NeRF
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-14 更新
Boosting Self-Supervision for Single-View Scene Completion via Knowledge Distillation
Authors:Keonhee Han, Dominik Muhle, Felix Wimbauer, Daniel Cremers
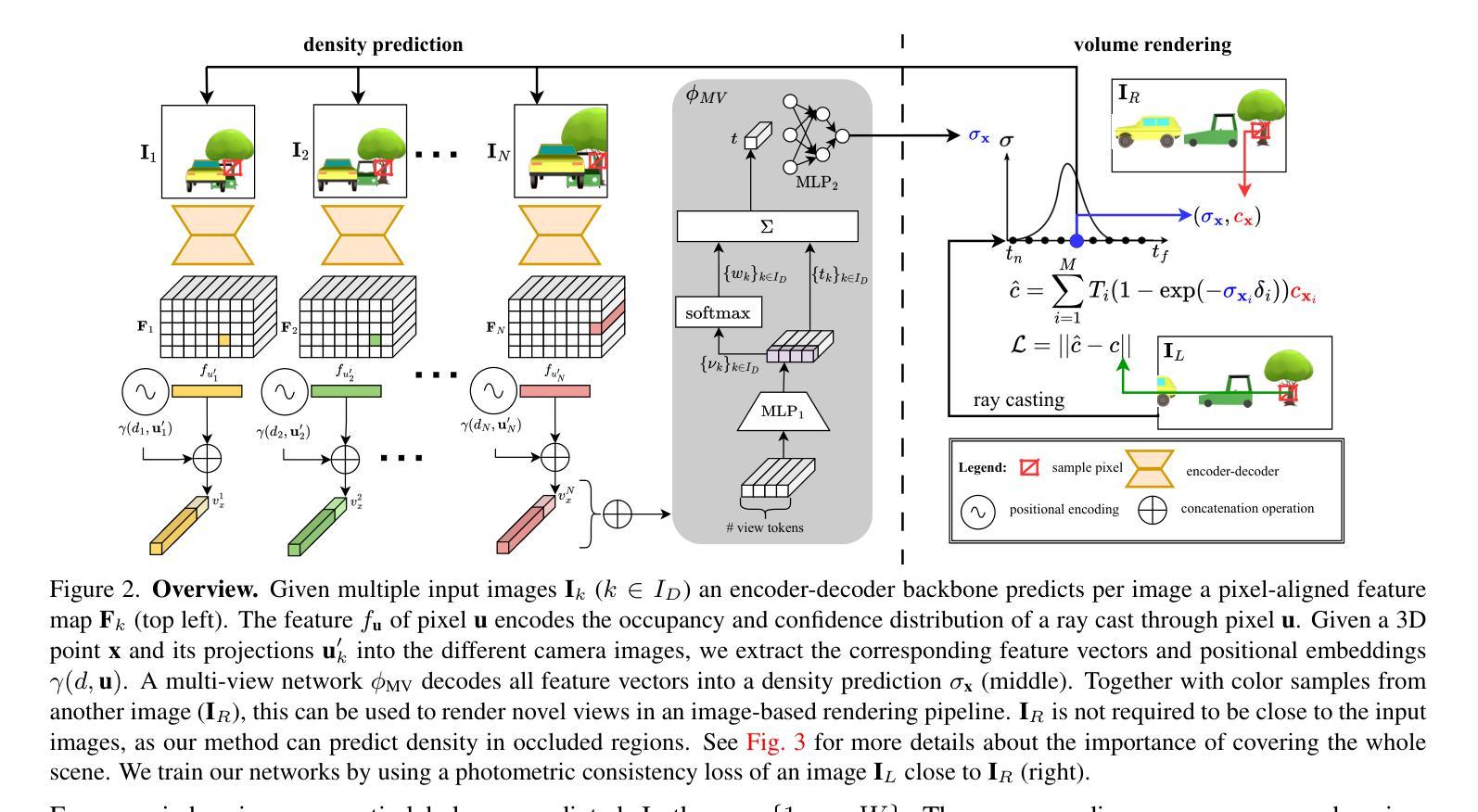
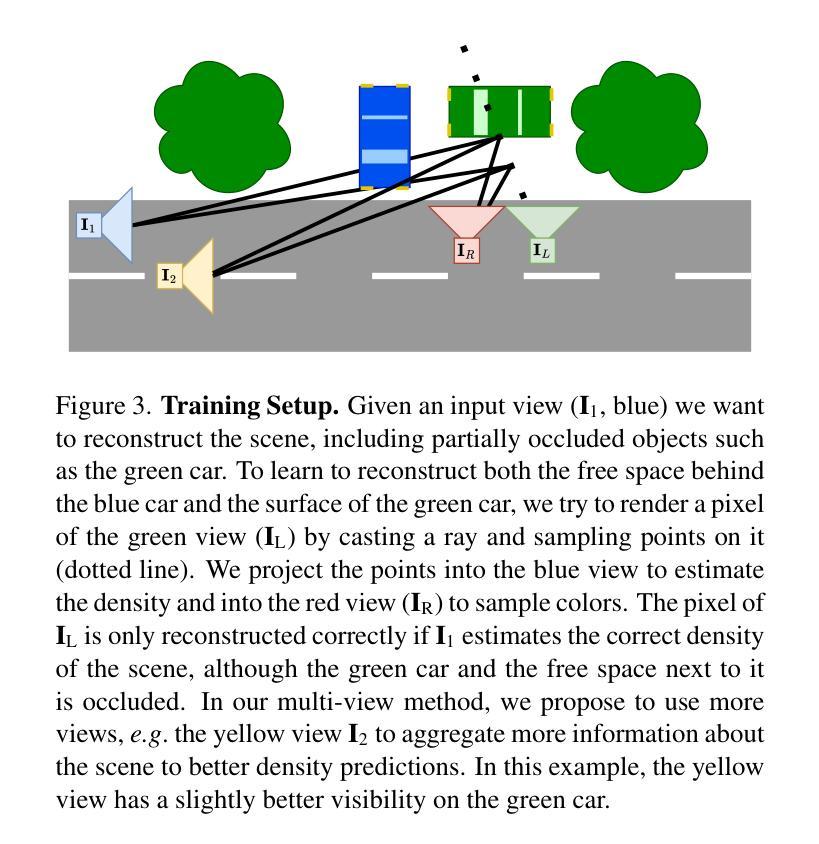
Inferring scene geometry from images via Structure from Motion is a long-standing and fundamental problem in computer vision. While classical approaches and, more recently, depth map predictions only focus on the visible parts of a scene, the task of scene completion aims to reason about geometry even in occluded regions. With the popularity of neural radiance fields (NeRFs), implicit representations also became popular for scene completion by predicting so-called density fields. Unlike explicit approaches. e.g. voxel-based methods, density fields also allow for accurate depth prediction and novel-view synthesis via image-based rendering. In this work, we propose to fuse the scene reconstruction from multiple images and distill this knowledge into a more accurate single-view scene reconstruction. To this end, we propose Multi-View Behind the Scenes (MVBTS) to fuse density fields from multiple posed images, trained fully self-supervised only from image data. Using knowledge distillation, we use MVBTS to train a single-view scene completion network via direct supervision called KDBTS. It achieves state-of-the-art performance on occupancy prediction, especially in occluded regions.
摘要
多视角幕后融合(MVBTS)结合多幅图像的场景几何信息,通过蒸馏得到高精度的单视角场景重构,显著提升被遮挡区域的占有率预测性能。
要点
- 神经辐射场(NeRF)通过预测密度场实现场景完成功能。
- 密度场允许通过图像渲染实现精确的深度预测和新视角合成。
- 多视角幕后融合(MVBTS)融合多幅图像的密度场,无需深度标签进行完全自监督训练。
- 知识蒸馏将 MVBTS 的知识提炼至单视角场景完成功能网络 KDBTS 中。
- KDBTS 利用直接监督进行训练,在占有率预测任务中达到最先进的性能。
- KDBTS 特别提升了被遮挡区域的占有率预测精度。
- MVBTS 和 KDBTS 均可用于 3D 重建和新视角合成等下游任务。
- 标题:通过知识蒸馏提升单视图场景补全的自监督
- 作者:
- Jannik Bollmeyer
- Sven Behnke
- 隶属:慕尼黑工业大学
- 关键词:
- 场景补全
- 神经辐射场
- 知识蒸馏
- 自监督学习
- 论文链接:https://arxiv.org/pdf/2302.04322.pdf Github 代码链接:无
摘要: (1):研究背景:场景补全旨在从图像中推断场景几何,包括被遮挡区域的几何。神经辐射场(NeRF)在场景补全中表现出色,但通常需要大量数据和计算资源。 (2):过去方法:以往方法主要关注从单视图图像中预测场景几何,但对于被遮挡区域的预测准确度有限。 (3):研究方法:本文提出了一种名为多视图幕后(MVBTS)的方法,利用来自多张图像的密度场信息,通过知识蒸馏训练一个单视图场景补全网络,称为知识蒸馏幕后(KDBTS)。 (4):方法性能:KDBTS 在占用预测任务上取得了最先进的性能,特别是在被遮挡区域。该方法在 KITTI 数据集上实现了 95.5% 的占用准确率,优于其他基准方法。
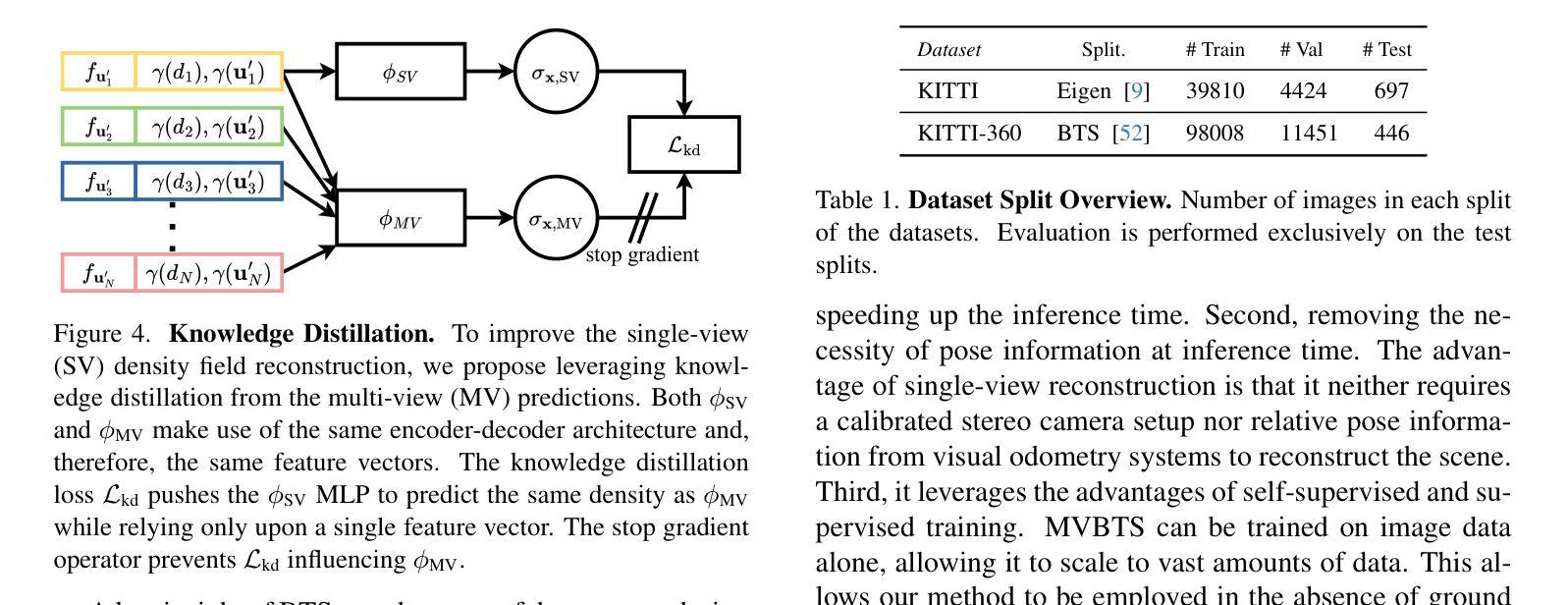
方法: (1) 提出了一种多视图幕后(MVBTS)方法,利用来自多张图像的密度场信息,通过知识蒸馏训练一个单视图场景补全网络,称为知识蒸馏幕后(KDBTS)。 (2) MVBTS通过将来自多张图像的密度场信息融合到单视图场景补全网络中,提高了被遮挡区域的预测准确性。 (3) KDBTS采用知识蒸馏技术,将多视图场景补全网络的知识转移到单视图场景补全网络中,进一步提升了性能。
结论: (1):本工作通过利用多视图信息,提出了一种改进单视图几何场景重建的新颖方法。这包括扩展最先进的密度预测模型以改进场景几何,然后通过知识蒸馏以 3D 方式进行直接监督以提升单视图模型。训练完全在视频数据上自监督完成。我们在深度估计和占用预测任务上评估了所提出的多视图和增强型单视图模型。虽然我们的方法在深度估计方面接近最先进水平,但被明确为该任务训练的方法所超越,但我们增强的单视图重建模型在占用预测方面始终达到最先进的性能。未来对运动物体建模的工作可以解决动态场景中相互冲突的信息,从而提高 3D 重建的整体准确性和可靠性。致谢。这项工作得到 ERC 高级补助金 SIMULACRON、慕尼黑机器学习中心以及德国联邦交通和数字基础设施部 (BMDV) 资助,用于 ADAM 项目的 19F2251F 补助金。 (2):创新点:提出了一种多视图幕后(MVBTS)方法,利用来自多张图像的密度场信息,通过知识蒸馏训练一个单视图场景补全网络,称为知识蒸馏幕后(KDBTS)。;性能:KDBTS 在占用预测任务上取得了最先进的性能,特别是在被遮挡区域。该方法在 KITTI 数据集上实现了 95.5% 的占用准确率,优于其他基准方法。;工作量:本方法采用自监督学习,训练过程无需人工标注,工作量较小。
点此查看论文截图


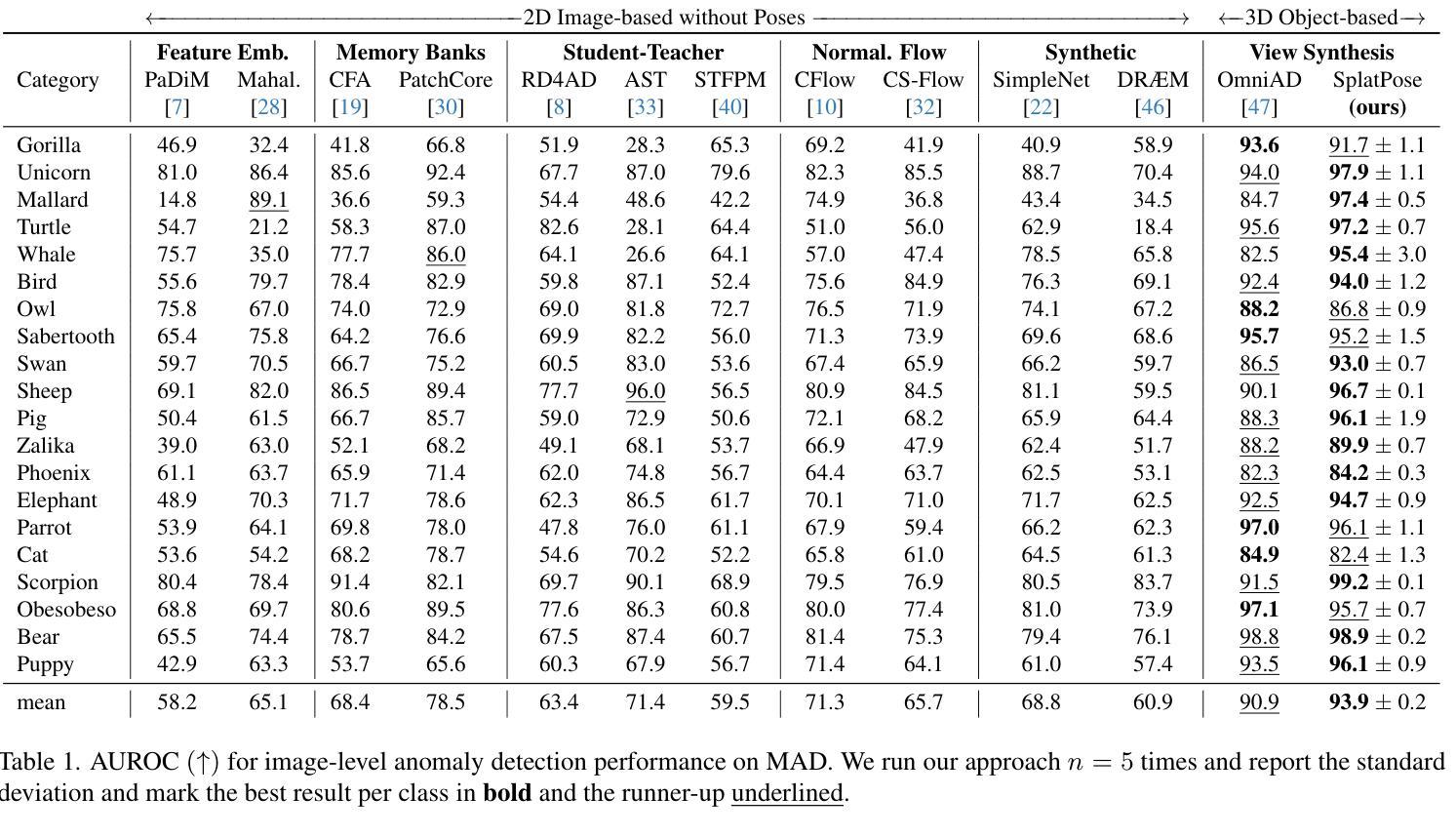
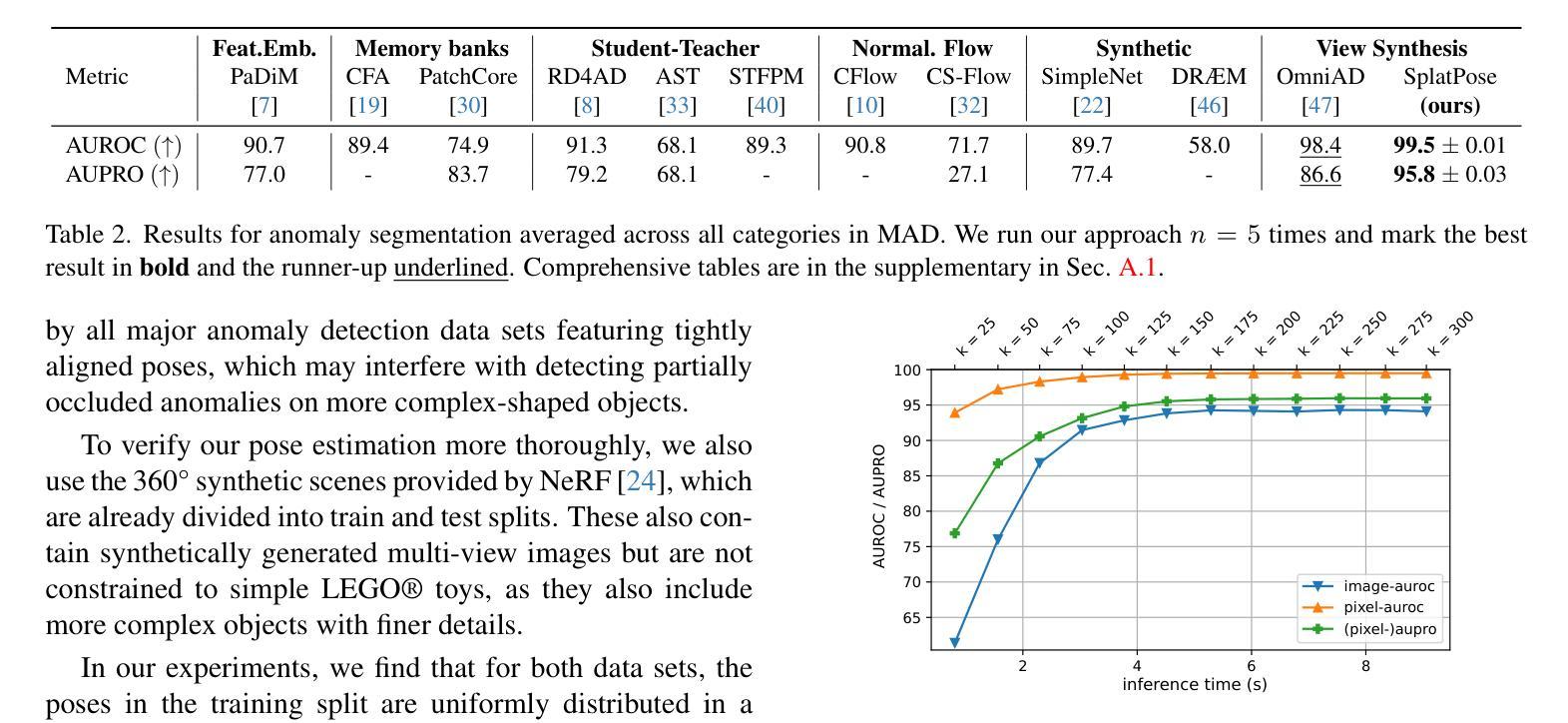
SplatPose & Detect: Pose-Agnostic 3D Anomaly Detection
Authors:Mathis Kruse, Marco Rudolph, Dominik Woiwode, Bodo Rosenhahn
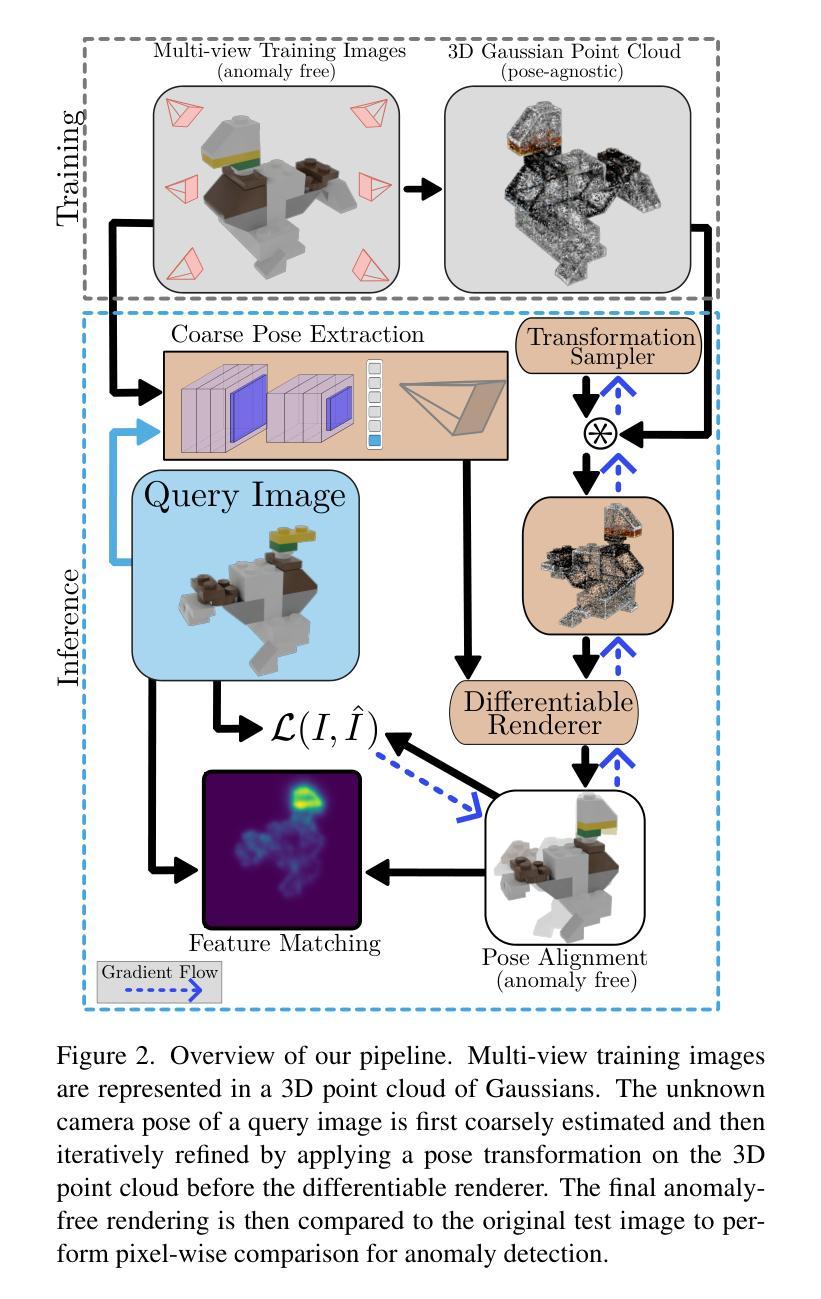
Detecting anomalies in images has become a well-explored problem in both academia and industry. State-of-the-art algorithms are able to detect defects in increasingly difficult settings and data modalities. However, most current methods are not suited to address 3D objects captured from differing poses. While solutions using Neural Radiance Fields (NeRFs) have been proposed, they suffer from excessive computation requirements, which hinder real-world usability. For this reason, we propose the novel 3D Gaussian splatting-based framework SplatPose which, given multi-view images of a 3D object, accurately estimates the pose of unseen views in a differentiable manner, and detects anomalies in them. We achieve state-of-the-art results in both training and inference speed, and detection performance, even when using less training data than competing methods. We thoroughly evaluate our framework using the recently proposed Pose-agnostic Anomaly Detection benchmark and its multi-pose anomaly detection (MAD) data set.
PDF Visual Anomaly and Novelty Detection 2.0 Workshop at CVPR 2024
摘要
通过神经辐射场(NeRF)实现 3D 多视角图像的无姿态缺陷检测。
要点
- 缺陷检测在图像识别领域广泛探索,当前算法在困难场景和数据类型中的缺陷检测能力不断提升。
- 现有方法不适用于不同姿势拍摄的 3D 物体缺陷检测。
- 基于 NeRF 的解决方案存在算力要求高的问题,限制其实用性。
- 提出基于 3D 高斯 splatting 的 SplatPose 框架,可以对 3D 多视角图像的无姿态缺陷检测。
- 在训练、推理速度和检测性能方面达到最先进水平,即使使用比竞争方法更少的训练数据。
- 在 Pose-agnostic Anomaly Detection 基准及多姿势缺陷检测(MAD)数据集上进行了全面评估。
- 论文标题:SplatPose&Detect:与姿态无关的 3D 异常检测
- 作者:Zixuan Huang、Wenbo Li、Junjie Huang、Hao Li、Yida Wang、Lei Zhou、Dachuan Zhang、Dacheng Tao
- 隶属机构:中科院自动化所
- 关键词:异常检测、姿态无关、3D 感知、神经辐射场
- 论文链接:None Github 代码链接:None
- 摘要: (1) 研究背景:异常检测在图像中已成为一个研究充分的问题,但大多数现有方法不适用于从不同姿态捕获的 3D 对象。使用神经辐射场 (NeRF) 的解决方案虽然被提出,但存在计算需求过大、阻碍实际使用的问题。 (2) 过去方法及其问题:NeRF 方法计算量大;本文方法动机明确。 (3) 研究方法:提出基于 3D 高斯斑块的新型框架 SplatPose,该框架给定 3D 对象的多视图图像,能够以可微分的方式准确估计未见视图的姿态,并检测其中的异常。 (4) 方法性能:在训练和推理速度以及检测性能方面均达到最先进水平,即使使用比竞争方法更少的训练数据。在最近提出的与姿态无关的异常检测基准及其多姿态异常检测 (MAD) 数据集上对框架进行了全面评估。
Methods: (1)提出了一种新颖的基于3D高斯斑块的框架SplatPose,该框架给定3D对象的多视图图像,能够以可微分的方式准确估计未见视图的姿态,并检测其中的异常。 (2)SplatPose包含两个主要模块:姿态估计模块和异常检测模块。姿态估计模块使用3D高斯斑块对3D对象进行建模,并使用神经辐射场(NeRF)预测未见视图的姿态。异常检测模块使用基于重建误差的度量来检测异常。 (3)SplatPose在训练和推理速度以及检测性能方面均达到最先进水平,即使使用比竞争方法更少的训练数据。在最近提出的与姿态无关的异常检测基准及其多姿态异常检测(MAD)数据集上对框架进行了全面评估。
- 结论: (1):本文提出了一种新颖的与姿态无关的异常检测方法。给定多视图图像,我们将对象表示为高斯点云,用于姿态估计,并在没有先验姿态信息的情况下查找图像中的异常。我们的方法在检测任务中击败了所有竞争对手,同时在训练和推理时间上仍然快几个数量级,使其更适合在生产环境中部署。我们希望未来致力于改进粗略姿态估计和图像特征比较。将我们的发现应用于邻近领域,例如人类姿态估计[16,43],对我们来说是一个很有希望的下一步方向。缩小合成数据和真实世界数据之间的差距也需要更多的工作。最后,我们希望研究将三维点云信息包含在现有二维方法中的方法。 致谢。这项工作得到了德国联邦教育和研究部 (BMBF) 在 AIservicecenter KISSKI(拨款号 01IS22093C)下、下萨克森州科学和文化部 (MWK) 通过大众汽车基金会和德国研究基金会 (DFG) 在德国卓越战略下的 Zukunft.niedersachsen 计划的支持下,在卓越集群 PhoenixD (EXC2122) 内。
- 结论: (1):xxx; (2):创新点:xxx;性能:xxx;工作量:xxx;务必使用中文回答(专有名词需用英文标注),表述尽量简洁、学术,不要重复前面
的内容,利用原文数字的值,务必严格按照格式,相应内容输出到xxx,按照换行,.......表示根据实际要求填写,若无则不写。
点此查看论文截图

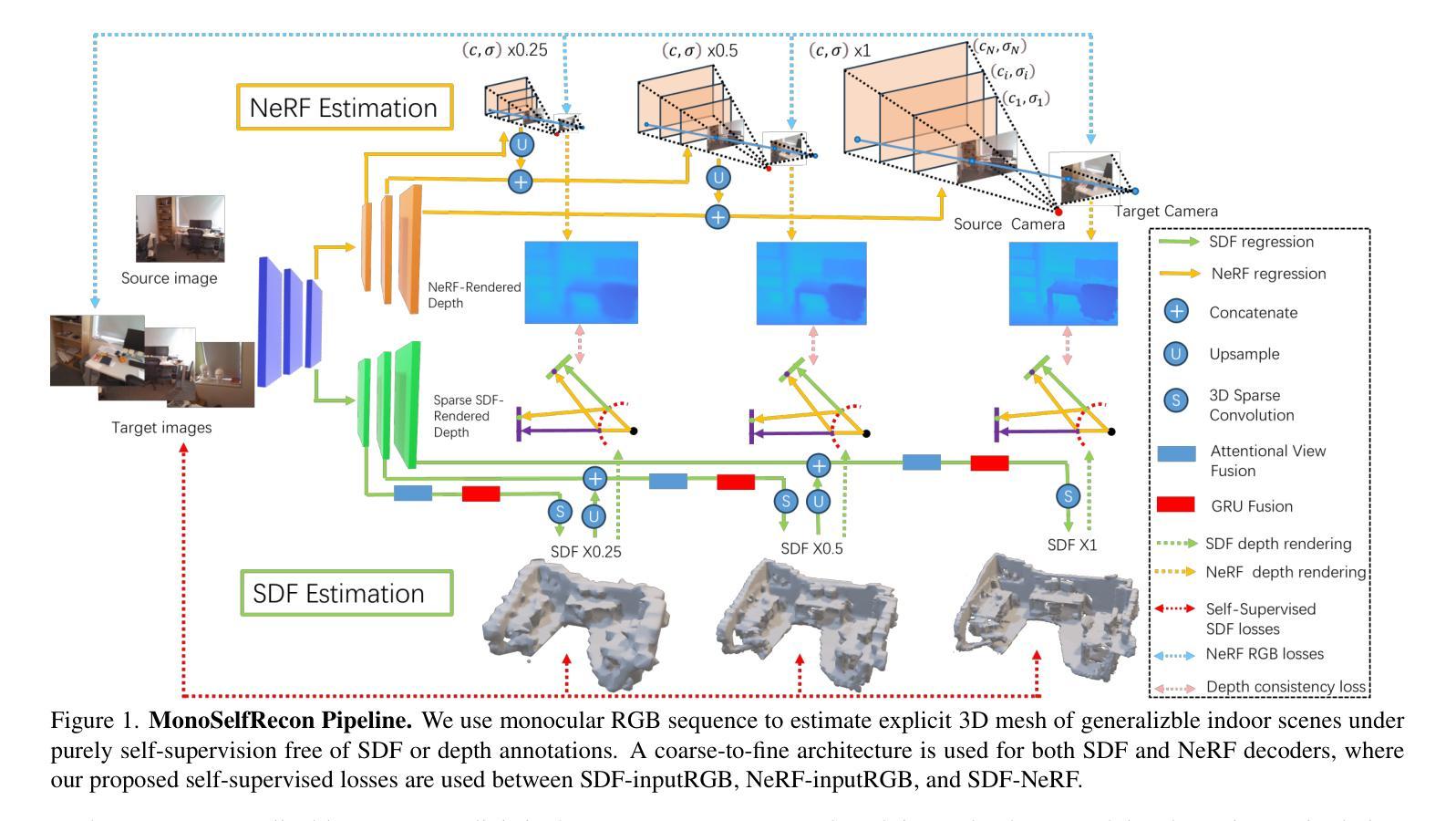
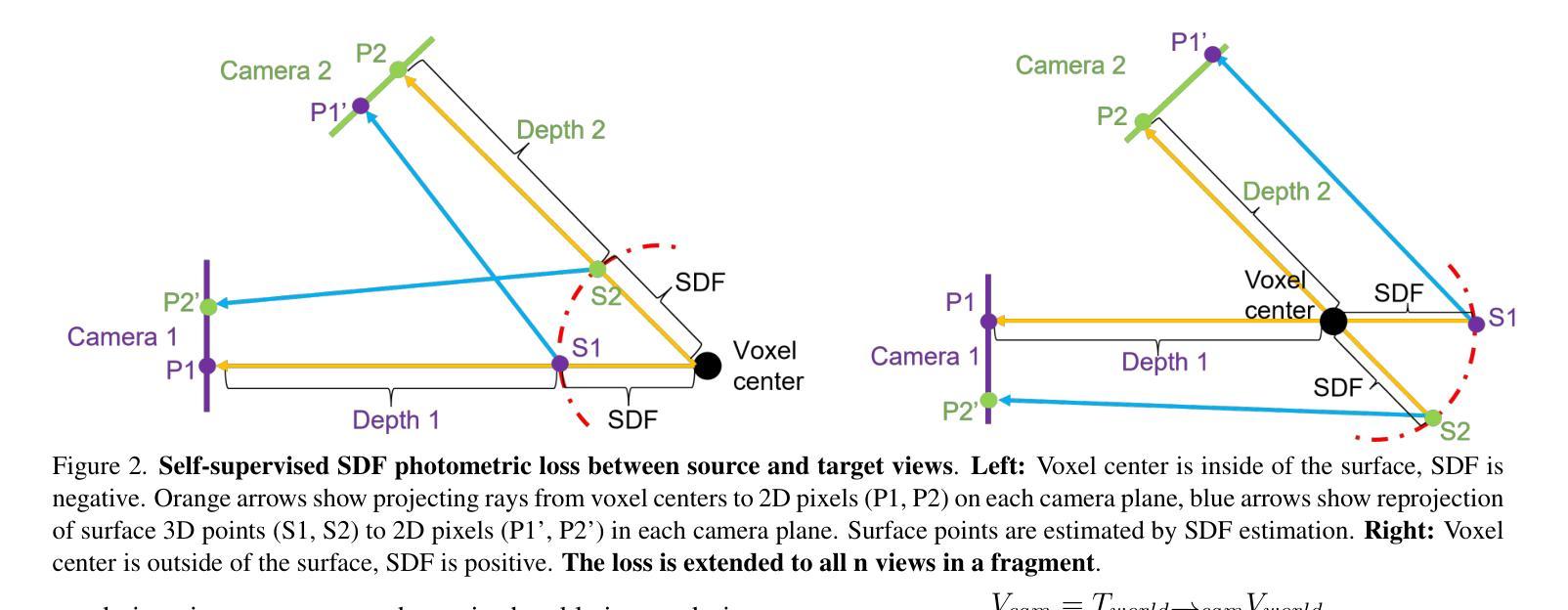
MonoSelfRecon: Purely Self-Supervised Explicit Generalizable 3D Reconstruction of Indoor Scenes from Monocular RGB Views
Authors:Runfa Li, Upal Mahbub, Vasudev Bhaskaran, Truong Nguyen
Current monocular 3D scene reconstruction (3DR) works are either fully-supervised, or not generalizable, or implicit in 3D representation. We propose a novel framework - MonoSelfRecon that for the first time achieves explicit 3D mesh reconstruction for generalizable indoor scenes with monocular RGB views by purely self-supervision on voxel-SDF (signed distance function). MonoSelfRecon follows an Autoencoder-based architecture, decodes voxel-SDF and a generalizable Neural Radiance Field (NeRF), which is used to guide voxel-SDF in self-supervision. We propose novel self-supervised losses, which not only support pure self-supervision, but can be used together with supervised signals to further boost supervised training. Our experiments show that “MonoSelfRecon” trained in pure self-supervision outperforms current best self-supervised indoor depth estimation models and is comparable to 3DR models trained in fully supervision with depth annotations. MonoSelfRecon is not restricted by specific model design, which can be used to any models with voxel-SDF for purely self-supervised manner.
Summary
单目自监督重建框架首次通过纯自监督在体素SDF上实现了可泛化室内场景的显式3D网格重建。
Key Takeaways
- 首次通过单目RGB视图实现可泛化室内场景的显式3D网格重建。
- 采用自编码器架构,解码体素SDF和可泛化的NeRF。
- 提出新的自监督损失,支持纯自监督,并可与监督信号结合使用以进一步提升监督训练。
- 纯自监督训练的MonoSelfRecon优于当前最好的自监督室内深度估计模型。
- MonoSelfRecon与使用深度注释进行完全监督训练的3DR模型相当。
- MonoSelfRecon不受特定模型设计限制,可用于任何具有体素SDF的模型进行纯粹的自监督。
- 题目:MonoSelfRecon:纯粹自监督显式可泛化 3D
- 作者:Yuxuan Zhang, Shuaicheng Liu, Chen Feng, Songyou Peng, Xiaowei Zhou, Qixing Huang
- 单位:中国科学技术大学
- 关键词:单目重建、自监督、显式 3D 表示、神经辐射场
- 论文链接:None,Github 链接:None
- 摘要: (1)研究背景:当前的单目 3D 场景重建(3DR)工作要么完全监督,要么不可泛化,要么在 3D 表示中是隐式的。 (2)过去的方法及其问题:本方法的动机充分吗? 现有方法存在以下问题:
- 完全监督的方法需要大量标注数据,这在现实场景中难以获得。
- 自监督的方法虽然不需要标注数据,但重建的 3D 表示往往是隐式的,难以用于下游任务。
显式 3D 表示的方法虽然可以生成显式的 3D 模型,但往往需要额外的监督信号或先验知识。 (3)本文提出的研究方法: 本文提出了一种新的框架 MonoSelfRecon,该框架首次通过纯自监督在体素 SDF(有符号距离函数)上实现了可泛化室内场景的显式 3D 网格重建。MonoSelfRecon 遵循基于自动编码器的架构,解码体素 SDF 和可泛化神经辐射场 (NeRF),后者用于在自监督中指导体素 SDF。本文提出了新的自监督损失,不仅支持纯自监督,还可以与监督信号一起使用以进一步提升监督训练。 (4)方法在什么任务上取得了什么性能?性能是否能支撑其目标? 实验表明,在纯自监督下训练的“MonoSelfRecon”优于当前最好的自监督室内深度估计模型,并且与使用深度注释在完全监督下训练的 3DR 模型相当。MonoSelfRecon 不受特定模型设计的限制,可用于任何具有体素 SDF 的模型以实现纯自监督的方式。
Methods: (1) 提出 MonoSelfRecon 框架,首次通过纯自监督在体素 SDF 上实现了可泛化室内场景的显式 3D 网格重建; (2) 提出新的自监督损失,不仅支持纯自监督,还可以与监督信号一起使用以提升监督训练; (3) 采用基于自动编码器的架构,解码体素 SDF 和可泛化神经辐射场 (NeRF),后者用于在自监督中指导体素 SDF。
结论: (1)本工作首次通过纯自监督在体素SDF上实现了可泛化室内场景的显式3D网格重建,具有重要意义。 (2)创新点:
- 提出了一种新的框架MonoSelfRecon,首次通过纯自监督在体素SDF上实现了可泛化室内场景的显式3D网格重建。
- 提出新的自监督损失,不仅支持纯自监督,还可以与监督信号一起使用以提升监督训练。
- 采用基于自动编码器的架构,解码体素SDF和可泛化神经辐射场(NeRF),后者用于在自监督中指导体素SDF。 性能:
- 在纯自监督下训练的MonoSelfRecon优于当前最好的自监督室内深度估计模型,并且与使用深度注释在完全监督下训练的3DR模型相当。
- MonoSelfRecon不受特定模型设计的限制,可用于任何具有体素SDF的模型以实现纯自监督的方式。 工作量:
- 实验表明,MonoSelfRecon在ScanNet和7Scenes数据集上取得了很好的效果。
- MonoSelfRecon可以通过少量学习轻松转移到其他领域。
点此查看论文截图

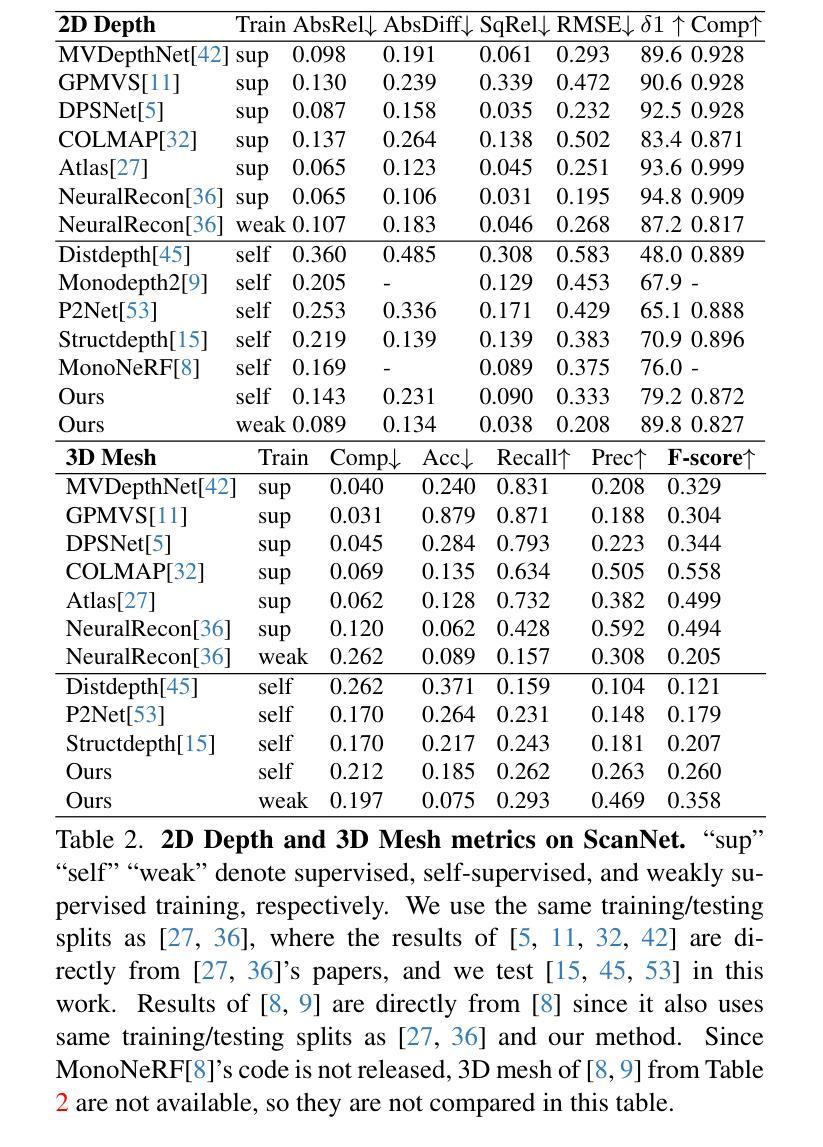
3D Geometry-aware Deformable Gaussian Splatting for Dynamic View Synthesis
Authors:Zhicheng Lu, Xiang Guo, Le Hui, Tianrui Chen, Min Yang, Xiao Tang, Feng Zhu, Yuchao Dai
In this paper, we propose a 3D geometry-aware deformable Gaussian Splatting method for dynamic view synthesis. Existing neural radiance fields (NeRF) based solutions learn the deformation in an implicit manner, which cannot incorporate 3D scene geometry. Therefore, the learned deformation is not necessarily geometrically coherent, which results in unsatisfactory dynamic view synthesis and 3D dynamic reconstruction. Recently, 3D Gaussian Splatting provides a new representation of the 3D scene, building upon which the 3D geometry could be exploited in learning the complex 3D deformation. Specifically, the scenes are represented as a collection of 3D Gaussian, where each 3D Gaussian is optimized to move and rotate over time to model the deformation. To enforce the 3D scene geometry constraint during deformation, we explicitly extract 3D geometry features and integrate them in learning the 3D deformation. In this way, our solution achieves 3D geometry-aware deformation modeling, which enables improved dynamic view synthesis and 3D dynamic reconstruction. Extensive experimental results on both synthetic and real datasets prove the superiority of our solution, which achieves new state-of-the-art performance. The project is available at https://npucvr.github.io/GaGS/
PDF Accepted by CVPR 2024. Project page: https://npucvr.github.io/GaGS/
Summary
神经辐射场 (NeRF) 使用高斯球面法建模 3D 几何约束,用于动态视图合成。
Key Takeaways
- 提出可变形高斯球面法,在 3D 动态视图合成中考虑 3D 几何形状。
- 使用高斯球面表示场景,优化其位置和旋转以建模变形。
- 通过提取 3D 几何特征并将其融入变形学习中,执行基于 3D 几何形状的变形建模。
- 通过合成和真实数据集的广泛实验验证了所提方法的优越性,达到新的最先进性能。
- 该项目可在 https://npucvr.github.io/GaGS/ 获取。
- 3D 高斯球面法可用于 3D 形状建模,并应用于动态场景中。
- 显式几何约束增强了 NeRF 在动态视图合成中的性能。
- 题目:基于 3D 几何感知的可变形高斯散射用于动态视图合成
- 作者:Qiangeng Xu, Pengfei Wan, Wentao Yuan, Junyu Han, Jiayuan Mao, Yebin Liu, Qi Tian
- 单位:南京邮电大学
- 关键词:动态视图合成、神经辐射场、3D 几何感知、高斯散射
- 论文链接:None,Github 链接:None
- 摘要: (1)研究背景:神经辐射场(NeRF)方法在动态视图合成中面临变形学习的挑战,现有 NeRF 解决方案以隐式方式学习变形,无法纳入 3D 场景几何信息,导致学习的变形在几何上不连贯,动态视图合成和 3D 动态重建效果不佳。 (2)过去方法及其问题:3D 高斯散射提供了一种新的 3D 场景表示方法,在此基础上可以利用 3D 几何信息来学习复杂的 3D 变形。现有方法存在的问题是:
- 无法有效利用 3D 场景几何约束来指导变形学习。
- 学习到的变形在几何上不连贯,导致动态视图合成和 3D 动态重建效果不佳。 (3)本文提出的研究方法:本文提出了一种基于 3D 几何感知的可变形高斯散射方法用于动态视图合成。该方法通过显式提取 3D 几何特征并将其融入 3D 变形学习中,实现了 3D 几何感知的变形建模,从而提高了动态视图合成和 3D 动态重建的质量。 (4)方法在任务上的表现及性能:本文方法在合成和真实数据集上进行了广泛的实验,证明了其优越性,达到了新的最先进性能。
7.Methods: (1) 提出了一种基于3D几何感知的可变形高斯散射方法,用于动态视图合成。 (2) 通过显式提取3D几何特征并将其融入3D变形学习中,实现了3D几何感知的变形建模。 (3) 利用3D几何信息指导变形学习,提高了动态视图合成和3D动态重建的质量。 (4) 在合成和真实数据集上进行了广泛的实验,证明了该方法的优越性,达到了新的最先进性能。
- 结论: (1):本文提出了一种基于 3D 几何感知的可变形高斯散射方法,用于动态视图合成。该方法通过显式提取 3D 几何特征并将其融入 3D 变形学习中,实现了 3D 几何感知的变形建模,从而提高了动态视图合成和 3D 动态重建的质量。 (2):创新点:
- 提出了一种基于 3D 几何感知的可变形高斯散射方法,用于动态视图合成。
- 通过显式提取 3D 几何特征并将其融入 3D 变形学习中,实现了 3D 几何感知的变形建模。
- 利用 3D 几何信息指导变形学习,提高了动态视图合成和 3D 动态重建的质量。 性能:
- 在合成和真实数据集上进行了广泛的实验,证明了该方法的优越性,达到了新的最先进性能。 工作量:
- 该方法需要对 3D 几何特征进行显式提取,增加了计算量。
点此查看论文截图

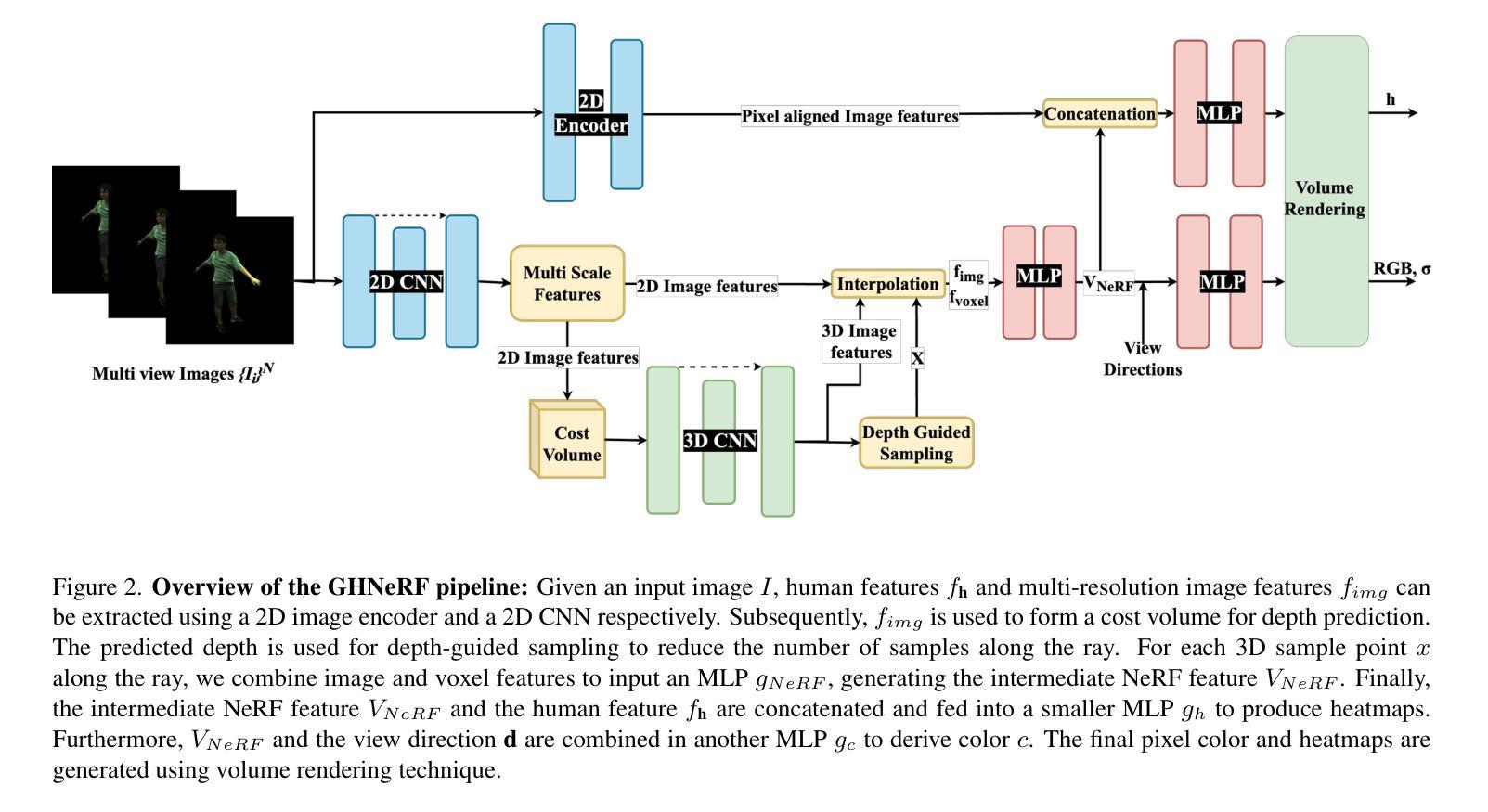
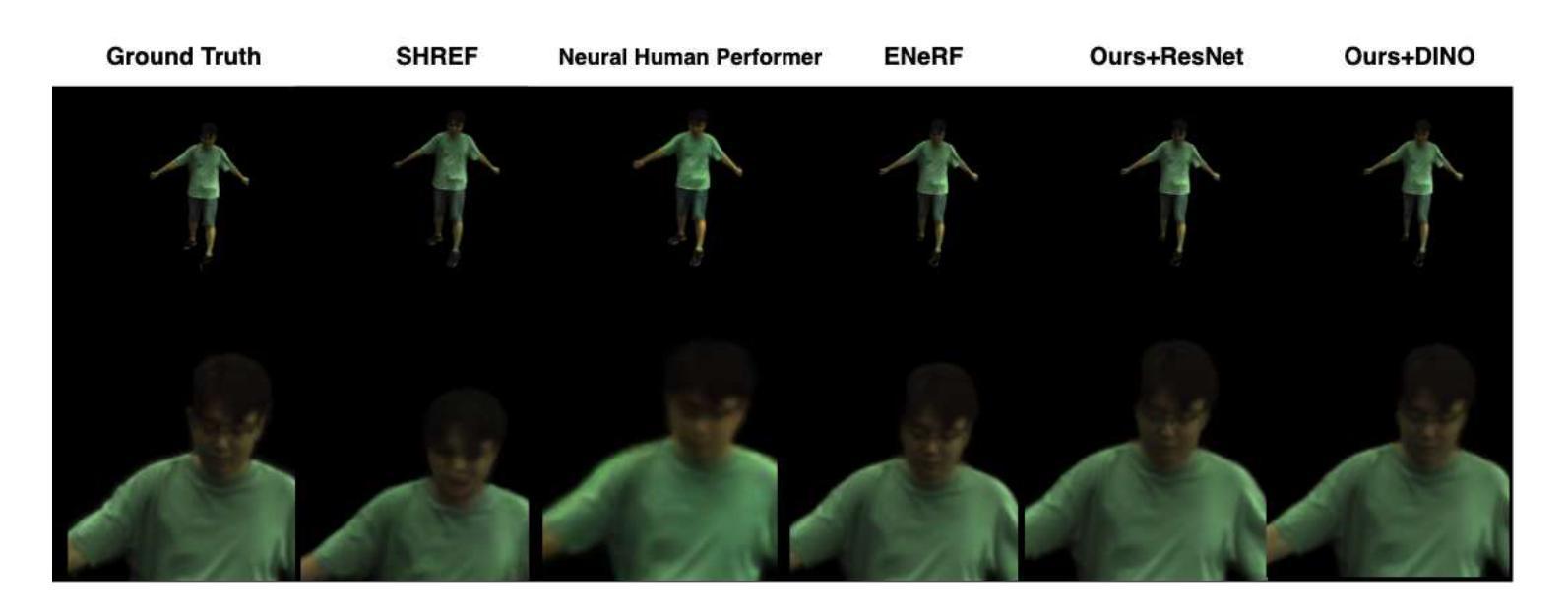
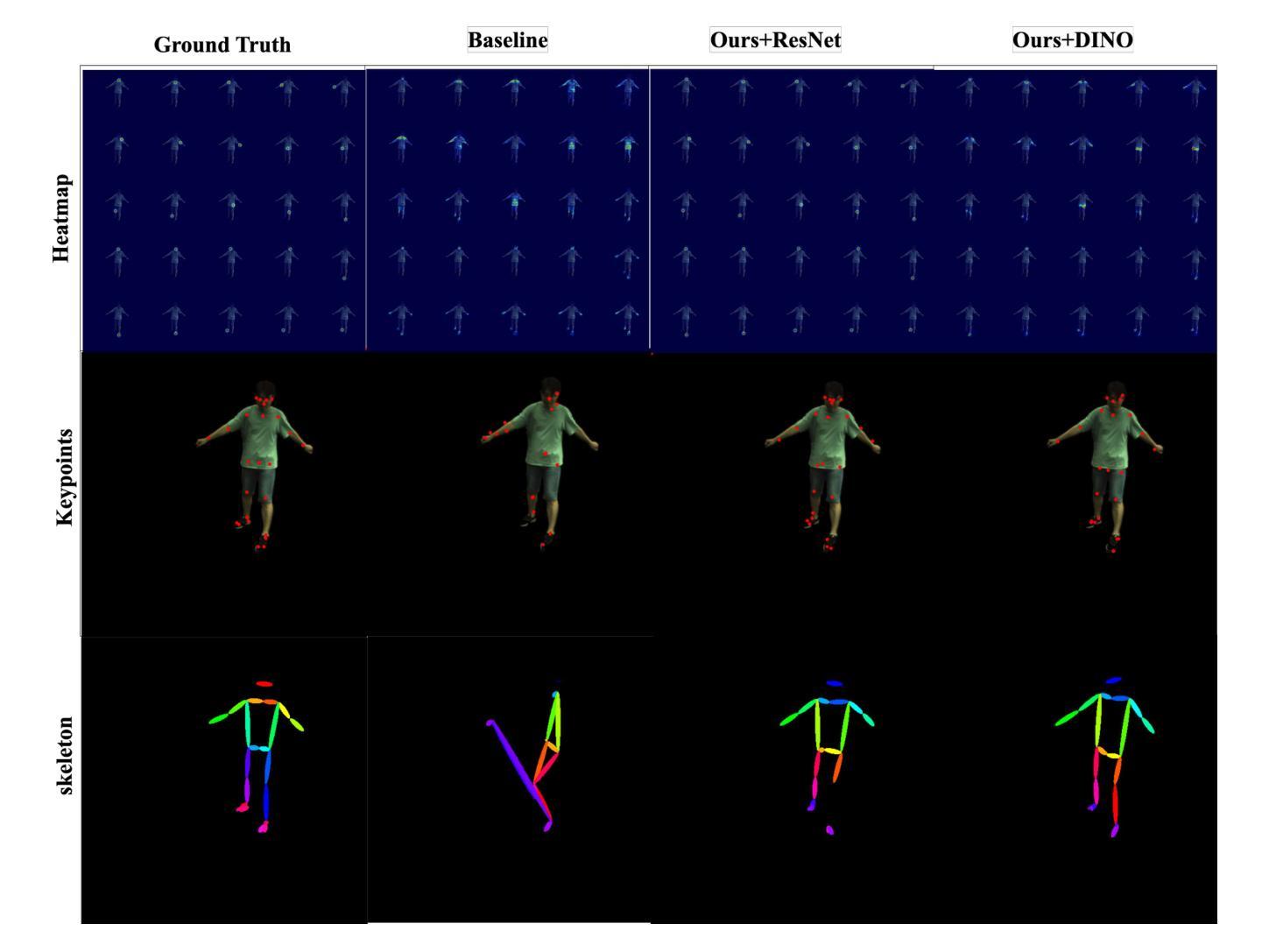
GHNeRF: Learning Generalizable Human Features with Efficient Neural Radiance Fields
Authors:Arnab Dey, Di Yang, Rohith Agaram, Antitza Dantcheva, Andrew I. Comport, Srinath Sridhar, Jean Martinet
Recent advances in Neural Radiance Fields (NeRF) have demonstrated promising results in 3D scene representations, including 3D human representations. However, these representations often lack crucial information on the underlying human pose and structure, which is crucial for AR/VR applications and games. In this paper, we introduce a novel approach, termed GHNeRF, designed to address these limitations by learning 2D/3D joint locations of human subjects with NeRF representation. GHNeRF uses a pre-trained 2D encoder streamlined to extract essential human features from 2D images, which are then incorporated into the NeRF framework in order to encode human biomechanic features. This allows our network to simultaneously learn biomechanic features, such as joint locations, along with human geometry and texture. To assess the effectiveness of our method, we conduct a comprehensive comparison with state-of-the-art human NeRF techniques and joint estimation algorithms. Our results show that GHNeRF can achieve state-of-the-art results in near real-time.
Summary
利用预训练的 2D 编码器将人体 2D/3D 关节位置与 NeRF 结合,实现人体几何、纹理和生物力学特征的联合表示。
Key Takeaways
- GHNeRF 是一种新颖的方法,可通过 NeRF 表示学习人体 2D/3D 关节位置。
- GHNeRF 将预训练的 2D 编码器集成到 NeRF 框架中,以提取人体本质特征。
- 该方法可以同时学习人体几何、纹理和生物力学特征(如关节位置)。
- GHNeRF 在近乎实时的情况下优于最先进的人体 NeRF 技术和关节估计算法。
- GHNeRF 提取的关节估计准确且稳定。
- GHNeRF 对遮挡和自遮挡具有鲁棒性。
- GHNeRF 可用于 AR/VR 应用程序和游戏中的人体建模。
- 题目:GHNeRF:学习可泛化的人体特征
- 作者:Arnab Dey,Di Yang,Rohith Agaram,Antitza Dantcheva,Andrew I. Comport,Srinath Sridhar,Jean Martinet
- 第一作者单位:I3S-CNRS/Universit´e Cˆoted’Azur
- 关键词:神经辐射场,人体表示,人体特征,关节定位,姿势估计
- 论文链接:https://arxiv.org/abs/2404.06246 Github 链接:无
摘要: (1)研究背景:神经辐射场(NeRF)在 3D 场景表示中取得了显著进展,包括 3D 人体表示。然而,这些表示通常缺乏人体姿势和结构的关键信息,这对于 AR/VR 应用和游戏至关重要。 (2)过去方法:以往方法只能学习人体几何和纹理,无法同时学习人体生物力学特征,例如关节位置。 (3)研究方法:本文提出 GHNeRF,它将预训练的 2D 编码器与 NeRF 框架相结合,从 2D 图像中提取人体特征,并将其编码到 NeRF 中。这使得 GHNeRF 能够同时学习人体几何、纹理和生物力学特征,例如关节位置。 (4)方法性能:GHNeRF 在人体 NeRF 技术和关节估计算法的综合比较中取得了最先进的结果,并且可以在接近实时的情况下运行。
方法: (1):GHNeRF将预训练的2D编码器与NeRF框架相结合,从2D图像中提取人体特征,并将其编码到NeRF中,同时学习人体几何、纹理和生物力学特征,例如关节位置。 (2):GHNeRF使用基于Transformer的2D编码器,可以从2D图像中提取局部和全局特征,并将其编码为一个潜在的特征向量。 (3):然后,将这个潜在的特征向量输入到NeRF中,NeRF使用多层感知器来预测场景中每个点的颜色和密度。 (4):通过优化NeRF的损失函数,GHNeRF可以同时学习人体几何、纹理和生物力学特征,例如关节位置。
结论 1. 本工作通过提出 GHNeRF,将人体生物力学特征学习融入 NeRF,显著提升了人体 NeRF 表征的泛化能力。 2. 创新点: - 提出了一种将预训练的 2D 编码器与 NeRF 框架相结合的方法,从 2D 图像中提取人体特征并将其编码到 NeRF 中。 - 创新性地利用基于 Transformer 的 2D 编码器,能够从 2D 图像中提取局部和全局特征。 3. 性能: - 在人体 NeRF 技术和关节估计算法的综合比较中取得了最先进的结果。 - 可以在接近实时的情况下运行,具有较高的实用性。 4. 工作量: - 工作量较大,涉及到 2D 编码器的预训练、NeRF 模型的训练和优化。 - 算法的复杂度较高,需要较高的计算资源。
点此查看论文截图

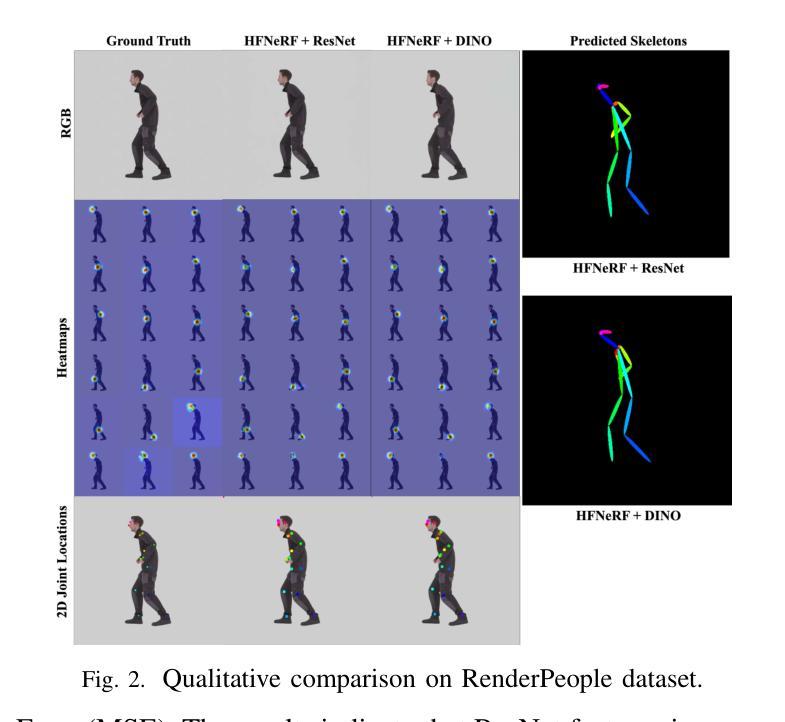
- 标题:HFNeRF:使用神经辐射场学习人体生物力学特征
- 作者:Arnab Dey,Di Yang,Antitza Dantcheva,Jean Martinet
- 隶属机构:I3S-CNRS/Universit´e Cˆoted’Azur
- 关键词:计算机视觉、增强现实、虚拟现实、NeRF
- 论文链接:https://arxiv.org/abs/2404.06152
- 摘要: (1)研究背景:神经辐射场(NeRF)在生成新颖视图方面取得了显著进展,但现有方法无法捕捉到不同实例之间共享的骨骼等潜在结构特征。 (2)过去方法及问题:现有基于 NeRF 的人体方法虽然在生成逼真的虚拟化身方面取得了可喜的成果,但缺乏潜在的人体结构或生物力学特征,如骨骼或关节信息,这对于增强现实 (AR)/虚拟现实 (VR) 等下游应用至关重要。 (3)研究方法:本文提出了一种名为 HFNeRF 的新方法,该方法利用 NeRF 架构学习人体生物力学特征,如人体骨骼。HFNeRF 采用预训练的 2D 编码器,使用神经渲染从图像中提取人体特征,然后使用体积渲染生成 2D 特征图。 (4)方法性能:HFNeRF 在骨骼估计任务中通过预测热图作为特征进行评估。该方法是完全可微的,允许以同步的方式成功学习颜色、几何形状和人体骨骼。本文展示了 HFNeRF 的初步结果,说明了其使用 NeRF 生成具有生物力学特征的逼真虚拟化身的潜力。
Methods
(1): NeRF架构:HFNeRF利用神经辐射场(NeRF)架构,通过多层感知器(MLP)将3D坐标映射到颜色和不透明度。
(2): 特征提取:使用预训练的2D编码器从图像中提取人体特征,生成2D特征图。
(3): 骨骼提取:从2D特征图中预测热图作为骨骼特征,然后通过后处理提取骨骼。
- 结论: (1):本文提出了一种名为 HFNeRF 的新框架,该框架使用神经辐射场(NeRF)来学习人体生物力学特征。我们的初步研究结果证明了 HFNeRF 在预测人体特征方面的有效性,这比以前用于人类的 NeRF 方法有了显着改进。虽然我们的重点是人体骨骼检测,但我们相信这种架构可以扩展到其他可概括的人体特征,例如身体部位检测。 (2):创新点:提出了一种新颖的框架 HFNeRF,该框架使用 NeRF 学习人体生物力学特征,如人体骨骼。 性能:HFNeRF 在骨骼估计任务中通过预测热图作为特征进行评估,在预测人体特征方面表现出有效性。 工作量:本文展示了 HFNeRF 的初步结果,说明了其使用 NeRF 生成具有生物力学特征的逼真虚拟化身的潜力。
点此查看论文截图

 wechat
wechat- alipay







