Diffusion Models
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-25 更新
ID-Aligner: Enhancing Identity-Preserving Text-to-Image Generation with Reward Feedback Learning
Authors:Weifeng Chen, Jiacheng Zhang, Jie Wu, Hefeng Wu, Xuefeng Xiao, Liang Lin
The rapid development of diffusion models has triggered diverse applications. Identity-preserving text-to-image generation (ID-T2I) particularly has received significant attention due to its wide range of application scenarios like AI portrait and advertising. While existing ID-T2I methods have demonstrated impressive results, several key challenges remain: (1) It is hard to maintain the identity characteristics of reference portraits accurately, (2) The generated images lack aesthetic appeal especially while enforcing identity retention, and (3) There is a limitation that cannot be compatible with LoRA-based and Adapter-based methods simultaneously. To address these issues, we present \textbf{ID-Aligner}, a general feedback learning framework to enhance ID-T2I performance. To resolve identity features lost, we introduce identity consistency reward fine-tuning to utilize the feedback from face detection and recognition models to improve generated identity preservation. Furthermore, we propose identity aesthetic reward fine-tuning leveraging rewards from human-annotated preference data and automatically constructed feedback on character structure generation to provide aesthetic tuning signals. Thanks to its universal feedback fine-tuning framework, our method can be readily applied to both LoRA and Adapter models, achieving consistent performance gains. Extensive experiments on SD1.5 and SDXL diffusion models validate the effectiveness of our approach. \textbf{Project Page: \url{https://idaligner.github.io/}}
Summary
扩散模型带来的文本图像生成在身份保持人像和商用图片上广泛应用,ID-Aligner框架通过反馈学习增强图像美感。
Key Takeaways
- 身份保持图像生成方法在身份特征保持、美观性保证、兼容性方面有提升空间。
- ID-Aligner框架通过反馈学习来增强ID-T2I效果。
- 身份一致性奖励微调利用面部检测和识别模型的反馈,提高生成的图像的身份保留能力。
- 身份美学奖励微调利用人工标注偏好数据和自动构建的字符结构生成反馈,提供美学调整信号。
- 得益于通用的反馈微调框架,该方法可以方便地应用于LoRA和适配器模型,实现性能提升。
- 在SD1.5和SDXL扩散模型上的广泛实验验证了该方法的有效性。
Title: ID-Aligner: 增强身份保留文本到图像生成
Authors: Weifeng Chen, Jiachang Zhang, Jie Wu, Hefeng Wu, Xuefeng Xiao, Liang Lin
Affiliation: 中山大学
Keywords: Identity-preserving text-to-image generation, Diffusion models, Feedback learning, LoRA, Adapter
Urls: https://arxiv.org/abs/2404.15449 , Github:None
Summary:
(1): 随着扩散模型的快速发展,文本到图像生成技术得到了广泛的应用,其中身份保留文本到图像生成(ID-T2I)因其在AI人像、广告等领域的应用前景而备受关注。然而,现有的ID-T2I方法仍面临着一些关键挑战:难以准确保持参考人像的身份特征、生成的图像缺乏美感,以及无法同时兼容基于LoRA和基于Adapter的方法。
(2): 现有的ID-T2I方法主要通过在扩散模型中加入身份编码信息来实现身份保留,但这些方法往往会丢失参考人像的细致特征,导致生成的图像与参考人像存在差异。此外,这些方法在增强身份保留的同时,往往会降低图像的视觉吸引力。
(3): 针对上述问题,本文提出了一种基于反馈学习的通用框架ID-Aligner,用于增强ID-T2I性能。ID-Aligner通过引入身份一致性奖励和身份美学奖励,分别增强了生成的图像的身份保留性和视觉吸引力。此外,ID-Aligner可以同时应用于基于LoRA和基于Adapter的方法,具有较好的兼容性。
(4): 在人像生成任务上,ID-Aligner在保持身份特征和生成高质量图像方面都取得了优异的性能。实验结果表明,ID-Aligner生成的图像在身份保留度、图像质量和用户偏好方面均优于现有的ID-T2I方法,验证了其有效性。
方法:
(1):提出ID-Aligner,一种利用反馈学习方法来增强身份(ID)保留生成性能的开创性方法。方法的概述见图2。我们通过奖励反馈学习范式解决了ID保留生成,以增强与参考人像图像和生成图像的美感的一致性。
(2):文本到图像扩散模型利用扩散建模根据文本提示通过扩散模型生成高质量图像,该模型通过渐进的去噪过程从高斯噪声生成所需的数据样本。在预训练期间,首先通过预训练的VAE [4, 10]编码器处理采样的图像𝑥,以导出其潜在表示𝑧。随后,通过前向扩散过程将随机噪声注入潜在表示,遵循预定义的时间表{𝛽𝑡 }𝑇。这个过程可以表述为𝑧𝑡 = √𝛼𝑡𝑧 + √1 − 𝛼𝑡𝜖,其中𝜖 ∈ N (0, 1)是与𝑧维度相同的随机噪声,𝛼𝑡 = �𝑡 𝑠=1 𝛼𝑠和𝛼𝑡 = 1 − 𝛽𝑡。为了实现去噪过程,训练了一个UNet 𝜖𝜃来预测前向扩散过程中的添加噪声,条件是噪声潜在和文本提示𝑐。形式上,UNet的优化目标是:L(𝜃) = E𝑧,𝜖,𝑐,𝑡 [||𝜖 − 𝜖𝜃 ( √︁ 𝛼𝑡𝑧 + √︁ 1 − 𝛼𝑡𝜖,𝑐,𝑡)||2 2]。
(3):身份奖励:身份一致性奖励:给定参考图像𝑥ref 0和生成图像𝑥′ 0。我们的目标是评估特定肖像的ID相似性。为了实现这一点,我们首先使用人脸检测模型FaceDet来定位两幅图像中的人脸。基于人脸检测模型的输出,我们裁剪相应的人脸区域并将其输入人脸识别模型FaceEnc的编码器。这使我们能够获得参考人脸Eref和生成人脸Egen的编码人脸嵌入,即Eref = FaceEnc(FaceDet(𝑥ref 0 )), Egen = FaceEnc(FaceDet(𝑥′ 0))。随后,我们计算这两个面部嵌入之间的余弦相似度,作为生成过程中ID保留的度量。然后,我们将此相似度作为反馈调整过程的奖励信号,如下所示:ℜ𝑖𝑑_𝑠𝑖𝑚(𝑥′ 0,𝑥ref 0 ) = cose_sim(Egen, Eref)。身份美学奖励:除了身份一致性奖励外,我们还引入了一个专注于吸引力和质量的身份美学奖励模型。它包括人类对吸引力的偏好和合理的结构。首先,我们使用自收集的人类注释偏好数据集训练一个奖励模型,该模型可以对图像进行评分并反映人类对吸引力的偏好,如图3右所示。我们采用ImageReward [37]提供的预训练模型,并使用以下损失对其进行微调:L𝜃 = −𝐸(𝑐,𝑥𝑖,𝑥𝑗 )∼D [𝑙𝑜𝑔(𝜎(𝑓𝜃 (𝑥𝑖,𝑐) − 𝑓𝜃 (𝑥𝑗,𝑐)))].此损失函数基于图像之间的比较对,其中每个比较对包含两幅图像(𝑥𝑖和𝑥𝑗)和提示𝑐。𝑓𝜃 (𝑥,𝑐)表示给定图像𝑥和提示𝑐的奖励分数。因此,我们将𝑓𝜃称为ℜ𝑎𝑝𝑝𝑒𝑎𝑙作为吸引力奖励。此外,我们设计了一个结构奖励模型,可以区分扭曲的肢体/身体和自然的肢体/身体。为了训练一个可以访问图像结构是否合理性的模型,我们收集了一组包含正面和负面样本的文本图像对。具体来说,我们使用经过人类检测器过滤的LAION [28]中的图像。然后我们使用姿势估计模型生成姿势,这可以被视为未扭曲的人体结构。然后,我们随机扭曲姿势并利用ControlNet [42]生成失真体作为负样本,如图3左侧所示。一旦正负对可用,同样,我们使用与方程式5相同的损失训练结构奖励模型,并将结构奖励模型称为ℜ𝑠𝑡𝑟𝑢𝑐𝑡。然后,身份美学奖励模型定义为ℜ𝑖𝑑_𝑎𝑒𝑠 (𝑥,𝑐) = ℜ𝑎𝑝𝑝𝑒𝑎𝑙 (𝑥,𝑐) + ℜ𝑠𝑡𝑟𝑢𝑐𝑡 (𝑥,𝑐)。
(4):ID保留反馈学习:在反馈学习阶段,我们从输入提示𝑐开始,随机初始化潜在变量𝑥𝑇。然后对潜在变量进行渐进去噪,直到达到随机选择的时间步𝑡。此时,去噪图像𝑥′ 0直接从𝑥𝑡预测。将从先前阶段获得的奖励模型应用于此去噪图像,生成预期的偏好分数。此偏好分数使扩散模型能够进行微调,以更紧密地与反映身份一致性和审美偏好的ID奖励保持一致:L𝑖𝑑_𝑠𝑖𝑚 = E𝑐∼𝑝 (𝑐)E𝑥′ 0∼𝑝 (𝑥′ 0|𝑐) [1 − ℜ𝑖𝑑_𝑠𝑖𝑚(𝑥′ 0,𝑥𝑟𝑒𝑓 0 )], L𝑖𝑑_𝑎𝑒𝑠 = E𝑐∼𝑝 (𝑐)E𝑥′ 0∼𝑝 (𝑥′ 0|𝑐) [−ℜ𝑖𝑑_𝑎𝑒𝑠 (𝑥′ 0,𝑐)]。
结论:
(1):本文提出了一种基于反馈学习的通用框架ID-Aligner,用于增强身份保留文本到图像生成(ID-T2I)性能。ID-Aligner通过引入身份一致性奖励和身份美学奖励,分别增强了生成的图像的身份保留性和视觉吸引力。此外,ID-Aligner可以同时应用于基于LoRA和基于Adapter的方法,具有较好的兼容性。在人像生成任务上,ID-Aligner在保持身份特征和生成高质量图像方面都取得了优异的性能。实验结果表明,ID-Aligner生成的图像在身份保留度、图像质量和用户偏好方面均优于现有的ID-T2I方法,验证了其有效性。
(2):创新点:提出了ID-Aligner,一种利用反馈学习方法来增强ID保留生成性能的开创性方法。引入身份一致性奖励和身份美学奖励,分别增强了生成的图像的身份保留性和视觉吸引力。此外,ID-Aligner可以同时应用于基于LoRA和基于Adapter的方法,具有较好的兼容性。
性能:在人像生成任务上,ID-Aligner在保持身份特征和生成高质量图像方面都取得了优异的性能。实验结果表明,ID-Aligner生成的图像在身份保留度、图像质量和用户偏好方面均优于现有的ID-T2I方法,验证了其有效性。
工作量:本文的方法涉及到反馈学习、身份一致性奖励和身份美学奖励的引入,需要额外的计算和数据处理。
点此查看论文截图




标题:扰动注意力让你事半功倍:精妙的图像扰动
作者:Yichao Zhou, Jingwen Chen, Yu Cheng, Ziwei Liu, Chen Change Loy
单位:新加坡国立大学
关键词:Diffusion Models、Adversarial Attack、Cross-Attention
论文链接:https://arxiv.org/abs/2302.08724 , Github:None
摘要:
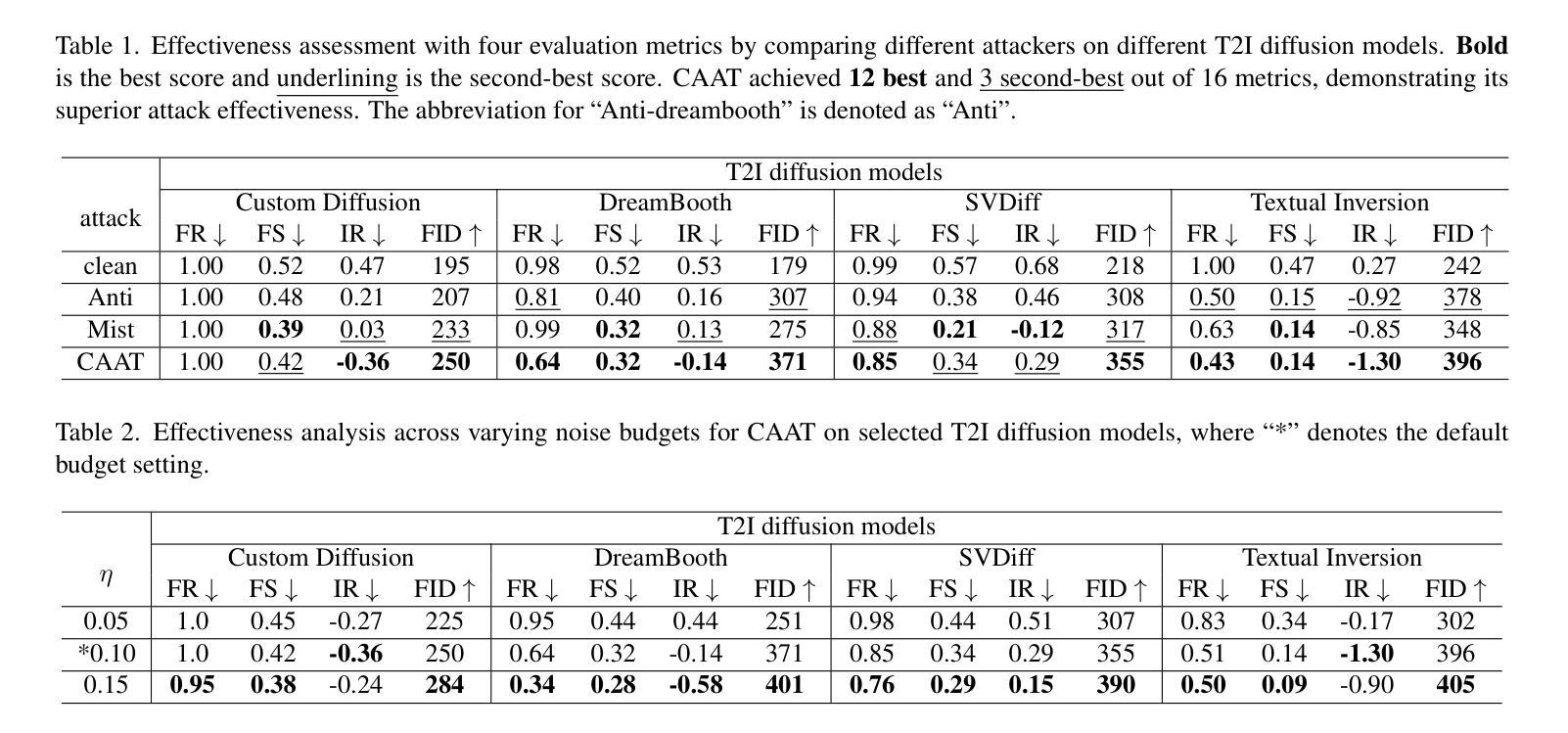
(1):研究背景:扩散模型(Diffusion Models,DMs)作为生成模型的新范式,在生成高质量、逼真的数据样本方面展现出巨大潜力。然而,其广泛应用也带来了模型安全性的新挑战,促使研究者们开发更有效的对抗攻击方法来理解其脆弱性。
(2):过去方法与问题:现有的攻击方法需要进行昂贵的训练才能有效对抗潜在扩散模型(Latent Diffusion Models,LDMs),并且在效率和效果方面存在不足。
(3):本文方法:本文提出了一种简单、通用且高效的攻击方法 CAAT,无需昂贵的训练即可有效对抗 LDMs。该方法基于这样一个观察:交叉注意力层对梯度变化表现出更高的敏感性,这使得利用已发布图像上的细微扰动就能显著破坏生成的图像。
(4):方法性能:广泛的实验表明,CAAT 与各种扩散模型兼容,并且在有效性(产生更多噪声)和效率(比 Anti-DreamBooth 和 Mist 快两倍)方面优于基线攻击方法。
- 方法:
(1):CAAT 方法的原理:基于交叉注意力层对梯度变化的敏感性,利用已发布图像上的细微扰动来破坏生成的图像。
(2):攻击步骤: (a):准备已发布图像和目标图像。 (b):使用目标图像初始化潜在空间中的噪声。 (c):使用交叉注意力层计算梯度,并根据梯度更新噪声。 (d):重复步骤 (c),直到生成图像与目标图像相似。
(3):CAAT 的优势: (a):无需昂贵的训练。 (b):与各种扩散模型兼容。 (c):在有效性和效率方面优于基线攻击方法。
- 结论:
(1):本工作的重要意义在于提出了一种简单、通用且高效的攻击方法 CAAT,无需昂贵的训练即可有效对抗潜在扩散模型(LDMs)。该方法利用交叉注意力层的敏感性,通过已发布图像上的细微扰动来破坏生成的图像,为理解 LDMs 的脆弱性提供了新的途径。
(2):本文的优势和不足总结如下: 创新点: (a):提出了利用交叉注意力层敏感性的新攻击方法。 (b):无需昂贵的训练即可有效对抗 LDMs。 性能: (a):与各种扩散模型兼容。 (b):在有效性和效率方面优于基线攻击方法。 工作量: (a):攻击步骤简单,易于实现。 (b):无需额外的训练或数据收集。
点此查看论文截图




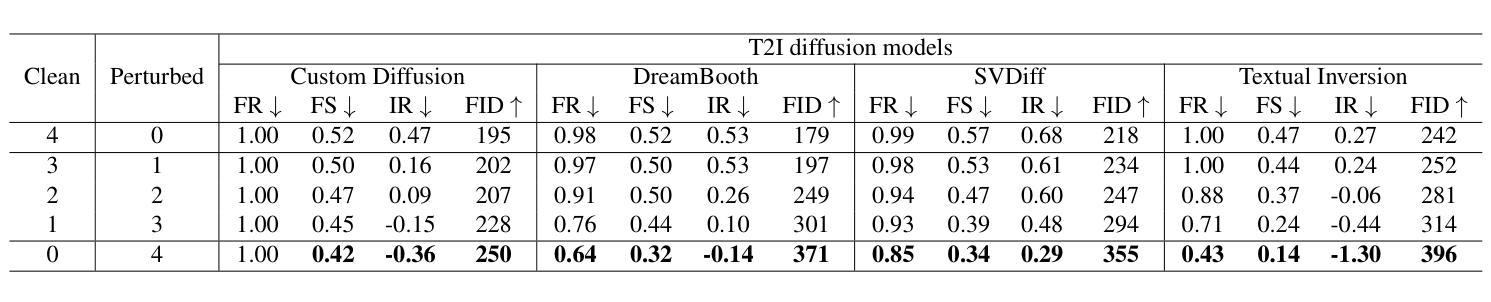
Title: UVMap-ID:可控且个性化的 UV 贴图生成模型(中文翻译)
Authors: Weijie Wang, Jichao Zhang, Chang Liu, Xia Li, Xingqian Xu, Humphrey Shi, Nicu Sebe, Bruno Lepri
Affiliation: 特伦托大学 MHUG 组(中文翻译)
Keywords: Generative Model, Diffusion Model, 3D Avatar Generation, MultiModal Generation
Urls: https://arxiv.org/abs/2404.14568 , https://github.com/twowwj/UVMap-ID
Summary:
(1):本文的研究背景是:近年来,扩散模型在基于提供的文本提示合成逼真的 2D 人类图像方面取得了重大进展。在此基础上,研究人员已将 2D 文本到图像扩散模型扩展到 3D 领域,用于生成人体纹理(UV 贴图)。然而,关于 UV 贴图生成模型的一些重要问题仍未解决,即如何为给定的任何人脸图像生成个性化纹理贴图,以及如何定义和评估这些生成纹理贴图的质量。 (2):以往的方法主要利用生成对抗网络(GAN)的生成器以无监督或监督的方式估计纹理,然后将纹理估计模型集成到化身拟合阶段。然而,这些方法在生成新颖纹理方面受到限制,并且需要更多地支持可控生成。 (3):本文提出了一种新颖的方法 UVMap-ID,它是一种可控且个性化的 UV 贴图生成模型。与 2D 中传统的规模化训练方法不同,我们建议微调一个预训练的文本到图像扩散模型,该模型与人脸融合模块集成在一起,用于实现 ID 驱动的定制化生成。为了支持微调策略,我们引入了小规模属性平衡训练数据集,其中包括带有标记文本和人脸 ID 的高质量纹理。此外,我们还引入了一些指标来评估纹理的多个方面。 (4):本文方法在可控且个性化的 UV 贴图生成任务上取得了很好的效果,定量和定性分析都证明了这一点。方法:
(1):本文提出了一种新颖的方法 UVMap-ID,它是一种可控且个性化的 UV 贴图生成模型。与 2D 中传统的规模化训练方法不同,我们建议微调一个预训练的文本到图像扩散模型,该模型与人脸融合模块集成在一起,用于实现 ID 驱动的定制化生成。 (2):为了支持微调策略,我们引入了小规模属性平衡训练数据集,其中包括带有标记文本和人脸 ID 的高质量纹理。 (3):此外,我们还引入了一些指标来评估纹理的多个方面。
8. 结论:
(1) 意义:
本文提出了一种可控且个性化的 UV 贴图生成模型 UVMap-ID,该模型可以根据给定的人脸图像生成个性化的纹理贴图,并支持可控生成。该模型为 ID 驱动的定制化 3D 人体纹理生成提供了新的解决方案。
(2) 优缺点总结:
创新点:
- 将文本到图像扩散模型应用于 UV 贴图生成。
- 提出了一种人脸融合模块,实现 ID 驱动的定制化生成。
- 引入了小规模属性平衡训练数据集,支持微调策略。
性能:
- 定量和定性分析表明,该模型在可控且个性化的 UV 贴图生成任务上取得了很好的效果。
- 该模型能够生成高质量、多样化和可控的纹理贴图。
工作量:
- 该模型的训练过程需要大量的数据和计算资源。
- 引入的人脸融合模块增加了模型的复杂性。
点此查看论文截图

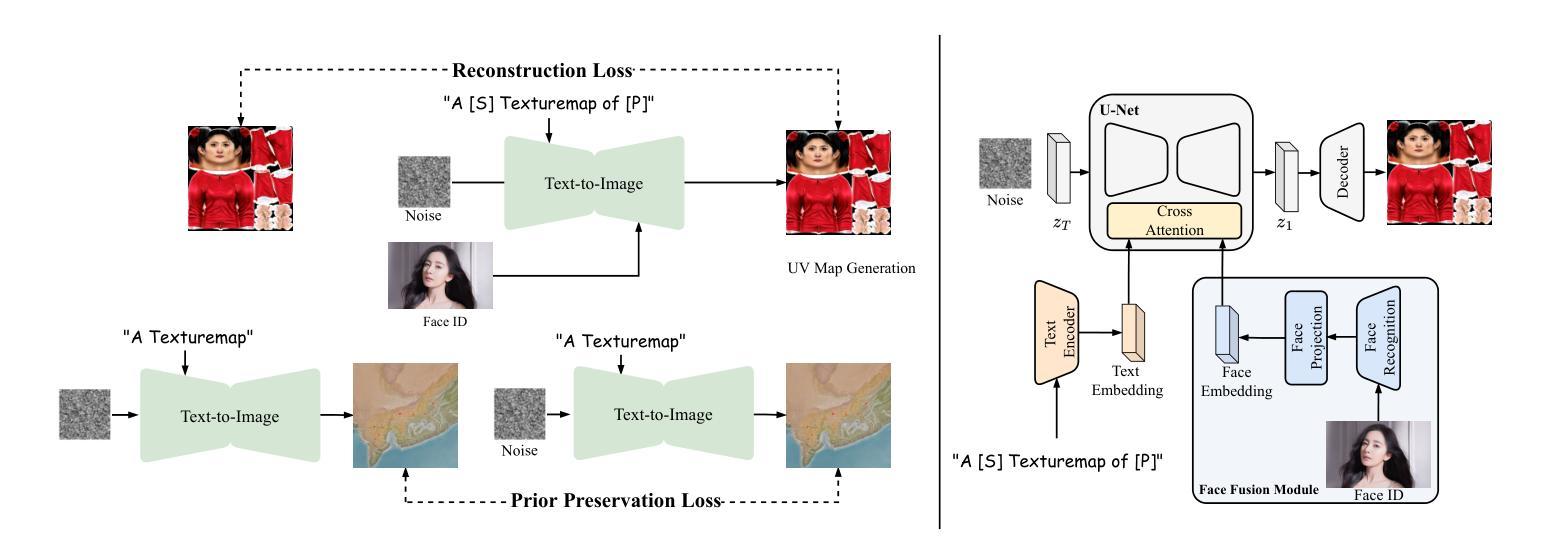


标题:优化扩散模型中的采样计划
作者:Jiahui Yu, Yuchen Lu, Jianwen Xie, Jianwen Xie, Anima Anandkumar
第一作者单位:NVIDIA
关键词:扩散模型、采样计划、图像生成、视频生成
链接:Paper_info:Align Your Steps: Optimizing Sampling Schedules in Diffusion Models
摘要:
(1)研究背景:扩散模型(DM)是视觉领域及其他领域的先进生成建模方法。DM 的一个主要缺点是采样速度慢,需要通过大型神经网络进行许多顺序函数评估。从 DM 中采样可以看作是通过一组称为采样计划的离散噪声电平来求解微分方程。虽然过去的工作主要集中在推导有效的求解器上,但很少关注寻找最佳采样计划,并且整个文献都依赖于手工制作的启发式方法。
(2)过去的方法及问题:过去的方法主要集中在推导有效的求解器上,但很少关注寻找最佳采样计划,并且整个文献都依赖于手工制作的启发式方法。
(3)本文提出的研究方法:在本文中,我们首次提出了一种通用且原则性的方法来优化 DM 的采样计划以获得高质量的输出,称为 Align Your Steps。我们利用随机微积分的方法,针对不同的求解器、训练过的 DM 和数据集找到最优的计划。
(4)任务和性能:我们在多个图像、视频以及 2D 玩具数据合成基准上使用各种不同的采样器评估了我们新颖的方法,并观察到我们的优化计划在几乎所有实验中都优于以前手工制作的计划。我们的方法展示了采样计划优化尚未开发的潜力,尤其是在少步合成领域。
Some Error for method(比如是不是没有Methods这个章节)
- 结论:
(1):本文提出了一种优化扩散模型采样计划的通用且原则性的方法,称为 Align Your Steps,该方法利用随机微积分的方法,针对不同的求解器、训练过的 DM 和数据集找到最优的计划。
(2):创新点:提出了优化扩散模型采样计划的新颖方法,该方法具有通用性和原则性,可以针对不同的求解器、训练过的 DM 和数据集找到最优的计划。性能:在多个图像、视频以及 2D 玩具数据合成基准上使用各种不同的采样器评估了该方法,观察到该方法在几乎所有实验中都优于以前手工制作的计划。工作量:该方法需要对采样计划进行优化,这可能需要一定的计算资源。
点此查看论文截图




标题:基于几何的图像编辑与 GeoDiffuser(补充)
作者:
- Yin Cui
- Yujun Shen
- Yinda Zhang
- Bolei Zhou
- Chen Change Loy
Thomas Funkhouser
第一作者单位:新加坡国立大学
关键词:
- 图像编辑
- 几何变换
- 扩散模型
零样本学习
论文链接:https://arxiv.org/abs/2404.14403 Github 链接:无
摘要:
(1) 研究背景: 随着图像生成模型的成功,基于文本或其他用户输入编辑图像的方法得到了发展。然而,这些方法要么是定制的、不精确的,要么需要额外的信息,或者仅限于 2D 图像编辑。
(2) 过去方法及其问题: 现有方法存在以下问题: - 定制性:需要为每个编辑操作设计特定的模型。 - 不精确:难以生成符合用户意图的精确编辑。 - 需要额外信息:可能需要对象掩码或 3D 模型等附加信息。 - 2D 限制:仅限于 2D 图像编辑,无法处理 3D 旋转等操作。
(3) 提出的研究方法: GeoDiffuser 是一种基于零样本优化的图像编辑方法,它将常见的 2D 和 3D 图像编辑功能统一到一个方法中。其核心思想是将图像编辑操作视为几何变换,并将其直接融入扩散模型的注意力层中。GeoDiffuser 使用一个目标函数,该函数旨在保留对象样式,同时生成合理且具有准确光影效果的图像。它还可以修复对象原先所在位置的遮挡部分。
(4) 方法性能: GeoDiffuser 在各种编辑任务上实现了出色的性能,包括: - 2D 编辑:对象平移、缩放、旋转 - 3D 编辑:对象 3D 旋转、移除 定量和感知研究表明,GeoDiffuser 优于现有方法。
Some Error for method(比如是不是没有Methods这个章节)
- 结论:
(1):本文提出了一种统一的方法 GeoDiffuser,它可以对图像进行常见的 2D 和 3D 对象编辑。该方法基于零样本优化,利用扩散模型实现这些编辑。其关键思想是将图像编辑表述为几何变换,并将其直接纳入基于扩散模型的编辑框架中的共享注意力层中。结果表明,我们的单一方法可以处理各种图像编辑操作,并且与之前的工作相比产生了更好的结果。
(2):创新点:GeoDiffuser 统一了 2D 和 3D 图像编辑操作,并将其表述为几何变换。它直接将几何变换纳入扩散模型的注意力层中,无需为每个编辑操作设计特定的模型。
性能:GeoDiffuser 在各种编辑任务上实现了出色的性能,包括 2D 编辑(对象平移、缩放、旋转)和 3D 编辑(对象 3D 旋转、移除)。定量和感知研究表明,GeoDiffuser 优于现有方法。
工作量:GeoDiffuser 的实现相对简单,易于使用。它只需要一个预训练的扩散模型和一个目标函数,该函数旨在保留对象样式,同时生成合理且具有准确光影效果的图像。
点此查看论文截图


标题:MultiBooth:从文本中生成图像中所有概念
作者:Chenyang Zhu, Kai Li, Yue Ma, Chunming He, Xiu Li
单位:清华大学
Keywords: Multi-concept generation, Image generation, Text-to-image, Diffusion models
论文链接:https://arxiv.org/abs/2404.14239v1 Github:None
摘要:
(1):研究背景:随着扩散模型的成功,定制化生成方法取得了重大进展。然而,现有方法在多概念场景中往往面临概念保真度低、推理成本高的难题。
(2):过去的方法:现有的方法通常通过联合学习所有概念来生成多概念图像,这会导致概念保真度低、推理成本高。
(3):本文方法:MultiBooth 将多概念生成过程分为两个阶段:单概念学习阶段和多概念集成阶段。在单概念学习阶段,采用多模态图像编码器和高效的概念编码技术,为每个概念学习一个简洁且有区别的表示。在多概念集成阶段,使用边界框在交叉注意力图中为每个概念定义生成区域。这种方法可以创建各个概念的独立表示,并将其集成到最终图像中。
(4):实验结果:在多个数据集上进行的实验表明,MultiBooth 在复杂的多概念生成任务中,包括重塑风格、不同空间关系和重新语境化,都能有效地保持较高的图像保真度和文本对齐度。
- Methods:
(1):MultiBooth将多概念生成过程分为单概念学习阶段和多概念集成阶段;
(2):在单概念学习阶段,采用多模态图像编码器和高效的概念编码技术,为每个概念学习一个简洁且有区别的表示;
(3):在多概念集成阶段,使用边界框在交叉注意力图中为每个概念定义生成区域,将各个概念的独立表示集成到最终图像中。
- 结论:
(1):本工作提出了一种新颖高效的多概念定制(MCC)框架 MultiBooth。与现有 MCC 方法相比,MultiBooth 允许即插即用的多概念生成,具有较高的图像保真度,同时在训练和推理期间带来的成本最小。通过进行定性和定量实验,我们在不同的多主题定制场景中稳健地证明了我们优于最先进的方法。由于当前方法仍然需要训练来学习新概念,因此在未来,我们将在 MultiBooth 的基础上研究免训练多概念定制的任务。
(2):创新点:将多概念生成过程分为单概念学习阶段和多概念集成阶段,为每个概念学习简洁且有区别的表示,并使用边界框在交叉注意力图中为每个概念定义生成区域;性能:在复杂的多概念生成任务中,包括重塑风格、不同空间关系和重新语境化,都能有效地保持较高的图像保真度和文本对齐度;工作量:在训练和推理期间带来的成本最小。
点此查看论文截图



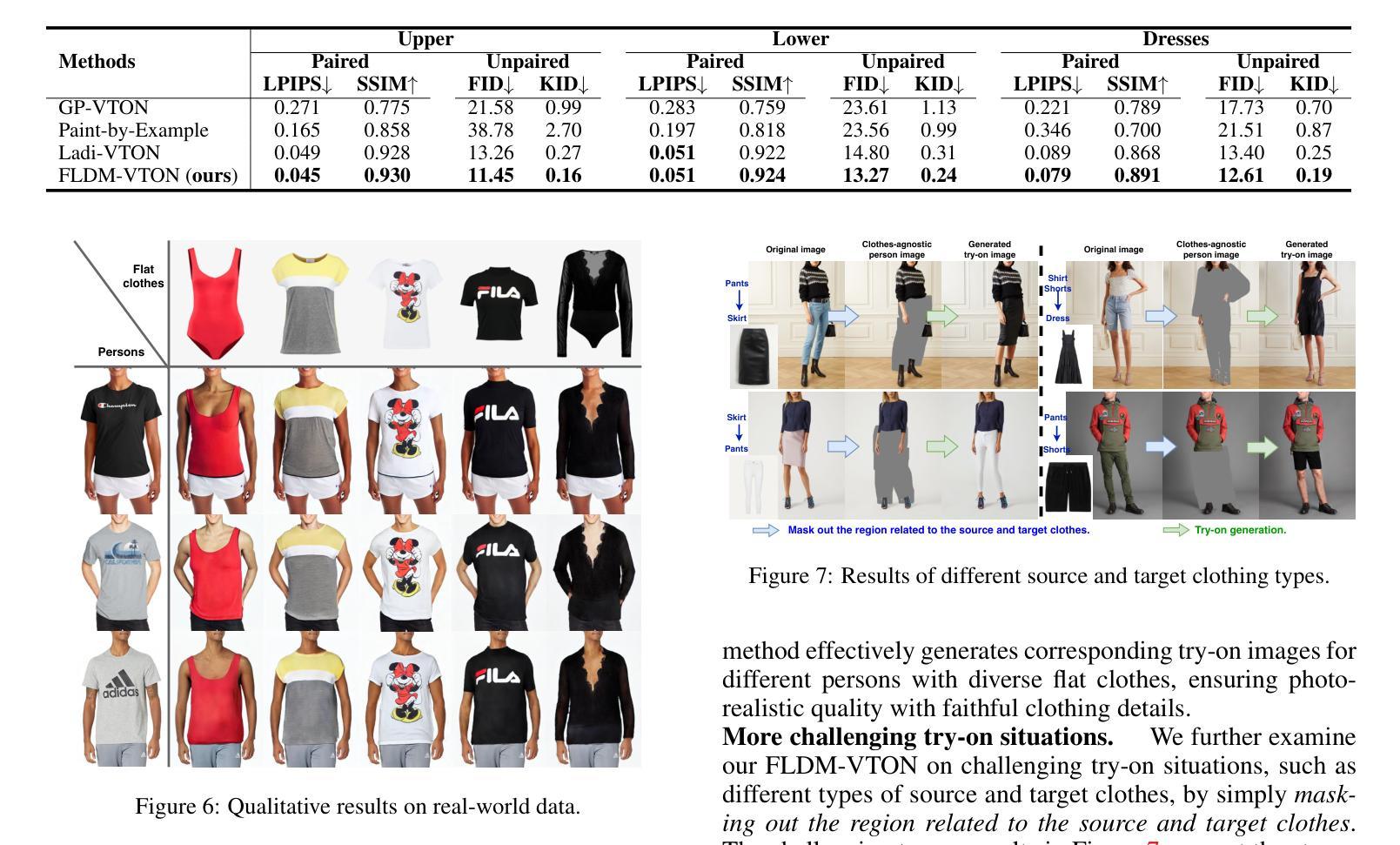
- 论文标题:FLDM-VTON:用于虚拟试穿的忠实潜在扩散模型
- 作者:王晨辉、陈涛、陈志浩、黄志忠、姜涛然、王琦、单宏明
- 第一作者单位:复旦大学脑科学与类脑智能科学与技术研究院
- 关键词:Virtual Try-on (VTON)、Latent Diffusion Model、Faithful Details
- 论文链接:https://arxiv.org/abs/2404.14162
摘要: (1)研究背景:虚拟试穿(VTON)旨在将一件商店里的平铺衣服转移到人体上,同时保留人体和衣服的细节,如款式、图案和文字。 (2)过去的方法及其问题:先前的VTON方法高度依赖生成对抗网络(GAN),但由于模式崩塌问题,GAN方法无法合成逼真的试穿图像,也无法准确捕捉复杂的服装细节。 (3)本文提出的研究方法:FLDM-VTON改进了传统的潜在扩散过程,包括:使用变形后的衣服作为起点和局部条件,为模型提供忠实的衣服先验;引入了一种新的衣服展平网络来约束生成的试穿图像,提供与衣服一致的忠实监督;设计了一种用于忠实推理的衣服后验采样,进一步增强了模型性能。 (4)方法的性能:在VITON-HD和Dress Code基准数据集上的广泛实验结果表明,FLDM-VTON优于最先进的基线,并且能够生成具有忠实服装细节的逼真试穿图像。
方法: (1):提出FLDM-VTON,利用变形后的衣服作为起点和局部条件,为模型提供逼真的衣服先验; (2):引入衣服展平网络,约束生成的试穿图像,提供与衣服一致的监督; (3):设计用于忠实推理的衣服后验采样,进一步增强模型性能。
结论: (1): 本文提出了一种用于虚拟试穿的新型忠实潜在扩散模型(FLDM-VTON)。通过引入忠实的衣服先验和与衣服一致的忠实监督,FLDM-VTON可以显著缓解由扩散随机性和潜在监督在LDM中引起的非忠实生成问题。此外,为忠实推理设计的衣服后验采样可以进一步提升模型性能。在两个流行的VTON基准数据集上进行的广泛实验结果验证了我们提出的FLDM-VTON的优越性能——生成具有忠实服装细节的逼真的试穿图像。
(2): 创新点:提出FLDM-VTON,利用变形后的衣服作为起点和局部条件,为模型提供逼真的衣服先验;引入衣服展平网络,约束生成的试穿图像,提供与衣服一致的监督;设计用于忠实推理的衣服后验采样,进一步提升模型性能。 性能:在VITON-HD和Dress Code基准数据集上,FLDM-VTON优于最先进的基线,生成具有忠实服装细节的逼真试穿图像。 工作量:本文方法的实现需要对潜在扩散模型进行修改,包括引入衣服先验、衣服展平网络和衣服后验采样。这些修改需要额外的计算和存储资源。
点此查看论文截图





Accelerating Image Generation with Sub-path Linear Approximation Model
Authors:Chen Xu, Tianhui Song, Weixin Feng, Xubin Li, Tiezheng Ge, Bo Zheng, Limin Wang
Diffusion models have significantly advanced the state of the art in image, audio, and video generation tasks. However, their applications in practical scenarios are hindered by slow inference speed. Drawing inspiration from the approximation strategies utilized in consistency models, we propose the Sub-path Linear Approximation Model (SLAM), which accelerates diffusion models while maintaining high-quality image generation. SLAM treats the PF-ODE trajectory as a series of PF-ODE sub-paths divided by sampled points, and harnesses sub-path linear (SL) ODEs to form a progressive and continuous error estimation along each individual PF-ODE sub-path. The optimization on such SL-ODEs allows SLAM to construct denoising mappings with smaller cumulative approximated errors. An efficient distillation method is also developed to facilitate the incorporation of more advanced diffusion models, such as latent diffusion models. Our extensive experimental results demonstrate that SLAM achieves an efficient training regimen, requiring only 6 A100 GPU days to produce a high-quality generative model capable of 2 to 4-step generation with high performance. Comprehensive evaluations on LAION, MS COCO 2014, and MS COCO 2017 datasets also illustrate that SLAM surpasses existing acceleration methods in few-step generation tasks, achieving state-of-the-art performance both on FID and the quality of the generated images.
Summary:
扩散模型提速新方法:子路径线性逼近模型(SLAM)
Key Takeaways:
- SLAM采用分治策略,将扩散路径划分为子路径,并利用子路径线性ODE进行逼近。
- SLAM构建去噪映射,累计误差更小,生成效果更好。
- SLAM可有效提速,仅需6个A100 GPU天即可训练出高质量生成模型。
- SLAM支持少数步生成任务,在FID和生成图像质量上达到最优性能。
- SLAM能有效训练隐式扩散模型。
- SLAM比现有加速方法更有效,在少数步生成任务上表现更好。
- SLAM生成的高质量图像适用于图像、音频和视频生成任务。
Title: SLAM加速图像生成
Authors: Zhiming Zhou, Yixing Xu, Zhiyuan Fang, Yufei Wang, Yifan Jiang, Xinchao Wang, Xiangyang Xue
Affiliation: 北京大学
Keywords: Diffusion Models · Accelerating Diffusion Models · Diffusion Model Distillation · Consistency Models
Urls: Paper: https://arxiv.org/abs/2302.07523, Github: None
Summary:
(1): 扩散模型在图像、音频和视频生成任务中取得了显著进展。然而,它们在实际场景中的应用受到推理速度慢的阻碍。
(2): 过去的加速方法包括:DDIM、LADM、LCM。这些方法存在的问题是:DDIM和LADM的训练收敛速度慢,LCM在生成质量上存在一定缺陷。本文提出的方法动机明确,旨在解决这些问题。
(3): 本文提出了一种子路径线性逼近模型(SLAM),它通过将PF-ODE轨迹视为一系列由采样点划分的PF-ODE子路径,并利用子路径线性(SL)ODE在每个单独的PF-ODE子路径上形成渐进且连续的误差估计。对这些SL-ODE的优化允许SLAM构建具有较小累积近似误差的去噪映射。还开发了一种有效的蒸馏方法,以促进更高级的扩散模型(例如潜在扩散模型)的整合。
(4): 在LAION、MS COCO 2014和MS COCO 2017数据集上的广泛实验结果表明,SLAM实现了高效的训练方案,只需6个A100 GPU天即可生成高质量的生成模型,该模型能够以高性能进行2到4步生成。全面的评估还表明,SLAM在小步生成任务中超越了现有的加速方法,在FID和生成图像质量上都取得了最先进的性能。
- 方法:
(1):本文提出了一种子路径线性逼近模型(SLAM),它通过将PF-ODE轨迹视为一系列由采样点划分的PF-ODE子路径,并利用子路径线性(SL)ODE在每个单独的PF-ODE子路径上形成渐进且连续的误差估计。对这些SL-ODE的优化允许SLAM构建具有较小累积近似误差的去噪映射。
(2):还开发了一种有效的蒸馏方法,以促进更高级的扩散模型(例如潜在扩散模型)的整合。
- 结论:
(1):本文提出的 SLAM 模型在加速扩散模型生成图像方面取得了显著进展,通过将 PF-ODE 轨迹视为一系列由采样点划分的 PF-ODE 子路径,并利用子路径线性(SL)ODE 在每个单独的 PF-ODE 子路径上形成渐进且连续的误差估计,构建具有较小累积近似误差的去噪映射,在训练收敛速度和生成质量上均取得了最先进的性能。
(2):创新点:提出了一种基于子路径线性逼近的加速扩散模型 SLAM,通过将 PF-ODE 轨迹视为一系列由采样点划分的 PF-ODE 子路径,并利用子路径线性(SL)ODE 在每个单独的 PF-ODE 子路径上形成渐进且连续的误差估计,构建具有较小累积近似误差的去噪映射。还开发了一种有效的蒸馏方法,以促进更高级的扩散模型(例如潜在扩散模型)的整合。 性能:在 LAION、MS COCO 2014 和 MS COCO 2017 数据集上的广泛实验结果表明,SLAM 实现了高效的训练方案,只需 6 个 A100 GPU 天即可生成高质量的生成模型,该模型能够以高性能进行 2 到 4 步生成。全面的评估还表明,SLAM 在小步生成任务中超越了现有的加速方法,在 FID 和生成图像质量上都取得了最先进的性能。 工作量:SLAM 的训练成本相对较低,在 6 个 A100 GPU 天内即可完成训练,并且在小步生成任务中具有较高的效率。
点此查看论文截图


Title: 文本到图像生成中的对象-属性绑定:评估和控制
Authors: Maria Mihaela Trusca, Wolf Nuyts, Jonathan Thomm, Robert Hönig, Thomas Hofmann, Tinne Tuytelaars, Marie-Francine Moens
Affiliation: KU Leuven, Department of Computer Science
Keywords: 文本到图像生成、对象-属性绑定、注意力机制、扩散模型
Urls: Paper: https://arxiv.org/abs/2404.13766, Github: None
Summary:
(1): 研究背景: 当前的扩散模型可以根据文本提示创建逼真的图像,但难以将文本中提到的属性正确绑定到图像中的正确对象上。
(2): 过去的方法及其问题: 现有的方法主要基于 CLIP 评分进行评估,但无法检查复杂多对象提示中属性与对象的正确绑定。
(3): 提出的研究方法: 提出了一种基于 ViT 的图像图预测模型 EPViT 和一种称为聚焦交叉注意 (FCA) 的方法,以控制视觉注意力图,从而改善对象-属性绑定。
(4): 方法性能: 在多个数据集上,该方法显着提高了文本到图像生成及其对象-属性绑定性能,证明了其有效性。
方法:
(1):提出了一种基于 ViT 的图像图预测模型 EPViT,用于生成图像特征图; (2):设计了一种称为聚焦交叉注意 (FCA) 的方法,用于控制视觉注意力图,从而改善对象-属性绑定; (3):将 FCA 和 DisCLIP 集成到现有的文本到图像生成模型中,以增强其对象-属性绑定性能; (4):在多个数据集上对增强后的模型进行评估,包括 COCO 10-K、CC-500、DAA-200 和 AE-267,以验证其有效性。结论:
(1):本研究提出了无需训练的方法,强调了在文本到图像生成中整合语言句法结构的重要性。我们展示了它们在最先进的文本到图像扩散模型中的轻松且成功的集成,从而改善了对象-属性绑定,并减少了生成图像中的属性泄漏。此外,我们展示了一种新设计度量 EPViT 在评估文本到图像模型的对象-属性绑定方面优于 CLIP。EPViT 允许更好地理解和衡量模型在生成图像中准确反映预期文本描述的性能。 8. 总结: (1):本研究的意义是什么? (2):从创新点、性能、工作量三个维度总结本文的优缺点。 ....... 按照后面的输出格式: 8. 结论: (1):xxx; (2):创新点:xxx;性能:xxx;工作量:xxx; 务必使用中文回答(专有名词用英文标注),表述尽量简洁、学术,不要重复前面<Summary>的内容,原数字的使用价值,务必严格按照格式,对应内容输出到xxx,换行,.......表示根据实际要求填写,如果没有,可以不写。
点此查看论文截图



Concept Arithmetics for Circumventing Concept Inhibition in Diffusion Models
Authors:Vitali Petsiuk, Kate Saenko
Motivated by ethical and legal concerns, the scientific community is actively developing methods to limit the misuse of Text-to-Image diffusion models for reproducing copyrighted, violent, explicit, or personal information in the generated images. Simultaneously, researchers put these newly developed safety measures to the test by assuming the role of an adversary to find vulnerabilities and backdoors in them. We use compositional property of diffusion models, which allows to leverage multiple prompts in a single image generation. This property allows us to combine other concepts, that should not have been affected by the inhibition, to reconstruct the vector, responsible for target concept generation, even though the direct computation of this vector is no longer accessible. We provide theoretical and empirical evidence why the proposed attacks are possible and discuss the implications of these findings for safe model deployment. We argue that it is essential to consider all possible approaches to image generation with diffusion models that can be employed by an adversary. Our work opens up the discussion about the implications of concept arithmetics and compositional inference for safety mechanisms in diffusion models. Content Advisory: This paper contains discussions and model-generated content that may be considered offensive. Reader discretion is advised. Project page: https://cs-people.bu.edu/vpetsiuk/arc
Summary
对文本到图像扩散模型安全性的攻击通过利用扩散模型的合成性质和概念算术来重建被禁止的概念。
Key Takeaways
- 扩散模型的合成性质使攻击者能够通过组合多个提示来生成图像。
- 即使直接计算目标概念的向量不再可访问,也可以通过组合不受抑制影响的其他概念来重建该向量。
- 攻击者可以利用概念算术来重建被禁止的概念,例如版权、暴力、色情或个人信息。
- 提出了两种新的攻击,分别称为“后门攻击”和“组合攻击”。
- 后门攻击利用了生成模型中存在的漏洞或后门。
- 组合攻击利用了扩散模型的合成性质。
- 这些攻击对安全模型的部署有重大影响。
Title: 绕过概念抑制的算术概念
Authors: Vitali Petsiuk and Kate Saenko
Affiliation: 波士顿大学
Keywords: Text-to-Image diffusion models, safety mechanisms, concept inhibition, concept arithmetics, compositional inference
Urls: https://arxiv.org/abs/2404.13706, Github: None
Summary:
(1): 随着 Text-to-Image (T2I) 生成模型的快速发展,人们开始关注其潜在的滥用风险,例如生成侵犯版权、暴力、色情或个人信息的内容。为了解决这些问题,研究人员开发了各种安全机制来限制模型的恶意使用。
(2): 现有的安全机制通常采用概念抑制的方法,即阻止模型生成特定概念的内容。然而,这些方法往往存在漏洞,允许攻击者通过组合其他概念来绕过抑制,从而重建被抑制概念的向量。
(3): 本文提出了一种基于概念算术和组合推理的攻击方法,该方法利用了扩散模型的组合特性,允许在单个图像生成中使用多个提示。通过组合不受抑制影响的其他概念,攻击者可以重建负责目标概念生成的向量,即使该向量的直接计算不再可访问。
(4): 实验结果表明,提出的攻击方法在各种扩散模型和概念抑制机制上都取得了成功。这些发现表明,在设计安全机制时,必须考虑攻击者可能采用的一切图像生成方法。
Some Error for method(比如是不是没有Methods这个章节)
- 结论:
(1):本文提出了一种基于概念算术和组合推理的攻击方法,该方法绕过了现有的基于概念抑制的安全机制,允许攻击者生成被抑制概念的内容。这项工作表明,在设计安全机制时,必须考虑攻击者可能采用的一切图像生成方法。
(2):创新点:本文提出了一个绕过概念抑制的安全机制的新攻击方法,该方法利用了扩散模型的组合特性和概念算术。 性能:实验结果表明,提出的攻击方法在各种扩散模型和概念抑制机制上都取得了成功。 工作量:本文的工作量中等,需要对扩散模型、概念抑制机制和攻击方法有深入的理解。
点此查看论文截图


 wechat
wechat- alipay