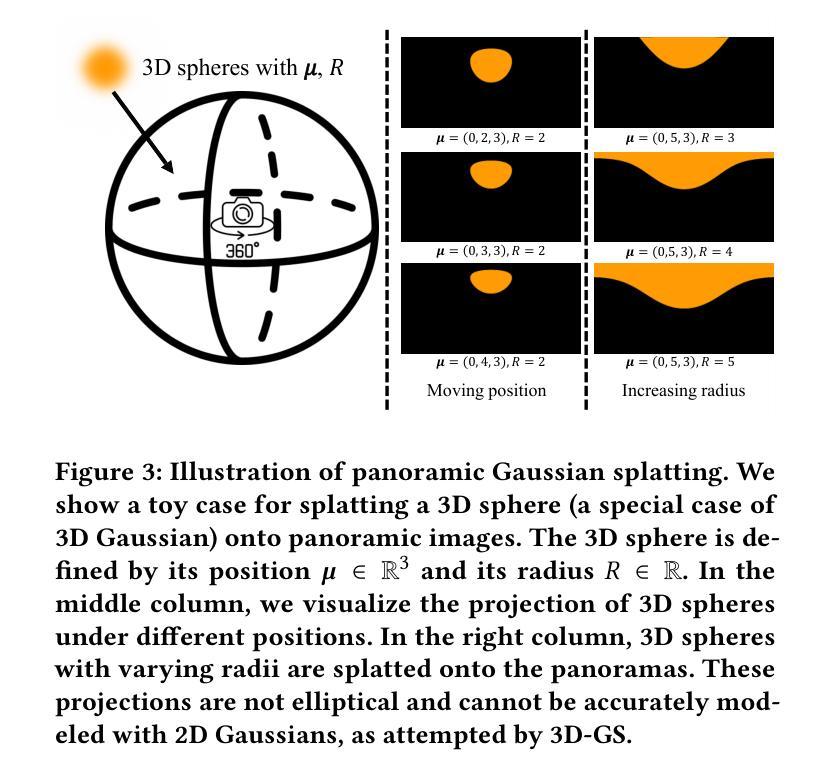
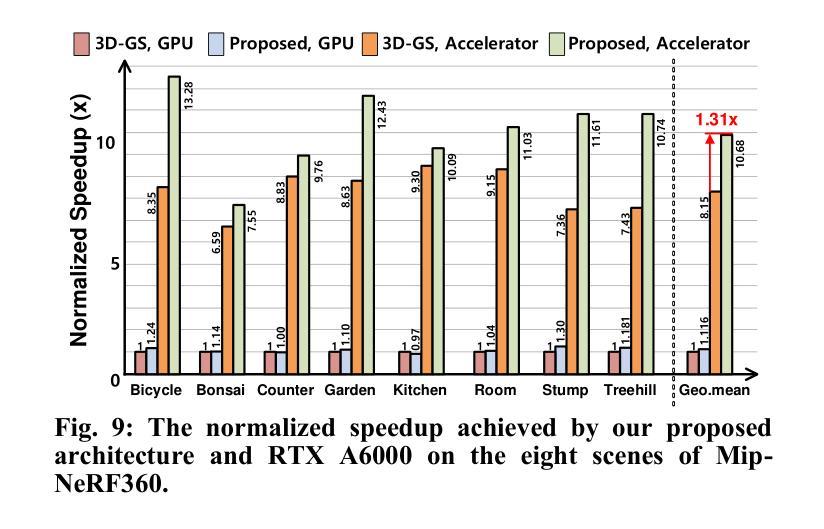
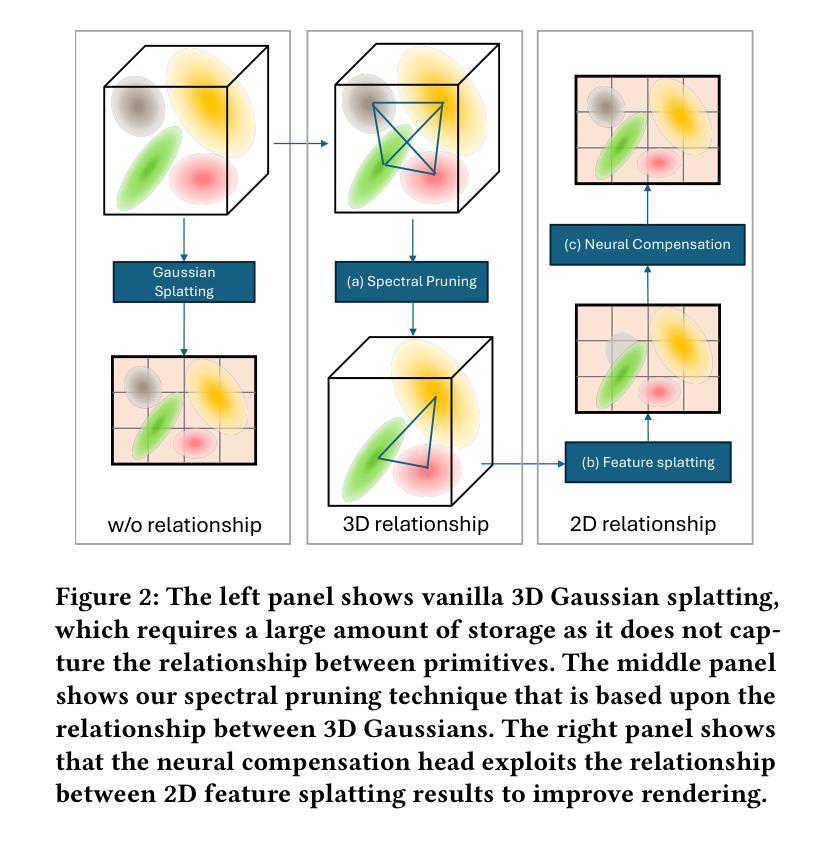
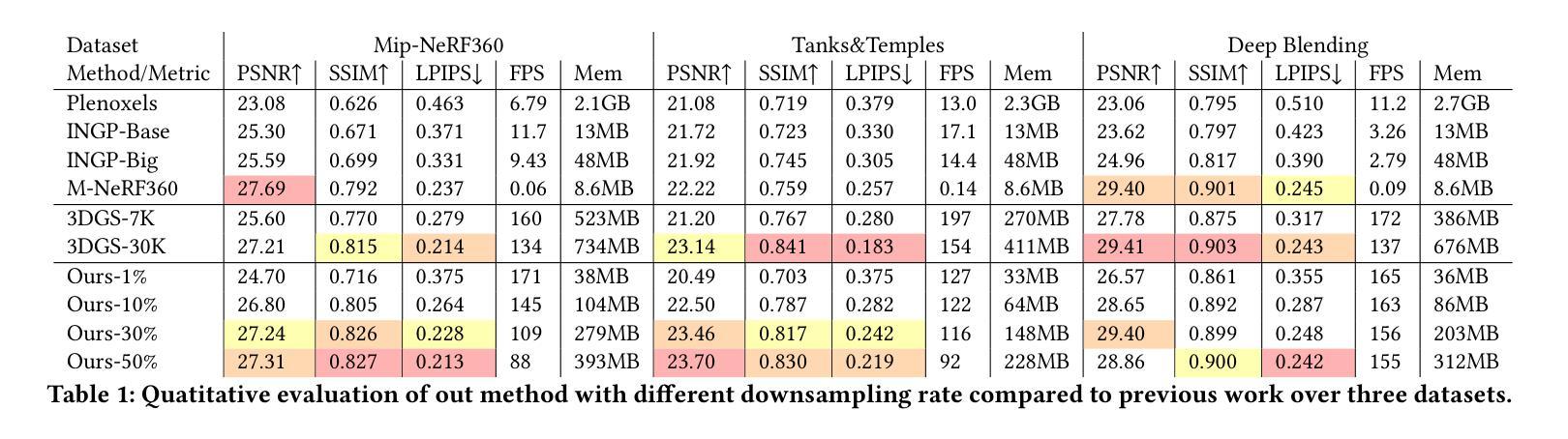
3DGS
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-05-02 更新
Spectrally Pruned Gaussian Fields with Neural Compensation
Authors:Runyi Yang, Zhenxin Zhu, Zhou Jiang, Baijun Ye, Xiaoxue Chen, Yifei Zhang, Yuantao Chen, Jian Zhao, Hao Zhao
Recently, 3D Gaussian Splatting, as a novel 3D representation, has garnered attention for its fast rendering speed and high rendering quality. However, this comes with high memory consumption, e.g., a well-trained Gaussian field may utilize three million Gaussian primitives and over 700 MB of memory. We credit this high memory footprint to the lack of consideration for the relationship between primitives. In this paper, we propose a memory-efficient Gaussian field named SUNDAE with spectral pruning and neural compensation. On one hand, we construct a graph on the set of Gaussian primitives to model their relationship and design a spectral down-sampling module to prune out primitives while preserving desired signals. On the other hand, to compensate for the quality loss of pruning Gaussians, we exploit a lightweight neural network head to mix splatted features, which effectively compensates for quality losses while capturing the relationship between primitives in its weights. We demonstrate the performance of SUNDAE with extensive results. For example, SUNDAE can achieve 26.80 PSNR at 145 FPS using 104 MB memory while the vanilla Gaussian splatting algorithm achieves 25.60 PSNR at 160 FPS using 523 MB memory, on the Mip-NeRF360 dataset. Codes are publicly available at https://runyiyang.github.io/projects/SUNDAE/.
PDF Code: https://github.com/RunyiYang/SUNDAE Project page: https://runyiyang.github.io/projects/SUNDAE/
Summary
3D高斯点渲染算法 SUNDAE 通过谱剪枝和神经补偿显著降低了内存消耗,同时保持了高质量的渲染效果。
Key Takeaways
- 3D高斯点渲染算法在渲染速度和质量方面表现出色,但内存占用高。
- SUNDAE 算法构建了高斯基元的关系图,并设计了谱下采样模块来剪除基元。
- SUNDAE 算法使用轻量级神经网络头对渲染特征进行混合,弥补了剪枝造成的质量损失。
- SUNDAE 算法显著降低了内存消耗,同时保持了较高的渲染质量。
- SUNDAE 在 Mip-NeRF360 数据集上以 104 MB 的内存实现了 26.80 PSNR 和 145 FPS,而原始高斯点渲染算法则以 523 MB 的内存实现了 25.60 PSNR 和 160 FPS。
- SUNDAE 代码已公开发布。
标题:SUNDAE:神经补偿光谱修剪高斯场
作者:Runyi Yang、Zhenxin Zhu、Zhou Jiang、Baijun Ye、Xiaoxue Chen、Yifei Zhang、Yuantao Chen、Jian Zhao、Hao Zhao
隶属机构:清华大学人工智能研究院
关键词:3D高斯喷射、图信号处理、神经渲染
论文地址:https://arxiv.org/abs/2405.00676 Github:https://github.com/runyiyang/SUNDAE
摘要:
(1):研究背景:3D高斯喷射作为一种新颖的3D表示,因其渲染速度快、渲染质量高而备受关注。然而,这带来了较高的内存消耗,例如,一个训练良好的高斯场可能需要使用300万个高斯原语和超过700MB的内存。我们认为这种高内存占用率是由于缺乏对原语之间关系的考虑。
(2):以往方法:以往方法是3D高斯喷射。其问题是:训练一个3D高斯喷射模型面临着高内存消耗的挑战。
(3):本文提出的研究方法:我们提出了一种名为SUNDAE的内存高效高斯场,它采用光谱修剪和神经补偿。一方面,我们在高斯原语集合上构建一个图来建模它们之间的关系,并设计了一个光谱下采样模块来剔除原语,同时保留所需的信号。另一方面,为了补偿修剪高斯体带来的质量损失,我们利用了一个轻量级的神经网络头来混合喷射特征,它有效地补偿了质量损失,同时在其权重中捕获了原语之间的关系。
(4):方法性能:我们在Mip-NeRF360数据集上,SUNDAE使用104MB内存实现了26.80 PSNR和145 FPS,而传统的3D高斯喷射算法使用523MB内存实现了25.60 PSNR和160 FPS。这些性能可以支持他们的目标。
方法:
(1):构建图模型,光谱下采样剔除原语,保留所需信号;
(2):利用神经网络头混合喷射特征,补偿修剪高斯体带来的质量损失;
(3):在权重中捕获原语之间的关系;
.......
结论:
(1):SUNDAE方法在保持3D高斯喷射效率的同时,尺寸大幅缩小,为3D场景表示和渲染提供了新的思路。
(2):创新点:图信号处理框架与神经网络补偿相结合,构建了谱修剪高斯场;性能:在Mip-NeRF360数据集上,SUNDAE使用104MB内存实现了26.80 PSNR和145 FPS,而传统的3D高斯喷射算法使用523MB内存实现了25.60 PSNR和160 FPS;工作量:构建图模型、光谱下采样、神经网络补偿。
点此查看论文截图



Title: RTG-SLAM: 基于高斯散射的大规模实时 3D 重建
Authors: Zhexi Peng, Tianjia Shao, Yong Liu, Jingke Zhou, Yin Yang, Jingdong Wang, Kun Zhou
Affiliation: 浙江大学计算机辅助设计与图形学国家重点实验室
Keywords: RGBD SLAM, Real-time 3D Reconstruction, Gaussian Splatting, NeRF
Urls: https://arxiv.org/abs/2404.19706v2, Github: None
Summary:
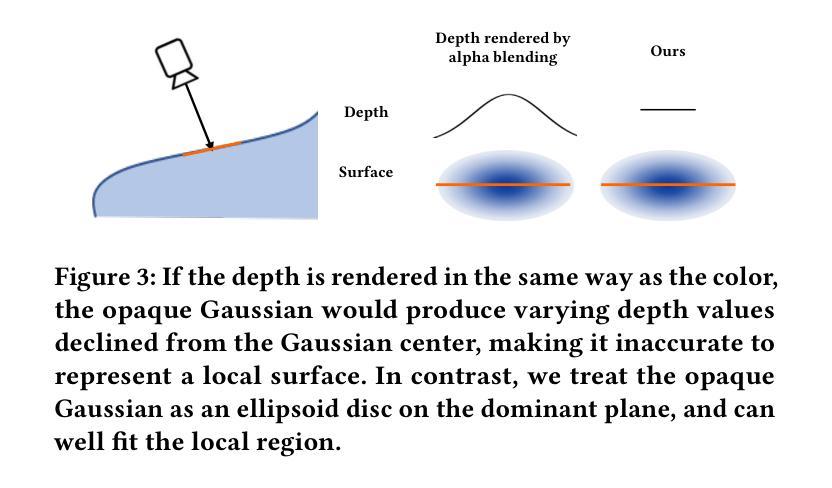
(1): RGBD SLAM 技术在实时大规模 3D 重建中受到广泛关注。然而,现有的基于 NeRF 的 RGBD SLAM 方法在重建速度、内存消耗和新颖视角合成方面仍面临挑战。 (2): 现有的方法通常使用多个重叠的高斯核来拟合局部表面区域,导致内存和计算成本高。此外,它们缺乏高效的在线高斯优化方案,这限制了实时性能。 (3): 本文提出了一种名为 RTG-SLAM 的实时 3D 重建系统,它采用高斯散射和高效的在线高斯优化方案。该系统强制每个高斯核要么不透明要么近乎透明,不透明的高斯核拟合表面和主要颜色,而透明的高斯核拟合残差颜色。通过以不同于颜色渲染的方式渲染深度,该系统可以让单个不透明高斯核很好地拟合局部表面区域,而无需多个重叠的高斯核,从而大大降低了内存和计算成本。对于在线高斯优化,该系统针对每帧的三类像素显式添加高斯核:新观测的像素、颜色误差大的像素和深度误差大的像素。该系统还将所有高斯核分类为稳定高斯核和不稳定高斯核,其中稳定高斯核有望很好地拟合先前观测的 RGBD 图像,否则为不稳定高斯核。该系统只优化不稳定高斯核,只渲染不稳定高斯核占据的像素。通过这种方式,该系统同时降低了高斯核的数量和渲染成本。 (4): 在酒店房间重建任务上,RTG-SLAM 在重建速度和内存消耗方面优于最先进的 NeRF-SLAM 方法,同时在合成新颖视角方面表现出更高的真实感。方法:
(1):提出了 RTG-SLAM 系统,该系统采用高斯散射和高效的在线高斯优化方案进行实时 3D 重建; (2):强制每个高斯核要么不透明要么近乎透明,不透明的高斯核拟合表面和主要颜色,而透明的高斯核拟合残差颜色; (3):针对每帧的三类像素显式添加高斯核:新观测的像素、颜色误差大的像素和深度误差大的像素; (4):将所有高斯核分类为稳定高斯核和不稳定高斯核,其中稳定高斯核有望很好地拟合先前观测的 RGBD 图像,否则为不稳定高斯核; (5):只优化不稳定高斯核,只渲染不稳定高斯核占据的像素,降低了高斯核的数量和渲染成本。结论:
(1):本文提出了一种基于高斯散射的大规模实时 3D 重建系统 RTG-SLAM,该系统采用紧凑的高斯表示来减少拟合表面的高斯数量,从而大大降低了内存和计算成本。对于在线高斯优化,该系统针对每帧的三类像素显式添加高斯:新观测的、颜色误差大的和深度误差大的,并且只优化不稳定的高斯,只渲染不稳定的高斯占据的像素,降低了高斯数量和渲染成本。该系统在大规模真实扫描场景中重建,并取得了优于最先进的 NeRF SLAM 方法和并发的 Gaussian SLAM 方法的性能。由于为了在大规模场景中实现实时重建,只使用不透明的高斯和透明的高斯来表示场景,因此与原始的高斯相比,渲染质量不可避免地会下降。如何在保持实时性能的同时提高渲染质量是未来值得探索的方向。此外,反射或透明的材料会导致表面颜色在不同视图之间发生很大变化,使得一些高斯频繁地在两种状态之间切换,并且无法得到很好的优化。未来,该系统还将扩展到处理户外场景、动态物体、快速摄像机运动和光照变化的场景。 (2):创新点:高斯散射、紧凑的高斯表示、在线高斯优化;性能:在大规模场景中实现实时重建、优于最先进的 NeRF SLAM 方法和并发的 Gaussian SLAM 方法;工作量:降低了内存和计算成本、降低了高斯数量和渲染成本。
点此查看论文截图


GS-LRM: Large Reconstruction Model for 3D Gaussian Splatting
Authors:Kai Zhang, Sai Bi, Hao Tan, Yuanbo Xiangli, Nanxuan Zhao, Kalyan Sunkavalli, Zexiang Xu
We propose GS-LRM, a scalable large reconstruction model that can predict high-quality 3D Gaussian primitives from 2-4 posed sparse images in 0.23 seconds on single A100 GPU. Our model features a very simple transformer-based architecture; we patchify input posed images, pass the concatenated multi-view image tokens through a sequence of transformer blocks, and decode final per-pixel Gaussian parameters directly from these tokens for differentiable rendering. In contrast to previous LRMs that can only reconstruct objects, by predicting per-pixel Gaussians, GS-LRM naturally handles scenes with large variations in scale and complexity. We show that our model can work on both object and scene captures by training it on Objaverse and RealEstate10K respectively. In both scenarios, the models outperform state-of-the-art baselines by a wide margin. We also demonstrate applications of our model in downstream 3D generation tasks. Our project webpage is available at: https://sai-bi.github.io/project/gs-lrm/ .
PDF Project webpage: https://sai-bi.github.io/project/gs-lrm/
Summary
三维高斯原语大重建模型,可从 2-4 个姿势稀疏图像预测高质量的三维高斯原语,在单个 A100 GPU 上仅需 0.23 秒。
Key Takeaways
- 使用变压器架构,从图像中预测三维高斯原语。
- 模型具有可扩展性,可预测具有大尺度和复杂度变化的场景。
- 在 Objaverse 和 RealEstate10K 数据集上均优于现有方法。
- 可用于下游三维生成任务,如视图合成和三维形状合成。
题目:GS-LRM:大型重建模型
作者:Kai Zhang、Sai Bi、Hao Tan、Yuanbo Xiangli、Nanxuan Zhao、Kalyan Sunkavalli、Zexiang Xu
单位:Adobe Research
关键词:Large Reconstruction Models · 3D Reconstruction · Gaussian Splatting
论文链接:https://arxiv.org/abs/2404.19702 , Github:None
摘要:
(1):研究背景:3D 场景重建是计算机视觉中的一个核心问题,传统方法依赖于复杂的光度测量系统和密集的多视图图像。神经表征和可微渲染的进步提高了重建和渲染质量,但速度慢且需要大量输入视图。基于 Transformer 的 3D 大型重建模型 (LRM) 学习了大量的 3D 对象的通用重建先验,实现了前所未有的稀疏视图 3D 重建质量。
(2):过去的方法:过去的方法采用三平面 NeRF 作为场景表示,存在三平面分辨率受限和体积渲染开销大的问题,导致训练和渲染速度慢、难以保留精细细节,以及无法扩展到对象中心输入之外的大场景。
(3):本论文方法:GS-LRM 是一种可扩展的大型重建模型,它采用了一种非常简单的基于 Transformer 的架构。将输入图像进行块状化,将连接后的多视图图像标记通过一系列 Transformer 块,并直接从这些标记解码最终的逐像素高斯参数以进行可微渲染。与只能重建对象的先前 LRM 不同,GS-LRM 通过预测逐像素高斯函数,自然地处理了规模和复杂性差异很大的场景。
(4):方法性能:GS-LRM 在 Objaverse 和 RealEstate10K 数据集上分别针对对象和场景捕捉进行了训练,在两种情况下都大幅优于最先进的基准。该模型还可以在下游 3D 生成任务中得到应用。
方法:
(1):采用 Transformer 模型,将一组已知相机位姿的图像回归为逐像素的 3D 高斯参数;
(2):通过 patchify 算子对输入图像进行标记化处理,将多视图图像标记连接起来,并通过一系列 Transformer 块进行处理,包括自注意力和 MLP 层;
(3):从每个输出标记中,使用线性层解码对应 patch 中像素对齐的高斯函数属性;
(4):利用线性层将 1D 向量映射到 d 维的图像 patch 标记,其中 d 是 Transformer 宽度;
(5):将多视图图像标记连接起来,并通过一系列 Transformer 块进行处理,包括残差连接、多头自注意力和 MLP;
(6):使用单个线性层将 Transformer 的输出标记解码为高斯参数。
- 结论:
(1):本工作的主要意义在于提出了一种简单且可扩展的基于 Transformer 的大型重建模型,用于高斯 splatting(GS)表示。该方法能够在单个 A100 GPU 上以约 0.23 秒的速度从一组已知相机位姿的图像中进行快速前馈高分辨率 GS 预测。该模型既适用于对象级捕捉,也适用于场景级捕捉,并且在大量数据上训练后,在两种情况下均达到最先进的性能。我们希望我们的工作能够激发未来在数据驱动的前馈 3D 重建领域开展更多工作。致谢感谢 Nathan Carr 和 Duygu Ceylan 提供有益的讨论。 (2):创新点:提出了一种基于 Transformer 的大型重建模型,用于高斯 splatting 表示,该模型简单且可扩展;性能:在对象级和场景级捕捉任务上均达到最先进的性能;工作量:在单个 A100 GPU 上以约 0.23 秒的速度进行前馈高分辨率 GS 预测。
点此查看论文截图



SAGS: Structure-Aware 3D Gaussian Splatting
Authors:Evangelos Ververas, Rolandos Alexandros Potamias, Jifei Song, Jiankang Deng, Stefanos Zafeiriou
Following the advent of NeRFs, 3D Gaussian Splatting (3D-GS) has paved the way to real-time neural rendering overcoming the computational burden of volumetric methods. Following the pioneering work of 3D-GS, several methods have attempted to achieve compressible and high-fidelity performance alternatives. However, by employing a geometry-agnostic optimization scheme, these methods neglect the inherent 3D structure of the scene, thereby restricting the expressivity and the quality of the representation, resulting in various floating points and artifacts. In this work, we propose a structure-aware Gaussian Splatting method (SAGS) that implicitly encodes the geometry of the scene, which reflects to state-of-the-art rendering performance and reduced storage requirements on benchmark novel-view synthesis datasets. SAGS is founded on a local-global graph representation that facilitates the learning of complex scenes and enforces meaningful point displacements that preserve the scene’s geometry. Additionally, we introduce a lightweight version of SAGS, using a simple yet effective mid-point interpolation scheme, which showcases a compact representation of the scene with up to 24$\times$ size reduction without the reliance on any compression strategies. Extensive experiments across multiple benchmark datasets demonstrate the superiority of SAGS compared to state-of-the-art 3D-GS methods under both rendering quality and model size. Besides, we demonstrate that our structure-aware method can effectively mitigate floating artifacts and irregular distortions of previous methods while obtaining precise depth maps. Project page https://eververas.github.io/SAGS/.
PDF 15 pages, 8 figures, 3 tables
Summary
利用结构驱动的优化策略,SAGS 在实时神经渲染中实现了压缩性和高保真性,通过利用局部-全局图表示来编码场景几何。
Key Takeaways
- SAGS 通过结构感知优化对 3DGS 进行了改进。
- SAGS 采用局部-全局图表示,捕获场景几何。
- SAGS 优化点位移以保持场景几何,提高表示能力和渲染质量。
- SAGS 提出了一种基于中点插值的轻量级变体,可显著减少模型大小。
- 实验表明 SAGS 在渲染质量和模型尺寸方面优于其他 3DGS 方法。
- SAGS 缓解了浮动伪影和不规则失真,并生成精确的深度图。
- SAGS 项目主页:https://eververas.github.io/SAGS/。
Title: 结构感知3D高斯斑点
Authors: Evangelos Ververas, Rolandos Alexandros Potamias, Jifei Song, Jiankang Deng, Stefanos Zafeiriou
Affiliation: 帝国理工学院
Keywords: Novel View Synthesis, 3D Gaussian Splatting, Structure-Aware, Local-Global Graph Representation
Urls: https://eververas.github.io/SAGS/, Github:None
Summary:
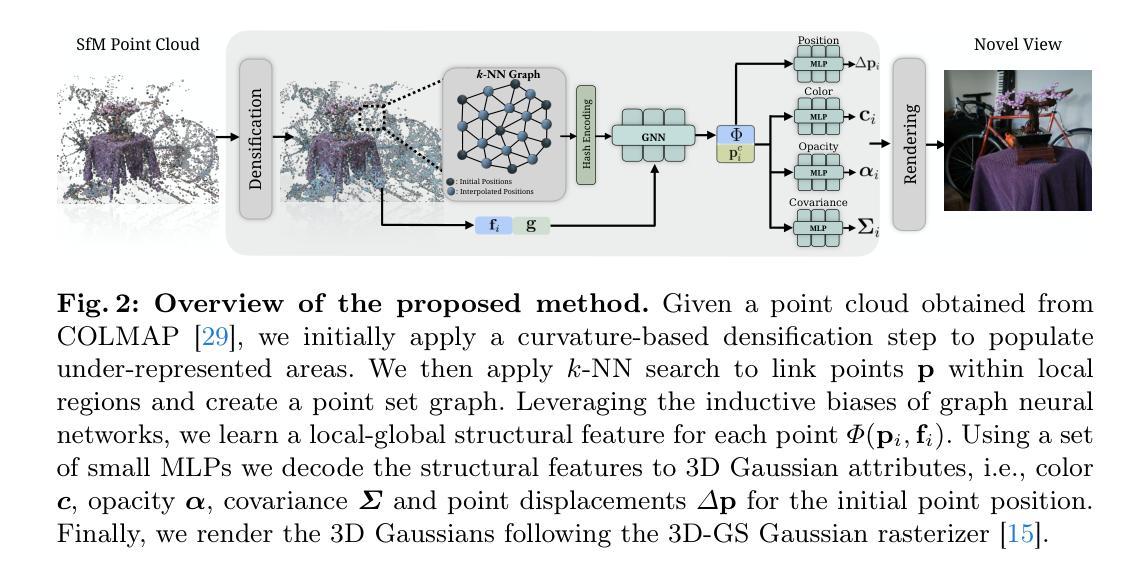
(1):随着NeRFs的出现,3D高斯斑点(3D-GS)为实时神经渲染铺平了道路,克服了体积方法的计算负担。在3D-GS的开创性工作之后,一些方法试图实现可压缩且高保真性能的替代方案。然而,通过采用与几何无关的优化方案,这些方法忽略了场景的固有3D结构,从而限制了表现力和表示的质量,导致各种浮点和伪影。 (2):以往的方法:3D-GS、存在问题:忽略场景的3D结构,导致表现力和表示质量受限,产生浮点和伪影。动机充分:提出一种结构感知的方法来解决这些问题。 (3):本文提出的研究方法:结构感知高斯斑点方法(SAGS),隐式编码场景的几何形状,在基准新视图合成数据集上反映了最先进的渲染性能和降低的存储需求。SAGS建立在局部-全局图表示的基础上,该表示有助于学习复杂场景并强制有意义的点位移以保留场景的几何形状。此外,我们使用简单但有效的中间点插值方案引入了SAGS的轻量级版本,该版本展示了场景的紧凑表示,尺寸最多减少了24倍,而无需依赖任何压缩策略。 (4):任务和性能:在多个基准数据集上的广泛实验表明,SAGS在渲染质量和模型大小方面都优于最先进的3D-GS方法。此外,我们证明了我们的结构感知方法可以有效减轻先前方法的浮动伪影和不规则失真,同时获得精确的深度图。方法:
(1):曲率感知稠密化:采用 Grad-PU 方法,对低曲率区域进行中点插值,生成密集点云,增强 3D-GS 的初始化; (2):结构感知编码器:基于 k-NN 图,使用图神经网络学习局部和全局结构特征,获得结构感知特征编码; (3):细化网络:使用 MLP 解码结构感知特征编码,预测 3D 高斯斑点的属性(位置、颜色、不透明度、协方差); (4):SAGS-Lite:利用中点插值,减少存储需求,生成紧凑的 3D 高斯斑点集合,无需压缩技术。结论:
(1):本文提出了一种结构感知高斯斑点方法(SAGS),该方法利用场景的内在结构进行高保真神经渲染。我们提出了一种基于图神经网络的方法,该方法以结构化的方式预测高斯斑点的属性,从而克服了当前 3D 高斯斑点方法的缺点,即天真地优化高斯属性而忽略了底层场景结构。使用所提出的图表示,相邻的高斯斑点可以共享和聚合信息,从而促进场景渲染及其几何形状的保留。我们展示了所提出的方法在新的视图合成中可以优于当前最先进的方法,同时保留 3D-GS 的实时渲染。我们进一步引入了一种简单但有效的中间点插值方案,与 3D-GS 方法相比,它可以实现高达 24 倍的存储减少,同时保留高质量的渲染,而无需使用任何压缩和量化算法。总体而言,我们的研究结果证明了在 3D-GS 中引入结构的好处。 (2):创新点:提出了一种基于图神经网络的结构感知方法,以结构化的方式预测高斯斑点的属性,从而克服了当前 3D 高斯斑点方法的缺点,即天真地优化高斯属性而忽略了底层场景结构;Performance:在新的视图合成中可以优于当前最先进的方法,同时保留 3D-GS 的实时渲染;Workload:引入了简单的中间点插值方案,与 3D-GS 方法相比,它可以实现高达 24 倍的存储减少,同时保留高质量的渲染,而无需使用任何压缩和量化算法。
点此查看论文截图



MeGA: Hybrid Mesh-Gaussian Head Avatar for High-Fidelity Rendering and Head Editing
Authors:Cong Wang, Di Kang, He-Yi Sun, Shen-Han Qian, Zi-Xuan Wang, Linchao Bao, Song-Hai Zhang
Creating high-fidelity head avatars from multi-view videos is a core issue for many AR/VR applications. However, existing methods usually struggle to obtain high-quality renderings for all different head components simultaneously since they use one single representation to model components with drastically different characteristics (e.g., skin vs. hair). In this paper, we propose a Hybrid Mesh-Gaussian Head Avatar (MeGA) that models different head components with more suitable representations. Specifically, we select an enhanced FLAME mesh as our facial representation and predict a UV displacement map to provide per-vertex offsets for improved personalized geometric details. To achieve photorealistic renderings, we obtain facial colors using deferred neural rendering and disentangle neural textures into three meaningful parts. For hair modeling, we first build a static canonical hair using 3D Gaussian Splatting. A rigid transformation and an MLP-based deformation field are further applied to handle complex dynamic expressions. Combined with our occlusion-aware blending, MeGA generates higher-fidelity renderings for the whole head and naturally supports more downstream tasks. Experiments on the NeRSemble dataset demonstrate the effectiveness of our designs, outperforming previous state-of-the-art methods and supporting various editing functionalities, including hairstyle alteration and texture editing.
PDF Project page: https://conallwang.github.io/MeGA_Pages/
Summary
根据多视角视频创建高保真头部形象是AR/VR应用的关键问题。MeGA通过为不同头部组件采用合适的表达方式,提高了渲染质量。
Key Takeaways
- MeGA采用FLAME网格表示面部,并使用UV位移图提供顶点偏移以提升个性化几何细节。
- 利用延迟神经渲染获得面部颜色,并将神经纹理分解为三个有意义的部分以实现真实感渲染。
- MeGA使用3D高斯泼溅构建静态经典头发,并应用刚性变换和基于MLP的变形场来处理复杂动态表情。
- 结合遮挡感知混合,MeGA为整个头部生成更高保真的渲染,并支持发型改变和纹理编辑等下游任务。
- 在NeRSemble数据集上的实验表明MeGA设计有效,优于之前最先进的方法。
论文标题:MeGA:用于高保真渲染和头部编辑的混合网格高斯头部头像
作者:Cong Wang, Di Kang, He-Yi Sun, Shen-Han Qian, Zi-Xuan Wang, Linchao Bao, Song-Hai Zhang
第一作者单位:清华大学
关键词:头部头像、高保真渲染、头部编辑、混合表示
论文链接:https://arxiv.org/abs/2404.19026
摘要:
(1)研究背景:创建高保真头部头像对于 AR/VR 应用至关重要,但现有的方法难以同时为所有头部组件(如皮肤、头发)获得高质量的渲染效果,因为它们使用单一表示来建模具有不同特征的组件。
(2)以往方法:以往方法探索了基于网格、基于 NeRF 和基于 3D 高斯的表示,取得了显着进展。然而,头部是一个复杂的“物体”,包含具有不同特征的组件,因此不存在单一的表示可以同时很好地建模所有组件。使用单一表示建模所有头部组件必然会牺牲一部分的渲染质量。
(3)本文方法:本文提出了一种混合网格高斯头部头像(MeGA),使用更合适的表示来建模不同的头部组件。具体来说,选择一个增强的 FLAME 网格作为面部表示,并预测一个 UV 位移图来提供每个顶点的偏移量,以改善个性化的几何细节。为了实现逼真的渲染,使用延迟神经渲染获得面部颜色,并将神经纹理分解为三个有意义的部分。对于头发建模,首先使用 3D 高斯泼溅构建一个静态的规范头发。进一步应用刚性变换和基于 MLP 的变形场来处理复杂的动态表情。结合遮挡感知混合,MeGA 为整个头部生成了更高保真的渲染效果,并自然地支持更多下游任务。
(4)实验结果:在 NeRSemble 数据集上的实验表明,本文方法有效,优于以往的先进方法,并支持各种编辑功能,包括发型更改和纹理编辑。这些性能支持了本文的目标。
Methods: (1): 提出混合网格高斯头部头像(MeGA),使用更合适的表示来建模不同的头部组件;
(2): 选择一个增强的 FLAME 网格作为面部表示,并预测一个 UV 位移图来提供每个顶点的偏移量,以改善个性化的几何细节; (3): 使用延迟神经渲染获得面部颜色,并将神经纹理分解为三个有意义的部分; (4): 对于头发建模,首先使用 3D 高斯泼溅构建一个静态的规范头发,进一步应用刚性变换和基于 MLP 的变形场来处理复杂的动态表情; (5): 结合遮挡感知混合,MeGA 为整个头部生成了更高保真的渲染效果,并自然地支持更多下游任务。结论:
(1):本文提出了一种混合网格高斯头部头像(MeGA),该方法使用神经网格建模人脸,使用 3DGS 建模头发,在高保真渲染和头部编辑方面取得了显着效果。
(2):创新点:创新性地提出了混合网格高斯头部头像(MeGA),使用更合适的表示来建模不同的头部组件,并设计了遮挡感知混合模块,实现了头部的高保真渲染和编辑。
性能:在 NeRSemble 数据集上的实验表明,本文方法在渲染质量和编辑功能方面均优于以往的先进方法。
工作量:本文方法的工作量相对较大,需要训练神经网格、3DGS 头发模型和遮挡感知混合模块。
点此查看论文截图



3D Gaussian Splatting with Deferred Reflection
Authors:Keyang Ye, Qiming Hou, Kun Zhou
The advent of neural and Gaussian-based radiance field methods have achieved great success in the field of novel view synthesis. However, specular reflection remains non-trivial, as the high frequency radiance field is notoriously difficult to fit stably and accurately. We present a deferred shading method to effectively render specular reflection with Gaussian splatting. The key challenge comes from the environment map reflection model, which requires accurate surface normal while simultaneously bottlenecks normal estimation with discontinuous gradients. We leverage the per-pixel reflection gradients generated by deferred shading to bridge the optimization process of neighboring Gaussians, allowing nearly correct normal estimations to gradually propagate and eventually spread over all reflective objects. Our method significantly outperforms state-of-the-art techniques and concurrent work in synthesizing high-quality specular reflection effects, demonstrating a consistent improvement of peak signal-to-noise ratio (PSNR) for both synthetic and real-world scenes, while running at a frame rate almost identical to vanilla Gaussian splatting.
Summary
高斯辐射场结合延时着色大幅提升反射效果,无需额外时间成本
Key Takeaways
- 神经和高斯辐射场方法在视图合成中取得巨大进展,但镜面反射处理困难。
- 提出了延时着色方法,使用高斯散射有效渲染镜面反射。
- 环境贴图反射模型的挑战在于需要准确的表面法线,而法线估计受断续梯度的限制。
- 利用延时着色生成的逐像素反射梯度,桥接了相邻高斯的优化过程。
- 准确的法线估计逐渐传播,最终覆盖所有反射物体。
- 方法大幅优于最先进技术,在合成高质量镜面反射效果方面达到领先水平。
- 在合成和真实场景中,峰值信噪比 (PSNR) 均得到一致提高,且运行帧速率几乎与原始高斯散射相同。
Title: 3D 高斯斑点与延迟反射
Authors: Keyang Ye, Qiming Hou, Kun Zhou
Affiliation: 浙江大学计算机辅助设计与图形学国家重点实验室
Keywords: Novel view synthesis, deferred shading, real-time rendering
Urls: Paper: https://arxiv.org/pdf/2404.18454.pdf, Github: None
Summary:
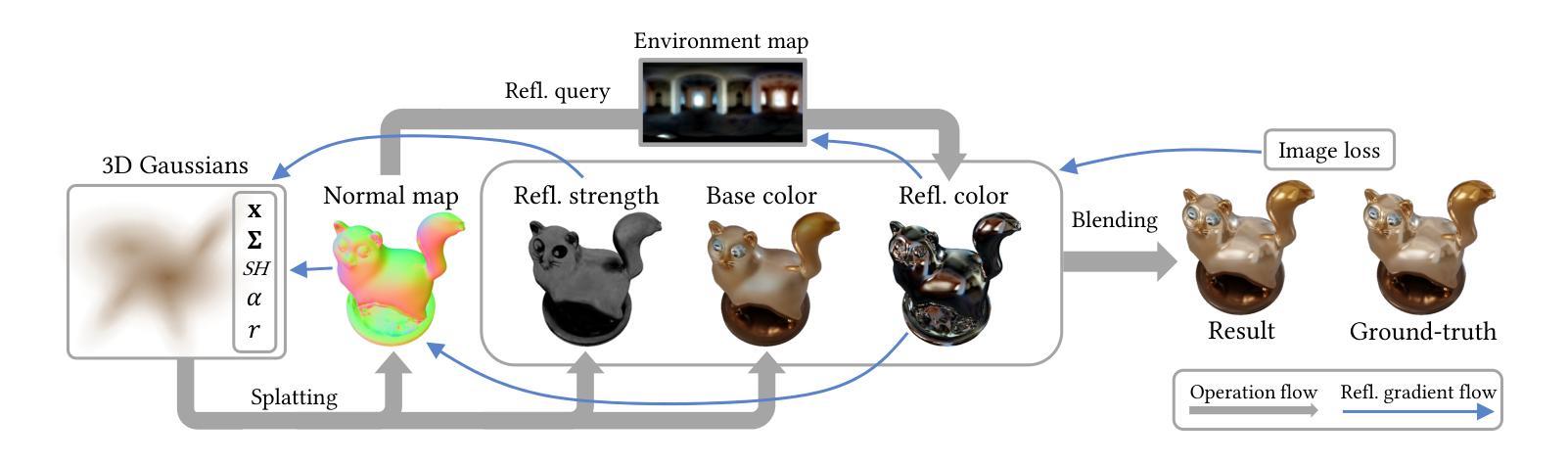
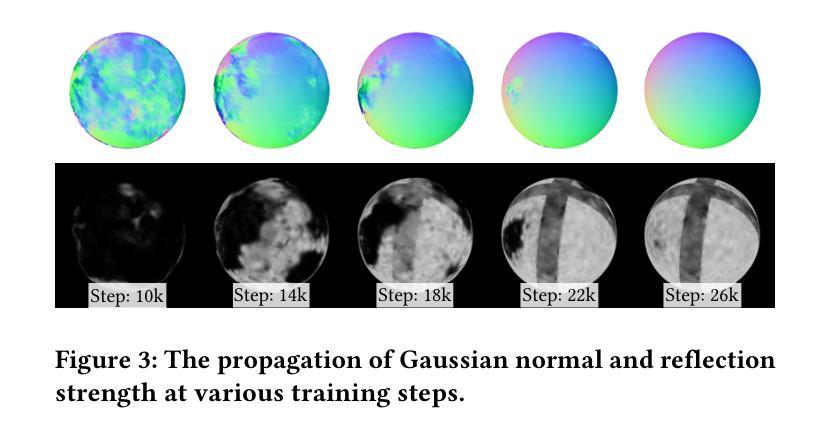
(1): 本文的研究背景是神经辐射场(NeRF)和基于高斯的体渲染方法在新型视图合成中取得了巨大成功,但镜面反射仍然具有挑战性。
(2): 过去的方法如 3D 高斯斑点(3DGS)虽然提供了基于每个高斯的球谐函数(SH)进行视点相关着色,但其方向频率太有限,无法建模镜面反射。训练过程会产生高斯,以显式地拟合镜面反射,但这种方法会导致视觉伪影和较差的性能。
(3): 本文提出的研究方法是延迟着色,它利用延迟着色生成的逐像素反射梯度来弥合相邻高斯优化过程之间的差距,允许近乎正确的法线估计逐渐传播,最终覆盖所有反射物体。
(4): 在合成高质量镜面反射效果的任务上,本文方法明显优于最先进的技术和同期工作,证明了合成和真实场景的峰值信噪比(PSNR)都有持续的提高,同时运行帧速率几乎与原始反射无关的高斯斑点相同。
- 方法:
(1):本方法采用延迟渲染模型,包含两个阶段;
(2):第一阶段是高斯斑点,利用高斯参数 Θ𝑖、每个高斯视点相关的球谐函数颜色 𝑐𝑖 (v) 计算像素颜色 𝐶(v);
(3):第二阶段是延迟反射,将法线向量 𝑛𝑖 和镜面反射强度标量 𝑟𝑖 融入高斯斑点,生成最终像素颜色 𝐶′(v)。
- 结论:
(1):本文提出了一种高质量的延迟高斯斑点渲染器,专门用于反射。它展示了稳定的训练和几乎与原始 3D 高斯斑点相同的帧速率的竞争性视觉质量,还生成了准确的表面法线和环境贴图。我们的延迟着色方法可能为未来的探索开辟了许多可能性。在高斯斑点的背景下探索渲染方程的更多创造性分割将是一件有趣的事情。我们的管道还可以扩展到超出环境贴图的高质量反射算法,包括屏幕空间反射 [McGuire and Mara 2014] 和硬件光线追踪。将 3D 高斯和可微渲染推广到此类方法可以显著提高反射质量。探索添加基于物理的粗糙度、将我们的方法推广到光泽材料的可能性也很有趣。致谢:这项工作部分得到了国家自然科学基金(编号 62227806 和 U23A20311)和 XPLORER PRIZE 的支持。源代码和数据可从 https://gapszju.github.com/3DGS-DR 获取。
(2):创新点:提出了延迟着色方法,利用延迟着色生成的逐像素反射梯度来弥合相邻高斯优化过程之间的差距,允许近乎正确的法线估计逐渐传播,最终覆盖所有反射物体。
性能:在合成高质量镜面反射效果的任务上,本文方法明显优于最先进的技术和同期工作,证明了合成和真实场景的峰值信噪比(PSNR)都有持续的提高,同时运行帧速率几乎与原始反射无关的高斯斑点相同。
工作量:本文方法的工作量与原始 3D 高斯斑点相似,在合成高质量镜面反射效果的任务上,本文方法明显优于最先进的技术和同期工作。
点此查看论文截图

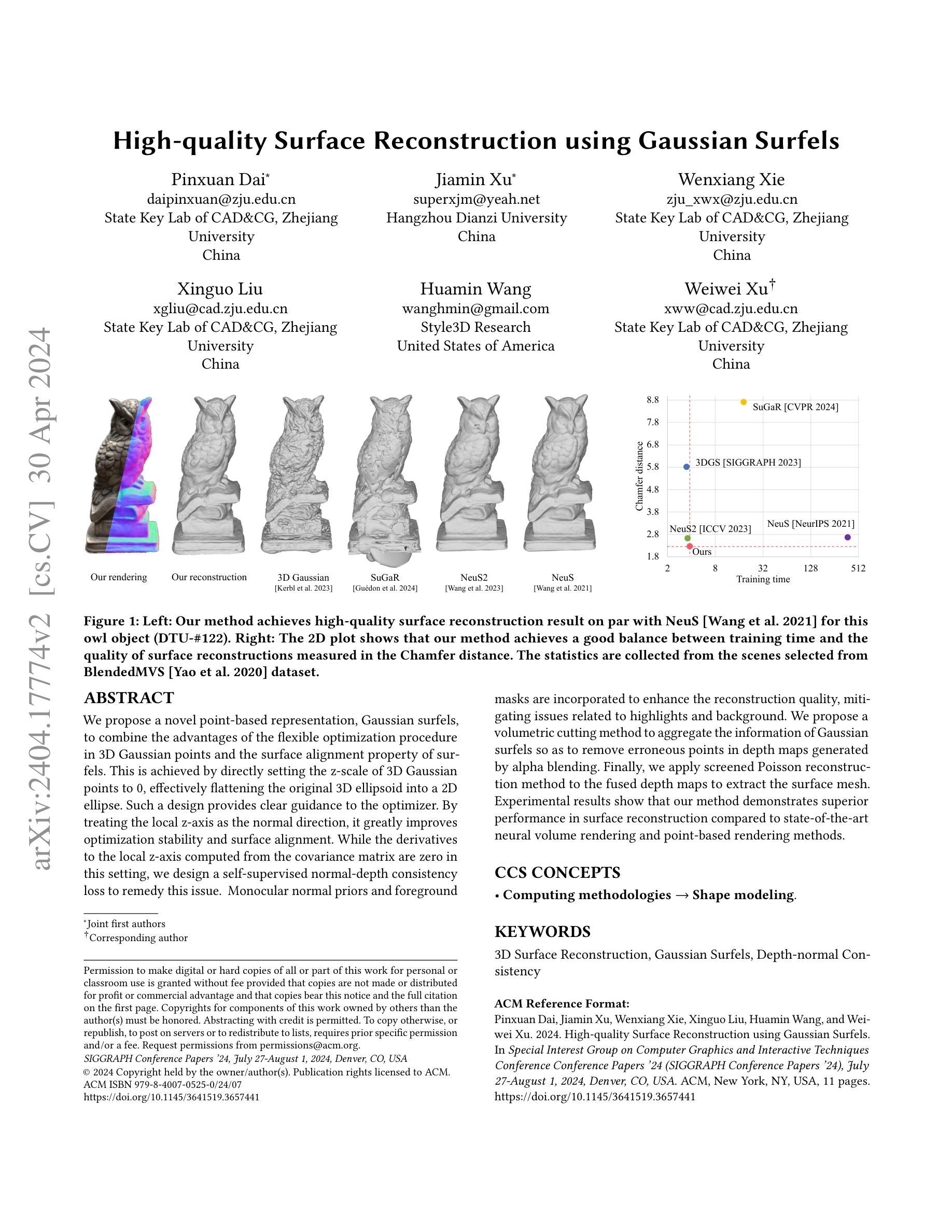
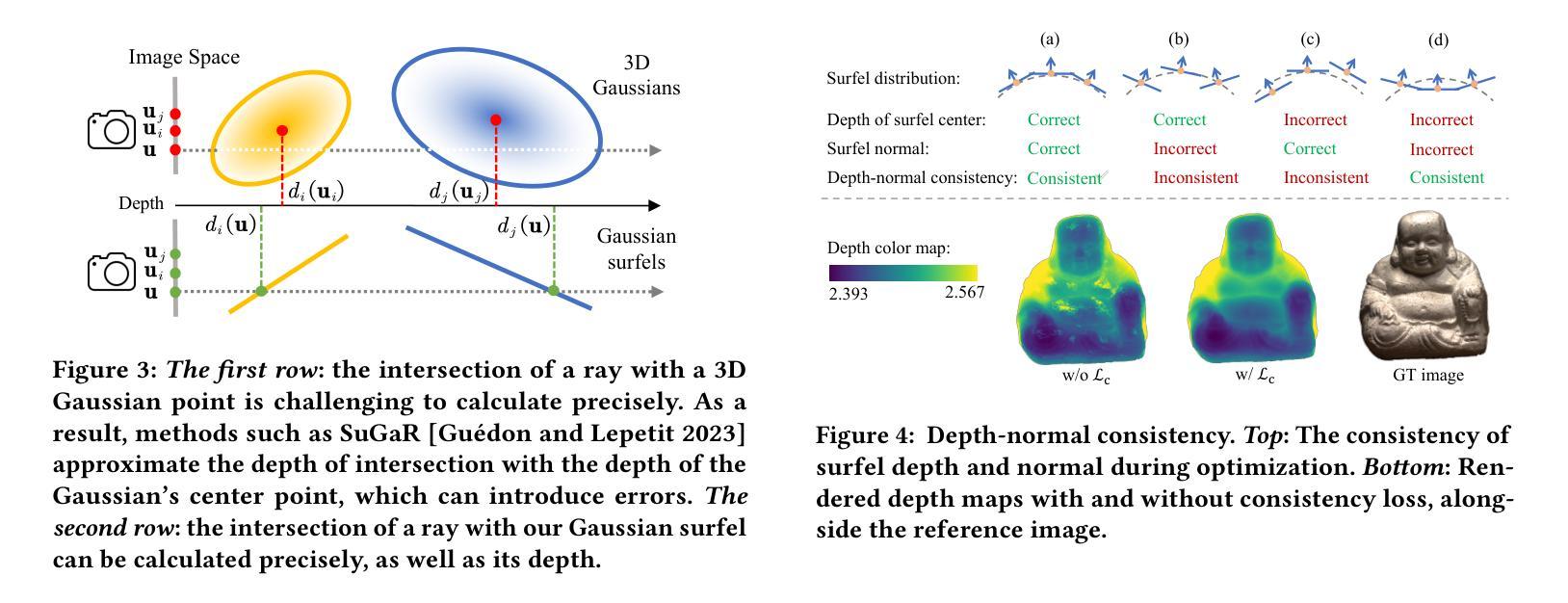
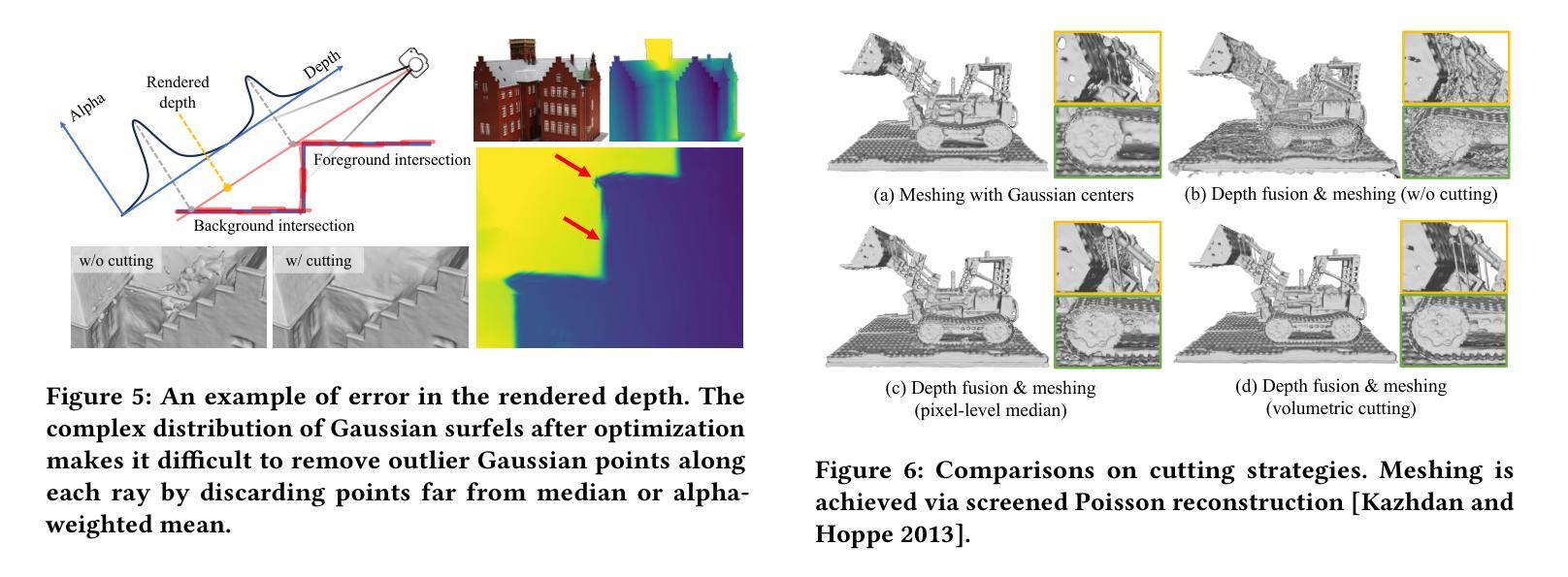
High-quality Surface Reconstruction using Gaussian Surfels
Authors:Pinxuan Dai, Jiamin Xu, Wenxiang Xie, Xinguo Liu, Huamin Wang, Weiwei Xu
We propose a novel point-based representation, Gaussian surfels, to combine the advantages of the flexible optimization procedure in 3D Gaussian points and the surface alignment property of surfels. This is achieved by directly setting the z-scale of 3D Gaussian points to 0, effectively flattening the original 3D ellipsoid into a 2D ellipse. Such a design provides clear guidance to the optimizer. By treating the local z-axis as the normal direction, it greatly improves optimization stability and surface alignment. While the derivatives to the local z-axis computed from the covariance matrix are zero in this setting, we design a self-supervised normal-depth consistency loss to remedy this issue. Monocular normal priors and foreground masks are incorporated to enhance the quality of the reconstruction, mitigating issues related to highlights and background. We propose a volumetric cutting method to aggregate the information of Gaussian surfels so as to remove erroneous points in depth maps generated by alpha blending. Finally, we apply screened Poisson reconstruction method to the fused depth maps to extract the surface mesh. Experimental results show that our method demonstrates superior performance in surface reconstruction compared to state-of-the-art neural volume rendering and point-based rendering methods.
PDF Results added and improved
Summary
针对三维高斯点和曲面元素的优点,提出一种新的点云表征方式高斯曲面元素,有效改善了优化稳定性和曲面对齐,并通过容积剪切和基于泊松的筛选重建方法提升了形状重建的精度。
Key Takeaways
- 提出高斯曲面元素,将三维高斯点的优化灵活性与曲面元素的对齐特性相结合。
- 通过将三维高斯点的 z 尺度设为 0,将三维椭圆体压平为二维椭圆,为优化器提供清晰指引。
- 将局部 z 轴视为法线方向,极大提高了优化的稳定性和表面对齐。
- 设计自监督法线深度一致性损失,弥补共方差矩阵中计算出的局部 z 轴导数为零的问题。
- 融合单目法线先验和前景掩码,增强重建质量,缓解高光和背景带来的影响。
- 提出体积切割方法,聚合高斯曲面元素的信息,去除深度图中由 alpha 混合产生的错误点。
- 采用带筛选的泊松重建方法对融合的深度图进行重建,提取表面网格。
- 实验结果表明,该方法在表面重建方面优于现有的神经体绘制和点云绘制方法。
Title: 高斯表面元的高质量表面重建
Authors: Pinxuan Dai, Jiamin Xu, Wenxiang Xie, Xinguo Liu, Huamin Wang, Weiwei Xu
Affiliation: 浙江大学计算机辅助设计与图形学国家重点实验室
Keywords: 3D Surface Reconstruction, Gaussian Surfels, Depth-normal Consistency
Urls: https://arxiv.org/abs/2404.17774 , Github:None
Summary:
(1):神经辐射场(NeRF)在图像合成的任务上取得了巨大的成功,但在表面重建任务上仍然存在一些问题,例如表面对齐不准确、优化不稳定以及对高光和背景区域的敏感性。
(2):以往的方法主要集中在优化损失函数和使用先验信息来解决这些问题,但效果有限。
(3):本文提出了一种新的点表示——高斯表面元,它结合了 3D 高斯点的灵活优化过程和表面元的表面对齐特性。具体来说,将 3D 高斯点的 z 尺度设置为 0,有效地将原始的 3D 椭球压扁成 2D 椭圆。这种设计为优化器提供了明确的指导,通过将局部 z 轴视为法线方向,极大地提高了优化稳定性和表面对齐。同时设计了一个自监督的法线深度一致性损失来解决此设置中从协方差矩阵计算的局部 z 轴的导数为零的问题。此外,本文还集成了单目法线先验和前景掩码以提高重建质量,减轻了与高光和背景相关的问题。提出了一种体积切割方法来聚合高斯表面元的信息,以去除 alpha 混合生成的深度图中的错误点。最后,将筛选泊松重建方法应用于融合的深度图以提取表面网格。
(4):实验结果表明,与最先进的神经体渲染和基于点的渲染方法相比,本文的方法在表面重建方面表现出优越的性能。
- 方法:
(1):提出了一种新的点表示——高斯表面元,它结合了 3D 高斯点的灵活优化过程和表面元的表面对齐特性;
(2):设计了一个自监督的法线深度一致性损失来解决此设置中从协方差矩阵计算的局部 z 轴的导数为零的问题;
(3):集成了单目法线先验和前景掩码以提高重建质量,减轻了与高光和背景相关的问题;
(4):提出了一种体积切割方法来聚合高斯表面元的信息,以去除 alpha 混合生成的深度图中的错误点;
(5):将筛选泊松重建方法应用于融合的深度图以提取表面网格。
- 结论:
(1):本文提出了一种新的点表示——高斯表面元,它结合了 3D 高斯点的灵活优化过程和表面元的表面对齐特性,设计了一个自监督的法线深度一致性损失来解决此设置中从协方差矩阵计算的局部 z 轴的导数为零的问题,集成了单目法线先验和前景掩码以提高重建质量,减轻了与高光和背景相关的问题,提出了一种体积切割方法来聚合高斯表面元的信息,以去除 alpha 混合生成的深度图中的错误点,将筛选泊松重建方法应用于融合的深度图以提取表面网格。通过实验,本文方法在表面重建方面表现出优越的性能。
(2):创新点:提出了一种新的点表示——高斯表面元,设计了一个自监督的法线深度一致性损失,集成了单目法线先验和前景掩码,提出了一种体积切割方法来聚合高斯表面元的信息;性能:与最先进的神经体渲染和基于点的渲染方法相比,本文的方法在表面重建方面表现出优越的性能;工作量:本文方法的计算成本相对较高。
点此查看论文截图

GaussianTalker: Real-Time High-Fidelity Talking Head Synthesis with Audio-Driven 3D Gaussian Splatting
Authors:Kyusun Cho, Joungbin Lee, Heeji Yoon, Yeobin Hong, Jaehoon Ko, Sangjun Ahn, Seungryong Kim
We propose GaussianTalker, a novel framework for real-time generation of pose-controllable talking heads. It leverages the fast rendering capabilities of 3D Gaussian Splatting (3DGS) while addressing the challenges of directly controlling 3DGS with speech audio. GaussianTalker constructs a canonical 3DGS representation of the head and deforms it in sync with the audio. A key insight is to encode the 3D Gaussian attributes into a shared implicit feature representation, where it is merged with audio features to manipulate each Gaussian attribute. This design exploits the spatial-aware features and enforces interactions between neighboring points. The feature embeddings are then fed to a spatial-audio attention module, which predicts frame-wise offsets for the attributes of each Gaussian. It is more stable than previous concatenation or multiplication approaches for manipulating the numerous Gaussians and their intricate parameters. Experimental results showcase GaussianTalker’s superiority in facial fidelity, lip synchronization accuracy, and rendering speed compared to previous methods. Specifically, GaussianTalker achieves a remarkable rendering speed up to 120 FPS, surpassing previous benchmarks. Our code is made available at https://github.com/KU-CVLAB/GaussianTalker/ .
PDF Project Page: https://ku-cvlab.github.io/GaussianTalker
Summary
高斯说话者:实时生成姿势可控会说话的头部
Key Takeaways
- 提出了一种名为高斯说话者的新框架,用于实时生成姿势可控的会说话的头部。
- 利用 3D 高斯 splatting(3DGS)的快速渲染能力,同时解决了直接使用语音音频控制 3DGS 的挑战。
- 构建头部规范的 3DGS 表示,并使其与音频同步变形。
- 关键的见解是将 3D 高斯属性编码成共享的隐式特征表示,并在其中与音频特征合并以控制每个高斯属性。
- 该设计利用了空间感知特征,并强制相邻点之间的交互。
- 将特征嵌入馈送到空间-音频注意模块,该模块预测每个高斯的属性的帧级偏移。
- 与以前的串联或乘法方法相比,它在处理大量高斯及其复杂参数时更稳定。
- 实验结果表明,与以前的方法相比,高斯说话者在面部保真度、唇形同步精度和渲染速度方面更胜一筹。
- 具体而言,高斯说话者以高达 120 FPS 的非凡渲染速度,超过了之前的基准。
Title: 高斯说话者:实时高保真说话头部合成
Authors: Kyusun Cho,Joungbin Lee,Heeji Yoon,Yeobin Hong,Jaehoon Ko,Sangjun Ahn,Seungryong Kim
Affiliation: 韩国大学
Keywords: Talking Head Generation, 3D Controllable Head, 3D Gaussian Splatting
Urls: https://ku-cvlab.github.io/GaussianTalker/ , https://github.com/ku-cvlab/GaussianTalker
Summary:
(1): 本文的研究背景是生成受任意语音音频驱动的说话头部视频,这项任务有很多用途,包括生成数字人、虚拟替身、电影制作和电话会议。
(2): 过去的方法有使用生成模型来解决此任务,但它们不专注于控制头部姿势,这限制了它们的真实性和适用性。最近,许多研究应用神经辐射场(NeRF)来创建可控姿势的说话人像。通过直接调节 NeRF 多层感知器(MLP)中的音频特征,这些方法可以合成与输入音频嘴唇同步的视图一致的 3D 头部结构。虽然这些基于 NeRF 的技术实现了高质量和一致的视觉输出,但它们缓慢的推理速度限制了它们的实用性。
(3): 本文提出的研究方法是利用 3D 高斯溅射(3DGS)的快速渲染能力。3DGS 被公认为 NeRF 的可行替代方案,它提供了可比的渲染质量,同时显着提高了推理速度。虽然 3DGS 最初被提议用于重建静态 3D 场景,但后续工作已将其扩展到动态场景。然而,很少有研究利用 3DGS 创建具有可控输入的动态 3D 场景,其中大多数都专注于使用中间网格表示来驱动 3D 高斯。然而,依赖中间 3D 网格表示(例如 FLAME)进行变形通常缺乏头发和面部皱纹的细节。
(4): 本文方法在任务和性能上取得了以下成就: - 与现有的 3D 说话人脸合成模型相比,本文方法在保真度、唇形同步和推理时间方面取得了优异的性能,并且以更高的 FPS 运行。 - 本文方法实现了高达 120 FPS 的显着渲染速度,超过了之前的基准。
- 方法:
(1):本文方法采用 3D 高斯溅射(3DGS)的快速渲染能力,3DGS 被公认为 NeRF 的可行替代方案,它提供了可比的渲染质量,同时显着提高了推理速度;
(2):本文方法通过学习具有三平面表示的规范 3D 高斯体来学习说话头的规范形状,多分辨率三平面表示利用 3DGS 的显式 3D 表示,同时还利用隐式神经辐射场的编码空间信息,对于每个规范 3D 位置,从多分辨率三平面表示中提取特征嵌入,这些特征嵌入用于计算每个点的比例、旋转、球谐函数和不透明度,这些计算出的属性构成了说话头的规范 3D 高斯体;
(3):本文方法采用语音动作交叉注意模块融合 3D 高斯体特征和音频特征,以准确建模由输入音频驱动的面部运动,空间音频注意模块包含多组交叉注意层和前馈层,每组通过跳跃连接相互连接,该模块将空间特征与第 n 帧的音频特征进行交叉注意计算,从而输出特征成功地将音频特征与每个 3D 高斯体捕获的丰富面部细节相融合;
(4):本文方法通过引入附加输入条件来捕获非语言动作,从而将与语音相关的运动与单目视频区分开来,遵循先前的工作,首先应用显式眨眼控制与眼睛特征,具体地,使用面部动作编码系统中的 AU45 来描述眨眼程度,并利用正弦位置编码以匹配输入维度,此外,将摄像机视点作为辅助输入以区分非语言场景变化,虽然将逐帧摄像机公式化为面部视点,但典型的视频是在头部连续移动时使用静态摄像机拍摄的,因此,肖像图像的变化(例如头发位移和光照变化)独立于语音音频,因此,使用面部视点嵌入作为附加输入条件来区分这些非听觉变化。
- 结论:
(1):本文提出了 GaussianTalker,一个新颖的实时姿态可控 3D 说话人脸合成框架,利用 3D 高斯体进行头部表示。我们的方法通过调节高斯原语实现了对高斯原语的精确控制,从而获得了比以往更好的保真度、唇形同步和推理时间,并且以更高的 FPS 运行。
(2):创新点:利用 3D 高斯体进行头部表示,实现了姿态可控的 3D 说话人脸合成;性能:在保真度、唇形同步和推理时间方面取得了优异的性能,实现了高达 120 FPS 的显着渲染速度;工作量:与现有的 3D 说话人脸合成模型相比,本文方法在保真度、唇形同步和推理时间方面取得了优异的性能,并且以更高的 FPS 运行。
点此查看论文截图


OMEGAS: Object Mesh Extraction from Large Scenes Guided by Gaussian Segmentation
Authors:Lizhi Wang, Feng Zhou, Jianqin Yin
Recent advancements in 3D reconstruction technologies have paved the way for high-quality and real-time rendering of complex 3D scenes. Despite these achievements, a notable challenge persists: it is difficult to precisely reconstruct specific objects from large scenes. Current scene reconstruction techniques frequently result in the loss of object detail textures and are unable to reconstruct object portions that are occluded or unseen in views. To address this challenge, we delve into the meticulous 3D reconstruction of specific objects within large scenes and propose a framework termed OMEGAS: Object Mesh Extraction from Large Scenes Guided by GAussian Segmentation. OMEGAS employs a multi-step approach, grounded in several excellent off-the-shelf methodologies. Specifically, initially, we utilize the Segment Anything Model (SAM) to guide the segmentation of 3D Gaussian Splatting (3DGS), thereby creating a basic 3DGS model of the target object. Then, we leverage large-scale diffusion priors to further refine the details of the 3DGS model, especially aimed at addressing invisible or occluded object portions from the original scene views. Subsequently, by re-rendering the 3DGS model onto the scene views, we achieve accurate object segmentation and effectively remove the background. Finally, these target-only images are used to improve the 3DGS model further and extract the definitive 3D object mesh by the SuGaR model. In various scenarios, our experiments demonstrate that OMEGAS significantly surpasses existing scene reconstruction methods. Our project page is at: https://github.com/CrystalWlz/OMEGAS
PDF arXiv admin note: text overlap with arXiv:2311.17061 by other authors
Summary
大型场景中特定物体的高精度三维重建框架:OMEGAS,通过高斯分割引导物体网格提取。
Key Takeaways
- OMEGAS 框架可从大型场景中高精度重建特定物体。
- 结合 Segment Anything Model (SAM) 和大型扩散先验,改善 3DGS 模型细节。
- 重新渲染 3DGS 模型,实现准确物体分割并去除背景。
- 使用目标图像,进一步优化 3DGS 模型并提取最终 3D 物体网格。
- OMEGAS 在各种场景中优于现有场景重建方法。
- 代码和数据可在 https://github.com/CrystalWlz/OMEGAS 获取。
- OMEGAS 适用于目标物体部分遮挡或不可见的情况。
Title: OMEGAS: 高斯分割引导的大场景物体网格提取
Authors: Lizhi Wang, Feng Zhou, Jianqin Yin
Affiliation: 北京邮电大学
Keywords: Mesh Reconstruction, 3D Gaussian Splatting, Diffusion Model
Urls: Paper: https://arxiv.org/abs/2404.15891 , Github: None
Summary:
(1): 随着 3D 重建技术的进步,复杂 3D 场景的高质量实时渲染成为可能。然而,从大场景中精确重建特定物体仍然是一个挑战。现有的场景重建技术经常导致物体细节纹理丢失,并且无法重建在视图中被遮挡或看不见的物体部分。
(2): 过去的重建方法难以处理大场景中复杂物体,并且在处理遮挡和不可见区域时存在问题。本文提出的方法以 3D 高斯点云(3DGS)为基础,利用扩散模型来细化细节,并结合目标分割和网格提取技术,以提高重建精度和效率。
(3): 本文提出 OMEGAS 框架,该框架采用多步方法,首先利用分割任何模型(SAM)指导 3DGS 的分割,创建目标物体的基本 3DGS 模型。然后,利用大规模扩散先验进一步细化 3DGS 模型的细节,特别是针对原始场景视图中不可见或被遮挡的物体部分。随后,将 3DGS 模型重新渲染到场景视图上,实现精确的目标分割并有效去除背景。最后,利用这些仅包含目标的图像进一步改进 3DGS 模型,并通过 SuGaR 模型提取最终的 3D 物体网格。
(4): 在各种场景中,实验表明 OMEGAS 明显优于现有的场景重建方法。该方法在处理复杂物体、遮挡和不可见区域方面表现出色,能够生成高质量的 3D 物体网格,为增强现实、游戏和大规模 3D 数据集生成等下游任务提供了支持。
- 方法:
(1):利用 SAM 引导 3DGS 分割,构建目标物体的基本 3DGS 模型;
(2):应用大规模扩散先验(Stable Diffusion)细化 3DGS 模型细节,特别是不可见或被遮挡部分;
(3):将 3DGS 模型重新渲染到场景视图上,获得精确目标分割并去除背景;
(4):使用仅包含目标的图像进一步改进 3DGS 模型,通过 SuGaR 模型提取最终 3D 物体网格。
- 结论:
(1):本文提出了一种基于高斯分割引导的大场景物体网格提取框架 OMEGAS,该框架能够从多视角场景图像中有效提取目标物体的精细网格,并能够重建被遮挡或不可见的物体部分。OMEGAS 创新性地融合了 SAM、3DGS、Stabled Diffusion 和 SuGaR 模型等多种优秀方法。与基线方法相比,我们的方法在目标的细节纹理和抗遮挡性方面均表现出极大的优势。我们希望 OMEGAS 能够为 3D 重建领域提供新的思路,并为下游任务提供更好的解决方案。
(2):创新点:提出了一种基于高斯分割引导的大场景物体网格提取框架 OMEGAS; 性能:在处理复杂物体、遮挡和不可见区域方面表现出色,能够生成高质量的 3D 物体网格; 工作量:与基线方法相比,OMEGAS 的计算成本较高,需要较长的处理时间。
点此查看论文截图



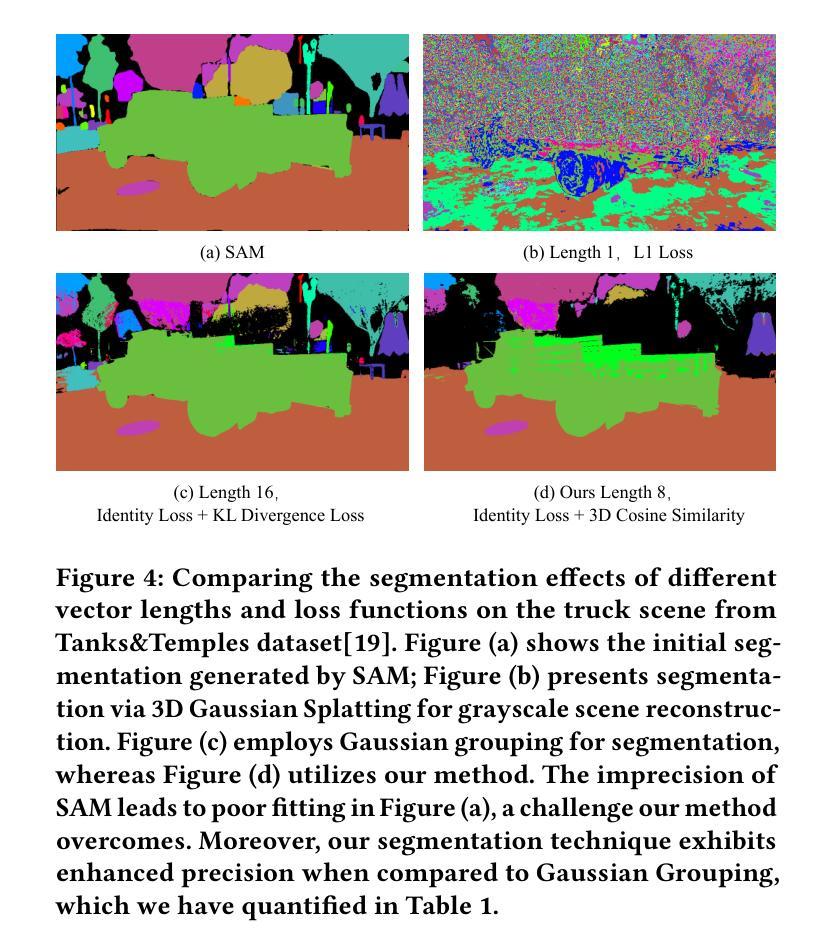

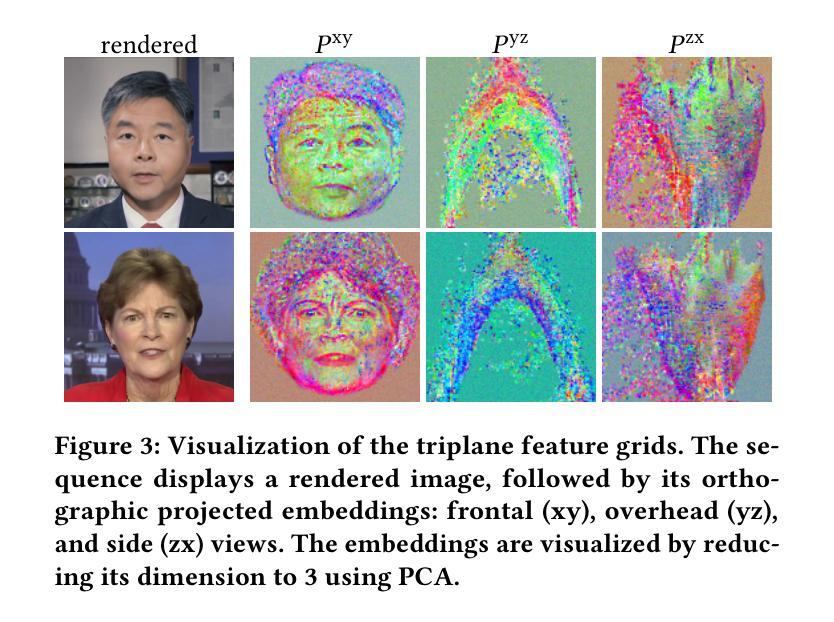
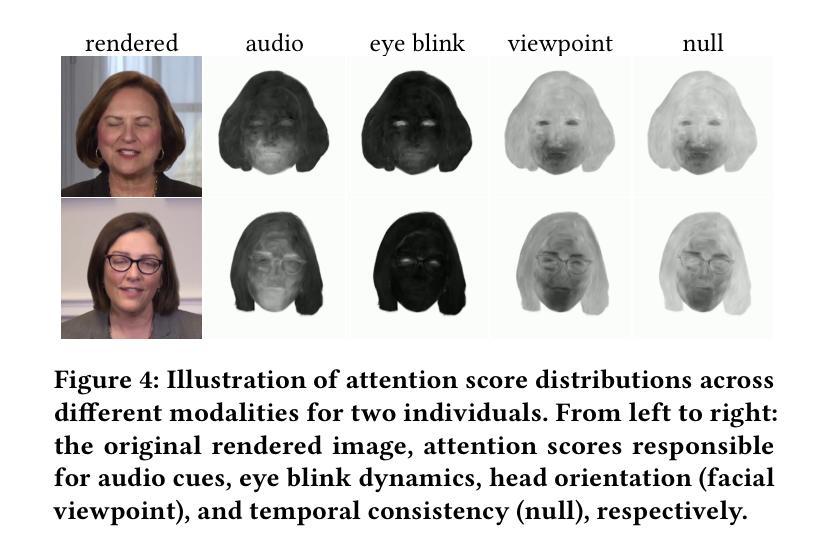
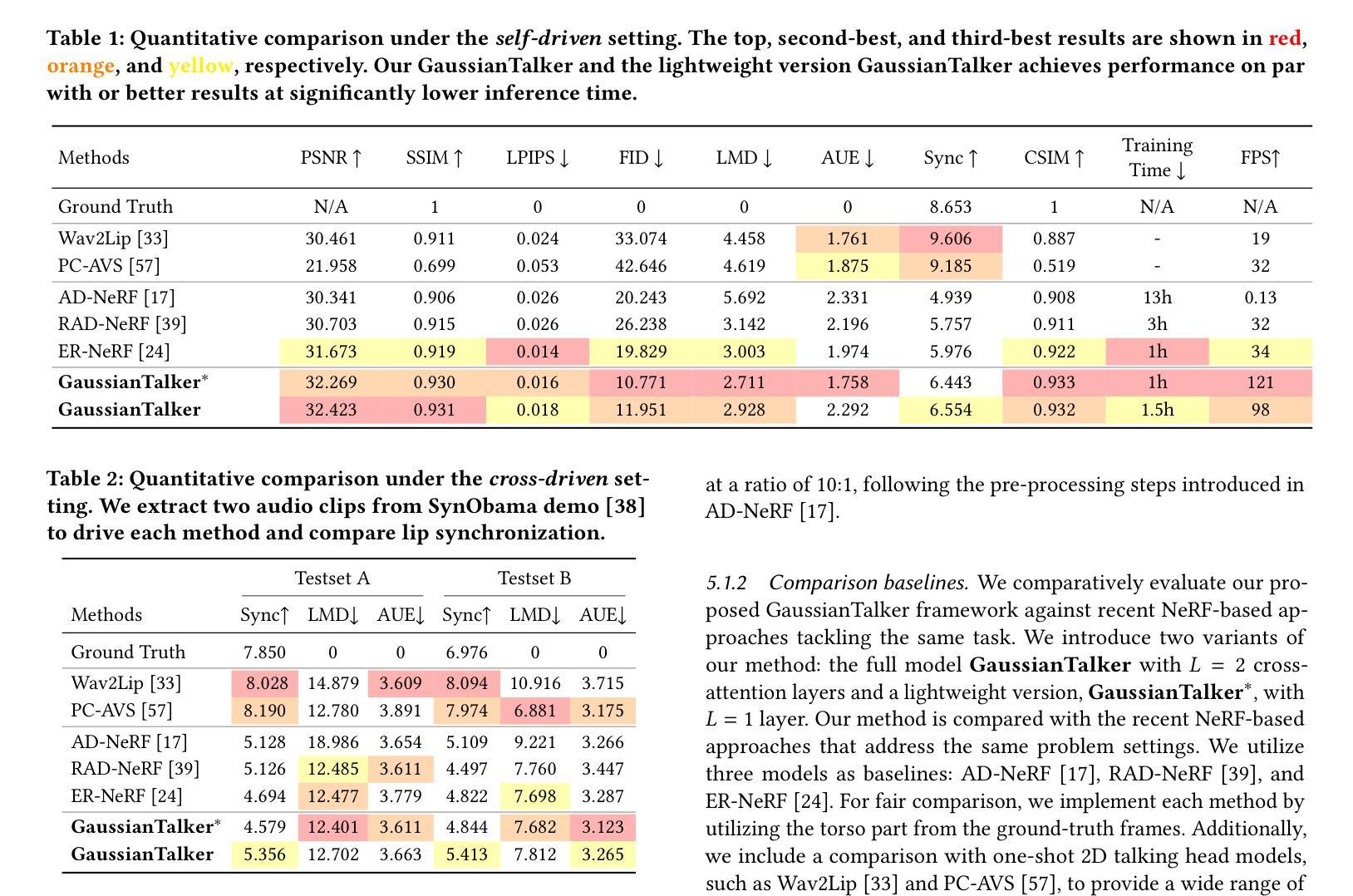
GaussianTalker: Speaker-specific Talking Head Synthesis via 3D Gaussian Splatting
Authors:Hongyun Yu, Zhan Qu, Qihang Yu, Jianchuan Chen, Zhonghua Jiang, Zhiwen Chen, Shengyu Zhang, Jimin Xu, Fei Wu, Chengfei Lv, Gang Yu
Recent works on audio-driven talking head synthesis using Neural Radiance Fields (NeRF) have achieved impressive results. However, due to inadequate pose and expression control caused by NeRF implicit representation, these methods still have some limitations, such as unsynchronized or unnatural lip movements, and visual jitter and artifacts. In this paper, we propose GaussianTalker, a novel method for audio-driven talking head synthesis based on 3D Gaussian Splatting. With the explicit representation property of 3D Gaussians, intuitive control of the facial motion is achieved by binding Gaussians to 3D facial models. GaussianTalker consists of two modules, Speaker-specific Motion Translator and Dynamic Gaussian Renderer. Speaker-specific Motion Translator achieves accurate lip movements specific to the target speaker through universalized audio feature extraction and customized lip motion generation. Dynamic Gaussian Renderer introduces Speaker-specific BlendShapes to enhance facial detail representation via a latent pose, delivering stable and realistic rendered videos. Extensive experimental results suggest that GaussianTalker outperforms existing state-of-the-art methods in talking head synthesis, delivering precise lip synchronization and exceptional visual quality. Our method achieves rendering speeds of 130 FPS on NVIDIA RTX4090 GPU, significantly exceeding the threshold for real-time rendering performance, and can potentially be deployed on other hardware platforms.
PDF https://yuhongyun777.github.io/GaussianTalker/
Summary
3D高斯散布技术合成音频驱动说话人头像,精准唇部动作及动态高斯渲染,实现逼真流畅的说话人头像合成。
Key Takeaways
- 基于3D高斯散布的音频驱动说话人头像合成新方法。
- 显式高斯表示,通过将高斯与3D面部模型绑定,实现面部运动的直观控制。
- 扬声器特定运动转换器,实现精准的扬声器特定唇部动作。
- 动态高斯渲染器,通过潜在姿势引入扬声器特定混合形状,增强面部细节表示。
- 广泛实验表明,GaussianTalker在说话人头像合成中优于现有最先进的方法。
- 渲染速度达到 130 FPS,显着超过实时渲染性能阈值。
- 可部署在其他硬件平台上,具有实际应用潜力。
Title: 高斯说话者:基于 3D 高斯喷射的特定说话者说话头合成
Authors: Hongyun Yu, Zhan Qu, Qihang Yu, Jianchuan Chen, Zhonghua Jiang, Zhiwen Chen, Shengyu Zhang, Jimin Xu, Fei Wu, Chengfei Lv, Gang Yu
Affiliation: 阿里巴巴集团
Keywords: Audio-driven talking head synthesis, 3D Gaussian Splatting, Lip motion control, Facial animation
Urls: Paper: https://arxiv.org/abs/2404.14037, Github: None
Summary:
(1): 研究背景:最近基于神经辐射场 (NeRF) 的音频驱动说话头合成工作取得了令人印象深刻的成果。然而,由于 NeRF 隐式表示导致的姿势和表情控制不足,这些方法仍然存在一些限制,例如不同步或不自然的唇部动作,以及视觉抖动和伪影。
(2): 过去的方法:现有方法存在唇部运动不同步、表情控制不足等问题。本文提出的方法动机明确。
(3): 研究方法:本文提出了一种基于 3D 高斯喷射的音频驱动说话头合成新方法 GaussianTalker。通过将高斯体绑定到 3D 面部模型,利用 3D 高斯体的显式表示特性,实现了对面部动作的直观控制。GaussianTalker 由两个模块组成:特定说话者运动转换器和动态高斯渲染器。特定说话者运动转换器通过通用音频特征提取和定制唇部动作生成,实现了特定于目标说话者的准确唇部动作。动态高斯渲染器引入了特定说话者的混合形状,以实现精确的表情控制。
(4): 性能:在说话头合成任务上,GaussianTalker 在唇部运动同步、表情控制和视觉质量方面均取得了最先进的性能。这些性能支持了本文提出的方法的目标。
- 方法:
(1):提出基于 3D 高斯喷射的音频驱动说话头合成新方法 GaussianTalker,通过将高斯体绑定到 3D 面部模型,利用 3D 高斯体的显式表示特性,实现了对面部动作的直观控制;
(2):GaussianTalker 由两个模块组成:特定说话者运动转换器和动态高斯渲染器。特定说话者运动转换器通过通用音频特征提取和定制唇部动作生成,实现了特定于目标说话者的准确唇部动作;
(3):动态高斯渲染器引入了特定说话者的混合形状,以实现精确的表情控制;
(4):在说话头合成任务上,GaussianTalker 在唇部运动同步、表情控制和视觉质量方面均取得了最先进的性能。
- 结论:
(1):本工作的主要贡献在于提出了一种基于 3D 高斯喷射的音频驱动说话头合成新方法 GaussianTalker,将高斯体与 FLAME 模型相结合,通过特定说话者的 FLAME 转换器和动态高斯渲染器,实现了唇部动作同步、表情控制和视觉质量的提升;
(2):创新点:提出基于 3D 高斯喷射的音频驱动说话头合成新方法 GaussianTalker,通过特定说话者的 FLAME 转换器和动态高斯渲染器,实现了唇部动作同步、表情控制和视觉质量的提升;性能:在说话头合成任务上,GaussianTalker 在唇部运动同步、表情控制和视觉质量方面均取得了最先进的性能;工作量:GaussianTalker 的渲染速度极快,远超其他方法;
点此查看论文截图

 wechat
wechat- alipay