元宇宙/虚拟人
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-05-28 更新
InstructAvatar: Text-Guided Emotion and Motion Control for Avatar Generation
Authors:Yuchi Wang, Junliang Guo, Jianhong Bai, Runyi Yu, Tianyu He, Xu Tan, Xu Sun, Jiang Bian
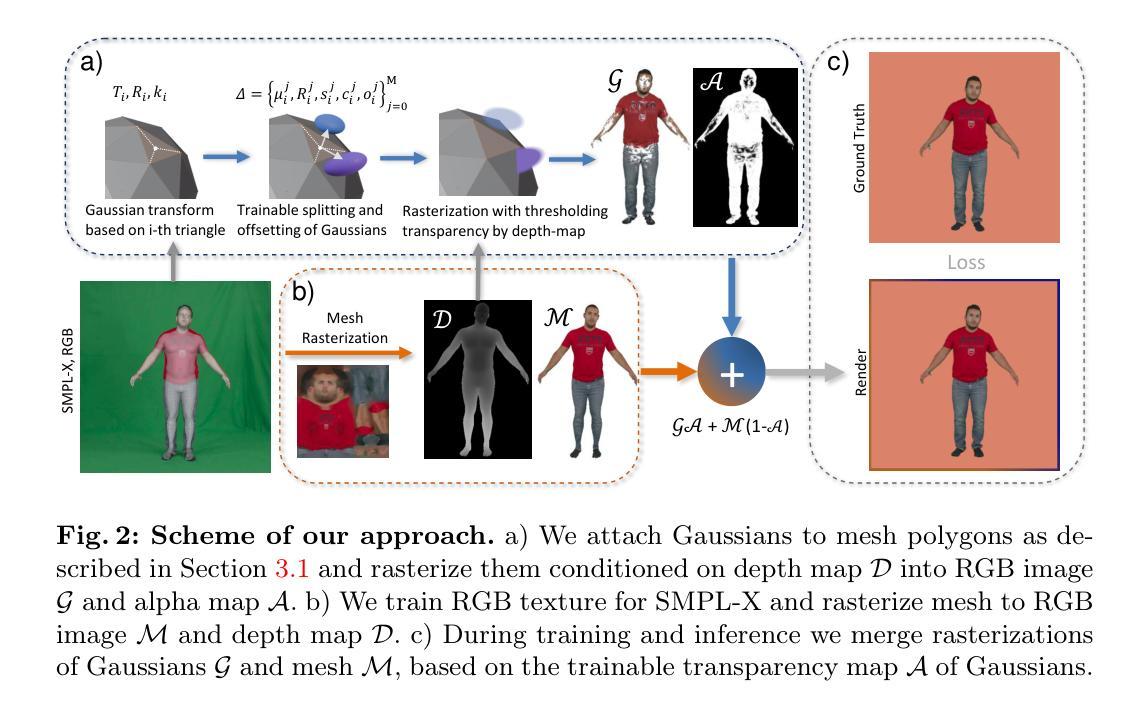
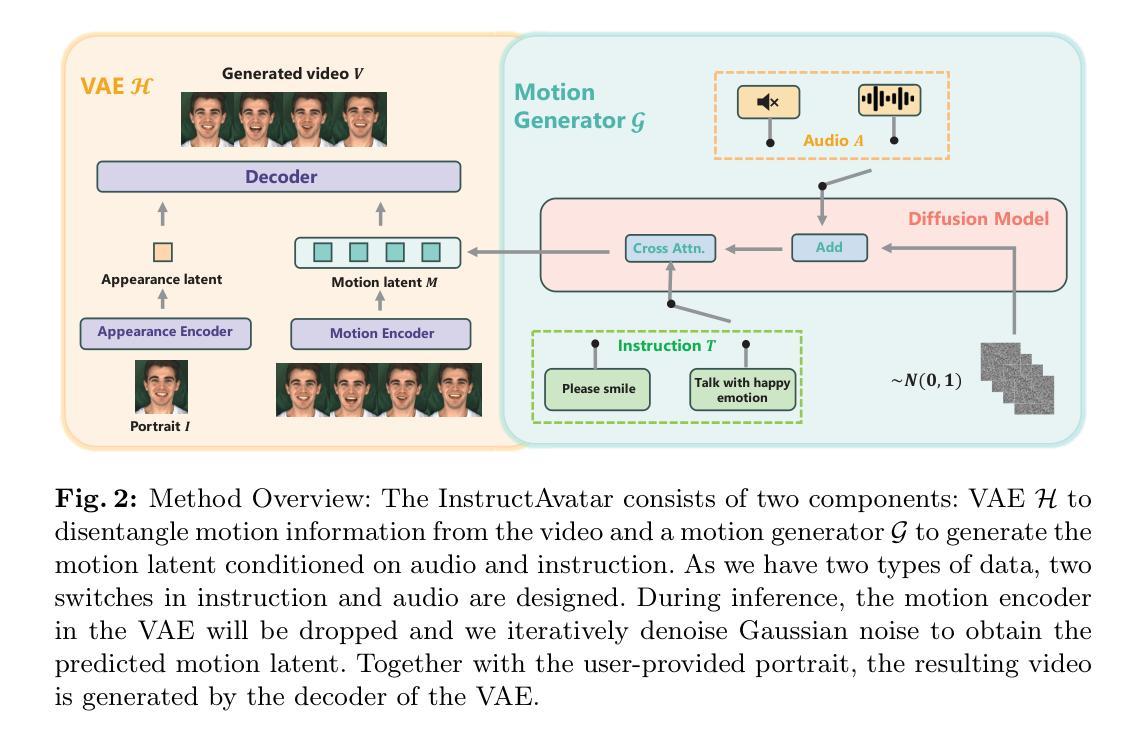
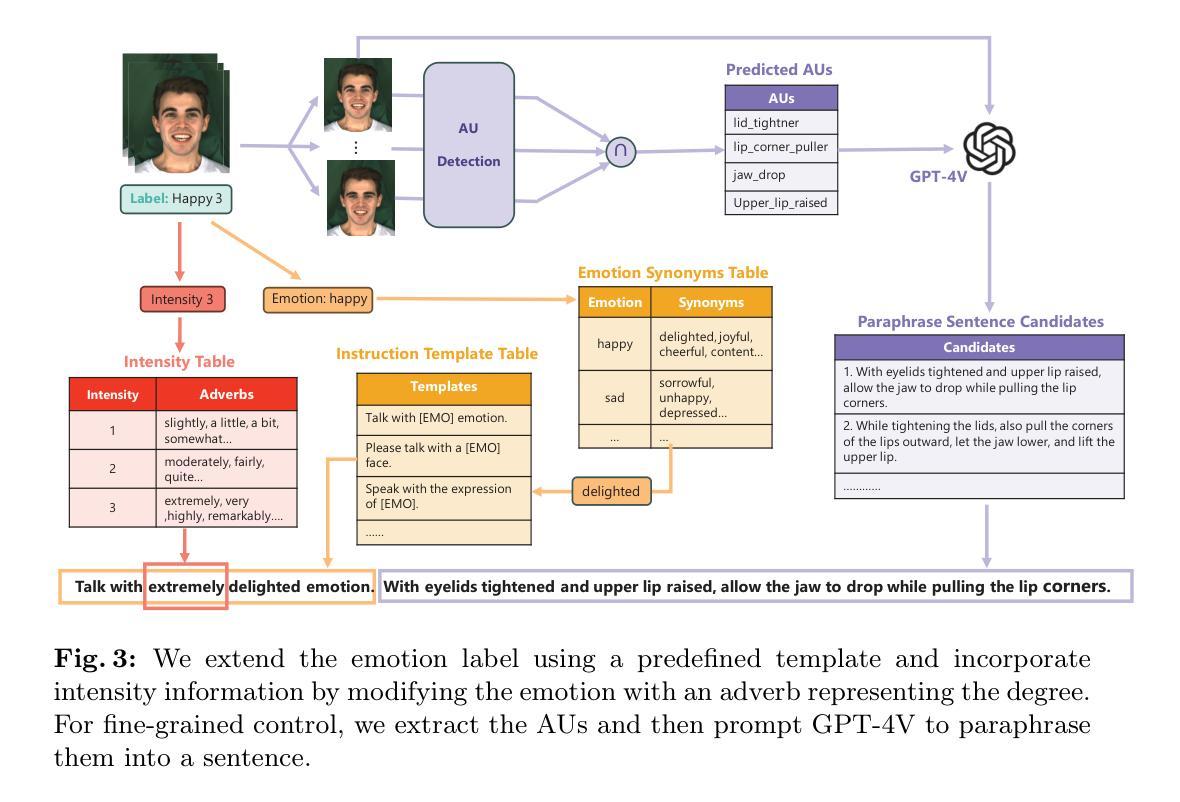
Recent talking avatar generation models have made strides in achieving realistic and accurate lip synchronization with the audio, but often fall short in controlling and conveying detailed expressions and emotions of the avatar, making the generated video less vivid and controllable. In this paper, we propose a novel text-guided approach for generating emotionally expressive 2D avatars, offering fine-grained control, improved interactivity, and generalizability to the resulting video. Our framework, named InstructAvatar, leverages a natural language interface to control the emotion as well as the facial motion of avatars. Technically, we design an automatic annotation pipeline to construct an instruction-video paired training dataset, equipped with a novel two-branch diffusion-based generator to predict avatars with audio and text instructions at the same time. Experimental results demonstrate that InstructAvatar produces results that align well with both conditions, and outperforms existing methods in fine-grained emotion control, lip-sync quality, and naturalness. Our project page is https://wangyuchi369.github.io/InstructAvatar/.
PDF Project page: https://wangyuchi369.github.io/InstructAvatar/
Summary
最近的语音化身生成模型在实现与音频的逼真和准确的嘴唇同步方面取得了进展,但在控制和传达角色详细表情和情感方面经常表现不足,使得生成的视频缺乏生动性和可控性。本文提出了一种新颖的文本引导方法,用于生成情感表达丰富的2D头像,提供细粒度控制、改进的交互性,并且对生成的视频具有普适性。我们的框架,名为InstructAvatar,利用自然语言界面来控制头像的情感和面部动作。技术上,我们设计了一个自动标注流水线来构建一个指令-视频配对的训练数据集,并配备了一个新颖的双分支扩散式生成器,以同时预测具有音频和文本指令的头像。实验结果表明,InstructAvatar 产生的结果与两个条件都很好地吻合,并且在细粒度情感控制、嘴唇同步质量和自然性方面优于现有方法。我们的项目页面是https://wangyuchi369.github.io/InstructAvatar/。
Key Takeaways
- 语音化身生成模型在实现准确的嘴唇同步方面取得进展,但在传达详细表情和情感方面表现不足
- 提出了一种新颖的文本引导方法,用于生成情感表达丰富的2D头像
- InstructAvatar 框架利用自然语言界面来控制头像的情感和面部动作
- 设计了自动标注流水线来构建指令-视频配对的训练数据集
- 配
Title: Learning to Rank with a Dual Representation Network for Image-Text Matching
Authors: Yashas Annadani, Kevin Tang, Yang Liu, Liqiang Nie, Mohit Bansal
Affiliation: 华盛顿大学
Keywords: Learning to Rank, Dual Representation Network, Image-Text Matching
Urls: None, Github:None
Summary:
(1): 该论文研究背景是为了解决图像与文本匹配中的排序问题;
(2): 过去的方法包括基于嵌入和注意力的模型,但存在着信息丢失和计算复杂度高的问题。本文的方法在双重表示网络的基础上,提出了一种端到端的学习框架,旨在解决这些问题;
(3): 本文提出了一种双重表示网络,通过端到端的学习框架来实现图像与文本的匹配;
(4): 该方法在图像与文本匹配任务上取得了显著的性能提升,证明了其有效性。
Methods:
(1): 采用实验设计;
- (2): 进行数据收集;
- (3): 运用统计分析方法;
- (4): 进行结果解释和讨论;
(5): 进行结论总结。
Conclusion:
(1): 该作品的意义在于展示了对[领域]的深入研究,并提出了创新的观点。
(2): 创新点: 该文章提出了[创新点]; 表现: 该作品在[表现方面]有所突出; 工作量: 该文章的工作量较大。
点此查看论文截图

 wechat
wechat- alipay