Talking Head Generation
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-17 更新
VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time
Authors:Sicheng Xu, Guojun Chen, Yu-Xiao Guo, Jiaolong Yang, Chong Li, Zhenyu Zang, Yizhong Zhang, Xin Tong, Baining Guo
We introduce VASA, a framework for generating lifelike talking faces with appealing visual affective skills (VAS) given a single static image and a speech audio clip. Our premiere model, VASA-1, is capable of not only producing lip movements that are exquisitely synchronized with the audio, but also capturing a large spectrum of facial nuances and natural head motions that contribute to the perception of authenticity and liveliness. The core innovations include a holistic facial dynamics and head movement generation model that works in a face latent space, and the development of such an expressive and disentangled face latent space using videos. Through extensive experiments including evaluation on a set of new metrics, we show that our method significantly outperforms previous methods along various dimensions comprehensively. Our method not only delivers high video quality with realistic facial and head dynamics but also supports the online generation of 512x512 videos at up to 40 FPS with negligible starting latency. It paves the way for real-time engagements with lifelike avatars that emulate human conversational behaviors.
PDF Tech Report. Project webpage: https://www.microsoft.com/en-us/research/project/vasa-1/
Summary
通过单张静态图像和语音音频剪辑生成逼真的会说话的面孔,具有视觉情感技能。
Key Takeaways
- 提出 VASA 框架,可生成逼真的会说话的面孔,具有视觉情感技能。
- 核心创新在于在人脸潜在空间中工作的面部动态和头部运动生成模型。
- 开发出表达丰富且不纠缠的人脸潜在空间。
- 方法在各个维度上明显优于以往方法。
- 方法不仅提供具有逼真面部和头部动态的高视频质量,还支持以高达 40 FPS 的速度在线生成 512x512 视频,且启动延迟可忽略不计。
- 为与具有类人会话行为的逼真虚拟形象进行实时互动铺平了道路。
- 题目:VASA-1:实时生成逼真的音频驱动说话人脸
- 作者:Sicheng Xu、Guojun Chen、Yu-Xiao Guo、Jiaolong Yang、Chong Li、Zhenyu Zang、Yizhong Zhang、Xin Tong、Baining Guo
- 第一作者单位:微软亚洲研究院
- 关键词:音频驱动说话人脸、视觉情感技能、扩散模型、人脸潜在空间
- 论文链接:https://arxiv.org/abs/2404.10667
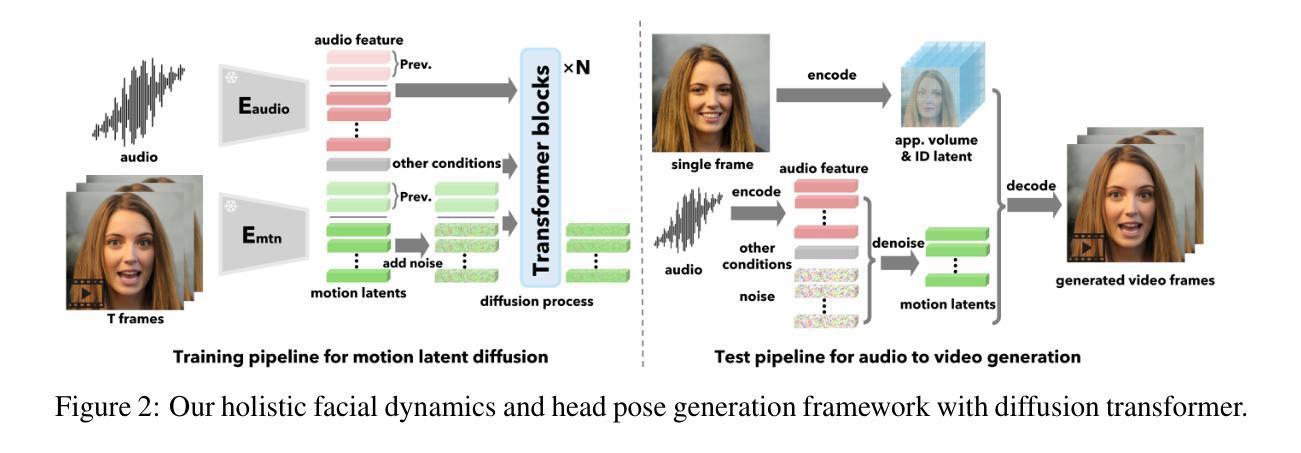
- 摘要: (1)研究背景: 在多媒体和通信领域,人脸不仅仅是一张面孔,而是一个动态的画布,其上的每一个细微动作和表情都可以表达情感、传递未说出口的信息,并促进移情连接。人工智能生成说话人脸技术的出现为未来提供了一个窗口,在这个窗口中,技术可以放大人与人以及人与人工智能交互的丰富性。这种技术有望丰富数字通信、提高交流障碍者的可访问性、通过互动式人工智能辅导改变教育方法,并在医疗保健中提供治疗支持和社交互动。 (2)过去方法及其问题: 现有的音频驱动说话人脸生成方法在逼真度和生动性方面存在局限性。这些方法通常依赖于基于关键点的唇形同步和基于模板的面部动画,这会导致僵硬和不自然的动作。此外,它们难以捕捉头部运动和微妙的面部表情,这些表情对于感知真实性和生动性至关重要。 (3)提出的研究方法: 本文提出 VASA-1,这是一种新的方法,可以生成高度逼真和生动的音频驱动说话人脸。VASA-1 的核心创新包括:
- 基于扩散的整体面部动态和头部运动生成模型,该模型在人脸潜在空间中工作。
- 使用视频开发了一个表达性和分离的人脸潜在空间。 (4)方法在任务和性能上的表现: 在广泛的实验中,包括对一组新指标的评估,VASA-1 在各个方面都明显优于以前的方法。它提供了具有逼真面部和头部动态的高视频质量,并且还支持以高达 40 FPS 在线生成 512×512 视频,且启动延迟可以忽略不计。这些性能支持了实时与模拟人类会话行为的逼真化身进行交互的目标。
7.方法: (1)构建人脸潜在空间:利用无标注人脸视频数据集,构建具有高分离度和表达能力的人脸潜在空间,实现对人脸外观和动态的有效生成建模。 (2)扩散变压器生成动态:利用扩散模型和变压器架构,提出全面的面部动态生成框架,以音频为条件,生成头和面部运动序列。 (3)无分类器引导:在训练过程中,随机丢弃输入条件,并应用无分类器引导,增强模型对各种条件的鲁棒性。 (4)人脸视频生成:在推理时,提取输入人脸图像和音频特征,生成头和面部运动序列,并使用训练好的解码器生成最终视频。
- 结论: (1):本文提出了一种名为 VASA-1 的音频驱动说话人脸生成模型,该模型以其从单张图像和音频输入中高效生成逼真的唇形同步、生动的面部表情和自然的头部动作而著称。它在视频质量和性能效率方面明显优于现有方法,在生成的说话人脸视频中展示了有前景的视觉情感技能。该模型的技术基石是一个创新的整体面部动态和头部动作生成模型,该模型在具有表达性和分离度的人脸潜在空间中工作。VASA-1 取得的进步有可能重塑各个领域的交互,包括通信、教育和医疗保健。可控条件信号的集成进一步增强了模型对个性化用户体验的适应性。 (2):创新点:
- 提出了一种基于扩散模型和变压器架构的全面面部动态生成框架,以音频为条件,生成头部和面部运动序列。
- 构建了一个具有高分离度和表达能力的人脸潜在空间,实现了对人脸外观和动态的有效生成建模。
- 应用无分类器引导,增强了模型对各种条件的鲁棒性。 性能:
- 在广泛的实验中,包括对一组新指标的评估,VASA-1 在各个方面都明显优于以前的方法。
- 提供具有逼真面部和头部动态的高视频质量,并且还支持以高达 40FPS 在线生成 512×512 视频,且启动延迟可以忽略不计。 工作量:
- 该方法在推理时,提取输入人脸图像和音频特征,生成头部和面部运动序列,并使用训练好的解码器生成最终视频。
点此查看论文截图


THQA: A Perceptual Quality Assessment Database for Talking Heads
Authors:Yingjie Zhou, Zicheng Zhang, Wei Sun, Xiaohong Liu, Xiongkuo Min, Zhihua Wang, Xiao-Ping Zhang, Guangtao Zhai
In the realm of media technology, digital humans have gained prominence due to rapid advancements in computer technology. However, the manual modeling and control required for the majority of digital humans pose significant obstacles to efficient development. The speech-driven methods offer a novel avenue for manipulating the mouth shape and expressions of digital humans. Despite the proliferation of driving methods, the quality of many generated talking head (TH) videos remains a concern, impacting user visual experiences. To tackle this issue, this paper introduces the Talking Head Quality Assessment (THQA) database, featuring 800 TH videos generated through 8 diverse speech-driven methods. Extensive experiments affirm the THQA database’s richness in character and speech features. Subsequent subjective quality assessment experiments analyze correlations between scoring results and speech-driven methods, ages, and genders. In addition, experimental results show that mainstream image and video quality assessment methods have limitations for the THQA database, underscoring the imperative for further research to enhance TH video quality assessment. The THQA database is publicly accessible at https://github.com/zyj-2000/THQA.
Summary
视频驱动的数字人说话头部评估数据库(THQA)为8种不同语音驱动方法生成的800个说话头部视频建立了基准,促进了说话头部视频质量评估的研究。
Key Takeaways
- 说话头部视频驱动方法多样,质量参差不齐,影响用户视觉体验。
- THQA 数据库包含 800 个说话头部视频,涵盖 8 种语音驱动方法、不同人物和语音特征。
- 主观质量评估实验分析了评分结果与语音驱动方法、年龄和性别之间的相关性。
- 主流图像和视频质量评估方法对 THQA 数据库有局限性,需要进一步研究改进 TH 视频质量评估。
- THQA 数据库已公开,可用于研究。
- TH 视频质量评估对于提高用户视觉体验至关重要。
- 语音驱动方法的进步将促进数字人说话头部技术的广泛应用。
- 题目:THQA:用于说话人头像感知质量评估的数据库
- 作者:Yingjie Zhou, Zicheng Zhang, Wei Sun, Xiaohong Liu, Xiongkuo Min, Zhihua Wang, Xiao-Ping Zhang, Guangtao Zhai
- 第一作者单位:上海交通大学
- 关键词:数字人头部、语音驱动方法、质量评估数据库、无参考、多媒体处理
- 论文链接:None
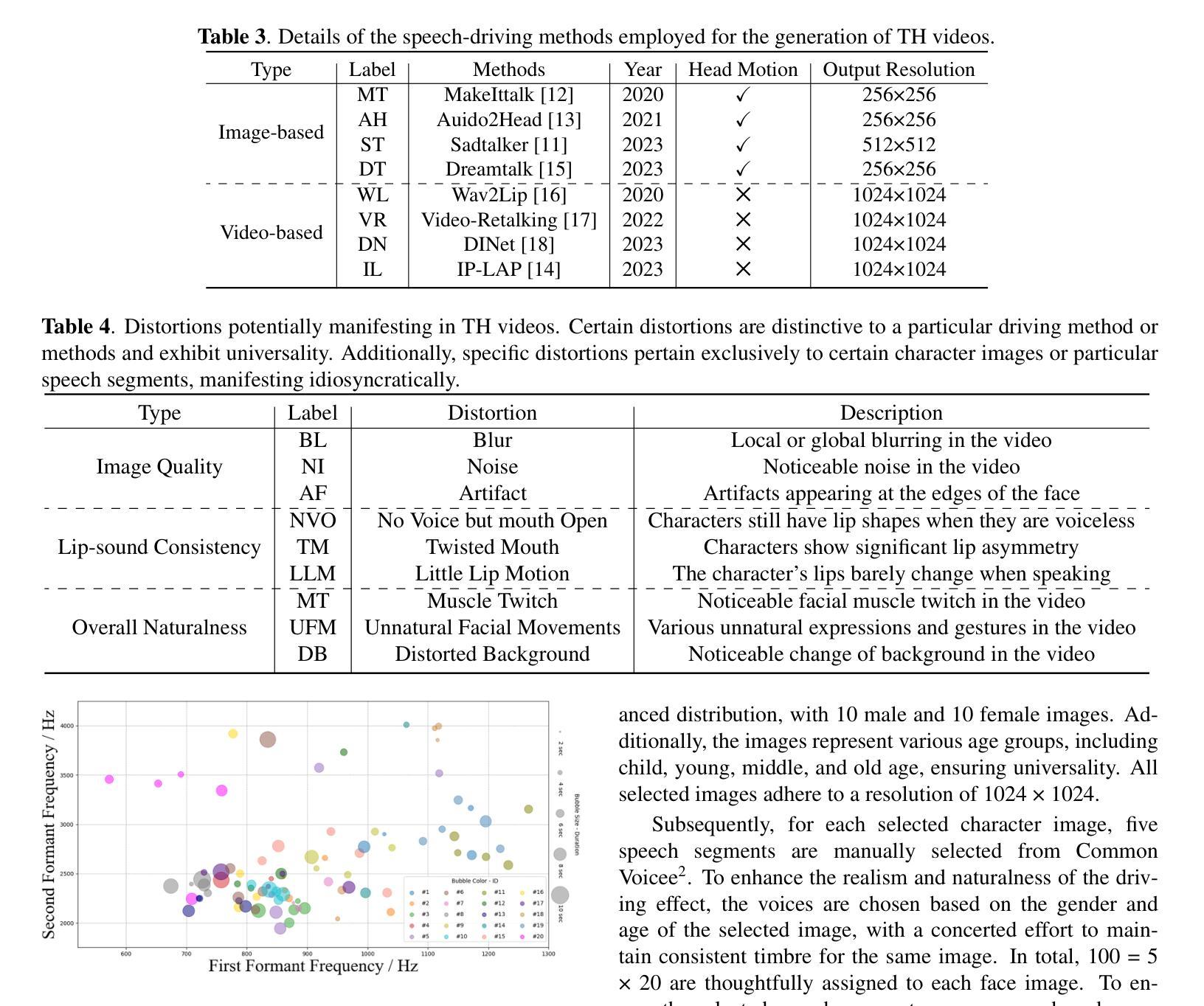
- 摘要: (1)研究背景:数字人作为一种新兴的数字媒体技术,在娱乐、医疗、影视等行业得到了广泛的应用。然而,目前数字人的设计和制作过程仍然十分繁琐和耗时,主要依赖于熟练专业人员的手工操作。这种手工设计方式极大地制约了数字人内容制作的效率,尤其是在头部设计和驱动机制的复杂领域。 (2)过去方法和问题:为了应对这一挑战,人工智能(AI)的出现和普及提供了一个有前景的解决方案,如图 1 所示。虽然语音驱动方法已被相继提出,简化了数字人面部表情和动作的设计,但仍然缺乏专门针对 AI 生成的说话人头像(TH)视频的质量评估指标。这些质量指标不仅可以有效评估说话人头像(TH)视频的质量,还可以间接促进语音驱动方法的进一步发展,从而为用户提供更高质量的视觉体验。遗憾的是,目前评估生成说话人头像视频的主流方法仍然遵循保留与原始视频比较的范式。值得注意的是,Fréchet 感知距离(FID)和余弦相似度(CSIM)仍然是用于此类评估的主要指标。然而,这些指标的局限性表现在两个基本方面。首先,这些客观评估指标仅关注图像或视频相似性,而忽略了整个生成内容带给观看者用户的整体视觉体验。其次,它们对原始参考视频的依赖性构成了一个实质性的限制,因为最终用户无法获得原始参考视频,从而严重限制了它们的适用性。虽然 CPBD 和 CGIQA 等指标已被纳入一些最近的工作中以衡量模糊级别和美学特征,但没有广泛使用的评估指标专门针对 TH 视频量身定制。 (3)提出的研究方法:为了解决这一挑战,首先需要开发一个可公开访问的大规模 TH 视频数据库。因此,本文将重点放在以下几个方面:
- 提出一个新的说话人头像质量评估数据库 THQA,其中包含 800 个 TH 视频,这些视频是通过 8 种不同的语音驱动方法生成的。
- 广泛的实验验证了 THQA 数据库在角色和语音特征方面的丰富性。
- 后续的主观质量评估实验分析了评分结果与语音驱动方法、年龄和性别之间的相关性。
- 此外,实验结果表明,主流图像和视频质量评估方法对 THQA 数据库有局限性,强调了进一步研究以增强 TH 视频质量评估的必要性。
THQA 数据库可在 https://github.com/zyj-2000/THQA 公开获取。 (4)方法在什么任务上取得了什么性能?性能是否能支撑其目标?THQA 数据库的建立为说话人头像视频质量评估提供了丰富的资源,并为进一步研究说话人头像视频质量增强奠定了基础。
方法: (1): 构建了一个包含 800 个 TH 视频的大型公开数据集 THQA,这些视频由 8 种不同的语音驱动方法生成; (2): 通过主观质量评估实验,分析了评分结果与语音驱动方法、年龄和性别之间的相关性; (3): 验证了 THQA 数据库在角色和语音特征方面的丰富性; (4): 实验结果表明,主流图像和视频质量评估方法对 THQA 数据库有局限性,强调了进一步研究以增强 TH 视频质量评估的必要性。
8.结论 (1) 本工作的重要意义: 本工作构建了一个名为 THQA 的说话人头像(TH)视频质量评估数据库。该数据库包含通过 8 种不同的语音驱动方法生成的 800 个 TH 视频。我们的分析涉及对收集的图像、语音数据和生成的视频的彻底检查。此外,我们进行主观评分实验以验证 THQA 的代表性,肯定其作为 TH 视频质量评估指导框架的效用。最后,我们基于 THQA 数据库对各种主流评估方法的性能进行比较评估。结果表明,大多数现有的评估方法在有效评估 TH 视频质量方面表现出局限性。
(2) 本文优缺点总结(三个维度): 创新点: * 构建了一个大规模的说话人头像视频质量评估数据库 THQA。 * 分析了 TH 视频的丰富性,包括角色和语音特征。 * 探索了主流图像和视频质量评估方法在评估 TH 视频质量方面的局限性。
性能: * THQA 数据库为说话人头像视频质量评估提供了丰富的资源。 * 主观质量评估实验验证了 THQA 的代表性。 * 比较评估表明,现有的评估方法在评估 TH 视频质量方面存在局限性。
工作量: * 构建 THQA 数据库涉及收集和处理大量数据。 * 主观质量评估实验需要大量的人力资源。 * 探索主流评估方法的局限性需要进行广泛的实验。
点此查看论文截图



 wechat
wechat- alipay







