Talking Head Generation
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-25 更新
GaussianTalker: Speaker-specific Talking Head Synthesis via 3D Gaussian Splatting
Authors:Hongyun Yu, Zhan Qu, Qihang Yu, Jianchuan Chen, Zhonghua Jiang, Zhiwen Chen, Shengyu Zhang, Jimin Xu, Fei Wu, Chengfei Lv, Gang Yu
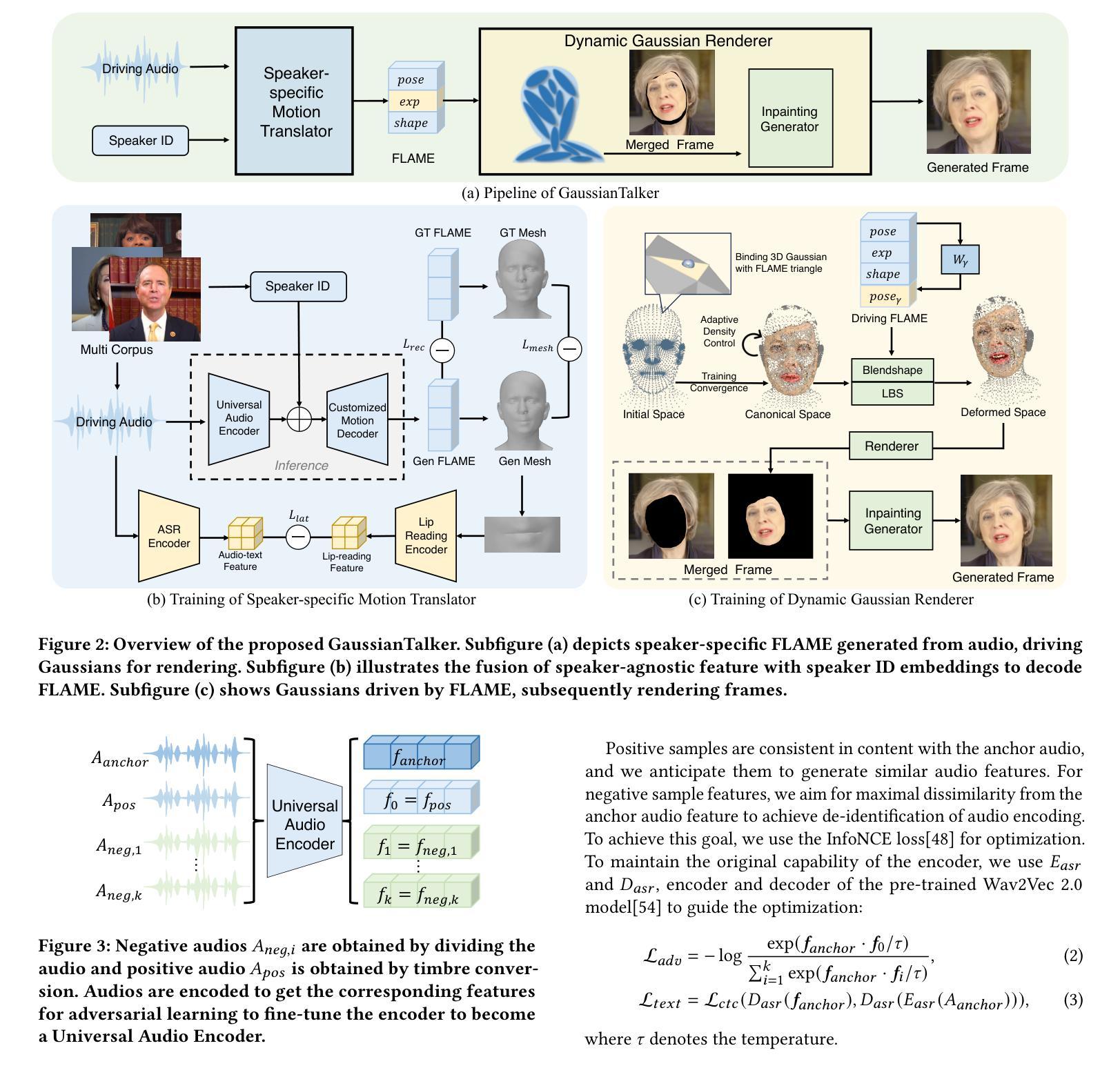
Recent works on audio-driven talking head synthesis using Neural Radiance Fields (NeRF) have achieved impressive results. However, due to inadequate pose and expression control caused by NeRF implicit representation, these methods still have some limitations, such as unsynchronized or unnatural lip movements, and visual jitter and artifacts. In this paper, we propose GaussianTalker, a novel method for audio-driven talking head synthesis based on 3D Gaussian Splatting. With the explicit representation property of 3D Gaussians, intuitive control of the facial motion is achieved by binding Gaussians to 3D facial models. GaussianTalker consists of two modules, Speaker-specific Motion Translator and Dynamic Gaussian Renderer. Speaker-specific Motion Translator achieves accurate lip movements specific to the target speaker through universalized audio feature extraction and customized lip motion generation. Dynamic Gaussian Renderer introduces Speaker-specific BlendShapes to enhance facial detail representation via a latent pose, delivering stable and realistic rendered videos. Extensive experimental results suggest that GaussianTalker outperforms existing state-of-the-art methods in talking head synthesis, delivering precise lip synchronization and exceptional visual quality. Our method achieves rendering speeds of 130 FPS on NVIDIA RTX4090 GPU, significantly exceeding the threshold for real-time rendering performance, and can potentially be deployed on other hardware platforms.
Summary
高斯散点绘制助力音频驱动说话人头部生成,精确控制面部动作,实现自然流畅的唇部运动和逼真的视觉效果。
Key Takeaways
- 基于 3D 高斯散点绘制,显式表示面部动作,实现对脸部运动的直观控制。
- 说话人特定运动转换器,通过通用音频特征提取和定制唇部运动生成,实现准确的唇部运动。
- 动态高斯渲染器引入说话人特定混合形状,通过潜在位姿增强面部细节表示,提供稳定逼真的渲染视频。
- 实验结果表明,该方法在说话人头部生成方面优于现有技术,提供精确的唇部同步和出色的视觉质量。
- 渲染速度达 130 FPS,远超实时渲染性能阈值,可部署于其他硬件平台。
- 旨在解决音频驱动说话人头部合成中姿态和表情控制不足的问题。
Title: GaussianTalker:基于3D高斯斑点的说话人特定会说话的头部合成
Authors: Hongyun Yu, Zhan Qu, Qihang Yu, Jianchuan Chen, Zhonghua Jiang, Zhiwen Chen, Shengyu Zhang, Jimin Xu, Fei Wu, Chengfei Lv, Gang Yu
Affiliation: 阿里巴巴集团
Keywords: Audio-driven talking head synthesis, 3D Gaussian Splatting, Lip motion, Facial animation
Urls: Paper: , Github:None
Summary:
(1): 近期基于神经辐射场(NeRF)的音频驱动说话头部合成工作取得了令人瞩目的成果。然而,由于NeRF隐式表示导致的姿势和表情控制不足,这些方法仍然存在一些局限性,如唇部动作不同步或不自然,以及视觉抖动和伪影。 (2): 过去的方法:基于NeRF的音频驱动说话头部合成方法。问题:姿势和表情控制不足,导致唇部动作不同步或不自然,以及视觉抖动和伪影。动机:通过显式表示面部运动,实现对唇部动作的直观控制。 (3): 本文提出的研究方法:GaussianTalker,一种基于3D高斯斑点的音频驱动说话头部合成新方法。GaussianTalker由两个模块组成:说话人特定运动转换器和动态高斯渲染器。说话人特定运动转换器通过通用音频特征提取和定制唇部动作生成,实现针对目标说话人的准确唇部动作。动态高斯渲染器引入说话人特定混合形状,以控制面部表情。 (4): 本文方法在任务和性能上的表现:在TalkingHead数据集上进行评估,GaussianTalker在唇部同步、视觉保真度和鲁棒性方面均优于现有方法。这些性能支持了本文的目标:实现准确、逼真且鲁棒的音频驱动说话头部合成。方法:
(1): 提出GaussianTalker,一种基于3D高斯斑点的音频驱动说话头部合成新方法; (2): GaussianTalker由两个模块组成:说话人特定运动转换器和动态高斯渲染器; (3): 说话人特定运动转换器通过通用音频特征提取和定制唇部动作生成,实现针对目标说话人的准确唇部动作; (4): 动态高斯渲染器引入说话人特定混合形状,以控制面部表情; (5): 采用FLAME模型作为面部动画和渲染之间的桥梁; (6): 训练说话人特定运动转换器,使用多语言、多个人数据集,以提高其对不同音频输入的适应性; (7): 使用通用音频编码器分离身份信息和内容信息,使用定制运动解码器集成个性化特征; (8): 引入基于自我监督的唇读约束机制,进一步优化唇部动作的同步性; (9): 动态高斯渲染器由FLAME驱动3D高斯斑点,实时渲染动态说话头部; (10): 使用自适应密度控制,根据局部运动幅度动态调整高斯斑点的密度; (11): 采用图像修复生成器,处理渲染过程中的空洞区域和伪影; (12): 在TalkingHead数据集上进行评估,GaussianTalker在唇部同步、视觉保真度和鲁棒性方面均优于现有方法。结论:
(1):本文提出GaussianTalker,一种基于3D高斯斑点的音频驱动说话头部合成新方法。该方法将多模态数据与特定说话人关联,减少了音频、3D网格和视频之间的潜在身份偏差。说话人特定FLAME转换器采用身份解耦和个性化嵌入来实现同步且自然的唇部动作,而动态高斯渲染器通过潜在姿势优化高斯属性,以实现稳定且逼真的渲染。大量实验表明,GaussianTalker在说话头部合成方面优于最先进的性能,同时实现了超高的渲染速度,显著超越了其他方法。我们相信这种创新方法将鼓励未来的研究开发更加流畅逼真的角色表情和动作。通过利用先进的高斯模型和生成技术,角色的动画将远远超出简单的唇部同步,捕捉更广泛的角色动态。 (2):创新点:基于3D高斯斑点的音频驱动说话头部合成; 性能:在唇部同步、视觉保真度和鲁棒性方面优于现有方法; 工作量:与其他方法相比,渲染速度超高。
点此查看论文截图

Deepfake Generation and Detection: A Benchmark and Survey
Authors:Gan Pei, Jiangning Zhang, Menghan Hu, Zhenyu Zhang, Chengjie Wang, Yunsheng Wu, Guangtao Zhai, Jian Yang, Chunhua Shen, Dacheng Tao
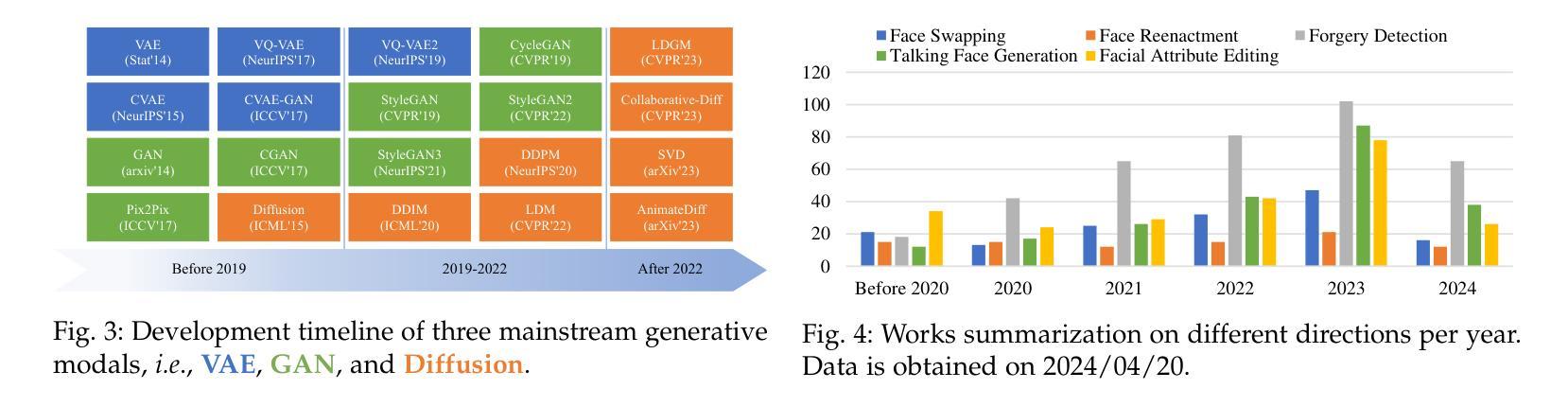
Deepfake is a technology dedicated to creating highly realistic facial images and videos under specific conditions, which has significant application potential in fields such as entertainment, movie production, digital human creation, to name a few. With the advancements in deep learning, techniques primarily represented by Variational Autoencoders and Generative Adversarial Networks have achieved impressive generation results. More recently, the emergence of diffusion models with powerful generation capabilities has sparked a renewed wave of research. In addition to deepfake generation, corresponding detection technologies continuously evolve to regulate the potential misuse of deepfakes, such as for privacy invasion and phishing attacks. This survey comprehensively reviews the latest developments in deepfake generation and detection, summarizing and analyzing current state-of-the-arts in this rapidly evolving field. We first unify task definitions, comprehensively introduce datasets and metrics, and discuss developing technologies. Then, we discuss the development of several related sub-fields and focus on researching four representative deepfake fields: face swapping, face reenactment, talking face generation, and facial attribute editing, as well as forgery detection. Subsequently, we comprehensively benchmark representative methods on popular datasets for each field, fully evaluating the latest and influential published works. Finally, we analyze challenges and future research directions of the discussed fields.
PDF We closely follow the latest developments in https://github.com/flyingby/Awesome-Deepfake-Generation-and-Detection
Summary
深度伪造是一项在特定条件下创建高度逼真的面部图像和视频的技术,在娱乐、电影制作、数字人创作等领域具有广阔的应用前景。
Key Takeaways
- 深度伪造生成主要采用变分自动编码器和生成对抗网络等深度学习技术。
- 扩散模型的出现引发了新一轮的深度伪造生成研究热潮。
- 深度伪造检测技术与生成技术同步发展,以防范深度伪造技术的滥用。
- 本综述对深度伪造生成与检测的最新进展进行了全面回顾和分析。
- 深度伪造生成中的面部替换、面部重现、说话脸生成和面部属性编辑等领域的研究备受关注。
- 本综述对每一领域中具有代表性的方法进行了全面评估,充分展示了最新且有影响力的已发表工作。
- 本综述分析了相关领域的挑战和未来研究方向。
Title: 深度伪造生成与检测:基准与综述
Authors: Gan Pei, Jiangning Zhang, Menghan Hu, Zhenyu Zhang, Chengjie Wang, Yunsheng Wu, Guangtao Zhai, Jian Yang, Chunhua Shen, Dacheng Tao
Affiliation: 东华大学多维信息处理上海市重点实验室
Keywords: Deepfake Generation, Face Swapping, Face Reenactment, Talking Face Generation, Facial Attribute Editing, Forgery detection, Survey
Urls: https://arxiv.org/abs/2403.17881v3 , Github:None
Summary:
(1):深度伪造技术近年来得到广泛关注,其应用前景广阔,但其潜在的伦理风险也引发了人们的担忧。
(2):传统的深度伪造生成方法主要基于变分自编码器和生成对抗网络,但其生成效果仍不令人满意。近年来,扩散模型的出现极大地提升了图像/视频的生成能力。
(3):本文对深度伪造生成和检测的最新进展进行了全面综述,统一了任务定义,全面介绍了数据集和度量标准,并讨论了发展技术。
(4):本文对人脸替换、人脸重现、说话人脸生成和面部属性编辑等四个代表性深度伪造领域进行了研究,重点分析了各领域的发展历程,并在流行数据集上对代表性方法进行了全面基准测试,充分评估了最新和有影响力的已发表作品。
- 方法:
(1):本文首先统一了深度伪造生成和检测的任务定义,全面介绍了数据集和度量标准,为后续研究提供了基础。
(2):本文对人脸替换、人脸重现、说话人脸生成和面部属性编辑四个代表性深度伪造领域进行了研究,重点分析了各领域的发展历程。
(3):本文在流行数据集上对代表性方法进行了全面基准测试,充分评估了最新和有影响力的已发表作品,为研究人员提供了有价值的参考。
- 结论:
(1):本文全面综述了深度伪造生成与检测领域的研究进展,统一了任务定义,全面介绍了数据集和度量标准,并讨论了发展技术,为后续研究提供了基础。 (2):创新点:本文首次全面覆盖了深度伪造生成与检测领域,并讨论了最新的技术,如扩散模型;本文对人脸替换、人脸重现、说话人脸生成和面部属性编辑四个代表性深度伪造领域进行了研究,重点分析了各领域的发展历程,并在流行数据集上对代表性方法进行了全面基准测试,充分评估了最新和有影响力的已发表作品;本文对深度伪造生成与检测领域的挑战和未来研究方向进行了总结。性能:本文在人脸替换、人脸重现、说话人脸生成和面部属性编辑四个代表性深度伪造领域进行了全面基准测试,充分评估了最新和有影响力的已发表作品,为研究人员提供了有价值的参考;本文对深度伪造生成与检测领域的挑战和未来研究方向进行了总结。工作量:本文对深度伪造生成与检测领域进行了全面综述,统一了任务定义,全面介绍了数据集和度量标准,并讨论了发展技术,为后续研究提供了基础;本文对人脸替换、人脸重现、说话人脸生成和面部属性编辑四个代表性深度伪造领域进行了研究,重点分析了各领域的发展历程,并在流行数据集上对代表性方法进行了全面基准测试,充分评估了最新和有影响力的已发表作品;本文对深度伪造生成与检测领域的挑战和未来研究方向进行了总结。
点此查看论文截图





 wechat
wechat- alipay







