NeRF
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-22 更新
AG-NeRF: Attention-guided Neural Radiance Fields for Multi-height Large-scale Outdoor Scene Rendering
Authors:Jingfeng Guo, Xiaohan Zhang, Baozhu Zhao, Qi Liu
Existing neural radiance fields (NeRF)-based novel view synthesis methods for large-scale outdoor scenes are mainly built on a single altitude. Moreover, they often require a priori camera shooting height and scene scope, leading to inefficient and impractical applications when camera altitude changes. In this work, we propose an end-to-end framework, termed AG-NeRF, and seek to reduce the training cost of building good reconstructions by synthesizing free-viewpoint images based on varying altitudes of scenes. Specifically, to tackle the detail variation problem from low altitude (drone-level) to high altitude (satellite-level), a source image selection method and an attention-based feature fusion approach are developed to extract and fuse the most relevant features of target view from multi-height images for high-fidelity rendering. Extensive experiments demonstrate that AG-NeRF achieves SOTA performance on 56 Leonard and Transamerica benchmarks and only requires a half hour of training time to reach the competitive PSNR as compared to the latest BungeeNeRF.
Summary
降低训练成本,实现多高度自由视角图像合成。
Key Takeaways
- 多高度神经辐射场(NeRF)能够合成自由视角图像。
- 提出图像选择方法和注意力特征融合,解决不同高度细节差异问题。
- AG-NeRF 在 56 Leonard 和 Transamerica 基准上达到最先进性能。
- AG-NeRF 训练时间仅需半小时,即可达到 BungeeNeRF 的竞争水平。
Title: AG-NeRF: 多高度大尺度户外场景渲染的注意力引导神经辐射场
Authors: Jingfeng Guo, Xiaohan Zhang, Baozhu Zhao, Qi Liu
Affiliation: 华南理工大学
Keywords: Novel View Synthesis, NeRF, Large-scale Outdoor Scene Rendering
Urls: https://arxiv.org/abs/2404.11897v1 , Github: None
Summary:
(1): 现有的基于神经辐射场 (NeRF) 的大规模户外场景新视角合成方法主要建立在单一高度上。此外,它们通常需要先验的相机拍摄高度和场景范围,当相机高度发生变化时,会导致低效且不实用的应用。
(2): 过去的方法: - 地理上将场景分解为几个单元格,并为每个单元格训练一个子 NeRF,然后将它们合并。 - 在位置编码中并行应用平面和网格特征以实现高效建模。 - 问题:它们在基础高度上重建大规模场景,当导航到更近的地方以检查大规模户外场景的微观细节时,表现出过度模糊的伪影和不完整的重建。
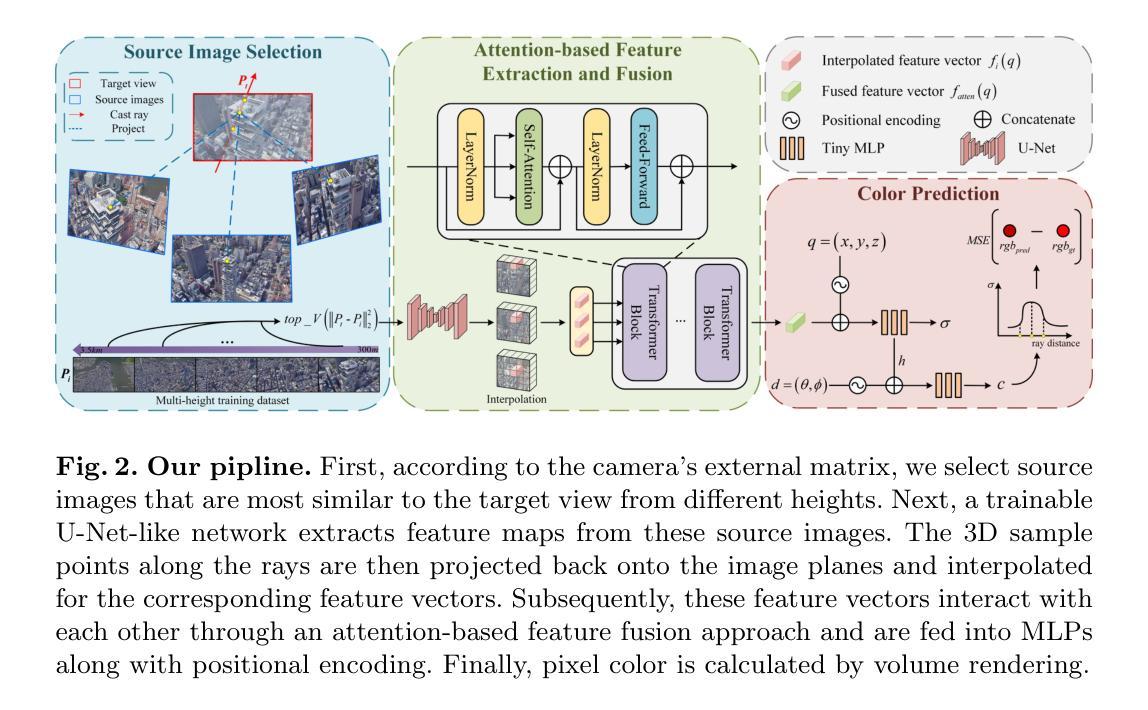
(3): 本文提出的研究方法: - 提出了一种端到端框架 AG-NeRF,通过合成基于场景不同高度的自由视角图像来降低构建良好重建的训练成本。 - 具体来说,为了解决从低高度(无人机级别)到高高度(卫星级别)的细节变化问题,开发了一种源图像选择方法和一种基于注意力的特征融合方法,从多高度图像中提取和融合目标视图最相关的特征,以实现高保真渲染。
(4): 本文方法在任务和性能上的表现: - 在 56 Leonard 和 Transamerica 基准测试中取得了 SOTA 性能。 - 只需要半小时的训练时间即可达到与最新 BungeeNeRF 相当的竞争性 PSNR。 - 性能支持了他们的目标:降低构建良好重建的训练成本。
- 方法:
(1):提出了一种端到端框架 AG-NeRF,通过合成基于场景不同高度的自由视角图像来降低构建良好重建的训练成本。
(2):开发了一种源图像选择方法和一种基于注意力的特征融合方法,从多高度图像中提取和融合目标视图最相关的特征,以实现高保真渲染。
(3):利用可训练的 U-Net 网络从源图像中提取特征图,并使用 Transformer 对提取的特征向量进行融合,以最大化融合特征与目标像素之间的相关性。
(4):采用分层采样方法,使用粗略网络和精细网络同时优化,并使用基于注意力的特征融合方法将多高度图像中的特征融合起来。
- 结论:
(1):本文针对不同高度拍摄的大场景渲染提出了端到端的 AG-NeRF 框架,降低了构建良好重建模型的训练成本。
(2):创新点:提出了一种源图像选择方法和基于注意力的特征融合方法,从多高度图像中提取和融合目标视图最相关的特征,以实现高保真渲染。 性能:在 56 Leonard 和 Transamerica 基准测试中取得了 SOTA 性能,只需要半小时的训练时间即可达到与最新 BungeeNeRF 相当的竞争性 PSNR。 工作量:采用分层采样方法,使用粗略网络和精细网络同时优化,并使用基于注意力的特征融合方法将多高度图像中的特征融合起来。
点此查看论文截图


SLAIM: Robust Dense Neural SLAM for Online Tracking and Mapping
Authors:Vincent Cartillier, Grant Schindler, Irfan Essa
We present SLAIM - Simultaneous Localization and Implicit Mapping. We propose a novel coarse-to-fine tracking model tailored for Neural Radiance Field SLAM (NeRF-SLAM) to achieve state-of-the-art tracking performance. Notably, existing NeRF-SLAM systems consistently exhibit inferior tracking performance compared to traditional SLAM algorithms. NeRF-SLAM methods solve camera tracking via image alignment and photometric bundle-adjustment. Such optimization processes are difficult to optimize due to the narrow basin of attraction of the optimization loss in image space (local minima) and the lack of initial correspondences. We mitigate these limitations by implementing a Gaussian pyramid filter on top of NeRF, facilitating a coarse-to-fine tracking optimization strategy. Furthermore, NeRF systems encounter challenges in converging to the right geometry with limited input views. While prior approaches use a Signed-Distance Function (SDF)-based NeRF and directly supervise SDF values by approximating ground truth SDF through depth measurements, this often results in suboptimal geometry. In contrast, our method employs a volume density representation and introduces a novel KL regularizer on the ray termination distribution, constraining scene geometry to consist of empty space and opaque surfaces. Our solution implements both local and global bundle-adjustment to produce a robust (coarse-to-fine) and accurate (KL regularizer) SLAM solution. We conduct experiments on multiple datasets (ScanNet, TUM, Replica) showing state-of-the-art results in tracking and in reconstruction accuracy.
Summary
Nerf-SLAM 通过采用从粗到细的跟踪模型和 KL 正则化器,在跟踪性能和重建精度上实现了最先进的成绩。
Key Takeaways
- SLAIM 提出了一种从粗到细的跟踪模型以提高 NeRF-SLAM 的跟踪性能。
- SLAIM 通过高斯金字塔滤波器实现从粗到细的跟踪优化策略。
- NeRF 系统难以使用有限的输入视图收敛到正确的几何形状。
- SLAIM 使用体积密度表示和一个新的 KL 正则化器来约束场景几何形状。
- SLAIM 实现局部和全局捆绑调整以提高鲁棒性和准确性。
- SLAIM 在多个数据集上进行了实验,在跟踪和重建精度上均显示出最先进的结果。
- SLAIM 解决了 NeRF-SLAM 在传统 SLAM 算法下表现出较差的跟踪性能这一难题。
标题:SLAIM:用于在线跟踪和建图的鲁棒稠密神经SLAM
作者:Vincent Cartillier、Grant Schindler、Irfan Essa
隶属关系:佐治亚理工学院
关键词:神经辐射场、SLAM、稠密建图、跟踪
论文链接:https://arxiv.org/abs/2404.11419,Github 代码链接:None
摘要:
(1)研究背景:稠密视觉SLAM是3D计算机视觉中的一个长期问题,在自动驾驶、室内外机器人导航、虚拟现实和增强现实等领域有着广泛的应用。
(2)过去的方法及问题:传统的SLAM系统通过估计图像对应关系来开始,这些对应关系可能是稀疏的,例如匹配的特征点。神经辐射场SLAM(NeRF-SLAM)方法通过图像对齐和光度捆绑调整来解决相机跟踪问题。由于图像空间中优化损失的吸引域窄(局部极小值)以及缺乏初始对应关系,此类优化过程难以优化。
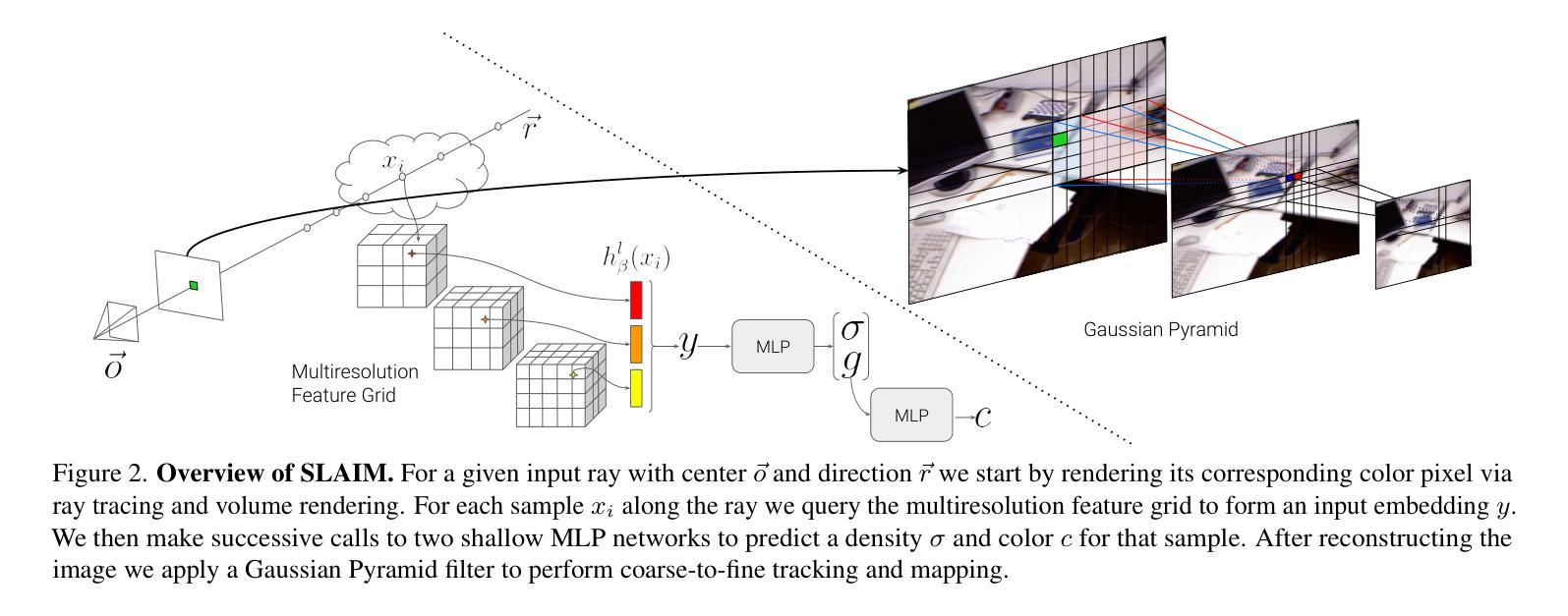
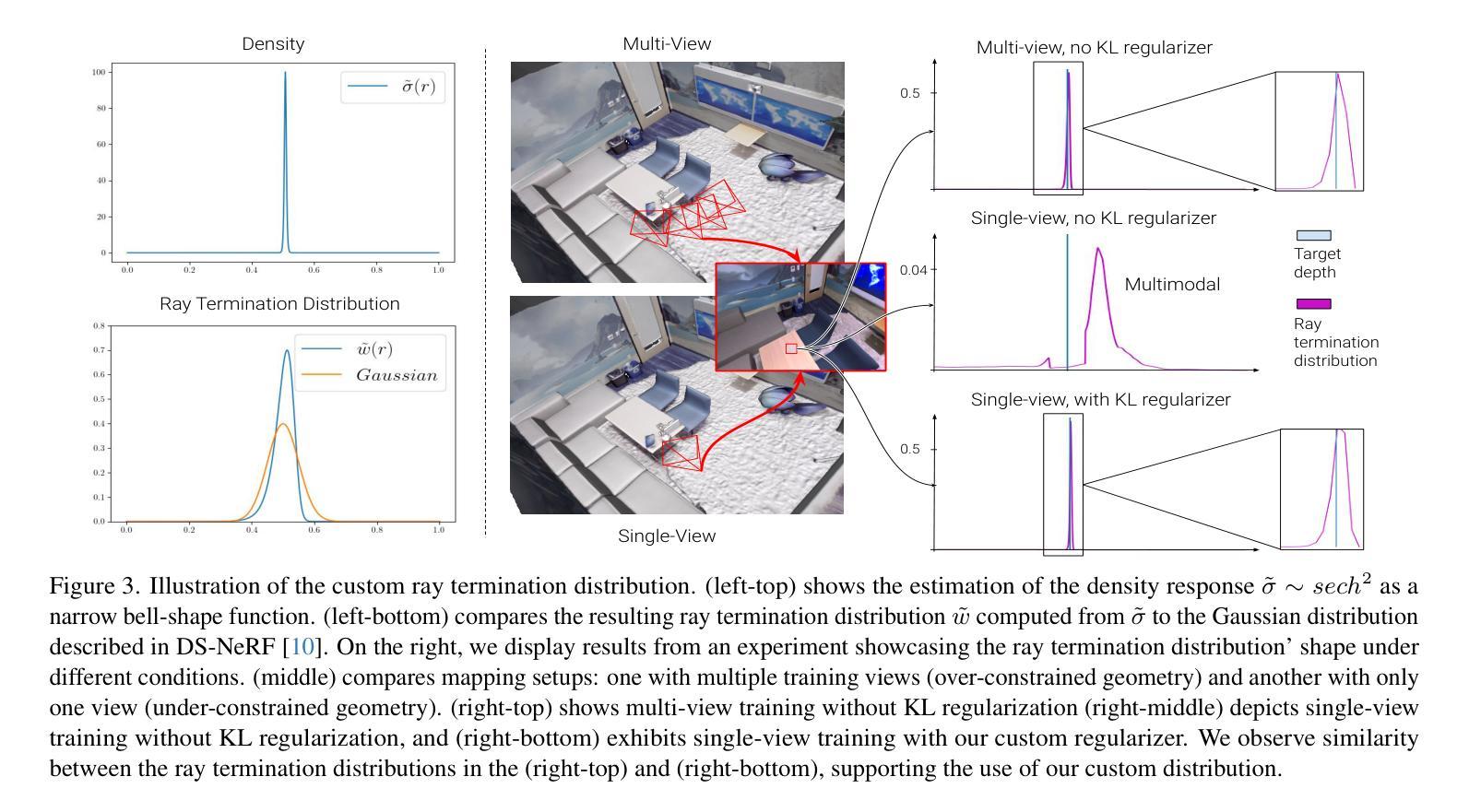
(3)提出的研究方法:本文提出了一种新的粗到细跟踪模型,专门针对NeRF-SLAM,以实现最先进的跟踪性能。此外,本文还引入了一种新的目标射线终止分布,并将其用于KL正则化器中,以约束场景几何由空空间和不透明表面组成。
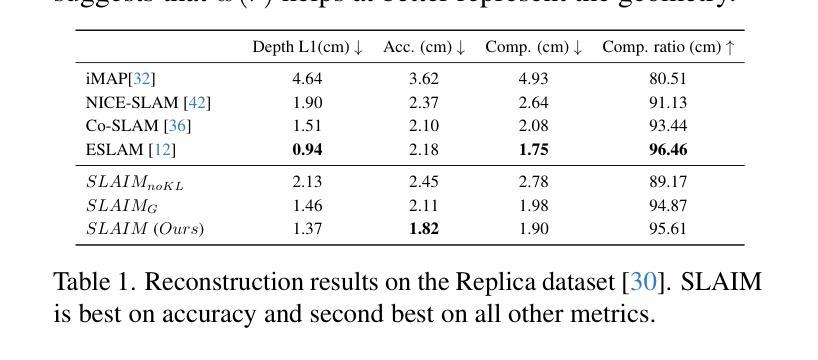
(4)任务和性能:本文方法在ScanNet、TUM、Replica等多个数据集上进行了实验,在跟踪和重建精度方面均取得了最先进的成果。这些性能支持了本文的目标。
方法:
(1):SLAIM 是一种用于稠密映射和跟踪的 RGB-D 输入流的 novel 方法; (2):SLAIM 采用了一种从粗到精的跟踪模型,以实现最先进的跟踪性能; (3):SLAIM 引入了一种新的目标射线终止分布,并将其用于 KL 正则化器中,以约束场景几何由空空间和不透明表面组成; (4):SLAIM 在 ScanNet、TUM、Replica 等多个数据集上进行了实验,在跟踪和重建精度方面均取得了最先进的成果。结论:
(1)本文的工作意义:本文提出了一种最先进的稠密实时 RGB-D NeRF-SLAM 系统 SLAIM,该系统具有最先进的相机跟踪和建图能力。
(2)本文的优缺点总结: - 创新点: - 采用从粗到精的跟踪模型,实现最先进的跟踪性能。 - 引入新的目标射线终止分布,并将其用于 KL 正则化器中,以约束场景几何由空空间和不透明表面组成。 - 性能: - 在 ScanNet、TUM、Replica 等多个数据集上取得了最先进的跟踪和重建精度。 - 工作量: - 内存效率高,在 Replica 和 ScanNet 数据集上与基准相比,跟踪和建图时间均有明显降低。
点此查看论文截图

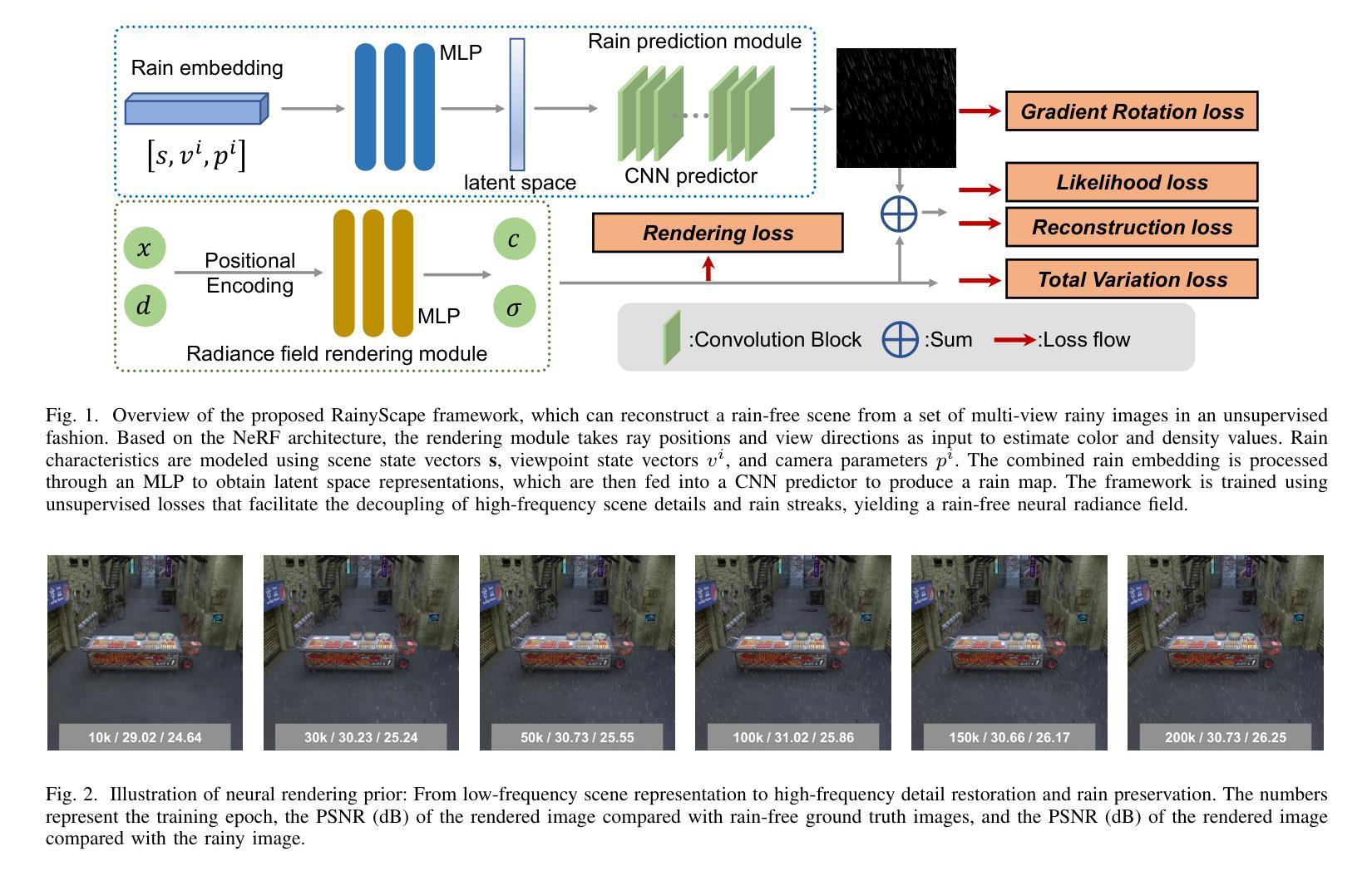
RainyScape: Unsupervised Rainy Scene Reconstruction using Decoupled Neural Rendering
Authors:Xianqiang Lyu, Hui Liu, Junhui Hou
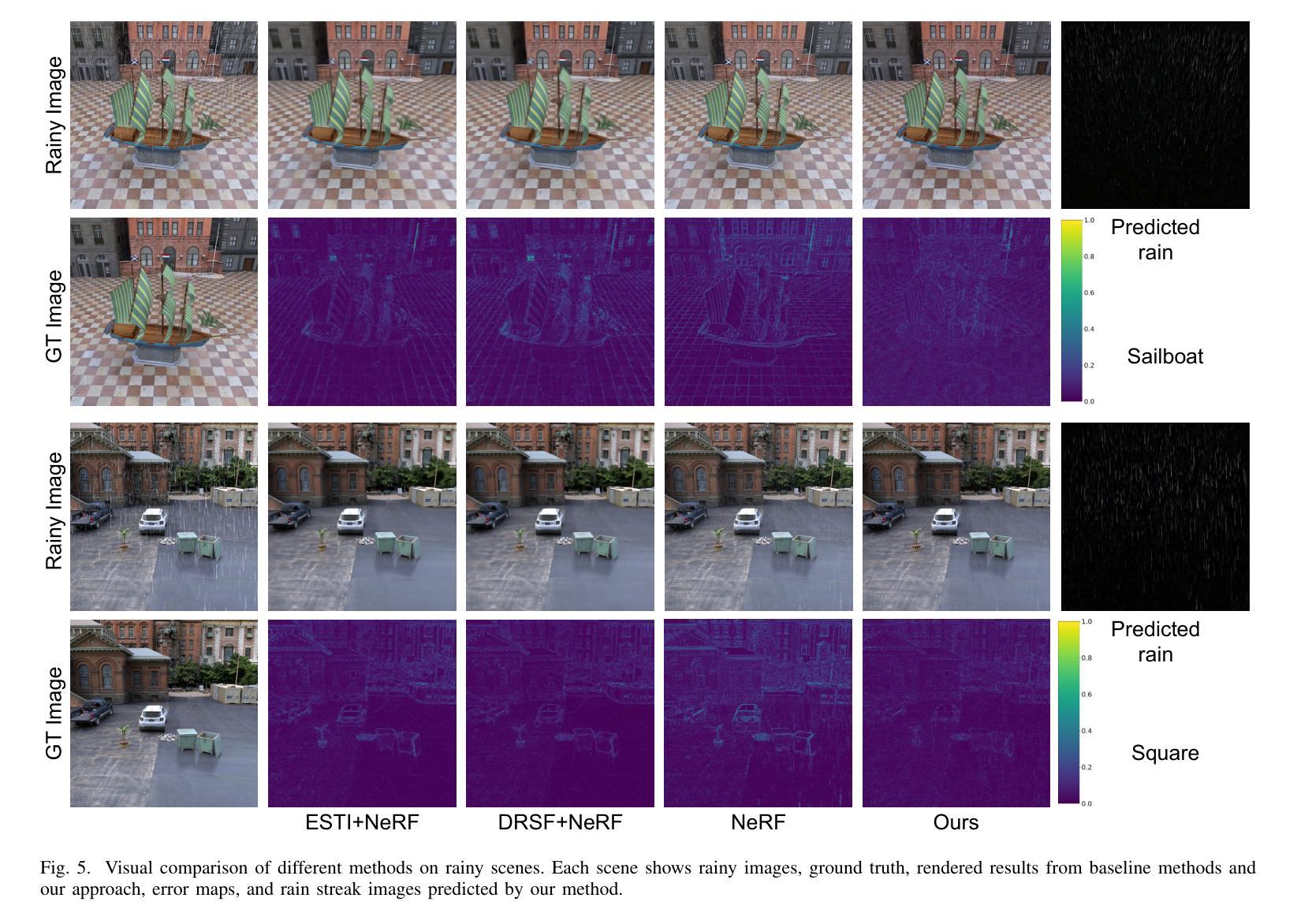
We propose RainyScape, an unsupervised framework for reconstructing clean scenes from a collection of multi-view rainy images. RainyScape consists of two main modules: a neural rendering module and a rain-prediction module that incorporates a predictor network and a learnable latent embedding that captures the rain characteristics of the scene. Specifically, based on the spectral bias property of neural networks, we first optimize the neural rendering pipeline to obtain a low-frequency scene representation. Subsequently, we jointly optimize the two modules, driven by the proposed adaptive direction-sensitive gradient-based reconstruction loss, which encourages the network to distinguish between scene details and rain streaks, facilitating the propagation of gradients to the relevant components. Extensive experiments on both the classic neural radiance field and the recently proposed 3D Gaussian splatting demonstrate the superiority of our method in effectively eliminating rain streaks and rendering clean images, achieving state-of-the-art performance. The constructed high-quality dataset and source code will be publicly available.
Summary
基于神经网络的光谱偏差特性,RainyScape利用无监督框架重建干净场景,包含神经渲染模块和雨滴预测模块。
Key Takeaways
- 利用神经网络的光谱偏差特性获得低频场景表示。
- 联合优化神经渲染模块和雨滴预测模块,以区分场景细节和雨滴条纹。
- 提出自适应方向敏感梯度重建损失,引导网络区分场景细节和雨滴条纹。
- 在经典神经辐射场和 3D 高斯斑点 splatting 数据集上均达到最先进的去雨性能。
- 提供高质量数据集和源代码,促进研究工作。
- 引入可学习潜在嵌入,捕捉场景的雨滴特征。
- 通过雨滴预测网络有效消除雨滴条纹,渲染干净图像。
Title: RainyScape: 无监督雨景重建使用解耦神经渲染
Authors: Xianqiang Lyu, Hui Liu, Junhui Hou
Affiliation: 香港城市大学计算机科学系
Keywords: Rainy scene reconstruction, Neural rendering, Unsupervised loss
Urls: https://arxiv.org/abs/2404.11401 , Github:None
Summary:
(1):随着神经辐射场(NeRF)在图像合成中的广泛应用,当输入图像受到模糊、噪声或雨水等因素影响时,渲染结果不可避免地会产生明显的伪影。
(2):现有的方法针对特定任务提出了各种解决方案,但对于雨景重建任务,它们无法有效表示三维空间中稀疏且间歇性的降雨。
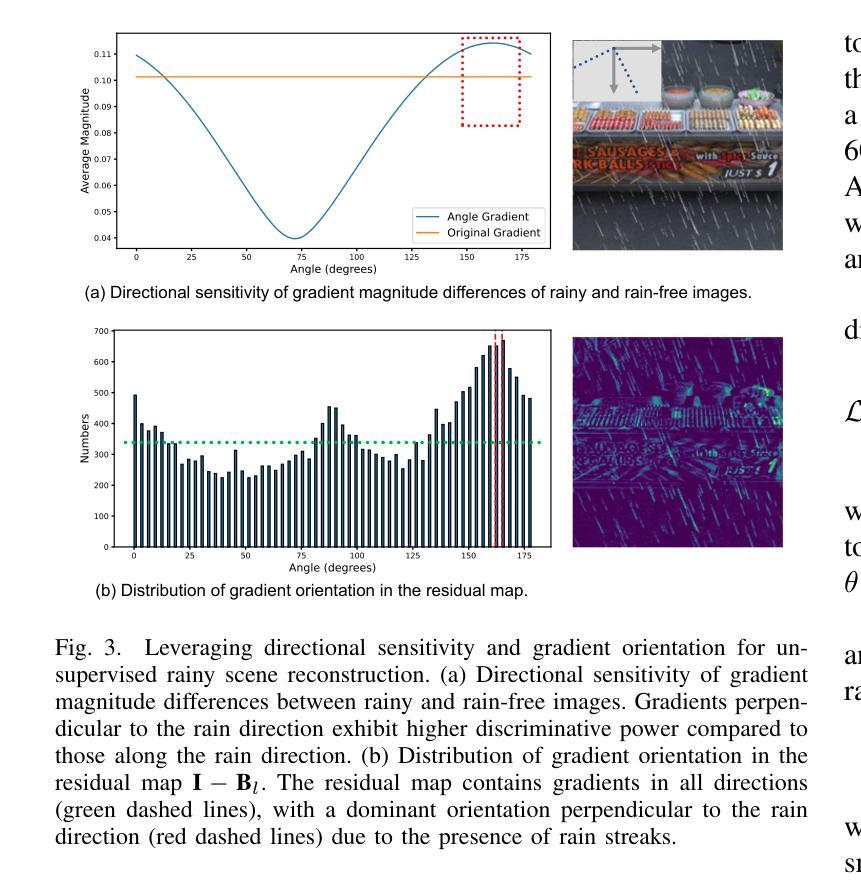
(3):本文提出RainyScape,一个解耦的神经渲染框架,它能够以无监督的方式从雨景图像中重建无雨场景。该框架通过神经渲染管道获得场景的低频表示,并使用可学习的雨水嵌入和预测器来表征雨水。此外,本文还提出了一个自适应角度估计策略和梯度旋转损失,以解耦场景高频细节和雨水条纹。
(4):在神经辐射场和三维高斯散射两种渲染技术上的广泛实验表明,该方法在有效消除雨水条纹和渲染清晰图像方面优于现有方法,达到了最先进的性能。
方法:
(1):提出RainyScape,一个解耦的神经渲染框架,可以无监督地从雨景图像中重建无雨场景;
(2):通过神经渲染管道获得场景的低频表示,并使用可学习的雨水嵌入和预测器来表征雨水;
(3):提出一个自适应角度估计策略和梯度旋转损失,以解耦场景高频细节和雨水条纹;
(4):在神经辐射场和三维高斯散射两种渲染技术上的广泛实验表明,该方法在有效消除雨水条纹和渲染清晰图像方面优于现有方法,达到了最先进的性能。
结论:
(1):RainyScape的意义在于,它提出了一种无监督的解耦神经渲染框架,可以从雨景图像中重建无雨场景,有效解决了雨景重建中的雨水条纹去除问题,为雨景图像处理提供了新的思路和方法。
(2):创新点:
提出了一种解耦的神经渲染框架,通过低频场景表示、可学习的雨水嵌入和预测器以及自适应角度估计策略和梯度旋转损失,有效解耦了场景高频细节和雨水条纹。
性能:
在神经辐射场和三维高斯散射两种渲染技术上的广泛实验表明,该方法在有效消除雨水条纹和渲染清晰图像方面优于现有方法,达到了最先进的性能。
工作量:
该方法需要对雨景图像进行预处理,包括图像分割、雨水条纹检测和雨水嵌入提取等步骤,增加了计算量和时间开销。
点此查看论文截图



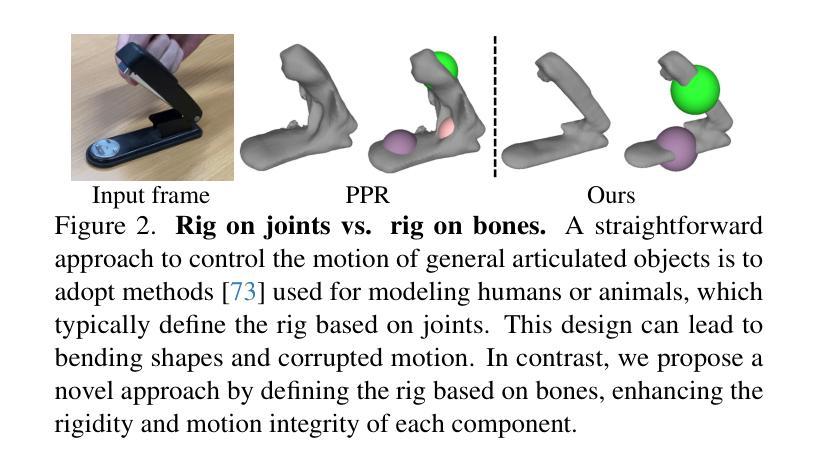
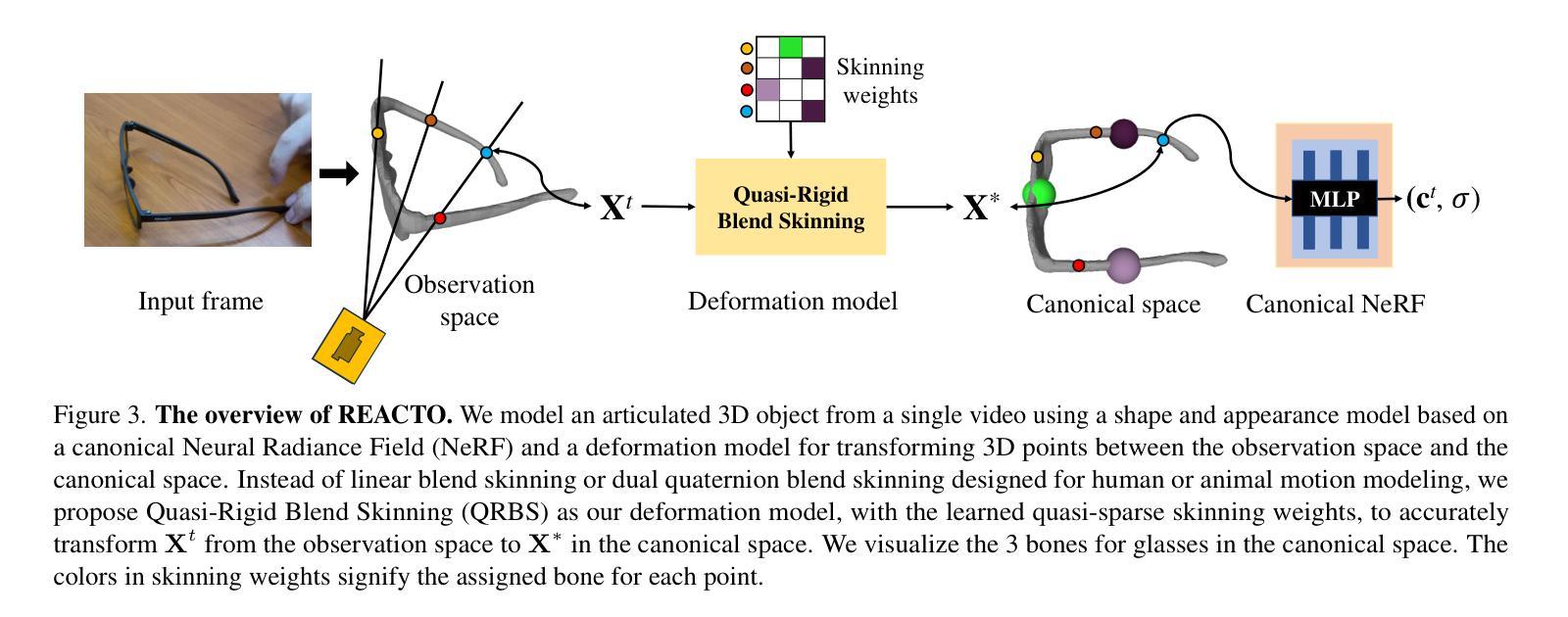
标题:REACTO:从单一视频中重建铰接物体
作者:Chaoyue Song、Jiacheng Wei、Chuan Sheng Foo、Guosheng Lin、Fayao Liu
隶属:南洋理工大学
关键词:铰接物体重建、动态神经辐射场、准刚性混合蒙皮
论文链接:https://arxiv.org/abs/2404.11151, Github:无
摘要:
(1):研究背景:重建铰接物体是计算机视觉中的一项重要任务,但现有方法在处理具有分段刚性的通用铰接物体时面临挑战。
(2):过去方法:NASAM和PARIS等方法需要多视角图像或多视图图像,在实际应用中受限。
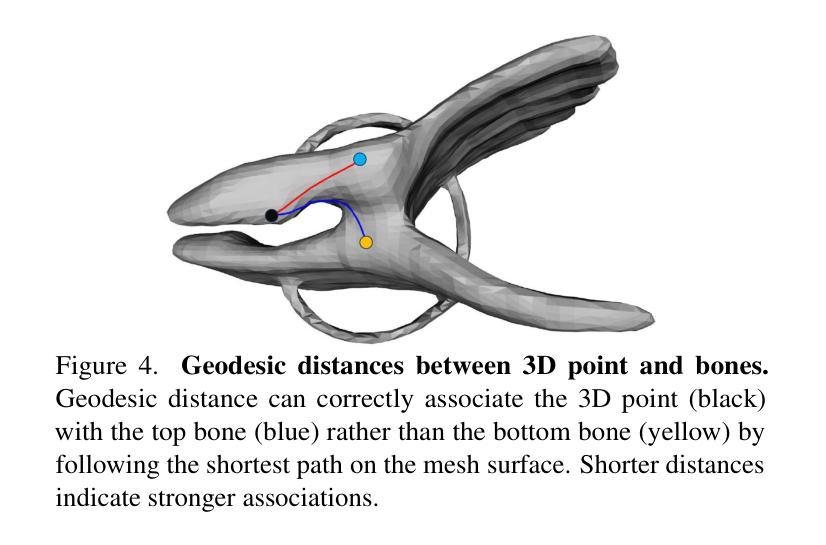
(3):研究方法:本文提出了一种准刚性混合蒙皮变形模型,该模型通过增强骨骼装配系统、使用准稀疏蒙皮权重和应用测地线点分配来提高刚性并保持关节的灵活变形。
(4):任务与性能:REACTO在真实和合成数据集上对通用铰接物体的3D重建任务中取得了较高的保真度,证明了其性能可以支持其目标。
7. Methods:
(1):提出准刚性混合蒙皮变形模型,增强骨骼装配系统,使用准稀疏蒙皮权重,并应用测地线点分配;
(2):构建REACTO框架,包括骨骼装配、蒙皮变形、体绘制和渲染模块;
(3):使用基于神经辐射场的渲染器,从单一视频中重建铰接物体;
(4):通过优化骨骼参数、蒙皮权重和神经辐射场参数,实现铰接物体的高保真重建;
(5):在真实和合成数据集上进行实验,验证REACTO的有效性。
- 结论:
(1):本工作提出REACTO,一种从单一视频中重建通用铰接3D物体的开创性方法,通过重新定义装配结构并采用准刚性混合蒙皮,实现了建模和精度的提升。准刚性混合蒙皮通过利用准稀疏蒙皮权重和测地线点分配,确保了每个部件的刚性,同时在关节处保持平滑变形。广泛的实验表明,REACTO在真实和合成数据集上都优于现有方法,保真度和细节方面都有所提升。
(2):创新点:提出准刚性混合蒙皮变形模型,增强骨骼装配系统,使用准稀疏蒙皮权重,并应用测地线点分配;
性能:在真实和合成数据集上,REACTO在保真度和细节方面都优于现有方法;
工作量:与需要多视角或多视图图像的现有方法相比,REACTO只需单一视频即可重建铰接物体,工作量更小。
点此查看论文截图

 wechat
wechat- alipay







