⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-05-13 更新
OneTo3D: One Image to Re-editable Dynamic 3D Model and Video Generation
Authors:Jinwei Lin
One image to editable dynamic 3D model and video generation is novel direction and change in the research area of single image to 3D representation or 3D reconstruction of image. Gaussian Splatting has demonstrated its advantages in implicit 3D reconstruction, compared with the original Neural Radiance Fields. As the rapid development of technologies and principles, people tried to used the Stable Diffusion models to generate targeted models with text instructions. However, using the normal implicit machine learning methods is hard to gain the precise motions and actions control, further more, it is difficult to generate a long content and semantic continuous 3D video. To address this issue, we propose the OneTo3D, a method and theory to used one single image to generate the editable 3D model and generate the targeted semantic continuous time-unlimited 3D video. We used a normal basic Gaussian Splatting model to generate the 3D model from a single image, which requires less volume of video memory and computer calculation ability. Subsequently, we designed an automatic generation and self-adaptive binding mechanism for the object armature. Combined with the re-editable motions and actions analyzing and controlling algorithm we proposed, we can achieve a better performance than the SOTA projects in the area of building the 3D model precise motions and actions control, and generating a stable semantic continuous time-unlimited 3D video with the input text instructions. Here we will analyze the detailed implementation methods and theories analyses. Relative comparisons and conclusions will be presented. The project code is open source.
PDF 24 pages, 13 figures, 2 tables
Summary
单张图片生成可编辑动态3D模型和视频,是单张图片到3D表示或图像3D重建研究领域的新方向和变革。
Key Takeaways
- 高斯散射法在隐式3D重建中表现出优势,优于原始的神经辐射场。
- 稳定扩散模型可以根据文本指令生成目标模型。
- 使用常规隐式机器学习方法难以精确控制运动和动作。
- 难以生成长时间内容和语义连续的3D视频。
- OneTo3D方法提出,使用单张图片生成可编辑的3D模型和目标语义连续且时间无限的3D视频。
- 使用基本高斯散射模型从单张图片生成3D模型,减少视频内存和计算需求。
- 设计了对象骨架的自动生成和自适应绑定机制。
- 结合可再编辑的运动和动作分析和控制算法,在3D模型精确运动和动作控制以及生成稳定语义连续时间无限的3D视频方面取得了优于SOTA项目的性能。
ChatPaperFree
Title: OneTo3D: One Image to Re-editable Dynamic 3D Model and Video Generation
Authors: JINWEI LIN
Affiliation: Monash University, Australia
Keywords: 3D, One image, Editable, Dynamic, Generation, Automation, Video, Self-adaption, Armature
Urls: Paper, Github: None
Summary:
(1): 3D表示或3D重建是计算机视觉领域长期存在的挑战。
(2): 现有的3D重建方法可分为显式方法和隐式方法。显式方法直接设计和完成3D重建或建模;隐式方法使用机器学习方法和理论来实现这些目标。近年来,Neural Radiance Fields (NeRF) 在隐式3D表示或重建方面取得了突出成就。
(3): 本文提出了一种OneTo3D方法,使用一张图像生成可编辑的3D模型并生成目标语义连续时间无限的3D视频。该方法使用基本的Gaussian Splatting模型从单张图像生成3D模型,然后设计了一种自动生成和自适应绑定机制来绑定对象骨架。结合提出的可编辑动作分析和控制算法,该方法在3D模型精确动作控制和生成稳定语义连续时间无限的3D视频方面取得了比SOTA项目更好的性能。
(4): 在生成可编辑3D模型和生成目标语义连续时间无限的3D视频的任务上,该方法取得了优异的性能,证明了其目标的可实现性。
- 方法:
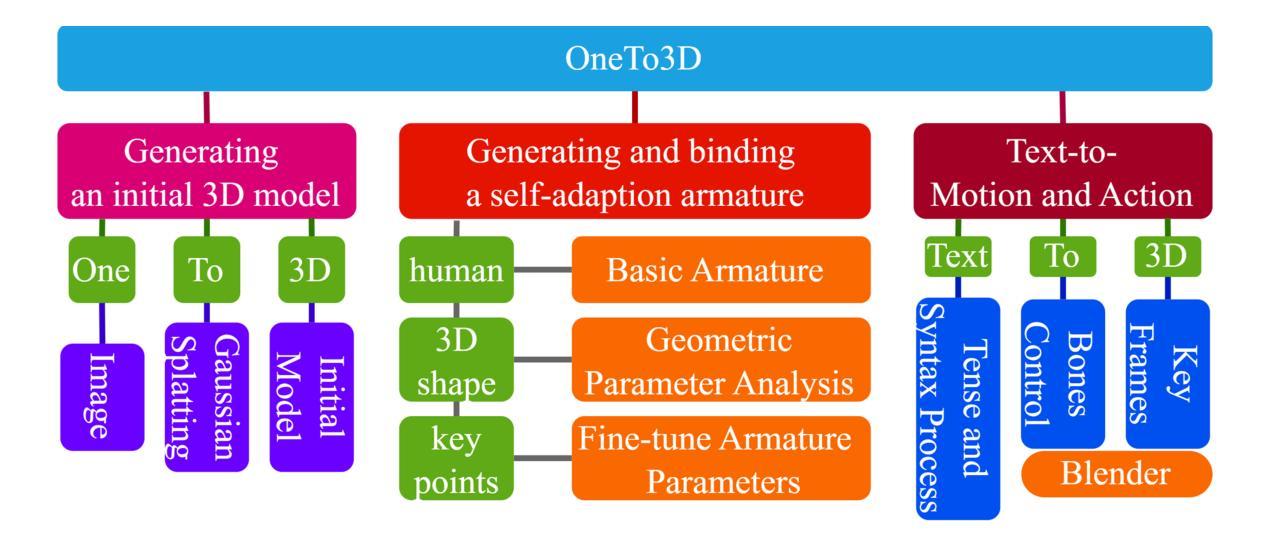
(1):OneTo3D 方法包含三个主要阶段:生成初始 3D 模型、生成和绑定自适应骨架、文本到动作和行为。
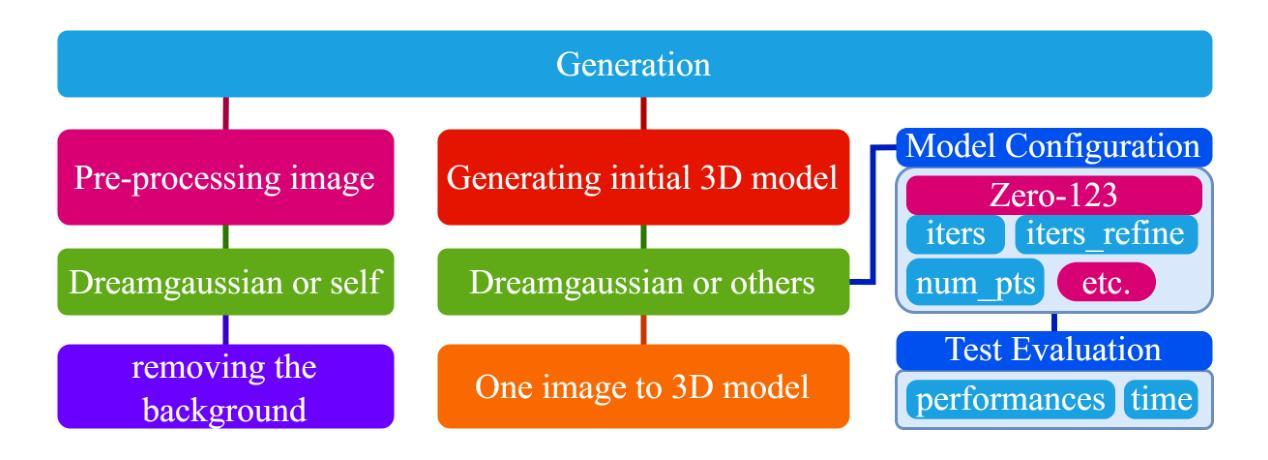
(2):初始 3D 模型生成基于 DreamGaussian,采用 Gaussian Splatting 模型处理预处理后的输入图像。
(3):自适应骨架生成通过分析初始 3D 模型的几何参数,调整 Blender 中的基本骨架,使其适应模型形状。
(4):文本到动作和行为分析用户输入指令,提取动作信息,控制骨架运动和动作生成。
(5):动作可重新编辑控制与 Blender 界面协作,将当前姿势插入为关键帧,组合关键帧生成最终 3D 视频。
- 结论:
(1)本工作提出了一种名为 OneTo3D 的方法,该方法可以从一张图像生成可编辑的 3D 模型和生成目标语义连续时间无限的 3D 视频。该方法在生成可编辑 3D 模型和生成目标语义连续时间无限的 3D 视频的任务上取得了优异的性能,证明了其目标的可实现性。
(2)创新点:OneTo3D 方法创新性地将显式建模和隐式表示相结合,提出了一种从单张图像生成可编辑 3D 模型和生成目标语义连续时间无限的 3D 视频的方法。 性能:OneTo3D 方法在生成可编辑 3D 模型和生成目标语义连续时间无限的 3D 视频的任务上取得了优异的性能,证明了其目标的可实现性。 工作量:OneTo3D 方法的工作量相对较大,需要大量的计算和训练。
点此查看论文截图

Title: 将扩散模型蒸馏到条件 GAN 中
Authors: Minguk Kang, Richard Zhang, Connelly Barnes, Sylvain Paris, Suha Kwak, Jaesik Park, Eli Shechtman, Jun-Yan Zhu, and Taesung Park
Affiliation: 韩国浦项科技大学
Keywords: Diffusion Models, Conditional GANs, Distillation, Image Generation
URLs: Paper, Github: None
Summary:
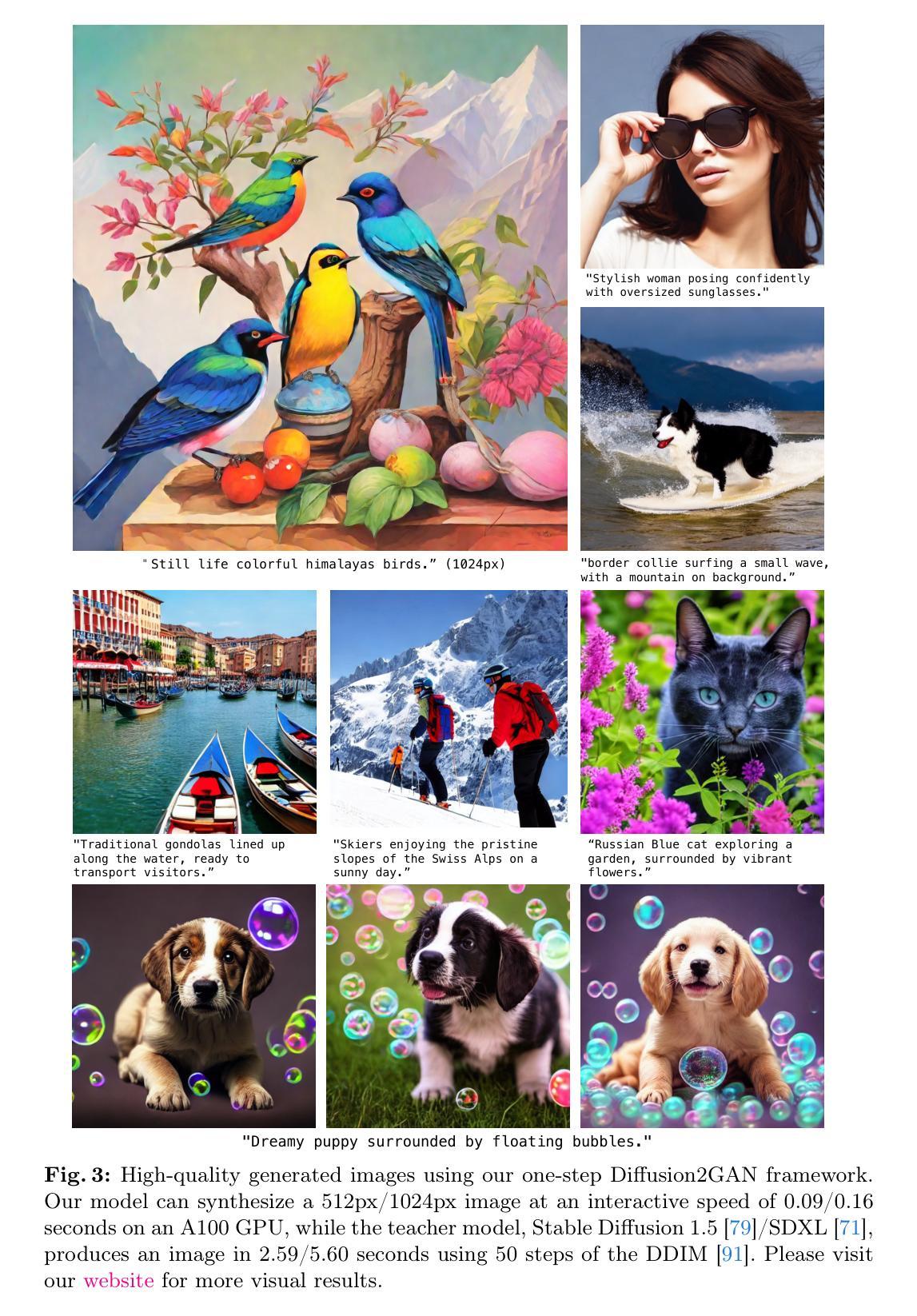
(1): 扩散模型在图像合成方面取得了显著进展,但其高延迟限制了其应用。
(2): 过去的方法要么从头开始训练单步模型,要么将扩散模型蒸馏到单步模型,但都存在训练困难或性能不足的问题。
(3): 本文提出了一种将复杂的多步扩散模型蒸馏到单步条件 GAN 学生模型的方法,通过将扩散蒸馏解释为配对图像到图像的翻译任务,并使用扩散模型 ODE 轨迹的噪声到图像对。
(4): 该方法在零样本 COCO 基准上优于最先进的单步扩散蒸馏模型,证明了其有效性。
- Methods:
(1): 将扩散模型蒸馏到条件 GAN 中,将扩散蒸馏解释为配对图像到图像的翻译任务;
(2): 使用扩散模型 ODE 轨迹的噪声到图像对作为翻译任务的数据集;
(3): 训练单步条件 GAN 学生模型,以最小化翻译任务的重建损失和对抗损失;
(4): 通过渐进式蒸馏,逐步增加扩散模型老师模型的蒸馏权重;
(5): 在零样本 COCO 基准上评估蒸馏后的单步条件 GAN 学生模型的性能。
- 结论:
(1): 本文提出了将复杂的多步扩散模型蒸馏到单步条件 GAN 学生模型的方法,在零样本 COCO 基准上优于最先进的单步扩散蒸馏模型,证明了其有效性。
(2): 创新点:将扩散蒸馏解释为配对图像到图像的翻译任务,使用扩散模型 ODE 轨迹的噪声到图像对作为翻译任务的数据集; 性能:在零样本 COCO 基准上优于最先进的单步扩散蒸馏模型; 工作量:训练单步条件 GAN 学生模型,以最小化翻译任务的重建损失和对抗损失,通过渐进式蒸馏,逐步增加扩散模型老师模型的蒸馏权重。
点此查看论文截图
标题:连续布朗桥扩散的帧插值
作者:Zonglin Lyu, Ming Li, Jianbo Jiao, Chen Chen
单位:犹他大学
关键词:Video Frame Interpolation, Diffusion Models, Brownian Bridge
论文链接:xxx,Github代码链接:None
摘要:
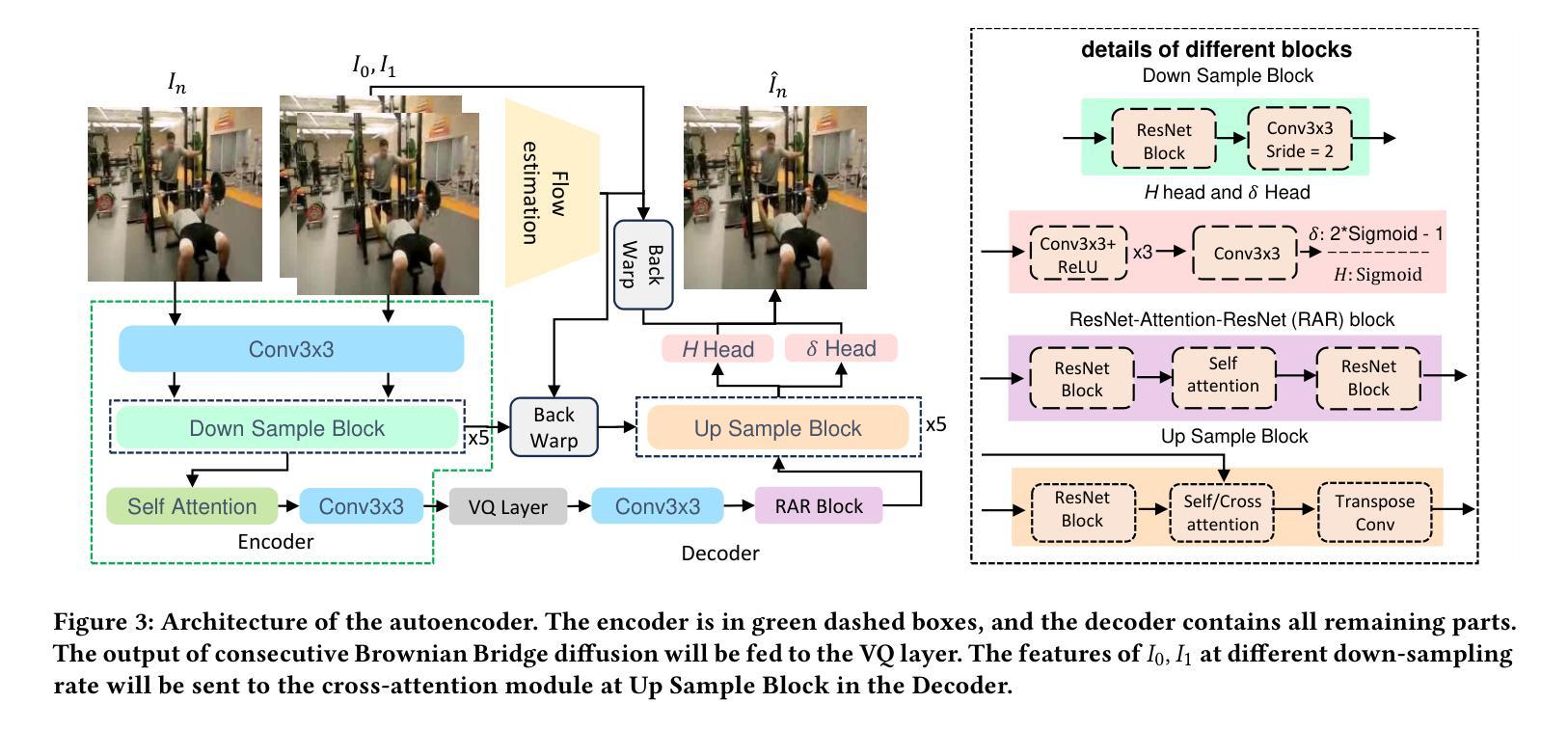
(1):该文章的研究背景是:近年来,视频帧插值(VFI)领域的研究工作将VFI表述为基于扩散的条件图像生成问题,在给定随机噪声和相邻帧的情况下合成中间帧。由于视频分辨率较高,因此采用潜在扩散模型(LDM)作为条件生成模型,其中自动编码器将图像压缩为潜在表示以进行扩散,然后从这些潜在表示中重建图像。这种表述提出了一个关键的挑战:VFI期望输出确定性地等于真实中间帧,但LDM在模型运行多次时会随机生成一组不同的图像。产生多样性的原因是LDM中生成潜在表示的累积方差(在生成过程中累积的方差)很大。这使得采样轨迹是随机的,导致产生多样性而不是确定性。
(2):过去的方法有:基于流的方法和基于核的方法。基于流的方法的问题是:依赖光流,而光流估计的准确性会影响插值结果的质量。基于核的方法的问题是:需要设计复杂的核函数,并且计算成本较高。
(3):本文提出的研究方法是:连续布朗桥扩散帧插值。具体来说,我们提出了连续布朗桥扩散,它以确定性初始值作为输入,从而导致生成潜在表示的累积方差大大减小。
(4):本文方法在VFI任务上取得了最先进的性能,证明了其有效性。
方法:
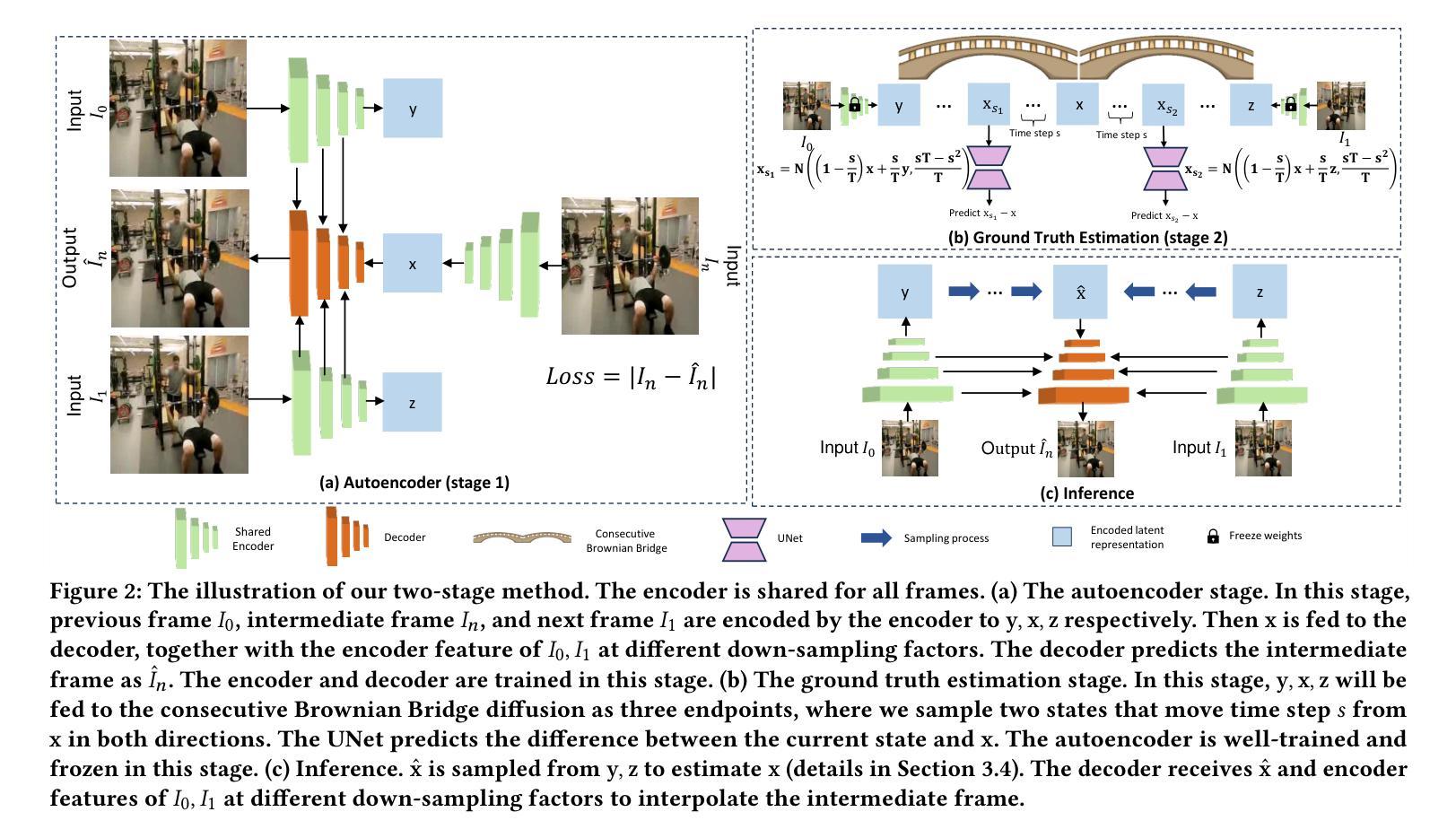
(1):本研究提出了一种连续布朗桥扩散帧插值方法,其通过引入确定性初始值来大幅减少生成潜在表示的累积方差,从而解决了LDM在VFI任务中产生多样性的问题。
(2):该方法将VFI任务分为两个阶段:自动编码器阶段和真实值估计阶段。自动编码器阶段使用VQModel对图像进行编码和解码,以压缩图像并提取潜在表示。真实值估计阶段使用连续布朗桥扩散模型对潜在表示进行扩散,并训练一个UNet网络来预测扩散状态与真实值的差值。
(3):在推理阶段,通过采样过程将扩散后的潜在表示转换为真实值,然后使用解码器和相邻帧的特征来插值中间帧。
结论:
(1):本研究将基于潜在扩散的 VFI 问题表述为两阶段问题:自动编码器和真实值估计。这种表述便于确定需要改进的部分,从而指导未来的研究。我们提出了连续布朗桥扩散,它由于累积方差低,可以更好地估计真实潜在表示。当自动编码器得到改进时,这种方法也会得到改进,并且通过简单而有效地设计自动编码器,实现了最先进的性能,展示了其在 VFI 中的强大潜力,因为精心设计的自动编码器可能会大幅提升性能。因此,我们相信我们的工作将为基于扩散的帧插值提供一个独特的研究方向。限制和未来研究。我们的方法使用二分法进行多帧插值:我们可以在 t = 0, 1 之间插值 t = 0.5,然后插值 t = 0.25, 0.75。然而,我们的方法不能直接从 t = 0, 1 插值 t = 0.1。未来的研究可以解决上述限制,或改进自动编码器或扩散模型以获得更好的插值质量。
(2):创新点:提出连续布朗桥扩散,大幅降低生成潜在表示的累积方差,解决 LDM 在 VFI 任务中产生多样性的问题;性能:在 VFI 任务上取得最先进的性能;工作量:方法设计简单有效,工作量较小。
点此查看论文截图
论文标题:预训练文本到图像扩散模型
作者:Yilun Du, Aravind Srinivas, Felix Hill, Adam Lerer, Lerrel Pinto, Pieter Abbeel
第一作者单位:加州大学伯克利分校
关键词:Embodied AI, Vision-Language Models, Text-to-Image Diffusion, Reinforcement Learning
论文链接:None,Github代码链接:None
摘要:
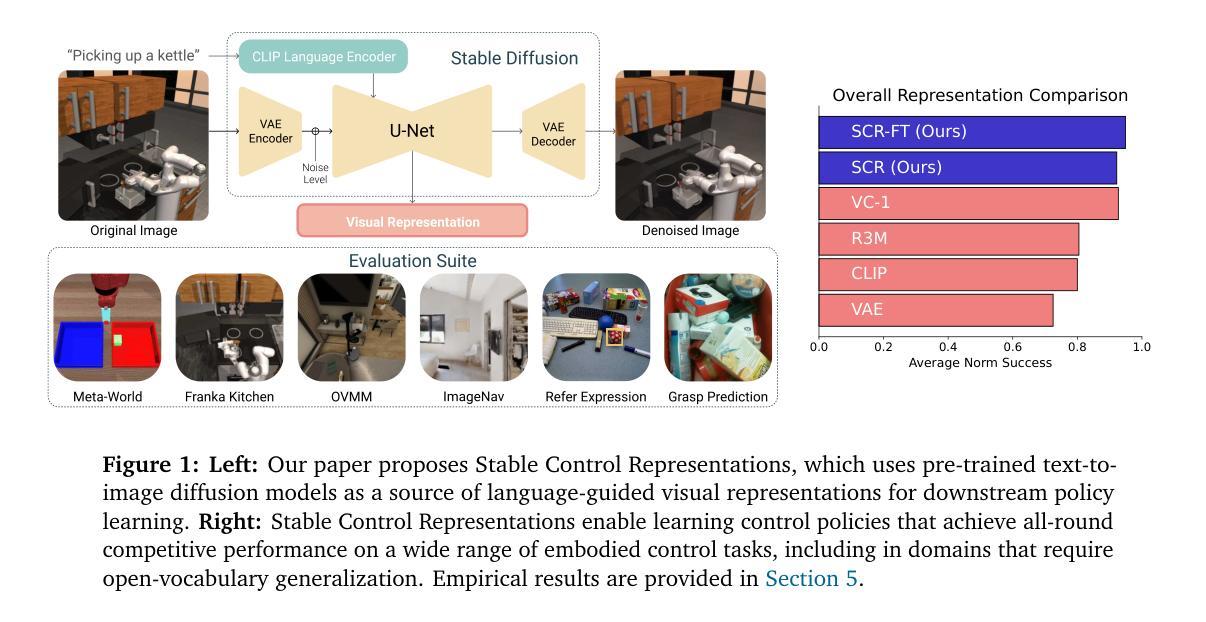
(1):研究背景:具身人工智能体需要对视觉和语言输入介导的物理世界有细粒度的理解。从特定任务数据中单独学习此类能力很困难。这导致预训练视觉语言模型成为将从互联网规模数据中学到的表征转移到下游任务和新领域的工具。然而,事实证明,诸如 CLIP 中常用的对比训练表征无法使具身代理获得足够细粒度的场景理解——这对控制至关重要。
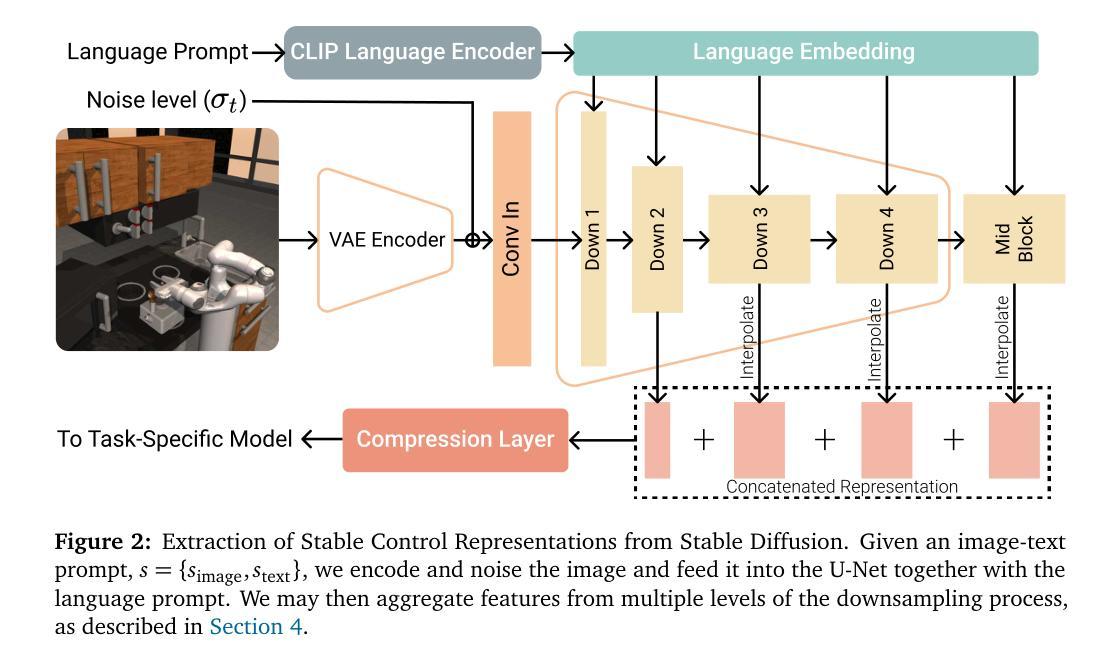
(2):过去的方法及问题:为了解决这一缺点,本文考虑了预训练文本到图像扩散模型中的表征,该表征经过明确优化以根据文本提示生成图像,因此包含反映高度细粒度视觉空间信息的文本条件表征。使用预训练文本到图像扩散模型,我们构建了稳定的控制表征,允许学习可推广到复杂、开放环境的下游控制策略。我们表明,使用稳定控制表征学习的策略在广泛的模拟控制设置中具有与最先进的表征学习方法相当的竞争力,包括具有挑战性的操作和导航任务。最值得注意的是,我们表明 Stable Control 表征能够学习在 OVMM(一个困难的开放词汇导航基准)上表现出最先进性能的策略。
- 方法:
(1):使用预训练文本到图像扩散模型,从互联网规模数据中学到的表征转移到下游控制任务和新领域;
(2):构建稳定的控制表征,允许学习可推广到复杂、开放环境的下游控制策略;
(3):使用稳定控制表征学习的策略在广泛的模拟控制设置中具有与最先进的表征学习方法相当的竞争力,包括具有挑战性的操作和导航任务;
(4):Stable Control 表征能够学习在 OVMM(一个困难的开放词汇导航基准)上表现出最先进性能的策略。
- 结论:
(1):本文提出了 Stable Control Representations,这是一种利用通用预训练扩散模型的表征进行控制的方法。我们展示了使用从文本到图像扩散模型中提取的表征进行策略学习可以提高广泛任务的泛化能力,包括操作、基于图像目标和基于对象目标的导航、抓取点预测和指代表达式接地。我们还展示了从预训练文本到图像扩散模型中提取注意力图的解释性优势,我们展示了它可以提高性能并帮助在开发过程中识别策略的下游失败。最后,我们讨论了本文提出的见解(例如,关于特征聚合和微调)可能适用于用于控制的其他基础模型的方式。我们希望 Stable Control Representations 能够帮助推进数据高效控制,并在扩散模型的能力不断提高的情况下实现具有挑战性的控制领域的开放词汇泛化。
(2):创新点:提出 Stable Control Representations,利用预训练扩散模型的表征进行控制;性能:在广泛的任务上取得与最先进的表征学习方法相当或更好的性能;工作量:需要预训练文本到图像扩散模型,计算成本较高。
点此查看论文截图
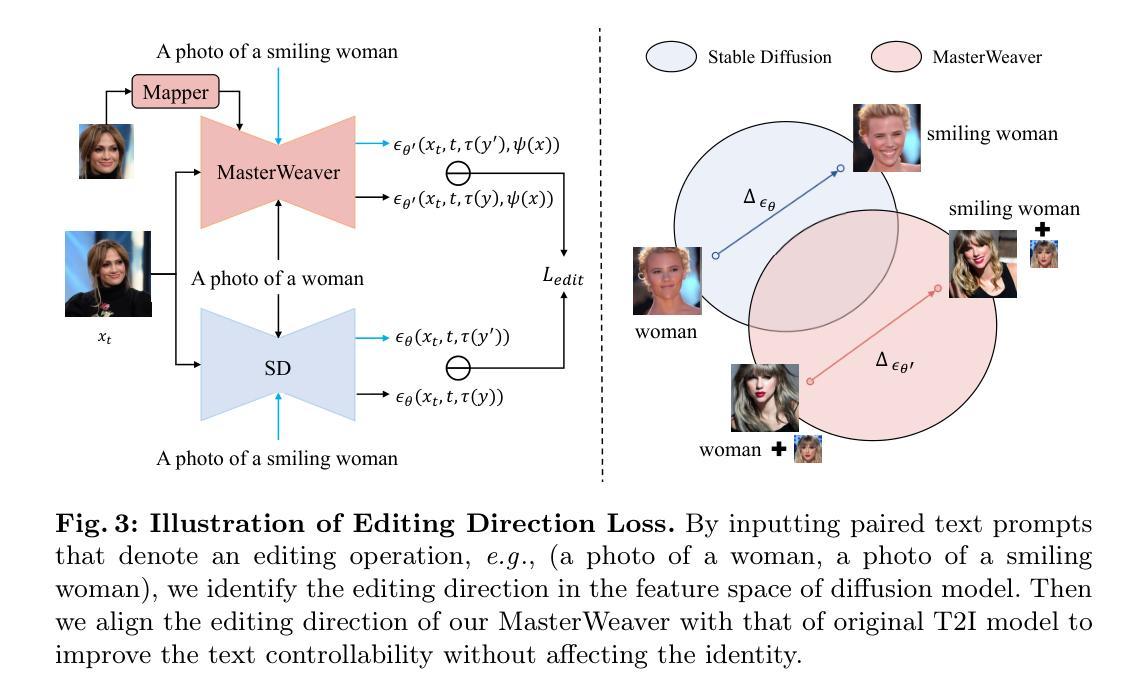
Title: MasterWeaver:驾驭可编辑性和身份
Authors: Shengyu Zhao, Yifan Jiang, Jingwen Chen, Yichang Shih, Zhe Gan, Lu Yuan, Xiaohui Shen, Bo Dai
Affiliation: 浙江大学
Keywords: Text-to-Image, Personalized Image Generation, Identity Control
Urls: Paper: https://arxiv.org/pdf/2405.05806.pdf, Github: None
Summary:
(1): 文本到图像(T2I)扩散模型在个性化文本到图像生成方面取得了显著成功,其目的是生成具有参考图像指示的人类身份的新颖图像。尽管几种无调优方法已经取得了有希望的身份保真度,但它们通常会出现过度拟合问题。学习到的身份往往会与无关信息纠缠在一起,导致文本可控性不佳,尤其是在人脸上。
(2): 现有的方法通常需要在训练或测试时进行微调,这会增加额外的时间和计算成本。此外,这些方法往往会过度拟合参考图像,导致生成图像缺乏多样性和可控性。
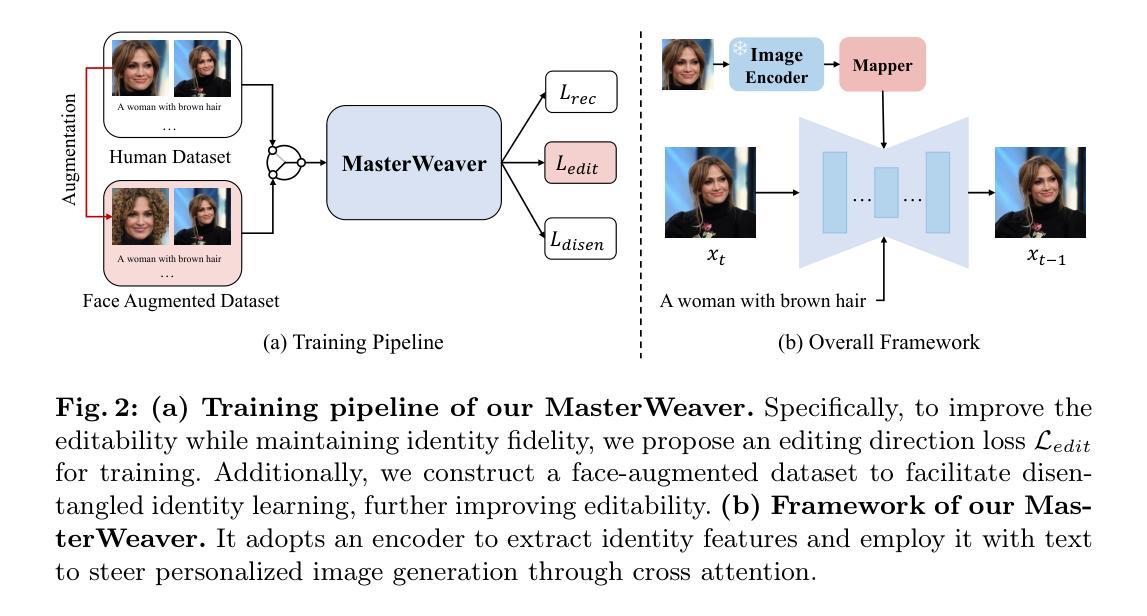
(3): 本文提出了一种名为 MasterWeaver 的测试时无调优方法,旨在生成具有高保真身份和可控文本的图像。MasterWeaver 通过在稳定扩散模型中引入一个身份映射器来实现,该映射器将参考图像的身份信息与文本信息融合在一起。身份映射器由一系列交叉注意块组成,这些块能够从参考图像中提取身份特征并将其与文本特征相结合,从而指导个性化生成。
(4): 在人脸数据集上的实验表明,MasterWeaver 在身份保真度和文本可控性方面都优于现有方法。此外,MasterWeaver 在生成多样化的图像方面也表现出良好的性能,即使在具有挑战性的提示下也是如此。这些结果支持了 MasterWeaver 在个性化文本到图像生成中的有效性和潜力。
- 方法:
(1):提出MasterWeaver,一种无调优方法,通过在稳定扩散模型中引入身份映射器,将参考图像的身份信息与文本信息融合,实现个性化文本到图像生成;
(2):身份映射器由一系列交叉注意块组成,能够从参考图像中提取身份特征并将其与文本特征相结合,指导个性化生成;
(3):提出id-preserved editability learning,包括编辑方向损失和人脸增强数据集,以提高模型的可编辑性,同时保持身份保真度。
8. 结论
(1):本文的意义在于提出了一种无调优方法MasterWeaver,该方法能够高效地生成具有真实身份和灵活可编辑性的个性化图像。提出的编辑方向损失和人脸增强数据集显著提高了模型的可编辑性,同时保持了身份保真度。大量的实验表明,我们的MasterWeaver优于最先进的方法,并且可以生成与身份和文本都相符的照片级真实图像。这种能力使我们的方法适用于各种应用,包括个性化数字内容创作和艺术创作。此外,所提出的编辑方向损失有可能应用于其他领域(例如动物和物体),从而增强其适用性。
(2):创新点:提出了一种无调优方法MasterWeaver,通过在稳定扩散模型中引入身份映射器,将参考图像的身份信息与文本信息融合,实现个性化文本到图像生成。 性能:在人脸数据集上的实验表明,MasterWeaver在身份保真度和文本可控性方面都优于现有方法。此外,MasterWeaver在生成多样化的图像方面也表现出良好的性能,即使在具有挑战性的提示下也是如此。 工作量:MasterWeaver是一种无调优方法,不需要在训练或测试时进行微调,从而减少了额外的时间和计算成本。
点此查看论文截图
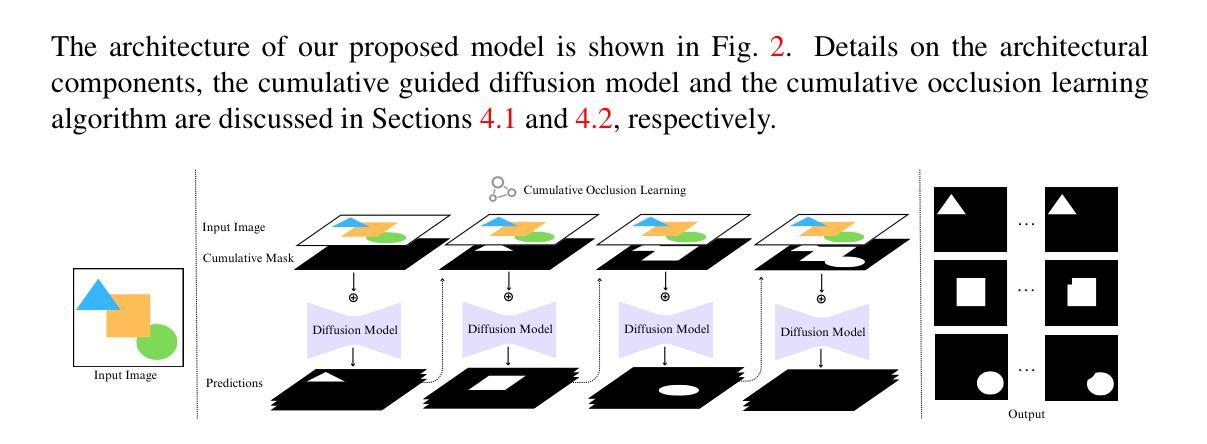
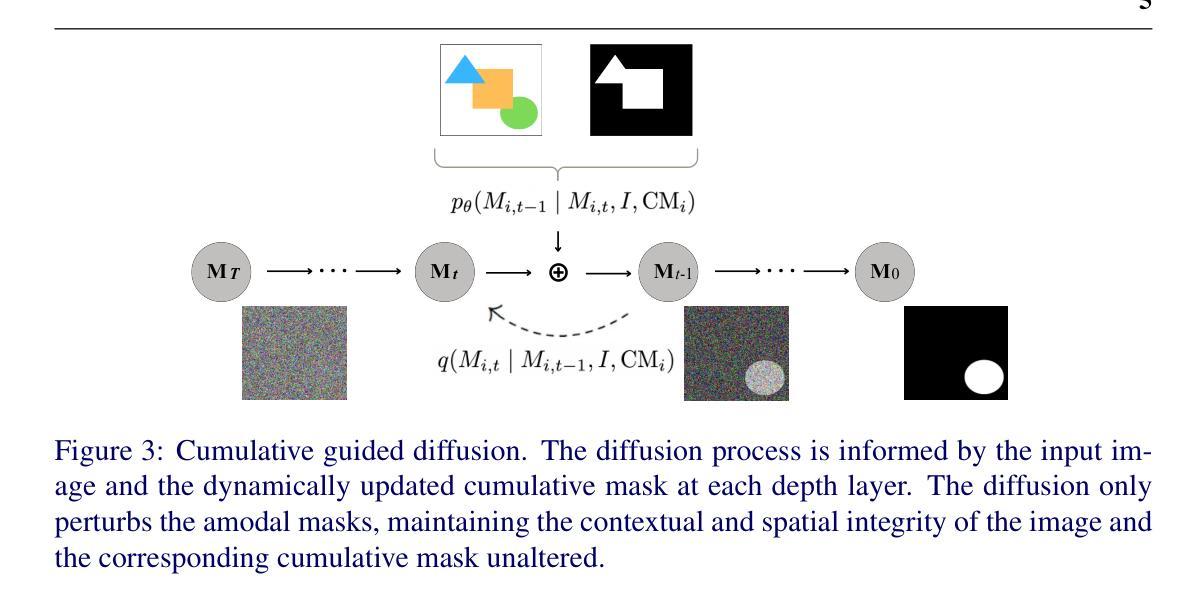
Title: 基于扩散模型的顺序遮挡感知的无模态分割
Authors: Seunghyeok Back, Joosoon Lee, Taewon Kim, Sangjun Noh, Raeyoung Kang, Seongho Bak, Kyoobin Lee
Affiliation: 韩国科学技术院
Keywords: Amodal segmentation, Diffusion model, Occlusion perception, Computer vision
Urls: Paper: https://arxiv.org/abs/2303.07993, Github: None
Summary:
(1): 对于理解复杂视觉场景(其中物体经常被遮挡)至关重要。
(2): 之前的无模态分割方法在处理未知物体类别和任意数量的遮挡层时存在局限性。
(3): 本文提出了一种基于扩散模型的无模态分割方法,该方法利用累积遮挡学习和基于扩散模型的掩码生成,可以实现鲁棒的遮挡感知和任意物体类别的无模态对象分割。
(4): 在三个公开的可用的无模态数据集上,该方法在产生合理多样化结果的同时,优于其他层感知无模态分割和扩散分割方法。
- 方法:
(1):本文提出了一种基于扩散模型的无模态分割方法,该方法利用累积遮挡学习和基于扩散模型的掩码生成,可以实现鲁棒的遮挡感知和任意物体类别的无模态对象分割;
(2):该方法引入累积掩码,它融合了对象的 spatial structures,促进了对可见和遮挡对象部分的理解;
(3):该方法采用累积引导扩散,扩散过程由输入图像和来自先前层的动态更新的累积掩码提供信息,扩散仅扰动无模态掩码,保持图像和相应累积掩码的上下文和 spatial integrity 不变;
(4):该方法提出累积遮挡学习算法,它采用分层程序,以有序感知的方式预测无模态掩码,它通过积累视觉信息来操作,其中观察到的数据(先前的分割掩码)的历史影响当前数据(要分割的当前对象)的感知;
(5):该方法在训练中利用 ground truth 累积掩码作为输入,而在推理中使用前一层预测的掩码来构建累积掩码。
- 结论:
(1):本文提出的基于扩散模型的无模态分割方法,利用累积遮挡学习和基于扩散模型的掩码生成,实现了鲁棒的遮挡感知和任意物体类别的无模态对象分割,对于理解复杂视觉场景至关重要。
(2):创新点:提出了累积掩码和累积引导扩散,促进了对可见和遮挡对象部分的理解,并采用累积遮挡学习算法,以有序感知的方式预测无模态掩码;性能:在三个公开可用的无模态数据集上,该方法优于其他层感知无模态分割和扩散分割方法;工作量:该方法在训练中利用 ground truth 累积掩码作为输入,而在推理中使用前一层预测的掩码来构建累积掩码。
点此查看论文截图
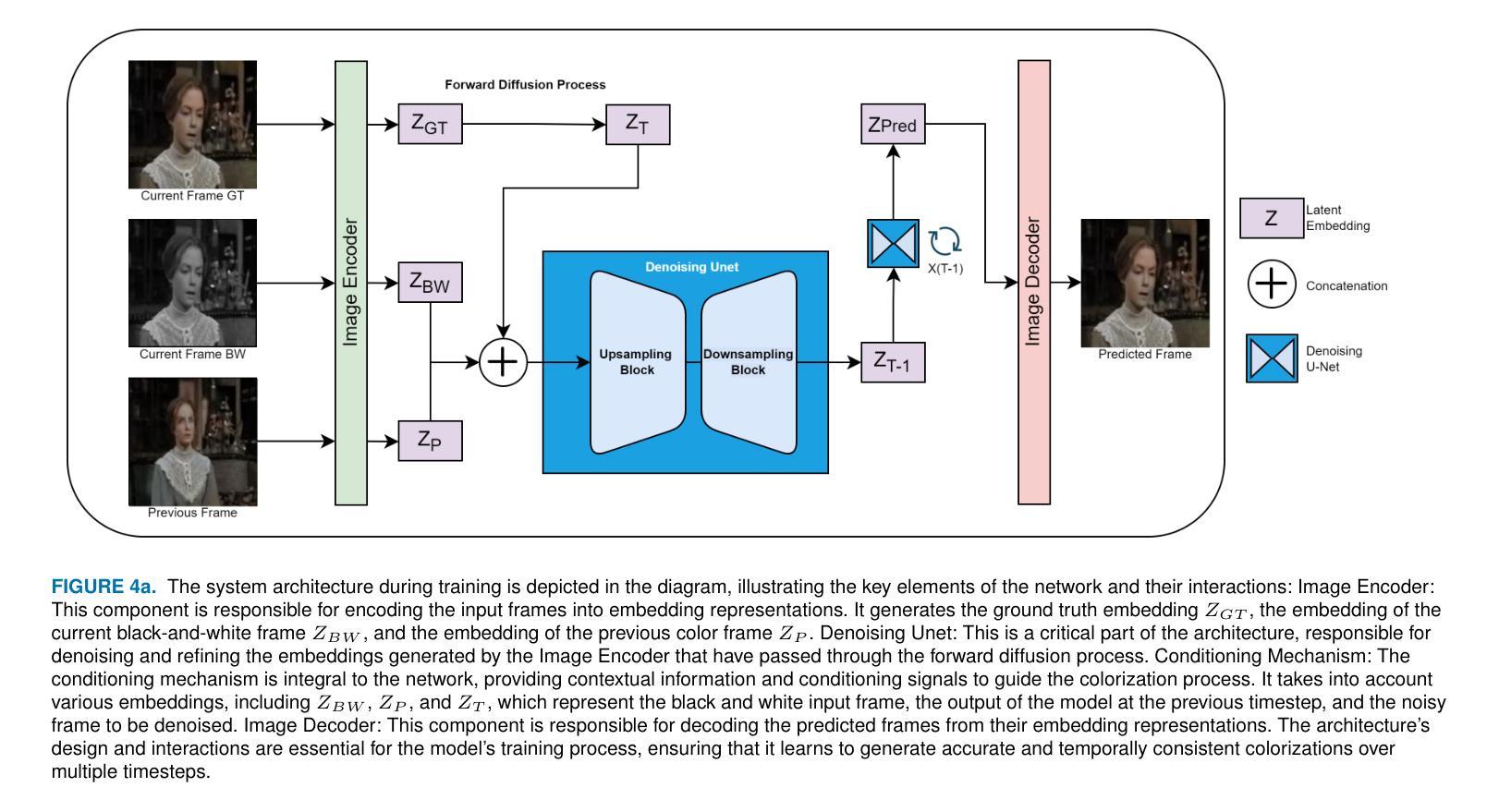
Title: 潜色化:基于潜在扩散的说话者视频着色
Authors: Rory Ward, Dan Bigioi, Shubhajit Basak, John G. Breslin, Peter Corcoran
Affiliation: 爱尔兰高威大学人工智能数据科学研究所
Keywords: 人工智能,人工神经网络,机器学习,计算机视觉,视频着色,潜在扩散,图像着色
Urls: Paper: https://arxiv.org/abs/2405.05707 , Github: None
Summary:
(1): 当前的研究主要集中在基于图像的着色上,而基于视频的着色领域仍然相对未被探索。大多数现有的视频着色技术都是逐帧进行的,常常忽略了连续帧之间的时间连贯性这一关键方面。这种方法会导致帧之间出现不一致,从而导致闪烁或帧之间突然的色彩转换等不良效果。
(2): 过去的方法:大多数现有的视频着色技术都是逐帧进行的,常常忽略了连续帧之间的时间连贯性这一关键方面。这种方法会导致帧之间出现不一致,从而导致闪烁或帧之间突然的色彩转换等不良效果。问题:这种方法无法保证视频中连续帧之间的一致性,导致视频着色结果出现闪烁或突然的色彩转换等问题。动机:为了解决这些问题,本文提出了一种基于潜在扩散的视频着色方法,该方法能够保证视频中连续帧之间的一致性,并提高视频着色的图像质量。
(3): 本文提出了一种基于潜在扩散的视频着色方法,该方法通过对潜在扩散模型进行微调,使其能够专门用于视频着色。该方法通过引入一种新的机制来实现视频着色的时间一致性,并通过与其他现有方法的比较,在既定的图像质量指标上展示了显著的改进。此外,本文还进行了一项主观研究,结果表明用户更喜欢本文的方法,而不是现有的最先进的方法。本文的数据集包含了传统数据集和来自电视/电影的视频的组合。简而言之,通过利用经过微调的基于潜在扩散的着色系统和时间一致性机制,我们可以通过解决时间不一致性问题来提高自动视频着色的性能。
(4): 本文的方法在视频着色任务上取得了较好的性能,在图像质量指标上优于其他现有方法。这些性能支持了本文的目标,即开发一种能够保证视频中连续帧之间一致性并提高视频着色图像质量的视频着色方法。
- 方法:
(1):本文提出了一种基于潜在扩散的视频着色方法,该方法通过对潜在扩散模型进行微调,使其能够专门用于视频着色。
(2):该方法通过引入一种新的机制来实现视频着色的时间一致性,该机制通过对连续帧之间的特征进行对齐,确保了视频中连续帧之间的颜色转换平滑且一致。
(3):该方法还利用了预训练的图像着色模型,该模型能够提供丰富的颜色信息,从而提高了视频着色的图像质量。
- 结论:
(1):本研究证明了基于扩散的模型,特别是 LatentColorization 方法,在多个数据集上取得了与最先进水平相当的结果。值得注意的是,该系统在“Sherlock Holmes Movie”数据集上执行与人类水平相当的着色,表明其实际意义和特定应用视频着色的潜力。使用潜在扩散模型并结合时间一致的着色方法有助于产生逼真且令人信服的着色结果,从而使该过程更容易获取并减少对传统人工着色方法的依赖。这项研究提供了对扩散模型在视频着色中的潜力的见解,并为该领域进一步发展提供了机会。
(2):创新点:提出了基于潜在扩散的视频着色方法,该方法通过引入一种新的机制来实现视频着色的时间一致性,确保了视频中连续帧之间的颜色转换平滑且一致。 性能:在图像质量指标上优于其他现有方法。 工作量:需要对潜在扩散模型进行微调,并引入新的机制来实现视频着色的时间一致性。
点此查看论文截图
Title: 注意力驱动的无训练效率增强扩散模型
Authors: Yifan Liu, Yixing Xu, Zizhao Zhang, Zhihao Xia, Qinghe Xiao, Xiyang Dai, Xianglong Liu, Xiaoguang Han
Affiliation: 中国科学院自动化研究所
Keywords: Diffusion Models, Attention Pruning, Efficient Inference, Generative Models
Urls: Paper: https://arxiv.org/abs/2303.00297, Github: None
Summary:
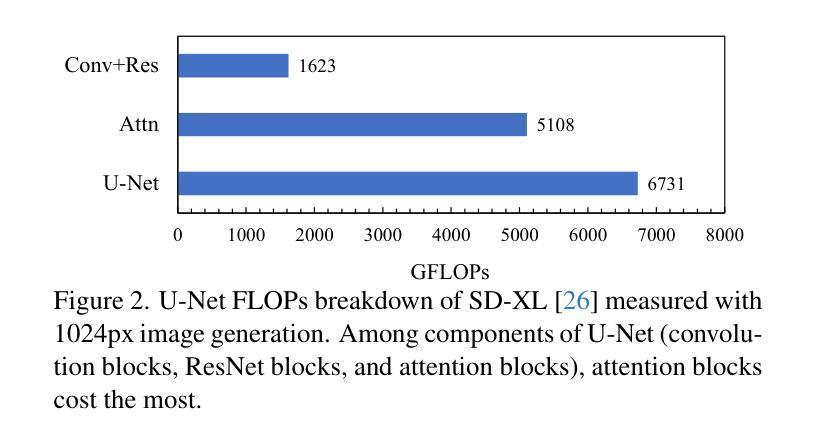
(1): 扩散模型 (DM) 在生成高质量且多样化的图像方面表现出优异的性能。然而,这种卓越的性能是以昂贵的架构设计为代价的,特别是由于领先模型中大量使用的注意力模块。
(2): 现有工作主要采用再训练过程来提高 DM 效率。这是计算成本高昂且可扩展性不强的。
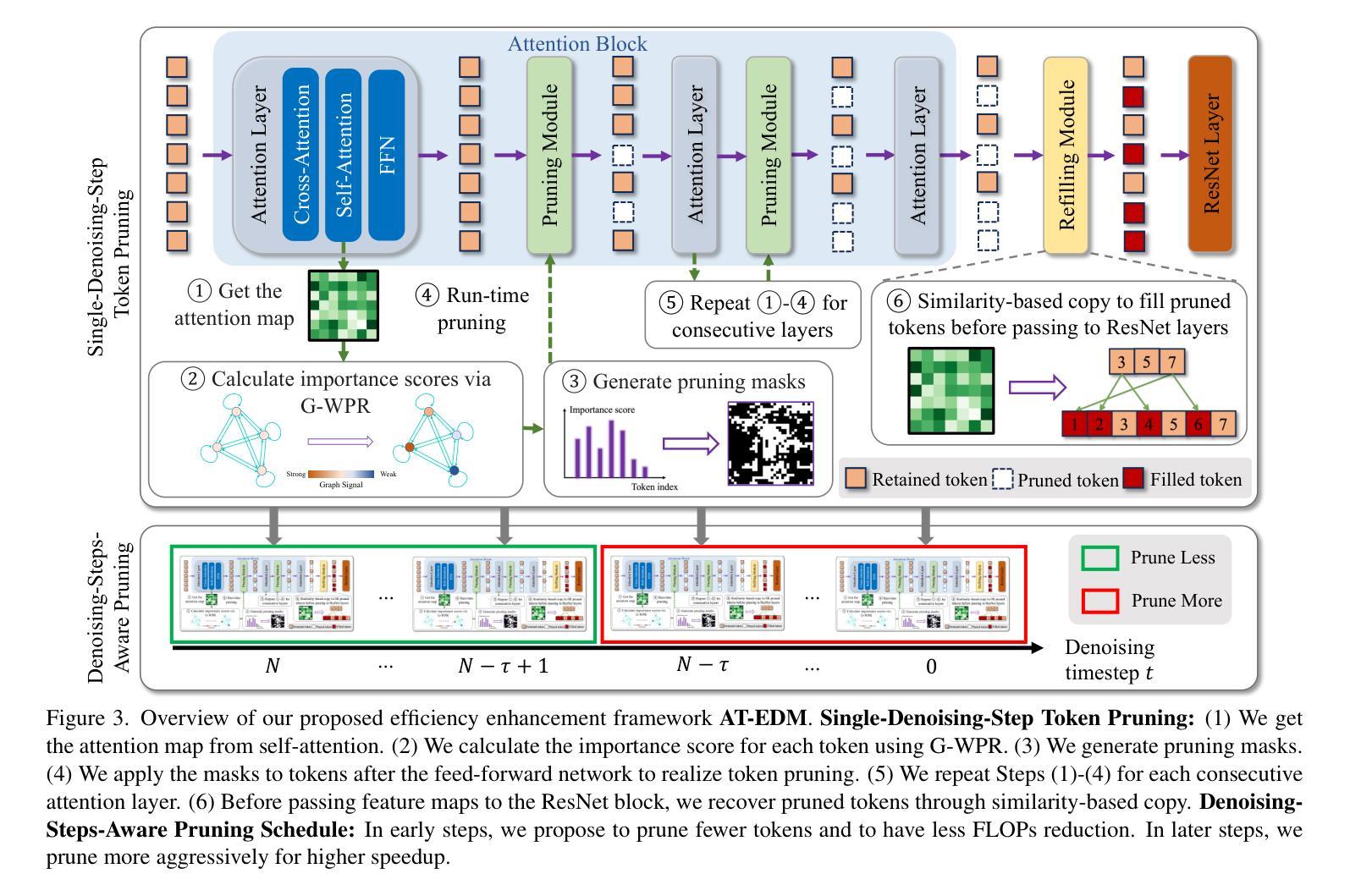
(3): 提出了一种注意力驱动的无训练高效扩散模型 (AT-EDM) 框架,该框架利用注意力图在运行时对冗余标记进行修剪,而无需任何再训练。具体来说,对于单去噪步骤修剪,开发了一种新颖的排名算法,即广义加权页面排名 (GWPR),以识别冗余标记,以及一种基于相似性的恢复方法来恢复卷积操作的标记。此外,提出了一种去噪步骤感知修剪 (DSAP) 方法来调整不同去噪时间步长的修剪预算,以获得更好的生成质量。
(4): 广泛的评估表明,AT-EDM 在效率方面优于现有技术(例如,比 Stable Diffusion XL 节省 38.8% 的 FLOP,速度提高 1.53 倍),同时保持与完整模型几乎相同的 FID 和 CLIP 分数。
方法:
(1): 本文提出了一种注意力驱动的无训练高效扩散模型(AT-EDM)框架,利用注意力图在运行时对冗余标记进行修剪,而无需任何再训练。
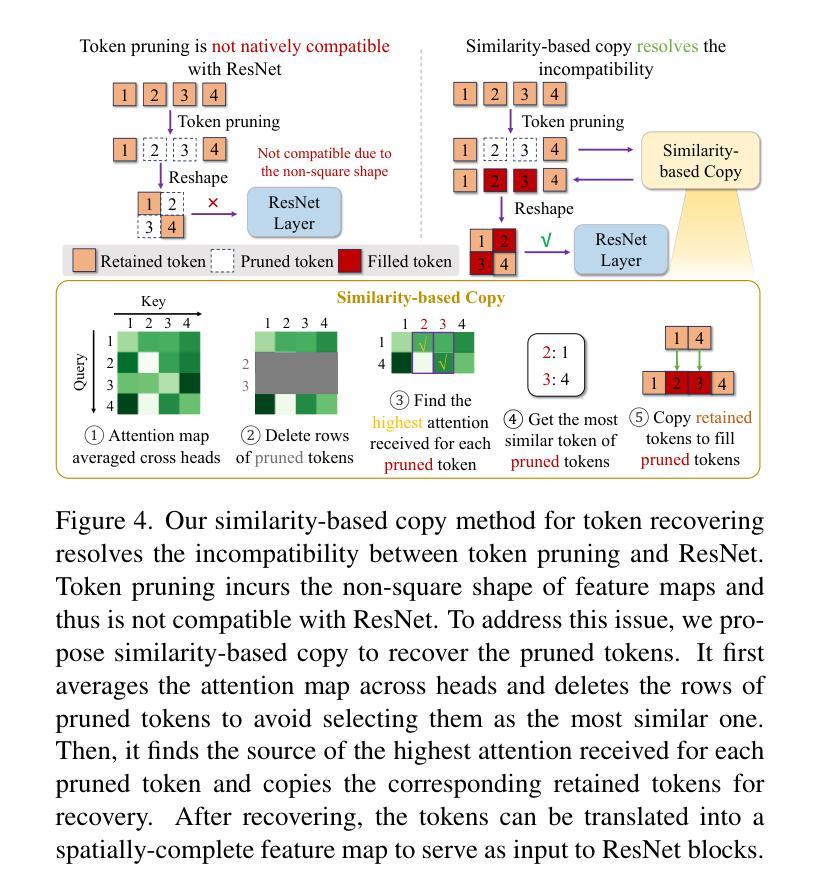
(2): 具体来说,对于单去噪步骤修剪,开发了一种新颖的排名算法,即广义加权页面排名(GWPR),以识别冗余标记,以及一种基于相似性的恢复方法来恢复卷积操作的标记。
(3): 此外,提出了一种去噪步骤感知修剪(DSAP)方法来调整不同去噪时间步长的修剪预算,以获得更好的生成质量。
结论:
(1):本文提出了 AT-EDM,这是一种无需重新训练即可在运行时加速 DM 的新颖框架。AT-EDM 有两个组成部分:单去噪步骤标记修剪算法和跨步长修剪调度(DSAP)。在单去噪步骤标记修剪中,AT-EDM 利用预训练 DM 中的注意力图来识别不重要的标记并对其进行修剪,以加速生成过程。为了使修剪后的特征图与后面的卷积块兼容,AT-EDM 再次使用注意力图来揭示标记之间的相似性,并将相似的标记复制到恢复被修剪的标记。DSAP 进一步提高了 AT-EDM 的生成质量。我们发现这样的修剪计划也可以应用于其他方法,如 ToMe。实验结果证明了 AT-EDM 在图像质量和文本图像对齐方面优于最先进的方法。具体来说,在 SD-XL 上,AT-EDM 节省了 38.8% 的 FLOP,速度提高了 1.53 倍,同时获得了与全尺寸模型几乎相同的 FID 和 CLIP 分数,优于现有技术。致谢 本工作得到了 Adobe 夏季实习和美国国家科学基金会 (NSF) 赠款号 CCF2203399 的部分支持。
(2):创新点:提出了 AT-EDM,一种无需重新训练即可在运行时加速 DM 的新颖框架;提出了广义加权页面排名 (GWPR) 算法来识别冗余标记,以及一种基于相似性的恢复方法来恢复卷积操作的标记;提出了去噪步骤感知修剪 (DSAP) 方法来调整不同去噪时间步长的修剪预算,以获得更好的生成质量。性能:在图像质量和文本图像对齐方面优于最先进的方法;在 SD-XL 上,AT-EDM 节省了 38.8% 的 FLOP,速度提高了 1.53 倍,同时获得了与全尺寸模型几乎相同的 FID 和 CLIP 分数。工作量:无需重新训练,在运行时进行修剪,工作量较小。
点此查看论文截图
题目:想象闪光:加速 Emu 扩散
作者:Jonas Kohler,Albert Pumarola,Edgar Schönfeld,Artsiom Sanakoyeu,Roshan Sumbaly,Peter Vajda 和 Ali Thabet
隶属关系:GenAI,Meta
关键词:Diffusion Models,Distillation,Image Generation,Inference Acceleration
论文链接:https://arxiv.org/abs/2405.05224,Github 代码链接:无
摘要:
(1):研究背景:扩散模型是一种强大的生成框架,但推理成本昂贵。现有的加速方法通常会影响图像质量,或者在极低步长条件下进行复杂条件处理时会失败。
(2):过去方法:现有方法包括量化、知识蒸馏和训练-推理不匹配校正。但它们在保持图像质量的同时实现极低步长推理方面存在局限性。
(3):研究方法:本文提出了一种新颖的蒸馏框架,旨在使用一到三步实现高保真、多样化的样本生成。该方法包括三个关键组成部分:反向蒸馏、移位重建损失和噪声校正。
(4):方法性能:在广泛的实验中,本文的方法在定量指标和定性评估中均优于现有竞争对手。在 ImageNet-64 数据集上,使用 1 步时 FID 为 5.57,使用 3 步时 FID 为 4.69。这些结果表明,该方法可以有效加速扩散模型的推理,同时保持图像质量。
- 方法:
(1):提出了一种新的蒸馏框架,该框架旨在使用一到三步实现高保真、多样化的样本生成。
(2):该框架包括三个关键组成部分:反向蒸馏、移位重建损失和噪声校正。
(3):反向蒸馏:使用教师模型的输出作为学生模型的输入,通过最小化学生模型输出与教师模型输出之间的差异来训练学生模型。
(4):移位重建损失:引入了一种新的损失函数,该函数鼓励学生模型重建教师模型在不同步长下的输出。
(5):噪声校正:应用了一种噪声校正机制,该机制通过添加噪声来平滑学生模型的输出,从而提高图像质量。
- 结论:
(1):本工作提出了 Imagine Flash,这是一种新颖的蒸馏框架,能够使用扩散模型进行高保真、少步图像生成。我们的方法包含三个关键组成部分:反向蒸馏以减少训练-推理差异,一个动态调整每个时间步长知识转移的移位重建损失(SRL),以及用于提高图像质量的噪声校正。通过广泛的实验,Imagine Flash 取得了显著的成果,仅使用三个去噪步骤即可与预训练教师模型的性能相匹配,并始终超越现有方法。这种前所未有的采样效率与高样本质量和多样性相结合,使我们的模型非常适合实时生成应用程序。我们的工作为超高效生成建模铺平了道路。未来的研究方向包括扩展到视频和 3D 等其他模态,进一步减少采样预算,以及将我们的方法与互补的加速技术相结合。通过启用即时高保真生成,Imagine Flash 为实时创意工作流和互动媒体体验开启了新的可能性。
(2):创新点:提出了一种新的蒸馏框架,该框架旨在使用一到三步实现高保真、多样化的样本生成。该框架包括三个关键组成部分:反向蒸馏、移位重建损失和噪声校正。;性能:在 ImageNet-64 数据集上,使用 1 步时 FID 为 5.57,使用 3 步时 FID 为 4.69。这些结果表明,该方法可以有效加速扩散模型的推理,同时保持图像质量。;工作量:该方法在定量指标和定性评估中均优于现有竞争对手。
点此查看论文截图
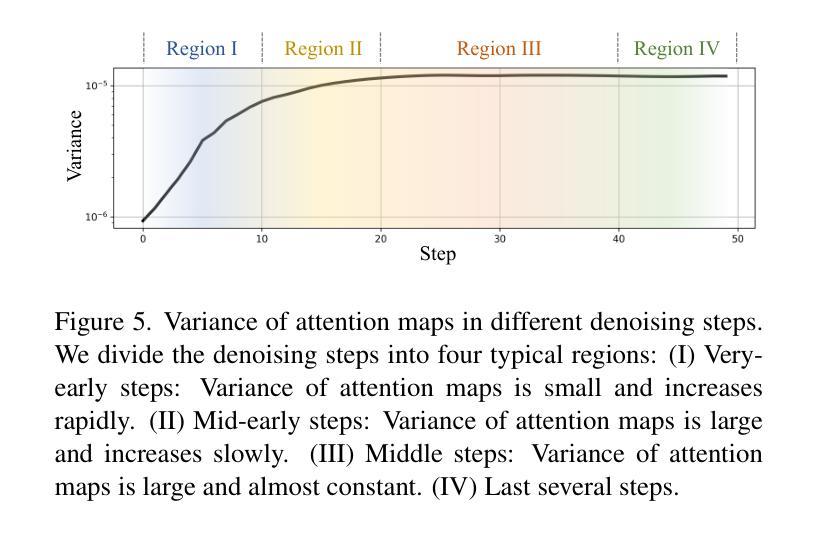
Title: 精细提示驱动的扩散模型在三维人体姿态估计中的应用
Authors: Yuxin Sun, Yajie Zhao, Yifan Zhang, Xiangyang Xue, Jian Cheng
Affiliation: 北京大学信息科学技术学院
Keywords: 3D Human Pose Estimation, Diffusion Model, Prompt Learning, Fine-grained Guidance
Urls: https://arxiv.org/abs/2302.06039, Github: None
Summary:
(1): 三维人体姿态估计(3D HPE)任务利用二维图像或视频预测三维空间中的人体关节坐标。尽管基于深度学习的方法最近取得了进展,但它们大多忽略了将可访问文本和人类自然可行的知识相结合的能力,错失了有价值的隐式监督来指导 3D HPE 任务。此外,以前的研究通常从整个人体的角度研究该任务,忽略了隐藏在不同身体部位中的细粒度指导。
(2): 现有的方法主要从整个人体的角度研究 3D HPE 任务,忽略了隐藏在不同身体部位中的细粒度指导。此外,现有的方法通常依赖于手工制作的提示,这限制了它们对复杂姿势和动作建模的能力。
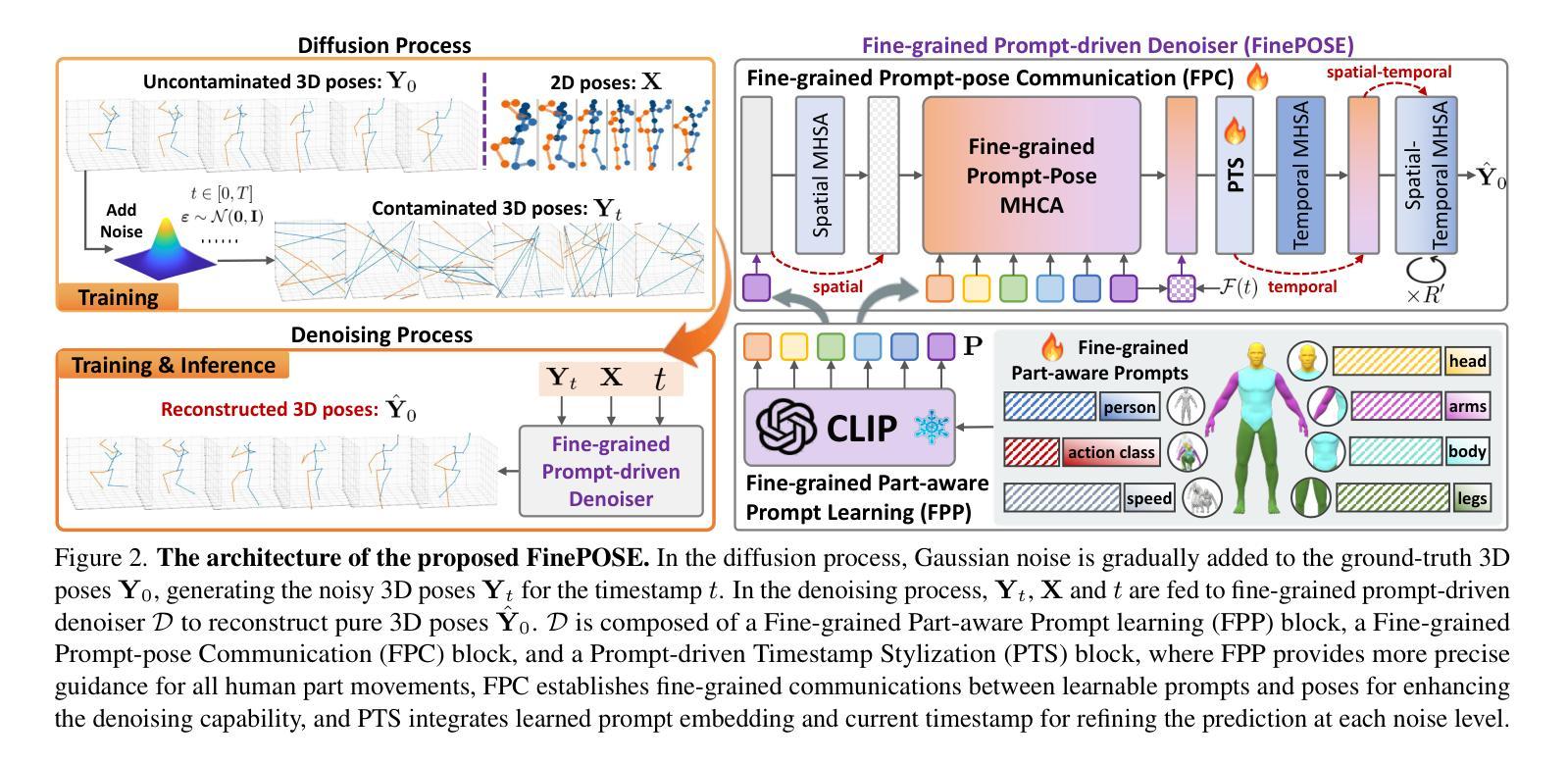
(3): 为了解决这些问题,本文提出了一种基于扩散模型的新型精细提示驱动的去噪器,用于 3D HPE,名为 FinePOSE。它由三个核心模块组成,增强了扩散模型的反向过程:(1)精细部分感知提示学习(FPP)模块通过将可访问的文本和身体部位的自然可行知识与可学习提示相结合来构建精细的部分感知提示,以建模隐式指导。(2)精细提示姿态通信(FPC)模块在学习的部分感知提示和姿态之间建立细粒度通信,以提高去噪质量。(3)提示驱动的时序风格化(PTS)模块集成了学习的提示嵌入和与噪声级别相关的时序信息,以在每个去噪步骤中进行自适应调整。
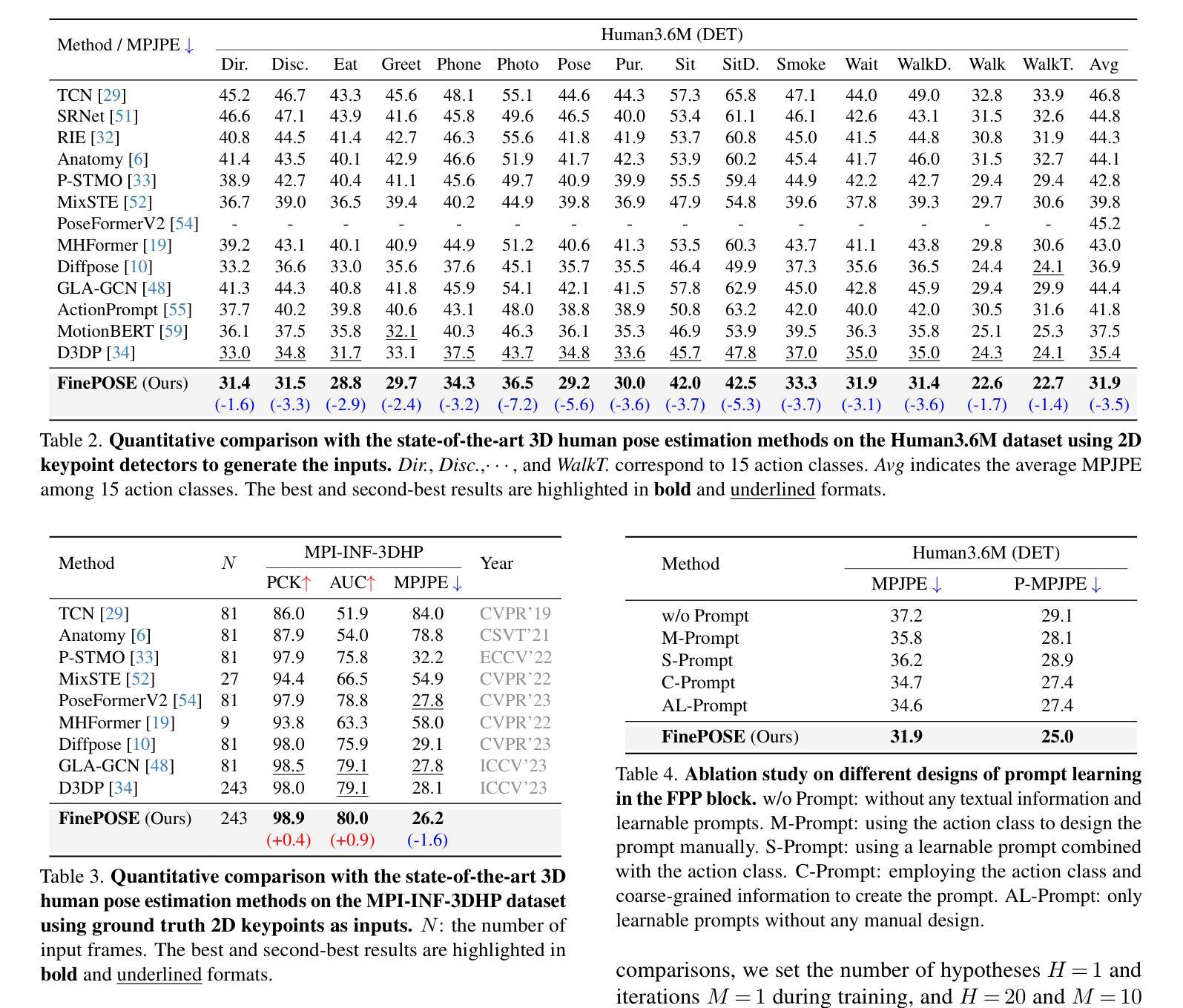
(4): 在公共单人姿态估计数据集上的广泛实验表明,FinePOSE 优于最先进的方法。我们进一步将 FinePOSE 扩展到多人姿态估计。在 EgoHumans 数据集上实现 34.3mm 的平均 MPJPE,证明了 FinePOSE 处理复杂多人场景的潜力。
- 方法:
(1):提出一种基于扩散模型的新型精细提示驱动的去噪器 FinePOSE,用于 3D HPE 任务;
(2):FinePOSE 由三个核心模块组成:精细部分感知提示学习(FPP)模块、精细提示姿态通信(FPC)模块和提示驱动的时序风格化(PTS)模块;
(3):FPP 模块通过将可访问的文本和身体部位的自然可行知识与可学习提示相结合来构建精细的部分感知提示,以建模隐式指导;
(4):FPC 模块在学习的部分感知提示和姿态之间建立细粒度通信,以提高去噪质量;
(5):PTS 模块集成了学习的提示嵌入和与噪声级别相关的时序信息,以在每个去噪步骤中进行自适应调整。
- 结论:
(1):本文提出了一种基于扩散模型的精细提示驱动的去噪器 FinePOSE,用于 3D HPE 任务。FinePOSE 通过将可访问的文本和身体部位的自然可行知识与可学习提示相结合,构建了精细的部分感知提示,以建模隐式指导。此外,FinePOSE 建立了学习的部分感知提示和姿态之间的细粒度通信,并集成了学习的提示嵌入和与噪声级别相关的时序信息,以在每个去噪步骤中进行自适应调整。
(2):创新点:本文提出了一种新的精细提示驱动的去噪器 FinePOSE,用于 3D HPE 任务。FinePOSE 利用可访问的文本和身体部位的自然可行知识,构建了精细的部分感知提示,并建立了学习的部分感知提示和姿态之间的细粒度通信,以提高去噪质量。此外,FinePOSE 集成了学习的提示嵌入和与噪声级别相关的时序信息,以在每个去噪步骤中进行自适应调整。
性能:在公共单人姿态估计数据集上的广泛实验表明,FinePOSE 优于最先进的方法。我们进一步将 FinePOSE 扩展到多人姿态估计。在 EgoHumans 数据集上实现 34.3mm 的平均 MPJPE,证明了 FinePOSE 处理复杂多人场景的潜力。
工作量:FinePOSE 的实现相对简单,易于部署和使用。然而,构建精细的部分感知提示和建立学习的部分感知提示和姿态之间的细粒度通信需要额外的计算成本。
点此查看论文截图
- Title:使用条件扩散模型进行快速激光雷达上采样
- Authors: Sander Elias Magnussen Helgesen, Kazuto Nakashima, Jim Tørresen, Ryo Kurazume
- Affiliation: 奥斯陆大学信息学系
- Keywords: 3D LiDAR, Conditional Diffusion Models, Image-based LiDAR data generation, Deep generative models
- Urls: Paper: https://arxiv.org/abs/2405.04889v1, Github: None
- Summary:
(1):本文的研究背景是,由于硬件限制和激光雷达传感器的成本,测量数据的质量和密度差异很大,这可能导致语义分割和目标检测等技术性能不一致,这对操作机器人来说不是最优的。
(2):过去的方法是使用无条件扩散模型解决上采样任务,但这些方法涉及复杂的过程,导致推理时间慢,不适合实时机器人导航管道。
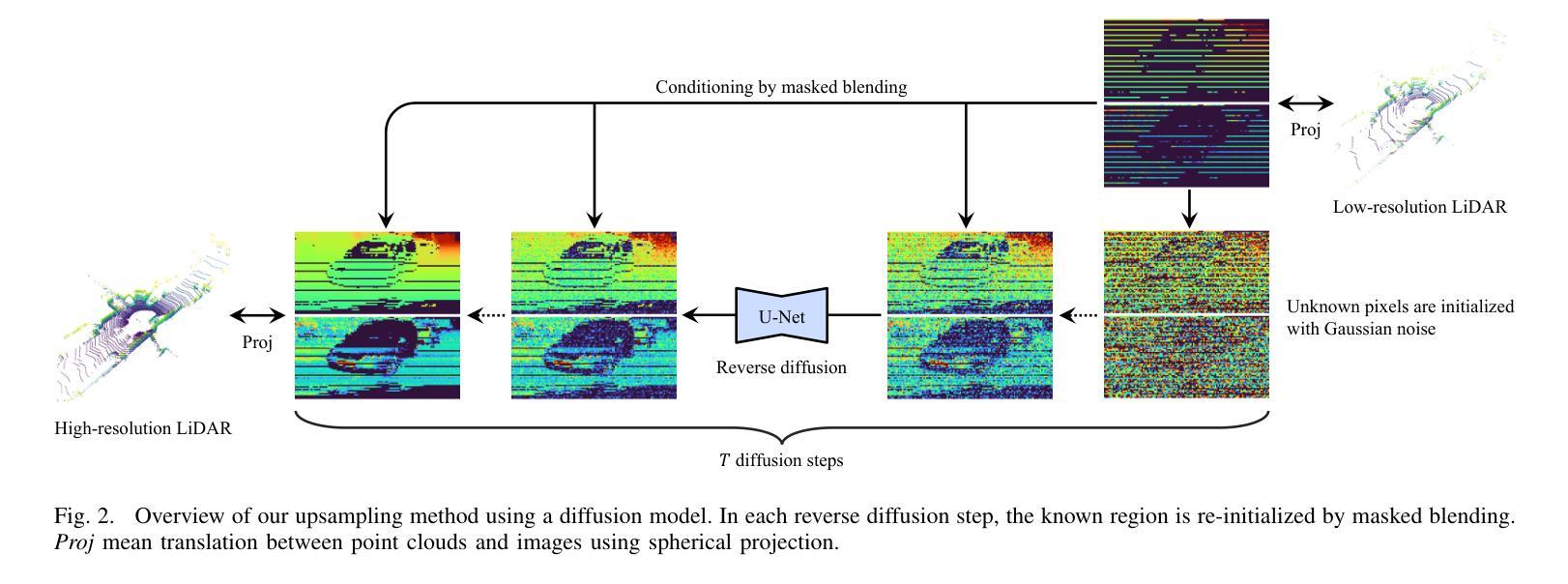
(3):本文提出的研究方法是在图像表示中建立条件扩散模型,学习给定部分观察的激光雷达数据生成。
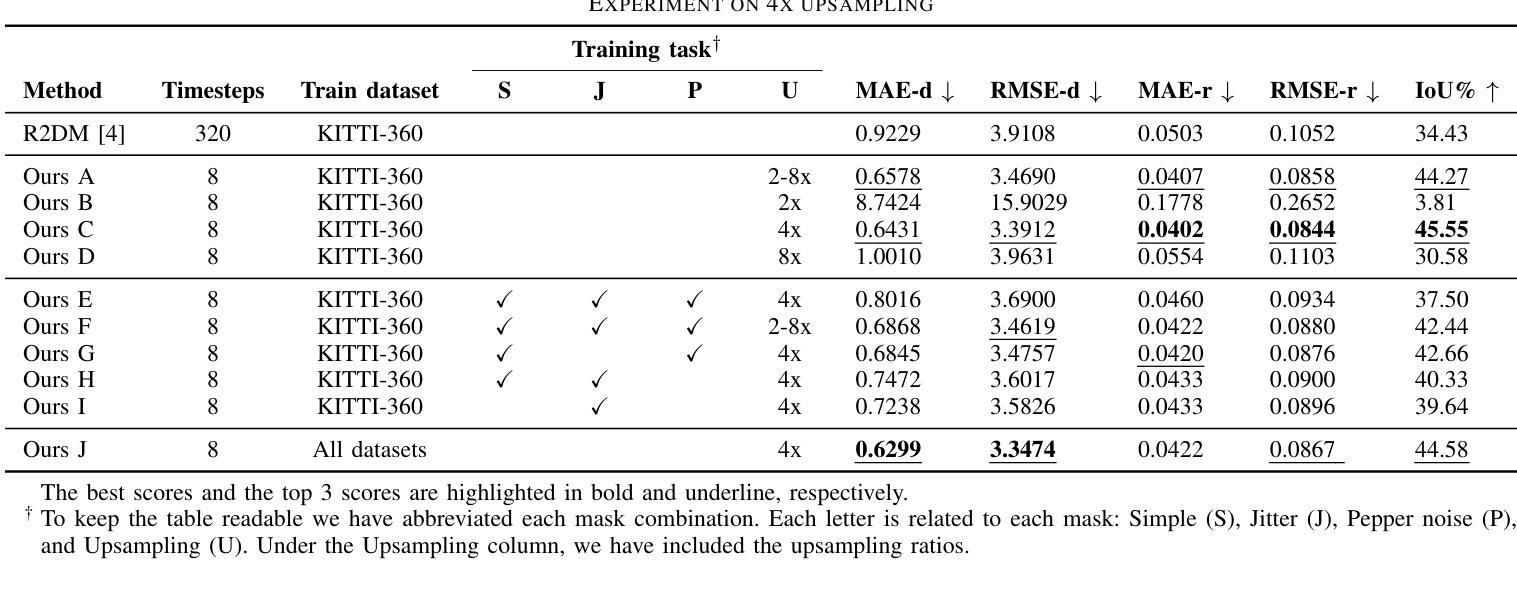
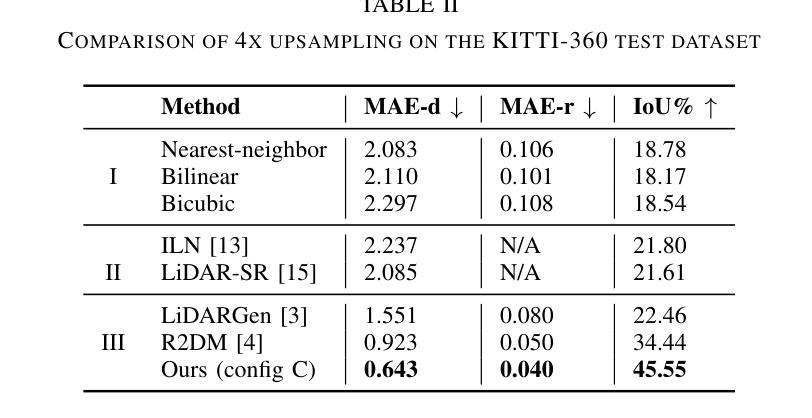
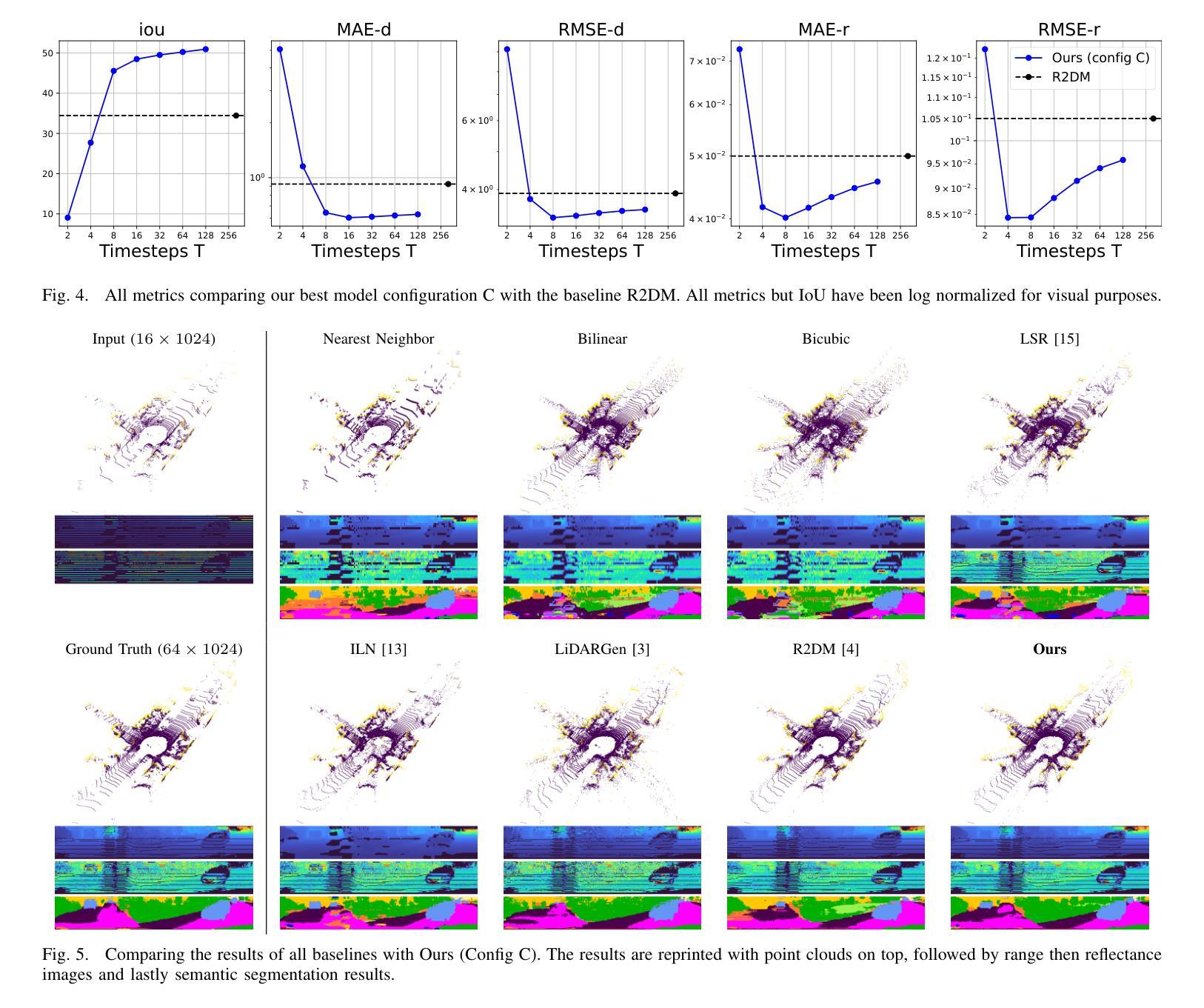
(4):本文方法在KITTI-360数据集上使用上采样任务,在采样速度和质量上优于基线。此外,还展示了该方法通过同时训练真实世界和合成数据集,引入质量和环境的变化,从而具有泛化能力。
- 方法:
(1):在图像表示中建立条件扩散模型,学习给定部分观察的激光雷达数据生成;
(2):使用KITTI-360数据集上采样任务,评估模型性能;
(3):通过同时训练真实世界和合成数据集,引入质量和环境的变化,提高模型泛化能力。
- 结论:
(1):本文提出了一种基于图像表示的条件扩散模型,可以快速生成给定部分观察的激光雷达数据,为提高激光雷达数据质量和密度提供了新的方法;
(2):创新点:提出了一种基于图像表示的条件扩散模型,该模型能够快速生成给定部分观察的激光雷达数据,并通过同时训练真实世界和合成数据集提高模型泛化能力;性能:在KITTI-360数据集上采样任务,该方法在采样速度和质量上优于基线;工作量:该方法涉及复杂的过程,导致推理时间慢,不适合实时机器人导航管道。
点此查看论文截图