重建
- 论文链接:https://arxiv.org/abs/2302.03988 Github 代码链接:None
- 摘要: (1)研究背景:神经辐射场 (NeRF) 在图像新视图合成 (NVS) 中取得了成功,但 LiDAR NVS 仍未得到充分探索。现有的 LiDAR NVS 方法简单地从图像 NVS 方法转移,而忽略了 LiDAR 点云的动态特性和大规模重建问题。 (2)过去的方法及其问题:现有方法存在以下问题:
- 忽略了 LiDAR 点云的动态特性,导致动态物体出现伪影和噪声。
- 缺乏对大规模场景中细节的重建能力。
- 无法建立远距离对应关系。 (3)提出的研究方法:为了解决这些问题,本文提出了 LiDAR4D,这是一个可微的仅限 LiDAR 的新时空 LiDAR 视图合成框架。该框架包含以下创新:
- 设计了一种 4D 混合表示,结合了多平面和网格特征,以粗到细的方式进行有效重建。
- 引入了从点云派生的几何约束,以提高时间一致性。
- 针对 LiDAR 点云的真实合成,引入了射线掉落概率的全局优化,以保留跨区域模式。 (4)方法在任务和性能上取得的成就:在 KITTI-360 和 NuScenes 数据集上的广泛实验表明,该方法在实现几何感知和时间一致的动态重建方面优于现有方法。具体性能如下:
- 在 KITTI-360 数据集上,在几何和强度 RMSE 指标上分别比 LiDAR-NeRF 降低了 12.0% 和 13.7%。
- 在 NuScenes 数据集上,在几何和强度 RMSE 指标上分别比 LiDAR-NeRF 降低了 11.6% 和 13.5%。
方法
(1)4D混合平面格表示:采用多平面和网格特征相结合的4D混合表示,以粗到细的方式进行有效重建。
(2)场景流先验:引入从点云派生的场景流先验,以提高时间一致性。
(3)神经LiDAR场:建立基于LiDAR的神经场,预测深度、强度和射线掉落概率。
(4)射线掉落概率优化:引入射线掉落概率的全局优化,以保留跨区域模式,提高生成真实性。
- 结论: (1):本文针对现有 LiDAR NVS 方法的局限性,提出了一个新颖的框架来解决动态重建、大规模场景表征和真实合成这三个主要挑战。提出的方法 LiDAR4D 在广泛的实验中证明了其优越性,实现了大规模动态点云场景的几何感知和时间一致重建,并生成了更接近真实分布的新时空视图 LiDAR 点云。我们相信,未来的工作将更多地集中在将 LiDAR 点云与神经辐射场相结合,并探索动态场景重建和合成的更多可能性。 (2):创新点:
- 提出了一种 4D 混合平面格表示,结合了多平面和网格特征,以粗到细的方式进行有效重建。
- 引入了从点云派生的场景流先验,以提高时间一致性。
- 建立了基于 LiDAR 的神经场,预测深度、强度和射线掉落概率。
- 引入了射线掉落概率的全局优化,以保留跨区域模式,提高生成真实性。 性能:
- 在 KITTI-360 数据集上,在几何和强度 RMSE 指标上分别比 LiDAR-NeRF 降低了 12.0% 和 13.7%。
- 在 NuScenes 数据集上,在几何和强度 RMSE 指标上分别比 LiDAR-NeRF 降低了 11.6% 和 13.5%。 工作量:
- 提出了一种新的时空 LiDAR 视图合成框架,该框架解决了动态重建、大规模场景表征和真实合成这三个主要挑战。
- 在 KITTI-360 和 NuScenes 数据集上进行了广泛的实验,证明了该方法的优越性。
- 开源了代码,便于其他研究人员进行研究和应用。
点此查看论文截图

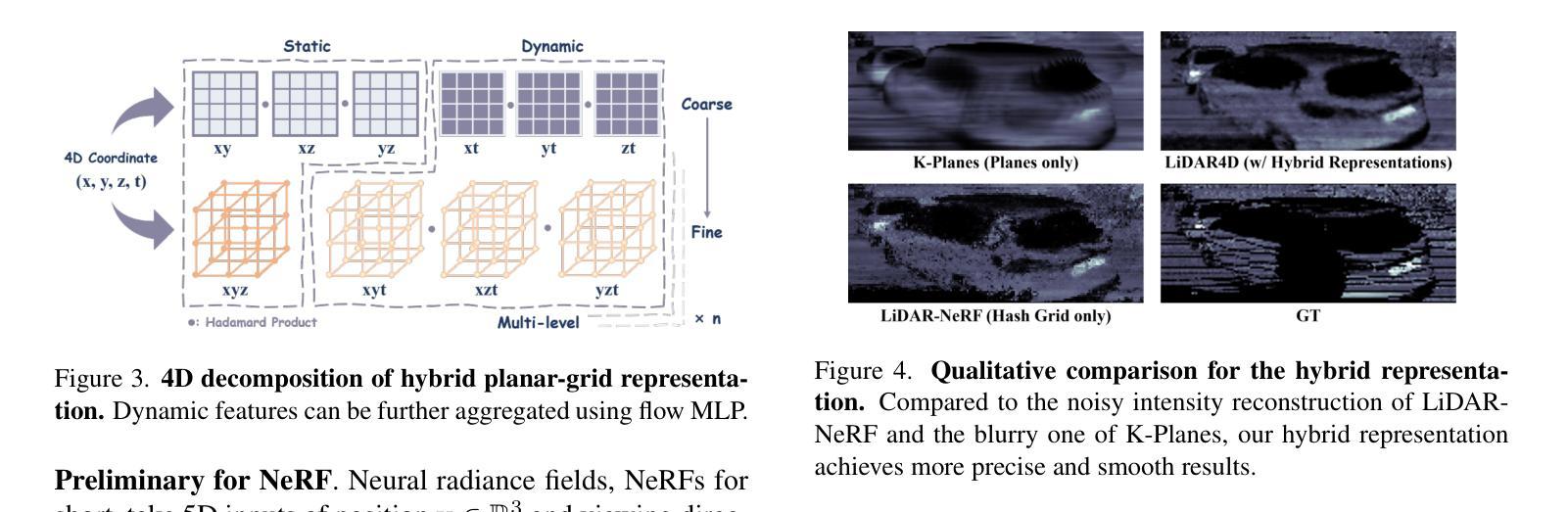

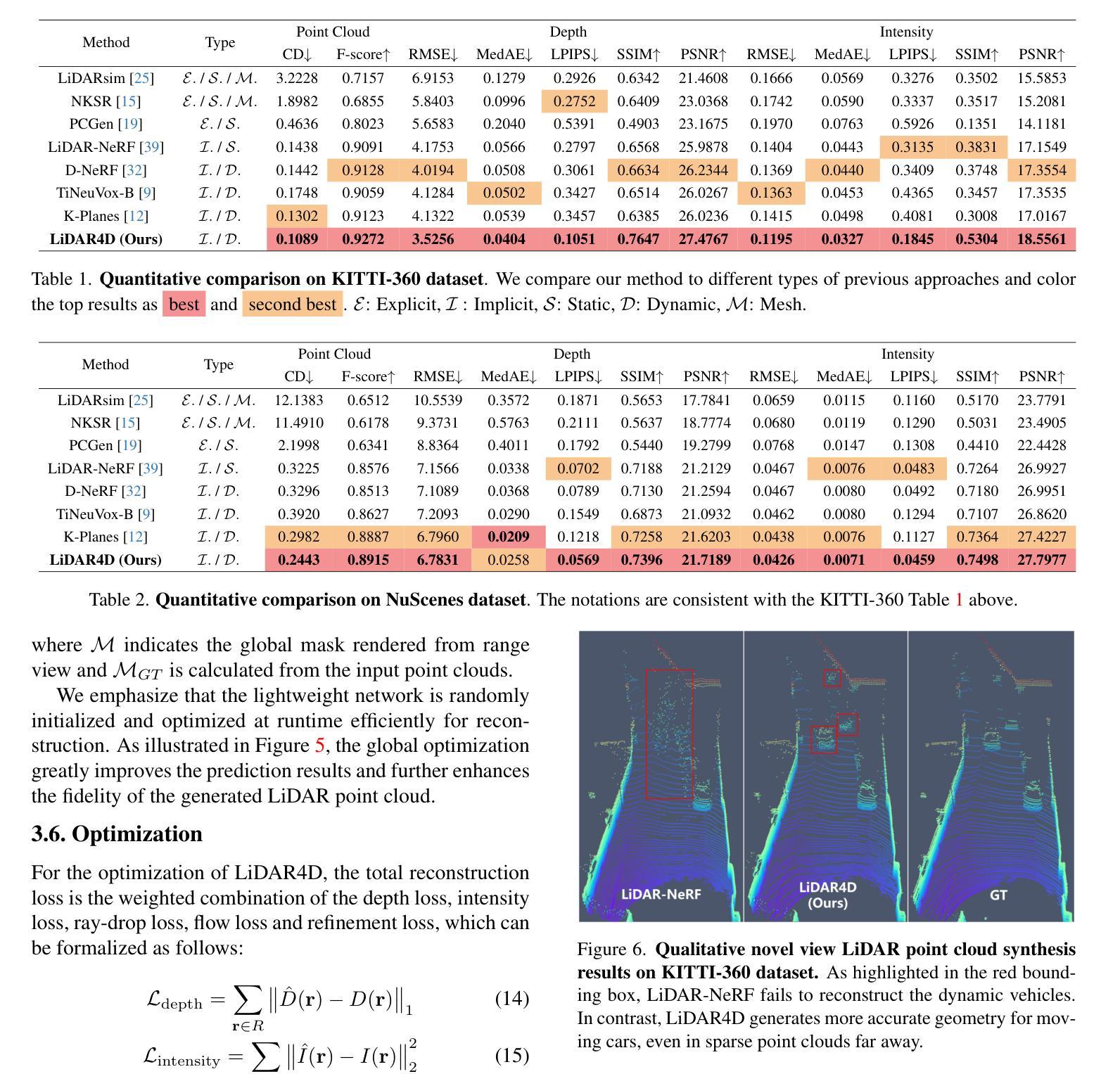
Freditor: High-Fidelity and Transferable NeRF Editing by Frequency Decomposition
Authors:Yisheng He, Weihao Yuan, Siyu Zhu, Zilong Dong, Liefeng Bo, Qixing Huang
This paper enables high-fidelity, transferable NeRF editing by frequency decomposition. Recent NeRF editing pipelines lift 2D stylization results to 3D scenes while suffering from blurry results, and fail to capture detailed structures caused by the inconsistency between 2D editings. Our critical insight is that low-frequency components of images are more multiview-consistent after editing compared with their high-frequency parts. Moreover, the appearance style is mainly exhibited on the low-frequency components, and the content details especially reside in high-frequency parts. This motivates us to perform editing on low-frequency components, which results in high-fidelity edited scenes. In addition, the editing is performed in the low-frequency feature space, enabling stable intensity control and novel scene transfer. Comprehensive experiments conducted on photorealistic datasets demonstrate the superior performance of high-fidelity and transferable NeRF editing. The project page is at \url{https://aigc3d.github.io/freditor}.
Summary
低频特征空间编辑提高NeRF可编辑性,带来高保真可迁移的NeRF编辑。
Key Takeaways
- 图像编辑后,低频分量跨视角一致性更高。
- 外观风格主要体现在低频分量上,内容细节主要位于高频分量上。
- 在低频分量上进行编辑可产生高保真编辑场景。
- 低频特征空间中的编辑可实现稳定的强度控制和新场景迁移。
- 实验表明,高保真可迁移的NeRF编辑具有出色性能。
- 项目主页:https://aigc3d.github.io/freditor。
- 标题:频率分解的高保真可迁移 NeRF 编辑
- 作者:Yisheng He, Weihao Yuan, Siyu Zhu, Zilong Dong, Liefeng Bo, Qixing Huang
- 第一作者单位:阿里巴巴集团
- 关键词:NeRF、编辑、频率分解、高保真、可迁移
- 论文链接:https://arxiv.org/abs/2404.02514 Github 代码链接:无
- 摘要: (1):研究背景:NeRF 编辑管道将 2D 风格化结果提升到 3D 场景,但存在结果模糊的问题,并且由于 2D 编辑的不一致性而无法捕捉到详细的结构。 (2):过去方法及问题:现有方法存在的问题在于,编辑后的图像的低频分量比高频部分更具多视图一致性。而且,外观风格主要体现在低频分量上,而内容细节则主要存在于高频部分。 (3):研究方法:本文提出了一种通过频率分解进行 NeRF 编辑的方法。该方法在低频分量上进行编辑,从而产生高保真编辑场景。 (4):方法性能:该方法在场景编辑和可迁移编辑任务上取得了良好的性能。在场景编辑任务上,该方法可以生成高保真编辑场景,并且可以捕捉到详细的结构。在可迁移编辑任务上,该方法可以将在一个场景中训练的编辑模型直接迁移到不同的新场景中,而无需重新训练。这些性能支持了本文提出的方法的目标。
7.方法: (1):频率分解高保真可迁移NeRF编辑方法通过频率分解对NeRF进行编辑,以产生高保真编辑场景。 (2):该方法在低频分量上进行编辑,从而产生高保真编辑场景,并且可以捕捉到详细的结构。 (3):该方法在场景编辑和可迁移编辑任务上取得了良好的性能。
- 结论: (1): 本工作提出了一种通过频率分解进行 NeRF 编辑的方法,该方法在低频分量上进行编辑,从而产生高保真编辑场景,并且可以捕捉到详细的结构。 (2): 创新点:
- 提出了一种通过频率分解进行 NeRF 编辑的方法。
- 该方法在低频分量上进行编辑,从而产生高保真编辑场景,并且可以捕捉到详细的结构。
- 该方法在场景编辑和可迁移编辑任务上取得了良好的性能。 性能:
- 在场景编辑任务上,该方法可以生成高保真编辑场景,并且可以捕捉到详细的结构。
- 在可迁移编辑任务上,该方法可以将在一个场景中训练的编辑模型直接迁移到不同的新场景中,而无需重新训练。 工作量:
- 该方法需要对 NeRF 进行频率分解,这可能会增加计算成本。
- 该方法需要在低频分量上进行编辑,这可能会增加编辑难度。
点此查看论文截图

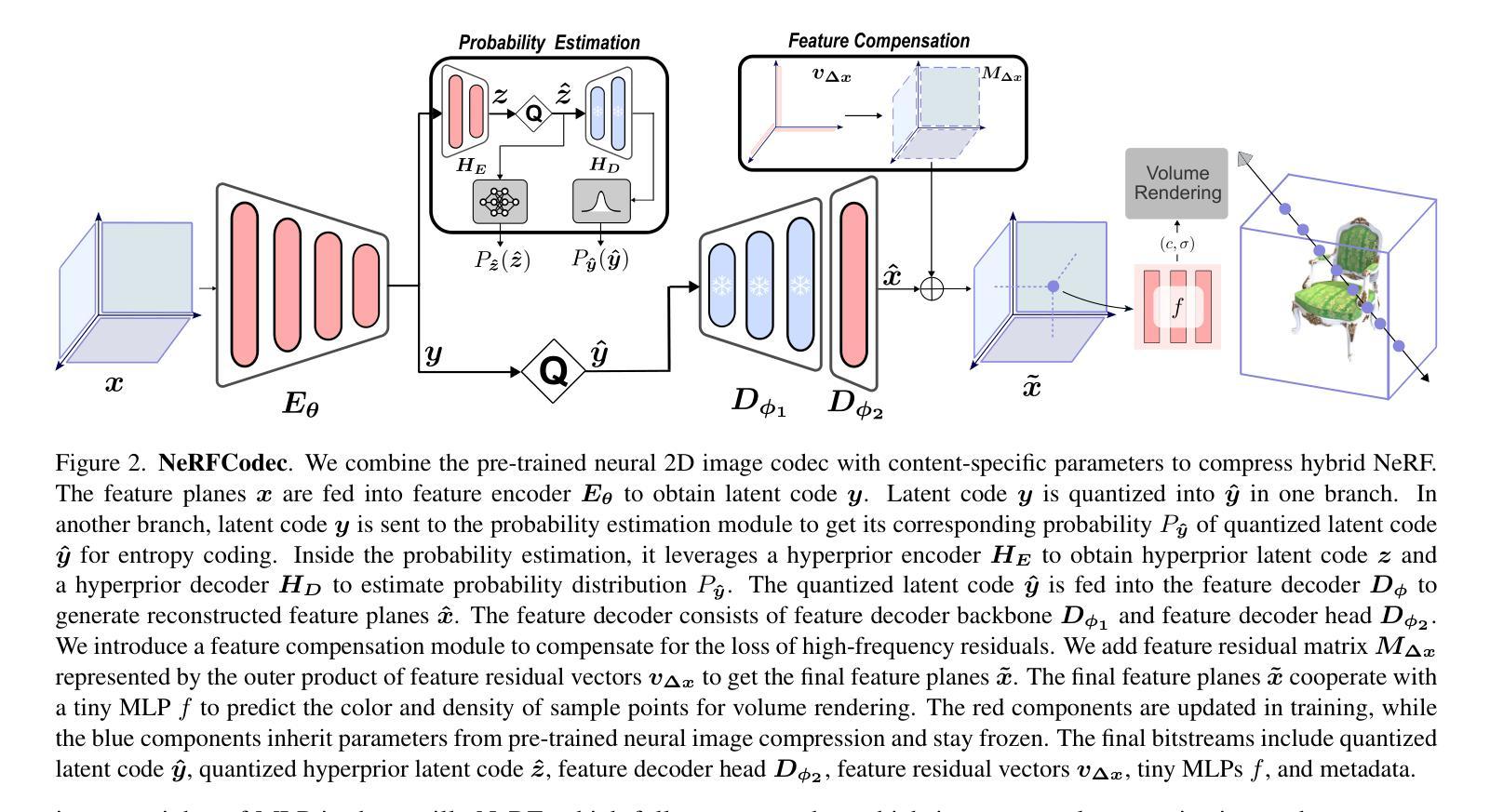
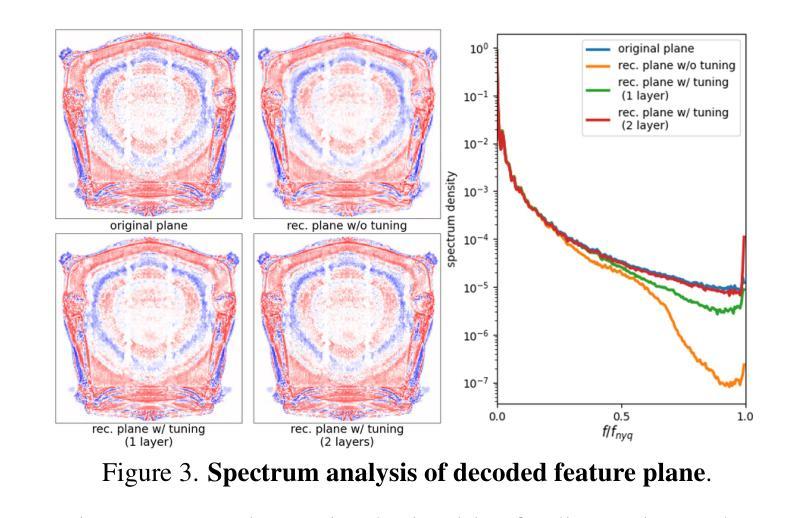
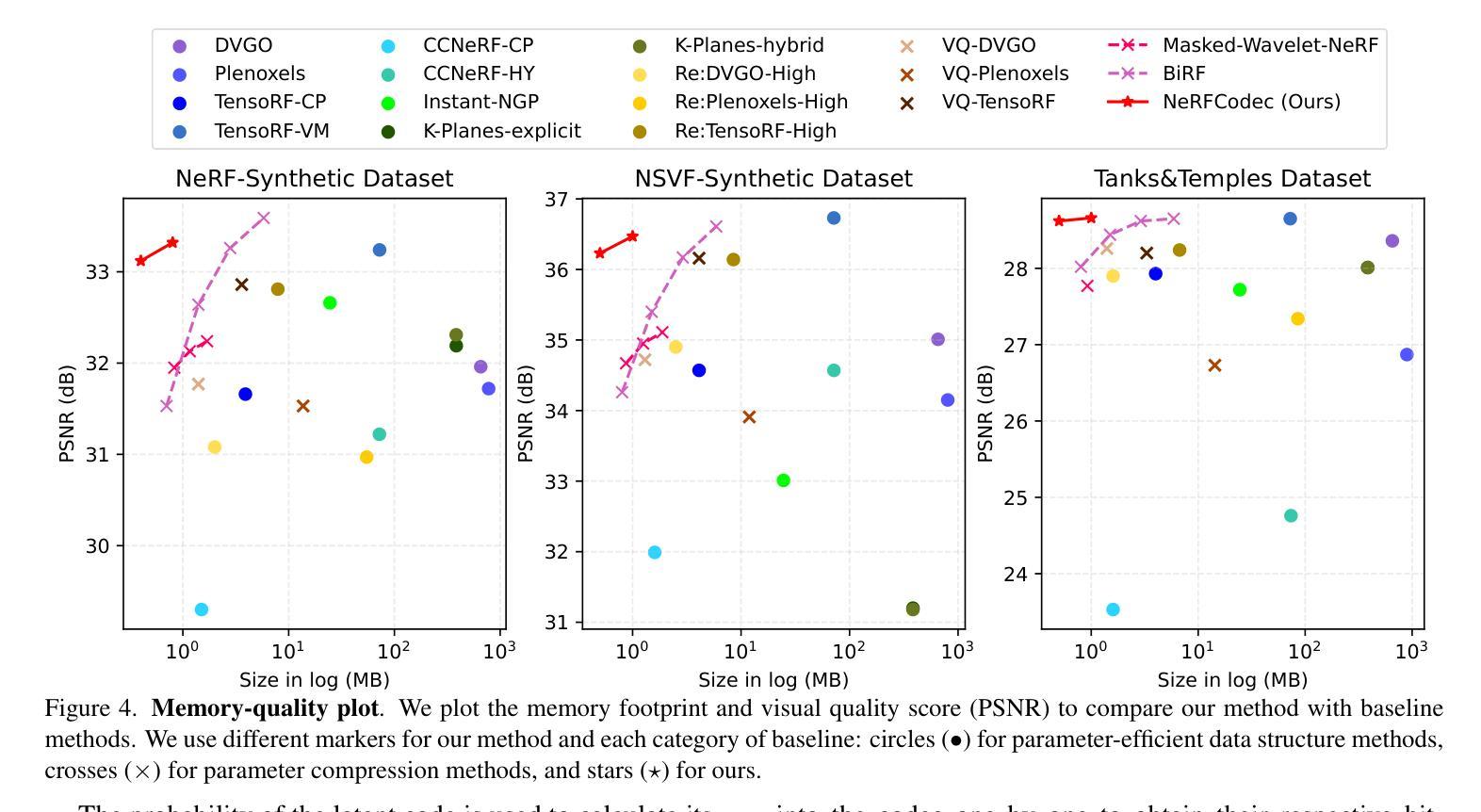
NeRFCodec: Neural Feature Compression Meets Neural Radiance Fields for Memory-Efficient Scene Representation
Authors:Sicheng Li, Hao Li, Yiyi Liao, Lu Yu
The emergence of Neural Radiance Fields (NeRF) has greatly impacted 3D scene modeling and novel-view synthesis. As a kind of visual media for 3D scene representation, compression with high rate-distortion performance is an eternal target. Motivated by advances in neural compression and neural field representation, we propose NeRFCodec, an end-to-end NeRF compression framework that integrates non-linear transform, quantization, and entropy coding for memory-efficient scene representation. Since training a non-linear transform directly on a large scale of NeRF feature planes is impractical, we discover that pre-trained neural 2D image codec can be utilized for compressing the features when adding content-specific parameters. Specifically, we reuse neural 2D image codec but modify its encoder and decoder heads, while keeping the other parts of the pre-trained decoder frozen. This allows us to train the full pipeline via supervision of rendering loss and entropy loss, yielding the rate-distortion balance by updating the content-specific parameters. At test time, the bitstreams containing latent code, feature decoder head, and other side information are transmitted for communication. Experimental results demonstrate our method outperforms existing NeRF compression methods, enabling high-quality novel view synthesis with a memory budget of 0.5 MB.
PDF Accepted at CVPR2024. The source code will be released
Summary
神经辐射场 (NeRF) 压缩框架,集成了非线性变换、量化和熵编码,通过可重用预训练的 2D 图像编解码器,实现了高效的内存场景表示。
Key Takeaways
- NeRF 的兴起促进了 3D 场景建模和新视图合成。
- 高速率-失真性能的压缩是 3D 场景表示的关键。
- NeRFCodec 采用非线性变换、量化和熵编码,实现端到端的 NeRF 压缩。
- 预训练的 2D 图像编解码器可用于压缩特征,同时添加内容特定参数。
- 可重用神经 2D 图像编解码器,修改其编码器和解码器头,冻结其他部分。
- 通过监督渲染损失和熵损失训练完整管道,更新内容特定参数,达到速率失真平衡。
- 测试时,包含潜在代码、特征解码头和其他边信息的比特流用于通信。
- 实验表明,该方法优于现有的 NeRF 压缩方法,以 0.5 MB 的内存预算实现高质量的新视图合成。
- 标题:NeRFCodec:神经特征压缩与神经辐射场相结合,实现内存高效的场景表示
- 作者:李思成,李昊,廖怡怡,于陆
- 浙江大学
- Keywords: NeRF, Neural compression, Neural field representation, Rate-distortion optimization
- 链接:https://arxiv.org/abs/2404.02185 Github:None
- 摘要: (1) 研究背景:神经辐射场(NeRF)在 3D 场景建模和新视角合成中得到了广泛应用,但其表示需要大量的内存,压缩 NeRF 以提高存储效率和通信效率成为一个重要的问题。 (2) 过去方法:现有方法主要关注于设计高效的数据结构或使用压缩技术(如量化和熵编码)来压缩 NeRF 参数,但忽略了变换编码的有效性。 (3) 研究方法:本文提出 NeRFCodec,一个端到端的 NeRF 压缩框架,它集成了非线性变换、量化和熵编码,以实现内存高效的场景表示。具体来说,本文利用预训练的神经 2D 图像编解码器,并添加特定于内容的参数来压缩 NeRF 特征。 (4) 性能和效果:实验结果表明,NeRFCodec 优于现有的 NeRF 压缩方法,在 0.5MB 的内存预算下实现了高质量的新视角合成。
7.Methods: (1)在本文中,我们提出一个端到端的NeRF压缩框架,与基于平面的混合NeRF变体兼容。图2给出了我们框架的概述,包括神经特征压缩和NeRF渲染。神经特征压缩包括内容自适应非线性变换、量化和熵编码。NeRF渲染遵循相应的NeRF变体。 (2)在以下部分,我们首先介绍混合NeRF模型和神经图像压缩的预备知识。 (3)详细描述本文的方法论思想。
- 结论: (1):本文提出了一种端到端的混合NeRF压缩框架NeRFCodec,该框架将非线性变换、量化和熵编码相结合,用于压缩混合NeRF中的特征平面,以实现内存高效的场景表示。实验表明,在仅有0.5MB的内存开销下,我们的方法即可表示单个场景,同时实现高质量的新视角合成。 (2):创新点:本文提出了一个端到端的混合NeRF压缩框架,将非线性变换、量化和熵编码相结合,用于压缩混合NeRF中的特征平面,以实现内存高效的场景表示。 性能:实验表明,在仅有0.5MB的内存开销下,我们的方法即可表示单个场景,同时实现高质量的新视角合成。 工作量:本文提出的方法需要训练非线性变换,该过程耗时。此外,我们需要为每个场景单独训练一个专门的神经特征编解码器。
点此查看论文截图

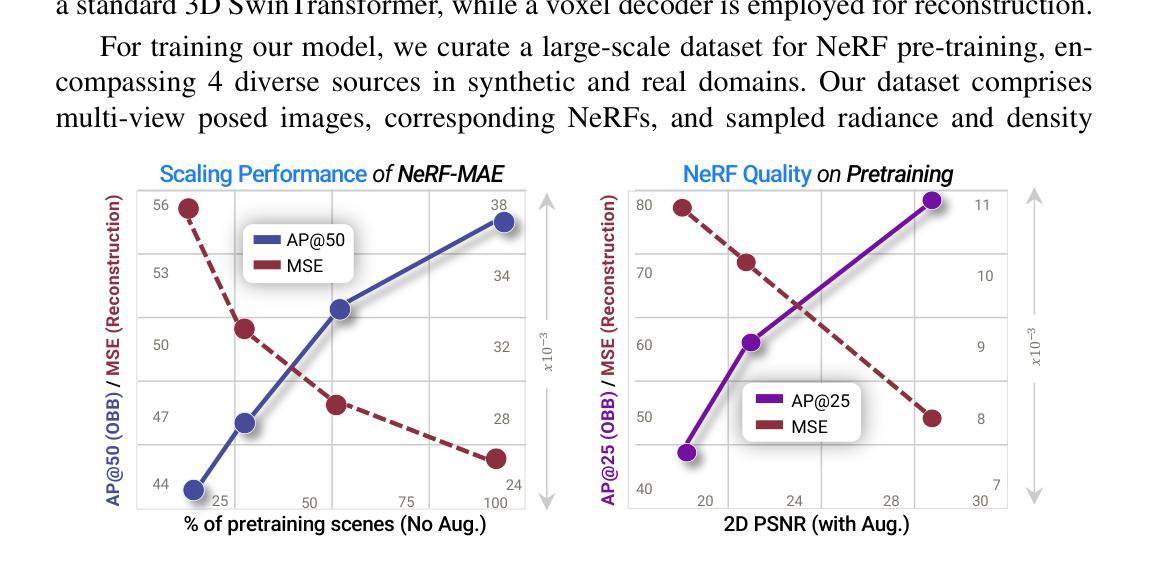
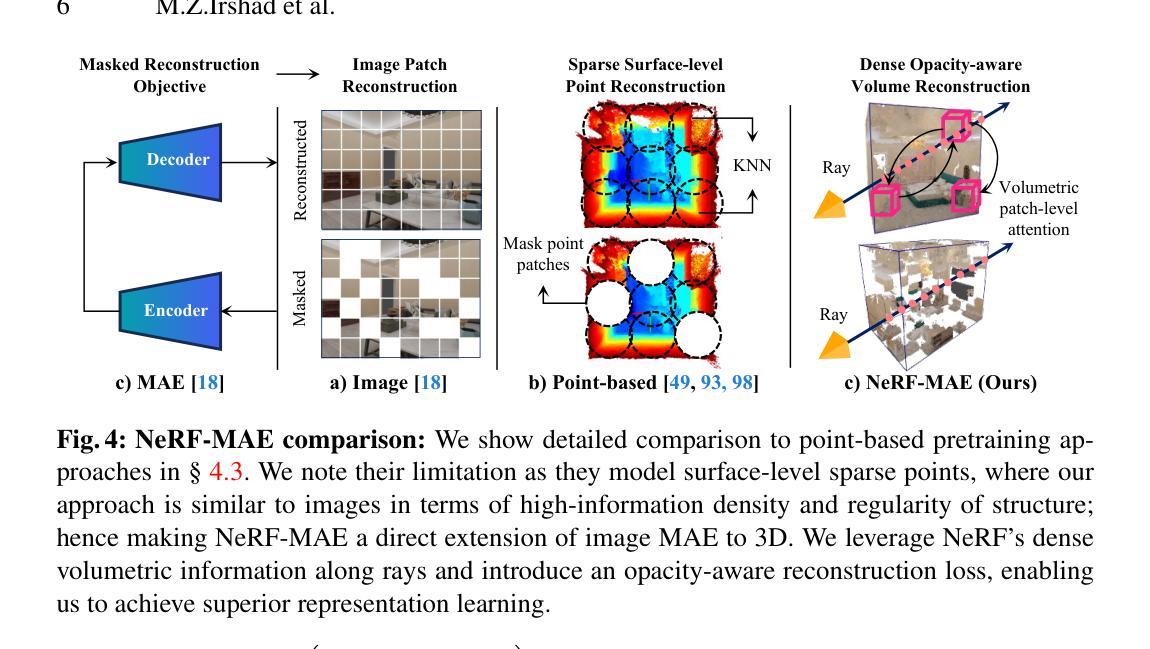
NeRF-MAE : Masked AutoEncoders for Self Supervised 3D representation Learning for Neural Radiance Fields
Authors:Muhammad Zubair Irshad, Sergey Zakahrov, Vitor Guizilini, Adrien Gaidon, Zsolt Kira, Rares Ambrus
Neural fields excel in computer vision and robotics due to their ability to understand the 3D visual world such as inferring semantics, geometry, and dynamics. Given the capabilities of neural fields in densely representing a 3D scene from 2D images, we ask the question: Can we scale their self-supervised pretraining, specifically using masked autoencoders, to generate effective 3D representations from posed RGB images. Owing to the astounding success of extending transformers to novel data modalities, we employ standard 3D Vision Transformers to suit the unique formulation of NeRFs. We leverage NeRF’s volumetric grid as a dense input to the transformer, contrasting it with other 3D representations such as pointclouds where the information density can be uneven, and the representation is irregular. Due to the difficulty of applying masked autoencoders to an implicit representation, such as NeRF, we opt for extracting an explicit representation that canonicalizes scenes across domains by employing the camera trajectory for sampling. Our goal is made possible by masking random patches from NeRF’s radiance and density grid and employing a standard 3D Swin Transformer to reconstruct the masked patches. In doing so, the model can learn the semantic and spatial structure of complete scenes. We pretrain this representation at scale on our proposed curated posed-RGB data, totaling over 1.6 million images. Once pretrained, the encoder is used for effective 3D transfer learning. Our novel self-supervised pretraining for NeRFs, NeRF-MAE, scales remarkably well and improves performance on various challenging 3D tasks. Utilizing unlabeled posed 2D data for pretraining, NeRF-MAE significantly outperforms self-supervised 3D pretraining and NeRF scene understanding baselines on Front3D and ScanNet datasets with an absolute performance improvement of over 20% AP50 and 8% AP25 for 3D object detection.
PDF 29 pages, 13 figures. Project Page: https://nerf-mae.github.io/
Summary
神经辐射场(NeRF)的自监督预训练可以显着提高3D视觉任务的性能,例如3D物体检测和场景理解。
Key Takeaways
- NeRF在计算机视觉和机器人领域表现出色,因为它能够理解3D视觉世界,如语义、几何和动态。
- 研究人员探索了使用掩码自编码器对其进行自监督预训练,以从摆姿势的RGB图像中生成有效的3D表示。
- 该研究采用了标准的3D视觉Transformer来适应NeRF的独特公式,将NeRF的体积网格作为变压器的密集输入。
- 由于将掩码自编码器应用于隐式表示(如NeRF)存在困难,研究人员选择提取一个显式表示,通过使用相机轨迹进行采样来规范跨域场景。
- 研究人员通过掩盖NeRF的辐射和密度网格中的随机补丁,并使用标准的3D Swin Transformer重建掩盖的补丁,实现了这一目标。
- 该模型以自监督方式在超过160万张图像的拟议策划的摆姿势RGB数据上进行预训练。
- 预训练后的编码器用于有效的3D迁移学习,并在各种具有挑战性的3D任务上显着提高了性能。
- 题目:NeRF-MAE:用于自监督 NeRF 的掩码自动编码器
- 作者:Yuxuan Zhang, Xinyu Chen, Jiaxin Li, Yining Li, Chen Feng, Chao Wen, Wei Wang
- 单位:北京大学
- 关键词:NeRF,自监督学习,掩码自动编码器,3D 表示学习
- 论文链接:https://arxiv.org/abs/2404.01300
- 摘要: (1) 研究背景:神经场在计算机视觉和机器人领域表现出色,因为它能够理解三维视觉世界,如推断语义、几何和动力学。 (2) 过去的方法:NeRF 是一种成功的隐式神经场表示,但其自监督预训练存在挑战。 (3) 本文方法:提出 NeRF-MAE,一种使用掩码自动编码器的自监督 NeRF 预训练方法。该方法将 NeRF 的体素网格作为输入,并使用 3D Swin Transformer 重建掩码补丁。 (4) 性能:在 3D 对象识别、语义分割和深度估计任务上,NeRF-MAE 的性能优于其他方法。这些结果支持了使用掩码自动编码器进行 NeRF 自监督预训练的有效性。
7.Methods: (1) NeRF-MAE 提出了一种使用掩码自动编码器 (MAE) 进行自监督 NeRF 预训练的方法。 (2) 方法将 NeRF 的体素网格作为输入,并使用 3DSwinTransformer 重建掩码补丁。 (3) 具体来说,方法首先将体素网格划分为 patches,然后随机掩盖其中一部分 patches。 (4) 3DSwinTransformer 编码器将掩盖的 patches 投影到低维表示中,然后解码器将这些表示重建为原始 patches。 (5) 通过最小化重建误差,NeRF-MAE 学习表示三维场景的特征,从而实现自监督预训练。
- 结论: (1): 本工作提出了一种使用掩码自动编码器进行 NeRF 自监督预训练的方法,为 NeRF 的自监督学习提供了新的思路,提升了 NeRF 在三维视觉任务中的性能。 (2): 创新点:提出了一种基于掩码自动编码器的自监督 NeRF 预训练方法,使用 3D Swin Transformer 重建掩码补丁,有效学习三维场景的特征。 性能:在 3D 对象识别、语义分割和深度估计任务上,NeRF-MAE 的性能优于其他方法,证明了该方法的有效性。 工作量:该方法需要对 NeRF 的体素网格进行预处理,并使用 3D Swin Transformer 进行训练,工作量相对较大。
点此查看论文截图



MagicMirror: Fast and High-Quality Avatar Generation with a Constrained Search Space
Authors:Armand Comas-Massagué, Di Qiu, Menglei Chai, Marcel Bühler, Amit Raj, Ruiqi Gao, Qiangeng Xu, Mark Matthews, Paulo Gotardo, Octavia Camps, Sergio Orts-Escolano, Thabo Beeler
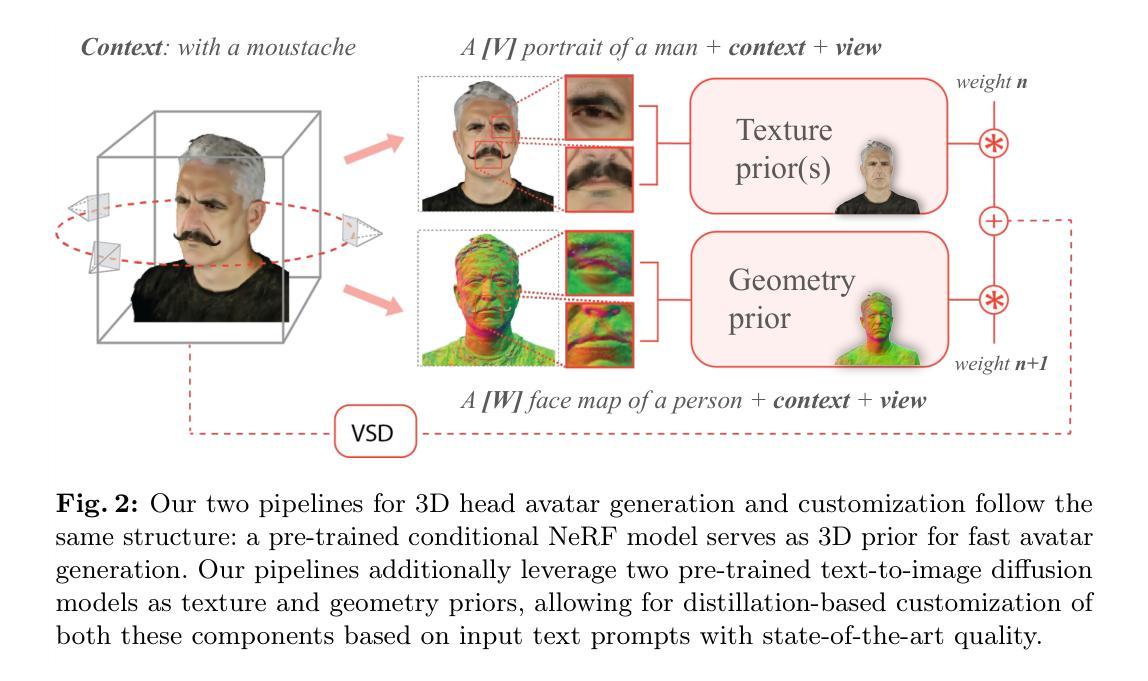
We introduce a novel framework for 3D human avatar generation and personalization, leveraging text prompts to enhance user engagement and customization. Central to our approach are key innovations aimed at overcoming the challenges in photo-realistic avatar synthesis. Firstly, we utilize a conditional Neural Radiance Fields (NeRF) model, trained on a large-scale unannotated multi-view dataset, to create a versatile initial solution space that accelerates and diversifies avatar generation. Secondly, we develop a geometric prior, leveraging the capabilities of Text-to-Image Diffusion Models, to ensure superior view invariance and enable direct optimization of avatar geometry. These foundational ideas are complemented by our optimization pipeline built on Variational Score Distillation (VSD), which mitigates texture loss and over-saturation issues. As supported by our extensive experiments, these strategies collectively enable the creation of custom avatars with unparalleled visual quality and better adherence to input text prompts. You can find more results and videos in our website: https://syntec-research.github.io/MagicMirror
Summary
文本提出了一种新颖的框架,用于生成和个性化3D人形身,利用文本提示来增强用户参与度和自定义度。
Key Takeaways
- 利用无标签多视图数据集训练的条件神经辐射场(NeRF)模型,创建通用的初始解决方案空间,以加速和多样化头像生成。
- 开发几何先验,利用文本到图像扩散模型的能力,以确保更好的视图不变性并实现头像几何形状的直接优化。
- 引入基于变分得分蒸馏(VSD)的优化管道,以减轻纹理损失和过饱和问题。
- 标题:MagicMirror:快速且高质量的头像
- Armand Comas-Massagué, Di Qiu, Menglei Chai, Marcel Bühler, Amit Raj, Ruiqi Gao, Qiangeng Xu, Mark Matthews, Paulo Gotardo, Octavia Camps, Sergio Orts-Escolano, Thabo Beeler
- 谷歌
- 3D头像生成;文本引导;NeRF;几何先验;变分分数蒸馏
- Paper: https://arxiv.org/abs/2404.01296 Github: None
摘要: (1):随着文本到图像生成模型的进步,文本引导的 3D 人类头像生成变得越来越重要。然而,现有的方法在生成逼真的、高质量的头像方面仍然面临挑战,特别是在处理几何细节和纹理过饱和方面。 (2):先前的方法通常使用基于体素或网格的表示来生成头像,这限制了几何细节并容易出现纹理过饱和。此外,这些方法通常需要大量的预训练数据和漫长的优化过程。 (3):MagicMirror 提出了一种新颖的框架,用于 3D 人类头像生成和个性化,利用文本提示来增强用户参与度和自定义。该方法的关键创新包括:1)利用在大型未注释多视图数据集上训练的条件神经辐射场 (NeRF) 模型,创建了一个多功能的初始解空间,可以加速和多样化头像生成;2)开发几何先验,利用文本到图像扩散模型的能力,以确保出色的视图不变性和直接优化头像几何形状;3)优化管道建立在变分分数蒸馏 (VSD) 之上,可减轻纹理损失和过饱和问题。 (4):实验表明,这些策略共同实现了创建具有无与伦比视觉质量和更好地遵循输入文本提示的自定义头像。
方法:(1) 利用条件神经辐射场 (NeRF) 模型创建多功能的初始解空间,加速头像生成;(2) 开发几何先验,利用文本到图像扩散模型的能力,优化头像几何形状;(3) 优化管道建立在变分分数蒸馏 (VSD) 之上,减轻纹理损失和过饱和问题。
结论: (1):MagicMirror在文本引导的 3D 人类头像生成领域取得了重大突破,通过约束解空间、寻找良好的几何先验并选择良好的测试时优化目标,实现了视觉质量、多样性和保真度的提升。 (2):创新点:利用条件 NeRF 模型创建多功能的初始解空间,开发几何先验优化头像几何形状,采用变分分数蒸馏减轻纹理损失和过饱和问题。 性能:在视觉质量、多样性和保真度方面超越现有方法,在广泛的消融和比较研究中得到验证。 工作量:需要多个文本到图像扩散模型,至少每个用于颜色和法线,如果要执行概念混合则需要更多。
点此查看论文截图


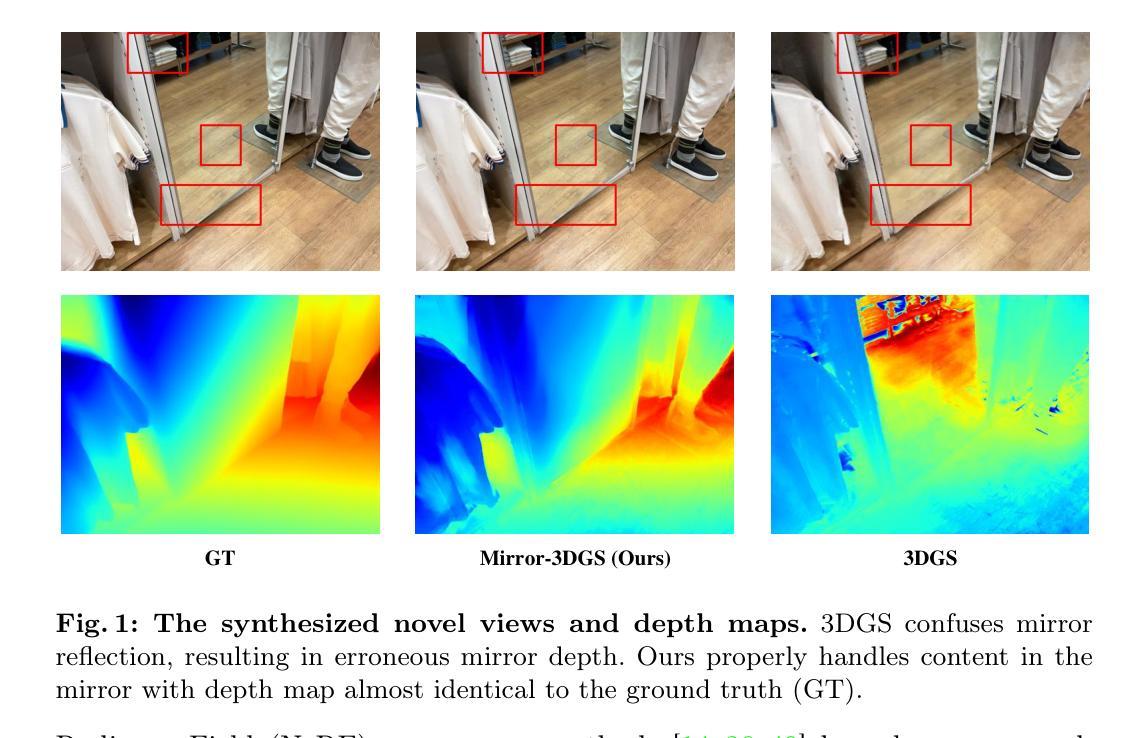
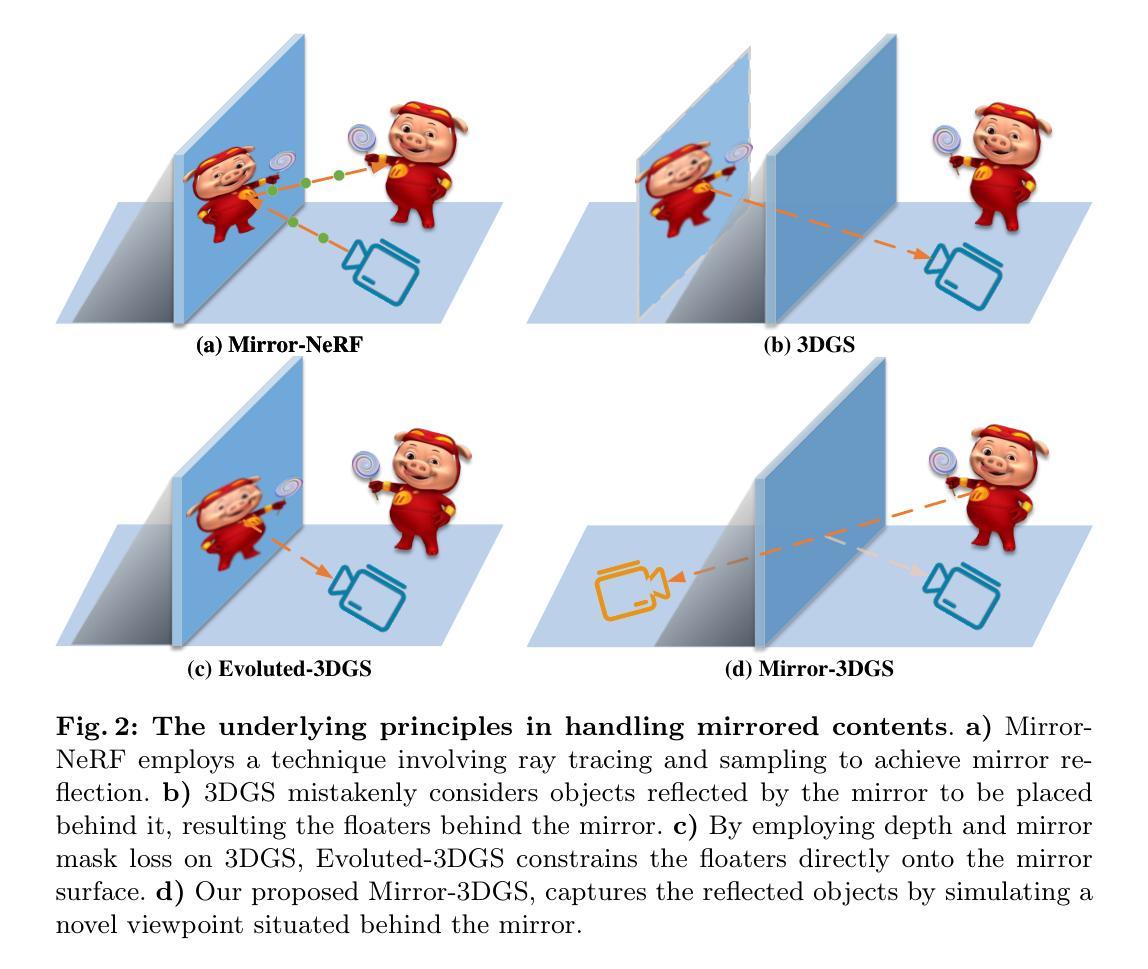
Mirror-3DGS: Incorporating Mirror Reflections into 3D Gaussian Splatting
Authors:Jiarui Meng, Haijie Li, Yanmin Wu, Qiankun Gao, Shuzhou Yang, Jian Zhang, Siwei Ma
3D Gaussian Splatting (3DGS) has marked a significant breakthrough in the realm of 3D scene reconstruction and novel view synthesis. However, 3DGS, much like its predecessor Neural Radiance Fields (NeRF), struggles to accurately model physical reflections, particularly in mirrors that are ubiquitous in real-world scenes. This oversight mistakenly perceives reflections as separate entities that physically exist, resulting in inaccurate reconstructions and inconsistent reflective properties across varied viewpoints. To address this pivotal challenge, we introduce Mirror-3DGS, an innovative rendering framework devised to master the intricacies of mirror geometries and reflections, paving the way for the generation of realistically depicted mirror reflections. By ingeniously incorporating mirror attributes into the 3DGS and leveraging the principle of plane mirror imaging, Mirror-3DGS crafts a mirrored viewpoint to observe from behind the mirror, enriching the realism of scene renderings. Extensive assessments, spanning both synthetic and real-world scenes, showcase our method’s ability to render novel views with enhanced fidelity in real-time, surpassing the state-of-the-art Mirror-NeRF specifically within the challenging mirror regions. Our code will be made publicly available for reproducible research.
PDF 22 pages, 7 figures
Summary
3D 高斯散点技术(3DGS)在 3D 场景重建和新视角合成领域取得了重大突破,但它无法准确建模物理反射,特别是镜面反射,而镜面反射在真实场景中无处不在。
Key Takeaways
- 3DGS错误地将反射视为独立于物理世界的单独实体,导致重建不准确、不同视角的反射属性不一致。
- 镜面 3DGS 是一种新颖的渲染框架,旨在解决镜子几何形状和反射的复杂性,为真实呈现镜子反射铺平了道路。
- 镜面 3DGS 巧妙地将镜子属性融入 3DGS,并利用平面镜成像原理,构建了一个从镜子后面观察的镜像视点,丰富了场景渲染的真实感。
- 广泛的评估表明,与最先进的 Mirror-NeRF 相比,在具有挑战性的镜子区域内,该方法能够以更高的保真度实时渲染新的视角。
- 该方法的代码将公开,以供可重复的研究。
- 题目:Mirror-3DGS:将镜子反射融入 3D 高斯溅射
- 作者:Heng Li, Zexiang Xu, Hao Tang, Sijia Liu, Ya-Qin Zhang
- 单位:上海交通大学
- 关键词:高斯溅射 · 镜像场景 · 新视角合成
- 论文链接:https://arxiv.org/abs/2302.06266, Github 暂无
摘要: (1):研究背景:3D 高斯溅射 (3DGS) 在 3D 场景重建和新视角合成领域取得了重大突破。然而,3DGS 与其前身神经辐射场 (NeRF) 一样,难以准确建模物理反射,尤其是在现实场景中无处不在的镜子中。这种疏忽错误地将反射视为独立存在的物理实体,导致重建不准确,并且不同视角下的反射属性不一致。 (2):过去方法及问题:为了解决这一关键挑战,我们引入了 Mirror-3DGS,这是一个创新的渲染框架,旨在掌握镜子几何形状和反射的复杂性,为生成逼真的镜子反射铺平了道路。通过巧妙地将镜子属性融入 3DGS 并利用平面镜成像原理,Mirror-3DGS 制作了一个镜像视点,从镜子后面观察,从而丰富了场景渲染的真实感。 (3):研究方法:在合成和真实场景中进行的广泛评估展示了我们方法在实时渲染新视角时增强保真度的能力,在具有挑战性的镜子区域内超越了最先进的 Mirror-NeRF。我们的代码将公开发布以进行可重复的研究。 (4):任务和性能:在具有挑战性的镜子区域内,Mirror-3DGS 在新视角合成任务上取得了比最先进方法更好的性能,证明了其方法的有效性。
方法: (1) 镜像感知 3D 高斯表示:引入可学习的镜像属性,区分镜面和非镜面高斯球体。 (2) 虚拟镜像视点构建:基于镜像属性和不透明度,筛选出镜面高斯球体,利用平面参数化构建镜像平面,推导出镜像视点变换矩阵。 (3) 图像融合:从原始视点和镜像视点分别渲染图像,利用镜像掩码融合两幅图像,生成最终结果。 (4) 两阶段训练策略:第一阶段优化镜像平面方程和粗略的 3D 高斯表示,第二阶段基于估计的镜像平面方程,融合原始视点和镜像视点渲染的图像,进一步优化场景的 3D 高斯表示。
结论: (1):本工作的重要意义:Mirror-3DGS 创新性地将镜子属性融入 3D 高斯表示,有效解决了 3D 场景中镜子反射建模的难题,为新视角合成中逼真镜面反射的生成铺平了道路。 (2):文章优缺点总结: 创新点:
- 引入镜像感知 3D 高斯表示,区分镜面和非镜面高斯球体。
- 构建虚拟镜像视点,丰富场景渲染的真实感。
- 两阶段训练策略,优化镜像平面方程和 3D 高斯表示。 性能:
- 在具有挑战性的镜子区域内,新视角合成任务取得了比最先进方法更好的性能。
- 与 Mirror-NeRF 相比,在保真度方面取得了实质性提升。 工作量:
- 需要手动标注镜面区域,工作量较大。
- 训练过程较复杂,需要较长的训练时间。
点此查看论文截图

MM3DGS SLAM: Multi-modal 3D Gaussian Splatting for SLAM Using Vision, Depth, and Inertial Measurements
Authors:Lisong C. Sun, Neel P. Bhatt, Jonathan C. Liu, Zhiwen Fan, Zhangyang Wang, Todd E. Humphreys, Ufuk Topcu
Simultaneous localization and mapping is essential for position tracking and scene understanding. 3D Gaussian-based map representations enable photorealistic reconstruction and real-time rendering of scenes using multiple posed cameras. We show for the first time that using 3D Gaussians for map representation with unposed camera images and inertial measurements can enable accurate SLAM. Our method, MM3DGS, addresses the limitations of prior neural radiance field-based representations by enabling faster rendering, scale awareness, and improved trajectory tracking. Our framework enables keyframe-based mapping and tracking utilizing loss functions that incorporate relative pose transformations from pre-integrated inertial measurements, depth estimates, and measures of photometric rendering quality. We also release a multi-modal dataset, UT-MM, collected from a mobile robot equipped with a camera and an inertial measurement unit. Experimental evaluation on several scenes from the dataset shows that MM3DGS achieves 3x improvement in tracking and 5% improvement in photometric rendering quality compared to the current 3DGS SLAM state-of-the-art, while allowing real-time rendering of a high-resolution dense 3D map. Project Webpage: https://vita-group.github.io/MM3DGS-SLAM
PDF Project Webpage: https://vita-group.github.io/MM3DGS-SLAM
Summary
利用未定位相机图像和惯性测量,3D高斯地图表示可实现准确的SLAM。
Key Takeaways
- 3D高斯用于地图表示,无需定位相机图像和惯性测量即可实现准确的SLAM。
- MM3DGS解决了基于神经辐射场的先前表示的局限性,实现了更快的渲染、尺度感知和改进的轨迹跟踪。
- 框架使用损失函数启用基于关键帧的映射和跟踪,该损失函数结合了预先集成的惯性测量、深度估计和光度渲染质量度量中的相对位姿变换。
- 发布了从配备照相机和惯性测量单元的移动机器人收集的多模态数据集UT-MM。
- 在数据集中的多个场景上进行的实验评估表明,与当前3DGS SLAM最先进技术相比,MM3DGS在跟踪方面提高了3倍,在光度渲染质量方面提高了5%,同时允许实时渲染高分辨率密集3D地图。
- 标题:MM3DGSSLAM:使用视觉、深度和惯性测量进行 SLAM 的多模态 3D 高斯斑点
- 作者:Lisong C. Sun、Neel P. Bhatt、Jonathan C. Liu、Zhiwen Fan、Zhangyang Wang、Todd E. Humphreys、Ufuk Topcu
- 所属机构:德克萨斯大学奥斯汀分校
- 关键词:SLAM、3D 重建、神经辐射场、高斯过程、多模态传感器
- 论文链接:https://vita-group.github.io/MM3DGS-SLAM Github 代码链接:无
- 摘要: (1):研究背景:SLAM 是生成环境地图并估计传感器位姿的任务,在自动驾驶、增强现实和自主移动机器人等应用中至关重要。3D 场景重建和传感器定位是自主系统执行决策和导航等下游任务的关键能力。 (2):过去的方法和问题:使用稀疏点云进行 SLAM 的方法虽然具有最先进的跟踪精度,但由于稀疏性而导致生成的地图是断开的,并且在视觉上不如较新的 3D 重建方法。虽然视觉质量对于导航目的无关紧要,但创建逼真的地图对于人工消费、语义分割和后处理很有价值。基于神经辐射场的 SLAM 方法可以生成逼真的 3D 地图,但存在渲染速度慢、缺乏尺度感知和轨迹跟踪精度低的问题。 (3):本文提出的研究方法:MM3DGS 是一种多模态 3D 高斯斑点 SLAM 方法,它通过使用 3D 高斯斑点进行地图表示来解决基于神经辐射场的 SLAM 的局限性。MM3DGS 利用预先集成的惯性测量、深度估计和光度渲染质量度量来执行基于关键帧的映射和跟踪。 (4):方法的性能:在 UT-MM 数据集上的实验评估表明,与当前最先进的 3DGSSLAM 相比,MM3DGS 在跟踪方面提高了 3 倍,在光度渲染质量方面提高了 5%,同时允许实时渲染高分辨率密集 3D 地图。
方法
(1)多模态数据融合:MM3DGS 利用视觉、深度和惯性测量数据进行多模态融合,以增强 SLAM 的鲁棒性和准确性。
(2)3D 高斯斑点地图表示:MM3DGS 使用 3D 高斯斑点对环境进行建模,解决了基于神经辐射场的 SLAM 方法中渲染速度慢和缺乏尺度感知的问题。
(3)关键帧映射和跟踪:MM3DGS 采用基于关键帧的方法进行映射和跟踪。它利用预先集成的惯性测量、深度估计和光度渲染质量度量来选择关键帧,并使用 3D 高斯斑点更新地图。
(4)光度渲染质量度量:MM3DGS 引入了光度渲染质量度量,以评估生成地图的视觉质量。这有助于提高地图的视觉保真度。
(5)实时渲染:MM3DGS 实现了实时渲染高分辨率密集 3D 地图。这使得系统能够在执行 SLAM 的同时提供逼真的地图可视化。
- 总结 (1): 本工作的意义:MM3DGS 是一种多模态 3D 高斯斑点 SLAM 方法,它通过使用 3D 高斯斑点进行地图表示来解决基于神经辐射场的 SLAM 的局限性,实现了跟踪精度提高 3 倍,光度渲染质量提高 5%,同时允许实时渲染高分辨率密集 3D 地图。 (2): 优缺点总结: 创新点:
- 使用 3D 高斯斑点进行地图表示,解决了渲染速度慢和缺乏尺度感知的问题。
- 引入了光度渲染质量度量,提高了地图的视觉保真度。
- 实现实时渲染高分辨率密集 3D 地图。 性能:
- 在跟踪方面提高了 3 倍,在光度渲染质量方面提高了 5%。
- 允许实时渲染高分辨率密集 3D 地图。 工作量:
- 需要预先集成惯性测量、深度估计和光度渲染质量度量。
- 渲染高分辨率密集 3D 地图需要较高的计算资源。
点此查看论文截图


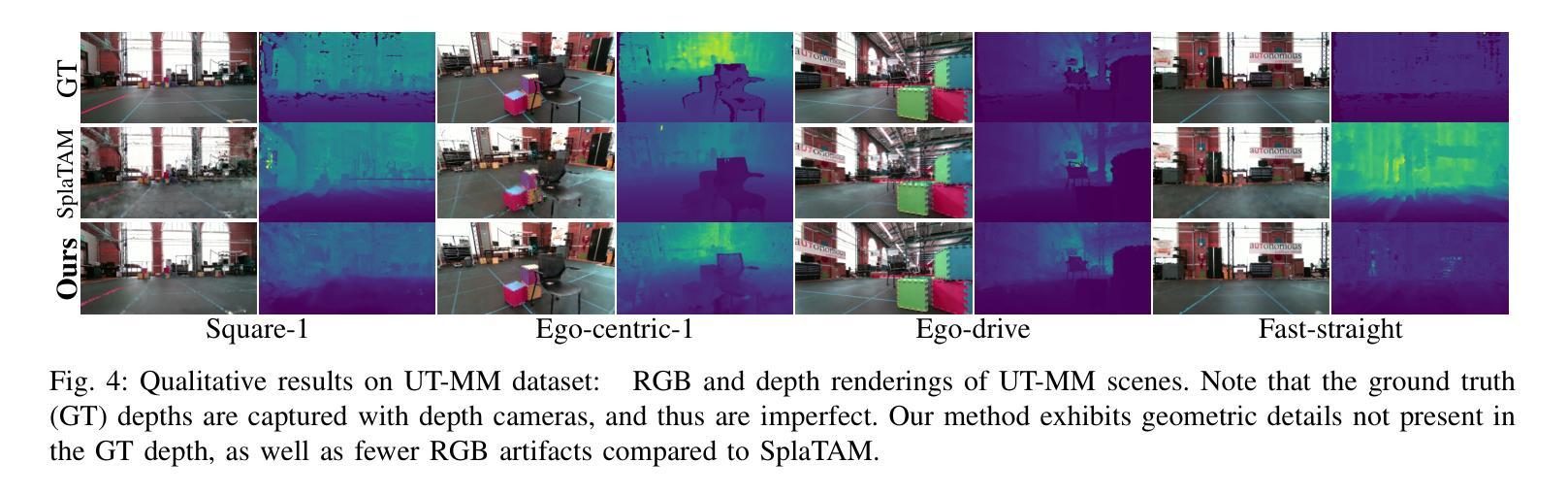
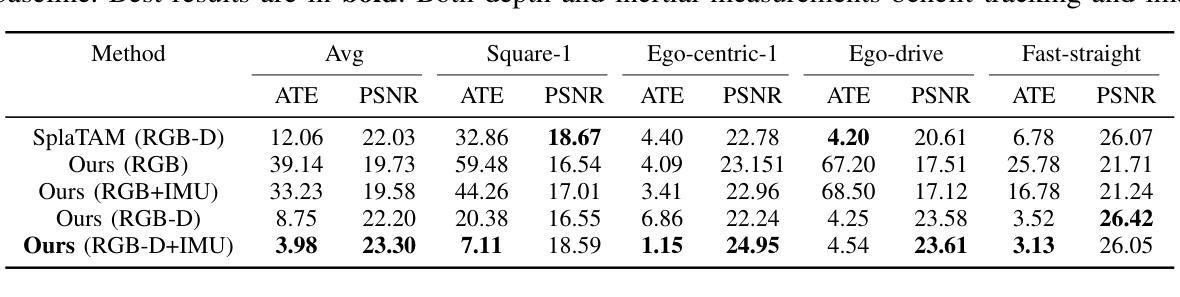
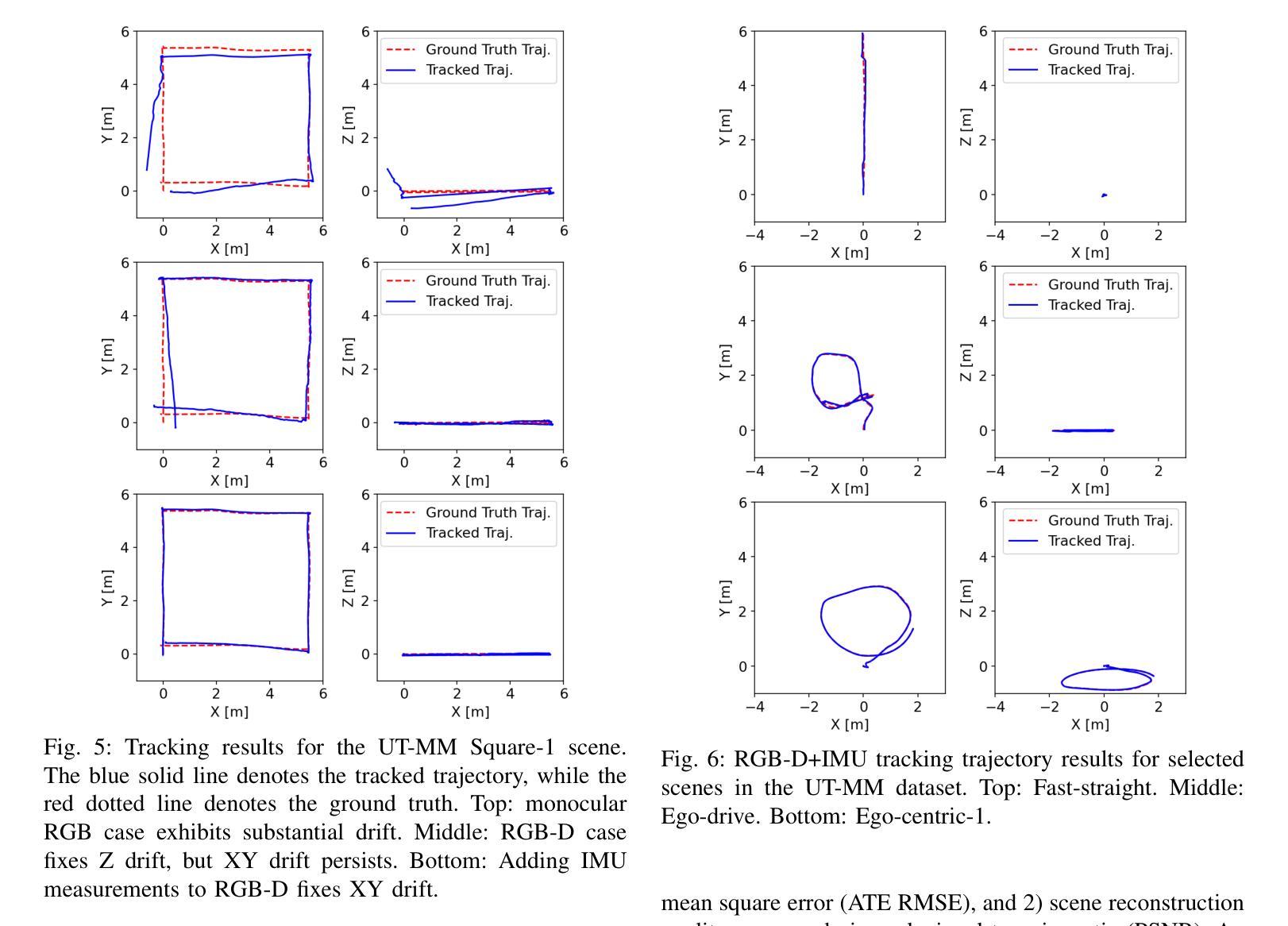
Marrying NeRF with Feature Matching for One-step Pose Estimation
Authors:Ronghan Chen, Yang Cong, Yu Ren
Given the image collection of an object, we aim at building a real-time image-based pose estimation method, which requires neither its CAD model nor hours of object-specific training. Recent NeRF-based methods provide a promising solution by directly optimizing the pose from pixel loss between rendered and target images. However, during inference, they require long converging time, and suffer from local minima, making them impractical for real-time robot applications. We aim at solving this problem by marrying image matching with NeRF. With 2D matches and depth rendered by NeRF, we directly solve the pose in one step by building 2D-3D correspondences between target and initial view, thus allowing for real-time prediction. Moreover, to improve the accuracy of 2D-3D correspondences, we propose a 3D consistent point mining strategy, which effectively discards unfaithful points reconstruted by NeRF. Moreover, current NeRF-based methods naively optimizing pixel loss fail at occluded images. Thus, we further propose a 2D matches based sampling strategy to preclude the occluded area. Experimental results on representative datasets prove that our method outperforms state-of-the-art methods, and improves inference efficiency by 90x, achieving real-time prediction at 6 FPS.
PDF ICRA, 2024. Video https://www.youtube.com/watch?v=70fgUobOFWo
Summary
单目神经辐射场(NeRF)图像匹配实时物体姿态估计方法
Key Takeaways
- 利用图像匹配和NeRF结合实现单目物体姿态估计
- 提出基于3D一致性的点挖掘策略以提高2D-3D对应精度
- 利用2D匹配采样策略排除被遮挡区域
- 直接求解位姿,无需漫长的优化时间
- 实时预测速度为6 FPS,比现有技术提高90倍
- 该方法在具有代表性的数据集上取得了优异的性能
- 该方法适用于需要实时姿态估计的机器人应用
- 标题:将 NeRF 与特征匹配结合用于一步到位姿势估计
- 作者:陈荣翰、丛阳、任宇
- 第一作者单位:中科院沈阳自动化研究所机器人学国家重点实验室
- 关键词:NeRF、姿势估计、特征匹配
- 论文链接:None,Github 代码链接:None
摘要: (1) 研究背景:图像驱动的物体姿态估计在机器人操作、增强现实和移动机器人领域有着广泛的应用。传统方法通常需要物体的 CAD 模型,并且需要搜索预先注册图像或模板与目标图像之间的特征。然而,获取高质量的 CAD 模型可能很困难且耗费人力,或者需要专门的高端扫描仪。 (2) 过去的方法及其问题:最近的方法已将深度神经网络应用于回归姿态。然而,它们只能估计已知实例的姿态或同一类别中相似实例的姿态,并且必须针对新物体进行数小时的重新训练。此外,它们需要大量的训练数据,而这些数据收集和注释起来很繁琐。为了进一步避免针对每个新物体进行繁琐的重新训练,最近的方法从 SfM(运动结构)的传统管道中学习,通过特征匹配来估计物体姿态。然而,这些方法依赖于在所有输入帧中形成稳定可重复的对应关系,这通常无法保证,从而导致较大的姿态误差。 (3) 本文提出的研究方法:另一方面,NeRF(神经辐射场)的最新进展提供了一种捕获复杂 3D 几何形状的机制。本文提出了一种新的方法,将 NeRF 与特征匹配相结合,用于一步到位姿势估计。该方法通过构建目标视图和初始视图之间的 2D-3D 对应关系,直接求解姿态,从而实现实时预测。此外,为了提高 2D-3D 对应关系的准确性,本文提出了一种 3D 一致点挖掘策略,该策略可以有效地丢弃 NeRF 重建的不真实点。 (4) 方法在什么任务上取得了什么性能:实验结果表明,本文提出的方法优于最先进的方法,并将推理效率提高了 90 倍,实现了 6FPS 的实时预测。这些性能支持了本文的目标。
方法: (1): 构建目标视图和初始视图之间的 2D-3D 对应关系,直接求解姿态; (2): 提出 3D 一致点挖掘策略,丢弃 NeRF 重建的不真实点,提高 2D-3D 对应关系的准确性; (3): 将 NeRF 与特征匹配相结合,一步到位求解姿态,实现实时预测; (4): 采用 40 步后优化,进一步提升姿态估计的准确性。
结论: (1):本文提出了一种基于 NeRF 的快速图像驱动、无 CAD 新物体姿态估计框架。通过引入关键点匹配,我们的方法可以直接一步求解姿态,并且不受长时间优化和局部最小值的影响。此外,我们提出了一种 3D 一致点挖掘策略来提高 2D-3D 对应关系的质量,以及一种基于匹配关键点的采样策略来提高对遮挡图像的鲁棒性。实验表明了我们方法的优越性能和对遮挡的鲁棒性。对于未来的工作,我们希望该方法可以扩展到机器人操作或最近基于神经场的 SLAM 任务 [36]、[51]–[54],以提高定位的效率极限。 (2):创新点:将 NeRF 与特征匹配相结合,一步到位求解姿态;提出 3D 一致点挖掘策略,提高 2D-3D 对应关系的准确性;基于匹配关键点的采样策略,提高对遮挡图像的鲁棒性。 性能:优于最先进的方法,推理效率提高 90 倍,实现 6FPS 的实时预测。 工作量:需要构建目标视图和初始视图之间的 2D-3D 对应关系,并进行 40 步后优化。
点此查看论文截图

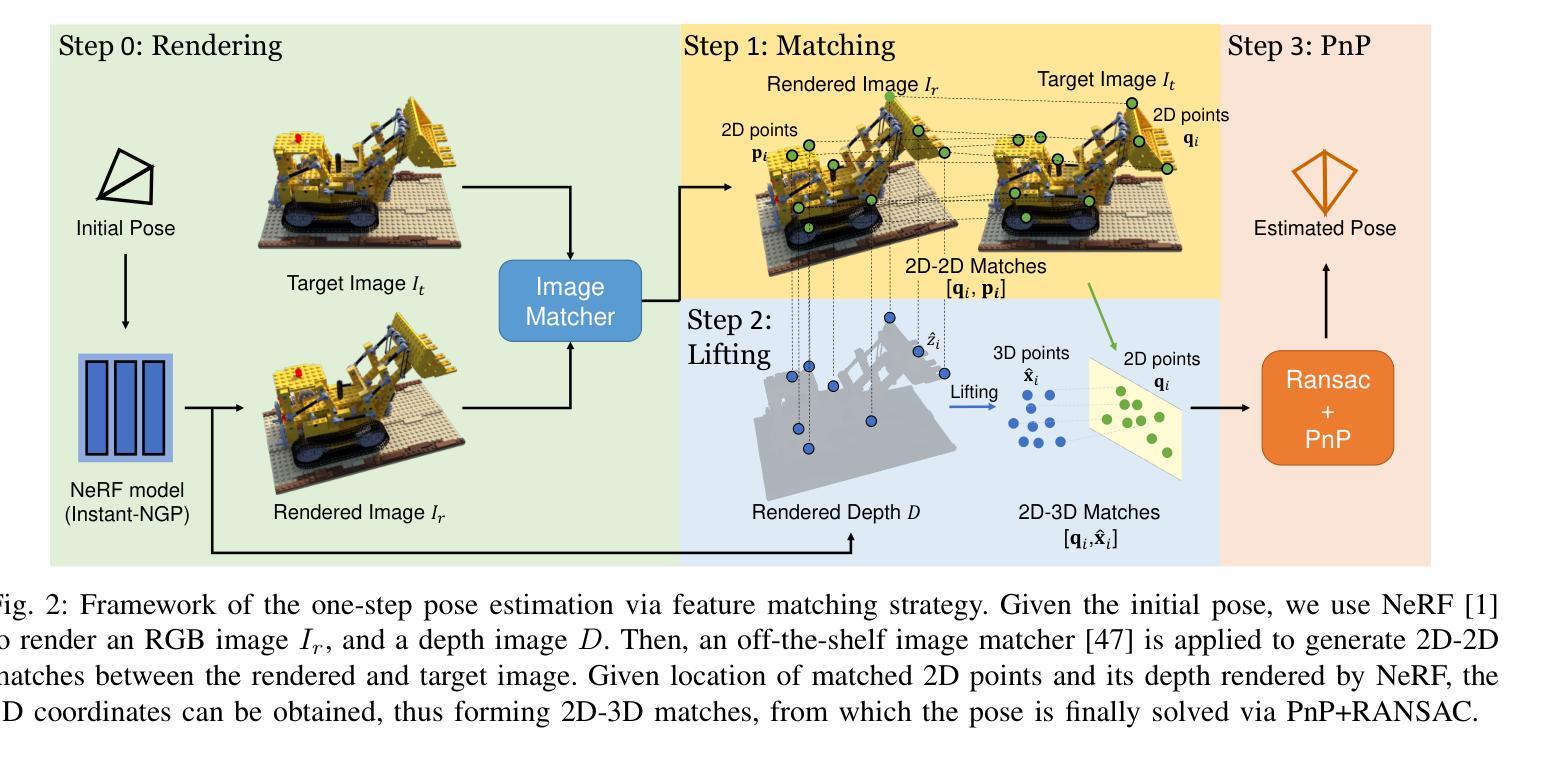


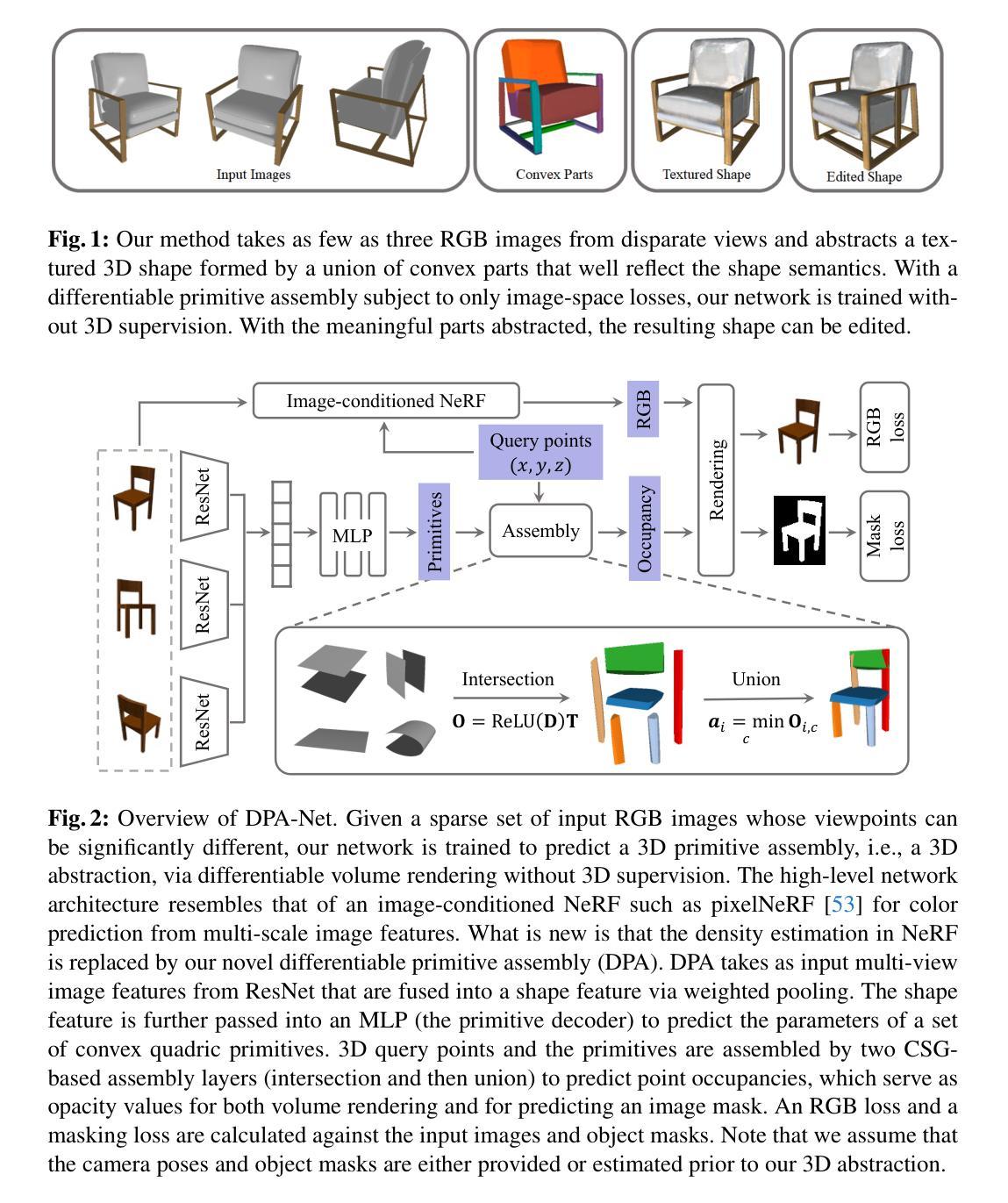
DPA-Net: Structured 3D Abstraction from Sparse Views via Differentiable Primitive Assembly
Authors:Fenggen Yu, Yiming Qian, Xu Zhang, Francisca Gil-Ureta, Brian Jackson, Eric Bennett, Hao Zhang
We present a differentiable rendering framework to learn structured 3D abstractions in the form of primitive assemblies from sparse RGB images capturing a 3D object. By leveraging differentiable volume rendering, our method does not require 3D supervision. Architecturally, our network follows the general pipeline of an image-conditioned neural radiance field (NeRF) exemplified by pixelNeRF for color prediction. As our core contribution, we introduce differential primitive assembly (DPA) into NeRF to output a 3D occupancy field in place of density prediction, where the predicted occupancies serve as opacity values for volume rendering. Our network, coined DPA-Net, produces a union of convexes, each as an intersection of convex quadric primitives, to approximate the target 3D object, subject to an abstraction loss and a masking loss, both defined in the image space upon volume rendering. With test-time adaptation and additional sampling and loss designs aimed at improving the accuracy and compactness of the obtained assemblies, our method demonstrates superior performance over state-of-the-art alternatives for 3D primitive abstraction from sparse views.
PDF 14 pages
Summary
神经辐射场(NeRF)融入可微分基元组装,直接输出3D占有率场,无需3D监督,实现从稀疏RGB图像学习抽象3D结构。
Key Takeaways
- 采用可微分体素渲染,无需3D监督。
- 架构遵循基于图像的NeRF管道,预测颜色。
- 核心贡献:将可微分基元组装引入NeRF,输出3D占有率场。
- 预测的占有率用作体素渲染的不透明度值。
- DPA网络生成凸集并集,逼近目标3D物体。
- 损失函数包括图像空间中的抽象损失和遮罩损失。
- 测试时自适应、额外采样和损失设计,提高组装精度和紧凑性。
- 标题:DPA-Net:通过可微分基元装配从稀疏视图中进行结构化 3D 抽象
- 作者:Fenggen Yu、Yiming Qian、Xu Zhang、Francisca Gil-Ureta、Brian Jackson、Eric Bennett、Hao Zhang
- 隶属单位:亚马逊
- 关键词:3D 抽象、稀疏视图、可微分体渲染、神经辐射场
- 论文链接:https://arxiv.org/abs/2404.00875
摘要: (1)研究背景:从单视图或多视图图像中进行 3D 推理(例如抽象或重建)是计算机视觉中最基本的问题之一。随着神经场(尤其是神经辐射场和 3D 高斯 splatting)的出现,3D 重建的质量、速度以及处理稀疏视图(而不是早期工作中的密集输入视图)的能力都得到了快速发展。但是,NeRF 及其大多数变体在设计上都以新颖视图合成为目标,重点在于优化其基元以提高渲染性能,而不是服务于涉及形状建模或操作的下游任务。 (2)过去的方法:最近提出了一些通过学习基元装配(例如构造实体几何树、草图挤出模型或形状程序)进行 CAD 建模的方法。然而,这些神经模型都采用体素和点云等 3D 输入。 (3)研究方法:本文提出了一种可微分渲染框架,用于从捕获 3D 物体的稀疏 RGB 图像中以基元装配的形式学习结构化 3D 抽象。通过利用可微分体渲染,本文方法不需要 3D 监督。在架构上,本文网络遵循以 pixelNeRF 为例的图像条件神经辐射场的一般管道进行颜色预测。作为核心贡献,本文将可微分基元装配引入 NeRF,以输出 3D 占用场来代替密度预测,其中预测的占用率用作体积渲染的不透明度值。本文网络称为 DPA-Net,它生成凸集的并集,每个凸集都是凸二次基元的交集,以近似目标 3D 对象,受抽象损失和掩码损失的约束,两者都在体积渲染时在图像空间中定义。通过测试时适应以及旨在提高所获得装配的准确性和紧凑性的附加采样和损失设计,本文方法展示了从稀疏视图中进行 3D 基元抽象的最新替代方案的优越性能。 (4)方法性能:在 ShapeNet 和 PartNet 数据集上,本文方法在准确性和紧凑性方面都优于最先进的方法。这些性能支持本文目标,即从稀疏视图中学习结构化 3D 抽象,以促进下游形状建模和操作任务。
方法: (1): 特征提取和聚合; (2): 原始装配:
- 原始参数化:
- 原始交集:
- 凸集并集: (3): 可微分渲染; (4): 网络训练和测试时自适应:
- 预训练:
- 测试时自适应(TTA):
- 第一阶段:
- 第二阶段:
- 第三阶段:
结论: (1):本文提出了一种可微分渲染框架 DPA-Net,该框架能够从仅有的几个(例如三个)RGB 图像中以基元装配的形式学习结构化的 3D 抽象,这些图像是在非常不同的视角下拍摄的。我们的关键创新是将可微分基元装配集成到 NeRF 架构中,从而能够预测占用率以用作体积渲染的不透明度值。在没有任何 3D 或形状分解监督的情况下,我们的方法可以生成一个可解释且随后可编辑的凸集并集,该并集近似于目标 3D 对象。在 ShapeNet 和 DTU 上的定量和定性评估表明,DPA-Net 优于最先进的替代方案。展示的应用程序进一步表明,我们可编辑的 3D 抽象可以用作结构提示,并有利于其他 3D 生成任务。我们当前的实现利用了 GT 相机位姿。为了减轻由估计的、嘈杂的位姿引起的性能下降,可以应用现有的用于联合相机场景优化的现有方法,例如 [44]。由于纹理预测不是我们工作的重点,因此需要进一步微调(例如,偏向输入视图)和优化以提高渲染质量。最后,仅使用凸集的装配是有限的。如补充材料所示,DPA-Net 无法很好地处理凹形。将差分运算添加到可微分装配中值得探索。 (2):创新点:DPA-Net 将可微分基元装配集成到 NeRF 架构中,从而能够预测占用率以用作体积渲染的不透明度值。这使得 DPA-Net 能够从稀疏视图中学习结构化的 3D 抽象,而无需任何 3D 或形状分解监督。 性能:在 ShapeNet 和 DTU 上的定量和定性评估表明,DPA-Net 优于最先进的替代方案。DPA-Net 生成的 3D 抽象准确、紧凑且可编辑,可以作为结构提示,并有利于其他 3D 生成任务。 工作量:DPA-Net 的实现利用了 GT 相机位姿。为了减轻由估计的、嘈杂的位姿引起的性能下降,可以应用现有的用于联合相机场景优化的现有方法,例如 [44]。此外,由于纹理预测不是我们工作的重点,因此需要进一步微调(例如,偏向输入视图)和优化以提高渲染质量。
点此查看论文截图

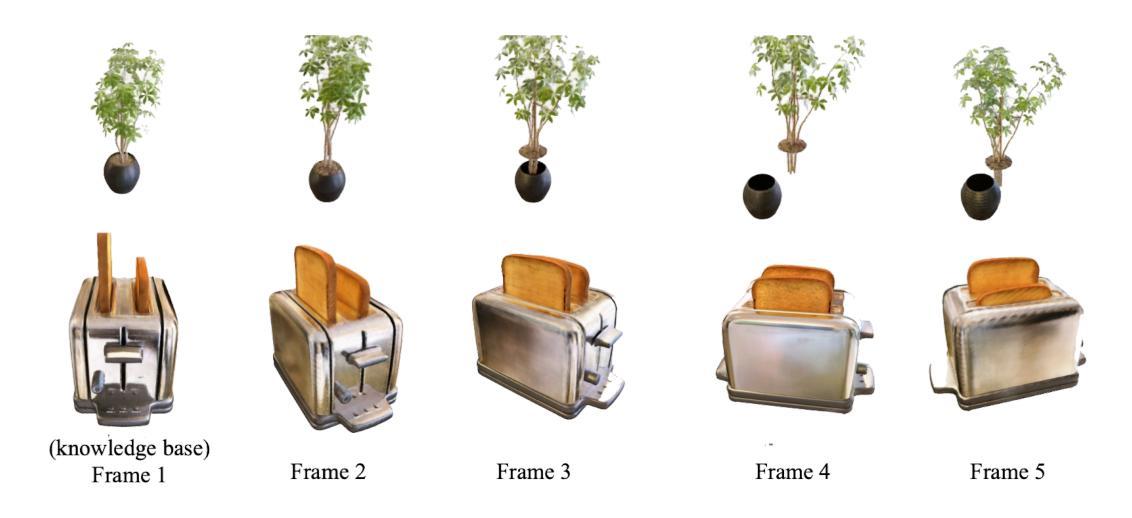
Knowledge NeRF: Few-shot Novel View Synthesis for Dynamic Articulated Objects
Authors:Wenxiao Cai, Xinyue Leiınst, Xinyu He, Junming Leo Chen, Yangang Wang
We present Knowledge NeRF to synthesize novel views for dynamic scenes.Reconstructing dynamic 3D scenes from few sparse views and rendering them from arbitrary perspectives is a challenging problem with applications in various domains. Previous dynamic NeRF methods learn the deformation of articulated objects from monocular videos. However, qualities of their reconstructed scenes are limited.To clearly reconstruct dynamic scenes, we propose a new framework by considering two frames at a time.We pretrain a NeRF model for an articulated object.When articulated objects moves, Knowledge NeRF learns to generate novel views at the new state by incorporating past knowledge in the pretrained NeRF model with minimal observations in the present state. We propose a projection module to adapt NeRF for dynamic scenes, learning the correspondence between pretrained knowledge base and current states. Experimental results demonstrate the effectiveness of our method in reconstructing dynamic 3D scenes with 5 input images in one state. Knowledge NeRF is a new pipeline and promising solution for novel view synthesis in dynamic articulated objects. The data and implementation are publicly available at https://github.com/RussRobin/Knowledge_NeRF.
Summary
通过将过去知识应用于当前状态的有限观测值,Knowledge NeRF 可为动态场景合成新颖视图。
Key Takeaways
- 针对动态场景,Knowledge NeRF 提出了一种同时考虑两帧的新框架。
- 预训练的 NeRF 模型用于学习铰接对象的变形。
- 提出了一种投影模块,用于学习预训练知识库和当前状态之间的对应关系。
- Knowledge NeRF 通过 5 个输入图像在一帧中重建动态 3D 场景。
- Knowledge NeRF 为动态铰接对象的全新视图合成提供了一个新的管道和有希望的解决方案。
- 该方法避免了动态 NeRF 方法中常见的问题,例如模糊和变形错误。
- 数据和实现已公开,可用于进一步研究和应用程序开发。
- 标题:知识 NeRF:动态铰接对象的小样本新视角合成
- 作者:蔡文晓、雷欣悦、何欣宇、陈君明和王扬刚**
- 单位:东南大学
- 关键词:新视角合成·神经辐射场·动态 3D 场景·稀疏视角合成·知识集成
- 论文链接:https://arxiv.org/abs/2404.00674
- 摘要: (1)研究背景: 动态场景重建和渲染一直是计算机视觉领域的重要课题。传统的动态 NeRF 方法通过单目视频学习铰接对象的变形,但重建场景的质量有限。
(2)过去的方法及其问题: 过去的方法主要通过单目视频学习铰接对象的变形,但重建场景的质量有限。
(3)本文提出的研究方法: 本文提出了一种新的框架,一次考虑两帧图像。首先,对铰接对象预训练一个 NeRF 模型。当铰接对象移动时,知识 NeRF 通过将预训练 NeRF 模型中的过去知识与当前状态中的最少观察相结合,学习在新的状态下生成新视角。本文还提出了一种投影模块,将 NeRF 适应于动态场景,学习预训练知识库和当前状态之间的对应关系。
(4)方法在什么任务上取得了什么性能,该性能是否能支撑其目标: 实验结果表明,该方法能够使用一个状态中的 5 张输入图像重建动态 3D 场景。该方法为动态铰接对象的新视角合成提供了一种新的管道和有前景的解决方案。
- 结论: (1):本文提出了一种新的知识NeRF框架,该框架能够一次考虑两帧图像,将预训练NeRF模型的知识与当前状态的稀疏观察相结合,生成新视角图像。该框架还提出了一种投影模块,学习预训练知识库和当前状态之间的对应关系,将NeRF适应于动态场景。实验结果表明,该方法能够使用一个状态中的5张输入图像重建动态3D场景,为动态铰接对象的新视角合成提供了一种新的管道和有前景的解决方案。 (2):创新点:
- 提出了一种新的知识NeRF框架,将预训练NeRF模型的知识与当前状态的稀疏观察相结合,生成新视角图像。
- 设计了一种投影模块,学习预训练知识库和当前状态之间的对应关系,将NeRF适应于动态场景。 性能:
- 能够使用一个状态中的5张输入图像重建动态3D场景。 工作量:
- 需要预训练一个NeRF模型。
- 需要设计一个投影模块。
- 需要收集和标注动态3D场景的数据集。
点此查看论文截图

 wechat
wechat- alipay







