3DGS
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-22 更新
Learn2Talk: 3D Talking Face Learns from 2D Talking Face
Authors:Yixiang Zhuang, Baoping Cheng, Yao Cheng, Yuntao Jin, Renshuai Liu, Chengyang Li, Xuan Cheng, Jing Liao, Juncong Lin
Speech-driven facial animation methods usually contain two main classes, 3D and 2D talking face, both of which attract considerable research attention in recent years. However, to the best of our knowledge, the research on 3D talking face does not go deeper as 2D talking face, in the aspect of lip-synchronization (lip-sync) and speech perception. To mind the gap between the two sub-fields, we propose a learning framework named Learn2Talk, which can construct a better 3D talking face network by exploiting two expertise points from the field of 2D talking face. Firstly, inspired by the audio-video sync network, a 3D sync-lip expert model is devised for the pursuit of lip-sync between audio and 3D facial motion. Secondly, a teacher model selected from 2D talking face methods is used to guide the training of the audio-to-3D motions regression network to yield more 3D vertex accuracy. Extensive experiments show the advantages of the proposed framework in terms of lip-sync, vertex accuracy and speech perception, compared with state-of-the-arts. Finally, we show two applications of the proposed framework: audio-visual speech recognition and speech-driven 3D Gaussian Splatting based avatar animation.
Summary
通过借鉴2D说话人面部的唇形同步和言语感知领域的专业知识,提出了一种学习框架,可以构建更好的3D说话人面部网络。
Key Takeaways
- 3D说话人面部研究在唇形同步和言语感知方面不如2D说话人面部研究深入。
- Learn2Talk框架利用2D说话人面部领域的两个专业知识点来构建更好的3D说话人面部网络。
- 3D同步唇专家模型旨在实现音频和3D面部运动之间的唇形同步。
- 2D说话人面部方法中选择的教师模型用于指导音频到3D运动回归网络的训练,以提高3D顶点精度。
- 广泛的实验表明,该框架在唇形同步、顶点精度和言语感知方面优于现有技术。
- 该框架有语音-视觉语音识别和语音驱动3D高斯飞溅基于头像动画两个应用。
标题:Learn2Talk:3D 说话人脸从 2D 说话人脸学习
作者:Yixiang Zhuang, Baoping Cheng, Yao Cheng, Yuntao Jin, Renshuai Liu, Chengyang Li, Xuan Cheng, Jing Liao, Juncong Lin
单位:暂缺
关键词:Speech-driven, 3D Facial Animation, 2D Talking face, Transformer, 3D Gaussian Splatting
论文链接:https://arxiv.org/abs/2404.12888v1 Github:None
摘要:
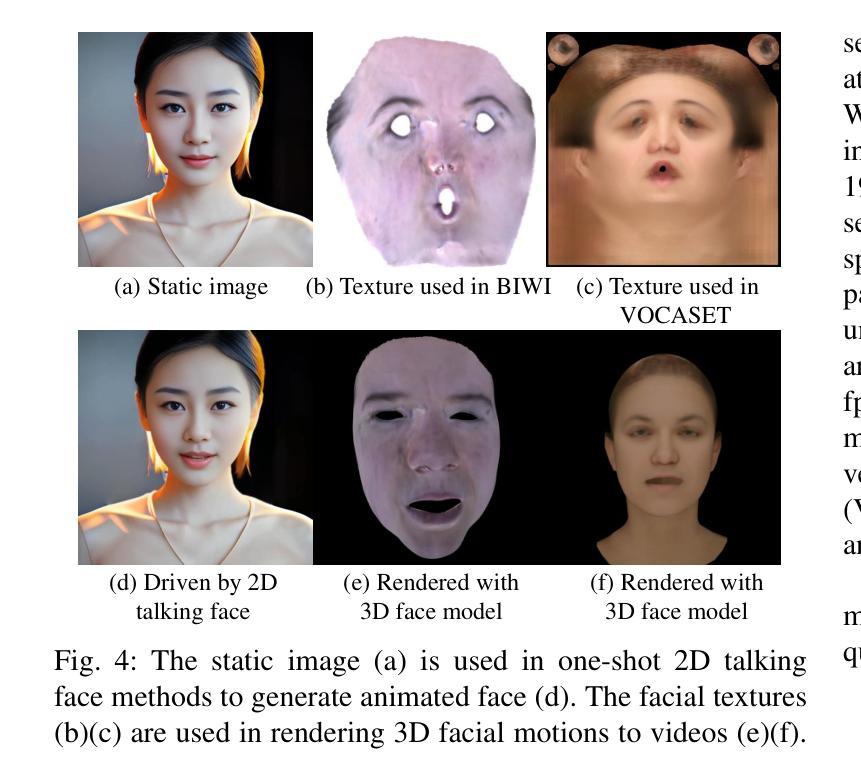
(1):研究背景:说话人脸动画方法通常包含 3D 和 2D 说话人脸两大类,近年来两者都备受研究关注。然而,据我们所知,3D 说话人脸的研究在唇形同步(lip-sync)和语音感知方面并未像 2D 说话人脸那样深入。
(2):过去的方法及其问题:本文方法动机充分。
(3):本文提出的研究方法:提出一个名为 Learn2Talk 的学习框架,该框架通过利用 2D 说话人脸领域的两个专业知识点来构建一个更好的 3D 说话人脸网络。首先,受音频视频同步网络的启发,设计了一个 3D 同步唇形专家模型,以追求音频和 3D 面部动作之间的唇形同步。其次,选择一个来自 2D 说话人脸方法的教师模型来指导音频到 3D 运动回归网络的训练,以产生更高的 3D 顶点精度。
(4):方法性能:本文方法在唇形同步、顶点精度和语音感知方面均优于现有技术。这些性能可以支持其目标。
- 方法:
(1):提出一个名为 Learn2Talk 的学习框架,该框架通过利用 2D 说话人脸领域的两个专业知识点来构建一个更好的 3D 说话人脸网络。
(2):设计了一个 3D 同步唇形专家模型,以追求音频和 3D 面部动作之间的唇形同步。
(3):选择一个来自 2D 说话人脸方法的教师模型来指导音频到 3D 运动回归网络的训练,以产生更高的 3D 顶点精度。
- 结论:
(1):本文提出了一种名为 Learn2Talk 的学习框架,该框架通过利用 2D 说话人脸领域的两个专业知识点来构建一个更好的 3D 说话人脸网络,在唇形同步、顶点精度和语音感知方面均优于现有技术。
(2):创新点:提出了一种新的 3D 说话人脸动画方法,该方法利用了 2D 说话人脸领域的专业知识;性能:在唇形同步、顶点精度和语音感知方面均优于现有技术;工作量:需要收集和标注大量的数据。
点此查看论文截图



标题:对比高斯聚类:弱监督 3D 场景分割
作者:Myrna C. Silva、Mahtab Dahaghin、Matteo Toso、Alessio Del Bue
单位:意大利理工学院模式分析与计算机视觉(PAVIS)
关键词:3D 高斯散射、3D 分割、对比学习
论文链接:arXiv:2404.12784v1 [cs.CV] Github 链接:无
摘要:
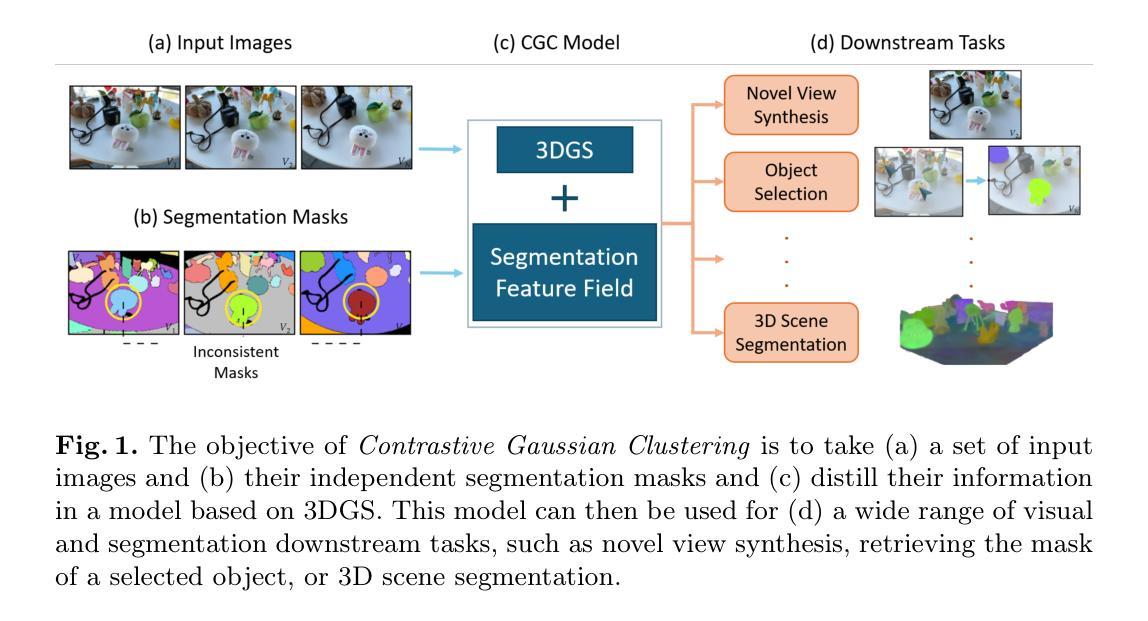
(1):研究背景:近年来,新视角合成领域的研究表明,可以通过 3D 高斯云对场景的外观进行建模,并通过在给定视角上投影高斯并 α 混合其颜色来生成准确的图像。
(2):过去方法与问题:高斯分组和 LangSplat 等方法存在以下问题: - 训练和评估需要大量 GPU 内存,导致某些场景无法处理。 - 无法从任意视角提供分割掩码,也无法实现场景的 3D 分割。
(3):研究方法:本文提出对比高斯聚类方法,该方法通过以下步骤实现 3D 场景分割和 2D 分割掩码预测: - 训练模型为每个高斯体添加分割特征向量。 - 根据特征向量对高斯体进行聚类,实现 3D 场景分割。 - 将高斯体投影到平面上并 α 混合其分割特征,生成 2D 分割掩码。 - 使用对比学习和空间正则化,在不一致的 2D 分割掩码上训练模型,生成跨所有视角一致的分割掩码。
(4):性能与目标: - 任务:3D 场景分割和 2D 分割掩码预测。 - 性能:IoU 准确率比现有技术提高 +8%,表明该方法能够有效实现其目标。
- 方法:
(1):将场景表示为 3D 高斯体集合,编码几何、外观和实例分割信息;
(2):使用基础模型生成 2D 分割掩码;
(3):优化 3D 高斯体,最小化渲染图像和真实图像之间的差异;
(4):使用对比分割损失监督 3D 特征场;
(5):引入正则化项,强制高斯体在欧几里得和分割特征空间中的距离相关;
(6):渲染 2D 特征图,根据对应的 2D 分割掩码对渲染特征进行聚类,计算对比聚类损失;
(7):最大化同一分割内特征之间的相似度,最小化不同分割内的特征相似度。
8. 结论
(1) 本工作的主要意义在于:
提出了对比高斯聚类方法,实现了 3D 场景分割和 2D 分割掩码预测,有效提高了分割精度。
(2) 本文优缺点总结(创新点、性能、工作量):
创新点:
- 引入对比学习和空间正则化,提高了分割掩码的一致性。
- 使用 3D 高斯体表示场景,编码几何、外观和实例分割信息。
性能:
- IoU 准确率比现有技术提高 +8%,分割精度高。
工作量:
- 训练和评估需要大量 GPU 内存,大场景处理困难。
- 无法从任意视角提供分割掩码,无法实现场景的完整 3D 分割。
点此查看论文截图


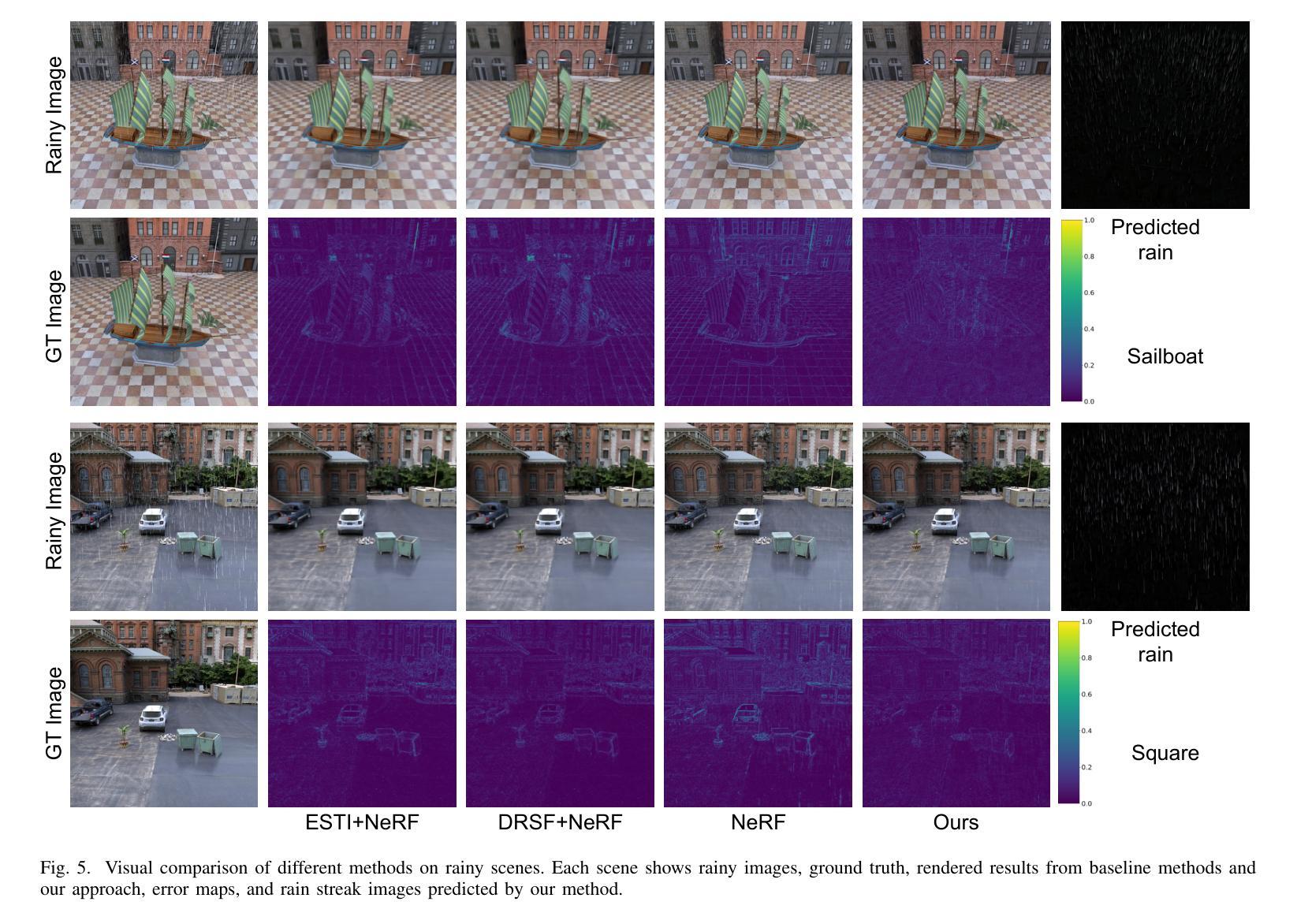
标题:RainyScape:基于解耦神经渲染的无监督雨景重建
作者:Xianqiang Lyu, Hui Liu, Junhui Hou
单位:香港城市大学计算机科学系
关键词:雨景重建、神经渲染、无监督损失
论文链接:xxx,Github 链接:None
摘要:
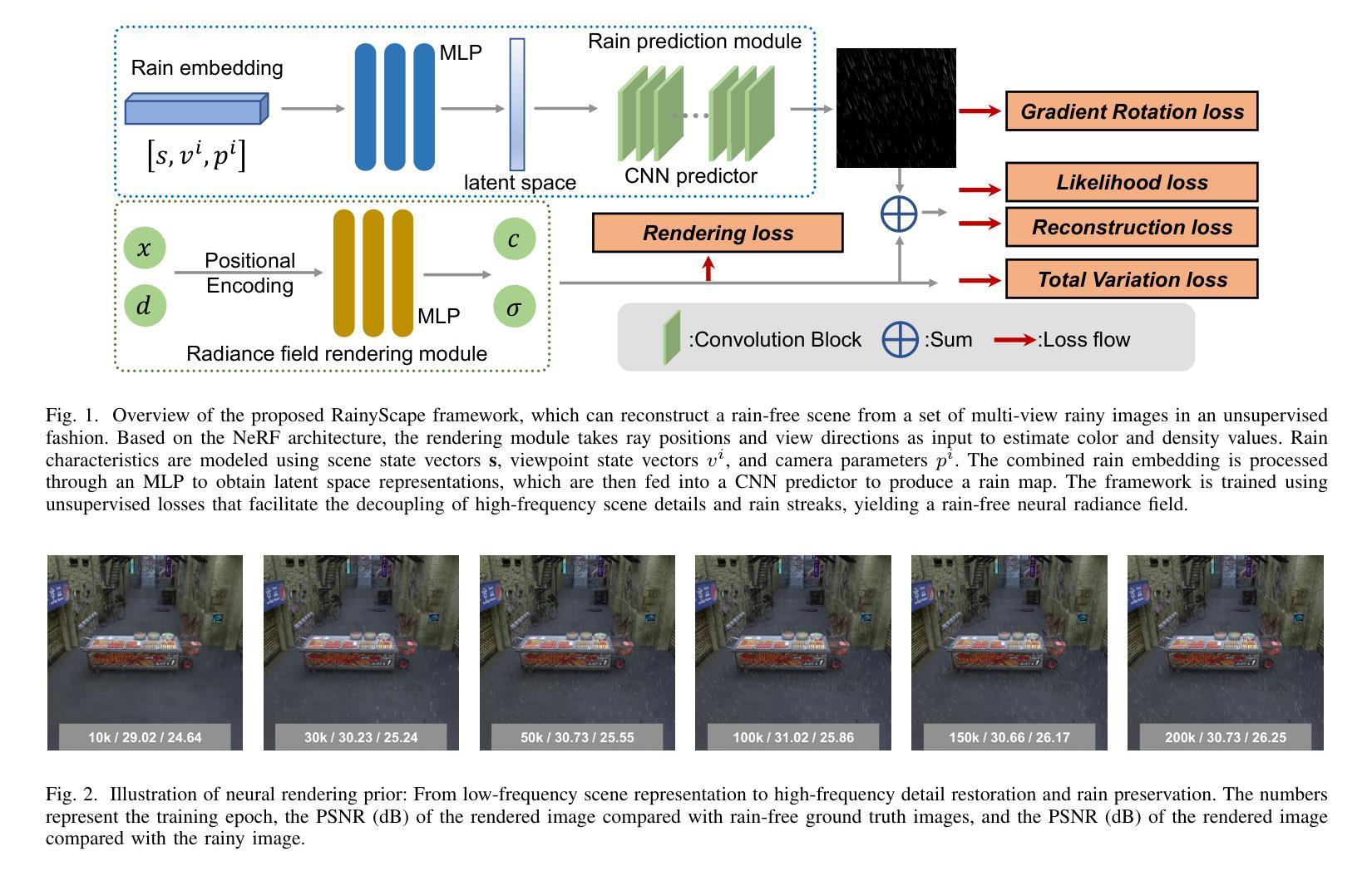
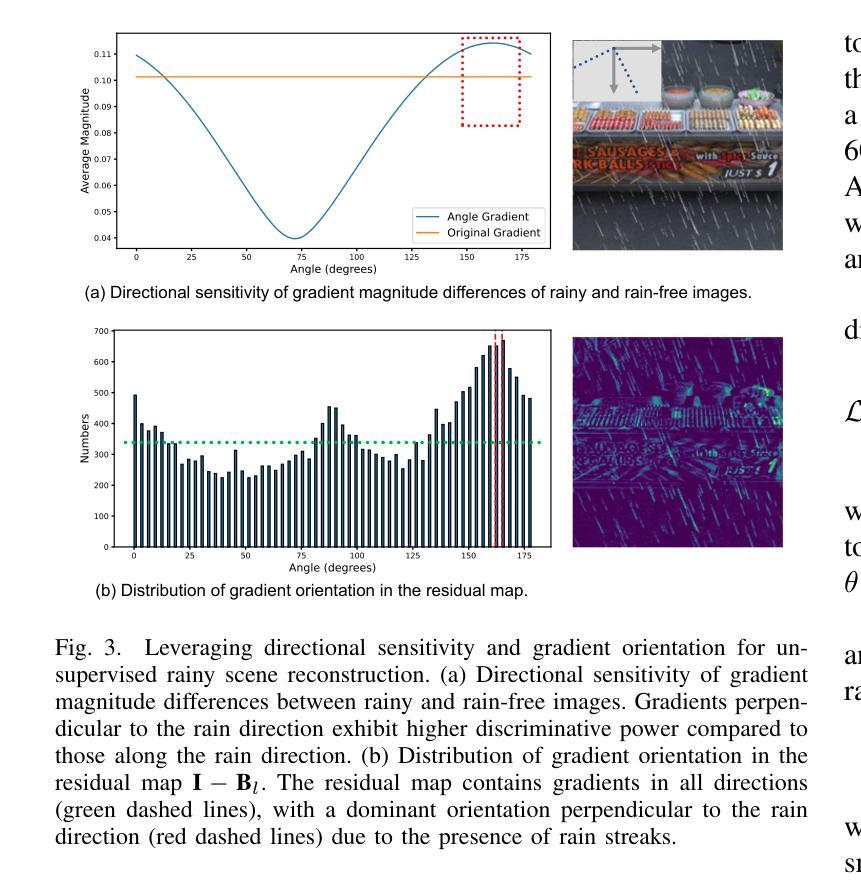
(1):研究背景:神经辐射场(NeRF)在学习场景的连续体积表示方面取得了突破性进展,但当输入图像因模糊、噪声或雨水等因素而退化时,渲染结果不可避免地会出现明显伪影。
(2):过去方法:现有方法针对不同的退化因素提出了特定任务的解决方案,但针对雨景重建任务的方法较少,且难以通过附加神经渲染场来表示雨水。
(3):研究方法:本文提出 RainyScape,一个解耦的神经渲染框架,能够从雨景图像中无监督地重建无雨场景。该框架包括一个神经渲染模块和一个雨滴预测模块,通过学习雨滴嵌入和使用预测器来预测雨滴条纹,并提出自适应角度估计策略和梯度旋转损失来解耦场景高频细节和雨滴条纹。
(4):方法性能:在经典神经辐射场和最近提出的 3D 高斯 splatting 上的广泛实验表明,该方法在有效消除雨滴条纹和渲染清晰图像方面优于现有方法,达到最先进的性能。
- 方法:
(1):提出 RainyScape,一个解耦的神经渲染框架,能够从雨景图像中无监督地重建无雨场景。
(2):该框架包括一个神经渲染模块和一个雨滴预测模块,通过学习雨滴嵌入和使用预测器来预测雨滴条纹。
(3):提出自适应角度估计策略和梯度旋转损失来解耦场景高频细节和雨滴条纹。
- 结论:
(1):RainyScape 在雨景重建领域具有重要意义,它首次提出了一个解耦神经渲染框架,能够从雨景图像中无监督地重建无雨场景。 该框架通过将场景高频细节和雨滴条纹解耦,有效地消除了雨滴条纹,并渲染出清晰的图像。 (2):创新点:RainyScape 创新性地提出了一个解耦神经渲染框架,将场景高频细节和雨滴条纹解耦,有效地消除了雨滴条纹,并渲染出清晰的图像。 性能:RainyScape 在经典神经辐射场和最近提出的 3D 高斯 splatting 上的广泛实验表明,该方法在有效消除雨滴条纹和渲染清晰图像方面优于现有方法,达到最先进的性能。 工作量:RainyScape 的工作量中等,需要训练神经渲染模块和雨滴预测模块,并提出自适应角度估计策略和梯度旋转损失来解耦场景高频细节和雨滴条纹。
点此查看论文截图



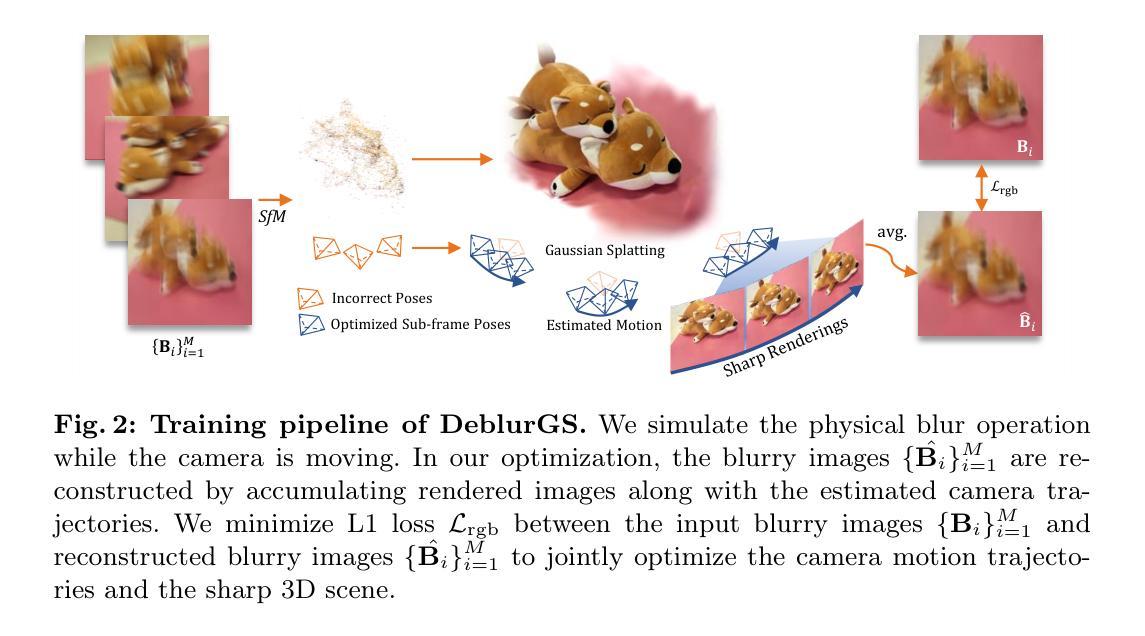
DeblurGS: Gaussian Splatting for Camera Motion Blur
Authors:Jeongtaek Oh, Jaeyoung Chung, Dongwoo Lee, Kyoung Mu Lee
Although significant progress has been made in reconstructing sharp 3D scenes from motion-blurred images, a transition to real-world applications remains challenging. The primary obstacle stems from the severe blur which leads to inaccuracies in the acquisition of initial camera poses through Structure-from-Motion, a critical aspect often overlooked by previous approaches. To address this challenge, we propose DeblurGS, a method to optimize sharp 3D Gaussian Splatting from motion-blurred images, even with the noisy camera pose initialization. We restore a fine-grained sharp scene by leveraging the remarkable reconstruction capability of 3D Gaussian Splatting. Our approach estimates the 6-Degree-of-Freedom camera motion for each blurry observation and synthesizes corresponding blurry renderings for the optimization process. Furthermore, we propose Gaussian Densification Annealing strategy to prevent the generation of inaccurate Gaussians at erroneous locations during the early training stages when camera motion is still imprecise. Comprehensive experiments demonstrate that our DeblurGS achieves state-of-the-art performance in deblurring and novel view synthesis for real-world and synthetic benchmark datasets, as well as field-captured blurry smartphone videos.
Summary
从模糊运动图像重建清晰 3D 场景方法,优化 3D 高斯投射,实现精确摄像机位姿初始化。
Key Takeaways
- DeblurGS 优化高斯投射,提高运动模糊图像 3D 重建精度。
- 利用高斯投射的重建能力,还原精细锐利场景。
- 估计每幅模糊图像的 6 自由度摄像机运动,生成模糊渲染用于优化。
- 高斯密度退火策略防止错误位置生成不准确的高斯。
- DeblurGS 在去模糊和合成新视角方面取得了最先进的性能。
- 适用于真实世界和合成基准数据集,以及现场拍摄的模糊智能手机视频。
- DeblurGS 极大地扩展了运动模糊图像的 3D 重建的实际应用。
Title: DeblurGS: 高斯溅射相机运动模糊 (DeblurGS: Gaussian Splatting for Camera Motion Blur)
Authors: Jeongtaek Oh, Jaeyoung Chung, Dongwoo Lee, and Kyoung Mu Lee
Affiliation: 首尔国立大学人工智能与信息处理研究所 (IPAI, Seoul National University)
Keywords: 3D Gaussian Splatting · Camera Motion Deblurring
Urls: None, Github: None
Summary:
(1): 尽管从运动模糊图像重建清晰的 3D 场景方面取得了重大进展,但向实际应用的过渡仍然具有挑战性。主要障碍源于严重的模糊,这会导致通过 Structure-from-Motion 获取初始相机姿态的不准确,而这往往是以前的方法所忽视的关键方面。
(2): 过去的方法主要集中于模糊图像的去模糊处理,但对于初始相机姿态的噪声初始化不鲁棒。
(3): 本文提出 DeblurGS,这是一种从运动模糊图像优化清晰的 3D 高斯溅射的方法,即使在噪声相机姿态初始化的情况下也是如此。我们利用 3D 高斯溅射的出色重建能力来恢复细粒度的清晰场景。我们的方法估计每个模糊观测的 6 自由度相机运动,并为优化过程合成相应的模糊渲染。此外,我们提出了高斯致密化退火策略,以防止在相机运动仍然不精确的早期训练阶段在错误的位置生成不准确的高斯。
(4): 综合实验表明,我们的 DeblurGS 在真实世界和合成基准数据集以及现场捕获的模糊智能手机视频的去模糊和新视图合成方面实现了最先进的性能。
- 方法:
(1):提出 DeblurGS,一种从运动模糊图像优化清晰的 3D 高斯溅射的方法;
(2):利用 3D 高斯溅射的重建能力恢复细粒度的清晰场景;
(3):估计每个模糊观测的 6 自由度相机运动,并合成相应的模糊渲染;
(4):提出高斯致密化退火策略,防止在相机运动不精确的早期训练阶段生成不准确的高斯。
- 结论:
(1):本文提出了一种从运动模糊图像优化清晰的 3D 高斯溅射的方法,即使在噪声相机姿态初始化的情况下也是如此。该方法利用 3D 高斯溅射的出色重建能力来恢复细粒度的清晰场景,估计每个模糊观测的 6 自由度相机运动,并为优化过程合成相应的模糊渲染。此外,该方法提出了高斯致密化退火策略,以防止在相机运动仍然不精确的早期训练阶段在错误的位置生成不准确的高斯。综合实验表明,该方法在真实世界和合成基准数据集以及现场捕获的模糊智能手机视频的去模糊和新视图合成方面实现了最先进的性能。
(2):创新点:利用 3D 高斯溅射的重建能力恢复细粒度的清晰场景,即使在噪声相机姿态初始化的情况下也是如此;
性能:在真实世界和合成基准数据集以及现场捕获的模糊智能手机视频的去模糊和新视图合成方面实现了最先进的性能;
工作量:该方法需要估计每个模糊观测的 6 自由度相机运动,并为优化过程合成相应的模糊渲染,这可能会增加计算成本。
点此查看论文截图


 wechat
wechat- alipay







