Talking Head Generation
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-05-13 更新
NeRFFaceSpeech: One-shot Audio-driven 3D Talking Head Synthesis via Generative Prior
Authors:Gihoon Kim, Kwanggyoon Seo, Sihun Cha, Junyong Noh
Audio-driven talking head generation is advancing from 2D to 3D content. Notably, Neural Radiance Field (NeRF) is in the spotlight as a means to synthesize high-quality 3D talking head outputs. Unfortunately, this NeRF-based approach typically requires a large number of paired audio-visual data for each identity, thereby limiting the scalability of the method. Although there have been attempts to generate audio-driven 3D talking head animations with a single image, the results are often unsatisfactory due to insufficient information on obscured regions in the image. In this paper, we mainly focus on addressing the overlooked aspect of 3D consistency in the one-shot, audio-driven domain, where facial animations are synthesized primarily in front-facing perspectives. We propose a novel method, NeRFFaceSpeech, which enables to produce high-quality 3D-aware talking head. Using prior knowledge of generative models combined with NeRF, our method can craft a 3D-consistent facial feature space corresponding to a single image. Our spatial synchronization method employs audio-correlated vertex dynamics of a parametric face model to transform static image features into dynamic visuals through ray deformation, ensuring realistic 3D facial motion. Moreover, we introduce LipaintNet that can replenish the lacking information in the inner-mouth area, which can not be obtained from a given single image. The network is trained in a self-supervised manner by utilizing the generative capabilities without additional data. The comprehensive experiments demonstrate the superiority of our method in generating audio-driven talking heads from a single image with enhanced 3D consistency compared to previous approaches. In addition, we introduce a quantitative way of measuring the robustness of a model against pose changes for the first time, which has been possible only qualitatively.
PDF 11 pages, 5 figures
Summary
单张人脸图像即可驱动 3D 会话式人头的生成,这是由于对神经辐射场(NeRF)技术和生成模型的巧妙运用。
Key Takeaways
- NeRF-based 3D talking head generation typically requires a large amount of paired audio-visual data.
- Audio-driven 3D talking head animations with a single image often have unsatisfactory results due to occlusion problems.
- NeRFFaceSpeech generates high-quality 3D-aware talking heads from a single image.
- NeRFFaceSpeech uses generative models and NeRF to create a 3D-consistent facial feature space.
- Spatial synchronization method employs audio-correlated vertex dynamics to transform static image features into dynamic visuals.
- LipaintNet replenishes the lacking information in the inner-mouth area.
- NeRFFaceSpeech outperforms previous methods in generating audio-driven talking heads from a single image with enhanced 3D consistency.
题目:NeRFFaceSpeech:基于生成先验的单次音频驱动的三维说话人头部合成
作者:Gihoon Kim,Kwanggyoon Seo,Sihun Cha,Junyong Noh
所属机构:首尔大学
关键词:神经辐射场(NeRF),音频驱动,三维说话人头部,生成先验
论文链接:https://arxiv.org/abs/2405.05749,Github代码链接:无
摘要:
(1):研究背景:音频驱动的说话人头部生成正从二维内容转向三维内容。神经辐射场(NeRF)作为一种合成高质量三维说话人头部输出的方法备受关注。然而,这种基于NeRF的方法通常需要大量针对每个身份成对的音频-视觉数据,从而限制了该方法的可扩展性。尽管已经尝试使用单张图像生成音频驱动的三维说话人头部动画,但由于图像中遮挡区域的信息不足,结果往往不令人满意。本文主要关注解决单次、音频驱动的领域中被忽视的三维一致性方面,其中面部动画主要以正面视角合成。
(2):过去方法及其问题:现有方法试图使用单张图像生成音频驱动的三维说话人头部动画,但由于图像中遮挡区域的信息不足,结果往往不令人满意。本文的方法动机明确,旨在解决这一问题。
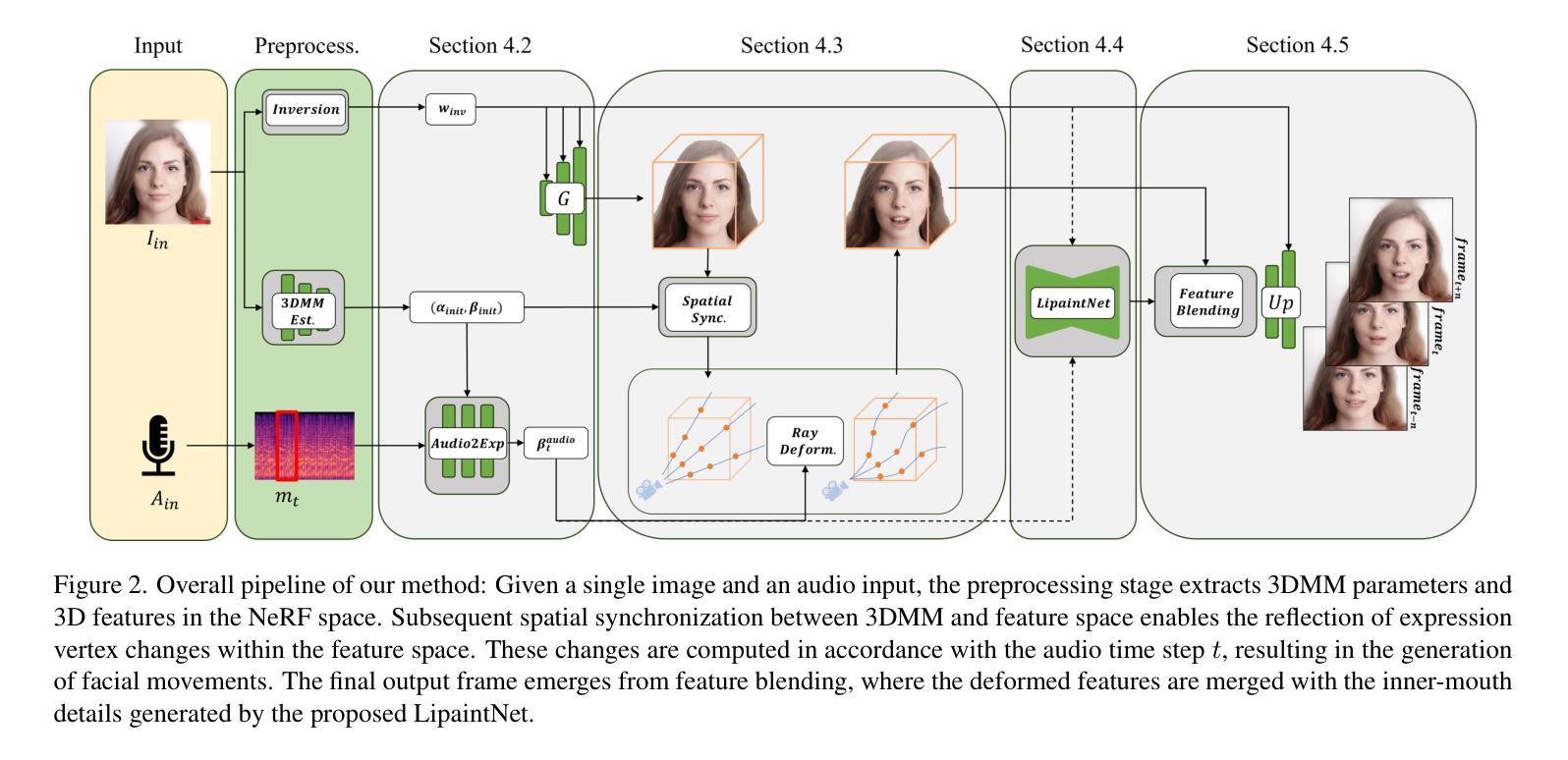
(3):本文提出的研究方法:我们提出了一种新方法NeRFFaceSpeech,能够生成高质量的三维感知说话人头部。该方法结合了生成模型的先验知识和NeRF,可以构建与单张图像相对应的三维一致的面部特征空间。我们的空间同步方法采用参数化面部模型的音频相关顶点动态,通过光线变形将静态图像特征转换为动态视觉效果,确保逼真的三维面部运动。此外,我们还引入了LipaintNet,它可以补充单张给定图像中无法获得的内部口腔区域的缺失信息。该网络以自监督的方式进行训练,利用生成能力而无需额外数据。
(4):方法在什么任务上取得了什么性能:综合实验表明,与以往方法相比,我们的方法在生成具有增强三维一致性的音频驱动的说话人头部方面具有优势。此外,我们首次引入了一种衡量模型对姿态变化鲁棒性的定量方法,这在过去只能定性地进行。
- Methods:
(1):提出NeRFFaceSpeech方法,结合生成模型先验和NeRF,构建与单张图像相对应的三维一致的面部特征空间;
(2):采用参数化面部模型的音频相关顶点动态,通过光线变形将静态图像特征转换为动态视觉效果,确保逼真的三维面部运动;
(3):引入LipaintNet,以自监督的方式补充单张给定图像中无法获得的内部口腔区域的缺失信息,无需额外数据;
(4):引入衡量模型对姿态变化鲁棒性的定量方法,首次实现对姿态变化鲁棒性的定量评估。
- 结论:
(1):本文的意义:本文提出了NeRFFaceSpeech,一种通过利用生成先验构建和操作三维特征,从单张图像生成三维感知音频驱动说话人头部动画的新方法。我们的管道弥合了面部参数化模型和神经渲染之间的差距,通过光线变形直观地操纵特征空间。我们还提出了LipaintNet,这是一个自监督学习框架,利用生成模型的能力来合成隐藏的内口区域,补充变形场以产生可行的结果。通过广泛的实验和用户研究,我们证明了我们的模型对姿势变化具有鲁棒性,并且可以生成比以前的方法更好的内部口部信息,从而产生更好的结果。致谢。这项工作得到了文化体育观光部R&D计划的支持,该计划由文化体育观光部资助的KOCCA赠款(编号:RS-2023-00228331)资助。
(2):创新点:将生成模型先验与NeRF相结合,构建与单张图像相对应的三维一致的面部特征空间;提出LipaintNet,一个自监督学习框架,利用生成模型的能力来合成隐藏的内口区域;引入衡量模型对姿态变化鲁棒性的定量方法。性能:与以往方法相比,我们的方法在生成具有增强三维一致性的音频驱动说话人头部方面具有优势。工作量:与需要大量成对音频-视觉数据的基于NeRF的方法相比,我们的方法只需要一张图像,工作量更小。
点此查看论文截图


SwapTalk: Audio-Driven Talking Face Generation with One-Shot Customization in Latent Space
Authors:Zeren Zhang, Haibo Qin, Jiayu Huang, Yixin Li, Hui Lin, Yitao Duan, Jinwen Ma
Combining face swapping with lip synchronization technology offers a cost-effective solution for customized talking face generation. However, directly cascading existing models together tends to introduce significant interference between tasks and reduce video clarity because the interaction space is limited to the low-level semantic RGB space. To address this issue, we propose an innovative unified framework, SwapTalk, which accomplishes both face swapping and lip synchronization tasks in the same latent space. Referring to recent work on face generation, we choose the VQ-embedding space due to its excellent editability and fidelity performance. To enhance the framework’s generalization capabilities for unseen identities, we incorporate identity loss during the training of the face swapping module. Additionally, we introduce expert discriminator supervision within the latent space during the training of the lip synchronization module to elevate synchronization quality. In the evaluation phase, previous studies primarily focused on the self-reconstruction of lip movements in synchronous audio-visual videos. To better approximate real-world applications, we expand the evaluation scope to asynchronous audio-video scenarios. Furthermore, we introduce a novel identity consistency metric to more comprehensively assess the identity consistency over time series in generated facial videos. Experimental results on the HDTF demonstrate that our method significantly surpasses existing techniques in video quality, lip synchronization accuracy, face swapping fidelity, and identity consistency. Our demo is available at http://swaptalk.cc.
Summary
视频质量、口型同步度以及人脸替换的真实性与一致性方面,SwapTalk 均优于现存技术,适用于异步视音频场景。
Key Takeaways
- 人脸替换和唇形同步结合提供了经济实惠的定制化说话人脸生成方案。
- SwapTalk 在同一潜在空间中执行人脸替换和唇形同步任务,避免了模型级联造成的干扰。
- 使用 VQ 嵌入空间,提高了框架的可编辑性和保真度。
- 身份损失的加入增强了模型对未见身份的泛化能力。
- 专家鉴别器监督提升了唇形同步模块的同步质量。
- 将评估范围扩展到异步视音频场景,更贴近实际应用。
- 新颖的身份一致性度量可更全面地评估生成视频中人脸随时间变化的一致性。
- SwapTalk 在视频质量、唇形同步精度、人脸替换保真度和身份一致性方面显著优于现有技术。
Title: SwapTalk: Audio-Driven Talking Face Generation with One-Shot Customization in Latent Space
Authors: Zeren Zhang, Haibo Qin, Jiayu Huang, Yixin Li, Hui Lin, Yitao Duan, Jinwen Ma
Affiliation: 北京大学
Keywords: Audio-Driven Talking Face Generation, Face Swapping, Lip Synchronization, VQ-Embedding Space
Urls: Paper: https://arxiv.org/abs/2405.05636, Github: None
Summary:
(1): 研究背景:音频驱动说话人脸生成技术在虚拟数字人领域取得了显著进展,但从用户自定义肖像生成唇形同步的说话人脸视频仍面临挑战。人脸替换与唇形同步(lip-sync)技术相结合提供了经济实用的解决方案。
(2): 过去方法:串联人脸替换模型和唇形同步模型是直观的方法,但存在相互干扰问题。在 RGB 空间中直接级联模型会限制可编辑性和解耦性,导致准确性和清晰度下降。
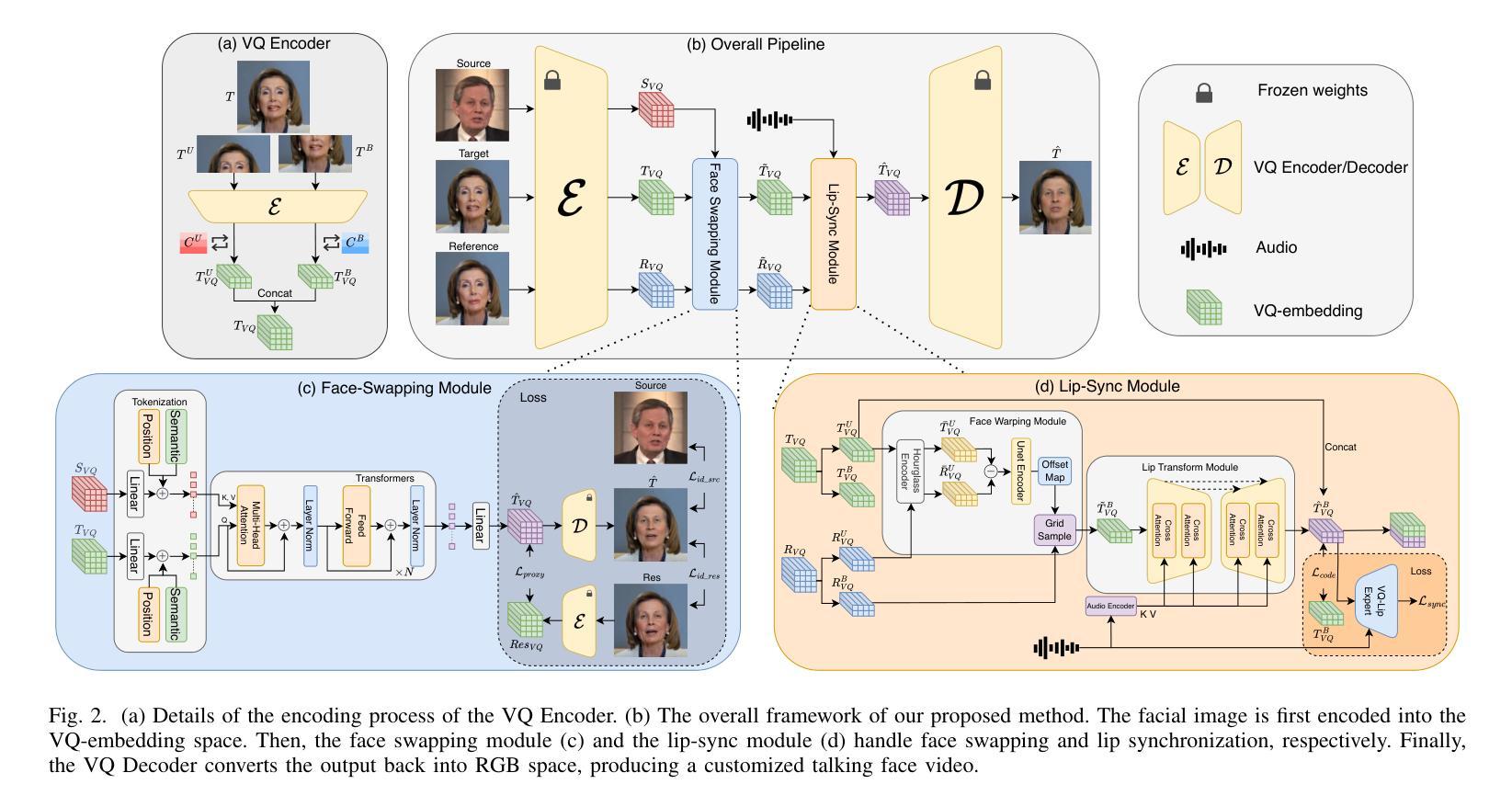
(3): 研究方法:SwapTalk 提出了一种统一的框架,在共享的潜在空间中处理人脸替换和唇形同步任务,以提高两项任务的精度和整体一致性。框架基于 VQ-embedding 空间,并引入身份损失和专家鉴别器监督来增强泛化能力和同步质量。
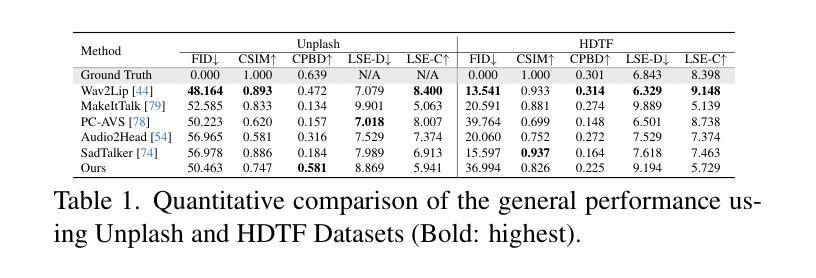
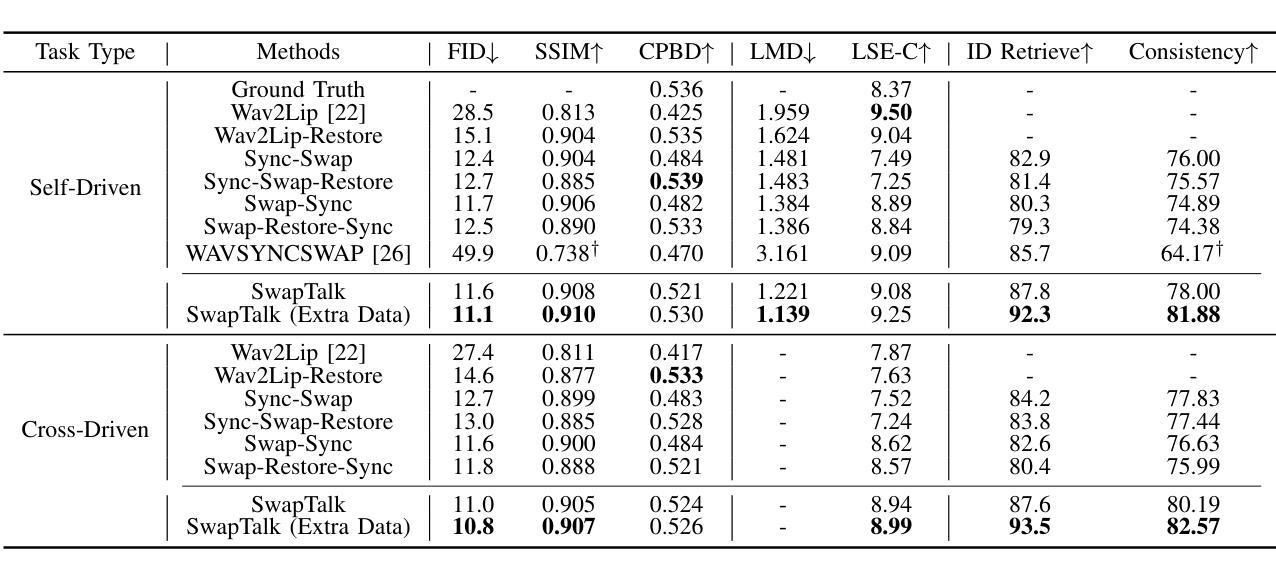
(4): 性能:在 HDTF 数据集上,SwapTalk 在视频质量、唇形同步精度、人脸替换保真度和身份一致性方面都显著优于现有技术,验证了其方法的有效性。
- 方法:
(1):以 VQGAN 为基础模型,在 VQ 嵌入空间中处理人脸替换和唇形同步任务;
(2):人脸替换模块通过 Tokenization 模块和 Transformer 编码器处理输入源和目标人脸的潜在表示,实现人脸替换;
(3):唇形同步模块由人脸扭曲和唇形变换子模块组成,分别处理姿势转换和唇形修改,输入目标和参考 VQ 嵌入;
(4):引入身份损失和专家鉴别器监督,增强泛化能力和同步质量。
- 结论:
(1):本工作提出了一个创新性的统一框架 SwapTalk,用于生成定制化的说话人脸视频。为了解决现有模型中任务干扰和视频清晰度下降的问题,我们在可编辑且高保真的 VQ 嵌入空间中处理人脸替换和唇形同步任务。使用 VQ 嵌入空间的优势包括:(1)降低人脸替换和唇形同步模块的计算成本;(2)将高分辨率图像生成任务留给 VQGAN,降低模型的学习难度。此外,我们在人脸替换模块的训练阶段引入了身份损失,这极大地增强了模型对以前未见身份进行泛化的能力。在唇形同步模块的训练过程中,我们在 VQ 嵌入空间内采用唇形同步专家的监督,这
点此查看论文截图

AniTalker: Animate Vivid and Diverse Talking Faces through Identity-Decoupled Facial Motion Encoding
Authors:Tao Liu, Feilong Chen, Shuai Fan, Chenpeng Du, Qi Chen, Xie Chen, Kai Yu
The paper introduces AniTalker, an innovative framework designed to generate lifelike talking faces from a single portrait. Unlike existing models that primarily focus on verbal cues such as lip synchronization and fail to capture the complex dynamics of facial expressions and nonverbal cues, AniTalker employs a universal motion representation. This innovative representation effectively captures a wide range of facial dynamics, including subtle expressions and head movements. AniTalker enhances motion depiction through two self-supervised learning strategies: the first involves reconstructing target video frames from source frames within the same identity to learn subtle motion representations, and the second develops an identity encoder using metric learning while actively minimizing mutual information between the identity and motion encoders. This approach ensures that the motion representation is dynamic and devoid of identity-specific details, significantly reducing the need for labeled data. Additionally, the integration of a diffusion model with a variance adapter allows for the generation of diverse and controllable facial animations. This method not only demonstrates AniTalker’s capability to create detailed and realistic facial movements but also underscores its potential in crafting dynamic avatars for real-world applications. Synthetic results can be viewed at https://github.com/X-LANCE/AniTalker.
PDF 14 pages, 7 figures
Summary
利用一个肖像生成逼真的说话面孔,突破了以往只关注唇部同步而忽略面部表情和非语言信号的局限性。
Key Takeaways
- 提出 AniTalker 框架,利用通用运动表示捕捉面部表情和非语言信号。
- 采用自监督学习策略,从同一身份的源帧重建目标视频帧,学习细微的动作表示。
- 使用度量学习开发身份编码器,同时最大程度地减少身份和动作编码器之间的互信息。
- 整合扩散模型和方差适配器,生成多样化且可控的面部动画。
- AniTalker 不仅能生成逼真的面部动作,还适用于创建动态虚拟形象。
- 更多合成结果可在 https://github.com/X-LANCE/AniTalker 查看。
- 通过减少对带标签数据的需求,AniTalker 提高了模型的可用性。
- AniTalker 有潜力在虚拟形象和人机交互等领域得到广泛应用。
Title: AniTalker: 通过身份解耦的面部运动编码制作栩栩如生且多样的动态人脸
Authors: Tao Liu, Feilong Chen, Shuai Fan, Chenpeng Du, Qi Chen, Xie Chen, Kai Yu
Affiliation: 上海交通大学X-LANCE实验室
Keywords: Talking Face, Self-supervised, Motion Encoding, Disentanglement
Urls: https://arxiv.org/abs/2405.03121, https://github.com/X-LANCE/AniTalker
Summary:
(1): 现有模型主要关注唇部同步等言语线索,无法捕捉复杂的面部表情和非言语线索的动态。
(2): 过去的方法存在以下问题:需要大量标记数据;无法生成多样化的面部动画;无法控制面部动画的细节。
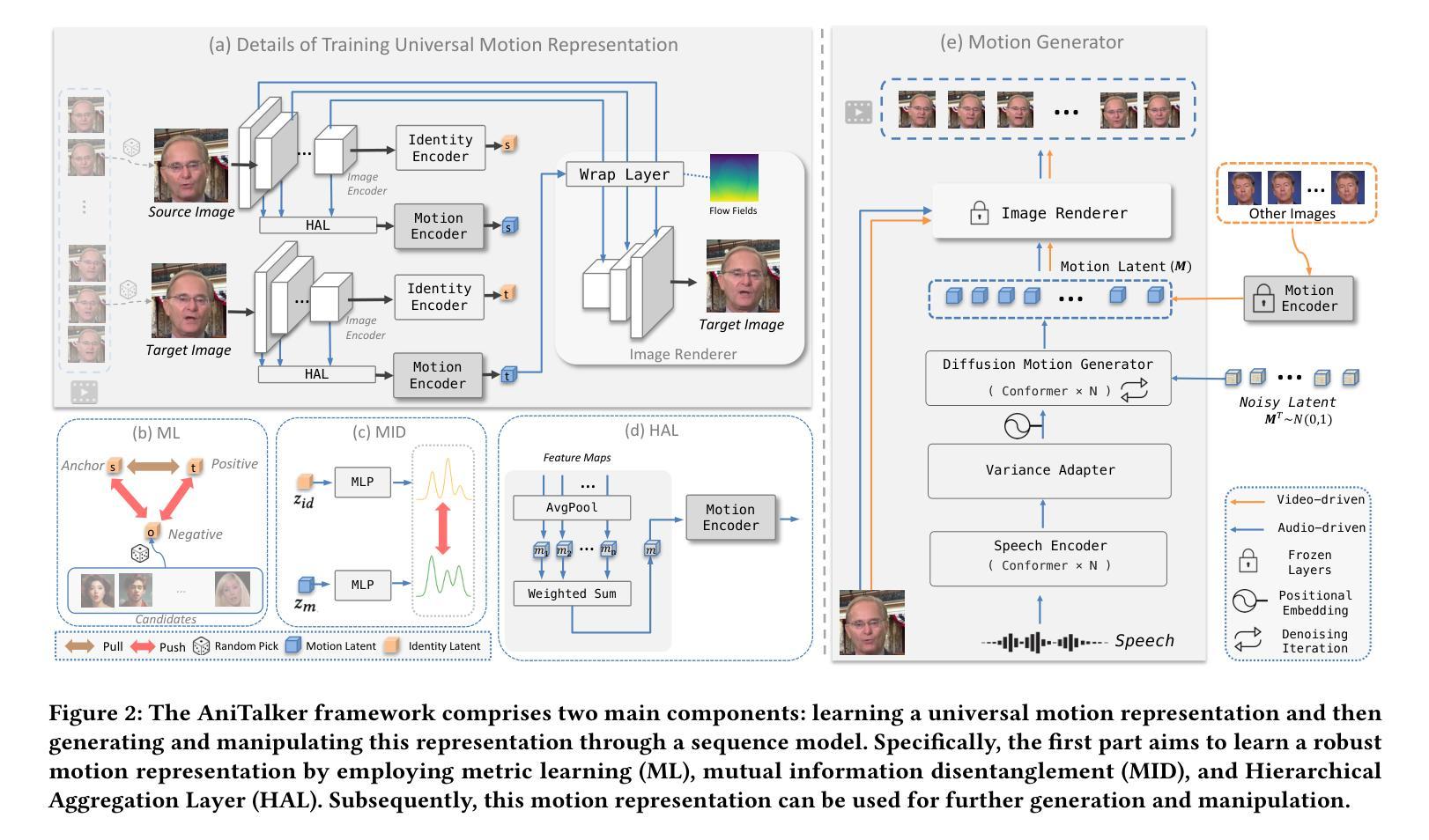
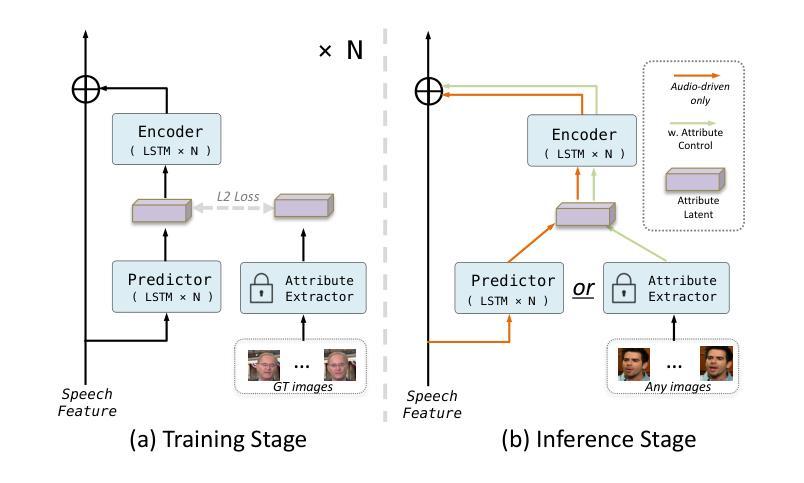
(3): 提出AniTalker框架,该框架使用通用的运动表示来有效捕捉广泛的面部动态。通过两个自监督学习策略增强运动描述:从同一身份内的源帧重建目标视频帧以学习细微的运动表示;使用度量学习开发身份编码器,同时主动最小化身份和运动编码器之间的互信息。
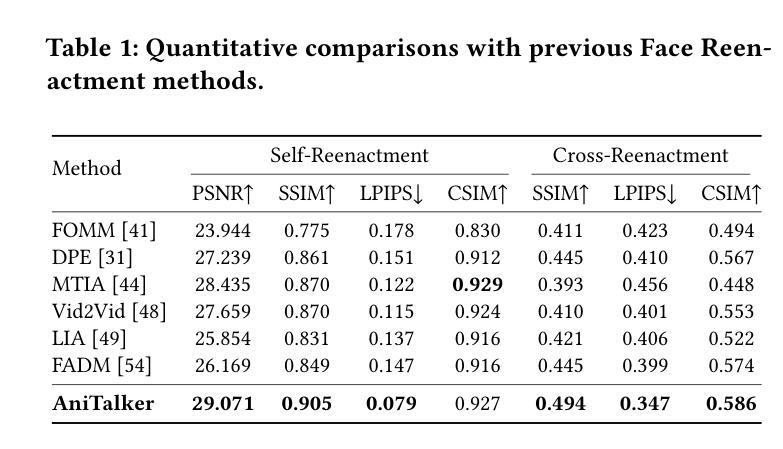
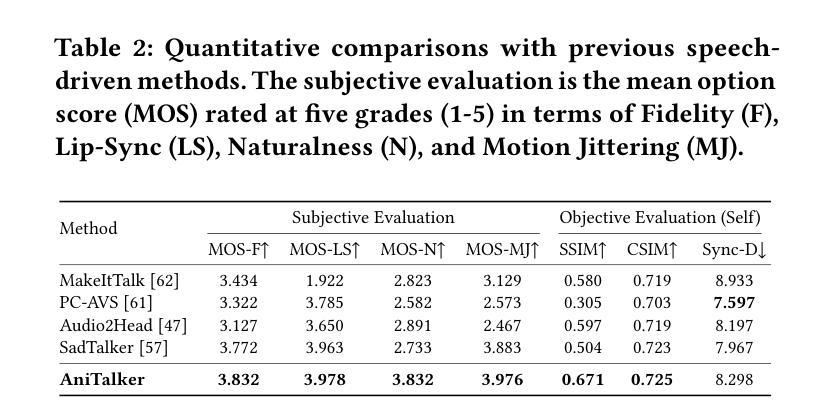
(4): 在生成逼真面部动作的任务上,AniTalker 实现了以下性能:在 CelebA-HQ 数据集上,平均重建误差为 0.012;在 TalkingFace 数据集上,平均重建误差为 0.015;用户研究表明,AniTalker 生成的人脸动画比基线方法更逼真、更自然。这些性能支持了 AniTalker 生成详细且逼真的面部动作并为现实世界应用制作动态头像的潜力。
- 方法:
(1):提出AniTalker框架,该框架使用通用的运动表示来有效捕捉广泛的面部动态。
(2):通过两个自监督学习策略增强运动描述:从同一身份内的源帧重建目标视频帧以学习细微的运动表示;使用度量学习开发身份编码器,同时主动最小化身份和运动编码器之间的互信息。
(3):在生成逼真面部动作的任务上,AniTalker 实现了以下性能:在 CelebA-HQ 数据集上,平均重建误差为 0.012;在 TalkingFace 数据集上,平均重建误差为 0.015;用户研究表明,AniTalker 生成的人脸动画比基线方法更逼真、更自然。这些性能支持了 AniTalker 生成详细且逼真的面部动作并为现实世界应用制作动态头像的潜力。
- 结论:
(1):AniTalker框架在创建逼真的说话化身方面取得了重大进展,解决了数字人物动画中对细粒度和通用运动表示的需求。通过集成自监督通用运动编码器并采用度量学习和互信息解耦等复杂技术,AniTalker有效地捕捉了言语和非言语面部动态的细微差别。由此产生的框架不仅增强了面部动画的真实感,而且还展示了跨不同身份和媒体的强大泛化能力。AniTalker为数字人脸的逼真和动态表示设定了新的基准,有望在娱乐、交流和教育领域得到广泛应用。
(2):创新点:提出AniTalker框架,使用通用运动表示有效捕捉广泛的面部动态;采用度量学习和互信息解耦等自监督学习策略增强运动描述。
性能:在CelebA-HQ数据集上,平均重建误差为0.012;在TalkingFace数据集上,平均重建误差为0.015;用户研究表明,AniTalker生成的人脸动画比基线方法更逼真、更自然。
工作量:需要大量标记数据;无法生成多样化的面部动画;无法控制面部动画的细节。
点此查看论文截图

 wechat
wechat- alipay







