⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-05-22 更新
MOSS: Motion-based 3D Clothed Human Synthesis from Monocular Video
Authors:Hongsheng Wang, Xiang Cai, Xi Sun, Jinhong Yue, Shengyu Zhang, Feng Lin, Fei Wu
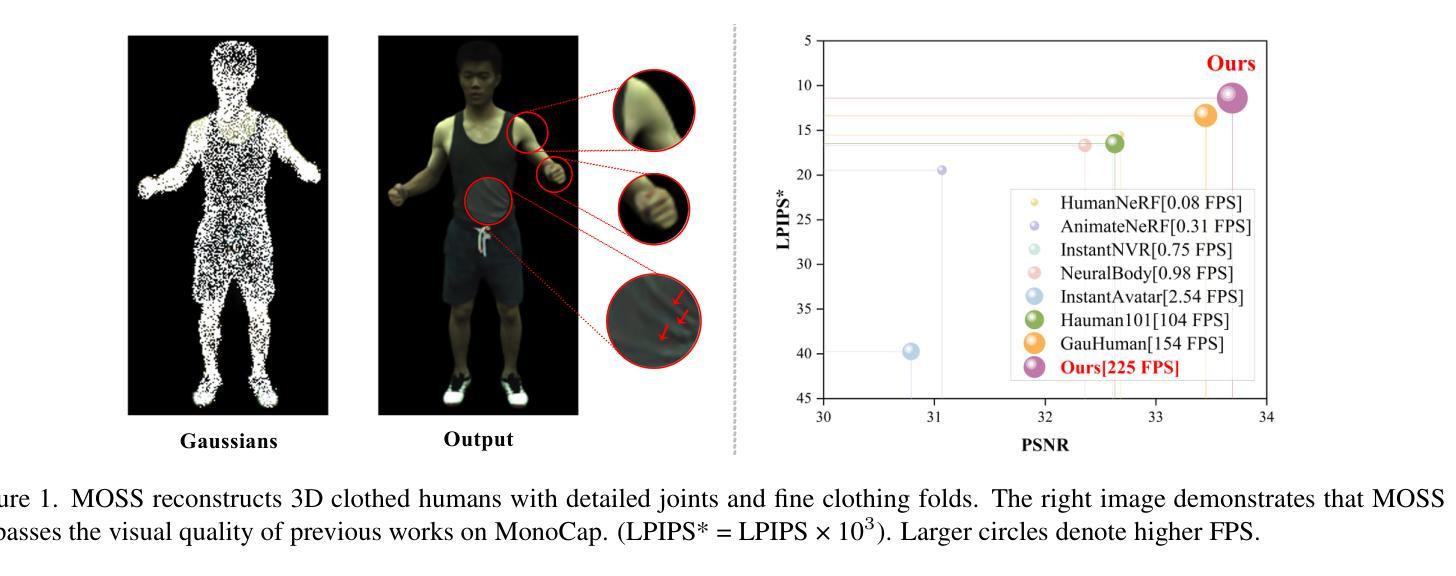
Single-view clothed human reconstruction holds a central position in virtual reality applications, especially in contexts involving intricate human motions. It presents notable challenges in achieving realistic clothing deformation. Current methodologies often overlook the influence of motion on surface deformation, resulting in surfaces lacking the constraints imposed by global motion. To overcome these limitations, we introduce an innovative framework, Motion-Based 3D Clothed Humans Synthesis (MOSS), which employs kinematic information to achieve motion-aware Gaussian split on the human surface. Our framework consists of two modules: Kinematic Gaussian Locating Splatting (KGAS) and Surface Deformation Detector (UID). KGAS incorporates matrix-Fisher distribution to propagate global motion across the body surface. The density and rotation factors of this distribution explicitly control the Gaussians, thereby enhancing the realism of the reconstructed surface. Additionally, to address local occlusions in single-view, based on KGAS, UID identifies significant surfaces, and geometric reconstruction is performed to compensate for these deformations. Experimental results demonstrate that MOSS achieves state-of-the-art visual quality in 3D clothed human synthesis from monocular videos. Notably, we improve the Human NeRF and the Gaussian Splatting by 33.94% and 16.75% in LPIPS* respectively. Codes are available at https://wanghongsheng01.github.io/MOSS/.
PDF
Summary
单视图衣着人体重建在虚拟现实应用中至关重要,尤其是在涉及复杂人体动作的情况下。它在实现逼真的衣物变形方面面临着巨大挑战。
Key Takeaways
- 基于运动的信息可用于实现对运动感知的高斯分裂。
- 运动学高斯定位散布(KGAS)使用矩阵-费舍尔分布来传播全局运动。
- 表面变形检测器(UID)基于 KGAS 识别重要表面并执行几何重建。
- 与单视图中的局部遮挡作斗争,UID 识别重要的表面并执行几何重建。
- 实验结果表明,MOSS 在从单目视频中合成 3D 衣着人体方面实现了最先进的视觉质量。
- 与人类 NeRF 和高斯散布相比,MOSS 分别将 LPIPS* 提高了 33.94% 和 16.75%。
- 代码可在 https://wanghongsheng01.github.io/MOSS/ 获得。
ChatPaperFree
Title: 基于运动的单目视频服装人物三维合成(MOSS)
Authors: Hongsheng Wang, Xiang Cai, Xi Sun, Jinhong Yue, Shengyu Zhang, Feng Lin, Fei Wu
Affiliation: 浙江大学
Keywords: 3D Gaussian Splatting, human reconstruction, matrix-Fisher
Urls: https://arxiv.org/abs/2405.12806 , Github:None
Summary:
(1):服装人物三维重建在虚拟现实应用中占据重要地位,特别是涉及复杂人体运动的场景。实现逼真的服装变形面临着巨大挑战。目前的方法往往忽视运动对表面变形的影,导致表面缺乏全局运动施加的约束。
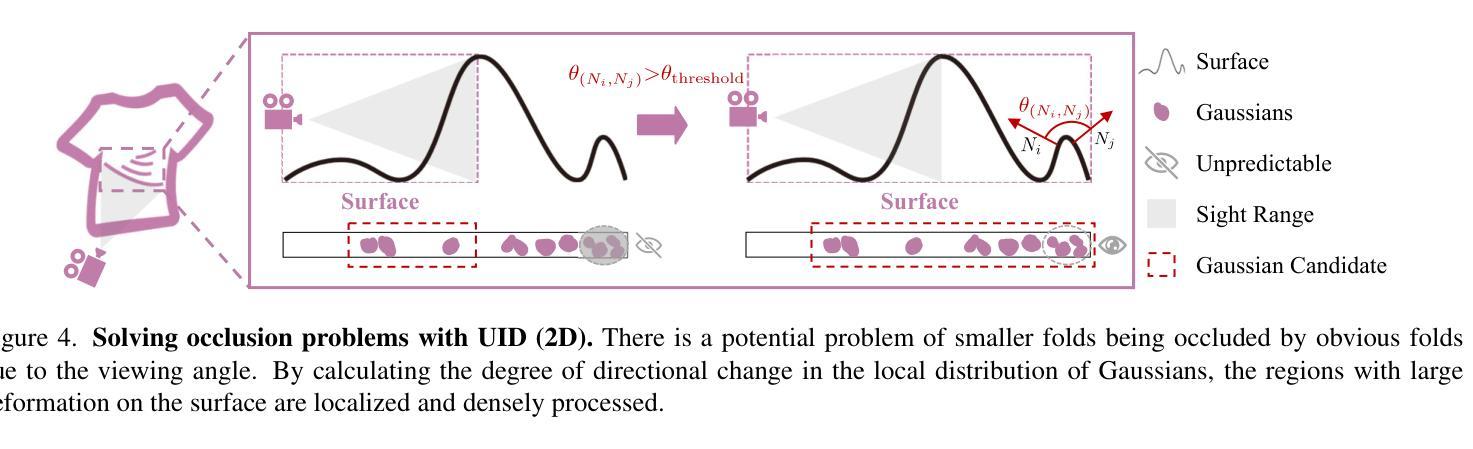
(2):现有的方法在重建人体表面时,利用SMPL作为人体先验,可以恢复更真实的人体,但忽略了运动树的层次结构约束和全局运动信息对重建人体表面的约束,导致关节细节模糊。此外,对恢复的表面变形探索不足。
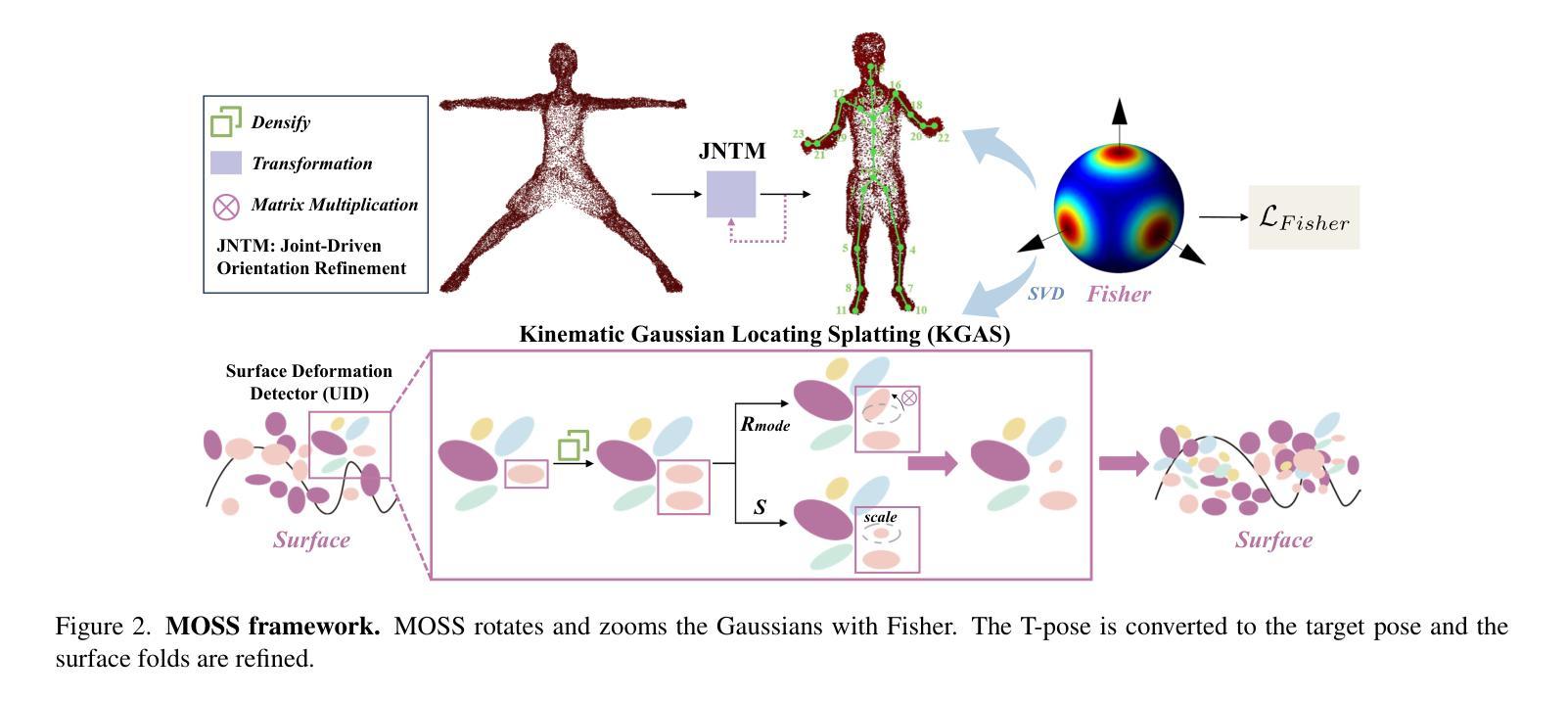
(3):本文提出了一种创新的框架Motion-Based Clothed 3D Humans Synthesis (MOSS)。MOSS从表面变形的成因出发,利用运动树中的运动因子(位移和旋转)进行高斯控制,提升大尺度运动下的人体重建效果。首先,针对变形重建,提出KGAS模块,通过分解matrix-Fisher分布参数,提取人体表面的主轴集中度和旋转因子,对3DGS渲染人体表面变形的高斯进行显式控制。在高斯布局过程中,主轴集中度作为密度因子,修正高斯分裂的采样概率,得到表面变形感知的高斯。在后续的分裂控制中,主轴集中度和旋转因子动态调整高斯的朝向和半径,增强了人体表面变形的真实性。
(4):在单目视频服装人物三维合成任务上,MOSS取得了最先进的视觉效果。具体而言,在LPIPS指标上,比Human NeRF和Gaussian Splatting分别提升了33.94%和16.75%。该性能提升支撑了本文的目标。
方法:
(1):提出KGAS模块,分解matrix-Fisher分布参数,提取人体表面的主轴集中度和旋转因子,显式控制3DGS渲染人体表面变形的高斯;
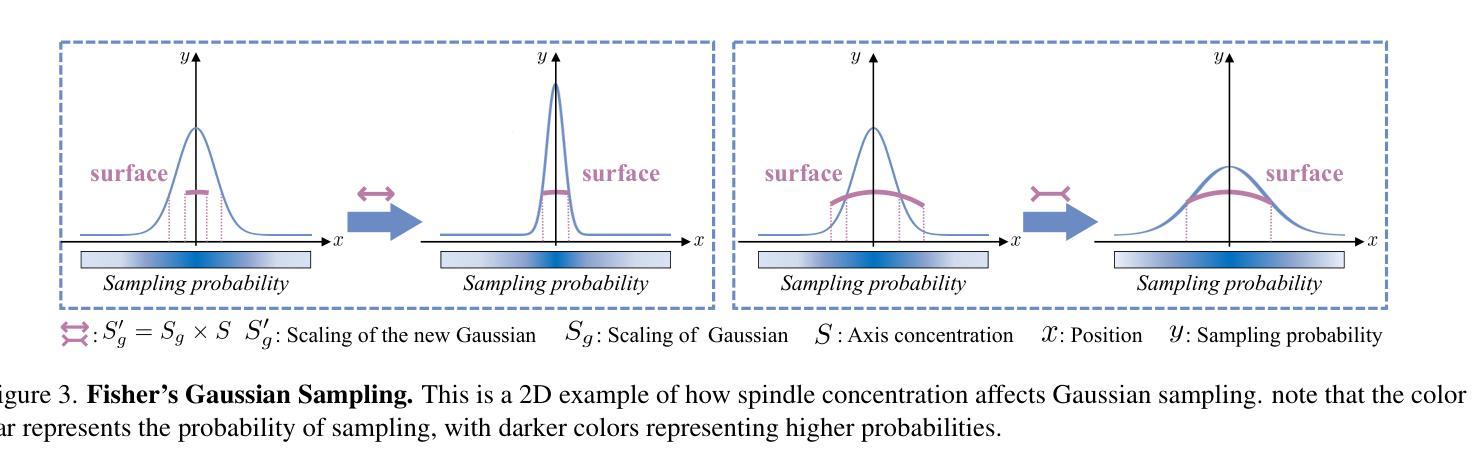
(2):在高斯布局过程中,主轴集中度作为密度因子,修正高斯分裂的采样概率,得到表面变形感知的高斯;
(3):在后续的分裂控制中,主轴集中度和旋转因子动态调整高斯的朝向和半径,增强了人体表面变形的真实性;
.......
结论:
(1):本文针对运动中着装人物三维重建中细节重建缺乏全局约束的问题,提出了 MOSS,该框架将运动先验引入到人体表面三维高斯渲染流程中,重点关注表面变形显著的位置。在未来的工作中,我们考虑结合图论来拓扑引导三维着装人物重建。此外,在虚拟现实和时尚产业等诸多领域存在着大量的真实人物运动场景,我们的技术具有潜在的应用前景。例如,它可以降低游戏制作成本、提升玩家体验、辅助时装设计师优化设计。
(2):创新点:提出 KGAS 模块,通过分解 Matrix-Fisher 分布参数,提取人体表面的主轴集中度和旋转因子,显式控制三维高斯渲染人体表面变形的分布;性能:在单目视频着装人物三维合成任务上,MOSS 取得了最先进的视觉效果,在 LPIPS 指标上,比 Human NeRF 和 Gaussian Splatting 分别提升了 33.94% 和 16.75%;工作量:需要较大的计算资源和较长的训练时间。
点此查看论文截图

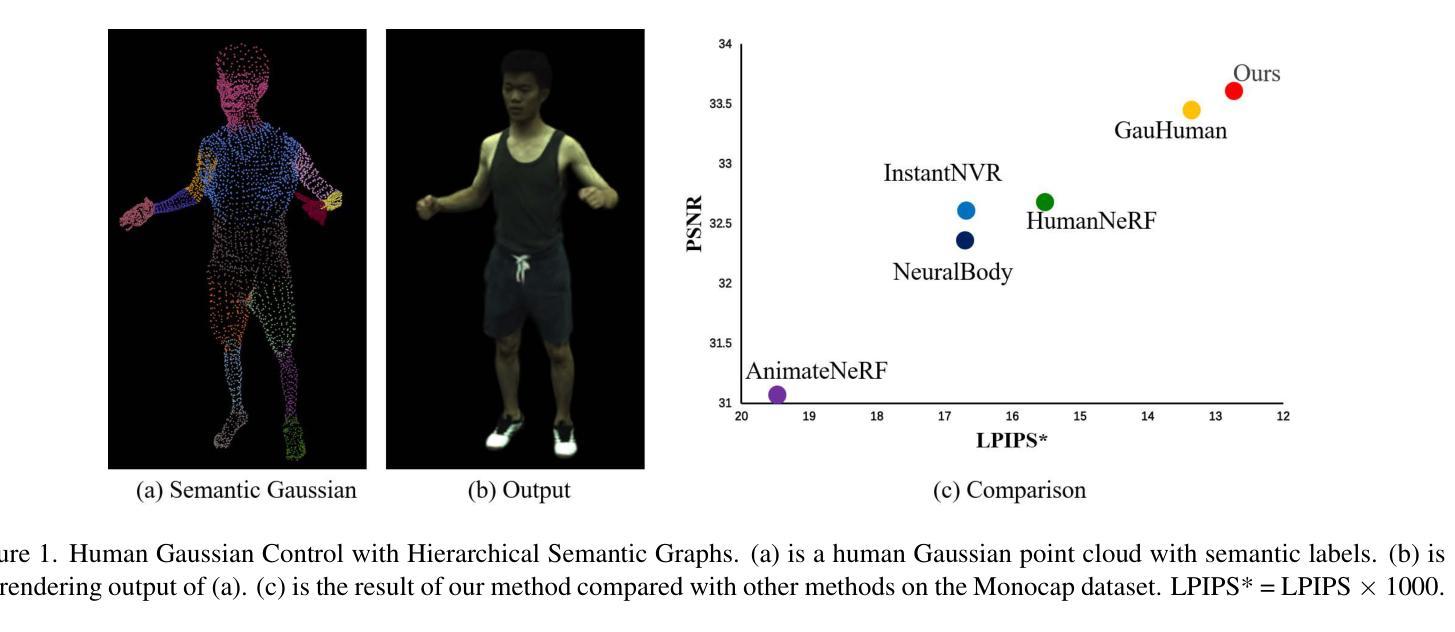
标题:高斯控制与分层语义图在三维人体恢复中的应用
作者:洪胜王、伟跃张、思浩刘、新睿周、胜宇张、飞吴、峰林
单位:浙江大学
关键词:3D高斯溅射、人体重建、人体语义、图聚类、高频解耦
论文链接:https://arxiv.org/abs/2405.12477v1,Github:https://wanghongsheng01.github.io/HUGS/
摘要:
(1):研究背景:三维高斯溅射(3DGS)在三维人体重建方面取得了进展,但主要依赖于二维像素级监督,忽略了不同身体部位的几何复杂性和拓扑关系。
(2):过去方法及其问题:基于像素级监督的3DGS人体重建方法忽略了身体部位的几何复杂性和运动相关性,导致局部几何失真和重要细节丢失。
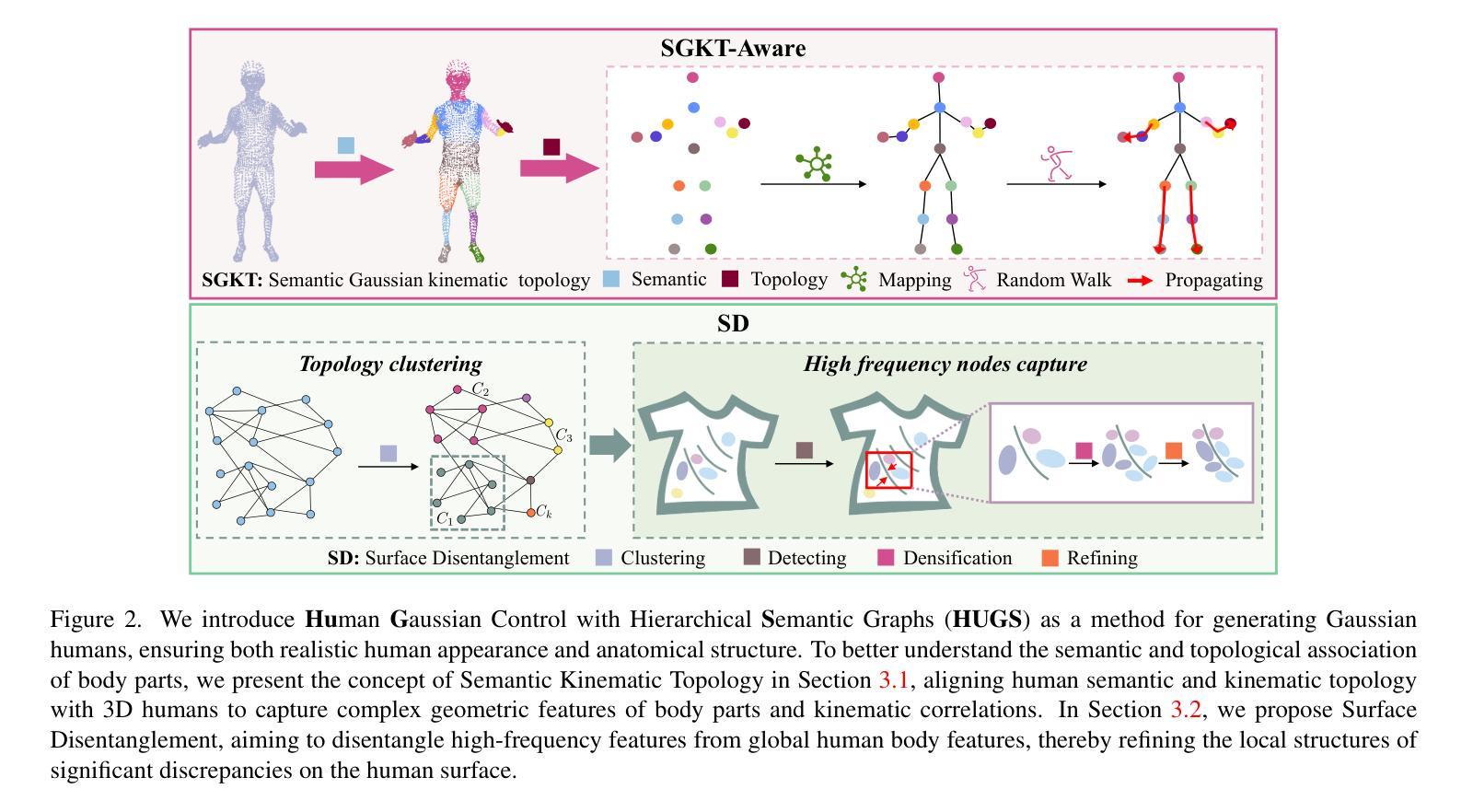
(3):本文方法:提出了一种高斯控制与分层语义图的人体重建框架(HUGS),通过语义运动拓扑模块学习语义属性一致性和每个高斯的运动拓扑关联,以捕捉身体部位的复杂几何结构和联动效应;同时,基于语义先验和拓扑关联,提出表面解耦模块,解耦高频特征和人体全局特征,细化高频差异显著的表面细节。
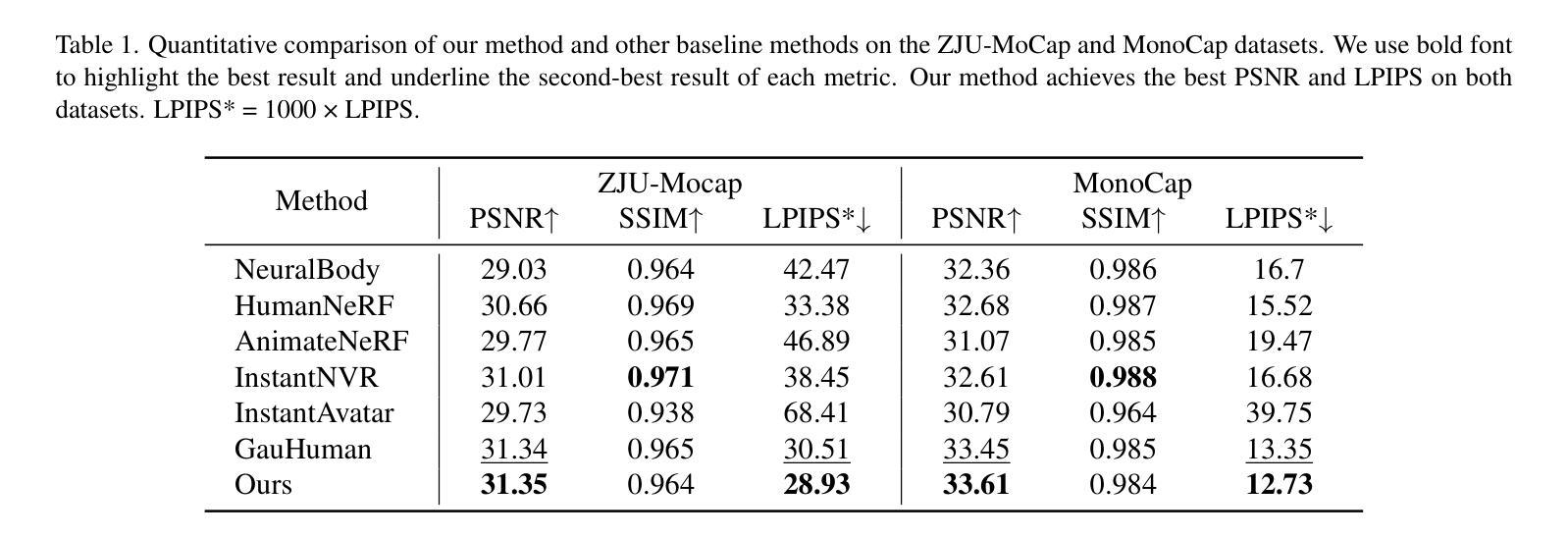
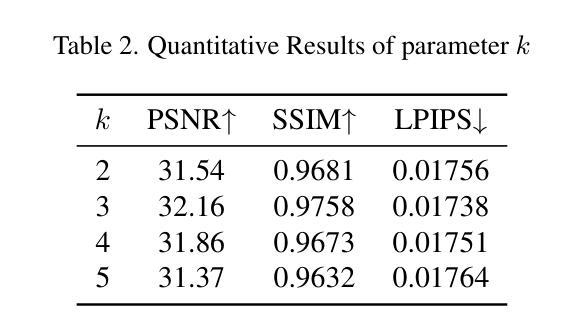
(4):方法性能:HUGS在人体重建任务上取得了优异的性能,特别是在增强表面细节和准确重建身体部位连接方面。实验结果表明,该方法能够有效解决局部遮挡导致的局部几何失真问题,并保留了重要细节,支持了本文的目标。
- Methods:
(1):提出高斯控制与分层语义图的人体重建框架(HUGS),通过语义运动拓扑模块学习语义属性一致性和每个高斯的运动拓扑关联,以捕捉身体部位的复杂几何结构和联动效应;
(2):基于语义先验和拓扑关联,提出表面解耦模块,解耦高频特征和人体全局特征,细化高频差异显著的表面细节;
(3):采用分层语义图,将身体部位划分为不同的语义级别,并根据语义关联和运动拓扑关系构建分层语义图,指导高斯控制模块生成具有语义一致性和运动关联性的高斯人。
- 结论:
(1):本文提出了一种高斯控制与分层语义图的人体重建框架(HUGS),通过语义运动拓扑模块学习语义属性一致性和每个高斯的运动拓扑关联,以捕捉身体部位的复杂几何结构和联动效应;基于语义先验和拓扑关联,提出表面解耦模块,解耦高频特征和人体全局特征,细化高频差异显著的表面细节。该框架在人体重建任务上取得了优异的性能,特别是在增强表面细节和准确重建身体部位连接方面,为解决局部遮挡导致的局部几何失真问题并保留重要细节提供了新的思路。
(2):创新点:提出了一种新的高斯控制与分层语义图的人体重建框架,通过语义运动拓扑模块学习语义属性一致性和每个高斯的运动拓扑关联,以捕捉身体部位的复杂几何结构和联动效应;基于语义先验和拓扑关联,提出表面解耦模块,解耦高频特征和人体全局特征,细化高频差异显著的表面细节。
性能:在人体重建任务上取得了优异的性能,特别是在增强表面细节和准确重建身体部位连接方面。
工作量:该框架涉及语义运动拓扑模块和表面解耦模块的构建,需要较高的算法设计和实现能力。
点此查看论文截图
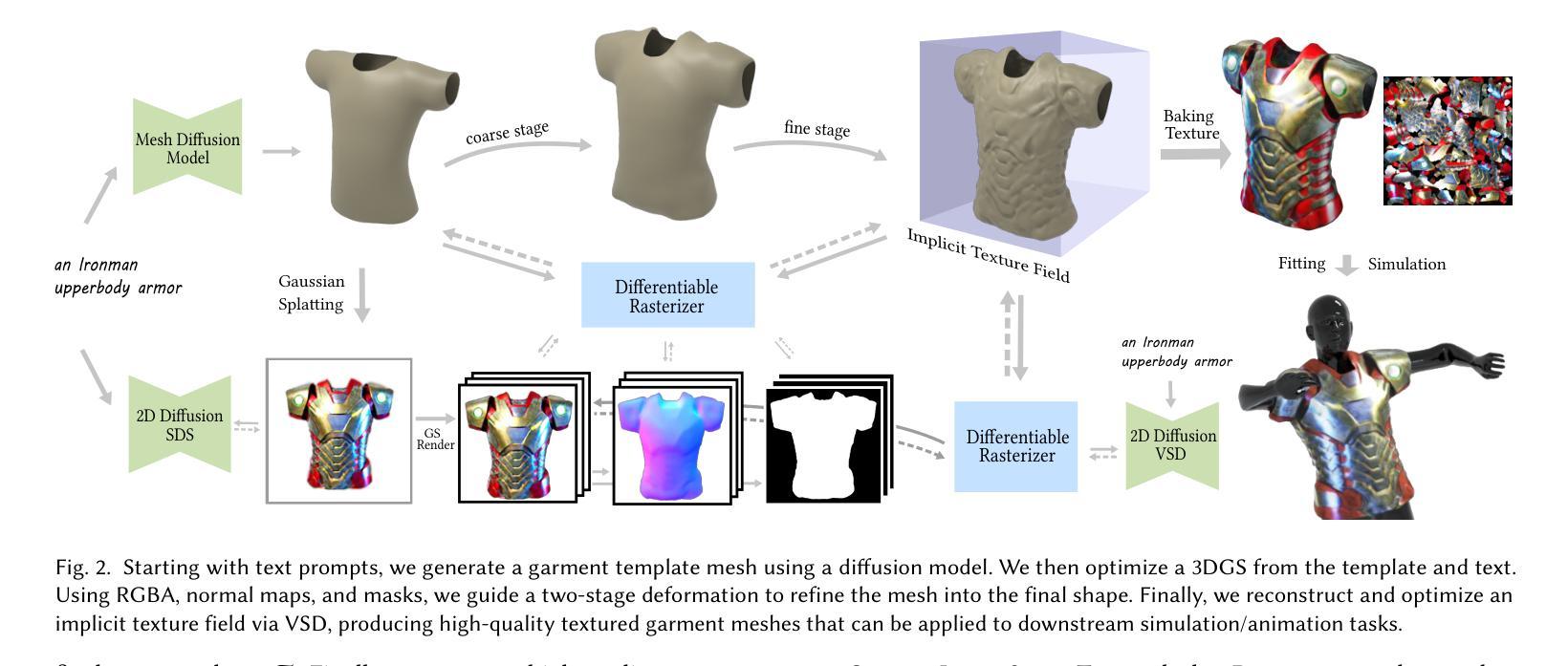
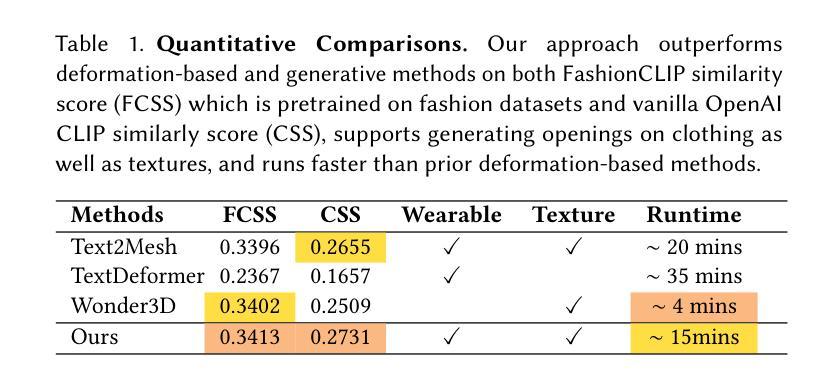
Title: GarmentDreamer:使用3D高斯喷绘作为指导的服装合成,具有多样化的几何和纹理细节
Authors: BOQIAN LI, XUAN LI, YING JIANG, TIANYI XIE, FENG GAO, HUAMIN WANG, YIN YANG, and CHENFANFU JIANG
Affiliation: 加州大学洛杉矶分校
Keywords: 3D garment synthesis, diffusion models, generative models, neural texture fields, variational score distillation
Urls: https://arxiv.org/abs/2405.12420 , https://xuan-li.github.io/GarmentDreamerDemo/ , Github:None
Summary:
(1): 服装的3D数字化至关重要,在时尚设计、虚拟试穿、游戏、动画、虚拟现实和机器人技术中有着广泛的应用。然而,传统的3D服装创建过程需要大量的人工操作,包括素描、建模、UV映射、纹理化、着色和模拟,耗费大量时间和人力成本。
(2): 基于扩散的生成模型的进步,从文本和图像生成3D服装的方法主要有两种:一种是从2D缝纫图案开始,然后从这些图案生成3D服装;另一种是生成模型直接预测基于图像和文本输入的3D目标形状的分布,无需依赖2D缝纫图案。但是,前一种方法需要大量的缝纫图案和相应的文本或图像之间的配对训练数据;后一种方法虽然更简单,但会遇到多视图不一致和缺乏高保真细节等问题,通常需要额外的后处理才能用于下游模拟任务。
(3): 本文提出了一种名为GarmentDreamer的新方法,利用3D高斯喷绘(GS)作为指导,从文本提示中生成可穿戴、可模拟的3D服装网格。与直接使用生成模型预测的多视图图像作为指导不同,本文的3DGS指导确保了服装变形和纹理合成中的一致优化。该方法引入了一个新颖的服装增强模块,由法线和RGBA信息指导,并采用隐式神经纹理场(NeTF)结合变分分数蒸馏(VSD)来生成多样化的几何和纹理细节。
(4): 通过全面的定性和定量实验验证了本文方法的有效性,展示了GarmentDreamer优于最先进的替代方案。
方法:
(1):从文本提示中生成服装模板网格,该网格利用了基于扩散的生成模型;
(2):基于文本提示和服装模板网格优化 3D 高斯喷绘(3DGS),该喷绘指导了服装变形和纹理合成;
(3):设计两阶段训练,利用 3DGS 指导,将服装模板网格细化为最终服装形状;
(4):优化隐式神经纹理场(NeTF),通过变分分数蒸馏(VSD)生成高质量纹理。
结论:
(1):本文提出了一种名为 GarmentDreamer 的新方法,该方法利用 3D 高斯喷绘(3DGS)作为指导,从文本提示中生成可穿戴、可模拟的 3D 服装网格。该方法引入了一个新颖的服装增强模块,并采用隐式神经纹理场(NeTF)结合变分分数蒸馏(VSD)来生成多样化的几何和纹理细节。通过全面的定性和定量实验验证了本文方法的有效性,展示了 GarmentDreamer 优于最先进的替代方案。
(2):创新点:GarmentDreamer 创新性地利用 3DGS 作为指导,确保了服装变形和纹理合成中的一致优化,并引入了新颖的服装增强模块和 NeTF+VSD 纹理生成管道。
性能:GarmentDreamer 在生成可穿戴、可模拟的 3D 服装方面表现出色,生成的服装具有多样化的几何和纹理细节。
工作量:GarmentDreamer 的训练过程需要大量的数据和计算资源,但生成单个服装的推理时间相对较快。
点此查看论文截图
标题:AtomGS:原子化高斯泼溅用于高保真辐射场
作者:Rong Liu, Rui Xu, Yue Hu, Meida Chen, Andrew Feng
单位:南加州大学创意技术学院
关键词:辐射场、高斯泼溅、原子化
论文链接:https://arxiv.org/abs/2405.12369v1 , Github:None
摘要:
(1):研究背景:3D高斯泼溅(3DGS)通过提供新颖的视图合成和实时渲染速度的卓越能力,最近在辐射场重建方面取得了进展。
(2):过去的方法及其问题:3DGS 混合优化和自适应密度控制的策略可能会导致次优结果;由于优先优化大高斯而牺牲了充分致密化小高斯的代价,它有时会出现噪声几何和模糊伪影。
(3):本文提出的研究方法:AtomGS,由原子化扩散和自适应密度控制组成,以解决 3DGS 中存在的问题。
(4):方法在什么任务上取得了什么性能:AtomGS 在渲染质量方面优于现有方法,并且通过将高斯约束为原子高斯并将其与自然几何精确对齐,在几何精度方面取得了有竞争力的结果。
方法:
(1): 原子化扩散:对输入的 SfM 点进行分析,确定原子尺度 Sa,将高斯约束为原子高斯,并优先扩散原子高斯以快速对齐场景的固有几何结构;
(2): 几何引导优化:利用提出的边缘感知法向量损失和修改的多尺度 SSIM 损失,确保增强重点放在保持几何精度上,而不会影响 RGB 场保真度。
结论:
(1):xxx;
(2):创新点:原子化扩散和几何引导优化;性能:渲染质量优异,几何精度有竞争力;工作量:与原有 3DGS 方法相比,GS 原语数量更少。
点此查看论文截图
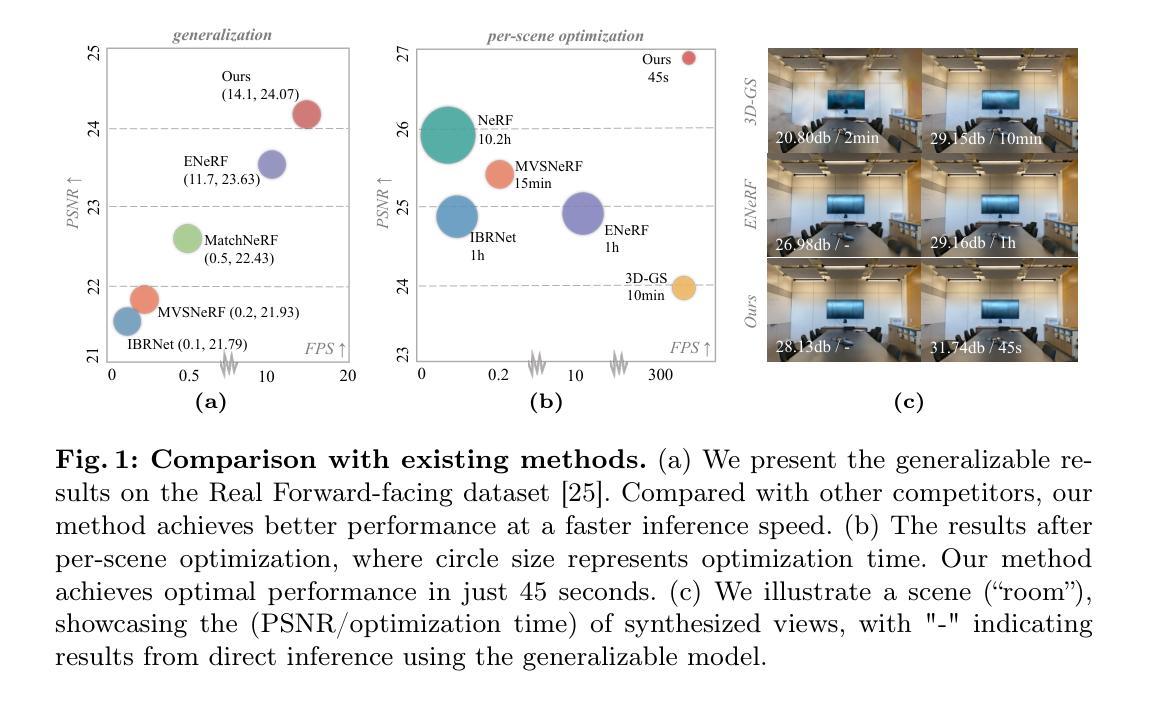
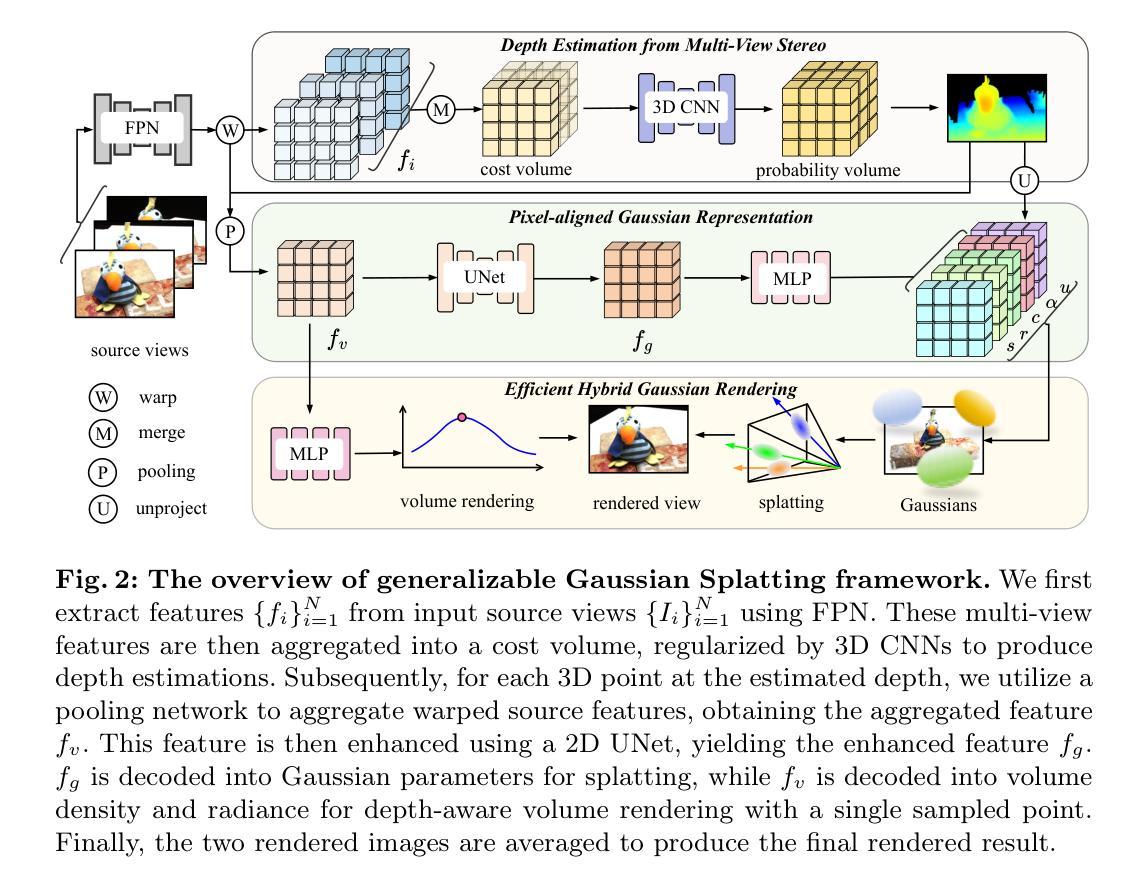
标题:快速可泛化的高斯散点表示法
作者:Tianqi Liu, Guangcong Wang, Shoukang Hu, Liao Shen, Xinyi Ye, Yuhang Zang, Zhiguo Cao, Wei Li, Ziwei Liu
第一作者单位:华中科技大学
关键词:Generalizable Gaussian Splatting · Multi-View Stereo · Neural Radiance Field · Novel View Synthesis
论文链接:https://mvsgaussian.github.io/ Github:None
摘要:
(1):研究背景:本文研究了如何从多视立体(MVS)中生成可泛化的 3D 高斯表示,以有效地重建未见场景。
(2):过去的方法:以前的基于 NeRF 的可泛化方法通常需要数分钟的微调和每张图片数秒的渲染时间。本文的方法动机明确,旨在解决这些问题。
(3):研究方法:本文提出了 MVSGaussian,它利用 MVS 编码具有几何感知的高斯表示,并将其解码为高斯参数。此外,还提出了混合高斯渲染,集成了高效的体积渲染设计,用于新颖的视图合成。最后,为了支持特定场景的快速微调,本文引入了一种多视图几何一致聚合策略,以有效地聚合可泛化模型生成的点云,作为场景优化初始化。
(4):任务和性能:MVSGaussian 在 DTU、Real Forward-facing、NeRF Synthetic 和 Tanks and Temples 数据集上进行了广泛的实验,验证了其在可泛化性、实时渲染速度和快速场景优化方面都达到最先进的性能。这些性能指标支持了本文的目标。
方法:
(1):MVSGaussian 采用多视立体(MVS)编码具有几何感知的高斯表示,并将其解码为高斯参数,以生成可泛化的 3D 高斯表示。
(2):提出了混合高斯渲染,集成了高效的体积渲染设计,用于新颖的视图合成。
(3):引入了一种多视图几何一致聚合策略,以有效地聚合可泛化模型生成的点云,作为场景优化初始化,支持特定场景的快速微调。
结论:
(1):本文提出的 MVSGaussian 是一种新颖的通用高斯散点表示法,可从 MVS 重建场景表示。具体而言,我们利用 MVS 编码具有几何感知的特征,建立像素对齐的高斯表示。此外,我们提出了一种混合高斯渲染方法,将高效的深度感知体积渲染集成到增强泛化中。除了卓越的泛化能力外,我们的模型还可以轻松地针对特定场景进行微调。为了促进快速优化,我们引入了多视图几何一致聚合策略,以有效地聚合可泛化模型生成的点云,作为场景优化初始化。
(2):创新点:提出了一种从 MVS 编码具有几何感知的高斯表示的新颖方法,并将其解码为高斯参数,以生成可泛化的 3D 高斯表示。提出了混合高斯渲染方法,将高效的体积渲染设计集成到新颖的视图合成中。引入了多视图几何一致聚合策略,以有效地聚合可泛化模型生成的点云,作为场景优化初始化。
性能:在 DTU、Real Forward-facing、NeRF Synthetic 和 Tanks and Temples 数据集上进行了广泛的实验,验证了其在可泛化性、实时渲染速度和快速场景优化方面都达到最先进的性能。
工作量:需要数分钟的微调和每张图片数秒的渲染时间。
点此查看论文截图
标题:CoR-GS:通过补充材料实现稀疏视图 3D 高斯散布
作者:Jiawei Zhou, Xiao Bai, Xiaowei Hu, Junhui Hou, Jingyi Yu, Sheng Liu
单位:北京航空航天大学
Keywords: radiance fields · 3d gaussian splatting · few-shot novel view synthesis · co-regularization
论文链接:https://arxiv.org/abs/2405.12110 Github:None
摘要:
(1):研究背景:3D 高斯散布(3DGS)通过由 3D 高斯体组成的辐射场来表示场景。在稀疏训练视图下,3DGS 容易过拟合,对重建质量产生负面影响。
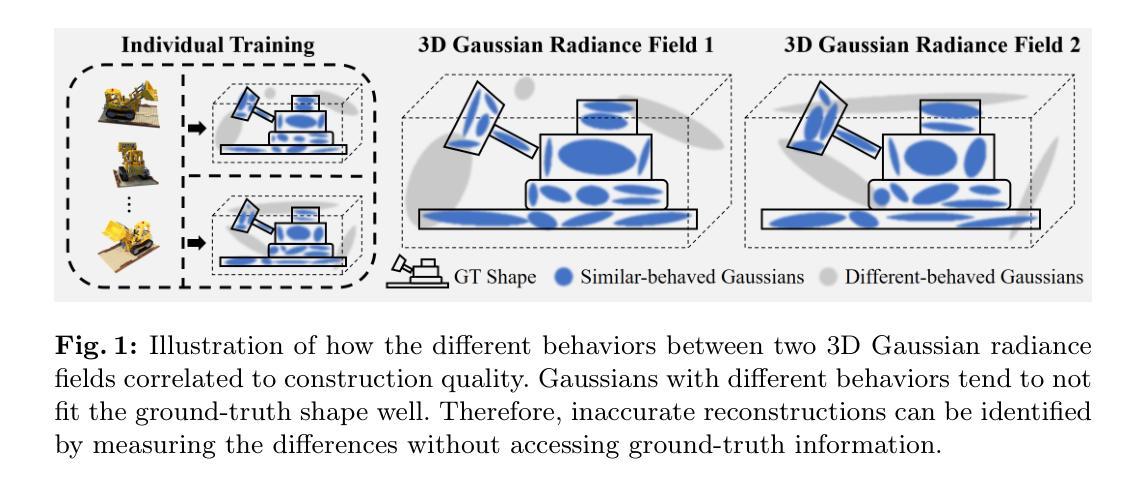
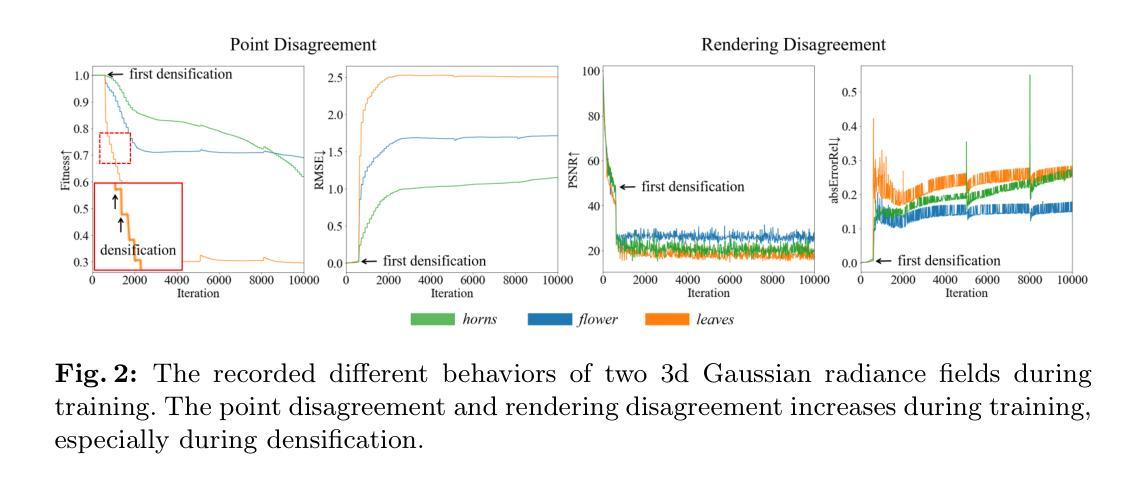
(2):以往方法及存在问题:本文提出了一种新的协同正则化视角来改进稀疏视图 3DGS。当使用场景的相同稀疏视图训练两个 3D 高斯辐射场时,我们观察到这两个辐射场表现出点位差异和渲染差异,这可以无监督地预测重建质量,源于致密化中的采样实现。方法动机明确。
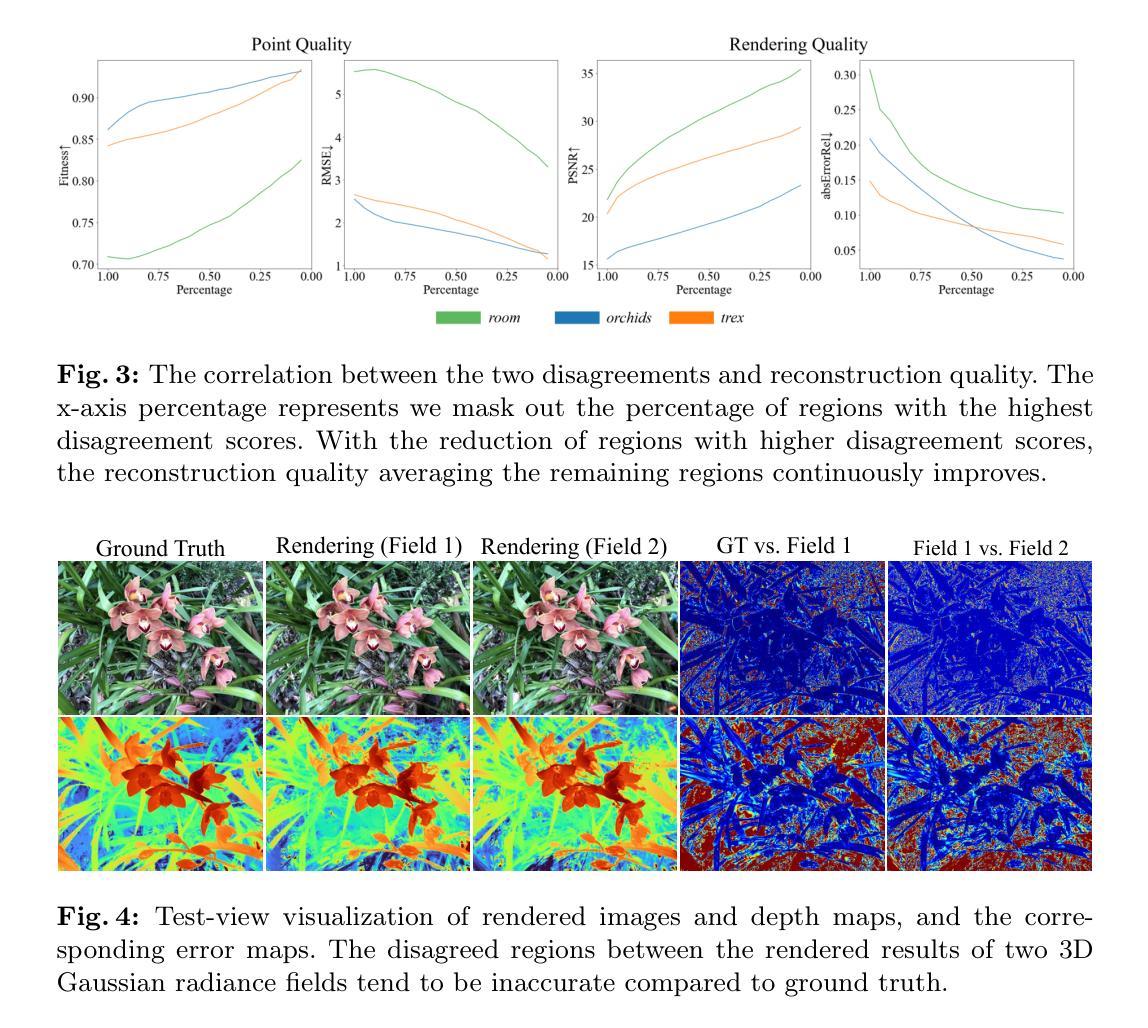
(3):本文提出的研究方法:我们进一步通过评估高斯体点表示之间的配准并计算其渲染像素的差异来量化点位差异和渲染差异。实证研究表明这两个差异与准确重建之间存在负相关性,这使我们无需访问真实信息即可识别不准确的重建。基于该研究,我们提出了 CoR-GS,它基于这两个差异识别并抑制不准确的重建:(i)协同剪枝考虑在不准确位置表现出高点位差异的高斯体并对其进行剪枝。(ii)伪视图协同正则化考虑表现出高渲染差异的像素被不准确地渲染,并抑制该差异。
(4):方法在什么任务上取得了什么性能?性能是否能支撑其目标?LLFF、Mip-NeRF360、DTU 和 Blender 上的结果表明,CoR-GS 在稀疏训练视图下有效地正则化了场景几何,重建了紧凑的表示,并实现了最先进的新颖视图合成质量。性能支撑其目标。
- Methods:
(1):我们提出了一种协同正则化(CoR)框架,通过评估高斯体点表示之间的配准(点位差异)和计算其渲染像素的差异(渲染差异)来识别和抑制不准确的重建。
(2):协同剪枝:识别并剪枝表现出高点位差异的高斯体,这些高斯体可能位于不准确的位置。
(3):伪视图协同正则化:抑制表现出高渲染差异的像素,这些像素可能被不准确地渲染。
- 结论:
(1):本文提出了一种协同正则化视角,通过评估高斯体点表示之间的配准(点位差异)和计算其渲染像素的差异(渲染差异)来识别和抑制不准确的重建,有效地正则化了场景几何,重建了紧凑的表示,并实现了最先进的新颖视图合成质量。
(2):创新点:提出了基于点位差异和渲染差异的协同正则化框架,识别并抑制不准确的重建; 性能:在稀疏训练视图下,有效地正则化了场景几何,重建了紧凑的表示,并实现了最先进的新颖视图合成质量; 工作量:工作量不大,但需要对高斯体点表示之间的配准和渲染像素的差异进行评估和计算。
点此查看论文截图
Title: MirrorGaussian:反射3D高斯体实现镜像反射重建
Authors: Jiayue Liu, Xiao Tang, Freeman Cheng, Roy Yang, Zhihao Li, Jianzhuang Liu, Yi Huang, Jiaqi Lin, Shiyong Liu, Xiaofei Wu, Songcen Xu, Chun Yuan
Affiliation: 清华大学
Keywords: 3D Gaussian Splatting, Mirror Scene Reconstruction, Real-time Rendering
Urls: https://arxiv.org/abs/2405.11921 , Github:None
Summary:
(1): 3D高斯体渲染在照片级真实感和实时新视角合成方面取得了显著进展。然而,它在建模镜像反射方面面临挑战,镜像反射在不同视点下表现出显着的外观变化。
(2): 过去的方法:3D高斯体渲染。问题:无法建模镜像反射。动机:镜像反射在现实世界中很常见,对场景重建和新视角合成至关重要。
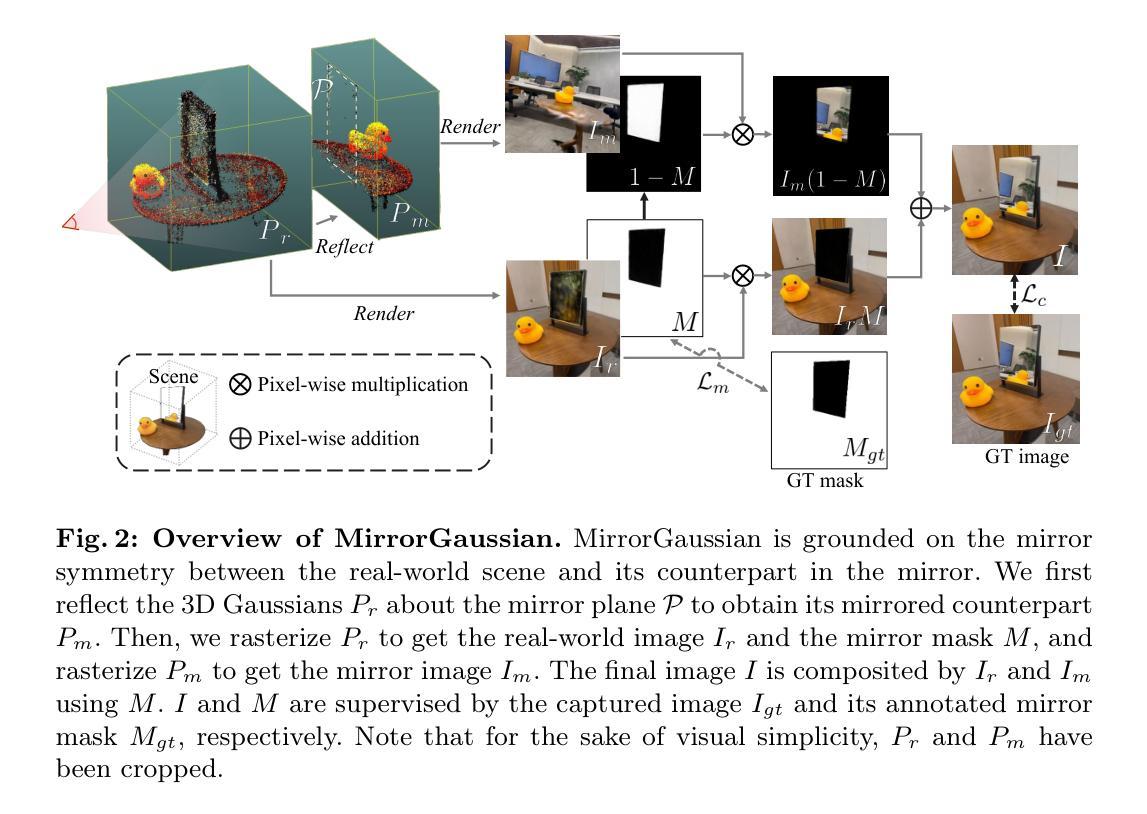
(3): 本文提出的研究方法:MirrorGaussian,一种基于3D高斯体渲染的镜像场景重建方法,首次实现实时渲染。关键思想是基于现实世界空间和虚拟镜像空间之间的镜像对称性。我们引入了一种直观的双渲染策略,能够对现实世界3D高斯体和通过镜像平面反射得到的镜像对应物进行可微分光栅化。所有3D高斯体都在端到端框架中与镜像平面联合优化。
(4): 任务和性能:在有镜子的场景中实现高质量和实时渲染,支持场景编辑,例如插入新物体和镜子。性能支持目标:定量和定性评估表明,MirrorGaussian在渲染质量、实时性能和场景编辑方面都优于现有方法。
- 方法:
(1):基于现实世界空间和虚拟镜像空间之间的镜像对称性,提出了一种双渲染策略,能够对现实世界3D高斯体和通过镜像平面反射得到的镜像对应物进行可微分光栅化;
(2):提出了一种三阶段流水线,用于端到端优化重建包含镜子的场景:首先优化3D高斯体以获得现实世界的3D高斯体;然后将3D高斯体反射到镜像空间中,并通过双渲染策略优化镜像平面方程;最后,优化3D高斯体和镜像掩码,实现从任意视点高质量渲染镜像反射;
(3):通过反射函数,将3D高斯体的均值、旋转和视点相关颜色反映到镜像空间中;
(4):利用稀疏SfM点云,估计镜像平面的粗略方程,并将其与3D高斯体联合优化;
(5):通过为3D高斯体分配镜像标签,并渲染这些镜像点,从任意视点生成镜像掩码;
(6):通过修改颜色渲染公式,使镜像表面的3D高斯体在渲染镜像掩码时分布均匀,同时不影响镜像图像的渲染。
- 结论:
(1):本文提出了 MirrorGaussian,一种基于 3D 高斯体渲染的镜像场景重建方法,首次实现了实时渲染,为照片级真实感和实时新视角合成提供了新的可能。
(2):创新点:基于现实世界空间和虚拟镜像空间之间的镜像对称性,提出双渲染策略,实现对现实世界 3D 高斯体和镜像对应物的可微分光栅化;提出三阶段流水线,端到端优化重建包含镜子的场景;通过反射函数,将 3D 高斯体的均值、旋转和视点相关颜色反映到镜像空间中。
性能:定量和定性评估表明,MirrorGaussian 在渲染质量、实时性能和场景编辑方面都优于现有方法。
工作量:MirrorGaussian 的实现需要解决一系列技术挑战,包括可微分光栅化、端到端优化和镜像掩码生成。
点此查看论文截图
Title: Dreamer XL: 基于轨迹匹配的高分辨率文本转 3D
Authors: Xingyu Miao, Haoran Duan, Varun Ojha, Jun Song, Tejal Shah, Yang Long, Rajiv Ranjan
Affiliation: Durham University
Keywords: Text-to-3D generation, Diffusion models, Trajectory Score Matching, Stable Diffusion XL
Urls: Paper: https://arxiv.org/abs/2405.11252, Github: https://github.com/xingy038/Dreamer-XL
Summary:
(1): 文本转 3D 生成方法能够直接从自然语言描述中创建准确的 3D 模型,从而减少传统 3D 建模流程中的手工输入。
(2): 现有的文本转 3D 生成方法利用预训练的文本转图像扩散模型作为图像先验来训练神经参数化 3D 模型,如神经辐射场 (NeRF) 和 3D 高斯分割,但存在伪 ground truth 不一致的问题。
(3): 本文提出了一种新的轨迹匹配 (TSM) 方法,通过利用 Denoising Diffusion Implicit Models (DDIM) 反演过程从同一起点生成两条路径进行计算,从而减少累积误差,缓解伪 ground truth 不一致问题。此外,本文还采用 Stable Diffusion XL 进行指导,并提出了一种逐像素梯度裁剪方法来解决 Stable Diffusion XL 在 3D 高斯分割过程中不稳定梯度导致的异常复制和分裂问题。
(4): 实验表明,本文方法在视觉质量和性能方面显著优于最先进的模型,支持其目标。
方法:
(1):提出轨迹匹配(TSM)方法,通过利用 Denoising Diffusion Implicit Models(DDIM)反演过程从同一起点生成两条路径进行计算,从而减少累积误差,缓解伪 ground truth 不一致问题。
(2):采用 Stable Diffusion XL 进行指导,并提出一种逐像素梯度裁剪方法来解决 Stable Diffusion XL 在 3D 高斯分割过程中不稳定梯度导致的异常复制和分裂问题。
(3):利用 DDIM 从同一起点生成两条路径,通过计算两条路径的差异来估计梯度,从而减少累积误差。
(4):采用 Stable Diffusion XL 作为图像先验,指导神经参数化 3D 模型的训练,提高生成 3D 模型的质量。
(5):提出逐像素梯度裁剪方法,通过裁剪不稳定梯度,解决 Stable Diffusion XL 在 3D 高斯分割过程中不稳定梯度导致的异常复制和分裂问题。
8. 结论:
(1)本文的工作意义在于,提出了轨迹匹配(TSM)方法,缓解了伪 ground truth 不一致问题,提高了文本转 3D 生成的质量。
(2)创新点:提出 TSM 方法,利用双路径计算梯度,减少累积误差;采用 Stable Diffusion XL 作为图像先验,提高生成 3D 模型的质量;提出逐像素梯度裁剪方法,解决 Stable Diffusion XL 在 3D 高斯分割过程中不稳定梯度导致的异常复制和分裂问题。
性能:实验表明,本文方法在视觉质量和性能方面显著优于最先进的模型。
工作量:本文方法需要利用 Denoising Diffusion Implicit Models (DDIM) 反演过程生成两条路径,并采用 Stable Diffusion XL 进行指导,工作量较大。
点此查看论文截图
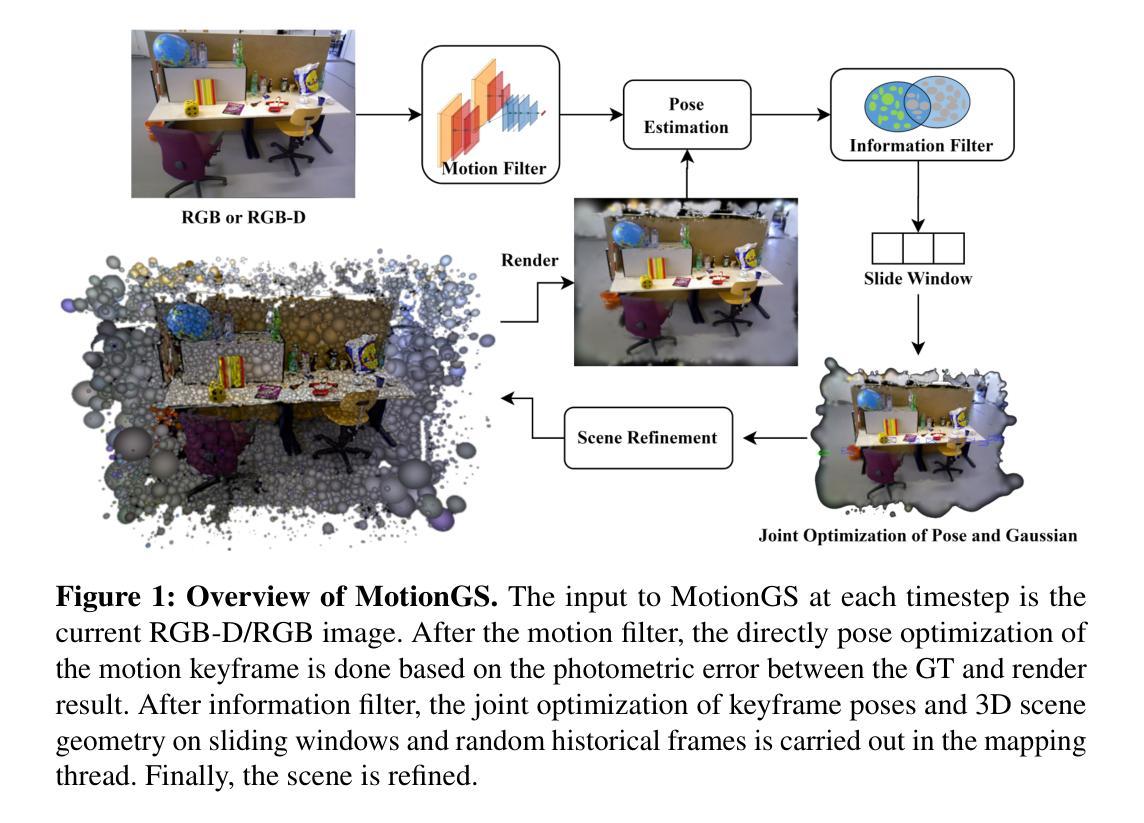
标题:MotionGS:紧凑高斯散射 SLAM
作者:Xinli Guo, Peng Han, Weidong Zhang, Hongtian Chen
单位:上海交通大学
关键词:SLAM、3D 高斯散射、神经辐射场、视觉特征
论文链接:https://arxiv.org/abs/2405.11129,Github 链接:https://github.com/Antonio521/MotionGS
摘要:
(1):随着高保真场景表示能力的发展,SLAM 领域对神经辐射场 (NeRF) 和 3D 高斯散射 (3DGS) 的关注日益加深。近年来,基于 NeRF 的 SLAM 蓬勃发展,而基于 3DGS 的 SLAM 却较为稀少。
(2):过去的方法包括:点云或曲面、网格、体素等。这些经典方法无法实现高保真表示,也无法重建精细纹理和重复场景。NeRF 是一种新颖的视图合成方法,具有隐式表示场景的能力。然而,NeRF 计算成本高,并且难以处理动态场景。
(3):本文提出了一种基于 3DGS 的 SLAM 新方法,融合了深度视觉特征、双关键帧选择和 3DGS。该方法通过对每一帧进行特征提取和运动滤波,实现了选择性跟踪。位姿和 3D 高斯的联合优化贯穿整个建图过程。此外,通过双关键帧选择和新颖的损失函数,实现了从粗到精的位姿估计和紧凑的高斯场景表示。
(4):在跟踪和建图任务上,该方法优于现有方法,并且内存占用更少。
- 方法:
(1):提出了一种基于 3D 高斯散射(3DGS)的 SLAM 新方法,该方法融合了深度视觉特征、双关键帧选择和 3DGS;
(2):采用特征提取和运动滤波实现选择性跟踪,并通过位姿和 3D 高斯的联合优化实现建图;
(3):通过双关键帧选择和新颖的损失函数,实现了从粗到精的位姿估计和紧凑的高斯场景表示;
(4):在跟踪和建图任务上,该方法优于现有方法,并且内存占用更少。
- 结论:
(1):本研究提出了一种基于 3DGS 的 SLAM,名为 MotionGS,它集成了深度视觉特征、双关键帧选择和 3DGS。凭借其精妙的设计,MonoGS 的最先进性能已在广泛的实验中得到充分证明。提出的方法进一步强调了 3DGS 在 SLAM 领域的广泛潜力。在此工作的基础上,针对大规模室外场景的多传感器 3DGS-based SLAM 将成为下一个研究方向。
(2):创新点:提出了一种基于 3DGS 的 SLAM 新方法,融合了深度视觉特征、双关键帧选择和 3DGS;性能:在跟踪和建图任务上,该方法优于现有方法,并且内存占用更少;工作量:该方法的计算复杂度较低,并且易于实现。
点此查看论文截图
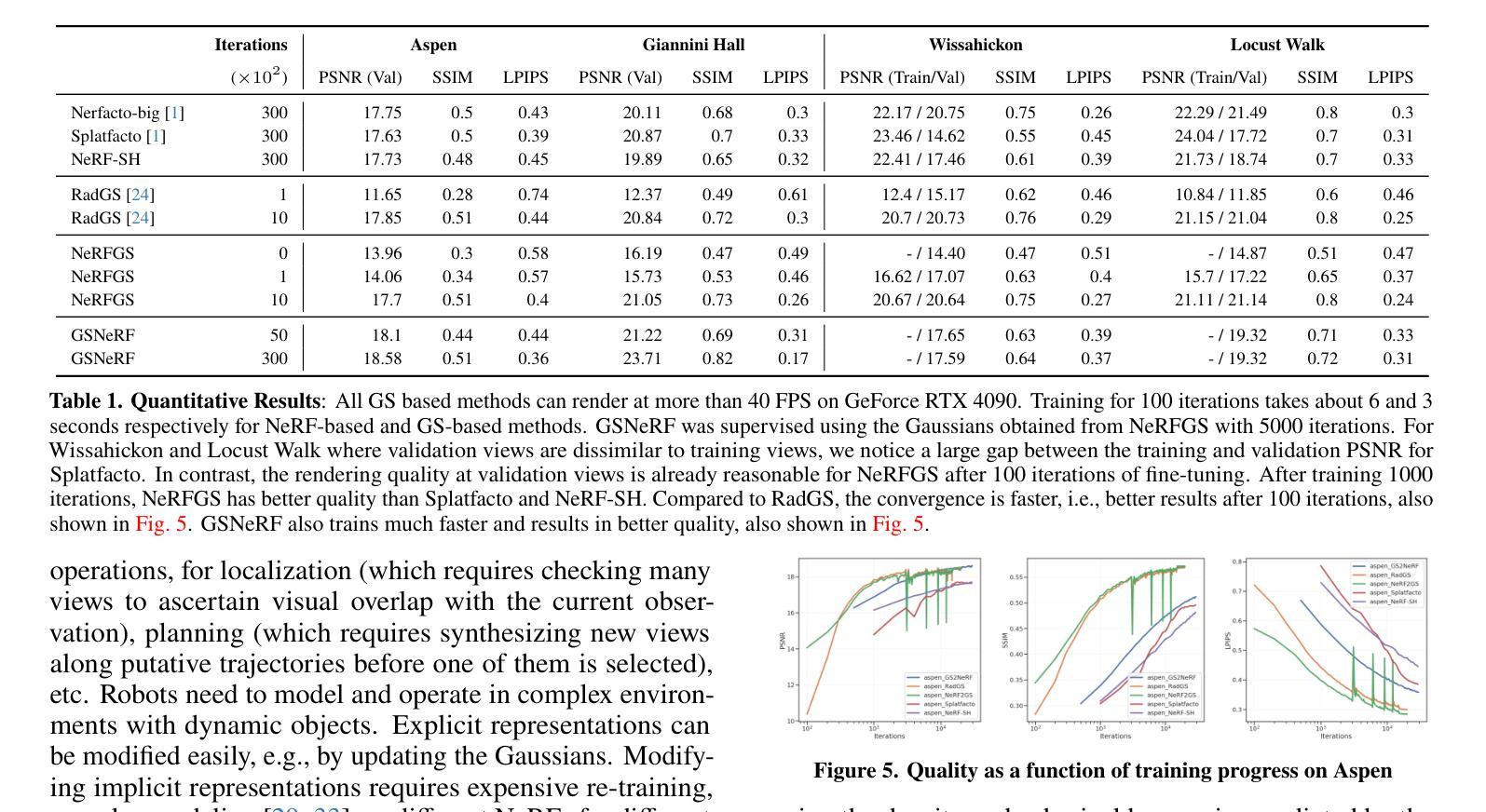
标题:从NeRF到高斯点,再回到NeRF
作者:Siming He, Zach Osman, Pratik Chaudhari
隶属机构:宾夕法尼亚大学通用机器人、自动化、传感和感知(GRASP)实验室
关键词:NeRF;高斯点;场景表示;机器人
论文链接:https://arxiv.org/abs/2405.09717 Github:None
摘要:
(1):研究背景:场景表示在机器人学中至关重要,但隐式表示(如NeRF)和显式表示(如高斯点)的选择一直是争论的焦点。
(2):过去方法:高斯点在训练和测试视图相似的场景中表现良好,但对新视图的泛化能力较差。NeRFs在有限视图下表现更好,但渲染速度较慢,内存消耗较大。
(3):研究方法:本文提出了一种将NeRF转换为高斯点(NeRF2GS)的方法,同时保持NeRF的泛化能力。还提出了一种将高斯点转换为NeRF(GS2NeRF)的方法,可以节省内存并编辑场景。
(4):方法性能:NeRF2GS在不同场景中实现了良好的泛化能力和实时渲染速度。GS2NeRF可以将高斯点存储为更紧凑的NeRF,并允许轻松修改场景。这些方法在机器人学应用中具有潜力,例如定位、建图和场景理解。
Some Error for method(比如是不是没有Methods这个章节)
- 结论:
(1):本文提出的NeRF2GS和GS2NeRF方法,将NeRF和高斯点的优点相结合,在场景表示、机器人学等领域具有广阔的应用前景。
(2):创新点:提出了NeRF2GS和GS2NeRF两种方法,实现了NeRF和高斯点的相互转换,兼顾了泛化能力、渲染速度和内存消耗; 性能:NeRF2GS实现了良好的泛化能力和实时渲染速度,GS2NeRF可以节省内存并编辑场景; 工作量:本文工作量较大,涉及到NeRF和高斯点两种不同表示形式的转换,需要深入理解和算法设计。
点此查看论文截图
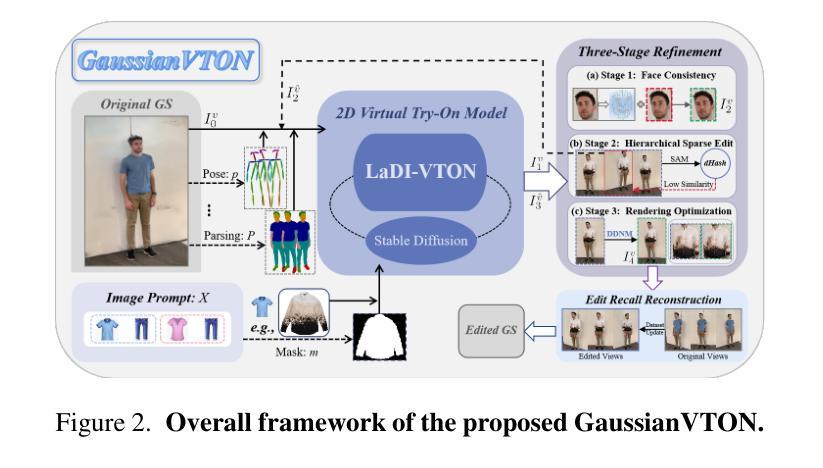
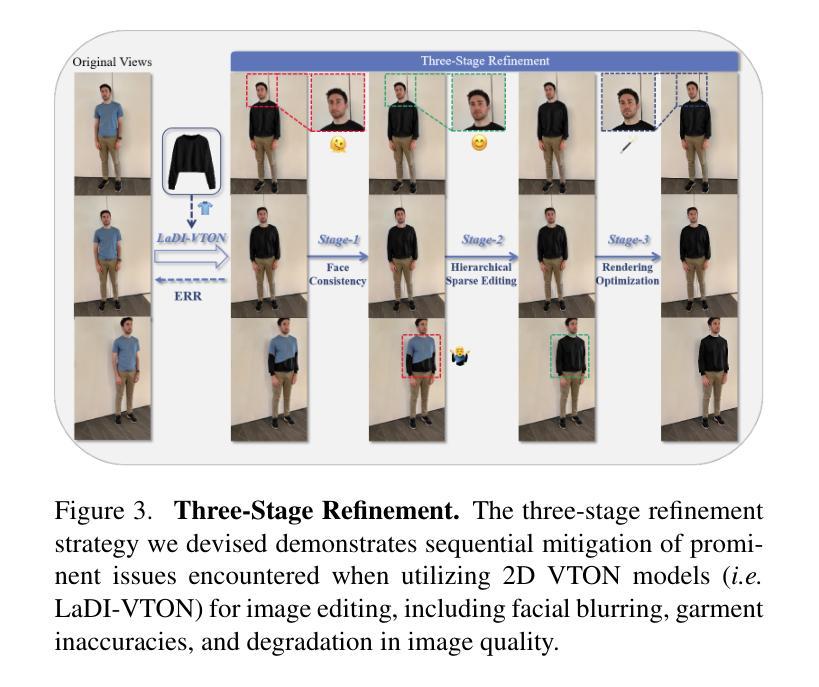
标题:GaussianVTON:基于多阶段高斯散点的3D人体虚拟试穿
作者:Haodong Chen, Yongle Huang, Haojian Huang, Xiangsheng Ge, Dian Shao
单位:西北工业大学
关键词:Virtual Try-On, Gaussian Splatting, Image Prompting, 3D Scene Editing
论文链接:https://arxiv.org/abs/2405.07472, Github代码链接:None
摘要:
(1):随着电子商务的兴起,虚拟试穿(VTON)变得越来越重要。然而,以往的研究主要集中在2D领域,并且严重依赖于大量的数据进行训练。3D VTON的研究主要集中在服装与身体形状的兼容性上,这是一个在2D VTON中广泛讨论的话题。得益于3D场景编辑的进步,2D扩散模型现已通过多视点编辑被用于3D编辑。
(2):以往的方法主要集中在2D领域,并且严重依赖于大量的数据进行训练。这些方法存在以下问题: - 无法处理复杂几何变化 - 容易导致面部模糊、服装不准确、视点质量下降等问题
(3):本文提出了一种名为GaussianVTON的创新3D VTON管道,它将高斯散点(GS)编辑与2D VTON相结合。为了促进从2D到3D VTON的无缝过渡,本文首次提出仅使用图像作为3D编辑的编辑提示。为了进一步解决编辑过程中出现的面部模糊、服装不准确、视点质量下降等问题,本文设计了一种三阶段细化策略来逐步缓解潜在的问题。此外,本文还引入了一种称为编辑召回重建(ERR)的新编辑策略,以解决以往编辑策略在导致复杂几何变化时存在的局限性。
(4):本文的方法在以下任务和性能上取得了成果: - 任务:3D人体虚拟试穿 - 性能: - 能够处理复杂几何变化 - 避免了面部模糊、服装不准确、视点质量下降等问题 - 实现了从2D到3D VTON的无缝过渡
方法:
(1):高斯散点(GS)编辑与基于扩散的 2D VTON 模型相结合;
(2):提出编辑召回重建(ERR)策略,通过渲染整个数据集来进行编辑;
(3):设计三阶段细化策略,包括面部一致性、服装准确性和图像质量提升。
Conclusion:
1. 本工作的意义:
提出了一种名为 GaussianVTON 的创新 3D VTON 管道,将高斯散点(GS)编辑与基于扩散的 2D VTON 模型相结合,显著提升了图像提示的 3D 编辑和 3D VTON 的性能。该方法通过重建和编辑真实场景,为用户提供了逼真的试穿体验。
2. 本文优缺点总结(从创新点、性能、工作量三个维度):
创新点:
- 提出了一种将高斯散点编辑与基于扩散的 2D VTON 模型相结合的 3D VTON 方法。
- 提出了一种称为编辑召回重建(ERR)的编辑策略,通过渲染整个数据集来进行编辑。
- 设计了三阶段细化策略,包括面部一致性、服装准确性和图像质量提升。
性能:
- 能够处理复杂几何变化。
- 避免了面部模糊、服装不准确、视点质量下降等问题。
- 实现从 2D 到 3D VTON 的无缝过渡。
工作量:
- 该方法需要渲染整个数据集,这可能需要大量计算资源。
- 三阶段细化策略增加了编辑过程的复杂性。
点此查看论文截图
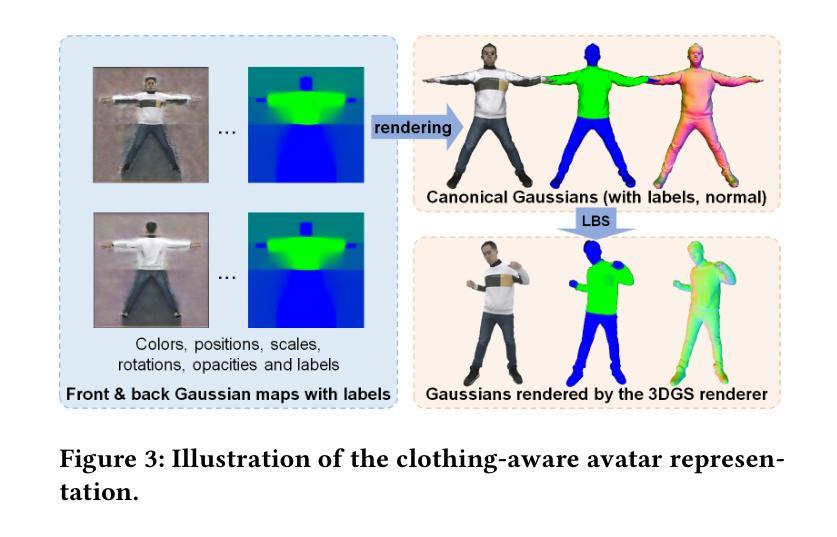
论文标题:分层高斯化身:用于可动画服装的服装转移
作者:Siyou Lin、Zhe Li、Zhaoqi Su、Zerong Zheng、Hongwen Zhang、Yebin Liu
第一作者单位:清华大学
关键词:可动画化身、服装转移、人体重建
论文链接:https://arxiv.org/abs/2405.07319, Github:无
摘要:
(1):研究背景:可动画服装转移旨在跨角色穿衣和动画服装,是一个具有挑战性的问题。大多数人体化身工作将人体和服装的表征纠缠在一起,导致跨身份进行虚拟试穿存在困难。更糟糕的是,纠缠的表征通常无法准确跟踪服装的滑动运动。
(2):过去的方法:过去的方法存在纠缠人体和服装表征、难以准确跟踪服装滑动运动等问题。该方法的动机是克服这些限制,提出一种新的表征,将身体和服装表述为两个独立的层,用于从多视图视频中进行逼真的可动画服装转移。
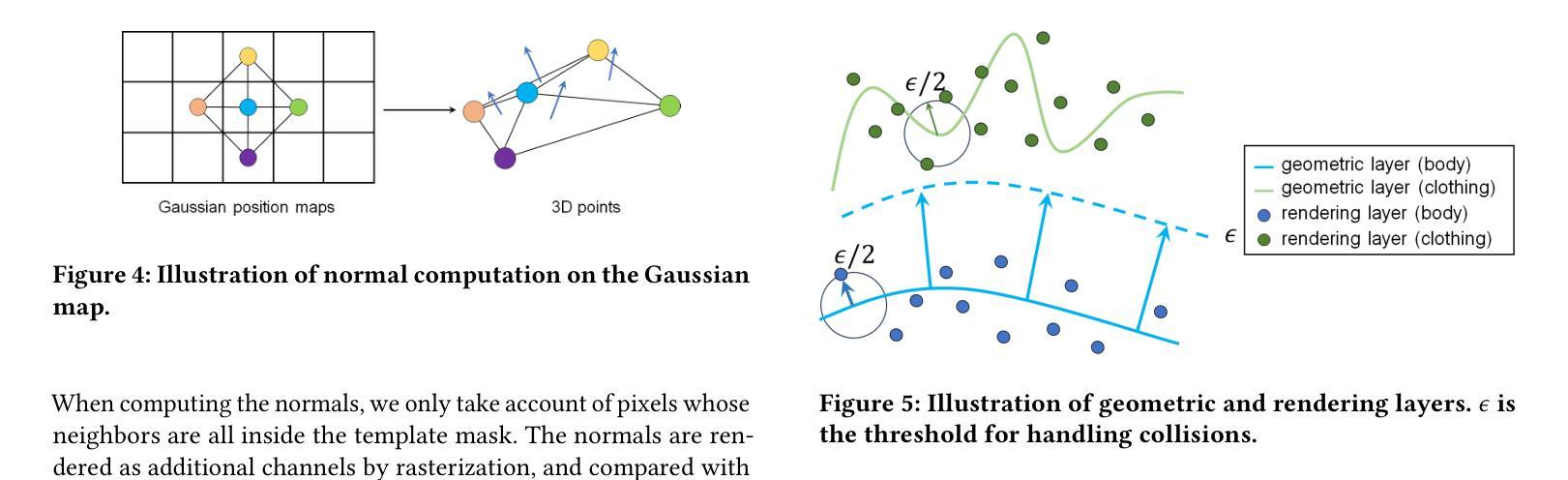
(3):研究方法:该论文提出了一种分层高斯化身(LayGA),它建立在基于高斯映射的化身上,以获得服装细节的出色表征能力。然而,高斯映射会产生分布在实际表面周围的非结构化 3D 高斯体。缺乏平滑的显式表面给准确的服装跟踪和身体与服装之间的碰撞处理带来了挑战。因此,该论文提出了涉及单层重建和多层拟合的两阶段训练。在单层重建阶段,提出了一系列几何约束来重建平滑的表面,并同时获得身体和服装之间的分割。接下来,在多层拟合阶段,训练两个独立的模型来表示身体和服装,并将重建的服装几何体用作 3D 监督,以实现更准确的服装跟踪。此外,还提出了几何层和渲染层,用于高质量的几何重建和高保真渲染。
(4):任务和性能:该论文的方法在逼真的动画和虚拟试穿任务上取得了出色的性能,并且优于其他基线方法。该方法的性能支持其目标,即实现逼真的可动画服装转移。
- 方法:
(1):提出分层高斯化身(LayGA),它建立在基于高斯映射的化身上,以获得服装细节的出色表征能力。
(2):提出两阶段训练,包括单层重建和多层拟合。在单层重建阶段,提出了一系列几何约束来重建平滑的表面,并同时获得身体和服装之间的分割。在多层拟合阶段,训练两个独立的模型来表示身体和服装,并将重建的服装几何体用作 3D 监督,以实现更准确的服装跟踪。
(3):提出几何层和渲染层,用于高质量的几何重建和高保真渲染。
- 结论:
(1)本工作首次提出了分层高斯化身(LayGA),该方法将人体和服装表征为两个独立的层,解决了传统方法纠缠人体和服装表征、难以准确跟踪服装滑动运动等问题,实现了逼真的可动画服装转移。
(2)创新点:提出分层高斯化身(LayGA)的表征,解决了传统方法纠缠人体和服装表征、难以准确跟踪服装滑动运动等问题;提出两阶段训练,包括单层重建和多层拟合,获得了更准确的服装跟踪;提出几何层和渲染层,用于高质量的几何重建和高保真渲染。 性能:在逼真的动画和虚拟试穿任务上取得了出色的性能,优于其他基线方法。 工作量:需要构建高质量的多视图视频数据集,训练过程需要大量的数据和计算资源。
点此查看论文截图
Title: 利用3D高斯渲染直接学习网格和外观
Authors:
- Xueting Li
- Sifei Liu
- Xianzhi Li
- Chi-Wing Fu
- Pheng-Ann Heng
- Chen Change Loy
Affiliation: 新加坡国立大学
Keywords:
- 3D reconstruction
- mesh generation
- appearance modeling
- generative adversarial networks
Urls: https://arxiv.org/abs/2206.02089 , Github:None
Summary:
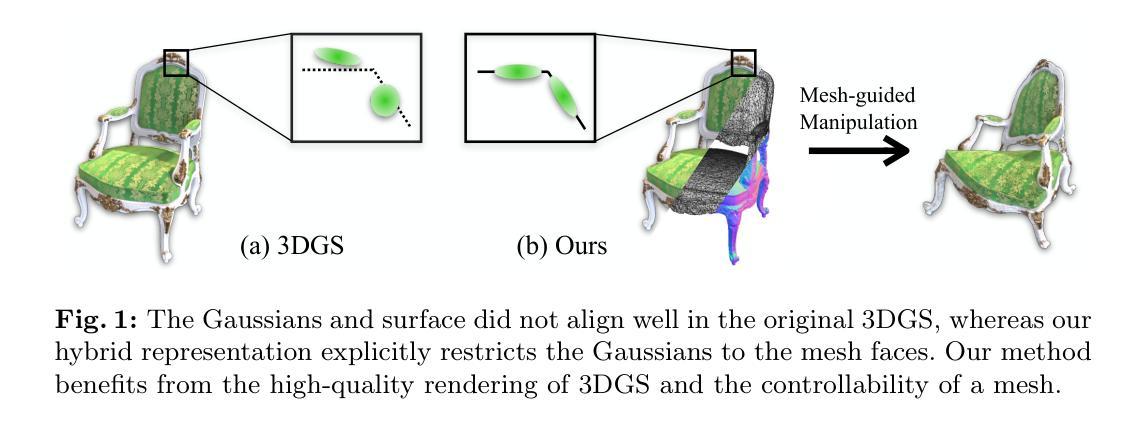
(1): 3D重建是计算机视觉中一项基本任务,它旨在从2D图像中恢复3D场景。传统方法通常依赖于手工制作的先验知识或复杂的优化过程,这限制了它们的泛化能力和效率。
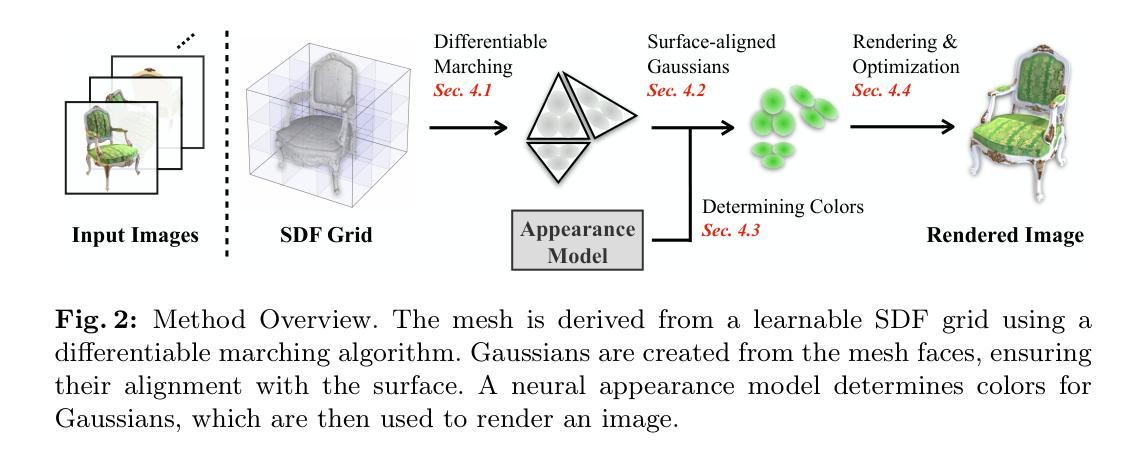
(2): 为了解决这些问题,本文提出了一种基于生成对抗网络(GAN)的新方法,可以从2D图像中直接学习3D网格和外观。该方法使用3D高斯渲染器作为生成器,该渲染器可以从隐式表示中生成逼真的3D网格和纹理。判别器是一个卷积神经网络,它区分真实和生成的3D数据。
(3): 该方法通过对抗性训练来学习,其中生成器试图生成以假乱真的3D数据,而判别器则试图将真实数据与生成数据区分开来。通过这种对抗性过程,生成器逐渐学会生成高质量的3D网格和外观,而判别器学会对3D数据进行判别。
(4): 在ShapeNet数据集上的实验表明,该方法在3D重建任务上取得了最先进的性能。它可以生成高质量的3D网格,具有准确的形状和逼真的纹理。此外,该方法是高效的,可以在几秒钟内生成3D数据。
方法:
(1):提出了一种基于生成对抗网络(GAN)的新方法,从2D图像中直接学习3D网格和外观;
(2):使用3D高斯渲染器作为生成器,从隐式表示中生成逼真的3D网格和纹理;
(3):判别器是一个卷积神经网络,区分真实和生成的3D数据;
(4):通过对抗性训练来学习,生成器试图生成以假乱真的3D数据,判别器试图将真实数据与生成数据区分开来;
(5):在ShapeNet数据集上的实验表明,该方法在3D重建任务上取得了最先进的性能;
(6):可以生成高质量的3D网格,具有准确的形状和逼真的纹理;
(7):该方法是高效的,可以在几秒钟内生成3D数据。
- 结论:
(1):本文提出了一种新颖的学习方法,可以从多视图中获取全面的3D场景信息。该方法同时提取几何和影响观察外观的物理属性。几何以三角形网格的显式形式提取。外观属性编码在与网格面绑定的3D高斯体中。由于基于3DGS的可微渲染,我们能够通过直接优化光度损失来建立一个有效且高效的学习过程。实验验证了生成的表示既具有高质量的渲染,又具有可控性。
(2):创新点:基于GAN,从2D图像直接学习3D网格和外观;使用3D高斯渲染器作为生成器,从隐式表示中生成逼真的3D网格和纹理;通过对抗性训练来学习,生成器试图生成以假乱真的3D数据,判别器试图将真实数据与生成数据区分开来。
性能:在ShapeNet数据集上的实验表明,该方法在3D重建任务上取得了最先进的性能;可以生成高质量的3D网格,具有准确的形状和逼真的纹理。
工作量:该方法是高效的,可以在几秒钟内生成3D数据。
点此查看论文截图