NeRF
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-05-13 更新
OneTo3D: One Image to Re-editable Dynamic 3D Model and Video Generation
Authors:Jinwei Lin
One image to editable dynamic 3D model and video generation is novel direction and change in the research area of single image to 3D representation or 3D reconstruction of image. Gaussian Splatting has demonstrated its advantages in implicit 3D reconstruction, compared with the original Neural Radiance Fields. As the rapid development of technologies and principles, people tried to used the Stable Diffusion models to generate targeted models with text instructions. However, using the normal implicit machine learning methods is hard to gain the precise motions and actions control, further more, it is difficult to generate a long content and semantic continuous 3D video. To address this issue, we propose the OneTo3D, a method and theory to used one single image to generate the editable 3D model and generate the targeted semantic continuous time-unlimited 3D video. We used a normal basic Gaussian Splatting model to generate the 3D model from a single image, which requires less volume of video memory and computer calculation ability. Subsequently, we designed an automatic generation and self-adaptive binding mechanism for the object armature. Combined with the re-editable motions and actions analyzing and controlling algorithm we proposed, we can achieve a better performance than the SOTA projects in the area of building the 3D model precise motions and actions control, and generating a stable semantic continuous time-unlimited 3D video with the input text instructions. Here we will analyze the detailed implementation methods and theories analyses. Relative comparisons and conclusions will be presented. The project code is open source.
PDF 24 pages, 13 figures, 2 tables
Summary
一键图像生成可编辑动态3D模型和视频,是图像到3D表示或图像3D重建研究领域的新方向和变革。
Key Takeaways
- 相比于原始神经辐射场,高斯溅射在隐式3D重建中表现出优势。
- 稳定扩散模型可用于根据文本指令生成目标模型。
- 传统的隐式机器学习方法难以获得精确的运动和动作控制。
- 难以生成长内容和语义连续的3D视频。
- OneTo3D方法可使用单张图像生成可编辑3D模型和生成目标语义连续且时间无限的3D视频。
- OneTo3D使用基本的高斯溅射模型从单张图像生成3D模型,减少了视频内存和计算机计算需求。
- OneTo3D设计了自动生成和自适应绑定机制,用于对象骨架。
- 结合OneTo3D提出的可重新编辑的运动和动作分析与控制算法,在3D模型精确定位运动和动作控制以及根据输入文本指令生成稳定的语义连续且时间无限的3D视频方面,OneTo3D的性能优于该领域的SOTA项目。
Title: 一张图像到可重新编辑的动态 3D 模型和视频生成
Authors: JINWEI LIN
Affiliation: 澳大利亚莫纳什大学
Keywords: 3D, One image, Editable, Dynamic, Generation, Automation, Video, Self-adaption, Armature
Urls: Paper: xxx, Github: None
Summary:
(1): 3D 表征或 3D 重建长期以来一直是计算机视觉领域的研究难题。
(2): 现有的 3D 重建方法可分为显式方法和隐式方法。显式方法直接设计和完成 3D 重建或建模;隐式方法使用机器学习方法和理论实现这些目标。近年来,Neural Radiance Fields (NeRF) 在隐式 3D 表征或重建方面取得了突出成就。
(3): 本文提出 OneTo3D 方法,使用单张图像生成可编辑的 3D 模型和语义连续的 3D 视频。该方法使用基本的 Gaussian Splatting 模型从单张图像生成 3D 模型,并设计了一种自动生成和自适应绑定机制来绑定对象骨架。结合重新编辑的运动和动作分析与控制算法,OneTo3D 在 3D 模型精确运动和动作控制以及生成稳定的语义连续无时间限制的 3D 视频方面取得了优于现有方法的性能。
(4): 本文方法在任务和性能上取得了以下成就:使用单张图像生成可编辑的 3D 模型;生成语义连续的 3D 视频;精确控制 3D 模型的运动和动作。这些性能支持了本文的目标,即实现从单张图像到可重新编辑的动态 3D 模型和视频的生成。
方法:
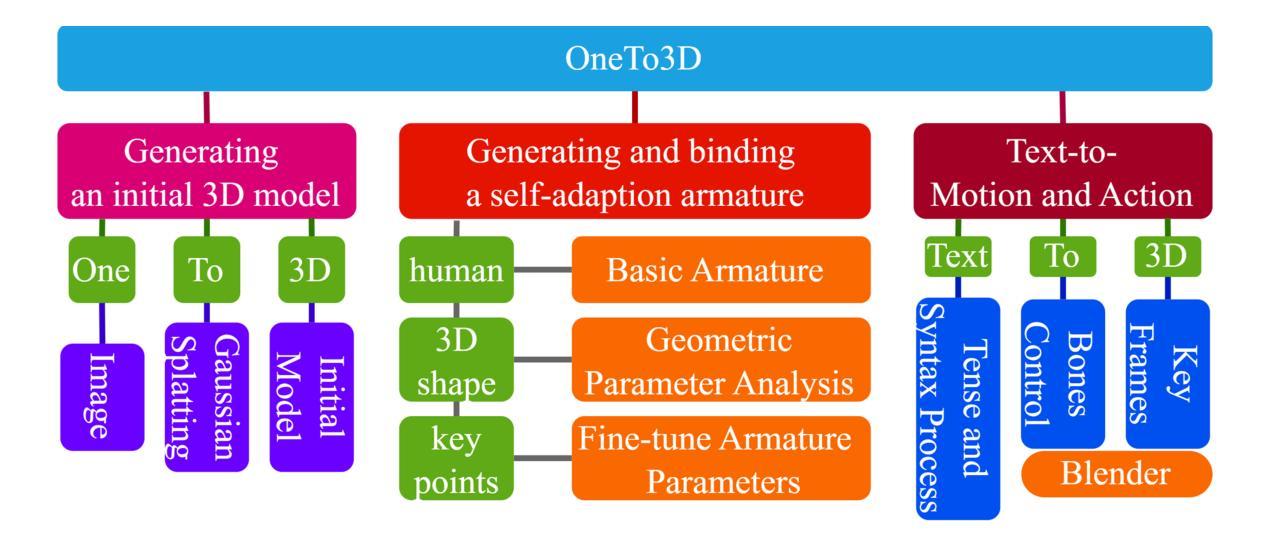
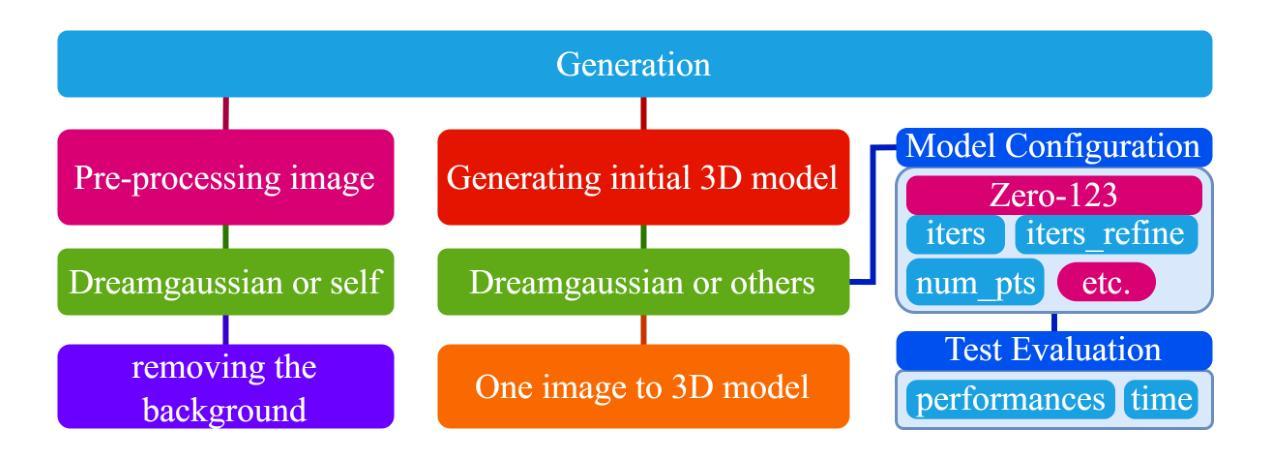
(1):生成初始3D模型,使用DreamGaussian模型和Zero-1-to-3方法; (2):生成并绑定自适应骨架,设计基本骨架,分析初始3D模型的几何参数信息,微调骨架参数以使其适合对象的身体; (3):文本到动作和动作,分析用户文本指令的命令意图,将命令转换为特定动作和骨架相对骨骼的修改数据,控制特定骨骼在Blender中实现相对运动; (4):背景去除,使用Dreamgaussian的process.py脚本或其他方法,可选使用图像检测或语义分割机器学习方法; (5):颜色分组去除背景,计算图像中每个主要颜色项的比例,将颜色值范围内的颜色项划分为不同的颜色组,去除配置比例范围内的颜色组。结论:
(1)本篇工作提出了一种从单张图像生成可编辑的动态 3D 模型和视频的方法,具有生成可编辑 3D 模型、生成语义连续的 3D 视频、精确控制 3D 模型的运动和动作等优点,在任务和性能上取得了创新。
(2)创新点:OneTo3D 方法首次实现了从单张图像到可重新编辑的动态 3D 模型和视频的生成;性能:OneTo3D 方法在生成 3D 模型的精度、视频的语义连续性、动作控制的精确性等方面优于现有方法;工作量:OneTo3D 方法的实现需要较大的计算资源和时间,需要进一步优化算法和设计。
点此查看论文截图

Title: 航拍NeRF:大规模航拍渲染的自适应空间划分和采样
Authors: Xiaohan Zhang, Yukui Qiu, Zhenyu Sun, Qi Liu
Affiliation: 华南理工大学未来技术学院
Keywords: View synthesis, large-scale scene rendering, neural radiance fields, fast rendering
Urls: https://arxiv.org/abs/2405.06214 , https://github.com/drliuqi/Aerial-NeRF
Summary:
(1):NeRF模型在小物体和室内场景渲染中取得了成功,但将其扩展到航拍渲染中面临两个挑战:单个NeRF无法渲染大规模航拍数据集中的整个场景,传统NeRF无法在单个GPU上训练以实现交互式浏览。
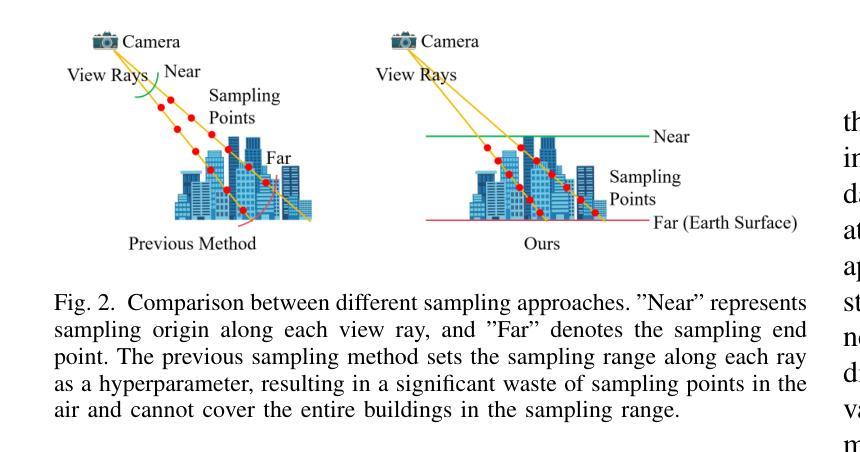
(2):以往方法将场景划分为多个区域,并在每个区域训练一个NeRF,但这些方法无法适应不同的飞行轨迹,渲染速度也较慢。
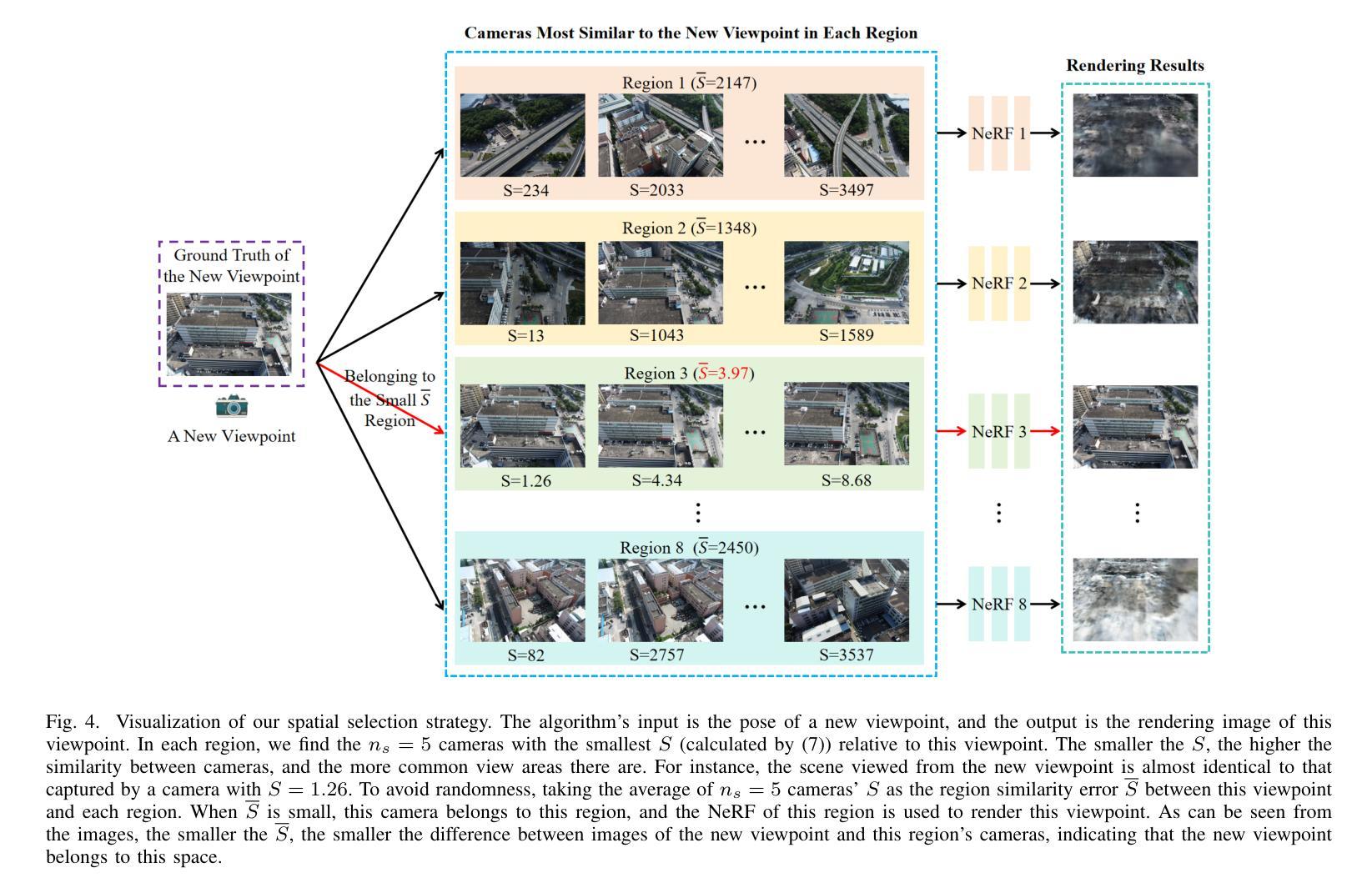
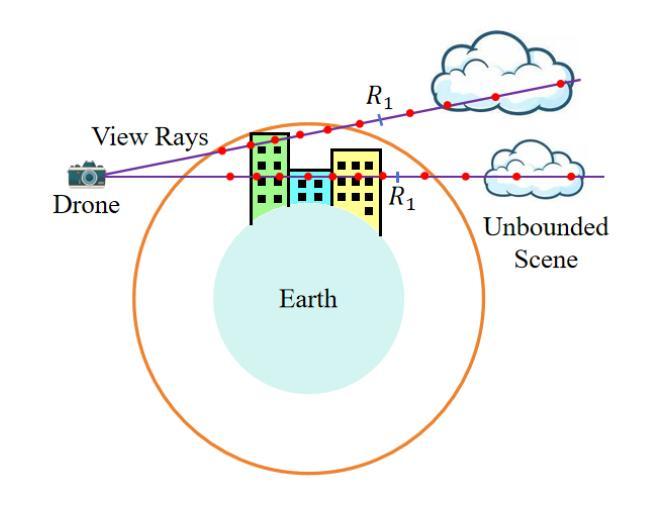
(3):本文提出Aerial-NeRF,通过自适应空间划分和选择、基于姿态相似性确定区域归属、自适应采样等方法,解决了上述问题。
(4):Aerial-NeRF在两个公开大规模航拍数据集和一个自建数据集上取得了最优性能,渲染速度比其他方法快4倍以上。
方法:
(1):自适应空间划分:根据航拍数据集的特征,提出了一种自适应空间划分方法,将大规模场景划分为多个小区域,每个区域使用一个NeRF进行渲染;
(2):基于姿态相似性确定区域归属:设计了一种基于姿态相似性的区域归属确定算法,根据相机的姿态信息将航拍图像分配到不同的区域;
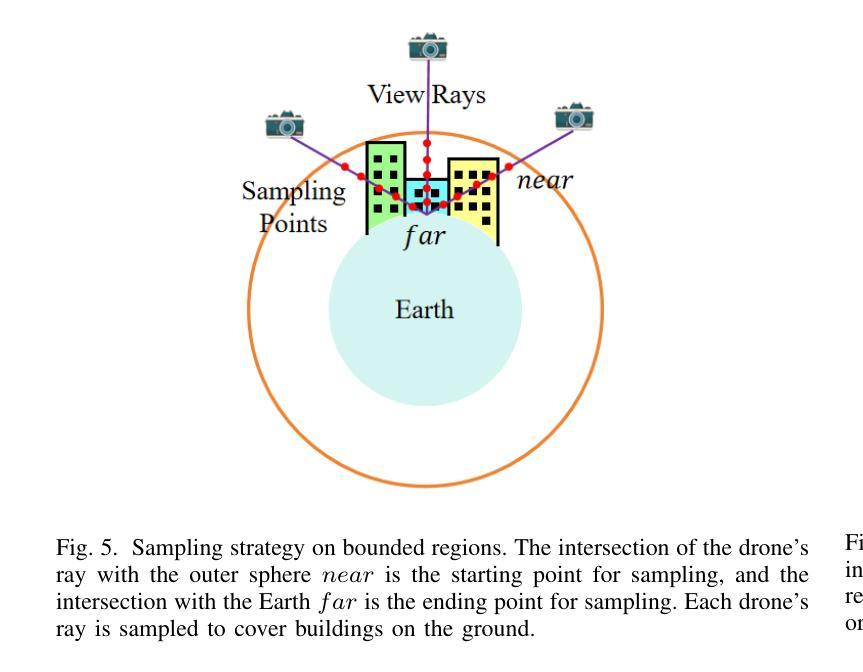
(3):自适应采样:提出了一种自适应采样算法,根据不同区域的复杂程度和渲染速度要求,动态调整采样点数,提高渲染效率;
(4):基于神经网络的区域融合:使用神经网络将不同区域的渲染结果融合成最终图像,保证渲染结果的连续性和准确性;
(5):基于概率密度函数的加速采样:利用概率密度函数对采样点进行优化,进一步提高渲染速度。
结论:
(1):本工作提出了 Aerial-NeRF,一种用于处理大规模航拍数据集的高效且鲁棒的渲染方法,在渲染速度上大幅优于现有的同类方法,几乎达到 4 倍。此外,在适当的划分区域数量下,Aerial-NeRF 可以使用单个 GPU 渲染任意大的场景。同时,我们为航拍场景引入了一种新颖的采样策略,该策略能够通过不同高度相机的采样范围覆盖建筑物。与 SOTA 模型进行更广泛的比较时,我们的方法明显更有效(仅使用 1/4 的采样点和 2 GB 的 GPU 内存节省),并且在多个常用指标方面具有可比性。最后,我们提出了 SCUTic,这是一个用于大规模大学校园场景的新型航拍数据集,具有不均匀的相机轨迹,可以验证渲染方法的鲁棒性。
(2):创新点:自适应空间划分和采样;性能:渲染速度快,内存占用低;工作量:数据集构建和模型训练复杂度较高。
点此查看论文截图


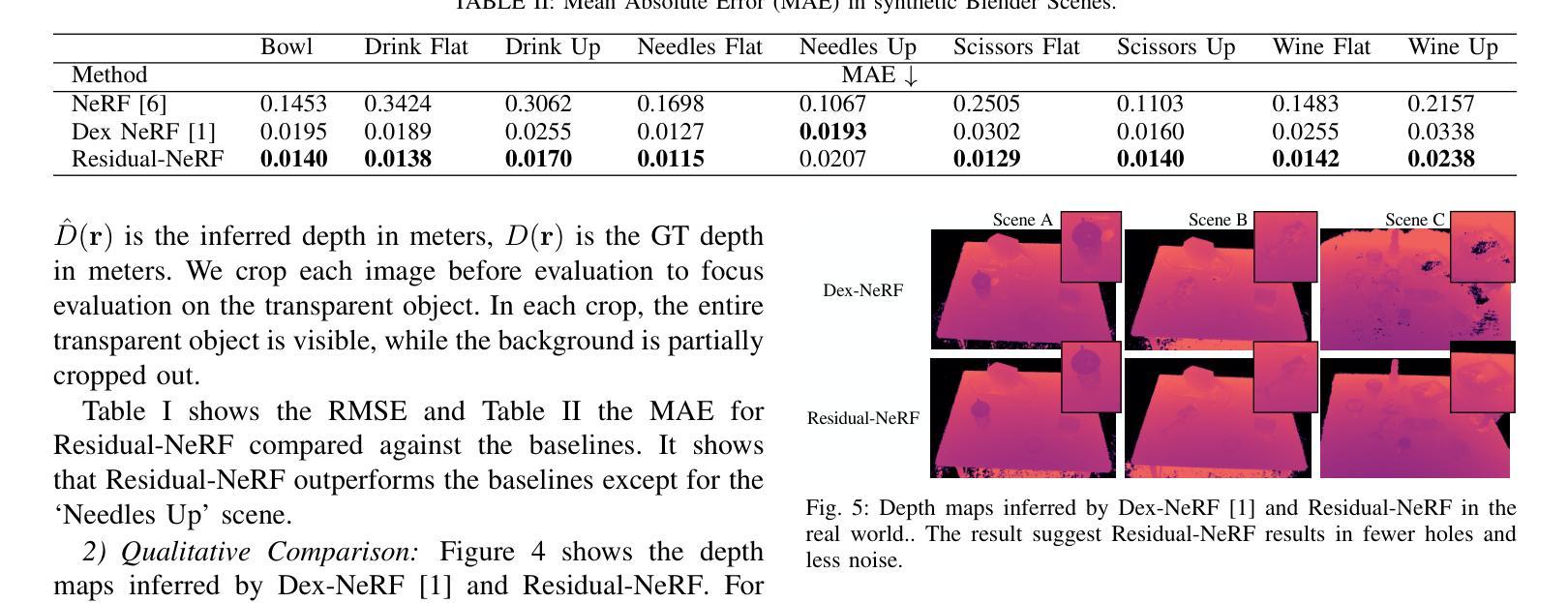
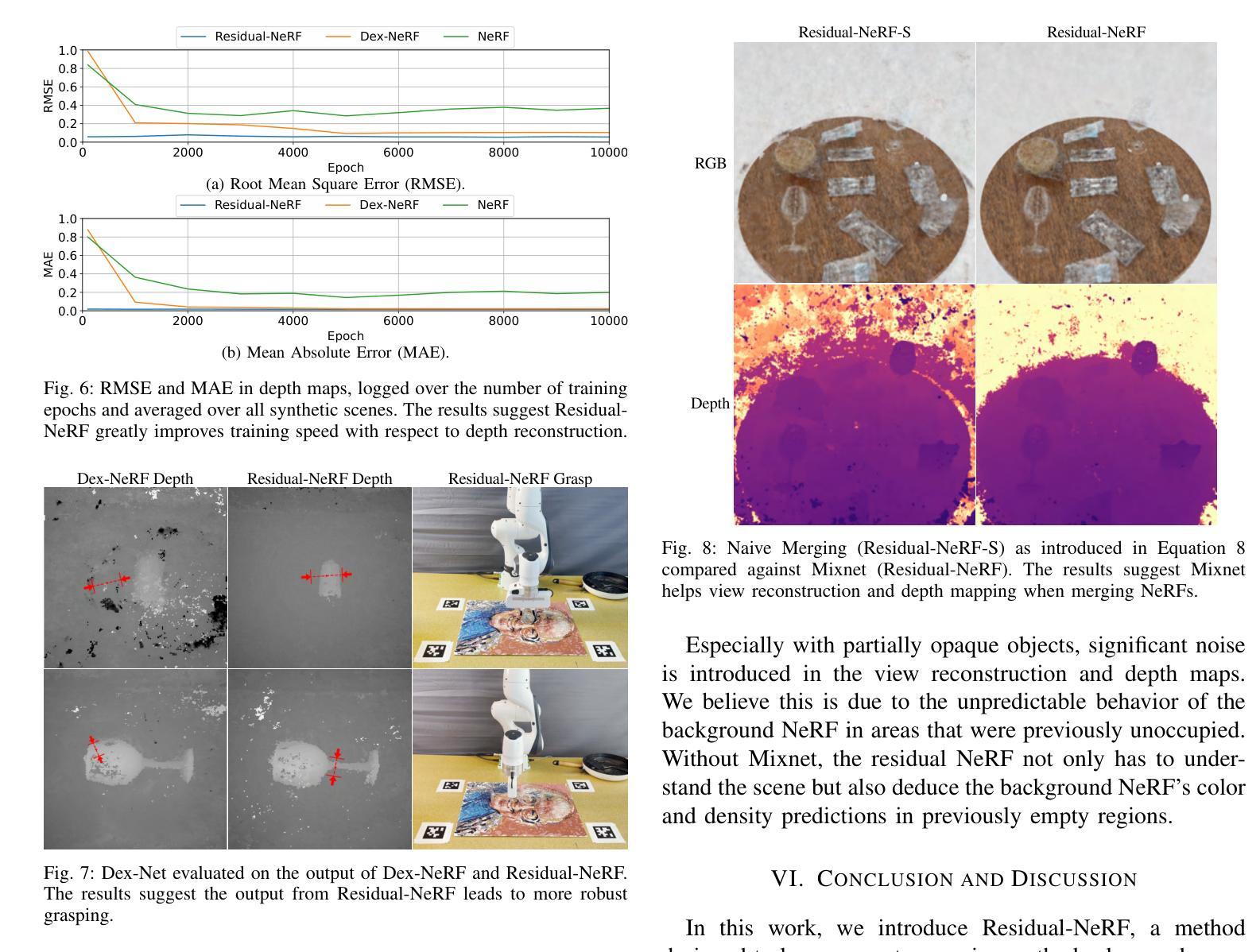
论文标题:Residual-NeRF:学习残差 NeRF 以实现透明物体操作
作者:Bardienus P. Duisterhof, Yuemin Mao, Si Heng Teng, Jeffrey Ichnowski
第一作者单位:卡内基梅隆大学机器人研究所
关键词:神经辐射场(NeRF)、深度感知、透明物体、残差学习、背景先验
论文链接:https://arxiv.org/abs/2405.06181 Github 链接:None
摘要:
(1):研究背景: 透明物体在工业、医药和家庭中无处不在。抓取和操纵这些物体对机器人来说是一个重大挑战。现有的方法难以重建具有挑战性的透明物体的完整深度图,从而在深度重建中留下孔洞。最近的研究表明,神经辐射场(NeRF)非常适合在有透明物体的场景中进行深度感知,并且这些深度图可用于高精度地抓取透明物体。基于 NeRF 的深度重建仍然难以处理特别具有挑战性的透明物体和照明条件。
(2):过去的方法和问题: Dex-NeRF 和 Evo-NeRF 等方法表明,NeRF 在透明物体的深度感知方面是有效的。然而,这些方法还表明,NeRF 往往难以处理特别具有挑战性的透明物体,例如具有挑战性光照条件的酒杯或厨房锡箔。透明物体的挑战源于缺乏特征以及外观中很大的视点依赖性变化。
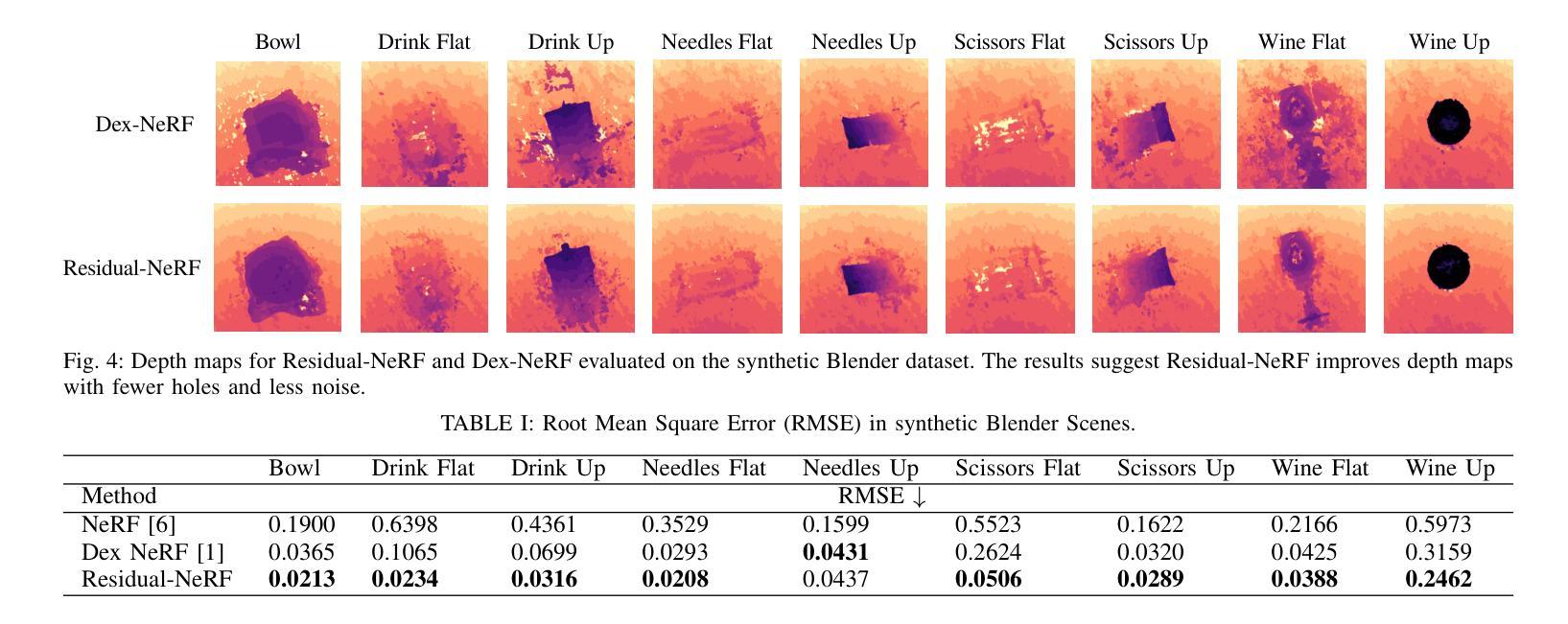
(3):本文提出的研究方法: 为了提高透明物体的深度感知并加快训练速度,我们提出了 Residual-NeRF。在许多情况下,机器人的工作区域的几何形状主要是静态且不透明的,例如架子、桌子和桌子。Residual-NeRF 利用场景的静态和不透明部分作为先验,以减少歧义并提高深度感知。Residual-NeRF 首先通过训练不包含透明物体的图像来学习整个场景的背景 NeRF。然后,Residual-NeRF 使用包含透明物体的完整场景的图像来学习残差 NeRF 和 Mixnet。
(4):方法的应用任务和性能: 我们对合成和真实数据进行了实验,表明 Residual-NeRF 提高了透明物体的深度感知。合成数据上的结果表明,Residual-NeRF 在 RMSE 上比基线低 46.1%,在 MAE 上低 29.5%。真实世界的定性实验表明,Residual-NeRF 产生了更稳健的深度图,噪点更少,孔洞更少。
- 方法:
(1):首先训练不包含透明物体的图像,学习整个场景的背景 NeRF;
(2):然后使用包含透明物体的完整场景的图像,学习残差 NeRF 和 Mixnet;
(3):利用场景的静态和不透明部分作为先验,减少歧义并提高深度感知;
(4):Residual-NeRF 提高了透明物体的深度感知。
结论
(1): 本工作通过提出 Residual-NeRF,提高了透明物体的深度感知,并加快了训练速度。
(2): 创新点: - 利用场景的静态和不透明部分作为先验,减少歧义并提高深度感知; - 提出了一种两阶段训练方法,首先学习背景 NeRF,然后学习残差 NeRF 和 Mixnet。 - 提出了一种新的 Mixnet,可以有效地融合背景 NeRF 和残差 NeRF 的输出。
性能:
- 在合成数据上,Residual-NeRF 在 RMSE 上比基线低 46.1%,在 MAE 上低 29.5%。
- 在真实世界的定性实验中,Residual-NeRF 产生了更稳健的深度图,噪点更少,孔洞更少。
工作量:
- 训练 Residual-NeRF 需要两个阶段的训练,这比基线方法更复杂。
- Residual-NeRF 需要额外的内存来存储背景 NeRF 和残差 NeRF 的权重。
点此查看论文截图



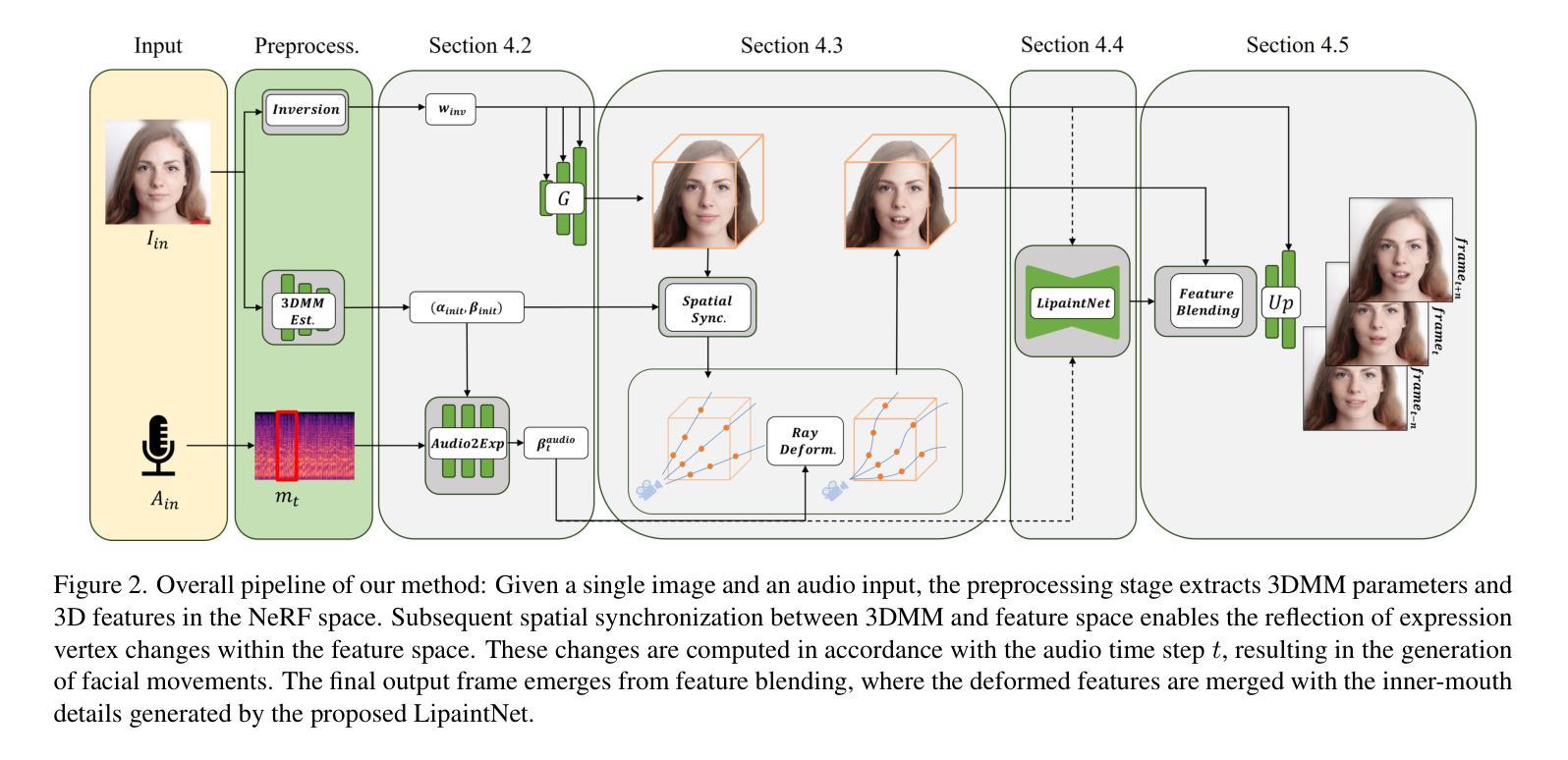
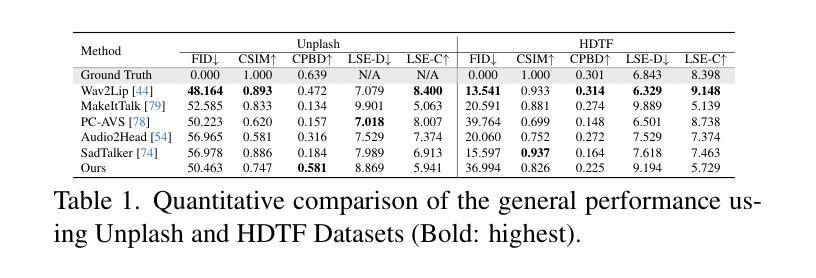
Title: NeRFFaceSpeech: 一次性音频驱动 3D 说话人头部合成,通过生成先验
Authors: Gihoon Kim, Kwanggyoon Seo, Sihun Cha, Junyong Noh
Affiliation: 首尔国立大学
Keywords: 音频驱动, 3D 说话人头部, 神经辐射场, 生成先验, 一次性学习
Urls: Paper: https://arxiv.org/abs/2405.05749, Github: None
Summary:
(1): 音频驱动说话人头部生成正从 2D 内容转向 3D 内容。值得注意的是,神经辐射场 (NeRF) 作为合成高质量 3D 说话人头部输出的一种手段而备受关注。不幸的是,这种基于 NeRF 的方法通常需要大量配对的每个身份的音频视觉数据,从而限制了该方法的可扩展性。尽管已经尝试使用单张图像生成音频驱动的 3D 说话人头部动画,但由于图像中遮挡区域的信息不足,结果通常不令人满意。在本文中,我们主要关注解决一次性音频驱动域中被忽视的 3D 一致性方面,其中面部动画主要在正面视角合成。
(2): 现有的方法: - 基于 NeRF 的方法通常需要大量配对的每个身份的音频视觉数据。 - 使用单张图像生成音频驱动的 3D 说话人头部动画的方法由于图像中遮挡区域的信息不足,结果通常不令人满意。
问题: - 可扩展性受限。 - 3D 一致性不足。
(3): 本文提出的研究方法: - 提出了一种新方法 NeRFFaceSpeech,它能够生成高质量的 3D 感知说话人头部。 - 使用生成模型的先验知识与 NeRF 相结合,我们的方法可以构建一个与单张图像相对应的 3D 一致的面部特征空间。 - 我们的空间同步方法采用参数化人脸模型的音频相关顶点动态,通过光线变形将静态图像特征转换为动态视觉效果,确保逼真的 3D 面部运动。 - 此外,我们引入了 LipaintNet,它可以补充单张给定图像中无法获得的内口区域中缺少的信息。该网络以自监督的方式进行训练,利用生成能力而无需额外数据。
(4): 在任务和性能上,本文方法取得了以下成就: - 全面的实验表明,与以前的方法相比,我们的方法在从单张图像生成音频驱动的说话人头部方面具有出色的性能,并增强了 3D 一致性。 - 此外,我们首次引入了一种衡量模型对姿势变化鲁棒性的定量方法,而以前只能定性地进行。
- Methods:
(1): 提出 NeRFFaceSpeech 方法,该方法结合了生成模型的先验知识与 NeRF,构建与单张图像相对应的 3D 一致的面部特征空间;
(2): 采用参数化人脸模型的音频相关顶点动态,通过光线变形将静态图像特征转换为动态视觉效果,确保逼真的 3D 面部运动;
(3): 引入 LipaintNet,补充单张给定图像中无法获得的内口区域中缺少的信息,该网络以自监督的方式进行训练,利用生成能力而无需额外数据;
(4): 设计定量方法衡量模型对姿势变化的鲁棒性。
- 结论:
(1):本文提出了 NeRFFaceSpeech,一种通过利用生成先验构建和操纵 3D 特征,从单幅图像生成 3D 感知音频驱动说话人头部动画的新方法;
(2):创新点:将生成模型先验与神经辐射场相结合,构建与单幅图像相对应的 3D 一致的面部特征空间;通过光线变形,采用参数化人脸模型的音频相关顶点动态,将静态图像特征转换为动态视觉效果,确保逼真的 3D 面部运动;引入了 LipaintNet,一个自监督学习框架,利用生成模型的能力合成隐藏的内口区域,补充变形场以产生可行结果;设计了定量方法来衡量模型对姿势变化的鲁棒性。性能:与以前的方法相比,我们的方法在从单幅图像生成音频驱动的说话人头部方面具有出色的性能,并增强了 3D 一致性;首次引入了一种衡量模型对姿势变化鲁棒性的定量方法,而以前只能定性地进行。工作量:本文提出的方法需要较大的计算资源和较长的训练时间。
点此查看论文截图


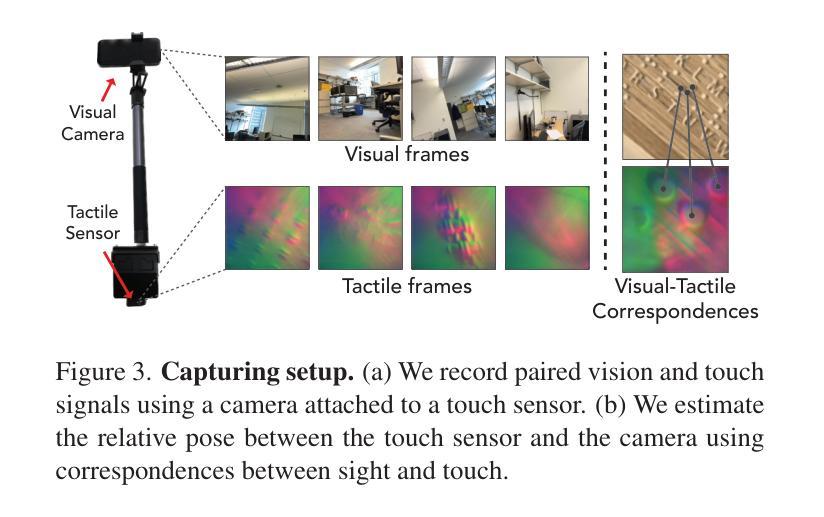
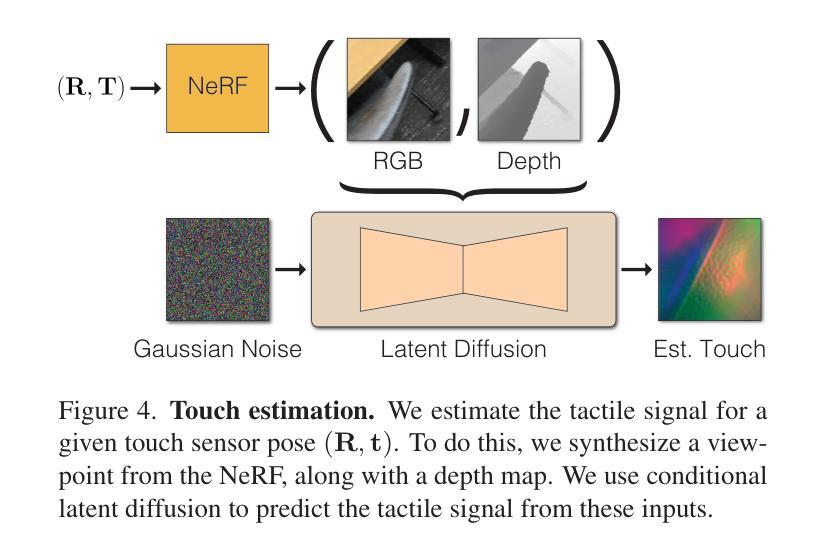
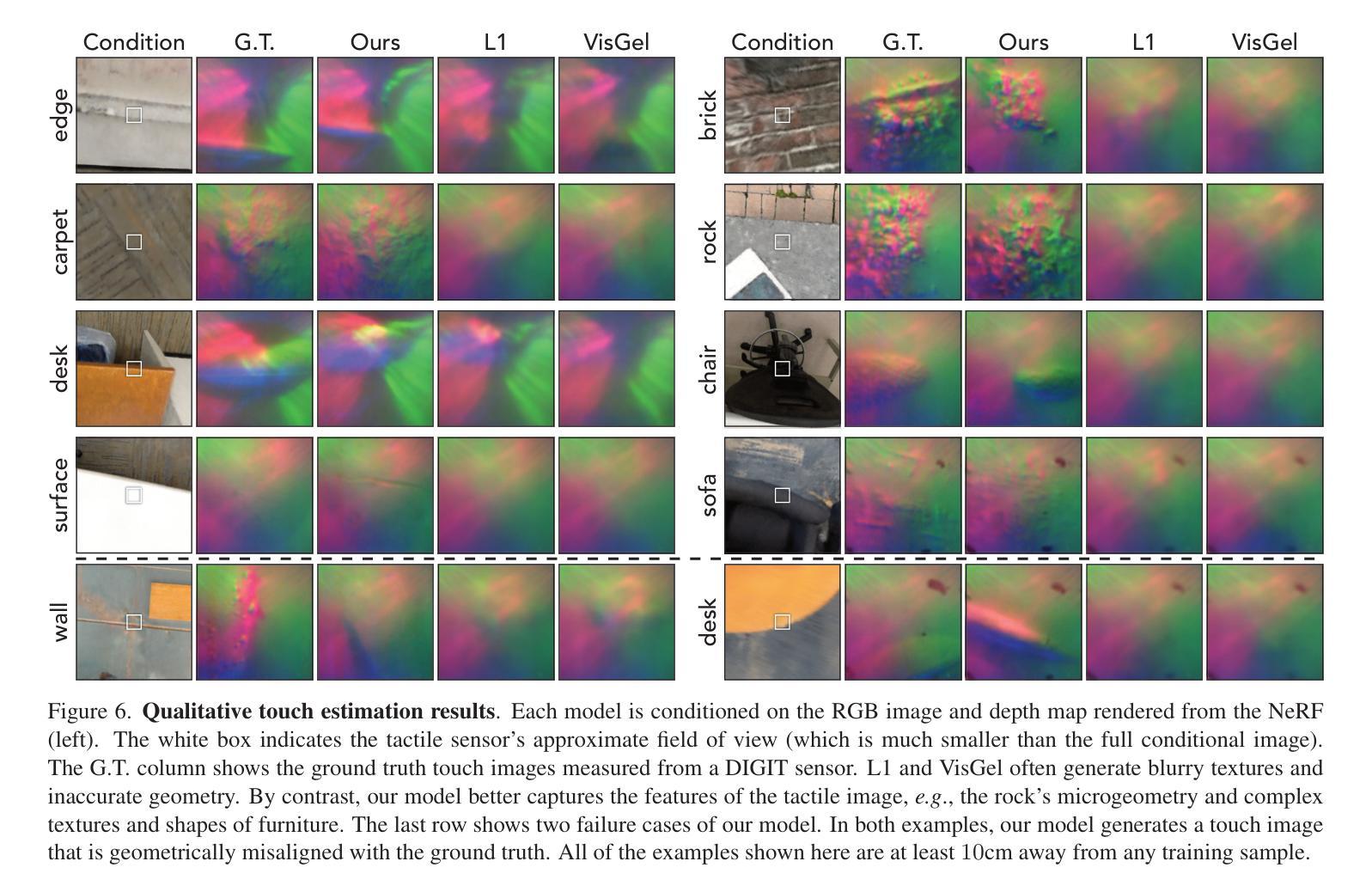
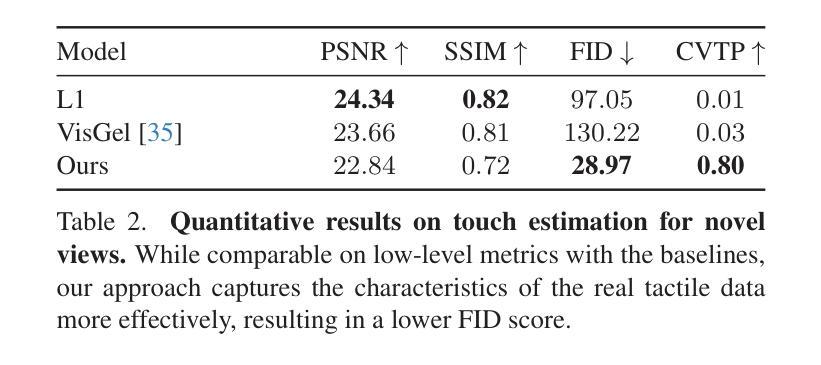
Title: 触觉增强辐射场:一种用于跨模态感知和生成的新型场景表示
Authors: Douyi Ming, Srinath Sridhar, Jiajun Wu, Angjoo Kanazawa, Peter Anderson, Wojciech Matusik, Jonathan Ragan-Kelley
Affiliation: 麻省理工学院
Keywords: Cross-modal perception, generative models, multi-view geometry, neural radiance fields, tactile sensing, vision
Urls: Paper: https://arxiv.org/abs/2301.09422, Github: https://github.com/douyiming/TaRF
Summary:
(1): 本文的研究背景是视觉和触觉感知在共享的 3D 空间中的表示问题。
(2): 过去的方法通常是将视觉和触觉信号视为独立的模态,这限制了跨模态感知和生成的任务。
(3): 本文提出了一种新的场景表示形式——触觉增强辐射场 (TaRF),它将视觉和触觉信号统一到一个 3D 空间中。TaRF 的构建利用了基于视觉的触觉传感器与图像之间的几何对应关系,以及场景中视觉和结构相似区域具有相同触觉特征的假设。
(4): 在 TaRF 数据集上,本文提出的方法在跨模态生成、触觉信号估计和触觉引导的视觉探索等任务上取得了良好的性能,证明了其在跨模态感知和生成方面的有效性。
- 方法:
(1):构建视觉和触觉增强辐射场(TaRF),将视觉和触觉信号统一到一个 3D 空间中;
(2):通过视觉-触觉对应关系和场景中视觉和结构相似区域具有相同触觉特征的假设,建立 TaRF;
(3):使用基于视觉的触觉传感器和图像之间的几何对应关系,估计 TaRF 中的视觉和触觉信号;
(4):利用生成模型,估计场景中其他位置的触觉信号;
(5):使用条件潜在扩散模型,从渲染的视觉信号中预测触觉信号;
(6):收集包含 19.3k 个图像对的视觉-触觉数据集,用于训练和评估 TaRF。
- 结论:
(1):本文提出了一种新的场景表示形式——触觉增强辐射场(TaRF),首次将视觉和触觉信号统一到一个共享的 3D 空间中,为跨模态感知和生成提供了新的可能性。 (2):创新点:提出了一种将视觉和触觉信号统一到一个 3D 空间中的场景表示形式 TaRF;提出了一种基于视觉-触觉对应关系和场景中视觉和结构相似区域具有相同触觉特征的假设,建立 TaRF 的方法;提出了一种使用生成模型,估计场景中其他位置的触觉信号的方法。性能:在跨模态生成、触觉信号估计和触觉引导的视觉探索等任务上取得了良好的性能;收集了包含 19.3k 个图像对的视觉-触觉数据集,为 TaRF 的训练和评估提供了丰富的素材。 workload:TaRF 的构建需要基于视觉的触觉传感器和图像之间的几何对应关系,以及场景中视觉和结构相似区域具有相同触觉特征的假设,这在某些情况下可能存在挑战;TaRF 的训练需要大量的视觉-触觉数据,这可能会增加数据收集和标注的工作量。
点此查看论文截图



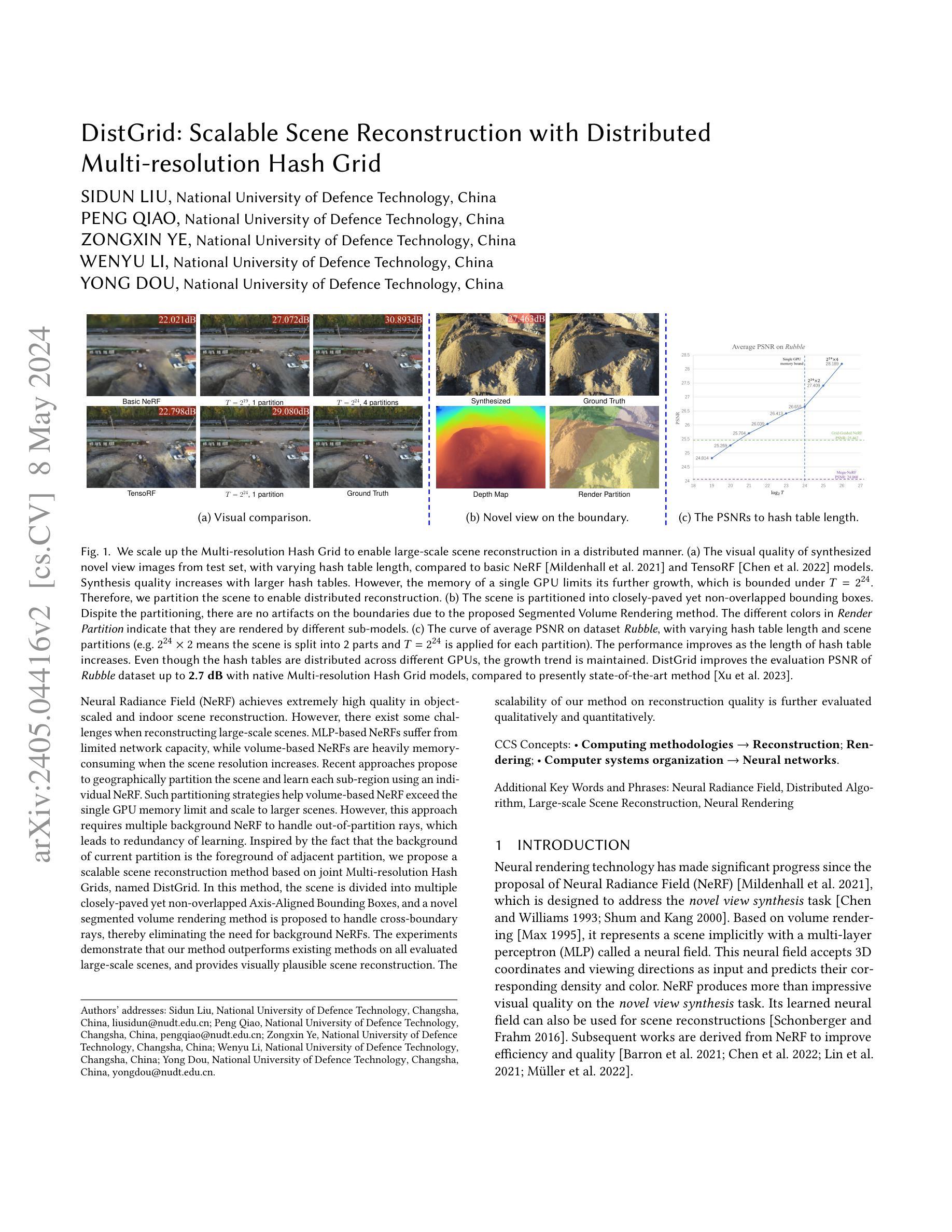
DistGrid: Scalable Scene Reconstruction with Distributed Multi-resolution Hash Grid
Authors:Sidun Liu, Peng Qiao, Zongxin Ye, Wenyu Li, Yong Dou
Neural Radiance Field~(NeRF) achieves extremely high quality in object-scaled and indoor scene reconstruction. However, there exist some challenges when reconstructing large-scale scenes. MLP-based NeRFs suffer from limited network capacity, while volume-based NeRFs are heavily memory-consuming when the scene resolution increases. Recent approaches propose to geographically partition the scene and learn each sub-region using an individual NeRF. Such partitioning strategies help volume-based NeRF exceed the single GPU memory limit and scale to larger scenes. However, this approach requires multiple background NeRF to handle out-of-partition rays, which leads to redundancy of learning. Inspired by the fact that the background of current partition is the foreground of adjacent partition, we propose a scalable scene reconstruction method based on joint Multi-resolution Hash Grids, named DistGrid. In this method, the scene is divided into multiple closely-paved yet non-overlapped Axis-Aligned Bounding Boxes, and a novel segmented volume rendering method is proposed to handle cross-boundary rays, thereby eliminating the need for background NeRFs. The experiments demonstrate that our method outperforms existing methods on all evaluated large-scale scenes, and provides visually plausible scene reconstruction. The scalability of our method on reconstruction quality is further evaluated qualitatively and quantitatively.
PDF Originally submitted to Siggraph Asia 2023
Summary
大规模场景只需用单一NeRF,通过多级Hash网格,而无需单独的背景NeRF,即可实现场景重建。
Key Takeaways
- NeRF 在对象和室内场景重建中表现出色,但在重建大型场景时存在问题。
- 基于 MLP 的 NeRF 网络容量有限,而基于体积的 NeRF 会随着场景分辨率的增加占用大量内存。
- 最近的方法将场景地理分区,并使用单独的 NeRF 学习每个分区。
- 这有助于基于体积的 NeRF 突破单 GPU 内存限制,并扩展到更大的场景。
- 但这种方法需要多个背景 NeRF 来处理分区外的光线,这导致学习冗余。
- 本文提出了 DistGrid,基于多级散列网格的分布式场景重建方法。
- 该方法将场景划分为多个紧密排列但不重叠的轴对齐包围盒,并提出了一种分割体积渲染方法来处理跨边界光线,从而消除了对背景 NeRF 的需求。
- 实验表明,该方法在所有评估的大型场景上都优于现有方法,并提供了视觉上合理的效果。
Title: DistGrid: 基于分布式多分辨率哈希网格的大规模场景重建
Authors: Sidun Liu, Peng Qiao, Zongxin Ye, Wenyu Li, Yong Dou
Affiliation: 国防科技大学
Keywords: Neural Radiance Field, Distributed Algorithm, Large-scale Scene Reconstruction, Neural Rendering
Urls: Paper: https://arxiv.org/pdf/2405.04416.pdf, Github: None
Summary:
(1): 神经渲染技术自 NeRF 提出以来取得了重大进展,NeRF 旨在解决新视角合成任务。它基于体积渲染,使用称为神经场的多分层感知器(MLP)隐式表示场景。该神经场接受 3D 坐标和观察方向作为输入,并预测其对应的密度和颜色。NeRF 在新视角合成任务上产生了令人印象深刻的视觉质量。其学习的神经场也可用于场景重建。
(2): NeRF 的后续工作旨在提高效率和质量。一种方法是将场景地理分区,并使用单独的 NeRF 学习每个子区域。这种分区策略帮助基于体积的 NeRF 超过单个 GPU 的内存限制,并扩展到更大的场景。但是,这种方法需要多个背景 NeRF 来处理分区外的光线,这导致了学习的冗余。
(3): 本文提出了一种基于联合多分辨率哈希网格的可扩展场景重建方法,称为 DistGrid。在此方法中,场景被划分为多个紧密相邻但非重叠的轴对齐边界框,并提出了一种新颖的分段体积渲染方法来处理跨边界光线,从而消除了对背景 NeRF 的需求。
(4): 实验表明,该方法在所有评估的大规模场景上都优于现有方法,并提供了视觉上合理的场景重建。该方法在重建质量上的可扩展性还通过定性和定量的方式进行了进一步评估。
方法:
(1): 本文提出了一种基于联合多分辨率哈希网格的可扩展场景重建方法,称为 DistGrid。
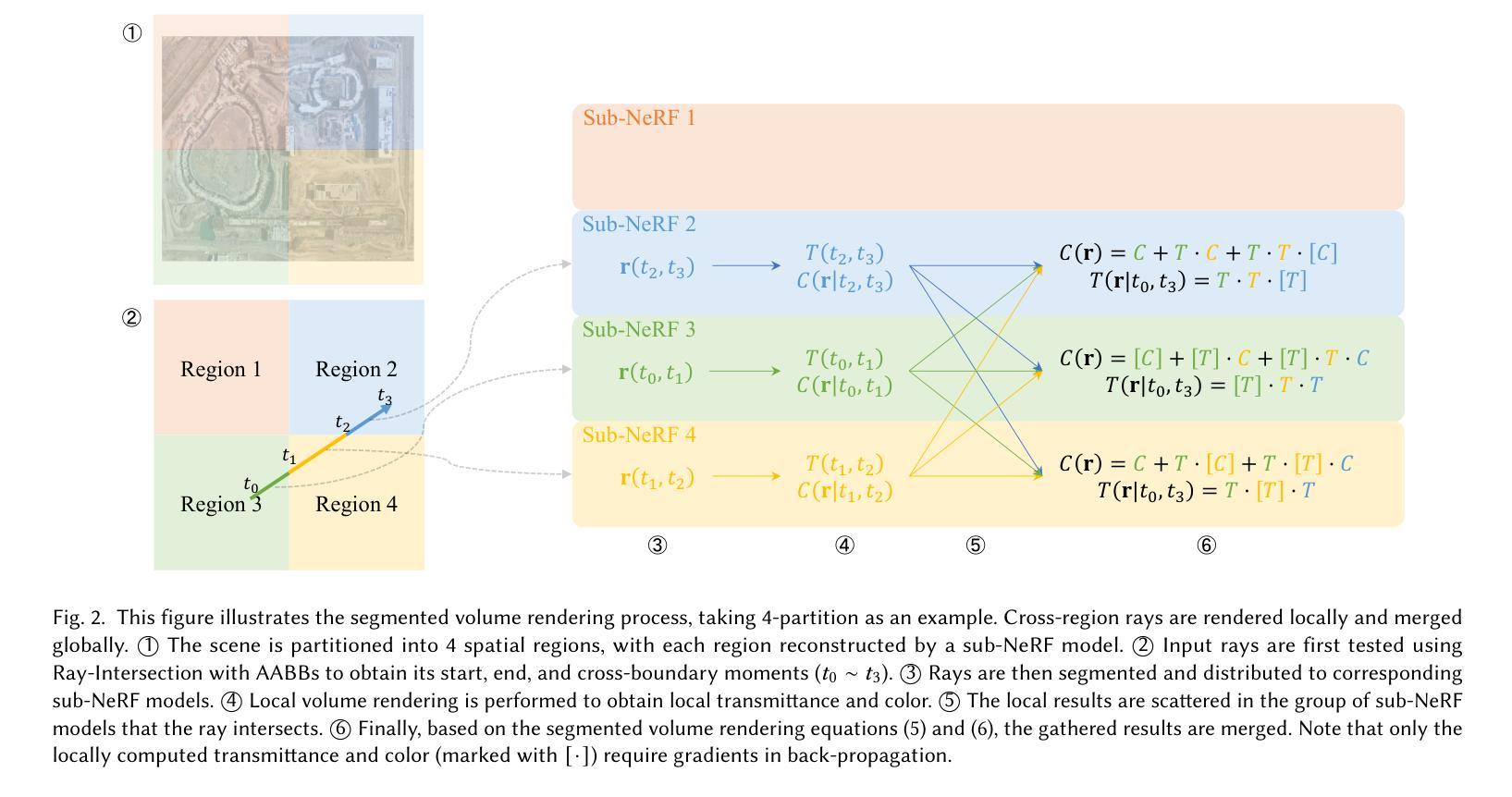
(2): DistGrid 将场景划分为多个紧密相邻但非重叠的轴对齐边界框 (AABB),并使用新颖的分段体积渲染方法来处理跨边界光线,从而消除了对背景 NeRF 的需求。
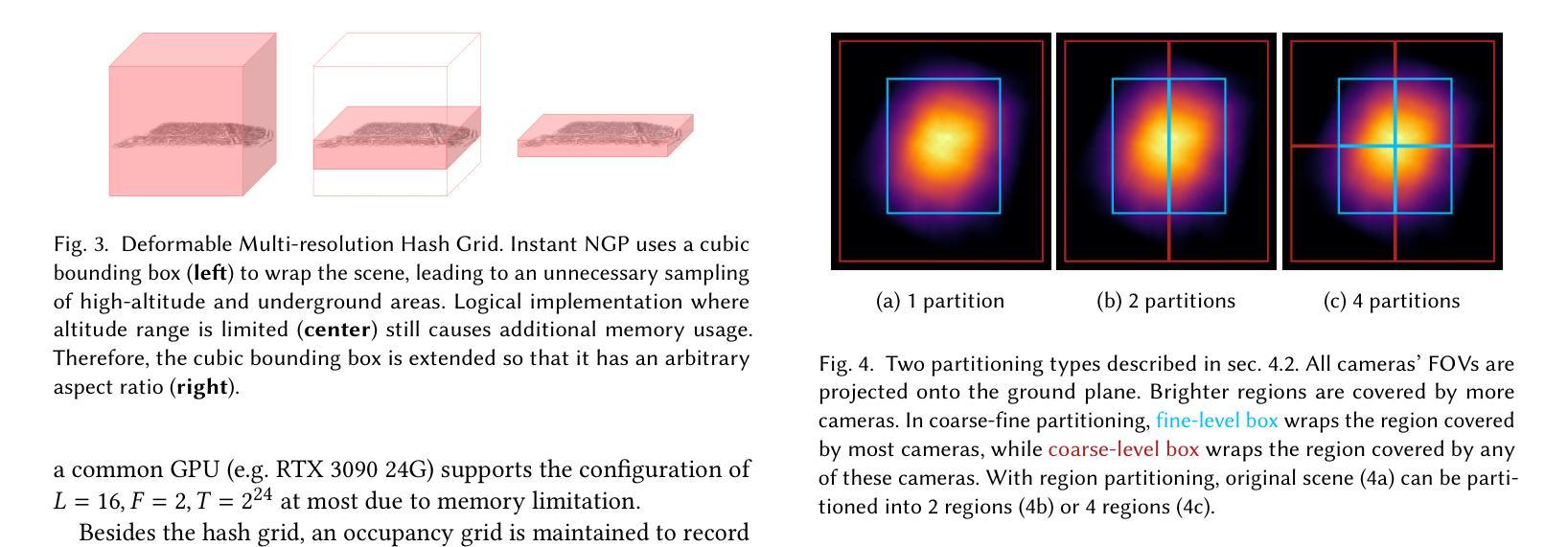
(3): DistGrid 采用两级级联结构,其中细粒度 NeRF 使用内层边界框作为其边界框,而粗粒度 NeRF 使用外层边界框。
(4): DistGrid 使用分段体积渲染方法来处理跨区域光线,该方法将体积渲染积分分解为多个部分,并使用部分颜色和部分透射率来计算渲染颜色和最终透射率。
结论:
(1):本文提出了 DistGrid,一种基于联合多分辨率哈希网格的可扩展场景重建方法,该方法在视觉质量和效率方面都优于现有方法。 (2):创新点:提出了一种新颖的分段体积渲染方法来处理跨边界光线,无需背景 NeRF,提高了效率;采用两级级联结构,细粒度 NeRF 和粗粒度 NeRF 协同工作,提高了重建质量。 性能:在所有评估的大规模场景上都优于现有方法,并提供了视觉上合理的场景重建。 工作量:与现有方法相比,DistGrid 在重建质量上的可扩展性得到了定性和定量的方式的进一步评估。
点此查看论文截图
Blending Distributed NeRFs with Tri-stage Robust Pose Optimization
Authors:Baijun Ye, Caiyun Liu, Xiaoyu Ye, Yuantao Chen, Yuhai Wang, Zike Yan, Yongliang Shi, Hao Zhao, Guyue Zhou
Due to the limited model capacity, leveraging distributed Neural Radiance Fields (NeRFs) for modeling extensive urban environments has become a necessity. However, current distributed NeRF registration approaches encounter aliasing artifacts, arising from discrepancies in rendering resolutions and suboptimal pose precision. These factors collectively deteriorate the fidelity of pose estimation within NeRF frameworks, resulting in occlusion artifacts during the NeRF blending stage. In this paper, we present a distributed NeRF system with tri-stage pose optimization. In the first stage, precise poses of images are achieved by bundle adjusting Mip-NeRF 360 with a coarse-to-fine strategy. In the second stage, we incorporate the inverting Mip-NeRF 360, coupled with the truncated dynamic low-pass filter, to enable the achievement of robust and precise poses, termed Frame2Model optimization. On top of this, we obtain a coarse transformation between NeRFs in different coordinate systems. In the third stage, we fine-tune the transformation between NeRFs by Model2Model pose optimization. After obtaining precise transformation parameters, we proceed to implement NeRF blending, showcasing superior performance metrics in both real-world and simulation scenarios. Codes and data will be publicly available at https://github.com/boilcy/Distributed-NeRF.
Summary
使用三阶段姿态优化对分布式NeRF进行精确对齐,以缓解建模大规模城市环境时出现的混叠伪影和姿态精度不足的问题。
Key Takeaways
- 分布式NeRF建模城市环境面临混叠伪影和姿态精度问题。
- 采用分阶段姿态优化解决问题,包括Mip-NeRF 360束调整、反向Mip-NeRF 360和Frame2Model优化。
- 利用Model2Model优化进一步细化不同NeRF之间的转换。
- 精确的姿态优化有效消除NeRF融合中的遮挡伪影。
- 在真实和模拟场景中展示出优越的NeRF融合性能。
- 代码和数据将在GitHub上公开。
题目:基于三阶段鲁棒位姿优化融合分布式NeRFs
作者:Baijun Ye∗1,2, Caiyun Liu∗1, Xiaoyu Ye1,2, Yuantao Chen1,3, Yuhai Wang4, Zike Yan1, Yongliang Shi1†, Hao Zhao1, Guyue Zhou1
第一作者单位:清华大学人工智能产业研究院(AIR)
关键词:分布式NeRF、位姿优化、NeRF融合、Mip-NeRF 360、iNeRF
论文链接:https://arxiv.org/abs/2405.02880 Github:None
摘要:
(1):研究背景: 在大规模场景建模领域,NeRF因其能够在保持紧凑模型结构的同时实现逼真的渲染而备受关注。然而,当前的分布式NeRF配准方法存在混叠伪影,这源于渲染分辨率差异和次优位姿精度。这些因素共同降低了NeRF框架内位姿估计的保真度,导致NeRF融合阶段出现遮挡伪影。
(2):以往方法及其问题: 以往方法主要有两种:批处理学习和增量学习。批处理学习需要大量的计算资源,而增量学习容易出现遗忘问题。此外,当前使用显式编码方法(如网格和八叉树)进行实时性能的NeRF方法,面临着随着场景规模的增加,编码组件呈指数级扩展的挑战,导致存储需求大幅增加。
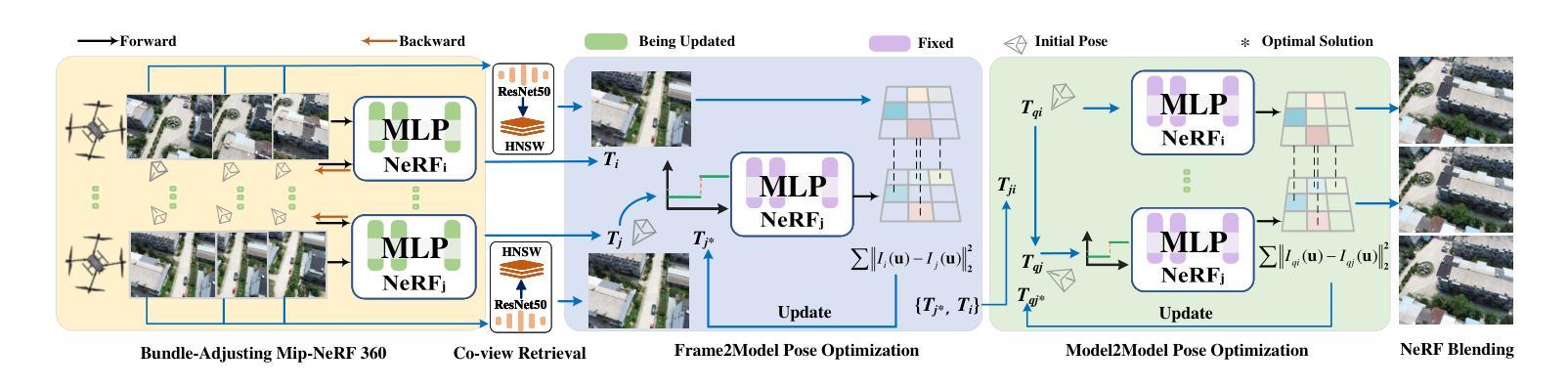
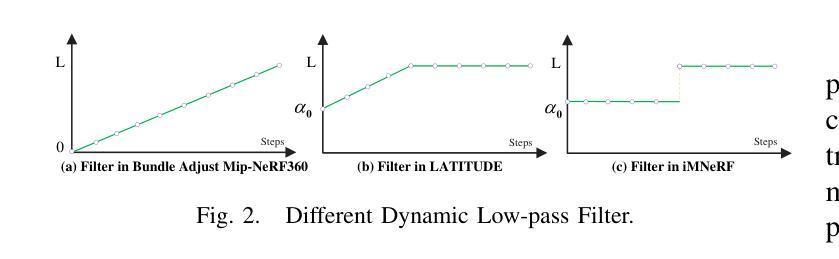
(3):本文提出的研究方法: 本文提出了一种基于三阶段鲁棒位姿优化的分布式NeRF框架。在第一阶段,通过捆绑调整Mip-NeRF 360并采用由粗到精的策略,实现了图像的精确位姿。在第二阶段,借鉴LATITUDE,利用截断动态低通滤波(TDLF)的原理对反向Mip-NeRF 360进行了优化,称为iMNeRF。此方法类似于模糊图像以使优化过程更加鲁棒,从而实现帧到模型的位姿优化。随后,采用协视图区域检索方法来搜索不同NeRF实例中最相似的图像,进而确定其关联的位姿。给定关联的位姿,利用iMNeRF通过渲染图像和观察图像之间的光度损失来优化这些位姿,从而获得可靠的帧到模型转换。在第三阶段,通过不同的帧到模型转换获得了NeRF之间粗略的模型到模型转换。然后,将不同的NeRF模型投影到一个统一的坐标系中,并使用渲染图像作为观测值进一步优化NeRF之间的相对转换,即通过模型到模型优化来获得NeRF之间的精确转换。
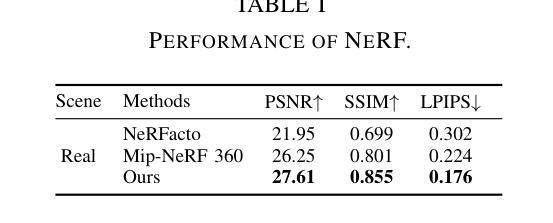
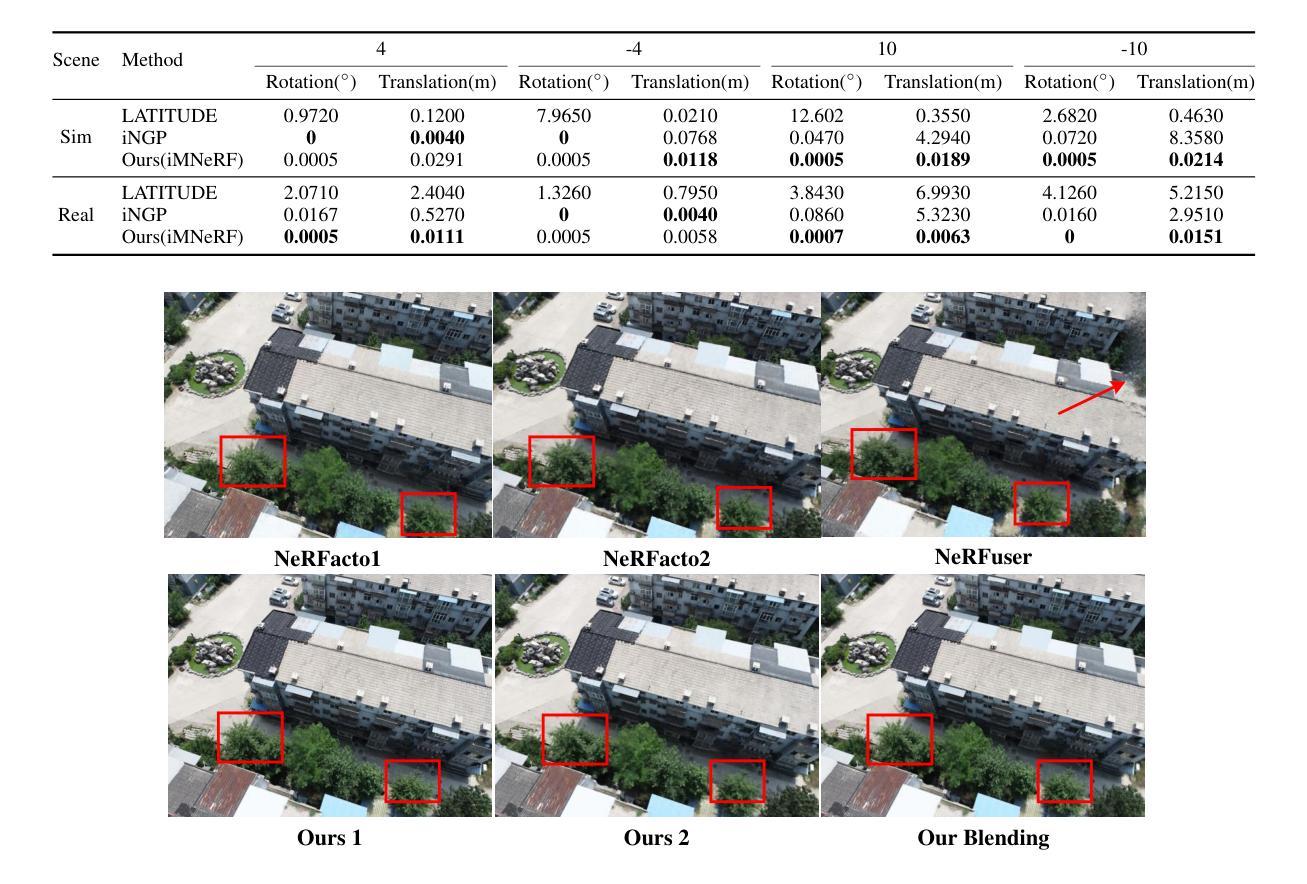
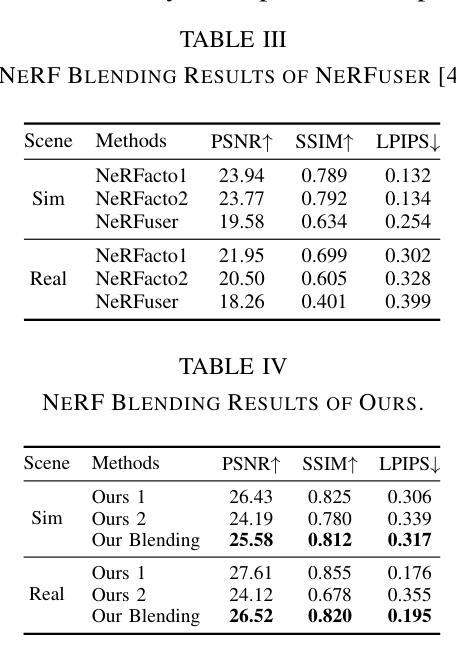
(4):方法在什么任务上取得了怎样的性能: 利用三阶段位姿优化,实现了NeRF融合并获得了更好的性能。为了验证本文方法,同时发布了真实世界和模拟数据集,展示了本文方法在性能上的优越性。
- 方法:
(1):提出了一种基于三阶段鲁棒位姿优化的分布式NeRF框架;
(2):第一阶段,通过捆绑调整Mip-NeRF 360并采用由粗到精的策略,实现了图像的精确位姿;
(3):第二阶段,借鉴LATITUDE,利用截断动态低通滤波(TDLF)的原理对反向Mip-NeRF 360进行了优化,称为iMNeRF;
(4):给定关联的位姿,利用iMNeRF通过渲染图像和观察图像之间的光度损失来优化这些位姿,从而获得可靠的帧到模型转换;
(5):第三阶段,通过不同的帧到模型转换获得了NeRF之间粗略的模型到模型转换;
(6):将不同的NeRF模型投影到一个统一的坐标系中,并使用渲染图像作为观测值进一步优化NeRF之间的相对转换,即通过模型到模型优化来获得NeRF之间的精确转换。
- 结论:
(1):本文提出了一种基于三阶段鲁棒位姿优化的分布式NeRF框架,解决了当前分布式NeRF配准方法中存在的混叠伪影问题,提高了NeRF融合的保真度;
(2):创新点:提出了三阶段鲁棒位姿优化方法,包括图像精确位姿估计、帧到模型位姿优化和模型到模型位姿优化;性能:在真实世界和模拟数据集上验证了本文方法的优越性;工作量:本文方法需要额外的计算资源进行位姿优化,但可以实现更好的NeRF融合效果。
点此查看论文截图



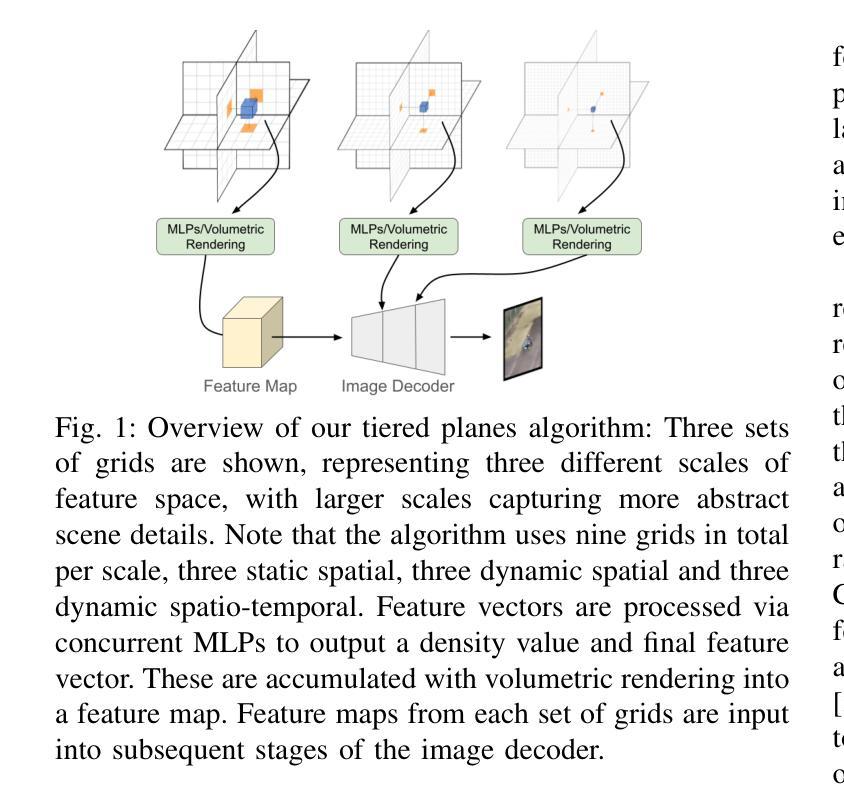
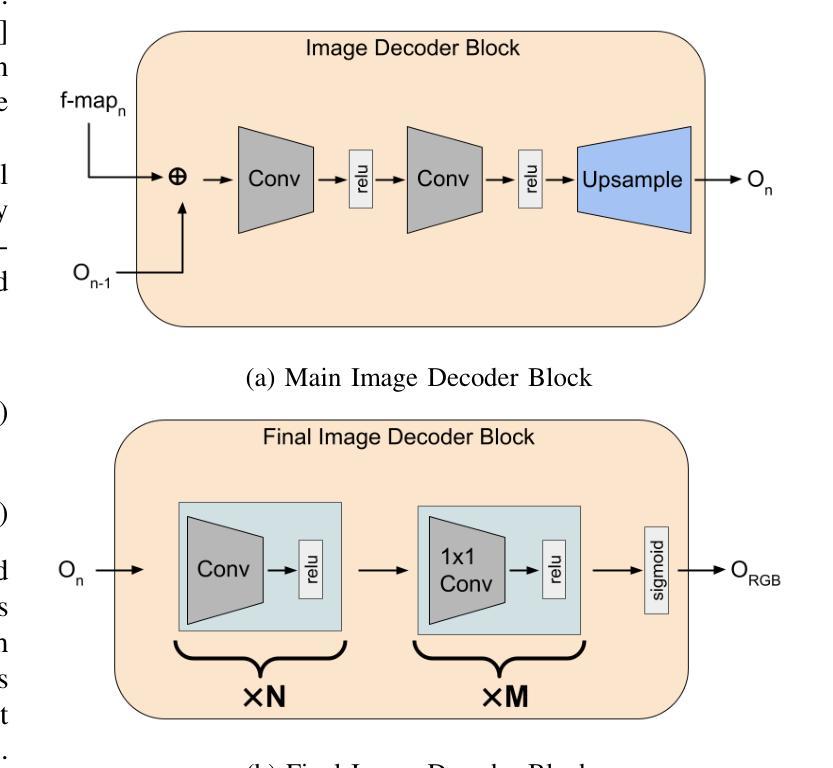
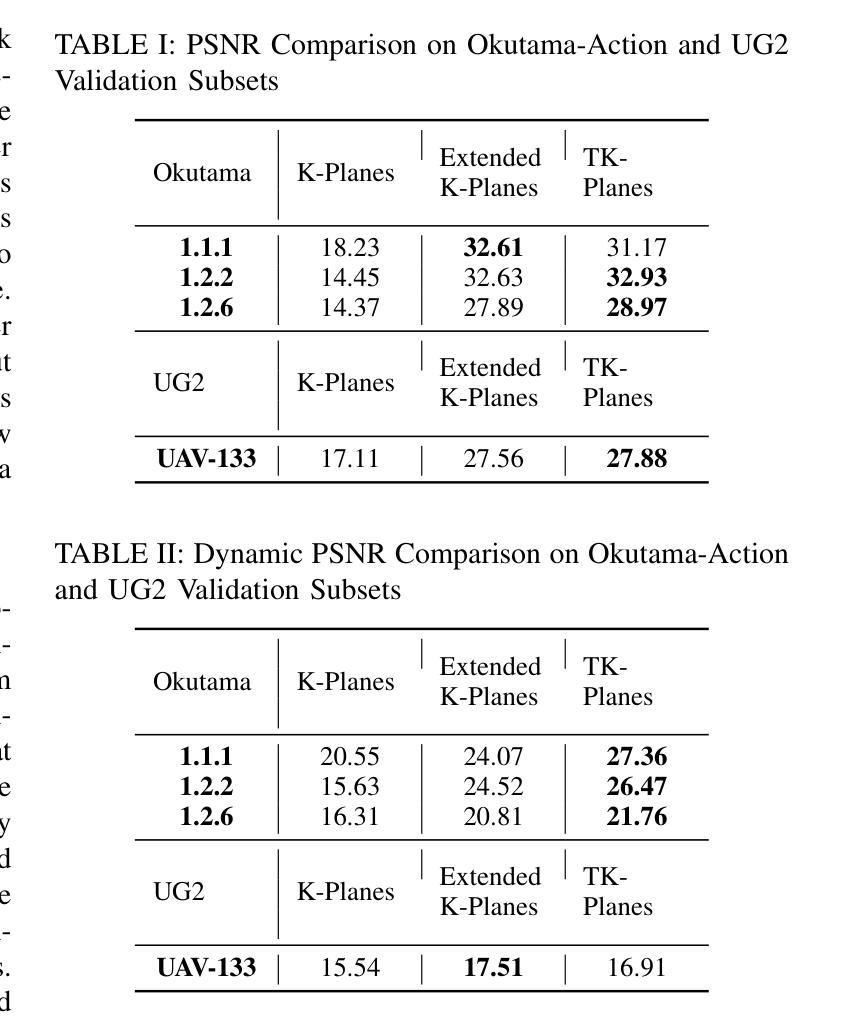
Title: TK-Planes:具有高维特征向量的分层 K-Planes
Authors: Christopher Maxey, Jaehoon Choi, Yonghan Lee, Hyungtae Lee, Dinesh Manocha, Heesung Kwon
Affiliation: 美国陆军研究实验室
Keywords: Neural Radiance Fields, Synthetic Data, UAV Perception, Dynamic Scenes, Feature Vectors
Urls: https://arxiv.org/abs/2405.02762, Github: None
Summary:
(1): 本文研究背景是合成数据在无人机感知中的应用,特别是动态场景的识别,如姿势或动作识别。
(2): 过去的方法主要基于 K-Planes 神经辐射场,但存在问题:动态对象建模困难、静态和动态元素分离困难、动态对象稀疏、姿态多样性受限。
(3): 本文提出的研究方法是 TK-Planes,一种分层 K-Planes 算法,输出和操作特征向量而不是 RGB 像素值。这些特征向量可以存储场景中特定对象或位置的概念信息,并为多个相应的相机光线输出时形成特征图,然后解码为最终图像。
(4): 该方法在 Okutama Action 和 UG2 等具有挑战性的无人机数据集上进行了评估,结果表明,与现有算法相比,基于 TK-Planes 的 NeRF 模型可以生成补充的无人机数据,从而提高动态场景的整体识别准确性。
- 方法:
(1):使用 NeRF(神经辐射场)在特征空间中生成新视角,以更好地捕获场景中的动态对象,如人物。
(2):采用基于网格的 NeRF,网格类似于 K-Planes,但存储的特征向量不直接编码 RGB 值,而是编码场景中的更高层次概念信息,如地面、树木和人物。
(3):使用分层网格在特征空间中操作,将场景分解为静态和动态特征,并使用图像解码器将特征图解码为最终图像。
(4):在具有挑战性的无人机数据集上评估模型,结果表明基于 TK-Planes 的 NeRF 模型可以生成补充的无人机数据,从而提高动态场景的识别准确性。
- 结论:
(1):本文提出的分层 K-Planes(TK-Planes)算法,通过在特征空间中操作特征向量,有效地解决了合成数据在无人机感知中的动态场景识别问题。 (2):创新点:TK-Planes 算法将场景分解为静态和动态特征,并使用分层网格在特征空间中操作,从而更好地捕获动态对象;性能:在 Okutama Action 和 UG2 等具有挑战性的无人机数据集上的评估结果表明,基于 TK-Planes 的 NeRF 模型可以生成补充的无人机数据,从而提高动态场景的识别准确性;工作量:TK-Planes 算法的实现和在无人机数据集上的评估需要一定的技术投入和计算资源。
点此查看论文截图



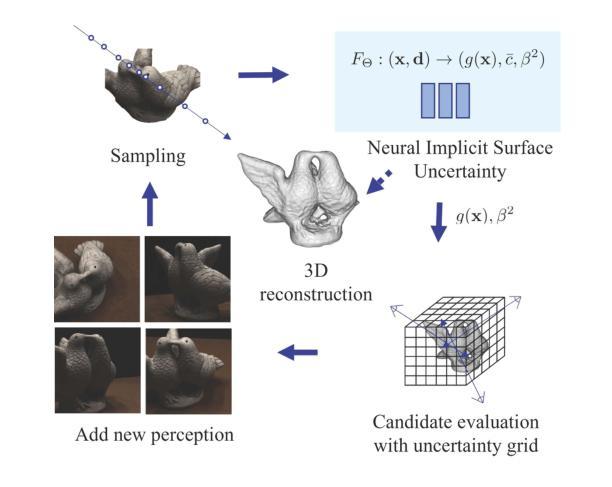
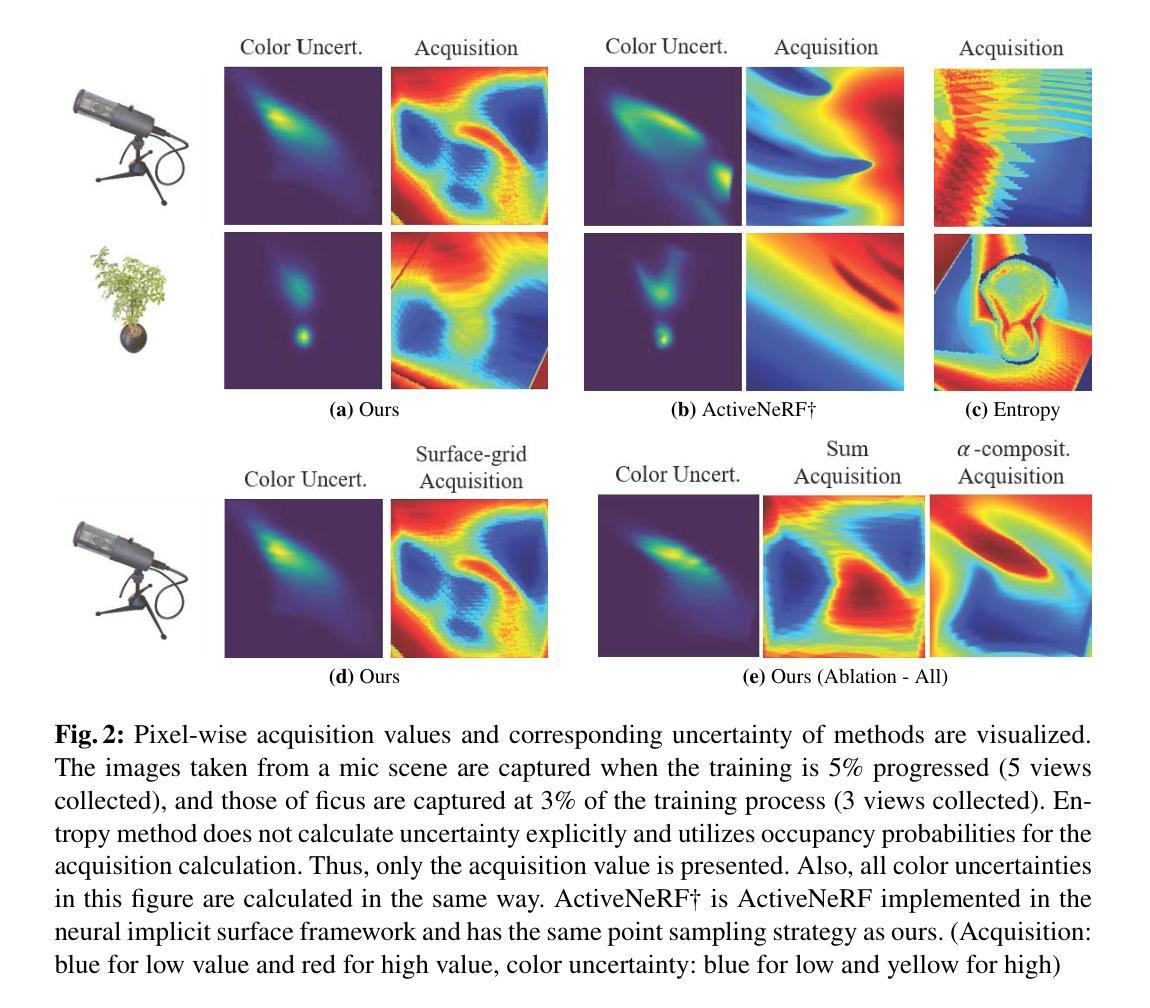
ActiveNeuS: Active 3D Reconstruction using Neural Implicit Surface Uncertainty
Authors:Hyunseo Kim, Hyeonseo Yang, Taekyung Kim, YoonSung Kim, Jin-Hwa Kim, Byoung-Tak Zhang
Active learning in 3D scene reconstruction has been widely studied, as selecting informative training views is critical for the reconstruction. Recently, Neural Radiance Fields (NeRF) variants have shown performance increases in active 3D reconstruction using image rendering or geometric uncertainty. However, the simultaneous consideration of both uncertainties in selecting informative views remains unexplored, while utilizing different types of uncertainty can reduce the bias that arises in the early training stage with sparse inputs. In this paper, we propose ActiveNeuS, which evaluates candidate views considering both uncertainties. ActiveNeuS provides a way to accumulate image rendering uncertainty while avoiding the bias that the estimated densities can introduce. ActiveNeuS computes the neural implicit surface uncertainty, providing the color uncertainty along with the surface information. It efficiently handles the bias by using the surface information and a grid, enabling the fast selection of diverse viewpoints. Our method outperforms previous works on popular datasets, Blender and DTU, showing that the views selected by ActiveNeuS significantly improve performance.
Summary
主动神经重建同时考虑图像渲染和几何不确定性,以选择信息丰富的训练视图来提高 3D 场景重建性能。
Key Takeaways
- 主动学习在 3D 场景重建中至关重要。
- NeRF 变体使用图像渲染或几何不确定性提高了主动 3D 重建的性能。
- ActiveNeuS 同时考虑了图像渲染和几何不确定性来选择信息丰富的视图。
- ActiveNeuS 积累图像渲染不确定性,同时避免估计密度引入的偏差。
- ActiveNeuS 计算神经隐式表面不确定性,提供颜色不确定性和表面信息。
- ActiveNeuS 使用表面信息和网格有效处理偏差,从而快速选择多样化的视点。
- ActiveNeuS 在 Blender 和 DTU 数据集上的表现优于以往的工作,表明 ActiveNeuS 选择的视图显著提高了性能。
- 标题:ActiveNeuS:基于神经隐式曲面不确定性的主动三维重建
- 作者:Hyunseo Kim, Hyeonseo Yang, Taekyung Kim, YoonSung Kim, Jin-Hwa Kim, Byoung-Tak Zhang
- 单位:首尔大学
- 关键词:主动学习、神经隐式曲面不确定性、曲面网格
- 论文链接:https://arxiv.org/pdf/2405.02568.pdf,Github代码链接:无
- 摘要:
方法:
(1): ActiveNeuS 提出了一种新的采集函数,该函数结合了几何重建和图像渲染的视角。 (2): ActiveNeuS 估计颜色预测的不确定性,以获取有关图像渲染质量的信息。 (3): 采集函数集成了估计的不确定性,同时不丢失几何属性。 (4): 首先,在第 4.1 节中,我们介绍了我们的采集函数,并解释了在积分过程中如何考虑曲面。 (5): 在第 4.2 节中,我们定义了 ActiveNeuS 中估计的神经隐式表面不确定性,并描述了如何在采集函数中利用不确定性。 (6): 然后,为了进行高效且稳健的计算,我们引入了存储曲面信息的曲面网格和选择多个次优视图 (NBV) 的策略(第 4.3 节)。结论:
- 极坐标投影将三维各向异性区域射影到平面,便于特征化。
- Ripmap编码通过各向异性预滤波可学习特征网格,对射影各向异性区域进行精确高效的特征化。
- 方法在合成数据集和实景数据集上均取得了最优渲染质量。
- 方法在重复结构和纹理的精细细节上表现优异。
- 方法训练时间相对较短。
- 该方法依赖于可学习特征网格。
- 该方法目前仅适用于静态场景。
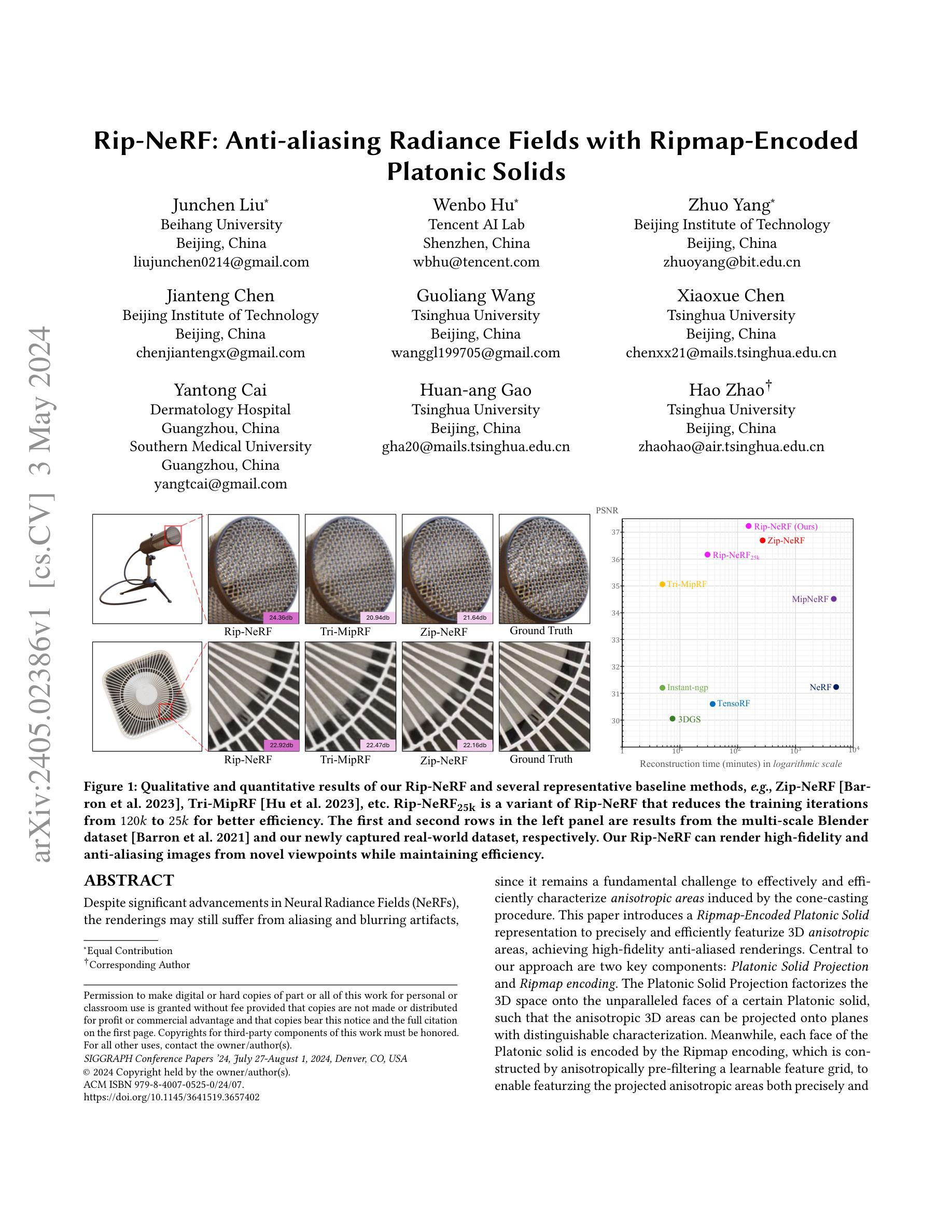
标题:Rip-NeRF:基于Ripmap编码的Platonic实体的反走样辐射场
作者:Junchen Liu, Wenbo Hu, Zhuo Yang, Jianteng Chen, Guoliang Wang, Xiaoxue Chen, Yantong Cai, Huan-ang Gao, Hao Zhao
第一作者单位:北京航空航天大学
关键词:神经辐射场(NeRFs)、反走样、Ripmap编码、Platonic实体
论文链接:https://arxiv.org/pdf/2405.02386.pdf,Github链接:None
摘要:
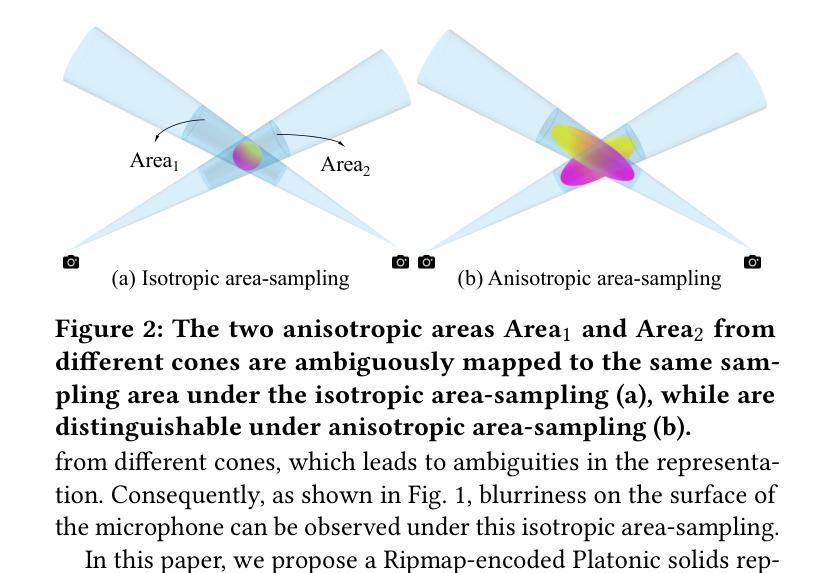
(1) 研究背景:尽管神经辐射场(NeRFs)取得了重大进展,但其渲染结果仍可能存在走样和模糊伪影,因为有效且高效地表征锥形投射过程产生的各向异性区域仍然是一个基本挑战。
(2) 过去的方法和问题:现有方法要么无法精确地表征各向异性区域,要么效率低下。
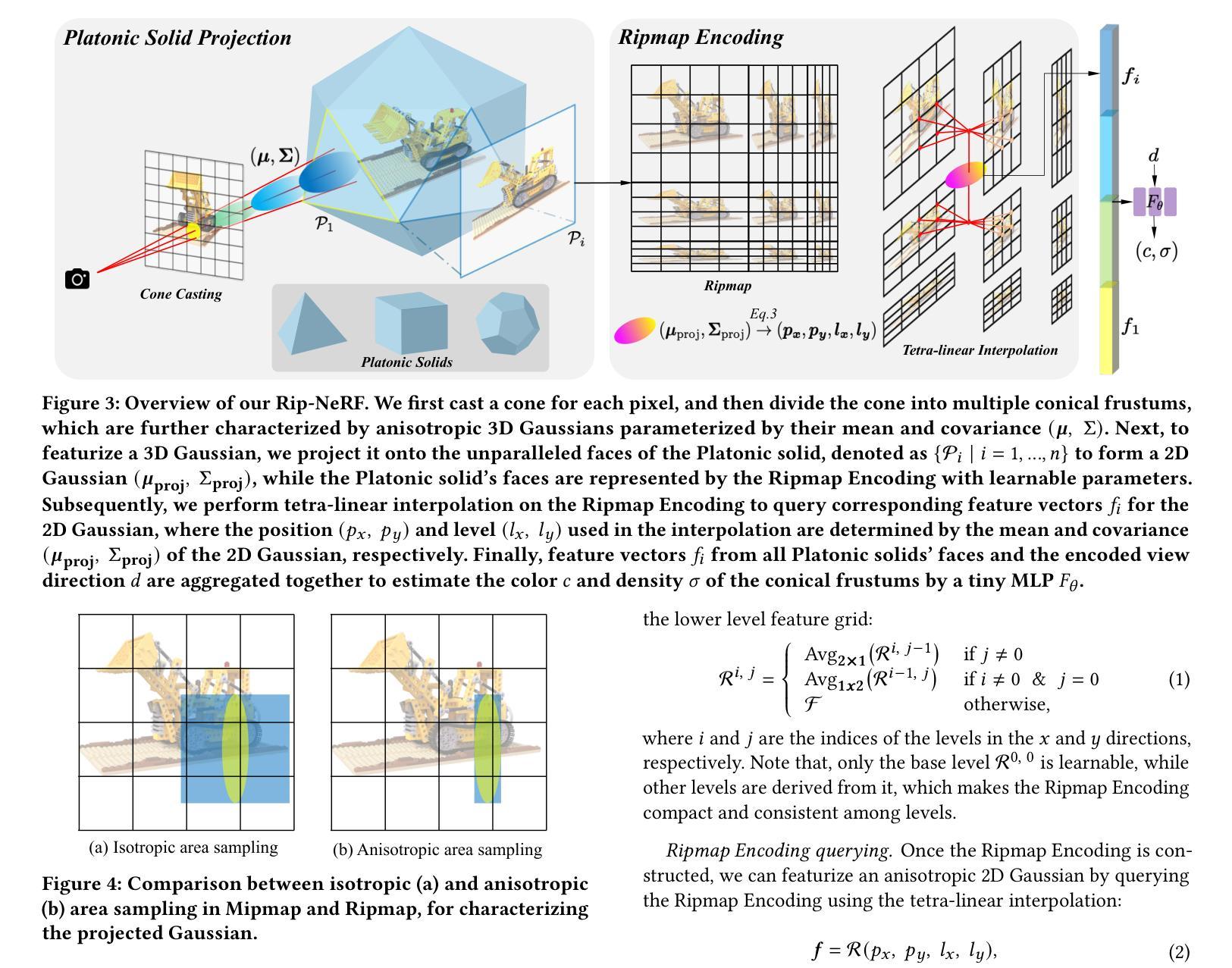
(3) 本文提出的研究方法:本文提出了一种基于Ripmap编码的Platonic实体表示,用于精确高效地表征3D各向异性区域,从而实现高保真反走样渲染。该方法的核心是两个关键组件:Platonic实体投影和Ripmap编码。Platonic实体投影将3D空间分解到特定Platonic实体的不平行面上,使得各向异性的3D区域可以投影到具有可区分特征的平面上。同时,Platonic实体的每个面都由Ripmap编码编码,该编码通过各向异性预过滤可学习的特征网格构建,以实现对投影各向异性区域的精确和高效表征。
(4) 方法性能:在多尺度Blender数据集和新捕获的真实世界数据集上,该方法在渲染质量和效率方面均优于现有方法。
方法:
</ol>
(1)研究背景:三维场景重建中的主动学习已被广泛研究,因为选择有信息的训练视图对于重建至关重要。最近,神经辐射场(NeRF)变体在使用图像渲染或几何不确定性进行主动三维重建方面表现出性能提升。然而,在选择信息视图时同时考虑两种不确定性仍然未被探索,而利用不同类型的不确定性可以减少在早期训练阶段由于输入稀疏而产生的偏差。
(2)过去的方法及其问题:传统的NeRF主动学习方法通常估计其输出中的不确定性:三维点的密度和颜色。Martin等人和Pan等人估计了颜色预测中的不确定性,方法是将颜色建模为高斯概率分布。然而,这些方法在早期训练阶段容易受到密度估计偏差的影响,这可能会导致信息视图选择不佳。
(3)提出的研究方法:本文提出了ActiveNeuS,它在评估候选视图时考虑了图像渲染不确定性和神经隐式曲面不确定性。ActiveNeuS提供了一种积累图像渲染不确定性的方法,同时避免了估计密度可能引入的偏差。ActiveNeuS计算神经隐式曲面不确定性,提供颜色不确定性和曲面信息。它通过使用曲面信息和网格有效地处理偏差,从而能够快速选择不同的视点。
(4)任务和性能:在流行的数据集Blender和DTU上,ActiveNeuS的性能优于以前的工作,表明ActiveNeuS选择的视图显著提高了性能。这些结果支持了作者的目标,即开发一种主动学习方法,该方法可以有效地选择信息视图以提高三维重建的性能。
(1):本文提出了一种有效的信息视图选择方法 ActiveNeuS,该方法同时考虑了几何重建和图像渲染的保真度。ActiveNeuS 引入了一种新的采集函数,该函数利用不确定性网格有效且稳健地利用神经隐式曲面不确定性。采集函数通过使用曲面网格并根据曲面的存在应用不同的积分策略来计算神经隐式曲面不确定性的积分。我们展示了 ActiveNeuS 的下一个最佳视图选择,与其他方法相比,它改进了网格重建和图像渲染质量。对于未来的工作,我们建议研究一种有效的方法来连接不同网络的不确定性以进行信息视图选择。此外,将 ActiveNeuS 应用于机器人主动 3D 重建中也很有趣,其中机器人手臂移动并收集数据。
(2):创新点:本文提出了一种新的采集函数,该函数同时考虑了图像渲染不确定性和神经隐式曲面不确定性,有效地提高了信息视图的选择。性能:在 Blender 和 DTU 等流行数据集上,ActiveNeuS 的性能优于以前的工作,表明 ActiveNeuS 选择的视图显着提高了性能。工作量:ActiveNeuS 的计算成本相对较高,因为它需要估计神经隐式曲面不确定性并使用曲面网格进行积分。
点此查看论文截图

Rip-NeRF: Anti-aliasing Radiance Fields with Ripmap-Encoded Platonic Solids
Authors:Junchen Liu, Wenbo Hu, Zhuo Yang, Jianteng Chen, Guoliang Wang, Xiaoxue Chen, Yantong Cai, Huan-ang Gao, Hao Zhao
Despite significant advancements in Neural Radiance Fields (NeRFs), the renderings may still suffer from aliasing and blurring artifacts, since it remains a fundamental challenge to effectively and efficiently characterize anisotropic areas induced by the cone-casting procedure. This paper introduces a Ripmap-Encoded Platonic Solid representation to precisely and efficiently featurize 3D anisotropic areas, achieving high-fidelity anti-aliasing renderings. Central to our approach are two key components: Platonic Solid Projection and Ripmap encoding. The Platonic Solid Projection factorizes the 3D space onto the unparalleled faces of a certain Platonic solid, such that the anisotropic 3D areas can be projected onto planes with distinguishable characterization. Meanwhile, each face of the Platonic solid is encoded by the Ripmap encoding, which is constructed by anisotropically pre-filtering a learnable feature grid, to enable featurzing the projected anisotropic areas both precisely and efficiently by the anisotropic area-sampling. Extensive experiments on both well-established synthetic datasets and a newly captured real-world dataset demonstrate that our Rip-NeRF attains state-of-the-art rendering quality, particularly excelling in the fine details of repetitive structures and textures, while maintaining relatively swift training times.
PDF SIGGRAPH 2024, Project page: https://junchenliu77.github.io/Rip-NeRF , Code: https://github.com/JunchenLiu77/Rip-NeRF
Summary
神经辐射场(NeRF)通过极坐标投影将三维各向异性区域射影到平面,再利用Ripmap编码对各平面进行编码,进而解决NeRF抗锯齿渲染中的混叠和模糊问题。
Key Takeaways
(1):基于Ripmap编码的Platonic实体投影,将3D空间分解到Platonic实体的不平行面上,将各向异性的3D区域投影到具有可区分特征的平面上。
(2):Platonic实体的每个面由Ripmap编码编码,该编码通过各向异性预过滤可学习的特征网格构建,以实现对投影各向异性区域的精确和高效表征。
(3):采用混合表示,包括显式和隐式表示,既能保证效率,又能保证灵活性。
(4):采用多采样和面积采样对圆锥截体进行特征化,其中面积采样采用各向异性3D高斯函数对圆锥截体进行表征,再利用提出的Platonic实体投影和Ripmap编码进行特征化。
(5):利用MLP估计圆锥截体的颜色和密度,并通过体积渲染渲染像素颜色。
(6):采用光度损失函数,对渲染图像和观测图像进行端到端优化。
8. 结论:
(1):本工作提出了一种基于Ripmap编码的Platonic实体表示,用于神经辐射场,称为Rip-NeRF。Rip-NeRF可以渲染高保真抗锯齿图像,同时保持效率,这得益于提出的Platonic实体投影和Ripmap编码。Platonic实体投影将3D空间分解到特定Platonic实体的不平行面上,使得各向异性的3D区域可以投影到具有可区分特征的平面上。Ripmap编码通过各向异性预过滤可学习的特征网格构建,能够对投影的各向异性区域进行精确高效的特征化。这两个组件协同工作,对各向异性的3D区域进行精确高效的特征化。它在合成数据集和真实世界捕捉上都实现了最先进的渲染质量,特别是在结构和纹理的精细细节方面表现出色,这验证了所提出的Platonic实体投影和Ripmap编码的有效性。
(2):创新点:提出了基于Ripmap编码的Platonic实体投影和Ripmap编码,用于对各向异性的3D区域进行精确高效的特征化。
性能:在渲染质量和效率方面均优于现有方法,特别是在精细细节方面表现出色。
工作量:与现有方法相比,工作量略大,因为需要对Platonic实体投影和Ripmap编码进行预处理。
点此查看论文截图

 wechat
wechat- alipay







