Diffusion Models
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-05-22 更新
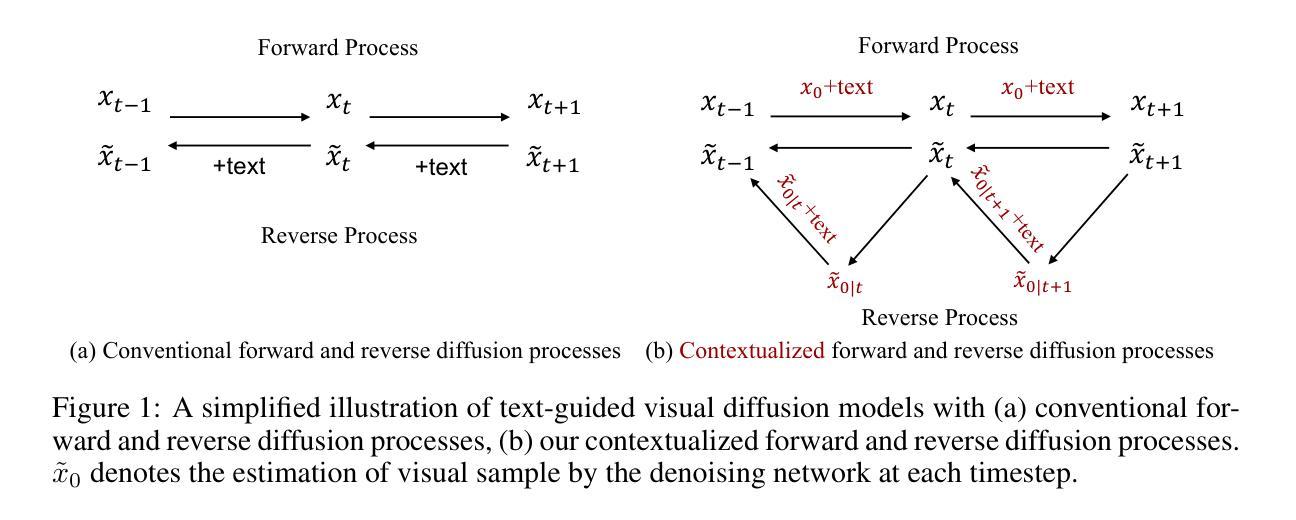
Diffusion-RSCC: Diffusion Probabilistic Model for Change Captioning in Remote Sensing Images
Authors:Xiaofei Yu, Yitong Li, Jie Ma
Remote sensing image change captioning (RSICC) aims at generating human-like language to describe the semantic changes between bi-temporal remote sensing image pairs. It provides valuable insights into environmental dynamics and land management. Unlike conventional change captioning task, RSICC involves not only retrieving relevant information across different modalities and generating fluent captions, but also mitigating the impact of pixel-level differences on terrain change localization. The pixel problem due to long time span decreases the accuracy of generated caption. Inspired by the remarkable generative power of diffusion model, we propose a probabilistic diffusion model for RSICC to solve the aforementioned problems. In training process, we construct a noise predictor conditioned on cross modal features to learn the distribution from the real caption distribution to the standard Gaussian distribution under the Markov chain. Meanwhile, a cross-mode fusion and a stacking self-attention module are designed for noise predictor in the reverse process. In testing phase, the well-trained noise predictor helps to estimate the mean value of the distribution and generate change captions step by step. Extensive experiments on the LEVIR-CC dataset demonstrate the effectiveness of our Diffusion-RSCC and its individual components. The quantitative results showcase superior performance over existing methods across both traditional and newly augmented metrics. The code and materials will be available online at https://github.com/Fay-Y/Diffusion-RSCC.
Summary
扩散模型应用于遥感图像变化描述,有效减轻像素差异对地形变化定位的影响,提高描述精度。
Key Takeaways
- 遥感图像变化描述旨在生成人类可理解的自然语言描述,以解释双时相遥感图像对之间的语义变化。
- 遥感图像变化描述不仅涉及跨模态相关信息的提取和流畅描述的生成,还需减轻像素级差异对地形变化定位的影响。
- 时间跨度长的像素问题会降低生成描述的准确度。
- 扩散模型具有杰出的生成能力,可用于遥感图像变化描述,解决上述问题。
- 在训练过程中,构建噪声预测器以学习从真实描述分布到标准高斯分布的分布。
- 在推理阶段,训练好的噪声预测器有助于估计分布的均值并逐步生成变化描述。
- 在 LEVIR-CC 数据集上的广泛实验表明了扩散模型在遥感图像变化描述中的有效性。
- 该方法在传统和新增加的指标上都优于现有方法。
题目:基于扩散模型的遥感图像变化描述
作者:Xiaofei Yu, Yitong Li, Jie Ma
第一作者单位:北京外国语大学信息科学与技术学院
关键词:遥感,扩散模型,变化描述,注意力机制
论文链接:https://arxiv.org/abs/2302.07736, Github:None
摘要:
(1):研究背景:遥感图像变化描述(RSICC)旨在生成类似人类语言的句子来描述双时相遥感图像对之间的语义变化。与传统的变化描述任务不同,RSICC 不仅涉及跨不同模态检索相关信息并生成流畅的描述,还要减轻像素级差异对地形变化定位的影响。
(2):过去方法及问题:现有的 RSICC 方法通常采用编码器-解码器结构,但它们难以区分语义变化和伪变化,从而影响描述的准确性。
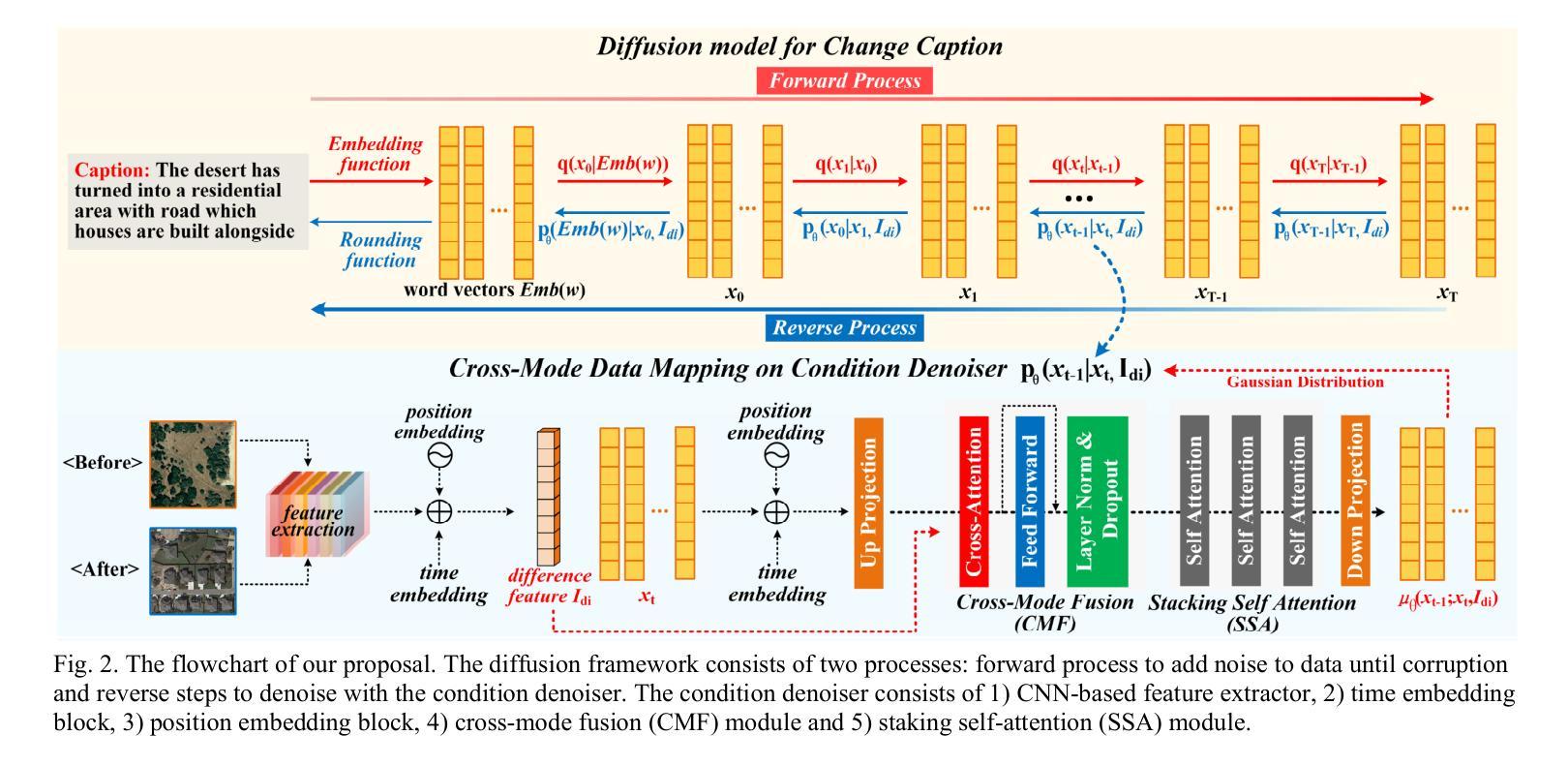
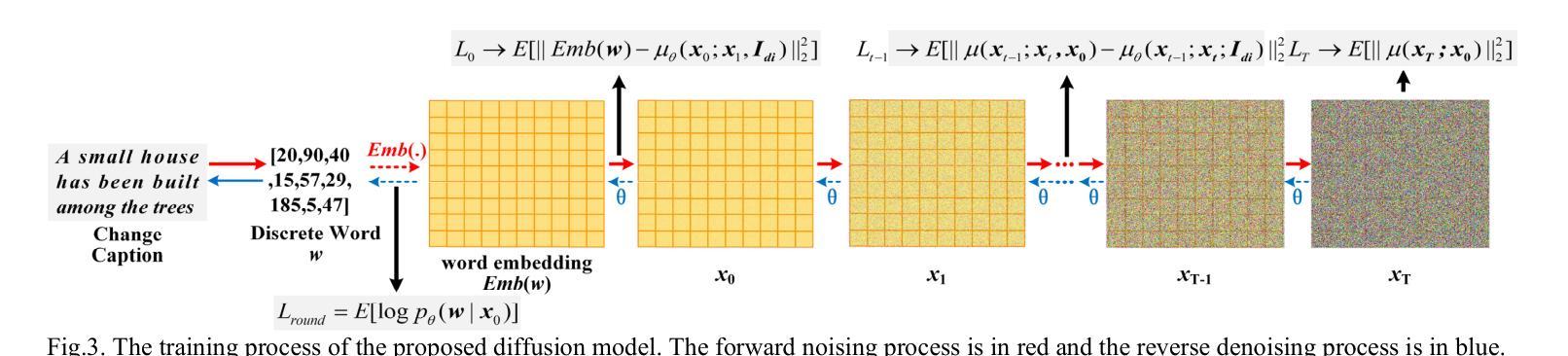
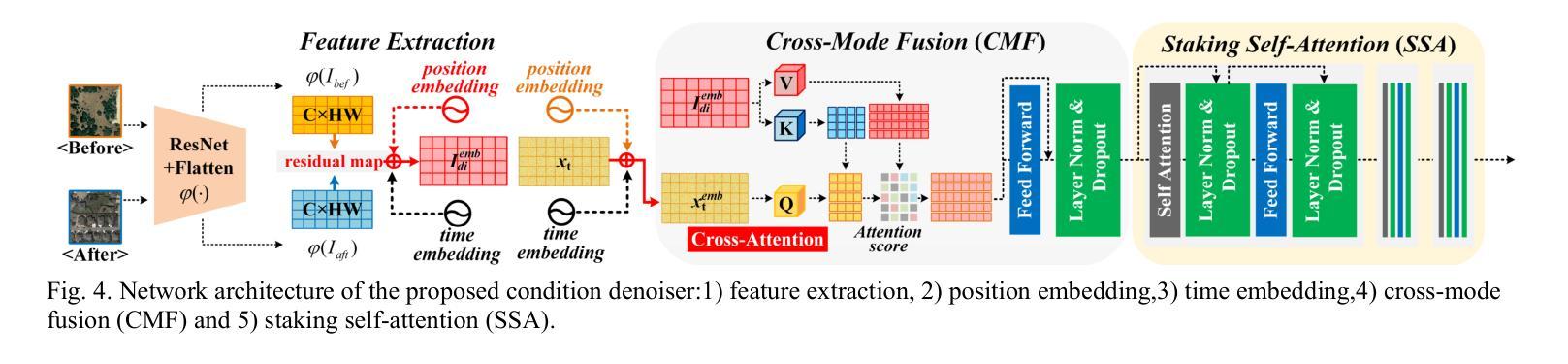
(3):本文方法:本文提出了一种基于扩散模型的 RSICC 方法。该方法构造了一个条件为交叉模态特征的噪声预测器,学习从真实描述分布到马尔可夫链下的标准高斯分布的分布。同时,在逆过程中设计了一个跨模态融合和一个堆叠自注意力模块用于噪声预测器。
(4):实验结果:在 LEVIR-CC 数据集上的广泛实验表明,本文方法在传统和新增加的指标上都优于现有方法。这些结果支持了本文方法区分语义变化和伪变化的能力,从而提高了描述的准确性。
Some Error for method(比如是不是没有Methods这个章节)
- 结论:
(1):本文工作的主要意义在于:提出了一个基于扩散模型的遥感图像变化描述方法,该方法通过构建条件为交叉模态特征的噪声预测器,学习从真实描述分布到马尔可夫链下的标准高斯分布的分布,并设计了跨模态融合和堆叠自注意力模块,有效区分语义变化和伪变化,提高了描述的准确性。
(2):本文的优点和不足总结如下:
创新点: - 提出了一种基于扩散模型的遥感图像变化描述方法,该方法通过构建条件为交叉模态特征的噪声预测器,学习从真实描述分布到马尔可夫链下的标准高斯分布的分布,有效区分语义变化和伪变化,提高了描述的准确性。 - 设计了跨模态融合和堆叠自注意力模块,进一步增强了模型的语义理解能力和变化定位能力。
性能: - 在 LEVIR-CC 数据集上的广泛实验表明,本文方法在传统和新增加的指标上都优于现有方法,验证了其有效性。
工作量: - 本文方法需要较大的训练数据量和较长的训练时间。
点此查看论文截图

Title: 世界建模的扩散:Atari 中的视觉细节至关重要
Authors: Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, François Fleuret
Affiliation: 日内瓦大学
Keywords: Diffusion, World Modeling, Reinforcement Learning, Atari
Urls: Paper: https://arxiv.org/abs/2405.12399, Github: https://github.com/eloialonso/diamond
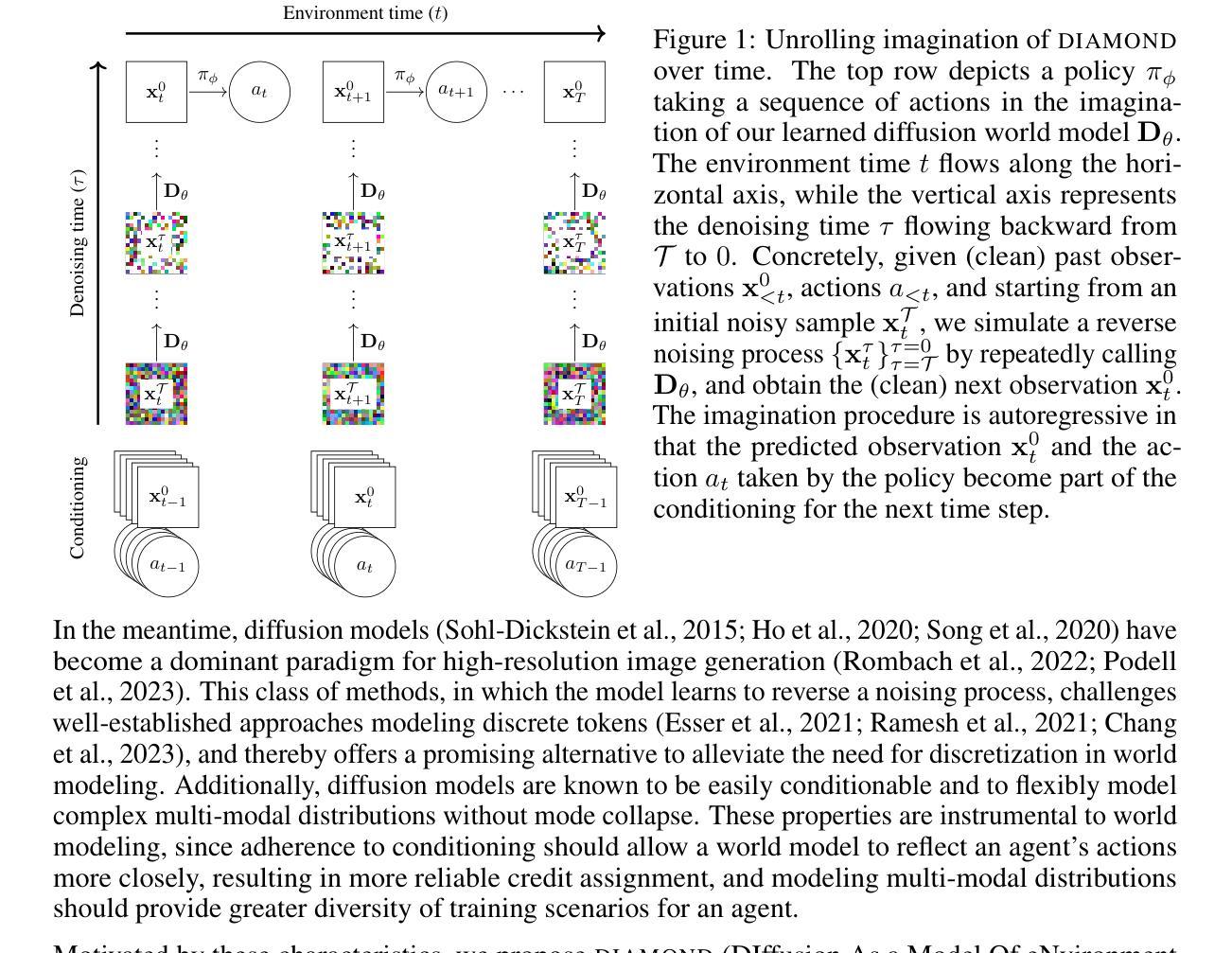
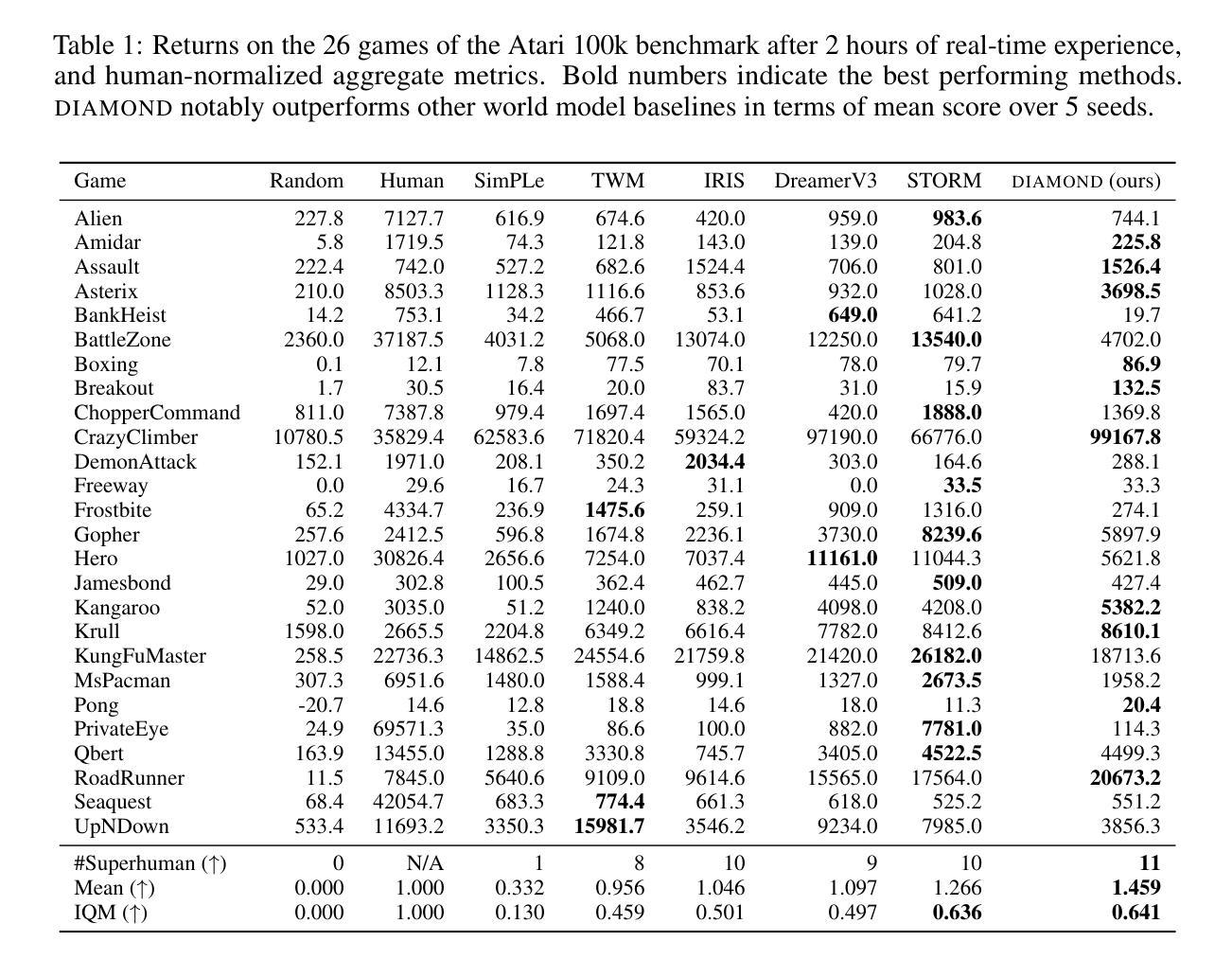
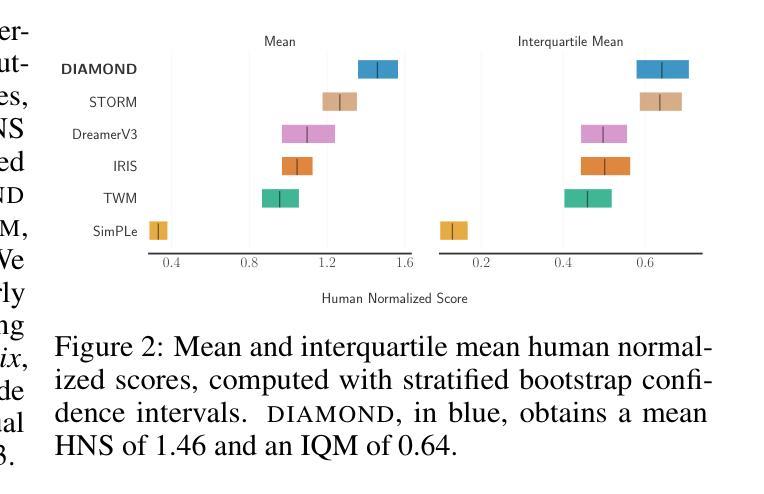
Summary:
(1): 世界模型是一种有前途的方法,可用于以安全且样本高效的方式训练强化学习智能体。最近的世界模型主要对离散潜在变量序列进行操作以建模环境动态。然而,这种压缩成紧凑的离散表示可能会忽略对强化学习很重要的视觉细节。与此同时,扩散模型已成为图像生成的主导方法,挑战了对离散潜在变量建模的成熟方法。受这种范式转变的启发,我们引入了 DIAMOND(DIffusion As a Model Of eNvironment Dreams),一种在扩散世界模型中训练的强化学习智能体。我们分析了使扩散适用于世界建模所需的关键设计选择,并展示了改进的视觉细节如何提高智能体性能。DIAMOND 在具有竞争力的 Atari 100k 基准测试中获得了 1.46 的平均人类归一化分数;这是在世界模型中完全训练的智能体的最新成绩。为了促进未来对世界建模扩散的研究,我们在 https://github.com/eloialonso/diamond 上发布了我们的代码、智能体和可玩世界模型。 (2): 最近的世界建模方法通常将环境动态建模为离散潜在变量序列。潜在空间的离散化有助于避免在多步时间范围内累积误差。然而,这种编码可能会丢失信息,从而导致泛化性和重建质量下降。这对于信息要求不太明确的更真实场景可能存在问题,例如训练自动驾驶汽车(Autonomous Vehicles)。在这种情况下,视觉输入中的小细节,例如远处的交通灯或行人,可能会改变智能体的策略。增加离散潜在变量的数量可以减轻这种有损压缩,但会增加计算成本。 (3): 本文提出的研究方法是:分析使扩散适合世界建模所需的关键设计选择,并展示了改进的视觉细节如何提高智能体性能。 (4): 在 Atari 100k 基准测试任务上,DIAMOND 取得了 1.46 的平均人类归一化分数。该性能支持了他们在世界模型中完全训练智能体的目标。Methods:
(1):本文提出了一种名为 DIAMOND 的强化学习智能体,该智能体在扩散世界模型中进行训练。 (2):DIAMOND 使用扩散模型来对环境动态进行建模,而不是离散潜在变量序列。 (3):作者分析了使扩散适用于世界建模所需的关键设计选择,并展示了改进的视觉细节如何提高智能体性能。 (4):DIAMOND 在 Atari 100k 基准测试任务上取得了 1.46 的平均人类归一化分数,这表明了扩散世界模型在强化学习中的潜力。结论:
(1):本文提出了一种名为 DIAMOND 的强化学习智能体,该智能体在扩散世界模型中进行训练。DIAMOND 在 Atari 100k 基准测试任务上取得了 1.46 的平均人类归一化分数,这表明了扩散世界模型在强化学习中的潜力。 (2):Innovation point: 本文提出了使用扩散模型对环境动态进行建模的方法,而不是离散潜在变量序列。 Performance: DIAMOND 在 Atari 100k 基准测试任务上取得了 1.46 的平均人类归一化分数,这表明了扩散世界模型在强化学习中的潜力。 Workload: DIAMOND 的训练成本高于使用离散潜在变量序列的世界模型的训练成本。
点此查看论文截图

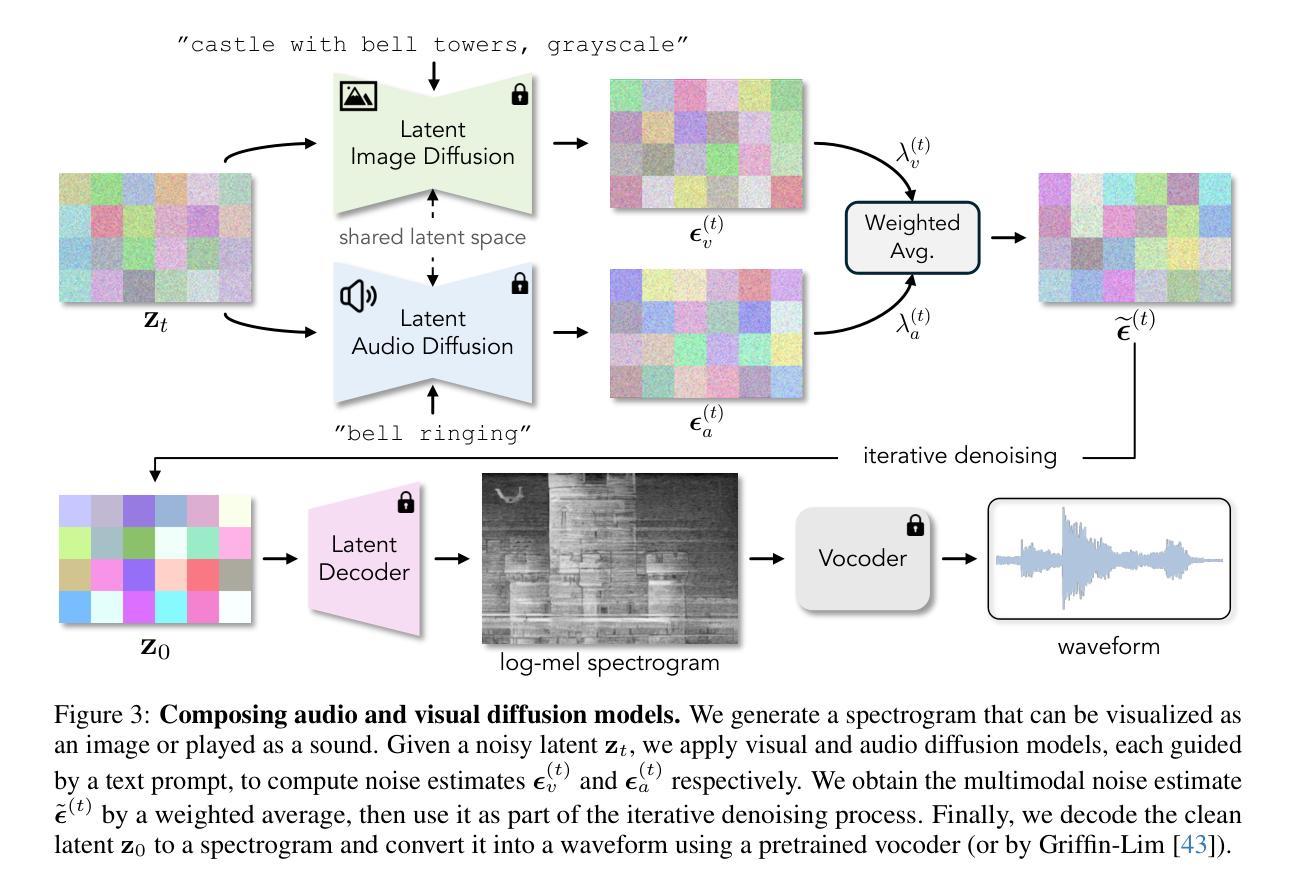
Images that Sound: Composing Images and Sounds on a Single Canvas
Authors:Ziyang Chen, Daniel Geng, Andrew Owens
Spectrograms are 2D representations of sound that look very different from the images found in our visual world. And natural images, when played as spectrograms, make unnatural sounds. In this paper, we show that it is possible to synthesize spectrograms that simultaneously look like natural images and sound like natural audio. We call these spectrograms images that sound. Our approach is simple and zero-shot, and it leverages pre-trained text-to-image and text-to-spectrogram diffusion models that operate in a shared latent space. During the reverse process, we denoise noisy latents with both the audio and image diffusion models in parallel, resulting in a sample that is likely under both models. Through quantitative evaluations and perceptual studies, we find that our method successfully generates spectrograms that align with a desired audio prompt while also taking the visual appearance of a desired image prompt. Please see our project page for video results: https://ificl.github.io/images-that-sound/
PDF Project site: https://ificl.github.io/images-that-sound/
Summary
自然图像的声谱图既能展现逼真的视觉效果,又能产生自然的声音。
Key Takeaways
- 声谱图是声音的二维表示,其外观与我们视觉世界中的图像截然不同。
- 自然图像作为声谱图播放时,会产生不自然的声音。
- 本研究合成出同时具有自然图像外观和自然音频声音的声谱图,称为“可视化声音”。
- 该方法采用零样本学习,利用共享潜在空间中的预训练文本到图像和文本到声谱图扩散模型。
- 逆向过程中,通过音频和图像扩散模型并行对噪声潜在变量进行去噪,生成满足两个模型要求的样本。
- 定量评估和感知研究表明,该方法成功生成了与目标音频提示一致、同时具有目标图像提示视觉外观的声谱图。
- 更详细的研究结果请见项目主页:https://ificl.github.io/images-that-sound/
标题:图像即声音:在单一画布上合成图像和声音
作者:Ziyang Chen, Daniel Geng, Andrew Owens
隶属单位:密歇根大学
关键词:图像到声音,扩散模型,零样本学习
论文链接:https://ificl.github.io/images-that-sound/,Github 代码链接:None
摘要:
(1):研究背景:声谱图是声音的二维表示,与我们视觉世界中的图像看起来非常不同。当自然图像以声谱图的形式播放时,会产生不自然的声音。
(2):过去的方法和问题:以往的方法无法同时生成既像自然图像又像自然音频的声谱图。
(3):本文提出的研究方法:本文提出了一种简单且零样本的方法,利用预训练的文本到图像和文本到声谱图扩散模型,在共享潜在空间中工作。在反向过程中,使用音频和图像扩散模型并行对噪声潜变量进行去噪,从而得到一个同时符合这两个模型的样本。
(4):方法的性能:通过定量评估和感知研究,本文的方法成功生成了与所需音频提示一致,同时具有所需图像提示视觉外观的声谱图。
方法:
(1):利用预训练的文本到图像和文本到声谱图扩散模型,在共享潜在空间中工作;
(2):在反向过程中,使用音频和图像扩散模型并行对噪声潜变量进行去噪;
(3):得到一个同时符合这两个模型的样本。
结论:
(1):本工作表明,自然图像的分布与自然声谱图的分布之间存在非平凡的重叠。我们通过从这两个分布的交集中进行采样来证明这一点,从而得到看起来像真实图像但听起来像自然声音的声谱图。我们注意到,由于声码器本质上是有损的,因此通常无法实现完美的循环一致性。 (2):创新点:提出了一个简单且零样本的方法,利用预训练的文本到图像和文本到声谱图扩散模型,在共享潜在空间中工作,在反向过程中并行对噪声潜变量进行去噪,得到一个同时符合这两个模型的样本;性能:通过定量评估和感知研究,本文的方法成功生成了与所需音频提示一致,同时具有所需图像提示视觉外观的声谱图;工作量:该方法简单易用,不需要额外的训练数据或模型。
点此查看论文截图


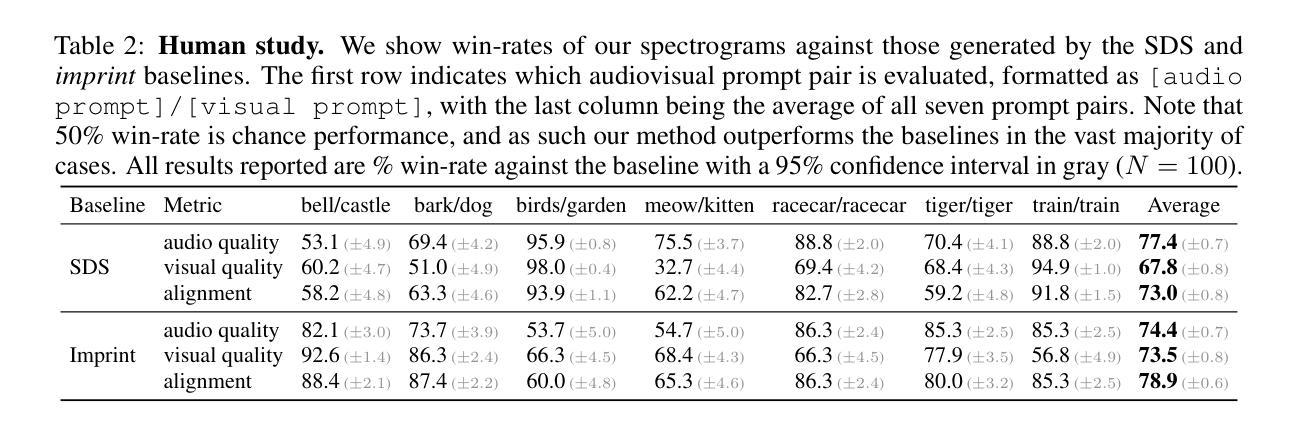
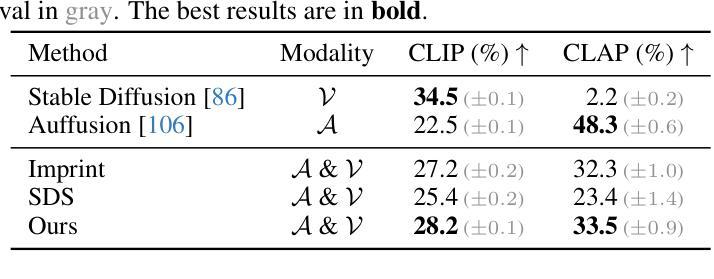
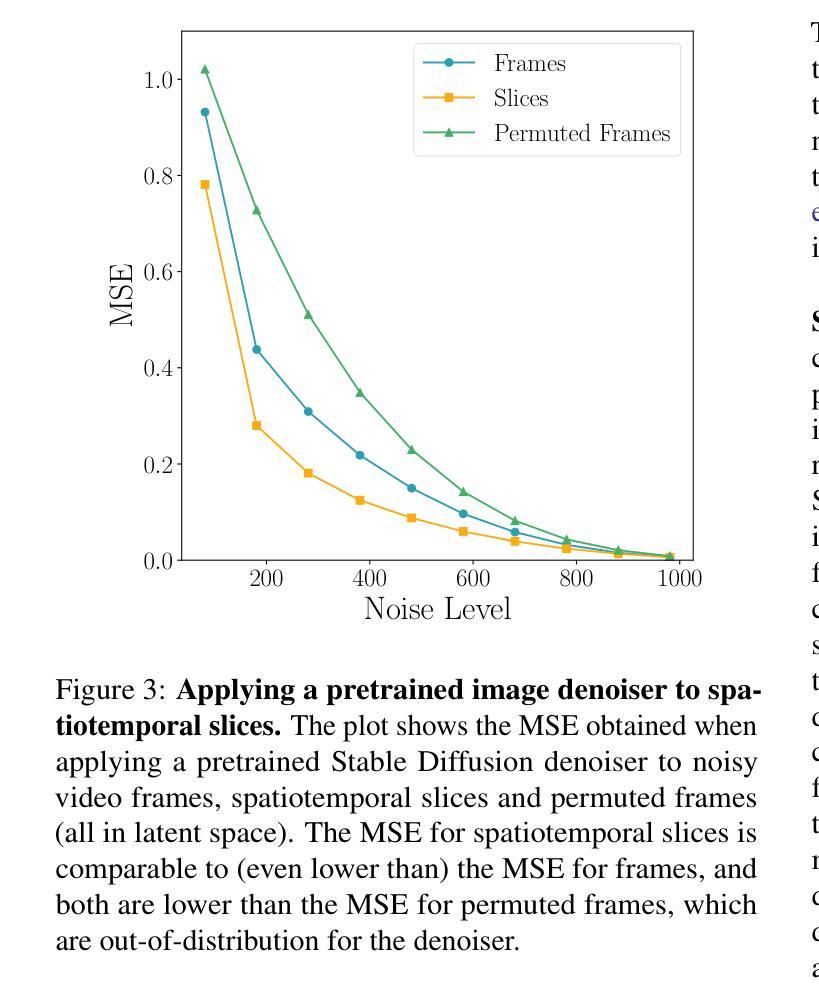
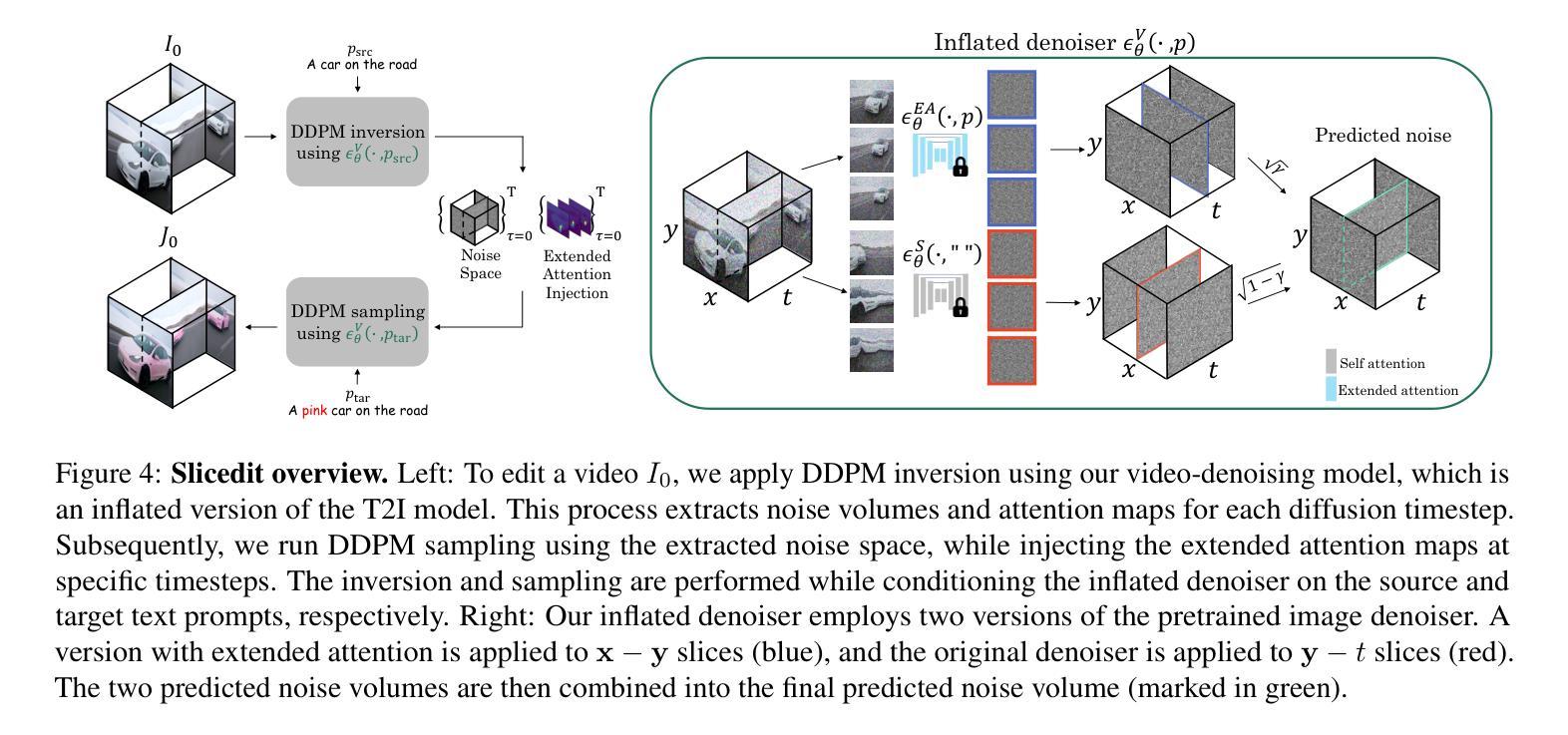
Slicedit: Zero-Shot Video Editing With Text-to-Image Diffusion Models Using Spatio-Temporal Slices
Authors:Nathaniel Cohen, Vladimir Kulikov, Matan Kleiner, Inbar Huberman-Spiegelglas, Tomer Michaeli
Text-to-image (T2I) diffusion models achieve state-of-the-art results in image synthesis and editing. However, leveraging such pretrained models for video editing is considered a major challenge. Many existing works attempt to enforce temporal consistency in the edited video through explicit correspondence mechanisms, either in pixel space or between deep features. These methods, however, struggle with strong nonrigid motion. In this paper, we introduce a fundamentally different approach, which is based on the observation that spatiotemporal slices of natural videos exhibit similar characteristics to natural images. Thus, the same T2I diffusion model that is normally used only as a prior on video frames, can also serve as a strong prior for enhancing temporal consistency by applying it on spatiotemporal slices. Based on this observation, we present Slicedit, a method for text-based video editing that utilizes a pretrained T2I diffusion model to process both spatial and spatiotemporal slices. Our method generates videos that retain the structure and motion of the original video while adhering to the target text. Through extensive experiments, we demonstrate Slicedit’s ability to edit a wide range of real-world videos, confirming its clear advantages compared to existing competing methods. Webpage: https://matankleiner.github.io/slicedit/
PDF ICML 2024. Code and examples are available at https://matankleiner.github.io/slicedit/
Summary
基于自然视频的时空切片与真实图像具有相似的特性,可利用预训练的 T2I 扩散模型对其进行处理,增强视频编辑中的时间一致性
Key Takeaways
- 利用预训练的 T2I 扩散模型来增强时空一致性
- Slicedit 方法同时处理空间和时空切片
- 生成视频保留原始视频的结构和运动,同时符合目标文本
- 在广泛实验中,证明 Slicedit 能够编辑各种真实视频
- 明显优于现有的竞争方法
Title: Slicedit:基于文本到图像扩散模型和时空切片的零样本视频编辑
Authors: Nathaniel Cohen, Vladimir Kulikov, Matan Kleiner, Inbar Huberman-Spiegelglas, Tomer Michaeli
Affiliation: 巴黎矿业-PSL研究大学
Keywords: 文本到图像, 视频编辑, 扩散模型, 时空切片
Urls:
Summary:
(1): 文本到图像(T2I)扩散模型在图像合成和编辑中取得了最先进的结果。然而,将这些预训练模型用于视频编辑被认为是一个重大挑战。许多现有工作试图通过像素空间或深度特征之间的显式对应机制来增强编辑视频中的时间一致性。然而,这些方法难以处理强烈的非刚性运动。
(2): 本文提出了一种从根本上不同的方法,该方法基于以下观察:自然视频的时空切片表现出与自然图像相似的特征。因此,通常仅用作视频帧先验的相同 T2I 扩散模型也可以通过在时空切片上应用它来作为增强时间一致性的强先验。
(3): 基于这一观察,我们提出了 Slicedit,这是一种基于文本的视频编辑方法,它利用预训练的 T2I 扩散模型处理空间和时空切片。我们的方法生成的视频保留了原始视频的结构和运动,同时遵循目标文本。
(4): 通过广泛的实验,我们证明了 Slicedit 编辑各种真实世界视频的能力,证实了其与现有竞争方法相比的明显优势。
方法:
(1):提出 Slicedit,这是一种基于文本的视频编辑方法,它利用预训练的 Text-to-Image(T2I)扩散模型处理空间和时空切片。
(2):该方法将时空切片作为增强时间一致性的强先验,通过在时空切片上应用 T2I 扩散模型来生成视频。
(3):Slicedit 编辑视频时保留了原始视频的结构和运动,同时遵循目标文本。
结论:
(1):本文提出了一种基于文本的零样本视频编辑方法 Slicedit,该方法利用预训练的文本到图像扩散模型。我们的方法对模型进行了修改,使其能够处理视频。最重要的是,它将最初设计用于图像的预训练去噪器也应用于视频的时空切片。为了编辑视频,我们在 DDPM 反演过程中使用我们膨胀的去噪器,同时将源视频的扩展注意力注入目标视频。我们的方法优于现有技术,在编辑视频时保留了未指定区域,同时不影响时间一致性。我们通过测量编辑保真度、结构保留和时间一致性指标对其进行了评估,并辅以用户研究。虽然我们的方法在保留输入视频的结构方面表现出色,但它在全局编辑任务中遇到了挑战,例如将自然视频的帧转换为绘画。此外,我们的方法仅限于保留结构的编辑。这是由于使用了带有注意力注入的 DDPM 反演。图 11 中显示了一个示例失败案例。
(2):创新点:提出了一种基于文本的零样本视频编辑方法,该方法利用预训练的文本到图像扩散模型,并将其应用于视频的时空切片以增强时间一致性。 性能:我们的方法在编辑保真度、结构保留和时间一致性方面优于现有技术。 工作量:我们的方法需要预训练文本到图像扩散模型,并且编辑过程可能需要大量计算。
点此查看论文截图



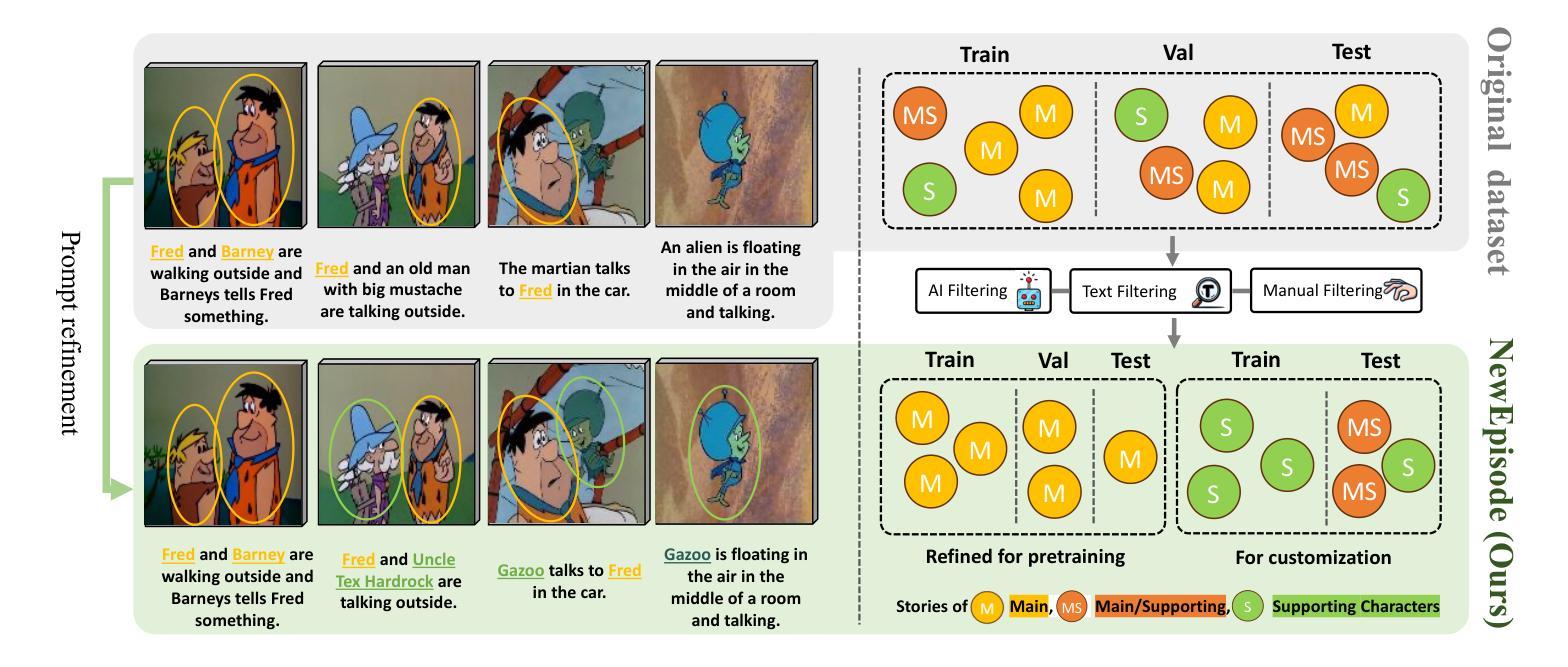
Title: 可演化的故事生成:用于新角色自定义的基准和方法
Authors: Xiyu Wang, Yufei Wang, Satoshi Tsutsui, Weisi Lin, Bihan Wen, Alex C. Kot
Affiliation: 南洋理工大学
Keywords: Generative Diffusion Model, Story Visualization, Generative Model Customization
Urls: Paper: https://arxiv.org/pdf/2405.11852.pdf , Github:None
Summary:
(1): 基于扩散的模型在故事可视化中展示了生成内容连贯图像的潜力。然而,如何在保持角色一致性的同时有效地将新角色融入现有叙事中仍然是一个难题,特别是在数据有限的情况下。有两个主要限制阻碍了进展:(1) 由于潜在的角色泄露和不一致的文本标记,缺少合适的基准;(2) 区分新角色和旧角色的挑战,导致结果模棱两可。
(2): 过去的方法包括:使用预训练的文本到图像生成模型来生成故事可视化。然而,这些方法存在以下问题:1)缺乏合适的基准来评估生成模型生成具有新角色的新故事的适应性。2)难以区分新角色和旧角色,导致生成结果模棱两可。
(3): 本文提出的研究方法包括:1)引入 NewEpisode 基准,该基准包含经过改进的数据集,旨在使用单个示例故事评估生成模型生成具有新角色的新故事的适应性。2)提出 EpicEvo,这是一种使用具有新角色的单个故事来自定义基于扩散的视觉故事生成模型的方法,将新角色无缝集成到既定的角色动态中。
(4): 本文方法在 NewEpisode 基准上取得了以下性能:1)定量评估表明,EpicEvo 在 NewEpisode 基准上优于现有的基线。2)定性研究证实了 EpicEvo 在扩散模型中对视觉故事生成的卓越定制。这些性能支持了本文的目标,即提供一种仅使用一个示例故事就能融合新角色的有效方法,为连载漫画等应用解锁了新的可能性。
方法:
(1): 提出 NewEpisode 基准,该基准包含经过改进的数据集,旨在使用单个示例故事评估生成模型生成具有新角色的新故事的适应性;
(2): 提出了 EpicEvo,这是一种使用具有新角色的单个故事来自定义基于扩散的视觉故事生成模型的方法,将新角色无缝集成到既定的角色动态中;
(3): 在 NewEpisode 基准上对 EpicEvo 进行了定量和定性评估,结果表明 EpicEvo 在生成具有新角色的新故事的适应性方面优于现有的基线,并且能够在扩散模型中对视觉故事生成进行卓越的定制。
结论:
(1):本文解决了故事角色定制的难题,提出 NewEpisode 基准和 EpicEvo 方法,使视觉故事生成模型能够生成从未见过的角色的新故事,为连载漫画等应用解锁了新的可能性。
(2):创新点:提出 NewEpisode 基准和 EpicEvo 方法;性能:在 NewEpisode 基准上优于现有的基线,能够在扩散模型中对视觉故事生成进行卓越的定制;工作量:需要收集和整理 NewEpisode 基准数据,训练 EpicEvo 模型。
点此查看论文截图

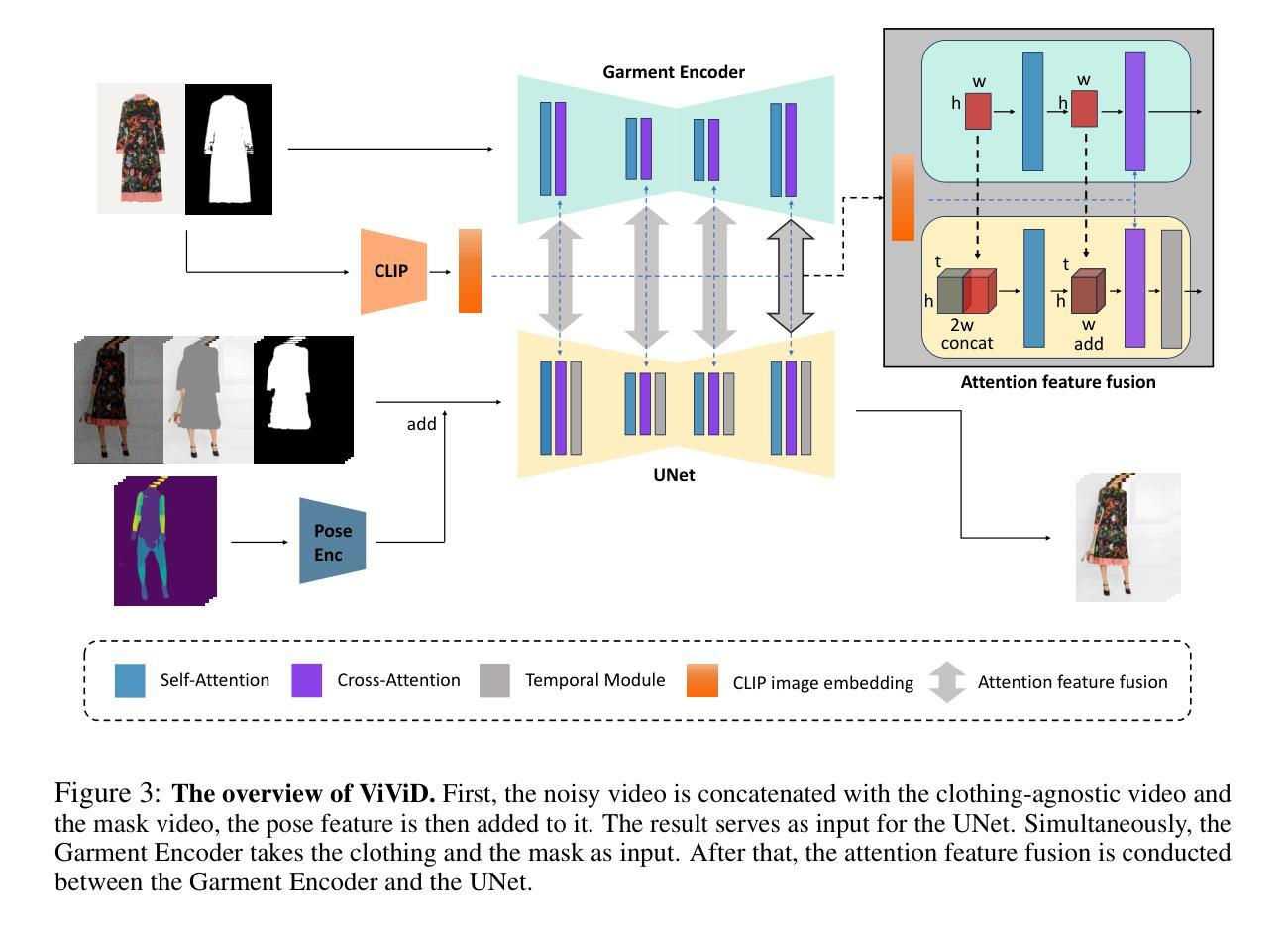
Title: ViViD: 使用扩散模型的视频虚拟试穿
Authors: Zixun Fang, Wei Zhai, Aimin Su, Hongliang Song, Kai Zhu, Mao Wang, Yu Chen, Zhiheng Liu, Yang Cao, Zheng-Jun Zha
Affiliation: 中国科学技术大学
Keywords: Video virtual try-on, Diffusion models, Pose encoding, Temporal consistency
Urls: Paper: https://arxiv.org/abs/2405.11794, Github: None
Summary:
(1): 视频虚拟试穿旨在将一件衣服转移到目标人物的视频上。将基于图像的试穿技术逐帧应用于视频领域会导致时间不一致的结果,而之前的基于视频的试穿解决方案只能生成低视觉质量和模糊的结果。
(2): 过去的基于图像的虚拟试穿方法无法直接应用于视频,因为这会导致灾难性的结果。基于视频的试穿解决方案虽然可以解决时间一致性问题,但它们通常会产生低视觉质量和模糊的结果。
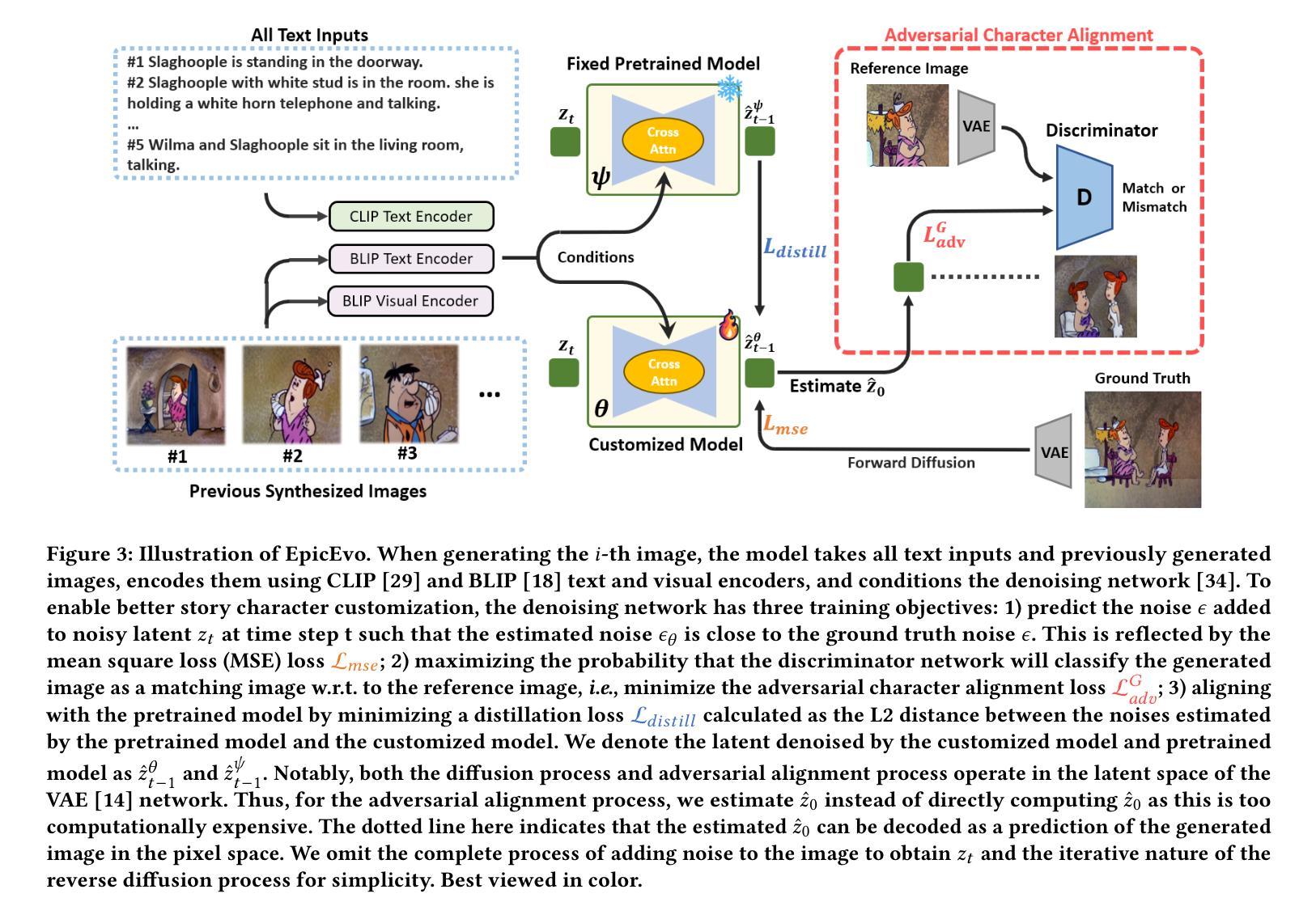
(3): 本文提出了 ViViD,一个使用强大的扩散模型来解决视频虚拟试穿任务的新框架。ViViD 包含一个服装编码器,用于提取细粒度的服装语义特征,指导模型捕捉服装细节并通过提出的注意力特征融合机制将其注入目标视频中。为了确保时空一致性,ViViD 引入了一个轻量级的姿势编码器来编码姿势信号,使模型能够学习服装和人体姿势之间的相互作用,并将分层的 Temporal 模块插入到文本到图像的稳定扩散模型中以实现更连贯和逼真的视频合成。此外,ViViD 还收集了一个新的数据集,这是迄今为止用于视频虚拟试穿任务的最大、服装类型最多、分辨率最高的数据集。
(4): 实验表明,ViViD 能够产生令人满意的视频试穿结果。在 ViViD 数据集上,ViViD 在 FID 和 LPIPS 度量方面优于最先进的方法。这些结果支持了 ViViD 在视频虚拟试穿任务中的有效性。
方法:
(1):该方法将视频虚拟试穿任务视为视频修复问题,将服装粘贴到与服装无关的区域; (2):提出服装编码器提取服装语义特征,通过注意力特征融合机制注入目标视频中; (3):引入轻量级姿势编码器编码姿势信号,使模型学习服装和人体姿势之间的相互作用; (4):在文本到图像的稳定扩散模型中插入分层的 Temporal 模块,实现更连贯、逼真的视频合成; (5):收集新数据集 ViViD,包含迄今为止用于视频虚拟试穿任务的最大、服装类型最多、分辨率最高的视频数据。结论:
(1): 本工作首次将强大的扩散模型应用于视频虚拟试穿任务,提出了 ViViD 框架,在视频虚拟试穿领域取得了显著进展。 (2):Innovation point: 创新点:提出了服装编码器、注意力特征融合机制、轻量级姿势编码器和分层的 Temporal 模块,有效解决了视频虚拟试穿任务中的服装细节捕捉、时间一致性、服装与人体姿势交互建模等关键挑战。Performance: 性能:在 ViViD 数据集上,ViViD 在 FID 和 LPIPS 度量方面均优于最先进的方法,证明了其在视频虚拟试穿任务中的有效性。Workload: 工作量:ViViD 的实现相对复杂,需要大量的训练数据和计算资源。
点此查看论文截图



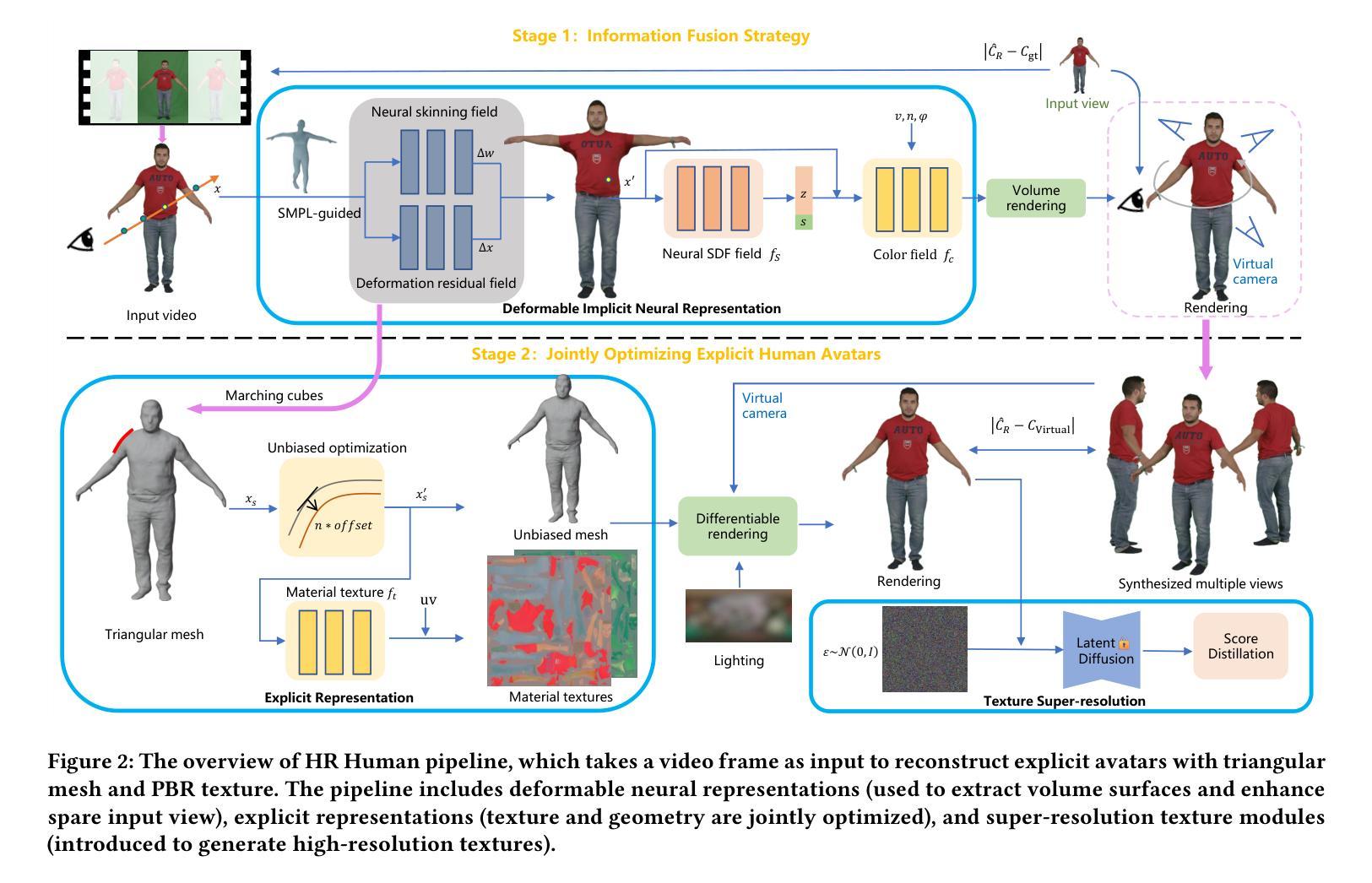
HR Human: Modeling Human Avatars with Triangular Mesh and High-Resolution Textures from Videos
Authors:Qifeng Chen, Rengan Xie, Kai Huang, Qi Wang, Wenting Zheng, Rong Li, Yuchi Huo
Recently, implicit neural representation has been widely used to generate animatable human avatars. However, the materials and geometry of those representations are coupled in the neural network and hard to edit, which hinders their application in traditional graphics engines. We present a framework for acquiring human avatars that are attached with high-resolution physically-based material textures and triangular mesh from monocular video. Our method introduces a novel information fusion strategy to combine the information from the monocular video and synthesize virtual multi-view images to tackle the sparsity of the input view. We reconstruct humans as deformable neural implicit surfaces and extract triangle mesh in a well-behaved pose as the initial mesh of the next stage. In addition, we introduce an approach to correct the bias for the boundary and size of the coarse mesh extracted. Finally, we adapt prior knowledge of the latent diffusion model at super-resolution in multi-view to distill the decomposed texture. Experiments show that our approach outperforms previous representations in terms of high fidelity, and this explicit result supports deployment on common renderers.
Summary
用单目视频获取带有物理材质纹理和三角形网格的可变形人体模型。
Key Takeaways
- 使用隐式神经表示生成可动画人体模型。
- 引入信息融合策略解决单目视频输入视图稀疏问题。
- 重建人体为可变形神经隐式曲面,提取三角形网格作为初始网格。
- 提出方法纠正粗糙网格边界和大小偏差。
- 采用多视图超分辨率潜扩散模型先验知识提取分解纹理。
- 实验表明该方法在高保真度方面优于以往表示,且显式结果支持在通用渲染器上部署。
Title: HR Human: 使用三角形网格和高分辨率纹理从视频中建模人体化身
Authors: Qifeng Chen, Rengan Xie, Kai Huang, Qi Wang, Wenting Zheng, Rong Li, Yuchi Huo
Affiliation: 中国杭州
Keywords: Human modeling;Rendering;Texture super resolution
Urls: Paper: https://arxiv.org/abs/2405.11270
Github: None
Summary:
(1): 近期,隐式神经表示已被广泛用于生成可动画的人体化身。然而,这些表示中的材质和几何形状在神经网络中耦合,难以编辑,这阻碍了它们在传统图形引擎中的应用。
(2): 过去的方法主要有:Implicit animatable human reconstruction、Relighting4D、Relightavatar。这些方法存在的问题是:隐式几何和纹理难以编辑,产生的纹理清晰度低,无法应用于传统图形引擎。
(3): 本文提出了一种从单目视频中获取具有高分辨率基于物理的材质纹理和三角形网格的人体化身的方法。该方法引入了一种新颖的信息融合策略,将单目视频中的信息与合成的虚拟多视图图像相结合,以解决输入视图的稀疏性。我们将人体重建为可变形的神经隐式曲面,并在行为良好的姿态中提取三角形网格作为下一阶段的初始网格。此外,我们还引入了一种方法来纠正提取的粗糙网格的边界和大小偏差。最后,我们采用了多视图超分辨率中潜在扩散模型的先验知识来提取分解的纹理。
(4): 在人体建模任务上,该方法在高保真度方面优于以往的表示,并且这种显式结果支持在通用渲染器上的部署。
方法:
(1):提出了一种从单目视频获取具有高分辨率基于物理的材质纹理和三角形网格的人体化身的方法;
(2):引入了一种新颖的信息融合策略,将单目视频中的信息与合成的虚拟多视图图像相结合,以解决输入视图的稀疏性;
(3):将人体重建为可变形的神经隐式曲面,并在行为良好的姿态中提取三角形网格作为下一阶段的初始网格;
(4):引入了一种方法来纠正提取的粗糙网格的边界和大小偏差;
(5):采用了多视图超分辨率中潜在扩散模型的先验知识来提取分解的纹理。
结论:
(1):本文提出了一种从单目视频中获取具有高分辨率基于物理的材质纹理和三角形网格的人体化身的方法,该方法在高保真度方面优于以往的表示,并且这种显式结果支持在通用渲染器上的部署。
(2):创新点:提出了一种新颖的信息融合策略,将单目视频中的信息与合成的虚拟多视图图像相结合,以解决输入视图的稀疏性;引入了一种方法来纠正提取的粗糙网格的边界和大小偏差;采用了多视图超分辨率中潜在扩散模型的先验知识来提取分解的纹理。 性能:在人体建模任务上,该方法在高保真度方面优于以往的表示。 工作量:该方法需要合成虚拟多视图图像,这可能会增加计算成本。
点此查看论文截图


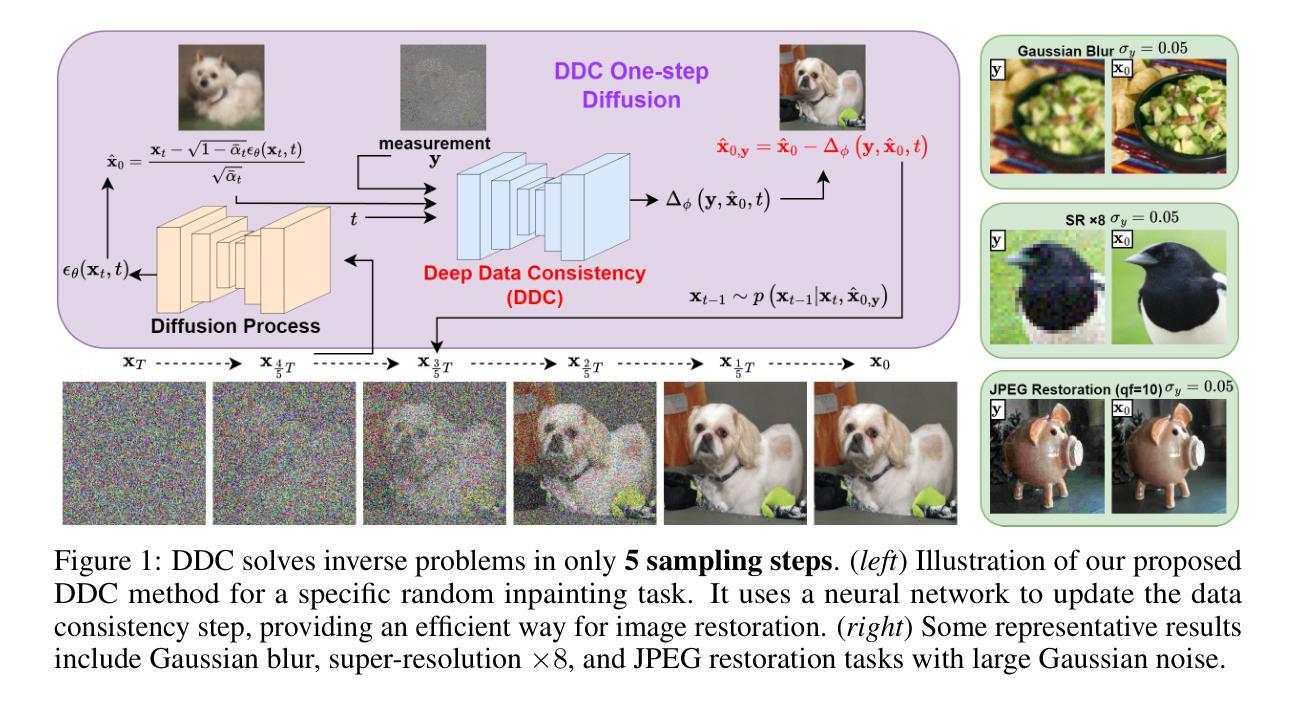
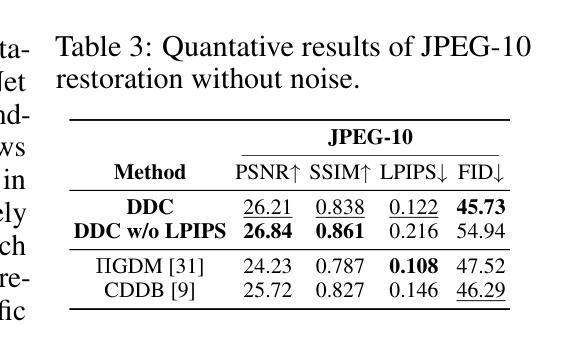
Deep Data Consistency: a Fast and Robust Diffusion Model-based Solver for Inverse Problems
Authors:Hanyu Chen, Zhixiu Hao, Liying Xiao
Diffusion models have become a successful approach for solving various image inverse problems by providing a powerful diffusion prior. Many studies tried to combine the measurement into diffusion by score function replacement, matrix decomposition, or optimization algorithms, but it is hard to balance the data consistency and realness. The slow sampling speed is also a main obstacle to its wide application. To address the challenges, we propose Deep Data Consistency (DDC) to update the data consistency step with a deep learning model when solving inverse problems with diffusion models. By analyzing existing methods, the variational bound training objective is used to maximize the conditional posterior and reduce its impact on the diffusion process. In comparison with state-of-the-art methods in linear and non-linear tasks, DDC demonstrates its outstanding performance of both similarity and realness metrics in generating high-quality solutions with only 5 inference steps in 0.77 seconds on average. In addition, the robustness of DDC is well illustrated in the experiments across datasets, with large noise and the capacity to solve multiple tasks in only one pre-trained model.
PDF Codes: https://github.com/Hanyu-Chen373/DeepDataConsistency
Summary:
深度数据一致性通过深度学习模型更新数据一致性步骤,解决了扩散模型求解逆问题的挑战,展现了卓越的相似性和真实性表现。
Key Takeaways:
- 提出深度数据一致性 (DDC) 方法,将数据一致性步骤用深度学习模型更新。
- 使用变分界训练目标,最大化条件后验,减少其对扩散过程的影响。
- 在线性和非线性任务中,DDC 在相似性和真实性指标上表现优异。
- DDC 仅需 5 步推理,平均耗时 0.77 秒,生成高质量的解决方案。
- DDC 在不同数据集、大噪声条件下表现稳健。
- DDC 可以用一个预训练模型解决多个任务。
Title: 深度数据一致性:一种快速且鲁棒的扩散模型求解逆问题的模型
Authors: 陈瀚宇,郝志修,肖丽英
Affiliation: 清华大学
Keywords: 扩散模型,逆问题,数据一致性,真实性
Urls: https://arxiv.org/abs/2405.10748v1, Github:None
Summary:
(1):扩散模型在解决图像逆问题方面取得了成功,但如何平衡数据一致性和真实性是一个挑战。
(2):现有方法包括替换得分函数、分解矩阵或使用优化算法,但它们在数据一致性和真实性之间难以平衡,且推理速度慢。
(3):本文提出深度数据一致性(DDC),使用神经网络更新扩散模型中的数据一致性步骤,通过变分界训练目标最大化条件后验概率,并减少其对扩散过程的影响。
(4):在图像超分辨率、修复、去模糊和JPEG恢复等任务上,DDC在仅需5个推理步骤且平均耗时0.77秒的情况下,在相似性和真实性指标上均取得了优异的性能,证明了其在平衡数据一致性和真实性方面的有效性。此外,DDC在不同数据集、大噪声和单一预训练模型解决多任务方面的鲁棒性也得到了证明。
- 方法:
(1)提出深度数据一致性(DDC),使用神经网络更新扩散模型中的数据一致性步骤,通过变分界训练目标最大化条件后验概率,并减少其对扩散过程的影响;
(2)利用神经网络拟合数据一致性项,并将其融入到扩散模型中,使得模型能够在保留数据一致性的同时,生成更真实的图像;
(3)在训练过程中,通过变分界训练目标最大化条件后验概率,使得模型能够专注于生成与条件数据一致的真实图像;
(4)通过减少数据一致性项对扩散过程的影响,使得模型能够在推理过程中快速生成图像,同时保持较高的真实性。
- 结论:
(1)本文提出的深度数据一致性(DDC)方法,在平衡数据一致性和真实性的同时,实现了快速推理,为扩散模型求解逆问题提供了新的思路和方法。
(2)创新点:提出深度数据一致性(DDC)方法,使用神经网络更新扩散模型中的数据一致性步骤,通过变分界训练目标最大化条件后验概率,并减少其对扩散过程的影响。
性能:在图像超分辨率、修复、去模糊和 JPEG 恢复等任务上,DDC 在仅需 5 个推理步骤且平均耗时 0.77 秒的情况下,在相似性和真实性指标上均取得了优异的性能。
工作量:DDC 的训练过程需要使用神经网络拟合数据一致性项,并将其融入到扩散模型中,这可能会增加训练时间和计算成本。
点此查看论文截图


 wechat
wechat- alipay