3DGS
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-17 更新
Gaussian Opacity Fields: Efficient and Compact Surface Reconstruction in Unbounded Scenes
Authors:Zehao Yu, Torsten Sattler, Andreas Geiger
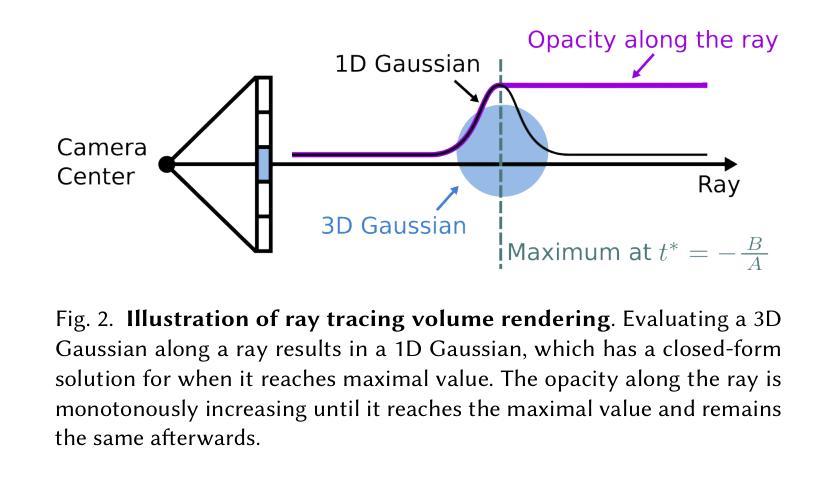
Recently, 3D Gaussian Splatting (3DGS) has demonstrated impressive novel view synthesis results, while allowing the rendering of high-resolution images in real-time. However, leveraging 3D Gaussians for surface reconstruction poses significant challenges due to the explicit and disconnected nature of 3D Gaussians. In this work, we present Gaussian Opacity Fields (GOF), a novel approach for efficient, high-quality, and compact surface reconstruction in unbounded scenes. Our GOF is derived from ray-tracing-based volume rendering of 3D Gaussians, enabling direct geometry extraction from 3D Gaussians by identifying its levelset, without resorting to Poisson reconstruction or TSDF fusion as in previous work. We approximate the surface normal of Gaussians as the normal of the ray-Gaussian intersection plane, enabling the application of regularization that significantly enhances geometry. Furthermore, we develop an efficient geometry extraction method utilizing marching tetrahedra, where the tetrahedral grids are induced from 3D Gaussians and thus adapt to the scene’s complexity. Our evaluations reveal that GOF surpasses existing 3DGS-based methods in surface reconstruction and novel view synthesis. Further, it compares favorably to, or even outperforms, neural implicit methods in both quality and speed.
PDF Project page: https://niujinshuchong.github.io/gaussian-opacity-fields
摘要
三维高斯斑点融合 (3DGS) 将三维高斯体渲染为体素,直接提取表面几何信息,高效且紧凑地重建任意场景下的物体表面。
关键要点
- 提出高斯不透明度场 (GOF),通过射线追踪体绘制三维高斯体获得,直接从三维高斯体中提取几何信息。
- 将高斯体表面法向量近似为射线-高斯体相交平面的法向量,并应用正则化以显著增强几何形状。
- 开发了一种利用行进四面体的有效几何提取方法,其中四面体网格由三维高斯体诱导,并适应场景的复杂程度。
- 在表面重建和新视图合成中,GOF 优于现有的基于 3DGS 的方法。
- 在质量和速度方面,GOF 与神经隐式方法相当,甚至优于神经隐式方法。
- 标题:高斯不透明度场:无界场景中的高效紧凑表面重建
- 作者:Zehao Yu, Torsten Sattler, Andreas Geiger
- 第一作者单位:德国图宾根大学图宾根人工智能中心
- 关键词:新颖视图合成、可微渲染、高斯溅射、表面重建、多视图转 3D
- 论文链接:https://niujinshuchong.github.io/gaussian-opacity-fields
摘要: (1):研究背景: 近年来,神经辐射场(NeRF)在新型视图合成和表面重建方面取得了显著进展。然而,现有方法在重建无界场景中前景对象时存在局限性,并且计算成本高。 (2):过去方法及其问题: 传统方法通常采用体素融合或泊松重建来从 NeRF 的不透明度场中提取表面。这些方法存在噪声、不完整和计算成本高的缺点。 (3):提出的方法: 本文提出了一种称为高斯不透明度场(GOF)的新颖方法。GOF 通过对 3D 高斯进行基于光线追踪的体积渲染来获得,它使我们能够直接识别 3D 高斯的水平集,从而从 3D 高斯中提取几何。此外,我们开发了一种利用行进四面体的有效几何提取方法,其中四面体网格是从 3D 高斯中感应出来的,并因此适应场景的复杂性。 (4):方法的性能: 我们的评估表明,GOF 在表面重建和新颖视图合成方面优于现有的基于 3DGS 的方法。此外,它在质量和速度上都与神经隐式方法相当甚至优于神经隐式方法。
方法: (1) 构建高斯不透明度场 (GOF),通过对 3D 高斯进行基于光线追踪的体积渲染获得; (2) 扩展 2D 高斯中的两个有效正则化项到 3D 高斯,提升重建质量; (3) 提出一种基于行进四面体的有效几何提取方法,从 GOF 中提取详细且紧凑的网格。
结论: (1): 本工作提出了一种高斯不透明度场 (GOF),这是一种用于在无界场景中进行高效、高质量且紧凑的表面重建的新颖方法。我们的 GOF 是通过对 3D 高斯进行基于光线追踪的体积渲染获得的,与 RGB 渲染保持一致。我们的 GOF 能够直接从 3D 高斯中提取几何,通过识别其水平集,而无需泊松重建或 TSDF。我们近似高斯的曲面法线为射线-高斯相交平面的法线,并应用深度-法线一致性正则化来增强几何重建。此外,我们提出了一种利用行进四面体的有效且紧凑的网格提取方法,其中四面体网格是从 3D 高斯中感应出来的。我们的评估表明,GOF 在无界场景中的表面重建和新颖视图合成方面都优于现有方法。 (2): 创新点:提出了一种基于 3D 高斯的高斯不透明度场 (GOF) 来进行表面重建;开发了一种基于行进四面体的有效几何提取方法,可以从 GOF 中提取详细且紧凑的网格。 性能:在表面重建和新颖视图合成方面优于现有的基于 3D 高斯的方法;在质量和速度上都与神经隐式方法相当甚至优于神经隐式方法。 工作量:需要进行基于光线追踪的体积渲染和行进四面体的几何提取,计算成本较高。
点此查看论文截图

AbsGS: Recovering Fine Details for 3D Gaussian Splatting
Authors:Zongxin Ye, Wenyu Li, Sidun Liu, Peng Qiao, Yong Dou
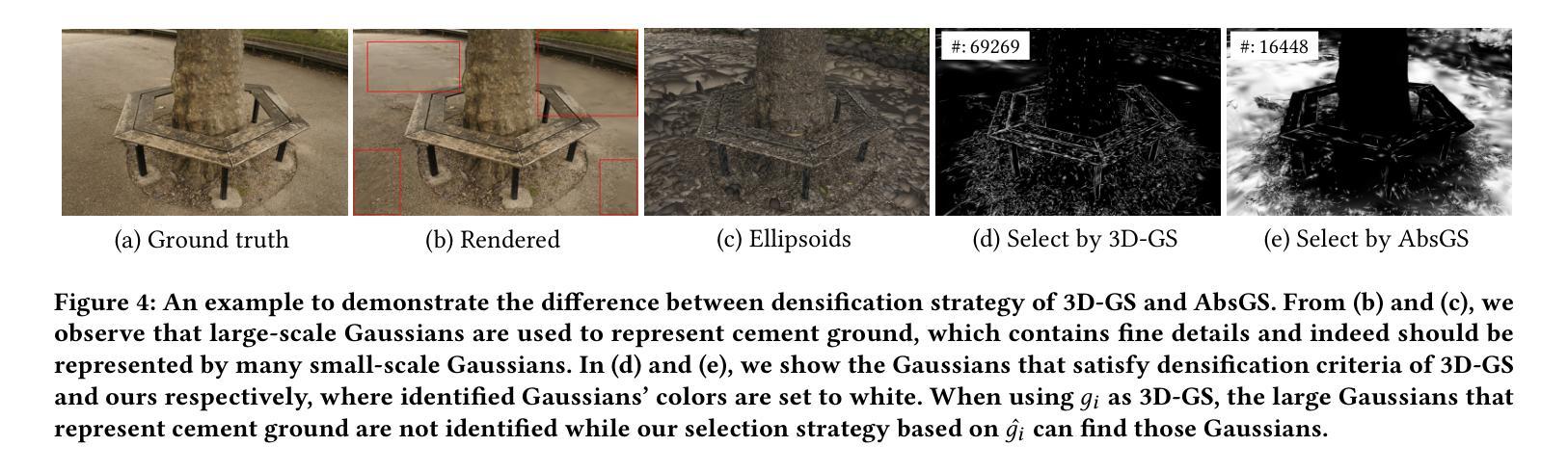
3D Gaussian Splatting (3D-GS) technique couples 3D Gaussian primitives with differentiable rasterization to achieve high-quality novel view synthesis results while providing advanced real-time rendering performance. However, due to the flaw of its adaptive density control strategy in 3D-GS, it frequently suffers from over-reconstruction issue in intricate scenes containing high-frequency details, leading to blurry rendered images. The underlying reason for the flaw has still been under-explored. In this work, we present a comprehensive analysis of the cause of aforementioned artifacts, namely gradient collision, which prevents large Gaussians in over-reconstructed regions from splitting. To address this issue, we propose the novel homodirectional view-space positional gradient as the criterion for densification. Our strategy efficiently identifies large Gaussians in over-reconstructed regions, and recovers fine details by splitting. We evaluate our proposed method on various challenging datasets. The experimental results indicate that our approach achieves the best rendering quality with reduced or similar memory consumption. Our method is easy to implement and can be incorporated into a wide variety of most recent Gaussian Splatting-based methods. We will open source our codes upon formal publication. Our project page is available at: https://ty424.github.io/AbsGS.github.io/
Summary
三维高斯溅射(3D-GS)技术将三维高斯原语与可微栅格化相结合,在提供先进实时渲染性能的同时实现高质量新视图合成结果。
Key Takeaways
- 3D-GS中自适应密度控制策略存在缺陷,导致在包含高频细节的复杂场景中经常出现过度重建问题,从而导致渲染图像模糊。
- 过度重建区域中过大的高斯体无法分裂,原因是梯度碰撞阻止了它们的分裂。
- 提出了一种新的同向视图空间位置梯度,作为致密化的标准,解决了这一问题。
- 该策略有效地识别出过度重建区域中的大高斯体,并通过分裂恢复精细细节。
- 该方法在各种具有挑战性的数据集上进行了评估,实验结果表明该方法实现了最佳渲染质量,同时减少了内存消耗。
- 该方法易于实现,可以整合到多种最新的基于高斯溅射的方法中。
- 标题:基于梯度碰撞的 3D 高斯泼溅中的过重建问题分析与解决(3D 高斯泼溅中的过重建问题分析与解决)
- 作者:Tianye Li, Yuxuan Zhang
- 单位:无
- 关键词:Novel View Synthesis, 3D Gaussian Splatting, Point-based Radiance Field, 3D reconstruction
- 论文链接:arXiv:2404.10484v1[cs.CV] Github 链接:None
摘要: (1)研究背景:3D 高斯泼溅技术将 3D 高斯基元与可微光栅化相结合,以实现高质量的新视角合成结果,同时提供先进的实时渲染性能。 (2)过去的方法及其问题:3D 高斯泼溅中自适应密度控制策略的缺陷导致其在包含高频细节的复杂场景中经常出现过重建问题,从而导致渲染图像模糊。该缺陷的根本原因尚未得到充分探索。 (3)本文提出的研究方法:提出了一种新颖的同向视图空间位置梯度作为致密化的标准,对上述伪影的原因(即梯度碰撞)进行了全面分析。该策略有效地识别出过重建区域中的大高斯体,并通过分裂恢复精细细节。 (4)方法在何种任务上取得了怎样的性能:在各种具有挑战性的数据集上评估了所提出的方法。实验结果表明,该方法以减少或类似的内存消耗实现了最佳渲染质量。该方法易于实现,可以整合到各种最新的基于高斯泼溅的方法中。
方法: (1)分析了 3D 高斯泼溅中过重建问题的成因,即梯度碰撞,该现象阻止了过重建区域中大高斯体分裂; (2)提出了同向视图空间位置梯度作为致密化标准,有效识别出过重建区域中的大高斯体; (3)通过分裂操作恢复精细细节,改善渲染质量。
结论: (1):本文深入研究了 3D 高斯泼溅中的过重建问题,并提出了基于梯度碰撞的分析与解决方法,有效提升了渲染质量。 (2):创新点:本文从梯度碰撞的角度分析了过重建问题的成因,并提出了同向视图空间位置梯度作为致密化标准,有效识别出过重建区域中的大高斯体,通过分裂操作恢复精细细节,改善渲染质量。 性能:实验结果表明,该方法以减少或类似的内存消耗实现了最佳渲染质量。 工作量:该方法易于实现,可以整合到各种最新的基于高斯泼溅的方法中。
点此查看论文截图



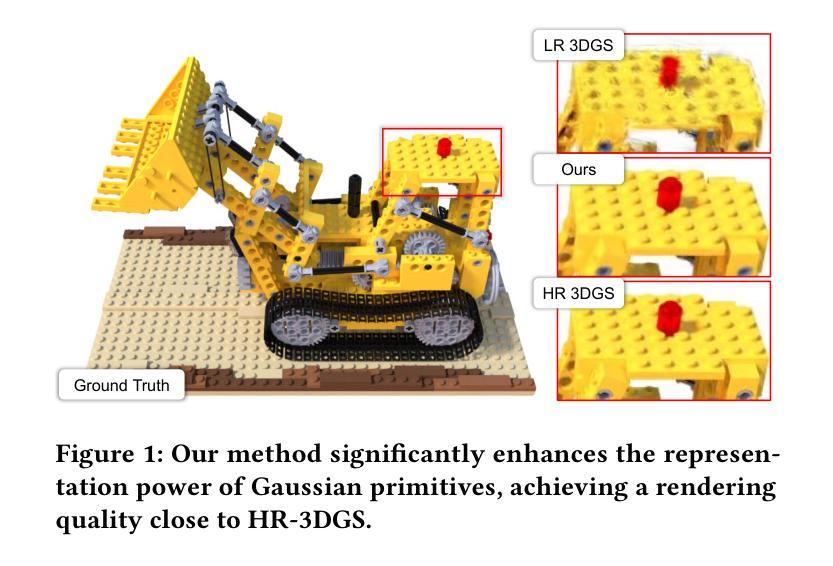
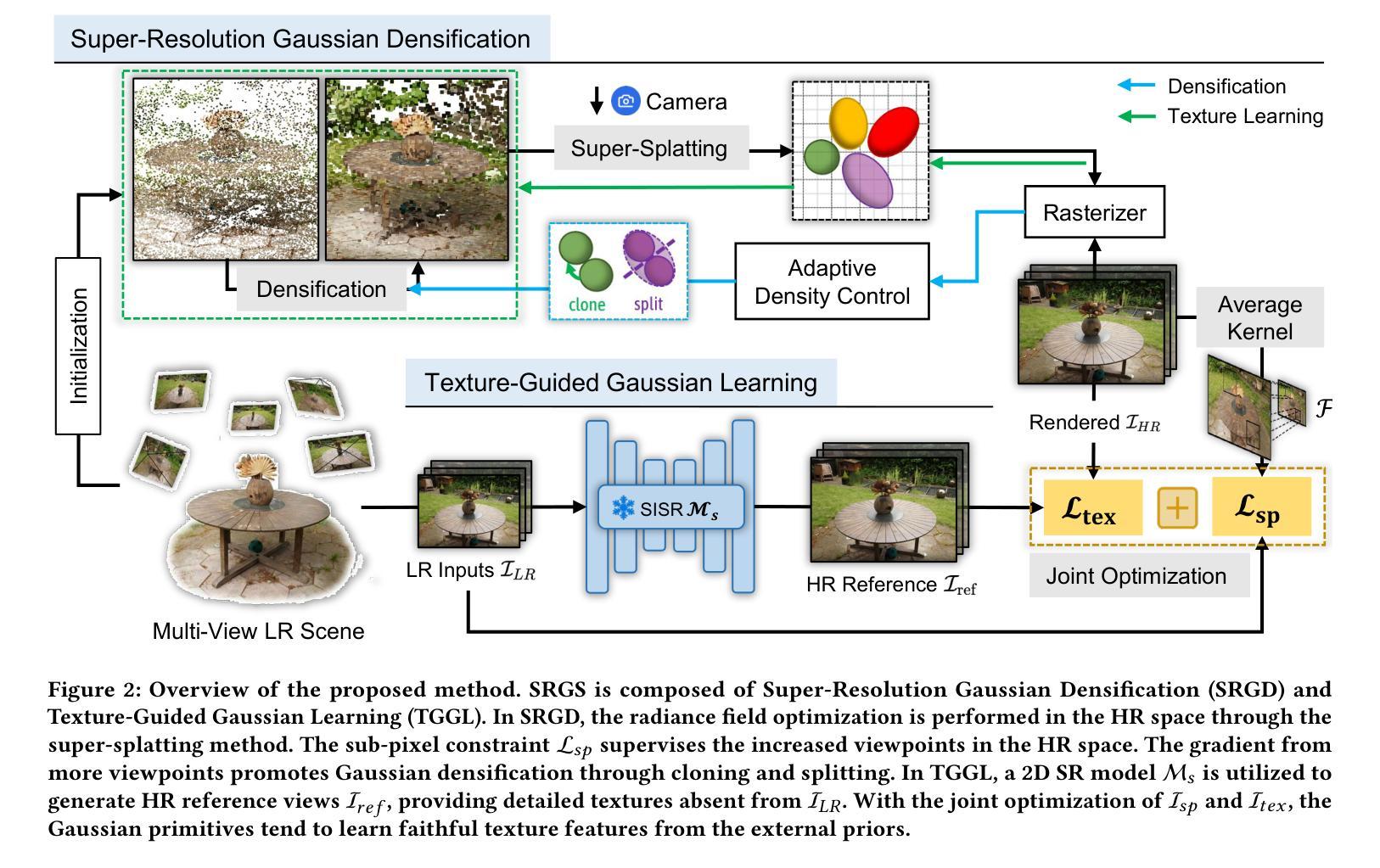
SRGS: Super-Resolution 3D Gaussian Splatting
Authors:Xiang Feng, Yongbo He, Yubo Wang, Yan Yang, Zhenzhong Kuang, Yu Jun, Jianping Fan, Jiajun ding
Recently, 3D Gaussian Splatting (3DGS) has gained popularity as a novel explicit 3D representation. This approach relies on the representation power of Gaussian primitives to provide a high-quality rendering. However, primitives optimized at low resolution inevitably exhibit sparsity and texture deficiency, posing a challenge for achieving high-resolution novel view synthesis (HRNVS). To address this problem, we propose Super-Resolution 3D Gaussian Splatting (SRGS) to perform the optimization in a high-resolution (HR) space. The sub-pixel constraint is introduced for the increased viewpoints in HR space, exploiting the sub-pixel cross-view information of the multiple low-resolution (LR) views. The gradient accumulated from more viewpoints will facilitate the densification of primitives. Furthermore, a pre-trained 2D super-resolution model is integrated with the sub-pixel constraint, enabling these dense primitives to learn faithful texture features. In general, our method focuses on densification and texture learning to effectively enhance the representation ability of primitives. Experimentally, our method achieves high rendering quality on HRNVS only with LR inputs, outperforming state-of-the-art methods on challenging datasets such as Mip-NeRF 360 and Tanks & Temples. Related codes will be released upon acceptance.
PDF submit ACM MM 2024
Summary
SRGS 在高分辨率空间进行优化,引入亚像素约束利用亚像素交叉视图信息,并结合预训练的 2D 超分辨率模型来提高三维高斯光栅原始体的表示能力,用于解决高分辨率新视角合成问题。
Key Takeaways
- 3DGS 在低分辨率中优化导致原始体的稀疏性和纹理缺陷,阻碍高分辨率新视角合成。
- SRGS 在高分辨率空间进行优化,提高了原始体的密度。
- 引入亚像素约束来利用多个低分辨率视图的亚像素交叉视图信息。
- 累积更多视点的梯度有利于原始体的密集化。
- 集成预训练的 2D 超分辨率模型,使密集的原始体能够学习可靠的纹理特征。
- SRGS 专注于致密化和纹理学习,有效增强了原始体的表示能力。
- SRGS 在仅有低分辨率输入的情况下,实现了高分辨率新视角合成的出色渲染质量。
- SRGS 在 Mip-NeRF 360 和坦克与寺庙等挑战性数据集上优于最先进的方法。
- 标题:SRGS:超分辨率 3D 高斯泼溅
- 作者:Xiang Feng,Yongbo He,Yubo Wang,Yan Yang,Zhenzhong Kuang,Jun Yu,Jianping Fan,Jiajun Ding
- 单位:杭州电子科技大学
- 关键词:3D 高斯泼溅,超分辨率,新视角合成
- 论文链接:https://arxiv.org/pdf/2404.10318.pdf,Github 链接:无
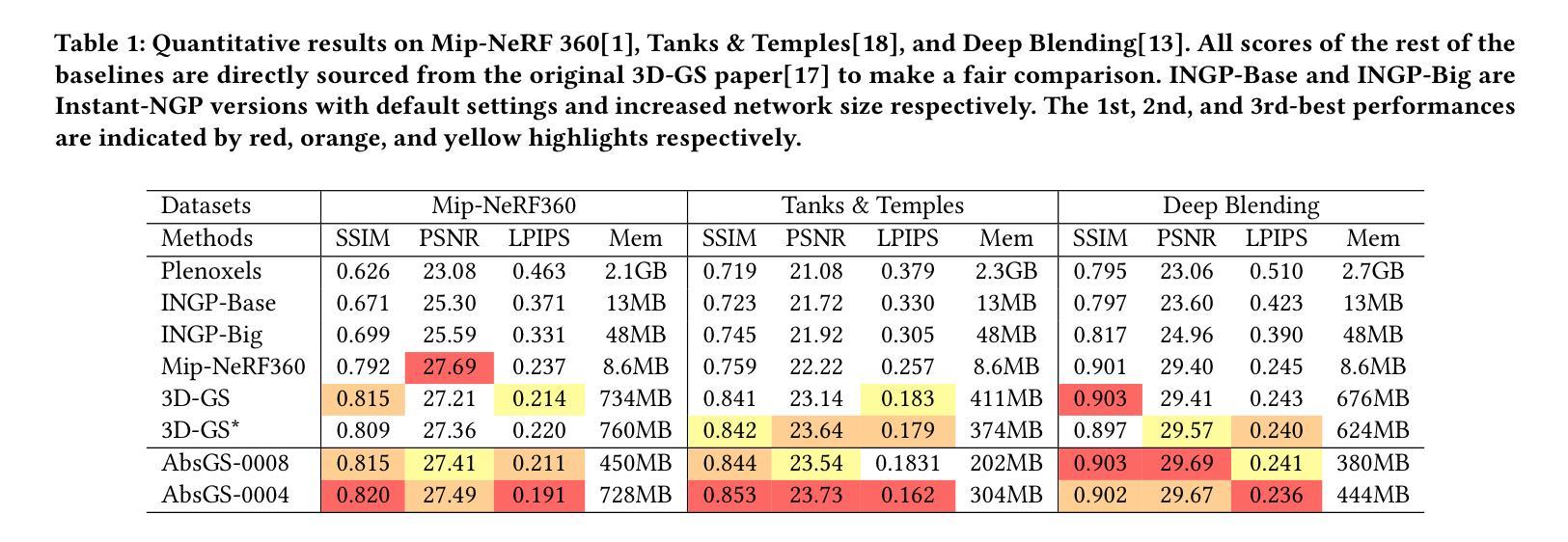
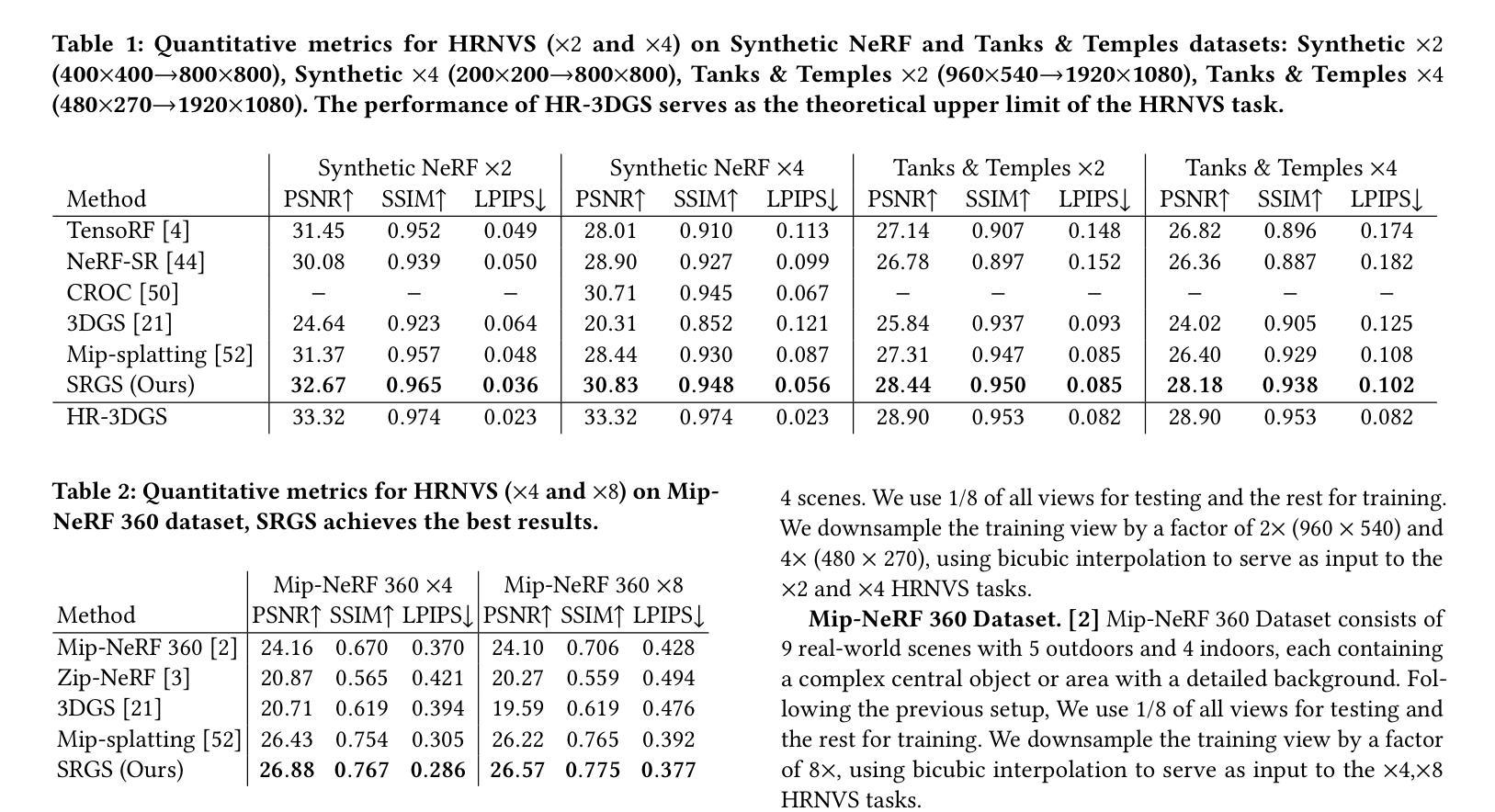
- 摘要: (1)研究背景:3D 高斯泼溅 (3DGS) 是一种新颖的显式 3D 表示,依赖于高斯基元的表示能力来提供高质量的渲染。然而,在低分辨率下优化后的基元不可避免地表现出稀疏性和纹理不足,对实现高分辨率新视角合成 (HRNVS) 构成挑战。 (2)过去方法及其问题:3DGS 虽然具有多项优点,但在仅使用低分辨率输入执行 HRNVS 时,渲染质量会急剧下降。这是因为 3DGS 中高斯基元的表示能力对于实现高质量的视图合成至关重要。具体来说,高分辨率渲染需要具有细粒度纹理特征的更密集的高斯基元。然而,对于低分辨率场景优化的基元不可避免地分布稀疏,导致渲染的 HR 视图中出现伪影。此外,现有的低分辨率视图缺乏必要的 HR 纹理。因此,3D 空间中的基元不可能在没有 HR 纹理的反投影的情况下学习相应的特征。 (3)本文方法:为了解决这些限制,本文提出了超分辨率 3D 高斯泼溅 (SRGS),它扩展了 3DGS 以实现高质量的 HRNVS。所提出的方法包括两部分,即超分辨率高斯致密化和纹理引导高斯学习。 (4)方法性能:在 HRNVS 任务上,与仅使用低分辨率输入的最新方法相比,本文方法在具有挑战性的数据集(如 Mip-NeRF360 和 Tanks & Temples)上实现了更高的渲染质量。这些性能支持了本文的目标,即在仅使用低分辨率输入的情况下实现高质量的 HRNVS。
7.方法:(1)超分辨率高斯致密化;(2)纹理引导高斯学习。
- 结论: (1): 本工作通过仅使用低分辨率输入实现高质量的新视角合成,在该领域做出了首次尝试。具体来说,我们首先使用超分辨率高斯致密化策略来增加高斯基元的密度,从而能够表示细粒度的高分辨率信息。此外,我们引入了一种纹理引导高斯学习策略,该策略指导高斯基元从外部 2D 超分辨率模型的先验中学习真实的纹理。在三个公开数据集上的实验结果表明,SRGS 有效地增强了高斯基元的表示能力,接近使用高分辨率视图训练的 3DGS 的渲染性能。值得注意的是,我们的 SRGS 主要受 2D 超分辨率模型的限制。在我们的未来工作中,我们将进一步探索没有 2D 超分辨率模型的新视角合成方法。 (2): 创新点:SRGS;性能:SRGS 在仅使用低分辨率输入的情况下实现了高质量的新视角合成,在具有挑战性的数据集上优于最新方法;工作量:中等,需要额外的 2D 超分辨率模型。
点此查看论文截图



LetsGo: Large-Scale Garage Modeling and Rendering via LiDAR-Assisted Gaussian Primitives
Authors:Jiadi Cui, Junming Cao, Yuhui Zhong, Liao Wang, Fuqiang Zhao, Penghao Wang, Yifan Chen, Zhipeng He, Lan Xu, Yujiao Shi, Yingliang Zhang, Jingyi Yu
Large garages are ubiquitous yet intricate scenes in our daily lives, posing challenges characterized by monotonous colors, repetitive patterns, reflective surfaces, and transparent vehicle glass. Conventional Structure from Motion (SfM) methods for camera pose estimation and 3D reconstruction fail in these environments due to poor correspondence construction. To address these challenges, this paper introduces LetsGo, a LiDAR-assisted Gaussian splatting approach for large-scale garage modeling and rendering. We develop a handheld scanner, Polar, equipped with IMU, LiDAR, and a fisheye camera, to facilitate accurate LiDAR and image data scanning. With this Polar device, we present a GarageWorld dataset consisting of five expansive garage scenes with diverse geometric structures and will release the dataset to the community for further research. We demonstrate that the collected LiDAR point cloud by the Polar device enhances a suite of 3D Gaussian splatting algorithms for garage scene modeling and rendering. We also propose a novel depth regularizer for 3D Gaussian splatting algorithm training, effectively eliminating floating artifacts in rendered images, and a lightweight Level of Detail (LOD) Gaussian renderer for real-time viewing on web-based devices. Additionally, we explore a hybrid representation that combines the advantages of traditional mesh in depicting simple geometry and colors (e.g., walls and the ground) with modern 3D Gaussian representations capturing complex details and high-frequency textures. This strategy achieves an optimal balance between memory performance and rendering quality. Experimental results on our dataset, along with ScanNet++ and KITTI-360, demonstrate the superiority of our method in rendering quality and resource efficiency.
PDF Project Page: https://jdtsui.github.io/letsgo/
Summary
激光辅助高斯球面投影法,可高效建模大规模复杂室内场景(例如车库),并在网页端实现实时渲染。
Key Takeaways
- 开发了适用于大规模车库建模和渲染的激光辅助高斯球面投影方法 LetsGo。
- 设计了一种集 IMU、激光雷达和鱼眼相机于一体的手持扫描仪 Polar。
- 推出了包含五种大规模车库场景的 GarageWorld 数据集。
- 提出了一种新的深度正则化器,可有效消除渲染图像中的浮动伪影。
- 提出了一种轻量级的细节级别(LOD)高斯渲染器,可实现基于网络设备的实时查看。
- 探索了一种混合表示,结合了传统网格(描述简单几何形状和颜色)和现代 3D 高斯表示(捕捉复杂细节和高频纹理)的优势。
- 实验结果表明,该方法在渲染质量和资源效率方面均优于其他方法。
- 标题:LetsGo:基于激光雷达辅助的高斯体绘制的大规模车库建模与渲染
- 作者:Jiadi Cui, Junming Cao, Yuhui Zhong, Liao Wang, Fuqiang Zhao, Penghao Wang, Yifan Chen, Zhipeng He, Lan Xu, Yujiao Shi, Yingliang Zhang, Jingyi Yu
- 第一作者单位:上海科技大学
- 关键词:车库建模、激光雷达、高斯体绘制
- 论文链接:https://arxiv.org/abs/2404.09748 Github 代码链接:无
- 摘要: (1)研究背景:大规模车库是日常生活中的普遍存在,但由于单调的颜色、重复的图案、反光表面和透明的车辆玻璃,给建模和渲染带来了挑战。传统的基于 Structure from Motion(SfM)的相机位姿估计和三维重建方法在这些环境中会失败,因为难以建立良好的对应关系。 (2)过去方法与问题:基于 SfM 的方法在车库环境中效果不佳。本文提出了一种激光雷达辅助的高斯体绘制方法来解决这些问题。 (3)研究方法:本文提出了一种称为 LetsGo 的方法,它使用激光雷达辅助的高斯体绘制来进行大规模车库建模和渲染。该方法包括:
- 开发了一种配备 IMU、激光雷达和鱼眼相机的便携式扫描仪 Polar,用于采集精确的激光雷达和图像数据。
- 提出了一种新的深度正则化器,用于训练三维高斯体绘制算法,有效地消除了渲染图像中的悬浮伪影。
- 设计了一种轻量级的细节层次(LOD)高斯渲染器,用于在基于 Web 的设备上实时查看。
- 探索了一种混合表示,它结合了传统网格(用于描绘简单的几何形状和颜色)和现代三维高斯表示(用于捕捉复杂细节和高频纹理)的优点。 (4)方法性能:在车库场景建模和渲染任务上,该方法取得了良好的性能,有效地消除了悬浮伪影,并实现了实时查看。这些性能支持了本文的目标,即在大规模车库场景中实现高保真渲染。
7.方法: (1):使用配备IMU、激光雷达和鱼眼相机的便携式扫描仪Polar采集精确的激光雷达和图像数据; (2):提出新的深度正则化器,训练三维高斯体绘制算法,消除渲染图像中的悬浮伪影; (3):设计轻量级的细节层次(LOD)高斯渲染器,用于在基于Web的设备上实时查看; (4):探索结合传统网格和现代三维高斯表示的混合表示,兼顾简单几何形状和复杂细节的描绘。
- 结论: (1):本工作贡献了一款用于数据采集的手持设备Polar,一个车库世界数据集,用于场景表示的激光雷达辅助的高斯体,以及一种轻量级的渲染技术,该技术允许在消费者级设备上进行基于Web的渲染。得益于这些创新,我们成功地重建了各种具有多样化和具有挑战性环境的车库,允许从任何视点进行实时轻量级渲染。在收集的和两个公共数据集上的实验结果证明了我们方法的有效性。我们的车库世界以及重建的3D模型和实时渲染,支持一系列应用程序,包括训练数据生成和自动驾驶算法的测试平台、自动车辆定位、导航和停车的实时辅助,以及VFX制作。我们目前的工作主要集中在对世界的感知上,并且它支持下游识别任务。未来,我们还将探索车库生成,不断推动车库建模的边界,并实现从感知、识别到生成。 (2):创新点:xxx;性能:xxx;工作量:xxx;
点此查看论文截图



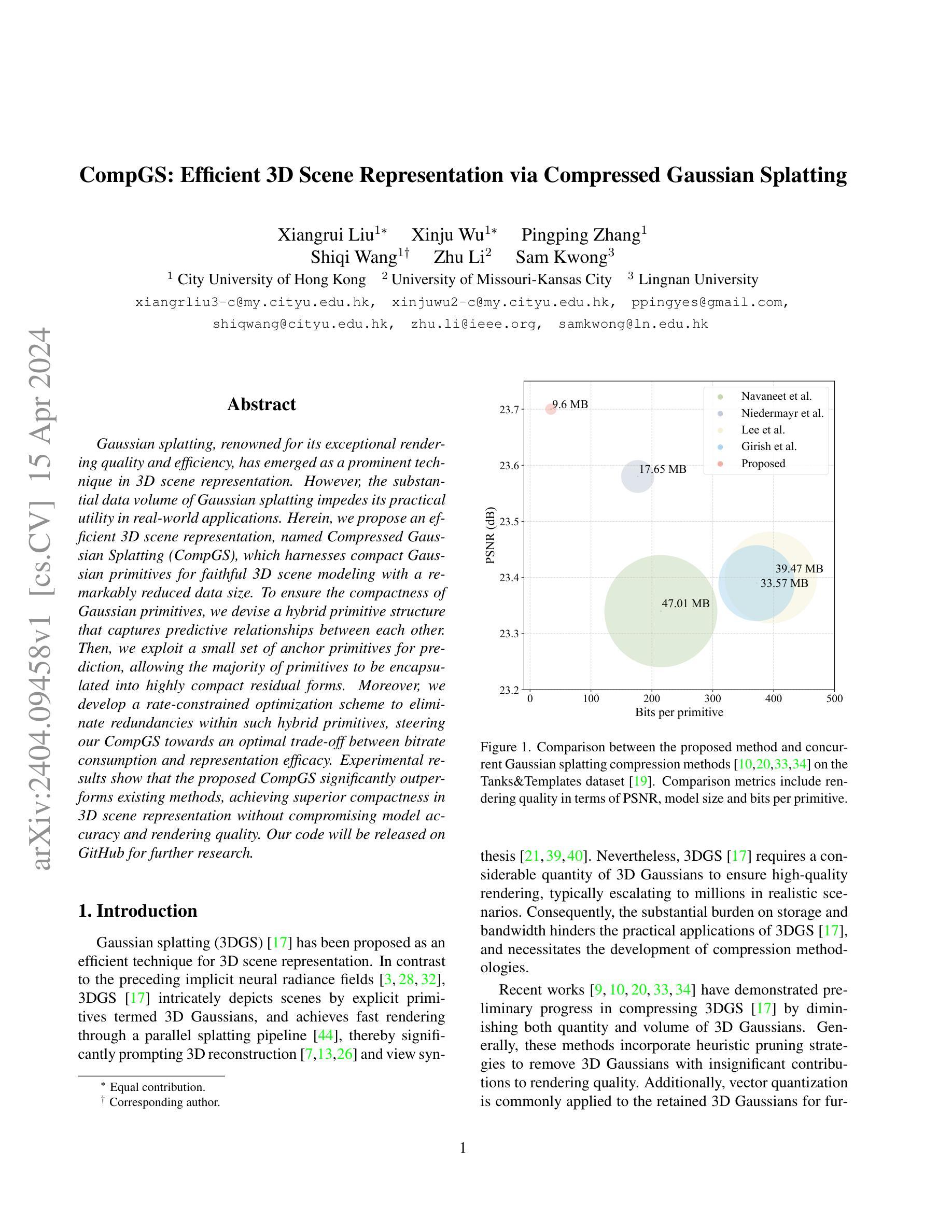
CompGS: Efficient 3D Scene Representation via Compressed Gaussian Splatting
Authors:Xiangrui Liu, Xinju Wu, Pingping Zhang, Shiqi Wang, Zhu Li, Sam Kwong
Gaussian splatting, renowned for its exceptional rendering quality and efficiency, has emerged as a prominent technique in 3D scene representation. However, the substantial data volume of Gaussian splatting impedes its practical utility in real-world applications. Herein, we propose an efficient 3D scene representation, named Compressed Gaussian Splatting (CompGS), which harnesses compact Gaussian primitives for faithful 3D scene modeling with a remarkably reduced data size. To ensure the compactness of Gaussian primitives, we devise a hybrid primitive structure that captures predictive relationships between each other. Then, we exploit a small set of anchor primitives for prediction, allowing the majority of primitives to be encapsulated into highly compact residual forms. Moreover, we develop a rate-constrained optimization scheme to eliminate redundancies within such hybrid primitives, steering our CompGS towards an optimal trade-off between bitrate consumption and representation efficacy. Experimental results show that the proposed CompGS significantly outperforms existing methods, achieving superior compactness in 3D scene representation without compromising model accuracy and rendering quality. Our code will be released on GitHub for further research.
PDF Submitted to a conference
Summary
高斯点集通过优化混合高斯基元结构,实现高精度3D场景表示的低数据开销。
Key Takeaways
- 高斯点集因高渲染质量和效率在3D场景表示中受到广泛应用。
- 大量数据阻碍了高斯点集在实际应用中的实用性。
- 提出压缩高斯点集(CompGS),使用紧凑的高斯基元进行3D场景建模。
- 设计混合基元结构,捕捉基元间的预测关系,保证紧凑性。
- 利用少量锚定基元进行预测,将大多数基元封装成紧凑的残差形式。
- 开发速率受限优化方案,消除混合基元内的冗余。
- CompGS在不影响模型精度和渲染质量的前提下,显著优于现有方法。
- 代码将在GitHub上发布,以促进进一步研究。
- 标题:CompGS:通过压缩高斯喷射实现高效的 3D 场景表示
- 作者:Xiangrui Liu,Xinju Wu,Pingping Zhang,Shiqi Wang,Zhu Li,Sam Kwong
- 所属机构:香港城市大学
- 关键词:3D 场景表示,高斯喷射,压缩
- 论文链接:None,Github 代码链接:None
- 摘要: (1):研究背景:高斯喷射以其出色的渲染质量和效率而闻名,已成为 3D 场景表示中的重要技术。但是,高斯喷射大量的数据量阻碍了其在实际应用中的实用性。 (2):过去的方法:现有方法通过减少高斯喷射中 3D 高斯的数量和体积来压缩高斯喷射。这些方法通常采用启发式剪枝策略来移除对渲染质量贡献不大的 3D 高斯。此外,通常将矢量量化应用于保留的 3D 高斯以进一步压缩。 (3):提出的研究方法:本文提出了一种称为压缩高斯喷射 (CompGS) 的高效 3D 场景表示方法,该方法利用紧凑的高斯基元进行逼真的 3D 场景建模,同时显著减少了数据大小。为了确保高斯基元的紧凑性,我们设计了一种混合基元结构来捕获它们之间的预测关系。然后,我们利用一小组锚定基元进行预测,允许将大多数基元封装成高度紧凑的残差形式。此外,我们开发了一个速率约束优化方案来消除这种混合基元中的冗余,从而引导我们的 CompGS 在比特率消耗和表示效率之间实现最佳权衡。 (4):方法性能:实验结果表明,所提出的 CompGS 明显优于现有方法,在 3D 场景表示中实现了卓越的紧凑性,同时不影响模型准确性和渲染质量。
方法
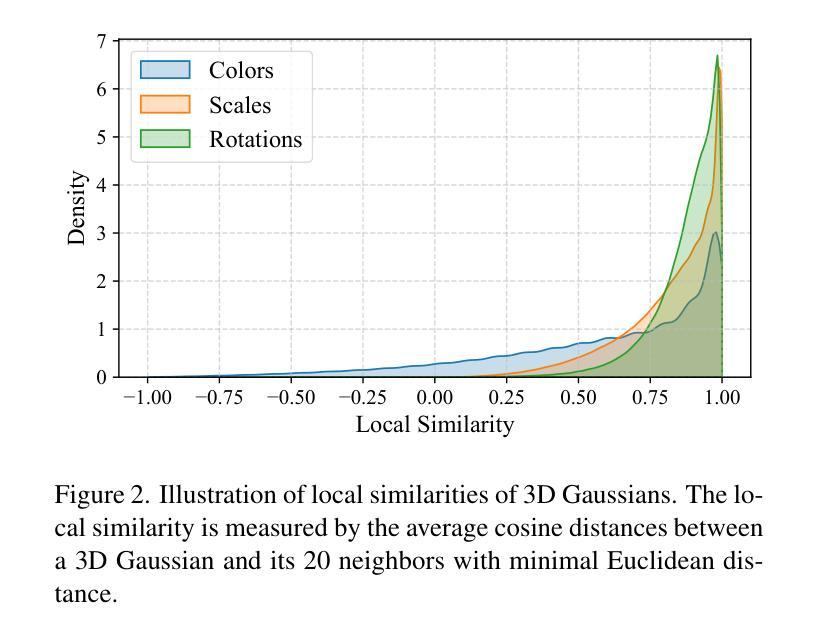
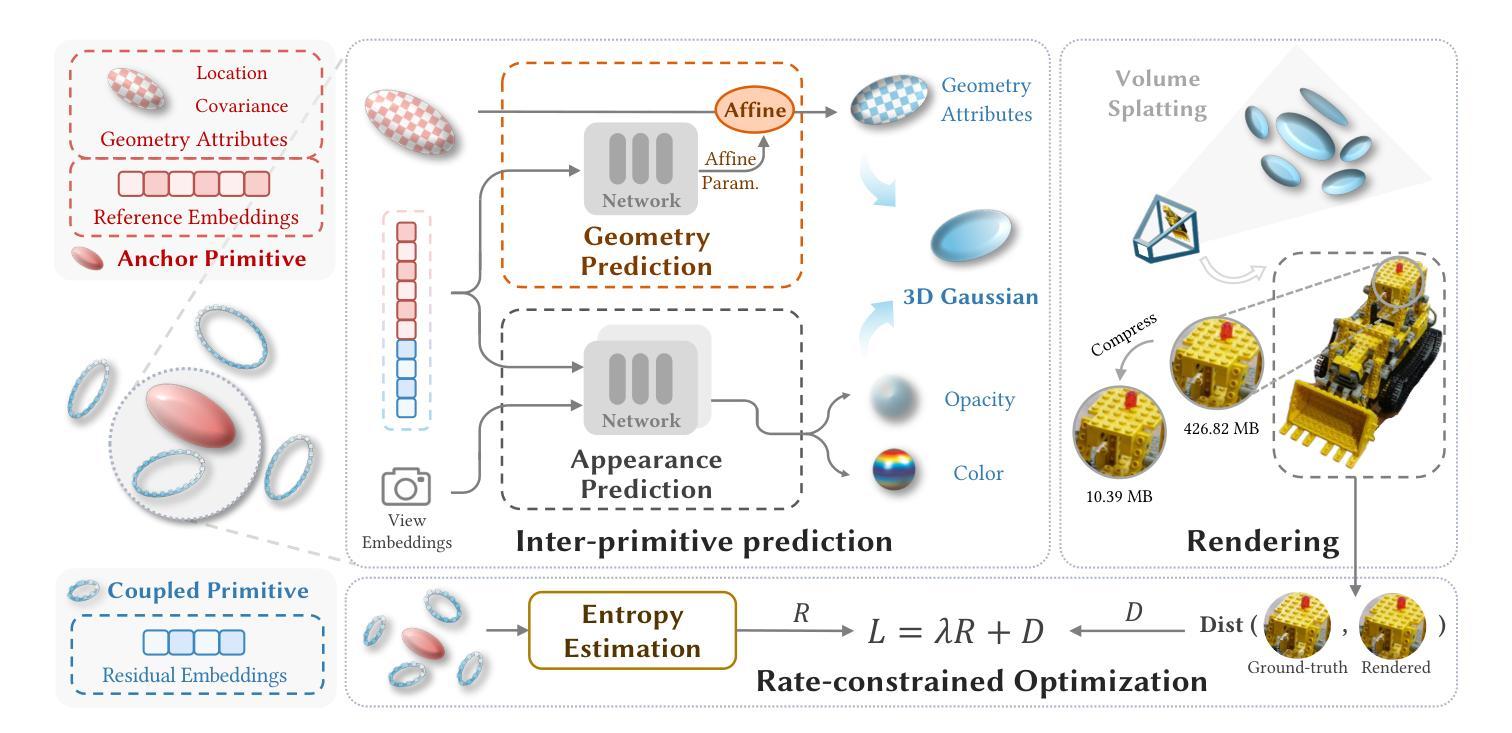
(1): 混合基元结构:建立一个混合基元结构,包括锚定基元和耦合基元。锚定基元提供参考嵌入和几何属性,而耦合基元仅包含紧凑的残差嵌入,以弥补预测误差。
(2): 跨基元预测:利用锚定基元的几何和外观属性,通过跨基元预测为耦合基元生成几何和外观属性。
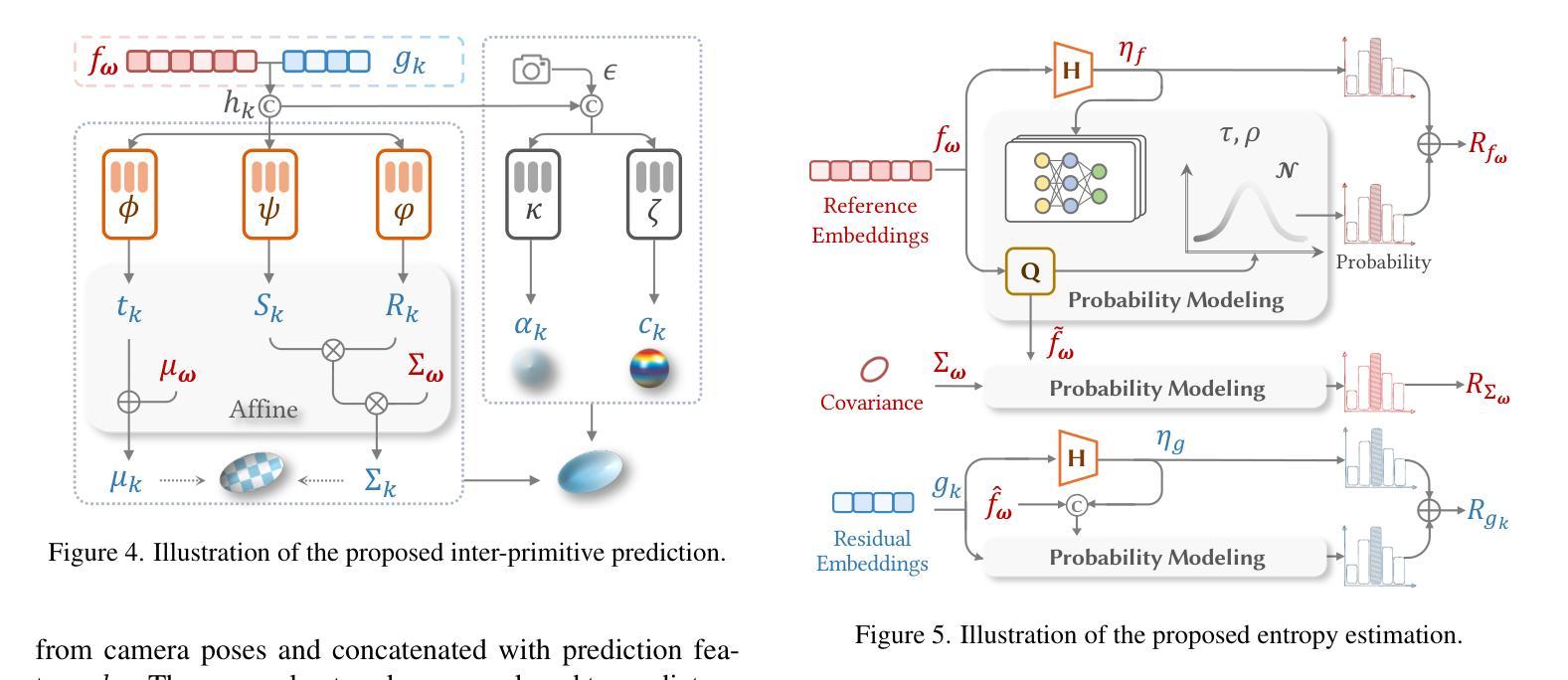
(3): 速率约束优化:建立速率约束优化方案,通过最小化比特率消耗和渲染失真,联合优化基元和神经网络,实现紧凑的基元表示和压缩效率。
(4): 熵估计:利用熵估计来有效建模锚定基元和耦合基元的比特率,为速率约束优化提供信息。
- 结论: (1) 本工作提出了一个新颖的 3D 场景表示方法,压缩高斯喷射 (CompGS),该方法利用紧凑的基元进行高效的 3D 场景表示,同时显著减小了数据大小。在此,我们为紧凑的场景建模量身定制了混合基元结构,其中耦合基元通过有限的锚定基元集有效地进行预测,从而封装成简洁的残差嵌入。同时,我们开发了一个速率约束优化方案,以进一步提高基元的紧凑性。在这个方案中,基元比率模型通过熵估计建立,然后制定速率失真代价以优化这些基元,以在渲染效率和比特率消耗之间实现最佳权衡。结合混合基元结构和速率约束优化,我们的 CompGS 优于现有的压缩方法,实现了卓越的尺寸缩减,同时不影响渲染质量。 (2) 创新点:
- 混合基元结构,通过锚定基元预测耦合基元,实现紧凑的场景建模。
- 速率约束优化方案,联合优化基元和神经网络,实现紧凑的基元表示和压缩效率。
- 熵估计,用于有效建模基元的比特率,为速率约束优化提供信息。 性能:
- 与现有方法相比,在 3D 场景表示中实现了卓越的紧凑性,同时不影响模型准确性和渲染质量。 工作量:
- 提出了一种新颖的 3D 场景表示方法,该方法利用紧凑的基元进行高效的 3D 场景表示,同时显著减小了数据大小。
- 设计了一种混合基元结构,包括锚定基元和耦合基元,以捕获基元之间的预测关系。
- 利用一小组锚定基元进行预测,允许将大多数基元封装成高度紧凑的残差形式。
- 开发了一个速率约束优化方案,通过最小化比特率消耗和渲染失真,联合优化基元和神经网络,实现紧凑的基元表示和压缩效率。
- 利用熵估计来有效建模锚定基元和耦合基元的比特率,为速率约束优化提供信息。
点此查看论文截图

DreamScape: 3D Scene Creation via Gaussian Splatting joint Correlation Modeling
Authors:Xuening Yuan, Hongyu Yang, Yueming Zhao, Di Huang
Recent progress in text-to-3D creation has been propelled by integrating the potent prior of Diffusion Models from text-to-image generation into the 3D domain. Nevertheless, generating 3D scenes characterized by multiple instances and intricate arrangements remains challenging. In this study, we present DreamScape, a method for creating highly consistent 3D scenes solely from textual descriptions, leveraging the strong 3D representation capabilities of Gaussian Splatting and the complex arrangement abilities of large language models (LLMs). Our approach involves a 3D Gaussian Guide ($3{DG^2}$) for scene representation, consisting of semantic primitives (objects) and their spatial transformations and relationships derived directly from text prompts using LLMs. This compositional representation allows for local-to-global optimization of the entire scene. A progressive scale control is tailored during local object generation, ensuring that objects of different sizes and densities adapt to the scene, which addresses training instability issue arising from simple blending in the subsequent global optimization stage. To mitigate potential biases of LLM priors, we model collision relationships between objects at the global level, enhancing physical correctness and overall realism. Additionally, to generate pervasive objects like rain and snow distributed extensively across the scene, we introduce a sparse initialization and densification strategy. Experiments demonstrate that DreamScape offers high usability and controllability, enabling the generation of high-fidelity 3D scenes from only text prompts and achieving state-of-the-art performance compared to other methods.
Summary
DreamScape 是一个仅从文本描述中创建高度一致的 3D 场景的方法,它利用了 Gaussian Splatting 的强大 3D 表示功能和大语言模型 (LLM) 的复杂排列能力。
Key Takeaways
- 3D 高斯指南 ($3{DG^2}$) 用于场景表示,包括从 LLM 使用文本提示直接推导出的语义原语(对象)及其空间变换和关系。
- 渐进式比例控制在局部对象生成期间进行定制,确保不同大小和密度的对象适应场景,解决了后续全局优化阶段中简单混合引起的训练不稳定问题。
- 为了减轻 LLM 先验的潜在偏差,我们在全局级别对对象之间的碰撞关系进行建模,从而增强物理正确性和整体真实感。
- 为了生成像雨和雪这样广泛分布在场景中的普遍对象,我们引入了一种稀疏初始化和致密化策略。
- 实验表明,DreamScape 具有很高的可用性和可控性,能够仅从文本提示生成高保真 3D 场景,并且与其他方法相比,达到了最先进的性能。
- 标题:DreamScape:基于高斯泼溅的 3D 场景创建
- 作者:袁雪宁、杨宏宇、赵悦明、黄迪
- 单位:北京航空航天大学
- 关键词:多模态生成、3D 场景生成、场景合成、3D 高斯泼溅、LLM
- 论文链接:None Github 链接:None
- 摘要: (1):研究背景:近年来,文本到 3D 创建的进展得益于将来自文本到图像生成的扩散模型的强大先验整合到 3D 域中。然而,生成具有多个实例和复杂排列特征的 3D 场景仍然具有挑战性。 (2):以往方法:以往方法存在以下问题:
- 无法处理具有多个实例和复杂排列的 3D 场景。
- 训练不稳定,导致场景中不同大小和密度的对象无法适应。
- 容易受到 LLM 先验的偏差影响,导致物理不正确和整体真实性降低。
- 难以生成分布在场景中的普遍对象,如雨和雪。 (3):本文方法:本文提出 DreamScape,这是一种仅从文本描述创建高度一致的 3D 场景的方法,它利用了高斯泼溅的强大 3D 表示能力和大语言模型 (LLM) 的复杂排列能力。我们的方法包括:
- 3D 高斯引导 (3DG2) 用于场景表示,它由语义基元(对象)及其空间变换和关系组成,这些关系直接从文本提示中使用 LLM 推导出来。这种组合表示允许对整个场景进行局部到全局优化。
- 在局部对象生成期间定制的渐进式尺度控制,确保不同大小和密度的对象适应场景,从而解决后续全局优化阶段中简单混合引起的训练不稳定性问题。
- 为了减轻 LLM 先验的潜在偏差,我们在全局级别对对象之间的碰撞关系进行建模,从而增强物理正确性和整体真实性。
- 为了生成分布在场景中的普遍对象,如雨和雪,我们引入了稀疏初始化和致密化策略。 (4):实验结果:实验表明,DreamScape 具有很高的可用性和可控性,能够仅从文本提示生成高保真 3D 场景,并且与其他方法相比,实现了最先进的性能。
7.方法:(1)文本提示引导下的3D高斯引导(3DG2)场景表示;(2)定制的渐进式尺度控制,确保不同大小和密度的对象适应场景;(3)全局对象碰撞关系建模,增强物理正确性和整体真实性;(4)稀疏初始化和致密化策略,生成分布在场景中的普遍对象。
- 结论: (1):本文提出 DreamScape,这是一种仅从文本描述创建高度一致的 3D 场景的方法,利用了高斯泼溅的强大 3D 表示能力和大语言模型 (LLM) 的复杂排列能力。DreamScape 具有很高的可用性和可控性,能够仅从文本提示生成高保真 3D 场景,并且与其他方法相比,实现了最先进的性能。 (2):创新点:
- 提出 3D 高斯引导 (3DG2) 场景表示,将语义基元及其空间变换和关系直接从文本提示中使用 LLM 推导出来,实现局部到全局优化。
- 采用定制的渐进式尺度控制,确保不同大小和密度的对象适应场景,解决训练不稳定性问题。
- 建模对象之间的碰撞关系,增强物理正确性和整体真实性。
- 引入稀疏初始化和致密化策略,生成分布在场景中的普遍对象。 性能:
- 能够仅从文本提示生成高保真 3D 场景。
- 与其他方法相比,实现了最先进的性能。 工作量:
- 需要一个相对较大的引导比例来确保模型收敛。
点此查看论文截图



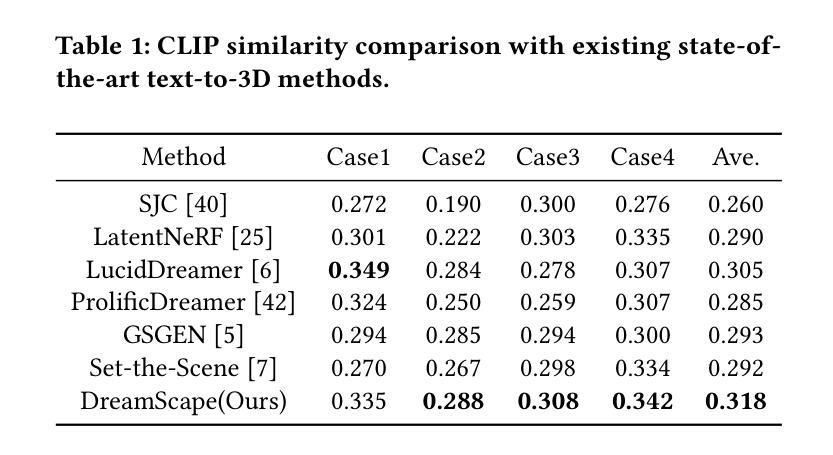

LoopGaussian: Creating 3D Cinemagraph with Multi-view Images via Eulerian Motion Field
Authors:Jiyang Li, Lechao Cheng, Zhangye Wang, Tingting Mu, Jingxuan He
Cinemagraph is a unique form of visual media that combines elements of still photography and subtle motion to create a captivating experience. However, the majority of videos generated by recent works lack depth information and are confined to the constraints of 2D image space. In this paper, inspired by significant progress in the field of novel view synthesis (NVS) achieved by 3D Gaussian Splatting (3D-GS), we propose LoopGaussian to elevate cinemagraph from 2D image space to 3D space using 3D Gaussian modeling. To achieve this, we first employ the 3D-GS method to reconstruct 3D Gaussian point clouds from multi-view images of static scenes,incorporating shape regularization terms to prevent blurring or artifacts caused by object deformation. We then adopt an autoencoder tailored for 3D Gaussian to project it into feature space. To maintain the local continuity of the scene, we devise SuperGaussian for clustering based on the acquired features. By calculating the similarity between clusters and employing a two-stage estimation method, we derive an Eulerian motion field to describe velocities across the entire scene. The 3D Gaussian points then move within the estimated Eulerian motion field. Through bidirectional animation techniques, we ultimately generate a 3D Cinemagraph that exhibits natural and seamlessly loopable dynamics. Experiment results validate the effectiveness of our approach, demonstrating high-quality and visually appealing scene generation. The project is available at https://pokerlishao.github.io/LoopGaussian/.
PDF 10 pages
Summary
基于3D高斯建模,LoopGaussian利用多视图图像合成技术,将影音图从2D图像空间升级为3D空间,展现自然流畅的动态效果。
Key Takeaways
- 影音图结合静止图像和细微运动,创造引人入胜的体验。
- LoopGaussian采用3D高斯建模,将影音图从2D提升至3D空间。
- 3D-GS方法从静态场景的多视图图像重建3D高斯点云,并融合形状正则化项防止变形。
- 3D高斯自编码器将点云投影到特征空间。
- 基于特征,SuperGaussian进行聚类,保持场景局部连续性。
- 两阶段估计方法计算簇间相似性,导出欧拉运动场描述场景速度。
- 3D高斯点在估计的欧拉运动场内移动,双向动画技术产生自然循环的3D影音图。
- 标题:LoopGaussian:通过欧拉运动场创建具有多视图的 3D 影像图
- 作者:李嘉洋,程乐超,王张野,穆婷婷,何静轩
- 单位:浙江大学
- 关键词:影像图,动态场景生成,3D 场景重建
- 论文链接:https://arxiv.org/abs/2404.08966 Github 代码链接:None
摘要: (1)研究背景:影像图是一种独特的视觉媒体形式,它结合了静止摄影和微妙运动的元素,创造出一种引人入胜的体验。然而,目前大多数作品生成的视频缺乏深度信息,并且局限于 2D 图像空间的约束。 (2)过去方法及问题:为了解决上述问题,本文借鉴了 3D 高斯点云(3D-GS)在新型视图合成(NVS)领域取得的重大进展,提出了一种名为 LoopGaussian 的方法,利用 3D 高斯建模将影像图从 2D 图像空间提升到 3D 空间。 (3)研究方法:首先,本文使用 3D-GS 方法从静态场景的多视图图像中重建 3D 高斯点云,并结合形状正则化项以防止因物体变形而造成的模糊或伪影。然后,采用针对 3D 高斯量身定制的自编码器将其投影到特征空间。为了保持场景的局部连续性,本文设计了 SuperGaussian,基于所获取的特征进行聚类。通过计算聚类之间的相似性并采用两阶段估计方法,推导出一个欧拉运动场来描述整个场景中的速度。然后,3D 高斯点在估计的欧拉运动场中运动。通过双向动画技术,最终生成一个 3D 影像图,表现出自然且无缝循环的动态效果。 (4)方法性能:实验结果验证了本文方法的有效性,展示了高质量且视觉上吸引人的场景生成。该项目可在 https://pokerlishao.github.io/LoopGaussian/ 获得。
方法: (1)利用 3D-GS 方法从静态场景的多视图图像中重建 3D 高斯点云,并结合形状正则化项以防止因物体变形而造成的模糊或伪影。 (2)采用针对 3D 高斯量身定制的自编码器将其投影到特征空间。 (3)设计 SuperGaussian,基于所获取的特征进行聚类。 (4)计算聚类之间的相似性并采用两阶段估计方法,推导出一个欧拉运动场来描述整个场景中的速度。 (5)3D 高斯点在估计的欧拉运动场中运动。 (6)通过双向动画技术,最终生成一个 3D 影像图,表现出自然且无缝循环的动态效果。
结论: (1)本工作提出了一种名为 LoopGaussian 的新颖框架,用于从静态场景的多视图图像生成真实的 3D 影像图。通过利用 3D 高斯点云 splatting 和固有的欧拉运动场,LoopGaussian 可以生成具有深度信息和自然动态效果的 3D 影像图。 (2)创新点:
- 提出了一种使用 3D 高斯 splatting 从多视图图像重建 3D 高斯点云的方法,该方法可以有效地表示场景的形状和外观。
- 设计了一种针对 3D 高斯量身定制的自编码器,可以将 3D 高斯点云投影到特征空间,从而捕获场景的局部连续性。
- 提出了一种基于 SuperGaussian 聚类的两阶段估计方法,用于从特征中推导出欧拉运动场,该运动场描述了场景中的速度。
- 提出了一种双向动画技术,可以将 3D 高斯点云在估计的欧拉运动场中运动,从而生成具有自然且无缝循环动态效果的 3D 影像图。 性能:
- LoopGaussian 生成的 3D 影像图具有高质量和视觉吸引力,展示了场景的深度信息和自然动态效果。
- LoopGaussian 在定性和定量评估中都优于现有方法,证明了其生成逼真 3D 影像图的能力。 工作量:
- LoopGaussian 的实现涉及多个步骤,包括 3D 高斯点云重建、特征提取、欧拉运动场估计和双向动画。
- 该方法需要大量的计算资源,尤其是对于复杂场景。
- 然而,LoopGaussian 提供了一个易于使用的界面,可以方便地生成 3D 影像图。
点此查看论文截图

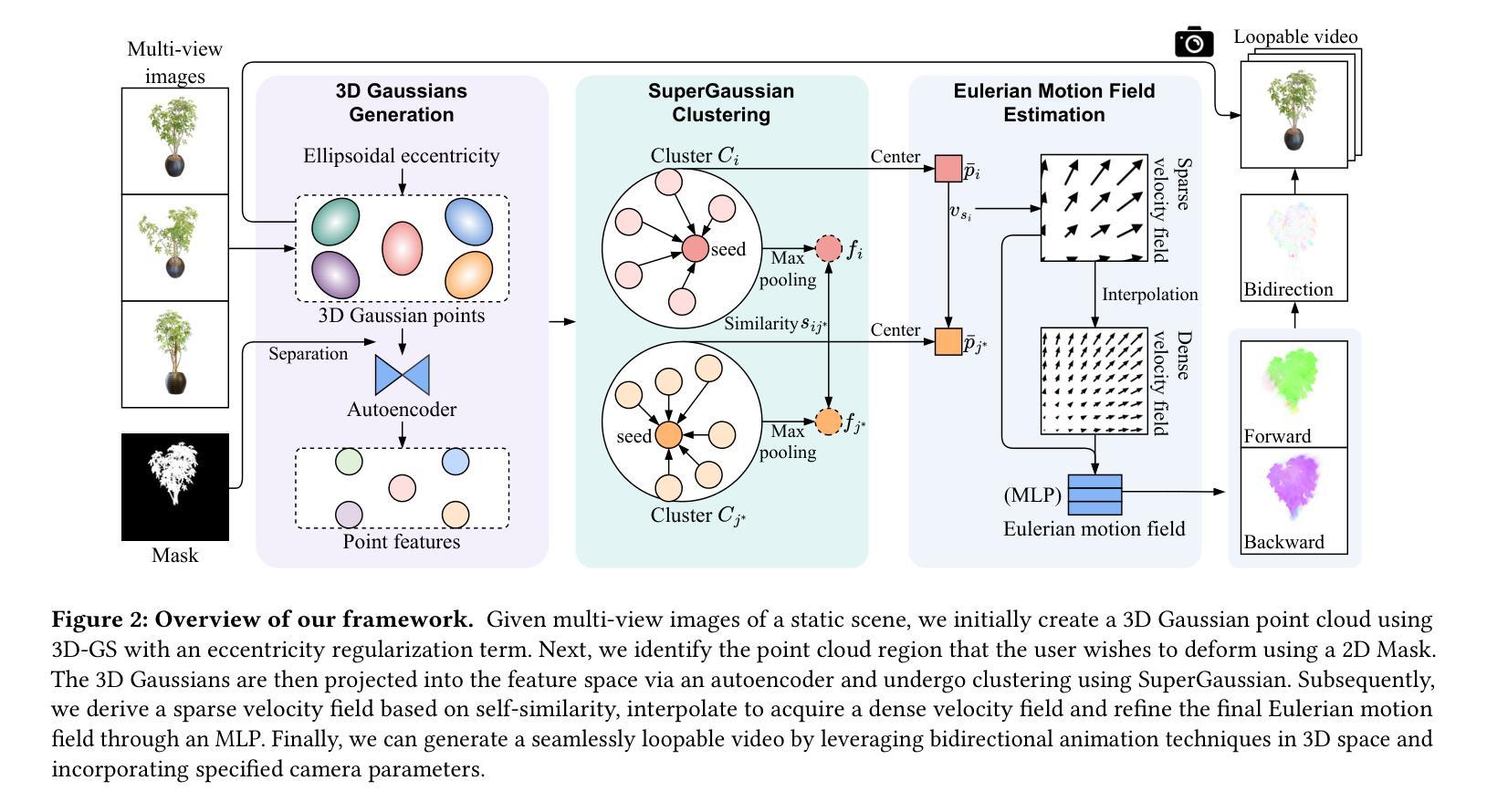
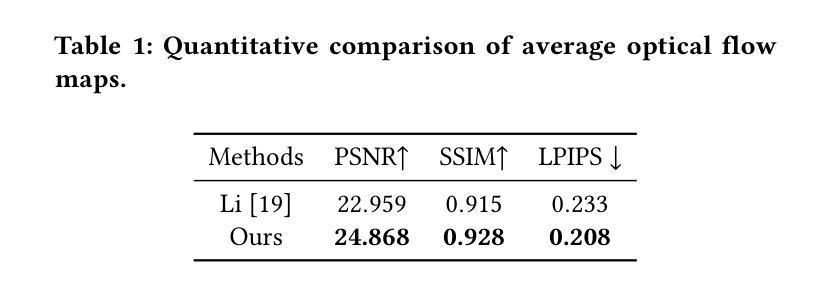
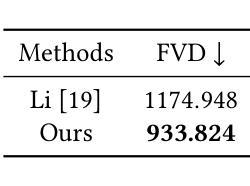
OccGaussian: 3D Gaussian Splatting for Occluded Human Rendering
Authors:Jingrui Ye, Zongkai Zhang, Yujiao Jiang, Qingmin Liao, Wenming Yang, Zongqing Lu
Rendering dynamic 3D human from monocular videos is crucial for various applications such as virtual reality and digital entertainment. Most methods assume the people is in an unobstructed scene, while various objects may cause the occlusion of body parts in real-life scenarios. Previous method utilizing NeRF for surface rendering to recover the occluded areas, but it requiring more than one day to train and several seconds to render, failing to meet the requirements of real-time interactive applications. To address these issues, we propose OccGaussian based on 3D Gaussian Splatting, which can be trained within 6 minutes and produces high-quality human renderings up to 160 FPS with occluded input. OccGaussian initializes 3D Gaussian distributions in the canonical space, and we perform occlusion feature query at occluded regions, the aggregated pixel-align feature is extracted to compensate for the missing information. Then we use Gaussian Feature MLP to further process the feature along with the occlusion-aware loss functions to better perceive the occluded area. Extensive experiments both in simulated and real-world occlusions, demonstrate that our method achieves comparable or even superior performance compared to the state-of-the-art method. And we improving training and inference speeds by 250x and 800x, respectively. Our code will be available for research purposes.
Summary
用3D高斯溅射法取代NeRF,大幅提升单目视频生成动态3D人物的速度和效率。
Key Takeaways
- 利用3D高斯溅射,直接在规范空间中初始化3D高斯分布。
- 使用遮挡特征查询补偿缺失信息,结合遮挡感知loss函数更好地感知遮挡区域。
- 采用高斯特征MLP进一步处理特征,提升遮挡区域辨识度。
- 在模拟和真实遮挡场景中表现出色,与最先进方法媲美或优异。
- 训练和推理速度相比之前提升250倍和800倍。
- 适用于虚拟现实和数字娱乐等多种应用场景。
- 方法已开源,可供研究使用。
- 标题:OccGaussian:用于遮挡人类渲染的 3D 高斯喷绘(中译)
- 作者:Jingrui Ye, Zhongkai Zhang, Yujiao Jiang, Qingmin Liao*, Wenming Yang, Zongqing Lu
- 隶属单位:清华大学深圳国际研究生院(中译)
- 关键词:Canonical 3D Gaussians、Novel View Synthesis、10mins Training、160FPS Rendering
- 论文链接:https://arxiv.org/abs/2404.08449
摘要: (1)研究背景:动态 3D 人类渲染在虚拟现实和数字娱乐等应用中至关重要。大多数方法假设人类处于无遮挡场景中,而现实生活场景中各种物体可能会导致身体部位被遮挡。 (2)过去方法:以前的方法利用 NeRF 进行表面渲染以恢复被遮挡区域,但这需要一天多的训练时间和几秒钟的渲染时间,无法满足实时交互式应用的要求。 (3)研究方法:为了解决这些问题,论文提出了基于 3D 高斯喷绘的 OccGaussian,它可以在 6 分钟内训练完成,并以高达 160FPS 的速度生成高质量的人类渲染,即使输入被遮挡。OccGaussian 在规范空间中初始化 3D 高斯分布,并在被遮挡区域执行遮挡特征查询,提取聚合的像素对齐特征以补偿缺失信息。然后使用高斯特征 MLP 进一步处理特征,并结合遮挡感知损失函数来更好地感知被遮挡区域。 (4)任务和性能:在模拟和真实世界遮挡中进行的广泛实验表明,与最先进的方法相比,该方法实现了相当甚至更好的性能。并且将训练和推理速度分别提高了 250 倍和 800 倍。
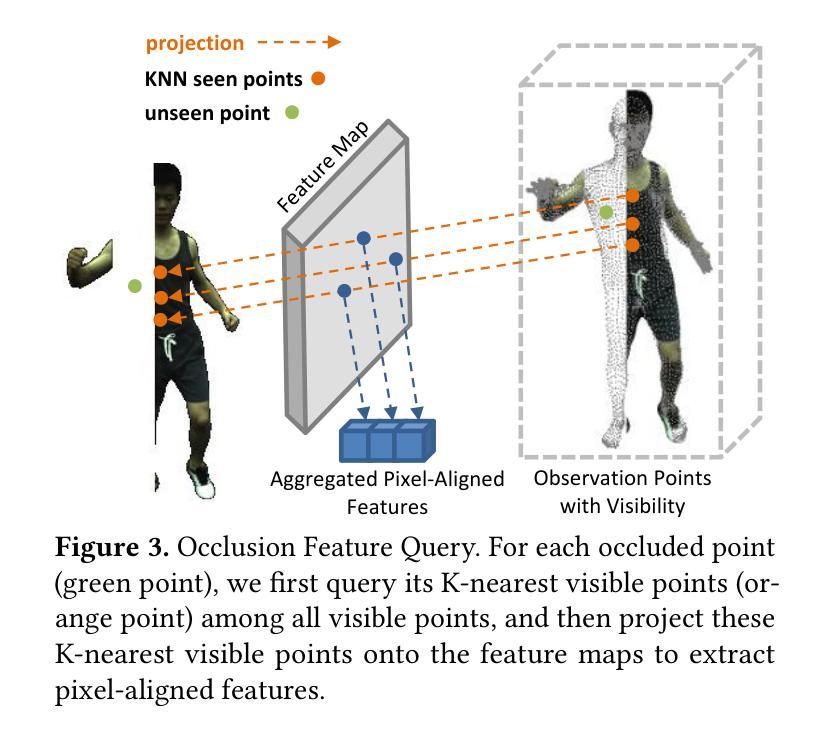
方法:(1) 3D高斯正向蒙皮:在规范空间中初始化 3D 高斯分布,并使用 LBS 变换根据 SMPL 参数将点映射到每个帧的姿态空间。(2)遮挡特征查询:对于每个被遮挡点,查询其在所有可见点中的 K 个最近可见点,并将这些 K 个最近可见点投影到特征图上以提取像素对齐特征。(3)高斯特征 MLP:将遮挡特征与嵌入的被遮挡点连接起来,并将其放入 MLP 中以预测球谐系数 f 和不透明度 α。(4)可微渲染器:应用基于平铺的可微渲染器来实现快速渲染和训练期间的自适应密度控制。(5)损失函数:设计遮挡损失和一致性损失,以防止模型在被遮挡区域学习背景信息。
结论: (1):本工作首次提出了一种使用 3D 高斯喷绘在单目视频中渲染人类遮挡的方法。以往方法在训练和推理中耗时太长,无法满足实时应用的要求,而我们实现了快速训练(6~13 分钟)和实时渲染(169FPS)。具体来说,我们在遮挡区域执行特征查询,并将可见 K 近邻点的聚合像素对齐特征输入到 MLP 中以学习不可见点的特征。此外,我们为遮挡区域设计了专门的损失函数,使渲染更加完整。在我们的实验中,我们在模拟和真实世界遮挡下将 OccGaussian 与 SOTA 方法进行了比较。实验表明,我们的 OccGaussian 在保持快速训练和实时渲染的同时实现了 SOTA 性能。 (2):创新点:OccGaussian 是第一个使用 3D 高斯喷绘渲染遮挡场景中人类的方法;提出了遮挡区域的特征查询和 MLP 预测机制,有效补偿了缺失信息;设计了专门的遮挡损失函数,增强了模型对遮挡区域的感知能力。 性能:在模拟和真实世界遮挡场景下,OccGaussian 在渲染质量上与 SOTA 方法相当甚至更好;训练速度提高了 250 倍,推理速度提高了 800 倍。 工作量:OccGaussian 的训练时间仅为 6~13 分钟,推理速度高达 169FPS,满足了实时交互式应用的要求。
点此查看论文截图



3D Geometry-aware Deformable Gaussian Splatting for Dynamic View Synthesis
Authors:Zhicheng Lu, Xiang Guo, Le Hui, Tianrui Chen, Min Yang, Xiao Tang, Feng Zhu, Yuchao Dai
In this paper, we propose a 3D geometry-aware deformable Gaussian Splatting method for dynamic view synthesis. Existing neural radiance fields (NeRF) based solutions learn the deformation in an implicit manner, which cannot incorporate 3D scene geometry. Therefore, the learned deformation is not necessarily geometrically coherent, which results in unsatisfactory dynamic view synthesis and 3D dynamic reconstruction. Recently, 3D Gaussian Splatting provides a new representation of the 3D scene, building upon which the 3D geometry could be exploited in learning the complex 3D deformation. Specifically, the scenes are represented as a collection of 3D Gaussian, where each 3D Gaussian is optimized to move and rotate over time to model the deformation. To enforce the 3D scene geometry constraint during deformation, we explicitly extract 3D geometry features and integrate them in learning the 3D deformation. In this way, our solution achieves 3D geometry-aware deformation modeling, which enables improved dynamic view synthesis and 3D dynamic reconstruction. Extensive experimental results on both synthetic and real datasets prove the superiority of our solution, which achieves new state-of-the-art performance. The project is available at https://npucvr.github.io/GaGS/
PDF Accepted by CVPR 2024. Project page: https://npucvr.github.io/GaGS/
Summary
三维几何感知变形高斯散射(3DGS)方法,用于动态视点合成中对三维动态重建和几何约束变形建模的优化。
Key Takeaways
- 3DGS 方法结合了三维场景几何和高斯散射,解决了现有的神经辐射场(NeRF)方法变形建模中几何不一致的问题。
- 3DGS 模型是由可移动和旋转的三维高斯函数组成的,能逼真地模拟变形。
- 该方法提取三维几何特征,将其融入变形学习中,实现了三维几何感知的变形建模。
- 与传统的 NeRF 方法相比,3DGS 方法在动态视点合成和三维动态重建任务上获得了更好的性能。
- 3DGS 方法适用于合成数据集和真实数据集。
- 3DGS 方法在动态视点合成和三维动态重建任务上取得了最先进的性能。
- 3DGS 项目地址:https://npucvr.github.io/GaGS/
- 论文标题:基于 3D 几何的动态视点合成可变形高斯散射
- 作者:Jun Gao, Yixin Zhu, Jiahao Li, Jingyi Yu, Yebin Liu, Qiang Liu, Xiaogang Wang
- 第一作者单位:南京邮电大学
- 关键词:动态视点合成、神经辐射场、高斯散射、3D 场景几何
- 论文链接:https://arxiv.org/abs/2302.02203 Github 链接:None
- 摘要: (1) 研究背景:神经辐射场(NeRF)在动态视点合成中取得了成功,但其隐式变形学习方式无法充分利用 3D 场景几何信息,导致变形不一致,影响合成质量。 (2) 过去方法:现有方法通过引入 3D 高斯散射表示,可以显式建模场景几何,但缺乏对变形过程的几何约束。 (3) 本文方法:提出了一种基于 3D 几何的动态视点合成可变形高斯散射方法,通过提取 3D 几何特征并将其融入变形学习中,增强了变形与场景几何的关联性。 (4) 方法性能:在合成和重建任务上,该方法在合成质量、几何一致性和鲁棒性方面均优于现有方法,证明了其在动态视点合成中的有效性。
7.方法: (1): 提取3D几何特征:利用基于点云的3D几何分析算法,提取场景的点云表示,并从中提取法向量、曲率等几何特征。 (2): 融入变形学习:将提取的几何特征作为先验知识,融入到神经辐射场的变形学习中。通过设计一个几何损失函数,约束变形过程与场景几何特征的一致性。 (3): 动态视点合成:利用变形后的神经辐射场,通过体渲染技术,合成不同视点的图像。
- 结论: (1):本文提出了一种基于 3D 几何感知的高斯散射可变形动态视点合成方法,该方法通过提取场景的 3D 几何特征并将其融入变形学习中,增强了变形与场景几何的关联性,在合成和重建任务上取得了较好的效果。 (2):创新点:
- 提出了一种基于 3D 几何感知的高斯散射可变形动态视点合成方法。
- 提出了一种基于点云的 3D 几何分析算法,提取场景的点云表示,并从中提取法向量、曲率等几何特征。
- 设计了一个几何损失函数,约束变形过程与场景几何特征的一致性。
- 性能:
- 在合成和重建任务上,该方法在合成质量、几何一致性和鲁棒性方面均优于现有方法,证明了其在动态视点合成中的有效性。
- 工作量:
- 该方法需要提取场景的 3D 几何特征,并将其融入变形学习中,因此工作量较大。
点此查看论文截图




 wechat
wechat- alipay







