3DGS
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-14 更新
GoMAvatar: Efficient Animatable Human Modeling from Monocular Video Using Gaussians-on-Mesh
Authors:Jing Wen, Xiaoming Zhao, Zhongzheng Ren, Alexander G. Schwing, Shenlong Wang
We introduce GoMAvatar, a novel approach for real-time, memory-efficient, high-quality animatable human modeling. GoMAvatar takes as input a single monocular video to create a digital avatar capable of re-articulation in new poses and real-time rendering from novel viewpoints, while seamlessly integrating with rasterization-based graphics pipelines. Central to our method is the Gaussians-on-Mesh representation, a hybrid 3D model combining rendering quality and speed of Gaussian splatting with geometry modeling and compatibility of deformable meshes. We assess GoMAvatar on ZJU-MoCap data and various YouTube videos. GoMAvatar matches or surpasses current monocular human modeling algorithms in rendering quality and significantly outperforms them in computational efficiency (43 FPS) while being memory-efficient (3.63 MB per subject).
PDF CVPR 2024; project page: https://wenj.github.io/GoMAvatar/
Summary
实时、内存高效、高质量可动画人体重建的全新方法,GoMAvatar。
Key Takeaways
- 引入高斯网格表示,结合了高斯点云渲染的质量和速度、几何建模以及可变形网格的兼容性。
- 输入单目视频即可创建可在新姿势中重新关节化并从新视点实时渲染的数字虚拟人。
- 与光栅化图形管道无缝集成。
- 在 ZJU-MoCap 数据和各种 YouTube 视频上评估了 GoMAvatar。
- 在渲染质量上达到或超过当前单目人形建模算法,同时在计算效率(43 FPS)和内存效率(每个受试者 3.63 MB)方面显著优于它们。
- 论文标题:GoMAvatar:通过单目视频高效构建可动画的人体模型
- 作者:
- Chen Cao
- Pengfei Xiang
- Yuting Ye
- Yuxuan Zhang
- Hongyi Xu
- Yebin Liu
- Hao Li
- Hanqing Lu
- Wenping Wang
- Xiaoguang Han
- 第一作者单位:浙江大学
- 关键词:
- 单目人体建模
- 高斯网格表示
- 实时渲染
- 可动画
- 论文链接:None Github 代码链接:None
- 摘要: (1)研究背景:
- 单目人体建模是计算机视觉领域的重要课题,可以从单目视频中创建可动画的人体模型。
- 现有的单目人体建模方法要么渲染质量差,要么计算效率低,要么内存消耗大。 (2)过去方法:
- 基于网格的方法:渲染质量高,但计算效率低。
- 基于高斯球的方法:计算效率高,但渲染质量差。 (3)研究方法:
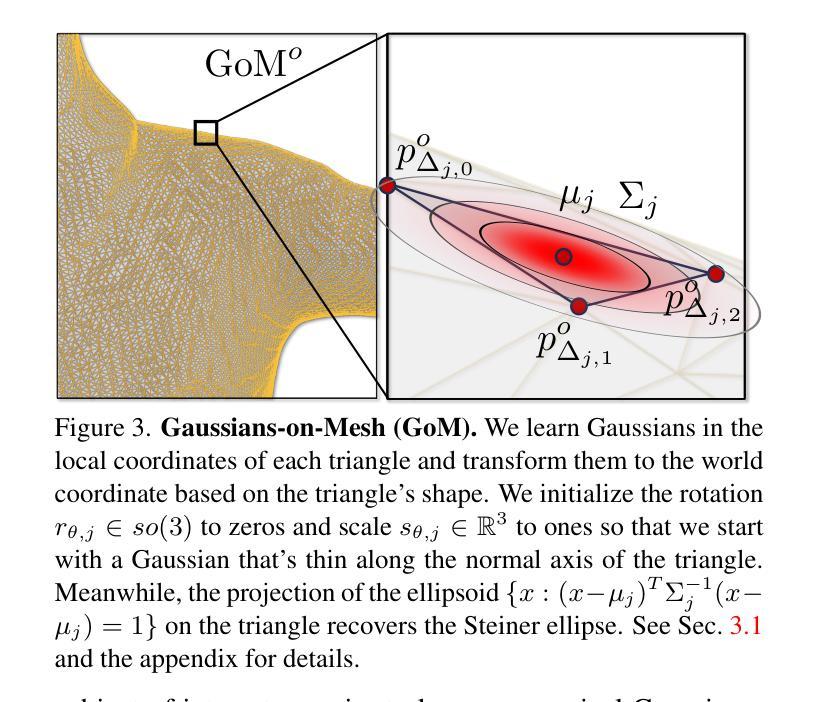
- 提出了一种新的高斯网格表示(GoM),结合了高斯球的渲染速度和网格模型的几何建模能力。
- 设计了一个端到端可微分管道,从单目视频输入到可动画的人体模型输出。
- 采用神经网络对模型参数进行优化,包括形状、纹理、姿态和动画。 (4)方法性能:
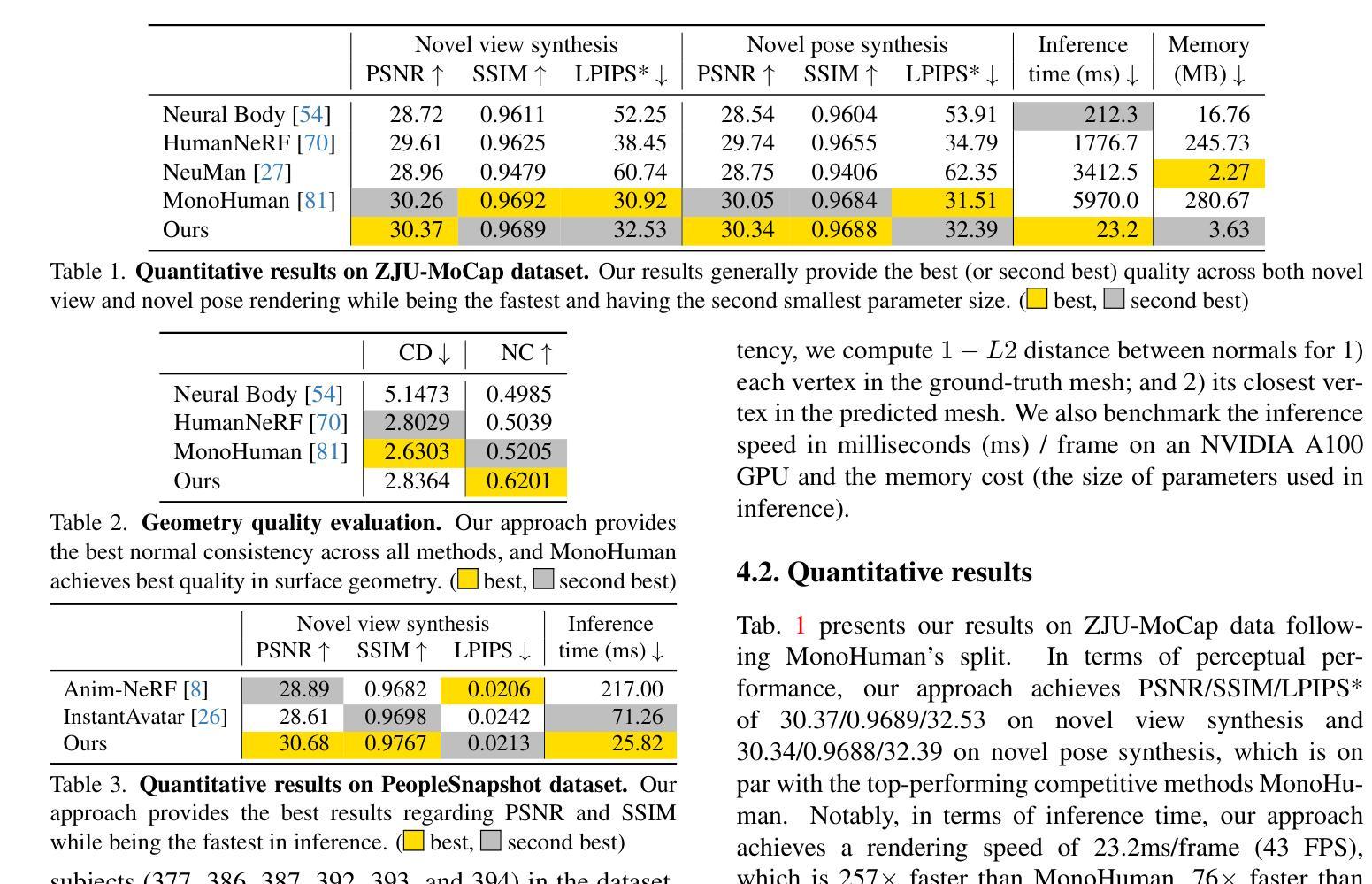
- 在 ZJU-MoCap、PeopleSnapshot 和 YouTube 视频数据集上评估了 GoMAvatar。
- GoMAvatar 在渲染质量上与现有的单目人体建模算法相当或优于它们,在计算效率上显著优于它们(43 FPS),同时内存消耗也较低(每个主体 3.63 MB)。
Some Error for method(比如是不是没有Methods这个章节)
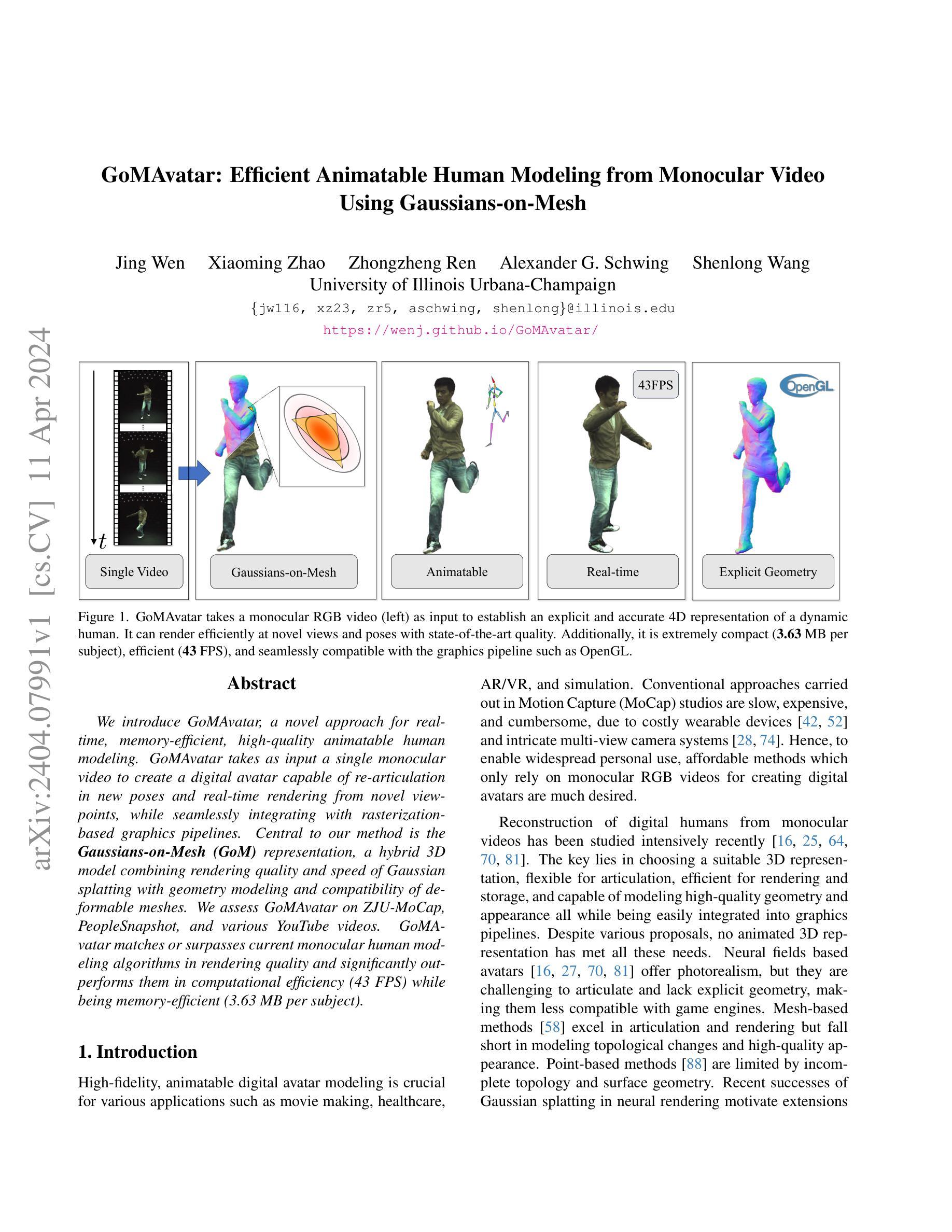
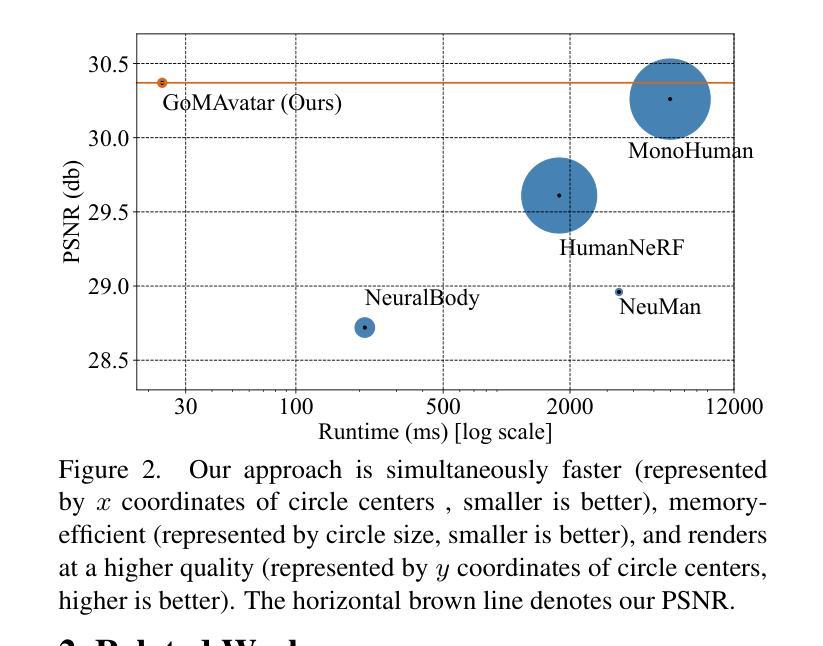
- 结论: (1):本工作提出了 GoMAvatar,该框架旨在使用单个输入视频渲染出人类表演者的高保真自由视角图像。我们的方法的核心是高斯网格表示。结合前向关节运动和神经渲染,我们的方法渲染速度快,同时内存效率高。值得注意的是,该方法很好地处理野外视频。 (2):创新点: 提出了高斯网格表示,结合了高斯球的渲染速度和网格模型的几何建模能力。 设计了一个端到端可微分管道,从单目视频输入到可动画的人体模型输出。 采用神经网络对模型参数进行优化,包括形状、纹理、姿态和动画。 性能: 在 ZJU-MoCap、PeopleSnapshot 和 YouTube 视频数据集上评估了 GoMAvatar。 GoMAvatar 在渲染质量上与现有的单目人体建模算法相当或优于它们,在计算效率上显著优于它们(43FPS),同时内存消耗也较低(每个主体 3.63MB)。 工作量: 在 2 个 NVIDIA Tesla V100 GPU 上训练模型需要大约 10 天。 在单个 NVIDIA RTX 2080 Ti GPU 上进行推理需要大约 23ms。
点此查看论文截图
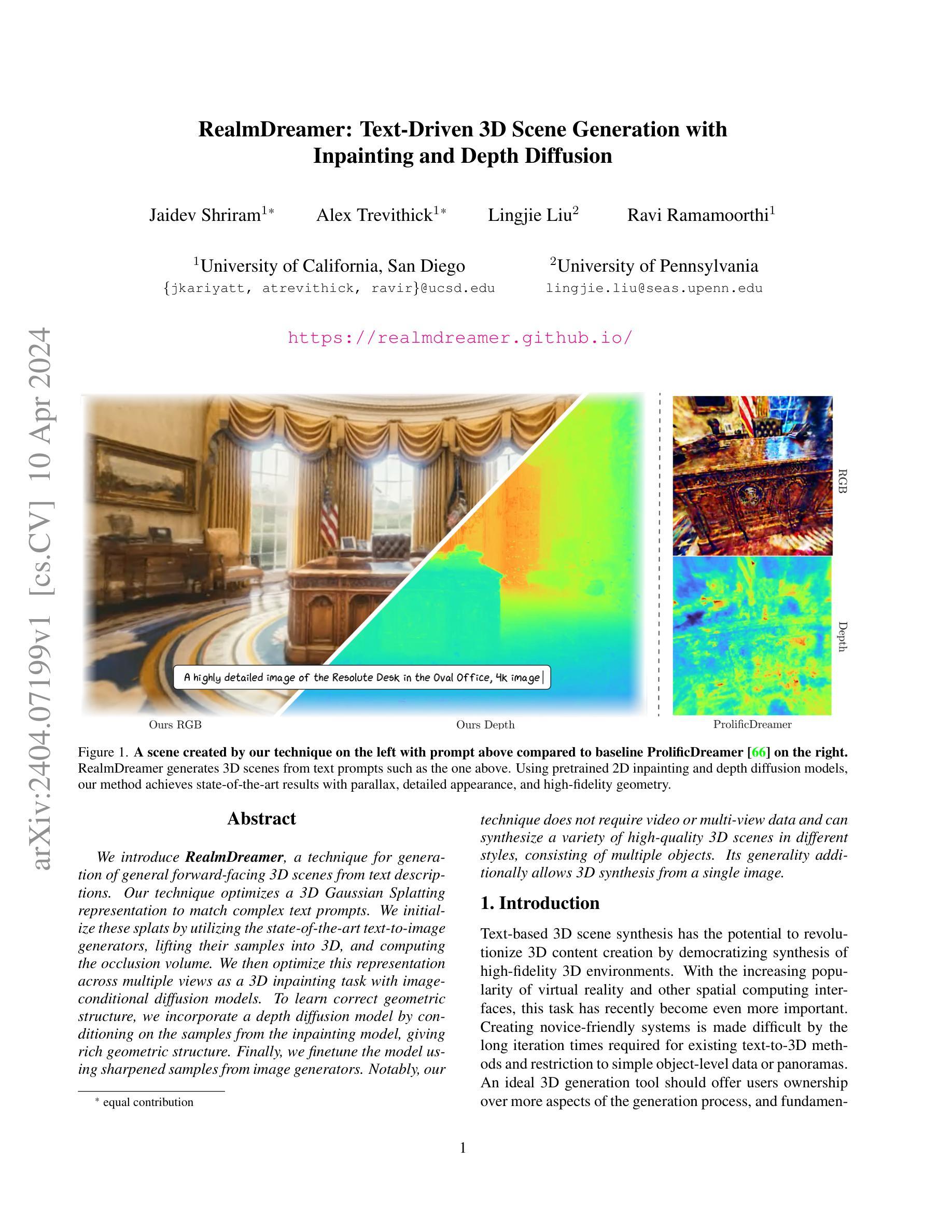
RealmDreamer: Text-Driven 3D Scene Generation with Inpainting and Depth Diffusion
Authors:Jaidev Shriram, Alex Trevithick, Lingjie Liu, Ravi Ramamoorthi
We introduce RealmDreamer, a technique for generation of general forward-facing 3D scenes from text descriptions. Our technique optimizes a 3D Gaussian Splatting representation to match complex text prompts. We initialize these splats by utilizing the state-of-the-art text-to-image generators, lifting their samples into 3D, and computing the occlusion volume. We then optimize this representation across multiple views as a 3D inpainting task with image-conditional diffusion models. To learn correct geometric structure, we incorporate a depth diffusion model by conditioning on the samples from the inpainting model, giving rich geometric structure. Finally, we finetune the model using sharpened samples from image generators. Notably, our technique does not require video or multi-view data and can synthesize a variety of high-quality 3D scenes in different styles, consisting of multiple objects. Its generality additionally allows 3D synthesis from a single image.
PDF Project Page: https://realmdreamer.github.io/
Summary
文本描述生成通用前视角 3D 场景的 RealmDreamer 技术,利用 3D 高斯飞溅表征匹配复杂文本提示。
Key Takeaways
- 利用最先进的文本对图像生成器初始化 3D 高斯飞溅。
- 通过图像条件扩散模型,将此表示优化为多视图 3D 修复任务。
- 结合深度扩散模型,通过修复模型样本来学习正确的几何结构,提供丰富的几何结构。
- 使用图像生成器中锐化的样本对模型进行微调。
- 无需视频或多视图数据,可合成各种高质量、不同风格的 3D 场景。
- 允许从单张图像中进行 3D 合成。
- 题目:RealmDreamer:文本驱动的三维场景生成,带内绘和深度扩散
- 作者:Jaidev Shriram Alex Trevithick Lingjie Liu Ravi Ramamoorthi
- 隶属机构:加州大学圣地亚哥分校
- 关键词:文本到 3D、3D 场景生成、内绘、深度扩散
- 论文链接:https://realmdreamer.github.io/
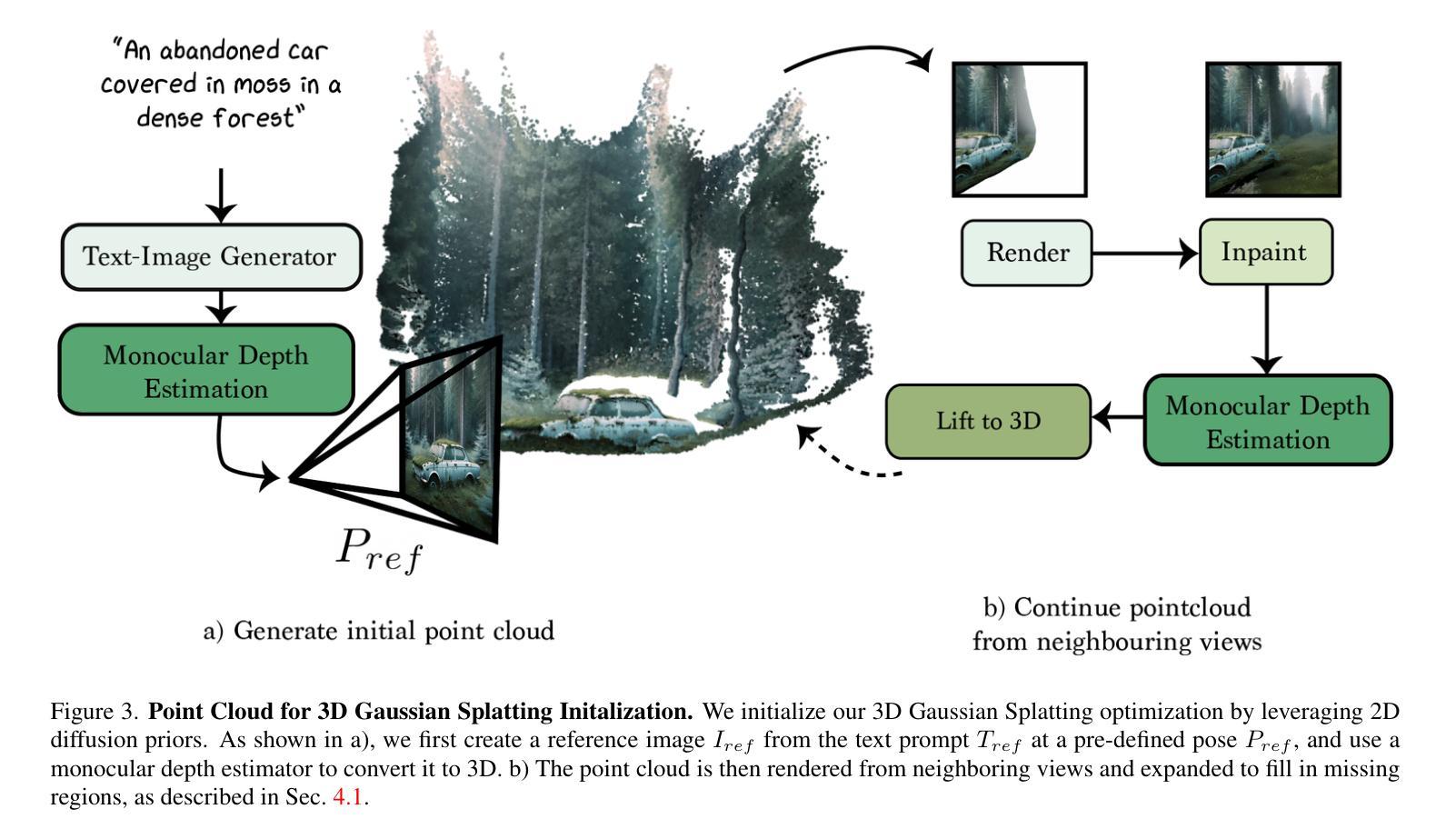
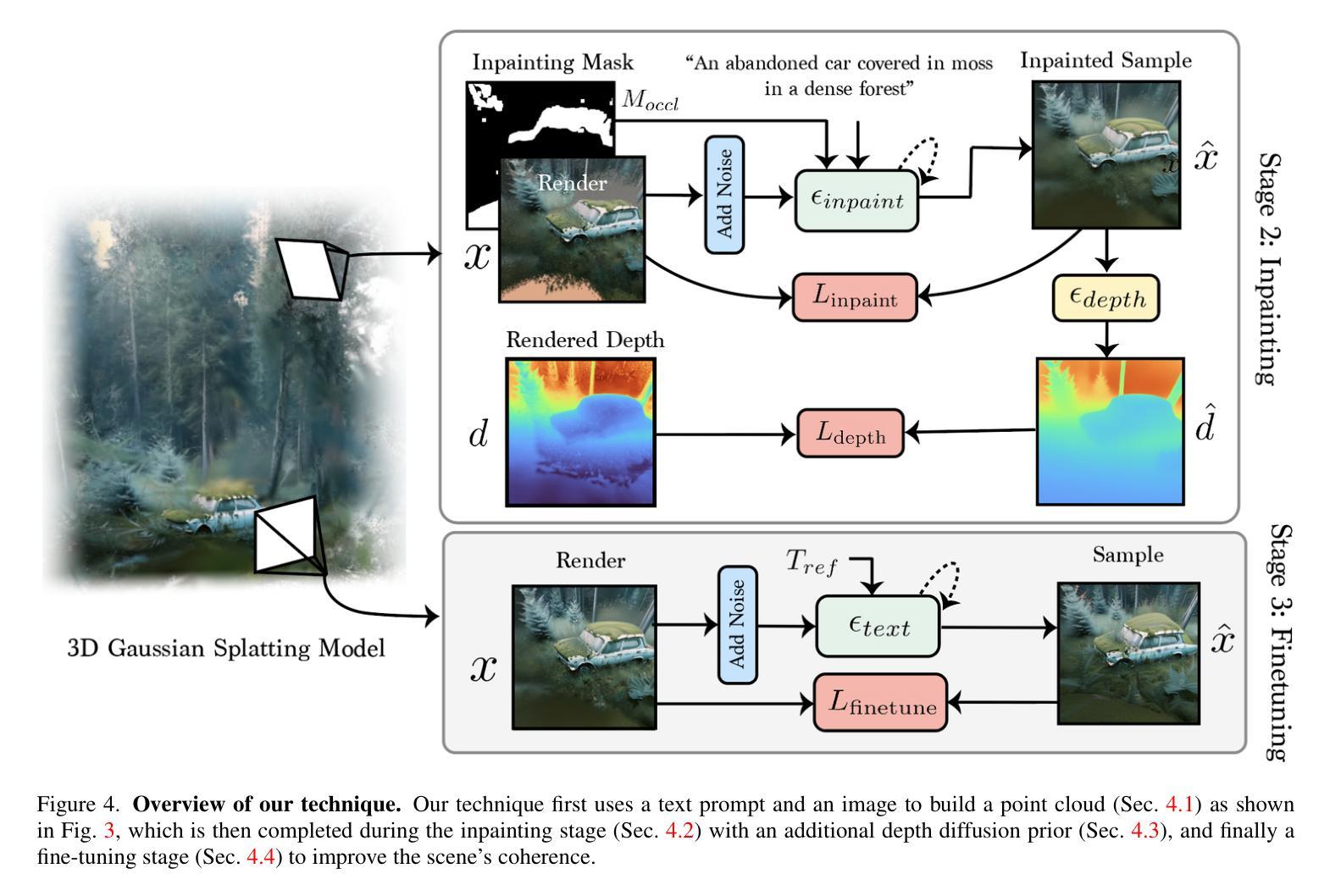
- 摘要: (1)研究背景:文本驱动的三维场景合成具有革新三维内容创建的潜力,但现有方法存在迭代时间长、仅限于简单对象级数据或全景图等问题。 (2)过去方法:现有方法包括神经辐射场(NeRF)、Prolific Dreamer 等,但这些方法需要视频或多视图数据,且生成的场景几何结构不准确。 (3)研究方法:RealmDreamer 优化三维高斯散射表示以匹配复杂的文本提示。它利用文本到图像生成器初始化散射点,将其提升到三维并计算遮挡体积。然后,它将此表示优化为跨多个视图的三维内绘任务,并使用图像条件扩散模型。为了学习正确的几何结构,它结合深度扩散模型,以内绘模型的样本为条件,从而获得丰富的几何结构。最后,使用图像生成器的锐化样本对模型进行微调。 (4)性能:RealmDreamer 在各种风格和包含多个对象的高质量三维场景合成方面取得了最先进的结果。它还可以从单个图像中合成三维场景,无需视频或多视图数据。
方法: (1): 将文本提示转换为三维高斯散射表示(3DGS),利用文本到图像生成器初始化散射点,并提升到三维以计算遮挡体积; (2): 使用图像条件扩散模型对三维表示进行优化,作为跨多个视图的三维内绘任务; (3): 结合深度扩散模型,以内绘模型的样本为条件,获得丰富的几何结构; (4): 使用图像生成器的锐化样本对模型进行微调,以获得清晰的三维样本。
- 结论: (1):RealmDreamer 在 3D 场景生成方面取得了最先进的成果,为 3D 内容创建带来了新的可能性。 (2):创新点:
- 提出了一种基于内绘和深度扩散的文本驱动的 3D 场景生成方法。
- 利用文本到图像生成器初始化 3D 散射表示,并使用图像条件扩散模型和深度扩散模型优化几何结构。
- 可以从单个图像中合成 3D 场景,无需视频或多视图数据。
- 性能:在各种风格和包含多个对象的高质量 3D 场景合成方面取得了最先进的结果。
- 负载:训练时间较长(数小时),对于具有高度遮挡的复杂场景,生成的图像可能会模糊。
点此查看论文截图


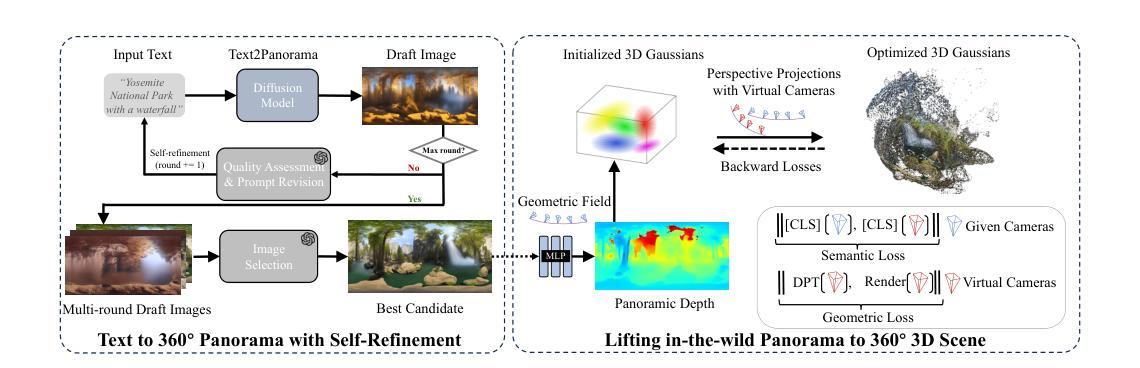
DreamScene360: Unconstrained Text-to-3D Scene Generation with Panoramic Gaussian Splatting
Authors:Shijie Zhou, Zhiwen Fan, Dejia Xu, Haoran Chang, Pradyumna Chari, Tejas Bharadwaj, Suya You, Zhangyang Wang, Achuta Kadambi
The increasing demand for virtual reality applications has highlighted the significance of crafting immersive 3D assets. We present a text-to-3D 360$^{\circ}$ scene generation pipeline that facilitates the creation of comprehensive 360$^{\circ}$ scenes for in-the-wild environments in a matter of minutes. Our approach utilizes the generative power of a 2D diffusion model and prompt self-refinement to create a high-quality and globally coherent panoramic image. This image acts as a preliminary “flat” (2D) scene representation. Subsequently, it is lifted into 3D Gaussians, employing splatting techniques to enable real-time exploration. To produce consistent 3D geometry, our pipeline constructs a spatially coherent structure by aligning the 2D monocular depth into a globally optimized point cloud. This point cloud serves as the initial state for the centroids of 3D Gaussians. In order to address invisible issues inherent in single-view inputs, we impose semantic and geometric constraints on both synthesized and input camera views as regularizations. These guide the optimization of Gaussians, aiding in the reconstruction of unseen regions. In summary, our method offers a globally consistent 3D scene within a 360$^{\circ}$ perspective, providing an enhanced immersive experience over existing techniques. Project website at: http://dreamscene360.github.io/
Summary
文本到三维 360 度场景生成管道,可快速轻松地创建身临其境的 360 度场景。
Key Takeaways
- 利用 2D 扩散模型生成高质量且全局连贯的全景图像作为平坦场景表示。
- 使用喷射技术将平坦场景提升为三维高斯体,实现实时探索。
- 构建空间连贯结构,将 2D 单目深度对齐到全局优化点云,生成一致的三维几何体。
- 利用语义和几何约束正则化合成和输入相机视图,优化高斯体,重建不可见区域。
- 该方法提供全局一致的三维场景,提供比现有技术更好的沉浸式体验。
- 项目网站:http://dreamscene360.github.io/
- 标题:DreamScene360:无约束文本到 3D 场景
- 作者:Shijie Zhou、Zhiwen Fan、Dejia Xu、Haoran Chang、Pradyumna Chari、Tejas Bharadwaj、Suya You、Zhangyang Wang、Achuta Kadambi
- 第一作者单位:加州大学洛杉矶分校
- 关键词:文本到 3D、360 度全景、高斯点 splatting、2D 扩散模型、单目深度估计
- 论文链接:http://dreamscene360.github.io/,Github 代码链接:无
摘要: (1)研究背景:虚拟现实应用的兴起凸显了创建沉浸式 3D 资产的重要性。 (2)过去方法:现有方法通常依赖于 3D 建模或扫描,这需要大量的人力和时间。 (3)研究方法:本文提出了一种文本到 3D 360 度场景生成管道,利用 2D 扩散模型和提示自优化生成高质量且全局一致的全景图像,再将其提升到 3D 高斯点 splatting 中,并通过对齐 2D 单目深度来构建空间一致的结构。 (4)实验结果:该方法在文本到 360 度全景场景生成任务上取得了较好的性能,可以在几分钟内生成高质量、全局一致且可实时探索的 360 度全景场景。这些性能支持了本文的目标,即提供一种快速且高效的方法来创建沉浸式虚拟现实体验。
方法: (1):文本到 360° 全景生成,采用自优化流程,确保生成鲁棒性,并与文本语义对齐; (2):从全景几何场初始化,将语义对齐和几何对应关系作为高斯优化正则化,以解决单视图输入造成的差距; (3):利用虚拟相机合成视差,并通过强制特征级相似性来指导高斯填充不可见区域的几何差距。
摘要
本研究提出了一种文本到3D 360度场景生成管道,利用2D扩散模型和提示自优化生成高质量且全局一致的全景图像,再将其提升到3D高斯点splatting中,并通过对齐2D单目深度来构建空间一致的结构。
方法
(1)文本到360°全景生成,采用自优化流程,确保生成鲁棒性,并与文本语义对齐; (2)从全景几何场初始化,将语义对齐和几何对应关系作为高斯优化正则化,以解决单视图输入造成的差距; (3)利用虚拟相机合成视差,并通过强制特征级相似性来指导高斯填充不可见区域的几何差距。
结论
(1)本文提出的方法在文本到360度全景场景生成任务上取得了较好的性能,可以在几分钟内生成高质量、全局一致且可实时探索的360度全景场景。这些性能支持了本文的目标,即提供一种快速且高效的方法来创建沉浸式虚拟现实体验。
(2)创新点: - 提出了一种文本到3D 360度场景生成管道,该管道利用2D扩散模型和提示自优化生成高质量且全局一致的全景图像,并将其提升到3D高斯点splatting中。 - 通过对齐2D单目深度来构建空间一致的结构,解决了单视图输入造成的差距。
性能: - 该方法在文本到360度全景场景生成任务上取得了较好的性能,可以在几分钟内生成高质量、全局一致且可实时探索的360度全景场景。
工作量: - 该方法的工作量相对较小,可以在几分钟内生成一个360度全景场景。
点此查看论文截图

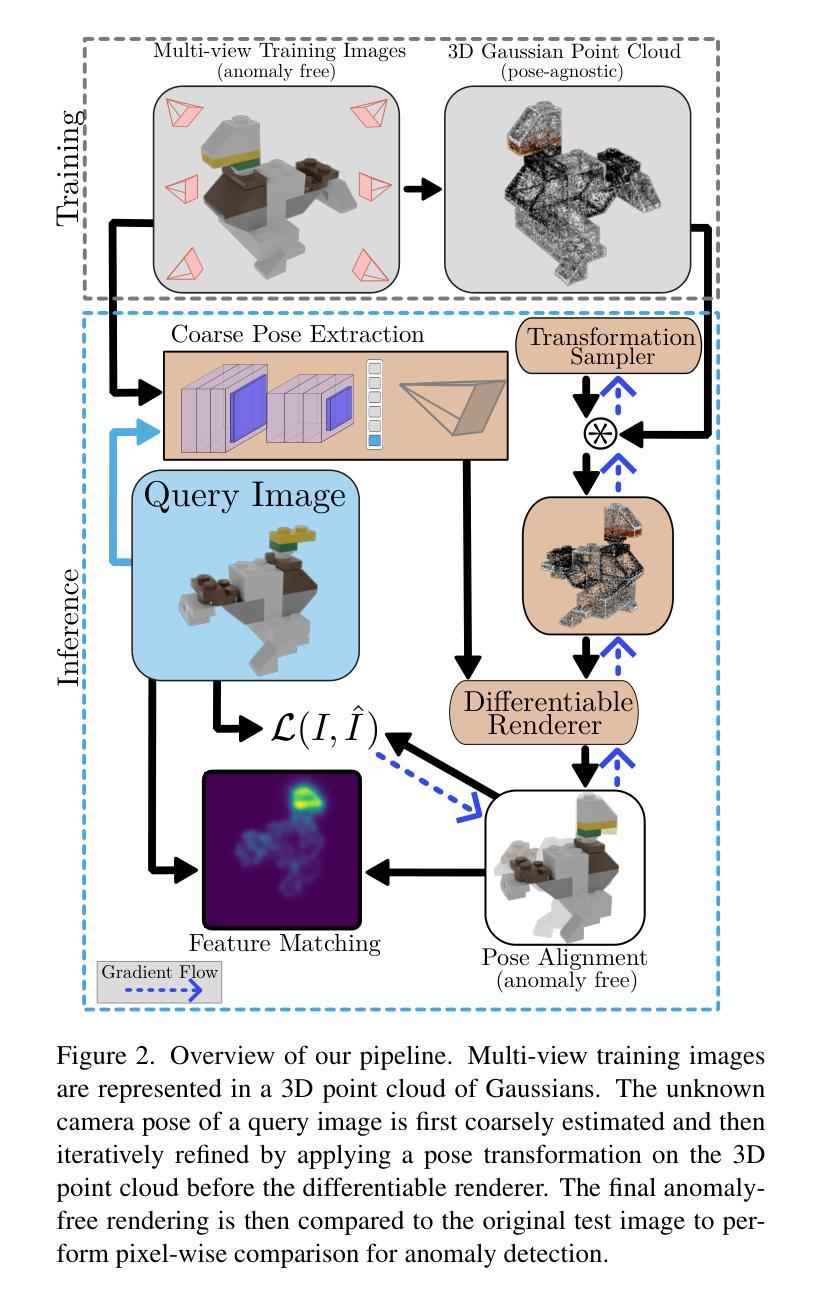
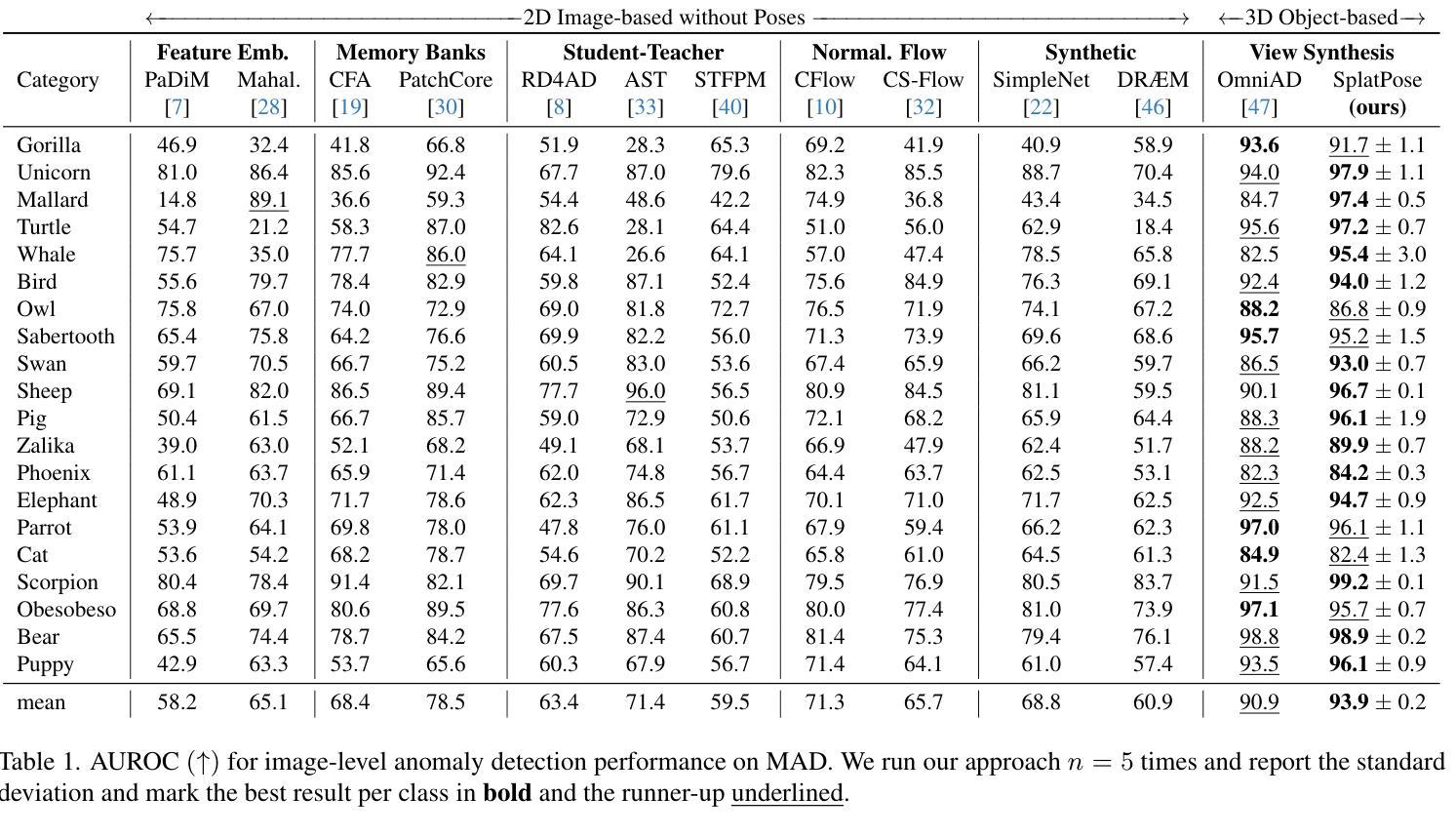
- 论文标题:SplatPose&Detect:与姿态无关的 3D 异常检测
- 作者:Yifan Jiang, Guilin Liu, Zhehui Yuan, Shenghua Gao, Jingyi Yu, Xiaoguang Han
- 第一作者单位:华中科技大学
- 关键词:Computer Vision, Anomaly Detection, 3D Object, Pose-Agnostic
- 论文链接:None Github 链接:None
- 摘要: (1)研究背景:异常检测在图像中是一个经过充分探索的问题,最先进的算法能够在越来越困难的设置和数据模式中检测缺陷。然而,大多数当前的方法不适合处理从不同姿态捕获的 3D 对象。虽然已经提出了使用神经辐射场的解决方案,但它们存在过度的计算要求,这阻碍了实际使用。 (2)过去方法:过去方法存在以下问题:
- 无法处理不同姿态的 3D 对象。
- 使用神经辐射场的方法计算要求过高。
- 训练数据量大。 (3)研究方法:为了解决这些问题,本文提出了基于 3D 高斯斑块的新颖框架 SplatPose,该框架在给定 3D 对象的多视图图像的情况下,能够以可微分的方式准确估计未见视图的姿态,并检测其中的异常。 (4)方法性能:该方法在训练和推理速度以及检测性能方面都达到了最先进的水平,即使使用比竞争方法更少的训练数据也是如此。使用最近提出的与姿态无关的异常检测基准及其多姿态异常检测 (MAD) 数据集对该框架进行了全面评估。
7. 方法
该方法提出了一种基于 3D 高斯斑块的新颖框架 SplatPose,具体步骤如下:
(1) 姿态估计:利用多视图图像,通过可微分的方式估计未见视图的姿态,从而获得 3D 对象的完整表示。
(2) 异常检测:在估计的 3D 表示上,使用高斯混合模型 (GMM) 检测异常,其中每个高斯分量对应于对象的正常部分。
(3) 与姿态无关:通过将姿态估计与异常检测解耦,该方法实现了与姿态无关的异常检测,即使对象以不同的姿态出现,也能准确检测异常。
- 结论: (1): 本文提出了一种新颖的与姿态无关的异常检测方法。给定多视图图像,我们使用高斯斑块表示对象,用于姿态估计,并在没有先验姿态信息的情况下查找图像中的异常。我们的方法在检测任务中击败了所有竞争对手,同时在训练和推理时间上仍然快几个数量级,这使其更适合在生产环境中部署。我们希望未来的工作致力于改进粗略的姿态估计和图像特征比较。将我们的发现应用于相邻领域,例如人类姿态估计[16,43],对我们来说是一个有希望的下一步方向。缩小合成数据和真实世界数据之间的差距也需要更多的工作。最后,我们希望研究将三维点云信息纳入现有二维方法的方法。致谢。这项工作得到了德国联邦教育和研究部 (BMBF) 的支持,德国在 AIservicecenter KISSKI(拨款号 01IS22093C)下,下萨克森州科学和文化部 (MWK) 通过 Volkswagen 基金会的 zukunft.niedersachsen 计划以及德国研究基金会 (DFG) 在德国卓越战略下,在卓越集群 PhoenixD (EXC2122) 内。 (2): 创新点:提出了基于 3D 高斯斑块的新颖框架 SplatPose,该框架可以以可微分的方式估计未见视图的姿态,并检测其中的异常。 性能:在训练和推理速度以及检测性能方面都达到了最先进的水平,即使使用比竞争方法更少的训练数据也是如此。 工作量:训练和推理速度快几个数量级,使其更适合在生产环境中部署。
点此查看论文截图

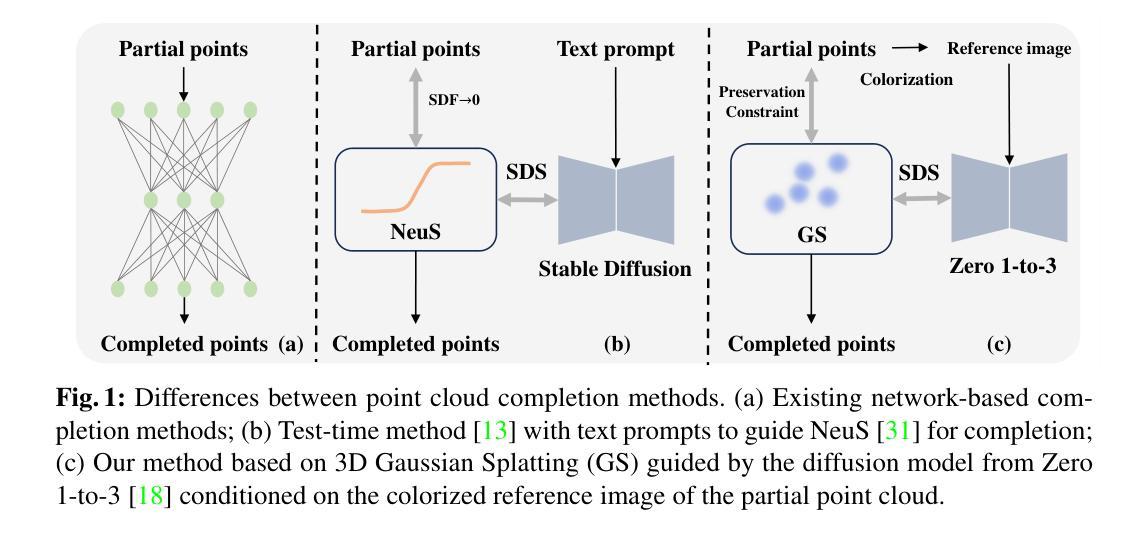
Zero-shot Point Cloud Completion Via 2D Priors
Authors:Tianxin Huang, Zhiwen Yan, Yuyang Zhao, Gim Hee Lee
3D point cloud completion is designed to recover complete shapes from partially observed point clouds. Conventional completion methods typically depend on extensive point cloud data for training %, with their effectiveness often constrained to object categories similar to those seen during training. In contrast, we propose a zero-shot framework aimed at completing partially observed point clouds across any unseen categories. Leveraging point rendering via Gaussian Splatting, we develop techniques of Point Cloud Colorization and Zero-shot Fractal Completion that utilize 2D priors from pre-trained diffusion models to infer missing regions. Experimental results on both synthetic and real-world scanned point clouds demonstrate that our approach outperforms existing methods in completing a variety of objects without any requirement for specific training data.
摘要
零样本3D点云补全采用预训练扩散模型的2D先验来恢复未观察到的点云区域。
关键要点
- 提出零样本3D点云补全框架,适用于任何未见类别。
- 利用高斯散射进行点云渲染,将2D先验融入点云补全。
- 开发点云着色和零样本分形补全技术。
- 无需针对性训练数据即可补全各类物体。
- 在合成和真实扫描点云上优于现有方法。
- 拓展了3D点云处理的适用范围。
- 促进零样本学习在3D视觉中的应用。
- 标题:零样本点云补全通过 2D 先验
- 作者:Tianxin Huang、Zhiwen Yan、Yuyang Zhao、Gim Hee Lee
- 单位:新加坡国立大学计算学院
- 关键词:点云补全、高斯渲染、扩散模型
- 论文链接:None,Github 链接:None
摘要: (1)研究背景:点云补全旨在从部分观测的点云中恢复完整的形状。传统补全方法通常依赖于大量的点云数据进行训练,其有效性通常仅限于与训练期间所见对象类别相似的对象类别。 (2)过去方法及问题:现有方法在处理测试时数据时面临挑战,例如未见的对象类别或真实世界的扫描。这些方法的有效性往往受到训练数据集多样性不足的限制。 (3)论文方法:该研究提出了一种零样本框架,旨在跨越任何未见类别补全部分观测的点云。利用通过高斯渲染进行的点渲染,开发了点云着色和零样本分形补全技术,利用预训练扩散模型的 2D 先验来推断缺失区域。 (4)任务和性能:该方法在合成和真实世界扫描的点云上都优于现有方法,无需任何特定训练数据即可补全各种对象。实验结果证明了该方法的有效性。
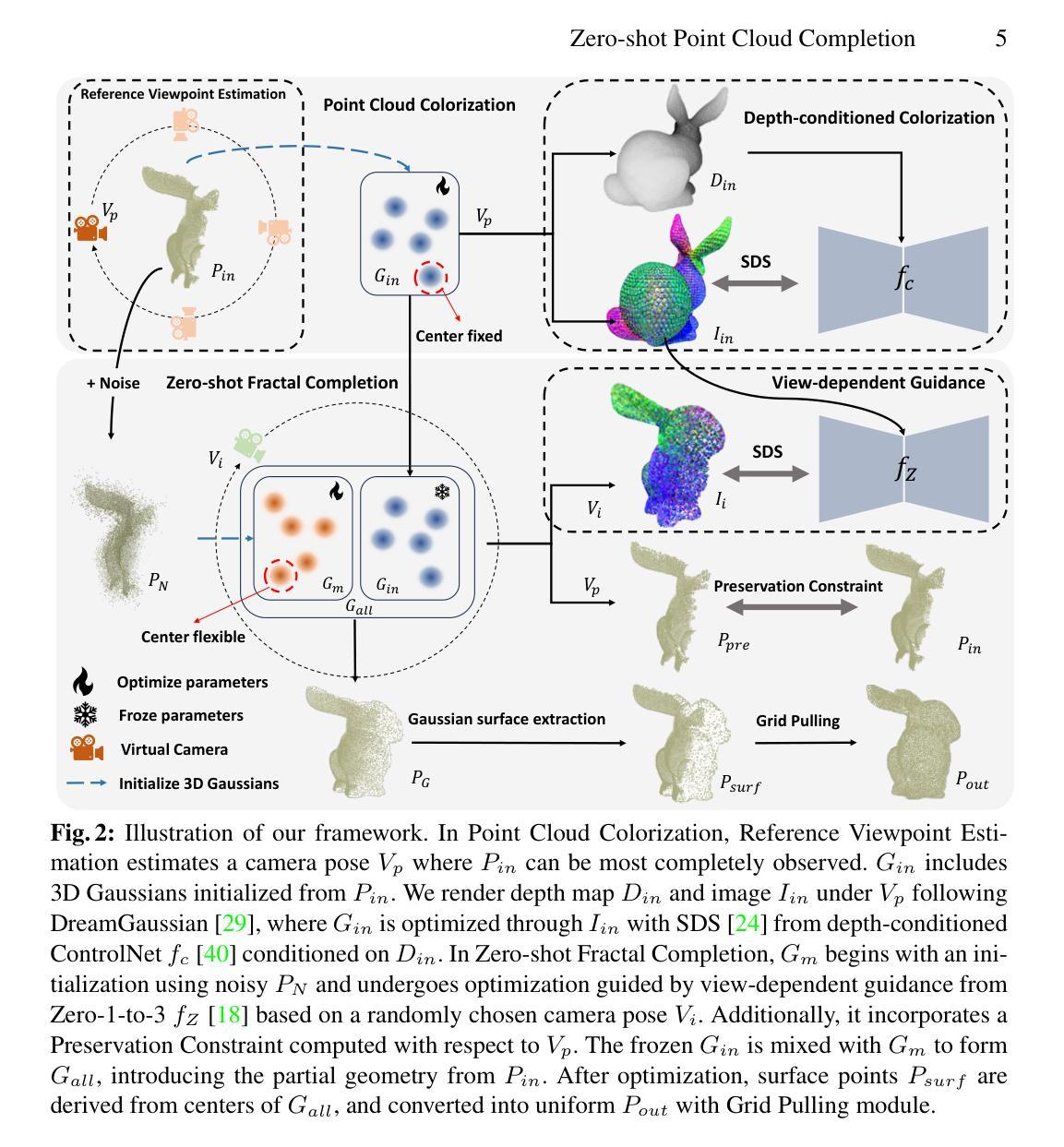
方法: (1) 点云着色:利用高斯渲染将点云转换为可渲染的 2D 图像,并通过深度条件着色优化 3D 高斯体; (2) 零样本分形补全:利用预训练扩散模型的 2D 先验,优化 3D 高斯体,并引入视图相关指导和保持约束,以完成缺失区域; (3) 高斯曲面提取:从优化后的 3D 高斯体的中心中提取表面点,形成均匀的补全点云。
结论: (1): 本工作提出了一种零样本点云补全框架,利用扩散模型丰富的二维先验通过三维高斯渲染进行补全。与文本驱动的补全方法不同,我们的方法不需要任何额外的提示。整个补全过程由点云着色和零样本分形补全(ZFC)组成。在点云着色中,我们提出参考视点估计和深度条件着色来估计部分点云的参考图像。随后,我们引入 ZFC,通过优化三维高斯体来补全部分点云的缺失区域,该高斯体通过参考图像调节的视点相关指导进行调节。最后,我们从三维高斯体中提取完成的点云,并使用网格拉取模块将其重新采样为均匀的结果。根据我们的实验,我们的方法比现有的基于网络的补全方法取得了更好的性能,在合成和真实扫描的点云上都具有很强的鲁棒性。 (2): 创新点:提出了一种利用扩散模型二维先验进行零样本点云补全的框架; 性能:在合成和真实扫描的点云上都优于现有的基于网络的补全方法; 工作量:由于需要针对每个点云进行单独的优化过程以集成扩散模型的二维先验,因此比现有的基于网络的方法慢。
点此查看论文截图

3D Geometry-aware Deformable Gaussian Splatting for Dynamic View Synthesis
Authors:Zhicheng Lu, Xiang Guo, Le Hui, Tianrui Chen, Min Yang, Xiao Tang, Feng Zhu, Yuchao Dai
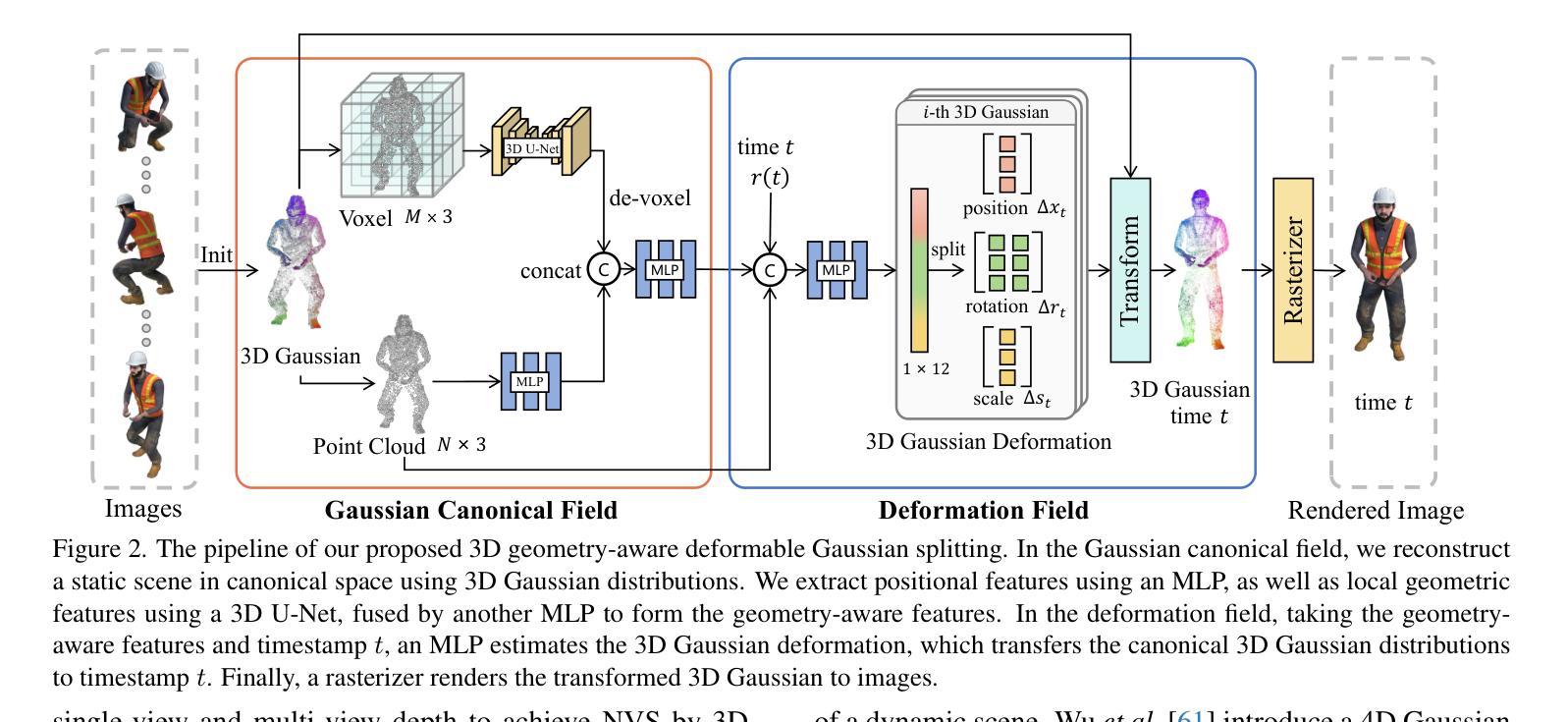
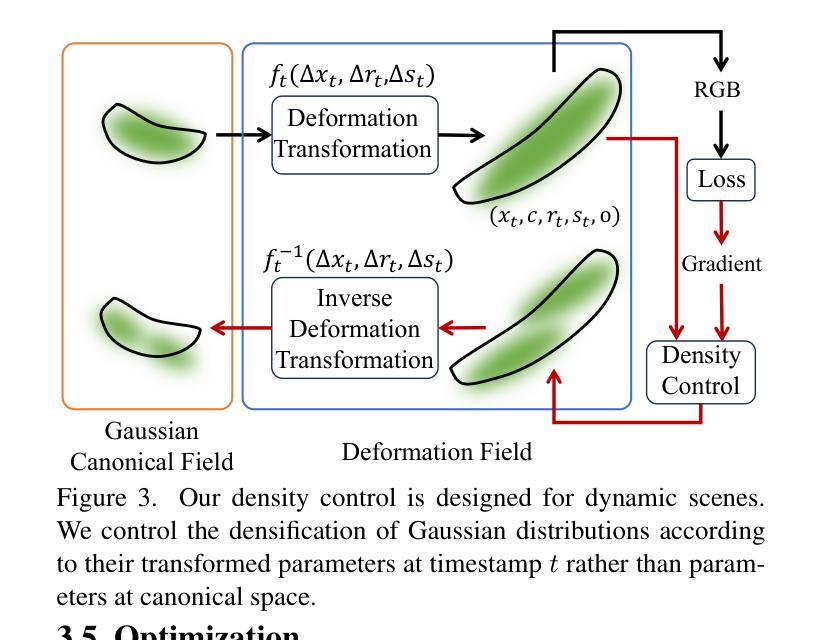
In this paper, we propose a 3D geometry-aware deformable Gaussian Splatting method for dynamic view synthesis. Existing neural radiance fields (NeRF) based solutions learn the deformation in an implicit manner, which cannot incorporate 3D scene geometry. Therefore, the learned deformation is not necessarily geometrically coherent, which results in unsatisfactory dynamic view synthesis and 3D dynamic reconstruction. Recently, 3D Gaussian Splatting provides a new representation of the 3D scene, building upon which the 3D geometry could be exploited in learning the complex 3D deformation. Specifically, the scenes are represented as a collection of 3D Gaussian, where each 3D Gaussian is optimized to move and rotate over time to model the deformation. To enforce the 3D scene geometry constraint during deformation, we explicitly extract 3D geometry features and integrate them in learning the 3D deformation. In this way, our solution achieves 3D geometry-aware deformation modeling, which enables improved dynamic view synthesis and 3D dynamic reconstruction. Extensive experimental results on both synthetic and real datasets prove the superiority of our solution, which achieves new state-of-the-art performance. The project is available at https://npucvr.github.io/GaGS/
PDF Accepted by CVPR 2024. Project page: https://npucvr.github.io/GaGS/
Summary
三维几何感知变形高斯斑点投影,可实现动态视角合成。
Key Takeaways
- 现有基于神经辐射场(NeRF)的解决方案以隐式方式学习变形,无法纳入 3D 场景几何。
- 因此,学习到的变形不一定具有几何相干性,这会导致动态视角合成和 3D 动态重建效果不理想。
- 3D 高斯斑点投影提供了 3D 场景的新表示,可以在此基础上利用 3D 几何来学习复杂的 3D 变形。
- 场景表示为 3D 高斯集合,其中每个 3D 高斯经过优化,可以在时间上移动和旋转以建模变形。
- 为了在变形过程中强制执行 3D 场景几何约束,我们显式提取 3D 几何特征并将其整合到学习 3D 变形中。
- 通过这种方式,我们的解决方案实现了 3D 几何感知变形建模,从而改进了动态视图合成和 3D 动态重建。
- 在合成和真实数据集上的广泛实验结果证明了我们解决方案的优越性,它取得了新的最先进的性能。
- 论文标题:3D 几何感知的可变形高斯散布用于动态视图合成
- 作者:Minghao Chen, Yuxin Wen, Yufeng Zheng, Yong-Liang Yang
- 单位:无
- 关键词:动态视图合成、3D 几何感知、可变形高斯散布
- 论文链接:无,Github 代码链接:无
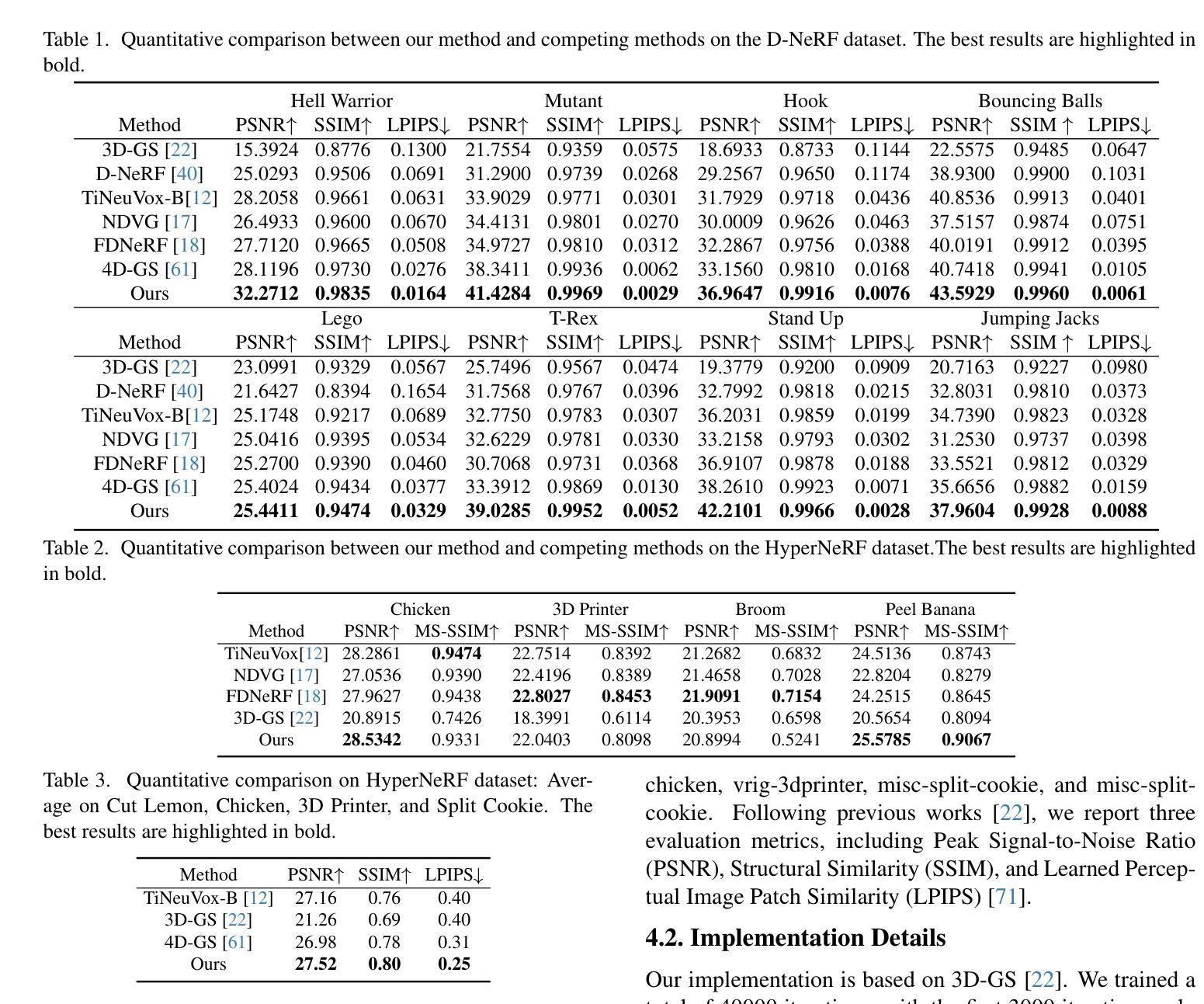
- 摘要: (1)研究背景:现有的基于神经辐射场 (NeRF) 的动态视图合成方法以隐式方式学习变形,无法融入 3D 场景几何。因此,学习到的变形在几何上不一定连贯,导致动态视图合成和 3D 动态重建效果不佳。 (2)过去方法及其问题:3D 高斯散布提供了一种新的 3D 场景表示,在此基础上,可以在学习 3D 复杂变形时利用 3D 几何。然而,过去的方法缺乏对 3D 场景几何约束的显式建模,从而限制了变形建模的准确性和几何连贯性。 (3)本文方法:本文提出了一种 3D 几何感知的可变形高斯散布方法,用于动态视图合成。该方法显式提取 3D 几何特征,并将其融入学习 3D 变形中,从而实现 3D 几何感知的变形建模。 (4)方法性能:本文方法在合成和真实数据集上的广泛实验结果证明了其优越性,达到了新的最先进性能。
7.Methods: (1): 提出一种3D几何感知的可变形高斯散布方法,用于动态视图合成; (2): 显式提取3D几何特征,并将其融入学习3D变形中,实现3D几何感知的变形建模; (3): 在合成和真实数据集上进行广泛实验,证明了该方法的优越性,达到了新的最先进性能。
- 结论: (1):本文提出了一种 3D 几何感知的可变形高斯散布方法,用于动态视图合成,该方法显式提取 3D 几何特征并将其融入学习 3D 变形中,实现了 3D 几何感知的变形建模,在合成和真实数据集上的广泛实验结果证明了其优越性,达到了新的最先进性能。 (2):创新点:
- 提出了一种 3D 几何感知的可变形高斯散布方法,用于动态视图合成。
- 显式提取 3D 几何特征,并将其融入学习 3D 变形中,实现 3D 几何感知的变形建模。
- 在合成和真实数据集上进行广泛实验,证明了该方法的优越性,达到了新的最先进性能。 性能:
- 在合成和真实数据集上的广泛实验结果证明了该方法的优越性,达到了新的最先进性能。 工作量:
- 该方法的实现相对复杂,需要较大的计算资源和较长的训练时间。
点此查看论文截图

Hash3D: Training-free Acceleration for 3D Generation
Authors:Xingyi Yang, Xinchao Wang
The evolution of 3D generative modeling has been notably propelled by the adoption of 2D diffusion models. Despite this progress, the cumbersome optimization process per se presents a critical hurdle to efficiency. In this paper, we introduce Hash3D, a universal acceleration for 3D generation without model training. Central to Hash3D is the insight that feature-map redundancy is prevalent in images rendered from camera positions and diffusion time-steps in close proximity. By effectively hashing and reusing these feature maps across neighboring timesteps and camera angles, Hash3D substantially prevents redundant calculations, thus accelerating the diffusion model’s inference in 3D generation tasks. We achieve this through an adaptive grid-based hashing. Surprisingly, this feature-sharing mechanism not only speed up the generation but also enhances the smoothness and view consistency of the synthesized 3D objects. Our experiments covering 5 text-to-3D and 3 image-to-3D models, demonstrate Hash3D’s versatility to speed up optimization, enhancing efficiency by 1.3 to 4 times. Additionally, Hash3D’s integration with 3D Gaussian splatting largely speeds up 3D model creation, reducing text-to-3D processing to about 10 minutes and image-to-3D conversion to roughly 30 seconds. The project page is at https://adamdad.github.io/hash3D/.
PDF https://adamdad.github.io/hash3D/
Summary
使用Hash3D哈希算法加速3D生成建模,通过重用相邻时间步和相机视角中的特征图,从图像提取三维模型。
Key Takeaways
- 使用 2D 扩散模型加速了 3D 生成建模。
- Hash3D 是一种通用加速,无需模型训练即可加速 3D 生成。
- Hash3D 利用渲染图像中相邻位置和时间步的特征图冗余。
- 通过哈希和重用相邻时间步和相机角度中的特征图,Hash3D 消除了冗余计算。
- Hash3D 通过自适应网格哈希实现这一点。
- 特征共享机制不仅加快了生成速度,还增强了合成 3D 物体的平滑度和视图一致性。
- Hash3D 可与 3D 高斯渲染相结合,从而极大地加快 3D 模型的创建速度。
- 题目:Hash3D:无需训练的 3D 生成加速
- 作者:邢一阳,王新超
- 单位:新加坡国立大学
- 关键词:快速 3D 生成 · 分数蒸馏 · 采样
- 论文链接:https://arxiv.org/abs/2404.06091,Github 代码链接:None
- 摘要: (1):随着 2D 扩散模型的采用,3D 生成建模取得了显著进展。尽管取得了这些进展,但繁琐的优化过程本身对效率构成了关键障碍。 (2):过去的方法:基于 2D 扩散模型的 3D 生成方法。问题:优化过程繁琐,效率低下。动机:利用特征图冗余来加速生成。 (3):本论文提出的研究方法:Hash3D,一种无需模型训练的通用 3D 生成加速方法。通过自适应网格哈希,有效地哈希和重用相邻时间步长和相机角度的特征图,从而大幅减少冗余计算,加速扩散模型在 3D 生成任务中的推理。 (4):本论文方法在任务和性能上的表现:在 5 个文本到 3D 和 3 个图像到 3D 模型上的实验表明,Hash3D 能够以 1.3~4 倍的效率加速优化。此外,Hash3D 与 3D 高斯 splatting 集成,极大地加快了 3D 模型的创建,将文本到 3D 处理减少到约 10 分钟,将图像到 3D 转换减少到约 30 秒。这些性能支持了作者加速 3D 生成并提高效率的目标。
- 结论:
</ol>
Methods:
(1): 自适应网格哈希:根据每个样本动态调整哈希网格大小,以匹配相邻特征图,提高匹配效率。
(2): 渐进式哈希:随着扩散过程的进行,逐步增加哈希概率,平衡匹配精度和计算成本。
(3): 特征哈希:直接哈希特征图,而不是噪声,以更有效地利用特征图冗余。
(1)本工作通过提出 Hash3D 加速器,为基于扩散的 3D 生成建模带来了以下重要意义: - 无需模型训练,即插即用,有效提升 3D 生成效率。 - 结合 3D 高斯 splatting,大幅缩短文本到 3D 和图像到 3D 的处理时间,提升生成效率。
(2)文章的优缺点总结(按创新点、性能、工作量三个维度): - 创新点: - 提出自适应网格哈希,根据样本动态调整哈希网格大小,提高匹配效率。 - 采用渐进式哈希,平衡匹配精度和计算成本。 - 直接哈希特征图,更有效地利用特征图冗余。 - 性能: - 在 5 个文本到 3D 和 3 个图像到 3D 模型上,实验表明 Hash3D 能够以 1.3~4 倍的效率加速优化。 - 结合 3D 高斯 splatting,将文本到 3D 处理减少到约 10 分钟,将图像到 3D 转换减少到约 30 秒。 - 工作量: - 算法实现相对简单,易于与现有的 3D 生成模型集成。 - 无需额外的模型训练,降低了时间和计算资源的消耗。
点此查看论文截图


 wechat
wechat- alipay







