元宇宙/虚拟人
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-05-22 更新
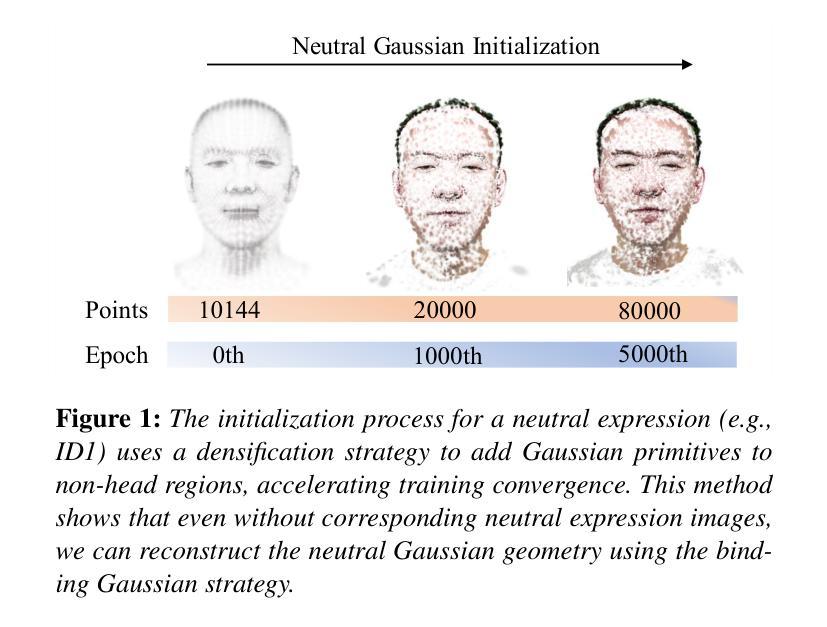
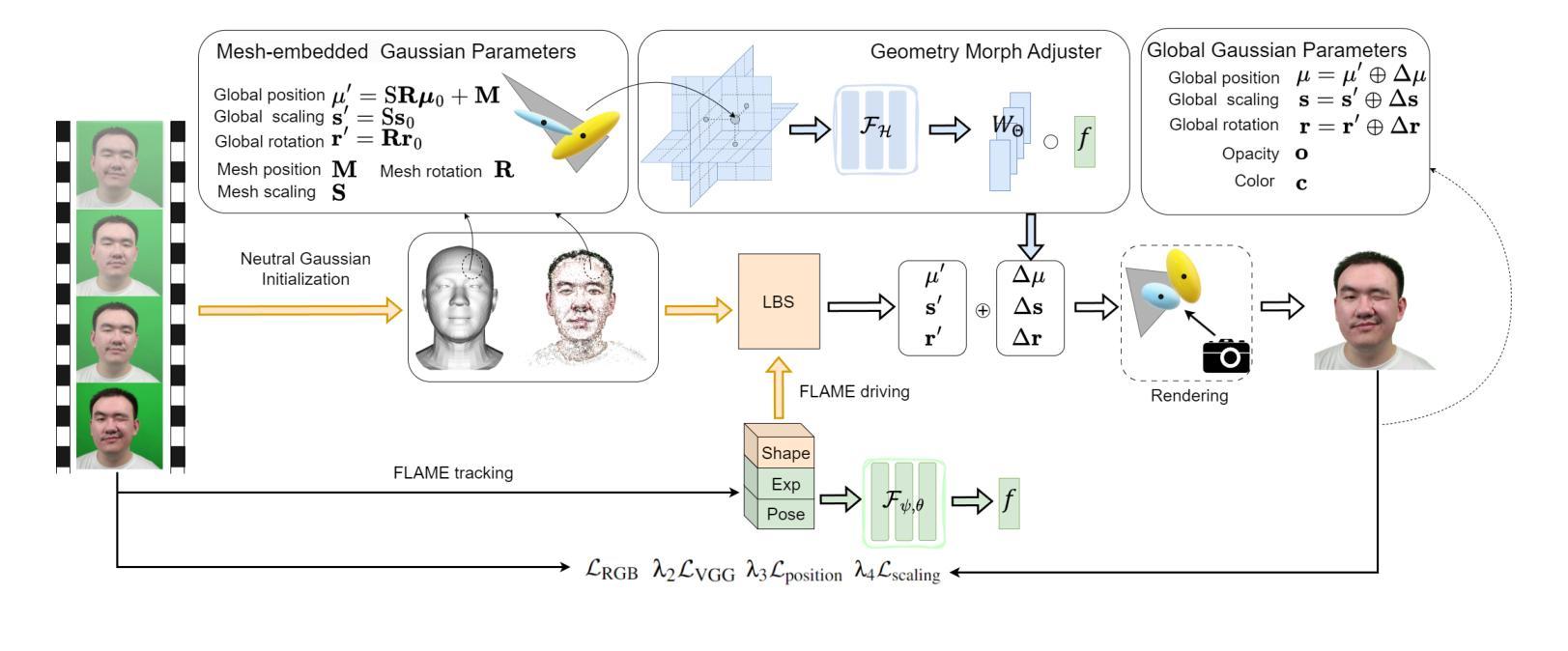
GGAvatar: Geometric Adjustment of Gaussian Head Avatar
Authors:Xinyang Li, Jiaxin Wang, Yixin Xuan, Gongxin Yao, Yu Pan
We propose GGAvatar, a novel 3D avatar representation designed to robustly model dynamic head avatars with complex identities and deformations. GGAvatar employs a coarse-to-fine structure, featuring two core modules: Neutral Gaussian Initialization Module and Geometry Morph Adjuster. Neutral Gaussian Initialization Module pairs Gaussian primitives with deformable triangular meshes, employing an adaptive density control strategy to model the geometric structure of the target subject with neutral expressions. Geometry Morph Adjuster introduces deformation bases for each Gaussian in global space, creating fine-grained low-dimensional representations of deformation behaviors to address the Linear Blend Skinning formula’s limitations effectively. Extensive experiments show that GGAvatar can produce high-fidelity renderings, outperforming state-of-the-art methods in visual quality and quantitative metrics.
PDF 9 pages, 5 figures
Summary
GGAvatar,一种新颖的3D虚拟形象表示,旨在稳健地塑造带有复杂特征和形变的动态头部虚拟形象。
Key Takeaways
- GGAvatar 采用了粗到细的结构,包括两个核心模块:中性高斯初始化模块和几何变形调节器。
- 中性高斯初始化模块将高斯基本体与可变形的三角形网格配对,采用自适应密度控制策略来模拟目标对象在中性表情下的几何结构。
- 几何变形调节器为全局空间中的每个高斯体引入形变基础,创建了细粒度、低维的形变行为表示,有效解决了线性混合蒙皮配方的局限性。
- 大量实验表明,GGAvatar 可以产生高保真渲染,在视觉质量和定量指标上优于最先进的方法。
标题:GGAvatar:高斯头部头像的几何调整
作者:Xinyang Li, Jiaxin Wang, Yixin Xuan, Gongxin Yao, Yu Pan
单位:浙江大学
关键词:3D Avatar、Gaussian Primitives、Geometric Deformation、Neutral Expression Initialization、Morph Adjuster
论文链接:https://arxiv.org/abs/2405.11993v1,Github:None
摘要:
(1):研究背景:创建高保真数字头像对于元宇宙和各种应用至关重要,但将这些头像推广到未见过的姿势或表情仍然是一个挑战。
(2):过去方法:3DMM技术或神经隐式表示,但前者缺乏结构灵活性,后者训练和渲染效率低。
(3):研究方法:提出GGAvatar,一种新的3D头像表示,它采用粗到细的结构,包括中性高斯初始化模块和几何变形调整器,分别用于对目标对象的中性表情几何结构建模和引入变形基以有效解决线性混合蒙皮公式的局限性。
(4):任务和性能:在高保真渲染任务上,GGAvatar优于最先进的方法,在视觉质量和定量指标上都取得了更好的性能,支持其目标。
- 方法:
(1):利用离散高斯基元(Gaussian primitives)对目标对象的中性表情几何结构建模,初始化3D头像;
(2):引入变形基,有效解决线性混合蒙皮公式(Linear Blending Skinning)的局限性,实现精细变形;
(3):通过多分辨率三平面存储头部周围的高频空间信息,学习额外的基,实现高精度变形;
(4):使用L1损失、D-SSIM损失和感知损失监督训练,并添加位置和缩放正则化项,保证高斯基元的合理性。
- 结论:
(1):本工作提出了一种新颖的3D头像表示GGAvatar,解决了现有方法在未见过的姿势或表情下的推广问题,为元宇宙和各种应用中的高保真数字头像创建提供了新的途径。
(2):创新点:提出了一种粗到细的结构,包括中性高斯初始化模块和几何变形调整器,分别用于对目标对象的中性表情几何结构建模和引入变形基以有效解决线性混合蒙皮公式的局限性。 性能:在高保真渲染任务上优于最先进的方法,在视觉质量和定量指标上都取得了更好的性能。 工作量:需要离散高斯基元对目标对象的中性表情几何结构建模,引入变形基,学习额外的基,并使用L1损失、D-SSIM损失和感知损失监督训练,工作量较大。
点此查看论文截图




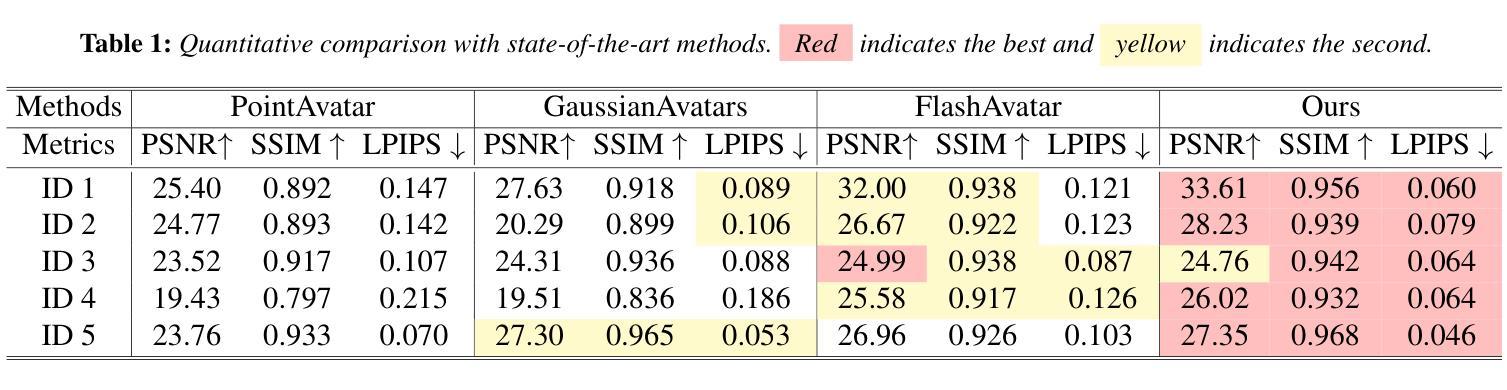
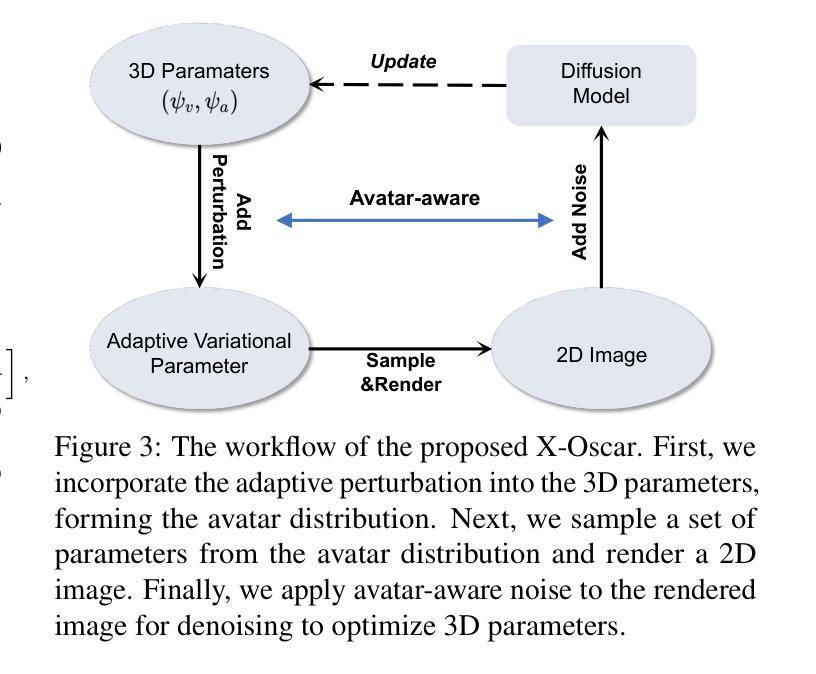
Title: 动作化身:生成具有任意动作的人类和动物化身
Authors: Zeyu Zhang, Yiran Wang, Biao Wu, Shuo Chen, Zhiyuan Zhang, Shiya Huang, Wenbo Zhang, Meng Fang, Ling Chen, Yang Zhao
Affiliation: 澳大利亚国立大学
Keywords: Motion Avatar, LLM planner, Zoo-300K, Animal motion dataset
Urls: https://steve-zeyu-zhang.github.io/MotionAvatar, Github: https://github.com/steve-zeyu-zhang/MotionAvatar
Summary:
(1): 近年来,人们对创建 3D 化身和动作产生了浓厚的兴趣,这得益于它们在电影制作、视频游戏、AR/VR 和人机交互等领域的广泛应用。然而,目前的研究主要集中在生成 3D 化身网格或产生动作序列,而将这两个方面集成在一起仍然是一个持续的挑战。此外,虽然化身和动作生成主要针对人类,但由于缺乏训练数据和方法,将这些技术扩展到动物仍然是一个重大挑战。
(2): 过去的方法要么专注于生成 3D 化身网格,要么专注于生成动作序列,但将这两个方面集成在一起仍然是一个挑战。此外,现有的方法主要针对人类,而将这些技术扩展到动物仍然存在困难。
(3): 本文提出了一种名为 Motion Avatar 的基于代理的新方法,它允许通过文本查询自动生成具有动作的高质量可定制人类和动物化身。该方法极大地推进了动态 3D 角色生成的进展。此外,我们引入了一个 LLM 规划器来协调动作和化身生成,它将判别规划转换为可定制的问答方式。最后,我们提出了一个名为 Zoo-300K 的动物动作数据集,其中包含大约 300,000 个跨越 65 个动物类别的文本-动作对及其构建管道 ZooGen,它为社区提供了宝贵的资源。
(4): 在生成具有任意动作的人类和动物化身方面,Motion Avatar 实现了最先进的性能。该方法在各种任务上都取得了出色的效果,包括动作生成、化身生成和动作到化身的重定向。这些结果证明了该方法在创建逼真且可定制的 3D 角色方面的潜力。
- 方法:
(1):基于代理的Motion Avatar方法,通过文本查询自动生成具有动作的高质量可定制人类和动物化身;
(2):LLM规划器协调动作和化身生成,将判别规划转换为可定制的问答方式;
(3):Zoo-300K动物动作数据集包含约300,000个跨越65个动物类别的文本-动作对;
(4):Motion Avatar在生成具有任意动作的人类和动物化身方面实现了最先进的性能,在动作生成、化身生成和动作到化身的重定向等各种任务上取得了出色的效果。
- 结论:
(1):本研究通过提出创新的解决方案,解决了动态 3D 化身生成中的持续挑战。我们引入了 Motion Avatar,一种新颖的基于代理的方法,它使我们能够根据文本查询自动创建具有动态动作的高质量可定制人类和动物化身,从而极大地推进了该领域的发展。此外,我们的 LLM 规划器促进了动作和化身生成的协调,增强了动态化身任务中的适应性和可用性。此外,Zoo-300K 数据集的开发以及 ZooGen 管道为研究人员提供了宝贵的资源,强调了我们致力于推进跨各种领域的动态化身生成。
(2):创新点:提出 Motion Avatar 方法,实现了动作和化身生成的一体化,并引入了 LLM 规划器,增强了适应性和可用性。 性能:在动作生成、化身生成和动作到化身的重定向等各种任务上取得了最先进的性能。 工作量:需要收集和标注大量的数据,并且训练过程可能需要大量的时间和计算资源。
点此查看论文截图

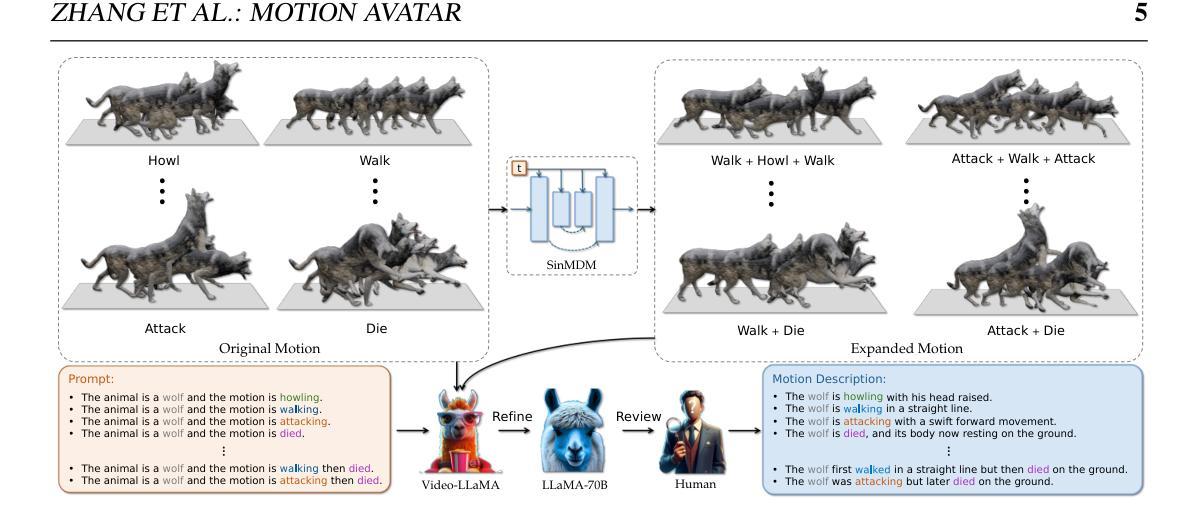

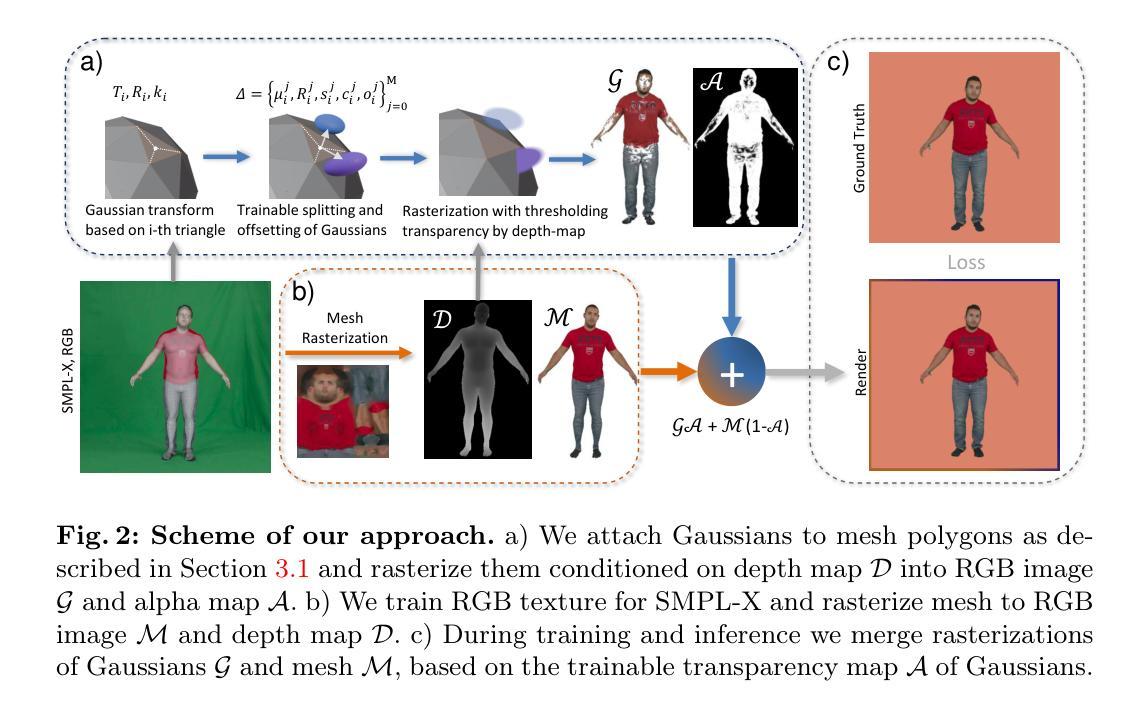
Title: HR Human: 利用三角形网格和高分辨率纹理从视频中建模人类化身
Authors: Qifeng Chen, Rengan Xie, Kai Huang, Qi Wang, Wenting Zheng, Rong Li, Yuchi Huo
Affiliation: 浙江大学
Keywords: 人体建模、渲染、材质纹理
Urls: Paper: https://arxiv.org/pdf/2405.11270.pdf, Github: None
Summary:
(1): 近期,隐式神经表示已被广泛用于生成可动画的人类化身。然而,这些表示中的材质和几何形状在神经网络中耦合,难以编辑,这阻碍了它们在传统图形引擎中的应用。
(2): 现有方法: - 隐式神经表示:几何和材质耦合,难以编辑。 - Relighting4D 和 Relightavatar:尝试用隐式表示恢复具有分离几何和材质的人类化身,但隐式几何和纹理难以编辑,且纹理清晰度较低。 - Nvdiffrec:专注于重建显式的一般静态对象,但无法处理非刚性物体和皮肤的动态运动。
(3): 本文提出了一种从单目视频中获取附有高分辨率基于物理的材质纹理和三角形网格的人类化身的方法。该方法引入了信息融合策略,结合单目视频信息和合成虚拟多视图图像,解决了输入视图的稀疏性。将人类重建为可变形神经隐式曲面,并提取良好姿势下的三角形网格作为下一阶段的初始网格。此外,还引入了一种方法来校正提取的粗网格的边界和尺寸偏差。最后,将多视图超分辨率中潜在扩散模型的先验知识用于分解纹理。
(4): 本文方法在高保真度方面优于以往的表示,显式结果支持在常见渲染器上部署。
- 方法:
(1):提出了一种从单目视频中获取附有高分辨率基于物理的材质纹理和三角形网格的人类化身的方法;
(2):引入信息融合策略,结合单目视频信息和合成虚拟多视图图像,解决了输入视图的稀疏性;
(3):将人类重建为可变形神经隐式曲面,并提取良好姿势下的三角形网格作为下一阶段的初始网格;
(4):引入了一种方法来校正提取的粗网格的边界和尺寸偏差;
(5):将多视图超分辨率中潜在扩散模型的先验知识用于分解纹理。
- 结论:
(1)本文提出的 HR Human 框架的意义在于,它能够从单目视频中重建出带有三角形网格和对应的 PBR 材质纹理的数字化身。我们引入了一种新颖的信息融合策略,将单目视频的信息与合成的虚拟多视图图像相结合,以弥补缺失的空间视图信息。此外,我们还修正了从隐式场中提取的网格的边界和尺寸偏差。最后,我们引入了一个经过预训练的潜在扩散模型,用于分解纹理。
(2)创新点:本文提出了一种从单目视频中重建带有三角形网格和 PBR 材质纹理的人类化身的方法,该方法具有以下创新点: - 引入信息融合策略,结合单目视频信息和合成虚拟多视图图像,解决了输入视图的稀疏性问题。 - 提出了一种方法来校正提取的粗网格的边界和尺寸偏差。 - 将多视图超分辨率中潜在扩散模型的先验知识用于分解纹理。
性能:本文方法在高保真度方面优于以往的表示,显式结果支持在常见渲染器上部署。
工作量:本文方法的工作量相对较大,需要训练一个潜在扩散模型来分解纹理。
点此查看论文截图

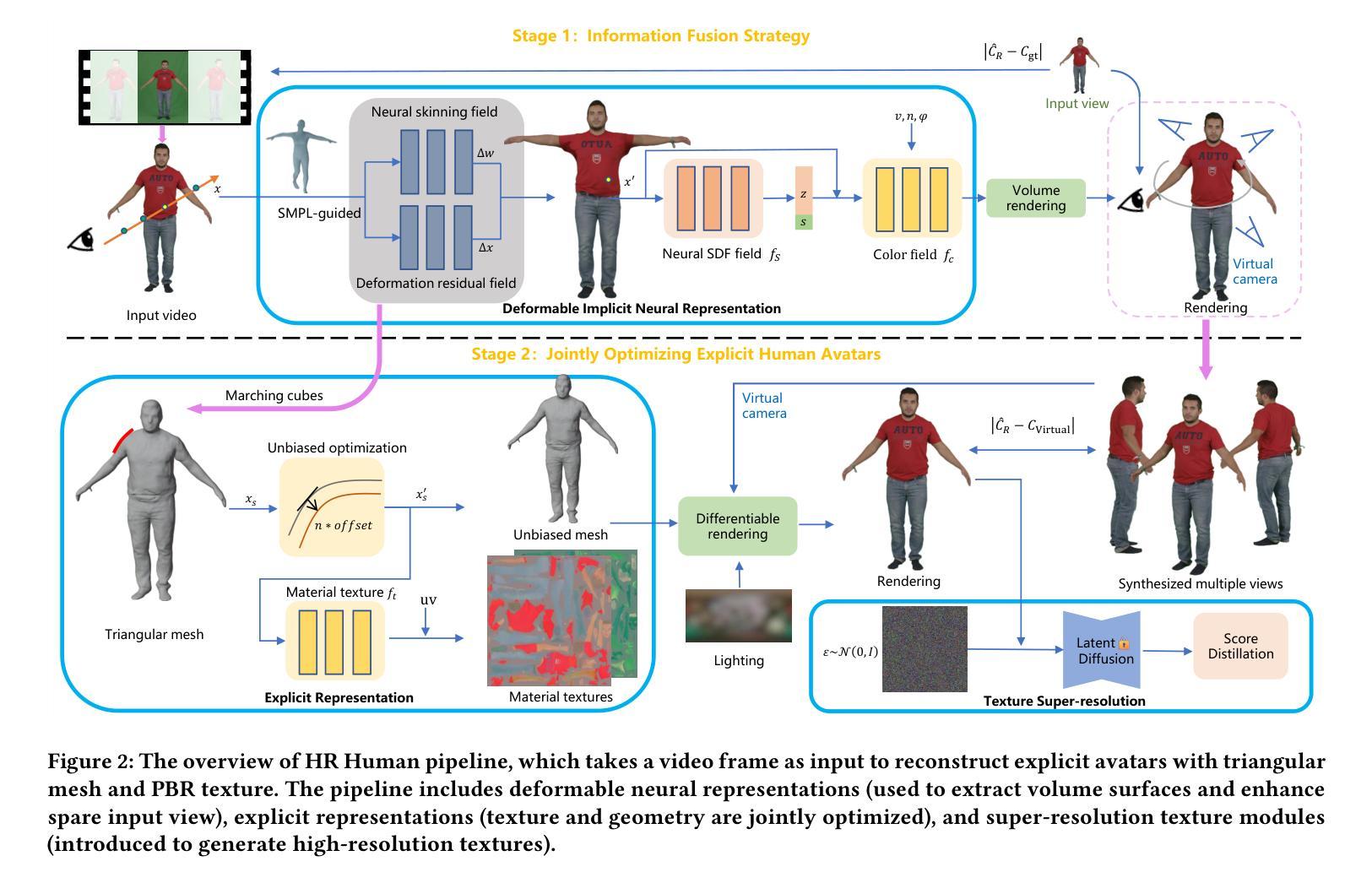

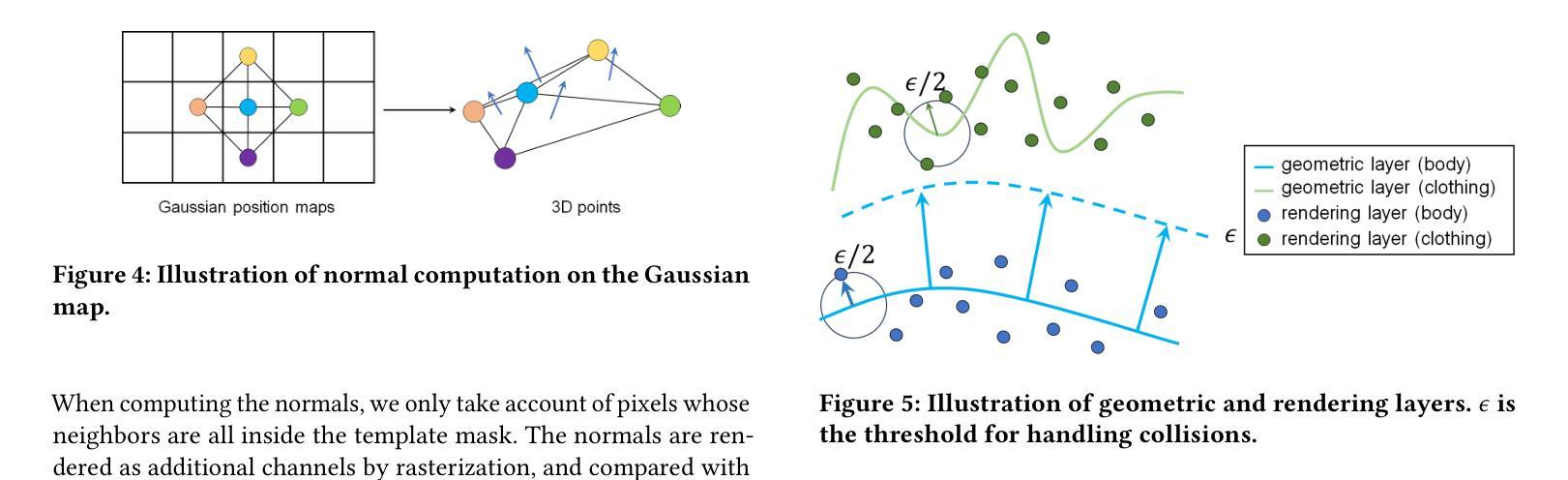
Title: Layered Gaussian Avatars for Animatable Clothing (基于分层高斯分布的动画服装化身)
Authors: Siyou Lin, Zhe Li, Zhaoqi Su, Zerong Zheng, Hongwen Zhang, Yebin Liu
Affiliation: 清华大学
Keywords: Animatable avatar, clothing transfer, human reconstruction
Urls: Paper: https://arxiv.org/pdf/2405.07319.pdf, Github: None
Summary:
(1): 动画服装传输旨在跨角色穿衣和动画服装,是一个具有挑战性的问题。大多数人体化身工作将人体和服装的表示纠缠在一起,这给不同身份的虚拟试穿带来了困难。更糟糕的是,纠缠的表示通常无法准确跟踪服装的滑动运动。
(2): 过去的方法将身体和服装表示为一个整体,这使得虚拟试穿跨身份困难,并且无法准确跟踪服装的滑动运动。
(3): 本文提出了一种新的表示形式——分层高斯化身 (LayGA),它将身体和服装表述为两个独立的层,用于从多视图视频中进行逼真的动画服装传输。LayGA 在单层重建阶段提出了一系列几何约束,以重建平滑曲面并同时获得身体和服装之间的分割。在多层拟合阶段,训练了两个独立的模型来表示身体和服装,并利用重建的服装几何作为 3D 监督,以实现更准确的服装跟踪。此外,还提出了几何层和渲染层,用于高质量的几何重建和高保真渲染。
(4): 在服装转移任务上,LayGA 实现了逼真的动画和虚拟试穿,并且优于其他基线方法。
- 方法:
(1):提出分层高斯化身(LayGA)表示,将身体和服装表示为两个独立的层,用于从多视图视频中进行逼真的动画服装传输。
(2):在单层重建阶段,提出了一系列几何约束,以重建平滑曲面并同时获得身体和服装之间的分割。
(3):在多层拟合阶段,训练了两个独立的模型来表示身体和服装,并利用重建的服装几何作为3D监督,以实现更准确的服装跟踪。
(4):此外,还提出了几何层和渲染层,用于高质量的几何重建和高保真渲染。
- 结论:
(1):该工作提出了分层高斯化身(LayGA)表示,用于从多视图视频中进行逼真的动画服装传输。LayGA 将身体和服装表示为两个独立的层,并提出了一系列几何约束和多层拟合策略,以实现更准确的服装跟踪和高质量的几何重建。 (2):创新点:提出了 LayGA 表示,将身体和服装表示为两个独立的层,并提出了几何约束和多层拟合策略,以实现更准确的服装跟踪和高质量的几何重建; 性能:在服装转移任务上,LayGA 实现了逼真的动画和虚拟试穿,并且优于其他基线方法; 工作量:该方法需要多视图视频输入,并且训练过程需要大量的数据和计算资源。
点此查看论文截图


 wechat
wechat- alipay